Результат интеллектуальной деятельности: СПОСОБ ДЛЯ КЛАССИФИЦИРОВАНИЯ ПОСЛЕДОВАТЕЛЬНОСТИ ДЕЙСТВИЙ ПОЛЬЗОВАТЕЛЯ (ВАРИАНТЫ)
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к способам для определения фрода, а именно для определения легитимных или мошеннических действий пользователя.
УРОВЕНЬ ТЕХНИКИ
 (от англ. anti-fraud - борьба с мошенничеством), или фрод-мониторинг - система, предназначенная для оценки финансовых транзакций в Интернете на предмет подозрительности с точки зрения мошенничества и предлагающая рекомендации по их дальнейшей обработке. Как правило, сервис антифрода состоит из стандартных и уникальных правил, фильтров и списков, по которым и проверяется каждая транзакция.
(от англ. anti-fraud - борьба с мошенничеством), или фрод-мониторинг - система, предназначенная для оценки финансовых транзакций в Интернете на предмет подозрительности с точки зрения мошенничества и предлагающая рекомендации по их дальнейшей обработке. Как правило, сервис антифрода состоит из стандартных и уникальных правил, фильтров и списков, по которым и проверяется каждая транзакция.
Практически все системы анти-фрода используют задаваемые ограничения или лимиты, строящиеся на простых правилах:
- ограничение количества покупок по одной банковской карте или одним пользователем за определенный период времени
- ограничение на максимальную сумму разовой покупки по одной карте или одним пользователем в определенный период времени
- ограничение на количество банковских карт, используемых одним пользователем в определенный период времени
- ограничение на количество пользователей, использующих одну карту
- учет истории покупок по банковским картам и пользователями (так называемые «черные» или «белые» списки).
Указанный подход не позволяет достоверно определять легитимность или фродовость операций.
Другим решением, известным из уровня техники, является использование сигнатур. Для поддержания актуальности выявления фродовости или легитимности действий, сигнатуры необходимо постоянно обновлять. Обычно сигнатуры формируются человеком-аналитиком, который анализирует последовательности действий на наличие признаков фрода и выявляет характерные признаки. Это является трудозатратным, а качество сигнатур может зависеть от профессионализма аналитика.
СУЩНОСТЬ
Данное техническое решение позволяет устранить недостатки, присущие решениям из уровня техники.
Данное техническое решение позволяет определять признаки, присущие необходимому классу операций в автоматическом режиме с высокой точностью.
Способ классифицирования последовательности действий пользователя, выполняемый на компьютерном устройстве (фиг. 2), содержит следующие шаги:
- устанавливают триггеры на элементы интерфейса и события, связанные с данными элементами интерфейса или другими действиями пользователя;
- записывают последовательность действий пользователей, возникающие при этом события и время осуществления действия или возникновения события, присваивая последовательности действий класс принадлежности по умолчанию;
- получают информацию о времени, пользователе и фактическом классе принадлежности последовательность действий данного пользователя произошедших в указанное время и изменяют класс принадлежности соответствующей последовательности действий на фактический;
- формируют обучающую выборку, содержащую последовательности действий пользователей с разными классами принадлежности;
- разбивают последовательности действий пользователей из обучающей выборки на подпоследовательности с учетом заданных параметров: максимальная длина подпоследовательности, минимальная длина подпоследовательности, количество наиболее информативных признаков (n);
- для каждой подпоследовательности определяют частоту ее принадлежности к каждому из классов;
- производят скоринг каждой подпоследовательности с учетом ее частоты принадлежности к каждому из классов и отбирают n наиболее информативных подпоследовательностей, указывающих на возможность принадлежности последовательности действий пользователя к заданному классу;
- производят поиск отобранных наиболее информативных n подпоследовательностей в каждой последовательности действий пользователей из обучающей выборки, формируя набор булевых признаков, где каждый признак показывает присутствие соответствующей ему подпоследовательности в данной последовательности действий
- сформированный набор булевых признаков подают в качестве обучающей выборки для алгоритма классификации.
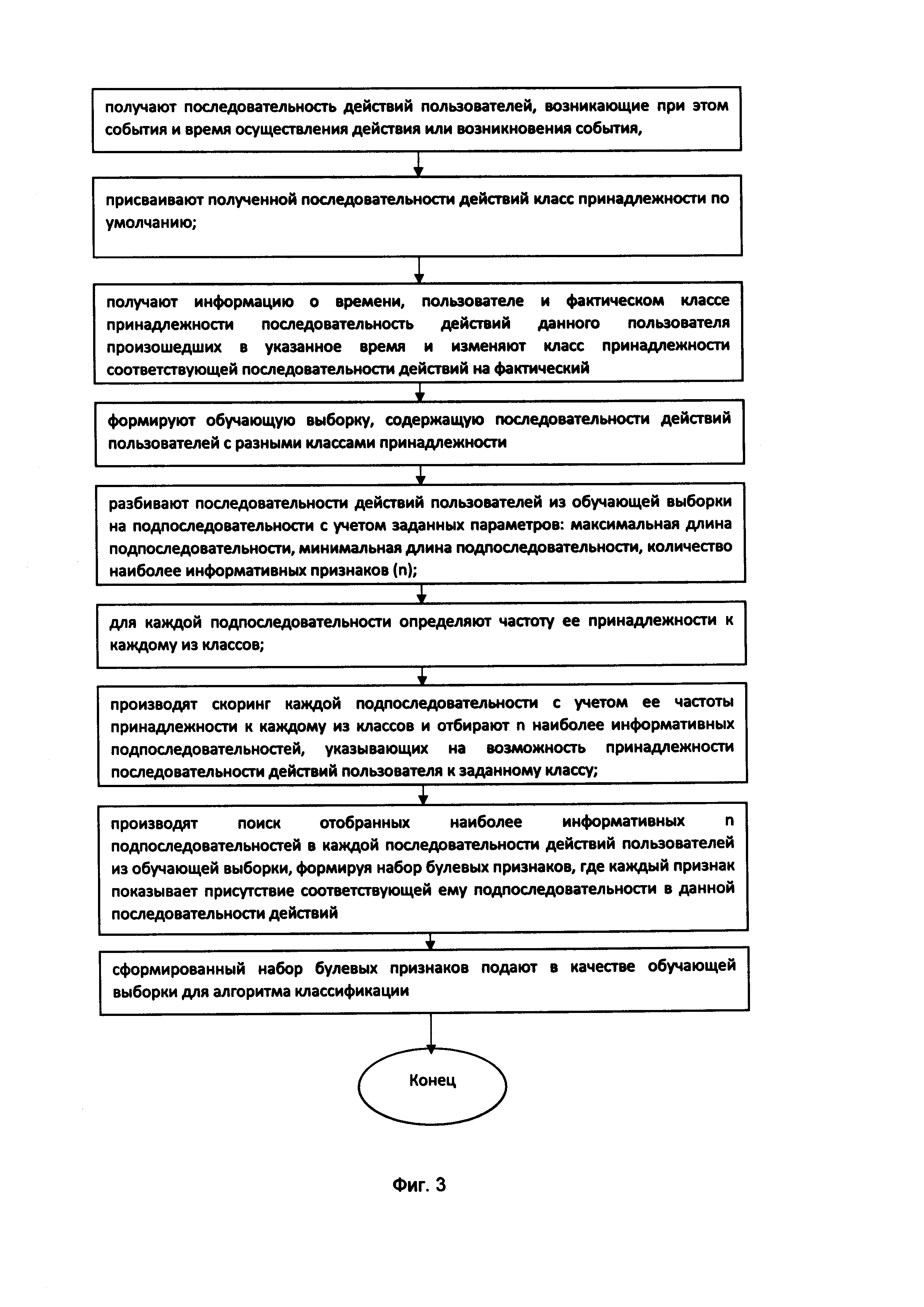
В одном из вариантов реализации способ классифицирования последовательности действий пользователя (фиг. 3), выполняемый на компьютерном устройстве, содержит следующие шаги:
- получают последовательность действий пользователей, возникающие при этом события и время осуществления действия или возникновения события,
- присваивают полученной последовательности действий класс принадлежности по умолчанию;
- получают информацию о времени, пользователе и фактическом классе принадлежности последовательность действий данного пользователя произошедших в указанное время и изменяют класс принадлежности соответствующей последовательности действий на фактический;
- формируют обучающую выборку, содержащую последовательности действий пользователей с разными классами принадлежности;
- разбивают последовательности действий пользователей из обучающей выборки на подпоследовательности с учетом заданных параметров: максимальная длина подпоследовательности, минимальная длина подпоследовательности, количество наиболее информативных признаков (n);
- для каждой подпоследовательности определяют частоту ее принадлежности к каждому из классов;
- производят скоринг каждой подпоследовательности с учетом ее частоты принадлежности к каждому из классов и отбирают n наиболее информативных подпоследовательностей, указывающих на возможность принадлежности последовательности действий пользователя к заданному классу;
- производят поиск отобранных наиболее информативных n подпоследовательностей в каждой последовательности действий пользователей из обучающей выборки, формируя набор булевых признаков, где каждый признак показывает присутствие соответствующей ему подпоследовательности в данной последовательности действий;
- сформированный набор булевых признаков подают в качестве обучающей выборки для алгоритма классификации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
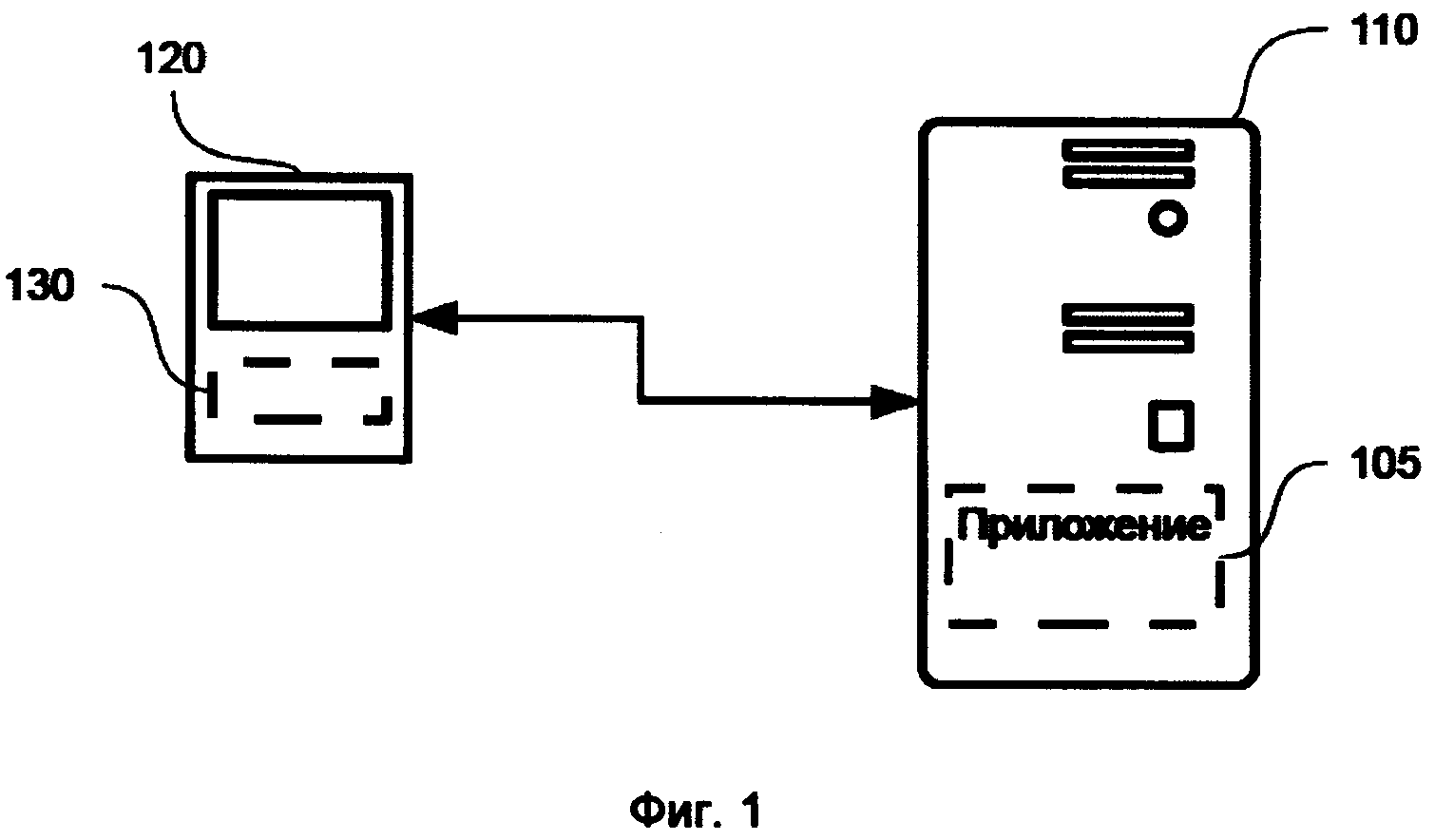
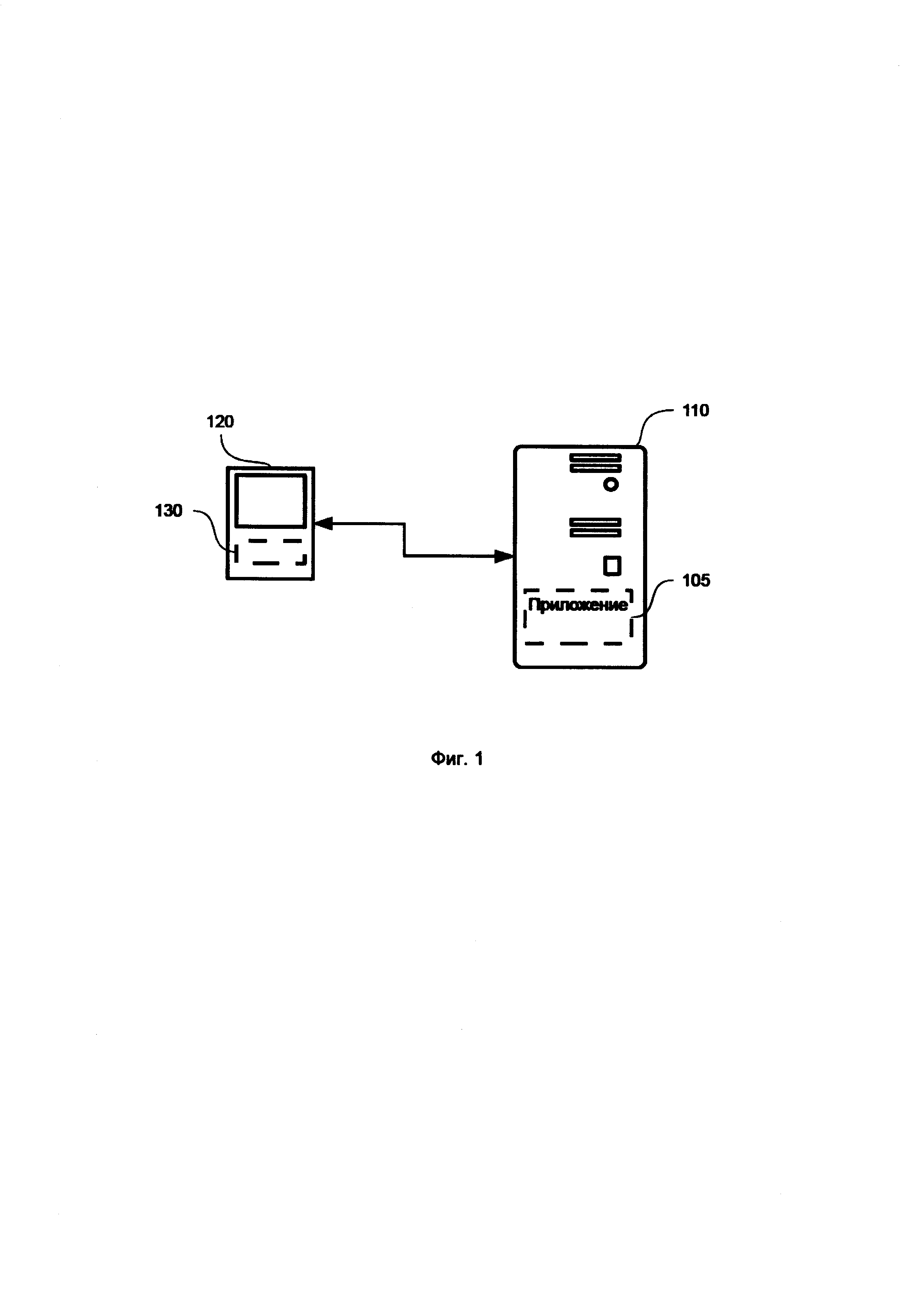
На фиг. 1 показан примерный вариант системы, в частном случае, реализующий способ, описываемый в рамках настоящего технического решения.
На фиг. 2 показана блок-схема способа согласно первому варианту реализации.
На фиг. 3 показана блок-схема способа согласно второму варианту реализации.
ПОДРОБНОЕ ОПИСАНИЕ
Пусть имеется сайт банка (105) с личным кабинетом, расположенным на сервере 110, для которого необходимо отслеживать легимность и фродовость действий пользователей. Пользователи загружают на своих персональных устройствах 120 страницы сайта в приложении (например, веб-браузере или мобильном банке) 130.
В некоторых вариантах реализации персональным мобильным устройством является смартфон, планшет, кпк, ноутбук, персональный компьютер, но не ограничиваясь.
Для определения легитимности и фродовости действий на каждой странице сайта (или экране, в случае мобильного приложения) определяют отслеживаемые элементы пользовательского интерфейса и события. Для отслеживания элементов интерфейса и событий, устанавливают триггеры, срабатывающие при взаимодействии пользователя с такими элементами интерфейса и/или при наступлении таких событий.
Примерами таких событий для сайта банка могут могут быть:
- вход на страницу регистрации;
- регистрация;
- подтверждение регистрации;
- ошибка регистрации;
- таймаут регистрации;
- главная страница;
- перевод клиенту банка;
- перевод клиенту другого банка;
- перевод организации (название организации);
- платеж на МТС, Билайн, Мегафон;
- подтверждение перевода;
- чек;
- ошибка, неверный пароль;
- ошибка, таймаут.;
- просмотр настроек (какие именно настройки);
- просмотр ОМС;
- просмотр карт;
- просмотр счетов;
- просмотр вкладов;
- просмотр кредитов;
- выход;
- оплата своего телефона;
Примерами действий пользователя могут быть:
- выбор элемента интерфейса;
- нажатие левой или правой кнопкой мыши;
- переход между страницами сайта, экранами приложения (например, страницами дистанционного банковского обслуживания);
- переход между фреймами в браузере, вкладками в приложении;
- нажатие на кнопки;
- нажатие на элемент интерфейса «флажок» (checkbutton), переключатель (radiobutton);
- выбор поля ввода, элемента списка (edit);
- нажатие кнопки (клавиши) клавиатуры;
При срабатывании на устройстве 120, в приложении 130 триггер сохраняет информацию, связанную с данным действием пользователя или наступлением события на сервере 110. Примером такой информации может быть запись вида: <event_MouseClick>, <01/09/2017 17:53>, <29073>, означающая что произошло событие «клик мыши» в 17:53 01/09/2017 у пользователя с идентификатором 29073.
В некоторых вариантах реализации триггер сохраняет информацию, связанную с данным действием пользователя или наступлением события на устройстве пользователя 120.
В некоторых вариантах реализации события и действия пользователя кодируются в других нотациях, например, событию или действию может быть назначен символ или число. Так, например, вместо <event_MouseClick> может использоваться число или последовательность символов и/или цифр.
Идентификатор пользователя или иные идентифицирующие данные о пользователе передаются на устройство пользователя 120 сервером 110 или другими серверами/системами, производящими идентификацию пользователей (в т.ч. косвенную).
При работе с сайтом пользователь взаимодействует с различными элементами интерфейса страниц и выполняет различные действия, что вызывает срабатывание триггеров и запись последовательности действий пользователя и возникающих событий.
Например, для пользователя с идентификатором 34092 (номер пользователя выбран в качестве примера, как и все остальные данные в примерах) в ходе работы с сайтом на устройстве 120 может быть сформирована следующая цепочка действий:

Такие последовательности действий пользователя сохраняются на сервере 110 (в некоторых вариантах реализации на устройстве пользователя 120) и им устанавливается класс принадлежности по умолчанию, например, легитимный (G).
Выбор количества классов зависит от поставленной задачи. В некоторых вариантах реализации используется разбиение на следующие классы: F - фродовый, G - легитимный или, например, класс действий анализируемого пользователя и действия всех остальных пользователей, или действия человека и действия бота и т.д.
В некоторых вариантах реализации может быть 3 и более класса. Например, действие каждого пользователя - это отдельный класс или действия различных групп пользователей (например, дети, взрослые, старики).
Если через некоторое время будет обнаружено, что в какой-то момент времени (промежуток времени) пользователь был скомпрометирован и вместо него действия осуществлял злоумышленник, то сервер 110 (в некоторых вариантах реализации на устройстве пользователя 120) определяет скомпрометированную последовательность действий пользователя и записывает (присваивает) ей класс принадлежности фродовый (F).
Из последовательностей действий пользователя (пользователей) с разными классами формируется обучающая выборка, используемая в дальнейшем для автоматического определения фрода в действиях.
Для автоматического определения фрода выполняют следующие действия:
Разбивают последовательности действий пользователей на подпоследовательности с учетом заданных параметров: максимальная длина подпоследовательности (max_subsequence_length), минимальная длина подпоследовательности (min_subsequence_length), количество наиболее информативных признаков (n). На данном этапе нам известен класс принадлежности для каждой последовательности.
Стоит отметить, что параметры, могут быть заданы администратором сервера 110 самостоятельно, например, с учетом (использованием) опыта, профессиональной интуиции.
В случае реализации основного функционала на устройстве пользователя 120, параметры могут быть заданы разработчиками или могут получаться с сервера настроек.
Так, в частном случае осуществления настоящего технического решения упомянутые параметры могут быть заданы (в частности, определены) посредством перебора всех разумных величин, где критерием разумности является итоговый результат. Так, например, администратор может задать максимальное и минимальное значения каждого параметра и выбрать наилучшие.
Рассмотрим разбиение на примере.
- max_subsequence_length = 6, т.е. в данном рассматриваемом примере максимальная длина подпоследовательности равна 6;
- min_subsequence_length = 3, т.е. в данном рассматриваемом примере минимальная длина подпоследовательности равна 3;
- n=400, т.е. в данном рассматриваемом примере количество признаков равно 400. Пусть имеется закодированная последовательность действий (s) = ABFDSAAADOO, где каждый символ обозначает действие пользователя или наступившее событие (остальные атрибуты, например, время и идентификатор пользователя не берутся в расчет). Разобьем ее на подпоследовательности с заданной максимальной длиной подпоследовательности max_subsequence_length = 6 и получим следующее множество: {ABFDSA, BFDSAA, FDSAAA, DSAAAD, SAAADO, AAADOO}. Каждый элемент из полученного множества так же разобьем на всевозможные подпоследовательности длины не меньше, чем min_subsequence_length, начинающиеся с начала закодированной последовательности действий пользователя:
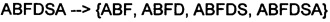

Для последней подпоследовательности AAADOO найдем еще окончания {AADOO, ADOO, DOO}
Далее, может быть выбрана общая совокупность, в частности, упорядоченная совокупность (А), как объединение всех совокупностей ({ABF, ABFD, ABFDS, ABFDSA}, {BFD, BFDS, BFDSA, BFDSAA}, … {AAA, AAAD, AAADO, AAADOO}, {AADOO, ADOO, DOO}) в одну совокупность, причем общая совокупность (А) включает в себя элементы а(1), а(2), …, a(U), где U является мощностью (количеством элементов) общей совокупности А, причем для каждой последовательности действий пользователя существует своя общая совокупность А.
Далее для каждого элемента совокупности (А) сервером 110 (в некоторых вариантах реализации устройством пользователя 120) определяется частота ее принадлежности к каждому из классов (например, легитимному или фродовому, в случае использования 2-х классов). Так, например, подпоследовательность ABFDS может встречаться 500 раз в фродовых последовательностях и 10 раз в легитимных.
Затем сервер 110 (в некоторых вариантах реализации на устройстве пользователя 120) производит скоринг каждого элемента совокупности (А) с учетом частоты принадлежности к каждому из классов и отбирает n (n было задано ранее) наиболее информативных, указывающих на возможность принадлежности элемента совокупности (подпоследовательности действий пользователя) к заданному классу.
В некоторых вариантах реализации для скоринга элементов используют индекс Джини  , где k - количество классов (например, 2 класса - легитимные и фродовые), pi - доля i-го класса.
, где k - количество классов (например, 2 класса - легитимные и фродовые), pi - доля i-го класса.
В некоторых вариантах реализации для скоринга элементов используется количество фродовых последовательностей.
В некоторых вариантах реализации для скоринга используется количество легитимных последовательностей.
Затем сервер 110 (в некоторых вариантах реализации устройство пользователя 120) производит поиск отобранных ранее наиболее информативных n элементов совокупности (А) в каждой последовательности действий пользователей из обучающей выборки, формируя набор булевых признаков (набор векторов размером n), где каждый элемент вектора (признак) показывает присутствие такого элемента (подпоследовательности) в данной последовательности действий.
Обучающая выборка содержит следующую последовательность действий пользователя (A): ABFFAADOSDOOG.
В качестве примера формирования признаков рассмотрим следующую ситуацию: было отобрано три подпоследовательности (элемента совокупности А) имеющих наибольшую информативность: DOO, BFDSA, AAD (при n=3). Количество отобранных признаков будет равно n.
Для данной последовательности действий сервер 110 (в некоторых вариантах реализации устройство пользователя 120) произведет поиск на наличие подпоследовательности DOO, BFDSA, AAD сформировав набор (вектор) из n (в данном иллюстративном примере n=3) булевых признаков {1, 0, 1}, где 1 - означает наличие данной подпоследовательности в последовательности, 0 - отсутствие.
В некоторых вариантах реализации для повышения эффективности и удобства для каждого отобранного информативного признака формируется собственная булева функция (f1, f2, …fn), которая определяет наличие или отсутствие признака в последовательности действий пользователя.
Сформированный набор векторов признаков совместно с классом принадлежности данного вектора далее подается в качестве обучающей выборки для алгоритма классификации (алгоритм машинного обучения).
Обучающая выборка должна содержать наборы признаков достоверно принадлежащие к разным классам, т.е., например, набор векторов признаков для легитимных последовательностей действий и набор векторов признаков для фродовых последовательностей действий пользователя.
В качестве алгоритмов машинного обучения, но не ограничиваясь, могут использоваться Random Forest (случайный лес), SVM (метод опорных векторов) или любой другой алгоритм классификации (в том числе ансамбль классификаторов).
После обучения алгоритма классификации (ансамбля классификаторов) сервер 110 (в некоторых вариантах реализации устройство пользователя 120) может использовать классификатор для определения легитимности действий во время выполнения пользователем действий. И в случае определения что действия пользователя не являются легитимными произвести соответствующие действия, например, заблокировать пользователя, отменить выполнение операции и др. действия, необходимые в данной ситуации.
В общем случае после обучения классификатора (ансамбля классификаторов) сервер 310 определяет принадлежность цепочки следующим образом:
записывают последовательность действий пользователя, определяют вектор булевых признаков используя n отобранных ранее информативных признаков для данной последовательности действий, данный вектор передается обученному классификатору, который выдает априорные вероятности принадлежности данной последовательности действий к каждому классу.
Стоит отметить, что в частном случае, для получения стабильных результатов по определению мошеннических действий, может быть использована обучающая выборка из не менее 2000 фактов мошенничества, произошедших за последние дни, например, за последние 90 дней.
Так, например, для создания описываемой обучающей выборки могут быть выбраны данные за последние несколько дней (например, с 85-го по 90-ый день). Такие данные используются для обучения классификатора, в частности для осуществления машинного обучения. Далее результаты осуществления обучения используются на данных с 1-го по 5-ый день указанного в качестве примера диапазона для осуществления проверки обученного классификатора. Стоит отметить, что упомянутое обучение может осуществляться, например, один раз в неделю.
Для надежности выдаваемого скоринга (в частности, описываемой функцией скоринга) может быть создан ансамбль из нескольких классификаторов, например, из трех классификаторов. В таком случае, например, осуществляется обучение первого классификатора на данных с -90 по -5 день, второго классификатора - с -97 по -13 день, третьего классификатора - с -104 по -19 день. Итоговый скоринг для ансамбля классификаторов может быть вычислен, например, как среднее по Колмогорову (https://ru.wikipedia.orq/wiki/Среднее_Колмогорова). Так, например, может быть использовано вычисление среднего арифметического.
Ниже будут рассмотрены частные варианты реализации данного технического решения.
Стоит отметить, что скоринговая функция (осуществляет скоринг), в частном случае, является функцией определения информативности. В качестве иллюстративного примера такой функций может являться функция calc_score, алгоритм которой приведен на языке Python:
'''python
def calc_score(g_count, f_count, ratio):
''''''
Функция подсчета скоринга
:param g_count: количество подлинных
:param f_count: количество фродовых
:param ratio: отношения общего количества всех рассмотренных легитимных ко всем рассмотренным фродовым
:return: число
0 - равновероятно
>0 - скорее фрод
<0 - скорее легитимные.
Чем дальше значение от нуля, тем более "вероятнее" классификация

В частном случае осуществления настоящего технического решения результат работы функции calc_score состоит в том, что если на вход модуль получает положительное число, то модуль осуществляет возврат данного числа, а если на вход модуль получает отрицательное число, то модуль умножает полученное число на минус единицу (-1).
Стоит также отметить, что упомянутая функция, например, calc_score, может зависеть от двух и более параметров, в частности трех параметров. В таком случае функция может осуществлять возврат числа информативности. Чем данное число больше, тем информативнее признак. Так, например, для трех равномощных классов такой функцией может являться следующая функция (example3), описанная на языке Python:

В частном случае осуществления настоящего технического решения классы являются равномощными для определенной выборки (например, для обучающей выборки), если для каждого класса существует одинаковое количество элементов (цепочек) в выборке, размеченных этим классом. Так, например, для двух классов: фродовых и легитимных, если выборка равномощна, то количество фродовых цепочек равно количеству легитимных цепочек.
Также, в частном случае, для не равномощных классов может быть введено, по крайней мере, три величины, например, ratio1, ratio2, ratio3, являющиеся отношением количества элементов каждого класса к количеству элементов самого большого класса. В частном случае, одна из этих трех величин всегда равна единице (поскольку один из классов самый крупный, то если его количество разделить на количество элементов в нем же самом, то результатом будет являться единица), причем может быть задана функция (являющейся поправкой к example3 с учетом ratio1, ratio2, ratio3):

С помощью функции информативности (example3_ratio) могут быть определены наиболее информативные (где информативность измеряется функцией example3_ratio) подпоследовательности в количестве n (описано ранее).
В одном из вариантов реализации технического решения может быть использован другой подход при для определения информативности последовательностей. Подход будет рассмотрен на иллюстративном примере.
Строят ориентированный лес и обозначим его как (gВ). Изначально лес пустой (не содержит ни одну вершину ни одного дерева). Каждое ребро на каждом дереве имеет два весовых значения (для класса F и для G) - это w(F) и w(G). Каждая вершина имеет подпись в виде буквы.
Берем последовательность (s)=ABFDSAAADOO и разбиваем ее на всевозможные подпоследовательности длины max_subsequence_length. Для каждой подпоследовательности:
- обходим все вершины графа (gВ) в данной подпоследовательности. Например, для ABFDSAA будет подграф (gi): А→В→F→D→S→А.
- если вершины нет, то добавляем ее с весами w(F)=0, w(G)=0. Затем увеличиваем вес на 1 в соответствии с типом классом принадлежности. Для фродовой подпоследовательности (F) это будет w(F): =w(F)+1, для легитимной (G) это w(G): =w(G)+1. Переходим к следующей подпоследовательности. После обхода подпоследовательности переходят к следующей последовательности.
В итоге получится граф (gВ). Далее строится множество ребер, таких, что путь к корню не меньше min_subsequence_length и для каждого ребра, используя веса w(F) и w(G) производят скоринг (описан ранее). Затем выбираются наиболее вероятные ребра в количестве n (параметр равный количеству информативных признаков). Затем по каждому ребру строиться одна последовательность следующим образом: выбираются оба узла ребра и все его предки. Полученные узлы выстраиваются в порядке следования ребер, где каждая подпоследовательность - отдельный признак.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего технического решения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего технического решения, согласующиеся с сущностью и объемом настоящего технического решения.

Способ и система выявления удаленного подключения при работе на страницах веб-ресурса
Способ и компьютерное устройство для кластеризации веб-ресурсов
Способ и система для автоматического определения нечетких дубликатов видеоконтента
Способ и система определения принадлежности программного обеспечения по его машинному коду
Способ и система определения принадлежности программного обеспечения по его исходному коду

