Результат интеллектуальной деятельности: КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА
Вид РИД
Изобретение
Область изобретения
[0001] Настоящее изобретение в целом относится к классификации изображений с использованием технологии оптического распознавания символов (OCR).
Описание предшествующего уровня техники
В современном обществе используется большое множество различных видов документов. Документы могут содержать только текст, могут содержать текст с различными рисунками, такими как фотографии, иллюстрации или иные графические материалы, либо они могут содержать только графический контент в зависимости от типа документов и/или их использования. Существует необходимость автоматической классификации документов по их типам. Как правило, перед классификацией бумажных документов эти документы обрабатываются для получения их цифровых представлений (изображений). Например, бумажные документы можно отсканировать или сфотографировать для получения их электронных изображений. Затем эти изображения классифицируются. Такая классификация является неотъемлемой частью обработки потока документов, включающего различные типы документов.
[0002] В общем случае для классификации полученных изображений можно использовать различные методики. Классификация изображений может быть основана, например, на анализе геометрических структур на цифровых изображениях. В некоторых методиках классификации используется математический морфологический анализ. На изображениях могут быть выявлены некоторые признаки, например графические, на основе которых может быть сделано предположение о том, что в документе имеется текстовый контент или некоторый другой тип контента. В некоторых вариантах осуществления изобретения, если определено, что изображение документа содержит текст, то этот текст затем распознается, чтобы получить цифровой контент этого документа в виде текста в коде ASCII.
[0003] Известные методы классификации документов часто ненадежны и неэффективны. Существует постоянная потребность развития методов классификации, которое приведет к более эффективной и воспроизводимой классификации изображений для широкого спектра типов документов.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0004] В целом один из аспектов предмета изобретения, раскрытых в данном описании, может быть реализован в способах, которые включают следующие действия: доступ к хранимому в памяти набору признаков; анализ изображения документа с целью определения расположения блоков (разметки); распознавание изображения документа для получения данных цифрового контента, представляющего текстовый контент или потенциальный графический контент; вычисление значений признаков изображения документа для одного или нескольких признаков из набора признаков, причем значения признаков основаны на данных цифрового контента и взаимного расположения блоков; и классификация изображения документа как принадлежащего к одному из классов документов из набора классов документов на основании вычисленных значений признаков. Другие осуществления этого аспекта изобретения включают соответствующие системы, аппаратуру и компьютерные программы.
[0005] Эти и другие аспекты могут дополнительно включать один или более следующих признаков. Этот способ может дополнительно включать: доступ к набору классов документов и одному или нескольким наборам эталонных изображений для по меньшей мере одного из классов документов; анализ эталонных изображений для определения расположения блоков (разметки); распознавание эталонных изображений; вычисление значений признаков класса объектов на основе результатов анализа эталонных изображений и результатов распознавания эталонных изображений; и сохранение значений признаков класса в памяти; причем классификация изображения документа как принадлежащего к одному из классов по меньшей мере частично основана на значениях признаков класса. Классификация изображения документа как принадлежащего к определенному классу из набора классов документов может дополнительно содержать вычисление одного или нескольких показателей достоверности того, что изображение документа принадлежит к одному или нескольким классам из набора классов документов. Этот способ может дополнительно включать этап предварительной обработки изображения документа для улучшения визуального качества изображения документа перед анализом изображения и этапами распознавания изображения, и вычисление по меньшей мере для одного признака из набора признаков вероятности наличия по меньшей мере одного признака в одном из классов документов; и вычисление общей вероятности того, что изображение документа принадлежит к одному из классов документов. Вероятностям одного или нескольких признаков может присваиваться весовой коэффициент, отличающийся от весов других признаков. Классификация документа может дополнительно включать сохранение вычисленной вероятности по меньшей мере для одного из набора признаков в базе данных классификации.
[0006] Эти и другие аспекты могут дополнительно включать один или более следующих признаков. Доступ к набору признаков может выключать доступ к библиотеке, содержащей по меньшей мере одно из следующего: относительное пространственное расположение текстового контента, частоту встречаемости слова, количество цифр на изображении, количество словарных слов на странице, количество штрих-кодов, количество вертикальных и горизонтальных разделителей, соотношение объектов на странице, вертикальную ориентацию текста, по меньшей мере одно ключевое слово, и расположение объекта на изображении в качестве по меньшей мере одного из набора признаков. Классификация документа как принадлежащего к выбранному набору классификаций документов может дополнительно включать классификацию документа как только графического документа, как только текстового документа или как комбинированного текстового и графического документа.
[0007] Детали одной или нескольких реализаций предмета изобретения, описанных в данном описании, показаны в прилагаемых чертежах и в приведенном ниже описании. Другие признаки, аспекты и преимущества предмета станут очевидными из описания, чертежей и формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ.
[0008] Для того чтобы преимущества настоящего изобретения стали понятнее, более конкретное описание изобретения, которое кратко описано выше, будет представлено со ссылками на конкретные варианты осуществления изобретения, которые иллюстрируются на прилагаемых чертежах. Учитывая, что эти чертежи отображают варианты осуществления изобретения, и поэтому не могут рассматриваться как ограничивающие его объем, изобретение будет описано и объяснено более конкретно и детально с использованием прилагаемых чертежей, на которых:
[0009] на Фиг. 1 приведена блок-схема алгоритма последовательности операций примера способа классификации изображения документа на основе контента, в котором могут быть реализованы аспекты настоящего изобретения;
[0010] на Фиг. 2 приведена блок-схема алгоритма дополнительного примера способа классификации изображения документа на основе контента в соответствии с механизмами осуществления настоящего изобретения;
[0011] Фиг. 3 представляет собой блок-схему различной архитектуры, включающей процессор, которая может использоваться для осуществления механизмов настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0012] Как уже упоминалось выше, внедрение и использование документов в современном обществе в различных формах продолжает расти. Документы, удостоверяющие личность, лицензии, контрольные списки, контракты и т.п. встречаются практически в каждом аспекте жизни. Многие современные документы содержат широкий спектр контента, в том числе текстовый (печатный или рукописный), фотографический контент, иллюстрации и другой графический контент. Некоторые документы включают только графический контент (картинки или фотографии) без текстового контента. Графический контент может представлять собой фотографию человека или цифровое изображение пейзажа. Документы могут быть бумажными или электронными. Обычно бумажные документы обрабатываются, чтобы получить их цифровые представления (то есть изображения), например, путем сканирования или фотографирования документа. В дальнейшем термин «изображение документа» будет относиться к цифровому представлению документа на бумажном носителе независимо от контента документа (текстового, графического или смешанного контента).
[0013] Несмотря на то, что известны некоторые решения для классификации изображений документов, в настоящее время отсутствует эффективный механизм организации документов, использующий классификацию, основанную на заранее заданных признаках, выявленных в результате процесса распознавания. Кроме того, существует постоянная потребность развивать методы классификации, которые приводят к более эффективной и воспроизводимой организации изображений документов самых разнообразных типов.
[0014] Для удовлетворения этой потребности предложено несколько механизмов, показанных в вариантах осуществления, которые используются при классификации изображений документов в различных формах на основе заранее заданных признаков, вычисленных на основе результатов оптического распознавания символов (OCR), как будет объяснено ниже. Как уже упоминалось выше, в отношении этих заранее заданных признаков в одном из вариантов реализации изобретения осуществляется доступ к набору заранее заданных признаков, который хранится в памяти. Если это необходимо, то перед использованием описанного метода документ подвергается оптическому сканированию для получения цифрового представления документа - изображения документа. Изображение документа распознается подсистемой OCR. Признаки вычисляются на основе результатов OCR. Изображение документа классифицируется как принадлежащее к одному выбранному типу документов.
[0015] Как отмечено выше, механизмы проиллюстрированных вариантов реализации используют технологии оптического распознавания символов (OCR), причем результаты таких операций OCR затем используются для классификации изображений документов в один из несколько заранее определенных классов.
[0016] Загруженное изображение документа обрабатывается с использованием технологии OCR; значения одного или нескольких признаков вычисляются на основе полученного результата распознавания изображений, а затем изображение документа относится к одному из заранее определенных классов на основе вычисленных значений одного или более заранее заданных признаков, или одной или более комбинаций заранее заданных признаков. Функциональные возможности, реализованные в этих механизмах, могут быть установлены и реализованы с помощью различных устройств, в том числе персональных компьютеров (ПК) (настольных компьютеров или ноутбуков), мобильных устройств, таких как планшет и смартфоны, и других вычислительных устройств.
[0017] Кроме того, изображения документов можно классифицировать в множество страниц документа или в группы изображений определенных типов на основании комбинации заранее заданных признаков. Признаки можно использовать на стадии обучения (то есть, на стадии обучения классификатора для определения модели классификации), а затем для фактической классификации (то есть с использованием модели классификации).
[0018] Хранимые в памяти признаки могут быть бинарными или они могут представлять собой диапазон величин. Бинарные признаки отражают факт наличия или отсутствия конкретного признака в результатах распознавания, например, в виде «Да»/«Нет» или «0»/«1». Признак в виде диапазона содержит информацию в диапазонах: [0,.…, 1] или [2, …, 5]. Различные значения пороговых величин заранее заданных признаков могут быть установлены пользователем, могут быть установлены системой или заданы иным образом. Отдельные пороговые значения могут использоваться для стадий обучения и работы (классификации). В дополнительных вариантах осуществления пороговые значения могут соответствовать заранее заданному диапазону значений признаков. Например пороговые значения для признака «количество словарных слов» могут быть установлены в следующих диапазонах: 0…1; 2…5; и свыше 5. Специалистам в этой области техники понятно, что диапазоны могут отличаться в зависимости от признака и назначения. Например, можно ожидать, что в определенном структурированном документе, например, водительском удостоверении, должно быть от двух до трех слов в поле ФИО водителя.
[0019] Как уже отмечалось выше, различные значения признаков для целей последующей классификации вычисляются на основе результатов распознавания изображения документа (например, при OCR). Другими словами, если это необходимо, на начальном этапе бумажный документ обрабатывают, чтобы получить его цифровое представление (бумажные документы можно отсканировать или сфотографировать). Затем полученное цифровое изображение распознается для поиска соответствующих признаков в документе, причем признаки рассчитываются на основе распознанных данных. Для одного или нескольких соответствующих признаков, которые вычисляются на основе результатов распознавания изображения, в одном варианте реализации изобретения вычисляется вероятность наличия этих признаков в конкретном классе изображений документов. Соответственно, в результате затем можно выбрать наиболее важные (т.е., наиболее вероятные) признаки. Для каждого признака можно вычислить общую вероятность того, что этот признак принадлежит конкретному классу. Другими словами, все вычисленные признаки можно использовать после процесса OCR для отнесения конкретного изображения к определенному классу.
[0020] Рассмотрим следующий пример. Механизмы показанных вариантов осуществления изобретения могут быть реализованы для классификации документов, переданных в страховую компанию. Связанные со страхованием документы могут быть объемными, они могут иметь различный объем и формат. Например, некоторые документы могут быть письменными договорами, другие документы могут содержать фотографии или другие иллюстрации, а третьи документы могут представлять собой квитанции. Каждый из этих документов может быть передан в большом объеме в определенное место для обработки. Механизмы представленных вариантов осуществления могут обеспечить эффективную и высокую по точности повторяемости классификацию каждого из этих типов документов (фотографий, квитанций и контрактов). В родственном варианте осуществления потенциальный клиент страховой компании может предоставить в страховую организацию ряд регистрационных документов для предварительной обработки или квалификации. При необходимости поставляемые документы обрабатываются для получения их цифровых представлений. При использовании функциональности классификатора в представленных вариантах осуществления смешанный пакет документов может быть разбит на составляющие классы документов, например фотография в паспорте, подписанный контракт, платежная информация и т.п.
[0021] В одном конкретном варианте реализации механизмы представленных вариантов реализации используют технологию OCR с последующей обработкой полученных результатов для разделения группы изображений документов по меньшей мере на две отдельные группы. Первая группа может представлять собой изображения документов, содержащих фотографию (или отсканированное изображение) текстового документа, а вторая группа может содержать файл только с изображением (т.е., фотографию без текстового контента). В этом варианте осуществления для классификации может использоваться по меньшей мере один признак, а именно наличие текста на изображении. Другими словами, при мгновенном осуществлении используются механизмы классификации документов на основе наличия текста в результатах распознавания изображений.
[0022] Заранее определенный признак «наличие текста на изображении» позволяет группировать изображения документов, содержащих текст, отдельно от изображений документов, содержащих иллюстрации (изображение документа, содержащее только графическую информацию, например, рисунки, иллюстрации или фотографии) на основе применения метода классификации, тем самым улучшая классификацию изображений в целом. В данной классификации в качестве заранее заданного признака для целей классификации также может использоваться «количество слов». Специалисту в этой области понятно; что эти механизмы могут применяться к контенту документа в целом (т.е. ко всему контенту страницы), а также к части контента в документе (то есть, к частям страницы, на которые она разделена).
[0023] Как уже отмечалось выше, в механизмах показанных вариантов реализации используются данные распознавания (результаты OCR), и эти данные распознавания сравниваются с заранее заданными признаками или комбинацией заранее заданных признаков, например, определяется наличие признака в данных распознавания, и рассчитывается значение этого признака. Затем эти механизмы используют методы классификации, основанные непосредственно на результатах процесса OCR, а не на других процессах, таких как морфологический анализ документа. Как уже отмечалось выше, в одном варианте осуществления изобретения эти механизмы реализованы на стадии обучения (на которой классификатор обучается, например, с помощью эталонных изображений для каждого класса) и стадии классификации (на которой классификатор производит классификацию нового полученного изображения документа на основе результатов стадии обучения).
[0024] Одна из целей классификации документов заключается в отнесении документов к разным предварительно определенным категориям. Эта классификация очень полезна при работе с потоком документов, который включает документы различных типов, когда требуется идентифицировать тип каждого документа. Например, может возникнуть необходимость отсортировать различные документы, такие как контракты, счета и квитанции, в разные папки или переименовать их в соответствии с их типами. Такую сортировку можно произвести автоматически с помощью заранее обученной системы.
[0025] В одном варианте осуществления изобретения создается база данных классификации. Эта база данных создается на этапе подготовки автоматически, пользователем, с участием пользователя или другими способами, известными специалисту в этой области техники. Может быть загружено несколько изображений документов каждого типа. Желательно, чтобы эти документы имели одинаковый контент. Эти изображения используются для создания базы данных классификации. Отсканированные изображения или фотографии могут быть подвергнуты некоторой предварительной обработке прежде, чем эти изображения могут использоваться для создания базы данных. Кроме того, на стадии обучения набор заранее заданных признаков может быть расширен путем добавления новых признаков. Эти новые признаки могут формироваться автоматически при машинном обучении или вручную пользователем.
[0026] Затем база данных классификации используется на стадии классификации для классификации различных входящих изображений документов. Изображения (отсканированные изображения и/или фотографии) документов могут передаваться, например, в заранее обученный классификатор, который использует базу данных классификации для определения соответствующего типа каждого документа.
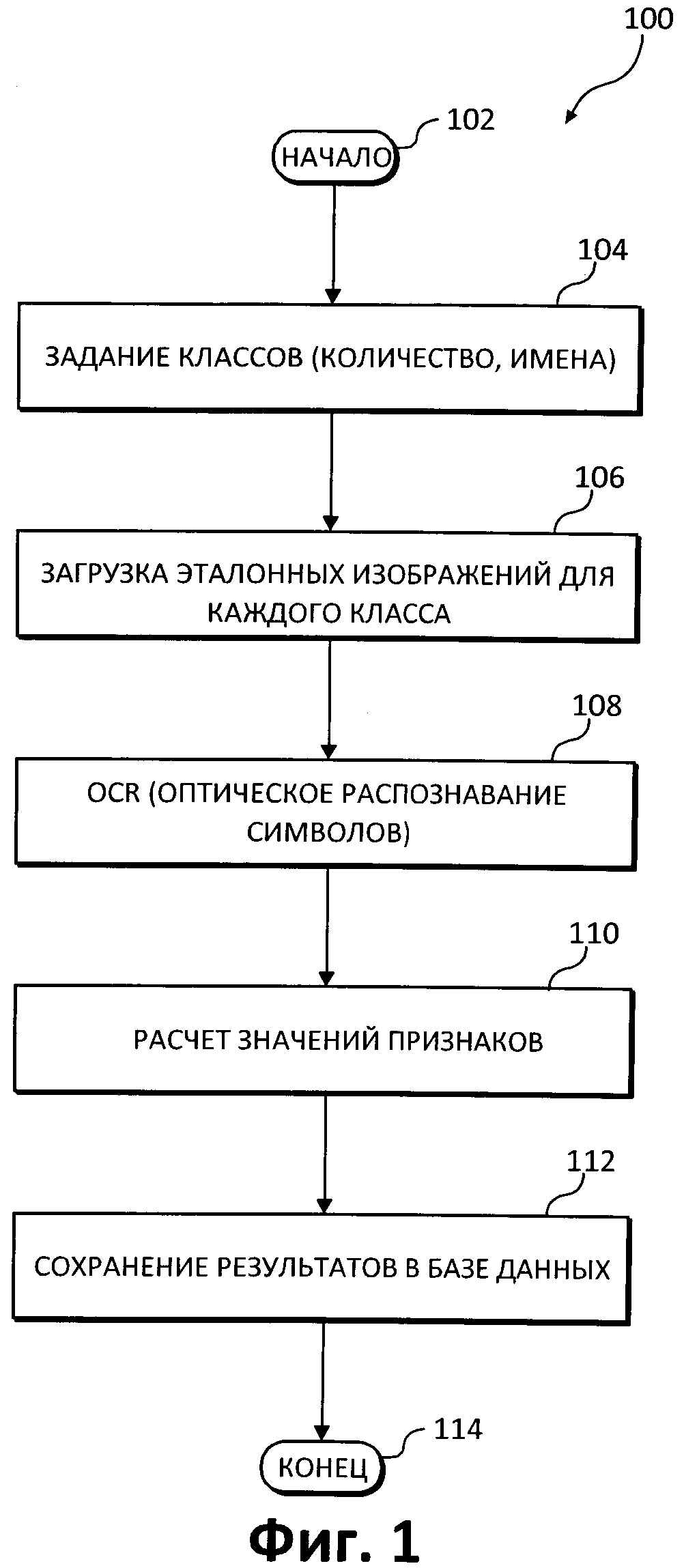
[00271 На Фиг. 1 приведена блок-схема, показывающая пример классификации изображений на основе контента (100), в которой могут быть реализованы различные аспекты иллюстрируемых вариантов реализации. Способ (100), наряду с другой функциональностью, связан с аспектами инициализации механизмов классификации (то есть описанной выше стадии обучения), например, с созданием базы данных классификации.
[0028] Способ создания базы данных классификации (100) начинается (этап 102) с указания различных классов (этап 104). Как было указано выше, и что понятно специалисту в этой области техники, классы могут быть определены пользователем, они могут быть определены с помощью системы, системой с участием пользователя или с помощью другого механизма. Кроме того, классы сами по себе могут изменяться в зависимости от конкретной реализации, например, по объему и/или по имени.
[0029] Описанный метод классифицирует изображения документов с использованием базы данных классификации. Здесь термин «документ» относится не только к документу, содержащему только текстовый контент, но и документу, содержащему смешанный контент (т.е. имеющему как текстовый, так и графический контент), и к документу, содержащему только иллюстрации (например, фотографии человека или пейзажа). Чтобы создать базу данных классификации, для каждого типа документов, которые должны быть обработаны, требуется набор эталонных изображений. Итак, бумажные документы подвергаются предварительной обработке для получения их цифровых представлений (изображений документов). Перейдем к этапу (106); способ (100) добавляет эталонные изображения для каждого из классов в классификатор (этап 106). Эталонное изображение может представлять собой составное представление различных заранее заданных признаков, с которыми в конечном счете будет связано изображение документа. Например, для каждого класса в конкретной модели классификации может быть задано и/или загружено отличающееся эталонное изображение. В одном из вариантов реализации этапа 106 пользователь может загрузить несколько эталонных изображений (n эталонных изображений) каждого заранее определенного класса, которые будут использоваться для обучения классификатора. Например, можно использовать три соответствующих изображения для одного класса. Как правило, эталонные изображения являются типичными представителями класса, и они содержат все представительные признаки класса, к которому они принадлежат. Как упоминалось ранее, изображения конкретного класса должны быть похожи по виду и/или по контенту и, возможно, для них может потребоваться несколько этапов предварительной обработки. Затем эти изображения, в свою очередь, используются для создания базы данных классификации.
[0030] В некоторых вариантах осуществления эталонные изображения, используемые для создания базы данных, подвергаются предварительной обработке для устранения некоторых искажений, таких как неправильная ориентация, геометрические искажения или другие дефекты.
[0031] В некоторых вариантах осуществления база данных классификации представляет собой список идентификаторов (имен) классов изображений документов. Каждый из идентификаторов класса связан со списком заранее заданных признаков, в котором будет записываться частота встречаемости определенных признаков в документе конкретного класса.
[0032] В некоторых вариантах осуществления эталонное изображение подвергается процессу анализа изображений (анализа документа). Во время анализа изображений определяется логическая структура (расположение блоков/разметка) эталонного изображения. Анализ может включать создание одной или нескольких гипотез об изображении для всего изображения, проверку каждой гипотезы путем создания гипотез о блоке для каждого блока на изображении на основании гипотезы об изображении и выбор наилучшей гипотезы о блоке для каждого блока. Затем выбирается лучшая гипотеза об изображении на основании степени соответствия между выбранными лучшими гипотезами о блоках для изображения. Как правило, в процессе анализа документа, выделяются различные области в изображении документа, их размеры и положения сохраняются в памяти, и их классы обнаруживаются на основании их контента, например текста, изображения, таблицы, диаграммы или шумов. Подробное описание анализа документа можно найти в патенте США №8260049, который целиком включен в настоящий документ посредством ссылки.
[0033] На следующем этапе 108 изображение образца подвергается процессу OCR. Системы OCR используются для преобразования изображений или представления бумажного документа (фотографии) в машиночитаемый редактируемый на компьютере электронный файл, допускающий поиск в нем. В результате распознавания изображения поступает информация о тексте (если в изображении обнаружен текст), такая как шрифт, используемый в изображении документа, координаты текста и координаты прямоугольников, охватывающих различные слова, блоки рисунков, разделители и т.д.
[0034] На основании результатов распознавания (OCR) эталонных изображений документов определяются заранее заданные признаки, например выявляется наличие некоторых признаков и вычисляются значения этих признаков (110). Например, вычисление значений признаков может включать определение количества цифр, количества словарных слов, частоты встречаемости слов, относительных размеров разметки страницы и т.д., в качестве распознанных данных, чтобы быть нормированными с эталонным изображением в качестве заранее заданного признака или признаков. Эти значения могут быть представлены в виде списка или в другом формате. Вычисленные значения признаков позднее используются на стадии классификации для отнесения поступающих изображений документов к определенным классам. Другими словами, распознанные данные подвергаются определенным вычислениям значений признаков для присвоения значений признакам; фактически формируются заранее заданные признаки, которые будут использованы в дальнейшем на стадии классификации (этап 110). Затем рассчитанные заранее заданные признаки сохраняются в базе данных классификации, как описано выше (этап 112).
[0035] Например, на основании результатов распознавания эталонного изображения документа рассчитывается количество словарных слов на изображении документа. Например, пусть количество словарных слов в распознанных данных равно 3. Поскольку признак «количество словарных слов» является признаком с диапазоном значений, вычисленному значению для определенного признака «количество словарных слов» присваивается соответствующий диапазон [2, …, 5]. При этом счетчик частоты появления определенных признаков в определенном классе обновляется, а именно он будет увеличен на 1. Таким образом формируется база данных классификации на основе результатов распознавания эталонных изображений.
[0036] Специалисту в этой области техники понятно, что различные этапы (104-112), которые описаны выше и в способе (100), могут быть повторены, например, если качество классификации недостаточно высоко для построения наилучшей модели классификации с использованием надлежащего сочетания признаков для одного или нескольких конкретных примеров изображений. Затем способ (100) завершается (этап (114)).
[0037] Как отмечалось выше, аспекты способа 100 можно рассматривать как стадию обучения, которую можно использовать для обучения на основании эталонных изображений документа модели классификации (методики классификации), которая будет использоваться в дальнейшем при классификации новых входящих изображений в режиме реального времени.
[0038] База данных классификации может быть обновлена и улучшена, например, путем добавления новых типов документов или изменения существующих. В одном из вариантов реализации изобретения пользователь может предварительно определить количество и имя класса, а также признак или комбинацию признаков, которые будут использоваться при обучении и далее при классификации (этап 104). Возможность добавить особые признаки может оказаться полезной при классификации уникальных изображений. Кроме того, с помощью специального графического интерфейса пользователя (GUI) могут быть добавлены особые признаки.
[0039] Возможность обновления может оказаться полезной, если база данных классификации уже создана, но пользователь хочет настроить ее или добавить классы. Эти способы также можно использовать для улучшения классификации с использованием определенных пользователем признаков или особых признаков. Как уже упоминалось выше, этот способ позволяет добавлять пользовательские признаки для документа в базу данных. Признак определяется его именем; пользователь может добавить более одного признака для одного изображения документа. Примером, когда использование пользовательских признаков улучшает результат классификации, является случай, когда изображения документа ненадежно определяются с помощью стандартного метода классификации, однако известно, что в документах одного класса всегда имеется логотип компании в верхнем левом углу, в то время как в документах другого класса такой логотип отсутствует. Добавление признака отсутствия/наличия логотипа улучшает качество классификации для таких изображений документов.
[0040] Специалистам в этой области техники понятно, что аспекты изображения, которые выбраны в качестве заранее заданных признаков для последующей классификации документов, могут широко варьироваться в зависимости от конкретной ситуации. В одном из вариантов реализации можно использовать четыре основных признака, включая частоту встречаемости слова, количество чисел или цифр в изображении, количестве словарных слов на странице, и относительные размеры разметки страницы (например, размеры описывающего прямоугольника охватывающего текст на странице).
В дополнение к четырем описанным выше основным признакам в конкретной ситуации можно использовать дополнительные признаки по отдельности и/или в комбинации. Эти дополнительные признаки включают, помимо прочего, следующие признаки: количество слов на изображении документа, количество штрих-кодов, количество таблиц и количество вертикальных/горизонтальных разделителей (при отсутствии штрих-кода, таблицы и разделителя значение этого признака будет равно нулю), процентное соотношение объектов на странице, содержание штрих-кодов (ключевое слово в штрих-коде) и тому подобное. При определении таких признаков, как ключевое слово или количество слов также можно рассматривать вертикальную ориентацию текста. Кроме того, в качестве признака можно использовать взаимное расположение объектов на изображении. Наконец, еще один признак может включать наличие фотографий, картинок, иллюстрации или другого графического объекта на изображении (например, наличие фотографии при сканировании паспорта). Как уже отмечалось выше, этот перечень возможных признаков не является исчерпывающим и может быть расширен в зависимости от конкретной ситуации или цели в методологии классификации.
[0041] В одном из примеров вариантов реализации при формировании модели классификации могут быть проверены результаты стадии обучения. Это дает возможность выбора наиболее точной возможной схемы классификации для конкретной ситуации. Например, для каждого указанного класса может быть выбран набор случайных изображений (например, около 80%). Остальные изображения (примерно 20%) можно использовать для тестирования (проверки) модели классификации. Затем эти оставшиеся изображения используются для оценки точности модели классификации, основанной на выбранных признаках. Если оставшиеся 20% (взятых вперемешку) программа смогла классифицировать ровно так, как они и были изначально классифицированы (пользователем, например, вручную), то модель считается хорошей и применяется уже на входящих изображениях документов. С другой стороны, если модель классифицировала оставшиеся изображения с ошибкой, ее нужно переобучить.
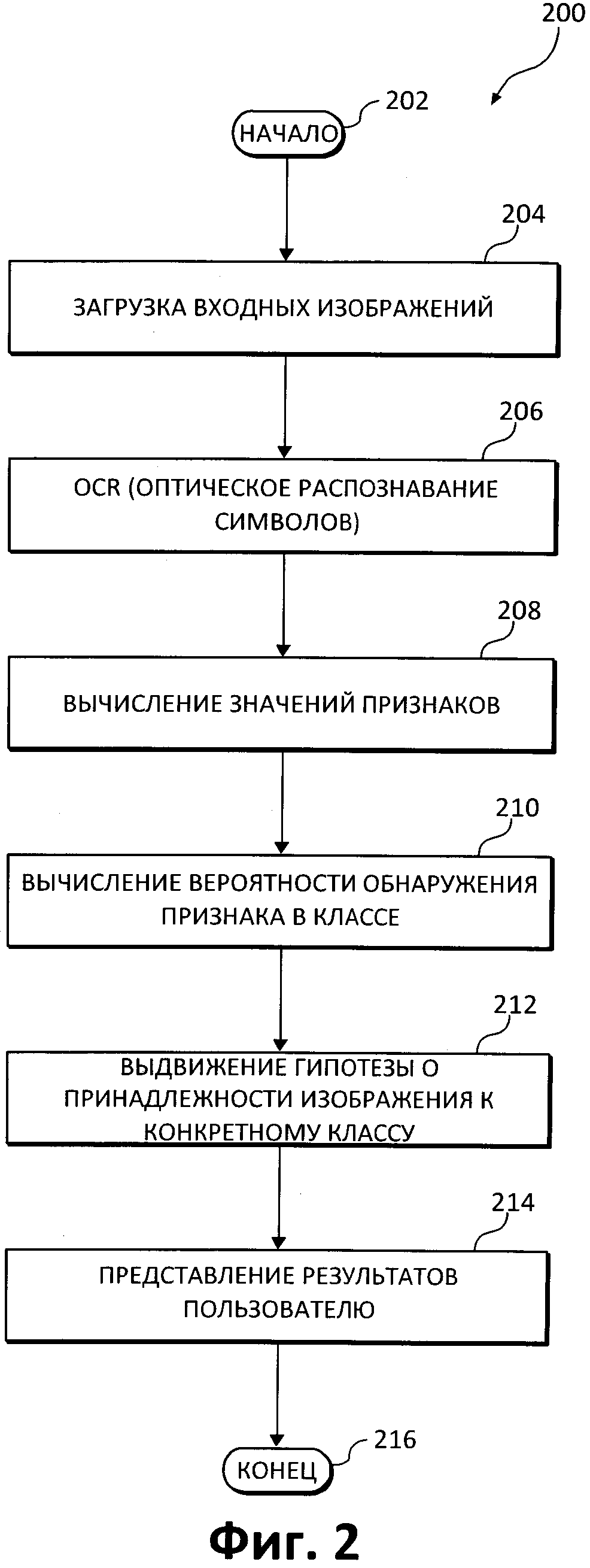
[0042] На следующей Фиг. 2 показана блок-схема, в которой приведено подробное описание различных аспектов того, что можно назвать примером стадии классификации как способа (200). В одном из вариантов реализации изобретения операции классификации выполняются на основании одного заранее заданного признака или на основании комбинации заранее заданных признаков, которые вычисляются на основе результатов распознавания рассматриваемых изображений. После начального этапа (202) способ (200) обрабатывает поступающие изображения, которые загружаются (204), например, в классификатор. На этом этапе стадии классификации поступает изображение (или набор изображений), которое должно быть отнесено к конкретному классу. Классификатор может получать эти входящие изображения случайным образом. В случае многостраничного документа классификация может быть проведена на основании анализа первой страницы документа или на основании информации о каждой странице документа в соответствии с настройками пользователя.
[0043] Подлежащие классификации загруженные входящие изображения могут быть предварительно обработаны, чтобы подготовить их к дальнейшей обработке или для улучшения их визуального качества (например, после сканирования или перед распознаванием). Этот этап предварительной обработки не является обязательным и его можно пропустить. Этапы предварительной обработки изображений могут производиться на стадии обучения и/или классификации. Этапы предварительной обработки могут привести к улучшению результатов процесса распознавания изображений. Изображения могут подвергаться дополнительной предварительной обработке, например: автоматическому детектированию ориентации страниц; автоматическому устранению перекоса изображения, удалению пятен с изображения; разделению страниц отсканированных книг на два отдельных изображения; разделению отсканированных страниц с несколькими визитными карточками на отдельные изображения; выпрямлению линий; фильтрации текстур; удалению смаза изображения и шумов ISO с цифровых фотографий; отсечению полей страницы и т.д.
[0044] На следующем этапе (206) к каждому из полученных или загруженных изображений применяется процесс распознавания (OCR). На основании результатов распознавания (206) способом, аналогичным способу, использованному на этапе вычисления значения признаков (110), который был описан ранее, вычисляются значения каждого из признаков текущего документа (этап 208) (например, в результате распознавания изображений рассчитываются частота встречаемости слов, количество чисел или разрядов (цифр) в изображении, количество словарных слов на странице, относительные размеры макета страницы, и т.д.).
[0045] На следующем этапе (210) рассчитывается вероятность P(Fi|Ck) встретить вычисленный признак Fi в конкретном классе Сk. Такие вероятности рассчитываются для каждого класса изображений Сk Таким образом, для класса С1 рассчитываются следующие вероятности: P(F1|C1), P(F2|C1), …, P(FN|C1). После вычисления вероятности P(Fi|Ck) присутствия вычисленного признака Fi в конкретном классе Сk рассчитывается общая вероятность отнесения изображения документа к определенному классу, если это изображение документа имеет некоторый набор вычисленных признаков.
[0046] На этапе (212) для определения вероятности отнесения изображения документа к классу может использоваться следующая формула (наивный байесовский классификатор), если заданы признаки F1, …, Fn:
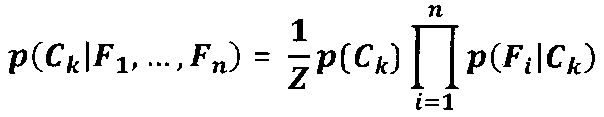
где p(Fi|C) - это условная вероятность присутствия признака Fi в классе; Сk - вычисляется на основе результатов, полученных из предыдущей стадии обучения; 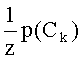 - это нормировочный множитель. Следует отметить, что в то время как может использоваться заявленный классификатор, ряд алгоритмов классификации может быть реализован в зависимости от конкретной ситуации. На этом этапе можно использовать другие методы классификации.
- это нормировочный множитель. Следует отметить, что в то время как может использоваться заявленный классификатор, ряд алгоритмов классификации может быть реализован в зависимости от конкретной ситуации. На этом этапе можно использовать другие методы классификации.
[0047] В одном из вариантов реализации изобретения некоторые выбранные признаки могут иметь более высокие весовые коэффициенты. Это позволяет определить самые необходимые признаки, наличие которых поможет быстрее и эффективнее идентифицировать класс конкретного входного изображения. Их можно вычислить по следующей формуле:
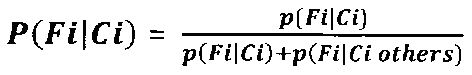 ,
,
где p(Fi|Ci) - это вероятность найти признак Fi в классе Ci; p(Fi|Ci others) - это вероятность найти признак Fi в других классах (не в классе Ci). Поэтому если p(Fi|Ci others)=0, то вероятность P(Fi|Ci)=1, если вероятность p(Fi|Ci others)≠0, то вероятность P(Fi|Ci)<1. Например, признак «наличие слова <паспорт>» может присутствовать в основном в классе «отсканированные паспорта», так что p(Fi|Ci others)->0, тогда вероятность найти присутствие признака слова «паспорт» в классе «отсканированные паспорта» почти равна 1.
[0048] Определение отнесения документа (изображения) к определенному типу (классу) может быть произведено с некоторой вероятностью (степенью достоверности). Метод классификации возвращает имена классов, к которым может принадлежать данное изображение. Для каждого класса также сохраняется показатель достоверности классификации, а имена сортируются по показателю достоверности в порядке убывания. Другими словами, на основании вычисленной вероятности pi(Ck|F1 ,…, Fn) выдвигается гипотеза об отнесении входящего изображения к существующему классу. Также можно предположить несколько гипотез (этап 212). Например, гипотеза H1, что входящие изображения должны быть включены в класс 1 с вероятностью 85%, гипотеза Н2, что входящие изображения должны быть включены в класс 2 с вероятностью 10%, гипотеза Н3, что входящие изображения должны быть включены в класс 3 с вероятностью 5%.
[0049] Дополнительный необязательный этап (214) может быть выполнен после завершения операции классификации, когда, например, классификатор обнаруживает возможность ошибки классификации. Затем классификатор выдает пользователю уведомление о возможной ошибке и отображает набор классифицированных документов (изображений) с вероятностями. Затем способ (200) завершается (этап (216)).
[0050] Здесь, как и ранее, этапы (202-214) могут выполняться повторно индивидуально либо совместно, либо в другом порядке, что понятно специалисту в данной области техники, в зависимости от конкретной ситуации и конкретных признаков или совокупности признаков.
[0051] Рассмотрим следующий пример функциональности классификации при выполнении механизмами представленных вариантов осуществления. В данном примере набор результирующих изображений должен быть классифицирован в два класса: изображения (фотографии) документов, содержащих информацию с текстовым или смешанным контентом, и отсканированные изображения, представляющие только картинки. Конкретным признаком, используемым в этом примере, является количество слов в распознанном изображении. В качестве первого шага пользователь заранее задает пороговое значение признака (количество слов). Затем изображение загружается в приложение. Для загруженного файла производится OCR. OCR применяется для распознавания контента изображения, штрих-кодов и других нетекстовых частей контекста. В результате OCR (если текст обнаружен в изображении) получается информация о тексте, шрифте, использованном в изображении документа, координатах текста и координатах прямоугольников, охватывающих разные слова. На следующем этапе в распознанном изображении (страницы или всего документа) рассчитываются значения этих признаков (количество слов). Если количество слов превышает заданный пользователем порог, то файл классифицируется как «изображение» (фотография, отсканированное изображение и т.д.) документа, содержащего текстовую или смешанную информацию. Если количество слов меньше заданного пользователем порога, то файл классифицируется как файл «только изображение», например, изображение документа, содержащего только графическую информацию (картинки). Классификация может производиться с определенной вероятностью, может предоставляться дополнительное или необязательное уведомление пользователя о возможной ложной классификации.
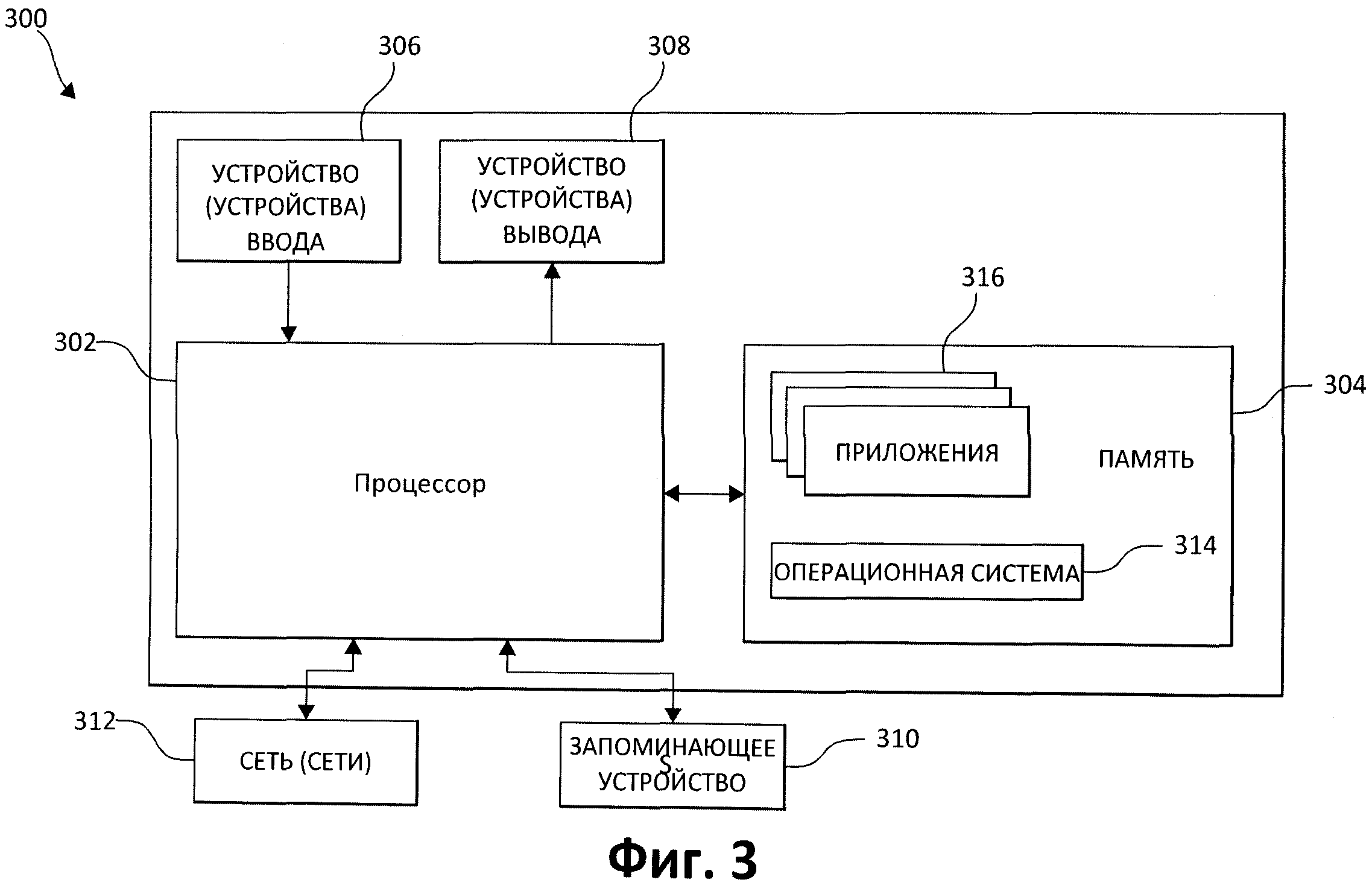
[0052] На следующей Фиг. 3 представлена блок-схема алгоритма, которая иллюстрирует пример компьютерной системы (300), которая используется в некоторых реализациях в настоящем изобретении, как описано выше. Система (300) включает один или несколько процессоров (302), соединенных с запоминающим устройством (304). Процессор(ы) (302) может(могут) содержать одно или несколько вычислительных ядер или могут представлять собой микросхему или другое устройство, способное выполнять вычисления (например, оператор Лапласа может быть реализован с помощью оптических процессов). Память 304 может представлять собой оперативное запоминающее устройство (ОЗУ), она может также содержать любые другие типы или виды памяти, в частности, энергозависимые запоминающие устройства (например, флэш-накопители) или постоянные запоминающие устройства, такие как жесткие диски, и т.д. Кроме того, можно рассмотреть схему, в которой память (304) включает удаленные носители информации, а также локальную память, такую как кэш-память в процессоре(процессорах) (302), используемую в качестве виртуальной памяти, и хранимую во внешнем или внутреннем энергонезависимом запоминающем устройстве 310.
[0053] Компьютерная система (300) также обычно имеет порты ввода-вывода для передачи и приема информации. Для взаимодействия с пользователем компьютерная система (300) может содержать одно или несколько устройств ввода (306) (таких как клавиатура, мышь, сканер или другое) и устройства вывода (308) (например, дисплеи или специальные индикаторы). Компьютерная система (300) может также иметь одно или несколько энергонезависимых запоминающих устройств (310) для хранения данных, такие как привод оптических дисков (формата CD, DVD или другого формата), накопитель на жестком диске или накопитель на магнитной ленте. Кроме того, компьютерная система (300) может иметь интерфейс с одной или несколькими сетями (312), которые обеспечивают соединение с другими сетями и компьютерным оборудованием. В частности, это может быть локальная сеть (LAN) или сеть Wi-Fi, причем она может быть подключена к сети Интернет, но может быть и не подключена к ней. Понятно, что компьютерная система (300) может включать аналоговые и/или цифровые интерфейсы между процессором (302) и каждым из компонентов (304), (306), (308), (310) и (312).
[0054] Компьютерная система (300) управляется операционной системой (314), она включает различные приложения, компоненты, программы, объекты, модули и другое, обозначенное сводным числом (316).
[0055] Программы, используемые для выполнения способов, соответствующих данному изобретению, могут представлять собой часть операционной системы либо они могут представлять собой специализированную периферийную компоненту, программу, динамически подключаемую библиотеку, модуль, сценарий или их сочетание.
[0056] Специалистам в этой области понятно, что аспекты настоящего изобретения могут быть реализованы в виде системы, способа или компьютерного программного продукта. Таким образом, аспекты данного изобретения могут иметь исключительно аппаратную реализацию, исключительно программную реализацию (включая встроенное программное обеспечение, резидентное программное обеспечение, микрокоманды и т.д.) либо вариант реализации, в котором сочетаются программные и аппаратные компоненты, что в целом может называться в этом документе «схемой», «модулем» или «системой». Кроме того, аспекты настоящего изобретения могут принимать форму компьютерного программного продукта, записанного на одном машиночитаемом носителе или нескольких машиночитаемых носителях, в которых записан читаемый компьютерный код программы.
[0057] Может использоваться любая комбинация одного машиночитаемого носителя или нескольких машиночитаемых носителей. Машиночитаемый носитель может представлять собой машиночитаемый носитель сигнала или машиночитаемый носитель информации. Машиночитаемый носитель информации может представлять собой, например, помимо прочего, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, устройство или аппарат, или любую подходящую комбинацию перечисленного выше. Более конкретные примеры машиночитаемых носителей включают следующее (неполный список): электрическое соединение, имеющее один провод или более, портативный компьютерный гибкий диск, жесткий диск, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), перезаписываемое программируемое постоянное запоминающее устройство (ППЗУ или флеш-память), оптическое волокно, портативный компакт-диск для однократной записи данных (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или любую подходящую комбинацию перечисленного выше. В контексте этого документа машиночитаемый носитель данных может быть любым материальным носителем данных, который может содержать или хранить программу для использования выполняющей команды системой, аппаратом или устройством, либо при подключении к выполняющей команды системе, аппарату или устройству.
[0058] Записанный в машиночитаемом носителе программный код может передаваться с использованием любой подходящей среды, включая, помимо прочего, следующие среды: беспроводная среда, проводная среда, оптоволоконный кабель, радиочастотная среда и т.д., либо с помощью любой подходящей комбинации перечисленных выше сред. Компьютерный программный код для выполнения операций для предметов раскрываемого изобретения может быть написан в виде любой комбинации на одном или нескольких языках программирования, включая объектно-ориентированные языки программирования, такие как Java, Smalltalk, С++ и т.п., а также традиционные процедурные языки программирования, такие как язык программирования С или похожие языки программирования. Код программы может полностью выполняться на компьютере пользователя, частично на компьютере пользователя, как автономный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть соединен с компьютером пользователя по сети любого типа, в том числе по локальной сети (LAN) или по глобальной сети (WAN), либо может быть организовано соединение с внешним компьютером (например, по сети Интернет с использованием поставщика услуг Интернета).
[0059] Аспекты настоящего изобретения были описаны выше со ссылкой на структурные схемы и/или блок-схемы способов, устройства (системы) и компьютерные программные продукты в соответствии с вариантами осуществления изобретения. Следует понимать, что каждый блок и комбинация блоков в структурных схемах и/или блок-схемах могут быть осуществлены с помощью команд компьютерной программы. Эти команды компьютерной программы могут быть переданы в процессор универсального компьютера, специализированного компьютера или другого программируемого устройства обработки данных для получения машины таким образом, чтобы команды, которые выполняются с помощью процессора компьютера или другого программируемого устройства обработки данных, создали средства для реализации функций или действий, указанных в блоке или блоках структурной схемы и/или блок-схемы.
[0060] Эти команды компьютерной программы также могут храниться в машиночитаемом носителе, который может заставить компьютер, другое программируемое устройство обработки данных, или другие устройства работать определенным образом так, чтобы эти команды, хранящиеся в машиночитаемом носителе, производили изделие, в том числе команды, реализующие функцию или действие, предусмотренное в блоке или блоках структурной схемы и/или блок-схемы. Команды компьютерной программы также могут быть загружены в компьютер, в другое программируемое устройство обработки данных или в другие устройства, чтобы вызвать выполнение последовательностей рабочих этапов, которые должны выполняться в компьютере, другом программируемом устройстве или в других устройствах для выполнения реализованного в компьютере процесса таким образом, чтобы команды, которые выполняются в компьютере или в другом программируемом устройстве, предоставляли процессы для выполнения функции или действия, предусмотренного в блоке или блоках структурной схемы и/или блок-схемы.
[0061] Структурные схемы и блок-схемы на приведенных выше чертежах иллюстрируют архитектуру, функциональность и работу возможных вариантов осуществления систем, способов и компьютерных программных продуктов в соответствии с различными вариантами осуществления раскрываемого изобретения. В связи с этим каждый блок в структурной схеме или блок-схеме может представлять собой модуль, часть кода или сегмент, который содержит одну или более исполняемых команд для осуществления указанной логической функции (указанных логических функций). Следует также отметить, что в некоторых альтернативных реализациях отмеченные в блоке функции могут выполняться в порядке, отличном от того, который указан в иллюстрациях. Например, два блока, которые показаны как последовательные, фактически могут выполняться по существу одновременно либо иногда блоки могут выполняться в обратном порядке, в зависимости от используемой функциональности. Кроме того, следует отметить, что каждый блок структурной схемы и/или блок-схемы и комбинации блоков в структурных схемах и/или блок-схемах могут быть реализованы с помощью специальных систем оборудования, которые выполняют заданные функции или действия, или с помощью комбинации специализированного оборудования и компьютерных команд.
Полифункциональный ступенчатый вихревой обогреватель
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Определение преобразований изображения для повышения качества оптического распознавания символов

