Результат интеллектуальной деятельности: КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ ДЛЯ ВИДЕОКОДИРОВАНИЯ
Вид РИД
Изобретение
Настоящая заявка испрашивает приоритет предварительной заявки США № 61/515,711, поданной 5 августа 2011 года, и является частичным продолжением заявки США № 13/413,497, поданной 6 марта 2012 года, содержание которых включено в настоящий документ посредством ссылки во всей своей полноте.
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к видеокодированию и, более конкретно, к способам сканирования и кодирования коэффициентов преобразования, сформированных в процессах видеокодирования.
УРОВЕНЬ ТЕХНИКИ
Возможности цифрового видео могут быть воплощены в широком диапазоне устройств, включающем цифровые телевизоры, системы цифрового прямого вещания, системы беспроводного вещания, карманные персональные компьютеры (PDA), портативные или настольные компьютеры, цифровые камеры, цифровые устройства записи, цифровые медиаплееры, устройства видеоигр, игровые видеоприставки, сотовые или спутниковые радиотелефоны, устройства видеоконференц-связи, и тому подобные. Устройства цифрового видео осуществляют способы сжатия видео, подобные описанным в стандартах MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, часть 10, Усовершенствованное видеокодирование (AVC), и Высокоэффективное видеокодирование (HEVC), который в настоящее время находится в разработке, и расширения этих стандартов, чтобы передавать, принимать и хранить информацию цифрового видео более эффективно.
Способы сжатия видео включают в себя пространственное прогнозирование и/или временное прогнозирование для сокращения или устранения избыточности, свойственной для последовательности видео. Для видеокодирования на основе блоков, видеокадр или слайс могут быть разделены на блоки. Каждый блок может быть дополнительно разделен. Блоки в кадре или слайсе с внутренним кодированием (I) кодируются с помощью пространственного прогнозирования с учетом опорных элементов дискретизации в соседних блоках в том же кадре или слайсе. Блоки в кадре или слайсе с внешним кодированием (P или B) могут использовать пространственное прогнозирование относительно опорных элементов дискретизации в соседних блоках в том же кадре или слайсе или временное прогнозирование относительно опорных элементов дискретизации в других опорных кадрах. Пространственное или временное прогнозирование имеет своим результатом прогнозный блок для блока, который должен быть кодирован. Остаточные данные представляют собой разности пикселов между исходным блоком, который должен быть кодирован, и прогнозным блоком.
Блок с внешним кодированием кодируется в соответствии с вектором движения, который указывает на блок опорных элементов дискретизации, формирующих прогнозный блок, и остаточные данные, указывающие разность между кодированным блоком и прогнозным блоком. Блок с внутренним кодированием кодируется в соответствии с режимом внутреннего кодирования и остаточными данными. Для дальнейшего сжатия, остаточные данные могут быть преобразованы из области пикселов в область преобразования, что приведет к остаточным коэффициентам преобразования, которые затем могут быть квантованы. Квантованные коэффициенты преобразования, первоначально расположенные в двумерной матрице, могут быть сканированы в конкретном порядке для получения одномерного вектора коэффициентов преобразования для энтропийного кодирования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В общем, это раскрытие описывает устройства и способы кодирования коэффициентов преобразования, связанных с блоком остаточных видеоданных, в процессе видеокодирования. Подходы, структуры и способы, описанные в этом раскрытии, применимы для процессов видеокодирования, которые используют энтропийное кодирование (например, Контекстно-адаптивное двоичное арифметическое кодирование (CABAC)) для кодирования синтаксических элементов, относящихся к коэффициентам преобразования. Аспекты настоящего изобретения включают в себя выбор порядка сканирования для кодирования карты значимости и уровней и кодирования знаков, для коэффициентов преобразования, а также выбор контекстов для энтропийного кодирования, соответствующего выбранному порядку сканирования. Структуры и способы настоящего изобретения применимы для использования в видеокодере и видеодекодере.
Это раскрытие предполагает гармонизацию порядка сканирования для кодирования карты значимости коэффициентов преобразования, а также для кодирования уровней коэффициента преобразования. То есть, в некоторых примерах, порядок сканирования карты значимости и кодирования уровней имеют одинаковый шаблон и направление. В другом примере, предполагается, что порядок сканирования карты значимости идет в обратном направлении (то есть, от коэффициентов с более высокими частотами к коэффициентам с более низкими частотами). В другом примере предполагается, что порядок сканирования карты значимости и кодирования уровней гармонизируются так, что каждый из них идет в обратном направлении.
Это раскрытие также предполагает, что, в некоторых примерах, коэффициенты преобразования сканируются по поднаборам. Более конкретно, коэффициенты преобразования сканируются в поднаборе, состоящем из некоторого количества следующих друг за другом коэффициентов, в соответствии с порядком сканирования. Такие поднаборы могут быть применимы к сканированию карты значимости и сканированию уровней коэффициентов.
Дополнительно, настоящее изобретение предполагает, что, в некоторых примерах, сканирование карты значимости и уровней коэффициентов выполняются последовательными сканированиями и в соответствии с одинаковым порядком сканирования. В одном аспекте, порядок сканирования является обратным порядком сканирования. Последовательные сканирования могут включать в себя несколько проходов сканирования. Каждый проход сканирования может включать в себя проход сканирования синтаксического элемента. Например, первое сканирование является сканированием карты значимости (также называемое бин 0 уровня коэффициентов преобразования), второе сканирование - это бин один уровней коэффициентов преобразования в каждом поднаборе (то есть коэффициенты преобразования, имеющие уровень больше 1), третье сканирование - бин два уровней коэффициентов преобразования в каждом поднаборе (то есть, коэффициенты преобразования, имеющие уровень больше 2), четвертое сканирование - это оставшиеся бины уровней коэффициентов преобразования (то есть, оставшийся уровень больше 2), и пятое сканирование - это знак уровней коэффициентов преобразования (то есть, знак плюс или минус). Проход знака может происходить в любой момент после прохода карты значимости. Дополнительно, число проходов сканирования может быть сокращено путем кодирования более чем одного синтаксического элемента за один проход. Например, может быть один проход сканирования синтаксических элементов с помощью кодированных бинов и второй проход сканирования синтаксических элементов с помощью бинов обхода (например, оставшиеся уровни и знак). В данном контексте, бин является частью строки бинов, которая кодирована энтропийным кодированием. Заданный недвоичный значимый синтаксический элемент отображается в двоичную последовательность (так называемую строку бинов).
Данное изобретение также предполагает, что в некоторых примерах коэффициенты преобразования кодированы энтропийным кодированием с помощью CABAC в двух различных областях контекста. Вывод контекста для первой области контекста зависит от положения коэффициентов преобразования, в то время как вывод контекста для второй области зависит от причинных соседей коэффициентов преобразования. В другом примере, вторая область контекста может использовать две различные контекстные модели в зависимости от местоположения коэффициентов преобразования.
В одном примере раскрытия, предлагается способ кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Способ содержит размещение блока коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования, кодирование первой части уровней коэффициентов преобразования в каждом поднаборе, причем первая часть уровней включает в себя, по меньшей мере, значимость коэффициентов преобразования в каждом поднаборе, и кодирование второй части уровней коэффициентов преобразования в каждом поднаборе.
В другом примере раскрытия, предлагается система кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Система содержит элемент видеокодирования, выполненный с возможностью размещать блок коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования, кодировать первую часть уровней коэффициентов преобразования в каждом поднаборе, причем первая часть уровней включает в себя, по меньшей мере, значимость коэффициентов преобразования в каждом поднаборе, и кодировать вторую часть уровней коэффициентов преобразования в каждом поднаборе.
В другом примере раскрытия, предлагается система кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Система содержит средство для размещения блока коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования, средство для кодирования первой части уровней коэффициентов преобразования в каждом поднаборе, причем первая часть уровней включает в себя, по меньшей мере, значимость коэффициентов преобразования в каждом поднаборе, и средство для кодирования второй части уровней коэффициентов преобразования в каждом поднаборе.
В другом примере раскрытия, компьютерный программный продукт содержит считываемый компьютером носитель данных, имеющий хранимые на нем инструкции, которые, которые при исполнении побуждают процессор устройства кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования, размещать блок коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования, кодировать первую часть уровней коэффициентов преобразования в каждом поднаборе, причем первая часть уровней включает в себя, по меньшей мере, значимость коэффициентов преобразования в каждом поднаборе, и кодировать вторую часть уровней коэффициентов преобразования в каждом поднаборе.
В другом примере раскрытия, способ кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования, содержит кодирование информации значимости для коэффициентов преобразования в набор коэффициентов преобразования, связанных с остаточными видеоданными, в соответствии с порядком сканирования в одном или более первых проходах, кодирование первого набора из одного или более бинов информации для коэффициентов преобразования, в соответствии с порядком сканирования в одном или более вторых проходах, причем один или более вторых проходов отличаются от одного или более первых проходов, и причем первый набор из одного или более бинов кодируются в первом режиме процесса кодирования, и кодирование второго набора из одного или более бинов информации для коэффициентов преобразования в соответствии с порядком сканирования в одном или более третьих проходах, причем один или более третьих проходов отличаются от одного или более первых и вторых проходов, и причем второй набор из одного или более бинов кодируются во втором режиме процесса кодирования.
В другом примере раскрытия, устройство кодирования коэффициентов преобразования, связанных с остаточными видеоданными, содержит один или более процессоров, выполненных с возможностью кодировать информацию значимости для коэффициентов преобразования в наборе коэффициентов преобразования, связанных с остаточными видеоданными, в соответствии с порядком сканирования в одном или более проходах, кодировать первый набор из одного или более бинов информации для коэффициентов преобразования в соответствии с порядком сканирования в одном или более вторых проходах, причем один или более вторых проходов отличаются от одного или более первых проходов, и причем первый набор из одного или более бинов кодируются в первом режиме процесса кодирования, и кодировать второй набор из одного или более бинов информации для коэффициентов преобразования, в соответствии с порядком сканирования в одном или более третьих проходах, причем один или более третьих проходов отличаются от одного или более первых и вторых проходов, и причем второй набор из одного или более бинов кодируются во втором режиме процесса кодирования.
В другом примере раскрытия, устройство кодирования коэффициентов преобразования, связанных с остаточными видеоданными, содержит средство для кодирования информации значимости для коэффициентов преобразования в наборе коэффициентов преобразования, связанных с остаточными видеоданными, в соответствии с порядком сканирования в одном или более первых проходах, средство для кодирования первого набора из одного или более бинов информации для коэффициентов преобразования, в соответствии с порядком сканирования в одном или более вторых проходах, причем одно или более вторых проходов отличаются от одного или более первых проходов, и причем первый набор из одного или более бинов кодируются в первом режиме процесса кодирования, и средство для кодирования второго набора из одного или более бинов информации для коэффициентов преобразования, в соответствии с порядком сканирования в одном или более третьих проходах, причем один или более третьих проходов отличаются от одного или более первых и вторых проходов, и причем второй набор из одного или более бинов кодируются во втором режиме процесса кодирования.
В другом примере раскрытия, обеспечен невременный считываемый компьютером носитель данных, имеющий инструкции, которые при исполнении побуждают один или более процессоров кодировать информацию значимости для коэффициентов преобразования в наборе коэффициентов преобразования, связанных с остаточными видеоданными, в соответствии с порядком сканирования в одном или более проходах, кодировать первый набор из одного или более бинов информации для коэффициентов преобразования в соответствии с порядком сканирования в одном или более вторых проходах, причем один или более вторых проходов отличаются от одного или более первых проходов, и причем первый набор из одного или более бинов кодируются в первом режиме процесса кодирования, и кодировать второй набор из одного или более бинов информации для коэффициентов преобразования в соответствии с порядком сканирования в одном или более третьих проходах, причем один или более третьих проходов отличаются от одного или более первых и вторых проходов, и причем второй набор из одного или более бинов кодируются во втором режиме процесса кодирования.
Детали одного или более примеров изложены в сопроводительных чертежах и последующем описании. Другие характеристики, объекты и преимущества будут очевидны из описания и чертежей, а также из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 является концептуальной схемой, изображающей процесс кодирования карты значимости.
Фиг. 2 является концептуальной схемой, изображающей шаблоны сканирования и направления для кодирования карты значимости.
Фиг. 3 является концептуальной схемой, изображающей способ сканирования для кодирования уровней единицы преобразования.
Фиг. 4 является структурной схемой, изображающей пример системы видеокодирования.
Фиг. 5 является структурной схемой, изображающей пример видеокодера.
Фиг. 6 является концептуальной схемой, изображающей обратные порядки сканирования для кодирования карты значимости и уровней коэффициентов.
Фиг. 7 является концептуальной схемой, изображающей первый поднабор коэффициентов преобразования, сканированных в соответствии с обратным порядком диагонального сканирования.
Фиг. 8 является концептуальной схемой, изображающей первый поднабор коэффициентов преобразования, сканированных в соответствии с обратным порядком горизонтального сканирования.
Фиг. 9 является концептуальной схемой, изображающей первый поднабор коэффициентов преобразования, сканированных в соответствии с обратным порядком вертикального сканирования.
Фиг. 10 является концептуальной схемой, изображающей пример областей контекста для кодирования карты значимости.
Фиг. 11 является концептуальной схемой, изображающей пример областей контекста для кодирования карты значимости с помощью обратного порядка сканирования.
Фиг. 12 является концептуальной схемой, изображающей пример причинных соседей для энтропийного кодирования с помощью прямого порядка сканирования.
Фиг. 13 является концептуальной схемой, изображающей пример причинных соседей для энтропийного кодирования с помощью обратного порядка сканирования.
Фиг. 14 является концептуальной схемой, изображающей пример областей контекста для энтропийного кодирования с помощью обратного порядка сканирования.
Фиг. 15 является концептуальной схемой, изображающей пример причинных соседей для энтропийного кодирования с помощью обратного порядка сканирования.
Фиг. 16 является концептуальной схемой, изображающей другой пример областей контекста для CABAC с помощью обратного порядка сканирования.
Фиг. 17 является концептуальной схемой, изображающей другой пример областей контекста для CABAC с помощью обратного порядка сканирования.
Фиг. 18 является концептуальной схемой, изображающей другой пример областей контекста для CABAC с помощью обратного порядка сканирования.
Фиг. 19 является структурной схемой, изображающей пример элемента энтропийного кодирования.
Фиг. 20 является структурной схемой, изображающей пример видеодекодера.
Фиг. 21 является структурной схемой, изображающей пример элемента энтропийного декодирования.
Фиг. 22 является блок-схемой последовательности операций, изображающей пример процесса сканирования карты значимости и уровней коэффициентов в гармонизированном порядке сканирования.
Фиг. 23 является блок-схемой последовательности операций, изображающей пример процесса сканирования карты значимости и уровней коэффициентов и выведения контекста энтропийного кодирования.
Фиг. 24 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов и выведения контекста энтропийного кодирования.
Фиг. 25 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов и выведения контекста энтропийного кодирования.
Фиг. 26 является блок-схемой последовательности операций, изображающей пример процесса кодирования карты значимости с помощью обратного направления сканирования.
Фиг. 27 является блок-схемой последовательности операций, изображающей пример процесса сканирования карты значимости и уровней коэффициентов в соответствии с поднаборами коэффициентов преобразования.
Фиг. 28 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов в соответствии с поднаборами коэффициентов преобразования.
Фиг. 29 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов в соответствии с поднаборами коэффициентов преобразования.
Фиг. 30 является блок-схемой последовательности операций, изображающей пример процесса энтропийного кодирования с помощью множественных областей.
Фиг. 31 является концептуальной схемой, изображающей пример упорядочивания бинов для кодирования коэффициентов преобразования, связанных с остаточными видеоданными.
Фиг. 32 является концептуальной схемой, изображающей пример упорядочивания и группирования бинов для кодирования коэффициентов преобразования, связанных с остаточными видеоданными.
Фиг. 33 является концептуальной схемой, изображающей пример процесса видеокодирования для кодирования коэффициентов преобразования, связанных с остаточными видеоданными.
ПОДРОБНОЕ ОПИСАНИЕ
Цифровые видеоустройства осуществляют способы сжатия видео для более эффективной передачи и приема цифровой видеоинформации. Процессы сжатия видео могут применять способы пространственного (внутрикадрового) прогнозирования и/или временного (межкадрового) прогнозирования для сокращения или устранения избыточности, свойственной для последовательностей видео.
Для видеокодирования в соответствии со стандартом высокоэффективного видеокодирования (HEVC), в настоящее время находящемся в разработке Объединенной команды (JCT-VC) по видеокодированию, в качестве примера, видеокадр может быть разделен на единицы кодирования. Последняя рабочая версия (WD) HEVC, здесь и далее именуемая как HEVC WD7, доступна на http://phenix.int-evry.fr/jct/doc_end_user/documents/9_Geneva/wg11/JCTVC-11003-v5.zip, а самая последняя версия доступна на http://phenix.int-evry.fr/jct/doc_end_user/documents/9_Geneva/wg11/JCTVC-11003-v6.zip, обе версии включены в настоящий документ посредством ссылки во всей полноте.
В соответствии с HEVC, единица кодирования, в общем, относится к области изображения, служащей базовой единицей, к которой применяются различные инструменты кодирования для сжатия видео. Единица кодирования, как правило, является квадратной (хотя это необязательно), и ее можно рассматривать в качестве подобной так называемому макроблоку, например, в других стандартах видеокодирования типа ITU-T H.264. Кодирование в соответствии с некоторыми из предложенных аспектов развивающегося стандарта HEVC будет описано в настоящей заявке с целью иллюстрации. Однако, способы, описанные в данном осуществлении, могут быть применены и в других процессах видеокодирования, как, например, процессах, определенных в стандарте H.264 или другом стандарте, или в частных процессах видеокодирования.
Чтобы достигнуть желаемого уровня эффективности кодирования, единица кодирования (CU) может быть различных размеров, в зависимости от видеоконтента. Дополнительно, единица кодирования может быть разделена на более мелкие блоки для прогнозирования или преобразования. Более конкретно, каждая единица кодирования может быть дополнительно разделена на единицы прогнозирования (PU) и единицы преобразования (TU). Единицы прогнозирования можно рассматривать как подобные так называемым разделам по другим стандартам видеокодирования, как, например, стандарт H.264. Единица преобразования (TU), в общем, относится к блоку остаточных данных, к которому применяется преобразование для получения коэффициентов преобразования.
Единица кодирования обычно имеет составляющую яркости, обозначенную Y, и две составляющие цветности, обозначенные U и V. В зависимости от формата дискретизации (выборки) видео, размер составляющих U и V для некоторого числа элементов дискретизации может быть таким же или отличным от размера составляющей Y.
Для кодирования блока (например, единицы прогнозирования видеоданных) сначала выводят предиктор для блока. Предиктор, также называемый прогнозным блоком, можно вывести либо с помощью внутреннего (I) прогнозирования (то есть пространственного прогнозирования) либо внешнего (P или B) прогнозирования (то есть временного прогнозирования). Следовательно, некоторые единицы прогнозирования могут быть с внутренним (I) кодированием с помощью пространственного прогнозирования по отношению к опорным элементам дискретизации в соседних опорных блоках в том же кадре (или слайсе), а другие единицы прогнозирования могут быть с однонаправленным внешним кодированием (P) или двунаправленным внешним кодированием (В) по отношению к блокам опорных элементов дискретизации в других ранее упомянутых кадрах (или слайсах). В каждом случае, опорные элементы дискретизации могут быть использованы для генерирования прогнозного блока для блока, который должен быть кодирован.
После идентификации прогнозного блока определяется разность между исходным блоком видеоданных и его прогнозным блоком. Эта разность называется остаточными данными прогнозирования, и она указывает разность пикселов между значениями пикселов в блоке, который должен быть кодирован, и значениями пикселов в прогнозном блоке, выбранном для представления кодированного блока. Для достижения лучшего сжатия, остаточные данные прогнозирования можно преобразовать, например, с помощью дискретного косинусного преобразования (DCT), целочисленного преобразования, преобразования Карунена-Лоэва (K-L) или другого преобразования.
Остаточные данные в блоке преобразования, таком как TU, могут быть размещены в двумерной (2D) матрице значений разности пикселов, находящейся в пространственной, пиксельной области. Преобразование переводит остаточные значения пикселов в двумерную матрицу коэффициентов преобразования в области преобразования, такую как область частот. Для дополнительного сжатия, коэффициенты преобразования квантуют до энтропийного кодирования. Устройство энтропийного кодирования далее применяет к квантованным коэффициентам преобразования энтропийное кодирование, такое как Контекстно-зависимое адаптивное кодирование (CAVLC) с переменной длиной кодового слова, Контекстно-адаптивное двоичное арифметическое кодирование (CABAC), Энтропийное кодирование (PIPE) с разбиением интервалов вероятности, и тому подобное.
Для энтропийного кодирования блока квантованных коэффициентов преобразования, обычно выполняют процесс сканирования, чтобы происходила обработка двумерной (2D) матрицы квантованных коэффициентов преобразования в блоке, в соответствии с конкретным порядком сканирования, в упорядоченной одномерной (1D) матрице, то есть, векторе коэффициентов преобразования. Энтропийное кодирование применяется в 1-D порядке коэффициентов преобразования. Сканирование квантованных коэффициентов преобразования в единице преобразования сериализирует 2D матрицу коэффициентов преобразования для энтропийного кодера. Карта значимости может быть сгенерирована для указания положений значимых (то есть ненулевых) коэффициентов. Сканирование можно применять для сканирования уровней значимых (то есть ненулевых) коэффициентов, и/или кодирования знаков значимых коэффициентов.
Для DCT, в качестве примера, часто вероятность ненулевых коэффициентов, выше в направлении верхнего левого угла (то есть, области с низкими частотами) 2D единицы преобразования. Может быть желательно, чтобы сканирование коэффициентов происходило так, чтобы увеличивалась вероятность группирования ненулевых коэффициентов, на одном конце сериализованной серии коэффициентов, а коэффициенты с нулевым значением, группировались вместе на другом конце сериализованного вектора и были более эффективно кодированы как серии нулей. По этой причине, порядок сканирования важен для эффективного энтропийного кодирования.
В качестве примера, так называемый диагональный (или волновой) порядок сканирования принят для использования в сканировании квантованных коэффициентов преобразования в стандарте HEVC. Альтернативно может быть применен зигзагообразный, горизонтальный, вертикальный или другой порядки сканирования. При преобразовании и квантовании, как указано выше, ненулевые коэффициенты преобразования, обычно расположены в низкочастотной области в верхнем левом участке блока для примера, в котором используется преобразование DCT. В результате, после процесса диагонального сканирования, который сначала проходит верхний левый участок, наиболее вероятно, что ненулевые коэффициенты преобразования, будут располагаться в передней части сканирования. При процессе диагонального сканирования, который сначала проходит нижний правый участок, наиболее вероятно, что ненулевые коэффициенты преобразования, будут располагаться в задней части сканирования.
Некоторое число коэффициентов с нулевым значением в основном будут сгруппированы на одном конце сканирования, в зависимости от направления сканирования, вследствие сокращенной энергии на более высоких частотах, и вследствие эффектов квантования, которые побуждают некоторые ненулевые коэффициенты, становиться коэффициентами с нулевым значением при сокращении битовой глубины. Эти характеристики распределения коэффициентов в сериализованной 1D матрице можно использовать при проектировании энтропийного кодера, чтобы улучшить эффективность кодирования. Другими словами, если ненулевые коэффициенты, могут быть эффективно размещены в одной части 1D матрицы посредством некоторого надлежащего порядка сканирования, то можно ожидать более эффективного кодирования вследствие упомянутого проектирования многих энтропийных кодеров.
Для достижения этой цели по размещению большего числа ненулевых коэффициентов, на одном конце 1D матрицы, можно использовать различные порядки сканирования в видеокодере-декодере (CODEC), чтобы кодировать коэффициенты преобразования. В некоторых случаях, эффективно диагональное сканирование. В других случаях, различные типы сканирования, такие как, зигзагообразное, вертикальное или горизонтальное сканирование могут быть более эффективны.
Различные порядки сканирования можно произвести множеством способов. В одном примере, для каждого блока коэффициентов преобразования «лучший» порядок сканирования выбирают из некоторого числа доступных порядков сканирования. Затем видеокодер обеспечивает указание декодеру, для каждого блока, индекса лучшего порядка сканирования среди набора порядков сканирования, обозначенных соответствующими индексами. Этот выбор лучшего порядка сканирования можно определить путем применения нескольких порядков сканирования и выбора того, который является наиболее эффективным в размещении ненулевых коэффициентов, близко к началу или концу 1D вектора, тем самым способствуя эффективному энтропийному кодированию.
В другом примере, порядок сканирования для текущего блока можно определить на основании различных факторов, относящихся к кодированию надлежащей единицы прогнозирования, как, например, режим (I, B, P) прогнозирования, размер блока, преобразование или другие факторы. В других случаях, так как одна и та же информация, например, режим прогнозирования, может выводиться на стороне кодера и декодера, то нет необходимости обеспечивать указание индекса порядка сканирования декодеру. Вместо этого, видеодекодер может хранить данные конфигурации, которые указывают надлежащий порядок сканирования с учетом знания режима прогнозирования для блока и одного или более критериев, которые отображают режим прогнозирования на конкретный порядок сканирования.
Для дополнительного улучшения эффективности кодирования, доступные порядки сканирования могут быть не всегда постоянными. Вместо этого, можно обеспечить адаптацию так, чтобы порядок сканирования адаптивно настраивался, например, на основании коэффициентов, которые уже кодированы. В общем, адаптация порядка сканирования может быть сделана так, чтобы в соответствии с выбранным порядком сканирования, ненулевые коэффициенты и коэффициенты с нулевым значением с наибольшей вероятностью были сгруппированы вместе.
В некоторых видео CODEC, первоначально доступные порядки сканирования могут быть в постоянной форме, такой как, только горизонтальной, вертикальной, диагональной или зигзагообразной. Альтернативно, порядки сканирования можно вывести в процессе обучения, следовательно, они могут возникать случайно. Процесс обучения может вовлекать применение различных порядков сканирования к блоку или последовательности блоков, чтобы идентифицировать порядок сканирования, который дает желаемые результаты, например, в отношении эффективного размещения ненулевых коэффициентов и коэффициентов с нулевым значением, как упомянуто выше.
Если порядок сканирования выведен в процессе обучения, либо если можно выбрать множество различных порядков сканирования, то предпочтительно будет сохранить конкретные порядки сканирования на стороне кодера и декодера. Количество данных, точно определяющих такие порядки сканирования, может быть существенным. Например, для блока 32х32 преобразования, один порядок сканирования может содержать 1024 положения коэффициента преобразования. Так как блоки могут быть с разными размерами, а для каждого размера блока преобразования может быть некоторое число различных порядков сканирования, общее количество данных, которое требуется сохранить, весьма существенно. Постоянные порядки сканирования, как, например, диагональный, горизонтальный, вертикальный или зигзагообразный, не требуют вовсе или почти места памяти. Однако диагональный, горизонтальный, вертикальный или зигзагообразный порядки сканирования могут не обеспечивать достаточное разнообразие, чтобы обеспечить эффективность кодирования, которая находится на одном уровне с обученными порядками сканирования.
В одном примере, для стандарта Н.264 и HEVC, который в настоящее время находится в разработке, когда используется устройство энтропийного кодирования CABAC, положения значимых коэффициентов (то есть, ненулевых коэффициентов преобразования), в блоке преобразования (то есть, единице преобразования в HEVC) кодируются до уровней коэффициентов. Процесс кодирования местоположений коэффициентов значимости называется кодированием карты значимости. Значимость коэффициента одинакова с бином ноль уровня коэффициента. Как изображено на Фиг. 1, кодирование карты значимости квантованных коэффициентов 11 преобразования производит карту 13 значимости. Карта 13 значимости является картой единиц и нулей, где единицы указывают местоположения значимых коэффициентов. Карта значимости обычно требует высокой доли частоты следования битов видео. Способы настоящего изобретения также можно применить для использования в других устройствах энтропийного кодирования (например, PIPE).
Пример процесса кодирования карты значимости описан в статье Д. Марпа, Х. Шварца и Т. Вейганда, «Контекстно-адаптивное двоичное арифметическое кодирование в стандартах Н.264/AVC сжатия видео», IEEE Trans. Схемы и системы для видеотехнологии, изд. 13, №7, июль 2003. В этом процессе, карта значимости кодируется, если есть по меньшей мере один значимый коэффициент в блоке, как указано флагом (CBF) кодируемого блока, который определяется так.
Флаг кодируемого блока: coded_block_flag является однобитным символом, который указывает, есть ли значимые, то есть ненулевые коэффициенты внутри одного блока коэффициентов преобразования, для которого шаблон кодируемого блока указывает ненулевые вхождения. Если coded_block_flag равен нулю, то никакая информация не будет передана для соответственного блока.
Если в блоке есть значимые коэффициенты, то осуществляется кодирование карты значимости посредством следующего порядка сканирования коэффициентов преобразования в блоке, а именно следующим образом.
Сканирование коэффициентов преобразования: двумерные матрицы уровней коэффициентов преобразования подблоков, для которых coded_block_flag указывает ненулевые вхождения, сначала отображаются в одномерный список с помощью заданного шаблона сканирования. Другими словами, подблоки со значимыми коэффициентами сканируют в соответствии с шаблоном сканирования.
При заданном шаблоне сканирования, карта значимости сканируется следующим образом.
Карта значимости: Если coded_block_flag указывает, что блок имеет значимые коэффициенты, то осуществляется кодирование карты значимости с двоичными значениями. Для каждого коэффициента преобразования в порядке сканирования, передается однобитный символ significant_coeff_flag. Если символ significant_coeff_flag равен единице, то есть, если в этом положении сканирования есть коэффициент, не равный нулю, то отправляется дополнительный однобитный символ last_significant_coeff_flag. Этот символ указывает, если текущий значимый коэффициент является последним внутри блока или если за ним следуют дополнительные значимые коэффициенты. Если достигнуто последнее положение сканирования, а кодирование карты значимости еще не завершено last_significant_coeff_flag с величиной один, то очевидно, что последний коэффициент должен быть значимым.
Последние поправки для HEVC предлагают отказаться от last_significant_coeff_flag. В этих поправках, до отправления карты значимости, отправляется указание положений X и Y для положения последнего значимого коэффициента.
В одной поправке для HEVC предлагается использовать три шаблона сканирования для карты значимости: диагональный, вертикальный и горизонтальный. Фиг. 2 изображает пример зигзагообразного сканирования 17, вертикального сканирования 19, горизонтального сканирования 21 и диагонального сканирования 15. Как изображено на Фиг. 2, каждое из этих сканирований идет в прямом направлении, то есть от коэффициентов преобразования с низкими частотами в верхнем левом углу блока преобразования к коэффициентам преобразования с высокими частотами в нижнем правом углу блока преобразования. После кодирования карты значимости, кодируется оставшаяся информация уровней (бины от 1 до N, где N - это общее число бинов) для каждого значимого коэффициента преобразования (то есть значение коэффициента).
В процессе САВАС, ранее указанном в стандарте Н.264, вслед за обработкой подблоков 4х4, каждый из уровней коэффициентов преобразования преобразуется в двоичную форму, например, в соответствии с унарным кодом, чтобы произвести последовательность бинов. В Н.264, множество контекстных моделей для каждого подблока состоит из контекстных моделей два на пять, по пять моделей для первого бина и всех оставшихся бинов (вплоть до и включая 14ый бин) синтаксического элемента coeff_abs_level_minus_one, который осуществляет кодирование абсолютного значения коэффициента преобразования. Следует отметить, что в одной предложенной версии HEVC оставшиеся бины включают в себя только бин 1 и бин 2. Остаток уровней коэффициентов кодируется в режиме обхода с помощью кода Голомба-Райса и экспоненциальных кодов Голомба. Кодирование обхода идет в обход механизма кодирования CABAC для бинов, кодируемых в режиме обхода.
В HEVC, выбор контекстных моделей может выполняться в качестве оригинального процесса САВАС, предложенного стандартом Н.264. Однако различные наборы контекстных моделей могут быть выбраны для различных подблоков. Более конкретно, выбор набора контекстных моделей для данного подблока зависит от некоторой статистической информации ранее кодированных подблоков.
Фиг. 3 изображает порядок сканирования и следующую за ним предложенную версию процесса HEVC для осуществления кодирования уровней коэффициентов преобразования (абсолютное значение уровня и знак уровня) в единице 25 преобразования. Следует отметить, что имеет место прямой зигзагообразный шаблон 27 для сканирования подблоков 4х4 большого блока, а обратный зигзагообразный шаблон 23 для сканирования уровней коэффициентов преобразования внутри каждого подблока. Другими словами, последовательность 4х4 подблоков сканируется по прямому зигзагообразному шаблону, так что подблоки сканируются последовательно. Затем, внутри каждого подблока, выполняется обратное зигзагообразное сканирование, чтобы сканировать уровни коэффициентов преобразования внутри подблока. Следовательно, коэффициенты преобразования в двумерной матрице, сформированной единицей преобразования, сериализуются в одномерную матрицу, так что за коэффициентами, которые сканированы в обратном порядке в заданном подблоке, затем следуют коэффициенты, которые сканированы в обратном порядке в последующем подблоке.
В одном примере, кодирование САВАС коэффициентов, сканированных в соответствии с подходом сканирования подблока, изображенном на Фиг. 3, может использовать 60 контекстов, то есть 6 наборов по 10 контекстов в каждом, распределенных как описано ниже. Для блока 4х4, может быть использовано 10 контекстных моделей (5 моделей для бина 1 и 5 моделей для бинов от 2 до 14), как изображено в Таблице 1:
|
Согласно Таблице 1, одна из контекстных моделей 0-4 во множестве контекстов используется для бина 1, если, соответственно, текущий кодируемый коэффициент, который сканируется в подблоке, кодируется после того, как закодирован коэффициент больше 1 в подблоке; текущий кодируемый коэффициент является первоначальным коэффициентом, сканированным в подблоке, либо в подблоке нет хвостовых единиц (нет ранее закодированных коэффициентов); в подблоке есть одна хвостовая единица (то есть, единица закодирована, но коэффициенты больше единицы не закодированы); в подблоке есть две хвостовые единицы либо в подблоке есть три или более хвостовых единиц. Для каждого из бинов 2-14 (хотя по меньшей мере один проект для HEVC кодирует только бин 2 с помощью САВАС, а последующие бины уровня коэффициентов кодируются с помощью экспоненциального кода Голомба), одна из контекстных моделей 0-4 может быть использована, соответственно, если коэффициент является первоначальным сканируемым коэффициентом в подблоке либо нет ранее закодированных коэффициентов больше единицы; есть один ранее закодированный коэффициент больше единицы; есть два ранее закодированных коэффициента больше единицы; есть три ранее закодированных коэффициента больше единицы либо есть четыре ранее закодированных коэффициента больше единицы.
Есть 6 различных наборов этих 10 моделей, в зависимости от числа коэффициентов больше 1 в ранее закодированном подблоке 4х4 в прямом порядке сканирования подблоков:
|
Согласно Таблице 2, наборы 0-5 контекстных моделей используются для заданного подблока если, соответственно, это подблок размером 4х4; есть от 0 до 3 коэффициентов больше 1 в ранее закодированном подблоке; есть от 4 до 7 коэффициентов больше 1 в ранее закодированном подблоке; есть от 8 до 11 коэффициентов больше 1 в ранее закодированном подблоке; есть от 12 до 15 коэффициентов больше 1 в ранее закодированном подблоке, или заданный подблок является первым подблоком 4х4 (верхний левый подблок) либо есть 16 коэффициентов больше 1 в ранее закодированном подблоке.
Вышеописанный процесс кодирования для Н.264 и процесс, предложенный для HEVC, имеет несколько недостатков. Как изображено на Фиг. 3, один недостаток - это то, что сканирование для уровней коэффициентов идет в прямом направлении для сканирования подблоков (то есть, начиная от верхнего левого подблока), но затем в обратном направлении для сканирования уровней коэффициентов внутри каждого подблока (то есть, начиная с нижнего правого коэффициента в каждом подблоке). Этот подход предполагает проход назад и вперед внутри блока, что может осложнить вывод данных.
Другой недостаток исходит из того факта, что порядок сканирования уровней коэффициентов отличен от порядка сканирования карты значимости. В HEVC есть три различных предложенных порядка сканирования для карты значимости: прямой диагональный, прямой горизонтальный и прямой вертикальный, как изображено на Фиг. 2. Все сканирования значимых коэффициентов отличны от сканирования уровней коэффициентов в проекте HEVC, так как сканирования уровней идут в обратном направлении. Так как направление и шаблон сканирования уровней коэффициентов не совпадает с направлением и шаблоном сканирования значимости, необходимо проверять больше уровней коэффициентов. Например, предположим, что для карты значимости применяется горизонтальное сканирование, и последний значимый коэффициент обнаружен в конце первого ряда коэффициентов. Сканирование уровней коэффициентов в HEVC требует диагонального сканирования через многочисленные ряды для сканирования уровней, тогда как только первый ряд содержит уровни коэффициентов, отличные от 0. Такой процесс сканирования приводит к нежелательным потерям эффективности.
В проекте для HEVC, сканирование карты значимости идет в прямом направлении в блоке, от коэффициента DC, обнаруженного в левом верхнем углу блока, к коэффициенту с самой высокой частотой, как правило, обнаруживаемому в нижнем правом углу блока, в то время как сканирование уровней коэффициентов идет в обратном направлении внутри каждого подблока 4х4. Это также может привести к более сложному и менее эффективному выводу данных.
Другой недостаток в некоторых проектах HEVC исходит из наборов контекстов. Набор контекстов (см. Таблицу 2 выше) для САВАС для блока размером 4х4 отличается от блоков других размеров. В соответствии с настоящим изобретением, желательно гармонизировать контексты для блоков всех размеров, чтобы меньше памяти было занято хранением различных наборов контекстов.
Также, как будет описано более детально ниже, некоторые предложенные контексты САВАС для карты значимости HEVC действительны только тогда, когда порядок сканирования является прямым. В таком случае, это не позволит провести обратные сканирования карты значимости.
Дополнительно, контексты, описанные выше для кодирования уровней квантованного коэффициента, применяют местную корреляцию уровней коэффициентов. Эти контексты зависят от корреляции среди подблоков 4х4 (см. набор контекстов в Таблице 2) и корреляции внутри каждого подблока (см. контекстные модели в Таблице 1). Недостаток этих контекстов заключается в том, что зависимость может быть слишком удаленной (то есть низкая зависимость между коэффициентами, которые отделены друг от друга несколькими другими коэффициентами, от одного подблока к другому). Также, зависимость может быть слабой внутри каждого подблока.
Настоящее изобретение предлагает несколько различных характеристик, которые могут сократить или устранить некоторые из недостатков, описанных выше. В некоторых примерах, эти характеристики могут обеспечивать более эффективный и гармонизированный порядок сканирования коэффициентов преобразования в видеокодировании. В других примерах настоящего изобретения, эти характеристики обеспечивают более эффективный набор контекстов для использования в основанном на САВАС энтропийном кодировании коэффициентов преобразования, согласующемся с предложенным порядком сканирования. Необходимо отметить, что все способы, описанные в настоящем изобретении, могут быть применены независимо либо вместе в любой комбинации.
Фиг. 4 является структурной схемой, изображающей пример системы 10 видеокодирования и декодирования, которая может быть выполнена с возможностью использовать способы кодирования коэффициентов преобразования в соответствии с примерами этого раскрытия. Как изображено на Фиг. 4, система 10 включает в себя устройство-источник 12, которое передает закодированное видео на устройство-адресат 14 по каналу 16 связи. Закодированное видео может также храниться на носителе 34 или файловом сервере 36 и устройство-адресат 14 может осуществлять к нему доступ при необходимости. Устройство-источник 12 и устройство-адресат 14 могут содержать любое из широкого диапазона устройств, включая настольные компьютеры, ноутбуки (то есть портативные компьютеры), планшеты, телевизионные приставки, телефонные трубки, как, например, так называемые смартфоны, телевизоры, фотоаппараты, устройства отображения, цифровые медиаплееры, игровые видеоприставки и тому подобное. Во многих случаях, такие устройства могут быть оборудованы беспроводной связью. Следовательно, канал 16 связи может содержать беспроводной канал, проводной канал или комбинацию беспроводного и проводного канала, подходящую для передачи закодированных видеоданных. Схожим образом, устройство-адресат 14 может получить доступ к файловому серверу 36 посредством любого стандартного соединения данных, включая интернет-соединение. Это может включать в себя беспроводной канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем и так далее) или их комбинацию, подходящую для доступа к закодированным видеоданным, хранящимся на файловом сервере.
Способы кодирования коэффициентов преобразования в соответствии с примерами настоящего изобретения могут быть применены к видеокодированию с поддержкой любого из разнообразных мультимедийных приложений, как, например, вещание по эфирному телевидению, передачи по кабельному телевидению, передачи по спутниковому телевидению, передачи потокового видео, например, по интернету, кодирование цифрового видео для хранения на носителе данных, декодирование цифрового видео, хранящегося на носителе данных, и другие приложения. В некоторых примерах, система 10 может быть выполнена с возможностью поддерживать одностороннюю или двустороннюю видео передачу для поддержки приложений, таких как потоковое видео, воспроизведение видео, широковещание видео и/или видеотелефонию.
В примере на Фиг. 4, устройство-источник 12 включает в себя источник 18 видео, видеокодер 20, модулятор/демодулятор (модем) 22 и передатчик 24. В устройстве-источнике 12, источник 18 видео может включать в себя источник, как, например, устройство видеозахвата, например, видеокамеру, видеоархив, содержащий ранее захваченное видео, интерфейс видеопотока для приема видео от провайдера видеоконтента, и/или систему компьютерной графики для формирования данных компьютерной графики в качестве исходного видео, либо комбинацию таких источников. В качестве примера, если источник 18 видео - это видеокамера, то устройство-источник 12 и устройство-адресат 14 могут составлять так называемые телефоны с камерой или видеотелефоны. Однако, способы, описанные в настоящем изобретении, могут быть применимы к видеокодированию в общем и к беспроводным и/или проводным приложениям.
Захваченное, предварительно захваченное или сформированное компьютером видео может быть закодировано видеокодером 20. Закодированная видеоинформация может быть модулирована модемом 22 в соответствии со стандартом связи, как, например, протокол беспроводной связи, и передана устройству-адресату 14 по передатчику 24. Модем 22 может включать в себя различные микшеры, фильтры, усилители и другие компоненты, предназначенные для модуляции сигнала. Передатчик 24 может включать в себя схемы, предназначенные для передачи данных, включая усилители, фильтры и одну или несколько антенн.
Захваченное, предварительно захваченное или сформированное компьютером видео, закодированное видеокодером 20, может также храниться на носителе 34 или файловом сервере 36 для дальнейшего использования. Носитель 34 может включать в себя диски Blu-ray, DVD, CD-ROM, флэш-память, или любой другой подходящий цифровой носитель для хранения закодированного видео. Устройство-адресат 14 может потом получить доступ к закодированному видео, хранящемуся на носителе 34, чтобы его декодировать и воспроизвести.
Файловый сервер 36 может быть любым типом сервера, способным хранить закодированное видео и передавать это закодированное видео на устройство-адресат 14. Примеры файловых серверов включают в себя вебсервер (например, для вебсайта), FTP-сервер, подключенные к сети устройства сетевого хранилища (NAS) данных, локальный диск, или любой другой тип устройства, способного хранить закодированные видеоданные и передавать их на устройство-адресат. Передача закодированных видеоданных от файлового сервера 36 может быть потоковой передачей, передачей загрузки или их комбинацией. Устройство-адресат 14 может осуществить доступ к файловому серверу 36 посредством любого стандартного соединения данных, включая интернет-соединение. Это может включать в себя беспроводное соединение (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем, сеть Ethernet, USB и так далее) или их комбинацию, которая подходит для доступа к закодированным видеоданным, хранящимся на файловом сервере.
Устройство-адресат 14, в примере на Фиг. 4, включает в себя приемник 26, модем 28, видеодекодер 30 и устройство 32 отображения. Приемник 26 устройства-адресата 14 принимает информацию по каналу 16, и модем 28 демодулирует информацию для получения демодулированного потока битов для видеодекодера 30. Информация, передаваемая по каналу 16, может включать в себя разнообразную синтаксическую информацию, сформированную видеокодером 20 для использования видеодекодером 30 при декодировании видеоданных. Такая синтаксическая информация может также быть включена вместе с закодированными видеоданными, хранящимися на носителе 34 или файловом сервере 36. Видеокодер 20 и видеодекодер 30 могут формировать часть соответствующего кодера-декодера (CODEC), который способен кодировать или декодировать видеоданные.
Устройство 32 отображения может быть интегрировано с устройством-адресатом 14 либо быть внешним по отношению к нему. В некоторых примерах, устройство-адресат 14 может включать в себя устройство отображения. В других примерах, устройство-адресат 14 может быть устройством отображения. В общем, устройство 32 отображения отображает декодированные видеоданные пользователю и может содержать любое из разнообразных устройств отображения, как, например, жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED), или любой другой тип устройства отображения.
В примере на Фиг. 4, канал 16 связи может содержать любую беспроводную или проводную среду связи, как, например, радиочастотный спектр или одну или несколько физических линий передачи, либо любую комбинацию беспроводной и проводной среды. Канал 16 связи может формировать часть пакетной сети, как, например, локальная сеть, широкомасштабная сеть или глобальная сеть, как, например, интернет. Канал 16 связи, в общем, представляет собой любую подходящую среду связи либо совокупность различных сред связи для передачи видеоданных от устройства-источника 12 к устройству-адресату 14, включая любую подходящую комбинацию проводных и беспроводных сред. Канал 16 связи может включать в себя роутеры, коммутаторы, базовые станции или любое другое оборудование, которое может понадобиться для облегчения связи между устройством-источником 12 и устройством-адресатом 14.
Видеокодер 20 и видеодекодер 30 могут работать в соответствии со стандартом видеосжатия, как, например, стандарт видеокодирования высокой эффективности (HEVC), который сейчас находится в разработке, и могут согласовываться с тестовой моделью (HM) HEVC. Альтернативно, видеокодер 20 и видеодекодер 30 могут работать в соответствии с другими частными или индустриальными стандартами, как, например, стандарт ITU-T H.264, иначе называемый MPEG-4, Часть 10, Усовершенствованное Видеокодирование (AVC), или расширения таких стандартов. Способы в настоящем изобретении, однако, не ограничены конкретным стандартом кодирования. Другие примеры включают в себя MPEG-2 и ITU-T H.263.
Хотя на Фиг. 4 это не изображено, в некоторых аспектах видеокодер 20 и видеодекодер 30 могут быть интегрированы с аудиокодером и декодером и могут включать в себя соответствующие элементы MUX-DEMUX либо другие технические средства и программное обеспечение, чтобы кодировать и аудио, и видео в общем потоке данных либо раздельных потоках данных. Если это применимо, в некоторых примерах элементы MUX-DEMUX могут согласовываться с протоколом ITU H.223 мультиплексирования или другими протоколами, как, например, протокол (UDP) пользовательских дейтаграмм.
Видеокодер 20 и видеодекодер 30 могут быть воплощены в качестве любой из разнообразных подходящих схем кодирования, как, например, один или более микропроцессоров, цифровые процессоры (DSP) сигнала, специализированные интегральные схемы (ASIC), программируемые пользователем вентильные матрицы (FPGA), дискретные логические схемы, программное обеспечение, технические средства, программно-аппаратные средства или любые их комбинации. Когда способы частично воплощены в программном обеспечении, устройство может хранить инструкции для программного обеспечения на подходящем, невременном считываемом компьютером носителе и исполнять эти инструкции на технических средствах с помощью одного или более процессоров, чтобы выполнить способы настоящего изобретения. Видеокодер 20 и видеодекодер 30 могут быть включены в один или более кодеров и декодеров, каждый из которых может быть интегрирован с комбинированным кодером/декодером (CODEC) в соответствующем устройстве.
Видеокодер 20 может воплощать любой или все способы настоящего изобретения для улучшения кодирования коэффициентов преобразования в процессе видеокодирования. Подобным образом, видеодекодер 30 воплощать любой или все эти способы улучшения декодирования коэффициентов преобразования в процессе видеокодирования. Видеокодер, как описано в настоящем изобретении, может относиться к видеокодеру или видеодекодеру. Подобным образом, элемент видеодекодера может относиться к видеокодеру или видеодекодеру. Подобным образом, видеокодирование может относиться к видеокодированию или видеодекодированию.
В одном примере раскрытия, видеокодер (как, например, видеокодер 20 или видеодекодер 30) может быть выполнен с возможностью кодировать множество коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Видеокодер может быть выполнен с возможностью кодировать информацию, указывающую значимые коэффициенты для множества коэффициентов преобразования в соответствии с порядком сканирования и кодировать информацию, указывающую уровни множества коэффициентов преобразования в соответствии с порядком сканирования.
В другом примере раскрытия, видеокодер (как, например, видеокодер 20 или видеодекодер 30) может быть выполнен с возможностью кодировать множество коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Видеокодер может быть выполнен с возможностью кодировать информацию, указывающую значимые коэффициенты преобразования в блоке коэффициентов преобразования со сканированием, идущим в обратном направлении сканирования от коэффициентов с высокими частотами в блоке коэффициентов преобразования к коэффициентам с низкими частотами в блоке коэффициентов преобразования.
В другом примере раскрытия, видеокодер (как, например, видеокодер 20 или видеодекодер 30) может быть выполнен с возможностью кодировать множество коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Видеокодер может быть выполнен с возможностью размещать блок коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования, кодировать первую часть уровней коэффициентов преобразования в каждом поднаборе, причем первая часть уровней включает в себя, по меньшей мере, значимость коэффициентов преобразования в каждом поднаборе, и кодировать вторую часть уровней коэффициентов преобразования в каждом поднаборе.
В другом примере раскрытия, видеокодер (как, например, видеокодер 20 или видеодекодер 30) может быть выполнен с возможностью кодировать информацию, указывающую значимые коэффициенты преобразования для множества коэффициентов преобразования, в соответствии с порядком сканирования, разделять закодированную информацию на по меньшей мере первую область и вторую область, кодировать энтропийным кодированием закодированную информацию в первой области в соответствии с первым набором контекстов с помощью критериев выведения контекстов, и кодировать энтропийным кодированием закодированную информацию во второй области в соответствии со вторым набором контекстов с помощью того же критерия выведения контекстов, что и в первой области.
Фиг. 5 является структурной схемой, изображающей пример видеокодера 20, который может применять способы кодирования коэффициентов преобразования, описанные в настоящем изобретении. Видеокодер 20 будет описан в контексте кодирования HEVC с целью иллюстрации, но это не ограничивает настоящее изобретение по отношению к другим стандартам кодирования или способам, которые могут требовать сканирование коэффициентов преобразования. Видеокодер 20 может выполнять внутреннее и внешнее кодирование единиц кодирования (CU) внутри видеокадров. Внутреннее кодирование полагается на пространственное прогнозирование для сокращения или устранения пространственной избыточности в видео внутри заданного видеокадра. Внешнее кодирование полагается на временное прогнозирование для сокращения или устранения временной избыточности между текущим кадром и ранее закодированными кадрами в видеопоследовательности. Внутренний режим (I-режим) может относиться к любому из пространственных режимов сжатия видео. Внешние режимы, как, например, однонаправленное прогнозирование (Р-режим) или двунаправленное прогнозирование (В-режим) могут относиться к любому из временных режимов сжатия видео.
Как изображено на Фиг. 5, видеокодер 20 принимает текущий видеоблок внутри видеокадра, который должен быть кодирован. В примере на Фиг. 5, видеокодер 20 включает в себя элемент 44 компенсации движения, элемент 42 оценки движения, модуль 46 внутреннего прогнозирования, буфер 64 опорного кадра, сумматор 50, модуль 52 преобразования, элемент 54 квантования и элемент 56 энтропийного кодирования. Модуль 52 преобразования, изображенный на Фиг. 5, является модулем, который применяет текущее преобразование к блоку остаточных данных, и его не следует путать с блоком коэффициентов преобразования, который также называют единицей преобразования (TU) для CU. Для восстановления видеоблока, видеокодер 20 также включает в себя элемент 58 обратного квантования, модуль 60 обратного преобразования и сумматор 62. Фильтр удаления блочности (не изображен на Фиг. 5) также может быть включен для фильтрации границ блока, чтобы устранить дефекты блочности из восстановленного видео. При желании, фильтр удаления блочности фильтрует выход сумматора 62.
Во время процесса кодирования, видеокодер 20 принимает видеокадр или слайс, который должен быть кодирован. Кадр или слайс может быть разделен на множество видеоблоков, например, наибольших единиц кодирования (LCU). Элемент 42 оценки движения и элемент 44 компенсации движения выполняют кодирование с внешним прогнозированием принятого видеоблока по отношению к одному или более блокам в одном или более опорных кадрах для обеспечения временного сжатия. Модуль 46 внутреннего прогнозирования может выполнять кодирование с внутренним прогнозированием принятого видеоблока по отношению к одному или более соседним блокам в том же кадре или слайсе, что и блок, который должен быть кодирован, чтобы обеспечить пространственное сжатие.
Элемент 40 выбора режима может выбирать один режим кодирования, внутренний или внешний, например, на основании результатов ошибки (то есть искажения) для каждого режима, и обеспечивает итоговый блок, закодированный во внутреннем или внешнем режиме, на сумматор 50, чтобы формировать остаточные данные блока, и на сумматор 62, чтобы восстановить закодированный блок для применения в опорном кадре. Некоторые видеокадры могут быть предназначены в качестве I-кадров, где все блоки в I-кадре закодированы в режиме внутреннего прогнозирования. В некоторых случаях, модуль 46 внутреннего прогнозирования может выполнять кодирование с внутренним прогнозированием блока в P- или B-кадре, например, когда поиск движения, выполненный элементом 42 оценки движения, не привел к достаточному прогнозированию блока.
Элемент 42 оценки движения и элемент 44 компенсации движения могут быть в высокой степени интегрированы, но изображены отдельно с целью улучшения восприятия. Оценка движения является процессом формирования векторов движения, которые оценивают движение видеоблоков. Вектор движения, например, может указывать смещение единицы прогнозирования текущего кадра по отношению к опорному элементу дискретизации опорного кадра. Опорный элемент дискретизации может быть блоком, который близко совпадает с частью CU, включающей PU, кодируемый с учетом разности пикселов, которая может быть определена путем суммирования (SAD) абсолютных разностей, суммирования (SSD) квадратов разностей или других метрик разности. Компенсация движения, выполненная элементом 44 компенсации движения, может включать загрузку или формирование величин для единицы прогнозирования, на основании вектора движения, определенного оценкой движения. Опять же, в некоторых примерах, элемент 42 оценки движения и элемент 44 компенсации движения могут быть функционально интегрированы.
Элемент 42 оценки движения вычисляет вектор движения для единицы прогнозирования кадра, кодируемого с внутренним прогнозированием, путем сравнения единицы прогнозирования с опорными элементами дискретизации опорного кадра, хранящимися в буфере 64 опорных кадров. В некоторых примерах, видеокодер 20 может вычислять значения для нецелочисленных положений пикселов опорных кадров, хранящихся в буфере 64 опорных кадров. Например, видеокодер 20 может вычислять значения одной четвертой положений пикселов, одной восьмой положений пикселов или других дробных положений пикселов опорного кадра. Следовательно, элемент 42 оценки движения может выполнять поиск движения по отношению к полным положениям пикселов и дробным положениям пикселов и выводить вектор движения с дробной точностью пиксела. Элемент 42 оценки движения отправляет вычисленный вектор движения на элемент 56 энтропийного кодирования и элемент 44 компенсации движения. Часть опорного кадра, идентифицированная вектором движения, может быть опорным элементом дискретизации. Элемент 44 компенсации движения может вычислять значение прогнозирования для единицы прогнозирования текущей CU, например, путем вывода опорного элемента дискретизации, идентифицированного вектором движения для PU.
Модуль 46 внутреннего прогнозирования может кодировать принятый блок с внутренним прогнозированием, в качестве альтернативы внешнему прогнозированию, выполняемому элементом 42 оценки движения и элементом 44 компенсации движения. Модуль 46 внутреннего прогнозирования может кодировать принятый блок по отношению к соседним, ранее закодированным блокам, например, блокам выше, выше и правее, выше и левее или левее текущего блока, при условии, что порядок кодирования для блоков слева направо, сверху вниз. Модуль 46 внутреннего прогнозирования может быть выполнен с разнообразными режимами внутреннего прогнозирования. Например, модуль 46 внутреннего прогнозирования может быть выполнен с конкретным числом режимов направленного прогнозирования, например, 33 режима направленного прогнозирования, на основании размера CU, которая кодируется.
Модуль 46 внутреннего прогнозирования может выбирать режим внутреннего прогнозирования, например, путем вычисления значений ошибки для различных режимов внутреннего прогнозирования и выбора режима с наименьшим значением ошибки. Режимы направленного прогнозирования могут включать в себя функции для объединения значений пространственно соседних пикселов и применения объединенных значений к одному или более положениям пикселов в PU. Как только значения всех положений пикселов в PU вычислены, модуль 46 внутреннего прогнозирования может вычислить значение ошибки для режима прогнозирования на основании разностей пикселов между PU и принятым блоком, который должен быть кодирован. Модуль 46 внутреннего прогнозирования может продолжить тестировать режимы внутреннего прогнозирования до тех пор, пока не будет обнаружен режим внутреннего прогнозирования с приемлемым значением ошибки. Модуль 46 внутреннего прогнозирования может затем отправить PU на сумматор 50.
Видеокодер 20 формирует остаточный блок путем вычитания данных прогнозирования, вычисленных элементом 44 компенсации движения или модулем 46 внутреннего прогнозирования из оригинального видеоблока, который кодируется. Сумматор 50 представляет собой компонент или компоненты, которые выполняют операцию вычитания. Остаточный блок может соответствовать двумерной матрице значений разностей пикселов, где число значений в остаточном блоке то же, что и число пикселов в PU, соответствующей остаточному блоку. Значения в остаточном блоке могут соответствовать разностям, то есть ошибке, между значениями совместно размещенных пикселов в PU и оригинальном блоке, который должен быть кодирован. Разности могут быть разностями цветности или яркости, в зависимости от типа блока, который кодируется.
Модуль 52 преобразования может формировать одну или более единиц преобразования (TU) из остаточного блока. Модуль 52 преобразования применяет преобразование, как, например, дискретное косинусное преобразование (DCT), направленное преобразование, или концептуально близкое преобразование, к TU, получая видеоблок, содержащий коэффициенты преобразования. В конкретных режимах видеокодирования, как, например, режим чередования преобразования, модуль 52 обработки преобразования может отправлять остаточный блок на элемент 54 квантования напрямую, не выполняя преобразования. В таких случаях, остаточные значения могут по-прежнему называться «коэффициентами преобразования», несмотря на то, что никакого преобразования не было в отношении остаточных значений.
Модуль 52 преобразования может отправлять получившиеся коэффициенты преобразования на элемент 54 квантования. Элемент 54 квантования может затем квантовать коэффициенты преобразования. Элемент 56 энтропийного кодирования может затем выполнять сканирование квантованных коэффициентов преобразования в матрице, в соответствии с установленным порядком сканирования. В настоящем изобретении элемент 56 энтропийного кодирования описан как выполняющий сканирование. Однако необходимо понимать, что в других примерах другие элементы обработки, как, например, элемент 54 квантования, могут выполнять сканирование.
Как указано выше, сканирование коэффициентов преобразования может вовлекать два сканирования. Одно сканирование идентифицирует, какие из коэффициентов являются значимыми (то есть, ненулевыми), чтобы сформировать карту значимости, а другое сканирование кодирует уровни коэффициентов преобразования. В одном примере, настоящее изобретение предполагает, что порядок сканирования, используемый для кодирования уровней коэффициентов в блоке, тот же, что и порядок сканирования, используемый для кодирования значимых коэффициентов в карте значимости для блока. В HEVC, блок может быть единицей преобразования. В настоящем документе, термин «порядок сканирования» относится к направлению сканирования и/или к шаблону сканирования. Как таковые, сканирования карты значимости и уровней коэффициентов могут быть одинаковыми в шаблоне сканирования и/или направлении сканирования. То есть, в качестве примера, если порядок сканирования, используемый для формирования карты значимости, является шаблоном горизонтального сканирования в прямом направлении, то тогда порядок сканирования уровней коэффициентов должен также быть шаблоном горизонтального сканирования в прямом направлении. Подобным образом, в качестве другого примера, если порядок сканирования карты значимости является шаблоном вертикального сканирования в обратном направлении, то тогда порядок сканирования уровней коэффициентов должен также быть шаблоном вертикального сканирования в обратном направлении. То же самое может применяться к диагональному, зигзагообразному и другим шаблонам сканирования.
Фиг. 6 изображает примеры обратных порядков сканирования для блока коэффициентов преобразования, то есть блока преобразования. Блок преобразования может быть сформирован с помощью преобразования, как, например, дискретное косинусное преобразование (DCT). Необходимо отметить, что обратный диагональный шаблон 9, обратный зигзагообразный шаблон 29, обратный вертикальный шаблон 31 и обратный горизонтальный шаблон 33 идут от коэффициентов с высокими частотами в нижнем левом углу блока преобразования к коэффициентам с низкими частотами в верхнем правом углу блока преобразования. Следовательно, один аспект настоящего изобретения представляет собой единый порядок сканирования для кодирования карты значимости и кодирования уровней коэффициентов. Сканирование может быть едино в том смысле, что сканирования для кодирования карты значимости и кодирования уровней коэффициентов идут в одинаковом направлении, например, в обратном направлении от коэффициентов с высокими частотами к коэффициентам с низкими частотами, и/или следуют одинаковому шаблону сканирования. Предложенный способ применяет порядок сканирования, используемый для карты значимости, к порядку сканирования, используемому для кодирования уровней коэффициентов. В общем, горизонтальный, вертикальный и диагональный шаблоны сканирования работают хорошо, сокращая необходимость в дополнительных шаблонах сканирования. Однако, общие способы настоящего изобретения применимы для использования с любым шаблоном сканирования.
В соответствии с другим аспектом, настоящее изобретение предполагает, что сканирование значимости выполняется в качестве обратного сканирования, от последнего значимого коэффициента в единице преобразования к первому коэффициенту (то есть коэффициенту DC) единицы преобразования. Примеры обратных порядков сканирования изображены на Фиг. 6. Более конкретно, сканирование значимости идет от последнего значимого коэффициента в положении высокой частоты к значимым коэффициентам в положениях низкой частоты и вплоть до положения коэффициента DC.
Чтобы обеспечить обратное сканирование, можно использовать способы идентификации последнего значимого коэффициента. Процесс идентификации последнего значимого коэффициента описан в работе Д. Соула, Р. Джоши, И. С. Чонга, М. Кобана, М. Карцевича «Параллельная обработка контекста для карты значимости в высокоэффективном кодировании», JCTVC-D262, 4ая встреча JCTVC, Даегу, Южная Корея, январь 2011, и в предварительной заявке № 61/419,740 на патент США, поданной 3 декабря 2010 года Джоэлем Соулом Роялсом и др., под названием «Кодирование положения последнего значимого коэффициента преобразования в видеокодировании». Как только последний значимый коэффициент в блоке идентифицирован, обратный порядок сканирования может быть применен к карте значимости и уровню коэффициентов.
Настоящее изобретение также предполагает, что сканирование значимости и сканирование уровней коэффициентов идут не в обратном и прямом порядке, соответственно, а, наоборот, имеют одинаковое направление сканирования и, более конкретно, только одно направление в блоке. А именно, предполагается, что сканирование значимости и сканирование уровней коэффициентов применяют обратный порядок сканирования, например, от последнего значимого коэффициента в единице преобразования к первому коэффициенту. Следовательно, в одном примере, порядок сканирования выполняется в обратном направлении (обратное направление по отношению к некоторым предложенным сканированиям для HEVC) от последнего значимого коэффициента к первому коэффициенту (коэффициент DC). Этот аспект настоящего изобретения представляет собой единый, однонаправленный порядок сканирования для кодирования карты значимости и кодирования уровней коэффициентов. Более конкретно, единый, однонаправленный порядок сканирования может быть единым обратным порядком сканирования. Порядки сканирования для сканирования значимости и уровней коэффициентов, в соответствии с единым обратным шаблоном сканирования, могут быть обратным диагональным, обратным зигзагообразным, обратным горизонтальным или обратным вертикальным, как изображено на Фиг. 6. Однако может быть использован любой шаблон сканирования.
Вместо определения наборов коэффициентов в двумерных подблоках, как изображено на Фиг. 3, для целей выведения контекста САВАС, настоящее изобретение предполагает определение наборов коэффициентов как нескольких коэффициентов, которые последовательно сканируются в соответствии с порядком сканирования. Более конкретно, каждый набор коэффициентов может содержать последовательные коэффициенты в порядке сканирования во всем блоке. Можно рассмотреть любой размер набора, хотя хорошо работает размер 16 коэффициентов во множестве сканирования. Размер набора может быть фиксированным или адаптивным. Это определение позволяет множествам быть 2-D блоками (если используется способ сканирования подблока), прямоугольниками (если используется горизонтальное или вертикальное сканирование) или диагональной формы (если используется зигзагообразное или диагональное сканирование). Наборы коэффициентов диагональной формы могут быть частью диагональной формы, последовательных диагональных форм или частями последовательных диагональных форм.
Фиг. 7-9 изображают примеры коэффициентов, размещенных по подблокам из 16 коэффициентов, в соответствии с конкретными порядками сканирования, размещенными в фиксированные блоки 4х4. Фиг. 7 изображает поднабор 51 из 16 коэффициентов, который состоит из первых 16 коэффициентов в обратном диагональном порядке сканирования. Следующий поднабор, в данном примере, будет состоять из следующих 16 следующих друг за другом коэффициентов вдоль обратного диагонального порядка сканирования. Подобным образом, Фиг. 8 изображает поднабор 53 из 16 коэффициентов, которое состоит из первых 16 коэффициентов в обратном горизонтальном порядке сканирования. Фиг. 9 изображает поднабор 55 из 16 коэффициентов для первых 16 коэффициентов в обратном вертикальном порядке сканирования.
Этот способ совместим с порядком сканирования для уровней коэффициентов, который тот же, что и порядок сканирования для карты значимости. В таком случае, нет необходимости в ином (и иногда сложном) порядке сканирования для уровней коэффициентов, как изображено на Фиг. 3. Сканирование уровней коэффициентов может быть сформировано как прямое сканирование, которое идет от положения последнего значимого коэффициента в единице преобразования к положению коэффициента DC.
В некоторых предложенных для HEVC процессах, для энтропийного кодирования с применением САВАС, коэффициенты преобразования кодируются следующим образом. Во-первых, идет один проход (в порядке сканирования карты значимости) в полной единице преобразования для кодирования карты значимости. Затем идут три прохода (в порядке сканирования уровней коэффициентов) для кодирования бина 1 уровня (первый проход), остальной части уровня коэффициентов (второй проход) и знака уровня коэффициентов (третий проход). Эти три прохода для кодирования уровней коэффициентов выполняются не в полной единице преобразования. Напротив, каждый проход выполняется в подблоке 4х4, как изображено на Фиг. 3. Когда все три прохода завершены в одном подблоке, происходит обработка следующего подблока путем последовательного выполнения тех же трех проходов кодирования. Этот подход обеспечивает распараллеливание кодирования.
Как описано выше, настоящее изобретение предполагает сканирование коэффициентов преобразования более гармонизированным способом, а именно порядок сканирования для уровней коэффициентов тот же, что и порядок сканирования значимых коэффициентов для формирования карты значимости. Дополнительно, предполагается, что сканирования уровней коэффициентов и значимых коэффициентов выполняются в обратном направлении, которое идет от последнего значимого коэффициента в блоке к первому коэффициенту (компоненте DC) в блоке. Это обратное сканирование противоположно сканированию, используемому для коэффициентов значимости в соответствии с некоторыми проектами для HEVC.
Как описано выше со ссылками на Фиг. 7-9, настоящее изобретение дополнительно предполагает, в одном примере, что контексты для уровней коэффициентов (включая карту значимости) разделены на поднаборы. То есть, контекст определяется для каждого поднабора коэффициентов. Следовательно, в данном примере, тот же контекст не обязательно используется для всего сканирования коэффициентов. Напротив, различные поднаборы коэффициентов внутри блока преобразования могут иметь различные контексты, которые определены индивидуально для каждого поднабора. Каждый поднабор может содержать одномерную матрицу последовательно сканируемых коэффициентов в порядке сканирования. Следовательно, сканирование уровней коэффициентов идет от последнего значимого коэффициента к первому коэффициенту (компоненте DC), где сканирование концептуально разделяют на различные поднаборы последовательно сканируемых коэффициентов в соответствии с порядком сканирования. Например, каждый поднабор может включать в себя n последовательно сканируемых коэффициентов, для конкретного порядка сканирования. Группирование коэффициентов в поднаборы в соответствии с их порядком сканирования может обеспечить лучшую корреляцию между коэффициентами и, таким образом, более эффективное энтропийное кодирование.
Настоящее изобретение дополнительно предполагает увеличение распараллеливания энтропийного кодирования на основании САВАС коэффициентов преобразования путем расширения концепции нескольких проходов уровня коэффициентов для включения дополнительного прохода для карты значимости. Таким образом, пример с четырьмя проходами может включать в себя: (1) кодирование значений флага значимых коэффициентов для коэффициентов преобразования, например, для формирования карты значимости; (2) кодирование бина 1 значений уровня для коэффициентов преобразования; (3) кодирование оставшихся бинов значений уровней коэффициентов; и (4) кодирование знаков уровней коэффициентов, - все в одинаковом порядке сканирования. Используя способы, описанные в настоящем изобретении, можно обеспечить кодирование с четырьмя проходами, описанное выше. То есть, сканирование значимых коэффициентов и уровней для коэффициентов преобразования в том же порядке сканирования, где порядок сканирования идет в обратном направлении от коэффициента с высокой частотой к коэффициенту с низкой частотой, поддерживает способ выполнения кодирования с несколькими проходами, описанный выше.
В другом примере, способ сканирования с пятью проходами может включать в себя: (1) кодирование значений флага значимых коэффициентов для коэффициентов преобразования, например, для формирования карты значимости; (2) кодирование бина 1 значений уровня для коэффициентов преобразования; (3) кодирование бина 2 значений уровня для коэффициентов преобразования; (4) кодирование знаков уровней коэффициентов (например, в режиме обхода); и (5) кодирование оставшихся бинов значений уровня коэффициентов (например, в режиме обхода), причем все проходы используют одинаковый порядок сканирования.
Также можно использовать пример с меньшим количеством проходов. Например, сканирование с двумя проходами, где информация уровней и знака обрабатывается параллельно, может включать в себя: (1) кодирование постоянных бинов в одном проходе (например, значимость, уровень бина 1 и уровень бина 2); и (2) кодирование бинов в режиме обхода в другом проходе (например, оставшиеся уровни и знак), причем каждый проход использует тот же порядок сканирования. Постоянные бины являются бинами, закодированными САВАС с применением обновленного контекста, определенного критериями выведения контекста. Например, как будет описано детально ниже, критерии выведения контекста могут включать в себя закодированную информацию уровней причинного соседнего коэффициента, относящегося к текущему коэффициенту преобразования. Бины в режиме обхода могут быть бинами, закодированными в САВАС и имеющими фиксированный контекст. В некоторых примерах, бины в режиме обхода могут быть закодированы с помощью кодирования Голомба-Райса и экспоненциальных кодов Голомба.
Примеры нескольких проходов сканирования, описанные выше, обобщенно включают в себя первый проход сканирования первой части уровней коэффициентов, причем первая часть включает в себя проход значимости, и второй проход сканирования второй части уровней коэффициентов.
В каждом из примеров, описанных выше, проходы могут быть выполнены последовательно в каждом поднаборе. Хотя применение одномерных поднаборов, содержащих последовательно сканируемые коэффициенты, может быть желательным, способ с несколькими проходами также может быть применен к подблокам, как, например, к подблокам 4х4. Пример обработок с двумя проходами и четырьмя проходами для последовательно сканируемых поднаборов описан детально ниже.
В упрощенной обработке с двумя проходами, для каждого поднабора единицы преобразования первый проход кодирует значимость коэффициентов в поднаборе, следуя порядку сканирования, а второй проход кодирует уровень коэффициентов в поднаборе, следуя тому же порядку сканирования. Порядок сканирования можно охарактеризовать с помощью направления сканирования (прямого или обратного) и шаблона сканирования (например, горизонтального, вертикального или диагонального). Алгоритм может быть более подходящим для параллельной обработки, если оба прохода в каждом поднаборе следуют одинаковому порядку сканирования, как описано выше.
В усовершенствованной обработке с четырьмя проходами, для каждого поднабора единицы преобразования первый проход кодирует значимость коэффициентов в поднаборе, второй проход кодирует бин 1 уровня коэффициентов в поднаборе, третий проход кодирует оставшиеся бины уровня коэффициентов в поднаборе, и четвертый проход кодирует знак уровня коэффициентов в поднаборе. Опять, чтобы больше подходить для параллельной обработки, все проходы в каждом поднаборе должны иметь одинаковый порядок сканирования. Как описано выше, хорошо работает порядок сканирования с обратным направлением. Необходимо отметить, что четвертый проход (то есть, кодирование знака уровней коэффициентов) может быть выполнен сразу после первого прохода (то есть, кодирования карты значимости) или сразу до оставшихся значений прохода уровней коэффициентов.
Для некоторых размеров преобразования, поднабор может быть полной единицей преобразования. В таком случае, есть единственный поднабор, соответствующий всем значимым коэффициентам для всей единицы преобразования, а сканирование значимости и сканирование уровней идут в одинаковом порядке сканирования. В таком случае, вместо ограниченного числа n (например, n=16) коэффициентов в поднаборе, поднабор может быть единственным поднабором для единицы преобразования, причем единственный поднабор включает в себя значимые коэффициенты.
Возвращаясь к Фиг. 5, как только коэффициенты преобразования сканированы, элемент 56 энтропийного кодирования может применять энтропийное кодирование, как, например, CAVLC или САВАС, к коэффициентам. Дополнительно, элемент 56 энтропийного кодирования может кодировать информацию вектора движения (MV) и любые синтаксические элементы, полезные при декодировании видеоданных в видеодекодере 30. Синтаксические элементы могут включать в себя карту значимости с флагами значимых коэффициентов, которые указывают, являются ли конкретные коэффициенты значимыми (например, ненулевыми), и флагом последнего значимого коэффициента, который указывает, является ли конкретный коэффициент последним значимым. Видеодекодер 30 может использовать эти синтаксические элементы для восстановления закодированных видеоданных. Вслед за энтропийным кодированием элементом 56 энтропийного кодирования, получившееся закодированное видео может быть передано на другое устройство, как, например, видеодекодер 30, или архивировано для дальнейшей передачи или вывода.
Чтобы закодировать синтаксические элементы энтропийным кодированием, элемент 56 энтропийного кодирования выполняет САВАС и выбирает контекстные модели на основании, например, числа значимых коэффициентов в ранее сканированных N коэффициентах, где N - это целочисленное значение, которое может относиться к размеру блока, который должен быть сканирован. Элемент 56 энтропийного кодирования может также выбирать контекстную модель на основании режима прогнозирования, применяемого для вычисления остаточных данных, которые были переданы в блок коэффициентов преобразования, и типа преобразования, применяемого для преобразования остаточных данных в блоке коэффициентов преобразования. Когда соответствующие данные прогнозирования были спрогнозированы с помощью режима внутреннего прогнозирования, элемент 56 энтропийного кодирования может дополнительно основывать выбор контекстной модели на направлении режима внутреннего прогнозирования.
Дополнительно, в соответствии с другим аспектом настоящего изобретения, предполагается, что контексты для САВАС разделяют на поднаборы коэффициентов (например, поднаборы, изображенные на Фиг. 7-9). Предполагается, что каждый поднабор состоит из следующих друг за другом коэффициентов в порядке сканирования в полном блоке. Можно рассмотреть любой размер поднаборов, хотя хорошо работает размер из 16 коэффициентов в сканируемом поднаборе. В данном примере, поднабор может быть из 16 следующих друг за другом коэффициентов в порядке сканирования, который может быть любым шаблоном сканирования, включая подблочный, диагональный, зигзагообразный, горизонтальный и вертикальный шаблоны сканирования. В соответствии с этим предположением, сканирование уровней коэффициентов идет от последнего значимого коэффициента в блоке. Следовательно, сканирование уровней коэффициентов идет от последнего значимого коэффициента к первому коэффициенту (компоненте DC) в блоке, где сканирование концептуально разделяют на различные поднаборы коэффициентов в порядке, чтобы вывести контексты для применения. Например, сканирование распределено в поднаборы n следующих друг за другом коэффициентов в порядке сканирования. Последний значимый коэффициент является первым значимым коэффициентом, обнаруженным в обратном сканировании от коэффициента с высокой частотой в блоке (как правило, обнаруженного в нижнем правом углу блока) к коэффициенту DC блока (верхний левый угол блока).
В другом аспекте настоящего изобретения, предполагается, что критерии выведения контекста САВАС гармонизируются для всех размеров блоков. Другими словами, вместо различных выведений контекстов на основании размера блока, как описано выше, каждый размер блока основывается на одинаковом выведении для контекстов САВАС. Таким образом, нет необходимости принимать в расчет конкретный размер блока для выведения контекста САВАС для блока. Выведение контекста также одинаково для кодирования значимости и кодирования уровней коэффициентов.
Также предполагается, что наборы контекстов САВАС зависят от того, является ли поднабор поднабором 0 (определенным как поднабор с коэффициентами для самых низких частот, то есть содержащий коэффициент DC и смежное с коэффициентами с низкой частотой) или нет (то есть критерием выведения контекста). Смотрите Таблицы 3а и 3б ниже.
Таблица 3а - Таблица наборов контекстов. Для сравнения с Таблицей 2. Есть зависимость от поднаборов, является ли поднабор 0 (низкие частоты) или нет.
|
Согласно Таблице 3а выше, наборы 0-2 контекстных моделей используются для поднаборов сканирования с самой низкой частотой (то есть, наборы n следующих друг за другом коэффициентов), если, соответственно, ноль коэффициентов больше единицы в ранее закодированном поднаборе; один коэффициент больше единицы в ранее закодированном поднаборе; или больше одного коэффициента больше единицы в ранее закодированном поднаборе. Наборы 3-5 контекстных моделей используются для всех поднаборов с частотой выше, чем у поднаборов с самой низкой частотой, если, соответственно, ноль коэффициентов больше единицы в ранее закодированном поднаборе; один коэффициент больше единицы в ранее закодированном поднаборе; или больше одного коэффициента больше единицы в ранее закодированном поднаборе.
|
Таблица 3б изображает таблицу наборов контекстов, которое показало хорошую производительность в отношении более точного подсчета числа коэффициентов больше единицы в предыдущем поднаборе. Таблица 3б может быть использована в качестве альтернативы Таблице 3а выше.
Таблица 3в показывает упрощенную таблицу наборов контекстов с критериями выведения контекста, которая также могут быть использованы в качестве альтернативы.
|
Дополнительно, поднабор, содержащий последний значимый коэффициент в единице преобразования, может использовать уникальный набор контекстов.
Настоящее изобретение также предполагает, что контекст для поднаборов зависит от числа коэффициентов больше 1 в предыдущих поднаборах. Например, если число коэффициентов в предыдущих поднаборах - скользящее окно, то пусть это число будет uiNumOne. Как только это значение проверяется для определения контекста для текущего сканируемого поднабора, то это значение не устанавливается равным нулю. Напротив, это значение нормализовано (например, используем uiNumOne=uiNumOne/4, которая эквивалентна uiNumOne >>=2, или uiNumOne=uiNumOne/2, которая эквивалентна uiNumOne >>=1). Таким образом, значения поднаборов до непосредственно предыдущих поднаборов могут быть рассмотрены, но при решении контекста САВАС их вес меньше для текущего кодируемого поднабора. Более конкретно, решение контекста САВАС для заданного поднабора принимает в расчет не только число коэффициентов больше единицы в непосредственно предшествующем поднаборе, но также и взвешенное число коэффициентов больше единицы в ранее закодированных поднаборах.
Дополнительно, набор контекстов может зависеть от следующего: (1) от числа значимых коэффициентов в текущем сканируемом поднаборе, и (2) того, является ли текущий поднабор последним поднабором со значимым коэффициентом (то есть, используя обратный порядок сканирования, это относится к тому, является ли поднабор первым сканируемым для уровней коэффициентов или нет). Дополнительно, контекстная модель для уровней коэффициентов может зависеть от того, является ли текущий коэффициент последним коэффициентом.
Высокоадаптивный подход к выбору контекста был ранее предложен для кодирования карты значимости блоков 16х16 и 32х32 коэффициентов преобразования в HEVC. Необходимо отметить, что этот подход к выбору контекста может быть расширен для всех размеров блоков. Как изображено на Фиг. 10, этот подход разделяет блок 16х16 на четыре области, где каждый коэффициент в области 41 с низкой частотой (четыре коэффициента в верхнем левом углу в х, у координатах [0,0], [0,1], [1,0], [1,1] в примере блока 16х16, где [0,0] указывает верхний левый угол, коэффициент DC) имеет свой собственный контекст, коэффициенты в верхней области 37 (коэффициенты в верхнем ряду х, у координат от [2,0] до [15,0] в примере блока 16х16) имеют 3 контекста, коэффициенты в левой области 35 (коэффициенты в левой колонке х, у координат от [0,2] до [0,15] в примере блока 16х16) имеют другие 3 контекста, и коэффициенты в оставшейся области 39 (оставшиеся коэффициенты в блоке 16х16) имеют 5 контекстов. Выбор контекста для коэффициента Х преобразования в области 39, в качестве примера, основан на сумме значимости максимально 5 коэффициентов преобразования B, E, F, H и I. Так как Х независим от других положений на той же диагональной линии Х вдоль направления сканирования (в этом примере зигзагообразный или диагональный шаблон сканирования), то контекст значимости коэффициентов преобразования вдоль диагональной линии в порядке сканирования может быть вычислен параллельно из предыдущих диагональных линий в порядке сканирования.
Предложенные контексты для карты значимости, как изображено на Фиг. 10, действительны, только если порядок сканирования прямой, так как контекст становится непричинным в декодере, если применяется обратный порядок сканирования. То есть, декодер еще не декодировал коэффициенты B, E, F, H и I, как изображено на Фиг. 10, если применяется обратный порядок сканирования. В результате, поток битов не подлежит декодированию.
Однако настоящее раскрытие предполагает использование обратного порядка сканирования. В таком случае, карта значимости имеет соответственную корреляцию среди коэффициентов, когда порядок сканирования идет в обратном направлении, как изображено на Фиг. 6. Следовательно, применение обратного сканирования для карты значимости, как описано выше, предлагает желаемую эффективность кодирования. Также, использование обратного сканирования для карты значимости служит для гармонизации сканирования, применяемого для кодирования уровней коэффициентов и карты значимости. Для поддержки обратного сканирования значимых коэффициентов, необходимо менять контексты так, чтобы они были сопоставимы с обратным сканированием. Предполагается, что кодирование значимых коэффициентов использует контексты, которые являются причинными по отношению к обратному сканированию.
Настоящее изобретение дополнительно предполагает, в одном примере, способ кодирования карты значимости, который применяется в контексте, изображенном на Фиг. 11. Каждый коэффициент в области 43 с низкой частотой (три коэффициента в верхнем левом углу в х, у координатах [0,0], [0,1], [1,0] в примере блока 16х16, где [0,0] указывает верхний левый угол, коэффициент DC) имеет свое собственное выведение контекста. Коэффициенты в верхней области 45 (коэффициенты в верхнем ряду х, у координат от [2,0] до [15,0] в примере блока 16х16) имеют контексты, зависящие от значимости двух предыдущих коэффициентов в верхней области 45 (например, два коэффициента непосредственно справа от коэффициента, который должен быть кодирован, где такие коэффициенты являются причинными соседями для целей декодирования, с учетом обратного сканирования).
Коэффициенты в левой области 47 (коэффициенты в левой колонке х, у координат от [0,2] до [0,15] в примере блока 16х16) имеют контекст, зависящий от значимости двух предыдущих коэффициентов (например, два коэффициента непосредственно под коэффициентом, который должен быть кодирован, где такие коэффициенты являются причинными соседями для целей декодирования, с учетом обратного направления сканирования). Необходимо отметить, что эти контексты в верхней области 45 и нижней области 47 на Фиг. 11 являются обратными контекстам, изображенным на Фиг. 10 (например, где коэффициенты в верхней области 37 имеют контекст, зависящий от коэффициентов слева, и коэффициенты в левой области 35 имеют контекст, зависящий от коэффициентов сверху). Возвращаясь к Фиг. 11, контексты для коэффициентов в оставшейся области 49 (то есть, оставшиеся коэффициенты вне низкочастотной области 43, верхней области 45 и левой области 47) зависят от суммы (или любой другой функции) значимости коэффициентов в положениях, обозначенных I, H, F, E и В.
В другом примере, коэффициенты в верхней области 45 и левой области 47 могут использовать то же выведение контекста, что и коэффициенты в области 49. При обратном сканировании это возможно, так как соседние положения, обозначенные как I, H, F, E и В, доступны для коэффициентов в верхней области 45 и левой области 47. В конце рядов/колонок, положения для причинных коэффициентов I, H, E, F и В могут быть вне блока. В таком случае, предполагается, что значение таких коэффициентов равно нулю (то есть, незначимо).
При выборе контекста есть больше опций. Основная идея заключается в использовании значимости коэффициентов, которые уже закодированы в соответствии с порядком сканирования. В примере, изображенном на Фиг. 10, контекст коэффициентов в положении Х выводят на основании суммы значимости коэффициентов в положениях B, E, F, H и I. Эти коэффициенты контекстов идут перед текущим коэффициентом в обратном порядке сканирования, предложенном в настоящем изобретении для карты значимости. Контексты, которые были причинными в прямом сканировании, становятся непричинными (недоступными) в обратном порядке сканирования. Способ решения этой проблемы - зеркально отобразить контексты в обычном случае на Фиг. 10 на те, которые изображены на Фиг. 11, для обратного сканирования. Для сканирования значимости, которое идет в обратном направлении от последнего значимого коэффициента к положению коэффициента DC, соседство контекстов для коэффициента Х состоит из коэффициентов B, E, F, H, I, которые связаны с положениями с высокой частотой по отношению к положению коэффициента Х, и которые уже обработаны кодером или декодером в обратном сканировании до кодирования коэффициента Х.
Как описано выше, контексты и контекстные модели, изображенные в Таблицах 1 и 2, нацелены на применение локальной корреляции уровней коэффициентов среди подблоков 4х4. Однако зависимость может быть слишком удаленной. То есть, зависимость может быть слишком маленькой между коэффициентами, которые удалены друг от друга на несколько коэффициентов, например, от одного подблока к другому. Также, внутри каждого подблока, зависимость между коэффициентами может быть очень слабой. Настоящее изобретение описывает способы решения этих проблем путем создания наборов контекстов для уровней коэффициентов, которые применяют более локальное соседство контекста.
Настоящее изобретение предполагает применение локального соседства для выведения контекста уровней коэффициентов преобразования, например, в видеокодировании, в соответствии с HEVC или другими стандартами. Соседство состоит из уже закодированных (или декодированных) коэффициентов, имеющих высокую корреляцию с уровнем текущего коэффициента. Коэффициенты могут соседствовать пространственно с коэффициентом, который должен быть кодирован, и могут включать в себя коэффициенты, которые привязаны к коэффициенту, который должен быть кодирован, и другие соседние коэффициенты, как, например, изображенные на Фиг. 11 или Фиг. 13. Причем коэффициенты, используемые для выведения контекста, не ограничены подблоком или предыдущим подблоком. Напротив, локальное соседство может содержать коэффициенты, которые расположены пространственно близко к коэффициенту, который должен быть кодирован, но не обязательно находятся в том же подблоке, что и коэффициент, который должен быть кодирован, либо в том же подблоке, что и другой, если коэффициенты были размещены в подблоки. Вместо того, чтобы полагаться на коэффициенты, расположенные в фиксированном подблоке, настоящее изобретение предполагает применение соседних коэффициентов, которые доступны (то есть уже закодированы), с учетом конкретного порядка сканирования.
Различные наборы контекстов САВАС могут быть установлены для различных поднаборов коэффициентов, например, на основании ранее закодированных поднаборов коэффициентов. Внутри заданного поднабора коэффициентов, контексты выводят на основании локального соседства коэффициентов, иногда называемого контекстным соседством. В соответствии с настоящим изобретением, пример контекстного соседства изображен на Фиг. 12. Коэффициенты в контекстном соседстве могут быть пространственно расположены рядом с коэффициентом, который должен быть кодирован.
Как изображено на Фиг. 12, для прямого сканирования, контекст уровней для коэффициента Х преобразования зависит от значений коэффициентов B, E, F, H и I. В прямом сканировании, коэффициенты B, E, F, H и I связаны с низкочастотными положениями по отношению к положению и коэффициенту Х, и уже обработаны кодером или декодером до кодирования коэффициента Х.
Для кодирования бина 1 для САВАС, контекст зависит от суммы чисел значимых коэффициентов в этом контекстном соседстве (то есть, в данном примере, коэффициентов B, E, F, H и I). Если коэффициент в контекстном соседстве выпадает из блока, что происходит вследствие потери данных, то можно считать, что его значение равно 0 для целей определения контекста коэффициента Х. Для кодирования оставшихся бинов для САВАС, контекст зависит от суммы чисел коэффициентов в соседстве, которые равны 1, а также от суммы чисел коэффициентов в соседстве, которые больше 1. В другом примере, контекст для бина 1 может зависеть от суммы значений бина 1 коэффициентов в локальном контекстном соседстве. В другом примере, контекст для бина 1 может зависеть от комбинации суммы значимых коэффициентов и значений бина 1 в этом контекстном соседстве.
Есть много возможностей для выбора контекстного соседства. Однако контекстное соседство должно быть составлено из коэффициентов так, чтобы кодер и декодер имели доступ к одной и той же информации. Более конкретно, коэффициенты B, F, E, I и H в соседстве должны быть причинными соседями в том смысле, что они ранее закодированы или декодированы и доступны для ссылки на них для определения контекста для коэффициента Х.
Контексты, описанные выше со ссылкой на Фиг. 12, являются одной из многих возможностей. Такие контексты могут быть применены к любому из трех сканирований, предложенных в настоящее время для использования в HEVC: диагональному, горизонтальному и вертикальному. Настоящее изобретение предполагает, что контекстное соседство, используемое для выведения контекста для уровней коэффициентов, может быть тем же, что и контекстное соседство, используемое для выведения контекста для карты значимости. Например, контекстное соседство, используемое для выведения контекста для уровней коэффициентов, может быть локальным соседством, как и в случае для кодирования карты значимости.
Как описано детально выше, настоящее изобретение предполагает применение обратного порядка сканирования для сканирования значимых коэффициентов для формирования карты значимости. Обратный порядок сканирования может быть обратным зигзагообразным шаблоном, вертикальным шаблоном или горизонтальным шаблоном, как изображено на Фиг. 6. Если порядок сканирования для сканирования уровней коэффициентов также идет по обратному шаблону, то контекстное соседство, изображенное на Фиг. 12, становится непричинным. Настоящее изобретение предполагает повернуть положение контекстного соседства так, чтобы оно было причинным со ссылкой на обратный порядок сканирования. Фиг. 13 изображает пример контекстного соседства для обратного порядка сканирования.
Как изображено на Фиг. 13, для сканирования уровней, которое идет в обратном направлении от последнего значимого коэффициента до положения коэффициента DC, контекстное соседство для коэффициента Х состоит из коэффициентов B, E, F, H и I, которые связаны с высокочастотными положениями по отношению к положению коэффициента Х. С учетом обратного порядка сканирования, коэффициенты B, E, F, H и I уже обработаны кодером или декодером, до кодирования коэффициента Х, и, следовательно, причинные в том смысле, что они доступны. Подобным образом, это контекстное соседство может быть применено к уровням коэффициентов.
Настоящее изобретение дополнительно предполагает, в одном примере, другой способ кодирования карты значимости, который применяет контексты, выбранные для поддержки обратного сканирования. Как описано выше, высокоадаптивный подход к выбору контекста предложен для HEVC для кодирования карты значимости блоков 16х16 и 32х32 коэффициентов преобразования. Например, как описано выше со ссылкой на Фиг. 10, этот подход разделяет блок 16х16 на четыре области, где каждое положение в области 41 имеет свой собственный набор контекстов, область 37 имеет контексты, область 35 имеет другие 3 контекста, и область 39 имеет 5 контекстов. Выбор контекста для коэффициента Х преобразования, в качестве примера, основан на сумме значимости максимум 5 положений B, E, F, H, I. Так как Х независим от других положений на той же диагональной линии Х вдоль направления сканирования, то контекст значимости коэффициентов преобразования вдоль диагональной линии в порядке сканирования может быть вычислен параллельно из предыдущих диагональных линий в порядке сканирования.
По меньшей мере, в одном подходе, предложенном для HEVC, выведение контекста имеет несколько недостатков. Один заключается в числе контекстов на блок. Чем больше контекстов, тем больше памяти и больше обработки требуется каждый раз, когда обновляются контексты. Следовательно, преимущественно иметь алгоритм, у которого мало контекстов и также мало способов генерировать контексты (например, меньше чем четыре способа, то есть четыре шаблона в предыдущем примере).
Один способ решить такие недостатки - кодирование карты значимости в обратном порядке, то есть от последнего значимого коэффициента (с высокой частотой) к компоненте DC (с самой низкой частотой). Следствием этого процесса в обратном порядке является то, что контексты в прямом порядке сканирования недействительны. Способы, описанные выше, включают в себя способ определения контекстов для контекстно-адаптивного двоичного арифметического кодирования (САВАС) информации, указывающей текущий из значимых коэффициентов, на основании ранее закодированных коэффициентов в обратном направлении сканирования. В примере обратного зигзагообразного сканирования, ранее закодированные значимые коэффициенты находятся в положениях справа от линии сканирования, на которой находится текущий из значимых коэффициентов.
Генерирование контекста может быть различным для различных положений блоков преобразования на основании, по меньшей мере, расстояния от границ и расстояния от компоненты DC. В примере способа, описанном выше, предлагается, что кодирование карты значимости использует наборов контекстов, изображенных на Фиг. 11.
Настоящее изобретение предполагает набор контекстов для обратного сканирования карты значимости, которое может привести к лучшей производительности посредством сокращения числа контекстов на блок. Со ссылкой на Фиг. 11, сокращение числа контекстов на блок можно достигнуть путем применения левой областью 47 и верхней областью 45 одинакового выведения контекста, что и у оставшейся области 49. При обратном сканировании это возможно, так как соседние положения, обозначенные как I, H, F, E и В, доступны для коэффициентов в областях 47 и 45.
Фиг. 14 изображает пример выведения контекста в соответствии с данным примером. В данном примере есть только две контекстные области: низкочастотная область 57 для коэффициента DC и оставшаяся область 59 для всех других коэффициентов. В таком случае, данный пример предполагает только два способа выведения контекста. В низкочастотной области 57 (коэффициент DC в х, у положении [0,0]) контекст выводят на основании положения, то есть коэффициент DC имеет свой собственный контекст. В оставшейся области 57 контекст выводят на основании значимости соседних коэффициентов в локальном соседстве для каждого коэффициента, который должен быть кодирован. В данном примере его выводят в зависимости от суммы значимости 5 соседей, обозначенных I, H, F, E и В на Фиг. 14.
Следовательно, число способов для выведения контекста внутри блока сокращается с 4 до 2. Также, число контекстов сокращается на 8 по отношению к предыдущему примеру на Фиг. 11 (2 для низкочастотной области 43 и по 3 для верхней области 45 и левой области 47). В другом примере, коэффициент DC может применять тот же способ, что и оставшийся блок, так что число способов выведения контекста внутри блока сокращается до 1.
Фиг. 15 изображает пример, где текущее положение коэффициента Х ведет к тому, что некоторые из соседних коэффициентов (в данном случае, H и В) находятся вне текущего блока. Если любые из соседних к текущему коэффициенту находятся вне блока, то можно предположить, что такие соседние коэффициенты имеют значимость 0 (то есть, у них нулевое значение и, следовательно, они незначимы). Альтернативно, один или более специальных контекстов могут быть установлены для одного или более коэффициентов в правом углу. В таком случае коэффициенты с высокими частотами могут иметь контексты в зависимости от положения, подобным образом, что и коэффициент DC. Однако если предположить, что соседи равны нулю, то можно обеспечить достаточные результаты, более конкретно вследствие того, что коэффициенты с низкими частотами будут иметь низкую вероятность значимых коэффициентов или, по меньшей мере, значимых коэффициентов с большими значениями.
Сокращение числа контекстов в примере на Фиг. 14 подходит для воплощения. Однако оно может привести к небольшой потере производительности. Настоящее изобретение предполагает дополнительный способ улучшения производительности и одновременного сокращения числа контекстов. Более конкретно, предполагается второй набор контекстов, который также основан на соседних коэффициентах. Алгоритм выведения контекста точно такой же, но используются два набора контекстов с различными моделями вероятности. Набор контекстов, которые используются, зависит от положения коэффициента, который должен быть кодирован, внутри единицы преобразования.
Более конкретно, рост производительности был продемонстрирован при использовании контекстной модели для коэффициентов с высокими частотами (например, нижние правые х, у положения коэффициентов), которая отличается от контекстной модели для коэффициентов в низких частотах (например, верхние левые х, у положения коэффициентов). Один способ отделить коэффициенты с низкими частотами от коэффициентов с высокими частотами и, таким образом, контекстную модель, используемую для них, заключается в вычислении значения х+у для коэффициента, где х - горизонтальное положение, а у - вертикальное положение коэффициента. Если это значение меньше, чем некое пороговое значение (например, хорошо работает 4), то используется набор 1 контекстов. Если значение равно или больше, чем пороговое значение, то выбирается набор 2 контекстов. Опять, наборы 1 и 2 контекстов имеют различные модели вероятности.
Фиг. 16 изображает пример контекстных областей для этого примера. Опять, коэффициент DC в положении (0,0) имеет свою собственную контекстную область 61. Низкочастотная контекстная область 63 состоит из коэффициентов преобразования в положении х+у, равном или меньше чем порог 4 (не включая коэффициент DC). Высокочастотная контекстная область 65 состоит из коэффициентов преобразования в положении х+у больше чем порог 4. Порог 4 используется в качестве примера и может быть установлен в любое число, которое обеспечивает лучшую производительность. В другом примере, порог может зависеть от размера TU.
Выведение контекста для низкочастотной контекстной области 63 и высокочастотной контекстной области 65 совершенно одинаково в смысле того, как используют соседей для выбора контекста, но применяемые вероятности (то есть контексты) отличаются. Более конкретно, может быть использован одинаковый критерий для выбора контекста на основании соседей, но применение такого критерия ведет к выбору различных контекстов для различных положений коэффициентов, так как различные положения коэффициентов могут быть связаны с различными наборами контекстов. В таком случае, знание того, что коэффициенты с низкой и высокой частотами имеют различные статистики, закладывается в алгоритм, так что можно применять различные наборы контекстов для различных коэффициентов.
В других примерах, функцию х+у можно сменить другими функциями в зависимости от положения коэффициента. Например, одна опция - это дать одинаковый набор контекстов всем коэффициентам с х<T и у<T, где Т является порогом. Фиг. 17 изображает пример блока коэффициентов преобразования с этими контекстными областями. Опять, коэффициент DC в положении (0,0) может иметь свою собственную контекстную область 61. Низкочастотная контекстная область 73 состоит из всех коэффициентов преобразования, чьи положения Х и У меньше или равны порогу 4 (не включая коэффициент DC). Высокочастотная контекстная область состоит из всех коэффициентов преобразования, чьи положения Х и У больше чем порог 4. Опять, порог 4 используется в качестве примера и может быть установлен как любое число, которое обеспечивает лучшую производительность. В одном примере, порог может зависеть от размера TU.
Вышеописанные способы, изображенные на Фиг. 16 и 17, имеют два набора из 5 контекстов, что по-прежнему меньше чем число контекстов, изображенное на Фиг. 10, и дает лучшую производительность. Это достигается путем разделения блока на различные области и определения различных наборов контекстов для коэффициентов в различных областях, но с применением одинаковых критериев выведения контекстов к каждой области.
Фиг. 18 изображает другой пример блока коэффициентов преобразования с контекстными областями. В данном примере, коэффициент DC в области 81 и коэффициенты в положениях х, у (1,0) и (0,1), в областях 83 и 85, имеют свои собственные контексты. Оставшаяся область 87 имеет другой контекст. В варианте этого примера, изображенном на Фиг. 18, области 83 и 85 имеют одинаковый контекст.
В общем, вышеописанные способы могут включать в себя сканирование значимых коэффициентов в блоке коэффициентов преобразования в обратном направлении от коэффициентов с высокими частотами в блоке коэффициентов преобразования к коэффициентам с низкими частотами в блоке коэффициентов преобразования для формирования карты значимости, и определение контекстов для контекстно-адаптивного двоичного арифметического кодирования (CABAC) значимых коэффициентов карты значимости на основании локального соседства ранее сканированных коэффициентов в блоке. Контексты могут быть определены для каждого значимого коэффициента на основании ранее сканированных коэффициентов преобразования в локальном соседстве, имеющем более высокие частоты, чем соответствующий коэффициент преобразования. В некоторых примерах, контексты могут быть определены на основании суммы числа значимых коэффициентов среди ранее закодированных коэффициентов контекстного соседства. Локальное соседство для каждого значимого коэффициента, который должен быть кодирован, может содержать набор коэффициентов преобразования, которые пространственно соседствуют с соответствующим коэффициентом в блоке.
Контекст для значимого коэффициента в положении DC (например, верхнем левом) блока коэффициентов преобразования может быть определен на основании индивидуального контекста, определенного для значимого коэффициента в положении DC. Также, контекст может быть определен для коэффициентов в левом крае и верхнем крае блока с помощью критерия, существенно похожего или идентичного критерию, используемому для определения контекста для коэффициентов, которые находятся не в левом краю и не в верхнем краю блока. В некоторых примерах, контекст для коэффициента в нижнем правом положении блока может быть определен с помощью критерия, который предполагает, что соседние коэффициенты вне блока являются нулевыми коэффициентами. Также, в некоторых примерах, определение контекста может содержать определение контекста для коэффициентов с помощью существенно похожего или идентичного критерия для выбора контекстов внутри не одного наборов контекстов, но различных наборов контекстов, на основании положений коэффициентов внутри блока коэффициентов преобразования.
Ссылка на верхний, нижний, правый, левый и так далее в настоящем изобретении используется в основном для удобства ссылки на соответственные положения коэффициентов с высокой частотой и низкой частотой в блоке коэффициентов преобразования, которые размещены традиционным образом так, что коэффициенты с низкой частотой находятся ближе к верхней левой части, а коэффициенты с высокой частотой - к нижней правой части блока, что не ограничивает те случаи, когда коэффициенты с высокой и низкой частотами могут быть размещены другим, нетрадиционным образом.
Возвращаясь к Фиг. 5, в некоторых примерах, модуль 52 преобразования может быть выполнен с возможностью обнулять некоторые коэффициенты преобразования (то есть, коэффициенты преобразования в некоторых местоположениях). Например, модуль 52 преобразования может быть выполнен с возможностью обнулять все коэффициенты преобразования вне верхнего левого квадранта TU исходя из преобразования. В качестве другого примера, элемент 56 энтропийного кодирования может быть выполнен с возможностью обнулять коэффициенты преобразования в матрице исходя их некоторого положения в матрице. В любом случае, видеокодер 20 может быть выполнен с возможностью обнулять некоторую часть коэффициентов преобразования, например, до или после сканирования. Фраза «обнулять» используется для обозначения того, что устанавливается нулевое значение коэффициента, но не обязательно этот коэффициент пропускается или не рассматривается. В некоторых примерах, это установление коэффициентов на нуле может быть дополнительно к обнулению, которое происходит в результате квантования.
Элемент 58 обратного квантования и модуль 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, для восстановления остаточного блока в области пикселов, например, для дальнейшего использования в качестве опорного блока. Элемент 44 компенсации движения может вычислять опорный блок путем добавления остаточного блока к блоку прогнозирования одного из кадров буфера 64 опорных кадров. Элемент 44 компенсации движения может также применять один или более интерполяционных фильтров к восстановленному остаточному блоку для вычисления нецелочисленных значений пикселов для применения при оценке движения. Сумматор 62 добавляет восстановленный остаточный блок к блоку прогнозирования с компенсированным движением, произведенному элементом 44 компенсации движения, для произведения восстановленного видеоблока для хранения в буфере 64 опорных кадров. Восстановленный видеоблок может быть использован элементом 42 оценки движения и элементом 44 компенсации движения в качестве опорного блока для временного кодирования блока в последующем видеокадре.
Фиг. 19 является структурной схемой, изображающей пример элемента 56 энтропийного кодирования для использования в видеокодере на Фиг. 5. Фиг. 19 иллюстрирует разнообразные функциональные аспекты элемента 56 энтропийного кодирования для выбора порядка сканирования и соответствующего набора контекстов, используемого в энтропийном кодировании САВАС. Элемент 56 энтропийного кодирования может включать в себя элемент 90 выбора порядка сканирования и контекста, элемент 92 сканирования 2D-в-1D, механизм 94 энтропийного кодирования и память 96 порядка кодирования.
Элемент 90 выбора порядка сканирования и контекста выбирает порядок сканирования, который будет использоваться элементом 92 сканирования 2D-в-1D для сканирования карты значимости и сканирования уровней коэффициентов. Как описано выше, порядок сканирования состоит из шаблона сканирования и направления сканирования. Память 96 сканирования может хранить инструкции и/или данные, которые определяют, какой порядок сканирования использовать в конкретных ситуациях. В качестве примеров, режим прогнозирования кадра или слайса, размер блока, преобразование или другие характеристики видеоданных могут быть использованы для выбора порядка сканирования. В одном предложении для HEVC, каждый из режимов внутреннего прогнозирования назначен конкретному порядку сканирования (подблочный диагональный, горизонтальный или вертикальный). Декодер анализирует режим внутреннего прогнозирования и определяет, какой порядок сканирования применить, с помощью справочной таблицы. Адаптивные способы могут быть использованы для отслеживания статистики самых частых значимых коэффициентов. В другом примере, сканирование может быть основано на самых часто используемых коэффициентах, первых в порядке сканирования. В качестве другого примера, элемент 90 выбора порядка сканирования и контекста может использовать порядок сканирования для всех ситуаций. Как описано выше, элемент 90 выбора порядка сканирования и контекста может выбирать порядок сканирования для сканирования карты значимости и уровней коэффициентов. В соответствии со способами настоящего изобретения, два сканирования могут иметь одинаковый порядок сканирования и, в частности, могут оба быть в обратном направлении.
На основании выбранного порядка сканирования, элемент 90 выбора порядка сканирования и контекста также выбирает контексты, которые будут применены в САВАС в механизме 94 энтропийного кодирования, как, например, контексты, описанные выше со ссылкой на Фиг. 11 и Фиг. 13-18.
Элемент 92 сканирования 2D-в-1D применяет выбранные сканирования к двумерной матрице коэффициентов преобразования. Более конкретно, элемент 92 сканирования 2D-в-1D может сканировать коэффициенты преобразования в поднаборы, как описано выше со ссылкой на Фиг. 7-9. Более конкретно, коэффициенты преобразования сканируют в поднаборы, состоящих из числа следующих друг за другом коэффициентов, в соответствии с порядком сканирования. Такие поднаборы применимы для сканирования карты значимости и сканирования уровней коэффициентов. Дополнительно, элемент 92 сканирования 2D-в-1D может выполнять сканирования карты значимости и уровней коэффициентов в качестве последовательных сканирований и в соответствии с одинаковым порядком сканирования. Последовательные сканирования могут состоять из нескольких сканирований, как описано выше. В одном примере, первое сканирование является сканированием карты значимости, второе сканирование - бина один уровней коэффициентов преобразования в каждом поднаборе, третье сканирование - оставшихся бинов уровней коэффициентов преобразования, и четвертое сканирование - знака уровней коэффициентов преобразования.
Механизм 94 энтропийного кодирования применяет процесс энтропийного кодирования к сканированным коэффициентам с помощью контекста, выбранного элементом 90 выбора порядка сканирования и контекста. В некоторых примерах контекст, используемый для САВАС, может быть определен заранее для всех случаев, и в таком случае, нет необходимости в том, чтобы процесс или элемент выбирал контекст. Процесс энтропийного кодирования может быть применен к коэффициентам после того, как они полностью сканированы в 1D вектор, или после того, как каждый коэффициент добавлен к 1D вектору. В других примерах, коэффициенты обрабатываются прямо в 2D матрице с помощью порядка сканирования. В некоторых случаях, механизм 94 энтропийного кодирования может быть выполнен с возможностью кодировать различные участки 1D вектора параллельно, чтобы способствовать распараллеливанию процесса энтропийного кодирования для увеличения скорости и эффективности. Механизм 94 энтропийного кодирования производит поток битов, несущий закодированное видео. Поток битов может быть передан на другое устройство или храниться в архиве данных для дальнейшего выведения. В дополнение к оставшимся данным коэффициентов преобразования, поток битов может нести данные вектора движения и различные синтаксические элементы, полезные для декодирования закодированного видео в потоке битов.
Дополнительно, элемент 56 энтропийного кодирования может обеспечить передачу сигналов в закодированном потоке битов видео, чтобы указать порядок сканирования и/или контексты, используемые в процессе САВАС. Порядок сканирования и/или контексты могут быть переданы, например, в качестве сигналов синтаксических элементов на различных уровнях, как, например, слайс, LCU, уровень CU или уровень TU. Если порядок сканирования и/или контекст установлены заранее, то нет необходимости в обеспечении передачи сигнала в закодированном потоке битов. Также, в некоторых примерах, видеодекодер 30 может выводить значения параметров без передачи сигнала. Чтобы разрешить определение различных порядков сканирования для различных TU, желательно передавать такие синтаксические элементы на уровень TU, например, в заголовок дерева квадрантов TU. Хотя передача сигналов в закодированном потоке битов видео описывается для целей иллюстрации, информация, указывающая значения параметров или функцию, может быть передана как внеполосная дополнительная информация.
В данном контексте, передача сигналов порядка сканирования и/или контекстов в закодированном потоке битов не требует передачи в режиме реального времени таких элементов от кодера к декодеру, но означает, что такие синтаксические элементы кодируются в поток битов и делаются доступными декодеру в любом виде. Это может включать в себя передачу в режиме реального времени (например, в видеоконференции), а также хранение закодированного потока битов на считываемом компьютером носителе для будущего использования декодером (например, при воспроизведении потокового видео, загрузке, доступа к диску, доступа к карте, DVD, Blu-ray и так далее).
Необходимо отметить, что хотя для более понятной иллюстрации они изображены как отдельные функциональные элементы, элемент 90 выбора порядка сканирования и контекстов, элемент 92 сканирования 2D-в-1D, механизм 94 энтропийного кодирования и память 96 порядка сканирования могут быть интегрированы друг с другом структурно и функционально.
Фиг. 20 является структурной схемой, изображающей пример видеодекодера 30, который декодирует закодированную видеопоследовательность. В примере на Фиг. 20, видеодекодер 30 включает в себя элемент 70 энтропийного кодирования, элемент 72 компенсации движения, модуль 74 внутреннего прогнозирования, элемент 76 обратного квантования, элемент 78 обратного преобразования, буфер 82 опорных кадров, сумматор 80. Видеодекодер 30 может, в некоторых примерах, выполнять проход декодирования в общем противоположный проходу кодирования, описанному по отношению к видеокодеру 20 (Фиг. 5).
Элемент 70 энтропийного декодирования декодирует закодированное видео в процессе, который противоположен процессу, используемому элементом 56 энтропийного кодирования на Фиг. 5. Элемент 72 компенсации движения может генерировать данные прогнозирования на основании векторов движения, принятых от элемента 70 энтропийного декодирования. Модуль 74 внутреннего прогнозирования может генерировать данные прогнозирования для текущего блока текущего кадра на основании переданных сигналов режима внутреннего прогнозирования и данных из ранее закодированных блоков текущего кадра.
В некоторых примерах, элемент 70 энтропийного декодирования (или элемент 76 обратного квантования) может сканировать принятые значения с помощью зеркального сканирования порядка сканирования, используемого элементом 56 энтропийного кодирования (или элементом 54 квантования) видеокодера 20. Хотя сканирование коэффициентов может быть выполнено в элементе 76 обратного квантования, с целью иллюстрации, будет описано сканирование, выполняемое элементом 70 энтропийного декодирования. Дополнительно, хотя для более понятной иллюстрации они изображены как отдельные функциональные элементы, элемент 70 энтропийного кодирования, элемент 76 обратного квантования и видеодекодер 30 могут быть интегрированы друг с другом структурно и функционально.
В соответствии со способами настоящего изобретения, видеодекодер 30 может сканировать карту значимости коэффициентов преобразования и уровни коэффициентов преобразования в соответствии с тем же порядком сканирования. То есть, порядок сканирования для карты значимости и уровня должен иметь одинаковый шаблон и направление. Дополнительно, видеодекодер 30 может использовать порядок сканирования для карты значимости в обратном направлении. В качестве другого примера, видеодекодер 30 может использовать порядок сканирования для карты значимости для кодирования уровня, который гармонизирован в обратном направлении.
В другом аспекте настоящего изобретения, видеодекодер 30 может сканировать коэффициенты преобразования в поднаборах. В частности, коэффициенты преобразования сканируют в поднаборе, состоящем из числа следующих друг за другом коэффициентов в соответствии с порядком сканирования. Такие поднаборы применимы к сканированию карты значимости и сканированию уровня коэффициентов. Дополнительно, видеодекодер 30 может выполнять сканирование карты значимости и сканирование уровня коэффициентов в соответствии с тем же порядком сканирования. В одном аспекте, порядок сканирования является обратным порядком сканирования. Последовательные сканирования могут состоять из нескольких сканирований. В одном примере, первое сканирование является сканированием карты значимости, второе сканирование - бина один уровней коэффициентов преобразования в каждом поднаборе, третье сканирование - оставшихся бинов уровней коэффициентов преобразования, и четвертое сканирование - знака уровней коэффициентов преобразования.
Видеодекодер 30 может принимать из закодированного потока битов передачу сигналов, которая указывает порядок сканирования и/или контексты для САВАС от видеокодера 20. Дополнительно, или альтернативно, порядок сканирования и контексты могут быть выведены видеодекодером 30 на основании характеристик закодированного видео, как, например, режим прогнозирования, размер блока, или других характеристик. В качестве другого примера, видеокодер 20 и видеодекодер 30 могут использовать заранее установленные порядки сканирования и контексты во всех случаях, при этом не требуется передавать сигналы в закодированном потоке битов.
Независимо от того, как определяют порядок сканирования, элемент 70 энтропийного декодирования использует обратный порядок сканирования, чтобы сканировать 1D вектор в 2D матрицу. 2D матрица коэффициентов преобразования, произведенная элементом 70 энтропийного декодирования, может быть квантована и в общем совпадать с 2D матрицей коэффициентов преобразования, сканированной элементом 56 энтропийного кодирования видеокодера 20, для создания 1D вектора коэффициентов преобразования.
Элемент 76 обратного квантования квантует, то есть деквантует, квантованные коэффициенты преобразования, обеспеченные в потоке битов и декодированные элементом 70 энтропийного декодирования. Процесс обратного квантования может включать в себя обычный процесс, например, похожий на процессы, предложенные для HEVC или определенные стандартом Н.264 декодирования. Процесс обратного квантования может включать в себя использование параметра QP квантования, вычисленного видеокодером 20 для CU для определения степени квантования и, подобным образом, степени обратного квантования, которая будет применена. Элемент 76 обратного квантования может квантовать обратно коэффициенты преобразования либо до, либо после того, как коэффициенты конвертированы из 1D вектора в 2D матрицу.
Модуль 78 обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование, обратное KLT, обратное преобразование вращения, обратное направленное преобразование, или другое обратное преобразование. В некоторых примерах, модуль 78 обратного преобразования может определять обратное преобразование на основании передачи сигналов от видеокодера 20, или путем вывода преобразования из одной или более характеристик кодирования, как, например, размер блока, режим кодирования и тому подобное. В некоторых примерах, модуль 78 обратного преобразования может определять преобразование для применения к текущему блоку на основании сигнализированного преобразования в корневом узле дерева квадрантов для LCU, включая текущий блок. В некоторых примерах, модуль 78 обратного преобразования может применять каскадное обратное преобразование.
Элемент 72 компенсации движения производит блоки с компенсированным движением, возможно выполняя интерполяцию на основании интерполяционных фильтров. Идентификаторы для интерполяционных фильтров, которые используют для оценки движения с точностью до подпиксела, могут быть включены в синтаксические элементы. Элемент 72 компенсации движения может использовать интерполяционные фильтры так же, как и видеокодер 20 во время кодирования видеоблока, для вычисления интерполяционных значений для подпикселов опорного блока. Элемент 72 компенсации движения может определять интерполяционные фильтры, используемые видеокодером 20, в соответствии с принятой синтаксической информацией для производства блоков прогнозирования.
Элемент 72 компенсации движения и модуль 74 внутреннего прогнозирования, в примере HEVC, могут использовать часть синтаксической информации (например, обеспеченной деревом квадрантов) для определения размеров LCU, используемых для кодирования кадра(ов) закодированной видеопоследовательности. Элемент 72 компенсации движения и модуль 74 внутреннего прогнозирования могут также использовать синтаксическую информацию для определения информации разделения, которая описывает, как разделяется каждая CU кадра закодированной видеопоследовательности (и, подобным образом, как разделяются под-CU). Синтаксическая информация может также включать в себя режимы, указывающие, как кодируется каждое разделение (например, внутреннее или внешнее прогнозирование, и для внутреннего прогнозирования режим кодирования внутреннего прогнозирования), один или более опорных кадров (и/или опорных списков, содержащих идентификаторы для опорных кадров) для каждой PU, кодируемой во внешнем прогнозировании, и другую информацию для декодирования закодированной видеопоследовательности.
Сумматор 80 комбинирует остаточные блоки с соответствующими блоками прогнозирования, сформированными элементом 72 компенсации движения или модулем 74 внутреннего прогнозирования, для формирования декодированных блоков. Если это желательно, фильтр удаления блочности может также применяться для фильтрации декодированных блоков, чтобы устранить дефекты блочности. Декодированные видеоблоки затем хранятся в буфере 82 опорного кадра, который обеспечивает опорные блоки для компенсации последовательного движения и также производит декодированное видео для представления на устройстве отображения (как, например, устройство 32 отображения на Фиг. 4).
Как указано выше, способы сканирования коэффициентов преобразования, представленные в настоящем изобретении, применимы для кодера и декодера. Видеокодер может применять порядок сканирования для сканирования коэффициентов преобразования из двумерной матрицы в одномерную матрицу, в то время как видеодекодер может применять порядок сканирования, например, обратным образом по сравнению с кодером, для сканирования коэффициентов преобразования из одномерной матрицы в двумерную матрицу. Альтернативно, видеодекодер может применять порядок сканирования для сканирования коэффициентов преобразования из одномерной матрицы в двумерную матрицу, и видеокодер может применять порядок сканирования обратным образом по сравнению с декодером для сканирования коэффициентов преобразования из двумерной матрицы в одномерную матрицу. Следовательно, сканирование кодером может относиться к 2D-в-1D сканированию кодером или к 1D-в-2D сканированию декодером. Дополнительно, сканирование в соответствии с порядком сканирования может относиться к сканированию в порядке сканирования для 2D-в-1D сканирования, сканированию в порядке сканирования для 1D-в-2D сканирования, сканированию в обратном порядке сканирования для 1D-в-2D сканирования, или сканированию в обратном порядке сканирования для 2D-в-1D сканирования. Следовательно, порядок сканирования может быть установлен для сканирования кодером или сканирования декодером.
Видеодекодер 30 может работать способом, по существу симметричным по отношению к тому, которым работает видеокодер 20. Например, видеодекодер 30 может принимать данные энтропийного кодирования, представляющие закодированную CU, включая закодированные данные PU и TU. Видеодекодер 30 может применять обратное энтропийное кодирование к принятым данным, формируя закодированные коэффициенты квантования. Когда видеокодер 20 энтропийно кодирует данные с помощью алгоритма арифметического кодирования (например, САВАС), видеодекодер 30 может использовать контекстную модель для декодирования данных, которая соответствует той же контекстной модели, используемой видеокодером 20 для кодирования данных.
Видеодекодер 30 может также обратно сканировать декодированные коэффициенты, используя обратное сканирование, которое зеркально отображает сканирование, используемое видеокодером 20. Чтобы обратно сканировать коэффициенты, видеодекодер 30 выбирает тот же порядок сканирования, используемый видеокодером 20, который может храниться в декодере или передаваться сигналами кодером в закодированном потоке битов. С помощью этого порядка сканирования, видеодекодер 30 формирует двумерную матрицу из одномерного вектора квантованных коэффициентов преобразования, получившихся в процессе энтропийного декодирования. В частности, видеодекодер 30 обратно сканирует коэффициенты из одномерной матрицы в двумерную матрицу в соответствии с порядком сканирования, используемом видеокодером 20.
Далее, видеодекодер 30 может обратно квантовать коэффициенты в двумерной матрице, произведенной обратным сканированием, выполненным в соответствии с порядком сканирования. Видеодекодер 30 может затем применять одно или более обратных преобразований к двумерной матрице. Обратные преобразования могут соответствовать преобразованиям, примененным видеокодером 20. Видеодекодер 30 может определять обратные преобразования, которые применит, на основании, например, информации, переданной сигналами в корне дерева квадрантов, соответствующей CU, которая декодируется в настоящий момент, или путем ссылки на другую информацию, указывающую соответственные обратные преобразования. При применении обратного преобразования(й), видеодекодер 30 восстанавливает остаточные видеоданные в области пикселов и применяет декодирование с внутренним прогнозированием или внешним прогнозированием, в зависимости от ситуации, чтобы восстановить оригинальные видеоданные.
Фиг. 21 является структурной схемой, изображающей пример элемента 70 энтропийного декодирования для применения в видеодекодере на Фиг. 20. Фиг. 21 изображает различные функциональные аспекты элемента 70 энтропийного декодирования для выбора порядка сканирования и контекстов, используемых для декодирования САВАС в процессе видеодекодирования. Как изображено на Фиг. 21, элемент 70 энтропийного декодирования может включать в себя элемент 100 выбора порядка сканирования и контекстов, элемент 102 сканирования 1D-в-2D, механизм 104 энтропийного декодирования и память 106 порядка сканирования.
Механизм 104 энтропийного декодирования энтропийно декодирует закодированное видео, переданное на видеодекодер 30 или выведенное видеодекодером 30 из устройства хранения. Например, механизм 104 энтропийного декодирования может применять процесс энтропийного декодирования, например, CAVLC, САВАС или другой процесс, к потоку битов, несущему закодированное видео, для восстановления 1D вектора коэффициентов преобразования. В дополнение к остаточным данным коэффициентов преобразования, механизм 104 энтропийного декодирования может применять энтропийное декодирование для воспроизводства данных вектора движения и различных синтаксических элементов, нужных при декодировании закодированного видео в потоке битов. Механизм 104 энтропийного декодирования может определять, какой процесс энтропийного декодирования, например, CAVLC, САВАС или другой процесс, выбрать на основании передачи сигналов в потоке битов закодированного видео или путем вывода соответственного процесса из другой информации в потоке битов.
В соответствии со способами настоящего изобретения, механизм 104 энтропийного декодирования может энтропийно декодировать закодированное видео, используя САВАС, в соответствии с двумя различными контекстными областями. Элемент 100 выбора порядка сканирования и контекстов может обеспечить вывод контекстов механизму 104 энтропийного декодирования. В соответствии с примерами настоящего изобретения, вывод контекстов для первой контекстной области зависит от положения коэффициентов преобразования, в то время как вывод контекстов для второй контекстной области зависит от причинных соседей коэффициентов преобразования. В другом примере, вторая контекстная область может использовать две различные контекстные модели, в зависимости от местоположения коэффициентов преобразования.
Элемент 100 выбора порядка сканирования и контекстов может также определять порядок сканирования, и/или указание порядка сканирования, на основании передачи сигналов в потоке битов закодированного видео. Например, элемент 70 энтропийного декодирования может принимать синтаксические элементы, которые явно сигнализируют порядок сканирования. Опять, хотя передача сигналов в потоке битов закодированного видео описывается для целей иллюстрации, порядок сканирования может быть принят элементом 70 энтропийного декодирования как внеполосная дополнительная информация. Также, в некоторых примерах, возможно, что элемент 100 выбора порядка сканирования и контекстов выводит порядок сканирования без передачи сигналов. Порядок сканирования может быть основан на режиме прогнозирования, размере блока, преобразовании и других характеристиках закодированного видео. Как память 96 на Фиг. 19, память 106 порядка сканирования на Фиг. 21 может хранить инструкции и/или данные, определяющие порядок сканирования.
Элемент 102 сканирования 1D-в-2D принимает порядок сканирования от элемента 100 выбора порядка сканирования и контекстов и применяет порядок сканирования либо напрямую, либо в обратном порядке для управления сканированием коэффициентов. В соответствии со способами настоящего изобретения, тот же порядок сканирования может быть использован для сканирования карты значимости и уровня коэффициентов. В другом аспекте настоящего изобретения, сканирование карты значимости может быть в обратном направлении. В другом аспекте настоящего изобретения, сканирование карты значимости и сканирование уровня коэффициентов могут быть в обратном направлении.
В соответствии с другим аспектом настоящего изобретения, элемент 102 сканирования 1D-в-2D может сканировать одномерную матрицу коэффициентов преобразования в один или более поднаборов коэффициентов преобразования, кодируя значимость коэффициентов преобразования в каждом поднаборе и кодируя уровни коэффициентов преобразования в каждом поднаборе. В другом аспекте настоящего изобретения, сканирование карты значимости и уровня коэффициентов выполняются последовательными сканированиями в соответствии с тем же порядком сканирования. В одном аспекте, порядок сканирования является обратным порядком сканирования. Последовательные сканирования могут состоять из нескольких сканирований, где первое сканирование является сканированием карты значимости, второе сканирование - бина один уровней коэффициентов преобразования, третье сканирование - оставшихся бинов уровней коэффициентов преобразования, и четвертое сканирование - знака уровней коэффициентов преобразования.
На стороне кодера, кодирование коэффициентов преобразования может содержать кодирование коэффициентов преобразования в соответствии с порядком сканирования для формирования одномерной матрицы коэффициентов преобразования. На стороне декодера, кодирование коэффициентов преобразования может содержать декодирование коэффициентов преобразования в соответствии с порядком сканирования для восстановления двумерной матрицы коэффициентов преобразования в блоке преобразования.
Необходимо отметить, что хотя для более понятной иллюстрации они изображены как отдельные функциональные элементы, элемент 100 выбора порядка сканирования и контекстов, элемент 102 сканирования 1D-в-2D, механизм 104 энтропийного декодирования и память 106 порядка сканирования могут быть интегрированы друг с другом структурно и функционально.
Фиг. 22 является блок-схемой последовательности операций, изображающей пример процесса сканирования карты значимости и уровней коэффициентов с гармонизированным порядком сканирования. Предлагается способ кодирования множества коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Способ может быть выполнен видеокодером, как, например, видеокодер 20 или видеодекодер 30 на Фиг. 4. Видеокодер может быть выполнен с возможностью выбирать порядок (120) сканирования. Порядок сканирования может быть выбран на основании режима прогнозирования, размера блока, преобразования и других характеристик видео. Дополнительно, порядок сканирования может быть установленным по умолчанию порядком сканирования. Порядок сканирования определяет шаблон сканирования и направление сканирования. В одном примере, направление сканирования является обратным направлением сканирования, идущим от коэффициентов с высокими частотами в совокупности коэффициентов преобразования к коэффициентам с низкими частотами в множестве коэффициентов преобразования. Шаблон сканирования может включать в себя любой из зигзагообразного шаблона, диагонального шаблона, горизонтального шаблона или вертикального шаблона.
Видеокодер может быть дополнительно выполнен с возможностью кодировать информацию, указывающую значимые коэффициенты для множества коэффициентов преобразования в соответствии с порядком сканирования (122) и определять контексты для кодирования уровней значимых коэффициентов для множества поднаборов значимых коэффициентов, причем каждая совокупность поднаборов содержит один или более значимых коэффициентов, сканируемых в соответствии с порядком сканирования (124). Видеокодер также кодирует информацию, указывающую уровни множества коэффициентов преобразования, в соответствии с порядком сканирования (126). Поднаборы могут быть различных размеров. Необходимо отметить, что этапы 122, 124 и 126 могут чередоваться, так как определение контекстов для информации уровней зависит от ранее закодированных соседних коэффициентов.
Фиг. 23 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов и вывода контекстов САВАС. Способ на Фиг. 23 слегка отличается от изображенного на Фиг. 22, так как контексты блоков различных размеров могут использовать одинаковый критерий выведения контекста. В качестве примера, видеокодер может выводить первый контекст для первого блока коэффициентов преобразования, причем первый блок имеет первый размер, в соответствии с критерием выведения контекста, и выводить второй контекст для второго блока коэффициентов преобразования, причем второй блок имеет второй, отличный размер, в соответствии с тем же критерием выведения контекста, что и для первого блока (123). Как на Фиг. 22, этапы 122, 123 и 126 могут чередоваться, так как определение контекстов для информации уровней зависит от ранее закодированных соседних коэффициентов.
Фиг. 24 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов и вывода контекстов САВАС. Способ на Фиг. 24 слегка отличается от изображенного на Фиг. 22, так как контексты для поднаборов определяются на основании присутствия коэффициента DC в поднаборе. В качестве примера, видеокодер может определять различные наборы контекстов для различных поднаборов коэффициентов на основании того, содержат ли соответственные поднаборы коэффициент DC преобразования (125). Как на Фиг. 22, этапы 122, 125 и 126 могут чередоваться, так как определение контекстов для информации уровней зависит от ранее закодированных соседних коэффициентов.
Фиг. 25 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов и вывода контекстов САВАС. Способ на Фиг. 25 слегка отличается от изображенного на Фиг. 22, так как контексты определяются на основании взвешенного числа значимых коэффициентов в других предшествующих поднаборах. В качестве примера, видеокодер может определять различные наборы контекстов для различных поднаборов коэффициентов на основании числа значимых коэффициентов в непосредственно предшествующем поднаборе коэффициентов и взвешенного числа значимых коэффициентов в других предшествующих поднаборах коэффициентов (127). Как на Фиг. 22, этапы 122, 127 и 126 могут чередоваться, так как определение контекстов для информации уровней зависит от ранее закодированных соседних коэффициентов.
Фиг. 26 является блок-схемой последовательности операций, изображающей пример процесса кодирования карты значимости с помощью обратного направления сканирования. Предлагается способ кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Способ может быть выполнен видеокодером, как, например, видеокодер 20 или видеодекодер 30 на Фиг. 4. Видеокодер может быть выполнен с возможностью выбирать порядок сканирования с обратным направлением (140) и определять контексты для контекстно-адаптивного двоичного арифметического кодирования (CABAC) информации, указывающей текущий из значимых коэффициентов, на основании ранее закодированных значимых коэффициентов в обратном направлении сканирования (142). Видеокодер может быть дополнительно выполнен с возможностью кодировать информацию, указывающую значимые коэффициенты преобразования вдоль направления обратного сканирования для формирования карты значимости (146).
В одном примере, сканирование имеет диагональный шаблон, и ранее закодированные значимые коэффициенты находятся в положениях справа от линии сканирования, на которой находится текущий из значимых коэффициентов. В другом примере, сканирование имеет горизонтальный шаблон, и ранее закодированные значимые коэффициенты находятся в положениях снизу от линии сканирования, на которой находится текущий из значимых коэффициентов. В другом примере, сканирование имеет вертикальный шаблон, и ранее закодированные значимые коэффициенты находятся в положениях справа от линии сканирования, на которой находится текущий из значимых коэффициентов.
Видеокодер может быть дополнительно выполнен с возможностью кодировать информацию, указывающую уровни значимых коэффициентов преобразования (148). Этап кодирования информации, указывающей уровни значимых коэффициентов преобразования, может идти в обратном направлении сканирования от коэффициентов с высокими частотами в блоке коэффициентов преобразования к коэффициентам с низкими частотами в блоке коэффициентов преобразования. Как на Фиг. 22, этапы 142, 146 и 148 могут чередоваться, так как определение контекстов для информации уровней зависит от ранее закодированных соседних коэффициентов.
Фиг. 27 является блок-схемой последовательности операций, изображающей пример процесса сканирования карты значимости и уровней коэффициентов в соответствии с поднаборами коэффициентов преобразования. Предлагается способ кодирования коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Способ может быть выполнен видеокодером, как, например, видеокодер 20 или видеодекодер 30 на Фиг. 4. Видеокодер может быть выполнен с возможностью размещать блок коэффициентов преобразования в один или более поднаборов коэффициентов преобразования (160), кодировать значимость коэффициентов преобразования в каждом поднаборе (162) и кодировать уровни коэффициентов преобразования в каждом поднаборе (164). В одном примере, размещение блока коэффициентов преобразования может включать в себя размещение блока коэффициентов преобразования в единый набор коэффициентов преобразования, соответствующий полной единице преобразования. В другом примере, размещение блока коэффициентов преобразования может включать в себя размещение блока коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования.
Видеокодер может быть выполнен с возможностью кодировать значимость коэффициентов преобразования в каждом поднаборе в соответствии с порядком сканирования и кодировать уровни коэффициентов преобразования в соответствии с порядком сканирования. Кодирование карты значимости (162) и уровней (164) может быть выполнено совместно в двух или более последовательных проходах на поднаборе (165).
Фиг. 28 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и уровней коэффициентов в соответствии с поднаборами коэффициентов преобразования. Видеокодер может выполнять последовательные сканирования (165), кодируя сначала значимость коэффициентов преобразования в поднаборе первого сканирования коэффициентов преобразования в соответственном поднаборе (170).
Кодирование уровней коэффициентов (164) в каждом поднаборе включает в себя по меньшей мере второе сканирование коэффициентов преобразования в соответственном поднаборе. Второе сканирование может включать в себя кодирование бина один уровней коэффициентов преобразования в поднаборе во втором сканировании коэффициентов преобразования в соответственном поднаборе (172), кодирование оставшихся бинов уровней коэффициентов преобразования в поднаборе в третьем сканировании коэффициентов преобразования в соответственном поднаборе (174), и кодирование знака уровней коэффициентов преобразования в поднаборе в четвертом сканировании коэффициентов преобразования в соответственном поднаборе (176).
Фиг. 29 является блок-схемой последовательности операций, изображающей другой пример процесса сканирования карты значимости и коэффициентов преобразования в соответствии с поднаборами коэффициентов преобразования. В этом примере, кодирование знака уровней коэффициентов преобразования (176) выполняется до кодирования уровней (172, 174).
Фиг. 30 является блок-схемой последовательности операций, изображающей пример процесса энтропийного кодирования с помощью множественных областей. Предлагается способ кодирования множества коэффициентов преобразования, связанных с остаточными видеоданными в процессе видеокодирования. Способ может быть выполнен видеокодером, как, например, видеокодер 20 или видеодекодер 30 на Фиг. 4. Видеокодер может быть выполнен с возможностью кодировать информацию, указывающую значимые коэффициенты для множества коэффициентов преобразования, в соответствии с порядком сканирования (180), разделять закодированную информацию на первую область и вторую область (182), энтропийно кодировать закодированную информацию в первой области, в соответствии с первым набором контекстов с помощью контекстно-адаптивного двоичного арифметического кодирования (184), и энтропийно кодировать закодированную информацию во второй области, в соответствии со вторым набором контекстов с помощью контекстно-адаптивного двоичного арифметического кодирования (186). В одном примере, порядок сканирования имеет обратное направление и диагональный шаблон сканирования. Этот способ может также быть применен более чем к двум областям, причем каждая область имеет набор контекстов.
Первая и вторая области могут быть разделены несколькими способами. В одном примере, первая область содержит, по меньшей мере, компоненту DC множества коэффициентов преобразования, а вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
В другом примере, первая область содержит все коэффициенты преобразования внутри области, определенной х+у<Т, где х - горизонтальное положение коэффициента преобразования, у - вертикальное положение коэффициента преобразования, а Т - порог. Первая область может содержать коэффициент DC. Вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
В другом примере, первая область содержит все коэффициенты преобразования внутри области, определенной х<Т и у<Т, где х - горизонтальное положение коэффициента преобразования, у - вертикальное положение коэффициента преобразования, а Т - порог. Вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
В другом примере, первая область содержит коэффициент DC, вторая область содержит все коэффициенты преобразования (за исключением коэффициента DC) внутри области, определенной х<Т и у<Т, где х - горизонтальное положение коэффициента преобразования, у - вертикальное положение коэффициента преобразования, а Т - порог, и третья область содержит оставшееся множество коэффициентов преобразования не в первой или второй областях. В другом примере, вторая и третья области, описанные выше, могут использовать тот же способ для вывода контекстов, но используются различные наборы контекстов для каждой области.
В другом примере, первая область включает в себя компоненту DC и коэффициенты преобразования в положениях (1,0) и (0,1). Вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
В другом примере, первая область содержит только компоненту DC множества коэффициентов преобразования, а вторая область содержит оставшееся множество коэффициентов преобразования.
В общем, первый контекст для каждого коэффициента преобразования в первой области основан на положении каждого коэффициента преобразования в первой области, в то время как второй контекст для каждого коэффициента преобразования во второй области основан на закодированной информации причинных соседей положения каждого коэффициента преобразования. В некоторых примерах, второй контекст дополнительно основан на положении каждого коэффициента преобразования во второй области. В другом примере, второй контекст каждого коэффициента преобразования во второй области основан на закодированной информации пяти причинных соседей каждого коэффициента преобразования.
Фиг. 31 изображает пример порядка бинов 190 для кодирования коэффициентов преобразования, связанных с остаточными видеоданными. Видеокодер (как, например, видеокодер 20 или видеодекодер 30) может кодировать бины 190 с помощью двух различных режимов кодирования. Например, видеокодер может определять, кодировать ли бины 190 с помощью контекстно-адаптивного режима кодирования, например, САВАС или другого контекстно-адаптивного процесса (каждый из которых здесь и далее именуется как «постоянный» режим), либо режима обхода кодирования (именуемого как режим обхода). В примере, изображенном на Фиг. 31, видеокодер может кодировать бины 192 (незатемненные блоки) в постоянном режиме и может кодировать бины 194 (затемненные блоки) в режиме обхода. Бины 192, закодированные в постоянном режиме, могут именоваться как «постоянные бины 192», а бины 194, закодированные в режиме обхода, могут именоваться как «бины 194 обхода».
Для кодирования бинов 192 в постоянном режиме кодирования, видеокодер может использовать контекстно-адаптивную модель вероятности, как описано выше, например, используя обычный механизм кодирования САВАС. То есть, постоянный режим процесса САВАС может использовать адаптивную контекстную модель, как описано выше, например, по отношению к элементу 56 энтропийного кодирования или элементу 70 энтропийного декодирования. Напротив, для кодирования бинов 194 в режиме обхода, видеокодер может использовать упрощенный арифметический процесс кодирования, имеющий фиксированную вероятность. Например, видеокодер может кодировать бины 194 обхода в САВАС, имеющие фиксированный контекст в качестве режима обхода. В некоторых примерах, видеокодер может кодировать бины 194 обхода с помощью кодирования Голомба-Райса и/или экспоненциальных кодов Голомба в качестве режима обхода кодирования. Видеокодер может определять, следует ли использовать постоянный режим или режим обхода на основании, например, того, насколько равномерно бины распределены в блоке коэффициентов преобразования. В некоторых примерах, видеокодер может быть заранее выполнен с возможностью кодировать определенные бины в постоянном режиме, а другие бины - в режиме кодирования.
В примере, изображенном на Фиг. 31, бины 190 включают в себя В1 (бин 1), В2 (бин 2), бин GR-EG (Голомб-Райс-Экспоненциальный Голомб), закодированные в режиме обхода, S (знак) и cu_header, все из которых могут быть обеспечены в CU. Бины 190 могут соответствовать следующим синтаксическим элементам: В1 может соответствовать coeff_abs_level_greater1_flag, В2 может соответствовать coeff_abs_level_greater2_flag, GR-EG может соответствовать coeff_abs_level_minus3, S может соответствовать coeff_sign_flag, и cu_header может соответствовать всем другим синтаксическим элементам в CU. То есть, в общем, бин 1 для конкретного коэффициента преобразования может указывать, имеет ли конкретный коэффициент преобразования значение больше 1. Подобным образом, бин 2 для конкретного коэффициента преобразования может указывать, имеет ли конкретный коэффициент преобразования значение больше 2. В других примерах, больше или меньше синтаксических элементов могут быть представлены бинами 190.
Как указано выше, в одном примере, также предложенном для использования со стандартом HEVC, видеокодер может кодировать коэффициенты преобразования множественными проходами кодирования, которые могут именоваться как сканирования. Например, видеокодер может выполнять первый проход в порядке сканирования карты значимости во всей TU для кодирования значимости коэффициентов преобразования в TU. Видеокодер может затем выполнять три дополнительных прохода для поднаборов коэффициентов преобразования в порядке сканирования уровней коэффициентов. Эти три прохода могут включать в себя: первый проход для первого бина (бин 1) абсолютного значения уровня коэффициентов, второй проход для второго бина (бин 2) абсолютного значения уровня коэффициентов и третий проход оставшегося значения уровня коэффициентов и знака уровня коэффициентов. Опять, в некоторых примерах, каждый из трех проходов уровней коэффициентов может быть выполнен в поднаборах n (например, n=16) следующих друг за другом коэффициентов в порядке сканирования, как описано выше. Когда три прохода завершены в одном поднаборе, видеокодер может последовательно обрабатывать следующий поднабор, выполняя те же три прохода кодирования. Этот подход к кодированию поднаборов может способствовать распараллеливанию кодирования для уровней коэффициентов преобразования.
В соответствии с аспектами настоящего изобретения, как отмечено выше, видеокодер может дополнительно усиливать распараллеливание и пропускную способность кодирования остаточных данных (например, используя процесс контекстно-адаптивного кодирования, как САВАС) с помощью дополнительных улучшений в переупорядочивании данных. Например, как описано выше, видеокодер может выполнять один или более проходов для кодирования значимости коэффициентов преобразования в поднаборе (например, следуя порядку сканирования). Видеокодер может затем выполнять один или более дополнительных проходов для кодирования уровня коэффициентов в поднаборе (например, следуя тому же порядку сканирования). Порядок сканирования может быть охарактеризован направлением сканирования (прямым или обратным) и шаблоном сканирования (например, горизонтальным, вертикальным, диагональным, зигзагообразным и так далее). В общем, проход может относиться к сканированию коэффициентов в поднаборе или во всей единице преобразования, в соответствии с порядком сканирования. В примерах, в которых используются поднаборы, видеокодер может выполнять проходы на основании поднабор за поднабором, причем поднабор содержит любой набор n коэффициентов преобразования (например, n=16 следующих друг за другом коэффициентов в непрерывном порядке сканирования). Дополнительно, видеокодер может выполнять проходы последовательно внутри каждого поднабора. Хотя применение одномерных поднаборов, содержащих последовательно сканируемые коэффициенты, может быть использовано в некоторых случаях, процесс кодирования может также быть применен к подблокам, как, например, подблоки 4х4.
В одном примере, в дополнение к трем проходам кодирования, описанным выше, видеокодер может выполнять четвертый проход кодирования для информации значимости. То есть, в дополнение к выполнению трех проходов кодирования, описанных выше для уровней коэффициентов, видеокодер может выполнять дополнительный проход кодирования для кодирования информации значимости. Соответственно, в одном примере, видеокодер может выполнять следующие четыре прохода: (1) кодировать значения флага значимых коэффициентов для коэффициентов преобразования, например, связанных с картой значимости, (2) кодировать бин 1 значений уровня для коэффициентов преобразования, (3) кодировать оставшиеся бины значений уровня коэффициентов, и (4) кодировать знаки уровней коэффициентов, причем все в одинаковом порядке сканирования. Видеокодер может сканировать флаги значимых коэффициентов и уровней для коэффициентов преобразования в одинаковом порядке сканирования, где порядок сканирования идет от коэффициента с высокой частотой к коэффициенту с низкой частотой.
Когда видеокодер выполняет вышеописанные три или четыре прохода кодирования, видеокодер может кодировать некоторые постоянные бины 192 вместе с бинами 194 обхода во время финального прохода кодирования. То есть, в примере, изображенном на Фиг. 31, постоянные бины В2 чередуются с бинами GR-EG и S обхода в цепочке бинов. Соответственно, видеокодер обязан переключаться между постоянным режимом и режимом обхода во время финального прохода кодирования. Переключение между режимами кодирования, в некоторых случаях, негативно влияет на производительность кодирования.
Фиг. 32 изображает пример порядка бинов 200 для кодирования коэффициентов преобразования, связанных с остаточными видеоданными. Как описано по отношению к примеру, изображенному на Фиг. 31, видеокодер (как, например, видеокодер 20 или видеодекодер 30) может кодировать бины 200 с помощью двух различных режимов кодирования, включая постоянный режим (например, САВАС или другой контекстно-адаптивный режим) и режим обхода. Режим обхода может быть режимом не контекстно-адаптивным. Например, режим обхода может быть фиксированным режимом контекстного двоичного арифметического кодирования, режимом кодирования Голомба-Райса, режимом кодирования экспоненциальных кодов Голомба или любой их комбинацией. В примере, изображенном на Фиг. 32, видеокодер может кодировать бины 202 (незатемненные блоки) в постоянном режиме и может кодировать бины 204 (затемненные блоки) в режиме обхода. Бины 202, закодированные в постоянном режиме, могут именоваться как «постоянные бины 202», а бины 204, закодированные в режиме обхода, могут именоваться как «бины 204 обхода».
В примере, изображенном на Фиг. 32, бины 200 включают в себя информацию значимости, В1 (бин 1), В2 (бин 2), бин GR-EG (Голомб Райс-Экспоненциальный Голомб), S (знак) и cu_header, все из которых могут быть обеспечены в единице кодирования (CU). Бины 200 могут соответствовать следующим синтаксическим элементам: SIG может соответствовать флагам значимости, В1 может соответствовать coeff_abs_level_greater1_flag, В2 может соответствовать coeff_abs_level_greater2_flag, GR-EG может соответствовать coeff_abs_level_minus3, S может соответствовать coeff_sign_flag, и cu_header может соответствовать всем другим синтаксическим элементам в CU. В других примерах, больше или меньше синтаксических элементов могут быть представлены бинами 200.
В примере, изображенном на Фиг. 32, видеокодер может выполнять проходы кодирования способом, который группирует постоянные бины 202 (то есть, бины, закодированные в постоянном режиме) и бины 204 обхода (то есть, бины, закодированные в режиме обхода). То есть, видеокодер может выполнять проходы для кодирования значимости (SIG), первого бина (бина 1) и второго бина (бин 2) уровней коэффициентов, которые закодированы в постоянном режиме, до выполнения проходов для кодирования знака (S) и оставшегося уровня (GR-EG), которые закодированы в режиме обхода. Таким образом, единицы, закодированные в режиме обхода, как, например, бины для знака и оставшегося уровня, могут быть сгруппированы вместе. То есть, бины обхода могут быть в последовательном порядке кодирования, который не разделен бинами, закодированными в постоянном режиме. В некоторых примерах, как описано по отношению к примеру на Фиг. 31, видеокодер может выполнять проходы кодирования на бинах 200 в поднаборы n (например, n=16) следующих друг за другом коэффициентов в порядке сканирования, как описано выше. Когда видеокодер завершил кодирование одного поднабора коэффициентов преобразования, видеокодер может последовательно обрабатывать следующий поднабор путем выполнения тех же проходов кодирования.
Группирование бинов 204 обхода во время кодирования может максимизировать пропускную способность, так как бины 204 обхода не требуют совпадения и адаптации контекста. Дополнительно, видеокодеру не нужно переключаться между постоянным режимом и режимом обхода. В результате, многие бины 204 обхода могут быть закодированы в одном цикле.
В соответствии с аспектами настоящего изобретения, видеокодер может выполнять проходы кодирования информации значимости и уровней коэффициентов, как описано выше, а также группировать вместе закодированные постоянные бины и закодированные бины обхода. То есть, например, видеокодер может сначала кодировать значимость коэффициентов преобразования в поднаборе (например, следуя порядку сканирования), затем уровень коэффициентов в поднаборе (например, следуя тому же порядку сканирования), как описано по отношению к Фиг. 31. Дополнительно, видеокодер может группировать вместе закодированные постоянные бины и закодированные бины обхода, как изображено на Фиг. 32.
В одном примере, для каждого поднабора в блоке коэффициентов преобразования, видеокодер может выполнять следующие проходы: (1) кодировать значимость коэффициентов в поднаборе в соответствии с порядком сканирования, (2) кодировать бин 1 уровня коэффициентов в поднаборе в соответствии с порядком сканирования, (3) кодировать бин 2 уровня коэффициентов в поднаборе в соответствии с порядком сканирования, и (4) кодировать бины, которые используют режим обхода (например, оставшееся абсолютное значение уровня коэффициентов и знака уровня коэффициентов) в поднаборе, в соответствии с порядком сканирования.
В вышеуказанном примере, информация значимости кодируется для коэффициентов преобразования в наборе коэффициентов преобразования в соответствии с порядком сканирования в первом проходе. Первый набор из одного или более бинов (например, бин 1 и бин 2) информации для коэффициентов преобразования кодируется в соответствии с порядком сканирования в одном или более вторых проходах, отличных от первого прохода. Один или более бинов (бин 1 и бин 2) в первом наборе кодируются в первом режиме, например, постоянном режиме, процесса кодирования (например, процесса САВАС). Второй набор из одного или более бинов информации (например, оставшееся абсолютное значение и знак уровня коэффициентов) для коэффициентов преобразования кодируется в соответствии с порядком сканирования в одном или более третьих проходах, отличных от первого и второго проходов. Второй набор кодируется во втором режиме, например, режиме обхода, процесса кодирования.
В другом примере, как описано выше по отношению к Фиг. 7-9, четвертый проход, описанный выше, может быть разделен на два отдельных прохода (например, один для оставшейся части уровня и один для знака уровня). То есть, видеокодер может выполнять следующие проходы: (1) кодировать значения флага значимых коэффициентов для коэффициентов преобразования; (2) кодировать бин 1 значений уровня для коэффициентов преобразования; (3) кодировать бин 2 значений уровня для коэффициентов преобразования; (4) кодировать знаки уровней коэффициентов (например, в режиме обхода); и (5) кодировать оставшиеся бины значений уровня коэффициентов (например, в режиме обхода), - причем все проходы используют одинаковый порядок сканирования.
В других примерах, видеокодер может использовать меньше проходов для кодирования коэффициентов преобразования. Например, видеокодер может выполнять два прохода сканирования, где информация уровня и знака обрабатывается параллельно. В этом примере, видеокодер может выполнять следующие проходы: (1) кодировать постоянные бины (например, значимость, уровень бина 1, уровень бина 2); и (2) кодировать бины обхода (например, оставшиеся уровни и знак), причем каждый проход использует одинаковый порядок сканирования.
В этих примерах, бины обхода группируются вместе. То есть бины обхода кодируют, не отделяя их друг от друга постоянными бинами в цепочке бинов. В других примерах, различные бины могут быть закодированы в режима контекста или закодированы в режиме обхода. В таких примерах, видеокодер может выполнять похожие проходы кодирования, в которых постоянные бины кодируются до бинов обхода, либо наоборот, так что бины обхода были сгруппированы. В некоторых примерах, как отмечено выше, видеокодер может начать сканирование от последнего значимого коэффициента в блоке.
Обработка всех данных коэффициентов преобразования в поднаборы (например, поднаборов из 16 коэффициентов преобразования в порядке сканирования) может способствовать распараллеливанию кодирования. То есть, в то время как поднабор кодируется, видеокодер может также заранее вычислить контексты САВАС для следующего поднабора. Соответственно, видеокодер может быть готов к началу кодирования следующего поднабора, когда завершено кодирование предыдущего поднабора. Также, соответствие данных ограничено размером поднаборов (например, 16 коэффициентов за раз), что может иметь преимущества в некоторых архитектурах технических средств.
Сканирования, описанные выше, однако, не ограничены выполнением в отношении подмножеств коэффициентов преобразования в TU. Например, каждый проход сканирования, описанный выше, может быть выполнен для множества коэффициентов преобразования, которое включает в себя весь TU (то есть, все коэффициенты преобразования в TU). В этом примере, каждое сканирование может расширяться до полного TU. Соответственно, в одном примере, видеокодер может выполнять следующие проходы: (1) кодировать значимость коэффициентов в TU в соответствии с порядком сканирования, (2) кодировать бин 1 уровня коэффициентов в TU в соответствии с порядком сканирования, (3) кодировать бин 2 уровня коэффициентов в TU в соответствии с порядком сканирования, и (4) кодировать бины, которые используют режим обхода (например, оставшееся абсолютное значение уровня коэффициентов и знака уровня коэффициентов) в TU, в соответствии с порядком сканирования. В другом примере, как описано выше, видеокодер может разделять четвертый проход на два раздельных прохода (например, один для оставшегося уровня и один для знака уровня). В этом примере, бины обхода все еще сгруппированы вместе.
В примерах, в которых проходы кодирования выполняются в полной TU, видеокодер по существу делает размер поднаборов равным размеру TU. Это подход может потерять некоторые способности распараллеливания, описанные выше для относительно небольших поднаборов (из n коэффициентов, где n может быть, например, 16). Однако выполнение проходов кодирования в полной TU может иметь другие преимущества, которые перевешивают потерю распараллеливания. Например, группирование всех бинов обхода вместе в TU в конце кодирования остаточных данных может увеличить пропускную способность, как описано выше, так как многие бины обхода могут быть закодированы за один цикл. То есть видеокодер может кодировать все бины, которые кодируются в постоянном режиме, до кодирования бинов, которые кодируются в режиме обхода.
Дополнительно, когда видеокодер выполняет проходы кодирования в полной TU, каждый синтаксический элемент кодируется отдельно от остальных синтаксических элементов внутри TU. Например, сначала видеокодер кодирует всю информацию значимости для коэффициентов. Видеокодер затем кодирует все бины 1 уровня коэффициентов, за которыми следуют все бины 2 уровня коэффициентов, затем следуют бины обхода (например, оставшийся уровень коэффициентов и знак, которые могут быть разделены на два прохода или закодированы за один проход). Следовательно, синтаксические элементы для TU могут быть включены вместе в строку бинов, отдельно от других синтаксических элементов, а не чередоваться с другими синтаксическими элементами. Избегание чередования синтаксических элементов может способствовать предложенному процессу кодирования. То есть, в некоторых случаях, видеокодер может выполнять предложенное кодирование (для параллельного кодирования). В таких случаях, видеокодер может оценивать некоторые значения бинов, чтобы заранее вычислить значения. Видеокодер может извлечь пользу из знания синтаксического элемента, который будет обрабатываться, заранее, так как требуется меньше оценок для следующих (незакодированных) бинов. Разделение достигает максимума в TU, когда каждый синтаксический элемент разделен для полной TU от остальных синтаксических элементов. В таких случаях, видеокодер может выполнять предложенное кодирование и максимизировать число бинов, которые будут кодироваться параллельно.
Фиг. 33 является блок-схемой последовательности операций примера процесса кодирования видео для кодирования коэффициентов преобразования, связанных с остаточными видеоданными. Хотя пример, изображенный на Фиг. 33, описан в общем по отношению к видеокодеру (как, например, видеокодер 20 и/или видеодекодер 30), необходимо понимать, что эти способы могут быть выполнены различными процессорами, элементами обработки, элементами кодирования на основе технических средств, как, например, кодеры/декодеры (CODEC), и тому подобное. Дополнительно, хотя пример, изображенный на Фиг. 33, в общем относится к «коэффициентам преобразования», необходимо понимать, что в некоторых случаях видеокодер может не выполнять преобразование остаточных данных, а, напротив, выполнять напрямую квантование остаточных значений (например, когда выполняет «режим пропуска преобразования»). Соответственно, «коэффициенты преобразования» могут в общем включать в себя преобразованные, а также и непреобразованные остаточные видеоданные.
В примере, изображенном на Фиг. 33, видеокодер кодирует информацию значимости (например, карту значимости) для коэффициентов преобразования, связанных с остаточными видеоданными, в соответствии с порядком сканирования в одном или более первых проходах (210). В некоторых примерах, набор коэффициентов преобразования может соответствовать поднабору коэффициентов преобразования, которое включает в себя меньше, чем все коэффициенты преобразования в TU. Например, поднабор может включать в себя n коэффициентов, где n меньше, чем число коэффициентов преобразования в TU. В другом примере, n может быть 16 коэффициентов преобразования. В других примерах, набор коэффициентов преобразования может соответствовать всему набору коэффициентов преобразования в TU (то есть, все коэффициенты преобразования в TU).
Видеокодер может также кодировать первый набор из одного или более бинов информации для коэффициентов преобразования, в соответствии с порядком сканирования в одном или более вторых проходах, причем один или более вторых проходов отличаются от одного или более первых проходов, и причем первый набор из одного или более бинов кодируется в первом режиме процесса кодирования (212). Например, первый набор из одного или более бинов информации может включать в себя информацию уровня, связанную с коэффициентами преобразования. Дополнительно, первый режим процесса кодирования может быть постоянным режимом контекстно-адаптивного процесса кодирования, как, например, САВАС. Соответственно, видеокодер может кодировать некоторую информацию уровня, связанную с коэффициентами преобразования, в том же порядке сканирования, что и информацию значимости, и в постоянном режиме. В некоторых примерах, постоянный режим кодирования может также быть использован для кодирования информации значимости.
Дополнительно, видеокодер может кодировать второй набор из одного или более бинов информации для коэффициентов преобразования в соответствии с порядком сканирования в одном или более третьих проходах, причем один или более третьих проходов отличаются от одного или более первых и вторых проходов, и причем второй набор из одного или более бинов кодируется во втором режиме процесса кодирования (214). Например, второй набор из одного или более бинов информации может включать в себя оставшуюся информацию уровня, связанную с коэффициентами преобразования, которая не включена в первый набор из одного или более бинов. Дополнительно, второй режим процесса кодирования может быть режимом обхода контекстно-адаптивного процесса кодирования, как, например, САВАС. Режим обхода может использовать фиксированный контекст. В некоторых примерах, бины обхода могут быть закодированы с помощью кодирования Голомба-Райса и/или экспоненциальных кодов Голомба. Соответственно, видеокодер может кодировать конкретную оставшуюся информацию уровня, связанную с коэффициентами преобразования, в том же порядке сканирования, что и информацию значимости и первый набор из одного или более бинов, но в режиме обхода. То есть, бины, закодированные с помощью режима обхода, могут быть сгруппированы в порядке кодирования, не разделяясь бинами, закодированным в постоянном режиме.
Соответственно в по меньшей мере одном примере, видеокодер может выполнять четыре прохода процесса кодирования, чтобы кодировать коэффициенты преобразования, связанные с блоком остаточных видеоданных. Например, как описано выше по отношению к Фиг. 7-9, видеокодер может выполнять следующие четыре прохода:
1. Кодировать значимость коэффициентов в поднаборе.
2. Кодировать бин 1 уровня коэффициентов в поднаборе.
3. Кодировать бин 2 уровня коэффициентов в поднаборе.
4. Кодировать бины, которые используют режим обхода (например, оставшаяся абсолютное значение уровня коэффициентов и знака уровня коэффициентов) в поднаборе.
В этом примере, первый набор из одного или более бинов может включать в себя бин 1 и бин 2, которые кодирует видеокодер с помощью постоянного режима (например, с помощью САВАС, CAVLC, PIPE и тому подобное), а оставшиеся бины кодируются в режиме обхода. Дополнительно, второй набор из одного или более бинов может включать в себя бины, которые используют режим обхода. То есть видеокодер может группировать вместе бины от бина 3 до бина n (где бин n представляет финальный бин) и кодировать бины в одном проходе. В других примерах, видеокодер может использовать больше или меньше проходов для кодирования коэффициентов преобразования. Например, видеокодер может кодировать первый набор из одного или более бинов в одном, первом проходе, и второй набор из одного или более бинов во втором проходе. В другом примере, четвертый проход, описанный выше, может быть разделен на два отдельных прохода (для знака и оставшегося уровня).
Группирование кодируемых бинов с помощью второго режима кодирования (например, бинов обхода) может увеличить эффективность кодирования и его пропускную способность. Например, вместо того, чтобы ждать, пока обновится контекстная модель после кодирования каждого бина (например, как требуется для контекстно-адаптивного кодирования), бины обхода могут быть сразу закодированы последовательно (например, вследствие фиксированной вероятности, используемой для кодирования обхода). Дополнительно, в то время как один набор бинов обхода кодируется, видеокодер может заранее вычислить контексты для следующего набора бинов обхода. Соответственно, видеокодер готов к началу процесса кодирования, когда завершено кодирование предыдущих бинов.
Как отмечено выше, набор коэффициентов преобразования может соответствовать поднабору коэффициентов преобразования, который включает в себя меньше, чем все коэффициенты преобразования в TU. В таких примерах, для некоторых архитектур технических средств может заключаться преимущество. Например, кодирование коэффициентов преобразования в поднаборах может быть эффективным с точки зрения использования памяти, так как меньше данных должно храниться и быть доступными во время кодирования. Дополнительно, видеокодер может кодировать один или более поднаборов параллельно.
В других примерах, набор коэффициентов преобразования может соответствовать всему набору коэффициентов преобразования в TU (то есть, все коэффициенты преобразования в TU). Кодирование коэффициентов преобразования для всей TU может привести к потере способности распараллеливания. Однако могут быть некоторые преимущества кодирования коэффициентов преобразования для TU. Например, группирование вместе всех бинов обхода для всей TU по завершению кодирования остаточных данных может увеличить пропускную способность, как описано выше. Дополнительно, видеокодер может выполнять предложенное кодирование конкретных синтаксических элементов, как описано выше.
Необходимо понимать, что этапы, изображенные и описанные по отношению к Фиг. 33, обеспечены в качестве примера. То есть, этапы способа на Фиг. 33 необязательно должны выполняться в том же порядке, что изображен на Фиг. 33, и может быть выполнено меньше этапов, дополнительные или альтернативные этапы.
В одном или более примерах, функции, описанные в настоящем изобретении, могут быть воплощены в технических средствах, программном обеспечении, программно-аппаратных средствах или их комбинации. Если они воплощены в программном обеспечении, функции могут быть выполнены элементом обработки на основе технических средств, как, например, один или более процессоров, которые выполняют программное обеспечение в форме считываемых компьютером инструкций или кода. Такие инструкции или код могут храниться или переноситься на считываемом компьютером носителе и выполняться элементом обработки на основе технических средств. Считываемый компьютером носитель может включать в себя считываемую компьютером среду хранения, которая соответствует материальному невременному носителю, как, например, среда хранения данных, или коммуникационную среду, включающую в себя любой носитель, который способствует передаче компьютерной программы от одного места к другому, например, в соответствии с протоколом связи. Таким образом, считываемый компьютером носитель в общем может соответствовать (1) материальному считываемому компьютером носителю, который не является временным; или (2) среде связи, как, например, сигнал или несущая волна. Носитель хранения данных может быть любым доступным носителем, доступ к которому может осуществляться одним или несколькими компьютерами или одним или несколькими процессорами для вывода инструкций, кода и/или структур данных для воплощения способов, описанных в настоящем изобретении. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
Для примера, но не ограничения, такие считываемые компьютером носители хранения могут содержать RAM, ROM, EEPROM, флэш-память, CD-ROM или любые другие твердотельные, оптические или магнитные носители хранения данных, включая накопитель на оптических дисках, накопитель на магнитных дисках или другие магнитные устройства хранения, или любые другие носители, которые могут быть использованы для хранения желаемого программного кода в форме инструкций или структур данных, и к которым может осуществить доступ компьютер. Также, любое соединение правильно называть считываемым компьютером носителем носителем. Например, если инструкции передаются с вебсайта, сервера или другого удаленного источника с помощью коаксиального кабеля, оптоволоконного кабеля, кабеля с витой парой, цифровой абонентской линии (DSL) или беспроводных технологий, как, например, инфракрасная, радио и микроволновая, то тогда коаксиальный кабель, оптоволоконный кабель, кабель с витой парой, DSL, или беспроводные технологии, как, например, инфракрасная, радио и микроволновая, включены в определение носителя. Необходимо понимать, что, однако, этот материальный считываемый компьютером носитель хранения и носитель хранения данных не включают в себя соединения, несущие волны, сигналы или другие изменяемые среды, но, напротив, направлены на невременные, материальные среды хранения. Диск [disk] и диск [disc], как использовано в настоящем документе, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), гибкий диск и диск Blu-ray, где диски [disks] обычно воспроизводят данные магнитным образом, а диски [discs] воспроизводят данные оптическим образом с помощью лазеров. Комбинации вышеуказанных включены в объем считываемых компьютером носителей.
Инструкции могут быть выполнены одним или несколькими процессорами, как, например, одним или несколькими цифровыми сигнальными процессорами (DSP), микропроцессорами общего назначения, специализированными интегральными микросхемами (ASIC), вентильными матрицами (FPGA), программируемыми пользователем, или другими эквивалентными интегрированными микросхемами или микросхемами с дискретной логикой. Соответственно, термин «процессор», как он использован в настоящем документе, может относиться к любой из вышеупомянутых структур или любой другой структуре, подходящей для воплощения способов, описанных в настоящем документе. Дополнительно, в некоторых аспектах, функциональность, описанная в настоящем документе, может быть обеспечена внутри специализированной аппаратуры и/или модулей программного обеспечения, выполненных с возможностью кодировать и декодировать, либо встроена в комбинированный кодер. Также, способы могут быть полностью воплощены в одной или более микросхемах или логических элементах.
Способы настоящего изобретения могут быть выполнены разнообразными устройствами или аппаратами, включая настольные компьютеры, ноутбуки (то есть переносные компьютеры), планшеты, телевизионные приставки, телефонные трубки, как, например, так называемые смартфоны, телевизоры, фотоаппараты, устройства отображения, цифровые медиаплееры, игровые видеоприставки и тому подобное. Во многих случаях, такие устройства могут быть оборудованы беспроводной связью. Дополнительно, такие способы могут быть воплощены интегральными микросхемами (IC) или множеством IC (например, комплект микросхем). Устройства, созданные с возможностью выполнять способы настоящего изобретения, могут включать в себя любые устройства, упомянутые выше, и, в некоторых случаях, могут быть видекодером или видеодекодером, либо комбинированным видеокодером-декодером, то есть, видео CODEC, который может быть сформирован комбинацией технических средств, программного обеспечения и программно-аппаратных средств. Различные компоненты, модули или элементы могут быть описаны в настоящем изобретения для усиления функциональных аспектов устройств, созданных с возможностью выполнять раскрытые способы, но необязательно требуют реализации различными элементами технических средств. Как описано выше, различные элементы могут быть скомбинированы в элементе технических средств кодека или быть обеспечены набором взаимодействующих элементов технических средств, включая один или более процессоров, как описано выше, в соединении с подходящим программным обеспечением и/или программно-аппаратными средствами.
Описаны различные примеры. Эти и другие примеры находятся внутри объема приложенной формулы изобретения.
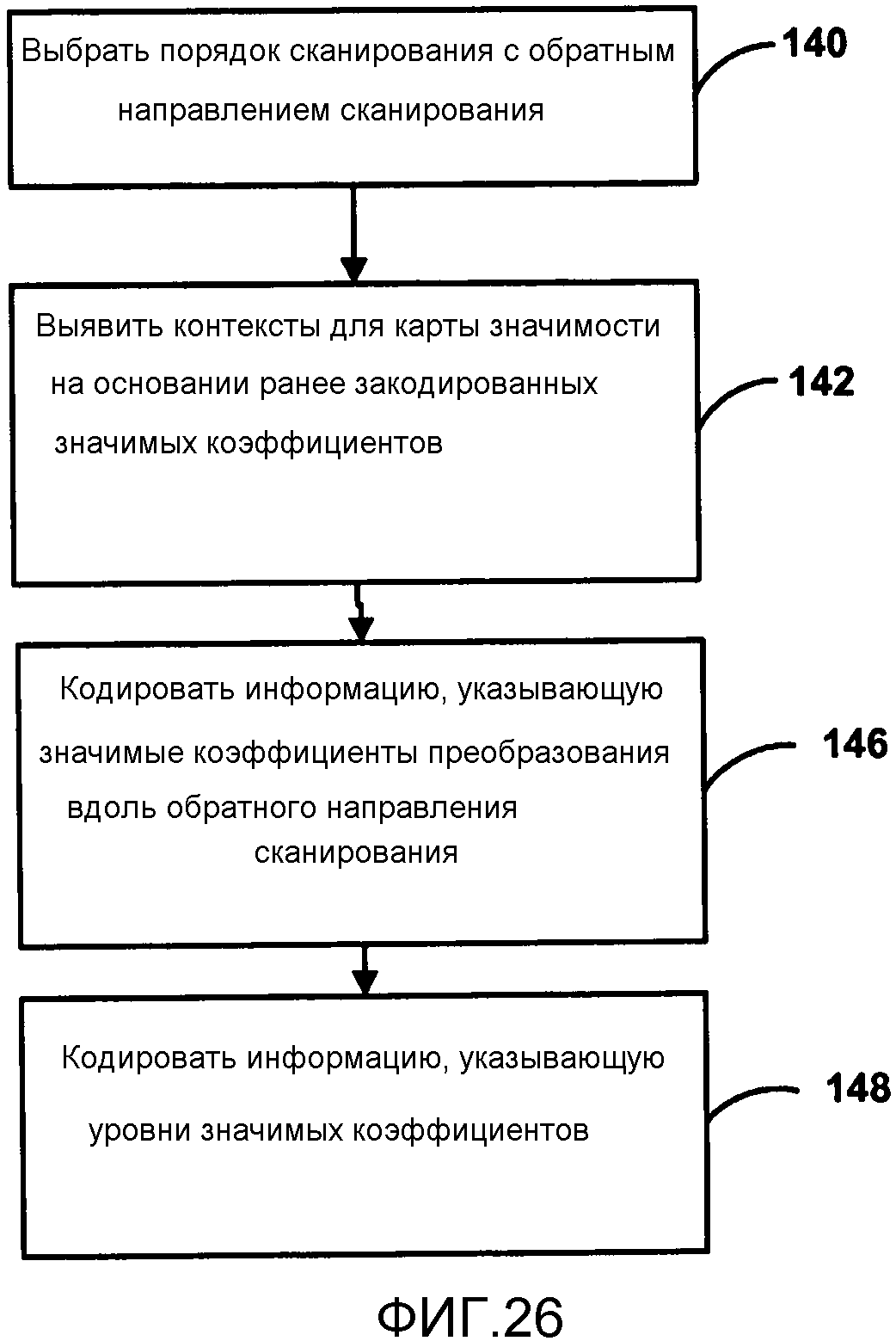
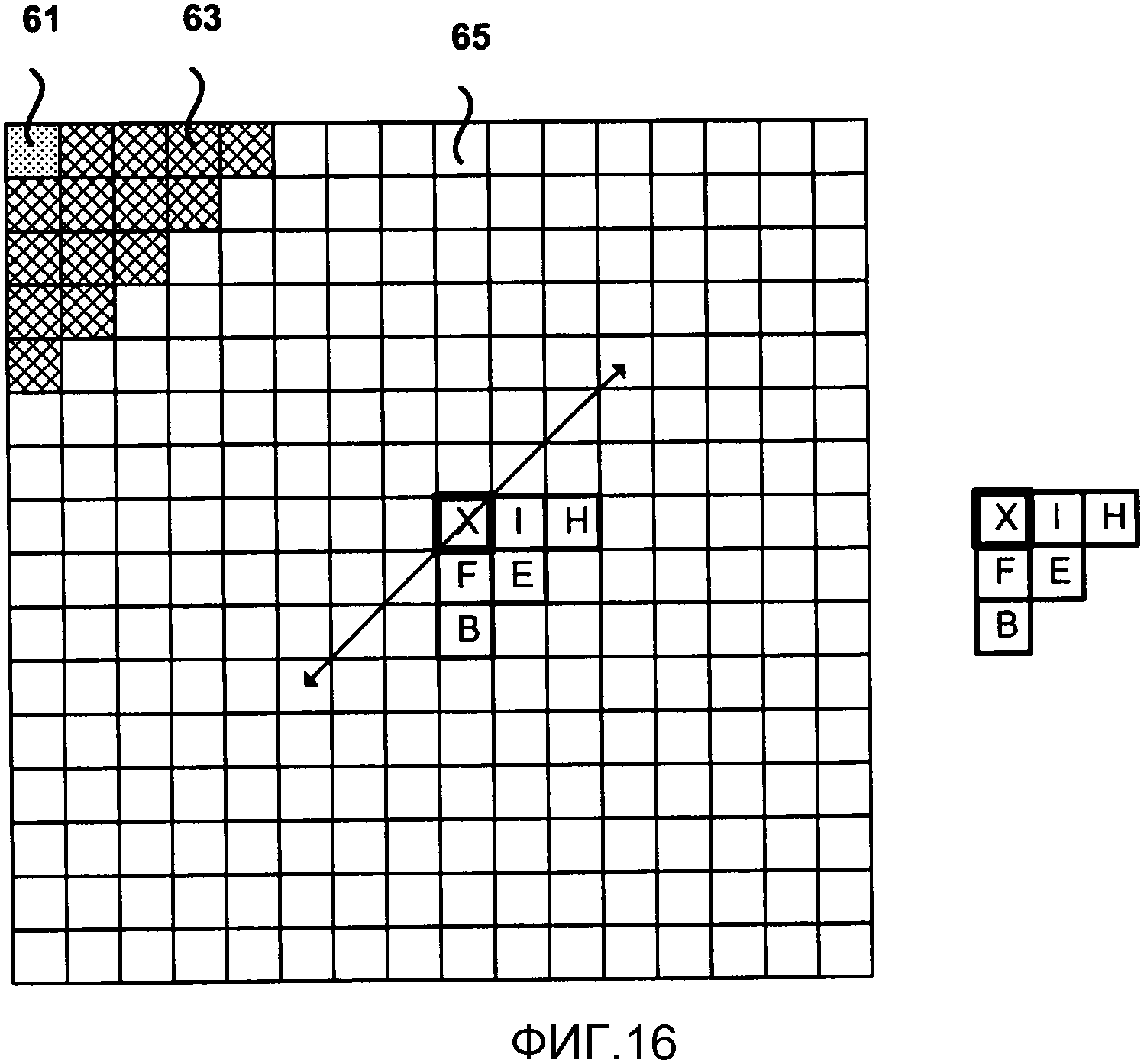
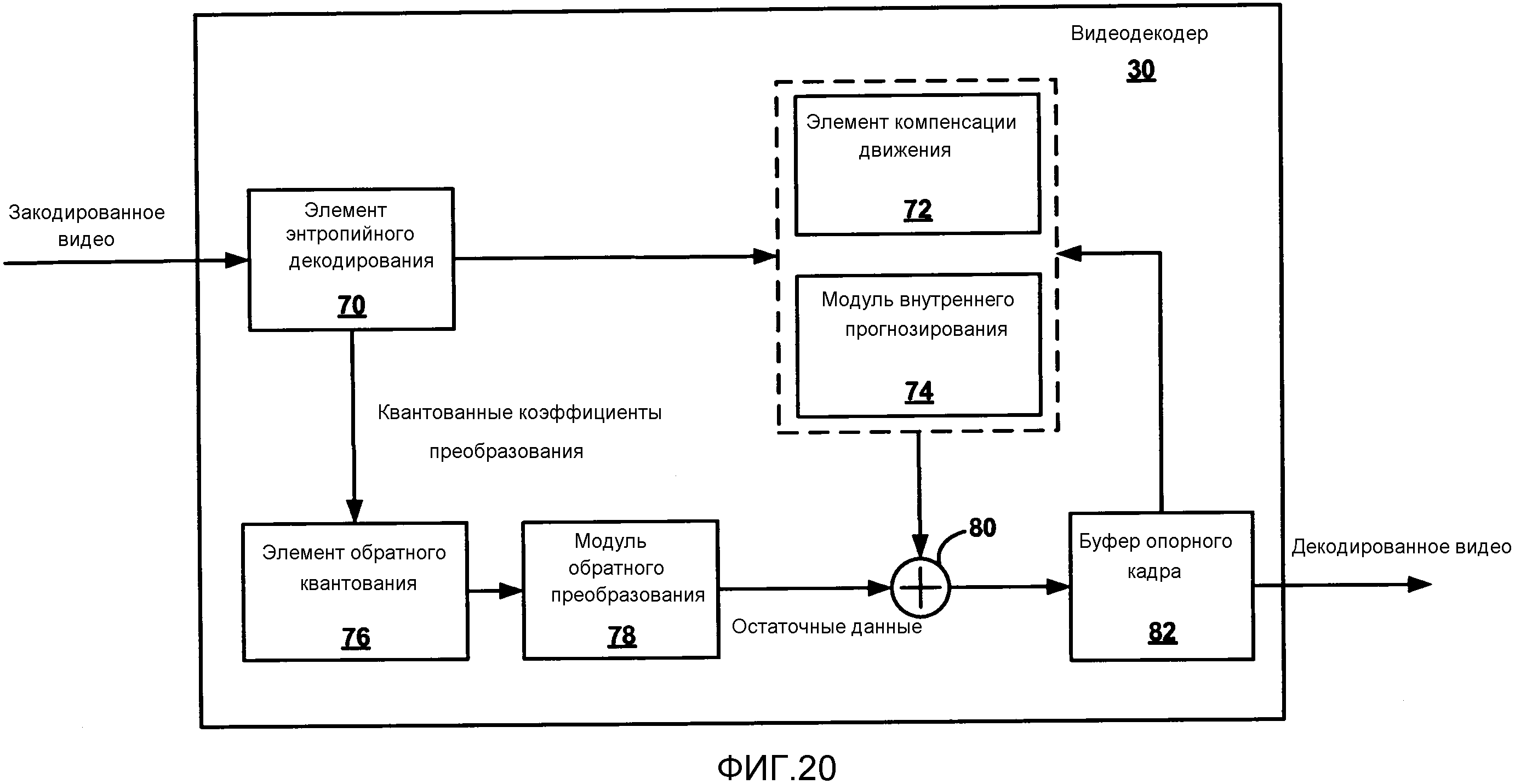
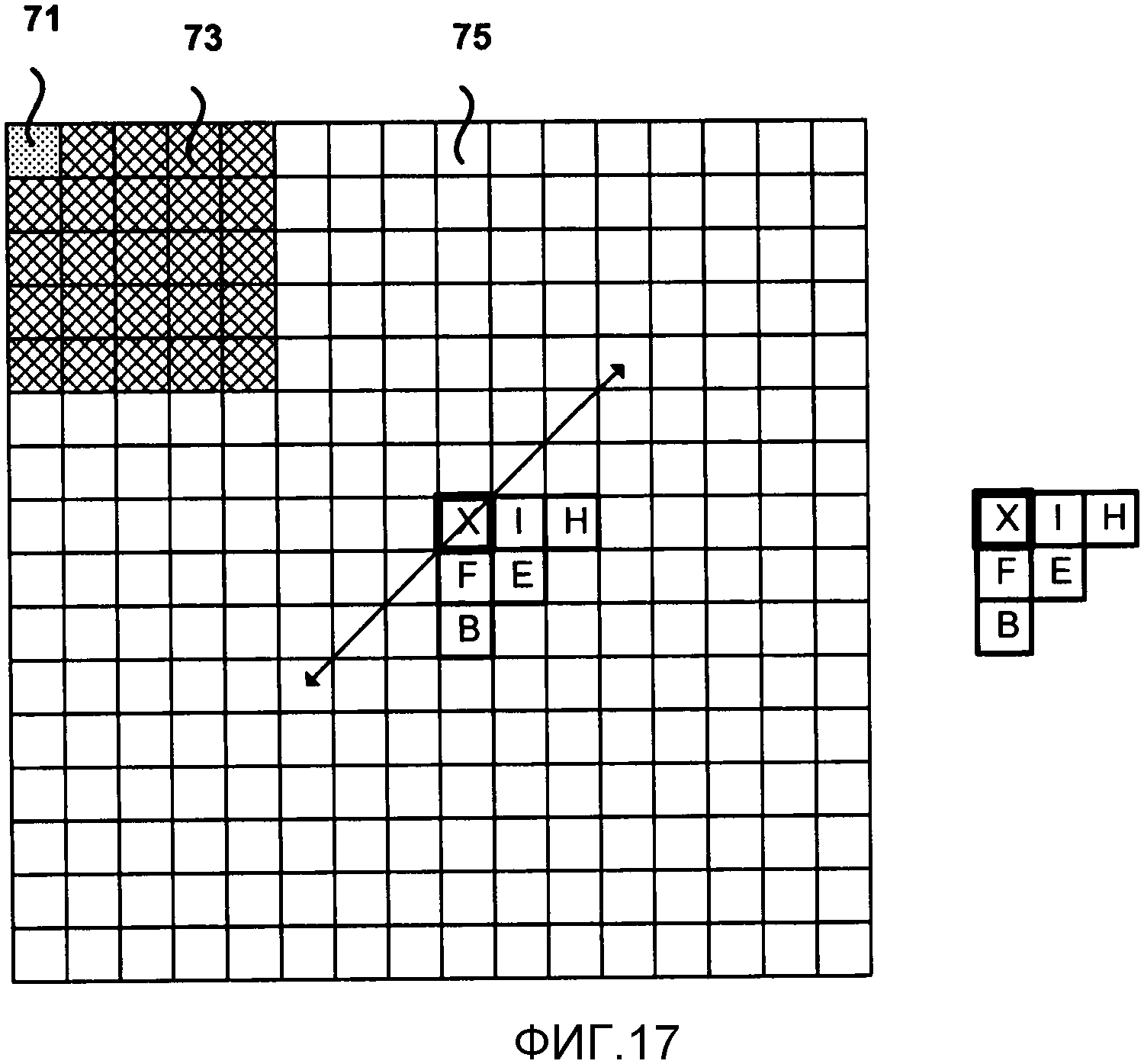
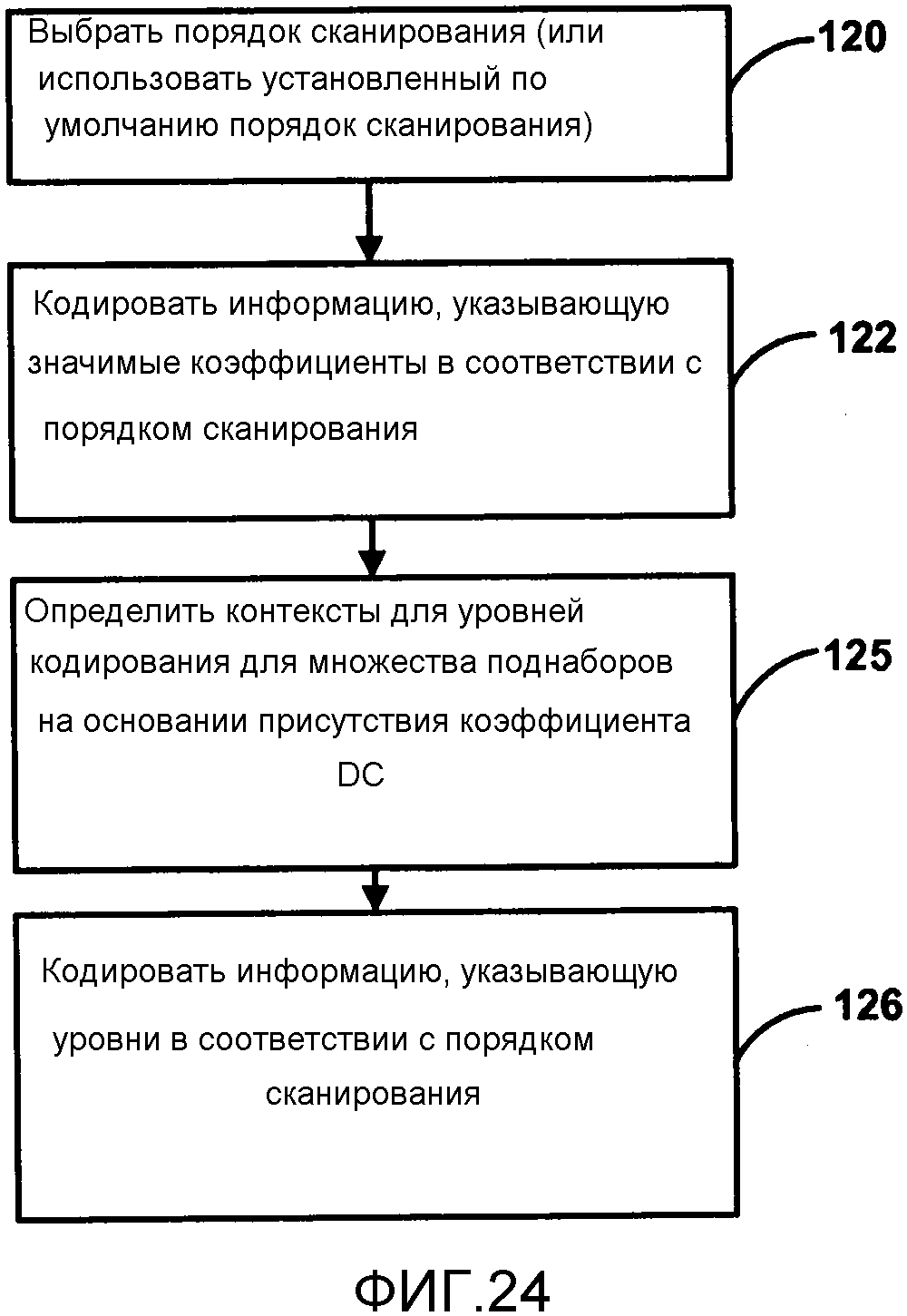
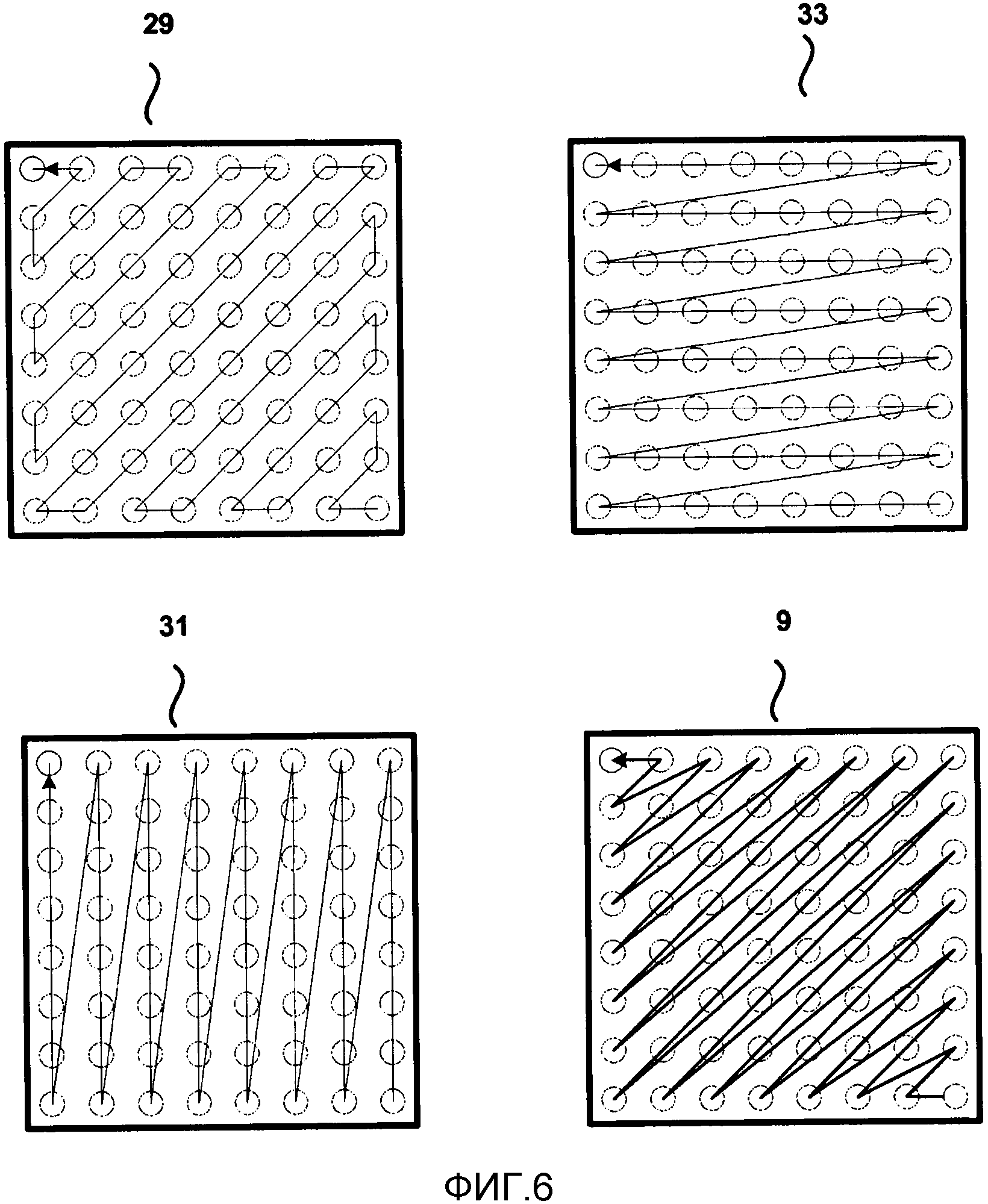
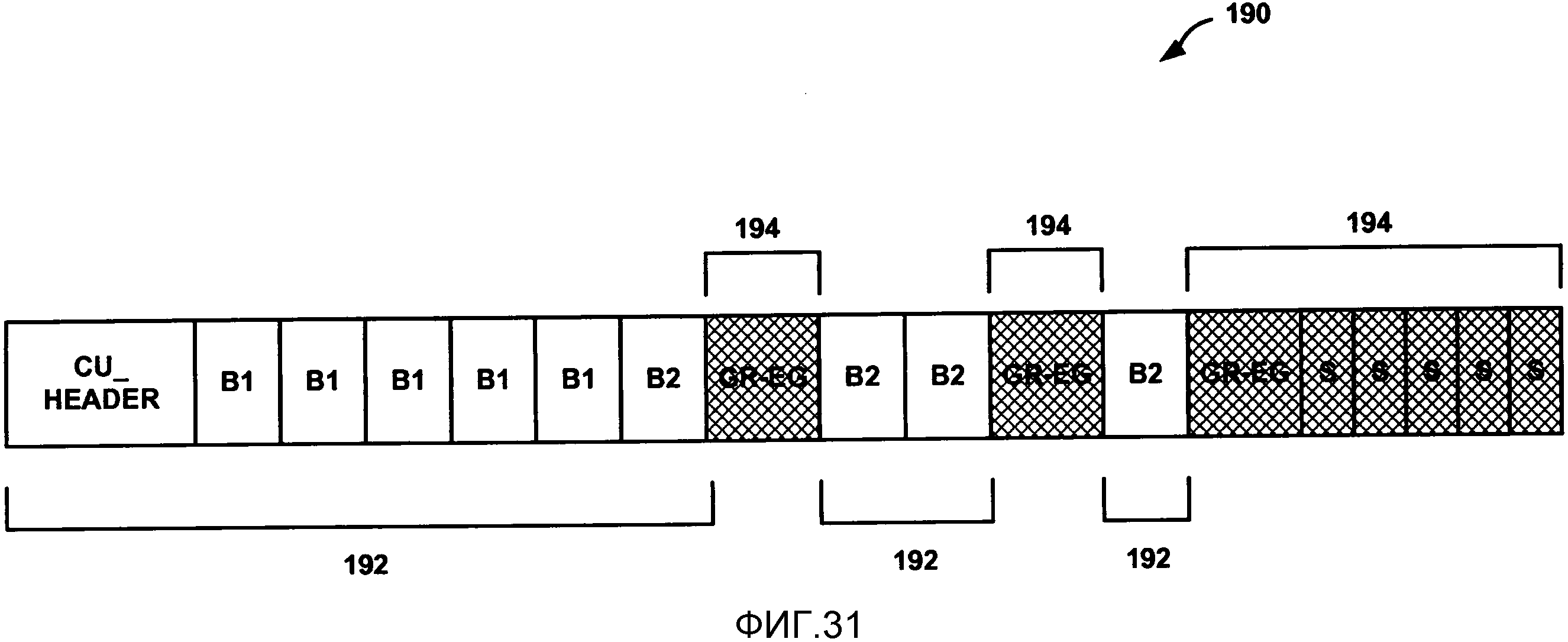
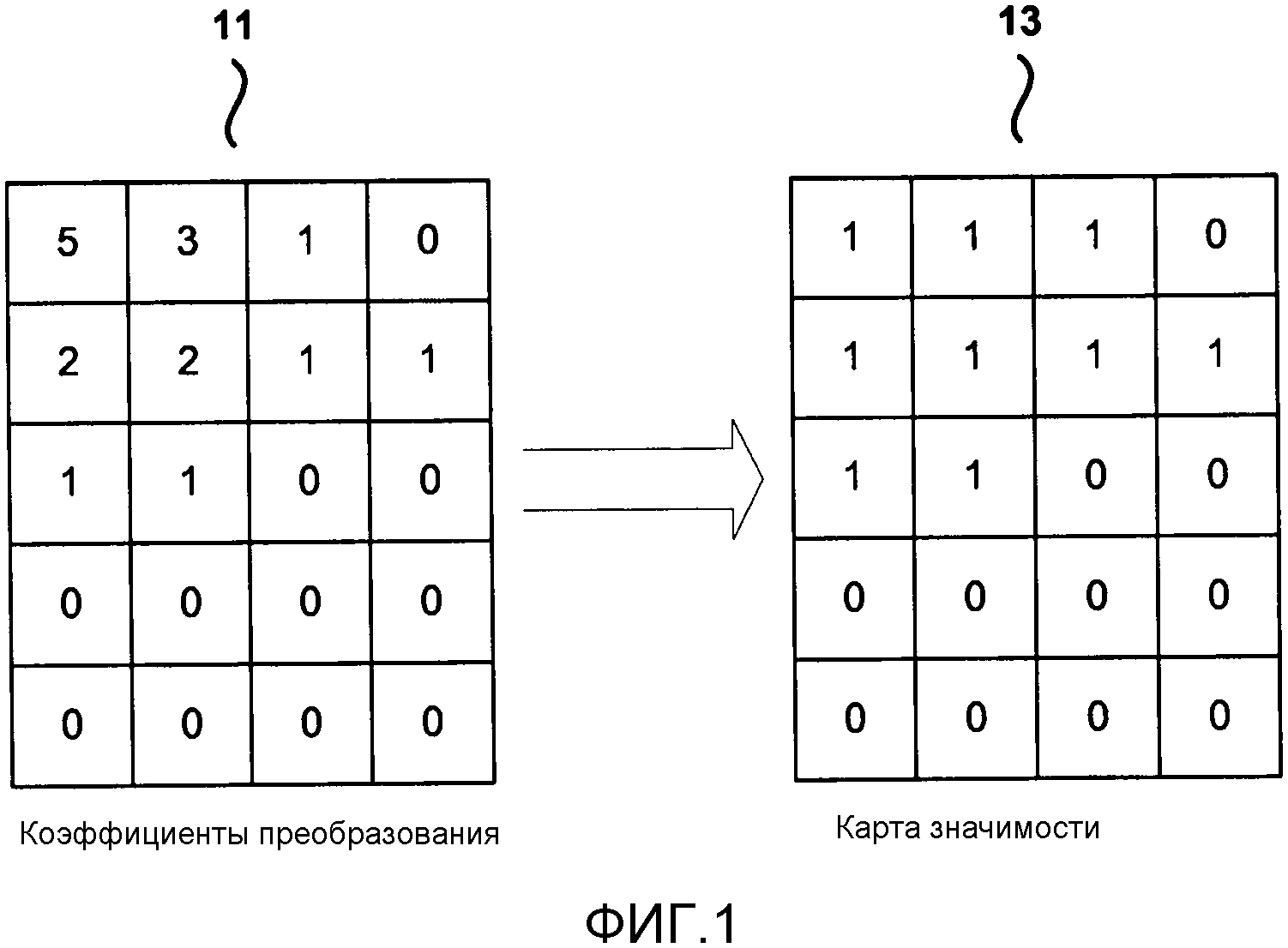
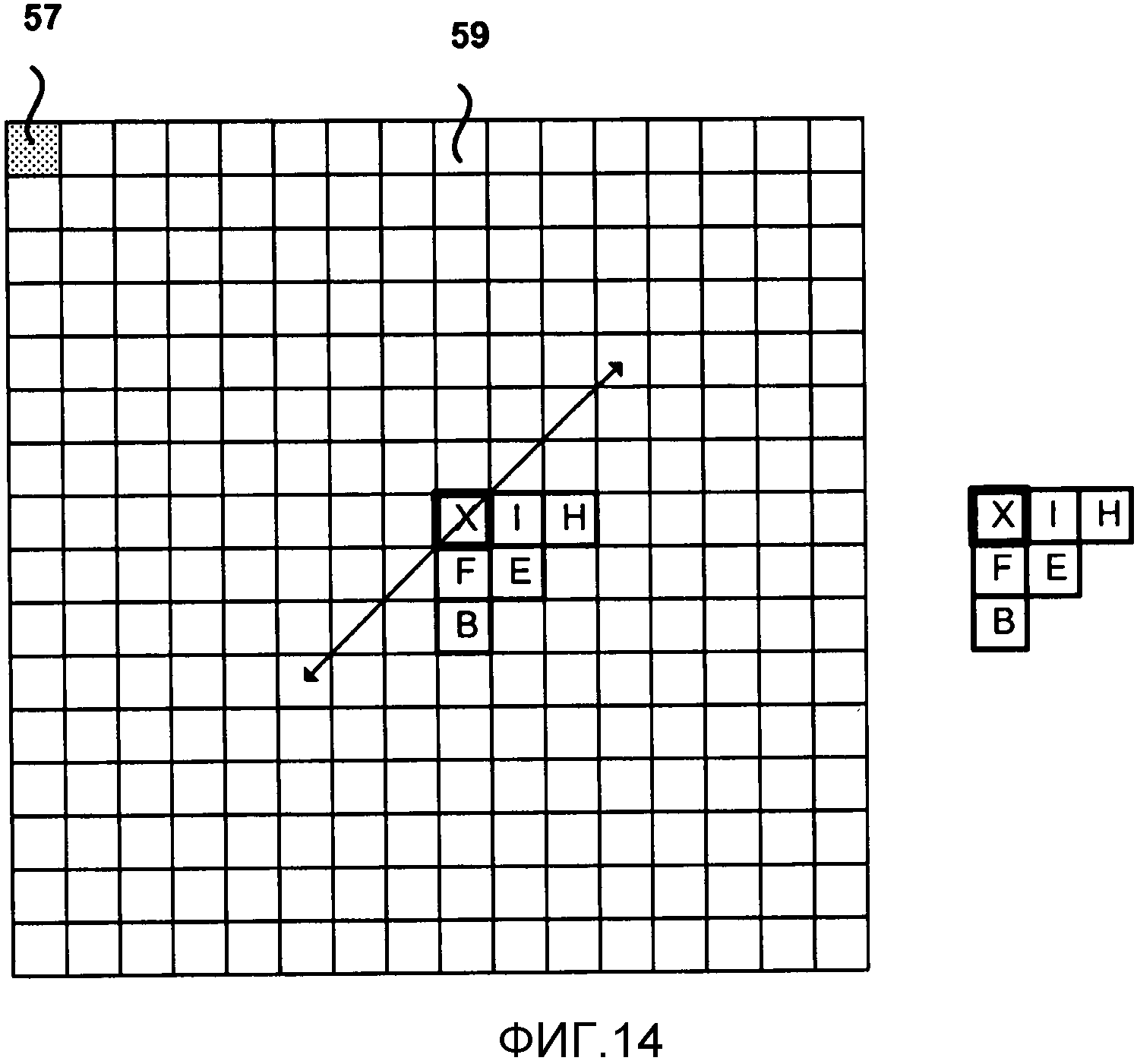
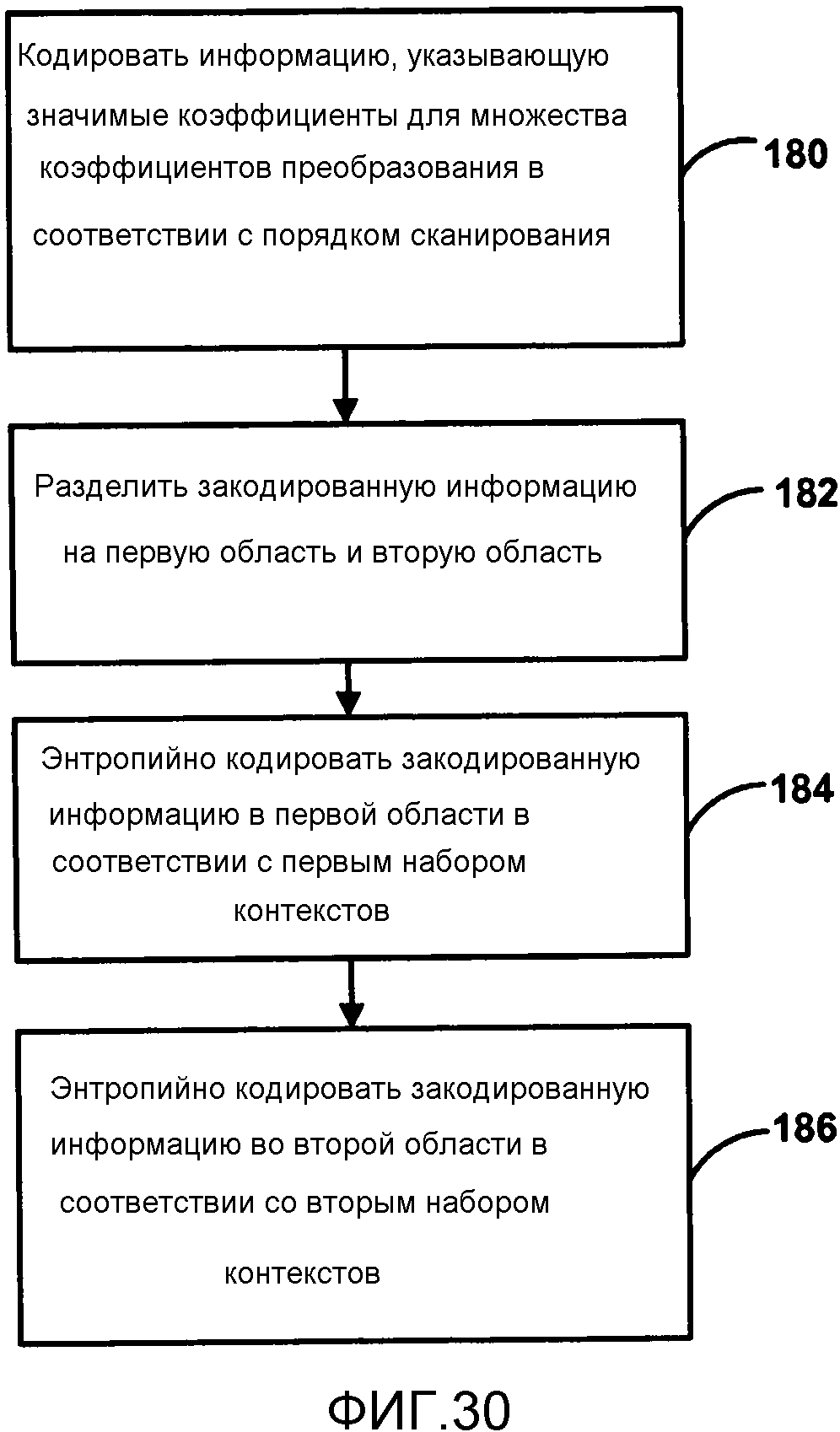
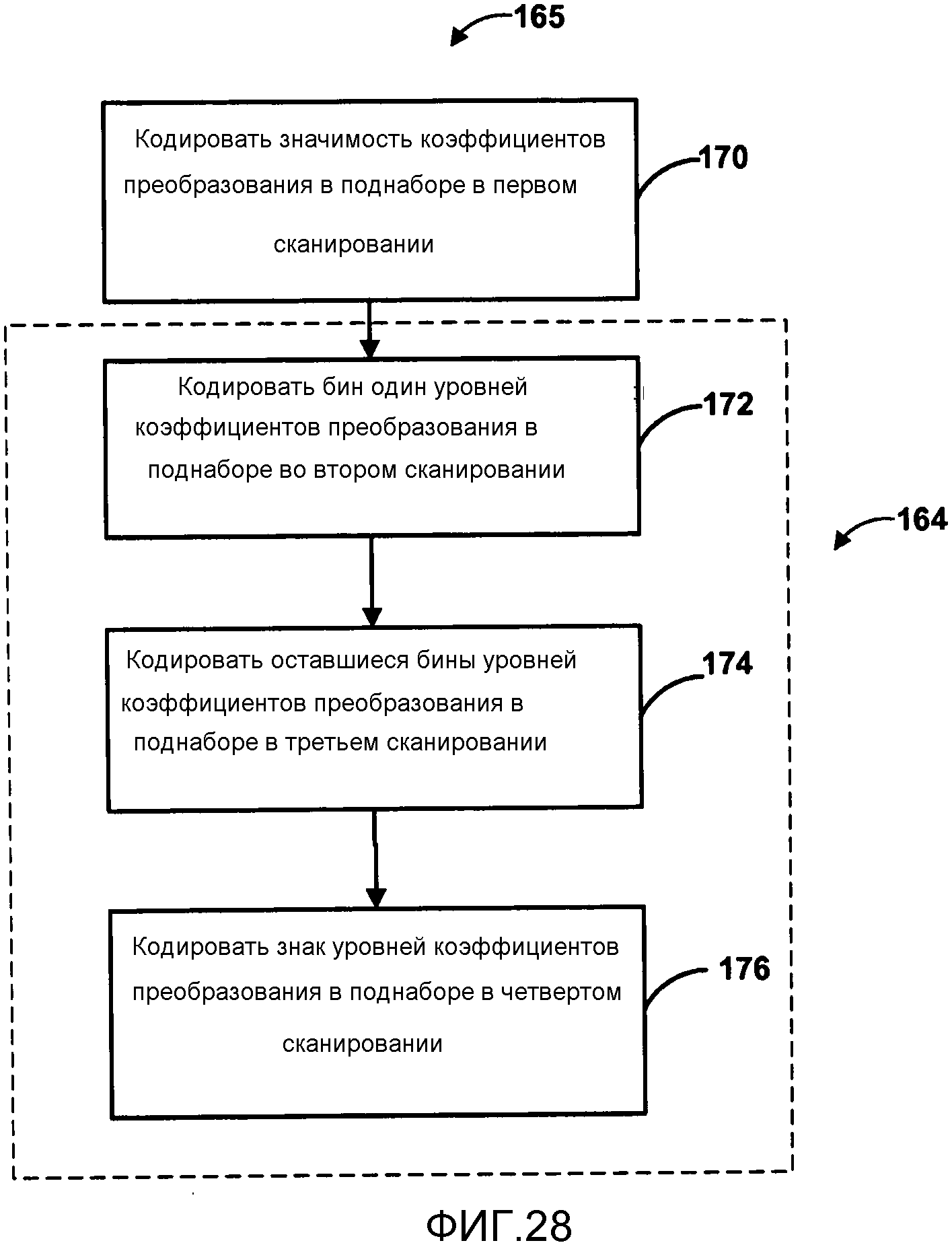
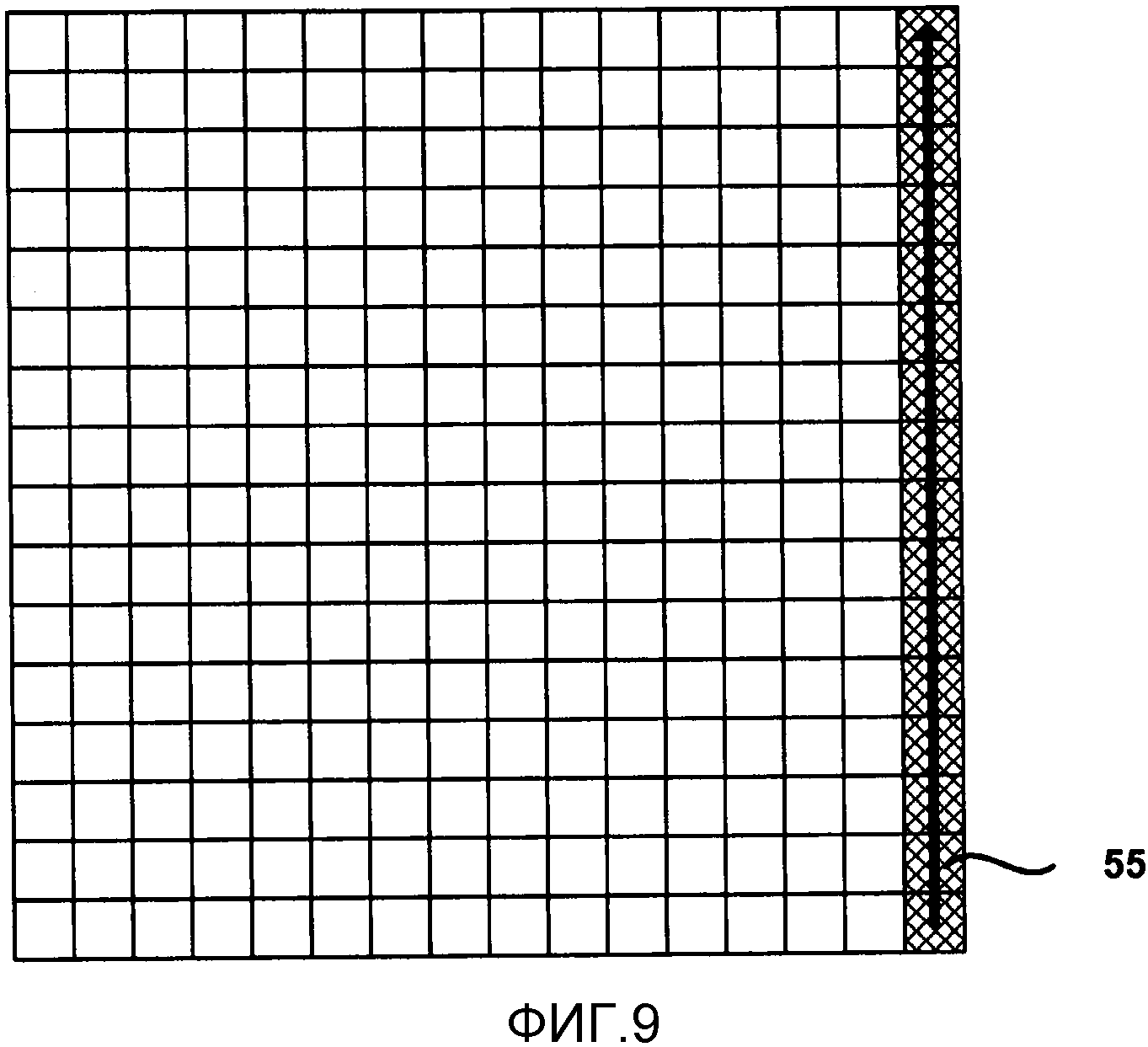
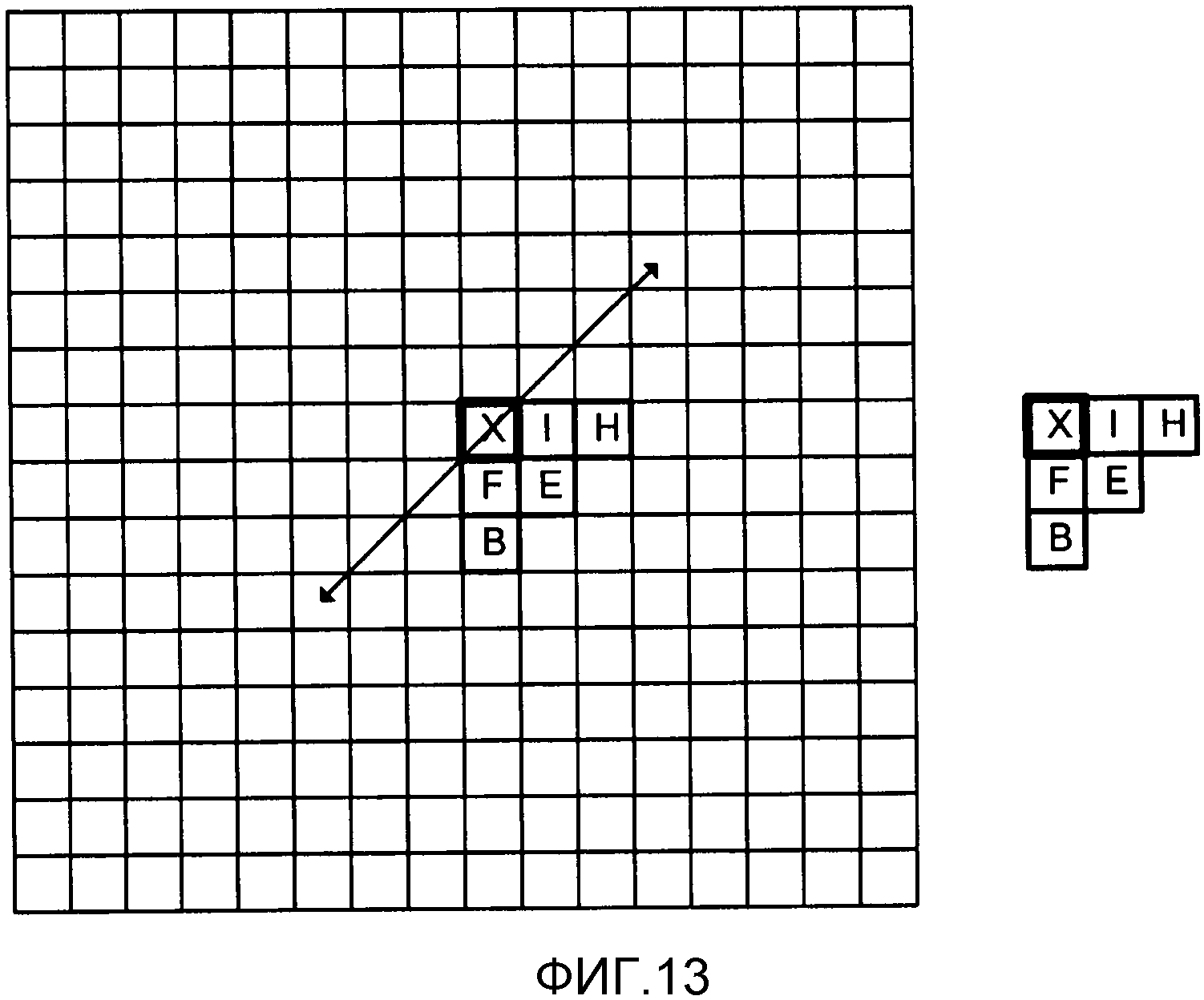
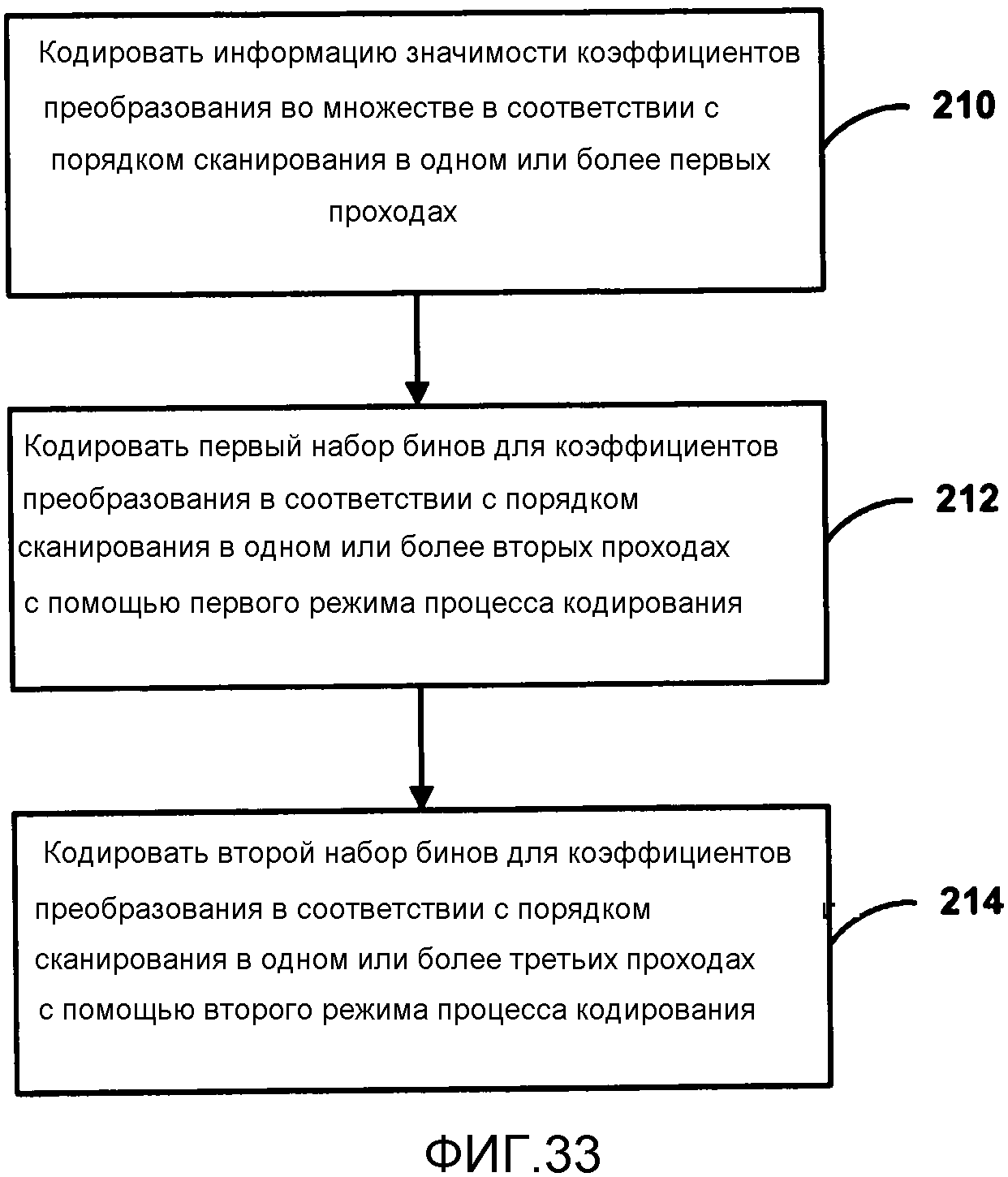
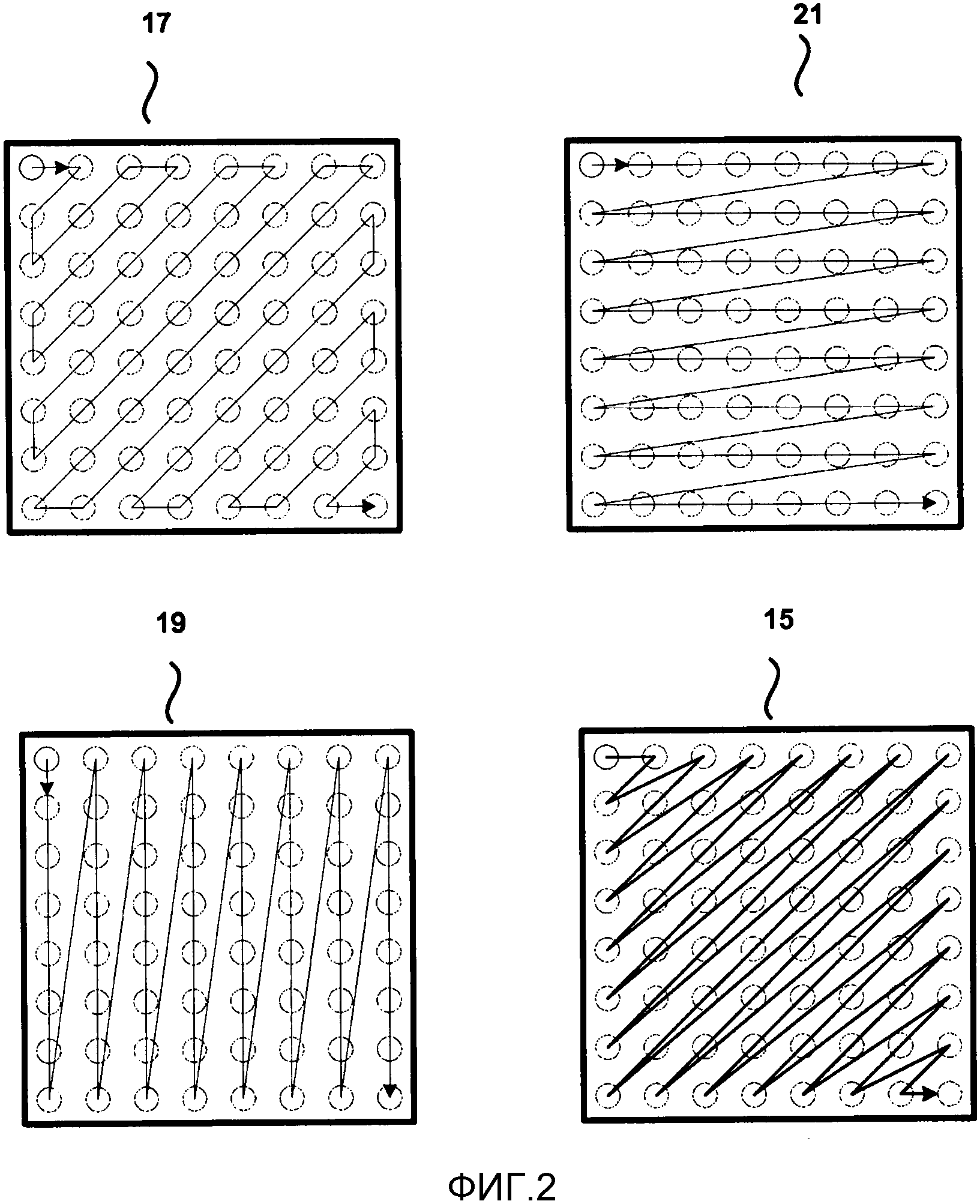
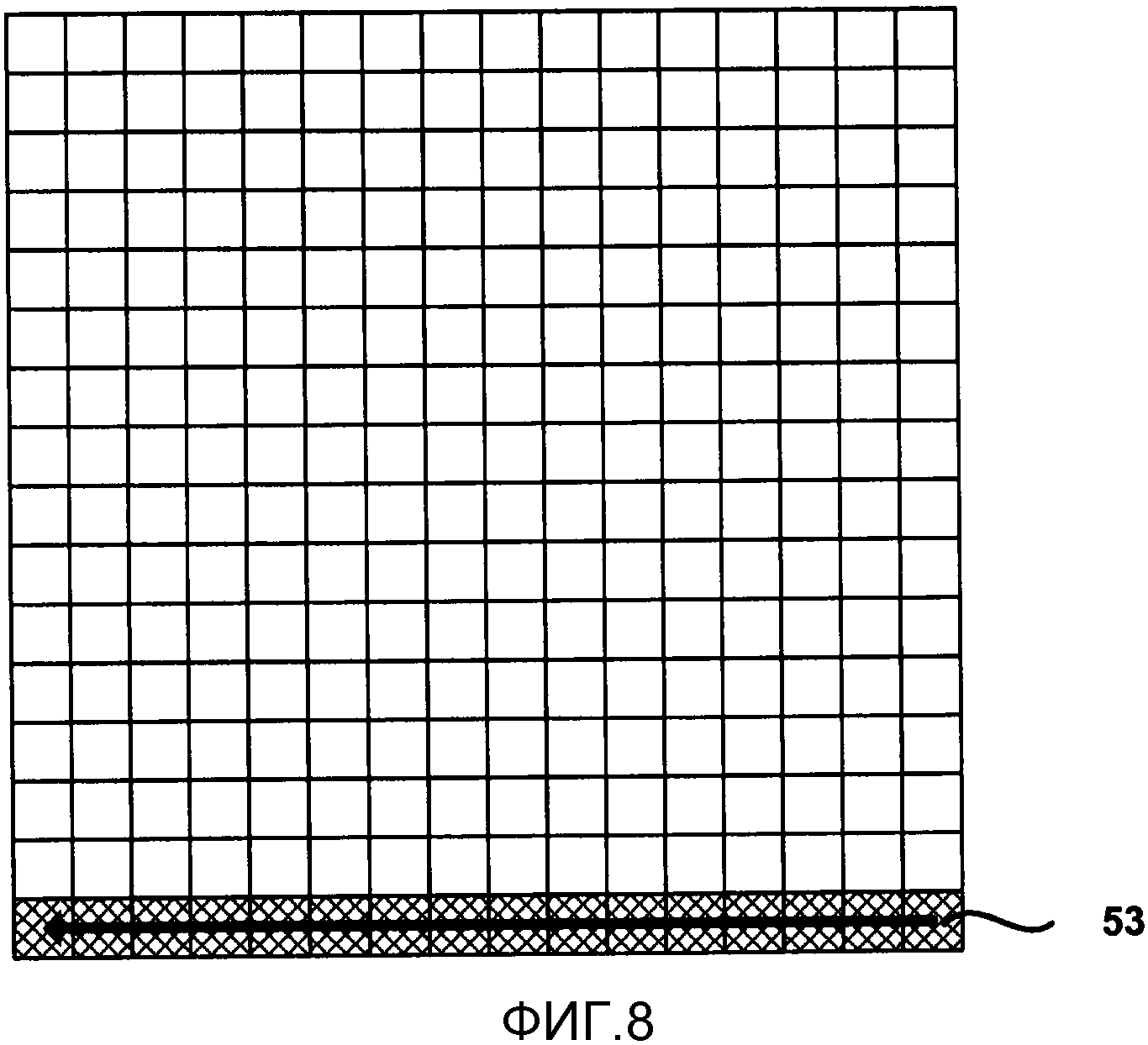
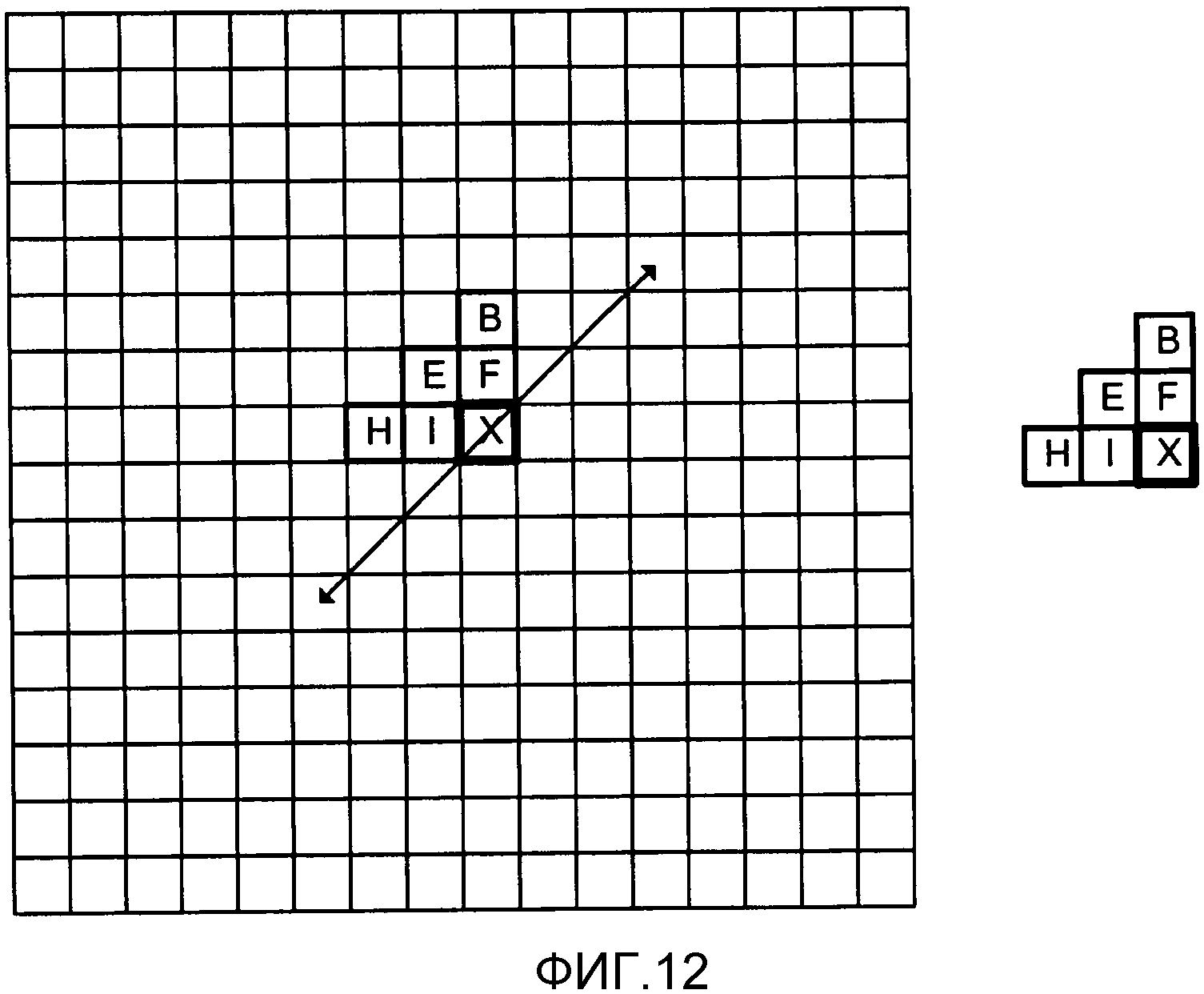
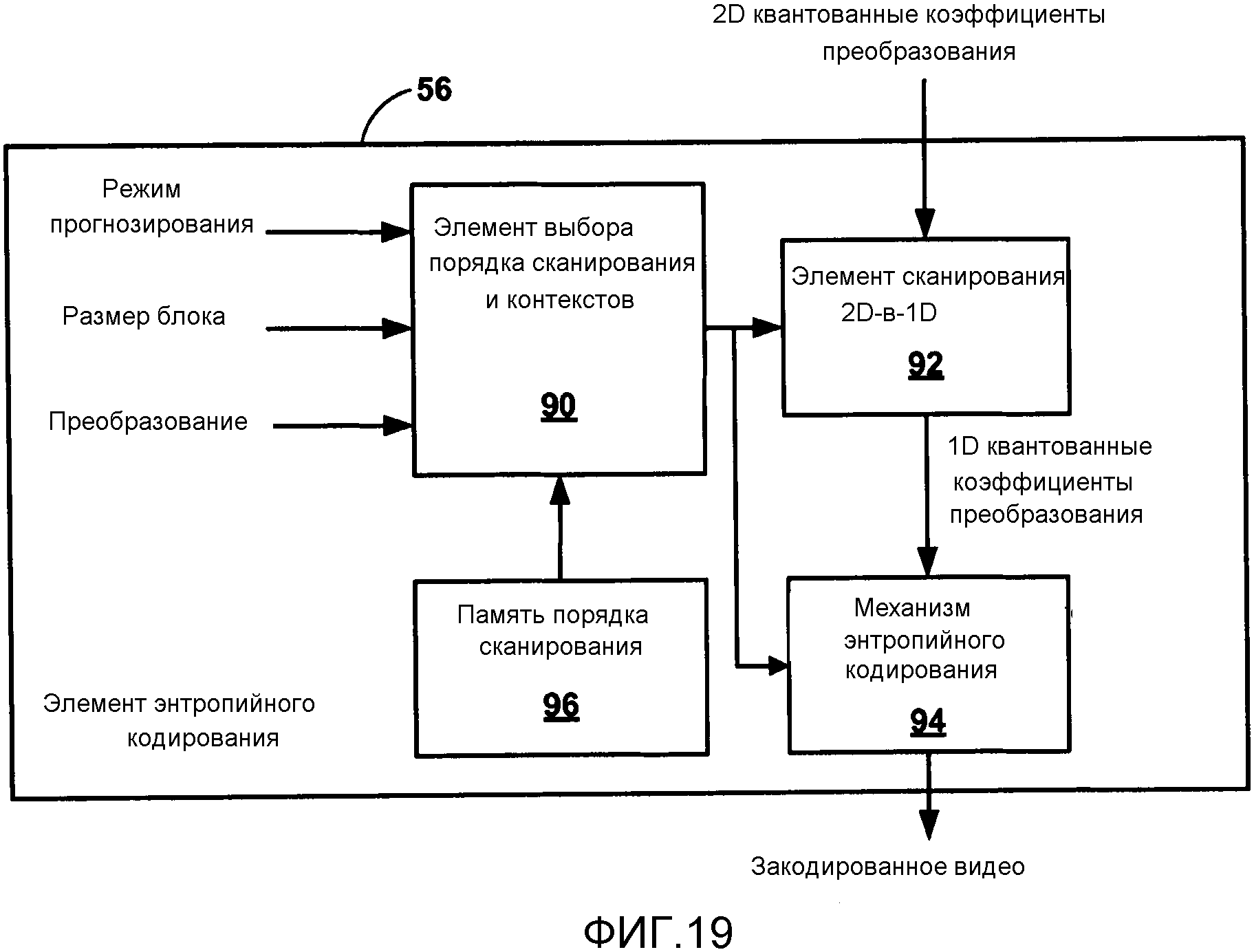
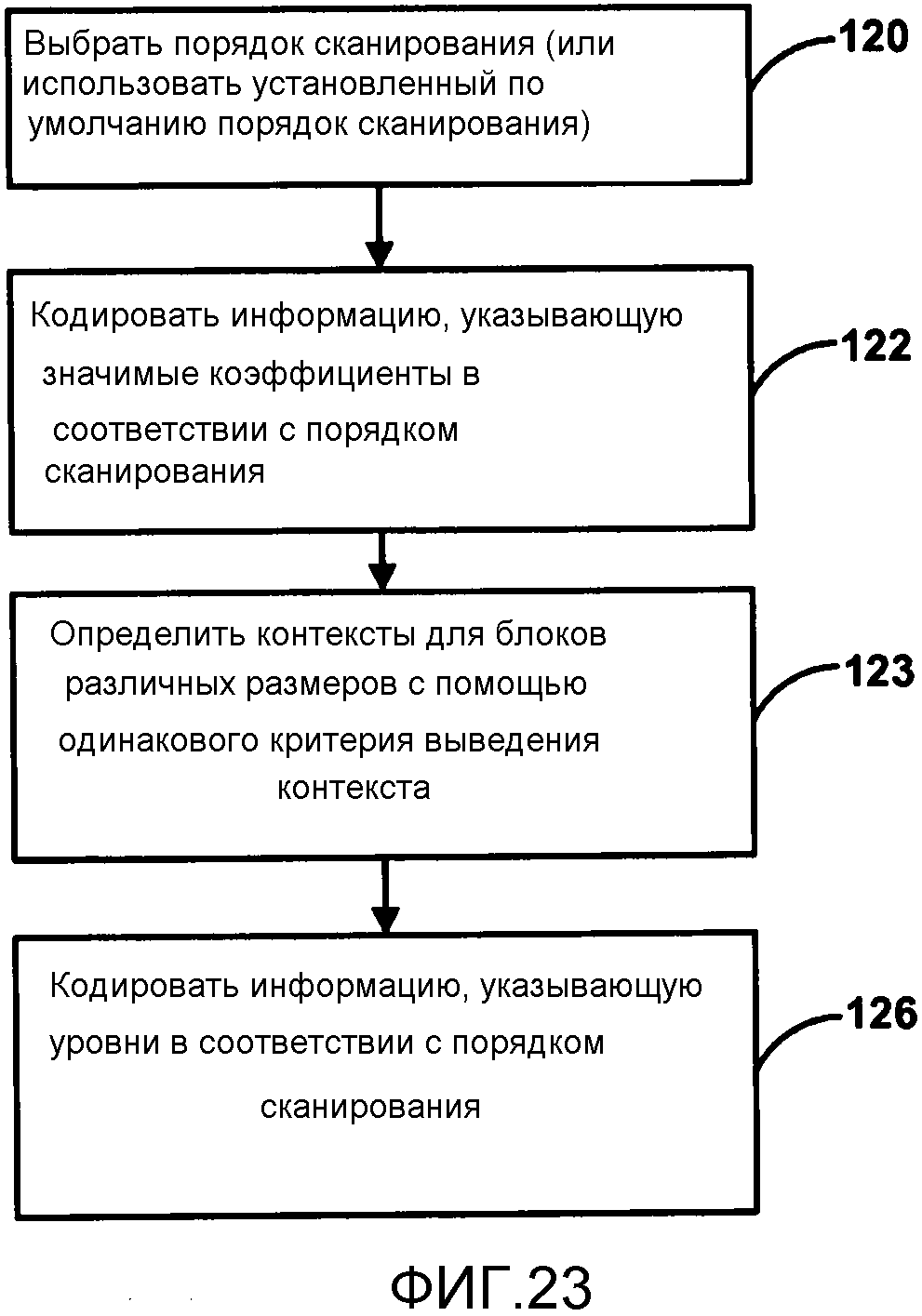
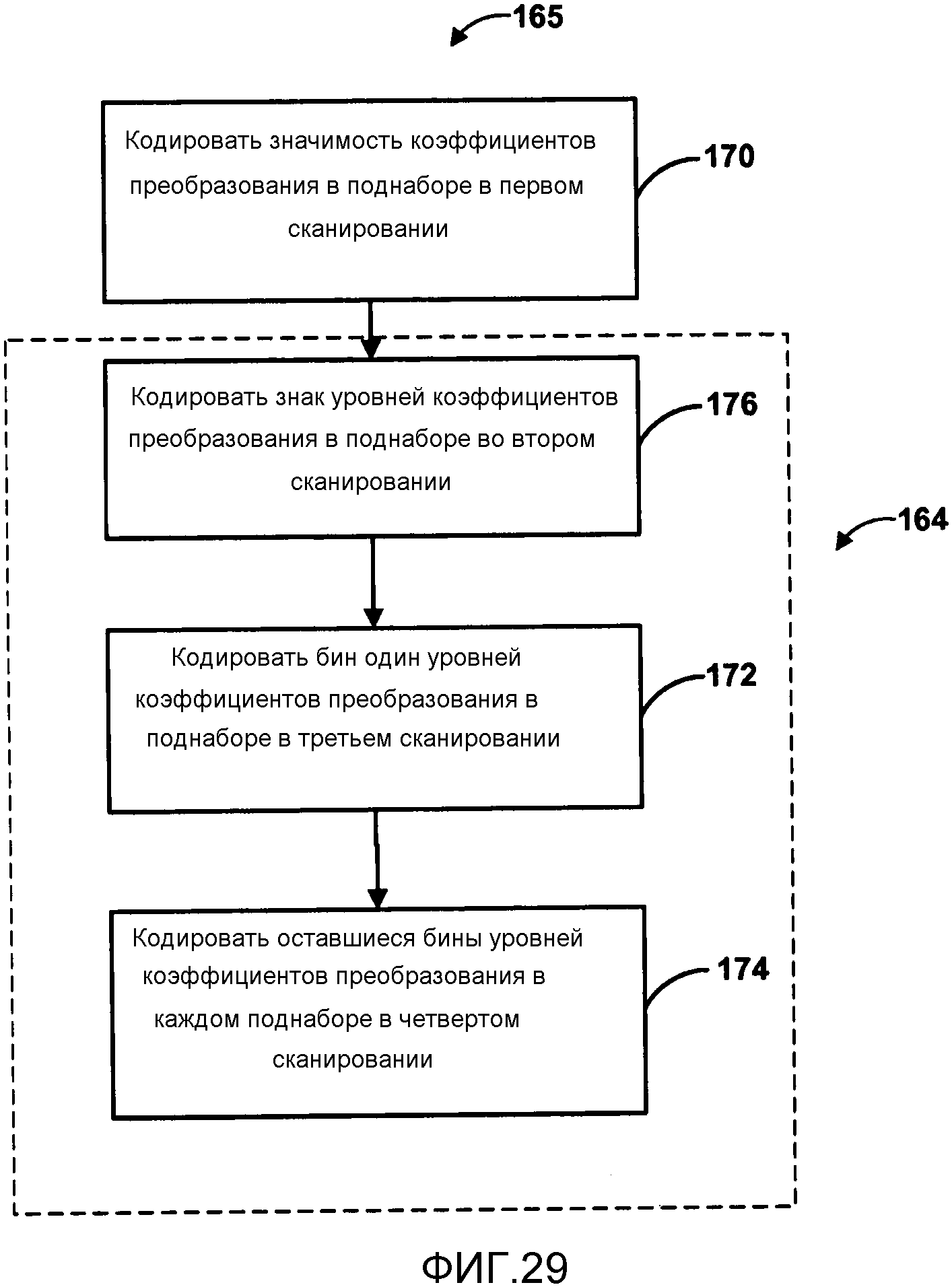
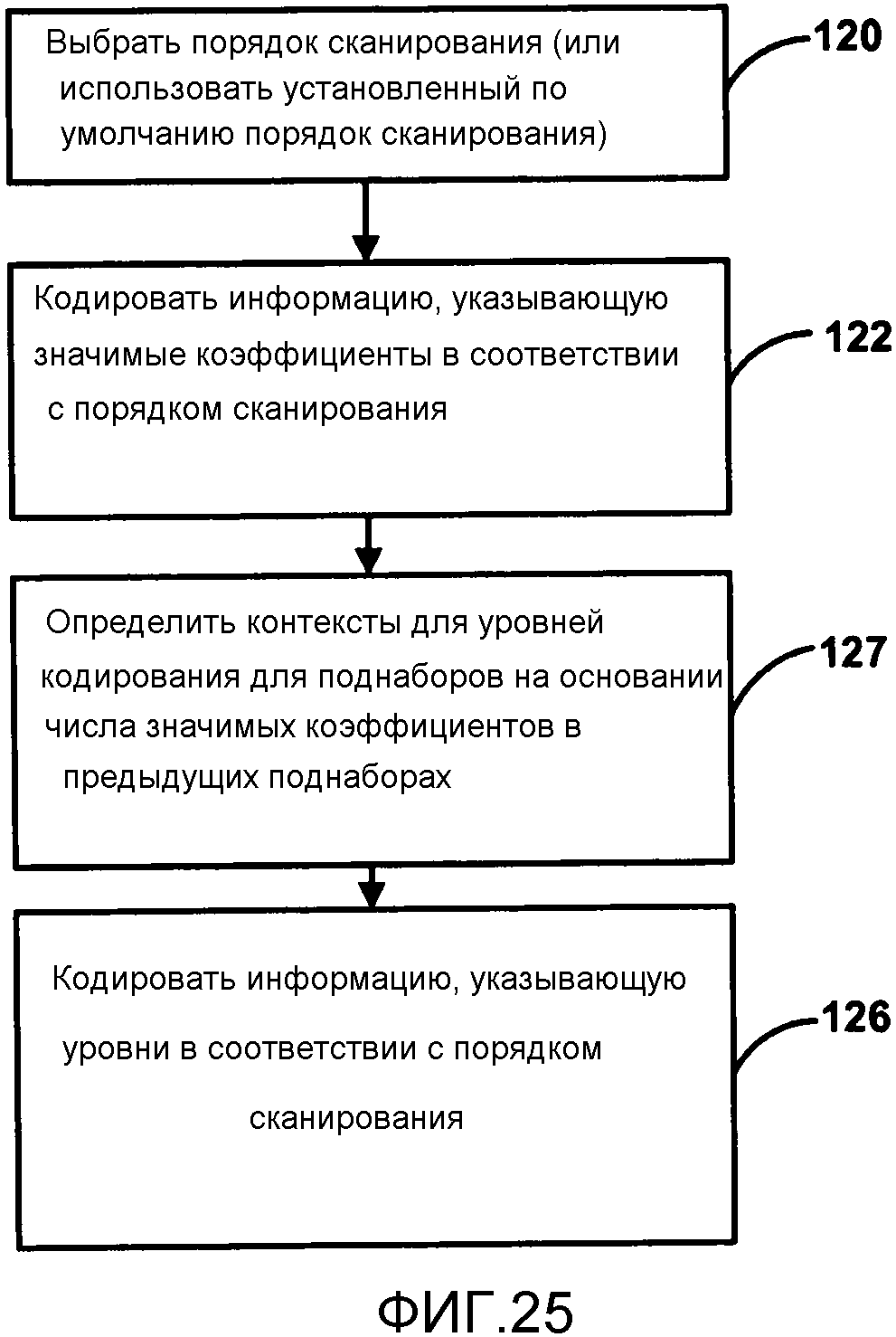
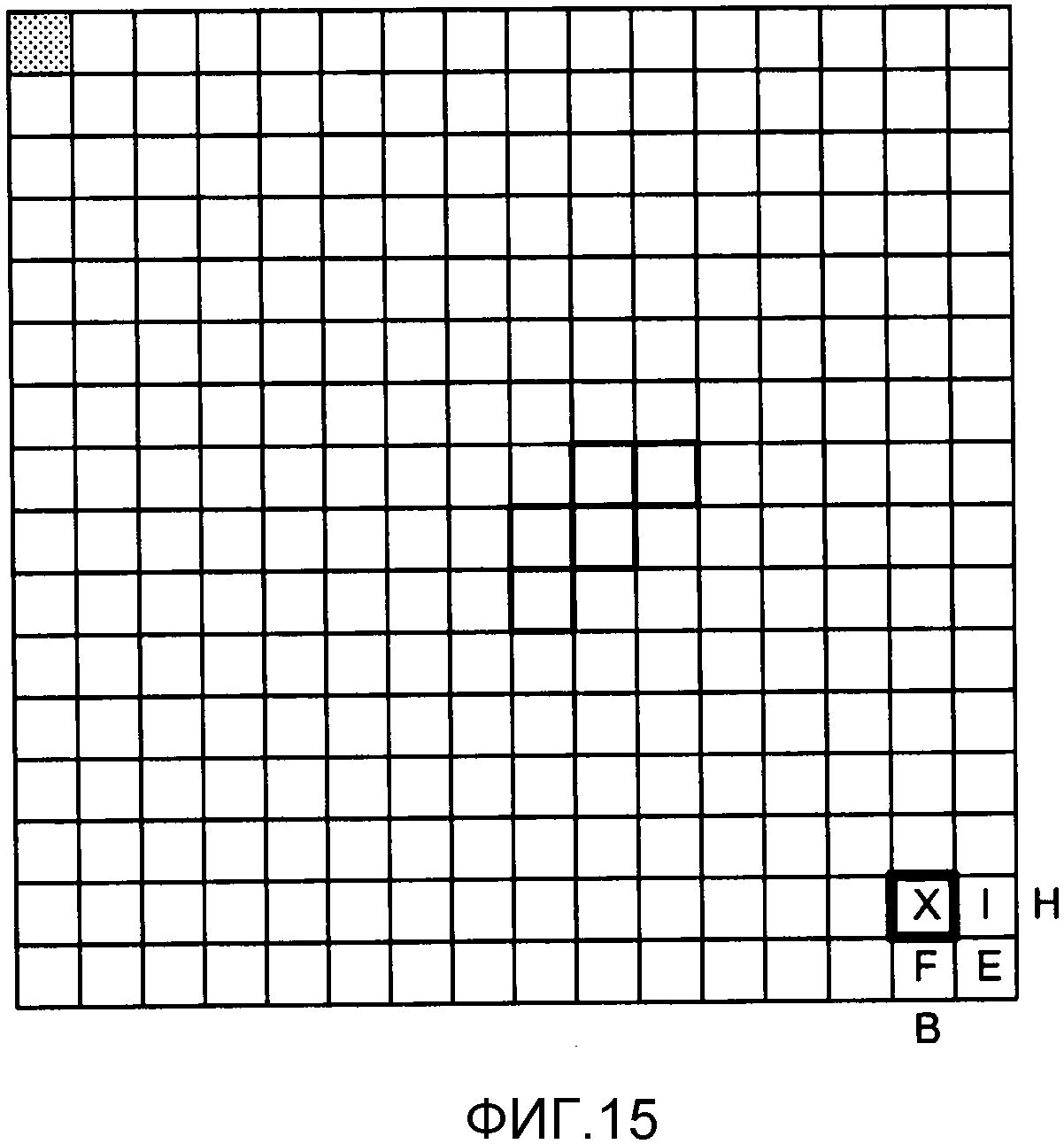
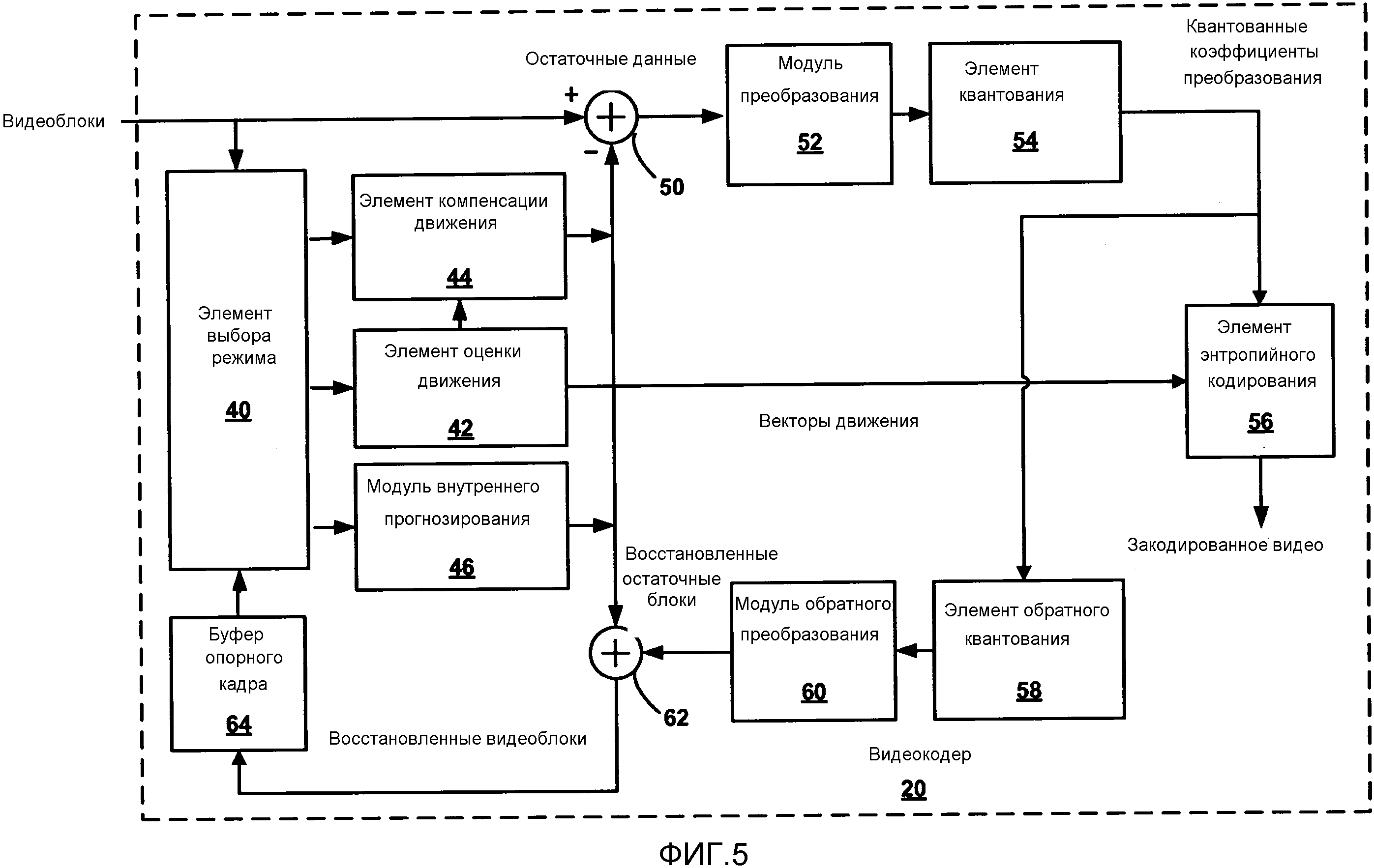
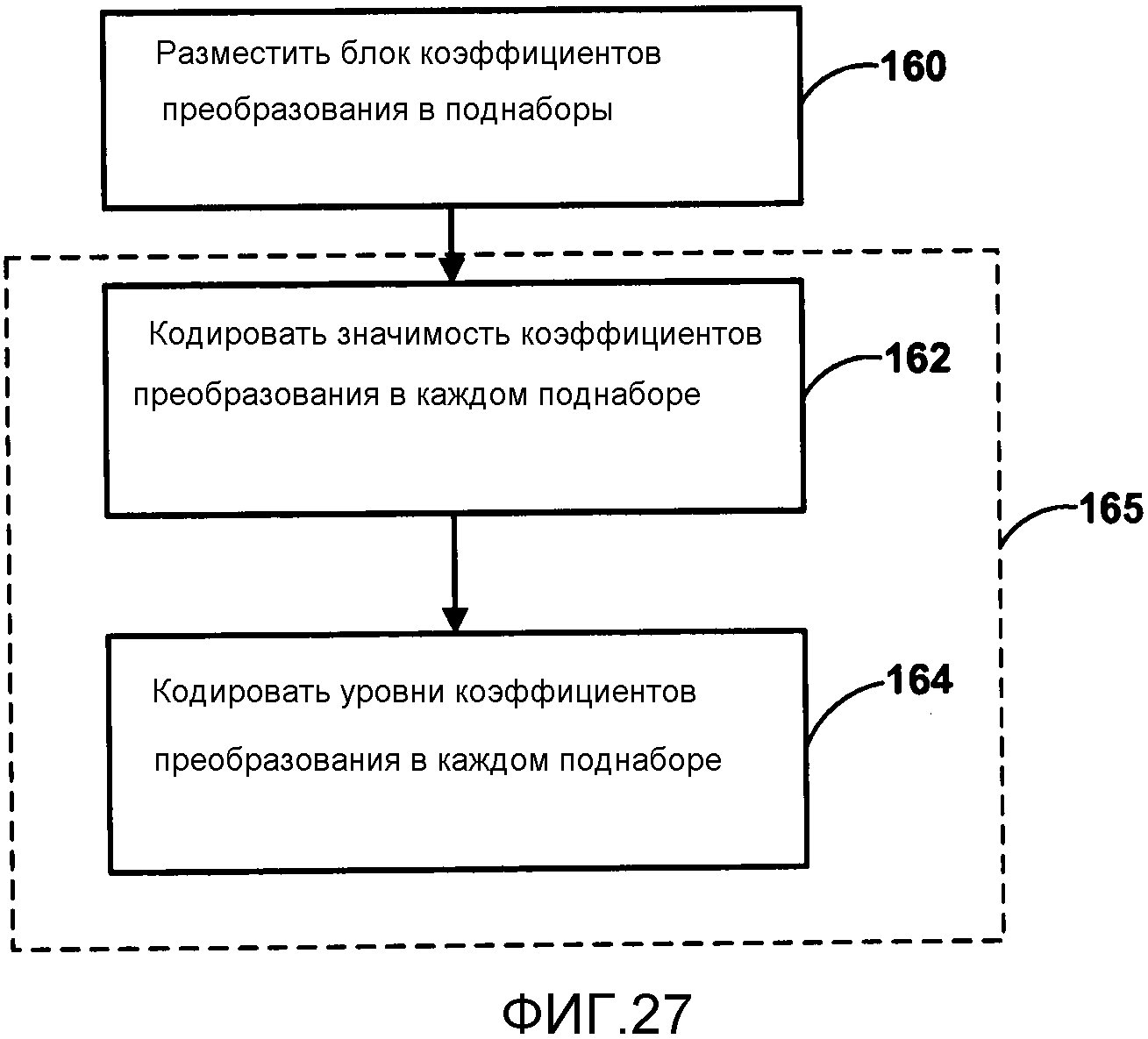
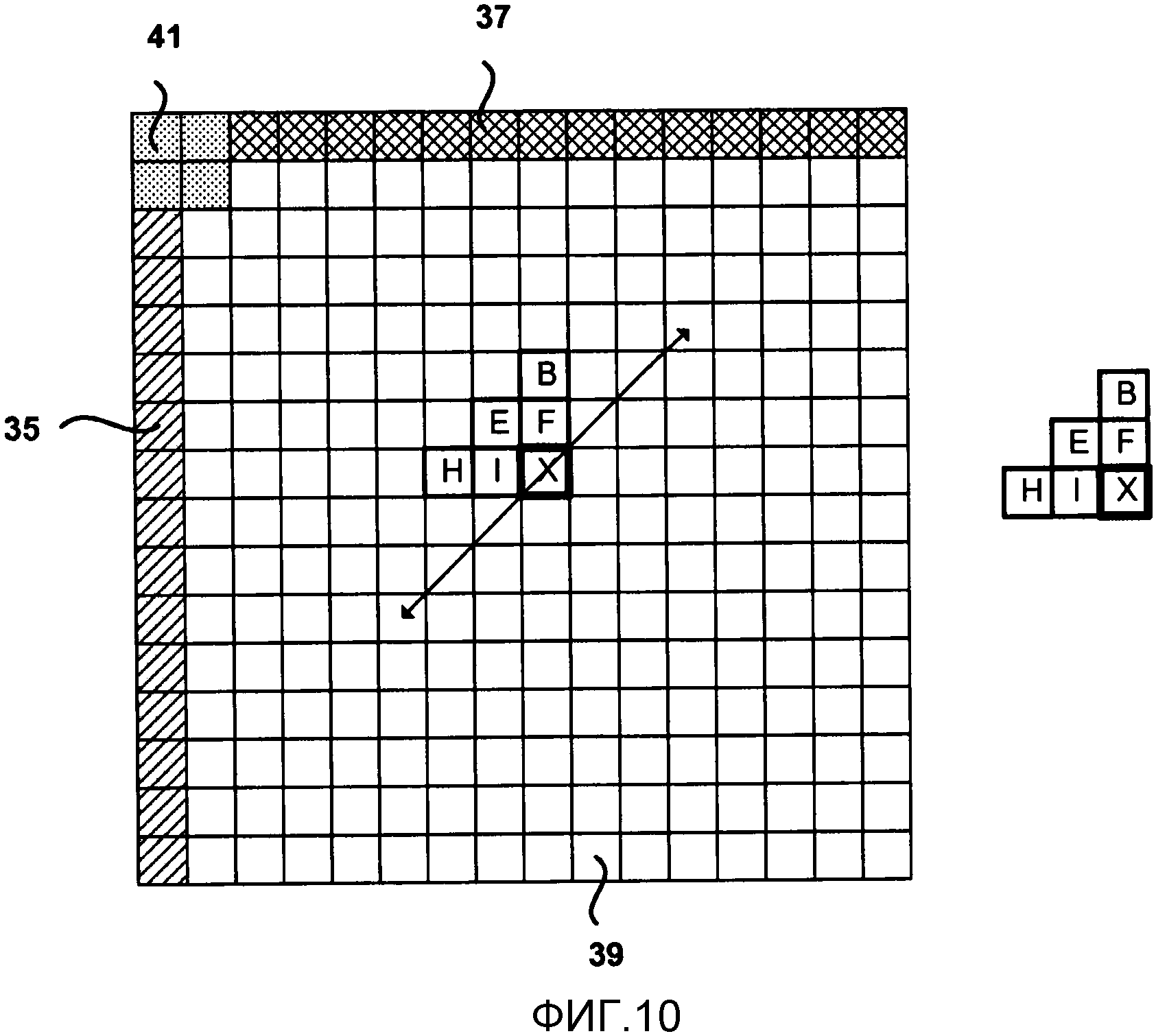
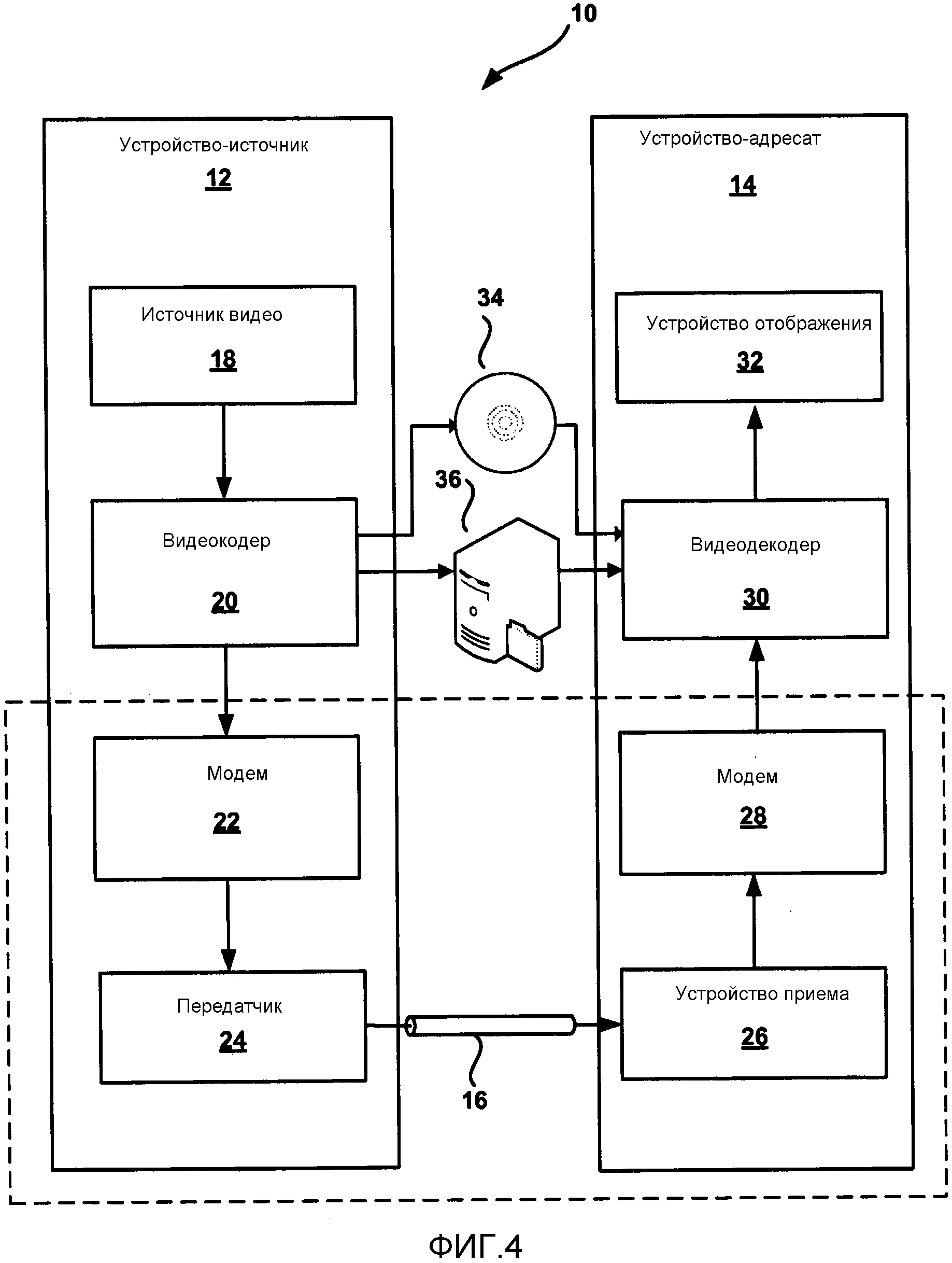
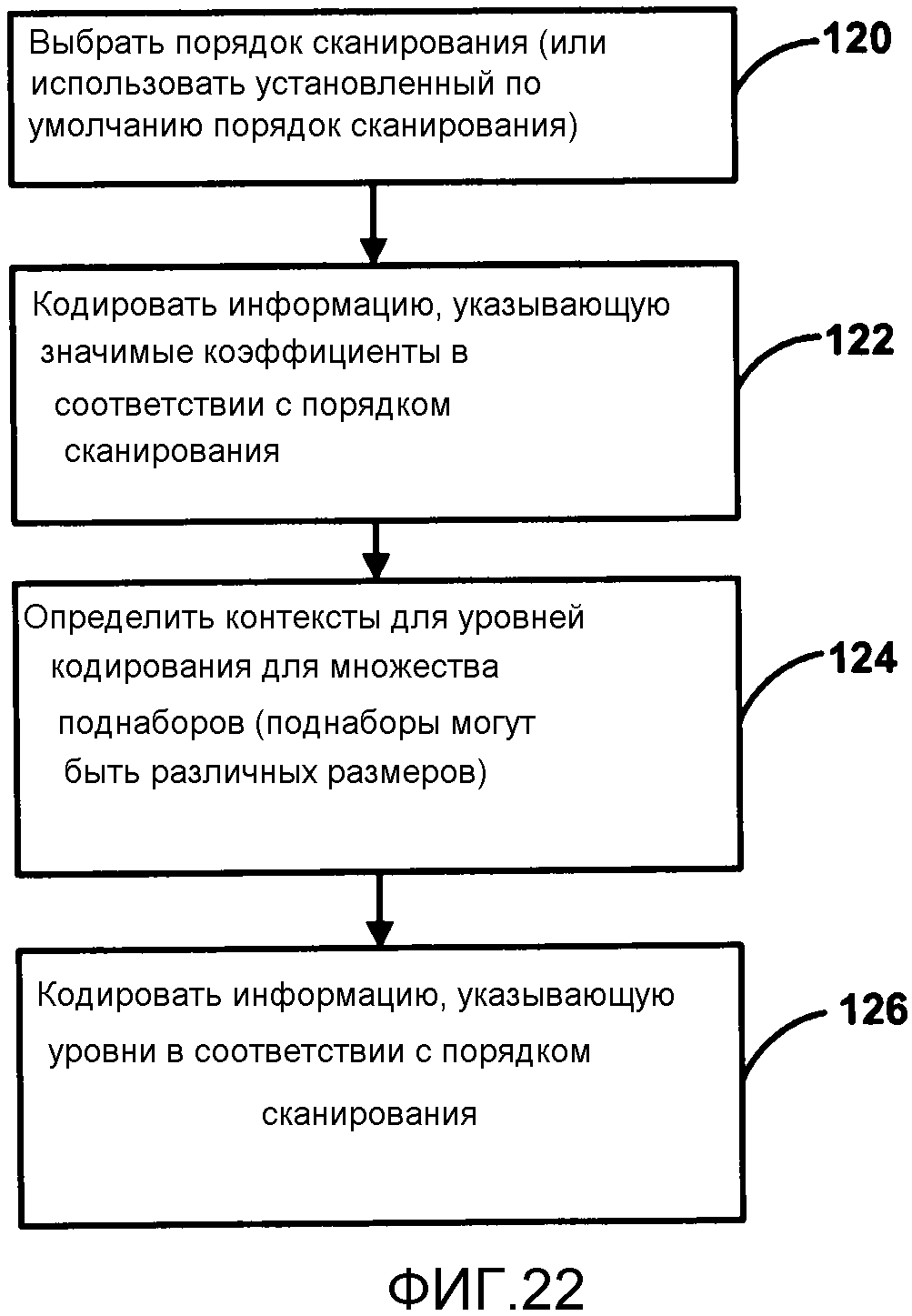
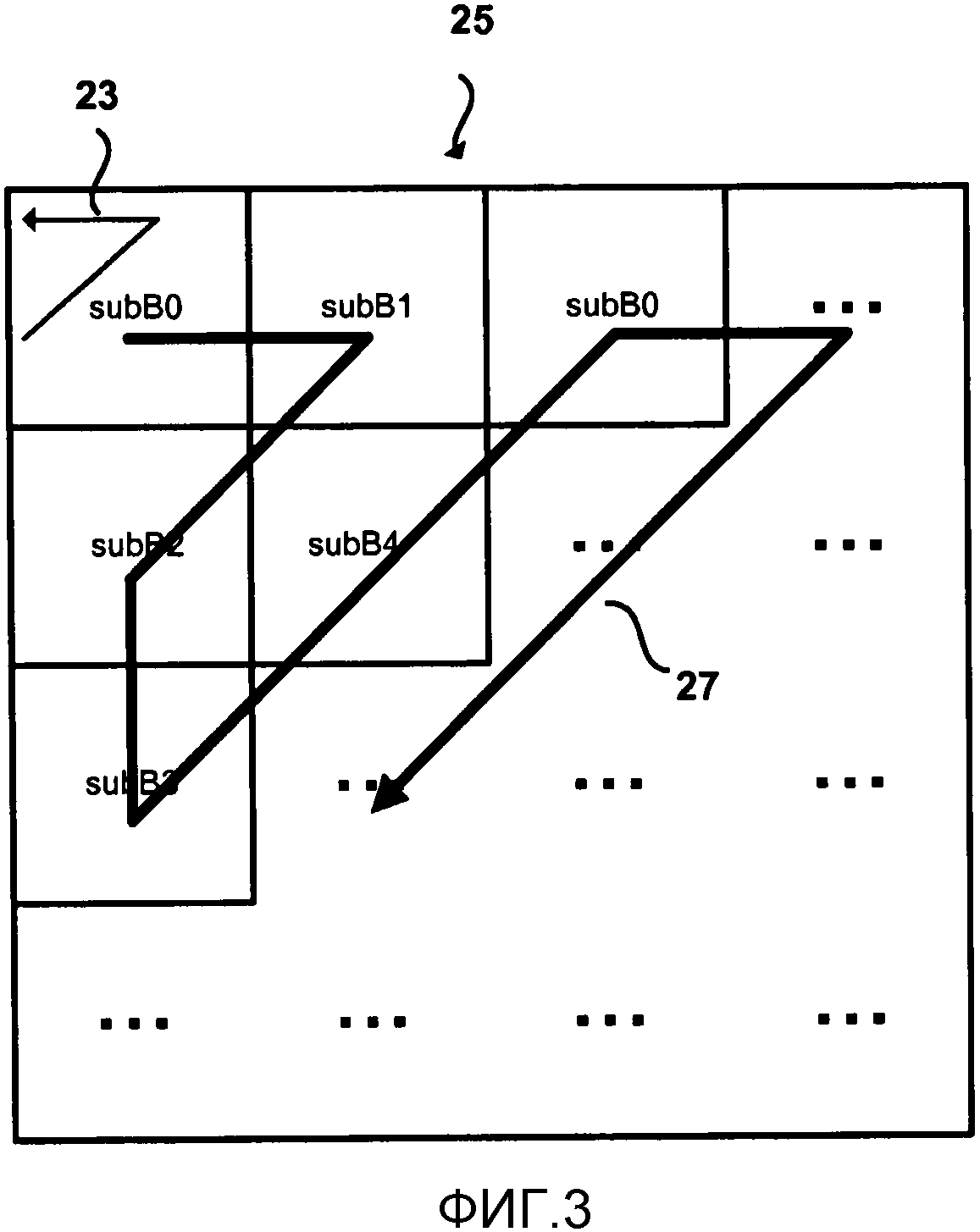
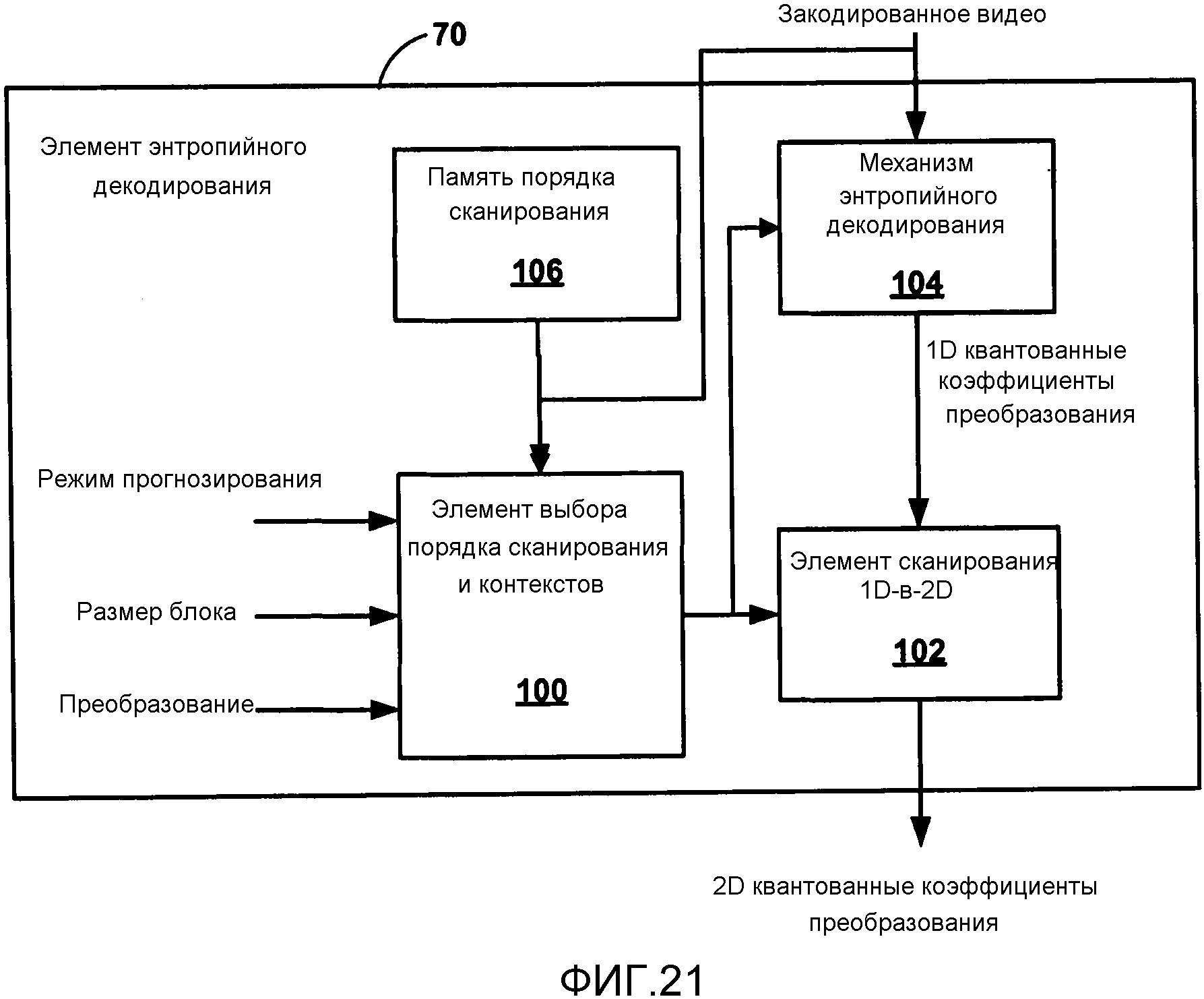
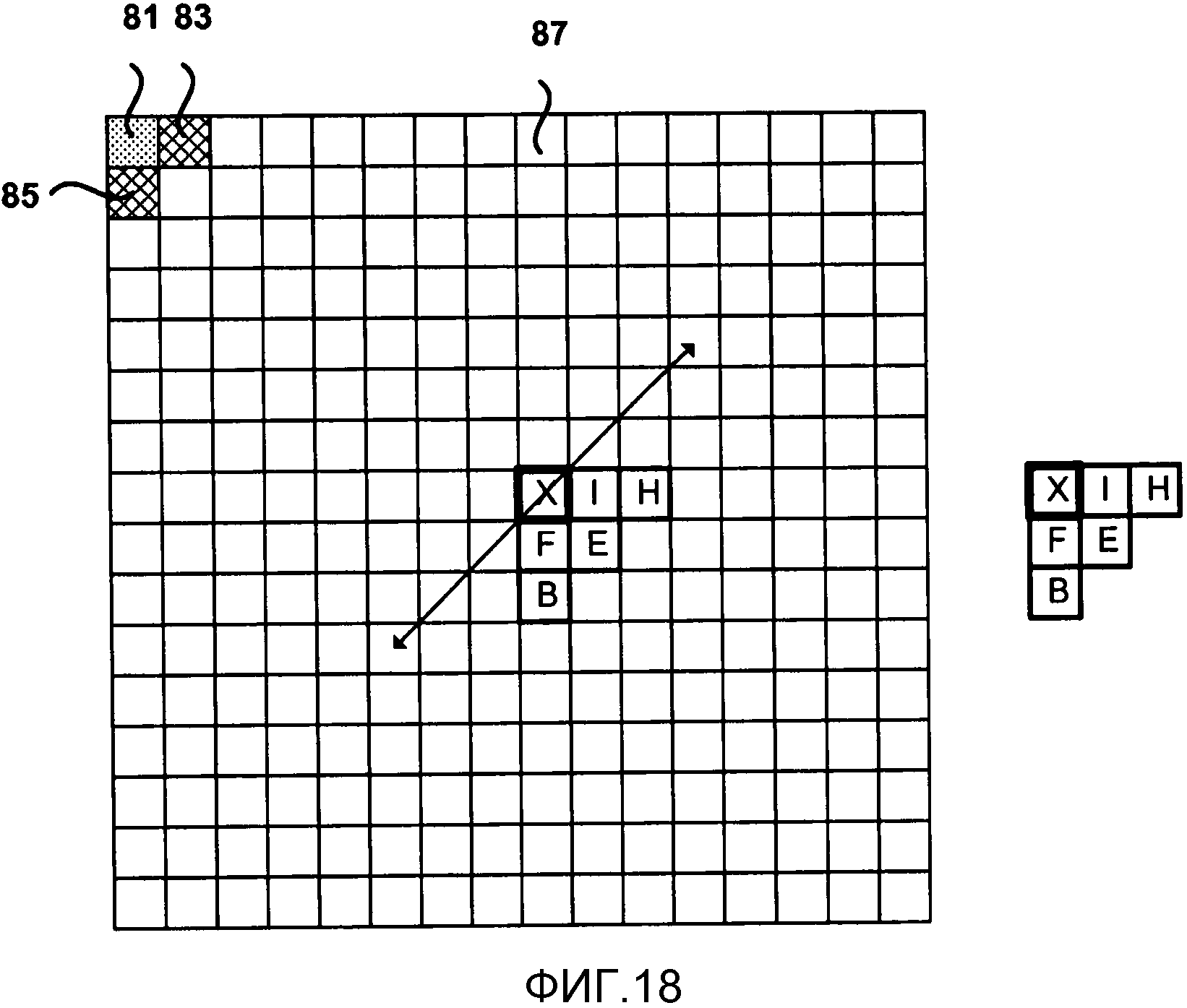
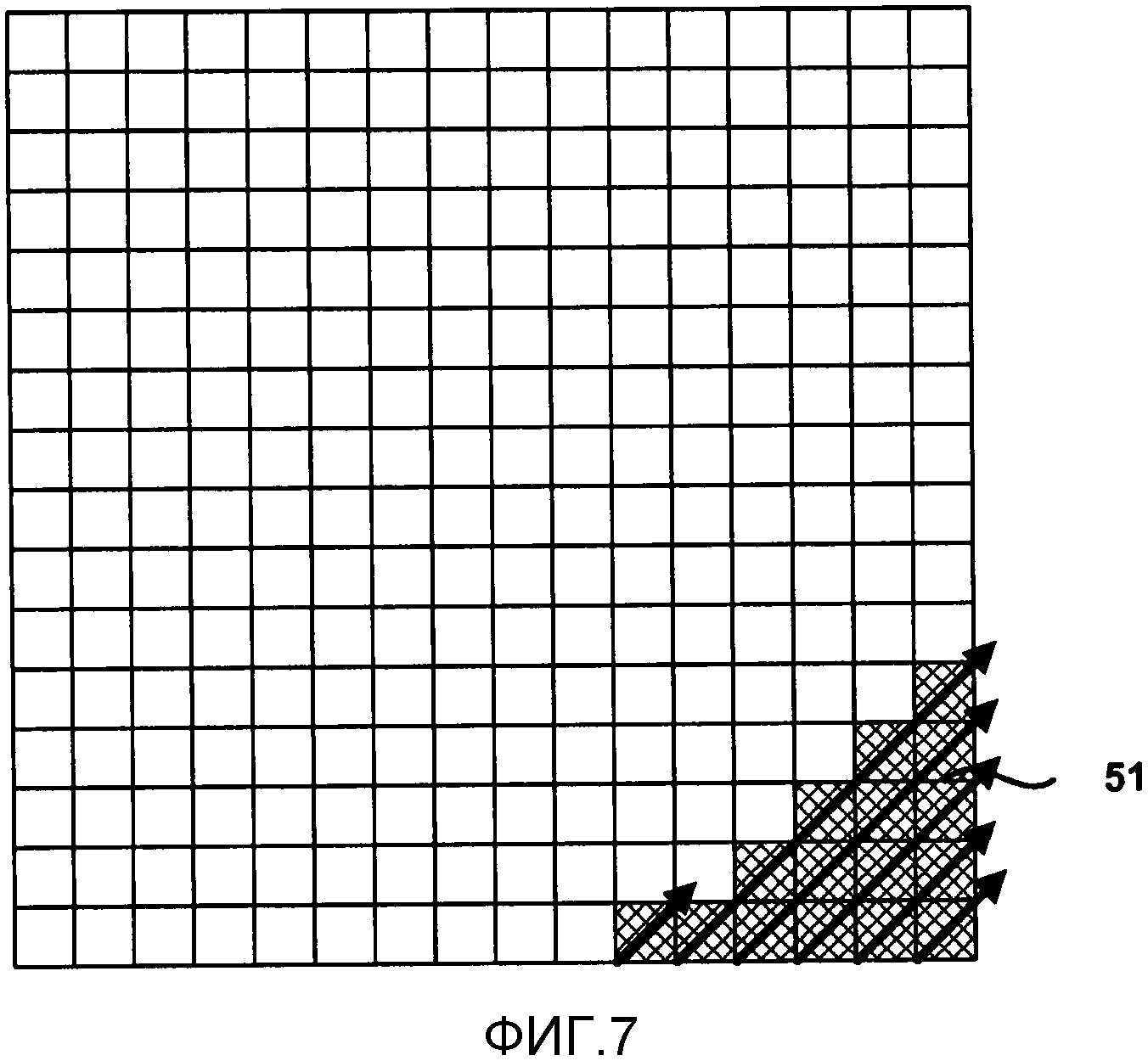
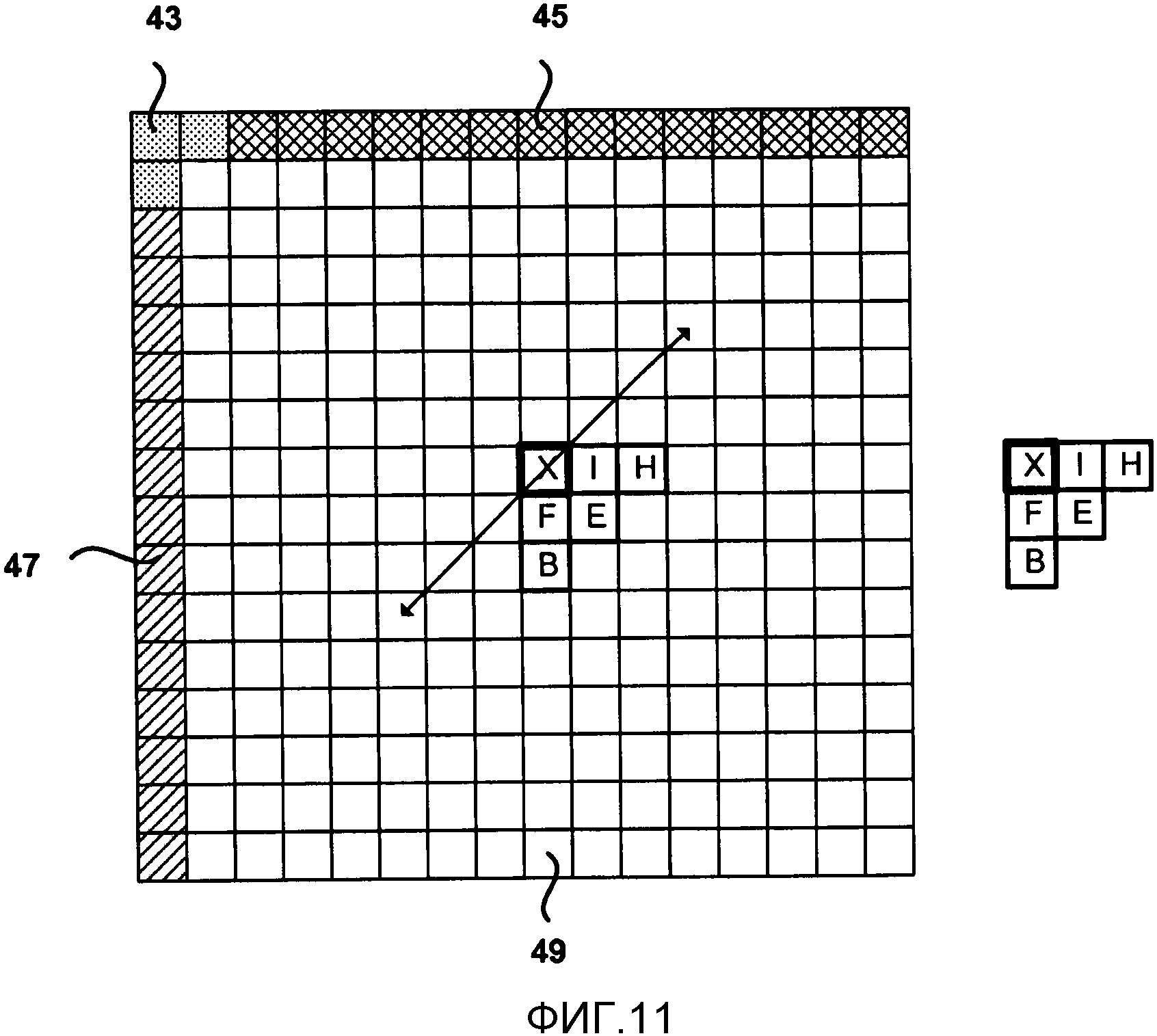
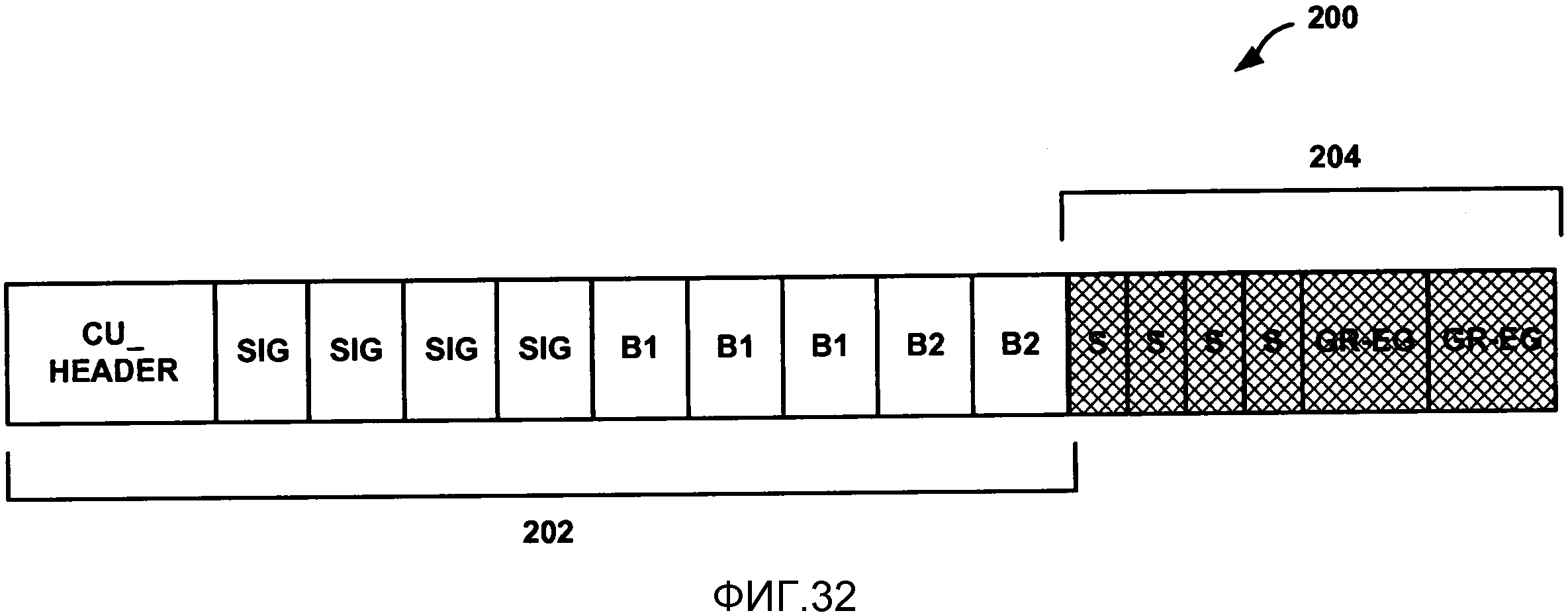
Поддержка интерполяционного фильтра для субпиксельного разрешения в видеокодировании
Подобная интерполяции фильтрация положений целочисленных пикселей при видеокодировании
Определение местоположений экстренных вызовов посредством фемтоточек доступа
Способы и устройства для уменьшения мощности в приемопередатчике
Распространение премиального контента со спонсорством рекламирования
Передача и прием выделенных опорных сигналов
Система и способ для внутриполосного модема для передачи данных по сетям цифровой беспроводной связи
Система и способ для выполнения управления доступом и поискового вызова, используя фемто соты
Энергоэффективное сканирование и захват малой базовой станции
Синхронизация базовой станции в системе беспроводной связи
Способ и устройство синхронизации активностей рч модулей
Способ интерполяции значений под-пикселов
Поддержка интерполяционного фильтра для субпиксельного разрешения в видеокодировании
Подобная интерполяции фильтрация положений целочисленных пикселей при видеокодировании
Определение местоположений экстренных вызовов посредством фемтоточек доступа
Способы и устройства для уменьшения мощности в приемопередатчике
Распространение премиального контента со спонсорством рекламирования
Передача и прием выделенных опорных сигналов
Система и способ для внутриполосного модема для передачи данных по сетям цифровой беспроводной связи
Система и способ для выполнения управления доступом и поискового вызова, используя фемто соты

