Результат интеллектуальной деятельности: РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА
Вид РИД
Изобретение
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Настоящее изобретение относится к технологиям информационного поиска, в частности, реализация данного изобретения имеет отношение к поиску электронного контента, например, в интернете и других электронных ресурсах, таких как текстовые корпуса, словари, глоссарии, энциклопедии и способам представления результатов поиска.
УРОВЕНЬ ТЕХНИКИ
[0002] Широко известны поисковые технологии, которые позволяют осуществлять поиск, основываясь на ключевых словах, вводимых пользователем в составе поискового запроса.
[0003] Однако, из-за омонимии и омографии, имеющейся в естественных языках, результат поиска, основанный на поиске по ключевым словам, может включать значительное количество нерелевантной и малорелевантной информации. Например, если пользователь ищет тексты, содержащие слово "page" в смысле "паж" (придворная должность), он получит множество нерелевантной информации, где "page" относится к интернет-страницам, страницам газет, журналов, страницам устройств памяти и т.д. Это происходит потому, что эти значения гораздо более частотны, чем "page" в лексическом значении "паж". Аналогично в русском языке по ключевому слову "стекло" можно получить все тексты, содержащие глагол "течь" во всевозможных словоформах.
[0004] Существующие системы позволяют использовать простые языки запросов для поиска документов, которые содержат, или не содержат слова или слово, указанные пользователем. Однако пользователь не имеет возможности указать, должны ли эти слова находиться в одном предложении или нет. Также, пользователь не может формулировать свой запрос сразу для некоторого множества слов, принадлежащих некоторому классу или обладающих некоторыми свойствами или характеристиками. Как правило, эти системы не позволяют формулировать запрос в виде обычного вопроса на естественном языке.
[0005] Для уточнения искомого значения часто приходится добавлять в запрос дополнительные слова. Кроме того, иногда сам пользователь не может определить, какое из значений слова его на самом деле интересует. Например, если он ищет варианты словоупотребления неизвестного ему слова на иностранном языке. Большой и несистематизированный объем выдачи позволяет увидеть все варианты значений искомого слова или словосочетания.
[0006] Другой проблемой является то, что одна и та же информация может быть представлена как в разных документах, так и в одном и том же документе при помощи разных слов и выражений, при этом могут использоваться синонимы и перефразировки (paraphases).
[0007] Данное изобретение является развитием решений, изложенных ранее в Патентных заявках США №13/173,649 и 13/173,369, поданных 30 июня 2011, и №12/983,220, поданной 31 декабря 2010, а также патентной заявки США №14/142,701, поданной 27 декабря 2013. Данное изобретение также частично использует технологию анализа, запатентованную в США (Патент №8,078,450).
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
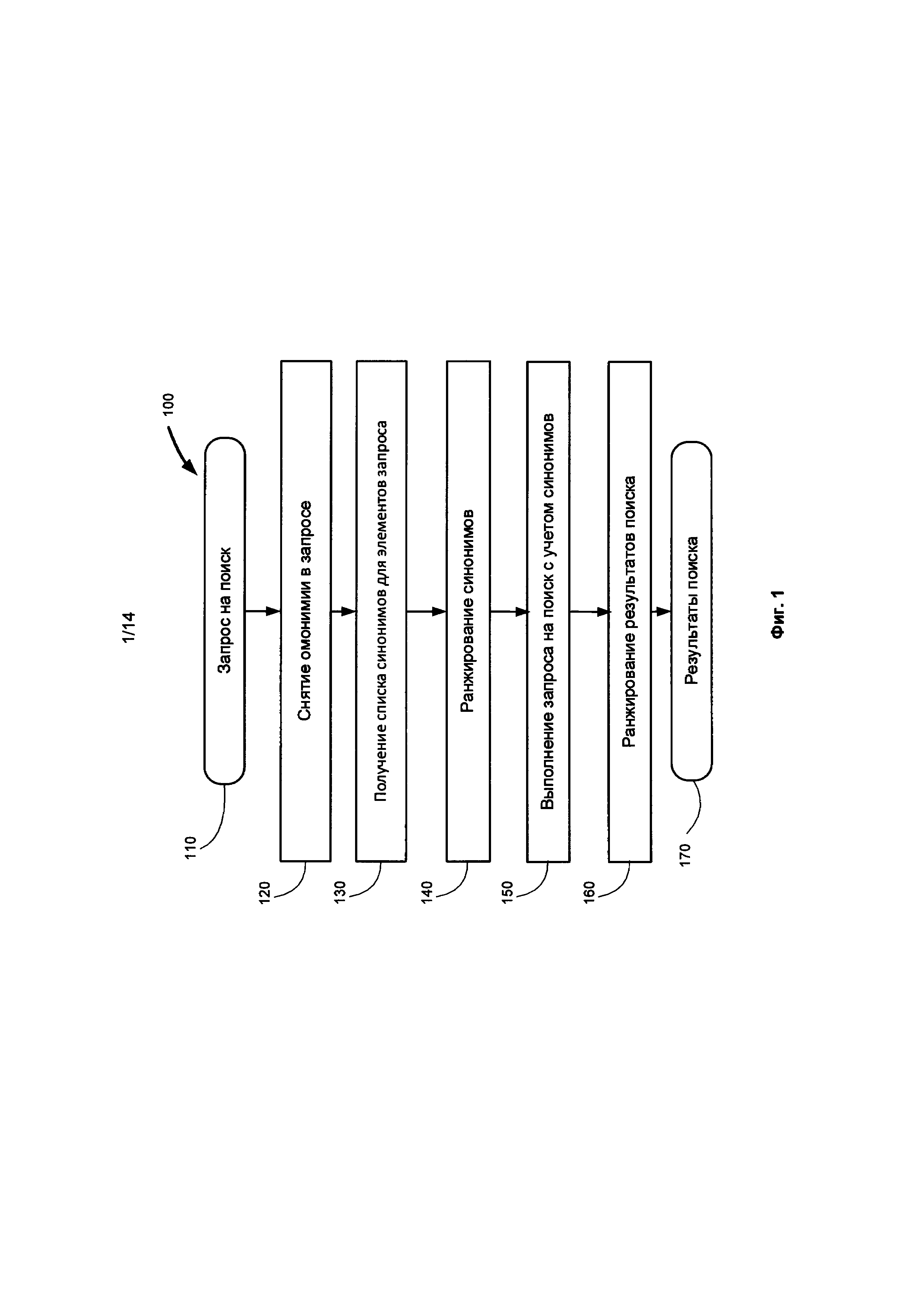
[0008] Настоящее изобретение представляет собой способ и систему организации информационного поиска в корпусах электронных текстов для компьютерной системы и показа результатов поиска в интерфейсе пользователя, метод, заключающийся в том, что, по меньшей мере, один раз производят следующую последовательность действий: получение запроса на поиск, включающего одну или несколько групп слов; снятие омонимии, т.е. для каждого слова запроса однозначно выбирается одно лексическое значение либо формируется список лексических значений с соответствующими весами. Лексическое значение является реализацией в конкретном языке некоторых семантических значений. Для того, чтобы получить наиболее полную информацию по заданному запросу, каждое лексическое значение запроса может быть "расширено" добавлением списка его синонимов. Однако синонимы могут быть не вполне эквивалентными, поэтому каждый синоним получает некоторую оценку (вес), и список ранжируется, так что каждый список упорядочивается по убыванию оценки. Выполняется поиск. Поиск производится таким образом, что запрашиваются не только слова или лексические значения, присутствующие в запрос, но и синонимы из полученного списка. В соответствии с оценкой (весом) синонима, найденный результат также получает некоторую оценку, которая непосредственно зависит от оценки (веса) синонима. Результаты поиска ранжируются в соответствии с полученными оценками.
[0009] Дополнительно, данный способ может быть применен не только к отдельным словам, но и к группам слов. Такие эквивалентные или частично эквивалентные речевые обороты будем называть перефразировками. Указанный способ также включает поиск фрагментов в корпусах электронных текстов, удовлетворяющих запросу, и показ пользователю результатов поиска. В некоторых реализациях список лексических значений для групп слов, образующих запрос, может формироваться на основе запроса к семантической иерархии и фильтроваться на основе семантико-синтаксического анализа запроса, чтобы исключить те лексические значения, сочетания которых невозможны.
[0010] В одной реализации выполняется полнотекстовый поиск, т.е. поиск на произвольных проиндексированных корпусах с последующим анализом найденных фрагментов фильтрации поисковой выдачи по возможным лексическим значениям поискового запроса.
[0011] В других реализациях может проводиться семантический поиск на предварительно обработанных по методу глубинного семантико-синтаксического анализа и проиндексированных корпусах текстов для поиска конкретных лексических значений.
[0012] Осуществление настоящего изобретения позволяет пользователю искать и находить наиболее полную и релевантную информацию и получать результаты поиска в ранжированном по релевантности виде. В случае, если запрос формулируется в виде вопроса на естественном языке, анализатор используется для анализа запроса, для распознавания его синтаксической структуры и построения семантической структуры и, таким образом, и "понимания" системой смысла запроса. Таким образом, пользователь может получить только релевантные результаты запроса. Техническим результатом, на достижение которого направлено заявленное изобретение, является повышение эффективности информационного поиска за счет получения результатов поиска, имеющих повышенную степень релевантности, с высокой скоростью.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
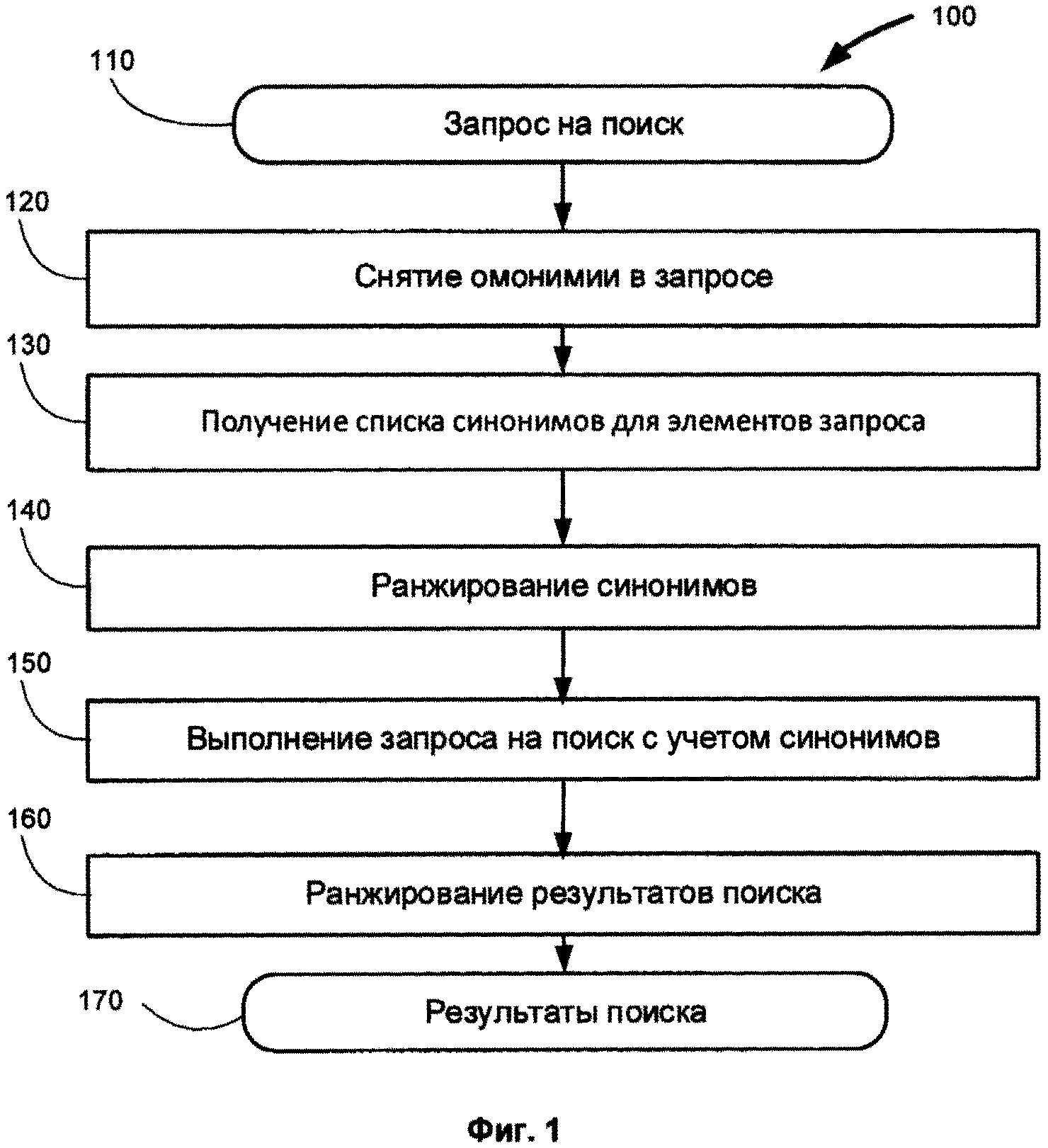
[0013] Фиг. 1 иллюстрирует общую схему одной из реализаций данного изобретения.
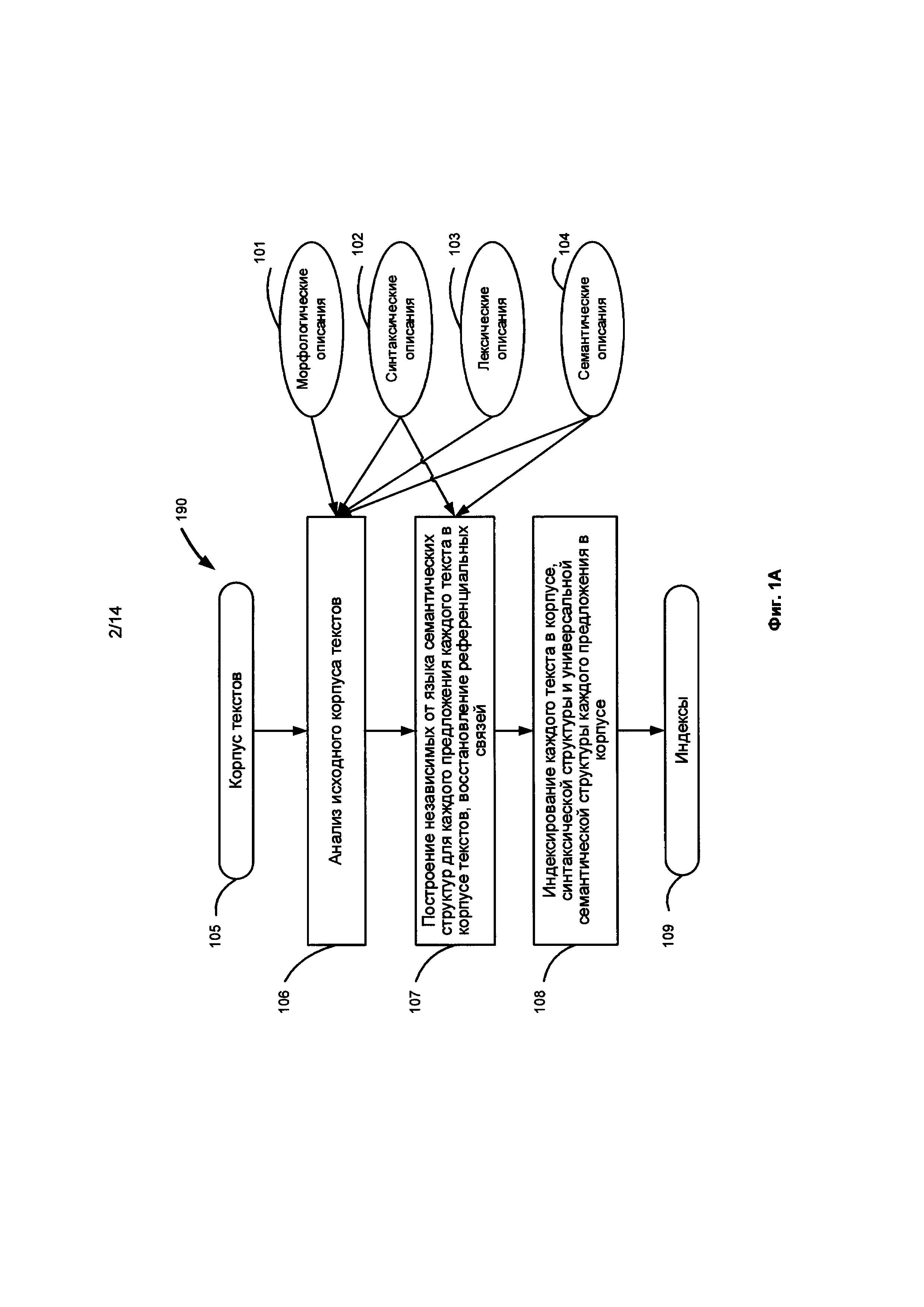
[0014] Фиг. 1А иллюстрирует общую схему метода глубинного анализа корпуса текстов и построения индексов согласно одной из реализаций данного изобретения.
[0015] Фиг. 2 иллюстрирует последовательность структур, строящихся в процессе анализа предложения согласно одной или нескольким реализациям изобретения.
[0016] Фиг. 3 иллюстрирует пример синтаксического дерева, полученного в результате точного синтаксического анализа предложения.
[0017] Фиг. 4 иллюстрирует схему семантической структуры, полученной в результате анализа предложения.
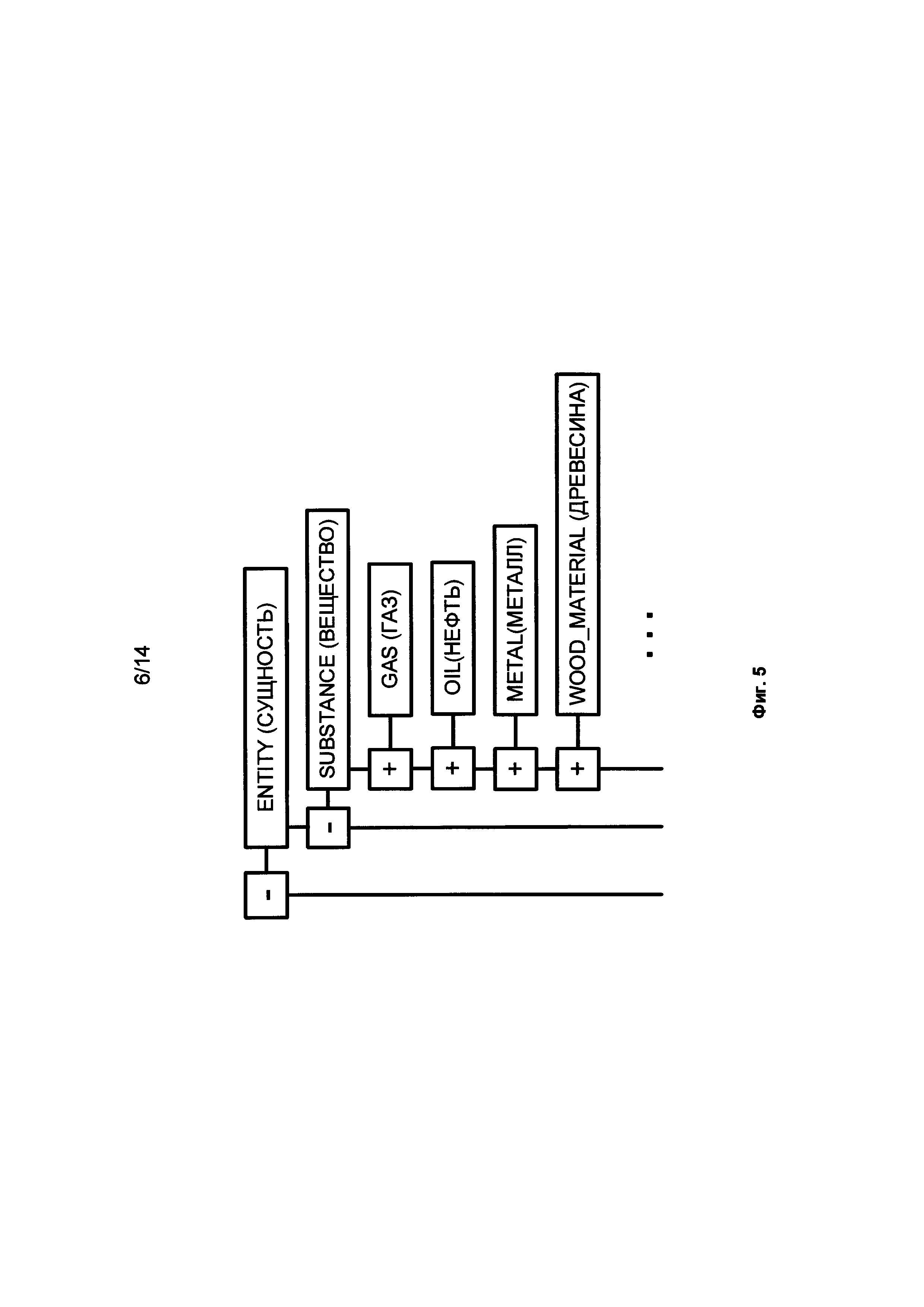
[0018] Фиг. 5 иллюстрирует фрагмент семантической иерархии, согласно одной или нескольким реализациям данного изобретения.
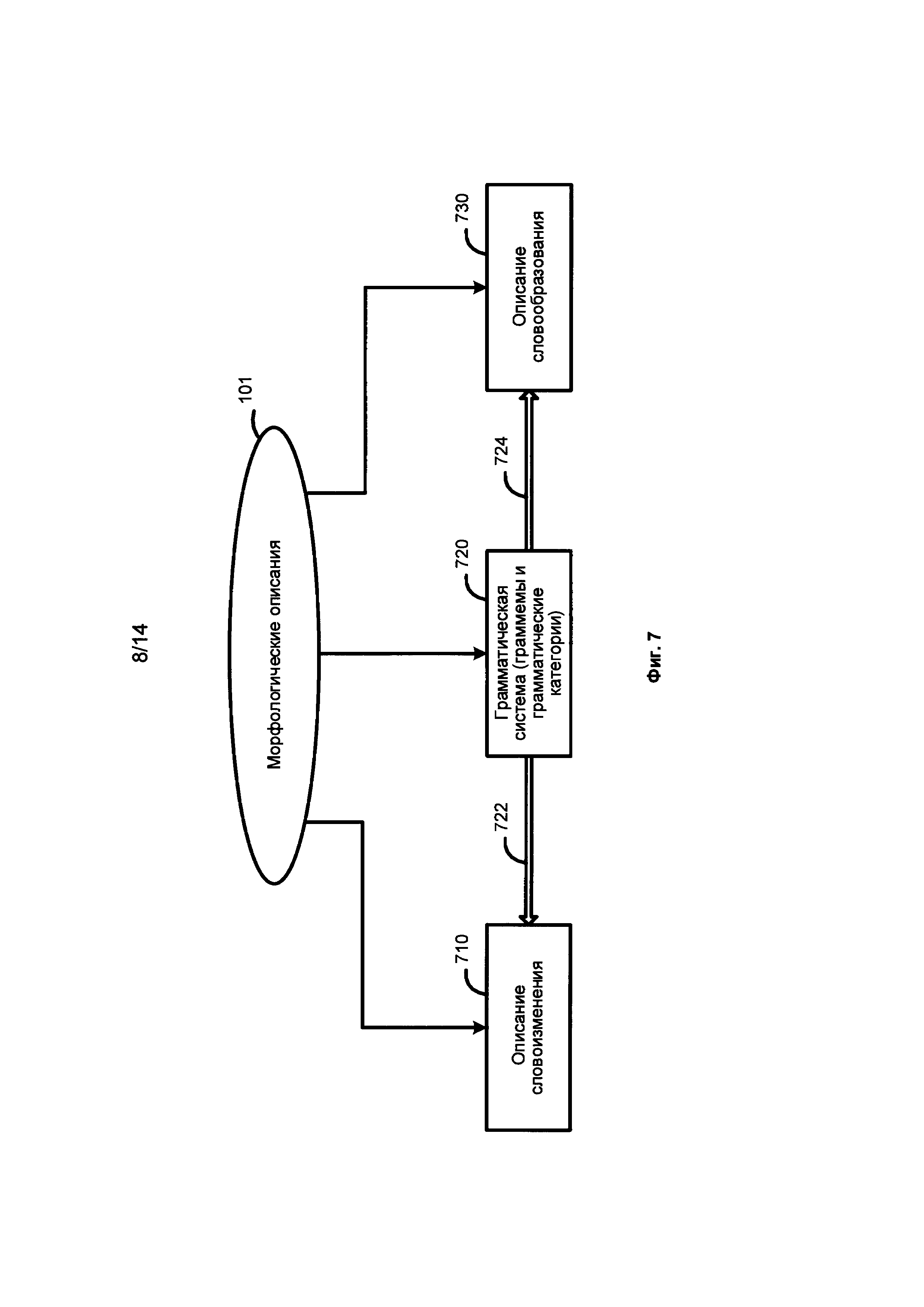
[0019] Фиг. 6 представляет собой схему, иллюстрирующую языковые описания 610, согласно одной из возможных реализаций изобретения.
[0020] Фиг. 7 представляет собой схему, иллюстрирующую морфологические описания, согласно одной из возможных реализаций изобретения.
[0021] Фиг. 8 иллюстрирует синтаксические описания, согласно одной из возможных реализаций изобретения.
[0022] Фиг. 9 иллюстрирует семантические описания, согласно одной из возможных реализаций изобретения.
[0023] Фиг. 10 является схемой, иллюстрирующей лексические описания, согласно одной или нескольким реализациям данного изобретения.
[0024] На Фиг. 11А-В представлены примеры запросов и полученных результатов поиска.
[0025] Фиг. 12 иллюстрирует пример схемы аппаратного обеспечения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0026] Реализация данного изобретения раскрывает способ расширенного информационного поиска в текстах на естественном языке и способы показа результатов поиска.
[0027] Среди методов информационного поиска различают полнотекстовый поиск и семантический поиск. Полнотекстовый поиск может выполняться на произвольных корпусах, имеющих обычный полнотекстовый (прямой или обратный) индекс. Для такого поиска не требуется длительная предобработка, индекс достаточно компактен, ресурсы для него практически не ограничены. По такой схеме работают известные поисковые системы - Google, Yahoo, Yandex и др. Недостатком является большой объем получаемой в некоторых случаях нерелевантной информации. Семантический поиск предполагает предварительную обработку корпуса текстов, на которых производится поиск, как правило, с разметкой, например, по частям речи, сущностям, классам и т.п. Это влечет сложность построения индекса, значительное увеличение его объема и, как следствие, снижение скорости поиска. Однако, достоинством является высокая точность поиска, релевантность получаемых результатов.
[0028] В Патенте США U.S. Patent 8,078,450 описан метод, включающий глубинный синтаксический и семантический анализ текстов на естественном языке, основанный на исчерпывающих лингвистических моделях. Метод использует широкий спектр лингвистических описаний, как универсальных семантических механизмов, так относящихся к конкретному языку, что позволяет отразить все реальные сложности языка без упрощения и искусственных ограничений, не опасаясь при этом неуправляемого роста сложности. Этот метод используется как для снятия омонимии в запросе на поиск, так и для построения семантического индекса, а созданные для него лингвистические описания применяются как для получения множества альтернативных способов формулирования запроса, так и для оценки степени релевантности найденных результатов.
[0029] С некоторыми модификациями метод применим и для полнотекстового, и для семантического поиска, поэтому опишем общую схему, указывая, что необходимо сделать дополнительно для того или другого типа поиска.
[0030] Фиг. 1 иллюстрирует общую схему метода 100 организации информационного поиска в корпусах текстов согласно одной из реализаций данного изобретения. Тексты, на которых будет производиться поиск, предварительно должны быть проиндексированы (не показано на Фиг. 1), это означает, что для каждого корпуса или текста строится один или более индексов. Для полнотекстового поиска это может быть обычный - прямой или обратный индекс. Для семантического поиска корпус подвергается глубинному семантико-синтаксическому анализу по методу U.S. Patent 8,078,450 и индексируются параметры текста, существенные для семантического поиска.
[0031] Последовательность операций, выполняемых на предварительном этапе, включающем семантико-синтаксический анализ, для последующего использования текстов в семантическом поиске проиллюстрирована на Фиг. 1А. Глубинный семантико-синтаксический анализ 190 включает лексико-морфологический, синтаксический и семантический анализ каждого предложения корпуса текстов, в результате которых строятся независимые от языка семантические структуры (language-independent semantic structures), в которых каждому слову текста сопоставлен соответствующий семантический класс. Это одновременно означает снятие омонимии (disambiguation), т.е. теперь для каждого слова в каждом предложении фиксируется, в каком именно лексическом значении в данном контексте используется данное слово языка.
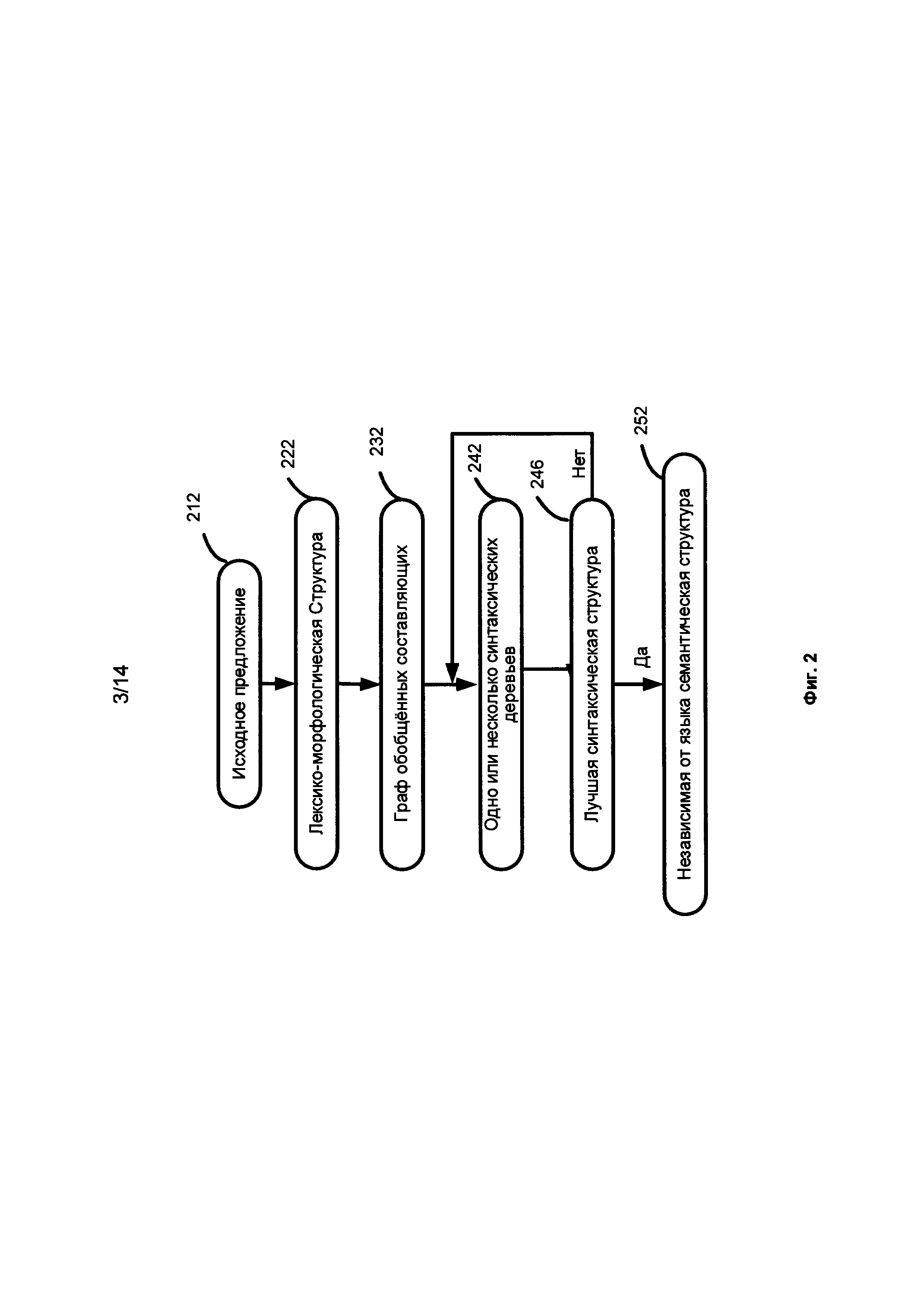
[0032] Глубинный семантико-синтаксический анализ 106 производится над каждым предложением каждого корпуса текстов 105 с использованием лингвистических описаний, как исходного языка, так и универсальных семантических описаний, что позволяет анализировать не только поверхностную синтаксическую структуру, но и глубинную, семантическую, выражающую смысл высказывания, содержащегося в каждом предложении, а также связи между предложениями или фрагментами текста. Лингвистические описания могут включать лексические описания 101, морфологические описания 102, синтаксические описания 103 и семантические описания 104. Анализ 106 включает синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа), использующий лингвистические модели и информацию различных уровней для вычисления вероятностей и генерации наиболее вероятной («лучшей») синтаксической структуры. Фиг. 2 иллюстрирует последовательность структур, строящихся в процессе анализа предложения согласно одной или нескольким реализациям изобретения. Затем строится независимая от языка семантическая структура (language-independent semantic structure) 252, которая представляет смысл исходного предложения.
[0033] Затем исходное предложение, синтаксическая структура исходного предложения и независимая от языка семантическая структура и другие параметры, извлеченные в процессе анализа, индексируются 108. Результатом является семантический индекс, представляющий собой набор коллекций индексов 109. Индекс в самом простом варианте реализации может быть представлен в виде таблицы, где каждому значению текстовой характеристики (например, слову, выражению или фразе, отношению между элементами предложения, морфологическое, лексическое, синтаксическое или семантическое свойство, а также и синтаксические и семантические структуры) в документе сопоставлен список адресов их вхождений в этот документ. Морфологические, синтаксические, лексические и семантические характеристики, а также структуры и фрагменты структур могут индексироваться тем же способом, как индексируются слова в документе.
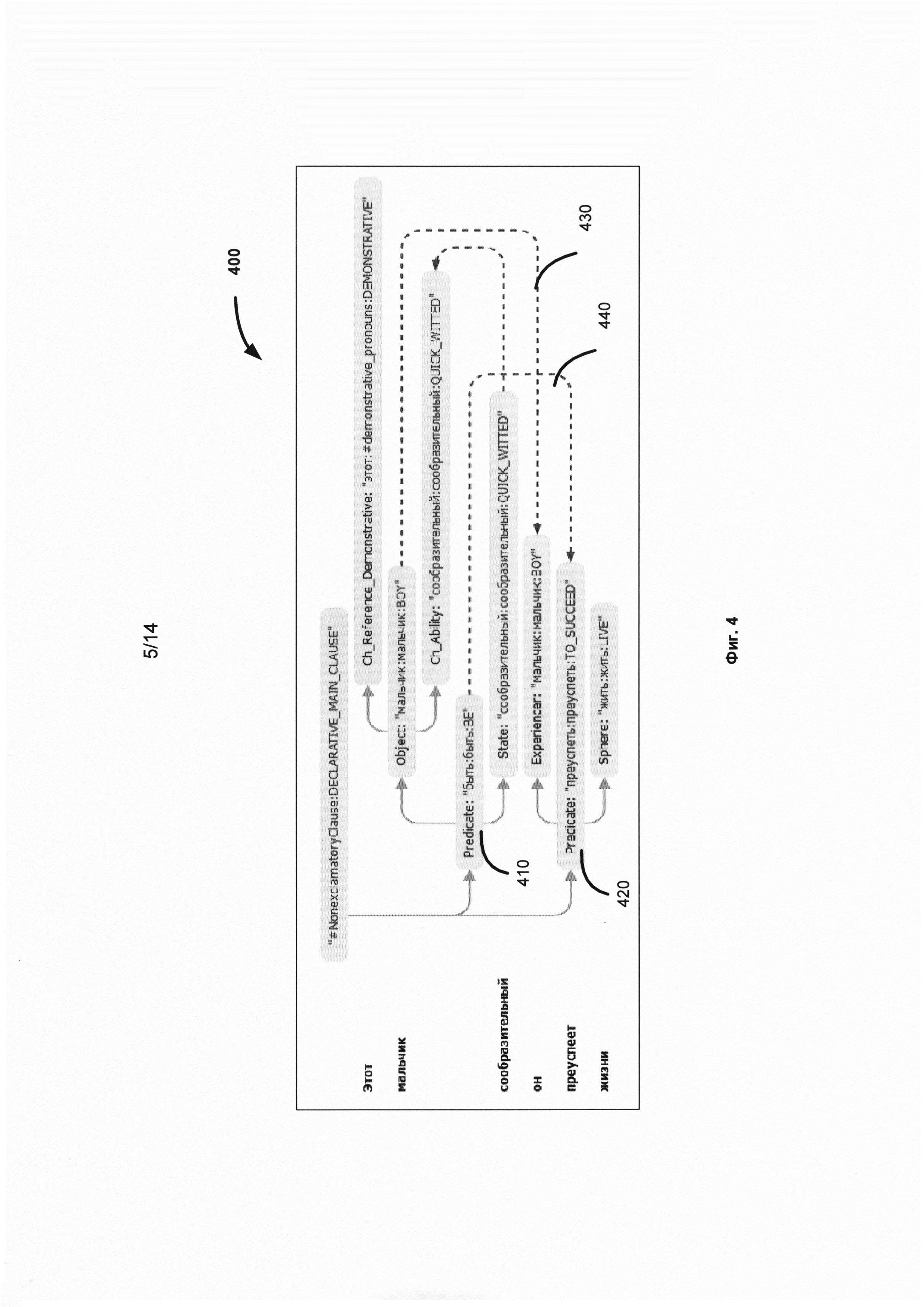
[0034] В одной из реализаций данного изобретения индексы могут включать все или, по крайней мере, одно значение морфологических, синтаксических, лексических и семантических характеристик (параметров). Эти значения или параметры генерируются во время двухэтапного семантического анализа, далее описанного более детально. Индексы могут использоваться во многих задачах обработки естественного языка, в частности, для организации семантического поиска. Согласно одной из реализаций данного изобретения, морфологические, синтаксические, лексические и семантические описания структурированы и сохраняются в базе данных. Это множество описаний может включать, по крайней мере, морфологическую модель языка, модели синтаксических конструкций языка, лексико-семантические модели. Согласно одной из реализаций данного изобретения, для анализа сложных языковых структур, распознавания смысла предложения и корректной передачи заключенной в нем информации используется интегральная модель для описания синтаксиса и семантики.
[0035] Фиг. 2 иллюстрирует детальную схему метода анализа предложения согласно одной или нескольким реализациям изобретения. Обратимся к Фиг. 1А и Фиг. 2, где лексико-морфологическая структура 222 определяется на этапе анализа 106 исходного предложения 212. Затем производится синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа), использующий лингвистические модели и информацию различных уровней для вычисления вероятностей и генерации наиболее вероятной («лучшей») синтаксической структуры.
[0036] Грубый синтаксический анализ применяется к исходному предложению и включает, в частности, генерацию всех потенциально возможных лексических значений слов, образующих предложение или словосочетание, всех потенциально возможных отношений между ними, всех потенциально возможных составляющих. Применяются все возможные поверхностные синтаксические модели для каждого элемента лексико-морфологической структуры, затем строятся и обобщаются все возможные составляющие так, чтобы были представлены все возможные варианты синтаксического разбора предложения. В результате формируется граф обобщенных составляющих 232 для последующего точного синтаксического анализа. Граф обобщенных составляющих 232 включает все потенциально возможные связи в предложении. За грубым синтаксическим анализом следует точный синтаксический анализ на графе обобщенных составляющих, в результате которого из него "извлекаются" одно или несколько синтаксических деревьев 242, представляющих структуру исходного предложения. Построение синтаксического дерева 242 включает лексический выбор для вершин графа и выбор отношений между вершинами графа. Множество априорных и статистических оценок может быть использовано при выборе лексических вариантов и при выборе отношений из графа. Априорные и статистические оценки могут также быть использованы как для оценивания частей графа, так и для оценивания всего дерева. В одной из реализаций одно или несколько синтаксических деревьев строятся или упорядочиваются по убыванию оценки. Таким образом, лучшее синтаксическое дерево может быть построено первым. В этот момент также проверяются и строятся недревесные связи. Если первое синтаксическое дерево оказывается неподходящим, например, из-за невозможности установить необходимые недревесные связи, в качестве лучше рассматривается второе синтаксическое дерево и т.д. Лексический выбор по сути и означает снятие омонимии (Фиг. 1, 120).
[0037] Поскольку упомянутый лексический выбор для вершин графа и выбор отношений между вершинами графа производится на основе априорных и статистических оценок, в одной из реализаций метода не только рассматриваются и оцениваются все варианты, но эти варианты также запоминаются и индексируются на этапе 108 с учетом их интегральных оценок. Т.е. в индексе 109 могут содержаться не только высоковероятные варианты разбора предложения, но и маловероятные с соответствующим весом, если такой разбор закончился успешно. Веса вариантов разбора используются впоследствии при вычислении оценки релевантности результата поиска. Для лучшей синтаксической структуры 246 затем строится независимая от языка семантическая структура 252.
[0038] Широкий спектр лексических, грамматических, синтаксических, прагматических, семантических характеристик извлекается на этом этапе анализа 106 и построения 107 семантических структур. Например, система может извлекать и хранить лексическую информацию и информацию о принадлежности лексических единиц семантическим классам, информацию о грамматических формах и линейном порядке, о синтаксических отношениях и поверхностных позициях, использовании определенных форм, аспектов, тональностей, таких как, положительная и негативная тональность, глубинных позиций, недревесных связей, семантем и т.д.
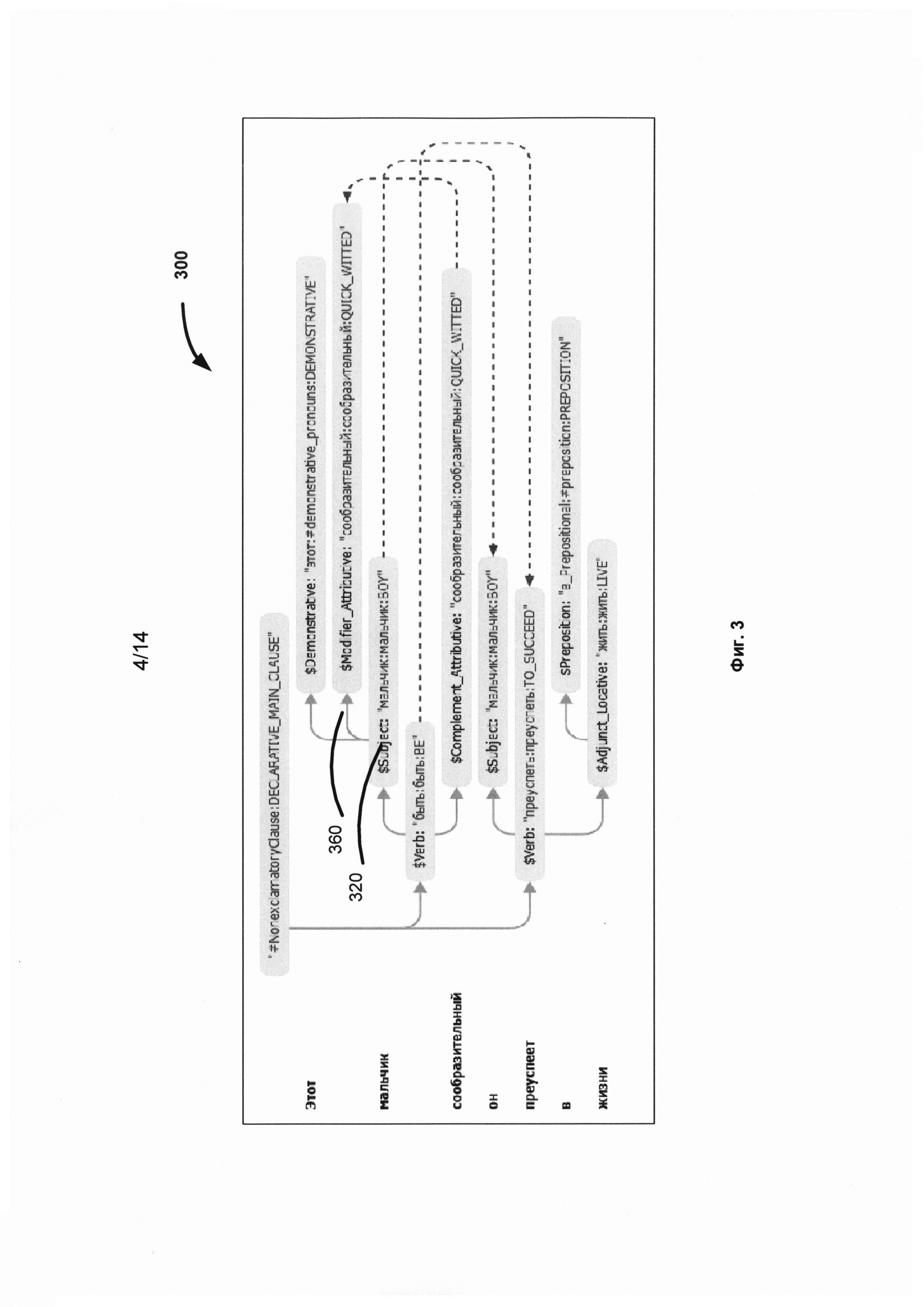
[0039] Фиг. 3 иллюстрирует пример 300 синтаксической структуры, полученного в результате точного синтаксического анализа предложения "Этот мальчик сообразительный, он преуспеет в жизни". Это дерево содержит всю синтаксическую информацию о предложении, такую как лексические значения, части речи, грамматические значения, синтаксические отношения (позиции), синтаксические модели, типы недревесных связей и др. Например, $Demonstrative, $Modiffier_Atributive, $Subject, $Verb, $Complement_Attributive, $Preposition и $Adjunct_Locative - идентификаторы поверхностных позиций, a BE, BOY, LIVE, PREPOSITION, TO_SUCCEED, QUICK_WITTED - идентификаторы семантических классов. Например, "сообразительный" заполняет поверхностную позицию "$Modifier_Attributive" 360 управляющего слова "мальчик" (320) лексического класса "мальчик", принадлежащего семантическому классу BOY, что выражается в обозначении "мальчик:мальчик:BOY" (320).
[0040] Как показано на Фиг. 2, этот подход двухэтапного синтаксического анализа приводит к построению синтаксической структуры исходного предложения, выбранной из одной или нескольких синтаксических структур и называемой "лучшей синтаксической структурой" 246. Так, Фиг. 3 иллюстрирует пример лучшей синтаксической структуры, полученной в результате синтаксического анализа предложения "Этот мальчик сообразительный, он преуспеет в жизни". Подход двухэтапного анализа следует принципу целостного и целенаправленного распознавания, то есть гипотезы о структуре части предложения проверяются с помощью доступных лингвистических описаний в рамках структуры всего предложения. При этом подходе отсутствует необходимость анализировать множество тупиковых вариантов разбора. В большинстве случаях такой подход позволяет существенно сократить количество вычислительных ресурсов, необходимых для анализа предложения.
[0041] Фиг. 4 иллюстрирует пример 400 семантической структуры, полученной для предложения "Этот мальчик сообразительный, он преуспеет в жизни". В соответствии с Фиг. 4, эта структура содержит всю синтаксическую и семантическую информацию, такую как семантический класс, семантемы (на рисунке не показаны), семантические отношения (глубинные позиции), недревесные связи и пр.
[0042] В соответствии с Фиг. 4 недревесная связь 440 соединяет две части - две составляющие 410 и 420 сложного предложения "Этот мальчик сообразительный, он преуспеет в жизни". Также, референциальная недревесная связь 430 отражает анафорическую связь между словами "мальчик" и "он", чтобы определить субъекты двух частей сложного предложения. Эта связь также изображается в синтаксическом дереве (Фиг. 3) после проведения анализа и установления недревесных связей.
[0043] Независимая от языка семантическая структура предложения представляется в виде ациклического графа (дерева, дополненного недревесными связями), где каждое слово определенного языка заменено универсальными (независимыми от языка) семантическими сущностями, называемыми здесь семантическими классами. Семантический класс - одна из самых важных семантических характеристик, которая может быть извлечена и использована для решения задач семантического поиска, классификации, кластеризации и фильтрации документов, написанных на одном или нескольких языках. Кроме семантических классов, также семантемы могут аккумулировать в независимых от языка структурах не только семантическую, но и синтаксическую, грамматическую и пр. зависимую от языка информацию.
[0044] Семантические классы в используемых лингвистических описаниях упорядочены в семантическую иерархию, где "дочерний" семантический класс и его "потомки" наследуют значительную часть свойств "родительского" и всех предшествующих семантических классов ("предков"). Например, семантический класс SUBSTANCE (вещество) является дочерним классом достаточно широкого класса ENTITY (сущность), и в то же время он является "родителем", среди прочих, для семантических классов GAS (газ), LIQUID (жидкость), METAL (металл), WOOD_MATERIAL (дерево как материал), и т.д. Каждый семантический класс в семантической иерархии снабжен глубинной (семантической) моделью. Фиг. 5 иллюстрирует фрагмент описанной семантической иерархии.
[0045] Таким образом, близкие по смыслу лексические значения в семантической иерархии сосредоточены, как правило, в одном "кусте", в одном семантическом классе или "родственных", т.е. расположенных близко, семантических классах.
[0046] В качестве другого примера, в семантической иерархии синонимичные лексические значения (синонимы), например, "еда", "пища", "продукты", как правило, находятся в одном семантическом классе и имеют те же или близкие семантические характеристики - семантемы. Тогда, если пользователь при поиске включает опцию "Искать синонимы", и хочет найти "пища", то сначала определяется его лексическое значение, семантический класс, и как результат, могут быть также найдены документы, где встречаются "еда" или "продукты" и, возможно, другие наиболее репрезентативные представители семантического класса FOOD. В таких случаях, результаты поиска могут быть более или менее релевантны, более или менее близки к искомому результату. Может быть введена мера релевантности, например, основанная на оценке "близости" лексического значения из запроса к найденному синониму, и, принимая во внимание контекст, порядок слов и другие факторы, она может быть распространена на предложение, фрагмент и т.п.
[0047] Глубинная модель представляет собой множество глубинных позиций (типов семантических отношений в предложениях). Глубинные позиции отражают семантические роли дочерних составляющих (структурных единиц предложения) в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей и возможные семантические классы в качестве заполнителей позиций. Эти глубинные позиции выражают семантические отношения между составляющими, например, "agent" (агенс), "addressee" (адресат), "instrument" (инструмент), "quantity" (количество), и т.д. Дочерний класс наследует и подстраивает глубинную модель родительского класса.
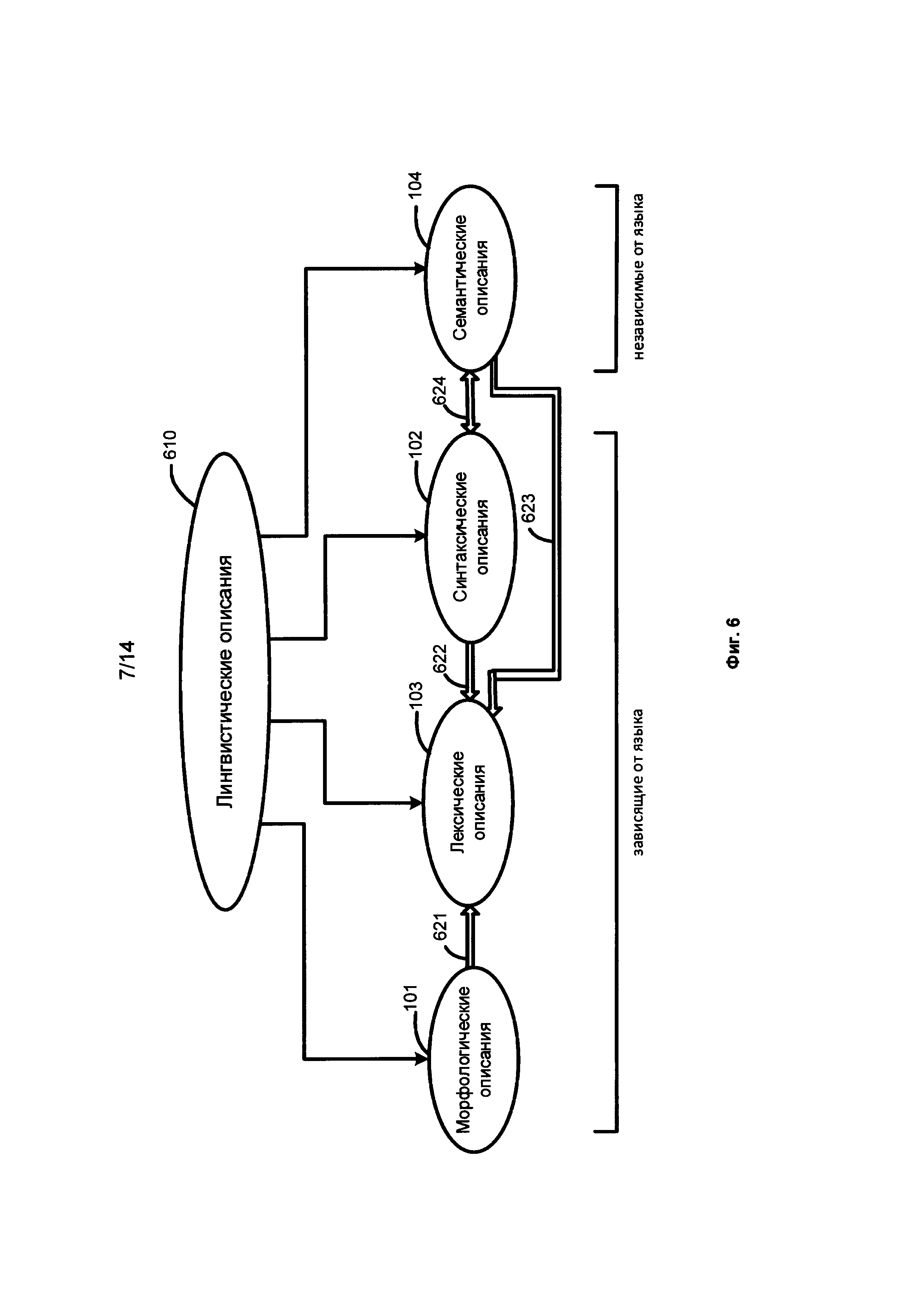
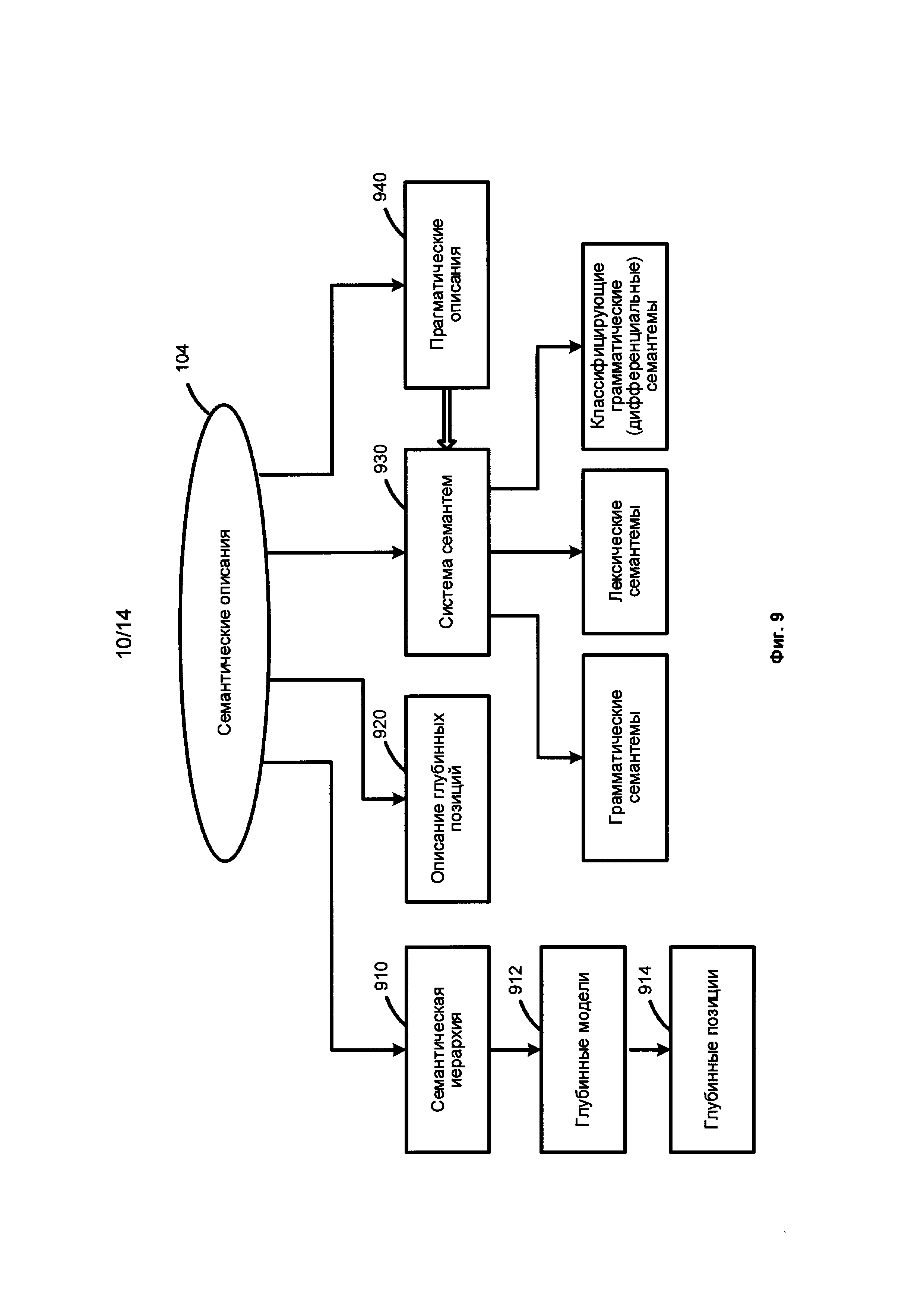
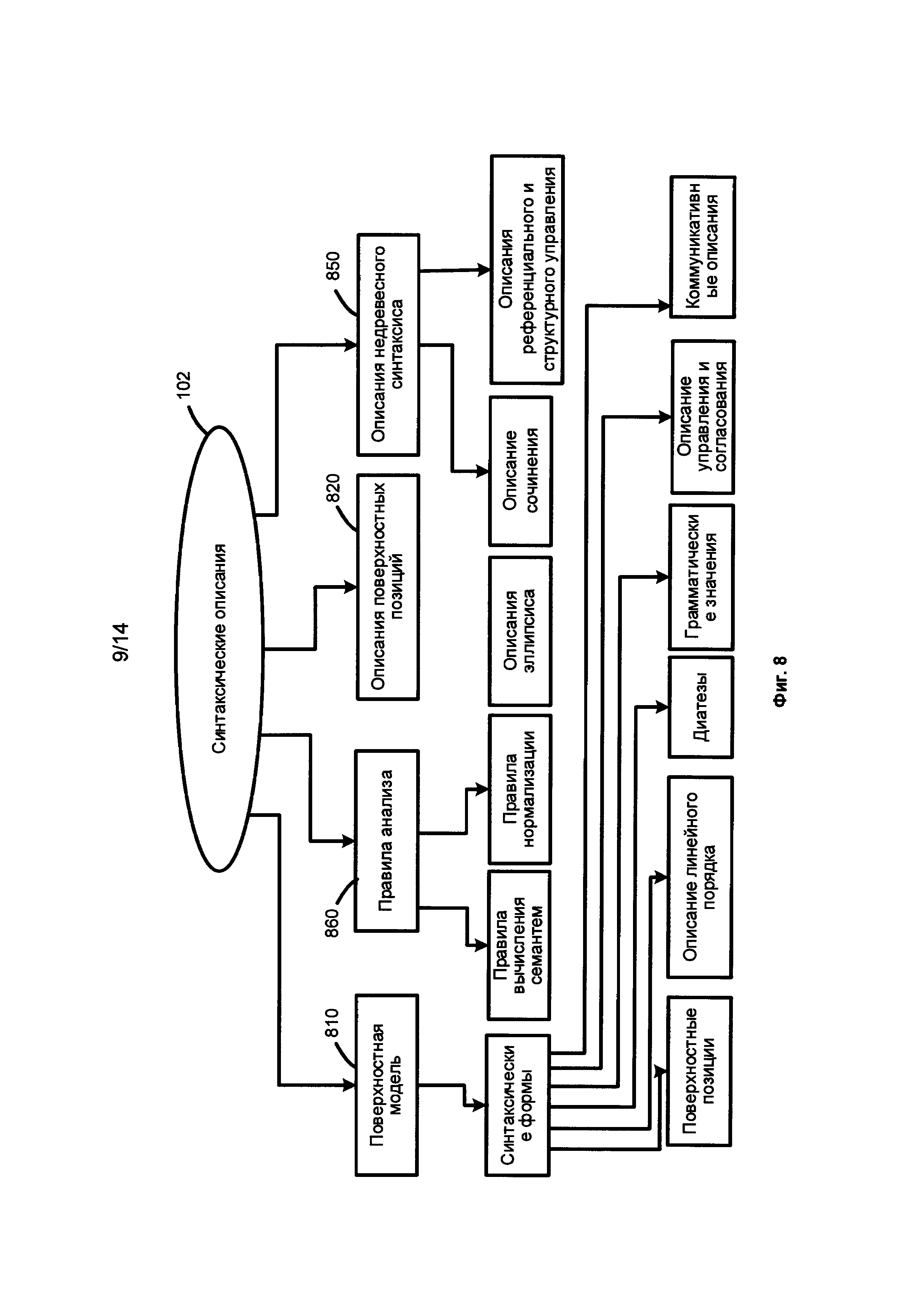
[0048] Фиг. 6 представляет собой схему, иллюстрирующую языковые описания 610, согласно одной из возможных реализаций изобретения. Языковые описания 610 включают морфологические описания 101, синтаксические описания 102, лексические описания, 103 и семантические описания 104. Фиг. 7 представляет собой схему, иллюстрирующую морфологические описания, согласно одной из возможных реализаций изобретения. Фиг. 8 иллюстрирует синтаксические описания, согласно одной из возможных реализаций изобретения. Фиг. 9 иллюстрирует семантические описания, согласно одной из возможных реализаций изобретения.
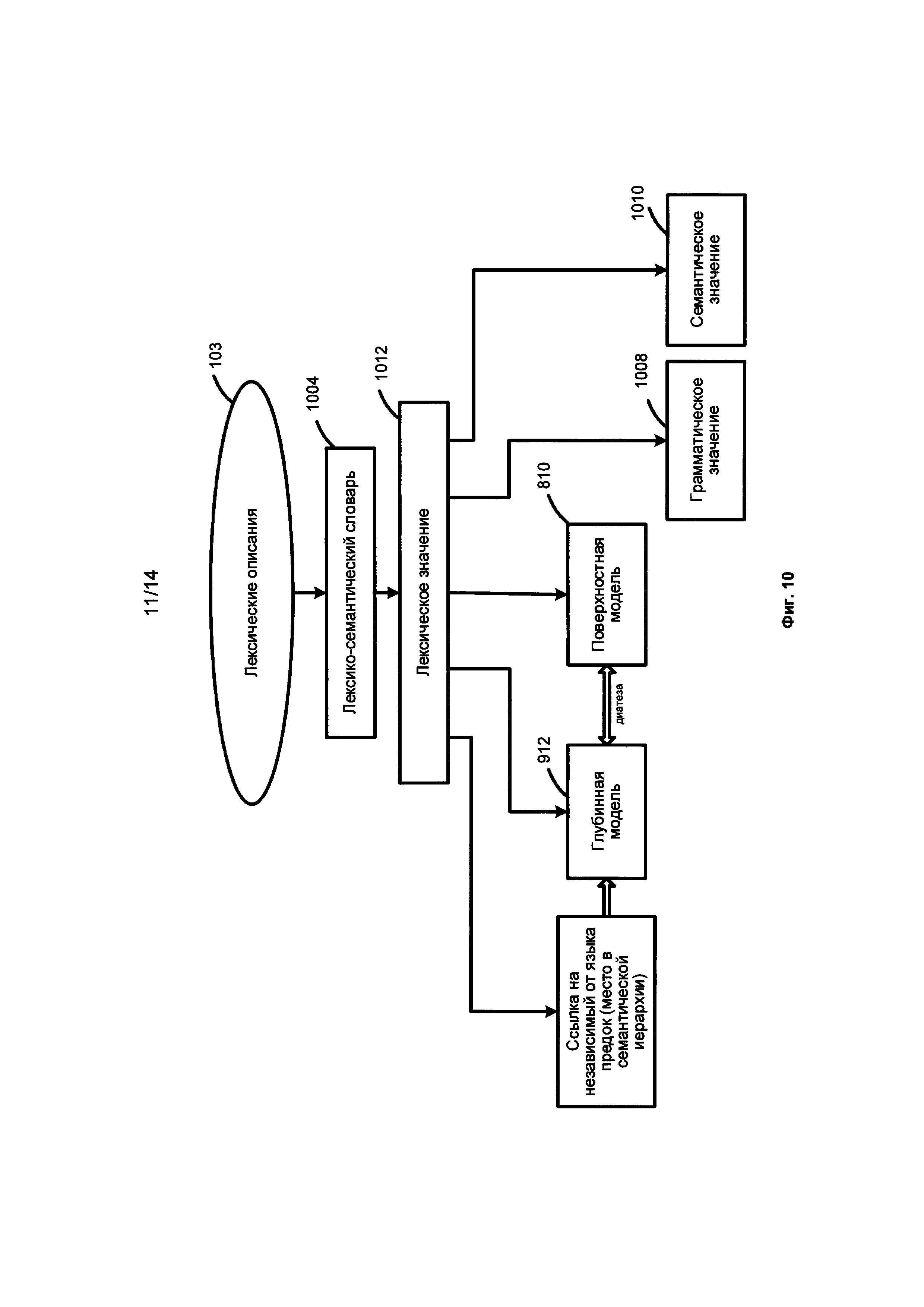
[0049] Обратимся к Фиг. 6 и Фиг. 9. Являясь частью семантических описаний 104, семантическая иерархия 910 является ядром языковых описаний 610, которая объединяет независимые от языка семантические описания 104 и зависимые от языка лексические описания 103, морфологические описания 101 и синтаксические описания 102. Между этими описаниями существуют связи, которые показаны двойными стрелками 621, 622, 623 и 624. Семантическая иерархия может быть создана однажды, а затем может быть заполнена для каждого определенного языка. Семантический класс в конкретном языке включает лексические значения с соответствующими моделями. Семантические описания 104 не зависят от языка. Семантические описания 104 могут содержать описания глубинных составляющих и могут содержать семантическую иерархию, описания глубинных позиций, систему семантем и прагматических описаний.
[0050] Лексическое значение может иметь несколько поверхностных (синтаксических) моделей, сопровождаемых семантемами и прагматическими характеристиками. Синтаксические описания 102 и семантические описания 104 также связаны. Например, диатеза синтаксических описаний 102 может рассматриваться как "интерфейс" между зависимыми от языка поверхностными моделями и независимыми от языка глубинными моделями семантического описания 104.
[0051] Фиг. 7 иллюстрирует пример морфологических описаний 101. Как показано на Фиг. 7, составляющие морфологических описаний 101 включают, но не ограничиваются описаниями словоизменения 710, грамматической системой (граммемами) 720, и описаниями словообразования 730. В одной из возможных реализаций изобретения грамматическая система 720 включает набор грамматических категорий, таких как «Часть речи», «Падеж», «Род», «Число», «Лицо», «Возвратность», «Время», «Вид» и их значения, здесь и далее называемые граммемами. Например, граммемы, означающие части речи, могут включать прилагательное, существительное, глагол и т.д.; граммемы в разных языках могут различаться, например, граммемы падежа для русского языка могут включать «Именительный», «Родительный», «Дательный» и т.д.; граммемы рода могут включать «Мужской», «Женский», «Средний» и т.д. Ссылаясь на Фиг. 7, описания словоизменения 710 описывают, как начальная форма слова может изменяться в зависимости от падежа, рода, числа, времени и т.д. и включают в широком смысле все возможные формы данного слова. Описания словообразования 730 описывают, какие новые слова могут быть построены с использованием данного слова. Граммемы - единицы грамматической системы 720 и, как показывает ссылка 722 и ссылка 724, граммемы могут быть использованы для построения описаний словоизменения 710 и описаний словообразования 730.
[0052] Фиг. 8 иллюстрирует синтаксические описания 102. В одной из реализаций компоненты синтаксических описаний 102 могут содержать поверхностные модели 810, описания поверхностных позиций 820, правила анализа 860, описания недревесного синтаксиса 850, а также описания референциального и структурного контроля, описания управления и согласования и др. Синтаксические описания 102 используются для построения возможных синтаксических структур предложения для данного исходного языка, учитывая порядок слов, недревесные синтаксические явления (например, согласование, эллипсис и т.д.), референциальный контроль (управление) и другие явления.
[0053] Фиг. 9 иллюстрирует семантические описания 104 согласно одной из возможных реализаций изобретения. В то время как поверхностные позиции 820 отражают синтаксические отношения и способы их реализации в конкретном языке, глубинные позиции 914 отражают семантические роли дочерних (зависимых) составляющих в глубинных моделях 912. Потому описания поверхностных позиций, и шире - поверхностные модели, могут быть специфичными для каждого конкретного языка.
Описания глубинных моделей 920 содержат грамматические и семантические ограничения для заполнителей этих позиций. Свойства и ограничения глубинных позиций 914 и их заполнители в глубинных моделях 912 очень похожи и часто идентичны для различных языков.
[0054] Система семантем 930 представляет множество семантических категорий. Семантемы могут отражать лексические, грамматические свойства и атрибуты, а также дифференциальные свойства и стилистические, прагматические и коммуникативные характеристики. Для примера, семантическая категория "DegreeOfComparison" (степень сравнения) может быть использована для описания степеней сравнения, выраженных разными формами прилагательных, например, "easy", "easier" and "easiest". Так, семантическая категория "DegreeOfComparison" может включать семантемы, например "Positive", "ComparativeHigherDegree", "SuperlativeHighestDegree". В качестве другого примера, семантическая категория "RelationToReferencePoint" может быть использована для описания того, в каком линейном порядке - до или после объекта или события находится в предложении ссылка на него, и ее семантемами являются "Previous", "Subsequent". Еще один пример - семантическая категория "EvaluationObjective" может фиксировать наличие объективной оценки, такой как "Bad", "Good" и т.д. Лексические семантемы могут описывать специфические свойства объектов, например "быть плоским" ("being flat") или "быть жидким" ("being liquid") и используются в ограничениях на заполнители глубинных позиций. Классифицирующие дифференциальные семантемы используются для выражения дифференциальных свойств внутри одного семантического класса. Например, в английском языке "парикмахер" для мужчин переводится как "barber", и ему в семантическом классе "HAIRDRESSER" будет приписана семантема "RelatedToMen", в то время как в том же семантическом классе есть "hairdresser" и "hairstylist" и др.
[0055] Прагматические описания 940 служат для того, чтобы в процессе анализа текста фиксировать соответствующую тему, стиль или жанр текста, а также возможно приписать соответствующие характеристики объектам семантической иерархии. Например, "Economic Policy", "Foreign Policy", "Justice", "Legislation", "Trade", "Finance", etc.
[0056] Фиг. 10 является схемой, иллюстрирующей лексические описания 103, согласно одной или нескольким реализациям данного изобретения. Лексические описания 103 включают лексико-семантический словарь 1004, который включает в себя набор лексических значений 1012, образующих вместе со своими семантическими классами семантическую иерархию, где каждое лексическое значение может сопровождаться, но не ограничивается своей глубинной моделью 912, поверхностной моделью 810, грамматическим значением 1008 и семантическим значением 1010. Лексическое значение является реализацией в конкретном языке некоторого семантического значения - смысла и может объединять различные дериваты (например, слова, выражения, фразы), выражающие смысл с помощью различных частей речи, различных форм слова, однокоренных слов и пр. В свою очередь, семантический класс объединяет лексические значения близких по смыслу слов и выражений на разных языках.
[0057] Любой параметр языковых описаний 610 - лексические значения, семантические классы, граммемы, семантемы и многое другое извлекается во время исчерпывающего анализа текста, и любой параметр может быть проиндексирован (создан индекс характеристики). Индексация семантических классов востребована во многих задачах, связанных с анализом текстов на естественном языке, таких как семантический поиск, классификация, кластеризация, фильтрация текстов и многие другие. Индексация лексических значений (в отличие от индексации просто слов) позволяет искать не просто слова или словоформы, но лексические значения, т.е. слова в определенном смысловом (семантическом) значении. Синтаксические структуры и семантические структуры также могут индексироваться и сохраняться для использования в семантическом поиске, классификации, кластеризации и фильтрации документов.
[0058] После того как построены универсальная семантическая структура для каждого предложения каждого текста в корпусе текстов, синтаксические и семантические структуры индексируются. Индексируются лексические значения как результат лексического выбора в каждой вершине семантической структуры, каждый параметр морфологических, синтаксических, лексических и семантических описаний может индексироваться таким же образом, как обычные слова. Индекс слов в документе обычно включает, по меньшей мере, одну таблицу, где каждое слово (лексема или словоформа), встретившееся в документе, сопровождается списком номеров или адресов позиций в этом документе. Согласно реализации данного изобретения, индекс может строиться для всех лексических и семантических значений, всех семантических классов, для любых значений морфологических, синтаксических, лексических и семантических параметров. Эти значения параметров генерируются в процессе двухступенчатого синтактико-семантического анализа, и полученные индексы могут быть использованы для достижения более высокой точности и релевантности семантического поиска в корпусах текстов на естественных языках. Например, пользователь может формулировать свой запрос с возможностью поиска предложений с существительными, имеющими свойство "being flat" или "being liquid" или предложений содержащих слова (существительные и/или глаголы), обозначающие какой-либо процесс, например, производства, разрушения, перемещения и т.п.
[0059] В одной из возможных реализаций способа изобретения, комбинация из двух, трех или, вообще говоря, N чисел может быть использована для индексирования различных синтаксических, семантических или других параметров. Например, чтобы индексировать поверхностные или глубинные позиции могут быть использованы комбинации из двух чисел - номеров слов, которые в тексте связаны отношением, соответствующим данной позиции. Например, для семантической структуры предложения "Этот мальчик сообразительный, он преуспеет в жизни", представленной на Фиг. 4, глубинная позиция 'Sphere' (450) соотносит лексическое значение "succeed:TO_SUCCEED" (460) с лексическим значением "life:LIVE (470)". Более конкретно, лексическое значение "life:LIVE" заполняет глубинную 'Sphere' глагола "succeed:TO_SUCCEED". Когда строится индекс лексических значений, в соответствии с методом данного изобретения, вхождениям данных лексических значений присваиваются номера в соответствии с их положением в тексте, например, N1 и N2. Когда строится индекс глубинных позиций, каждой глубинной позиции ставится в соответствие список ее встречаемости в документе. Для примера, индекс глубинной позиции 'Sphere' будет, среди прочих, включать пару (N1, N2).
[0060] Т.к. индексируются не только слова, но их лексические значения, семантические классы, синтаксические и семантические отношения, любые другие элементы синтаксических и семантических структур, становится возможным искать контекст не только по ключевым словам, но также контекст, содержащий определенные лексические или семантические значения, значения, принадлежащие определенным семантическим классам, контекст, включающий элементы с определенными синтаксическими и/или семантическими свойствами и/или морфологическими свойствами или наборами (комбинациями) таких свойств. Также, могут быть найдены предложения с недревесными синтаксическими явлениями, например, эллипсис, сочинение и др. Т.к. можно искать семантические классы, становится возможным искать семантически связанные слова и понятия.
[0061] Вернемся к описанию собственно метода изобретения, представленному на Фиг. 1. Запрос пользователя 110 может представлять собой, в общем случае, группу слов, в том числе, предложение, словосочетание и т.п. В частном случае - набор ключевых слов, которые должны встретиться в искомом фрагменте. Запрос подвергается семантико-синтаксическому анализу, как описано на Фиг. 2, результатом которого является семантическая структура и снятие омонимии (disambiguation) 120. Т.е. для каждого слова в запросе, в лучшем случае, определяется, в каком именно лексическом значении следует искать вхождение этого слова. Это возможно, если все прочие варианты разбора, т.е. лексические варианты, кроме первого, имеют существенно более низкую (ниже некоторого порогового значения) оценку. В худшем случае, если оценки вариантов различаются несущественно, для каждого слова определяется набор лексических вариантов (лексических значений), с соответствующими весами, т.е. ранжированный список лексических значений.
[0062] Вес каждого лексического варианта в итоговой семантической структуре вычисляется и зависит от множества факторов - связности (сочетаемости слов) исходного запроса, интегральной оценки полученной в результате разбора семантической структуры, от априорной оценки (rating) лексического варианта, от статистической оценки сочетаемости и т.п.
[0063] Далее на этапе 130 для одного или более элементов (слов) запроса могут быть подобраны один или более синонимов. В одной из возможных реализаций могут быть использованы готовые списки синонимов, например, синсеты (synsets) WordNet. В реализации, данного изобретения списки синонимов формируются по крайней мере на основе взаимного расположения лексических значений в семантической иерархии и наличия у лексического значения тех или иных различительных и классифицирующих семантем. Например, в семантической иерархии имеется семантический класс PRINTED_MATTER, в котором есть лексические классы "пресса" и "печать". Может считаться, что эти лексические классы "достаточно близко" расположены по отношению друг к другу, и поэтому, в зависимости от совпадения/несовпадения прочих семантических характеристик (например, наличия/отсутствия каких-то различительных семантем) могут заменять друг друга с весом 1 или, например, 0.9. Т.е., например, имея запрос "В прессе появились сообщения о приближающейся к Земле комете", можно также искать запрос "В печати появились сообщения о приближающейся к Земле комете".
[0064] Однако семантический класс PRINTED_MATTER включает также другие семантические классы, например, EDITION_AS_TEXT, PERIODICAL, NEWSPAPER и др. Они также содержат лексические классы, например, "периодика", "газета" и др. Сопоставляя их с исходным лексическим значением "пресса", может быть вычислен вес синонима "газета" относительно "пресса", который, грубо говоря, зависит от "расстояния" между ними в семантической иерархии, а также от наличия/отсутствия различительных семантем. "Расстояние" может быть вычислено с использованием метрики.
[0065] В зависимости от требований в отношении точности и (или) сложности вычислений метрика также может учитывать различные факторы, в том числе: наличие отношений родитель-потомок между родительскими семантическими классами в семантической иерархии, так чтобы родитель и потомок были разделены не более, чем определенным числом уровней семантической иерархии; наличие общего предка по определенным семантическим классам и расстояния между узлами, представляющими данные классы. Если обнаруживается, что лексические классы (значения) являются "близкими", метрика может учитывать наличие или отсутствие определенных различительных семантем и (или) другие факторы, например, схожесть/различие поверхностных моделей, в том числе, наличие идентичных поверхностных позиций и возможных их заполнителей.
[0066] Таким образом, на этапе 130 для одного или более элементов (слов) запроса могут быть подобраны один или более синонимов, причем каждый имеет свой коэффициент (вес, rating) относительно слова, первоначально присутствующего в запросе. Например, вес может иметь значения на отрезке (0; 1]. При этом наивысший вес (1), как правило, может иметь исходное слово, присутствующее в запросе.
[0067] На этапе 140 синонимы ранжируются, т.е. располагаются в соответствии с убыванием ранга. С учетом полученных синонимов формулируются дополнительные строки запроса. Эти дополнительные строки формируются как все возможные сочетания (декартово произведение) синонимов с сохранением линейного порядка. С учетом веса каждого входящего в запрос синонима. При этом опять наивысший вес (1) будет иметь исходная строка запроса.
[0068] На этапе 150 выполняется собственно запрос на поиск. Точнее, для поиска может использоваться более одной строки запроса. Фактически может выполняться несколько запросов одновременно или последовательно. Может использоваться вычислительная система, имеющая более одного процессора или компьютера. Строка запроса представлена искомыми лексическими значениям. Каждая строка запроса имеет свой вес, вычисленный на этапе 140 в зависимости от присутствия в запросе синонимов и веса каждого из входящих в запрос синонимов.
[0069] На этапе 150 может применяться полнотекстовый или семантический поиск. Для полнотекстового поиска каждая строка запроса преобразуется в слова, и поиск выполняется на индексе, представляющем собой, в общем случае, индекс слов. Может также использоваться индекс N-грамм. В случае полнотекстового поиска может потребоваться дополнительный этап фильтрации результатов, включающий семантико-синтаксический разбор найденного фрагмента для того, чтобы убедиться, что слова в найденном фрагменте используются именно в том лексическом значении, которое имелось в строке запроса.
[0070] В случае семантического поиска на этапе 150 выполняется поиск в семантическом индексе, т.е. выполняется поиск конкретных лексических значений. Еще одной возможностью семантического поиска может являться поиск по семантическим классам с последующим уточнением по лексическим значениям. В еще одной реализации при семантическом поиске может выполняться поиск соответствующей запросу семантической структуры с последующим вычислением оценки степени совпадения. Индекс семантических структур, входящий в семантический индекс, также строится на предварительном этапе
[0071] В обоих случаях каждый из найденных результатов (фрагментов) получает вес в зависимости от веса используемой строки запроса. Дополнительные штрафы, уменьшающие вес, могут использоваться в случае, например, ненулевого расстояния между словами запроса в найденном фрагменте и в случае изменения линейного порядка.
[0072] На этапе 160 выполняется общее ранжирование найденных результатов. Ранжирование может производиться на основе полученных весов, также может применяться функция преобразования. Результаты, имеющие вес меньше некоторого порогового значения могут отбрасываться. Дополнительно, результаты поиска 170 могут отображаться на дисплее вычислительной системы в интерфейсе пользователя в соответствии с требованиями поисковой системы.
[0073] Аналогично тому, как строятся дополнительные строки запросов с использованием синонимов, для получения альтернативных строк запроса, выражающих тот же самый смысл, могут использоваться перефразировки. Перефразировки представляют собой множество пар строк, где любая строка может содержать одно или более слов. Такие пары могут быть получены, например, в результате сбора статистики обработки множества текстов. Например, такими перефразировками могут быть "в процессе решения задачи" и "при поиске решения задачи". В случае полнотекстового поиска они могут быть использованы аналогично использованию синонимов. Всякая пара перефразировок также может иметь априорно присвоенный им вес в зависимости от того, насколько можно считать их эквивалентными. Например, вес перефразировки может вычисляться в зависимости от частотности встречаемости в одинаковых или похожих контекстах.
[0074] При семантическом поиске также могут использоваться перефразировки. В одной из реализаций перефразировка может заменять фрагмент строки запроса до синтаксического анализа, если это оказывается целесообразным, например, по причине того, что другое, эквивалентное словосочетание является более частотным. Также может осуществляться динамическая генерация перефразировок, заключающаяся в следующем. После того, как строка запроса на этапе 120 подверглась семантико-синтаксическому анализу для снятия омонимии, для исходной строки построена семантическая структура. В соответствии с описанной технологией анализа, которая является составной частью общей технологии машинного перевода, описанной в ряде патентов US Patent US 8,195,447, US Patent 8,214,199 и др. на основе этой семантической структуры может быть произведен синтез эквивалентного предложения на любом языке, включая также исходный язык. Технология предполагает синтез не одного, а множества вариантов поверхностных синтаксических структур таких предложений с последующей оценкой каждого варианта и выбором вариантов с наивысшей оценкой. Поверхностные синтаксические структуры могут включать также различные лексические варианты. При решении задачи поиска перефразировок могут выбираться несколько лучших вариантов поверхностных структур с оценкой, превышающей некоторое пороговое значение.
[0075] При оценке вариантов поверхностных структур могут действовать те или иные правила. Например, для исходного предложения "Джон купил дом у реки" могут быть синтезированы различные поверхностные структуры перефразировок, например, "Дом у реки был куплен Джоном" и даже "Дом у реки был продан Джону". Эти варианты имеют вычисляемые оценки, которые зависят от ряда факторов, в том числе от степени подобия синтезируемой структуры по отношению к структуре исходного предложения, наличия соответствующих семантических классов, глубинных и поверхностных позиций и семантем, "степени родства" лексических классов, выбранных грамматических форм и т.д. Устанавливается некоторый порог "отклонения" от исходного предложения, и тогда варианты с оценкой, превышающей это значение, могут быть выбраны в качестве используемых перефразировок.
[0076] На Фиг. 11А представлен пример запроса с использованием синонимов и полученных результатов поиска. На Фиг. 11В представлен пример запроса и полученных результатов поиска с использованием перефразировок.
[0077] На Фиг. 12 приведен возможный пример вычислительного средства 1200, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 1200 включает в себя, по крайней мере, один процессор 1202, соединенный с памятью 1204. Процессор 1202 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер. Память 1204 может представлять собой оперативную память (ОЗУ), а также содержать любые другие типы и виды памяти, в частности, устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например, жесткие диски и т.д. Кроме того, может считаться, что память 1204 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 1200, например, кэш-память в процессоре 1202, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 1210.
[0078] Вычислительное средство 1200 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 1200 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 1208 (например, жидкокристаллический дисплей). Вычислительное средство 1200 также может иметь одно или более постоянных запоминающих устройств 1210, например, привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 1200 может иметь интерфейс с одной или более сетями 1212, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные со всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 1200 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 1202 и каждым из компонентов 1204, 1206, 1208, 1210 и 1212.
[0079] Вычислительное средство 1200 работает под управлением операционной системы 1214 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 1216.
[0080] Вообще программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию.
[0081] Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались ранее. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.


Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Способ и система для глобальной идентификации в коллекции документов
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Способ и система для глобальной идентификации в коллекции документов

