Результат интеллектуальной деятельности: ОБРАБОТКА И АНАЛИЗ ДАННЫХ НА ИЗОБРАЖЕНИЯХ КОМПЬЮТЕРНОЙ ТОМОГРАФИИ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в общем относится к вычислительным системам, а более конкретно - к системам и способам обработки изображений и анализа данных в компьютерной томографии.
УРОВЕНЬ ТЕХНИКИ
[0002] Компьютерная томография (КТ) - это процедура визуализации, которая использует специализированное рентгеновское оборудование для создания подробных изображений, или сканов, областей внутри объекта исследования (например, живого организма). Множество рентгеновских изображений, снятых под разными углами, могут использоваться для получения томографических изображений поперечного сечения (виртуальных «срезов») определенных областей объекта исследования. Наиболее часто используемым применением КТ является медицинская визуализация. Изображения поперечного сечения используются для диагностических и терапевтических целей в различных областях медицины.
[0003] Позитронная эмиссионная томография (ПЭТ) представляет собой способ визуализации на основе радиоизотопной эмиссии (РЭ), которая обнаруживает пары гамма-лучей, излучаемых косвенно позитронно-активным радиоизотопом (маркером), который вводится внутрь организма в биологически активной молекуле. Затем с помощью компьютерного анализа конструируются трехмерные изображения концентрации маркера внутри организма.
[0004] Позитронная эмиссионная компьютерная томография (ПЭТ-КТ) - это технология визуализации, которая сочетает на единой платформеПЭТ-сканер и рентгеновский КТ-сканер, что позволяет получать последовательные изображения с обоих устройств за один сеанс и совмещать их в одно наложенное изображение.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0005] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа обработки изображения и анализа данных может включать: получение множества исходных изображений исследуемого организма; обработку, с помощью первой сверточной нейронной сети, множества исходных изображений для получения одного или более изображений псевдо-радиоизотопной эмиссии (псевдо-РЭ) исследуемого организма; и обработка, с помощью второй сверточной нейронной сети, множества псевдо-РЭ изображений для классификации одного или более исходных изображений из множества исходных изображений относительно предопределенного медицинского диагноза для исследуемого организма.
[0006] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа обработки изображения и анализа данных может содержать память и процессор, соединенный с памятью, при этом процессор выполнен с возможностью: получения множества исходных изображений исследуемого организма; обработки, с помощью первой сверточной нейронной сети, множества исходных изображений для получения одного или более изображений псевдо-радиоизотопной эмиссии (псевдо-РЭ) исследуемого организма; и обработки, с помощью второй сверточной нейронной сети, множества псевдо-РЭ изображений для классификации одного или более исходных изображений из множества исходных изображений относительно предопределенного медицинского диагноза для исследуемого организма.
[0007] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их вычислительным устройством приводят к выполнению вычислительным устройством операций, включающих: получение множества исходных изображений исследуемого организма; обработку, с помощью первой сверточной нейронной сети, множества исходных изображений для получения одного или более изображений псевдо-радиоизотопной эмиссии (псевдо-РЭ) исследуемого организма; и обработку, с помощью второй сверточной нейронной сети, множества псевдо-РЭ изображений для классификации одного или более исходных изображений из множества исходных изображений относительно предопределенного медицинского диагноза для исследуемого организма.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0008] Настоящее изобретение иллюстрируется с помощью примеров, не с целью ограничения, станет более ясно при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
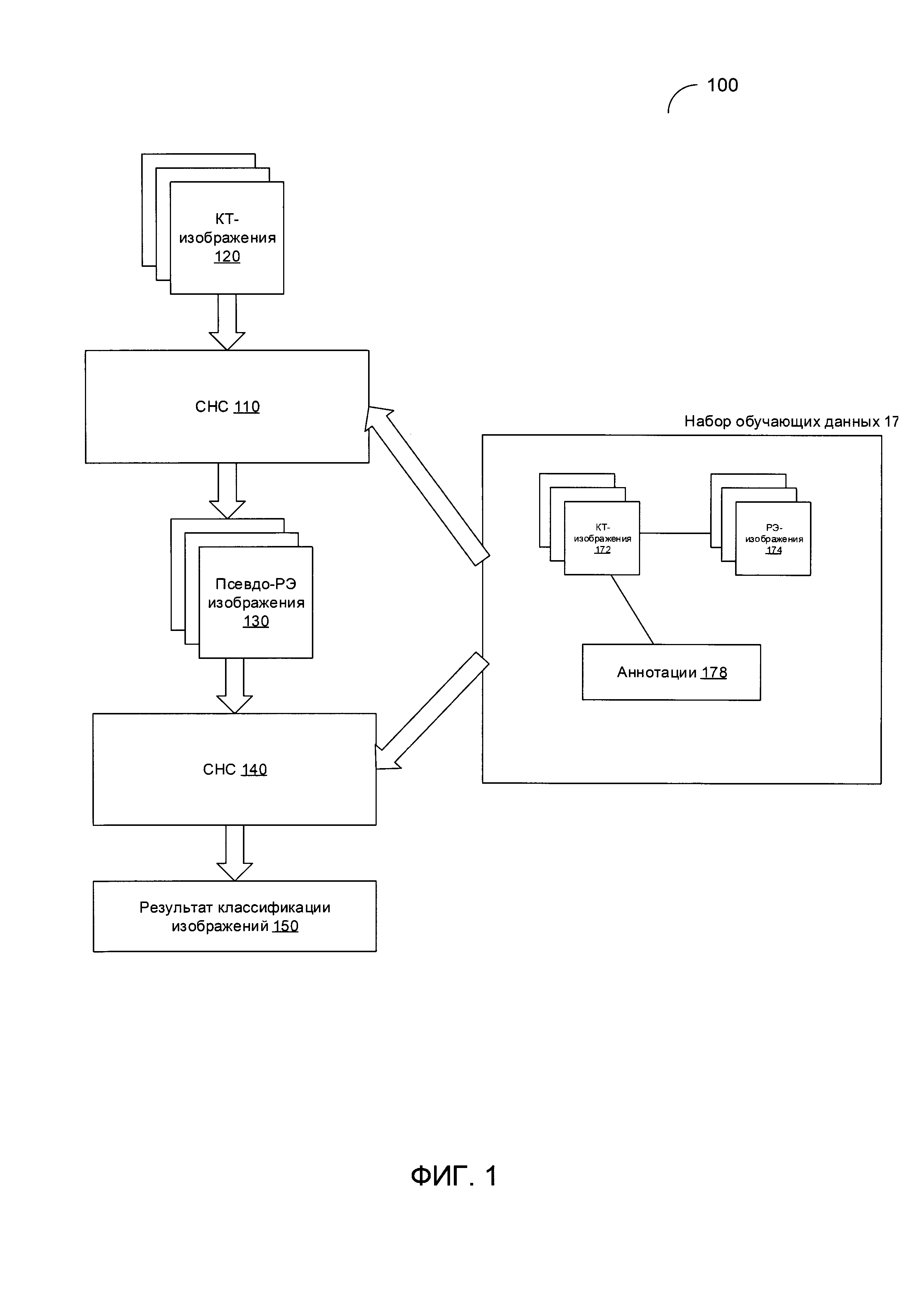
[0009] На Фиг. 1 схематически иллюстрируется пример системы обработки и анализа данных на изображениях, полученных способом компьютерной томографии (КТ), в соответствии с одним или более вариантами реализации настоящего изобретения;
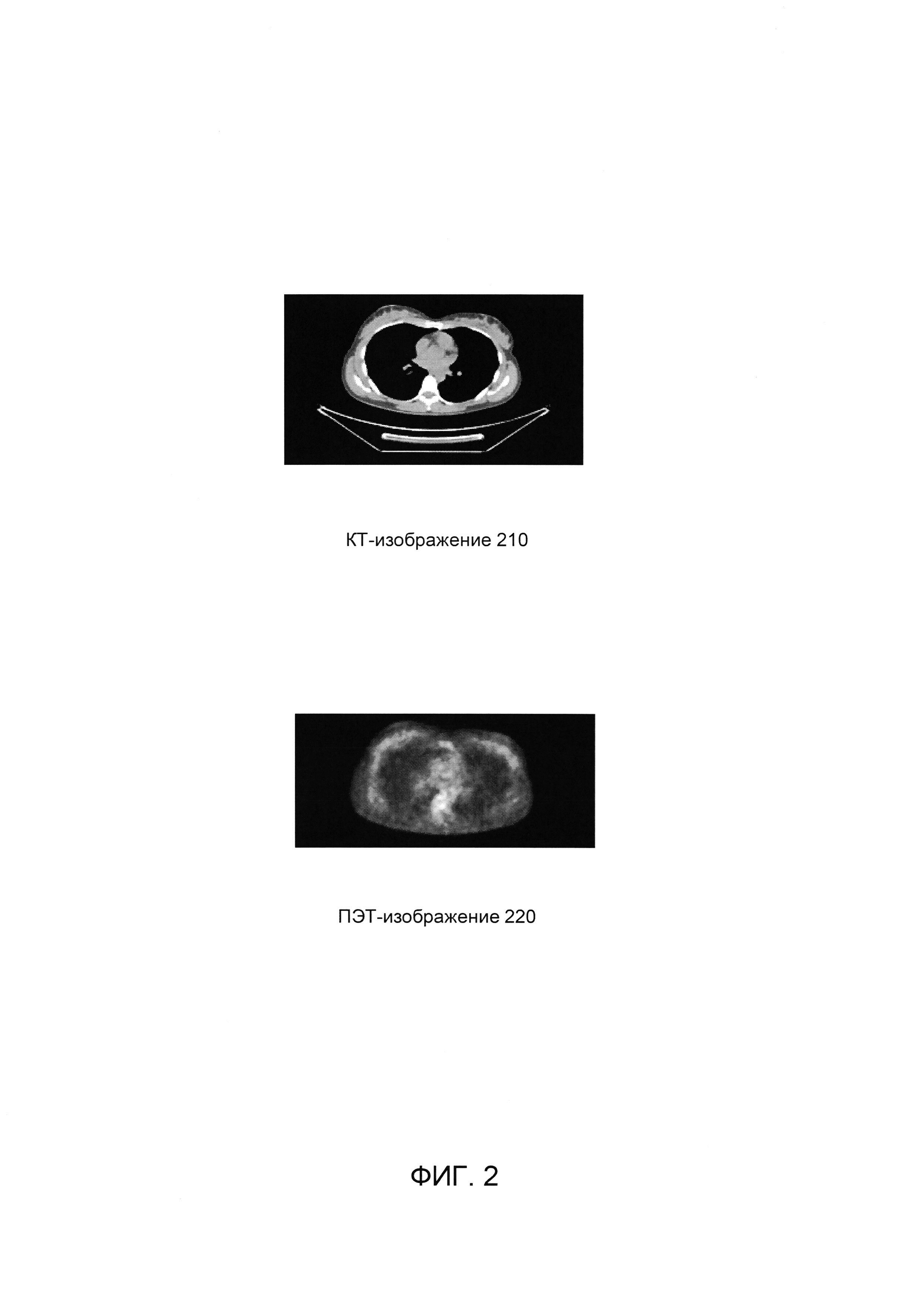
[00010] На Фиг. 2 схематически иллюстрируется пример КТ-изображения и соответствующего изображения позитронной эмиссионной томографии (ПЭТ) исследуемого организма в соответствии с одним или более вариантами реализации настоящего изобретения;
[00011] На Фиг. 3 схематически иллюстрируется пример упрощенного КТ-изображения, обработанного сверточной нейронной сетью (СНС) для получения соответствующего псевдо-ПЭТ изображения в соответствии с одним или более вариантами реализации настоящего изобретения;
[00012] На Фиг. 4 схематически иллюстрируется пример структуры СНС, которая может использоваться для обработки множества КТ-изображений исследуемого организма для получения соответствующих псевдо-радиоизотопных (псевдо-РЭ) изображений в соответствии с одним или более вариантами реализации настоящего изобретения;
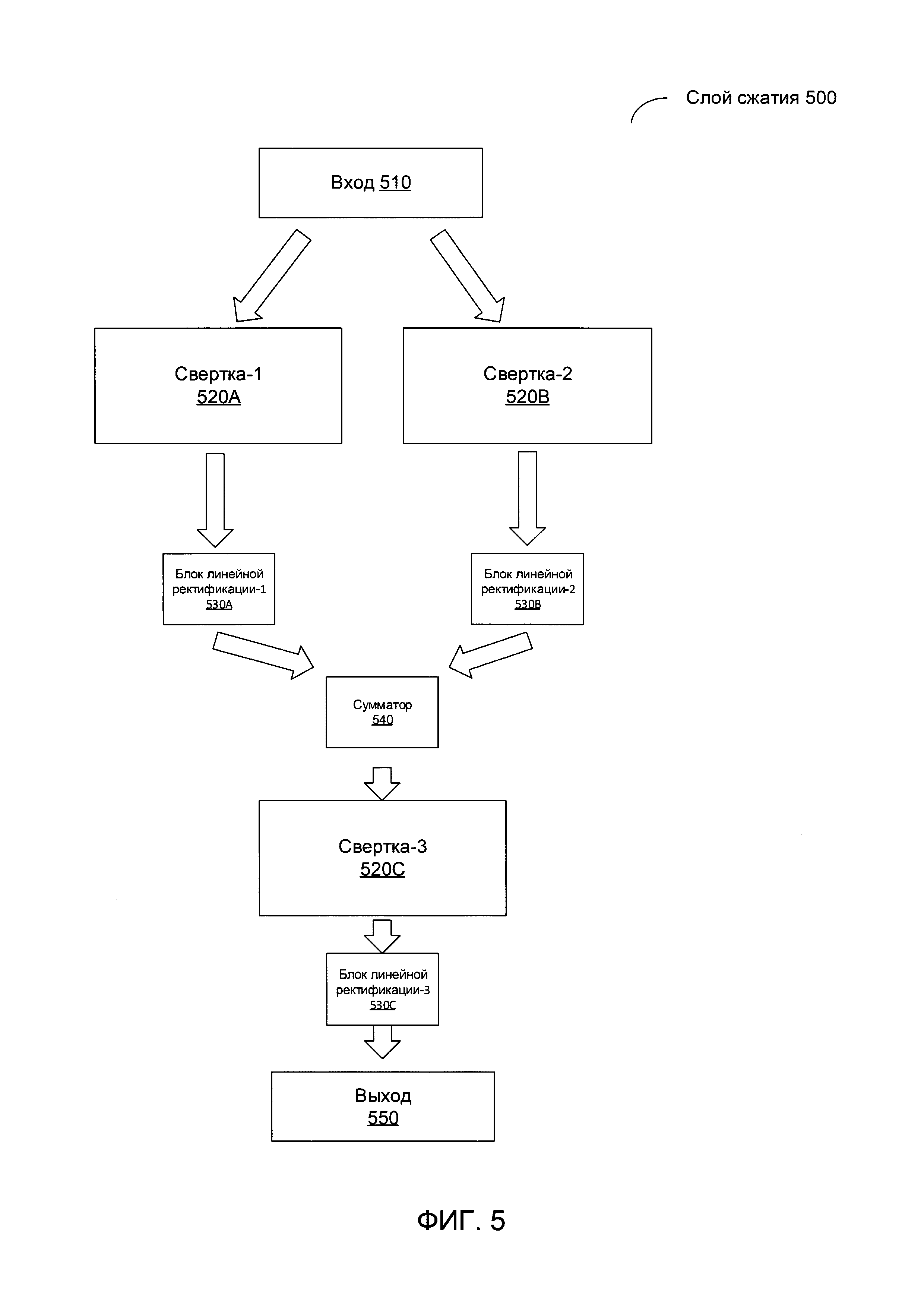
[00013] На Фиг. 5 схематически иллюстрируется пример структуры слоев сжатия первой СНС, реализованной в соответствии с одним или более вариантами реализации настоящего изобретения;
[00014] На Фиг. 6 схематически иллюстрируется пример структуры второй СНС, которая может использоваться для обработки псевдо-РЭ изображений, полученных от первой СНС для выполнения классификации изображений для исходных КТ-изображений относительно некоторого предполагаемого диагноза в соответствии с одним или более вариантами реализации настоящего изобретения;
[00015] На Фиг. 7 представлена блок-схема одного иллюстративного примера способа обработки изображений 700 и анализа данных для компьютерной томографии в соответствии с одним или более вариантами реализации настоящего изобретения; и
[00016] На Фиг. 8 представлена блок-схема иллюстративного примера вычислительного устройства, реализующего системы и способы, описанные в этом документе.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[00017] В настоящем документе описываются способы и системы обработки изображений и анализа данных для компьютерной томографии (КТ).
[00018] Получение изображений с помощью КТ, позитронной эмиссионной томографии (ПЭТ) и ПЭТ-КТ широко используется в медицинской диагностике, например, для обнаружения опухолей и других патологических образований внутри живых организмов. Раковые клетки потребляют глюкозу значительно быстрее, чем здоровые, выделяя в результате избыточную энергию, что может быть зарегистрировано с помощью аппаратуры ПЭТ. С другой стороны, множество КТ-изображений, снятых под разными углами, может использоваться для получения поперечных срезов определенных областей объекта исследования. Сочетание ПЭТ-изображений и КТ-изображений можно использовать для получения трехмерных изображений концентрации маркера внутри организма на клеточном уровне.
[00019] Однако чрезмерно высокая цена современного оборудования для ПЭТ делает его недоступным для многих пациентов. Кроме того, широкое использование способов визуализации ПЭТ и ПЭТ-КТ могут затруднять различные другие факторы, например, ограниченное время пригодности большинства позитронно-активных радионуклидов (маркеров), которые необходимо вводить внутрь организма для получения изображений ПЭТ. Кроме того, расшифровка результатов ПЭТ и ПЭТ-КТ может производиться только высококвалифицированными профессиональными медиками, которые могут отсутствовать в некоторых медицинских учреждениях. В современной медицинской практике изображения ПЭТ или ПЭТ-КТ сначала обрабатываются специалистом по томографии, который выявляет области интереса (ОИ), после чего эти области анализируются лечащим врачом. Двухэтапная обработка может привести к задержкам в получении результатов диагностики, таким образом отрицательно сказываясь на лечении пациента. Кроме того, анализ ПЭТ-изображения может быть затруднен визуальной схожестью раковых образований и доброкачественных опухолей.
[00020] С другой стороны, КТ-оборудование обычно доступно в большинстве современных медицинских учреждений. Однако точность диагностики рака только на основе КТ-сканирования крайне низка и в большинстве случаевявляется недостаточной.
[00021] Настоящее изобретение устраняет перечисленные выше и другие недостатки, предоставляя системы и способы обработки изображений и анализа данных, которые могут использоваться для медицинской диагностики. В некоторых вариантах реализации описанные в этом документе системы и способы могут производить анализ изображений на пиксельном уровне для выявления диагностически значимых ОИ. Описанные в настоящем документе системы и способы могут также определять, содержат ли анализируемые изображения области, которые могут указывать на наличие диагностически значимых признаков, таким образом позволяя лечащему врачу определять, нуждается ли конкретный пациент в более сложных и дорогостоящих анализах (например, ПЭТ или ПЭТ-КТ). Хотя описанные в этом документе системы и способы не включают дорогостоящие способы (например, ПЭТ или ПЭТ-КТ) или радиоактивные маркеры, точность диагностических результатов, получаемых с помощью описываемых систем и способов, близка к точности различных передовых способов диагностики. Хотя примеры систем и способов, описываемые в этом документе, используют КТ-изображения для получения псевдо-ПЭТ изображений, другие варианты реализации могут использовать другие технологии визуализации, например, однофотонную эмиссионную компьютерную томографию (ОФЭКТ), магнитно-резонансную томографию (МРТ), фазово-контрастную магнитно-резонансную томографию (ФК-МРТ), магнитно-резонансную электроэнцефалографию (МРТ-ЭЭГ), контрастную КТ, диффузионную МРТ, дифффузионно-тензорную томографию (ДТТ), диффузионно-взвешенную томографию (ДВТ), магнитно-резонансную ангиографию (МРА), магнитно-резонансную спектроскопию (МРС) и/или функциональную магнитно-резонансную томографию (фМРТ). Таким образом, описанные в этом документе системы и способы могут использоваться для широкого спектра диагностических методов на основе медицинской визуализации, которые могут включать различные сочетания разных визуализирующих и/или других медицинских исследований.
[00022] Описанные в этом документе системы и способы используют пару сверточных нейронных сетей (СНС) таким образом, что первая СНС обрабатывает КТ-изображения для получения псевдо-РЭ изображений (например, псевдо-ПЭТ изображений), а вторая СНС обрабатывает псевдо-РЭ изображения для классификации КТ-изображений в соответствии с определенным предполагаемым диагнозом. В некоторых вариантах реализации вторая СНС может производить корреляцию псевдо-РЭ изображений с КТ-изображениями, чтобы получить вероятность того, что одно или более КТ-изображений содержат диагностически значимые элементы изображения, связанные с предполагаемым диагнозом. Благодаря корреляции псевдо-РЭ изображений с КТ-изображениями вторая СНС может далее выделять одну или более областей интереса (ОИ) на КТ-изображениях, таких, что каждая ОИ содержит диагностически значимые элементы изображения, связанные с предполагаемым диагнозом. Хотя примеры систем и способов, описываемые в этом документе, включают отдельные примеры структуры и параметров СНС, другие варианты реализации могут использовать другую структуру и/или параметры СНС. Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, но не с целью ограничения.
[00023] СНС представляет собой вычислительную модель, основанную на многоэтапном алгоритме, который применяет набор заранее определенных функциональных преобразований ко множеству исходных данных (например, пикселей изображения), а затем использует преобразованные данные для выполнения распознавания образов. СНС может быть реализована в виде искусственной нейронной сети с прямой связью, в которой схема соединений между нейронами подобна тому, как организована зрительная зона коры мозга животных. Отдельные нейроны коры откликаются на раздражение в ограниченной области пространства, известной под названием рецептивного поля. Рецептивные поля различных нейронов частично перекрываются, образуя поле зрения. Отклик отдельного нейрона на раздражение в границах его рецептивного поля может быть аппроксимирован математически с помощью операции свертки.
[00024] В иллюстративном примере СНС может содержать несколько слоев, в том числе слои свертки, нелинейные слои (например, реализуемые блоками линейной ректификации (ReLU)), субдискретизирующие слои и слои классификации (полносвязные). Сверточные слои могут извлекать элементы из исходного изображения, применяя один или более обучаемых фильтров пиксельного уровня к исходному изображению. В иллюстративном примере фильтр пиксельного уровня может быть представлен матрицей целых значений, производящей свертку по всей площади исходного изображения для вычисления скалярных произведений между значениями фильтра и исходного изображения в каждом пространственном положении, создавая таким образом карту признаков, представляющих собой отклики фильтра в каждом пространственном положении исходного изображения. Сверточные фильтры определяются на этапе обучения сети, исходя из обучающего набора данных для определения шаблонов и областей, указывающих на наличие диагностически значимых признаков на исходном изображении.
[00025] К карте признаков, созданной сверточным слоем, могут применяться нелинейные операции. В иллюстративном примере нелинейные операции могут быть представлены блоком линейной ректификации (ReLU), который заменяет нулями все отрицательные значения пикселей на карте признаков. В различных других реализациях нелинейные операции могут быть представлены функцией гиперболического тангенса, сигмоидальной функцией или другой подходящей нелинейной функцией.
[00026] Слой субдискретизации (другие названия - пулинга, подвыборки) может выполнять подвыборку для получения карты признаков с пониженным разрешением, которая будет содержать наиболее актуальную информацию. Подвыборка может включать усреднение и/или определение максимального значения групп пикселей.
[00027] В некоторых вариантах реализации сверточные, нелинейные слои и слои субдискретизации могут применяться к исходному изображению несколько раз, прежде чем результат будет передан в классифицирующий (полносвязный) слой. Совместно эти слои извлекают важные признаки из исходного изображения, вводят нелинейность и снижают разрешение изображения, делая признаки менее чувствительными к масштабированию, искажениям и мелким трансформациям исходного изображения.
[00028] Результат работы сверточного слоя и слоя субдискретизации позволяет получить признаки высокого уровня исходного изображения. Задачей классифицирующего слоя является использование этих признаков для классификации исходных изображений на различные классы. В иллюстративном примере классифицирующих слой может быть представлен искусственной нейронной сетью, содержащей множество нейронов. Каждый нейрон получает свои исходные данные от других нейронов или из внешнего источника и генерирует результат, применяя функцию активации к сумме взвешенных исходных данных и полученному при обучении значению смещения. Нейронная сеть может содержать множество нейронов, расположенных по слоям, включая входной слой, один или несколько скрытых слоев и выходной слой. Нейроны соседних слоев соединены взвешенными ребрами. Термин «полносвязный» означает, что каждый нейрон предыдущего слоя соединен с каждым нейроном следующего слоя.
[00029] Веса ребер определяются на стадии обучения сети, исходя из набора данных для обучения. В иллюстративном примере все веса ребер инициализируются случайными значениями. Нейронная сеть активируется в ответ на любые исходные данные из набора данных для обучения. Наблюдаемый результат работы нейронной сети сравнивается с ожидаемым результатом работы, включенным в набор данных для обучения, и ошибка распространяется обратно, на предыдущие слои нейронной сети, в которых регулируются веса соответствующим образом. Этот процесс итерируется до тех пор, пока ошибка в результатах не станет ниже заранее заданного порогового значения.
[00030] На Фиг. 1 схематично изображен пример системы 100 для обработки изображений и анализа данных КТ в соответствии с одним или более вариантами реализации настоящего изобретения. Как схематично изображено на Фиг. 1, первая СНС 110 может использоваться для обработки множества КТ-изображений 120 исследуемого организма для получения псевдо-РЭ изображений 130. Псевдо-РЭ изображения, например такие, как псевдо-ПЭТ изображения, эмулируют распределение радиоактивного маркера в исследуемом организме на клеточном уровне и обычно имеют меньшее разрешение, чем соответствующие КТ-изображения.
[00031] Псевдо-РЭ изображения 130 могут быть обработаны второй СНС 140, которая может выдать результаты классификации изображений 150 в соответствии с определенным предполагаемым диагнозом. В иллюстративном примере вторая СНС 140 может связать псевдо-РЭ изображения с КТ-изображениями для получения одного или более КТ-изображений 120, содержащих диагностически значимые признаки изображений, связанные с предполагаемым диагнозом. За счет связывания псевдо-РЭ изображений с КТ-изображениями вторая СНС 140 может далее выделить одну или более областей интереса (ОИ) внутри КТ-изображений 120, таким образом, чтобы в каждой ОИ содержались диагностически значимые признаки изображений, связанные с предполагаемым диагнозом.
[00032] СНС 110 и 140 могут быть повторно обучены с помощью набора обучающих данных 170, который содержит данные изображений для множества (например, тысяч) пациентов. Для каждого пациента набор обучающих данных содержит множество аннотированных КТ-срезов на пиксельном уровне 172 и соответствующие ПЭТ-изображения 174, так что КТ-срезы и ПЭТ-изображения относятся к одной и той же части исследуемого организма.
[00033] В некоторых вариантах реализации СНС 110 может включать активацию СНС 110 для каждого набора исходных изображений КТ в наборе данных для обучения. Наблюдаемый результат (например, псевдо-РЭ изображение, полученное СНС 110) сравнивается с ожидаемым результатом (например, изображением РЭ, соответствующим набору исходных изображений КТ), приведенным в наборе данных для обучения, вычисляется ошибка, и параметры СНС 110 регулируются соответствующим образом. Этот процесс повторяется, пока ошибка в результатах не станет ниже заранее заданного порогового значения.
[00034] В некоторых вариантах реализации СНС 140 может включать активацию СНС 140 для каждого набора изображений РЭ в наборе данных для обучения. Наблюдаемый результат (например, вероятность того, что одно или более исходных изображений из множества исходных изображений содержат диагностически значимые признаки изображения, связанные с определенным медицинским диагнозом, относящимся к исследуемому организму) сравнивается с ожидаемым результатом (например, аннотациями на пиксельном уровне для набора исходных КТ-изображений, соответствующих РЭ-изображению, обработанному СНС 140), приведенным в наборе данных для обучения, вычисляется ошибка, и параметры СНС 140 регулируются соответствующим образом. Этот процесс повторяется, пока ошибка в результатах не станет ниже заранее заданного порогового значения.
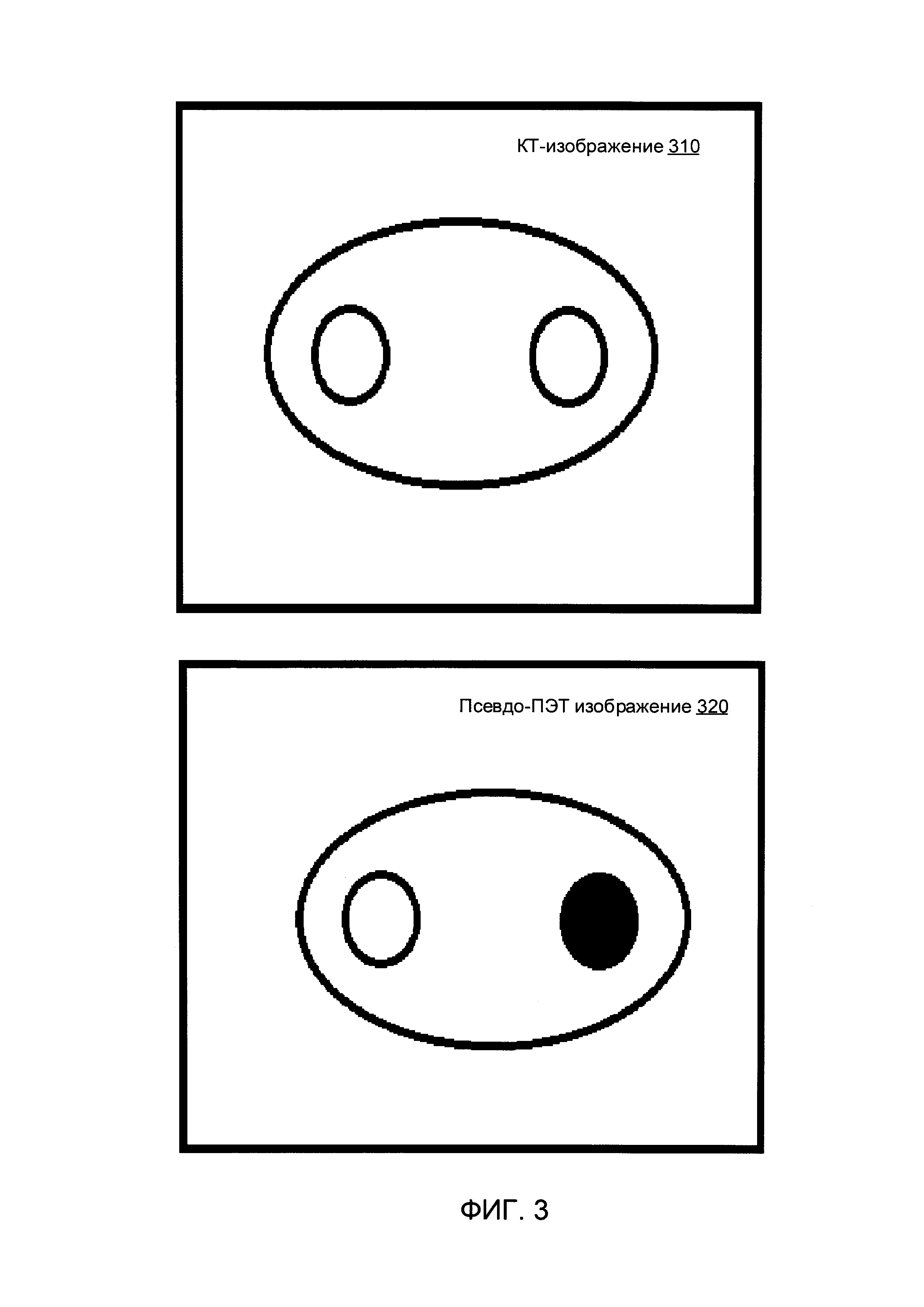
[00035] На Фиг. 2 схематически иллюстрируется пример КТ-изображения 210 и соответствующего ПЭТ-изображения 220 исследуемого организма. ПЭТ-изображение 220 показывает распределение радиоактивного маркера внутри исследуемого организма на клеточном уровне и имеет пониженное разрешение, которое соответствует КТ-изображению 210. На Фиг. 3 схематически иллюстрируется пример упрощенного КТ-изображения 310, обработанного СНС 110 для получения соответствующего псевдо-ПЭТ изображения 320.
[00036] Возвращаясь к Фиг. 1, аннотация на пиксельном уровне 178, связанная с КТ-срезами 172, может быть создана медицинским специалистом на основе ПЭТ-изображений и/или других данных диагностики. Аннотация на пиксельном уровне может определять пространственное расположение точек или областей интереса (ОИ) и связанных с ними клинических маркеров (например, опухолей, переломов костей, тромбов и т.д.). В иллюстративном примере данные каждого пациента могут содержать несколько сотен КТ и ПЭТ-изображений, связанных с отдельной частью исследуемого организма и имеющих соответствующее разрешение 512×512 пикселей и 256×256 пикселей.
[00037] В некоторых вариантах реализации изображения из набора обучающих данных могут быть предварительно обработаны, например, путем обрезки, которая может быть выполнена для удаления отдельных, не имеющих значения частей каждого кадра. В иллюстративном примере КТ-изображения, имеющие разрешение 512×512 пикселей, могут быть обрезаны для удаления полей изображения шириной 80 пикселей с каждой стороны прямоугольного изображения, а ПЭТ-изображения, имеющие разрешение 256×256 пикселей, могут быть обрезаны для удаления полей изображения шириной 40 пикселей с каждой стороны прямоугольного изображения.
[00038] Набор обучающих данных может быть разделен на два поднабора, таких что первый поднабор (например, 80% данных визуализации) используется для обучения СНС, а второй поднабор (например, 20% данных визуализации) используется для тестирования СНС.
[00039] Обучение СНС 110 и 140 для получения псевдо-РЭ изображения основано на сериях КТ-изображений, включающих определение сверточных фильтров, подстройку весов ребер полносвязного слоя и/или определение других параметров СНС путем обработки серий последующих изображений КТ-срезов и связанных с ними аннотаций на пиксельном уровне набора данных для обучения 170.
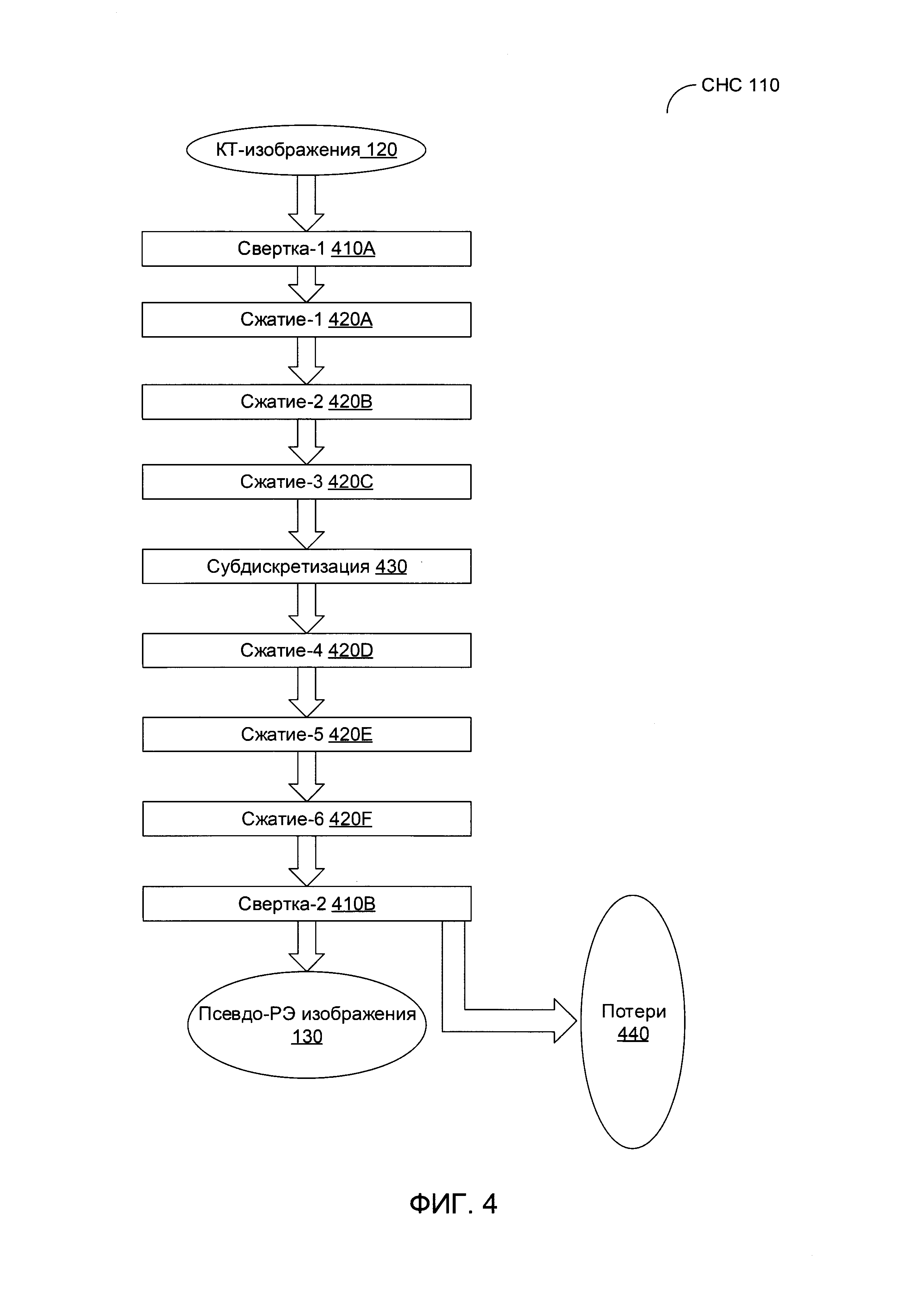
[00040] На Фиг. 4 схематически иллюстрируется пример структуры СНС 110, которая может использоваться для обработки множества КТ-изображений исследуемого организма для получения соответствующих псевдо-РЭ изображений в соответствии с одним или более вариантами реализации настоящего изобретения. В некоторых вариантах реализации полученные КТ-изображения могут быть предварительно обработаны, например, путем обрезки, которая может быть выполнена для удаления отдельных, не имеющих значения частей каждого кадра. В иллюстративном примере КТ-изображения, имеющие разрешение 512×512 пикселей, могут быть обрезаны для удаления полей изображения шириной 80 пикселей с каждой стороны прямоугольного изображения.
[00041] Как схематически показано на Фиг. 4, СНС 110 может включать первый сверточный слой 410А, который получает множество исходных КТ-изображений 120. За первым сверточным слоем 410А следуют несколько слоев сжатия 420А-420С и слой субдискретизации 430, который в свою очередь сопровождается несколькими слоями сжатия 420D-420F и вторым сверточным слоем 410В. Второй сверточный слой 410 В выдает множество псевдо-РЭ изображений 130, соответствующих исходным КТ-изображениям 120, а также значение потерь 440, отражающее разницу между генерируемыми данными и набором обучающих данных. В некоторых вариантах реализации значение потерь может быть определено эмпирически или установлено в качестве пред заданного значения (например, 0,1).
[00042] В некоторых вариантах реализации значение потерь определяется следующим образом:
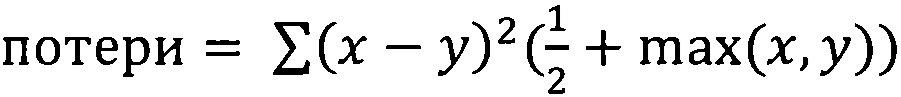 ,
,
где х - значение пикселя, полученное от второго сверточного слоя 410В, а у - значение соответствующего пикселя псевдо-РЭ изображения.
[00043] Каждый сверточный слой 410 может извлекать признаки из последовательности исходных КТ-изображений, применяя один или более обучаемых фильтров пиксельного уровня к трехмерной матрице, отображающей последовательность исходных КТ-изображений. Фильтры пиксельного уровня могут быть представлены матрицей целых значений, производящей свертку по всему объему исходного изображения для вычисления скалярных произведений между значениями фильтра и исходного изображения в каждом пространственном положении, создавая таким образом карту признаков, представляющую собой отклики первого сверточного слоя 410А в каждом пространственном положении исходного изображения. В иллюстративном примере первый сверточный слой 410А может содержать шестнадцать фильтров размерностью 3×3×3. Второй сверточный слой может объединять все значения, полученные в предыдущих слоях, для получения матрицы, представляющей множество пикселей псевдо-РЭ изображения. В иллюстративном примере результирующая матрица может иметь размерность 88×88×25.
[00044] На Фиг. 5 схематически иллюстрируется пример структуры слоев сжатия 420А-420F СНС 110, реализованной в соответствии с одним или более вариантами реализации настоящего изобретения. Как схематически изображено на Фиг. 5, модуль сжатия 500 может подавать полученный результат 510 в параллельные сверточные слои 520А-520В, за которыми следуют соответствующие слои ReLU 530А-530 В. Результаты работы слоев ReLU 530А-530В суммируются в модуле сумматора 540 и поступают в третий сверточный слой 520С, за которым следует третий слой ReLU 530С, который выдает результат 550.
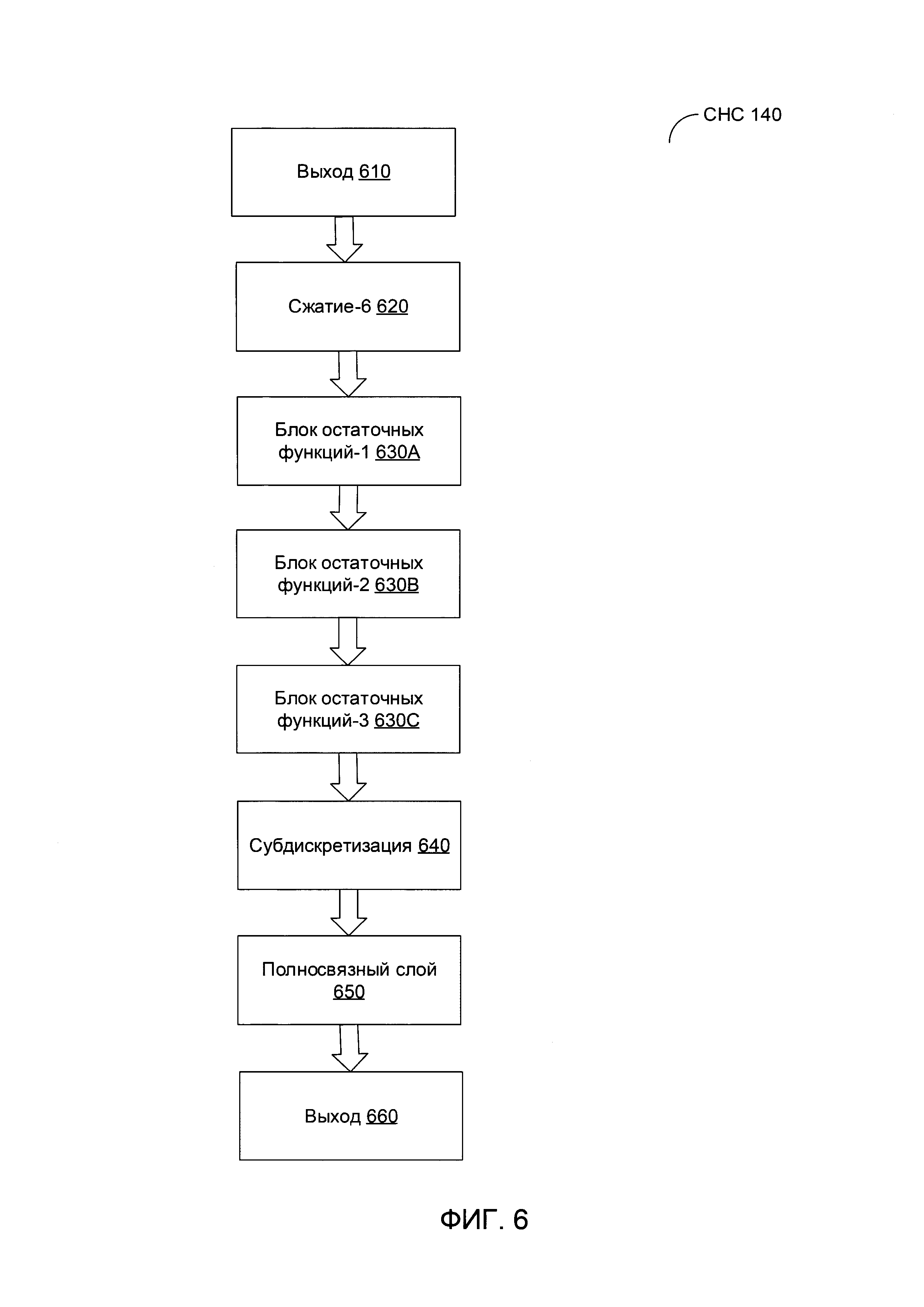
[00045] На Фиг. 6 схематически иллюстрируется пример структуры СНС 140, которая может использоваться для обработки псевдо-РЭ изображений, полученных от СНС 110 для выполнения классификации изображений для исходных КТ-изображений относительно некоторого предполагаемого диагноза в соответствии с одним или более вариантами реализации настоящего изобретения. Как схематически иллюстрируется на Фиг. 6, СНС 140 может включать слой сжатия 620, который получает множество псевдо-РЭ изображений 610, создаваемых СНС 110. За слоем сжатия 620 следует несколько остаточных слоев 630А-630С и слой субдискретизации 640, за которым в свою очередь следуют несколько остаточных слоев 630D-630F и полносвязный слой 650. Результатом работы полносвязного слоя 650 является классификация изображений исходных КТ-изображений относительно некоторого предполагаемого диагноза в соответствии с одним или более вариантами реализации настоящего изобретения. В иллюстративном примере СНС 140 может выдать вероятности одного или более КТ-изображений 120, содержащих диагностически значимые признаки изображений, связанные с предполагаемым диагнозом. В другом иллюстративном примере вторая СНС 140 может выдать одну или более областей интереса (ОИ) 160 внутри КТ-изображений 120, таких что каждая ОИ содержит диагностически значимые признаки изображений, связанные с предполагаемым диагнозом.
[00046] В некоторых вариантах реализации вероятность КТ-изображения, содержащего диагностически значимые признаки, может быть определена с помощью функции перекрестной энтропии, в которой сигнал ошибки, связанный с выходным слоем, прямо пропорционален разнице между ожидаемым и реальным выходным значением. Предельное значение ошибки может быть заранее задано в виде некоторого значения или отрегулировано при обработке тестового поднабора обучающего набора данных.
[00047] В некоторых вариантах реализации предельное значение ошибки примера системы 100 для корректной классификации одного или более диагностических изображений может быть определено с использованием кривой рабочей характеристики приемника (кривой РХП так же называемой ROC-кривая или кривая ошибок), которая может быть представлена в виде графического изображения, иллюстрирующего способность системы к диагностике по мере изменения предельного значения ошибки. В иллюстративном примере кривая РХП может быть создана путем построения графика уровня истинно положительных результатов (УИПР) относительно уровня ложно положительных результатов (УЛПР) при различных настройках предельного значения ошибки. Уровень истинно положительных результатов также известен как чувствительность, повторяемость или вероятность обнаружения. Уровень ложно положительных результатов также известен как побочный эффект или вероятность ложной тревоги и может быть вычислен как (1 - специфичность). Таким образом, кривая РХП представляет собой график чувствительности как функции побочного эффекта. В некоторых вариантах реализации предельное значение ошибки может быть выбрано так, чтобы оно отражало ожидаемое соотношение истинно положительных и ложно положительных результатов.
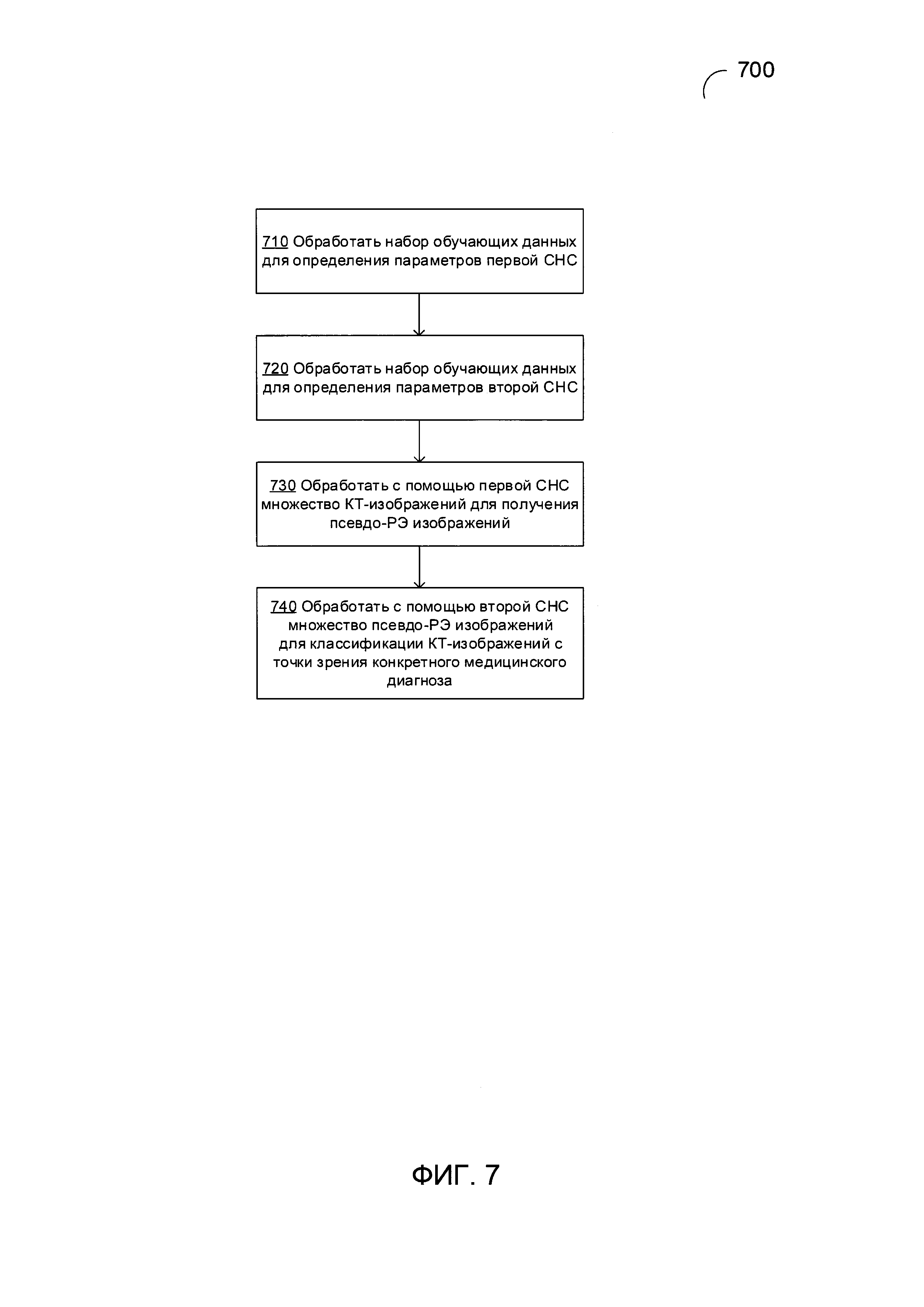
[00048] На Фиг. 7 приведена блок-схема иллюстративного примера способа обработки изображений 700 и анализа данных компьютерной томографии в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 700 и/или каждая из его отдельных функций, процедур, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, обрабатывающим устройством 100 на Фиг. 1), выполняющей этот способ. В некоторых реализациях изобретения способ 700 может выполняться с помощью одного потока обработки. Кроме того, способ 700 может выполняться, используя два или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В иллюстративном примере потоки обработки, реализующие способ 700, могут быть синхронизированы (например, с помощью семафоров, критических секций и/или других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 700, могут выполняться асинхронно друг относительно друга.
[00049] На шаге 710 блок-схемы обрабатывающее устройство, реализующее способ, может обрабатывать набор обучающих данных, содержащий первое множество аннотированных исходных изображений и второе множество соответствующих псевдо-РЭ изображений для определения одного или более параметров первой СНС, используемой для обработки множества КТ-изображений исследуемого организма с целью получения соответствующих изображений псевдорадиоизотопной эмиссии (псевдо-РЭ). В различных иллюстративных примерах параметры первой СНС могут включать значения сверточных фильтров и/или веса ребер полносвязного слоя.
[00050] В одном из иллюстративных примеров множество исходных изображений содержит одно или более изображений компьютерной томографии (КТ). В другом иллюстративном примере множество псевдо-РЭ изображений эмулирует изображения позитронной эмиссионной томографии (ПЭТ). Множество псевдо-РЭ изображений может иллюстрировать моделируемое распределение радиоактивного маркера в исследуемом организме. В некоторых вариантах реализации разрешение пикселей исходного изображения для множества исходных изображений может превосходить разрешение пикселей псевдо-РЭ изображения из множества псевдо-РЭ изображений, как более подробно описано выше в этом документе.
[00051] На шаге 720 блок-схемы обрабатывающее устройство может обрабатывать набор обучающих данных, чтобы определить один или более параметров второй сверточной нейронной сети, которая производит обработку псевдо-РЭ изображений, получаемых от первой СНС, для получения классификации изображений исходных КТ-изображений в соответствии с определенным предполагаемым диагнозом. В различных иллюстративных примерах параметры первой СНС могут включать значения сверточных фильтров и/или веса ребер полносвязного слоя, как более подробно описано выше в этом документе.
[00052] На шаге 730 блок-схемы обрабатывающее устройство может обрабатывать с помощью первой сверточной нейронной сети множество исходных изображений для получения одного или более изображений псевдорадиоизотопной эмиссии (псевдо-РЭ) исследуемого организма, как более подробно описано выше в этом документе.
[00053] На шаге 740 обрабатывающее устройство может обрабатывать с помощью второй сверточной нейронной сети множество псевдо-РЭ изображений для классификации одного или более исходных изображений из множества исходных изображений с точки зрения конкретного медицинского диагноза для исследуемого организма. В одном из иллюстративных примеров обработка множества псевдо-РЭ изображений позволяет получить вероятность того, что одно или более исходных изображений из множества исходных изображений содержат диагностически значимые признаки изображения, связанные с определенным медицинским диагнозом, относящимся к исследуемому организму. Вероятность того, что одно или более исходных изображений из множества исходных изображений содержат диагностически значимые признаки изображения, может быть определена с помощью функции перекрестной энтропии, в которой сигнал ошибки, связанный с выходным слоем, прямо пропорционален разнице между ожидаемым и реальным выходным значением.
[00054] В другом иллюстративном примере обработка множества псевдо-РЭ изображений позволяет получить одну или более областей интереса (ОИ) на одном или более исходных изображений из множества исходных изображений, причем каждая ОИ содержит диагностически значимые признаки изображения, связанные с определенным медицинским диагнозом, относящимся к исследуемому организму, как более подробно описано выше в этом документе.
[00055] В другом иллюстративном примере обработка множества псевдо-РЭ изображений позволяет получить одно или более аннотированных изображений, причем каждое аннотированное изображение связано с соответствующим исходным изображением из множества исходных изображений. Аннотация на пиксельном уровне может определять пространственное расположение точек или областей интереса (ОИ) и связанных с ними клинических маркеров (например, опухолей, переломов костей, тромбов и т.д.).
[00056] Фиг. 8 иллюстрирует пример вычислительного устройства 1000, внутри которого может исполняться набор команд, которые вызывают выполнение вычислительным устройством любого из способов или нескольких способов настоящего изобретения. Вычислительное устройство 1000 может подключаться к другому вычислительному устройству по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительное устройство 1000 может работать в качестве сервера или клиента в сетевой среде «клиент-сервер», в качестве сервера или клиента в облачной среде или в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительное устройство 1000 может быть предоставлено в виде персонального компьютера (ПК), планшетного компьютера, приставки (STB), персонального цифрового помощника (PDA), сотового телефона или любого вычислительного устройства, способного выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этим вычислительным устройством. Кроме того, в то время как показано только одно вычислительное устройство, следует принять, что термин «вычислительное устройство» также может включать любую совокупность вычислительных устройств, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или нескольких методик, описанных в настоящем документе.
[00057] Пример вычислительного устройства 1000 включает процессор 502, основную память 504 (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 518, которые взаимодействуют друг с другом по шине 530.
[00058] Процессор 502 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.д. В частности, процессор 502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW) или процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 502 также может представлять собой одно или более устройств обработки специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 502 выполнен с возможностью выполнения команд 526 для осуществления рассмотренных в настоящем документе операций и функций.
[00059] Вычислительное устройство 1000 может дополнительно включать устройство сетевого интерфейса 522, устройство визуального отображения 510, устройство ввода символов 512 (например, клавиатуру) и устройство ввода - сенсорный экран 514.
[00060] Устройство хранения данных 518 может содержать машиночитаемый носитель данных 524, в котором хранится один или несколько наборов команд 526 и реализован один или несколько из методов или функций настоящего изобретения. Команды 526 также могут находиться полностью или по меньшей мере частично в основной памяти 504 и/или в процессоре 502 во время выполнения их в вычислительном устройстве 1000, при этом оперативная память 504 и процессор 502 также составляют машиночитаемый носитель данных. Команды 526 дополнительно могут передаваться или приниматься по сети 516 через устройство сетевого интерфейса 522.
[00061] В некоторых вариантах реализации команды 526 могут включать команды способа 500 для обработки изображений и анализа данных компьютерной томографии. В то время как машиночитаемый носитель данных 524 показан в примере на Фиг. 4 как единый носитель, термин «машиночитаемый носитель данных» следует понимать как единый носитель либо множество таких носителей (например, централизованную или распределенную базу данных и/или соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять любую одну или несколько из методик, описанных в настоящем раскрытии изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельной памяти, а также к оптическим и магнитным носителям.
[00062] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например, ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00063] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00064] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00065] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они представляют собой просто удобные метки, применяемые к этим величинам. Если в дальнейшем обсуждении иное не указано особо в явной форме, подразумевается, что используемые в описании термины, такие как «определение», «вычисление», «получение», «идентификация», «изменение» и т.п., относятся к действиям и процессам, которые выполняет вычислительное устройство, осуществляющее обработку и преобразование данных, представленных в физическом (например, электронном) виде в регистрах и запоминающих устройствах вычислительного устройства либо в иных подобных устройствах для хранения, передачи и отображения информации.
[00066] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо всего прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00067] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
Извлечение сущностей из текстов на естественном языке
Классификация текстов на естественном языке на основе семантических признаков
Подбор параметров текстового классификатора на основе семантических признаков
Способ извлечения фактов из текстов на естественном языке
Метод и система для генерации статей в словаре естественного языка
Система для создания документов на основе анализа текста на естественном языке
Определение степеней уверенности, связанных со значениями атрибутов информационных объектов
Автоматическое обучение программы синтаксического и семантического анализа с использованием генетического алгоритма
Сентиментный анализ на уровне аспектов и создание отчетов с использованием методов машинного обучения
Использование глубинного семантического анализа текстов на естественном языке для создания обучающих выборок в методах машинного обучения
Система и метод семантического поиска
Разрешение семантической неоднозначности при помощи семантического классификатора
Разрешение семантической неоднозначности при помощи не зависящей от языка семантической структуры
Фильтрация дуг в синтаксическом графе
Разрешение семантической неоднозначности при помощи статистического анализа
Способ и подсистема определения содержащих документ фрагментов цифрового изображения
Способ и система определения протяженных контуров на цифровых изображениях
Исчерпывающая автоматическая обработка текстовой информации
Автоматизированное определение и обрезка неоднозначного контура документа на изображении
Способы и системы сегментации документа

