Результат интеллектуальной деятельности: УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее описание в целом относится к устройствам, системам, способам и компьютерным программам/алгоритмам, которые могут применяться для обработки изображений, документов и/или текстов с использованием, например, оптического распознавания символов (OCR) и сравнения документов с целью поиска различий между ними.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время в документообороте, делопроизводстве и во многих аспектах ведения бизнеса зачастую встречается задача по сравнению двух или более документов, содержащих текст или другую информацию, с целью определения их идентичности или поиска различий между анализируемыми документами. Одним из конкретных способов реализации является сравнение копии документа с его исходной версией, например, чтобы исключить возможность ошибок, совершенных при заполнении документа или шаблона или намеренной его модификации.
[0003] Например, при заключении договора, после прохождения множества этапов согласования, возможна следующая ситуация. Одна из сторон соглашения, условно обозначенная как сторона A, отправляет вариант договора другой стороне, условно обозначенной как сторона B, для его последующего подписания. После подписания договора стороной B сторона A может захотеть убедиться в том, что подписанный договор соответствует исходному договору (оригиналу) и не содержит изменений, непредусмотренных правок и т.п. Если вся процедура подписания происходит в цифровом виде с использованием цифровых подписей, задача сравнения упрощается. Однако зачастую соглашения и другие юридические документы подписывают на бумаге, после чего сторона A отправляет бумажную или сканированную (сфотографированную или факсовую) копию с подписью.
[0004] Задача по проверке идентичности документов становится более трудоемкой, если в документообороте присутствует бумажная версия документа. В настоящее время проблемы такого типа решаются путем сравнения электронного варианта и бумажного варианта документа вручную. В результате после тщательного и внимательного изучения двух вариантов документа человек (оператор) убеждается, что варианты совпадают либо в них присутствуют существенные различия. Процесс существенно усложняется, если договор содержит десятки или сотни страниц.
[0005] Как правило, для сравнения печатных электронных версий документов, данные документы конвертируются в текст, после чего происходит сравнение именно текстовых файлов. В результате пользователю отображаются результаты данного текстового сравнения. Однако сравнения текстов не всегда бывает достаточным. В частности, сравнения текстов недостаточно в том случае, если необходимо найти различия не только в тексте, но и в разметке, координатах, наличии таблиц, печатей, подписей, штампов или других элементов. Кроме того, для каждого изменения в электронной версии пользователь должен просмотреть документы, чтобы найти соответствующие места в двух исходных бумажных документах и затем понять, является ли найденное изменение существенным различием или не является.
[0006] Необходим способ анализа документов с целью выявления различий между документами и представления документов простым и понятным для пользователя способом.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0007] Один из способов реализации настоящего изобретения относится к способу представления различий в множестве документов. Способ включает в себя обнаружение одного или более различий между первым документом и, по меньшей мере, одним вторым документом из множества документов с использованием вычислительного устройства, содержащего один или более процессоров. Способ дополнительно включает в себя определение с использованием вычислительного устройства того факта, является ли найденное различие существенным различием или несущественным. Определение того, является ли найденное различие существенным различием или несущественным, выполняется в автоматическом режиме без участия пользователя вычислительного устройства. Способ дополнительно включает в себя предоставление пользователю обозначения существенных различий. Способ дополнительно включает в себя либо скрытие несущественных различий от пользователя, либо предоставление обозначения несущественных различий способом, отличным от того, согласно которому происходит предоставление существенных различий.
[0008] Другой способ реализации относится к системе, включающей в себя, по меньшей мере, одно вычислительное устройство, функционально связанное с, по меньшей мере, одним устройством памяти. Это, по меньшей мере, одно вычислительное устройство выполнено с возможностью установить одно или более различий между первым документом и, по меньшей мере, одним вторым документом из множества документов. Это, по меньшей мере, одно вычислительное устройство дополнительно выполнено с возможностью определить является ли каждое найденное различие существенным различием или несущественным. Это, по меньшей мере, одно вычислительное устройство выполнено с возможностью определения того, является ли каждое найденное различие существенным различием или несущественным различием, в автоматическом режиме без вмешательства пользователя этого, по меньшей мере, одного вычислительного устройства. Это, по меньшей мере, одно вычислительное устройство дополнительно выполнено с возможностью предоставления пользователю обозначение существенных различий. Это, по меньшей мере, одно вычислительное устройство дополнительно выполнено с возможностью либо скрытия несущественных различий от пользователя, либо предоставления обозначения несущественных различий иным способом, чем предоставляется обозначение существенных различий.
[0009] Другой способ реализации относится к машиночитаемому носителю данных, на котором хранятся команды, исполнение которых процессором приводит к выполнению им операций. Операции включают в себя выполнение оптического распознавания символов в первом документе и, по меньшей мере, в одном втором документе. Операции дополнительно включают в себя обнаружение одного или более различий между первым документом и, по меньшей мере, одним вторым документом из множества документов, основанное, по меньшей мере, частично на оптическом распознавании символов. Операции дополнительно включают в себя определение, является ли каждое найденное различие существенным различием или несущественным. Определение того, является ли каждое найденное различие существенным различием или несущественным, выполняется в автоматической режиме без участия пользователя. Операции дополнительно включают в себя предоставление пользователю обозначения существенных различий. Операции дополнительно включают в себя либо скрытие несущественных различий от пользователя, либо предоставление обозначения несущественных различий иным способом, чем предоставляется обозначение существенных различий.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0010] Описание будет более понятным после изучения последующего подробного описания в сочетании с прилагаемыми чертежами, на которых одинаковыми цифрами обозначены одинаковые элементы:
[0011] На Фиг.1 представлен типовой настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в оцифрованные электронные документы для хранения на запоминающих устройствах и/или в электронной памяти в соответствии с одним из примеров способа реализации изобретения.
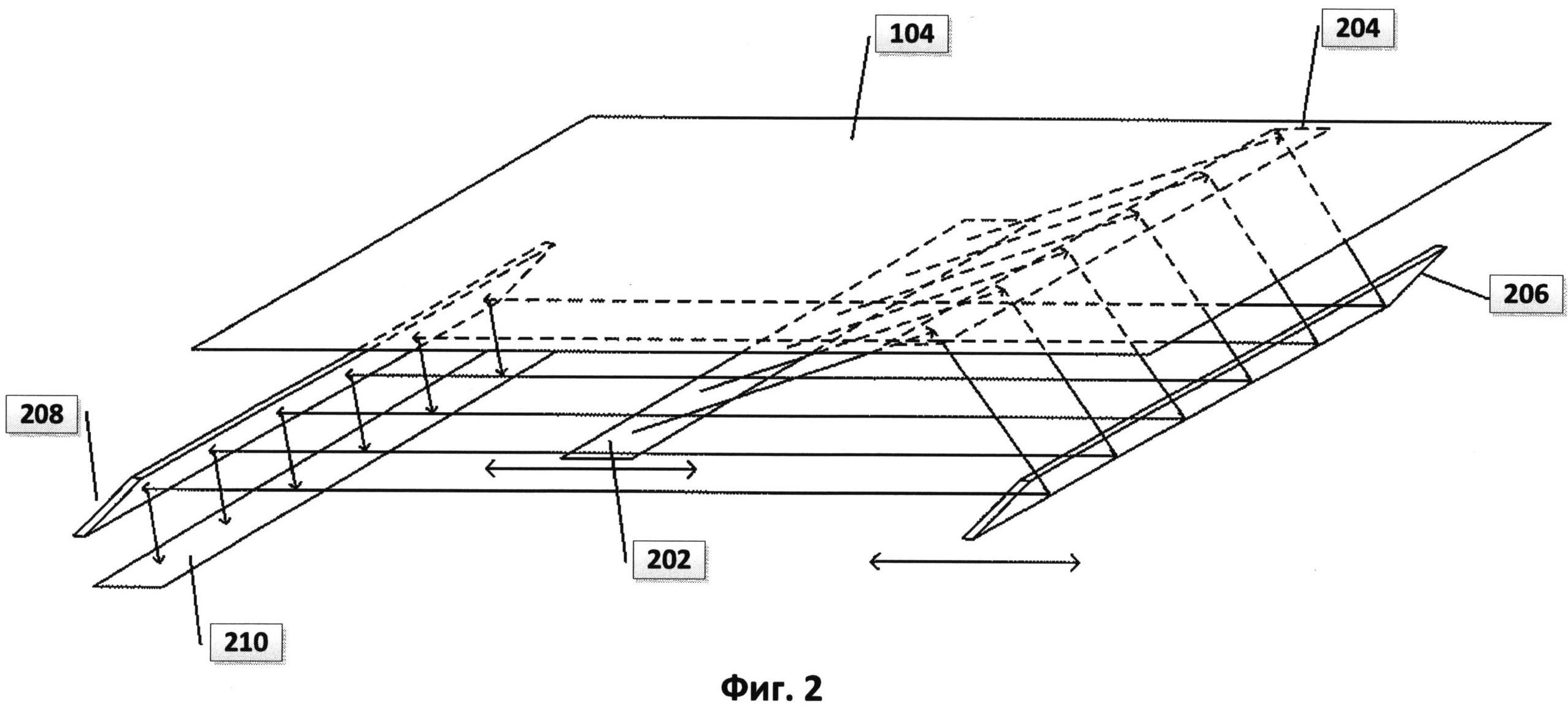
[0012] На Фиг.2 представлена схема работы оптических компонентов настольного сканера, показанного на Фиг.1, в соответствии с одним из примеров способа реализации изобретения.
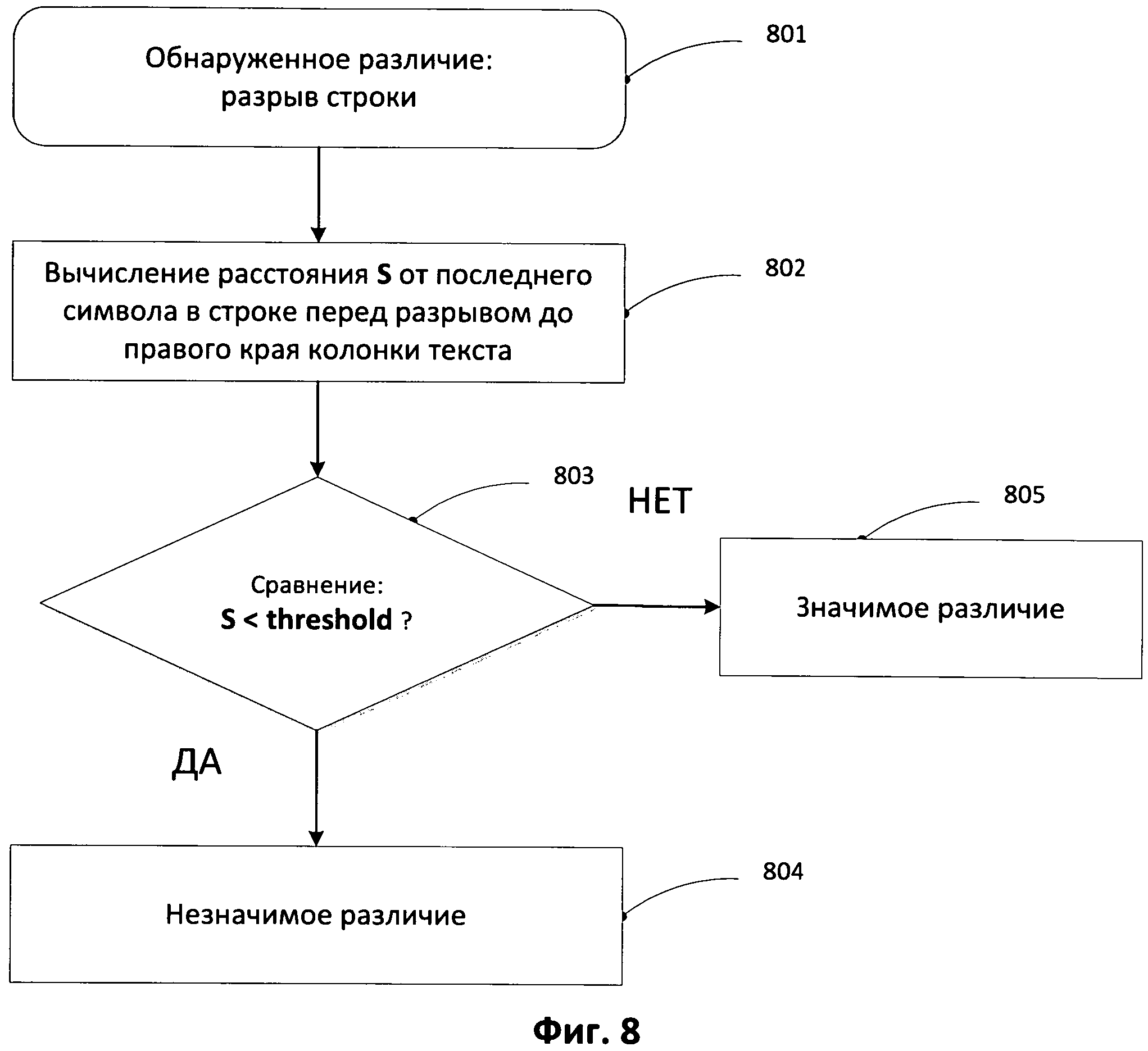
[0013] На Фиг.3 представлена общая схема архитектуры различных типов компьютеров и других устройств с процессорным управлением в соответствии с одним из примеров способа реализации изобретения.
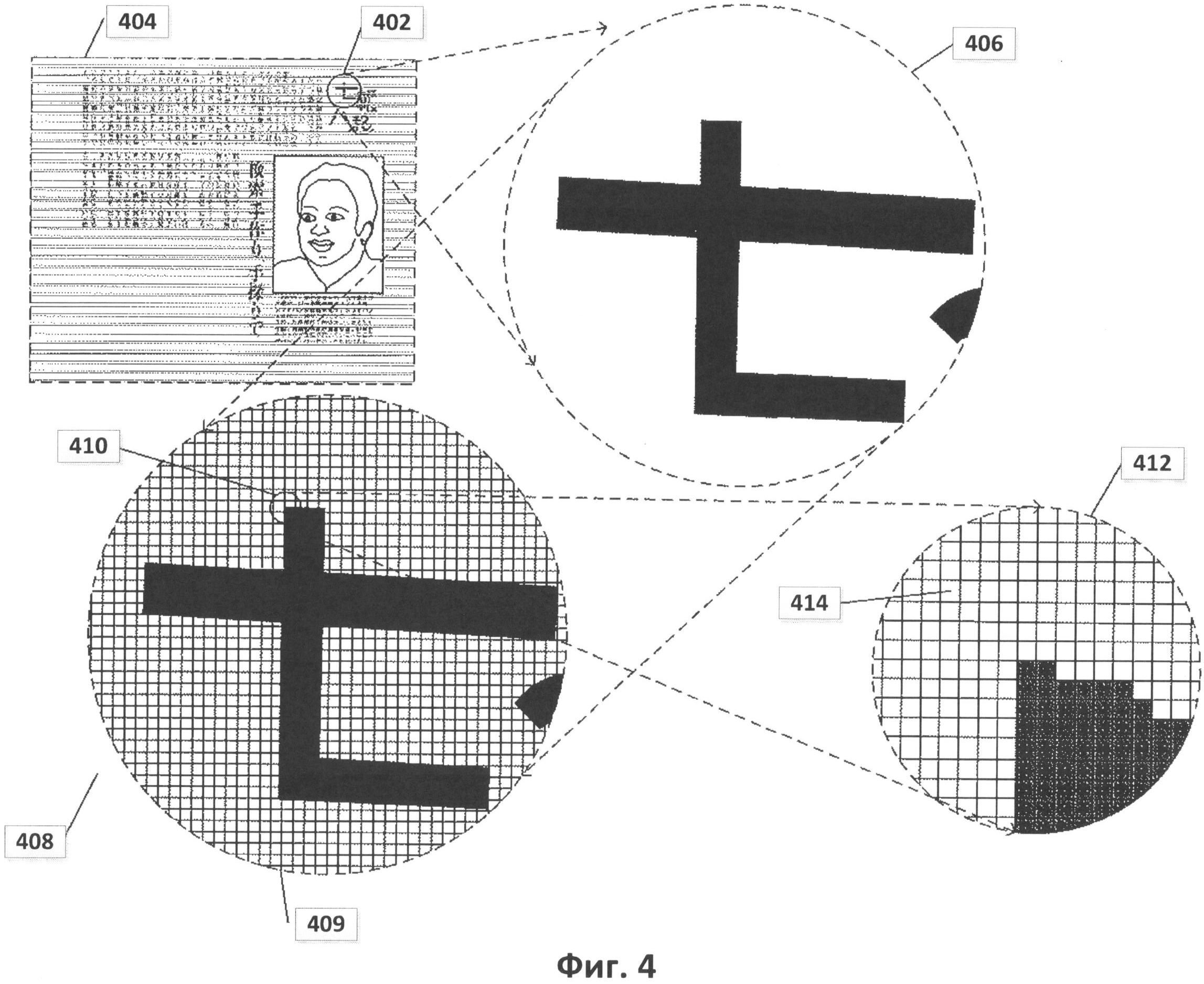
[0014] На Фиг.4 показано цифровое представление отсканированного документа в соответствии с одним из примеров способа реализации изобретения.
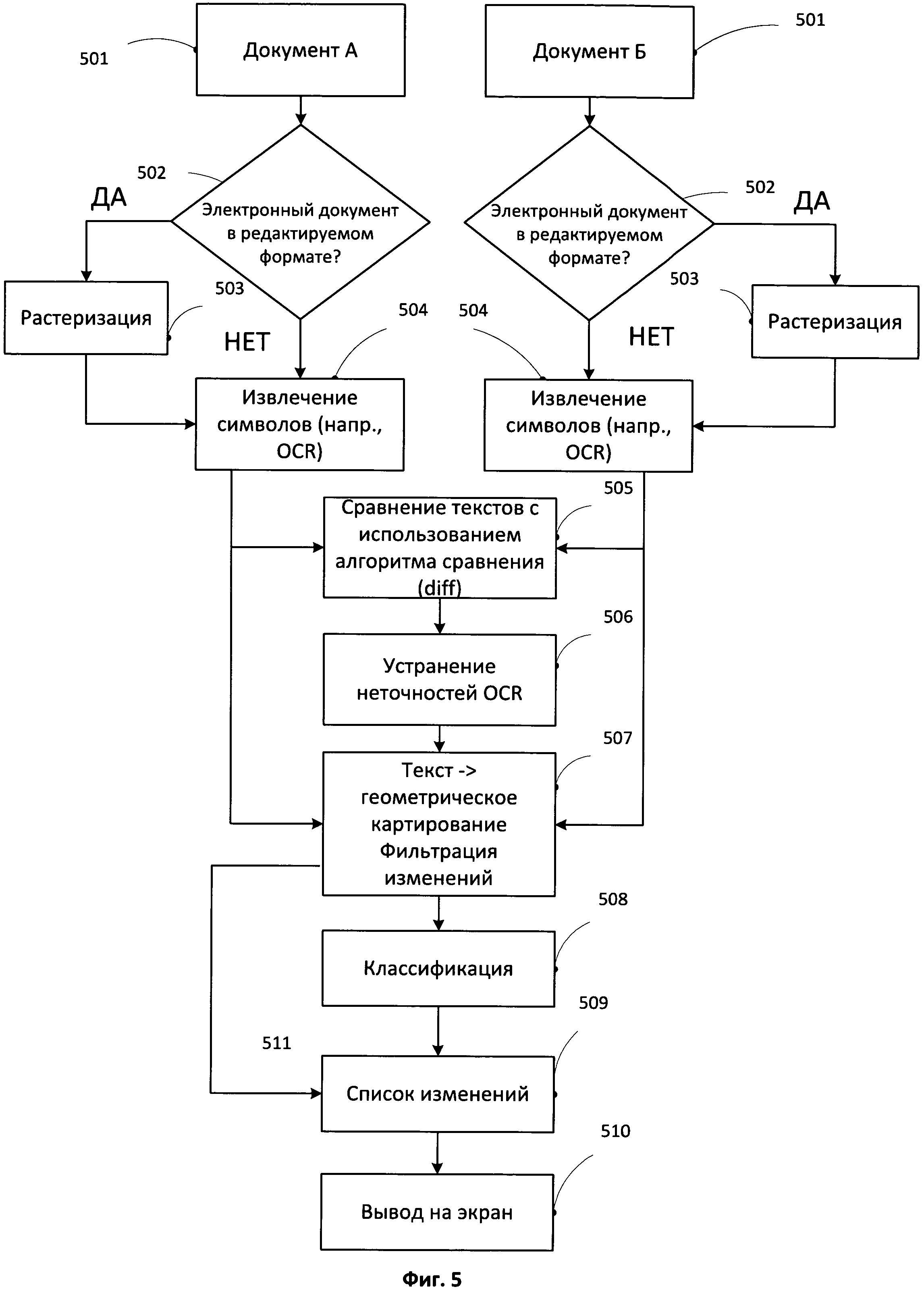
[0015] На Фиг.5 представлена блок-схема процесса сравнения документов в соответствии с одним из примеров способа реализации изобретения.
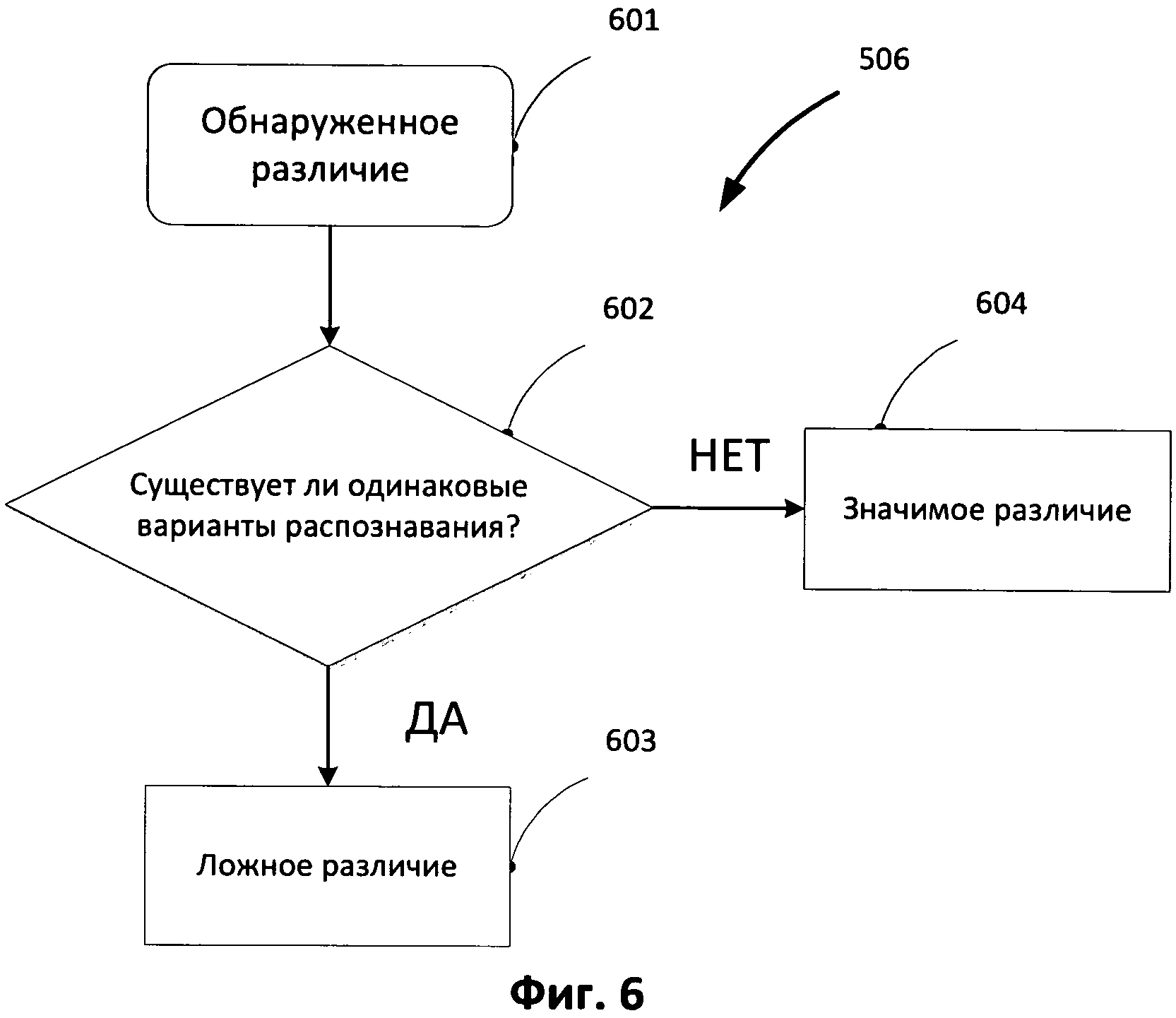
[0016] На Фиг.6 представлена блок-схема процесса поиска «ложных» различий, возникших в результате распознавания символов в соответствии с одним из примеров способа реализации изобретения.
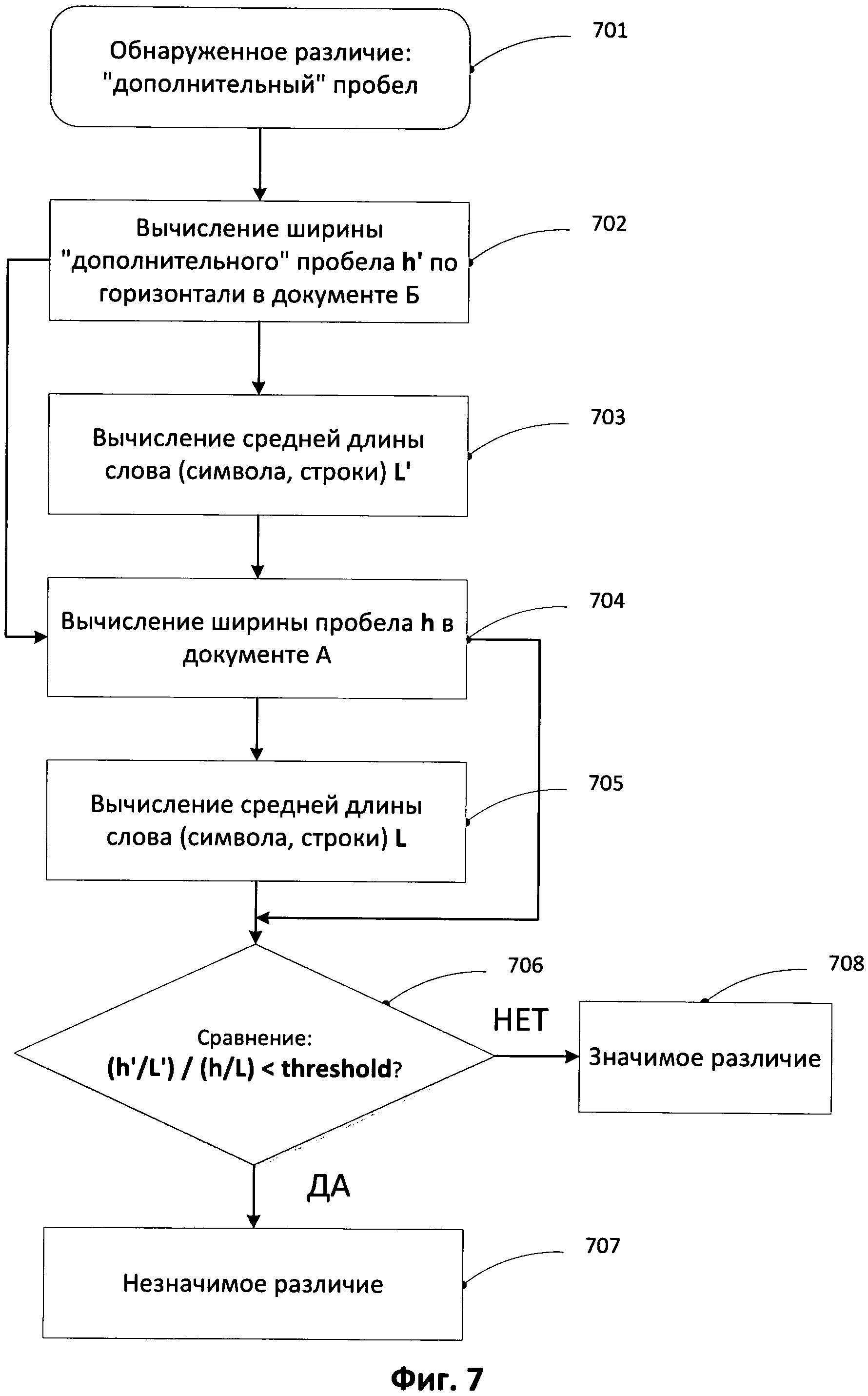
[0017] На Фиг.7 представлена блок-схема процесса проверки на предмет наличия «дополнительного» пробела в соответствии с одной из реализации представленного изобретения.
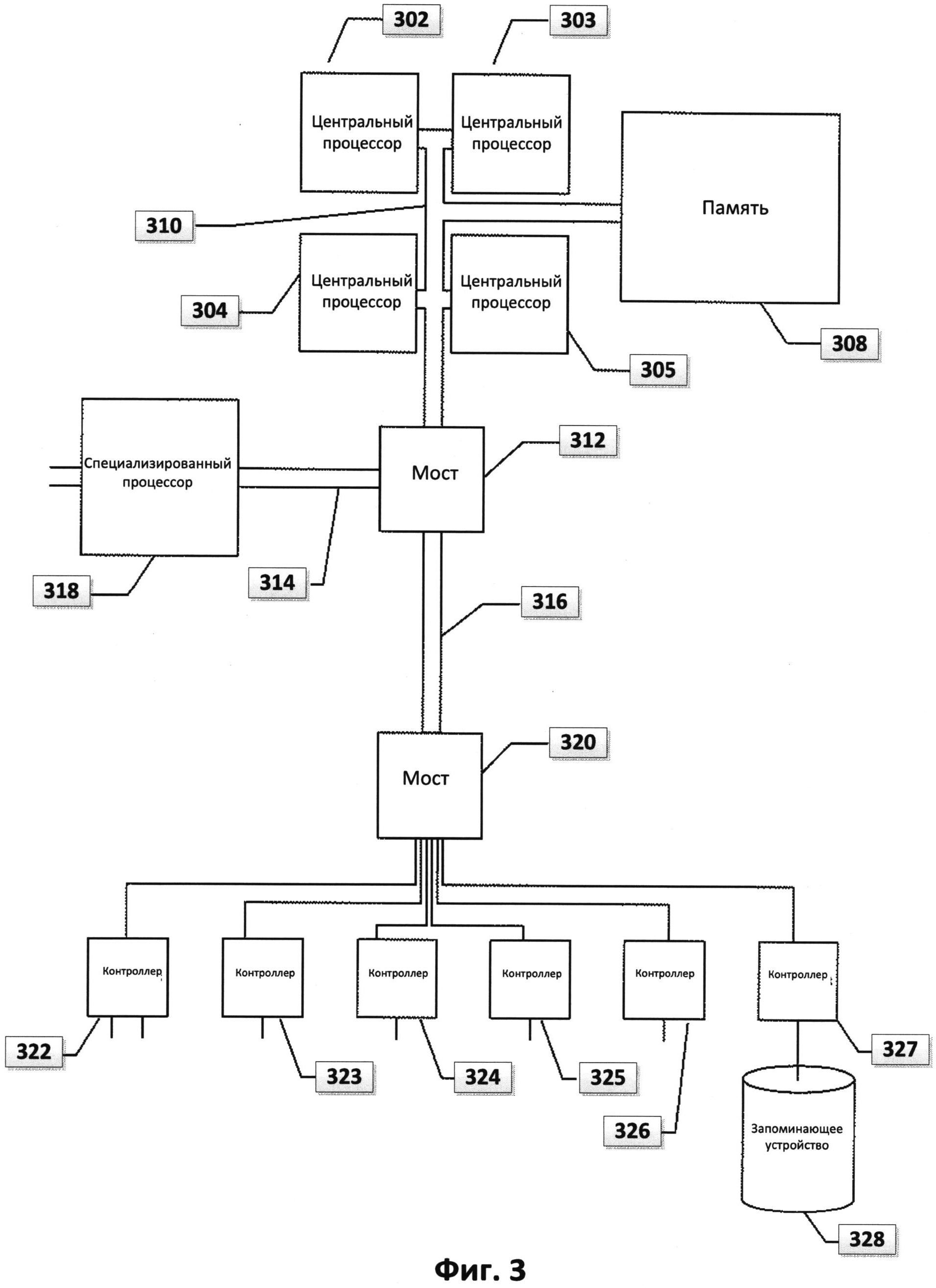
[0018] На Фиг.8 представлена блок-схема процесса проверки «разрывов строки» в соответствии с одной из реализации представленного изобретения.
[0019] На Фиг.9А и 9Б представлены примеры текстов, проанализированных в соответствии с иллюстративным способом реализации описываемого изобретения.
[0020] На Фиг.10А и 10Б представлены дополнительные примеры текстов, проанализированных в соответствии с иллюстративным способом реализации описываемого изобретения.
[0021] На Фиг.11 представлен пример интерфейса в соответствии с иллюстративным способом реализации описываемого изобретения.
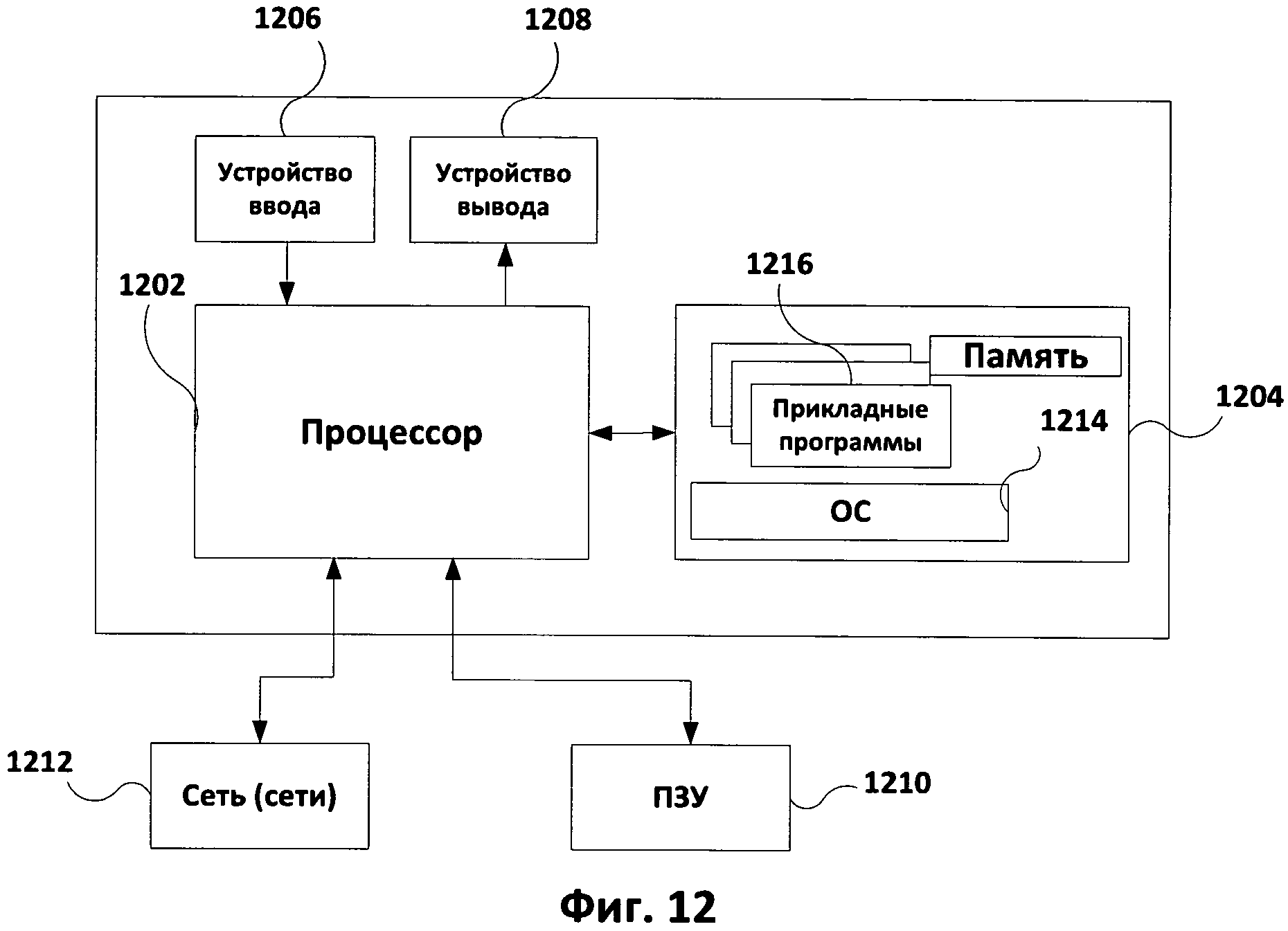
[0022] На Фиг.12 представлен пример компьютерной системы, на которой могут быть реализованы методы настоящего описания, в соответствии с иллюстративным способом реализации описываемого изобретения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0023] Настоящее описание в целом направлено на осуществление сравнения документов (копий или версий документов) на предмет наличия или отсутствия в них различий или изменений. В соответствии с различными вариантами осуществления предложены системы и способы, которые могут облегчить задачу сравнения документов для пользователя (оператора) путем отображения различий не в оцифрованном тексте, а отображение различий непосредственно на изображениях обоих анализируемых документов. С помощью средств графического пользовательского интерфейса (ГПИ) система может осуществить синхронное отображение сравниваемых документов и визуальное выделение непосредственно тех мест, на которые следует обратить внимание пользователя (оператора). Кроме того, система может проводить фильтрацию и не отображать пользователю те различия, что не влияют на идентичность документов. Иными словами, данная система может быть сконфигурирована таким образом, чтобы отображать лишь значимые различия (изменения) в сравниваемых версиях документа. В результате фильтрации различий, некоторые из них могут определиться как «ложные», и в результате чего оператору могут быть не отображены. Некоторые различия, например, сдвинутые переносы строк или разрывы страниц, важны в совокупности, но по отдельности для оператора могут не представлять интереса. В некоторых способах реализации, предлагаемые системы и способы могут помочь избежать вышеописанного недостатка, и позволяют отображать лишь сводку значимых изменений, классифицированных по их типу. Определение существенности или несущественности различий может выполняться автоматическим способом (например, без вмешательства человека/пользователя системы).
[0024] Обнаружение различий при сравнении исходной и распознанной версий текста на ранней стадии сравнения документов, не свидетельствует в полной мере о том, что в анализируемых документах действительно существуют различия, так как возможны «ложные» различия, возникшие в процессе распознавания (OCR). В связи с этим, согласно уже известным системам сравнения документов, пользователь (оператор) вынужден вручную проверять ошибки распознавания. Различные способы реализации настоящего изобретения могут помочь снизить количество «ложных» различий, представляемых пользователю.
[0025] При использовании примеров систем и способов настоящего описания можно существенно упростить для пользователя (оператора) задачу сравнения документов и поиска в них потенциально различающихся мест. Так как задача сравнения документов может происходить при помощи участия человека, данные системы и способы могут позволить отображать пользователю (оператору) расположение проблемных мест в каждом из сравниваемых документов. Пользователю могут отображаться лишь значимые различия (изменения) в документах, причем данные изменения (или другими словами, различия) могут быть отфильтрованы и сгруппированы по их типу и представлены в виде списка. Задача обнаружения каждого потенциального различия в документах может быть выполнена автоматически. Примеры вариантов осуществления настоящего изобретения могут позволить сократить временные затраты на сравнение документов и избежать ошибок, обусловленных человеческим фактором. Различные примеры вариантов осуществления могут быть реализованы с использованием команды загрузки, операционной системы и других типов программного и/или аппаратного обеспечения.
[0026] Печатные документы могут быть преобразованы в оцифрованные, отсканированные изображения документов с помощью различных средств, включающих в себя электронные оптико-механические сканирующие устройства и цифровые камеры. На ФИГ.1 представлен типовой настольный сканер и персональный компьютер, которые используются для преобразования печатных документов в оцифрованные электронные документы для хранения их на запоминающих устройствах и/или в электронной памяти. Настольное сканирующее устройство 102 включает в себя прозрачное стеклянное дно 104, на которое лицевой стороной вниз помещается документ 106. Запуск сканирования приводит к получению оцифрованного изображения отсканированного документа, которое можно передать на персональный компьютер (ПК) 108 для хранения на запоминающем устройстве. Программа, предназначенная для отображения отсканированного документа, может вывести оцифрованное изображение отсканированного документа на экран 110 устройства отображения ПК 112.
[0027] На ФИГ.2 представлена схема работы оптических компонентов настольного сканера, показанного на ФИГ.1. Оптические компоненты этого сканера с полупроводниковым приемником света (CCD) расположены под прозрачным стеклянным дном 104. Перемещаемый фронтально источник яркого света 202 освещает часть сканируемого документа 204, свет от которой отражается вниз. Этот свет отражается от перемещаемого фронтально зеркала 206 на неподвижное зеркало 208, которое отражает излучаемый свет на массив CCD-элементов 210, генерирующих электрические сигналы пропорционально интенсивности света, поступающего на каждый из них. Цветные сканеры могут включать в себя три отдельных строки или массива CCD-элементов с красным, зеленым и синим фильтрами. Перемещаемые фронтально источник яркого света и зеркало двигаются вместе вдоль документа для получения изображения сканируемого документа. Другой тип сканера, использующего контактный датчик изображения, называется CIS-сканером. В CIS-сканере подсветка документа осуществляется перемещаемыми цветными светодиодами (LED), при этом отраженный свет светодиодов улавливается массивом фотодиодов, который перемещается вместе с цветными светодиодами.
[0028] На ФИГ.3 представлена общая схема архитектуры различных типов компьютеров и других устройств с процессорным управлением. Схема архитектуры высокого уровня позволяет описать современную компьютерную систему (например, ПК, представленный на ФИГ.1), в которой программы отображения отсканированного документа и программы оптического распознавания символов хранятся на запоминающих устройствах для передачи в электронную память и выполнения одним или более процессорами, что преобразует компьютерную систему в специализированную систему оптического распознавания символов. Компьютерная система содержит один или множество центральных процессоров (ЦП) 302-305, один или более модулей электронной памяти 308, соединенных с ЦП при помощи шины ЦП/память подсистемы 310 или множества шин, первый мост 312, который соединяет шину ЦП/память подсистемы 310 с дополнительными шинами 314 и 316 или другими средствами высокоскоростного взаимодействия, включающими в себя множество высокоскоростных последовательных линий. Эти шины или последовательные линии в свою очередь соединяют ЦП и память со специализированными процессорами, такими как графический процессор 318, а также с одним или более дополнительными мостами 320, взаимодействующими с высокоскоростными последовательными линиями или с множеством контроллеров 322-327, например, с контроллером 327, которые предоставляют доступ к различным типам запоминающих устройств 328, электронным дисплеям, устройствам ввода и другим подобным компонентам, подкомпонентам и вычислительным ресурсам.
[0029] На ФИГ.4 показано цифровое представление отсканированного документа. На ФИГ.4 небольшой круглый фрагмент изображения 402 печатного документа 404, используемого в качестве примера, показан в увеличенном виде (406). Соответствующий фрагмент оцифрованного изображения отсканированного документа 408 также представлен на ФИГ.4. Оцифрованный отсканированный документ включает в себя данные, которые представляют собой двухмерный массив значений пикселей. В представлении 408 каждая ячейка сетки под символами (например, ячейка 409) представляет собой квадратную матрицу пикселей. Небольшой фрагмент 410 сетки показан с еще большим увеличением (412 на ФИГ.4), при котором отдельные пиксели представлены в виде элементов матрицы (например, элемента матрицы 414). При таком уровне увеличения края символов выглядят зазубренными, поскольку пиксель является наименьшим элементом детализации, который можно использовать для излучения света заданной яркости. В файле оцифрованного отсканированного документа каждый пиксель представлен фиксированным числом битов, при этом кодирование пикселей осуществляется последовательно. Заголовок файла содержит информацию о типе кодировки пикселей, размерах отсканированного изображения и другую информацию, позволяющую программе отображения оцифрованного отсканированного документа получать данные кодирования пикселей и передавать команды устройству отображения или принтеру с целью воспроизведения двухмерного изображения исходного документа по этим кодировкам. Для представления оцифрованного отсканированного документа в виде монохромных изображений с оттенками серого обычно используют 8-разрядное или 16-разрядное кодирование пикселей, в то время как при представлении цветного отсканированного изображения может выделяться 24 или более бит для кодирования каждого пикселя, в зависимости от стандарта кодирования цвета. Например, в широко применяемом стандарте RGB для представления интенсивности красного, зеленого и синего цветов используются три 8-разрядных значения, закодированных с помощью 24-разрядного значения. Таким образом, оцифрованное отсканированное изображение по существу представляет собой документ в той же степени, в какой цифровые фотографии представляют визуальные образы. Каждый закодированный пиксель содержит информацию о яркости света в определенных крошечных областях изображения, а для цветных изображений в нем также содержится информация о цвете. В оцифрованном изображении отсканированного документа отсутствует какая-либо информация о значении кодирования пикселей, например указание на то, что небольшая двухмерная зона соседних пикселей представляет собой текстовый символ. Фрагменты изображения, соответствующие изображениям символов, могут обрабатываться для получения битов изображения символа, в котором биты со значением «1» соответствуют изображению символа, а биты со значением «0» соответствуют фону. Растровое отображение удобно для представления как полученных изображений символов, так и эталонов, используемых системой OCR для распознавания конкретных символов.
[0030] В отличие от этого обычный электронный документ, созданный с помощью текстового редактора, содержит различные типы команд рисования линий, ссылки на представления изображений, таких как оцифрованные фотографии, а также текстовые символы, закодированные в цифровом виде. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяется 8-разрядный байт для кодирования символов ASCII и 16-разрядные слова для кодирования символов и знаков множества языков, включая японский, китайский и другие неалфавитные текстовые языки. Большая часть вычислительной работы, которую выполняет программа OCR, связана с распознаванием изображений текстовых символов, полученных из оцифрованного изображения отсканированного документа, и с преобразованием изображений символов в соответствующие кодовые комбинации стандарта Юникод. Очевидно, что для хранения текстовых символов стандарта Юникод будет требоваться гораздо меньше места, чем для хранения растровых изображений текстовых символов. Кроме того, текстовые символы стандарта Юникод можно редактировать, используя различные шрифты, а также обрабатывать всеми доступными в текстовых редакторах способами, в то время как оцифрованные изображения отсканированного документа можно изменить только с помощью специальных программ редактирования изображений.
[0031] На начальном этапе преобразования изображения отсканированного документа в электронный документ печатный документ анализируется для определения в нем различных областей. Во многих случаях области могут быть логически упорядочены в виде иерархического ациклического дерева, состоящего из корня, представляющего документ как единое целое, промежуточных узлов, представляющих области, содержащие меньшие области, и конечных узлов, представляющих наименьшие области. Дерево, представляющее документ, включает в себя корневой узел, соответствующий всему документу, и шесть конечных узлов, каждый из которых соответствует одной определенной области. Области можно определить, применяя к изображению разные методы, включая различные типы статистического анализа распределения кодов пикселей или значений пикселей по изображению. Например, в цветном документе фотографию можно выделить по большему изменению цвета в области фотографии, а также по более частым изменениям значений яркости пикселей по сравнению с областями, содержащими текст.
[0032] Как только начальный анализ определит различные области на изображении отсканированного документа, области, которые с большой вероятностью содержат текст, дополнительно обрабатываются подпрограммами OCR с целью выявления и преобразования текстовых символов в символы стандарта Юникод или любого другого стандарта кодировки символов. Для того чтобы подпрограммы OCR могли обработать содержащие текст области, определяется начальная ориентация содержащей текст области, благодаря чему в подпрограммах OCR эффективно используются различные способы сопоставления с эталоном для определения текстовых символов. Следует отметить, что изображения в документах могут быть не выровнены должным образом в рамках изображений отсканированного документа из-за погрешности в позиционировании документа на сканере или другом устройстве, создающем изображение, из-за нестандартной ориентации содержащих текст областей или по другим причинам. Области, содержащие текст, затем делят на фрагменты изображений, содержащие отдельные знаки или символы, после чего эти фрагменты целиком масштабируются и ориентируются, а изображения символов центрируются внутри этих фрагментов для облегчения последующего автоматического распознавания символов, соответствующих изображениям символов.
[0033] Следует понимать, что представленные способы реализации, показанные и описанные применительно к ФИГ.1-4, приводятся только в качестве примера, и способы, представленные в настоящем описании, не ограничиваются конкретными способами реализации, представленными на этих чертежах. В различных способах реализации изображения документов могут быть получены со сканирующего устройства, фотографирующего устройства (например, фотокамеры), другого устройства, оснащенного камерой (например, мобильных устройств, таких как смартфоны, телефоны, планшетные ПК, ноутбуки и т.п.), из файла, хранимого в памяти компьютерного устройства, из учетной записи электронной почты, из оперативного хранилища или из любого другого устройства, из которого могут быть получены данные с изображением документа.
[0034] На ФИГ.5 представлена блок-схема процесса сравнения документов и обнаружения различий (изменений) в документах в соответствии с одним из способов реализации. Могут сравниваться различные копии или версии документа. Например, могут существовать различные версии юридических соглашений или актов в виде схожих копий. В задаче сравнения документов могут быть задействованы документы любых форматов и представлений. Например, на вход для сравнения могут поступать только бумажные документы, либо только электронные документы. Также в качестве входной информации могут предоставляться комбинированные варианты, например, печатная версия и электронная версия и т.п. В этом случае бумажные версии документа, при необходимости, могут быть оцифрованы; например, бумажные версии могут быть отсканированы, отправлены по факсу или сфотографированы. В результате на этапе 501 могут использоваться только электронные версии документов. Один из документов может быть главным или, иными словами, оригиналом, а другие документы представляют собой документы для сравнения. Это обозначение является произвольным и не ограничивает область настоящего изобретения.
[0035] Таким образом, в соответствии с одним из способов реализации изобретения, оригинальные документы, предназначенные для сравнения, могут быть представлены в бумажной форме в виде файла изображения, например, в формате .jpeg или .tiff и т.п.; PDF-файла (векторный, отсканированный или отсканированный и содержащий текстовый слой); файла из текстового редактора (например, MS Word или OpenOffice); или иным способом (например, в другом электронном формате файла).
[0036] На ФИГ.5 проиллюстрирован способ сравнения двух версий документов для обнаружения различий между ними. Однако количество сравниваемых документов может не ограничиваться только двумя версиями. На этапе 501 первоначально для сравнения может быть предоставлено более двух версий документов; например, возможно наличие трех (или более) разных версий документов. Для наглядности, в описываемых ниже примерах реализации мы будем называть эталонный документ документом А, а документ, который будет с ним сравниваться - документом Б.
[0037] На этапе 502 проверяется тот факт, содержит ли электронный документ редактируемый текст. Данная процедура выполняется для всех версий сравниваемых документов. Если текст в документе представлен в редактируемом формате, то на следующем шаге 103 выполняется растеризация текста. Наглядным примером растеризации может служить конвертация документа типа (.doc) в формат (.pdf), либо печать документа с последующим его сканированием. Иными словами, растеризация может быть выполнена одним из известных способов.
[0038] Если текст представлен не в редактируемом формате, для данного документа может быть выполнен этап (504) оптического распознавания символов (OCR). Процедура распознавания OCR также может проводиться после растеризации документа (этап 503). В некоторых способах реализации процедура распознавания OCR в некоторых ситуациях может не использоваться, например, если доступна информация о размерах страницы, текста и/или геометрических координатах всех символов текста. Например, если текстовый файл получен с дополнительной информацией о координатах символов (например, в электронном документе PDF), этап OCR может быть необязательным.
[0039] Системы оптического распознавания символов (OCR) применяются для преобразования изображений или представлений бумажных документов, например, файлов документов в формате Portable Document Format (PDF), в машиночитаемые и машиноредактируемые электронные файлы с возможностью осуществления поиска по ним. Типовая система OCR состоит из устройства получения изображения, которое создает изображение документа, и/или программного обеспечения, которое запускается на компьютере и выполняет обработку изображений. Такое программное обеспечение включает в себя программу OCR, способную распознавать символы, буквы, знаки, цифры и другие элементы и сохранять их в машиноредактируемом формате, т.е. в кодированном формате.
[0040] На этапе 505 система может сравнивать тексты, полученные с использованием оптического распознавания символов анализируемых документов. Сравнение может осуществляться с использованием любых известных алгоритмов сравнения текстов. В альтернативном варианте осуществления может использоваться способ универсального сравнения документов, описанный в заявке на патент US 20130054612 под названием «Universal Document Similarity». В результате выполнения метода сравнения текстов формируется первоначальный черновой список различий для сравниваемых документов, в нашем примере для документов А и Б.
[0041] Этот черновой список различий не является окончательным и может включать в себя одну или более последующих итераций проверок, сортировок и удалений несущественных различий. Эти процедуры могут применяться для того, чтобы определить те различия, которые имеются в наличии, но с точки зрения идентичности документов, различиями не являются. Это могут быть неточности распознавания, по-другому распознанные части текста и т.п. Поэтому список различий может позже быть отфильтрован, и незначимые для пользователя (оператора) или «ложные» различия могут быть отброшены.
[0042] Как уже было сказано ранее, так как на шаге 504 поступают различные версии документов для распознавания, один и тот же текст в различных документах может распознаваться по-разному. Различия, возникающие при распознавании, могут быть вызваны некоторыми дефектами на сравниваемых документах, например в виде смаза, расфокусировки текста, блика или большой зашумленности. В некоторых реализациях причинами данных дефектов могут быть сканирование или фотографирование текста. В некоторых реализациях изобретения дефекты в виде смаза или расфокусировки текста могут быть обнаружены и устранены при помощи метода, описанного в заявке 13/305′768 «Detecting and Correcting Blur and Defocusing». Однако полностью вероятность возникновения ошибок распознавания не исключается. В результате даже после распознавания небольшого документа могут возникать различия, которые реально в документе отсутствуют, и как следствие, задача сравнения документов становится еще более трудоемкой.
[0043] Ввиду того, что неточности распознавания для сравниваемых документов могут отличаться, данные неточности могут попасть в первоначальный черновой список различий, сформированный на этапе 505. Различия, возникшие в результате распознавания, также могут войти в черновой список различий сравниваемых документов, однако представляют собой «ложные», или незначимые для оператора различия. Например, текст "if в версии документа А может быть распознан как "if, в то время как в версии документа Б может быть распознан как "it". Чтобы отображать пользователю (оператору) меньшее число различий там, где данных различий фактически не существует, можно проанализировать выявленные различия. Подобные неточности могут быть обнаружены и исключены из списка различий в сравниваемых документах.
[0044] Обнаружение и устранение различий, возникших в результате особенностей процесса распознавания (OCR), происходит на этапе 506. Анализ различий может быть выполнен с использованием одной или более из следующих особенностей в соответствии с различными примерами реализации изобретения. На ФИГ.6 представлена блок-схема, описывающая способ выявления «ложных» различий в соответствии с примером одного из способов реализации. Известно, что для каждого распознанного символа (слова) OCR-движок (OCR-engine) формулирует множество гипотез о вариантах распознавания символа (слова). Для каждого из вариантов распознавания рассчитаны соответствующие весовые значения, отображающие некую степень уверенности распознавания данного символа (слова). Обнаруженное различие в документах (601) из первоначального чернового списка анализируется путем сопоставления части различия, которая относится к эталонному документу А, и части различия, которая относится к сравниваемому документу Б. Множества вариантов распознавания для каждой из различающихся частей в документах А и Б сравниваются. Если в списках вариантов распознавания (гипотезы) для различающихся фрагментов присутствуют одинаковые варианты (гипотезы) распознавания данного фрагмента (например, если в списках вариантов появляется один и то же вариант слова для обоих документов), то с большей долей вероятности, данное различие (601) возникло в процессе распознавания, и оно может быть признано «ложным» различием (603). В ином случае, различие 601 признается значимым различием (604).
Визуально похожие символы
[0045] Альтернативный способ проверки различий заключается в сравнении отличающихся символов (слов) в сравниваемых документах. Если отличающиеся символы графически схожи, то с большей вероятностью данные различия были порождены особенностями распознавания. Если различие состоит из визуально похожих символов с разными кодами стандарта Юникод, такое различие также считается несущественным и может не отображаться для пользователя.
[0046] Ниже приведены примеры различий, которые вызваны визуальной схожестью символов: буква "О" и цифра ноль "0"; различия в алфавитах, например, буквы "ABC" на кириллице и аналогичные буквы по написанию "ABC" на латинице; различия, вызванные разной шириной знаков, например, тире и дефисы разной длины; моноширные и обычные иероглифы; дроби вида ¾ и 3/4 и т.п.
Вставка и удаление пробелов
[0047] Как уже было сказано, в виду того, что распознаваемый документ может содержать некие дефекты, например, такие как смаз или расфокусировка текста, либо некоторые структурные дефекты, существует вероятность того, что распознавание может быть не идеальным, т.е. могут присутствовать неточности распознавания. Например, при распознавании могут быть вставлены пробелы в тех местах, где их на самом деле нет, либо пробелы могут быть потеряны и объединены подряд идущие слова. Для того чтобы данные неточности не были включены в список значимых различий, при фильтрации неточности распознавания признаются отличными от результатов редактирования документа.
[0048] На ФИГ.7 проиллюстрирован пример блок-схемы проверки «дополнительно» обнаруженного пробела в соответствии с одной из реализации представленного изобретения. Например, в документе Б может быть обнаружен дополнительный пробел (701). На шаге 702 в документе Б вычисляется ширина h′ данного дополнительного пробела по горизонтали. Затем на шаге 704 вычисляется расстояние h между символами в той версии распознанного текста документа А, в котором дополнительный пробел не был обнаружен. Поскольку версии документа могут иметь разное разрешение и разный формат шрифта, расстояние пробела можно сравнивать относительно значения некоторого фиксированного характерного размера. Например, найденную величину h′ можно нормировать на длину слова, вычисленную на шаге 703, в котором был обнаружен дополнительный пробел. Либо найденную величину h′ можно нормировать на среднюю ширину символа или на среднюю длину строчки. Аналогично на шаге 705 может быть рассчитана нормировочная величина средней длины слова в документе А.
[0049] Далее нормированные значения расстояний между крайними символами сравниваются между собой (706). Если значения расстояний между крайними символами отличаются незначительно, например не более некоторого порогового значения th, то считается, что появление дополнительного пробела вызвано особенностью распознавания, в результате чего различие признается ложным и оператору данное различие может быть не отображено. Величина порогового значения th может быть заранее установленной или подобранной (например, пользователем). Например, величина порогового значения может быть установлена на уровне 1.7. В том случае, если отношение нормированных расстояний между символами больше некоторого порогового значения th, то на это место может быть привлечено внимание пользователя/оператора, путем включения данного различия в конечный список различий и/или путем предоставления пользователю обозначения (например, визуального отображения) местонахождения данного различия в документе.
[0050] Вышеописанные способы проверки различий, выявленных на этапах 505 и/или 506 (например, определение происхождения этих различий), могут выполняться автоматически. В некоторых способах реализации, в качестве дополнения или альтернативы, проверка погрешностей OCR может проводиться вручную человеком с использованием известных способов.
Фильтрация различий
[0051] В некоторых реализациях, помимо ошибок распознавания могут существовать другие изменения, которые могут быть отфильтрованы на этапе 507. Фильтрация различий предназначена для того, чтобы определить, является ли найденное изменение значимым. Незначимые различия могут быть не отображены пользователю, в то время как значимые различия формируют конечный список различий, предназначенный для пользователя (оператора). Для корректного выполнения фильтрации изменений в некоторых реализациях изобретения может быть применено геометрическое картирование (geometry mapping). Например, система может быть сконфигурирована таким образом, что будут фиксироваться не только изменение в тексте, но и координаты найденного изменения в документе.
[0052] Геометрическое картирование может быть использовано для визуального отображения найденных различий непосредственно в сравниваемых документах, например на экране электронного вычислительного устройства. Геометрическое картирование предназначено для сравнения совпадающих частей распознанного текста в сравниваемых документах. Совпадающие части распознанного текста представляют собой некоторое множество словарных единиц, расположенных в одинаковом порядке в документах. Каждое слово описывается неким прямоугольником, координаты которого восстанавливаются по координатам символов, полученных в результате распознавания (OCR). Дальнейшее оперирование может происходить именно с координатами данных прямоугольников, содержащих словарные единицы.
Анализ разрывов строки/переносов
[0053] Например, в некоторых случаях в документах могут присутствовать незначительные изменения ввиду различий форматов документов, например, возникших при распечатывании документа (например, формат «Letter» и формат «A4»), либо ввиду использования другого шрифта, изменения размеров полей или изменения, возникшие вследствие несущественного редактирования в документе. В результате чего могут обнаружиться изменения в виде дополнительных переносов, разрывов страниц, изменении нумерация страниц и т.д. Подобного вида изменения могут не отображаться пользователю, ему представляются лишь сводки вида «Форматирование изменено» или «Существуют различия в переводах строк и колонтитулах» и т.д.
[0054] Анализ изменения, вызванного разрывом строки, продемонстрирован в блок-схеме на Фиг.8, согласно примеру варианта осуществления изобретения. Если различием является разрыв строки 801, то на этапе 802 высчитывается расстояние S от последнего символа в строке перед разрывом строки до правого края текста в колонке. Если расстояние от последней буквы перед разрывом строки до правого края текста в колонке больше, чем некоторая характерная пороговая величина t (например, данная величина может быть равной ширине 4 букв), то свободное пространство до конца строки позволяет впечатать слово, и система на это место может обратить внимание оператора, то есть визуально отобразить значимость 805 данного изменения в тексте. Иначе изменения могут быть признаны незначимыми 804 и пользователю могут не отображаться.
[0055] В некоторых способах реализации, изменения, обусловленные разрывом строки, могут анализироваться следующим образом. Если отступ от левого края текста в колонке больше, чем характерная величина, это место визуально отображается оператору. Если расстояния меньше, чем некая характерная величина, то перенос является незначительным изменением, и указание на данный тип изменения не происходит.
[0056] На ФИГ.9А и 9Б представлены примеры фрагментов версий сравниваемых документов. Например, на ФИГ.9А, перенос на новую строку в словосочетании "the->day" фрагмента предложения "Amendment to be executed by their duly authorized representatives on the day and year first above written." не позволяет напечатать какое-либо новое слово в образовавшуюся пустую область (901) документа, поскольку эта область слишком мала. Такое различие в соответствии с настоящим изобретением считается несущественным. В то же время на ФИГ.10А перенос во фразе "this->Amendment" фрагмента предложения "IN WITNESS THEREOF, the parties hereto have caused this Amendment to be executed by their duly authorized representatives on the day and year first above" может быть признан значимым изменением, так как данный перенос слова на новую строку образует достаточную область (1001), которая например, позволяет после подписания договора впечатать небольшое слово.
Вычисление геометрических параметров при сравнении
[0057] Текст в одной из сравниваемых версий документа может быть модифицирован таким образом, что в тексте могут образоваться пропуски, в которые можно что-то впечатать. Такие места могут быть отслежены в тексте, путем отслеживания для каждого абзаца расстояния между последовательными словами в абзаце. Если данное расстояние больше допустимого максимального пробела, то это важное различие, и его можно визуально отобразить оператору. Отслеживания пропусков аналогично поиску лишних пробелов в сравниваемых документах, описание которого представлено выше и проиллюстрировано на Фиг.7.
Верхние и нижние колонтитулы
[0058] Если существует изменение количества строк на одной из первых страниц документа, возможны многочисленные различия типа «удален верхний/нижний колонтитул на странице N» в одном месте и «вставлен верхний/нижний колонтитул на странице N» в другом месте. В некоторых вариантах осуществления эти различия могут быть сгруппированы и отображены для пользователя в сводной форме: изменено K колонтитулов. Внесенные в текст верхних и нижних колонтитулов изменения могут либо отображаться, либо не отображаться.
[0059] Данный фильтр использует информацию, полученную на основе результатов распознавания (OCR), из которых известно, что данный текст является колонтитулом. Помимо этого можно определить, что текст является колонтитулом по совокупности некоторых признаков, например, на основе следующих признаков: центрированный текст, текст с отступом от основного текста, число в строчке и т.д.
[0060] Типы различий, представленные выше, могут быть расширены и приведены лишь для наглядной демонстрации сравнения документа на предмет наличия в них изменений или значимых различий. Приведенные выше примеры не ограничивают область применения данного изобретения.
[0061] Помимо сравнения текстовой информации с учетом геометрического картирования, может быть осуществлено сравнение других информационных блоков, содержащихся в документе, таких как таблицы, картиночные изображения, печати, подписи и т.д. Сравнение изображений, присутствующих в документе, может быть осуществлено одним из известных способов, например путем попиксельного сравнения. Сравнение таблиц учитывает не только текстовую информацию, содержащуюся в них, сравнение которой может быть осуществлено согласно методу, описанному выше, но и с учетом структуры самих таблиц. Иными словами, в ходе сравнения учитывается соответствие числа колонок, строк и их соответствующие координаты в документе.
[0062] После того как все возможные изменения и различия в сравниваемых документах найдены и зафиксированы, данные изменения могут быть классифицированы по их типу. Классификация найденных изменений происходит на шаге 508. Данный шаг опционален и может быть пропущен (511). Классификация изменений согласно некоторым реализациям данного изобретения направлена на решение задачи удобного и понятного для пользователя отображения различий в виде компактного списка. Например, пользователю могут быть отображены типы значимых изменений, таких как «вставка», «удаление», «замена текста» и т.д. Данная возможность позволяет пользователю визуально быстро определить, какие сформированные типы различий для него представляют значимость, а какие являются несущественными. Например, тип различия вида «замена символа X на символ Y» для пользователя может оказаться несущественным, в то время как различие вида «замена слова A на слово B» может оказаться значимым. В некоторых способах реализации для пользователя при необходимости может отображаться список различий, признанных несущественными. Такой список может быть представлен иным образом (например, может отображаться только при выборе пользователя, отображаться ниже в пользовательском интерфейсе и т.п.), чем список существенных различий.
[0063] Помимо этого в некоторых способах реализации данное изобретение предполагает настройку режима отображения пользователю результатов проведенного сравнения. Отображение результатов сравнения также может быть задано по умолчанию в настройках. Согласно некоторым реализациям в настройках может быть выбрана функция отображения для пользователя максимально подробного отчета о результатах проведенного анализа, в котором содержатся все найденные различия, в том числе те, которые были вызваны неточностью распознавания OCR. Кроме того, вручную пользователем могут быть выбраны те типы значимых различий, которые должны быть включены в конечный список различий, и те которые из этого списка могут быть исключены. В некоторых способах реализации, могут быть установлены различные варианты найденных различий.
Итоговый список различий.
[0064] На шаге 509 происходит построение окончательного списка значимых и отфильтрованных различий, которые были найдены в сравниваемых документах, поступивших на обработку в систему. Данный список (или другими словами отчет) может быть представлен одним из возможных способов. Например, в одной из реализации изобретения список изменений может быть представлен, как показано на Фиг.11 в виде перечисления различий 1101 с указанием страницы, на которой данное различие было обнаружено. Список 1101 может отображать замену вида «было»->«стало» ["was"->"became"], также может показываться дополнительная информация, например, номер страницы, на котором зафиксировано различие. Так, Фиг.11 демонстрирует пример пользовательского интерфейса, который отображает список значимых различий (1101) и изображения двух сравниваемых документов (1102) и (1103). Сравниваемые документы могут отображаться на экране синхронно.
[0065] Для каждого значимого различия (изменения) в списке, (т.е. для тех изменений, которые прошли процедуры фильтрации), находятся его координаты на изображении А и на изображении Б соответственно. Для этого могут использоваться данные соответствия текста и изображения при помощи геометрического картирования на шаге 507. Причем пользователю отображаются части изображений документов А (1102) и Б (1103), содержащие место с различием.
[0066] В результате пользователь может быстро определить, имеется ли в этом месте изменение документа, или же это незначимое различие и его стоит пропустить. В качестве визуального представления пользователю могут быть использованы различные способы выделения информации.
[0067] Одним из результатов сравнения документов, может быть, например, вывод на экран визуальных отображений различающихся областей. Например, если обнаружено различие в документах, на экране выделяется цветом именно та область (текст), в которой этот различие присутствует. Определенный цвет области может сигнализировать пользователю о типе обнаруженного различия. В некоторых способах реализации изобретения цвет области может быть предоставлен пользователю заранее в настройках. Так, например желтый цвет может быть условным сигналом того, что в данной области обнаружен тип различия вида «удалено»; в то время как красный цвет может сигнализировать о «вставке», и т.д. Согласно возможной альтернативной реализации, например, если обнаружено изменение в слове, то желтым цветом подсвечивается все слово, а красным - измененный символ в нем. В различных способах реализации изобретения могут применяться другие способы представления (например, визуального представления) различий.
[0068] На Фиг.12 приведен возможный пример вычислительного средства 1200, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 1200 включает в себя, по крайней мере, один процессор 1202, соединенный с памятью 1204. Процессор 1202 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер или представлять собой чип или другое устройство, способное производить вычисления (например, лапласиан может быть получен оптически). Память 1204 может представлять собой оперативную память (ОЗУ), а также содержать любые другие типы и виды памяти, в частности, устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например, жесткие диски и т.д. Кроме того, может считаться, что память 1204 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 1200, например, кэш-память в процессоре 1202, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 1210.
[0069] Вычислительное средство 1200 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 1200 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 1208 (например, жидкокристаллический дисплей или сигнальные индикаторы). Вычислительное средство 1200 также может иметь одно или более постоянных запоминающих устройств 1210, например, привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 1200 может иметь интерфейс с одной или более сетями 1212, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные с всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 1200 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 1202 и каждым из компонентов 1204, 1206, 1208, 1210 и 1212.
[0070] Вычислительное средство 1200 работает под управлением операционной системы 1214 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 1216.
[0071] Программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию.
[0072] Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались ранее. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.





Полифункциональный ступенчатый вихревой обогреватель
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Определение преобразований изображения для повышения качества оптического распознавания символов

