Результат интеллектуальной деятельности: СИСТЕМА ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБНАРУЖЕНИЯ ЗАТОРА В СИСТЕМЕ ОБРАБОТКИ ДАННЫХ
Вид РИД
Изобретение
Область техники
Настоящая технология относится к способам и системам для обнаружения затора в системе обработки данных.
Уровень техники
Во многих системах требуется последовательная обработка данных, выполняемых последовательностью обрабатывающих элементов, образующих конвейер для обработки данных. В случае системы распределенного хранения данных, в которой различные задачи передаются между различными элементами, для таких задач по обработке данных может использоваться множество конвейеров.
В идеальном конвейере задачи, подаваемые в потоке на конвейер, обрабатываются одна за другой, в обрабатывающих элементах не возникают входные очереди задач и каждый обрабатывающий элемент конвейера одновременно обрабатывает не более одной задачи.
Тем не менее, во многих случаях обрабатывающие элементы имеют различные характеристики обработки и поэтому обрабатывающим элементам в конвейере может требоваться различное время для обработки задачи. Вследствие этого в некотором обрабатывающем элементе могут возникать очереди задач, приводящие к затору в конвейере. Эта ситуация известна как проблема «узких мест», когда обрабатывающие элементы, которым требуется больше времени для обработки задачи, снижают общую пропускную способность конвейера обработки данных.
Одно из решений такой проблемы заключается в контроле очередей каждого обрабатывающего элемента. Для этого часто требуется отправка из каждого обрабатывающего элемента в центральную надзорную компьютерную систему информации, содержащейся в сообщении некоторого вида, которое каждый обрабатывающий элемент должен формировать в дополнение к задаче обработки, выполняемой обрабатывающим элементом. При этом обычно создаются дополнительные данные, предназначенные для обработки системой, и возникает дополнительная нагрузка на каждый обрабатывающий элемент, еще более замедляющая работу конвейера обработки данных.
Другое решение для устранения проблемы «узких мест» представляет собой использование дополнительного программного обеспечения в каждом обрабатывающем элементе для контроля очередей, что также приводит к замедлению конвейера. Это решение также повышает сложность системы и обычно требует дополнительных затрат ресурсов для работы такого программного обеспечения.
Поэтому существует потребность в способах определения или контроля заторов в конвейере обработки данных, свободных от по меньшей мере некоторых из недостатков описанных выше способов.
Раскрытие изобретения
Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков, характерных для уровня техники.
Согласно одному из аспектов настоящей технологии реализованы система и способ для определения затора в конвейере последовательной обработки данных. Конвейер обработки данных обрабатывает поток компьютерных задач. Конвейер обработки данных состоит из множества последовательно расположенных обрабатывающих узлов. Каждый обрабатывающий узел имеет уникальный системный идентификатор (SUID, System-Unique Identifier). Пакет задачи последовательно обрабатывается каждым узлом конвейера и в доступное для записи поле индикатора затора записывается идентификатор SUID каждого узла, в котором имеется очередь задач, ожидающих обработки. Каждый раз, когда пакет попадает в узел с очередью, идентификатор SUID этого узла заменяет ранее записанный идентификатор SUID в поле индикатора затора. Таким образом, когда пакет задачи покидает конвейер обработки данных, поле индикатора затора этого пакета задачи содержит идентификатор SUID наиболее удаленного от начала конвейера узла, вызывающего затор. При этом система распределенной обработки данных в течение некоторого времени может собирать статистику, чтобы определить узел, наиболее часто указывавшийся в качестве наиболее удаленного от начала конвейера узла, вызывающего затор. Затем на основании этой статистики система может скорректировать один или несколько параметров такого узла, чтобы уменьшить заторы в конвейере обработки данных. Благодаря такой системе и способу конкретный обрабатывающий узел, создающий затор в конвейере обработки данных, можно определить без дополнительных программных приложений с незначительными дополнительными затратами вычислительных ресурсов и энергии и с добавлением лишь небольшого количества информации в пакет задачи, обрабатываемый конвейером. В результате при некоторых обстоятельствах возможно сокращение времени обработки данных в конвейере и энергозатрат по сравнению с другими способами управления заторами в конвейере. Это может быть особенно выгодно для систем распределенной обработки данных, в которых возможна реализация большого количества конвейеров обработки данных и затраты на управление заторами (с точки зрения энергии, полосы пропускания и т.д.) многократно увеличиваются.
Согласно другому аспекту настоящей технологии реализован способ обнаружения затора в компьютерной системе, содержащей источник задач для формирования потока компьютерных задач, которые должны обрабатываться этой компьютерной системой, и множество последовательно расположенных обрабатывающих узлов, образующих конвейер обработки данных для обработки потока компьютерных задач. Каждый узел из множества обрабатывающих узлов имеет соответствующий уникальный системный идентификатор (SUID). Способ выполняется компьютерной системой и включает в себя прием пакета задачи обрабатывающим узлом из множества обрабатывающих узлов, представляющим собой следующий обрабатывающий узел после предыдущего обрабатывающего узла конвейера обработки данных, при этом пакет задачи содержит тело задачи, указывающее на соответствующую компьютерную задачу, и доступное для записи поле индикатора затора; обработку обрабатывающим узлом тела задачи из пакета задачи; определение обрабатывающим узлом наличия в этом обрабатывающем узле соответствующей входной очереди, содержащей более одного пакета задачи; обновление обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID этого обрабатывающего узла, если определено наличие соответствующей входной очереди в этом обрабатывающем узле.
В некоторых вариантах осуществления изобретения определение наличия соответствующей входной очереди выполняется после обработки тела задачи обрабатывающим узлом.
В некоторых вариантах осуществления изобретения способ дополнительно включает в себя обработку пакета задачи предыдущим обрабатывающим узлом, которая включает себя формирование предыдущим обрабатывающим узлом доступного для записи поля индикатора затора и добавление к телу задачи предыдущим обрабатывающим узлом доступного для записи поля индикатора затора.
В некоторых вариантах осуществления изобретения обработка пакета задачи дополнительно включает в себя определение предыдущим обрабатывающим узлом наличия соответствующей входной очереди в предыдущем обрабатывающем узле; запись предыдущим обрабатывающем узлом в доступное для записи поле индикатора затора соответствующего идентификатора SUID предыдущего обрабатывающего узла, если определено наличие соответствующей входной очереди в предыдущем обрабатывающем узле.
В некоторых вариантах осуществления изобретения формирование предыдущим обрабатывающим узлом доступного для записи поля индикатора затора выполняется, только если определено наличие соответствующей входной очереди в предыдущем обрабатывающем узле.
В некоторых вариантах осуществления изобретения способ дополнительно включает в себя прием пакета задачи следующим обрабатывающим узлом из множества обрабатывающих узлов, представляющим собой следующий обрабатывающий узел после упомянутого выше обрабатывающего узла конвейера обработки данных; обработку следующим обрабатывающим узлом тела задачи из пакета задачи; определение следующим обрабатывающим узлом наличия в следующем обрабатывающем узле соответствующей входной очереди; обновление следующим обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID следующего обрабатывающего узла, если определено наличие соответствующей входной очереди в следующем обрабатывающем узле.
В некоторых вариантах осуществления изобретения способ дополнительно включает в себя считывание компьютерной системой доступного для записи поля индикатора затора из пакета задачи, покинувшего конвейер обработки данных, и определение последнего записанного в доступном для записи поле индикатора затора идентификатора SUID, указывающего на наиболее удаленный от начала конвейера обрабатывающий узел из множества обрабатывающих узлов, создающий затор в конвейере обработки данных.
В некоторых вариантах осуществления изобретения способ дополнительно включает в себя регистрацию компьютерной системой в течение заранее заданного периода времени последних записанных идентификаторов SUID из пакетов задач, покинувших конвейер обработки данных.
В некоторых вариантах осуществления изобретения способ дополнительно включает в себя определение компьютерной системой наиболее часто встречающегося последнего записанного идентификатора SUID среди отслеживаемых последних записанных идентификаторов SUID; формирование компьютерной системой сообщения, содержащего наиболее часто встречающийся последний записанный идентификатор SUID и способствующего устранению затора, вызванного соответствующим обрабатывающим узлом, связанным с наиболее часто встречающимся последним записанным идентификатором SUID.
В некоторых вариантах осуществления изобретения компьютерная система дополнительно содержит надзорный компьютер, а способ дополнительно включает в себя считывание надзорным компьютером доступного для записи поля индикатора затора из пакета задачи, покинувшего конвейер обработки данных, и определение последнего записанного в доступном для записи поле индикатора затора идентификатора SUID, указывающего на наиболее удаленный от начала конвейера обрабатывающий узел из множества обрабатывающих узлов, создающий затор в конвейере обработки данных.
В некоторых вариантах осуществления изобретения компьютерная система дополнительно включает в себя множество конвейеров обработки данных, а способ дополнительно включает в себя регистрацию надзорным компьютером в течение заранее заданного периода времени последних записанных идентификаторов SUID из пакетов задач, покинувших каждый конвейер из множества конвейеров обработки данных.
В некоторых вариантах осуществления изобретения определение наиболее часто встречающегося последнего записанного идентификатора SUID, зарегистрированного в статистике заторов, включает в себя определение последнего записанного идентификатора SUID, наиболее часто регистрировавшегося в течение заранее заданного периода времени.
В некоторых вариантах осуществления изобретения множество обрабатывающих узлов включает в себя по меньшей мере одно из множества программно реализованных узлов, множества аппаратно реализованных узлов и множества устройств хранения данных.
Согласно другому аспекту настоящей технологии реализован способ устранения затора, вызываемого определенным обрабатывающим узлом компьютерной системы. Компьютерная система содержит множество имеющих уникальные системные идентификаторы обрабатывающих узлов, последовательно организованных для последовательной обработки, формирующий задачи источник для формирования множества компьютерных задач, которые должны обрабатываться этим множеством узлов, и надзорный компьютер. Способ выполняется в надзорном компьютере и включает в себя сбор статистики заторов от множества обрабатывающих узлов в течение заранее заданного периода времени, выполняемый путем повторения в течение заранее заданного периода времени следующих действий: прием пакета задачи обрабатывающим узлом из множества обрабатывающих узлов, представляющим собой следующий обрабатывающий узел после предыдущего обрабатывающего узла конвейера обработки данных, причем пакет задачи содержит тело задачи, указывающее на соответствующую компьютерную задачу, и доступное для записи поле индикатора затора; обработка обрабатывающим узлом тела задачи из пакета задачи; определение обрабатывающим узлом наличия в этом обрабатывающем узле соответствующей входной очереди, содержащей более одного пакета задачи; обновление обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID этого обрабатывающего узла, если определено наличие соответствующей входной очереди в этом обрабатывающем узле; прием пакета задачи следующим обрабатывающим узлом из множества обрабатывающих узлов, причем следующий обрабатывающий узел представляет собой следующий обрабатывающий узел после упомянутого выше обрабатывающего узла конвейера обработки данных; обработка следующим обрабатывающим узлом тела задачи из пакета задачи; определение следующим обрабатывающим узлом наличия в следующем обрабатывающем узле соответствующей входной очереди; обновление следующим обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID следующего обрабатывающего узла, если определено наличие соответствующей входной очереди в следующем обрабатывающем узле; считывание надзорным компьютером доступного для записи поля индикатора затора из пакета задачи, покинувшего конвейер обработки данных, и определение последнего записанного в доступном для записи поле индикатора затора идентификатора SUID, указывающего на наиболее удаленный от начала конвейера обрабатывающий узел из множества обрабатывающих узлов, создающий затор в конвейере обработки данных; регистрация последнего записанного идентификатора SUID в статистике заторов; определение надзорным компьютером наиболее часто встречающегося последнего записанного идентификатора SUID, зарегистрированного в статистике заторов; определение конкретного узла, соответствующего наиболее часто встречающемуся последнему записанному идентификатору SUID; инициирование изменения по меньшей мере одного параметра, связанного с этим конкретным узлом.
В некоторых вариантах осуществления изобретения определение наличия соответствующей входной очереди выполняется после обработки тела задачи обрабатывающим узлом.
В некоторых вариантах осуществления изобретения множество обрабатывающих узлов включает в себя по меньшей мере одно из множества программно реализованных узлов, множества аппаратно реализованных узлов и множества устройств хранения данных.
Согласно другому аспекту настоящей технологии реализована компьютерная система, содержащая источник задач для формирования потока компьютерных задач, которые должны обрабатываться этой компьютерной системой, и множество последовательно расположенных обрабатывающих узлов, образующих конвейер обработки данных для обработки потока компьютерных задач, причем каждый обрабатывающий узел из множества обрабатывающих узлов имеет соответствующий уникальный системный идентификатор (SUID) и выполнен с возможностью: приема пакета задачи от предыдущего обрабатывающего узла конвейера обработки данных, причем пакет задачи содержит тело задачи, указывающее на соответствующую компьютерную задачу, и доступное для записи поле индикатора затора; обработки тела задачи из пакета задачи; определения наличия в обрабатывающем узле соответствующей входной очереди, содержащей более одного пакета задачи; обновления доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID этого обрабатывающего узла, если определено наличие соответствующей входной очереди в этом обрабатывающем узле.
В некоторых вариантах осуществления изобретения компьютерная система дополнительно содержит надзорный компьютер, связанный с по меньшей мере одним узлом из множества обрабатывающих узлов и выполненный с возможностью: считывания доступного для записи поля индикатора затора из пакета задачи, покинувшего конвейер обработки данных; определения последнего записанного в доступном для записи поле индикатора затора идентификатора SUID, указывающего на наиболее удаленный от начала конвейера обрабатывающий узел из множества обрабатывающих узлов, создающий затор в конвейере обработки данных; определения конкретного узла, соответствующего последнему записанному идентификатору SUID.
В некоторых вариантах осуществления изобретения компьютерная система дополнительно выполнена с возможностью инициирования изменения по меньшей мере одного параметра, связанного с конкретным узлом, соответствующим последнему записанному идентификатору SUID.
В некоторых вариантах осуществления изобретения компьютерная система представляет собой систему распределенной компьютерной обработки данных.
Согласно другому аспекту настоящей технологии реализован способ обнаружения затора в компьютерной системе, содержащей множество последовательно расположенных обрабатывающих узлов, образующих конвейер обработки данных для обработки потока компьютерных задач, сформированных источником задач, причем каждый узел из множества обрабатывающих узлов имеет соответствующий уникальный системный идентификатор (SUID). Способ включает в себя сбор статистики заторов от множества обрабатывающих узлов в течение заранее заданного периода времени. Сбор статистики выполняется путем повторения в течение заранее заданного периода времени следующих действий: прием пакета задачи обрабатывающим узлом из множества обрабатывающих узлов, представляющим собой следующий обрабатывающий узел после предыдущего обрабатывающего узла конвейера обработки данных, причем пакет задачи содержит тело задачи, указывающее на соответствующую компьютерную задачу, и доступное для записи поле индикатора затора; обработка обрабатывающим узлом тела задачи из пакета задачи; определение обрабатывающим узлом наличия в этом обрабатывающем узле соответствующей входной очереди, содержащей более одного пакета задачи; обновление обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID этого обрабатывающего узла, если определено наличие соответствующей входной очереди в этом обрабатывающем узле; прием пакета задачи следующим обрабатывающим узлом из множества обрабатывающих узлов, причем следующий обрабатывающий узел представляет собой следующий обрабатывающий узел после упомянутого выше обрабатывающего узла конвейера обработки данных; обработка следующим обрабатывающим узлом тела задачи из пакета задачи; определение следующим обрабатывающим узлом наличия в следующем обрабатывающем узле соответствующей входной очереди; обновление следующим обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID следующего обрабатывающего узла, если определено наличие соответствующей входной очереди в следующем обрабатывающем узле; считывание компьютерной системой доступного для записи поля индикатора затора из пакета задачи, покинувшего конвейер обработки данных, и определение последнего записанного в доступном для записи поле индикатора затора идентификатора SUID, указывающего на наиболее удаленный от начала конвейера обрабатывающий узел из множества обрабатывающих узлов, создающий затор в конвейере обработки данных; регистрация последнего записанного идентификатора SUID в статистике заторов; определение компьютерной системой наиболее часто встречающегося последнего записанного идентификатора SUID, зарегистрированного в статистике заторов; определение конкретного узла, связанного с наиболее часто встречающимся последним записанным идентификатором SUID; и инициирование изменения по меньшей мере одного параметра, связанного с этим конкретным узлом.
В некоторых вариантах осуществления изобретения определение наличия соответствующей входной очереди выполняется после обработки тела задачи обрабатывающим узлом.
В некоторых вариантах осуществления изобретения множество обрабатывающих узлов включает в себя по меньшей мере одно из множества программно реализованных узлов, множества аппаратно реализованных узлов и множества устройств хранения данных.
В некоторых вариантах осуществления изобретения определение наиболее часто встречающегося последнего записанного идентификатора SUID, зарегистрированного в статистике заторов, включает в себя определение последнего записанного идентификатора SUID, наиболее часто регистрировавшегося в течение заранее заданного периода времени.
В контексте настоящего описания, если специально не указано другое, под электронным устройством, пользовательским устройством, сервером, компьютерным элементом и компьютерной системой понимаются любые аппаратные и/или программные средства, подходящие для решения поставленной задачи. Таким образом, некоторые не имеющие ограничительного характера примеры аппаратных и/или программных средств включают в себя компьютеры (серверы, настольные, ноутбуки, нетбуки и т.п.), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и т.п.) и/или их сочетания.
В контексте настоящего описания, если специально не указано иное, выражения «машиночитаемый физический носитель информации» и «запоминающее устройство» означают носители любого вида, в качестве не имеющих ограничительного характера примеров которых можно привести ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, карты флэш-памяти, твердотельные накопители и накопители на магнитных лентах.
В контексте настоящего описания, если специально не указано другое, числительные «первый», «второй», «третий» и т.д. используются только для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, вида, хронологии, иерархии или классификации, в данном случае, серверов, и что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
Краткое описание чертежей
Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
На фиг. 1 представлена схема системы, пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера.
На фиг. 2 представлено соответствующее некоторым вариантам осуществления настоящей технологии устройство хранения данных подсистемы распределенного хранения данных системы, представленной на фиг. 1.
На фиг. 3 приведена схема конвейера обработки данных, используемого в системе, представленной на фиг. 1.
На фиг. 4-7 приведены схематические иллюстрации задачи на различных этапах обработки в конвейере обработки данных, представленном на фиг. 3.
На фиг. 8 приведена блок-схема способа обнаружения затора в конвейере обработки данных, представленном на фиг. 3.
На фиг. 9 приведена блок-схема способа устранения затора в конвейере обработки данных, представленном на фиг. 3.
На фиг. 10 приведена схема другого варианта реализации конвейера обработки данных, используемого в системе, представленной на фиг. 1.
Осуществление изобретения
Дальнейшее подробное описание представляет собой лишь описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций, которые способствуют пониманию, но не определяют объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего списка, возможны и другие модификации.
Кроме того, если в некоторых случаях примеры модификаций не описаны, это не означает, что модификации невозможны и/или что описание содержит единственный вариант осуществления определенного аспекта настоящей технологии. Кроме того, следует понимать, что настоящее подробное описание в некоторых случаях касается упрощенных вариантов реализации настоящей технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Различные варианты реализации настоящей технологии могут быть значительно сложнее.
На фиг. 1 представлена система 100 распределенной компьютерной обработки данных или сокращенно система 100 распределенной обработки данных. Система 100 распределенной обработки данных позволяет реализовать не имеющие ограничительного характера варианты осуществления настоящей технологии. Очевидно, что система 100 распределенной обработки данных приведена только для иллюстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой лишь описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии.
В некоторых случаях также приводятся полезные примеры модификаций системы 100 распределенной обработки данных. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего списка. Специалисту в данной области должно быть очевидно, что возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть очевидно, что это не так. Кроме того, следует понимать, что система 100 распределенной обработки данных в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии, и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалисту в данной области должно быть очевидно, что различные варианты реализации настоящей технологии могут быть значительно сложнее.
Система 100 распределенной обработки данных содержит источник 102 запросов, сеть 103 связи, подсистему 104 предварительной обработки запросов, подсистему 105 обработки транзакций, подсистему 106 маршрутизации транзакций, подсистему 108 распределенного хранения данных, подсистему 110 базы данных и операционную подсистему 111.
Далее описана реализация указанных выше элементов системы 100 распределенной обработки данных в соответствии с различными не имеющими ограничительного характера вариантами осуществления настоящей технологии.
Источник запросов
Источник 102 запросов может представлять собой электронное устройство, связанное с конечным пользователем (например, клиентское устройство), или любую другую подсистему системы 100 распределенной обработки данных, способную формировать пользовательские запросы к системе 100 распределенной обработки данных. На фиг. 1 показан только один экземпляр источника 102 запросов, но должно быть очевидно, что система 100 распределенной обработки данных может содержать несколько экземпляров источников 102 запросов. Как показано в данном документе, источник 102 запросов входит в состав системы 100 распределенной обработки данных. Тем не менее, в некоторых вариантах осуществления настоящей технологии источник 102 запросов может быть внешним по отношению к системе 100 распределенной обработки данных и может подключаться с использованием линии связи (не обозначена).
На практике типовой вариант осуществления системы 100 распределенной обработки данных может содержать большое количество источников 102 запросов (сотни, тысячи, миллионы и т.д.).
В некоторых вариантах осуществления настоящей технологии, когда система 100 распределенной обработки данных используется в среде бизнес-потребитель (В2С, business-to-customer), источник 102 запросов может представлять собой клиентское устройство, такое как смартфон, связанное с пользователем системы 100 распределенной обработки данных. Например, система 100 распределенной обработки данных может предоставлять услуги удаленного хранилища данных для клиентского устройства пользователя.
В других вариантах осуществления настоящей технологии, когда система 100 распределенной обработки данных используется в среде бизнес-бизнес (В2В, business-to-business), источник 102 запросов может представлять собой подсистему, такую как удаленный сервер, обеспечивающую пользовательские запросы к системе 100 распределенной обработки данных. Например, в некоторых вариантах осуществления настоящей технологии система 100 распределенной обработки данных может предоставлять услуги отказоустойчивой обработки и/или хранения данных для оператора такой подсистемы.
В целом, независимо от реализации системы 100 распределенной обработки данных в виде системы В2С или В2В (или любого другого варианта системы), источник 102 запросов может представлять собой клиентское устройство или другую подсистему, которые могут быть внутренними или внешними по отношению к системе 100 распределенной обработки данных.
Как было упомянуто выше, источник 102 запросов способен выдавать множество запросов 180, каждый из которых далее называется запросом 180. Характер запроса 180 зависит от вида источника 102 запросов. Один из примеров запроса 180 представляет собой запрос, сформированный на языке структурированных запросов (SQL, Structured Query Language). Поэтому предполагается, что в некоторых вариантах осуществления настоящей технологии запрос 180 может быть сформирован на языке декларативного программирования, т.е. запрос 180 может представлять собой запрос декларативного вида.
В общем случае, декларативное программирование предполагает построение структуры и элементов компьютерных программ, отражающих логику вычислений без описания потока управления. Распространенные языки декларативного программирования включают в себя SQL, XQuery и другие языки запросов к базе данных, но не ограничиваются ими. В целом, запрос декларативного вида определяет действие в выражениях «что требуется выполнить», а не «как это требуется выполнить».
Это означает, что запрос декларативного вида может быть связан с условием выполнения действия. В качестве условия, например, может быть указано, в каком элементе должно выполняться действие или откуда должны быть получены значения для выполнения этого действия.
В качестве не имеющих ограничительного характера примеров можно привести следующие запросы декларативного вида: «Вставить значение 5 в ячейку, связанную с ключом, который равен значению ячейки, связанной с ключом А» и «Для всех ключей, связанных с ячейкой, имеющих значение 5, заменить это значение на значение 10». Тем не менее, должно быть понятно, что представленные выше примеры декларативных языков и примеры запросов декларативного вида приведены исключительно для лучшего понимания, и что другие декларативные языки и другие запросы декларативного вида могут использоваться источником 102 запросов в пределах объема настоящей технологии.
В некоторых вариантах осуществления настоящей технологии источник 102 запросов также способен принимать множество ответов 181, каждый из которых далее называется ответом 181. В общем случае, в ответ на запрос 180, обработанный или не обработанный системой 100 распределенной обработки данных, система 100 распределенной обработки данных может формировать ответ 181, предназначенный для источника 102 запросов, связанного с соответствующим запросом 180. Характер ответа 181 зависит, среди прочего, от вида источника 102 запросов, вида соответствующего запроса 180 и от того, обработала или не обработала система 100 распределенной обработки данных соответствующий запрос 180. В некоторых вариантах осуществления настоящей технологии система 100 распределенной обработки данных может формировать ответ 181, только если не удалось обработать запрос, или только в случае успешной обработки запроса, или в обоих случаях.
В одном примере во время обработки запроса 180 система 100 распределенной обработки данных может быть способна запрашивать дополнительные данные от источника 102 запросов для продолжения или завершения обработки запроса 180. В этом случае система 100 распределенной обработки данных может быть способна формировать ответ 181 в форме сообщения с запросом данных, в котором указывается, какие дополнительные данные запрашиваются системой 100 распределенной обработки данных для продолжения или завершения обработки запроса 180.
В другом примере, если система 100 распределенной обработки данных успешно обработала соответствующий запрос 180, она может быть способна формировать ответ 181 в форме сообщения об успешном завершении, указывающего на успешную обработку соответствующего запроса 180.
В еще одном примере, если системе 100 распределенной обработки данных не удалось успешно обработать соответствующий запрос 180, система 100 распределенной обработки данных может быть способна формировать ответ 181 в форме сообщения о неудачном завершении, оповещающего о том, что соответствующий запрос 180 обработать не удалось. В этом случае источник 102 запросов может быть способен выполнять дополнительные действия, такие как повторная выдача запроса 180, выполнение диагностического анализа для определения причины неудачного завершения обработки запроса 180 системой 100 распределенной обработки данных, выдача нового запроса, предназначенного для системы 100 распределенной обработки данных, и т.д.
Сеть связи
Источник 102 запросов связан с сетью 103 связи для направления запроса 180 в систему 100 распределенной обработки данных и для приема ответа 181 от системы 100 распределенной обработки данных. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 103 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 103 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (отдельно не обозначена) между источником 102 запросов и сетью 103 связи зависит, среди прочего, от реализации источника 102 запросов.
Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, в которых источник 102 запросов реализован как беспроводное устройство связи (такое как смартфон), линия связи может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, в которых источник 102 запросов реализуется как удаленный сервер, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение по сети Ethernet).
Следует отметить, что сеть 103 связи способна, среди прочего, передавать пакет данных запроса, содержащий запрос 180 от источника 102 запросов, в подсистему 104 предварительной обработки запросов системы 100 распределенной обработки данных. Например, этот пакет данных запроса может содержать выполняемые компьютером команды, составленные на языке программирования декларативного вида, на котором представлен запрос 180. Сеть 103 связи также способна, среди прочего, передавать пакет данных ответа, содержащий ответ 181 от системы 100 распределенной обработки данных, в источник 102 запросов. Например, этот пакет данных ответа может содержать выполняемые компьютером команды, представляющие ответ 181.
Тем не менее, предполагается, что в некоторых вариантах осуществления настоящей технологии, когда источник 102 запросов представляет собой, например, подсистему системы 100 распределенной обработки данных, сеть 103 связи может быть реализована способом, отличным от описанного выше, или в некоторых случаях может даже отсутствовать, что остается в пределах объема настоящей технологии.
Операционная подсистема (улей)
Как было упомянуто выше, система 100 распределенной обработки данных содержит операционную подсистему 111 или, сокращенно, улей. В общем случае улей 111 представляет собой программное приложение (например, конечный автомат), способное управлять по меньшей мере некоторыми подсистемами системы 100 распределенной обработки данных, такими как подсистема 104 предварительной обработки запросов и подсистема 105 обработки транзакций. Иными словами, улей 111 может быть реализован как конечный автомат (SM, State Machine), способный формировать, удалять и/или выравнивать нагрузку других автоматов SM, образующих по меньшей мере некоторые подсистемы системы 100 распределенной обработки данных.
Должно быть понятно, что автомат SM представляет собой вычислительную модель, реализуемую компьютерными системами и определяемую списком состояний. Автомат SM может изменять свое текущее состояние в ответ на некоторые внешние входные данные и в каждый момент времени может находиться только в одном состоянии. Переход автомата SM из одного состояния в другое состояние называется изменением состояния.
Следует отметить, что в контексте настоящей технологии автоматы SM, образующие по меньшей мере некоторые подсистемы системы 100 распределенной обработки данных, являются детерминированными по своей природе, т.е. каждое изменение состояния каждого автомата SM однозначно определено (а) текущим состоянием соответствующего автомата SM и (б) внешними входными данными соответствующего автомата SM. Иными словами, для текущего состояния автомата SM и для внешних входных данных существует единственное следующее состояние автомата SM. Этот детерминированный характер изменения состояния не зависит от того, какой именно автомат SM системы 100 распределенной обработки данных подвергается изменению состояния.
Поэтому, как это описано ниже, в некоторых вариантах осуществления настоящей технологии система 100 распределенной обработки данных должна принимать внешние входные данные определенного вида, соответствующие свойству детерминированности конечных автоматов по меньшей мере некоторых подсистем системы 100 распределенной обработки данных.
Подсистема распределенного хранения данных
Как было упомянуто выше, система 100 распределенной обработки данных также содержит подсистему 108 распределенного хранения данных. В общем случае подсистема 108 распределенного хранения данных способна, среди прочего, хранить системные данные, относящиеся к состояниям, изменениям состояний, внешним входным данным и/или выходным данным по меньшей мере некоторых автоматов SM системы 100 распределенной обработки данных. Например, системные данные, связанные с автоматом SM системы 100 распределенной обработки данных, могут храниться в форме журнала, содержащего хронологический список состояний, изменений состояний, внешних входных и/или выходных данных этого автомата SM.
Подсистема 108 распределенного хранения данных также способна хранить клиентские данные, т.е. данные, связанные с внешними входными данными, обработанными системой 100 распределенной обработки данных. Например, в некоторых вариантах осуществления настоящей технологии клиентские данные могут храниться как часть системных данных в подсистеме 108 распределенного хранения данных в пределах объема настоящей технологии.
Для хранения системных и/или клиентских данных подсистема 108 распределенного хранения данных включает в себя множество устройств 112 хранения данных, каждое из которых далее называется устройством 112 хранения данных. Согласно различным вариантам осуществления настоящей технологии, некоторые или все устройства из множества устройств 112 хранения данных могут располагаться в одном или в различных местах. Например, некоторые или все устройства из множества устройств 112 хранения данных могут располагаться в одной серверной стойке, и/или в одном центре обработки данных, и/или могут быть распределены по множеству серверных стоек в одном или нескольких центрах обработки данных.
В некоторых вариантах осуществления настоящей технологии системные и/или клиентские данные, хранящиеся в устройстве 112 хранения данных, могут дублироваться и храниться в нескольких других устройствах 112 хранения данных. В некоторых вариантах осуществления такое дублирование и хранение системных и/или клиентских данных может обеспечивать отказоустойчивое хранение системных и/или клиентских данных в системе 100 распределенной обработки данных. Отказоустойчивое хранение системных и/или клиентских данных позволяет предотвращать потерю данных, когда устройство 112 хранения данных подсистемы 108 распределенного хранения данных становится временно или постоянно недоступным для хранения и извлечения данных. Такое отказоустойчивое хранение системных и/или клиентских данных также позволяет предотвращать потерю данных, когда автомат SM системы 100 распределенной обработки данных становится временно или постоянно недоступным.
Предполагается, что устройство 112 хранения данных может быть реализовано как компьютерный сервер. Компьютерный сервер содержит по меньше мере одно физическое запоминающее устройство (т.е. накопитель 126) и одно или несколько программных приложений, способных выполнять машиночитаемые команды. Накопитель 126 может представлять собой твердотельный накопитель (SSD, Solid State Drive), накопитель на жестких дисках (HDD, Hard Disk Drive) и т.п.Поэтому можно сказать, что по меньшей мере одно физическое запоминающее устройство может быть реализовано как устройство с подвижным или неподвижным диском.
Например, как показано на фиг. 1, устройство 112 хранения данных способно хранить, среди прочего, следующие программные приложения: приложение 114 виртуального накопителя (Vdrive), приложение 115 физического накопителя (Pdrive), по меньшей мере одно приложение 118 моделирования накопителя, по меньшей мере одно приложение 120 планирования работы, приложение 122 для обеспечения работы в реальном времени и по меньшей мере один прокси-сервер 124 автомата SM. Функции указанных выше программных приложений и накопителя 126, обеспечивающие хранение по меньшей мере некоторых системных и/или клиентских данных, более подробно описаны ниже со ссылками на фиг. 2.
Подсистема предварительной обработки запросов
Как было упомянуто выше, подсистема 105 обработки транзакций может содержать несколько детерминированных автоматов SM, которые должны получать входные данные определенного вида и которые соответствуют свойству детерминированности детерминированных автоматов. Также следует еще раз отметить, что источник 102 запросов выдает запрос 180 в форме запроса декларативного вида.
Соответственно, подсистема 104 предварительной обработки запросов способна принимать запрос 180 декларативного вида от источника 102 запросов и предварительно обрабатывать или преобразовывать запрос 180 во множество детерминированных транзакций 182, соответствующих свойству детерминированности нескольких детерминированных автоматов, образующих подсистему 105 обработки транзакций.
В целом, подсистема 104 предварительной обработки запросов предназначена для предварительной обработки или преобразования запроса 180 во множество детерминированных транзакций 182, которые могут быть обработаны детерминированными автоматами в составе подсистемы 105 обработки транзакций.
Следует отметить, что подсистема 104 предварительной обработки запросов также способна формировать ответ 181 для передачи в источник 102 запросов. Иными словами, подсистема 104 предварительной обработки запросов связана с подсистемой 105 обработки транзакций не только для передачи множества детерминированных транзакций 182, но и для приема информации об обработке множества детерминированных транзакций 182. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии множество детерминированных транзакций 182 может содержать одну или несколько транзакций вида «считывание» и/или «запись».
В некоторых вариантах осуществления настоящей технологии подсистема 104 предварительной обработки запросов реализована в виде по меньшей мере одного автомата SM в пределах объема настоящей технологии.
В некоторых вариантах осуществления настоящей технологии предполагается, что представленная на фиг. 1 система 100 распределенной обработки данных способна поддерживать транзакции ACID (Atomicity, Consistency, Isolation and Durability). В целом, ACID - это аббревиатура для набора свойств транзакции (атомарность, согласованность, изолированность, долговечность), обеспечивающих надежность базы данных при выполнении транзакций. Поэтому в некоторых вариантах осуществления настоящей технологии предполагается, что транзакции, предназначенные для подсистемы 105 обработки транзакций, могут быть атомарными, согласованными, изолированными и долговечными в пределах объема настоящей технологии.
Подсистема обработки транзакций
В общем случае подсистема 105 обработки транзакций способна принимать и обрабатывать множество детерминированных транзакций 182 и, таким образом, обрабатывать запрос 180 от источника 102 запросов. Подсистема 105 обработки транзакций включает в себя (а) подсистему 106 маршрутизации транзакций и (б) подсистему 110 базы данных, которые описаны далее.
Подсистема 110 базы данных включает в себя множество мест назначения транзакции (TDL, Transaction Destination Location) и разделяется на множество сегментов 109, каждый из которых далее называется сегментом 109. В не имеющем ограничительного характера примере подсистема 110 базы данных может содержать базу данных, включающую в себя одну или несколько таблиц базы данных. Таблица базы данных может состоять из по меньшей мере двух столбцов, таких как первый столбец, содержащий ключи, и второй столбец, содержащий записи, в которых хранятся данные, связанные с соответствующими ключами. В этом не имеющем ограничительного характера примере место TDL может соответствовать строке таблицы базы данных, т.е. место TDL может соответствовать ключу и соответствующей записи в таблице базы данных.
В этом не имеющем ограничительного характера примере каждый сегмент 109 подсистемы 110 базы данных содержит часть таблицы базы данных. Следовательно, множество мест TDL, сопоставленных с соответствующими строками таблицы базы данных, разделено между множеством сегментов 109 так, чтобы каждый сегмент 109 содержал соответствующее подмножество (например, диапазон) множества мест TDL.
В некоторых вариантах осуществления настоящей технологии предполагается, что каждый сегмент из множества сегментов 109 может быть реализован с использованием соответствующего детерминированного автомата SM. Это означает, что после приема транзакции, предназначенной для места TDL сегмента 109, реализованного с использованием автомата SM, этот автомат SM может обработать транзакцию и перейти из текущего состояния в новое состояние, в зависимости от транзакции, как описано выше.
Подсистема 106 маршрутизации транзакций способна маршрутизировать транзакции из множества детерминированных транзакций 182 в соответствующие места TDL и, таким образом, в соответствующие сегменты 109 подсистемы 110 базы данных. С этой целью подсистема 106 маршрутизации транзакций может включать в себя множество портов, который обычно способны (а) принимать множество детерминированных транзакций 182 от подсистемы 104 предварительной обработки запросов, (б) разделять множество детерминированных транзакций 182 на подмножества детерминированных транзакций, предназначенных для соответствующих сегментов 109, и (в) формировать для каждого сегмента централизованный порядок выполнения детерминированных транзакций соответствующими сегментами 109.
Следует отметить, что каждый порт из множества портов, образующих подсистему 106 маршрутизации транзакций, может быть реализован как соответствующий автомат SM. В некоторых вариантах осуществления предполагается, что множество портов может включать в себя порты двух различных видов для маршрутизации транзакций из множества детерминированных транзакций 182 в соответствующие сегменты 109. В других вариантах осуществления по меньшей мере некоторые функции множества портов могут выполняться автоматами SM, соответствующими множеству сегментов 109.
Также, как показано на фиг. 1, по меньшей мере некоторые из автоматов SM подсистемы 105 обработки транзакций могут быть связаны с подсистемой 108 распределенного хранения данных с использованием соответствующей линии 160 связи. В целом, линия 160 связи предназначена для передачи системных данных о состояниях, изменениях состояний, внешних входных данных и/или выходных данных соответствующих автоматов SM и т.д. в подсистему 108 распределенного хранения данных для хранения. Далее со ссылками на фиг. 2 более подробно описан порядок реализации линий 160 связи и порядок конфигурирования подсистемы 108 распределенного хранения данных для хранения системных данных.
На фиг. 2 представлено устройство 112 хранения данных, входящее в состав подсистемы 108 распределенного хранения данных. Как было упомянуто выше, устройство 112 хранения данных содержит по меньшей мере один прокси-сервер 124 автомата SM. Прокси-сервер автомата SM предназначен для управления связью между автоматом SM и подсистемой 108 распределенного хранения данных. В некоторых вариантах осуществления настоящей технологии предполагается, что по меньшей мере один прокси-сервер 124 автомата SM устройства 112 хранения данных может представлять собой прикладной программный интерфейс (API, Application Programing Interface), управляющий связью между автоматом SM и устройством 112 хранения данных. В других вариантах осуществления настоящей технологии по меньшей мере один прокси-сервер 124 автомата SM сам может быть реализован в виде автомата SM. В других вариантах осуществления настоящей технологии по меньшей мере один прокси-сервер 124 автомата SM может быть реализован как программный модуль (не как автомат SM) для выполнения описанных выше функций.
В некоторых вариантах осуществления настоящей технологии прокси-сервер 124 автомата SM может быть способен (а) принимать системные данные обновления журнала автомата SM с использованием соответствующей линии 160 связи, (б) обрабатывать системные данные и (в) передавать обработанные системные данные соответствующему приложению 114 Vdrive для дальнейшей обработки.
По меньшей мере один прокси-сервер 124 автомата SM может быть способен обрабатывать системные данные, например, для обеспечения непротиворечивости и отказоустойчивости системных данных. В некоторых вариантах осуществления настоящей технологии предполагается, что по меньшей мере один прокси-сервер 124 автомата SM может быть способен выполнять стойкое к потере кодирование системных данных. В целом, стойкое к потере кодирование представляет собой способ кодирования, предусматривающий избыточность данных и разделение их на несколько фрагментов. Такие избыточность и фрагментирование способны упростить восстановление данных в случае потери одного или нескольких фрагментов вследствие отказов в системе.
Предполагается, что обработанные таким образом по меньшей мере одним прокси-сервером 124 автомата SM системные данные принимаются по меньшей мере одним соответствующим приложением 114 Vdrive устройства 112 хранения данных. Приложение 114 Vdrive предназначено для обработки системных данных, принятых от по меньшей мере одного прокси-сервера 124 автомата SM, и для ответного формирования соответствующих операций ввода/вывода (I/O, Input/Output), которые должны выполняться накопителем 126 для сохранения системных данных в накопителе 126 устройства 112 хранения данных. После формирования по меньшей мере одним приложением 114 Vdrive операций I/O, соответствующих принятым системным данным, по меньшей мере одно приложение 114 Vdrive передает операции I/O в приложение 116 Pdrive.
Таким образом, предполагается, что устройство 112 хранения данных может содержать несколько прокси-серверов 124 автомата SM для обработки и передачи системных данных нескольким соответствующим приложениям 114 Vdrive, которые обрабатывают системные данные, формируют соответствующие операции I/O и передают соответствующие операции I/O в единое приложение 116 Pdrive устройства 112 хранения данных.
В целом, приложение 116 Pdrive предназначено для управления работой накопителя 126. Например, приложение 116 Pdrive может быть способным выполнять кодирование операций I/O, которые должны выполняться в накопителе 126, и различные другие функции, способствующие надежному хранению данных в накопителе 126.
Приложение 116 Pdrive связано с приложением 120 планирования работы для передачи ему операции I/O. Приложение 120 планирования работы способно планировать передачу операций I/O в накопитель 126. Предполагается, что приложение 120 планирования работы, или сокращенно планировщик, способно выполнять различные схемы планирования для определения порядка передачи операций I/O в накопитель 126 для дальнейшего их выполнения.
Предполагается, что в некоторых вариантах осуществления настоящей технологии планировщик 120 может быть реализован как часть приложения 116 Pdrive. Иными словами, приложением 116 Pdrive могут выполняться различные схемы планирования в пределах объема настоящей технологии.
В одном случае планировщик 120 может реализовывать схему «справедливого» планирования. Должно быть понятно, что для устройства 112 хранения данных может потребоваться хранение операций I/O, соответствующих системным данным, связанным с несколькими автоматами SM. Кроме того, каждый из нескольких автоматов SM связан с заранее заданной долей полосы пропускания накопителя, которую накопитель 126 может выделить для выполнения операций I/O, связанных с соответствующим автоматом SM. В целом, схемы «справедливого» планирования способны упорядочивать операции I/O, передаваемые в накопитель 126, таким образом, чтобы полоса пропускания накопителя 126, предназначенная для выполнения упорядоченных операций I/O, использовалась согласно заранее заданным долям, выделенным нескольким автоматам SM.
В другом случае планировщик 120 может обеспечивать схему планирования «в реальном времени». Следует еще раз отметить, что система 100 распределенной обработки данных может использоваться для обеспечения услуг удаленного хранилища данных. Во многих таких вариантах осуществления может быть желательным обрабатывать и сохранять системные данные в реальном времени, т.е. в пределах очень короткого интервала времени. Чтобы обеспечить требования к режиму реального времени системы 100 распределенной обработки данных, операции I/O могут связываться с соответствующими предельными сроками, указывающими момент времени, по прошествии которого соответствующие операции I/O уже не попадают в пределы допустимого времени, отвечающие требованиям к режиму реального времени системы 100 распределенной обработки данных. В целом, схемы планирования реального времени способны упорядочивать операции I/O, передаваемые в накопитель 126, таким образом, чтобы операции I/O выполнялись накопителем 126 с соблюдением соответствующих предельных сроков.
В другом случае планировщик 120 может обеспечивать гибридную схему планирования. Иными словами, планировщик 120 может обеспечивать схему планирования, позволяющую упорядочивать операции I/O, передаваемые для выполнения в накопитель 126, так, чтобы учитывались и заранее заданные доли полосы пропускания накопителя для каждого соответствующего автомата SM, и соответствующие предельные сроки операций I/O.
Как было упомянуто ранее, накопитель 126 представляет собой носитель информации для выполнения операций I/O и, соответственно, для хранения системных данных, переданных в устройство 112 хранения данных. Например, накопитель 126 может быть реализован в виде накопителя HDD или накопителя SSD. Накопитель 126 включает в себя внутреннее логическое устройство 250 накопителя для выбора операции I/O среди всех переданных в накопитель операций I/O для выполнения в текущий момент времени.
Следует отметить, что операции I/O могут направляться для выполнения в накопитель 126 по одной, но это может приводить к увеличению задержек между накопителем 126 и другими элементами устройства 112 хранения данных. Поэтому операции I/O могут предаваться в накопитель 126 пакетами или группами. После приема пакета или группы операций I/O накопителем 126 внутреннее логическое устройство 250 накопителя способно выбрать для выполнения наиболее эффективную операцию I/O среди имеющихся в пакете операций I/O.
Например, наиболее эффективная операция I/O может выбираться на основе различных критериев, таких как место выполнения предыдущей операции I/O в накопителе 126 и место выполнения операций I/O, имеющихся в накопителе 126. Иными словами, внутреннее логическое устройство 250 накопителя способно выбирать для текущего выполнения наиболее эффективную операцию (с точки зрения накопителя 126) среди всех операций I/O, имеющихся в накопителе 126 в текущий момент времени.
Поэтому в некоторых случаях, несмотря на то, что планировщик 120 упорядочил операции I/O для передачи определенным образом с учетом требований к режиму реального времени системы 100 распределенной обработки данных, внутреннее логическое устройство 250 накопителя 126 может выдавать в накопитель 126 команды для формирования порядка выполнения операций I/O, отличного от порядка передачи, выбранного планировщиком 120. Следовательно, порядок выполнения иногда может не соответствовать требованиям режима реального времени системы 100 распределенной обработки данных (в частности, когда от планировщика 120 принимаются дополнительные операции I/O, которые могут быть более «эффективными» с точки зрения накопителя 126 и могут выбираться среди еще не выполненных операций I/O).
Чтобы обеспечить работу устройства 112 хранения данных в реальном времени и предотвратить описанную выше проблему, также известную как «торможение работы» (operation stagnation), устройство 112 хранения данных может содержать приложение 122 для обеспечения работы в реальном времени. В целом, приложение 122 для обеспечения работы в реальном времени позволяет управлять тем, какие операции I/O из числа уже упорядоченных планировщиком 120 передаются в текущий момент времени для выполнения в накопитель 126.
Предполагается, что в некоторых вариантах осуществления настоящей технологии приложение 122 для обеспечения работы в реальном времени может быть реализовано как часть приложения 116 Pdrive. Иными словами, вышеупомянутые функции приложения 122 для обеспечения работы в реальном времени могут выполняться приложением 116 Pdrive в пределах объема настоящей технологии.
Устройство 112 хранения данных также может содержать по меньшей мере одно соответствующее приложение 118 моделирования накопителя для каждого накопителя 126 устройства 112 хранения данных. В целом, приложение 118 моделирования накопителя способно эмулировать идеальную работу накопителя 126 для диагностического анализа накопителя 126. Тем не менее, в других вариантах осуществления планировщик 120 также может использовать приложение 118 моделирования накопителя, чтобы упорядочивать операции I/O для передачи в накопитель 126.
Предполагается, что в некоторых вариантах осуществления настоящей технологии по меньшей мере одно соответствующее приложение 118 моделирования накопителя может быть реализовано как часть приложения 116 Pdrive. Иными словами, вышеупомянутые функции по меньшей мере одного соответствующего приложения 118 моделирования накопителя могут выполняться приложением 116 Pdrive в пределах объема настоящей технологии.
Далее описан представленный на фиг. 3 конвейер 300 обработки данных системы 100 распределенной обработки данных в соответствии с настоящей технологией. Следует отметить, что для удобства объяснения конвейер 300 представлен схематически, при этом возможны различные описанные ниже варианты.
В целом, конвейер 300 обработки данных способен обрабатывать поток задач с использованием последовательности обрабатывающих узлов 312. Система 100 распределенной обработки данных (или, для краткости, система 100) содержит различные варианты осуществления конвейера 300 обработки данных. В не имеющем ограничительного характера примере прокси-сервер 124 автомата SM, обрабатывающий системные данные, переданные из автомата SM, и формирующий операции I/O, которые должны выполняться накопителем 126 для сохранения системных данных, может представлять собой конвейер 300 обработки данных, в котором используются описанные ниже способы.
В другом не имеющем ограничительного характера примере конвейер 300 обработки данных может представлять собой вариант осуществления подсистемы 106 маршрутизации транзакций, где обрабатывающие узлы 312 соответствуют множеству портов для маршрутизации транзакций из множества детерминированных транзакций 182 в соответствующие сегменты 109. Поэтому в таком варианте описанные в данном документе способы управления заторами в конвейере 300 обработки данных могут быть реализованы для управления заторами в подсистеме 106 маршрутизации транзакций.
В другом не имеющем ограничительного характера примере конвейер 300 обработки данных может представлять собой вариант осуществления всей системы 100 распределенной обработки данных, представленной на фиг. 1 и описанной выше. В этом случае каждый обрабатывающий узел 312 представляет один из компьютерных элементов системы 100 распределенной обработки данных. Поэтому в таком варианте описанные здесь способы управления заторами в конвейере 300 обработки данных могут быть реализованы для управления заторами при обработке данных в системе 100 распределенной обработки данных.
Следует отметить, что конвейер 300 обработки данных описан здесь применительно к системе 100 распределенной обработки данных, но настоящая технология не ограничивается таким вариантом. Ниже описаны другие варианты применения настоящей технологии.
Конвейер 300 обработки данных содержит множество обрабатывающих узлов 312-318, которые далее обобщенно называются обрабатывающими узлами 312. Несмотря на то, что конвейер 300 обработки данных показан на чертежах с семью обрабатывающими узлами 312, он может содержать большее или меньшее количество узлов 312, в зависимости от конкретного варианта осуществления изобретения. Каждый обрабатывающий узел 312 имеет уникальный системный идентификатор (SUID), который представляет собой просто буквенно-цифровой идентификатор, связанный с каждым обрабатывающим узлом 312. Идентификатор SUID каждого обрабатывающего узла 312 является уникальным в пределах системы 100, чтобы можно было идентифицировать каждый конкретный узел, как более подробно описано ниже.
Обрабатывающие узлы 312 упоминаются здесь обобщенно, поскольку настоящая технология применима для разнообразных вариантов реализаций обрабатывающих узлов. Обрабатывающие узлы 312 могут, например, быть реализованы в виде программных модулей, программных приложений, аппаратных узлов, сочетания аппаратных и программных средств, узлов на основе встроенного программного обеспечения, множества устройств хранения данных и т.д. Также предполагается, что обрабатывающие узлы 312 могут быть реализованы в виде распределенных конечных автоматов, таких как реплицированный конечный автомат (Replicated State Machine), конечный автомат для совместно используемых журналов (SMSL, State Machine over Shared Logs) и т.д. Пример одного такого варианта реализации автомата SMSL описан в патентной заявке этого же заявителя с номером дела 40700-110, содержание которой полностью включено в настоящий документ посредством ссылки. В некоторых не имеющих ограничительного характера вариантах осуществления один конвейер 300 обработки данных может содержать несколько вариантов узлов 312.
Как показано на чертежах, обрабатывающие узлы 312 расположены в одну линию, объединены в последовательность и образуют конвейер 300. Следует отметить, что узлы 312 связаны так, чтобы последовательно обрабатывать задачи, но физическое распределение узлов 312 не обязательно должно соответствовать представленному на чертежах варианту, т.е. возможны и другие варианты.
Поскольку обрабатывающие узлы 312-318 работают последовательно, наличие нескольких задач, ожидающих обработки в любом узле 312, замедляет обработку задач в конвейере 300 обработки данных в целом. Согласно настоящей технологии предлагаются способы определения заторов в конвейере 300 обработки данных и, в частности, для определения конкретного узла 312 в конвейере 300, создающего узкое место. Согласно настоящей технологии также предлагаются способы анализа информации о заторах в конвейере 300 обработки данных с целью определения обрабатывающих узлов, требующих принятия корректирующих мер, таких как перепрограммирование, ремонт, замена и т.д.
Несмотря на то, что обрабатывающие узлы 312 показаны как различные модули (312-318), предполагается, что последовательность узлов 312 в конкретном конвейере 300 обработки данных может включать в себя многократное использование конкретного узла 312. Например, узлы 313 и 315 представляют собой второй и четвертый узлы 312 в конвейере 300 обработки данных, представленном на фиг. 3. Но в некоторых вариантах осуществления узлы 313 и 315 могут представлять собой один и тот же аппаратный узел 312, используемый на втором и четвертом шагах в конкретном варианте осуществления конвейера 300 обработки данных. Также следует отметить, что конкретный обрабатывающий узел 312 может использоваться в нескольких конвейерах 300 обработки данных системы 100.
Система 100 содержит по меньшей мере один источник 306 задач, формирующий поток компьютерных задач, которые должны обрабатываться конвейером 300 обработки данных. Здесь описан только один источник 306 задач, но предполагается, что система 100 может содержать несколько источников 306 задач. Источник 306 задач связан с конвейером 300 обработки данных так, чтобы конвейер 300 обработки данных мог принимать поток задач от источника 306 задач для обработки, как описано ниже. В частности, источник 306 задач связан по меньшей мере с первым узлом 312 конвейера 300 обработки данных.
Источник 306 задач описан здесь обобщенно, но предполагается, что в качестве источника 306 задач могут использоваться различные элементы системы 100. Источник 306 задач может быть реализован с использованием аппаратных средств системы 100, программных приложений, используемых в системе 100, или любого их сочетания. Также предполагается, что в любом варианте осуществления системы 100 может быть предусмотрено несколько источников 306 задач, которые могут представлять собой любое сочетание аппаратных и программных источников 306 задач, формирующих задачи для обработки одним или несколькими конвейерами 300 обработки данных. В некоторых других не имеющих ограничительного характера вариантах осуществления настоящей технологии источник 306 задач может быть реализован в виде клиентского устройства за пределами системы 100.
В некоторых не имеющих ограничительного характера вариантах реализации конвейера 300 обработки данных, содержащего описанный выше прокси-сервер 124 автомата SM, источник 306 задач может соответствовать автомату SM, для которого прокси-сервер 124 обрабатывает команды. Подобным образом, в некоторых не имеющих ограничительного характера вариантах реализации конвейера 300 обработки данных, содержащего всю описанную выше систему 100, источник 306 задач может соответствовать источнику 102 запросов, подсистеме 104 предварительной обработки запросов и/или подсистеме 105 обработки транзакций.
Источник 306 задач может формировать компьютерные задачи в различных формах, таких как операции I/O, обновления журналов и транзакции, но не ограничиваясь ими. Предполагается, что могут обрабатываться компьютерные задачи различных видов, в зависимости от конкретного варианта реализации конвейера 300 обработки данных. Очевидно, что варианты осуществления настоящей технологии могут применяться для любых видов задач, обрабатываемых в конвейере 300 обработки данных. Также следует отметить, что форма задачи может изменяться по мере ее продвижения в конвейере 300 обработки данных. Например, задача может преобразовываться из транзакции в операцию I/O в некоторой точке при обработке с использованием конвейера 300 обработки данных.
Система 100 также содержит надзорный компьютер 350. Несмотря на то, что надзорный компьютер 350 показан на фиг. 1 как отдельный компьютерный элемент, предполагается, что другие элементы описанной выше системы 100 могут выполнять функции надзорного компьютера 350. Также предполагается, что надзорный компьютер 350 может быть реализован с использованием программного приложения, а не аппаратного компьютера.
Надзорный компьютер 350 связан с конвейером 300 обработки данных. Надзорный компьютер 350 способен принимать информацию о задачах, выполненных и покидающих конвейер 300 обработки данных. В некоторых вариантах осуществления надзорный компьютер 350 способен принимать информацию о выполненной задаче от по меньше мере одного из обрабатывающих узлов. Также предполагается, что надзорный компьютер 350 способен принимать информацию о выполненной задаче из другого элемента системы 100. При этом следует отметить, что обрабатывающие узлы 312 могут включать в себя любой элемент системы 100 в зависимости от конкретного варианта осуществления изобретения. Также предполагается, что конвейер 300 обработки данных может содержать дополнительные компьютерные элементы, в зависимости от конкретного варианта осуществления изобретения.
Далее со ссылками на фиг. 4-7 более подробно описан пример работы конвейера 300, который содержит различные описанные выше элементы конвейера 300 и обрабатывает конкретную компьютерную задачу 302 в соответствии с настоящей технологией. В частности, описаны определение и устранение затора в конвейере 300 обработки данных в соответствии с настоящей технологией.
Источник 306 задач формирует последовательность компьютерных задач 302 и 303 для передачи в обрабатывающие узлы 312 и обработки в них. Для целей настоящего описания задачи, сформированные источником 306 задач перед конкретной задачей 302 и после нее, обозначаются как компьютерные задачи 303, чтобы отличать их от рассматриваемой здесь компьютерной задачи 302.
Задачи 303 из последовательности компьютерных задач, для простоты представленные на чертежах точками, показаны в момент времени, когда некоторые из них продвинулись по конвейеру 300 обработки данных. Компьютерная задача 302, рассматриваемая при прохождении через конвейер 300 обработки данных, показана на чертежах квадратом.
Обработка компьютерной задачи 302 начинается с создания компьютерной задачи 302 источником 306 задач. Источник 306 задач создает пакет 330 задачи, содержащий тело 332 задачи, указывающее на компьютерную задачу 302.
Первый обрабатывающий узел 312 принимает пакет 330 задачи и обрабатывает его. Как показано на фиг. 4, за пакетом 330 задачи нет очереди и тело 332 задачи обрабатывается и направляется в следующий обрабатывающий узел 313. Узел 313 подобным образом обрабатывает тело 332 задачи и передает пакет 330 задачи в следующий узел 314.
Затем узел 314 принимает и обрабатывает пакет 330 задачи. После обработки пакета 330 задачи обрабатывающий узел 314 определяет, что имеется очередь компьютерных задач 303, ожидающих обработки узлом 314. Затем, как показано на фиг. 5, обрабатывающий узел 314 добавляет в пакет 330 задачи данные об очереди в узле 314. В частности, обрабатывающий узел 314 дополняет тело 332 задачи доступным для записи полем 334 индикатора затора и записывает в него идентификатор SUID обрабатывающего узла 314. Затем узел 314 передает пакет 330 задачи, который теперь содержит тело 332 задачи и доступное для записи поле 334 индикатора затора в следующий узел 315. Как описано ниже, предполагается, что обрабатывающий узел 314 способен определять наличие очереди компьютерных задач 303, ожидающих обработки узлом 314, во время обработки тела 332 задачи или перед этой обработкой.
Узел 315 принимает и обрабатывает тело 332 задачи из пакета 330 задачи. После обработки тела 332 задачи обрабатывающий узел 315 аналогичным образом определяет, что имеется очередь компьютерных задач 303, ожидающих обработки узлом 315, как показано на фиг. 6. Определив наличие входной очереди, обрабатывающий узел 315 обновляет доступное для записи поле 334 индикатора затора с использованием идентификатора SUID обрабатывающего узла 315, заменяющего ранее записанный здесь идентификатор SUID обрабатывающего узла 314.
Затем, как показано на фиг. 7, компьютерная задача 302 обрабатывается обрабатывающими узлами 316, 317, 318, которые не обнаруживают очереди. Покидающий конвейер 300 обработки данных пакет 330 задачи содержит идентификатор SUID обрабатывающего узла 315, сохраненный в доступном для записи поле 334 индикатора затора. Таким образом, пакет 330 задачи содержит информацию о том, что обрабатывающий узел 315 представляет собой наиболее удаленный от начала конвейера обрабатывающий узел 312, создающий затор. В результате данные, передаваемые в пакете 330 задачи, ограничиваются только информацией о наиболее удаленном от начала конвейера обрабатывающем узле 312, создающем затор, т.е. последним записанным идентификатором SUID в доступном для записи поле 334 индикатора затора.
Затем система 100 считывает доступное для записи поле 334 индикатора затора пакета 330 задачи, покинувшего конвейер 300 обработки данных. В соответствии с настоящей технологией, доступное для записи поле 334 индикатора затора считывается надзорным компьютером 350, тем не менее, предполагается, что другие компьютерные элементы системы 100 также могут считывать поле 334 индикатора затора.
Затем надзорный компьютер 350 считывает и регистрирует последний записанный идентификатор SUID, чтобы определить обрабатывающий узел 312, создающий затор в конвейере 300 обработки данных. Несмотря на то, что в описанном случае информация из доступного для записи поля 334 индикатора затора отправляется в надзорный компьютер 350 последним обрабатывающим узлом 312 конвейера 300, также предполагается, что надзорный компьютер способен получать информацию из узла 312 или из другого компьютерного элемента системы 100 в некоторый более поздний момент обработки.
В некоторых вариантах осуществления изобретения надзорный компьютер 350 затем определяет конкретный узел 312, соответствующий последнему записанному идентификатору SUID. В представленном на фиг. 7 примере надзорный компьютер 350 считывает идентификатор SUID из пакета 330 задачи, а затем определяет, что в узле 315 имелась очередь, и что он, возможно, создает затор в конвейере 300 обработки данных. В некоторых вариантах осуществления изобретения надзорный компьютер 350 может определять только узел, соответствующий наиболее часто встречающемуся последнему записанному идентификатору SUID, чтобы указать такой узел 312, который наиболее вероятно или наиболее часто создает затор в конвейере 300 обработки данных.
Затем, как более подробно описано ниже, система 100 на основе статистики заторов может выполнить действия для устранения затора, создаваемого наиболее удаленным от начала конвейера узлом 312.
Как было упомянуто выше, покидающий конвейер 300 обработки данных пакет 330 задачи содержит только идентификатор SUID наиболее удаленного от начала конвейера узла 312, в котором определено наличие очереди. Независимо от расположенных ближе к началу конвейера узлов 312, наиболее удаленный от начала конвейера узел 312, определенный как имеющий очередь, создает узкое место в конвейере 300 и если требуется повысить скорость обработки всего конвейера 300 обработки данных, то должны быть приняты меры для устранения этой проблемы.
Например, если конвейер 300 обработки данных содержит несколько создающих заторы узлов 312, то после устранения проблемы, связанной с наиболее удаленным от начала конвейера создающим заторы узлом 312, могут быть устранены проблемы, связанные с узлами 312, расположенными ближе к началу конвейера. Когда параметры изменены так, чтобы первый узел 312, определенный как создающий затор, больше не создавал заторов, второй узел 312, расположенный ближе к началу конвейера, чем первый узел 312, становится новым наиболее удаленным от начала конвейера узлом 312, создающим затор. Таким образом, заторы, вызванные узлами 312, могут устраняться по одному за счет простого и энергоэффективного способа определения заторов согласно настоящей технологии.
Поскольку устраняется проблема, связанная только с наиболее удаленным от начала конвейера создающим затор узлом 312, в настоящей системе и способе ограничен объем данных, которые требуется передавать для определения, идентификации и устранения затора в конвейере 300 обработки данных. Несмотря на то, что в некоторых случаях можно сохранять все идентификаторы SUID для всех имеющих очереди узлов 312, часто такой вариант не является идеальным. В больших конвейерах 300 обработки данных с множеством узлов 312 может потребоваться сохранение очень большого количества идентификаторов SUID узлов 312, имеющих очереди. В некоторых случаях доступное для записи поле 334 индикатора затора к концу конвейера может содержать больше информации, чем тело 332 исходной задачи. Между тем, если определяется только наиболее удаленный от начала конвейера создающий затор узел 312, то пакет 330 задачи может иметь небольшой размер, пригодный для быстрой и энергоэффективной обработки (вместо постоянной передачи из узла в узел пакетов, содержащих большое количество информации).
Описанная выше архитектура позволяет реализовать способ 400 для определения места затора в конвейере 300 обработки данных, как в целом описано выше. Далее представленный на фиг. 8 способ 400 обнаружения и идентификации затора в конвейере 300 обработки данных описан более подробно.
Способ 400 выполняется в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии. В целом, способ 400 выполняется системой 100, содержащей конвейер 300 обработки данных. В частности, способ 400 выполняется обрабатывающими узлами 312 и надзорным компьютером 350, но при этом предполагается, что способ 400 может выполняться различными компьютерными устройствами системы 100. Также предполагается, что способ может выполняться конвейером обработки данных и надзорным компьютером, которые образуют часть другой системы обработки данных, включая системы нераспределенной обработки данных.
Шаг 410 - прием пакета задачи обрабатывающим узлом из множества обрабатывающих узлов, представляющим собой следующий обрабатывающий узел после предыдущего обрабатывающего узла конвейера обработки данных.
На шаге 410 обрабатывающий узел 312 принимает пакет 330 задачи от предыдущего обрабатывающего узла 312 конвейера 300 обработки данных. Если узел 312 представляет собой первый узел 312 в конвейере 300 обработки данных, то узел 312 принимает пакет 330 задачи от источника 306 задач. Как было упомянуто выше, пакет 330 задачи содержит по меньшей мере тело 332 задачи, которое включает в себя информацию, необходимую для обработки компьютерной задачи 302. В некоторых вариантах осуществления изобретения обрабатывающий узел 312 просто принимает тело 332 задачи и формирует пакет 330 задачи.
Шаг 420 - обработка обрабатывающим узлом тела задачи из пакета задачи.
На шаге 420 обрабатывающий узел 312 обрабатывает тело 332 задачи из пакета 330 задачи. В процессе обработки обрабатывающий узел 312 может дополнительно обновлять тело 332 задачи. Например, в некоторых случаях обрабатывающий узел 312 может выполнять операцию с данными, содержащимися в теле 332 задачи, и заменять информацию в теле 332 задачи (которое затем становится обновленным телом 332 задачи) информацией, полученной в результате выполнения этой операции.
Шаг 430 - определение обрабатывающим узлом наличия в этом обрабатывающем узле соответствующей входной очереди, содержащей более одного пакета задачи.
На шаге 430 обрабатывающий узел 312 определяет наличие входной очереди в этом обрабатывающем узле 312. Входная очередь определяется, если имеется несколько пакетов 330 задач, ожидающих обработки данным обрабатывающим узлом 312.
Наличие входной очереди может определяться любым известным в данной области техники способом, который не рассматривается как ограничивающий объем настоящей технологии. Определяется просто наличие входной очереди без учета количества компьютерных задач 302 в очереди, времени, в течение которого компьютерные задачи 302 находятся в очереди, или места любой конкретной компьютерной задачи 302 в очереди.
В общем случае определение наличия соответствующей входной очереди выполняется на шаге 430 после обработки тела задачи обрабатывающим узлом 312 на шаге 420. Таким образом, обнаружение и оповещение о формировании очереди осуществляется во время обработки пакета 330 задачи. Тем не менее, предполагается, что шаг 430 определения наличия очереди в обрабатывающем узле 312 может выполняться перед шагом 420 обработки тела 332 задачи этим обрабатывающим узлом 312. Также предполагается, что шаг 430 определения наличия очереди в обрабатывающем узле 312 может выполняться одновременно с шагом 420 обработки тела 332 задачи этим обрабатывающим узлом 312. Тем не менее, в общем случае это не обязательно, поскольку определение наличия очереди перед обработкой тела 332 может привести к пропуску очереди, образовавшейся во время обработки тела 332 задачи.
Шаг 440 - обновление обрабатывающим узлом доступного для записи поля индикатора затора с использованием соответствующего идентификатора SUID этого обрабатывающего узла, если определено наличие соответствующей входной очереди в этом обрабатывающем узле.
На шаге 440 узел 312 обновляет доступное для записи поле 334 индикатора затора с использованием соответствующего идентификатора SUID этого обрабатывающего узла 312, если определено наличие входной очереди в этом обрабатывающем узле 312. После этого пакет 330 задачи содержит уникальный идентификатор узла 312, в котором обнаружена очередь.
Если определено, что входная очередь имелась в предыдущем узле 312 и идентификатор SUID предыдущего узла 312 записан в поле 334 индикатора затора, то обновление доступного для записи поля 334 индикатора затора включает в себя удаление предыдущего идентификатора SUID из доступного для записи поля 334 индикатора затора и замену его идентификатором SUID текущего узла 312. Если данный узел 312 представляет собой первый узел 312 в конвейере 300, то с целью определения наличия входной очереди обновление доступного для записи поля 334 индикатора затора включает в себя запись текущего идентификатора SUID в доступное для записи поле 334 индикатора затора.
В некоторых вариантах осуществления изобретения обрабатывающий узел 312 просто принимает тело 332 задачи и формирует пакет 330 задачи, как было упомянуто выше. Формирование пакета 330 задачи включает в себя формирование доступного для записи поля 334 индикатора затора и добавление доступного для записи поля 334 индикатора затора к телу 332 задачи. В некоторых случаях первый обрабатывающий узел 312 может формировать и добавлять к телу 332 задачи доступное для записи поле 334 индикатора затора при приеме тела 332 задачи от источника 306 задач. В некоторых случаях первый обнаруживший очередь узел 312 может формировать и добавлять к телу 332 задачи доступное для записи поле 334 индикатора затора.
Затем обрабатывающий узел 312 дополнительно вставляет соответствующий идентификатор SUID этого обрабатывающего узла 312 в доступное для записи поле 334 индикатора затора если определено наличие входной очереди в этом обрабатывающем узле 312.
В некоторых вариантах осуществления изобретения способ 400 дополнительно включает в себя регистрацию в течение заранее заданного времени последнего записанного идентификатора SUID, соответствующего наиболее удаленному от начала конвейера создающему затор узлу 312, из всех или из многих покинувших конвейер пакетов 330 задач. В зависимости от конкретного варианта осуществления изобретения, регистрацию может выполнять надзорный компьютер 350 или другой компьютерный элемент системы 100.
В некоторых вариантах осуществления изобретения способ 400 дополнительно включает в себя определение системой 100 наиболее часто встречающегося последнего записанного идентификатора SUID среди отслеживаемых в течение заранее заданного периода времени последних записанных идентификаторов SUID. Аналогично предполагается, что надзорный компьютер 350 способен определять наиболее часто встречающийся последний записанный идентификатор SUID.
В некоторых случаях система 100 способна дополнительно формировать сообщение, содержащее наиболее часто встречающийся последний записанный идентификатор SUID, чтобы оповещать пользователя, другую компьютерную систему или один из компьютерных элементов системы 100 об обрабатывающем узле 312, создающем затор в конвейере 300 обработки данных. Сообщение способствует устранению затора, вызванного конкретным обрабатывающим узлом 312, путем определения наиболее часто встречающегося последнего записанного идентификатора SUID и, следовательно, узла 312, наиболее часто вызывающего заторы в конвейере 300 обработки данных.
В некоторых вариантах осуществления изобретения система 100 может содержать много конвейеров 300 обработки данных. В таком случае способ 400 может дополнительно включать в себя регистрацию надзорным компьютером 350 или другим элементом системы 100 в течение заранее заданного периода времени последних записанных идентификаторов SUID из пакетов 330 задач, покинувших каждый конвейер 300 обработки данных. Таким образом, любой или все конвейеры 300 обработки данных могут быть оптимизированы с целью управления заторами в системе 100.
Описанная выше архитектура конвейера 300 обработки данных и системы 100, а также способ 400 определения затора позволяют реализовать способ 500 устранения затора в конвейере 300 обработки данных. Далее представленный на фиг. 10 способ 500 устранения затора в конвейере 300 обработки данных описан более подробно.
Способ 500 выполняется в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии. В целом, способ 500 выполняется системой 100, содержащей конвейер 300 обработки данных. В частности, способ 500 выполняется обрабатывающими узлами 312 и надзорным компьютером 350, но при этом предполагается, что способ 500 или его часть может выполняться различными компьютерными устройствами системы 100. Также предполагается, что такой способ может выполняться конвейером обработки данных и надзорным компьютером, которые входят в состав систем нераспределенной обработки данных.
Шаг 510 - сбор статистики заторов от множества обрабатывающих узлов в течение заранее заданного периода времени путем повторения в течение заранее заданного периода времени шагов обработки задач и регистрации последнего записанного идентификатора SUID в статистике заторов.
На шаге 510 надзорный компьютер 350 в течение заранее заданного времени собирает статистику заторов путем многократной регистрации последних записанных идентификаторов SUID из множества компьютерных задач 302, обработанных конвейером 300 обработки данных.
Последние записанные идентификаторы SUID из множества компьютерных задач 302 регистрируются во время итераций способа 400, описанного выше, причем последний записанный идентификатор SUID регистрируется для многих или для каждой из компьютерных задач 302, сформированных источником 306 задач и обработанных конвейером 300 обработки данных.
Шаг 520 - определение надзорным компьютером наиболее часто встречающегося последнего записанного идентификатора SUID, зарегистрированного в статистике заторов.
На шаге 520 надзорный компьютер 350 определяет наиболее часто встречающийся последний записанный идентификатор SUID, зарегистрированный в статистике заторов. Наиболее часто встречающийся последний записанный идентификатор SUID указывает на наиболее удаленный от начала конвейера обрабатывающий узел 312 из множества обрабатывающих узлов 312, наиболее часто создававший заторы в конвейере 300 обработки данных в течение заранее заданного периода времени, в течение которого надзорный компьютер 350 собирал статистику заторов.
В некоторых случаях статистика заторов может собираться для нескольких конвейеров 300 обработки данных в системе, а надзорный компьютер 350 может определять наиболее часто встречающиеся последние записанные идентификаторы SUID в каждом конвейере 300 или в подмножестве конвейеров 300 обработки данных.
Шаг 530 - определение конкретного узла, соответствующего наиболее часто встречающемуся последнему записанному идентификатору SUID.
На шаге 530 надзорный компьютер 350 определяет конкретный узел 312, соответствующий наиболее часто встречающемуся последнему записанному идентификатору SUID. В некоторых случаях это определение может включать в себя сравнение наиболее часто встречающегося последнего идентификатора SUID с таблицей идентификаторов SUID и узлов 312.
Шаг 540 - инициирование изменения по меньшей мере одного параметра, связанного с конкретным узлом.
На шаге 540 надзорный компьютер 540 инициирует изменение по меньшей мере одного параметра, связанного с конкретным узлом 312, чтобы способствовать устранению затора в конкретном узле 312. В некоторых вариантах осуществления изобретения надзорный компьютер 350 может соотносить конкретный узел 312 с некоторым другим компьютерным элементом системы 100. Затем другой компьютерный элемент может скорректировать один или несколько параметров конкретного узла 312, чтобы способствовать уменьшению заторов в этом конкретном узле 312.
Далее описан представленный на фиг. 10 другой не имеющий ограничительного характера пример конвейера 301 обработки данных, содержащего по меньшей мере три узла 372, 373, 374, которые представляют собой примеры узла 312. Следует отметить, что для определения наиболее удаленного от начала конвейера узла 312, создающего заторы в конвейерах 301 обработки данных, содержащих ветви, может потребоваться дополнительная информация.
В представленном конвейере 301 обработки данных узел 372 способен направлять пакеты 330 задач в два возможных узла 373 и 374. В зависимости от взаимодействия между узлами 372, 373, 374, очередь в узлах 373 и/или 374 может зависеть не только от параметров узлов 373, 374. В некоторых случаях управление узлом 372 может также влиять на очереди в узлах 373, 374. Например, узел 373 способен выполнять обработку быстрее, чем узел 374, но если узел 372 направляет больше пакетов 330 задач в узел 373, то очередь с большей степенью вероятности образуется в узле 373.
Чтобы избежать неправильной интерпретации очередей, образующихся в ветвях конвейера 301 обработки данных, такого как конвейер с узлами 372, 373, 374, в некоторых вариантах осуществления изобретения может предоставляться дополнительная информация. В некоторых случаях помимо обновления доступного для записи поля 334 индикатора затора, когда узел 312 определяет, что в нем имеется входная очередь, такой узел 312 может дополнительно обновлять доступное для записи поле 334 индикатора затора с использованием признака, указывающего на устранение очереди в этом узле 312. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии узел 312 способен формировать отдельное сообщение, указывающее на устранение очереди в этом узле 312.
В некоторых случаях признак устранения очереди в узле 312 может записываться как дополнительная информация в доступное для записи поле 334 индикатора затора. В некоторых других вариантах осуществления изобретения признак устранения очереди в узле 312 может просто использоваться для замены идентификатора SUID из предыдущего узла в доступном для записи поле 334 индикатора затора. В таком случае, если узлы 312, расположенные дальше от начала конвейера, чем узлы 373, 374 ветвей, определяют соответствующую очередь, признак из узлов 373, 374 ветвей просто заменяется идентификатором SUID более удаленного от начала конвейера узла. Далее очередь в узлах 373, 374 ветвей, причиной возникновения которой являются узлы 373, 374 ветвей или распределение узлом 372, может рассматриваться как не имеющая значения. С другой стороны, если узлы 373, 374 ветвей представляют собой наиболее удаленные от начала конвейера узлы 312 с входной очередью, система 100 получает дополнительную информацию об устранении очереди, которая учитывается при определении необходимости устранения затора в узлах 373, 374 ветвей.
Несмотря на то, что описанный в данном документе конвейер 300 обработки данных применяется в системе 100, описанная здесь технология также может применяться для компьютерных систем различных видов и не должна ограничиваться системами распределенной обработки данных. Настоящая технология способна обеспечить преимущества для разнообразных систем с конвейером обработки данных, включая следующие сферы применения, но не ограничиваясь ими: обработку данных с использованием центрального процессора, аппаратную обработку данных, сети связи и конечные автоматы.
Несмотря на то, что описанные выше варианты реализации приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или что их порядок может быть изменен без отклонения от настоящей технологии. Соответственно, порядок и группировка шагов не носят ограничительного характера для настоящей технологии.
Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте реализации настоящей технологии. Например, возможны варианты реализации настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технические эффекты отсутствуют.
Некоторые из этих шагов и передаваемых или принимаемых сигналов хорошо известны в данной области техники и по этой причине опущены в некоторых частях описания для упрощения. Сигналы могут передаваться или приниматься с использованием оптических средств (таких как волоконно-оптическое соединение), электронных средств (таких как проводное или беспроводное соединение) и механических средств (например, основанных на давлении, температуре или любом другом подходящем физическом параметре).
Специалисту в данной области могут быть очевидны возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в качестве примера, но не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
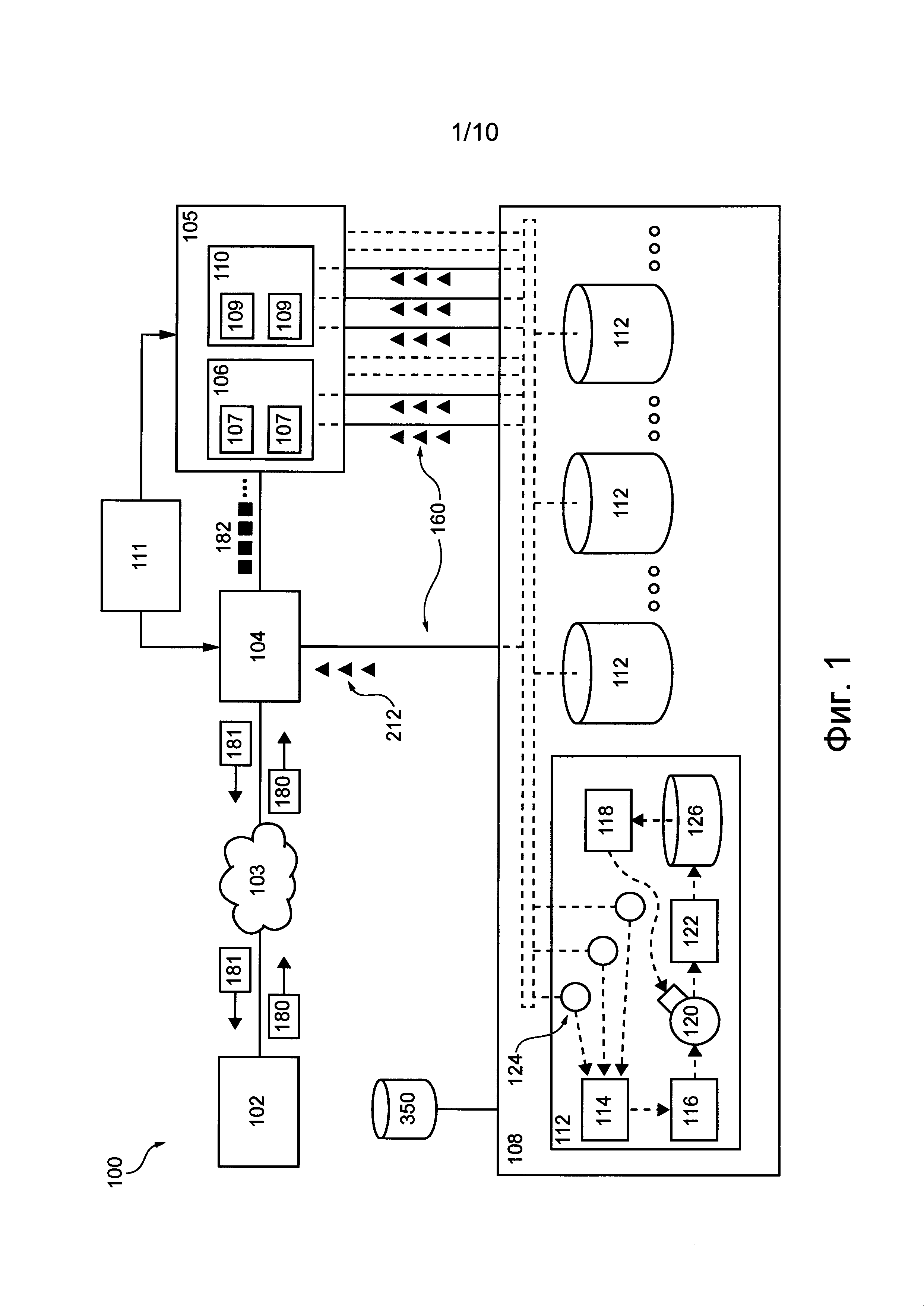
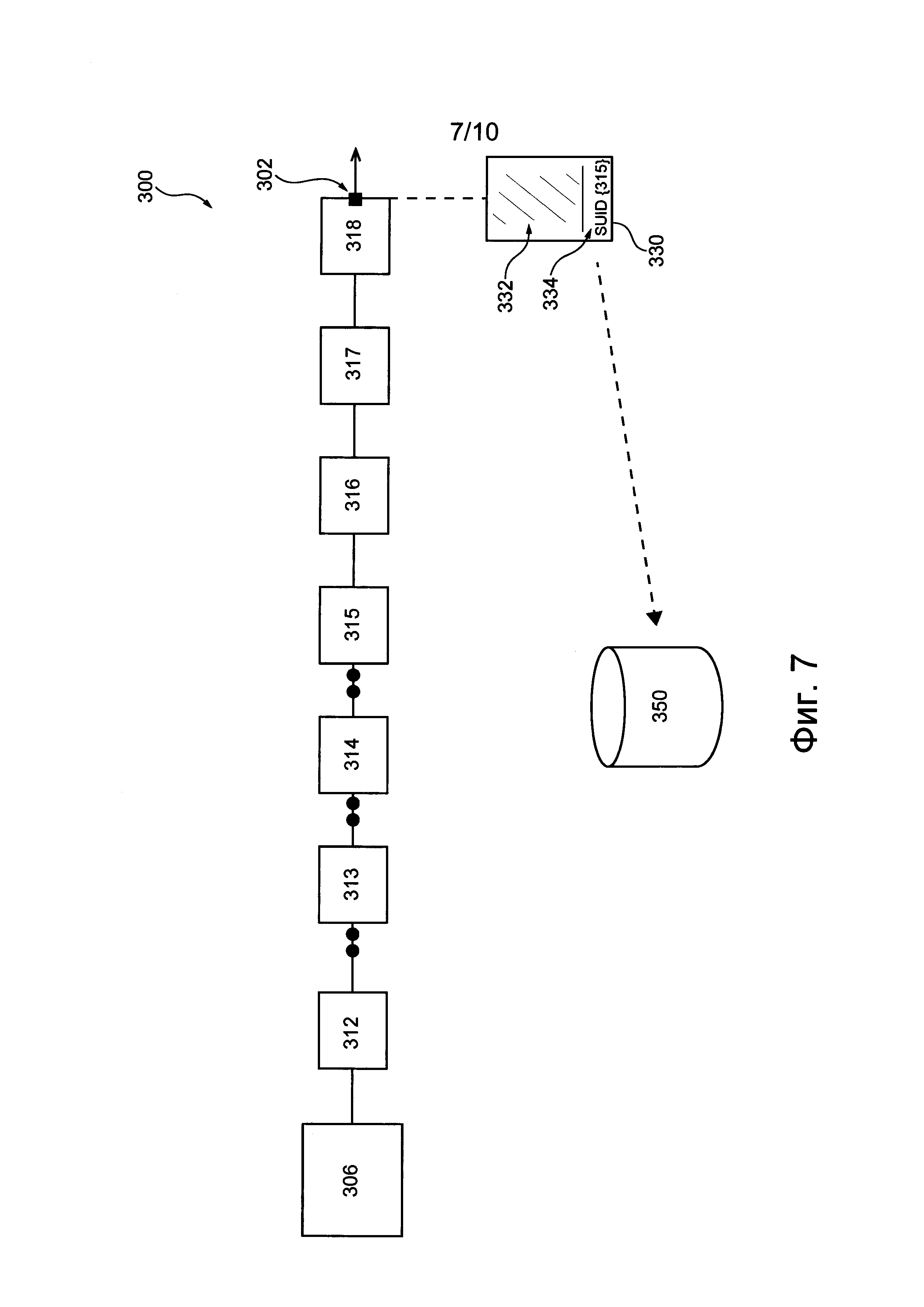
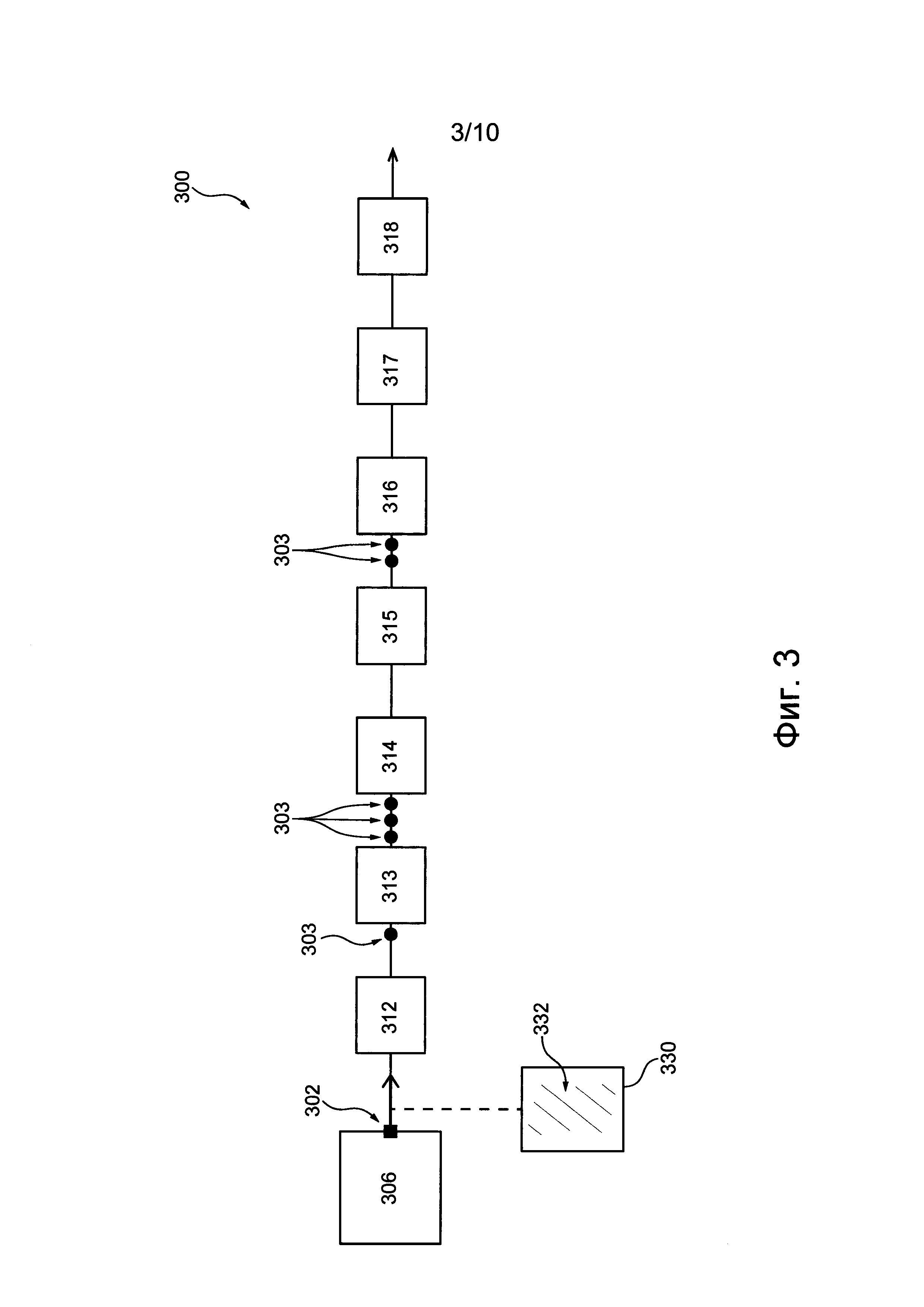
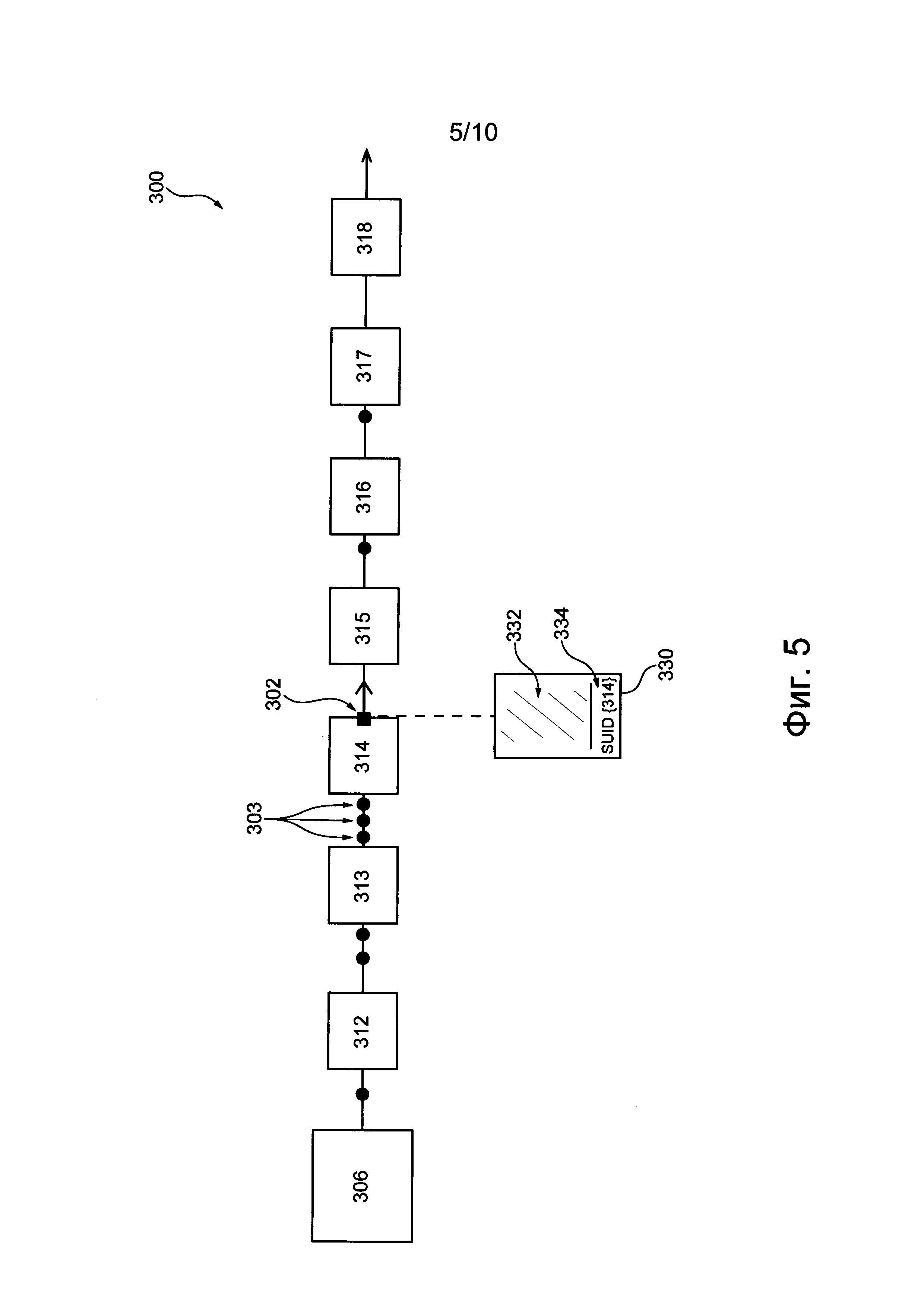
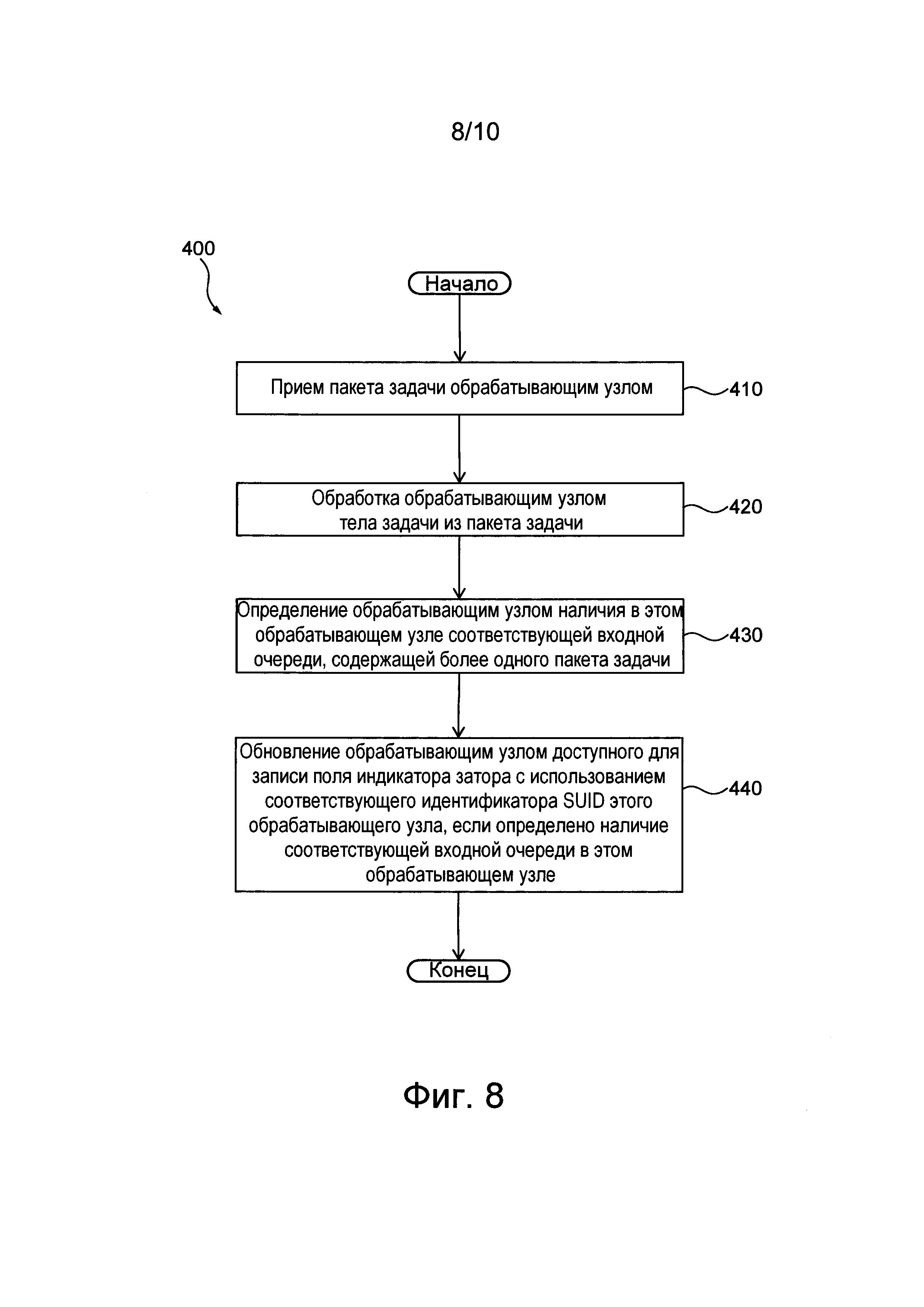
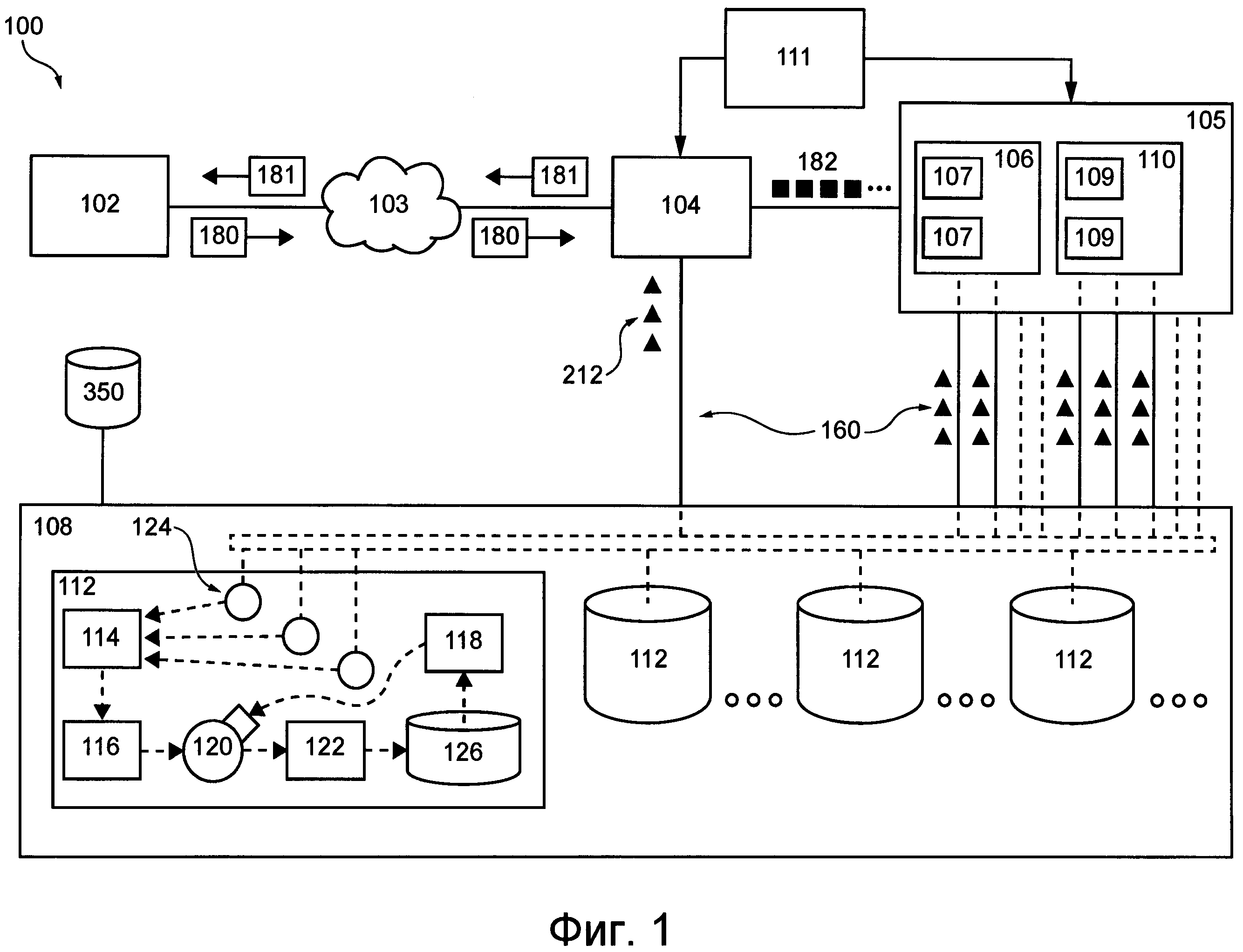
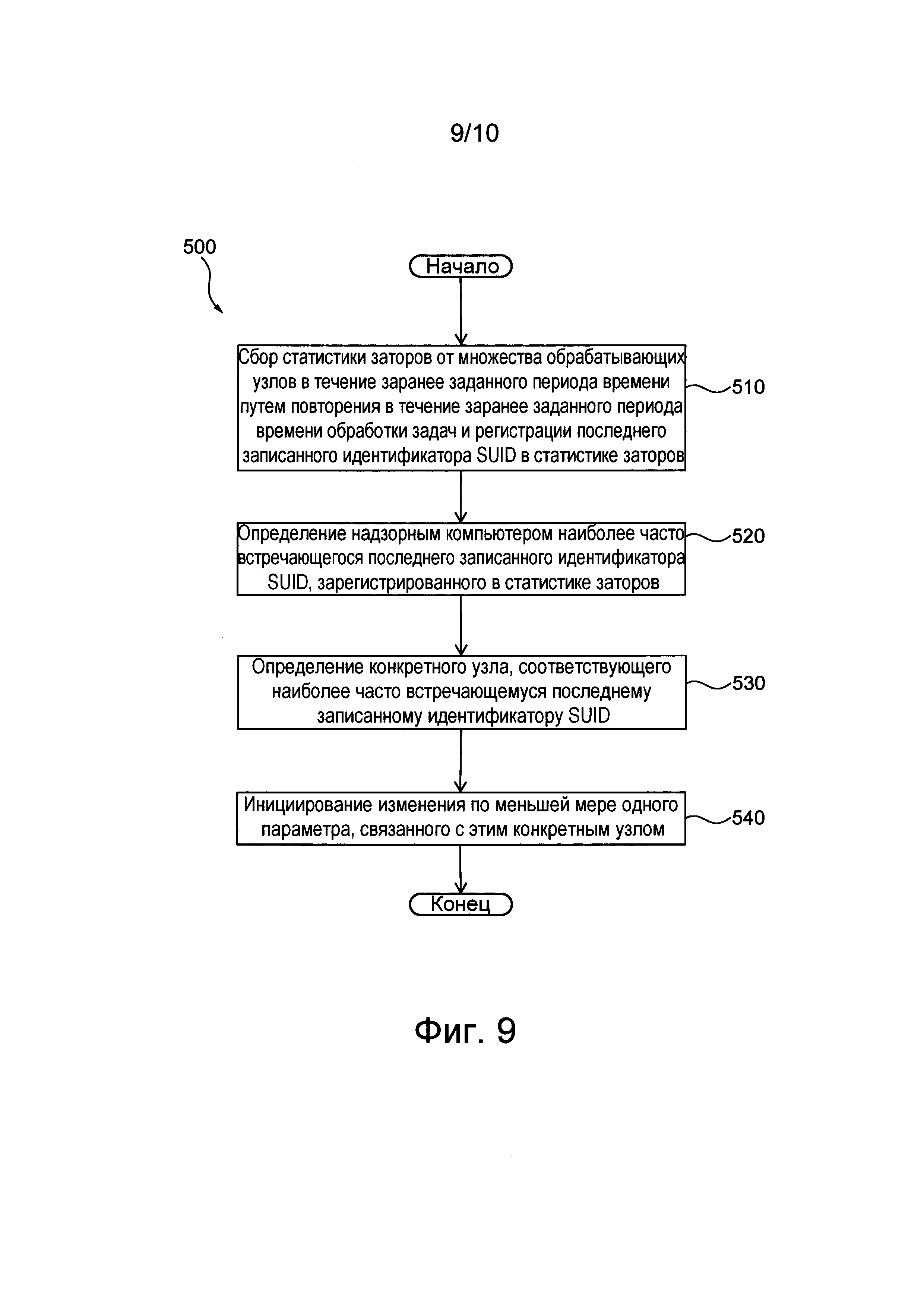
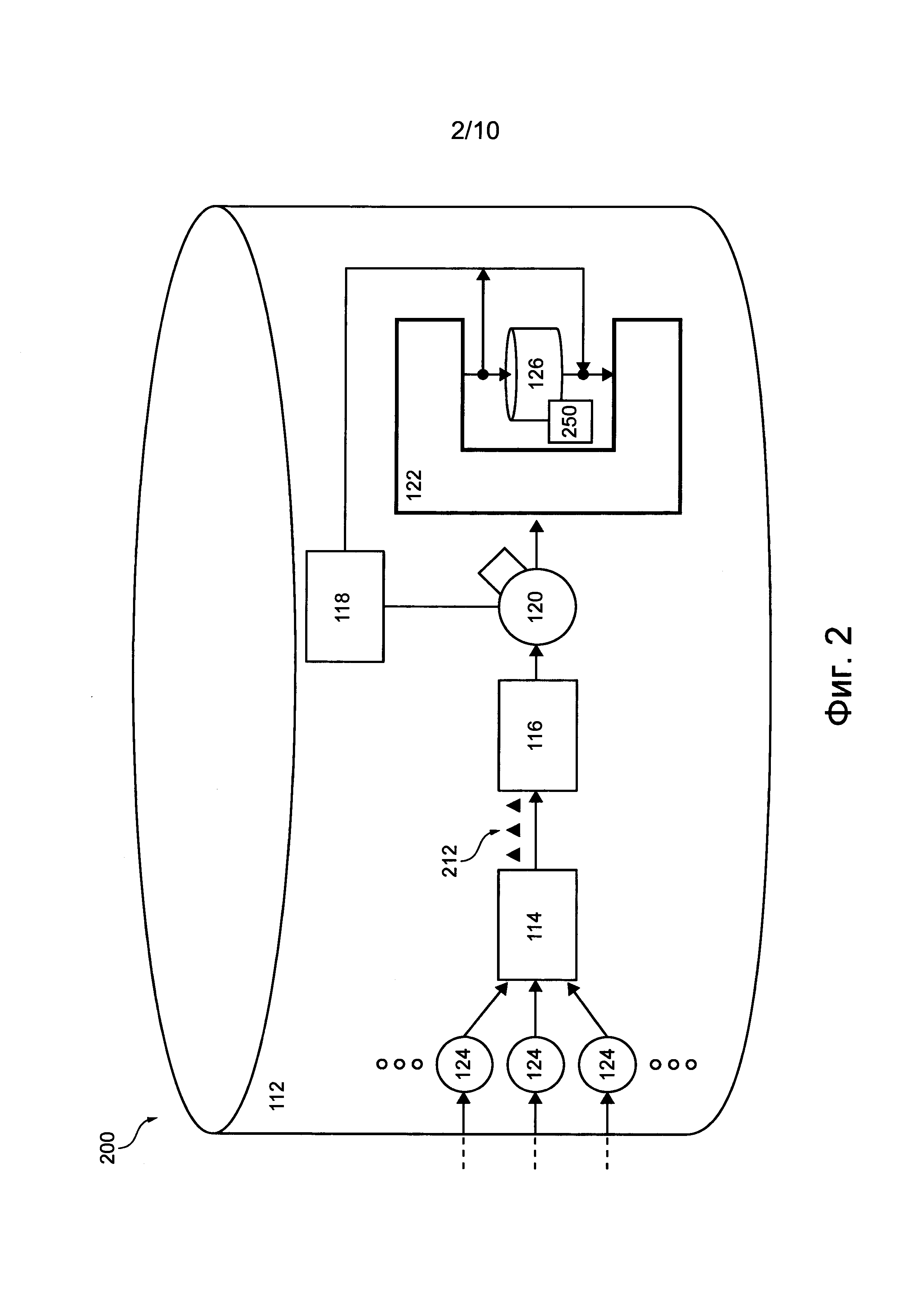
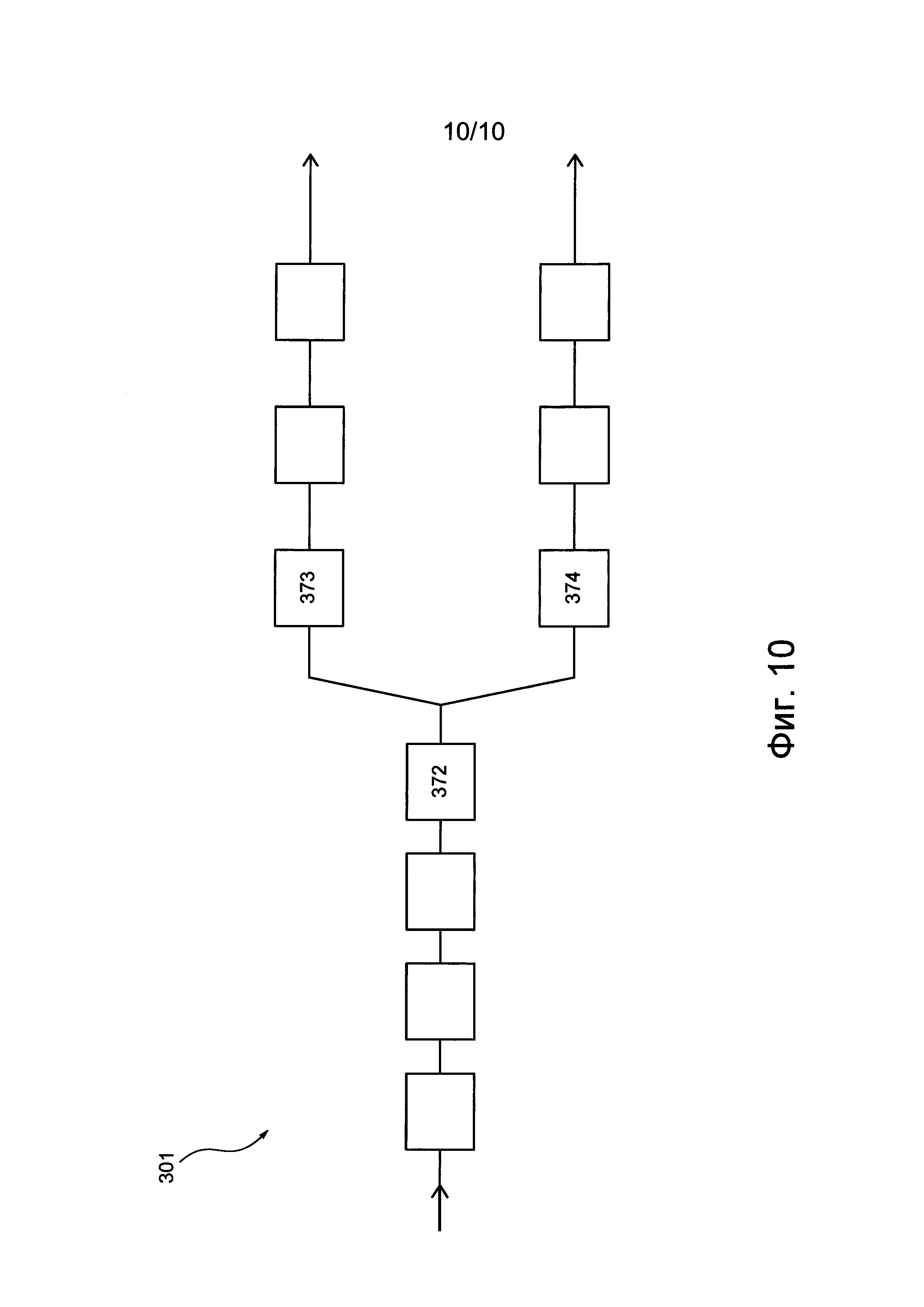
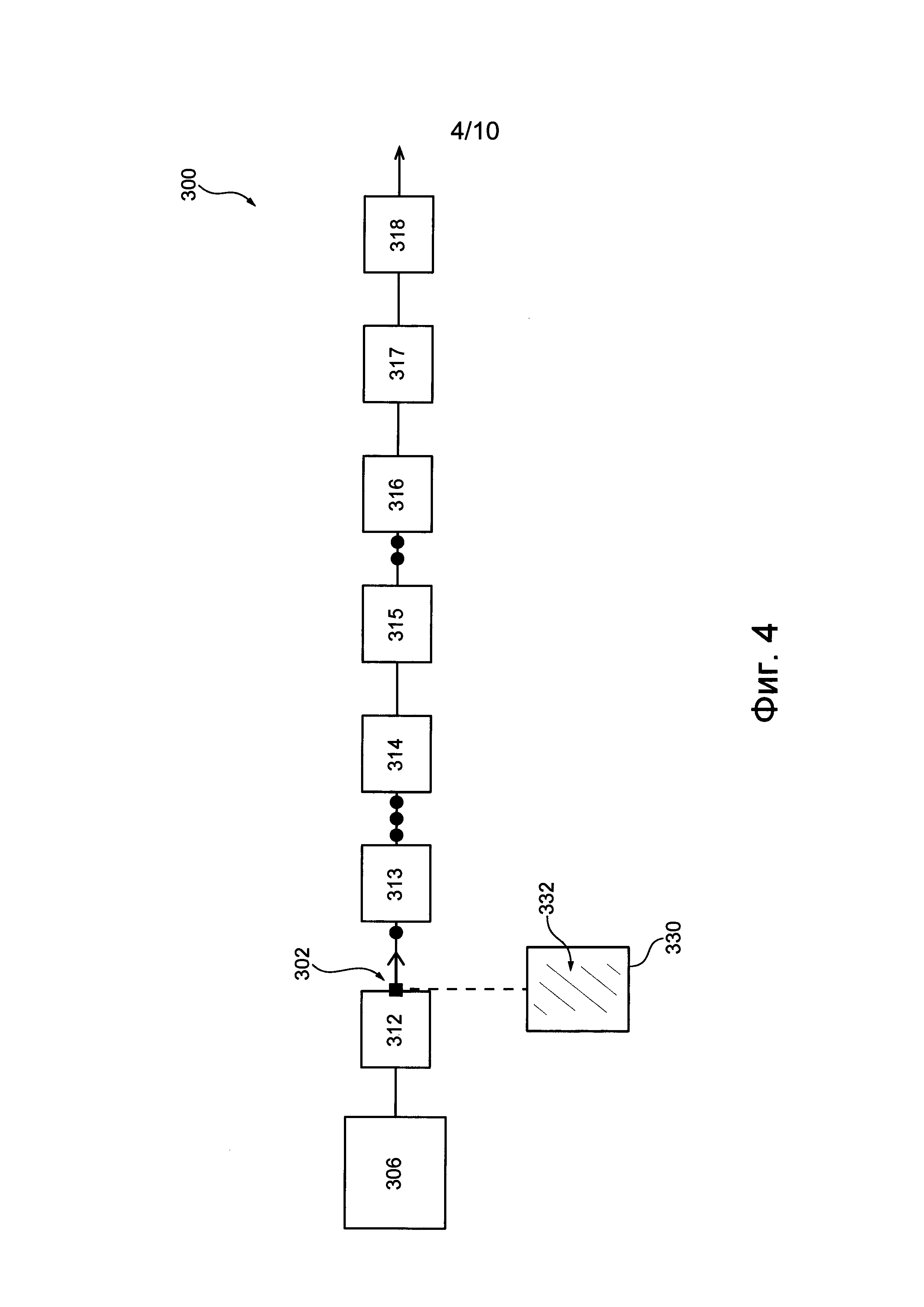
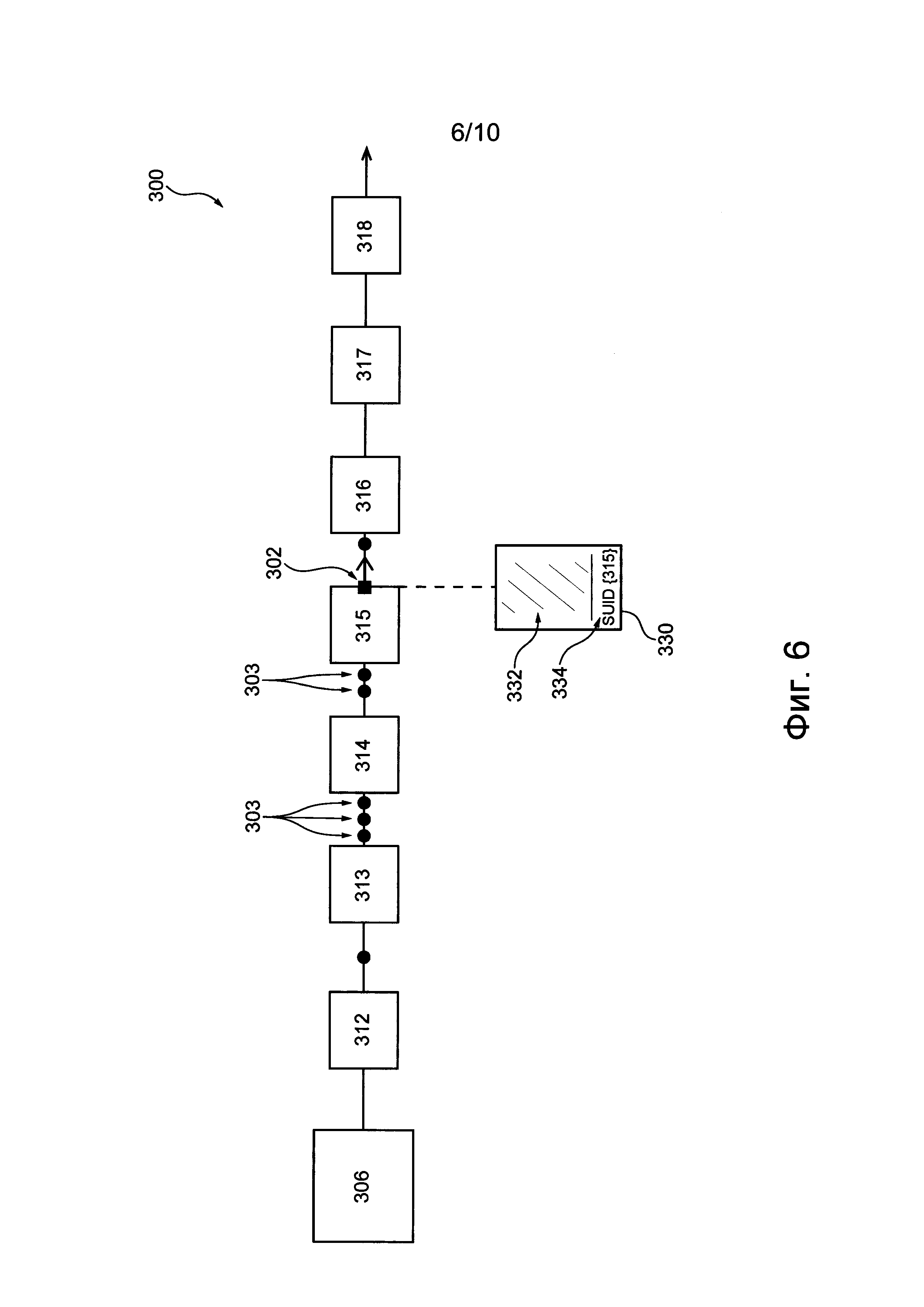
Пластинчатый конвейер для сыпучих материалов, ячейка пластинчатого конвейера и грузонесущий лоток пластинчатого конвейера
Способ получения катализатора дегидрирования парафиновых углеводородов
Способ и система для планирования передачи операций ввода/вывода
Способ и система для планирования выполнения операций ввода/вывода
Способ и распределенная компьютерная система для обработки данных

