Результат интеллектуальной деятельности: СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ СЕМАНТИЧЕСКИХ СЛОВАРЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
Вид РИД
Изобретение
Область техники
[0001] Настоящее изобретение в целом относится к области обработки текстов на естественном языке, в частности к системам, способам и компьютерным программам для создания и использования пользовательских онтологических моделей и пользовательских семантических словарей для обработки пользовательских текстов на естественном языке.
Уровень техники
[0002] В настоящее время важнейшим элементом процесса автоматической обработки текстовой информации на естественных языках являются технологии, связанные с онтологиями. Онтология - это особое формализованное представление знаний о некой предметной области. Другими словами, онтология образует репрезентацию некой предметной области, включающую в себя описание понятий данной предметной области и отношений между ними. Онтологии разрабатываются инженерами и требуют колоссальных усилий и знаний в области компьютерной лингвистики. Онтологии не имеют универсальной общепринятой структуры, поэтому число существующих на данный момент онтологий достаточно велико. Нет единственно правильного способа создания онтологий. Это связано с тем, что представление о том, как должно быть организовано представление некой предметной области, носит субъективный характер и отражает картину мира конкретного разработчика, а также цели, для которых данная онтология была создана.
[0003] Ввиду перечисленных выше особенностей существует необходимость создания способа, который бы позволил расширять основную онтологию онтологиями, предназначенными для конечного пользователя.
Раскрытие изобретения
[0004] В настоящем описании представлены системы, способы и компьютерные программы для создания и использования пользовательских онтологий и пользовательских семантических словарей для обработки предоставленных пользователем текстов на естественном языке.
[0005] В одном из аспектов типовой способ создания и использования пользовательского семантического словаря для обработки предоставленного пользователем текста на естественном языке включает: получение первого определения элементов пользовательского словаря, соотнесенного с пользовательским онтологическим объектом; создание аппаратным процессором пользовательского семантического словаря на основе первого определения элементов пользовательского словаря, при этом созданный пользовательский семантический словарь включает: первую структуру семантического словаря, содержащую семантико-синтаксические данные, и идентификатор пользовательского онтологического объекта; анализ пользовательского текста аппаратным процессором для определения части пользовательского текста, соответствующей семантико-синтаксическим данным; создание аппаратным процессором как минимум одного узла в семантико-синтаксическом дереве, при этом семантико-синтаксическое дерево включает множество связанных узлов, при этом данный как минимум один узел содержит ссылку на пользовательский онтологический объект или ссылку на первую структуру семантического словаря; и выполнение аппаратным процессором дальнейшей обработки пользовательского текста на естественном языке с использованием созданного семантико-синтаксического дерева.
[0006] В другом аспекте типовая система для создания и использования пользовательского словаря для обработки предоставленного пользователем текста на естественном языке включает: модуль ввода данных в пользовательский семантический словарь, выполненный с возможностью получения первого определения элементов пользовательского словаря, соотнесенного с неким пользовательским онтологическим объектом; модуль создания пользовательского семантического словаря, выполненный с возможностью создания пользовательского семантического словаря на основе первого определения элементов пользовательского словаря, при этом созданный пользовательский семантический словарь включает: первую структуру семантического словаря, состоящую из семантико-синтаксических данных, и идентификатор данного пользовательского онтологического объекта; модуль анализа текста, выполненный с возможностью: анализа пользовательского текста для определения части пользовательского текста, соответствующей семантико-синтаксическим данным; модуль создания дерева, выполненный с возможностью создания как минимум одного узла в семантико-синтаксическом дереве, при этом семантико-синтаксическое дерево включает множество связанных узлов, при этом данный как минимум один узел содержит ссылку на пользовательский онтологический объект или ссылку на первую структуру семантического словаря; а также модуль обработки естественного языка, выполненный с возможностью выполнения дальнейшей обработки пользовательского текста на естественном языке с использованием созданного семантико-синтаксического дерева.
[0007] Еще в одном аспекте типовой программный продукт, который хранится в памяти постоянного машиночитаемого носителя данных, содержит исполняемые компьютером команды на создание и использование пользовательского семантического словаря для обработки предоставленного пользователем текста на естественном языке, в том числе команды на: получение первого определения элементов пользовательского словаря, соотнесенного с пользовательским онтологическим объектом; создание аппаратным процессором пользовательского семантического словаря на основе первого определения элементов пользовательского словаря, при этом созданный пользовательский семантический словарь включает: первую структуру семантического словаря, содержащую семантико-синтаксические данные и идентификатор пользовательского онтологического объекта; анализ пользовательского текста аппаратным процессором для определения части пользовательского текста, соответствующей семантико-синтаксическим данным; создание аппаратным процессором как минимум одного узла в семантико-синтаксическом дереве, при этом семантико-синтаксическое дерево включает множество связанных узлов, при этом данный как минимум один узел содержит ссылку на пользовательский онтологический объект или ссылку на первую структуру семантического словаря; и выполнение аппаратным процессором дальнейшей обработки пользовательского текста на естественном языке с использованием созданного семантико-синтаксического дерева.
[0008] В некоторых аспектах первое определение элементов пользовательского словаря содержит идентификатор родительского семантического класса, а часть пользовательского текста соответствует семантико-синтаксическим данным из структуры родительского семантического класса, определяемого идентификатором родительского семантического класса. В некоторых аспектах структура родительского семантического класса входит в состав основного семантического словаря. В некоторых аспектах первое определение элементов пользовательского словаря содержит синтаксическую парадигму, соотнесенную с данным элементом пользовательского словаря, семантико-синтаксические данные содержат данную синтаксическую парадигму, а часть пользовательского текста соответствует данной синтаксической парадигме. В некоторых аспектах первое определение элементов пользовательского словаря содержит строку текста на естественном языке, соотнесенную с элементом пользовательского словаря, семантико-синтаксические данные содержат данную строку текста на естественном языке, а часть пользовательского текста соответствует данной строке текста на естественном языке. В некоторых аспектах первая структура семантического словаря является временной пользовательской структурой или структурой пользовательского лексического класса, а создание первого определения элементов пользовательского словаря включает в себя семантико-синтаксический анализ данной строки текста на естественном языке. В некоторых аспектах первое определение элементов пользовательского словаря содержит идентификатор пользовательского онтологического объекта. В некоторых аспектах первое определение элементов пользовательского словаря формируется на основе определения пользовательского онтологического объекта. Некоторые аспекты далее включают получение второго определения элементов пользовательского словаря, соотнесенного с пользовательским онтологическим объектом, а созданный пользовательский семантический словарь включает: вторую структуру семантического словаря, содержащую идентификатор пользовательского онтологического объекта.
[0009] Вышеприведенные упрощенное раскрытие типовых аспектов изобретения дает базовое представление о настоящем изобретении. Настоящее раскрытие изобретения не является широким обзором всех подразумеваемых аспектов изобретения и не предназначено ни для определения ключевых или критических элементов всех аспектов, ни для общего описания объема всех или некоторых аспектов настоящего изобретения. Его единственная цель заключается в том, чтобы описать один или более аспектов в упрощенной форме в качестве вводной части к более подробному описанию настоящего изобретения, представленному ниже. Для выполнения вышеуказанных задач один или несколько аспектов настоящего изобретения включают характеристики, описанные и особенным образом отмеченные в пунктах формулы изобретения.
Краткое описание чертежей
[0010] Прилагаемые чертежи, включенные в настоящее патентное описание и являющиеся его частью, иллюстрируют один или более типовых аспектов раскрытия настоящего изобретения и, вместе с описанием предпочтительных вариантов реализации, объясняют их принципы и варианты реализации.
[0011] На Фиг. 1А иллюстрируется типовой способ создания и использования пользовательской онтологической модели и пользовательского семантического словаря в соответствии с одним из типовых аспектов изобретения.
[0012] На Фиг. 1В иллюстрируется пример иерархической структуры в основной онтологии в соответствии с одним из типовых аспектов изобретения.
[0013] На Фиг. 1С иллюстрируется процесс компиляции определения пользовательской онтологии в рамках существующей основной онтологической модели для получения пользовательской онтологической модели в соответствии с одним из типовых аспектов изобретения.
[0014] На Фиг. 1D иллюстрируется типичный способ создания пользовательского семантического словаря в соответствии с одним из типовых аспектов изобретения.
[0015] На Фиг. 2 иллюстрируется типовой способ выполнения семантико-синтаксического анализа в соответствии с одним из типовых аспектов изобретения.
[0016] На Фиг. 3 иллюстрируется типовой способ использования пользовательской онтологической модели в соответствии с одним из типовых аспектов изобретения.
[0017] На Фиг. 4 иллюстрируется пример языковых описаний в соответствии с одним из типовых аспектов изобретения.
[0018] На Фиг. 5 иллюстрируется пример морфологических описаний в соответствии с одним из типовых аспектов изобретения.
[0019] На Фиг. 6 иллюстрируется пример синтаксических описаний в соответствии с одним из типовых аспектов изобретения.
[0020] На Фиг. 7 иллюстрируется пример семантических описаний в соответствии с одним из типовых аспектов изобретения.
[0021] На Фиг. 8 иллюстрируется пример лексических описаний в соответствии с одним из типовых аспектов изобретения.
[0022] На Фиг. 9 иллюстрируется типовой способ глубинного анализа предложения в соответствии с одним из типовых аспектов изобретения.
[0023] На Фиг. 10А иллюстрируется семантико-синтаксическая структура предложения, полученная в результате семантико-синтаксического анализа, в соответствии с одним из типовых аспектов изобретения.
[0024] На Фиг. 10В иллюстрируется семантико-синтаксическая структура предложения, полученная в результате семантико-синтаксического анализа, в соответствии с одним из типовых аспектов изобретения.
[0025] На Фиг. 11А, 11В иллюстрируются результаты работы модуля извлечения информации без использования пользовательской онтологической модели и пользовательского семантического словаря на примере предложения «Takayama does а part-time job for IBM».
[0026] На Фиг. 12А, 12В иллюстрируются результаты работы модуля извлечения информации с использованием пользовательской онтологической модели и пользовательского семантического словаря на примере предложения «Takayama does а part-time job for IBM».
[0027] На Фиг. 13 иллюстрируется пример компьютерной системы, такой как сервер или персональный компьютер, подходящей для осуществления систем и способов настоящего изобретения, в соответствии с типовыми аспектами изобретения.
[0028] На Фиг. 14 иллюстрируется схема типовой системы для создания и использования пользовательской онтологической модели и пользовательского семантического словаря для обработки предоставленного пользователем текста на естественном языке.
[0029] На Фиг. 15 показан типовой способ создания и использования пользовательской онтологической модели и пользовательского семантического словаря для обработки предоставленного пользователем текста на естественном языке.
[0030] На Фиг. 16 иллюстрируется схема потоков данных по типовому способу создания и использования пользовательской онтологической модели для обработки предоставленного пользователем текста на естественном языке.
[0031] На Фиг. 17 иллюстрируется схема потоков данных по типовому способу создания и использования пользовательского семантического словаря для обработки предоставленного пользователем текста на естественном языке.
[0032] В представленном ниже подробном описании даются ссылки на сопровождающие чертежи. Одинаковые обозначения на чертежах соответствуют одинаковым компонентам, если не указано иное. Типовые аспекты, указанные в подробном описании, чертежах и пунктах формулы изобретения, не являются единственно возможными. Типовые аспекты могут быть использованы или изменены в рамках других, не описанных ниже способов, без нарушения их области применения или сущности. Различные варианты, приведенные в описании типовых аспектов и проиллюстрированные на чертежах, могут располагаться, заменяться и группироваться в широком диапазоне различных конфигураций, которые подробно рассмотрены в настоящем описании.
Описание предпочтительных вариантов реализации
[0033] Типовые аспекты описываются в настоящем раскрытии в контексте системы и способа создания и использования пользовательской онтологической модели и пользовательского семантического словаря для обработки пользовательского текста на естественном языке. Однако специалисты в этой области техники поймут, что нижеследующее описание носит исключительно иллюстративный, а не ограничивающий в каком-либо отношении характер. Другие аспекты настоящего раскрытия будут очевидны для специалистов в данной области на основании настоящего раскрытия. Далее будут подробно описаны варианты осуществления типовых аспектов, проиллюстрированных на приложенных чертежах. При упоминании в чертежах и нижеследующем описании тех же или аналогичных объектов будут по мере возможности использованы те же исходные индикаторы.
[0034] Онтология представляет собой формальное явное описание некой предметной области. Основными компонентами онтологии являются концепты (или другими словами, классы), экземпляры, отношения, атрибуты. Концепты онтологии представляют собой формально описанное номинативное множество экземпляров, обобщенных по какому-либо признаку. Примером концепта является множество персон, входящих в концепт «Person» («Персона»). Концепты в онтологии объединены в таксономию, т.е. в иерархическую структуру. Экземпляр представляет собой конкретный объект или явление предметной области, которое входит в концепт. Например, экземпляр Yury_Gagarin («Юрий Гагарин») входит в концепт «Person» («Персона»). Отношения - это формальные описания между концептами, которые обуславливают то, какие связи могут быть установлены между экземплярами данных концептов. Помимо этого экземпляры имеют функции или свойства.
[0035] В связи с тем, что информация, представленная в онтологии, не является исчерпывающей, в зависимости от области применения онтологии информация в ней может быть дополнена знаниями из изучаемой области, или, другими словами, онтология может быть расширена.
[0036] В настоящем раскрытии изобретения приводятся способы и системы для создания пользовательских онтологических моделей, которые позволяют дополнить существующие основные онтологические модели новыми пользовательскими подклассами и экземплярами, что существенно повышает точность обработки текстовых данных на естественном языке.
[0037] Онтологическая модель - это сочетание онтологии и заданных онтологических правил извлечения информации из текста, как описано ниже. Пользователю может предоставляться основная онтологическая модель, тогда как пользовательская онтологическая модель может создаваться пользователем путем компилирования определений, описывающих пользовательскую онтологию, вместе с основной онтологической моделью.
[0038] Целью создания пользовательских онтологий (которые затем компилируются в пользовательские онтологические модели) является пополнение основных онтологий (которые компилируются в основные онтологические модели) пользовательскими концептами и экземплярами, отсутствующими в основных онтологиях. Это связано с тем, что пользовательские онтологические объекты (а именно пользовательские концепты и экземпляры) зачастую уникальны и специфичны для конкретной области знаний и, следовательно, могут быть недоступны через открытые источники информации. Примерами пользовательских онтологических объектов являются названия компаний в некой области, имена сотрудников некой компании, названия продуктов, выпускаемой данной компанией и т.д. В результате, уникальные и специфичные онтологические объекты могут отсутствовать в основных онтологиях, и, если данная информация не будет предоставлена непосредственно конечным пользователем, данные концепты и экземпляры не могут быть включены в основные онтологии. Однако, несмотря на эти недостатки, зачастую возникает необходимость обработки текстовых данных, содержащих информацию о вышеупомянутых объектах. Поэтому создание способа, позволяющего любому пользователю создавать пользовательскую онтологическую модель в зависимости от поставленных перед ним задач, является важным аспектом в области обработки неструктурированной текстовой информации.
[0039] Создание пользовательской онтологической модели способствует повышению точности обработки текстовых данных на естественном языке, а именно повышению точности семантико-синтаксического анализа текста и работы алгоритма и системы для извлечения информации (фактов, сущностей).
[0040] Помимо этого, представленный ниже способ позволяет устранить неоднозначность в тексте: во время семантико-синтаксического анализа текста система способна различать различные объекты с одинаковыми наименованиями исходя из контекста, например, извлекать объекты, имеющие одинаковые наименования, как в качестве организации, так и в качестве персоны. Более того, система способна выбирать наиболее подходящий объект для конкретного случая и извлекать факты, фигурантами которых являются данные объекты.
[0041] Основные принципы семантико-синтаксического анализа на базе лингвистических описаний приведены в патенте США №8,078,450, и данные принципы лежат в основе данного изобретения и полностью включены в настоящее описание изобретения посредством ссылки. Так как такой анализ основан на использовании независимых от языка семантических единиц, настоящий типовой аспект также не зависит от языка и применим к одному или нескольким естественным языкам.
[0042] В рамках настоящего описания возможны два способа осуществления предлагаемых типовых аспектов. Первый способ осуществления связан с возможностью проведения вторичного семантико-синтаксического и онтологического анализа текста (текстовых корпусов) с целью извлечения информации, которая с использованием только основных онтологий и основного словаря была извлечена на первом этапе семантико-синтаксического анализа с недостаточной точностью. Второй способ осуществления относится к так называемому превентивному использованию. Согласно превентивному использованию заранее создается пользовательская онтологическая модель, которая используется совместно с уже существующей основной онтологией для извлечения информации (сущностей и фактов) из анализируемых текстовых данных.
[0043] На Фиг. 1А иллюстрируется типовой способ создания пользовательской онтологической модели в соответствии с одним из типовых аспектов изобретения. Данный способ представляет собой превентивное использование. Превентивное использование в данном контексте означает, что пользователь может заранее знать, какая информация может содержаться в текстовых данных и, следовательно, знать, какие информационные объекты могут быть извлечены из этих текстовых данных 109 (коллекций/корпусов текстов) в процессе глубинного семантико-синтаксического анализа 111 и в процессе извлечения информации 113, которые будут более подробно описаны ниже. Информацией в данном контексте могут быть сущности и явления реального мира, а именно персоны, организации, местоположения и т.д., а также связанные с ними факты.
[0044] В одном из типовых аспектов извлечение информации из текста предполагает и ведет к созданию информационных объектов, представляющих собой онтологические объекты (такие как сущности и факты), описание которых, ссылка на которые или упоминание которых приводится в тексте.
[0045] Согласно Фиг. 1А, на этапе 101 пользователь может предоставить описание (описания) пользовательской онтологии, которое включает в себя информацию, которая по мнению пользователя может содержаться в коллекции (корпусе) текстов 109 и которая после глубинного семантико-синтаксического анализа (111) может быть извлечена из данной коллекции (корпуса) текстов 109 с помощью модуля извлечения информации 113. В число извлеченных информационных объектов (115), таких как извлеченные по онтологическим правилам (правилам извлечения) сущности и факты, входят информационные объекты, основанные на онтологических объектах, определенных пользователем при создании пользовательской онтологии (101). Данные информационные объекты не были бы извлечены из текстов 109, если бы не использовались пользовательские онтологические модели, так как соответствующий класс (семантический класс, лексический класс или термин) отсутствовал бы в семантическом словаре и правила извлечения не позволили бы установить, какой класс следует использовать. Так, в предложении "Takayama does a part-time job for IBM" система может не дать определение слову "Takayama" (без пользовательского семантического словаря и пользовательской онтологической модели) ввиду его уникальности либо, в ином случае, может отнести его либо к персонам, либо к организациям, при этом правила извлечения не позволят определить, что имеется в виду, если такая информация не будет предоставлена пользователю через пользовательские онтологические определения.
[0046] Как было упомянуто выше, определение пользовательской онтологии 101 может включать информацию следующего содержания: списки городов определенного региона, списки сотрудников определенной компании и так далее. Определение пользовательской онтологии может вноситься в виде подготовленного пользователем файла предустановленного формата (например, файл в формате .txt) либо создаваться автоматически на основе данных, собранных из различных источников и (или) введенных пользователем через программу с пользовательским интерфейсом. Определение пользовательской онтологии (101) может содержать определение пользовательского онтологического экземпляра (-ров) или пользовательского онтологического концепта (-ов). Данный файл с определением пользовательской онтологии (101) вводится в компилятор (103). Формат представления информации пользователем в определении пользовательской онтологии 101 дает возможность расширять уже существующие в системе основные онтологии и добавлять в основные онтологии пользовательские концепты и экземпляры. Структура основных онтологий будет представлена ниже.
[0047] Основные онтологии (Фиг. 1С 1200, Фиг. 1В, 1200) вместе с онтологическими правилами (131, Фиг. 1С) формируют основную онтологическую модель 108, которая является формализованным представлением определенной предметной области. В рамках настоящего раскрытия изобретения термин "онтологическая модель" означает сочетание онтологии и онтологических правил. Онтология включает формальное описание элементарных (неделимых) единиц предметной области (экземпляров), формальное описание различных объединений (концептов/классов) экземпляров и формальное описание отношений между экземплярами. Согласно предлагаемым типовым аспектам основные онтологии объединяются в иерархическую систему онтологий. Так, на Фиг. 1В иллюстрируются основные онтологии Basic Entity (Основная Сущность) (121), Basic Fact (Основной факт) (122), Economic Crisis (Экономический Кризис) (123), Economics (Экономика) (124), Finance (Финансы) (125), Geo (География) (126), Jurisprudence (Юриспруденция) (127), Military (Армия) (128), Org (Организация) (129) и т.д., которые наследуются от онтологии Basic (Основная) (120). Приведенный перечень существующих базовых онтологий не является исчерпывающим. Данный перечень основных онтологий носит иллюстративный характер и не ограничивает область данных типовых аспектов. При наследовании концепты, экземпляры и отношения, принадлежащие родительской онтологии Basic (Основная) (120), также принадлежат и онтологиям-потомкам.
[0048] Концепт (другими словами, класс) является элементом онтологии, который отражает то или иное понятие предметной области. Множество экземпляров (элементы онтологии нижнего уровня) объединяется в один концепт. Например, все экземпляры, соответствующие персонам, объединяются в концепт «Person» («Персона»). Каждому концепту в онтологии соответствует группа отношений, областью которых является данный концепт. Эта группа отношений определяет то, какие связи может иметь экземпляр данного концепта. Кроме того, с этим концептом связывается группа простых ограничений и группа родительских концептов. Все это также определяет, какими могут быть экземпляры данного концепта.
[0049] Все концепты в онтологии могут быть представлены в виде древовидной структуры, в которой более «толстые ветки» представляют общие понятия, а более «тонкие» - узкие понятия. Например, толстая ветвь "Организации" ("Organizations") разделяется на более тонкие: "Коммерческие организации" ("Commercial organizations"), "Правительственные организации" ("Governmental organizations ") и т.д. Помимо этого в описываемой структуре концептов может допускаться множественное наследование. Например, «Коммерческие организации» ("Commercial organizations") являются подконцептом концепта «Организации» и подконцептом концепта «Объекты купли-продажи» одновременно. Концепты могут образовывать не древовидную структуру, а граф более общего вида, в котором может быть несколько корневых вершин, что означает, что граф не обязательно является связным, т.е. является ориентированным ациклическим графом.
[0050] Экземпляр является компонентом онтологии нижнего уровня, членом группы конкретных представителей концепта. Так, например, концепт "Season" ("Сезон") имеет 4 экземпляра: "Spring" ("Весна"), "Summer" ("Лето"), "Autumn" ("Осень") и "Winter" (Зима"). Экземпляры создаются для пополнения базы знаний о предметной области. Каждый экземпляр относится к одному единственному концепту. Каждый экземпляр соотносится с группой связей. Согласно предлагаемым типовым аспектам в онтологии может храниться следующая информация об экземпляре: идентификатор онтологии, к которой относится экземпляр, уникальный идентификатор внутри онтологии, имя (на различных языках), список концептов, к которым относится экземпляр, именованные связи с другими экземплярами и свойства (значения строковых свойств могут быть представлены на различных естественных языках). Вышеупомянутое описание организации онтологии распространяется как на основные онтологии, так и на пользовательские онтологии, которые будут включаться в состав существующих основных онтологий.
[0051] На Фиг. 1С более детально иллюстрируется процесс компиляции описания пользовательской онтологии (101). Как уже было упомянуто выше, существуют основные онтологии (Basic Entity (Основная Сущность) (121), Basic Fact (Основной факт) (122), Economic Crisis (Экономический Кризис) (123), Economics (Экономика) (124), Finance (Финансы) (125), Geo (Гео) (126), Jurisprudence (Юриспруденция) (127), Military (Армия) (128), Org (Организация) (129), и т.д.), которые объединены в иерархическую структуру. Данные онтологии совместно с определенными онтологическими правилами (131) составляют основную онтологическую модель (108), которая используются в работе модуля извлечения информации (113). Основная онтологическая модель (108) создается путем компиляции основных онтологии (1200) с библиотеками онтологических правил (131). Далее в рамках скомпилированной основной онтологической модели (108) происходит компиляция (103) описания пользовательской онтологии (101). В результате создается пользовательская онтологическая модель (107), которая наряду с основной онтологической моделью может использоваться модулем извлечения информации. Скомпилированная пользовательская онтологическая модель может включать структуры пользовательских экземпляров и структуры пользовательских концептов, которые хранятся в памяти и дают информацию о созданных пользовательских экземплярах и пользовательских концептах. Структура пользовательского экземпляра и структура пользовательского концепта создаются на основе определения пользовательской онтологии (101). Каждый из созданных пользовательских экземпляров и пользовательских концептов может иметь уникальные идентификаторы. Скомпилированной пользовательской онтологической модели (107) может быть присвоено имя, с помощью которого может осуществляться обращение к данной онтологической модели. В одном из аспектов основная и пользовательская онтологические модели формируют расширенную онтологическую модель, однако основная онтологическая модель может использоваться независимо от пользовательской онтологической модели.
[0052] Вернемся к Фиг. 1А и 1В, на которых демонстрируется компиляция описания пользовательской онтологии (101). Формат представления информации пользователем в определении пользовательской онтологии 101 позволяет при введении нового пользовательского онтологического объекта (который в зависимости от целей пользователя может быть как пользовательским экземпляром, так и пользовательским концептом) указать, к какому уже существующему концепту основной или пользовательской онтологии (1200) будет отнесен новый онтологический объект, имя данного пользовательского онтологического объекта, а также текстовую строку, из которой данный объект может быть извлечен.
[0053] Ниже представлен один из возможных примеров такого формата. Примеры формата внесения информации в определение пользовательской онтологии (101) носят демонстративный характер и не ограничивают область возможных аспектов. Так, например, запись
Geo: InhabitedLocality, northern_Kachin_IndividualName, northern Kachin
Указывает на то, что необходимо создать пользовательский экземпляр с именем northern_Kachin_IndividualName (северный_Качин_ИндивидуальноеИмя), который является потомком существующего концепта InhabitedLocality (НаселенныйПункт) в рамках основной онтологии Geo (География) (126, Фиг. 1В), где InhabitedLocality - это название концепта в основной онтологии Geo, который включает в себя населенные пункты: города, деревни, поселки, станицы, хутора и т.д. Помимо этого, строка на естественном языке указывает на словосочетание, из которого должен извлекаться пользовательский экземпляр: northern_Kachin_IndividualName - "northern Kachin (северный Качин)". После компиляции (103) данной записи в описании пользовательской онтологии (101), в результате чего создается пользовательский экземпляр northern_Kachin_IndividualName, который является потомком существующего концепта InhabitedLocality в основной онтологии Geo, в тексте «John works in northern Kachin» (Джон работает в северном Качине), объект northern_Kachin_IndividualName на этапе 113 будет извлечен в качестве местоположения.
[0054] Например, пользователь хочет извлечь из текста организацию, известную под названием "Bloomberg", упоминание которой встречается в предложении: "Bloomberg, the global business and financial information and news leader, gives influential decision makers a critical edge by connecting them to a dynamic network of information, people and ideas" (Bloomberg, глобальная организация и лидер в области финансовой информации и новостей, обеспечивает влиятельных лиц, принимающих решения, критической линией, связывающей их в динамическую сеть информации, людей и идей.). Для этого запись в файле, содержащая определение пользовательской онтологии, может быть следующей:
Org: Organization, Bloomberg_IndividualName, "Bloomberg"
Данная запись указывает на то, что необходимо создать пользовательский экземпляр Bloomberg_IndividualName, который должен быть подключен в основную онтологию Org (129, Фиг. 1В), хранящую в себе информацию о всех видах организации, в качестве потомка концепта Organization (Организация), где Organization - это название концепта в основной онтологии Org, который включает в себя долговременные структурированные объединения людей. Строкой на естественном языке, указывающей на текстовое словосочетание, из которого должен извлекаться пользовательский экземпляр, является: "Bloomberg". После компиляции (103) данной записи в определении пользовательской онтологии (101), в исходном предложении объект Bloomberg_IndividualName на этапе 113 будет извлечен в качестве организации.
[0055] В случае если одно и то же наименование может относиться к различным объектам (например, и к персоне и к географическому объекту), необходимо внести в определение пользовательской онтологии (101) все возможные варианты, указав, каким существующим концептам основной онтологии (-ий) принадлежат данные пользовательские экземпляры. Например, пользователь хочет извлечь из текста персону "Takayama". Упоминание персоны "Takayama" встречается в английском предложении "Takayama is a Japanese professional boxer who is the current mini flyweight champion." (Такаяма - японский боксер-профессионал, являющийся действующим чемпионом в минимальной весовой категории.). Соответственно запись в txt-файле может быть следующей:
Be: Person, Takayama_IndividualName, "Takayama"
Данная запись указывает на то, что необходимо создать пользовательский экземпляр с именем Takayama_IndividualName (Такаяма_ИндивидуальноеИмя), который должен быть подключен в основную онтологию Basic Entity (Основная Сущность) (121, Фиг. 1В), хранящую в себе информацию об основных сущностях, в качестве потомка концепта Person (Персона) (который включает в себя персоны) в основной онтологии BasicEntity (ОсновнаяСущность). Строкой на естественном языке, указывающей на текстовое словосочетание, из которого должен извлекаться данный пользовательский объект, является: "Takayama". После компиляции (103) данной записи в определении пользовательской модели (101), в предложении на этапе 113 информационный объект Takayama_IndividualName будет извлечен в качестве персоны.
[0056] Возможна ситуация, в которой помимо персоны, пользователь хочет выделять местоположение "Takayama". Упоминание местоположения "Takayama" встречается в английском предложении "Takayama is a city located in Gifu Prefecture, Japan."(Такаяма - город в Японии, находящийся в префектуре Гифу). Запись в файле описания пользовательской онтологии может быть следующей:
Geo: InhabitedLocality, Takayama_IndividualName, 'Takayama"
Данная запись указывает на то, что необходимо создать пользовательский экземпляр с именем Takayama_IndividualName (Такаяма_ИндивидуальноеИмя) который должен быть включен в основную онтологию Geo Фиг. 1В) в качестве потомка концепта InhabitedLocality (НаселенныйПункт). Строкой на естественном языке, указывающей на текстовое словосочетание, из которого должен извлекаться пользовательский, является: "Takayama". После компиляции (103) данной записи в определении пользовательской модели (101) в предложении объект Takayama_IndividualName на этапе 113 будет извлекаться в качестве местоположения (локации).
[0057] Помимо создания пользовательских экземпляров, которые являются наследниками концептов основной онтологии (1200, Фиг. 1С), пользователь имеет возможность создавать пользовательские концепты, которые являются наследниками концептов основной онтологии. Для этого пользователь во входном файле (101), например, может указать:
Be: Person, Cosmonaut
что означает, что необходимо создать пользовательский концепт Cosmonaut (Космонавт), который является наследником концепта Person (Персона) в основной онтологии Basic Entity (Основная Сущность) (121, Фиг. 1В).
[0058] Согласно настоящим типовым аспектам можно создавать пользовательские экземпляры, которые могут являться не только наследниками существующих концептов основной онтологии, но и наследниками концептов, введенных пользователем (пользовательских концептов). Для этого пользователь может указать следующее:
Concepts: Be, Person, CosmonautInstances: Cosmonaut, Yuri_Gagarin_IndividualName, "Yuri Gagarin"
Данная запись в определении пользовательской онтологии (101) означает, что необходимо создать пользовательский концепт Cosmonaut (Космонавт), который является наследником концепта Person (Персона) в основной онтологии Basic Entity (Основная Сущность) (121, Фиг. 1В). Помимо этого, необходимо создать пользовательский экземпляр Yuri_Gagarin_IndividualName, который является наследником созданного пользовательского концепта Cosmonaut и который может быть извлечен из текстовой строки на естественном языке "Yuri Gagarin". После компиляции (103) данной записи в определении пользовательской онтологии (101) в предложении объект Yuri_Gagarin_IndividualName на этапе 113 будет извлекаться в качестве персоны.
[0059] На Фиг. 1А файл, содержащий определение пользовательской онтологии (101), например, в описанном выше формате, компилируется на этапе (103). Компиляция пользовательской онтологической модели происходит в рамках скомпилированной ранее основной онтологической модели (108). В результате компиляции 103 входного определения пользовательской онтологии (101) создается пользовательская онтологическая модель 107, которая встраивается в существующую основную онтологическую модель 108, и результаты компиляции пользовательской онтологической модели используются для создания пользовательского семантического словаря 105, который встраивается в существующий основной семантический словарь 106. Результатами компиляции 103 определения пользовательской онтологии 101 в составе основной онтологической модели 108 являются хранящиеся в памяти структуры пользовательских экземпляров или структуры пользовательских концептов. У структур пользовательских экземпляров и структур пользовательских концептов есть свои уникальные идентификаторы.
[0060] Согласно одному из типовых аспектов основные онтологии (Фиг. 1В, 121-129) могут быть связаны с элементами универсальной семантической иерархии (СИ) (Фиг. 7, 710). Семантическая иерархия (СИ) образует лексико-семантический словарь, в котором содержится весь лексикон языка, необходимый для анализа и синтеза текста. Семантическая иерархия может быть организована в виде дерева родо-видовых отношений, в узлах которого находятся семантические классы (СК) - универсальные (единые для всех языков) единицы, отражающие определенное концептуальное содержание, и лексические классы (ЛК) - конкретноязыковые единицы, являющиеся потомками определенного семантического класса. Совокупность лексических классов одного семантического класса определяет семантическое поле - лексическое выражение концептуального содержания семантического класса. Наиболее распространенные концепты находятся на верхних уровнях иерархии.
[0061] Лексический класс - это конкретноязыковой потомок некого семантического класса. Лексический класс - это выражение скрытого значения в конкретном языке. Например, лексические классы "male" (мужской) и "female" (женский) являются выражениями семантического класса ANIMAL_BY_SEX (ЖИВОТНЫЕ_ПО_ПОЛУ) конкретного (английского) языка. Сочетание лексических классов, принадлежащих одному и тому же семантическому классу, определяет семантическое поле - лексическое выражение понятийного содержания семантического класса. Один лексический класс - это одно значение слова. Например, так как слово (или, скорее лексема) "key" (ключ) имеет несколько значений, для данного слова может быть создано несколько лексических классов. В один лексический класс входят все слова (или формы слова), различающиеся только грамматически, но семантически идентичные.
[0062] Термин - это сочетание нескольких слов. Термин - это прямой потомок семантического класса. Термин не является идиомой, он не формирует абсолютно новую концепцию. Словосочетание, образующее термин (например, "средняя школа", "интернет-сайт", "унифицированный указатель ресурса"), представляет собой вид ядерного концепта данного термина. Термин - это, как правило, устойчивое словосочетание, выражающее некоторое цельное понятие. Часто термин обозначает более узкое понятие, являющееся видовым по отношению к ядру термина..
[0063] Так, фраза "морская свинка" не имеет ничего общего с обычными свиньями и не обозначает вид свиней. Поэтому фраза "морская свинка" не может являться термином - это, очевидно, идиома. С другой стороны, "чайная роза" и "мускусная роза" означают вид розы и должны классифицироваться как термины, принадлежащие семантическому классу ROSE (РОЗА). Словосочетания, образующие термины, как правило, переводятся с помощью другого аналогичного словосочетания, реже с помощью отдельного лексического класса и еще реже с помощью другого лексического класса (определяется ядром термина). Так, английский термин "advance corporate tax" (1:3081579) переводится на русский язык как "авансовый корпоративный налог" (1:3081580); английский термин "air freight" (1:2776800) переводится на русский язык как "авиагруз" (1:2776797).
[0064] Термин не является лексическим классом. У него нет собственной глубинной или поверхностной модели. Глубинные и поверхностные характеристики термина заимствуются из его ядра. Поэтому все компоненты термина должны описываться в рамках модели ядра данного термина, а ядро термина должно иметь глубинную и поверхностную модель для анализа термина.
[0065] Дочерний семантический класс в семантической иерархии может наследовать большинство свойств своего прямого родителя и всех семантических классов его предков. Например, семантический класс SUBSTANCE (ВЕЩЕСТВО) является дочерним семантическим классом класса ENTITY (СУЩНОСТЬ) и родительским семантическим классом для классов GAS (ГАЗ), LIQUID (ЖИДКОСТЬ), METAL (МЕТАЛЛ), WOOD_MATERIAL (ДРЕВЕСИНА) и т.д.
[0066] Для концепта в основных онтологиях (Фиг. 1В, 121-129) определенный семантический класс из семантической иерархии может быть указан как типичный для данного концепта. Данный семантический класс связывает концепт онтологии с семантической иерархией. Например, концепту InhabitedLocality (НаселенныйПункт) в основной онтологии Geo (Гео) может быть приписан семантический класс из семантической иерархии TOWN_BY_NAME (ГОРОД_ПО_НАЗВАНИЮ).
[0067] На Фиг. 1D иллюстрируется типичный способ создания пользовательского семантического словаря (105) в соответствии с одним из типичных аспектов раскрытия. Как показано на Фиг. 1С, одним из результатов компиляции (103) определения пользовательской онтологии (101), помимо создания пользовательской онтологической модели, является создание определения пользовательского семантического словаря (150), который далее компилируется (152) в рамках основного семантического словаря (106) в пользовательский семантический словарь (105). В одном из типовых аспектов основной и пользовательский семантические словари могут образовывать расширенный семантический словарь, при этом основной семантический словарь может использоваться независимо от пользовательского семантического словаря. Определение пользовательского семантического словаря (150) может включать как минимум одно определение элемента словаря. После компиляции (152) определения (-ний) пользовательского семантического словаря (150) в рамках основного семантического словаря (106) создается пользовательский семантический словарь. Пользовательский семантический словарь включает структуры семантического словаря.
[0068] Например, в процессе создания пользовательского семантического словаря 105, согласно предыдущему примеру, определение пользовательской онтологии 101 содержит запись:
Geo: InhabitedLocality, Takayama_IndividualName, 'Takayama"
Как было упомянуто выше, в данной записи содержится информация о том, что необходимо создать пользовательский экземпляр с именем Takayama_IndividualName, который должен быть включен в основную онтологию Geo (126, Фиг. 1В) в качестве потомка концепта InhabitedLocality. Кроме того, текстовой строкой, из которой может быть извлечен пользовательский экземпляр, является: "Takayama".
[0069] В результате компиляции пользовательского семантического словаря 105 для строк на естественном языке, указывающих на текст, в пределах которого предполагается извлечение пользовательского онтологического объекта (т.е. пользовательский экземпляр), создается пользовательский лексический класс или термин (в данном примере - пользовательский лексический класс "Takayama"), который является наследником семантического класса, отнесенного к родительскому концепту пользовательского экземпляра Takayama_IndividualName в основной онтологии, а именно концепту InhabitedLocality основной онтологии Geo. Так как в приведенном примере концепту InhabitedLocality присвоен семантический класс TOWN_BY_NAME, то пользовательский лексический класс Takayama относится к основному семантическому классу TOWN_BY_NAMΕ.
[0070] Процесс создания пользовательского семантического словаря 105 может выглядеть следующим образом. В компилятор (152) пользовательского семантического словаря (150) вводится следующая информация, содержащаяся в определении пользовательского семантического словаря (то есть по крайней мере одно определение элементов словаря): семантический класс из основного семантического словаря (106), к которому должен быть отнесен пользовательский семантический класс или пользовательский лексический класс или пользовательский термин; синтаксическая парадигма или часть речи; строка текста на естественном языке, указывающая на текст вводимого пользовательского термина или пользовательского лексического класса; идентификатор, который обеспечивает ссылку на созданный в процессе компиляции пользовательской онтологической модели пользовательский онтологический объект (пользовательский экземпляр). Данный идентификатор, присваиваемый пользовательскому экземпляру, затем также используется в процессе извлечения информационных объектов для извлечения пользовательских объектов. Данный идентификатор может хранить информацию, включающую в себя идентификатор пользовательского онтологического объекта в пользовательской онтологической модели, идентификаторы родительских классов и т.д. Хранимая идентификатором информация позволяет использовать пользовательский семантический словарь (105) отдельно от пользовательской онтологической модели (107). Так, пользовательский семантический словарь 105 может быть использован при переводе текста с исходного языка на целевой язык. Например, в компилятор 152 пользовательского семантического словаря может быть введена следующая информация (определение элементов словаря):
TOWN_BY_NAME; Noun; "Takayama"; id_Takayama_IndividualName.
Здесь TOWN_BY_NAME (ГОРОД_ПО_НАЗВАНИЮ) - семантический класс из основного семантического словаря (106), Noun (Существительное) - часть речи или синтаксическая парадигма, "Takayama" - строка текста на естественном языке, указывающая на текст вводимого пользовательского термина или пользовательского лексического класса, id_Takayama_IndividualName (ид_Такаяма_ИндивидуальноеИмя) - идентификатор-ссылка на пользовательский онтологический объект (пользовательский экземпляр), созданный в процессе компиляции пользовательской онтологической модели. Примером формата, в котором представляется информация в определении пользовательского семантического словаря (150) носит показательный характер и не ограничивает область предлагаемых типовых аспектов.
[0071] Компиляция определения пользовательского семантического словаря (150) происходит в рамках уже существующего семантического словаря (106).
[0072] В результате компиляции (152) данной строки в рамках основного семантического словаря (106) создается пользовательский лексический класс "Takayama", который относится к существующему семантическому классу TOWN_BY_NAME.
[0073] Основной семантический словарь может создаваться на основе семантической иерархии (СИ), которая была описана выше. Основной семантический словарь имеет следующую структуру. Основной семантический словарь может содержать перечень идентификаторов семантических классов, лексических классов и терминов. Идентификаторы семантических классов отсылают напрямую к определениям (описаниям) семантических классов, которые также содержатся в основном семантическом словаре. Определение (описание) семантического класса включает перечень родительских семантических классов, дочерних семантических классов, лексических классов или терминов данного семантического класса и могут также содержать дополнительную информацию, такую как свойства семантического класса, диатеза, глубинные позиции и так далее.
[0074] Скомпилированный пользовательский семантический словарь (105) обладает аналогичной структурой. То есть пользовательский семантический словарь также содержит перечень идентификаторов семантических классов, терминов или лексических классов, за тем исключением, что в данный перечень входят как идентификаторы семантических классов, содержащихся в основном семантическом словаря, так и идентификаторы пользовательских семантических классов (либо лексических классов или терминов). Пользовательский семантический или лексический класс закрепляются за определенным семантическим классом в основном семантическом словаре. Помимо этого, пользовательский семантический словарь включает описания пользовательских семантических или лексических классов или терминов. Описание пользовательских семантических классов содержит перечень родительских семантических классов, дочерних терминов или семантических или лексических классов, свойства данного семантического класса, диатезу, глубинную позицию, которая может быть унаследована от родительского семантического класса основного семантического словаря. Идентификаторы семантических классов отсылают к описанию семантического класса как из пользовательского семантического словаря, так и из основного семантического словаря.
[0075] Более того, в пользовательский семантический словарь могут вноситься не только семантические и лексические классы, но и термины. Для создания терминов в пользовательском семантическом словаре проводится семантический анализ строки естественного языка, содержащей текст вводимого пользовательского термина или пользовательского семантического или лексического класса, с использованием основного семантического словаря (106). Например, для (Geo: InhabitedLocality, northern Kachin IndividualName, "northern Kachin") при компиляции пользовательского семантического словаря (105) будет проведен семантический анализ (111) текстовой фразы "northern Kachin" с помощью лишь основного семантического словаря (106).
[0076] В некоторых типовых аспектах пользовательский семантический словарь, в зависимости от информации, предоставленной в определении пользовательской онтологии (см. Фиг 1, 101), также может включать синонимичные слова или фразы. В результате компиляции данного определения создается пользовательская онтологическая модель и определение пользовательского семантического словаря. Синонимичные лексические классы и термины в созданном с использованием данного определения пользовательском семантическом словаре принадлежат одному и тому же специально для этого созданному пользовательскому семантическому классу. Так, определение пользовательской онтологии может содержать несколько записей для одного и того же экземпляра под наименованием RosBusinessConsulting_IndividualName.
Org: Organization, RosBusinessConsulting_IndividualName, "RosBusinessConsulting"
Org: Organization, RosBusinessConsulting_IndividualName, "РБК"
Org: Organization, RosBusinessConsulting_IndividualName, "RBC"
Org: Organization, RosBusinessConsulting_IndividualName, "Russian Business Consulting"
[0077] После компиляции для пользовательской онтологической модели будет создан один экземпляр под наименованием RosBusinessConsulting_IndividualName. Путем ввода следующих данных будет создан семантический словарь:
OGANIZATION_BY_NAME; Noun; "RosBusinessConsulting"; (id_RosBusinessConsulting)
OGANIZATION_BY_NAME; Noun; "PБK"(id_RosBusinessConsulting)
OGANIZATION_BY_NAME; Noun; "RBC"; (id_RosBusinessConsulting)
OGANIZATION_BY_NAME; Noun; "Russian Business Consulting"; (id_RosBusinessConsulting)
[0078] К одному пользовательскому экземпляру RosBusinessConsulting_IndividualName отсылает одна метка или идентификатор id_RosBusinessConsulting. Пользовательский семантический словарь будет содержать несколько пользовательских лексических классов ("RosBusinessConsulting", "РБК", "RBC") и пользовательский термин ("Russian Business Consulting"), которые являются потомками одного пользовательского семантического класса, который в свою очередь является потомком семантического класса (OGANIZATION_BY_NAME) в основном семантическом словаре.
[0079] Описанный выше процесс создания синонимичных слов или фраз в пользовательском семантическом словаре может использоваться в различных сферах обработки естественного языка. Так, он может быть использован в области семантического поиска.
[0080] Как показано на Фиг. 1А, пользовательский семантический словарь (105) вместе с основным семантическим словарем (106) могут впоследствии использоваться в процессе семантико-синтаксического анализа текстовых данных (111). Семантико-синтаксический анализ текстов определенного корпуса (111, Фиг. 1) позволяет получать синтаксические и семантические структуры предложений из корпуса текстов и соотносить их с элементами семантической иерархии (СИ) и онтологии (107, 108), что в свою очередь дает возможность извлекать информацию из анализируемой коллекции (корпуса) текстов 109. Ниже приводится подробное описание процесса семантико-синтаксического анализа.
[0081] После получения семантико-синтаксических структур (208) предложений исходного текста (109) пользовательский семантический словарь вместе с основным семантическим словарем могут использоваться как для работы модуля извлечения информации (113), так и для перевода текстов (109) с одного (исходного) естественного языка на другой (целевой) язык.
[0082] На Фиг. 3 иллюстрируется типовой способ использования пользовательской онтологической модели в соответствии с одним из типовых аспектов. Как показано на блок-схеме, пользовательская онтологическая модель создается с использованием только основного семантического словаря (106) и основной онтологической модели (108) соответственно после завершения первого этапа семантико-синтаксического анализа (303) и извлечения информации (305). Результаты работы модуля извлечения могут быть неточными, о чем свидетельствует тот факт, что из текста (307) извлекаются не все объекты. После этого пользователь создает описание пользовательской онтологии (309), на основе компиляции (311) которой создается пользовательская онтологическая модель (314) и пользовательский семантический словарь (313), которые включаются в основную онтологическую модель (108) и основной семантический словарь (106). Семантико-синтаксический анализ (103) с помощью пользовательского семантического словаря (313) и онтологический анализ (305) с помощью расширенной онтологической модели (108, 314) становятся более точными. На этапе 305 извлекаются объекты, которые не были извлечены ранее.
[0083] Семантико-синтаксический анализ (Фиг. 1А, 111) может проводиться по каждому предложению документа, текста или корпуса пользовательских текстов (109). Семантико-синтаксический анализ осуществляется с использованием пользовательского семантического словаря (105), скомпилированного на этапе 152 и включенного в существующий семантический словарь (106) системы. Вход 109 системы может получать не только тесты в редактируемом формате, но и их изображения, полученные путем сканирования или фотографии. Тогда добавляется дополнительный этап предварительного преобразования полученных изображений в текстовый формат, например, с помощью технологии оптического (интеллектуального) распознавания символов (OCR/ICR). Еще один дополнительный этап добавляется в случае работы с речевыми или аудиофайлами - этап распознавания речи.
[0084] На Фиг. 2 приводится общая схема способа глубинного синтаксического и семантического анализа (Фиг. 1А, 111) текстов на естественном языке 109 на основе лингвистических описаний. Более подробно данный способ описывается в патенте США 8,078,450 и полностью включается в настоящее раскрытие путем ссылки. Данный способ основан на использовании широкого набора лингвистических описаний в качестве универсальных семантических механизмов. В основе данных способов анализа лежат принципы всестороннего и нацеленного распознавания, т.е. гипотезы в отношении структуры части предложения проверяются в контексте проверки гипотезы в отношении структуры всего предложения. Это позволяет избегать необходимости анализировать большое число вариантов.
[0085] Глубинный анализ включает лексико-морфологический, синтаксический и семантический анализ каждого предложения корпуса текстов и ведет к построению независимых от языка семантических структур, каждое слово текста в которых относится к соответствующему семантическому классу (СК) из универсальной семантической иерархии (СИ). Следует отметить, что пользовательский семантический словарь вместе с основным семантическим словарем (Фиг. 2, 105) используются на всех вышеупомянутых этапах анализа предложения (205, 206).
[0086] Исходные предложения в тексте/коллекции текстов (109) подвергаются семантико-синтаксическому анализу 205 с использованием лингвистических описаний, как исходного языка, так и универсальных семантических описаний, что позволяет анализировать не только поверхностную синтаксическую структуру, но и распознавать глубинную, семантическую структуру, выражающую смысл высказывания, содержащегося в каждом предложении, а также связи между предложениями или фрагментами текста. Лингвистические описания могут включать лексические 203, морфологические 201, синтаксические 202 и семантические описания 204. Анализ 205 включает синтаксический анализ, выполняемый в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа) с использованием лингвистических моделей и информации различных уровней для вычисления вероятностей и генерации множества синтаксических структур. Как следствие, на этапе 206 осуществляется построение семантико-синтаксической структуры (208). Пользовательский семантический словарь используется вместе с основным семантическим словарем на этапе глубинного анализа предложения (205) и на этапе построения семантико-синтаксических структур (деревьев) предложения (206), при этом такие семантико-синтаксические деревья содержат множество узлов.
[0087] Глубинный анализ (Фиг. 1А, 111) текста или коллекции текстов (109) начинается с установления морфологических значений слов предложения. Предложение разбирается на лексические элементы, после чего определяются их потенциальные леммы (исходные или окончательные формы), а также соответствующие варианты грамматических значений. Обычно для каждого элемента устанавливается множество вариантов, имеющее место ввиду омонимии и совпадения словоформ с различными грамматическими значениями.
[0088] Затем устанавливаются лексические значения элементов предложения. Большинство систем автоматической обработки текстов на естественном языке основаны на статистическом подходе, и, как правило, в качестве наиболее вероятного выбирается наиболее частый лексический вариант либо наиболее подходящий по результатам предварительного обучения по корпусу текста с учетом контекста. Лексический выбор в рамках способа согласно настоящим типовым аспектам осуществляется с учетом многих факторов - применимость синтаксических моделей каждого из возможных лексических значений в данном предложении, прагматические характеристики каждого лексического значения, прагматические характеристики контекста, темы текста и корпуса в целом, априорные и статистические оценки как лексических значений, так и поверхностных и глубинных позиций.
[0089] В общем смысле лексическому выбору предшествует синтаксический анализ. Это предполагает инициализацию синтаксических моделей одного или более потенциальных лексических значений конкретного слова и установление всех потенциальных поверхностных позиций в предложении, что отражается в построении структуры данных, известной как граф обобщенных составляющих. Далее из графа обобщенных составляющих формируется как минимум одна структура данных, выступающая в роли структуры синтаксического дерева предложения. Также устанавливаются необходимые недревесные связи. Описание данного процесса приведено в Патенте США 8,078,450 и полностью включается в настоящее раскрытие путем ссылки. В общем смысле ввиду, прежде всего, наличия различных вариантов лексического выбора, а также возможности использования различных моделей формируется несколько таких структур. Каждому варианту синтаксической структуры дается собственная оценка, организация структур осуществляется в порядке от наиболее вероятных до наименее вероятных.
[0090] Возможен условно-вероятностный лексический выбор как один вариант, в котором могут сначала рассматриваться различные гипотезы в отношении лексических значений, а затем каждой гипотезе будет присвоена определенная степень вероятности, и данные несколько вариантов будут выдаваться параллельно следующему этапу.
[0091] Далее определяются семантические значения элементов предложения. Каждое лексическое значение соотносится со своим семантическим классом, а также группой семантических и дифференциальных лексических и грамматических свойств. На основе каждой синтаксической структуры предложения выстраивается структура данных, известная как семантическая структура предложения. В одном из типовых аспектов семантическая структура предложения сначала строится для лучшей гипотезы (с наивысшей интегральной оценкой). Как правило, семантическая структура предложения - это графовая структура с отчетливой вершиной. В узлах данной структуры находятся семантические значения, а ее ветви формируют основополагающие семантические отношения.
[0092] Также используется пользовательский семантический словарь. Как было описано выше, исходное предложение текста может быть поделено на определенное число лексем, элементов или единиц, включая все присутствующие в исходном предложении слова, пробелы, разделители, знаки пунктуации и т.д., и использовано для построения лексической структуры предложения. Лексема - это значимая лингвистическая единица, являющаяся также элементом лексикона, таким как лексические описания 103 языка. К каждой единице в поделенном предложении применяется морфологический модуль (с морфологическими описаниями). Данный морфологический модуль может определять все известные системе единицы (или слова). Если единица (слово) известна системе, для начальной формы данной единицы (или слова) устанавливается лексема.
[0093] Если единица (слово) не известна морфологическому модулю и отсутствует в основном семантическом словаре (например, данное слово было внесено в систему пользователем в определении пользовательской онтологии (101)), то проводится процедура псевдолемматизации. Процедура псевдолемматизации может проводиться любым общеизвестным способом. Процедура псевдолемматизации подразумевает разделение единицы (слова) на возможные леммы и генерирование возможных вариантов словоизменения. Если один из таких сгенерированных вариантов словоизменения совпадает со строкой естественного языка в исходном тексте предложения, данная единица (слово) в предложении относится к лексическому классу из пользовательского семантического словаря.
[0094] На всех этапах описываемого способа может использоваться широкий набор лингвистических описаний. Ниже подробно описываются группа указанных лингвистических описаний и отдельные этапы данного способа. На Фиг. 4 представлена схема, иллюстрирующая языковые описания (410) согласно одному из типовых аспектов. Языковые описания (410) включают морфологические описания (201), синтаксические описания (202), лексические описания (203) и семантические описания (204), а также отношения между ними. Морфологические описания (201), лексические описания (203), а также синтаксические описания (202) создаются для каждого языка по установленным эталонам. Каждое из этих языковых описаний (410) может создаваться для каждого исходного языка, и все вместе они образуют модель исходного языка. Однако семантические описания (204) носят универсальный характер и используются для описания независимых от языка семантических свойств различных языков и построения независимых от языка семантических структур.
[0095] Лексические (203) и морфологические описания (201) связаны между собой, так как любое лексическое значение в лексическом описании (230) может иметь морфологическую модель, представленную в виде одного или нескольких грамматических значений для указанного лексического значения. Более того, как следует из связи (222), любое лексическое значение в лексических описаниях (203) также может иметь одну или более поверхностных моделей, соответствующих синтаксическим описаниям (202) для данного лексического значения. Как следует из связи (223), лексические описания (203) связаны с семантическими описаниями (204), образуя вместе с ними основной семантический словарь. Ключевой особенностью предлагаемых типовых аспектов является то, что данный основной семантический словарь 106 может быть расширен пользовательским семантическим словарем (105). Расширенный семантический словарь (который содержит как основной словарь (106), так и пользовательский (105) семантический словарь) обеспечивает более высокую точность семантико-синтаксического анализа.
[0096] На Фиг. 5 показаны примеры морфологических описаний (201). Составляющие морфологических описаний (201) включают: изменения формы слов (510), грамматическую структуру (520) (в том числе граммемы), описания словообразования (530) и т.д. Граммемы - это единицы грамматических систем (520). Как следует из связи (522) и связи (524), граммемы могут использоваться для построения описания словоизменения (510) и описания словообразования (530).
[0097] Согласно одному из типовых аспектов для установления синтаксических отношений между элементами исходного предложения используются модели составляющих. Составляющая может содержать группу смежных слов в предложении, функционирующих как единое целое. Ядром составляющей является слово. Оно также может содержать дочерние составляющие на более низких уровнях. Дочерняя составляющая - это зависимая составляющая. Она может прикрепляться к другим составляющим (выступающим в роли родительских компонентов) для построения синтаксического описания (202) исходного предложения.
[0098] На Фиг. 6 приведены примеры синтаксических описаний. Синтаксические описания (202) используются для построения возможных синтаксических структур исходного предложения конкретного исходного языка с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, согласование, эллипсис и т.д.), референциальных отношений и других факторов. Компоненты синтаксических описаний (202) могут включать: поверхностные модели (610), описания поверхностных позиций (620), референциальные описания и описания структурного контроля (630), описания управления и согласования (640), описание недревесного синтаксиса (650) и правила анализа (660). Поверхностные модели (610) представлены в виде множества синтаксических форм (612), описывающих возможные синтаксические структуры предложений, включенных в синтаксическое описание (202). В целом, любое данное лексическое значение языка связано с поверхностными (синтаксическими) моделями (610), которые являются возможными составляющими, в случае если данное лексическое значение играет роль "ядра" и включает множество поверхностных позиций дочерних элементов, описание линейного порядка, диатезу и т.д. Поверхностные модели (610) представлены синтаксическими формами (612). Каждая синтаксическая форма (612) может включать определенное лексическое значение, которое играет роль "ядра", и дополнительно включать множество поверхностных позиций (615) своих дочерних составляющих, описание линейного порядка (616), диатезу (617), грамматические значения (614), описания управления и согласования (640), коммуникативные описания 680 и т.д., связанные с ядром данного компонента. Описания поверхностных позиций (620) в синтаксических описаниях (202) используются для описания общих свойств поверхностных позиций (615), которые используются в поверхностных моделях (610) различных лексических значений в исходном языке. Поверхностные позиции (615) используются для выражения синтаксических отношений между составляющими предложения. Примеры поверхностных позиций (615) могут включать "Subject" (Подлежащее), "Object_Direct" (Дополнение_прямое), "Object_Indirect" (Дополнение_Косвенное), "Relative Clause" (Определительное придаточное предложение) и т.д.
[0099] Во ходе синтаксического анализа модель составляющих использует множество поверхностных позиций (615) дочерних составляющих и описания их линейного порядка (616) и описывает грамматические значения (614) возможных заполнителей данных поверхностных позиций (615). Диатеза (617) представляет соответствия между поверхностными позициями (415) и глубинными позициями (714) (как показано на Фиг. 7). Коммуникативные описания (680) описывают коммуникативный порядок в предложении.
[00100] Синтаксические формы (612) образуют собой коллекцию поверхностных позиций (615), связанных с описаниями линейного порядка (616). Одна или более составляющих, которые могут быть построены для лексического значения формы слова исходного предложения, могут быть представлены поверхностными синтаксическими моделями, такими как поверхностные модели (610). Каждая составляющая рассматривается как реализация модели составляющих посредством выбора соответствующей синтаксической формы (612). Выбранные синтаксические формы (612) образуют собой множества поверхностных позиций (615) с указанным линейным порядком. Для каждой поверхностной позиции в синтаксической форме могут существовать грамматические и семантические ограничения на ее заполнители.
[00101] Описание линейного порядка (616) представлено в виде выражений линейного порядка, которые строятся для выражения последовательности, в которой различные поверхностные позиции (415) могут встречаться в предложении. Выражения линейного порядка могут включать имена переменных, имена поверхностных позиций, круглые скобки, граммемы, оценки, оператора "или" и т.д. Например, описание линейного порядка для простого предложения "Boys play football" (Мальчики играют в футбол) может быть представлено как "Subject Core Object_Direct" (Существительное Ядро Дополнение_Прямое), где "Subject", "Core" и "Object_Direct" являются именами поверхностных позиций (615), соответствующих порядку слов.
[00102] Различные поверхностные позиции (615) могут находиться в синтаксической форме (612) в отношении строгого и (или) нестрогого порядка.
[00103] Коммуникативные описания (680) описывают порядок слов в синтаксической форме (612) с точки зрения коммуникативных актов, представленных в виде коммуникативных выражений порядка, аналогичных выражениям линейного порядка. Описание управления и согласования (640) содержит правила и ограничения в отношении грамматических значений прикрепленных составляющих, которые используются при синтаксическом анализе.
[00104] Недревесные синтаксические описания (650) могут использоваться при обработке различных языковых явлений, таких как эллипсис и согласование. Они используются при трансформациях синтаксических структур, которые создаются на различных этапах анализа в различных типовых аспектах. Недревесные синтаксические описания (650) включают описание эллипсиса (652), описание согласования (654), а также описание референциального и структурного контроля (630).
[00105] Правила анализа (660) в составе синтаксических описаний (202) могут включать: правила расчета семантем (662) и правила нормализации (664). Несмотря на то что правила анализа (660) используются на данном этапе семантического анализа, правила анализа (660) описывают свойства конкретного языка, будучи связанными с синтаксическими описаниями (202). Правила нормализации (664) используются в качестве правил трансформации для описания трансформаций семантических структур, которые могут отличаться в разных языках.
[00106] На Фиг. 7 приведен пример, иллюстрирующий семантические описания. Компоненты семантических описаний (204) не зависят от языка. Они могут включать: семантическую иерархию (710), описания глубинных позиций (720), систему семантем (730) и прагматические описания (740).
[00107] Каждый семантический класс в семантической иерархии (710) сопровождается глубинной моделью (712). Глубинная модель (712) семантического класса представляет собой группу глубинных позиций (714), которые отражают семантические роли дочерних составляющих в различных предложениях с объектами семантического класса, выступающего в качестве ядра родительской составляющей, и возможных семантических классов, выступающих в качестве заполнителей глубинных позиций. Глубинные позиции (714) выражают семантические отношения, в том числе такие как "агент", "получатель", "инструмент", "количество" и т.д. Дочерний семантический класс наследует и уточняет глубинную модель (712) родительского семантического класса.
[00108] Описания глубинных позиций (720) используются для описания общих свойств глубинных позиций (714) и отражения семантических ролей дочерних составляющих в глубинных моделях (712). Описания глубинных позиций (720) также содержат грамматические и семантические ограничения в отношении заполнителей глубинных позиций (714). Свойства и ограничения глубинных позиций (714) и их возможных заполнителей очень похожи, а зачастую идентичны в различных языках. Таким образом, глубинные позиции (714) не зависят от языка.
[00109] Система семантем (730) представляет собой коллекцию семантических категорий и семантем, представляющих собой значения семантических категорий. В качестве примера, семантическую категорию «DegreeOfComparison» (Степень Сравнения) можно использовать для описания степени сравнения прилагательных, ее семантемами могут быть, например, "Positive" (Положительная), "ComparativeHigherDegree" (Сравнительная степень сравнения), "SuperlativeHighestDegree" (Превосходная степень сравнения) и т.д.
[00110] Система семантем (730) включает независимые от языка семантические свойства, выражающие не только семантические, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы могут использоваться для выражения атомарного значения, которое находит регулярное грамматическое и (или) лексическое выражение в языке. По назначению и использованию система семантем (730) может принимать различные формы, включая: грамматические семантемы (732), лексические семантемы (734) и классифицирующие грамматические (дифференцирующие) семантемы (736).
[00111] Грамматические семантемы (732) используются для описания грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы (734) описывают конкретные свойства объектов (например, "быть плоским" или "являться жидким"). Они используются в описаниях глубинных позиций (720) как ограничение в отношении заполнителей глубинных позиций (например, для глаголов "face (with)" (быть обращенным к) и "flood" (заливать), соответственно). Классифицирующие грамматические (дифференцирующие) семантемы (736) выражают дифференциальные свойства объектов внутри одного семантического класса.
[00112] Прагматическое описание (740) позволяет системе присваивать текстам и объектам семантической иерархии (710) соответствующие тему, стиль или жанр.
[00113] На Фиг. 8 представлен иллюстративный пример лексических описаний. Лексические описания (203) образуют коллекцию лексических значений (812) определенного языка для каждого компонента предложения. Для каждого лексического значения (812) может быть установлена связь (802) с его независимым от языка семантическим родителем для указания положения определенного лексического значения в семантической иерархии (710). Аналогичная зависимость устанавливается для каждого вводимого термина в пользовательском семантическом словаре, а именно: каждому термину пользовательского семантического словаря 105 присваивается семантический класс из семантической иерархии.
[00114] Каждое лексическое значение (812) связано со собственной глубинной моделью (712), описанной независимыми от языка терминами, и с зависимой от языка поверхностной моделью (610). Диатеза может использоваться в качестве границы раздела между поверхностными моделями (610) и глубинными моделями (712) для каждого лексического значения (612). Каждая поверхностная позиция (615) в каждой синтаксической форме (612) поверхностной модели (610) может быть соотнесена с одной или несколькими диатезами (617).
[00115] В то время как поверхностная модель (610) описывает синтаксические роли заполнителей поверхностных позиций, глубинная модель (712) обычно описывает их семантические роли. Описание глубинной позиции (720) выражает семантический тип возможного заполнителя и отражает реальные аспекты ситуаций, свойства или атрибуты объектов, обозначенных словами любого данного естественного языка. Каждое описание глубинной позиции (720) не зависит от языка, поскольку в различных языках для описания подобных семантических отношений или выражения подобных аспектов ситуаций используется одна и та же глубинная позиция, а заполнители глубинных позиций (714) обычно обладают одними и теми же семантическими свойствами даже в разных языках. Каждое лексическое значение (812) лексического описания языка наследует семантический класс своего родителя и уточняет его глубинную модель (712).
[00116] Кроме того, лексические значения (812) могут содержать свои собственные характеристики, также они могут наследовать другие характеристики от родительского семантического класса. Эти характеристики лексических значений (812) включают грамматические значения (808), которые могут выражаться в виде граммем, и семантическое значение (810), которое может выражаться в виде семантем.
[00117] Каждая поверхностная модель (610) лексического значения включает одну или несколько синтаксических форм (612). Каждая синтаксическая форма (612) поверхностной модели (610) может включать одну или несколько поверхностных позиций (615) со своими описаниями линейного порядка (616), одно или несколько грамматических значений (614), выраженных в виде набора грамматических характеристик (граммем), одно или несколько семантических ограничений на заполнители поверхностных позиций и одну или несколько диатез (617). Семантические ограничения на заполнитель поверхностной позиции представляют собой набор семантических классов, объекты которых могут заполнить эту поверхностную позицию. Диатезы (617) являются частью отношений (424) между синтаксическими описаниями (202) и семантическими описаниями (204), они отражают соответствия между поверхностными позициями (615) и глубинными позициями (714) глубинной модели (712).
[00118] Для определения лексических значений каждое предложение на исходном языке подвергается разбору в соответствии с технологией семантико-синтаксического анализа, подробное описание которой приведено в патенте США №8,078,450, включенном в настоящий документ посредством ссылки. В этой технологии используются все указанные лингвистические описания (210), в том числе морфологические описания (201), лексические описания (203), синтаксические описания (202) и семантические описания (204).
[00119] На Фиг. 9 показаны этапы этого метода, включающего последовательность структур данных, которые строятся в процессе анализа. Пользовательский семантический словарь наряду с основным семантическим словарем используется на всех этапах проведения анализа предложения (910, 920, 930, 936, Фиг. 9). Предварительно исходное предложение 200 на исходном языке подвергается лексико-морфологическому анализу 910 для построения лексико-морфологической структуры (912) исходного предложения. Лексико-морфологический анализ проводится с использованием как основного семантического словаря, так и пользовательского семантического словаря. Лексико-морфологическая структура (912) представляет собой набор всех возможных пар «лексическое значение - грамматическое значение» для каждого лексического элемента (слова) в предложении.
[00120] Затем проводится первый этап синтаксического анализа на лексико-морфологической структуре - грубый синтаксический анализ (920) исходного предложения для построения графа обобщенных составляющих (922). В процессе грубого синтаксического анализа (920) к каждому элементу лексико-морфологической структуры (912) применяются все возможные синтаксические модели возможных лексических значений, они проверяются для того, чтобы найти все потенциальные синтаксические связи в этом предложении, которые отражаются в графе обобщенных составляющих (922).
[00121] Граф обобщенных составляющих (922) представляет собой ациклический граф, узлами котором являются обобщенные (это означает, что они хранят все варианты) лексические значения слов в предложении, а ветви - это поверхностные (синтаксические) позиции, выражающие различные типы отношений между обобщенными лексическими значениями. Все возможные поверхностные синтаксические модели проверяются для каждого элемента лексико-морфологической структуры предложения в качестве потенциального ядра составляющих. Затем строятся все возможные составляющие и обобщаются в графе обобщенных составляющих (922). Соответственно, рассматриваются все возможные синтаксические модели и синтаксические структуры исходного предложения (200), и в результате на основе набора обобщенных составляющих строится граф обобщенных составляющих (922). Граф обобщенных составляющих (922) на уровне поверхностной модели отражает все потенциальные связи между словами исходного предложения (200). Поскольку количество вариаций синтаксического разбора в общем случае может оказаться большим, граф обобщенных составляющих (922) является избыточным, он имеет большое число вариаций как в отношении выбора лексического значения для вершины, так и в отношении выбора поверхностных позиций для ветвей графа.
[00122] Для каждой пары «лексическое значение - грамматическое значение» инициализируется его поверхностная модель, другие составляющие слева и справа добавляются в поверхностные позиции (615) синтформы (синтаксической формы) (612) ее поверхностной модели (610) и соседних составляющих. Синтаксические описания показаны на Фиг. 6. Если соответствующая синтаксическая форма найдена в поверхностной модели (610) для соответствующего лексического значения, то выбранное лексическое значение может использоваться в качестве ядра нового компонента.
[00123] Граф обобщенных составляющих (922) изначально строится в виде дерева, начиная с листьев и перемещаясь в сторону корня (снизу вверх). Дополнительные компоненты получаются снизу вверх путем добавления дочерних компонентов к родительским составляющим, они заполняют поверхностные позиции (615) родительских составляющих для того, чтобы охватить все первоначальные лексические единицы исходного предложения (9).
[00124] Как правило, корень дерева, который является главной вершиной графа (922), представляет собой предикат. В ходе этого процесса дерево обычно становится графом, поскольку составляющие более низкого уровня могут включаться в несколько составляющих более высокого уровня. Несколько составляющих, построенных для одних и тех же элементов лексико-морфологической структуры, в дальнейшем могут быть обобщены для получения обобщенных составляющих. Составляющие обобщаются на основе лексических значений или грамматических значений (614), например, основанных на частях речи и отношениях между ними.
[00125] Точный синтаксический анализ (930) выполняется для выделения синтаксического дерева (932) из графа обобщенных составляющих (922). Строится одно синтаксическое дерево или несколько синтаксических деревьев, и для каждого из них вычисляется общая оценка на основе использования множества априорных и вычисляемых оценок, затем дерево с наилучшей оценкой выбирается для построения наилучшей синтаксической структуры (946) исходного предложения.
[00126] Синтаксические деревья формируются в процессе выдвижения и проверки гипотез о возможной синтаксической структуре предложения, в этом процессе гипотезы о структуре частей предложения формируются в рамках гипотезы о структуре всего предложения.
[00127] В процессе перехода от выбранного синтаксического дерева к синтаксической структуре (936) устанавливаются недревесные связи. Если недревесные связи не могут быть установлены, то выбирается синтаксическое дерево, имеющее следующий самый высокий рейтинг, и производится попытка установить недревесные связи в нем. Результатом точного анализа (930) является улучшенная синтаксическая структура (946) анализируемого предложения. Фактически в результате выбора наилучшей синтаксической структуры (936) также производится лексический выбор, т.е. определение лексических значений элементов предложения.
[00128] Далее производится построение независимой от языка структуры (206 Фиг. 9, 206 Фиг. 2), которая отражает смысл предложения на основе универсальных, не зависимых от языка понятий. Независимая от языка семантическая структура предложения (206) представляется в виде ациклического графа (деревьев, дополненных недревесными связями), причем все слова на конкретном языке заменяются универсальными (независимыми от языка) семантическими сущностями, называемыми в этом документе «семантическими классами». Этот переход осуществляется с помощью семантических описаний (204) и правил анализа (660), в результате получается структура в виде графа с главной вершиной, в котором узлы представляют собой семантические классы, сопровождающиеся наборами атрибутов (атрибуты выражают лексические, синтаксические и семантические свойства конкретных слов исходного предложения), а ветви представляют глубинные (семантические) отношения между теми словами (узлами), которые они соединяют.
[00129] Вернемся к Фиг. 1А, на шаге 113 процессор осуществляет извлечение информации из текстовых данных на основе использования основной онтологической модели 108, расширенной с помощью пользовательской онтологической модели 107. Задачей извлечения информации является автоматизированное машинное извлечение информации (сущностей, фактов) на основе обработки неструктурированных электронных документов (текстов или массивов текстов 109). В данном изобретении модуль извлечения информации 113 реализует способ, основанный на использовании результатов глубинного семантико-синтаксического анализа (111, Фиг. 1, Фиг. 2, Фиг. 9), результатом которого является создание множества семантико-синтаксических деревьев (208), а также на использовании онтологических правил 131 (правил извлечения информации), создаваемых вручную. Онтологические правила (131) основной онтологической модели (Фиг. 1А, 108) описывают, как сущности и факты выражаются в текстах.
[00130] Использование результатов предварительного семантико-синтаксического анализа текстов 111 (Фиг. 9) позволяет создавать и использовать онтологические правила 131 непосредственно на структурированных данных, а именно: в глубинных (семантических) структурах деревьев с учетом лексических, синтаксических и семантических атрибутов, полученных на предыдущем этапе 111 во время предварительного семантико-синтаксического разбора.
[00131] Так на шаге 113 (Фиг. 1А) модуль извлечения информации получает на вход семантико-синтаксические деревья (Фиг. 2, Фиг. 9, 208), полученные в результате работы парсера 111. Семантико-синтаксические деревья включают множество соединенных узлов. Узлы семантико-синтаксических деревьев соответствуют словам предложения и содержат информацию о соответствующем конкретном лексическом классе из семантического словаря. Помимо того, узлы также содержат грамматическую и семантическую информацию о языке (наборы граммем и семантем), которая характеризует конкретное применение соответствующего слова в контексте предложения. Дуги семантико-синтаксических деревьев представляют глубинные позиции (т.е. семантические роли зависимого слова, например "агент") и поверхностные позиции (т.е. синтаксические функции зависимого слова, например $Subject (подлежащее)). При проведении семантико-синтаксического анализа предложения помимо основного семантического словаря 106 используется пользовательский словарь 105. Узлы семантико-синтаксического дерева могут содержать идентификатор пользовательского экземпляра из сформированной онтологической модели или ссылку на структуру (например, лексические или семантические классы), включающую идентификатор пользовательского экземпляра структуры. Идентификатор используется для извлечения сущностей, основанных на пользовательском экземпляре в пользовательской онтологической модели.
[00132] Семантико-синтаксические деревья могут быть дополнительно обработаны. Например, может быть осуществлена обработка эллипсиса, добавление недревесных связей от сочиненных составляющих и т.д. К результатам предобработки семантико-синтаксического разбора применяется набор правил извлечения информации (онтологических правил), упорядоченных и сгруппированных в момент компиляции описания предметной области (расширенной онтологической модели) на основании информации о зависимостях между правилами. В результате работы модуля извлечения информации строится ориентированный граф, узлы которого представляют собой информационные объекты различных классов, а ребра описывают связи между информационными объектами.
[00133] Семантико-синтаксические деревья обрабатываются модулем извлечения информации 113. Правила извлечения (онтологические правила) применяются к семантико-синтаксическим деревьям для извлечения информации. Правила извлечения информации создаются вручную. Каждое семантико-синтаксическое дерево анализируется с целью выявления поддерева или фрагмента семантико-синтаксического дерева, соответствующих шаблону узлов в правилах извлечения информации.
[00134] Интерпретация правил извлечения информации: левая сторона (сторона условий) правила в системе может содержать так называемые "объектные условия", которые предполагают, что для успешного применения правила определенному узлу разбора в дереве назначен информационный объект определенного типа. Если такой объект обнаружен, к нему можно получить доступ и изменить его при применении правой стороны правила.
[00135] Правила извлечения информации позволяют определять свойства извлеченных информационных объектов и значение этих свойств.
[00136] Предполагается, что информационным объектам присущи некоторые свойства. Свойства информационного объекта могут быть заданы, например, с помощью триплета <s,p,o>, в котором s обозначает уникальный идентификатор объекта, p - идентификатор свойства (предикат), о - значение простого типа (строка, число и т.п.).
[00137] Информационные объекты могут быть связаны друг с другом с помощью объектных свойств или связей. Объектное свойство задается с помощью тройки "объект-свойство-значение",<s,p,õ>, где s - уникальный идентификатор объекта, p - идентификатор отношения (предикат), õ - уникальный идентификатор другого объекта.
[00138] Извлеченная из текста информация может быть представлена в соответствии с концепцией RDF (Resource Definition Framework). Как уже было уже упомянуто ранее, в процессе извлечения информации используется система онтологических правил. Данные декларативные правила представляют собой некие шаблоны, сопоставление которых с фрагментами семантико-синтаксического дерева порождает извлеченные информационные объекты и элементы информационного RDF графа.
[00139] Порожденный модулем извлечения информации RDF-граф согласован с формальным описанием предметной области, или онтологиями. Преимуществом данного метода является использование расширенной онтологической модели (впоследствии скомпилированной с правилами извлечения информации в онтологическую модель), которая включает в себя помимо основной онтологической модели (108) пользовательские онтологические модели(107), хранящие в себе описание специфичной для пользователя предметной области. Информация, хранящаяся в расширенной онтологической модели совместно с правилами извлечения информации, позволяет извлекать такие объекты, которые бы без использования пользовательских онтологий не выделялись, или выделялись бы лишь частично (в случае многословных объектов, например «Kaiser Permanente»), либо выделялись бы, но уже в виде других объектов.
[00140] Создание пользовательской онтологической модели и пользовательского семантического словаря в первую очередь помогает избежать тех случаев, когда сущность извлекается из текста неверно. Например, в предложении "Bloomberg, the global business and financial information and news leader, gives influential decision makers a critical edge by connecting them to a dynamic network of information, people and ideas" (Bloomberg, глобальная организация и лидер в области финансовой информации и новостей, обеспечивает влиятельных лиц, принимающих решения, критической линией, связывающей их в динамическую сеть информации, людей и идей.) по результатам работы семантико-синтаксического анализа 111 (без использования пользовательского семантического словаря) и модуля извлечения информации (без использования пользовательских онтологических моделей) сущность "Bloomberg" может выделиться в качестве персоны, что не является верным с точки зрения знания о том, что "Bloomberg" является организацией. Поэтому после внесения в пользовательскую онтологическую модель соответствующего пользовательского экземпляра с указанием на то, что данный пользовательский экземпляр «Bloomberg» должен являться потомком концепта Organization (Org: Organization, Bloomberg_IndividualName, "Bloomberg"), в указанном предложении "Bloomberg" выделится как организация.
[00141] Анализ без использования пользовательского семантического словаря в семантико-синтаксическом анализе и пользовательской онтологической модели не позволяет извлекать сущности из текстовых данных с достаточной точностью. Рассмотрим пример частичного выделения объекта в тексте. В предложении «The adjuster, working for Colonial Claims on behalf of Fidelity National Indemnity Insurance, estimated that the work on the floor joists would cost a mere $425, compared with the $2,927 projected by the contractor hired by the homeowners» ("Регулятор, работающий на Colonial Claims от имени Fidelity National Indemnity Insurance, оценил, что работа над балками пола будет стоить $ 425, по сравнению с $ 2927, прогнозируемыми подрядчиком, нанятым домовладельцами") по результатам работы семантико-синтаксического анализа (без использования пользовательского семантического словаря) и модуля извлечения информации при помощи онтологический правил (без использования пользовательских онтологических моделей) выделяется организация Fidelity National вместо Fidelity National Indemnity Insurance.
[00142] После того, как пользователь создаст пользовательскую онтологическую модель, внося в список 101 запись вида
Org: Organization, Fidelity_National_Indemnity_Insurance_IndividualName, Fidelity National Indemnity Insurance
пользовательская организация в указанном выше предложении будет выделена полностью: Fidelity National Indemnity Insurance.
[00143] При анализе предложения "Takayama does a part-time job for IBM", при анализе без использования пользовательской онтологической модели и пользовательского словаря сущность "Takayama" не была извлечена. А именно в результате проведения глубинного семантико-синтаксического анализа (111), описанного выше, без использования пользовательского семантического словаря была получена следующая семантико-синтаксическая структура для первого предложения, показанная на Фиг. 10А. На Фиг. 10А видно, что "Takayama" приписан семантический класс UNKNOWN_SUBSTUNTIVE (1001). Т.е. в результате работы модуля извлечения информации 113, который получил на вход семантико-синтаксическую структуру (Фиг. 10А), без использования пользовательских онтологических моделей сущность "Takayama" не была извлечена. На Фиг. 11А, 11Б представлены результаты работы модуля извлечения информации для предложения "Takayama does a part-time job for IBM". Была извлечена только сущность «IBM» (1101, 1102).
[00144] На Фиг. 10А и 10В, слова, начинающиеся со знака доллара ($Verb (глагол), $Subject (подлежащее), и т.д.) представляют поверхностные позиции. Слова, следующие за поверхностными позициями (Predicate, Agent, BeneMalefactive, и т.д.), представляют глубинные позиции.
[00145] На Фиг. 10В представлена структура семантико-синтаксического дерева, полученная в результате анализа с использованием пользовательской онтологической модели 107 и пользовательского семантического словаря 105, скомпилированного на этапе 103. "Takayama" приписан пользовательский лексический класс "Takayama"(1005). На Фиг. 12А, 12В приведены результаты работы модуля извлечения информации на основе использования расширенной онтологической модели, включающей в себя пользовательские онтологические модели. Помимо сущности «IBM» (1102) была извлечена сущность «Takayama» (1201, 1202).
[00146] Помимо указанных выше примеров, использование пользовательских онтологических моделей позволяет избежать омонимичности. Омонимия - это явление в языке, связанное с существованием двух или большего числа разных по значению, но одинаковых по звучанию или написанию слов.
[00147] Если один и тот же текстовый фрагмент может обозначать различные объекты, как например, "Takayama" может быть локацией (например, в предложении His office is located in Takayama) и персоной (в предложении Takayama does a part-time job for IBM), то в рамках представленного примера для задач анализа существует возможность различать данные объекты, то есть завести в описании пользовательской онтологии (101) два объекта разных классов с одинаковым текстовым фрагментом.
Например, если в описание пользовательской онтологии 101 занести только локацию:
Geo: InhabitedLocality, Takayama_IndividualName, "Takayama"
то в предложении "His office is located in Takayama" будет выделена сущность - локация (Takayama).
Для того чтобы сущность "Takayama" выделялась в качестве персоны, пользователю нужно занести в список все омонимичные объекты:
Be: Person, Takayama_IndividualName, "Takayama" Geo: InhabitedLocality,
Takayama_IndividualName, "Takayama"
Тогда в исходном предложении (Takayama does a part-time job for IBM) сущность Takayama будет выделена как персона. Выбор между локацией и персоной происходит на основе контекстного анализа в рамках семантико-синтаксического 111 и онтологического анализа.
[00148] Рассмотрим еще один пример исходного текста, в котором сущность "Arakan" может быть как персоной, организацией, так и локацией: "Takayama works in western Arakan". 113, Если пользователь предварительно описал сущность "Arakan" в описании пользовательской онтологии (101) как:
Geo: InhabitedLocality, Arakan_IndividualName, "Arakan" Org: Organization,
Arakan_IndividualName, "Arakan" Be: Person, Arakan_IndividualName, "Arakan"
То в результате учета контекста при семантико-синтаксическом анализе 111 исходного предложения сущность Arakan выделяется в качестве локации. В данном случае будет происходить конкуренция заведенных семантических классов для каждой сущности, а именно семантических классов Geo: InhabitedLocality, Org: Organization, и Be: Person. В ходе конкуренции в каждом конкретном примере победит только один семантический класс и создастся тот пользовательский экземпляр, который соответствует данному семантическому классу. Выбор семантического класса зависит от контекста и результатов выбора наилучшей семантико-синтаксической структуры, по результатам присвоения различных рейтингов в процессе глубинного анализа, а именно от сочетаемости данных семантических классов и поверхностных позиций.
[00149] На Фиг. 13 приведена схема аппаратного обеспечения (1300), которая может быть использована для внедрения настоящего изобретения. Аппаратное средство (1300) должно включать в себя, по крайней мере, один процессор (1302) соединенный с памятью (1304). Слово "процессор" на схеме (1302) может обозначать один или несколько процессоров с одним или несколькими вычислительными ядрами, вычислительное устройство или любой иной имеющийся на рынке ЦП. Цифрами 1304 обозначается устройство оперативной памяти (RAM), являющееся основным хранилищем, а также дополнительные уровни памяти - кэш, энергонезависимая, резервная память (например, программируемая или флэш-память), ПЗУ и т.д. Кроме того, обозначение памяти (1304) может подразумевать также и хранилище, расположенное в другой части системы (например, кэш процессора (1302) или иное хранилище, используемое в качестве виртуальной памяти, такое как внутреннее или внешнее ПЗУ (1310).
[00150] Аппаратное средство (1300), как правило, располагает некоторым количеством входов и выходов для передачи и получения информации извне. В качестве пользовательского или операторского интерфейса аппаратного средства (1300) может применяться одно или несколько устройств пользовательского ввода (1306), таких как клавиатура, мышь, формирователь изображений и пр., а также одно или несколько устройств вывода (жидкокристаллический дисплей или иное (1308)) и устройства воспроизведения звука (динамик).
[00151] Для получения дополнительного объема для хранения данных используются накопители данных (1310), такие как дискеты или иные съемные диски, жесткие диски, ЗУ прямого доступа (DASD), оптические приводы (компакт-диски и пр.), DVD-приводы, магнитные ленточные накопители и пр. Аппаратное средство (1300) может также включать в себя интерфейс сетевого подключения (1312) - LAN, WAN, Wi-Fi, Интернет и пр. - для связи с другими компьютерами, находящимися в сети. В частности, можно использовать локальную сеть (LAN) или беспроводную сеть Wi-Fi, не подключенную ко всемирной сети Интернет. Необходимо учесть, что аппаратное средство (1300) также включает в себя различные аналоговые и цифровые интерфейсы соединения процессора (1302) и других компонентов системы (1304, 1306, 1308, 1310 и 1312).
[00152] Аппаратное средство (1300) работает под управлением Операционной Системы (ОС) (1314), которая запускает различные приложения, компоненты, программы, объекты, модули, и пр. с целью осуществления описанного здесь процесса. В состав прикладного ПО должно быть включено приложение по выявлению семантической неоднозначности языка. Также могут быть включены клиентский словарь, приложение для автоматизированного перевода и прочие установленные приложения для отображения тестового и графического содержимого (текстовый процессор и пр). Помимо этого приложения, компоненты, программы и иные объекты, собирательно обозначенные числом 1316 на Фиг. 13, могут также запускаться на процессорах других компьютеров, соединенных с аппаратным обеспечением (1300) по сети (1312). В частности, задачи и функции компьютерной программы могут распределяться между компьютерами в распределенной вычислительной среде.
[00153] На Фиг. 14 показан один из примеров системы для создания и использования пользовательской онтологической модели (107, 314) и пользовательского семантического словаря (105, 313) для обработки пользовательского текста (109, 301) на естественном языке. На Фиг. 15 показан пример способа для создания и использования пользовательской онтологической модели (107, 314) и пользовательского семантического словаря (105, 313) для обработки пользовательского текста (109, 301) на естественном языке, как показано на Фиг. 1А и 3.
[00154] Как показано на Фиг. 14 и 15, система (9001) включает входной модуль пользовательской онтологии (9002) для получения от пользователя определений пользовательской онтологии (включая определения пользовательских объектов онтологии, таких как экземпляры и концепты), которые, например, могут быть представлены в виде подготовленного пользователем текстового файла, либо создаваться автоматически на основе данных, собранных из различных источников и (или) введенных пользователем через программу с пользовательским интерфейсом. Определения используются для формирования (или создания) пользовательской онтологической модели (107, 314) и для формирования входных данных для пользовательского семантического словаря (105, 313).
[00155] В одном из примеров реализации данные включают определения пользовательских онтологических объектов в определении пользовательской онтологии (101), например, пользовательских экземпляров онтологических концептов, которые включены, по меньшей мере, в одну существующую основную онтологию. Данные также могут включать определения пользовательских онтологических концептов, являющихся наследниками онтологических концептов в основной онтологии. Помимо этого, данные также могут включать определения пользовательских онтологических концептов, которые наследуются у онтологических концептов в пользовательской отнологии. Определения онтологических объектов (например, пользовательских экземпляров и пользовательских концептов) указывают на концепты, к которым они принадлежат и содержат некоторый идентификатор пользователя, позволяющий уникально определить онтологические объекты пользователя (пользовательские экземпляры и концепты) в рамках онтологической модели. Онтология формирует пространство имен, содержащее идентификаторы онтологических объектов. Определения пользовательских экземпляров также включают строку на естественном языке, выражающую экземпляр, связанную с экземпляром или соответствующую экземпляру. Определения пользовательских экземпляров также могут определять конкретный язык для строки на естественном языке, например, английский или русский.
[00156] В одном из вариантов реализации модуль (9003) формирования (или создания) пользовательской отнологической модели на этапе (8003) создает данные определения (101) и формирует соответствующие структуры пользовательских онтологических объектов в памяти компьютера (1304). Эти структуры могут быть выявлены и найдены с помощью их идентификаторов. Идентификаторы могут быть, например, числовыми, текстовыми, значимыми или произвольными. Их роль заключается в предоставлении уникальной идентификации для структур пользовательских онтологических объектов в рамках онтологии и онтологической модели.
[00157] В одном из вариантов реализации на этапе (8013) ((103) на Фиг 1А и 1С) модуль (9003) формирования пользовательской онтологической модели также формирует файл, содержащий определения пользовательского семантического словаря (150) с определениями пользовательских семантических классов, пользовательских лексических классов и/или пользовательских терминов, соответствующих пользовательским онтологическим объектам в пользовательской онтологической модели (107, 314). Такие определения и такие файлы могут быть также записаны пользователем.
[00158] В одном из вариантов реализации модуль ввода (9004) пользовательского семантического словаря получает на этапе (8004) определения (150, Фиг. 1) пользовательского семантического словаря (включая идентификаторы (маркеры), используемые для идентификации пользовательских онтологических объектов) и передает их в модуль (9005) формирования пользовательского семантического словаря для формирования на этапе (8005) пользовательского семантического словаря (105, 313), содержащего идентификаторы, используемые для определения пользовательских онтологических объектов, на основе чего создаются пользовательские семантические классы, пользовательские лексические классы и пользовательские термины.
[00159] В одном из вариантов реализации модуль анализа текста (9006) на этапе (8006) выполняет анализ представленного пользователем текста в соответствии с описанием на Фиг. 2 и Фиг. 9 с использованием основного семантического словаря и пользовательского семантического словаря. В ходе глубинного анализа используется процесс псевдолемматизации. В частности, процесс псевдолемматизации применяется к неизвестному системе слову (например, слово, изначально введенное в систему путем определения в пользовательской онтологии (101), например, слово "Takayama"). В соответствии с представленным выше описанием процесс псевдолемматизации включает разделение определенной единицы (слова, например "Takayama") на возможные леммы и формирование возможных вариантов словоизменения. Все сформированные возможные варианты форм неизвестного слова сравниваются с исходным текстом до тех пор, пока не будет найдена часть представленного пользователем текста, а форма слова не будет соответствовать форме, представленной в тексте. Если один из сформированных вариантов форм слова соответствует строке на естественном языке в исходном тексте, за этой единицей (словом) закрепляется пользовательский лексический класс из пользовательского семантического словаря.
[00160] В одном из вариантов реализации для этого требуется согласование грамматических и синтаксических требований для всех частей текста. Такие требования могут храниться в пользовательском семантическом словаре (105, 313) или могут быть унаследованы из основного семантического словаря (106). Для обеспечения работы этого механизма унаследования, элементы в пользовательском семантическом словаре (105, 313) содержат идентификатор родительского семантического класса. При наличии нескольких совпадений, при выборе предпочтение отдается совпадениям по элементам из пользовательского семантического словаря. После того, как в результате такого анализа будет выявлена часть текста, модуль (9007) формирования дерева на этапе (8007) формирует узел семантико-синтаксического дерева. Этот узел определяет пользовательский онтологический объект, соответствующий части текста, для которой модуль анализа текста (9006) определил наличие ссылки на пользовательский онтологический объект или наличие ссылки на семантический класс или лексический класс или термин, содержащий ссылку (или идентификатор) на онтологический объект.
[00161] Строка текста, представленная пользователем в определении пользовательского экземпляра имеет лемматизированную или словарную форму (единственное число, именительный падеж и т.д.). При этом, в анализируемом тексте эта текстовая строка может быть представлена в иной морфологической форме. В некоторых вариантах реализации эта не лемматизированная форма может быть найдена в морфологическом словаре, после чего находится лемма для согласования с экземпляром пользовательского словаря. В иных случаях лемматизированная форма строки текста достигается за счет использования морфологических описаний (201); этот процесс называется "псевдолемматизация".
[00162] В одном из вариантов реализации онтологическая модель представлена сочетанием онтологических правил и онтологических объектов. Объект, содержащийся в онтологической модели, может также называться онтологическим объектом. Онтологические правила используются для извлечения информации из семантико-синтаксических деревьев (как показано на Фиг. 10А и 10В). Информация извлекается в виде информационных объектов, которые могут формировать тройки "объект-свойство-значение", в которых объект представлен информационным объектом (например, персоной), имеющим свойство, например, имя, возраст, семейное положение, наличие детей, а значение может быть представлено строкой на естественном языке, например, именем, числом или булевым значением или иным объектом (например, информационный объект, представляющий ребенка персоны). Также возможны иные значения. Поскольку тройка может относиться к другому объекту (например, значению), тройки могут формировать граф, например, RDF-граф (как показано на Фиг. 12В).
[00163] Извлечение информации в одном из вариантов реализации происходит в следующие два этапа.
[00164] На первом этапе из семантико-синтаксического дерева извлекаются информационные объекты, соответствующие пользовательским экземплярам. На этом этапе из семантико-синтаксического дерева, построенного из предложения "Takayama does a part-time job for IBM" извлекается информационный объект, соответствующий пользовательскому экземпляру Takayama_IndividualName. Информационный объект, соответствующий пользовательскому экземпляру Takayama_IndividualName извлекается из семантико-синтаксического дерева (Фиг. 10В) на основе идентификатора, связанного с одним из узлов семантико-синтаксического дерева. Этот идентификатор, в частности, связан с узлом, содержащим пользовательский лексический класс Takayama в семантико-синтаксическом дереве (Фиг. 10В).
[00165] На этом этапе также определяются возможные свойства пользовательского экземпляра. Возможные свойства пользовательского экземпляра могут быть унаследованы из родительского концепта. Например, возможные свойства "фамилия", "имя", "отчество" пользовательского экземпляра Takayama_IndividualName наследуются от родительского концепта Персона. Значение свойства может определяться правилами и фрагментом семантико-синтаксического дерева. Значение свойства пользовательского экземпляра, назначенного соответствующему извлеченному информационному объекту, который соответствует пользовательскому экземпляру, например, Takayama_IndividualName.
[00166] На втором этапе к семантико-синтаксическому дереву применяются правила для извлечения информационных объектов, соответствующих фактам или сущностям. Результаты первого этапа используются на втором этапе. В частности, для извлечения иных информационных объектов могут использоваться информационные объекты, соответствующие пользовательским экземплярам, вместе с правилами. В некоторых случаях информационные объекты, соответствующие пользовательским экземплярам, позволяют извлекать информационные объекты, которые не могут быть извлечены без пользовательских онтологических объектов. Например, на этом этапе из семантико-синтаксического дерева извлекается информационный объект, соответствующий факту рода занятий. Этот информационный объект имеет свойства "работодатель" и "работник", которые заполняются информационным объектом, соответствующим экземпляру, который представляет IBM Corporation, и информационным объектом, соответствующим "пользовательскому экземпляру Takayama_IndividualName, соответственно.
[00167] Если бы пользовательский экземпляр Takayama_IndividualName отсутствовал в пользовательской онтологической модели, семантико-синтаксическое дерево соответствовало бы Фиг. 10А. Слово "Takayama" в этом случае не имеет лексического класса. В этом случае из предложения извлекается только информационный объект, представляющий IBM Corporation. Информационный объект, соответствующий факту рода занятий не извлекается из семантико-синтаксического дерева, построенного на основе предложения, т.к. свойство "заказчик" не будет доступно из семантико-синтаксического дерева.
[00168] В одном из вариантов реализации это семантико-синтаксическое дерево обрабатывается модулем анализа (9008) семантико-синтаксического дерева для определения на этапе (8008) поддерева или фрагмента семантико-синтаксического дерева, который соответствует шаблону узлов с помощью онтологических правил основной онтологической модели (108). Шаблон узлов может содержать узел, ссылающийся на информационный объект, созданные на основе пользовательской онтологической модели (107, 314) и может обеспечивать формирование иных информационных объектов. Этот шаблон узлов позволяет определить значение, которое должно быть назначено свойству информационного объекта, на который ссылается узел, и сформировать на этапе (8009) тройку "объект-свойство-значение" (которая может быть частью RDF-графа) с помощью модуля формирования графа (9009).
[00169] Информационные объекты, соответствующие пользовательским онтологическим объектам, могут использоваться на втором этапе извлечения информации, а именно, на этапе извлечения информации с использованием правил. Это может привести к формированию новых информационных объектов, заполняющих свойства этих новых сформированных информационных объектов информационными объектами, соответствующими пользовательским онтологическим объектам. В этом случае информационные объекты, соответствующие пользовательским онтологическим объектам, могут представлять значение какого-либо свойства второго информационного объекта.
[00170] С другой стороны, свойства информационных объектов, соответствующих пользовательским онтологическим объектам, могут заполняться информационными объектами, сформированными на втором этапе. В этом случае вновь сформированным информационным объектом является информационный объект, соответствующий пользовательскому онтологическому объекту, а также значение его свойства.
[00171] Этот граф представлен для второго модуля обработки естественного языка (9010) для дальнейшей обработки, например, для семантического поиска, машинного перевода или представления пользователю на этапе (8010).
[00172] На Фиг. 16 показана блок-схема по типовому способу создания и использования пользовательской онтологической модели для пользовательского текста. Способ (1601) может выполняться системой (9001) на Фиг. 14. Как показано на этапе (1602), способ (1601) включает получение от пользователя определения онтологического объекта. На этапе (1603) способ (1600) включает формирование пользовательской онтологической модели (107, 314) на основе полученного определения пользовательского онтологического объекта, как показано на Фиг. 1А и 3. Сформированная пользовательская онтологическая модель (107, 314) может включать структуру пользовательского онтологического объекта, содержащую идентификатор пользовательского онтологического объекта. На этапе (1608) способ (1601) включает оценку семантико-синтаксического дерева, сформированного из представленного пользователем текста с использованием пользовательского семантического словаря и основного семантического словаря. Семантико-синтаксическое дерево может включать множество соединенных узлов, из которых, по меньшей мере, один узел включает идентификатор онтологического объекта из пользовательской онтологической модели (107, 314). Например, узел включает пользовательский лексический класс, связанный с пользовательским онтологическим объектом с помощью идентификатора. На этапе (1608) способ (1601) включает анализ семантико-синтаксического дерева для выявления поддерева или фрагмента семантико-синтаксического дерева, соответствующего шаблону узлов, которая может включать, по меньшей мере, один узел с идентификатором пользовательского онтологического объекта из пользовательской онтологической модели (107, 314). Этап анализа (1608) может дополнительно включать использование идентификатора пользовательского онтологического объекта, по меньшей мере, в одном узле для определения по пользовательской онтологической модели (107, 314) свойства пользовательского онтологического объекта и для определения значения свойства с помощью шаблона узлов. На этапе (1609) способ (1601) включает формирование тройки "объект-свойство-значение" для выявленного шаблона узлов. Сформированная тройка "объект-свойство-значение" может включать идентификатор пользовательского онтологического объекта из пользовательской онтологической модели (107, 314), свойство пользовательского онтологического объекта и значение свойства пользовательского онтологического объекта. Сформированная тройка может представлять часть RDF-графа. На этапе (1610) способ (1601) дополнительно включает выполнение вторичной обработки представленного пользователем текста на естественном языке с помощью сформированной тройки "объект-свойство-значение". Извлеченные информационные объекты могут подсвечиваться в исходном тексте или представляться пользователю иным известным способом. На Фиг. 17 показана блок-схема по типовому способу создания и использования пользовательского семантического словаря (105, 313) для обработки пользовательского текста на естественном языке. Способ (1701) может выполняться системой (1400) на Фиг. 14. Как показано, на этапе (1704) способ (1701) включает получение модуля формирования онтологической модели (9002) от пользователя (т.е., от пользовательского компилятора онтологической модели) или определения семантического и/или лексического класса и/или термина, связанного с пользовательским онтологическим объектом, напрямую от пользователя. На этапе (1705) способ (1701) включает формирование пользовательского семантического словаря (105, 313) на основе полученного определения пользовательских семантических классов, пользовательских лексических классов и/или пользовательских терминов, как показано на Фиг. 1А и 3. Сформированный пользовательский семантический словарь (105, 313) может включать: структуру семантического словаря, содержащую идентификатор пользовательского онтологического объекта, или структуру лексического класса или структуру термина или структуру семантического словаря. На этапе (1706) способ (1701) включает анализ текста, описанный выше для элемента (9006) на Фиг. 14. На этапе (1707) способ (1701) включает формирование, по меньшей мере, одного узла семантико-синтаксического дерева. Семантико-синтаксическое дерево может включать множество соединенных узлов, где один узел включает идентификатор пользовательского онтологического объекта из структуры семантического словаря в пользовательском семантическом словаре (105, 313). На этапе (1710) способ дополнительно включает выполнение вторичной обработки представленного пользователем текста на естественном языке с использованием сформированного семантико-синтаксического дерева.
[00173] Все рутинные операции в ходе применения вариантов реализации могут выполняться операционной системой или отдельными приложениями, компонентами, программами, объектами, модулями или последовательными инструкциями, обобщенно именуемыми "компьютерными программами". Обычно компьютерные программы представляют собой ряд инструкций, выполняемых в разное время разными устройствами памяти и хранения данных на компьютере. После прочтения и выполнения инструкций процессоры выполняют операции, необходимые для запуска элементов описанного осуществления. Несколько вариантов реализации было описано в контексте полностью функционирующих компьютеров и компьютерных систем. Специалисты отрасли по достоинству оценят возможности распространения некоторых модификаций в форме различных программных продуктов на любых типах информационных носителей. Примерами таких носителей являются как энергозависимые, так и энергонезависимые устройства памяти, такие как дискеты и другие съемные диски, жесткие диски, оптические диски (напр., CD-ROM, DVD, флэш-диски) и многое другое. Также программный пакет может быть загружен через Интернет.
[00174] В вышеизложенном описании множество конкретных деталей изложено исключительно для пояснения. Специалистам в данной области техники очевидно, что эти конкретные детали являются лишь примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание неоднозначности толкований.
[00175] В различных примерах системы и способы, описанные в этом документе, могут быть реализованы в оборудовании, программах, встроенном программном обеспечении или различных комбинациях этих средств. При реализации в программном обеспечении способы могут храниться в виде одной или нескольких инструкций или кода на энергонезависимом машинно-читаемом носителе. К машинно-читаемым носителям относятся и накопители данных. В качестве примера, но не для введения ограничений, подобные машинно-читаемые носители могут включать RAM, ROM, EEPROM, CD-ROM, флэш-память или другие типы электрических, магнитных или оптических носителей информации, или другие носители, которые могут использоваться для переноса или хранения требуемого программного кода в виде инструкций или структур данных, и доступ к которым может осуществляться процессором компьютера общего назначения.
[00176] Для наглядности в этом документе не приводятся все обычные свойства описываемых примеров. Следует понимать, что при разработке любых реальных реализаций настоящего изобретения для достижения конкретных целей разработчиков необходимо будет предпринимать множество решений по реализации, и что эти конкретные цели могут быть различными для разных реализаций и разных разработчиков. Следует понимать, что разработка может быть сложной и ресурсоемкой задачей, но при этом останется обычной инженерной работой для специалистов среднего уровня, использующих преимущества этого изобретения.
[00177] Кроме того, следует понимать, что используемая в этом документе фразеология или терминология предназначена для описания, но не ограничения, так что терминология или фразеология настоящего описания может быть интерпретирована специалистом среднего уровня с учетом имеющихся в этом документе принципов и инструкций в сочетании со знаниями специалиста соответствующего профиля. Кроме того, не предполагается назначение терминам, используемым в описании или пунктах формулы изобретения, необычного или особого значения, если об этом не сказано особо.
[00178] Различные примеры, приводимые в этом документе, охватывают существующие и будущие известные эквиваленты известных модулей, упомянутых в настоящем документе в качестве иллюстрации. Кроме того, несмотря на приведенные и описываемые примеры и варианты применения, для специалистов данной области техники, использующих преимущества этого изобретения, ясно, что многие модификации, не описанные выше, можно осуществить, не отходя от описанных здесь принципов изобретения.
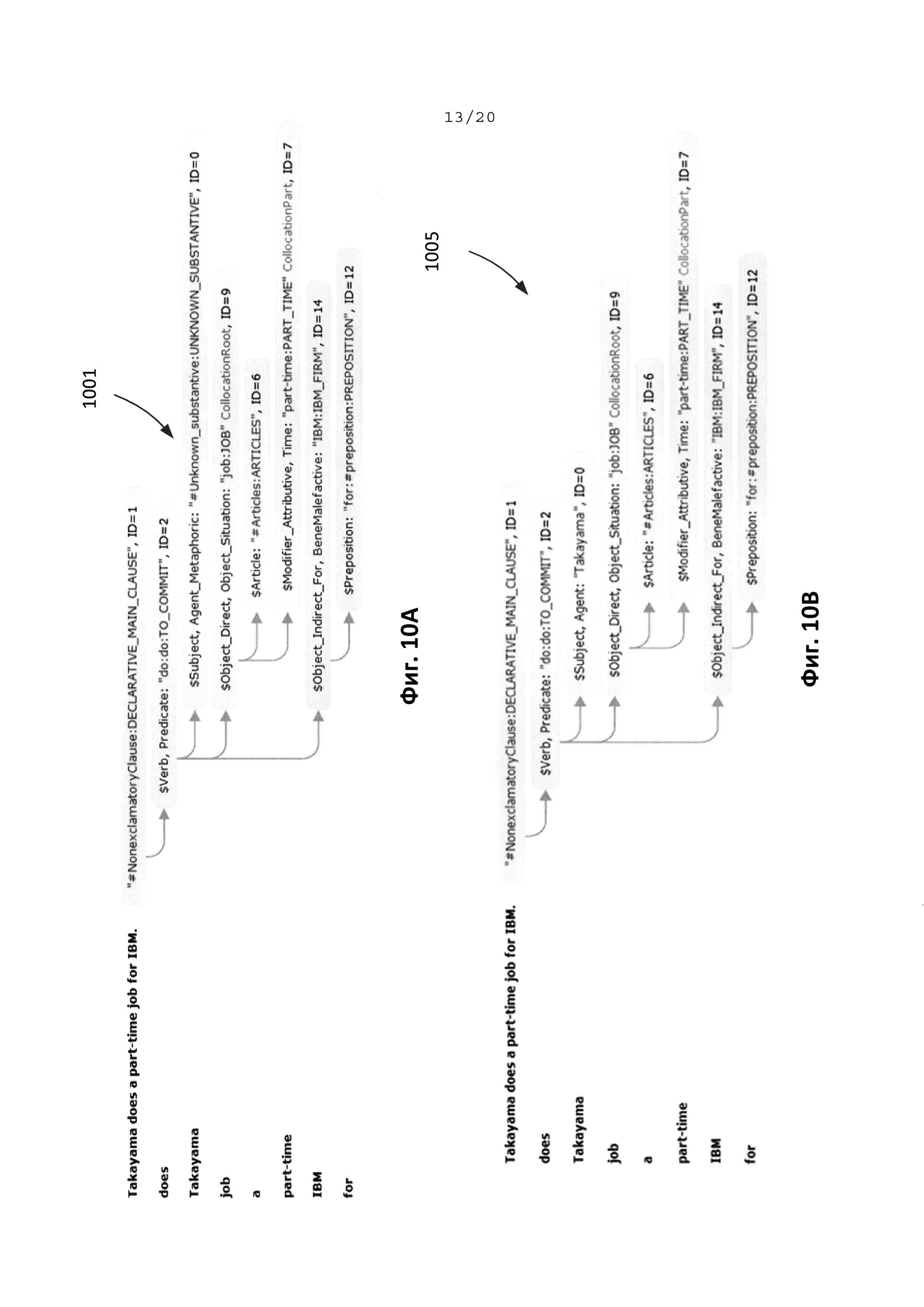
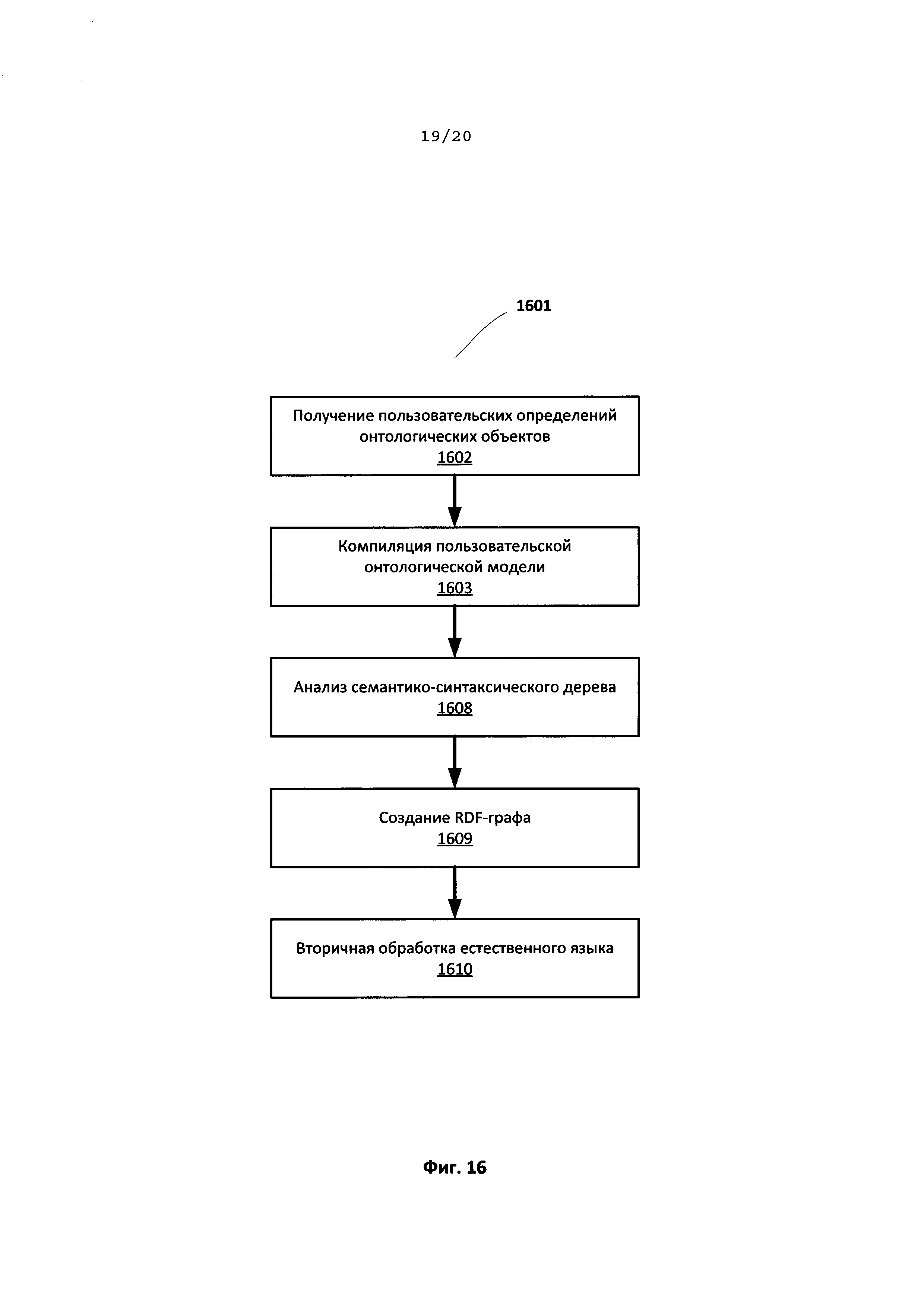
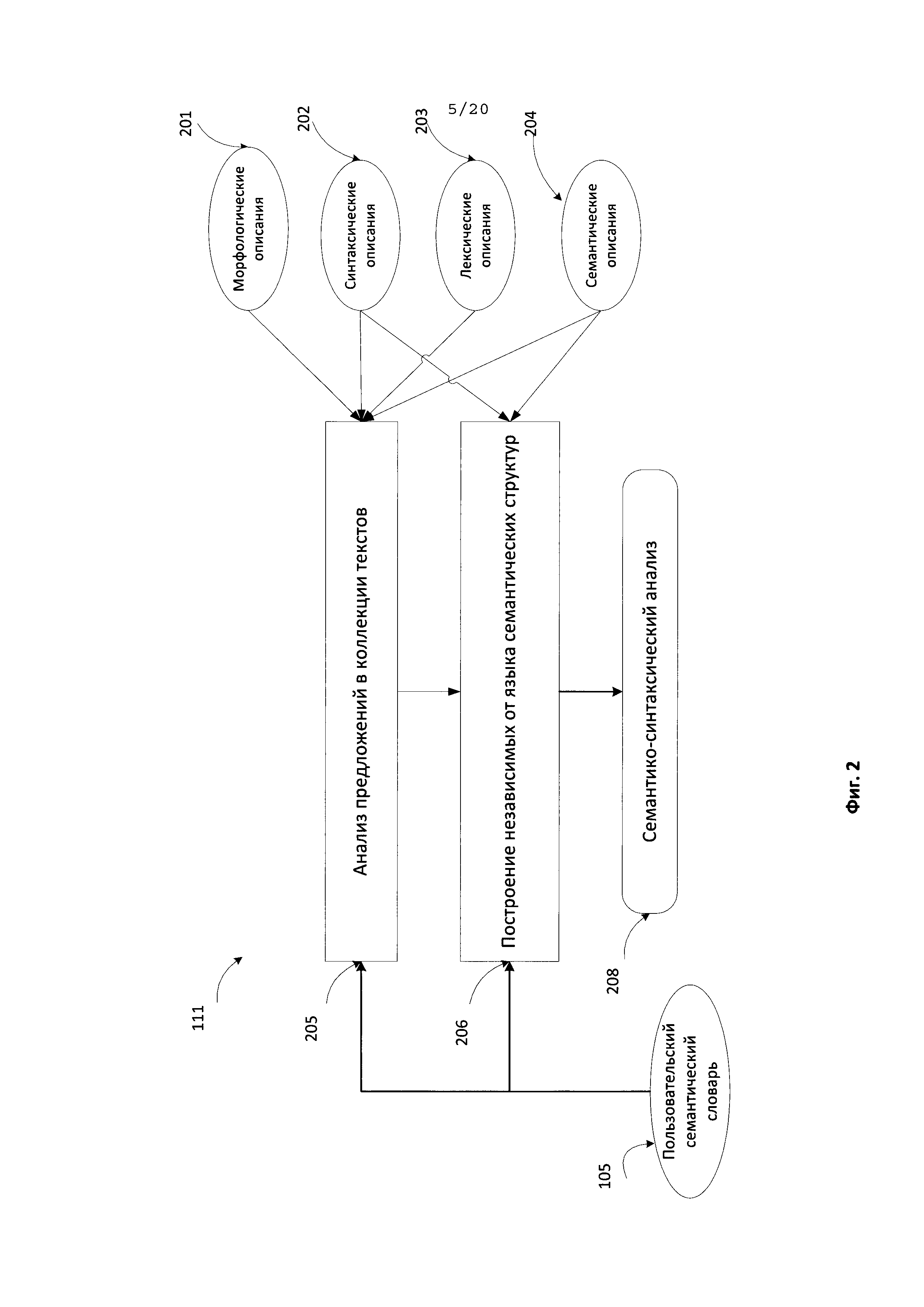
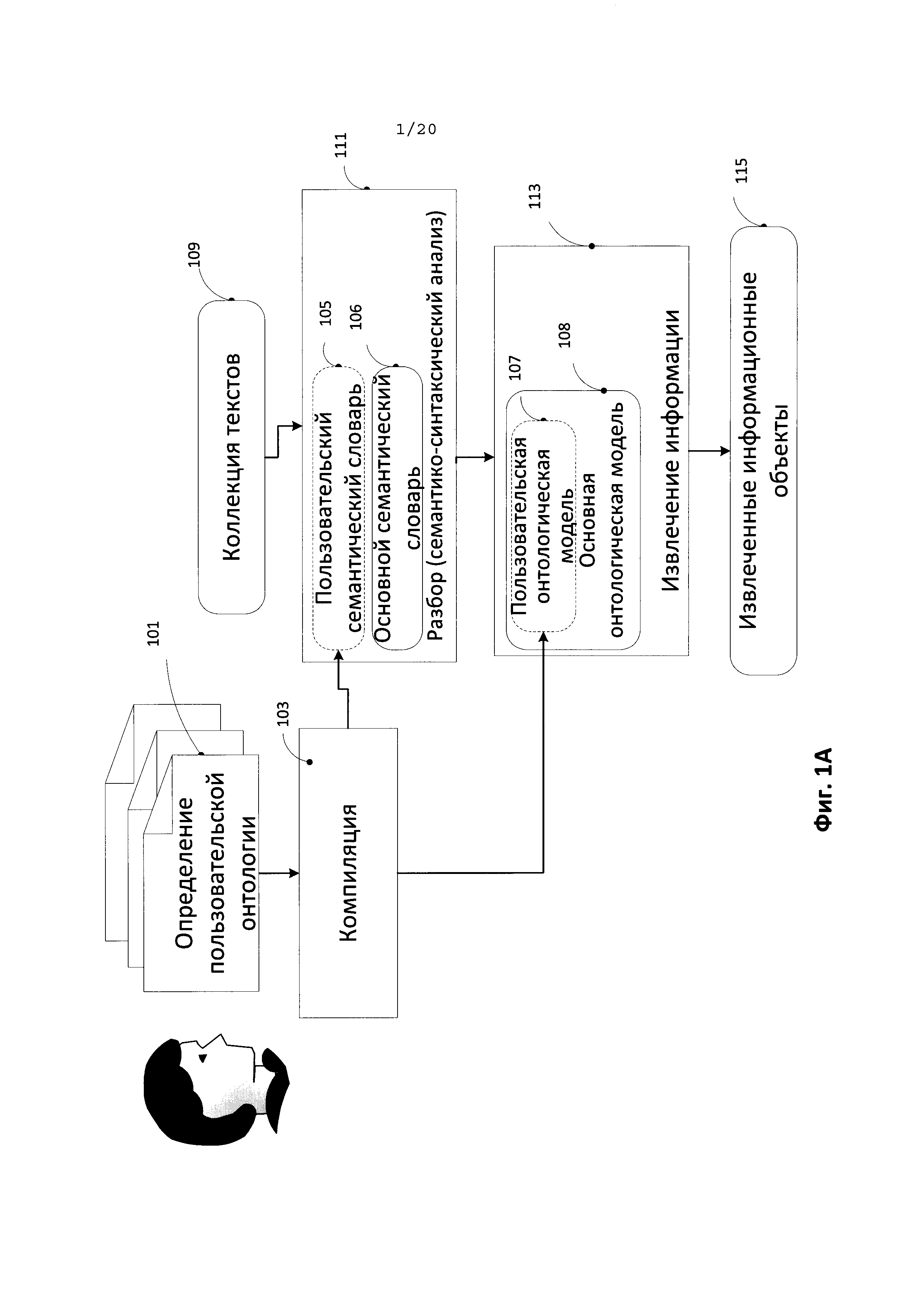
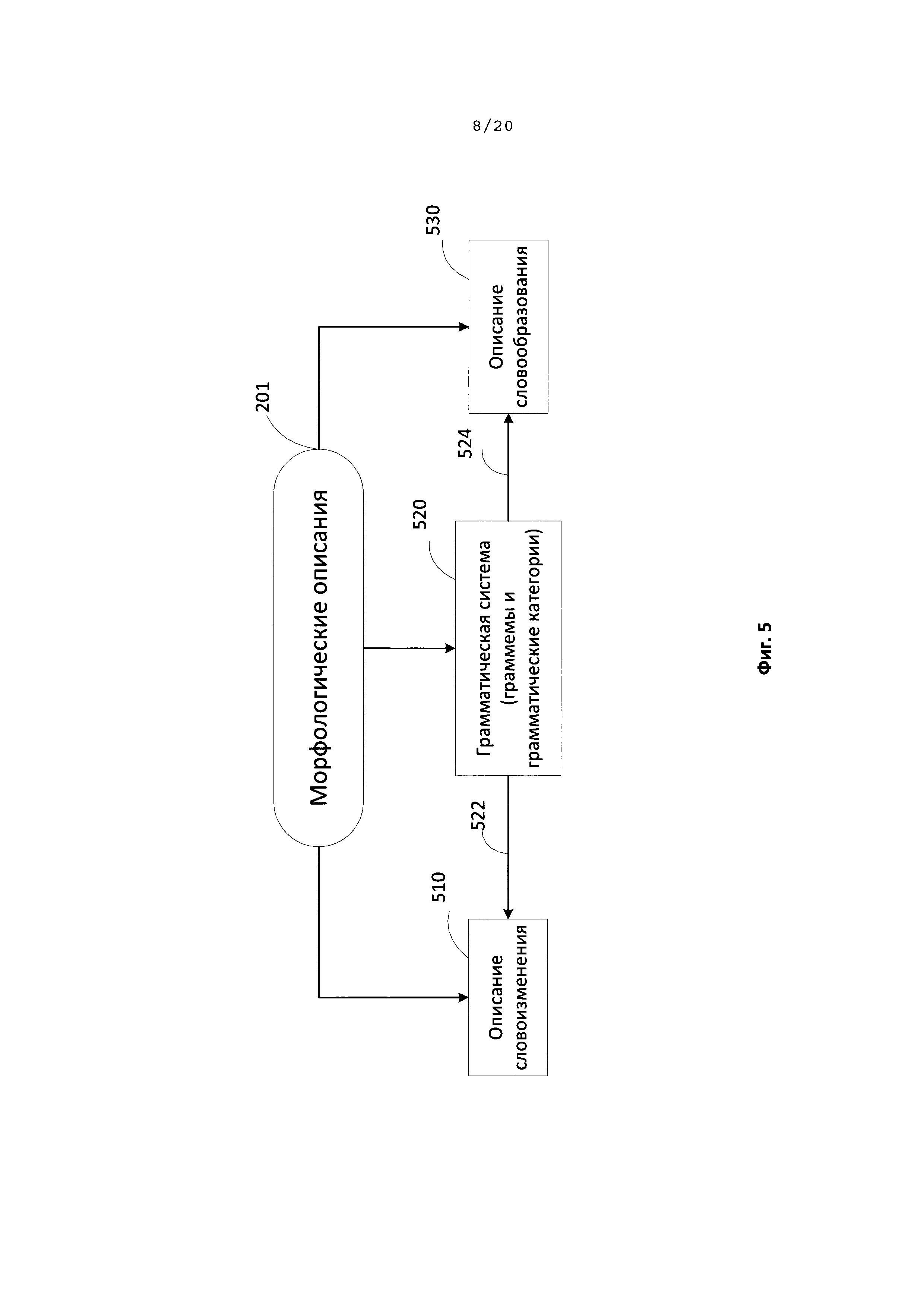
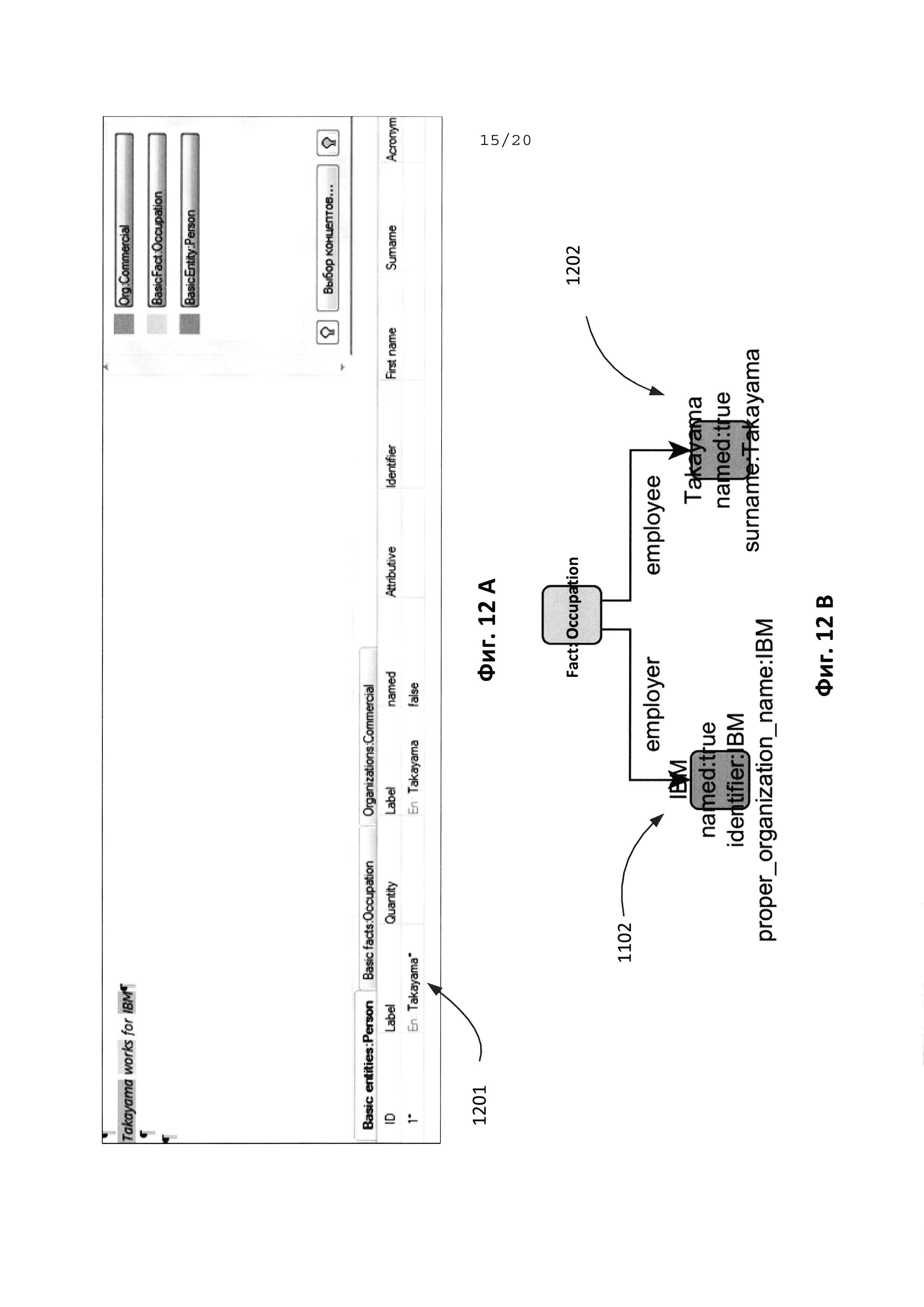
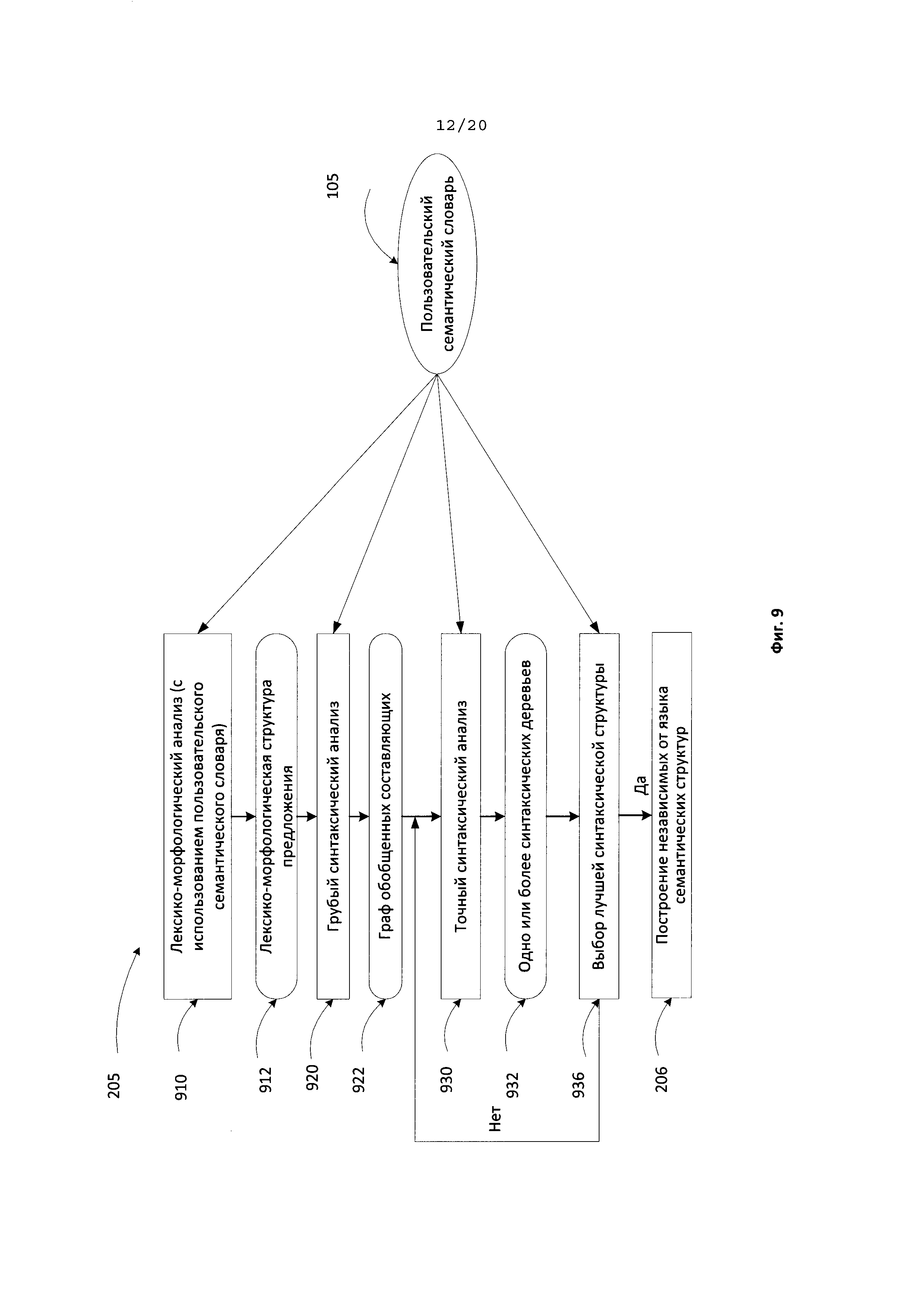
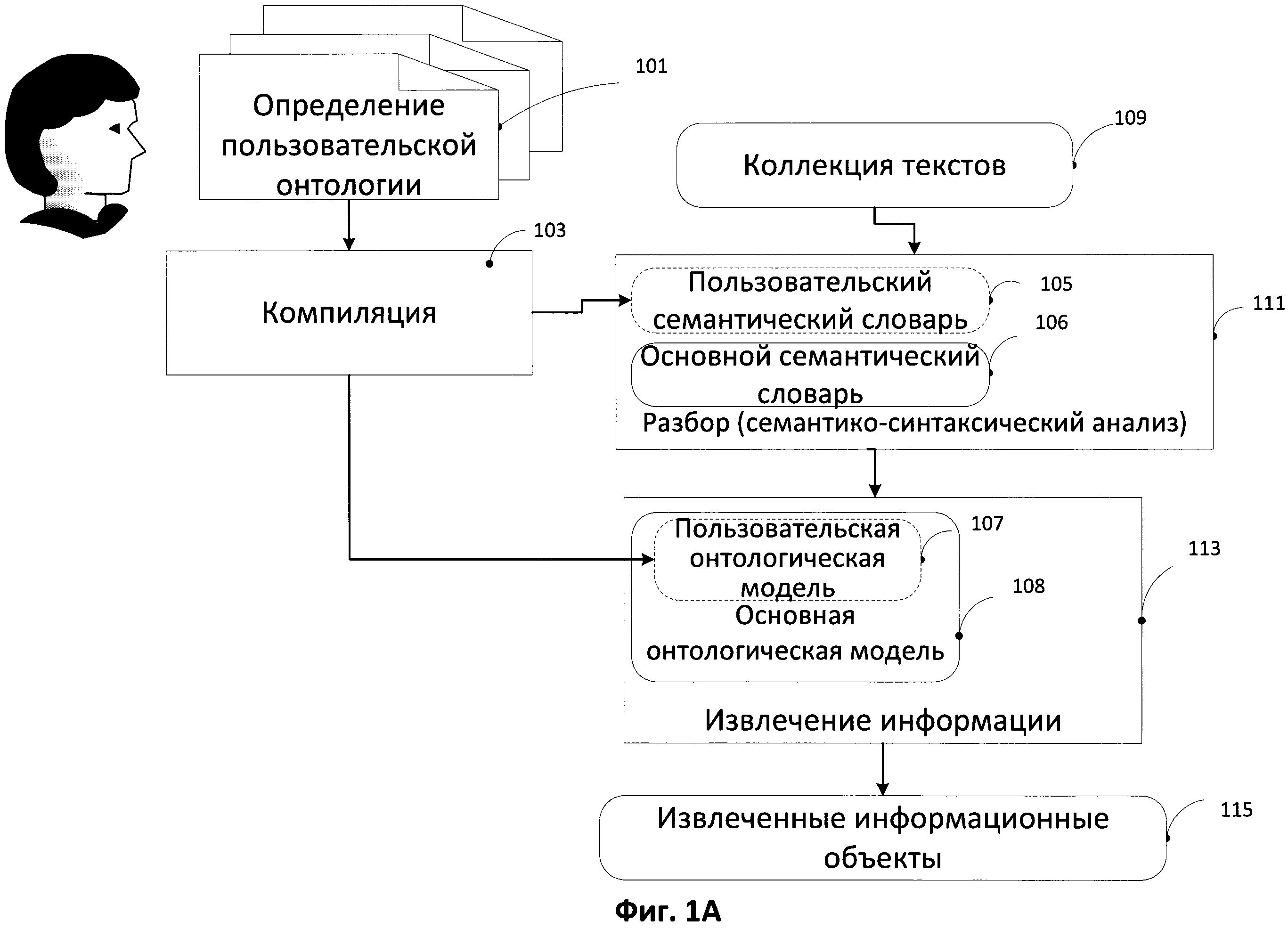
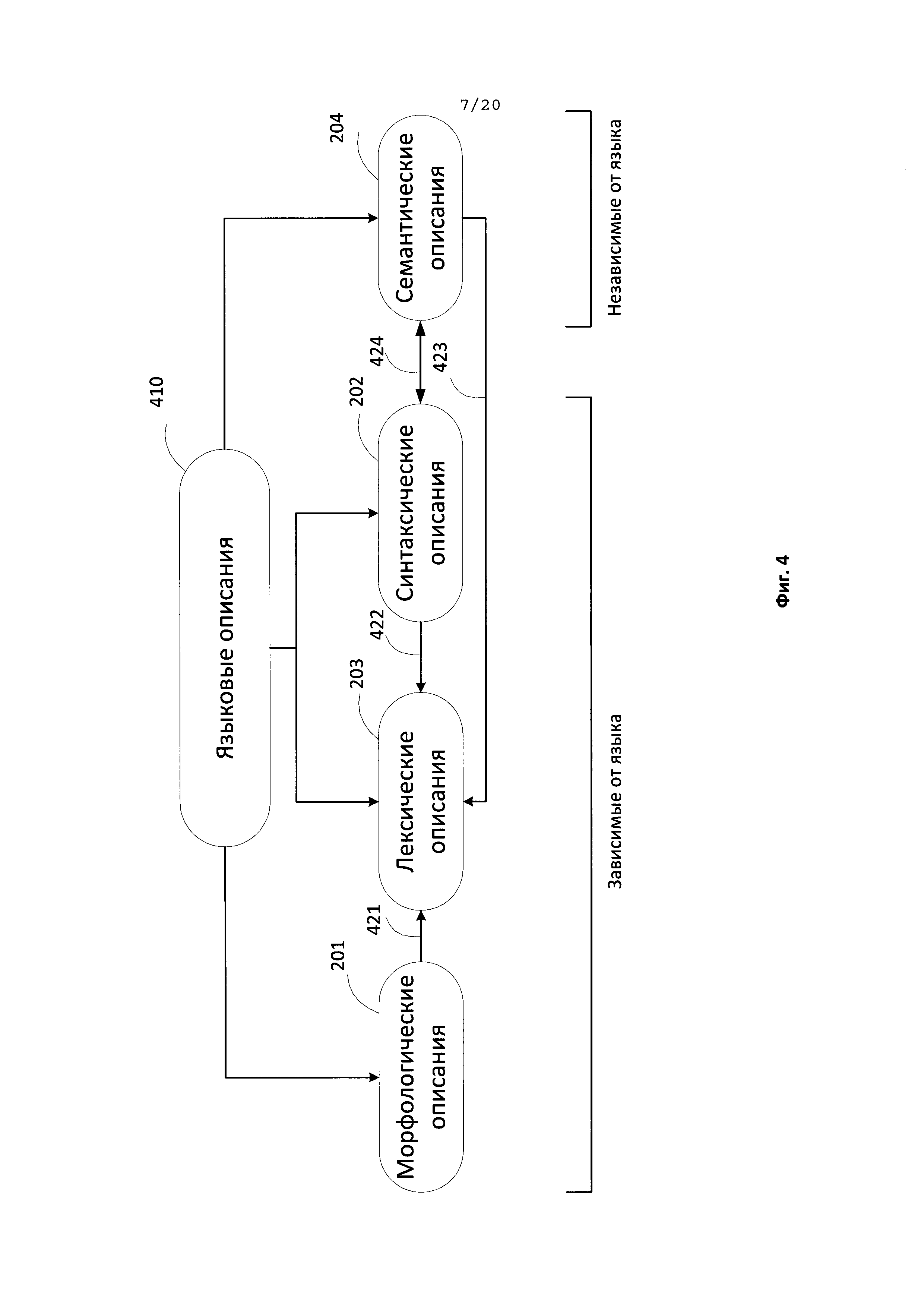
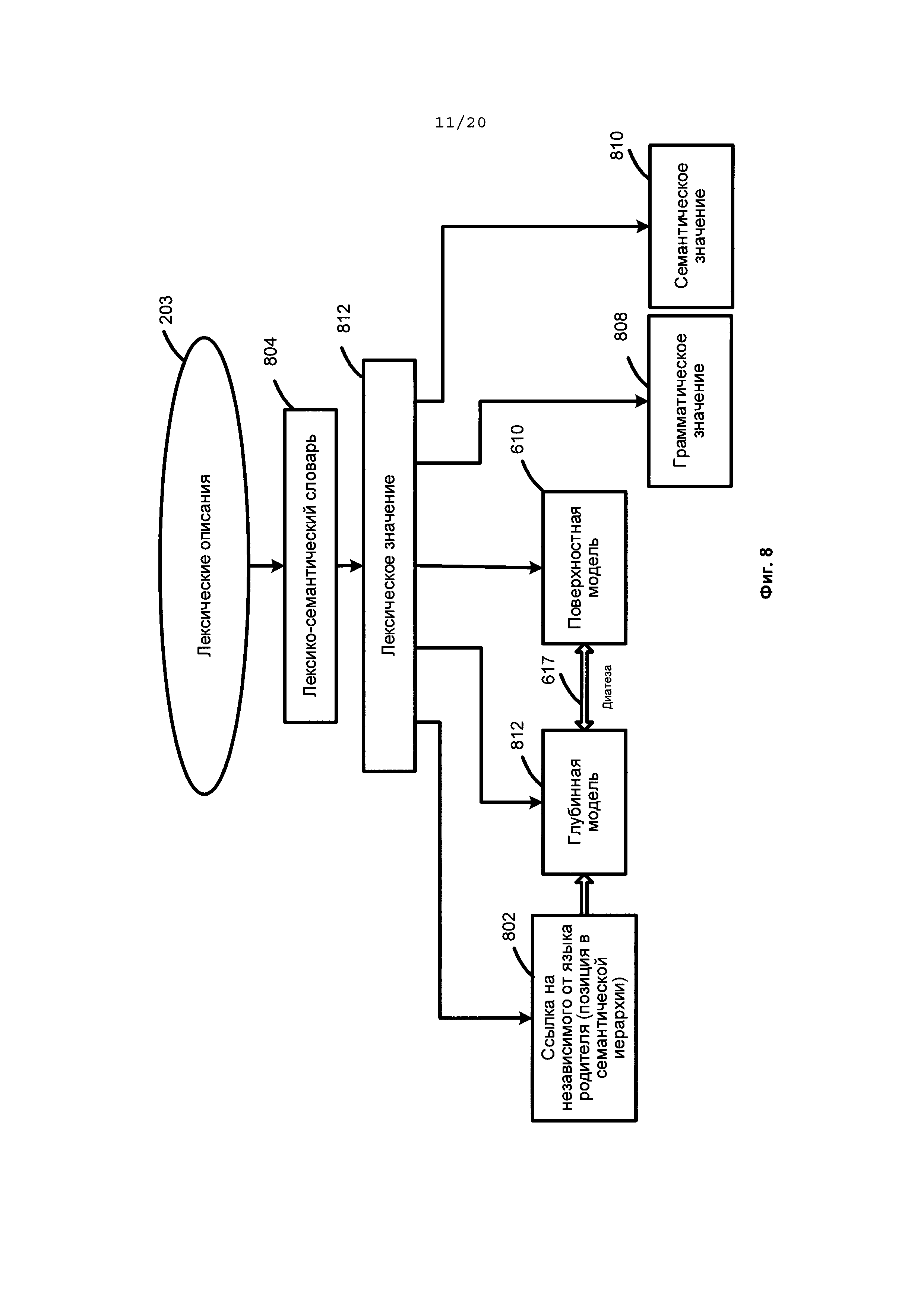

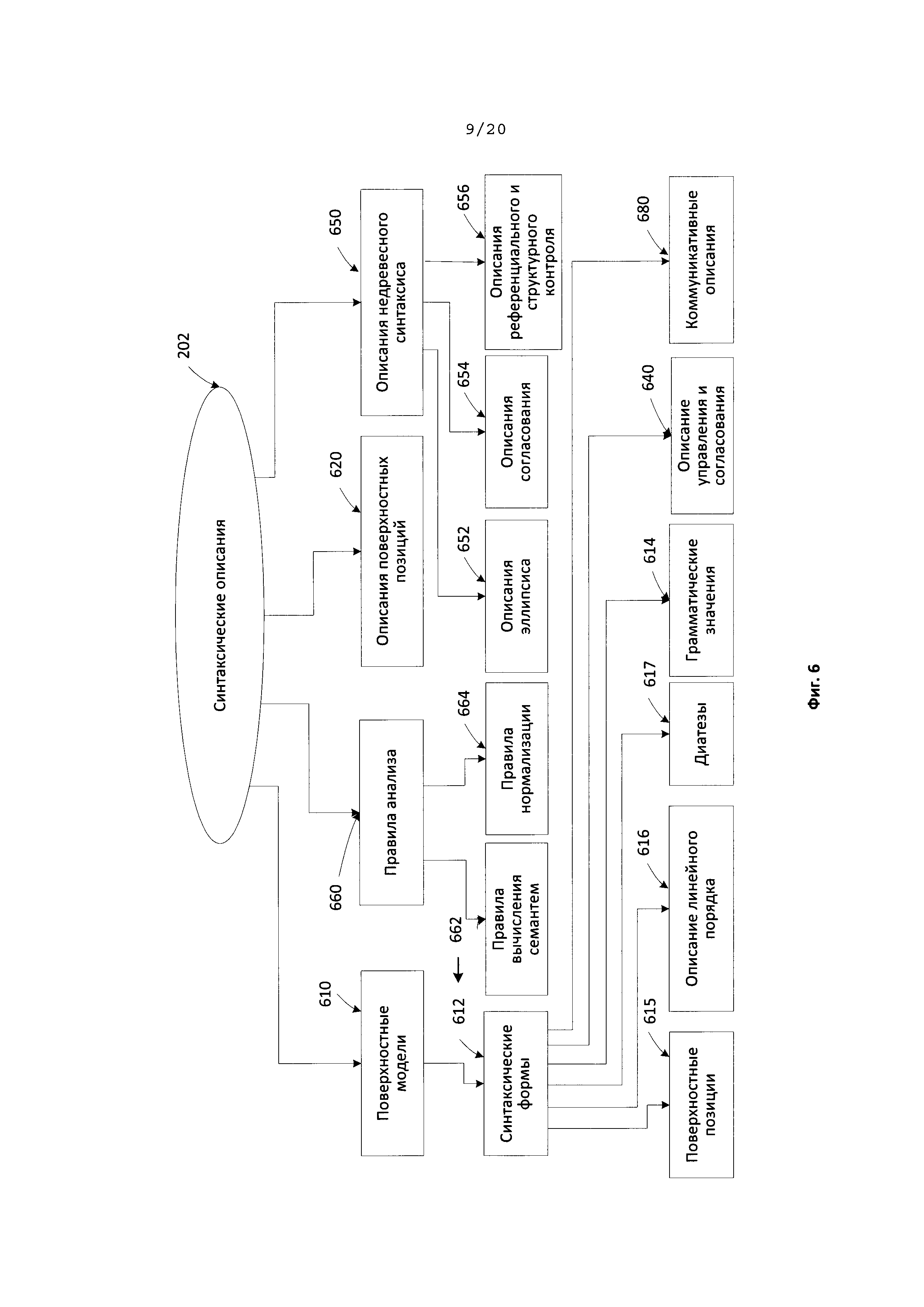
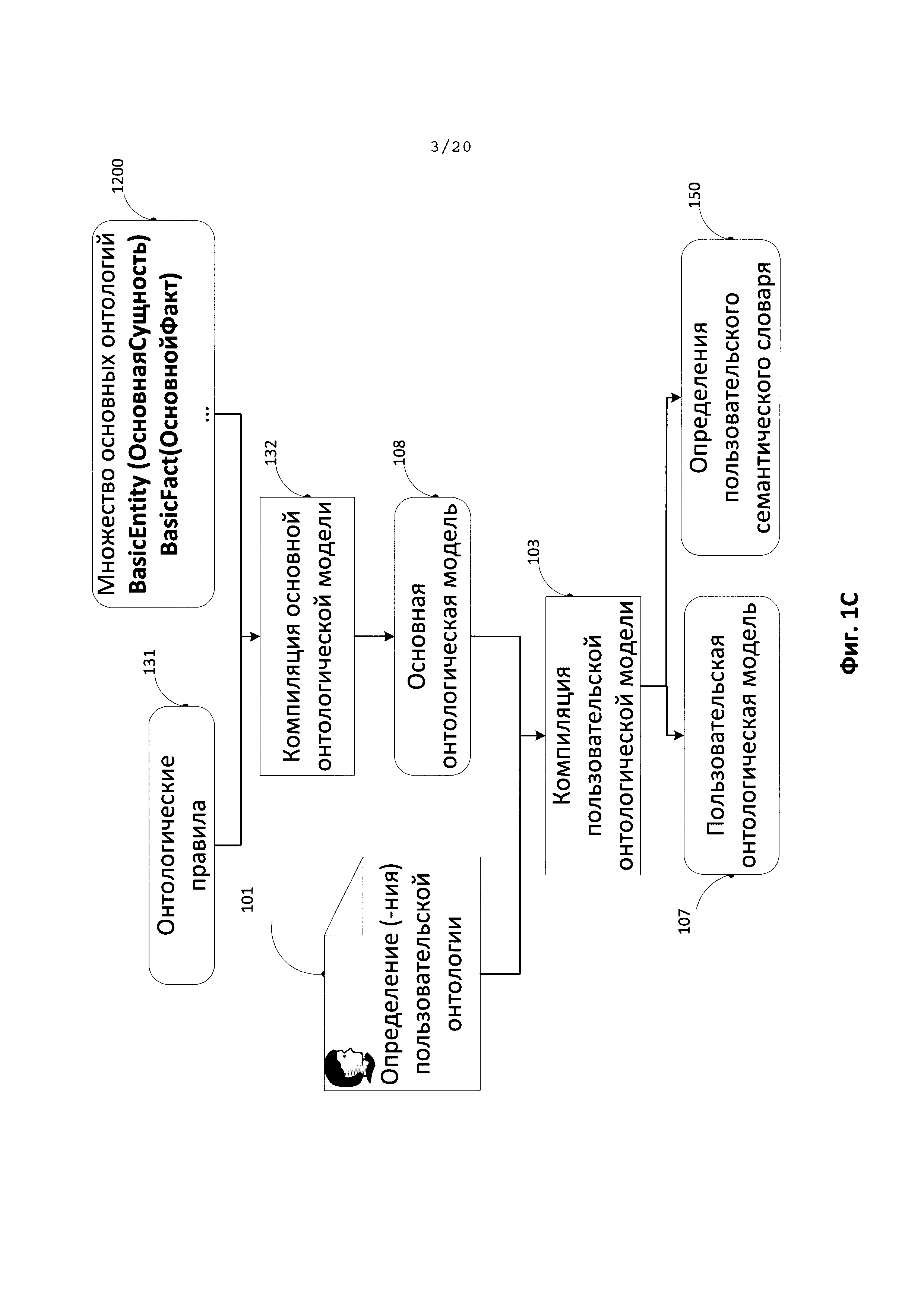
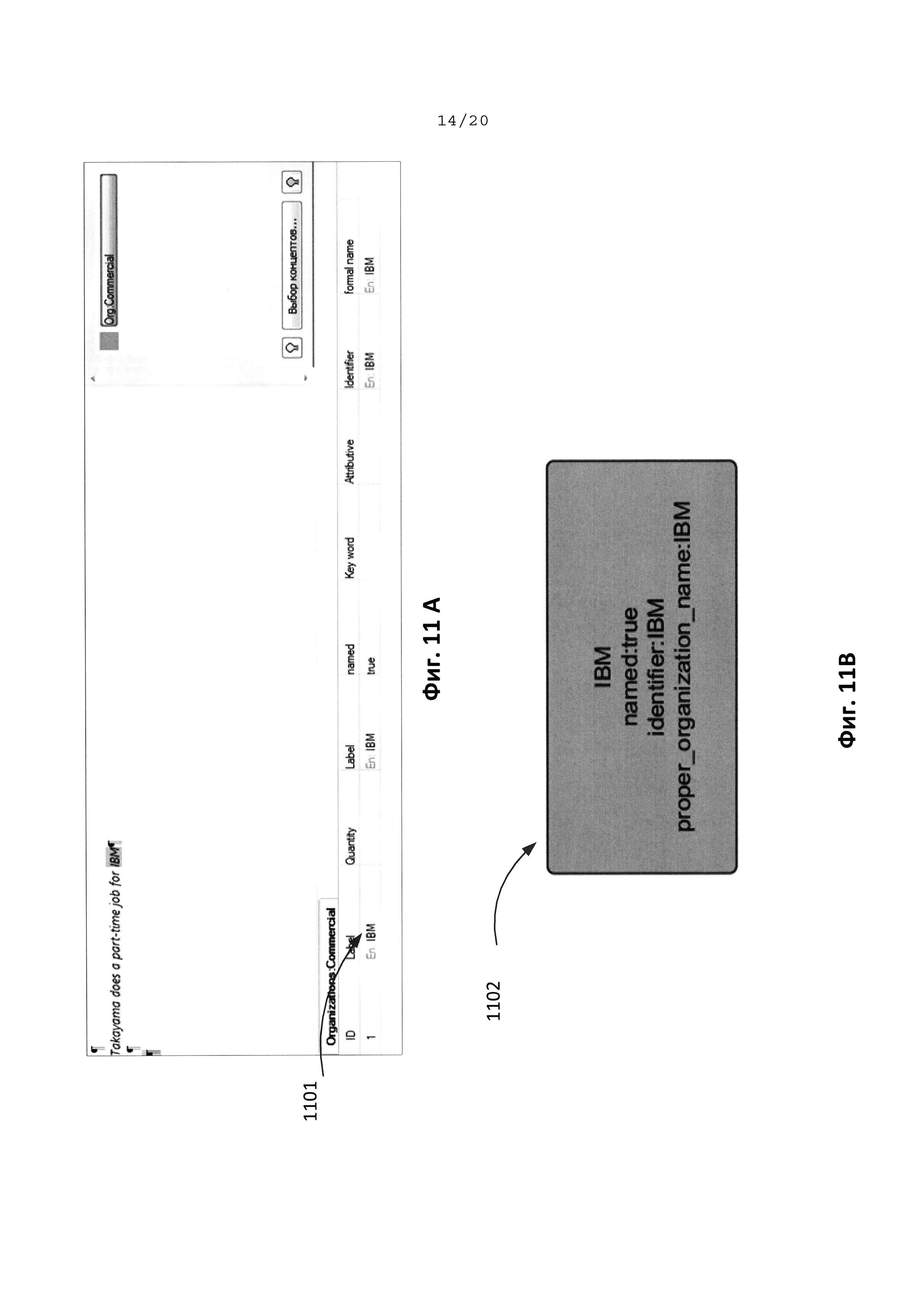

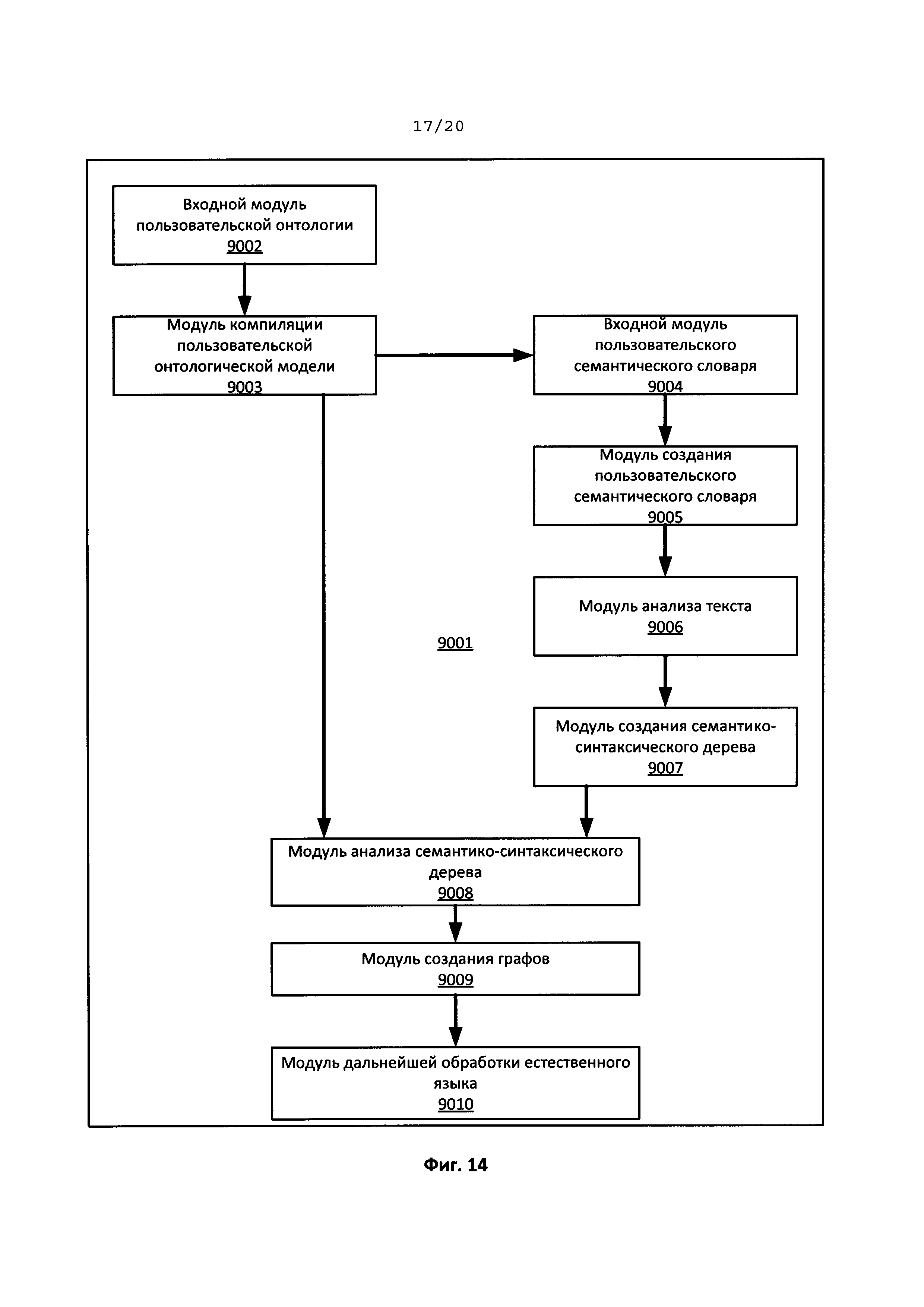
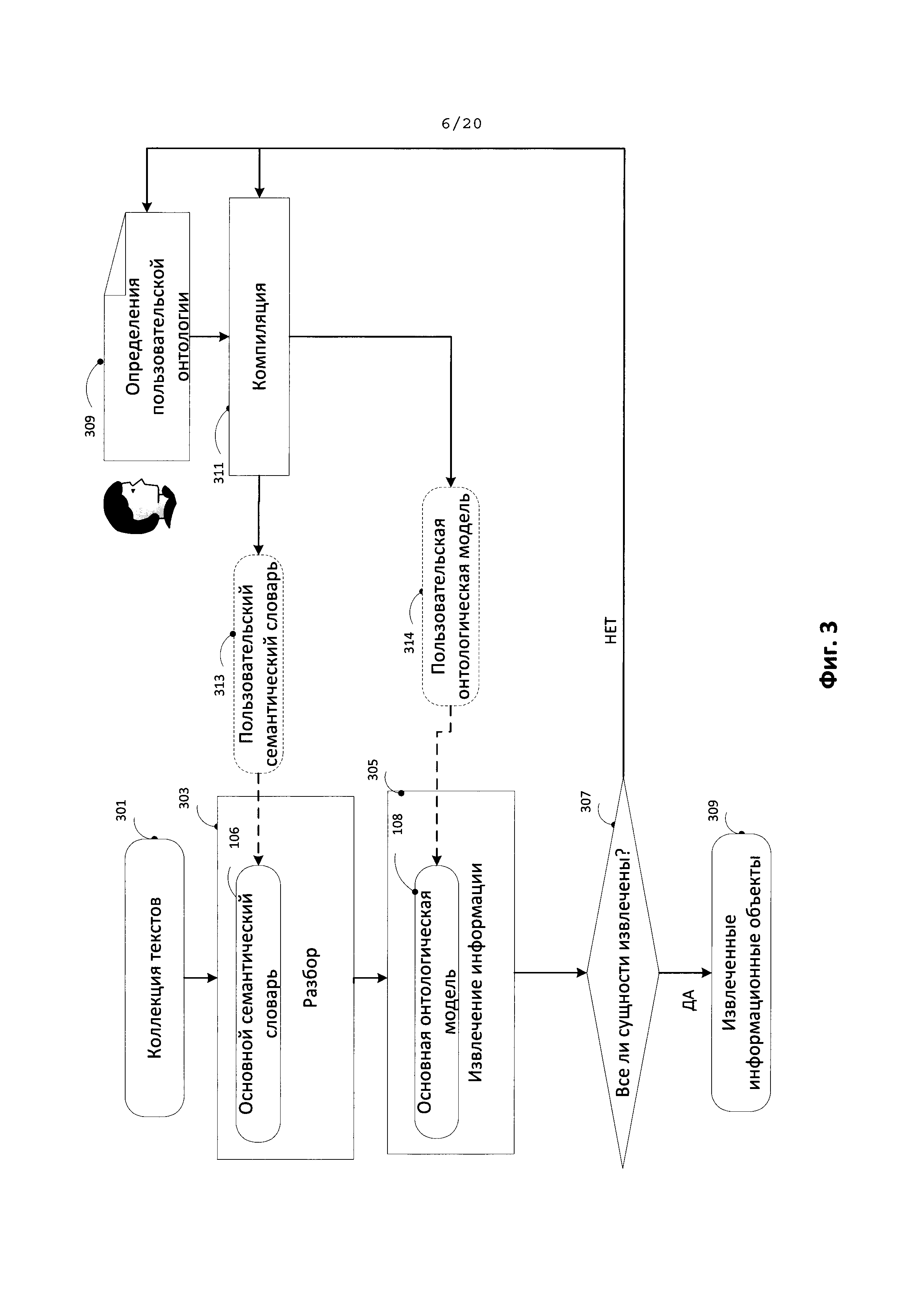
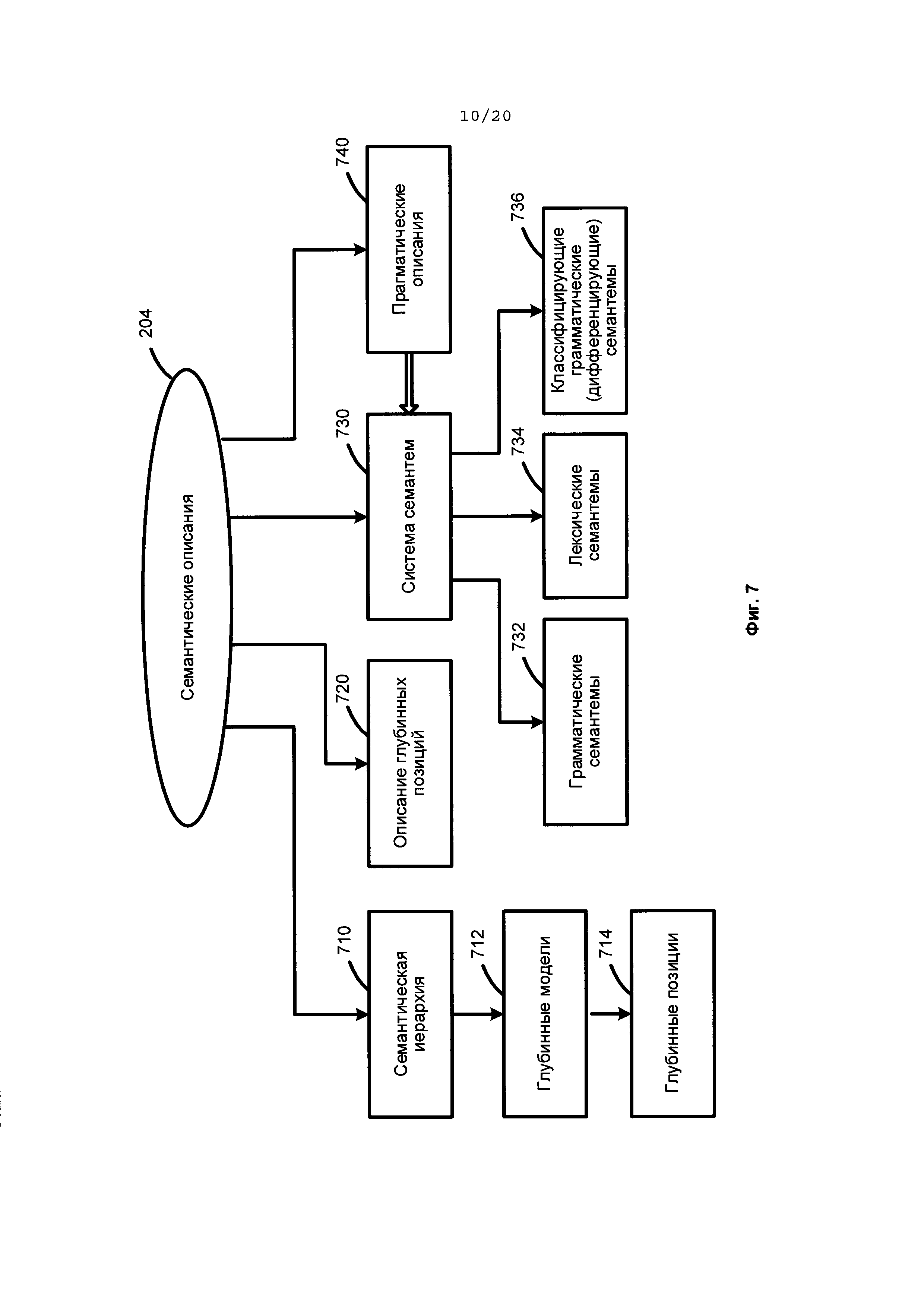
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Фильтрация дуг в синтаксическом графе
Способ и система для глобальной идентификации в коллекции документов
Разрешение семантической неоднозначности при помощи статистического анализа
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Фильтрация дуг в синтаксическом графе
Способ и система для глобальной идентификации в коллекции документов
Разрешение семантической неоднозначности при помощи статистического анализа

