Результат интеллектуальной деятельности: Способ количественного определения содержания ДНК в сложных растительных смесях методами массового параллельного секвенирования
Вид РИД
Изобретение
Область техники
Изобретение относится к области молекулярной генетики, геносистематики и биоинформатики, и описывает способ количественной оценки присутствия каждого из нескольких видов растений в сложном образце с помощью расчета поправочных коэффициентов. Изобретение может быть использовано для количественного анализа состава пищевой продукции растительного происхождения, в том числе с целью контроля такой продукции на соответствие заявленному составу, декларируемому производителем.
Уровень техники
Среди большого количества методов генодиагностики с целью идентификации присутствия ДНК различных растительных организмов в составе сложного образца (смеси различных организмов) ДНК-метабаркодинг является одним из наиболее перспективных подходов в силу своей универсальности, а также в связи с развитием и удешевлением технологий высокопроизводительного секвенирования ДНК в последнее десятилетие. Так, для проведения анализа не требуется разработка отдельных олигонуклеотидов для каждого анализируемого рода или вида организма, что характерно для наиболее популярных в настоящее время систем, основанных на ПЦР (полимеразная цепная реакция) в реальном времени. При использовании метода ДНК-метабаркодинга достаточно разработки нескольких олигонуклеотидов, универсальных для всех растительных организмов, определение всех компонентов продукта при этом производится с использованием массового параллельного секвенирования и последующего биоинформатического анализа. Одним из таких маркеров может быть маркер ITS1 (внутренний транскрибируемый спейсер, от англ. Intemal Transcribed Spacer). Однако существенным недостатком описанного метода является практическая невозможность количественного определения различных видов организмов в образце исходя из количества полученных прочтений в конечном файле. Существенные погрешности вносят несколько основных факторов, такие как: (1) эффективность выделения ДНК из отдельно взятого растения (включая эффективность выделения из различных частей растения), (2) копийность (количество копий фрагмента генома), (3) длина и (4) ГЦ-состав (процент гуанинов и цитозинов) используемого маркера, которые разнятся у различных растений, а также (5) размер генома растения. Таким образом, при проведении анализа сложного образца результат количественной оценки может отличаться от реального распределения в образце в десятки и более раз, что фактически делает невозможным количественный анализ состава сложной смеси с использованием ДНК-метабаркодинга и технологий высокопроизводительного секвенирования.
Существуют также другие решения для количественной детекциинуклеиновых кислот (например, CN 102628082 B, US 8981068, US 9096896, US 20090042183), но все они имеют ограниченную применимость.
В настоящий момент не существует способов, корректирующих количественную оценку состава сложной смеси с использованием ДНК-метабаркодинга и технологий высокопроизводительного секвенирования. Настоящее изобретение позволяет увеличить точность таких оценок при помощи создания и использования базы данных поправочных коэффициентов.
Сущность изобретения
Задачей настоящего изобретения является создание методики количественного определения состава пищевой продукции растительного происхождения с использованием высокопроизводительного секвенирования. Ключевой особенностью разработанного способа является создание и использование базы данных поправочных коэффициентов для наиболее часто используемых в пищевой и фармацевтической промышленности растительных организмов.
Указанная задача решается путем создания способа определения количественного состава двухкомпонентной смеси растений, включающего следующие стадии:
(а) выделяют тотальную ДНК из части указанной смеси;
(б) амплифицируют ДНК-маркер ITS1 с помощью полимеразной цепной реакции (ПЦР);
(в) секвенируют продукты реакции ПЦР, используя одну из платформ для высокопроизводительного секвенирования;
(г) сравнивают результаты секвенирования с данными референсной базы данных маркеров ITS1 растений;
(д) подсчитывают количество прочтений, полученное при секвенировании, для каждого из двух идентифицированных родов или видов растений;
(е) рассчитывают массовые доли для каждого из двух идентифицированных родов или видов растений по формуле
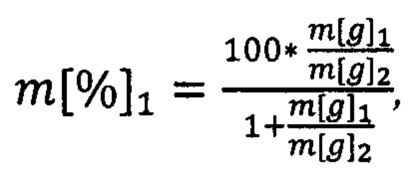
m[%]2=100-m[%]1,
где
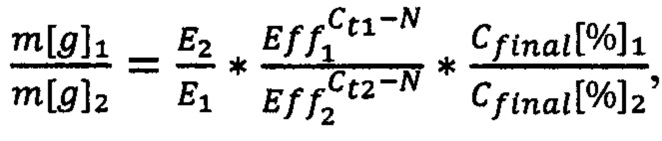 и коэффициенты El, Е2, Eff1, Eff2, Ct1, Ct2 получают из референсной базы данных маркеров ITS1 растений, при этом
и коэффициенты El, Е2, Eff1, Eff2, Ct1, Ct2 получают из референсной базы данных маркеров ITS1 растений, при этом
E1, Е2 - значения эффективности выделения ДНК для растений 1 и 2,
Eff1, Eff2 - значения эффективности ПЦР для растений 1 и 2,
Ct1, Ct2 - значения пороговых циклов для растений 1 и 2,
N - количество проведенных циклов реакции ПЦР,
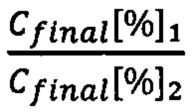 - отношение количества прочтений, полученных при секвенировании, для растений 1 и 2.
- отношение количества прочтений, полученных при секвенировании, для растений 1 и 2.
В предпочтительных вариантах изобретения данный способ характеризуется тем, что при амплификации ДНК-маркера ITS1 используют праймеры с последовательностями 5'-GGAAGGAGAAGTCGTAACAAGG-3' (SEQ ID NO:1) и 5'-AGATATCCGTTGCCGAGAGT-3' (SEQ ID NO:2).
Данный способ позволяет производить количественную оценку для наиболее часто используемых в пищевой и фармацевтической промышленности растительных организмов. Техническим результатом настоящего изобретения является повышение точности определения количественного состава пищевой продукции растительного происхождения с использованием высокопроизводительного секвенирования.
Подробное раскрытие изобретения
В описании данного изобретения термины «включает» и «включающий» интерпретируются как означающие «включает, помимо всего прочего». Указанные термины не предназначены для того, чтобы их истолковывали как «состоит только из». Если не определено отдельно, технические и научные термины в данной заявке имеют стандартные значения, общепринятые в научной и технической литературе.
Универсальный маркер ITS1 (внутренний транскрибируемый спейсер, от англ. InternalTranscribedSpacer) может быть использован для методов ДНК-метабаркодинга растений (например, Cheng Т, et al., "Barcoding the kingdom Plantae: new PCR primers for ITS regions of plants with improved universality andspecificity. MolEcolResour. 2016 Jan; 16(1):138-49"). Уэукариот есть два маркера ITS; ITS1 находится между 18S и 5.8S генами рРНК, в то время как ITS2 находится у растений между 5.8S и 26S генами рРНК. Уэукариот гены, кодирующие рибосомную РНК и спейсеры, встречаются в тандемных повторах длиной в тысячи копий, каждый из которых разделен участками нетранскрибированной ДНК, называемыми межгенным спейсером (IGS) или нетранскрибированным спейсером (NTS). Каждый эукариотический рибосомный кластер содержит 5' внешнюю транскрибируемую последовательность (5' ETS), ген 18SpPHK, ITS1, ген 5.8SpPHK, ITS2, ген 26S или 28SpРНКи, наконец, 3' ETS (BenaG, etal., Ribosomal Extemaland lnternal Transcribed Spacers: Combined Use in the Phylogenetic Analysis of Medicago (Leguminosae). JMolEvol. 1998 Mar; 46(3):299-306).
Данное изобретение описывает разработку методики по наполнению базы данных поправочных коэффициентов для количественной оценки образцов, состоящих из компонентов растительного происхождения, на основе метода ДНК-метабаркодинга с использованием универсального маркера ITS1 и технологий массового параллельного секвенирования. Для работы с базой данных и результатами секвенирования используется разработанное программное обеспечение (ПО), с помощью которого производится количественная оценка.
Для наполнения базы данных поправочных коэффициентов часто используемых растений используются следующие этапы измерения:
1) эффективности выделения ДНК из монокомпонентного растительного образца;
2) Ct (количество циклов, необходимое для того, чтобы флуоресценция достигла порогового уровня) для каждого растительного образца с использованием праймеров для амплификации ДНК-маркера ITS1 и ДНК-полимеразы;
3) эффективности ПЦР реакции -Eff.
В результате измерения описанных переменных можно оценить интегральный показатель амплификации, учитывающий копийность маркера, ГЦ-состав, размер генома и эффективность выделения ДНК и ПЦР реакции. Так, при высоком ГЦ-составе, большом размере генома и низкой копийности маркера параметр С, будет значительно повышен относительно типовых средних значений. При низкой эффективности ПЦР реакции для конкретного вида растения концентрация амплифицируемого участка будет расти медленнее по сравнению с образцом с высокой эффективностью ПЦР реакции. Эффективность выделения нуклеиновых кислот позволяет оценить исходное количество ДНК каждого растения в образце.
Важно отметить, что наполнение базы данных поправочных коэффициентов производится при единых условиях для каждого исследуемого организма:
1) у каждого растения берутся максимально схожие фрагменты (например, листья);
2) производится сушка фрагментов растений в одинаковых условиях;
3) экстракция ДНК осуществляется с помощью одного и того же набора для выделения нуклеиновых кислот по стандартному протоколу, рекомендованному производителем;
4) концентрация выделенной ДНК измеряется с помощью флуориметра;
5) для проведения ПЦР реакции берется 5 мкл. раствора с концентрацией 5 нг/мкл.;
6) ПЦР реакция осуществляется с помощью специфичных праймеров для ДНК-маркера ITS1 и с использованием ДНК-полимеразы по стандартному протоколу;
7) эффективность ПЦР реакции Eff измеряется с помощью 5 серийных разведений.
Таким образом формируется референсная база данных маркеров ITS1 растений для всех растений, количественное содержание которых в составе смесей необходимо будет оценить. Референсная база данных маркеров ITS1 растений содержит информацию о последовательности маркера ITS1, а также параметры Е, Eff, Ct, для каждого вида или рода растений. Как правило, полиморфизм в гене ITS1 растений достаточен для идентификации конкретного вида растений. Идентификация рода растений происходит в случае, когда межвидовые различия в маркере ITS1 растений недостаточны для идентификации конкретного вида растений.
Для наполнения референсной базы данных используют количественную полимеразную цепную реакцию в реальном времени (ПЦР-РВ). Для проведения ПЦР-РВ может быть использован, любой набор, предназначенный для проведения ПЦР с детекцией продуктов амплификации в реальном времени. Например, можно использовать коммерческий набор реагентов Encyclo Plus PCR kit (Евроген, Россия) с добавлением флуоресцентного интеркалирующего красителя SYBR Green I для ПЦР-РВ (Евроген, Россия). Анализ результатов амплификации и определение О осуществляется с помощью соответствующего программного обеспечения, разработанного производителем.
В предпочтительных вариантах изобретения при амплификации ДНК-маркера ITS1 используют праймеры с последовательностями 5'- GGAAGGAGAAGTCGTAACAAGG -3' (SEQ ID NO:1) и 5'- AGATATCCGTTGCCGAGAGT-3' (SEQ ID NO:2), однако возможно использование и других праймеров, комплементарных консервативным областям спейсера, содержащего/Ж/, и способных амплификацировать маркер ITS1.
С использованием разработанной базы данных и программного обеспечения количественная оценка производится способом, описанным далее. Из исследуемого образца выделяется тотальная ДНК при помощи стандартных методов, известных специалистам (например, набора для выделения ДНК из растений Qiagen DNeasy Plant Mini Kit); далее производится амплификация ДНК-маркера ITS1, например, с помощью специализированных праймеров SEQ ID NO:1 и SEQ ID NO:2. Могут быть использованы и другие праймеры на ITS1. В данном случае для анализа конкретной смеси можно использовать как реакцию ПЦР-РВ, так и стандартную реакцию ПЦР.
Далее выполняют приготовление геномных библиотек для секвенирования по протоколу от производителя прибора для секвенирования, и производится секвенирование с использование модной из существующих высокопроизводительных платформ (например, IonGeneStudioS5 или IlluminaMiSeq).
Далее, с помощью специализированного разработанного программного обеспечения производят обнаружение растительных организмов в образце, и подсчитывают количества прочтений, полученных при секвенировании, приходящихся на каждый из идентифицированных видовили родов растений. Для этого производятся следующие шаги:
1) «сырые» данные с секвенатора фильтруются с использованием порогов по минимальной длине и качеству (т.н. «Phred-score»);
2) из прочтений вырезаются праймерные участки и консервативные области для увеличения разрешающей способности маркера;
3) производится выравнивание прочтений, прошедших фильтрацию, на референсную (эталонную) базуданных маркеров ITS1 растений;
4) подсчитывается количество прочтений на каждый род/вид;
5) в промежуточный отчет выводится относительное распределение компонент в сложном образце.
С использованием описанной ранее базы данных производится нормирование количества прочтений на наиболее представленный вид с использованием параметров Ct, эффективности ПЦР реакции Eff и эффективности выделения ДНК.
Параметр Ct (СТ - величина) - это количество циклов в ПЦР реакции, необходимое для того, чтобы флуоресценция достигла порогового уровня (над шумом).
Эффективность выделения ДНК из образца рассчитывается следующим образом:
E=mDNA/msamle,
где mDNA - масса ДНК, получившейся в результате выделения, msample - масса образца, взятого для выделения.
Эффективность ПЦР реакции Eff можно оценить методами, известными специалисту, например, выполнив серию экспериментов с разведением целевого образца (Белов Д.А. и др., Экспериментальное определение параметров амплификации полимеразной цепной реакции анализатора нуклеиновых кислот", НАУЧНОЕ ПРИБОРОСТРОЕНИЕ, 2016, том 26, №1, с. 34-40). Обычно используются десятикратные разведения. После получения значения Ct для каждого разведения строится график зависимости Ct от начальной концентрации в логарифмическом масштабе. После этого по получившимся точкам на графике строится прямая и вычисляется ее наклон. Эффективность ПЦР вычисляется следующим образом:
Eff=-1+10(-1/наклон).
Далее показаны расчеты для получения поправочных коэффициентов для двухкомпонентных смесей. При большем количестве растительных компонент целесообразно брать одно из них в качестве референсного и считать поправочные коэффициенты по отношению к нему.
Исходя из равенства молярных (допущение) концентраций (Ca) при значении количества циклов Ct, можем записать уравнение (1):
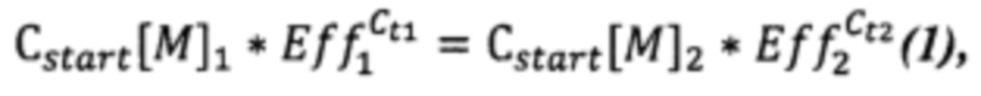
где Cstart[M]1 и Cstart[M]2 - начальные молярные концентрации растений 1 и 2 соответственно;
Eff1 и Eff2 - измеренные значения эффективности ПЦР для растений 1 и 2 соответственно;
Ct1 и Ct2 - измеренные значения пороговых циклов для растений 1 и 2 соответственно.
Следовательно, можно вычислить отношение начальных молярных концентраций растений 1 и 2 как (2):
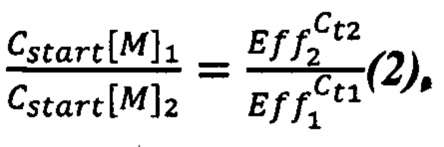
Отметим, что уравнение (2) связывает молярные концентрации, т.е. количества участков геномов, которые в дальнейшем будут амплифицироваться. Для перехода к массам ДНК нужно ввести поправочные коэффициенты X1 и Х2, которые показывают сколько таких участков приходится на единицу массы ДНК (3):
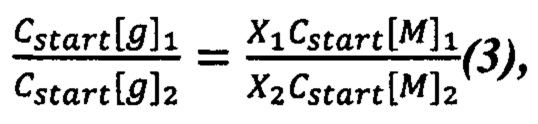
где Cstart[g]1 и Csart[g]2 - начальные концентрации ДНК в г/мл. растений 1 и 2 соответственно;
Х1 и Х2 - поправочные коэффициенты для растений 1 и 2 соответственно.
Так как для всех реакций в одном эксперименте были взяты одинаковые количества ДНК (по массе), то уравнение (3) можно переписать следующим образом (4):
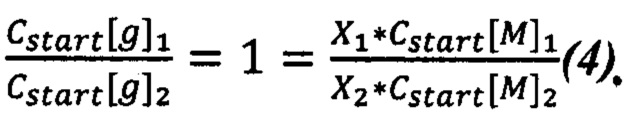
Отношение 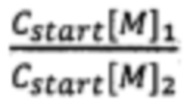 известно из уравнения (2). Подставляем это значение в уравнение (4) и узнаем отношение
известно из уравнения (2). Подставляем это значение в уравнение (4) и узнаем отношение 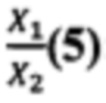 :
:
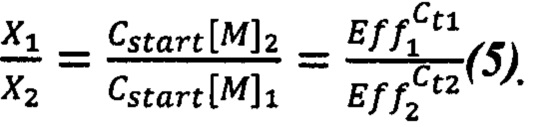
Таким образом, для определения отношения массовых концентраций ДНК растений 1 и 2 в эксперименте:
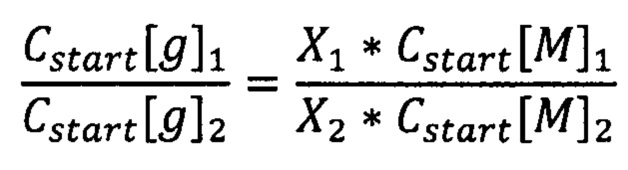
или
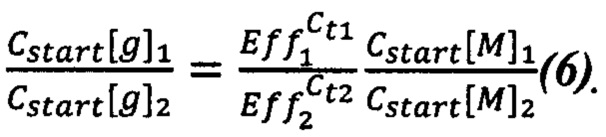
Начальная молярная концентрация может быть рассчитана через конечную концентрацию, если известно количество циклов ПЦР реакции (7):
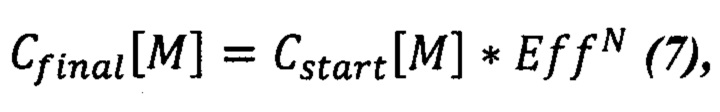
где N - количество проведенных циклов ПЦР.
Подставляем (7) в (6) и получаем (8):
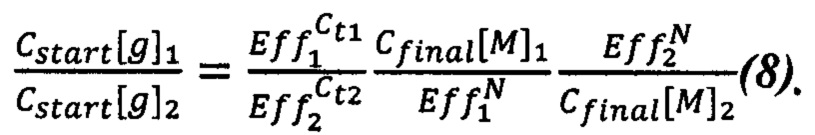
В дальнейшем мы считаем (допущение), что при секвенировании не возникают дополнительные искажения в концентрациях. Таким образом, вместо истинных значений концентраций, мы можем использовать количества прочтений Nreads, которые прямо пропорциональны молярным концентрациям с коэффициентом В:
Cfinal[Nreads]=В*Cfinal[M].
Также отметим, что отношение количеств прочтений равно отношению процентных содержаний компонентов, получаемых при анализе:
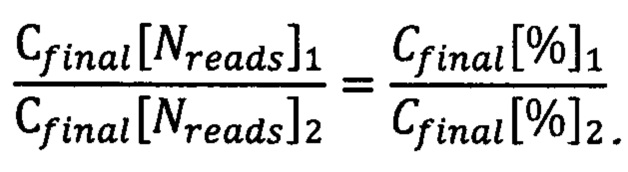
При этом считаем, что коэффициенты В для всех растений одинаковы, и в уравнении (8) они сокращаются. Перепишем уравнение (8) с учетом этого, а также преобразуем степенные выражения:
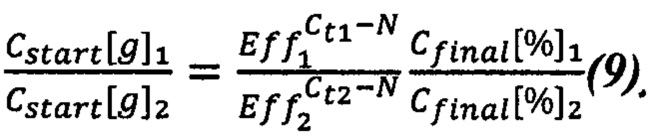
Таким образом, можно вычислить исходное соотношение концентраций для пары растений. Если растений несколько, то целесообразно брать одно из них в качестве референсного и считать поправочные коэффициенты по отношению к нему.
Чтобы от концентраций ДНК перейти к массам растений, нужно ввести коэффициенты эффективности выделения ДНК:
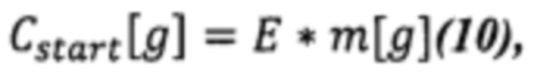
где Е - коэффициент эффективности выделения ДНК;
m[g] - масса сухого вещества.
Таким образом, соотношение масс считается следующим образом (11):
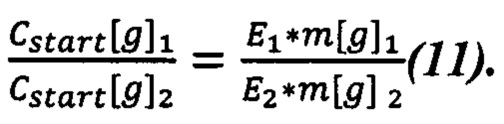
Подставляем (11) в (9) и получаем (12):
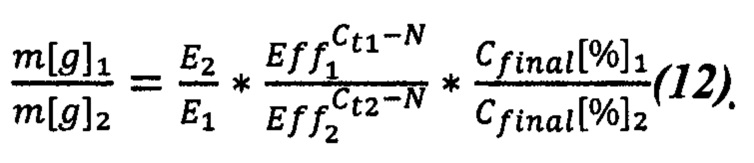
При известном итоговом соотношении компонент можем вычислить отношение массы m[g]1 к m[g]2. Принимая во внимание, что в сумме они составляют 100% образца, можем записать (13):
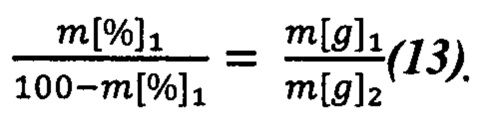
Из чего находим доли растений 1 и 2:
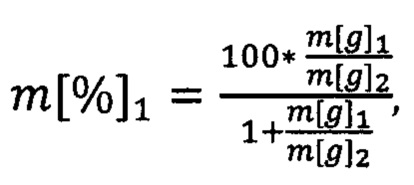
m[%]2=100-m[%]1.
Таким образом, после завершения описанных шагов, получается нормированное количество прочтений для каждого из видов. Далее рассчитывается процентное соотношение компонентов в образце, и выводится окончательный отчет.
Нижеследующие примеры осуществления способа приведены в целях раскрытия характеристик настоящего изобретения и их не следует рассматривать как каким-либо образом ограничивающие объем изобретения.
Пример 1
Для подтверждения теоретически полученных результатов были поставлены эксперименты со следующими растениями: Arabidopsisthaliana, Cucurbitapepo, Fagopyrum esculentum, Helianthus annuus и Solanum lycopersicum. Для выделения ДНК использовали набор для выделения ДНК из растений (Qiagen DNeasy Plant Mini Kit).
Для каждого из указанных растений в трех повторах были измерены коэффициенты Е, Ct и Eff после проведения реакции ПЦР-РВ с использованием праймеров с последовательностями 5'- GGAAGGAGAAGTCGTAACAAGG -3' (SEQ ID NO:1) и 5'-AGATATCCGTTGCCGAGAGT-3' (SEQ ID NO:2).
Реакцию ПЦР-РВ осуществляли в объеме 25 мкл. на реакцию в трех повторах для каждой точки 10-кратных серийных разведений образца ДНК на ПЦР. То есть, каждый образец ДНК трехкратно амплифицировали в серии разведений со следующими концентрациями: 10, 1, 0.1, 0.01, 0.001 нг на реакцию. Амплификацию и анализ результатов ПЦР-РВ проводили с помощью анализатора, позволяющего осуществлять детекцию продуктов амплификации в реальном времени (Roche LightCycler 96 (Roche, США)).
Программа реакции ПЦР-РВ представлена в таблице 1.
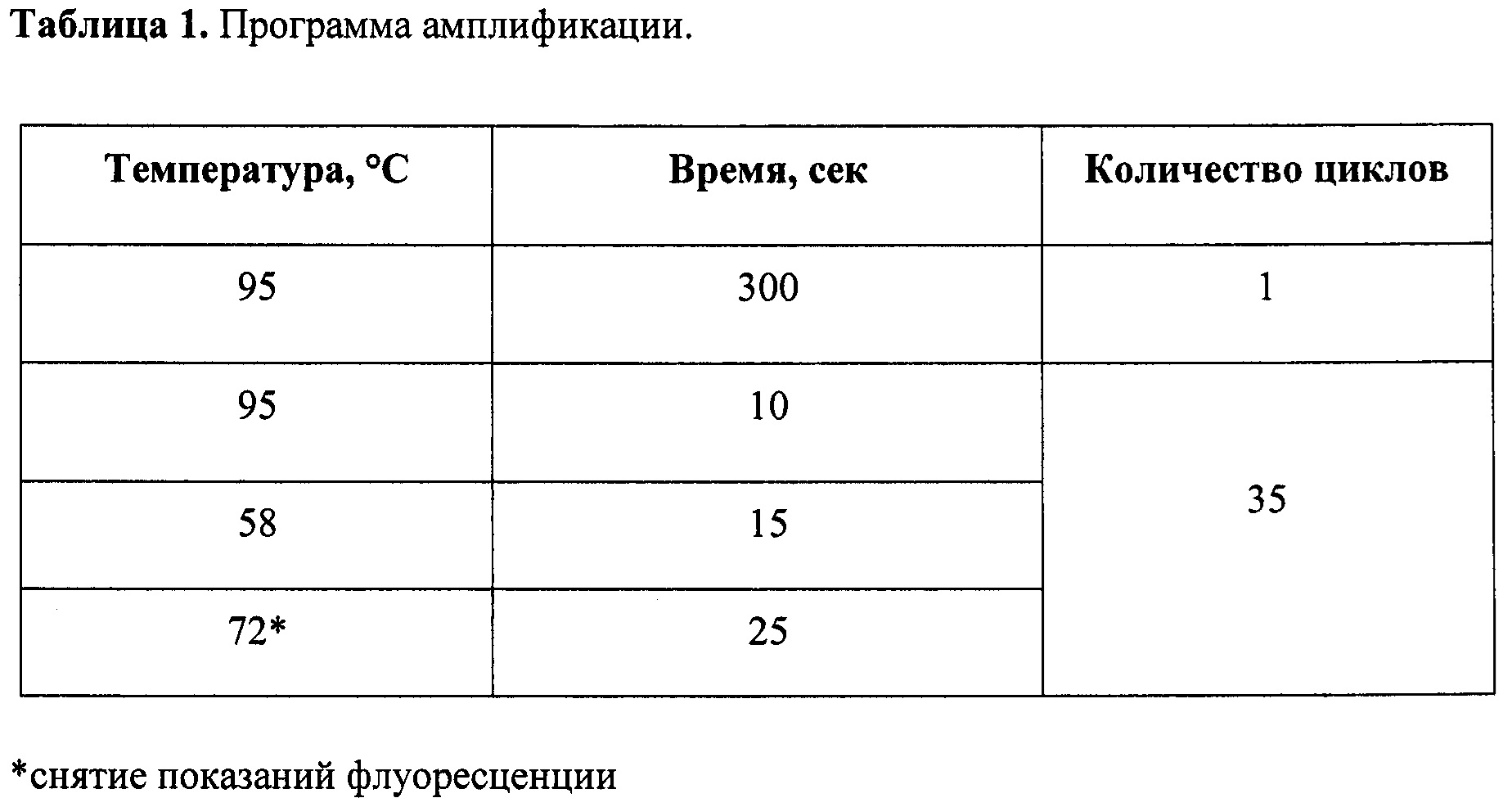
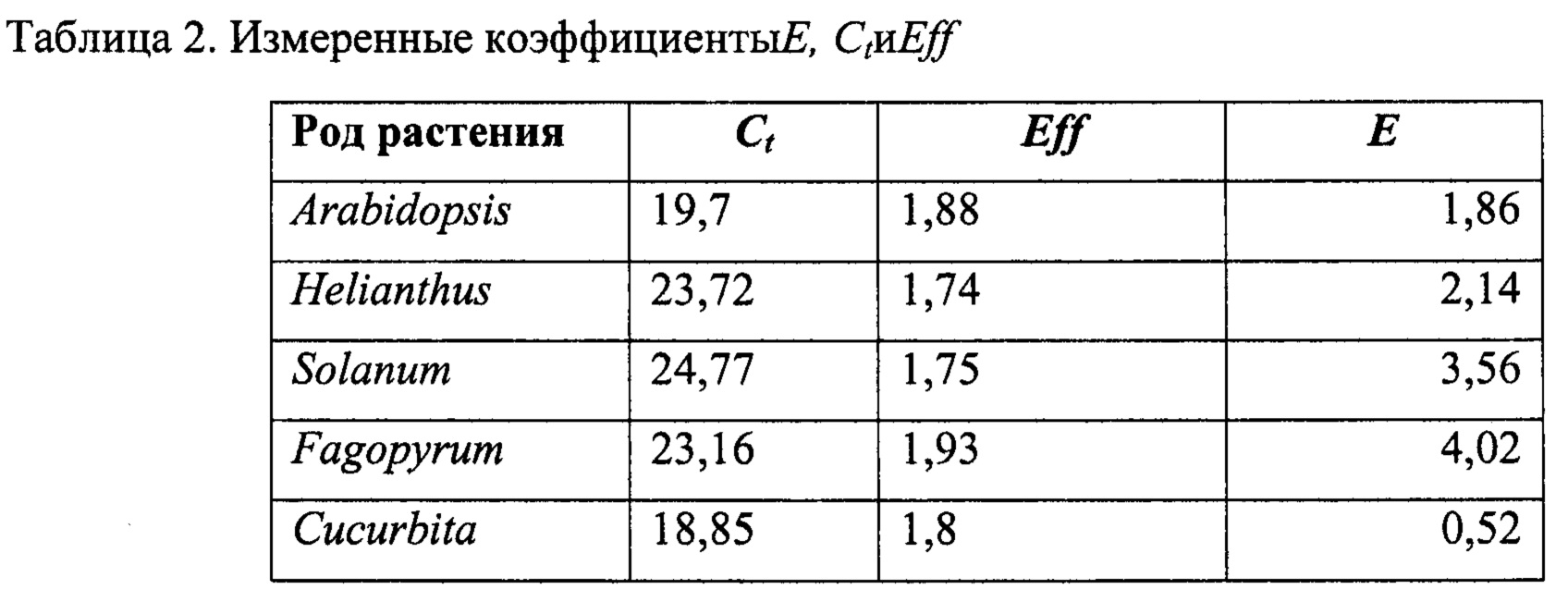
Анализ результатов амплификации и определение Ct осуществляли с помощью соответствующего программного обеспечения (LightCycler® 96 Software (v. 1.1.0.1320)) В Таблице 2 приведены средние значения измеренных коэффициентов по 3 повторам.
Далее, были подготовлены попарные смеси растений с равными массовыми долями каждого из двух компонентов(брали по 1 г каждого растения): Al (Arabidopsis/Cucurbita), А2 (Helianthus/Fagopyrum), A3 (Arabidopsis/Helianthus), А4 (Helianthus/Solanum).каждая смесь была подготовлена в 3х повторах. Был произведен анализ смесей с помощью разработанного в настоящем изобретении способа. После выделения ДНК из смесей проводили амплификацию анализируемых фрагментов генома в тех же условиях, в которых проводилась ПЦР-РВ (см. описание выше). Для создания библиотек для высокопроизводительного секвенирования полученные фрагменты генома очищали от реакционной среды с помощью магнитных частиц Agencourt AMPure ХР, в соотношении образец 20 мкл: магнитные частицы 30 мкл. Процедуру очистки проводили в соответствии с рекомендациями производителя (см. например, https://research.fhcrc.org/content/dam/stripe/hahn/methods/mol_biol/Agencourt%20AMPure%20XP.pdf). По окончании очистки проводили измерение концентрации полученного препарата ДНК с помощью реагентов Qubit dsDNA HS Assay Kit (Thermo Fisher Scientific). Далее осуществляли подготовку библиотек для высокопроизводительного секвенирования методом лигирования адаптеров. Для этого использовали подготовленные очищенные амплифицированные анализируемые фрагменты генома в количестве 45-65 нг на реакцию. Для подготовки библиотеки для секвенирования на полупроводниковых секвенаторах Ion Torrent использовали реагенты Ion Xpress Plus Fragment Library Kit (Thermo Fisher Scientific). Альтернативно, для подготовки библиотеки для секвенирования на секвенаторах Illumina использовали реагенты NEBNext® Ultra II DNA Library Prep Kit for Illumina (NEB). Подготовку библиотек проводили по протоколам и в соответствии с рекомендациями производителей, за исключением стадии амплификации. Амплификацию библиотек осуществляли с помощью того же набора реагентов, который был изначально выбран для амплификации анализируемых фрагментов генома. Очистку библиотек от реакционной среды проводили с помощью магнитных частиц Agencourt AMPure ХР, в соотношении: библиотека 20 мкл: магнитные частицы 20 мкл. Подготовленные библиотеки секвенировали на полупроводниковых секвенаторах Ion Torrent (Ion S5, 530 чипы), либо на секвенаторах Illumina (MiSeq, 500 циклов) в соответствии с рекомендациями производителей.
Далее, на основе рассчитанных ранее для этих растений коэффициентов вычисляли массовые доли компонентов в каждой смеси (Таблица 3).

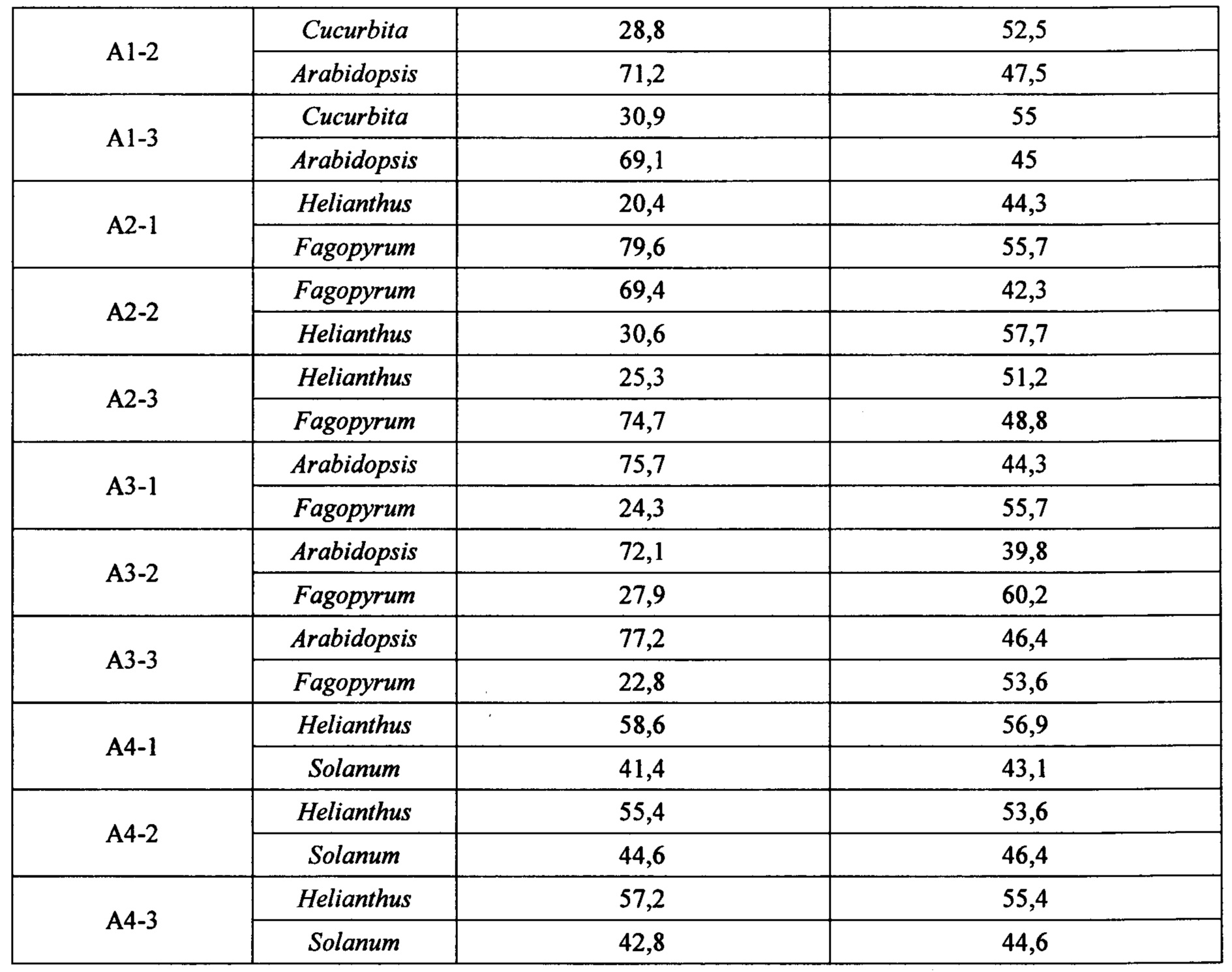
Как видно из Таблицы 3, во всех случаях использование поправочных коэффициентов для расчета массовых долей компонентов в смесях приводило к заметному улучшению результатов. Вычисленные соотношения сдвигались в сторону истинных значений 1:1.
Несмотря на то, что изобретение описано со ссылкой на раскрываемые варианты воплощения, для специалистов в данной области должно быть очевидно, что конкретные подробно описанные случаи приведены лишь в целях иллюстрирования настоящего изобретения, и их не следует рассматривать как каким-либо образом ограничивающие объем изобретения. Должно быть, понятно, что возможно осуществление различных модификаций без отступления от сути настоящего изобретения.
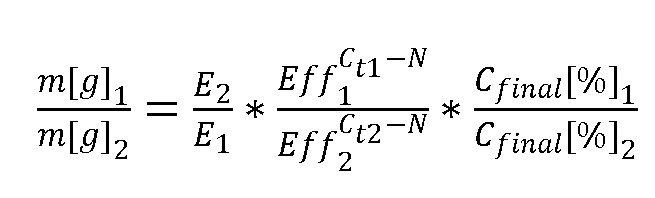
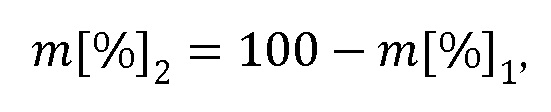
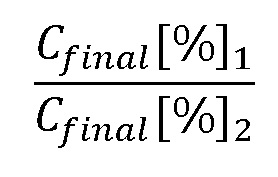
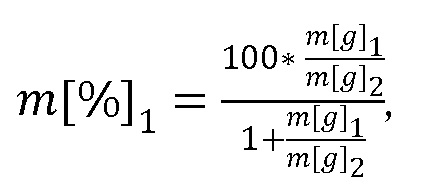
Метод получения прочного и токопроводящего волокна путем вытягивания пленок из углеродных нанотрубок
Устройство для переключения режимов работы оптоволоконного лазера и способ его изготовления
Средство разрезания днк на основе cas9 белка из defluviimonas sp.
Средство разрезания днк на основе cas9 белка из биотехнологически значимой бактерии clostridium cellulolyticum
Пептидный антагонист нмда-рецептора
Snp-панель для генотипирования и геномной селекции подсолнечника по содержанию жирных кислот в масле семян
Способ идентификации веществ с использованием масс-спектрометра
Средство разрезания днк на основе cas9 белка из бактерии demequina sediminicola
Средство разрезания днк на основе cas9 белка из бактерии pasteurella pneumotropica
Применение cas9 белка из бактерии pasteurella pneumotropica для модификации геномной днк в клетках
Способ диагностики гриппа с
Способ диагностики светлоклеточной почечноклеточной карциномы и набор для его осуществления

