Результат интеллектуальной деятельности: СОПОСТАВЛЕНИЕ РАЗМЕТКИ ДЛЯ ПОХОЖИХ ДОКУМЕНТОВ
Вид РИД
Изобретение
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[001] Настоящее изобретение относится к вычислительным системам, в частности к системам и способам извлечения информации из текстов на естественном языке.
УРОВЕНЬ ТЕХНИКИ
[002] Извлечение информации - одна из важнейших операций при автоматической обработке текстов на естественном языке. Извлечение информации из текстов на естественном языке может быть затруднено многозначностью, которая является неотъемлемой особенностью естественных языков. Точное и своевременное извлечение информации, в свою очередь, может требовать значительных ресурсов. Извлечение информации можно оптимизировать за счет использования правил извлечения, с помощью которых идентифицируется конкретная информация в этих документах.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] Варианты реализации настоящего изобретения описывают создание разметки в документе на основе разметки похожих документов. В соответствии с различными аспектами настоящего изобретения пример способа для системы проецирования разметки документа получает целевой документ, включающий текстовый контент, определяет множество похожих документов с использованием индекса сохраненных документов, при этом каждый из похожих документов из полученного множества похожих документов похож на целевой документ, и выбирает первый похожий документ из набора похожих документов, который наиболее похож на целевой документ. Система проецирования разметки документа определяет одно или более различий между текстовым контентом целевого документа и текстовым контентом первого похожего документа, определяет первую координату первой разметки в первом похожем документе, определяет проецируемую позицию разметки для целевого документа с учетом одного или более различий между текстовым контентом целевого документа и текстовым контентом первого похожего документа и сохраняет проецируемую разметку для целевого документа.
[004] В соответствии с различными аспектами настоящего изобретения пример системы проецирования разметки документа получает целевой документ, включающий текстовый контент, определяет множество похожих документов с использованием индекса сохраненных документов, при этом каждый из похожих документов из полученного множества похожих документов похож на целевой документ, и выбирает первый похожий документ из набора похожих документов, который наиболее похож на целевой документ. Система проецирования разметки документа определяет одно или более различий между текстовым контентом целевого документа и текстовым контентом первого похожего документа, определяет первую координату первой разметки в первом похожем документе, определяет проецируемую позицию разметки для целевого документа с учетом одного или более различий между текстовым контентом целевого документа и текстовым контентом первого похожего документа и сохраняет проецируемую разметку для целевого документа.
[005] В соответствии с различными аспектами настоящего изобретения пример машиночитаемого носителя данных может включать инструкции, которые при обращении к ним обрабатывающего устройства приводят к выполнению операций обрабатывающим устройством, которое получает целевой документ, включающий текстовый контент, определяет множество похожих документов с использованием индекса сохраненных документов, при этом каждый из похожих документов из полученного множества похожих документов похож на целевой документ, и выбирает первый похожий документ из набора похожих документов, который наиболее похож на целевой документ. Далее, обрабатывающее устройство определяет одно или более различий между текстовым контентом целевого документа и текстовым контентом первого похожего документа, определяет первую координату первой разметки в первом похожем документе, определяет проецируемую позицию разметки для целевого документа с учетом одного или более различий между текстовым контентом целевого документа и текстовым контентом первого похожего документа и сохраняет проецируемую разметку для целевого документа.
Технический результат от внедрения системы проецирования разметки документов на основе анализа похожих документов состоит в повышении эффективности извлечения информации за счет сокращения времени предобработки документов и в повышении точности извлекаемой информации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[006] Для более полного понимания настоящего изобретения ниже приводится подробное описание, в котором для примера, а не способом ограничения, оно иллюстрируется со ссылкой на чертежи, на которых:
[007] На Фиг. 1 представлена высокоуровневая схема типовой системы проецирования разметки в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[008] На Фиг. 2А представлен пример целевого документа в соответствии с одним или более вариантами реализации настоящего изобретения.
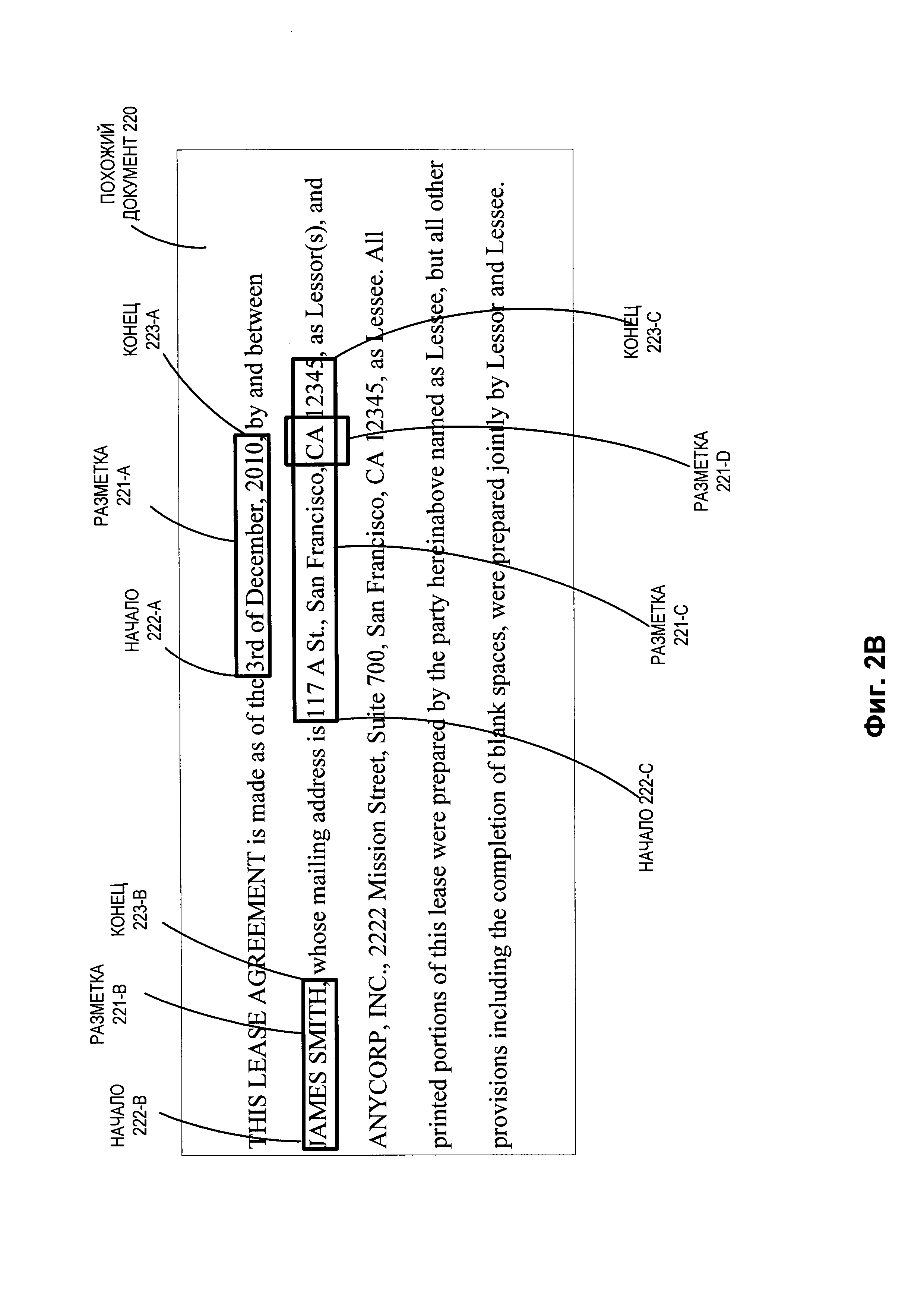
[009] На Фиг. 2В представлен пример похожего документа с разметкой в соответствии с одним или более вариантами реализации настоящего изобретения.
[0010] На Фиг. 2С представлен пример измененного целевого документа с разметкой на основе разметки для похожего документа на Фиг. 2В, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0011] На Фиг. 3 представлена блок-схема одного из способов создания проецируемой разметки на основе похожих документов в соответствии с одним или более вариантами реализации настоящего изобретения.
[0012] На Фиг. 4 представлена блок-схема одного из способов определения позиций проецируемой разметки на основе похожего документа, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0013] На Фиг. 5 представлена блок-схема одного из способов выявления вложенной проецируемой разметки целевого документа на основе контекста в соответствии с одним или более вариантами реализации настоящего изобретения.
[0014] На Фиг. 6 представлена блок-схема типовой вычислительной системы, взятой как пример и работающей в соответствии с примерами реализации настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0015] В настоящем документе описаны способы и системы проецирования разметки документа на основе анализа похожих документов. Извлечение данных может быть оптимизировано с помощью применения правил извлечения. Однако этот тип оптимизации может быть ограниченным, поскольку различные типы документов могут быть связаны с различными правилами. Таким образом, применение одного набора правил для различных типов документов может не обеспечивать требуемой эффективности. Аналогичным образом применение различных наборов правил для различных типов документов может приводить к выполнению большого объема затратных операций для определения типа документа, прежде чем появится возможность выбора конкретного правила извлечения. В некоторых вариантах реализации документы могут содержать «разметку», с помощью которой маркируются или иным образом определяются подлежащие извлечению области текста в документе. Использование разметки может сократить объем и, как следствие, время обработки, требуемые для извлечения данных, однако выявление размечаемых фрагментов и собственно разметка текста зачастую могут требовать значительного объема ручного труда.
[0016] Указанные выше и другие недостатки устраняются в настоящем изобретении за счет применения механизмов автоматической обработки текстов на естественном языке для создания разметки целевого документа на основе анализа документов, похожих на целевой документ. Таким образом разметка, связанная с похожим документом (документами), может быть «спроецирована» с похожего документа на целевой документ на основе анализа точек расхождения между документами. Документы считаются похожими, если у них похожая структура, имеется определенный процент похожих слов, определенный процент похожих символов и т.п. В различных вариантах реализации похожесть документов может быть определена за счет применения семантического анализа, синтаксического анализа, сопоставления структур, сопоставления контекстов или иным способом (например, такими методами определения похожести как алгоритм шинглов, n-грамма, MinHash, набор слов и т.п.).
[0017] В иллюстративном примере система проецирования разметки документа получает целевой документ на естественном языке без какой-либо разметки. Под целевым документом на естественном языке понимается документ, содержащий текстовый контент (например, текстовый документ, документ в редактируемом формате, документ после оптического распознавания символов (OCR)). Затем система проецирования разметки документов может обратиться к индексу документов для определения документов, похожих на целевой документ. После чего система проецирования разметки документов может сопоставить наиболее похожие документы с целевым для выявления различий между документами и использовать выявленные различия для формирования разметки целевого документа. Затем точки похожих разметок объединяются с точками различий между документами и могут использоваться для определения координат соответствующей разметки в целевом документе.
[0018] Таким образом, варианты реализации настоящего изобретения способствуют более эффективному выявлению значимого контента для целевого текстового документа при минимальном ручном труде или без такового. Объем обработки для создания разметки новых целевых документов может быть значительно сокращен за счет выявления похожих документов, уже содержащих информацию о разметке.
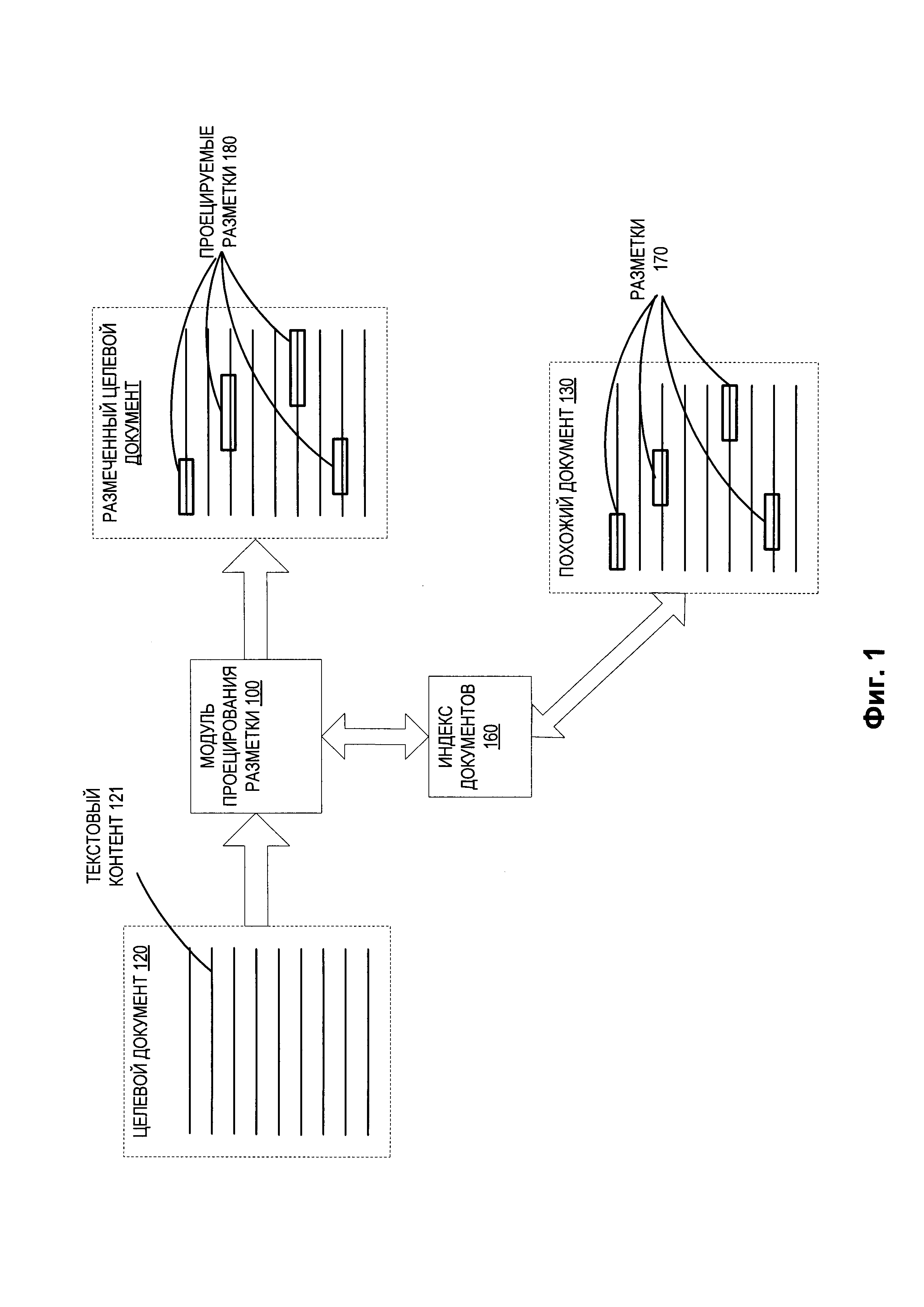
[0019] На Фиг. 1 приведена схема компонентов для типовой системы проецирования разметки документов в соответствии с одним или более вариантами реализации настоящего изобретения. Система проецирования разметки документов может включать модуль проецирования разметки 100 и индекс документов 160. Модуль проецирования разметки 100 может представлять собой клиентское приложение или сочетание компонентов, базирующихся на рабочей станции клиента и на сервере. В некоторых вариантах реализации изобретения модуль проецирования разметки 100 может работать на вычислительном устройстве клиента - к примеру, это может быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.п. В альтернативном варианте реализации клиентский компонент модуля проецирования разметки 100, исполняемый на клиентском вычислительном устройстве, может получать документ и передавать его на серверный компонент модуля проецирования разметки 100, исполняемый на серверном устройстве, который выполняет проецирование разметки документа. Серверный компонент модуля проецирования разметки 100 затем может возвратить документ с разметкой на клиентский компонент модуля проецирования разметки 100, исполняемый на клиентском вычислительном устройстве для хранения или отображения для пользователя. В других вариантах реализации изобретения модуль проецирования разметки 100 может быть запущен на исполнение на серверном устройстве в качестве интернет-приложения, доступ к которому обеспечивается через интерфейс интернет-браузера. Примером серверного устройства могут быть одна или несколько вычислительных систем - одно или более таких устройств, как серверы, рабочие станции, большие ЭВМ (мейнфреймы), персональные компьютеры (ПК) и т.д.
[0020] В иллюстративном примере модуль проецирования разметки 100 может получать целевой документ 120, содержащий текстовый контент 121 на естественном языке. В одном из вариантов реализации изобретения модуль проецирования разметки 100 может принимать целевой документ 120 через приложение для ввода текста, представленный уже существующим документом, содержащим текстовый контент (например, электронный документ, включающий текстовый контент, такой как текстовый документ, документ в редактируемом формате, документ после оптического распознавания символов (OCR), документ в формате PDF с текстовым слоем и т.д.) или иным аналогичным способом. В качестве альтернативного варианта реализации изобретения, модуль проецирования разметки 100 может принимать изображение текста (снятое, к примеру, на камеру мобильного устройства), а затем выполнять оптическое распознавание символов (OCR) в пределах изображения. Помимо этого, модуль проецирования разметки 100 может принимать от пользователя речевую аудиозапись (к примеру, надиктованную на микрофон вычислительного устройства) и преобразовывать ее в текстовую форму при помощи программного средства расшифровки диктофонных записей.
[0021] Затем модуль проецирования разметки 100 может сформировать разметку проецируемого документа для целевого документа 120 на основе разметки документов, связанной с документами, похожими на целевой документ 120. Разметка документа является указанием на последовательность символов (например, цепочку символов) для текстового документа на естественном языке, описывающим значение этой последовательности символов. Разметка может использоваться системами обработки документов для извлечения текста, связанного с разметкой. Например, в документе типа «договор» может быть важным извлечь наименования и адреса сторон договора, существенные факты и (или) параметры договора и иную подобную информацию. Разметка может быть определена координатами этих фрагментов текста внутри соответствующего документа (исходная точка, конечная точка и т.д.), а также по типу или категории (например, наименование, адрес, страна, почтовый индекс, местонахождение собственности и т.д.). В некоторых вариантах реализации разметка может храниться в виде метаданных, связанных с документом. В качестве альтернативного варианта разметка может быть определена как расположение полей в документе (например, поле формы в документе PDF, поле формы в редактируемом документе и т.д.)
[0022] Для создания проецируемой разметки для целевого документа 120 модуль проецирования разметки 100 может сначала выявить документы, похожие на целевой документ 120. В некоторых вариантах реализации модуль проецирования разметки 100 может выполнить это путем доступа к поисковому индексу документов 160, содержащему индекс одного или более документов, имеющих соответствующие разметки. Индекс документов 160 может быть расширен на основе процесса обучения, при этом информация, связанная с одним или более документами, хранится в индексе 160. Каждый документ, содержащий связанную информацию в индексе 160, может включать собственную разметку, которая также может храниться в индексе. В некоторых вариантах реализации в индексе хранится текст документа. В альтернативном варианте реализации в индексе хранятся идентификаторы, ссылающиеся на выраженные в координатах положения в пределах соответствующих индексированных документов, чтобы была возможность быстро найти соответствующий текст.
[0023] В различных вариантах реализации индекс 160 может быть представлен таблицей, в которой каждое слово (например, лексема или словоформа) документа связано с перечнем идентификаторов или адресов экземпляров слова в документе. В некоторых вариантах реализации при выполнении морфологического, синтаксического, лексического и (или) семантического анализа индекс 160 может быть создан для индексации результатов анализа (например, параметров, сформированных в результате анализа). В некоторых вариантах реализации индекс 160 также может содержать ссылки на любые содержащиеся в документе разметки. В индексе 160 могут храниться ссылки на разметки аналогично способам хранения слов, символов и т.д. В таких случаях в индексе 160 могут храниться ссылки на идентификатор разметки (например, тег заголовка, наименования, дескриптора), чтобы можно было определить координаты разметок с похожими идентификаторами с помощью индекса 160. Например, если в индексе 160 хранится информация для многочисленных документов об аренде, каждый из которых содержит разметку со словом «арендодатель», индекс 160 может использоваться для поиска документов, чтобы найти имена «арендодателей» в документах аренды, используя поисковый запрос.
[0024] В некоторых вариантах реализации модуль проецирования разметки 100 может получать доступ непосредственно к индексу документов 160. В альтернативном варианте реализации модуль проецирования разметки 100 может инициировать запуск другого системного компонента или модуля (не показаны), которые имеют доступ к индексу 160, для определения документов, похожих на целевой документ 120. Модуль проецирования разметки 100 может определить похожесть документов за счет применения семантического анализа, синтаксического анализа, сопоставления структур, сопоставления контекстов или иным способом (например, такими методами определения похожести как алгоритм шинглов, n-грамма, MinHash, набор слов и т.п.). В одном из вариантов реализации модуль проецирования разметки 100 может определить набор похожих документов, при этом каждый документ из набора документов похож на целевой документ 120, и каждый похожий документ из набора имеет соответствующую меру похожести. В другой реализации набор похожих документов может выбираться при помощи одного или комбинации нескольких классификаторов.
[0025] Значение меры похожести может быть вычислено в результате выполнения процесса, направленного на выявление похожих документов, и может быть принята в виде процентного отношения похожих слов в целевом документе, процентного отношения похожих символов в целевом документе и т.п. В некоторых вариантах реализации мера похожести может быть представлена в виде числового значения. Например, мера похожести со значением 0 может указывать на то, что документ не похож на целевой документ 120, а мера похожести 1 может указывать на то, что документ полностью совпадает с целевым документом. В других вариантах реализации мера похожести может быть представлена диапазоном числовых значений от 0 до 10, диапазоном числовых значений от 0 до 100, процентным диапазоном, диапазоном буквенных символов (от А до Z) и т.д.
[0026] Затем модуль проецирования разметки 100 может выбрать один или более наиболее похожих документов 130 из набора похожих документов для получения документов, «наиболее похожих» на целевой документ 120. В некоторых вариантах реализации модуль проецирования разметки 100 может сделать такой выбор путем ранжирования и (или) фильтрации набора похожих документов, полученных при выполнении поиска в индексе документов 160. В одном из вариантов реализации изобретения модуль проецирования разметки 100 может выполнить ранжирование набора похожих документов по связанной с ними мере похожести и выбрать документы из отсортированного перечня, который соответствует пороговому значению. Например, модуль проецирования разметки 100 может выбрать документы, у которых мера похожести больше 8 по шкале от 0 до 10. Модуль проецирования разметки 100 также может выбрать «наиболее похожие» документы путем выявления документа, мера похожести которого больше, чем соответствующие меры похожести у других документов в созданном индексом наборе документов. В другой реализации модуль проецирования разметки 100 выбирает наиболее похожие документы при помощи одного или комбинации нескольких классификаторов. В еще одной реализации модуль проецирования разметки 100 выбирает наиболее похожие документы методом попарного сравнения документов.
[0027] Затем модуль проецирования разметки 100 может начать процесс проецирования разметок 170 похожего документа 130 на целевой документ 120 путем определения одного или более отличий между текстовым контентом целевого документа 120 и текстовым контентом похожего документа 130. При определении различий между текстовым контентом целевого документа 120 и текстовым контентом похожего документа 130 модуль проецирования разметки 100 может определить места нахождения точек совпадения и точек несовпадения текста в этих двух документах. Поскольку похожесть документов уже была установлена, различия в текстовом контенте этих документов не должны существенно изменяться за пределами отдельных частей текста, в которых, вероятно, содержится разметка документа (например, наименования, адреса, места, серийные номера и т.д.). Таким образом, при определении точек соответствия и несоответствия модуль проецирования разметки может эффективно определить границы частей текста в целевом документе 120, соответствующие тексту в похожем документе 130 и включенные в разметку 170.
[0028] В некоторых реализациях, модуль проецирования разметки 100 может выбрать два или более наиболее похожих документов для использования в установлении проецируемой разметки. В таких случаях описанная выше процедура сравнения с целевым документом может быть повторена для каждого документа из набора наиболее похожих. Проецируемая разметка для целевого документа в этих случаях может определяться на основе процесса "голосования", который учитывает расположение общих точек совпадения текста и несовпадения текста по каждому из наиболее похожих документов (например, количество «перекрытий» совпадения текста и несовпадение текста между целевым документом и наиболее похожими документами). В таких случаях проецируемая разметка для целевого документа может быть определена на основе комбинации нескольких вариантов соответствующих разметок из похожих документов, где каждый вариант разметки является результатом сравнения одного из выбранных документов из множества наиболее похожих документов с целевым документом. Чтобы определить начальную и конечную координату комбинированной проецируемой разметки, для каждого интервала текста в целевом документе вычисляется число «голосов», соответствующих интервалу текста в выбранных наиболее похожих документах. Таким образом, количество голосов может представлять число наиболее похожих документов, для которых определенный диапазон текста находится в общем интервале. Интервалы, имеющие число голосов отдельных разметок, превышающие пороговое значение, могут быть использованы для определения границ комбинированной проецируемой разметки.
[0029] Модуль проецирования разметки 100 может определить отличия за счет выявления одной или более частей текстового контента в одном или более похожем документе 130, отличающихся от соответствующей одной или более частей текстового контента в целевом документе 120. В некоторых вариантах реализации модуль проецирования разметки 100 может определить отличия за счет сопоставления целевого документа 120 с похожим документом 130 по каждому символу. Таким образом, при выполнении этого процесса можно определить координаты (или иную информацию о положении) отличающихся фрагментов текста в каждом документе. Иными словами, модуль проецирования разметки 100 может определить расположения точек несовпадения (и точек совпадения текста) между целевым документом 120 и похожим документом 130.
[0030] После установления различий между документами модуль проецирования разметки 100 может определить координаты разметки 170 в похожем документе 130, при этом каждая разметка 170 может быть связана с частью текстового контента похожего документа 170. Затем модуль проецирования разметки 100 может определить проецируемые разметки 180 для целевого документа 120 путем анализа различий между документами. Таким образом, в ходе этого процесса может создаваться проецируемая разметка 180, соответствующая разметке 170 похожего документа. В некоторых вариантах реализации разметка 180 создается путем определения координат для частей текста в целевых документах 120 для частей несовпадения целевого документа 120 и похожего документа 130 или множества наиболее похожих документов. Аспекты настоящего процесса более подробно описаны ниже со ссылкой на Фиг. 2А-2С.
[0031] После определения проецируемой разметки 180 для целевого документа 120 модуль проецирования разметки 100 затем может сохранить разметки 180 для целевого документа 120. Как показано на Фиг. 1, получившийся в результате документ может быть сохранен как новый размеченный документ 140, содержащий текстовый контент целевого документа 120, а также проецируемую разметку 180. В других вариантах реализации проецируемая разметка 180 может сохраняться в исходном целевом документе 120, а не создавать новый документ. Как описано выше, проецируемая разметка 180 может быть вложена в сам документ или сохраняться отдельно в виде ассоциированных с документом метаданных. В некоторых вариантах реализации размеченный целевой документ 140 и его соответствующая проецируемая разметка 180 далее могут быть проиндексированы в индексе документов 160 для использования с дальнейшей обработкой документов. Например, размеченный целевой документ 140 и соответствующая ему проецируемая разметка 180 могут быть включены обучающую выборку данных, которая может использоваться для дальнейшего совершенствования проекций разметки. Следует отметить, что за счет этого обеспечивается дополнительная эффективность, поскольку выполнение разметки вручную обычно является весьма затратным.
[0032] В некоторых вариантах реализации размеченный целевой документ 140 и соответствующие ему проецируемые разметки 180 могут быть получены для использования в системе извлечения данных на основе проецируемых разметок 180. В некоторых вариантах реализации система извлечения данных может принимать размеченный целевой документ 140, определять места расположения проецируемых разметок 180 и извлекать части текста в этих местах. Затем извлеченный текст может использоваться для заполнения онлайн-форм, полей баз данных и т.п. Например, проецируемая разметка 180 для договора аренды может извлекать особые детали договора и вносить их в базу данных. Размеченные документы могут также использоваться системами машинного перевода для перевода информации, включенной в разметку, на другие языки. Поскольку с помощью разметки в документе обычно можно определить именованные сущности или иное важное содержимое, которое необходимо перевести на другой язык определенным образом, внедрение разметки в системы машинного перевода может способствовать повышению эффективности перевода. Таким образом, при применении настоящего изобретения может быть обеспечен более эффективный способ определения важной информации в текстовых документах для извлечения данных. Следует отметить, что модуль проецирования разметки 100 может выполнять проецирование разметки в соответствии с приведенным выше описанием без применения комплексного, глубокого семантического и синтаксического анализа текстовых документов, применяемого традиционными системами.
[0033] На Фиг. 1 показан в простой форме один похожий документ 130, однако, следует отметить, что может быть выявлено несколько похожих документов 130 для использования при создании проецируемой разметки 180. В иллюстративном примере модуль проецирования разметки 100 может принять целевой документ, содержащий два абзаца текста и выявить похожие документы - один документ, наиболее похожий на первый абзац целевого документа, а другой - наиболее похожий на второй абзац целевого документа. Затем модуль проецирования разметки 100 с помощью разметки первого похожего документа может создать проецируемую разметку для первого абзаца целевого документа. Аналогичным образом модуль проецирования разметки 100 с помощью разметки второго похожего документа может создать проецируемую разметку для второго абзаца целевого документа.
[0034] На Фиг. 2А-2С показан пример проецирования разметок для целевого документа на основе разметок выявленных похожих документов, как описано выше со ссылкой на Фиг. 1. На Фиг. 2А-2С в простой форме показаны конкретные типы текстовых документов и разметок, однако следует отметить, что могут быть проанализированы и другие типы разметок для создания проецируемых разметок для других типов текстового контента. На Фиг. 2А показан пример целевого документа 200, включающего часть текстового контента договора аренды между двумя сторонами. Как показано на Фиг. 2А, договор аренды датирован 12 декабря 2010 года и заключен между «John Doe» и «АВС, INC.».
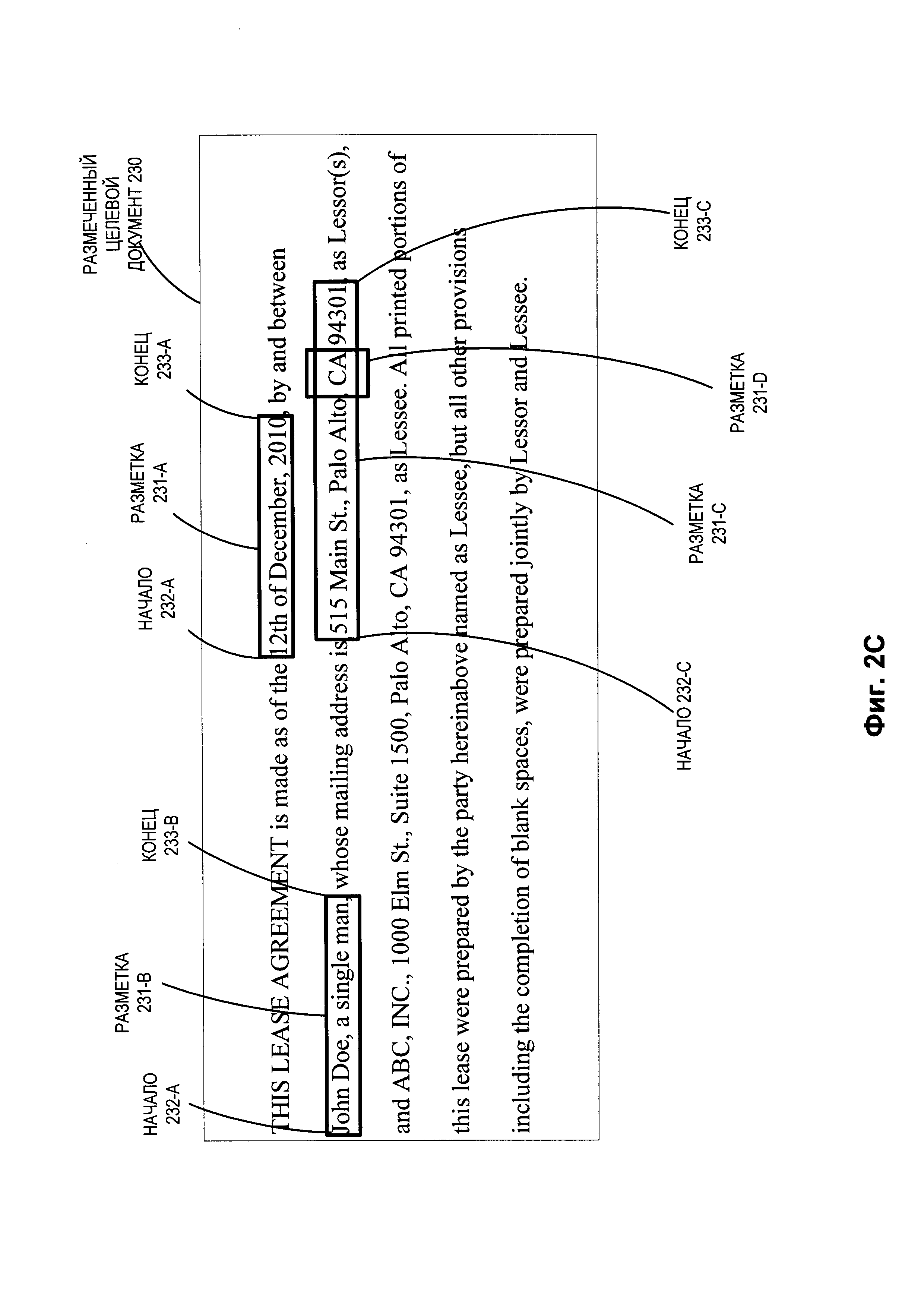
[0035] На Фиг. 2В показан пример похожего документа 220, включающего часть текстового контента для договора аренды с похожей структурой между двумя сторонами, а также разметки, соотнесенные с несколькими фрагментами текста в договоре. Как показано на Фиг. 2В, договор аренды датирован 3 декабря 2010 года и заключен между «JAMES SMITH» и «ANYCORP, INC.». Похожий документ 220 содержит разметки 221-А, 221-В, 221-С и 221-D. Разметка 221-А связана с фрагментом текстового контента, содержащим дату договора аренды с начальной координатой разметки (начало) 222-А и конечной координатой разметки (конец) 223-А. Разметка 221-В связана с фрагментом текстового контента, который содержит наименование одной из сторон договора аренды ("JAMES SMITH") с начальной координатой разметки (начало) 222-В и конечной координатой разметки (конец) 223-В. Разметка 221-С связана с фрагментом текстового контента, который содержит адрес одной из сторон договора аренды с начальной координатой разметки (начало) 222-С и конечной координатой разметки (конец) 223-С. Разметка 221-D связана с фрагментом текстового контента, который содержит часть, относящуюся к штату в адресе одной из сторон договора аренды с начальной координатой разметки (начало) 222-D и конечной координатой разметки (конец) 223-D. Следует отметить, что разметка 221-D связана с фрагментом текста, которая связан с разметкой 221-А (т.е. вложенная разметка).
[0036] Как указано выше со ссылкой на Фиг. 1, модуль проецирования разметки 100 может использовать информацию разметки, хранящуюся с похожим документом 220, для определения координат разметок 221-А, 221-В, 221-С и 221-В (например, информацию о соответствующих координатах начала и конца для каждой разметки). После определения всех этих координат модуль проецирования разметки 100 может использовать координаты разметки в сочетании с точками расхождения между целевым документом 200 и похожим документом 220 (например, координаты, в которых имеются различия между текстом документов) для создания проецируемых разметок для целевого документа 200. Этот процесс более подробно описан ниже со ссылкой на Фиг. 2С.
[0037] На Фиг. 2С показан пример измененного целевого документа, содержащего разметки на основе разметок похожего документа 220 на Фиг. 2В. Проецируемые разметки 231-А, 231-В, 231-С и 231-D могут быть созданы для целевого документа 200 с помощью модуля проецирования разметки 100, как описано выше со ссылкой на Фиг. 1. В некоторых вариантах реализации модуль проецирования разметки 100 может определить точку расхождения между целевым документом 200 и похожим документом 220 на основе различий между текстовым контентом двух документов. Например, как показано выше со ссылкой на Фиг. 2А-2В, текстовый контент двух документов является идентичным во фрагментах текста, содержащих контент «THIS LEASE AGREEMENT is made as of the» (НАСТОЯЩИЙ ДОГОВОР АРЕНДЫ заключен). Первое выявленное отличие между двумя документами (и, следовательно, первая точка расхождения) находится в начале фрагмента текста, который включает дату договора в каждом документе (например, 12, а не 3 декабря).
[0038] Затем модуль проецирования разметки 100 может определить, находится ли точка расхождения между начальной и конечной точкой разметки в похожем документе 220. Если да, то модуль проецирования разметки 100 может задать начальную координату проецируемой разметки в целевом документе 200 в соответствии с конечным положением предыдущего фрагмента текста, который является идентичным для похожего документа 220. Например, как указано выше, первая точка расхождения между целевым документом 200 и похожим документом 220 находится в начальной координате содержащего дату текста. Это расхождение находится между началом 222-А и концом 223-А (координаты начала и конца разметки 221-А). Модуль проецирования разметки 100 может определить, что фрагмент текстового контента в похожем документе 220, предшествующего началу 222-А («ТНК LEASE AGREEMENT is made as of the» (НАСТОЯЩИЙ ДОГОВОР АРЕНДЫ заключен)), соответствует фрагменту текста в целевом документе 200. Затем модуль проецирования разметки 100 может задать начальную координату для проецируемой разметки 231-А в размеченном целевом документе 230 в соответствии с конечной координатой совпадающего фрагмента текста в целевом документе. Таким образом, начало 232-А может быть задано в месте окончания текста «THIS LEASE AGREEMENT is made as of the» (НАСТОЯЩИЙ ДОГОВОР АРЕНДЫ заключен).
[0039] Затем модуль проецирования разметки 100 может определить конечную координату проецируемой разметки 231-А для целевого документа. Модуль проецирования разметки 100 может выполнить такое определение за счет установления фрагмента текстового контента после конечной координаты разметки в похожем документе 220 (координаты конца 223-А разметки 221-А на Фиг. 2В), которое соответствует фрагменту текста в целевом документе 200. Как показано на Фиг. 2А-2В, фрагмент текста «by and between» (между) следует за разметкой 221-А в похожем документе 220 и соответствует фрагменту текста после текста с указанием даты в целевом документе 200. Затем модуль проецирования разметки 100 может задать конечную координату для проецируемой разметки в целевом документе в соответствии с начальной координатой совпадающего фрагмента текста. Таким образом, конец 233-А на Фиг. 2С может быть задан в соответствии с начальным положением текста «by and between» (между).
[0040] Описанный выше процесс может повторяться для каждой разметки 221-В и 221-С похожего документа 220 для создания проецируемых разметок 231-В и 231-С для размеченного целевого документа 230. В некоторых случаях, поскольку проецируемые разметки целевого документа частично основаны на точках расхождения между целевым и похожим документами, начальные или конечные координаты проецируемых разметок могут содержать дополнительный текст в сопоставлении с соответствующей разметкой похожего документа. Такой случай показан в проецируемой разметке 231-В на Фиг. 2С. При анализе разметки 221-В на Фиг. 2В (похожий документ 220) для определения конечной координаты 231-В в целевом документе, показанном на Фиг. 2С, модуль проецирования разметки 100 определяет фрагмент текста в похожем документе 220, который следует за конечной координатой разметки 221-В в похожем документе 220 (конечная координата 223-В на Фиг. 2В) и соответствует фрагменту текста в целевом документе 200. Как показано на Фиг. 2А-2В, фрагмент текста «whose mailing address is» (имеющим почтовый адрес) следует за разметкой 221-В в похожем документе 220 и соответствует фрагменту текста в целевом документе 200. Таким образом, конец 233-В на Фиг. 2С может быть задан в соответствии с начальной координатой текста «whose mailing address is» (имеющим почтовый адрес). Это может привести к тому, что разметка 231-В, связанная с именем одного из участников договора аренды, будет включать текст «а single man» (физическое лицо). Следует отметить, что этот текст включается в разметку для имени, но он может быть дополнительно проанализирован при последующей обработке, когда данные окончательно извлекаются из размеченного целевого документа 230. Таким образом, проецируемые разметки для целевого документа могут создаваться более быстро без дополнительных затрат на последующий анализ.
[0041] В некоторых вариантах реализации в похожих документах может присутствовать вложенная разметка. Например, как показано на Фиг. 2В, координаты разметки 221-D (штат нахождения Арендодателя) вложено в координаты разметки 221-А (полный адрес Арендодателя). В таких случаях модуль проецирования разметки 100 может применять эвристические правила для определения контекста разметки 221-D относительно разметки 221-А для создания соответствующей проецируемой разметки для целевого документа (например, разметка 231-D на Фиг. 2С). В иллюстративном примере модуль проецирования разметки 100 определяет координаты второй разметки 221-D в похожем документе 220, где вторая разметка связана с частью текстового контента похожего документа 220, который расположен между начальной координатой (начало 222-А) и конечной координатой (223-А) разметки 221-А (на Фиг. 2В). Затем модуль проецирования разметки 100 определяет контекст части текста, связанной с разметкой 221-D («СА»), как часть текста в разметке 221-А (весь адрес). Модуль проецирования разметки 100 может выполнить это определение путем применения семантического анализа, синтаксического анализа, сопоставления структуры, сопоставления контекста или любым иным способом.
[0042] После определения контекста вложенной разметки в похожем документе модуль проецирования разметки 100 может определить проецируемую разметку для целевого документа путем применения определяемого контекста к тексту в целевом документе. Например, как показано на Фиг. 2В, разметка 221-D расположена между начальной координатой (начало 222-С) и конечной координатой (конец 223-С) разметки 221-С. Модуль проецирования разметки 100 определяет, что текстовый контент разметки 221-D, включенный в текстовый контент всей разметки 221-С, соответствует штату в адресе. При создании соответствующей проецируемой разметки для разметки 221-D модуль проецирования разметки 100 может определить разметку, связанную с адресом в целевом документе (разметка 231-С на Фиг. 2С), и проанализировать текст этой разметки относительно выявленного контекста с целью определения текста, представляющего часть, соответствующую штату в адресе. Таким образом положение разметки 231-D может быть закреплено за частью текстового контента между началом 232-С и концом 233-С, который включает часть адреса, содержащую информацию о штате.
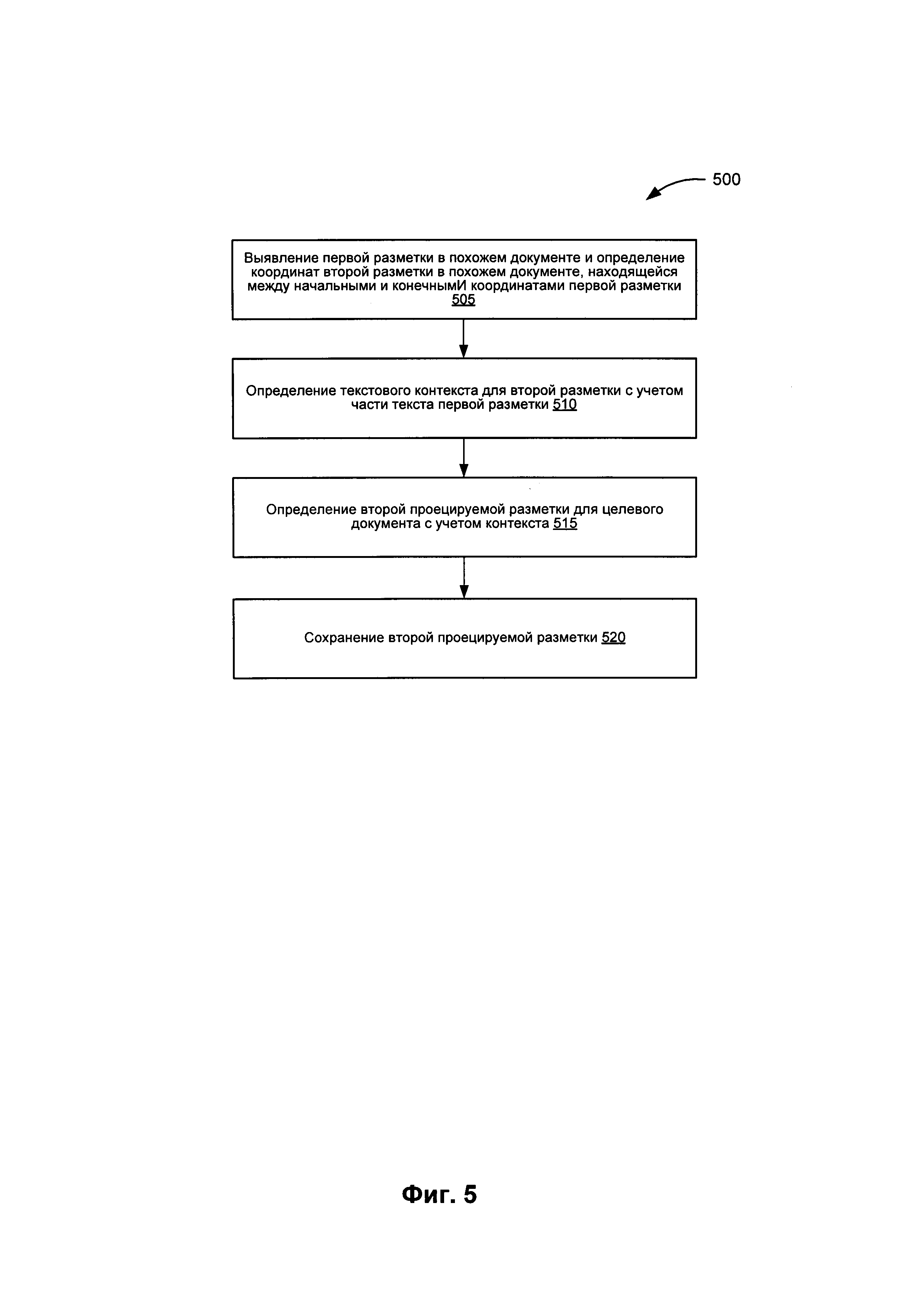
[0043] На Фиг. 3-5 представлены блок-схемы различных вариантов реализации способов, связанных с созданием проецируемых разметок для целевого документа на основе разметок похожих документов. Эти способы могут осуществляться при помощи системы обработки данных, которая может включать аппаратные средства (электронные схемы, специализированную логическую плату и т.д.), программное обеспечение (например, выполняться на универсальной ЭВМ или же на специализированной вычислительной машине) или комбинацию первого и второго. Представленные способы и (или) каждая из отдельно взятых функций, процедур, подпрограмм или операций могут быть реализованы с помощью одного или более процессоров вычислительного устройства (например, вычислительной системы 600 на Фиг. 6), в котором реализованы данные способы. В некоторых вариантах реализации изобретения представленные способы могут выполняться в одном потоке обработки. В альтернативных вариантах реализации изобретения представленные способы могут выполняться в двух и более потоках обработки в режиме обработки, при этом в каждом потоке реализована одна (или более) отдельно взятая функция, процедура, подпрограмма или операция, относящаяся к указанным способам. Некоторые из представленных способов могут осуществляться благодаря использованию модуля проецирования разметки, к примеру, модуля проецирования разметки 100 на Фиг. 1.
[0044] Ради простоты объяснения способы в настоящем описании изобретения изложены и наглядно представлены в виде последовательности действий. Однако действия в соответствии с настоящим описанием изобретения могут выполняться в различном порядке и (или) одновременно с другими действиями, не представленными и не описанными в настоящем документе. Кроме того, не все действия, приведенные для иллюстрации сущности изобретения, могут оказаться необходимыми для реализации способов в соответствии с настоящим описанием изобретения. Специалистам в данной области техники должно быть понятно, что эти способы могут быть представлены и иным образом - в виде последовательности взаимосвязанных состояний через диаграмму состояний или событий.
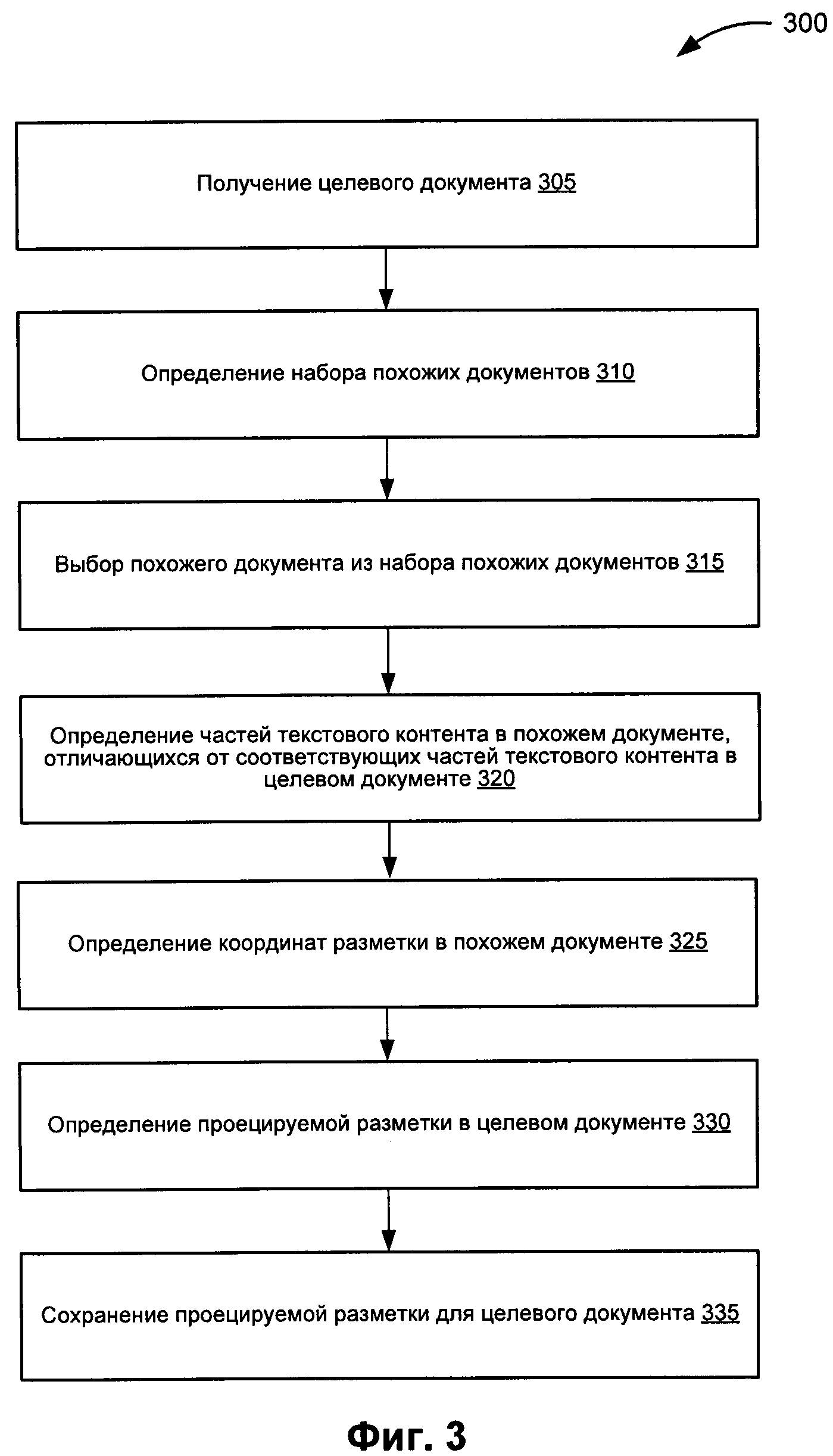
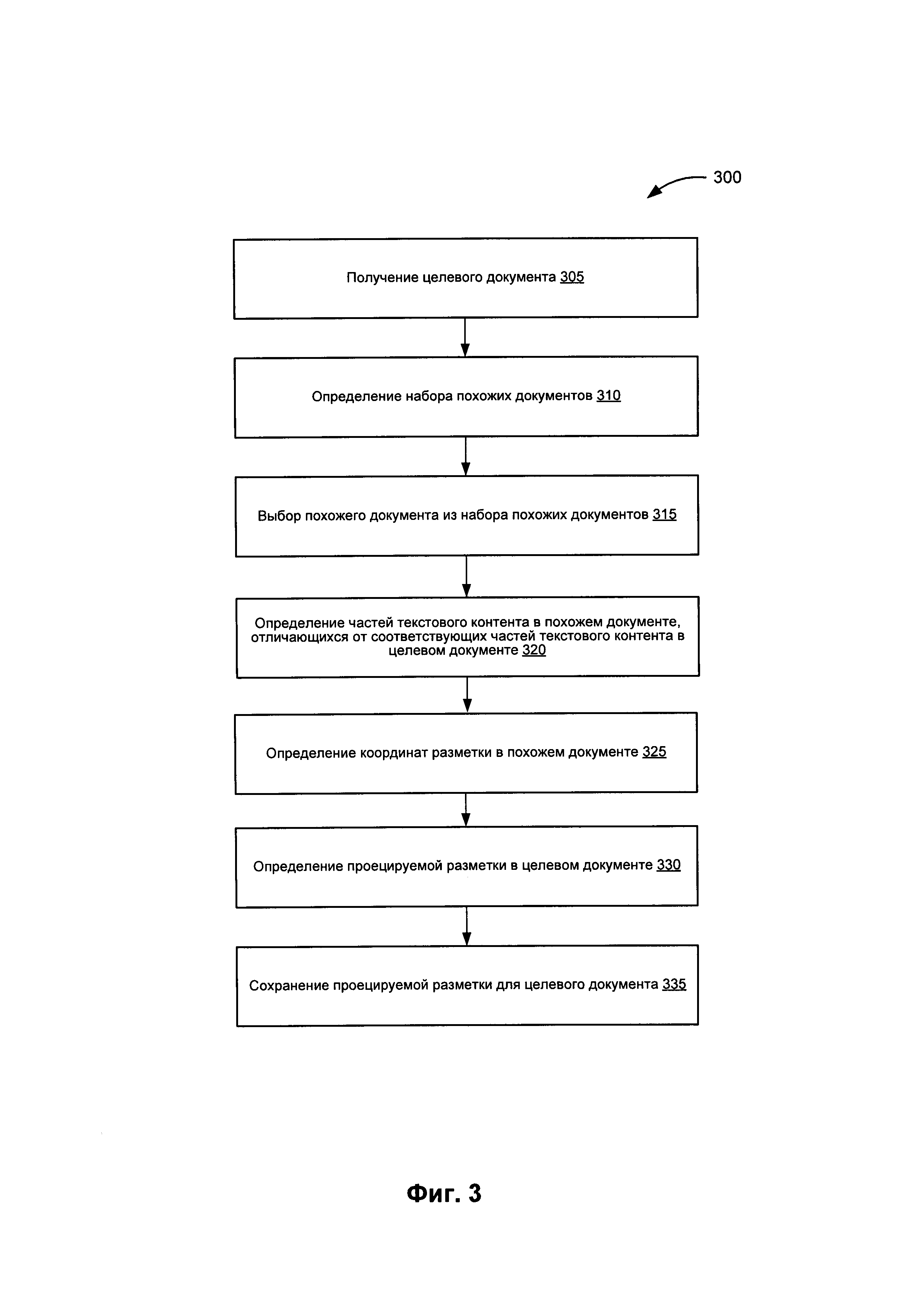
[0045] На Фиг. 3 представлена блок-схема примера реализации способа 300 для создания проецируемых разметок для целевого документа на основе похожих документов. На шаге 305 способа 300 алгоритм обработки получает целевой документ, включающий текстовый контент. На шаге 310 алгоритм обработки определяет набор похожих документов, при этом набор похожих документов содержит документы, похожие на целевой документ (например, похожие документы и целевой документ имеют похожую структуру, имеют определенное процентное содержание похожих слов, имеют определенное процентное содержание похожих символов и т.п.), и каждый похожий документ из набора похожих документов имеет соответствующее значение меры похожести. В некоторых вариантах реализации алгоритм обработки выполняет эту операцию с помощью индекса хранимых документов.
[0046] На шаге 315 блок-схемы алгоритм обработки выбирает похожий документ из набора похожих документов, выбранных на шаге 310. В некоторых вариантах реализации выбранный похожий документ является наиболее похожим на целевой документ с точки зрения соответствия меры похожести, связанной с выбранным похожим документом. В других вариантах реализации может быть выбрано более одного наиболее похожих документов, тогда последующие сравнения с целевым документом для каждого из выбранных документов могут выполняться последовательно или одновременно. На шаге 320 блок-схемы алгоритм обработки определяет одно или более различий между текстовым контентом целевого документа и текстовым контентом похожего документа, выбранного на шаге 315. В некоторых вариантах реализации алгоритм обработки может определить отличия за счет выявления одной или более частей текстового контента в похожем документе, отличающихся от соответствующей одной или более частей текстового контента в целевом документе. Например, алгоритм обработки может выполнить сопоставление текста похожего документа с текстом целевого документа с целью определения координат фрагментов текста, отличающихся у этих документов, а также координат фрагментов текста, одинаковых для обоих документов.
[0047] На шаге 325 алгоритм обработки определяет координаты разметки в похожем документе, при этом такая разметка связана с частью текстового контента в похожем документе. На шаге 330 алгоритм обработки определяет проецируемую разметку для целевого документа. В одном из иллюстративных примеров схема обработки может определять проецируемую разметку, как описано ниже со ссылкой на Фиг. 4. На шаге 335 с алгоритм обработки сохраняет проецируемую разметку для целевого документа. После шага 335 блок-схемы способ, представленный на Фиг. 3, завершается.
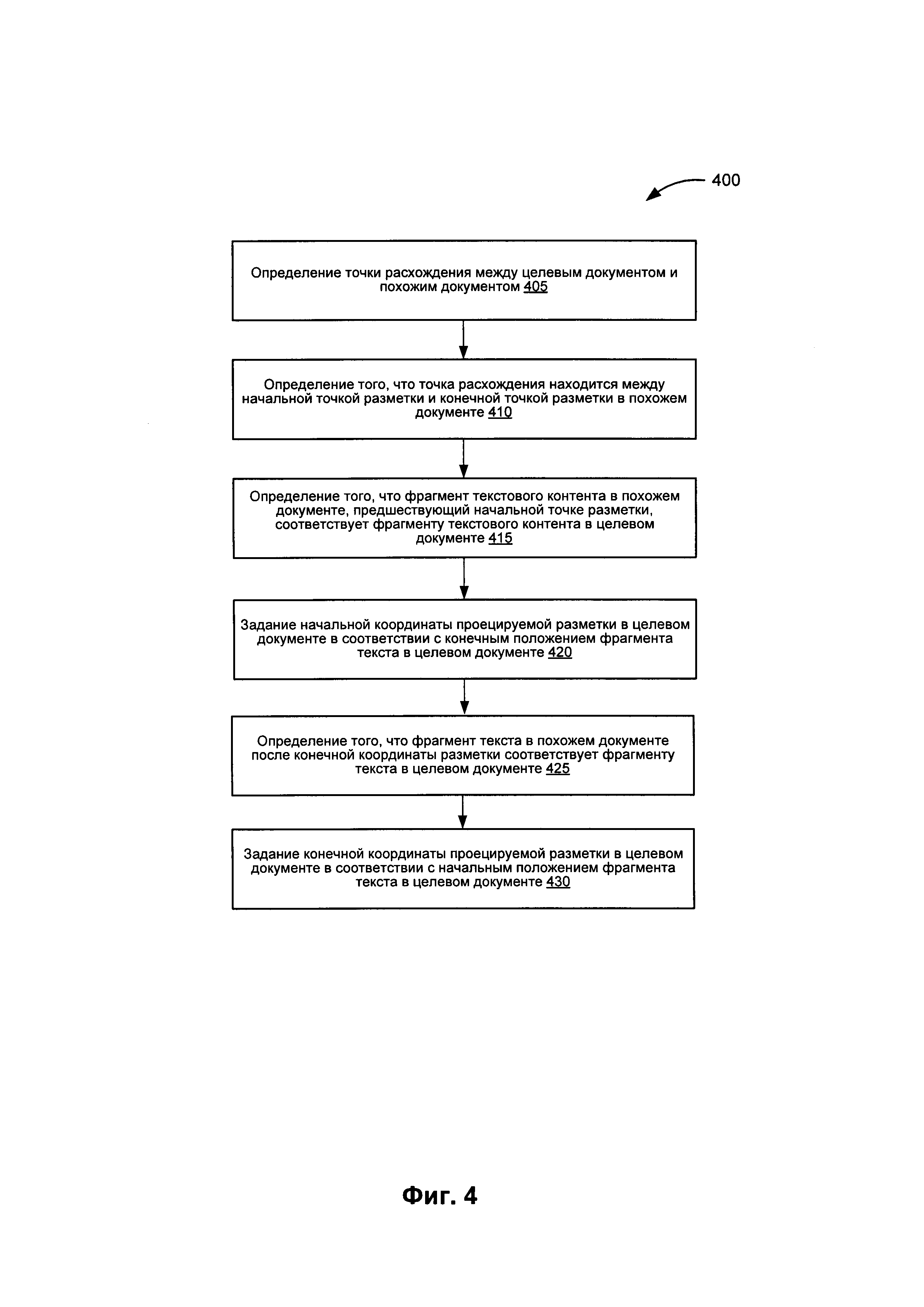
[0048] На Фиг. 4 представлена блок-схема примера реализации способа 400 для определения координат проецируемой разметки для целевого документа на основе похожего документа. На шаге 405 способа 400 алгоритм обработки определяет точку расхождения между целевым документом и похожим документом. В некоторых вариантах реализации такое определение выполняется на основе различий между текстовым контентом целевого документа и текстовым контентом похожего документа. На шаге 410 алгоритм обработки определяет, что точка расхождения находится между начальным положением координат разметки и конечным положением координат разметки в похожем документе.
[0049] На шаге 415 алгоритм обработки определяет, что фрагмент текстового контента в похожем документе, предшествующий начальному значению координат разметки, соответствует фрагменту текстового контента в целевом документе. На шаге 420 алгоритм обработки задает начальное значение координат проецируемой разметки в целевом документе в соответствии с конечным положением фрагмента текста в целевом документе. На шаге 425 алгоритм обработки определяет, что фрагмент текста в похожем документе, находящийся после конечного значения координат разметки, соответствует фрагменту текста в целевом документе. На шаге 430 алгоритм обработки задает конечное значение координат проецируемой разметки в целевом документе в соответствии с начальным положением соответствующего фрагмента текста в целевом документе, выявленным на шаге 425. После шага 430 представленный на Фиг. 4 способ завершается.
[0050] Следует отметить, что в реализациях, где при определении проецируемой разметки целевого документа для сравнения выбрано более одного наиболее похожего документа, вышеуказанные шаги способа, представленного на Фиг. 4, могут быть повторены для каждого выбранного из наиболее похожих документов. Проецируемая разметка для целевого документа в этих случаях может определяться на основе процесса "голосования", который учитывает расположение общих точек совпадения текста и несовпадения текста по каждому из наиболее похожих документов (например, количество «перекрытий» совпадения текста и несовпадение текста между целевым документом и наиболее похожими документами). В таких случаях проецируемая разметка для целевого документа может быть определена на основе комбинации нескольких вариантов соответствующих разметок из похожих документов, где каждый вариант разметки является результатом сравнения одного из выбранных документов из множества наиболее похожих документов с целевым документом. Чтобы определить начальную и конечную координату комбинированной проецируемой разметки, для каждого интервала текста в целевом документе вычисляется число «голосов», соответствующих интервалу текста в выбранных наиболее похожих документах. Таким образом, количество голосов может представлять число наиболее похожих документов, для которых определенный диапазон текста находится в общем интервале. Интервалы, имеющие число голосов отдельных разметок, превышающие пороговое значение, могут быть использованы для определения границ комбинированной проецируемой разметки.
[0051] На Фиг. 5 представлена блок-схема примера реализации способа 500 для определения координат вложенной разметки для целевого документа на основе контекста. На шаге 505 способа 500 алгоритм обработки определяет первую разметку похожего документа и определяет координаты второй разметки в похожем документе, находящиеся между начальной и конечной координатами первой разметки. На шаге 510 алгоритм обработки определяет контекст части текста для второй разметки с учетом части текста первой разметки. Для выполнения такого определения алгоритм обработки анализирует текст внутри второй разметки с целью определения его значения относительно текста первой разметки. Например, если текст первой разметки содержит весь адрес, а текст второй разметки содержит информацию о штате в этом адресе, алгоритм обработки может определить, что контекст текста второй разметки соответствует штату в адресе. В некоторых вариантах реализации алгоритм обработки может выполнить такое определение за счет применения семантического анализа, синтаксического анализа, сопоставления структур, сопоставления контекстов и т.п.
[0052] На шаге 515 алгоритм обработки определяет вторую проецируемую разметку для целевого документа с учетом контекста, определенного на шаге 510. Алгоритм обработки может использовать контекст разметок в похожем документе для определения похожего взаимоотношения контекстов в целевом документе. В продолжение приведенного выше примера Алгоритм обработки может сначала определить фрагмент текста в целевом документе, включающего адрес. После этого алгоритм обработки может определить часть адреса, содержащую штат, в целевом документе с помощью контекстных отношений похожего документа (например, штат в адресе). Как указано выше, алгоритм обработки может выполнить такое определение за счет применения семантического анализа, синтаксического анализа, сопоставления структур, сопоставления контекстов и т.п. На шаге 520 алгоритм обработки сохраняет вторую проецируемую разметку для целевого документа. После шага 520 показанный на Фиг. 5 способ завершается.
[0053] На Фиг. 6 приведен пример вычислительной системы 600, которая может выполнять любой описанный здесь способ или несколько таких способов. В одном из примеров вычислительная система 600 может соответствовать вычислительному устройству, способному выполнять модуль проецирования разметки 100, представленный на Фиг. 1. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то, что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для выполнения любого из описанных здесь способа или нескольких таких способов.
[0054] Пример вычислительной системы 600 включает устройство обработки 602, основную память 604 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например, синхронное DRAM (SDRAM)), статическую память 606 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 616, которые взаимодействуют друг с другом по шине 608.
[0055] Устройство обработки 602 представляет собой одно или несколько универсальных устройств обработки, таких как микропроцессор, центральный процессор и т.п. В частности, устройство обработки 602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборов команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 602 также может представлять собой одно или несколько устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 602 настраивается для выполнения интеллектуального модуля формирования документов 626 для выполнения рассматриваемых в этом документе операций и шагов.
[0056] Вычислительная система 600 может дополнительно включать устройство сопряжения с сетью 622. Вычислительная система 600 может также включать видео дисплей 610 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 612 (например, клавиатуру), устройство управления курсором 614 (например, мышь) и устройство для формирования сигналов 620 (например, громкоговоритель). В одном иллюстративном примере видеодисплей 610, устройство буквенно-цифрового ввода 612 и устройство управления курсором 614 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0057] Запоминающее устройство 616 может включать машиночитаемый носитель 624, в котором хранится модуль проецирования разметки 626 (например, соответствующий способам, показанным на Фиг. 3-5 и т.д.), отражающий одну или более методологий или функций, описанных в данном документе. Кроме того, модуль проецирования разметки 626 может находиться полностью или, по меньшей мере, частично в основной памяти 604 и (или) в устройстве обработки 602 во время выполнения способа вычислительной системой 600, основной памятью 604 и устройством обработки 602, также представляющими собой машиночитаемую среду. Модуль проецирования разметки 626 может дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 622.
[0058] Несмотря на то что машиночитаемый носитель данных 624 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как включающий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0059] Несмотря на то что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться, по крайней мере частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0060] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты осуществления станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Область применения изобретения поэтому должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0061] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0062] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сконструирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0063] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если специально не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «настройка» и т.п., относятся к действиям компьютерной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах компьютерной системы и памяти в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[0064] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, например (помимо прочего): диск любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0065] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[0066] Варианты осуществления настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) для выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство («ПЗУ»), оперативное запоминающее устройство («ОЗУ»), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[0067] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в настоящем документе как «пример», не должна обязательно рассматриваться как предпочтительная или преимущественная по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает A или B» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя A; X включает в себя B; или X включает и A и B, то высказывание «X включает в себя A или B» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «an», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» или «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.

Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений

