Результат интеллектуальной деятельности: ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ФУНКЦИЙ ПОТЕРЬ, ОТРАЖАЮЩИХ ЗАВИСИМОСТИ МЕЖДУ СОСЕДНИМИ ТОКЕНАМИ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в общем относится к вычислительным системам, а более конкретно - к системам и способам обучения нейронной сети посредством специализированных функций потерь.
УРОВЕНЬ ТЕХНИКИ
[0002] «Нейронная сеть» в настоящем документе означает вычислительную модель, идея которой отчасти была взята из биологических нейронных сетей, которые образуют человеческий мозг. Нейронная сеть сама по себе является не алгоритмом, а основой для множества различных алгоритмов машинного обучения для совместной работы и обработки сложных исходных данных. Такая система может «обучаться» для выполнения задач путем рассмотрения примеров, обычно без программирования специальных правил для решения данной задачи.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа обучения нейронных сетей с использованием функций потерь, отражающих зависимости между соседними токенами, может включать: получение обучающей выборки данных, содержащей множество размеченных токенов; определение с помощью нейронной сети первого тега, связанного с текущим токеном, обрабатываемым нейронной сетью, второго тега, связанного с предыдущим токеном, обработанным нейронной сетью до обработки текущего токена, и третьего тега, связанного со следующим токеном, который будет обрабатываться нейронной сетью после текущего токена; вычисление, для обучающей выборки данных, значения функции потерь, отражающего первое значение потерь, второе значение потерь и третье значение потерь, где первое значение потерь представлено первой разницей между первым тегом и первой меткой, связанной с текущим токеном обучающей выборки данных, где второе значение потерь представлено второй разницей между вторым тегом и второй меткой, связанной с предыдущим токеном обучающей выборки данных, где третье значение потерь представлено третьей разницей между третьим тегом и третьей меткой, связанной со следующим токеном обучающей выборки данных; и регулировка параметра нейронной сети на основе значения функции потерь.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения другой пример способа обучения нейронных сетей с использованием функций потерь, отражающих зависимости между соседними токенами, может включать: получение обучающей выборки данных, содержащей множество размеченных слов естественного языка, где каждая метка идентифицирует часть речи (POS), связанную с соответствующим словом; определение, с помощью нейронной сети, первого тега, идентифицирующего первую POS, связанную с текущим словом, которое обрабатывает нейронная сеть, второго тега, идентифицирующего вторую POS, связанную с предыдущим словом, которое было обработано нейронной сетью, и третьего тега, идентифицирующего третью POS, связанную со следующим словом, которое будет обрабатываться нейронной сетью после обработки текущего слова; вычисление, для обучающей выборки данных, значения функции потерь, отражающего первое значение потерь, второе значение потерь и третье значение потерь, где первое значение потерь представлено первой разницей между первым тегом и первой меткой, связанной с текущим словом обучающей выборки данных, где второе значение потерь представлено второй разницей между вторым тегом и второй меткой, связанной с предыдущим словом обучающей выборки данных, где третье значение потерь представлено третьей разницей между третьим тегом и третьей меткой, связанной со следующим словом обучающей выборки данных; и регулировка параметра нейронной сети на основе значения функции потерь.
[0005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их вычислительной системой обеспечивают выполнение вычислительной системой операций, включающих: получение обучающей выборки данных, содержащей множество размеченных слов естественного языка, где каждая метка идентифицирует часть речи (POS), связанную с соответствующим словом; определение, с помощью нейронной сети, первого тега, идентифицирующего первую POS, связанную с текущим словом, которое обрабатывает нейронная сеть, второго тега, идентифицирующего вторую POS, связанную с предыдущим словом, которое было обработано нейронной сетью, и третьего тега, идентифицирующего третью POS, связанную со следующим словом, которое будет обрабатываться нейронной сетью после обработки текущего слова; вычисление, для обучающей выборки данных, значения функции потерь, отражающего первое значение потерь, второе значение потерь и третье значение потерь, где первое значение потерь представлено первой разницей между первым тегом и первой меткой, связанной с текущим словом обучающей выборки данных, где второе значение потерь представлено второй разницей между вторым тегом и второй меткой, связанной с предыдущим словом обучающей выборки данных, где третье значение потерь представлено третьей разницей между третьим тегом и третьей меткой, связанной со следующим словом обучающей выборки данных; и регулировку параметра нейронной сети на основе значения функции потерь.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
[0007] Фиг. 1 схематически иллюстрирует пример исходной нейронной сети, которая может использоваться для выполнения задачи последовательной разметки, например, тегами частей речи (POS), в соответствии с одним или более аспектами настоящего изобретения;
[0008] Фиг. 2 схематически иллюстрирует пример нейронной сети, работающей в соответствии с одним или более вариантами реализации настоящего изобретения;
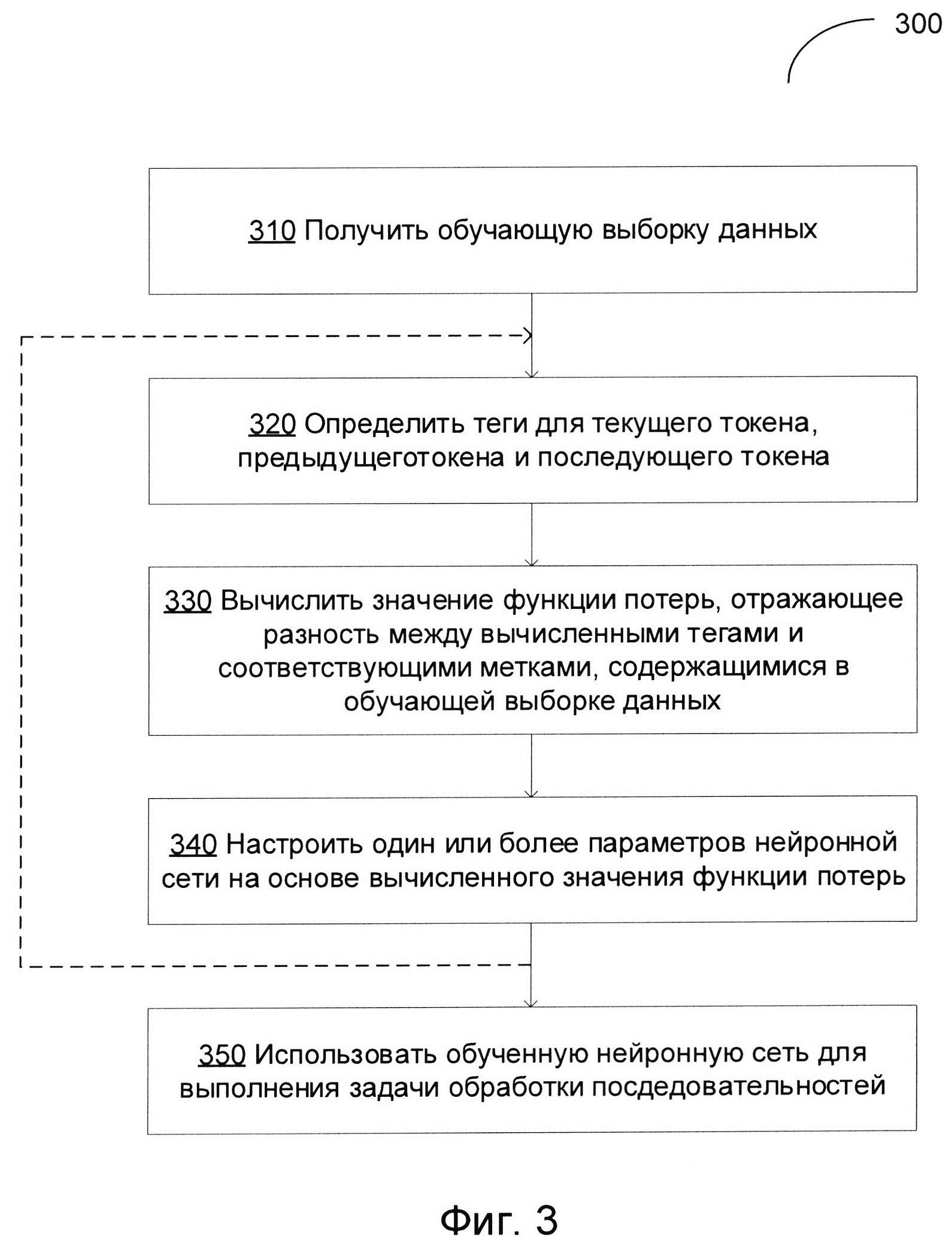
[0009] На Фиг. 3 изображена блок-схема примера способа обучения нейронной сети с использованием функций потерь, отражающих зависимости между соседними токенами, в соответствии с одним или более вариантами реализации настоящего изобретения;
[00010] На Фиг. 4 изображена блок-схема примера способа разметки последовательностей на основе нейронной сети, в соответствии с одним или более вариантами реализации настоящего изобретения;
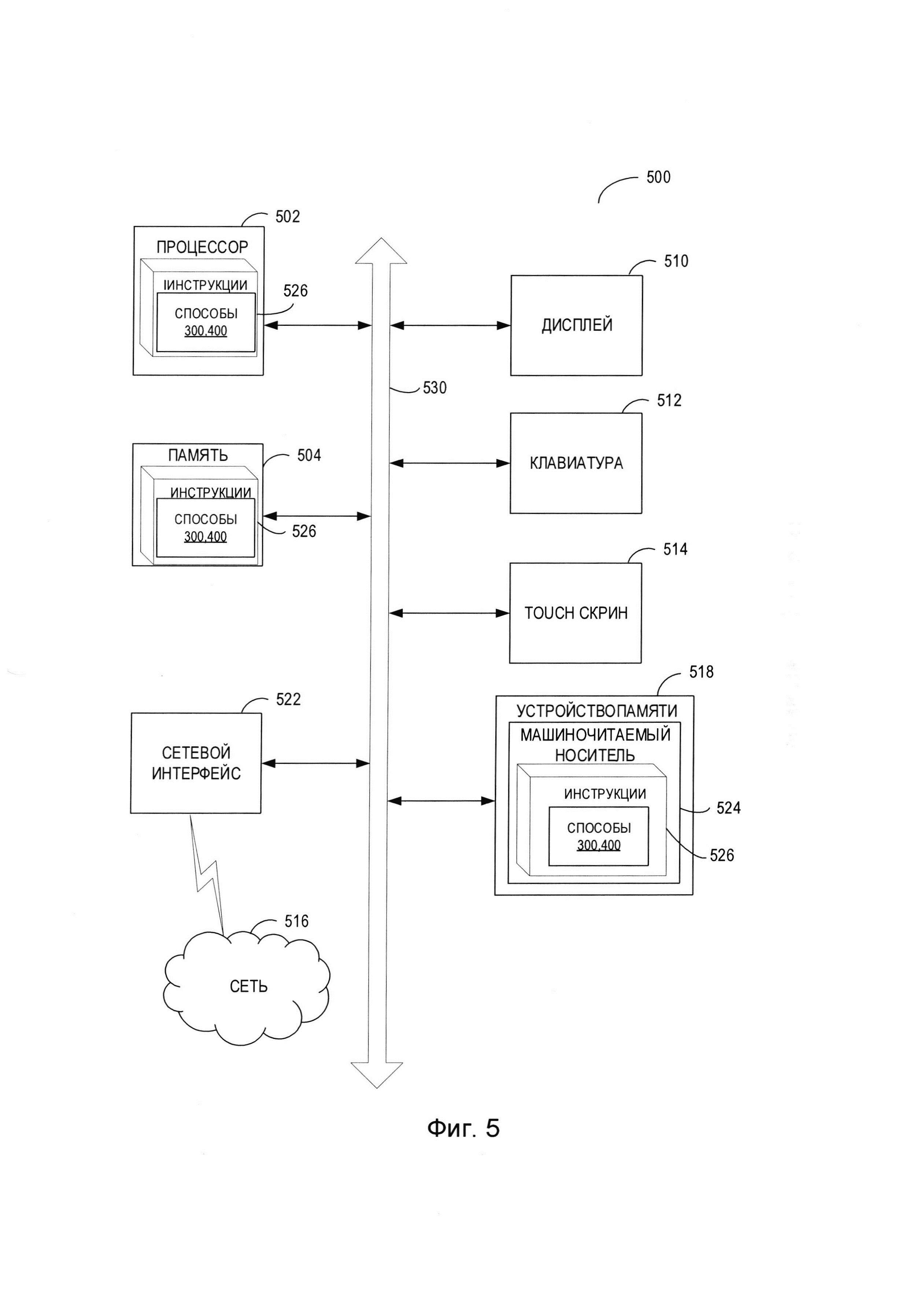
[00011] На Фиг. 5 представлена схема примера вычислительной системы, которая может использоваться для реализации описанных в этом документе способов.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00012] В настоящем документе описываются способы и системы обучения нейронной сети с использованием функций потерь, отражающих зависимости между соседними токенами (то есть отношения между токенами в исходной последовательности, обрабатываемой нейронной сетью). Нейронные сети, обученные посредством способов, описанных в этом документе, могут использоваться для разметки последовательностей, то есть обработки входной последовательности токенов и связывания каждого токена с меткой из предварительно определенного набора меток. Задача разметки последовательностей может быть определена следующим образом: создание, для входной последовательности токенов w1, …, wn =: w1n, соответствующей последовательности тегов t1, …, tn=: tn1; ti∈Т, где Т обозначает набор возможных тегов.
[00013] Примером задачи разметки последовательностей может быть присваивание тегов частей речи (POS), таким образом, что нейронная сеть будет обрабатывать текст на естественном языке и назначать каждому слову естественного языка тег, указывающий на POS. «Часть речи» в данном документе означает категорию слов. Слова, которым назначена одинаковая часть речи, обычно демонстрируют схожие морфологические атрибуты (то есть схожие шаблоны изменения). В английском языке обычно выделяются такие части речи, как существительное, глагол, прилагательное, деепричастие, местоимение, предлог, союз, междометие и артикль. В некоторых реализациях под POS-тегом может пониматься не только принадлежность части речи, но некоторый набор грамматических, морфологических и/или семантических атрибутов.
[00014] Таким образом, задачу разметки POS можно определить следующим образом: создание, для исходного текста на естественном языке, представленного последовательностью слов w1, …, wn=:w1n, соответствующей последовательности тегов t1, …, tn=: tn1; ti∈Т, где Т обозначает набор определенных частей речи (или совокупностей атрибутов). В частности, нейронная сеть, обученная посредством способов, описанных в этом документе, может разрешать омонимию, то есть использовать контекст (отношения между словами) для различения внешне одинаковых слов, имеющих различный смысл.
[00015] В других примерах теги, создаваемые нейронными сетями, обученными по способам, описанным в данном документе, могут идентифицировать различные другие грамматические и (или) морфологические атрибуты слов из текста на естественном языке, обрабатываемого этими нейронными сетями. Каждый тег может быть представлен в виде кортежа грамматических и (или) морфологических признаков, связанных со словом естественного языка. Эти теги могут использоваться для выполнения широкого спектра задач обработки естественного языка, например, выполнения синтаксического и (или) семантического анализа текстов на естественном языке, автоматического перевода, распознавания именованных сущностей и т.д.
[00016] Нейронная сеть содержит множество соединенных узлов, которые называются «искусственными нейронами» и немного похожи на нейроны человеческого мозга. Каждое соединение, как синапс в человеческом мозге, может передавать сигнал от одного искусственного нейрона к другому. Искусственный нейрон, получивший сигнал, обрабатывает его и пересылает измененный сигнал другим дополнительным искусственным нейронам. В обычной реализации нейронной сети выход каждого искусственного нейрона вычисляется с помощью функции, которая является линейной комбинацией входов. Соединения между искусственными нейронами на схемах нейросетей изображаются «ребрами». Веса ребер, которые усиливают или ослабляют сигнал, передаваемый по соответствующим ребрам, определяются на этапе обучения нейронной сети на базе обучающей выборки данных, которая содержит множество размеченных исходных данных (то есть исходных данных с известной классификацией). В одном из иллюстративных примеров все веса ребер инициализируются случайными или заранее определенными значениями. Нейронная сеть активируется в ответ на любые исходные данные из набора данных для обучения. Наблюдаемый результат работы нейронной сети сравнивается с ожидаемым результатом работы, включенным в обучающую выборку данных, и ошибка передается назад на предыдущие слои нейронной сети, в которых веса соответственно корректируются. Этот процесс может повторяться, пока ошибка в результатах не станет ниже заранее определенного порогового значения.
[00017] Описанные в данном документе способы используют рекуррентные нейронные сети, которые в состоянии поддерживать состояние сети, отражающее информацию об исходных данных, обрабатываемых сетью, таким образом позволяя сети использовать свое внутреннее состояние для обработки последующих исходных данных. Однако обычные нейронные сети подвержены эффекту затухания градиента, который делает сеть практически бесполезной при обработке длинных входных последовательностей (таких как входные последовательности из более чем пяти токенов).
[00018] Эффекта затухания градиента можно избежать, если использовать нейросети долгой краткосрочной памяти (LSTM), использующие механизм селекции, который позволяет сети самостоятельно делать выбор при выполнении следующего этапа обработки между собственным состоянием и входными данными. Поскольку нейронные сети LSTM демонстрируют очень слабое затухание градиента, эти сети в состоянии обрабатывать очень длинные входные последовательности (например, входные последовательности из десятков токенов).
[00019] Однако обычные нейронные сети LSTM могут выдавать информацию только об одном из двух обычно доступных контекстов (левом или правом) данного слова. По этой причине системы и способы по настоящему изобретению используют двунаправленные сети LSTM (BiLSTM). Результатом работы BiLSTM является объединение проходов одиночной LSTM вперед и назад.
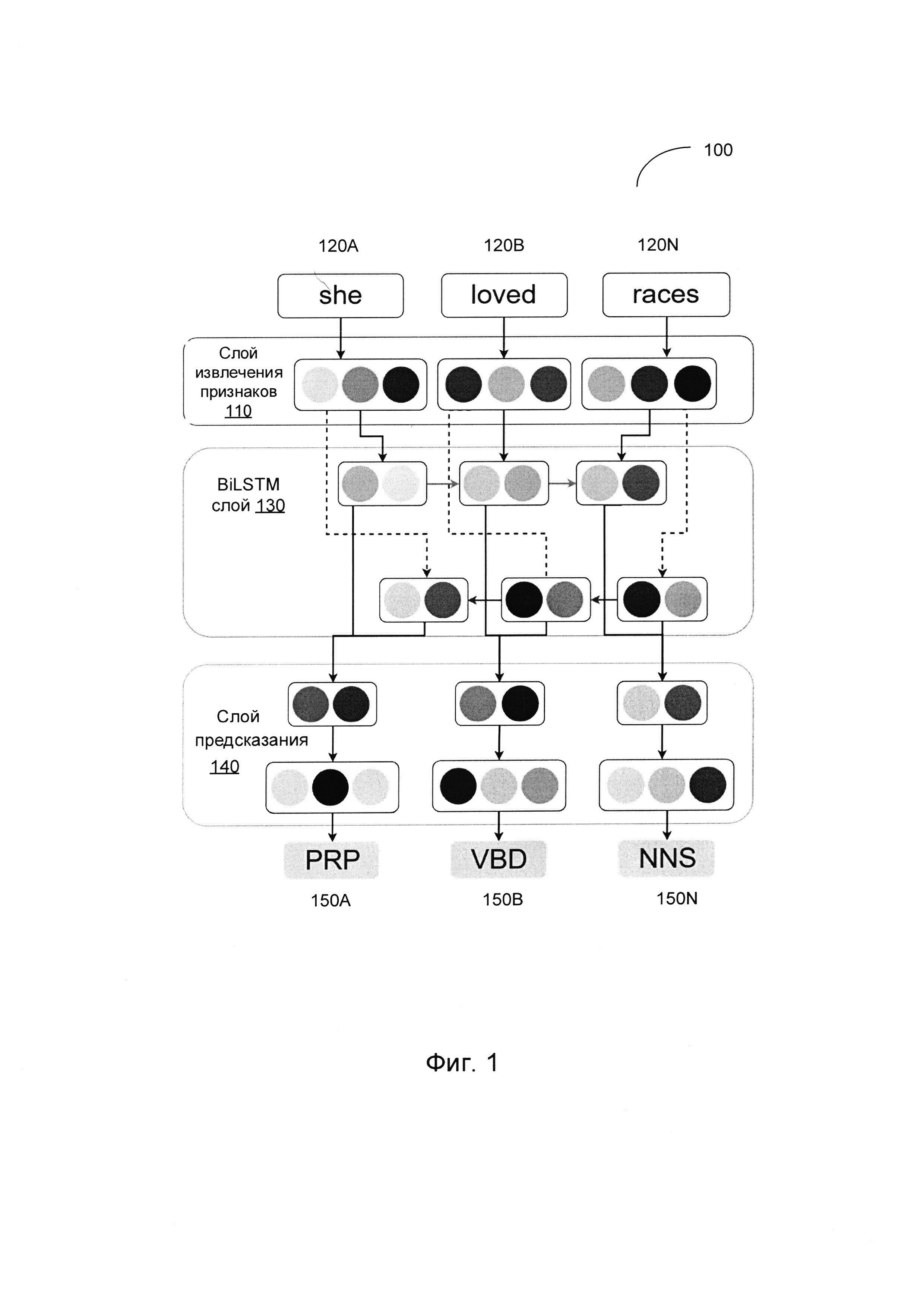
[00020] На Фиг. 1 схематически иллюстрируется пример исходной нейронной сети, которая может использоваться для выполнения задач разметки последовательностей, например, тегов POS. Как схематически показано на Фиг. 1, базовая нейронная сеть включает слой извлечения признаков 110, слой BiLSTM 120, и слой предсказания 140.
[00021] Слой извлечения признаков 110 предназначен для получения векторов признаков, представляющих исходные токены 120A-120N, которые последовательно поступают на слой извлечения признаков 110. В некоторых вариантах осуществления каждый вектор признаков может быть представлен соответствующим эмбеддингом, то есть вектором действительных чисел, которые могут быть получены, например, нейронной сетью, реализующей математическое преобразование из пространства с одним измерением на слово в непрерывное пространство вектора со значительно меньшей размерностью. В одном из иллюстративных примеров слой извлечения признаков 110 может использовать заранее предварительно определенный набор эмбеддингов, который может быть заранее построен на базе большого корпуса текстов на естественном языке. Таким образом, словные эмбеддинги будут содержать семантическую информацию и как минимум часть морфологической информации о словах, например, об использовании слов в сходных контекстах, а также о синонимах, которым будут назначены векторы признаков, расположенные близко друг к другу в пространстве признаков.
[00022] Слой BiLSTM 130 обрабатывает векторы признаков, созданные слоем извлечения признаков 110, и выдает набор векторов, таких, что каждый вектор содержит информацию о соответствующих входных токенах и их контексте. Слой предсказания 140, который может быть реализован в виде нейронной сети прямого распространения (feed-forward), обрабатывает набор векторов, созданных слоем BiLSTM 130, и для каждого вектора выдает тег из заранее определенного набора тегов 150A-150N (например, тег указывает на POS соответствующего входного токена).
[00023] Обучение сети может включать обработку нейронной сетью обучающей выборки данных, которая может содержать одну или более входных последовательностей с классифицирующими тегами, назначенными каждому токену (например, корпус текстов на естественном языке с указанными для каждого слова частями речи). Значение функции потерь может вычисляться, исходя из наблюдаемых выходных данных нейронной сети (то есть тега, созданного нейронной сетью для данного токена) и ожидаемого результата, определенного в обучающей выборке данных для этого токена. Ошибка (т.е. расхождение между ожидаемым результатом и полученным), отражаемая функцией потерь, может быть распространена назад на предыдущие слои нейронной сети, в которых может проводиться соответствующая настройка весов ребер и других параметров для минимизации функции потерь. Данный процесс можно повторять до тех пор, пока значение функции потерь не стабилизируется в окрестности определенного значения или не опустится ниже предварительно заданного порогового значения.
[00024] Соответственно, базовую нейронную сеть 100 можно дополнить, добавив два вторичных выхода, которые будут, дополнительно к выводу тегов слоем предсказания 140 для текущего тега, выводить тег, связанный с предыдущим токеном и тег, связанный с последующим токеном, как схематично показано на Фиг. 2. Три тега могут использоваться на стадии обучения сети для вычисления функции потерь, таким образом вынуждая сеть распознавать отношения между соседними токенами.
[00025] По этой причине нейронные сети и способы обучения, описанные в настоящем документе, представляют собой значительное улучшение по сравнению с различными общеизвестными системами и способами. В частности, использование функций потерь, специально предназначенных для обучения нейронной сети распознаванию зависимостей между соседними токенами (то есть отношений между соседними токенами во входных последовательностях), дает значительное улучшение общего качества и эффективности способов разметки последовательностей. Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не с целью ограничения.
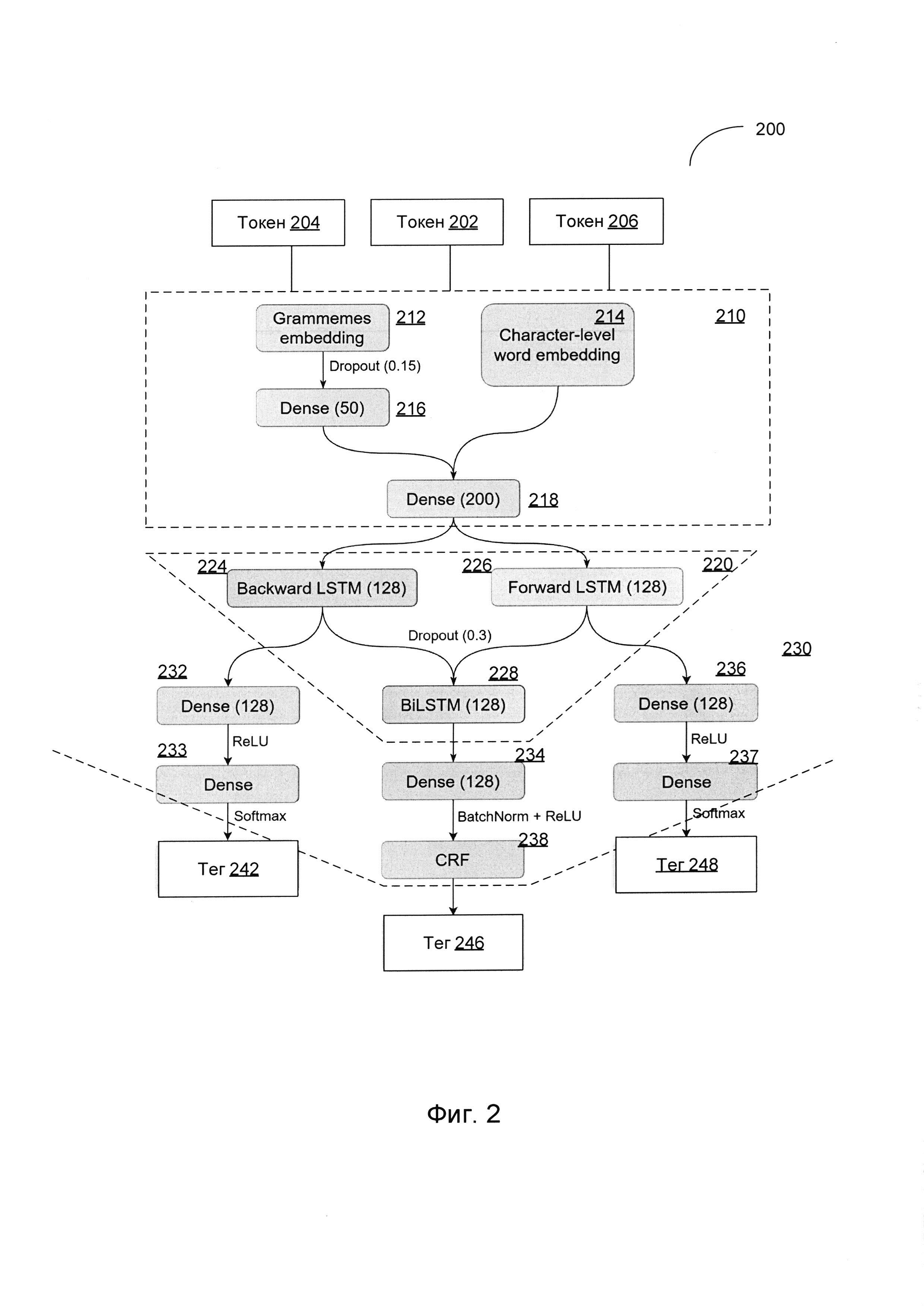
[00026] Фиг. 2 схематически иллюстрирует пример нейронной сети, работающей в соответствии с одним или более вариантами реализации настоящего изобретения. Пример нейронной сети 200 может использоваться для выполнения задачи разметки последовательностей, например, тегов POS. Как схематически показано на Фиг. 2, пример нейронной сети 200 включает слой извлечения признаков 210, слой BiLSTM 220 и слой предсказания 230.
[00027] Как отмечено выше в настоящем документе, базовая нейронная сеть 100 может обрабатывать словные эмбеддинги, построенные так, что словам, используемым в сходном контексте, а также синонимам, должны назначаться векторы признаков, расположенные близко друг к другу в пространстве признаков. Однако матрица словных эмбеддингов, в которой каждое словарное слово отображается на вектор в пространстве признаков, даже если она имеет огромный размер, все же не в состоянии создавать эмбеддинги, соответствующие словам, которые отсутствуют в словаре. Кроме того, относительно большой размер вектора словных эмбеддингов объясняется тем, что вектор содержит семантическую информацию об исходном слове, хотя эта информация не всегда полезна для задачи разметки (например, тегов POS), выполняемой нейронной сетью. Таким образом, нейронные сети, реализованные в соответствии с одним или более вариантами реализации настоящего изобретения, предназначены для обработки входных данных, которые, в дополнение к словным эмбеддингам, могут содержать символьные эмбеддинги и граммемные эмбеддинги.
[00028] Символьные эмбеддинги не используют словарь, вместо этого они рассматривают каждый входящий токен как последовательность символов. Вектор может быть назначен данному входному токену, например, путем обработки входной последовательности токенов (например, текста на естественном языке, представленного последовательностью слов) нейронной сетью (например, сетью LSTM и (или) полносвязной сетью). В некоторых вариантах осуществления входящие токены могут быть обрезаны до предварительно заданного размера (например, 12 символов). Символьные эмбеддинги содержат грамматическую и (или) морфологическую информацию о токенах на входе.
[00029] Граммемный эмбеддинг для данного слова может быть создан нейронной сетью, которая для каждого слова на входе создает вектор, каждый элемент которого относится к определенному грамматическому атрибуту слова (то есть, отражает для слова на входе вероятность связи с определенным грамматическим атрибутом). Нейронная сеть может использовать дополнительный плотный слой для промежуточного представления слова таким образом, что результирующий вектор, полученный нейронной сетью, будет представлять не только отдельные грамматические атрибуты, но и определенное взаимодействие между ними.
[00030] В иллюстративном примере на Фиг. 2 нейронная сеть 200 предназначена для обработки символьных эмбеддингов и граммемных эмбеддингов. Слой извлечения признаков 210 предназначен для получения векторов признаков, представляющих токены на входе, которые последовательно поступают на него. Таким образом, в любой данный момент времени состояние сети отражает «текущий» токен 202, обрабатываемый сетью, а также предыдущий токен 204, уже обработанный сетью, и пытается предсказать некоторые признаки «следующего» токена 206, который будет обрабатываться сетью.
[00031] Слой извлечения признаков 210 создает граммемные эмбеддинги (Grammemes embeddings) - 212 (например, путем обработки входных токенов сетью LSTM и (или) полносвязной сетью) и символьные эмбеддинги (Character-level word embeddings) - 214 (например, путем обработки входных токенов другой сетью LSTM и (или) полносвязной сетью). Граммемный эмбеддинг 212 затем поступает на полносвязный (Dense) слой 216, выход которого объединяется с символьным эмбеддингом 214 и поступает на полносвязный слой 218. Полносвязный слой выполняет преобразование, при котором каждый вход соединяется с каждым выходом линейным преобразованием, описываемым значением веса, которое может сопровождаться нелинейной функцией активации (например, ReLU, Softmax и т.п.).
[00032] Следует отметить, что в различных других вариантах осуществления нейронные сети, реализующие способ, описанный в настоящем документе, могут обрабатывать входные векторы, представляющие собой различные комбинации (например, объединения) словных эмбеддингов, символьных эмбеддингов и (или) граммемных эмбеддингов.
[00033] Рассмотрим снова Фиг. 2, выход полносвязного слоя 218 поступает на обратную LSTM 224 и прямую LSTM 226 слоя LSTM 220. Выходные данные LSTM 224-226 поступают в BiLSTM 228, выходные данные которой в основном режиме работы обрабатываются основным конвейером (pipeline) предсказания слоя предсказания 230 (то есть результат полносвязного слоя 234 дополнительно может быть усилен результатом применения метода условных случайных полей (CRF) 238) для получения тега 246, связанного с текущим токеном 202.
[00034] С другой стороны, в режиме обучения могут использоваться два вспомогательных предыдущих конвейера слоя предсказания 230, так что первый вспомогательный конвейер предсказания, включающий полносвязные слои 232 и 233, получает входные данные из обратной LSTM 224 и создает тег 242, связанный с предыдущим токеном 204; а второй вспомогательный конвейер предсказания, включающий полносвязные слои 236 и 237, получает входные данные из прямой LSTM 226 и создает тег 248, связанный со следующим токеном 206. Можно вычислить функцию потерь, которая учитывает разницу между соответствующими предсказанными тегами и тегами, указанными в обучающей выборке данных для текущего, предыдущего и следующего токенов. Таким образом, два вспомогательных конвейера предсказания слоя предсказания 230 используются только в режиме обучения сети.
[00035] В иллюстративном примере функция потерь может быть представлена в виде взвешенной суммы, отражающей разницу между соответствующими предсказанными тегами и тегами, приведенными в обучающей выборке данных для текущего, предыдущего и следующего токенов:
[00036] L=w1d(Tprev, T'prev)+w2d(Tcur, T'cur)+w3d(Tnext, T'next)
[00037] где L - значение функции потерь,
[00038] d - метрика расстояния в пространстве тегов,
[00039] w1, w2, м w3 - весовые коэффициенты,
[00040] Tprev - тег, созданный нейронной сетью для предыдущего токена,
[00041] T'prev - тег, связанный с предыдущим токеном в обучающей выборке данных,
[00042] Tcur - тег, созданный нейронной сетью для текущего токена,
[00043] Т'cur - тег, связанный с текущим токеном в обучающей выборке данных,
[00044] Tnext - тег, созданный нейронной сетью для следующего токена, и
[00045] T'next - тег, связанный со следующим токеном в обучающей выборке данных.
[00046] Обучение сети может включать обработку нейронной сетью обучающей выборки данных, которая может содержать одну или более входных последовательностей с классифицирующими тегами, назначенными каждому токену (например, корпус текстов на естественном языке с указанными для каждого слова частями речи). Значение функции потерь может вычисляться, исходя из наблюдаемых выходных данных нейронной сети (то есть тега, созданного нейронной сетью для данного токена) и ожидаемого результата, определенного в обучающей выборке данных для этого токена. Ошибка, отражаемая функцией потерь, может быть распространена назад на предыдущие слои нейронной сети, в которых может проводиться соответствующая регулировка весов ребер и других параметров для минимизации функции потерь. Данный процесс можно повторять до тех пор, пока значение функции потерь не стабилизируется в окрестности определенного значения или не опустится ниже предварительно заданного порогового значения.
[00047] Как отмечено выше в настоящем документе, использование функции потерь, исходя из трех тегов, побудит нейронную сеть распознавать зависимости между соседними токенами (то есть отношения между соседними токенами входных последовательности) и таким образом обеспечит значительное улучшение общего качества и эффективности способов разметки последовательностей.
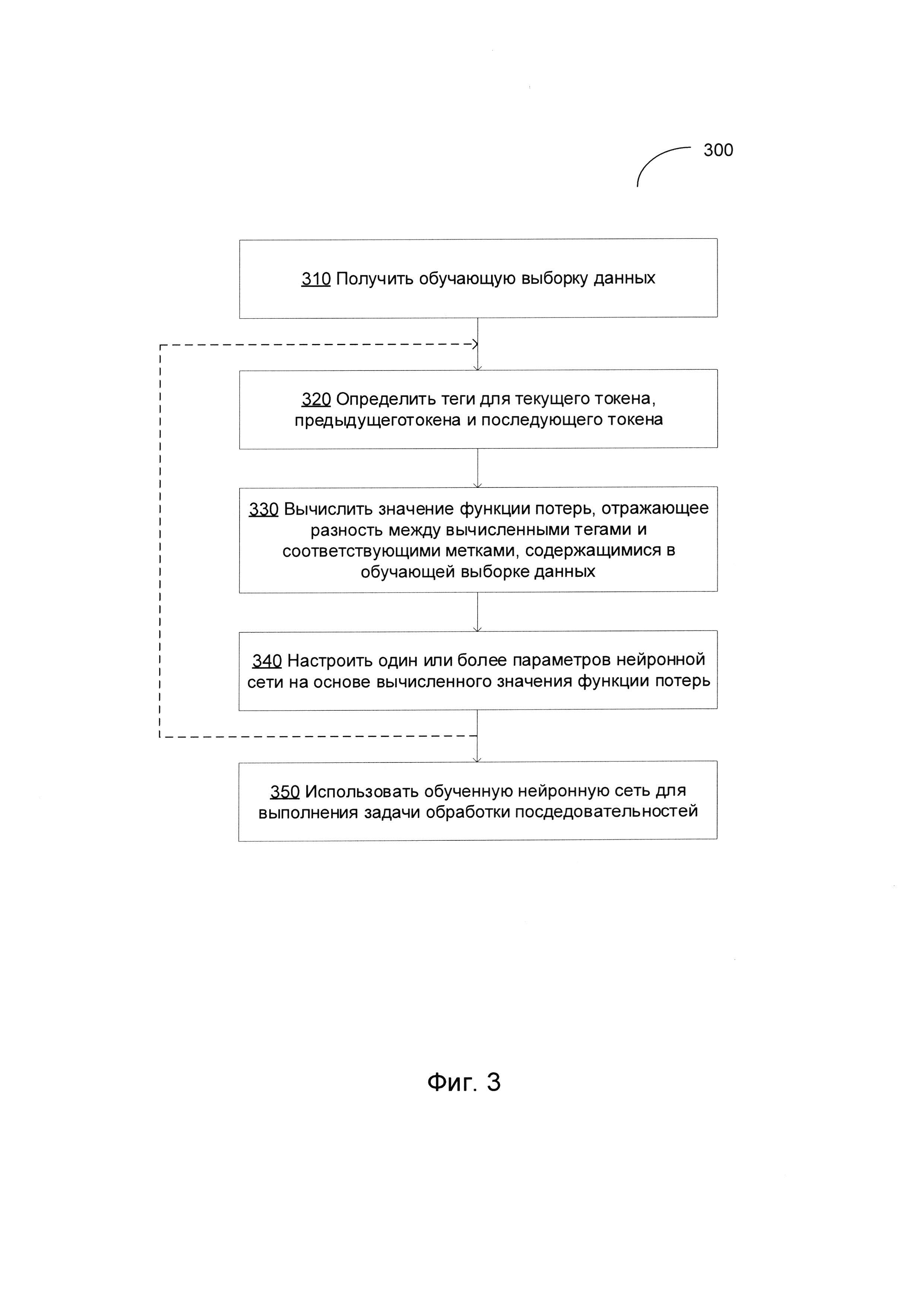
[00048] На Фиг. 3 изображена блок-схема примера способа 300 обучения нейронной сети с помощью функции потерь, отражающей зависимости соседних токенов, в соответствии с одним или более вариантами настоящего изобретения. Способ 300 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 500 на Фиг. 5), реализующей этот способ. В некоторых вариантах реализации способ 300 может выполняться в одном потоке обработки. В качестве альтернативы, способ 300 может выполняться с использованием двух и более потоков обработки, при этом каждый поток выполняет одну или более отдельную функцию, стандартную программу, подпрограмму или операцию способа. В иллюстративном примере потоки обработки, реализующие способ 300, могут быть синхронизированы {например, с помощью семафоров, критических секций и/или других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, реализующие способ 300, могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то, что Фиг. 3 и соответствующее описание содержат список операций для метода 300 в определенном порядке, в различных вариантах осуществления способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[00049] На шаге 310 вычислительная система, реализующая способ, может получать обучающую выборку данных, содержащую множество размеченных токенов (например, текст на естественном языке, в котором каждое слово помечено тегом, определяющим грамматический атрибут слова, например, POS, связанный с этим словом).
[00050] На шаге 320 вычислительная система может определять, при помощи нейронной сети, первый тег, связанный с текущим токеном, который обрабатывает нейронная сеть, второй тег, связанный с предыдущим токеном, который был обработан нейронной сетью перед обработкой текущего токена, и третий тег, связанный со следующим токеном, который будет обработан нейронной сетью после обработки текущего токена. В иллюстративном примере теги могут отражать соответствующие грамматические атрибуты (такие как POS), связанные с токенами. Нейронная сеть может включать слой извлечения признаков, двунаправленный слой долгой краткосрочной памяти (BiLSTM) и слой предсказания, такие, что слой BiLSTM дополнительно содержит BiLSTM, обратную LSTM и прямую LSTM, и результаты работы обратной LSTM и прямой LSTM поступают в BiLSTM, как более подробно было описано выше в настоящем документе.
[00051] На шаге 330 вычислительная система может вычислять, для обучающей выборки данных, значение функции потерь, отражающее разность между соответствующими вычисленными тегами и соответствующими метками, содержащимися в обучающей выборке данных. В одном из иллюстративных примеров функция потерь может быть представлена взвешенной суммой разности вычисленных тегов для текущего токена и меткой, связанной с текущим токеном в обучающей выборке данных, разности вычисленных тегов для предыдущего токена и меткой, связанной с предыдущим токеном в обучающей выборке данных, и разности вычисленных тегов для следующего токена и меткой, связанной со следующим токеном в обучающей выборке данных, как более подробно было описано выше в настоящем документе.
[00052] На шаге 340 вычислительная система может настраивать на основе вычисленного значения функции потерь один или более параметров нейронной сети, обучение которой было выполнено. В иллюстративном примере ошибка, отображаемая значением функции потерь, подвергается обратному распространению начиная с последнего слоя нейронной сети, а веса и (или) другие параметры сети настраиваются так, чтобы свести к минимуму значение функции потерь.
[00053] Данный процесс, описанный шагами 320-340, можно повторять до тех пор, пока значение функции потерь не стабилизируется в окрестности определенного значения или не опустится ниже предварительно заданного порогового значения.
[00054] На шаге 350 вычислительная система может использовать обученную нейронную сеть для выполнения задачи разметки последовательностей, например, задачи обработки естественного языка (например, расстановки тегов POS tagging) одного или более текстов на естественном языке, а способ может завершить данный процесс.
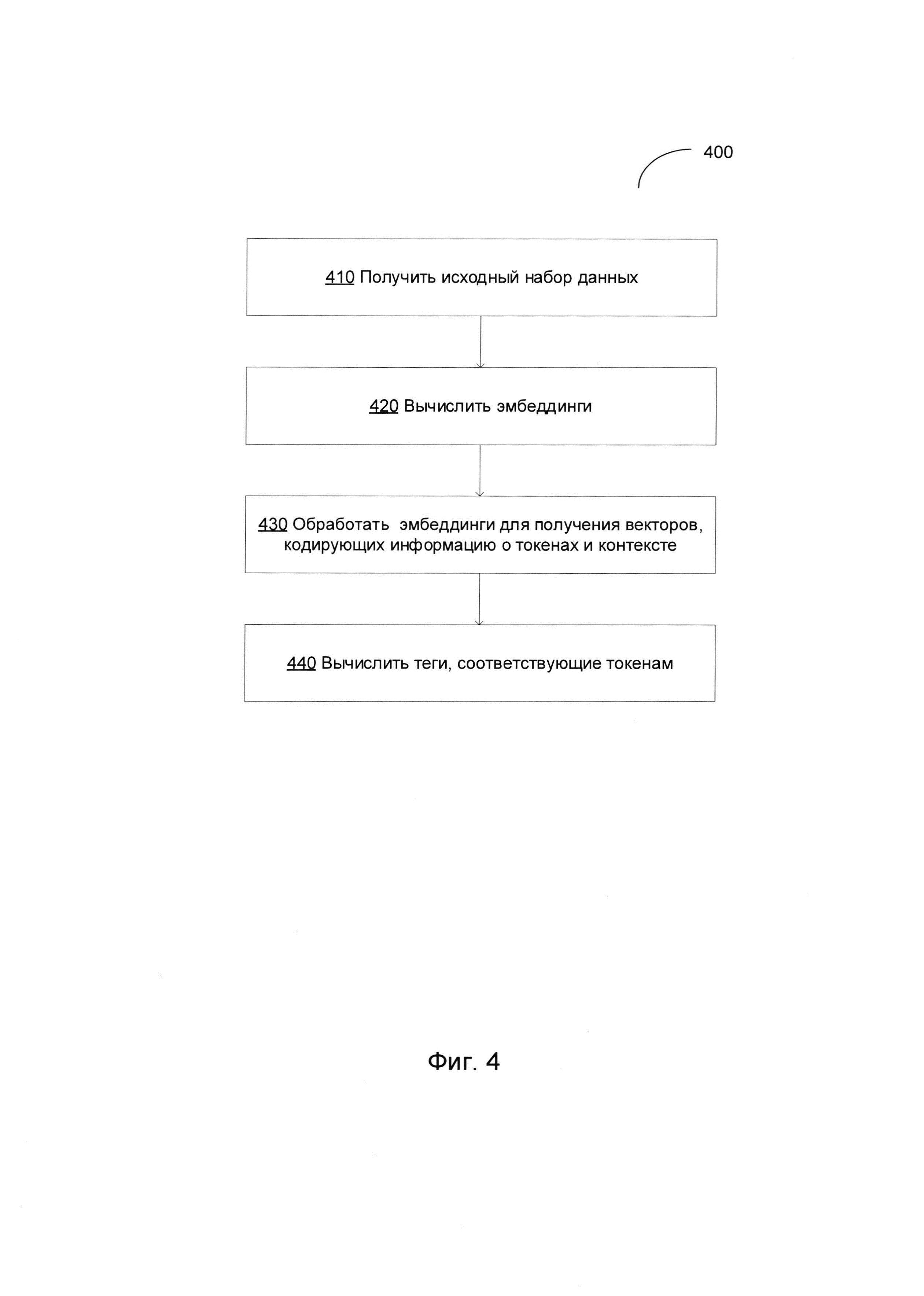
[00055] На Фиг. 4 изображена блок-схема примера способа 400 разметки последовательностей на основе нейронной сети, в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 400 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы {например, вычислительной системы 500 на Фиг. 5), реализующей этот способ. В некоторых реализациях изобретения способ 400 может выполняться с помощью одного потока обработки. В качестве альтернативы, способ 400 может выполняться с использованием двух и более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций способа. В иллюстративном примере потоки обработки, реализующие способ 400, могут быть синхронизированы {например, с помощью семафоров, критических секций и/или других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, реализующие способ 400, могут выполняться асинхронно по отношению друг к другу. Поэтому, хотя Фиг. 4 и соответствующее описание содержат операции способа 400 в определенном порядке, различные варианты реализации способа могут выполнять по крайней мере некоторые из перечисленных операций, параллельно и (или) в произвольно выбранном порядке.
[00056] На шаге 410 вычислительная система, в котором реализован этот способ, может получить исходную выборку данных, содержащую множество токенов (например, текст на естественном языке, содержащий множество слов).
[00057] На шаге 420 вычислительная система может использовать нейронную сеть (например, нейронную сеть с архитектурой нейронной сети 200 на Фиг. 2) для вычисления векторов признаков, представляющих соответствующие токены. Каждый вектор признаков может быть представлен комбинацией словного эмбеддинга, символьного эмбеддинга и (или) граммемного эмбеддинга, представляющего соответствующий токен, как описано более подробно выше.
[00058] На шаге 430 вычислительная система может обрабатывать векторы признаков, создаваемые слоем извлечения признаков, и выдавать набор векторов таким образом, чтобы каждый вектор кодировал информацию о соответствующих входных токенах и их контексте, как описано более подробно выше.
[00059] На шаге 440 вычислительная система может обрабатывать набор векторов кодирования информации и для каждого вектора может выдавать тег из заранее определенного набора тегов (например, тег, указывающий на грамматический атрибут соответствующего входного токена). После завершения операций способа 450 выполнение способа может быть завершено.
[00060] На Фиг. 5 представлена схема компонентов примера вычислительной системы, которая может использоваться для реализации описанных в этом документе способов. Вычислительная система 500 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 500 может работать в качестве сервера или клиента в сетевой среде «клиент - сервер», либо в качестве одноранговой вычислительной системы в одноранговой (или распределенной) сетевой среде. Вычислительная система 500 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то, что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для применения одного или более способов, описанных в настоящем документе.
[00061] Пример вычислительной системы 500 включает процессор 502, основное запоминающее устройство 504 {например, постоянное запоминающее устройство (ПЗУ) или динамическое оперативное запоминающее устройство (ДОЗУ)) и устройство хранения данных 518, которые взаимодействуют друг с другом по шине 530.
[00062] Процессор 502 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.п.В частности, процессор 502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW) или процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 502 также может представлять собой одно или более устройств обработки специального назначения, например заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п.Процессор 502 реализован с возможностью выполнения команд 526 для осуществления способов настоящего изобретения.
[00063] Вычислительная система 500 может дополнительно включать устройство сетевого интерфейса 522, устройство визуального отображения 510, устройство ввода символов 512 {например, клавиатуру) и устройство ввода в виде сенсорного экрана 514.
[00064] Устройство хранения данных 518 может содержать машиночитаемый носитель данных 524, в котором хранится один или более наборов команд 526, реализующих один или более из способов или функций настоящего изобретения. Команды 526 также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 504 и (или) в процессоре 502 во время выполнения их в вычислительной системе 500, при этом основное запоминающее устройство 504 и процессор 502 также представляют собой машиночитаемый носитель данных. Команды 526 дополнительно могут передаваться или приниматься по сети 516 через устройство сетевого интерфейса 522.
[00065] В иллюстративном примере инструкции 526 могут содержать инструкции способа 300 обучения нейронной сети с использованием функций потерь, отражающих зависимости между соседними токенами, реализованных в соответствии с одним или более вариантами настоящего изобретения. В другом иллюстративном примере инструкции 526 могут содержать инструкции способа 400 оптического распознавания символов, реализованного в соответствии с одним или более вариантами настоящего изобретения. Хотя машиночитаемый носитель данных 524, показанный в примере на Фиг. 5, является единым носителем, термин «машиночитаемый носитель» может включать один носитель или более носителей {например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд при исполнении их машиной обеспечивают выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00066] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например, ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00067] В приведенном выше описании изложены многочисленные детали. Однако, любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях, хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00068] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять с ними другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, графем, символов, терминов, цифр и т.д.
[00069] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано дополнительно, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п.относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и запоминающих устройствах вычислительной системы, в другие данные, аналогично представленные в виде физических величин в запоминающих устройствах или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00070] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00071] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
Извлечение сущностей из текстов на естественном языке
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Способ извлечения фактов из текстов на естественном языке
Метод и система для генерации статей в словаре естественного языка
Система для создания документов на основе анализа текста на естественном языке
Определение степеней уверенности, связанных со значениями атрибутов информационных объектов
Автоматическое обучение программы синтаксического и семантического анализа с использованием генетического алгоритма
Сентиментный анализ на уровне аспектов и создание отчетов с использованием методов машинного обучения
Использование глубинного семантического анализа текстов на естественном языке для создания обучающих выборок в методах машинного обучения
Выявление словосочетаний в текстах на естественном языке
Расширение возможностей информационного поиска
Многоэтапное распознавание именованных сущностей в текстах на естественном языке на основе морфологических и семантических признаков
Классификация текстов на естественном языке на основе семантических признаков
Сопоставление разметки для похожих документов
Восстановление текстовых аннотаций, связанных с информационными объектами
Сегментация текста
Использование автоэнкодеров для обучения классификаторов текстов на естественном языке
Извлечение информационных объектов с использованием комбинации классификаторов, анализирующих локальные и нелокальные признаки
Предсказание вероятности появления строки с использованием последовательности векторов

