Результат интеллектуальной деятельности: СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА
Вид РИД
Изобретение
Заявленное изобретение относится к системам классификации документов и может использоваться в системах электронного документооборота, базах данных, электронных хранилищах (электронных архивах) в случаях, когда существует необходимость классификации формализованных документов, поступающих из внешних автоматизированных систем, по тематическим признакам, видам (структурам) документов. Обеспечивает возможность априорного задания информационных областей, к которым относится электронный документ, в том числе с учетом всевозможных взаимосвязей таких информационных областей.
Известен аналог - способ автоматической классификации документов (Li Y., Jain A. "Classification of text documents", The Computer Journal 41, 8, pp.537-546, 1998), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления, на этапе обучения, по предъявленному набору классифицированных вручную документов, формируют набор классификационных признаков, а при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе простого байесовского классификационного критерия и классификационных признаков определяют принадлежность документа информационной области. Отметим, что данный способ предназначен для обработки машиночитаемых текстов на естественном языке. Данный способ простой байесовской классификации документов использует гипотезу о независимости слов документа друг от друга. При этом как документ, так и информационные области рассматриваются как вероятностные системы, для которых вычисляются вероятности появления словоформ как независимых событий. Для определения вероятности принадлежности документа категории вычисляется мера близости между этими двумя вероятностными системами. Способ простой байесовской классификации может использоваться как для бинарной классификации (необходимо определить, принадлежит документ категории или нет), так и для множественной (необходимо из списка категорий найти ту, которой принадлежит документ). В последнем случае документ может принадлежать лишь одной информационной области из списка. В тех задачах, где документ может одновременно принадлежать нескольким информационным областям, используют одновременно несколько бинарных классификаторов рассмотренного типа, каждый из которых определяет, принадлежит ли текущий документ данной информационной области. При этом принимается гипотеза о независимости информационных областей друг от друга.
Однако данный способ обладает недостатками:
не позволяет классифицировать документы в случае, когда информационные области тематически зависимы друг от друга, например, когда они иерархически подчинены друг другу;
не позволяет классифицировать документы по степени конфиденциальности;
анализ всего содержимого документа, а не только его информативной части.
Известен также аналог - способ автоматической классификации документов (Пат. 6327581 Соединенные Штаты Америки, МПК G06F 015/18. Methods and apparatus for building a support vector machine classifier [Текст] / Carlton J.; заявитель и патентообладатель Microsoft Corporation. - №09/055477; заявл. 06.04.98; опубл. 04.12.01), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе классификационного критерия SVM (Support Vector Machines) и классификационных признаков определяют принадлежность документа к информационной области. Данный способ, как и предыдущий, предназначен для обработки машиночитаемых текстов на естественном языке. Способ, описанный в [2], основан на классификации по методу SVM, который позволяет построить в многомерном пространстве признаков гиперплоскость, отделяющую признаки документов, принадлежащих информационной области, от признаков документов, не принадлежащих ей. Данный способ также может использоваться в случаях, когда документ может принадлежать сразу нескольким информационным областям.
Способ обладает недостатками:
не позволяет классифицировать документы в случае, когда информационные области тематически зависимы друг от друга, например, когда они иерархически подчинены друг другу;
не позволяет классифицировать документы по степени конфиденциальности;
анализ всего содержимого документа, а не только его информативной части.
Известен также аналог - способ мультиклассовой классификации (Schapire R.E., Singer Y. "BoosTexter: A boosting-based system for text categorization". Machine Learning 39, 2/3, 2000, pp.135-168), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из информационной области. В этом способе также под текстами на естественном языке понимаются машиночитаемые тексты. Данный способ для классификации использует слабые гипотезы о принадлежности документа множеству информационных областей для итеративного уточнения функции распределения информационный областей на множестве документов. Для получения слабых гипотез используются методы бинарной классификации документов; а при классификации используют построенное распределение для определения списка информационных областей, которым принадлежит документ. Данный способ проявляет хорошую работоспособность, поскольку он многократно применяет простые методы классификации, что приводит к большей точности классификации. Кроме того, в рамках указанного способа категории не считаются независимыми. Зависимость между ними задается на этапе обучения посредством представления соответствующей обучающей выборки документов.
Недостатком данного способа является:
невозможность использования при классификации априорной информации о зависимостях информационных областей друг от друга;
не позволяет классифицировать документы по степени конфиденциальности;
анализ всего содержимого документа, а не только его информативной части.
Наиболее близким по технической сущности к предлагаемому является способ автоматической классификации документов (Пат. 2254610 Российская Федерация, МПК G06F 17/30. Способ автоматической классификации документов [Текст] / Аграновский А.В., Арутюнян Р.Э., Хади Р.А., Телеснин Б.А.; заявитель и патентообладатель Государственное научное учреждение научно-исследовательский институт "СПЕЦВУЗАВТОМАТИКА". - №2003126907/09; заявл. 04.09.03; опубл. 20.06.05), принятый за прототип, заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в упомянутом документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из категорий, отличающийся тем, что на этапе определения принадлежности документа каждой из категорий используют априорную информацию о зависимостях категорий друг от друга, задаваемую деревом категорий, при этом используют бинарные классификаторы для определения принадлежности документа категориям, после чего осуществляют анализ принадлежности каждой категории документа категориям более высокого уровня, и если число вершин дерева, которым принадлежит документ, превосходит число вершин, которым он не принадлежит, то принимают решение о соответствии документа текущей вершине, после чего производят корректировку решений классификатора на протяжении всего пути от текущей вершины до корня дерева и классифицируют этот документ по всем промежуточным вершинам дерева.
Недостатком прототипа является:
не позволяет классифицировать документы по степени конфиденциальности;
анализ всего содержимого документа, а не только его информативной части.
Технический результат заключается в извлечении заданных метаданных и классификации формализованных документов в соответствии с ними (в том числе по степени конфиденциальности) и проведении анализа текста не всего содержимого документа, а только его информативной части при определении относимости документа к информационной области, что сократит время работы (повысит оперативность) системы.
Данный технический результат получают за счет того, что осуществляют выделение характеристик одинаковых участков текста Z={z1, z2,…, zn} (реквизитов) формализованного документа. Каждый реквизит выразим конечным предикатом P(Z, Т, L), где Т - множество характеристик текста t, L={l1, l2,…, lq} - множество конечных предикатов узнавания ключевых слов реквизита l, q - количество всех используемых ключевых слов.
Правило построения предиката узнавания реквизита формализованного документа, выразится следующей формулой [5]:
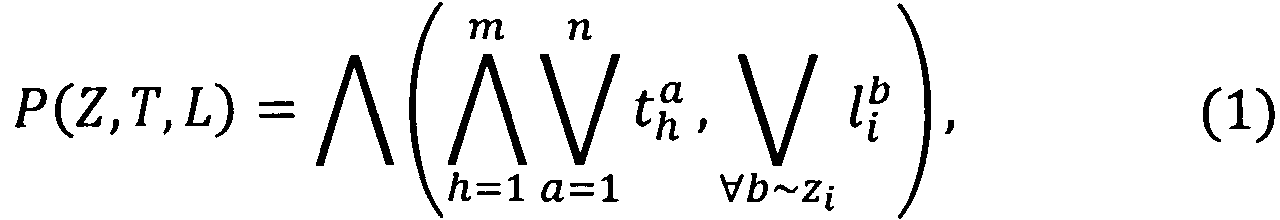
где 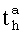 - предикат узнавания значения а h-той переменной текста; m - количество переменных текста, n - величина алфавита h-той переменной текста;
- предикат узнавания значения а h-той переменной текста; m - количество переменных текста, n - величина алфавита h-той переменной текста; 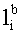 - предикат узнавания значения b ключевого слова соответствующего i-той зоне.
- предикат узнавания значения b ключевого слова соответствующего i-той зоне.
В связи с небольшим количеством различных реквизитов формализованного документа (согласно ГОСТ Р 6.30-2003 подразумевает перечень 30 реквизитов документов) некоторое количество из них не определяют индивидуальность формы документа, например те, которые свойственны всем формам (текст) или вообще не свойственны в данных условиях применения (Государственный герб Российской Федерации в частной организации).
Форма документа выразится конечным предикатом P(V, Z, L), где V={ν1, ν2,…, νm} - множество форм документа, j={1, 2,…, m}; m - количество всех используемых форм документов, Z={z1, z2,…, zn} - множество конечных предикатов реквизитов документа, n - количество всех реквизитов документов, L={l1, l2,…, lq} - множество ключевых слов, q - количество всех используемых ключевых слов.
Правило построения предиката узнавания формы документа выразится следующей формулой [5]:
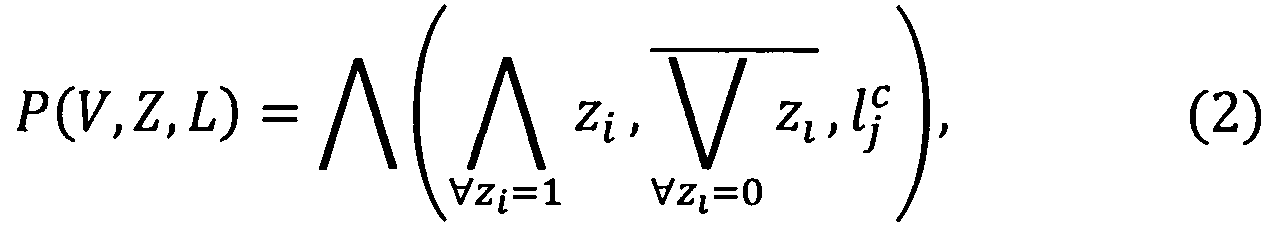
где 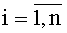 ; z1 - предикат узнавания реквизита для j-той формы документа;
; z1 - предикат узнавания реквизита для j-той формы документа; 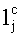 - предикат узнавания уникального значения ключевого слова с-той формы документа.
- предикат узнавания уникального значения ключевого слова с-той формы документа.
С использованием правил (1, 2) создаются системы предикатов идентификации реквизитов и форм документов.
Форма документа однозначно задает места расположения реквизитов документа что позволяет:
классифицировать документы по форме документа и степени конфиденциальности по соответствующему реквизиту из списка возможных значений;
проводить анализ только информативной части содержимого документа, например, только текста.
Информативную часть документа (далее - текст) преобразуют из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в тексте в соответствии с частотами их появления и тем самым формируют предикаты идентификации признаков текста. На этапе обучения по предъявленному набору классифицированных вручную текстов формируют систему предикатов идентификации признаков текста, где количество предикатов в системе предикатов определяется количеством информационных областей, на которые необходимо классифицировать документы (количество исполнителей в автоматизированной системе). Сохраняют систему предикатов в базе данных. Количество предикатов в системе предикатов будет равно количеству информационных областей (количеству исполнителей в системе).
Правило построения системы предикатов P(U, W) узнавания информационной области uj∈U=[u1, u2,…, us], выразится следующей формулой:
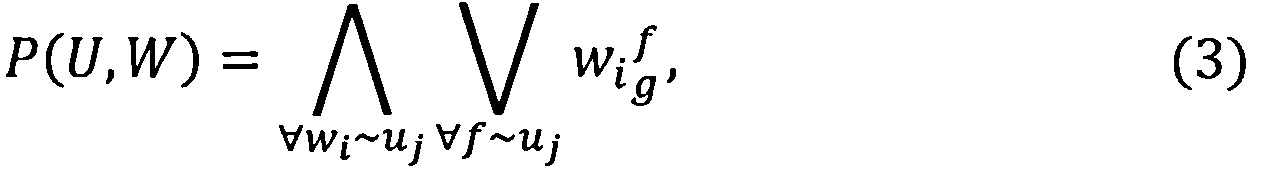
где 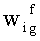 - предикат узнавания значения веса f значимого слова wi∈W={w1, w2,…, wp} - множество значимых слов текстов, в тексте документа d uj-той информационной области по g-тому значению веса слова; р - количество значимых слов текстов.
- предикат узнавания значения веса f значимого слова wi∈W={w1, w2,…, wp} - множество значимых слов текстов, в тексте документа d uj-той информационной области по g-тому значению веса слова; р - количество значимых слов текстов.
На этапе работы системы, при классификации текста, осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова текста в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в тексте, получившиеся значения подставляют в систему предикатов (3), находящуюся в базе данных. По предикатам в системе предикатов, принявшим значение истинности «1», определяется принадлежность к соответствующей информационной области или областям. При этом, в случае необходимости использования априорной информации о зависимостях информационных областей друг от друга, например, для задания дерева информационных областей, используем алгебру конечных предикатов [6], позволяющую проводить полный спектр операций над логическими выражениями, а соответственно и над информационными областями, описанными конечными предикатами (добавление, исключение, сложение информационных областей и т.д.). Данный способ классификации позволяет с учетом этого по входному документу определить, каким узлам дерева информационных областей он принадлежит, а каким нет. Отметим, что данный способ предназначен для обработки машиночитаемых текстов на естественном языке.
Вес f wi словоформы в тексте документа dj, рассчитывается по формуле:
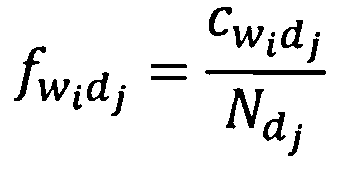
Здесь 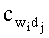 - количество раз, которое wi-я словоформа встречается в dj-м тексте документа,
- количество раз, которое wi-я словоформа встречается в dj-м тексте документа, 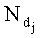 - общее количество словоформ в i-м тексте документа.
- общее количество словоформ в i-м тексте документа.
Документы для классификации могут быть представлены в различных форматах, допускающих выделение из них текстового содержания. Это могут быть текстовые файлы различных форматов, графические файлы с графическим представлением некоторого текста, звуковые файлы с записью речи и другие файлы, для которых существует механизм выделения из них текста, отражающего их содержание. Каждый документ (либо обучающий, либо подвергающийся классификации) предварительно проходит стадию первичной обработки, на которой производится определение формата документа и установление того, возможно ли извлечение текста из документа данного формата. В случае положительного решения производится извлечение текста из документа. После разбиения текста на слова происходит определение для каждого слова его базовой словоформы по одному из способов [7-10]. Наиболее часто для решения подобных задач используется алгоритм Портера [10], заключающийся в использовании специальных правил отсечения и замены окончаний слов.
Согласно предлагаемому способу каждый документ di представляется декартовым произведением переменных из множеств T×L×W, где для инициализации классификатора и построения классификационных признаков служит этап обучения классификатора. При этом должно быть задано множество обучающих документов, заранее классифицированных вручную. После извлечения из них текстового содержания происходит построение словаря значимых слов. Словарь содержит базовые словоформы всех слов, встречающихся в обучающих документах.
При классификации документа в расчет берутся не все словоформы из словаря документов, а лишь те из них, которые входят в рабочий словарь классификатора данной информационной области (данного исполнителя), что и определяет (3). В рабочий словарь классификатора включаются наиболее информативные словоформы с точки зрения определения принадлежности документа данной категории, не попавшие в стоп-словарь. Информативность словоформы wi для классификатора по информационной области uj определяется по следующей формуле [11]:
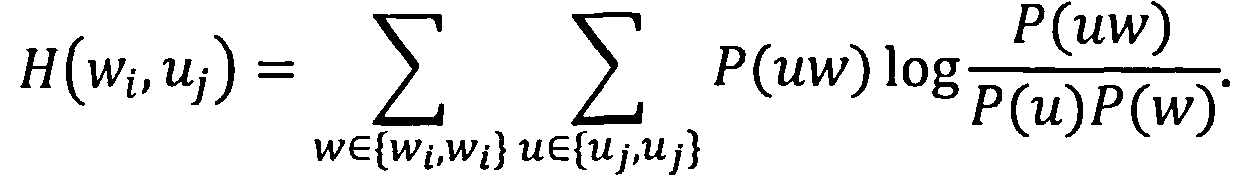
При этом устанавливается порог информативности ε; в рабочий словарь классификатора включаются все словоформы, не попавшие в стоп-словарь, информативность которых превышает этот порог. Стоп-словарь состоит из словоформ, частоты встречаемости которых во множестве обучающих документов превышают заранее установленный порог δ. При этом отсекаются слова, не несущие смысловой нагрузки, такие как предлоги, союзы, вводные и общие слова и т.д. Значения коэффициента δ, согласно данному способу, устанавливаются в пределах от 0.05 до 0.7 в зависимости от специфики использования способа. Значения порога информативности δ могут быть различны в различных условиях использования способа.
Классификация текстов (информативных частей) документов производится путем вычисления значений системы предикатов, описывающей информационные области. Система предикатов строится по правилу (3).
Изобретение поясняется чертежом.
На чертеже представлена блок-схема вычислительного устройства для реализации способа.
Устройство для реализации способа (см. чертеж) состоит из блоков:
1 источника документов;
2 анализатора характеристик текста;
3 распознавания реквизитов документа;
4 распознавания формы документа;
5 выделения метаданных;
6 определения базовых словоформ;
7 создания рабочего словаря;
8 определение весов словоформ текста документа;
9 распознавания информационной области;
10 учета документа по метаданным;
11 обучения;
12 адресации документа;
13 отправки в соответствии с полученной классификацией.
Согласно способу устройство работает следующим образом:
1. В режиме классификации.
При появлении в источнике документов 1 нового документа он поступает в блок 2, который выявляет значения характеристик текста t участков документа и ключевых слов l в них. Значения t и l участков документа поступают в блок 3, где с помощью системы предикатов, построенных по правилу (1) распознаются реквизиты документа. Информация о распознанных реквизитах документа поступает в блок 4, где система предикатов, построенная по правилу (2), осуществляет распознавание формы документа.
В блоке 5 из поступившего документа от блока 2, используя сведения об определенной форме документа из блока 4, которая однозначно задает места расположения значений реквизитов документа, выделяются требуемые значения реквизитов, которые являются метаданными документа. Документ и соответствующие ему метаданные поступают в блок 10, где документ учитывается по своим метаданным и организуется хранение его эталонной копии. Также однозначно определенная в блоке 5 информативная часть документа поступает в блок 6, где слова преобразуются в словоформы. Полученные в блоке 6 словоформы поступают в блок 7, где в процессе работы системы происходит создание рабочего словаря из значимых слов.
Полученные в блоке 6 словоформы поступают в блок 8, где производится расчет весов f словоформ информативной части документа, попавших в рабочий словарь. Из блока 8 значения весов полученных словоформ поступают в блок 9, где происходит распознавание информационной области ui путем вычисления значений предикатов системы предикатов, построенной по правилу (3).
Поступившему документу и метаданным из блока 10 в блок 12, с использованием полученных значений из блока 9 присваиваются адреса соответствующие информационной области. Далее в блоке 13 происходит отправка документа по адресам (классификация в соответствии с информационной областью).
2. В режиме обучения.
Режим обучения системой используется в трех случаях:
в случае невозможности распознавания системой предикатов реквизитов документа в блоке 3 по значениям переменных документа t и l. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 3 или определяется реквизит документа «вручную»;
в случае невозможности распознавания системой предикатов формы документа в блоке 4 по значениям предикатов системы предикатов блока 3. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 4 или определяется форма документа «вручную»;
в случае невозможности распознавания системой предикатов информационной области в блоке 9 по значениям весов значимых слов из рабочего словаря, извлеченных из информативной части документа. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 9 или определяется информационная область документа «вручную».
Таким образом, способ позволяет классифицировать документы с учетом степени конфиденциальности и любых других атрибутов (отраженных в метаданных), анализа только информативной части документа с учетом априорных зависимостей между информационными областями, чем достигается поставленный выше технический результат.
Источники информации
1. Li Y., Jain A. "Classification of text documents". The Computer Journal 41, 8, pp.537-546, 1998.
2. Пат. 6327581 Соединенные Штаты Америки, МПК G06F 015/18. Methods and apparatus for building a support vector machine classifier [Текст] / Carlton J.; заявитель и патентообладатель Microsoft Corporation. - №09/055477; заявл. 06.04.98; опубл. 04.12.01.
3. Schapire R.E., Singer Y. "BoosTexter: A boosting-based system for text categorization". Machine Learning 39, 2/3, 2000, pp.135-168.
4. Пат. 2254610 Российская Федерация, МПК G06F 17/30. Способ автоматической классификации документов [Текст] / Аграновский А.В., Арутюнян Р.Э., Хади Р.А., Телеснин Б.А.; заявитель и патентообладатель Государственное научное учреждение научно-исследовательский институт "СПЕЦВУЗАВТОМАТИКА". - №2003126907/09; заявл. 04.09.03; опубл. 20.06.05 - прототип.
5. Подходы к оперативной идентификации формализованных электронных документов в автоматизированных делопроизводствах / И.Д. Королев, С.В. Носенко // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета (Научный журнал КубГАУ) [Электронный ресурс]. - Краснодар: КубГАУ, 2013. - №08(092). - IDA [article ID]: 0921308074. - Режим доступа: http://ej.kubagro.ru/2013/08/pdf/74.pdf, 0,875 у.п.л.
6. М.Ф. Бондаренко, Ю.П. Шабанов-Кушнаренко. Об алгебре конечных предикатов. [Текст] // Научно-технический журнал «Бионика интеллекта». ХНУРЭ, г. Харьков, Украина - 2011, №3(77).
7. Porter M.F. "An algorithm for suffix stripping", Program, Vol.14, No.3, 1980, pp.130-137.
8. Пат. 2096825 Российская Федерация, МПК G06F 17/00, G06F 17/30. Устройство обработки информации для информационного поиска [Текст] / Ковалев М.В., Виргунов И.В., Наймушин И.А., Четверов В.В; заявитель и патентообладатель Общество с ограниченной ответственностью "Информбюро". - №96119820/09; заявл. 14.10.96; опубл. 20.11.97, Бюл. №14.
9. Пат. 6308149 Соединенные Штаты Америки, МПК G06F 17/27. Grouping words with equivalent substrings by automatic clustering based on suffix relationships [Текст] / Gaussier E., Grefenstette G., Chanod J.-P.; заявитель и патентообладатель Xerox Corporation. - №09/213309; заявл. 16.12.98; опубл. 23.10.01.
10. Пат. 6430557 Соединенные Штаты Америки, МПК G06F 017/30; G06F 017/27; G06F 017/21. Identifying a group of words using modified query words obtained from successive suffix relationships [Текст] / Gaussier E., Grefenstette G., Chanod J.-P.; заявитель и патентообладатель Xerox Corporation. - №09/212662; заявл. 16.12.98; опубл. 06.08.02.
11. Craven M., DiPasquo D., Freitag D. et al. "Learning to construct knowledge bases from the World Wide Web", Artificial Intelligence, Vol.118(1-2), 2000, pp.69-113.
Способ автоматической классификации формализованных документов в системе электронного документооборота, заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют признаки документа: на этапе обучения по набору классифицированных вручную документов формируют набор классифицированных признаков, сохраняют классифицированные признаки в базе данных; при классификации документа на основании полученных классифицированных признаков с помощью базы данных принимают решение об относимости документа каждой из информационных областей, на этапе определения принадлежности документа каждой информационной области используют априорную информацию о зависимостях категорий друг от друга, отличающийся тем, что перед преобразованием документа из формата хранения в текст на естественном языке определяются области информационного документа для извлечения метаданных и информативной части, на этапе обучения по классификационным признакам (весам значимых слов) формируют систему предикатов идентификации признаков информационной части документа, систему предикатов сохраняют в базе данных; на этапе работы системы получившиеся значения весов значимых словоформ подставляют в систему предикатов, находящуюся в базе данных; в случае необходимости использования априорной информации о зависимостях информационных областей между собой используется алгебра конечных предикатов, позволяющая проводить операции над логическими выражениями, с помощью которых описаны информационные области.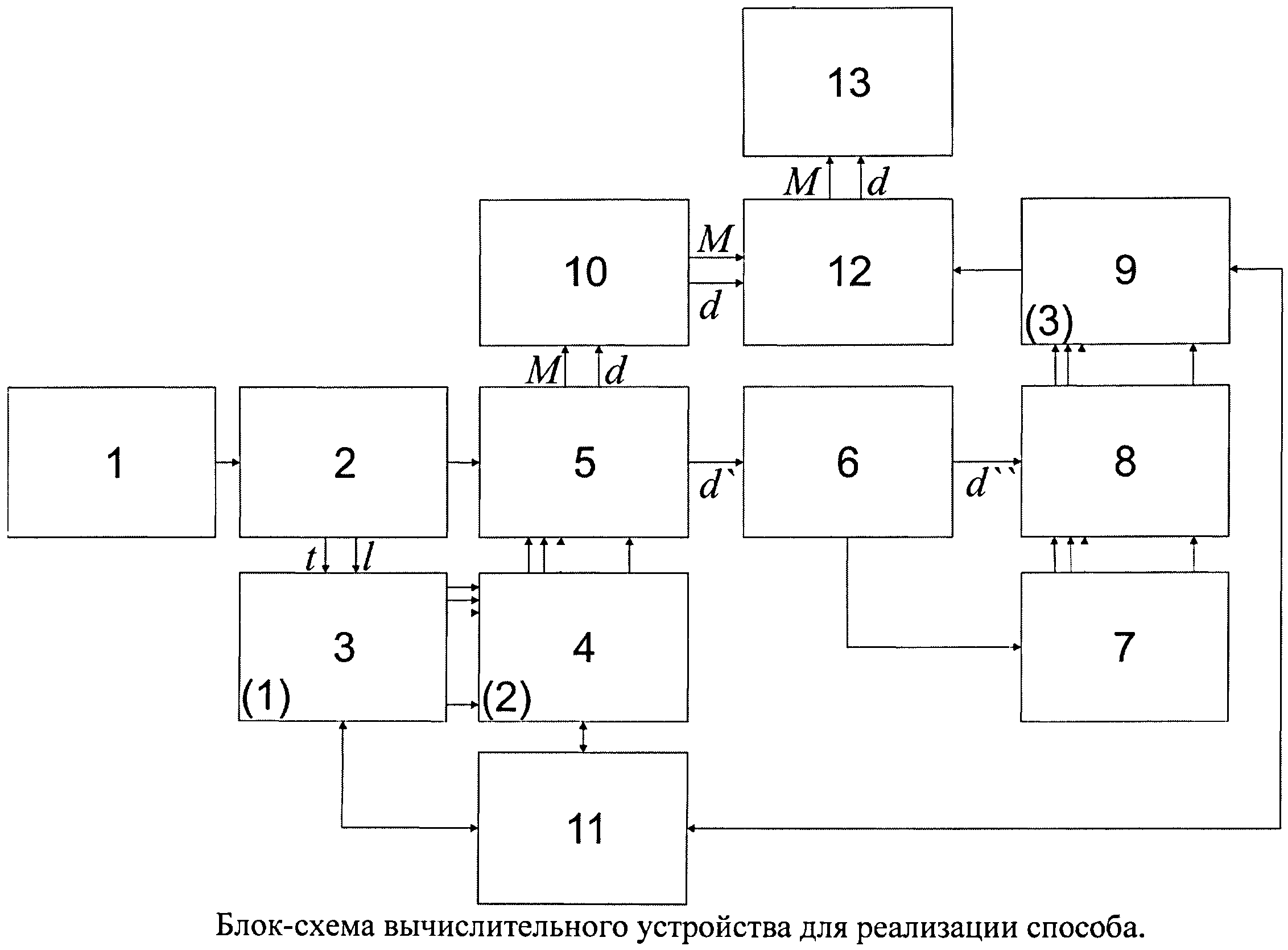
Самопроверяемый специализированный вычислитель систем булевых функций
Способ ускоренного поиска широкополосных сигналов и устройство для его реализации
Устройство формирования систем двукратных производных нелинейных рекуррентных последовательностей
Способ компенсации узкополосных помех
Способ мониторинга безопасности автоматизированных систем
Способ автоматического обнаружения сигналов
Способ поляризационной адаптации коротковолновых радиолиний, работающих ионосферными волнами (варианты)
Самопроверяемый специализированный вычислитель систем булевых функций
Способ и устройство формирования сигналов квадратурной амплитудной манипуляции
Многоканальный оптический мультиплексор ввода-вывода
Способ ускоренного поиска широкополосных сигналов и устройство для его реализации
Устройство формирования систем двукратных производных нелинейных рекуррентных последовательностей
Способ компенсации узкополосных помех
Способ мониторинга безопасности автоматизированных систем
Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота

