Результат интеллектуальной деятельности: МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к устройству, системе, способу и компьютерной программе в области автоматического определения значений в естественном языке, а именно к способам и системам обработки естественного языка (natural language processing), обработки текстов и массивов текстов на естественном языке. Одной из целей изобретения является анализ текстовой информации для последующего определения его тональности (Sentiment Analysis).
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время задачи прикладной лингвистики, а именно семантический анализ, извлечение информации (Fact Extraction), анализ тональности (Sentiment Analysis) особенно популярны в связи с развитием современных технологий и стремительно растущим спросом на технологические продукты, способные качественно обрабатывать текстовые данные и предоставлять результаты в доступном и понятном для пользователя виде.
[0003] Одним из источников текстовых данных могут служить всевозможные сообщения в социальных сетях, форумах, электронной почте и т.д. Извлечение информации из текстовых данных является наиболее актуальной задачей современного мира. Умение анализировать текстовые данные на уровне понимания смысла, вложенного в текст, открывает множество возможностей: от изучения мнений пользователей о недавно вышедшем в прокат фильме до построения прогнозов на финансовых рынках.
[0004] В настоящее время многие компании сталкиваются с проблемой эффективного управления сотрудниками в виду отсутствия объективной информации о внутренней атмосфере в компании, эмоциональном состоянии и настрое персонала, наиболее актуальных и вызываемых беспокойство у сотрудников проблем, наиболее обсуждаемых и популярных тем. Задачами поддержания здорового корпоративного духа в компаниях занимаются целые подразделения, однако даже эти специализированные подразделения не в состоянии объективно оценить атмосферу в компании, понять насколько полезны и необходимы проводимые ими действия, каковы будут последствия этих действий и насколько они будут оправданы в будущем. Не всегда предоставляется возможным выявить пожелания сотрудников по организации комфортных условий их работы, бесконфликтного взаимодействия различных подразделений и т.д.
[0005] Одним из предлагаемых способов эффективного управления компанией является инструмент, который может быть полезен как руководству компании, так и подразделению по работе с сотрудниками, инструмент, направленный на анализ текстовых данных, содержащейся в корпоративных форумах и других средствах обмена сообщений между сотрудниками (например, корпоративной почты).
[0006] Целью анализа текстовых данных, например, сообщений, является выявление лидеров в компании, контролирование внутренней атмосферы (temperature measuring) как во всей компании, так и ее подразделениях, выявление социальных связей (social networks) между коллегами и подразделениями, выявление острых проблем, существующих в коллективе, особо популярных тем для обсуждения и т.д. Анализ текстовых данных основан на использовании методов прикладной лингвистики, а именно семантического анализа на основе Семантической Иерархии, анализа тональности, извлечении фактов и т.д.
[0007] Изобретение полезно для повышения эффективности работы компании за счет анализа настроения коллектива, может быть применено при прогнозировании организующихся событий, проведения анализа проведенных мер. Позволяет осуществлять более гибкое руководство компанией за счет более полного представления о сотрудниках. [0008] Анализ тональности может осуществляться на одном из нижеуказанных уровней. А именно анализ тональности может происходить на уровне предложения (sentence level SA), на уровне документа (document level SA), или на уровне сущностей и аспектов (entity and aspect level), или другими словами направленный анализ тональности.
[0009] Анализ тональности на уровне предложения позволяет определить, какое мнение (эмоцию) выражает предложение в целом, негативную, положительную или нейтральную. Определение тональности на уровне предложения может быть осуществлено на основе лингвистического подхода. Лингвистический подход не требует большой коллекции размеченных корпусов, предназначенных для обучения, однако использует тональные словари эмоционально окрашенной лексики. Существует множество способов создания тональных словарей, но все они требуют участия человека. Ввиду этого лингвистический подход достаточно ресурсозатратный, что делает его практически неприменимым на практике в чистом виде.
[0010] Анализ тональности на уровне документа использует статистический подход. Статистический подход имеет ряд преимуществ, он достаточно нетрудоемок в реализации. Однако статистический подход требует наличия большой базы обучающей коллекции размеченных текстов. Обучающая коллекция текстов должна быть при этом достаточно репрезентативной, или другими словами, должна содержать достаточное количество лексики, необходимой для обучения классификатора в различных предметных областях. В результате применения обученного классификатора к неразмеченному тексту, исходный документ (текстовое сообщение) классифицируется в целом, как выражающее отрицательное или положительное мнение (эмоцию). Количество классов может быть отличным от приведенного выше примера. Например, классы могут быть расширены до сильно негативных, сильно положительных и т.д.
[0011] Ни один из вышеупомянутых уровней анализа тональности (а именно sentence level, document level) не позволяет выявить тональность на локальном уровне, а именно не позволяет извлечь информацию о конкретных сущностях, их аспектах и их тональной окраске в текстовых данных.
[0012] Методы анализа тональности на уровне предложения или документа обобщают имеющуюся информацию, что в конечно итоге приводит к потере данных.
[0013] Согласно представленному изобретению используется метод анализа тональности на уровне сущностей и аспектов, или другими словами направленный анализ тональности текстовых данных. Преимуществом направленного анализа тональности (aspect and entity level) является тот факт, что он позволяет выявить не только саму тональность (sentiment) (отрицательную, положительную и т.д.), но и объект, и субъект тональности ("Object of Sentiment" or "Target of Sentiment").
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0014] Один из аспектов настоящего изобретения относится к способу проведения анализа текстовых данных. Способ включает в себя получение вычислительным устройством текстовых данных, выполнение глубинного синтактико-семантический анализа полученных текстовых данных, извлечение сущностей и фактов из текстовых данных на основе результатов глубинного синтактико-семантического анализа, которое включает в себя извлечение тональностей с использованием тонального словаря построенного с использованием семантической иерархии. Способ, дополнительно включает этап определения знака извлеченных тональностей. Способ дополнительно включает этап определения общей тональности текстовых данных. Способ дополнительно включает этап выделения социальных связей на основе извлеченных сущностей и фактов. Способ дополнительно включает этап выделения тем на основе извлеченных сущностей и фактов. Способ дополнительно включает выполнение анализа атмосферы в коллективе на основе извлеченных тональностей. Способ, дополнительно включает этап классификации текстовых данных на основе извлеченных тональностей.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0015] Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
[0016] Фиг.1 иллюстрирует пример блок-схемы, демонстрирующей последовательность шагов в соответствии с одним из способов реализации данного изобретения.
[0017] Фиг.2 иллюстрирует пример лексической структуры для предложения "This child is smart, he'll do well in life".
[0018] Фиг.3 иллюстрирует последовательность шагов выполнения глубинного анализа в соответствии с одним из способов реализации данного изобретения.
[0019] Фиг.4 иллюстрирует схему этапа, включающего грубый синтаксический анализатор в соответствии с одним из способов реализации данного изобретения.
[0020] Фиг.5 иллюстрирует синтаксические описания в соответствии с одним из способов реализации данного изобретения.
[0021] Фиг.6 иллюстрирует детально процесс грубого синтаксического анализа в соответствии с одним из способов реализации данного изобретения.
[0022] Фиг.7 иллюстрирует пример графа обобщенных составляющих, иллюстрирующих граф обобщенных составляющих для предложения «This child is smart, he′ll do well in life» в соответствии с одним из способов реализации данного изобретения.
[0023] Фиг.8 иллюстрирует точный синтаксический анализ в соответствии с одним из способов реализации данного изобретения.
[0024] Фиг.9 иллюстрирует пример синтаксического дерева в соответствии с одним из способов реализации данного изобретения.
[0025] Фиг.10 иллюстрирует схему метода анализа предложения в соответствии с одним из способов реализации данного изобретения.
[0026] Фиг.11 иллюстрирует схему, демонстрирующую языковые описания в соответствии с одним из способов реализации данного изобретения.
[0027] Фиг.12 иллюстрирует пример морфологических описаний в соответствии с одним из способов реализации данного изобретения.
[0028] Фиг.13 иллюстрирует семантические описания в соответствии с одним из способов реализации данного изобретения.
[0029] Фиг.14 иллюстрирует схему, демонстрирующую лексические описания в соответствии с одним из способов реализации данного изобретения.
[0030] Фиг.15 иллюстрирует схему семантической структуры, полученной в результате анализа предложения "Москва - город красивый и богатый, как и полагается столице" в соответствии с одним из способов реализации данного изобретения.
[0031] Фиг.16 иллюстрирует модель, которая может быть выбрана для определения тональности текстовых данных в соответствии с одним из способов реализации данного изобретения.
[0032] Фиг.17 иллюстрирует пример информационного RDF графа для примера разбора предложения «Москва - город красивый и богатый, как и полагается столице» в соответствии с одним из способов реализации данного изобретения.
[0033] Фиг.18 иллюстрирует пример построенной древовидной структуры в соответствии с одним из способов реализации данного изобретения.
[0034] Фиг.19 иллюстрирует пример схемы аппаратного обеспечения, который может быть использован в соответствии с одним из способов реализации данного изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0035] Изобретение предоставляет собой метод, который включает в себя команду для устройства, операционной системы, программно-аппаратных средств и программного обеспечения, который представляет собой решение задачи анализа тональности текстовых данных (сообщений), основанный на комбинации статистического и лингвистического подходов.
[0036] Настоящее изобретение предназначено для анализа тональности текстовых данных (сообщений). В основе метода лежит использование двухступенчатого синтаксического анализа на базе исчерпывающих лингвистических описаний, представленных в патенте US 8,078,450.
[0037] Так как согласно описываемому изобретению метод анализа текстовых данных (сообщений) основан на использовании независимых от языка смысловых единиц, данное изобретение также не зависит от языка и позволяет работать с одним или несколькими естественными языками. Другими словами данное изобретение может выполнять анализ тональности многоязычных текстов в том числе.
[0038] Фиг.1 иллюстрирует пример блок-схемы, иллюстрирующей последовательность шагов в соответствии с одним из способов реализации изобретения.
Этап подготовки данных
[0039] На шаге 110 данные, представляющие собой текстовые данные (например, сообщения), например, в виде электронных писем или сообщений на форуме, могут быть предварительно подготовлены для анализа. Во-первых, могут должны быть стандартизированы, единообразно структурированы. А именно последовательность текстовых данных (например, электронных писем, сообщений на форуме) может быть разделена на составляющие, представляющие собой единые целостные текстовые сообщения. Если во время переписки как на форуме, так и по электронной почте, сообщения содержат историю переписки, которая при отправке ответа автоматически копируется, тем самым сообщения дублируются в базе данных. Данные дубли могут помешать дальнейшему анализу. Одним из критериев того, что письмо не содержит в треде истории переписки, может быть наличие одной даты отправления.
[0040] Далее после разделения текстовых данных (например, сообщений) на целостные независимые единицы, происходит очистка данных. На этом этапе происходит исключение дублированных сообщений. Дублированные сообщения часто появляются в треде письма, или в качестве цитаты (например, на форумах).
Лексический анализ (Lexical Analysis)
[0041] Прежде чем приступать к анализу текстовых данных (сообщений), необходимо провести лексический анализ предложений.
[0042] Лексический анализ выполняется над исходным предложением, представленным в исходном языке. Исходным языком может быть любой естественный язык, для которого созданы все необходимые языковые описания. Например, исходное предложение может быть разделено на некоторое число лексем, элементов, или единиц, включающих все слова, словарные формы, пробелы, пунктуаторы и т.д., присутствующие в исходном предложении для построения лексической структуры предложения. Лексемой называется значимая лингвистическая единица, которая является пунктом в словаре, такие как лексические описания языка.
[0043] Фиг.2. иллюстрирует пример лексической структуры для предложения 220, "This child is smart, he′ll do well in life", на английском языке, в которой все слова и пунктуаторы представлены двенадцатью (12) элементами 201-212 или сущностями, и девятью (9) пробелами 221-229. Пробелы 221-229 могут быть представлены одними или несколькими пунктуаторами, пустыми местами, и т.д.
[0044] На основе элементов 201-212 предложения строится граф лексической структуры. Вершинами графа являются координаты символов начала и конца сущностей, а дугами являются слова, промежутки между сущностями 201-212 (словарными формами и пунктуаторами), или пунктуаторами. Например, вершины графа показаны на Фиг.2 как координаты: 0,4,5.
[0045] Исходящие и входящие дуги проиллюстрированы для каждой координаты, дуги могут быть созданы для соответствующих сущностей 201-212, так же как и для промежутков 221-229. Лексическая структура для предложения 220 может быть использованы позднее в ходе выполнения грубого синтаксического анализа 330.
Анализ тональности
[0046] Подготовленная база текстовых данных (например, сообщений) подвергается анализу на тональность. Анализ тональности (sentiment analysis) является одной из самых развивающихся в настоящее время областей прикладной лингвистики (Natural Language Processing), целью которой является выявление в тексте тональной окраски, мнений (позиции) авторов на основе эмоционально окрашенной лексики по отношению к описываемому им объекту (лицу, предмете, теме и т.д.).
[0047] Согласно данному изобретению анализ тональности опирается на лингвистический подход, основанный на использовании универсальной Семантической Иерархии (СИ), описание которой подробно представлено в патенте US 8,078,450, а именно на выполнение синтаксического и семантического анализа, с применением правил (rule based approach).
[0048] Согласно представленному изобретению используется метод анализа тональности на уровне сущностей и аспектов, или другими словами направленный анализ тональности текстовых данных. Под объектом тональности понимается оцениваемый объект (некая сущность - entity), упоминаемый в тексте, или другими словами носитель тональности. Под субъектом понимается автор выявленной оценки (opinion/sentiment holder). Автор может быть явно упомянут в тексте, однако зачастую информация о нем может отсутствовать, что значительно усложняет решаемую задачу.
[0049] Описываемый метод анализа тональности предполагает использование тонального словаря (sentiment lexicon approach) и декларативных правил (rule-based approach).
[0050] Данное изобретение предполагает выделение тональностей, явно представленных в тексте (explicit sentiment).
[0051] Представленное изобретение позволяет осуществить выделение локальной тональности в текстовых данных (например, сообщениях) и определить знак тональности по двухбалльной шкале, например позитивная тональность или негативная тональность. Приведенный в качестве одной из реализации вид шкалы вводится для наглядности и не ограничивает область применения данного изобретения.
[0052] Данное изобретение адаптирует статистический и лингвистический подход к определению тональности, используя в качестве исходных данных результаты работы семантико-синтаксического анализатора. Например, в качестве семантико-синтаксического анализатора может быть использована технология ABBYY Compreno.
[0053] В Патенте США U.S. Patent 8,078,450 описан метод, включающий глубинный синтаксический и семантический анализ текстов на естественном языке, основанный на исчерпывающих лингвистических описаниях. Данная технология может быть использована для анализа тональности текста на одном из естественных языков. Метод использует широкий спектр лингвистических описаний, как универсальных семантических механизмов, так относящихся к конкретному языку, что позволяет отразить все реальные сложности языка без упрощения и искусственных ограничений, не опасаясь при этом комбинаторного взрыва, неуправляемого роста сложности. Сверх того, указанные способы анализа основаны на принципах целостного и целенаправленного распознавания, т.е. гипотезы о структуре части предложения верифицируются в рамках проверки гипотезы о структуре всего предложения. Это позволяет избежать анализа большого множества аномалий и вариантов.
[0054] Глубинный анализ включает лексико-морфологический, синтаксический и семантический анализ каждого предложения корпуса текстов, в результате которого строятся семантические структуры, независимые от языка (language-independent semantic structures), в которых каждому слову текста сопоставляется соответствующий семантический класс. Фиг.3 иллюстрирует общую схему метода глубинного анализа текстов. Текст 305 подвергается исчерпывающему семантико-синтаксическому анализу 306 с использованием лингвистических описаний, как исходного языка, так и универсальных семантических описаний, что позволяет анализировать не только поверхностную синтаксическую структуру, но и глубинную, семантическую, выражающую смысл высказывания, содержащегося в каждом предложении, а также связи между предложениями или фрагментами текста. Лингвистические описания могут включать лексические описания 303, морфологические описания 301, синтаксические описания 302 и семантические описания 304. Анализ 306 включает синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа), использующий лингвистические модели и информацию различных уровней для вычисления вероятностей и генерации множества синтаксических структур.
Грубый синтаксический анализ (Rough syntactic analysis)
[0055] Фиг.4 иллюстрирует схему этапа 306, включающего, грубый синтаксический анализатор 422 или его аналоги, которые применяются для выявления всех потенциально возможных синтаксических связей в предложении, что находит свое выражение в создании графа 460 обобщенных составляющих на основе лексико-морфологической структуры 450 с использованием поверхностных моделей 510, глубинных моделей, и лексико-семантического словаря 414. Граф 460 обобщенных составляющих представляет собой ациклический граф, в котором узлы представляют собой обобщенные (в смысле - хранящие все варианты) лексические значения слов предложения, а дуги - поверхностные (синтаксические) позиции, выражающие разные типы отношений между соединяемыми лексическими значениями. Применяются все возможные поверхностные синтаксические модели для каждого элемента лексико-морфологической структуры предложения в качестве потенциального ядра составляющих, далее строятся все возможные составляющие и обобщаются в граф обобщенных составляющих. Соответственно, рассматриваются все возможные синтаксические модели и синтаксические структуры для исходного предложения 402, и в качестве результата, строится граф 460 обобщенных составляющих на основе множества обобщенных составляющих. Граф 460 обобщенных составляющих на уровне поверхностной модели (surface models) отражает все потенциальные связи (links) между словами исходного предложения 402. Поскольку число вариантов синтаксического разбора, в общем случае, может быть велико, граф 460 обобщенных составляющих избыточен и содержит множество вариантов - как для выбора лексического значения для вершины, так и поверхностной позиции для дуги графа.
[0056] Для каждой пары «лексическое-грамматическое значение инициализируется ее поверхностная модель, прикрепляются другие составляющие в поверхностных позициях 515 синтформ (syntform - syntactic form) 512 ее поверхностной модели 510 к правым и левым соседним составляющим. Синтаксические описания приведены на Фиг.5. Если подходящая синтаксическая форма найдена в поверхностной модели 510 соответствующего лексического значения, выбранное лексическое значение может служить ядром (core) новой составляющей (constituents).
[0057] Граф обобщенных составляющих 460 сначала строится в виде дерева, начиная от листьев к корням (снизу вверх). Построение дополнительных составляющих происходит снизу вверх путем прикрепления дочерних составляющих (child constituents) к родительским составляющим (parent constituents) посредством заполнения поверхностных позиций (surface slots) 515 родительских составляющих для того, чтобы охватить все начальные лексические единицы (lexical unit) исходного предложения 402.
[0058] Корень дерева является главной частью, представляющей специальную составляющую, соответствующую различным типам максимальных единиц текстового анализа (завершенные предложения, нумерация, заглавия, и т.д.) Ядром главной части является обычно предикат (сказуемое). В ходе этого процесса дерево обычно становится графом, так как составляющие нижнего уровня (листья) могут быть включены в различные составляющие верхнего уровня (корень).
[0059] Некоторые составляющие, которые построены для одних и тех же составляющих лексико-морфологической структуры могут быть впоследствии обобщены для того, чтобы получить обобщенные составляющие. Составляющие обобщаются на основе лексических значений, грамматических значений 514, например, на основе частей речи, их связями среди остальных. Составляющие обобщаются границами (связями), так как существует множество различных синтаксических связей в предложении, и одно и то же слово может быть включено в несколько составляющих. В качестве результата грубого синтаксического анализа 330, строится граф 460 обобщенных составляющих, который представляет все предложение целиком. [0060] Фиг.6 иллюстрирует более детально процесс грубого синтаксического анализа 330 в соответствии с одним или несколькими способами реализации изобретения. Грубый синтаксический анализ 330 обычно включает предварительный сбор 610 составляющих, построение обобщенных составляющих 620, фильтрацию 170, построение 640 моделей обобщенных составляющих, обработку согласований 650, и восстановление эллипсисов 660 среди остальных.
[0061] Предварительный сбор 610 составляющих на этапе грубого синтаксического анализа 330 выполнятся на основе лексико-морфологической структуры 450 анализируемого предложения, включая определенные группы слов, слова в скобках, перевернутые запятые, и т.д. Только одно слово в группе (ядро составляющей) может присоединять или быть присоединенным к составляющей за пределами группы. Предварительный сбор 610 выполняется в начале грубого синтаксического анализа 330 перед построением обобщенных составляющих 620 и построением моделей обобщенных составляющих 630 для того, чтобы охватить все связи во всем предложении. В ходе грубого синтаксического анализа 330, число различных составляющих, которые могут быть построены и синтаксические связи среди них очень велико, некоторые из поверхностных моделей 510 составляющих выбираются, чтобы отсортировать в процессе фильтрации 670 до и после построения составляющих для того, чтобы значительно уменьшить число различных составляющих, которые необходимо рассмотреть. Поэтому, на начальном этапе грубого синтаксического анализа 330, выбираются наиболее подходящие поверхностные модели и синтформы на основе априорных оценок. Подобные априорные оценки включают оценки лексических значений, оценки заполнителей, оценки семантических описаний. Фильтрация 670 на этапе грубого синтаксического анализа 330 включает фильтрацию множества синтаксических форм (синфторм) 512 выполняется заранее перед и во время построения обобщенных составляющих 620. Синтформы 512 и поверхностные позиции 515 фильтруются заранее, в то время как составляющие фильтруются только после того, как они уже построены. Процесс фильтрации 670 позволяет существенно уменьшить число рассматриваемых вариантов разбора. Однако, существуют и маловероятные варианты значений, поверхностных моделей и синтформ, исключение которых из последующего рассмотрения может привести к потере маловероятного, но, тем не менее, возможного смысла.
[0062] Когда все возможные составляющие построены, выполняется процедура обобщения для построения обобщенных составляющих 620. Все возможные омонимы и все возможные значения для элементов исходного предложения, которые могут быть представленными той же частью речи, собираются и обобщаются, и все возможные составляющие, построенные в такой манере, группируются в обобщенные составляющие 622.
[0063] Обобщенная составляющая 622 описывает все составляющие со всеми возможными связями в данном исходном предложении, которое имеет словарные формы в качестве основных составляющих, и различные лексические значения этой формы слова. Далее выполняется построение моделей обобщенных составляющих 630 и строится множество моделей 632 обобщенных составляющих, имеющих обобщенные модели всех обобщенных лексем. Модели обобщенных составляющих лексем содержат обобщенную глубинную модель и обобщенную поверхностную модель. Обобщенная глубинная модель лексем включает список всех глубинных позиций, которые имеют одинаковое лексическое значение для лексемы, совместно с описаниями всех требований для заполнителей глубинных позиций. Обобщенная поверхностная модель содержит информацию о синтформах 512, в которых может быть лексема, о поверхностных позициях 515, о диатезах 517, (соответствиях поверхностных позиций 515 глубинным позициям), и описание линейного порядка 516.
[0064] Диатеза 517 строится на этапе грубого синтаксического анализа 330 как соответствие между обобщенными поверхностными моделями и обобщенными глубинными моделями. Список всех возможных семантических классов для всех диатез 517 лексемы вычисляется для каждой поверхностной позиции 515.
[0065] Как показано на Фиг.6, информация из синтформ 512 синтаксического описания 302, так же как и семантические описания 304 используется для построения моделей 632 обобщенных составляющих. Например, зависимые составляющие прикрепляются к каждому лексическому значению и грубый синтаксический анализ 330 необходим для того чтобы установить, может ли кандидат в составляющие или зависимая составляющая быть заполнителем соответствующей глубинной позиции семантического описания 304 для основной составляющей. Такой сравнительный анализ позволяет отсечь на ранней стадии неверные синтаксические связи.
[0066] Далее выполняется построение 640 графа обобщенных составляющих. Строится граф 460 обобщенных составляющих, который описывает все возможные синтаксические структуры всего предложения путем связи и сбора обобщенных составляющих 622 друг с другом.
[0067] Фиг.7 демонстрирует пример графа 700 обобщенных составляющих, иллюстрирующих граф обобщенных составляющих для предложения «This child is smart, he′ll do well in life». Составляющие представлены в виде прямоугольников, причем каждая из составляющих имеет в качестве ядра лексему. Морфологическая парадигма (paradigm) (как правило, это часть речи) ядра составляющей выражена граммемами частей речи и изображена в угловых скобках ниже под лексемами. Морфологическая парадигма как часть описания словоизменений 410 морфологического описания содержит всю информацию о словоизменении одной или нескольких частей речи. Например, так как «do» может иметь две части речи: <Verb>, <Noun> (которая представлена обобщенной морфологической парадигмой <Noun&Pronoun>), в графе 700 представлены две составляющие для «do». Помимо этого на графе представлены две составляющих для «well». Так как в исходном предложении использовалось сокращение для «′ll», то а графе представлены два возможных варианта для сокращения «will» и «shall». Задача точного синтаксического анализа будет состоять в выборе из всех возможных составляющих лишь те, которые будут образовывать синтаксическую структуру исходного предложения.
[0068] Связи в графе 700 представляют заполненные поверхностные позиции ядра составляющей. Имя позиции отображено на стрелке графа. Составляющая сформирована ядром лексемы, которая может иметь исходящие именованные стрелки, которые обозначают поверхностные позиции 515 заполненные дочерними составляющими совместно с дочерними составляющими как таковыми. Входящая стрелка обозначает прикрепление этой составляющей к поверхностной позиции другой составляющей. Граф 700 настолько сложен и имеет настолько много стрелок (ветвей) в связи с тем, что он отображает все возможные связи, которые могут быть установлены между составляющими предложения. Среди них, конечно, существуют связи, которые будут отвергнуты. Значение упомянутых ранее грубых методов оценки сохраняется каждой стрелки, обозначающей заполненную глубинную позицию. Только поверхностные позиции и связи с высоким значений рейтинговых оценок в первую очередь будут выбраны на следующем этапе синтаксического анализа.
[0069] Зачастую несколько ветвей могут соединять одни и те же пары составляющих. Это означает, что существует несколько подходящих поверхностных моделей для этой пары составляющих, и несколько поверхностных позиций родительских составляющих могут быть независимо заполнены этими дочерними составляющими. Так, три поверхностных позиции Idiomatic_Adverbial 710, Modifier_Adverbial 720 и AdjunctTime 730 родительской составляющей "do<Verb>" 750 могут быть независимо заполнены дочерней составляющей "well<Verb>" 740 в соответствии с поверхностной моделью составляющей "do<Verb>". Поэтому, грубо говоря, "do<Verb>" 750+"well<Verb>" образуют новую составляющую с ядром "do<Verb>", который соединен с другой родительской составляющей, например с #NormalSentence<Clause>660 в поверхностной позиции Verb 770 и к "child<Noun&Pronoun>" 790 в поверхностной позиции RelativClause_DirectFinite 790. Помеченный элемент #NormalSentence<Clause>, будучи «корнем», соответствует всему предложению.
[0070] Как показано на Фиг.6, обработка сочинения (coordination) 650 также выполняется на графе 460 обобщенных составляющих. Сочинение - это явление языка, которое представлено в предложениях с нумерацией и/или соединительными союзами, такими как «и», «или», «но», и т.д. Простой пример предложения с координацией - "John, Mary and Bill come home." В этом случае только одна из дочерних составляющих прикрепляется к поверхностной позиции родительской составляющей на этапе построения 640 графа обобщенных составляющих. Если составляющая, которая может быть родительской составляющей, имеет поверхностную позицию, заполненную для согласованной составляющей, тогда все согласованные составляющие берутся и делается попытка прикрепить все эти дочерние составляющие к родительской составляющей, даже если нет контакта или прикреплений между согласованными составляющими. На этапе обработки согласования 650, определяются линейный порядок и возможность множественного заполнения поверхностной позиции. Если прикрепление возможно, то предварительная форма, которая относится к общей дочерней составляющей создается, и прикрепляется. Как показано на Фиг.6, обработчик сочинения 682 или другие алгоритмы могут быть адаптированы для выполнения обработки сочинения 650 с использованием описаний сочинения (coordination) 554 в построении 640 графа обобщенных составляющих.
[0071] Построение 640 графа обобщенных составляющих может быть невозможным без восстановления эллипсиса (ellipsis) 660. Эллипсис это явление языка, которое представлено отсутствием основной составляющей. Процесс восстановление эллипсиса 660 также необходим для восстановления пропущенных составляющих. Примером эллиптического предложения на английском может быть следующее предложение: «The President signed the agreement and the secretary [signed] the protocol.» Обработка сочинения 650 и восстановление эллипсиса 660 выполняются на этапе каждого цикла программы диспетчера 690 после построения 640 графа обобщенных составляющих, и затем построения 640 может быть продолжено, как указано с помощью стрелки 642. Если необходимо, восстановление эллипсиса 660 и вызванные в ходе этапа грубого синтаксического анализа 330 вследствие, например, наличия составляющих, оставшихся без любой другой составляющей, только эти составляющие будут обработаны.
Точный синтаксический анализ (Precise syntactic analysis)
[0072] Точный синтаксический анализ 340 выполняется для выделения синтаксического дерева из графа обобщенных составляющих. Это дерево по совокупности оценок представляет собой дерево лучшей синтаксической структуры 470 для исходного предложения. Может быть построено множество синтаксических деревьев, причем наиболее вероятная синтаксическая структура принимается за наилучшую синтаксическую структуру 470. Как показано на Фиг.4, точный синтаксический анализатор 432 или его аналоги предназначены для выполнения точного синтаксического анализа 340 и создания наилучшей синтаксической структуры 470 на основе вычисления оценок с использованием априорных оценок 436 из графа 460 обобщенных составляющих. Априорные оценки 436 включают оценки лексических значений, таких как частота (или вероятность), оценки каждой синтаксической конструкции (например, идиомы, словосочетания и т.д.) для каждого элемента в предложении, и степень соответствия выбранной синтаксической конструкции и семантического описания глубинных позиций. Помимо априорных оценок могут использоваться статистические оценки, полученные в результате обучения анализатора на больших текстовых корпусах. Вычисляются интегральные оценки и сохраняются.
[0073] Затем выдвигаются гипотезы об общей синтаксической структуре предложения. Каждая гипотеза представлена в виде дерева, которое в свою очередь является подграфом графа 460 обобщенных составляющих, покрывающее все предложение полностью, рассчитываются оценки для каждого синтаксического дерева. В ходе выполнения точного синтаксического анализа 340, гипотезы о синтаксической структуре предложения проверяются путем расчета различных типов оценок. Эти оценки высчитываются как степень соответствия заполнителя глубинных позиций 515 составляющей к их грамматическим и семантическим описаний, таких как грамматические ограничения (например, грамматические значения 514) в синтформах и семантические ограничения на заполнители глубинных позиций в глубинной модели. Другими типами оценок могут являться степени свободы лексических значений к прагматическим описаниям, которые могут абсолютными и/или условными вероятностными оценками синтаксических конструкций, которые обозначены как поверхностные модели 510, и степень сочетаемости их лексических значений среди остальных.
[0074] Вычисленные оценки для каждого вида гипотез могут быть получены на основе априорных грубых оценок, полученных в результате грубого синтаксического анализа 330. Например, грубая оценка рассчитывается для каждой обобщенной составляющей в графе 460 обобщенных составляющих, в результате чего могут быть посчитаны рейтинговые оценки. Различные синтаксические деревья могут быть построены с различными оценками. Рейтинговые оценки рассчитываются, и далее эти оценки используются при создании гипотез о полной синтаксической структуре предложения. Для этого выбирается гипотеза с наибольшей оценкой. Рейтинг рассчитывается во время выполнения точного синтаксического анализа до тех пор, пока не будет получен удовлетворительный результат, пока не будет построено лучшее синтаксическое дерево с наибольшей оценкой.
[0075] Затем, могут быть также сгенерированы и получены те гипотезы, которые отражают наиболее вероятную синтаксическую структуру всего предложения.. Из синтаксической структуры 470 варианты с более высокими оценками до вариантов синтаксической структуры с более низкими оценками 470, гипотезы о синтаксических структурах создаются в ходе точного синтаксического анализа до тех пор, пока не будет получен удовлетворительный результат, и не будет построено лучшее синтаксическое дерево с наибольшей оценкой.
[0076] Лучшее синтаксическое дерево выбирается как гипотеза о синтаксической структуре с наибольшей оценкой, которая отражена в графе 460 обобщенных составляющих. Это синтаксическое дерево считается наилучшей (наиболее вероятной) гипотезой о синтаксической структуре исходного предложения 402. Затем, строятся недревесные связи в предложении, и соответственно, синтаксическое дерево трансформируется в граф как лучшая синтаксическая структура 470, представляя собой наилучшую гипотезу о синтаксической структуре исходного предложения. Если в лучшей синтаксической структуре недревесные связи не могут быть восстановлены, тогда выбирается следующая в рейтинге структура для выполнения последующего анализа.
[0077] Если точный синтаксический анализ завершился неуспешно или наиболее вероятная гипотеза не может быть найдена после точного синтаксического анализа, происходит возврат 434 от построения неудачной синтаксической структуры на этапе точного синтаксического анализа 340 к этапу проведения грубого синтаксического анализа 330, причем в процессе синтаксического анализа рассматриваются все синтформы (не только лучшие синтформы). Если ни одно лучшее синтаксическое дерево не найдено или система не смогла восстановить недревесные связи во всех выбранных «наилучших структурах», тогда проводится дополнительный грубый синтаксический анализ 330, который учитывает «плохие» синтформы, которые не были проанализированы ранее согласно описываемому методу изобретения.
[0078] Фиг.8 более детально иллюстрирует точный синтаксический анализ 340, который выполняется для выбора множества наилучших синтаксических структур 470 в соответствии с одним или более способами реализации изобретения. Точный синтаксический анализ 340 выполняется сверху вниз от более высоких уровней до более низких уровней, от узла потенциальной вершины графа 460 обобщенных составляющих вниз к его нижнему уровню дочерних составляющих.
[0079] Точный синтаксический анализ 340 может содержать различные этапы, включая первоначальный этап, этап 850 для создания графа точных составляющих, этап 860 для создания синтаксических деревьев и дифференциального выбора наилучшей синтаксической структуры, этап 870 восстановления не древесных связей (non-tree links) и получение лучшей синтаксической структуры, среди остальных. Граф 460 обобщенных составляющих анализируется на этапе предварительного анализа, который подготавливает данные для точного синтаксического анализа 340.
[0080] В ходе точного синтаксического анализа 340 строятся точные составляющие. Обобщенные составляющие 622 используются для построения графа 830 точных составляющих для создания одного или более деревьев точных составляющих. Для каждой обобщенной составляющей, все возможные связи и их дочерние составляющие индексируются, маркируются.
[0081] Этап 860 генерации синтаксических деревьев выполняется для получения наилучшего синтаксического дерева 820. Этап 870 для восстановления недревесных связей может использовать правила установления недревесных связей и информацию о синтаксической структуре 875 предыдущих предложений для того, чтобы проанализировать одно или более синтаксических деревьев 820 и выбрать наилучшую синтаксическую структуру 870 среди различных синтаксических структур. Каждая дочерняя обобщенная составляющая может быть включена в одну или несколько родительских составляющих в одном или нескольких фрагментах. Точные составляющие являются узлами графа 830, и одно или несколько деревьев точных составляющих создается на основе графа 830 точных составляющих.
[0082] Граф 830 точных составляющих является промежуточным представлением между графом 360 обобщенных составляющих и синтаксическими деревьями. В отличие от синтаксического дерева, граф 830 точных составляющих может иметь несколько альтернативных заполнителей для одной поверхностной позиции. Точные составляющие выстраиваются в виде графа таким образом, что конкретная составляющая может быть включена в несколько альтернативных родительских составляющих для того, чтобы оптимизировать дальнейший анализ для выбора синтаксического дерева. Таким образом, структура промежуточного графа достаточно компактная для подсчета структурного рейтинга.
[0083] В ходе рекурсивного этапа 850 для создания графа точных составляющих, точные составляющие строятся на графе 840 линейного деления с помощью левых и правых связей ядра составляющих. Для каждого строится путь в графе линейного деления, определяется множество синтформ, для каждой из синтформ проверяется и оценивается линейный порядок. Соответственно, точная составляющая создается для каждой синтформы, и построение точных дочерних составляющих инициируется рекурсивно.
[0084] В качестве результата этапа 850 строится граф точных составляющих, который покрывает все предложение. Если этап 850 создания графа точных составляющих завершился неудачно при создании графа точных составляющих 830, который должен был покрыть все предложение, инициируется процедура, с попыткой покрыть предложение с синтаксически отдельными фрагментами.
[0085] Как показано на Фиг.8, если граф точных составляющих 830, который покрывает все предложение, построен, одно или более синтаксических деревьев могут быть построены на этапе создания 860 в ходе точного синтаксического анализа 340. Этап генерации 860 синтаксических деревьев позволяет создавать одно или несколько деревьев с конкретной синтаксической структурой. Так как поверхностная структура фиксирована в заданной составляющей, могут быть сделаны поправки в оценках структурного рейтинга, включая наложенные штрафные синтформы, которые могут быть сложными или не соответствовать стилю, или рейтингу контактного линейного порядка, и т.д.
[0086] Граф точных составляющих 830 представляет несколько альтернатив, соответствующих различными фрагментациям предложения и/или различным наборам поверхностных позиций. Итак, граф точных составляющих представляет собой множество возможных деревьев - синтаксических деревьев, так как каждая позиция может иметь несколько альтернативных заполнителей. Заполнители с наилучшим рейтингом могут образовывать точные составляющие (дерево) с наилучшим рейтингом. Поэтому точные составляющие представляют собой недвусмысленные (однозначное) синтаксическое дерево с наилучшим рейтингом. На этапе 860, эти альтернативы ищутся, и строится одно или несколько деревьев с фиксированной синтаксической структурой. Недревесные связи в построенном дереве на этом этапе еще не установлены. Результатом данного шага является получение множеств в наилучших синтаксических деревьев 820, которые имеют наилучшие рейтинговые значения.
[0087] Синтаксические деревья строятся на основе графа точных составляющих. Различные синтаксические деревья строятся в порядке убывания их структурных рейтинговых оценок. Лексические рейтинги не могут быть использованы в полной мере, так как их глубинная семантическая структура к этому моменту еще не определена. В отличие от изначальных точных составляющих, каждое результирующее синтаксическое дерево имеет фиксированную синтаксическую структуру, и каждая точная составляющая в ней имеет своего собственного заполнителя для каждой поверхностной позиции.
[0088] В ходе этапа 860, лучшее синтаксическое дерево 820 может, как правило, быть сгенерировано рекурсивно и траверсально на основе графа точных составляющих 830. Лучшие синтаксические поддеревья строятся для лучших дочерних точных составляющих, синтаксическая структура строится на основе заданной точной составляющей, и дочерние поддеревья прикрепляются к сформированной синтаксической структуре. Лучшее синтаксическое дерево 820 может быть построено, например, путем выбора поверхностной позиции с наилучшим качеством среди остальных поверхностных позиций данной составляющей, и создания копии дочерней составляющей, чье поддерево обладает наилучшим качеством. Это процедура применяется рекурсивно к дочерней точной составляющей.
[0089] На основе каждой точной составляющей может быть сгенерировано некоторое множество наилучших синтаксических деревьев с конкретной рейтинговой оценкой. Эта рейтинговая оценка может быть рассчитано заранее и специфицирована в точных составляющих. После того как лучшие деревья сгенерированы, новая составляющая создается на основе предыдущей точной составляющей. Эта новая составляющая в свою очередь генерирует синтаксические деревья со вторым по количеству начисленных оценок. Соответственно, на основе точной составляющей, может быть получено наилучшее синтаксическое дерево, которое может быть построено на основе этой точной составляющей.
[0090] Например, два вида рейтинга могут быть составлены для каждой точной составляющей в течение этапа 860, качество лучшего синтаксического дерева, которое может быть построено на основе этой точной составляющей, и качество второго наилучшего дерева. Помимо этого рейтинг синтаксического дерева высчитывается на основе этой точной составляющей.
[0091] Рейтинг синтаксического дерева вычисляется на основе следующих значений: структурный рейтинг составляющей; верхний рейтинг для набора лексических значений; верхняя глубинная статистика для дочерних позиций; рейтинг дочерних составляющих. Когда проанализирована точная составляющая для того, чтобы посчитать рейтинг синтаксического дерева, который может быть создан на основе точной составляющей, дочерние составляющие с наилучшими рейтингами анализируются в поверхностной позиции.
[0092] В ходе этапа 860, вычисление рейтинга для второго по качеству синтаксического дерева отличается только тем фактом, что для одной из дочерних позиций, выбирается его вторая по качеству составляющая. Любое синтаксическое дерево с минимальными потерями в рейтинге относительно лучшего синтаксического дерева должно выбраться в течение этапа 860.
[0093] На стадии завершения этапа 860, строится синтаксическое дерево с полностью определенной синтаксической структурой, т.е. определяются синтаксическая форма, дочерние составляющие и поверхностной позиции, которые они заполняют. После того как это дерево создано на основе лучшей гипотезы о синтаксической структуре исходного предложения, это дерево считается лучшим синтаксическим деревом 820. Возврат 862 от создания синтаксических 860 деревьев к построению 850 графа обобщенных составляющих обеспечивается, когда нет синтаксических деревьев с удовлетворяющим рейтингом, или точный синтаксический анализ не успешен.
[0094] Фиг.9 схематично иллюстрирует пример синтаксического дерева в соответствии с одной из возможных реализации изобретения. На Фиг.9, составляющие показаны в качестве прямоугольников, стрелки показывают заполненные поверхностные позиции. Составляющая имеет в качестве ядра (Core) слово (word) с его морфологическим значением (M-value) и семантического предка (Семантический класс.Semantic Class) и может иметь прикрепленные дочерние составляющие более низкого уровня. Это прикрепление изображено посредством стрелок, именованных как "Позиция" (Slot). Каждая составляющая имеет также синтаксическое значение (S-value), выраженное как граммемы синтаксических категорий. Эти граммемы являются качеством синтаксических форм, выбранных для составляющей в ходе выполнения точного синтаксического анализа 340.
[0095] Возвращаясь к Фиг.3, на этапе 307 строится независимая от языка семантическая структура (language-independent semantic structure), которая представляет смысл исходного предложения. Этот этап может включать также восстановление референциальных связей между предложениями. Примером референциальной связи является анафора - использование языковых конструкций, которые могут быть проинтерпретированы лишь с учетом другого, как правило, предшествующего, фрагмента текста.
[0096] Фиг.10 иллюстрирует детальную схему метода анализа предложения согласно одной или нескольким реализациям изобретения. Ссылаясь на Фиг.3 и Фиг.10, лексико-морфологическая структура 1022 определяется на этапе анализа 306 исходного предложения 305.
[0097] Затем производится синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа), использующий лингвистические модели и информацию различных уровней для вычисления вероятностей и создания множества синтаксических структур.
[0098] Как уже было отмечено выше, грубый синтаксический анализ применяется к исходному предложению и включает, в частности, генерацию всех потенциально возможных лексических значений слов, образующих предложение или словосочетание, всех потенциально возможных отношений между ними, всех потенциально возможных составляющих. Применяются все вероятные поверхностные синтаксические модели для каждого элемента лексико-морфологической структуры, затем строятся и обобщаются все возможные составляющие так, чтобы были представлены все возможные варианты синтаксического разбора предложения. В результате формируется граф обобщенных составляющих 1032 для последующего точного синтаксического анализа. Граф обобщенных составляющих 1032 включает все потенциально возможные связи в предложении. За грубым синтаксическим анализом следует точный синтаксический анализ на графе обобщенных составляющих, в результате которого из него "извлекаются" некоторое множество синтаксических деревьев 1042, представляющих структуру исходного предложения. Построение синтаксического дерева 1042 включает лексический выбор для вершин графа и выбор отношений между вершинами графа. Множество априорных и статистических оценок может быть использовано при выборе лексических вариантов и при выборе отношений из графа. Априорные и статистические оценки могут также быть использованы как для оценивания частей графа, так и для оценивания всего дерева. В этот момент также проверяются и строятся недревесные связи.
[0099] Независимая от языка семантическая структура предложения представляется в виде ациклического графа (дерева, дополненного недревесными связями), где каждое слово определенного языка заменено универсальными (независимыми от языка) семантическими сущностями, называемыми здесь семантическими классами. Ядром существующей системы, включающей различные приложения NLP является Семантическая иерархия, организованная как иерархия семантических классов, где "дочерний" семантический класс и его "потомки" наследуют значительную часть свойств "родительского" и всех предшествующих семантических классов ("предков"). Например, семантический класс SUBSTANCE (вещество) является дочерним классом достаточно широкого класса ENTITY (сущность), и в то же время он является "родителем" для семантических классов GAS (газ), LIQUID (жидкость), METAL (металл), WOOD_MATERIAL (дерево как материал), и т.д. Каждый семантический класс в семантической иерархии снабжен глубинной (семантической) моделью. Глубинная модель представляет собой множество глубинных позиций (типов семантических отношений в предложениях). Глубинные позиции отражают семантические роли дочерних составляющих (структурных единиц предложения) в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей и возможные семантические классы в качестве заполнителей позиций. Эти глубинные позиции выражают семантические отношения между составляющими, например, "agent" (агенс), "addressee" (адресат), "instrument" (инструмент), "диапйу"(количество), и т.д. Дочерний класс наследует и подстраивает глубинную модель родительского класса.
[00100] Семантическая иерархия устроена таким образом, что более общие понятия находятся на верхних уровнях иерархии. Например, в случае документов, типы которых проиллюстрированы. Например, семантические классы - PRINTEDJMATTER (печатное издание), SCIENTIFIC_AND_LITERARY_WORK (научные труды и литература), TEXT_AS_PART_OF_CREATIVE_WORK (творческие тексты) и другие являются потомками класса TEXT_OBJECTS_AND_DOCUMENTS (текстовые объекты и документы), а класс PRINTED_MATTER (печатное издание), в свою очередь, является родительским для семантического класса EDITION_AS_TEXT (издание как текста), содержащего классы PERIODICAL (периодические издания) и NONPERIODICAL (непериодические издания), где PERIODICAL (периодические издания) - родительский класс для классов ISSUE (выпуск), MAGAZINE (журнал), NEWSPAPER (газета) и т.д. Подход к делению на классы может отличаться. Данное изобретение в первую очередь основано на использовании понятий, не зависящих от языка.
[00101] Фиг.11 представляет собой схему, иллюстрирующую языковые описания 1110, согласно одной из возможных реализации изобретения. Языковые описания 1110 включают морфологические описания 301, синтаксические описания 302, лексические описания, 303 и семантические описания 304. Языковые описания 1110 объединены в общее понятие. Фиг.12 представляет собой схему, иллюстрирующую морфологические описания, согласно одной из возможных реализации изобретения. Фиг.5 иллюстрирует синтаксические описания, согласно одной из возможных реализации изобретения. Фиг.13 иллюстрирует семантические описания, согласно одной из возможных реализации изобретения.
[00102] Семантическая иерархия может быть создана единовременно, а затем может быть заполнена для каждого определенного языка. Семантический класс в конкретном языке включает лексические значения с соответствующими моделями. Семантические описания 304 не зависят от языка. Семантические описания 304 могут содержать описания глубинных составляющих и могут содержать семантическую иерархию, описания глубинных позиций, систему семантем и прагматических описаний.
[00103] Ссылаясь на Фиг.11, в одной из возможных реализации изобретения морфологические описания 301, лексические описания 303, синтаксические описания 302 и семантические описания 304 связаны. Лексическое значение может иметь несколько поверхностных (синтаксических) моделей, обусловленных семантемами и прагматическими характеристиками. Синтаксические описания 302 и семантические описания 304 также связаны. Например, диатеза синтаксических описаний 302 может рассматриваться как "интерфейс" между зависимыми от языка поверхностными моделями и независимыми от языка глубинными моделями семантического описания 304.
[00104] Фиг.12 иллюстрирует пример морфологических описаний 301. Как показано, составляющие морфологических описаний 301 включают, но не ограничиваются описаниями словоизменения 1210, грамматической системой (граммемами) 1220, и описаниями словообразования 1230. В одной из возможных реализации изобретения грамматическая система 1220 включает набор грамматических категорий, таких как «Часть речи», «Падеж», «Род», «Число», «Лицо», «Возвратность», «Время», «Вид» и их значения, здесь и далее называемые граммемами.
[00105] Фиг.5 иллюстрирует синтаксические описания 302. Компоненты синтаксических описаний 302 могут содержать поверхностные модели 510, описания поверхностных позиций 520, описания референциального и структурного управления 556, описания управления и согласования 540, недревесные описания 550 и правила анализа 560. Синтаксические описания 402 используются для построения возможных синтаксических структур предложения для данного исходного языка, учитывая порядок слов, недревесные синтаксические явления (например, согласование, эллипсис и т.д.), референциальный контроль (управление) и другие явления.
[00106] Фиг.13 иллюстрирует семантические описания 304 согласно одной из возможных реализации изобретения. В то время как поверхностные позиции 520 отражают синтаксические отношения и способы их реализации в конкретном языке, глубинные позиции 1314 отражают семантические роли дочерних (зависимых) составляющих в глубинных моделях 1312. Потому описания поверхностных позиций, и шире - поверхностные модели, могут быть специфичными для каждого конкретного языка. Описания глубинных моделей 1320 содержат грамматические и семантические ограничения для заполнителей этих позиций. Свойства и ограничения глубинных позиций 1314 и их заполнители в глубинных моделях 1312 очень похожи и часто идентичны для различных языков.
[00107] Система семантем 1330 представляет множество семантических категорий. Семантемы могут отражать лексические, грамматические свойства и атрибуты, а также дифференциальные свойства и стилистические, прагматические и коммуникативные характеристики. Для примера, семантическая категория "DegreeOfComparison" (степень сравнения) может быть использована для описания степеней сравнения, выраженных разными формами прилагательных, например, "easy", "easier" and "easiest". Так, семантическая категория "DegreeOfComparison" может включать семантемы, например "Positive", "ComparativeHigherDegree", "SuperlativeHighestDegree". Лексические семантемы могут описывать специфические свойства объектов, например "быть плоским" ("being flat") или "быть жидким" ("being liquid") и используются в ограничениях на заполнители глубинных позиций. Классифицирующие дифференциальные семантемы используются для выражения дифференциальных свойств внутри одного семантического класса. Прагматические описания 1340 служат для того, чтобы в процессе анализа текста фиксировать соответствующую тему, стиль или жанр текста, а также возможно приписать соответствующие характеристики объектам семантической иерархии. Например, "Economic Policy", "Foreign Policy", "Justice", "Legislation", "Trade", "Finance", etc.
[00108] Фиг.14 является схемой, иллюстрирующей лексические описания 303, согласно одной или нескольким реализациям данного изобретения. Лексические описания 303 включают лексико-семантический словарь 1404, который включает в себя набор лексических значений 1412, образующих вместе со своими семантическими классами семантическую иерархию, где каждое лексическое значение может включать, но не ограничивается своей глубинной моделью 1412, поверхностной моделью 410, грамматическим значением 1408 и семантическим значением 1410. Лексическое значение может объединять различные дериваты (например, слова, выражения, фразы), выражающие смысл с помощью различных частей речи, различных форм слова, однокоренных слов и пр. В свою очередь, семантический класс объединяет лексические значения близких по смыслу слов и выражений на разных языках.
[00109] Таким образом, происходит лексический, морфологический, синтаксический и семантический анализ предложения. В результате для каждого предложения строится оптимальное семантико-синтаксическое дерево. Узлами данного семантико-синтаксического графа являются словарные единицы исходного предложения, которым приписаны Семантические классы (СК), являющиеся элементами Семантической Иерархии.
[00110] Фиг.15 иллюстрируют схему семантической структуры, полученной в результате анализа предложения "Москва - город красивый и богатый, как и полагается столице". Эта структура независима от языка исходного предложения и содержит всю информацию для установления смысла, передаваемого предложением. Эта структура данных содержит синтаксическую и семантическую информацию, такую как семантические классы, семантемы (которые не показаны на рисунке), семантические отношения (глубинные позиции), недревесные связи и т.д., достаточную для восстановления смысла исходного предложения на том же или другом языке.
Модуль извлечения информации
[00111] Описываемое изобретение предполагает использование модуля извлечения информации (information extraction, fact extraction). Задачей извлечение информации является автоматизированное машинное извлечение сущностей, фактов на основе обработки текстов или массивов текстов. Одним из извлеченных фактов является извлеченная тональность. В результате подобного анализа текстовых сообщений в рамках описываемого изобретения могут быть извлечены основные обсуждаемые темы, события, действия и т.д. Модуль извлечения информации основан на проведенных ранее на шаге 330 (Фиг.1) этапах работы парсера (а именно лексического, морфологического, синтаксического и семантического) анализа предложения.
[00112] На шаге 340 модуль извлечения информации получает на вход семантико-синтаксические деревья разбора предложений, полученные в результате работы парсера. В результате работы модуля извлечения информации строится ориентированный граф, узлы которого представляют собой информационные объекты различных классов, а ребра описывают связи между объектами. Извлеченная информация может быть представлена в соответствии с концепцией RDF (Resource Definition Framework).
[00113] Предполагается, что информационным объектам присущи некоторые свойства. Свойства информационного объекта могут быть заданы, например, с помощью вектора <s,p,o>, в котором s обозначает уникальный идентификатор объекта, р - идентификатор свойства (предикат), о - значение простого типа (строка, число и т.п.).
[00114] Информационные объекты могут быть связаны друг с другом с помощью объектных свойств или связей. Объектное свойство задается с помощью тройки <s,p,o>, где s - уникальный идентификатор объекта, р - идентификатор отношения (предикат), о - уникальный идентификатор другого объекта.
[00115] В процессе извлечения информации используется система декларативных правил (rule-based approach). Данные декларативные правила представляют собой некие шаблоны, сопоставление которых с фрагментами семантико-синтаксическим дерева порождает элементы информационного RDF графа.
[00116] Примером такого правила может быть следующее правило:

[00117] Порожденные модулем извлечения информации графы согласованы с формальным описанием предметной области, или онтологией. Онтология представляет собой систему понятий и отношений, которая описывает некую область знаний. Онтология включает информацию о том, к каким классам могут относиться информационные объекты, какие атрибуты могут иметь объекты различных классов, какими могут быть значения тех или иных атрибутов.
Построение древовидных структур для обсуждаемых тем
[00118] В одной из реализации изобретения возможно построение графа, например в виде древовидной структуры. В основе построения графа лежит информация об извлеченных из анализируемых сообщений сущностей, а именно ключевых тем обсуждения.
[00119] Извлечение тем сообщений может быть осуществлено на основе содержащегося текста в поле «Тема сообщения/Subject». Помимо этого, тема сообщений может быть получена на основе работы модуля извлечения информации на шаге 140. Также для каждой темы может быть посчитан коэффициент, отражающий частоту встречаемости данной темы в текстовых данных (сообщениях). Может быть проведена сортировка извлеченных тем, так как наиболее популярные темы обсуждений представляют наибольший интерес. В результате сортировки наиболее обсуждаемые темы могут быть отобраны для построения графа на основе использования некого порогового значения для коэффициента, отражающего частоту встречаемости темы в текстовых сообщениях. Пороговое значение может быть задано заранее или подобрано. Более того граф может быть построен на основе всего множества извлеченных тем.
[00120] Зачастую в процессе обсуждения какой-либо темы (события и т.д.), одна тема может порождать другую и т.д. Данное изобретение представляет возможным отследить, каким образом обсуждаемые темы связаны друг с другом. Наиболее актуально это для наиболее обсуждаемых тем, нашедших наибольший отклик среди сотрудников.
[00121] Вершиной графа будет являться извлеченная тема сообщения. Дуги (ребра) графа отображают связь между темами сообщений. Помимо этого каждый элемент графа может быть раскрыт подробнее таки образом, что расширенная (дополнительная) информация может включать участников сообщения, их мнения, время отправления сообщения и т.д. То есть пользователь, имеет возможность выбрать тему сообщения и получить всплывающее окно, содержащее подробную информацию об участниках обсуждения темы.
[00122] Пример подобной построенной структуры проиллюстрирован на Фиг.18. Из Фиг.18 видно, что в ходе анализа текстовых сообщений выявлена тема «1» (1801). Тема «1» (1801) порождает три новых темы сообщений «2» (1802), «3» (1803), «4» (1804), которые также связаны между собой. Пользователь имеет возможность посмотреть на текстовые сообщения (1808, 1809) по каждой из выбранных тематик.
Выявление лидеров
[00123] При помощи метода анализа текстовых данных, коими могут являться письма и сообщения на форуме, на основе извлеченных сущностей и фактов, можно определять неформальных лидеров.
[00124] На основе извлеченных сущностей и фактов, или содержания поля «Отправитель» (или другого характерного (опорного) слова) строится граф, отражающий социальное взаимодействие сотрудников компании. Данный граф может быть визуально представлен на экране для пользователя. Вершина графа соответствует сотруднику компании (отправителю/получателю письма), дуга (ребро графа) отражает факт их взаимодействия. То есть если сотрудники компании ни разу не общались по электронной почте, то между вершинами не будет соответствующей соединяющей дуги (ребро графа). Если факт общения был зафиксирован, то дуга будет выходить из вершины первого сотрудника в вершину второго. Данный граф может быть построен на основе информации за различный промежуток времени: день, неделю, месяц и т.д.
[00125] Построенный таким образом граф, отражающий социальное взаимодействие между сотрудниками, помогает выявить наиболее активных участников переписки. На графе вершины наиболее активных участников будут иметь наибольшее число соединительных дуг (ребер). Такой критерий может быть задан для поиска лидеров среди сотрудников.
[00126] Граф может быть построен как между сотрудниками, так и между подразделениями. Помимо этого он может быть построен для отражения взаимодействия с внешними компаниями (на основе переписки с сотрудниками из внешних компаний).
Модель для выделения тональностей
[00127] На Фиг.16 представлена модель, которая может быть выбрана для определения тональности текстовых данных.
[00128] Согласно иллюстративной модели "SentimentTag" 1601 является «тегом» тональности, который можно понимать как гипотезу о наличии эмоциональной окраски. Может характеризоваться знаком тональности. Например, в атрибут типа «word» записываются последовательность слов, на основе которых принимается решение о знаке тональности.
[00129] Тег "SentimentOrientation" 1603 обозначает знак тональности. В одной из реализации описываемого изобретения знак тональности может принимать два значения: позитивную тональность или негативную тональность.
[00130] Тег "Sentiment" 1605 обозначает тональность. Наследует отношения от SentimentTag′ 1601 а, и кроме того, может ссылаться на объект и субъект тональности. Объектом в данном случае могут быть любые сущности и факты, описанные в онтологии и выделяемые модулем извлечения информации. Субъектом может быть любая сущность, указанная в онтологии. Например, субъектами могут быть экземпляры концепта Subject, объединяющего в себе персон, организаций и локаций. Субъект и объект тональности определяется на основе извлеченных сущностей.
[00131] Объекты тональности, не описанные в онтологии, выделяются как экземпляры этого концепта. Помимо этого может быть вспомогательный концепт AbstractObject 1607, который может использоваться для выделения объектов тональности.
[00132] На Фиг.17 приведен пример информационного RDF графа для примера разбора предложения «Москва - город красивый и богатый, как и полагается столице».
Тональный словарь
[00133] Как известно, в естественном языке существуют слова и фразы, которые могут содержать эмоциональный окрас, например положительный (positive) или отрицательный (negative). Подобные слова (sentiment words) могут служить одним из инструментов семантического анализа.
[00134] Описываемый метод определения тональности в тексте основан на использовании тонального словаря (sentiment lexicon). Тональный словарь может быть построен вручную на основе использования Семантической Иерархии (СИ), описанной в патенте США U.S. Patent 8,078,450. Для формирования тонального словаря могут быть использованы прагматические классы и семантемы.
[00135] Например, могут быть использованы прагматические классы, непосредственно отражающие вид тональности. Negative или Positive. Прагматические классы могут отражать некую область знаний (domain). Прагматические классы могут создаваться вручную и приписываться на уровне Семантических Классов и Лексических Классов.
[00136] Система семантем представляет множество семантических категорий. Семантемы могут отражать лексические, грамматические свойства и атрибуты, а также дифференциальные свойства и стилистические, прагматические и коммуникативные характеристики. Для примера, семантическая категория "DegreeOfComparison" (степень сравнения) может быть использована для описания степеней сравнения, выраженных разными формами прилагательных, например, "easy", "easier" and "easiest".
[00137] Семантемы "PolarityPlus", "PolarityMinus", "NonPolarityPlus", "NonPolarityMinus" могут быть использованы для различий антонимов, которые являются семантическими дериватами одного лексического класса. Так как Прагматические классы (ПК) приписываются на уровне Лексических классов (ЛК) и Семантических классов (СК) для различения антонимов (они, как правило, разного знака), используются семантемы антонимической полярности, например PolarityPlus.
[00138] При формировании словаря лексика разделяется на несколько классов, заданных заранее. В одной из реализации изобретения лексика разделяется на два класса, а именно, на позитивную лексику и негативную лексику. При этом лексика в данном словаре отражает положительную или отрицательную окраску независимо от окружения (или другими словами, от контекста) либо в нейтральном окружении, т.е. в отсутствии других тонально окрашенных слов. Примерами слов, входящих с тональный словарь, являются «шикарный», «прорыв» (в значении «величайшее достижение»), «бдительный», «удобство», и т.п.
Определение знака тональности
[00139] Тональный словарь (словарь тональной лексики - (sentiment lexicon)) лежит в основе процесса извлечения тональности. В тексте согласно тональному словарю выделяются экземпляры концепта «тег» тональности (SentimentTag), или другими словами, выдвигается гипотеза о наличии эмоциональной окраски. Затем происходит дальнейшая обработка выделенных экземпляров, их модификация, в результате чего принимается решения, действительно ли являются выделенные экземпляры концепта SentimentTag тональностью или нет. Другими словами происходит уточнение экземпляров концепта (SentimentTag) до концепта Sentiment.
[00140] В данном случае обработка подразумевает собой нахождение объектов и субъектов тональности, а также определение знака тональности, в зависимости от различных факторов. Наличие субъектов и объектов тональности может давать право утверждать о наличии тональности.
Отрицания и другая инверсия знака тональности
[00141] Оценка тональности согласно одной из реализации описываемого изобретения производится, как уже было упомянуто выше, по двухбалльной шкале, имеющей две категории, положительную и отрицательную.
[00142] Считается, что «отрицания» (negation words) должны менять знак тональности на противоположный. Примерами «отрицаний» служат следующие слова not, never, nobody и т.д.
Кроме «отрицаний» существуют и другие инверторы знака.
[00143] Ниже приведены примеры правил и ситуаций, в которых принимается решение об инвертировании или не инвертировании знака:
[00144] Например, одним из инверторов знака являются «отрицания» на эмоционально окрашенном слове или группе слов (или другими словами, на любой составляющей, к которой привязан тег вида SentimentTag). «Отрицания» выделяются на основе семантем, вычисляемых в процессе семантического анализа. Это позволяет единообразно обрабатывать случаи с явным отрицанием (частицы «не», «без») и примеры вида: «Nobody gives a good performance here».
[00145] Другим инвертором является отрицание степени («(not very) good»). Сама степень, однако, на знак не влияет.
[00146] Инверторами знака тональности являются так называемые «шифтеры». Примерами шифтеров являются слова «прекратить», «передумать», и т.д. Тональные шифтеры (sentiment shifters) это выражения, которые используются для изменения тональной ориентации, например для изменения отрицательной ориентации (негативной) на положительную ориентацию, и наоборот.Если на шифтере есть отрицание, то на знак тональности он влиять не должен. Аналогично для антонимов шифтеров («продолжить», etc.): они влияют на знак тональности, если стоят под отрицанием.
[00147] Согласно описываемому изобретению, существует счетчик, который учитывает количество инвенторов с экземпляром тональности, после чего определяется основной знак тональности.
Модальность
[00148] При определении знака тональности учитывается модальность. Модальность - это семантическая категория естественного языка, которая отражает отношение говорящего к объекту его высказывания, например желательная (оптативная) модальность, модальность намерения (интенциональная), модальность необходимости и долженствование (дебитивная модальность), побудительная модальность (императивная), вопросительное (общие и специальные вопросы) и т.д.
[00149] Модальность в модуле извлечения информации обрабатывается и выделяется отдельно, независимо от тональности. В онтологии модальность представлена концептами «Optative» и «Optativelnformation». Несмотря на название, обрабатывается не только оптативная модальность, но и дебитивная, императивная и интенциональная модальности. Таким образом, покрываются: желание, намерение, долженствование и императив. Кроме того, все вопросительные предложения рассматриваются как желание получить некоторую информацию. При этом также выделяются объект и экспериенсер оптативности.
[00150] Таким образом, если тональность является объектом оптативности, то:
- в случае концепта «Optative» тональность либо меняет знак на противоположный, либо должна быть аннулирована. Так должно быть по той причине, что «желание чего-то хорошего» может присутствовать как само по себе, так и из-за наличия противоположной ситуации. По этой же причине автоматически определить, какое именно из действий должно быть произведено над SentiimentTag'OM, в общем случае не представляется возможным;
- в случае вопросительных предложений решение зависит от типа вопроса.
Сочетаемость
[00151] Помимо этого при определении знака учитывается сочетаемость. Сочетаемость может быть учтена на основе правил сочетаемости или словарей коллокаций. Коллокацией называется некоторое словосочетание, которое имеет синтаксические и семантические признаки целостной единицы. В качестве примера правила для учета сочетаемости могут быть приведены именные группы (ИГ), представляющих собой словосочетания существительного и прилагательного. В предложении может встретиться несколько эмоциональных слов или их групп (SentimentTag′ов), как одинакового знака, так и разного. При этом эмоциональная окраска их совокупности зависит от окраски каждого.
[00152] В частности для именных групп (существительное + прилагательное), если в словосочетании существительное несет отрицательный оттенок, следовательно, вся ИГ может быть помечена как негативная. Пример: «Такого качественного БРЕДА я еще никогда не видела!!!». Или если существительное несет позитивный окрас, тогда знак ИГ может определиться знаком зависимого прилагательного.
Выделение объектов и субъектов
[00153] Связь между тональностью (SentimentTag′ами) и объектами и субъектами определяется на основе их ролей в предложении, и эта связь позволяет утверждать наличие тональности в данном предложении. Выделение происходит в ряде контекстов, некоторые из которых приведены ниже. В качестве субъектов могут выступать Персоны и Организации и т.д. Все объекты выделяются как экземпляры концепта ObjectOfSentiment, однако, при наличии извлеченных и привязанных к той же составляющей разбора сущностей, описанных в онтологии, объектами становятся эти сущности.
[00154] Ниже приведены примеры контекстов:
- Быть, являться чем-л. (отношение тождества), считаться чем-либо.
- Инхоатив («N похорошела»).
- Авторство («шедевр режиссера N»).
- Характеристика («замечательный N», «преступник N»).
- Характеристики, которые сами по себе нейтральны, но могут приобретать окраску (в контексте их увеличения-уменьшения). Примерами могут служить: безработица, зарплата, и т.п.
- Любить, нравиться, etc. такие эмоционально окрашенные глаголы выделены в отдельную группу на уровне словаря.
- И т.п.
[00155] Также используется небольшая «предобработка» объектов, позволяющая считать, что оценка каких-либо свойств рассматриваемого объекта относится и к самому объекту (для этого используется концепт AbstractObject). В качестве примеров такой предобработки можно привести: «поведение N», «сюжет фильма» (здесь на «поведении» нельзя выделять персону, однако объект оценки там как-то увидеть нужно).
[00156] По результатам работы модуля на коллекции текстов было выявлено, что в объект тональности чаще всего попадают характеристики и параметры объектов. Так, на коллекции из 874 текстов (275 отзывов о книгах, 329 о фильмах, 270 о цифровых фотокамерах):
- Для книг наиболее частотными оказались: книга, чтение, автор, человек, герой, роман, впечатление, литература, язык, сюжет, том, женщина, мысль, история, и т.п.
- Для фильмов: фильм, актер, часть, герой, том, кино, момент, сюжет, персонаж, человек, идея, спецэффект, сцена, и т.п.
- Для камер: качество, снимок, покупка, камера, фотография, аппарат, видео, съемка, фотоаппарат, фотка, изображение, режим, зум, модель, меню, цена, картинка, функция, объектив, и т.п.
Таким образом, можно получать информацию о том, какие именно аспекты сущностей чаще всего упоминаются в текстовых сообщения, а также использовать систему в качестве модуля извлечения аспектов (feature-extractor′а).
[00157] Извлечение авторов мнений (эмоции) (opinion holders), времени написания (time extraction) в текстовых сообщений может быть осуществлен на основе заранее известной структуры данных сообщений. Обычно электронное сообщение (или сообщение на форуме) имеет соответствующие поля, содержащие информацию об отправителе и дате отправления сообщения.
Определение общей тональности для текста (aggregate function)
[00158] Первичной целью является выделение тональности локально в рамках аспекта. Однако во многих ситуациях важно определить общую объективную тональность текстовых данных, то есть агрегированную тональность всего текста. В рамках направленного анализа тональности (Aspect based sentiment analysis) для (entities) аспектов и сущностей приписываются некие веса. Затем по некой формуле рассчитывается общая тональность для всего предложения или текста. Например, для вычисления тональности в i-м предложении/тексте может быть использована следующая формула:
Sentimenti=w1e1+..wkek
[00159] На основе каждого слова в письме, рассчитывается тональность всего текстового сообщения. Способ подсчета общей тональности может быть осуществлен различными способами.
[00160] В результате проведенного анализа на тональность каждое из писем и классифицируется по эмоциональной окраске. Однако число кластеров может быть различным. Например, письма могут быть классифицированы как negative - neutral - positive. Каждое письмо может иметь в соответствии с определенной эмоциональной окраской некую метку. Данная метка может по-разному отражать эмоциональную окраску письма: в виде цветовой метки, символа, ключевого слова и т.д.
Классификация документов по тональности (Document Sentiment Classification)
[00161] В другой реализации изобретения метод определения тональности текстовых сообщений может быть основан помимо лингвистического метода на статистическом методе классификации. (Supervised machine learning).
[00162] Для этого используется выделенная локально тональность в качестве признаков для обучения, а также подбор новых признаков, полученных из синтактико-семантических разборов предложений. Важно правильно осуществить выбор признаков для классификатора. Чаще всего используются лексические признаки, например, отдельные слова, сочетания слов, специфические суффиксы, префиксы, заглавные буквы и т.п.
[00163] Например, признаками могут быть наличие термина (term) в тексте и его частота (frequency) употребления (TF-IDF); часть речи (Part of Speach); тональные слова и фразы; некие правила (rules); шифтеры (shifters); синтаксическая зависимость (syntactic dependency) и т.д. Согласно описываемому методу определения тональности текста признаками могут быть высокоуровневые признаки, например Семантические Классы, Лексические Классы, и т.д.
[00164] Результаты анализа текстовых сообщений могут быть представлены всеми возможными известными способами. Например, результаты могут быть отображены графически, в отдельном окне, во всплывающем окне (pop-up window), в виде vidget на «рабочем столе», в отдельном письме, присылаемом раз в сутки или как-либо иначе. Один из вариантов отображения - диаграмма, состоящая из нескольких столбцов; высота каждого столбца пропорциональна количеству писем данного «цвета».
[00165] Благодаря описываемому изобретению, руководители могут также видеть результаты мониторинга, общие по подчиненному отделу, руководители высокого ранга - также общие результаты по всей компании. Иными словами, для руководителя отображаемый результат может выводиться совокупно, для всех подчиненных ему людей, или раздельно, сгруппировано по указанному подразделению.
[00166] В рамках мониторинга может также выполняться «прогноз», то есть вычисление и отображение ожидаемого результата, последующий будущий промежуток времени и т.д.
[00167] Анализ текстовых сообщений (например, в виде корпоративной почты и сообщений на профессиональных корпоративных форумах) может осуществляться непосредственно на корпоративных серверах. Другими словами это означает, что программа-агент, реализующая метод описываемого изобретения, физически может находиться на сервере, используемом для почты компании. Альтернативно, анализ может осуществляться распределено. В этом случае программа-агент может находиться на всех компьютерах, на которых запущен почтовый клиент; в частности, агент может быть plug-in или add-on к почтовому клиенту.
[00168] На Фиг.19 приведен возможный пример вычислительного средства 1900, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 1900 включает в себя, по крайней мере, один процессор 1902, соединенный с памятью 1904. Процессор 1902 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер или представлять собой чип или другое устройство, способное производить вычисления (например, лапласиан может быть получен оптически). Память 1904 может представлять собой оперативную память (ОЗУ), а также содержать любые другие типы и виды памяти, в частности, устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например, жесткие диски и т.д. Кроме того, может считаться, что память 1904 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 1900, например, кэш-память в процессоре 1902, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 1910
[00169] Вычислительное средство 1900 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 1900 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 1908 (например, жидкокристаллический дисплей или сигнальные индикаторы). Вычислительное средство 1900 также может иметь одно или более постоянных запоминающих устройств 1910, например, привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 1900 может иметь интерфейс с одной или более сетями 1912, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные со всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 1900 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 1902 и каждым из компонентов 1904, 1906,1908, 1910 и 1912.
[00170] Вычислительное средство 1900 работает под управлением операционной системы 1914 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 1916.
[00171] Программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию.
[00172] Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались ранее. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.

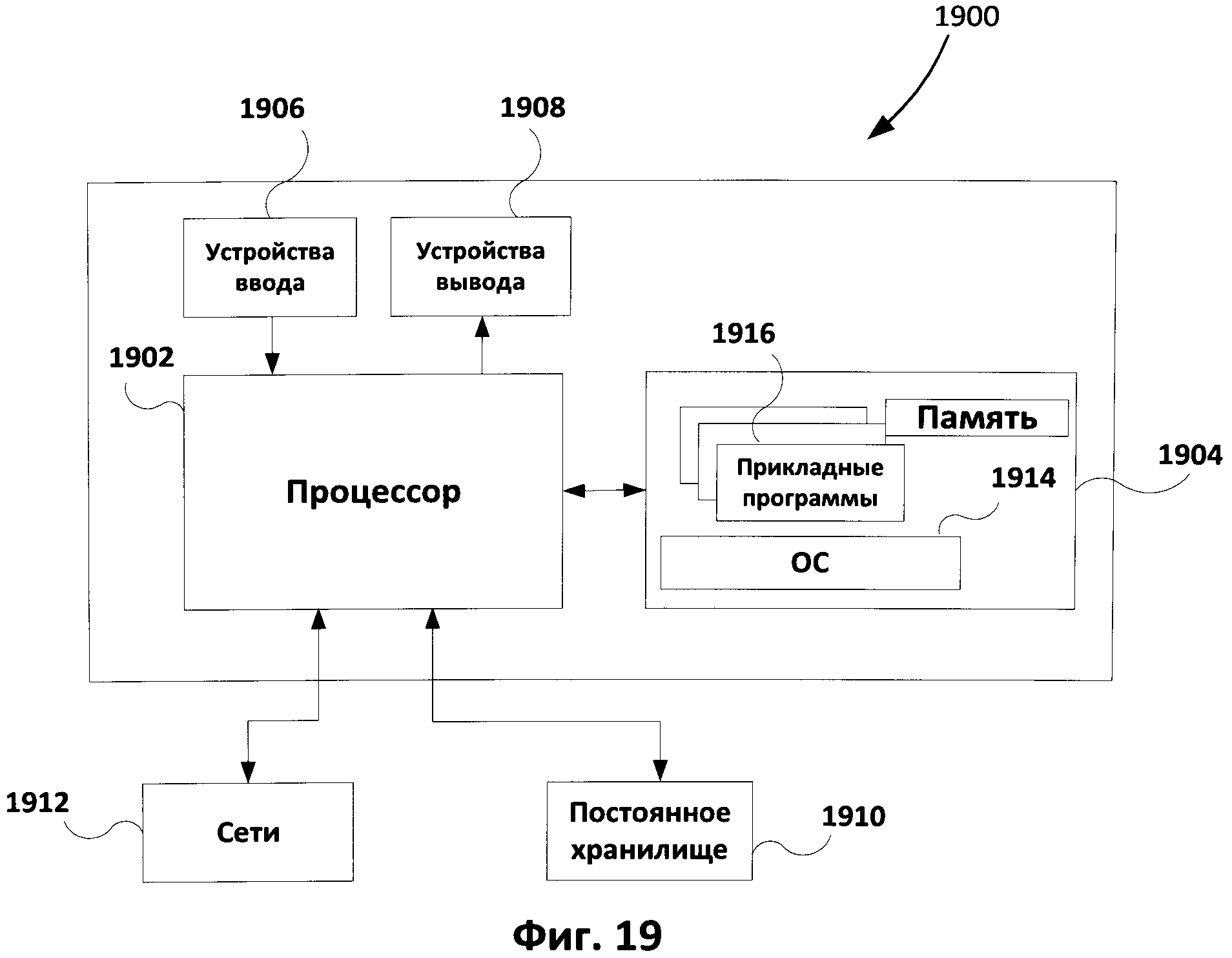

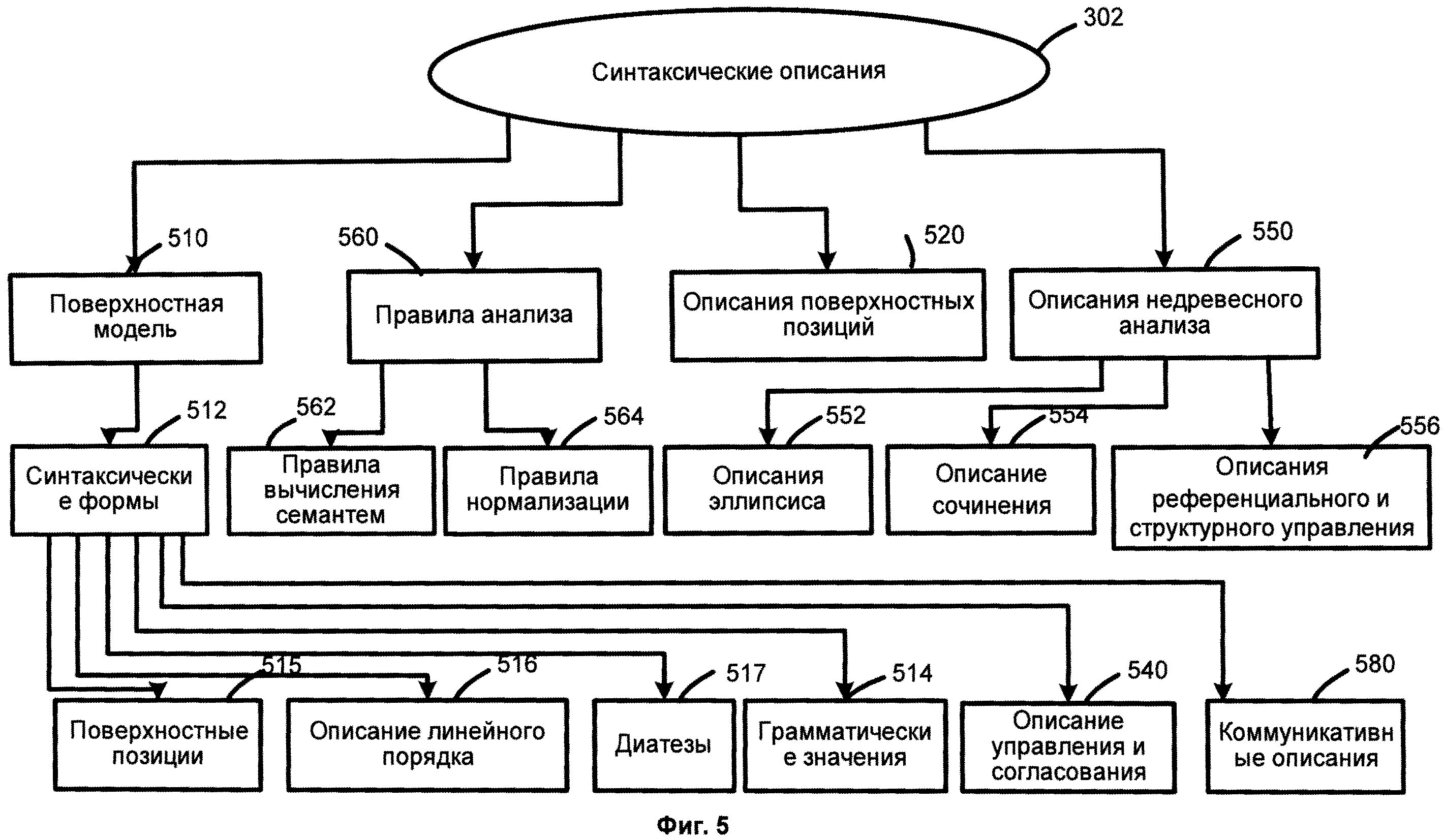
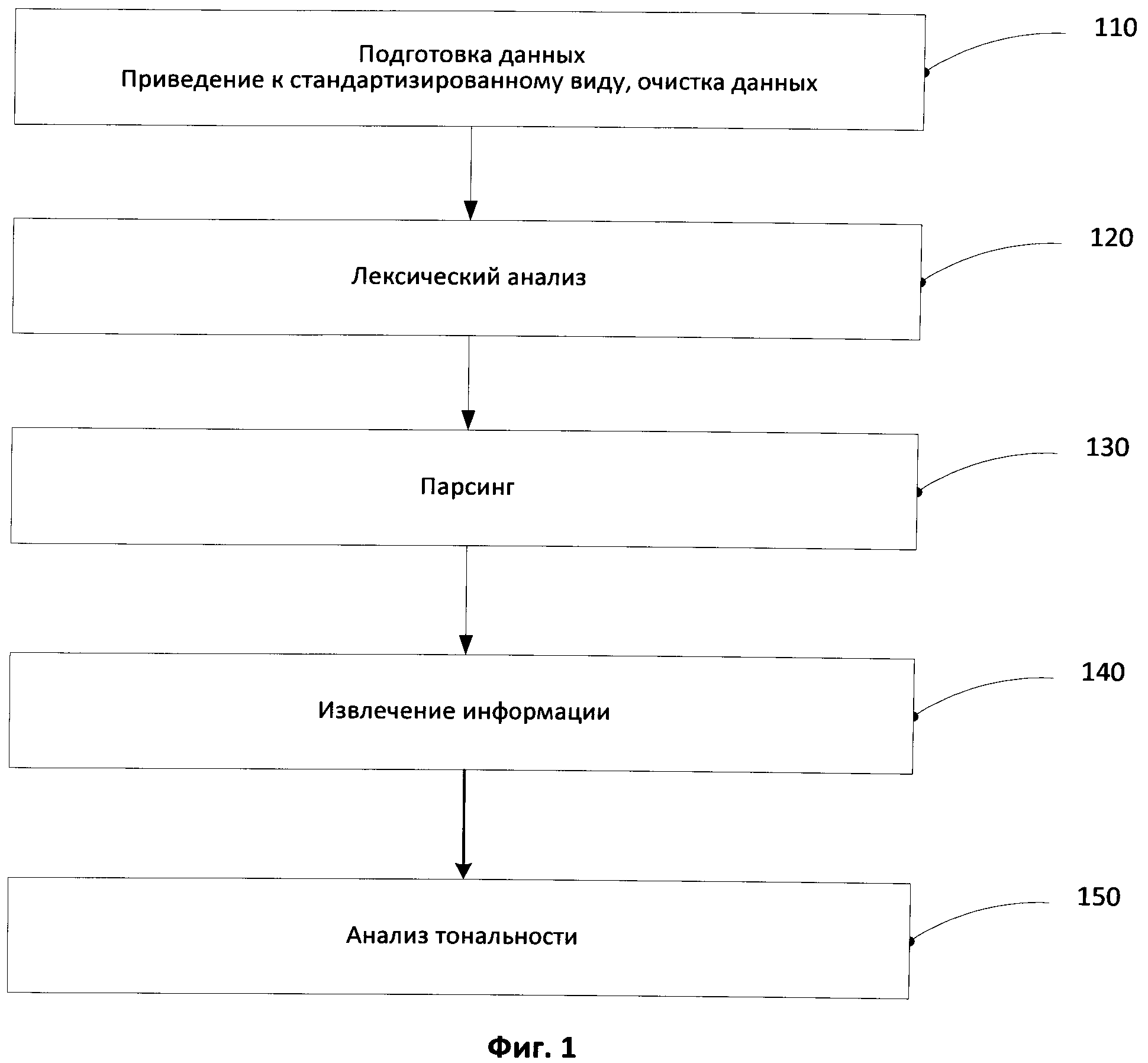
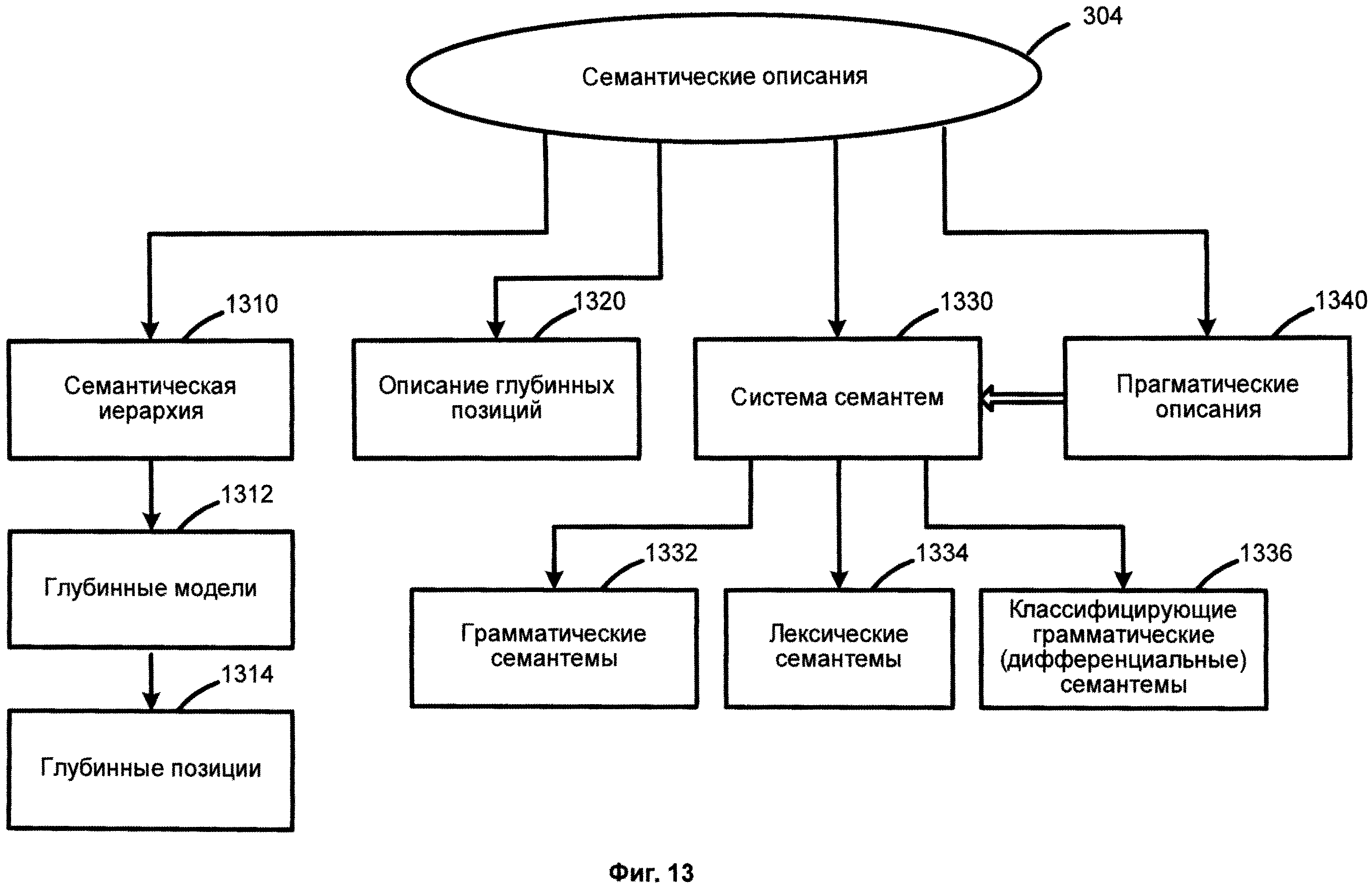
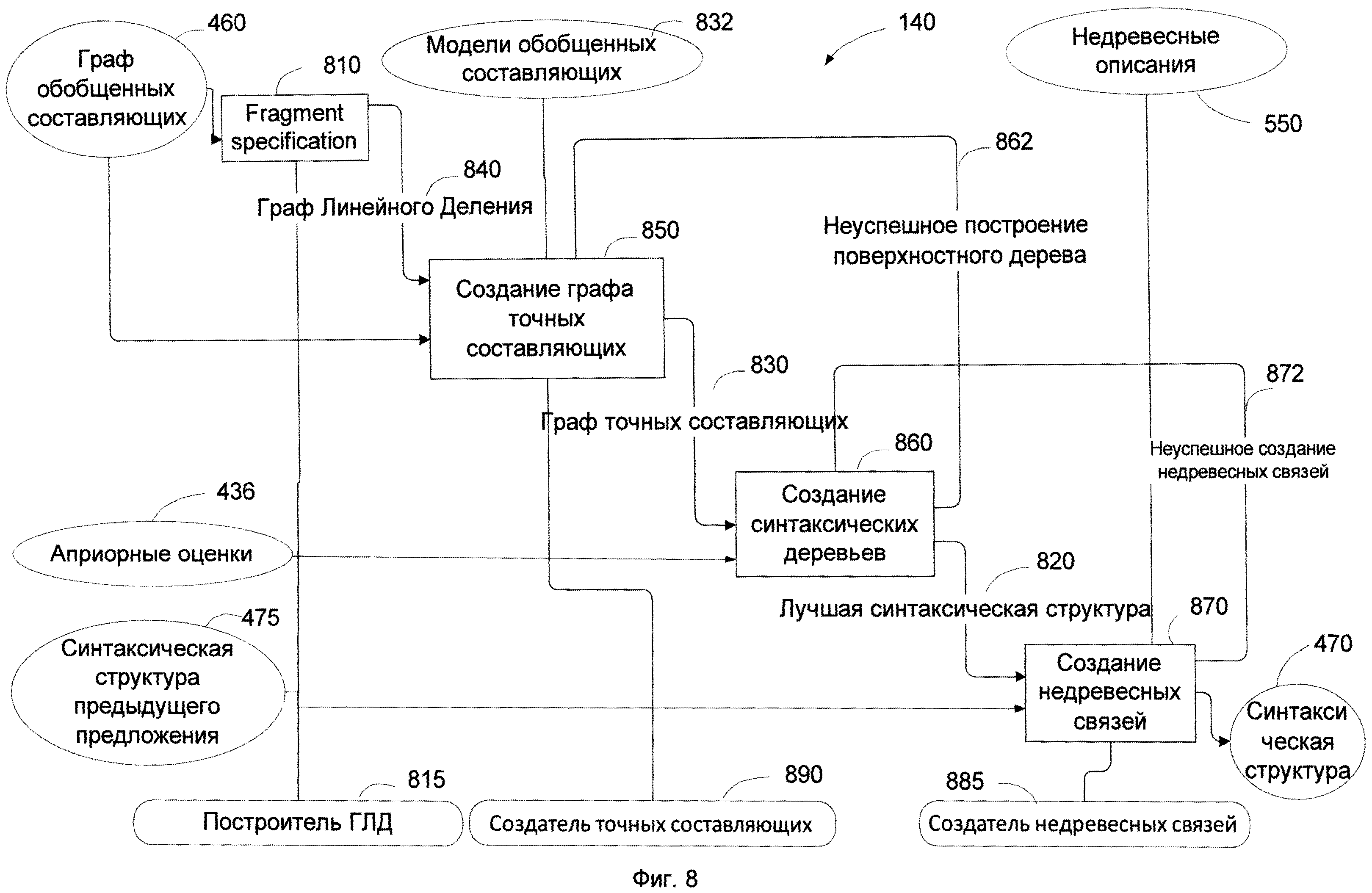
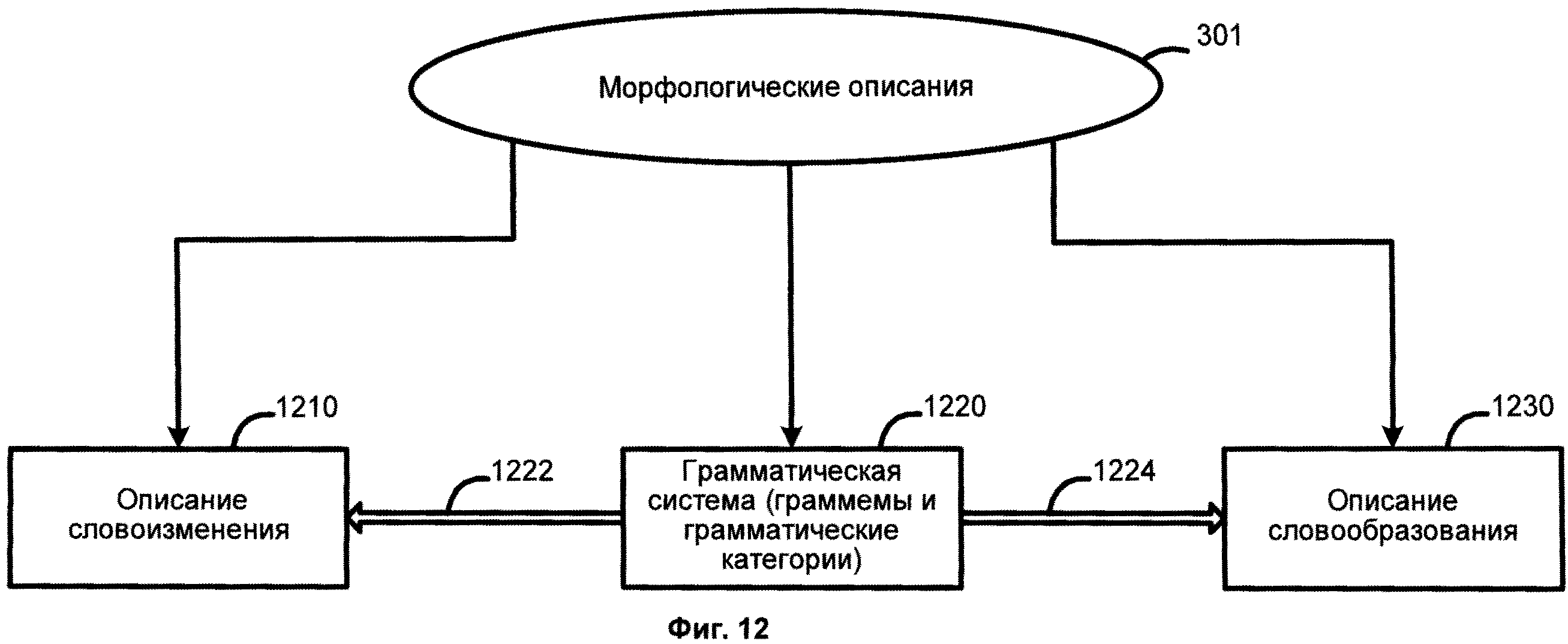
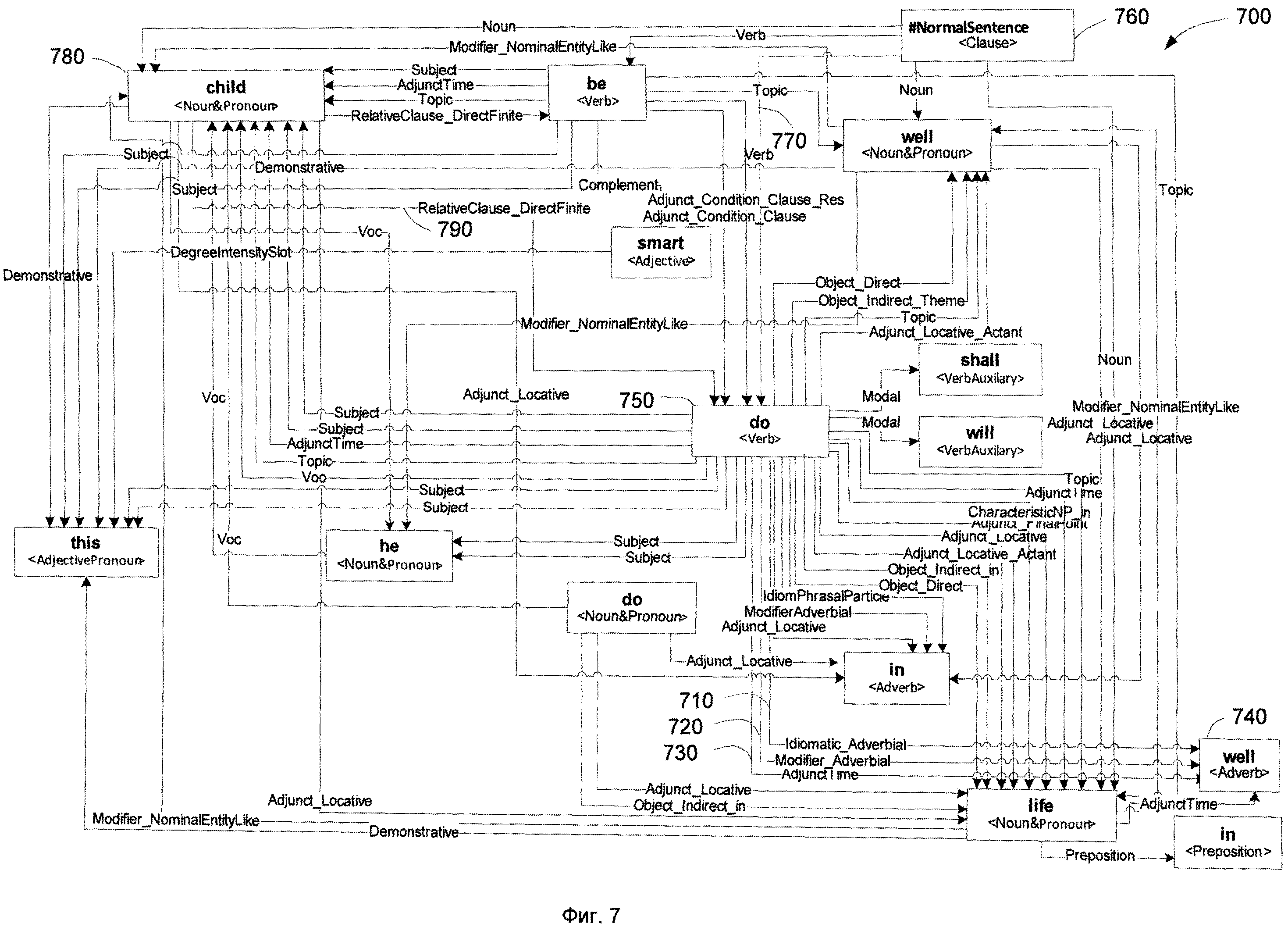
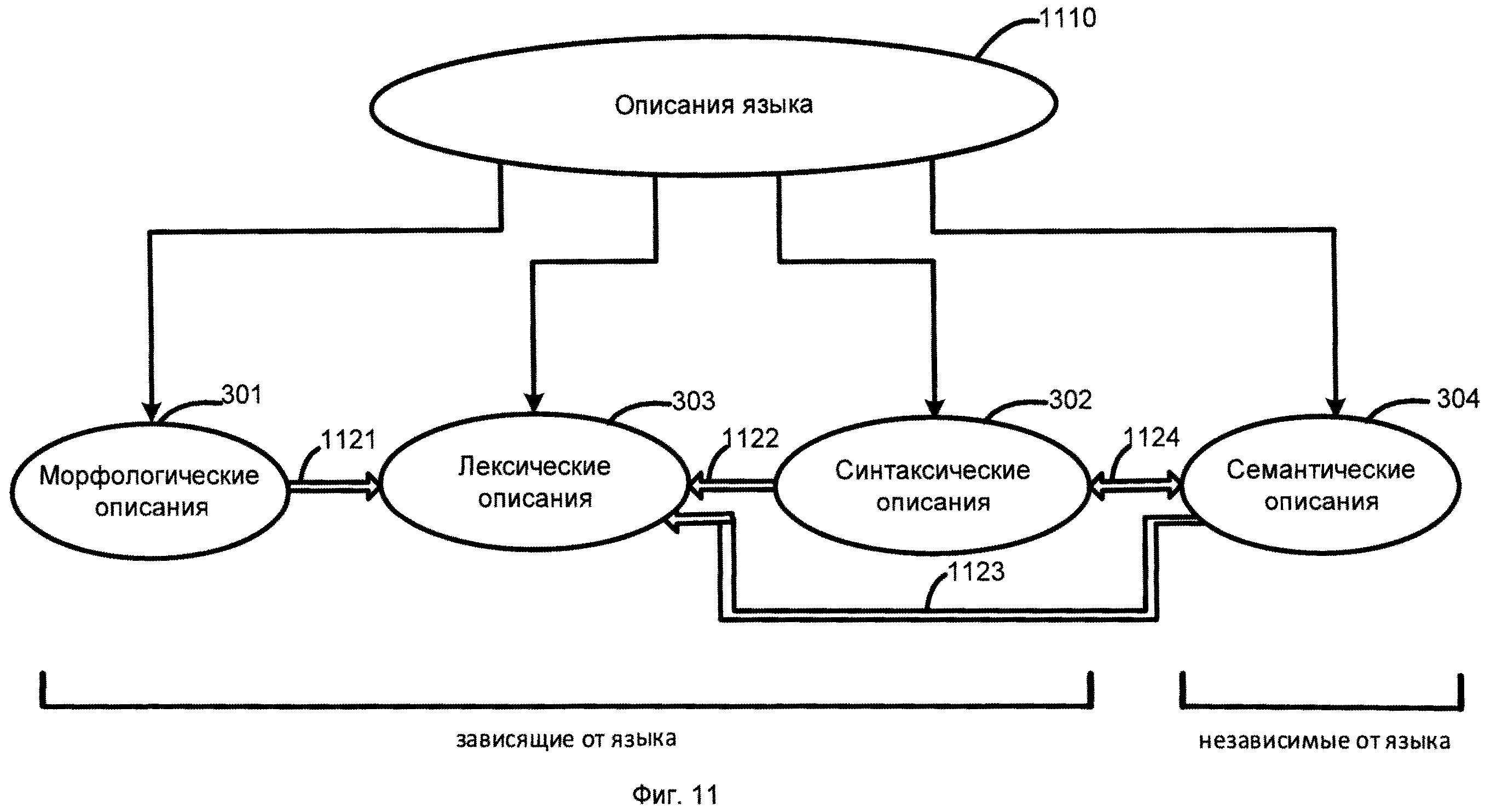
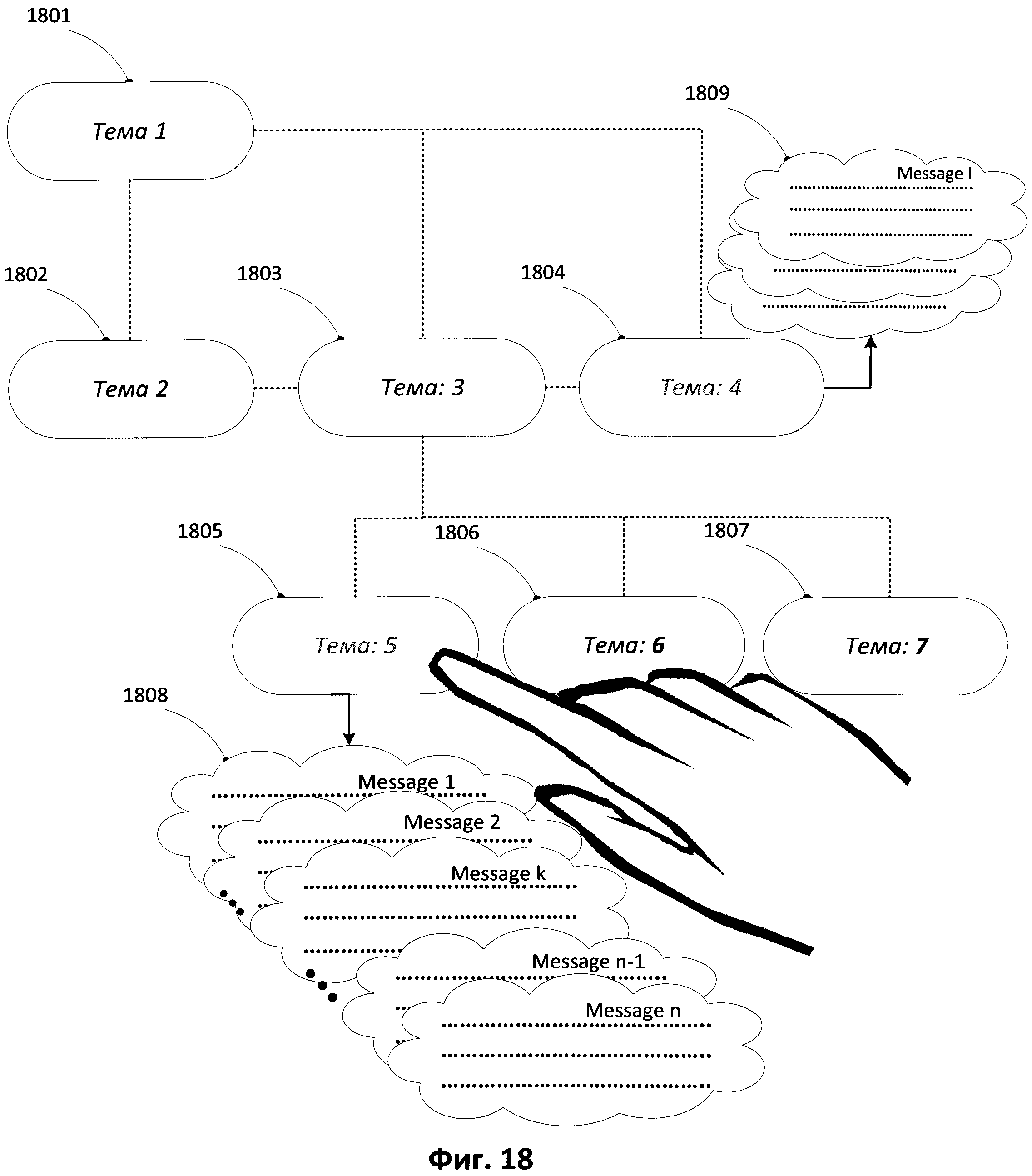
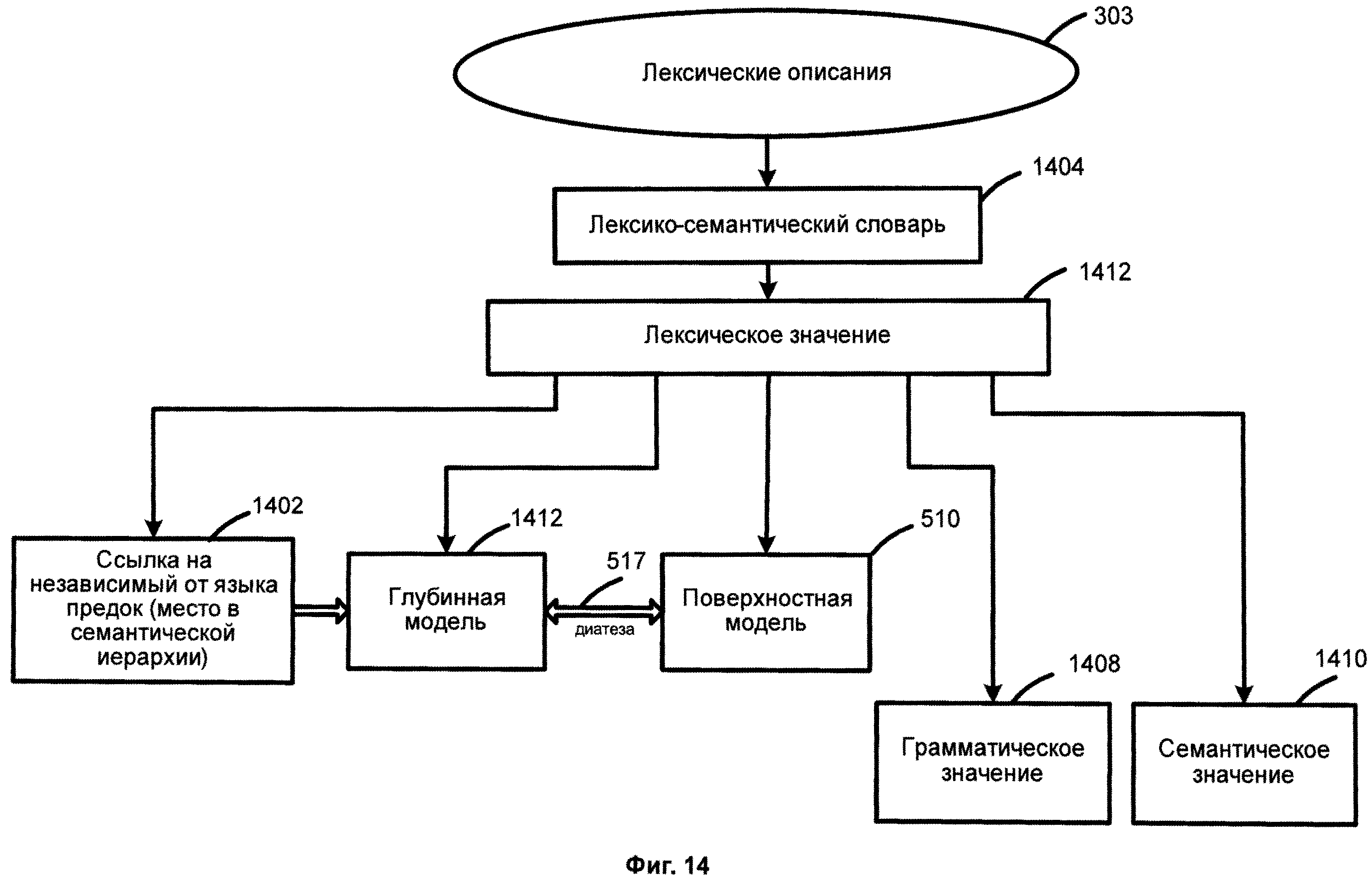
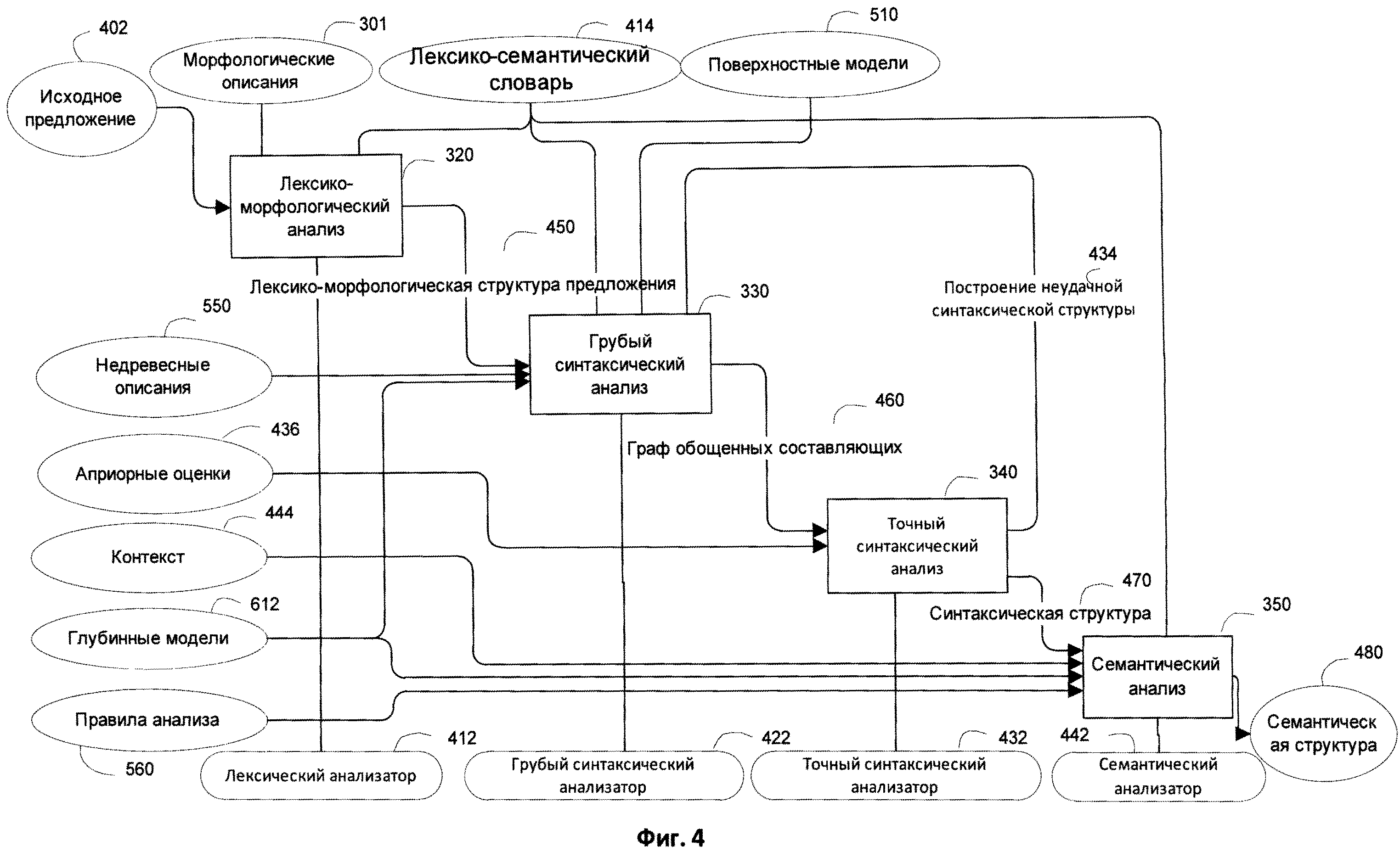
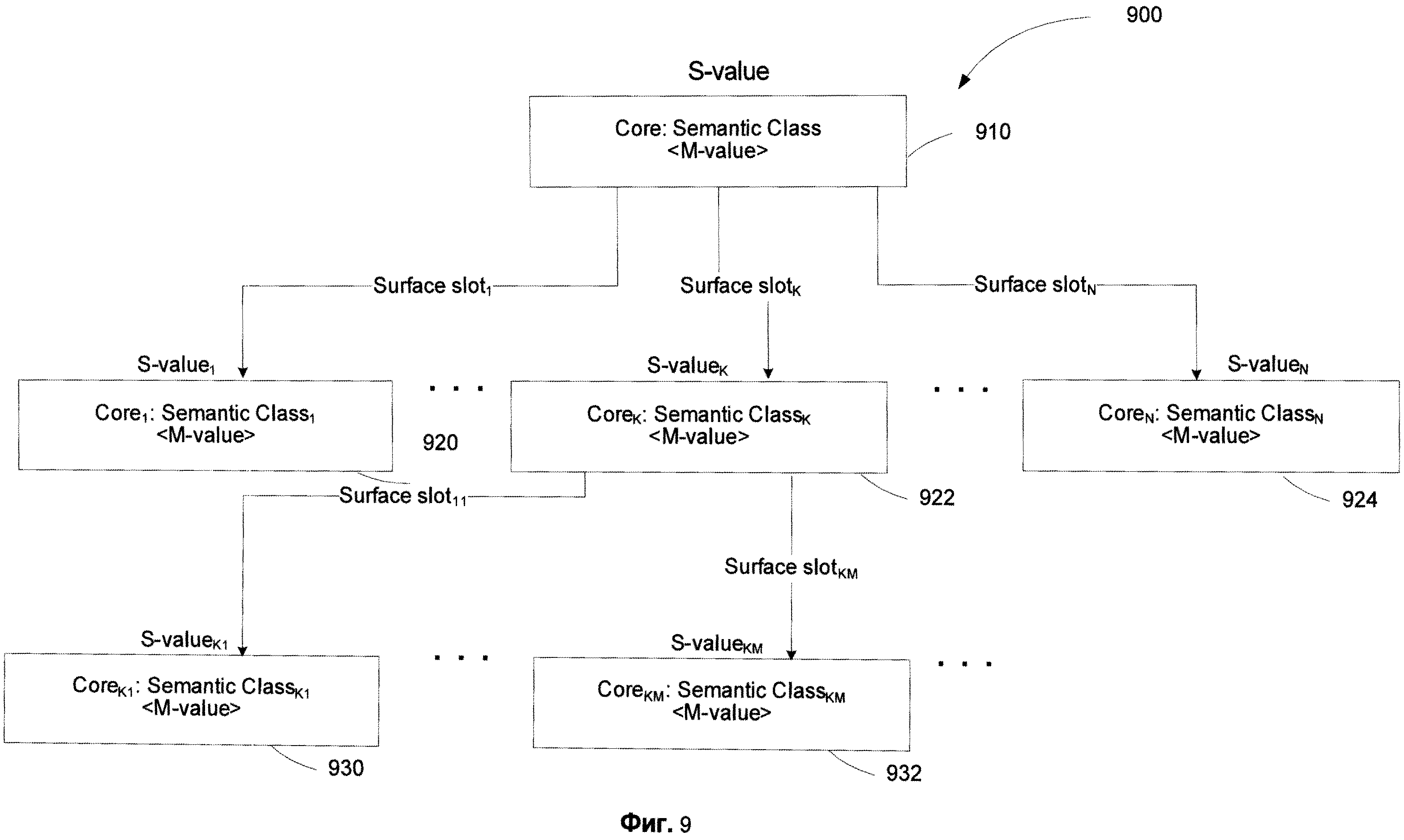
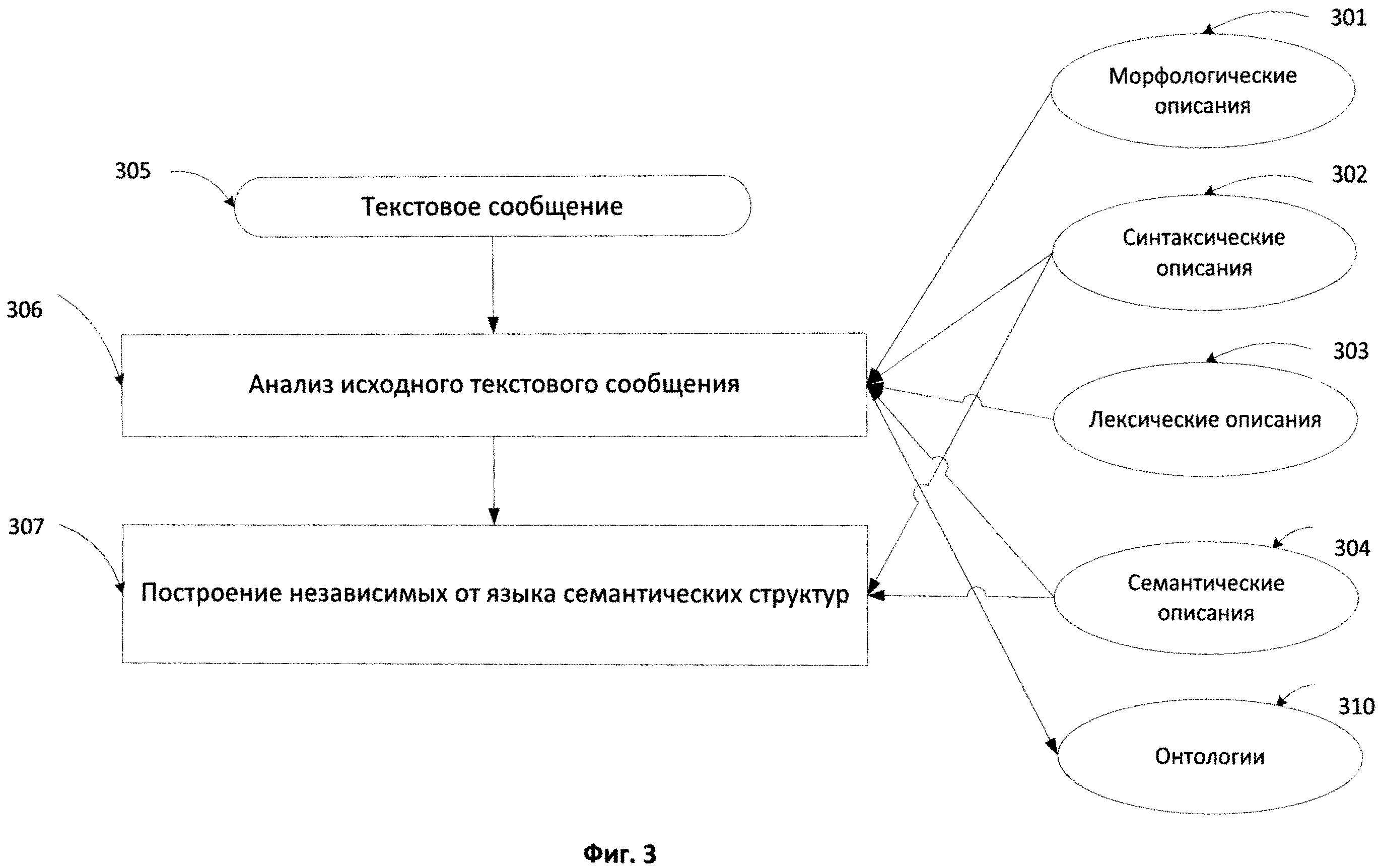
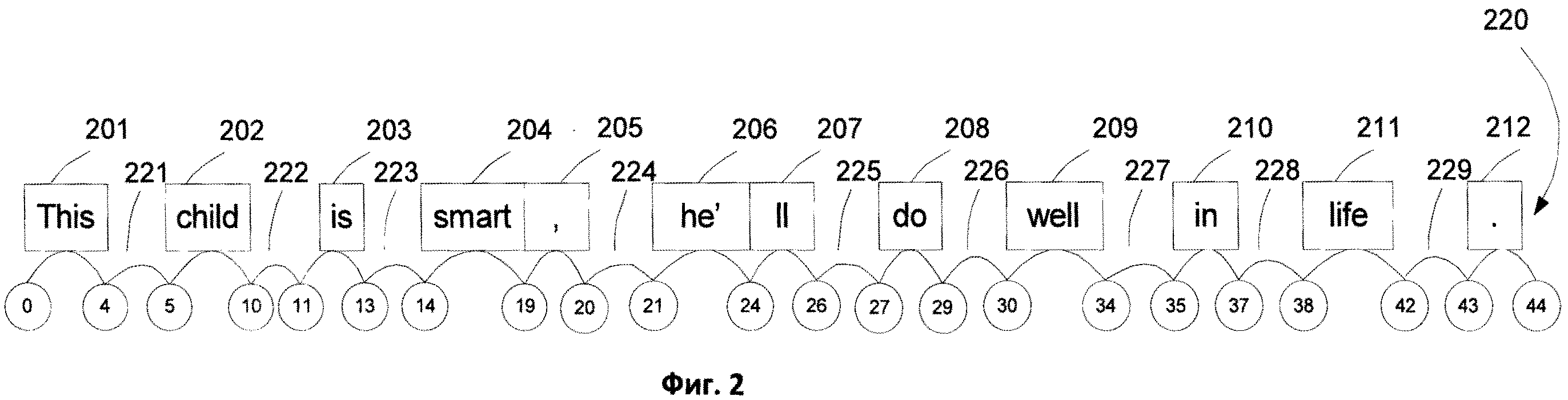
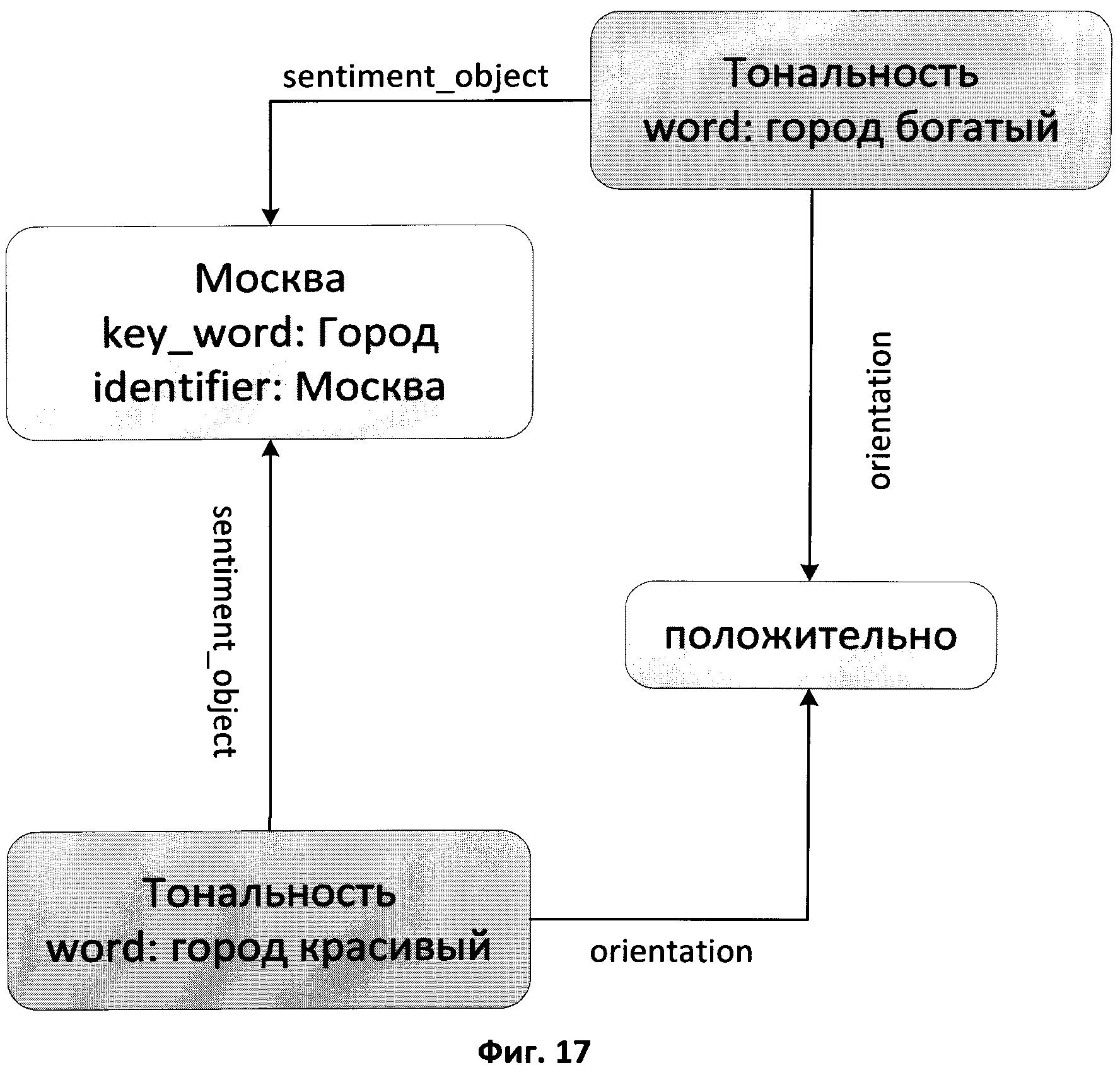
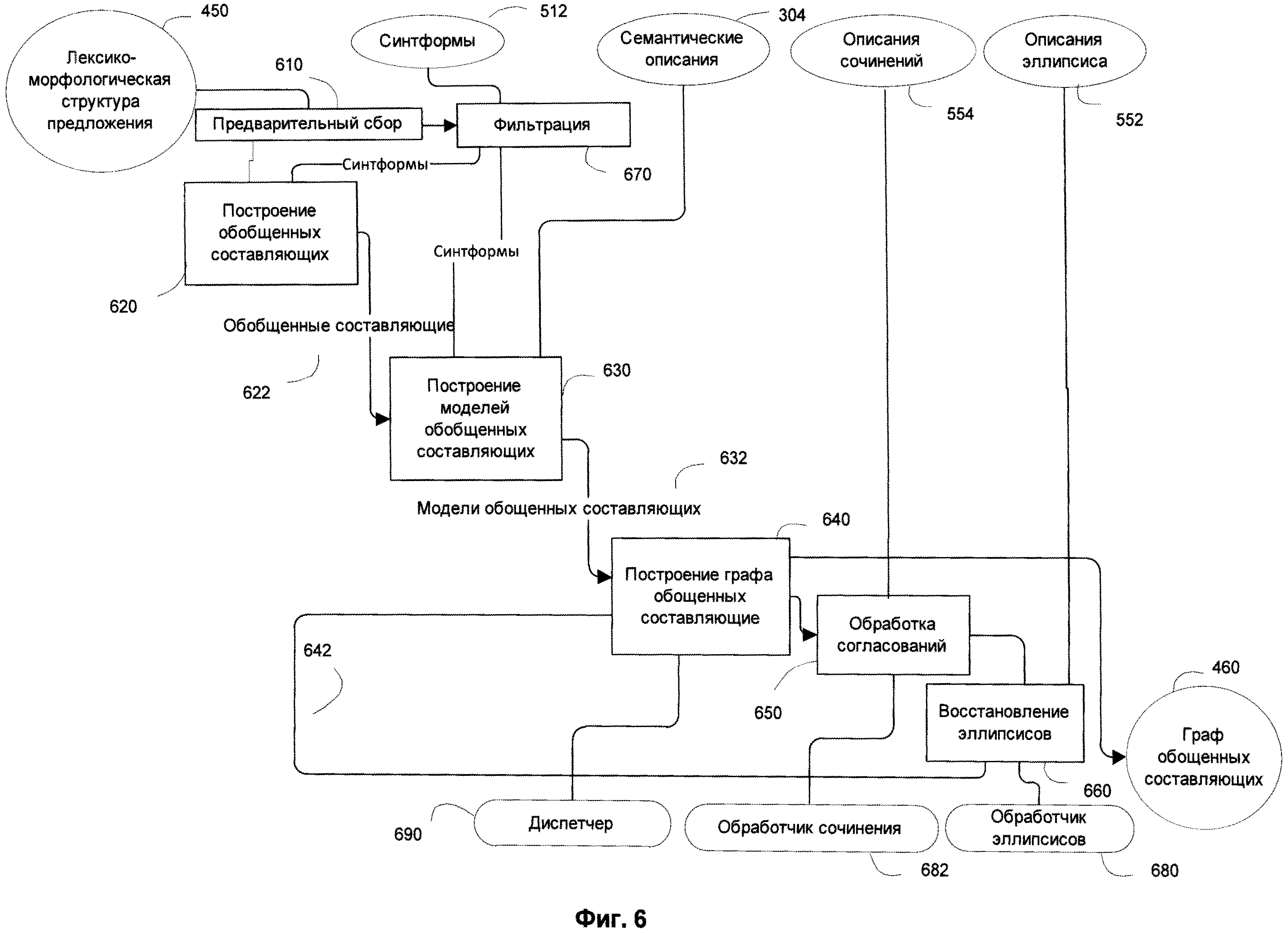
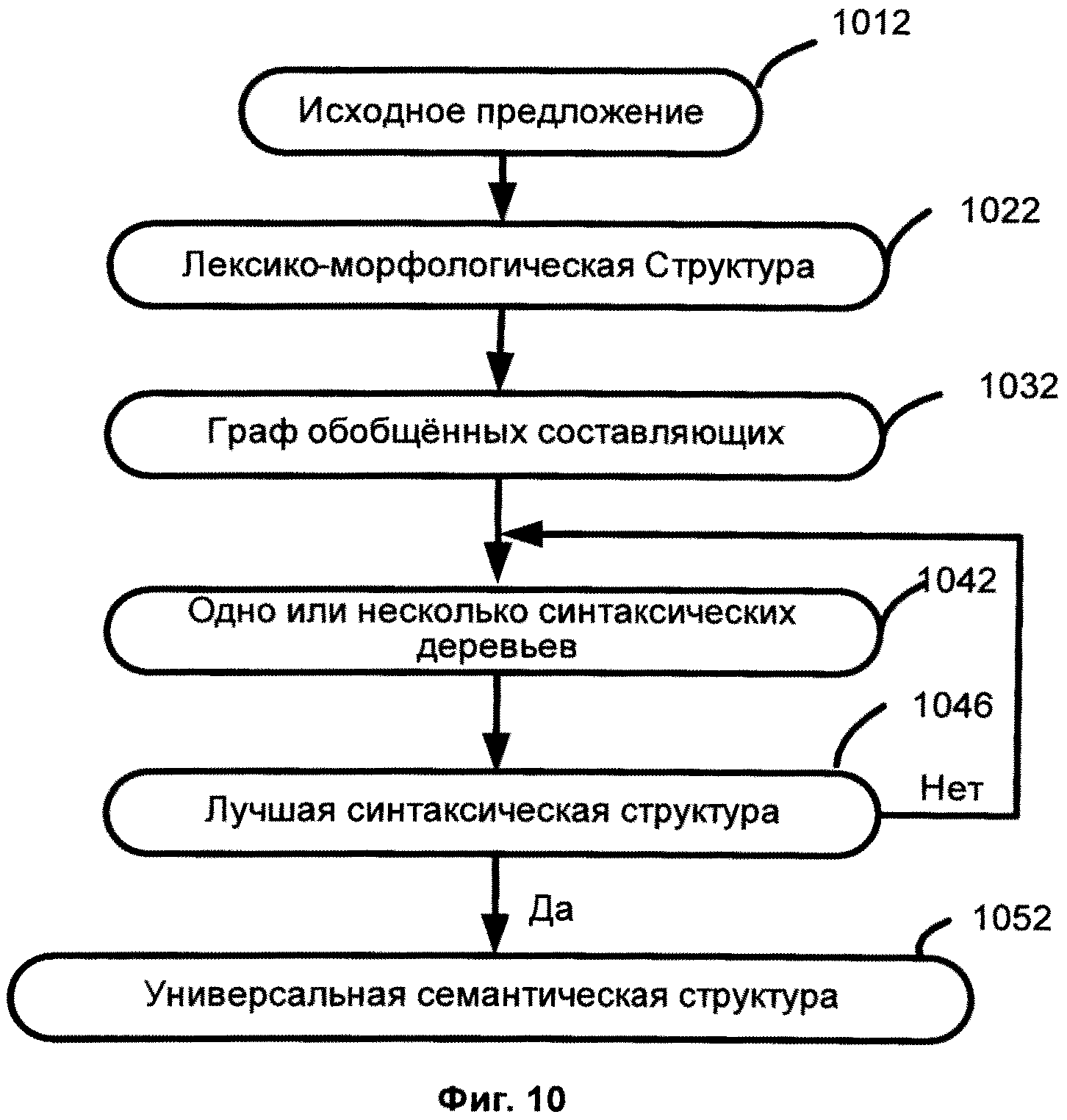
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Способ и система для глобальной идентификации в коллекции документов
Разрешение семантической неоднозначности при помощи статистического анализа
Способ распределения задач сервером вычислительной системы, машиночитаемый носитель информации и система для реализации способа
Итеративное пополнение электронного словника
Система и метод семантического поиска
Способ кластеризации результатов поиска в зависимости от семантики
Разрешение семантической неоднозначности при помощи семантического классификатора
Метод построения и обнаружения тематической структуры корпуса
Система и способ создания и использования пользовательских семантических словарей для обработки пользовательского текста на естественном языке
Фильтрация дуг в синтаксическом графе
Способ и система для глобальной идентификации в коллекции документов
Разрешение семантической неоднозначности при помощи статистического анализа

