Результат интеллектуальной деятельности: ДИФФЕРЕНЦИАЛЬНАЯ КЛАССИФИКАЦИЯ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ НЕЙРОННЫХ СЕТЕЙ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в целом относится к вычислительным системам, а в частности - к системам и способам распознавания текста на изображении с помощью нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[002] Распознавание текста на изображении - это одна из важных операций в автоматической обработке изображений, содержащих тексты на естественном языке. Определение графем на изображении может выполняться с помощью глубоких нейронных сетей. Точное определение и классификация графем в изображениях документов, однако, могут быть затруднены нейронными сетями, которые включают большое количество слоев. Кроме того, каждый слой в таких нейронных сетях может быть вызван для анализа изображения, исходя из большого количества возможных целевых графем. Точное и своевременное извлечение информации может требовать значительных ресурсов.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] Варианты реализации настоящего изобретения описывают дифференциальную классификацию изображений графем с помощью нескольких нейронных сетей. Система классификации хранит в памяти несколько нейронных сетей, каждая из которых обучена распознавать множество из одного или более множеств путающихся графем, определенных в данных распознавания множества изображений документов, причем каждое множество из одного или более множеств путающихся графем включает множество различных графем, которые графически похожи одна на другую. Система классификации получает входное изображение графемы, связанное с изображением документа, содержащим множество графем, определяет множество вариантов распознавания входного изображения графемы, где множество вариантов распознавания включает множество целевых символов, сходных с входным изображением графемы, выбирает первую нейронную сеть из множества нейронных сетей, причем первая нейронная сеть обучена распознавать первое множество путающихся графем, причем первое множество графем содержит как минимум часть множества вариантов распознавания для входного изображения графемы и определяет класс графемы для входного изображения графемы с помощью выбранной первой нейронной сети.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[004] Для более полного понимания настоящего изобретения ниже приводится подробное описание, в котором для примера, а не с целью ограничения, оно иллюстрируется со ссылкой на чертежи, на которых:
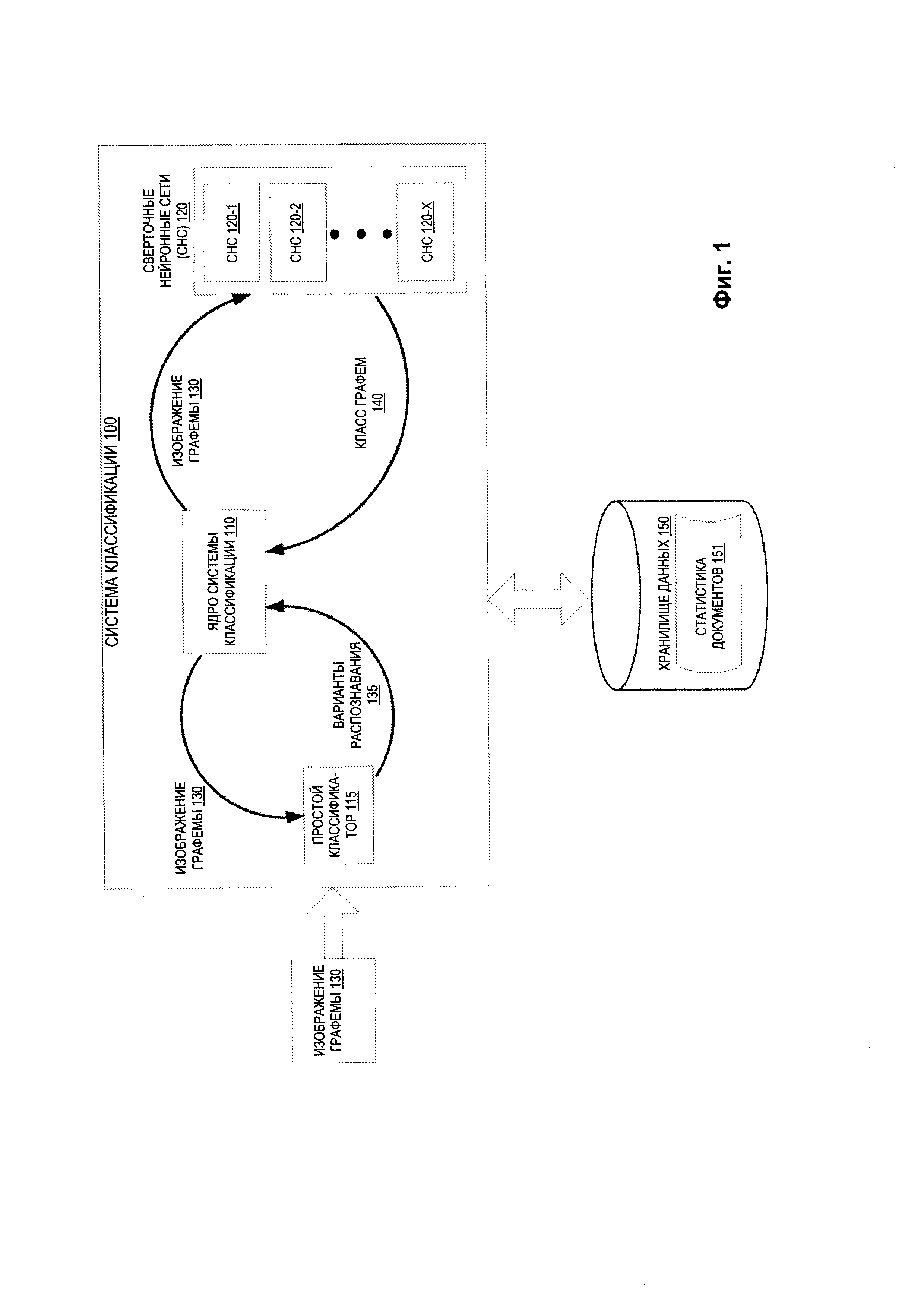
[005] На Фиг. 1 приведена схема верхнего уровня для примера системы классификации в соответствии с одним или более вариантами реализации настоящего изобретения.
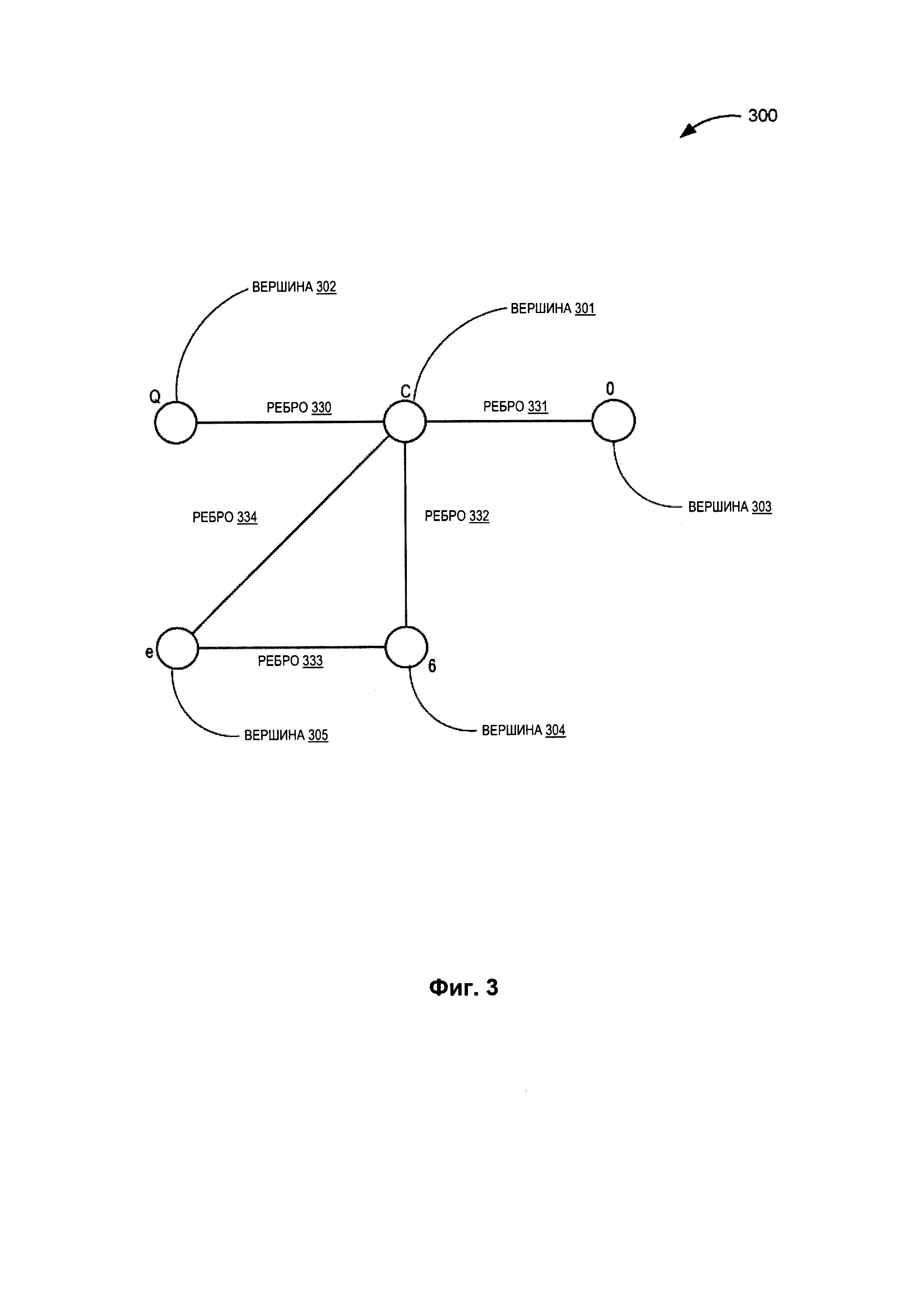
[006] Фиг. 2 иллюстрирует пример вариантов распознавания входного изображения графемы, который может быть выполнен простым классификатором в соответствии с одним или более вариантами реализации настоящего изобретения.
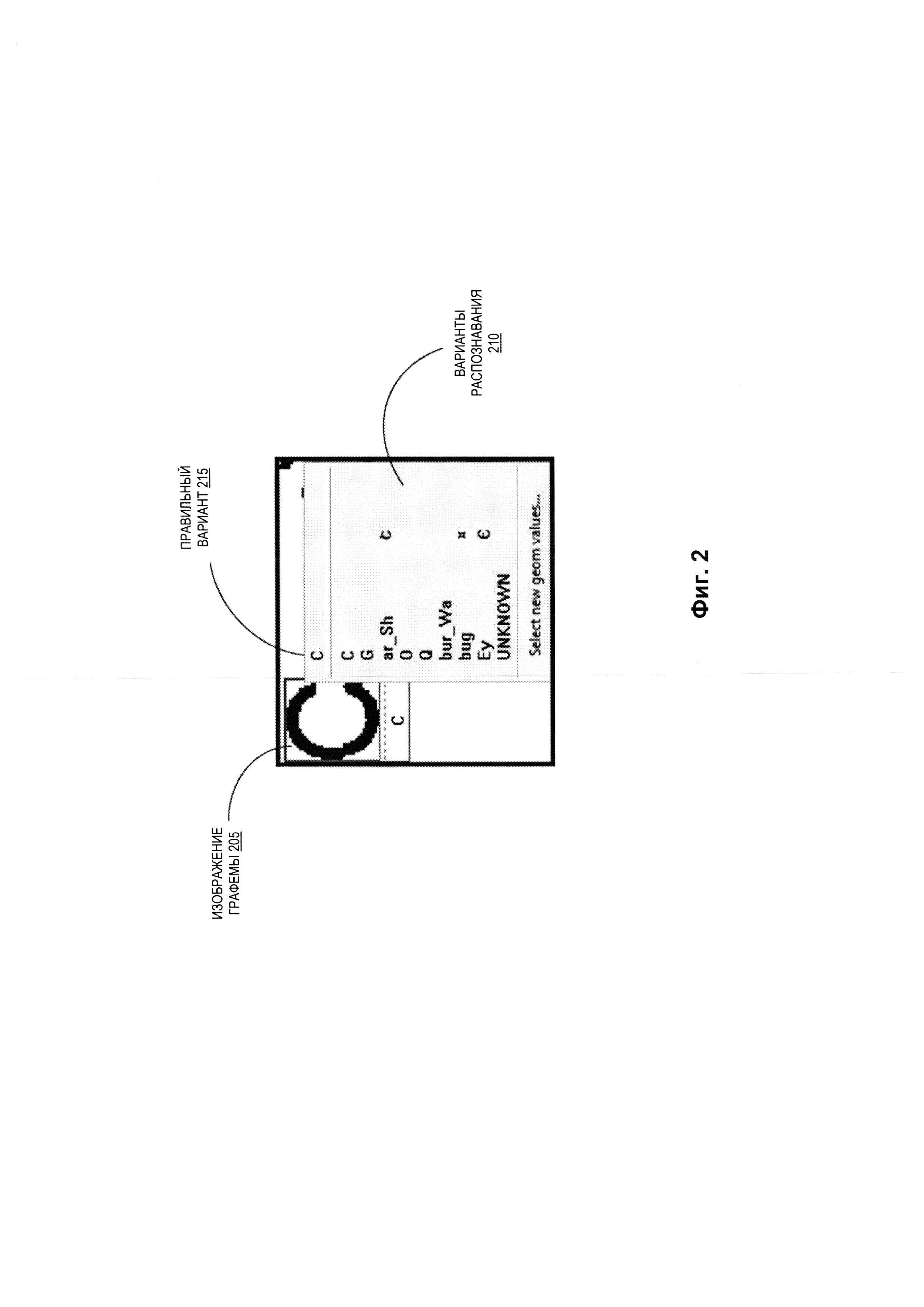
[007] Фиг. 3 иллюстрирует пример взвешенного графа, который может использоваться для определения множества путающихся графем в соответствии с одним или более вариантами реализации настоящего изобретения.
[008] Фиг. 4 иллюстрирует пример множества путающих графем в соответствии с одним или более вариантами реализации настоящего изобретения.
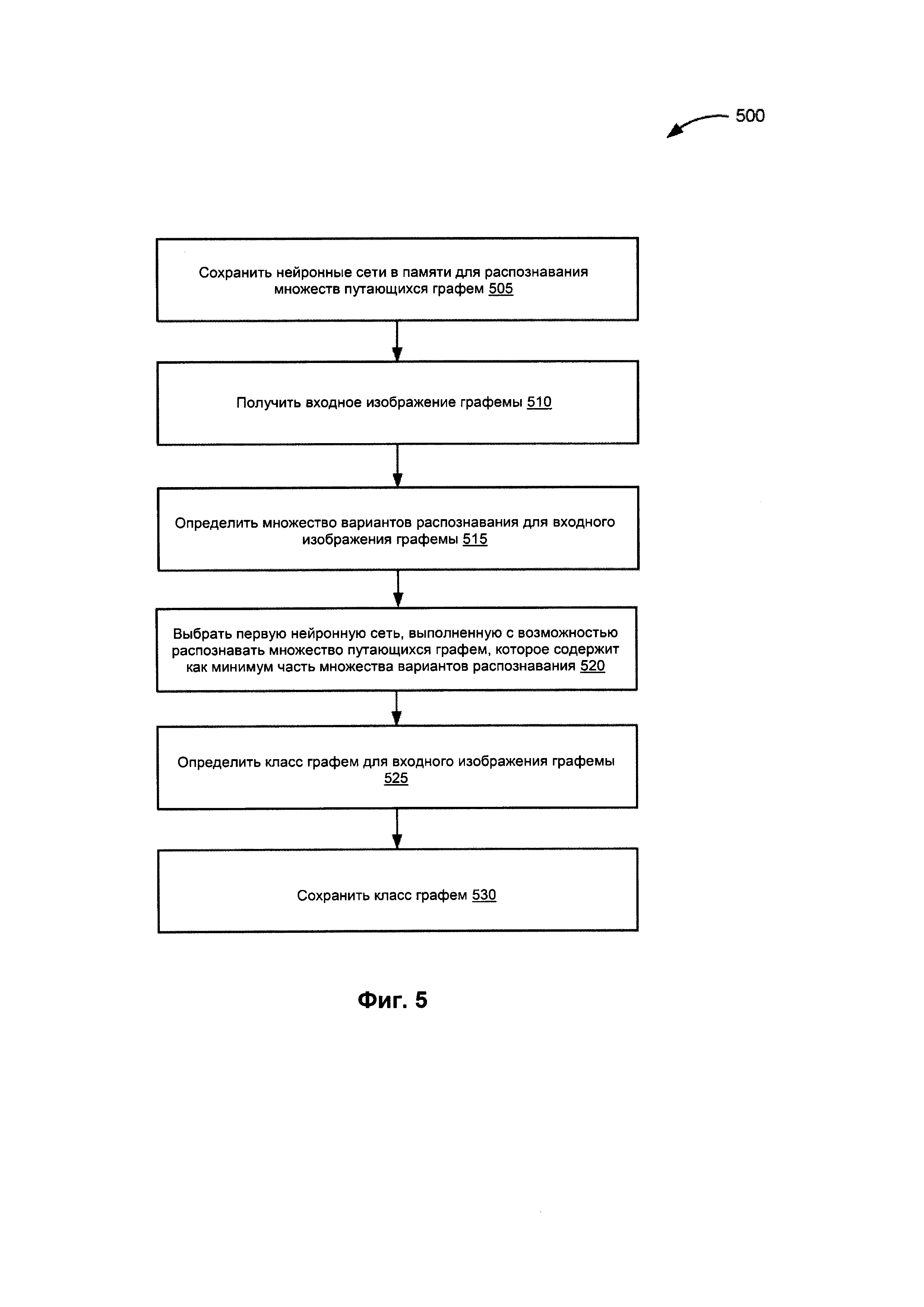
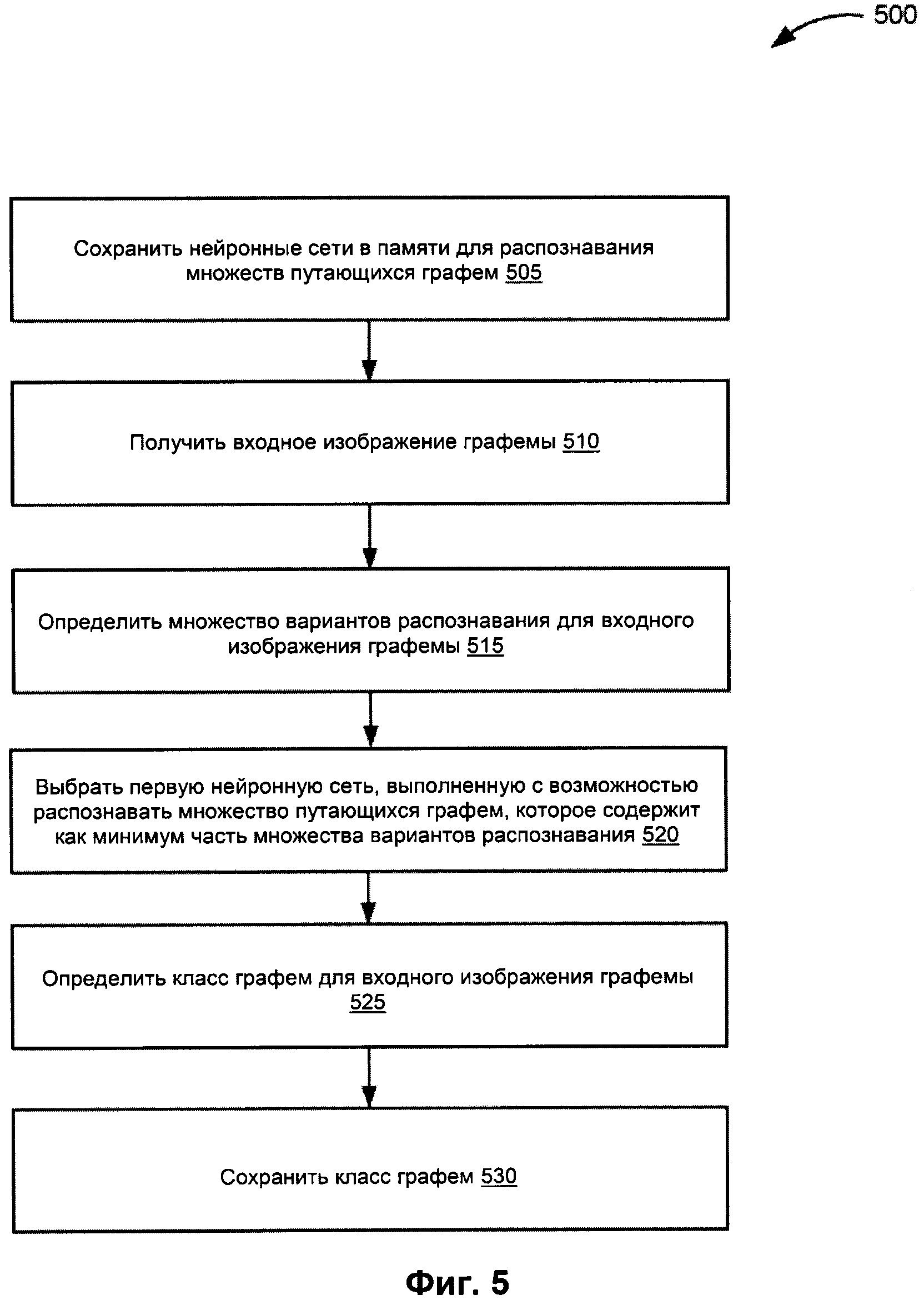
[009] На Фиг. 5 изображена блок-схема способа определения класса графемы с помощью нескольких сверточных нейронных сетей в соответствии с одним или более вариантами реализации настоящего изобретения.
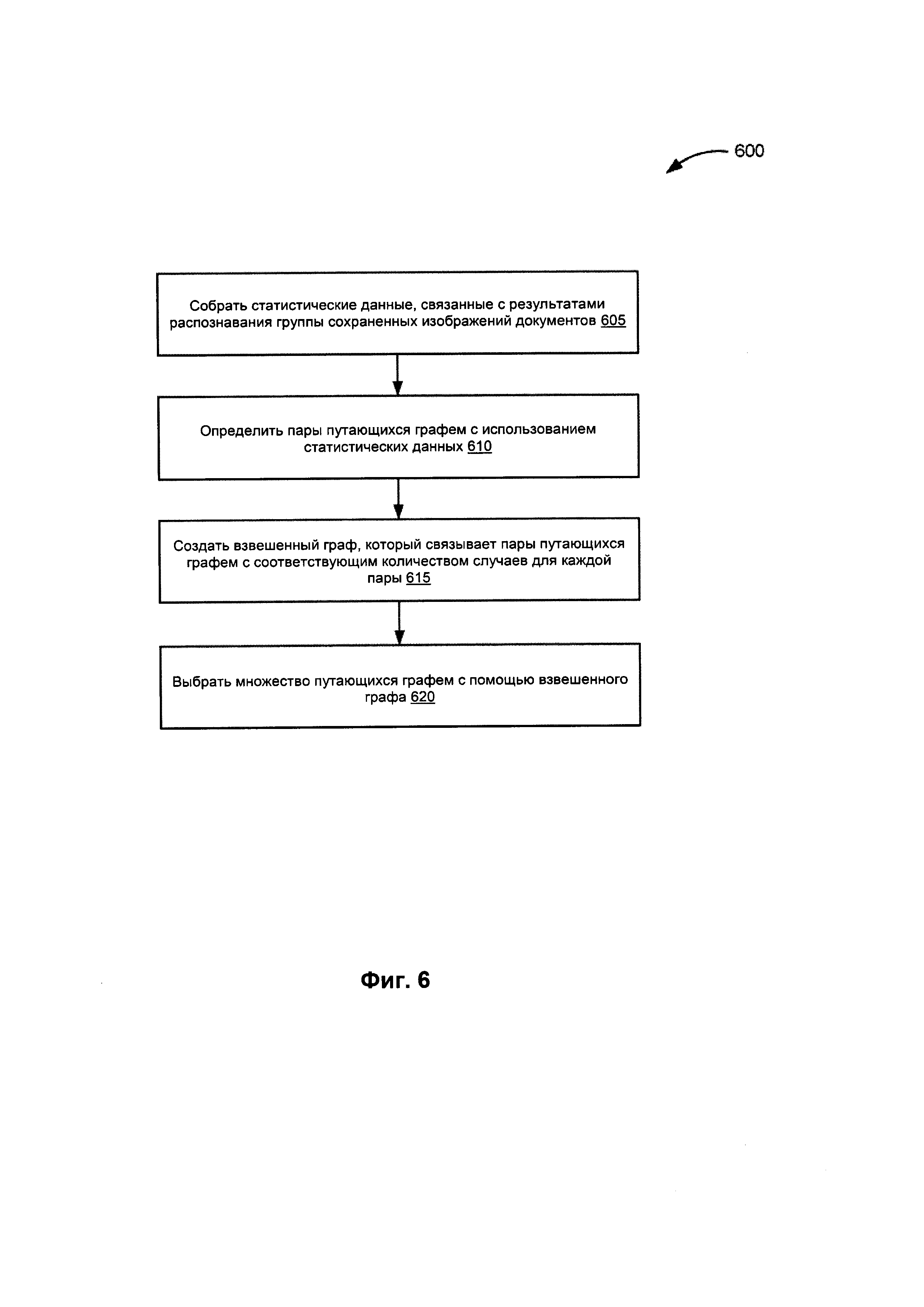
[0010] На Фиг. 6 изображена блок-схема способа определения множества путающихся графем в соответствии с одним или более вариантами реализации настоящего изобретения.
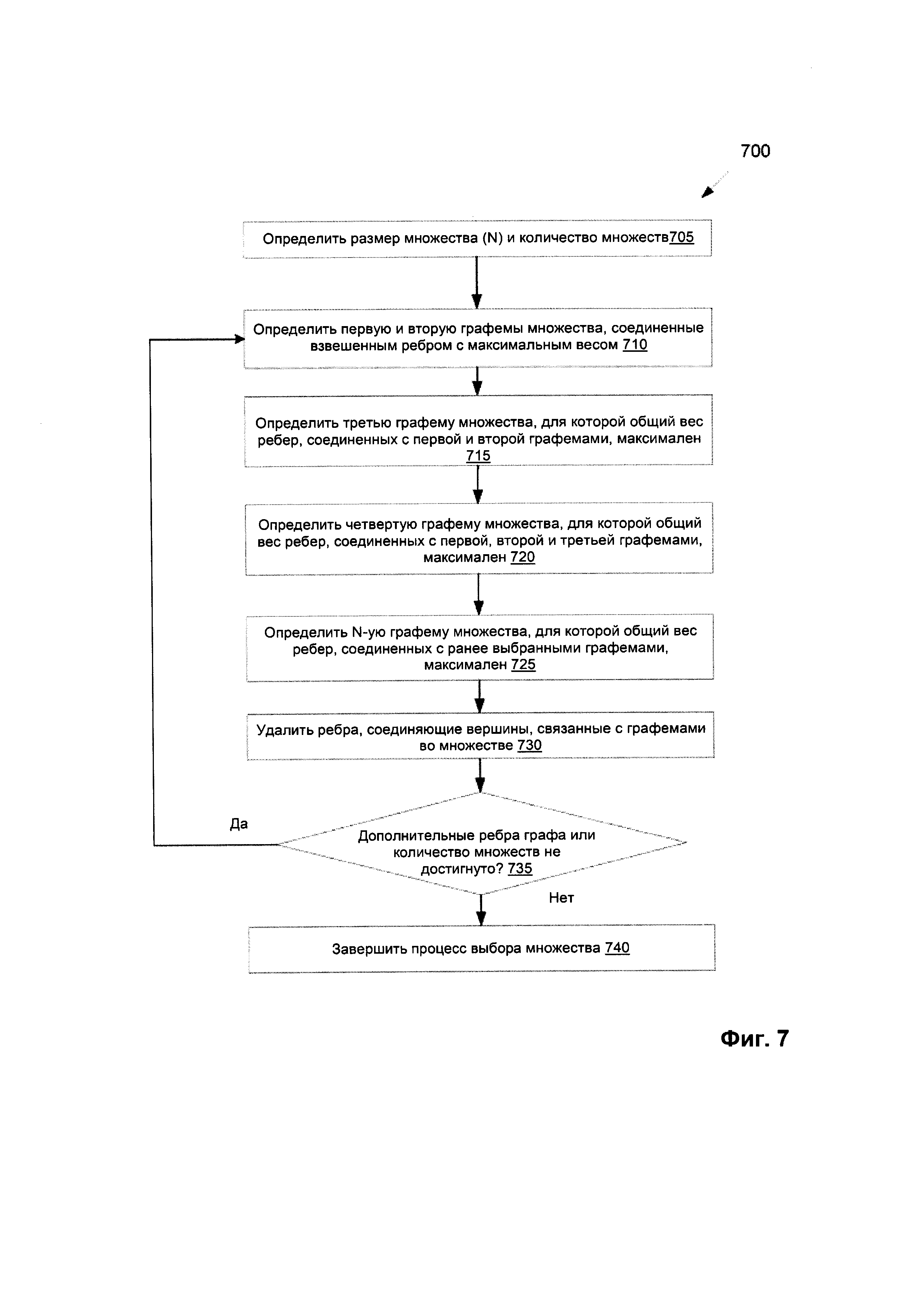
[0011] На Фиг. 7 изображена блок-схема способа для выбора множеств путающихся графем с помощью взвешенного графа в соответствии с одним или более вариантами реализации настоящего изобретения.
[0012] На Фиг. 8 представлена блок-схема типовой вычислительной системы, взятой как пример и работающей в соответствии с примерами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0013] В настоящем документе описываются способы и системы дифференциальной классификации изображений графем с помощью нескольких нейронных сетей. Распознавание текста на изображении может производиться с использованием классификаторов. Некоторые классификаторы могут создавать полное множество возможных гипотез распознавания графемы на изображении. Результаты работы таких классификаторов, однако, обычно могут страдать отсутствием точности. Для повышения точности часто используются дифференциальные классификаторы, более точно пересчитывающие степень уверенности различных возможных вариантов графемы на изображении. Во многих стандартных реализациях для пересчета степени уверенности каждого варианта и сортировки списка вариантов для повышения точности результатов могут использоваться сверточные нейронные сети (СНС). Однако СНС обычно реализуются в виде глубоких нейронных сетей, которые предназначены для классификации всех графем фиксированного алфавита. Хотя такой подход позволяет получать результаты распознавания высокого качества, эти типы архитектур СНС могут требовать для получения ожидаемого результата значительных ресурсов обработки. Традиционные аппаратные реализации могут привести к значительному повышению времени обработки, что иногда может быть решено только с помощью выделенных серверов для распознавания, снабженных мощными графическими процессорами, что может значительно повысить стоимость системы.
[0014] Варианты реализации настоящего изобретения служат для устранения этого и других недостатков, настраивая и используя несколько дифференциальных классификаторов, каждый из которых содержит небольшое количество слоев СНС вместо одной глубокой нейронной сети с большим количеством слоев СНС. Множества графем генерируются исходя из статистического анализа данных распознавания (т.е., различных вариантов/гипотез распознавания и их степени уверенности для каждого изображения графемы в каждом изображении документа) сохраненных изображений документов. Каждое множество может содержать графемы, наиболее часто путающиеся с другими графемами, на основе статистических данных. Каждое множество может быть назначено конкретной СНС, которая может быть обучена распознавать только графемы, включенные в это назначенное множество, а не весь алфавит. Благодаря малому числу графем во множестве, которое следует дифференцировать, требуется меньше признаков для отделения одной графемы от другой. Таким образом, для проведения анализа всего алфавита (или нескольких алфавитов) можно использовать более простые структуры нейронных сетей, разделив графемы алфавита между несколькими нейронными сетями.
[0015] Таким образом, варианты реализации настоящего изобретения могут позволить более эффективно идентифицировать текст на изображении, используя значительно меньшее количество ресурсов. Используя несколько СНС, которые имеют малое количество слоев, процесс можно реализовать на стандартном оборудовании, не используя специализированные системы обработки графики. Кроме того, снижая сложность нейронных сетей, можно значительно уменьшить время обработки, необходимое для идентификации графемы на изображении. Также, используя множества часто путающихся графем для каждой СНС, можно добавлять в систему новые языки или новые множества графем без необходимости значительной перестройки нейронных сетей или использования дополнительных аппаратных ресурсов. Для нового языка могут создаваться новые множества путающихся графем, и СНС могут автоматически переучиваться для использования новых множеств путающихся графем без изменения архитектуры системы.
[0016] На Фиг. 1 приведена схема верхнего уровня для примера системы классификации 100 в соответствии с одним или более вариантами реализации настоящего изобретения. Система классификации 100 может включать ядро системы классификации 110, которое взаимодействует с простым классификатором 115 и одной или более сверточными нейронными сетями (СНС) 120 (например, с СНС 120-1 по 120-Х). Ядро системы классификации 110 может представлять собой клиентское приложение или же сочетание компонентов, базирующихся на рабочей станции клиента и на сервере. В некоторых вариантах реализации изобретения ядро системы классификации 110 может быть запущено на исполнение на вычислительном устройстве клиента, например, это могут быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.д. В альтернативном варианте реализации клиентский компонент ядра системы классификации 110, исполняемый на клиентском вычислительном устройстве, может получать документ и передавать его на серверный компонент ядра системы классификации 110, исполняемый на серверном устройстве, который выполняет классификацию графем. Серверный компонент ядра системы классификации 110 затем может возвратить класс графемы на клиентский компонент ядра системы классификации 110, исполняемый на клиентском вычислительном устройстве для хранения или предоставления другому приложению. В других вариантах реализации изобретения ядро системы классификации 110 может быть запущено на исполнение на серверном устройстве в качестве интернет-приложения, доступ к которому обеспечивается через интерфейс браузера. Примером серверного устройства может быть одна или более вычислительная система, например, одно или более таких устройств, как серверы, рабочие станции, большие ЭВМ (мейнфреймы), персональные компьютеры (ПК) и т.д.
[0017] В иллюстративном примере система классификации 100 может быть выполнена с возможностью идентификации и классификации изображений графем 130 с помощью нескольких сверточных нейронных сетей (СНС) 120. В некоторых вариантах реализации СНС (например, СНС со 120-1 по 120-Х) может быть нейронной сетью со специализированной архитектурой, направленной на эффективное распознавание изображения. Каждая СНС может содержать последовательность слоев, причем все слои будут разного типа. Слои могут включать, например, сверточные слои, субдискретизирующие слои, слои блока линейной ректификации (ReLU) и полносвязные слои, каждый из которых выполняет отдельную операцию в процессе идентификации изображения. В подобной сети входное изображение проходит через несколько таких слоев, и в последнем слое создается результат, который классифицирует изображение. Тип каждого слоя может отличаться от типа предыдущего слоя и типа следующего слоя. Результат одного слоя может быть исходными данными для следующего слоя. В различных вариантах реализации настоящего изобретения каждая СНС 120 может быть выполнена с возможностью определять, связано ли входное изображение графемы с конкретным классом графемы, исходя из его графической схожести с другими известными графемами (например, классом графемы, который наилучшим образом соответствует изображению графемы).
[0018] В некоторых вариантах реализации изобретения графема представляет собой наименьший распознаваемый элемент в системе записи данного языка (или множества схожих языков). Графема может содержать буквы алфавита, типографские лигатуры, символы китайского языка, цифры, знаки препинания и другие отдельные символы или знаки. Каждая СНС 120 может быть выполнена с возможностью анализа и классификации входного изображения графемы на предмет принадлежности к одной из определенного множества графем с последующим выводом класса графемы, связанного с входным изображением графемы. В некоторых вариантах реализации класс графемы может быть идентификатором, который связан с символом, наилучшим образом соответствующим исходному изображению графемы. Например, если брать семейство европейских языков (то есть языки с написанием слева направо, в которых символы разделяются промежутками), графема английской буквы «А» и графема русской буквы «А» могут быть отнесены к одному классу графем, несмотря на то, что они являются разными символами.
[0019] В одном из вариантов реализации изобретения ядро системы классификации 110 может настроить несколько СНС 120 путем предварительного анализа данных распознавания для группы изображений документов (например, документов, сохраненных в хранилище данных 150) для идентификации одного или более множеств путающихся графем. С другой стороны, вместо анализа данных распознавания для изображений документов ядро системы классификации 110 может получать одно или более множеств путающихся графем от другого компонента системы классификации 100, который проводит соответствующий анализ. В некоторых вариантах реализации множество путающихся графем может содержать группу различных графем, которые часто могут быть перепутаны друг с другом (например, графически сходных графем). Например, в одном из вариантов реализации изобретения для входного изображения графемы, соответствующей символу «С», множество путающихся графем может включать «С», «е», «6», «0», «Q», «G» и т.д. В некоторых вариантах реализации множество путающих графем может быть определено с использованием статистической информации, связанной с данными распознавания для группы изображений документов (например, статистикой документа 151), которая определяет графемы, часто путающиеся друг с другом, исходя из гипотез распознавания символов, которые создаются в ходе распознавания группы изображений документов.
[0020] Например, если сохраненное изображение документа обрабатывается с использованием оптического распознавания символов (OCR), этот процесс может использовать простой классификатор (например, простой классификатор 115) для определения различных вариантов распознавания (то есть гипотез) для каждой графемы в сохраненном изображении документа. Простой классификатор может содержать любой тип компонента или подсистемы классификатора, который может получать входное изображение графемы и создавать одну или более гипотезу о том, чем может быть это изображение графемы. Например, простой классификатор может быть наивным байесовским классификатором, классификатором дерева решений и т.п. В некоторых вариантах реализации простой классификатор может быть выполнен как простой вероятностный классификатор, где процесс классификации основан на предположении о независимости влияния на вероятность различных признаков входного изображения графемы. Таким образом, этот тип классификатора содержит упрощенные расчеты и в результате может быть выполнен значительно быстрее, чем реализация глубокой нейронной сети.
[0021] В некоторых вариантах реализации простой классификатор (или другой процесс, используемый для анализа группы сохраненных изображений документов) может сохранять различные гипотезы для каждой графемы в статистике документов 151 для последующего использования. Иллюстративный пример различных гипотез для графемы приведен ниже со ссылкой на Фиг. 2. В одном из вариантов реализации изобретения статистика 151 может анализироваться для идентификации пар графем, которые часто путаются между собой в группе сохраненных изображений документов (например, при выполнении OCR сохраненных изображений документов), для определения множества путающихся графем. В некоторых вариантах реализации может создаваться взвешенный граф, который связывает пары путающихся графем друг с другом, исходя из количества вхождений каждой пары по сохраненной статистике. Иллюстративный пример определения множества путающихся графем с использованием взвешенного графа описан ниже со ссылкой на Фиг. 3. Иллюстративный пример полученного множества путающихся графем описан ниже со ссылкой на Фиг. 4.
[0022] После идентификации одного или более множеств путающихся графем ядро системы классификации 110 может настроить и сохранить СНС 120 так, что каждая СНС 120 будет обучена распознавать определенное множество путающихся графем, обнаруженных в данных распознавания множества изображений документов, описанных выше. Например, СНС 120-1 может быть обучена распознавать одно множество путающихся графем, СНС 120-2 может быть обучена распознавать другое множество путающихся графем, а СНС 120-Х может быть обучена распознавать Х-ое множество путающихся графем, где X соответствует количеству множеств. В некоторых вариантах реализации ядро системы классификации 110 может обучить каждую СНС 120, инициируя процесс обучения для обучения СНС распознаванию назначенного ей множества путающихся графем. Каждая СНС 120 может быть отдельно обучена распознавать изображения графем из назначенного ей множества. Каждая СНС может обучаться с использованием способа обратного распространения ошибки или другого сходного способа обучения нейронных сетей. В различных вариантах реализации изобретения каждая СНС может быть сконфигурирована с разным количеством слоев (сверточных, субдискретизирующих, ReLU и т.д.), исходя из размера или содержимого назначенного множества путающихся графем. Таким образом, множество путающихся графем, которые более графически сходны (и поэтому могут быть спутаны чаще, чем графемы в других множествах) может быть назначено СНС 120 с большим количеством слоев для улучшения производительности и результатов анализа.
[0023] После того, как каждая СНС 120 будет настроена и обучена, ядро системы классификации 110 может вызывать СНС со 120-1 по 120-Х для классификации получаемых изображений графем. В одном из вариантов реализации изобретения ядро системы классификации 110 может получить изображение графемы 130. Изображение графемы 130 может быть получено в виде части изображения документа или в виде одиночного изображения графемы от клиентского устройства или от приложения, которое связано с системой классификации 100. Затем ядро системы классификации 110 может вызвать простой классификатор 115 для определения множества вариантов распознавания 135 изображения графемы 130. Как указано выше, простой классификатор 115 может быть простым вероятностным классификатором, который может быстро определить наиболее вероятные варианты распознавания 135 для входного изображения графемы 130. В некоторых вариантах реализации простой классификатор 115 может определить множество целевых символов, которые максимально похожи на входное изображение графемы 130. В одном из вариантов реализации изобретения простой классификатор 115 может определить один или более целевых символов, которые имеют графические характеристики или признаки, сходные с входным изображением графемы 130 и присвоить эти целевые символы множеству вариантов распознавания.
[0024] В некоторых вариантах реализации простой классификатор 115 может дополнительно определить степень уверенности, связанную с каждым из целевых символов, которые входят в варианты распознавания 135. В одном из вариантов реализации изобретения степень уверенности для каждого целевого символа в вариантах распознавания 135 может быть процентным значением вероятности для этого целевого символа. Например, если простой классификатор 115 анализирует графему 130 и определяет, что существует 70% вероятность того, что входное изображение графемы 130 было символом «С», соответствующая степень уверенности может быть представлена значением 70%. Простой классификатор 115 может вернуть ядру системы классификации 110 все множество вариантов распознавания 135. В некоторых вариантах реализации ядро системы классификации 110 может затем сортировать символы множества вариантов распознавания 135 по соответствующим степеням уверенности и выбирать те целевые символы, связанная степень уверенности которых соответствует пороговому значению. Например, ядро системы классификации 110 может вернуть те целевые символы вариантов распознавания 135, которые имеют связанную степень уверенности выше 70%. В некоторых вариантах реализации ядро системы классификации 110 может затем сортировать целевые символы из множества вариантов распознавания 135 по соответствующим степеням уверенности и выбирать первые N целевых символов с наибольшей измеренной степенью уверенности, где N - заранее определенное пороговое количество выбираемых символов.
[0025] Ядро системы классификации 110 может затем использовать варианты распознавания 135 для выбора одной из СНС 120 для дальнейшей классификации изображения графемы 130. В некоторых вариантах реализации выбранная СНС 120 может быть сконфигурирована с возможностью распознавания определенного множества путающихся графем, где множество путающихся графем содержит как минимум часть вариантов распознавания 135, возвращенных простым классификатором 115 для графемы 130. В одном из вариантов реализации изобретения ядро системы классификации 110 может выбирать СНС 120, сравнивая множество вариантов распознавания 135 с каждым из множеств путающихся графем, связанных с СНС 120. Ядро системы классификации 110 может далее определить пересечение между множеством вариантов распознавания и каждым из множеств путающихся графем, и выбрать определенное множество путающихся графем, в котором пересечение больше, чем для всех остальных множеств путающихся графем. Другими словами, ядро системы классификации 110 может выбрать множество путающихся графем, которое содержит больше целевых символов, входящих в варианты распознавания 135, чем другие множества путающихся графем, связанные с СНС 120. Таким образом, СНС 120, которая была обучена распознаванию и классификации большего количества вариантов распознавания, чем любая другая СНС 120, может быть выбрана для классификации изображения графемы 130.
[0026] В некоторых вариантах реализации ядро системы классификации 110 может принимать во внимание степени уверенности вариантов распознавания при выборе множества путающихся графем для СНС. Например, когда ядро системы классификации 110 может сначала выбрать подмножество вариантов распознавания, которое включает варианты распознавания с максимальной степенью уверенности. Таким образом, когда ядро системы классификации 110 определяет описанное выше пересечение, можно выбрать множество путающихся графем, которое содержит больше целевых символов, включенных в подмножество вариантов распознавания (например, вариантов распознавания с максимальной степенью уверенности). Например, если взять множество вариантов распознавания с рангами от 1 до 5 (1 для максимальной степени уверенности и 5 для минимальной), ядро системы классификации 110 может определить пересечение множеств путающихся графем и целевых символов, которые ранжированы между 1 и 2. Таким образом, будет выбрано множество путающихся графем, которое содержит целевые символы со степенью уверенности 1 и 2, а не множество путающихся графем, которое содержит целевые символы со степенью уверенности между 2 и 5.
[0027] Ядро системы классификации 110 может определить класс графемы для входного изображения графемы 130, используя выбранную СНС 120. В некоторых вариантах реализации ядро системы классификации может произвести определение, вызывая выбранную СНС 120 для классификации изображения графемы 130. Как было указано ранее, СНС 120 может быть заранее обучена распознаванию определенного множества часто путающихся графем с использованием нескольких сверточных слоев. После определения класса графемы 140 с помощью СНС 120 ядро системы классификации 110 может сохранить класс графемы 140 в хранилище данных 150, передавая класс графемы 140 вызывающей программе или компоненту системы, передавая класс графемы другому компоненту системы для более тщательного анализа распознаваемого изображения или других действий.
[0028] Фиг. 2 иллюстрирует пример вариантов распознавания входного изображения графемы, который может быть сгенерирован простым классификатором. В некоторых вариантах реализации варианты распознавания, которые иллюстрируются на Фиг. 2, могут определяться с помощью простого классификатора 115 с Фиг. 1. Как показано на Фиг. 2, изображение графемы 205 может быть предоставлено в качестве входных данных простому классификатору. Простой классификатор затем может использовать вероятностный анализ в соответствии с описанием выше для идентификации вариантов распознавания 210. В некоторых вариантах реализации простой классификатор может анализировать изображение графемы 205 и определять один и более целевых символов с характеристиками, наиболее схожими с изображением графемы 205. Как показано на Фиг. 2, изображение графемы 205 представляет собой символ «С». Простой классификатор анализирует графему 205 и определяет, что наиболее вероятные целевые символы, наиболее похожие на графему 205, включают «С», «G», «ar_Sh», «О», «Q», и т.д. Таким образом, варианты распознавания 210 содержат целевые символы, определенные простым классификатором. В некоторых вариантах реализации простой классификатор может также определять степень уверенности каждого из вероятных целевых символов и сортировать их по степени уверенности. В этих случаях варианты распознавания 210 могут быть выбраны с включением только тех целевых символов, степень уверенности которых соответствует пороговому значению. Например, если пороговое значение уверенности установлено в 75%, выбираться в качестве части множества вариантов распознавания могут только целевые символы со степенью уверенности 75% или выше.
[0029] Фиг. 3 иллюстрирует пример взвешенного графа 300, который может использоваться для определения множества путающихся графем в соответствии с одним вариантом реализации настоящего изобретения. В некоторых вариантах реализации взвешенный граф 300 может быть создан ядром системы классификации, например, ядром системы классификации 110 с Фиг. 1. Как было описано выше со ссылкой на Фиг. 1, ядро системы классификации может анализировать сохраненную статистику по графемам в группе сохраненных изображений документов. В некоторых вариантах реализации ядро системы классификации может использовать сохраненную статистику для идентификации пар графем, графически похожих друг на друга. В одном из вариантов реализации ядро системы классификации может использовать результат работы простого классификатора, который идентифицирует варианты распознавания входного изображения графемы и сохраняет связи между входным изображением графемы и каждым из вариантов распознавания, идентифицированных простым классификатором.
[0030] Используя сохраненную статистику, ядро системы классификации может построить взвешенный граф 300, так что каждая вершина графа представляет графему из данных статистики, а каждое ребро графа, соединяющее две вершины, представляет количество появлений пары, соединенной этим ребром. Как показано на Фиг. 3, взвешенный граф 300 содержит вершины 301, 302, 303, 304 и 305 с соединяющими их ребрами 330, 331, 332, 333 и 334. Вершина 301 соответствует графеме «С», вершина 302 соответствует графеме «Q», вершина 303 соответствует графеме «0», вершина 304 соответствует графеме «6», а вершина 305 соответствует графеме «е». Также, как показано на Фиг. 3, ребро 331 соответствует весу пары, определяемой вершинами 301 и 303 (то есть количеством случаев, когда «С» и «0» определялись в сохраненной статистике как связанные варианты распознавания). Аналогично, ребра 330, 332, 333 и 334 определяют веса пар, определенных вершинами, которые они соединяют.
[0031] В некоторых вариантах реализации ядро системы классификации может обходить взвешенный граф 300 для идентификации множества путающихся графем, назначенного СНС для использования с классифицированными входными изображениями графем. В одном из вариантов реализации изобретения ядро системы классификации может обходить взвешенный граф 300 в соответствии с принципом жадного алгоритма. Жадный алгоритм - это алгоритмическая парадигма, которая делает локально оптимальный выбор на каждой стадии анализа с целью поиска глобального оптимума для множества путающихся графем.
[0032] В иллюстративном примере ядро системы классификации может сначала определить размер множества для множества путающихся символов и общее количество идентифицируемых множеств. Размер множества и общее количество множеств могут быть предварительно определенными параметрами, определяемыми на основе анализа статистических данных, получаемых от пользователя, или иным способом. В одном из вариантов реализации изобретения общее количество множеств может быть определено на основании соотношения весов множеств при их создании. Таким образом, общее количество множеств может динамически определяться при создании каждого множества.
[0033] В некоторых вариантах реализации ядро системы классификации может идентифицировать ребро графа, имеющее наибольшее значение веса (т.н. «самое тяжелое» ребро). Ребро, имеющее наибольшее значение веса, соответствует наиболее часто встречающейся паре графем, которые путаются друг с другом, исходя из сохраненных вариантов распознавания. Графемы, связанные с вершинами, которые соединены ребром, имеющим наибольшее значение веса, могут быть выбраны для множества путающихся графем. Например, если ребро 331 соответствует ребру с наибольшим количеством случаев для соответствующих вершин (графемы «С» и «0» чаще всего путаются друг с другом), то ребро 331 должно быть идентифицировано как «самое тяжелое» ребро. Графемы «С» (вершина 301) и «0» (вершина 303) должны быть добавлены во множество путающихся графем.
[0034] Ядро системы классификации затем может идентифицировать во взвешенном графе вершину, соединенную с одним или двумя уже идентифицированными вершинами, при этом сумма взвешенных значений этих двух соединительных ребер больше чем для любой другой вершины графа. Графема, связанная с этой вершиной, может быть добавлена во множество. Например, пусть вершины 301 и 303 уже были выбраны, следующей выбираемой вершиной должна быть вершина, соединенная с одной или обеими вершинами 301 и 303, причем сумма их ребер должна быть больше, чем для любой другой вершины. Как показано на Фиг. 3, с вершиной 303 не соединена никакая другая вершина, так что ядро системы классификации может выбрать вершину, соединенную с вершиной 301, ребро которой больше ребра любой другой вершины, соединенной с вершиной 301. С вершиной 301 соединены вершины 302, 304 и 305. Так, если ребро 332 имеет больший вес, во множество будет отобрана вершина 304. Аналогично, если ребро 330 имеет больший вес, во множество будет отобрана вершина 302 и т.д.
[0035] Ядро системы классификации может затем повторить процесс, идентифицируя следующую невыбранную вершину, соединенную как минимум с одной из уже выбранных вершин так, что сумма ребер, соединяющих невыбранную вершину с выбранными вершинами, максимальна. Например, допустим, что вершины 301, 303 и 304 уже были выбраны. Вершина 305 может быть выбрана, если сумма ребер 333 и 334 больше значения для ребра 330. В некоторых вариантах реализации этот процесс повторяется, пока не будет достигнут указанный размер множества. Когда указанный размер множества достигнут, ядро системы классификации может обновить взвешенный граф 300, удаляя из взвешенного графа ребра, соединяющие вершины, связанные с графемами, выбранными для множества. Этот процесс может быть повторен для построения дополнительных множеств путающихся графем, исходя из оставшихся ребер взвешенного графа 300.
[0036] Хотя для простоты взвешенный граф 300 на Фиг. 3 описан как используемый для создания одного множества путающихся графем, следует заметить, что в других реализациях один взвешенный граф может использоваться для создания нескольких множеств путающихся графем.
[0037] Фиг. 4 иллюстрирует пример множества путающих графем 400 в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 4, множество путающихся графем 400 содержит коллекцию графем, которые наиболее часто путаются друг с другом. Множество путающихся графем 400 содержит графемы, относящиеся к семейству европейских языков. В одном из вариантов реализации изобретения множество путающихся графем 400 может быть создано путем обхода взвешенного графа, как описано выше со ссылкой на Фиг. 3.
[0038] На Фиг. 5-7 представлены блок-схемы различных вариантов реализации способов, относящихся к определению класса графемы для входного изображения графемы с помощью нескольких сверточных нейронных сетей. Эти способы могут осуществляться при помощи логической схемы обработки данных, которая может включать аппаратные средства (электронные схемы, специализированную логическую плату и т.д.), программное обеспечение (например, выполняться на универсальной ЭВМ или же на специализированной вычислительной машине) или комбинацию первого и второго. Представленные способы и (или) каждая из отдельно взятых функций, процедур, подпрограмм или операций могут быть реализованы с помощью одного или более процессоров вычислительного устройства {например, вычислительной системы 800 на Фиг. 8), в котором реализованы данные способы. В некоторых вариантах реализации изобретения представленные способы могут выполняться в одном потоке обработки. В альтернативных вариантах реализации изобретения представленные способы могут выполняться в двух и более потоках обработки, при этом в каждом потоке реализована одна (или более) отдельно взятая функция, процедура, подпрограмма или операция, относящаяся к указанным способам. Некоторые способы могут выполняться ядром системы классификации, например, ядром системы классификации 115 на Фиг. 1.
[0039] Для простоты объяснения способы в настоящем описании изобретения изложены и наглядно представлены в виде последовательности действий. Однако действия в соответствии с настоящим описанием изобретения могут выполняться в различном порядке и(или) одновременно с другими действиями, не представленными и не описанными в настоящем документе. Кроме того, не все действия, приведенные для иллюстрации сущности изобретения, могут оказаться необходимыми для реализации способов в соответствии с настоящим описанием изобретения. Специалистам в данной области техники должно быть понятно, что эти способы могут быть представлены и иным образом - в виде последовательности взаимосвязанных состояний через диаграмму состояний или событий.
[0040] На Фиг. 5 изображена блок-схема примера способа 500 для определения класса графемы с помощью нескольких сверточных нейронных сетей. На шаге 505 способа 500 логическая схема обработки данных хранит множество нейронных сетей в памяти, при этом каждая нейронная сеть из множества нейронных сетей обучается распознаванию множества путающихся графем из одного или более множеств путающихся графем, определенных на множестве изображений документов, причем множество путающихся графем включает множество различных графем, графически сходных между собой. В некоторых вариантах реализации каждая нейронная сеть обучена распознавать другое множество путающихся графем из одного или более множеств путающихся графем. В иллюстративном примере логическая схема обработки данных может определять множества путающихся графем, как описано ниже со ссылкой на Фиг. 6.
[0041] На шаге 510 логическая схема обработки данных получает входное изображение графемы в виде изображения. На шаге 515 логическая схема обработки данных определяет множество вариантов распознавания входного изображения графемы. На шаге 520 логическая схема обработки данных выбирает первую нейронную сеть из множества нейронных сетей, причем первая нейронная сеть выполнена с возможностью распознавать первое множество путающихся графем, которое содержит как минимум часть множества вариантов распознавания, полученных на шаге 515 блок-схемы. На шаге 525 логическая схема обработки данных определяет класс графемы для входного изображения графемы, используя первую нейронную сеть, выбранную на шаге 520 блок-схемы. На шаге 530 логическая схема обработки данных сохраняет связь между классом графемы и входным изображением графемы. После шага 530 блок-схемы показанный на Фиг. 5 способ завершается.
[0042] На Фиг. 6 изображена блок-схема примера способа 600 для определения множества путающихся графем. На шаге 605 способа 600 логическая схема обработки данных собирает статистические данные, связанные с данными распознавания группы сохраненных изображений документов. На шаге 610 блок-схемы логическая схема обработки данных идентифицирует пары путающих графем, используя статистические данные. На шаге 615 блок-схемы логическая схема обработки данных строит взвешенный граф, который связывает пары путающих графем с соответствующим количеством появлений каждой пары. На шаге 620 логическая схема обработки данных выбирает множество путающихся графем, используя взвешенный граф. В иллюстративном примере логическая схема обработки данных может выбрать множество путающихся графем, используя взвешенный граф, как описано ниже со ссылкой на Фиг. 7. После шага 630 блок-схемы показанный на Фиг. 6 способ завершается.
[0043] На Фиг. 7 изображена блок-схема примера способа 500 для выбора множеств путающихся графем с помощью взвешенного графа. На шаге 705 блок-схемы способа 700 логическая схема обработки данных определяет размер множества (N), где N - положительное целое число, и общее количество множеств для множеств путающихся графем. На шаге 710 логическая схема обработки данных определяет первую и вторую графемы для множества, связанные с которыми вершины взвешенного графа соединены взвешенным ребром с максимальным весом относительно других взвешенных ребер взвешенного графа. На шаге 715 логическая схема обработки данных определяет третью графему множества, связанная с которой вершина соединена с вершинами первой и второй графем взвешенными ребрами, сумма которых максимальна по сравнению с другими вершинами взвешенного графа. В некоторых вариантах реализации изобретения вершина третьей графемы может соединяться с обеими вершинами, соответствующими первой и второй графемам. В других вариантах реализации изобретения вершина третьей графемы соединена как минимум с одной из вершин, связанной с первой графемой, и одной из вершин, связанной со второй графемой (но не обязательно с обеими).
[0044] На шаге 720 логическая схема обработки данных определяет четвертую графему множества, связанная с которой вершина взвешенного графа соединена с вершинами первой, второй и третьей графемы взвешенными ребрами, сумма которых максимальна по сравнению с другими вершинами взвешенного графа. В некоторых вариантах реализации изобретения вершина четвертой графемы может быть соединена с каждой из вершин, связанных с первой, второй и третьей графемами. В других вариантах реализации изобретения вершина четвертой графемы соединена как минимум с одной вершиной из вершин, связанных с первой, второй и третьей графемой (но не обязательно с каждой из них).
[0045] На шаге 725 логическая схема обработки данных может определить N-ую (где N - размер множества, определенный на шаге 705) графему для множества, связанная с которой вершина взвешенного графа соединена с вершинами ранее выбранных графем взвешенными ребрами, сумма которых максимальна по сравнению с другими вершинами взвешенного графа. В некоторых вариантах реализации процесс, описанный на шагах 715-720 блок-схемы, может повторяться до идентификации N-ой графемы, завершающей построение множества размера N. Хотя для простоты иллюстрации Фиг. 7 определяет процесс выбора как минимум 4 графем, следует отметить, что размер множества может быть меньше 4.
[0046] На шаге 730 логическая схема обработки данных завершает построение множества, удаляя из взвешенного графа взвешенные ребра, соединяющие вершины, связанные с графемами, которые отобраны во множество на шагах 710-725 блок-схемы. На шаге 735 логическая схема обработки данных разветвляется, исходя из того, существуют ли дополнительные взвешенные ребра в взвешенном графе для анализа или необходимое количество множеств не достигнуто (т.е. существуют дополнительные множества для создания). Если существуют дополнительные множества для создания, обработка возвращается к шагу 710 для повторения процесса для следующего множества путающихся графем. В противном случае обработка переходит к шагу 740, в котором заканчивается процесс выбора множеств для группы множеств. После шага 740 способ по Фиг. 7 заканчивается.
[0047] На Фиг. 8 приведен пример вычислительной системы 800, которая может выполнять любой описанный здесь способ или несколько таких способов. В одном из примеров вычислительная система 800 может соответствовать вычислительному устройству, способному выполнять ядро системы классификации 110 представленное на Фиг. 1. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то, что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных здесь способов или нескольких таких способов.
[0048] Пример вычислительной системы 800 включает устройство обработки 802, основную память 804 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например, синхронное DRAM (SDRAM)), статическую память 806 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 816, которые взаимодействуют друг с другом по шине 808.
[0049] Устройство обработки 802 представляет собой одно или более устройств обработки общего назначения, например, микропроцессоров, центральных процессоров или аналогичных устройств. В частности, устройство обработки 802 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW), процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 802 также может представлять собой одно или более устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Устройство обработки 802 настраивается для выполнения ядра системы классификации 826 в целях выполнения рассматриваемых в этом документе операций и шагов.
[0050] Вычислительная система 800 может дополнительно включать устройство сопряжения с сетью 822. Вычислительная система 800 может также включать видеомонитор 810 (например, жидкокристаллический дисплей (LCD) или электронно-лучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 812 (например, клавиатуру), устройство управления курсором 814 (например, мышь) и устройство для формирования сигналов 820 (например, громкоговоритель). В одном из иллюстративных примеров видео дисплей 810, устройство буквенно-цифрового ввода 812 и устройство управления курсором 814 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0051] Запоминающее устройство 816 может включать машиночитаемый носитель 824, в котором хранится ядро системы классификации 826 (например, соответствующее способам, показанным на Фиг. 5-7 и т.д.), отражающий одну или более методологий или функций, описанных в данном документе. Ядро системы оптимизации 826 может находиться полностью или по меньшей мере частично в основной памяти 804 и(или) в устройстве обработки 802 во время выполнения способа вычислительной системой 800, основной памятью 804 и устройством обработки 802, также содержащими машиночитаемый носитель информации. Ядро системы оптимизации 826 может дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 822.
[0052] Несмотря на то, что машиночитаемый носитель данных 824 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять одну или более методик, описанных в настоящем описании изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как включающий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0053] Несмотря на то, что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться, по крайней мере частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и(или) попеременно.
[0054] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0055] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0056] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сконструирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0057] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемые к этим величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «анализ» и т.п., относятся к действиям вычислительной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах и памяти вычислительной системы в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[0058] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0059] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[0060] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[0061] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя А; X включает в себя В; или X включает и А, и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «аn», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» или «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.

Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Фильтрация дуг в синтаксическом графе
Многоэтапное распознавание именованных сущностей в текстах на естественном языке на основе морфологических и семантических признаков
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Автоматическое обучение программы синтаксического и семантического анализа с использованием генетического алгоритма
Использование глубинного семантического анализа текстов на естественном языке для создания обучающих выборок в методах машинного обучения
Исчерпывающая автоматическая обработка текстовой информации
Использование автоэнкодеров для обучения классификаторов текстов на естественном языке
Распознавание текста с использованием искусственного интеллекта
Способ распознавания текстовой информации из графического файла с использованием словарей и дополнительных данных

