Результат интеллектуальной деятельности: МЕТОД ПОСТРОЕНИЯ И ОБНАРУЖЕНИЯ ТЕМАТИЧЕСКОЙ СТРУКТУРЫ КОРПУСА
Вид РИД
Изобретение
УРОВЕНЬ ТЕХНИКИ
[0001] Построение корпуса документов можно осуществить с помощью двухэтапного сбора электронных документов с последующим анализом всего корпуса. Двухэтапный способ построения корпуса может включать в себя (1) изначальное создание предполагаемой структуры тем, (2) сбор документов корпуса и выполнение категоризации документов по темам. После создания корпуса категоризацию корпуса по темам можно производить путем классификации документов корпуса. Документам, входящим в корпус, на основе категоризации можно присвоить тему или несколько тем. Категоризацию можно выполнять методом машинного обучения с использованием метода классификации. Анализ корпуса также может включать в себя сортировку электронных документов и/или кластеризацию электронных документов.
[0002] Такой подход имеет ряд недостатков. Необходимо заранее задать список возможных тем, и все документы должны соответствовать заданным темам. Последнее делает данный подход неприменимым при работе с неизвестными темами, например с корпусом, полученным из широкого спектра разнообразных документов. Например, документы могут быть получены из сети, такой как Интернет, охватывающей множество тем. Если тема документа в корпусе не входит в список заданных категорий, это означает, что способ создания исходной структуры тем не соответствовал действительности. Кроме того, ручной анализ корпуса с целью определения тем корпуса не является допустимым решением, поскольку корпус может включать в себя документы, добавляемые позже. Более того, значительный объем данных в корпусе делает ручной анализ для создания структуры тем недопустимым.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Приводится описание системы, машиночитаемых носителей и способов создания структуры тем корпуса в процессе создания корпуса. Сначала получают первый набор документов, и каждый документ конвертируют в текстовое представление. Текстовое представление первого набора документов кластеризуют по исходным темам. Каждый документ в первом наборе документов маркируют в зависимости от кластеризации первого набора документов. Классификатор строят на основе маркировок каждого документа в первом наборе документов. Затем получают второй набор документов, и каждый документ во втором наборе классифицируют с использованием классификатора по темам из числа исходных тем.
[0004] Также в настоящем документе описывают системы, машиночитаемые носители и способы одновременного выполнения предварительной оценки структуры тем корпуса перед формированием всего корпуса и формированием структуры тем. Изначально собирают относительно небольшой набор данных. Этот набор данных может представлять конечный полный корпус, но это условие необязательно. К собранному набору данных применяют метод кластеризации. Далее к набору данных применяют кластерную маркировку с получением маркированных данных. Маркированные данные можно использовать в качестве обучающего набора для классификации дополнительных, немаркированных данных. Далее можно принять и классифицировать немаркированные данные. Метод классификации, применяемый для классификации полученных немаркированных данных, может представлять собой классификацию с открытым классом. В данном варианте реализации изобретения тексты, которым изначально не присвоили класс с помощью метода классификации, можно кластеризовать и маркировать в новый класс. В результате получают маркированный корпус, для которого не нужно задавать структуру тем корпуса.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0005] Вышеизложенные и другие элементы настоящего описания будут в более полной мере понятны из нижеследующего описания и прилагаемой формулы изобретения в сочетании с прилагаемыми рисунками. Описание будет обладать дополнительной специфичностью и детализацией при помощи прилагаемых рисунков с учетом того, что данные рисунки изображают лишь несколько вариантов реализации, соответствующих описанию и, следовательно, не могут считаться ограничивающими область его действия.
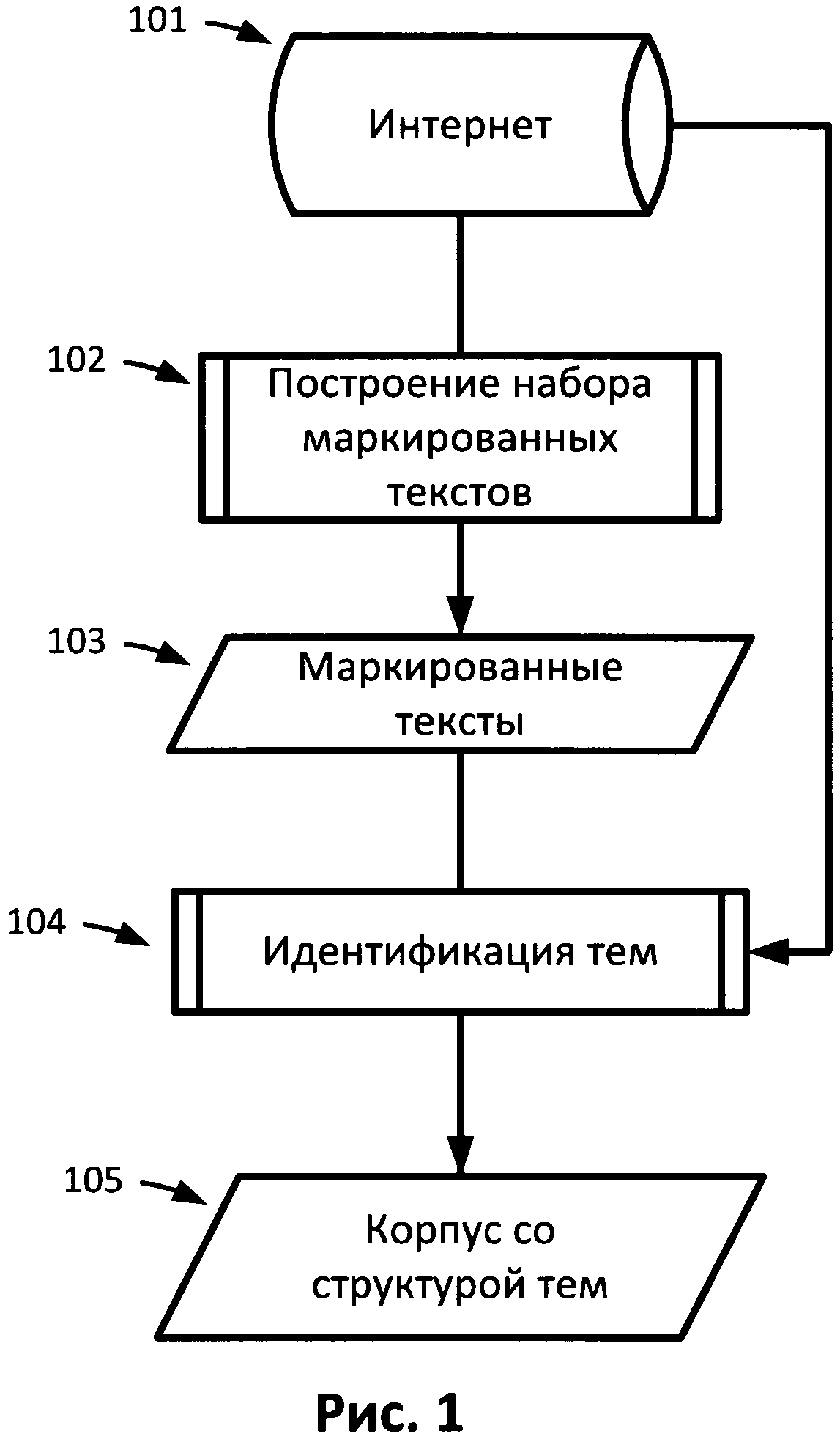
[0006] На Рис.1 представлена блок-схема операций по построению корпуса с создаваемой структурой тем в соответствии с одним вариантом реализации.
[0007] На Рис.2A представлена блок-схема операций по построению набора маркированных текстов в соответствии с одним из вариантов реализации.
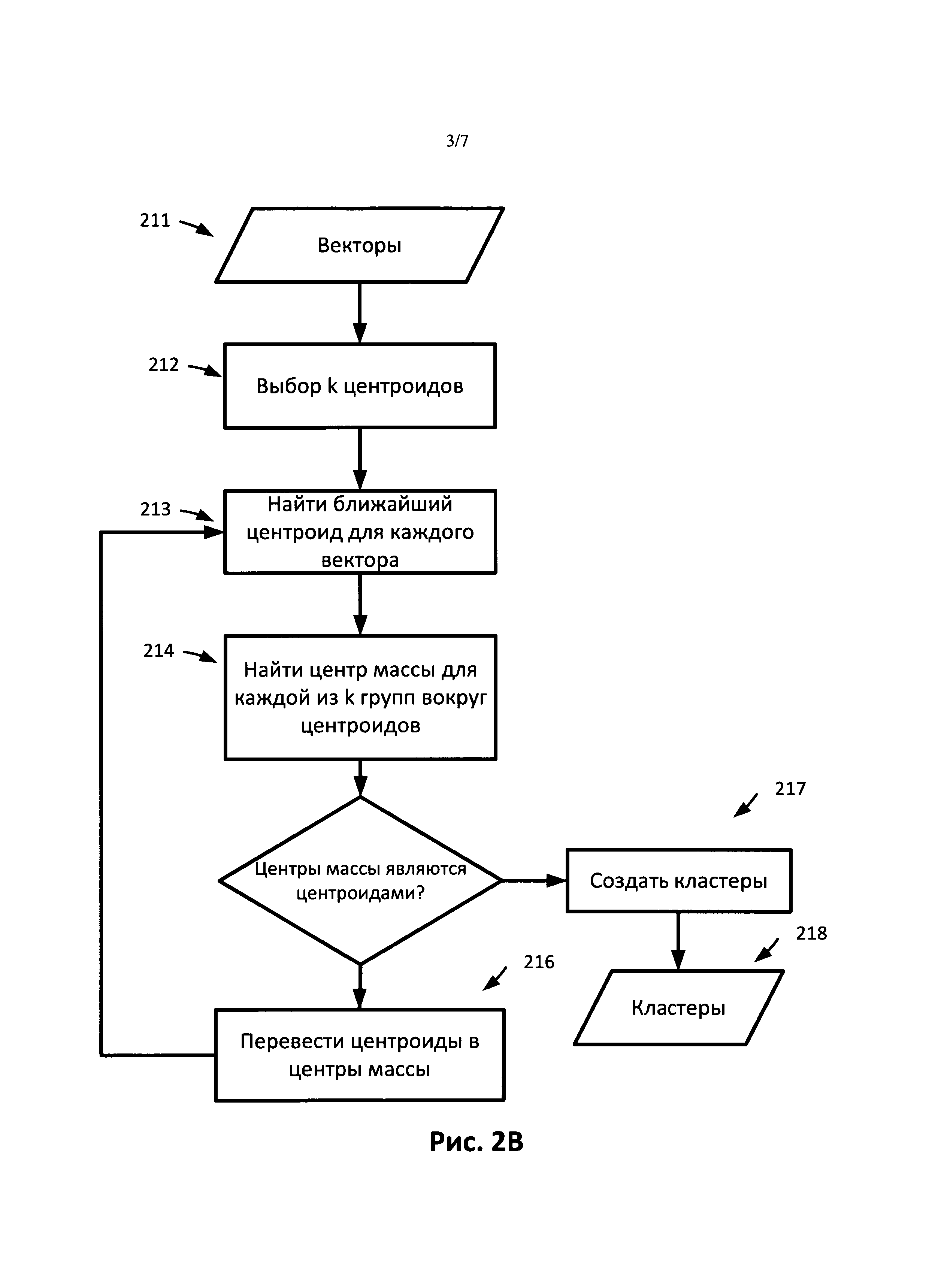
[0008] На Рис.2B представлена блок-схема операций по кластеризации в соответствии с одним вариантом реализации.
[0009] На Рис.3 представлена блок-схема операций по классификации в соответствии с одним вариантом реализации.
[0010] На Рис.4 представлена блок-схема операций по присвоению тем документам в соответствии с одним вариантом реализации.
[0011] На Рис.5 представлена блок-схема операций по классификации документов с использованием тематического классификатора с открытыми классами в соответствии с одним вариантом реализации.
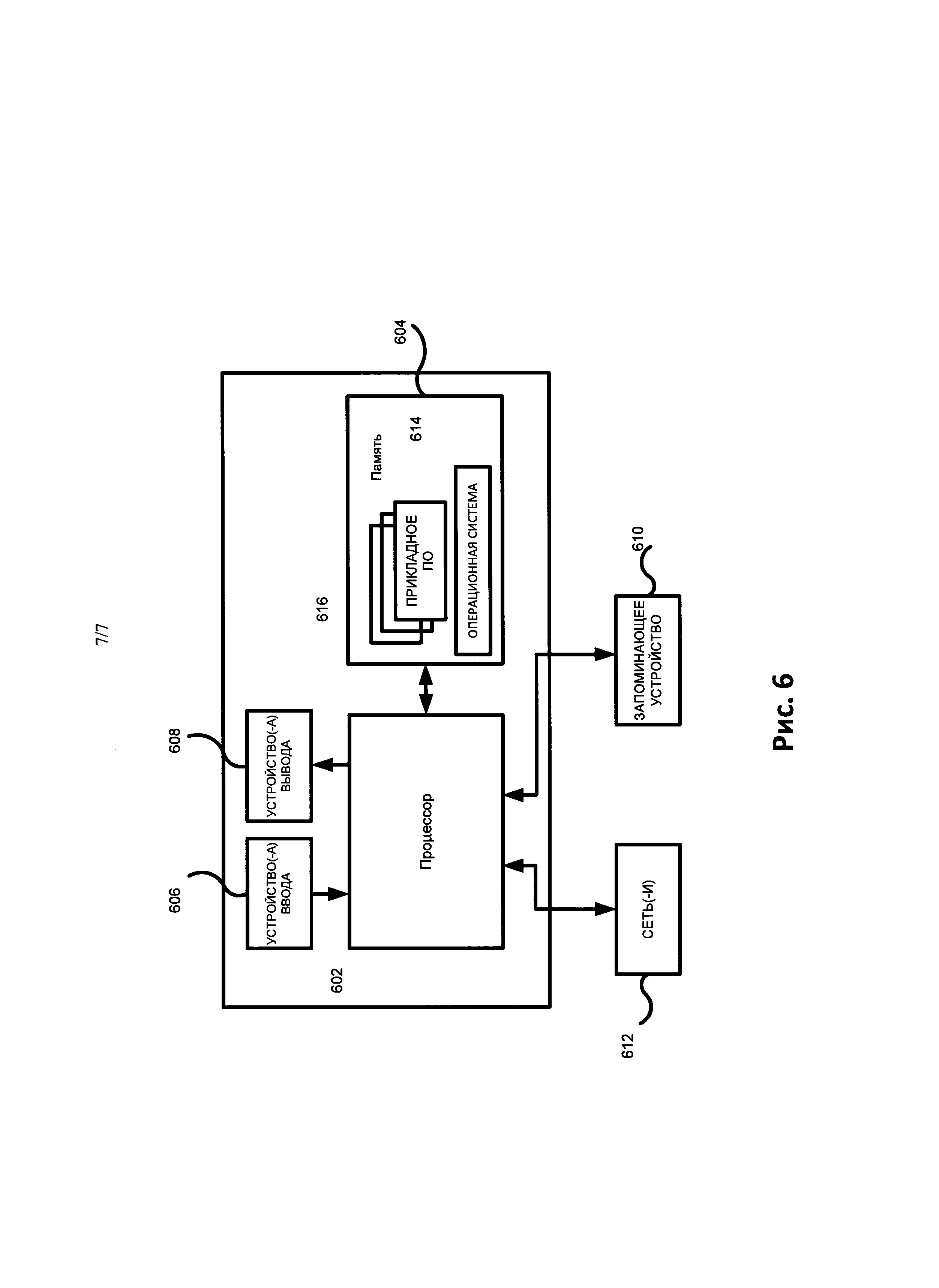
[0012] На Рис.6 представлено аппаратное оборудование 600, которое можно использовать для реализации методов, описанных в настоящем документе.
[0013] Последующее детальное описание содержит ссылки на прилагаемые рисунки. Как правило, на рисунках схожими символами обозначены сходные компоненты, если только контекст не предполагает иное. Не предполагается ограничение изобретения иллюстративными вариантами реализации, описанными в подробном описании, рисунках и формуле изобретения. Можно использовать другие варианты реализации и осуществлять прочие изменения, без отступления от сущности и объема представленного объекта изобретения. Легко становится понятным, что аспекты настоящего описания, представленные в настоящем документе и проиллюстрированные рисунками, можно перераспределять, заменять, комбинировать и моделировать, создавая широкий спектр различных конфигураций, и все эти конфигурации явным образом предусмотрены настоящим описанием и являются его частью.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0014] Многие исследовательские работы, в том числе, относящиеся к компьютерной лингвистике, анализу тональности (сентимент-анализ) и т.п., основываются на корпусе текстов. Исследования проводят путем анализа корпуса текстов. Например, корпус можно проанализировать с целью получения достоверной статистики по использованию конкретного слова, или для определения частотности использования слова разными тендерными и возрастными группами. В некоторых исследованиях используют большой корпус, сбалансированный и репрезентативный для группы людей. Текстовый корпус можно аннотировать в зависимости от целей его использования. Аннотирование может происходить на уровне слов или предложений, например морфологическое или синтаксическое аннотирование. Аннотирование также может происходить на уровне текстов, т.е. текстам могут присваиваться метки, содержащие информацию об их содержании, авторе и т.п., например, указать тему, жанр, пол и возраст автора и т.п. Аннотирование тем является распространенным аннотированием на уровне текстов. Тексты в корпусе можно связывать с маркером темы или несколькими маркерами темы. Например, текст о лечении травм в футболе может иметь два маркера тем: «Спорт» и «Медицина», или любой из них.
[0015] Текущие способы выполняют конструирование корпуса и идентификацию тем отдельно. Например, для получения корпуса с аннотацией тем, во-первых, производят сбор документов; и, во-вторых, выполняют идентификацию тем по полученным документам. Реализации различных описанных вариантов реализации изобретения относятся к конструированию корпуса одновременно с формированием структуры тем корпуса. Описанные варианты реализации изобретения не используют заранее заданную структуру тем. Вместо этого, структура тем автоматически оценивается в процессе формирования корпуса. Соответственно, нет необходимости в заданном наборе тем или получении текстовой информации с целью определения заданной структуры тем. Структуру тем корпуса можно сформировать из большого числа «неизвестных» документов, принимаемых при просмотре сети, например, из Интернета. Структура тем неизвестна до поиска документов. В изложенных вариантах реализации изобретения описывается, каким образом можно оценивать структуру тем по большому числу «неизвестных» документов в процессе формирования корпуса.
[0016] Идентификацию тем можно осуществлять при помощи метода машинного обучения, например метода классификации. Имея обучающий набор данных, например набор документов, маркированных темами, непросмотренным документам с помощью классификатора могут быть присвоены метки документов, входящих в обучающий набор. В некоторых вариантах реализации изобретения каждому документу может быть присвоен один маркер. В других вариантах реализации могут присваиваться один или более маркеров. Кроме того, классификаторы с открытыми классами могут назначить каждому документу ноль, один или более маркеров. Назначение нескольких маркеров может быть уместно для многих документов, поскольку в документах может рассматриваться несколько тем.
[0017] Корпус текстов можно сформировать на основе социальных сетевых сервисов, например сетевых блогов, чатов, форумов, обзоров и т.п. Тексты, полученные из этих источников, могут охватывать значительное количество тем. Учитывая неструктурированную природу этих текстов, темы со временем могут меняться. В одном варианте реализации исходный набор документов/текстов для корпуса может быть получен из сети Интернет при помощи методов поиска поисковыми роботами. Например, можно получить распечатку всех сообщений в блогах из сервиса блогов, форума и т.п. Позже можно получить все новые сообщения в блогах из того же сервиса блогов, например, через несколько недель. В корпус можно добавить новые документы. Структура тем новых документов может отличаться от структуры тем первого набора документов или корпуса. Это может быть связано с новыми сообщениями в блогах, относящимися к недавно произошедшим событиям. В таких случаях, когда категории заранее неизвестны, можно применить не требующую контроля методику, например, кластеризацию. Однако, методы, использующие набор заданных кластеров, сами по себе работать не будут, поскольку темы заранее неизвестны и кластеры невозможно задать заранее. Кроме того, объем текста может быть слишком большим для иерархической кластеризации и кластеризации по плотности.
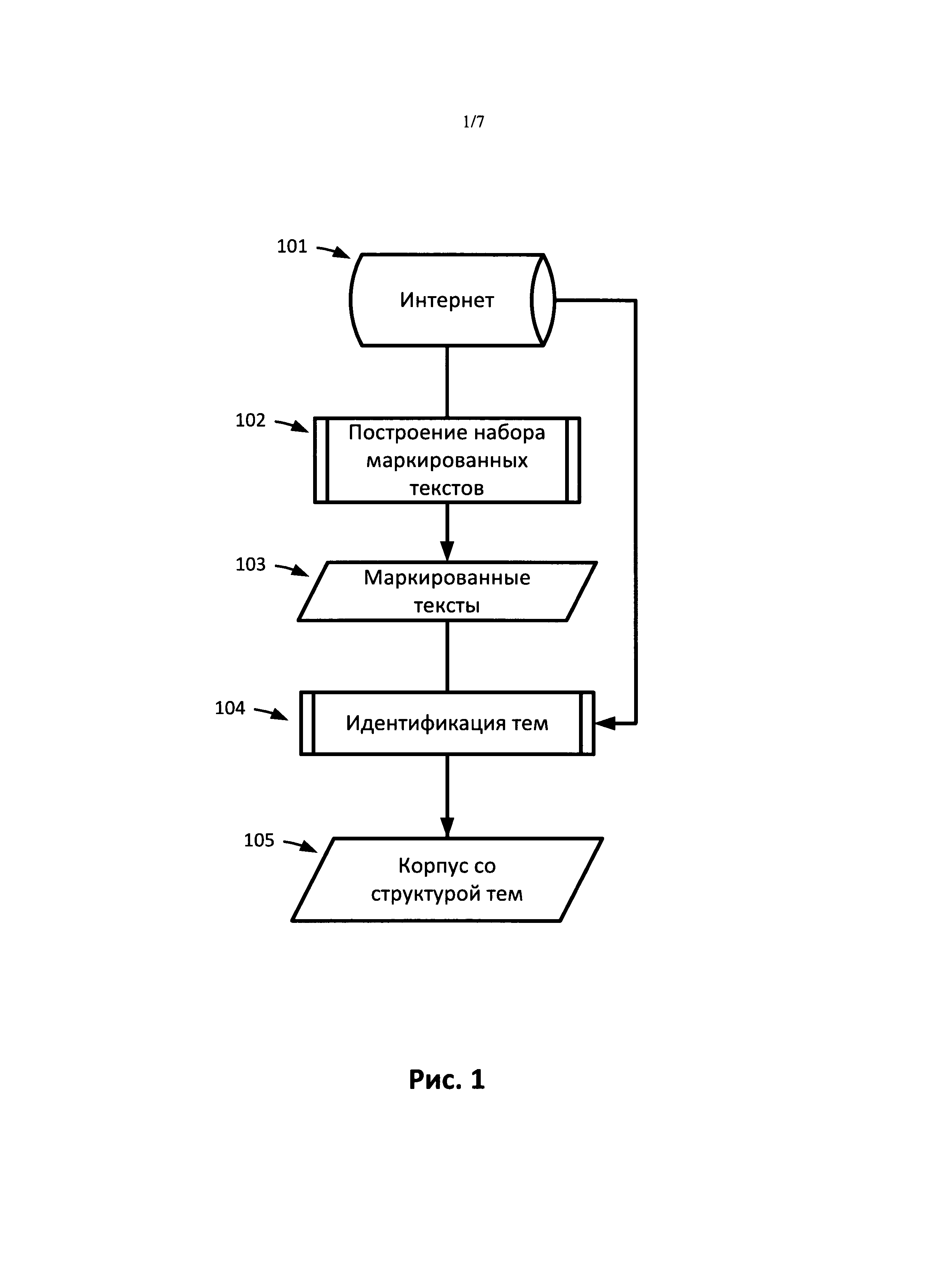
[0018] На Рис.1 представлена блок-схема операций по построению корпуса с создаваемой структурой тем, в соответствии с одним из вариантов реализации. Для формирования предварительной структуры тем корпуса выбирают один или более документов (101). Эти документы можно получить из базы данных или из сети, например из Интернета. Набор маркированных текстов (103) конструируется (102) из одного или более документов. Дополнительные документы можно получить из той же базы данных, которая использовалась для получения исходных документов, или из иной базы данных, или из той же сети, которая использовалась для получения исходных документов, или из иной сети, ля этих дополнительных документов может быть выполнена идентификация тем (104). В качестве обучающего набора при идентификации тем (104) можно использовать набор маркированных текстов (103). Дополнительные документы добавляют в корпус. После идентификации тем дополнительных документов получают корпус со структурой тем (105).
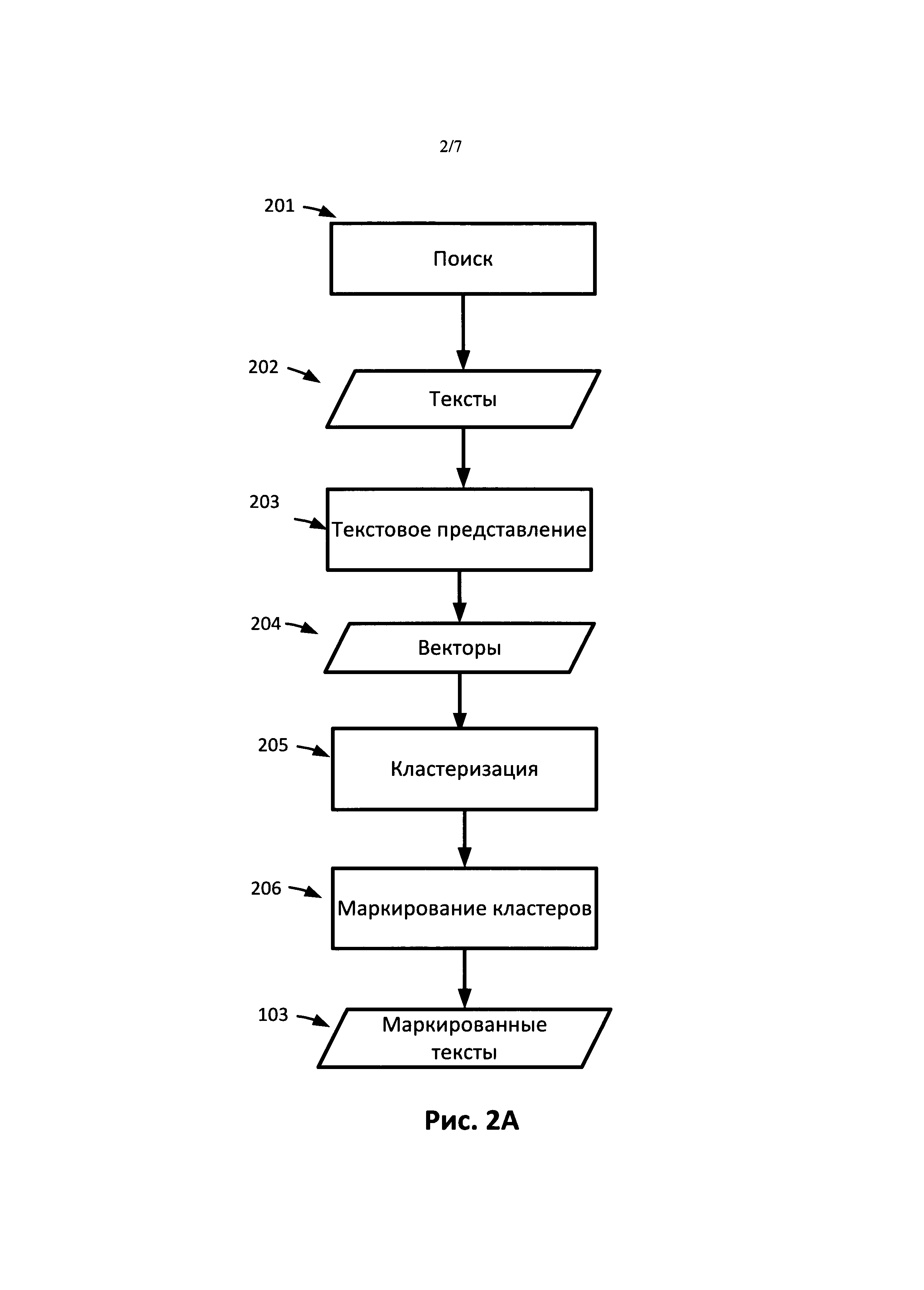
[0019] На Рис.2A представлена блок-схема операций по конструированию набора маркированных текстов (102) в соответствии с одним из вариантов реализации. В этом примере документы получают путем поиска при помощи поискового робота (201) в базе данных или в сети, например, в Интернете, с получением одного или более документов/текстов (202). В одном варианте реализации стадию поиска при помощи поискового робота можно выполнять с использованием известного способа поиска, например, описанного в следующей статье: J. Pomikalek. Removing Boilerplate and Duplicate Content from Web Corpus, диссертация кандидата наук, г. Брно, Университет им. Масарика, 2011 г. Стратегия поиска поисковым роботом может основываться на концепции коэффициента отдачи. В одном варианте реализации коэффициент отдачи для каждой страницы представляет собой отношение размера текста (в байтах), подходящего для корпуса, к размеру всего текста, извлеченного в процессе поиска при помощи поискового робота (201), например, 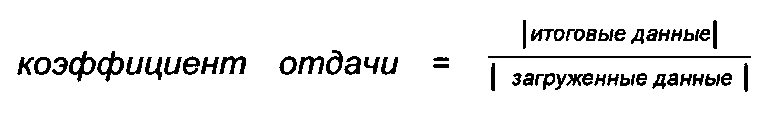 . В другом варианте реализации, основываясь на общем объеме текста корпуса, выбирают пороговое значение. Поисковый робот выбирает только те страницы, для которых значение коэффициента отдачи выше порогового значения. Пороговое значение можно выбирать динамически, в зависимости от количества уже просмотренных поисковым роботом страниц. Например, пороговое значение можно определить следующим образом: threshold (total)=0,01∗(log10(total)-1), где total - это общее количество страниц, уже просмотренных поисковым роботом или присутствующих в корпусе, a threshold(total) - это пороговое значение. Таким образом, чем больше количество страниц, просмотренных или присутствующих в корпусе, тем выше пороговое значение. Например, если в корпусе в данный момент имеется только 10 страниц, пороговое значение равно 0. Когда количество документов в корпусе достигает 10000 страниц, пороговое значение становится равным 0,03. Использование концепции коэффициента отдачи позволяет гарантировать, что в корпусе будет представлена каждая область знаний и каждая область в какой-то момент достигнет порогового значения, так что ни одна из областей не будет представлена избыточно. Следовательно, такой способ позволяет создать сбалансированный корпус.
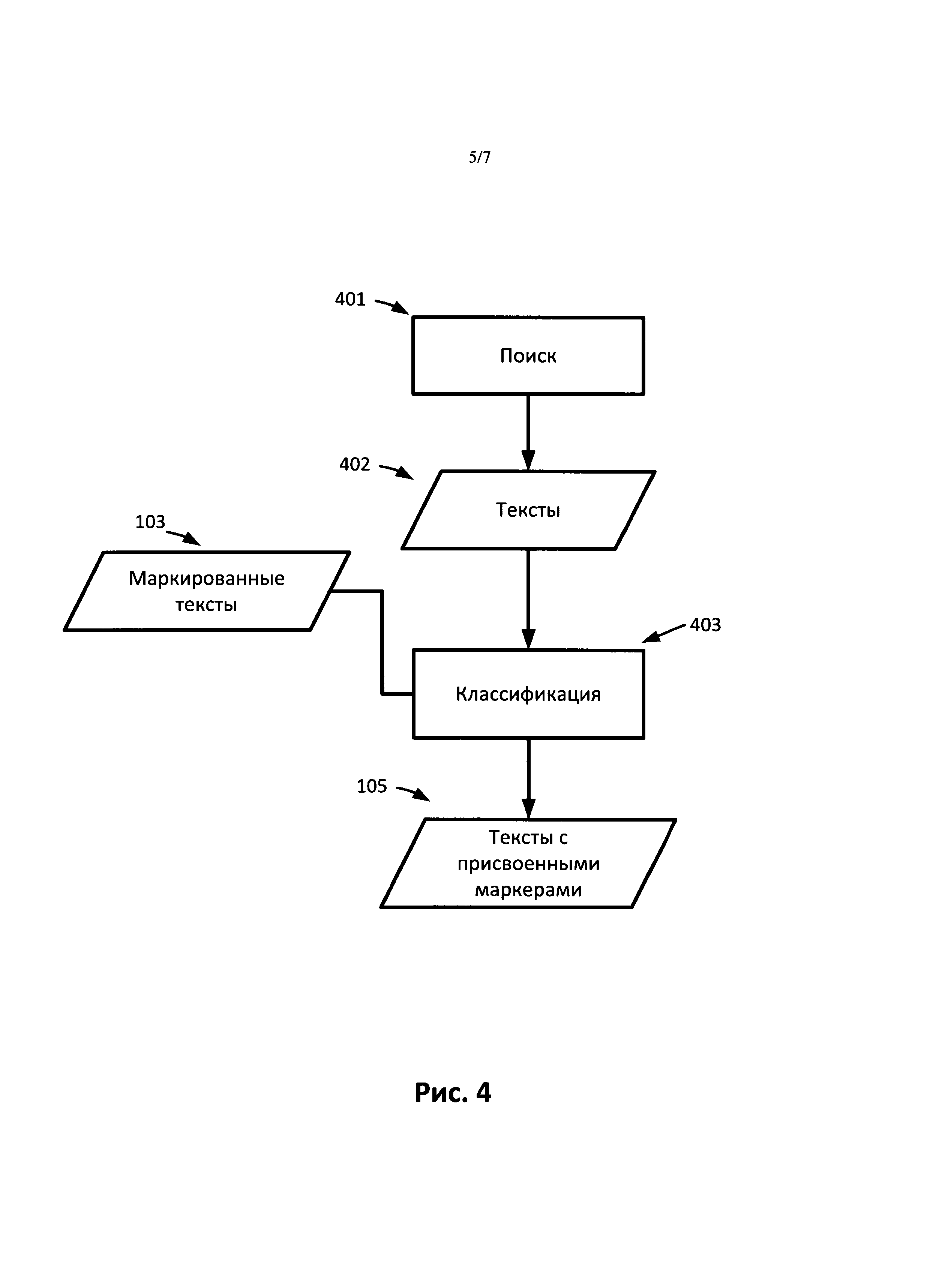
. В другом варианте реализации, основываясь на общем объеме текста корпуса, выбирают пороговое значение. Поисковый робот выбирает только те страницы, для которых значение коэффициента отдачи выше порогового значения. Пороговое значение можно выбирать динамически, в зависимости от количества уже просмотренных поисковым роботом страниц. Например, пороговое значение можно определить следующим образом: threshold (total)=0,01∗(log10(total)-1), где total - это общее количество страниц, уже просмотренных поисковым роботом или присутствующих в корпусе, a threshold(total) - это пороговое значение. Таким образом, чем больше количество страниц, просмотренных или присутствующих в корпусе, тем выше пороговое значение. Например, если в корпусе в данный момент имеется только 10 страниц, пороговое значение равно 0. Когда количество документов в корпусе достигает 10000 страниц, пороговое значение становится равным 0,03. Использование концепции коэффициента отдачи позволяет гарантировать, что в корпусе будет представлена каждая область знаний и каждая область в какой-то момент достигнет порогового значения, так что ни одна из областей не будет представлена избыточно. Следовательно, такой способ позволяет создать сбалансированный корпус.
[0020] Результатом стадии поиска с помощью поискового робота является набор документов/текстов (202). Далее тексты могут быть конвертированы в другое представление, например, в текстовое (203). Например, документы можно преобразовать в числовые векторы. Далее можно анализировать числовые векторы, а не напрямую документы/тексты. В одном варианте реализации можно применять способы, основанные на частотности или вхождениях слов, например, способы, представленные в статье: Salton G; McGill M J (1986 г.). Introduction to Modern Information Retrieval. McGraw-Hill. ISBN 0-07-054484-0. В одном варианте реализации для создания текстового представления документов собирают список всех слов во всех документах. Пусть N - общее количество различных слов во всех документах. Далее каждый документ преобразуют в вектор размерностью N, где каждый компонент вектора соответствует одному из слов из списка всех слов во всех документах. Значение каждого компонента показывает, содержит ли документ соответствующее слово. Значение может зависеть от частотности слова в этом документе и/или в других документах. В одном варианте реализации значение каждого компонента можно вычислить как произведение частотности слова и величины, обратной частотности документа. Частотность слова можно вычислить различными способами. Например, частотность слова wf(w,d) можно вычислить как частоту f(w,d) слова w в документе d, т.е. wf(w,d)=f(w,d). В другом варианте реализации частотность слова можно вычислить как wf(w,d)=log(f(w,d)+1). В еще одном варианте реализации частотность слова можно вычислить как 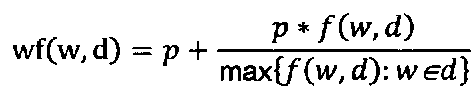 , где p - некоторое небольшое значение, например, p=0,5. Применение этой формулы позволяет предотвращать отклонения в сторону более длинных документов. Величину, обратную частотности документа idf(w,d), можно вычислить следующим образом:
, где p - некоторое небольшое значение, например, p=0,5. Применение этой формулы позволяет предотвращать отклонения в сторону более длинных документов. Величину, обратную частотности документа idf(w,d), можно вычислить следующим образом: 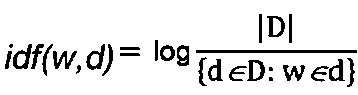 , где D - набор всех документов. Итоговое значение для компонента вычисляют как произведение двух значений, wf(w,d)∗idf(w,d). При вычислении значения каждого компонента для каждого вектора создают векторы (204), представляющие документы в корпусе.
, где D - набор всех документов. Итоговое значение для компонента вычисляют как произведение двух значений, wf(w,d)∗idf(w,d). При вычислении значения каждого компонента для каждого вектора создают векторы (204), представляющие документы в корпусе.
[0021] По векторам (204) можно выполнить кластеризацию (205). Можно использовать метод, не требующий заранее заданного количества кластеров, например, метод, представленный в следующей статье: Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu (1996 г.). "A density-based algorithm for discovering clusters in large spatial databases with noise," в Evangelos Simoudis, Jiawei Han, Usama M. Fayyad. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). AAAI Press, стр.226-231.
[0022] В другом варианте реализации можно использовать метод кластеризации, требующий предварительно задать количество кластеров, например, метод k-средних. Количество кластеров можно корректировать с использованием любого существующего метода оценки количества кластеров. На Рис.2B представлена блок-схема операций по кластеризации в соответствии с одним вариантом реализации. Операции можно повторять многократно с использованием разных значений k. Векторы (211) могут быть представлены как показано на Рис.2A (204). В одном варианте реализации случайные векторы количеством к определяют как центроиды (212). Каждый вектор, представляющий документ в корпусе, закрепляют за ближайшим центроидом (213) в соответствии с некоторым заранее заданным коэффициентом сходства/расстояния. В другом варианте реализации можно использовать подмножество векторов. После того как документы в корпусе закрепляют за ближайшим центроидом, центр массы каждого центроида определяют на основе векторов, представляющих документы, закрепленные за конкретным центроидом. Далее центральную точку центроида переносят в этот центр массы (216). Далее выполняют повторное закрепление векторов за центроидами, и процесс повторяется. Процесс завершается, когда центр массы не перемещается или перемещение меньше заданного порогового значения. Для каждого центроида (217) создают кластер, в результате чего получают несколько кластеров (218). Процесс можно повторить для множества разных значений k. На основе статистического анализа полученных кластерных структур можно выбрать наилучшее значение k.
[0023] В другом варианте реализации кластеризацию можно производить по двум параметрам, mnp, минимальному количеству точек в кластере, и thr, пороговому значению. При наличии этих двух значений выбирают случайную точку в пространстве векторов корпуса. Все векторы документов, дистанция между которыми равна или меньше порогового значения thr, соединяют. В другом варианте реализации можно использовать подмножество векторов. Если общее количество векторов, связанных с точкой, больше значения mnp, на основе этих векторов создают кластер. В противном случае векторы маркируют как выпадающие. Далее выбирают не использовавшуюся точку в пространстве векторов, и процесс повторяется. В одном варианте реализации в последующих итерациях используют только выпадающие векторы. В другом варианте реализации в каждой итерации используют все векторы документов, т.е. конкретный вектор может быть связан с несколькими точками. Процесс продолжается до тех пор, пока все векторы документов не будут связаны по меньшей мере с одной точкой. В другом варианте реализации процесс продолжается, пока не будут перебраны все точки. В данном процессе создают список кластеров, где каждый вектор ассоциируется по меньшей мере с одной точкой в пространстве векторов корпуса. Полученные кластеры далее могут быть маркированы (206). Маркировку кластеров (206) можно выполнять при помощи существующего метода, например, метода на основе критерия отбора признаков. В результате получают набор маркированных текстов 103.
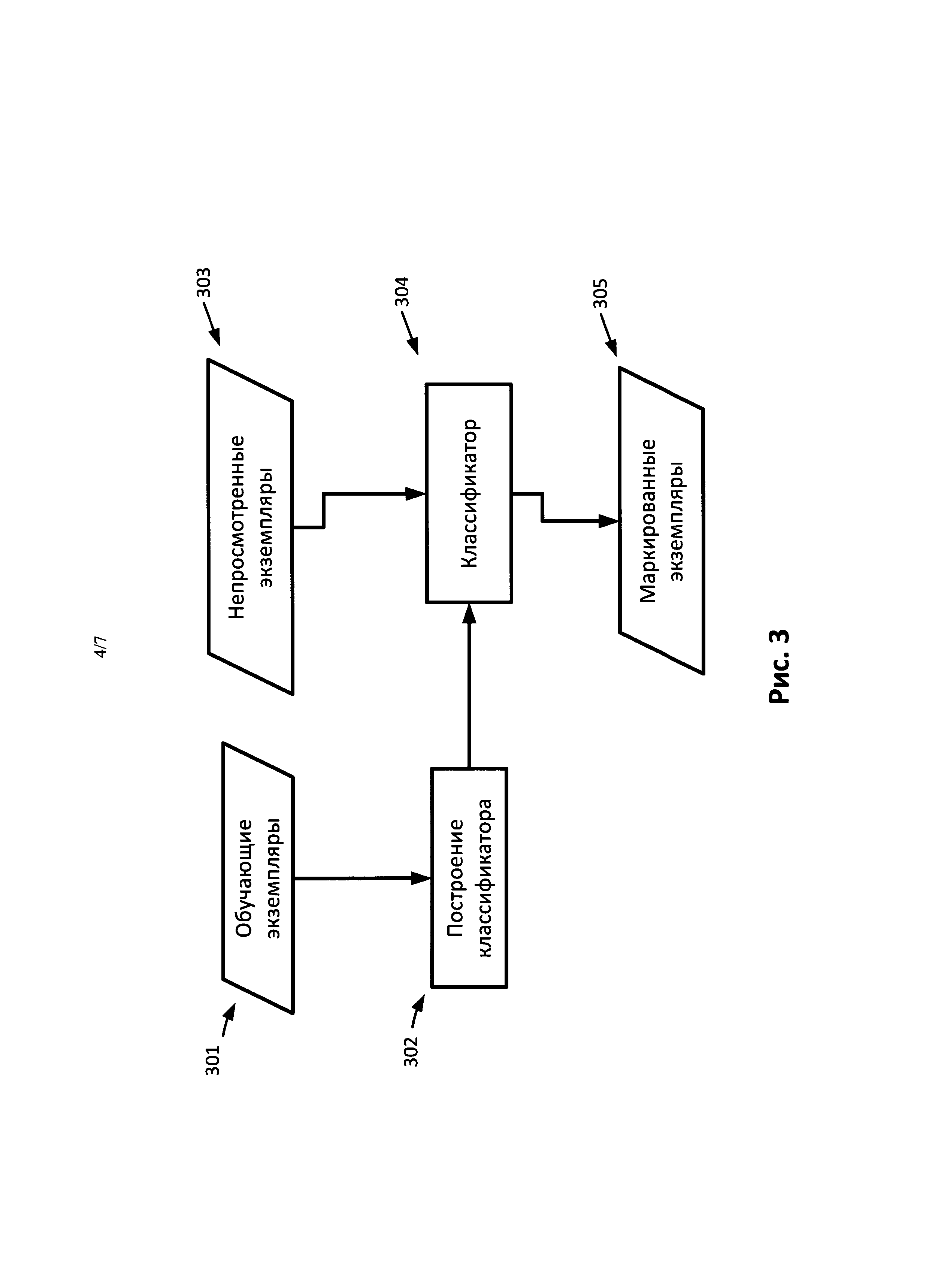
[0024] Как показано на Рис.1, идентификацию тем 104 можно осуществлять при помощи метода классификации. На Рис.3 представлена блок-схема операций по классификации в соответствии с одним вариантом реализации. Метод классификации назначает категорию (класс) непросмотренным экземплярам (303). Непросмотренный экземпляр может представлять собой документ или текст, добавляемый в корпус. В одном варианте реализации метод классификации предоставляют обучающие экземпляры (301), например, набор экземпляров маркированных категориями. Метод анализирует обучающий набор и строит классификатор (302). Далее классификатор назначает (304) категорию документу, добавляемому в корпус, например, непросмотренному экземпляру. В результате получают набор маркированных экземпляров (305). Экземпляру можно назначать один или более маркеров. Этап классификации можно выполнять при помощи существующего метода классификации. В одном варианте реализации используют метод классификации на основе модели условной вероятности, где параметры оценивают по частотности различных признаков. В другом варианте реализации, при наличии заданного значения k, классификацию можно производить путем анализа обучающих данных и создания обучающих векторов. Далее для каждого нового документа конструируют его вектор и находят один или более ближайших обучающих векторов по какому-либо коэффициенту сходства/дистанции. Далее документу назначают категории этого одного или более обучающих векторов.
[0025] В другом варианте реализации стадию классификации выполняют путем сведения проблемы множества классов к нескольким проблемам бинарной классификации, как описано в соответствующей статье: Duan, Kai-Bo; и Keerthi, S. Sathiya (2005 г.). "Which Is the Best Multiclass SVM Method? An Empirical Study". Proceedings of the Sixth International Workshop on Multiple Classifier Systems. Lecture Notes in Computer Science 3541: 278. При бинарной классификации экземпляры классифицируют по двум классам. Подход со сведением проблемы множества классов к нескольким бинарным проблемам включает в себя выполнение для каждого класса/категории бинарной классификации «один против всех». Например, непросмотренный документ можно сравнивать с одной категорией и со всеми оставшимися категориями в качестве второго класса. В одном варианте реализации бинарную классификацию можно основывать на построении гиперплоскостей, например, гиперплоскостей, описанных в следующей статье: Cortes, Corinna; и Vapnik, Vladimir N.; "Support-Vector Networks", Machine Learning, 20, 1995 г. и Патент США №5,950,146. В одном варианте реализации конструирование классификатора включает в себя представление всех документов в виде векторов с использованием вышеописанных методов. Обучающие документы представляются в виде {(x,y): y∈{-1,1}}, где -1 и 1 представляют собой маркеры первого и второго класса, соответственно. Далее строят гиперплоскость w·x-b=0, отделяющую обучающие документы, где y=1, от обучающих документов, где y=-1, так чтобы запас был максимальным. Таким образом, пространство разделяют гиперплоскостями на два подпространства. Для любого непросмотренного документа x бинарный выбор заключается в том, имеет ли документ y=1 или y=-1, и выполняется следующим образом: знак (w·x-b).
[0026] На Рис.4 представлена блок-схема операций по присвоению тем документам в соответствии с одним вариантом реализации. Все документы корпуса извлекают или ищут в базе данных или в сети, например, в Интернете (401). В результате получают набор текстов (402). К текстам 402 применяют метод классификации. В некоторых вариантах реализации метод классификации применяют в качестве обучающего набора (403) набор 103. Для классификации документов можно применять любой существующий метод классификации. В результате классификации документы маркируют темами (105).
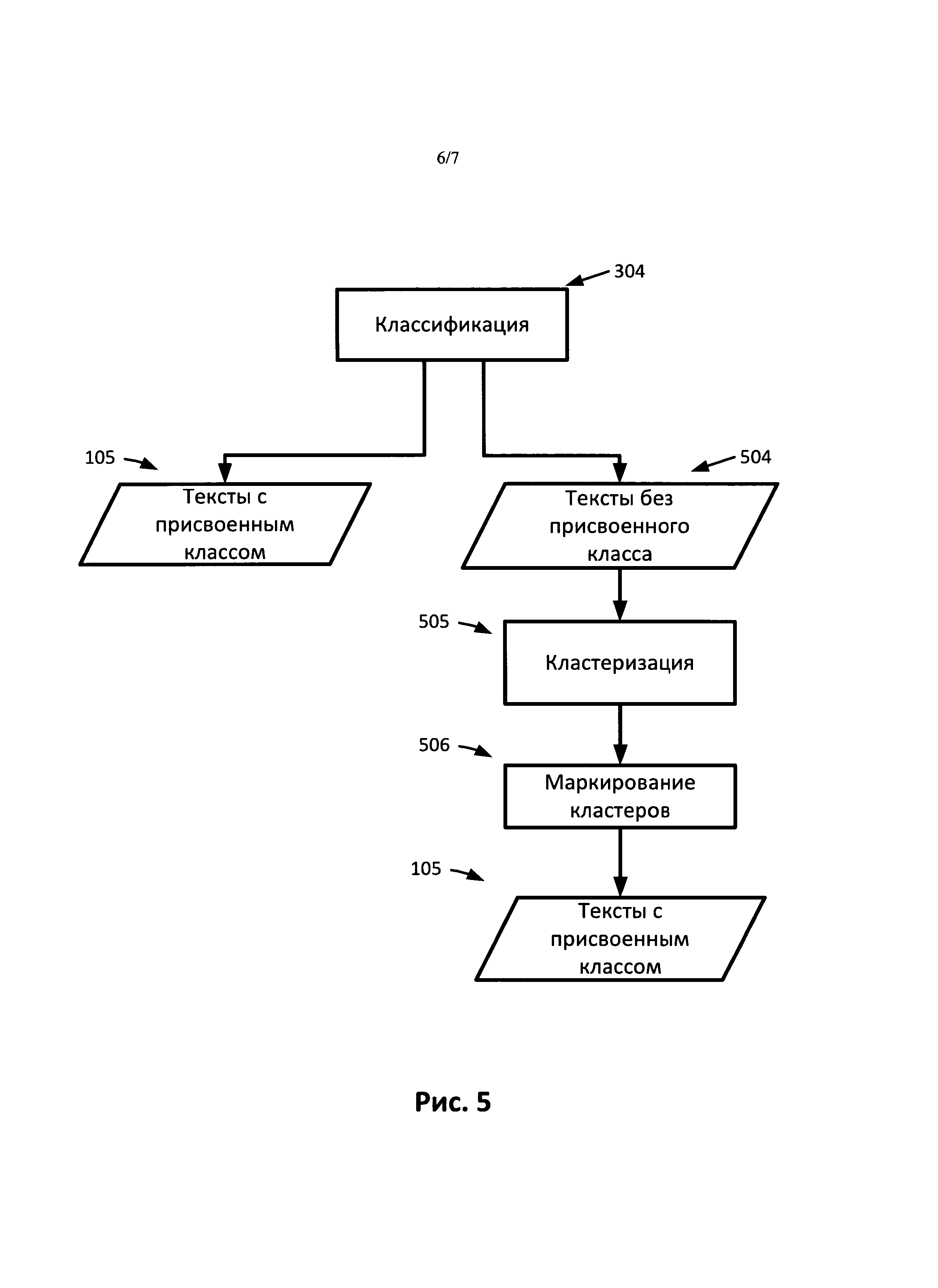
[0027] Как показано на Рис.1, Рис.2 и Рис.4, если корпус включает в себя тексты, извлеченные из сети, получить относительно сбалансированный и репрезентативный набор текстов 103 при первом поиске 201 может быть сложно. В некоторых вариантах реализации маркированные тексты 103 могут быть недостаточно репрезентативными для обучения классификатора 403, например, категории маркированных текстов 103 могут включать в себя не все категории, необходимые для маркирования текстов 402, получаемых при втором поиске 401. Чтобы учесть это, можно использовать метод классификации с открытыми классами. В классификаторе с открытыми классами набор присваиваемых маркеров не ограничивают маркерами, имеющимися в обучающем наборе. На Рис.5 представлена блок-схема операций по классификации документов с использованием тематического классификатора с открытыми классами в соответствии с одним вариантом реализации. В данном случае при классификации 304 получают не только тексты с присвоенными маркерами 105, но и тексты, которым маркеры не присвоены 504. Тексты, которым не присвоен маркер, представляют собой тексты, для которых не было найдено подходящего маркера среди обучающих экземпляров. Эти тексты без маркеров далее можно подвергнуть кластеризации 505. Полученные кластеры маркируют 506, как описано выше. В результате всем непросмотренным текстам 303 присваивают маркеры.
[0028] Обучающий набор можно обновить на основе документов из второй выборки. В одном примере кластеризацию корпуса, содержащего документы из второй выборки, применяют для создания нового обучающего набора. В еще одном примере подмножество корпуса и некоторые документы из второй выборки кластеризуют с получением обновленного обучающего набора.
[0029] На Рис.6 представлено аппаратное оборудование 600, которое можно использовать для реализации методов, описанных в настоящем документе. Как показано на Рис.6, аппаратное оборудование 600, как правило, включает по меньшей мере один процессор 602, соединенный с памятью 904 и имеющий среди устройств вывода 608 сенсорный экран, который в данном случае также выполняет функции устройства ввода 606. Процессор 602 может представлять собой любое имеющееся на рынке ЦПУ. Процессор 602 может представлять собой один или более из имеющихся на рынке процессоров (например, микропроцессоров), а память 604 может представлять собой оперативное запоминающее устройство (ОЗУ), содержащее главное устройство памяти аппаратного оборудования 600, а также любые дополнительные уровни памяти, например, кэш-память, энергонезависимую память или резервные запоминающие устройства (например, программируемую или флэш-память), ПЗУ и т.п. Кроме того, память 604 может включать в себя запоминающие устройства, физически расположенные в другом месте аппаратного оборудования 600, например, какая-либо кэш-память в процессоре 602, а также любые запоминающие устройства, используемые в качестве виртуальной памяти, например, съемные запоминающие устройства 610.
[0030] Аппаратное оборудование 600 также, как правило, имеет ряд входов и выходов для обмена информацией с внешними устройствами. Для работы с пользователем или оператором, аппаратное оборудование 600, как правило, содержит одно или более устройств пользовательского ввода 606 (например, клавиатуру, мышь, устройство, формирующее изображения, сканер и т.п.) и одно или более устройств вывода 608 (например, жидкокристаллический дисплей (ЖКД), устройство воспроизведения звука (динамик)). Для реализации различных вариантов реализации изобретения аппаратное оборудование 600 должно включать в себя по меньшей мере одно устройство с сенсорным экраном (например, сенсорный дисплей), интерактивную доску для письма или иное устройство, позволяющее пользователю взаимодействовать с компьютером путем прикосновения к участкам экрана. В различных описанных вариантах реализации изобретения клавиатура не является обязательной.
[0031] В качестве дополнительного устройства памяти аппаратное оборудование 600 также может включать в себя одно или более съемных запоминающих устройств 610, например, среди прочих, накопитель на гибких магнитных или иных съемных дисках, накопитель на жестком диске, запоминающее устройство с прямым доступом (DASD), оптический привод (например, привод компакт-дисков (CD), компакт-дисков в формате DVD и т.п.) и/или ленточный накопитель. Более того, аппаратное оборудование 600 может включать в себя интерфейс для взаимодействия с одной или более сетями 612 (например, среди прочих, локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и/или Интернетом) для обмена информацией с другими компьютерами, подключенными к сетям. Следует принимать во внимание, что аппаратное оборудование 600, как правило, включает в себя подходящие аналоговые и/или цифровые интерфейсы между процессором 602 и каждым из компонентов 604, 606, 608 и 612, что хорошо известно специалистам в данной области.
[0032] Аппаратное оборудование 600 работает под управлением операционной системы 614, и на нем выполняются различные компьютерные программные приложения 616, компоненты, программы, объекты, модули и т.п., с целью реализации описанных методов. Более того, различные приложения, компоненты, программы, объекты и т.п., в совокупности обозначенные пунктом 616 на Рис.6, также могут выполняться на одном или более процессорах другого компьютера, соединенного с аппаратным обеспечением 600 через сеть 612, например, в среде распределенных вычислений, причем вычисления, необходимые для реализации функций компьютерной программы, могут быть распределены по множеству компьютеров в сети.
[0033] В общем случае, процедуры, выполняемые для реализации вариантов реализации настоящего изобретения, могут быть реализованы в виде компонента операционной системы или специального приложения, компонента, программы, объекта, модуля или последовательности команд, которые именуют «компьютерными программами». Компьютерные программы, как правило, содержат один или более наборов команд в разное время в разных устройствах памяти и хранения в компьютере, которые, при их считывании и исполнении одним или более процессорами компьютера, приводят к выполнению компьютером операций, необходимых для исполнения элементов описанных вариантов реализации изобретения. Более того, различные варианты реализации изобретения описаны в контексте полностью функциональных компьютеров и компьютерных систем, и специалистам в данной области будет понятно, что различные варианты реализации можно распространять в качестве программного продукта в различных формах, и что распространение не зависит от конкретного типа машиночитаемого носителя, используемого для реализации распространения. Примеры машиночитаемых носителей включают в себя, без ограничений, носители с возможностью записи, такие как устройства оперативной и энергонезависимой памяти, гибкие магнитные и другие съемные диски, жесткие диски, оптические диски (например, ПЗУ на компакт-дисках (CD-ROM), компакт диски в формате DVD, флэш-память и т.п.). Также могут быть использованы другие типы распространения, такие как загрузка из Интернета.
[0034] В приведенном выше описании конкретные детали приводятся в разъяснительных целях. Однако специалисту в данной области очевидно, что эти конкретные детали являются только примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание затруднения процесса объяснения.
[0035] Упоминание в данном описании терминов «один вариант реализации изобретения» или «вариант реализации» означает, что конкретный элемент, структура или характеристика, описанная вместе с вариантом реализации, включается по меньшей мере в один вариант реализации изобретения. Фраза «в одном варианте реализации», встречающаяся в различных местах описания, не обязательно обозначает один и тот же вариант реализации изобретения или же отдельные или альтернативные варианты реализации, взаимоисключающие другие варианты реализации. Более того, некоторые описываемые особенности могут присутствовать в некоторых вариантах реализации, но не присутствовать в других вариантах реализации изобретения. Аналогично, описываются различные требования, которые могут относиться к одним вариантам реализации и не относиться к другим вариантам реализации изобретения.
[0036] Хотя некоторые примеры реализации изобретения описаны и представлены на прилагаемых рисунках, следует понимать, что такие варианты реализации являются лишь иллюстративными, но не ограничивающими, и что эти варианты реализации не ограничены конкретными показанными и описанными схемами и комбинациями, поскольку обычному специалисту в данной области после изучения описания будут очевидны и другие модификации. В такой области технологий, как данная, где рост происходит быстро, и дальнейшие достижения предвидеть непросто, описанные варианты реализации можно легко подвергать модификациям по компоновке и деталям, чему будут способствовать технологические достижения, и это не будет отклонением от принципов настоящего описания.
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод построения корпуса текстов на основе интернет-форумов
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Разрешение семантической неоднозначности при помощи не зависящей от языка семантической структуры
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод построения корпуса текстов на основе интернет-форумов
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Разрешение семантической неоднозначности при помощи не зависящей от языка семантической структуры
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе

