Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ПРИНАДЛЕЖНОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ПО ЕГО ИСХОДНОМУ КОДУ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Данное техническое решение относится к области вычислительной техники, а именно к способам и системам определения принадлежности программного обеспечения (ПО) к известному семейству ПО, а также принадлежности ПО той или иной группе авторов ПО.
УРОВЕНЬ ТЕХНИКИ
Предлагаемый способ будет описан ниже на примере определения принадлежности некоторого вредоносного ПО к известному семейству вредоносных программ. Однако, данный способ может быть без ограничений использован применительно к любым программам, необязательно вредоносным. Кроме того, данный способ может быть без ограничений использован для атрибуции авторства, то есть установления факта принадлежности данного ПО известному автору или группе авторов ПО.
Известно, что профессиональные киберпреступники тщательно разрабатывают стратегию атаки и редко ее меняют, притом обычно они длительное время используют одни и те же вредоносные программы, лишь незначительно модифицируя их.
С другой стороны, разработчики вредоносного ПО (ВПО), создающие инструментарий для киберпреступников, могут на протяжении длительного времени использовать одно и то же программное решение, например, функцию, реализующую алгоритм шифрования, в различных образцах ВПО, притом создаваемого для разных киберпреступных группировок и относящихся к разным семействам ВПО.
Поэтому в области кибербезопасности знание о том, что данный образец вредоносного ПО (ВПО) принадлежит к определенному семейству ВПО, как и знание о том, что данный образец ВПО создан определенным автором или группой авторов, может быть весьма важно.
Хорошо известен такой метод обнаружения вредоносного ПО, как сигнатурный анализ. Этот метод основан на поиске в файлах уникальной последовательности байтов, то есть сигнатуры, которая характерна для данного конкретного вредоносного ПО. Для каждого нового образца ВПО специалисты антивирусной лаборатории выполняют анализ кода, на основании которого определяют сигнатуру этого нового ВПО. Полученную сигнатуру помещают в базу данных вирусных сигнатур, с которой работает антивирусная программа, и это впоследствии помогает антивирусу обнаруживать данное ВПО.
Данный метод хорошо известен и киберпреступникам. Поэтому почти все современные вредоносные программы так или иначе постоянно модифицируются, притом целью подобной модификации не является изменение основной функциональности ВПО. В результате модификации файлы очередной версии ВПО должны приобрести, с точки зрения антивирусных сигнатурных анализаторов, новые свойства. Тогда они перестанут "опознаваться" как вредоносные при помощи существующих баз сигнатур, что повысит скрытность действий киберпреступников.
Помимо модификации также широко используется прием, называемый обфускацией. Он представляет собой приведение исходного текста или исполняемого кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ и понимание алгоритмов работы. Перечисленные изменения ВПО могут осуществляться как человеком, так и автоматически, например, так называемым полиморфным генератором, входящим в состав вредоносной программы.
При этом важно, что основные функции ВПО, как правило, не подвергаются существенным изменениям. После модификации вредоносная программа будет "выглядеть" иначе для сигнатурных анализаторов, ее код может быть обфусцирован и непригоден для анализа человеком, но набор функций, который эта программа исполняла до модификации, с большой вероятностью после модификации останется прежним.
Из уровня техники известны разнообразные решения, позволяющие определять авторство тех или иных текстов: художественных, публицистических, научных. В качестве примеров могут быть названы:
• "Stylometric Autorship Attribution in Collaborative Documents", Dauber et al., материалы International Conference on Cyber Security Cryptography and Machine Learning (CSCML) 2017, стр. 115-135,
• "DECEPTION IN AUTHORSHIP ATTRIBUTION", S.Afroz, http://hdl.handle.net/1860/4431
• «Текстовый анализатор», Александр Гранин, https://habr.com/ru/post/114186/
• Программа «Определение авторства» компании NeoNeuro, https://neoneuro.com
Tools for Software Analysis and Forensic Engineering, S.A.F.E., https://www.safe-corp.com/index.htm Большинство подобных решений построено на принципах стилометрии, реализуемых при помощи тех или иных технических приемов. Однако, в тех случаях, когда речь заходит об авторстве программного кода, стилометрия, то есть исследование стилистики текста, не является оптимальным решением. Вне зависимости от языка программирования, на котором написан код, выявление авторского стиля в нем будет крайне затруднено в силу специфики предметной области. В тех же случаях, когда исходный код программы обфусцирован (а таких случаев в сфере кибербезопасности подавляющее большинство), использование стилометрических методов для анализа образцов ВПО бессмысленно.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В рамках настоящего описания, если это не оговорено непосредственно по месту применения, нижеперечисленные специальные термины используются в следующих значениях:
Платформа или компьютерная платформа - это среда, в которой должно исполняться исследуемое программное обеспечение. Платформа включает в себя как аппаратное обеспечение (например, оперативную память, жесткий диск), так и программное обеспечение (BIOS, операционную систему и т.д). Например, платформа Win32 API.
Обфускация или запутывание кода - это приведение исходного текста программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы.
Логгирование или журналирование - это автоматическая запись в хронологическом порядке действий, выполняемых программой, в специальный файл, который называют лог или отчет.
Устойчивые конструкции - это фрагменты кода, которые можно найти в самых разных программах. Такие конструкции встречаются не только в ПО какого-то определенного назначения или определенного автора, а практически повсеместно. В качестве примера устойчивых конструкций могут быть названы, например, прологи функций. Фреймворк - программная платформа, определяющая структуру программной системы; например, фреймворк Django.
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание компьютерно-реализуемого способа и системы определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду, которые охарактеризованы в независимых пунктах формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в обеспечении автоматической идентификации программного обеспечения по его исходному коду.
В предпочтительном варианте реализации заявлен компьютерно-реализуемый способ определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду, заключающийся в выполнении этапов, на которых с помощью вычислительного устройства:
- получают файл, содержащий исходный код программного обеспечения;
- определяют платформу и язык программирования, на котором в полученном файле написан исходный код;
- извлекают и сохраняют код функций, присутствующих в полученном файле;
- удаляют из сохраненного кода функции, которые являются библиотечными;
- выделяют в каждой функции команды;
- выделяют в каждой команде пару «действие, аргумент»;
- преобразуют каждую пару «действие, аргумент» в число;
- сохраняют, отдельно для каждой выделенной функции, полученную последовательность чисел.
- накапливают заранее заданное количество результатов анализа исходного кода;
- анализируют накопленные данные, а именно выявляют повторяющиеся последовательности чисел (паттерны);
- для каждого выявленного паттерна вычисляют набор параметров, характеризующих его частотность;
- сохраняют заданное количество паттернов и на основе вычисленных для каждого паттерна набора параметров обучают по меньшей мере один классификатор определять принадлежность программного обеспечения по последовательности пар «действие, аргумент»;
- применяют обученный по меньшей мере один классификатор для последующего определения принадлежности программного обеспечения к определенному семейству программ.
В другом предпочтительном варианте реализации заявлен компьютерно-реализуемый способ определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду, заключающийся в выполнении этапов, на которых с помощью вычислительного устройства:
- получают файл, содержащий исходный код программного обеспечения;
- определяют платформу и язык программирования, на котором в полученном файле написан исходный код;
- запускают файл в изолированной среде, имеющей функцию логтирования;
- получают список обращений исполняющегося файла к фреймворку и платформе;
- выделяют в каждом обращении пару «действие, аргумент»;
- преобразуют каждую пару «действие, аргумент» в целое число;
- сохраняют полученную последовательность чисел.
- накапливают заранее заданное количество результатов анализа исходного кода;
- выявляют в результатах анализа исходного кода повторяющиеся последовательности чисел (паттерны);
- для каждого выявленного паттерна вычисляют параметр, характеризующий его частотность;
- сохраняют заданное количество паттернов и на основе вычисленных для каждого паттерна набора параметров обучают по меньшей мере один классификатор определять принадлежность программного обеспечения по последовательности пар «действие, аргумент»;
- применяют обученный по меньшей мере один классификатор для последующего определения принадлежности программного обеспечения к определенному семейству программ.
В частном варианте реализации способа после удаления библиотечных функций дополнительно удаляют из сохраненного кода устойчивые конструкции;
В другом частном варианте реализации способа дополнительно определяют принадлежность программы определенному, заранее известному разработчику программ или коллективу разработчиков программ.
В другом частном варианте реализации способа после обучения классификатора выбирают пороговое значение, превышение которого свидетельствует о принадлежности программы, исходный код которой подвергался анализу, тому семейству программ, на наборах данных которого был обучен классификатор.
В другом частном варианте реализации способа после обучения классификатора выбирают пороговое значение, превышение которого свидетельствует о принадлежности программы, исходный код которой подвергался анализу, тому разработчику или коллективу разработчиков программ, на наборах данных которого был обучен классификатор.
В другом частном варианте реализации способа обучают классификатор методом машинного обучения.
Еще в одном частном варианте реализации способа паттернам, содержащим по меньшей мере две строковые константы, дополнительно присваивают повышенный вес, величина которого задана заранее.
В другом частном варианте реализации способа паттернам, по меньшей мере на 80% состоящим из математических операций, дополнительно присваивают повышенный вес, величина которого задана заранее.
В другом частном варианте реализации способа паттернам, не содержащим ни строковых констант, ни математических операций, дополнительно присваивают пониженный вес, величина которого задана заранее.
Возможен также частный вариант реализации способа, характеризующийся тем, что повышенные и пониженные веса, присвоенные паттернам, учитывают при обучении классификатора таким образом, чтобы паттерны с повышенным весом оказывали пропорционально большее, а паттерны с пониженным весом пропорционально меньшее влияние на итоговое решение классификатора.
Заявленное решение также осуществляется за счет системы определения принадлежности программного обеспечения по его исходному коду, содержащей:
- долговременную память, выполненную с возможностью хранения базы данных;
- вычислительное устройство, выполненное с возможностью выполнения описанного способа.
В другом из возможных вариантов реализации заявленное решение является составной частью системы обеспечения кибернетической безопасности.
В другом из возможных вариантов реализации заявленное решение является составной частью системы сбора устойчивых индикаторов компрометации.
В другом из возможных вариантов реализации заявленное решение является составной частью системы автоматизированного определения авторства программного обеспечения.
В другом из возможных вариантов реализации заявленное решение является составной частью системы автоматизированного выявления плагиата.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг. 1А-1Б иллюстрируют компьютерно-реализуемый способ определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду;
Фиг. 2А-2Е иллюстрируют различные этапы обработки исходного кода программного обеспечения, выполняемые в соответствии с описанным способом;
Фиг. 3 иллюстрирует этапы изготовления вспомогательной программы, используемой на одном из необязательных этапов обработки исходного кода.
Фиг. 4 иллюстрирует накопление данных для обучения классификатора, используемого для определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду;
Фиг. 5 иллюстрирует пример общей схемы компьютерного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение компьютерно-реализуемого способа и системы определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду.
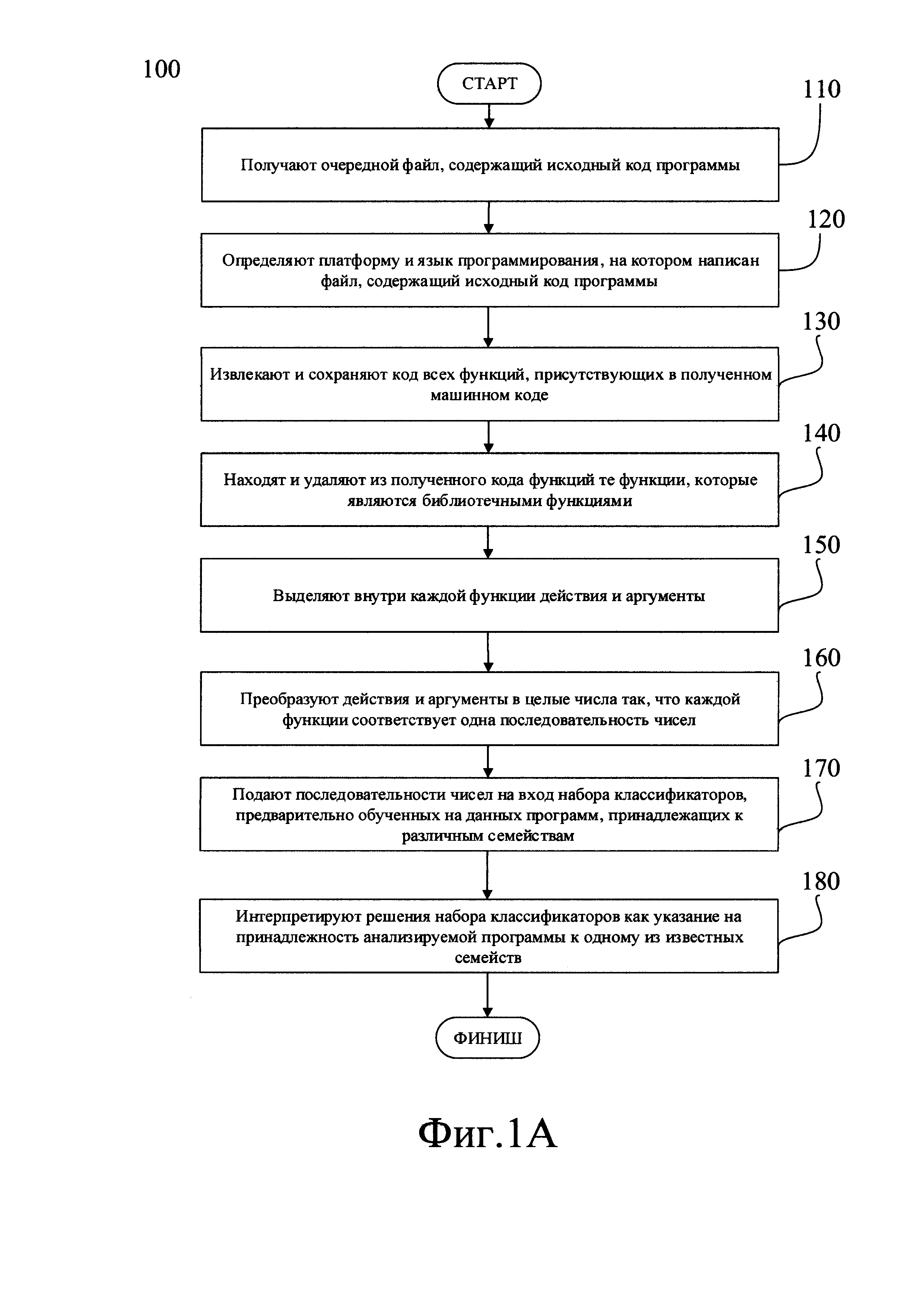
Как представлено на Фиг. 1, заявленный компьютерно-реализуемый способ определения принадлежности программного обеспечения к определенному семейству программ по его исходному коду (100) реализован следующим образом:
На этапе (110) получают файл, содержащий исходный код программы, подлежащей анализу. Это может быть как файл, содержащий исходный код программы, например, файл с расширением *.срр или *.bas, так и проект в одной из современных "визуальных" сред разработки, таких как Visual Studio.
В том случае, если объект анализа состоит из множества взаимосвязанных файлов (например, представляет собой проект в одной из современных "визуальных" сред разработки), то для анализа по описываемому способу из множества файлов проекта отбирают только те файлы, которые содержат исходный код. Для проекта, созданного на языке программирования C/C++ это будут файлы с расширением *.срр, для проекта на языке ассемблера - файлы с расширением *.asm, и т.д. Отбор файлов может выполняться любым известным способом, например, скриптом, который копирует во входную папку системы, реализующей способ, все файлы проекта, имеющие заданное расширение. Последующий анализ этих файлов производят поочередно.
Далее на этапе (120) определяют платформу анализируемого файла и язык программирования, на котором написан анализируемый файл, и выбирают соответствующее средство анализа кода. Определение платформы и языка программирования может быть выполнено любым известным способом. Например, платформа может быть определена перебором, а язык программирования может быть определен, например, посредством программы Linguist (https://github.com/github/linguist) или посредством программы Ohcount (https://github.com/blackducksoftware/ohcount).
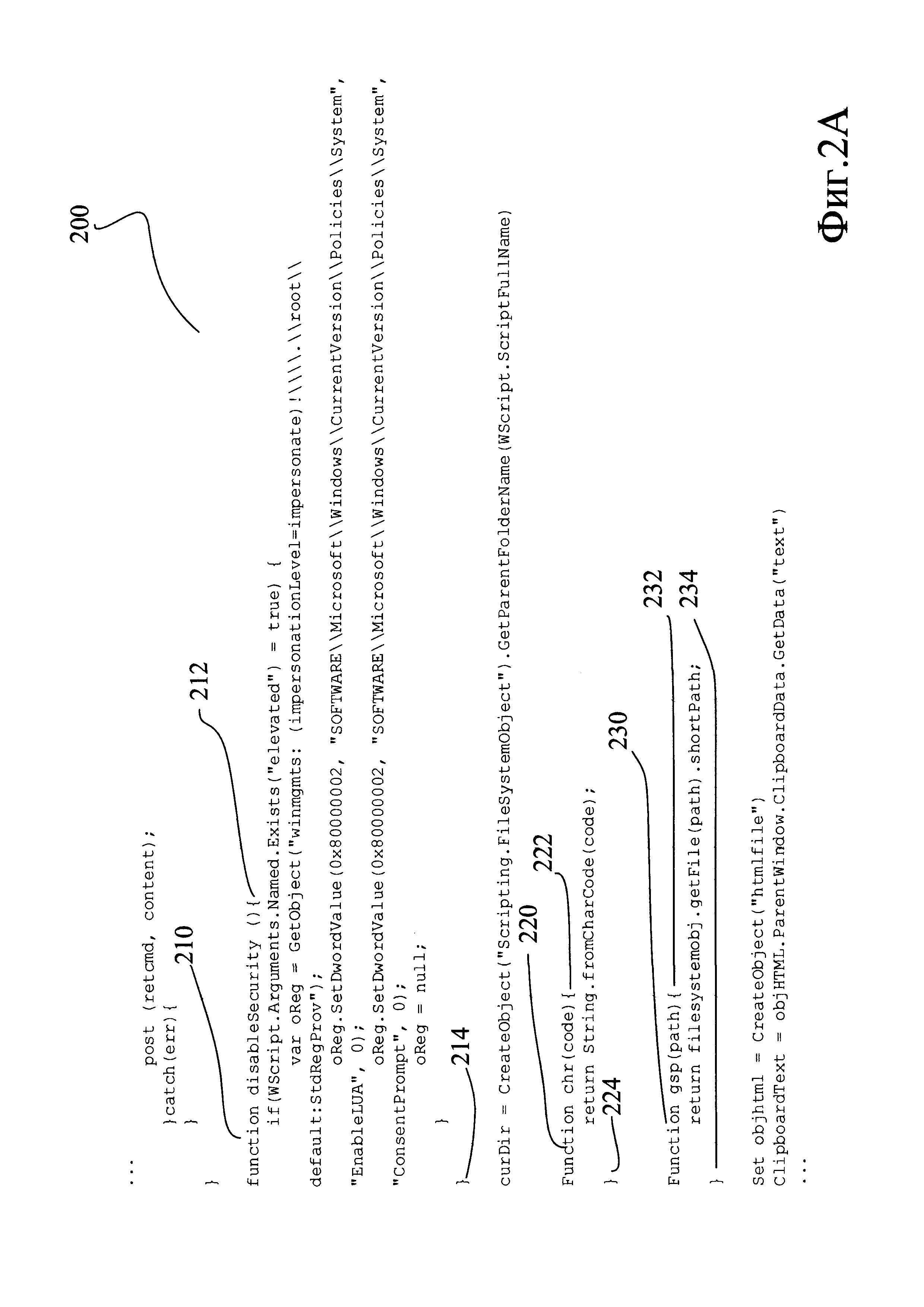
Так, например, на Фиг. 2А представлен фрагмент исходного кода 200. Определяя его платформу и язык программирования посредством программы Linguist, устанавливают, что данный исходный код написан для платформы Win32 на языке программирования JavaScript.
Дальнейший анализ файла выполняют заблаговременно подготовленной программой-парсером, алгоритм действия которой основан на синтаксисе того языка программирования, на котором написан исходный код в данном файле. В рассматриваемом примере используют программу-парсер, алгоритм которой основан на синтаксисе JavaScript.
Как показано на Фиг. 1А, на этапе (130) из исходного кода извлекают и сохраняют в виде списка функции. Функцией в данном описании будем называть фрагмент программного кода, к которому можно обратиться из другого места программы. В большинстве случаев с функцией связывается идентификатор, но многие языки допускают и безымянные функции. С именем функции неразрывно связан адрес первой инструкции (оператора), входящей в функцию, которой передается управление при обращении к функции. После выполнения функции управление возвращается обратно в адрес возврата, то есть ту точку программы, где данная функция была вызвана.
Парсером находят в анализируемом исходном коде границы, фрагменты кода внутри которых являются функциями. Для этого может использоваться, например, тот общеизвестный факт, что в большинстве языков программирования высокого уровня тело функции заключается в блочный оператор. Соответственно, одним из возможных алгоритмов работы парсера может быть выявление в коде пар слов или символов, которыми в синтаксисе данного языка обозначается блочный оператор, дополнительная проверка того факта, что найденный блочный оператор содержит именно тело функции, а также перемещение кода, составляющего тела найденной функции, в файл, где сохраняют результаты обработки. Проверка того факта, что блочный оператор содержит именно тело функции может выполняться, например, путем поиска на строке, предшествующей открытию блочного оператора, символьного выражения, соответствующего в синтаксисе данного языка программирования имени функции.
Альтернативно, если исходный код написан на С-подобном языке программирования, например, на JavaScript, то каждая функция будет начинаться с заголовка функции, имеющего известный формат. Например, в коде 200, написанном на JavaScript, как показано на Фиг. 2А, заголовок функции может быть идентифицирован по наличию ключевого слова function (210), (220), (230), (240). За заголовком в таком коде будет следовать тело функции, также заключенное в блочный оператор, в данном случае обозначаемый парой фигурных скобок: {и}. Например, на Фиг. 2А блочный оператор образуют фигурные скобки (212) и (214), (222) и (224), (232) и (234). В таком случае парсером обнаруживают заголовки функций, после чего весь код, находящийся между открывающей фигурной скобкой, следующей непосредственно после заголовка, и соответствующей ей закрывающей фигурной скобкой, переносят в список функций. Сформированный таким образом список (250) показан на Фиг. 2Б; список в данном примере содержит фрагменты кода трех функций (251), (252), (252).
Действия над исходным кодом, оставшимся за пределами блочных операторов (то есть границ функций), выполняют в зависимости от того, позволяет ли синтаксис данного языка программирования исполнение кода за пределами функций. Например, для исходного кода, написанного на языке С или С#, такой код игнорируют. В рассматриваемом примере, для кода, написанного на языке JavaScript, такой код считают относящимся еще к одной функции, отдельной от всех уже выделенных. Код этой «главной функции» также переносят в список функций и в дальнейшем обрабатывают аналогично всему остальному коду, помещенному в этот список. Таким образом на этапе (130) получают и сохраняют в виде отдельного файла код всех функций, имеющихся в анализируемом файле.
Затем, как показано на Фиг. 1А, на этапе (140) анализируют файл, содержащий фрагменты кода функций. При помощи сигнатурного анализа из списка исключают те функции, которые относятся к библиотечным. Библиотечные функции представляют собой стандартный инструментарий. Они широко используются самыми разными программами, поэтому их наличие в исходном коде или в рабочих процессах не специфично ни для какой-то одной определенной программы, ни для какого-то определенного разработчика. Исключение библиотечных функций в описываемом методе позволяет существенно упростить анализ и в то же время получить более качественный результат обучения за счет того, что решающие правила будут обучаться именно на тех командах, которые наилучшим образом характеризуют конкретную анализируемую программу.
Сигнатурный анализ и удаление библиотечных функций выполняют вспомогательной программой-скриптом. Алгоритм этого скрипта может представлять собой, например, поочередное сравнение каждой из функций с подготовленным заранее набором сигнатур (регулярных выражений). Каждая из этих сигнатур соответствует определенной, заранее описанной в виде сигнатуры библиотечной функции; при обнаружении функции, соответствующей какой-либо сигнатуре, весь код, составляющий тело и заголовок такой функции, исключают. Так, в рассматриваемом примере, из кода функций (250), показанного на Фиг. 2Б, будет исключен код библиотечной функции (252). По завершении обработки скриптом файл, содержащий оставшиеся функции, сохраняют и таким образом получают текст кода функций, присутствующих в анализируемом файле, и притом не являющихся библиотечными. В описываемом примере такой текст (260) показан на Фиг 2 В.
Затем, как показано на Фиг. 1А, на этапе (150) анализируют файл, полученный на предыдущем этапе, и выделяют внутри каждой функции команды, а внутри каждой команды - действие и, возможно, аргумент. Притом в одном из возможных вариантов реализации описываемого способа строки, состоящие из одного, двух или трех символов на данном этапе исключаются и в дальнейшей обработке не участвуют.
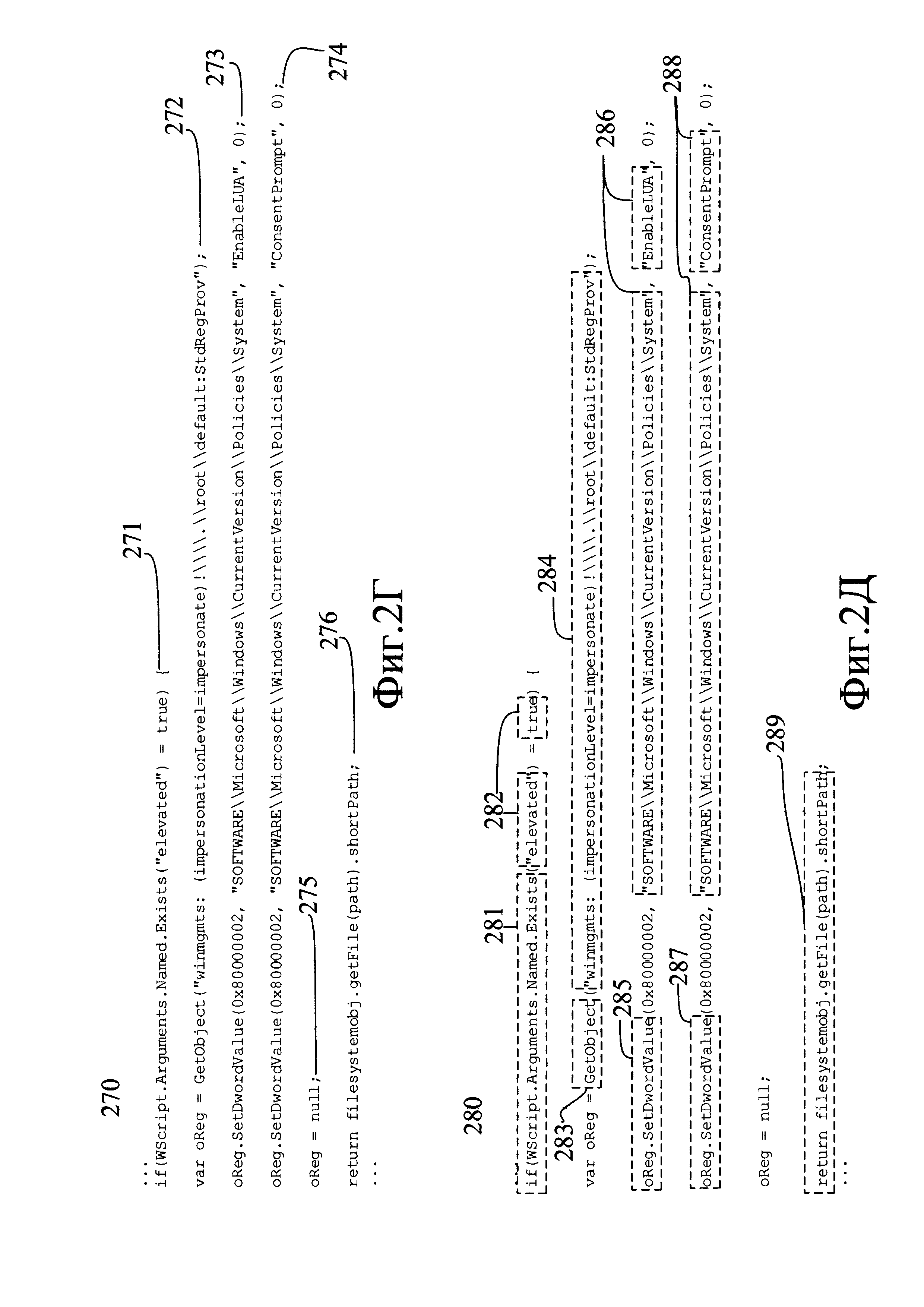
Что именно считают отдельной командой, зависит от синтаксиса языка программирования, на котором написан исследуемый код. Так, в одном из возможных вариантов реализации началом команды может считаться начало строки, а окончанием - ближайший к началу строки символ, означающий в данном языке программирования окончание команды, как, например, символ «точка с запятой» (;) в языке С. В альтернативном варианте реализации способа командой могут считать последовательность символов, расположенную на отдельной строке. Так, например, в тексте (270), показанном на Фиг. 2Г, командами считают строки (271), (272), (273), (274), (275), (276).
Идентификацию соответствующего каждой команде действия и обнаружение аргумента, если таковой присутствует, выполняют заблаговременно подготовленной программой-парсером, алгоритм действия которой основан на том факте, что набор возможных действий в данном языке программирования кодируется заранее известным набором символов.
Программа-парсер последовательно перебирает строки кода и сравнивает набор символов, расположенный на каждой строке, с набором заранее подготовленных регулярных выражений, соответствующих действиям, возможным в данном языке программирования. В том случае, если ни одно из регулярных выражений не соответствует символам анализируемой строки, такая строка игнорируется. В том случае, если соответствие строки какому-либо известному действию обнаружено, программа-парсер определяет наличие в строке аргумента, соответствующего данному действию, а также значение этого аргумента.
То, какой вид может иметь аргумент обнаруженного действия (десятичное число, символьная строка в кавычках и и.д.), также определяется синтаксисом языка программирования и выявляется при помощи соответствующего обнаруженному действию регулярного выражения. Каждую найденную пару "действие - аргумент" сохраняют в файле с результатами. В том случае, если обнаружено некоторое действие, а соответствующий ему аргумент отсутствует или имеет неподходящий формат, в результаты помещают пару "действие - аргумент", где аргумент имеет нулевое значение. Например, в тексте (280), показанном на Фиг. 2Д, в результате выполнения описанных действий находят пары "действие - аргумент" (281) - (282), (283) - (284), (285) - (286), (287) - (288), а также пару "действие - аргумент" с нулевым аргументом (289). При этом ненулевой аргумент может состоять более чем из одного значения, как, например, аргументы (282), (286) и (288).
Затем, как показано на Фиг. 1А, на этапе (160) производят преобразование полученных на предыдущем этапе пар "действие - аргумент" в одно численное значение и сохраняют, отдельно для каждой выделенной ранее функции, получившиеся последовательности чисел. Эти числа могут быть как десятичными, так и шестнадцатиричными, двоичными и т.д.
Преобразование может быть выполнено различным образом, например, взятием одной хэш-функции от действия, а второй хэш-функции - от аргумента. Затем полученный таким образом числа, соответствующие действию и аргументу, подвергают операции конкатенации, получая таким образом одно число. В тех случаях, когда аргумент состоит из более чем одного значения, хэш-функция может быть взята от строки, представляющей собой конкатенированные строки всех значений, составляющих аргумент.
Например, в ходе описанного преобразования в составе функции (251), показанной на Фиг. 2Б, будут, как это показано на Фиг. 2Г, выделены команды (271), (272), (273), (274), (275), а в составе функции (253) - команда (276). Затем, как показано на Фиг. 2Д, в команде (271) будут найдены действие (281) и аргумент (282), в команде (272) - действие (283) и аргумент (284), в команде (273) - действие (285) и аргумент (286), в команде (274) - действие (287) и аргумент (288). В составе команды (276) выделено действие (289) и нулевой аргумент.
В ходе дальнейшего преобразования команда (271), например, будет преобразована в шестнадцатеричное число
C21812f4d00522bd21c014228f948063b18de4875ffe533b830ff18a0326348a9160afafc8ada44db,
где C21812f4d00522bd21c014228f948063b18de487 является результатом взятия хэш-функции от действия (281), a 5ffe533b830ro8a0326348a9160afafc8ada44db - результатом взятия хэш-функции от аргумента (282). Аналогично, команда (272) окажется преобразована в шестнадцатеричное число
70233cdf6b130df09a0fd4fd84ro56e08b1cf51636c6f169e67d0cro2fc3433b2112402804d9a6a3, команда (273) в шестнадцатеричное число
eef70649fc977965dabbe7516c55f7951a40ca1513be4d3d8b43d0d4ecf268ff7c16fa7944139e99, команда (274) в шестнадцатеричное число
eef70649fc977965dabbe7516c55f7951a40ca1591c305309bf156bb2da46a2fed619951c852dd45, а команда (276) - в шестнадцатеричное число
bd4ee045946f5de9bba8059a9304ae5539d6730d0b6589fc6ab0dc82cf12099d1c2d40ab994e8410c.
В альтернативном варианте реализации данного способа преобразование пар «действие - аргумент» в пары чисел может выполняться сложнее. Например, перед хэшированием может проводиться сериализация, что позволит дополнительно сохранять информацию о типе исходных данных. В этом примере величина, подвергаемая хэшированию, представляет собой строку, первый байт которой кодирует тип данных аргумента (указывает, строка ли это, целое число, число в представлении с плавающей точкой или ноль, т.е. отсутствующий аргумент), второй байт хранит информацию об общей длине строки аргумента, затем следует собственно строка аргумента, преобразованная в ASCII-код. Альтернативно или дополнительно, аналогичным образом перед хэшированием может быть преобразовано действие. В рассматриваемом примере, действие (285) будет сначала в результате сериализации преобразовано в строку вида 033E534f4654574152455c5c4d6963726f736f66745c5c57696e646f77735c5c43757272656e7456657273696f6e5c5c506f6c69636965735c5c53797374656d, затем, в результате хэширования, в число cc3c144bb04455bdaabcd9e199b1cdc9c5ed3d93b37b0b533f5c9b18a4137bbd. Обработанный аналогичным образом аргумент (286) после хэширования приобретет вид числа ffa1ace8dba62cdbd33d8c09ad07e46ccb0da176eeaf4cc67b4860c7d2bb531b.
Таким образом, из исходного кода анализируемого образца ПО получают упорядоченные последовательности чисел. Поскольку анализ включал в себя разбиение кода на функции, числа, полученные в результате описанных преобразований, оказываются сгруппированы по принадлежности к определенной функции.
Таким образом, для функции (251) будет сохранена последовательность четырех чисел
c21812f4d00522bd21c014228f948063b18de4875ffe533b830f08a0326348a9160afafc8ada44db,
70233cdf6b130da9a0fd4fd84f056e08b1cf51636c6f169e67d0cf02fc3433b2112402804d9a6a3,
eef70649fc977965dabbe7516c55f7951a40ca1513be4d3d8b43d0d4ecf268ff7c16fa7944139e99,
eef70649fc977965dabbe7516c55f7951a40ca1591c305309bf156bb2da46a2fed619951c852dd45,
а для функции (253) - последовательность, состоящая из одного числа
bd4ee045946f5de9bba8059a9304ae5539d6730d0b6589fc6ab0dc82cf12099d1c2d40ab994e8410c.
Последовательностью далее в рамках данного описания будем называть множество чисел, полученных в ходе анализа одной функции, подобно приведенному выше примеру.
В дальнейшем для простоты будем обозначать числа каждой последовательности как Pij, где различное значение i указывает на порядковый номер функции F, в которой была выявлена данная пара "действие - аргумент", а значение j указывает на порядковый номер данной пары "действие - аргумент" внутри той функции, в которой эта пара была обнаружена.
Понятно, что исходный код большинства современных программ содержит значительное количество функций. Поэтому в результате вышеописанной обработки анализируемый образец ВПО окажется преобразован в набор из n строк следующего вида (n - общее количество не библиотечных функций, обнаруженных в ходе анализа):
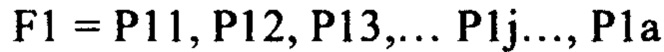

Индексы a, b, с в данном случае указывают на тот факт, что в разных функциях в общем случае будет различное количество чисел (т.е. пар "действие - аргумент").
Как это показано на Фиг. 1А, на следующем этапе (170) анализируют данные, полученные в ходе вышеописанного анализа исходного кода программы, принадлежность которой неизвестна. Все эти данные, преобразованные к виду (1), подаются на входы классификаторов, предварительно обученных на ВПО различных семейств или авторов.
Решение каждого классификатора представляет собой численную оценку вероятности того, что анализируемый образец ВПО принадлежит к тому семейству ВПО или той группе авторов, на массиве данных которого или которой был обучен классификатор. Эти решения постоянно обновляются, т.е. пересматривается при поступлении каждой порции данных вида (1).
Решения классификаторов могут накапливаться, либо обрабатываться любым другим общеизвестным образом. Но в любом случае, на заключительном этапе (180) исследуемое ВПО относят к тому семейству ВПО или той группе авторов, классификаторы которого или которой выдают наибольшее значение уверенности.
Разработчики ПО зачастую прибегают к такому приему как обфускация, делая анализ исходного кода программы затруднительным или невозможным. В ряде случаев в ходе анализа обфусцированного кода удается определить, какая именно методика обфускация была использована. В таких случах задействуют соответствующий деобфускатор, то есть заранее подготовленную программу, предназначенную для восстановления исходного вида кода, обфусцированного по некоторой конкретной методике.
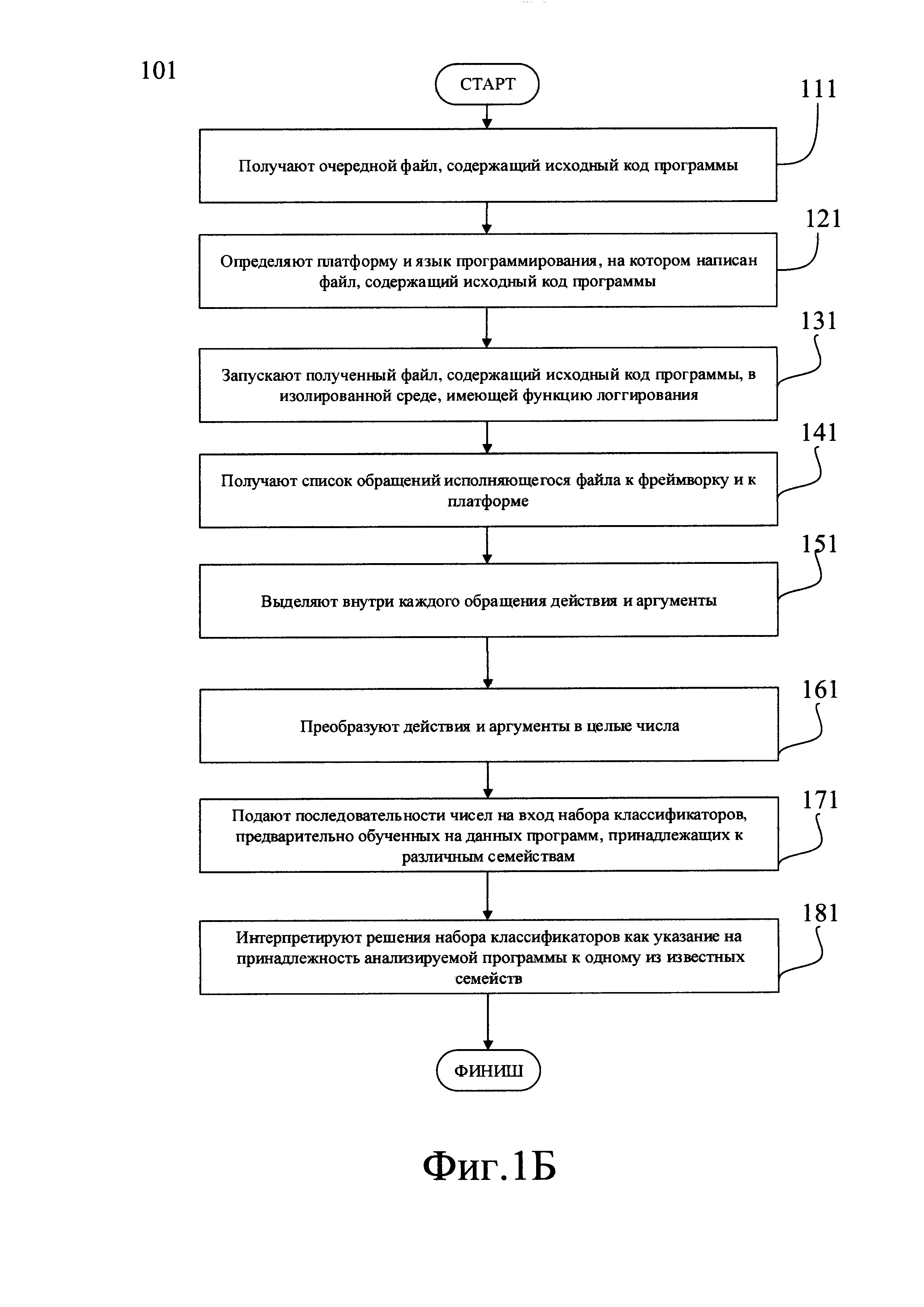
Однако, возможны ситуации, когда определить конкретную методику обфускации не удается. В таких случаях может быть задействован альтернативная разновидность заявленного компьютерно-реализуемого способа определения принадлежности программного обеспечения по его исходному коду (101), показанная на Фиг. 1Б. Он может быть реализован следующим образом:
На этапе (111) получают файл, содержащий исходный код программы, подлежащей анализу. Это может быть выполнено полностью аналогично этапу (110) описанному применительно к Фиг. 1А.
Далее на этапе (121) определяют платформу анализируемого файла и язык программирования, на котором написан анализируемый файл, и выбирают соответствующее средство анализа кода. Это может быть выполнено полностью аналогично этапу (120) описанному применительно к Фиг. 1А.
Как показано на Фиг. 1Б, на этапе (131) запускают файл, содержащий анализируемый исходный код в среде, предоставляющей возможность логгирования (журналирования). Понятно, что данная операция, как и вся разновидность описываемого способа, показанная на Фиг. 1Б, может быть применима только к файлам, содержащим исходный код на одном из интерпретируемых языков программирования. К интерпретируемым языкам программирования относят, например, Python, Perl, PHP, Ruby, JavaScript и некоторые другие языки. На данном этапе для запуска файла может быть использована любая известная среда, имеющая функцию логгирования (журналирования). Например, для скриптов, написанных на Powershell, могут использоваться встроенные средства журналирования операционной системы Windows 10; альтернативно может быть использована специализированная библиотека журналирования Log4j.
В результате исполнения файла, содержащего анализируемый исходный код, в среде, предоставляющей возможность логгирования, на этапе (141) получают список обращений исполняющегося файла к фреймворку и к платформе. Примером обращения к фреймворку может служить вызов СОМ-объекта или управляющего элемента ActiveX. Примером обращения к платформе может служить вызов программного прерывания или системной функции. Полученный список обращений сохраняют, например, в виде текстового файла.
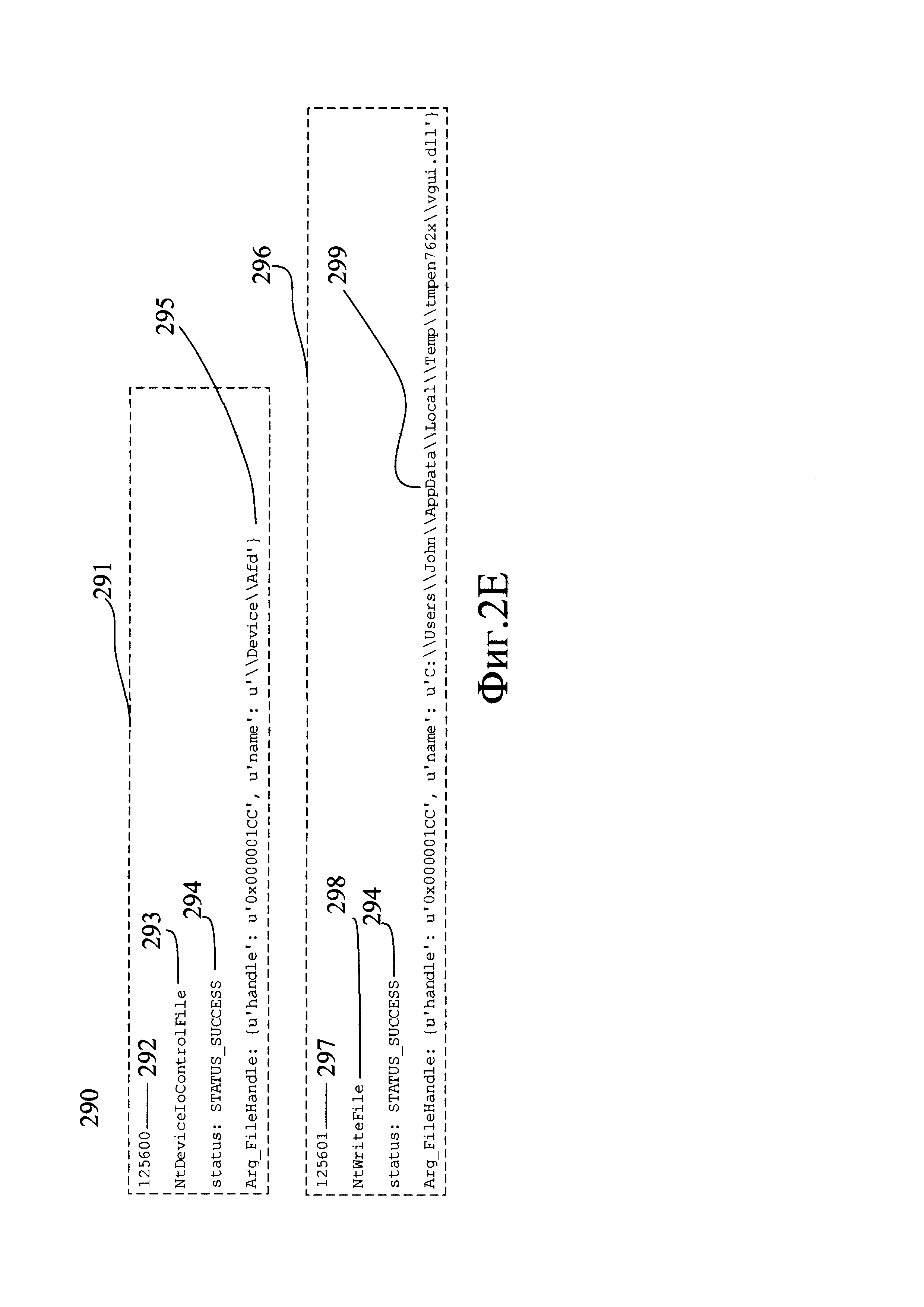
На Фиг. 2Е в качестве примера показан фрагмент списка обращений (290) файла к фреймворку и платформе. Он содержит два обращения, обращение (291) и обращение (296).
На последующем этапе (151) выделяют в списке обращений отдельные обращения, а в каждом обращении - действие и аргумент. Для выделения отдельного обращения из общего списка обращений может быть использован тот факт, что все записи, создаваемые одним средством логгирования в одном сеансе работы, как правило, имеют идентичный, заранее известный формат. Так, например, на Фиг. 2Е каждое обращение содержит следующие элементы: порядковый номер записи (292) и (297), имя вызванной функции (293) или (298), статус вызова (294), аргумент (295) и (299). Поэтому в данном примере отдельным обращением может считаться каждая последовательность символов, расположенная между двумя соседними номерами, например, последовательность (291) расположена между номерами (292) и (297), и так далее. Для выполнения описанных действий используют заранее подготовленную программу-парсер, которая создана с учетом заранее известного формата записей, создаваемых используемым средством логгирования.
Посредством этой же программы-парсера на этапе (151) в каждом из обращений (291), (296), находят действия, то есть имена функций (293), (298) и значения аргументов (295), (299). Каждую найденную пару "действие - аргумент" сохраняют в файле с результатами. В том случае, если обнаружено некоторое действие, а соответствующий ему аргумент отсутствует или имеет неподходящий формат, в результаты помещают пару "действие - аргумент", где аргумент имеет нулевое значение.
Затем, как показано на Фиг. 1Б, на этапе (161) производят преобразование полученных на предыдущем этапе пар "действие - аргумент" в одно численное значение и сохраняют, отдельно для каждой выделенной ранее функции, получившиеся последовательности чисел. Преобразование может быть выполнено аналогично описанному выше применительно к шагу (160) и Фиг. 1А.
В рассматриваемом примере действие (293) с аргументом (295) может быть преобразовано в шестнадцатеричное число
00b66f89be96d7fa40e584d7eb9728f9b43e29d241d0544c3f658c6b193d81f7e5e7201d0c02ef3a,
где 00b66f89be96d7fa40e584d7eb9728f9b43e29d2 является результатом взятия хэш-функции от действия (293), a 41d0544c3f658c6b193d81f7e5e7201d0c02ef3a - результатом взятия хэш-функции от аргумента (295). Аналогично, действие (295) с аргументом (299) может быть преобразовано в шестнадцатеричное число
18ede0448e4ad01e04175beb0c5216977ddf8b74a94d5f2d650020e4467fa02e979c295ab252f415.
Аналогично описанному выше применительно к шагу (160), возможны и более сложные преобразования действий и аргументов в числа, например, преобразования, включающие сериализацию и т.д.
На следующем этапе (171) все полученные данные, преобразованные к виду (1), подаются на входы классификаторов, предварительно обученных на ВПО различных семейств или авторов.
Решение каждого классификатора представляет собой численную оценку вероятности того, что анализируемый образец ВПО принадлежит к тому семейству ВПО или той группе авторов, на массиве данных которого или которой был обучен классификатор. Эти решения постоянно обновляются, т.е. пересматривается при поступлении каждой порции данных вида (1).
Решения классификаторов могут накапливаться, либо обрабатываться любым другим общеизвестным образом. Но в любом случае, на заключительном этапе (181) исследуемое ВПО относят к тому семейству ВПО или той группе авторов, классификаторы которого или которой выдают наибольшее значение уверенности.
В некоторых возможных вариантах реализации способа после завершения этапов (140) на Фиг. 1А и (141) на Фиг. 1Б может быть выполнен еще один, не показанный на Фиг. 1А и Фиг. 1Б, этап обработки.
На этом этапе удаляют устойчивые конструкции, то есть фрагменты кода, которые одинаково часто встречаются в любых программах. Устойчивыми конструкциями являются, например, прологи функций. Удаление устойчивых конструкций выполняют посредством заблаговременно изготовленной программы.
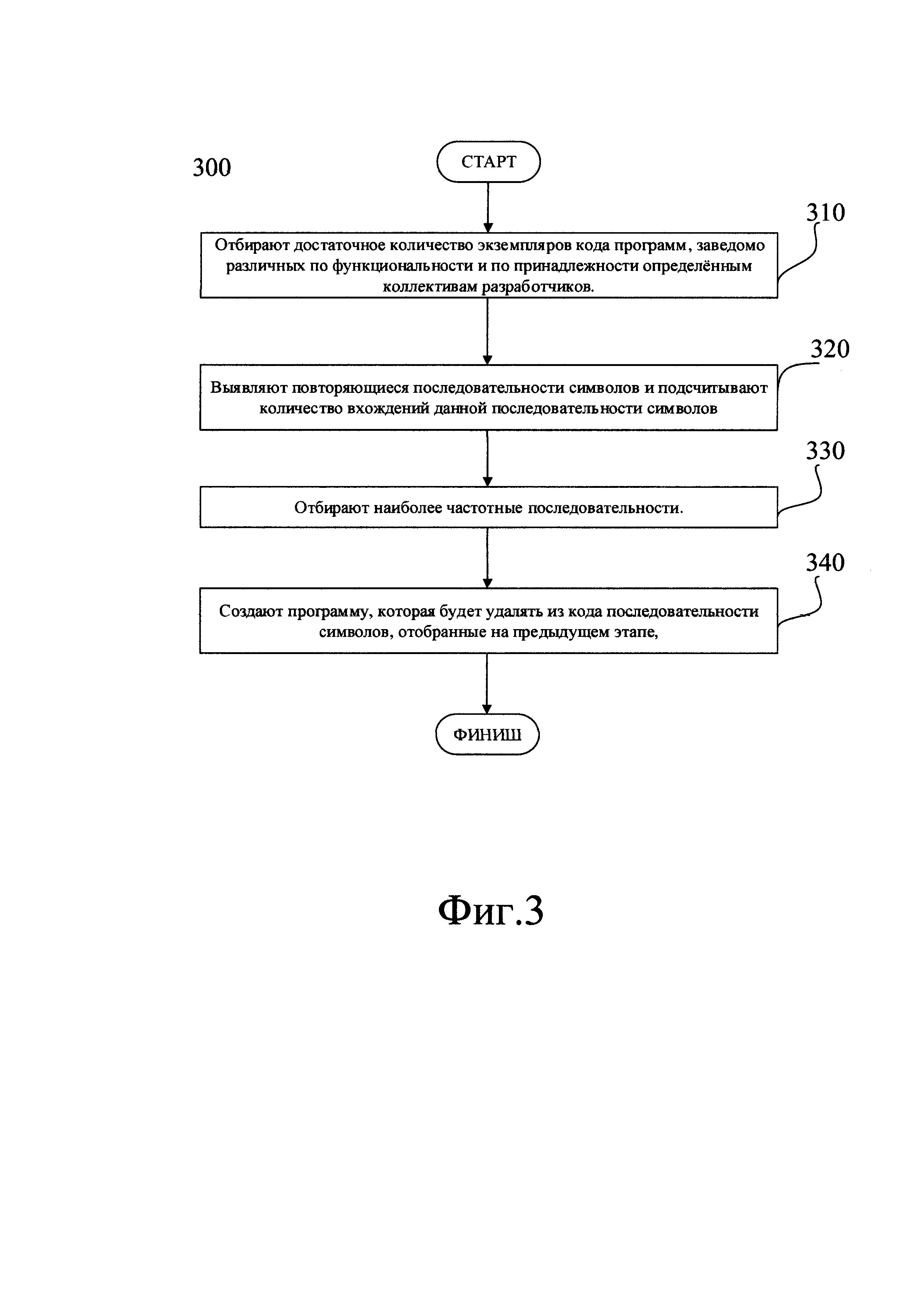
Такая программа может быть изготовлена для каждого распространенного языка программирования (например, С\С++, JavaScript, Common Lisp и т.д.). Изготовление названной программы (300) может быть выполнено, как это показано на Фиг. 3, следующим образом.
На этапе (310) отбирают достаточное количество, например, 100, экземпляров кода программ, заведомо различных по функциональности и по принадлежности определенным коллективам разработчиков.
На следующем этапе (320) обрабатывают отобранный массив кода алгоритмом, который выявляет повторяющиеся последовательности символов и подсчитывает количество вхождений данной последовательности символов в массиве кода. При этом задают минимальную длину последовательности, например, равной 20 символам, а максимальную длину последовательности не ограничивают. Описанный алгоритм возвращает список найденных повторяющихся последовательностей символов, где каждой последовательности поставлено в соответствие количество ее вхождений в массиве кода.
Затем на этапе (330) из списка устойчивых последовательностей, возвращенного алгоритмом, отбирают наиболее частотные последовательности. Например, отбирают те последовательности, которые встречаются минимум один раз в каждой программе, т.е. в данном примере, такие, которые встретились 100 раз или больше.
На следующем этапе (340) создают программу, которая будет удалять из анализируемого кода наиболее частотные последовательности, отобранные на предыдущем этапе.
Таким образом получают программу, способную обрабатывать произвольные фрагменты кода, удаляя из них те последовательности символов, которые включены в "список удаления" как часто встречающиеся в разных программах.
После обработки такой программой получают файл, в котором из функций, реализованных в анализируемом экземпляре ВПО, удалены устойчивые конструкции, то есть такие фрагменты кода, которые достаточно часто встречаются в любых, произвольно выбранных программах. По окончании данного этапа переходят к показанному на Фиг. 1А этапу (150) или к показанному на Фиг. 1Б этапу (151), дальнейшие шаги аналогичны описанным выше.
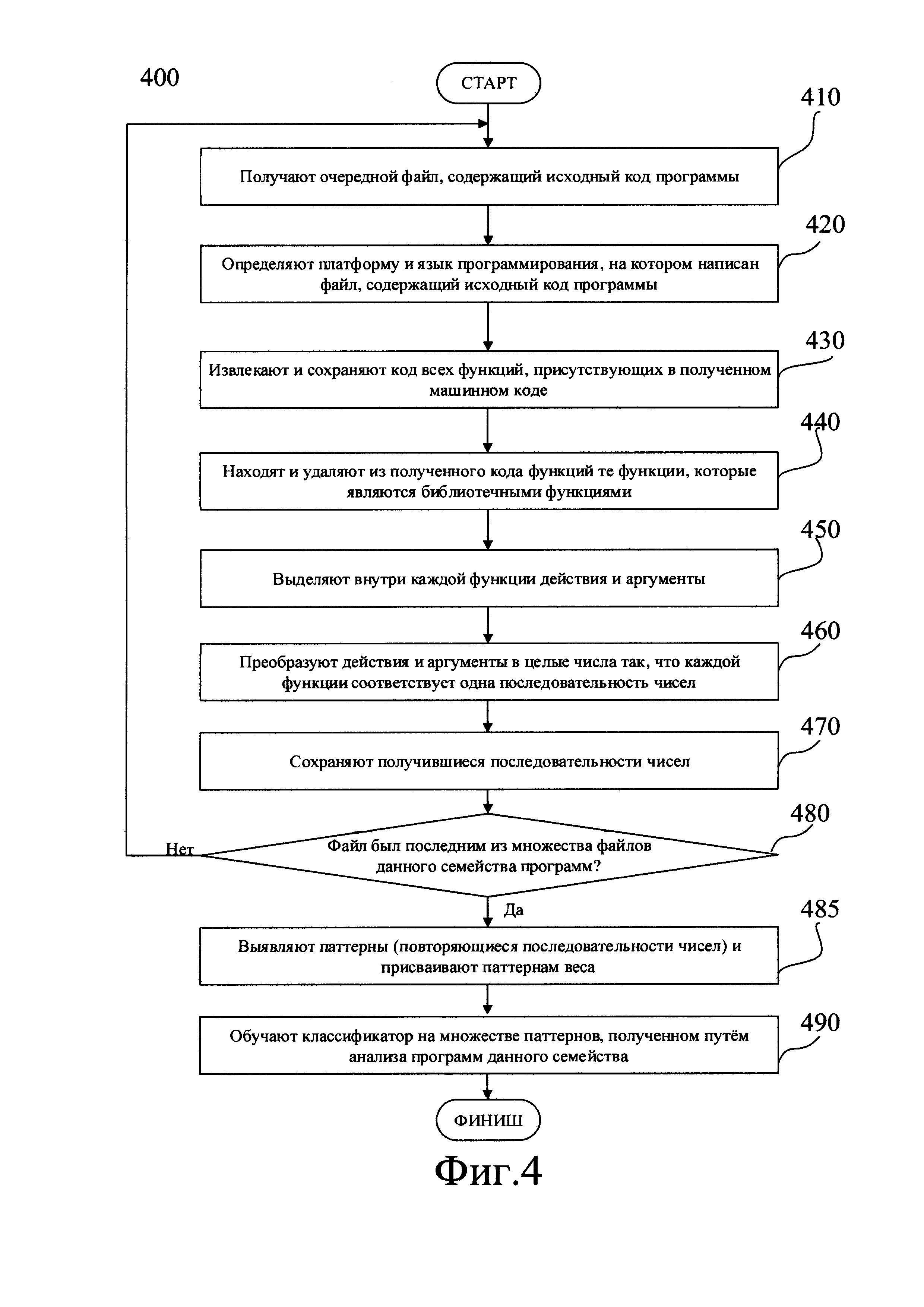
Фиг. 4 иллюстрирует один из возможных способов обучения (400) классификаторов, используемых на этапах (170) в соответствии с Фиг. 1А и (171) в соответствии с Фиг. 1Б.
На этапе (410) получают очередной файл, содержащий исходный код программы. Общее количество таких файлов с исходным кодом определяют заранее. Например, для целей обучения могут быть отобраны по 30-70 файлов с исходным кодом для каждого семейства программ, принадлежность к которому необходимо научиться определять. Альтернативно, могут быть отобраны по 20-30 файлов с исходным кодом, авторство которого априори известно. Анализ отобранных файлов производят поочередно.
На этапе (420) определяют платформу и язык программирования, на котором написан анализируемый файл, и выбирают соответствующее средство анализа кода. Определение платформы и языка программирования может быть выполнено любым известным способом, например, как это было описано выше применительно к шагу (120) на Фиг. 1А.
Дальнейший анализ файла выполняют на этапе (430) заблаговременно подготовленной программой-парсером, алгоритм действия которой основан на синтаксисе того языка программирования, на котором написан исходный код в данном файле. На этапе (430) из исходного кода извлекают и сохраняют в виде списка функции. Это может быть сделано аналогично тому, как описано выше применительно к шагу (130) на Фиг. 1А.
На следующем этапе (440) из списка исключают те функции, которые относятся к библиотечным. Аналогично описанному выше применительно к шагу (140) на Фиг. 1А, удаление библиотечных функций выполняют вспомогательной программой-скриптом.
В некоторых возможных вариантах реализации способа после завершения этапа (440) может быть выполнен дополнительный этап обработки, не показанный на Фиг. 4, на котором из оставшегося кода функций удаляют устойчивые конструкции. Удаление устойчивых конструкций выполняют посредством программы, заблаговременно изготовленной для данного языка программирования, как это было показано выше применительно к Фиг. 3.
Затем на этапе (450) выделяют внутри каждой функции команды, а внутри каждой команды - действие и, возможно, аргумент. Это выполняют заблаговременно подготовленной программой-парсером аналогично тому, как было описано выше применительно к шагу (150) на Фиг. 1.
Затем, как показано на Фиг. 4, на этапе (460) производят преобразование полученных на предыдущем этапе пар "действие - аргумент" в одно численное значение. Это выполняют аналогично описанному выше этапу (160) на Фиг. 1. Наконец, на этапе (470) полученные последовательности сохраняют, отдельно для каждой функции, выделенной на этапе (430).
На этапе (480) проверяют, достигнут ли конец множества файлов с исходным кодом, отобранных для обучения. Если нет, возвращаются к шагу (410). Таким образом система, реализующая способ, накапливает данные. В результате получают массив данных, сохраненных в файлах, где данные, полученные в ходе анализа каждой программы, имеют вид (1). Притом все программы, исходный код которых был проанализирован, принадлежат к одному, заранее известному семейству программ, либо, альтернативно, к одному автору или коллективу авторов программ.
Когда общее количество данных для данного семейства ПО или данной группы авторов превышает заранее заданный порог, массив данных на шаге (485) анализируют, выявляя паттерны. Этим термином в данном случае будем называть повторяющуюся последовательность чисел Pij, или, что то же самое, повторяющиеся последовательности команд, характерных для данного семейства ПО или группы авторов.
Длина паттерна, т.е. какое именно количество чисел, расположенных последовательно, будет считаться паттерном, выбирается заранее. В одном варианте реализации данного способа длина паттерна может быть задана интервалом, например, длина паттерна может быть от 4 до 10 или, альтернативно, от 60 до 80. В другом возможном варианте реализации длина паттерна может быть заранее задана фиксированной величиной, например, 40.
Еще в одном возможном варианте реализации длина паттерна может выбираться автоматически в зависимости от количества паттернов, выявляемых для данного массива данных (данного семейства программ). В этом варианте поиск паттернов начинается, например, при заданной длине 8. Если и когда количество выявленных паттернов превышает установленный при настройке системы порог (например, их найдено более 100), длину паттерна увеличивают на единицу и повторяют поиск, отбросив ранее найденные короткие паттерны. Такой цикл выполняется до тех пор, пока не будет найдено меньшее пороговой величины количество паттернов, имеющих максимально возможную длину.
Возможен такой вариант реализации, при котором на данном шаге также проводится предварительная модификация некоторых найденных паттернов. В ходе модификации некоторым паттернам присваивают дополнительные априорные веса, связанные со смыслом соответствующих команд.
Говоря о весе паттерна, в данном случае подразумеваем некое наперед заданное число, ассоциированное с данным паттерном и хранящееся в системе, реализующей описываемый способ.
Например, паттернам, на 80% состоящим из команд с математическими операциями, может быть присвоен повышенный вес, например, в 2 раза превышающий вес других паттернов, а паттернам, содержащим свыше 2 строковых констант, может быть присвоен повышенный вес, например, в 3 раза превышающий вес других паттернов. Подобный вес может присваиваться любым паттернам, удовлетворяющим заданным условиям, вне зависимости от того, в данных какого именно образца ПО найдены данные паттерны.
Аналогично, паттернам, вообще не содержащим ни команд с математическими операциями, ни строковых констант, может быть присвоен пониженный вес, например, в 0.3 от веса немодифицированных паттернов.
Для каждого выявленного паттерна вычисляется частотность. Ее значение вычисляется на основании того же массива данных. Это численная величина, показывающая, насколько часто данный паттерн встречается в исходном коде программ данного семейства, т.е. насколько часто в программах изучаемого семейства встречается такой набор команд. Частотность равна отношению количества вхождений данного паттерна L к общему количеству программ, относящихся к данному семейству программ. Этот параметр может быть, как меньше единицы, если паттерн встречается не в каждой программе, так и больше, если паттерн в среднем встречается несколько раз на протяжении каждой программы.

Найденные паттерны и вычисленные для каждого из них значения частотности сохраняют, образуя коллекцию паттернов.
Затем для каждого семейства программ, используя его коллекцию паттернов, на шаге (490) обучают экспертную систему (классификатор). Техническая реализация классификатора может быть любой общеизвестной; он может быть реализован, например, как графовая вероятностная модель (Random Forest) или как SVM-классификатор.
Если каким-то паттернам при составлении коллекции паттернов были присвоены повышенные и\или пониженные веса, то эти веса могут учитываться при выборе или обучении классификатора таким образом, чтобы соответствующие паттерны оказывали пропорционально большее или меньшее влияние на итоговое решение. Аналогичным образом, в роли повышающего или понижающего коэффициента, на данном этапе может использоваться также частотность.
Ниже приведены дополнительные варианты реализации настоящего изобретения.
В частном варианте реализации способа после обучения классификатора выбирают пороговое значение, превышение которого свидетельствует о принадлежности программы, исходный код которой подвергался анализу, тому семейству программ, на наборах данных которого был обучен классификатор.
В другом частном варианте реализации способа после обучения классификатора выбирают пороговое значение, превышение которого свидетельствует о принадлежности программы, исходный код которой подвергался анализу, тому разработчику или коллективу разработчиков программ, на наборах данных которого был обучен классификатор.
В другом частном варианте реализации способа обучают классификатор методом машинного обучения.
Еще в одном частном варианте реализации способа что паттернам, содержащим по меньшей мере две строковые константы, дополнительно присваивают повышенный вес, величина которого задана заранее.
В другом частном варианте реализации способа паттернам, по меньшей мере на 80% состоящим из математических операций, дополнительно присваивают повышенный вес, величина которого задана заранее.
В другом частном варианте реализации способа паттернам, не содержащим ни строковых констант, ни математических операций, дополнительно присваивают пониженный вес, величина которого задана заранее.
В другом частном варианте реализации способа повышенные и пониженные веса, присвоенные паттернам, учитывают при обучении классификатора таким образом, чтобы паттерны с повышенным весом оказывали пропорционально большее, а паттерны с пониженным весом пропорционально меньшее влияние на итоговое решение классификатора.
Заявленное решение также осуществляется за счет системы определения принадлежности программного обеспечения по его исходному коду, содержащей:
- долговременную память, выполненную с возможностью хранения базы данных;
- вычислительное устройство, выполненное с возможностью выполнения описанного способа.
В другом из возможных вариантов реализации заявленное решение является составной частью системы обеспечения кибернетической безопасности.
В другом из возможных вариантов реализации заявленное решение является составной частью системы сбора устойчивых индикаторов компрометации.
В другом из возможных вариантов реализации заявленное решение является составной частью системы автоматизированного определения авторства программного обеспечения.
В другом из возможных вариантов реализации заявленное решение является составной частью системы автоматизированного выявления плагиата.
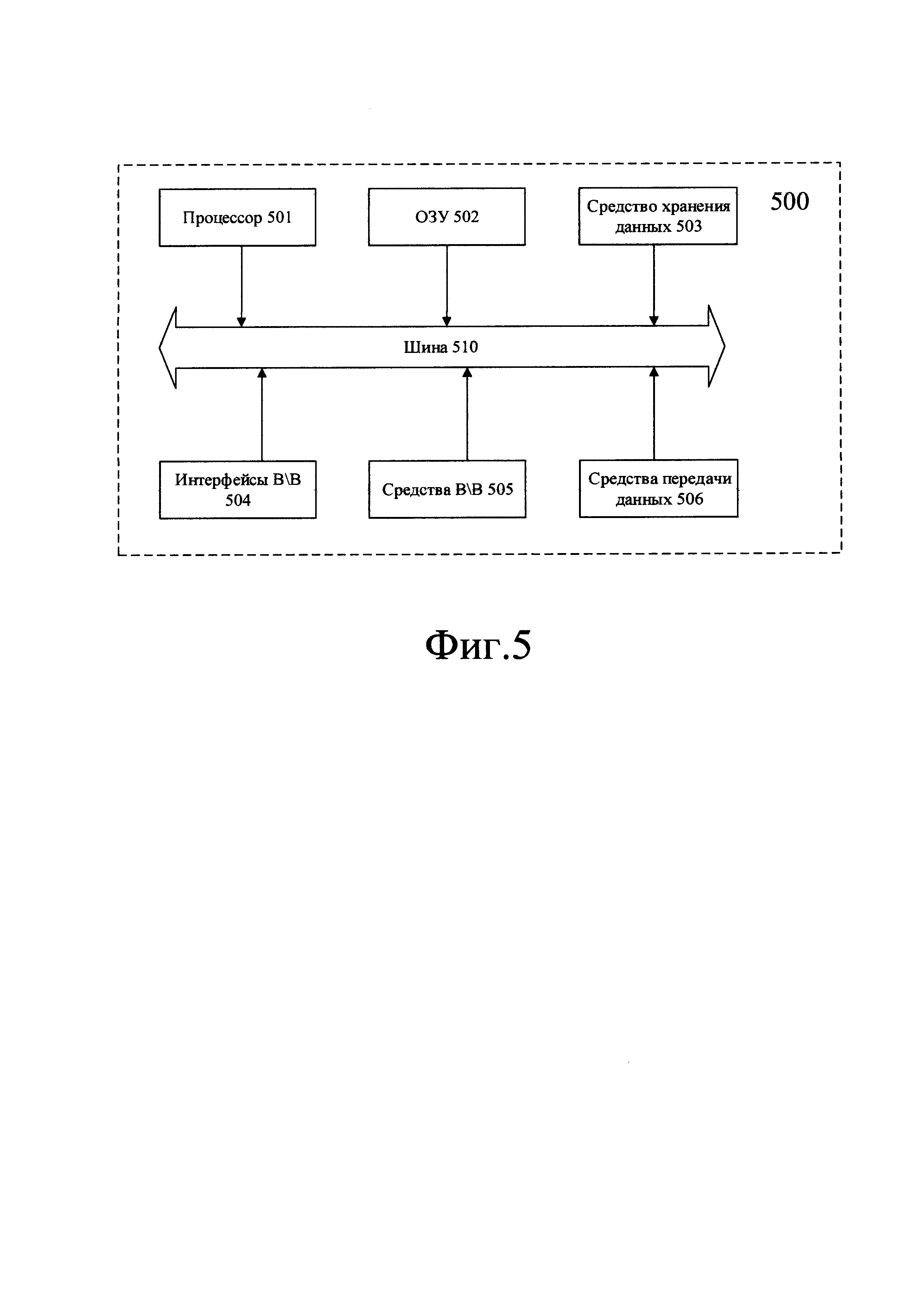
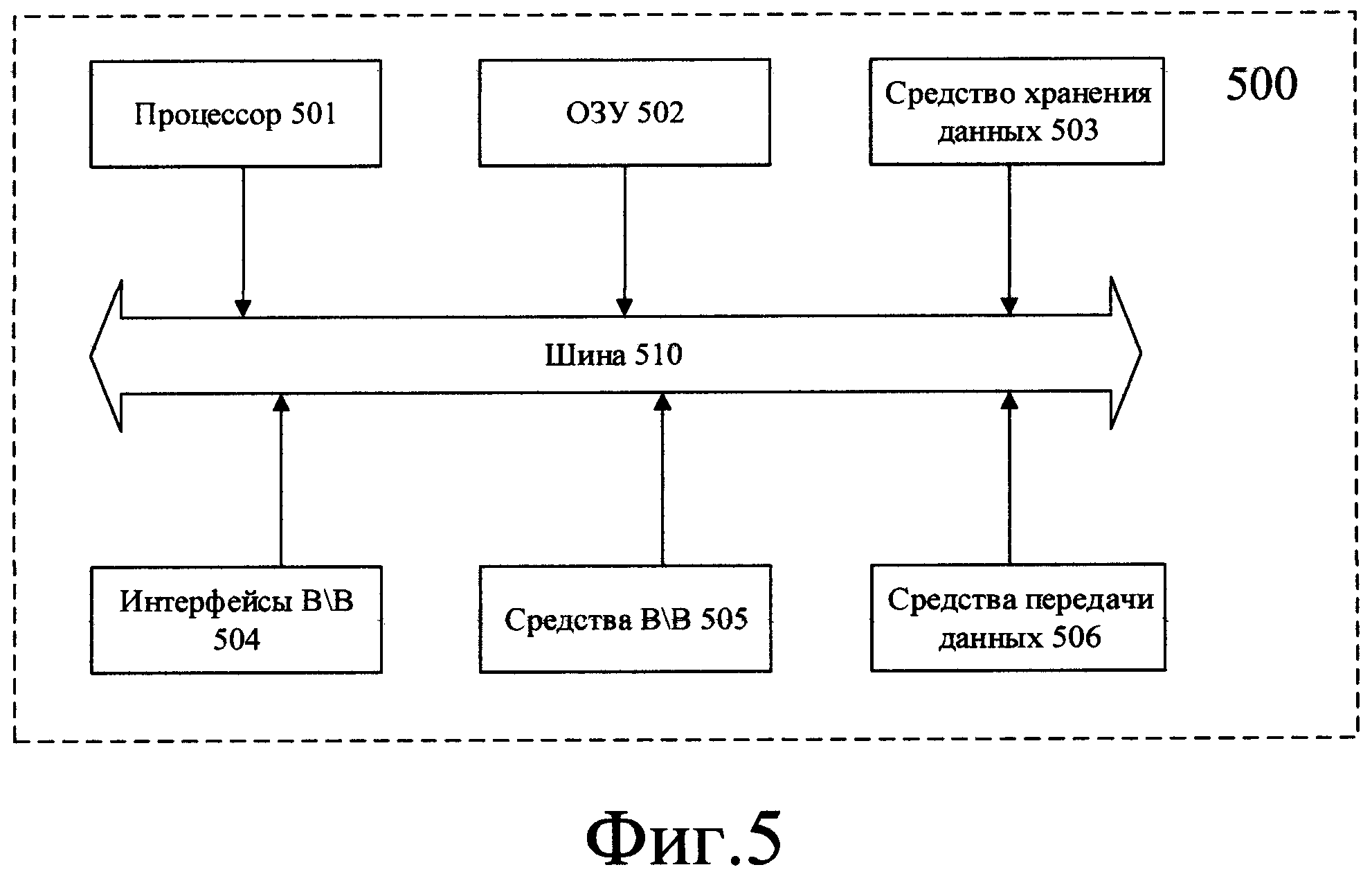
На Фиг. 5 далее будет представлена общая схема компьютерного устройства (500), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (500) содержит такие компоненты, как: один или более процессоров (501), по меньшей мере одну память (502), средство хранения данных (503), интерфейсы ввода/вывода (504), средство В/В (505), средства сетевого взаимодействия (506).
Процессор (501) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (500) или функциональности одного или более его компонентов. Процессор (501) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (502).
Память (502), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (503) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (503) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с исходным кодом, с наборами промежуточных данных, с вычисленными последовательностями и т.п.
Интерфейсы (504) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (504) зависит от конкретного исполнения устройства (500), которое может представлять собой персональный компьютер, мейнфрейм, сервер, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (505) может использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (506) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств (505) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (500) сопряжены посредством общей шины передачи данных (510).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.

Система и способ автогенерации решающих правил для систем обнаружения вторжений с обратной связью
Вычислительное устройство и способ для обнаружения вредоносных доменных имен в сетевом трафике
Сервер и способ для определения вредоносных файлов в сетевом трафике
Способ и система определения принадлежности программного обеспечения по его машинному коду
Способ и система туннелирования трафика в распределенной сети для детонации вредоносного программного обеспечения
Способ и компьютерное устройство для кластеризации веб-ресурсов
Способ и система для автоматического определения нечетких дубликатов видеоконтента
Способ для классифицирования последовательности действий пользователя (варианты)
Способ и система определения принадлежности программного обеспечения по его машинному коду

