Результат интеллектуальной деятельности: ЗАХВАТ ВИДЕО В СЦЕНАРИИ ВВОДА ДАННЫХ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в целом относится к вычислительным системам, а более конкретно - к облегчению ввода данных из видеопотоков.
УРОВЕНЬ ТЕХНИКИ
[002] Оптическое распознавание символов (OCR) представляет собой электронное преобразование отсканированных или сфотографированных изображений машинописного или печатного текста в машиночитаемый текст.OCR является общепринятым методом оцифровки печатных текстов, чтобы их можно было редактировать в электронном виде, производить в них поиск, отображать их в режиме онлайн, и используется в таких процессах, как преобразование текста в речь, извлечение данных и интеллектуальный анализ текста. Некоторые коммерческие системы OCR могут воспроизводить форматированный вывод, который очень точно отображает исходную отсканированную страницу, включая изображения, колонки и другие нетекстовые компоненты. Специализированные системы ввода данных позволяют пользователю сканировать физический документ, который может быть впоследствии представлен для OCR и обработан с целью идентификации значимых полей в целевых частях документа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
В соответствии с одним или несколькими аспектами настоящего изобретения компонент ввода данных мобильного устройства может получать информацию для идентификации поля данных в физическом документе. Компонент ввода данных может получать видеопоток, включающий в себя множество кадров, причем каждый кадр содержит часть физического документа. Кадр может быть выбран из множества кадров в видеопотоке. Может быть выявлена одна или несколько текстовых зон в заданном кадре. Каждая выявленная текстовая зона в кадре может обрабатываться для выявления данных каждой из выявленных текстовых зон, а также для выбора одной из выявленных текстовых зон, данные которой соответствуют набору признаков, связанных с этим полем данных. Затем можно сопоставить выбранные данные с данными текстовых зон следующего кадра. Если данные текстовых зон следующего кадра обеспечивают более точное соответствие набору признаков, то выбранные данные могут быть обновлены. Затем отображаемое поле с выбранными данными может быть обеспечено для представления в интерфейсе пользователя.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[003] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, его можно лучше понять при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
[004] На Фиг. 1 изображена схема компонентов верхнего уровня для примера архитектуры вычислительного устройства в соответствии с одним или несколькими аспектами настоящего изобретения.
[005] На Фиг. 2 показан пример графического интерфейса пользователя (GUI) мобильного устройства для захвата видео в сценарии ввода данных в соответствии с одним или несколькими аспектами настоящего изобретения.
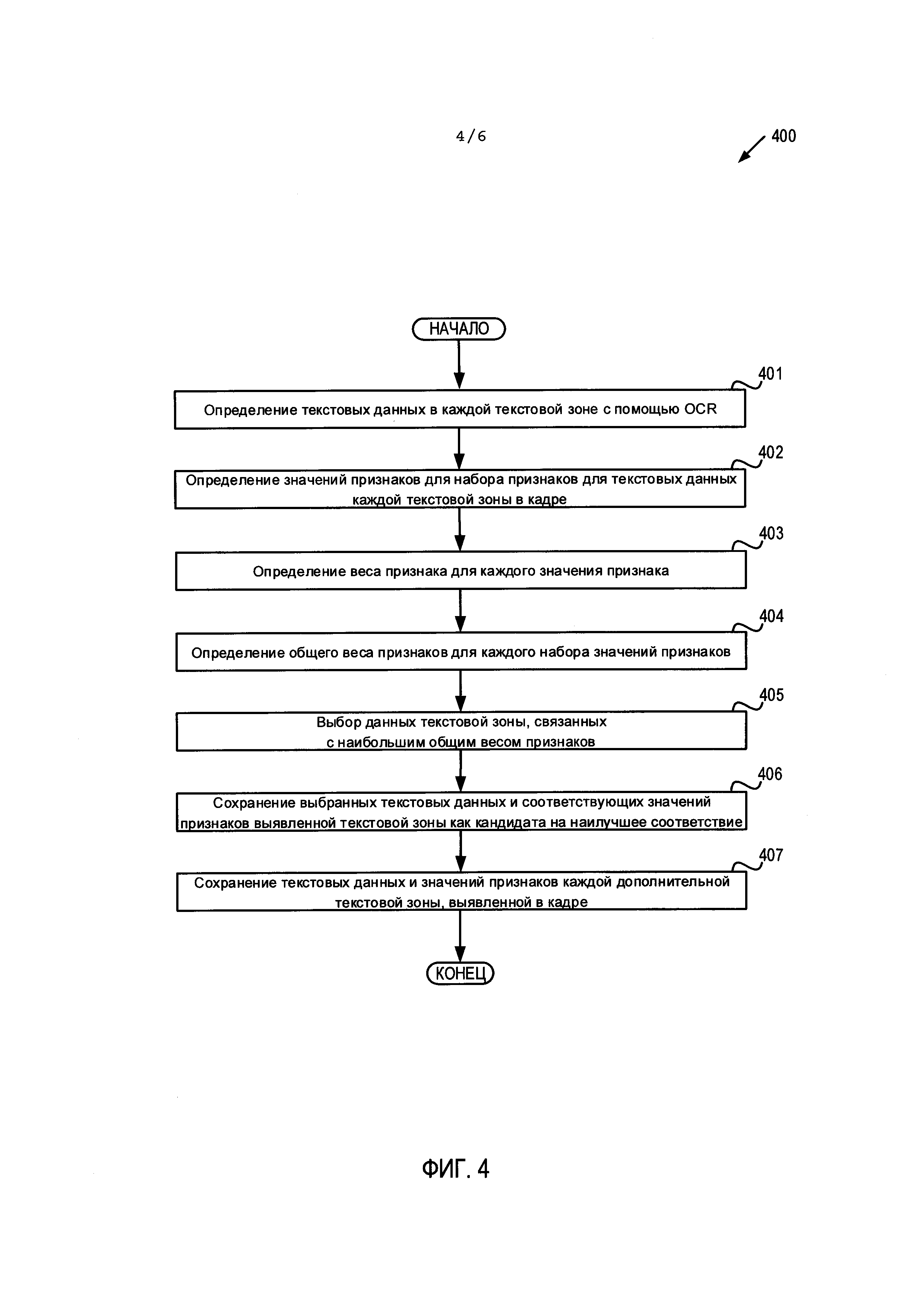
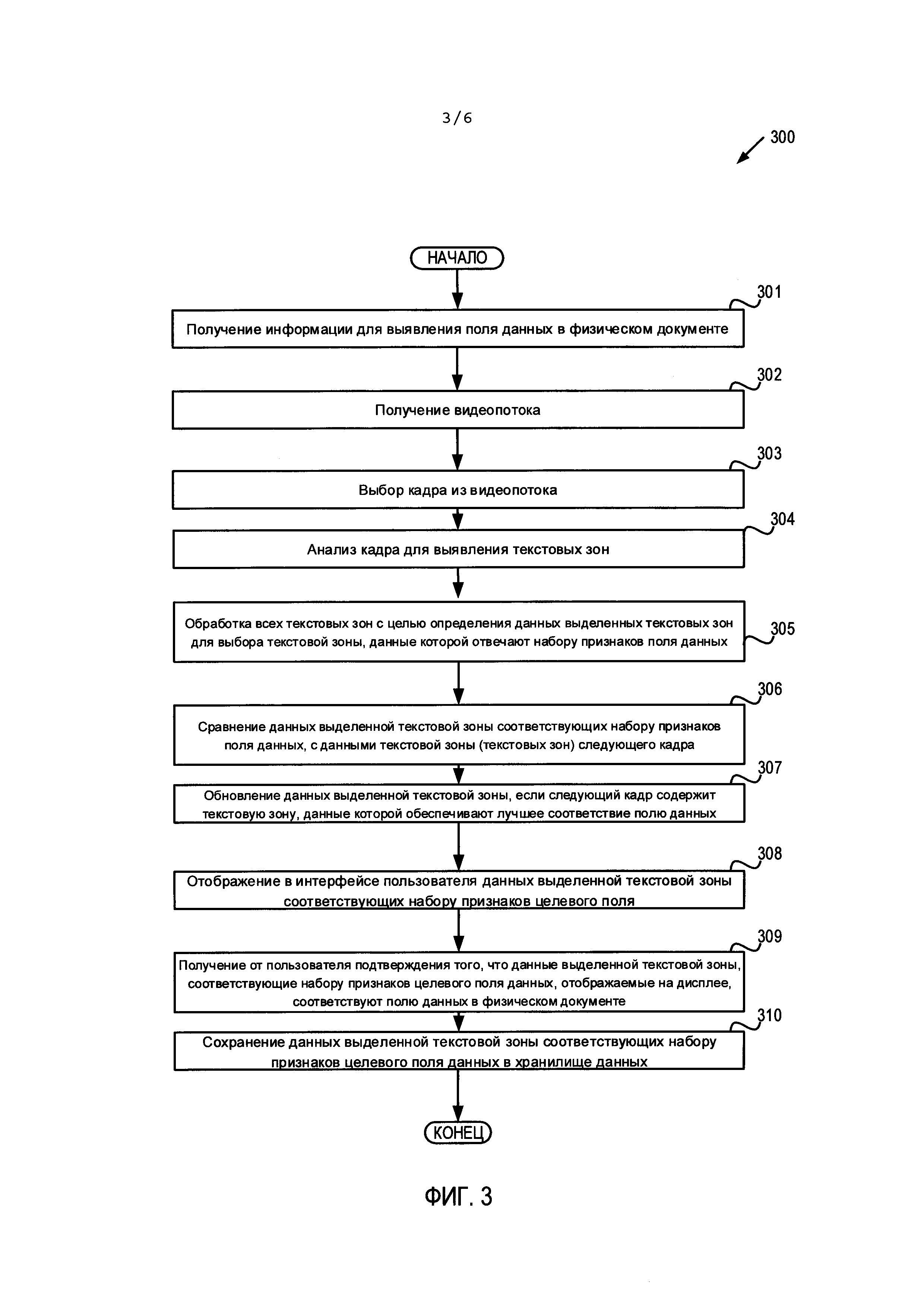
[006] На Фиг. 3 приведена блок-схема последовательности операций для способа захвата видео в сценарии ввода данных в соответствии с одним или несколькими аспектами настоящего изобретения.
[007] На Фиг. 4 приведена блок-схема способа обработки текстовых зон в кадре в соответствии с одним или несколькими аспектами настоящего изобретения.
[008] На Фиг. 5 приведена блок-схема последовательности операций способа для обновления данных в выявленной текстовой зоне данными следующих кадров в соответствии с одним или несколькими аспектами настоящего изобретения.
[009] На Фиг. 6 изображена блок-схема иллюстративной вычислительной системы, работающей в соответствии с примерами осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0010] В этом документе приведено описание способов и систем для захвата видео в сценарии ввода данных. Специализированные системы ввода данных позволяют пользователю сканировать физический документ и затем передавать его для распознавания и обработки с целью выявления значимых полей в целевых частях этого документа. Однако системы такого типа могут быть громоздкими, так как часто им требуется один или несколько персональных компьютеров, одно или несколько устройств сканирования, программное обеспечение для OCR или программное обеспечение для ввода данных, а также цифровые шаблоны. Для создания цифровых шаблонов может потребоваться специальный набор навыков, который может оказаться труднодоступным, и, возможно, что для этого потребуются значительные расходы. Оборудование, программное обеспечение и создание шаблона могут оказаться неприемлемо дорогими. Кроме того, аппаратное обеспечение, необходимое для реализации такой системы, является нецелесообразным для тех пользователей, которым требуется мобильность при обработке документов (например, обработка страхового возмещения, продажи, отчеты о расходах и т.д.).
[0011] Аспекты настоящего раскрытия устраняют отмеченные выше и другие недостатки путем использования гибкой и более дешевой альтернативной платформы для ввода данных из физических документов с помощью мобильных устройств (например, смартфонов, планшетных компьютеров и т.д.). Данные могут вводиться из полей данных физических документов (форм, анкет, финансовых документов и т.д.) с помощью мобильных устройств со встроенными камерами, обрабатываться с помощью OCR и сохраняться локально или передаваться в удаленные базы данных все в приделах одного приложения, выполняющегося на мобильном устройстве. Поля данных в физическом документе могут быть выбраны в качестве цели с помощью видоискателя встроенной камеры. Пользователь мобильного устройства может сразу увидеть их и проверить на экране мобильного устройства. В видеопотоке могут быть захвачены несколько полей данных физического документа, причем каждый кадр потока может быть проанализирован, чтобы сравнить все выявленные текстовые зоны в каждом кадре потока для выявления наилучшего соответствия для конкретного целевого поля данных в физическом документе.
[0012] В иллюстративном примере вычислительная система, в которой реализованы описанные здесь способы, может предоставлять интерфейс пользователя, помогающий пользователю выявлять целевые поля данных в физическом документе. Интерфейс пользователя может быть вызван компонентом ввода данных, выполняемым в мобильном устройстве. Компонент ввода данных может быть мобильным приложением (или частью мобильного приложения), установленным на мобильном устройстве с камерой, способной создавать видеопоток, например, мобильным телефоном, карманным компьютером (PDA), фотокамерой, видеокамерой, ноутбуком и т.д. Например, пользователь может запустить приложение на мобильном телефоне с камерой, затем может выводиться интерфейс пользователя, помогающий пользователю выявить целевое поле, данные которого требуется распознать. В одном иллюстративном примере интерфейс пользователя может выводить графический индикатор на экран мобильного устройства (например, перекрестие, значок цели и т.д.), чтобы направить пользователя установить это перекрестие видоискателя мобильного устройства на конкретное поле данных в документе для ввода. В другом иллюстративном примере интерфейс пользователя может выводить сообщение, предлагающее пользователю установить перекрестие на конкретное поле данных в физическом документе.
[0013] Компонент ввода данных может быть настроен для обработки конкретных типов документов (платежных поручений, уставов и т.д.). Он может включать список полей документа, содержащих вводимые данные (например, название компании, банковский идентификационный код (БИК), номер счета, основание платежа и сумму платежа), а также тип данных, обычно используемых в каждом поле (например, адрес, время, дату, сумму, наименование, код, текст, номер и т.д.), количество знакомест, а также дополнительные правила контроля данных, позволяющие проверять распознанные поля данных (например, словари, регулярные выражения, контрольные суммы и т.д.), и т.п. В качестве иллюстративного примера компонент ввода данных может быть настроен на обработку документов конкретного типа. При альтернативном подходе компонент ввода данных может быть настроен на обработку документов нескольких типов и запрашивать тип документа у пользователя через интерфейс пользователя при активации этого компонента (например, когда приложение запускается в мобильном телефоне). Компонент ввода данных также может быть настроен на прием поддерживаемых типов документов с сервера. Компонент ввода данных может определить обрабатываемый документ (например, с помощью конкретного запроса пользователя, информации о местоположении, контекстной информации приложения и т.д.), отправить запрос на сервер по полям, обычно используемым в документах запрашиваемого типа, и сохранить информацию на мобильном устройстве для обработки этого документа.
[0014] В дополнение к представлению интерфейса пользователя, помогающего пользователю выявить целевое поле данных, компонент ввода данных может включить камеру мобильного устройства (например, до вывода интерфейса пользователя, во время вывода интерфейса пользователя и т.д.). Затем компонент ввода данных может получить видеопоток с камеры мобильного устройства. Этот видеопоток может состоять из множества кадров, в котором каждый кадр может включать часть физического документа, содержащего целевое поле данных. Кадр может включать контент (например, изображение) отображаемый на экране мобильного устройства и его можно получить с использованием видоискателя камеры. Кадр может передаваться в режиме реального времени без записи видео, захвата изображения или сохранения изображения в памяти или в постоянном хранилище данных. Видоискатель может поддерживать передачу видеоданных в реальном времени с камеры мобильного устройства на его дисплей. Как уже отмечалось в приведенном выше примере, пользователю может быть направлен запрос о необходимости навести перекрестие видоискателя мобильного устройства на целевое поле данных.
[0015] Затем компонент ввода данных может выбрать кадр из множества кадров видеопотока. В некоторых вариантах реализации изобретения кадры можно выбрать для обработки в мобильном устройстве, используя заранее заданную частоту. Например, кадры могут выбираться из видеопотока с частотой каждый 10-й кадр в секунду. Также можно использовать другие частоты (например, каждый первый, второй, четвертый, шестой кадр в секунду и т.д.). Кроме того, кадр может быть выбран при фокусировке камеры мобильного устройства на захватываемый объект (например, часть физического документа, потенциально содержащую требуемое поле данных) в течение определенного периода времени (например, 1/2 секунды, одной секунды, двух секунд и т.д.).
[0016] После выбора кадра компонент ввода данных может проанализировать кадр, чтобы выявить в кадре одну или несколько текстовых зон. В некоторых вариантах реализации компонент ввода данных может определить данные каждой текстовой зоны. Данные каждой выявленной текстовой зоны могут включать текстовые данные (результат OCR текстовой зоны) и значения признаков для текстовых данных. Затем компонент ввода данных может проанализировать данные каждой текстовой зоны в кадре изображения, чтобы определить текстовую зону, данные которой соответствуют набору признаков, связанных с этим полем данных (или описанию поля данных). Текстовые зоны могут выявляться, например, используя идентификацию связанных компонентов (элементарных объектов, построенных по соприкасающимся точкам изображения одной цветности), и затем группируя их в потенциальные слова. При альтернативном подходе текстовые зоны могут выявляться с использованием любого подобного метода обнаружения текста на изображениях.
[0017] Затем компонент ввода данных может определить текстовые данные в каждой из выявленных в кадре текстовых зон, используя оптическое распознавание символов (OCR). Таким образом, изображение текстовой зоны может быть преобразовано в текстовые данные (например, последовательности кодов, используемые для представления символов в компьютере или в мобильном устройстве). Полученные текстовые данные могут включать гипотезу для каждого символа, а также расположение каждого символа в кадре (например, координаты каждого символа в кадре). Кроме того, чтобы ограничить ложное распознавание, каждому символу может быть назначен уровень уверенности гипотезы для каждого символа в соответствии с заранее определенным набором правил. Уровень уверенности может представлять собой заранее определенное различие между уверенно и неуверенно распознанными символами. Если уровень уверенности символа соответствует заранее определенному пороговому значению, символ может быть обозначен как «уверенно распознанный». Если уровень уверенности для символа не соответствует заранее определенному пороговому значению, компонент ввода данных может создать сообщение с просьбой подтвердить распознанный символ. В некоторых вариантах реализации порог можно повысить или понизить, чтобы изменить количество символов, которым может потребоваться верификация.
[0018] Кроме того, компонент ввода данных может определить набор признаков, связанных с целевым полем данных физического документа. Такие признаки могут включать правила, особенности или характеристики, связанные с целевым полем данных, чтобы помочь компоненту ввода данных выявить текстовую зону в кадре, данные которой наилучшим образом соответствуют целевому полю данных физического документа. В качестве иллюстративного примера признак может включать тип вводимых данных (например, свойство поля данных такое как: числовые данные, текстовые данные, имя клиента, номер социального страхования и т.д.). Например, если целевое поле в физическом документе представляет собой поле даты, то любые выявленные текстовые зоны в кадре можно сравнить с форматом даты (например, мм/дд/гггг, дд/мм/гггг, гггг/мм и т.д.), чтобы определить, содержит ли любая из текстовых зон кадра действительную дату.
[0019] В другом иллюстративном примере признаком может являться близость к перекрестью видоискателя. В некоторых вариантах реализации можно использовать перекрестие (или аналогичный графический индикатор) в видоискателе, чтобы помочь пользователю выявить целевое поле данных физического документа. Соответственно, чем ближе выявленная текстовая зона в кадре к точке перекрестия в видоискателе камеры мобильного устройства, тем выше вероятность того, что выявленная текстовая зона соответствует целевому полю данных физического документа.
[0020] В другом иллюстративном примере признаки могут включать дополнительные правила проверки данных. Правила проверки данных могут включать определенные условия, применяемые к данным в полях, и автоматически проверяться компонентом ввода данных. Примеры правил проверки данных включают проверку текстовых данных по базам данных (например, словарь имен, словарь БИК и т.д.), сравнение текстовых данных со списками известных допустимых значений. Кроме того, могут также сравниваться текстовые данные в нескольких текстовых зонах. Например, если документ содержит несколько числовых полей, а также связанную с ними сумму, то правило проверки данных можно использовать, чтобы независимо пересчитать сумму распознанных данных всех подходящих выявленных текстовых зонах и сравнить результат с распознанными данными соответствующей текстовой зоны.
[0021] В другом иллюстративном примере признак может включать качество распознавания символов в текстовой зоне. В некоторых вариантах реализации изобретения качество распознавания можно измерить числом неуверенно распознанных символов (что описано выше). Чем больше количество неуверенно распознанных символов, тем ниже качество распознавания текстовой зоны. Аналогично, чем меньше количество неуверенно распознанных символов, тем выше качество распознавания текстовой зоны.
[0022] В другом иллюстративном примере признак может включать количество случаев определения конкретной текстовой зоны компонентом ввода данных как более точного соответствия целевому полю данных, которое отображается в интерфейсе пользователя, что описано более подробно ниже. Если конкретная текстовая зона была определена как более точное соответствие целевому полю данных в нескольких обработанных кадрах, но результат не был подтвержден пользователем через интерфейс пользователя, то компонент ввода данных может определить, что выявленная текстовая зона не соответствует этому полю данных. Если количество полученных кадров изображения превышает пороговое значение, то компонент ввода данных может попытаться отобразить текстовую зону, которая определяется как менее точное соответствие целевому полю данных. Например, компоненту ввода данных может потребоваться конкретное поле цены, если в кадре присутствуют несколько полей цен. Если поле цены выявлено в кадре на основе его близости к перекрестью видоискателя в десяти последовательных кадрах без подтверждения пользователем, то компонент ввода данных может попытаться выявить другое поле цены в этом кадре.
[0023] В другом иллюстративном примере признак может включать формат данных, например, формат сокращения или кавычки. Например, если текстовая зона содержит сокращение «Со.» в текстовых данных, то компонент ввода данных может определить, что данная текстовая зона представляет собой название компании. Кроме того, формат данных может включать интервалы между строками выше и ниже текстовой зоны, разделительные линии (вертикальные или горизонтальные линии, которые могут указывать на поле в таблице) или аналогичные индикаторы форматирования, которые могут присутствовать в физическом документе.
[0024] Выше были описаны некоторые иллюстративные примеры признаков, однако также могут использоваться признаки других типов. После того как компонент ввода данных определил признаки, связанные с требуемым полем данных, для текстовых данных каждой текстовой зоны в кадре могут быть определены значения набора признаков. Каждому признаку может быть также приписан вес, который указывает его относительную важность при выявлении текстовой зоны, которая может соответствовать целевому полю данных. Например, близости текстовой зоны к перекрестию может быть назначен больший вес, поскольку можно ожидать, что пользователь установит перекрестие в целевое поле данных физического документа, когда камера принимает видеопоток. В другом случае, если в кадре имеется большое число текстовых зон, и только одна из них по-видимому имеет правильный формат, формату данных можно приписать больший вес, чем признаку, определенному на основании близости к перекрестию.
[0025] Компонент ввода данных может определить вес признака для каждого значения признака, а затем определить общий вес признаков для текстовых данных каждой текстовой зоны путем суммирования весов отдельных значений признаков, связанных с текстовыми данными каждой текстовой зоны. В некоторых вариантах реализации изобретения текстовые данные, значения признаков и их соответствующие весовые коэффициенты могут сохраняться для последующего использования при сравнении с данными текстовых зон других кадров, полученных позднее. Затем компонент ввода данных может выявить данные текстовой зоны, связанные с суммарным весом признаков, имеющих наибольшее значение среди сумм весов признаков данных других выявленных в кадре текстовых зон. Данные выявленной текстовой зоны с наибольшим общим весом признаков могут быть выбраны как данные текстовой зоны, которая наиболее точно соответствует целевому полю данных физического документа (т.е. обеспечивает «наилучшее» возможное соответствие для полученного кадра).
[0026] Затем компонент ввода данных может сохранить выбранные текстовые данные и связанные с ними признаки выявленной текстовой зоны как кандидата на наилучшее совпадение. Компонент ввода данных может дополнительно сохранить текстовые данные и признаки каждой выявленной в кадре дополнительной текстовой зоны. Компонент ввода данных может сохранить эту информацию в хранилище данных для использования при сравнении с ранее полученными кадрами, а также кадрами, полученными позднее из видеопотока. Хранилище данных может представлять собой постоянную память мобильного устройства, память мобильного устройства или сетевое устройство хранения данных сервера. В некоторых вариантах реализации изобретения компонент ввода данных может использовать информацию, хранящуюся в хранилище данных, для сравнения текстовых данных выявленной текстовой зоны с текстовыми данными соответствующей текстовой зоны всех кадров, полученных из видеопотока.
[0027] После того, как компонент ввода данных выявил текстовую зону в принятом кадре, данные которой соответствуют набору признаков, связанному с целевым полем данных (т.е. обеспечивают наилучшее соответствие полю данных), данные совпадающей текстовой зоны могут быть отображены в отображаемом поле интерфейса пользователя для подтверждения пользователем. Например, данные совпадающей текстовой зоны могут отображаться в нижней части экрана мобильного телефона под видоискателем с перекрестием. Пользователь может подтвердить то, что данные выявленной текстовой зоны соответствуют целевому полю данных, используя пользовательский ввод указывающий на подтверждение в интерфейсе пользователя. Такое подтверждение может быть выполнено в виде ввода команды сенсорного экрана (например, нажатием отображаемой кнопки на экране), выбором пункта меню, вводом голосовой команды или любым другим способом.
[0028] В некоторых вариантах реализации изобретения описанный выше процесс может повторяться для полученных позднее кадров видеопотока. Затем компонент ввода данных может сравнить данные выявленной текстовой зоны с данными текстовых зон в полученном позднее кадре, чтобы определить, не содержит ли последующий кадр текстовую зону, которая лучше соответствует целевому полю данных, чем зона в ранее принятом кадре. Сравнение текстовых зон из разных кадров может обеспечить возможность выявления текстовой зоны, которая хорошо соответствует целевому полю данных, даже если в конкретном кадре перекрестие видоискателя находится в соседнем поле данных физического документа, а не в целевом поле данных.
[0029] В некоторых вариантах реализации изобретения выявленную в последующих кадрах текстовую зону можно сравнить с той же текстовой зоной в предыдущих кадрах, чтобы определить лучший захват изображения и результат распознавания поля данных среди всех полученных кадров в видеопотоке.
[0030] Для сравнения данных выявленной текстовой зоны с данными соответствующей текстовой зоны более позднего кадра видеопотока компонент ввода данных может сначала выбрать кадр видеопотока, который был получен позднее. Позднее принятый кадр может быть следующим кадром в видеопотоке. При альтернативном подходе позднее принятый кадр можно определить с использованием заранее заданной частоты, как описано выше (например, для каждого второго, четвертого, шестого кадра в секунду и т.д.).
[0031] В некоторых вариантах реализации изобретения компонент ввода данных может определить сдвиг между ранее выбранным кадром и принятым позднее кадром. Это смещение может представлять собой разность между координатами выявленной текстовой зоны ранее выбранного кадра и координат соответствующей текстовой зоны более позднего принятого кадра. При альтернативном подходе смещение может представлять собой разность между координатами любой текстовой зоны, которая появляется в ранее выбранном кадре и позже принятом кадре. Смещение между двумя последовательно полученными кадрами можно вычислить, например, используя компонент мобильного устройства - гироскоп.
[0032] Затем компонент ввода данных может выявить соответствующую текстовую зону более позднего принятого кадра видеопотока. В некоторых вариантах реализации изобретения соответствующую текстовую зону можно выявить путем повторения описанного выше процесса выявления. При альтернативном подходе компонент ввода данных может использовать координаты текстовой зоны в первом кадре и смещение между первым кадром и более поздним принятым кадром для выявления соответствующей текстовой зоны в следующем кадре (например, для выявления той же текстовой зоны в последующем кадре). Затем компонент ввода данных может определить общий вес признаков для набора признаков, связанных с соответствующей текстовой зоной, и сравнить общий вес признаков для двух текстовых зон, чтобы определить, данные какой текстовой зоны лучше соответствуют целевому полю данных.
[0033] В некоторых вариантах реализации изобретения компонент ввода данных может дополнительно посимвольно сравнивать данные текстовой зоны первого кадра и данные соответствующей текстовой зоны последующего кадра. Одинаковые символы (например, символ, имеющий одинаковое положение в каждой текстовой зоне) можно сравнить с использованием уровня уверенности для символа, определенного в описанном выше процессе OCR. Если уровень уверенности распознавания символов последующего кадра выше, чем в ранее выбранном кадре, то текстовые данные, распознанные в соответствующей текстовой зоне позже принятого кадра, могут заменить текстовые данные текстовой зоны ранее выбранного кадра. Этот процесс можно повторить для каждого символа текстовой зоны, чтобы определить текстовые данные, которые наиболее точно отображают данные целевого поля данных.
[0034] В некоторых вариантах реализации изобретения компонент ввода данных может дополнительно рассматривать несколько раз один и тот же символ в соответствующей текстовой зоне в разных кадрах. Если при этом один и тот же символ был распознан с таким же результатом в нескольких предыдущих кадрах, и только для последующего кадра получен другой результат, то компонент ввода данных может посчитать это ошибкой распознавания символа и исключить отличающийся символ из рассмотрения. Поэтому если символ распознан с одинаковым результатом несколько раз, то можно сохранить его как наиболее подходящий символ (например, символ, который наиболее точно соответствует символу в том же положении в целевом поле данных) независимо от уровня уверенности для символа. Компонент ввода данных может сохранить в хранилище данных эту информацию, а также другую статистическую информацию, связанную с распознаванием символов, которая будет использоваться для сравнения с данными, полученными из следующих кадров.
[0035] Если компонент ввода данных определяет, что данные в соответствующей текстовой зоне следующего кадра обеспечивают лучшее соответствие целевому полю данных в отношении набора признаков, связанного с целевым полем данных, то данные из выделенной текстовой зоны предыдущего кадра могут быть обновлены или заменены. В некоторых вариантах реализации изобретения компонент ввода данных может сначала определить, что значение общего веса признаков для соответствующей текстовой зоны больше, чем общий вес признаков для выбранной текстовой зоны предыдущего кадра. Затем компонент ввода данных может заменить данные выбранной текстовой зоны данными соответствующей текстовой зоны, и после этого сохранить данные соответствующей текстовой зоны в хранилище данных как контент, который более точно соответствует целевому полю данных. В некоторых вариантах реализации изобретения логика обработки может сохранять данные соответствующей текстовой зоны в памяти мобильного устройства. При ином подходе логика обработки может сохранить данные соответствующей текстовой зоны в постоянной памяти мобильного устройства.
[0036] Затем компонент ввода данных может предоставить отображаемое поле, которое включает данные выявленной текстовой зоны для представления в интерфейсе пользователя. Поэтому каждый кадр, полученный компонентом ввода данных, может дополнительно уточнять текстовые данные кадра, которые лучше соответствуют полю данных физического документа. Отображаемое поле может постоянно обновляться после обработки каждого позднее принятого кадра видеопотока, пока пользователь не подтвердит, что текстовые данные в отображаемом поле являются правильными.
[0037] Как уже отмечалось выше, пользователь может подтвердить правильность данных путем ввода информации в интерфейсе пользователя. Например, пользователь может нажать кнопку в пользовательском интерфейсе приложения. Затем компонент ввода данных может получить подтверждение от пользователя, которое указывает, что данные выявленной текстовой зоны в отображаемом поле соответствуют полю данных физического документа. Если эти данные не совпадают, то пользователь может продолжить указывать перекрестьем видоискателя на целевое поле данных, чтобы повторить этот процесс. Если компонент ввода данных не получил подтверждение в течение определенного периода времени, который соответствует заранее определенному порогу, то процесс может автоматически выбрать следующий кадр для обработки. Если компоненту ввода данных не удается определить точное совпадение для поля данных, то пользователь может отказаться от дальнейших попыток выявления целевого поля данных и ввести текстовые данные вручную.
[0038] Затем данные выявленной текстовой зоны можно сохранить в хранилище данных как правильные данные. В некоторых вариантах реализации изобретения логика обработки может сохранять текстовые данные выявленной текстовой зоны в локальной постоянной памяти мобильного устройства. При альтернативном подходе логика обработки может передавать данные выявленной текстовой зоны на сервер для записи в базе данных или в сетевом хранилище данных. Затем компонент ввода данных может повторить весь процесс для любых дополнительных полей данных физического документа, которые должны быть введены. После выявления всех полей данных и записи проверенных данных собранные из всех полей данные можно сохранить в виде единой коллекции для последующего использования другим приложением в мобильном устройстве. При альтернативном подходе набор данных может передаваться на сервер для обработки другим приложением или системой.
[0039] Таким образом, аспекты настоящего изобретения могут устранить необходимость предварительного формирования цифрового шаблона и использования оборудования для специализированного ввода данных из физических документов. Более конкретно, аспекты настоящего изобретения позволяют легко захватывать, распознать и проверять поля данных физического документа, используя видеопоток мобильного устройства.
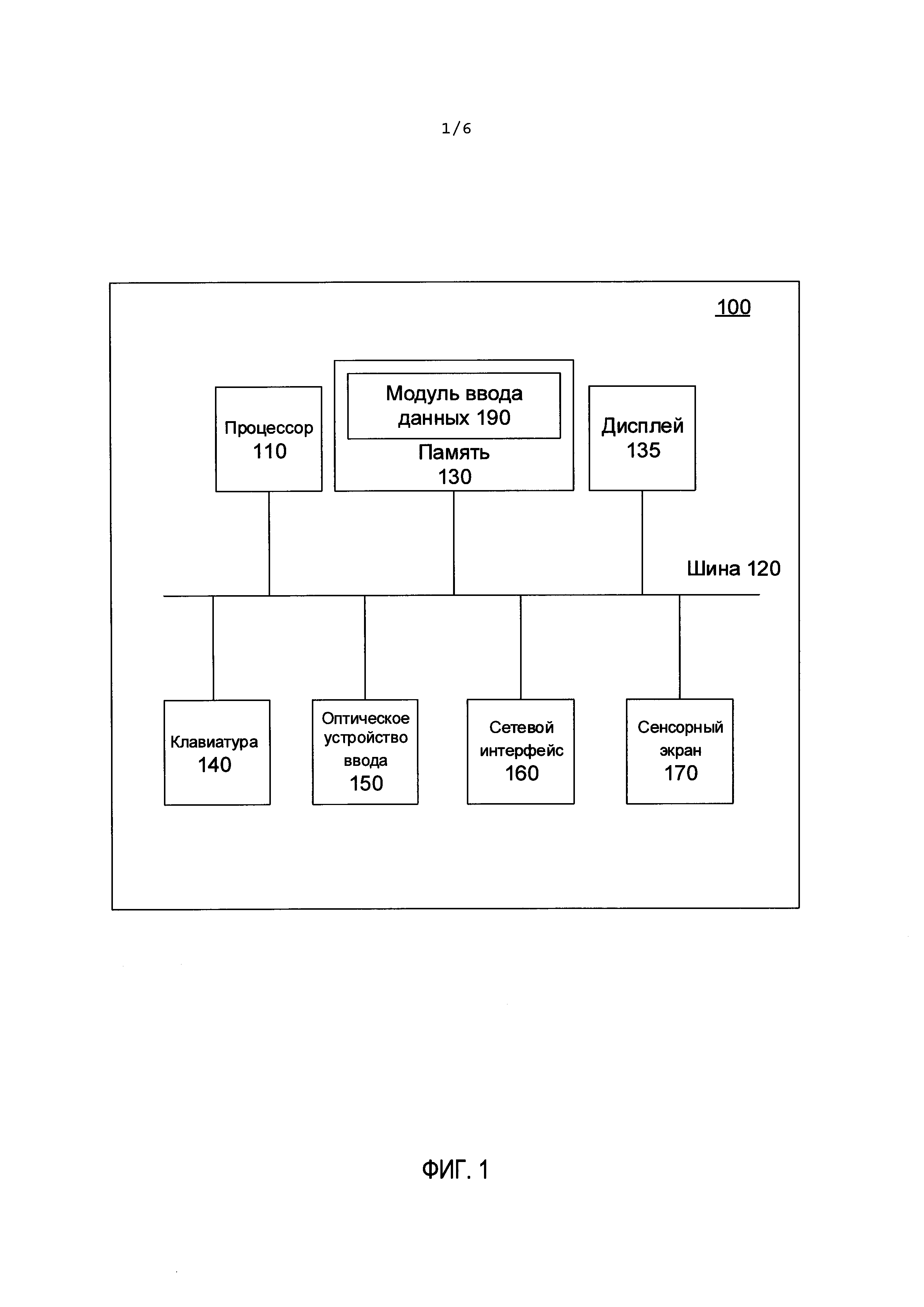
[0040] На Фиг. 1 показана схема компонентов верхнего уровня для примера архитектуры вычислительного устройства в соответствии с одним или несколькими аспектами настоящего изобретения. В иллюстративных примерах вычислительное устройство 100 может представлять собой разнообразные вычислительные устройства, включая планшетный компьютер, смартфон, ноутбук, фотокамеру, видеокамеру и т.д.
[0041] Вычислительное устройство 100 может содержать процессор 110, подключенный к системной шине 120. Другие устройства, подключенные к системной шине 120, могут включать память 130, дисплей 135 с сенсорным экраном 170, клавиатуру 140, сетевой интерфейс 160 и оптическое устройство ввода 150. В этом документе термин «подключенный» относится к устройствам, которые соединены электрически или подключены через один или несколько интерфейсных устройств, адаптеров и т.д.
[0042] Процессор 110 может представлять собой одно или несколько устройств обработки, включая универсальные процессоры и (или) специализированные процессоры. Память 130 может включать одно или несколько устройств энергозависимой памяти (например, микросхем ОЗУ), одно или несколько устройств энергонезависимой памяти (например, микросхем ПЗУ или EEPROM) и одно или несколько запоминающих устройств (например, оптические или магнитные диски). Оптическое устройство ввода 150 может представлять собой и (или) содержать одну или более камер, сканеров, считывателей штрих-кодов и (или) любых других устройств, способных формировать изображения документа.
[0043] В некоторых вариантах реализации изобретения вычислительное устройство 100 может содержать сенсорный экран 170, выполненный в виде сенсорной области ввода и (или) чувствительной поверхности, наложенной на дисплей 135. Пример вычислительного устройства, в котором реализованы аспекты настоящего изобретения, будет рассмотрен более подробно ниже при описании Фиг. 6.
[0044] В некоторых вариантах реализации изобретения память 130 может хранить команды модуля ввода данных 190 для облегчения захвата видео в сценарии ввода данных, как описано выше, а также более подробно ниже со ссылкой на Фиг. 3-6. В качестве иллюстративного примера модуль ввода данных 190 может быть реализован в виде функции, которая вызывается через интерфейс пользователя другого приложения (например, приложения сканирования документов). При альтернативном подходе модуль 190 может быть реализован в виде автономного приложения.
[0045] На Фиг. 2 показан пример графического интерфейса пользователя (GUI) мобильного устройства 220 для захвата видео в сценарии ввода данных. GUI мобильного устройства 220 может представлять собой автономное приложение, компонент интерфейса пользователя для менеджера документов или т.п. Например, GUI мобильного устройства 220 может быть предоставлен пользователю модулем ввода данных 190, показанным на Фиг. 1; это описано подробно ниже со ссылкой на Фиг. 3-6.
[0046] Мобильное устройство 220 может включать приложение, настроенное для захвата счета 210 с помощью камеры мобильного устройства. Как показано на Фиг. 2, это приложение может отображать GUI в мобильном устройстве 220, чтобы помочь пользователю выявить поле промежуточного итога в счете 210. Затем приложение может активировать камеру, чтобы начать получать кадры видеопотока через камеру мобильного устройства 220. Кадры видеопотока могут отображаться пользователю с помощью дисплея 230. Перекрестье 240 может представляться приложением на дисплее в виде визуального средства, помогающего пользователю определить целевое поле данных (в данном случае поле промежуточного итога) счета 210. Могут быть выявлены текстовые зоны отображаемого на дисплее принятого кадра. Могут быть определены и проанализированы данные выявленных текстовых зон, причем данные выявленной текстовой зоны 250 могут быть выбраны в качестве данных, которые соответствуют полю промежуточного итога на основании признаков, связанные с полем данных Subtotal (Промежуточный итог) в настройках этого приложения. Затем приложение может представить данные выявленной текстовой зоны 250 в отображаемом поле 260 для подтверждения пользователем. Пользователь может подтвердить данные отображаемого поля 260, нажав кнопку Done (Готово), отображаемую на дисплее мобильного устройства 220.
[0047] На Фиг. 3 приведена блок-схема примера способа 300 для захвата видео в сценарии ввода данных. Этот способ может осуществляться логикой обработки, которая может содержать аппаратные средства (электронные схемы, специализированную логику и т.д.), программное обеспечение (например, выполняться в вычислительной системе общего назначения или в специальной машине) или комбинацию первого и второго. В одном иллюстративном примере способ 300 может выполняться модулем ввода данных 190 на Фиг. 1. При альтернативном подходе некоторые или все способы 300 могут выполняться другим модулем или машиной. Следует отметить, что блоки, изображенные на Фиг. 3, могут выполняться одновременно или в порядке, отличающемся от показанного порядка.
[0048] В блоке 301 логика обработки может получать информацию для выявления поля данных в физическом документе. Эта информация может включать имя поля содержащего данные (например, название компании, банковский идентификационный код (БИК), номер счета, назначение платежа и сумму платежа), а также тип данных, общий для этого поля (например, адрес, время, дата, сумма, наименование, код, текст, число и т.д.), количество символов пробелов, дополнительные правила, позволяющие верифицировать распознанное поле данных (например, словари, регулярные выражения, контрольные суммы и т.д.) и т.п. Например, пользователь может запустить приложение в мобильном телефоне с камерой, и логика обработки может получать информацию для выявления поля данных в физическом документе. Затем на основании полученной информации логика обработки может вызывать интерфейс пользователя в мобильном телефоне, чтобы помочь пользователю выявить поле данных в физическом документе. В качестве иллюстративного примера интерфейс пользователя может представлять собой графический индикатор на экране мобильного устройства (например, перекрестие, целевой значок и т.д.), чтобы помочь пользователю выявить поле данных в физическом документе. Логика обработки может запросить пользователя разместить перекрестие видоискателя мобильного устройства на конкретном поле данных документа для ввода.
[0049] В блоке 302 логика обработки может получать видеопоток (например, после того, как пользователь включит камеру устройства пользователя). Видеопоток может состоять из множества кадров, причем каждый кадр может включать часть физического документа, содержащего поле данных документа. Кадр может содержать контент (например, изображение), отображаемый на экране мобильного устройства, полученный с помощью видоискателя камеры. Кадр может передаваться в режиме реального времени без записи видео, захвата изображения или сохранения изображения в памяти или в постоянном хранилище данных. Видоискатель может поддерживать передачу видеоданных с камеры мобильного устройства на дисплей в реальном времени, показывая снятое изображение.
[0050] В блоке 303 логика обработки может выбрать кадр из множества кадров в видеопотоке. В некоторых вариантах реализации изобретения кадры, представленные в видоискателе мобильного устройства, могут выбираться с заданной частотой. Например, кадры могут выбираться из видеопотока с частотой каждый 10-й кадр в секунду. Также можно использовать другие частоты (например, каждый первый, второй, четвертый, шестой кадр в секунду и т.д.). Кроме того, можно выбрать кадр, при фокусировке камеры мобильного на захватываемом объекте (например, часть физического документа, содержащая поле данных) в течение определенного периода времени (например, 1/2 секунды, одной секунды, двух секунд и т.д.).
[0051] В блоке 304 логика обработки может проанализировать кадр, чтобы выявить одну или несколько текстовых зон в этом кадре. Текстовые зоны можно обнаружить, например, используя идентификацию связанных компонентов, а затем сгруппировать их в потенциальные слова. При альтернативном подходе текстовые зоны можно обнаружить, используя любой подобный метод выявления текстовых зон на изображении.
[0052] В блоке 305 логика обработки может обрабатывать выявленные текстовые зоны. Для обработки выявленных текстовых зон логика обработки может определять данные в каждой выявленной текстовой зоне (например, с помощью OCR). Данные каждой выявленной текстовой зоны могут включать текстовые данные (результат OCR текстовой зоны) и значения признаков для текстовых данных. Затем логика обработки может анализировать данные выявленных текстовых зон в кадре, чтобы выбрать текстовую зону, данные которой соответствуют набору признаков, связанному с полем данных. В иллюстративном примере логика обработки может обрабатывать текстовые зоны, как описано ниже со ссылкой на Фиг. 4.
[0053] В блоке 306 логика обработки может сравнивать данные выявленной текстовой зоны, которая соответствует набору признаков, связанных с целевым полем данных, с данными текстовой зоны (текстовых зон) принятого позднее кадра. Логика обработки может произвести такое сравнение для определения того, содержит ли последующий кадр текстовую зону, данные которой более точно соответствуют целевому полю данных, чем в ранее принятом кадре. В блоке 307 логика обработки может обновить данные выявленной текстовой зоны, которые соответствуют набору признаков, связанных с целевым полем данных, если данные текстовой зоны (текстовых зон) позже принятого кадра лучше соответствуют целевому полю с учетом набора признаков. В иллюстративном примере логика обработки может сравнивать данные дополнительных текстовых зон предыдущего кадра с данными соответствующей текстовой зоны (соответствующих текстовых зон) последующего кадра и обновлять данные дополнительно определенной текстовой зоны (определенных текстовых зон), как описано ниже со ссылкой на Фиг. 5. Слово «дополнительный» относится ко всем выявленным текстовым зонам, за исключением одной зоны, данные которой в настоящее время рассматриваются в качестве кандидата на наилучшее соответствие.
[0054] В блоке 308 логика обработки может отображать в интерфейсе пользователя данные выявленной текстовой зоны, соответствующие набору признаков целевого поля данных. Отображаемые данные представляют собой наилучшее соответствие целевому полю данных (например, на основе соответствующего суммарного веса признаков). Данные в отображаемом поле могут постоянно обновляться при обработке каждого позже принятого кадра из видеопотока до тех пор, пока пользователь не подтвердит, что данные в отображаемом поле представляют собой правильные данные.
[0055] В блоке 309 логика обработки может получить подтверждение пользователя через интерфейс пользователя, что указывает на то, что данные выявленной текстовой зоны в отображаемом поле соответствует полю данных физического документа. Например, пользователь может нажать кнопку в пользовательском интерфейсе приложения. В блоке 310 логика обработки может сохранить данные выявленной текстовой зоны в хранилище данных. В некоторых вариантах реализации изобретения логика обработки может сохранять данные выявленной текстовой зоны в локальную постоянную память мобильного устройства. При альтернативном подходе логика обработки может передавать данные выявленной текстовой зоны на сервер для записи в базе данных или в сетевом хранилище данных. После блока 310 показанный на Фиг. 3 способ завершает работу.
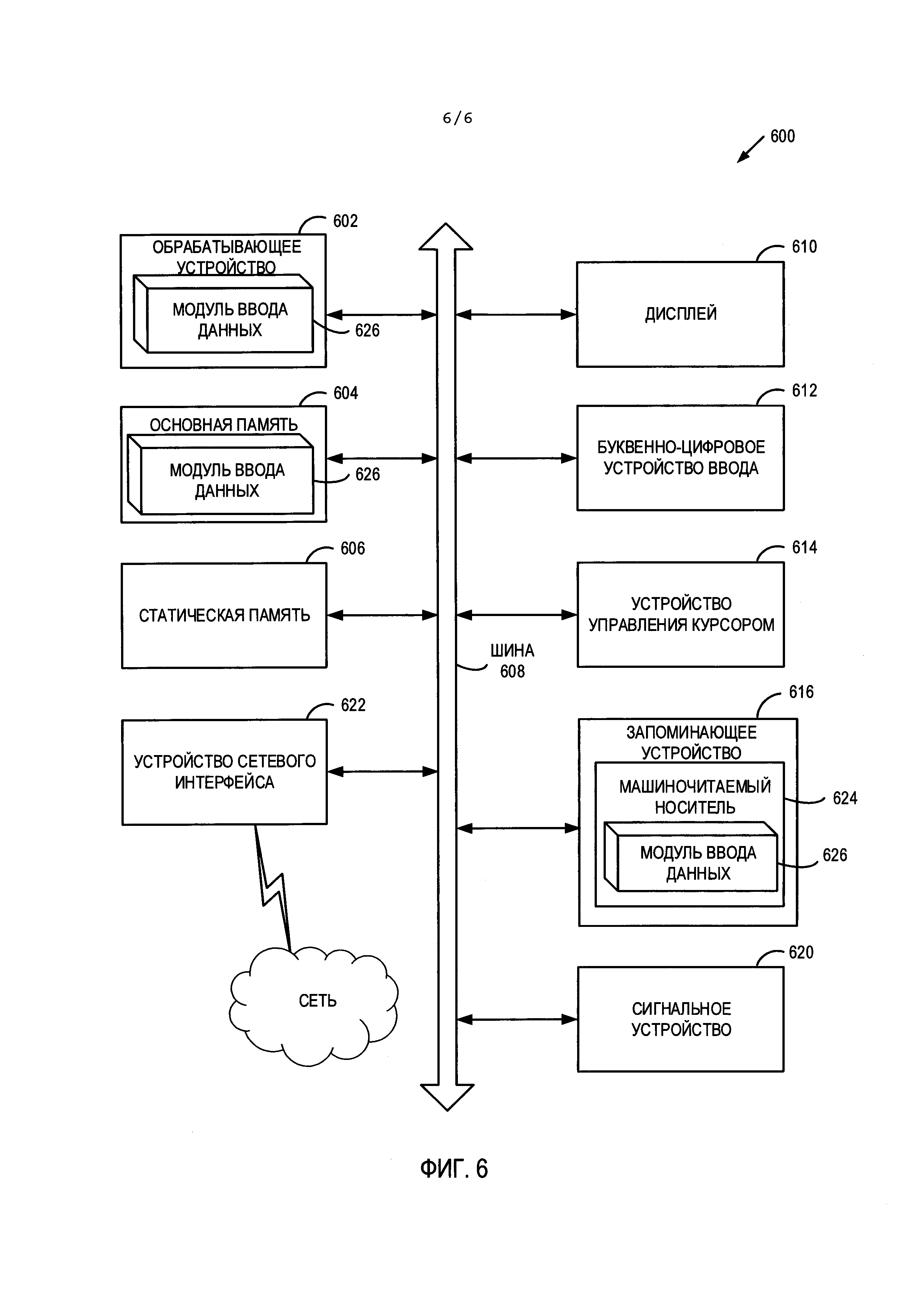
[0056] На Фиг. 4 приведена блок-схема примера способа 400 обработки текстовых зон, содержащихся в кадре. Этот способ может осуществляться логикой обработки, которая может содержать аппаратные средства (электронные схемы, специализированную логику и т.д.), программное обеспечение (например, выполняться в вычислительной системе общего назначения или в специальной машине) или комбинацию первого и второго. В одном иллюстративном примере способ 400 может осуществляться модулем ввода данных 190, показанном на Фиг. 1. При альтернативном подходе способ 400 может осуществляться полностью или частично другим модулем, или другой машиной. Следует отметить, что блоки, показанные на Фиг. 4, могут выполняться одновременно или в порядке, отличном от показанного порядка.
[0057] В блоке 401 логика обработки может определить текстовые данные каждой текстовой зоны, используя OCR. При этом изображение текстовой зоны может быть преобразовано в текстовые данные (например, в строку кодов, используемых для представления символов текстовой зоны). Полученные текстовые данные могут включать гипотезу для каждого символа, уровень уверенности гипотезы, а также расположение каждого символа в кадре (например, координаты текста в кадре).
[0058] В блоке 402 логика обработки может определять значения признаков для набора признаков для текстовых данных каждой текстовой зоны в кадре. В блоке 403 логика обработки может определять вес признака для значения каждого признака. Значение веса может указывать относительную важность признака в выявлении текстовой зоны, данные которой могут соответствовать целевому полю данных. Например, близости текстовой зоны к перекрестию может быть приписан больший вес, так как можно ожидать, что когда камера получает видеопоток, пользователь установит перекрестие на целевом поле данных физического документа. При ином подходе формату данных может быть приписан больший вес, чем близости, если в кадре имеется большое количество текстовых зон, только одна из которых по-видимому имеет правильный формат.
[0059] На этапе 404 логика обработки может определять общий вес признака для каждого набора значений признаков. Общий вес признаков можно определить путем суммирования весов отдельных значений признаков, связанных с каждой текстовой зоной. В блоке 405 логика обработки может выбрать данные текстовой зоны, связанные с общим весом признака, имеющим наибольшее значение (например, имеющим максимальное значение). Выявленная текстовая зона с наибольшим общим весом признака может быть выбрана в качестве текстовой зоны, которая лучше всего соответствует целевому полю данных физического документа (т.е. «лучшее» соответствие для принятого кадра). Затем в блоке 406 логика обработки может сохранить выбранные текстовые данные и связанные с ними признаки выявленной текстовой зоны в качестве кандидата на наилучшее совпадение. В блоке 408 логика обработки может сохранить текстовые данные и признаки каждой дополнительной текстовой зоны, выявленной в кадре. В блоках 406 и 407 логика обработки может сохранить информацию в хранилище данных для использования при сравнении с ранее полученными кадрами, а также кадрами, получаемыми из видеопотока позднее. Хранилище данных может представлять собой постоянную память мобильного устройства, память мобильного устройства или сетевое устройство хранения данных сервера, взаимодействующего с мобильным устройством. После блока 407 показанный на Фиг. 4 метод завершается.
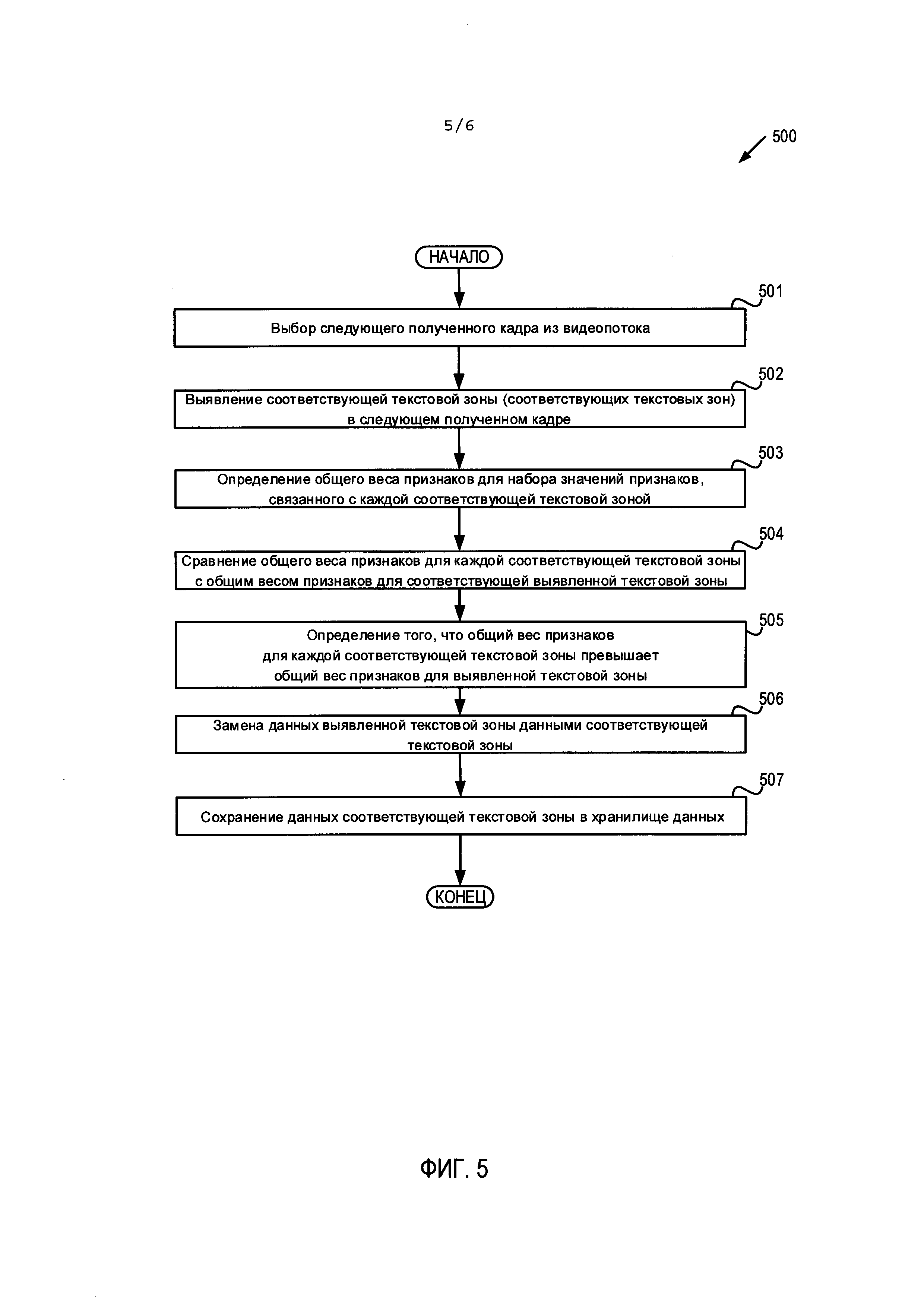
[0060] На Фиг. 5 приведена блок-схема примера способа 500 для обновления данных одной или нескольких выявленных текстовых зон данными одной или нескольких соответствующих текстовых зон последующих кадров. Этот способ может осуществляться логикой обработки, которая может содержать аппаратные средства (электронные схемы, специализированную логику и т.д.), программное обеспечение (например, выполняться в вычислительной системе общего назначения или в специальной машине) или комбинацию первого и второго. В одном иллюстративном примере метод 500 может осуществляться модулем ввода данных 190, показанным на Фиг. 1. При альтернативном подходе некоторая часть способа 500 или весь этот способ может выполняться другим модулем или машиной. Следует отметить, что блоки, изображенные на Фиг. 5, могут выполняться одновременно или в порядке, отличающемся от показанного порядка.
[0061] В блоке 501 логика обработки может выбрать кадр, полученный из видеопотока позднее. Позднее принятый кадр может быть следующим кадром в видеопотоке. При альтернативном подходе принятый позже кадр может быть определен с использованием их частоты (например, каждый второй, четвертый, шестой кадр в секунду и т.д.).
[0062] В блоке 502 логика обработки может выявить соответствующую текстовую зону (соответствующие текстовые зоны) в полученном позже кадре. В некоторых вариантах реализации соответствующая текстовая зона (соответствующие текстовые зоны) может быть выявлена при повторении процесса выявления, описанного выше со ссылкой на Фиг. 3. При альтернативном подходе логика обработки может использовать координаты каждой выявленной текстовой зоны в первом кадре и смещение между первым кадром и позже принятым кадром, чтобы определить соответствующую текстовую зону в последующем кадре (например, для выявления той же текстовой зоны в последующем кадре).
[0063] В блоке 503 логика обработки может для каждой соответствующей текстовой зоны определить общий вес признаков для набора признаков, связанного с соответствующей текстовой зоной. В блоке 504 для каждой выявленной текстовой зоны из предыдущего кадра логика обработки может сравнить общий вес признаков для соответствующей текстовой зоны с общим весом признаков для выявленной текстовой зоны предыдущего кадра. В блоке 506 в каждой выявленной текстовой зоне из предыдущего кадра логика обработки может заменить данные выявленной текстовой зоны на данные соответствующей текстовой зоны, если значение общего веса признаков для соответствующей текстовой зоны больше значения общего веса признаков для выбранной текстовой зоны предыдущего кадра, определенного в блоке 505. В блоке 507 логика обработки может сохранить данные соответствующей текстовой зоны (соответствующих текстовых зон) в хранилище данных. В некоторых вариантах реализации логика обработки может сохранять данные соответствующей текстовой зоны (соответствующих текстовых зон) в памяти мобильного устройства. При альтернативном подходе логика обработки может сохранять данные соответствующей текстовой зоны (соответствующих текстовых зон) в постоянной памяти мобильного устройства. После блока 507 показанный на Фиг. 5 способ завершается.
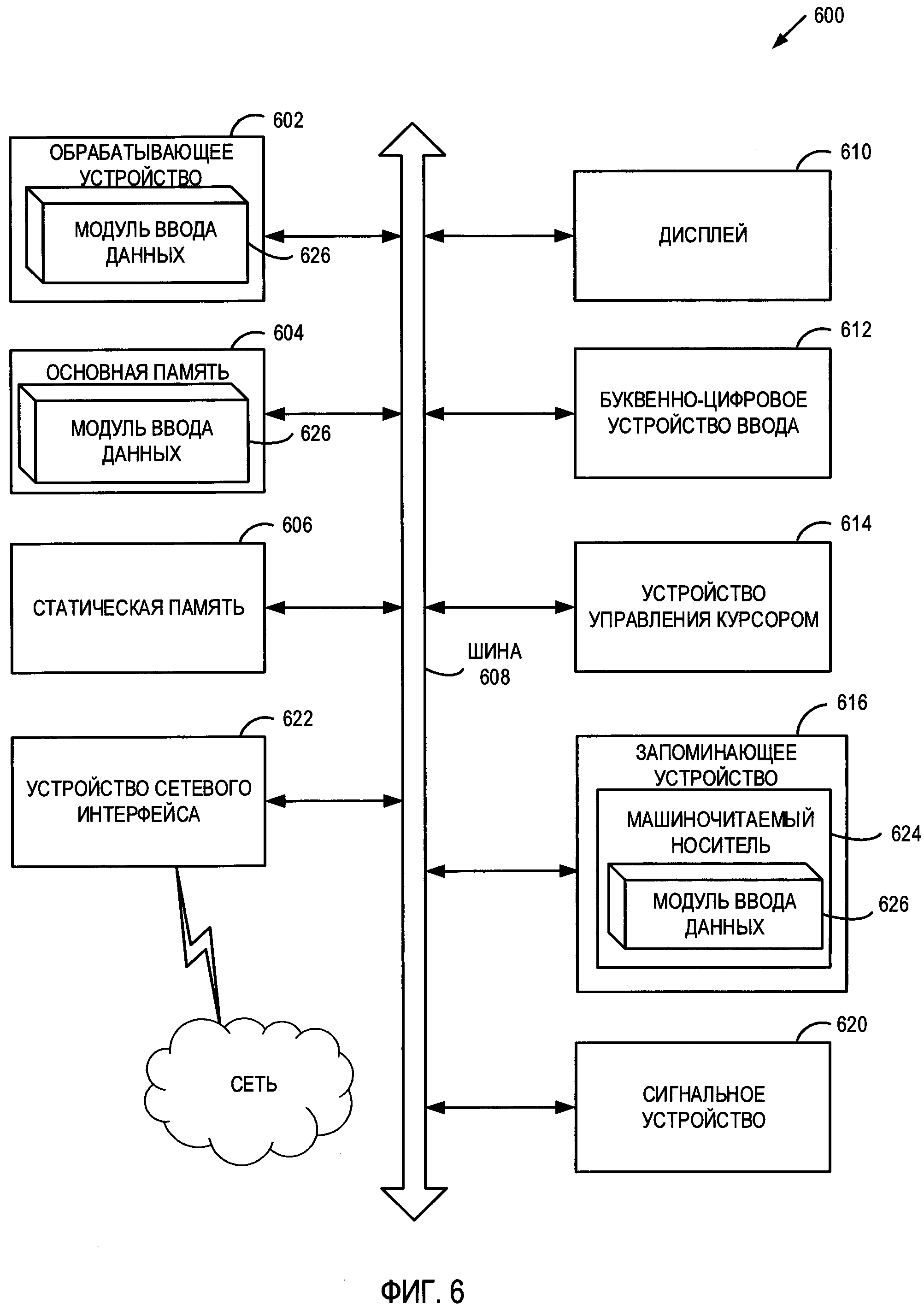
[0064] На Фиг. 6 приведен пример вычислительной системы 600, которая может выполнять любой описанный здесь способ или несколько таких способов. В одном примере вычислительная система 600 может соответствовать вычислительному устройству 100, показанному на Фиг. 1. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет, вычислительная система может играть роль сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то, что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для выполнения любого из описанных здесь способа или нескольких таких способов.
[0065] Пример вычислительной системы 600 включает устройство обработки 602, основную память 604 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например, синхронное DRAM (SDRAM)), статическую память 606 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 616, которые взаимодействуют друг с другом по шине 608.
[0066] Устройство обработки 602 представляет собой одно или несколько универсальных устройств обработки, таких как микропроцессор, центральный процессор и т.п. В частности, устройство обработки 602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборов команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 602 также может представлять собой одно или несколько устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Устройство обработки 602 настроено на модуль ввода данных 626 для выполнения описанных здесь операций и этапов (например, соответствующих методов, показанных на Фиг. 3-5 и т.д.).
[0067] Вычислительная система 600 может дополнительно включать устройство сопряжения с сетью 622. Вычислительная система 600 может также включать видео дисплей 610 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 612 (например, клавиатуру), устройство управления курсором 614 (например, мышь) и устройство для формирования сигналов 620 (например, громкоговоритель). В одном иллюстративном примере видео дисплей 610, устройство буквенно-цифрового ввода 612 и устройство управления курсором 614 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0068] Запоминающее устройство 616 может включать машиночитаемый носитель 624, в котором хранится модуль ввода данных 626 (например, соответствующий способам, показанным на Фиг. 3-5 и т.д.), отражающий одну или несколько методологий или функций, описанных в данном документе. Кроме того, модуль ввода данных 626 может находиться полностью или по меньшей мере частично в основной памяти 604 и (или) в устройстве обработки 602 во время выполнения способа вычислительной системой 600, основной памятью 604 и устройством обработки 602, также представляющими собой машиночитаемую среду. Модуль ввода данных 626 может дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 622.
[0069] В то время как машиночитаемый носитель данных 624 показан в иллюстративных примерах как единый носитель, термин «машиночитаемый носитель данных» следует понимать, как единый носитель либо множество таких носителей (например, централизованную или распределенную базу данных, и (или) соответствующие кэши и серверы), в которых хранится один или несколько наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или нескольких методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельной памяти, а также к оптическим и магнитным носителям.
[0070] Несмотря на то, что операции способов показаны и описаны в определенном порядке, порядок операций каждого способа можно изменить таким образом, чтобы некоторые операции могли выполняться в обратном порядке или так, чтобы некоторые операции могли выполняться, по крайней мере частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0071] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты осуществления станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Область применения изобретения поэтому должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0072] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники будет очевидно, что это изобретение может быть осуществлено практически без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схемы, а не детально, чтобы не усложнять описание настоящего изобретения.
[0073] Некоторые части подробного описания выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сконструирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти этапы требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и манипулировать ими. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.п.
[0074] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если специально не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «отправка», «прием», «создание», «выявление», «обеспечение», «выполнение», «определение» и т.п., относятся к действиям вычислительной системы или подобного электронного вычислительного устройства или и процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах вычислительной системы и памяти в другие данные, также представленные в виде физических величин в памяти или регистрах вычислительной системе или в других подобных устройствах хранения, передачи или отображения информации.
[0075] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей или оно может содержать универсальный компьютер, который избирательно активируется или реконфигурируется с помощью вычислительной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, например (помимо прочего): диск любого типа, в том числе гибкий диск, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0076] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании ниже. Кроме того, изложение сущности изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов излагаемого изобретения могут использоваться различные языки программирования.
[0077] Сущность изобретения может быть представлена в виде вычислительного программного продукта или программы, которая может содержать машинно-читаемый носитель с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) для выполнения процесса в соответствии с сущностью раскрываемого изобретения. Машиночитаемый носитель включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство («ПЗУ»), оперативное запоминающее устройство («ОЗУ»), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[0078] Слова «пример» или «примерный» используется здесь для обозначения использования в качестве примера отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в настоящем документе как «пример», не должна обязательно рассматриваться как предпочтительная или преимущественная по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения, включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть, если X содержит А; X включает в себя В; или X включает и А и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «an», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны как правило означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант осуществления» или «один вариант осуществления» или «реализация» или «одна реализация» не означает одинаковый вариант реализации, если такое описание не приложено. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используется как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.

Полифункциональный ступенчатый вихревой обогреватель
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Способ и система оптического распознавания символов, которые сокращают время обработки изображений, потенциально не содержащих символы
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений

