Результат интеллектуальной деятельности: Автоматическое обучение программы синтаксического и семантического анализа с использованием генетического алгоритма
Вид РИД
Изобретение
УРОВЕНЬ ТЕХНИКИ
[0001] Одной из основных задач машинного перевода является предоставление качественного результата. Различные технологии используют разные методы и подходы в решении данной задачи. Например, для перевода исходного предложения на другой язык может использоваться глубинный анализ исходного предложения на основе исчерпывающих лингвистических описаний исходного языка и независимая семантическая структура, раскрывающая смысл исходного предложения. Также они могут использоваться для синтеза перевода, который передает смысл исходного предложения на целевом языке с использованием универсальных семантических описаний и лингвистических описаний целевого языка. Для повышения точности перевода стадия анализа и/или синтеза может использовать разного рода статистику и оценки, полученные с помощью анализа параллельных текстовых корпусов. Например, система Natural Language Compiler (который ниже именуется «NLC») использует лингвистические описания (морфологические, синтаксические, семантические, прагматические и пр.) для построения независимой синтаксической структуры предложения и синтеза соответствующего предложения на языке перевода. Система Natural Language Compiler (NLC) основана на технологии универсального языкового моделирования и получения языковых структур (система машинного перевода на основе языковых моделей), ее описание приведено в заявке на патент США No. 11/548,214, которая была подана 10 октября 2006 года, а также в заявках на патент США No. 11/690,099, 11/690,102 и 11/690,104, которые были поданы 22 марта 2007 года. В целом, чем более точно описана лексика языка, тем выше вероятность получения точного перевода.
[0002] Неоднозначность естественного языка, омонимия, наличие множества лексических вариантов и различающихся синтаксических моделей в процессе машинного перевода иногда приводят к довольно большому количеству возможных вариантов разбора и перевода исходного предложения. Обычно человек интуитивно легко справляется с этой проблемой, основываясь на своих знаниях о мире и знании контекста исходного предложения, однако решение этого вопроса может оказаться проблематичным для системы машинного перевода. Для достижения лучших результатов машинного перевода (максимального приближения к человеческому переводу) используется множество оценок связей, полученных на этапе обучения системы и необходимых NLC для анализа естественного языка. Применяются различные виды оценок, например, оценки лексических значений (частота и вероятность употребления) слов, оценки заполнителей поверхностных, глубинных позиций, оценки семантического описания и пр. От точности подобранных оценок зависит качество перевода, так как по сумме оценок на этапе анализа система делает выбор наилучшей синтаксической структуры исходного предложения. Общая синтаксическая структура предложения представляет собой структуру, которая описывает конструкцию предложения и указывает главные слова, зависимые слова и связи между ними.
[0003] В настоящее время этот подбор осуществляется вручную с использованием параллельного анализа размеченных текстовых корпусов. Размеченный вручную корпус представляет собой корпус, в котором каждому слову поставлен в соответствие набор грамматических значений, а каждому предложению - одна синтаксическая структура. Грамматическое значение - это элемент грамматической категории, то есть замкнутой системы, задающей разбиение обширной совокупности словоформ на непересекающиеся классы, различия между которыми существенно сказывается на грамматическом значении текста. Примерами грамматических категорий являются род, число, падеж, одушевленность, переходность и так далее.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0004] В настоящем описании приводятся способы, системы и машиночитаемые носители данных для автоматического обучения синтаксического и семантического анализатора с использованием генетического алгоритма. Один вариант осуществления относится к способу, который включает создание с помощью устройства обработки данных начальной популяции, содержащей вектор параметров для элементов синтаксических и семантических описаний исходного предложения. Этот способ дополнительно включает использование системы Natural Language Compiler (NLC) для перевода исходного предложения в итоговый перевод на основе синтаксических и семантических описаний исходного предложения. Этот способ дополнительно включает построение вектора оценок качества, в котором каждая оценка качества в векторе оценок качества имеет соответствующий параметр в векторе параметров. Этот способ дополнительно включает замену нескольких параметров в векторе параметров скорректированными параметрами, причем такая корректировка нескольких параметров включает следующее: случайный выбор первого параметра из вектора параметров и корректировку первого параметра для получения первого скорректированного параметра; вычисление оценки качества первого скорректированного параметра; сравнение оценки качества для первого скорректированного параметра с оценкой качества первого параметра и замену первого параметра первым скорректированным параметром, если оценка качества первого скорректированного параметра, лучше оценки качества первого параметра.
[0005] Другой вариант осуществления относится к системе, включающей устройство обработки данных. Это устройство обработки настроено на создание начальной популяции, содержащей вектор параметров для элементов синтаксических и семантических описаний исходного предложения. Это устройство обработки дополнительно настроено на возможность использования системы Natural Language Compiler (NLC) для перевода исходного предложения в итоговый перевод на основе синтаксических и семантических описаний исходного предложения. Это устройство обработки данных дополнительно настроено на получение вектора оценок качества, в котором каждая оценка качества в векторе оценок качества имеет соответствующий параметр в векторе параметров. Это устройство обработки данных дополнительно настроено на замену ряда параметров в векторе параметров скорректированными параметрами, причем для замены нескольких параметров схема обработки настроена на возможность случайным образом выбирать первый параметр из вектора параметров и скорректировать первый параметр для создания первого скорректированного параметра; вычислить оценку качества для первого скорректированного параметра; сравнить оценку качества для первого скорректированного параметр с оценкой качества для первого параметра, и заменить первый параметр первым скорректированным параметром, если оценка качества для первого скорректированного параметр лучше оценки качества для первого параметра.
[0006] Другой вариант осуществления относится к постоянному машиночитаемому носителю, на который записаны команды, причем эти команды содержат команды для создания начальной популяции, содержащей вектор параметров для элементов синтаксических и семантических описаний исходного предложения. Эти команды дополнительно содержат команды, используемые системой Natural Language Compiler (NLC) для перевода исходного предложения в итоговый перевод на основе синтаксических и семантических описаний исходного предложения. Эти команды дополнительно содержат команды для построения вектора оценок качества, в котором каждая оценка качества в векторе оценок качества имеет соответствующий параметр в векторе параметров. Эти команды дополнительно содержат команды для замены нескольких параметров в векторе параметров скорректированными параметрами, причем команды для замены нескольких параметров включают следующее: команды для случайного выбора первого параметра из вектора параметров и корректировки первого параметра для получения первого скорректированного параметра; команды для вычисления оценки качества для первого скорректированного параметра; команды для сравнения оценки качества первого скорректированного параметра, с оценкой качества для первого параметра, а также инструкции по замене первого параметра первым скорректированным параметром, если оценка качества для первого настроенного параметру лучше оценки качества для первого параметра.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Указанные выше и другие признаки настоящего изобретения будут более понятны из приведенного ниже описания и прилагаемой формулы изобретения, которые рассматриваются совместно с прилагаемыми чертежами. Указанные чертежи иллюстрируют только отдельные варианты осуществления данного изобретения в соответствии с его раскрытием. Поэтому возможности раскрытия изобретения не ограничиваются вариантами, представленными в чертежах. Чертежи прилагаются для более подробного и точного описания.
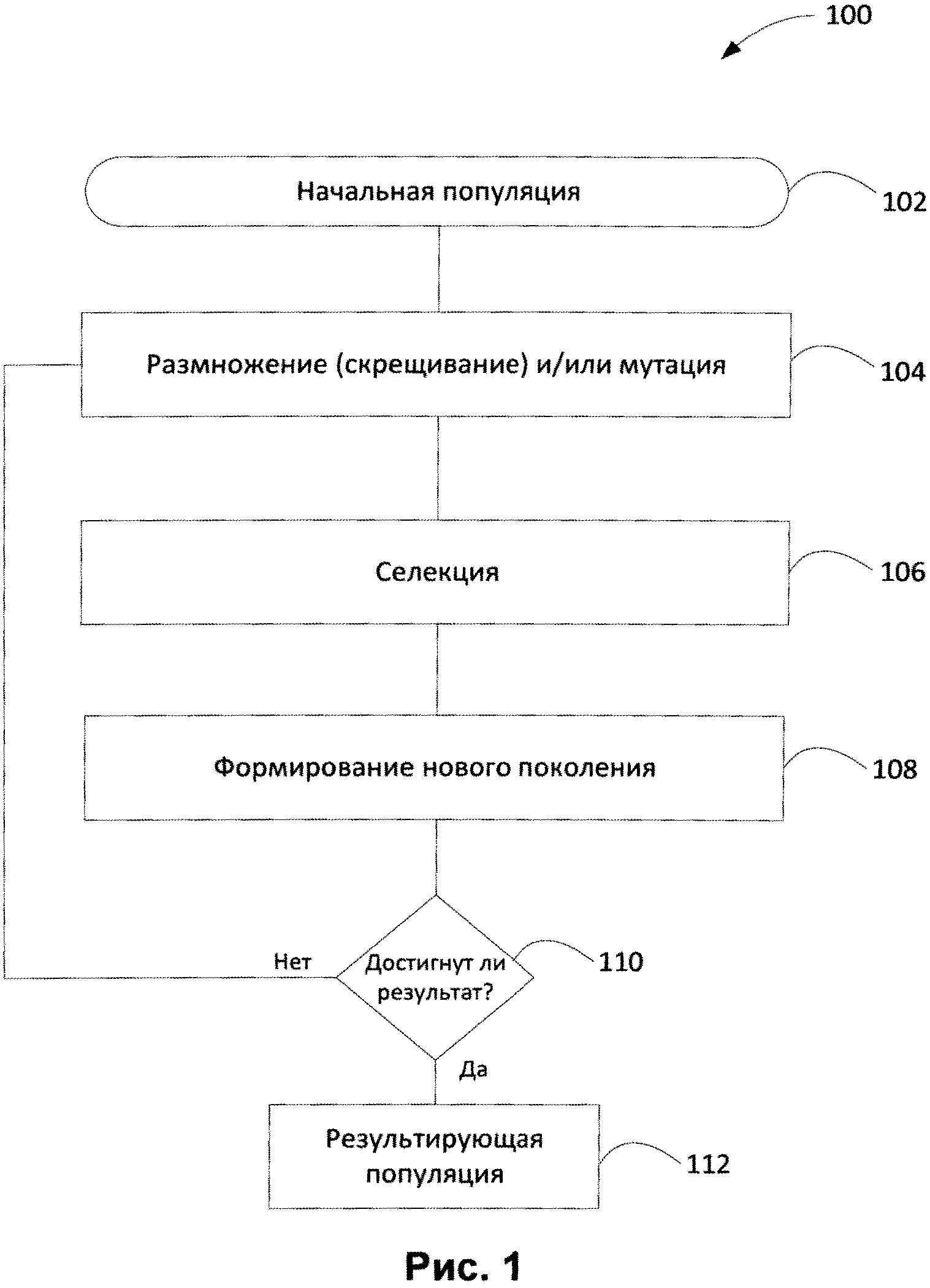
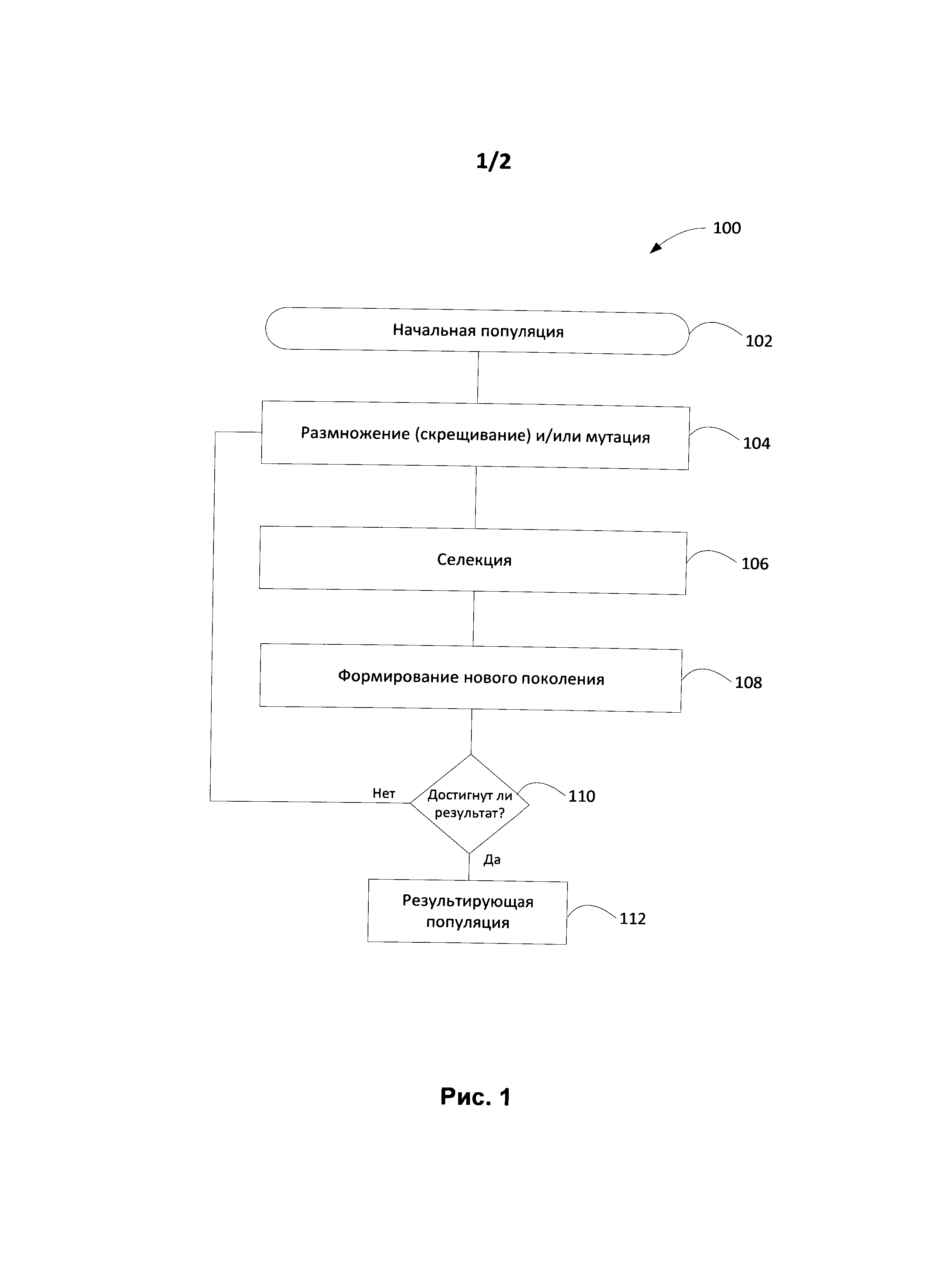
[0008] На Фиг. 1 показана блок-схема генетического алгоритма согласно одному из возможных вариантов реализации изобретения.
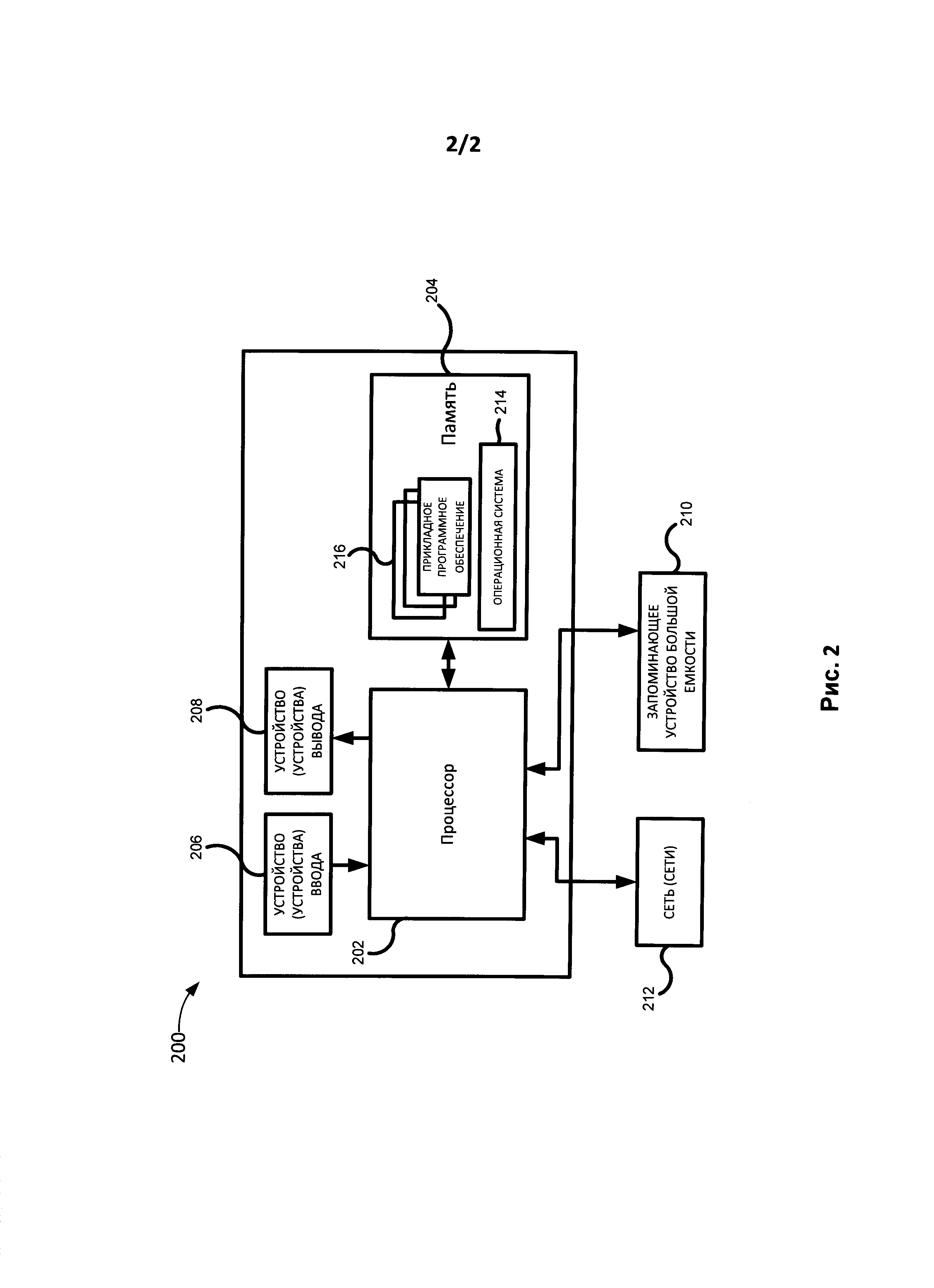
[0009] На Фиг. 2 показано вычислительное средство, которое можно использовать для реализации методов и способов, раскрытых в настоящем описании, в соответствии с одним из вариантов реализации изобретения.
[0010] На протяжении всего приведенного ниже подробного описания делаются ссылки на эти прилагаемые чертежи. На этих чертежах одинаковые символы обычно означают аналогичные компоненты, если контекст не требует иного. Иллюстрирующие варианты осуществления, приведенные в подробном описании, на чертежах и пунктах формулы изобретения, не являются единственно возможными. Возможны другие варианты осуществления изобретения, возможны и другие изменения, не затрагивающие его объект и сущность. Различные аспекты настоящего изобретения, приведенные в настоящем описании изобретения и проиллюстрированные чертежами, можно комбинировать, заменять, группировать и конструировать для получения широкого спектра различных вариантов применения, все они явно подразумеваются настоящим описанием изобретения и считаются его частью.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0011] Как правило, ручная разметка корпуса - это очень трудоемкий и дорогостоящий процесс, требующий колоссальной человеческой работы. Потому число таких корпусов и их объемы весьма ограничены и зачастую бывают недостаточными для набора необходимой статистики. Более того, оценки, соответствующие нужным статистикам, могут зависеть друг от друга, поэтому не получится улучшить качество перевода, последовательно подбирая значения этих оценок, из-за огромного числа вариантов разбора. Предлагаемые способы, системы и машиночитаемые носители дают возможность справиться с задачей подбора оценок (настроечных параметров) для различных элементов синтаксического/семантического описания автоматически с использованием генетического алгоритма.
[0012] Описание генетического алгоритма
[0013] В целом генетический алгоритм - это эвристический алгоритм поиска, применяемый для решения оптимизационных задач и моделирования путем случайного подбора, комбинирования и вариации параметров. Использование таких механизмов аналогично естественному отбору в природе. Задача формализуется таким образом, чтобы ее решение могло быть закодировано в виде вектора элементов, где каждый элемент может быть битом, числом или неким другим объектом. Некоторым, обычно случайным, образом создается множество элементов начальной популяции. Это множество элементов оценивается с использованием «функции приспособленности», в результате чего с каждым элементом ассоциируется определенное значение («приспособленность»), которое определяет, насколько хорошо данный элемент решает поставленную задачу.
[0014] Из полученного множества решений («поколения») с учетом значения «приспособленности» выбираются решения (обычно лучшие особи имеют большую вероятность быть выбранными), к которым применяются «генетические операторы» (в большинстве случаев «скрещивание» (crossover) и «мутация» (mutation)). Результатом этого является получение новых решений. Для каждого из новых решений также вычисляется значение приспособленности, и затем производится отбор («селекция») лучших решений в следующее поколение. Этот набор действий повторяется итеративно; так моделируется «эволюционный процесс», продолжающийся несколько жизненных циклов (поколений), пока не будет выполнен критерий остановки алгоритма. Например, таким критерием может быть следующее: нахождение глобального либо локального оптимального решения; исчерпание числа поколений, отпущенных на эволюцию, и исчерпание времени, отпущенного на эволюцию.
[0015] Таким образом, выделяются следующие основные этапы генетического алгоритма: задание целевой функции (приспособленности) для особей в популяции; создание начальной популяции и запуск итеративных циклов. Итеративные циклы могут включать в себя: размножение (скрещивание) и/или мутацию; вычисление значения целевой функции для всех особей, формирование нового поколения (селекция), а затем, если выполняется одно или несколько условий остановки, то окончание этого цикла (в противном случае, если условия остановки не выполняются, цикл может повторяться).
[0016] Перейдем к Фиг. 1, на которой приведена блок-схема последовательности этапов генетического алгоритма 100 в соответствии с одним из вариантов реализации изобретения. На шаге 102 с помощью случайного процесса создается начальная популяция. Даже если эта начальная популяция окажется совершенно неконкурентоспособной, то вполне вероятно, что генетический алгоритм все равно быстро переведет ее в жизнеспособную популяцию (с помощью селекции). Таким образом, на шаге 102 достаточно, чтобы элементы популяции можно было использовать для подсчета функции приспособленности (Fitness). Итогом шага 102 является популяция Н, состоящая из N особей.
[0017] Как правило, размножение или скрещивание (шаг 104) аналогичны половому размножению (т.е. чтобы произвести потомка, нужны несколько родителей, обычно два). Тем не менее, в некоторых вариантах осуществления размножение определяется по-разному, оно может зависеть от представления используемых данных. Главное требование к размножению заключается в том, чтобы потомок или потомки имели возможность унаследовать черты обоих родителей (например, «перемешав» их каким-либо способом и т.д.).
[0018] Для размножения особи обычно выбираются из всей популяции Н, а не из выживших на первом шаге элементов Н0. Дело в том, что генетический алгоритм довольно часто страдает от недостатка разнообразия в особях. Например, быстро выделяется один-единственный элемент популяции, который представляет собой локальный максимум, после чего все остальные элементы популяции проигрывают ему отбор. Таким образом, вся популяция «забивается» копиями этой особи, которая является локальным максимумом, что является нежелательным. Существуют различные способы противодействия этому эффекту. Например, для размножения можно выбирать всех особей, а не самых приспособленных, что приводит к более разнообразной популяции.
[0019] В зависимости от поставленной задачи этап размножения 104 может сопровождаться или заменяться этапом мутации. Доля мутантов (m) может являться параметром генетического алгоритма 100. На шаге мутации нужно выбрать mN особей, а затем скорректировать их в соответствии с заранее определенными операциями мутации.
[0020] На шаге селекции 106 нужно из всей популяции выбрать определенную ее долю, которая останется «в живых» на этом этапе эволюции. Есть разные способы проводить отбор, при этом вероятность выживания особи h должна зависеть от значения функции приспособленности Fitness (h). Сама доля выживших обычно является параметром генетического алгоритма, и ее задают заранее. По итогам отбора происходит формирование нового поколения Н' (шаг 108). Новое поколение Н' состоит из sN особей, а остальные не выбранные особи погибают. Если желаемый результат достигнут (например, если выполняется условие остановки на шаге 110), то полученная популяция 112 может считаться решением поставленной проблемы. Если желаемый результат является неудовлетворительным (шаг 110), то генетический алгоритм 100 может быть повторен с другим этапом размножения (скрещивания) и/или мутации 104 для получения нового поколения.
[0021] Как уже обсуждалось выше, один из вариантов реализации изобретения включает в себя способ автоматического вычисления оценок (оценочных параметров) различных элементов в синтактико-семантическом описании. Вычисление оценок происходит на этапе обучения системы. Для обучения используются неразмеченные параллельные корпуса (на исходном языке и целевом языке). Обычно каждый корпус состоит из не менее 100000 фрагментов, однако можно использовать корпуса другого объема. В параллельных корпусах каждому фрагменту из корпуса исходного языка соответствует фрагмент из корпуса целевого языка, который рассматривается в качестве эталонного перевода. В процессе обучения системы корпус исходного языка подвергается переводу с помощью системы NLC, как описано выше. Полученные переведенные фрагменты сравниваются с эталонными фрагментами, на основании чего делается вывод о качестве проделанной системой работы.
[0022] В общем случае генетический алгоритм (например, генетический алгоритм 100) используется для решения задач оптимизации. Таким образом, в одном из вариантов реализации изобретения генетический алгоритм 100 используется для решения задачи максимального повышения качества перевода. Таким образом, целевой функцией является оценка качества перевода. Генетический алгоритм подбирает множество оценок связей, используемое системой NLC на этапе синтаксического анализа для максимального повышения качества перевода по некоторому критерию. Уровень качества можно определить заранее, до запуска алгоритма. Подбор оценок происходит до тех пор, пока качество полученного перевода не достигнет заданного уровня.
[0023] Критерий качества перевода представляет совокупность двух параметров: оценки BLEU (Bilingual Evaluation Understudy) и количества аварийных предложений (аварийных состояний). Оценка BLEU - эта метрика, используемая для оценки качества машинного перевода, ее более подробное описание приведено ниже. Оценка BLEU принимает значения от 0 до 1, она показывает близость машинного перевода к эталонному переводу (например, переводу, сделанному человеком). Аварийные предложения - это предложения, разобранные в специальном аварийном режиме, который включается автоматически, если система NLC не может построить его корректное синтактико-семантическое описание.
[0024] Формально задачу максимального повышения качества можно записать следующим образом: 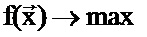 где
где 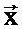 представляет собой вектор оценок или настроечных параметров,
представляет собой вектор оценок или настроечных параметров, 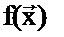 является функцией оценки качества, такой, что
является функцией оценки качества, такой, что 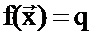 , а q является оценкой качества перевода, где q=q (bleu, Ecount), которая включает в себя две числовые характеристики: blue (оценку BLEU) и Ecount (число аварийных предложений). Функция представляет собой систему перевода NLC, запущенную с данным набором настроечных параметров на корпусе. Результаты перевода вычисляются с использованием оценки BLEU и числа аварийных предложений.
, а q является оценкой качества перевода, где q=q (bleu, Ecount), которая включает в себя две числовые характеристики: blue (оценку BLEU) и Ecount (число аварийных предложений). Функция представляет собой систему перевода NLC, запущенную с данным набором настроечных параметров на корпусе. Результаты перевода вычисляются с использованием оценки BLEU и числа аварийных предложений.
[0025] Возвратимся к Фиг. 1; в одном из вариантов реализации изобретения на шаге 102 генетического алгоритма 100 создается начальная популяция, которая в соответствии с настоящим изобретением является вектором наборов настоечных параметров 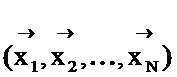 . Затем описанная выше система перевода NLC может быть запущена для каждого элемента популяции (например, для каждого набора настроечных параметров). После завершения перевода системой NLC итоговый перевод сравнивается с эталонным переводом, и можно вычислить оценку качества перевода на основе оценки BLEU и числа аварийных предложений. При этом получается вектор оценок качества перевода (q1, q2, …, qN) для каждого элемента популяции.
. Затем описанная выше система перевода NLC может быть запущена для каждого элемента популяции (например, для каждого набора настроечных параметров). После завершения перевода системой NLC итоговый перевод сравнивается с эталонным переводом, и можно вычислить оценку качества перевода на основе оценки BLEU и числа аварийных предложений. При этом получается вектор оценок качества перевода (q1, q2, …, qN) для каждого элемента популяции.
[0026] На шаге 104 алгоритма 100 производятся «мутации». Мутации можно реализовать путем случайного выбора нескольких элементов популяции (наборов настроечных параметров) и изменения по меньшей мере одного параметра в каждом из выбранных наборов. Затем вектор оценки качества 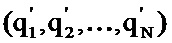 можно вычислить для набора с «мутировавшими» элементами
можно вычислить для набора с «мутировавшими» элементами 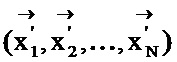 .
.
[0027] На шаге селекции 106 две оценки качества (т.е. оценки качества перевода и оценки качества мутация) сравниваются поэлементно, чтобы определить, какая из них лучше. Если 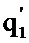 лучше q1, то
лучше q1, то 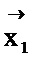 в векторе заменяется
в векторе заменяется 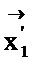 . В противном случае элемент популяции не заменяется «мутировавшим» элементом. При выполнении описанных выше замен формируется новое поколение (108), и алгоритм 100 можно снова применить к этому корпусу, начиная с этапа 104.
. В противном случае элемент популяции не заменяется «мутировавшим» элементом. При выполнении описанных выше замен формируется новое поколение (108), и алгоритм 100 можно снова применить к этому корпусу, начиная с этапа 104.
[0028] Как уже отмечалось выше, генетический алгоритм является итеративным алгоритмом. Так, в одном из вариантов реализации изобретения все три основных шага (например, шаги 104, 106 и 108) повторяются последовательно на каждой итерации. Этот алгоритм может быть остановлен при выполнении условия остановки. В одном из вариантов реализации изобретения могут использоваться следующие условия остановки алгоритма: 1) по меньшей мере один из элементов вектора оценки качества достиг необходимого уровня качества; и/или 2) популяция выродилась [т.е. после выполнения последнего шага 108 алгоритма сформированное поколение состоит из одинаковых элементов 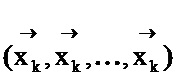 ].
].
[0029] Таким образом, когда будет достигнут заданный уровень качества перевода для одного из элементов популяции, при том что алгоритм не был остановлен (то есть, желаемый результат достигнут, на что указывает решение на этапе 110), полученная популяция 112 (т.е. набор настроечных параметров или оценок) обеспечивает наилучшую структуру с точки зрения синтаксических и семантиких описаний.
[0030] Дополнительное пояснение по оценке BLEU
[0031] Как уже упоминалось выше, оценка BLEU является хорошо известным инструментом, используемым для сравнения качества машинного перевода с переводом, выполненным человеком. Эта оценка определяет, насколько качественно был сделан машинный перевод с одного естественного языка на другой естественный язык. Уровень качества определяется на основе результатов сравнения переводов, выполненных машиной и человеком (например, чем ближе они друг к другу, тем выше качество машинного перевода). Оценка BLEU может вычисляться с помощью метрики, характеризующей точность перевода по n-граммам (т.е. последовательностей из n слов) в предложении. Данную метрику можно определять следующим образом: в машинном переводе предложения выделяют все n-граммы. Затем эти n-граммы ищут в нескольких вариантах человеческого перевода. Максимальное число повторений n-граммы в одном из вариантов перевода обозначаются mmax. Если количество повторений этой n-граммы в машинном переводе mw превышает mmax, то mw уменьшают до mmax, (в противном случае mw остается без изменения). Аналогичным образом поступают с остальными n-граммами. После обработки n-грамм описанным выше способом суммируются количество повторений mw для всех n-грамм, и полученную сумму делят на общее количество n-грамм в машинном переводе. Этот вариант вычисления оценки BLEU учитывает адекватность перевода и частоту употребления тех или иных словосочетаний (fluency).
[0032] Для вычисления метрики в тестовом корпусе используют аналогичный подход, так как значимой единицей корпуса является предложение. Обычно существует несколько вариантов перевода исходного предложения, как возможны и различные лексические варианты, что может приводить к искажению смысла и терминологии в различных частях одного и того же текста. Поэтому производится выделение n-грамм, совпадающих от предложения к предложению. Затем производится суммирование значений mw (после описанной выше процедуры урезания) для всех n-грамм в корпусе и деление данной суммы на общее число n-грамм в тестовом корпусе. Затем может быть вычислена оценка точности перевода рn:
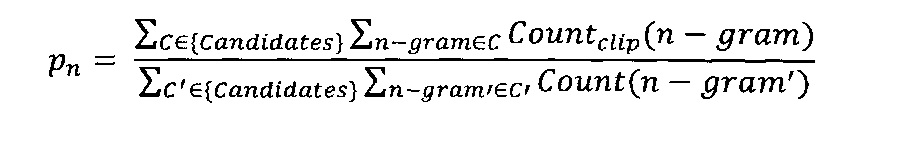
[0033] С учетом того, что точность перевода экспоненциально падает с ростом длины n-грамм, вычисление оценка BLEU необходимо проводить как 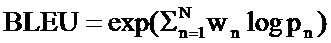 , где wn - это постоянные веса (Σnwn=1). Соответственно, для учета длины машинного перевода вводится метрика, названная штрафом за краткость (brevity penalty). Эта метрика определяется как:
, где wn - это постоянные веса (Σnwn=1). Соответственно, для учета длины машинного перевода вводится метрика, названная штрафом за краткость (brevity penalty). Эта метрика определяется как:
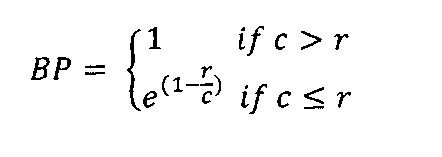
[0034] где с - это длина машинного перевода, а r является эффективной длиной корпуса человеческого перевода. В этом случае итоговая оценка BLEU имеет следующий вид:
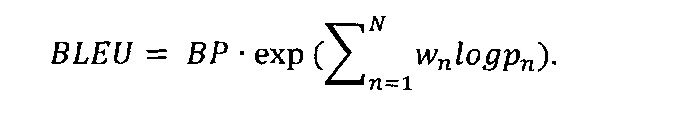
[0035] Или для удобства вычисления:
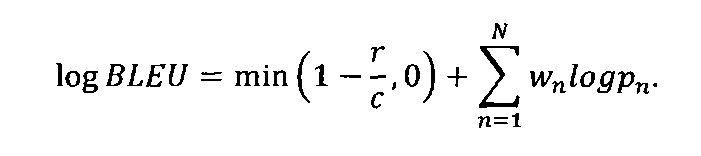
[0036] Значения оценки BLEU лежат в диапазоне от 0 до 1, причем машинный перевод получает оценку 1, если он идентичен переводу, выполненному человеком. В некоторых вариантах осуществления эта оценка учитывает одновременно и длину предложения, выбор слов и порядок слов. Преимущество вычисления оценки BLEU таким способом заключается в том, что эта оценка сильно коррелирует с оценкой качества перевода, сделанного вручную.
[0037] Дополнительные пояснения по аварийным предложениям
[0038] Как уже отмечалось выше, аварийное предложение - это предложение, разбираемое в специальном аварийном режиме, который может включаться автоматически при обнаружении ошибки. Например, может произойти ошибка, когда система NLC анализирует исходное предложение или синтезирует перевод исходного предложения на целевом языке. Такие ошибки могут включать следующие ошибки, но не ограничиваться ими:
1) Наличие синтаксической ошибки, в том числе несогласованность слов в предложении, например, «You was't haрpy.» (Вы не был счастлив.); пропуск предлога, например, «Не went _the house and shut the door.» (Он вошел_дом и закрыл дверь.) или употребление лишнего предлога;
2) Отсутствие запятой после слова, если описание этого слова в соответствующей семантической иерархии требует обязательной ее постановки;
3) Отсутствие описания (например, при отсутствии соответствующей лексемы в словаре) или если слово содержит редкую конструкцию;
4) Слишком длинное предложение (например, предложение, которое является слишком длинным по количеству слов, может инициировать аварийный режим).
[0039] Также возможны и другие ошибки. Если программа сталкивается с такими трудностями, то она может перейти в аварийный режим, в котором выбирается приемлемый вариант разбора.
[0040] Одним из преимуществ, описанных в настоящем документе, вариантов осуществления является использование неразмеченных текстовых корпусов вместо корпусов с ручной разметкой. Это позволяет избежать применения квалифицированного, но дорогостоящего человеческого труда и существенно сократить затраты на разработку. Кроме того, автоматическое вычисление основанных на функциях оценок различных элементов синтаксико-семантического описания повышает качество результатов выполненных системой переводов и ускоряет весь процесс обработки.
[0041] На Фиг. 2 приведен пример вычислительного средства (200), которое может быть использовано для внедрения методов и способов, описанных в настоящем документе. На Фиг. 2 показано вычислительное средство 200, которое может использоваться для внедрения методов и способов, описанных в настоящем документе. В качестве процессора (202) можно использовать любой серийный цифровой процессор (ЦП). Под «процессором» (202) подразумевается один или несколько процессоров, которые могут использоваться в виде процессора общего назначения, специализированной интегральной схемы (ASIC), одной или нескольких программируемых вентильных матриц (FPGA), цифрового сигнального процессора (DSP), группы обрабатывающих компонентов или иных подходящих электронных компонентов для обработки данных. Память 204 может включать оперативное запоминающее устройство (RAM) устройства, включающие основную память вычислительного средства 200, а также любые дополнительные уровни памяти, например, кэш-память, энергонезависимую или резервную память (например, программируемую или флэш-память), постоянные запоминающие устройства и т.д. Кроме того, память 204 может включать память, физически расположенную в другом месте в вычислительном средстве 200, например, любую кэш-память в процессоре 202, а также любую емкость запоминающего устройства, используемую в качестве виртуальной памяти, например, при хранении в запоминающем устройстве большой емкости 210. В памяти (204) могут храниться (отдельно или во взаимодействии с запоминающим устройством (210)) компоненты базы данных, компоненты объектного кода, компоненты сценария или иные типы структур данных для поддержки различных действий и информационных структур, описанных в настоящем документе. Память (204) или запоминающее устройство (210) могут передавать компьютерный код или команды в процессор (202) для выполнения процессов, описанных в настоящем документе.
[0042] Вычислительное средство (200) обычно имеет несколько входов и выходов для обмена информацией с другими устройствами и системами. В качестве интерфейса пользователя в вычислительном средстве (200) может применяться одно или несколько устройств ввода (206) (например, клавиатура, мышь, сенсорная панель, формирователь изображения, сканер и пр.), а также одно или несколько устройств вывода (208) (например, панель с жидкокристаллическим дисплеем и устройство для воспроизведения звука (динамик)). В качестве дополнительной памяти вычислительное средство 200 может также включать одно или несколько устройств памяти большой емкости 210, например, накопитель на дискете или на другом съемном диске, на жестком диске, запоминающее устройство с прямым доступом (DASD), оптический привод (например, с диском формата компакт-диск (CD), с диском формата «цифровой универсальный диск» (DVD) и т.д.) и/или накопитель на магнитной ленте и др. Вычислительное средство (200) может также включать интерфейс с одной или несколькими сетями (212), например, с локальной сетью, глобальной сетью (WAN), беспроводной сетью и/или сетью Интернет и т.д. для обеспечения обмена информацией с другими компьютерами, подключенными к этим сетям. Необходимо учесть, что вычислительное средство (200) обычно имеет различные аналоговые и цифровые интерфейсы между процессором (202) и каждым из компонентов (204, 206, 208 и 212), что хорошо известно специалистам.
[0043] Вычислительное средство (200) может работать под управлением операционной системы (214), на нем можно запускать различные программные приложения (216), включая компоненты, программы, объекты, модули и т.д. для осуществления описанных выше процессов. Например, программные приложения для компьютера могут включать приложение системы NCL, приложение с генетическим алгоритмом, и приложение для получения оценки BLEU. Все описанные выше приложения могут быть частью единого приложения или являться отдельными приложениями, подключаемыми модулями и т.д. Приложения (216) также могут запускаться на одном или нескольких процессорах других компьютеров, соединенных с вычислительным средством (200) по сети (212), например, в распределенной вычислительной среде, где обработка, необходимая для реализации функций компьютерной программы, может распределяться по сети между несколькими компьютерами.
[0044] Все подпрограммы, выполняемые для реализации вариантов осуществления, могут выполняться частью операционной системы или специальным приложением, компонентой, программой, объектом, модулем или последовательностью команд, обобщенно именуемыми «компьютерными программами». Как правило, компьютерные программы представляют собой ряд команд, записанных в разное время в разных устройствах хранения данных в компьютере; после прочтения и выполнения команд одним или несколькими процессорами в компьютере они заставляют этот компьютер выполнять операции, требуемые для выполнения элементов описанных вариантов осуществления. Различные варианты осуществления были описаны в контексте полностью работоспособных компьютеров и компьютерных систем. Специалисты в этой отрасли оценят возможности различных вариантов осуществления для распространения в виде различных программных продуктов в разных формах, они равно применимы независимо от конкретного типа машиночитаемого носителя, используемого для фактического распространения. Примеры таких машиночитаемых носителей включают такие записываемые типы носителей, как энергозависимые и энергонезависимые устройства памяти, дискеты и другие съемные диски, накопители на жестких дисках, оптические диски (например, CD-ROM, DVD, флэш-накопители) и многие другие, но не ограничиваются ими. Различные варианты осуществления также могут распространяться в виде загружаемых через Интернет или сеть программных продуктов.
[0045] В приведенном выше описании многие подробности даны в целях пояснения. Однако специалистам в данной области техники будет очевидно, что эти конкретные детали являются просто примерами. В других случаях структуры и устройства показаны в форме блок-схемы для облегчения изложения.
[0046] Упоминание в настоящем описании «одного из вариантов реализации» или «варианта реализации» подразумевает, что определенный признак, структура или характеристика, описанная в связи с этим осуществлением, включена по меньшей мере в один из вариантов реализации. Выражение «в одном из вариантов реализации» в разных частях описания не обязательно относится к одному и тому же варианту реализации, а различные и альтернативные варианты реализации не являются взаимоисключающими и не исключают других вариантов реализации. Более того, различные описанные здесь признаки могут относиться к одним вариантам осуществления, но не относиться к другим вариантам осуществления. Подобным образом некоторые описанные здесь требования могут относиться к одним вариантам осуществления, но не относиться к другим вариантам осуществления.
[0047] Примеры некоторых вариантов осуществления описаны и проиллюстрированы на прилагаемых чертежах. Однако необходимо помнить, что эти варианты осуществления приводятся исключительно в иллюстративных целях, что они не ограничиваются описанными вариантами осуществления, а также то, что последние не привязаны конкретно к описанным модификациям и вариантам, и что специалисты могут создавать другие модификации на основе информации этого раскрытия изобретения. В столь быстро развивающейся области технологии многие улучшения сложно предусмотреть заранее. Поэтому описанные варианты осуществления могут видоизменяться по компоновке или деталями и облегчаться технологическими достижениями, что, однако, не будет означать отступления от сути настоящего раскрытия изобретения.
Фильтрация дуг в синтаксическом графе
Многоэтапное распознавание именованных сущностей в текстах на естественном языке на основе морфологических и семантических признаков
Извлечение сущностей из текстов на естественном языке
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Способ извлечения фактов из текстов на естественном языке
Метод и система для генерации статей в словаре естественного языка
Система для создания документов на основе анализа текста на естественном языке
Определение степеней уверенности, связанных со значениями атрибутов информационных объектов
Сентиментный анализ на уровне аспектов и создание отчетов с использованием методов машинного обучения
Фильтрация дуг в синтаксическом графе
Многоэтапное распознавание именованных сущностей в текстах на естественном языке на основе морфологических и семантических признаков
Извлечение сущностей из текстов на естественном языке
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Способ извлечения фактов из текстов на естественном языке
Метод и система для генерации статей в словаре естественного языка
Система для создания документов на основе анализа текста на естественном языке
Определение степеней уверенности, связанных со значениями атрибутов информационных объектов
Сентиментный анализ на уровне аспектов и создание отчетов с использованием методов машинного обучения

