Результат интеллектуальной деятельности: КОНТЕКСТНО-АДАПТИВНОЕ ЭНТРОПИЙНОЕ КОДИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ КОДИРОВАНИЯ СЕРИЙ ВЫСОКОВЕРОЯТНЫХ СИМВОЛОВ
Вид РИД
Изобретение
Заявляемое изобретение относится к области обработки цифровых сигналов, частности к сжатию данных и улучшению энтропийного кодирования видеопоследовательностей.
В ранних стандартах кодирования видеопоследовательностей, таких как MPEG-2 [1], Н.263 [2], энтропийное кодирование основано на применении фиксированных таблиц кодов переменной длины. Для кодирования разностных данных в этих стандартах блок амплитуд коэффициентов преобразования сначала отображается в одномерный список с помощью заранее заданной таблицы отображения. Затем этот список кодируется с использованием комбинации кодирования длин серий и кодирования кодами переменной длины. Такая комбинация используется в силу того, что кодирование кодами переменной длины не позволяет эффективно закодировать символы с вероятностью больше 0.5. Поэтому в схемах энтропийного кодирования стандартов MPEG-2 и Н.263 используется, так называемое, расширение алфавита символов дополнительными символами («сериями»), каждый из которых обозначает непрерывную последовательность определенной длины нулевых амплитуд коэффициентов преобразования.
Энтропийное кодирование в современных стандартах кодирования видеопоследовательностей, таких как H.264/AVC [3] и HEVC, основано на контекстно-адаптивном двоичном арифметическом кодировании (CABAC - Context-Based Adaptive Binary Arithmetic Coding) [4]. В основу СABAC положено выполнение трех основных действий: бинаризация, контекстное моделирование и битовое арифметическое кодирование. Бинаризация позволяет эффективно применять двоичное арифметическое кодирование, отображая синтаксические элементы с недвоичными значениями в последовательность битов (двоичных элементов). Каждый двоичный элемент такой строки (bin) и каждое значение простого двоичного синтаксического элемента могут иметь свой набор контекстных моделей и могут быть закодированы арифметическим кодером. Двоичные элементы адаптивно кодируются с помощью оценки их текущей функции плотности вероятности. Оценка функции плотности вероятности и двоичное арифметическое кодирование/декодирование основаны на табличном подходе.
Одно из важнейших свойств арифметического кодирования заключается в возможности простого разделения этапов моделирования и кодирования данных. На этапе моделирования символу (двоичному элементу) присваивается модель распределения вероятности, а затем на этапе кодирования формируется последовательность битов (код), представляющая этот символ, в соответствии с присвоенной моделью распределения. Код и его эффективность определяются в первую очередь моделью, поэтому первостепенное значение приобретает создание адекватной модели, которая учитывает статистические связи высших порядков и при этом сохраняет адаптивность к кодируемым данным.
Пусть, например, задан так называемый контекстный шаблон - некое множество уже закодированных символов T и соответствующее ему множество контекстов С={0, … C-1}, где контексты определяются моделирующей функцией F:T→C, заданной на множестве T. Для каждого кодируемого символа x устанавливается (оценивается) условная вероятность p(x\F(z)) путем выбора одной из нескольких моделей вероятности в соответствии с ранее закодированными соседними символами z∈T. Символ x кодируется с использованием установленной условной вероятности p(x|F(z)), а выбранная модель вероятности обновляется в соответствии со значением закодированного символа x. Таким образом, условная вероятность p(x|F(z)) оценивается «на лету» (каждый раз во время кодирования очередного символа) путем отслеживания текущих статистических параметров источника. В CABAC используются контекстные шаблоны очень небольшого размера, включающие в себя всего лишь несколько соседних символов, что позволяет эффективно использовать небольшое число контекстных моделей.
В CABAC введено несколько основных типов контекстных моделей. Один из типов использует контекстный шаблон, включающий в себя максимум два уже закодированных соседних синтаксических элемента, а конкретное определение типа соседства зависит от самого кодируемого синтаксического элемента. Обычно определение этого типа контекстной модели для конкретного двоичного элемента задается моделирующей функцией от значений двоичных элементов соседних синтаксических элементов, которые соответствуют текущему синтаксическому элементу. Эти соседи расположены слева и сверху от текущего синтаксического элемента.
Рассмотрим кодирующий метод CABAC. Как определено в [4], диапазон табличных значений оценок вероятностей для наименее вероятного символа (LPS - Less Probable Symbol) задан на отрезке [0.01875,0.5]. Следовательно, максимально возможная оценка вероятности будет составлять 0.98125=1-0.01875. Значит, длина кода для сообщения, состоящего из символов с фактической вероятностью, находящейся в полуинтервале (0.98125,1], будет больше, чем теоретически возможная. Заявляемое изобретение направлено на решение указанной проблемы.
Один из известных подходов к решению обозначенной проблемы заключается в модификации таблицы оценок вероятностей, используемой в САВАС, с целью расширения диапазона оценок вероятностей в сторону единицы. Однако такая таблица используется для всех синтаксических элементов, поэтому ее оптимизация представляется весьма сложной задачей. Кроме того, модуль кодирования, содержащий эту таблицу, является фактическим индустриальным стандартом, и его замена требует больших материальных затрат.
Другой путь - это так называемое расширение алфавита символов таким образом, чтобы вероятность символов расширенного алфавита стала ближе к диапазону значений таблицы оценок вероятностей, используемой в CABAC. Поэтому из уровня техники известно предложение об использовании кодирования длин серий для кодирования нескольких высоковероятных символов одним новым символом, что в результате должно приводить к увеличению эффективности сжатия. Кроме того, как следует из анализа уровня техники, такой подход позволяет уменьшить количество кодируемых символов, что увеличивает его пропускную способность.
Действующие стандарты MPEG-2, Н.263 и Н.264 основаны на блочной схеме кодирования, в которой кадр разделяют на меньшие элементы, называемые макроблоками. Макроблок имеет размер 16×16 пикселей и может разделяться на отдельные блоки. Блок представляет собой группу пикселей с минимальным размером 4×4 в стандарте Н.264 и 8×8 пикселей в стандарте Н.263. Макроблоки обрабатываются один за другим в растровом порядке, как кодером, так и декодером. Последовательности макроблоков группируют в слои (slice), которые кодируются независимо друг от друга для повышения устойчивости к ошибкам. Макроблоки кодируются с помощью нескольких возможных режимов. Из множества этих режимов выделяют, так называемый, режим пропуска (skip mode). Закодированные в этом режиме макроблоки называют пропущенными макроблоками, а макроблоки, закодированные во всех остальных режимах, называют непропущенными макроблоками. Для обнаружения пропущенных макроблоков в потоке данных используют специальный индикатор. В качестве такого индикатора, в зависимости от используемого энтропийного кодера, может быть применен либо двоичный флаг (флаг пропуска), либо кодовое слово, кодирующее длину серии пропущенных макроблоков. Каждый непропущенный макроблок, расположенный в потоке данных, включает в себя заголовок макроблока, состоящий из нескольких элементов, в частности, режим кодирования макроблока, и разностные данные макроблока. Когда в потоке данных обнаружен пропущенный макроблок, то больше в потоке данных нет других элементов, относящихся к этому пропущенному макроблоку (ни его заголовка, ни разностных данных). Декодер реконструирует относящиеся к пропущенному макроблоку пиксели с помощью описанных в стандарте правил.
Из уровня техники известны многочисленные технические решения, направленные на повышение эффективности энтропийного кодирования видеопоследовательностей, но использующие для этого различные подходы (см., например, патент РФ 2447612 [5], патентные заявки РФ 2010107598 [6], 2011105660 [7] и патентные заявки США 20120299757 [8], 20130003858 [9], а также патенты США 8,189,676 [10], 8,306,124 [11], 6,677,868 [12]).
В патенте [10] предложен удобный для кодирования данных синтаксис, предназначенный для использования в стандартах MPEG-2, Н.263 и MPEG4, и использующий кодирование кодами переменной длины. Вместо поочередного кодирования индикатора пропущенного макроблока, заголовка макроблока и разностных данных макроблока предлагается переупорядочить эти данные и кодировать сначала все данные заголовков макроблоков для всего кадра, причем так же отдельными частями, соответствующими отдельным элементам заголовков макроблоков, затем все разностные данные макроблоков. Это позволяет при кодировании каждого набора одинаковых элементов заголовков макроблоков или индикаторов пропущенных макроблоков использовать кодирование длин серий. При этом кодирование длин серий возможно, только когда элемент заголовка предыдущего макроблока и заголовка текущего макроблока одновременно равны «нулю», в противном случае используется стандартное кодирование элементов. Такой способ использует информацию о значении только предыдущего элемента относительно кодируемого и никак не использует информацию о вероятности появления элемента. Поэтому поток данных не может быть закодирован эффективно, особенно, когда используется энтропийный кодер, подобный CABAC.
В патенте [11] описан метод кодирования пропущенных макроблоков для кодирования видеопоследовательностей, который включает в себя следующие шаги:
- добавляют один двоичный индикатор в заголовок кадра для индикации типа кодирования флагов пропуска в текущем кадре;
- выбирают тип кодирования флагов пропуска в текущем кадре в зависимости от количества пропущенных макроблоков. Если выбран тип, использующий кодирование длин серий, то устанавливают двоичный индикатор в заголовке кадра в значение, обозначающее кодирование длин серий, и кодируют флаги пропуска в кадре с использованием кодирования длин серий. Если выбран тип, использующий объединенное кодирование, то устанавливают двоичный индикатор в заголовке кадра в значение, обозначающее объединенное кодирование, и кодируют флаги пропуска, обозначающие пропущенный макроблок, используя новый режим кодирования макроблока. Новый режим заносится в таблицу режимов кодирования макроблока, а флаги пропуска, обозначающие непропущенные макроблоки, не записываются в поток.
Это метод предназначен только для использования совместно с кодированием кодами переменной длины и малопригоден для энтропийных кодеров, подобных CABAC.
Наиболее близким к предлагаемому изобретению является метод, описанный в [12]. Сутью изобретения-прототипа является сохранение эффективности сжатия при кодировании кодами переменной длины путем изменения синтаксиса потока данных, подаваемого на энтропийный кодер, в том случае, если в потоке данных возможно наличие символов с вероятностью появления выше пороговой. При этом символ с вероятностью появления, превышающей порог, заменяют символом с низкой вероятностью появления. Недостатки прототипа заключаются в следующем. Оценка вероятности каждого символа и последующая замена символов с высокой вероятностью появления производятся без учета информации о контексте заменяемых символов. Учет информации о контексте может привести к увеличению эффективности сжатия данных. Другим недостатком прототипа является отсутствие индикации на уровне заголовка кадра о том, осуществляется ли предлагаемая замена или нет. Это может приводить к снижению эффективности кодирования в том случае, если в замене нет необходимости, а также к повышению вычислительной сложности в том случае, если декодер вычисляет вероятность появления символа, в то время как вычисленная вероятность всегда меньше порога.
Задача, на решение которой направлено заявляемое изобретение, состоит в разработке усовершенствованного способа для более эффективного энтропийного кодирования 3D видеопоследовательностей в рамках стандартов Н.264 и AVC и их расширения.
Технический результат достигается за счет разработки способа обработки потока данных, состоящего из множества синтаксических элементов, при этом способ основан на замене синтаксических элементов, значения которых имеют высокую вероятность появления, синтаксическими элементами, значения которых имеют низкую вероятность. Отличительные признаки заявляемого решения заключаются в выполнении следующих операций:
- определяют контекст для синтаксического элемента;
- вычисляют вероятность появления значений тех синтаксических элементов в модели потока данных, которые имеют определенный контекст;
- заменяют синтаксические элементы потока данных, имеющие определенный контекст, если вычисленная вероятность появления значения синтаксического элемента выше заданного порога, на синтаксические элементы, значения которых имеют низкую вероятность.
Таким образом, предлагаемый новый подход заключается в субоптимальном энтропийном кодировании символов потока данных, если эти символы имеют фактическую вероятность появления, не укладывающуюся в диапазон оценок вероятности, используемый модулем кодирования CABAC, который определен в стандартах кодирования видеопоследовательностей. Такое возможно, например, в видео потоках, закодированных в соответствии с одним из расширений стандарта Н.264, где могут встретиться новые символы с более высокой вероятностью появления или вероятность появления существующих символов может увеличиться из-за изменения способа обработки данных. В этом случае указанная субоптимальность приведет к увеличению объема выходного потока данных, формируемого арифметическим кодером, относительно объема данных, формируемого арифметическим кодером, который учитывает возможность появления высоковероятных символов.
Заявляемый способ включает в себя обнаружение и замену символов, которые кодируются субоптимально вследствие проблемы, обозначенной выше, с учетом информации о контексте заменяемого символа. Кроме того, некоторые аспекты изобретения дают детальное описание того, как заявляемое изобретение может быть реализовано в современных и будущих стандартах кодирования видеопоследовательностей, основанных на использовании энтропийного кодера CABAC.
Первый аспект изобретения заключается в способе обработки потока данных, который поступает на энтропийный кодер. Поток данных состоит из множества синтаксических элементов, расположенных в потоке данных в определенном порядке. Каждый синтаксический элемент имеет несколько возможных значений. Современные контекстно-адаптивные арифметические кодеры для кодирования значения синтаксического элемента в каждой конкретной позиции потока используют модель вероятности, выбираемую в зависимости от контекста, который имеет данный элемент. Контекст элемента в общем случае вычисляется по заранее определенным правилам с использованием любой информации, которая была закодирована предшествующими синтаксическими элементами. Для решения проблемы обозначенной выше, необходимо определить синтаксический элемент, его значение и определенный контекст элемента такие, что вероятность появления значения синтаксического элемента, который имеет определенный контекст, может превышать заранее заданный порог. Величина порога определяется реализацией энтропийного кодера. Например, для кодеров, основанных на кодах переменной длины, это 0.5. Для различных реализаций арифметических кодеров величина порога определяется максимально возможным в данной реализации размером подинтервала, отводимого на интервале наиболее вероятному значению синтаксического элемента. Многие реализации двоичных арифметических кодеров, в том числе CABAC, оперируют счетным ограниченным множеством возможных оценок вероятностей. Для таких кодеров максимальный размер подинтервала соответствует максимально возможной в данной реализации оценке вероятности. Для CABAC это 1-0.01875=0.98125. Увеличение фактической вероятности появления значения синтаксического элемента выше такого порога не приводит к изменению оценки, поскольку оценка достигает возможного в реализации максимума, подинтервал не увеличивается, и выходной поток не уменьшается. Таким образом, для повышения эффективности кодирования обнаруженные синтаксические элементы, значения которых имеют вероятность, превышающую порог, должны быть заменены на новые синтаксические элементы, причем таким образом, чтобы количество новых элементов в потоке данных могло быть меньше, чем количество замененных. Это должно приводить к тому, что фактические вероятности появления значений нового синтаксического элемента попадут в рабочий диапазон оценок вероятности, поддерживаемый кодером, что приведет к уменьшению количества данных, формируемых энтропийным кодером. Для заявляемого способа является важным то, что заменяются не все однотипные синтаксические элементы, а только те, что расположены в заранее определенном контексте. Это также позволяет сократить количество вычислений, поскольку шаги способа выполняются не для всех элементов, а только для тех элементов, которые имеют заранее определенный контекст. Отличительной особенностью заявляемого изобретения является то, что в сравнении с прототипом, где вычисляется безусловная вероятность, в заявляемом изобретении предлагается вычислять условную вероятность появления значения синтаксического элемента.
Другой аспект заявляемого изобретения касается формирования модельного потока данных. Оценку вероятности, которая используется для кодирования значения синтаксического элемента энтропийным кодером, имеет смысл осуществлять на основе модельного потока данных. Заявляемый способ позволяет добавлять в модельный поток данных уже закодированные синтаксические элементы обрабатываемого потока данных. Таким образом, оценка вероятности адаптируется к обрабатываемому потоку данных.
Другой аспект изобретения относится к выбору синтаксического элемента, который впоследствии должен быть заменен. Исходя из анализа вероятностей появления различных синтаксических элементов в сжатых видеопоследовательностях, предложено заменять синтаксический элемент, который кодирует признак пропущенного макроблока. Основным аргументом в пользу такого выбора является то, что при кодировании кадра видеопоследовательности возникает большое число пропущенных макроблоков, поэтому вероятность появления признака пропущенного макроблока очень высока. При этом для вычисления контекста этого синтаксического элемента имеет смысл использовать уже закодированные признаки пропущенных макроблоков в кодируемом потоке данных.
Другой аспект изобретения относится к новым синтаксическим элементам, которыми должны быть заменены синтаксические элементы, имеющие значения, вероятность которых превышает порог. Новые элементы имеют возможность кодировать число повторений значений тех синтаксических элементов, которые заменяются. Таким образом, количество новых элементов может быть меньше, чем количество тех, которые заменяются, что соответственно снизит вероятность их появления. При этом допустимое число повторений заменяемого элемента имеет смысл фиксировать и задавать заранее. Это позволяет использовать только один новый синтаксический элемент, имеющий двоичное значение (например, двоичный флаг). Одно значение обозначает, что было заменено фиксированное число идущих подряд синтаксических элементов, имеющих одно значение. Другое значение нового синтаксического элемента обозначает, что замена не была произведена, например, потому что вслед за идущими подряд одинаковыми значениями синтаксических элементов, имеющими определенный контекст, в потоке данных имеется синтаксический элемент с иным значением, имеющий определенный контекст.
Другой аспект изобретения определяет тип энтропийного кодирования, которое будет использоваться для кодирования обрабатываемого потока данных. Это, в частности, реализуется на основе контекстно-адаптивного битового арифметического кодирования с использованием счетного ограниченного множества вероятностей (например, CABAC). При этом в качестве порога имеет смысл задавать разность единицы и наименьшего значения из используемого в CABAC множества вероятностей.
Другой аспект изобретения касается способа энтропийного кодирования потока данных, состоящего из множества синтаксических элементов. Синтаксические элементы в потоке данных расположены в определенном порядке. Каждый синтаксический элемент имеет несколько возможных значений. Поток данных формируется с использованием замены синтаксических элементов, значения которых имеют высокую вероятность, синтаксическими элементами, значения которых имеют низкую вероятность. При этом энтропийное кодирование осуществляется с помощью контекстно-адаптивного битового арифметического кодирования с использованием счетного ограниченного множества вероятностей. Таким образом, заявляемый способ включает в себя следующие шаги:
- определяют для синтаксического элемента в потоке данных контекст;
- вычисляют вероятность появления значений синтаксических элементов в модели потока данных, которые имеют определенный на предыдущем шаге контекст;
- задают пороговое значение как функцию от наименьшего значения из счетного ограниченного множества вероятностей;
- заменяют синтаксические элементы потока данных, имеющие определенный контекст, если вычисленная вероятность появления значения синтаксического элемента выше заданного порогового значения, на синтаксические элементы, значения которых имеют низкую вероятность и которые используют для кодирования числа повторений заменяемых синтаксических элементов.
Вычисление вероятности появления значения синтаксического элемента осуществляется только тогда, когда элемент имеет определенный контекст. Если синтаксический элемент имеет контекст, отличный от определенного контекста, то он не участвует в расчете вероятности и замене. Это является существенным новым признаком заявляемого изобретения.
Другой аспект заявляемого изобретения касается способа кодирования кадра видеопоследовательности, где кадр представляет собой совокупность неперекрывающихся макроблоков, обрабатываемых построчно слева направо сверху вниз. В данном способе формируют поток данных, включающий в себя двоичный флаг пропуска для каждого макроблока, указывающий, является макроблок пропущенным или нет. Способ предполагает замену флагов пропуска с высоковероятными значениями новыми синтаксическими элементами, имеющими меньшую вероятность появления, а также кодирование потока данных с помощью контекстно-зависимого битового арифметического кодирования. Способ включает в себя следующие шаги:
- рассчитывают вероятность появления значения флага пропуска, обозначающего пропущенный макроблок. Вероятность рассчитывают только для тех флагов пропуска, которые имеют заранее определенный контекст. При расчете вероятности используют модель появления такого значения (например, упрощенную модель потока данных, содержащую только флаги пропуска). Контекст либо определяют заранее на основе модельных потоков данных, либо рассчитывают на основе значений уже закодированных флагов пропуска из соседних макроблоков, например левого и верхнего макроблока. Данный шаг целесообразно выполнять еще до кодирования всей видеопоследовательности с помощью модельного потока данных. В этом случае при кодировании обрабатываемой видеопоследовательности вероятность уже известна и не рассчитывается. Также имеет смысл определять дополнительные признаки, которые влияют на вероятность, например, коэффициент квантования. В этом случае при кодировании конкретной видеопоследовательности эти дополнительные признаки анализируют, и по ним определяют вероятность появления того или иного значения флага пропуска, имеющего определенный контекст;
- добавляют в поток данных признак того, превышает ли рассчитанная вероятность заранее заданный порог или нет. Например, такая информация может записываться в заголовок слайса в соответствии со стандартом Н.264. Эта информация может понадобиться на этапе декодирования. В случае если эта информация имеется, вероятность можно не рассчитывать в процессе декодирования. В том случае, если рассчитанная вероятность превышает порог, то используют кодирование длин серий при кодировании значений флагов пропуска, имеющих определенный контекст. Это означает, что вместо кодирования нескольких идущих подряд одинаковых значений флагов пропуска в поток кладется один синтаксический элемент, обозначающий количество флагов пропуска. Кодирование длин серий осуществляется только для синтаксических элементов, имеющих определенный контекст, при этом выполняют следующие действия:
- Накапливают в счетчике количество следующих подряд пропущенных макроблоков, у которых флаг пропуска имеет определенный контекст. Таким образом, определяют, сколько пропущенных макроблоков, а значит и флагов пропуска в значении «пропуск», следующих подряд, находится в серии.
- Добавляют в поток данных один двоичный флаг серии пропусков. Одно значение показывает, что счетчик достиг заранее заданного значения, или очередной флаг пропуска имеет контекст, отличный от определенного контекста. Другое значение показывает, что в определенном контексте кодируется макроблок, который не является пропущенным, то есть серия флагов пропуска в значении «пропуск» прервана флагом пропуска в значении «макроблок не пропущен», и счетчик не достиг заранее заданного значения.
- Если флаг серии пропусков обозначает, что счетчик достиг заранее заданного значения, или произошло изменение контекста, то удаляют из потока данных флаги пропуска макроблока, имеющие определенный контекст.
Таким образом, вместо нескольких флагов пропуска макроблока, каждый из которых обозначает пропущенный макроблок, в поток данных записывается один новый флаг, обозначающий серию пропущенных макроблоков заранее заданной длины. Если длина серии больше заранее заданной, то таких новых флагов добавляется несколько. Если флаг пропуска очередного макроблока имеет контекст, отличный от определенного контекста, и при этом счетчик не достиг целевого значения, то новый флаг, добавляемый в поток, обозначает серию пропущенных макроблоков. При этом длина такой серии меньше, чем заранее заданная длина, и определяется исходя из того, сколько подряд флагов пропуска макроблока имеют определенный контекст. Как только декодируемый флаг пропуска очередного макроблока имеет контекст, отличный от определенного, серия прерывается.
Данный аспект изобретения впервые описывает конкретный способ замены синтаксических элементов, значения которых имеют высокую вероятность, синтаксическими элементами, значения которых имеют низкую вероятность, при кодировании потока данных с помощью контекстно-зависимого битового арифметического кодирования.
Далее существо заявляемого изобретения поясняется с привлечением графических материалов.
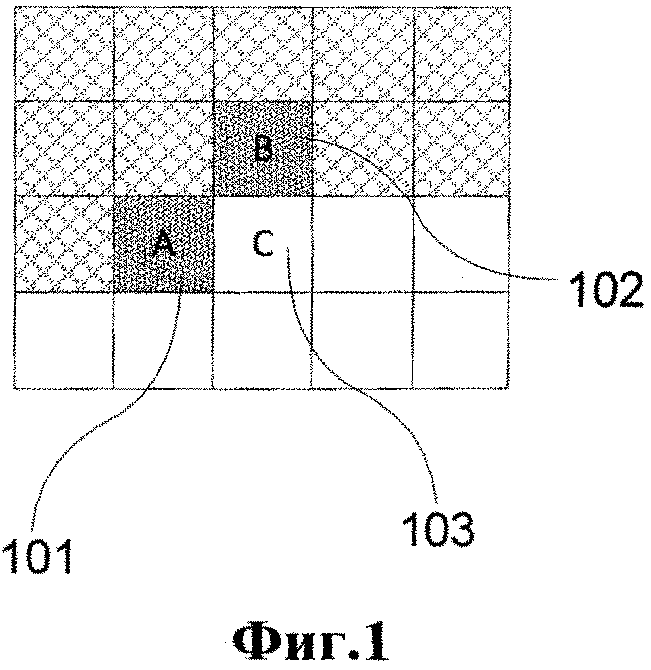
Фиг.1. Контекстный шаблон расположения элементов, включающий в себя соседние синтаксические элементы слева A и сверху B, используемый для вычисления контекста текущего синтаксического элемента С.
Фиг.2. Блок-схема стандартного алгоритма кодирования флагов пропущенных макроблоков, используемая в стандарте Н.264.
Фиг.3. Блок-схема предлагаемого алгоритма кодирования флагов пропущенных макроблоков, применимая в расширении стандарта Н.264.
Фиг.4. Блок-схема алгоритма декодирования флагов пропущенных макроблоков.
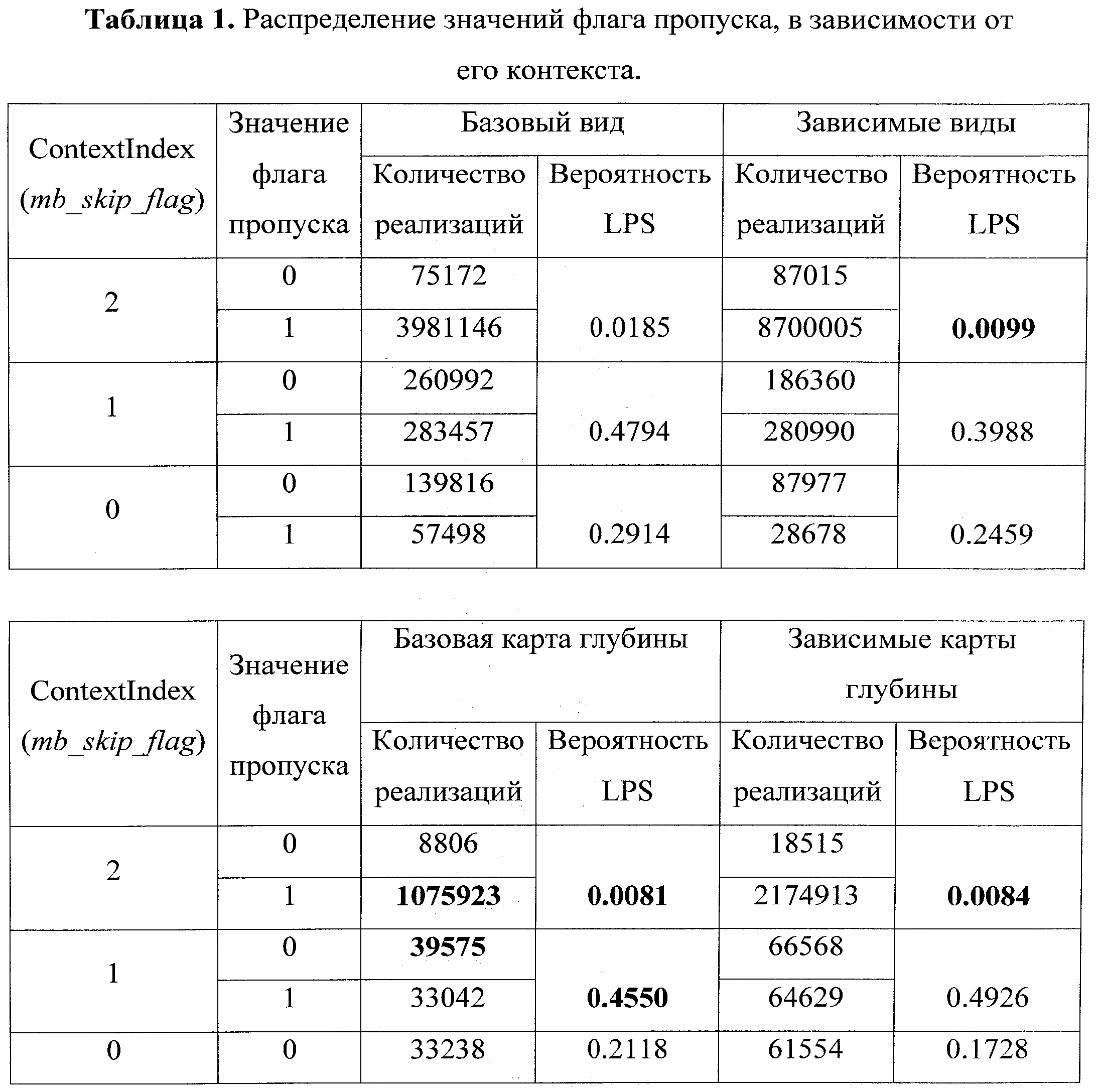
Режим кодирования, называемый режимом пропуска, является одним из самых эффективных режимов и интенсивно используется в кодировании видео- и 3D-видеопоследовательностей, а также поддерживается в предварительной версии стандарта 3D-ATM [13]. В режиме пропуска информация о движении и разностные данные не передаются в потоке данных. Информация о движении для пропущенного макроблока выводится из доступной информации о движении в соседних уже декодированных макроблоках с помощью заранее заданных правил. Иерархическое двунаправленное прогнозирование является одним их эффективных подходов для увеличения эффективности кодирования всей 3D-видеопоследовательности, при этом параметры квантования в слоях, использующих двунаправленное прогнозирование, постепенно увеличиваются с увеличением уровня иерархии. Кроме того, кодирование 3D-видеопоследовательностей, реализованное в 3D-ATM, подразумевает дополнительное увеличение параметра квантования зависимых видов с целью увеличения эффективности кодирования (например, параметр QPOffset для текстуры равен 4). Увеличение параметра квантования и улучшение прогнозирования приводит к уменьшению количества разностных данных и, как следствие, к увеличению количества пропущенных макроблоков. Еще большее увеличение числа пропущенных макроблоков в двунаправленных слоях (B-slice) зависимых видов обеспечивается использованием в 3D-ATM улучшенных способов прогнозирования информации о движении, которые основаны на информации из декодированного базового вида и декодированных картах глубин. Вероятности появления значений флага пропуска, который используется при кодировании пропущенных макроблоков, для тестовых видеопоследовательностей представлены в таблице 1. Вероятность LPS (LPS - Lowest Probable Symbol) - это, как правило, вероятность появления непропущенных макроблоков, так как их, чаще всего, меньше, чем пропущенных.
Как указывалось выше, эффективность кодирования с помощью CABAC высоковероятных значений (MPS - Most Probable Symbol) двоичных элементов, вероятность появления низковероятных значений (LPS) которых меньше чем 0.01875, существенно снижена относительно теоретически возможной. Из таблицы 1 можно сделать вывод о том, что вероятность появления LPS для флага пропуска стремится к нулю (mb_skip_flag - это используемое в стандарте Н.264 обозначение синтаксического элемента для флага пропуска). При этом вероятность появления LPS существенно меньше, чем минимально возможная оценка вероятности, используемая в CABAC, в том случае, когда контекст флага пропуска mb_skip_flag (ContextIndex) равен двум. Отметим, что mb_skip_flag - это двоичный синтаксический элемент, и его значение совпадает с двоичным элементом, который кодируется модулем кодирования (coding engine) CABAC. Таким образом, наиболее вероятное единичное значение mb_skip_flag, когда он имеет контекст 2, кодируется не оптимально в большинстве случаев.
Контекст флага пропуска ContextIndex - это номер контекстной модели (номер контекста далее также будет именоваться как контекст), используемой для синтаксического элемента mb_skip_flag при его кодировании. Как описывалось выше, в CABAC [4] используется несколько типов контекстных моделей. Один из типов, который используется для кодирования mb_skip_flag, основан на шаблоне контекста, показанном на фиг.1. Контекстный шаблон включает в себя два соседних синтаксических элемента, которые принадлежат соседним макроблокам. Соседние макроблоки расположены слева (А) 101 и сверху (В) 102 относительно макроблока, которому принадлежит текущий синтаксический элемент. Для mb_skip_flag определяются три контекста. Один контекст (ContextIndex=0) обозначает, что левый и верхний макроблоки имеют нулевой флаг пропуска (их mb_skip_flag=0), то есть левый и верхний макроблоки не являются пропущенными. Другой контекст (ContextIndex=2) обозначает, что левый и верхний макроблоки являются пропущенными (их mb_skip_flag=1). Оставшийся контекст (ContextIndex=1) обозначает, что один из соседних макроблоков является пропущенным, а другой нет.
Таким образом, в данном случае известен синтаксический элемент (mb_skip_flag), его значение (1) и его конкретный контекст (ContextIndex=2), где вероятность значения двоичного элемента превышает порог оптимального кодирования 0.98125. Этот конкретный контекст (ContextIndex=2) далее будет называться выбранным или определенным контекстом. В соответствии с предложенным способом необходимо заменить неэффективно кодируемые синтаксические элементы на новые синтаксические элементы.
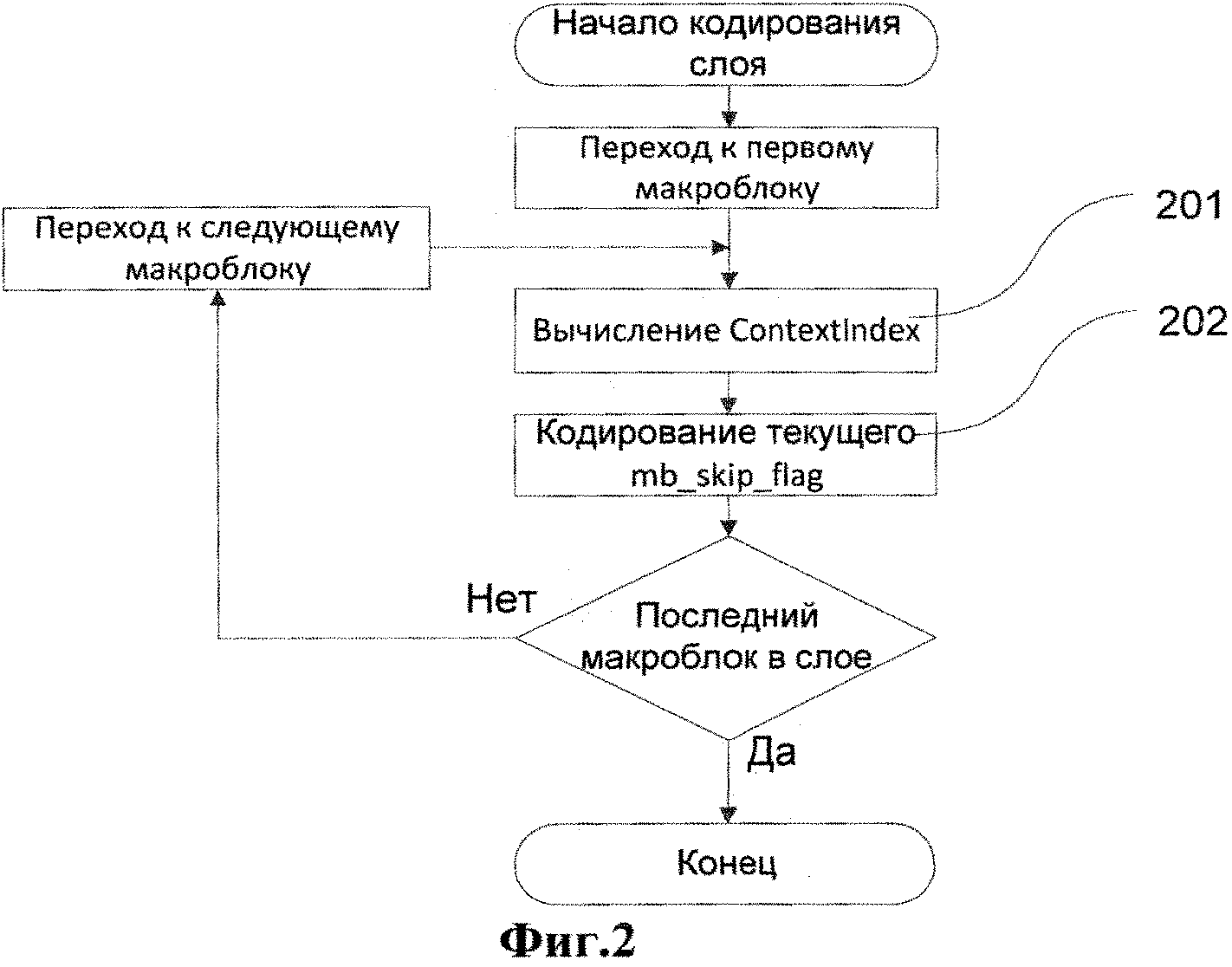
Рассмотрим сначала стандартный алгоритм кодирования синтаксического элемента mb_skip_flag, который используется в Н.264. Этот алгоритм представлен на фиг.2. Алгоритм включает в себя следующие шаги. Вычисляют номер контекста ContextIndex 201 для синтаксического элемента mb_skip_flag, принадлежащего текущему макроблоку. Рассчитанный контекст ContextIndex используется для выбора модели распределения вероятности, которая будет использована при двоичном арифметическом кодировании 202 значения синтаксического элемента mb_skip_flag.
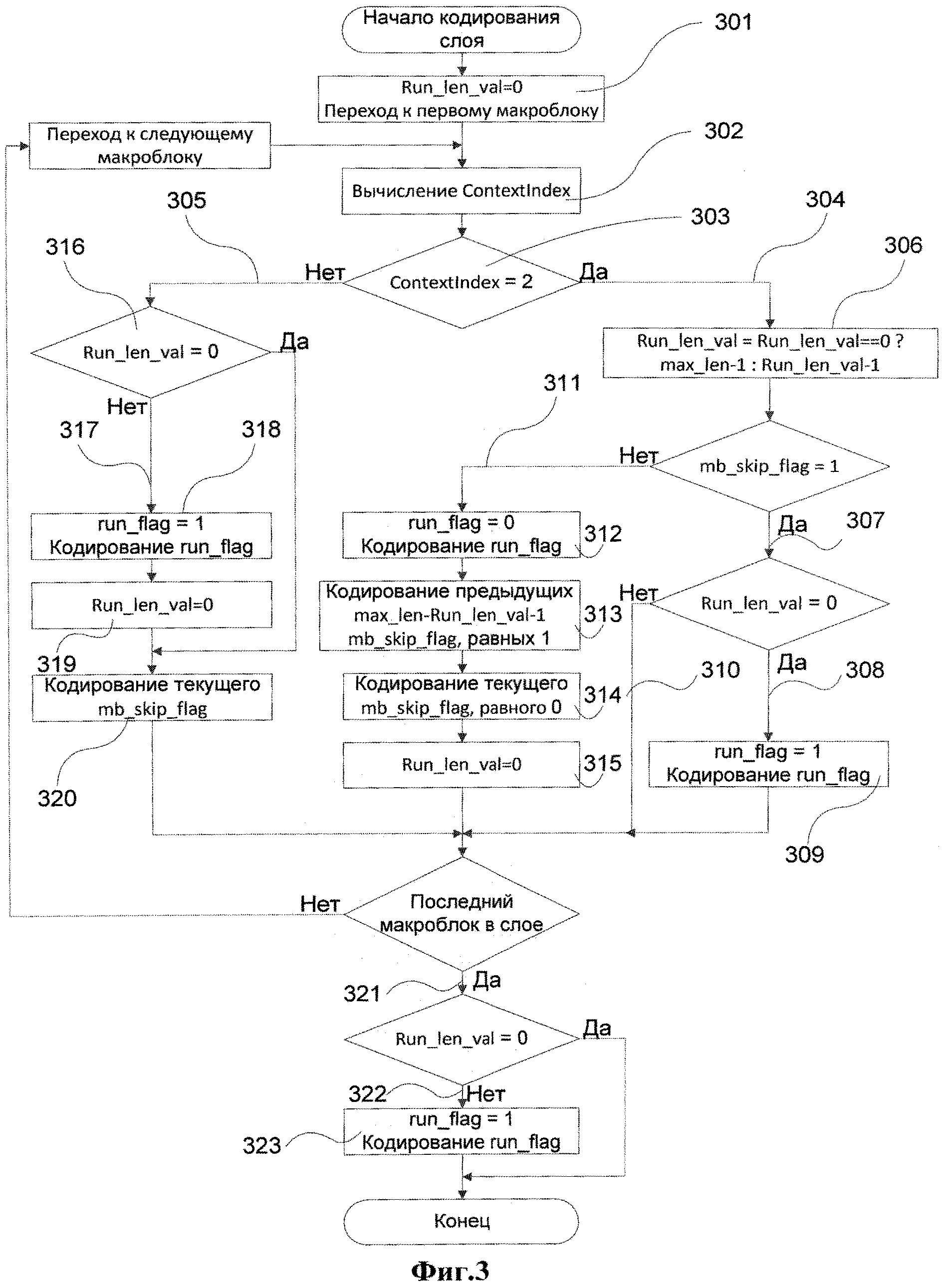
Алгоритм кодирования флагов пропуска, реализующий предложенный в заявляемом изобретении способ кодирования с использованием замены синтаксических элементов, представлен на фиг.3. Главной идеей является использование одного нового флага (ему соответствует новый синтаксический элемент run_flag) вместо непрерывной серии флагов пропуска, обозначающих пропущенные макроблоки (mb_skip_flag=1), только для тех флагов пропуска, которые имеют выбранный контекст (в нашем случае это ContextIndex=2). Серия флагов обычно имеет определенную фиксированную длину (max_len). Это позволяет использовать только один новый флаг и упростить реализацию кодера. В случае если фактическая серия больше этой длины, то она разбивается на несколько серий. Одно из значений нового флага (run_flag=1) обозначает серию флагов, обозначающих пропущенные макроблоки. Кодер записывает в поток данных run_flag с этим значением вместо max_len флагов пропуска, обозначающих пропущенные макроблоки. Другое значение нового флага (run_flag=0) обозначает, что серия имеет длину меньшую, чем max_len, по той причине, что один из флагов пропуска обозначает непропущенный макроблок и при этом имеет выбранный контекст. Такая серия далее будет называться прерванной серией. В этом случае кодер должен записать в поток данных дополнительную информацию о реальной длине серии флагов, обозначающих пропущенные макроблоки, имеющих выбранный контекст. Есть несколько способов сделать это. Например, кодер может записывать в поток данных после run_flag=0 еще один новый синтаксический элемент, кодирующий длину серии. Но это усложняет синтаксис. Поэтому в описываемом алгоритме используется другой способ. Как только прерванная серия обнаружена, кодер записывает в поток run_flag=0, для обозначения прерванной серии. Затем, как и в стандартном алгоритме кодирования, записывает то число флагов пропуска, обозначающих пропущенные макроблоки, которое было выявлено до флага пропуска, обозначающего непропущенный макроблок. Затем кодер записывает флаг пропуска, обозначающий непропущенный макроблок, который и прервал серию. Таким образом, в случае прерванной серии в стандартный поток данных записывается один дополнительный флаг, обозначающий, что дальнейший синтаксис не изменился до первого флага пропуска, обозначающего непропущенный макроблок, имеющий выбранный контекст. Если очередной кодируемый флаг пропуска имеет отличный от выбранного контекст и серия флагов, обозначающих пропущенные макроблоки, еще не завершена, то кодер записывает в поток данных run_flag=1, обозначающий серию пропущенных макроблоков обычной длины max_len. Так как декодер определяет контекст по тем же правилам что и кодер, то декодер определяет изменение контекста для флага пропуска очередного макроблока и прервать серию, если его контекст не равен выбранному контексту.
Вернемся к фиг.3. Перед кодированием слоя кодер инициализирует переменную Run_len_val нулевым значением (шаг 301). Эта переменная используется для подсчета количества флагов пропущенных макроблоков в серии. Она хранит число флагов, которые требуется обработать для того чтобы серия была полностью завершена, то есть длина серии достигла max_len. В конкретной реализации наибольшая эффективность кодирования достигается при max_len=16. Следующие шаги выполняются кодером для каждого макроблока кодируемого слоя. Рассчитывают номер контекста ContextIndex (шаг 302) для текущего mb_skip_flag (текущий синтаксический элемент принадлежит тому макроблоку, который обрабатывается в данный момент). Равенство номера контекста двум (шаг 303) обозначает, что контекст mb_skip_flag является выбранным контекстом и возможно появление высоковероятного значения mb_skip_flag. Кодер применяет кодирование длин серий для mb_skip_flag (шаг 304). Если номер контекста не равен двум, то кодер использует стандартное кодирование для mb_skip_flag (шаг 305).
В случае когда используется кодирование длин серий, выполняют следующие шаги. Кодер обновляет переменную Run_len_val (шаг 306). Если перед обновлением нет незавершенной серии (Run_len_val равна нулю), тогда Run_len_val устанавливается в значение max_len-1. Это означает, что требуется обработать еще max_len-1 макроблоков, помимо текущего макроблока. Если есть незавершенная серия (Run_len_val не равна нулю), то значение переменной уменьшается на единицу. Далее если текущий mb_skip_flag равен единице (шаг 307) (т.е. текущий макроблок является пропущенным) и текущее значение переменной Run_len_val достигло нуля (шаг 308) (серия достигла максимальной длины), то кодер записывает в поток двоичный флаг run_flag в значении 1 (шаг 309). Таким образом, текущая серия флагов, обозначающих пропущенные макроблоки, успешно завершена. Если текущий mb_skip_flag равен единице (шаг 307), но текущее значение переменной Run_len_val не достигло нуля (шаг 310), то кодер ничего не записывает в поток данных и переходит к обработке следующего макроблока (это обозначает, что текущая серия продолжается). Если же текущий mb_skip_flag не равен единице (шаг 311) (т.е. текущий макроблок является непропущенным), то кодер выполняет операции 312, 313, 314, 315. Это обозначает, что серия флагов, обозначающих пропущенные макроблоки, в выбранном контексте прервана флагом, обозначающим непропущенный макроблок. Поэтому кодер должен записать в поток run_flag, равный нулю, обозначающий прерванную серию (шаг 312). Затем кодер записывает в поток флаги mb_skip_flag, равные единице (шаг 313), которые являются ранее не записанными в поток данных флагами пропуска предыдущих пропущенных макроблоков. Затем кодер записывает текущий mb_skip_flag, равный нулю (шаг 314). После этого кодер обнуляет переменную Run_len_val (шаг 315), что обозначает, что текущая прерванная серия завершена и на следующем макроблоке может быть начата новая серия.
Так как кодер в момент кодирования текущего макроблока может не иметь информации о режиме кодирования следующих макроблоков, то при изменении контекста синтаксического элемента mb_skip_flag после перехода к следующему макроблоку слоя или когда заканчиваются макроблоки, принадлежащие текущему слою, серия может остаться незавершенной. Ее необходимо завершить для корректного декодирования. Когда контекст ContextIndex не равен двум (шаг 305) (эта ветвь обозначает, что должно использоваться стандартное кодирование mb_skip_flag), то кодер проверяет переменную Run_len_val (шаг 316), для того чтобы определить, завершена ли серия или нет. Если серия не завершена (шаг 317), то кодер записывает в поток двоичный флаг run_flag в значении единица (шаг 318) и завершает серию, обнуляя переменную Run_len_val (шаг 319). Затем текущий mb_skip_flag записывается в поток данных (шаг 320). В случае когда завершается кодирование слоя (шаг 321) и серия не завершена (шаг 322), то кодер также записывает в поток двоичный флаг run_flag в значении единица (шаг 323).
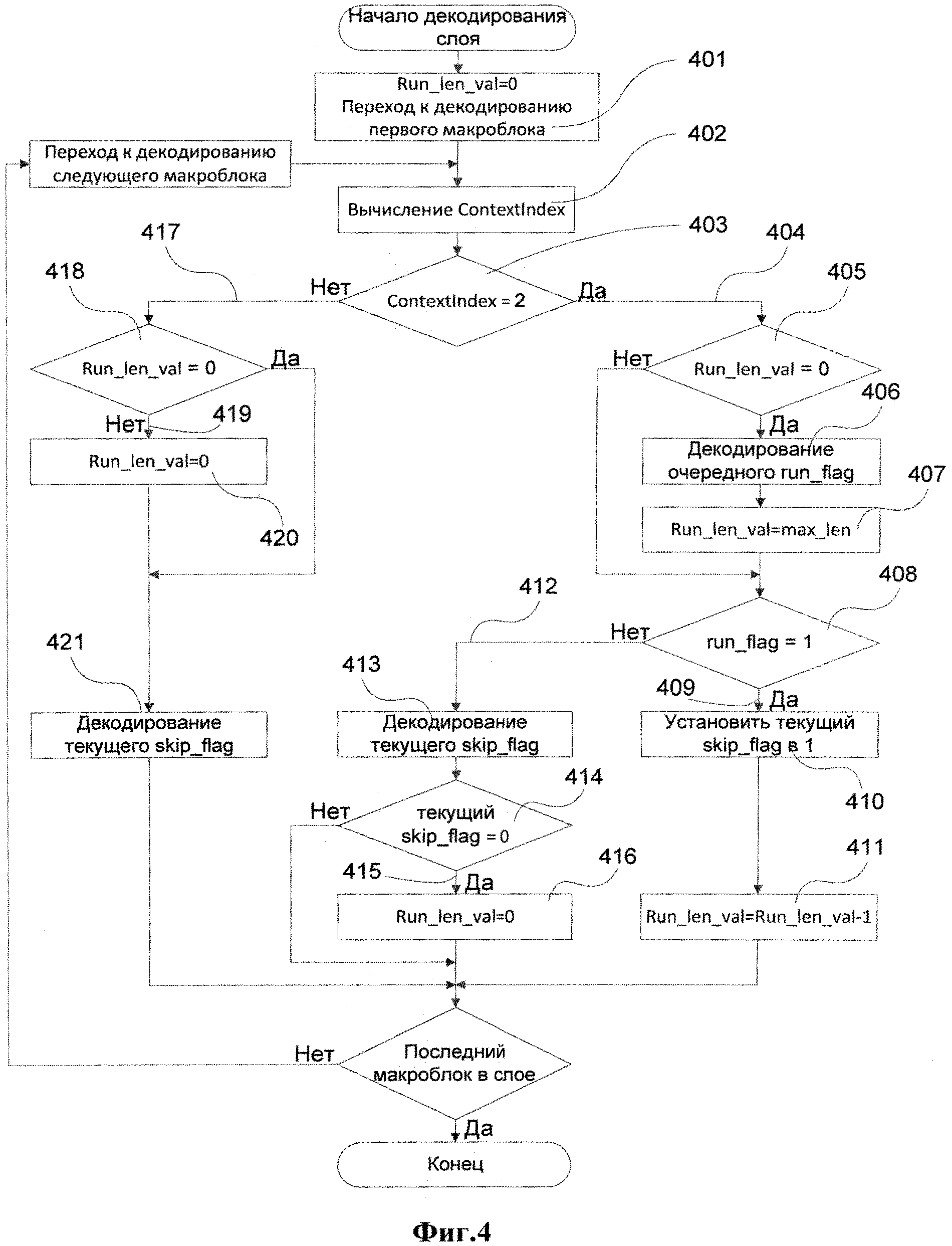
Алгоритм декодирования сформированного потока данных представлен на фиг.4. Перед декодированием макроблоков слоя декодер инициализирует переменную Run_len_val нулевым значением (шаг 401). Эта переменная используется для подсчета количества обработанных макроблоков в серии. Следующие шаги выполняются декодером для всех макроблоков слоя. Номер контекста ContextIndex вычисляется (шаг 402) для каждого mb_skip_flag, принадлежащего очередному макроблоку слоя, перед декодированием самого флага пропуска этого макроблока. Если ContextIndex равен 2 (шаг 403) (т.е. контекст является выбранным), то это означает, что было использовано кодирование длин серий для кодирования флага пропуска и декодер должен декодировать его соответствующим образом (шаг 04). Декодер проверяет значение переменной Run_len_val (шаг 405), чтобы определить, начата серия или нет. Если переменная равна нулю, то серия еще не начата и декодер считывает из потока и декодирует флаг run_flag (шаг 406). Значение флага определяет, была ли серия прерванной или нет. После того как флаг декодирован, переменная Run_len_val инициализируется значением max_len (шаг 407). Затем декодер проверяет значение последнего считанного флага run_flag (шаг 408). Если это значение равно единице (шаг 409) (это обозначает, что была закодирована непрерывная серия флагов пропусков, обозначающих пропущенные макроблоки), то mb_skip_flag текущего макроблока устанавливается в значение единица (шаг 410) (обозначающее пропущенный макроблок) и декодер уменьшает значение переменной Run_len_val на единицу (шаг 411). Если значение последнего считанного флага run_flag не равно единице (шаг 412) (это обозначает, что текущая серия является прерванной), то декодер считывает из потока и декодирует mb_skip_flag как и в стандартном случае (шаг 413). Прерванная серия состоит из нескольких флагов пропуска, обозначающих пропущенный макроблок, и одного флага пропуска, обозначающего непропущенный макроблок. Поэтому декодер должен проверять каждый считанный mb_skip_flag (шаг 414), чтобы найти первый флаг пропуска, обозначающий непропущенный макроблок. Этот флаг в данном случае одновременно служит индикатором завершения прерванной серии и дает возможность начать новую серию. Когда нулевой mb_skip_flag обнаружен (шаг 415), декодер завершает текущую прерванную серию, обнуляя переменную Run_len_val (шаг 416). Серия флагов пропущенных макроблоков (когда run_flag=1) завершается автоматически во время декрементирования переменной Run_len_val (шаг 411). После этого может быть начата новая серия.
В случае когда ContextIndex не равен 2 (шаг 417), применяется стандартный процесс декодирования mb_skip_flag с одним дополнительным шагом, заключающимся в проверке того, завершена ли серия или нет (шаг 418). Если обнаруживается незавершенная серия (шаг 419) (это может случиться, если флаг пропуска предыдущего макроблока имел выбранный контекст, а флаг пропуска текущего имеет контекст, отличный от выбранного), то она завершается декодером (шаг 420). Затем выполняется стандартное декодирование mb_skip_flag (шаг 421).
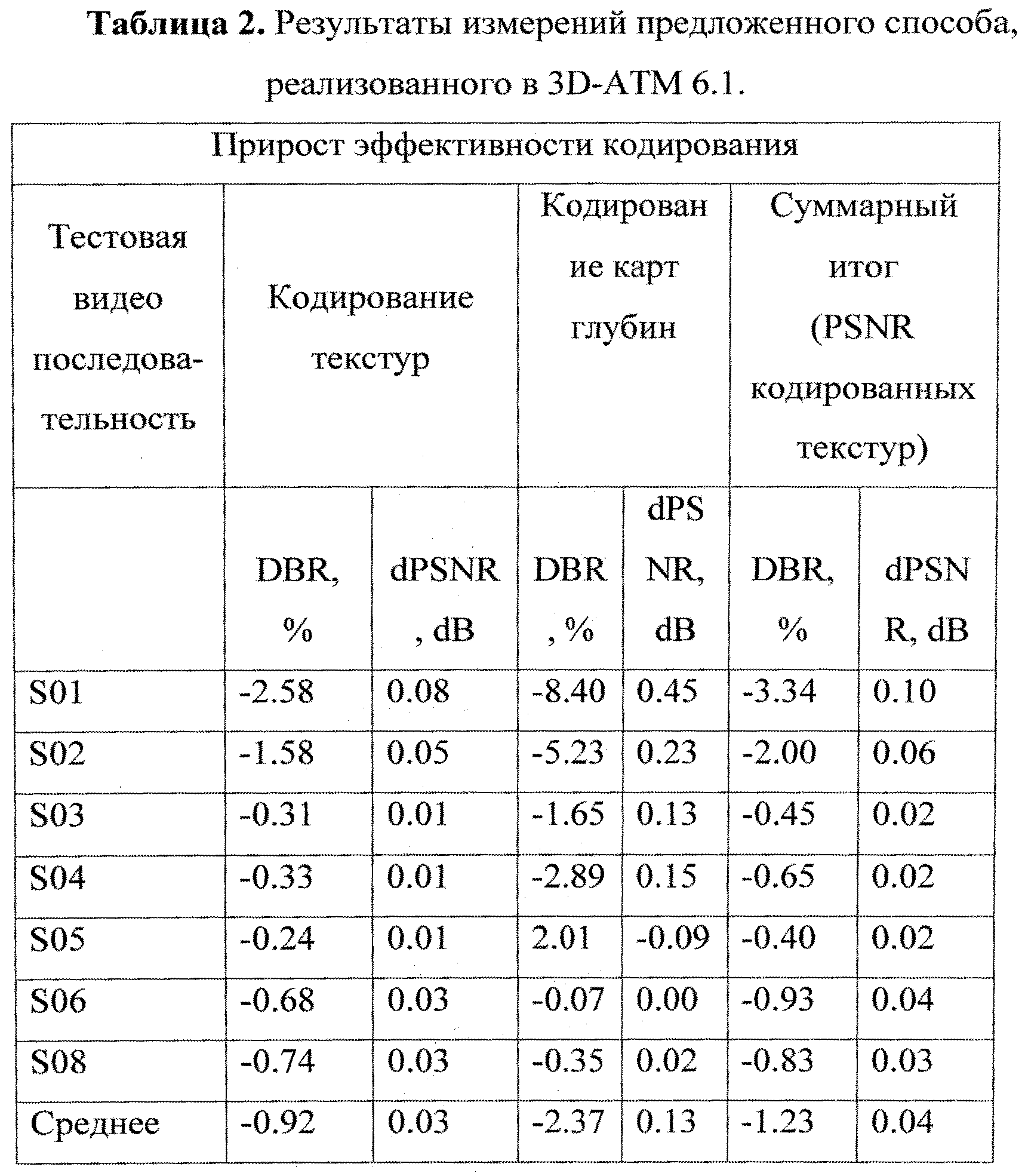
Описанные выше алгоритмы были реализованы в эталонной тестовой программной модели 3D-ATM 6.1, которая реализует предварительную версию стандарта кодирования 3D-видеопоследовательностей [13], основанного на стандарте Н.264. Переменная max_len была установлена в значение 16, а сам способ применялся для кодирования двунаправленных слоев (B-slice) зависимых видов текстур и всех видов карт глубин. Результаты представлены в таблице 2.
Измерения были выполнены в соответствии с документом "Common Test Conditions of 3DV Core Experiments" [14], и были получены следующие результаты: итоговый прирост эффективности кодирования - 1.23% BD-Rate; средний прирост эффективности кодирования текстур: - 0.92% BD-Rate; средний прирост эффективности кодирования карт глубин: - 237% BD-Rate [15]. Вычислительная сложность кодера и декодера остается приблизительно той же, что и в эталонной тестовой программной модели. Кроме того, было измерено количество двоичных элементов, которое обрабатывает модуль кодирования, и установлено, что при использовании предложенного способа количество обработанных двоичных элементов снижается на 40% для некоторых 3D-видеопоследовательностей и параметров квантования.
Изложенные в данном описании подход и способ обеспечивают уменьшение скорости потока данных при кодировании 3D-видеопоследовательностей способами, основанными на расширении стандартов Н.264 и AVC. Технология напрямую применима для стандартизации вследствие своей простоты и тесной связи со стандартами Н.264, AVC и их расширением, связанным с кодированием 3D-видеопоследовательностей.
Источники информации
1. "Generic Coding of Moving Pictures and Associated Audio Information-Part 2: Video," ITU-T and ISO/IEC JTC1, ITU-T Recommendation H.262-ISO/IEC 13 818-2 (MPEG-2), 1994.
2. "Video Coding for Low Bitrate Communications, Version 1," ITU-T, ITU-T Recommendation H.263, 1995.
3. ITU-T Rec. H.264. Advanced video coding for generic audiovisual services. 2010.
4. Detlev Marpe, Heiko Schwarz, and Thomas Wiegand, "Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video Compression Standard", IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 13, NO. 7, JULY 2003.
5. Патент РФ 2447612. [6], [7] и [8], [9], а также [10], [11], [12].
6. Патентная заявка РФ 2010107598.
7. Патентная заявка РФ 2011105660.
8. Патентная заявка США 20120299757.
9. Патентная заявка США 20130003858.
10. Патент США 8,189,676.
11. Патент США 8,306,124.
12. Патент США 6,677,868.
13. 3D-AVC Draft Text 5, JCT3V-C1002, Joint Collaborative Team on 3D Video Coding Extension Development of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11; 3rd Meeting: Geneva, CH, 17-23 January 2013.
14. Common Test Conditions of 3DV Core Experiments, JCT3V-B1100, Joint Collaborative Team on 3D Video Coding Extension Development of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11; 2nd Meeting: Shanghai, CN, 13-19 October 2012.
15. G. Bjontegaard, "Calculation of Average PSNR Differences between RD curves", ITU-T SG16/Q6, 13th VCEG Meeting, Austin, Texas, USA, April 2001, Doc. VCEG-M33.
Непрерывно электрически управляемая линзовая антенна
Оптическая измерительная система и способ измерения критического размера наноструктур на плоской поверхности
Адаптивный способ создания и печати цветных анаглифных изображений
Беспроводной электромагнитный приемник и система беспроводной передачи энергии
Резонансная структура на основе объемного акустического резонатора
Беспроводной электромагнитный приемник и система беспроводной передачи энергии
Беспроводной электромагнитный приемник и система беспроводной передачи энергии
Способ детектирования сигнала в системах связи с mimo каналом
Способ осаждения наночастиц золота на микросферы кремнезема
Способ ускорения обработки множественных запросов типа select к rdf базе данных с помощью графического процессора
Непрерывно электрически управляемая линзовая антенна
Оптическая измерительная система и способ измерения критического размера наноструктур на плоской поверхности
Адаптивный способ создания и печати цветных анаглифных изображений
Беспроводной электромагнитный приемник и система беспроводной передачи энергии
Резонансная структура на основе объемного акустического резонатора
Беспроводной электромагнитный приемник и система беспроводной передачи энергии
Беспроводной электромагнитный приемник и система беспроводной передачи энергии
Способ детектирования сигнала в системах связи с mimo каналом
Способ осаждения наночастиц золота на микросферы кремнезема
Способ ускорения обработки множественных запросов типа select к rdf базе данных с помощью графического процессора

