Результат интеллектуальной деятельности: ПРЕДСКАЗАНИЕ ВЕРОЯТНОСТИ ПОЯВЛЕНИЯ СТРОКИ С ИСПОЛЬЗОВАНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ ВЕКТОРОВ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в целом относится к вычислительным системам, а более конкретно - к системам и способам предсказания вероятности появления строки с помощью языковой модели.
УРОВЕНЬ ТЕХНИКИ
[002] Языковая модель может использоваться для предсказания распределения вероятностей определенных лингвистических единиц, таких как символы, слова, предложения и пр. Например, вероятностная языковая модель может предсказывать следующее слово в последовательности слов исходя из предшествующих ему слов. Языковая модель может назначать вероятность для возможности того, что последовательность слов или символов будет продолжена данным словом или символом. Языковая модель может обучиться определению вероятности исходя из примеров текста, речи и пр.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа может включать получение множества строк, где каждая строка из множества строк содержит множество символов; для каждой строки из множества строк создание обрабатывающим устройством первой последовательности векторов исходя по меньшей мере из максимальной длины слова для каждого символа в строке; передачу модулю машинного обучения первой последовательности векторов для каждой строки из множества строк; и получение от модуля машинного обучения вероятности появления каждой строки из множества строк.
[004] В соответствии с одним или более вариантами реализации настоящего изобретения пример системы может включать устройство памяти, в котором хранятся инструкции; обрабатывающее устройство, соединенное с устройством памяти, причем это обрабатывающее устройство выполнено с возможностью получения множества строк, где каждая строка из множества строк содержит множество символов; для каждой строки из множества строк создания обрабатывающим устройством первой последовательности векторов исходя по меньшей мере из максимальной длины слова для каждого символа в строке; передачи модулю машинного обучения первой последовательности векторов для каждой строки из множества строк; и получения от модуля машинного обучения вероятности появления каждой строки из множества строк.
[005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных можетвключать исполняемые команды, которые при исполнении их обрабатывающим устройством приводят к выполнению обрабатывающим устройством операций, включающих получение множества строк, где каждая строка из множества строк содержит множество символов; для каждой строки из множества строк создание обрабатывающим устройством первой последовательности векторов исходя по меньшей мере из максимальной длины слова для каждого символа в строке; передачу модулю машинного обучения первой последовательности векторов для каждой строки из множества строк; и получение от модуля машинного обучения вероятности появления каждой строки из множества строк.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[006] Для более полного понимания настоящего изобретения ниже приводится подробное описание, в котором для примера, а не способом ограничения, оно иллюстрируется со ссылкой на чертежи, на которых:
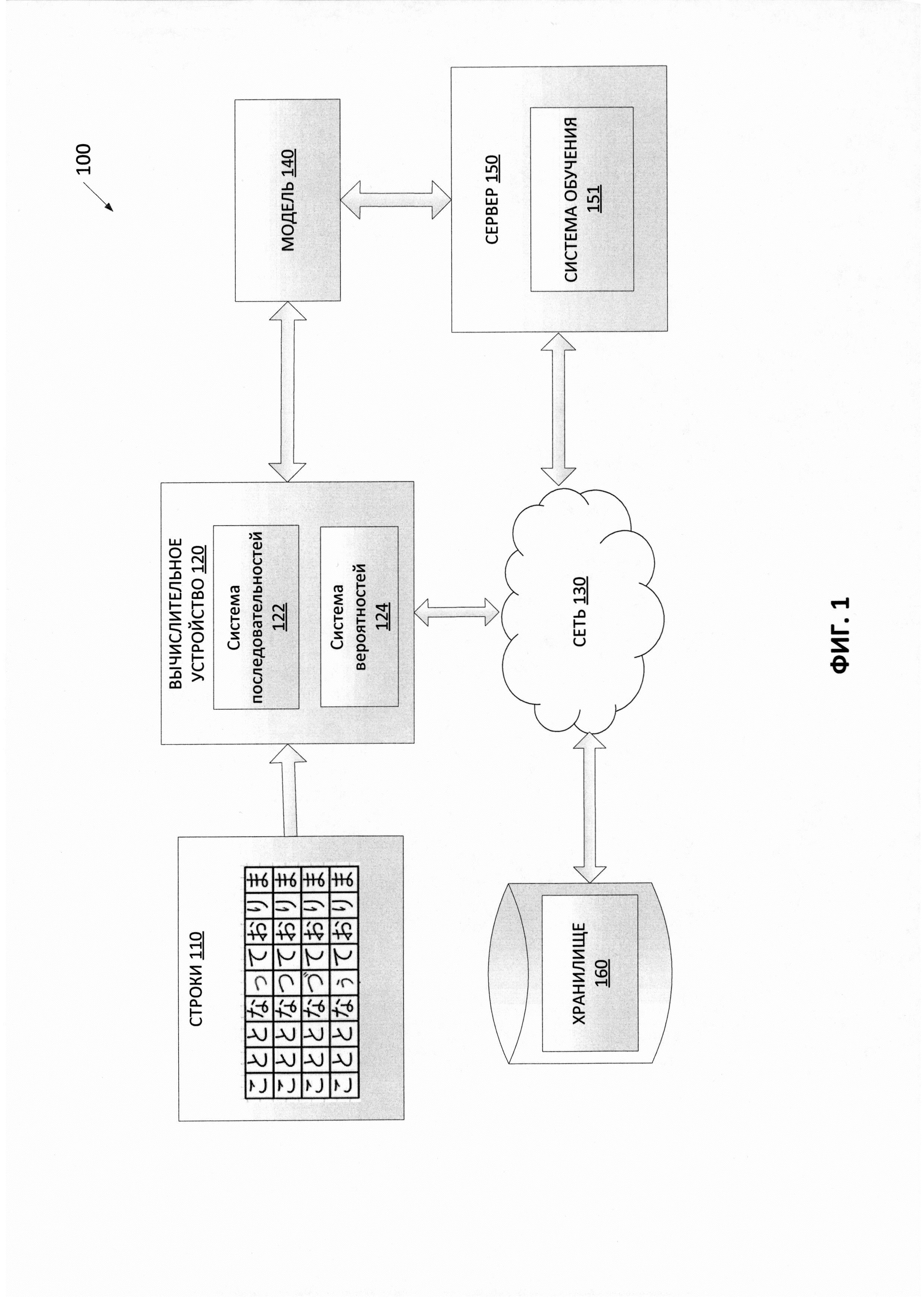
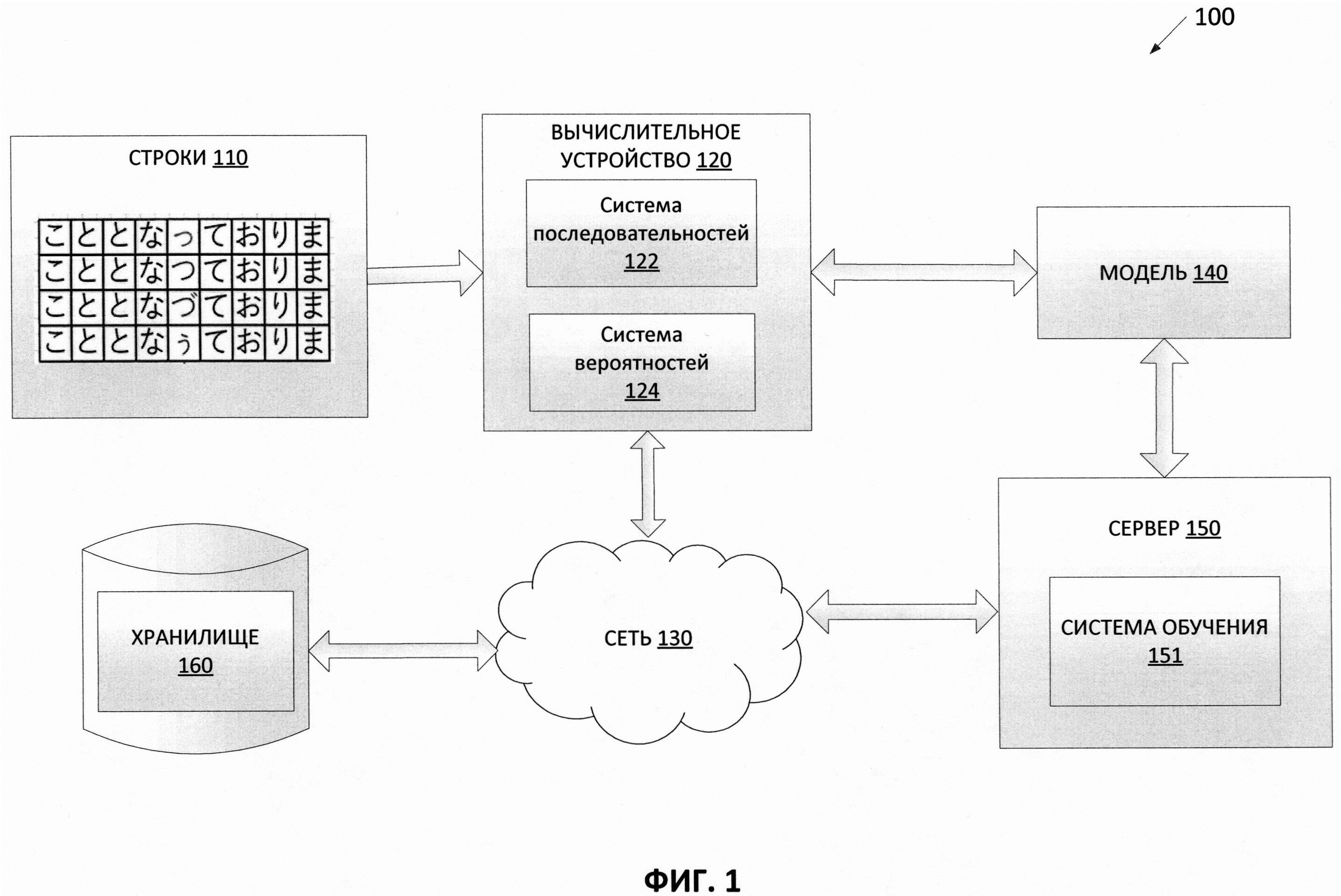
[007] На Фиг. 1 изображена схема компонентов верхнего уровня для примера архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения.
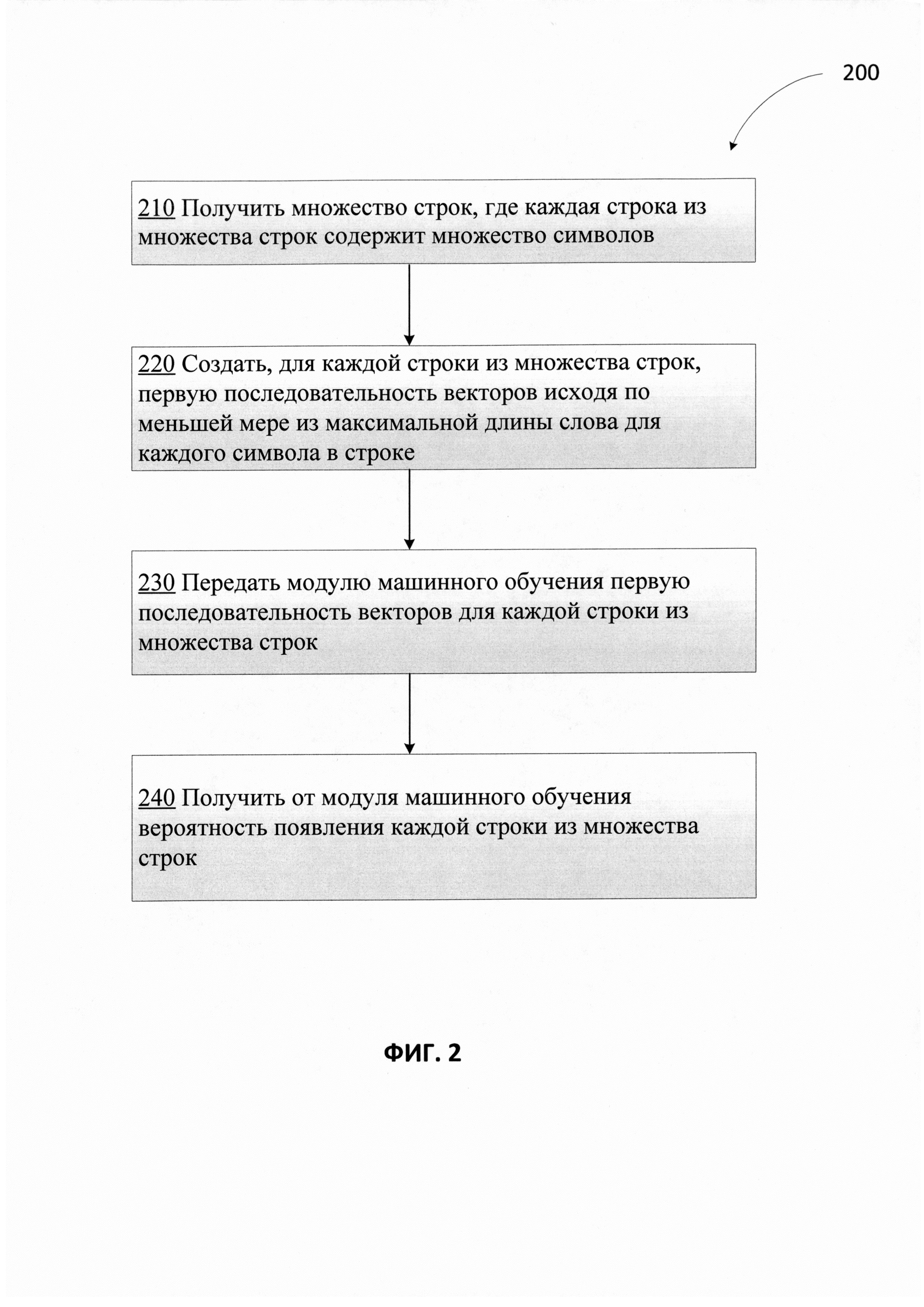
[008] На Фиг. 2 приведена блок-схема одного иллюстративного примера способа предсказания вероятности появления строки в соответствии с одним или более вариантами реализации настоящего изобретения.
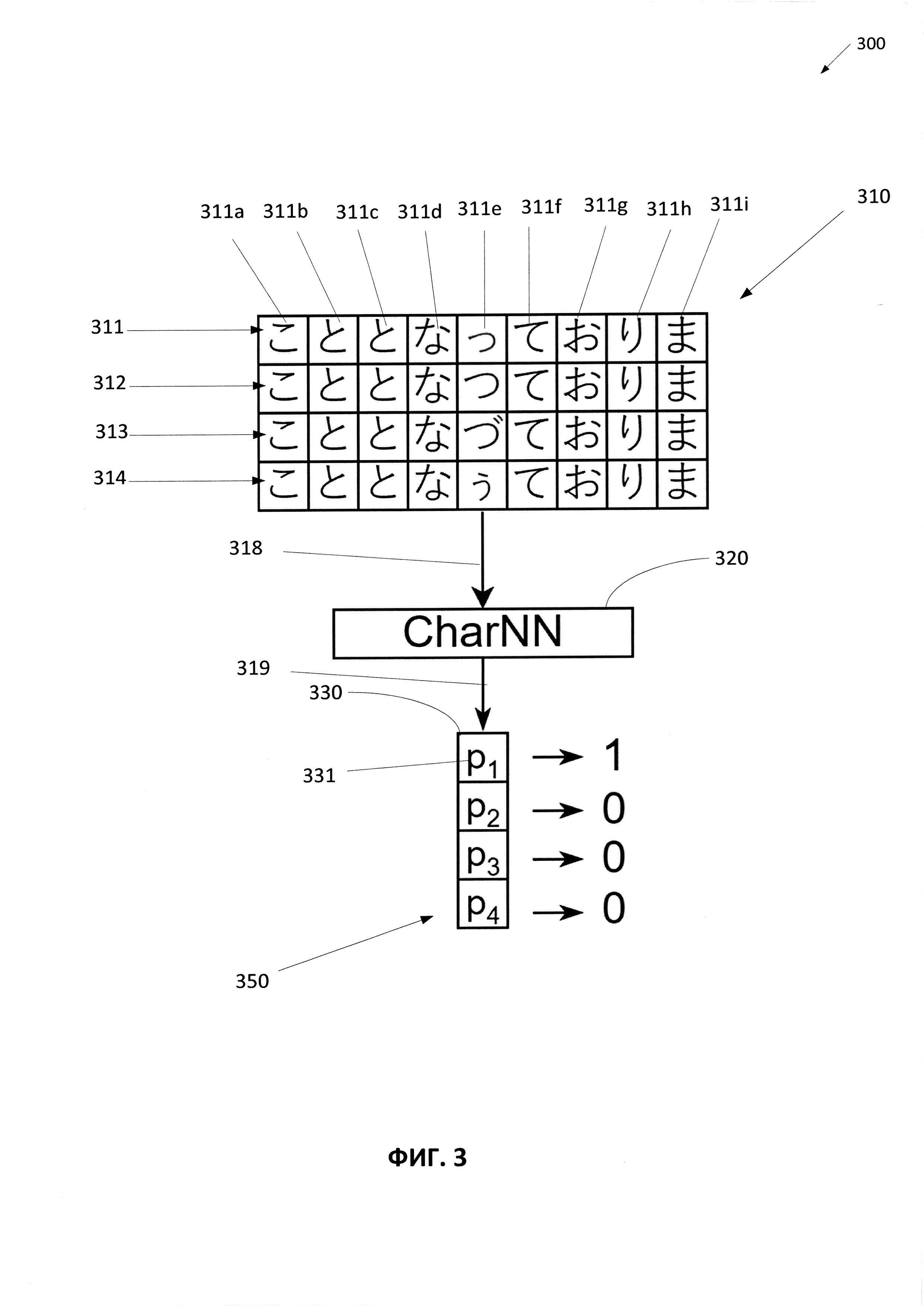
[009] На Фиг. 3 приведен один иллюстративный пример получения множества строк и определения вероятности появления для каждой из множества строк в соответствии с одним или более вариантами реализации настоящего изобретения.
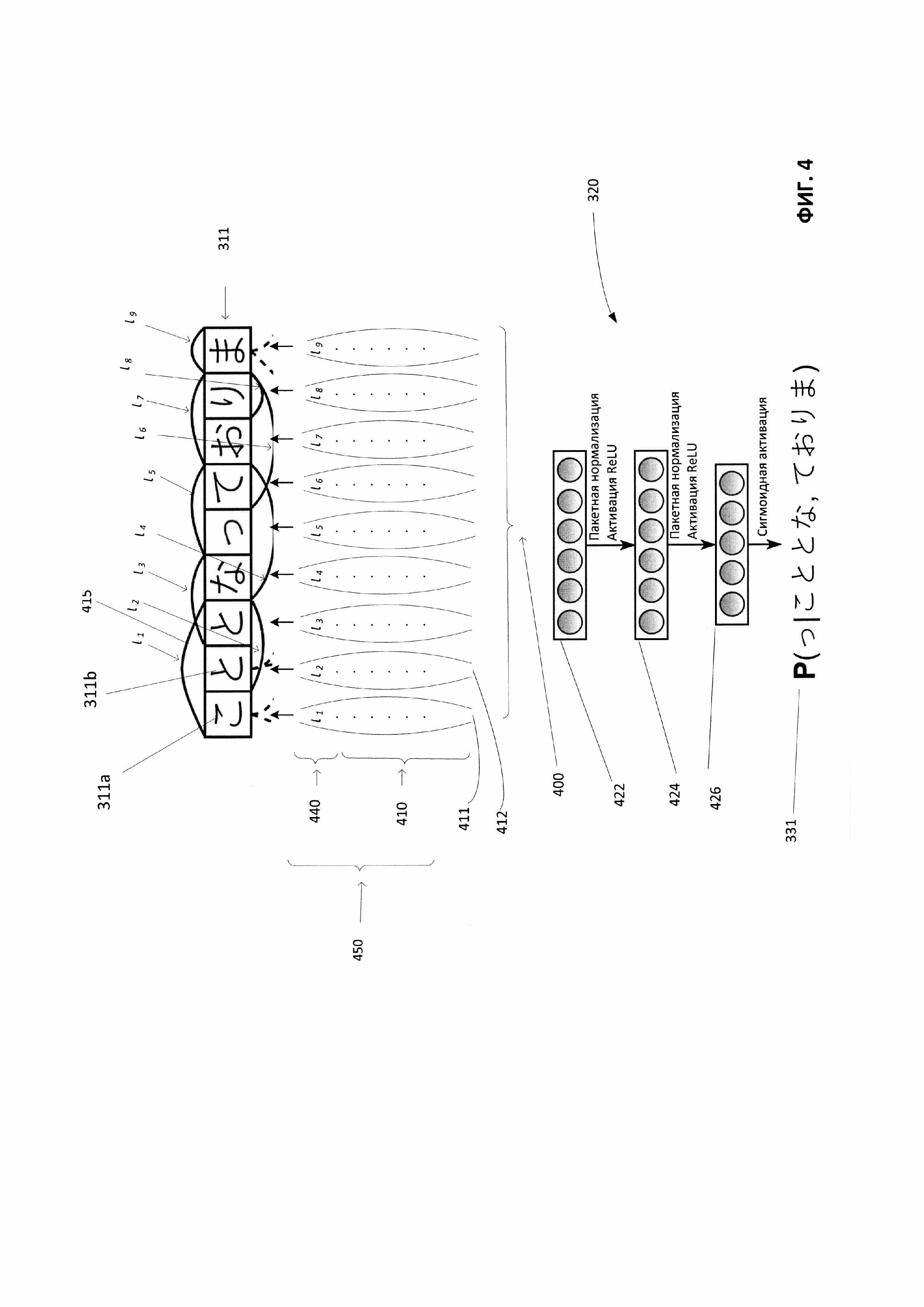
[0010] На Фиг. 4 приведен один иллюстративный пример создания последовательности векторов для предоставления модулю машинного обучения для определения вероятности появления в соответствии с одним или более вариантами реализации настоящего изобретения.
[0011] На Фиг. 5 приведен пример вычислительной системы, которая может выполнять один или более способов, описанных в настоящем документе, в соответствии с одним или более вариантами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0012] Языковая модель может использоваться для предсказания распределения вероятностей определенных лингвистических единиц, таких как символы, слова, предложения и пр. Языковое моделирование используется в различных задачах обработки естественного языка, таких как машинный перевод, распознавание речи, оптическое распознавание символов, проверка орфографии, распознавание рукописного текста и пр. Использование нейронных сетей в языковом моделировании может называться нейронным языковым моделированием или языковым моделированием на основе нейронных сетей. Нейронные языковые модели могут использовать непрерывные представления или эмбединги слов для предсказания вероятности появления отдельной языковой единицы, такой как символ, слово, предложение и пр. Эмбединги слов используются для представления слов или фраз из словаря естественного языка путем отображения слов или фраз на векторы действительных чисел. Языковые модели на основе нейронных сетей могут быть созданы и обучены как вероятностные классификаторы, которые обучаются предсказывать распределение вероятностей. Вероятностный классификатор может быть машинно-обучаемым классификатором, который может предсказывать для входящих данных наблюдений распределение вероятности на наборе классов, а не просто выводить наиболее вероятный класс, к которому должны принадлежать данные наблюдений.
[0013] Обычно нейронная сеть, используемая в нейронной языковой модели, может обучаться предсказывать распределение вероятностей для лингвистической единицы, получая определенный лингвистический контекст. Лингвистический контекст можно определить в терминах того, что следует или предшествует отдельной лингвистической единице. Например, контекст может быть окном предыдущих слов фиксированного размера. В одном из других примеров контекст может быть окном последующих слов фиксированного размера. Например, окно фиксированного размера может содержать четыре слова. В некоторых случаях каждое слово может содержать определенное число букв, например пять букв. В одном из примеров окно фиксированного размера может содержать одно слово. В этом случае контекст может быть словом, непосредственно предшествующим или следующим за искомым словом или символом. Традиционно языковое моделирование может включать анализ определенной лингвистической единицы (например, искомого слова или символа) с учетом контекста, который предшествует слову или символу, и (или) контекста, который следует за словом или символом, для предсказания вероятности появления определенной лексической единицы или ее части. В одном из примеров с использованием как предшествующего, так и последующего контекста значение вероятности может быть выражено как:
P (Ut| CР, Cf),
где P - вероятность появления Ut, определяемая контекстом Cр и Cf;
Ut - искомая единица (то есть символ, слово, предложение и т.д.);
Ср - предшествующий контекст;
Cf - последующий контекст.
[0014] Системы и способы, изложенные в настоящем документе, вносят значительные усовершенствования, лучше предсказывая вероятность появления лингвистической единицы (например, строки, слова) не только за счет использования предшествующего и (или) последующего контекста, но и используя максимальную длину слова, которое начинается с каждого символа лингвистической единицы (например, строки, слова). Представленные в этом документе механизмы позволяют обучить модель машинного обучения (например, нейронную сеть), получая множество строк, предсказывать вероятность появления каждой строки из множества строк. Этот механизм может включать получение множества строк, для которых следует предсказать значения вероятности появления. Каждая из множества строк может содержать множество символов. Символы могут следовать один за другим, образуя каждую из строк. Множество строк могут отличаться друг от друга на один символ. Этот один символ может находиться в одной и той же позиции каждой строки. Эти строки могут передаваться в модуль машинного обучения для предсказания вероятности появления каждой строки. До передачи строк в модуль машинного обучения каждая из строк может быть представлена в виде последовательности векторов.
[0015] В некоторых вариантах реализации эти механизмы могут создавать последовательность векторов, содержащую один или более векторов. Каждый вектор в последовательности векторов может соответствовать каждому символу в данной строке. Каждый вектор в последовательности векторов может порождаться путем объединения первого вектора и второго вектора для данного символа в строке. Первый вектор может содержать максимальную длину слова для данного символа в данной строке. Максимальная длина может соответствовать длине самого длинного возможного слова (то есть слова, которое можно найти в словаре) в строке, которая начинается с данного символа. Второй вектор может содержать вектор символа для данного символа в данной строке. Вектор символов может формироваться на базе одного или более из: эмбедингов символов, единого вектора для символов алфавита, который отличается от алфавита, используемого в строке, векторов для частотных знаков пунктуации, векторов для редких знаков пунктуации, векторов для цифр и пр. Первый и второй векторы для каждого символа могут быть объединены в один вектор для каждого символа.
[0016] После создания последовательности векторов механизмы могут передать последовательность векторов в модуль машинного обучения в качестве входных данных. В некоторых вариантах реализации модуль машинного обучения может содержать полносвязную нейронную сеть с несколькими слоями. Эта нейронная сеть может получать каждую последовательность векторов для каждой строки и применять последовательность матричных преобразований. В одном из вариантов реализации модуль машинного обучения может содержать два полносвязных слоя и полносвязный выходной слой. К выходным данным первых двух полносвязных слоев могут быть применены функция пакетной нормализации (Batch Normal ization)n ректификационная линейная функция активации (ReLU activation), а к выходным данным выходного слоя может быть применена сигмоидная функция активации (Sigmoid activation). Модуль машинного обучения может предоставлять в качестве выходных данных вероятность появления каждой строки из множества строк. Значение вероятности может быть выражено с помощью вектора, где каждый компонент вектора соответствует одной строке. Значение компонента вектора, наиболее близкое к значению «один» по сравнению со значениями других компонентов, соответствует строке, имеющей самую высокую вероятность появления. Таким образом, если множество строк отражает различные варианты распознавания слова, то строка, которая дает наивысшее значение вероятности, может быть строкой, которая представляет наиболее вероятный вариант распознавания слова.
[0017] В настоящем документе могут попеременно использоваться термины «символ», «буква» и «кластер». Кластер может означать элементарный неделимый графический элемент (например, графемы или лигатуры), который связывается общим логическим значением. Кроме того, термин «слово» может означать последовательность символов, а термин «предложение» может означать последовательность слов.
[0018] Нейронная языковая модель может использоваться на различных стадиях обработки естественного языка (NLP), например при постобработке распознанного текста, проверке правописания, распознавании текста, генерации текста, переводе и т.д. Этот способ легко применим к различным вариантам использования. Методики, описанные в настоящем документе, позволяют повысить точность предсказания вероятности появления в языковом моделировании. Использование максимальной длины слов обеспечивает улучшенное предсказание вероятности за счет использования слов с известным значением, например слов, имеющихся в словаре. Словарь содержит обширное хранилище слов с их актуальными значениями, в то время как нейронная сеть с относительно малой выборкой данных может быть не обучена запоминать каждое из этих слов. Таким образом, совместное рассмотрение слов со словарными словами, а также использование максимальной длины слов, найденных в словаре, обеспечивают простую топологию сети и позволяют быстро обучить сеть на относительно малой выборке данных.
[0019] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
[0020] На Фиг. 1 изображена диаграмма компонентов верхнего уровня для пояснения системной архитектуры 100 в соответствии с одним или более вариантами реализации настоящего изобретения. Системная архитектура 100 включает вычислительное устройство 120, хранилище 160 и сервер 150, подключенный к сети 130. Сеть 130 может быть общественной сетью (например, Интернет), частной сетью (например, локальная сеть (LAN, local area network) или распределенной сетью (WAN, wide area network)), а также их комбинацией.
[0021] Вычислительное устройство 120 может осуществлять предсказание вероятности появления, используя искусственный интеллект. Вычислительное устройство 120 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, способным использовать технологии, описанные в этом изобретении. Вычислительное устройство 120 может получать множество строк. В одном из примеров строки 110 могут быть получены вычислительным устройством 120. В некоторых вариантах реализации строки 110 могут создаваться алфавитно-цифровым устройством ввода, голосовым устройством или другим устройством, способным производить множество строк. Каждая строка из множества строк 110 может содержать множество символов. В одном из примеров может возникнуть необходимость распознать отдельное слово на изображении документа. Система распознавания текста может выдать набор строк - потенциальных кандидатов для распознаваемого слова. Чтобы принять окончательное решение о том, какого из этих потенциальных кандидатов следует выбрать в качестве результата распознавания слова, можно подать этот набор строк в виде строк 110 на вход вычислительного устройства 120. Вычислительное устройство 120 может предсказать вероятность появления каждой из строк 110 и выдать эту вероятность в качестве результата. Строка с максимальной вероятностью появления из строк 110 может быть выбрана из набора строк -потенциальных кандидатов - в качестве результата распознавания слова.
[0022] В одном из вариантов реализации изобретения вычислительное устройство 120 может содержать систему последовательностей 122 и систему вероятностей 124. Каждая из систем последовательностей 122 и вероятностей 124 может содержать инструкции, хранящиеся на одном или более физических машиночитаемых носителях данных вычислительного устройства 120 и выполняемые одним или более обрабатывающими устройствами вычислительного устройства 120. В одном из вариантов реализации изобретения система последовательностей 122 может генерировать последовательность векторов на основе строк 110. Например, каждый вектор в последовательности может быть порожден путем комбинирования вектора символа для данного символа в данной строке из строк 110 и вектора максимальной длины слова для данного символа в данной строке из строк 110.
[0023] В одном из вариантов реализации изобретения система вероятностей 124 может использовать обученную модель машинного обучения 140, которая обучена и применяется для предсказания вероятности появления каждой из строк 110, используя последовательность векторов для строк 110, созданную системой последовательностей 122. Модель машинного обучения 140 может быть обучена с использованием обучающей выборки строк и соответствующих векторов последовательностей. В некоторых вариантах реализации модель машинного обучения 140 может быть частью системы вероятностей 124 или может быть доступна на другой машине (например, на сервере 150) через систему вероятностей 124. Исходя из результата, получаемого от обученной системы машинного обучения 140, система вероятностей 124 может предсказывать вероятность появления каждой строки из строк 110.
[0024] Сервер 150 может быть стоечным сервером, маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, портативным компьютером, планшетным компьютером, фотокамерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или их сочетанием. Сервер 150 может содержать систему обучения 151. Модель машинного обучения 140 может ссылаться на артефакт модели, созданный обучающей системой 151 с использованием обучающих данных, которые содержат обучающие входные данные и соответствующие искомые выходные данные (правильные ответы на соответствующие обучающие входные данные). В процессе обучения могут быть найдены шаблоны обучающих данных, которые преобразуют входные данные обучения в искомый результат (ответ, который следует предсказать) и впоследствии могут быть использованы моделями машинного обучения 140 для будущих прогнозов. Как более подробно будет описано ниже, модель машинного обучения 140 может быть составлена, например, из одного уровня линейных или нелинейных операций (например, машина опорных векторов [SVM, support vector machine]) или может представлять собой глубокую сеть, то есть модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или более скрытыми слоями и полносвязаные нейронные сети.
[0025] Как отмечалось выше, модель машинного обучения 140 может быть обучена определять вероятность появления для множества строк, используя обучающие данные, как более подробно будет описано ниже. После обучения модели машинного обучения 140 эта модель машинного обучения 140 может быть предоставлена системе вероятностей 124 для анализа строк 110. Например, система вероятностей 124 может получать в качестве входных данных последовательность векторов строк 110 для анализа в модели машинного обучения 140. В некоторых примерах модель 140 может содержать полносвязную нейронную сеть из нескольких слоев. Например, такая нейронная сеть может состоять из двух полносвязных слоев сети и полносвязного выходного слоя сети. Система вероятностей 124 может получать от обученной модели машинного обучения 140 один или более результатов. Такой результат может быть последовательностью значений вероятности появления каждой строки из строк 110.
[0026] Хранилище 160 представляет собой постоянную память, которая в состоянии сохранять строки 110, а также структуры данных для разметки, организации и индексации строк 110. Хранилище 160 может располагаться на одном или более запоминающих устройствах, таких как основное запоминающее устройство, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то что хранилище изображено отдельно от вычислительного устройства 120, в одной из реализаций изобретения хранилище 160 может быть частью вычислительного устройства 120. В некоторых вариантах реализации хранилище 160 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище 160 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, такой как объектно-ориентированная база данных, реляционная база данных и т.д., которая может находиться на сервере или на одной или более различных машинах, подключенных к нему через сеть 130.
[0027] На Фиг. 2 приведена блок-схема одного иллюстративного примера способа предсказания вероятности появления строки в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 200 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 500 на Фиг. 5), реализующей этот способ. В некоторых реализациях способ 200 может быть реализован в одном потоке обработки. Кроме того, способ 200 может выполняться, используя два или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В качестве иллюстративного примера потоки обработки, реализующие способ 200, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы реализующие способ 200 потоки обработки могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то что Фиг. 2 и соответствующее описание содержат список операций для способа 200 в определенном порядке, в различных вариантах реализации способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке. В одном из вариантов реализации способ 200 может выполняться с помощью одного или более различных компонентов на Фиг. 1, например системы последовательностей 122, системы вероятностей 124 и т.п.
[0028] На шаге 210 вычислительная система, реализующая способ, может получить множество строк. Каждая строка из множества строк может содержать множество символов. Например, полученное множество строк может быть аналогично строкам 110 с Фиг. 1. Для каждой строки из множества строк предсказываются значения вероятности появления. В некоторых вариантах реализации каждая строка из множества строк может отличаться от других строк из множества одним символом, который в этом документе может называться «искомым символом». Этот искомый символ может находиться в одной и той же позиции каждой строки.
[0029] В некоторых примерах множество строк может соответствовать набору потенциальных строк, созданных системой перевода для слова, которое переводится с одного языка на другой. В некоторых примерах множество строк может соответствовать набору строк-кандидатов, созданных системой распознавания текста для слова, которое распознается на изображении документа. В одном из примеров для слова на изображении документа, которое требуется распознать, система распознавания текста может создать набор строк-кандидатов, включающий строки: 1) «steamboat», 2) «sleamboat», 3) «sleamboat» и 4) «sieamboat». Такой набор строк-кандидатов может быть получен в качестве последовательности строк от системы распознавания текста, так что может быть предсказана вероятность появления каждой строки из набора строк. Система распознавания текста может выбрать строку, для которой предсказанная вероятность будет самой высокой из всего набора строк-кандидатов.
[0030] Например, на Фиг. 3 приведен один пример получения множества строк для определения вероятности появления каждой из множества строк в соответствии с одним или более вариантами реализации настоящего изобретения. В этом примере вычислительная система 300, реализующая способ предсказания вероятности появления, может получать множество строк 310. Множество строк 310 может содержать строки 311, 312, 313 и 314. Каждая строка из множества строк 310 может содержать множество символов. Например, строка 311 может содержать множество символов 311а-311i. Все символы из множества символов 311а-311i следуют один за другим, образуя последовательность, представленную строкой 311. Каждая из строк 311, 312, 313 и 314 может отличаться от других одним символом, который может называться в этом документе «искомым символом». Этот искомый символ может находиться в одной и той же позиции каждой строки. Как здесь показано, для множества строк 310 искомый символ находится на пятой позиции в последовательности символов, представляющей каждую из строк. Искомый символ 311е строки 312 отличается от искомых символов других строк 312, 313 и 314, находящихся на той же самой пятой позиции каждой строки. Как можно видеть, остальные символы каждой строки одинаковы для всех остальных строк в данном положении символа.
[0031] В одном из примеров каждая строка 311, 312, 313 и3 14 может быть строкой-кандидатом для распознаваемого слова. Система 300 может получать строку 310 для предсказания вероятности появления каждой из строк 311-314 с целью определения строки, соответствующей максимальной вероятности. В одном из примеров строка, соответствующая максимальной вероятности, может быть выбрана в качестве итогового распознанного слова. В другом примере для определения выбранного распознанного слова могут быть использованы какие-то другие критерии, которые будут иметь отношение к предсказанным значениям вероятности.
[0032] Согласно Фиг. 2 в шаге 220 вычислительная система может, для каждой строки из множества строк, генерировать первую последовательность векторов исходя как минимум из максимальной длины слова для каждого символа строки. Каждый вектор в первой последовательности векторов может соответствовать каждому символу в данной строке. Каждый вектор в первой последовательности векторов может создаваться путем объединения первого вектора, содержащего максимальную длину слова для данного символа строки, и второго вектора, содержащего вектор символа для данного символа строки. Максимальная длина слова для каждого символа строки может соответствовать длине самого длинного возможного слова в строке, которая начинается с этого символа. В некоторых примерах самое длинное возможное слово берется из словаря. Вектор символа для каждого символа в строке может строиться на основе одного из: эмбединга символов; единого вектора для символов алфавита, который отличается от алфавита, используемого в строке; вектора для частотных знаков пунктуации; вектора для редко встречающихся знаков пунктуации; или вектора для цифр.
[0033] Например, на Фиг. 4 приведен пример создания последовательности векторов 400 для передачи в модуль машинного обучения 320 с целью получения вероятности появления 331. Этот пример демонстрирует создание последовательности векторов 400 для строки 311 из множества строк 310, представленной на Фиг. 3. Каждый вектор в последовательности векторов 400 может соответствовать каждому символу в строке 311. Например, вектор 411 может соответствовать символу 311а строки 311, а вектор 412 может соответствовать символу 311b строки 311. Каждый вектор (например, вектор 411, вектор 412 и т.д.) последовательности векторов 400 может создаваться путем объединения первого вектора 440 и второго вектора 410 для каждого символа (то есть символа 311а, символа 311b и т.д.) строки 311 соответственно.
[0034] Первый вектор 440 может содержать максимальную длину слова для данного символа в данной строке. Например, первый вектор 440 вектора 411 может состоять из одного элемента с максимальным значением для символа 311а. Максимальная длина слова для каждого символа может соответствовать длине самого длинного возможного слова в строке, которая начинается с этого символа. В некоторых примерах самое длинное возможное слово берется из словаря. Например, для символа 311а самое длинное возможное слово в строке 311, найденное в словаре, которое начинается с символа 311а, состоит из трех символов в диапазоне 415. Таким образом, для символа 311а длина самого длинного возможного слова в строке - 3, оно представлено как «l1». Таким образом, значение элемента первого вектора 440, соответствующего первому символу 311а строки 311, - это «l1». Аналогично, самое длинное возможное слово в строке 311, начинающееся с символа 311b, содержит два символа и представлено как «l2». Таким образом, самое длинное возможное слово для символа 311b указано как «l2». Максимальную длину (то есть, l1-l9) каждого символа можно определить, используя одну и ту же методику, и ввести в первый вектор 440, соответствующий каждому символу в строке 311.
[0035] В рассмотренных выше примерах, касающихся строк, полученных из системы распознавания текстов, множество строк состоит из строк: 1) «steamboat», 2) «sleamboat», 3) «sleamboat» и 4) «sieamboat». Для строки «steamboat», «steam» -это слово, a «steamboat» - другое слово внутри строки, начинающейся с символа «s». Максимальная длина слова для символа «s» равна длине самого длинного из возможного слова steamboat» внутри строки, найденной в словаре. Таким образом, длина, соответствующая символу «s», - 9. В другом примере, для символа «t», «tea» - это слово из словаря, a «team» - другое слово из словаря, и «team» будет самым длинным возможным словом в строке. Таким образом, максимальная длина, соответствующая символу «t», - 4. Вектор, содержащий значение максимальной длины, может быть получен аналогичным образом для каждого символа строки. При отсутствии в словаре символьных последовательностей, начинающихся с определенного символа, максимальная длина будет равна нулю.
[0036] Второй вектор 410 для данного символа может содержать вектор символа для данного символа. В одном из вариантов реализации вектор символа для данного символа может быть создан на основе эмбедингов символов. При использовании эмбедингов символов (или эмбедингов слов) символ или слово можно представить в виде вектора. Эмбединги символов используются для представления символов алфавита путем отображения символов в векторы действительных чисел. При использовании эмбедингов символов весь алфавит можно формализовать в таблицу соответствия. Таблица соответствия может быть хэш-таблицей с уникальным вектором для каждого символа алфавита. Кроме того, таблица соответствия может содержать или иметь в основании дополнительные векторы, отличающиеся от векторов символов. В некоторых примерах эти дополнительные векторы могут включать одиночные единственный или единый вектор для символов алфавита, отличающегося от алфавита строки. Таблица соответствия также может включать вектор для всех часто встречающихся знаков пунктуации, вектор для всех редких знаков пунктуации, вектор для цифр и т.д. Векторы в таблице соответствия могут быть предварительно обученными эмбедингами. При создании вектора символа для данного символа строки таблица соответствия может использоваться для определения соответствующих значений данного символа в строке. В некоторых вариантах реализации изобретения вектор символа может иметь размер 24. То есть вектор символа для данного символа может содержать 24 элемента в векторе символа.
[0037] Каждый вектор из последовательности векторов 400, соответствующий каждому символу, может быть порожден путем соединения первого вектора 440 и второго вектора 410 в один вектор 450. Например, вектор 411 создан для символа 311а строки 311 путем соединения первого вектора 440 для символа 311а и второго вектора 410 для символа 311а. Каждый из объединенных векторов для каждого из символов затем собирается вместе с образованием последовательности векторов 400. На примере на Фиг. 4 последовательность векторов 400 состоит из девяти векторов, один вектор для одного символа 311а-311i строки 311. Каждый из девяти векторов был получен объединением первого вектора 440 максимальной длины и второго вектора 410 вектора символов для соответствующего символа.
[0038] Согласно Фиг. 2 на шаге 230 вычислительная система может передать в модуль машинного обучения первую последовательность векторов для каждой строки из множества строк. Например, на Фиг. 3 показана стрелка 318, входящая в качестве входных данных в модуль машинного обучения 320. Как показано более подробно на Фиг. 4, первая последовательность векторов 400 передается в модуль машинного обучения 320 для строки 311. Модуль машинного обучения может содержать первый полносвязный слой 422 и второй полносвязный слой 424 для применения матричных преобразований к первой последовательности векторов 400 для строки 311. К первому результату первого полносвязного слоя и ко второму результату второго полносвязного слоя применяются функция пакетной нормализации (Batch Normalization) и ректификационная линейная функция активации (ReLU activation). В одном из примеров размеры первого и (или) второго слоя могут быть равны 256. Третий полносвязный слой, который используется в качестве выходного слоя. К третьему результату третьего полносвязного слоя может быть применена сигмоидальная функция активации (Sigmoid activation).
[0039] Согласно Фиг. 2 на шаге 240 вычислительная система может получить из модуля машинного обучения вероятность появления каждой строки из множества строк. Вероятность появления данной строки, имеющей значение, близкое к «один» по сравнению со значениями вероятности появления остальных строк, указывает на то, что у этой строки максимальная вероятность появления. Значение вероятности может быть указано действительным числом, обычно в диапазоне от 0 до 1, но значения могут представлять собой промежуточные значения, такие как 0,1, 0,2, или 0,9 и т.д. На Фиг. 3 выходные данные показаны в виде стрелки 319, выходящей из модуля машинного обучения 320. Модуль машинного обучения может обеспечивать в качестве выходных данных вероятность появления каждой строки из множества строк. Значение вероятности может быть выражено с помощью вектора, где каждый компонент вектора соответствует одной строке. Например, вектор 350, содержащий четыре значения вероятности, получен в качестве выходных данных из модуля машинного обучения 320. Значение каждого компонента вектора 350 может представлять значение вероятности появления для каждой из строк 310. Значение компонента вектора, наиболее близкое к значению «один» по сравнению со значениями других компонентов, соответствует строке, имеющей самую высокую вероятность появления. Например, первый компонент вектора 350 содержит наивысшее значение вероятности 331 со значением «1», в то время как все остальные значения равны «0». Таким образом, если множество строк отражает различные варианты распознавания слова, то строка, которая дает наибольшее значение вероятности, может быть строкой, которая представляет наиболее вероятный вариант распознавания слова. На Фиг. 4 представлено получение из модуля машинного обучения 320 вероятности появления 331 для строки 311. Вероятность 331 приведена для искомого символа 311е, исходя из контекста до искомого символа и контекста после искомого символа.
[0040] На Фиг. 5 приведен пример вычислительной системы 500, которая может выполнять один или более способов, описанных в настоящем документе, в соответствии с одним или более вариантами реализации настоящего изобретения. В одном из примеров вычислительная система 500 может соответствовать вычислительному устройству, способному выполнять способ 200, представленный на Фиг. 2. Эта вычислительная система 500 может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система 500 может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система 500 может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB, set-top box), карманный персональный компьютер (PDA, Personal Digital Assistant), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных здесь способов или нескольких таких способов.
[0041] Пример вычислительной системы 500 включает устройство обработки 502, основную память 504 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например синхронное DRAM (SDRAM)), статическую память 506 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 518, которые взаимодействуют друг с другом по шине 530.
[0042] Устройство обработки 502 представляет собой одно или более устройств обработки общего назначения, например микропроцессоров, центральных процессоров или аналогичных устройств. В частности, устройство обработки 502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборов команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 502 также может представлять собой одно или более устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Устройство обработки 502 реализовано с возможностью выполнения инструкций в целях выполнения рассматриваемых в этом документе операций и шагов.
[0043] Вычислительная система 500 может дополнительно включать устройство сопряжения с сетью 508. Вычислительная система 500 может также включать видеомонитор 510 (например, жидкокристаллический дисплей (LCD) или электронно-лучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 512 (например, клавиатуру), устройство управления курсором 514 (например, мышь) и устройство для формирования сигналов 516 (например, громкоговоритель). В одном иллюстративном примере видеодисплей 510, устройство буквенно-цифрового ввода 512 и устройство управления курсором 514 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0044] Устройство хранения данных 518 может содержать машиночитаемый носитель данных 528, в котором хранятся инструкции 522, реализующие одну или более методик или функций, описанных в настоящем документе. Инструкции 522 могут также находиться полностью или по меньшей мере частично в основном запоминающем устройстве 504 и (или) в устройстве обработки 502 во время выполнения вычислительной системой 500, основным запоминающим устройством 504 и устройством обработки 502, также содержащими машиночитаемый носитель информации. Инструкции 522 могут дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 508.
[0045] Несмотря на то что машиночитаемый носитель данных 528 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как содержащий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0046] Несмотря на то что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться по крайней мере частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0047] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0048] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0049] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сформулирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0050] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «настройка» и т.п., относятся к действиям компьютерной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах компьютерной системы и памяти в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[0051] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0052] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[0053] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает процедуры хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютер) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[0054] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя А; X включает в себя В; или X включает А и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «аn», использованные в англоязычной версии этой заявки и в прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» или «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
Извлечение сущностей из текстов на естественном языке
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Способ извлечения фактов из текстов на естественном языке
Метод и система для генерации статей в словаре естественного языка
Система для создания документов на основе анализа текста на естественном языке
Определение степеней уверенности, связанных со значениями атрибутов информационных объектов
Автоматическое обучение программы синтаксического и семантического анализа с использованием генетического алгоритма
Сентиментный анализ на уровне аспектов и создание отчетов с использованием методов машинного обучения
Использование глубинного семантического анализа текстов на естественном языке для создания обучающих выборок в методах машинного обучения
Выявление словосочетаний в текстах на естественном языке
Расширение возможностей информационного поиска
Многоэтапное распознавание именованных сущностей в текстах на естественном языке на основе морфологических и семантических признаков
Классификация текстов на естественном языке на основе семантических признаков
Сопоставление разметки для похожих документов
Восстановление текстовых аннотаций, связанных с информационными объектами
Сегментация текста
Использование автоэнкодеров для обучения классификаторов текстов на естественном языке
Извлечение информационных объектов с использованием комбинации классификаторов, анализирующих локальные и нелокальные признаки
Обучение нейронных сетей с использованием функций потерь, отражающих зависимости между соседними токенами

