Результат интеллектуальной деятельности: Способ и распределенная компьютерная система для обработки данных
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Данная технология относится к распределенной обработке данных и, в частности, к способу и распределенной компьютерной системе для обработки данных.
Уровень техники
Требования к запоминающим устройствам для хранения цифровых данных постоянно повышаются, поскольку большие объемы цифровых данных создаются ежедневно. Например, хранения могут требовать различные виды пользовательских данных, данных организаций и/или данных приложений. Это повышает требования к емкости хранилищ данных. Растущие потребности пользователей и/или организаций способны удовлетворить «облачные» системы удаленного хранения данных.
В общем случае «облачное» хранилище данных представляет собой вид компьютерного запоминающего устройства, в котором цифровые данные хранятся в логических пулах. Физическая память, в которой фактически хранятся цифровые данные, распределена между несколькими серверами, возможно, расположенными в различных местах (т.е. в различных центрах обработки данных), и обычно управляется компанией, предоставляющей услуги «облачного» хранения данных. Пользователи и/или организации обычно покупают или арендуют некоторый объем памяти у поставщиков услуг «облачного» хранения данных, чтобы хранить свои цифровые данные. Со своей стороны, поставщики услуг «облачного» хранения данных отвечают за доступность цифровых данных и защиту физической памяти с целью предотвращения утраты данных.
Раскрытие изобретения
Разработчики данной технологии обнаружили определенные технические недостатки, связанные с известными решениями.
Разработчики данной технологии реализовали способы и распределенные компьютерные системы для обработки данных, в некотором смысле, способные поддерживать «доверие» клиентов к системам распределенного хранения данных.
Для лучшего пояснения можно предположить, что клиент передает данные в распределенную компьютерную систему для хранения. Если клиент во время сохранения данных не получает уведомление об успешном сохранении его данных распределенной компьютерной системой, то он по сути и не «ожидает» того, что данные будут извлечены и предоставлены по запросу доступа к данным в будущий момент времени. В результате, если когда-либо эти данные не будут восстановлены в будущий момент времени (например, вследствие нарушения работоспособности системы), клиент не утрачивает «доверие» к способности распределенной компьютерной системы надежно хранить данные, поскольку распределенная компьютерная система не предоставила уведомления об их успешном сохранении.
Если же клиент во время сохранения данных получает уведомление об успешном сохранении его данных, то он по сути «ожидает», что данные будут извлечены и предоставлены по запросу доступа к данным в будущий момент времени. В результате, если клиент получает уведомление об успешном сохранении его данных (при сохранении данных), но распределенная компьютерная система оказывается неспособной восстановить эти данные в будущий момент времени (например, вследствие нарушения работоспособности системы), то клиент, в некотором смысле, утрачивает «доверие» к способности распределенной компьютерной системы надежно хранить данные.
Следовательно, можно сказать, что «доверие» клиента к распределенной компьютерной системе связано не с возможностью извлечения данных в будущий момент времени, а с возможностью извлечения данных в то время, когда клиенту было предоставлено уведомление об их успешном сохранении.
В соответствии с некоторыми вариантами осуществления данной технологии реализованы способы и распределенные компьютерные системы, способные выдавать клиенту уведомления об успешном сохранении данных, если возможно обеспечить сохранение данных таким образом, чтобы их возможно было извлечь/восстановить, даже если определенное максимальное количество устройств хранения данных в распределенной компьютерной системе окажется недоступным в будущий момент времени. Иными словами, разработчики данной технологии реализовали способы и распределенные компьютерные системы, где данные считаются «успешно сохраненными» (например, когда подтверждено успешное сохранение данных), когда гарантировано восстановление этих данных в будущий момент времени, даже если максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени.
Как показано ниже, в некоторых вариантах осуществления изобретения описанные способы и распределенные компьютерные системы также способны при запросах доступа к данным помогать однозначно определять, выдала ли распределенная компьютерная система клиенту подтверждение успешного сохранения данных при сохранении данных. Это может быть полезным в некоторых вариантах осуществления данной технологии, поскольку в зависимости от наличия подтверждения распределенной компьютерной системой успешного сохранения данных во время сохранения данных, распределенная компьютерная система может быть способна обеспечивать клиенту ответы различных видов (например, если когда-либо данные не будут восстановлены по запросу доступа к данным).
В не имеющем ограничительного характера примере, если распределенная компьютерная система однозначно определяет, что она не подтвердила успешное сохранение данных и что при запросе доступа к данным невозможно восстановить данные, она может предоставлять ответ вида «нет данных». В этом не имеющем ограничительного характера примере распределенная компьютерная система может быть способна обеспечивать этот ответ первого вида, поскольку она по сути не подтверждала, что данные были успешно сохранены.
В другом не имеющем ограничительного характера примере, если распределенная компьютерная система однозначно определяет, что она подтвердила успешное сохранение данных и что при запросе доступа к данным невозможно восстановить данные, она может предоставлять ответ вида «ошибка данных». В этом не имеющем ограничительного характера примере распределенная компьютерная система может быть способна обеспечивать этот ответ второго вида, поскольку она по сути подтвердила, что данные были успешно сохранены.
Согласно первому аспекту данной технологии предложен реализуемый компьютером способ реализации распределенной компьютерной системы для обработки данных. Данные поступают от клиента распределенной компьютерной системы. Распределенная компьютерная система содержит множество устройств хранения данных и координирующий компьютер. Способ выполняется координирующим компьютером. Способ включает в себя прием координирующим компьютером указания на алгоритм обеспечения избыточности, который должен использоваться для формирования данных с избыточностью на основе поступающих данных. Данные с избыточностью должны сохраняться набором устройств хранения данных. Алгоритм обеспечения избыточности указывает на количество устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных. Способ включает в себя прием координирующим компьютером указания на алгоритм моделирования нарушений работоспособности, который должен использоваться для выдачи клиенту подтверждения успешного сохранения данных. Успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени. Способ включает в себя выдачу во время сохранения данных координирующим компьютером команд набору устройств хранения данных для сохранения данных с избыточностью. Устройство хранения данных способно оповещать координирующий компьютер о сохранении им данных с избыточностью. Способ включает в себя прием координирующим компьютером во время доступа к данным указания на запрос доступа к данным. Способ включает в себя применение координирующим компьютером во время доступа к данным алгоритма моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных, для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных во время сохранения данных.
В некоторых вариантах осуществления способа успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание максимального количества устройств хранения данных окажется недоступным в будущий момент времени.
В некоторых вариантах осуществления способа успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание устройств хранения данных окажется недоступным в будущий момент времени.
В некоторых вариантах осуществления способа алгоритм обеспечения избыточности представляет собой алгоритм репликации.
В некоторых вариантах осуществления способа данные с избыточностью включают в себя реплики данных.
В некоторых вариантах осуществления способа алгоритм обеспечения избыточности представляет собой алгоритм стойкого к потере кодирования (erasure coding).
В некоторых вариантах осуществления способ дополнительно включает в себя применение координирующим компьютером алгоритма моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных во время сохранения данных, для определения того, следует ли предоставлять клиенту подтверждение успешного сохранения данных.
В некоторых вариантах осуществления способа применение алгоритма моделирования нарушений работоспособности во время сохранения данных включает в себя итеративное применение алгоритма моделирования нарушений работоспособности во время сохранения данных в отношении уведомлений, принятых от устройств хранения данных, при приеме каждого нового уведомления.
В некоторых вариантах осуществления способа итеративное применение алгоритма моделирования нарушений работоспособности включает в себя ожидание выдачи новых уведомлений другими устройствами хранения данных, образующими набор устройств хранения данных.
В некоторых вариантах осуществления способа итеративное применение алгоритма моделирования нарушений работоспособности включает в себя отслеживание новых уведомлений, выданных другими устройствами хранения данных, образующими набор устройств хранения данных.
В некоторых вариантах осуществления способа координирующий компьютер определяет, что во время сохранения данных требуется предоставить подтверждение успешного сохранения данных, если определенное количество устройств хранения данных оповещает о сохранении ими данных с избыточностью.
В некоторых вариантах осуществления способа это количество устройств хранения данных превышает количество устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных.
В некоторых вариантах осуществления способа это количество устройств хранения данных находится в диапазоне между (а) количеством устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных, и (б) общим количеством устройств хранения данных во множестве устройств хранения данных, включительно.
В некоторых вариантах осуществления способа успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если различные сочетания максимального количества устройств хранения данных окажутся недоступными в будущий момент времени.
В некоторых вариантах осуществления способа успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если различные сочетания устройств хранения данных окажутся недоступными в будущий момент времени.
В некоторых вариантах осуществления способа эти различные сочетания включают в себя по меньшей мере некоторые из всех возможных сочетаний среди множества устройств хранения данных.
В некоторых вариантах осуществления способа, если однозначно определено, что во время сохранения данных клиенту было предоставлено подтверждение успешного сохранения данных, способ дополнительно включает в себя предоставление ответа вида «ошибка данных» на запрос доступа к данным от клиента.
В некоторых вариантах осуществления способа, если однозначно определено, что во время сохранения данных клиенту не было предоставлено подтверждение успешного сохранения данных, способ дополнительно включает в себя предоставление ответа вида «нет данных» на запрос доступа к данным от клиента.
Согласно второму аспекту данной технологии предложен реализуемый компьютером способ реализации распределенной компьютерной системы для обработки данных. Данные поступают от клиента распределенной компьютерной системы. Распределенная компьютерная система содержит множество устройств хранения данных и координирующий компьютер. Способ выполняется координирующим компьютером. Способ включает в себя прием координирующим компьютером указания на алгоритм обеспечения избыточности, который должен использоваться для формирования данных с избыточностью на основе поступающих данных. Данные с избыточностью должны сохраняться набором устройств хранения данных. Алгоритм обеспечения избыточности указывает на количество устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных. Способ включает в себя прием координирующим компьютером указания на алгоритм моделирования нарушений работоспособности, который должен использоваться для выдачи клиенту подтверждения успешного сохранения данных. Успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание устройств хранения данных окажется недоступным в этот будущий момент времени. Способ включает в себя выдачу во время сохранения данных координирующим компьютером команд набору устройств хранения данных для сохранения данных с избыточностью. Устройство хранения данных способно оповещать координирующий компьютер о сохранении им данных с избыточностью. Способ включает в себя прием координирующим компьютером во время доступа к данным указания на запрос доступа к данным. Способ включает в себя применение координирующим компьютером во время доступа к данным алгоритма моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных, для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных во время сохранения данных.
Согласно третьему аспекту данной технологии реализована распределенная компьютерная система для обработки данных. Данные поступают от клиента распределенной компьютерной системы. Распределенная компьютерная система содержит множество устройств хранения данных и координирующий компьютер. Координирующий компьютер способен принимать указание на алгоритм обеспечения избыточности, который должен использоваться для формирования данных с избыточностью на основе поступающих данных. Данные с избыточностью должны сохраняться набором устройств хранения данных. Алгоритм обеспечения избыточности указывает на количество устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных. Координирующий компьютер способен принимать указание на алгоритм моделирования нарушений работоспособности, который должен использоваться для выдачи клиенту подтверждения успешного сохранения данных. Успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени. Координирующий компьютер во время сохранения данных способен выдавать команды набору устройств хранения данных для сохранения данных с избыточностью. Устройство хранения данных способно оповещать координирующий компьютер о сохранении им данных с избыточностью. Координирующий компьютер во время доступа к данным способен принимать указание на запрос доступа к данным. Координирующий компьютер во время доступа к данным способен применять алгоритм моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных, для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных во время сохранения данных.
В некоторых вариантах осуществления распределенной компьютерной системы успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание максимального количества устройств хранения данных окажется недоступным в этот будущий момент времени.
В некоторых вариантах осуществления распределенной компьютерной системы успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание устройств хранения данных окажется недоступным в этот будущий момент времени.
В некоторых вариантах осуществления распределенной компьютерной системы алгоритм обеспечения избыточности представляет собой алгоритм репликации.
В некоторых вариантах осуществления распределенной компьютерной системы данные с избыточностью включают в себя реплики данных.
В некоторых вариантах осуществления распределенной компьютерной системы алгоритм обеспечения избыточности представляет собой алгоритм стойкого к потере кодирования.
В некоторых вариантах осуществления распределенной компьютерной системы координирующий компьютер дополнительно способен применять алгоритм моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных во время сохранения данных, для определения того, следует ли предоставлять клиенту подтверждение успешного сохранения данных.
В некоторых вариантах осуществления распределенной компьютерной системы применение алгоритма моделирования нарушений работоспособности во время сохранения данных включает в себя способность координирующего компьютера итеративно применять алгоритм моделирования нарушений работоспособности во время сохранения данных в отношении уведомлений, принятых от устройств хранения данных, при приеме каждого нового уведомления.
В некоторых вариантах осуществления распределенной компьютерной системы итеративное применение алгоритма моделирования нарушений работоспособности включает в себя способность координирующего компьютера ожидать выдачи новых уведомлений другими устройствами хранения данных, образующими набор устройств хранения данных.
В некоторых вариантах осуществления распределенной компьютерной системы итеративное применение алгоритма моделирования нарушений работоспособности включает в себя способность координирующего компьютера отслеживать новые уведомления, выданные другими устройствами хранения данных, образующими набор устройств хранения данных.
В некоторых вариантах осуществления распределенной компьютерной системы координирующий компьютер определяет, что во время сохранения данных требуется предоставлять подтверждение успешного сохранения данных, если определенное количество устройств хранения данных оповещает о сохранении ими данных с избыточностью.
В некоторых вариантах осуществления распределенной компьютерной системы это количество устройств хранения данных превышает количество устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных.
В некоторых вариантах осуществления распределенной компьютерной системы это количество устройств хранения данных находится в диапазоне между (а) количеством устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных, и (б) общим количеством устройств хранения данных во множестве устройств хранения данных, включительно.
В некоторых вариантах осуществления распределенной компьютерной системы успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если различные сочетания максимального количества устройств хранения данных окажутся недоступными в этот будущий момент времени.
В некоторых вариантах осуществления способа успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если различные сочетания устройств хранения данных окажутся недоступными в этот будущий момент времени.
В некоторых вариантах осуществления распределенной компьютерной системы различные сочетания включают в себя по меньшей мере некоторые из всех возможных сочетаний среди множества устройств хранения данных.
В некоторых вариантах осуществления распределенной компьютерной системы, если однозначно определено, что во время сохранения данных клиенту было предоставлено подтверждение успешного сохранения данных, координирующий компьютер дополнительно способен предоставлять ответ вида «ошибка данных» на запрос доступа к данным от клиента.
В некоторых вариантах осуществления распределенной компьютерной системы, если однозначно определено, что во время сохранения данных клиенту не было предоставлено подтверждение успешного сохранения данных, координирующий компьютер дополнительно способен предоставлять ответ вида «нет данных» на запрос доступа к данным от клиента.
Согласно четвертому аспекту данной технологии предложена распределенная компьютерная система для обработки данных. Данные поступают от клиента распределенной компьютерной системы. Распределенная компьютерная система содержит множество устройств хранения данных и координирующий компьютер. Координирующий компьютер способен принимать указание на алгоритм обеспечения избыточности, который должен использоваться для формирования данных с избыточностью на основе поступающих данных. Данные с избыточностью должны сохраняться набором устройств хранения данных. Алгоритм обеспечения избыточности указывает на количество устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных. Координирующий компьютер способен принимать указание на алгоритм моделирования нарушений работоспособности, который должен использоваться для выдачи клиенту подтверждения успешного сохранения данных. Успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание устройств хранения данных окажется недоступным в этот будущий момент времени. Координирующий компьютер во время сохранения данных способен выдавать команды набору устройств хранения данных для сохранения данных с избыточностью. Устройство хранения данных способно оповещать координирующий компьютер о сохранении им данных с избыточностью. Координирующий компьютер во время доступа к данным способен принимать указание на запрос доступа к данным. Координирующий компьютер во время доступа к данным способен применять алгоритм моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных, для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных во время сохранения данных.
В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему и это не существенно для данной технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или запускать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, при этом оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения некоторой задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса, либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
В контексте настоящего описания выражение «компонент» включает в себя программное обеспечение (подходящее для определенных аппаратных средств), необходимое и достаточное для выполнения соответствующей определенной функции (или нескольких функций).
В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого типа и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, вида, хронологии, иерархии или классификации, в данном случае, серверов, и что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
Каждый вариант осуществления данной технологии имеет отношение к по меньшей мере одной из вышеупомянутых целей и/или к одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты данной технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления данной технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
Дальнейшее описание приведено для лучшего понимания данной технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
На фиг. 1 представлена схема системы, пригодной для реализации не имеющих ограничительного характера вариантов осуществления данной технологии.
На фиг. 2 представлено соответствующее некоторым вариантам осуществления данной технологии устройство хранения данных подсистемы распределенного хранения данных, представленной на фиг. 1.
На фиг. 3 представлена распределенная компьютерная система, реализованная согласно не имеющим ограничительного характера вариантам осуществления данной технологии.
На фиг. 4 представлен реализованный согласно не имеющим ограничительного характера вариантам осуществления данной технологии координирующий компьютер распределенной компьютерной системы, показанной на фиг. 3, выполняющий алгоритм обеспечения избыточности.
На фиг. 5 представлен реализованный согласно не имеющим ограничительного характера вариантам осуществления данной технологии координирующий компьютер, выполняющий алгоритм моделирования нарушений работоспособности.
На фиг. 6 представлены первый сценарий нарушения работоспособности и второй сценарий нарушения работоспособности, моделируемые алгоритмом моделирования нарушений работоспособности, представленным на фиг. 5, во время сохранения данных в соответствии с не имеющими ограничительного характера вариантами осуществления данной технологии.
На фиг. 7 представлен третий сценарий нарушения работоспособности, моделируемый алгоритмом моделирования нарушений работоспособности, представленным на фиг. 5, во время доступа к данным в соответствии с не имеющими ограничительного характера вариантами осуществления данной технологии.
На фиг. 8 приведена блок-схема способа, выполняемого координирующим компьютером и реализованного согласно не имеющим ограничительного характера вариантам осуществления данной технологии.
Осуществление изобретения
Дальнейшее подробное описание представляет собой лишь описание примеров, иллюстрирующих данную технологию. Это описание не предназначено для определения объема или границ данной технологии.
Кроме того, если в некоторых случаях не описаны примеры модификаций, это не означает, что модификации невозможны и/или что описание содержит единственный вариант осуществления определенного аспекта данной технологии. Кроме того, следует понимать, что настоящее подробное описание в некоторых случаях касается упрощенных вариантов осуществления данной технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Различные варианты осуществления данной технологии могут быть значительно сложнее.
На фиг. 1 представлена распределенная система 100 компьютерной обработки информации или сокращенно распределенная система 100 обработки информации. Распределенная система 100 обработки информации позволяет реализовать не имеющие ограничительного характера варианты осуществления данной технологии. Очевидно, что распределенная система 100 обработки информации приведена лишь в качестве иллюстративного варианта осуществления данной технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих данную технологию. Это описание не предназначено для определения объема или границ данной технологии.
В некоторых случаях также приводятся полезные примеры модификаций распределенной системы 100 обработки информации. Они способствуют пониманию, но также не определяют объема или границ данной технологии. Эти модификации не составляют исчерпывающего списка. Специалисту в данной области должно быть понятно, что возможны и другие модификации. Кроме того, если в некоторых случаях примеры модификаций не описаны, это не означает, что модификации невозможны и/или что описание содержит единственный вариант осуществления определенного элемента данной технологии. Специалисту в данной области должно быть понятно, что это не так. Кроме того, следует понимать, что распределенная система 100 обработки информации в некоторых случаях может представлять собой упрощенную реализацию данной технологии, и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
Распределенная система 100 обработки информации содержит источник 102 запросов, сеть 103 связи, подсистему 104 предварительной обработки запросов, подсистему 105 обработки транзакций, подсистему 106 маршрутизации транзакций, подсистему 108 распределенного хранения данных, подсистему 110 базы данных и операционную подсистему 111.
Далее описана реализация указанных выше компонентов распределенной системы 100 обработки информации в соответствии с различными не имеющими ограничительного характера вариантами осуществления данной технологии.
Источник запросов
Источник 102 запросов может представлять собой электронное устройство, связанное с конечным пользователем (например, клиентское устройство), или любую другую подсистему распределенной системы 100 обработки информации, способную обеспечивать пользовательские запросы к распределенной системе 100 обработки информации. Несмотря на то, что на фиг. 1 показан лишь один источник 102 запросов, распределенная система 100 обработки информации может содержать несколько источников 102 запросов. Как показано в данном документе, источник 102 запросов входит в состав распределенной системы 100 обработки информации. Тем не менее, в некоторых вариантах осуществления данной технологии источник 102 запросов может быть внешним по отношению к распределенной системе 100 обработки информации и может подключаться с использованием линии связи (не обозначена).
На практике типовой вариант осуществления распределенной системы 100 обработки информации может включать в себя большое количество источников 102 запросов (сотни, тысячи, миллионы и т.д.).
В некоторых вариантах осуществления данной технологии, когда распределенная система 100 обработки информации используется в среде бизнес-потребитель (В2С, Business-to-Customer), источник 102 запросов может представлять собой клиентское устройство, такое как смартфон, связанное с пользователем распределенной системы 100 обработки информации. Например, распределенная система 100 обработки информации может обеспечивать услуги «облачного» хранения данных для клиентского устройства определенного пользователя.
В некоторых вариантах осуществления данной технологии, когда распределенная система 100 обработки информации используется в среде бизнес-бизнес (В2В, Business-to-Business), источник 102 запросов может представлять собой подсистему, такую как удаленный сервер, обеспечивающую пользовательские запросы к распределенной системе 100 обработки информации. Например, в некоторых вариантах осуществления данной технологии распределенная система 100 обработки информации может обеспечивать услуги отказоустойчивой обработки и/или хранения данных для оператора такой подсистемы.
В целом, независимо от реализации распределенной системы 100 обработки информации в виде системы В2С или В2В (или любого другого варианта системы), источник 102 запросов может представлять собой клиентское устройство или другую подсистему, которые могут быть внутренними или внешними по отношению к распределенной системе 100 обработки информации.
Как указано выше, источник 102 запросов способен выдавать множество запросов 180, каждый из которых далее называется запросом 180. Характер запроса 180 зависит от вида источника 102 запросов. В частности, один из примеров запроса 180 представляет собой запрос, сформированный на языке структурированных запросов (SQL, Structured Query Language). Поэтому предполагается, что в некоторых вариантах осуществления данной технологии запрос 180 может быть сформирован на языке декларативного программирования, т.е. запрос 180 может представлять собой запрос декларативного вида.
В общем случае декларативное программирование относится к реализации структуры и элементов компьютерных программ, отражая логику вычислений без описания потока управления. Распространенные языки декларативного программирования включают в себя SQL, XQuery и другие языки запросов к базам данных. В целом, запрос декларативного вида определяет действие в выражениях «что требуется выполнить», а не «как это требуется выполнить».
Это означает, что запрос декларативного вида может быть связан с условием выполнения определенного действия. В качестве условия, например, может быть указано, в каком элементе должно выполняться это действие или где следует получать значения для выполнения этого действия.
В качестве не имеющих ограничительного характера примеров можно привести следующие запросы декларативного вида: «Вставить значение 5 в ячейку, связанную с ключом, который равен значению ячейки, связанной с ключом А» и «Для всех ключей, связанных с ячейкой, имеющей значение 5, заменить это значение на значение 10». Тем не менее, должно быть понятно, что представленные выше примеры декларативных языков и примеры запросов декларативного вида приведены исключительно для лучшего понимания, и что другие декларативные языки и другие запросы декларативного вида могут использоваться источником 102 запросов в пределах объема данной технологии.
В некоторых вариантах осуществления данной технологии источник 102 запросов также способен принимать множество ответов 181, каждый из которых далее называется ответом 181. В общем случае в ответ на запрос 180, обработанный или не обработанный распределенной системой 100 обработки информации, распределенная система 100 обработки информации может формировать ответ 181, предназначенный для источника 102 запросов, связанного с соответствующим запросом 180. Характер ответа 181, среди прочего, зависит от вида источника 102 запросов, вида соответствующего запроса 180 и от того, обработала или не обработала распределенная система 100 обработки информации соответствующий запрос 180. В некоторых вариантах осуществления данной технологии распределенная система 100 обработки информации может формировать ответ 181, только если не удалось обработать запрос, или только в случае успешной обработки запроса, или в обоих случаях.
Например, во время обработки запроса 180 распределенная система 100 обработки информации может быть способна запрашивать дополнительные данные от источника 102 запросов для продолжения или завершения обработки запроса 180. В этом случае распределенная система 100 обработки информации может быть способна формировать ответ 181 в виде сообщения с запросом данных, в котором указываются дополнительные данные, запрашиваемые распределенной системой 100 обработки информации для продолжения или завершения обработки запроса 180.
В другом примере, если распределенная система 100 обработки информации успешно обработала соответствующий запрос 180, распределенная система 100 обработки информации может быть способна формировать ответ 181 в виде сообщения об успешном завершении, оповещающего об успешной обработке соответствующего запроса 180.
В еще одном примере, если распределенной системе 100 обработки информации не удалось успешно обработать соответствующий запрос 180, распределенная система 100 обработки информации может быть способна формировать ответ 181 в виде сообщения о неудачном завершении, оповещающий о том, что соответствующий запрос 180 обработать не удалось. В этом случае источник 102 запроса может быть способен выполнять дополнительные действия, такие как повторное направление запроса 180, выполнение диагностического анализа для определения причины неудачного завершения обработки запроса 180 распределенной системой 100 обработки информации, направление нового запроса, предназначенного для распределенной системы 100 обработки информации, и т.д.
Сеть связи
Источник 102 запросов связан с сетью 103 связи для направления запроса 180 в распределенную систему 100 обработки информации и для приема ответа 181 от распределенной системы 100 обработки информации. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии в качестве сети 103 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 103 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (отдельно не обозначена) между источником 102 запросов и сетью 103 связи зависит, среди прочего, от реализации источника 102 запросов.
Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления данной технологии, где источник 102 запросов реализован как беспроводное устройство связи (такое как смартфон), линия связи может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где источник 102 запросов реализован как удаленный сервер, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение по сети Ethernet).
Следует отметить, что сеть 103 связи, среди прочего, способна передавать пакет данных запроса, содержащий запрос 180, от источника 102 запросов в подсистему 104 предварительной обработки запросов распределенной системы 100 обработки информации. Например, этот пакет данных запроса может содержать выполняемые компьютером команды, составленные на языке программирования декларативного вида, на котором представлен запрос 180. Сеть 103 связи, среди прочего, также способна передавать пакет данных ответа, содержащий ответ 181, из распределенной системы 100 обработки информации в источник 102 запросов. Например, этот пакет данных ответа может содержать выполняемые компьютером команды, представляющие ответ 181.
Тем не менее, предполагается, что в некоторых вариантах осуществления данной технологии, где источник 102 запросов представляет собой, например, подсистему распределенной системы 100 обработки информации, сеть 103 связи может быть реализована способом, отличным от описанного выше, или в некоторых случаях может вовсе отсутствовать в пределах объема данной технологии.
Операционная подсистема (улей)
Как указано выше, распределенная система 100 обработки информации содержит операционную подсистему 111 или, сокращенно, улей. В общем случае улей 111 представляет собой программное приложение (например, конечный автомат), способное управлять по меньшей мере некоторыми подсистемами распределенной системы 100 обработки информации, такими как подсистема 104 предварительной обработки запросов и подсистема 105 обработки транзакций. Можно сказать, что улей 111 может быть реализован как конечный автомат (SM, State Machine), способный формировать, удалять и/или выравнивать нагрузку других автоматов SM, образующих по меньшей мере некоторые подсистемы распределенной системы 100 обработки информации.
Должно быть понятно, что автомат SM представляет собой вычислительную модель, реализованную в виде компьютерной системы и определяемую списком состояний. Автомат SM может изменять свое текущее состояние в ответ на некоторые внешние входные данные и может в конкретный момент времени находиться лишь в одном состоянии. Переход автомата SM из одного состояния в другое состояние называется изменением состояния.
Следует отметить, что в контексте данной технологии автоматы SM, образующие по меньшей мере некоторые подсистемы распределенной системы 100 обработки информации, являются детерминированными по свое природе, т.е. каждое изменение состояния каждого автомата SM однозначно определено (а) текущим состоянием соответствующего автомата SM и (б) внешними входными данными соответствующего автомата SM. Иными словами, для текущего состояния автомата SM и для конкретных внешних входных данных существует единственное следующее состояние этого автомата SM. Этот детерминированный характер изменения состояния не зависит от того, у какого именно автомата SM распределенной системы 100 обработки информации происходит изменение состояния.
Поэтому, как описано ниже, в некоторых вариантах осуществления данной технологии распределенная система 100 обработки информации должна принимать внешние входные данные определенного вида, соответствующие свойству детерминированности автоматов SM по меньшей мере некоторых подсистем распределенной системы 100 обработки информации.
Подсистема распределенного хранения данных
Как упомянуто выше, распределенная система 100 обработки информации также содержит подсистему 108 распределенного хранения данных. В общем случае подсистема 108 распределенного хранения данных способна, среди прочего, хранить системные данные, указывающие состояния, изменения состояний, внешние входные и/или выходные данные по меньшей мере некоторых автоматов SM распределенной системы 100 обработки информации. Например, системные данные, связанные с автоматом SM распределенной системы 100 обработки информации, могут храниться в виде журнала, содержащего хронологический список состояний, изменений состояний, внешних входных и/или выходных данных данного автомата SM.
Подсистема 108 распределенного хранения данных также способна хранить клиентские данные, т.е. данные, связанные с внешними входными данными, обрабатываемыми распределенной системой 100 обработки информации. Например, в некоторых вариантах осуществления данной технологии клиентские данные могут храниться как часть системных данных в подсистеме 108 распределенного хранения данных в пределах объема данной технологии.
Для хранения системных и/или клиентских данных подсистема 108 распределенного хранения данных содержит множество устройств 112 хранения данных, каждое из которых далее называется устройством 112 хранения данных. Согласно различным вариантам осуществления данной технологии, некоторые или все устройства из множества устройств 112 хранения данных могут располагаться в одном или в различных местах. Например, некоторые или все устройства из множества устройств 112 хранения данных могут располагаться в одной серверной стойке, и/или в одном центре обработки данных, и/или могут быть распределены среди множества серверных стоек в одном или нескольких центрах обработки данных.
В некоторых вариантах осуществления данной технологии системные и/или клиентские данные, хранящиеся в одном устройстве 112 хранения данных, могут дублироваться и храниться в нескольких других устройствах 112 хранения данных. В некоторых вариантах осуществления изобретения такое дублирование и хранение системных и/или клиентских данных может обеспечивать отказоустойчивое хранение системных и/или клиентских данных в распределенной системе 100 обработки информации. Отказоустойчивое хранение системных и/или клиентских данных способно предотвращать утрату данных, когда устройство 112 хранения данных подсистемы 108 распределенного хранения данных становится временно или постоянно недоступным для хранения и извлечения данных. Такое отказоустойчивое хранение системных и/или клиентских данных также позволяет предотвращать утрату данных, когда автомат SM распределенной системы 100 обработки информации становится временно или постоянно недоступным.
Предполагается, что устройство 112 хранения данных может быть реализовано в виде компьютерного сервера. Компьютерный сервер содержит по меньшей мере одно физическое запоминающее устройство (т.е. накопитель 126) и одно или несколько программных приложений, способных выполнять машиночитаемые команды. Накопитель 126 может представлять собой твердотельный накопитель (SSD, Solid State Drive), накопитель на жестких дисках (HDD, Hard Disk Drive) и т.п. Поэтому можно сказать, что по меньшей мере одно физическое запоминающее устройство может быть реализовано как устройство с подвижным или неподвижным диском.
Например, как показано на фиг. 1, устройство 112 хранения данных способно содержать, помимо прочего, следующие программные приложения: приложение 114 виртуального накопителя (Vdrive), приложение 116 физического накопителя (Pdrive), по меньшей мере одно приложение 118 моделирования накопителя, по меньшей мере одно приложение 120 планирования работы, приложение 122 обеспечения работы в реальном времени и по меньшей мере один прокси-сервер 124 автомата SM. Функции указанных выше программных приложений и накопителя 126, обеспечивающие хранение по меньшей мере некоторых системных и/или клиентских данных, более подробно описаны ниже со ссылками на фиг. 2.
Подсистема предварительной обработки запросов
Как указано выше, подсистема 105 обработки транзакций может содержать несколько детерминированных автоматов SM, которые должны получать входные данные определенного вида и которые соответствуют свойству детерминированности автоматов SM. Также следует еще раз отметить, что источник 102 запросов выдает запрос 180 в виде запроса декларативного вида.
Соответственно, подсистема 104 предварительной обработки запросов способна принимать запрос 180 декларативного вида от источника 102 запросов и предварительно обрабатывать или преобразовывать запрос 180 во множество 182 детерминированных транзакций, соответствующих свойству детерминированности нескольких автоматов SM, образующих подсистему 105 обработки транзакций.
В целом, подсистема 104 предварительной обработки запросов предназначена для предварительной обработки или преобразования запроса 180 во множество детерминированных транзакций 182, которые могут быть обработаны детерминированными автоматами SM из подсистемы 105 обработки транзакций, обеспечивая возможность обработки запроса 180 подсистемой 105 обработки транзакций.
Следует отметить, что подсистема 104 предварительной обработки запросов также способна формировать ответ 181 для передачи в источник 102 запросов. Разумеется, что подсистема 104 предварительной обработки запросов связана с подсистемой 105 обработки транзакций не только для передачи множества 182 детерминированных транзакций, но и для приема информации об обработке множества 182 детерминированных транзакций. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии множество 182 детерминированных транзакций может содержать одну или несколько транзакций вида «считывание» или «запись».
В некоторых вариантах осуществления данной технологии подсистема 104 предварительной обработки запросов реализована в виде по меньшей мере одного автомата SM в пределах объема данной технологии.
В некоторых вариантах осуществления данной технологии предполагается, что представленная на фиг. 1 распределенная система 100 обработки информации способна поддерживать транзакции ACID (Atomicity, Consistency, Isolation and Durability). В целом, ACID - это аббревиатура для обозначения набора свойств транзакции (атомарность, согласованность, изолированность, долговечность), обеспечивающих надежность базы данных при выполнении транзакций. Поэтому в некоторых вариантах осуществления данной технологии предполагается, что транзакции, предназначенные для подсистемы 105 обработки транзакций, могут быть атомарными, согласованными, изолированными и долговечными в пределах объема данной технологии.
Подсистема обработки транзакций
В общем случае подсистема 105 обработки транзакций способна принимать и обрабатывать множество 182 детерминированных транзакций и, таким образом, обрабатывать запрос 180 от источника 102 запросов. Подсистема 105 обработки транзакций содержит (а) подсистему 106 маршрутизации транзакций и (б) подсистему 110 базы данных, которые описаны ниже.
Подсистема 110 базы данных содержит множество мест назначения транзакции (TDL, Transaction Destination Location) и разделена на множество сегментов 109, каждый из которых далее называется сегментом 109. В не имеющем ограничительного характера примере подсистема 110 базы данных может содержать базу данных, включающую в себя одну или несколько таблиц базы данных. Таблица базы данных может состоять из по меньшей мере двух столбцов, таких как первый столбец, содержащий ключи, и второй столбец, содержащий записи, в которых хранятся данные, связанные с соответствующими ключами. В этом не имеющем ограничительного характера примере место TDL может соответствовать строке таблицы базы данных, т.е. место TDL может соответствовать ключу и соответствующей записи в таблице базы данных.
В этом не имеющем ограничительного характера примере каждый сегмент 109 подсистемы 110 базы данных содержит часть таблицы базы данных. Следовательно, множество мест TDL, сопоставленных с соответствующими строками таблицы базы данных, разделено на множество сегментов 109 так, чтобы каждый сегмент 109 содержал соответствующее подмножество (например, диапазон) множества мест TDL.
В некоторых вариантах осуществления данной технологии предполагается, что каждый сегмент из множества сегментов 109 может быть реализован с использованием соответствующего детерминированного автомата SM. Это означает, что после приема транзакции, предназначенной для места TDL сегмента 109, реализованного с использованием автомата SM, этот автомат SM может обработать транзакцию и перейти из текущего состояния в новое состояние в соответствии с транзакцией, как описано выше.
Подсистема 106 маршрутизации транзакций способна маршрутизировать транзакции из множества 182 детерминированных транзакций в соответствующие места TDL и, таким образом, направлять их в соответствующие сегменты 109 подсистемы 110 базы данных. С этой целью подсистема 106 маршрутизации транзакций может включать в себя множество портов, которые обычно способны (а) принимать множество 182 детерминированных транзакций от подсистемы 104 предварительной обработки запросов, (б) разделять множество 182 детерминированных транзакций на подмножества детерминированных транзакций, предназначенных для соответствующих сегментов 109, и (в) формировать для каждого сегмента централизованный порядок выполнения детерминированных транзакций соответствующими сегментами 109.
Следует отметить, что каждый порт из множества портов, образующих подсистему 106 маршрутизации транзакций, может быть реализован как соответствующий автомат SM. В некоторых вариантах осуществления изобретения предполагается, что множество портов может включать в себя порты двух различных видов для маршрутизации транзакций из множества 182 детерминированных транзакций в соответствующие сегменты 109. В других вариантах осуществления изобретения по меньшей мере некоторые функции множества портов могут выполняться автоматами SM, соответствующими множеству сегментов 109.
Кроме того, как показано на фиг. 1, по меньшей мере некоторые из автоматов SM подсистемы 105 обработки транзакций могут быть связаны с подсистемой 108 распределенного хранения данных с использованием соответствующей линии 160 связи. В целом, линия 160 связи предназначена для передачи системных данных, среди прочих, таких как данные о состояниях, изменениях состояний, внешние входные и/или выходные данные соответствующих автоматов SM и т.д., в подсистему 108 распределенного хранения данных для хранения. Ниже со ссылками на фиг. 2 более подробно описана реализация линий 160 связи и конфигурация подсистемы 108 распределенного хранения данных для хранения системных данных.
На фиг. 2 представлено устройство 112 хранения данных, входящее в состав подсистемы 108 распределенного хранения данных. Как описано выше, устройство 112 хранения данных содержит по меньшей мере один прокси-сервер 124 автомата SM. Прокси-сервер автомата SM предназначен для управления связью между автоматом SM и подсистемой 108 распределенного хранения данных. В некоторых вариантах осуществления данной технологии предполагается, что по меньшей мере один прокси-сервер 124 автомата SM устройства 112 хранения данных может представлять собой прикладной программный интерфейс (API, Application Programing Interface), управляющий связью между автоматом SM и устройством 112 хранения данных. В других вариантах осуществления данной технологии по меньшей мере один прокси-сервер 124 автомата SM сам может быть реализован как автомат SM. В других вариантах осуществления данной технологии по меньшей мере один прокси-сервер 124 автомата SM может быть реализован как программный модуль (не как автомат SM) для выполнения описанных выше функций.
В некоторых вариантах осуществления данной технологии прокси-сервер 124 автомата SM может быть способен (а) принимать системные данные обновления журнала этого автомата SM с использованием соответствующей линии 160 связи, (б) обрабатывать системные данные и (в) передавать обработанные системные данные соответствующему приложению 114 Vdrive для дальнейшей обработки.
По меньшей мере один прокси-сервер 124 автомата SM может быть способен обрабатывать системные данные, например, для обеспечения целостности и отказоустойчивости системных данных. В некоторых вариантах осуществления данной технологии предполагается, что по меньшей мере один прокси-сервер 124 автомата SM может быть способен выполнять стойкое к потере кодирование (erasure coding) системных данных. В целом, стойкое к потере кодирование представляет собой способ кодирования, предусматривающий получение данных с избыточностью и разделение их на несколько фрагментов. Такие избыточность и фрагментация способствуют восстановлению данных в случае потери одного или нескольких фрагментов вследствие нарушений работоспособности в системе.
Предполагается, что обработанные таким образом по меньшей мере одним прокси-сервером 124 автомата SM системные данные принимаются по меньшей мере одним соответствующим приложением 114 Vdrive устройства 112 хранения данных. Приложение 114 Vdrive предназначено для обработки системных данных, полученных от по меньшей мере одного прокси-сервера 124 автомата SM, и для ответного формирования соответствующих операций ввода/вывода (I/O, Input/Output), которые должны выполняться накопителем 126 для сохранения системных данных в накопителе 126 устройства 112 хранения данных. После формирования по меньшей мере одним приложением 114 Vdrive операций I/O, соответствующих принятым системным данным, по меньшей мере одно приложение 114 Vdrive передает операции I/O приложению 116 Pdrive.
Иными словами, предполагается, что устройство 112 хранения данных может содержать несколько прокси-серверов 124 автомата SM для обработки и передачи системных данных нескольким соответствующим приложениям 114 Vdrive, которые обрабатывают системные данные, формируют соответствующие операции I/O и передают соответствующие операции I/O в единое приложение 116 Pdrive устройства 112 хранения данных.
В целом, приложение 116 Pdrive предназначено для управления работой накопителя 126. Например, приложение 116 Pdrive может быть способным выполнять кодирование операций I/O, которые должны выполняться в накопителе 126, и различные другие функции, способствующие надежному хранению данных в накопителе 126.
Приложение 116 Pdrive связано с приложением 120 планирования работы для передачи операции I/O. Приложение 120 планирования работы способно планировать передачу операций I/O в накопитель 126. Предполагается, что приложение 120 планирования работы или сокращенно планировщик может использовать различные схемы планирования для определения порядка передачи операций I/O в накопитель 126 для их дальнейшего выполнения.
Предполагается, что в некоторых вариантах осуществления данной технологии планировщик 120 может быть реализован как часть приложения 116 Pdrive. Иными словами, приложением 116 Pdrive могут выполняться различные схемы планирования в пределах объема данной технологии.
Предполагается, что планировщик 120 может обеспечивать гибридную схему планирования. Например, планировщик 120 может обеспечивать схему «справедливого» планирования, которая при определенных условиях также представляет собой схему планирования «в реальном времени».
Следует отметить, что для данного устройства 112 хранения данных может потребоваться хранение операций I/O, соответствующих системным данным, связанным с несколькими автоматами SM. Кроме того, каждый из нескольких автоматов SM связан с заранее заданной долей производительности накопителя, которую накопитель 126 может выделить для выполнения операций I/O, связанных с соответствующим автоматом SM. В целом, схемы «справедливого» планирования способны упорядочивать операции I/O, передаваемые в накопитель 126, так, чтобы производительность накопителя 126, предназначенная для выполнения упорядоченных операций I/O, использовалась согласно заранее заданным долям, связанным с несколькими автоматами SM.
Следует еще раз отметить, что распределенная система 100 обработки информации может использоваться для предоставления услуг «облачного» хранения данных. Во многих таких вариантах осуществления может быть желательным обрабатывать и сохранять системные данные в реальном времени, т.е. в течение очень короткого интервала времени. Чтобы обеспечить выполнение требования режима реального времени к распределенной системе 100 обработки информации, операции I/O могут быть связаны с соответствующими предельными сроками, которые указывают момент времени, по прошествии которого соответствующие операции I/O уже не попадают в пределы допустимого времени, соответствующие требованиям режима реального времени к распределенной системе 100 обработки информации. В целом, схемы планирования реального времени способны упорядочивать операции I/O, передаваемые в накопитель 126, так, чтобы операции I/O выполнялись накопителем 126 с соблюдением соответствующих предельных сроков.
Вкратце, планировщик 120 может обеспечивать гибридную схему планирования, позволяющую упорядочивать операции I/O, передаваемые для выполнения в накопитель 126, так, чтобы учитывались и заранее заданные доли производительности накопителя для каждого соответствующего автомата SM, и соблюдались соответствующие предельные сроки операций I/O.
Как было упомянуто выше, накопитель 126 представляет собой носитель информации для выполнения операций I/O и, соответственно, для хранения системных данных, переданных в устройство 112 хранения данных. Например, накопитель 126 может быть реализован в виде накопителя HDD или накопителя SSD. Накопитель 126 включает в себя внутреннее логическое устройство 250 накопителя для выбора операции I/O среди всех переданных в накопитель операций I/O с целью выполнения в текущий момент времени.
Следует отметить, что операции I/O могут направляться для выполнения в накопитель 126 по одной, но это может приводить к увеличению задержек между накопителем 126 и другими компонентами устройства 112 хранения данных. Поэтому операции I/O могут предаваться в накопитель 126 пакетами или группами. После приема пакета или группы операций I/O накопителем 126 внутреннее логическое устройство 250 накопителя способно выбрать для выполнения наиболее эффективную операцию I/O среди имеющихся в пакете операций I/O.
Например, наиболее эффективная операция I/O может выбираться на основе различных критериев, таких как место выполнения предыдущей операции I/O в накопителе 126 и место выполнения операций I/O, имеющихся в накопителе 126. Иными словами, внутреннее логическое устройство 250 накопителя способно выбирать для текущего выполнения наиболее эффективную операцию (с точки зрения накопителя 126) среди всех операций I/O, имеющихся в накопителе 126 в текущий момент времени.
Поэтому в некоторых случаях, несмотря на то, что планировщик 120 упорядочил операции I/O для передачи определенным образом с учетом требований режима реального времени к распределенной системе 100 обработки информации, внутреннее логическое устройство 250 накопителя 126 может выдавать в накопитель 126 команды для формирования порядка выполнения операций I/O, отличного от порядка передачи, выбранного планировщиком 120. Поэтому порядок выполнения иногда может не соответствовать требованиям режима реального времени распределенной системы 100 обработки информации (в частности, когда от планировщика 120 принимаются дополнительные операции I/O, которые могут быть более «эффективными» с точки зрения накопителя 126 и могут выбираться среди еще не выполненных операций I/O).
Чтобы обеспечить работу устройства 112 хранения данных в реальном времени и предотвратить описанную выше проблему, также известную как «торможение работы» (operation stagnation), устройство 112 хранения данных может содержать диспетчерский контроллер операций I/O, который далее называется приложением 122 обеспечения работы в реальном времени. В целом, приложение 122 обеспечения работы в реальном времени позволяет управлять тем, какие операции I/O из числа уже упорядоченных планировщиком 120 передаются в текущий момент времени для выполнения в накопитель 126.
Предполагается, что в некоторых вариантах осуществления данной технологии приложение 122 обеспечения работы в реальном времени может быть реализовано как часть приложения 116 Pdrive. Иными словами, вышеупомянутые функции приложения 122 обеспечения работы в реальном времени могут выполняться приложением 116 Pdrive в пределах объема данной технологии.
Устройство 112 хранения данных также может содержать по меньшей мере одно соответствующее приложение 118 моделирования накопителя для каждого накопителя 126 в устройстве 112 хранения данных. В целом, приложение 118 моделирования накопителя способно эмулировать идеальную работу накопителя 126 для анализа накопителя 126 в диагностических целях. Тем не менее, в других вариантах осуществления изобретения планировщик 120 также может использовать приложение 118 моделирования накопителя, чтобы упорядочивать операции I/O для их передачи в накопитель 126.
Предполагается, что в некоторых вариантах осуществления данной технологии по меньшей мере одно соответствующее приложение 118 моделирования накопителя может быть реализовано как часть приложения 116 Pdrive. Иными словами, вышеупомянутые функции по меньшей мере одного соответствующего приложения 118 моделирования накопителя могут выполняться приложением 116 Pdrive в пределах объема данной технологии.
Распределенная компьютерная система
В соответствии с некоторыми вариантами осуществления данной технологии реализована распределенная компьютерная система 308, представленная на фиг. 3. Предполагается, что распределенная компьютерная система 308 может быть реализована в виде подсистемы 108 распределенного хранения данных распределенной системы 100 обработки информации, представленной на фиг. 1.
Распределенная компьютерная система 308 предназначена для сохранения данных, предоставленных клиентом распределенной компьютерной системы 308, и для извлечения этих данных по запросам доступа к данным. Клиент может быть реализован, например, в виде автомата SM распределенной системы 100 обработки информации. В других вариантах осуществления изобретения предполагается, что предназначенные для хранения данные могут быть связаны с источником 102 запросов распределенной системы 100 обработки информации.
Распределенная компьютерная система 308 содержит множество устройств хранения данных (не обозначено), распределенных между различными группами хранения. Например, первая группа 310 хранения может содержать первое устройство 312 хранения данных, второе устройство 314 хранения данных и третье устройство 316 хранения данных. Аналогично, вторая группа 320 хранения может содержать четвертое устройство 322 хранения данных, пятое устройство 324 хранения данных и шестое устройство 326 хранения данных. Аналогично, третья группа 330 хранения может содержать седьмое устройство 332 хранения данных, восьмое устройство 334 хранения данных и девятое устройство 336 хранения данных. Предполагается, что группа хранения может содержать больше или меньше трех устройств хранения данных и что количество устройств хранения данных в группе хранения может зависеть, среди прочего, от различных вариантов осуществления данной технологии.
В целом, группа хранения может представлять собой общую зону или инфраструктуру, нарушение работоспособности которой может приводить к нарушению работоспособности входящих в ее состав устройств хранения данных (одного, некоторых или всех). В некоторых не имеющих ограничительного характера примерах группа хранения может представлять собой центр обработки данных, серверную стойку, сервер хранения данных, содержащий несколько устройств хранения данных, и т.п. Группа хранения также может содержать другие компоненты (помимо устройств хранения данных, показанных на фиг. 3), такие как источники питания, компоненты для обеспечения связи, компоненты для резервирования или резервного копирования, компоненты для управления состоянием окружающей среды, например, системы кондиционирования воздуха, системы пожаротушения и т.д. Группы хранения обычно содержат такие дополнительные компоненты, чтобы избежать сценариев нарушения работоспособности, когда в результате нарушения работоспособности группы хранения становится недоступным одно или несколько устройств хранения данных из этой группы, что может привести к повреждению или утрате данных.
Помимо первой группы 310 хранения, второй группы 320 хранения и третьей группы 330 хранения (например, множества устройств хранения данных) распределенная компьютерная система 308 содержит координирующий компьютер 300. Координирующий компьютер 300 способен управлять (а) сохранением данных множеством устройств хранения данных распределенной компьютерной системы 308 и (б) запросами доступа к данным в отношении этих данных. Координирующий компьютер 300 может быть реализован в виде физического электронного устройства или автомата SM.
Управление сохранением данных может, среди прочего, включать в себя (а) подтверждение приема данных распределенной компьютерной системой 308, (б) формирование данных с избыточностью для уменьшения риска повреждения или утраты данных (например, за счет применения одного или нескольких алгоритмов обеспечения избыточности), (в) выдачу команд устройствам хранения данных для сохранения данных с избыточностью, (г) отслеживание уведомлений от устройств хранения данных, подтверждающих сохранение данных с избыточностью, и (д) определение вида ответа, если он предусмотрен, который должен быть предоставлен клиенту относительно сохранения данных (например, с применением одного или нескольких дополнительных алгоритмов).
Управление запросами доступа к данным может, среди прочего, включать в себя определение достаточности доступного устройства (или нескольких устройств) хранения данных, хранящего данные с избыточностью, для извлечения данных клиента. Если это так, то в некоторых вариантах осуществления изобретения координирующий компьютер 300 может быть способен осуществлять доступ к этим доступным данным с избыточностью для извлечения данных. Если это не так, координирующий компьютер 300 может быть способен однозначно определять, было ли предоставлено клиенту подтверждение успешного сохранения данных при сохранении данных. Предполагается, что координирующий компьютер 300 может быть способен однозначно определять, было ли подтверждено успешное сохранение данных, для определения вида ответа, если он предусмотрен, который должен быть предоставлен клиенту относительно данных.
Разработчики данной технологии реализовали способы и распределенные компьютерные системы для обработки данных, которые, в некотором смысле, позволяют поддерживать «доверие» клиента к распределенной компьютерной системе 308. Например, если клиент не получает уведомление об успешном сохранении его данных распределенной компьютерной системой 308, то он по сути и не «ожидает», что данные будут извлечены и предоставлены по запросу доступа к данным в будущий момент времени. В результате, если когда-либо эти данные не будут извлечены в будущий момент времени, клиент не утрачивает «доверие» к способности распределенной компьютерной системы 308 надежно хранить данные, поскольку распределенная компьютерная система 308 не предоставила уведомления об их успешном сохранении.
Если же клиент получает уведомление об успешном сохранении его данных, то он по сути «ожидает», что данные будут извлечены и предоставлены по запросу доступа к данным. В результате, если клиент получает уведомление об успешном сохранении его данных, но распределенная компьютерная система 308 не способна извлечь эти данные в будущий момент времени, то клиент, в некотором смысле, утрачивает «доверие» к способности распределенной компьютерной системы 308 надежно хранить данные.
Следовательно, можно сказать, что «доверие» клиента к распределенной компьютерной системе 308 связано не с возможностью извлечения данных в будущий момент времени, а с возможностью извлечения данных в то время, когда клиенту было предоставлено уведомление об их успешном сохранении.
В соответствии с некоторыми вариантами осуществления данной технологии реализованы способы и распределенные компьютерные системы, способные выдавать клиентам уведомления об успешном сохранении данных, если обеспечивается сохранение данных таким образом, чтобы их возможно было извлечь, даже если определенное максимальное количество устройств хранения данных в распределенной компьютерной системе 308 окажется недоступным в будущий момент времени. Иными словами, разработчики данной технологии реализовали способы и распределенные компьютерные системы, где данные считаются «успешно сохраненными», когда гарантировано восстановление этих данных в будущий момент времени, даже если максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени.
Как описано ниже, в некоторых вариантах осуществления изобретения реализованные способы и распределенные компьютерные системы также могут при запросах доступа к данным помогать однозначно определять, выдала ли распределенная компьютерная система 308 подтверждение успешного сохранения данных клиенту.
Например, если при поступлении запросов доступа к данным распределенная компьютерная система 308 не способна извлечь данные, распределенной компьютерной системе 308 может потребоваться определить вид ответа, если он предусмотрен, который должен быть предоставлен клиенту относительно этих данных. Ответы, которые могут предоставляться клиенту, могут зависеть от того, подтвердила распределенная компьютерная система 308 успешное сохранение данных или нет.
В одном случае, если во время сохранения данных распределенная компьютерная система 308 подтвердила успешное их сохранение и данные возможно извлечь по запросу доступа к данным, то распределенная компьютерная система 308 может быть способна извлечь и предоставить данные клиенту. Во втором случае, если во время сохранения данных распределенная компьютерная система 308 не подтвердила успешное их сохранение и данные возможно извлечь по запросу доступа к данным, то распределенная компьютерная система 308 может быть способна извлечь и предоставить данные клиенту. В третьем случае, если во время сохранения данных распределенная компьютерная система 308 подтвердила успешное их сохранение, но данные невозможно извлечь по запросу доступа к данным, то распределенная компьютерная система 308 может быть способна сформировать ответ вида «ошибка данных». В четвертом случае, если во время сохранения данных распределенная компьютерная система 308 не подтвердила успешное их сохранение и данные невозможно извлечь по запросу доступа к данным, то распределенная компьютерная система 308 может быть способна сформировать ответ вида «нет данных», поскольку клиент - потребитель этих данных по сути не «ожидает», что данные должны быть извлечены, и, следовательно, по сути не «ожидает», что данные были успешно сохранены распределенной компьютерной системой 308.
Далее описана конфигурация распределенной компьютерной системы 308 для управления сохранением данных и запросами доступа к данным.
Можно предположить, что представленная на фиг. 4 распределенная компьютерная система 308 получает данные 400 для сохранения. Вид данных 400, на который не накладывается каких-либо особых ограничений, может, среди прочего, зависеть от различных вариантов осуществления данной технологии.
Распределенная компьютерная система 308 может реализовывать алгоритм 450 обеспечения избыточности. Например, координирующий компьютер 300 может быть способен применять алгоритм 450 обеспечения избыточности во время сохранения данных и/или во время доступа к данным. В некоторых случаях координирующий компьютер 300 может принимать указание на алгоритм 450 обеспечения избыточности от оператора распределенной компьютерной системы 308. В других случаях координирующий компьютер 300 может принимать указание на алгоритм 450 обеспечения избыточности от клиента - потребителя данных 400.
В целом, алгоритм 450 обеспечения избыточности способен формировать на основе данных 400 «блоки данных с избыточностью», которые должны сохраняться в различных устройствах хранения данных, чтобы способствовать восстанавливаемости данных 400 за счет избыточности в ситуациях, когда одно или несколько устройств хранения данных оказывается недоступным.
Следует отметить, что алгоритм 450 обеспечения избыточности может представлять собой (а) алгоритм репликации или (б) алгоритм стойкого к потере кодирования. Иными словами, избыточность данных, которую обеспечивает алгоритм 450 обеспечения избыточности, может достигаться с использованием (а) способа репликации данных или (б) способа стойкого к потере кодирования. Размер и количество блоков данных с избыточностью, которые должны храниться и поддерживаться распределенной компьютерной системой 308, зависят, среди прочего, от конкретного способа, используемого алгоритмом 450 обеспечения избыточности.
В некоторых вариантах осуществления изобретения, где алгоритм 450 обеспечения избыточности представляет собой алгоритм репликации, алгоритм 450 обеспечения избыточности способен использовать способ репликации данных. В целом, способы репликации данных используются для формирования одной или нескольких реплик данных 400, которые должны сохраняться в различных устройствах хранения данных. В первом не имеющем ограничительного характера примере способа репликации данных, который может использоваться алгоритмом 450 обеспечения избыточности, алгоритм 450 обеспечения избыточности может быть способен формировать две реплики (например, используя способ репликации «Зеркало-2») данных 400 для их сохранения в соответствующих различных устройствах хранения данных. Во втором не имеющем ограничительного характера примере способа репликации данных, который может использоваться алгоритмом 450 обеспечения избыточности, алгоритм 450 обеспечения избыточности может быть способен формировать три реплики (например, используя способ репликации «Зеркало-3») данных 400 для их сохранения в соответствующих различных устройствах хранения данных. Независимо от способа репликации данных, используемого алгоритмом 450 обеспечения избыточности, если некоторые устройства хранения данных оказываются неисправными и становятся недоступными при поступлении запросов доступа к данным, для восстановления данных 400 достаточно доступности только одной из реплик данных 400. Иными словами, в этом случае достаточно доступности только одного устройства хранения данных, хранящего реплику (например, данные с избыточностью), для восстановления данных 400.
В других вариантах осуществления изобретения, где алгоритм 450 обеспечения избыточности представляет собой алгоритм стойкого к потере кодирования, алгоритм 450 обеспечения избыточности способен использовать способ стойкого к потере кодирования. В целом, способ стойкого к потере кодирования может использоваться, чтобы разделять данные 400 на фрагменты, затем разделять каждый фрагмент на М блоков данных и формировать N блоков данных четности для обеспечения избыточности данных 400. Блоки данных затем должны сохраняться в соответствующих различных устройствах хранения данных. Различные способы стойкого к потере кодирования обычно обозначаются как стойкое к потере кодирование M+N с различными значениями М и N. В некоторых примерах алгоритм 450 обеспечения избыточности может быть способен использовать по меньшей мере одно из следующего: стойкое к потере кодирование 1+2, стойкое к потере кодирование 3+2, стойкое к потере кодирование 5+2, стойкое к потере кодирование 7+2, стойкое к потере кодирование 17+3 и т.п. Независимо от способа стойкого к потере кодирования, используемого алгоритмом 450 обеспечения избыточности, данные 400 возможно восстановить, если становятся недоступными любые N или меньшее количество устройств хранения данных.
Вкратце, можно сказать, что координирующий компьютер 300 может быть способен использовать алгоритм 450 обеспечения избыточности для формирования данных 420 с избыточностью на основе данных 400. Только для иллюстрации можно предположить, что алгоритм 450 обеспечения избыточности представляет собой алгоритм репликации данных и способен выполнять способ репликации данных «Зеркало-5», где данные 420 с избыточностью включают в себя пять блоков данных с избыточностью (пять реплик), которые должны сохраняться в соответствующих различных устройствах хранения данных. Следует отметить, что в этом случае алгоритм 450 обеспечения избыточности указывает, что необходимо по меньшей мере одно устройство хранения данных (среди пяти устройств хранения данных, которые должны хранить соответствующие реплики), которое должно хранить соответствующий блок данных с избыточностью (соответствующую реплику), чтобы обеспечить восстановление данных 400.
Предполагается, что в пределах объема данной технологии один или несколько алгоритмов обеспечения избыточности могут быть реализованы в распределенной компьютерной системе 308 подобно тому, как реализован алгоритм 450 обеспечения избыточности. Например, первый алгоритм обеспечения избыточности может использоваться координирующим компьютером 300 для первых данных. В другом примере второй алгоритм обеспечения избыточности может использоваться координирующим компьютером 300 для вторых данных. Какой алгоритм должен использоваться для тех или иных данных, может быть определено оператором распределенной компьютерной системы 308 и/или клиентами - потребителями данных.
Предполагается, что во время сохранения данных (когда данные 400 сохраняются распределенной компьютерной системой 308) координирующий компьютер 300 способен выдавать команды набору устройств хранения данных для сохранения данных 420 с избыточностью. В этом случае координирующий компьютер 300 может быть способен выдавать команды набору из пяти устройств хранения данных для сохранения соответствующих блоков данных с избыточностью (в этом случае соответствующих реплик данных 400) из данных 420 с избыточностью.
Также, как указано выше, координирующий компьютер 300 может быть способен отслеживать уведомления от устройств хранения данных, подтверждающие сохранение. Устройства хранения данных способны оповещать координирующий компьютер 300 (например, посредством подтверждающих уведомлений) после сохранения ими данных в соответствии с командами координирующего компьютера 300. В этом случае после выдачи координирующим компьютером 300 команд набору из пяти устройств хранения данных для сохранения соответствующих блоков данных с избыточностью из данных 420 с избыточностью эти устройства хранения данных способны оповещать координирующий компьютер 300 о сохранении ими соответствующих блоков данных с избыточностью.
Также, как указано выше, координирующий компьютер 300 может быть способен выполнять один или несколько дополнительных алгоритмов для определения вида ответа, если он предусмотрен, который должен быть предоставлен клиенту относительно состояния сохранения данных 400. Например, координирующий компьютер 300 может быть способен формировать или не формировать ответ, среди прочего, в зависимости от количества подтверждающих уведомлений, принятых координирующим компьютером 300 от запоминающих устройств, которым были даны команды на сохранение данных 420 с избыточностью, как описано выше.
В некоторых вариантах осуществления данной технологии координирующий компьютер 300 может быть способен использовать алгоритм 550 моделирования нарушений работоспособности, как показано на фиг. 5, для определения во время сохранения данных вида ответа, если он предусмотрен, который должен быть предоставлен клиенту относительно состояния сохранения данных 400. Иными словами, координирующий компьютер 300 может использовать алгоритм 550 моделирования нарушений работоспособности во время сохранения данных для определения того, требуется ли предоставить клиенту подтверждение успешного сохранения данных 400.
Предполагается, что координирующий компьютер 300 может принимать указание на алгоритм 550 моделирования нарушений работоспособности от оператора распределенной компьютерной системы 308. Как описано ниже, в некоторых вариантах осуществления данной технологии алгоритм 550 моделирования нарушений работоспособности может быть реализован оператором распределенной компьютерной системы 308, среди прочего, на основе сценариев нарушений работоспособности распределенной компьютерной системы 308, при которых оператор хотел бы, чтобы данные 400 возможно было восстановить, т.е. чтобы распределенная компьютерная система 308 было способна восстановить данные 400 для клиента.
Алгоритм 550 моделирования нарушений работоспособности указывает на максимальное количество устройств хранения данных, которые потенциально могут оказаться неисправными в будущий момент времени, но чтобы при этом распределенная компьютерная система 308 гарантировала возможность восстановления данных 400. Координирующий компьютер 300 может быть способен применять алгоритм 550 моделирования нарушений работоспособности для подтверждающих уведомлений, принятых от устройств хранения данных, для определения того, возможно ли восстановление данных 400 в будущий момент времени, если это максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени. Также предполагается, что алгоритм 550 моделирования нарушений работоспособности может быть способен проверять, возможно ли восстановление данных 400 при различных сочетаниях максимального количества устройств хранения данных, недоступных в будущий момент времени.
Ниже более подробно описана конфигурация координирующего компьютера 300 для использования алгоритма 550 моделирования нарушений работоспособности во время сохранения данных.
Можно предположить, что в определенный момент времени после выдачи координирующим компьютером 300 команд набору устройств хранения данных для сохранения данных 420 с избыточностью, координирующий компьютер принимает два подтверждающих уведомления. Например, как показано на фиг. 6, можно предположить, что координирующий компьютер 300 принимает подтверждающее уведомление от четвертого устройства 322 хранения данных и от седьмого устройства 332 хранения данных. Это означает, что в этот момент времени четвертое устройство 322 хранения данных и седьмое устройство 332 хранят соответствующие блоки данных с избыточностью (в этом случае соответствующие реплики данных 400).
Следует еще раз отметить, что согласно алгоритму 450 обеспечения избыточности, используемому для формирования данных 420 с избыточностью на основе данных 400, данные 400 могут быть восстановлены в будущий момент времени, если по меньшей мере один блок данных с избыточностью из данных 420 с избыточностью доступен в этот будущий момент времени.
На первый взгляд, поскольку по меньшей мере одно устройство хранения данных подтвердило сохранение соответствующего блока данных с избыточностью, данные 400 могут быть восстановлены в будущий момент времени.
Тем не менее, вместо предоставления клиенту подтверждения успешного сохранения данных 400, координирующий компьютер 300 способен применять алгоритм 550 моделирования нарушений работоспособности для определения того, возможно ли восстановление данных 400 в будущий момент времени, если максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени.
Можно предположить, что это максимальное количество устройств хранения данных равно четырем. Это означает, что алгоритм 550 моделирования нарушений работоспособности может быть использован для определения того, возможно ли восстановление данных 400 в будущий момент времени, если максимальное количество (четыре) устройств хранения данных окажется недоступным в этот будущий момент времени.
По сути, алгоритм 550 моделирования нарушений работоспособности способен определять, возможно ли восстановление данных 400 при различных сочетаниях четырех устройств хранения данных из множества устройств хранения данных, недоступных в будущий момент времени. Иными словами, алгоритм 550 моделирования нарушений работоспособности, в некотором смысле, может быть способен моделировать множество сценариев нарушения работоспособности, при которых в различных сочетаниях недоступны четыре устройства хранения данных из множества устройств хранения данных.
На фиг. 6 приведена схема 602 первого сценария нарушения работоспособности, моделируемого алгоритмом 550 моделирования нарушений работоспособности и схема 604 второго сценария нарушения работоспособности, моделируемого алгоритмом 550 моделирования нарушений работоспособности.
При первом сценарии нарушения работоспособности алгоритм 550 моделирования нарушений работоспособности может быть способен определять, возможно ли восстановление данных 400, если недоступно первое сочетание 612 устройств хранения данных с нарушением работоспособности. Первое сочетание 612 устройств хранения данных с нарушением работоспособности содержит четыре устройства хранения данных (максимальное количество устройств хранения данных, как указано выше): первое устройство 312 хранения данных, второе устройство 314 хранения данных, третье устройство 316 хранения данных и шестое устройство 326 хранения данных. В первом сценарии нарушения работоспособности координирующий компьютер 300 может определить, что восстановление данных 400 возможно, поскольку доступно по меньшей мере одно устройство хранения данных, хранящее соответствующий блок данных с избыточностью (в этом случае соответствующую реплику данных 400).
При втором сценарии нарушения работоспособности алгоритм 550 моделирования нарушений работоспособности может быть способен определять, возможно ли восстановление данных 400, если недоступно второе сочетание 614 устройств хранения данных с нарушением работоспособности. Второе сочетание 614 устройств хранения данных с нарушением работоспособности также содержит четыре устройства хранения данных (максимальное количество устройств хранения данных, как указано выше): четвертое устройство 322 хранения данных, седьмое устройство 332 хранения данных, восьмое устройство 334 хранения данных и девятое устройство 336 хранения данных. Во втором сценарии нарушения работоспособности координирующий компьютер 300 может определить, что восстановление данных 400 невозможно, поскольку оказываются недоступными все устройства хранения данных, хранящие соответствующие блоки данных с избыточностью.
В результате, в момент времени, когда координирующий компьютер 300 принимает подтверждающие уведомления от четвертого устройства 322 хранения данных и от седьмого устройства 332 хранения данных, координирующий компьютер 300 определяет, что не следует формировать подтверждение успешного сохранения данных 400 для клиента. Следует отметить, что, несмотря на то, что два устройства хранения данных подтвердили сохранение соответствующих блоков данных с избыточностью в случае, когда для восстановления данных 400 требуется, чтобы по меньшей мере одно устройство хранения данных хранило данные, координирующий компьютер 300 не предоставляет клиенту подтверждение успешного сохранения данных 400, поскольку не гарантируется восстановление данных 400 в будущий момент времени, если в этот будущий момент времени окажется недоступным максимальное количество устройств хранения данных (например, четыре устройства хранения данных).
Таким образом, можно сказать, что координирующий компьютер 300 способен формировать и предоставлять клиенту подтверждение успешного сохранения данных 400, только если данные 400 рассматриваются как успешно сохраненные. При этом данные 400 рассматриваются как успешно сохраненные, если гарантируется возможность восстановления данных 400 в будущий момент времени, даже если в этот будущий момент времени окажется недоступным максимальное количество устройств хранения данных.
Предполагается, что во время сохранения данных 400 координирующий компьютер 300 может быть способен итеративно применять алгоритм 550 моделирования нарушений работоспособности для подтверждающих уведомлений, принятых от устройств хранения данных. Иными словами, это означает, что после применения алгоритма 550 моделирования нарушений работоспособности в отношении двух принятых в этот момент времени подтверждающих уведомлений координирующий компьютер 300 решает не выдавать уведомление об успешном сохранении данных 400, как описано выше. Тем не менее, после приема дополнительного подтверждающего уведомления координирующий компьютер 300 может применять алгоритм 550 моделирования нарушений работоспособности в отношении трех подтверждающих уведомлений для определения того, следует ли выдавать уведомление об успешном сохранении данных 400. Таким образом, можно сказать, что в некоторых вариантах осуществления данной технологии координирующий компьютер 300 может быть способен итеративно применять алгоритм 550 моделирования нарушений работоспособности в отношении подтверждающих уведомлений, принятых от устройств хранения данных, при приеме каждого нового подтверждающего уведомления координирующим компьютером 300.
В некоторых случаях сочетания максимального количества устройств хранения данных с нарушением работоспособности, моделируемые алгоритмом 550 моделирования нарушений работоспособности, могут включать в себя все возможные сочетания максимального количества устройств хранения данных в распределенной компьютерной системе 308. В других случаях моделируемые сочетания максимального количества устройств хранения данных с нарушением работоспособности могут включать в себя только сочетания максимального количества устройств хранения данных, соответствующие заданному оператором ограничению.
Например, согласно заданному оператором ограничению, моделируемые сочетания максимального количества устройств хранения данных с нарушением работоспособности должны полностью охватывать одну группу хранения. Первое сочетание 612 устройств хранения данных с нарушением работоспособности полностью охватывает первую группу 310 хранения. Второе сочетание 614 устройств хранения данных с нарушением работоспособности полностью охватывает третью группу 330 хранения. Предполагается, что оператор распределенной компьютерной системы 308 может выдавать заданные оператором ограничения, чтобы ограничить количество сочетаний максимального количества устройств хранения данных с нарушением работоспособности среди всех возможных сочетаний максимального количества устройств хранения данных, которые алгоритм 550 моделирования нарушений работоспособности может быть способен моделировать при его применении в отношении подтверждающих уведомлений, принятых координирующим компьютером 300.
Разработчики данной технологии установили, что может быть полезно применять алгоритм 550 моделирования нарушений работоспособности для определения того, следует ли подтверждать успешное сохранение данных 400 во время сохранения данных. Как описано ниже, применение во время сохранения данных алгоритма 550 моделирования нарушений работоспособности для определения того, следует ли подтверждать успешное сохранение данных 400, позволяет при поступлении запросов доступа к данным однозначно определять, было ли подтверждено успешное сохранение данных 400.
В этом случае, согласно алгоритму 450 обеспечения избыточности для восстановления данных 400, требуется только одна реплика из пяти реплик. Тем не менее, предполагается, что в результате использования алгоритма 550 моделирования нарушений работоспособности для выдачи подтверждения успешного сохранения данных 400 может потребоваться, чтобы были сохранены от одной до пяти реплик включительно. Например, несмотря на то, что для извлечения данных 400 требуется только одна реплика из пяти реплик, в некоторых случаях подтверждение успешного сохранения данных 400 может выдаваться после сохранения пяти реплик соответствующими устройствами хранения данных.
Следует отметить, что менее важно, определено ли в ответ на запросы доступа к данным, что данные недоступны, повреждены или утрачены. Более важно определить вид ответа, если он предусмотрен, который должен быть предоставлен, если данные недоступны, повреждены или утрачены (т.е. не могут быть восстановлены или извлечены). Иными словами, если было подтверждено успешное сохранение данных, координирующий компьютер 300 может быть способен (а) предоставлять данные (если возможно их восстановление) или ответ вида «все в порядке» либо (б) предоставлять ответ, указывающий, что данные недоступны, повреждены или утрачены, например, ответ вида «ошибка данных». Если же успешное сохранение данных не было подтверждено, координирующий компьютер 300 может быть способен (а) предоставлять данные (если возможно их восстановление) или ответ вида «все в порядке» либо (б) предоставлять ответ, указывающий, что в распределенной компьютерной системе 308 отсутствуют данные, например, ответ вида «нет данных».
Для иллюстрации можно предположить, что координирующий компьютер 300 подтверждает успешное сохранение данных 400 (поскольку данные 400 потенциально восстановимы). В этом случае, если при поступлении запроса доступа к данным имеет место второй сценарий нарушения работоспособности, распределенной компьютерной системе 308 может потребоваться предоставлять ответ вида «ошибка данных», поскольку было подтверждено, что данные 400 успешно сохранены, в отличие от предоставления ответа вида «нет данных», если успешное сохранение данных 400 не было подтверждено.
Как описано выше, координирующий компьютер 300 также может быть способен управлять запросами доступа к данным. Предполагается, что в некоторых вариантах осуществления данной технологии алгоритм 550 моделирования нарушений работоспособности может использоваться координирующим компьютером 300 не только во время сохранения данных, но также и при поступлении запросов доступа к данным. Как описано ниже, координирующий компьютер 300 может использовать алгоритм 550 моделирования нарушений работоспособности при поступлении запросов доступа к данным, для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных во время сохранения данных.
Можно предположить, что в момент времени доступа к данным координирующий компьютер 300 принимает указание на запрос доступа для других данных от другого клиента. Координирующий компьютер 300 мог управлять другими данными от другого клиента во время сохранения данных аналогично тому, как осуществлялось управление данными 400 клиента в соответствующий момент времени сохранения данных. Например, алгоритм 450 обеспечения избыточности мог использовать способ репликации «Зеркало-5» и координирующий компьютер 300 мог выдавать команды в устройства хранения данных для сохранения соответствующих реплик других данных.
В момент времени доступа к данным, когда координирующий компьютер 300 принимает указание на запрос доступа к другим данным, он может быть способен применять алгоритм 550 моделирования нарушений работоспособности в отношении подтверждающих уведомлений, принятых от устройств хранения данных, которым были выданы команды для сохранения соответствующих реплик других данных.
Можно предположить, что, как показано на фиг. 7, координирующий компьютер 300 принял подтверждающие уведомления от пятого устройства 324 хранения данных, шестого устройства 326 хранения данных и восьмого устройства 334 хранения данных, указывающие на то, что пятое устройство 324 хранения данных, шестое устройство 326 хранения данных и восьмое устройство 334 хранения данных сохранили соответствующие реплики других данных.
Координирующий компьютер 300 может использовать алгоритм 550 моделирования нарушений работоспособности в отношении этих подтверждающих уведомлений, для однозначного определения того, было ли предоставлено другому клиенту подтверждение успешного сохранения других данных во время сохранения этих других данных. Предполагается, что не допускающие двоякого толкования сведения о предоставлении другому клиенту подтверждения успешного сохранения других данных во время сохранения этих других данных могут быть полезны для определения вида ответа, если он предусмотрен, который должен быть предоставлен другому клиенту в ответ на запрос доступа к данным.
Алгоритм 550 моделирования нарушений работоспособности может быть, в некотором смысле, способен моделировать множество сценариев нарушений работоспособности аналогично тому, как описано выше, но в данном случае - в момент времени доступа к данным.
На фиг. 7 представлена схема 702 третьего сценария нарушения работоспособности, моделируемого алгоритмом 550 моделирования нарушений работоспособности в момент времени доступа к данным.
В третьем сценарии нарушения работоспособности алгоритм 550 моделирования нарушений работоспособности может быть способен определять, возможно ли восстановление других данных, если недоступно третье сочетание 712 устройств хранения данных с нарушением работоспособности. Третье сочетание 712 устройств хранения данных с нарушением работоспособности включает в себя четыре устройства хранения данных (максимальное количество устройств хранения данных, как указано выше): четвертое устройство 322 хранения данных, пятое устройство 324 хранения данных, шестое устройство 326 хранения данных и восьмое устройство 334 хранения данных. В третьем сценарии нарушения работоспособности координирующий компьютер 300 может определить, что восстановление других данных невозможно, поскольку недоступны все устройства хранения данных, хранящие соответствующие реплики других данных. По сути, координирующий компьютер 300 однозначно определяет, что подтверждение успешного сохранения других данных не было предоставлено другому клиенту во время сохранения других данных.
На основе этого однозначного определения того, что подтверждение успешного сохранения других данных не было предоставлено другому клиенту, координирующий компьютер 300 может быть способен определять вид ответа, если он предусмотрен, который должен быть предоставлен другому клиенту. Например, можно предположить, что другие данные фактически невозможно извлечь во время получения запроса доступа к данным. Поскольку координирующий компьютер 300 однозначно определил, что другие данные не были подтверждены как успешно сохраненные, координирующий компьютер 300 может быть способен предоставить ответ вида «нет данных» по запросу доступа к данным вместо предоставления ответа вида «ошибка данных».
Если же предположить, что координирующий компьютер 300 однозначно определил, что подтверждение успешного сохранения других данных было предоставлено другому клиенту, то в этом случае, если другие данные невозможно извлечь во время получения запроса доступа к данным, координирующий компьютер 300 может быть способен предоставить ответ вида «ошибка данных» вместо предоставления ответа вида «нет данных».
В соответствии с некоторыми вариантами осуществления данной технологии реализован реализуемый компьютером способ 800 (блок-схема которого представлена на фиг. 8) для распределенной компьютерной системы для обработки данных. Например, способ 800 может быть предназначен для реализации распределенной компьютерной системы 308. Предполагается, что по меньшей мере некоторые шаги способа 800 могут выполняться координирующим компьютером 300. В других вариантах осуществления изобретения по меньшей мере некоторые другие шаги могут выполняться другими возможными компьютерными системами распределенной компьютерной системы 308 в пределах объема данной технологии. Ниже способ 800 описан более подробно.
Шаг 802: прием указания на алгоритм обеспечения избыточности.
Способ 800 начинается на шаге 802, где координирующий компьютер 300 распределенной компьютерной системы 308 принимает указание на алгоритм 450 обеспечения избыточности. Алгоритм 450 обеспечения избыточности может использоваться распределенной компьютерной системой 308 для формирования данных с избыточностью на основе принимаемых данных, например, для формирования данных 420 с избыточностью на основе данных 400. Данные 420 с избыточностью должны сохраняться набором устройств хранения данных из множества устройств хранения данных распределенной компьютерной системы 308. Алгоритм обеспечения избыточности указывает на количество устройств хранения данных, необходимых для сохранения данных 420 с избыточностью, чтобы обеспечить восстановление данных 400.
В некоторых вариантах осуществления изобретения алгоритм 450 обеспечения избыточности может представлять собой алгоритм репликации. Например, алгоритм 450 обеспечения избыточности может использовать алгоритм репликации «Зеркало-5» для формирования данных 420 с избыточностью, включающих в себя пять реплик данных 400. В этом случае алгоритм 450 обеспечения избыточности может указывать, что достаточно только одного устройства хранения данных, хранящего соответствующий блок данных с избыточностью из данных 420 с избыточностью, для восстановления данных 400. Иными словами, поскольку алгоритм 450 обеспечения избыточности представляет собой алгоритм репликации, формирующий данные 420 с избыточностью в виде реплик данных 400 (в этом примере), алгоритм 450 обеспечения избыточности указывает, что достаточно только одного устройства хранения данных, хранящего соответствующую реплику, для восстановления данных 400. Тем не менее, предполагается, что в других вариантах осуществления изобретения алгоритм 450 обеспечения избыточности может представлять собой алгоритм стойкого к потере кодирования, как описано выше.
Шаг 804: прием указания на алгоритм моделирования нарушений работоспособности.
Способ 800 продолжается на шаге 804, где координирующий компьютер 300 принимает указание на алгоритм 550 моделирования нарушений работоспособности. Алгоритм моделирования нарушений работоспособности должен использоваться для подтверждения успешного сохранения данных 400 во время сохранения данных. Следует отметить, что успешно сохраненные данные гарантировано могут быть восстановлены в будущий момент времени, даже если в этот будущий момент времени окажется недоступным максимальное количество устройств хранения данных, как описано выше.
В некоторых вариантах осуществления данной технологии данные также могут рассматриваться как успешно сохраненные, когда они гарантировано могут быть восстановлены в будущий момент времени, даже если по меньшей мере одно сочетание максимального количества устройств хранения данных окажется недоступным в этот будущий момент времени.
Алгоритм 550 моделирования нарушений работоспособности также может использоваться во время получения запроса доступа к данным для однозначного определения того, было ли подтверждено успешное сохранение данных 400 во время сохранения данных 400.
Шаг 806: выдача команд набору устройств хранения данных для сохранения данных с избыточностью.
Способ 800 продолжается на шаге 806, где координирующий компьютер 300 во время сохранения данных выдает команды набору устройств хранения данных (из множества устройств хранения данных) для сохранения данных 420 с избыточностью.
Например, если алгоритм 450 обеспечения избыточности использует способ репликации «Зеркало-5», набор устройств хранения данных может содержать пять устройств хранения данных, которым выдаются команды для сохранения соответствующих реплик из пяти реплик данных 400. Эти устройства хранения данных способны оповещать (выдавать подтверждающее уведомление) координирующий компьютер 300 о сохранении ими данных 420 с избыточностью. Например, когда первое устройство от набора устройств хранения данных сохраняет соответствующую реплику данных 400, первое устройство от набора устройств хранения данных способно выдавать подтверждающее уведомление относительно сохраненной им реплики данных 400.
В некоторых вариантах осуществления изобретения координирующий компьютер 300 во время сохранения данных способен применять алгоритм 550 моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных, для определения того, следует ли предоставлять клиенту подтверждение успешного сохранения данных 400.
В некоторых вариантах осуществления изобретения координирующий компьютер 300 во время сохранения данных может быть способен итеративно применять алгоритм 550 моделирования нарушений работоспособности. Иными словами, координирующий компьютер 300 во время сохранения данных может итеративно применять алгоритм 550 моделирования нарушений работоспособности в отношении уведомлений, принятых от устройств хранения данных, при приеме каждого нового уведомления.
Например, можно предположить, что в определенный момент времени два устройства, входящие в набор из пяти устройств хранения данных, выдали подтверждающие уведомления. Координирующий компьютер 300 может применить алгоритм 550 моделирования нарушений работоспособности для двух подтверждающих уведомлений. Можно предположить, что в результате применения алгоритма 550 моделирования нарушений работоспособности координирующий компьютер 300 решает не выдавать клиенту подтверждение успешного сохранения данных 400. В этом случае координирующий компьютер 300 может быть способен снова применить алгоритм 550 моделирования нарушений работоспособности для трех подтверждающих уведомлений после приема третьего подтверждающего уведомления от третьего устройства, входящего в набор из пяти устройств хранения данных.
В некоторых вариантах осуществления изобретения с целью итеративного применения алгоритма 550 моделирования нарушений работоспособности координирующий компьютер 300 может быть способен ожидать выдачи новых уведомлений другими устройствами хранения данных, образующими набор устройств хранения данных. В описанном выше примере координирующий компьютер 300 может быть способен ожидать, пока третье подтверждающее уведомление не будет принято от третьего устройства, входящего в набор из пяти устройств хранения данных. Координирующий компьютер 300 также может быть способен ожидать, пока четвертое подтверждающее уведомление не будет принято от четвертого устройства, входящего в набор из пяти устройств хранения данных. Координирующий компьютер 300 также может быть способен ожидать, пока пятое подтверждающее уведомление не будет принято от пятого устройства, входящего в набор из пяти устройств хранения данных.
Также предполагается, что с целью итеративного применения алгоритма 550 моделирования нарушений работоспособности координирующий компьютер 300 для выдачи новых уведомлений может быть способен отслеживать подтверждающие уведомления от других устройств хранения данных, образующих набор устройств хранения данных. В описанном выше примере координирующий компьютер 300 может быть способен отслеживать, выдали ли соответствующие подтверждающие уведомления третье устройство, четвертое устройство и пятое устройство, входящие в набор из пяти устройств хранения данных.
В некоторых вариантах осуществления изобретения координирующий компьютер 300 во время сохранения данных может предоставлять подтверждение успешного сохранения данных 400, если определенное количество устройств хранения данных оповещает о сохранении ими данных 420 с избыточностью.
В некоторых случаях это количество устройств хранения данных превышает количество устройств хранения данных, необходимых для сохранения данных 420 с избыточностью, чтобы обеспечить восстановление данных 400. Например, если алгоритм 450 обеспечения избыточности представляет собой алгоритм репликации, это означает, что координирующий компьютер 300 во время сохранения данных может предоставлять подтверждение успешного сохранения данных 400, если несколько устройств хранения данных выдают соответствующие подтверждающие уведомления.
В других случаях это количество устройств хранения данных находится в диапазоне между (а) количеством устройств хранения данных, необходимых для сохранения данных с избыточностью, чтобы обеспечить восстановление данных, и (б) общим количеством устройств хранения данных во множестве устройств хранения данных, включительно. Например, если алгоритм 450 обеспечения избыточности представляет собой алгоритм репликации, это означает, что координирующий компьютер 300 во время сохранения данных может предоставлять подтверждение успешного сохранения данных 400, если соответствующие подтверждающие уведомления выдали устройства хранения данных в количестве от (а) одного устройства хранения данных до (б) общего количества устройств хранения данных во множестве устройств хранения данных.
В некоторых вариантах осуществления изобретения данные могут рассматриваться как успешно сохраненные, если они гарантировано могут быть восстановлены в будущий момент времени, если различные сочетания максимального количества устройств хранения данных окажутся недоступными в этот будущий момент времени. Предполагается, что эти различные сочетания могут включать в себя по меньшей мере некоторые из всех возможных сочетаний среди множества устройств хранения данных.
Шаг 808: прием указания на запрос доступа к данным.
Способ 800 продолжается на шаге 808, где координирующий компьютер 300 принимает указание на запрос доступа к данным 400. Например, клиент - потребитель данных 400 может быть способен выдавать запрос доступа к данным для данных 400.
Шаг 810: применение алгоритма моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных, для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных.
Способ 800 продолжается на шаге 810, где координирующий компьютер 300 во время получения запроса доступа к данным способен применять алгоритм 550 моделирования нарушений работоспособности в отношении уведомлений, принятых от набора устройств хранения данных. Координирующий компьютер 300 применяет алгоритм 550 моделирования нарушений работоспособности для однозначного определения того, было ли предоставлено клиенту подтверждение успешного сохранения данных 400.
Например, если во время получения запроса доступа к данным данные 400 невозможно извлечь, координирующий компьютер 300 может предоставлять клиенту различные ответы в зависимости от того, подтвердила ли распределенная компьютерная система 308 успешное сохранение данных 400 во время сохранения данных.
В некоторых вариантах осуществления изобретения, если однозначно определено, что во время сохранения данных клиенту было предоставлено подтверждение успешного сохранения данных, координирующий компьютер 300 может предоставлять ответ вида «ошибка данных» на запрос доступа к данным от клиента.
В других вариантах осуществления изобретения, если однозначно определено, что во время сохранения данных клиенту не было предоставлено подтверждение успешного сохранения данных, координирующий компьютер может предоставлять ответ вида «нет данных» на запрос доступа к данным от клиента.
Как описано выше, в некоторых вариантах осуществления данной технологии данные могут быть подтверждены как успешно сохраненные, если их восстановление гарантируется в будущий момент времени, когда (а) по меньшей мере одно сочетание устройств хранения данных окажется недоступным в этот будущий момент времени, (б) максимальное количество устройств хранения данных окажется недоступным в этот будущий момент времени, (в) по меньшей мере одно сочетание максимального количества устройств хранения данных окажется недоступным в этот будущий момент времени, (г) набор сочетаний устройств хранения данных окажется недоступным в этот будущий момент времени и/или (д) набор сочетаний максимального количества устройств хранения данных окажется недоступным в этот будущий момент времени. Предполагается, что заданные оператором распределенной компьютерной системы 308 ограничения могут обеспечивать, как описано выше, сочетание (или несколько сочетаний), набор (или несколько наборов) сочетаний и/или максимальное количество устройств хранения данных, которые алгоритм 550 моделирования нарушений работоспособности может учитывать при определении того, следует ли выдавать уведомление об успешном сохранении данных. Таким образом, можно сказать, что успешное сохранение данных может быть подтверждено, если выполняется заранее заданное условие. Заранее заданное условие может быть представлено в виде сочетания максимального количества устройств хранения данных или сочетания устройств хранения данных (представленного в виде количества устройств хранения данных, и/или центров обработки данных, где они находятся, и/или их сочетания).
Специалисту в данной области могут быть очевидны возможные изменения и усовершенствования описанных выше вариантов осуществления данной технологии. Предшествующее описание приведено лишь в качестве примера, но не для ограничения объема изобретения. Объем охраны данной технологии определяется исключительно объемом приложенной формулы изобретения.
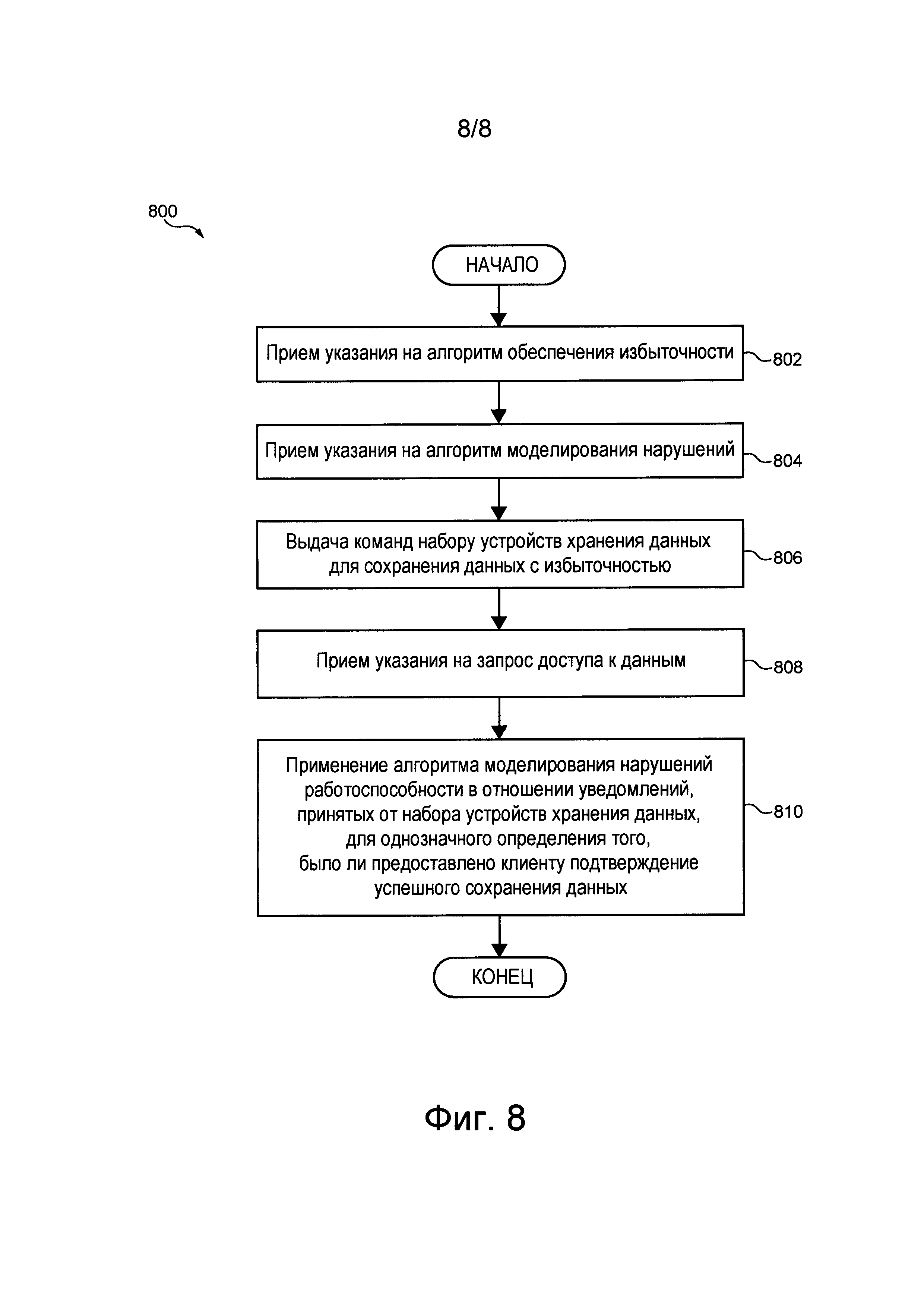
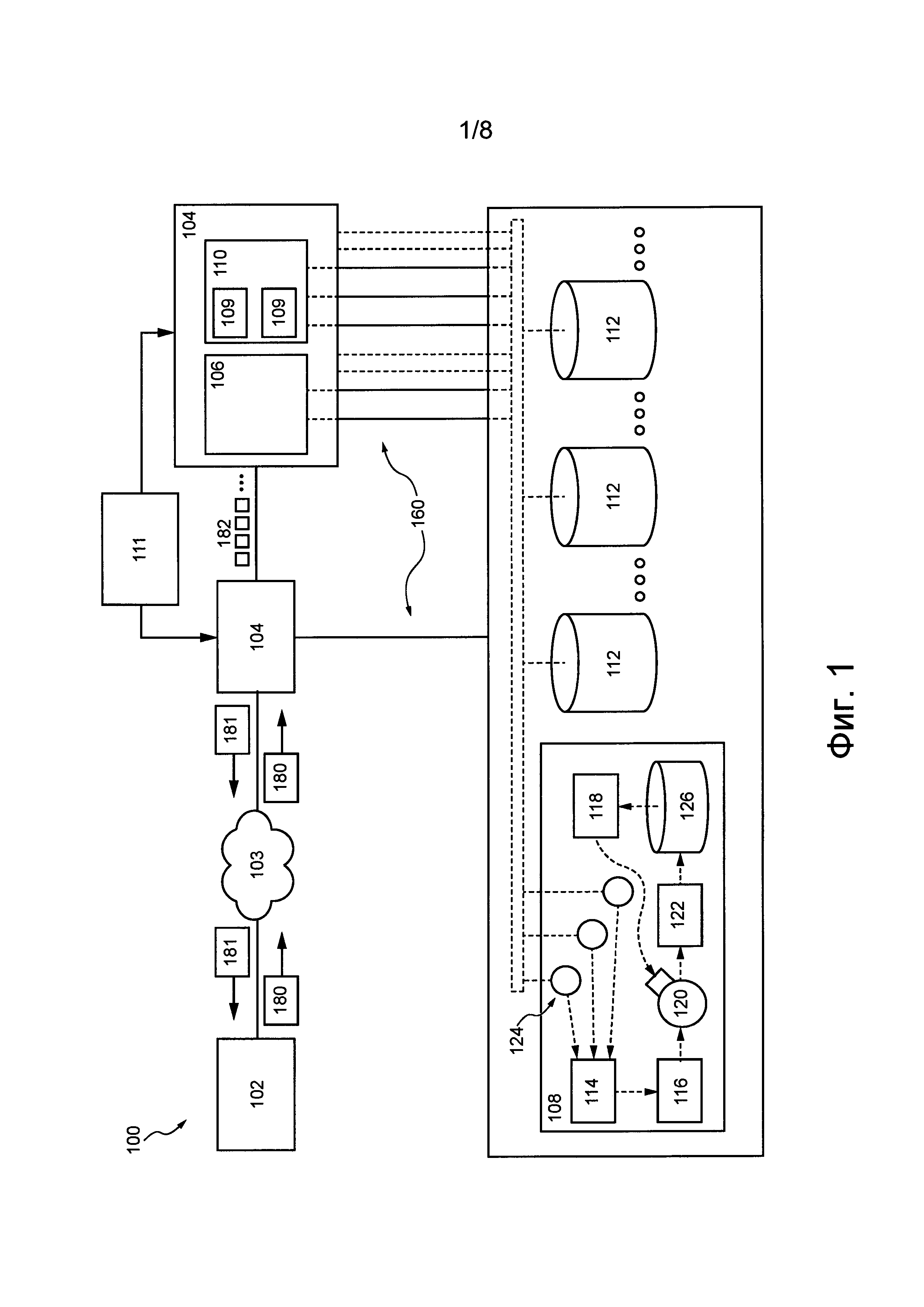
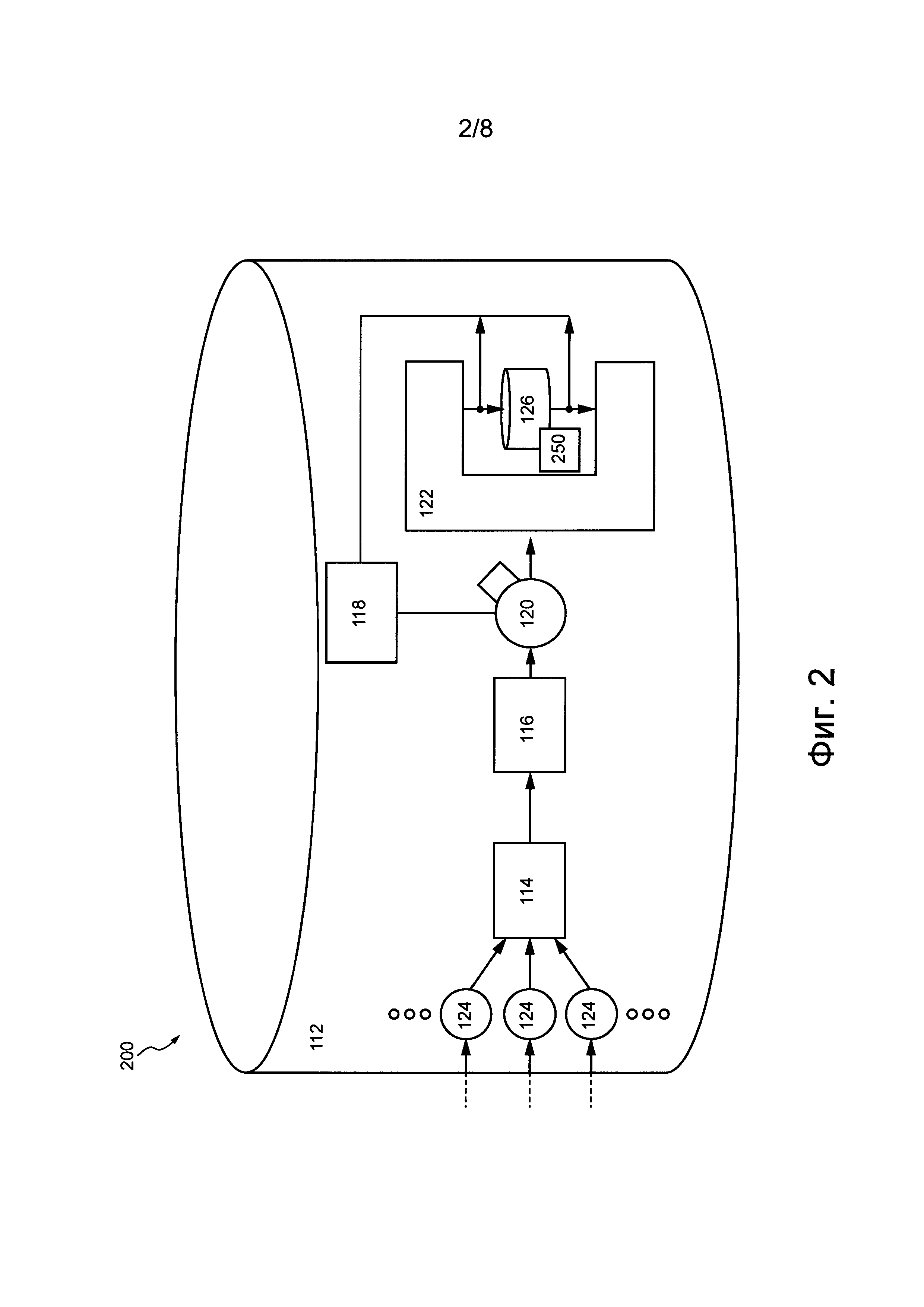
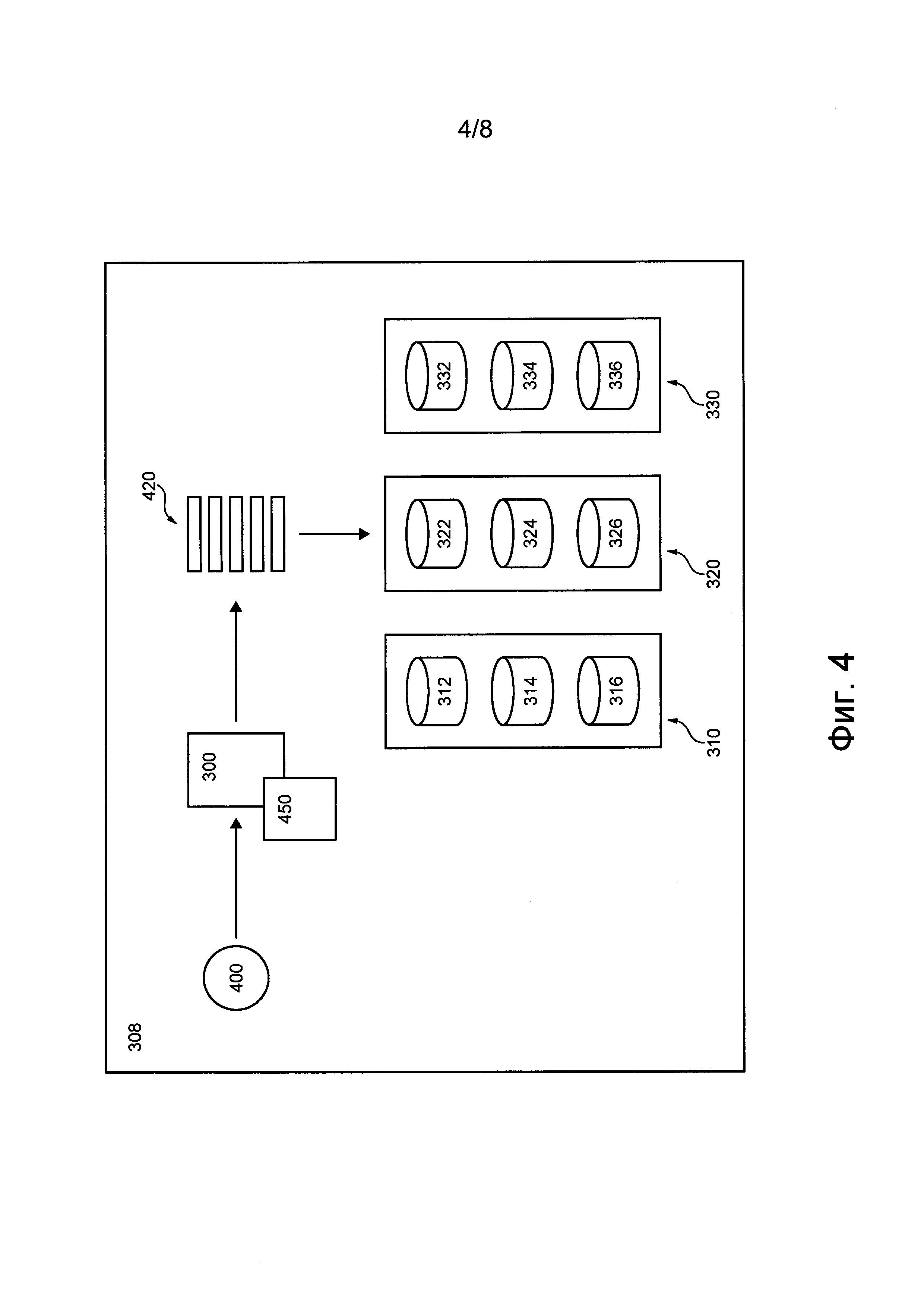
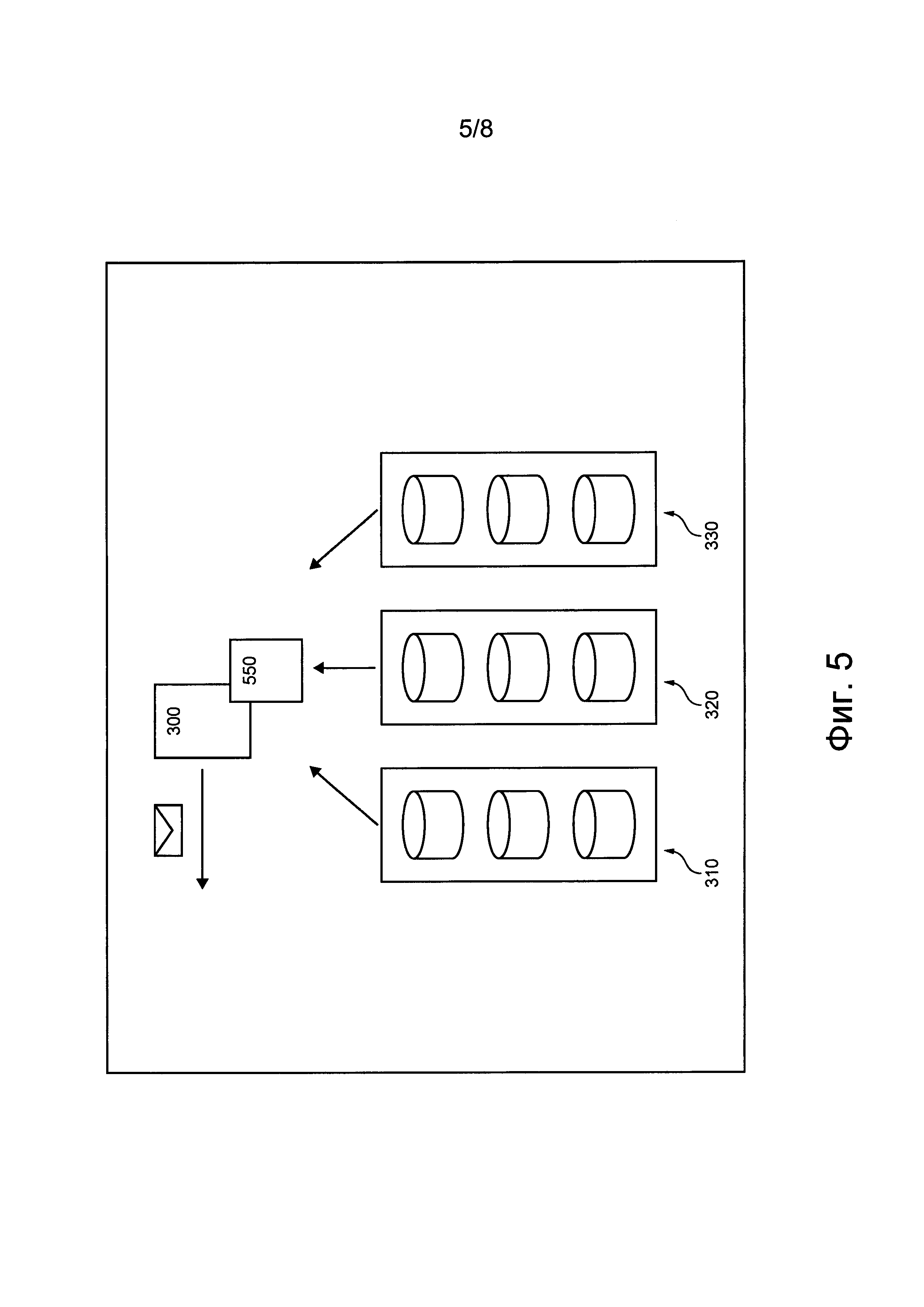
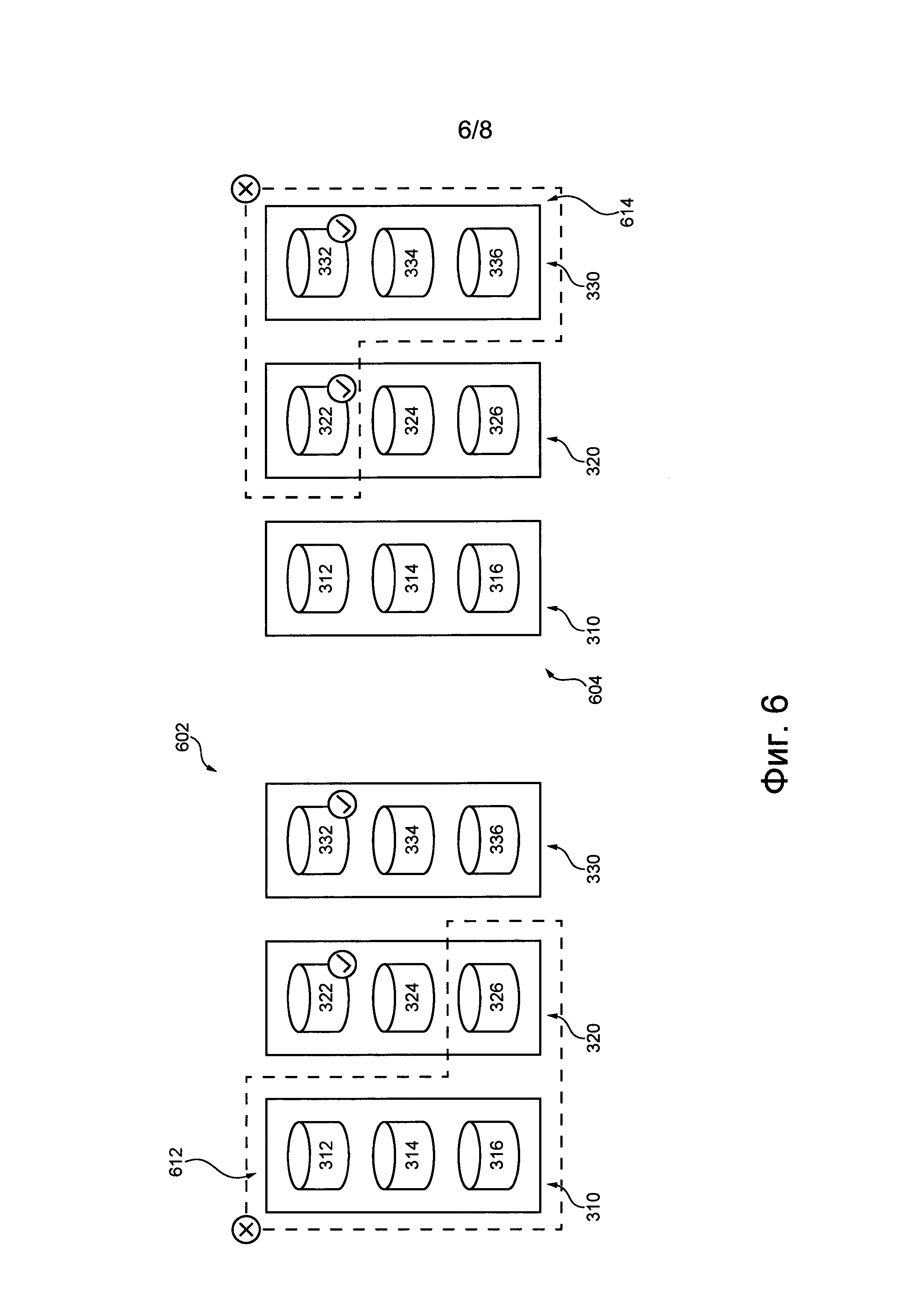
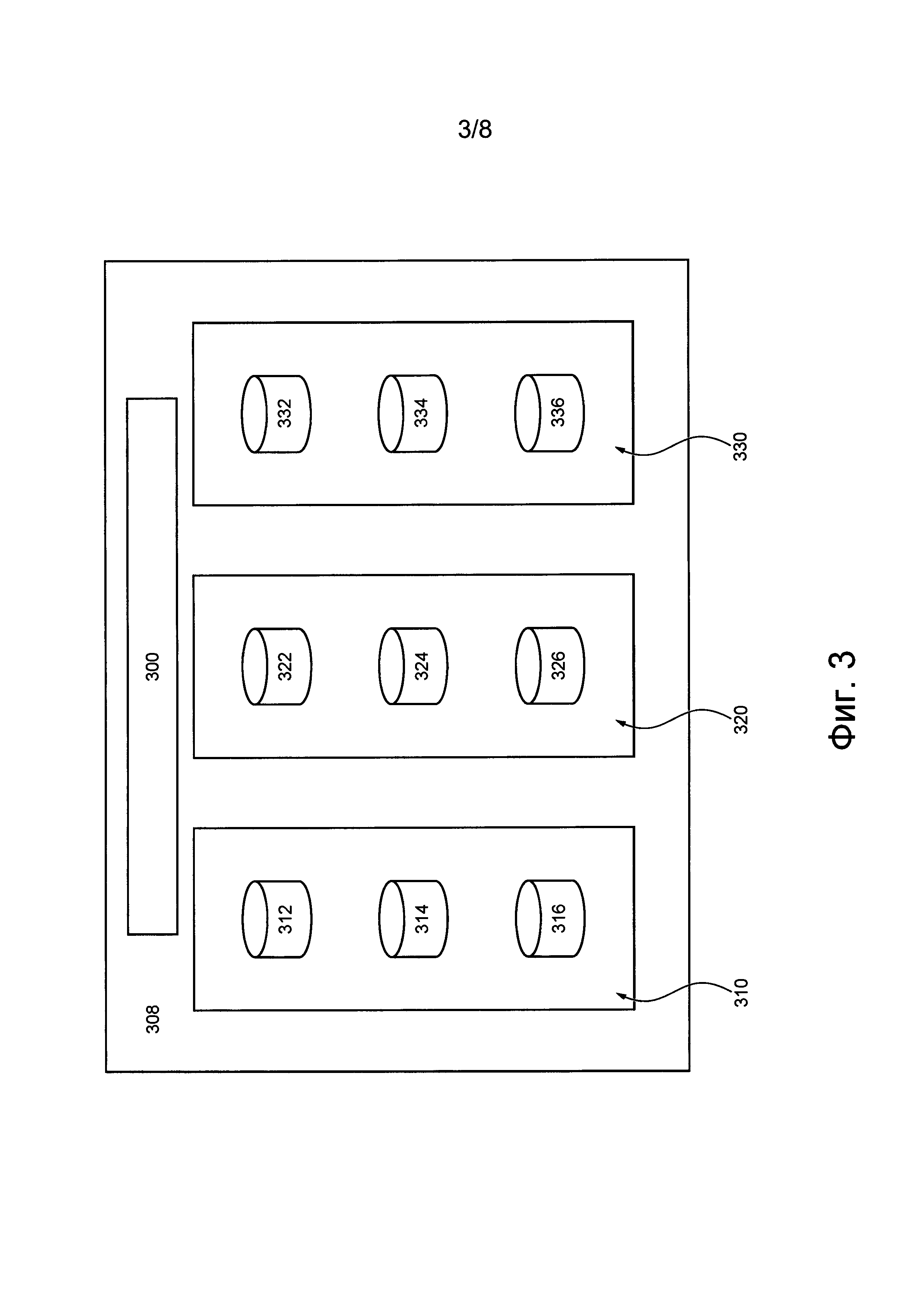
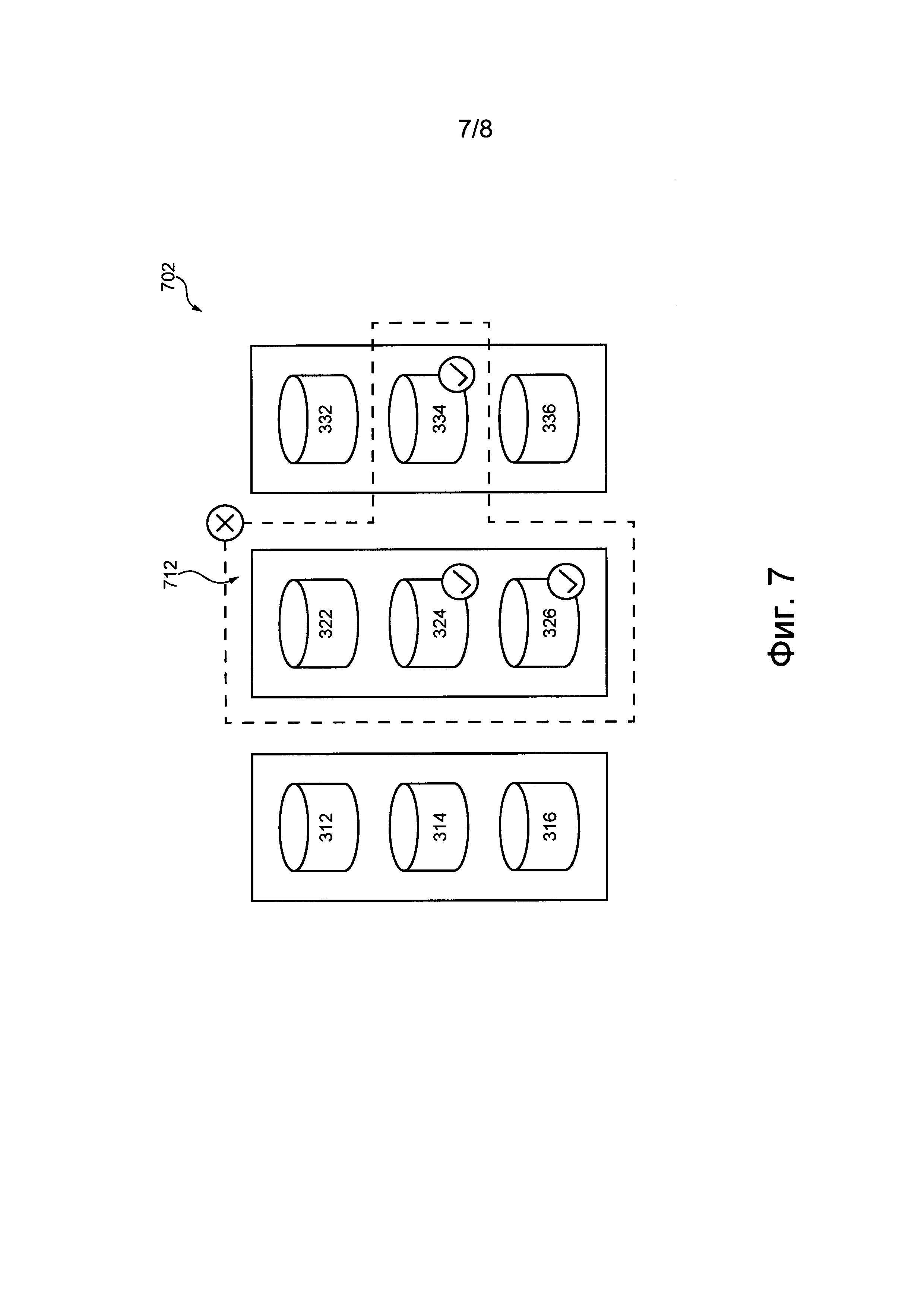
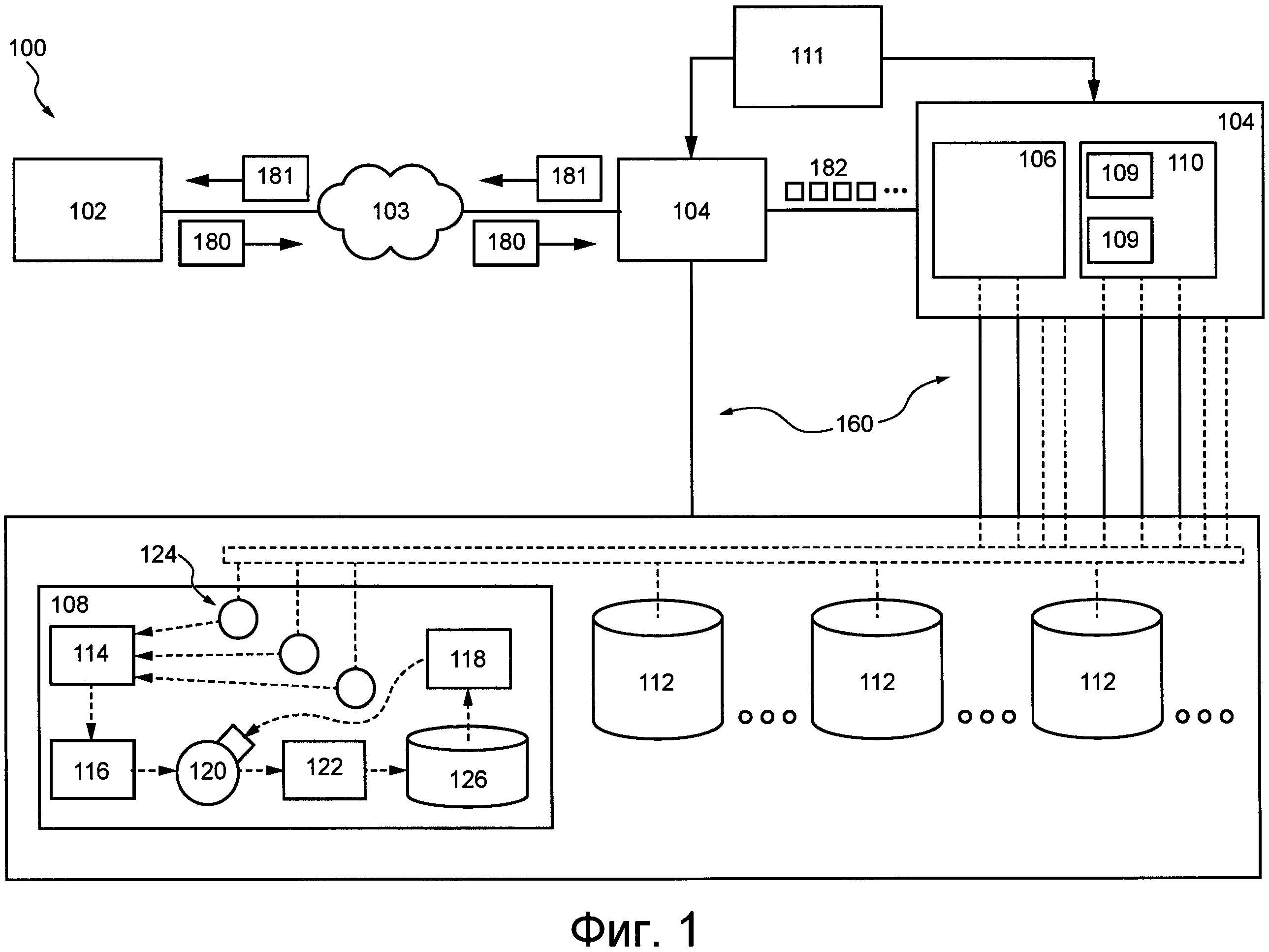
Способ и система для планирования передачи операций ввода/вывода
Способ и система для планирования выполнения операций ввода/вывода
Способ и система для обработки данных
Система обработки данных и способ обнаружения затора в системе обработки данных
Способ и система для маршрутизации и выполнения транзакций

