Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА ДЛЯ ГЛОБАЛЬНОЙ ИДЕНТИФИКАЦИИ В КОЛЛЕКЦИИ ДОКУМЕНТОВ
Вид РИД
Изобретение
[0001] Изобретение относится к области обработки естественного языка (Natural language processing), извлечению информации и поиску информации по коллекции документов.
УРОВЕНЬ ТЕХНИКИ
[0002] Изобретение относится к области обработки текстов на естественном языке (Natural language processing), извлечению информации и поиску информации по коллекции документов.
[0003] Поиск нужной информации в многочисленных и разнородных текстовых ресурсах неизбежно сталкивается с тем, что одно и то же явление, объект, персона, событие выражается в разных документах различным образом - с использованием разных слов, выражений, обозначений и т.п. Например, система извлечения информации должна понимать, что "Зимние Олимпийские игры 2014", "Олимпийские игры в Сочи", "Олимпиада в Сочи" и т.п. обозначают одно и то же событие, как "Юрий Гагарин", "Юрий Алексеевич Гагарин" и "первый космонавт Земли", "первый советский космонавт" отсылают к одной и той же персоне.
[0004] Для того, чтобы обеспечить надежность и полноту поиска и установить, что, например, два объекта из разных документов соответствуют одному и тому же объекту реального мира, должны быть идентифицированы свойства таких объектов, которые должны быть известны или определены. Однако, даже если какие-то идентифицирующие уникальные свойства для двух объектов определены, может оказаться, что эти объекты различны, как, например, полные тезки.
[0005] Для хранения информации об объектах в коллекции документов используются специальные модели представления данных, такие как RDF (Resource Description Framework, т.н. "среда описания ресурса"). RDF является графовой структурой, представляющей множество утверждений о сущностях, являющихся объектами реального мира (напр, персоны, организации, локации), а также факты (например, факт работы некой персоны в некоторой организации).
Каждое утверждение представлено в виде тройки {субъект, предикат, объект}, которая называется триплетом. Множество утверждений-триплетов формируют граф с вершинами, соответствующими объектам и субъектам, соединяемыми дугами - предикатами, направленными от субъектов к объектам. Такие RDF-графы могут быть построены как для отдельного предложения, так и для всего документа в коллекции документов.
[0006] Объект реального мира в коллекции ассоциируется с одним или более свойств RDF-графа, и различные копии того же объекта реального мира в различных документах могут быть охарактеризованы при помощи тех же свойств. Таким образом, задача глобальной идентификации состоит в сопоставлении объектов из текстов на естественном языке друг с другом и с объектами реального мира, и в построении RDF-графа и одного или более индекса коллекции документов таким образом, что различные объекты с идентичными свойствами представлены как один и тот же объект RDF-графа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0007] В соответствии с настоящим изобретением, представлен способ машинной идентификации одного или более объектов в документе и в хранилище документов, объектов, соответствующих одному и тому же объекту реального мира, способ, включающий: (а) поиск шаблонов для глобальной идентификации и комбинаций шаблонов для глобальной идентификации в документе; (b) поиск тех же самых шаблонов для глобальной идентификации и комбинаций шаблонов для глобальной идентификации в хранилище документов; (с) поиск пар информационных объектов, информационного объекта из документа и информационного объекта из хранилища, удовлетворяющих одним и тем же комбинациям шаблонов; (d) проверка найденных пар на непротиворечивость и выбор из них тех информационных объектов, которые могут быть объединены сохранены в хранилище в один объект; и (е) добавление информации об одном или более информационном объекте из документа в хранилище документов. При этом, если указанные информационные объекты из документа и из хранилища соответствуют одному и тому же объекту реального мира, то на этапе (е) происходит только добавление одного или более свойств информационных объектов документа в хранилище, если указанные одно или более свойств отсутствуют в хранилище.
[0008] В противном случае на этапе (е) происходит добавление одного или более информационных объектов документа в хранилище как новый информационный объект, если указанные один или более информационных объектов из документа не имеют в хранилище информационных объектов, соответствующих тому же объекту реального мира.
[0009] Способ изобретения основан на том, что шаблоны глобальной идентификации соответствуют свойствам и атрибутам объектов реального мира. А сам документ и хранилище извлеченной информации могут быть представлены в формате RDF-графов.
[0010] Способ изобретения также предусматривает использование языка SPARQL для взаимодействия с хранилищем документов. Кроме того, для найденных пар проверяется условие непротиворечивости и выполнение условия согласованности с онтологией для свойств информационных объектов.
[0011] Различные аспекты изобретения и его возможных реализаций детально представлены в нижеследующем описании. Предполагается, что черты и свойства одной из реализаций, данной в описании, могут быть распространены и на другие возможные реализации.
[0012] Данное краткое введение не является исчерпывающим и не ограничивает сферу данного описания. Все объекты, свойства и преимущества данного изобретения станут понятны из нижеследующего детального описания и сопровождающих его чертежей.
[0013] Новизна изобретения отражена в формуле изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
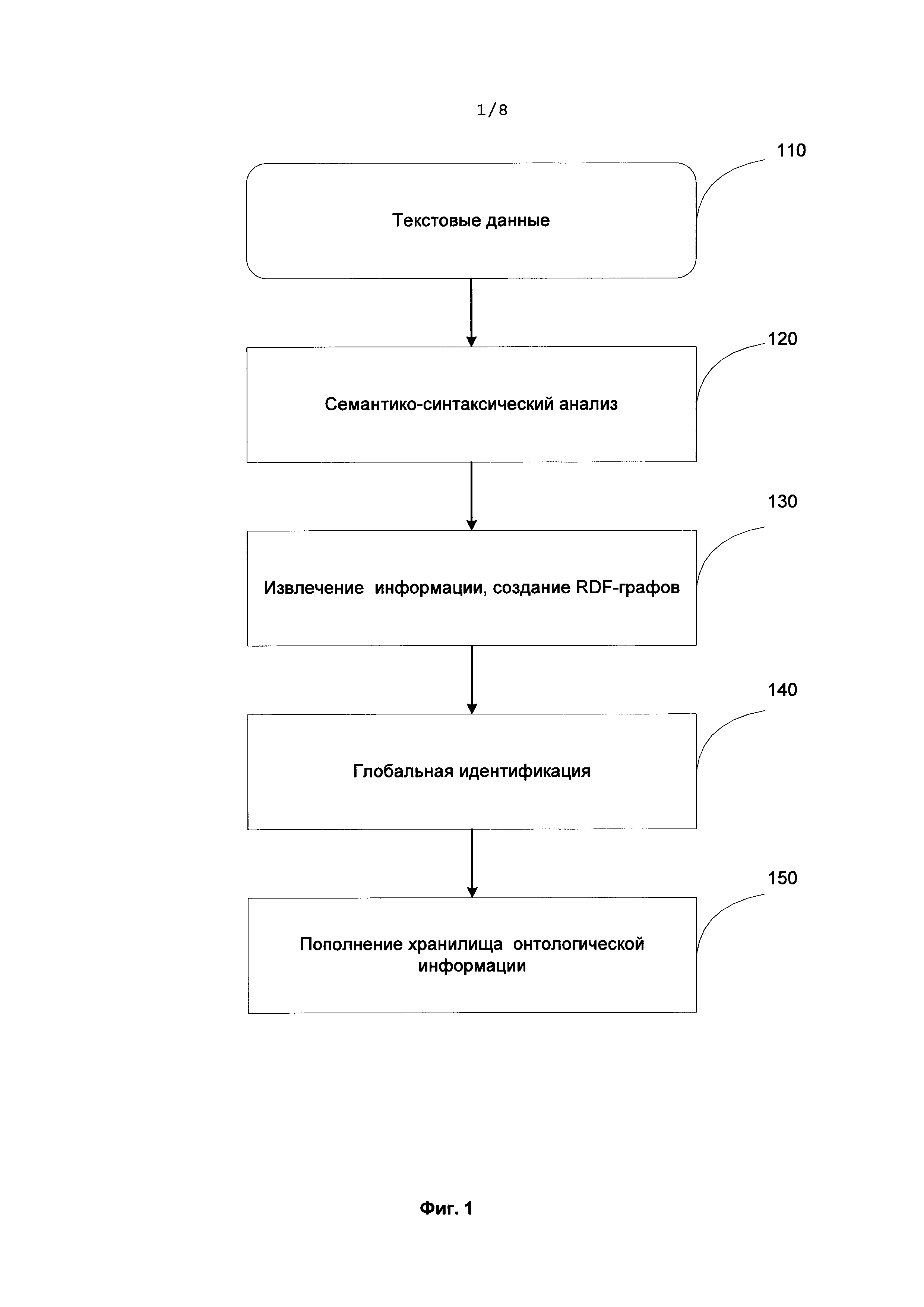
[0014] Фиг. 1 иллюстрирует процесс извлечения информации в соответствии с одним вариантом реализации изобретения.
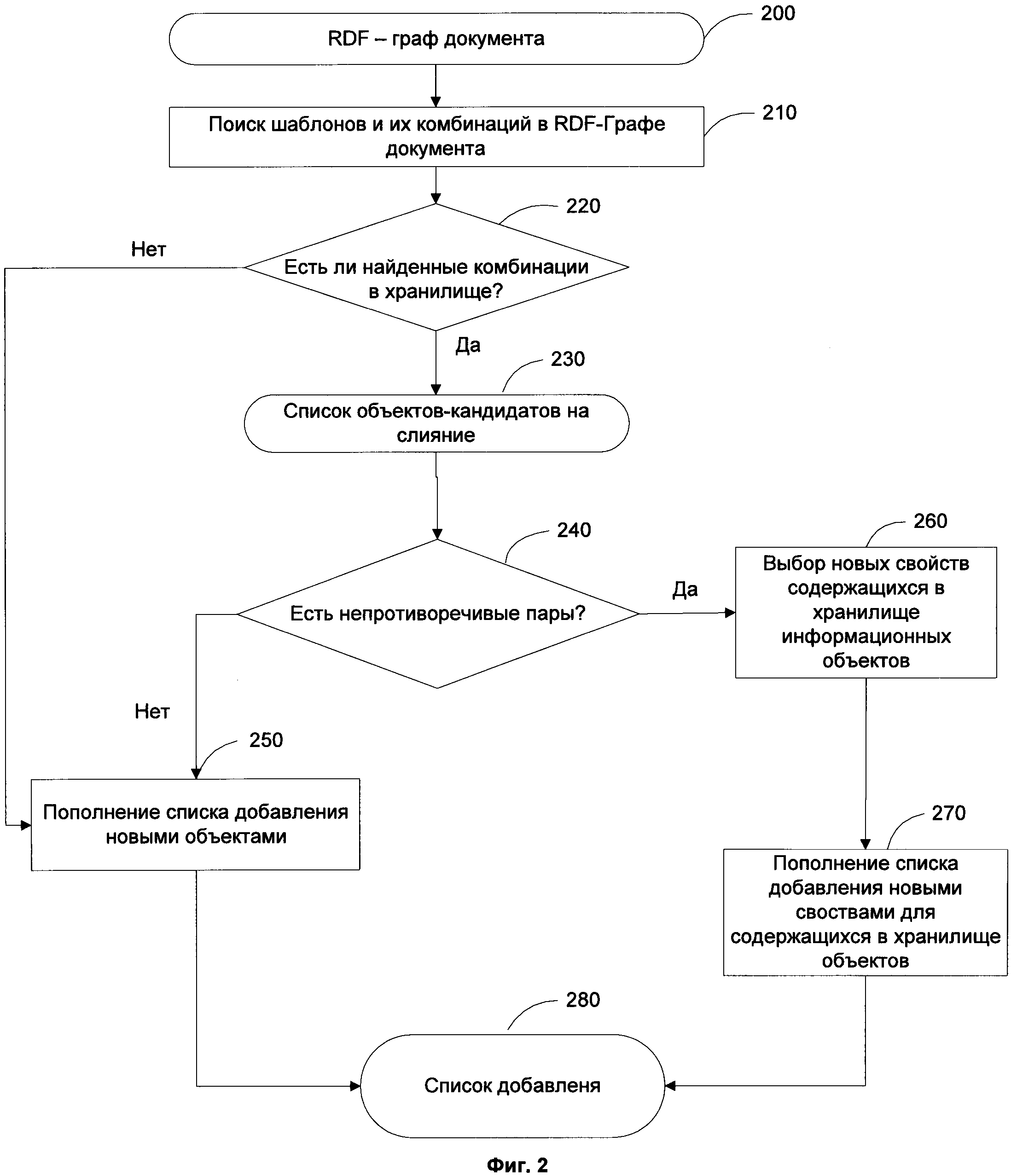
[0015] Фиг. 2 иллюстрирует процесс глобальной идентификации в соответствии с одним вариантом реализации изобретения.
[0016] Фиг. 3 содержит пример шаблона глобальной в соответствии с одним вариантом осуществления данного изобретения.
[0017] Фиг. 4 является блок-схемой процесса поиска шаблона в графе документа в соответствии с одним вариантом осуществления данного изобретения.
[0018] Фиг. 5 является блок-схемой процесса поиска комбинаций шаблонов в хранилище в соответствии с одним вариантом осуществления данного изобретения.
[0019] Фиг. 5A и 5B иллюстрируют пример поиска комбинаций шаблонов в хранилище информации в соответствии с одним вариантом осуществления данного изобретения.
[0020] Фиг. 6 является схематичным изображением вычислительной системы в соответствии с одним вариантом осуществления данного изобретения.
[0021] Изображения на рисунках упрощены для иллюстративных целей и не являются масштабированными.
[0022] Чтобы облегчить понимание, на чертежах для обозначения могут использоваться идентичные цифры для обозначения идентичных по существу элементов, встречающихся на разных чертежах. При необходимости к ним могут добавляться буквенно-цифровые индексы и/или суффиксы, чтобы различать такие элементы.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0023] Объекты, свойства и преимущества настоящего описания обсуждаются ниже в применении к выполняемой компьютером семантической идентификации искомой информации, доступной в коллекциях текстовых документов в электронной форме на одном из естественных языков.
[0024] Предусматривается, что по крайней мере частично, настоящее изобретение может применяться для анализа документов других типов (напр., мультиязычных). Будем различать объекты реального мира и их упоминания, именования, ссылки на них в текстах на естественном языке, которые ниже будем называть информационными объектами.
[0025] Глобальной идентификацией в коллекции документов называют слияние информационных объектов, относящихся к одному объекту реального мира, в процессе извлечения информации из текста (или корпуса текстов) на естественном языке для последующего слияния RDF-графов множества документов в один RDF-граф посредством слияния сопоставленных объектов. В одной реализации для достижения этой цели выполняется слияние информации из большого набора документов путем применения процесса глобальной идентификации для каждого документа и последовательного сопоставления всех документов друг с другом. Такой процесс продолжается до тех пор, пока последняя пара информационных объектов не будет "слита" в общем RDF-графе. Другая возможность заключается в слиянии информационных объектов при последовательном добавлении информационных объектов из нового документа в хранилище. Для того, чтобы указанное слияние было эффективным, информация из документов должна сохраняться в специальных структурах - RDF-графах.
[0026] Глобальная идентификация состоит в сопоставлении информационных объектов из документа с информационными объектами, уже существующими в хранилище, и в слиянии идентичных информационных объектов. Поскольку информация об объектах представлена в виде графа, задача глобальной идентификации может быть сформулирована как задача поиска идентичного подграфа и сохранение новой информации об объекте.
[0027] Глобальная идентификация реализуется с помощью шаблонов глобальной идентификации. Для определения шаблонов используется язык SPARQL. Один шаблон определяет только одно из возможных свойств информационного объекта. Потому для надежной идентификации обычно используют комбинацию шаблонов. Например, комбинация шаблонов <"First name" (Имя), "Surname" (Фамилия)> используется для идентификации информационного объекта типа "Person" (Персона). Комбинация может состоять из произвольного количества шаблонов. Все шаблоны глобальной идентификации включаются в специальную библиотеку. Она структурирована таким образом, что шаблоны, разработанные для идентификации разных объектов реального мира, хранятся раздельно.
[0028] Различные комбинации могут иметь разную степень надежности, которая определяется тремя параметрами. Первым является вес, который отражает, насколько точно комбинация может идентифицировать объекты. Вес принимает значение от 0 до 1, и чем выше это значение, тем вероятней, что два объекта представляют один объект реального мира. Другими двумя параметрами надежности являются особенность и однозначность. Особенность показывает, сколько различных значений есть у комбинации, а однозначность - как часто одно и то же значение комбинации встречается у различных объектов. Значения этих параметром могут находиться между 0 и 1. Если значение однозначности равно 0, это соответствует тому, что у объекта есть более одного значения признака, а значение особенности, равное 0 означает, что найдется более одного объекта с таким значением признака. И наоборот, если однозначность и особенность равна 1, то у признака объекта есть ровно одно значение, и существует ровно один объект с данным значением признака соответственно. Например, комбинация <"имя", "фамилия"> обладает низкой надежностью, так как найдется много различных персон, у которых будут совпадать имя и отчество, а комбинация из трех <"имя", "отчество", "фамилия"> будет иметь высокую надежность, так как полных тезок практически нет.
[0029] В одном варианте реализации надежные комбинации определяются с помощью одного или более классификатора. Классификатор обучается на размеченном корпусе текстов, запоминая, по каким комбинациям шаблонов было произведено слияние информационных объектов. Результатом обучения классификатора является набор комбинаций.
[0030] В одном варианте реализации используется один или более линейных классификаторов. Результатом его обучения является массив коэффициентов - весов, присвоенных шаблонам глобальной идентификации. Затем, при осуществлении глобальной идентификации классификатор для каждого информационного объекта сможет определить наборы шаблонов с суммой весов, превышающей заданный порог, и считать такие наборы комбинациями, по которым будет приниматься решение о слиянии.
[0031] В каждом шаблоне обязательно присутствуют переменные this и that, называемые выделенными. «This» - это имя для идентифицируемого информационного объекта. Переменная this соответствует в документе информационному объекту, являющемуся кандидатом на слияние. «That» - имя для идентифицирующего информационного объекта (или значения свойства). После сопоставления шаблона графу that может соответствовать как некоторый информационный объект из документа, так и значение простого свойства (строка, число или булевское значение true/false), по которому будет идти глобальная идентификация. Значение, соответствующее that при сопоставлении, называется значением шаблона на данном информационном объекте.
[0032] Помимо this и that шаблон могут включать и локальные переменные. Эти переменные задают информационные объекты, через которые в RDF-графе документа должны быть связаны идентифицируемый информационный объект (this) и идентифицирующий объект (that). Если удается найти такую группу информационных объектов в документе, что при замене переменных на объекты данной группы получается реальный существующий подграф из графа документа, то шаблон считается сопоставленным (или выполненным) на данном документе. Результатом поиска и сопоставления шаблонов глобальной идентификации в RDF-графе документа является список троек <this, that, шаблон>, которые носят название мэтчинг (matching). На месте переменной this в списке стоят идентификаторы информационных объектов - кандидатов на слияние, вместо переменной that стоят либо идентификаторы информационных объектов, либо конкретные значения простых свойств (строка, число, булевская переменная), в зависимости от признака, заданного шаблоном.
[0033] Коллекция документов, точнее, их RDF-графы размещаются в хранилище. Прежде чем документ будет помещен в хранилище, информация из текста должна быть извлечена и представлена с помощью структур данных, позволяющих осуществлять быстрый поиск и в то же время хранить эту информацию достаточно компактно. Сам процесс извлечения информации представляет собой довольно сложную техническую задачу и выполняется в рамках настоящего изобретения с использованием системы продукционных правил, которая, в свою очередь, работает со структурами, полученными в результате полного семантико-синтаксического анализа.
[0034] Основные шаги метода извлечения информации из документа схематично изображены на Фиг. 1. На вход системе на этапе 110 поступают текстовые данные (размеченные или не размеченные), которые подвергаются семантико-синтаксическому анализу 120. В Патенте США U.S. Patent 8,078,450 описан способ, включающий глубинный синтаксический и семантический анализ текстов на естественном языке, основанный на исчерпывающих лингвистических описаниях. Метод использует широкий спектр лингвистических описаний, как универсальных семантических механизмов, относящихся к конкретному языку, что позволяет отразить все реальные сложности языка без упрощения и искусственных ограничений, не опасаясь при этом неуправляемого роста сложности. Сверх того, указанные способы анализа основаны на принципах целостного и целенаправленного распознавания, т.е. гипотезы о структуре части предложения верифицируются в рамках проверки гипотезы о структуре всего предложения. Это позволяет избежать анализа большого множества аномалий и вариантов. Подробнее семантико-синтаксический анализ будет описан ниже.
[0035] Результаты полного семантико-синтаксического анализа затем используются в процессе извлечения информации 130, на выходе которого формируется RDF (Resource Description Framework) - граф. Модуль извлечения информации обрабатывает лес семантико-синтаксических деревьев, по одному дереву на каждое предложение исходного текста. Согласно концепции RDF извлеченные данные представляются в виде множества триплетов <субъект, предикат, объект> (<s, p, o>). Субъект - это некоторая сущность, или информационный объект, характеризующая объект реального мира. Предикат - некоторое свойство, описывающее субъект. Есть два вида предикатов (свойств): атрибуты и отношения. Атрибут - это необъектное свойство, значение которого представляется простым типом данных: строкой, числом, либо булевским значением. Отношение - это объектное свойство, значение которого представляет собой другой информационный объект, описывающий другую сущность реального мира. Объект, таким образом, есть значение данного предиката для данного субъекта, и ' может либо относится к простому типу данных (число, строка и т.п.), либо являться идентификатором другого информационного объекта. Есть различные типы информационных объектов, например, таких: Персона, Локация, Организация, Работодатель и пр. Все извлеченные из текста RDF-данные согласуются с моделью предметной области (типы информационных объектов совпадают с концептами из соответствующей онтологии), в рамках которой функционирует модуль извлечения информации.
[0036] Для добавления извлеченной из документов информации в хранилище необходима глобальная идентификация 140, целью которой является поиск информационных объектов, описывающих один и тот же объект реального мира, в RDF-графах хранилища и добавляемого документа.
[0037] Процесс глобальной идентификации завершается на этапе 150 импортированием в хранилище онтологической информации данных, извлеченных из нового документа.
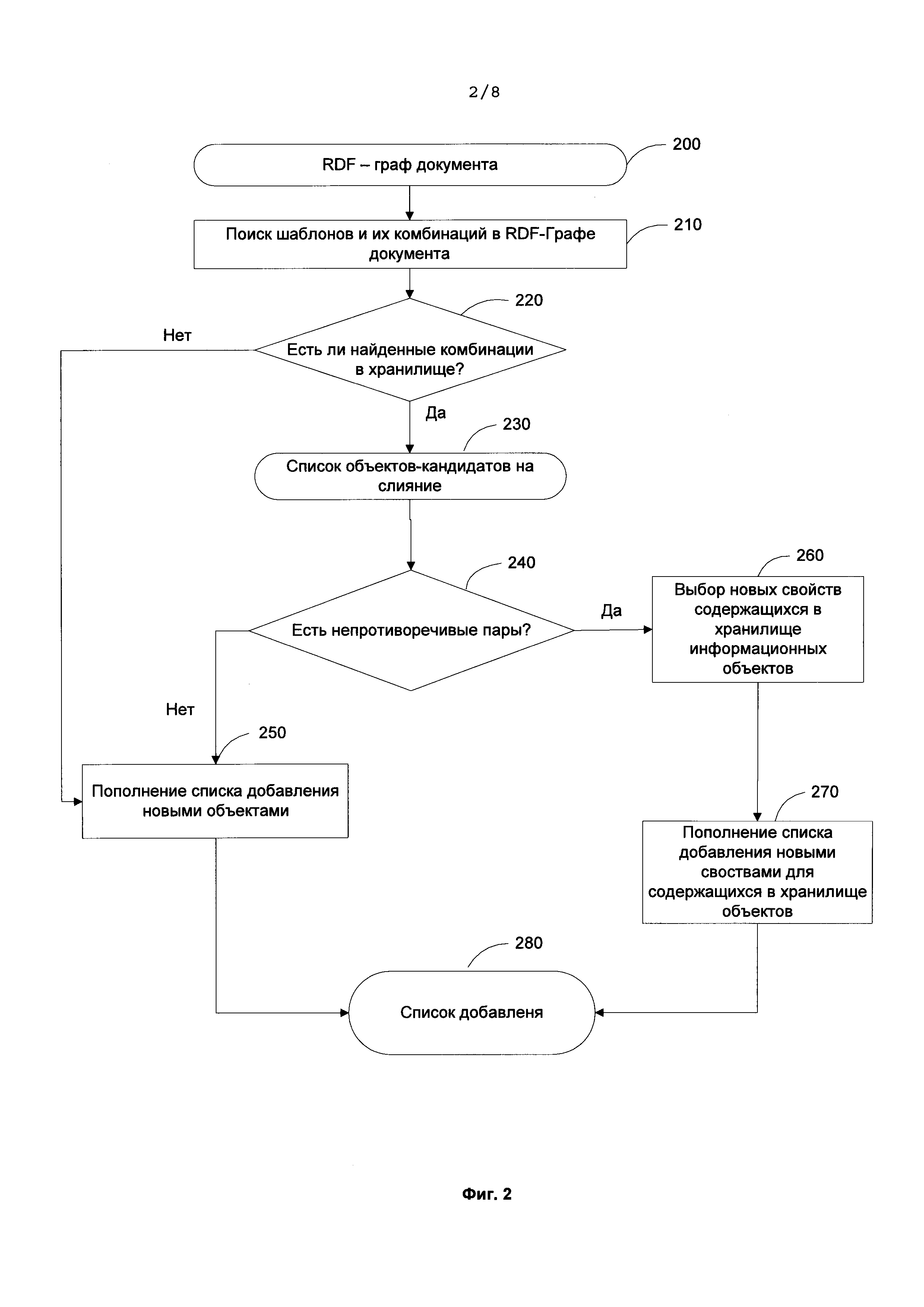
[0038] На Фиг. 2 изображена схема процесса глобальной идентификации. В описываемом методе механизм глобальной идентификации ступенчатый. То есть, идентификация запускается последовательно для каждого нового документа, добавляемого в хранилище, которое содержит уже идентифицированную коллекцию документов.
[0039] На вход процессу глобальной идентификации поступает RDF-граф документа 200. Считаем, что проведена идентификация объектов внутри одного документа, и все информационные объекты в графе различные. На первом этапе идентификации запускается поиск известных шаблонов и их комбинаций 210 в RDF-графе документа 200. Затем поиск соответствующих шаблонов и комбинаций проводится и в хранилище 220. Если соответствующие друг другу шаблоны и комбинации найдены в хранилище и документе, то составляется список объектов-кандидатов на слияние 230, которые проходят проверку на непротиворечивость 240. Непротиворечивость означает, что слияние информационных объектов не нарушает кардинальности их отношений (не нарушается согласованность с онтологией). Если пара не проходит проверку, это значит, что найденные в документе информационные объекты являются новыми, и совершается пополнение списка добавления этими новыми объектами 250. Если же проверка на непротиворечивость 240 пройдена, это означает, что объект из документа уже содержится в хранилище, и в него только необходимо добавить новые свойства данного объекта, извлеченные из документа. Эти новые свойства выбираются 260 после чего помещаются в список добавления 270. Если комбинации, найденные в RDF-графе документа во время выполнения этапа 220, не имеют соответствующих комбинаций в хранилище, это означает, что документ содержит новые информационный объекты, и эти информационные объекты должны быть добавлены в список для пополнения 250. На последнем этапе формируется общий список добавления 270. Он содержит новые информационные объекты из документа, а также новые свойства уже существующих в хранилище объектов.
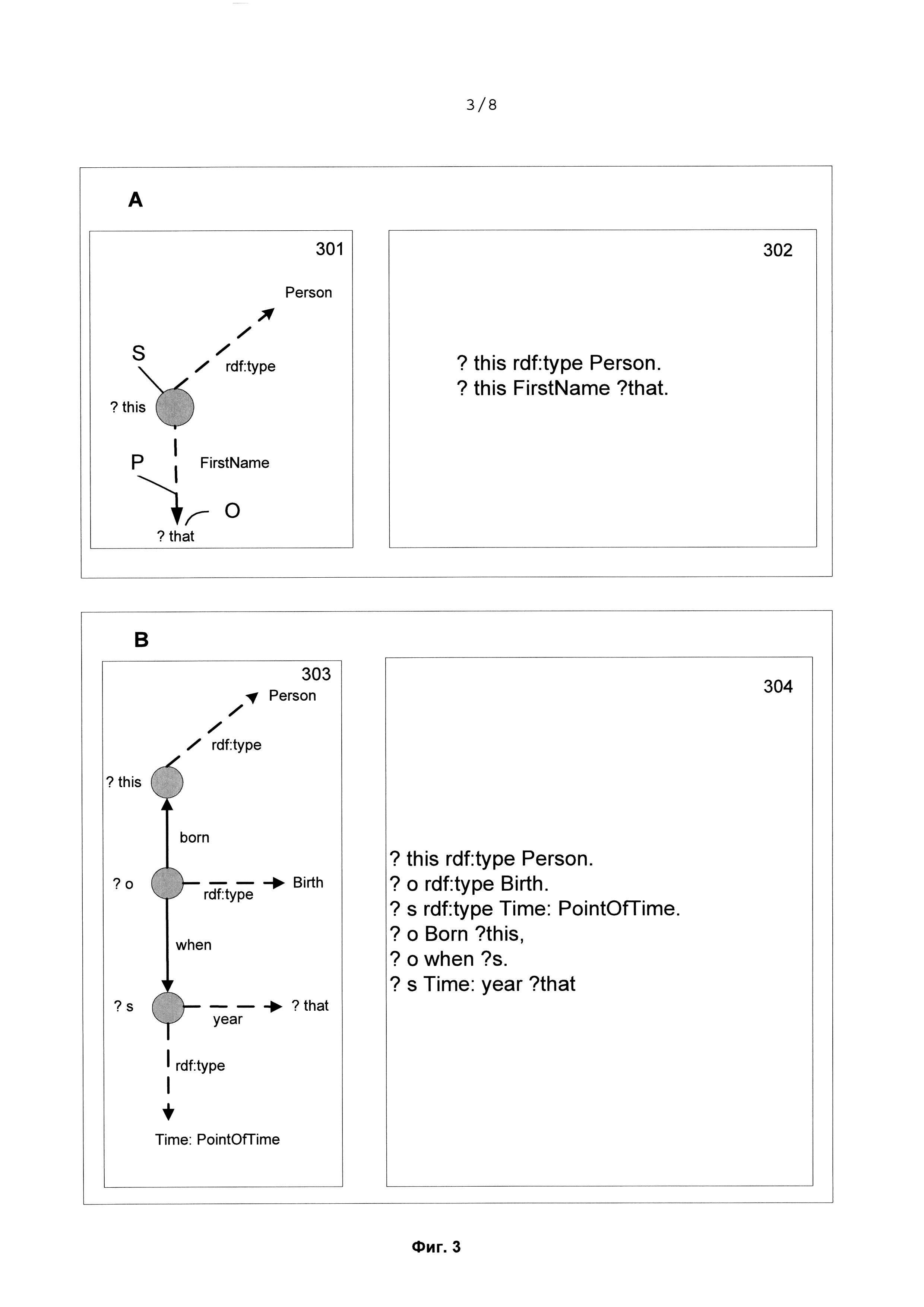
[0040] Примеры на Фиг. 3 позволяют более подробно проиллюстрировать шаблон глобальной идентификации. Шаблон А задает свойство информационного объекта типа <Person> "иметь конкретное имя". Шаблон имеет графовое представление 301 и триплетное представление 302. Для описания указанного признака достаточно задать тип информационного объекта (rdf:type <Person>) и необъектное свойство FirstName. Пунктирные стрелки соответствуют необъектным свойствам (атрибутам), направление именованной стрелки задается от субъекта s к объекту о триплета, имя стрелки соответствует предикату р.
[0041] Шаблон В более сложный, он задает признак информационного объекта типа <Person> "быть рожденным в конкретном году". Данный шаблон также имеет графовое 303 и триплетное 304 представление. Информационный объект типа <PointOfTime>, который задает год, связан с информационным объектом типа Person не напрямую, а через факт рождения <Birth>. Этот факт в RDF-графе представляет собой отдельный информационный объект. Таким образом, для описания указанного признака необходимо задать информационные объекты типа <Person>, типа <PointOfTime> и типа <Birth>, объектные связи между ними, а также атрибуты для каждого информационного объекта. Сплошные стрелки соответствуют объектным связям, пунктирные - необъектным. Направление стрелки задается от субъекта s к объекту о, стрелка помечена предикатом р.
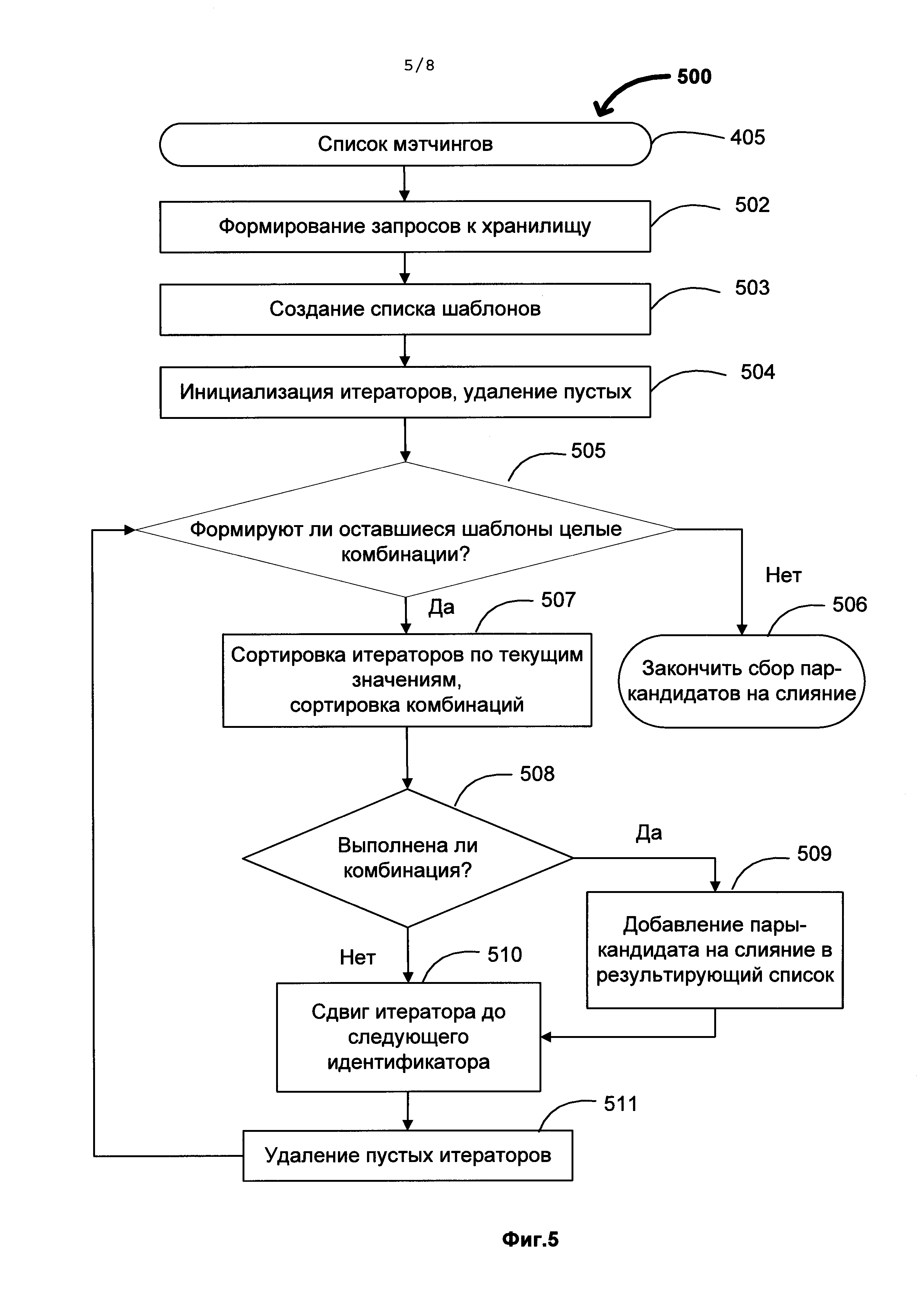
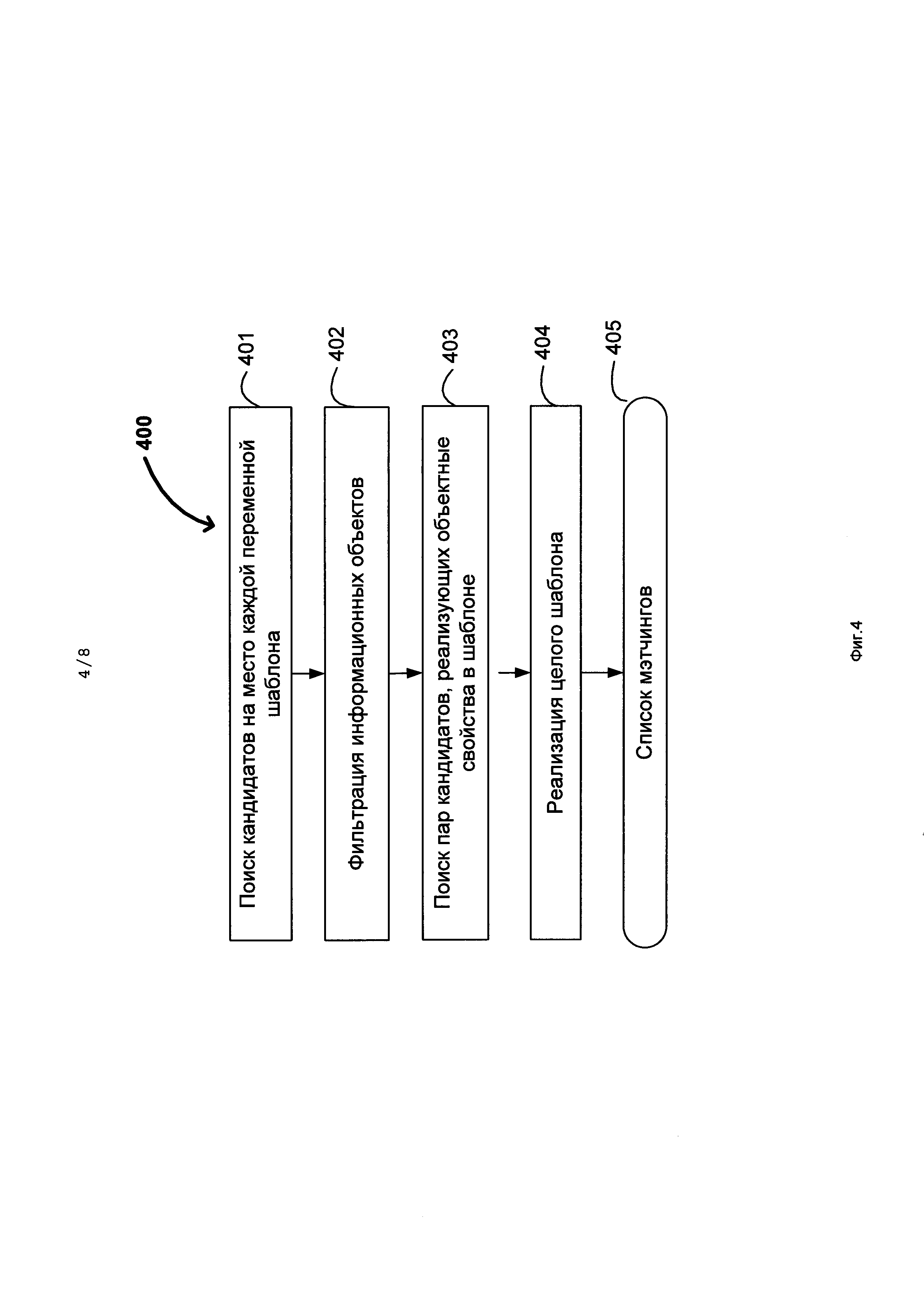
[0042] На Фиг. 4 изображена блок-схема процесса 400 поиска шаблона в графе документа. Процесс поиска шаблона в графе документа начинается с того, что для каждой переменной осуществляется выбор 401 информационных объектов-кандидатов на место каждой переменной шаблона. В качестве кандидатов на место переменной могут выступать только те информационные объекты, чей набор концептов содержит все концепты указанной переменной. У информационного объекта может быть несколько концептов, например, различные роли в рамках нескольких онтологий. После того, как из множества информационных объектов выбраны множества кандидатов на позицию каждой переменной, необходимо произвести фильтрацию кандидатов 402. В результате фильтрации те информационные объекты, которые не удовлетворяют необъектным свойствам, заданным в шаблоне, удаляются из списка кандидатов для данного шаблона и далее не рассматриваются. Затем среди оставшихся информационных объектов осуществляется поиск пар 403, согласующихся с объектными свойствами шаблона. Такие свойства задают триплеты, в которых на месте субъекта и объекта находятся информационные объекты. Таким образом, ищутся пары информационных объектов, таких что, субъект s из триплета находится во множестве кандидатов на место переменной-субъекта, а объект о из триплета находится во множестве кандидатов на место переменной-объекта, и запоминаются те из них, для которых в графе документа существует ребро, соответствующее отношению из триплета. [0043] Затем необходимо реализовать весь шаблон целиком 404, для этого надо проверить, имеется ли путь от переменной that до переменной this в графе документа. Вначале для переменной this перебираются все кандидаты. Затем для каждого кандидата ищутся кандидаты для соседних переменных (соседней называется переменная, соединенная ребром с данной). Затем для соседей соседей и так далее до тех пор, пока не закончатся кандидаты для соседей или не будет найден конфликт. Отсутствие конфликта означает, что шаблон полностью реализовался и можно запомнить все наборы объектов, попавшие под this и that переменные одновременно. Из таких троек <this, that, шаблон> составляется список мэтчингов 405.
[0044] После того, как в графе документа были найдены все возможные шаблоны идентификации, для this - объектов мэтчингов находятся такие, для которых выполняется целая комбинация. Комбинация считается выполненной, если выполнены все шаблоны, входящие в нее. После этого для всех комбинаций собираются все мэтчинги и запоминаются.
[0045] Возвращаясь к Фиг. 4, иллюстрирующей поиск шаблонов в графе документа, следует отметить, что найти и запомнить информационные объекты - кандидаты на слияние в документе возможно за один проход, в то время, как осуществить поиск по этим кандидатам в хранилище не так просто. Предположим, нужно провести идентификацию человека по признаку «работает в организации N». <Организация> в RDF-представлении - это полноценный информационный объект, и в шаблон под переменную that попадет информационный объект-организация из документа. Также для идентификации самой организации есть признак, например, ее полное наименование, либо юридический адрес. И до тех пор, пока организация в хранилище не распознается как та, что указана в документе, то есть не произойдет их идентификация, человек, работающий в данной организации, также не будет идентифицирован. Таким образом, потребуется как минимум два цикла поиска в хранилище и импорта объектов: первый для идентификации организации, второй - для идентификации ее сотрудника. Такой способ обработки данных называется каскадным.
[0046] Необходимость в каскадной глобальной идентификации может возникнуть только на шаблонах, под переменную that которых должен попадать информационный объект. Если этот информационный объект ни с кем не идентифицирован, то this-объект также нельзя идентифицировать, так как, по сути, отсутствует идентифицирующий признак, а точнее его значение.
[0047] При добавлении в хранилище информационного объекта ему присваивается числовой идентификатор. В одной из реализаций данного изобретения, хранилище содержит таблицы поисковых индексов, чтобы обеспечивать поиск (итерацию) для различных видов запросов:
a) Индекс двоек <subject(s), document (d)>. Для каждого информационного объекта этот индекс дает возможность увидеть список документов, которые содержат этот объект. Поиск документов, содержащих наиболее востребованный информационный объект, может быть эффективно реализован благодаря тому, что все пары <s, d> для s расположены последовательно в таблице;
b) Индекс триплетов (троек) <subject (s), predicate (p), object (о)>:<s, p, o>;
c) Индекс четверок <document (d), subject (s), predicate (p), object (o)>, т.е. для каждого документа запоминается список троек, извлеченных из этого документа.
[0048] Таблицы содержат идентификаторы концептов, предикатов, информационных объектов, документов и значений простых свойств. В одном варианте реализации, идентификаторы концептов и предикатов (атрибутов и отношений) могут приписываться, если задается некая специальная область. Присвоение идентификатора информационному объекту происходит, когда добавляется новая вершина в RDF-граф (он же является номером объекта в индексе хранилища). Идентификатор документу также назначается в тот момент, когда он добавляется в хранилище. Идентификаторы простых свойств являются идентификаторами строк и числовых значений. Идентификаторы строк вычисляются с использованием специальной структуры данных - двоичного дерева, имеющего ключи для каждого из листьев (trie). Это позволяет использовать строку для быстрого поиска идентификатора и поиска троек, когда она является значением объекта. Числовые идентификаторы также могут вычисляться и храниться при помощи таких структур. Когда запрос направляется в хранилище, ответ содержит итератор, перечисляющий все объекты, удовлетворяющие запросу, упорядоченные, например, по возрастанию значения идентификаторов.
[0049] На Фиг. 5 изображена блок-схема 500 поиска шаблонов и их комбинаций в хранилище в одной из возможных реализаций изобретения. Из шаблонов, собранных в списке мэтчингов 405 для информационных объектов документа формируются запросы к хранилищу 502. Запрос представляет собой тот же набор триплетов, что содержится в шаблоне, но вместо переменной that подставляется ее значение из графа документа.
[0050] Для сформированных запросов создается список шаблонов 503 с итераторами, которые указывают на идентификаторы информационных объектов из хранилища, реализовавших шаблон. Комбинация считается выполненной, если идентификатор какого-либо объекта встречается во всех итераторах, соответствующих входящим в нее шаблонам. После того, как список шаблонов составлен, итераторы необходимо инициализировать 504. При инициализации итератора проверяется наличие в хранилище информационных объектов, реализующих каждый шаблон, пустые итераторы удаляются. Итератор остается пустым, когда в хранилище отсутствуют информационные объекты, реализующие соответствующий шаблон.
[0051] Затем проверяется, формируют ли оставшиеся шаблоны целые комбинации 505. Если нет, значит, в хранилище отсутствуют информационные объекты, найденные в документе, и можно завершить процесс поиска пар-кандидатов на слияние 506. Если же из оставшегося списка шаблонов можно сформировать комбинацию, то можно начать поиск кандидатов.
[0052] Вначале производится сортировка итераторов по значениям идентификаторов. В упорядоченном списке шаблонов для каждой комбинации ищется первый и последний итератор. Затем выбираем минимальную комбинацию. Минимальная комбинация - это такая комбинация, у которой индекс последнего итератора в упорядоченном списке шаблонов минимален. Далее нужно проверить, выполнилась ли комбинация 508. Комбинация выполняется, если под все ее шаблоны попал один и тот же информационный объект, это достаточно проверить для первого и последнего итератора комбинации. Если минимальная комбинация не выполнилась, следует произвести сдвиг итераторов до следующего идентификатора 510, причем в данном случае следует сдвинуть первые итераторы до того идентификатора, который является текущим значением последнего итератора невыполненной минимальной комбинации. Если минимальная комбинация выполнилась, то в результирующий список пар-кандидатов на слияние добавляется 509 пара <исходный объект комбинации, найденный идентификатор>. После этого просматривают остальные комбинации и проверяют, что найденная пара-кандидат на слияние также выполнилась и на других комбинациях. Затем переходят к шагу 510, но теперь сдвигаются первые итераторы до идентификатора, равного текущему значению последнего итератора минимальной комбинации плюс один. После сдвига итераторов, некоторые списки шаблонов могут опустеть, пустые итераторы удаляются из списка 511 и выполняется возврат к шагу 505.
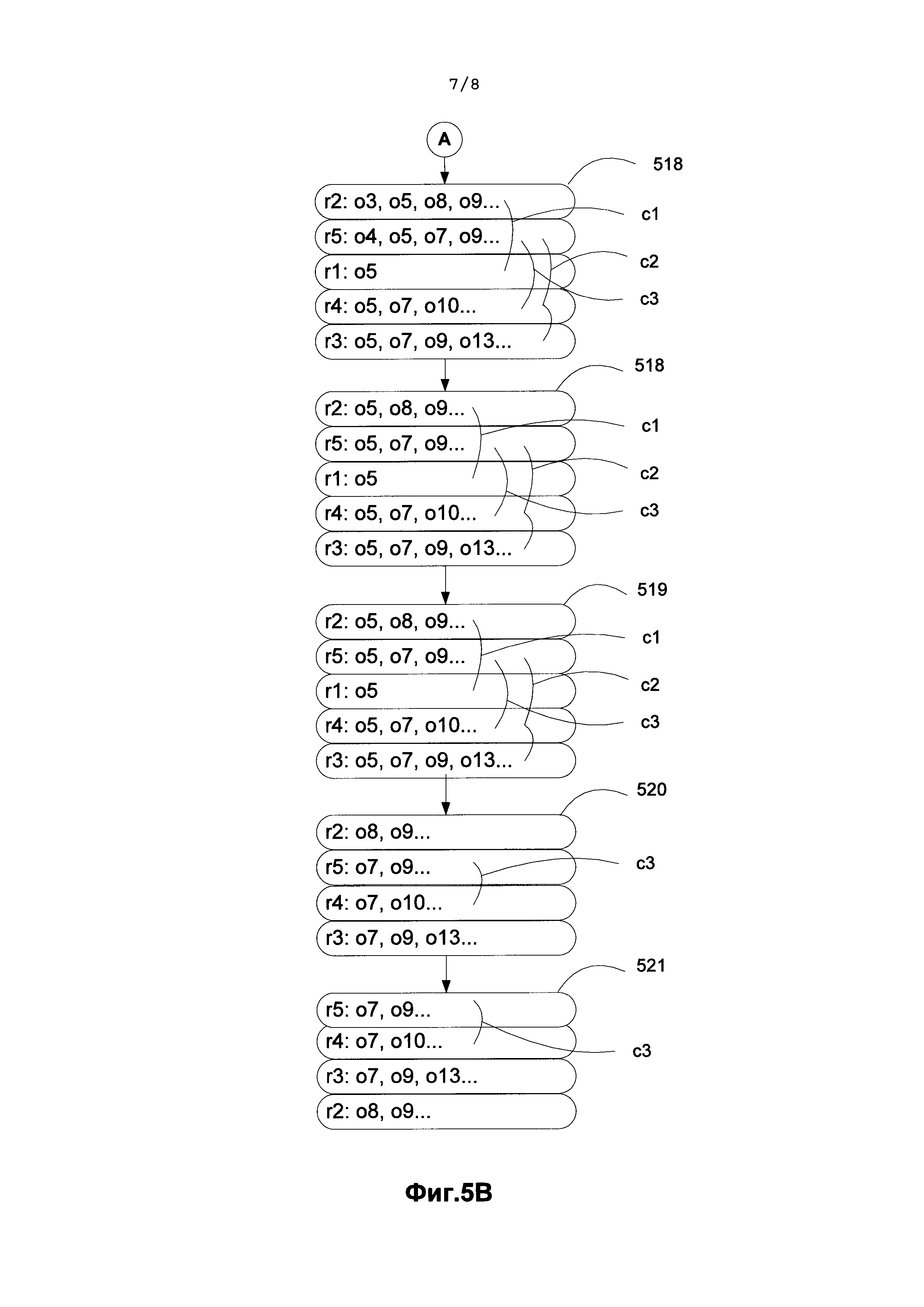
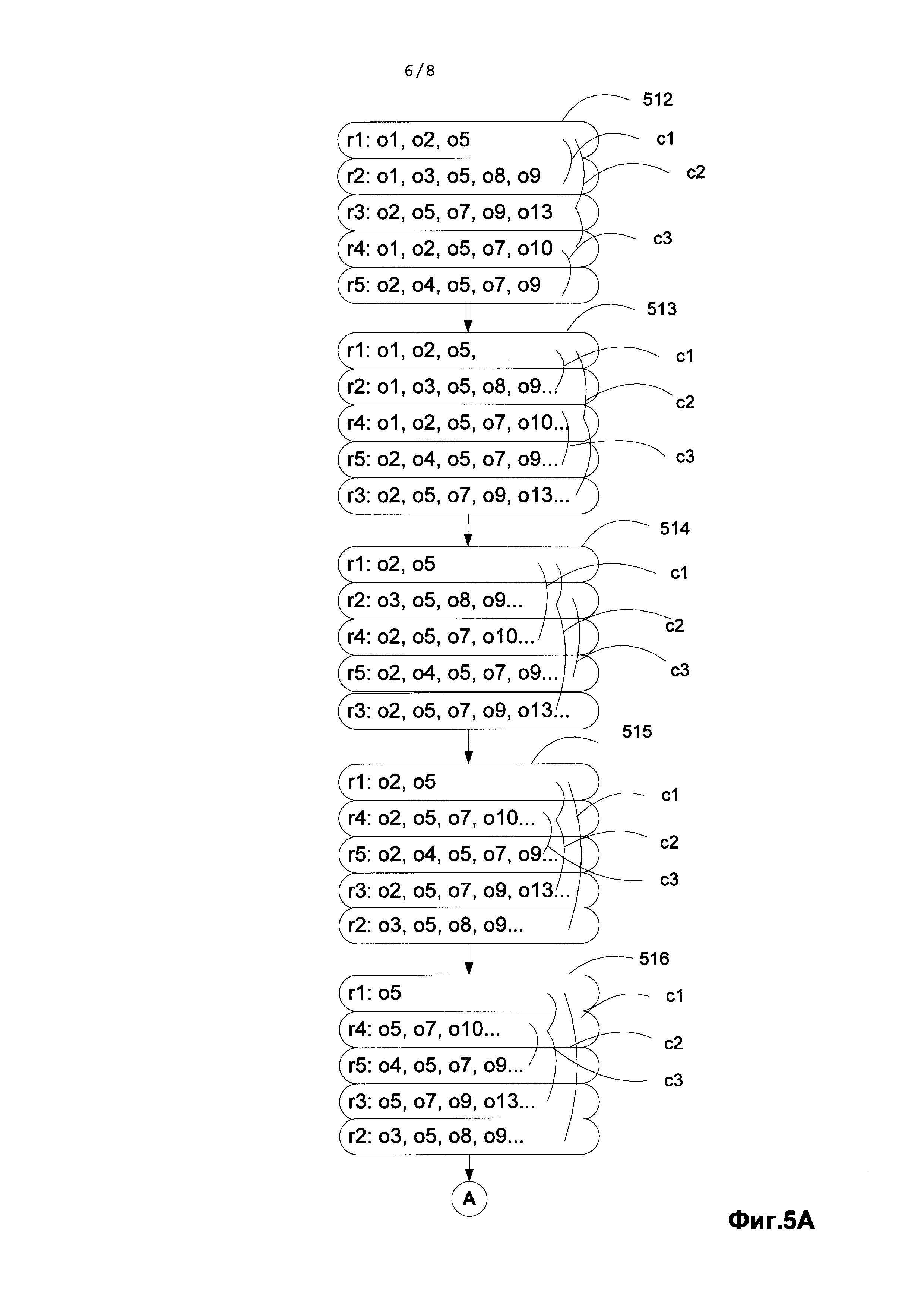
[0053] Пример поиска комбинаций в хранилище, приведен на Фиг. 5A и Фиг. 5B. Пусть в документе было найдено 5 шаблонов (r1, r2, r3, r4, r5), которые объединены в комбинации следующим образом: c1={r1, r2}, c2={r1, r3, r4}, c3={r4, r5}. На рисунке Фиг. 5A элементы 512-521 обозначают последовательные стадии поиска, r1, r2, r3, r4, r5 обозначают номер шаблона, которому соответствует итератор, o1, o2, o3, идентификаторы объектов, удовлетворяющих запросу, по которому итератор был получен. Рисунок 512 соответствует инициализации итераторов, т.е. показано, что шаблону r1 соответствуют объекты с идентификаторами o1, o2, o3, а шаблону r2 - объекты o1, o3, o5, o8, o9 и т.д. Соответственно, шаблону r5 соответствуют объекты с идентификаторами o2, o4, o5, o7, o9. Дугами показаны возможные комбинации шаблонов c1={r1, r2}, с2={r1, r3, r4},c3={r4, r5}.
[0054] Элемент 513 соответствует сортировке итераторов по возрастающим текущим номерам объектов, на которые они указывают. Дуги указывают на те же комбинации. На рисунке 513 сначала проверяется комбинация c1 - она является минимальной для данной сортировки итераторов: на первой локальной позиции r1 и r2 в данной комбинации стоит объект o1, то есть, объект o1 одновременно реализует шаблоны r1 и r2, а значит, и вся комбинация выполнена для него. Далее проверяется комбинация c2: на первой позиции (r1) снова стоит объект 1, которую в (r4) занимает объект 2. Это означает, что комбинация c2 не выполняется, при этом номер объекта у итератора 4 учитывать не обязательно. После выполнения минимальной комбинации удаляется идентификатор объекта, для которого данная комбинация выполнена, а итераторы сдвигаются к значению, не меньшему, чем 1+1=2. На рис. 514 изображены итераторы после сдвига. На рисунке 515 получившиеся итераторы отсортированы по значениям идентификаторов. Минимальной комбинацией на этот раз оказалась комбинация c3, она выполнилась на объекте o2. Комбинация c2 при этом также выполнилась, a c1 нет. На 516 первые итераторы сдвинуты до значения 2+1=3. На 517 после сортировки итераторов минимальная комбинация c1 оказалась невыполненной. Это означает, что следует произвести сдвиг итераторов. На 518 итераторы сдвигаются до идентификатора o5. На 519 итераторы отсортированы, и все комбинации выполнены, сдвигаться нужно до идентификатора, следующего за o5 в шаблоне r1. В шаблоне r1 больше нет объектов, а значит комбинации c1 и c2 больше не могут быть выполнены, и дальнейший поиск, как показано на рисунке 521, будет производиться только для комбинации c3. Процесс остановится, когда для каждой комбинации закончатся объекты, реализующие хотя бы один шаблон.
[0055] На Фиг. 6 показан пример вычислительных средств для реализации описанных в настоящем документе методов и систем в соответствии с одним из вариантов осуществления настоящего изобретения. Обратимся к Фиг. 6, пример вычислительного средства включает по меньшей мере один процессор (602), соединенный с запоминающим устройством (604). Процессор (602) может представлять один или более процессоров (например, микропроцессоров), а память (604) может представлять собой устройства оперативной памяти (RAM), представляющие собой основное запоминающее устройство вычислительного средства, а также любые дополнительные уровни памяти, например, кэш-память, энергонезависимые или резервные запоминающие устройства (например, программируемые запоминающие устройства или флэш-накопители), постоянные запоминающие устройства, и т.д. Кроме того, можно считать, что память (604) включает запоминающее устройство, физически расположенное в другой части вычислительного средства, например, любую кэш-память в процессоре (602), а также любое запоминающее устройство, используемое в качестве виртуальной памяти, например, память, хранящуюся в запоминающем устройстве большой емкости (610).
[0056] Как правило, вычислительное средство имеет ряд входов и выходов для обмена информацией с другими устройствами. В качестве интерфейса пользователя или оператора вычислительное средство может содержать одно или более пользовательских устройств ввода (606) (например, клавиатуру, мышь, устройство обработки изображений, сканер и микрофон), а также одно или более устройств вывода (608) (например, панель жидкокристаллического дисплея (LCD) и устройство воспроизведения звука (динамик)). Для реализации настоящего изобретения вычислительное средство, как правило, содержит как минимум одно устройство с экраном.
[0057] Для дополнительного хранения вычислительное средство может также содержать одно или более устройство большой емкости (610), например, накопитель на гибком диске или на другом съемном диске, накопитель на жестком диске, запоминающее устройство с прямым доступом (ЗУПД), оптический привод (например, привод оптических дисков (формата CD), привод с цифровым универсальным диском (формата DVD)) и/или стример и т.д. Кроме того, вычислительное средство (1400) может включать в себя интерфейс с одной или более сетями (612) (например, локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и/или Интернет и т.д.) для обеспечения обмена информацией с другими компьютерами, подключенными к сетям. Следует иметь в виду, что вычислительные средства обычно содержат необходимые аналоговые и/или цифровые интерфейсы между процессором (602) и каждым из компонентов (604), (606), (608), (612), что хорошо известно специалистам в данной области.
[0058] Вычислительное средство работает под управлением операционной системы (614), на нем выполняются различные компьютерные программные приложения, компоненты, программы, объекты, модули и т.д. для реализации описанных выше способов. Кроме того, различные приложения, компоненты, программы, объекты и т.д., которые совместно обозначены на Фиг. 6 как прикладное программное обеспечение (616), также могут выполняться в одном или более процессорах в другом компьютере, подключенном к вычислительному средству (600) через сеть (612), например, в распределенной вычислительной среде, в результате чего обработка, необходимая для реализации функций компьютерной программы, может быть распределена по нескольким компьютерам в сети.
[0059] В целом, стандартные программы, выполняемые для реализации вариантов осуществления настоящего изобретения, могут быть реализованы как часть операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности команд, которые называются «программа для компьютера». Обычно программа для компьютера содержит один набор команд или несколько наборов команд, записанных в различные моменты времени в различных запоминающих устройствах и системах хранения в компьютере; после считывания и выполнения одним или несколькими процессорами в компьютере эти команды приводят к тому, что компьютер выполняет операции, необходимые для выполнения элементов, связанных с различными аспектами настоящего изобретения. Кроме того, несмотря на то, что это изобретение описано в контексте полностью работоспособных компьютеров и компьютерных систем, специалистам в данной области техники будет понятно, что различные варианты осуществления этого изобретения могут распространяться в виде программного продукта в различных формах, и что это изобретение в равной степени применимо для фактического распространения независимо от используемого конкретного типа машиночитаемых носителей. Примеры машиночитаемых носителей включают в том числе: записываемые носители, такие как энергонезависимые и энергозависимые устройства памяти, гибкие диски и другие съемные диски, накопители на жестких дисках, оптические диски (например, постоянные запоминающие устройства на компакт-диске (формата CD-ROM), накопители на цифровом универсальном диске (формата DVD), флэш-память и т.д.) и т.п. Другой тип распространения можно реализовать в виде загрузки из сети Интернет.
[0060] Аспекты настоящего раскрытия были описаны выше в отношении методов машинной интерпретации информации в текстовых документах. Тем не менее, было предусмотрено, что части данного описания могут быть альтернативно или дополнительно реализованы в виде отдельных программных продуктов или элементов других программных продуктов.
[0061] Все утверждения, принципы цитирования, аспекты и варианты реализации настоящего изобретения и соответствующие конкретные примеры охватывают как структурные и функциональные эквиваленты раскрытия изобретения.
[0062] Специалистам в данной области техники должно быть очевидно, что возможны различные модификации устройств, способов и программных продуктов настоящего изобретения без отхода от сущности или объема раскрытия изобретения. Таким образом, подразумевается, что настоящее изобретение включает модификации, которые включены в объем настоящего изобретения, а также их эквиваленты.
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Разрешение семантической неоднозначности при помощи статистического анализа
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Метод анализа тональности текстовых данных
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Разрешение семантической неоднозначности при помощи статистического анализа

