Результат интеллектуальной деятельности: СИСТЕМЫ И СПОСОБЫ ОЦЕНКИ ЭФФЕКТИВНОСТИ ЛЕКАРСТВЕННОГО СРЕДСТВА
Вид РИД
Изобретение
ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящая заявка испрашивает приоритет согласно предварительной заявке на патент США №62/593802, поданной 1 декабря 2017 г., содержимое которой полностью включено в настоящую заявку посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
[0002] Обнаружение патологических или раковых клеток в организме - важная задача иммунной системы. Одним из участвующих механизмов является иммунная контрольная точка. Например, контрольные точки белка программируемой клеточной смерти 1 (PD-1) и цитотоксического Т-лимфоцит-ассоциированного белка 4 (CTLA-4) на Т-клетках отрицательно регулируют иммунную функцию и предотвращают чрезмерную реакцию (т.е. стимулируют самораспознавание иммунной системы). Однако этот механизм может использоваться опухолевыми клетками для ухода от иммунных атак. Иммунотерапия, как, например, ингибирование PD-1 (например, анти-PD1 антитела) и CTLA-4 (например, антитела к CTLA-4), блокирует активность контрольной точки, тем самым способствуя Т-клеточной идентификации болезни или опухолевых клеток как таковых.
[0003] Однако, хотя терапевтические средства на основе иммунных контрольных точек могут быть эффективными, отвечаемость у всех онкологических больных не гарантирована. Терапевтические средства на основе иммунной контрольной точки продемонстрировали улучшение, по сравнению с традиционными терапиями рака, длительного выживания пациентов с различными онкологическими заболеваниями. Однако на одобренные в настоящее время лекарственные средства-ингибиторы контрольных точек, содержащие анти-CTLA-4 антитело (например, ипилимумаб), и терапевтические средства, нацеленные на путь контрольной точки PD-1, такие как анти-PD-1 антитело (например, ниволумаб) или антитело к анти-лиганду 1 программируемой смерти (анти-PD-L1) (например, атезолизумаб), реагирует только подмножество онкологических пациентов. Поэтому было бы полезно иметь возможностью выбирать пациентов, которые будут реагировать на конкретные терапевтические средства на основе контрольных точек, и прогнозировать, какая контрольная точка-мишень сделает возможным наилучший результат у данного пациента.
[0004] Вклад в эффективность иммунотерапии конкретного человека могут вносить многие различные геномные и клеточные признаки. Более высокая мутационная нагрузка опухоли (MHO), например, может положительно влиять на частоту ответа за счет увеличения антигенов, присутствующих на опухолевых клетках, что приводит к повышенному распознаванию Т-клетками при блокировании PD-1. CD4/CD8/CD19-экспрессирующий лейкоцитарный опухолевый инфильтрат коррелирует с более хорошими клиническими результатами, так как такие клетки помогают иммунологической атаке опухолевых клеток и последующему высвобождению антигенов. Супрессорные клетки миелоидного происхождения и регуляторные Т-клетки (Treg) секвестрируют наличие Т-клеток и коррелируют с наихудшим выживанием у различных пациентов. Поскольку они являются взаимодействующими друг с другом признаками, которые могут быть обнаружены и выведены из данных секвенирования нового поколения (СНП), важно создать приложение машинного обучения, которое детально исследует их взаимосвязь с ответами на иммунотерапию и составляет прогноз отвечаемости на терапию, такую как ингибирование контрольной точки или другое лечение рака, соединяя контекст многих признаков, действующих совместно у данного индивида, на основе отвечаемости других людей с учетом их индивидуальных многофакторных контекстов.
[0005] Кроме того, учитывая потенциально большое количество взаимодействующих геномных, клеточных и других признаков, которые могут взаимодействовать, для определения того, будет ли данный индивид реагировать положительно на ингибирование контрольной точки, требуется усовершенствованный способ предоставления отчета о прогнозировании отвечаемости. Например, при прогнозировании отвечаемости возможно комбинаторное взаимодействие множества разных признаков. При применении способа машинного обучения для оценки того, может ли пациент более или менее отвечать на данное ингибирование контрольной точки, некоторые признаки могут быть определены как более или менее важные, чем другие, причем разные признаки могут отличаться в разных степенях от уровня, который предполагает возможность влияния каждого из них на отвечаемость, и разные факторы могут сигнализировать о большей или меньшей отвечаемости пациента на разные терапии ингибированием контрольной точки у разных индивидов. Таким образом, требуется контекстный отчет об отвечаемости данного пациента, включающий идентификацию признаков, играющих важную роль при прогнозировании отвечаемости, и направленность их влияния на прогноз. Однако, учитывая данное ограниченное пространство для представления всех таких потенциальных аспектов отчета о прогнозировании, современные способы предоставления отчета недостаточные. Поэтому требуется новый способ предоставления отчета о множестве элементов, относящихся к прогнозированию отвечаемости.
[0006] Настоящее изобретение направлено на преодоление этих и других недостатков в данной области.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0007] Согласно одному аспекту раскрыт реализуемый на компьютере способ, включающий введение в натренированный машинно-обучаемый классификатор геномной информации нетренировочного субъекта, где геномная информация нетренировочного субъекта содержит признаки из профиля опухоли, полученного от нетренировочного субъекта, причем натренированный машинно-обучаемый классификатор натренирован на геномной информации множества тренировочных субъектов и отвечаемости каждого из множества тренировочных субъектов на лечение, включающее ингибирование контрольной точки, геномная информация множества тренировочных субъектов содержит признаки образцов опухоли, полученных от каждого из множества тренировочных субъектов, причем машинно-обучаемый классификатор натренирован на прогнозирование отвечаемости на лечение; формирование классификации отвечаемости на ингибирование контрольной точки для нетренировочного субъекта с использованием натренированного машинно-обучаемого классификатора, причем классификация отвечаемости на ингибирование контрольной точки позволяет прогнозировать ответ нетренировочного субъекта на ингибирование контрольной точки; и предоставление отчета о классификации отвечаемости на ингибирование контрольной точки нетренировочного субъекта с использованием графического пользовательского интерфейса. В одном примере по меньшей мере некоторые из признаков из профиля опухоли, полученного от нетренировочного субъекта, или по меньшей мере некоторые из признаков из профиля опухоли, полученного от одного или более тренировочных субъектов, выбирают из следующей группы признаков: общая мутационная нагрузка, состоящая из всех мутаций; общая мутационная нагрузка, состоящая из несинонимичных мутаций, экспрессия бета-2-микроглобулина (В2М), экспрессия бета-10-субъединицы протеасомы (PSMB10), экспрессия переносчика антигенных пептидов 1 (ТАР1), экспрессия транспортера антигенных пептидов 2 (ТАР2), экспрессия лейкоцитарного антигена человека A (HLA-A), экспрессия главного комплекса гистосовместимости, класс I, В (HLA-B), экспрессия главного комплекса гистосовместимости, класс I, С (HLA-C), экспрессия главного комплекса гистосовместимости класс II, DQ альфа-1 (HLA-DQA1), экспрессия антигена гистосовместимости HLA класса II, бета-цепь DRB1 (HLA-DRB1), экспрессия антигена гистосовместимости HLA класса I, альфа-цепь Е (HLA-E), экспрессия гранулярных белков естественной клетки-киллера 7 (NKG7), экспрессия хемокиноподобного рецептора 1 (CMKLR1), инфильтрация опухоли клетками, экспрессирующими кластер дифференцировки 8 (CD8), инфильтрация опухоли клетками, экспрессирующими кластер дифференцировки 4 (CD4), инфильтрация опухоли клетками, экспрессирующими кластер дифференцировки 19 (CD19), экспрессия гранзима A (GZMA), экспрессия перфорина-1 (PRF1), экспрессия цитотоксического Т-лимфоцит-ассоциированного белка 4 (CTLA4), экспрессия белка программируемой клеточной смерти 1 (PD1), экспрессия лиганда 1 программируемой смерти (PDL1), экспрессия лиганда 2 программируемой клеточной смерти 1 (PDL2), экспрессия гена активации лимфоцитов 3 (LAG3), экспрессия Т-клеточного иммунорецептора с доменами Ig и ITIM (TIGIT), экспрессия кластера дифференцировки 276 (CD276), экспрессия хемокинового (С-С мотива) лиганда 5 (CCL5), экспрессия CD27, экспрессия хемокинового (С-Х-С мотива) лиганда 9 (CXCL9), экспрессия хемокинового (С-Х-С мотива) рецептора 6 (CXCR6), экспрессия индоламин-2,3-диоксигеназы (IDO), экспрессия сигнального трансдуктора и активатора транскрипции 1 (STAT1), экспрессия 3-фукозил-N-ацетил-лактозамина (CD15), экспрессия альфа-цепи рецептора интерлейкина-2 (CD25), экспрессия сиглека-3 (CD33), экспрессия кластера дифференцировки 39 (CD39), экспрессия кластера дифференцировки (CD118), экспрессия транскрипционного фактора forkhead box Р3 (FOXP3) и любая комбинация двух или более вышеперечисленных признаков.
[0008] В другом примере по меньшей мере некоторые из тренировочных признаков или по меньшей мере некоторые из нетренировочных признаков включают наборы генов. Еще в одном примере наборы генов выбирали с использованием анализа обогащения набора генов одного образца. Еще в одном примере машинно-обучаемый классификатор представляет собой случайный лес. Еще в одном примере при тренировке машинно-обучаемого классификатора используют по меньшей мере 50000 деревьев решений. Еще в одном примере классификация отвечаемости на ингибирование контрольной точки содержит оценку прогноза и один или более идентификаторов признаков, причем один или более идентификаторов признаков выбирают из группы, состоящей из валентности признака, важности признака и веса признака.
[0009] В другом примере графический пользовательский интерфейс предоставляет отчет об идентификаторах признаков в виде характеристик кольцевого сектора, причем угол кольцевого сектора указывает важность признака, наружный радиус кольцевого сектора указывает вес признака, а цвет кольцевого сектора указывает валентность признака. Еще в одном примере важность признака включает снижение индекса Джини признака. Еще в одном примере графический пользовательский интерфейс предоставляет отчет об идентификаторе признака тогда, и только тогда, когда важность признака выше порогового значения. Еще в одном примере важность признака не превышает пороговое значение, если квадрат важности признака не превышает 0,1. Еще в одном примере каждый из кольцевых секторов содержит внутреннюю дугу, и внутренние дуги кольцевых секторов расположены так, что они образуют круг.
[0010] Другой пример также включает ввод в натренированный машинно-обучаемый классификатор отвечаемости нетренировочного субъекта на лечение и дальнейшую тренировку машинно-обучаемого классификатора, причем дальнейшая тренировка включает тренировку натренированного машинно-обучаемого классификатора на признаках образцов опухоли, полученных от нетренировочного субъекта, и отвечаемости нетренировочного субъекта на лечение. Еще один пример также включает выбор лечения на основе сформированной классификации отвечаемости на ингибирование контрольной точки.
[0011] Согласно другому аспекту раскрыта компьютерная система, содержащая один или более микропроцессоров и один или более блоков памяти для хранения натренированного машинно-обучаемого классификатора и геномной информации нетренировочного субъекта, причем натренированный машинно-обучаемый классификатор натренирован на геномной информации множества тренировочных субъектов и отвечаемости каждого из множества тренировочных субъектов на лечение, включающее ингибирование контрольной точки, геномная информация множества тренировочных субъектов содержит признаки профилей опухоли, полученных от каждого из множества тренировочных субъектов, машинно-обучаемый классификатор натренирован на прогнозирование отвечаемости на лечение, геномная информация нетренировочного субъекта содержит признаки из профиля опухоли, полученного от нетренировочного субъекта, одна или более блоков памяти хранят инструкции, исполнение которых одним или более микропроцессорами вызывает формирование компьютерной системой классификации отвечаемости на ингибирование контрольной точки для нетренировочного субъекта с использованием натренированного машинно-обучаемого классификатора и предоставление отчета о классификации отвечаемости на ингибирование контрольной точки нетренировочного субъекта с использованием графического пользовательского интерфейса, причем классификация отвечаемости на ингибирование контрольной точки позволяет прогнозировать ответ нетренировочного субъекта на ингибирование контрольной точки.
[0012] В одном примере по меньшей мере некоторые из признаков из профиля опухоли, полученного от нетренировочного субъекта, или по меньшей мере некоторые из признаков из профиля опухоли, полученного от одного или более тренировочных субъектов, выбирают из следующей группы: общая мутационная нагрузка, состоящая из всех мутаций, общая мутационная нагрузка, состоящая из несинонимичных мутаций, экспрессия бета-2-микроглобулина (В2М), экспрессия бета-10-субъединицы протеасомы (PSMB10), экспрессия переносчика антигенных пептидов 1 (ТАР1), экспрессия транспортера антигенных пептидов 2 (ТАР2), экспрессия лейкоцитарного антигена человека A (HLA-A), экспрессия главного комплекса гистосовместимости, класс I, В (HLA-B), экспрессия главного комплекса гистосовместимости, класс I, С (HLA-C), экспрессия главного комплекса гистосовместимости, класс II, DQ альфа-1 (HLA-DQA1), экспрессия антигена гистосовместимости HLA класса II, бета-цепь DRB1 (HLA-DRB1), экспрессия антигена гистосовместимости HLA класса I, альфа-цепь Е (HLA-E), экспрессия гранулярного белка естественной клетки-киллера 7 (NKG7), экспрессия хемокиноподобного рецептора 1 (CMKLR1), инфильтрация опухоли клетками, экспрессирующими кластер дифференцировки 8 (CD8), инфильтрация опухоли клетками, экспрессирующими кластер дифференцировки 4 (CD4), инфильтрация опухоли клетками, экспрессирующими кластер дифференцировки 19 (CD19), экспрессия гранзима А (GZMA), экспрессия перфорина-1 (PRF1), экспрессия цитотоксического Т-лимфоцит-ассоциированного белка 4 (CTLA4), экспрессия белка программируемой клеточной смерти 1 (PD1), экспрессия лиганда 1 программируемой смерти (PDL1), экспрессия лиганда 2 программируемой клеточной смерти 1 (PDL2), экспрессия гена активации лимфоцитов 3 (LAG3), экспрессия Т-клеточного иммунорецептора с доменами Ig и ITIM (TIGIT), экспрессия кластера дифференцировки 276 (CD276), экспрессия хемокинового (С-С мотива) лиганда 5 (CCL5), экспрессия CD27, экспрессия хемокинового (С-Х-С мотива) лиганда 9 (CXCL9), экспрессия хемокинового (С-Х-С мотива) рецептора 6 (CXCR6), экспрессия индоламин-2,3-диоксигеназы (IDO), экспрессия сигнального трансдуктора и активатора транскрипции 1 (STAT1), экспрессия 3-фукозил-N-ацетил-лактозамина (CD15), экспрессия альфа-цепи рецептора интерлейкина-2 (CD25), экспрессия сиглека-3 (CD33), экспрессия кластера дифференцировки 39 (CD39), экспрессия кластера дифференцировки (CD118), экспрессия транскрипционного фактора forkhead box Р3 (FOXP3) и любая комбинация двух или более вышеперечисленных признаков.
[0013] В другом примере по меньшей мере некоторые из тренировочных признаков или по меньшей мере некоторые из нетренировочных признаков содержат наборы генов. Еще в одном примере наборы генов выбирали с использованием анализа обогащения набора генов одного образца. Еще в одном примере машинно-обучаемый классификатор представляет собой случайный лес. Еще в одном примере в машинно-обучаемом классификаторе используют по меньшей мере 50000 деревьев решений. Еще в одном примере классификация отвечаемости на ингибирование контрольной точки содержит оценку прогноза и один или более идентификаторов признаков, причем один или более идентификаторов признаков выбирают из группы, состоящей из валентности признака, важности признака и веса признака. Инструкции, при исполнении их одним или более микропроцессорами, вызывают предоставление графическим пользовательским интерфейсом отчета об идентификаторах признаков в виде характеристик кольцевого сектора, причем угол кольцевого сектора указывает важность признака, наружный радиус кольцевого сектора указывает вес признака, а цвет кольцевого сектора указывает валентность признака.
[0014] Еще в одном примере важность признака включает снижение индекса Джини признака. Еще в одном примере инструкции, при исполнении их одним или более микропроцессорами, вызывают предоставление графическим пользовательским интерфейсом отчета об идентификаторе признака тогда, и только тогда, когда важность признака выше порогового значения. Еще в одном примере важность признака не превышает пороговое значение, если квадрат важности признака не превышает 0,1. Еще в одном примере инструкции, при исполнении их одним или более микропроцессорами, вызывают предоставление графическим пользовательским интерфейсом отчета о внутренней дуге каждого из кольцевых секторов и круге, содержащем внутренние дуги кольцевых секторов. Еще в одном примере инструкции, при выполнении их одним или более микропроцессорами, вызывают дальнейшую тренировку компьютерной системой машинно-обучаемого классификатора, причем дальнейшая тренировка включает тренировку натренированного машинно-обучаемого классификатора на признаках образцов опухоли, полученных от нетренировочного субъекта, и отвечаемости нетренировочного субъекта на лечение.
[0015] Согласно еще одному аспекту раскрыт основанный на машинном обучении классификатор для классификации отвечаемости на ингибирование контрольной точки, который содержит основанный на машинном обучении классификатор, выполняющийся на множество процессоров, который натренирован на прогнозирование отвечаемости нетренировочного субъекта на лечение ингибированием иммунной контрольной точки, причем основанный на машинном обучении классификатор натренирован путем ввода в основанный на машинном обучении классификатор геномной информации множества тренировочных субъектов и отвечаемости каждого из множества тренировочных субъектов на лечение, геномная информация множества тренировочных субъектов содержит признаки профилей опухоли, полученных от каждого из множества тренировочных субъектов; входной процессор, который вводит признаки образцов опухоли, полученных от нетренировочного субъекта, в основанный на машинном обучении классификатор, причем машинно-обучаемый классификатор выполнен с возможностью формирования классификации отвечаемости на ингибирование контрольной точки нетренировочного субъекта, классификация отвечаемости на ингибирование контрольной точки позволяет прогнозировать ответ субъекта на лечение ингибированием контрольной точки; и выходной процессор, который предоставляет отчет о классификации отвечаемости на ингибирование контрольной точки. В одном примере классификация отвечаемости на ингибирование контрольной точки содержит оценку прогноза и множество идентификаторов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0016] Эти и другие признаки, аспекты и преимущества настоящего изобретения станут более понятными при прочтении следующего подробного описания со ссылкой на прилагаемые чертежи, на которых:
[0017] на ФИГ. 1 приведена сетевая диаграмма, показывающая варианты выполнения способа в соответствии с аспектами настоящего изобретения;
[0018] на ФИГ. 2 показаны некоторые не имеющие ограничительного характера примеры признаков, которые могут быть актуальны при тренировке классификатора и прогнозировании отвечаемости пациента на лечение в соответствии с аспектами настоящего изобретения;
[0019] на ФИГ. 3 приведена сетевая диаграмма, показывающая пример возможного выполнения способа тренировки классификатора в соответствии с аспектами настоящего изобретения;
[0020] на ФИГ. 4 приведена сетевая диаграмма, показывающая пример возможного выполнения способа использования натренированного классификатора для прогнозирования отвечаемости субъекта в соответствии с аспектами настоящего изобретения;
[0021] на ФИГ. 5 приведен пример способа предоставления отчета об отвечаемости субъекта на лечение, которая спрогнозирована натренированным основанном на машинном обучении классификатором, в соответствии с аспектами настоящего изобретения;
[0022] на ФИГ. 6 приведен пример способа предоставления отчета об отвечаемости субъекта на лечение, которая спрогнозирована натренированным основанном на машинном обучении классификатором, в соответствии с аспектами настоящего изобретения;
[0023] на ФИГ. 7 приведен пример способа предоставления отчета и сравнении с другими лечениями отвечаемости субъекта на лечение, которая спрогнозирована натренированным основанном на машинном обучении классификатором, в соответствии с аспектами настоящего изобретения;
[0024] на ФИГ. 8 приведен пример способа предоставления отчета и сравнении с другими лечениями отвечаемости субъекта на лечение, которая спрогнозирована натренированным основанном на машинном обучении классификатором, в соответствии с аспектами настоящего изобретения;
[0025] на ФИГ. 9 приведен пример способа предоставления отчета и сравнения с другими лечениями отвечаемости субъекта на лечение, которая спрогнозирована натренированным основанном на машинном обучении классификатором, когда наборы генов не включены в качестве признаков, в соответствии с аспектами настоящего изобретения;
[0026] на ФИГ. 10 приведен пример способа предоставления отчета об отвечаемости субъекта на лечение, которая спрогнозирована натренированным основанном на машинном обучении классификатором, в соответствии с аспектами настоящего изобретения;
[0027] на Фиг. 11A-11D приведены сравнительные графики и цифры, демонстрирующие, что использование 38 признаков обеспечивает превосходную эффективность классификатора по сравнению с использованием отдельно взятых факторов;
[0028] на Фиг. 12A-12D приведены графики и цифры, сравнивающие рабочие характеристики машинно-обучаемых классификаторов, использующих 38 признаков без наборов генов или 44 признаков с использованием наборов генов.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0029] Настоящее изобретение относится к способу машинного обучения для получения прогноза относительно того, может ли индивид отвечать на лечение ингибированием контрольной точки или другое лечение рака. Разные индивиды могут отвечать или не отвечать на данное лечение. Отвечаемость на лечение может зависеть не просто от наличия или отсутствие данного признака или количественной величины данного признака в отдельности. Скорее, несколько признаков могут по-разному сочетаться у разных людей, что делает ответ на данное лечение более вероятным у некоторых индивидов, и менее вероятным у других индивидов. Таким образом, стандартные способы прогнозирования отвечаемости пациента на основе одного признака или даже нескольких признаков не позволяют точно прогнозировать отвечаемость в условиях, когда большое количество факторов, которые могут меняться независимо друг о друга, действуют согласованно.
[0030] Способ машинного обучения представляет новое решение для устранения этого недостатка преобладающих способов диагностического прогнозирования. В машинном обучении с учителем, например, в запоминающее устройство компьютера могут быть загружены большие наборы данных, представляющих множество многочисленных характеристик индивидов в паре с каждой известной отвечаемостью на данное лечение. Носитель информации компьютера содержит инструкции, которые дают команду процессору компьютера на обработку информации о признаке и отвечаемости индивида для идентификации в информации о признаке структур, которые сигнализируют о высокой или низкой вероятности ответа индивида на данное лечение. Преимущество использования способа машинного обучения для такого анализа заключается в том, что он позволяет идентифицировать структуры в признаках и определять их актуальность для прогнозирования отвечаемости на лечение, что невозможно без больших возможностей по хранению и извлечению данных компьютерных систем и их способности обрабатывать большие количества информации. Компьютеризированная система машинного обучения может обрабатывать десятки или сотни признаков или более десятков или сотен субъектов для идентификации структур признаков и их совокупных корреляций с отвечаемостью индивида. Идентифицируемые таким образом структуры могут быть не обнаруживаемыми иным образом, поскольку они действительно требуют обработки больших количеств данных в сложных наборах информации.
[0031] Для определения признаков индивида можно получать образец ткани индивида, такого как индивид с онкологическим заболеванием, и определять характеристики такой ткани. В некоторых примерах полученная ткань может быть образцом клеток, взятых из опухоли. В других примерах полученная ткань может быть неопухолевой тканью, взятой у индивида.
[0032] При этом ингибирование контрольной точки относится к лечениям, блокирующим процесс, посредством которого опухолевые клетки активируют пути самораспознавания в иммунной системе и тем самым предотвращают атаку иммунных клеток и цитолиз опухолевых клеток. Как полагают, активация таких путей опухолевыми клетками вносит вклад в рефрактерность некоторых пациентов к иммуноонкологическим лечениям, например, когда создают иммунные клетки для распознавания опухолевых клеток и выбора их в качестве мишени. В число примеров ингибирования контрольной точки входит путь CTLA4. CTLA4 является белковым рецептором, экспрессируемым на регуляторных Т-клетках. Он может быть также экспрессирован на обычных Т-клетках после их активации, что часто наблюдается при раке. Когда CTLA4 связывает CD80 или CD87, экспрессируемые на поверхности антигенпредставляющей клетки белки, это приводит к иммуносупрессии. В здоровых клетках этот механизм способствует самораспознаванию и предотвращает иммунологическую атаку своих клеток организма. Однако при раке повышенная регуляция этого пути помогает опухолевым клеткам избегать обнаружения и атаки иммунной системой. Примеры лечения ингибитором контрольной точки, который ингибирует этот путь (таким, как анти-CTLA4-антитело ипилимумаб), могут активизировать способность иммунной системы выцеливать и разрушать опухолевые клетки, например, в сочетании с другими иммуноонкологическими лечениями, которые стимулируют противоопухолевую иммуноотвечаемость.
[0033] Аналогичным образом, другим примером ингибирования контрольной точки является путь PD-1. Связывание PD-1 на Т-клетках посредством рецептора PD1-L1, экспрессируемого на своих клетках организма, вызывает иммуносупрессивный ответ. Как и в случае пути CTLA4, этот путь тоже используется опухолевыми клетками для избежания обнаружения и атаки иммунной системой. Примеры лечения ингибитором контрольной точки, который ингибирует этот путь (таким, как анти-PD-1-антитела пембролизумаб, ниволумаб и семиплимаб и анти-PD-L1-антитела атезолизумаб, авелумаб и дурвалумаб), могут активизировать способность иммунной системы выцеливать и разрушать опухолевые клетки, например, в сочетании с другими иммуноонкологическими лечениями, которые стимулируют противоопухолевую иммуноотвечаемость.
[0034] Используемый в настоящем документе термин «ингибитор контрольной точки» или «лечение ингибированием контрольной точки» и т.п. включает эти лечения, а также другие лечения, которые ингибируют пути ингибитора контрольной точки, в том числе лечения с помощью других антител или фармацевтических составов, которые функционируют путем предотвращения взаимодействия CTLA4 или PD-1 с их когнатными лигандами или рецепторами или активации последствий их нисходящей сигнализации или клеточных функций.
[0035] При создании прогноза в отношении отвечаемости индивида на данное лечение могут быть актуальны многие признаки. К примерам можно отнести информацию о генетической последовательности, содержащуюся в геноме клеток, взятых у индивида, информацию о генетической последовательности, выраженную в РНК, транскрибируемой из генома клетки индивида, величины экспрессии транскриптов геномных последовательностей, которые могут быть отражены в величинах соответствующего РНК-транскрипта или его белковом продукте, или типы клеток, присутствующие в образце. В одном примере, где образец содержит опухолевую ткань или клетки индивида, такая информация может указывать характеристики опухолевых клеток, т.е. клеток в пределах модифицированной геномной последовательности или последовательностях в сравнении с обычной популяцией неопухолевых клеток индивида или референсным геномом, упоминаемым в концепции генетического секвенирования. Онкогенез может быть результатом одного или более изменений нуклеотидной последовательности и/или нескольких последовательностей в геномной ДНК. В некоторых случаях, например, накопление нескольких таких модификаций последовательности может в совокупности функционировать таким образом, чтобы преобразовывать небольную клетку в опухолевую клетку. В других случаях начальное накопление одной или более таких модификаций в клетке может предрасположить клетку к дальнейшему накоплению таких модификаций. Еще в одних случаях пролиферация таких модификаций в клетке может не означать, что какие-либо конкретные модификации непосредственно участвуют в развитии опухоли или отвечают за нее. Скорее, онкогенный процесс может привести к некоторым модификациям, которые непосредственно вызывают преобразование клетки в опухолевую клетку, но может также создавать другие модификации, которые не делают этого.
[0036] Таким образом, опухолевые клетки некоторых индивидов могут иметь большое количество таких модификаций последовательностей геномной ДНК, тогда как у других индивидов их может быть немного. Из них некоторые могут приводить к транскриптам или белковым продуктам с аминокислотными последовательностями, измененными в результате геномной модификации, например, когда модификация последовательности ДНК в геномной ДНК приводит к продуцированию белка или молекулы ДНК, имеющей последовательность, которая отличается от той, которая была бы получена, если бы модификация не произошла. Такие модификации называют несинонимичными мутациями. Другие модификации могут быть модификациями некодирующей ДНК, или могут быть модификациями кодирующей ДНК, которые не изменяют аминокислотные последовательности белков. Например, модификации интронных последовательностей или нетранскрибированной ДНК могут не приводить к белковым продуктам, аминокислотная последовательность которых отличается от аминокислотной последовательности белков, полученной из генома, не имеющего такой же модификации. Такие модификации называют синонимичными мутациями. Таким образом разные опухоли могут содержать разные общие количества модификаций геномной ДНК, в том числе разные количества несинонимичных мутаций, разные количества синонимичных мутаций или разные количества и тех, и других (или одинаковое общее количество геномных мутаций, но разные количества синонимичных мутаций и разные количества несинонимичных мутаций). Количество мутаций, содержащихся в клетке, называют ее мутационной нагрузкой или общей мутационной нагрузкой, тогда как общее количество несинонимичных мутаций, содержащихся в ней, называют ее несинонимичной мутационной нагрузкой, а количество синонимичных мутаций, содержащихся в ней, называют ее синонимичной мутационной нагрузкой.
[0037] Превращение клетки из неопухолевой в опухолевую может соответствовать накоплению таких модификаций в геномной ДНК. Такое накопление может быть накоплением синонимичных мутаций, несинонимичных мутаций или мутаций обоих типов. Так или иначе, общая мутационная нагрузка может возрастать, приводя к началу, развитию и последующему превращению неопухолевой клетки в опухолевую клетку. Кроме того, мутационная нагрузка опухолевой клетки может влиять на вероятность того, будет ли ингибитор контрольной точки эффективным в стимуляции противоопухолевого ответа иммунной системой. Чем больше мутаций содержит опухолевая клетка, тем больше шанс, что подавление ингибирования контрольной точки может разингибировать распознавание ее иммунной системой как больной клетки и атаковать ее. В частности, несинонимичная опухолевая мутационная нагрузка может быть положительно коррелирована со способностью ингибирования контрольной точки разингибировать противоопухолевый иммунный ответ. Белки с мутированными аминокислотными последовательностями, продуцированные после несинонимичных мутаций, могут быть идентифицированы в клетках как патологические и присутствующие на мембранах клеток в качестве сигнала болезненного состояния, имеющего место внутри клетки. Например, опухоли могут экспрессировать белки с мутированными аминокислотными последовательностями, называемыми неоантигенами. Опухолевые клетки, экспрессирующие такие неоантигены, могут экспрессировать мутированные фрагменты таких неоантигенов на своих клеточных мембранах.
[0038] Такое представление неоантигенов может стимулировать распознавание иммунной системой того, что клетка больна (например, опухолевая клетка), и способствовать нацеленному разрушению таких клеток иммунной системой. Однако противодействующий процесс в опухолях может использовать путь контрольной точки для избежания обнаружения иммунной системой. Таким образом, может ли ингибитор контрольной точки помочь в улучшении иммуноонкологического лечения, может зависеть от опухолевой мутационной нагрузки. Более высокая нагрузка может соответствовать более высокому уровню представления неоантигенов, что повышает шансы стимулированной противоопухолевой иммуногенности при оказании лечения ингибированием контрольной точки. Более высокая общая мутационная нагрузка может означать более высокую экспрессию неоантигенов в том смысле, что в среднем более высокая общая мутационная нагрузка может означать более высокую несинонимичную мутационную нагрузку. Кроме того, более высокая несинонимичная мутационная нагрузка опухоли может также означать более высокую экспрессию и, следовательно, более высокую вероятность того, что ингибирование контрольной точки будет эффективным. Также возможно, что синонимичная мутационная нагрузка опухоли может быть коррелирована с отвечаемостью на ингибирование контрольной точки, и/или что некоторые комбинации синонимичной и несинонимичной опухолевой мутационной нагрузки, например, которые могут быть отражены в общей мутационной нагрузке, могут коррелировать с отвечаемостью на ингибирование контрольной точки. Таким образом, общая мутационная нагрузка, несинонимичная опухолевая мутационная нагрузка, синонимичная опухолевая мутационная нагрузка или любая комбинация двух или более из них может позволять прогнозировать отвечаемость контрольной точки и может быть признаком или признаками, включаемыми в способ машинного обучения, как описано в настоящем документе.
[0039] Помимо или в дополнение к тому, является ли мутация синонимичной или несинонимичной, также могут присутствовать другие или дополнительные характеристики мутации, и их количество и тип, как и то, являются ли мутация или мутации синонимичными или несинонимичными, могут быть актуальны при прогнозировании отвечаемости на лечение. Например, некоторые мутации, называемые нонстоп-мутациями, представляют собой мутации в пределах стоп-кодона, которые приводят к продукции РНК-продукта, трансляция которого продолжается после того, где она остановилась бы из-за мутированной части транскрипта РНК. Другой формой мутации является мутация со сдвигом рамки считывания, которая включает в себя инсерцию (инсерцию со сдвигом рамки) или делецию (делеция со сдвигом рамки) некоторого количества непрерывно следующих нуклеотидов, которое не делится на три (например, инсерцию или делецию одного нуклеотида), приводящую к сдвигу последовательности прочтения кодонов, возникающему таким образом при рекрутинге разных молекул тРНК во время трансляции получающегося в результате транскрипта РНК, и, следовательно, к изменению аминокислотных последовательностей транслированного белка. Другие мутации могут представлять собой мутации сайта сплайсинга, которые происходят на или возле сайтов сплайсинга, модифицируя тем самым нормальный сплайсинг мРНК и приводя к модифицированным транскриптам РНК, Или мутация может быть миссенс-мутацией, в которой один нуклеотид изменяется таким образом, что содержащий его кодон изменяется так, чтобы рекрутировать другие виды тРНК во время трансляции с продуцированием тем самым белка с другой аминокислотной последовательностью.
[0040] Другой возможной мутацией может быть мутация инициации, которая представляет собой мутацию сайта инициации транскрипции или инициирующего кодона, приводящую к изменению места начала транскрипции или трансляция, соответственно. Например, мутация сайта инициации может предотвратить инициирование транскрипции с этого сайта инициации. Или, мутация может создавать сайт инициации транскрипции, который ранее отсутствовал. Мутация сайта инициации транскрипции может привести к транскрипции РНК-транскрипта, который, хотя и имеет другую длину, чем была бы в противном случае, находится внутри той же рамки считывания, что и транскрипт, продуцированный в отсутствии мутации, или который может при этом находиться вне рамки считывания. Аналогичные мутации могут происходить также с инициирующим кодоном, приводя к транскрипции РНК-продукта, из которого не происходит инициирования трансляции, или где инициирование трансляции происходит оттуда, откуда она ранее не инициировалась. Такие мутации стоп-кодона тоже могут быть внутри рамки считывания или вне рамки считывания. Или, мутация может быть нонсенс-мутацией, т.е. мутацией, которая приводит к транскрипту РНК с преждевременным стоп-кодоном. Любая из вышеупомянутых мутаций может быть однонуклеотидным полиморфизмом (ОНП). Любые одна или более мутаций вышеуказанных типов могут быть признаками, имеющими отношение к прогнозированию отвечаемости индивида на данное лечение, такое как с помощью данного ингибитора точки контроля.
[0041] В другом примере возможность прогнозирования отвечаемости на ингибитор контрольной точки может обеспечивать величина инфильтрации опухоли лимфоцитами. Опухоли содержат не только клетки, которые трансформированы из неопухолевых клеток в опухолевые, но и другие, нетрансформированные клетки. В число примеров входят клетки иммунной системы, которые играют или могут играть роль в стимулировании иммунного ответа против трансформированных клеток внутри опухоли. Иммунные клетки, в частности, лимфоциты, которые смешались с трансформированными клетками в опухоли, называют опухолеинфильтрующими лимфоцитами. Уровни опухолеинфильтрующих лимфоцитов и опухолеинфильтрующие лимфоциты, экспрессирующие разные маркеры, которые служат в качестве идентификаторов фенотипа лимфоцитов, могут позволять прогнозировать, будет ли субъект, у которого был взят образец опухоли, отвечать на ингибирование контрольной точки. Поскольку опухоль является гетерогенной смесью, например, опухолевых клеток и опухолеинфильтрующих лимфоцитов, было бы целесообразно различать экспрессию маркера лимфоцитов на опухолеинфильтрующих лимфоцитах, присутствующих в образце, и маркера лимфоцитов, потенциально экспрессируемого на других клетках в образце опухоли, таких как трансформированные опухолевые клетки.
[0042] Например, опухолеинфильтрующие лимфоциты могут экспрессировать транскрипты (например, РНК) генов, кодирующих кластер дифференцировки 8 (CD8), кластер дифференцировки 4 (CD4) или кластер дифференцировки 19 (CD19), каждый из которых может служить в качестве маркера фенотипа лимфоцитов при экспрессировании в клетке. Таким образом, уровни экспрессии CD8, CD4, CD19 или любой комбинации любых двух или более из них, могут быть определены из образца опухоли. Поэтому, например, из образца может быть, соответственно, определено количество РНК. Поскольку такое определение может отражать не только экспрессию их опухолеинфильтрующими лимфоцитами, но и другими клетками в образце опухоли, такими как трансформированные опухолевые клетки, было бы целесообразно определять, какая часть обнаруженной величины их экспрессии обусловлена опухолеинфильтрующими лимфоцитами, а какая нет. Для этого может быть применен процесс деконволюции, в результате чего может быть пределен уровень экспрессии опухолеинфильтрующими лимфоцитами по сравнению с экспрессией другими клетками. Существуют различные варианты выполнения деконволюции опухолеинфильтрующих лимфоцитов, в том числе описанный, например, в работах под авторством Gaujoux и др. (2013), «CellMix: a comprehensive toolbox for gene expression deconvolution». Bioinformatics 29:2211-2212, и под авторством Finotello и др. (2018), «Quantifying tumor-infiltrating immune cells from transcriptomics data», Cancer Immunology, Immunotherapy 67:1031-1040. В качестве не имеющего ограничительного характера примера анализ деконволюции может быть выполнен на языке программирования R.
[0043] В частности, посредством процесса, называемого деконволюцией опухолеинфильтрующих лимфоцитов, уровень экспрессии данного лимфоцитарного транскрипта (например, CD8, CD4 или CD19) может быть использован для определения процента лимфоцитарных клеток в образце опухоли, которые экспрессируют CD4, или CD8, или CD19. То есть, деконволюция опухолеинфильтрующих лимфоцитов может не просто показывать величину лимфоцитарной инфильтрации опухоли, представленной величиной данного лимфоцитарного транскрипта, который может быть идентифицирован в опухоли, но и указывать, на какой тип лимфоцита, идентифицированный по видам экспрессируемого транскрипта, какой процент общей инфильтрации опухоли приходится. Общая величина лимфоцитарной инфильтрации опухоли может быть актуальна при прогнозировании того, будет ли индивид отвечать на данное лечение, такое как ингибирование контрольной точки, и конкретный вклад лимфоцитарной инфильтрации опухоли, внесенный лимфоцитами, экспрессирующими данный транскрипт (CD4, или CD8, или CD19), тоже может быть актуален при составлении такого прогноза.
[0044] При прогнозировании того, будет ли индивид отвечать на ингибирование контрольной точки, могут быть актуальны различные другие признаки. Такие признаки могут быть в целом классифицированы в соответствии с процессами, теоретически связанными с тем, может ли ингибитор контрольной точки быть эффективным в стимулировании или усилении онкоиммунологического ответа, или нет. Например, некоторые признаки могут относиться к тому, могут ли, и в какой степени, опухолевые клетки с большей или меньшей вероятностью выражать антигены мутированных белков на поверхностях своих клеток и тем самым увеличивать шансы противоопухолевого иммунного ответа. В число таких уже рассмотренных признаков входят типы опухолевой мутационной нагрузки, такие как, например, общая опухолевая мутационная нагрузка или несинонимичная опухолевая мутационная нагрузка. В число других примеров входят уровни экспрессии различных белков или транскриптов генов, кодирующих белки, известные участием в представлении антигена, для стимуляции иммунного ответа. В число таких не имеющих ограничительного характера примеров входят бета-2-микроглобулин (В2М), бета-10-субъединица протеасомы (PSMB10), переносчик антигенных пептидов 1 (ТАР1), транспортер антигенных пептидов 2 (ТАР2), лейкоцитарный антиген человека A (HLA-A), главный комплекс гистосовместимости, класс I, В (HLA-B) главный комплекс гистосовместимости, класс I, С (HLA-C), главный комплекс гистосовместимости, класс II, DQ альфа-1 (HLA-DQA1) и антиген гистосовместимости HLA класса II, бета-цепь DRB1 (HLA-DRB1). Известно, что эти генные продукты играют роль на разных этапах в представлении фрагментов белков, или антигенов, или поверхности клетки и распознавании иммунными Т-клетками.
[0045] Уровни экспрессии любого одного, или любой комбинации двух или более, или любого из этих генных продуктов в опухоли могут указывать уровни экспрессии антигена на поверхности опухолевых клеток. Например, экспрессия таких продуктов может влиять на степень представления белковых продуктов геномной ДНК, содержащей несинонимичные мутации на поверхности клеток. Когда экспрессия повышает представление антигена, вероятность представления мутированных антигенов, которые Т-клетки, по-видимому, будут распознавать как означающие больную клетку и, следовательно, запускать противоопухолевый иммунный ответ, может повысить шансы того, что данный ингибитор контрольной точки может быть эффективным в продуцировании ответа у субъекта. Таким образом, когда уровень экспрессии любого или комбинации двух или более вышеуказанных продуктов положительно или отрицательно коррелирован со степенью представления антигена на клетках в образце опухоли, такой уровень экспрессии может быть положительно или отрицательно коррелирован, соответственно, с вероятностью того, что субъект, у которого были взяты образцы опухоли, будет отвечать на данный ингибитор контрольной точки.
[0046] Другой тип признака может включать уровень экспрессии Т-клеток или NK-клеток, присутствующих в образце опухоли, взятом у субъекта, и который тоже могут быть актуален для прогнозирования отвечаемости на лечение, такое как ингибирование контрольной точки. Например, уровень экспрессии антигена гистосовместимости HLA класса I, альфа-цепь Е (HLA-E), гранулярных белков естественной клетки-киллера 7 (NKG7), хемокиноподобного рецептора 1 (CMKLR1) или любой комбинации двух или более из них, может также позволять прогнозировать ответ на ингибитор контрольной точки. Таким образом, признак может включать меру экспрессии одного или более из этих продуктов или, соответственно, РНК-транскриптов.
[0047] Другой тип признака может относиться к наличию или уровням экспрессии белков или их транскриптов, которые связаны или указывают на усиленную цитолитическую активность, такую, которая может быть стимулирована противоопухолевым иммунным ответом, или которая может ингибировать такую активность. Примерами таких признаков могут быть измерения деконволюции опухолеинфильтрующих лимфоцитов, рассмотренные выше (например, деконволюция инфильтрации опухоли клетками, экспрессирующими кластер дифференцировки 8 (CD8), кластер дифференцировки 4 (CD4) или кластер дифференцировки 19 (CD19)). Другие не имеющие ограничительного характера примеры данной категории признаков могут включать уровни экспрессии гранзима A (GZMA) или перфорина-1 (PRF1) или любую комбинацию двух или более вышеперечисленных признаков.
[0048] Еще одни признаки могут относиться к процессам или функциям в ингибировании контрольной точки противоопухолевой иммунной отвечаемости. Уровни экспрессии различных белковых продуктов или их транскриптов участников ингибирования контрольной точки в пределах образца опухоли субъекта могут быть актуальны в прогнозировании того, будет ли субъект отвечать на лечение с применением онкотерапии, такой как лечение ингибированием контрольной точки. Примеры таких признаков могут включать экспрессию, самих или их РНК-транскриптов, цитотоксического Т-лимфоцит-ассоциированного белка 4 (CTLA4), белка программируемой клеточной смерти 1 (PD1), лиганда 1 программируемой смерти (PDL1), лиганда 2 программируемой клеточной смерти 1 (PDL2), гена активации лимфоцитов 3 (LAG3), Т-клеточного иммунорецептора с доменами Ig и ITIM (TIGIT), кластера дифференцировки 276 (CD276) или любых двух или более из вышеперечисленных.
[0049] Для прогнозирования того, будет ли индивид отвечать на лечение, могут быть актуальные другие признаки, включая экспрессию белков или их РНК-транскриптов, относящихся к активности интерферона-γ, таких как продукты, экспрессия которых следует за высвобождением и, вследствие этого, активностью интерферона-γ на рецепторе. Примеры таких признаков могут включать экспрессию, самих или их РНК-транскриптов, хемокинового (С-С мотива) лиганда 5 (CCL5), CD27, хемокинового (С-Х-С мотива) лиганда 9 (CXCL9), хемокинового (С-Х-С мотива) рецептора 6 лиганда (CXCR6), индоламин-2,3-диоксигеназы (IDO), сигнального трансдуктора и активатора транскрипции 1 (STAT1) или любой комбинации двух или более вышеперечисленных. Другие индикаторы активности интерферона-γ могут тоже позволять прогнозировать отвечаемость на лечение, такое как ингибирование контрольной точки.
[0050] При прогнозировании того, будет ли индивид отвечать на лечение, могут быть актуальны другие признаки, включая экспрессию белков или их РНК-транскриптов, относятся к супрессорным клеткам миелоидного происхождения или регуляторным Т-клеткам (Treg), которые могут оказывать иммуносупрессивное действие на противоопухолевую иммунную отвечаемость и снижать или предотвращать эффективность иммуноонкологических терапий. Примеры таких признаков могут включать экспрессию из взятого у субъекта образца опухоли 3-фукозил-N-ацетил-лактозамина (CD15), альфа-цепи рецептора интерлейкина-2 (CD25), сиглека-3 (CD33), кластера дифференцировки 39 (CD39), кластера дифференцировки (CD118), транскрипционного фактора forkhead box Р3 (FOXP3) или любой комбинации двух или более вышеперечисленных. Кроме того, для прогнозирования того, будет ли индивид отвечать на лечение ингибитором контрольной точки или другие противораковые терапии, также могут быть актуальны уровни экспрессии опухолью других видов белка или соответствующих РНК-транскриптов, указывающих на присутствие таких клеток или их активность.
[0051] Для создания прогноза в отношении того, будет ли индивид отвечать на лечение с применением данного противоракового лечения включая лечение ингибитором контрольной точки, могут быть актуальны любые один или более из любых вышеуказанных признаков. Любой из этих признаков может иметь отношение или заключать в себе геномную информацию об опухоли субъекта, образец которой был взят и протестирован для определения признаков. В данном случае термин «геномная» используют для включения не только информации, относящейся к последовательности нуклеотидов в геномной ДНК (такой как, например, признаки, относящиеся к мутационной нагрузке). В данном случае геномная информация, представленная измерениями признаков, также включает измерения уровней экспрессии различных продуктов транскрипции генома или белковых продуктов, продуцированных из таких транскриптов. Таким образом, уровни экспрессии любого из различных белковых продуктов, описанных выше, или других белковых продуктов, участвующих в путях, подобных специально идентифицированным, или, соответственно, уровни экспрессии РНК-транскриптов могут быть включены в геномную информацию, так как она относится к прогностическим признакам, как описано в настоящем документе Кроме того, в геномную информацию, относящуюся к признакам, могут быть включены признаки измерения деконволюции опухолеинфильтрующих лимфоцитов.
[0052] В дополнение к измерениям отдельных признаков признаками, имеющими отношение к прогнозированию отвечаемости на ингибирование контрольной точки или другое лечение рака, также могут быть структуры коррелированных уровней экспрессии признаков, которые, как известно или предположительно, относятся к данному пути, или функции, или типу клеток. Например, из вышеперечисленных признаков могут быть идентифицированы группы некоторых общих особенностей путей, или клеточной или физиологической отвечаемости, или индикаций клеточного фенотипа, и на основе измерения отдельных признаков может быть определено, являются ли они, как группа, скоординированно избыточно или недостаточно регулированными или, в более общем смысле, экспрессированными или иным образом присутствующими как группа на скоординированно высоком или низком уровне в образце опухоли данного субъекта. В некоторых примерах мера такого обобщенного измерения сгруппированных признаков сама может быть введена в качестве признака в дополнение к отдельным признакам для тренировки машинно-обучаемого классификатора, прогнозирующего отвечаемость субъекта на ингибирование контрольной точки или другое лечение, либо на то и другое. В настоящем документе такие группировки признаков для получения дополнительного признака, представляющего уровень экспрессии и т.д. группировки в целом, называют набором генов. Таким образом, набор генов может включать комбинаторную меру, представляющую корреляционную индикацию присутствия геномной мутации, уровней экспрессии конкретных РНК-транскриптов, наличия идентифицированных типов клеток и т.д.
[0001] [0053] В качестве не имеющего ограничительного характера примера некоторые из вышеуказанных признаков относятся к представлению антигена, посредством которого клетки, например, опухолевые, экспрессируют белковые фрагменты на своих клеточных мембранах для контроля иммунной системой. Как описано выше, представление антигена может увеличивать вероятность стимулирования противоопухолевого иммунного ответа, например, с помощью ингибитора контрольной точки. Некоторые примеры таких характеристик могут включать общую мутационную нагрузку, несинонимичную мутационную нагрузку или другую мутационную нагрузку (нагрузку нонстоп-мутации, нагрузку мутации со сдвигом рамки считывания (инсерционную, делеционную или каждую из них), нагрузку мутации сайта сплайсинга, нагрузку миссенс-мутации, нагрузку мутации инициации (в рамке считывания, вне рамки считывания или каждая из них), нагрузку нонсенс-мутации, нагрузку мутации инициирующего кодона (включая ОНП инициирующего кодона или другую), нагрузку инсерционной мутации в рамке считывания, нагрузку делеционной мутации в рамке считывания или другую нагрузку ОНП-мутации или любую комбинацию двух или более вышеперечисленных. В число других не имеющих ограничительного характера примеров признаков, относящихся к представлению антигена, входят бета-2-микроглобулин (В2М), бета-10-субъединица протеасомы (PSMB10), переносчик антигенных пептидов 1 (ТАР1), транспортер антигенных пептидов 2 (ТАР2), лейкоцитарный антиген человека A (HLA-A), главный комплекс гистосовместимости, класс I, В (HLA-B) главный комплекс гистосовместимости, класс I, С (HLA-C), главный комплекс гистосовместимости, класс II, DQ альфа-1 (HLA-DQA1) и антиген гистосовместимости HLA класса II, бета-цепь DRB1 (HLA-DRB1). В дополнение к функциям, связанным с наличием или уровнями экспрессирования и т.д., относящимся к отдельным примерам из числа вышеуказанных признаков, дополнительный признак может представлять степень, в которой некоторые или все из вышеуказанных признаков скоординированно избыточно или недостаточно регулированы или иным образом присутствуют в высоких или низких уровнях в опухоли субъекта (будь то для тренировки машинно-обучаемого классификатора или прогнозирования).
[0054] В качестве еще одного не имеющего ограничительного характера примера некоторые признаки относятся к уровню экспрессии Т-клеток или NK-клеток, присутствующих в образце опухоли, взятом у субъекта, и тоже могут быть актуальны для прогнозирования отвечаемости на лечение, такое как ингибирование контрольной точки. Например, уровень экспрессии антигена гистосовместимости HLA класса I, альфа-цепь Е (HLA-E), гранулярных белков естественной клетки-киллера 7 (NKG7), хемокиноподобного рецептора 1 (CMKLR1) или любой комбинации двух или более из них, может также позволять прогнозировать ответ на ингибитор контрольной точки. В дополнение к функциям, связанным с наличием или уровнями экспрессирования и т.д., относящимся к отдельным примерам из числа вышеуказанных признаков, дополнительный признак может представлять степень, в которой некоторые или все из вышеуказанных признаков скоординированно избыточно или недостаточно регулированы или иным образом присутствуют в высоких или низких уровнях в опухоли субъекта (будь то для тренировки машинно-обучаемого классификатора или прогнозирования).
[0055] В качестве еще одного не имеющего ограничительного характера примера некоторые признаки относятся к индикаторам иммунологически стимулируемого цитолиза, например, когда иммунный ответ способствует гибели клеток и лизису клеток, таких как опухолевые клетки, присутствующие в образце опухоли, взятом у субъекта, и которые тоже могут быть актуальны для прогнозирования отвечаемости на лечение, такое как ингибирование контрольной точки. Например, деконволюированная экспрессия CD8, деконволюированная экспрессия CD4, деконволюированная экспрессия CD19 (деконволюция, представляющая пропорциональный вклад экспрессирующих CD8, CD4 и CD19 клеток, соответственно, относительно количества опухолеинфильтрующих лимфоцитов, присутствующих в образце опухоли), уровни экспрессии гранзима А (GZMA) или перфорина-1 (PRF1), или любая комбинация вышеуказанных, или, соответственно, РНК-транскриптов, тоже могут позволять прогнозировать ответ на ингибитор контрольной точки. В дополнение к функциям, связанным с наличием или уровнями экспрессирования и т.д., относящимся к отдельным примерам из числа вышеуказанных признаков, дополнительный признак может представлять степень, в которой некоторые или все из вышеуказанных признаков скоординированно избыточно или недостаточно регулированы или иным образом присутствуют в высоких или низких уровнях в опухоли субъекта (будь то для тренировки машинно-обучаемого классификатора или прогнозирования).
[0056] В качестве еще одного не имеющего ограничительного характера примера некоторые признаки относятся к клеточным и молекулярным процессам, участвующим в функциях ингибирования контрольной точки, присутствующих в образце опухоли, взятом у субъекта, и которые тоже могут быть актуальны для прогнозирования отвечаемости на лечение, такое как ингибирование контрольной точки. Не имеющие ограничительного характера примеры таких признаков могут включать экспрессию, самих или их РНК-транскриптов, цитотоксического Т-лимфоцит-ассоциированного белка 4 (CTLA4), белка программируемой клеточной смерти 1 (PD1), лиганда программируемой смерти 1 (PDL1), лиганда 2 программируемой клеточной смерти 1 (PDL2), гена активации лимфоцитов 3 (LAG3), Т-клеточного иммунорецептора с доменами Ig и ITIM (TIGIT), кластера дифференцировки 276 (CD276) или любых двух или более из вышеперечисленных. В дополнение к функциям, связанным с наличием или уровнями экспрессирования и т.д., относящимся к отдельным примерам из числа вышеуказанных признаков, дополнительный признак может представлять степень, в которой некоторые или все из вышеуказанных признаков скоординированно избыточно или недостаточно регулированы или иным образом присутствуют в высоких или низких уровнях в опухоли субъекта (будь то для тренировки машинно-обучаемого классификатора или прогнозирования).
[0057] В качестве еще одного не имеющего ограничительного характера примера некоторые признаки относятся к индикаторам или клеточным и молекулярным путям, участвующим в активности интерферона-γ, присутствующего в образце опухоли, взятом у субъекта, и которые могут быть тоже актуальны для прогнозирования отвечаемости на лечение, такое как ингибирование контрольной точки. Не имеющие ограничительного характера примеры таких признаков могут включать экспрессию, самих или их РНК-транскриптов, хемокинового (С-С мотива) лиганда 5 (CCL5), CD27, хемокинового (С-Х-С мотива) лиганда 9 (CXCL9), хемокинового (С-Х-С мотива) рецептора 6 (CXCR6), индоламин-2,3-диоксигеназы (IDO), сигнального трансдуктора и активатора транскрипции 1 (STAT1) или любой комбинации двух или более вышеперечисленных. В дополнение к функциям, связанным с наличием или уровнями экспрессирования и т.д., относящимся к отдельным примерам из числа вышеуказанных признаков, дополнительный признак может представлять степень, в которой некоторые или все из вышеуказанных признаков скоординированно избыточно или недостаточно регулированы или иным образом присутствуют в высоких или низких уровнях в опухоли субъекта (будь то для тренировки машинно-обучаемого классификатора или прогнозирования).
[0058] В качестве еще одного не имеющего ограничительного характера примера некоторые признаки относятся к наличию или активности MDSC или Treg, присутствующей в образце опухоли, взятом у субъекта, и которые тоже могут быть актуальны для прогнозирования отвечаемости на лечение, такое как ингибирование контрольной точки. Не имеющие ограничительного характера примеры таких признаков могут включать экспрессию из взятого о субъекта образца опухоли 3-фукозил-N-ацетил-лактозамина (CD15), альфа-цепи рецептора интерлейкина-2 (CD25), сиглека-3 (CD33), кластера дифференцировки 39 (CD39), кластера дифференцировки (CD118), транскрипционного фактора forkhead box Р3 (FOXP3) или любой комбинации двух или более вышеперечисленных. В дополнение к функциям, связанным с наличием или уровнями экспрессирования и т.д., относящимся к отдельным примерам из числа вышеуказанных признаков, дополнительный признак может представлять степень, в которой некоторые или все из вышеуказанных признаков скоординированно избыточно или недостаточно регулированы или иным образом присутствуют в высоких или низких уровнях в опухоли субъекта (будь то для тренировки машинно-обучаемого классификатора или прогнозирования).
[0059] Таким образом, в некоторых примерах могут быть идентифицированы один или более наборов генов, а мера скоординированной или скоррелированной степени излишней или недостаточной регуляции признаков в опухоли субъекта, относящихся к такому набору генов, может быть предоставлена в качестве дополнительного признака для тренировки машинно-обучаемого классификатора или прогнозирования отвечаемости субъекта на ингибирование контрольной точки или другое лечение, либо на то и другое. В число примеров наборов генов входят наборы генов, относящиеся к представлению антигенов, сигнатурам Т-клеток и NK-клеток, индикаторам цитолиза, ингибированию контрольной точки, интерферону-γ и наличию или активности MSDC/Treg. В некоторых случаях один или более наборов генов вместе с одним или более любых других отдельных признаков, рассмотренных выше, могут быть включены в тренировку или использованы машинно-обучаемым классификатором в прогнозировании отвечаемости пациента на ингибирование контрольной точки или другое лечение. Для определения обобщенной меры того, насколько признаки в наборе генов скоординированно избыточно или недостаточно регулированы или иным образом экспрессированы или присутствуют на высоких или низких уровнях скоординированным или скоррелированным образом, могут быть использованы различные способы. Один из примеров может включать анализ, называемый анализом обогащения набора генов одного образца (ssGSEA). Для определения такого сгруппированного обогащения набора генов ssGSEA использует эмпирическую кумулятивную функцию распределения, как описано, например, в работе под авторством Barbie и др. (2009), «Systematic RNA interference reveals that oncogenic KRAS-driven cancers require TBK1», Nature 462:108-112. В качестве не имеющего ограничительного характера примера ssGSEA может быть выполнен на языке программирования R.
[0060] Некоторая или любая комбинация любых двух или более вышеуказанных признаков может быть использована как для тренировки машинно-обучаемого классификатора, так и для применения в машинно-обучаемом классификаторе для прогнозирования того, будет ли субъект, или с какой вероятностью, отвечать на лечение, например, с помощью ингибитора контрольной точки. Однако для тренировки машинно-обучаемого классификатора вовсе необязательно использовать все вышеуказанные признаки. Машинно-обучаемый классификатор может быть натренирован посредством набора характеристик, который включает все вышеупомянутые характеристики или исключает любые одну или более из них. Все комбинации и перестановки, предполагаемые этим необязательным включением и исключением, включены таким образом во всей их полноте, хотя и не обязательно перечислены дословно в явном виде. Специалист в данной области способен представить себе подмножества, комбинации, подкомбинации и перестановки, возможные с вышеуказанными признаками. Аналогичным образом также могут быть включены дополнительные признаки, будь то в дополнение ко всем вышеуказанным признакам, или просто комбинации, подкомбинации, перестановки или другие сочетаниям из меньшего, чем все, количества вышеуказанных признаков. Все такие различные примеры в прямой форме включены в настоящее изобретение.
[0061] В некоторых примерах признаки любого субъекта, используемые для тренировки машинно-обучаемого классификатора, те же самые, что и признаки, используемые для любого и всех остальных субъектов при тренировке машинно-обучаемого классификатора. Однако в других примерах для другого субъекта, используемого для тренировки машинно-обучаемого классификатора, могут быть предусмотрены другие признаки. Другими словами, некоторые субъекты могут иметь признаки, включенные в их тренировочный набор, которые не входят в признаки из тренировочных наборов других субъектов. Аналогичным образом в некоторых примерах для получения от машинно-обучаемого классификатора прогноза, относящегося к отвечаемости субъекта на лечение, признаки, полученные из образца пробы субъекта для получения прогноза, могут быть теми же, что и признаки, используемые для тренировки классификатора. То есть признаки всех субъектов, используемых для тренировки машинно-обучаемого классификатора, могут быть такими же, как у друг друга, а также такими же, что и у субъекта, для которого требуется получить прогноз от машинно-обучаемого классификатора. В других примера возможно несовпадение между признаками тренировочных субъектов, используемыми для тренировки машинно-обучаемого классификатора, и признаками субъекта, для которого требуется получить прогноз от машинно-обучаемого классификатора. Признаки некоторых или всех субъектов, используемые для тренировки машинно-обучаемого классификатора, могут включать признаки, для которых нет соответствующих признаков субъекта, для которого требуется получить прогноз от машинно-обучаемого классификатора.
[0062] В некоторых примерах субъект, для которого требуется получить прогноз от машинно-обучаемого классификатора, может не иметь признака, который соответствует признаку одного, или некоторых, или всех субъектов, используемому для тренировки машинно-обучаемого классификатора. В других примерах субъект может иметь аналогичный признак, но не идентичный признак, и этот аналогичный признак может быть использован вместо отсутствующего идентичного признака субъекта. Например, машинно-обучаемый классификатор может быть натренирован на признаках, которые, для по меньшей мере некоторых тренировочных субъектов, включают один или более таких признаков набора генов, которые могут быть получены с использованием ssGSEA, как описано выше. Для некоторых из тренировочных субъектов, наборы генов которых использовали для тренировки машинно-обучаемого классификатора, некоторые такие наборы могли быть получены из одних и тех же лежащих в основе отдельных признаков. Например, набор генов признака набора генов, относящегося к представлению антигена, мог быть получен из одних и тех же лежащих в основе признаков для всех субъектов, используемых для тренировки машинно-обучаемого классификатора. В других примерах некоторый относящийся к представлению антигена набор генов для тренировочного субъекта может быть основан на лежащих в основе признаках, которое включают некоторые такие признаки, которые не были бы включены в определение относящегося к представлению антигена набору генов другого тренировочного субъекта. Это может быть справедливо для других наборов генов. Кроме того, при получении прогноза может быть использован субъект признака набора генов, для которого требуется получить прогноз от машинно-обучаемого классификатора, а значение признака для набора генов, могло быть получено из лежащего в основе набора отдельных признаков субъекта, которые не включают по меньшей мере один или более лежащих в основе признаков, использованных при получении соответствующего значения признака набора генов одного или более тренировочных субъектов и при тренировке машинно-обучаемого классификатора.
[0063] Признаки могут быть определены известными способами определения данных генетического секвенирования, или уровней белка, или экспрессии РНК-транскрипта в биологическом образце. Например, значительное количество информации о нуклеотидной последовательности, которая может быть получена с использованием технологий секвенирования нового поколения, могут обеспечивать как относящиеся к геному признаки (например, общую мутационную нагрузку и т.д.), так и уровни экспрессии, например, РНК-транскриптов в зависимости от типа секвенирования нового поколения, используемого для получения данного признака. В число примеров подходящих способов входят полное секвенирование генома, полное секвенирование экзома, секвенирование мРНК, анализ генного чипа, анализ РНК-чипа, анализ белков, такой как анализ белкового чипа, или другие соответствующие способы определения наличия, или уровней, или количеств признаков, используемых для тренировки и/или получения прогноза от машинно-обучаемого классификатора в соответствии с аспектами настоящего изобретения. В некоторых примерах один и тот же набор методов может быть использован для получения признаков всех тренировочных субъектов для тренировки машинно-обучаемого классификатора и субъекта, для которого требуется получить прогноз. В других примерах возможны методологические различия между способом получения признака или некоторых признаков разных тренировочных субъектов и/или способом получения используемых для получения прогноза признаков субъекта, для которого требуется получить прогноз.
[0064] Кроме того, для тренировки машинно-обучаемого классификатора с помощью признаков тренировочных субъектов в машинно-обучаемый классификатор также загружают отвечаемость тренировочных субъектов на лечение. Таким образом, тренировочный субъект представляет собой субъект, признаки и отвечаемость которого предоставляют для тренировки машинно-обучаемого классификатора. Отвечаемость может быть двоичной классификацией, например, когда тренировочного субъекта классифицируют как ответившего на лечение, если субъект продемонстрировал предварительно определенный ответ, в том числе продленный срок жизни, сокращение опухоли, частичную или полную ремиссию и т.д. В других примерах отвечаемость может быть оценкой или значением на основе полученной степени отвечаемости, а не двоичной оценкой того, была ли получена отвечаемость или нет. Например, в зависимости от типа искомого прогноза машинно-обучаемый классификатор согласно настоящему изобретению может включать, в качестве не имеющего ограничительного характера примера, деревья классификации и регрессии.
[0065] Машинно-обучаемый классификатор может представлять собой классификатор, который подходит для машинного обучения на основе компьютера. В число не имеющих ограничительного характера примеров входит машинно-обучаемый классификатор на основе случайного леса. В машинно-обучаемом классификаторе на основе случайного леса создают деревья принятия решений на основе признаков тренировочных субъектов и значения отвечаемости на лечение, причем узлы, представляют точки принятия решения о классификации, а листья, представляют результаты не основе тренировочных входных данных. Классификатор на основе случайного леса может создавать несколько деревьев решений, используя подмножества признаков и подмножества тренировочных субъектов для создания многочисленных деревьев решений, которые затем объединяют. Такие многочисленные деревья принятия решений, содержащие подмножества водных данных, предотвращают чрезмерно близкую подгонку и уменьшают погрешность и систематическую ошибку при прогнозировании. В некоторых примерах, чем больше деревьев принятия решения, созданных во время тренировки, тем более точным может быть результат машинно-обучаемого классификатора. В некоторых примерах во время тренировки может быть создано примерно от 5000 до 500000 деревьев принятия решения. Например, в машинно-обучаемом классификаторе на основе случайного леса могут быть выполнены и объединены 5000, 10000, 15000, 20000, 25000, 30000, 50000, 75000, 90000, 100000, 125000, 150000, 175000, 200000, 225000, 250000, 275000, 300000, 325000, 350000, 375000, 400000, 425000, 450000, 475000 или 500000 деревьев принятия решений. Вместо этого могут быть выполнены больше или меньше деревьев решений, а также в количествах, попадающих в промежутки между этими приведенными для примера возможными вариантами.
[0066] Существуют различные варианты выполнения тренировки случайного леса и формирования прогноза посредством классификатора на основе случайного леса. В качестве примера, не имеющего ограничительного характера, может быть использован язык программирования R. Также могут быть использованы и другие классификаторы в соответствии с аспектами настоящего изобретения, в том числе, без ограничения, нейросетевой классификатор, машина опорных векторов, классификатор на основе максимальной энтропии, классификатор на основе экстремального градиентного бустинга и классификатор на основе случайного папоротника.
[0067] Согласно способу, раскрытому в настоящем документе, получают признаки от каждого из некоторого количества тренировочных субъектов, как и отвечаемость каждого субъекта. Такие признаки и отвечаемости, или входные данные, вводят в запоминающее устройство компьютера, такое как накопитель на жестких дисках, сервер или другой компонент памяти. Кроме того, на запоминающем устройстве, которым оборудован такой компьютер, хранят инструкции, содержащиеся в программном обеспечении, которые командуют одним или более микропроцессорами. В число этих инструкций входят инструкции для использования входных данных от тренировочных субъектов для создания машинно-обучаемого классификатора. Затем натренированный машинно-обучаемый классификатор сохраняют в одном или более блоках памяти компьютера и могут впоследствии выполнять на признаках субъекта, для которого требуется получить прогноз отвечаемости.
[0068] В качестве не имеющего ограничительного характера примера инструкции могут давать команду одному или более микропроцессорам на выполнение тренировки случайного леса с созданием деревьев принятия решения из входных данных тренировочного субъекта для определения того, указывают ли наличие, отсутствие, уровень и т.д. различных признаков с большей или меньшей вероятностью на отвечаемость на лечение, и команду на объединение многочисленных деревьев принятия решения в натренированный машинно-обучаемый классификатор на основе случайного леса. Затем натренированный машинно-обучаемый классификатор согласно данному примеру, основанный на объединении деревьев принятия решения, созданных одним или более микропроцессорами при обработке признаков и отвечаемости в соответствии с инструкциями, может быть сохранен в одном или более блоках памяти. Впоследствии при прогнозировании того, будет ли нетренировочный субъект (т.е. субъект, значения признаков которого не использовали для тренировки натренированного машинно-обучаемого классификатора) отвечать на лечение, например, с помощью конкретного ингибитора контрольной точки, полученные из образца опухоли данного нетренировочного субъекта признаки могут быть загружены в один или более блоков памяти. Один или более микропроцессоров могут обрабатывать инструкции таким образом, чтобы анализировать признаки нетренировочного субъекта посредством натренированного машинно-обучаемого классификатора, доступ к которому осуществляется из одного или более блоков памяти одним или более микропроцессором, и предоставлять отчет о прогнозе в отношении отвечаемости субъекта.
[0069] В таком примере машинно-обучаемый классификатор представлял собой натренированный машинно-обучаемый классификатор, натренированный на признаках образцов опухоли, полученных от каждого из множества тренировочных субъектов, и отвечаемости каждого из множества тренировочных субъектов на лечение, включающее ингибирование контрольной точки, причем машинно-обучаемый классификатор тренировали на прогнозирование отвечаемости на лечение. Кроме того, в натренированный машинно-обучаемый классификатор вводили геномную информацию нетренировочного субъекта, содержащую нетренировочные признаки из профиля опухоли субъекта, чтобы формировать классификацию отвечаемости на лечение для нетренировочного субъекта, например, классификацию или оценку, указывающую прогноз того, как нетренировочный субъект будет отвечать на лечение. Лечение может представлять собой ингибирование контрольной точки.
[0070] Отчет о сформированной машинно-обучаемым классификатором отвечаемости на ингибирование контрольной точки для нетренировочного субъекта может быть предоставлен пользователю. Отчет может включать классификацию субъекта, указывающую в двоичной форме, прогнозируется ли ответ нетренировочного субъекта на лечение или нет. В других примерах в дополнение или вместо двоичной классификации того, прогнозируется ли ответ нетренировочного субъекта или нет, может быть указана вероятность отвечаемости посредством числовой оценки по шкале. В других примерах может быть предоставлен отчет о конкретных степенях отвечаемости. Например, отчет может указывать высокую вероятность отвечаемости, но отвечаемость может быть квалифицирована относительно продолжительности или степени. В других примерах отчет может указывать прогноз относительно низкой вероятности отвечаемости, но большей продолжительности или степени, если спрогнозировано, что такой нетренировочный субъект ответит.
[0071] Отчет о прогнозе в виде оценки или двоичного прогноза вероятности или, наоборот, маловероятности ответа может быть предоставлен с помощью графического пользовательского интерфейса (ГПИ). Например, соединенные с одним или более блоками памяти и одним или более микропроцессорами компьютер или компьютерная система, в которые ввели профиль значений признаков нетренировочного субъекта и проанализировали с помощью натренированного машинно-обучаемого классификатора, могут быть также соединены с устройством отображения, на котором в визуальном виде предоставляют отчет о прогнозе. ГПИ может принимать любую из множества форм. Например, ГПИ может быть представлять собой выполненные в виде таблицы различные аспекты признаков или подмножества признаков с более высокой степенью важности или весом при формировании прогноза с указанием также для каждого фактора большей или меньшей вероятности ответа нетренировочного субъекта на лечение (т.е. валентность признака) с учетом значения признака для нетренировочного субъекта, как дополнительно объяснено ниже. Или, для сообщения такой информации отчет может содержать различные формы, штриховки или цветные схемы.
[0072] Объект изобретения, раскрытый в настоящем документе, отличается от традиционных способов прогнозирования отвечаемости на лечение отчетом о классификации прогнозирования с использованием совокупности признаков, как описано в настоящем документе. В отличие от традиционных способов прогнозирования отвечаемости на лечение, в настоящем документе раскрыт способ использования комбинаторного подхода, где в некоторых примерах при формировании прогноза большое количество признаков могут быть проверены в контексте друг с другом, а не просто по отдельности. Такое отличие изложенного в настоящем документе изобретения от традиционных способов обеспечивает преимущество, заключающееся в том, что предпринимавшиеся прежде усилия по прогнозированию того, будет ли индивид отвечать на данное лечение, такое как ингибирование контрольной точки, до сих пор имели весьма ограниченную точность и обобщаемость из-за ограниченных количеств признаков. Как описано в настоящем документе, нетрадиционный процесс машинного обучения для оценки вкладов многочисленных факторов и того, как каждый из них может независимо или в совокупности с другими влиять на результаты прогнозирования, преодолевает ограничения попыток традиционного прогнозирования.
[0073] Традиционные способы определения прогноза отвечаемости связаны с идентификацией признака или ограниченного количества признаков, которые могут указывать на более высокую или более низкую вероятность отвечаемости на лечение. В настоящем документе, напротив, раскрыт нетрадиционный подход, в котором для формулирования прогноза одновременно оценивают относительные вклады десятков или более потенциальных признаков в контексте друг с другом, используя машинно-обучаемый классификатор. Такой многофакторный подход посредством нетрадиционного применения машинно-обучаемого классификатора обеспечивает значительные преимущества над ныне имеющимися способами.
[0074] Предпочтительной особенностью некоторых примеров ГПИ для предоставления отчета о прогнозе отвечаемости может быть представление многосторонней информации, относящейся к признакам, актуальным для сообщаемого прогноза, в относительно тесном или маленьком пространстве так, чтобы пользователь мог получать значимую информацию в компактном виде. В частности, преимущество определенных примеров ГПИ, используемых в соответствии с настоящим изобретением, может заключаться в их подборе размеров и конфигурации для отображения на дисплее ограниченного или уменьшенного размера или на дисплее, на котором необходимо или желательно отображать также уйму другой информации. ГПИ для предоставления отчета о классификации прогноза в соответствии с настоящим изобретением может служить для компактного размещения легко распознаваемых и узнаваемых аспектов классификации прогноза и/или признаков, актуальных для его формирования, на дисплее ограниченного размера или его ограниченной части. Такое компактное предоставление отчета улучшает взаимодействие пользователя с компьютерной системой, предоставляющей отчет, в том смысле, что оно облегчает получение и интерпретацию отчета и экономит пространство дисплея, которое может потребоваться для других целей или ограничено, например, когда дисплей представляет собой экран переносного электронного устройства, такого как телефон или другие устройства беспроводной связи (например, компьютерный планшет, или телефон, или другое переносное проводное или беспроводное устройство). В одном примере, где отчет предоставляют с помощью ГПИ, который в сжатой форме изображает большое количество характеристик и аспектов признаков в ограниченном пространстве, сохраняя при этом способность быстро сообщать большие количества информации, которая остается быстро и легко доступной, используемость компьютерной системы улучшается в том смысле, что при этом для дополнительных целей остается больше пространства дисплея или сохраняется возможность использования дисплеев меньшего размера.
[0075] Отчет может содержать идентификаторы признаков либо аспекты или характеристики некоторых или всех признаков, используемых при формировании классификации отвечаемости. Например, отчет может содержать индикацию валентности признака, т.е. указывает ли его значение в профиле пациента на повышенную или пониженную вероятностью того, что субъект будет отвечать на лечение. А именно, в случае профиля нетренировочного пациента признак может иметь положительную валентность или отрицательную валентность. Положительная валентность может означать либо то, что значение признака у тренировочных субъектов имеет тенденцию к положительной корреляции с отвечаемостью на лечение, и значение нетренировочного субъекта для этого признака было высоким, либо то, что значение признака у тренировочных субъектов имело тенденцию к отрицательной корреляции с отвечаемостью, и значение нетренировочного субъекта для этого признака было низким.
[0076] Другой идентификатор может представлять собой индикацию важности признака при формировании прогноза для данного машинно-обучаемого классификатора. Важность признака может указывать на то, что он, по всей вероятности, направит прогноз в одном или другом направлении относительно других признаков, используемых при тренировке. Например, в некоторых примерах во время тренировки для одного или более признаков может быть определен индекс снижения Джини. Индекс снижения Джини указывает важность признака в том смысле, что он учитывает влияние признака на функционирование классификатора в отношении того, каково влияние других признаков в направлении формируемого прогноза. Индекс снижения Джини может быть определен с помощью различных программных пакетов, например, с использованием языка программирования R. В некоторых примерах важность признаков может быть использована для определения того, какие идентификаторы признаков следует включать в отчет отдельно от оценки прогноза или в дополнение к нему. Например, для данного отчета, предоставляемого в форме ГПИ, ГПИ может отображать признаки только тех признаков, важность которых удовлетворяет предварительно определенному минимальному порогу важности. Например, отчет может содержать идентификаторы только тех признаков, квадрат важности которых, представленной численно в виде индекса снижения Джини, превышает 0,1. Вместо этого пороги минимальной важности могут быть установлены более или менее строгими или изменены для данных отчетов в зависимости от того, сколько информации требуется включать вместе с оценкой прогноза. Чем выше порог минимальной важности, тем меньше идентификаторов признаков может быть включено в отчет, и наоборот. Например, порог минимальной важности может быть таким, чтобы квадрат выраженной в численном виде важности (например, коэффициент снижения Джини) был выше, чем примерно от 0,01 до 0,5. Могут быть выбраны другие пороги минимальной важности в любом месте внутри или за пределами этого диапазона.
[0077] Другим примером идентификатора признака, который может быть включен в отчет, является вес признака. Вес признака является мерой степени, в которой значение признака субъекта само по себе предполагает, что субъект будет или не будет отвечать на лечение. Например, для каждого признака может быть определена граница однофакторного принятия решения. Граница однофакторного принятия решения представляет собой значение для данного признака, которое наилучшим образом устанавливает различие между наличием и отсутствием ответа на лечение у тренировочных субъектов. Например, если все тренировочные субъекты, которые отвечают на лечение, имели значение признака выше данной величины, тогда как все не отвечающие на лечение субъекты имели значения ниже этой величины, данная величина может быть границей однофакторного принятия решения. В некоторых других примерах некоторые отвечающие тренировочные субъекты могли иметь значение признака выше, чем у некоторых неотвечающих тренировочных субъектов, а другие отвечающие тренировочные субъекты могли иметь значение признака ниже, чем у этих тренировочных субъектов. Таким образом, в некоторых примерах для значения признака может существовать четкая разграничительная линия, которая недвусмысленно устанавливает различие между теми, кто отвечает, и теми, кто не отвечает, тогда как в других примерах возможно большее перекрытые на границе значений признака между тем, кто отвечают, и теми, кто не отвечают. В примерах последнего типа граница однофакторного принятия решения может быть выбрана в виде значения, которое обеспечивает максимально возможное отличие между теми, кто отвечают, и теми, кто не отвечают, в наборе тренировочных субъектов.
[0078] Вес признака является мерой или индикацией того, насколько значение признака нетренировочного субъекта отличается от границы однофакторного принятия решения для этого признака. Чем больше значение признака нетренировочного субъекта отличается от границы однофакторного принятия решения для данного признака на основе тренировочных субъектов, тем больший вес может иметь признак при определении прогноза классификации отвечаемости. Например, признак может иметь отрицательную валентность, означающую, что нетренировочный субъект имеет низкое значение признака, положительно коррелируемого с отвечаемостью тренировочных субъектов, или высокое значение признака, отрицательно коррелируемого с отвечаемостью тренировочных субъектов. Если значение нетренировочного субъекта для данного признака отличается существенно от границы однофакторного принятия решения для этого признака, вес этого признака может быть высоким. Однако, если другой признак имеет более высокую важность и положительную валентность (т.е. высокое значение для нетренировочного субъекта и положительную корреляцию с отвечаемостью у тренировочных субъектов, или низкое значение для нетренировочного субъекта и отрицательную корреляцию с отвечаемостью у тренировочных субъектов), он может иметь пропорционально более сильное влияние на классификацию прогнозирования отвечаемости, даже если его значение отличается меньше от границы принятия однофакторного решения (т.е. имеет меньший вес).
[0079] Для представления идентификаторов признаков в виде компонентов отчета о прогнозе отвечаемости и ГПИ имеются множество возможностей. Некоторые конкретные примеры представлены в настоящем документе достаточно подробно. Однако специалисту в данной области понятно, что может быть много других возможностей для сообщения валентности, веса и важности в отчете в ГПИ, и что примеры, приведенные в настоящем документе, не имеют ограничительного характера, или каждый из них сам по себе никоим образом не является особенно существенным.
[0080] ГПИ может представлять признаки в табличном виде посредством строк и столбцов. Признаки могут быть представлены, например, в строках, а различные характеристики данных признаков могут быть представлены в нескольких столбцах. Например, различные столбцы могут указывать важность признака, его валентность, границу однофакторного принятия решения для этого признака, значение нетренировочного субъекта для этого признака, необязательно с визуальной индикацией того, насколько значение нетренировочного субъекта для этого признака отличается от граница однофакторного принятия решения для этого признака, и был бы ли спрогнозирован ответ нетренировочного субъект, если прогноз основывался бы только на этом признаке. Табличный ГПИ может включать любые комбинации двух или более вышеперечисленных столбцов. Табличный отчет в ГПИ может также включать общую оценку прогноза.
[0081] Отчет в ГПИ может быть также гистограммой. Например, столбики могут указывать значение для данного признака нетренировочного субъекта вместе с линией, также указывающей границу однофакторного решения для данного признака. Разница между значением признака нетренировочного пациента и линией, указывающей границу однофакторного принятия решения, является идентификатором веса для данного признака. Кроме того, между высотой столбца и линией, указывающей границу однофакторного принятия решения, может быть проведена линия. Длина линии между ними двумя тоже является индикатором веса. Валентность может быть указана символом ниже столбца. Например, знак плюса или минуса может указывать положительную или отрицательную валентность, соответственно. Другие пары могут включать направленные вверх и вниз стрелки, ориентированные вверх и вниз треугольники и т.д., где одно направление указывает положительную валентностью этого признака, а другая ориентация указывает отрицательную валентность. Валентность может быть также указана цветом или штриховкой столбца, причем столбы одного цвета или рисунка штриховки, указывают одну ценность (положительную или отрицательную), а столбцы другого цвета и или рисунка штриховки, указывают противоположную ценность. Цвет или штриховка линии между значением признака нетренировочного субъекта в гистограмме и границей однофакторного принятия решения для этого признака тоже могут указывать ценность. Например, если значение признака отрицательно коррелировано с отвечаемостью тренировочных субъектов, а значение этого признака нетренировочного субъекта меньше границы однофакторного принятия решения, то линия, соединяющая значение этого признака нетренировочного субъекта в столбике гистограммы отчета и границу однофакторного принятия решения, может иметь цвет или штриховку, указывающие положительную ценность. А если значение признака положительно коррелировано с отвечаемостью тренировочных субъектов, а значение этого признака нетренировочного субъекта меньше границы однофакторного принятия решения, то линия, соединяющая значение этого признака нетренировочного субъекта в столбике гистограммы отчета и границу однофакторного принятия решения, может иметь цвет или штриховку, указывающие отрицательную ценность. Отметим, что в обоих случаях значение признака нетренировочного субъекта меньше границы однофакторного принятия решения для данного признака, но его ценность отличается в зависимости от того, был ли признак коррелирован отрицательно (отрицательная ценность) или положительно (положительная ценность) с отвечаемостью тренировочных субъектов. Верно и обратное (т.е., когда граница однофакторного принятия решения признака меньше значения этого признака нетренировочного субъекта, он может иметь положительную или отрицательную ценность в зависимости от того, имеет ли признак тенденцию быть положительно или отрицательно коррелированы с отвечаемостью тренировочных субъектов, соответственно).
[0082] Важность признака может быть указана символом или другим индикатором возле, внутри или ниже столбика признака в гистограмме. Например, важность признака может быть указана размером символа ниже столбика признака. Или важность может быть кодирована цветом путем указания степени важности окрашиванием или штриховкой столбиков или связанных символов. Гистограмма может быть дополнена условными обозначениями, указывающими спектр цветов или штриховок, где более высокая важность указана цветом или штриховкой, которые больше напоминают один конец спектра, а более низкая важность указана цветом или штриховкой, которые больше напоминают другой конец спектра. В некоторых примерах символ, например, помещенный в гистограмме отчета в ГПИ под столбцом признака нетренировочного субъекта, может указывать, были ли значения этого признака коррелированы отрицательно или положительно с отвечаемостью тренировочных субъектов. Например, положительно и отрицательно коррелированные признаки могут быть указаны знаком плюса и знаком минуса, стрелкой вверх и стрелкой вниз, ориентированным вверх треугольником и ориентированным вниз треугольником или другими парами. В таких случаях относительные размеры этих символов могут обозначать их относительную важность.
[0083] В другом примере отчет в ГПИ содержит формы, которые выражают идентификаторы признаков. Например, каждый признак, идентификаторы которого включены в отчет в ГПИ, может быть представлен формой, размеры, цвет, штриховка или другие аспекты которого могут обозначать разные идентификаторы. Например, каждый признак может быть представлен прямоугольником, ширина которого представляет важность, а высота представляет вес. Ценность могут указывать цвет, штриховка или стиль контура прямоугольников. Или признаки могут быть представлены треугольниками, где основание представляет важность, а высота представляет вес, или наоборот. Треугольник может быть ориентирован вверх для признака положительной ценности, и наоборот. Или цветом, рисунком штриховки или линиями контура треугольника может быть указана валентность.
[0084] В другом примере идентификаторы признаков могут быть указаны в форме сектора кольца или кольцевого сектора. Угол кольцевого сектора может указывать важность, а его внешний радиус может указывать вес, или наоборот. Валентность может быть указана цветом кольцевого сектора, или рисунком его штриховки, или стилем линий, которыми нарисован его контур. В других примерах идентификаторы признаков могут быть представлены сектором круга, или круговым сектором, причем угол и радиус представляют важность и вес, или наоборот, а цвет или штриховка и т.д. представляют валентность, как в примере с кольцевым сектором, приведенном выше. Когда идентификаторы признаков представлены кольцевыми секторами, в некоторых примерах такие кольцевые секторы могут быть нарисованы так, чтобы они имели одинаковый внутренний радиус, а кольцевые секторы могут быть расположены так, чтобы их внутренние дуги вместе образовывали внутренний круг. В пределах самого внутреннего круга могут быть указаны оценка прогноза или другая общая сводная индикация прогноза или классификации отвечаемости. Цвет или штриховка этого внутреннего круга могут указывать, прогнозирует ли классификация отвечаемости вероятность или маловероятность ответа нетренировочного пользователя. Например, когда прогноз заключается в том, что нетренировочный субъект, вероятно, ответит, внутренний круг может иметь один цвет или рисунок штриховки, или может быть нарисован линией одного стиля, ну а если прогноз состоит в том, что нетренировочный субъект вряд ли ответит, внутренний круг может иметь другой цвет или рисунок штриховки. В других примерах вместо внутреннего круга может быть другая внутренняя форма, такая как квадрат, звезда, треугольник или пятиугольник либо другая форма. Размер внутренней формы может указывать состоятельность прогноза - чем больше внутренняя форма, тем достовернее прогноз, и наоборот.
[0085] Отчет в ГПИ может также предоставлять пользователю возможность поиска дополнительной информации или запуска дополнительных приложений в зависимости от конкретного представляющего интерес признака, сообщенного в отчете в ГПИ. Например, ГПИ может быть выполнен таким образом, чтобы пользователь мог наводить указатель или другой элемент, которым можно управлять с помощью устройства ввода, такого как мышь, на идентификаторы признаков или указывать их касанием сенсорного экрана. Ориентирование элемента или касание дисплея в месте нахождения признака может открывать раскрывающееся меню с пунктами, которые затем могут быть выбраны. Например, раскрывающееся меню может отображать аспекты признака, специфичные для нетренировочного субъекта, такие как его значение, или когортный диапазон для признака, каков процент значения признака нетренировочного субъекта, представленный относительно диапазона значений, имеющихся в тренировочных данных, или по сравнению только с тренировочными данными для тренировочных субъектов, которые ответили в соответствии с ответом, спрогнозированным для нетренировочного субъекта, или для других тренировочных субъектов, или границу однофакторного принятия решения для признаков, или важность или корреляцию признака с отвечаемостью на другие лечения, или любую комбинацию двух или более вышеуказанных аспектов. Раскрывающееся меню может также предоставлять ссылки на другие программы, к которым могут получить доступ один или более микропроцессоров, чтобы дополнительно оценить признак или оценку прогноза нетренировочных субъектов, например, путем выполнения другого машинно-обучаемого классификатора. Благодаря такому компактному размещению интерактивных возможностей в отчете в ГПИ можно значительно сэкономить пространство и вычислительные ресурсы и существенно улучшить взаимодействие пользователя с компьютерной системой. Например, для одновременного непрерывного отображения отчета в ГПИ во время доступа к пунктам раскрывающегося меню потребуется меньше места на дисплее. Кроме того, можно экономить время и вычислительные ресурсы, так как такое взаимодействие сделает возможным доступ к множеству функций компьютера без переключения между экранами дисплея или приложениями.
[0086] В некоторых примерах возможна дальнейшая тренировка натренированного машинно-обучаемого классификатора. Например, после того, как определена отвечаемость нетренировочного субъекта, машинно-обучаемый классификатор может быть повторно натренирован на признаках, включая значения признаков и отвечаемости тренировочных субъектов, на которых его первоначально тренировали, плюс значения признаков и отвечаемость нетренировочного субъекта, для которого был предоставлен прогноз и получена отвечаемость. В других примерах натренированный машинно-обучаемый классификатор может быть повторно натренирован с использованием дополнительных значений признаков и отвечаемости нетренировочного субъекта, для которого не получали прогноз от этого натренированного машинно-обучаемого классификатора.
[0087] В некоторых примерах по получении классификации прогноза ответа для субъекта может быть принято решение, применять или нет данное лечение ингибированием контрольной точки. Высокая оценка прогноза в отношении лечения с использованием конкретной контрольной точки, полученного от машинно-обучаемого классификатора, натренированного, как описано в настоящем документе, может привести к принятию решения лечить субъекта с применением лечения, для прогнозирования ответа на которое был натренирован машинно-обучаемый классификатор. Или, низкая оценка может привести к принятию решения не применять такое лечение. Получив классификацию или оценку прогноза ответа, указывающую на достаточно высокую вероятность отвечаемости, или указания лечить субъекта в результате получения такой классификации или оценки прогноза ответа в соответствии со способами, системами или машинно-обучаемым классификатором, как описано в настоящем документе, можно лечить субъекта с использованием данного лечения. Настоящее изобретение включает онкотерапию субъекта путем применения лечения ингибированием контрольной точки в ответ на получение классификации прогноза или оценки прогноза ответа, сформированной в соответствии с настоящим изобретением, которая указывает на то, что субъект будет отвечать на такое лечение, или применение такого лечения по указаниям того, кто получил такую классификацию прогноза или оценку прогноза.
ПРИМЕРЫ
[0088] Следующие примеры предназначены для иллюстрации конкретных вариантов реализации настоящего изобретения, но никоим образом не предназначены для ограничения его объема.
[0089] На ФИГ. 1 приведена сетевая диаграмма, показывающая варианты выполнения способа в соответствии с аспектами настоящего изобретения. Показаны потенциальные не имеющие ограничительного характера примеры источников значений признаков, такие как атлас ракового генома (TCGA) или данные клинических исследований (таких, как исследование лечения с помощью анти-PD1, лечения с помощью анти-CTLA4 или другого лечения с помощью ингибитора контрольной точки или другого лечения рака). Также указаны некоторые не имеющие ограничительного характера примеры анализов, которые могут быть использованы для получения информации о признаках, используемой для определения значений признаков, например, секвенирование РНК и полное секвенирование экзома (ПСЭ) в качестве двух примеров, не имеющих ограничительного характера. Указаны также другие не имеющие ограничительного характера примеры типов признаков, которые являются примерами того, какие анализ или анализы могут обеспечивать измерения, актуальные для определения значения такого признака. В число примеров входят HLA, экспрессия генов, ssGSEA, опухолевая мутационная нагрузка, цитолитическая инфильтрация, например, посредством опухолеинфильтрующих лимфоцитов (деконволюирированная), CGA, неоантигены, наличие клональной и/или субклональной мутаций (т.е. мутаций, которые присутствуют в потомках клетки, первоначально имеющейся в данной мутации, и в других потомках клетки, из которой первоначально мутировала клетка, впоследствии полученная другой мутацией) и т.д. Признаки обрабатывают с использованием модели машинного обучения (МО), при помощи которой тренируют машинно-обучаемый классификатор, и в натренированный машинно-обучаемый классификатор вводят значения признаков нетренировочного субъекта, после чего получают отклик пациента для маркировки пациента, как вероятно или маловероятно отвечающего на лечение.
[0090] На ФИГ. 2 показаны некоторые не имеющие ограничительного характера примеры признаков, которые могут быть актуальны при тренировке классификатора и прогнозировании отвечаемости пациента на лечение в соответствии с аспектами настоящего изобретения. Как понятно специалистам в данной области, признаки, идентифицированные на ФИГ. 2, являются примерами, не имеющими ограничительного характера. Кроме того, не все они являются обязательными. При выполнении способа согласно аспектам настоящего изобретения помимо показанных на ФИГ. 2 могут быть использованы другие признаки, а некоторые из показанных признаков могут быть опущены. В данном случае признаки показаны сгруппированными в соответствии с функцией, клеточным или молекулярным путем, ответом и т.п. Примеры таких группировок включают представление антигена, сигнатуры Т-клетки или NK-клетки, сигнатуры иммуноопосредованного цитолиза, участников пути контрольной точки, участников пути интерферона-γ и сигнатуры MDSC/Treg. В дополнение или вместо любых группировок, показанных в настоящем документе в качестве не имеющих ограничительного характера примеров, могут быть включены другие группировки, представляющие другие функции либо клеточные или молекулярные процессы и т.д.
[0091] На ФИГ. 3 приведена сетевая диаграмма, показывающая пример возможного выполнения способа тренировки классификатора в соответствии с аспектами настоящего изобретения. Как понятно специалистам в данной области, признаки, идентифицированные на ФИГ. 3, являются примерами, не имеющими ограничительного характера. Кроме того, не все они являются обязательными. При выполнении способа согласно аспектам настоящего изобретения помимо показанных на ФИГ. 3 могут быть использованы другие признаки, а некоторые из показанных признаков могут быть опущены. В данном случае признаки показаны сгруппированными в соответствии с функцией, клеточным или молекулярным путем, ответом и т.п. Примеры таких группировок включают представление антигена, сигнатуры Т-клетки или NK-клетки, сигнатуры иммуноопосредованного цитолиза, участников пути контрольной точки, участников пути интерферона-γ и сигнатуры MDSC/Treg. Как указано на ФИГ. 3, признаки тренировочных субъектов, такие как показанные, вводят в машинно-обучаемый классификатор, например, классификатор на основе случайного леса, в виде меток, соответствующих тому, как тренировочные субъекты отвечали на данное лечение, такое как лечение ингибированием контрольной точки. Таким образом можно тренировать классификатор. Как отмечалось, могут быть также использованы другие машинно-обучаемые классификаторы.
[0092] ФИГ. 4 представляет собой расширение ФИГ. 3, показывающее сетевую диаграмму, демонстрирующую пример возможного выполнения способа использования натренированного классификатора для прогнозирования отвечаемости субъекта в соответствии с аспектами настоящего изобретения. Машинно-обучаемый классификатор (классификатор на основе случайного леса в данном не имеющем ограничительного характера примере), натренированный на признаках (не имеющие ограничительного характера примеры которых, например, показаны в настоящем документе), принимает входные данные, полученные от нетренировочного субъекта. В частности, в машинно-обучаемый классификатор вводят значения признаков нетренировочного субъекта. После этого при предоставлении отчета о прогнозе натренированный машинно-обучаемый классификатор формирует классификацию прогноза ответа, которая может содержать оценку, указывающую вероятность отвечаемости (в данном случае указанную в виде иммунных оценок) и/или идентификаторы признаков.
[0093] Признаки и отвечаемость на ингибирование PD-1 были получены из работы под авторством Hugo и др. (2016) «Genomic and Transcriptomic Features of Response to Anti-PD-1 Therapy in Metastatic Melanoma». Cell. 2016; 165(1):35-44 (doi:10.1016/j.cell.2016.02.065). В этом исследовании были получены данные полного секвенирования экзома и данные секвенирования РНК из образцов опухоли 26 пациентов с меланомой до и после лечения с помощью антитела к ингибитору пути контрольной точки PD-1 (анти-PD-1) (ниволумаб) или антитела к анти-PD-L1 (пембролизумаб). Необработанные данные были общедоступны и приведены в качестве примеров в настоящем документе. Данные транскриптома, полученные посредством секвенирования РНК (включая уровни экспрессии транскриптов в образцах) были доступны в Интернете в базе данных Gene Expression Omnibus Национального центра биотехнологической информации (NCBI) под входящим номером GSE78220 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE78220). Данные полного секвенирования экзома, полученные методами СНП, были доступны в Интернете в базе данных Sequence Read Archive Национального центра биотехнологической информации (NCBI) (https://www.ncbi.nlm.nih.gov/sra) под входящими номерами SRA: SRP067938 и SRA: SRP090294. Отвечаемость пациентов, для которых были доступны такие данные, тоже была получена из результатов опубликованных исследований. Из этих источников выбирали данные для создания признаков тренировочных субъектов и отвечаемостей тренировочных субъектов, чтобы тренировать машинно-обучаемый классификатор на прогнозирование отвечаемости на ингибиторы пути контрольной точки анти-PD1. Из этих же источников получали данные признаков для получения прогноза от натренированного машинно-обучаемого классификатора.
[0094] Признаки и отвечаемость на ингибирование CTLA-4 были получены из работы под авторством Van Allen и др. (2015) «Genomic correlates of response to CTLA-4 blockade in metastatic melanoma». Science 350:207-211 (doi: 10.1126/science.aad0095). В этом исследовании были получены данные полного секвенирования экзома и данные секвенирования РНК из образцов опухоли 30 пациентов с меланомой до и после лечения с помощью ингибитора CTLA-4 (ипилимумаб). Необработанные данные были общедоступны и приведены в качестве примеров в настоящем документе. Данные полного секвенирования экзома и данные транскриптома, полученные посредством СНП, были доступны в базе данных генотипов и фенотипов (Genotypes and Phenotypes, dbGaP), входящий номер phs000452.v2.p1 (https://www.ncbi.nlm.nih.gov/gap/?term=phs000452.v2.p1). Отвечаемость пациентов, для которых были доступны такие данные, тоже была получена из результатов опубликованных исследований. Из этих источников выбирали данные для создания признаков тренировочных субъектов и отвечаемостей тренировочных субъектов, чтобы тренировать машинно-обучаемый классификатор на прогнозирование отвечаемости на ингибиторы пути контрольной точки анти-CTLA4. Из этих же источников получали данные признаков для получения прогноза от натренированного машинно-обучаемого классификатора.
[0095] Данные, полученные из обоих исследований, предварительно обрабатывали для создания входных признаков для тренировки машинно-обучаемых классификаторов. Затем на этих тренировочных данных тренировали машинно-обучаемые классификаторы на основе случайного леса, принявшие такие входные данные. После этого признаки некоторых субъектов использовали для формирования прогноза с помощью одного или обоих натренированных классификаторов и посредством ГПИ предоставляли отчеты о классификации прогноза отвечаемости, в том числе оценку прогноза и идентификаторы признаков. На ФИГ. 1, которая описана выше, приведен обзор примера некоторых способов, используемых в данных примерах. На ФИГ. 2 показаны 38 признаков, которые выбирали для ввода в машинно-обучаемый классификатор. Признаки выбирали на основе ожиданий, что они могут относиться к прогнозу того, может ли субъект отвечать на ингибирование контрольной точки или нет, исходя из текущего понимания ролей таких признаков. allMut обозначает опухолевую мутационную нагрузку всех мутаций, а nonSynMut обозначает опухолевую мутационную нагрузку, приписываемую несинонимичным мутациям. cd8_dec, cd4_dec и cd19_dec обозначают измерения деконволюции опухолефильтрующих лимфоцитов для CD8, CD4 и CD19, соответственно. Остальные признаки, идентифицированные на ФИГ. 2, получены из данных секвенирования РНК и содержат измерения относительных уровней экспрессии. Для некоторых примеров также получали ssGSEA для наборов признаков (представление антигена, сигнатура Т-клетки/NK-клетки, путь контрольной точки, интерферон-γ и сигнатуры MDSC/Treg). Некоторые машинно-обучаемые классификаторы тренировали только на первоначальных 38 признаках, а остальные тренировали на 38 первоначальных признаках плюс наборы генов, полученные посредством анализа ssGSEA, что в итоге дало 44 признака для таких примеров.
[0096] Данные субъектов в расчете на значение признака нормализовали по порядку ранжирования их значений как процента каждого значения в расчете на признак относительно диапазона значений для всех значений субъекта для этого признака в наборе. В этих примерах отвечаемость для тренировки была двоичной, причем субъекта помечали либо как отвечающего (включая как частичные отвечаемости, так и полную отвечаемость или долгосрочную пользу от лечения, о чем сообщалось в соответствующем исследовании, лежащем в основе) или неотвечающего (включая субъектов, о прогрессировании болезни которых в ответ на лечение сообщалось в соответствующих исследованиях, что их болезнь прогрессировала в ответ на лечение, и не сообщалось о пользе лечения).
[0097] Признаки вводили в компьютерную систему, содержащую одно или более запоминающих устройств и один или более микропроцессоров. Одно или более запоминающих устройств содержали инструкции, которые при выполнении их одним или более микропроцессорами тренировали машинно-обучаемый классификатор на основе случайного леса, используя язык программирования R. Признаки субъектов сохраняли в одном или более запоминающих устройствах и анализировали с помощью одного или более микропроцессоров в соответствии с инструкциями. В этих примерах использовали 50000 деревьев решений. После тренировки в натренированный машинно-обучаемый классификатор вводили признаки субъекта, которые хранились в одном или более запоминающих устройствах компьютерной системы, и формировали оценку классификации прогноза ответа и отображали ее посредством ГПИ на дисплее компьютера. Пример тренировки показан на ФИГ. 3, а пример формирования прогноза показан на ФИГ. 4.
[0098] Окончательные оценки прогноза формировали с помощью вероятности классификации по шкале оценок от 0 до 10. В качестве пример и в порядке пояснения вероятность 0,75 классификации события «имел ответ» на данную иммунотерапию, переводили в оценку 7,5 прогноза. Кроме того, для каждого признака в качестве границы однофакторного принятия решения определяли значение, которое максимально повышает точность классификации. Направление корреляции того, был ли признак положительно или отрицательно коррелирован с классификацией субъекта как отвечающего, определяли с помощью коэффициента корреляции Спирмена между признаком и ответом. Вышеуказанные анализы выполняли с использованием полных образцов без разделения на тренировочных и нетренировочных субъектов. Анализ эффективности проводили отдельно. Для 3-кратной перекрестной проверки и создания графика площади под кривой (ППК) использовали пакеты «care» и «cvAUC» языка программирования R с используемыми по умолчанию функцией и параметром.
[0099] На ФИГ. 5 показан пример отчета 500 в ГПИ, предоставляющего оценку прогноза классификации ответа и идентификаторы признаков. В этих примерах идентификаторы признаков предоставляли только в том случае, если квадрат важности признака (важность признака определяли по уменьшению индекса Джини признака) был больше 0,1. На ФИГ. 5 показан отчет в ГПИ для субъекта, данные которого были получены при пробном прогоне анти-PD1 на машинно-обучаемом классификаторе, натренированном на прогнозирование отвечаемости на лечение с использованием анти-PD1 (например, анти-PD1 или антитело к анти-PD1-L1). 15 признаков с важностью, превышающей минимальный порог важности, показаны в столбце 510 ПРИЗНАКИ. Важность признаков показана в столбце 520 ВАЖН. Группа, с которой связана признак согласно ФИГ. 2, показана в столбце 530 ГРУППА. Положительная или отрицательная корреляция признака с отвечаемостью показана в столбце 540 КОРР. В данном примере для указания направления корреляции использованы треугольники, где ориентированный вверх треугольник указывает положительную корреляцию, а ориентированный вниз треугольник указывает отрицательную корреляцию между значением признака и отвечаемостью. Граница однофакторного принятия решения показана в столбце 550 Г1ФПР. В данном примере граница однофакторного принятия решения определена в числовом виде как процент в диапазоне значений субъекта для данного образца, выше и ниже которого обеспечивалось наивысшее достижимое различие между отвечающими и неотвечающими (т.е. значение ниже или выше этого процента было менее точным в целом при установлении различия между отвечающим и неотвечающим субъектами). В каждой ячейке признака в столбце Г1ФПР также указана граница однофакторного принятия решения в виде штриховки слева направо, представляющей процент, указанный границей однофакторного принятия решения (т.е., чем ниже процент, тем меньше штриховки, и чем выше процент, тем больше штриховки пропорционально значению границы). Значение субъекта для каждого признака показано в столбце 560 ВВОД (в данном случае ВВОД ПТ5, идентифицирующий пациента, о прогнозе которого сообщается здесь, как пациента под номером 5, ПТ5). Число в столбце 560 ВВОД ПТ5 указывает значение субъекта для данного признака, как и штриховка, указывающая в процентах ранг значения признака субъекта относительно диапазона значений тренировочных субъектов.
[0100] В столбце 570 1Ф.ПРОГ сообщается, будет ли субъект реагировать на лечение согласно прогнозу на основе только значения данного признака. Таким образом, если для положительно коррелированных признаков значение в столбце 560 ВХОД ПТ5 выше значения в столбце 550 Г1ФПР, то в столбце 570 1Ф.ПРОГ указано ДА (означающее, что прогноз на основе этого признака будет указывать на то, субъект будет отвечать на лечение). Если для положительно коррелированных признаков значение в столбце 560 ВХОД ПТ5 ниже значения в столбце 550 Г1ФПР, то в столбце 570 1Ф.ПРОГ указано НЕТ (означающее, что прогноз на основе этого признака будет указывать на то, что субъект не будет отвечать на лечение). Если для отрицательно коррелированных признаков значение в столбце 560 ВХОД ПТ5 выше значения в столбце 550 Г1ФПР, то в столбце 570 1Ф.ПРОГ указано НЕТ (означающее, что прогноз на основе этого признака будет указывать на то, что субъект не будет отвечать на лечение). А если для отрицательно коррелированных признаков значение в столбце 560 ВХОД ПТ5 ниже значения в столбце 550 Г1ФПР, то в столбце 570 1Ф.ПРОГ указано ДА (означающее, что прогноз на основе этого признака будет указывать на то, субъект будет отвечать на лечение). В данном примере ячейки в столбце 570 1Ф.ПРОГ могут быть также кодированы цветом в соответствии с тем, будет ли взятый в отдельности признак прогнозировать отвечаемость. Ячейки ДА могут быть окрашены, например, в зеленый цвет (З), тогда как ячейки НЕТ могут быть окрашены в красный цвет (К). Нижняя строка 580 ПОЛНАЯ МОДЕЛЬ сообщает оценку классификации ответа, в данном случае 5,5. Можно определить пороговое значение, выше или ниже которого лечение может быть спрогнозировано как эффективное или неэффективное. Например, оценка ниже 5,0 может быть принята как прогноз того, что лечение не будет действовать для данного пациента, а оценка выше 5,0 может быть принята как прогноз того, что лечение будет действовать для этого пациента. В данном случае, когда оценку выше 5 принимают как указание на то, что лечение будет действовать для данного пациента, можно увидеть, что ценность тренировки и использования машинно-обучаемого классификатора, как описано в настоящем документе, заключается в обеспечении значительно улучшенной основы для прогнозирования, чем была бы основа для прогнозирования с использованием только одного из признаков, индикаторы которого присутствуют в отчете в ГПИ, в том смысле, что некоторые признаки по отдельности прогнозировали неотвечаемость (в том числе признак с наивысшей важностью), но машинно-обучаемый классификатор в целом прогнозирует, что пациент будет реагировать.
[0101] В данном примере отчет об оценке прогноза ответа предоставлен в ГПИ в виде индикаторов для каждого признака, включенного в отчет в ГПИ, включая вес (за счет сравнения между столбцом 560 ВХОД ПТ5 и столбцом 550 Г1ФПР), важность 520 и валентность 1Ф.ПРОГ. В некоторых примерах у пользователя может быть возможность получения доступа к открывающимся меню из разных аспектов ГПИ, такая как касание части отображения сенсорного экрана, соответствующей части отчета в ГПИ, или перемещение графического элемента, такого как курсор, с помощью устройства, например, мыши, на признак или его соответствующие индикаторы или оценки, чтобы получить доступ к дополнительной информации или выбрать дополнительный анализ, который может быть выполнен одним или более микропроцессорами посредством разных программных инструкций, хранящихся в одном или более запоминающих устройствах.
[0102] Другой отчет 610 в ГПИ для данного субъекта представлен на ФИГ. 6. В примере на ФИГ. 6 несколько отчетов в ГПИ объединены в один отчет. В верхней части на ФИГ. 6 представлено кольцо из кольцевых секторов 610, каждый из которых соответствует признаку, имеющему важность выше минимального порога важности, как объяснено для ФИГ. 5. Признак, которому соответствует каждый кольцевой сектор, также указан надписью. Например, кольцевой сектор 630 соответствует признаку HLA.B. Каждый кольцевой сектор имеет угол, внешний радиус и внутренний радиус, и внутреннюю дугу. В данном примере угол соответствует важности признака. В данном примере углы признаков пропорциональны друг другу, чтобы можно было непосредственно сравнивать их визуально. Также в этом примере разница между внешним радиусом и внутренним радиусом сектора соответствует его весу (т.е. разнице значения признака субъекта по сравнению с границей однофакторного принятия решения). В данном примере также сообщается валентность признака с помощью стиля лини, которая очерчивает кольцевой сектор признака. Признак, кольцевой сектор которого имеет положительную валентность для субъекта (например, для все опухолевой мутационной нагрузки 640), очерчен сплошной линией, тогда как признак, кольцевой сектор которого имеет отрицательную валентность для субъекта (например, HLA.B 630), очерчен пунктирной линией.
[0103] В данном примере внутренние дуги расположены так, что они образуют внутренний круг. Также в этом примере во внутреннем круге сообщается оценка классификации прогноза отвечаемости для этого пациента, в данном случае 5,5. Также в этом примере общий прогноз указан сплошной линией, образующей внутренний круг, которая означает, что оценка классификации прогноза ответа превышает предварительно заданный уровень различия между прогнозом отвечаемости и неотвечаемости. В других примерах внутренний круг мог бы быть образован пунктирной линией, если бы оценка классификации прогноза ответа была ниже такого предварительно определенного порога оценки. В других примерах цвет или разные рисунки штриховки внутри кольцевого сектора и/или внутреннего круга и/или разная окраска контуров кольцевого сектора или внутреннего сектора могут указывать валентность.
[0104] В данном примере верхняя часть 610 отчета 600 в ГПИ, представленного на ФИГ. 6, содержит отчет об оценке классификации прогноза ответа и указывает важность, валентность и вес признаков. Другой пример такого отчета 1010 в ГПИ представлен на ФИГ. 10. Кольцевые секторы признаков представлены отдельно, а не с образование круга их внутренними дугами. В целях иллюстрации показаны примеры внешней дуги 1002, внутренней дуги 1001 и разность 1003 между внешним и внутренним радиусами для кольцевого сектора для CD15 и пример угла 1004 кольцевого сектора ниже кольцевого сектора 1030 для HLA.B. Внешние радиусы признаков (или разности между внутренними радиусами и внешними радиусами) указывают вес, углы указывают важность, а стиль линии, очерчивающей кольцевой сектор, указывает, имеет ли признак положительную (сплошная линия, например, кольцевой сектор для всей опухолевой мутационной нагрузки, all_tmb 1040) или отрицательную (пунктирная линия, например, кольцевой сектор для CD15) валентность. Не показано, но такой отчет 1010 в ГПИ необязательно включает оценку классификации прогноза ответа. Валентность может быть указана не контурами разных стилей, а разными цветами или штриховками разных рисунков. Также вместо кольцевых секторов могут быть использованы другие формы. Например, признаки могут быть представлены в отчете в виде прямоугольников, ширина и высота которых представляют важность и вес, или треугольников, в которых ширина основания отражает важность, высота представляет вес, а ориентация представляет валентность. Специалисту в данной области понятно, что в целях предоставления в ГПИ отчета о множестве индикаторов нескольких признаков в соответствии с аспектами настоящего изобретения могут быть адаптированы множество возможностей.
[0105] Возвращаясь к отчету 600 в ГПИ, изображенному на ФИГ. 6, ниже верхней части 610 отчета, которая содержит кольцевые секторы, в ГПИ представлена часть 620 отчета в виде гистограммы. Отчет в ГПИ может иметь обе эти части, или только одну, или ни одной. Гистограмма 620 показывает столбики для каждого признака, значение которого в отчете по субъекту превышает минимальный порог важности, установленный для этого признака. Шкала 650 слева указывает в процентах ранг значения субъекта для каждого признака. Каждый столбик признака представляет значение признака субъекта для этого признака в виде процента от диапазона значений тренировочных субъектов. В качестве примера указано значение 660 субъекта для признака CD15. Также в каждом столбике представлена граница однофакторного принятия решения для данного признака, в данном случае в виде горизонтальной линии. В качестве примера указана граница 670 принятия однофакторного решения для признака CD15. Треугольники под каждым столбиком указывают, является ли признак положительно (треугольник, ориентированный вверх) или отрицательно (треугольник, ориентированный вниз) коррелированным с отвечаемостью. Пример 680 указан для CD15. Кроме того, размеры треугольников пропорциональны относительной важности каждого признака - чем больше треугольники, тем выше важность, и чем меньше треугольники, тем ниже важность. Линия между значением признака субъекта и границей однофакторного принятия решения для этого признака указывает вес признака. В качестве примера веса признака в отчете указан вес 690 для признака CD15. Валентность признака указана посредством того, является ли линия веса сплошной (положительная валентность) или пунктирной (отрицательная валентность). Как понятно специалисту в данной области, каждый из этих конкретных примеров предоставления отчета о различных индикациях разных признаков может быть опущен или замен другими графическими представлениями. Цвета и штриховка могут представлять валентность и/или корреляции для признаков, стрелки или другие направленные формы могут представлять валентность или корреляции, важность может быть представлена масштабированной схемой цветового кодирования и т.д.
[0106] В некоторых примерах для тренировки машинно-обучаемого классификатора и формирования прогноза от натренированного машинно-обучаемого классификатора использовали наборы генов. Пример наборов генов, формируемых посредством ssGSEA, показан на ФИГ. 7. Показаны шесть наборов, сгруппированных из отдельных признаков, используемых для определения набора генов. В число примеров входят путь процессирования антигена, т.е. относящийся к представлению антигенов (710), сигнатуры 720 Т-клеток и NK-клеток, цитолитические сигнатуры 730, путь 740 контрольной точки, интерферон-гамма 750 и сигнатуры 760 MSDC/Treg. Корреляции и важности для каждого признака, включая наборы генов, когда они используются для тренировки машинно-обучаемого классификатора PD1 и CTLA4, указаны в столбцах 770 и 780, соответственно. В некоторых случаях выделенный в ячейках, обведенных пунктирными рамками, набор генов обеспечивал либо корреляцию более высокой величины, либо более высокую важность, чем любой отдельный признак, на котором был определен набор генов с использованием ssGSEA, что указывает на ценность включения наборов генов в качестве признаков. Полезность включения ssGSEA также показана на ФИГ. 9. На ФИГ. 9 показаны два отчета в ГПИ о прогнозе отвечаемости для того же субъекта с использованием двух разных машинно-обучаемых классификаторов. Прогноз 910 слева был получен путем формирования прогноза без использования наборов генов ssGSEA в качестве признаков во время тренировки или прогнозирования. Прогноз 920 справа был получен путем формирования прогноза с использованием наборов генов ssGSEA в качестве признаков во время тренировки и прогнозирования. Когда включали наборы генов, полученные с помощью ssGSEA, меньше признаков превышали минимальную пороговую границу (11 против 15), в том числе некоторые наборы генов (которые по определению не были включены в прогноз 910, получаемый без наборов генов), без ущерба для общего прогнозирования (например, в обоих случаях прогноз превышал оценку 5,0, установленную в качестве минимальной оценки классификации прогноза ответа, инициирующей классификацию субъекта как отвечающего).
[0107] На ФИГ. 8 показаны два отчета в ГПИ, полученные для одного и того же пациента, для которого прогноз формировали с использованием двух разных машинно-обучаемых классификаторов - один 810 натренированный на прогнозирование отвечаемости на лечение при помощи анти-CTLA4, а другой 820 натренированный на прогнозирование отвечаемости на лечение с помощью анти-PD1, с использованием в обоих классификаторах признаков, изображенных на ФИГ. 2. Машинно-обучаемый классификатор 810 для анти-CTLA4 дал оценку классификации прогноза ответа 3,8, предсказывающую, что субъект не будет отвечать на лечение с помощью анти-CTLA4 (при использовании порога оценки классификации прогноза ответа 5,0). В данном случае 810 валентность оценки классификации прогноза ответа (неотвечаемость) указана пунктирными линиями 815 вокруг внутреннего круга, в котором изображена оценка классификации прогноза ответа. Точность такого прогноза подкреплена классификацией ответа данного пациента в использованном в качестве источника клиническом исследовании (Van Allen и др.) как «прогрессирование болезни», указывающей на то, что субъект не отвечал на лечение с помощью анти-CTLA4. Однако машинно-обучаемый классификатор 820 для анти-PD1 сформировал оценку классификации прогноза ответа 6,7, предсказывающую, что субъект будет отвечать на лечение с помощью анти-PD1 (например, анти-PD1 или антитела к анти-PD-L1) (опять же при использовании порога оценки классификации прогноза ответа 5,0). В данном случае 820 оценка классификации прогноза ответа (отвечаемости) указана сплошной линией 817 вокруг внутреннего круга, в котором изображена оценка классификации прогноза ответа.
[0108] Разные оценки классификации прогноза ответа (и соответствующие различия в валентности, весе и важности различных параметров) в зависимости от используемого машинно-обучаемого классификатора отражают мощь способов, раскрытых в настоящем документе. Например, индикаторы, сообщенные для HLA.A 830, указывают на то, что он имеет отрицательную валентность для прогнозирования отвечаемости пациента на лечение с помощью анти-CTLA4, но положительную валентность для прогнозирования отвечаемости субъекта на лечение с помощью анти-PD1. Кроме того, значения признаков для несинонимичной опухолевой мутационной нагрузки и всей опухолевой мутационной нагрузки 840 не превзошли минимального порога важности в машинно-обучаемом классификаторе для анти-CTLA4, но превзошли в машинно-обучаемом классификаторе для анти-PD1.
[0109] Как и в примере, изображенном на ФИГ. 4, примеры отчетов в ГПИ, изображенные на ФИГ. 6, 8, 9 и 10, могут включать возможность взаимодействия с пользователем. Таким образом, в некоторых примерах у пользователя может быть возможность получения доступа к открывающимся меню из разных аспектов ГПИ, такая как касание части отображения сенсорного экрана, соответствующей части отчета в ГПИ, или перемещение графического элемента, такого как курсор, с помощью устройства, например, мыши, на признак (например, кольцевой сектор или столбик в гистограмме или другие индикаторы), чтобы получить доступ к дополнительной информации или выбрать дополнительный анализ, который может быть выполнен одним или более микропроцессорами посредством разных программных инструкций, хранящихся в одном или более запоминающих устройств.
[0110] На Фиг. 11А-11D показано, что при использовании всех 38 признаков, изображенных на ФИГ. 2, эффективность формируемого классификатора выше, чем при использовании отдельно взятых факторов. Это было справедливо в отношении машинно-обучаемых классификаторов, натренированы ли они на прогнозирование отвечаемости на лечение с помощью анти-PD1 или с помощью анти-CTLA4. На ФИГ. 11А показано, что при использовании всех 38 признаков для тренировки и тестирования машинно-обучаемого классификатора на прогнозирование отвечаемости, например, на лечение с помощью анти-PD1, ППК рабочей характеристики приемника (auROC) отношения ложно положительных прогнозов к истинно положительным составила 1,00, когда машинно-обучаемый классификатор был перетренирован без перекрестной проверки (CV), причем auROC достигала 1,00 по сравнению с auROC, равным 0,64, для усредненных отдельных факторов, как показано на ФИГ. 11В. На ФИГ. 11С и 11D также показано, что использование 38 признаков, изображенных на ФИГ. 2, дает более точный результат, что все три лучших однофакторных признаков, HLA-B, nonSyn_tmb и all_tmb.
[0111] На ФИГ. 12A-12D приведены графики, показывающие влияние использования наборов генов, полученных посредством ssGSEA, на эффективность классификатора. Эффективность ssGSEA сравнима с эффективностью при использовании 38 признаков, изображенных на ФИГ. 2. На ФИГ. 12А, 12В и 12С приведен отчет по auROC с 3-кратной перекрестной проверкой в случае использования 38 признаков, изображенных на ФИГ. 2, для прогнозирования отвечаемости на лечение с помощью анти-PD1 (ФИГ. 12А) или анти-CTLA4 (ФИГ. 12В), или в случае использования 38 признаков плюс 6 наборов генов, изображенных на ФИГ. 7, для прогнозирования отвечаемости на лечение с помощью анти-PD1 (ФИГ. 12С). Хотя при включении 6 наборов генов, полученных посредством ssGSEA, эффективность прогнозирования лечения с помощью анти-PD1 была снижена с 0,69 до 0,64 (если сравнивать ФИГ. 12А с ФИГ. 12С), количество признаков, которые превысили минимальный порог важности, сократилось с 15 до 11 (как обсуждалось выше; см., например, ФИГ. 8). На ФИГ. 12D показаны сравнимые результаты t-критерия Стьюдента для ложно и истинно положительных результатов по оценке классификации прогноза ответа для машинно-обучаемых классификаторов (без перекрестной проверки). Поэтому в некоторых примерах включение наборов генов в качестве признаков может улучшить общую устойчивость к ошибкам классификатора, помочь избежать перетренировки и позволяет более четко интерпретировать важные признаки и их идентификаторы.
[0112] Данные, использованные в этих примерах, принадлежат субъектам, включенным в исследование по проверке эффективности ингибиторов контрольной точки - антитела к анти-CTLA4, антитела к анти-PD1 и антитела к анти-PD1-L1 - у пациентов с меланомой. Однако, как понятно специалистам в данной области, исходя из роли блокировок контрольных точек, известных своей ролью в снижении эффективности иммуноонкологического лечения других раков, и роли признаков, вроде включенных в настоящий документ, в функции пути контрольной точки, раскрытые в настоящем документе способы, системы и классификаторы будут в равной степени полезны и эффективны также при формировании прогнозов отвечаемости субъекта на эти ингибиторы контрольной точки в случае других раков, включая рак молочной железы, раки пищеварительной системы, рак печени, рак мочевого пузыря, лимфому, лейкемию, раки костной ткани, раки нервной системы, раки легких, раки поджелудочной железы или другие. Кроме того, как также понятно специалистам в данной области, с помощью способов, систем и классификаторов, раскрытых в настоящем документе, можно также прогнозировать отвечаемость на ингибиторы контрольной точки в дополнение к тем, что специально указаны в вышеприведенных примерах, описанных в настоящем документе, которые служат просто не имеющими ограничительного характера примерами применимости этих способов, систем и классификаторов.
[0113] Недостатком данного анализа эффективности является малый размер выборки. Даже при десятках признаков перетренировка неизбежна. Между тем результаты кратной перекрестной проверки очень неустойчивые и демонстрируют дискретизацию точек auROC вместо непрерывной кривой. Однако в рамках имеющихся ограничений полная модель явно эффективнее факторов, взятых в отдельности.
[0114] Хотя в настоящем документе подробно изображены и описаны предпочтительные варианты реализации, специалистам в данной области техники очевидно, что могут быть внесены различные модификации, добавления, изъятия и т.п. в пределах сущности настоящего изобретения, и поэтому они считаются входящими в объем настоящего изобретения, как определено в нижеследующей формуле изобретения.
[0115] Следует понимать, что все сочетания вышеупомянутых понятий и дополнительных понятий, обсуждаемых более подробно в настоящем документе (при условии, что такие понятия не являются взаимно несовместимыми), рассматриваются как часть патентоспособного предмета изобретения, описанного в настоящей заявке. В частности, все сочетания заявленного предмета изобретения в конце данного описания рассматриваются как часть патентоспособного предмета изобретения, описанного в настоящей заявке.
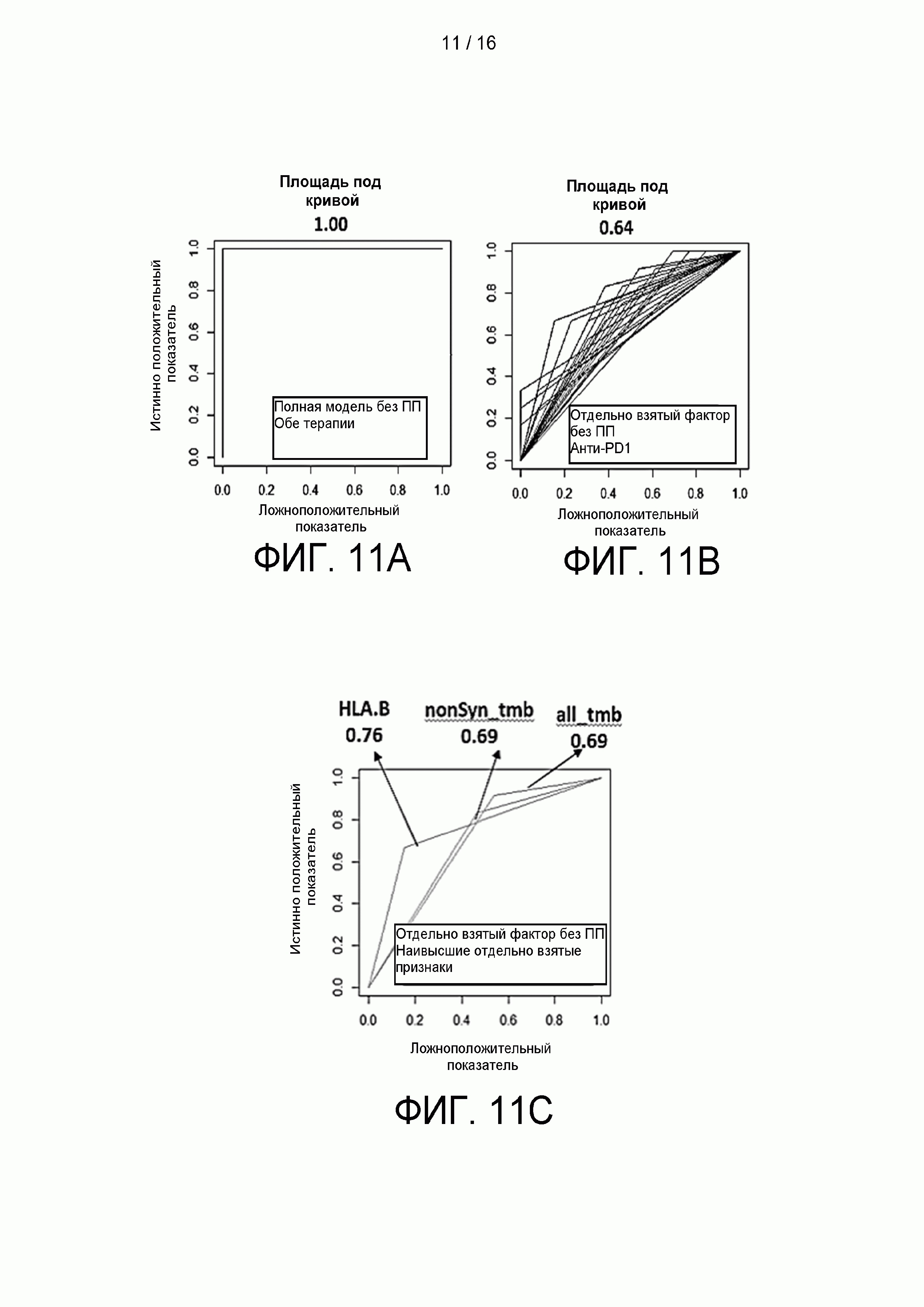
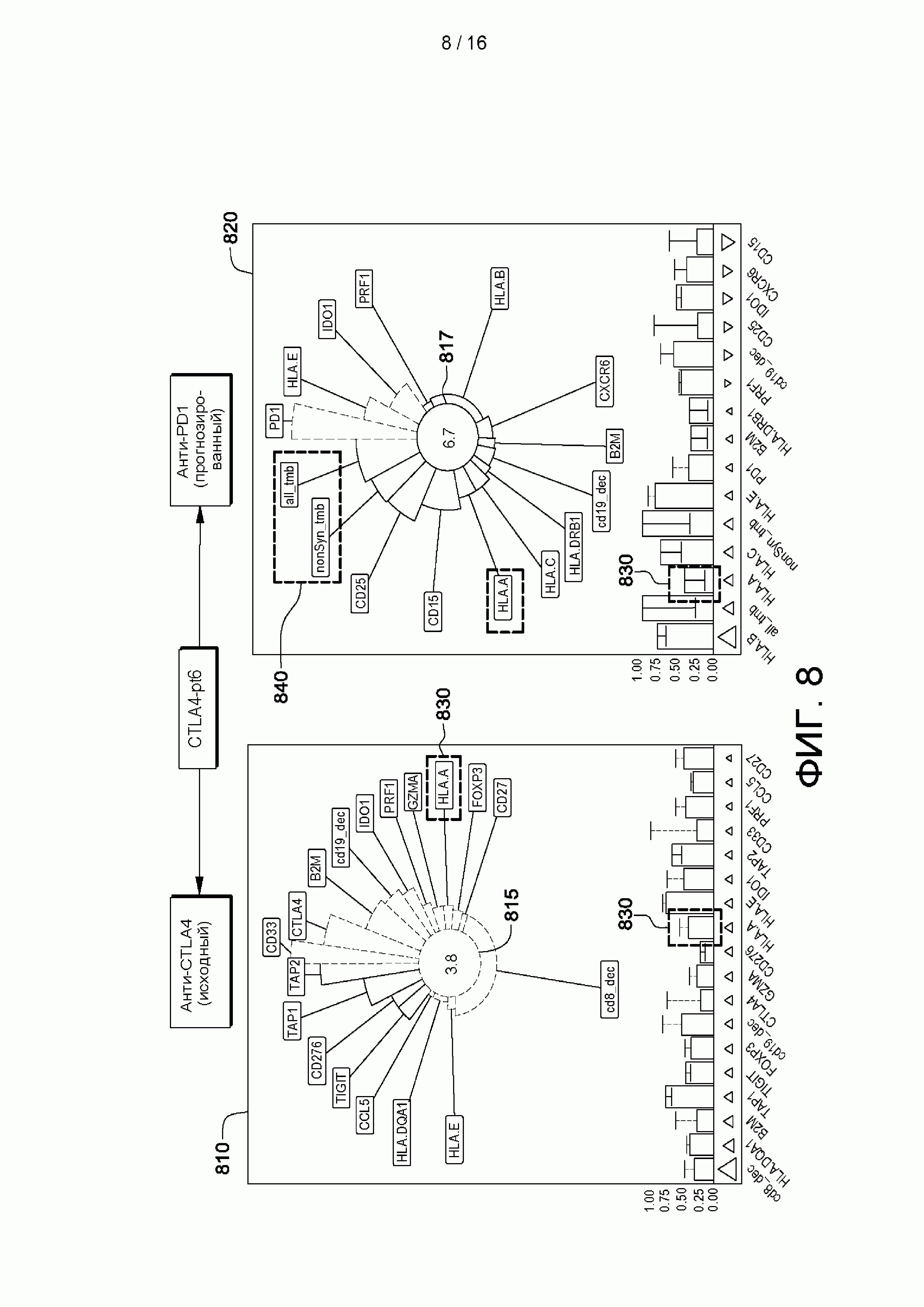
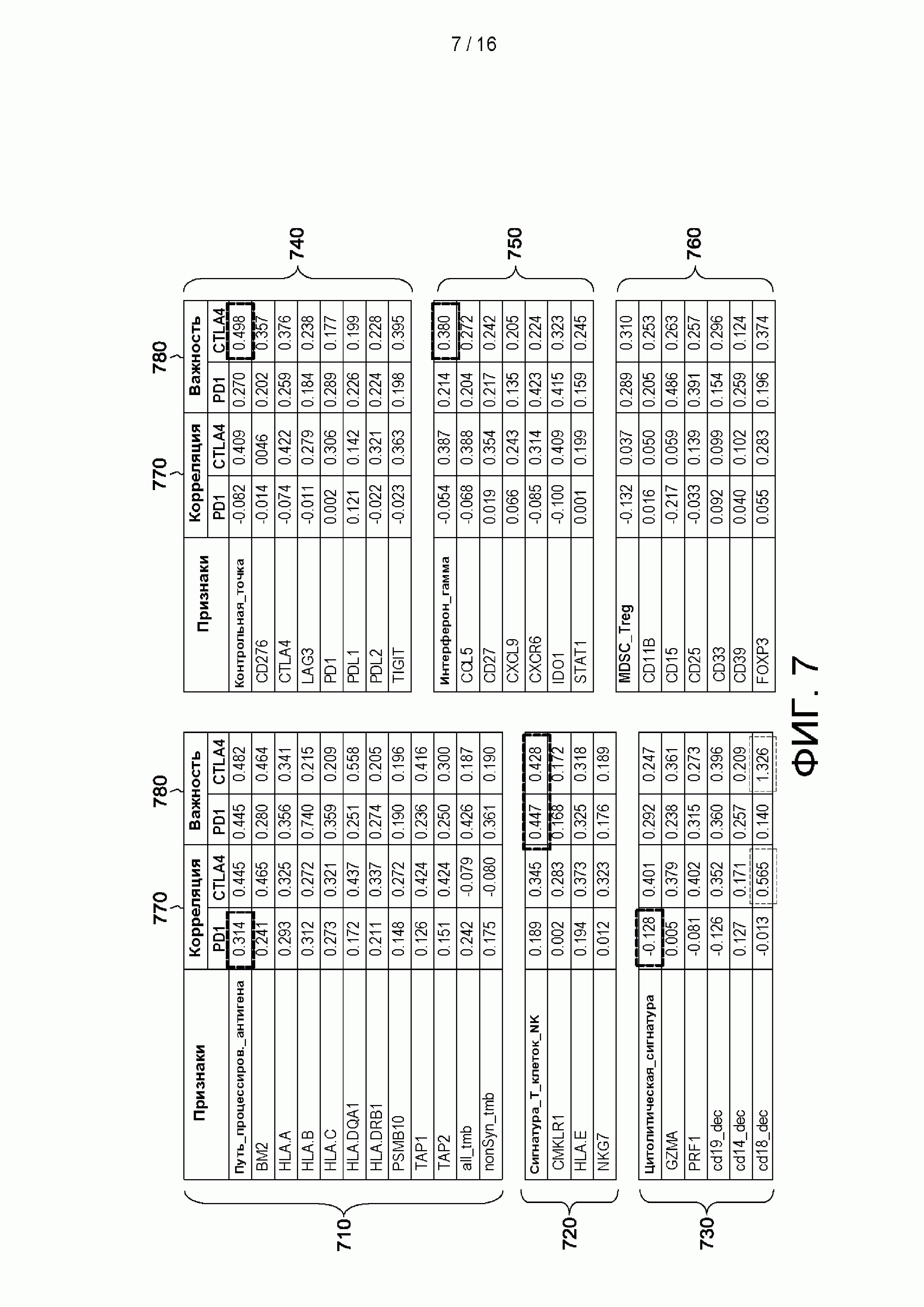
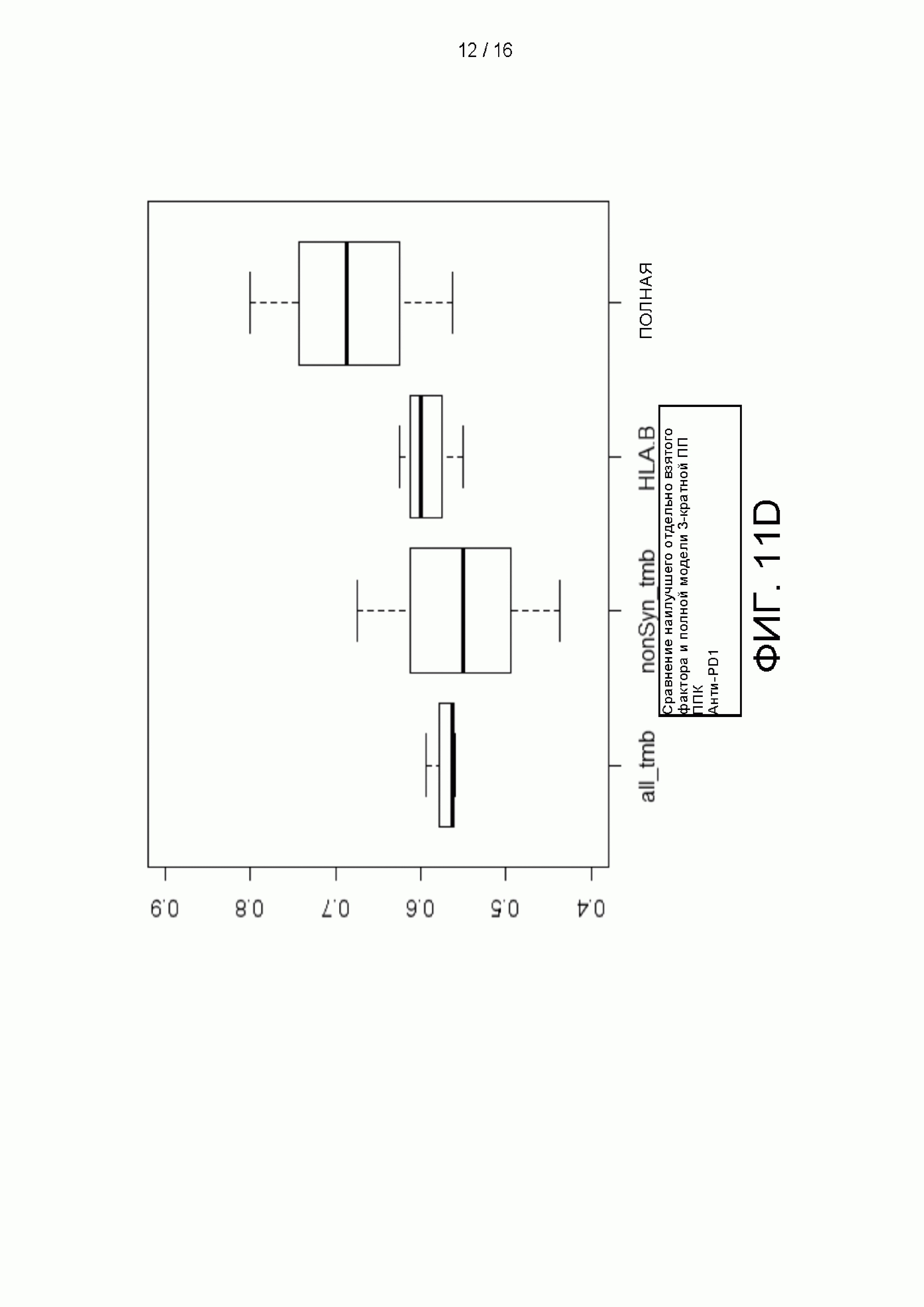
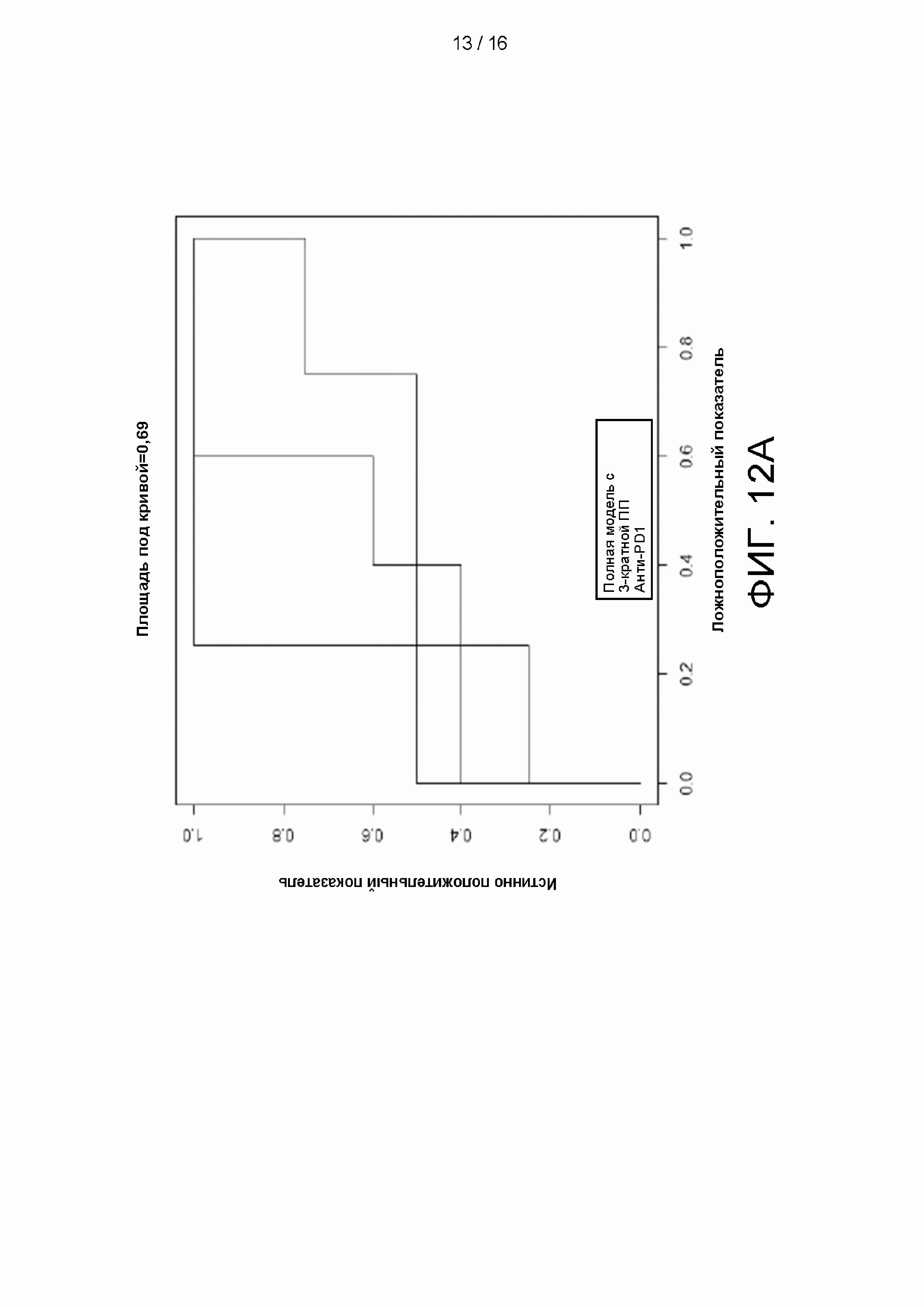
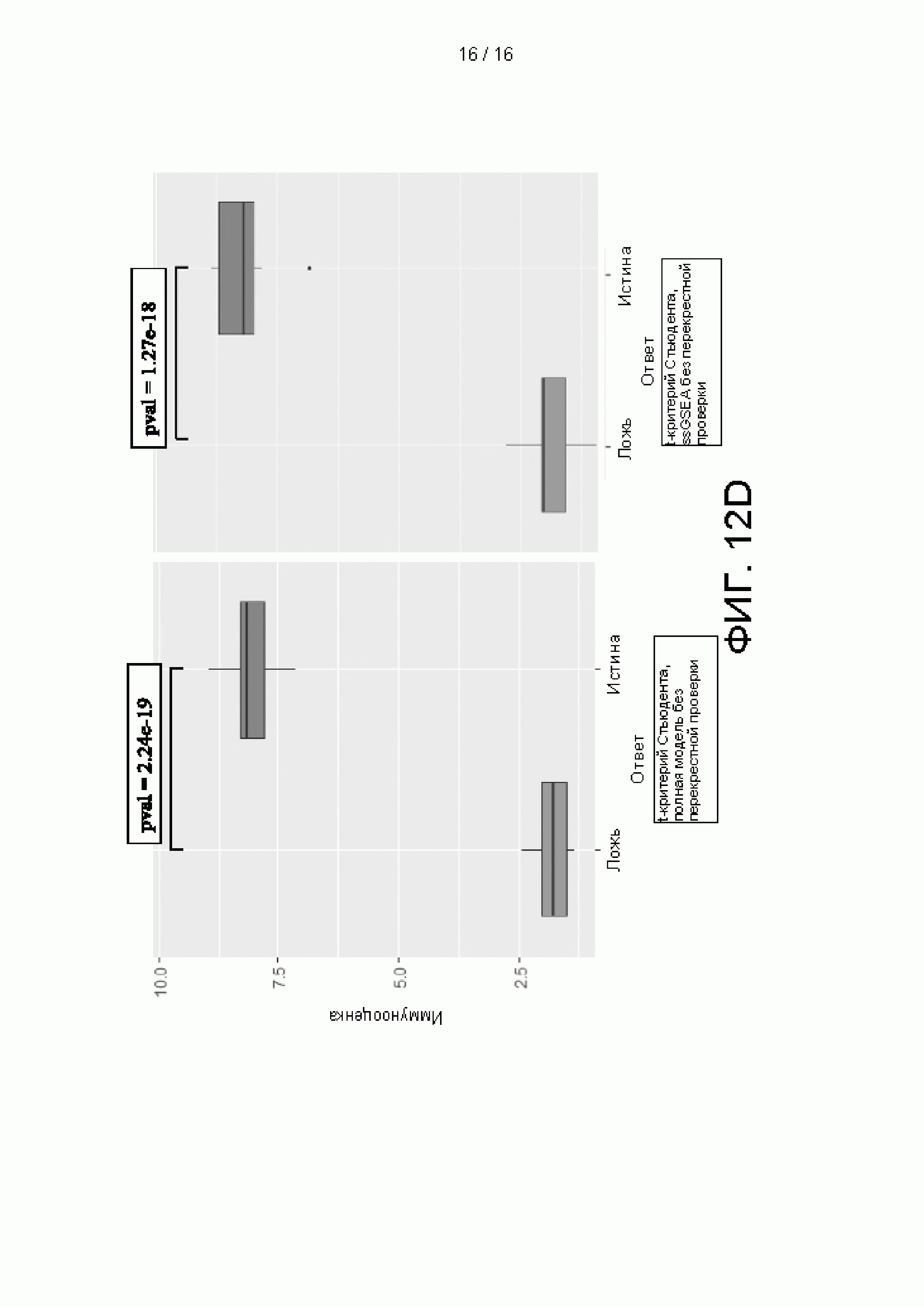
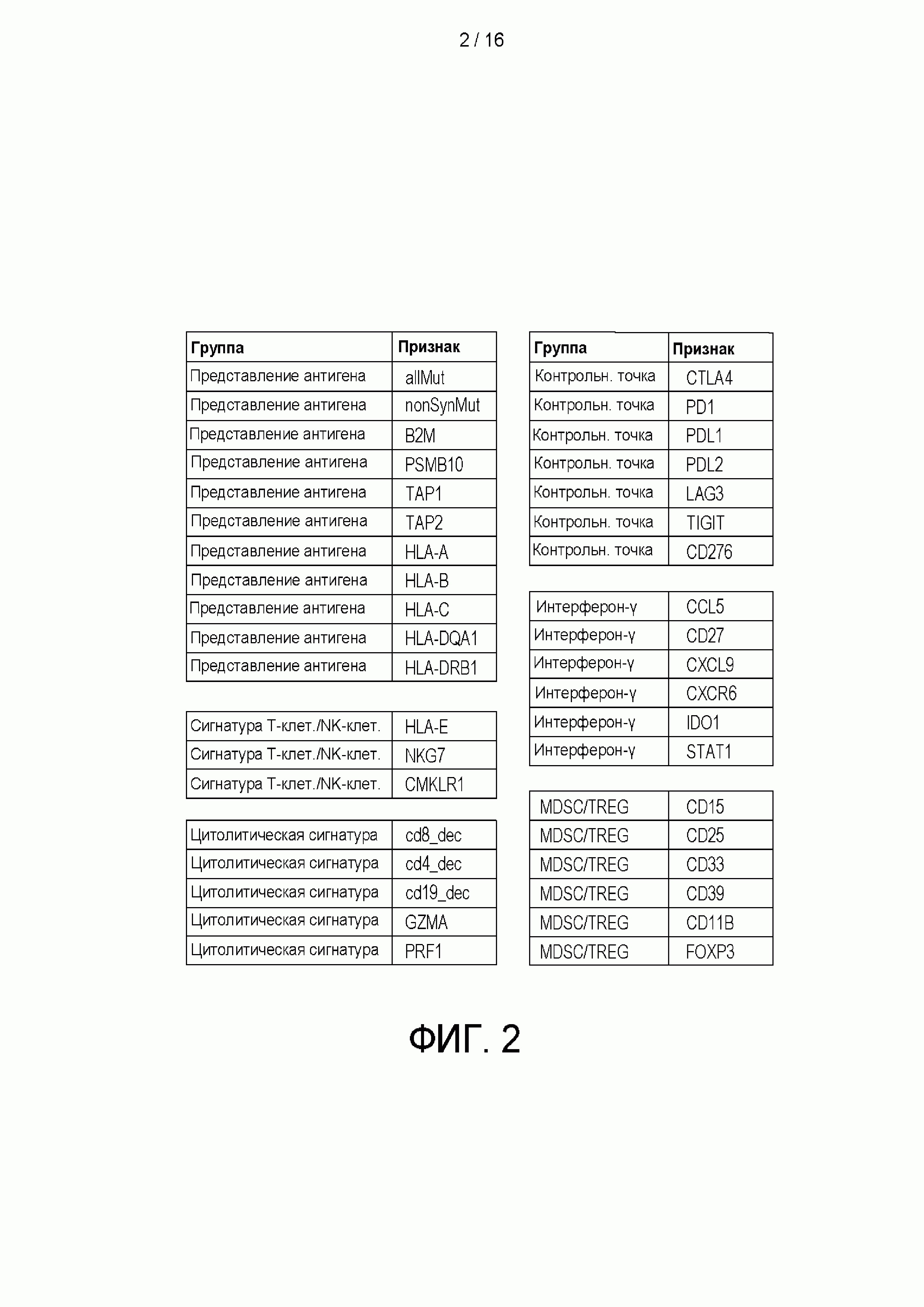
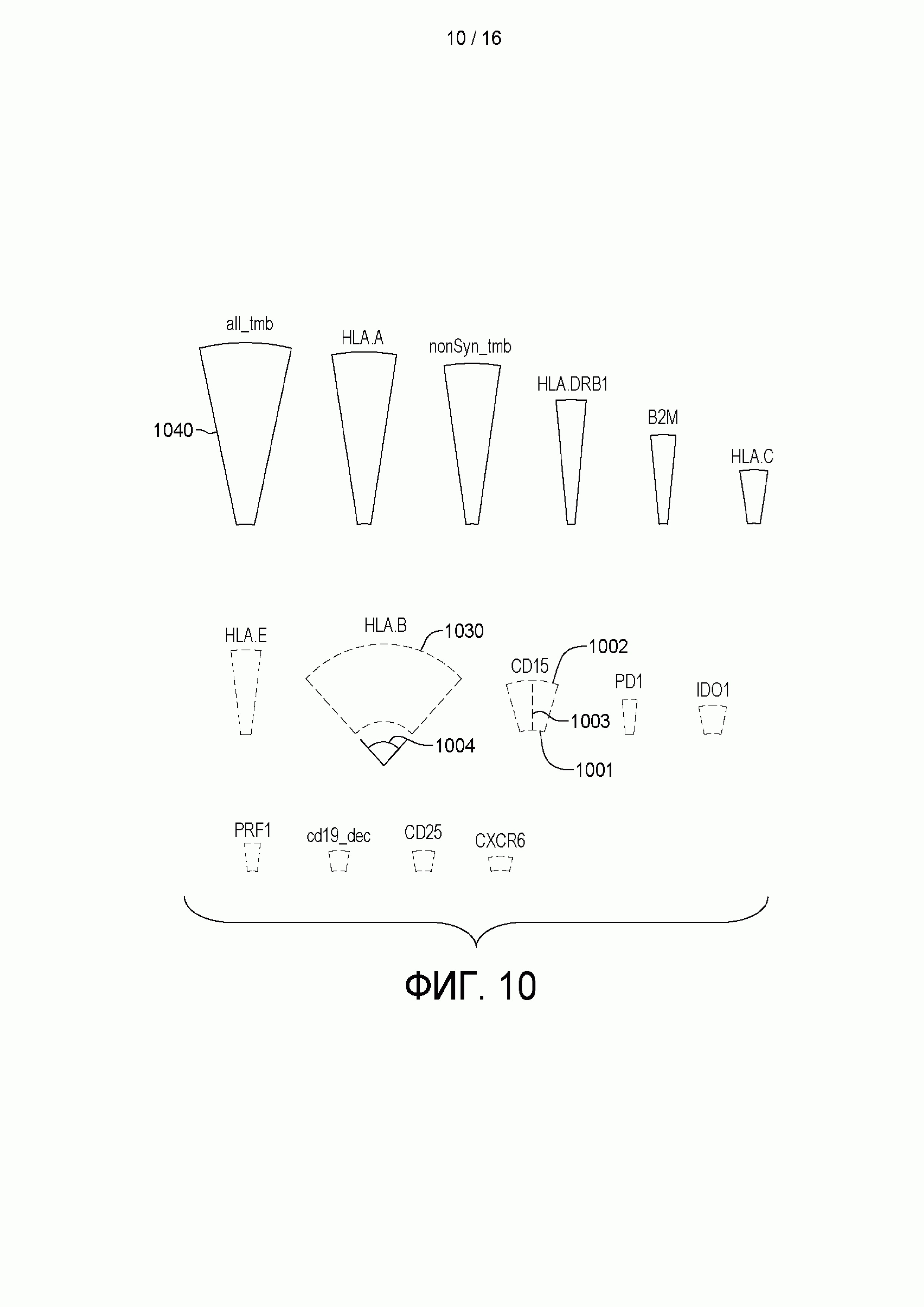
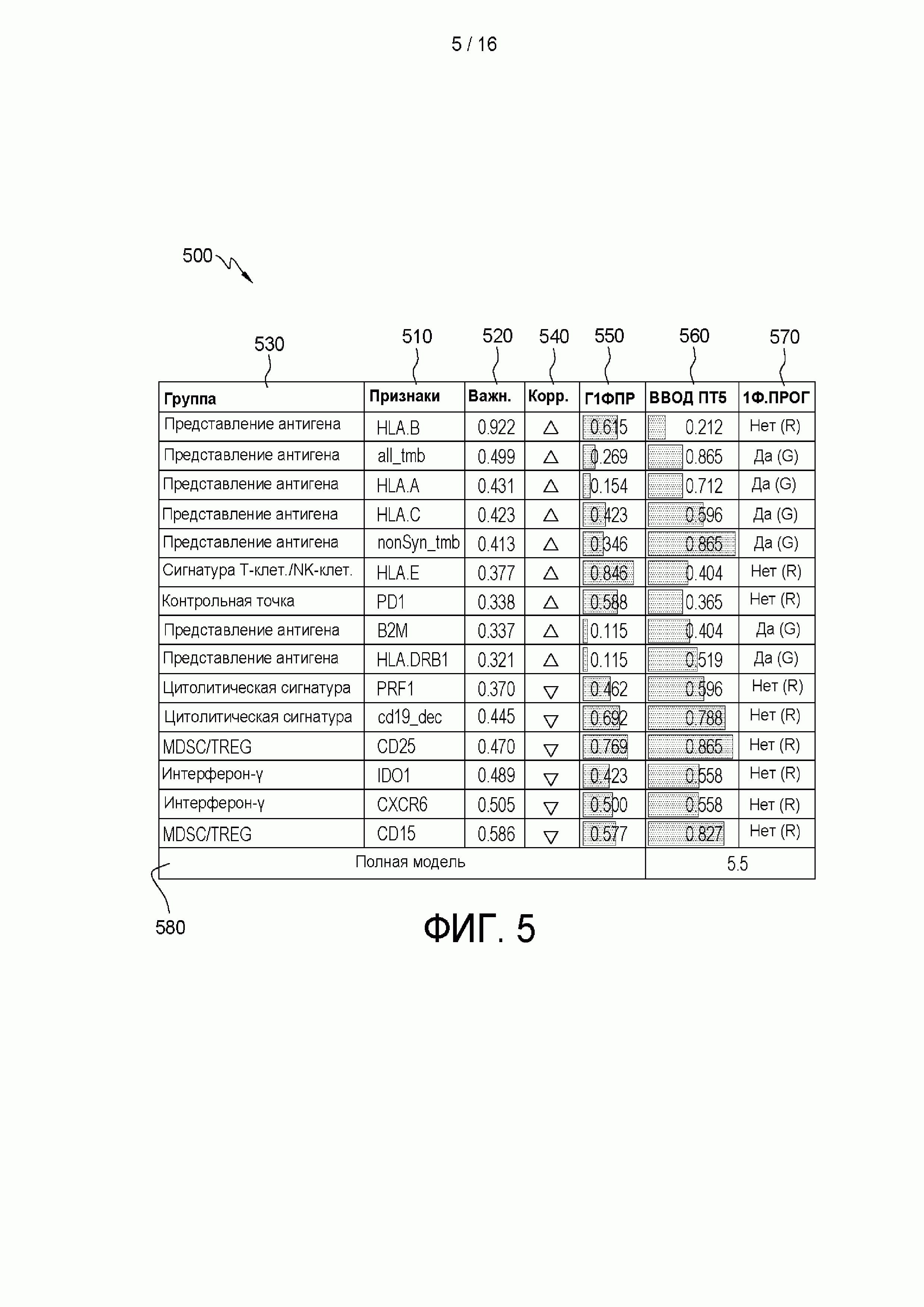
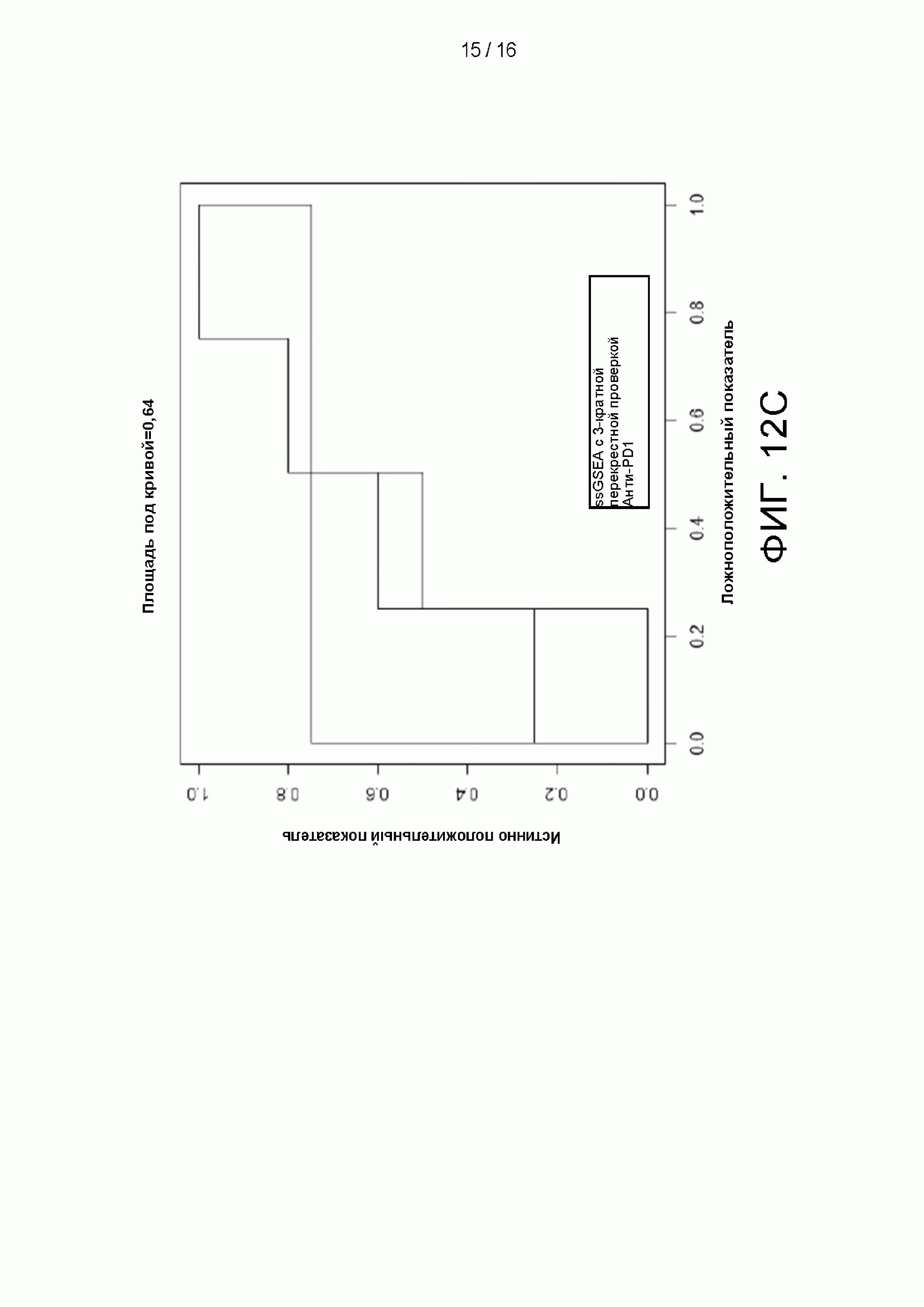
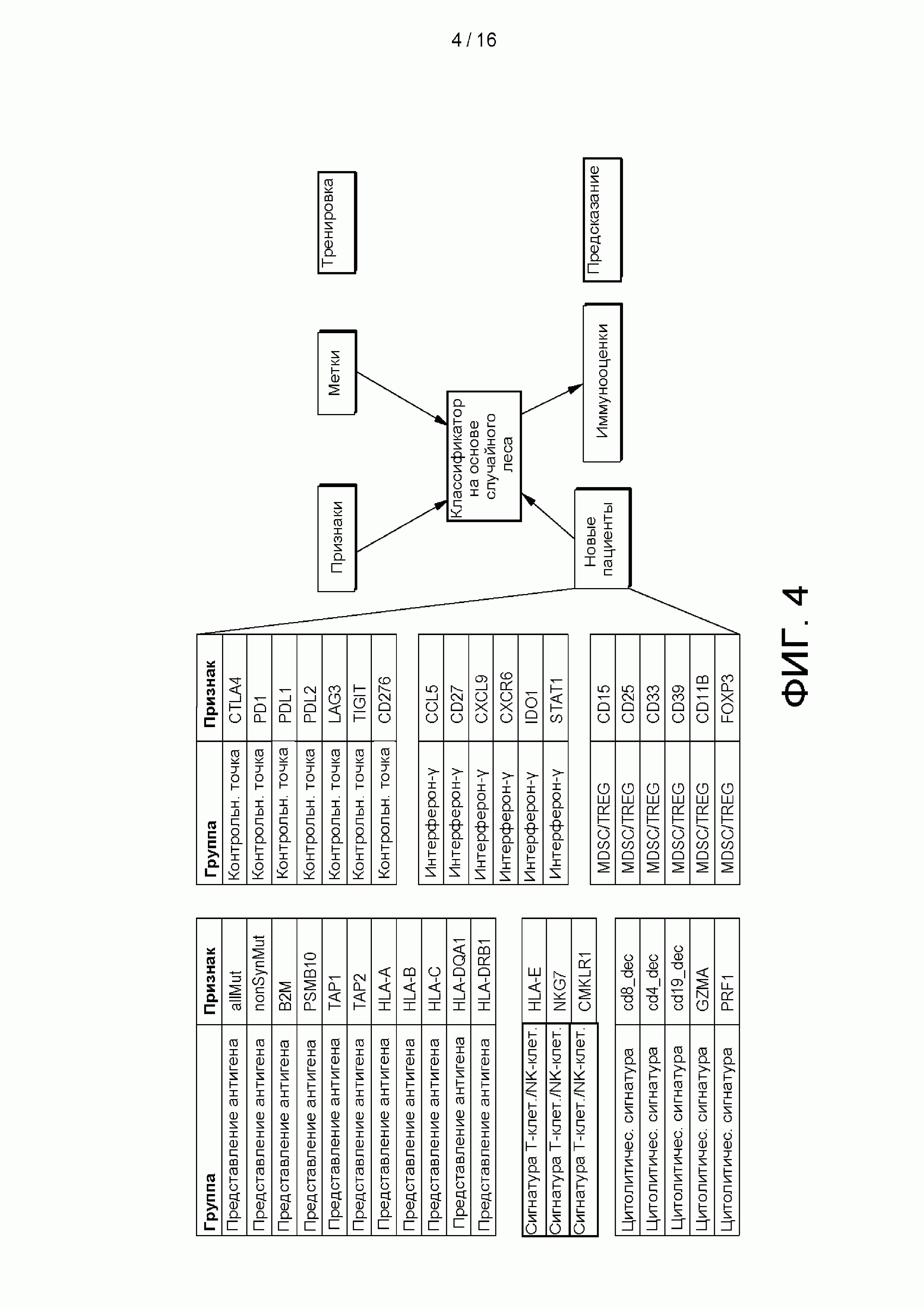
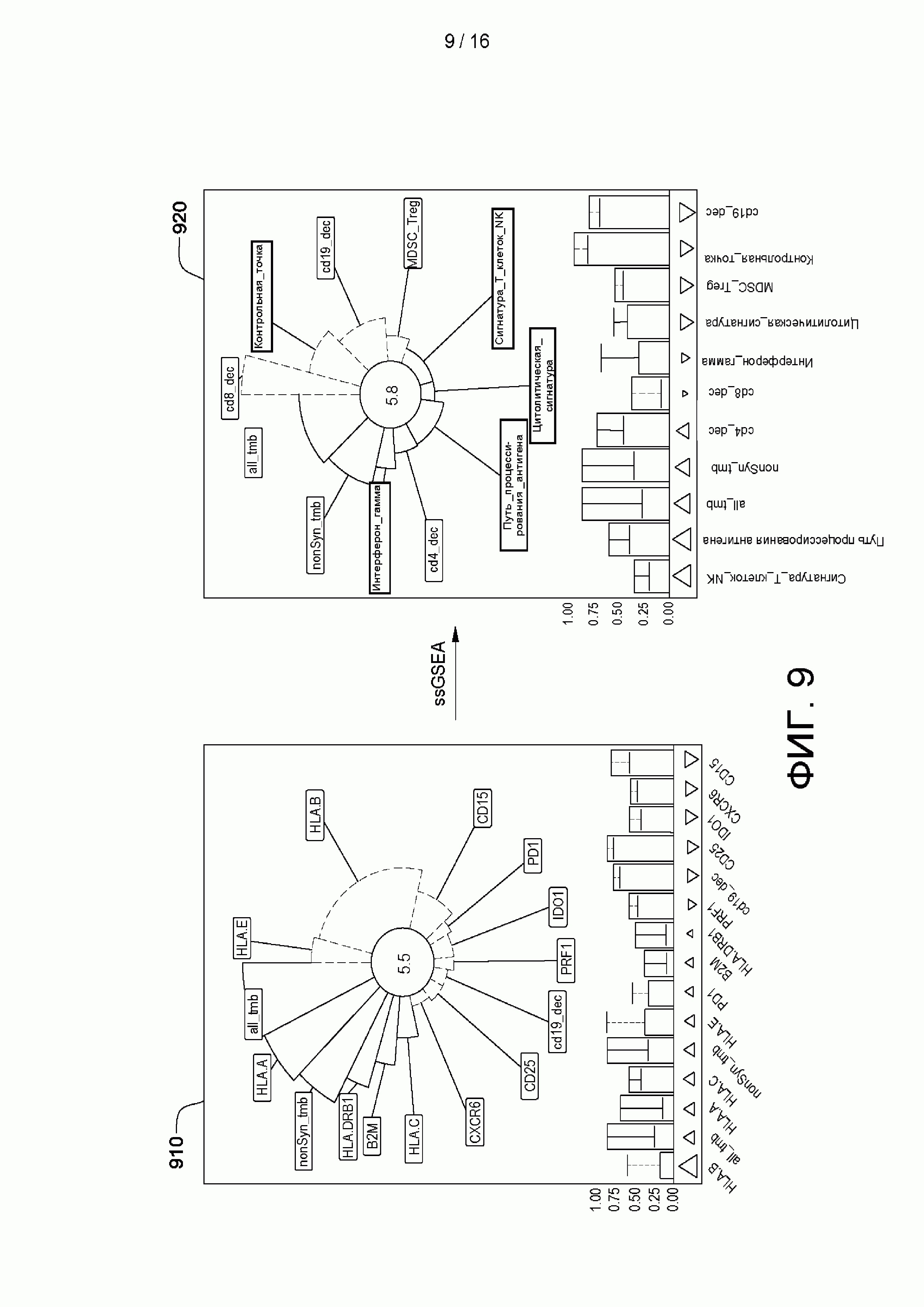
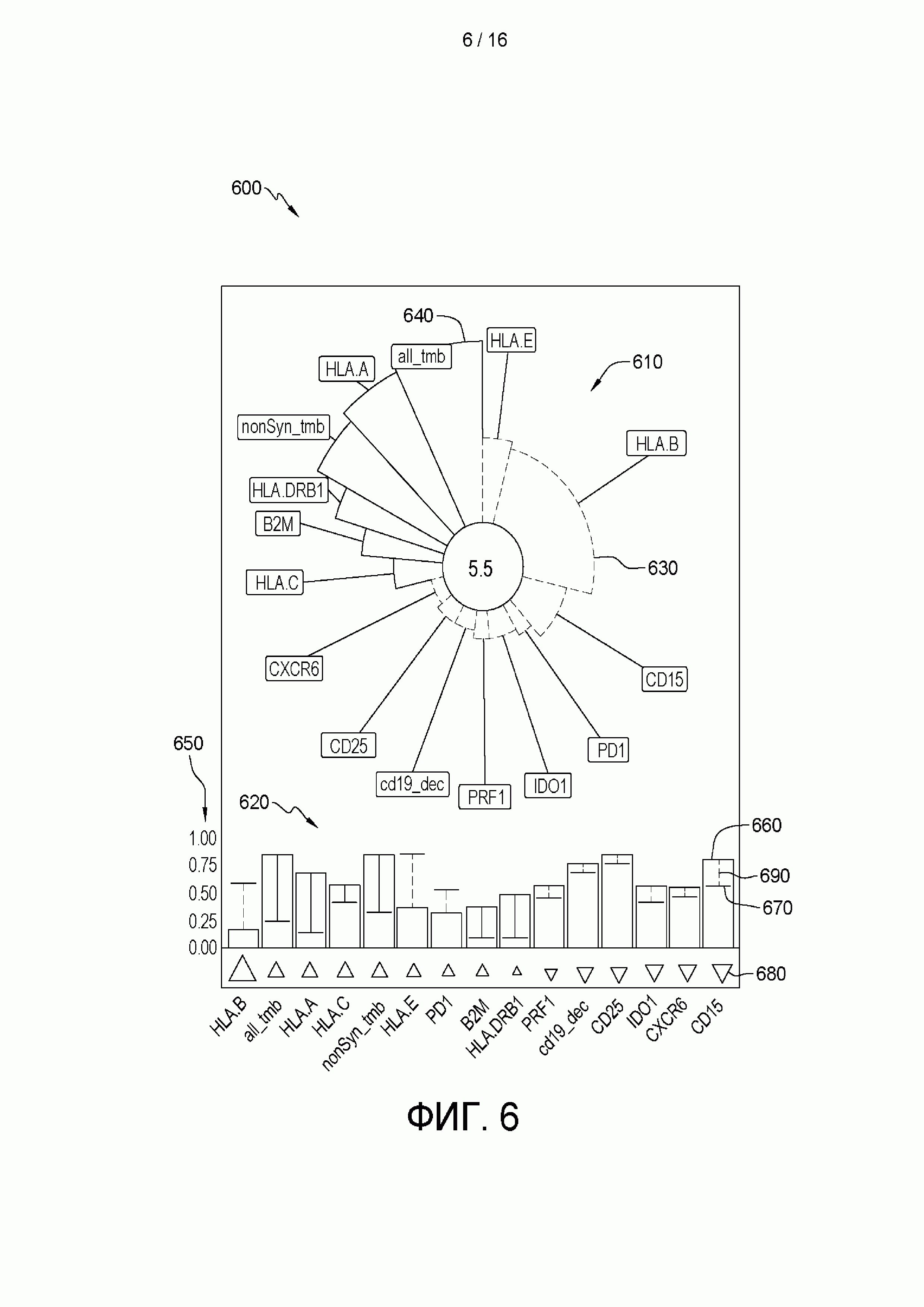
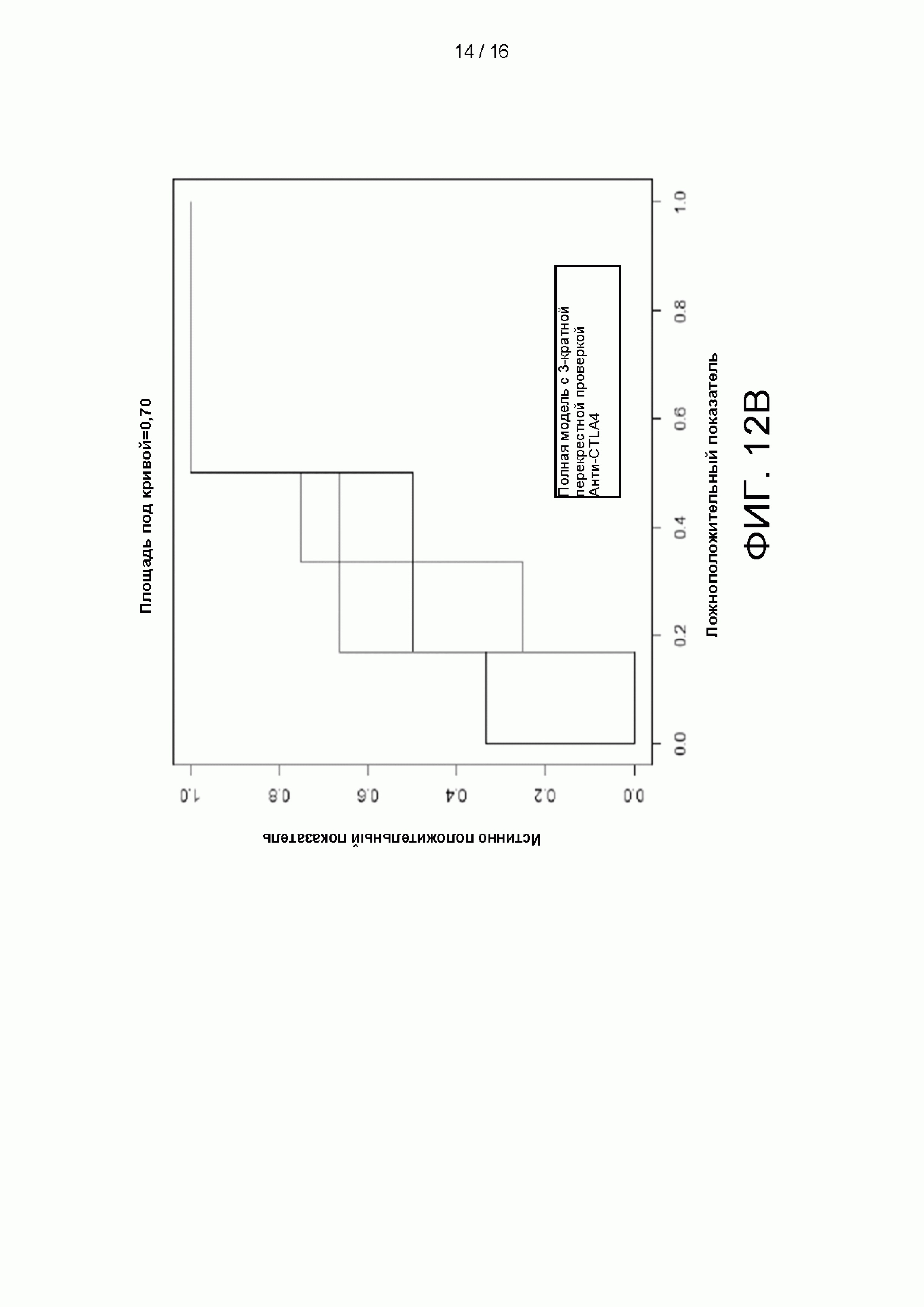
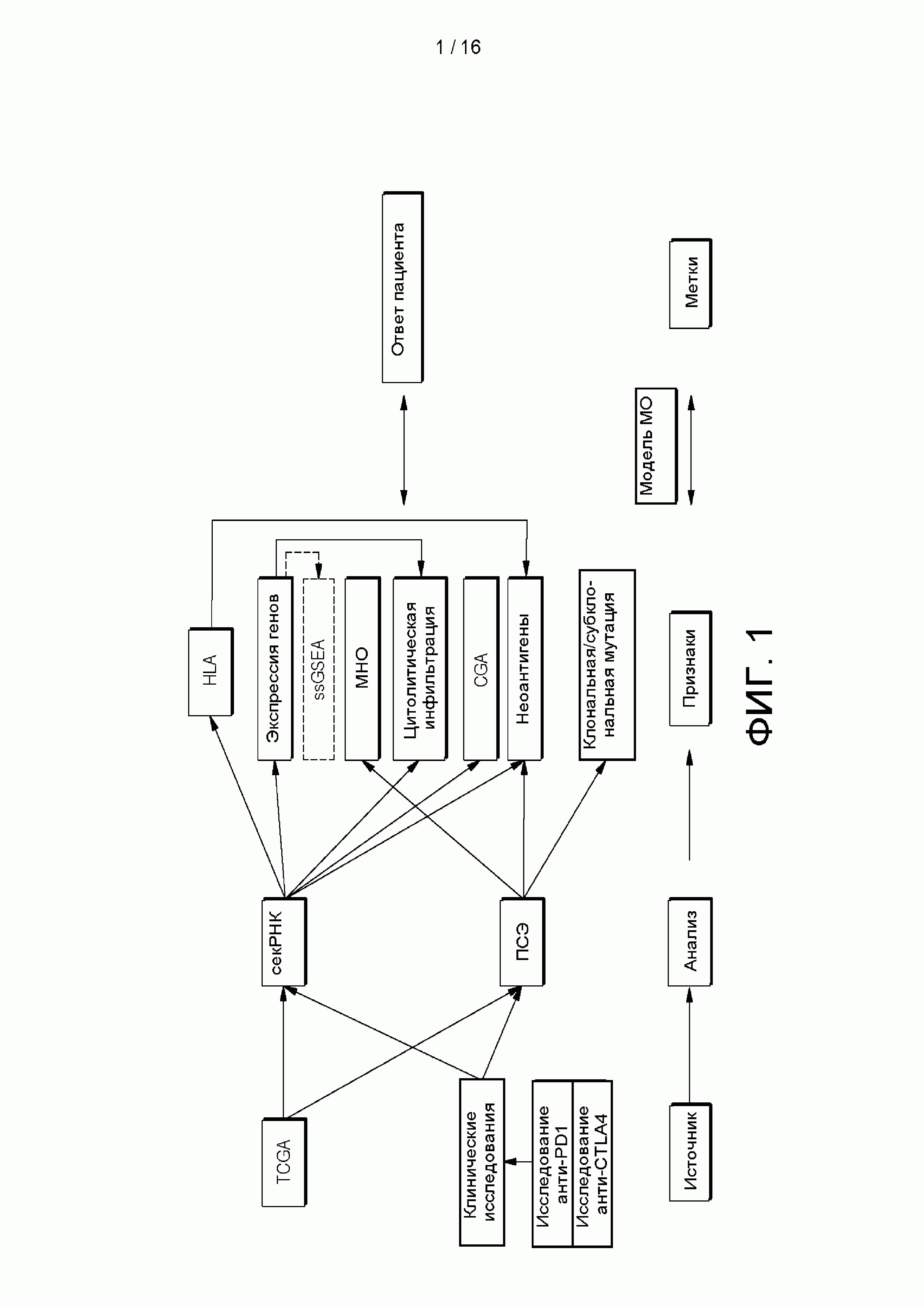
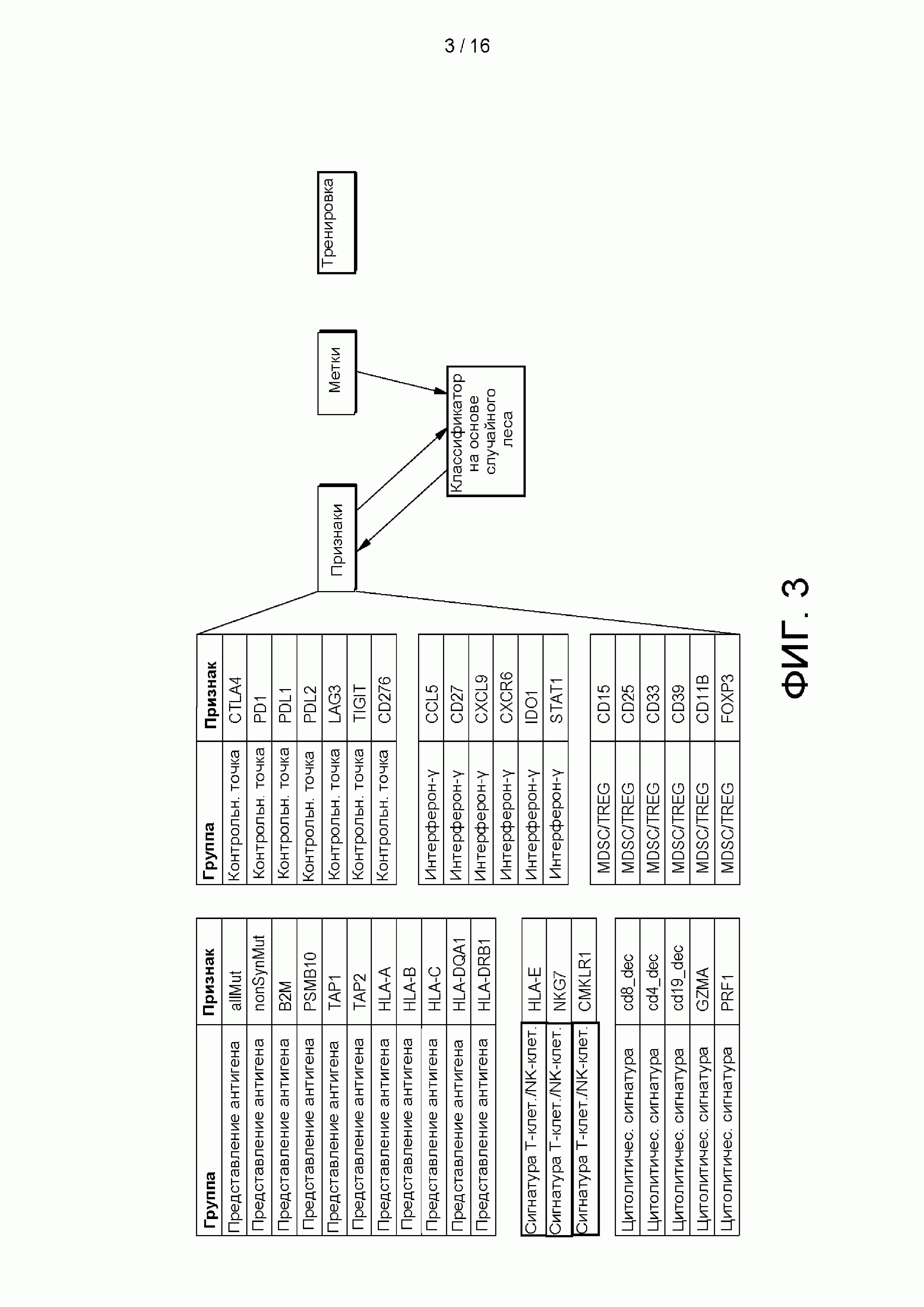
Полевое устройство и способы секвенирования нуклеиновых кислот
Способ и устройство для разделения несмешиваемых жидкостей с целью эффективного отделения по меньшей мере одной из жидкостей
Кассета для образцов и аналитическая система для проведения определенных реакций
Устройство для тестирования и способ его применения
Картридж проточной кюветы с плавающим уплотнительным кронштейном
Подавление ошибок в секвенированных фрагментах днк посредством применения избыточных прочтений с уникальными молекулярными индексами (umi)
Системы и способы применения магниточувствительных датчиков для определения генетической характеристики
Устройство и способы для предиктивного отслеживания фокуса
Устройства для текучих сред и способы изготовления таких устройств
Пробоотборная трубка с встроенной смесительной поршневой головкой

