Результат интеллектуальной деятельности: СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ И ОЦЕНКИ ЕЕ ПОЛНОТЫ В ЭЛЕКТРОННЫХ ДОКУМЕНТАХ СЕТИ ИНТЕРНЕТ
Вид РИД
Изобретение
Изобретение относится к области обработки данных, а именно к способам распознавания текстовой информации, полученной из электронного документа сети Интернет, и может быть использовано для автоматизированного формирования контента корпоративных информационных систем, систем мониторинга и анализа новостной информации.
Известен метод автоматизированного извлечения знаний из слабоструктурированных источников информации, активно применяемый в современных корпоративных информационных системах (Березкин Д.В. Метод автоматизированного извлечения знаний из слабоструктурированных источников и его применение для создания корпоративных информационных систем, НИС НУК ИУ МГТУ им. Н.Э. Баумана, 2007 г.).
Метод основан на анализе HTML-структуры страниц источника информации и предполагает использование механизма посредника - программы, идентифицирующей искомую информацию на веб-странице и отображающей ее в некоторый промежуточный формат данных, например XML.
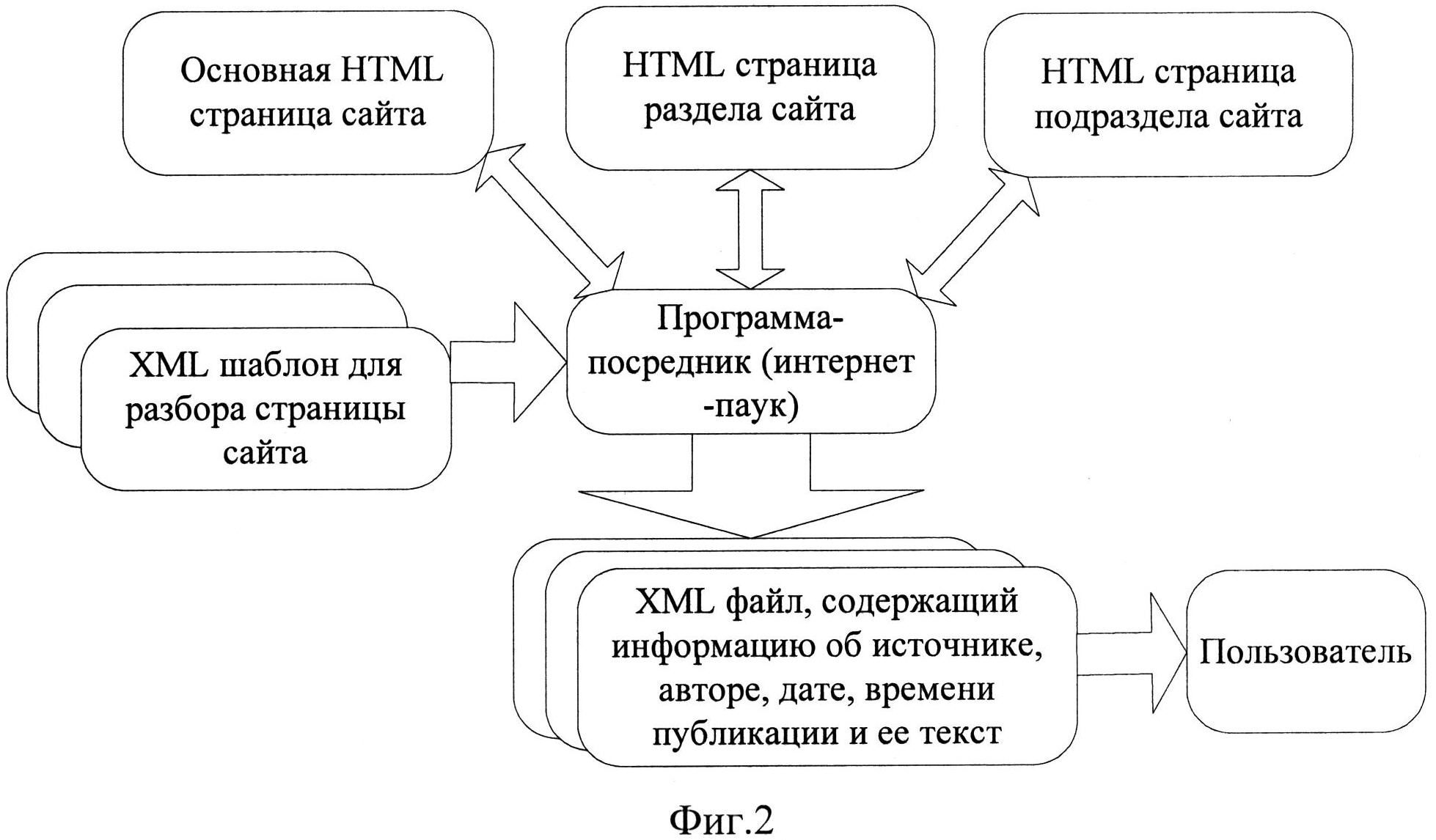
На практике использование данного подхода, как правило, предполагает получение априорной информации о структуре HTML-страниц источника. Для этого, в ходе настройки системы автоматизированного извлечения, изучаются образцы всех типов страниц сайта (основной страницы, страниц разделов и всех подразделов). По результатам анализа элементов логической и визуальной разметки для каждого типа страниц на языке регулярных выражений разрабатывается так называемый шаблон разбора страницы. Физически данный шаблон представляет собой файл формата XML, загружаемый в настройки интернет-паука, программы-посредника, которая на основании регулярных выражений шаблона извлекает с заданных веб-страниц требуемые фрагменты информации. Применительно к новостным сообщениям, к таким фрагментам относятся текст новости, ее заголовок, автор, источник, дата и время публикации. Результаты извлечения информации также хранятся в файле формата XML, который в последующем, на этапе анализа полученной информации, может быть преобразован к любому другому удобному для информационного работника формату (DOC, DOCX, TXT, RTF, PDF, FB2). Общий подход к извлечению информации, ориентированный на анализ HTML-структуры сайта, поясняет схема, изображенная на фиг.2.
Недостатком данного метода является необходимость знания априорной информации о структуре веб-страницы, а также необходимость корректировать сформированные шаблоны разбора каждый раз при изменении дизайна сайта, что существенно сокращает число анализируемых источников.
Наиболее близким по своей сущности к заявляемому изобретению (прототипом) является способ распознавания текстовой информации из векторно-растрового изображения (см. патент РФ №2309456, МПК G06K 9/36, опубл. 20.06.2007), заключающийся в том, что электронный документ разбивают на области, предположительно содержащие абзацы и строки текста, причем разбивку документа выполняют до получения областей, содержащих неразрывный логически связанный текст наибольшего размера, после чего осуществляют обработку текстовых объектов удалением избыточной и излишней информации, затем проводят анализ корректности кодировки символов путем анализа текста на принадлежность букв к алфавиту и слов текста к словарю с учетом заданного языка.
Недостатком данного способа является отсутствие возможности оценивать полноту распознанной текстовой информации, таким образом, снижается производительность системы содержательной обработки электронных документов.
Задачей изобретения является способ распознавания текстовой информации и оценки ее полноты в электронных документах сети Интернет, позволяющий повысить производительности системы содержательной обработки электронных документов и увеличить число анализируемых источников информации.
Задача изобретения решается тем, что способ распознавания текстовой информации и оценки ее полноты в электронных документах сети Интернет, заключающийся в том, что электронный документ разбивают на области, предположительно содержащие абзацы и строки текста, причем разбивку документа выполняют до получения областей, содержащих неразрывный логически связанный текст наибольшего размера, после чего осуществляют обработку текстовых объектов удалением избыточной и излишней информации, затем проводят анализ корректности кодировки символов путем анализа текста на принадлежность букв к алфавиту и слов текста к словарю с учетом заданного языка, согласно изобретению дополнен тем, что после процедуры анализа корректности кодировки символов вычисляют статистические характеристики частей речи и их форм, затем из полученных значений статистических характеристик формируют вектор признаков рабочего словаря системы распознавания, который с помощью процедур компонентного анализа преобразуют в вектор главных компонент и классифицируют с помощью предварительно обученных классификаторов, после чего осуществляют процедуру оценки полноты текстовой информации на основе мажоритарного способа принятия решения.
Перечисленная новая совокупность существенных признаков позволяет повысить производительности системы содержательной обработки электронных документов и увеличить число анализируемых источников информации.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие изобретения условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения преобразований на решение указанной задачи. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
«Промышленная применимость» способа обусловлена наличием элементной базы, на основе которой могут быть выполнены устройства, реализующие данный способ с достижением указанного в изобретении назначения.
Заявленный способ поясняется чертежами, на которых показаны:
фиг.1 - последовательность операций способа распознавания текстовой информации из электронного документа сети Интернет и оценки ее полноты:
1 - процедура разбиения электронного документа на области, предположительно содержащие абзацы и строки текста;
2 - процедура обработки текстовых объектов;
3 - процедура анализа корректности кодировки символов с учетом заданного языка;
4 - процедура вычисления статистических характеристик частей речи и их форм;
5 - процедура формирования вектора признаков рабочего словаря системы распознавания;
6 - процедура компонентного анализа;
7 - процедура классификации текстовой информации;
8 - процедура оценки полноты текстовой информации мажоритарным методом;
9 - процедура обучения классификаторов;
фиг.2 - схема реализации метода извлечения информации, основанного на анализе HTML-структуры страниц источника;
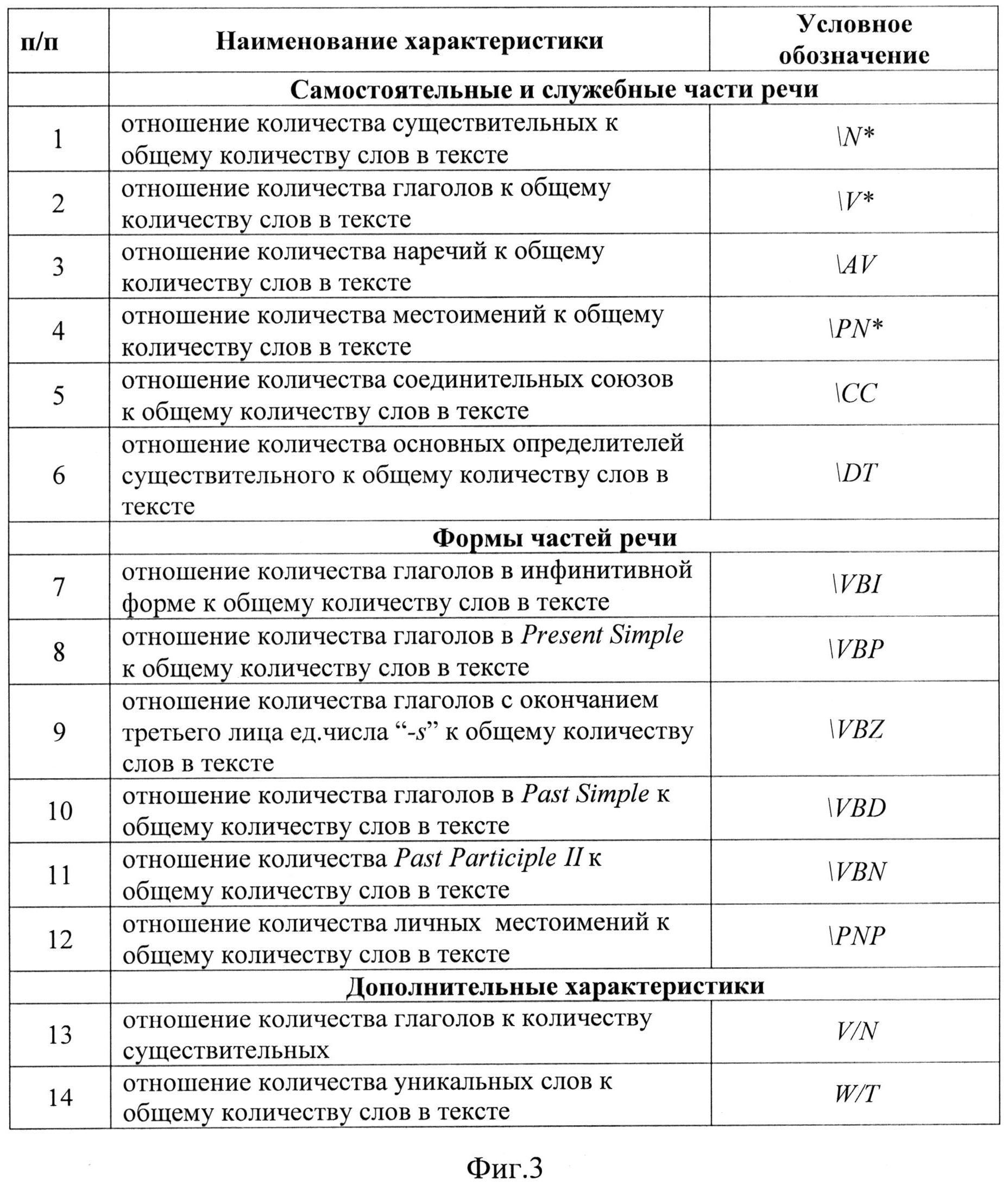
фиг.3 - статистические характеристики частей речи и их форм для английского языка;
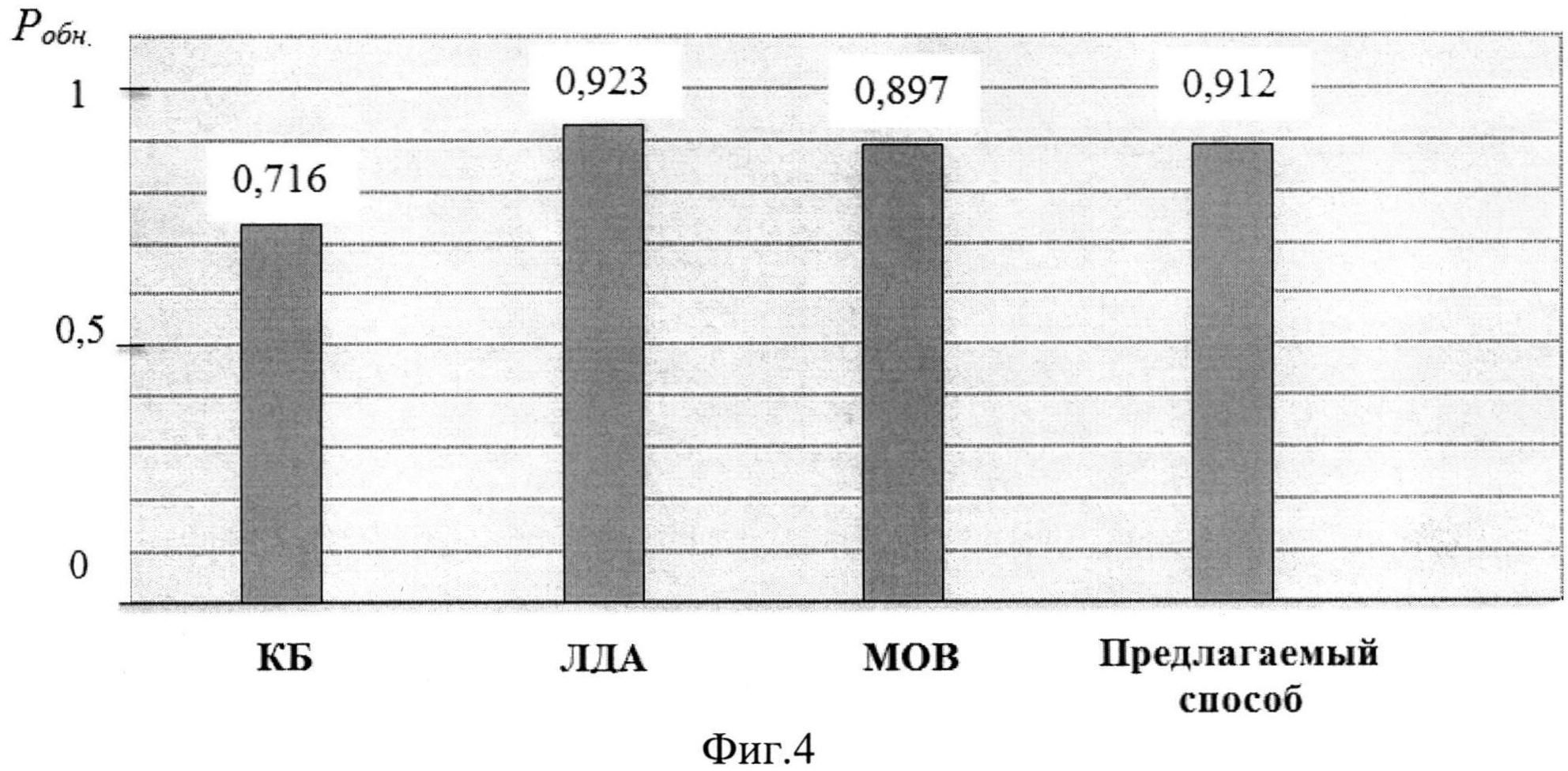
фиг.4 - вероятности обнаружения документов при использовании различных классификаторов и предлагаемого способа;
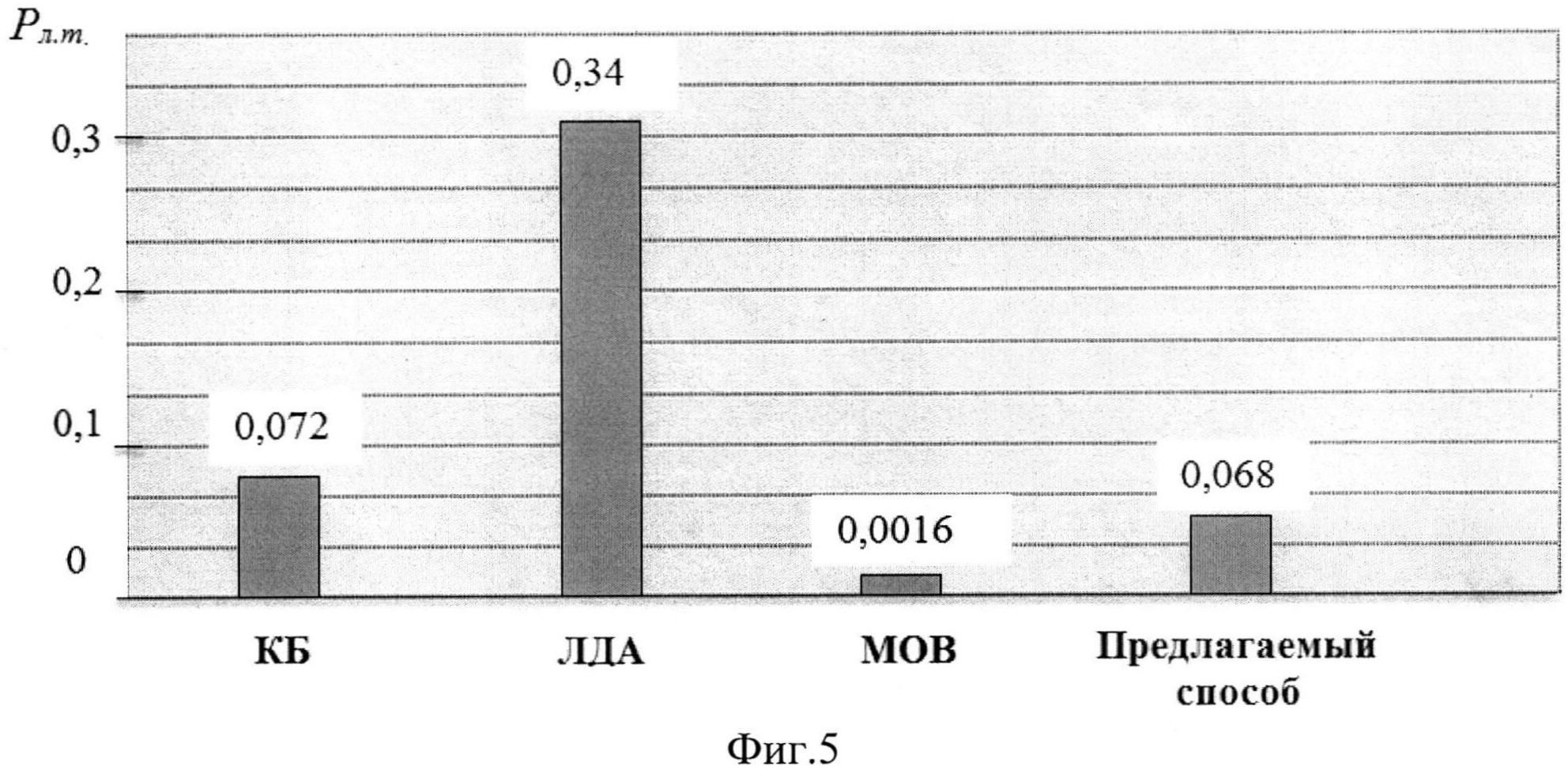
фиг.5 - вероятности ложной тревоги при использовании различных классификаторов и предлагаемого способа.
На фиг.1 представлена последовательность операций способа распознавания текстовой информации из электронного документа сети Интернет и оценки ее полноты. Из входного информационного потока сети Интернет на вход системы распознавания поступает электронный документ, который подвергается процедуре разбиения на области, предположительно содержащие абзацы и строки текста, причем разбивка документа осуществляется до получения областей, содержащих неразрывный логически связанный текст наибольшего размера (блок 1). После выделения из документа текстовых объектов они подвергаются обработке, в результате которой из них удаляется избыточная и излишняя информация (блок 2). Обработанные таким образом текстовые объекты подвергаются анализу корректности кодировки символов путем анализа текста на принадлежность букв к алфавиту и слов текста к словарю с учетом заданного языка (блок 3). После процедуры анализа корректности кодировки символов с помощью морфоанализатора для заданного языка осуществляется процедура вычисления статистических характеристик частей речи и их форм (блок 4). Например, для английского языка, набором таких характеристик выступают характеристики, указанные на фиг.3. Далее выполняется процедура формирования вектора признаков рабочего словаря системы распознавания, элементами которого являются рассчитанные характеристики (блок 5):
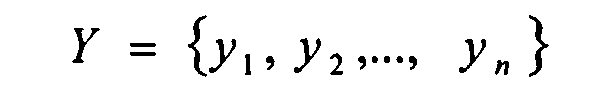
Сформированный вектор признаков рабочего словаря системы распознавания с помощью математического аппарата компонентного анализа преобразуется в вектор главных компонент (блок 6). В результате данного преобразования получается вектор исходной размерности, элементами которого становятся безразмерные некоррелированные между собой величины, представляющие собой некоторую линейную комбинацию признаков исходного вектора и называемые главными компонентами:
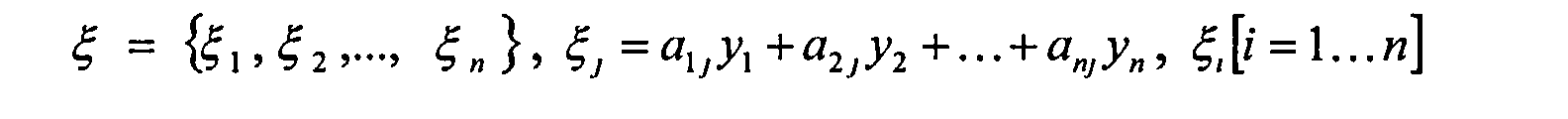
где yij - исходное значение признака;
a ij - вес i-й компоненты в j-м признаке сформированного вектора признаков.
Полученный вектор главных компонент классифицируется тремя предварительно обученными классификаторами (блок 7). В качестве первого классификатора используются классификатор Байеса (КБ)
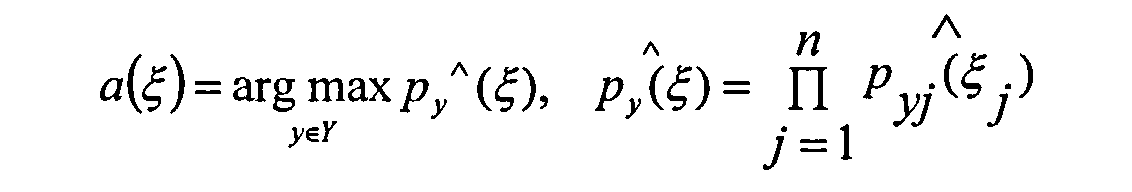
где Y - множество классов распознавания;
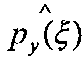 - оценка функции правдоподобия класса (плотность распределения объекта ξ, в классе y∈Y).
- оценка функции правдоподобия класса (плотность распределения объекта ξ, в классе y∈Y).
Значение оценки 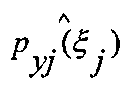 рассчитывается по гистограмме значений, как частота появления j-го признака в классе y∈Y.
рассчитывается по гистограмме значений, как частота появления j-го признака в классе y∈Y.
В качестве второго классификатора используются линейно-дискриминантный анализ (ЛДА)
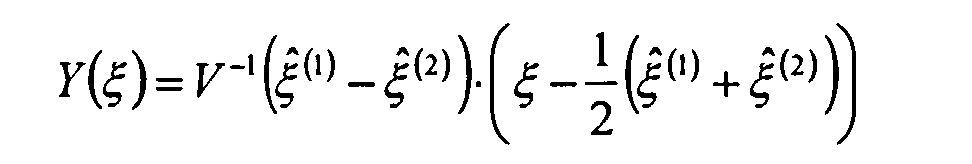
где  - сформированная на этапе обучения классификатора матрица объектов распознавания в i-м классе, у которой по строкам расположены координаты центрированных векторов
- сформированная на этапе обучения классификатора матрица объектов распознавания в i-м классе, у которой по строкам расположены координаты центрированных векторов  , j=1,…n; i=1, 2;
, j=1,…n; i=1, 2;
V - оценка ковариационной матрицы.
В качестве третьего классификатора используются метод опорных векторов с радиальной базисной функцией Гаусса (MOB)
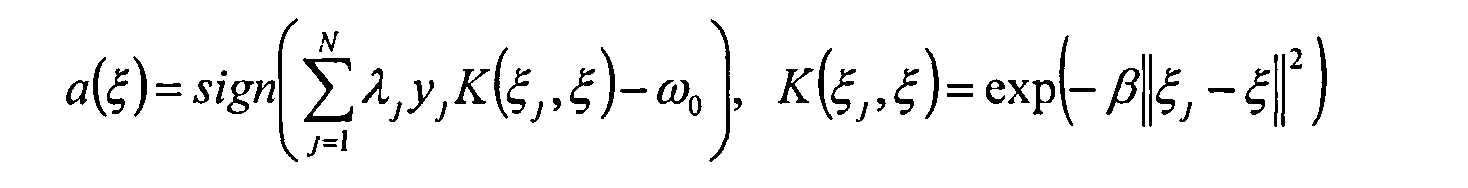
где yj - анализируемый класс;
λj - множители Лагранжа;
K(ξj,ξ) - ядровая функция, вычисляющая оценку близости объекта ξ к опорному вектору ξj;
ω0 - скалярный порог;
β - параметр алгоритма, подбираемый экспериментально.
В результате классификации каждый из вышеперечисленных классификаторов выносит решение о том, описывает ли данный вектор признаков электронный документ, содержащий полный текст статьи о событии или явлении реального мира (например, веб-страница, содержащая новостную статью в ее полном виде), или только некоторые ее фрагменты (например, веб-страница, содержащая лишь заголовки новостных статей с их кратким описанием). Формально решение классификатора оформляется в виде значения переменной, называемой коэффициентом принадлежности
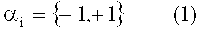
при этом, когда отдельный классификатор делает вывод о том, что вектор признаков описывает электронный документ, содержащий текст статьи в полном виде, он присваивает коэффициенту значение αi=-1, в противном случае αi=+1.
После процедуры классификации на основе рассчитанных значений коэффициентов принадлежности αi, (выражение 1) вычисляется мажоритарная сумма (блок 8)
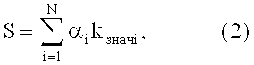
где N - количество используемых классификаторов;
kзнач.i - значения весовых коэффициентов значимости классификаторов, рассчитываемых на этапе их обучения (блок 9) по следующей формуле:
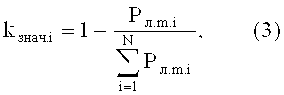
где N - количество используемых классификаторов;
Рл.т.i - значения вероятностей ложной тревоги, допущенные классификаторами при классификации объектов из обучающей выборки на этапе обучения классификаторов.
На основе значения полученной мажоритарной суммы (выражение 2) осуществляется принятие решение по следующему правилу: если значение мажоритарной суммы S>0, то анализируемый электронный документ содержит текст статьи в полном виде, в противном случае, документ не содержит текст статьи в полном виде.
Для проверки эффективности заявляемого способа была сформирована тестовая выборка из 10000 веб-страниц (по 5000 страниц каждого класса), источниками которых стали 10 зарубежных новостных порталов, предоставляющих своим пользователям информацию прессового характера на английском языке. В качестве частных показателей эффективности способа были использованы значения вероятности обнаружения документов, содержащих текст статьи в полном виде Робн., и значения вероятности ложной тревоги Рл.т.. В результате классификации объектов тестовой выборки с помощью предварительно обученных классификаторов частные показатели эффективности составили следующие значения Робн.=0,912, Рл.т.=0,068 (фиг.4, 5). Таким образом, результаты эксперимента подтверждают, что разработанный способ позволяет повысить производительности системы содержательной обработки электронных документов и увеличить число анализируемых источников информации.
Способ распознавания текстовой информации и оценки ее полноты в электронных документах сети Интернет, заключающийся в том, что электронный документ разбивают на области, предположительно содержащие абзацы и строки текста, причем разбивку документа выполняют до получения областей, содержащих неразрывный логически связанный текст наибольшего размера, после чего осуществляют обработку текстовых объектов удалением избыточной и излишней информации, затем проводят анализ корректности кодировки символов путем анализа текста на принадлежность букв к алфавиту и слов текста к словарю с учетом заданного языка, отличающийся тем, что после процедуры анализа корректности кодировки символов вычисляют статистические характеристики частей речи и их форм, затем из полученных значений статистических характеристик формируют вектор признаков рабочего словаря системы распознавания, который с помощью процедур компонентного анализа преобразуют в вектор главных компонент и классифицируют с помощью предварительно обученных классификаторов, после чего осуществляют процедуру оценки полноты текстовой информации на основе мажоритарного способа принятия решения.
Способ сжатия графического файла фрактальным методом с использованием кольцевой классификации сегментов
Способ оценки эффективности информационно-технических воздействий на сети связи
Устройство защиты средств электронно-вычислительной техники от электромагнитных излучений
Способ формирования защищенной системы связи, интегрированной с единой сетью электросвязи в условиях внешних деструктивных воздействий
Устройство обнаружения атак в беспроводных сетях стандарта 802.11g
Способ анализа информационного потока и определения состояния защищенности сети на основе адаптивного прогнозирования и устройство для его осуществления
Способ встраивания информации в изображение, сжатое фрактальным методом, с учетом мощности пикселей домена
Способ (варианты) определения психофизиологического состояния
Устройство контроля ошибок в цифровых системах передачи на базе технологии ethernet
Способ структурно-функционального синтеза защищенной иерархической сети связи
Способ обслуживания разноприоритетных пакетов в мультисервисных сетях
Способ стеганографической передачи информации через главный оптический тракт и устройство для его осуществления
Система связи по многопарному кабелю связи
Способ динамического резервирования пропускной способности обратных каналов в сети спутниковой связи интерактивного доступа
Способ динамического обнаружения малогабаритных скрытых средств, способствующих утечке информации, несанкционированно установленных на подвижном объекте
Способ удаленного мониторинга и управления информационной безопасностью сетевого взаимодействия на основе использования системы доменных имен
Способ создания кодовой книги и поиска в ней при векторном квантовании данных
Способ определения ложности передаваемой информации по динамике параметров невербального поведения человека
Способ идентификации кадров-вставок в потоке мультимедийных данных
Способ мониторинга динамического процесса

