Результат интеллектуальной деятельности: Способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием электронных дел
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Изобретение относится к системам классификации и аннотирования документов и может использоваться в системах электронного документооборота, базах данных, автоматизированных системах, где существует необходимость классификации формализованных электронных документов по степеням конфиденциальности, содержащейся в них информации и областям информационной ответственности должностных лиц с учетом уровня их допуска к указанной информации, а также необходимость автоматического формирования электронных дел по результатам аннотирования информативной части каждого документа.
Уровень техники
а) Описание аналогов
Известен аналог - способ мультиклассовой классификации (Schapire R.E., Singer Y. "BoosTexter: A boosting-based system for text categorization". MachineLearning 39, 2/3, 2000, pp. 135-168), заключающийся в осуществлении преобразования документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывании незначимых слов, осуществлении подсчета весов слов в документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных; при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой информационной области.
Недостатком данного способа является:
невозможность классифицировать формализованные электронные документы по электронным делам с учетом ограничений при обращении с конфиденциальными документами.
Известен также аналог - Methods and apparatus for building a support vector machine classifier (Пат. 6327581 Соединенные Штаты Америки, МПК G06F 015/18), заключающийся в осуществлении преобразования документа из формата хранения в текст на естественном языке, преобразовании слов документа в базовые словоформы, отбрасывании незначимых слов, осуществлении подсчета весов слов в документе в соответствии с частотами их появления; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков; при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе классификационного критерия SVM (Support Vector Machines) и классификационных признаков определяют принадлежность документа к информационной области.
Недостатком данного способа является:
невозможность классифицировать формализованные электронные документы по электронным делам с учетом ограничений при обращении с конфиденциальными документами.
Также известен аналог - способ автоматической классификации документов (Пат. 2254610 Российская Федерация, МПК G06F 17/30), заключающийся в осуществлении преобразования документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в упомянутом документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных; при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из категорий.
Недостатком данного способа является:
невозможность классифицировать формализованные электронные документы по электронным делам с учетом ограничений при обращении с конфиденциальными документами.
Также известен аналог - способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота (Пат. 2647640 Российская Федерация, МПК G06F 17/30, G06F 17/21), заключающийся в определении области формализованного документа для извлечения метаданных и информативной части, осуществлении преобразования документа из формата хранения в текст на естественном языке, преобразовании слов преобразованного документа в базовые словоформы, отбрасывании незначимых слов, осуществлении подсчета весов слов в документе в соответствии с частотами их появления и тем самым формировании классификационных признаков документа; на этапе обучения по набору классифицированных вручную документов формировании набора классификационных признаков, сохранении классификационных признаков в базе данных; при классификации документа на основании полученных классификационных признаков с помощью базы данных принимают решение об относимости документа к каждой из информационных областей и к каждой из меток конфиденциальности, заданных в информационной системе, на этапе определения принадлежности документа к каждой информационной области и метке конфиденциальности используют априорную информацию о зависимостях категорий друг от друга.
Недостатком данного способа является:
невозможность классифицировать формализованные электронные документы по электронным делам, чем достигается заявленный технический результат.
б) Описание ближайшего аналога (прототипа)
Наиболее близким по технической сущности к предлагаемому является способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием реквизита резолюции руководителя (Пат. 2692972 Российская Федерация, МПК G06F 17/30, G06F 17/21), заключающийся в выделении и анализе формальной части поступившего документа (реквизитов), осуществлении преобразования информативной части документа в текст на естественном языке, преобразования слов преобразованного документа (за исключением отдельных слов и словосочетаний, соответствующих временным интервалам выполнения определенной документом деятельности) в базовые словоформы, отбрасывании незначимых слов, осуществлении подсчета весов слов в документе в соответствии с частотами их появления и формировании признаков документа. На этапе обучения по набору классифицированных вручную документов формируют системы предикатов идентификации признаков текста поступившего документа и сохраняют их в базе данных. При классификации документа на основании полученных классификационных признаков с помощью базы данных принимают решение об относимости документа к компетенции должностного лица (исполнителя поручений руководителя), определяют соответствующую ему метку конфиденциальности и поручения по нему, формируя реквизит «резолюция».
Недостатком данного способа является отсутствие возможности классифицировать формализованные электронные документы по электронным делам с учетом ограничений при обращении с конфиденциальными документами, чем достигается заявленный технический результат.
Раскрытие сущности изобретения
а) технический результат, на достижение которого направлено изобретение
Целью настоящего изобретения является автоматизация классификации формализованных электронных документов в системе электронного документооборота по электронным делам, проверка соответствия метки конфиденциальности исполненного документа и дела, в которое распределяется исполненный документ.
б) совокупность существенных признаков
Для достижения указанного технического результата предложен способ автоматической классификации формализованных электронных документов в системе электронного документооборота с автоматическим формированием электронных дел, заключающийся в определении области формализованного документа для извлечения метаданных и информативной части, осуществлении преобразования документа из формата хранения в текст на естественном языке, преобразовании слов обработанного документа в базовые словоформы, отбрасывании незначимых слов, осуществлении подсчета весов слов в документе в соответствии с частотами их появления и формировании набора классификационных признаков; на основе распознанных реквизитов и значений ключевых слов этих реквизитов определяют конкретный вид электронного документа; при преобразовании слов документа в базовые словоформы выделяют и оставляют без изменений отдельные слова и словосочетания, соответствующие временным интервалам выполнения определяемой документом деятельности, формируют, тем самым, вектор данных о сроках исполнения документа; на основе определенных областей информационной ответственности, а также априорных сведений о структуре организации (учреждения), в том числе об отношениях подчиненности между должностными лицами организации (учреждения) и уровнях их допуска к различным степеням конфиденциальности документов, формируют первый набор классификационных признаков; на основе определенных вида документа и области информационной ответственности, к которым относится документ, при помощи предикатов узнавания ключевых слов и отдельных реквизитов формальной части формируют второй набор классификационных признаков; на этапе обучения по набору классифицированных вручную документов формируют систему предикатов определения области информационной ответственности; формируют систему предикатов идентификации метки конфиденциальности документа; сохраняют указанные системы предикатов в базе данных; по набору документов, для которых вручную заполнен реквизит «резолюция», формируют систему предикатов идентификации исполнителя поручения по поступившему документу и систему предикатов идентификации поручения, сохраняют системы предикатов в базу данных; при классификации документов на основании полученного набора классификационных признаков с помощью базы данных принимают решение об относимости документа каждой из информационных областей и каждой из меток конфиденциальности, подставляют первый набор классификационных признаков в систему предикатов идентификации исполнителя поручения и по предикатам, принявшим значение «истина», принимают решение об отнесении документа к компетенции конкретных сотрудников, подчиненных руководителю; подставляют второй набор классификационных признаков в систему предикатов идентификации поручения и по предикатам, принявшим значение «истина», принимают решение о назначении исполнителям конкретных поручений по исполнению поступившего документа; полученные данные об исполнителе, поручении и сроке исполнения, а также полученные любым способом данные о дате рассмотрения документа, объединяют в кортеж данных и присваивают его реквизиту документа «резолюция», отличающийся тем, что на основе определенных области информационной ответственности и вида документа формируют третий классификационный признак и определяют статью Перечня документов со сроками их хранения (далее - Перечень), хранящуюся в базе данных, к которой может быть отнесен исполненный документ; на основании ранее определенных реквизитов и уникальных ключевых слов, относящихся к этим реквизитам, формируют четвертый классификационный признак, определяют контур системы электронного документооборота (далее - СЭД), в котором был разработан документ; на основании определенных статьи Перечня и контура СЭД формируют пятый классификационный признак и определяют срок хранения исполненного документа; на основании определенной статьи Перечня, определенного срока хранения исполненного документа и исполнителя документа формируют шестой классификационный признак и определяют дело, в которое будет распределен исполненный документ; на основании определенной метки конфиденциальности документа и известной метки конфиденциальности дела, в которое будет распределен документ, проверяют соответствие меток конфиденциальности документа и дела, в которое его распределяют; на этапе обучения, по набору классифицированных вручную документов, формируют систему предикатов определения статьи Перечня, формируют систему предикатов определения контура СЭД, в котором был разработан документ, формируют систему предикатов определения срока хранения документа, сохраняют указанные системы предикатов в базе данных; формируют систему предикатов определения дела, в которое будет распределен исполненный документ, формируют систему предикатов проверки соответствия меток конфиденциальности документа и дела, в которое будет распределен документ, и сохраняют указанные системы предикатов в базе данных; при классификации документов на основании полученного набора классификационных признаков с помощью базы данных принимают решение об относимости документа к каждой из статей Перечня, подставляют третий набор классификационных признаков в систему предикатов определения статьи Перечня и по предикатам, принявшим значение «истина», принимают решение об отнесении документа к конкретной статье Перечня; подставляют четвертый набор классификационных признаков в систему предикатов определения контура СЭД и по предикатам, принявшим значение «истина», принимают решение о контуре СЭД, в котором был разработан документ; подставляют пятый набор классификационных признаков в систему предикатов узнавания срока хранения документа, и по предикатам, принявшим значение «истина», принимают решение о присвоении срока хранения исполненному документу; подставляют шестой набор классификационных признаков в систему предикатов определения дела, в которое будет распределен исполненный документ и по предикатам, принявшим значение «истина», принимают решение об определении дела, в которое требует распределить исполненный документ.
Краткое описание чертежей
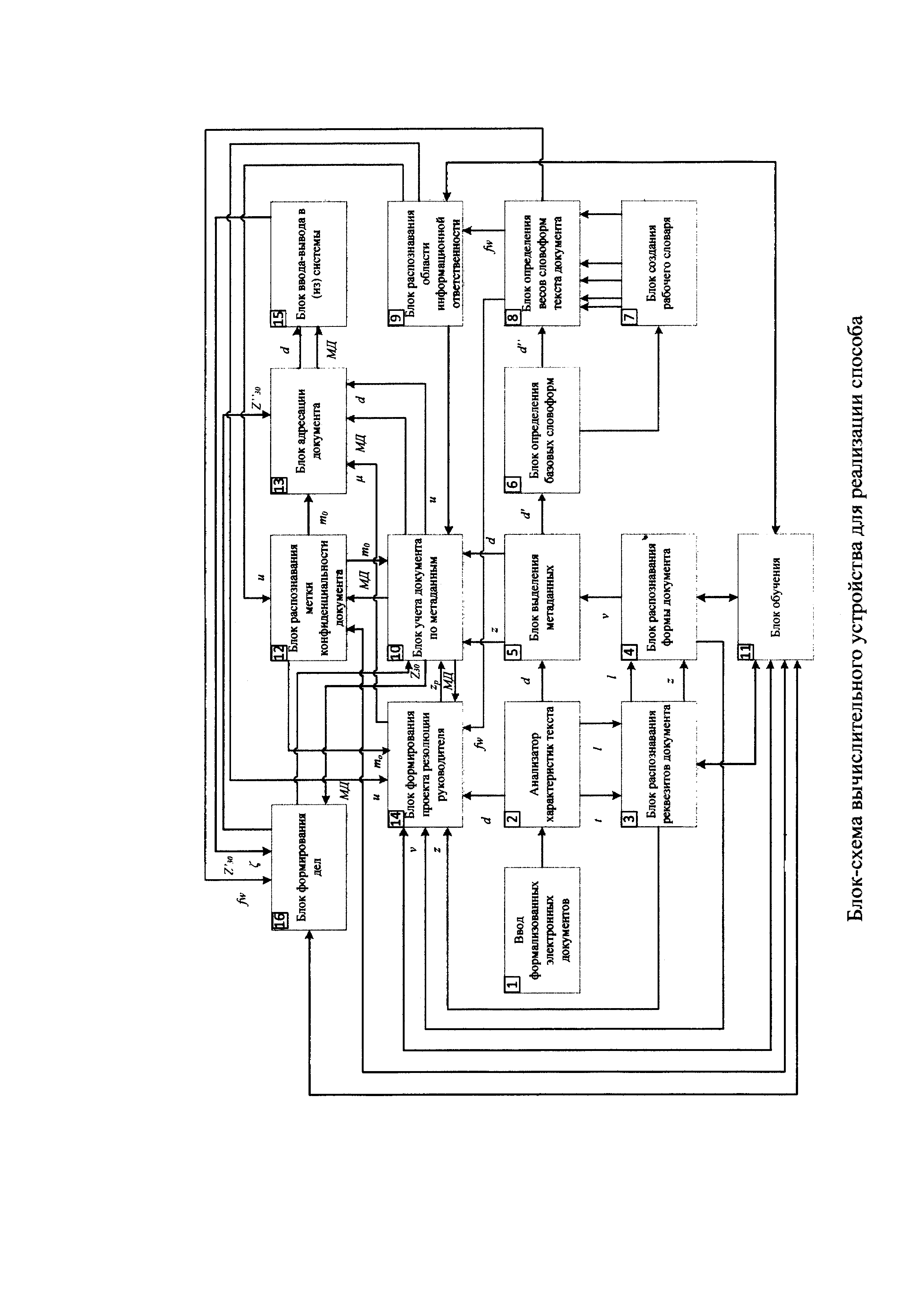
На фигуре представлена блок-схема вычислительного устройства для реализации способа. Устройство для реализации способа состоит из блоков: ввода формализованных электронных документов (1), анализа характеристик текста (2), распознавания реквизитов документа (3), распознавания вида документа (4), выделения метаданных (5), определения базовых словоформ (6), создания рабочего словаря (7), определения весов словоформ текста документа (8), распознавания области информационной ответственности (9), учета документа по метаданным (10), обучения (11), распознавания метки конфиденциальности документа (12), адресации документа (13), формирования проекта резолюции руководителя (14) и ввода - вывода системы (15), формирования дела (16).
Осуществление изобретения
При поступлении электронного документа (далее - ЭД) выделяют характеристики одинаковых участков текста Z - реквизитов. При этом априорно известно, что количество реквизитов формализованного ЭД ограничено. Каждый реквизит представим конечным предикатом PZ(T, L), где Т - конечное множество характеристик текста 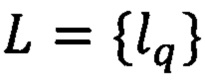 - множество ключевых слов
- множество ключевых слов 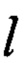 реквизита, где
реквизита, где 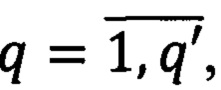 q' - количество всех используемых ключевых слов. Для написания правил построения предикатов используем математический аппарат логики предикатов.
q' - количество всех используемых ключевых слов. Для написания правил построения предикатов используем математический аппарат логики предикатов.
Правило построения предиката узнавания реквизита формализованного документа выразится следующей формулой:
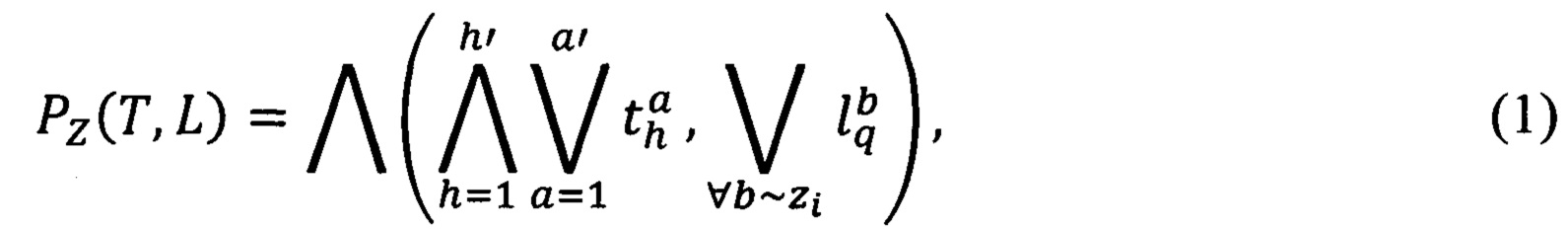
где {b} - множество значимых слов в реквизитах формализованных документов;
{h'} - множество характеристик текста, 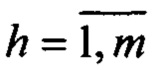 - возможные характеристики текста;
- возможные характеристики текста;
{а'} - множество переменных характеристик текста, 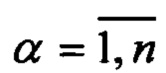 - возможные характеристики текста;
- возможные характеристики текста;
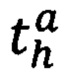 - предикат узнавания α-ой переменной h-ой характеристики текста;
- предикат узнавания α-ой переменной h-ой характеристики текста;
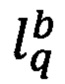 - предикат узнавания значимых слов в реквизитах.
- предикат узнавания значимых слов в реквизитах.
Вид документа определяется при помощи конечного предиката PV(Z, L), где V={νj} - множество видов документов, 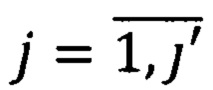 - значения в множестве видов документов, j' - количество всех используемых видов документов, Z - множество предикатов узнавания реквизитов документа, n - количество всех реквизитов документов. Правило построения предиката узнавания вида документа выразится следующей формулой:
- значения в множестве видов документов, j' - количество всех используемых видов документов, Z - множество предикатов узнавания реквизитов документа, n - количество всех реквизитов документов. Правило построения предиката узнавания вида документа выразится следующей формулой:
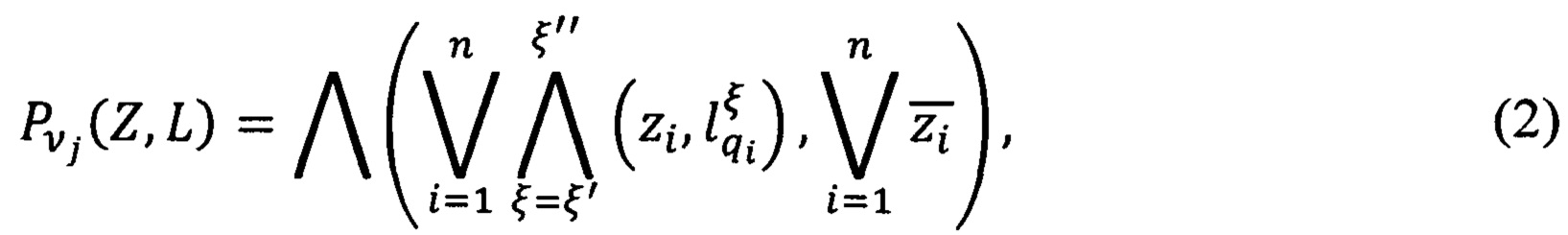
где {νj} - множество видов документов, 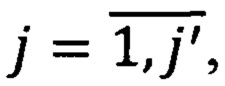 j - все используемые виды формализованных документов, j' - конечное значение множества видов формализованных документов;
j - все используемые виды формализованных документов, j' - конечное значение множества видов формализованных документов;
Z=zi - множество предикатов узнавания i-го реквизита для j-го вида документа, 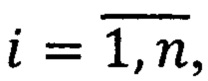 n - количество всех возможных реквизитов, нанесенных на документ;
n - количество всех возможных реквизитов, нанесенных на документ;
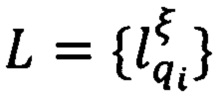 - множество предикатов узнавания уникального значения ξ ключевого слова q i-го реквизита j-го вида документа;
- множество предикатов узнавания уникального значения ξ ключевого слова q i-го реквизита j-го вида документа;
zi - предикат узнавания i-го реквизита для j-го вида документа.
С использованием правил (1, 2) создаются системы предикатов идентификации формуляров (расположения и значений реквизитов) и видов поступающих документов. Формуляр документа однозначно задает места расположения реквизитов документа, что позволяет классифицировать документы по виду и степени ограничения доступа.
Затем информативную часть документа (далее - текст) преобразуют из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в тексте в соответствии с частотами их появления и тем самым формируют предикаты идентификации признаков текста.
Вес ƒ словоформы wp в тексте документа dy, рассчитывается по формуле:
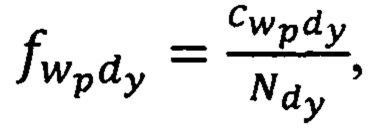
где 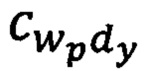 - количество раз, которое wp-я словоформа встречается в dy-м тексте документа;
- количество раз, которое wp-я словоформа встречается в dy-м тексте документа;
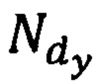 - общее количество словоформ в dy-м тексте документа.
- общее количество словоформ в dy-м тексте документа.
Классифицируемые документы могут быть представлены в различных форматах: текстовые файлы различных форматов, графические файлы с графическим представлением некоторого текста, звуковые файлы с записью речи и другие файлы, для которых существует механизм выделения из них текста, отражающего их содержание.
Каждый документ предварительно проходит стадию первичной обработки, на которой производится определение формата документа и установление того, возможно ли извлечение текста из документа данного формата. В случае положительного решения производится извлечение текста из документа. После разбиения текста на слова происходит определение для каждого слова его базовой словоформы по одному из способов. Для документов на естественном языке славянской группы предпочтительными являются алгоритмы лемматизации (процесса приведения слова к его нормальной форме (лемме), допустимо применение алгоритмов усечения окончаний, стохастических и статистических алгоритмов; для документов на естественном языке западногерманской группы - алгоритмов усечения окончаний, например, стемер Портера (использование специальных правил отсечения и замены окончаний слов).
Правило построения предиката РU(W) узнавания информационной области U={uβ}, где 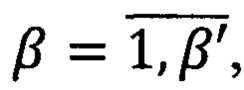 β' - количество областей информационной ответственности, выражается следующей формулой:
β' - количество областей информационной ответственности, выражается следующей формулой:
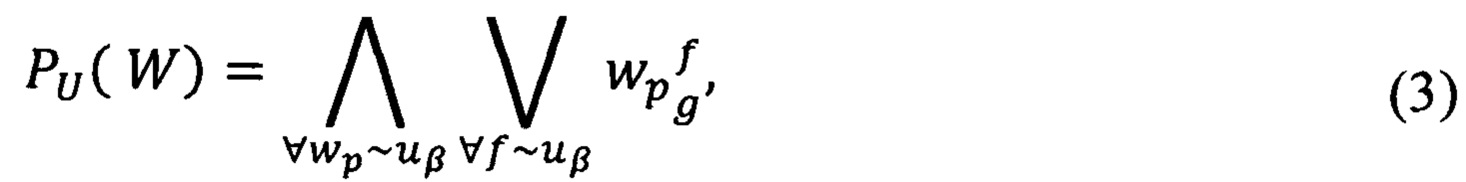
где W={wp} - множество значимых слов текстов, где 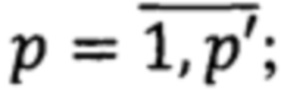
р' - количество значимых слов текстов;
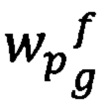 - предикат узнавания значения веса ƒ значимого слова wp, в тексте документа dy uβ-той информационной области по g-тому значению веса слова.
- предикат узнавания значения веса ƒ значимого слова wp, в тексте документа dy uβ-той информационной области по g-тому значению веса слова.
Правило построения предиката PM(U,Z) узнавания метки конфиденциальности документа М={mλ}, где 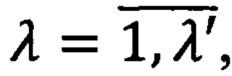 λ' - количество определенных в системе меток конфиденциальности выразится следующей формулой:
λ' - количество определенных в системе меток конфиденциальности выразится следующей формулой:
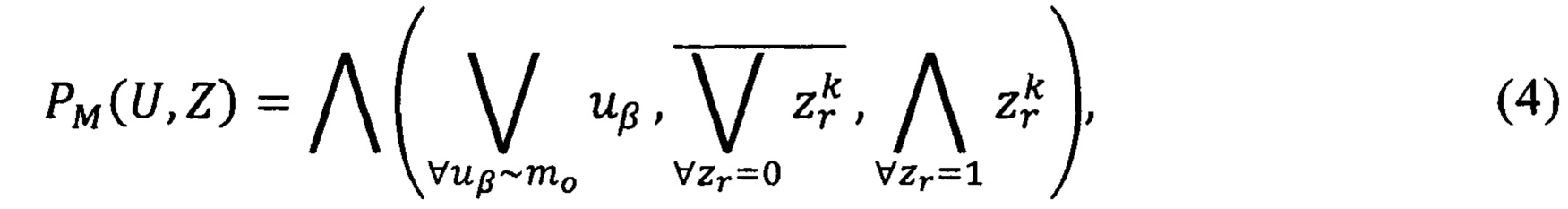
где 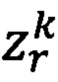 - предикат узнавания k-го значения r-ого реквизита;
- предикат узнавания k-го значения r-ого реквизита;
mo - метка конфиденциальности документа dy, при этом mo ∈ М;
uβ - предикат узнавания β-ой области, где 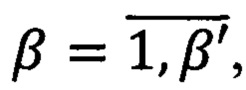 β' - количество информационных областей системы.
β' - количество информационных областей системы.
После определения метки конфиденциальности документа переходят к формированию проекта резолюции руководителя организации. Реквизит «резолюция», исходя из его определения, представим в виде кортежа данных:

где μϕ - наименование должности, либо фамилии и инициалов ϕ-го должностного лица организации (учреждения), 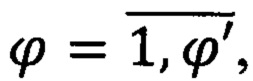 ϕ' - количество должностных лиц, непосредственно подчиненных руководителю и являющихся исполнителями его поручений по поступающим электронным документам;
ϕ' - количество должностных лиц, непосредственно подчиненных руководителю и являющихся исполнителями его поручений по поступающим электронным документам;
sϕχ - χ-ое поручение руководителя ϕ-му должностному лицу;
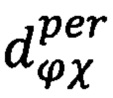 - срок исполнения -ого поручения руководителя ϕ-му должностному лицу и соответствующий ему атомарный предикат узнавания дат и сроков в информативной части документа;
- срок исполнения -ого поручения руководителя ϕ-му должностному лицу и соответствующий ему атомарный предикат узнавания дат и сроков в информативной части документа;
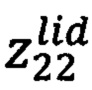 - подпись руководителя.
- подпись руководителя.
Правило построения предиката Pμ(U,M) узнавания должностного лица организации (учреждения), компетентного в uβ-ой области информационной ответственности, имеющего соответствующий степени ограничения λ допуск и являющегося исполнителем формируемого поручения руководителя (далее - исполнитель) по поступившему электронному документу dy выразится следующим образом:
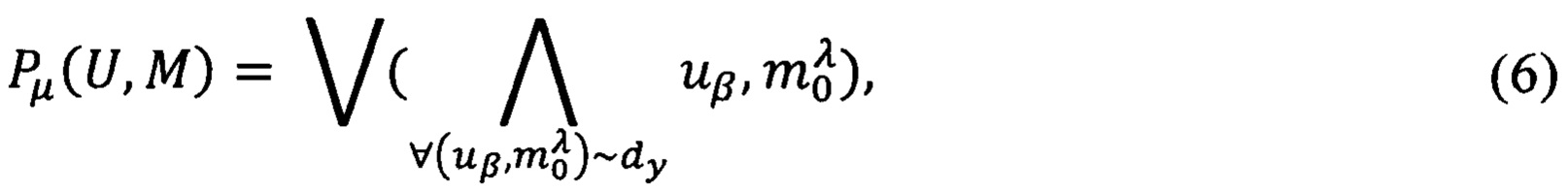
где 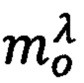 - предикат узнавания значения λ метки конфиденциальности mo поступившего документа dy,
- предикат узнавания значения λ метки конфиденциальности mo поступившего документа dy, 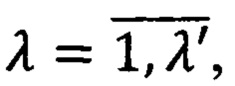 λ' - общее количество меток конфиденциальности в системе.
λ' - общее количество меток конфиденциальности в системе.
Правило построения предиката выбора поручения из списка готовых поручений будет иметь вид:
После исполнения всех пору
чений начальника (резолюции) по документу переходят к распределению документа в дело.
Для этого определяют статью Перечня, к которой может быть отнесен документ. Правило построения предиката узнавания статьи Перечня 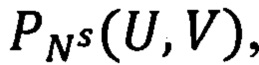 который примет значение «истина» при условии, что документ относится к конкретной области информационной ответственности (uβ) и имеет конкретный вид (νj), выражают следующей формулой
который примет значение «истина» при условии, что документ относится к конкретной области информационной ответственности (uβ) и имеет конкретный вид (νj), выражают следующей формулой
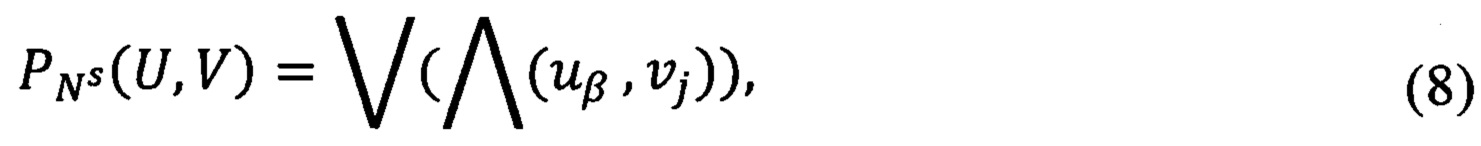
где Ns - статья Перечня;
uβ - область информационной ответственности, к которой относится документ;
νj - вид формализованного документа.
Прежде чем определить срок хранения исполненного документа, необходимо определить контур системы электронного документооборота, в котором был разработан и хранится документ (γ).
Правило записи предиката узнавания контура, в котором исполненный документ был разработан, Pγ(Z,L), выразится следующей формулой, которая примет значение «истина» при условии, что в реквизитах «место составления», «адресат», «отметка о поступлении» есть уникальные слова 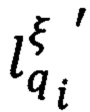 , соответствующие искомому контуру:
, соответствующие искомому контуру:

где γ - контур СЭД, в котором был разработан ЭД;
zi - предикат узнавания i-го реквизита;
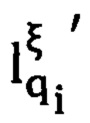 - предикат узнавания уникального значения ξ' ключевого слова q i-того реквизита электронного документа, относящегося γ-му контуру;
- предикат узнавания уникального значения ξ' ключевого слова q i-того реквизита электронного документа, относящегося γ-му контуру;
i={13,16,22} - реквизиты документа в соответствии с ГОСТ 7.0.97 2016 года;
zi - предикат узнавания i-го реквизита для ЭД, относящегося к контуру.
Далее определяют срок хранения исполненного документа (τ) при помощи предиката узнавания срока хранения ЭД Pτ(U,V,K), который примет значение истина при условии, что ЭД отнесен к конкретной статье Перечня и разработан в конкретном контуре СЭД, правило построения которого выразится следующей формулой:
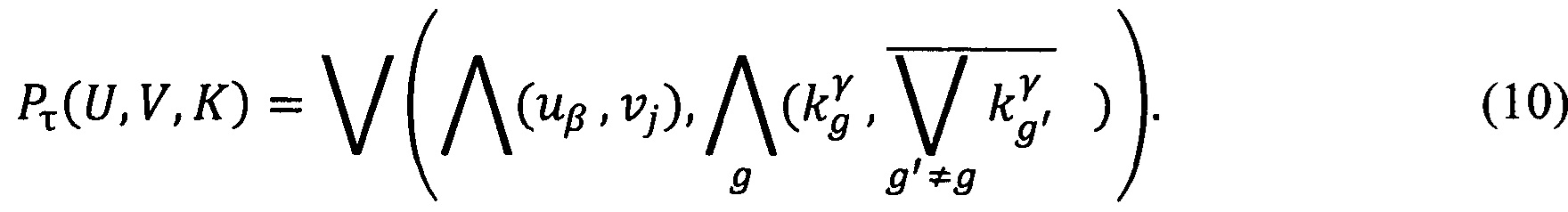
где Pτ(U, V, K) - предикат узнавания срока хранения (τ) документа;
uβ - область информационной ответственности, к которой относится документ;
νj - вид формализованного документа;
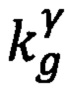 - предикат узнавания
- предикат узнавания 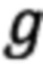 контура СЭД, в котором разработан и хранится исполненный документ;
контура СЭД, в котором разработан и хранится исполненный документ;
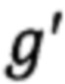 - контур СЭД, отличный от контура, в котором разработан и хранится исполненный документ.
- контур СЭД, отличный от контура, в котором разработан и хранится исполненный документ.
На основании значений, полученных в (6, 8, 10) определяют дело 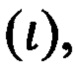 в которое будет распределен исполненный документ, используя предикат
в которое будет распределен исполненный документ, используя предикат 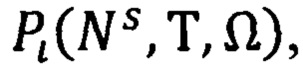 который примет значение «истина» при условии, что документ отнесен к конкретной статье Перечня и обладает конкретным сроком хранения и относится к области деятельности конкретного подразделения (должностного лица). Правило построения предиката
который примет значение «истина» при условии, что документ отнесен к конкретной статье Перечня и обладает конкретным сроком хранения и относится к области деятельности конкретного подразделения (должностного лица). Правило построения предиката 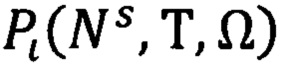 выражают следующей формулой:
выражают следующей формулой:
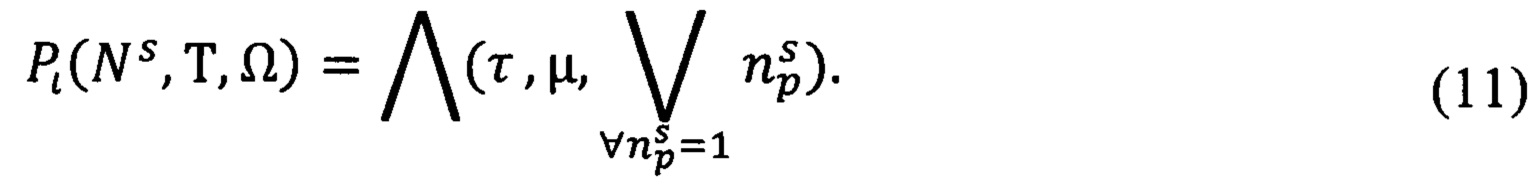
где 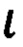 - электронное дело, в котором будет храниться исполненный ЭД;
- электронное дело, в котором будет храниться исполненный ЭД;
Ns - предикат узнавания статьи Перечня, к которой отнесен ЭД;
Т - предикат узнавания срока хранения документа;
Ω - предикат узнавания должностного лица, к области деятельности которого относится документ;
τ - срок хранения документа;
μ - должностное лицо (структурное подразделение), к области информационной ответственности которого отнесен документ;
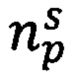 - статья Перечня, к которой отнесен документ.
- статья Перечня, к которой отнесен документ.
Перед распределением документа в дело необходимо проверить соответствие ограничительных меток конфиденциальности документа и дела. На основании данных, полученных в (4), построят правило записи предиката узнавания разрешения на распределение документа в дело:
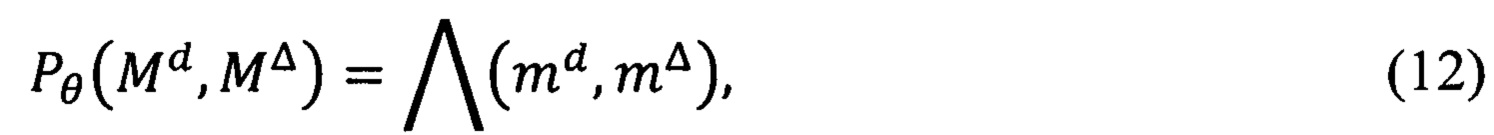
где Pθ(Md, МΔ) - предикат узнавания возможности распределения документа в дело;
md - предикат узнавания ограничительной метки конфиденциальности дела;
mΔ - предикат узнавания ограничительной метки конфиденциальности документа.
Согласно предлагаемому способу каждый документ dy представляется декартовым произведением переменных из множеств Т×L×W, где для инициализации классификатора и построения классификационных признаков служит этап обучения классификатора. При этом должно быть задано множество обучающих документов, заранее вручную классифицированных по делам, с учетом соответствия меток конфиденциальности документа и дела, а также содержащих непустой реквизит «отметка об исполнении и направлении в дело». После извлечения из них текстового содержания происходит построение словаря значимых слов. Словарь содержит базовые словоформы всех слов, встречающихся в обучающих документах.
При классификации документа в расчет берутся не все словоформы из словаря документов, а лишь те из них, которые входят в рабочий словарь классификатора. В рабочий словарь классификатора включаются наиболее информативные словоформы с точки зрения определения принадлежности документа данной области (метке). Информативность словоформы wp для классификатора по информационной области uβ определяется по следующей формуле:
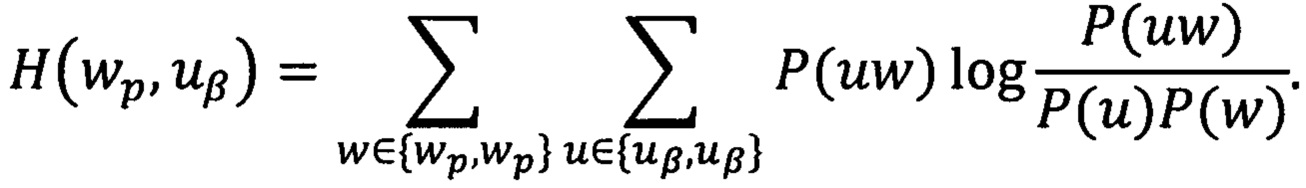
В рабочий словарь классификатора включаются все словоформы, не попавшие в стоп-словарь, информативность которых превышает заданный порог информативности ε. Стоп-словарь состоит из словоформ, частоты встречаемости которых во множестве обучающих документов превышают заранее установленный порог δ. При этом могут отсекаться слова, не несущие смысловой нагрузки, такие как предлоги, союзы, вводные и общие слова и т.д. Значения коэффициента δ, согласно данному способу, устанавливаются в пределах от 0.05 до 0.7 и могут быть различны в зависимости от специфики и условий его использования.
В режиме обучения, по предъявленному набору классифицированных вручную текстов формируют систему предикатов идентификации признаков текста, где количество предикатов в системе предикатов определяется количеством статей Перечня, на которые необходимо классифицировать документы. Сохраняют предикаты в базе данных.
В режиме обучения, по предъявленному набору классифицированных вручную документов формируют системы предикатов определения контура СЭД, в котором был разработан исполненный документ. Количество предикатов в системе определяется количеством контуров, заданных в информационной системе. Сохраняют системы предикатов в базе данных.
В режиме обучения, по предъявленному набору классифицированных документов, определяют срок хранения исполненного документа, формируют системы предикатов определения срока хранения исполненного документа. Количество предикатов в системе определения сроков хранения определяется количеством возможных сроков хранения, определенных Перечнем. Сохраняют системы предикатов в базе данных.
В режиме обучения, по предъявленному набору классифицированных документов, определяют дело, в которое будет распределен исполненный документ, формируют системы предикатов определения дела, в которое будет распределен исполненного документа. Количество предикатов в системе определения дела, в которое будет распределен исполненный документ, определяется количеством возможных дел, определенных номенклатурой дел организации. Сохраняют системы предикатов в базе данных.
В режиме классификации документов осуществляют преобразование документа из формата хранения в текст на естественном языке, затем - слов текста в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в тексте, получившиеся значения подставляют в систему предикатов (3), находящуюся в базе данных. По предикатам, принявшим значение «истина», однозначно определяют области информационной ответственности, к которым относится документ. Используя извлеченные метаданные документа, полученные по (1), определяют соответствующую ему метку конфиденциальности, для чего указанные значения подставляют в систему предикатов, построенных по (4). По предикату, принявшему значение «истина», определяют метку конфиденциальности, после чего переходят к построению проекта реквизита «резолюция». Для этого, во-первых, определенные по (3) значения областей информационной ответственности и определенное по (4) значение метки конфиденциальности документа подставляют в систему предикатов, построенных по (5), и по предикатам, принявшим значение «истина», определяют исполнителя. Во-вторых, подставляя в систему предикатов, построенных по (6), значения определенных по (1) реквизитов документа, по (2) вида документа и по (3) области информационной ответственности, а также значения отдельных ключевых слов, по предикатам, принявшим значения «истина» определяют конкретные поручения. Дополняя полученные значения исполнителя и поручения определенными атомарными предикатами узнавания значениями сроков исполнения и определенной любым способом даты поступления документа, получают кортеж данных, который присваивается реквизиту «резолюция» поступившего документа. Используя значения области информационной ответственности, полученные по (3), и значение вида документа, полученные по (2), подставляют в систему предикатов, построенных по правилу (8), и по предикатам, принявшим значение «истина», определяют статью Перечня, к которой можно отнести исполненный документ. Значения, определенные по (8) статьи Перечня и значения, определенные по (6) и (10), подставляют в систему предикатов, построенных по правилу (11) и по предикатам, принявшим значение «истина», определяют дело, в которое будет распределен исполненный документ. Далее, используя значения определенные по (4) метки конфиденциальности документа и предиката узнавания метки конфиденциальности выбранного дела, подставляя их в систему предикатов, построенных по правилу (12) и по предикатам, принявшим значение «истина», определяют возможность распределения исполненного документа в идентифицированное дело.
Отметим, что данный способ предназначен для обработки машиночитаемых текстов на естественном языке.
Сопоставительный анализ заявляемого решения с прототипом показывает, что предлагаемый способ отличается определением дела, в которое будет распределен исполненный документ, выполнением проверки, на предмет возможности распределения в дело документа с использованием правил (8, 9, 10, 11, 12), а также усовершенствованными правилами определения реквизита документа (1) и определения вида документа (2).
Благодаря новой совокупности существенных признаков способ позволяет автоматизировать процесс распределения исполненных документов в дела СЭД, учитывая степени конфиденциальности документа и дела СЭД, в которое документ распределен, когда число меток конфиденциальности (степеней ограничения доступа) не ограничено.
Анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обуславливающих тот же технический результат, который достигнут в заявленном способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Автоматическая классификация электронных документов в системе электронного документооборота с автоматическим формированием дела осуществляется следующим образом:
1. В режиме классификации. При появлении в блоке ввода 1 нового формализованного ЭД d он поступает в блок 2, в котором выявляют значения характеристик текста t участков документа и ключевых слов 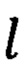 в них. Значения t и
в них. Значения t и 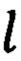 участков документа поступают в блок 3, где с помощью системы предикатов, построенных по правилу (1), распознают реквизиты документа z. Информация о распознанных реквизитах документа z поступает в блок 4, где по системе предикатов, построенной по правилу (2), осуществляют распознавание вида документа v.
участков документа поступают в блок 3, где с помощью системы предикатов, построенных по правилу (1), распознают реквизиты документа z. Информация о распознанных реквизитах документа z поступает в блок 4, где по системе предикатов, построенной по правилу (2), осуществляют распознавание вида документа v.
В блоке 5 из поступившего от блока 2 документа d, используя сведения об определенном в блоке 4 виде документа ν, который, обладая установленным требованиями нормативных документов формуляром, задает места расположения и значения реквизитов документа, выявляют требуемые значения реквизитов, которые используются как метаданные документа. Из блока 5 документ d и соответствующие ему метаданные z поступают в блок 10, где документ учитывается по своим метаданным и организуется хранение его эталонной копии. Определенная в блоке 5 информативная часть документа d' поступает в блок 6, где слова преобразуются в словоформы, и поступают далее в блок 7, где в процессе работы системы происходит создание рабочего словаря из значимых слов.
Полученные в блоке 6 словоформы d'' поступают также в блок 8, где производится расчет весов ƒw словоформ информативной части документа, попавших в рабочий словарь. Из блока 8 значения весов ƒw полученных словоформ поступают в блок 9, где происходит распознавание информационной области uβ путем вычисления значений предикатов системы предикатов, построенной по правилу (3). После чего данные об информационной области uβ, к которой относится документ, передаются в блок 10 и присоединяются к метаданным документа.
В блоке 12 на основе поступивших из блока 10 реквизитов документа z и полученных в блоке 9 областей информационной ответственности uβ на основе системы предикатов, построенной по правилу (4), определяют соответствующую классифицируемому документу метку конфиденциальности mо. После чего данные о метке конфиденциальности передаются в блок 10 и присоединяются к метаданным документа.
В блоке 14 на основе поступивших из блоков 10 и 12 данных при помощи системы предикатов, построенных по правилу (5), определяют исполнителя поступившего документа Zp, передают в блок 10, где сохраняют его для дальнейшей обработки, включая в набор метаданных, а также передают его в блок 13 для выбора адресата. В блоке 14 на основе данных, поступивших из блока 8 и 10, при помощи системы предикатов, построенных по правилу (6), определяют поручение исполнителю. В блоке 14 информативная часть документа проходит обработку с применением атомарных предикатов узнавания сроков исполнения. Все полученные данные объединяются в кортеж и передаются в блок 10, где добавляются в метаданные и присваиваются реквизиту «резолюция».
Из блока 10 документ d и метаданные МД поступают в блок 13. В блоке 13 на основе значений, поступивших из блоков 10, формируют соответствующее метке конфиденциальности ограничение доступа mо к классифицируемому документу и направляют исполнителю.
Далее через блок 15 происходит загрузка документа в информационную систему в соответствии с определенными классами.
Далее, после исполнения документа (выполнения всех указаний (поручений), определенных в резолюции) исполнителем из блока 15 в блок 16 передаются: метаданные о документе МД, находящиеся в системе (реквизиты, нанесенные на документ, вид документа, область информационной ответственности, к которой отнесен документ, сведения о метке конфиденциальности), информация об исполнителе (структурном подразделении организации), исполнившем документ, а также из блока 8 в блок 16, передают веса значимых слов ƒw, содержащихся в документе и при помощи системы предикатов, построенных по правилам (7, 8, 9, 10), определяют дело, в которое будет распределен исполненный документ. При помощи системы предикатов, построенной по правилу 11, проверяют соответствие уровня меток конфиденциальности исполненного документа md и дела mΔ, в которое распределяется исполненный документ. Полученные данные объединяются в кортеж и передаются в блок 10, где присваиваются реквизиту «отметка об исполнении и направлении в дело» Z30.
Из блока 10 документ d и метаданные МД поступают в блок 13. В блоке 13 на основе значений, поступивших из блоков 10, 16, формируют соответствующее метке конфиденциальности ограничение доступа к классифицируемому документу и направляют в соответствующее дело с учетом установленных ограничений.
2. В режиме обучения.
Режим обучения системой используется в следующих случаях: в случае отсутствия возможности распознавания системой предикатов реквизитов документа в блоке 3 по значениям переменных документа t и  (в этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 3 или определяется реквизит документа «вручную»); в случае отсутствия возможности распознавания системой предикатов вида документа в блоке 4 по значениям предикатов системы предикатов блока 3 (в этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 4 или определяется вид документа «вручную»); в случае отсутствия возможности распознавания системой предикатов информационной области в блоке 9 по значениям весов значимых слов из рабочего словаря, извлеченных из информативной части документа (в этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 9 или определяется информационная область документа «вручную»); в случае невозможности распознавания системой предикатов метки конфиденциальности документа в блоке 12 по значениям предикатов системы предикатов блока 9 и метаданным блока 10 (в этом случае оператором системы через блок И вносятся изменения в систему предикатов блока 12 или определяется метка конфиденциальности «вручную»); в случае внесения в проект резолюции изменений, в части, касающейся поручений, выбранных из списка готовых поручений, через блок 11 осуществляется автоматическое добавление скорректированных поручений в указанный список; в случае невозможности распознавания предикатом в блоке 16 дела, в которое должен быть распределен исполненный документ, по значениям, поступившим из блоков 10, 15 (в этом случае оператором системы через блок 11 вносятся изменения в системы предикатов блока 16 или определяется дело, в которое надо распределить исполненный документ, «вручную»).
(в этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 3 или определяется реквизит документа «вручную»); в случае отсутствия возможности распознавания системой предикатов вида документа в блоке 4 по значениям предикатов системы предикатов блока 3 (в этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 4 или определяется вид документа «вручную»); в случае отсутствия возможности распознавания системой предикатов информационной области в блоке 9 по значениям весов значимых слов из рабочего словаря, извлеченных из информативной части документа (в этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 9 или определяется информационная область документа «вручную»); в случае невозможности распознавания системой предикатов метки конфиденциальности документа в блоке 12 по значениям предикатов системы предикатов блока 9 и метаданным блока 10 (в этом случае оператором системы через блок И вносятся изменения в систему предикатов блока 12 или определяется метка конфиденциальности «вручную»); в случае внесения в проект резолюции изменений, в части, касающейся поручений, выбранных из списка готовых поручений, через блок 11 осуществляется автоматическое добавление скорректированных поручений в указанный список; в случае невозможности распознавания предикатом в блоке 16 дела, в которое должен быть распределен исполненный документ, по значениям, поступившим из блоков 10, 15 (в этом случае оператором системы через блок 11 вносятся изменения в системы предикатов блока 16 или определяется дело, в которое надо распределить исполненный документ, «вручную»).
Таким образом, способ позволяет автоматически классифицировать формализованные ЭД по электронным делам с учетом ограничений при обращении с конфиденциальными документами, чем достигается заявленный технический результат.
Способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием электронных дел, заключающийся в том, что определяют области формализованного документа для извлечения метаданных и информативной части, осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и формируют набор классификационных признаков, на основе распознанных реквизитов и значений ключевых слов этих реквизитов определяют конкретный вид электронного документа, при преобразовании слов документа в базовые словоформы выделяют и оставляют без изменений отдельные слова и словосочетания, соответствующие временным интервалам выполнения определяемой документом деятельности, формируют тем самым вектор данных о сроках исполнения документа, на основе определенных областей информационной ответственности, а также априорных сведений о структуре организации (учреждения), в том числе об отношениях подчиненности между должностными лицами организации (учреждения) и уровнях их допуска к различным степеням конфиденциальности документов, формируют первый набор классификационных признаков, на основе определенных вида документа и области информационной ответственности, к которым относится документ, при помощи предикатов узнавания ключевых слов и отдельных реквизитов формальной части формируют второй набор классификационных признаков, на этапе обучения по набору классифицированных вручную документов формируют систему предикатов определения области информационной ответственности; формируют систему предикатов идентификации метки конфиденциальности документа, сохраняют указанные системы предикатов в базе данных, по набору документов, для которых вручную заполнен реквизит «резолюция», формируют систему предикатов идентификации исполнителя поручения по поступившему документу и систему предикатов идентификации поручения, сохраняют системы предикатов в базу данных, при классификации документов на основании полученного набора классификационных признаков с помощью базы данных принимают решение об относимости документа каждой из информационных областей и каждой из меток конфиденциальности, подставляют первый набор классификационных признаков в систему предикатов идентификации исполнителя поручения и по предикатам, принявшим значение «истина», принимают решение об отнесении документа к компетенции конкретных сотрудников, подчиненных руководителю, подставляют второй набор классификационных признаков в систему предикатов идентификации поручения и по предикатам, принявшим значение «истина», принимают решение о назначении исполнителям конкретных поручений по исполнению поступившего документа, объединяют полученные данные об исполнителе, поручении и сроке исполнения, а также полученные любым способом данные о дате рассмотрения документа в кортеж данных и присваивают его реквизиту документа «резолюция», отличающийся тем, что на основе определенных области информационной ответственности и вида документа формируют третий классификационный признак и определяют статью ведомственного Перечня документов со сроками их хранения (далее - Перечень), хранящуюся в базе данных, к которой может быть отнесен исполненный документ, на основании ранее определенных реквизитов и уникальных ключевых слов, относящихся к этим реквизитам, формируют четвертый классификационный признак, определяют контур системы электронного документооборота (далее - СЭД), в котором был разработан документ, на основании определенных статьи Перечня и контура СЭД формируют пятый классификационный признак и определяют срок хранения исполненного документа, на основании определенной статьи Перечня, определенного срока хранения исполненного документа и исполнителя документа формируют шестой классификационный признак и определяют дело, в которое будет распределен исполненный документ, на основании определенной метки конфиденциальности документа и известной метки конфиденциальности дела, в которое будет распределен документ, проверяют соответствие меток конфиденциальности документа и дела, в которое его распределяют, на этапе обучения, по набору классифицированных вручную документов, формируют систему предикатов определения статьи Перечня, формируют систему предикатов определения контура СЭД, в котором был разработан документ, формируют систему предикатов определения срока хранения документа, сохраняют указанные системы предикатов в базе данных, формируют систему предикатов определения дела, в которое будет распределен исполненный документ, формируют систему предикатов проверки соответствия меток конфиденциальности документа и дела, в которое будет распределен документ, и сохраняют указанные системы предикатов в базе данных, при классификации документов на основании полученного набора классификационных признаков с помощью базы данных принимают решение об относимости документа к каждой из статей Перечня, подставляют третий набор классификационных признаков в систему предикатов определения статьи Перечня и по предикатам, принявшим значение «истина», принимают решение об отнесении документа к конкретной статье Перечня, подставляют четвертый набор классификационных признаков в систему предикатов определения контура СЭД и по предикатам, принявшим значение «истина», принимают решение о контуре СЭД, в котором был разработан документ, подставляют пятый набор классификационных признаков в систему предикатов узнавания срока хранения документа и по предикатам, принявшим значение «истина», принимают решение о присвоении срока хранения исполненному документу, подставляют шестой набор классификационных признаков в систему предикатов определения дела, в которое будет распределен исполненный документ, и по предикатам, принявшим значение «истина», принимают решение об определении дела, в которое требует распределить исполненный документ.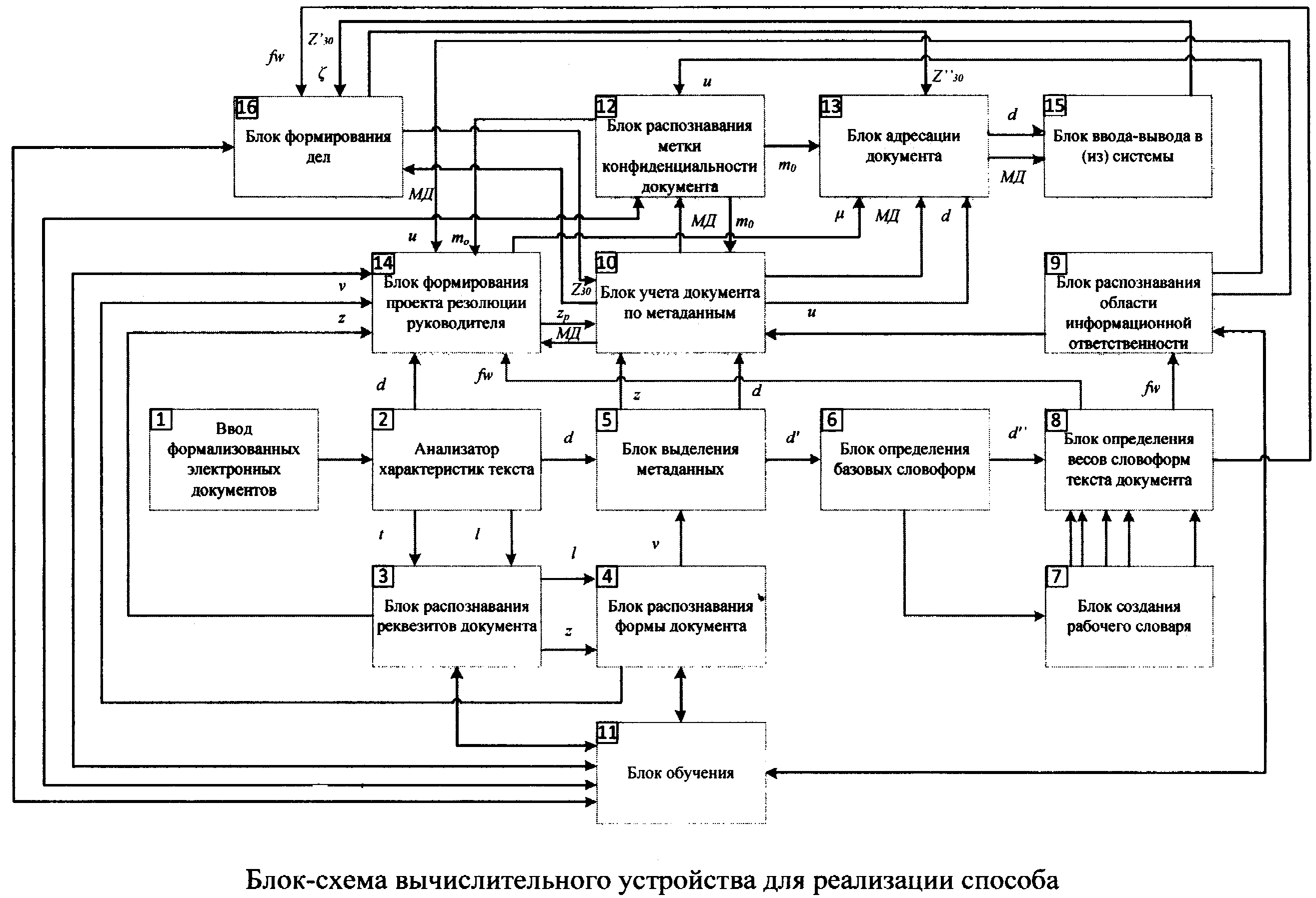
Способ криптографического рекурсивного 2-d контроля целостности метаданных файлов электронных документов
Способ асимметричного шифрования сообщений на основе модифицированной задачи о рюкзаке
Способ автоматической классификации формализованных документов в системе электронного документооборота
Способ мониторинга безопасности автоматизированных систем
Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота
Способ автоматической классификации формализованных текстовых документов и авторизованных пользователей системы электронного документооборота
Способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием реквизита резолюции руководителя
Система и способ обнаружения программно-аппаратных воздействий на беспилотные робототехнические комплексы

