Результат интеллектуальной деятельности: ИДЕНТИФИКАЦИЯ ПОЛЕЙ И ТАБЛИЦ В ДОКУМЕНТАХ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ГЛОБАЛЬНОГО КОНТЕКСТА ДОКУМЕНТА
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в общем относится к вычислительным системам, более конкретно к системам и способам детектирования текстовых полей в неструктурированных электронных документах с использованием нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[0002] Обнаружение текстовых полей в неструктурированных электронных документах является фундаментальной задачей в обработке, хранении и сопоставлении документов. Традиционные подходы обнаружения полей могут включать использование большого количества настраиваемых вручную эвристик и поэтому могут требовать большого количества ручного труда.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Варианты реализации настоящего изобретения описывают механизмы обнаружения текстовых полей и таблиц в неструктурированных документах в электронном виде с использованием нейронных сетей.
[0004] Способ по настоящему изобретению включает: получение множества последовательностей символов из документа включающего множество текстовых полей; определение множества векторов, в котором вектор из множества векторов принадлежит одной из множества последовательностей символов; обработка процессорным устройством множества векторов с использованием первой нейронной сети для получения множества пересчитанных векторов, при этом каждый из множества пересчитанных векторов пересчитывается на основе значений множества векторов; определение процессорным устройством взаимосвязи между первым пересчитанным вектором из множества пересчитанных векторов и первым текстовым полем из множества текстовых полей, при этом первый пересчитанный вектор принадлежит первой последовательности символов из множества последовательностей символов; а также определение взаимосвязи между первой последовательностью символов и первым текстовым полем на основе взаимосвязи между первым пересчитанным вектором и первым текстовым полем.
[0005] Система по настоящему изобретению включает: получение множества последовательностей символов из документа, при этом документ содержит множество текстовых полей; определение множества векторов, в котором вектор из множества векторов принадлежит одной из множества последовательностей символов; обработка посредством процессорного устройства множества векторов с использованием первой нейронной сети для получения множества пересчитанных векторов, при этом каждый из множества пересчитанных векторов пересчитывается на основе значений множества векторов; определение процессорным устройством связи между первым пересчитанным вектором из множества пересчитанных векторов и первым текстовым полем из множества текстовых полей, при этом первый пересчитанный вектор принадлежит первой последовательности символов из множества последовательностей символов; а также определение взаимосвязи между первой последовательностью символов и первым текстовым полем на основе взаимосвязи между первым пересчитанным вектором и первым текстовым полем.
[0006] Постоянный машиночитаемый носитель данных в соответствии с настоящим изобретением содержит инструкции, которые при обращении к ним процессорным устройством приводят его к выполнению операций,: получение множества последовательностей символов из документа, при этом документ содержит множество текстовых полей; определение множества векторов, в котором вектор из множества векторов принадлежит одной из множества последовательностей символов; обработку посредством устройства обработки данных множества векторов с использованием первой нейронной сети для получения множества пересчитанных векторов, при этом каждый из множества пересчитанных векторов пересчитывается на основе значений множества векторов; определение устройством обработки данных связи между первым пересчитанным вектором из множества пересчитанных векторов и первым текстовым полем из множества текстовых полей, при этом первый пересчитанный вектор является представителем первой последовательности символов из множества последовательностей символов; а также определение взаимосвязи между первой последовательностью символов и первым текстовым полем на основе взаимосвязи между первым пересчитанным вектором и первым текстовым полем.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Изложение сущности изобретения будет лучше понятно из приведенного ниже подробного описания и приложенных чертежей различных вариантов осуществления изобретения. Однако не следует считать, что чертежи ограничивают сущность изобретения конкретными вариантами осуществления; они предназначены только для пояснения и улучшения понимания сущности изобретения.
[0008] На ФИГ. 1 представлена блок-схема примера вычислительной системы 100, в которой может выполняться реализация настоящего изобретения.
[0009] На ФИГ. 2 представлена принципиальная схема, иллюстрирующая пример системы нейронной сети, которая использует общий контекст документа для выявления полей и таблиц в соответствии с некоторыми реализациями настоящего изобретения.
[0010] На ФИГ. 3А представлена принципиальная схема, иллюстрирующая пример подсистемы нейронной сети, которая пересчитывает значения векторных представлений различных последовательностей символов исходного документа на основе общего контекста документа в соответствии с некоторыми реализациями настоящего изобретения.
[0011] На ФИГ. 3В представлена принципиальная схема, иллюстрирующая пример модификации подсистемы нейронной сети в соответствии с ФИГ. 3А, способной выявлять признаки таблицы исходного документа на основе общего контекста документа в соответствии с некоторыми реализациями настоящего изобретения.
[0012] На ФИГ. 4 представлена принципиальная схема, иллюстрирующая пример подсистемы нейронной сети, которая предсказывает класс поля, заполненного последовательностью символов, определенной на изображении документа, в соответствии с некоторыми реализациями настоящего изобретения.
[0013] На ФИГ. 5 представлена блок-схема последовательности операций, иллюстрирующая один примерный способ, который использует нейронные сети для определения векторных представлений (например, словные эмбеддинги) для последовательностей символов, определенных на изображении документа, в соответствии с некоторыми реализациями настоящего изобретения.
[0014] На ФИГ. 6 представлена блок-схема последовательности операций, иллюстрирующая один примерный способ, который использует нейронные сети для определения связей между последовательностями символов и полями/таблицами документа, используя общий контекст документа, в соответствии с некоторыми реализациями настоящего изобретения.
[0015] На ФИГ. 7 представлена блок-схема последовательности операций, иллюстрирующая один примерный способ, который использует нейронные сети для создания и проверки множества гипотез о связях между последовательностями символов и полями/таблицами документа, в соответствии с некоторыми реализациями настоящего изобретения.
[0016] На ФИГ. 8 проиллюстрирована блок-схема компьютерной системы в соответствии с некоторыми реализациями настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0017] Описываются варианты реализации изобретения для обнаружения полей и таблиц в неструктурированных электронных документах с использованием нейронных сетей. Один из традиционных подходов к определению полей и соответствующих типов полей в таких документах основан на эвристических правилах. В случае эвристического подхода рассматривается большое количество (например, несколько сотен) документов, например, ресторанных счетов или квитанций, и накапливается статистика относительно того, какой текст (например, ключевые слова) используется рядом с определенным полем и где такой текст можно поместить относительно поля (например, в поле, справа, слева, выше, ниже). Например, эвристический подход может отслеживать, какое слово или слова часто расположены рядом с полем, указывающим общую сумму покупки, какое слово или слова находятся внутри или рядом с полем, указывающим на применимые налоги, какое слово или слова написаны внутри или рядом с полем, указывающим общую сумму оплаты по кредитной карте и т.д. На основе таких статистических данных при обработке нового счета можно определить, какие данные, обнаруженные в документе, соответствуют определенному полю. Однако эвристический подход не всегда работает точно, поскольку если по какой-либо причине счет был распознан с ошибками, а именно в словосочетаниях «ОБЩИЙ НАЛОГ» и «ОБЩИЙ ПЛАТЕЖ» слова «налог» и «платеж» были распознаны плохо, то соответствующие значения могут не пройти классификацию.
[0018] Аспекты настоящего изобретения устраняют отмеченные выше и другие недостатки, предоставляя механизмы обнаружения текстовых полей и (или) таблиц в документах с использованием нейронных сетей. Такие механизмы могут автоматически обнаруживать текстовые поля и (или) таблицы, имеющиеся в документе, и связывать каждое из текстовых полей с типом поля. Используемый в данном документе термин «неструктурированный электронный документ» (также называемый в данном документе просто «документ») может относиться к любому документу, изображение которого может быть доступно для вычислительной системы, которая выполняет выявление полей и (или) таблиц. Изображение может быть отсканированным изображением, сфотографированным изображением или любым другим представлением документа, который может быть преобразован в форму данных, доступную для компьютера. Например, под термином «неструктурированный электронный документ» может подразумеваться файл, содержащий один или несколько элементов цифрового содержимого, которые могут быть переданы визуально для создания визуального представления электронного документа (например, на дисплее или на печатном носителе). В соответствии с различными реализациями настоящего изобретения документ может быть представлен в виде файла любого подходящего формата, например, PDF, DOC, ODT, JPEG и др. Несмотря на то что документ может быть представлен в электронном (например, цифровом) формате, предполагается, что документ не имеет электронной структуры и что компоновка документа - места расположения различных текстовых полей, таблиц и т.д. - не указана в электронном виде. (Как, например, было бы, если бы документ был первоначально выпущен в электронном формате - электронный счет (e-invoice) или другие подобные электронные документы - с заранее заданными и определенными местоположениями полей и таблиц.)
[0019] Документ может представлять собой финансовый документ, юридический документ или любой другой документ, например, документ, который создается путем заполнения полей текстовыми символами (например, словами) или изображениями. Документ может представлять собой документ, который напечатан, набран или написан от руки (например, путем заполнения стандартной формы). Документ может представлять собой документ, который содержит множество полей, таких как текстовые поля (содержащие цифры, буквы, слова, предложения), графическое поле (содержащее логотип или любое другое изображение), таблицы (содержащие строки, столбцы, ячейки) и так далее. Под термином «текстовое поле» может подразумеваться поле данных в документе, которое содержит буквенно-цифровые символы. «Таблица» может относиться к любой графической структуре, например, структуре, образованной линиями. Линии могут определять множество строк (например, когда линии горизонтальные), множество столбцов (например, когда линии вертикальные) или множество ячеек (например, определенных вертикальными и горизонтальными линиями, если они присутствуют в документе). Реализации настоящего изобретения могут также применяться к документам, которые включают таблицы, определенные наклонными линиями. Такие случаи могут возникать в результате оформления документа или по причине смещения, которое происходит во время формирования изображения документа. Таблица может включать в себя ячейки, содержащие другие поля, такие как любые поля, заполненные буквенно-цифровыми символами, и (или) поля, содержащие изображения (например, логотипы) и т.д.
[0020] Под термином «тип поля» может подразумеваться тип содержимого, находящегося в поле. Например, типом поля может быть «имя», «наименование компании», «телефон», «факс», «адрес, «имя поставщика», «тип оплаты», «способ оплаты», «тип товара», «количество товара» или любая другая запись, которая может присутствовать в документе. Поле изображения может включать логотип компании, подпись, изображение товара, используемого вместо описания товара (или в дополнение к описанию товара), или любое другое изображение, которое может быть включено в документ.
[0021] Описанные в данном документе методы позволяют автоматически обнаруживать поля в документах с использованием искусственного интеллекта. Методы могут обучать нейронную сеть обнаруживать поля в документах и классифицировать поля по предопределенным классам. Каждый из предопределенных классов может соответствовать типу поля. Нейронная сеть может содержать множество нейронов, связанных с получаемыми при обучении весами и смещениями. Такие нейроны могут быть организованы в слои. Нейронная сеть может быть обучена на обучающей выборке данных документов, содержащих известные поля и (или) таблицы. Например, обучающая выборка данных может содержать примеры документов, содержащих одно или более полей/таблиц, в качестве исходных данных для обучения и один или более идентификаторов типа поля и (или) таблицы, которые правильно соответствуют одному или более полям/таблицам в качестве целевого результата. Нейронная сеть может построить наблюдаемый результат для всех исходных данных для обучения. Наблюдаемый результат работы нейронной сети можно сравнить с ожидаемым результатом работы, включенным в обучающую выборку данных, и ошибка может распространяться назад, на предыдущие слои нейронной сети, параметры которой (веса и смещения нейронов) могут регулироваться соответствующим образом. В ходе обучения нейронной сети параметры нейронной сети могут быть отрегулированы для оптимизации точности предсказания.
[0022] После обучения нейронная сеть может быть использована для автоматического распознавания полей/таблиц в исходном документе и выбора наиболее вероятного типа поля для каждого из обнаруженных полей. Использование нейронных сетей может избавить от необходимости ручной разметки полей, типов полей и таблиц в документах. Использование описанных в данном документе механизмов обнаружения полей в документе может повысить качество результатов обнаружения за счет выполнения обнаружения полей с использованием обученной нейронной сети, которая сохраняет информацию о контексте всего документа. Например, нейронные сети, настроенные и обученные в соответствии с реализациями настоящего изобретения, могут быть способны повысить точность обнаружения полей/таблиц и классификации типов полей на основе того, какие виды буквенно-цифровых последовательностей встречаются во всем документе. Например, нейронная сеть может определить числовую последовательность в нижнем левом углу документа, помеченную характерным жирным двоеточием, в качестве кода банка. Следовательно, нейронная сеть, обученная принимать во внимание контекст всего документа, может быть способна более точно обнаруживать другие поля того же документа, например, адрес, количество, номер счета группы, подпись или другие поля, обычно присутствующие на счете. Нейронная сеть, обученная в соответствии с реализациями настоящего изобретения, может применяться для идентификации документов любого типа и может обеспечивать эффективное обнаружение полей, таким образом повышая как точность обнаружения, так и скорость обработки вычислительного устройства, реализующего такое обнаружение.
[0023] На ФИГ. 1 представлена блок-схема примера вычислительной системы 100, в которой может выполняться реализация данного изобретения. Как показано на изображении, система 100 включает вычислительное устройство 110, хранилище 120 и сервер 150, подключенный к сети 130. Сеть 130 может быть общественной сетью (например, Интернет), частной сетью (например, локальной сетью (LAN) или распределенной сетью (WAN)), а также их комбинацией.
[0024] Вычислительное устройство 11 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, которое в состоянии использовать технологии, описанные в настоящем изобретении. В некоторых вариантах реализации изобретения вычислительное устройство 110 может быть и (или) включать одно или более вычислительных устройств 800 с ФИГ. 8.
[0025] Документ 140 может быть получен вычислительным устройством 110. Документ 140 может содержать любой подходящий текст, изображения или таблицы, например один или более символов (буквы и (или) цифры), слов, предложений и т.д. Документ 140 может относиться к любому подходящему типу, например «визитная карточка», «счет», «паспорт», «полис медицинского страхования», «опросный лист» и т.д. Тип документа 140 может быть указан пользователем и сообщен вычислительному устройству 110 вместе с документом 140 в некоторых реализациях.
[0026] Документ 140 может быть получен любым подходящим способом. Например, вычислительное устройство 110 может получить цифровую копию документа 140 путем сканирования документа или фотографирования документа. Кроме того, в тех вариантах реализации изобретения, где вычислительное устройство 110 представляет собой сервер, клиентское устройство, которое подключается к серверу по сети 130, может загружать цифровую копию документа 140 на сервер. В тех вариантах реализации изобретения, где вычислительное устройство 110 является клиентским устройством, соединенным с сервером по сети 130, клиентское устройство может загружать документ 140 с сервера или из хранилища 120.
[0027] Документ 140 может быть использован для обучения набора моделей машинного обучения или может быть новым документом, для которого следует выполнить обнаружение и (или) классификацию полей/таблиц. В некоторых вариантах реализации при использовании для обучения одной или более моделей 114 машинного обучения для последующего распознавания, документ 140 может быть соответствующим образом подготовлен для облегчения обучения. Например, в документе 140 могут быть вручную или автоматически выбраны текстовые последовательности или элементы таблиц, могут быть отмечены символы, текстовые последовательности или элементы таблиц могут быть нормализованы, масштабированы и (или) бинаризованы. В некоторых вариантах реализации изобретения текст в документе 140 может распознаваться с использованием любого подходящего метода оптического распознавания символов (OCR).
[0028] В одном из вариантов реализации изобретения вычислительное устройство 110 может содержать ядро 111 системы распознавания полей. Ядро 111 системы распознавания полей может содержать ядро 112 системы распознавания таблиц. В некоторых вариантах реализации ядро системы 112 распознавания таблиц может быть интегрировано в ядро системы распознавания полей, так что одно ядро выполняет оба распознавания. В некоторых вариантах реализации ядро 111 системы распознавания полей и ядро 112 системы распознавания таблиц могут представлять собой два независимых компонента. В других реализациях ядро 111 системы распознавания полей и ядро 112 системы распознавания таблиц могут совместно использовать некоторые общие компоненты (например, некоторые функции нейронной сети), но могут содержать другие компоненты, предназначенные для использования только одним из ядер. Ядро 111 системы распознавания полей и (или) ядро системы 112 распознавания таблиц может содержать инструкции, сохраненные на одном или более физических машиночитаемых носителях данных вычислительного устройства 110 и выполняемые на одном или более устройствах обработки данных вычислительного устройства 110.
[0029] В одном из вариантов реализации изобретения ядро 111 системы распознавания полей и (или) ядро 112 системы распознавания таблиц может использовать для обнаружения и (или) классификации полей/таблиц набор обученных моделей 114 машинного обучения. Модели 114 машинного обучения обучаются и используются для обнаружения и (или) классификации полей/таблиц в исходном документе. Некоторые из моделей 114 машинного обучения могут совместно использоваться ядром системы 111 распознавания полей и ядром системы 112 распознавания таблиц, тогда как некоторые модели могут использоваться только одним из ядер. В остальной части настоящего изобретения термин «ядро системы 111 распознавания полей» следует понимать как охватывающий также ядро системы 112 распознавания таблиц.
[0030] Ядро системы 111 распознавания полей также может предварительно обрабатывать любые документы перед использованием таких электронных документов для обучения модели (моделей) 114 машинного обучения и (или) применения обученной модели (моделей) 114 машинного обучения к документам. В некоторых вариантах реализации обученная модель (модели) 114 машинного обучения может быть частью ядра системы 111 распознавания полей или может быть доступна для другой машины (например, сервера 150) через ядро системы 111 распознавания полей. На основе результатов работы обученной модели (моделей) распознавания полей 114 ядро системы 111 распознавания полей может обнаруживать в электронном документе одно или более полей и (или) таблиц и может классифицировать каждое из полей, относя их к одному из множества классов, соответствующих заранее определенным типам полей.
[0031] Ядро системы 111 распознавания полей может быть клиентским приложением или же сочетанием клиентского компонента и серверного компонента. В некоторых вариантах реализации изобретения ядро системы 111 распознавания полей может быть запущено на исполнение на вычислительном устройстве клиента, например, это могут быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.д. В альтернативном варианте реализации клиентский компонент ядра системы 111 распознавания полей, исполняемый на клиентском вычислительном устройстве, может получать документ и передавать его на серверный компонент ядра системы 111 распознавания полей, исполняемый на серверном устройстве, который выполняет обнаружение и (или) классификацию полей. Серверный компонент ядра системы 111 распознавания полей может затем возвращать результаты распознавания (например, определенный тип поля для обнаруженного поля или обнаруженной таблицы или связи слова с ячейкой таблицы) в клиентский компонент ядра системы 111 распознавания полей, исполняемый на клиентском вычислительном устройстве, для сохранения. При альтернативном подходе, это может быть серверный компонент ядра системы распознавания полей или компонент для передачи в другое приложение. В других вариантах реализации изобретения ядро системы 111 распознавания полей может исполняться на серверном устройстве в качестве Интернет-приложения, доступ к которому обеспечивается через интерфейс браузера. Серверное устройство может быть представлено в виде одной или более вычислительных систем, например одним или более серверов, рабочих станций, больших ЭВМ (мейнфреймов), персональных компьютеров (ПК) и т.д.
[0032] Сервер 150 может быть стоечным сервером, маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, портативным компьютером, планшетным компьютером, фотокамерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или их сочетанием и (или) содержать указанное оборудование. Сервер 150 может содержать обучающую систему 151. Обучающая система 151 может строить модель (модели) 114 машинного обучения для обнаружения полей. Модель (модели) 114 машинного обучения, приведенная на ФИГ. 1, может быть обучена обучающей системой 151 с использованием обучающих данных, которые содержат обучающие входные данные и соответствующие целевые выходные данные (правильные ответы на соответствующие обучающие входные данные). Обучающая система 151 может находить в обучающих данных шаблоны, которые связывают обучающие входные данные с целевыми выходными данными (предсказанным ответом), и предоставлять модели 114 машинного обучения, которые используют такие шаблоны. Как более подробно будет описано ниже, набор моделей 114 машинного обучения может быть составлен, например, из одного уровня линейных или нелинейных операций (например, машина опорных векторов [SVM]) или может представлять собой глубокую нейронную сеть, то есть модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких нейронных сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети (RNN) с одним или более скрытыми слоями и полносвязанные нейронные сети. В некоторых вариантах реализации изобретения модель (модели) 114 машинного обучения может включать одну или несколько нейронных сетей, описанную применительно к ФИГ. 2-4.
[0033] Модель (модели) 114 машинного обучения может обучаться обнаружению полей в документе 140 и определять наиболее вероятный тип поля для каждого из полей в электронном документе 140. Например, обучающая система 151 может создавать обучающие данные для обучения модели (моделей) 114 машинного обучения. Обучающие данные могут храниться в хранилище 120 и включать в себя один или более наборов обучающих входных данных 122 и один или более наборов целевых выходных данных 124. Такие обучающие данные могут также содержать данные о сопоставлении 126 обучающих входных данных 122 с целевыми выходными данными 124. Обучающие входные данные 122 могут включать обучающую выборку документов, содержащих текст, изображения или таблицы (также - «обучающие документы»). Каждый из обучающих документов может быть документом, содержащим известные поля. Целевые выходные данные 124 могут быть классами, представляющими типы полей, соответствующие известным полям. Например, первый обучающий документ в первой обучающей выборке может содержать первое известное текстовое поле (например, «Джон Смит»). Первый обучающий документ может быть первым набором обучающих входных данных 122, который можно использовать для обучения модели (моделей) 114 машинного обучения. Первые целевые выходные данные 124, соответствующие первым обучающим входным данным 122, могут содержать класс, соответствующий типу поля для известного текстового поля (например, «имя»). В ходе обучения исходного классификатора обучающая система 151 может находить в обучающих данных шаблоны, которые можно использовать для сопоставления обучающих входных данных с целевыми выходными данными. Такие шаблоны могут быть впоследствии использованы моделью (моделями) 114 машинного обучения для дальнейшего предсказания. Например, после получения исходных данных с неизвестными текстовыми полями, содержащими неизвестный текст (например, одно или более неизвестных слов), обученная модель (модели) 114 машинного обучения может предсказать тип поля, к которому относится каждое неизвестное текстовое поле, и может вывести предсказанный класс, определяющий тип поля, в качестве результата.
[0034] Хранилище 120 может представлять собой постоянную память, которая в состоянии сохранять электронные документы, а также структуры данных для выполнения распознавания символов в соответствии с реализациями настоящего изобретения. Хранилище 120 может располагаться на одном или более запоминающих устройствах, таких как основное запоминающее устройство, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то, что хранилище изображено отдельно от вычислительного устройства 110, в одной из реализаций изобретения хранилище 120 может быть частью вычислительного устройства 110. В некоторых вариантах реализации хранилище 120 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище содержимого 120 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, например, объектно-ориентированную базу данных, реляционную базу данных и т.д., которая может находиться на сервере или одной или более различных машинах, подключенных к нему через сеть 130.
[0035] В некоторых вариантах реализации изобретения обучающая система 151 может обучать искусственную нейронную сеть, которая содержит множество нейронов, выполнению обнаружения полей в соответствии с некоторыми вариантами реализации настоящего изобретения. Каждый нейрон может получать свои исходные данные от других нейронов или из внешнего источника и генерировать результат, применяя функцию активации к сумме взвешенных исходных данных и полученному при обучении значению смещения. Нейронная сеть может содержать множество нейронов, распределенных по слоям, включая входной слой, один или более скрытых слоев и выходной слой. Нейроны соседних слоев соединены взвешенными ребрами. Веса ребер определяются на этапе обучения сети на основе обучающей выборки данных, которая содержит множество документов с известной классификацией полей. В иллюстративном примере все веса ребер инициализируются некоторыми изначально назначенными случайными значениями. Для каждого набора входных данных 122 в обучающей выборке система обучения 151 может активировать нейронную сеть. Наблюдаемый выход нейронной сети OUTPUTNN (ИСХОДНЫЕ ДАННЫЕ ОБУЧЕНИЯ) сравнивается с желаемыми выходными данными 124, заданными обучающей выборкой:
Сравнение: OUTPUTNN (ИСХОДНЫЕ ОБУЧАЮЩИЕ ДАННЫЕ) в сравнении с РЕЗУЛЬТАТОМ ОБУЧЕНИЯ
Полученная ошибка - разница между выходом нейронной сети OUTPUTNN и желаемым РЕЗУЛЬТАТОМ ОБУЧЕНИЯ - распространяется обратно на предыдущие слои нейронной сети, в которых веса настраиваются таким образом, чтобы изменить OUTPUTNN и приблизить его к РЕЗУЛЬТАТУ ОБУЧЕНИЯ. Такая корректировка может повторяться до тех пор, пока ошибка в результатах для конкретных исходных обучающих данных 122 не будет удовлетворять заранее определенным условиям (например, станет ниже заранее определенного порогового значения). Впоследствии могут быть выбраны другие исходные обучающие данные 122, может быть сгенерирован новый OUTPUTNN, может быть реализован новый ряд корректировок и т.д. до тех пор, пока нейронная сеть не будет обучена с достаточной степенью точности. В некоторых вариантах реализации данный метод обучения может применяться для обучения одной или более искусственных нейронных сетей, проиллюстрированных на ФИГ. 2-4.
[0036] После обучения моделей 114 машинного обучения множество моделей 114 машинного обучения может использоваться ядром системы 111 распознавания полей для анализа новых документов. Например, ядро системы 111 распознавания полей может вводить новый документ 140 и (или) признаки документа 140 в набор моделей 114 машинного обучения в качестве исходных данных. Ядро системы 111 распознавания полей может получать один или более итоговых результатов от множества обученных моделей машинного обучения и может извлекать из итоговых результатов один или более типов полей для каждого поля и/или таблиц, обнаруженных в документе 140. Предполагаемый тип поля может включать определенный тип поля, соответствующий типу обнаруженного поля (например, «имя», «адрес», «наименование компании», «логотип», «адрес электронной почты» и т.д.).
[0037] На ФИГ. 2 представлена принципиальная схема, иллюстрирующая пример 200 системы нейронной сети, которая использует общий контекст документа для выявления полей и таблиц, в соответствии с некоторыми реализациями настоящего изобретения. Нейронная сеть 200 может содержать множество нейронов, связанных с получаемыми при обучении весами и смещениями. Такие нейроны могут быть организованы в слои. Как показано, система нейронной сети 200 может включать в себя подсистему А 240, подсистему В 260 и подсистему С 270. Каждая из подсистем 240, 260 и 270 может включать несколько нейронных слоев и может быть настроена для выполнения одной или более функций для обнаружения полей/таблиц в соответствии с настоящим изобретением.
[0038] Система нейронной сети 200 может работать с изображением 210 документа, которое в некоторых вариантах реализации может являться изображением документа 140. Изображение 210 документа может быть получено путем визуализации (например, сканирования, фотографирования и т.д.) документа 140. В некоторых вариантах реализации визуализация может выполняться непосредственно перед обработкой изображения 210 документа нейросетевой системой 200. В некоторых вариантах реализации визуализация может выполняться в некоторый момент в прошлом, и изображение 210 документа может быть получено из локального или сетевого (например, облачного) хранилища. Изображение 210 документа может подвергаться оптическому распознаванию символов (OCR) либо непосредственно перед дальнейшей обработкой системой нейронной сети 200, либо в некоторый момент в прошлом. Оптическое распознавание символов может сопровождаться предварительной обработкой изображения 210 документа для улучшения его качества, например, масштабирования, изменения соотношения сторон, масштабирования серого, нормализации, увеличения данных, усиления, бинаризации и так далее.
[0039] Результатом оптического распознавания символов изображения 210 документа может быть набор распознанных последовательностей символов SymSeq(x,y), связанных с координатами х, у изображения 210 документа. Последовательности символов SymSeq могут содержать один или несколько буквенно-цифровых символов, которые могут быть объединены в слоги, слова и (или) предложения. Последовательности символов SymSeq могут представлять собой один или несколько знаков препинания, такие как запятая, точка, эллипсисы или любые другие знаки. Последовательности SymSeq могут быть горизонтальными, вертикальными или наклонными линиями таблиц, или трехсторонними или четырехсторонними пересечениями линий. Строки могут быть одинарными, двойными и т.д. Последовательности символов SymSeq могут быть любыми комбинациями символов, знаков пунктуации и (или) строк. В некоторых вариантах реализации для генерации последовательностей символов SymSeq, содержащихся в изображении 210 документа, ядро системы 111 распознавания полей (или любой другой компонент, который выполняет или выполнил оптическое распознавание символов на изображении 210 документа) может использовать подходящие способы распознавания символов, разделять текст документа на несколько слов и извлекать несколько последовательностей символов из слов.
[0040] Выявленные последовательности символов SymSeq могут отображаться в соответствующих областях изображения 210 документа, где расположены такие последовательности. Например, каждая последовательность SymSeq может быть связана с одним или несколькими наборами координат (х,у), которые определяют местоположения последовательностей. Координаты могут быть декартовыми или любыми другими (например, полярными) координатами, которые могут быть удобными при определении местоположений последовательностей символов. В одном из вариантов реализации отдельный символ, знак пунктуации или короткая строка могут быть определены одним набором координат (х,у), тогда как более длинные последовательности (слова, предложения, длинные строки) могут быть определены несколькими наборами (х,у), такими как координаты четырех углов области, содержащей последовательность. Линии могут быть определены по координатам двух концов линии. Пересечение двух линий (например, трехстороннее или четырехстороннее пересечение) может быть определено по координатам концов всех линий, а также по координатам пересечения. В настоящем изобретении (х,у) обозначает любое определение последовательностей символов с одним или более наборами координат, которые могут потребоваться для конкретной последовательности SymSeq.
[0041] Ядро системы 111 распознавания полей может вводить последовательности символов SymSeq(x,y) в подсистему А 240 для того, чтобы генерировать представления векторов (vector embeddings) в пространстве признаков для каждой из последовательностей символов: SymSeq(x,y) → vec(x,y). Каждый из векторов в пространстве признаков vec(x,y) может представлять собой векторное представление символа одной из последовательностей символов (например, слов/предложений, знаков пунктуации и (или) линий), что также упоминается как словный эмбеддинг. В некоторых вариантах реализации изобретения каждое векторное представление символа в таблицах может иметь определенную длину (то есть заранее определенную длину). Если длина последовательности символов меньше определенной длины, то к ней могут быть добавлены заранее определенные значения для того, чтобы создать векторное представление символа заранее определенной длины (например, к векторам могут добавлены нули). Термин «векторное представление символа» (symbolic vector embedding), используемый в данном документе, может означать вектор действительных чисел или любое другое цифровое представление последовательности символов. Векторное представление слова можно получить, например, с помощью нейронной сети, реализующей математическое преобразование символов (слов/знаков пунктуации/строк таблиц) с помощью функций вложения, отображая такие символы на их цифровые представления.
[0042] Векторные представления (vector embeddings) vec(x,y) - также называемые в данном документе как векторные представления последовательностей символов SymSec(x,y) или просто как «векторы» - могут быть созданы с использованием любой подходящей модели или комбинации моделей, таких как Word2Vec, GloVe, FastText и др. Подсистема А 240 может использовать множество нейронных слоев, таких как входной слой, выходной слой и один или несколько скрытых слоев. Подсистема А 240 может представлять собой рекуррентную нейронную сеть (RNN), RNN на уровне символов, сеть с долгой краткосрочной памятью (LSTM) или любую другую подобную сеть, включая любую комбинацию таких сетей. Подсистема А 240 может работать со словарем вложений (словарь эмбеддингов, embeddings dictionary), который может включать в себя векторные представления типичных слов, найденных в документах соответствующих типов. Подсистема А 240 может быть обучена генерировать такие векторные представления последовательностей символов SymSeq(x,y), которые имеют близкие числовые значения vec(x,y) для слов, имеющих близкие семантические значения (например, «число» и «количество»)), или которые могут быть найдены в непосредственной близости друг от друга (например, «сумма» и «предложенная»). Подсистема А 240 может быть предварительно обучена с использованием исходных обучающих данных 122 и результатов 124 обучения, как описано выше. Документы, используемые на этапе обучения - исходные обучающие данные 122 и результаты 124 обучения - могут быть документами того же типа, что и целевые документы (например, счета-фактуры, чеки, заказы на закупку и т.д.), которые следует использовать на этапе прогнозирования. Соответственно, несмотря на то что словарь для векторных вложений слов SymSec(x,y) может разрабатываться на этапе обучения для конкретного класса целевых документов, векторные вложения слов SymSec(x,y) не обязательно должны принадлежать словарю вложений, предварительно обученному на некотором более широком классе документов (например, книги, газеты, журналы), которые не связаны с конкретным классом целевых документов. Обученная первая подсистема 240 может быть способна предсказать, какая последовательность символов SymSeq следует (или предшествует или примыкает в вертикальном или горизонтальном направлении) за конкретной последовательностью SymSeq. Прогнозы первой подсистемы 240 могут быть представлены в виде вероятностей. Например, обученная подсистема А 240 может быть в состоянии предсказать, что слову «сумма» предшествует слово «общая» с вероятностью 30%, а за ним следует слово «предложенная» с вероятностью 15%.
[0043] В некоторых вариантах реализации выходные векторные представления в пространстве признаков vec(x,y) могут быть независимыми от конкретного местоположения (х,у) последовательности символов SymSeq. Более конкретно, координаты (х,у) последовательности символов SymSeq(x,y) могут служить геометрическим идентификатором последовательности, но ее векторное представление vec(x,y) может быть одинаковым независимо от того, где на изображении находится последовательность. Например, подсистема А 240 может назначать одинаковые вероятности того, что различные последовательности символов SymSeq (например, «город», штат») находятся в непосредственной близости от слова «улица». В других вариантах реализации векторные представления vec(x,y) одной и той же последовательности символов SymSeq могут отличаться в зависимости от местоположения последовательности в документе (или в пределах изображения 210 документа). Например, выходные данные подсистемы А 240 - векторные представления слов, например, «условное депонирование» - могут варьироваться в зависимости от местоположения (х,у) слова внутри изображения 210 документа. Соответственно, векторное представление фразы «условное депонирование» может быть ближе (в векторном пространстве) к представлениям одного множества слов, если «условное депонирование» встречается в середине документа, но ближе к представлениям другого множества слов, если «условное депонирование» находится в нижней части документа. Векторные представления конкретного слова могут также зависеть от типа документа. Например, слово «сумма» может быть по-разному представлено в договоре, передающем право в недвижимости, и в заказе на покупку.
[0044] В результате, если М последовательностей символов (символов, знаков пунктуации, слов, предложений) определены на изображении 210 документа и введены в подсистему А 240, выходные данные первой подсистемы могут представлять собой множество из М векторов (векторов в пространстве признаков) {vec(x,y)}. Каждый из М векторов vec(x,y) может зависеть от контекста всего документа - типа документа, количества слов в документе, расположения текста в документе, расположения некоторых или всех слов в документе и так далее.
[0045] Векторное пространство для векторов vec(x,y) может иметь ряд измерений N, выбранных в зависимости от сложности документа. В некоторых вариантах реализации N может быть равно 128 (32, 64 или любому другому числу). Число N может быть выбрано большим с целью представления последовательности символов сложного документа, и, наоборот, меньшим для более простых документов, имеющих ограниченный словарный запас слов. Для заданного числа измерений N каждый вектор может иметь N компонентов, vec(x,y)=(z1, z2,…zN), где zj может быть двоичным числом, десятичным числом или любым другим числом, доступным для компьютера. В некоторых вариантах реализации некоторые из векторов vec(x,y), определенных подсистемой А 240, например более короткие слова или знаки пунктуации, могут содержать меньше N чисел. В таких вариантах реализации остальным компонентам вектора могут быть назначены нулевые значения, так что общая длина всех векторов может быть одинаковой.
[0046] Выходные данные подсистемы А 240 могут быть схематически представлены в виде параллелепипеда (куба) 250, составленного из компонентов отдельных векторов в множестве {vec(x,y)}. В направлениях плоскостей х и у область изображения 210 документа может быть дискретизирована на р ячеек в направлении х и s ячеек в направлении у (например, р=32 и s=64, в одном примерном варианте реализации). Слово (символ, предложение) с центром в конкретной ячейке (х,у) может иметь свое векторное представление vec(x,y)=(z1, z2, … zN), визуализированное в виде последовательности блоков (ячеек), расположенных в третьем направлении, как схематически показано на ФИГ. 2 для углового вектора. Другие векторы могут быть аналогичным образом размещены в других ячейках параллелепипеда 250, называемого в данном документе «кубом», при этом следует помнить, что число ячеек в каждом из трех направлений может отличаться от количества ячеек в двух других, где s×p×N - общее количество ячеек в «кубе». Для формирования куба можно использовать функцию Map (например, Gather).
[0047] Некоторые ячейки (или вертикальные грани) куба 250 могут быть пустыми (например, заполнены нулями). Например, ячейки, расположенные над координатами (х,у), которые соответствуют пустым пространствам изображения 210 документа, могут содержать все нули. Строка (в направлении х) или столбец (в направлении у) могут содержать все нули для всех своих векторов, если такая строка или столбец не содержит символов (например, попадает между строками текста). Даже в тех строках/столбцах, которые содержат символы, некоторые ячейки (или даже большинство ячеек) могут быть заполнены нулями. Например, если j-я строка содержит десять слов, а горизонтальный размер изображения 210 документа дискретизирован на 32 ячейки, в данной строке могут присутствовать только 10 ненулевых векторов vec(x,y), разделенных 22 нулевыми векторами. В некоторых вариантах реализации векторы (х,у), которые не имеют по меньшей мере одного ненулевого компонента, могут быть исключены из куба.
[0048] Куб 250, имеющий s×р×N ячеек, содержащих множество {vec(x,y)} из М выявленных векторов, соответствующих выявленным последовательностям символов, может быть введен в подсистему В 260 для пересчета векторов {vec(x,y)} → {VEC (х,у)} с учетом общего контекста всего документа. Подсистема В 260 может содержать одну или более нейронных сетей (как поясняется ниже со ссылкой на ФИГ. 3А), которые могут модифицировать компоненты векторных представлений vec(x,y) последовательностей символов с учетом всех других векторов куба 250. В результате пересчитанные значения VEC(x,y)=(Z1, Z2, … Z2N) могут учитывать контекст всего документа. Более конкретно, пересчитанные значения VEC(x,y)=(Z1, Z2, … Z2N), выводимые подсистемой В 260, могут учитывать наличие всех других последовательностей символов в документе, а также содержимое каждого из таких символов последовательности.
[0049] Новый куб 270, содержащий множество пересчитанных векторов {VEC(x,y)}, может быть введен в подсистему С 280 для прогнозирования класса каждой последовательности символов, выявленной в изображении 210 документа. В некоторых вариантах реализации ядро системы 111 распознавания полей может использовать модель (модели) 114 машинного обучения для генерации гипотез о последовательностях символов SymSeq 220 документа (представленного набором векторов {VEC(x,y)}), принадлежащих различным классам полей в исходном документе 140, как описано более подробно ниже со ссылкой на ФИГ. 4. Классами поля могут быть: «название поставщика», «тип товара», «количество товара», «номер заказа», «тип отправки», «место доставки», «дата заказа», «вид оплаты» и так далее. В некоторых вариантах реализации различные классы полей могут быть предварительно определены для по меньшей мере некоторых типов документов и введены в третью подсистему 280 в виде множества внешних параметров. В других вариантах реализации различные классы, которые могут присутствовать в документе, могут быть определены третьей подсистемой 280, которая может быть обучена определять тип исходного документа (например, «счет-фактура», «заказ», «счет» и т.д.) и предсказывать классы полей, которые могут присутствовать в определенном типе исходного документа.
[0050] Некоторые из компонентов, показанных на ФИГ. 2, могут быть объединены. Например, в одном из вариантов реализации подсистемы А, В и С могут быть реализованы в виде одной нейронной сети. В некоторых вариантах реализации подсистемы А и В могут быть реализованы как одна сеть, в то время как подсистема С может быть реализована как отдельная сеть. В некоторых вариантах реализации подсистемы В и С могут быть реализованы как одна сеть, в то время как подсистема А может быть реализована как отдельная сеть. В тех вариантах реализации, где множество подсистем реализуются объединенной единой сетью, функции разных подсистем объединенной сети могут быть реализованы отдельными выделенными слоями или совместно используемыми слоями или их комбинацией.
[0051] На ФИГ. 3А представлена принципиальная схема, иллюстрирующая пример подсистемы 300 нейронной сети, которая пересчитывает значения векторных представлений различных последовательностей символов исходного документа на основе общего контекста документа в соответствии с некоторыми вариантами реализации настоящего изобретения. В одном из вариантов реализации подсистема 300 нейронной сети может быть подсистемой В 240. Подсистема 300 нейронной сети может быть реализована ядром системы 111 распознавания полей.
[0052] Куб 250, содержащий множество {vec(x,y)} векторов, соответствующих выявленным последовательностям символов SymSeq, может быть введен в подсистему 300. Подсистема 300 может включать в себя одну или более нейронных сетей, каждая из которых содержит множество слоев нейронов. В некоторых вариантах реализации подсистема 300 может включать в себя две нейронные сети, сеть 310 горизонтального прохода и сеть 320 вертикального прохода. В некоторых вариантах реализации сеть 310 горизонтального прохода и сеть 320 вертикального прохода могут быть сетями с долгой краткосрочной памятью (LSTM). В других вариантах реализации сеть 310 горизонтального прохода и сеть 320 вертикального прохода могут быть сетями RNN или LSTM, основанными на механизме внимания.
[0053] Сеть 310 горизонтального прохода и сеть 320 вертикального прохода могут выполнять множество проходов в горизонтальном (x) и вертикальном (у) измерениях куба 250. Более конкретно, сеть 310 горизонтального прохода может выбирать в последовательных итерациях каждый из s столбцов основания (нижняя плоскость ячеек), а сеть 320 вертикального прохода может аналогично выбирать каждую из р строк основания. Нулевые векторы (те, которые содержат все нули) могут игнорироваться, например, могут быть пропущены. Сеть 310 горизонтального прохода и сеть 320 вертикального прохода могут пересчитывать векторные компоненты, vec(x,y)=(z1, z2, … zN) → VEC(x,y)=(Z1, Z2, … ZN) для некоторых или всех векторов {vec(x,y)}, так что значения VEC(x,y)=(Z1, Z2, … ZN) пересчитываются на основе значений всех векторов {vec(x,y)} документа и, следовательно, новые значения {VEC(x,y)} могут зависеть от контекста (типа, содержимого) всего документа.
[0054] В одном примерном варианте реализации векторный пересчет может быть выполнен следующим образом. Сеть 310 горизонтального прохода может итеративно выбирать последовательные значения столбцов j, так что 1≤j≤s. Для каждого j сеть 310 горизонтального прохода может определять плоскость векторных компонентов z1n (xj,yk), z1 (xj,yk), … zN (xj,yk), расположенных в ячейке куба 250, имеющих один и тот же индекс столбца j, но разные возможные индексы строк k. Сеть 310 горизонтального прохода может затем использовать параметры (например, весовые коэффициенты и смещения) сети 310 для изменения значений векторных компонентов z1 (xj,yk), z1 (xj,yk), … zN (xj,yk) на основе значений в предыдущей плоскости, z1 (xj-1,yk), z1 (xj-1,yk), … zN (xj-1,yk), или фиксированного числа (два, три, десять или любое другое число) предыдущих плоскостей. В некоторых вариантах реализации значения для плоскости столбца j могут быть пересчитаны на основе всех предыдущих плоскостей, имеющих индексы от 1 до j-1. После пересчета значений компонентов вектора z1 (xj,yk), z1 (xj,yk), … zN (xj,yk)) для плоскости столбца j сеть 310 горизонтального прохода может приступить к пересчету значений компонентов вектора для следующей плоскости, z1 (xj+1,yk), z1 (xj+1,yk), … zN (xj+1,yk) и так далее, пока все столбцы куба 250 не будут пересчитаны.
[0055] Сеть 310 горизонтального прохода может выполнять несколько горизонтальных проходов, как описано выше. В некоторых вариантах реализации некоторые из проходов могут выполняться в обратном направлении, например, начиная с j=s и продолжая в направлении меньших значений j, пока столбец j=1 не будет достигнут и пересчитан.
[0056] Сеть 320 вертикального прохода может также выбирать в последовательных итерациях каждую из р строк базовой плоскости ячеек куба 250 и аналогичным образом пересчитывать компоненты вектора на основе значений всех векторов {vec(x,y)} документа. Например, сеть 320 вертикального прохода может итеративно выбирать последовательные значения строк к, так что 1≤k≤р. Для каждого А: сеть 320 вертикального прохода может определять плоскость векторных компонентов z1 (xj,yk), z1 (xj,yk), … zN (xj,yk), расположенных в ячейке куба 250, имеющих один и тот же индекс строки k, но различные возможные индексы столбцов j. Сеть 320 вертикального прохода может затем использовать параметры (например, весовые коэффициенты и смещения) сети 320 для изменения значений компонент вектора z1 (xj,yk), z1 (xj,yk), … zN (xj,yk) на основе значений в предыдущей плоскости, z1 (xj,yk-1), z1 (xj,yk-1), … zN (xj,yk-1), или фиксированного числа (два, три, десять или любое другое число) предыдущих плоскостей. В некоторых вариантах реализации значения для плоскости строк к могут быть пересчитаны на основе всех предыдущих плоскостей строк, имеющих индексы от 1 до k-1. После пересчета значений компонентов вектора z1 (xj,yk), z1 (xj,yk), … zN (xj,yk) для плоскости строк k сеть 310 горизонтального прохода может приступить к пересчету значений компонентов вектора для следующей плоскости, z 1(xj,yk+1), z1 (xj,yk+1), … zN (xj,yk+1) и так далее, до тех пор, пока все строки куба 250 не будут пересчитаны.
[0057] Параметры сети 310 горизонтального прохода могут отличаться от параметров сети 320 вертикального прохода. Параметры двух сетей могут быть определены на этапе обучения путем выбора одного или более наборов обучающих входных данных 122, определения выходных данных объединенной сети (подсистемы 300), сравнения выходных данных с результатами 124 обучения и обратного распространения ошибок через слои сетей по сети 310 горизонтального прохода и сети 320 вертикального прохода.
[0058] На этапе обучения сеть 310 горизонтального прохода и сеть 320 вертикального прохода могут выполнять множество проходов, пока ошибка выходных данных подсистемы 300 не станет ниже некоторой предварительно определенной ошибки. Проходы по сети 310 горизонтального прохода и сети 320 вертикального прохода могут выполняться в различных последовательностях. Например, в одной реализации первый проход может быть прямым проходом по сети 310 горизонтального прохода, второй путь может быть обратным путем по сети 310 горизонтального прохода, третий проход может быть прямым путем по сети 320 вертикального прохода, четвертый проход может быть обратным путем по сети 320 вертикального прохода и так далее. Данный процесс может повторяться несколько раз. Альтернативно, в другом варианте реализации первый проход может быть прямым проходом по сети 310 горизонтального прохода, второй путь может быть прямым путем по сети 320 вертикального прохода, третий проход может быть обратным путем по сети 310 горизонтального прохода, четвертый проход может быть обратным путем по сети 320 вертикального прохода и так далее. В другом варианте реализации каждая из двух сетей может выполнять несколько (например, два, три или более) проходов в одном и том же направлении (вперед или назад), прежде чем одна и та же сеть сможет выполнить несколько проходов в противоположном направлении или перед тем, как другие сети выполнят несколько проходов (в любом направлении). Специалист в данной области техники поймет, что возможно реализовать практически неограниченное количество различных комбинаций двух сетей, выполняющих проходы в двух направлениях.
[0059] Результатом этапа обучения может быть множество параметров (например, смещения и весовые коэффициенты) для сети 310 горизонтального прохода и множество параметров для сети 320 вертикального прохода. Такие два множества могут быть разными. Кроме того, каждая из двух сетей может содержать множество параметров, которое отличается для прямых и обратных проходов. Кроме того, несмотря на то что в некоторых вариантах реализации параметры (например, для обратных проходов сети 310 горизонтального прохода) могут быть независимыми от того, где находится пересчитанная плоскость столбца, в других вариантах реализации параметры могут зависеть от таких местоположений. Например, параметры могут отличаться для плоскостей столбцов (плоскостей строк), расположенных вблизи краев документа, от плоскостей, расположенных вблизи середины документа.
[0060] Выходные данные сети 310 горизонтального прохода и сети 320 вертикального прохода могут быть объединены для получения пересчитанного куба 270. (Операция объединения обозначена на ФИГ. 3А белым крестом.) Связанные векторы могут иметь пересчитанные значения VEC(x,y)=(Z1, Z2, … ZN, ZN+1, … Z2N), содержащие первые N компонентов, которые представляют выходные данные сети 310 горизонтального прохода, и последние N компонентов, которые представляют выходные данные сети 320 вертикального прохода (или наоборот). Например, в одном примерном варианте реализации, если исходные векторы vec(x,y), которые формируют (исходный) куб 250, содержат 128 компонентов, пересчитанные векторы VEC(x,y), которые формируют (выходной) куб 270, могут содержать 256 компонентов.
[0061] В одном из вариантов реализации на этапе прогнозирования подсистема 300 может работать в том же порядке комбинаций, что и на этапе обучения. В других вариантах реализации количество проходов на этапе прогнозирования может быть меньше (или больше), чем на этапе обучения. Например, если количество анализируемых документов является значительным, число проходов (на один документ) на этапе прогнозирования может быть значительно уменьшено по сравнению с этапом обучения.
[0062] На этапе прогнозирования, после завершения заранее определенного количества проходов (количество проходов может быть заранее определено на этапе обучения, как число, достаточное для достижения требуемой точности), подсистема 300 может выводить куб 270, содержащий пересчитанные значения компонентов вектора VEC(x,y)=(Z1, Z2, … ZN, ZN+1, … Z2N), функция 330 Unmap (например, Scatter) может отображать пересчитанный куб 270 в множестве пересчитанных векторов 340, имеющих исходную длину (N компонентов). К примеру, в некоторых вариантах реализации функция 330 Unmap может объединять два компонента вектора (Z1, Z2, … ZN, ZN+1, … Z2N), например, согласно Zk+ZN+k → Zk., или согласно некоторой другой схеме установления соответствия, которая уменьшает количество векторных компонентов от 2N до N. В других вариантах реализации функция 330 Unmap может сначала исключить нулевые компоненты вектора (Z1, Z2, … ZN, ZN+1, … Z2N) и выбрать N первых (N последних, N наибольших и т.д.) оставшихся компонентов. В другом варианте реализации слой плотной нейронной сети, имеющий 2N входов и N выходов, может сокращать вектор VEC(x,y)=(Z1, Z2, … ZN, ZN+1, … Z2N) до упрощенного вектора VEC(x,y)=(Z1, Z2, … ZN). Упрощенные (несопоставленные) векторы 340 могут содержать координаты соответствующих последовательностей символов SymSeq. В некоторых вариантах реализации уменьшение длины каждого из векторов с 2N до N может включать только один данный вектор; а именно, определение компонентов упрощенного вектора, определенного по координатам (х,у), может не включать компоненты других векторов (например, определенных по другим координатам). Поскольку несопоставленные векторы 340, выводимые подсистемой 300, пересчитываются на основе значений всех векторов документа, несопоставленные векторы 340 зависят от контекста всего документа.
[0063] На ФИГ. 3В представлена принципиальная схема, иллюстрирующая пример модификации 350 подсистемы 300 нейронной сети в соответствии с ФИГ. 3А, способной выявлять признаки таблицы исходного документа на основе общего контекста документа, в соответствии с некоторыми вариантами реализации настоящего изобретения. В одном из вариантов реализации подсистема 350 нейронной сети может быть подсистемой В 240. Подсистема 350 нейронной сети может быть реализована ядром системы 111 распознавания полей.
[0064] Подсистема 350 нейронной сети может работать аналогично подсистеме 300 нейронной сети, но может иметь дополнительный выход для обнаружения таблиц, такой как механизм 360 распознавания признаков таблицы. Подсистема 350 нейронной сети может содержать сеть 310 горизонтального прохода и сеть 320 вертикального прохода, которые могут выполнять множество горизонтальных и вертикальных проходов в прямом и обратном направлениях, как описано выше со ссылкой на ФИГ. 3А. При каждом проходе в последовательных итерациях сеть 310 горизонтального прохода и сеть 320 вертикального прохода могут пересчитывать векторы vec(x,y)=(z1, z2, … zN). Среди таких векторов могут быть как векторы, соответствующие буквенно-цифровым символам, так и векторы, соответствующие строкам таблиц. Пересчитанные векторы VEC(x,y)=(Z1, Z2, … ZN) основаны на значениях всех векторов документа, описывающих буквенно-цифровые последовательности и строки таблиц, и, следовательно, новое множество векторов {VEC(x,y)} может зависеть от контекста (типа, содержимого) всего документа, включая относительное расположение буквенно-цифровых последовательностей, а также строк и разделов таблиц.
[0065] Механизм 370 распознавания признаков таблицы может включать в себя выход горизонтальных линий 370, который может использоваться для выявления строк таблиц. Механизм 360 распознавания признаков таблицы также может включать в себя выход 380 вертикальных линий, который может использоваться для выявления столбцов таблиц. Выход 370 горизонтальных линий и выход 380 вертикальных линий могут определять протяженность строк и столбцов, соответственно, и могут дополнительно различать строки, столбцы и ячейки нескольких таблиц, которые могут присутствовать в документе. Более конкретно, выход 370 горизонтальных линий и выход 380 вертикальных линий могут определять, является ли данная строка левой/правой или верхней/нижней строкой таблицы. Механизм 360 распознавания признаков таблицы может дополнительно содержать выход 390 соответствия слов и таблиц, который может содержать информацию о принадлежности конкретной буквенно-цифровой последовательности к конкретной строке, столбцу или ячейке таблицы.
[0066] На ФИГ. 4 представлена принципиальная схема 400, иллюстрирующая пример подсистемы 410 нейронной сети, которая предсказывает класс поля, заполненного последовательностью символов, определенной на изображении документа, в соответствии с некоторыми вариантами реализации настоящего изобретения. Подсистема 410 нейронной сети, показанная на ФИГ. 4, в одном из вариантов реализации может быть подсистемой С 280. Подсистема 410 нейронной сети может быть реализована ядром 111 системы распознавания полей. Подсистема 410 нейронной сети может использовать в качестве исходных данных выходной сигнал подсистемы В (например, подсистемы 300 или подсистемы 350). Более конкретно, подсистема С 410 нейронной сети может вводить пересчитанные значения векторных компонентов VEC(x,y)=(Z1, Z2, … ZN), соответствующих выявленным последовательностям символов SymSeq(x,y). Подсистема С 410 может иметь один или несколько полностью связанных/плотных нейронных слоев, например, слои 412, 414, 416. Некоторые из полностью связанных слоев могут использовать функцию softmax. В некоторых вариантах реализации один или более полностью соединенных слоев 412, 414 и (или) 416 могут быть соединены друг с другом слоями, которые не являются полностью связанными.
[0067] В некоторых вариантах реализации подсистема 410 может использовать дополнительный вход 420 типа поля, который может включать в себя списки полей для различных типов документов. Например, в некоторых вариантах реализации вход 420 типа поля может содержать информацию о том, что документ счета может включать в себя такие поля, как «продавец», «покупатель», «адрес продавца», «адрес покупателя», «тип товара», «количество товара, «способ оплаты», «сумма депозита», «дата доставки», «дата доставки», «подпись» и т.д. В некоторых вариантах реализации вход типа поля может предоставляться как часть обучающих входных данных 122, а результаты 124 обучения и подсистема 410 могут определять количество и тип полей, встречающихся в документах различных типов, как часть процесса обучения (этапа).
[0068] Подсистема С 410 может классифицировать каждую из последовательностей символов SymSec(x,y) в качестве одного из множества предопределенных классов. Каждый из заранее определенных классов может соответствовать одному из обнаруженных типов полей. Для классификации последовательности символов подсистема С 410 может строить гипотезы о том, что некоторые или каждая из выявленных последовательностей символов, описанных соответствующими векторами 340, принадлежат одному из полей документа. Подсистема С 410 может дополнительно определять вероятности того, что конкретная последовательность символов принадлежит различным типам полей в документе (определяется на этапе обучения или вводится явно). Выход 430 прогнозирования класса поля подсистемы С 410 может включать в себя связь каждой из последовательностей символов SymSeq(x,y) с различными классами K1, K2, K3, K4 и т.д. Например, как указано на ФИГ. 4, связи могут быть созданы посредством назначения различных вероятностей для последовательностей SymSeq(x,y), принадлежащих соответствующим типам полей, которые должны быть обнаружены. Например, подсистема С 410 может определить, что конкретная последовательность SymSeq(x,y) может принадлежать классу K3 с вероятностью 60%, классу K1 с вероятностью 20%, классу K6 с вероятностью 15% и классу K2 с вероятностью 5%.
[0069] Для определения предсказаний 430 класса поля для различных последовательностей символов документа подсистема С 410 может сначала построить множество гипотез о том, что каждая из выявленных SymSeq(x,y) может принадлежать данному классу Kn. Например, гипотеза может состоять в том, что множество нескольких слов, расположенных рядом друг с другом (например, в одной и той же строке), может принадлежать одному и тому же полю (например, адресу поставщика). Другая гипотеза может заключаться в том, что одни и те же слова могут принадлежать адресу покупателя. Гипотеза для слова может быть построена на основе одной или более характеристик слова (или предложения), которые известны с определенностью, таких как местоположение слова, количество символов в слове и т.д. Генератор гипотез, реализованный подсистемой С 410 и (или) ядром 111 системы распознавания полей, может строить множественные гипотезы для каждого SymSeq(x,y) на основании известных признаков данной последовательности.
[0070] Затем множество сгенерированных гипотез может быть введено в одну или более нейронных сетей подсистемы С 410 для оценки/про верки сгенерированных гипотез и для присвоения значений вероятности каждой сгенерированной гипотезе. Для проверки гипотез может использоваться функция тестирования. Функция тестирования может быть определена на основе оценки обучающих входных данных 122, сравнения фактических выходов подсистемы С 410 с результатами 124 обучения и коррекции параметров функции тестирования таким образом, чтобы минимизировать разницу между фактическими выходами подсистемы 410 и результатами 124 обучения. Обучение функции тестирования может выполняться с использованием методов повышения градиента, методов дерева решений или аналогичных методов.
[0071] Затем подсистема С 410 может формировать и проверять цепочки (множества) гипотез. Например, подсистема С 410, возможно, определила, что последовательность символов Word-1 с вероятностью 95% принадлежит полю F1, а слово Word-2 принадлежит полю F2 с вероятностью 60% и полю А с вероятностью 30%. Вместо того, чтобы решить, что слово Word-2 должно быть связано с полем В (в соответствии с более высокой вероятностью), подсистема С 410 может проанализировать две цепочки гипотез: 1) Word-1 относится к классу K1, a Word 2 относится к классу K2, и 2) и Word-1, и Word-2 относятся к классу K1. Подсистема 410 может затем определить, что Word-1 и Word-2 должны иметь более высокую вероятность принадлежности одному и тому же полю, чем к другим полям, и, следовательно, гипотеза 2) должна быть предпочтительной гипотезой, несмотря на индивидуальное определение Word-2 в пользу его принадлежности к классу K1. В другом примере цепочка гипотез, которая оставляет некоторые поля пустыми, может быть проигнорирована по сравнению с цепочкой, которая присваивает по меньшей мере одно слово каждому из полей.
[0072] Построение и проверка гипотез для обнаружения таблиц могут выполняться аналогично построению и проверке гипотез, связанных со словами. Выход горизонтальных линий 370 может использоваться для построения гипотез, связанных с расположением строк таблиц в документе. Выход 380 вертикальных линий может использоваться для построения гипотез, связанных с расположением столбцов таблиц в документе. Выход 390 соответствия слов и таблиц может использоваться для построения гипотез, связанных с принадлежностью различных буквенно-цифровых последовательностей различным разделам таблицы - строкам, столбцам и ячейкам. Например, при построении гипотез может быть сгенерировано множество гипотез о расположении буквенно-цифровых последовательностей (например, слов) относительно различных горизонтальных и вертикальных линий, о связи слов с ячейками таблиц и т.д. Во время проверки гипотез нейронная сеть (например, подсистема С 410) определяет вероятности для различных гипотез, цепочек гипотез и анализирует конфликты между гипотезами (и (или) цепочками гипотез). В результате выбираются наиболее вероятные гипотезы, которые могут связывать разделы таблицы с буквенно-цифровыми предложениями, связанными (например, принадлежащими) с такими разделами. Оценка гипотез (определение вероятностей) может выполняться с помощью эвристических методов, методов дерева решений, методов повышения градиента и так далее. Классификация типов разделов таблицы может быть выполнена с помощью функции, обученной оценивать признаки (векторы) слов, принадлежащие различным разделам таблицы, в обучающих входных данных 122.
[0073] После выбора наиболее вероятных гипотез и (или) цепочек гипотез последовательности символов SymSeq(x,y) могут быть классифицированы в соответствии с гипотезами (цепочками гипотез), которые определены как имеющие самые высокие вероятности. Множество последовательностей символов может быть связано с каждым полем документа и (или) разделом таблицы (таблиц), представленной в документе. Каждый раздел поля/таблицы может содержать одну или более последовательностей символов (например, отдельные буквенно-цифровые символы, отдельные слова, несколько слов, предложения и т.д.). Некоторые поля/разделы таблицы могут не содержать обнаруженных символов. Содержимое выявленных полей/разделов таблицы документа может храниться, например, в хранилище 120 или любом другом устройстве хранения, включая локальное или сетевое (например, облачное) устройство хранения. Содержимое выявленных полей/разделов таблицы может быть сохранено как часть профиля документа. В одном из вариантов реализации профиль документа может храниться в выделенном файле или папке, связанной с получателем документа. В других вариантах реализации профиль документа может быть сохранен как часть файла или папки, связанной с автором документа, с типом документа, временем выпуска документа и т.п.
[0074] В одном из вариантов реализации после выявления полей/разделов таблицы в документе информация о выявленных полях/разделах таблицы может быть сохранена, например, в хранилище 120 или любом другом устройстве хранения, включая локальное или сетевое (например, облачное) устройство хранения. Поля/разделы таблицы могут быть определены по их абсолютным местоположениям (например, координатам) или относительным местоположениям (относительно других полей/разделов). Данная информация может повторно использоваться при вводе последующего документа того же или подобного типа для выявления полей. В таких случаях после оптического распознавания символов последующего документа поля/разделы таблицы могут быть заполнены (и сохранены в профиле последующего документа) последовательностями символов для уже определенных полей/разделов таблицы на основе координат (х,у) последовательностей символов в последующем документе. В таких случаях нейронные сети, возможно, не должны использоваться для обнаружения полей/разделов таблицы в последующих документах. В других вариантах реализации, где можно ожидать, что последующий документ (или форма) может иметь другую компоновку или макет, поля/разделы таблицы (и их местоположения), определенные для исходного документа, могут использоваться во время выявления полей последующего документа в качестве гипотез. Такие гипотезы могут быть проверены вместе с другими гипотезами, которые могут генерироваться нейронными сетями, как описано выше. Новая компоновка полей/разделов таблицы, обнаруженная в каждом дополнительном документе, может быть аналогичным образом добавлена в пул гипотез для обнаружения полей/таблиц в будущих документах.
[0075] В одном примерном варианте реализации после получения последующего документа и выявления конкретной последовательности символов последующего документа может быть определено, что местоположение последовательности символов в последующем документе совпадает, в пределах предварительно определенной точности, с местоположением первого текстового поля или с первым разделом таблицы в одном из ранее обработанных документов. Затем может быть определено, что последовательность символов последующего документа связана с первым текстовым полем или с первым разделом таблицы.
[0076] В некоторых вариантах реализации местоположение текстового поля или раздела таблицы может быть определено на основе размещения буквенно-цифровой последовательности относительно по меньшей мере одной другой последовательности символов из множества последовательностей символов. Например, размещение буквенно-цифровой последовательности «предложенная» может быть определено относительно местоположения другой последовательности «общая сумма».
[0077] На ФИГ. 5, 6 и 7 показаны блок-схемы, иллюстрирующие примерные способы 500, 600 и 700, которые используют нейронные сети для учета общего контекста документа при выявлении полей и таблиц в соответствии с некоторыми реализациями настоящего изобретения. Каждый из способов 500, 600 и 700 может выполняться логикой обработки, которая может включать аппаратные средства (электронные схемы, специализированную логику, программируемую логику, микрокоманды и т.д.), программное обеспечение (например, инструкции, выполняемые обрабатывающим устройством), встроенное программное обеспечение или комбинацию всех таких средств. В одном из вариантов реализации изобретения способы 500, 600 и 700 могут выполняться устройством обработки данных (например, устройством 802 обработки данных на ФИГ. 8) вычислительного устройства 110 и (или) сервера 150, как показано применительно к ФИГ. 1. В некоторых вариантах реализации способы 500, 600 и 700 могут выполняться в одном потоке обработки. При альтернативном подходе способы 500, 600 и 700 могут выполняться с помощью двух или более потоков обработки, причем каждый поток выполняет одну или несколько отдельных функций, процедур, подпрограмм или операций способа. В иллюстративном примере потоки обработки реализации способов 500, 600 и 700 могут быть синхронизированы (например, с использованием семафоров, критических секций и/или других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, реализующие способы 500, 600 и 700, могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то, что ФИГ. 5, 6, и 7 и соответствующее описание содержат список операций для способов 500, 600 и 700 в определенном порядке, в различных вариантах осуществления способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[0078] На ФИГ. 5 представлена блок-схема последовательности операций, иллюстрирующая один примерный способ 500, который использует нейронные сети для определения векторных представлений (например, словные эмбеддинги, word embeddings) для последовательностей символов, определенных на изображении документа, в соответствии с некоторыми вариантами реализации настоящего изобретения. В блоке 510 устройство обработки данных (например, компьютер), реализующее способ 500, может выполнять оптическое распознавание символов изображения документа, чтобы получить распознанный текст документа 510. В некоторых вариантах реализации документ может содержать множество текстовых полей, заполненных буквенно-цифровыми последовательностями символов. В некоторых вариантах реализации документ также может содержать по меньшей мере одну таблицу, имеющую множество разделов, таких как ячейки, строки и (или) столбцы.
[0079] В блоке 520 устройство обработки данных, реализующее способ 500, может разделить распознанный текст на множество последовательностей символов SymSeq(x,y) документа. Последовательности символов могут быть буквенно-цифровыми, графическими или комбинированными. Буквенно-цифровые последовательности могут представлять собой текст (слоги, слова, предложения), цифры, символические знаки и т.д. Графические последовательности могут представлять собой элементы графической таблицы, такие как горизонтальная линия, вертикальная линия, наклонная линия, угол (двухстороннее пересечение линий, которое может указывать на угловой раздел таблицы), трехстороннее пересечение линий (которое может указывать на краевой раздел таблицы) или четырехстороннее пересечение линий (которое может указывать на внутренний раздел таблицы). Комбинированная последовательность может представлять собой комбинацию одного или более буквенно-цифровых символов и одного или более графических элементов таблицы. Последовательность может состоять из множества символов, но в некоторых случаях может быть одним символом.
[0080] В блоке 530 устройство обработки данных, реализующее способ 500, может вводить множество последовательностей символов в нейронную сеть А. Нейронная сеть А может быть подсистемой А (240), описанной со ссылкой на ФИГ. 2. Целью нейронной сети А может быть определение множества словных эмбеддингов, представляющих последовательности символов, определенные в блоке 520. В частности, в блоке 540 нейронная сеть А может определять внедрение слова для каждой из множества последовательностей символов. Словные эмбеддинги могут быть векторами vec(x,y)=(Z1, Z2, … ZN), соответствующими обнаруженным последовательностям символов SymSeq(x,y), как описано выше со ссылкой на ФИГ. 2. Нейронная сеть А может быть предварительно обучена на исходных документах, которые могут быть такого же типа, что и целевой документ.
[0081] Определенные векторы (например, словные эмбеддинги) vec(x,y)=(Z1, Z2, … ZN) могут быть введены в нейронную сеть В (550). Нейронная сеть В может быть подсистемой В (260), описанной со ссылкой на ФИГ. 2. Целью нейронной сети В может быть пересчет векторов {vec(x,y)} → {VEC(x,y)} с учетом общего контекста всего документа.
[0082] На ФИГ. 6 представлена блок-схема последовательности операций, иллюстрирующая один примерный способ 600, который использует нейронные сети для определения связей между последовательностями символов и полями/таблицами документа, используя общий контекст документа, в соответствии с некоторыми вариантами реализации настоящего изобретения. В блоке 610 устройство обработки данных, реализующее способ 600, может получить множество последовательностей символов документа, содержащего множество текстовых полей и, необязательно, одну или несколько таблиц. В одном из вариантов реализации операции, выполняемые в блоке 610, могут быть аналогичны операциям, выполняемым в блоках 510 и 520 способа 500. В блоке 620 устройство обработки данных может определить множество векторов vec(x,y), представляющих последовательности символов. В одном из вариантов реализации операции, выполняемые в блоке 610, могут быть аналогичны операциям, выполняемым в блоках 530 и 540 способа 500.
[0083] В блоке 630 способ 600 может продолжаться с обработки множества векторов {vec(x,y)} с использованием нейронной сети В. Выходные данные нейронной сети В могут являться множеством векторов, {vec(x,y)} → {VEC(x,y)}, пересчитанных на основе значений всех или некоторых векторов из множества векторов (640). Для получения множества пересчитанных векторов устройство обработки данных, реализующее способ 600, может использовать сеть 310 горизонтального прохода и (или) сеть 320 вертикального прохода, как описано со ссылкой на ФИГ. 3А-В. Выходные данные сетей 310 и 320 могут быть объединены, и множество пересчитанных векторов {VEC(x,y)} может быть определено по объединенным результатам, как описано выше.
[0084] В блоке 650 способ может продолжаться с определения связи между первым пересчитанным вектором и первым текстовым полем, причем первый пересчитанный вектор принадлежит первой последовательности символов. Например, текстовое поле «Итого» может быть связано с пересчитанным вектором, который соответствует сумме, указанной в документе счета. Дополнительный блок 652 может выполняться в тех случаях, когда документ содержит по меньшей мере одну таблицу. В частности, в блоке 652 устройство обработки данных, реализующее способ 600, может определять связь между первым пересчитанным вектором и вторым пересчитанным вектором, первым пересчитанным вектором, представляющим буквенно-цифровую последовательность, и вторым пересчитанным вектором, связанным с разделом таблицы, таким как ячейка, строка или столбец. В некоторых вариантах реализации первый пересчитанный вектор блока 652 может быть таким же, как первый пересчитанный вектор блока 650. Например, первый пересчитанный вектор, представляющий величину (буквенно-цифровую последовательность) и связанный с полем «Итого» в блоке 650, также может быть определен в блоке 652 как связанный с разделом таблицы (например, последней строкой или ячейкой таблицы), представленным вторым пересчитанным вектором. Однако в некоторых реализациях первый пересчитанный вектор блока 652 может отличаться от первого пересчитанного вектора блока 650. В блоке 660 способ 600 может продолжаться с определения связи между первой последовательностью символов и первым текстовым полем или (когда присутствует по меньшей мере одна таблица) связи между буквенно-цифровой последовательностью и разделом таблицы.
[0085] На ФИГ. 7 представлена блок-схема последовательности операций, иллюстрирующая способ 700, который использует нейронные сети для создания и проверки множества гипотез о связях между последовательностями символов и полями/таблицами документа, в соответствии с некоторыми вариантами реализации настоящего изобретения. В некоторых вариантах реализации способ 700 может реализовывать блоки 650, 652 и 660 способа 600. Например, в блоке 710 способ 700 может принимать множество пересчитанных векторов {VEC(x,y)} от нейронной сети В. В блоке 720 устройство обработки данных, реализующее способ 700, может построить с помощью нейронной сети С множество гипотез о связи, содержащих связи одного из множества пересчитанных векторов с первым текстовым полем или с разделом таблицы. В некоторых вариантах реализации нейронная сеть С может быть подсистемой С (410) по ФИГ. 4. Например, гипотеза может состоять в том, что n-й вектор, представляющий буквенно-цифровую последовательность «$ 128», связан с полем «предложенная сумма», которая, как известно, присутствует (или может присутствовать с некоторой вероятностью) в документе. В качестве другого иллюстративного примера гипотеза может состоять в том, что m-й вектор, представляющий буквенно-цифровую последовательность «итого», связан с самой правой ячейкой в первой строке таблицы, которая может присутствовать в документе.
[0086] В блоке 730 способ может продолжаться с определения вероятности возникновения для каждой из множества гипотез о связи. В одном из вариантов реализации это может быть выполнено с использованием одного или нескольких нейронных слоев сети С с использованием функции тестирования. Функция тестирования может быть определена на основе оценки обучающих входных данных (например, обучающих входных данных 122) и сравнения выходов сети С с результатами 124 обучения и параметров настройки функции тестирования для того, чтобы минимизировать разницу между текущими выходами и результатами обучения.
[0087] В блоке 740 может быть определено, что первая гипотеза о связи из множества гипотез о связи имеет наибольшую вероятность возникновения. Например, первая гипотеза о связи может включать в себя связь первого пересчитанного вектора со вторым пересчитанным вектором. Наибольшая вероятность может относиться к связи данной последовательности символов с конкретным полем или с конкретным разделом таблицы в одной возможной реализации. Другими словами, гипотезы могут быть сгруппированы по последовательностям символов (например, все возможные гипотезы о связи последовательности символов «$ 128» с различными полями могут быть сгруппированы вместе). Соответственно, в пределах данной группы может быть проанализировано множество гипотез о возможных связях конкретной последовательности символов с различными полями/разделами таблицы, и может быть выбрана гипотеза с наибольшей вероятностью. В другом возможном варианте реализации гипотезы могут быть сгруппированы по полям или по разделам таблицы. Например, все возможные гипотезы о связи ячейки таблицы (2,4) - например, ячейки в четвертом столбце второй строки - с различными буквенно-цифровыми последовательностями могут быть сгруппированы вместе, и может быть выбрана гипотеза о наибольшей вероятности связи ячейки (2, 4).
[0088] В блоке 750 способ 700 может продолжаться, когда устройство обработки данных выбирает гипотезу с наибольшей вероятностью и связывает первый пересчитанный вектор с первым текстовым полем или с первым разделом таблицы
[0089] На ФИГ. 8 приведен пример вычислительной системы 800, которая может выполнять один или более методов настоящего изобретения. Данная вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Данная вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяет действия данного устройства. Кроме того, несмотря на то что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных в данном документе способов или нескольких таких способов.
[0090] Пример вычислительной системы 800 включает устройство 802 обработки данных, основное запоминающее устройство 804 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например, синхронное DRAM (SDRAM)), статическое запоминающее устройство 806 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство 816 хранения данных, которые взаимодействуют друг с другом по шине 808.
[0091] Устройство 802 обработки данных представляет собой одно или более устройств обработки общего назначения, например, микропроцессоров, центральных процессоров или аналогичных устройств. В частности, устройство 802 обработки может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW), процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Устройство 802 обработки также может представлять собой одно или более устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.д. Устройство 802 обработки реализовано с возможностью выполнения инструкций 826 для реализации ядра 111 системы распознавания полей и (или) обучающей системы 151 на Фиг. 1, а также выполнения операций и шагов, описанных в данном документе (то есть способов 600-700 на Фиг. 6-7).
[0092] Вычислительная система 800 может дополнительно включать устройство 822 сетевого интерфейса. Вычислительная система 800 может также включать видеомонитор 810 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство 812 буквенно-цифрового ввода (например, клавиатуру), устройство 814 управления курсором (например, мышь) и устройство 820 для формирования сигналов (например, громкоговоритель). В одном из иллюстративных примеров видео дисплей 810, устройство 812 буквенно-цифрового ввода и устройство 814 управления курсором могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0093] Устройство 816 хранения данных может содержать машиночитаемый носитель 824 данных, в котором хранятся инструкции 826, реализующие одну или более из методик или функций, описанных в данном документе. Инструкции 826 могут также находиться полностью или по меньшей мере частично в основном запоминающем устройстве 804 и (или) в устройстве 802 обработки во время их выполнения вычислительной системой 800, основным запоминающим устройством 804 и устройством 802 обработки, также содержащим машиночитаемый носитель информации. В некоторых вариантах осуществления изобретения инструкции 826 могут дополнительно передаваться или приниматься по сети через устройство 822 сопряжения с сетью.
[0094] Несмотря на то что машиночитаемый носитель 824 данных показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет данную машину выполнять одну или более методик, описанных в настоящем описании изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как включающий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0095] Несмотря на то, что операции способов показаны и описаны в данном документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться (по крайней мере частично) одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0096] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0097] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без таких конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, для того, чтобы не усложнять описание настоящего изобретения.
[0098] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных для того, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный в данном документе (и в целом) алгоритм сконструирован в общем как непротиворечивая последовательность шагов, ведущих к требуемому результату. Такие шаги требуют физических манипуляций с физическими величинами. Обычно, но не обязательно, такие величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать, а также можно выполнять другие манипуляции с ними. Иногда удобно, прежде всего для обычного использования, описывать такие сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0099] Однако следует иметь в виду, что все такие и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемые к таким величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «анализ» и т.п., относятся к действиям вычислительной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах и памяти вычислительной системы в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[00100] Настоящее изобретение также относится к устройству для выполнения операций, описанных в данном документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнито-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[00101] Алгоритмы и изображения, приведенные в данном документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной в данном документе информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации настоящего изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[00102] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (то есть считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и пр.).
[00103] Слова «пример» или «примерный» используются в данном документе для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в данном документе как «пример», не должна обязательно рассматриваться как предпочтительная или преимущественная по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В данной заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя А, X включает в себя В или X включает и А, и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, неопределенные артикли, использованные в данной заявке и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант осуществления» или «один вариант осуществления» либо «реализация» или «одна реализация» не означает одинаковый вариант реализации, если такое описание не приложено. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
[00104] Принимая во внимание множество вариантов и модификаций раскрываемого изобретения, которые, без сомнения, будут очевидны специалисту в уровне техники, после прочтения изложенного выше описания, следует понимать, что любой частный вариант осуществления изобретения, приведенный и описанный для иллюстрации, ни в коем случае не должен рассматриваться как ограничение. Таким образом, ссылки на подробности различных вариантов реализации изобретения не должны рассматриваться как ограничение объема притязания, который содержит только признаки, рассматриваемые в качестве сущности изобретения.
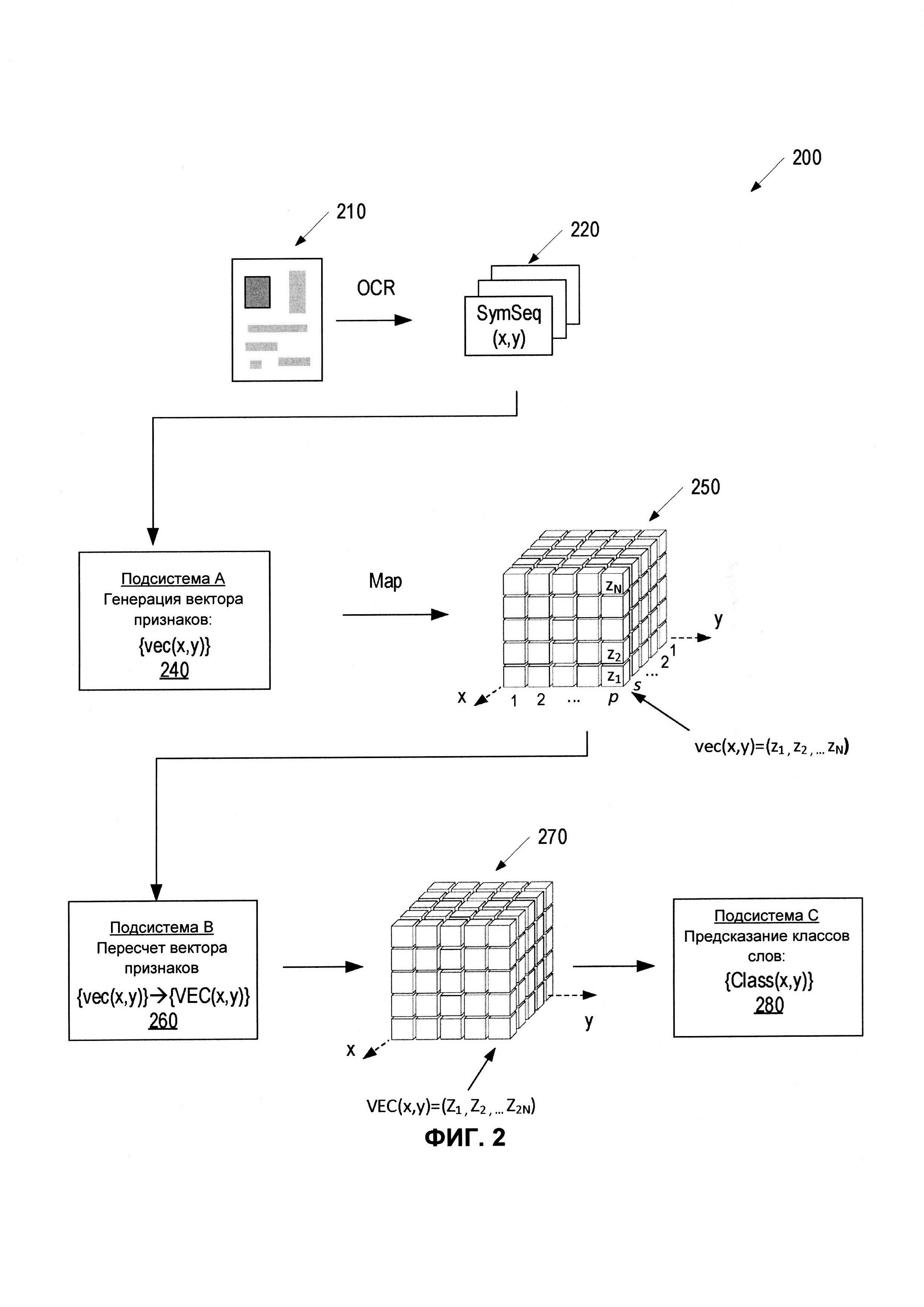
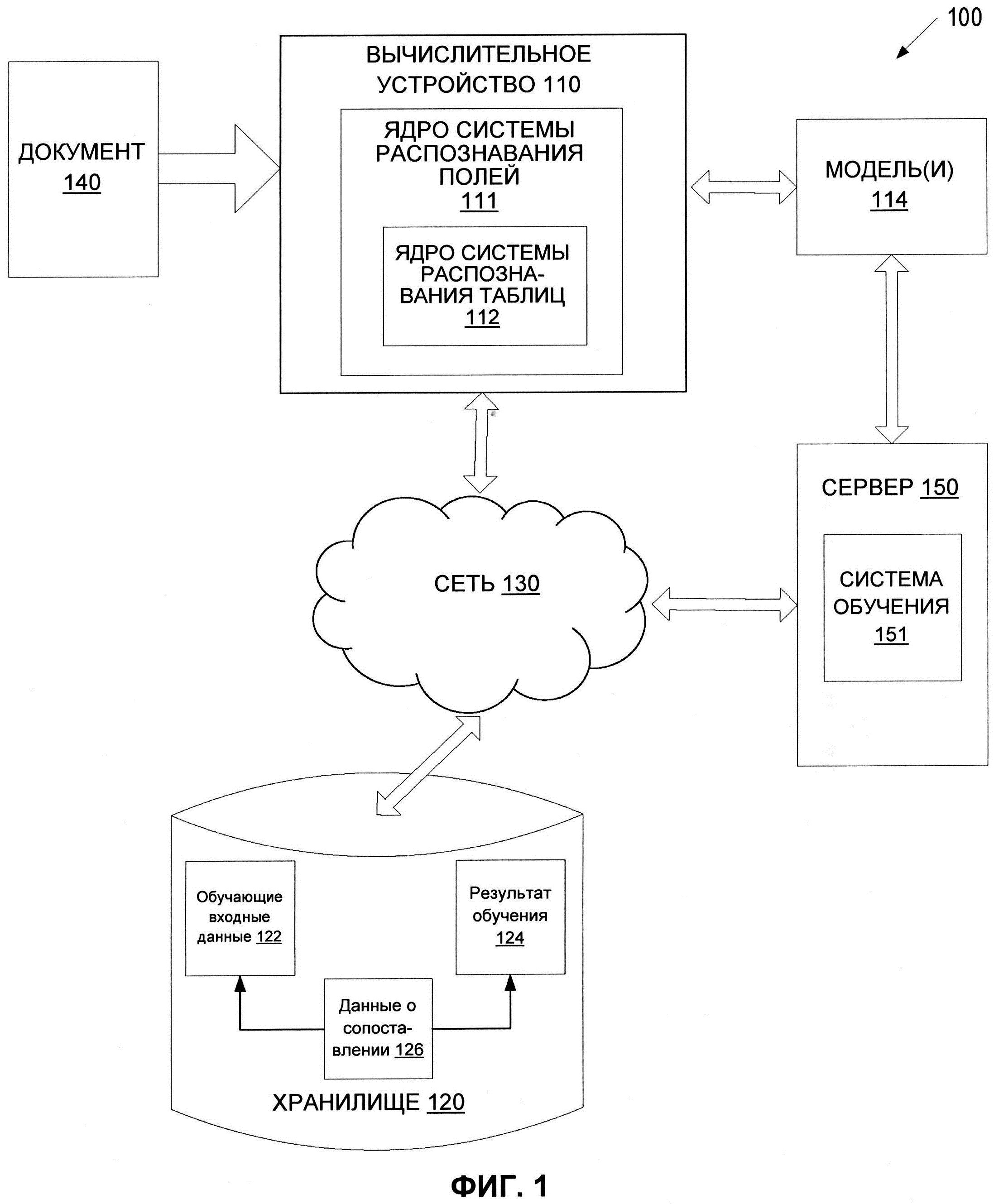
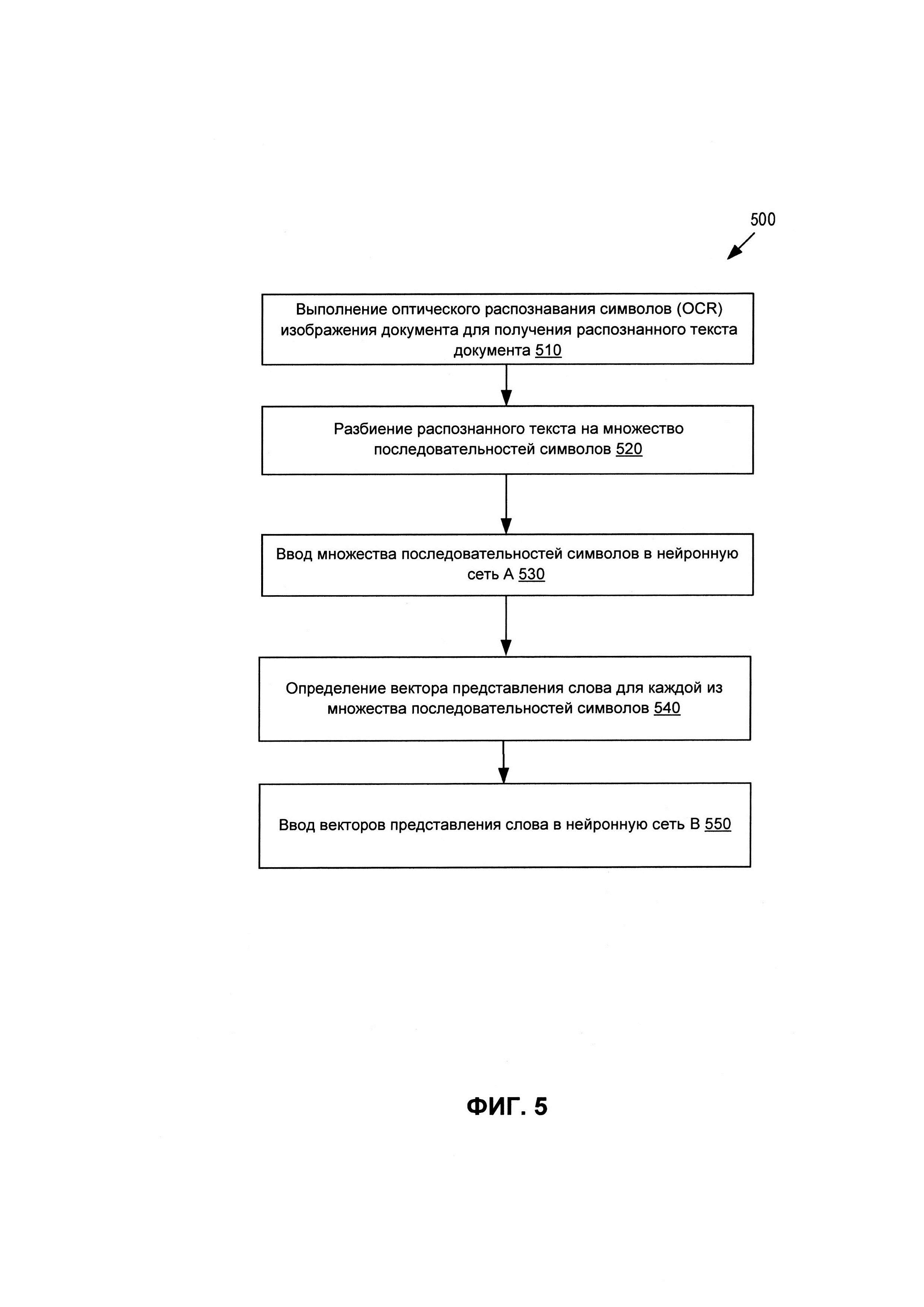
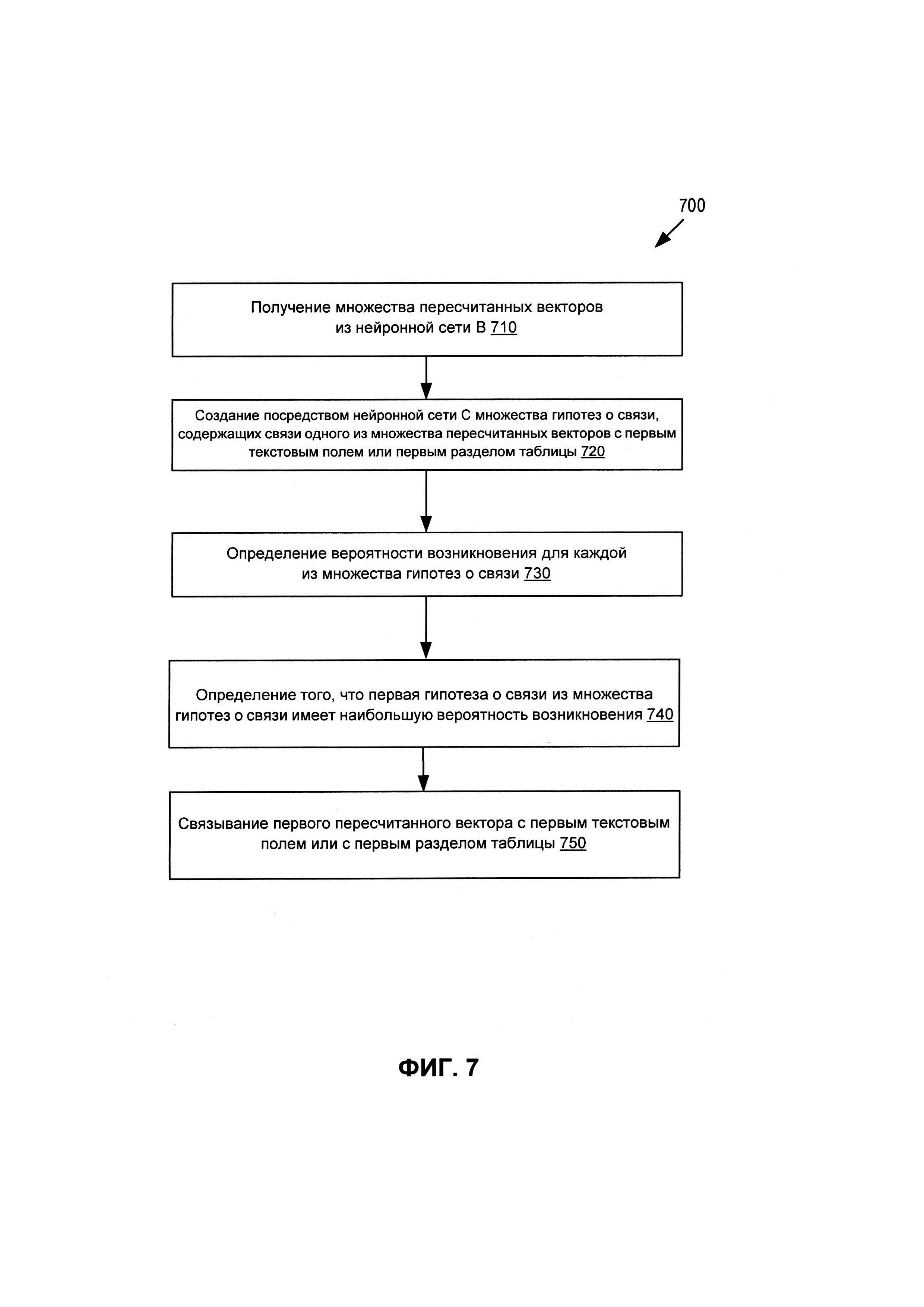
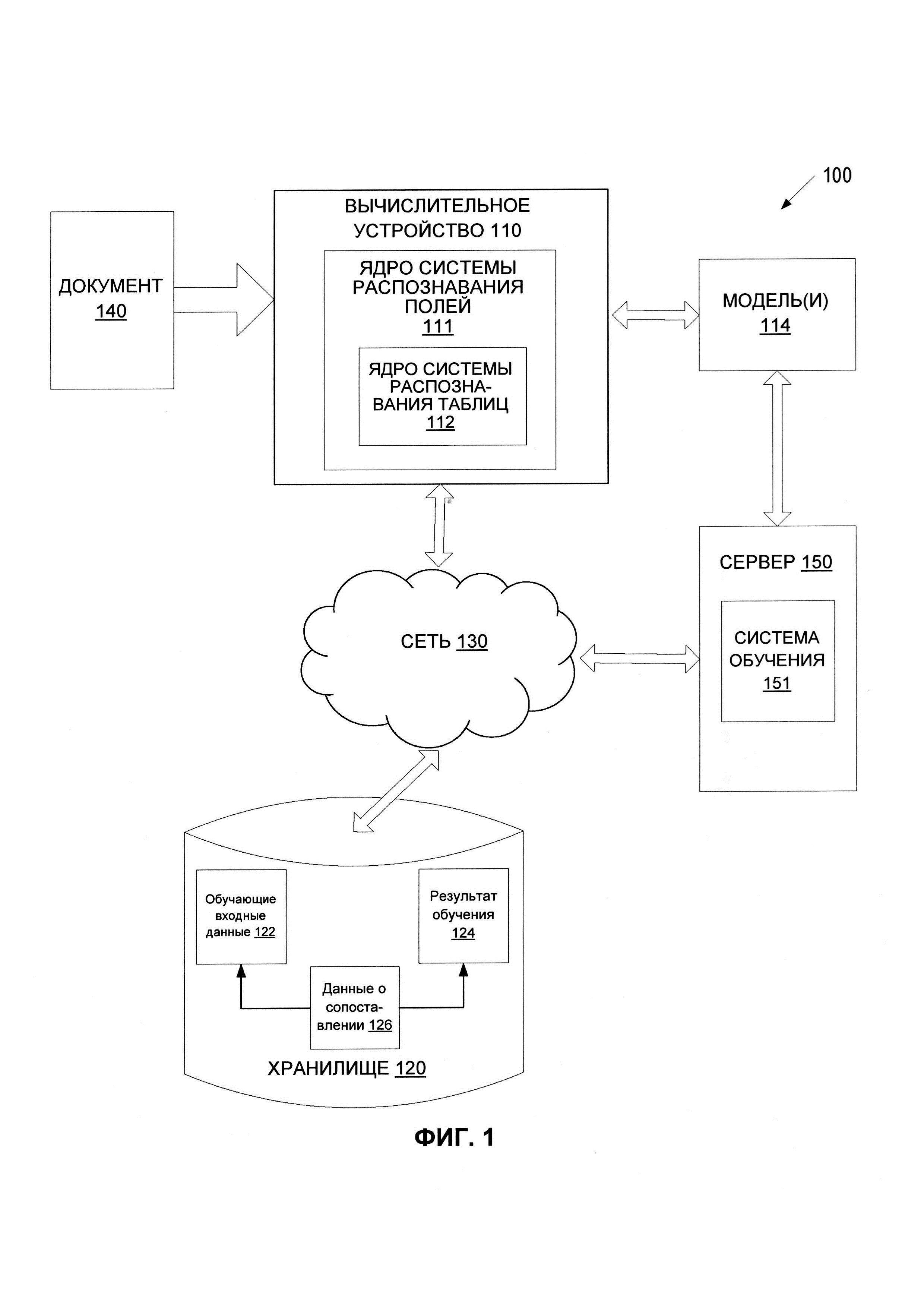
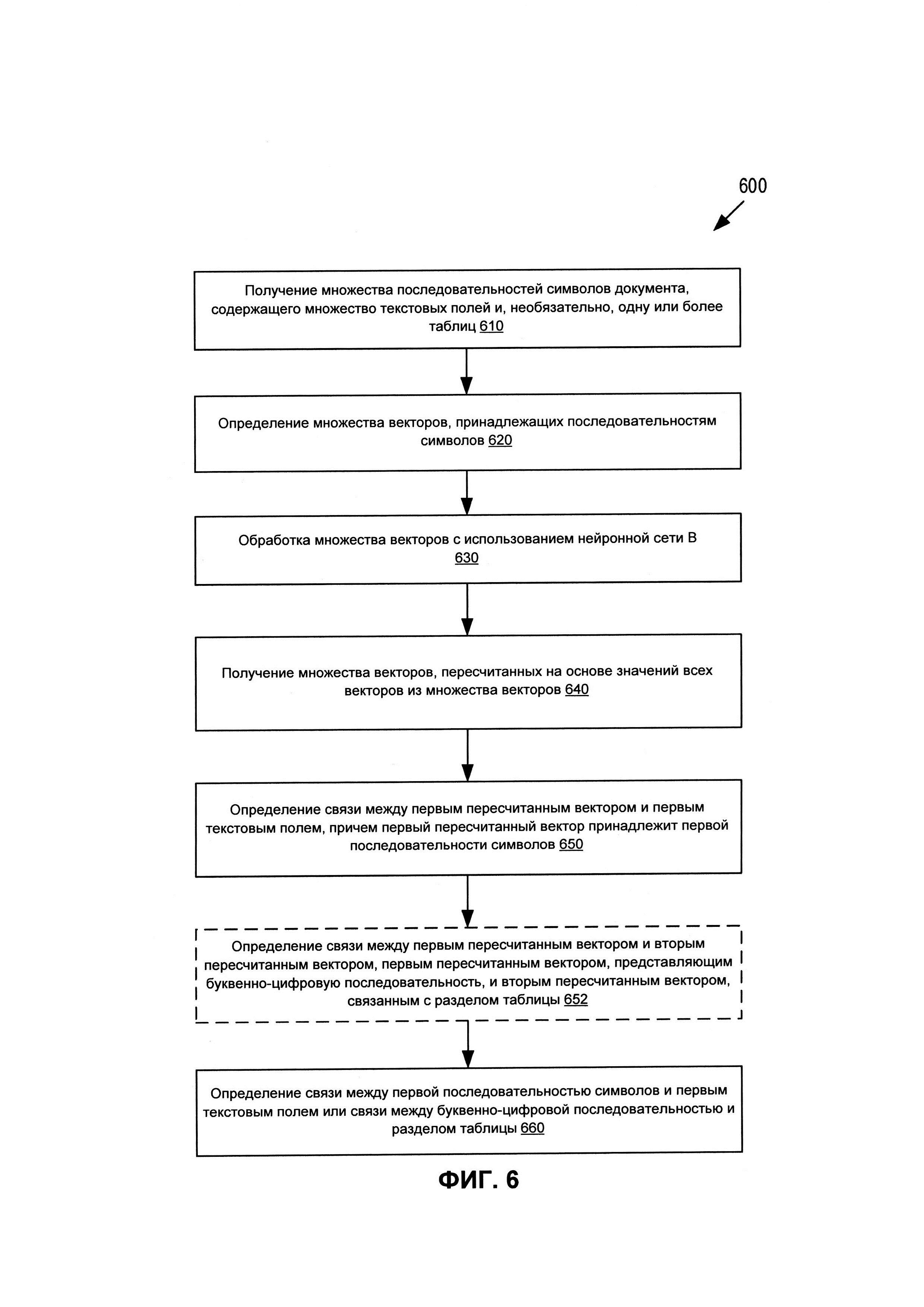
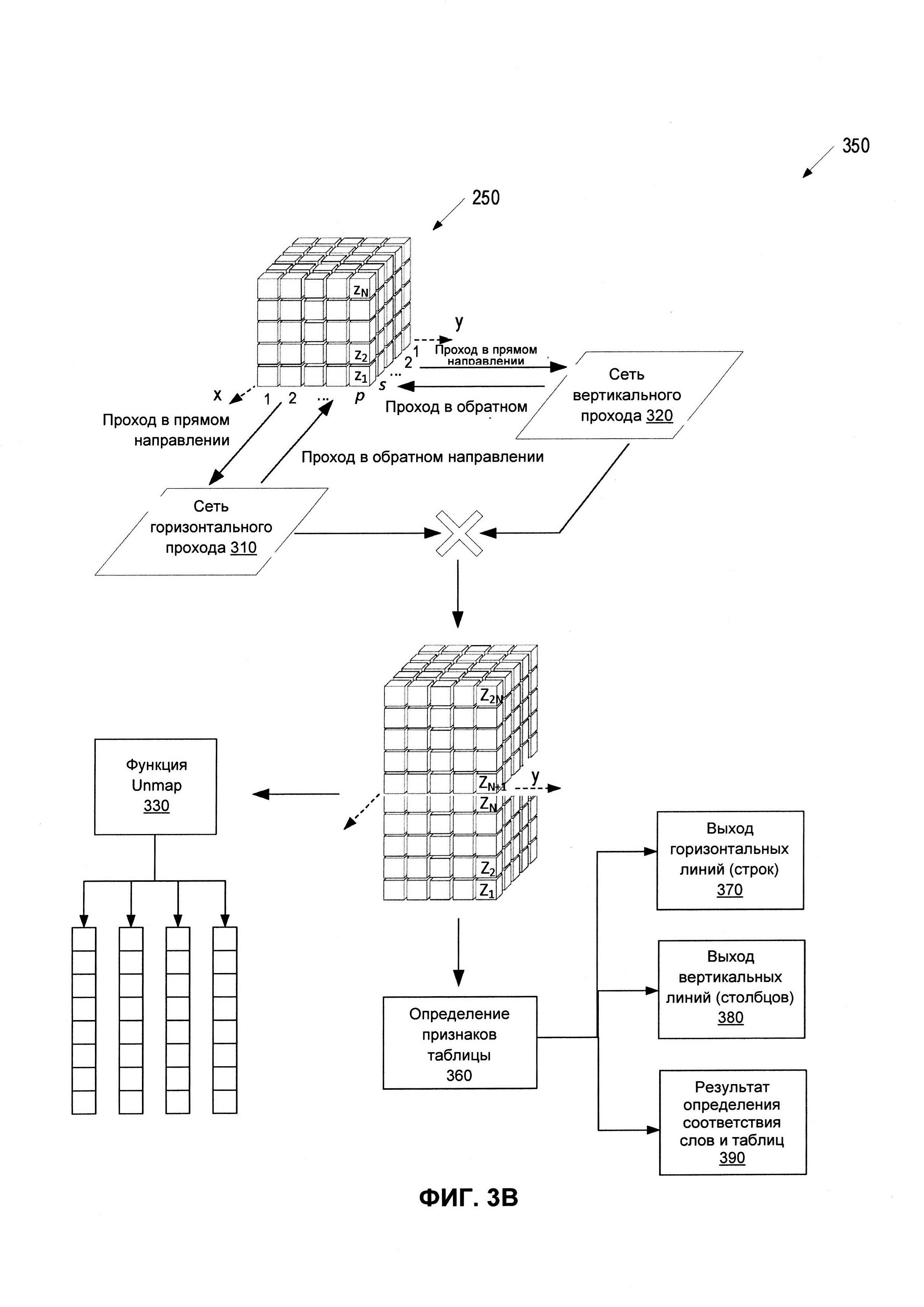
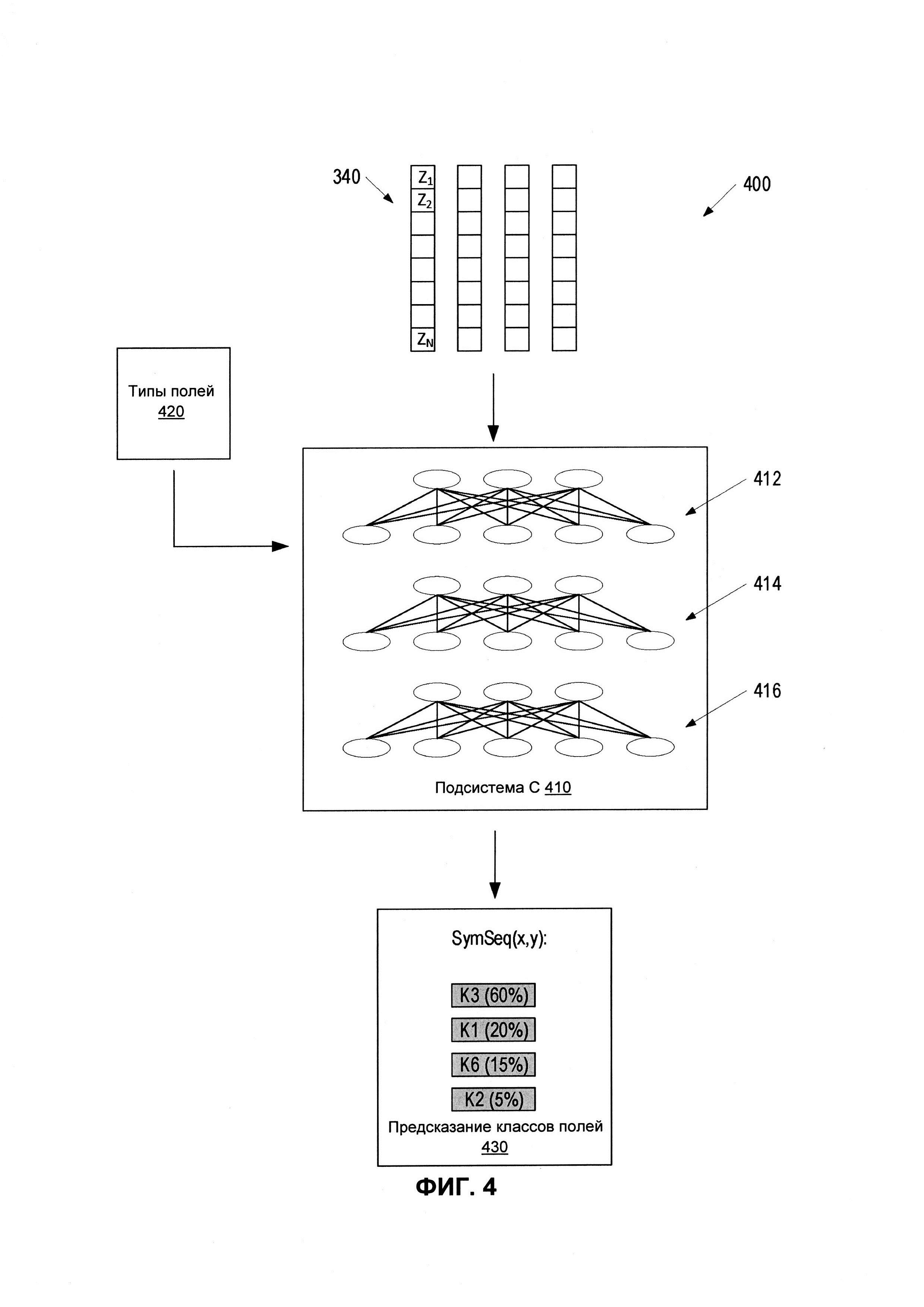
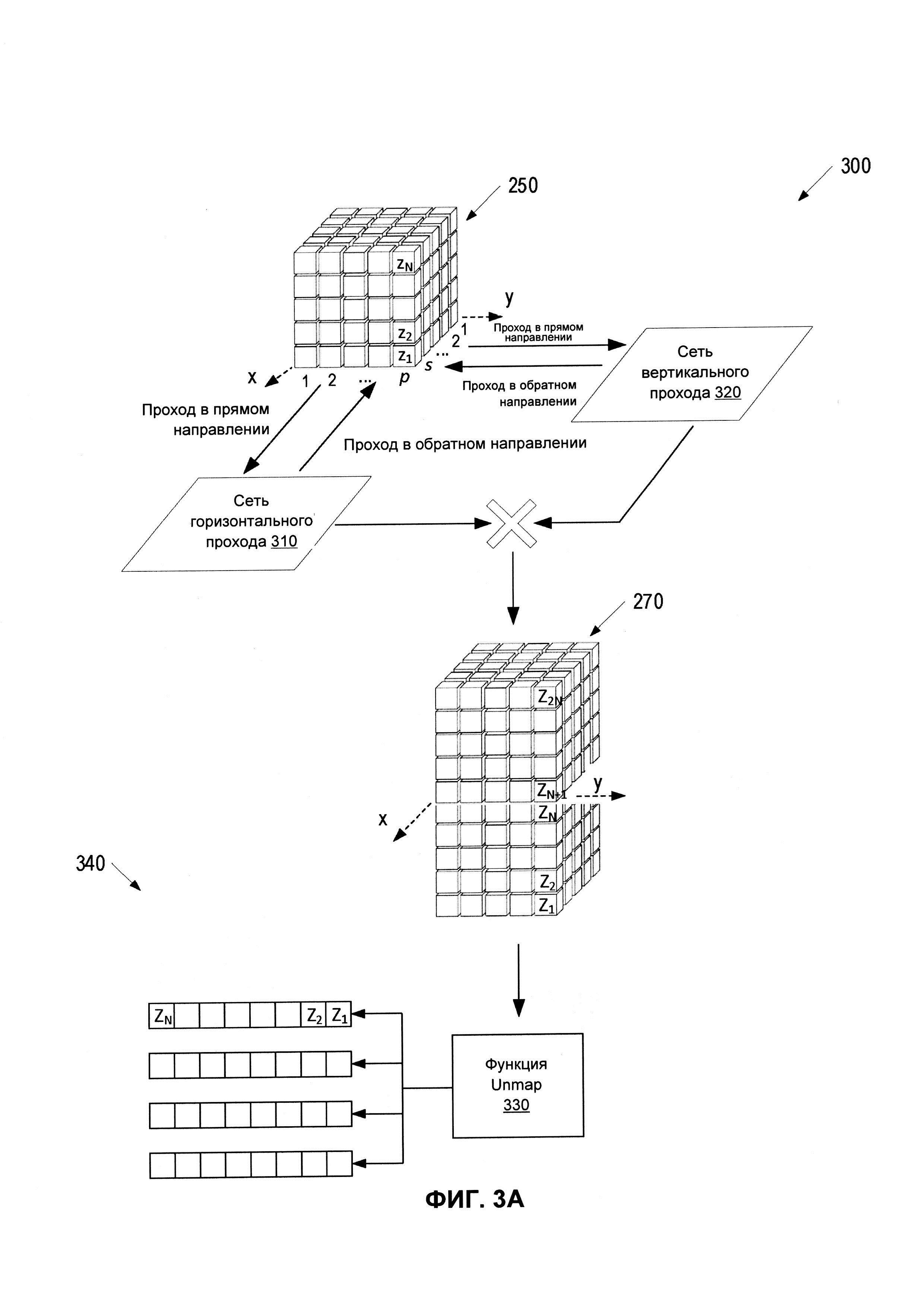
Извлечение сущностей из текстов на естественном языке
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Способ извлечения фактов из текстов на естественном языке
Метод и система для генерации статей в словаре естественного языка
Система для создания документов на основе анализа текста на естественном языке
Определение степеней уверенности, связанных со значениями атрибутов информационных объектов
Автоматическое обучение программы синтаксического и семантического анализа с использованием генетического алгоритма
Сентиментный анализ на уровне аспектов и создание отчетов с использованием методов машинного обучения
Использование глубинного семантического анализа текстов на естественном языке для создания обучающих выборок в методах машинного обучения
Детектирование разделов таблиц в документах нейронными сетями с использованием глобального контекста документа
Нечеткий поиск с использованием форм слов для работы с большими данными

