Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ УПРАВЛЕНИЯ МАСКИРОВКОЙ ПОТЕРИ АУДИОКАДРОВ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Заявка относится к способам и устройствам для управления способом маскировки для потерянных аудиокадров принятого аудиосигнала.
Уровень техники
Традиционные системы аудиосвязи передают речевые и аудиосигналы в кадрах, что означает, что посылающая сторона сначала организует сигнал в коротких сегментах или кадрах, например, по 20-40 мс, которые затем кодируются и передаются как логические блоки, например, в пакете передачи. Приемник декодирует каждый из этих блоков и восстанавливает соответствующие кадры сигнала, которые, в свою очередь, наконец выводятся как непрерывная последовательность восстановленных семплов (отсчетов) сигнала. До кодирования обычно имеется этап аналого-цифрового (A/D) преобразования, который преобразует аналоговый речевой или аудиосигнал от микрофона в последовательность аудиосемплов. С другой стороны, на принимающем конце обычно имеется конечный этап цифро-аналогового (D/A) преобразования, который преобразует последовательность восстановленных цифровых семплов сигнала в непрерывный во времени аналоговый сигнал для воспроизведения громкоговорителем.
Однако такая система передачи для речевых и аудио-сигналов может страдать от ошибок передачи, которые могут приводить к ситуации, в которой один или несколько переданных кадров отсутствуют в приемнике для восстановления. В этом случае декодер должен генерировать подстановочный сигнал для каждого из стертых, то есть недоступных кадров. Это делается в так называемом блоке маскировки потери кадров или ошибок декодера сигнала принимающей стороны. Цель маскировки потери кадров состоит в том, чтобы сделать потерю кадров настолько неслышимой, насколько это возможно, и, следовательно, смягчить воздействие потери кадров на качество восстановленного сигнала в максимально возможной степени.
Традиционные способы маскировки потери кадров могут зависеть от структуры или архитектуры кодека, например, путем применения формы повторения ранее принятых параметров кодека. Такие методики повторения параметров явно зависят от конкретных параметров используемого кодека и, следовательно, не так легко применимы для других кодеков с другой структурой. Текущие способы маскировки потери кадров могут, например, применять концепцию замораживания и экстраполяции параметров ранее полученного кадра для генерации подстановочного кадра для потерянного кадра.
Эти способы маскировки потери кадров существующего уровня техники включают в себя некоторые схемы обработки пакетных потерь. Обычно, после потери множества кадров подряд синтезируемый сигнал ослабляется, пока он полностью не заглушается после длинных пакетов ошибок. Кроме того, параметры кодирования, которые, по сути, повторяются и экстраполируются, изменяются так, что выполняется ослабление, и так, что спектральные пики сглаживаются.
Методики маскировки потери кадров существующего уровня техники обычно применяют концепцию замораживания и экстраполяции параметров ранее полученного кадра для генерации подстановочного кадра для потерянного кадра. Многие параметрические кодеки для разговорных сигналов, такие как кодеки с линейным предсказанием, такие как AMR или AMR-WB, как правило замораживают ранее принятые параметры или используют некоторую их экстраполяцию и используют с ними декодер. В сущности, принцип состоит в том, что должна быть заданная модель для кодирования/декодирования, и в том, чтобы применять одну и ту же модель с замороженными или экстраполируемыми параметрами. Методики маскировки потери кадров AMR и AMR-WB могут рассматриваться как типичные представители. Они подробно описаны в соответствующих описаниях стандартов.
Многие кодеки из класса аудиокодеков применяют методики кодирования в частотной области. Это означает, что после некоторого преобразования в частотную область к спектральным параметрам применяется модель кодирования. Декодер восстанавливает спектр сигнала из принятых параметров и, наконец, преобразует спектр обратно во временной сигнал. Как правило, временной сигнал восстанавливается кадр за кадром. Такие кадры объединяются с помощью добавляющих перекрытие методик в конечный восстановленный сигнал. Даже в этом случае аудиокодеков маскировка ошибок существующего уровня техники обычно применяется к одной и той же или по меньшей мере к аналогичной модели декодирования для потерянных кадров. Параметры частотной области из ранее полученного кадра замораживаются или соответствующим образом экстраполируются и затем используются в преобразовании из частотной во временную область. Примеры таких методик обеспечены аудиокодеками 3GPP в соответствии со стандартами 3GPP.
Сущность изобретения
Решения для маскировки потери кадров существующего уровня техники, как правило, страдают от ухудшения качества. Основная проблема состоит в том, что методика замораживания и экстраполяции параметров и повторное применение той же самой модели декодирования даже для потерянных кадров не всегда гарантирует плавное и точное развертывание сигнала из ранее декодированных кадров сигнала в потерянный кадр. Это обычно приводит к нарушениям непрерывности звукового сигнала с соответствующим влиянием на качество.
Описаны новые схемы маскировки потери кадров для систем передачи разговорных и аудио-сигналов. Новые схемы улучшают качество в случае потери кадров по сравнению с качеством, достижимым с помощью методик маскировки потери кадров предшествующего уровня техники.
Целью настоящих вариантов воплощения является управление схемой маскировки потери кадров, которая, предпочтительно, имеет тип соответствующих описанных новых способов, так что достигается наилучшее возможное качество звука восстановленного сигнала. Варианты воплощения направлены на оптимизацию этого качества восстановления и относительно свойств сигнала, и относительно временного распределения потерь кадров. Особенно проблематично обеспечить хорошее качество для маскировки потери кадров случаи, когда аудиосигнал имеет сильно изменяющиеся свойства, такие как энергетические всплески и спады, или если он спектрально сильно флуктуирует. В этом случае описанные способы маскировки могут повторять всплески, спады или спектральную флуктуацию, приводя к большим отклонениям от исходного сигнала и соответствующей потери качества.
Другой проблемный случай имеет место, когда пакеты потерь кадров происходят подряд. Концептуально, схема маскировки потери кадров в соответствии с описанными способами может справиться с такими случаями, хотя оказалось, что раздражающие тональные артефакты могут по-прежнему иметь место. Другой целью настоящих вариантов воплощения является уменьшение таких артефактов в максимально возможной степени.
В соответствии с первым аспектом способ для декодера маскировки потерянного аудиокадра содержит этапы, на которых обнаруживают в свойстве ранее принятого и восстановленного аудиосигнала или в статистическом свойстве наблюдаемых потерь кадров условие, для которого подстановка потерянного кадра обеспечивает относительно более низкое качество. В случае, если такое условие обнаружено, модифицируют способ маскировки путем выборочной настройки фазы или амплитуды спектра подстановочного кадра.
В соответствии со вторым аспектом декодер сконфигурирован реализовывать маскировку потерянного аудиокадра и содержит контроллер, сконфигурированный обнаруживать в свойстве ранее принятого и восстановленного аудиосигнала или в статистическом свойстве наблюдаемых потерь кадров условие, для которого подстановка потерянного кадра обеспечивает относительно более низкое качество. В случае, если такое условие обнаружено, контроллер сконфигурирован модифицировать способ маскировки путем выборочной настройки фазы или амплитуды спектра подстановочного кадра.
Декодер может быть реализован в устройстве, таком как, например, мобильный телефон.
В соответствии с третьим аспектом приемник содержит декодер в соответствии со вторым аспектом, описанным выше.
В соответствии с четвертым аспектом определена компьютерная программа для маскировки потерянного аудиокадра, и компьютерная программа содержит инструкции, которые при исполнении процессором предписывают процессору маскировать потерянный аудиокадр в соответствии с первым аспектом, описанным выше.
В соответствии с пятым аспектом компьютерный программный продукт содержит машиночитаемый носитель, хранящий компьютерную программу в соответствии с описанным выше четвертым аспектом.
Преимущество варианта воплощения решает проблему управления адаптацией способами маскировки потери кадров, позволяя уменьшить слышимое влияние потери кадров при передаче кодированных речевых сигналов и аудиосигналов даже больше, по сравнению с качеством, достигаемым только с помощью описанных способов маскировки. Общее преимущество вариантов воплощения состоит в обеспечении плавного и точного развертывания восстановленного сигнала даже для потерянных кадров. Слышимое влияние потери кадров значительно уменьшается по сравнению с использованием методик существующего уровня техники.
Краткое описание чертежей
Для более полного понимания иллюстративных вариантов воплощения настоящего изобретения теперь дается нижеследующее описание в сочетании с прилагаемыми чертежами, на которых:
Фигура 1 показывает прямоугольную оконную функцию.
Фигура 2 показывает комбинацию окна Хемминга с прямоугольным окном.
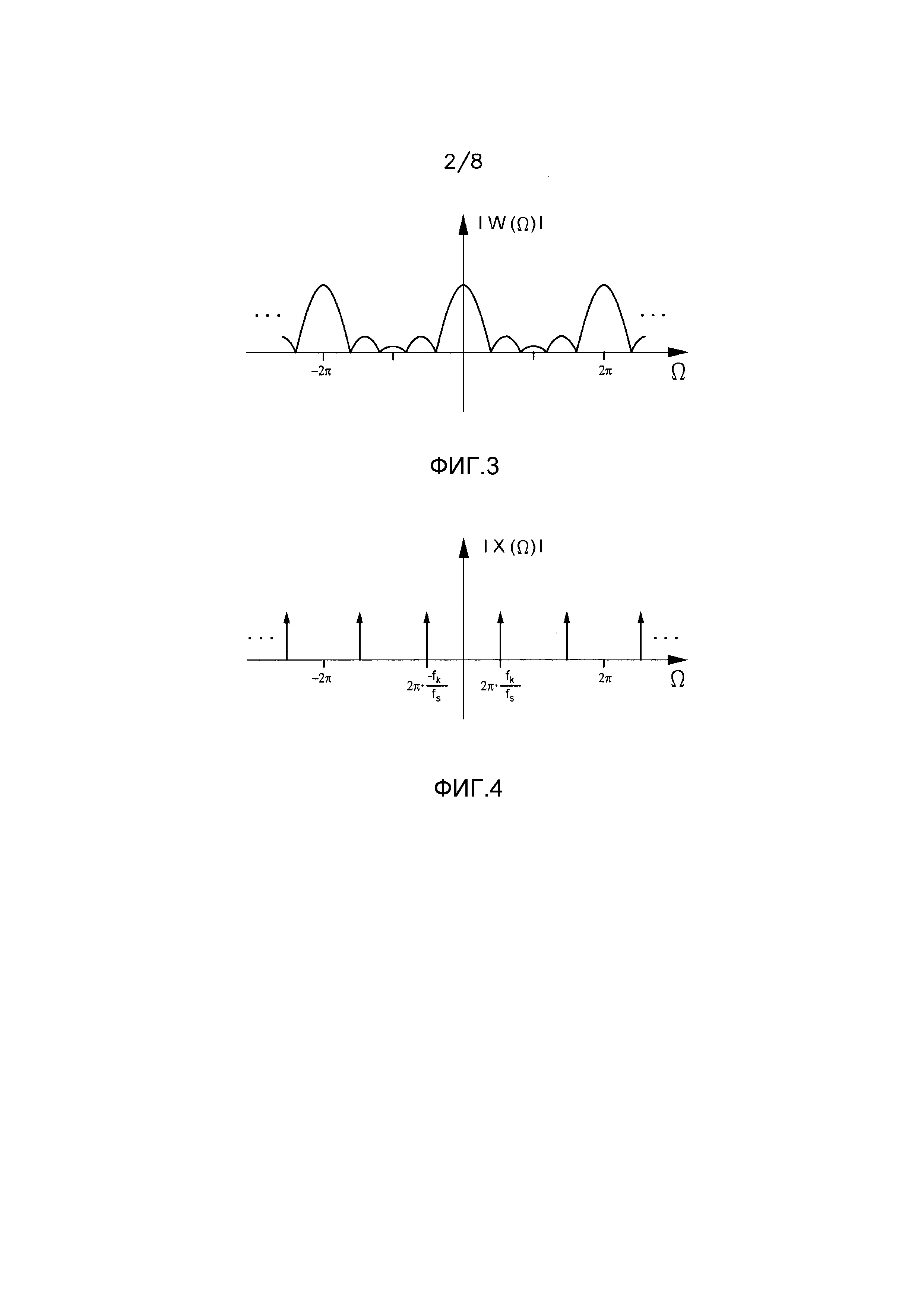
Фигура 3 показывает пример амплитудного спектра оконной функции.
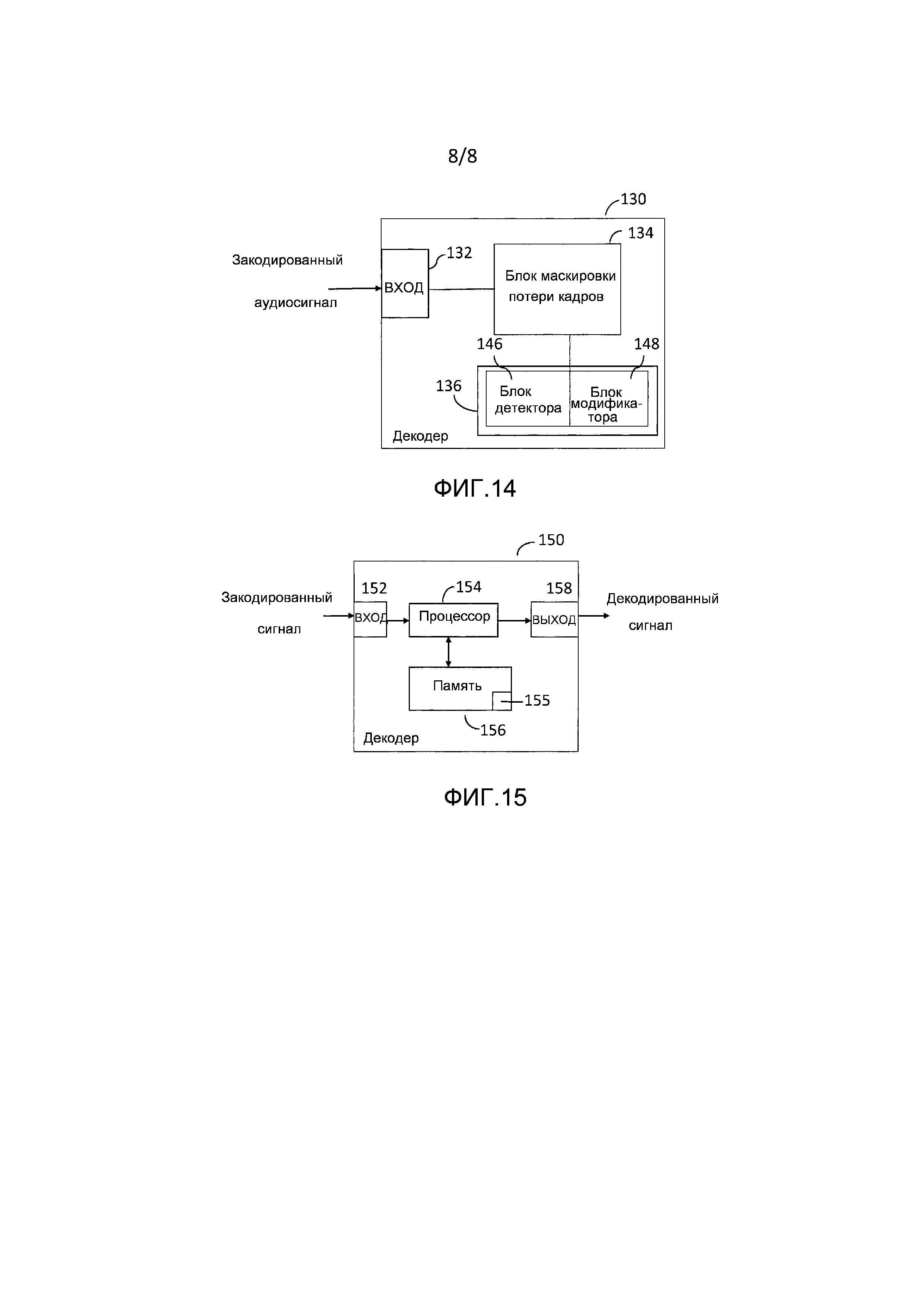
Фигура 4 изображает линейчатый спектр иллюстративного синусоидального сигнала с частотой 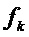 .
.
Фигура 5 показывает спектр обработанного с помощью оконной функции синусоидального сигнала с частотой 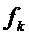 .
.
Фигура 6 изображает вертикальные линии, соответствующие величине узлов решетки DFT, на основании кадра анализа.
Фигура 7 изображает параболу, совмещенную с узлами P1, P2 и P3 решетки DFT.
Фигура 8 изображает совмещение основного лепестка спектра окна.
Фигура 9 изображает совмещение функции P аппроксимации основного лепестка с узлами P1 и P2 решетки DFT.
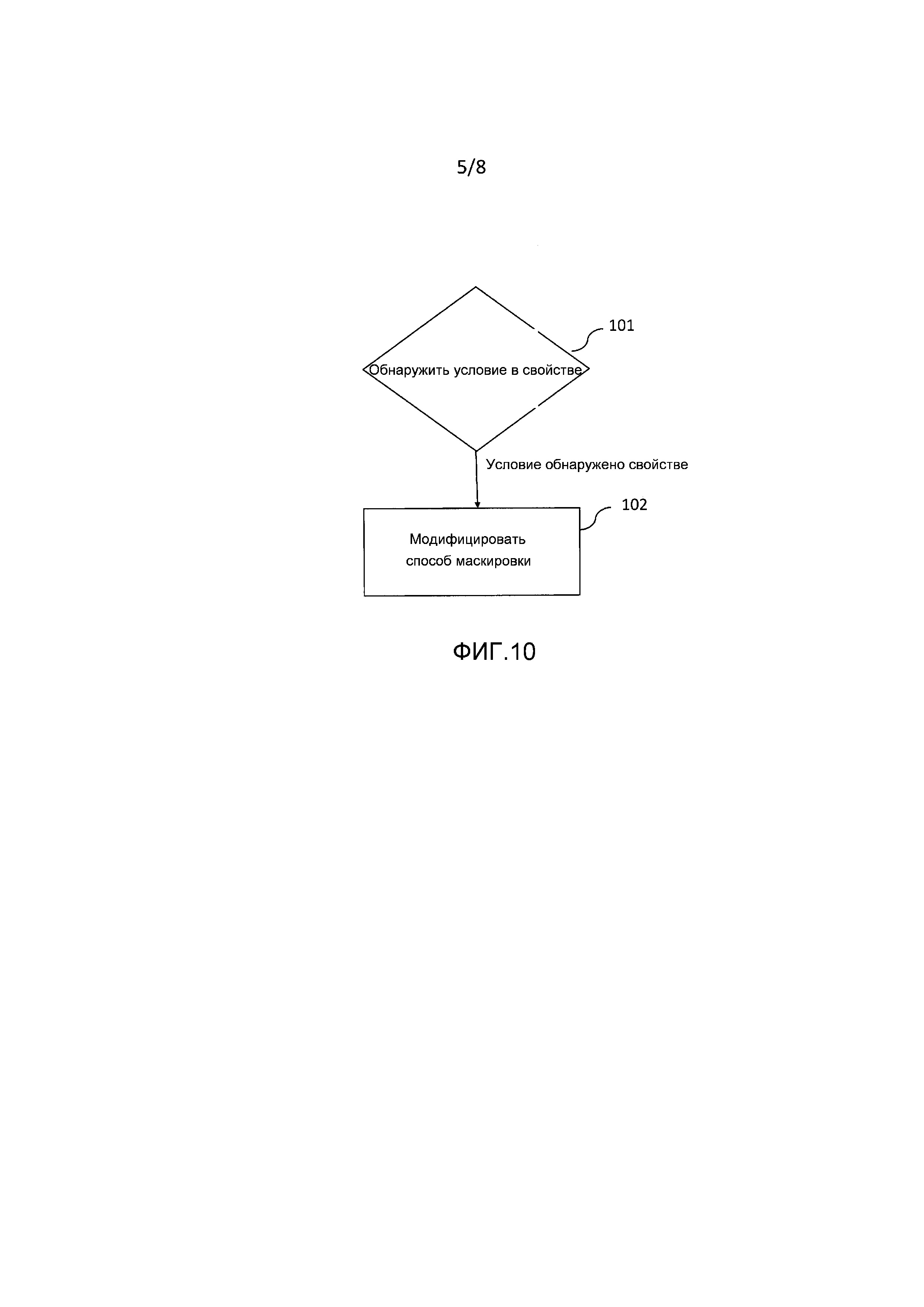
Фигура 10 является схемой последовательности операций, изображающей иллюстративный способ в соответствии с вариантами воплощения изобретения для управления способом маскировки для потерянного аудиокадра принятого аудиосигнала.
Фигура 11 является схемой последовательности операций, изображающей другой иллюстративный способ в соответствии с вариантами воплощения изобретения для управления способом маскировки для потерянного аудиокадра принятого аудиосигнала.
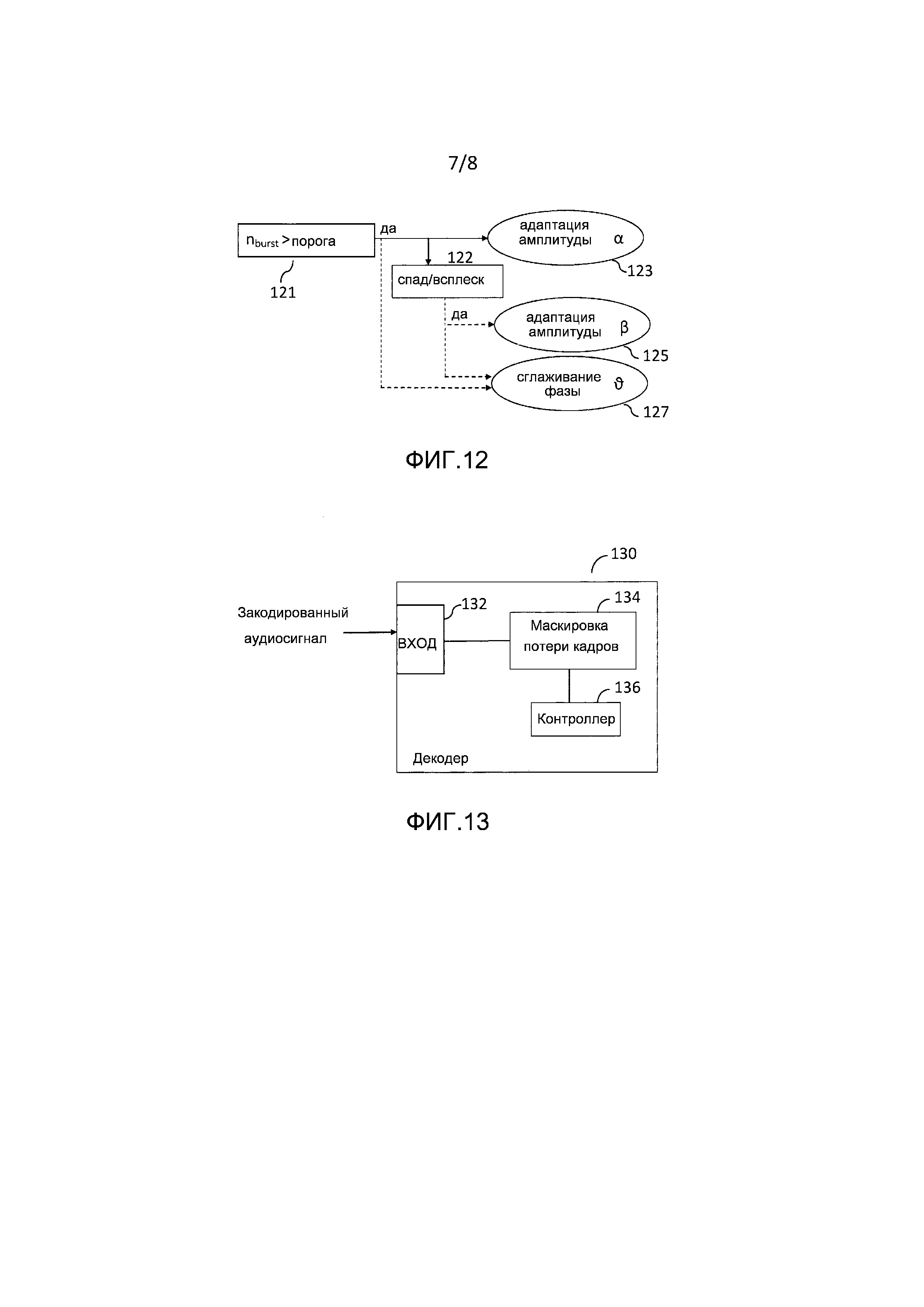
Фигура 12 изображает другой иллюстративный вариант воплощения изобретения.
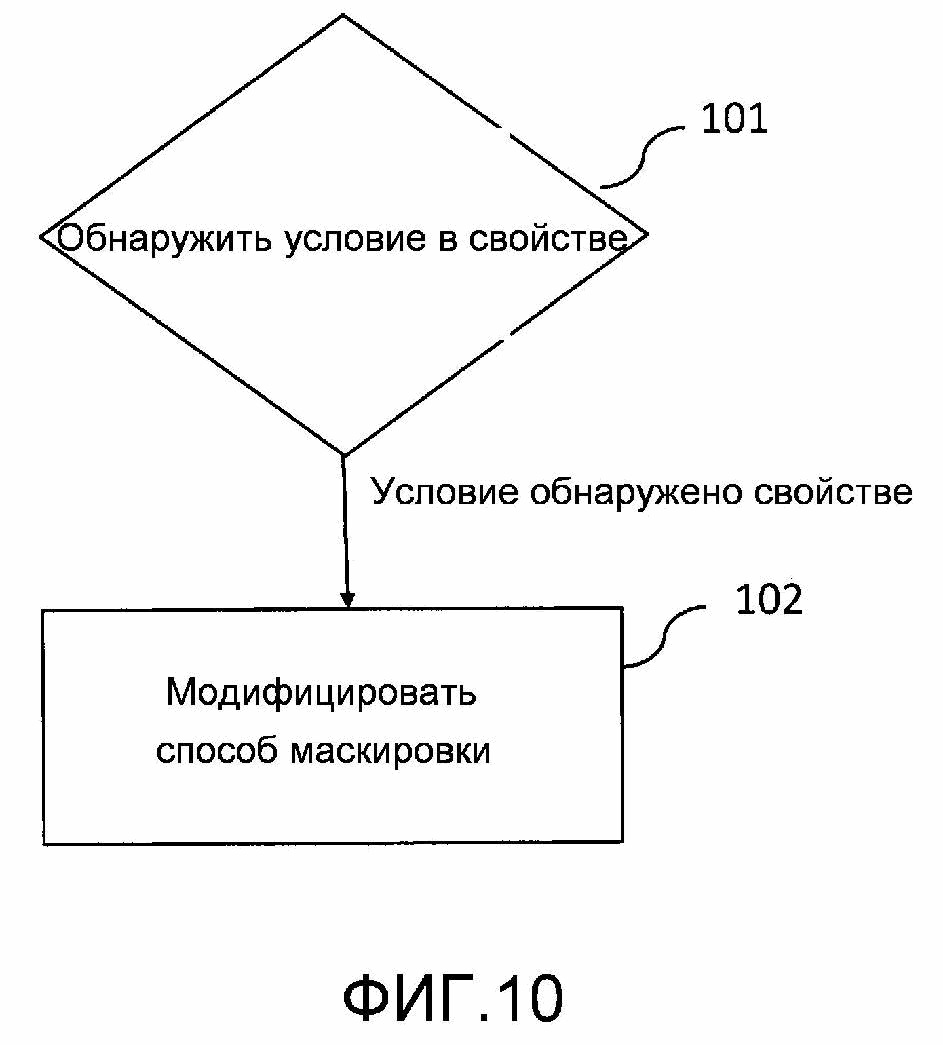
Фигура 13 показывает пример устройства в соответствии с вариантом воплощения изобретения.
Фигура 14 показывает другой пример устройства в соответствии с вариантом воплощения изобретения.
Фигура 15 показывает другой пример устройства в соответствии с вариантом воплощения изобретения.
Подробное описание
Новая схема управления для новых описанных методик маскировки потери кадров включает в себя следующие этапы, как показано на фигуре 10. Следует отметить, что способ может быть реализован в контроллере в декодере.
1. Обнаружить условия в свойствах ранее принятого и восстановленного аудиосигнала или в статистических свойствах наблюдаемых потерь кадров, для которых подстановка потерянного кадра в соответствии с описанными способами обеспечивает относительно более низкое качество, 101.
2. В случае, если такое условие обнаружено на этапе 1, модифицировать элемент способов, в соответствии с которыми спектр подстановочного кадра вычисляется с помощью 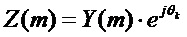 , путем выборочной регулировки фаз или спектральных амплитуд, 102.
, путем выборочной регулировки фаз или спектральных амплитуд, 102.
Синусоидальный анализ
Первый этап методики маскировки потери кадров, к которой может быть применена новая методика управления, включает в себя синусоидальный анализ части ранее принятого сигнала. Цель этого синусоидального анализа состоит в том, чтобы найти частоты основных синусоид этого сигнала, и лежащее в основе допущение состоит в том, что сигнал состоит из ограниченного числа отдельных синусоид, то есть что это мультисинусоидальный сигнал следующего типа:
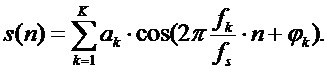
В этом уравнении K является числом синусоид, из которых, как предполагается, состоит сигнал. Для каждой из синусоид с индексом 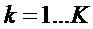 ,
, 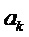 является амплитудой, является частотой, а
является амплитудой, является частотой, а 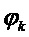 является фазой. Частота дискретизации обозначена с помощью
является фазой. Частота дискретизации обозначена с помощью 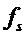 , а временной индекс дискретных по времени семплов сигнала
, а временной индекс дискретных по времени семплов сигнала 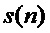 с помощью
с помощью 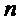 .
.
Главное значение имеет нахождение частот синусоид настолько точно, насколько это возможно. В то время как идеальный синусоидальный сигнал будет иметь линейчатый спектр с линейчатыми частотами , нахождение их истинных значений будут, в принципе, требовать бесконечного времени измерения. Следовательно, на практике трудно найти эти частоты, так как они могут быть оценены только на основании короткого периода измерения, который соответствует сегменту сигнала, используемому для синусоидального анализа, описанного в настоящем документе; этот сегмент сигнала именуется в дальнейшем кадром анализа. Другая трудность состоит в том, что сигнал может на практике изменяться со временем, что означает, что параметры вышеупомянутого уравнения изменяются с течением времени. Следовательно, с одной стороны, желательно использовать длинный кадр анализа, делая измерение более точным; с другой стороны, будет необходим короткий период измерения, чтобы лучше справляться с возможными изменениями сигнала. Хорошим компромиссом является использование длины кадра анализа порядка, например, 20-40 мс.
Предпочтительная возможность для идентификации частот синусоид состоит в проведении анализа в частотной области кадра анализа. С этой целью кадр анализа преобразуется в частотную область, например, с помощью DFT, или DCT, или аналогичных преобразований в частотную область. В случае, если используется DFT кадра анализа, спектр дается выражением:

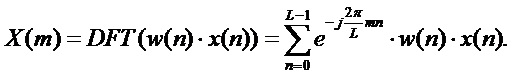
В этом уравнении 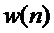 обозначает оконную функцию, с помощью которой извлекается и умножается на весовую функцию кадр анализа длины
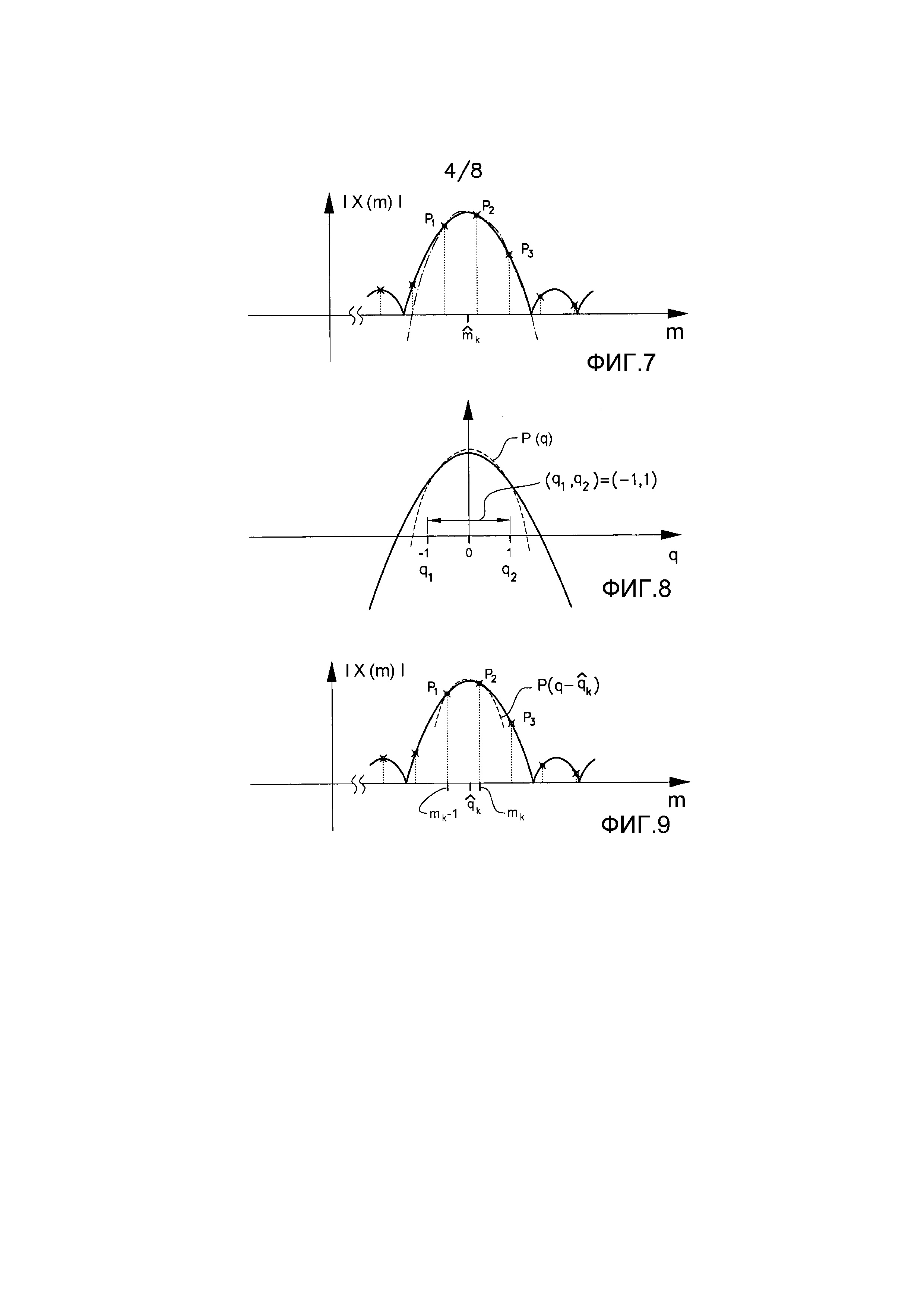
обозначает оконную функцию, с помощью которой извлекается и умножается на весовую функцию кадр анализа длины 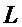 . Типичными оконными функциями являются, например, прямоугольные окна, которые равны 1 для
. Типичными оконными функциями являются, например, прямоугольные окна, которые равны 1 для 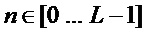 и 0 в противном случае, как показано на фигуре 1. Здесь предполагается, что временные индексы ранее принятого аудиосигнала заданы так, что кадр анализа обозначается временными индексами
и 0 в противном случае, как показано на фигуре 1. Здесь предполагается, что временные индексы ранее принятого аудиосигнала заданы так, что кадр анализа обозначается временными индексами 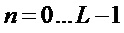 . Другими оконными функциями, которые могут быть более подходящими для спектрального анализа, являются, например, окно Хемминга, окно Хеннинга, окно Кайзера или окно Блекмана. Оконная функция, которая оказалось особенно полезной, является комбинацией окна Хемминга с прямоугольным окном. Это окно имеет форму нарастающего фронта как левая половина окна Хемминга длины
. Другими оконными функциями, которые могут быть более подходящими для спектрального анализа, являются, например, окно Хемминга, окно Хеннинга, окно Кайзера или окно Блекмана. Оконная функция, которая оказалось особенно полезной, является комбинацией окна Хемминга с прямоугольным окном. Это окно имеет форму нарастающего фронта как левая половина окна Хемминга длины 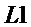 и форму убывающего фронта как правая половина окна Хемминга длины
и форму убывающего фронта как правая половина окна Хемминга длины 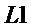 , а между нарастающим и убывающим фронтами окно равно 1 на длине
, а между нарастающим и убывающим фронтами окно равно 1 на длине 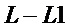 , как показано на фигуре 2.
, как показано на фигуре 2.
Пики амплитудного спектра умноженного на оконную функцию кадра 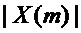 анализа составляют аппроксимацию требуемых синусоидальных частот. Точность этой аппроксимации, однако, ограничена частотным интервалом DFT. Для DFT с длиной блока L точность ограничена величиной
анализа составляют аппроксимацию требуемых синусоидальных частот. Точность этой аппроксимации, однако, ограничена частотным интервалом DFT. Для DFT с длиной блока L точность ограничена величиной 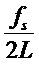 .
.
Эксперименты показывают, что этот уровень точности может быть слишком низким в рамках способов, описанных в настоящем документе. Улучшенная точность может быть получена на основании следующих соображений:
Спектр умноженного на оконную функцию кадра анализа дается сверткой спектра оконной функции с линейчатым спектром синусоидального модельного сигнала 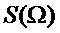 , которая далее дискретизируется в узлах решетки DFT:
, которая далее дискретизируется в узлах решетки DFT:
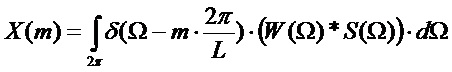 .
.
Путем использования спектрального выражения для синусоидального модельного сигнала это может быть записано как
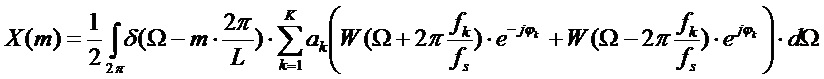 .
.
Следовательно, дискретизированный спектр дается выражением
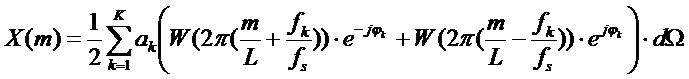 , где m=0…L-1.
, где m=0…L-1.
На основании этих соображений предполагается, что наблюдаемые пики в амплитудном спектре кадра анализа происходят от умноженного на оконную функцию синусоидального сигнала с K синусоидами, где истинные частоты синусоид находятся вблизи пиков.
Пусть 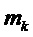 будет индексом DFT (узлом решетки) наблюдаемого k-го пика, тогда соответствующая частота
будет индексом DFT (узлом решетки) наблюдаемого k-го пика, тогда соответствующая частота 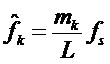 , которая может рассматриваться как аппроксимация истинной синусоидальной частоты
, которая может рассматриваться как аппроксимация истинной синусоидальной частоты 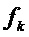 . Можно предположить, что истинная частота
. Можно предположить, что истинная частота 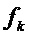 синусоиды лежит в пределах интервала
синусоиды лежит в пределах интервала 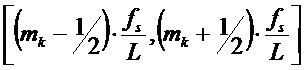 .
.
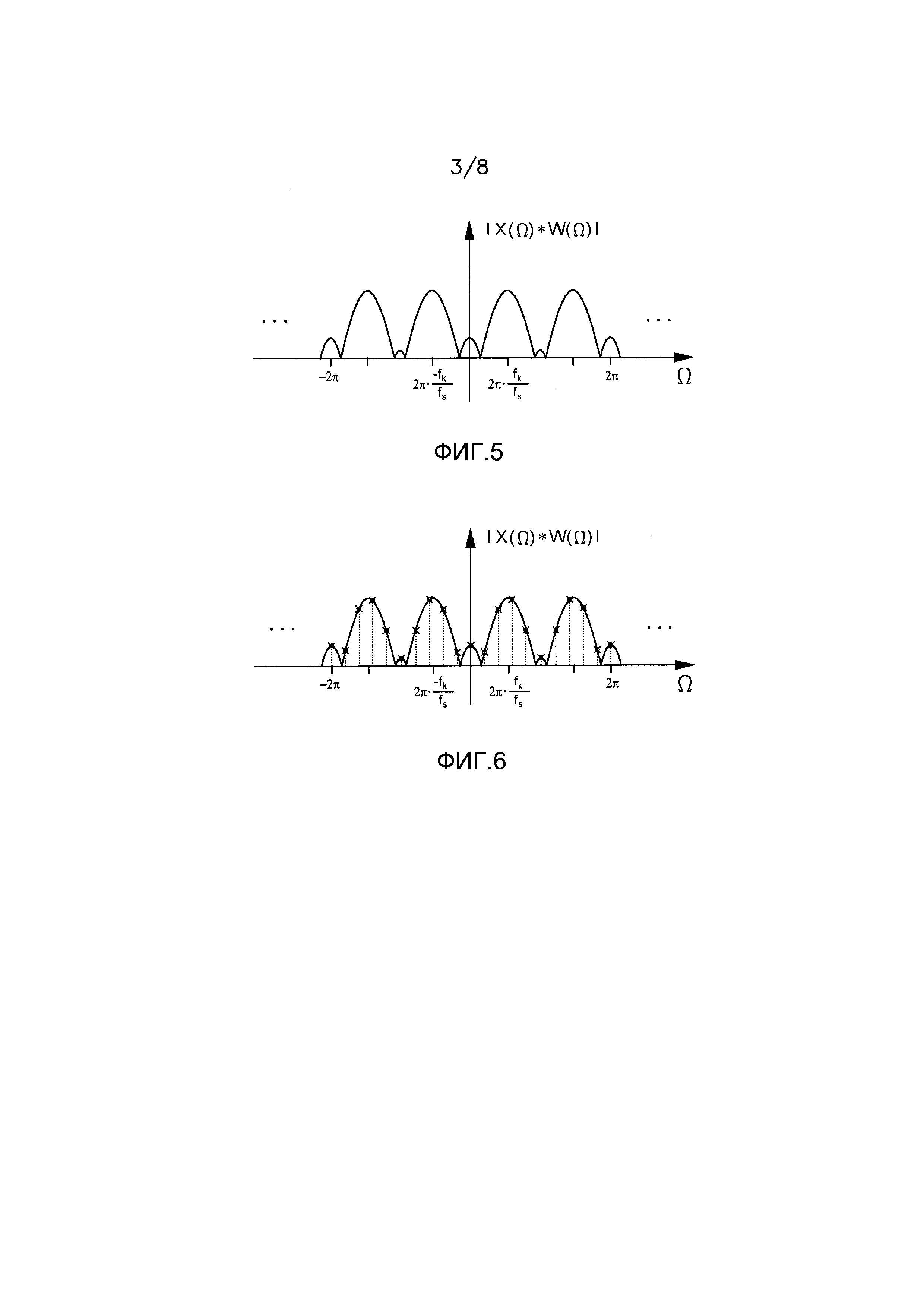
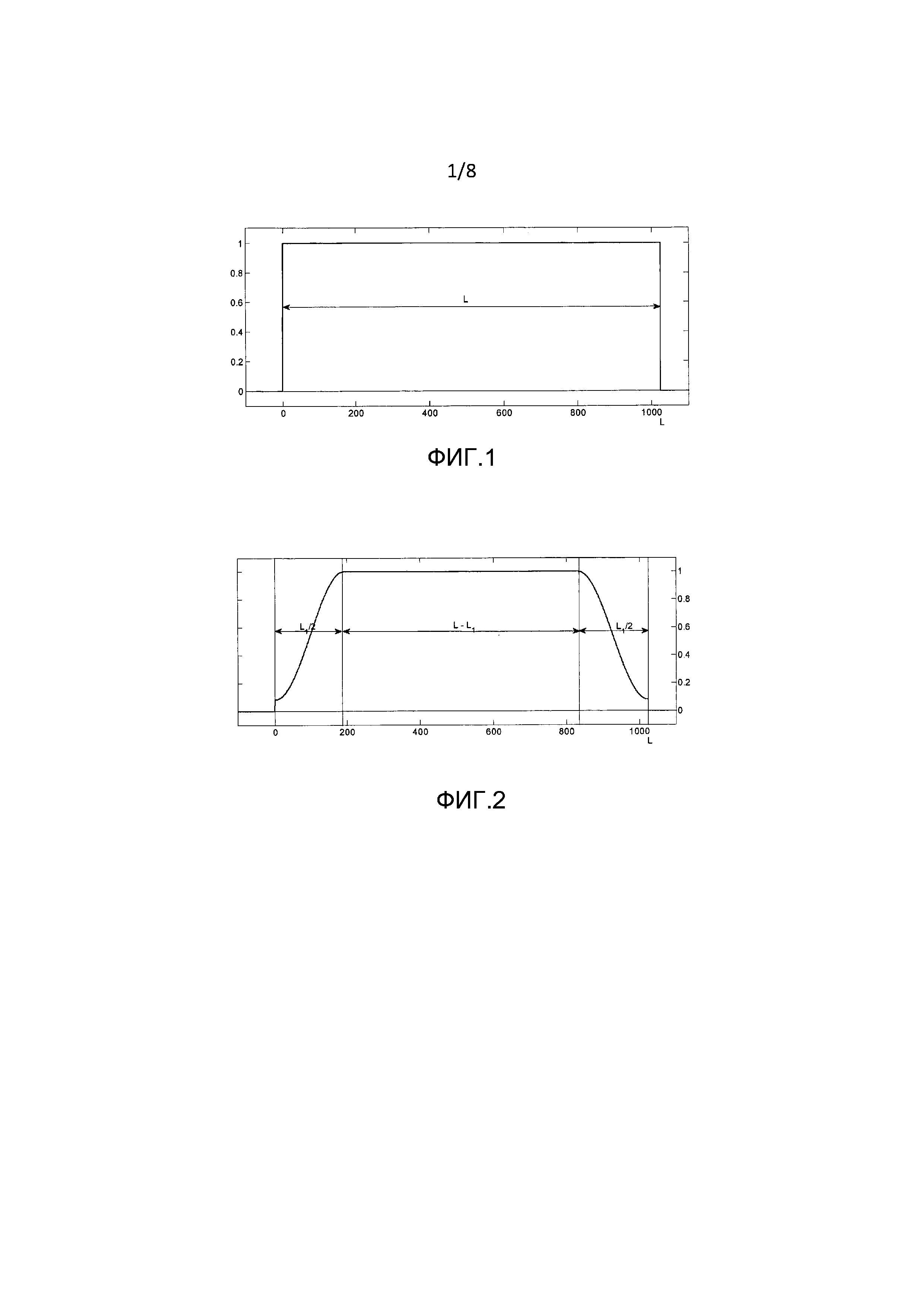
Для ясности следует отметить, что свертка спектра оконной функции со спектром линейчатого спектра синусоидального модельного сигнала может пониматься как суперпозиция смещенных по частоте версий спектра оконной функции, в результате чего частоты сдвига являются частотами синусоид. Эта суперпозиция затем дискретизируется в узлах решетки DFT. Эти этапы изображены с помощью следующих фигур. Фигура 3 изображает пример амплитудного спектра оконной функции. Фигура 4 показывает амплитудный спектр (линейчатый спектр) иллюстративного синусоидального сигнала с одной синусоидой частоты. Фигура 5 показывает амплитудный спектр умноженного на оконную функцию синусоидального сигнала, который повторяет и накладывает смещенный по частоте спектр окна на частоты синусоиды. Вертикальные линии на фигуре 6 соответствуют величинам узлов решетки DFT умноженной на оконную функцию синусоиды, которые получены путем вычисления DFT кадра анализа. Следует отметить, что все спектры являются периодическими с нормированным частотным параметром 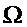 , где
, где 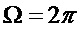 , что соответствует частоте
, что соответствует частоте 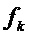 дискретизации.
дискретизации.
Предыдущее обсуждение и иллюстрация фигуры 6 предполагают, что более хорошая аппроксимация истинных синусоидальных частот может быть найдена только путем увеличения разрешения поиска по частотному разрешению используемого преобразования в частотную область.
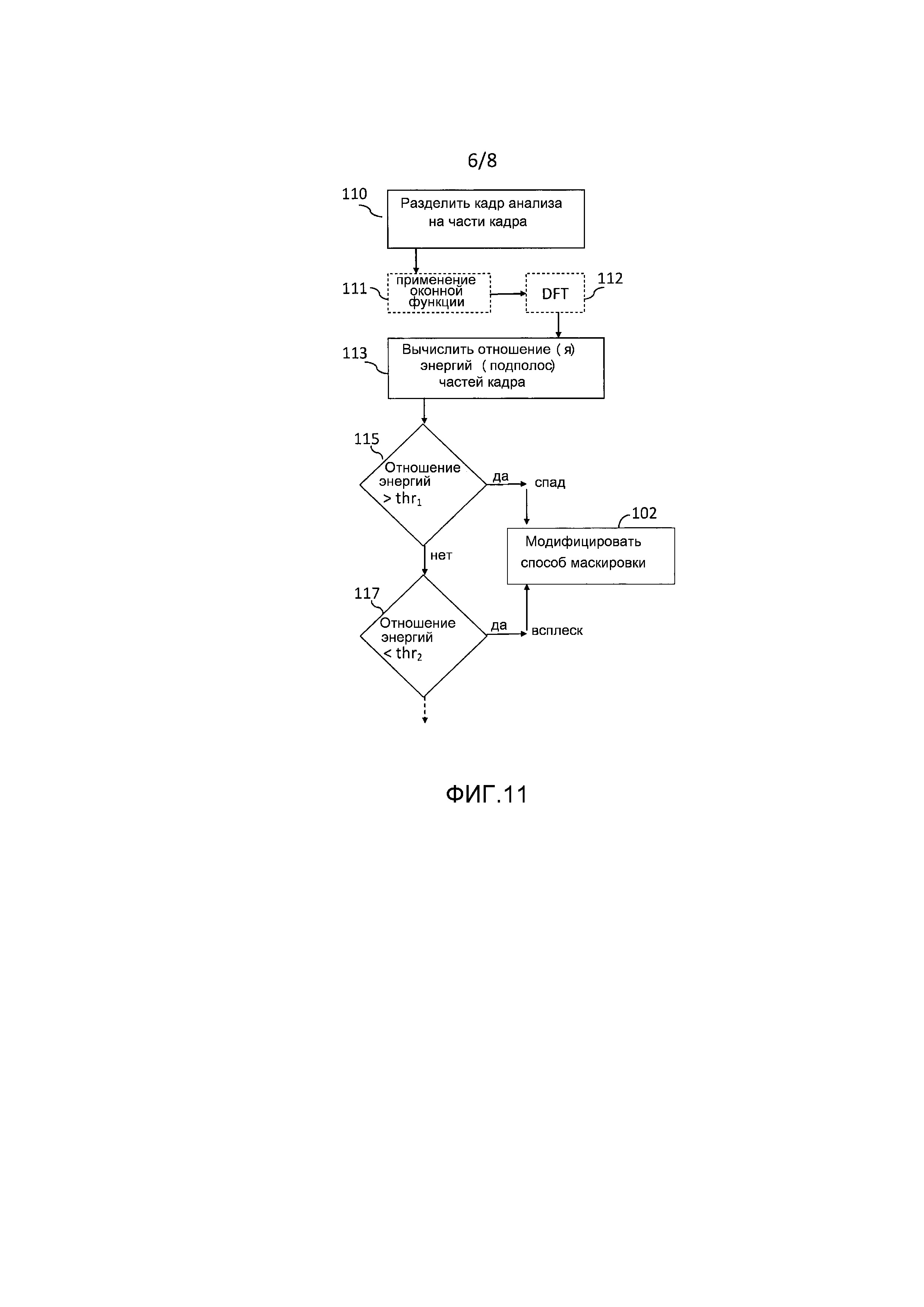
Один предпочтительный путь найти более хорошую аппроксимацию частот 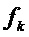 синусоид состоит в том, чтобы применить параболическую интерполяцию. Один такой подход состоит в том, чтобы совместить параболы с узлами решетки амплитудного спектра DFT, которые окружают пики, и вычислить соответствующие частоты, принадлежащие максимумам параболы. Подходящим выбором для порядка парабол является 2. Говоря более подробно, может быть применена следующая процедура:
синусоид состоит в том, чтобы применить параболическую интерполяцию. Один такой подход состоит в том, чтобы совместить параболы с узлами решетки амплитудного спектра DFT, которые окружают пики, и вычислить соответствующие частоты, принадлежащие максимумам параболы. Подходящим выбором для порядка парабол является 2. Говоря более подробно, может быть применена следующая процедура:
1. Идентифицировать пики DFT умноженного на оконную функцию кадра анализа. Поиск пиков предоставит число пиков K и соответствующие индексы DFT пиков. Поиск пиков обычно может выполняться на амплитудном спектре DFT или логарифмическом амплитудном спектре DFT.
2. Для каждого пика 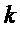 (с
(с 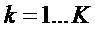 ) с соответствующим индексом
) с соответствующим индексом 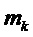 DFT совместить параболу с тремя точками
DFT совместить параболу с тремя точками 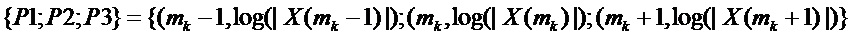 . Результатом этого являются коэффициенты
. Результатом этого являются коэффициенты 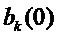 ,
, 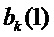 ,
, 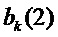 параболы, определенной выражением
параболы, определенной выражением
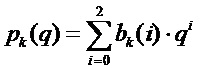 .
.
Это совмещение параболы изображено на фигуре 7.
3. Для каждой из K парабол вычислить интерполированный частотный индекс 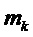 , соответствующий значению
, соответствующий значению 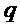 , для которого парабола имеет свой максимум. Использовать
, для которого парабола имеет свой максимум. Использовать 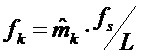 как аппроксимацию для частоты
как аппроксимацию для частоты 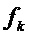 синусоиды.
синусоиды.
Описанный подход обеспечивает хорошие результаты, но может иметь некоторые ограничения, так как параболы не аппроксимируют форму основного лепестка амплитудного спектра 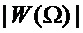 оконной функции. Альтернативной схемой, делающей это, является усовершенствованная оценка частоты, использующая аппроксимацию основного лепестка, которая может быть описана следующим образом. Основная идея этой альтернативы состоит в том, чтобы совместить функцию
оконной функции. Альтернативной схемой, делающей это, является усовершенствованная оценка частоты, использующая аппроксимацию основного лепестка, которая может быть описана следующим образом. Основная идея этой альтернативы состоит в том, чтобы совместить функцию 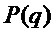 , которая аппроксимирует основной лепесток
, которая аппроксимирует основной лепесток 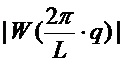 , с узлами решетки амплитудного спектра DFT, которые окружают пики, и вычислить соответствующие частоты, принадлежащие максимумам функции. Функция
, с узлами решетки амплитудного спектра DFT, которые окружают пики, и вычислить соответствующие частоты, принадлежащие максимумам функции. Функция 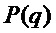 может быть идентичной смещенному по частоте амплитудному спектру
может быть идентичной смещенному по частоте амплитудному спектру 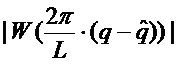 оконной функции. Для численной простоты, однако, это должен быть скорее, например, многочлен, который позволяет выполнить простое вычисление максимума функции. Может применяться следующая подробная процедура:
оконной функции. Для численной простоты, однако, это должен быть скорее, например, многочлен, который позволяет выполнить простое вычисление максимума функции. Может применяться следующая подробная процедура:
1. Идентифицировать пики DFT умноженного на оконную функцию кадра анализа. Поиск пиков предоставит число пиков K и соответствующие индексы DFT пиков. Поиск пиков обычно может выполняться на амплитудном спектре DFT или логарифмическом амплитудном спектре DFT.
2. Получить функцию , которая аппроксимирует амплитудный спектр оконной функции или логарифмический амплитудный спектр 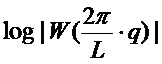 для данного интервала
для данного интервала 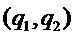 . Выбор аппроксимирующей функции, аппроксимирующей основной лепесток спектра окна, изображен на фигуре 8.
. Выбор аппроксимирующей функции, аппроксимирующей основной лепесток спектра окна, изображен на фигуре 8.
3. Для каждого пика 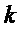 (с
(с 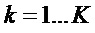 ) с соответствующим индексом
) с соответствующим индексом 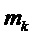 DFT совместить смещенную по частоте функцию
DFT совместить смещенную по частоте функцию 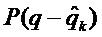 с двумя узлами решетки DFT, которые окружают ожидаемый истинный пик непрерывного спектра умноженного на оконную функцию синусоидального сигнала. Следовательно, если
с двумя узлами решетки DFT, которые окружают ожидаемый истинный пик непрерывного спектра умноженного на оконную функцию синусоидального сигнала. Следовательно, если 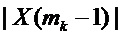 больше, чем
больше, чем 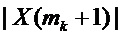 , совместить с точками
, совместить с точками 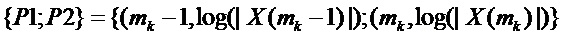 , и в противном случае с точками
, и в противном случае с точками 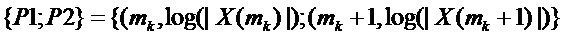 .
. 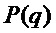 может, для простоты, являться многочленом 2 или 4 порядка. Это делает аппроксимацию на этапе 2 вычислением простой линейной регрессии, и вычисление
может, для простоты, являться многочленом 2 или 4 порядка. Это делает аппроксимацию на этапе 2 вычислением простой линейной регрессии, и вычисление 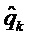 простым. Интервал может быть выбран фиксированным и идентичным для всех пиков, например,
простым. Интервал может быть выбран фиксированным и идентичным для всех пиков, например, 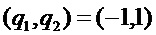 , или адаптивным. В адаптивном подходе интервал может быть выбран так, что функция совмещается с основным лепестком спектра оконной функции в диапазоне соответствующих узлов {P1; P2} решетки DFT. Процесс совмещения визуализирован на фигуре 9.
, или адаптивным. В адаптивном подходе интервал может быть выбран так, что функция совмещается с основным лепестком спектра оконной функции в диапазоне соответствующих узлов {P1; P2} решетки DFT. Процесс совмещения визуализирован на фигуре 9.
4. Для каждого из K сдвинутых по частоте параметров , для которых непрерывный спектр умноженного на оконную функцию синусоидального сигнала, как ожидается, будет иметь свой пик, вычислить 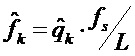 как аппроксимацию для частоты
как аппроксимацию для частоты 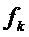 синусоиды.
синусоиды.
Есть много случаев, когда переданный сигнал является гармоническим, то есть сигнал состоит из синусоидальных волн, частоты которых кратны некоторой основной частоте 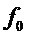 . Это имеет место, когда сигнал является очень периодическим, как, например, для вокализованной речи или длительных тонов некоторого музыкального инструмента. Это означает, что частоты синусоидальной модели вариантов воплощения не являются независимыми, а скорее имеют гармоническую зависимость и происходят от одной и той же основной частоты. Следовательно, принятие во внимание этого гармонического свойства может значительно улучшить анализ синусоидальных составляющих частот.
. Это имеет место, когда сигнал является очень периодическим, как, например, для вокализованной речи или длительных тонов некоторого музыкального инструмента. Это означает, что частоты синусоидальной модели вариантов воплощения не являются независимыми, а скорее имеют гармоническую зависимость и происходят от одной и той же основной частоты. Следовательно, принятие во внимание этого гармонического свойства может значительно улучшить анализ синусоидальных составляющих частот.
Одну возможность улучшения можно описать следующим образом:
1. Проверить, является ли сигнал гармоническим. Это может быть сделано, например, путем оценки периодичности сигнала до потери кадра. Один простой способ состоит в выполнении автокорреляционного анализа сигнала. Максимум такой автокорреляционной функции для некоторой временной задержки 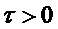 может использоваться в качестве индикатора. Если значение этого максимума превышает заданный порог, сигнал может расцениваться гармоническим. Соответствующая временная задержка
может использоваться в качестве индикатора. Если значение этого максимума превышает заданный порог, сигнал может расцениваться гармоническим. Соответствующая временная задержка 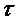 тогда соответствует периоду сигнала, который связан с основной частотой как
тогда соответствует периоду сигнала, который связан с основной частотой как 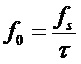 .
.
Многие способы кодирования речи с линейным предсказанием применяют так называемое предсказание высоты тона с обратной или без обратной связи или кодирование CELP с использованием адаптивных кодовых книг. Параметры усиление высоты тона и соответствующей задержки высоты тона, полученные с помощью таких способов кодирования, также являются полезными индикаторами, если сигнал является гармоническим и, соответственно, для временной задержки.
Дополнительный способ для получения 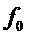 описывается ниже.
описывается ниже.
2. Для каждого индекса 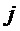 гармоники в пределах целочисленного диапазона
гармоники в пределах целочисленного диапазона 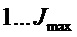 проверить, есть ли пик в (логарифмическом) амплитудном спектре DFT кадра анализа в окресности частоты
проверить, есть ли пик в (логарифмическом) амплитудном спектре DFT кадра анализа в окресности частоты 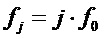 гармоники. Окрестность
гармоники. Окрестность 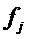 может быть определена как дельта-область вокруг
может быть определена как дельта-область вокруг 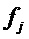 , где дельта соответствует частотному разрешению DFT
, где дельта соответствует частотному разрешению DFT 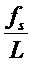 , то есть интервал
, то есть интервал 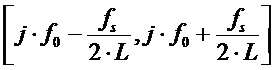 .
.
В случае, если такой пик с соответствующей оценочной синусоидальной частотой присутствует, заменить 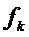 частотой
частотой 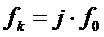 .
.
Для двухэтапной процедуры, данной выше, существует также возможность осуществления проверки, является ли сигнал гармоническим, и получение основной частоты неявно и, возможно, итеративным образом, не обязательно с использованием индикаторов из некоторого отдельного способа. Пример для такой методики дается следующий:
Для каждого 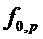 из набора потенциальных значений
из набора потенциальных значений 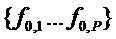 применить этап 2 процедуры, хотя без замены , но с подсчетом, сколько пиков DFT присутствует в окрестности вблизи частот гармоник, то есть кратных . Идентифицировать основную частоту
применить этап 2 процедуры, хотя без замены , но с подсчетом, сколько пиков DFT присутствует в окрестности вблизи частот гармоник, то есть кратных . Идентифицировать основную частоту 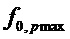 , для которой получено наибольшее число пиков на или вблизи от частот гармоник. Если это наибольшее число пиков превышает заданный порог, то сигнал предполагается гармоническим. В этом случае можно предположить, что
, для которой получено наибольшее число пиков на или вблизи от частот гармоник. Если это наибольшее число пиков превышает заданный порог, то сигнал предполагается гармоническим. В этом случае можно предположить, что 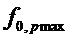 является основной частотой, с которой затем выполняется этап 2, приводя к улучшенным синусоидальным частотам. Более предпочтительной альтернативой является, однако, оптимизация сначала основной частоты
является основной частотой, с которой затем выполняется этап 2, приводя к улучшенным синусоидальным частотам. Более предпочтительной альтернативой является, однако, оптимизация сначала основной частоты 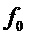 на основании частот пиков, которые были найдены совпадающими с частотами гармоник. Предположим есть набор M гармоник, то есть кратных
на основании частот пиков, которые были найдены совпадающими с частотами гармоник. Предположим есть набор M гармоник, то есть кратных 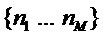 некоторой основной частоты, которые были найдены совпадающими с некоторым набором M спектральных пиков на частотах
некоторой основной частоты, которые были найдены совпадающими с некоторым набором M спектральных пиков на частотах 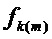 ,
, 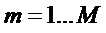 , тогда лежащая в основе (оптимизированная) основная частота
, тогда лежащая в основе (оптимизированная) основная частота 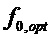 может быть вычислена для минимизации ошибки между частотами гармоник и частотами спектральных пиков. Если ошибка, которая должна быть минимизирована, является среднеквадратичной ошибкой
может быть вычислена для минимизации ошибки между частотами гармоник и частотами спектральных пиков. Если ошибка, которая должна быть минимизирована, является среднеквадратичной ошибкой 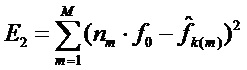 , тогда оптимальная основная частота вычисляется как
, тогда оптимальная основная частота вычисляется как
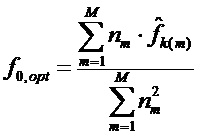 .
.
Начальный набор потенциальных значений может быть получен из частот пиков DFT или оценочных синусоидальных частот 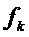 .
.
Дальнейшая возможность улучшить точность оценочных синусоидальных частот 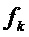 состоит в рассмотрении их развертывания во времени. С этой целью оценки синусоидальных частот по нескольким кадрам анализа могут комбинироваться, например, посредством усреднения или предсказания. До усреднения или предсказания может быть применено отслеживание пиков, которое соединяет оценочные спектральные пики с соответствующими теми же самыми лежащими в основе синусоидами.
состоит в рассмотрении их развертывания во времени. С этой целью оценки синусоидальных частот по нескольким кадрам анализа могут комбинироваться, например, посредством усреднения или предсказания. До усреднения или предсказания может быть применено отслеживание пиков, которое соединяет оценочные спектральные пики с соответствующими теми же самыми лежащими в основе синусоидами.
Применение синусоидальной модели
Применение синусоидальной модели для выполнения операции по маскировке потери кадров, описанной в настоящем документе, может быть описано следующим образом.
Предполагается, что данный сегмент кодированного сигнала не может быть восстановлен декодером, так как соответствующая закодированная информация не доступна. Дополнительно предполагается, что часть сигнала до этого сегмента доступна. Пусть 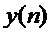 с
с 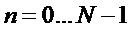 является недоступным сегментом, для которого должен быть сгенерирован подстановочный кадр
является недоступным сегментом, для которого должен быть сгенерирован подстановочный кадр 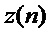 , и
, и 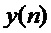 с n<0 является доступным ранее декодированным сигналом. Затем, на первом этапе прототипный кадр доступного сигнала длины L и начальным индексом
с n<0 является доступным ранее декодированным сигналом. Затем, на первом этапе прототипный кадр доступного сигнала длины L и начальным индексом 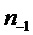 извлекается с помощью оконной функции
извлекается с помощью оконной функции 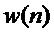 и преобразуется в частотную область, например, с помощью DFT:
и преобразуется в частотную область, например, с помощью DFT:
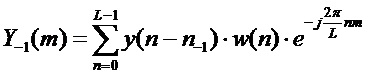 .
.
Оконная функция может быть одной из оконных функций, описанных выше в синусоидальном анализе. Предпочтительно, чтобы уменьшить сложность численных расчетов, преобразованный в частотную область кадр должен быть идентичен кадру, используемому во время синусоидального анализа.
На следующем этапе применяется допущение синусоидальной модели. В соответствии с этим DFT прототипного кадра может быть записано следующим образом:
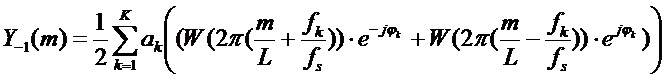 .
.
Следующий этап состоит в том, чтобы понять, что спектр используемой оконной функции имеет значительный вклад только в диапазоне частот вблизи нуля. Как изображено на фигуре 3, амплитудный спектр оконной функции больше для частот вблизи нуля и мал в противном случае (в пределах нормированного диапазона частот от 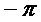 до
до 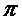 , соответствующего половине частоты дискретизации). Следовательно, в качестве аппроксимации предполагается, что спектр
, соответствующего половине частоты дискретизации). Следовательно, в качестве аппроксимации предполагается, что спектр 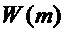 окна является ненулевым только для интервала M=[-mmin,mmax], где mmin и mmax являются небольшими положительными числами. В частности, аппроксимация спектра оконной функции используется так, что для каждого k вклады смещенных спектров окна в вышеупомянутом выражении являются строго неперекрывающимися. Следовательно, в вышеупомянутом уравнении для каждого частотного индекса в максимуме всегда есть вклад только от одного слагаемого, то есть от одного смещенного спектра окна. Это означает, что выражение выше сводится к следующему приближенному выражению:
окна является ненулевым только для интервала M=[-mmin,mmax], где mmin и mmax являются небольшими положительными числами. В частности, аппроксимация спектра оконной функции используется так, что для каждого k вклады смещенных спектров окна в вышеупомянутом выражении являются строго неперекрывающимися. Следовательно, в вышеупомянутом уравнении для каждого частотного индекса в максимуме всегда есть вклад только от одного слагаемого, то есть от одного смещенного спектра окна. Это означает, что выражение выше сводится к следующему приближенному выражению:
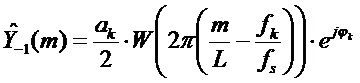 для неотрицательных
для неотрицательных 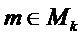 и для каждого k.
и для каждого k.
Здесь 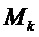 обозначает целочисленный интервал
обозначает целочисленный интервал 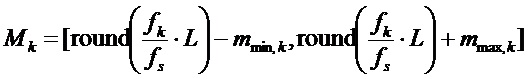 , где mmin,k и mmax,k выполняют объясненное выше ограничение, так что интервалы не перекрываются. Подходящим выбором для mmin,k и mmax,k является задание их равными небольшому целочисленному значению δ, например, δ=3. Однако если индексы DFT, относящиеся к двум соседним синусоидальным частотам
, где mmin,k и mmax,k выполняют объясненное выше ограничение, так что интервалы не перекрываются. Подходящим выбором для mmin,k и mmax,k является задание их равными небольшому целочисленному значению δ, например, δ=3. Однако если индексы DFT, относящиеся к двум соседним синусоидальным частотам 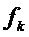 и
и 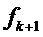 , меньше, чем 2δ, то δ задается равным
, меньше, чем 2δ, то δ задается равным 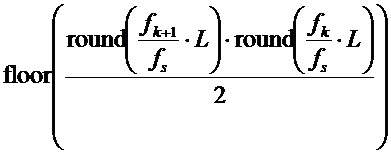 , так что оно гарантирует, что интервалы не перекрываются. Функция
, так что оно гарантирует, что интервалы не перекрываются. Функция 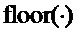 является ближайшим целым числом к аргументу функции, которое меньше или равно ему.
является ближайшим целым числом к аргументу функции, которое меньше или равно ему.
Следующий этап в соответствии с вариантом воплощения состоит в применении синусоидальной модели в соответствии с вышеупомянутым выражением и развертывании ее K синусоид во времени. Допущение, что временные индексы удаленного сегмента по сравнению с временными индексами прототипного кадра отличаются на 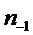 семплов, означает, что фазы синусоид сдвинуты на
семплов, означает, что фазы синусоид сдвинуты на
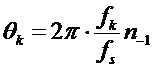 .
.
Следовательно, спектр DFT развернутой синусоидальной модели дается выражением:
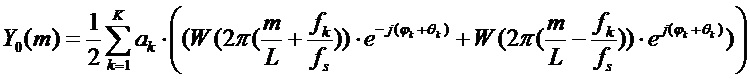 .
.
Применение снова аппроксимации, в соответствии с которой смещенные спектры оконной функции не перекрываются, дает выражение:
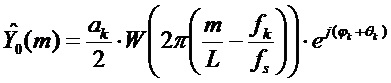 для неотрицательных и для каждого k.
для неотрицательных и для каждого k.
Сравнивая DFT прототипного кадра 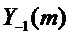 с DFT развернутой синусоидальной модели
с DFT развернутой синусоидальной модели 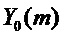 с использованием аппроксимации, найдено, что амплитудный спектр остается неизменным, в то время как фаза смещается на
с использованием аппроксимации, найдено, что амплитудный спектр остается неизменным, в то время как фаза смещается на 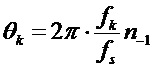 для каждого . Следовательно, коэффициенты спектра частот прототипного кадра в окрестности каждой синусоиды смещены пропорционально синусоидальной частоте
для каждого . Следовательно, коэффициенты спектра частот прототипного кадра в окрестности каждой синусоиды смещены пропорционально синусоидальной частоте 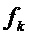 и разнице во времени между потерянным аудиокадром и прототипным кадром
и разнице во времени между потерянным аудиокадром и прототипным кадром 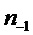 .
.
Следовательно, в соответствии с вариантом воплощения подстановочный кадр может быть вычислен с помощью следующего выражения:
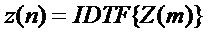 с
с 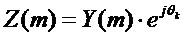 для неотрицательных и для каждого k.
для неотрицательных и для каждого k.
Конкретный вариант воплощения решает вопросы, связанные с фазовой рандомизацией для индексов DFT, не принадлежащих какому-либо интервалу 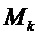 . Как было описано выше, интервалы
. Как было описано выше, интервалы 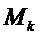 , k=1…K должен быть заданы так, чтобы они являлись строго неперекрывающимися, что достигается с использованием некоторого параметра δ, который управляет размером интервалов. Может получиться, что δ является небольшим относительно частотного расстояния между двумя соседними синусоидами. Следовательно, в этом случае получается, что имеется разрыв между двумя интервалами. Следовательно, для соответствующих индексов m DFT фазовый сдвиг в соответствии с вышеупомянутым выражением не определен. Подходящим выбором в соответствии с этим вариантом воплощения является рандомизация фазы для этих индексов, что дает
, k=1…K должен быть заданы так, чтобы они являлись строго неперекрывающимися, что достигается с использованием некоторого параметра δ, который управляет размером интервалов. Может получиться, что δ является небольшим относительно частотного расстояния между двумя соседними синусоидами. Следовательно, в этом случае получается, что имеется разрыв между двумя интервалами. Следовательно, для соответствующих индексов m DFT фазовый сдвиг в соответствии с вышеупомянутым выражением не определен. Подходящим выбором в соответствии с этим вариантом воплощения является рандомизация фазы для этих индексов, что дает 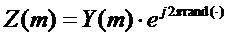 , где функция
, где функция  возвращает некоторое случайное число.
возвращает некоторое случайное число.
Было найдено выгодным для качества восстановленных сигналов оптимизировать размер интервалов . В частности, интервалы должны быть больше, если сигнал является очень тональным, то есть когда он имеет четкие и явные спектральные пики. Это имеет место, например, когда сигнал является гармоническим с четкой периодичностью. В других случаях, когда сигнал имеет менее выраженную спектральную структуру с более широкими спектральными максимумами, было найдено, что использование небольших интервалов приводит к лучшему качеству. Это открытие приводит к дополнительному улучшению, в соответствии с которым размер интервала настраивается в соответствии со свойствами сигнала. Одна реализация состоит в использовании детектора тональности или периодичности. Если этот детектор идентифицирует сигнал как тональный, δ-параметр, управляющий размером интервала, устанавливается равным относительно большому значению. В противном случае δ-параметр устанавливается равным относительно небольшому значению.
На основании приведенного выше способы маскировки потери аудиокадров включают в себя следующие этапы:
1. Анализ сегмента доступного, ранее синтезированного сигнала для получения составляющих синусоидальных частот 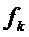 синусоидальной модели, опционально c использованием усовершенствованной оценки частоты.
синусоидальной модели, опционально c использованием усовершенствованной оценки частоты.
2. Извлечение прототипного кадра  из доступного ранее синтезированного сигнала и вычисление DFT этого кадра.
из доступного ранее синтезированного сигнала и вычисление DFT этого кадра.
3. Вычисление фазового сдвига 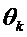 для каждой синусоиды k в ответ на синусоидальную частоту
для каждой синусоиды k в ответ на синусоидальную частоту 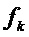 и сдвиг (опережение)
и сдвиг (опережение) 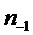 по времени между прототипным кадром и подстановочным кадром. Опционально на этом этапе может быть настроен размер интервала M в ответ на тональность аудиосигнала.
по времени между прототипным кадром и подстановочным кадром. Опционально на этом этапе может быть настроен размер интервала M в ответ на тональность аудиосигнала.
4. Для каждой синусоиды k сдвиг фазы прототипного кадра DFT на выборочно для индексов DFT, относящихся к окрестности вокруг частоты синусоиды.
5. Вычисление обратного DFT спектра, полученного на этапе 4.
Анализ и обнаружение свойства сигнала и потери кадров
Способы, описанные выше, основаны на допущении, что свойства аудиосигнала не изменяются значительно за короткое время от ранее принятого и восстановленного кадра сигнала до потерянного кадра. В этом случае очень хорошим выбором является сохранение амплитудного спектра ранее восстановленного кадра и развертывание фазы синусоидальных основных компонентов, обнаруженных в ранее восстановленном сигнале. Однако существуют случаи, где это допущение является неправильным, которые являются, например, транзиентами с внезапными изменениями энергии или внезапными спектральными изменениями.
Первый вариант воплощения детектора транзиентов в соответствии с изобретением может, следовательно, быть основан на изменениях энергии в пределах ранее восстановленного сигнала. Этот способ, изображенный на фигуре 11, вычисляет энергию в левой части и правой части некоторого кадра анализа, 113. Кадр анализа может быть идентичен кадру, используемому для синусоидального анализа, описанного выше. Часть (левая или правая) кадра анализа может быть первой или, соответственно, последней половиной кадра анализа или, например, первой или, соответственно, последней четвертью кадра анализа, 110. Соответствующее вычисление энергии выполняется путем суммирования квадратов семплов в этих частях кадра:
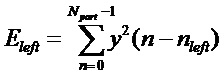 , и
, и 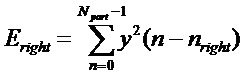 .
.
Здесь 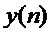 обозначает кадр анализа,
обозначает кадр анализа, 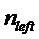 и
и 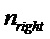 обозначают соответствующие индексы начала частей кадра, оба из которых имеют размер Npart.
обозначают соответствующие индексы начала частей кадра, оба из которых имеют размер Npart.
Теперь энергия левой и правой частей кадра используются для обнаружения нарушения непрерывности сигнала. Это выполняется путем вычисления отношения
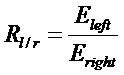 .
.
Нарушение непрерывности с внезапным уменьшением энергии (спад, окончание звука) может быть обнаружено, если отношение 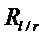 превышает некоторый порог (например, 10), 115. Аналогично, нарушение непрерывности с внезапным увеличением энергии (всплеск, начало звука) может быть обнаружено, если отношение
превышает некоторый порог (например, 10), 115. Аналогично, нарушение непрерывности с внезапным увеличением энергии (всплеск, начало звука) может быть обнаружено, если отношение 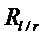 ниже некоторого другого порога (например, 0.1), 117.
ниже некоторого другого порога (например, 0.1), 117.
В контексте описанных выше способов маскировки было найдено, что определенное выше отношение энергий во многих случаях может быть слишком нечувствительным индикатором. В частности, в реальных сигналах и особенно музыке есть случаи, когда тон на некоторой частоте внезапно появляется, в то время как некоторый другой тон на некоторой другой частоте внезапно останавливается. Анализ такого сигнального кадра с помощью определенного выше отношения энергий в любом случае приведет к неправильному результату обнаружения по меньшей мере для одного из тонов, так как этот индикатор не чувствителен к различным частотам.
Решение этой проблемы описано в следующем варианте воплощения. Обнаружение транзиентов теперь выполняется в частотно-временной плоскости. Кадр анализа снова разделяется на левую и правую часть кадра, 110. Хотя теперь, эти две части кадра (после умножения на подходящую оконную функцию, например, окно Хемминга, 111) преобразуются в частотную область, например, посредством Npart-точечного DFT, 112.
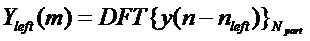 и
и
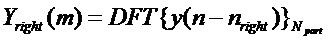 , где m=0…Npart-1.
, где m=0…Npart-1.
Теперь обнаружение транзиентов может быть выполнено частотно-избирательно для каждого отрезка DFT с индексом m. Используя энергии амплитудных спектров левой и правой частей кадра, для каждого индекса m DFT соответствующее отношение энергий может быть вычислено 113 в виде
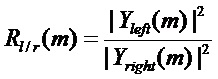 .
.
Эксперименты показывают, что частотно-избирательное обнаружение транзиентов с разрешением отрезков DFT является относительно неточным из-за статистических флуктуаций (ошибок оценки). Было найдено, что качество операции довольно сильно увеличивается, если делать частотно-избирательное обнаружение транзиентов на основе полос частот. Пусть 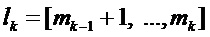 указывают k-ый интервал, k=1…K, охватывающий отрезки DFT от
указывают k-ый интервал, k=1…K, охватывающий отрезки DFT от 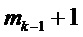 до
до 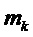 , тогда эти интервалы определяют K полос частот. Выборочное по группе частот обнаружение транзиентов теперь может быть основано на отношении для полос между соответствующими энергиями полос левой и правой частей кадра:
, тогда эти интервалы определяют K полос частот. Выборочное по группе частот обнаружение транзиентов теперь может быть основано на отношении для полос между соответствующими энергиями полос левой и правой частей кадра:
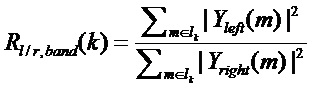 .
.
Следует отметить, что интервал соответствует полосе частот 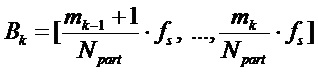 , где
, где 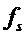 обозначает частоту дискретизации звука.
обозначает частоту дискретизации звука.
Самая низкая граница m0 нижней полосы частот может быть задана равной 0, но может быть также задана равной индексу DFT, соответствующему большей частоте, чтобы снизить ошибки оценки, которые увеличиваются для более низких частот. Самая высокая граница mk верхней полосы частот может быть задана равной 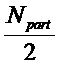 , но предпочтительно выбирается так, чтобы соответствовать некоторой более низкой частоте, на которой транзиент все еще имеет значительный слышимый эффект.
, но предпочтительно выбирается так, чтобы соответствовать некоторой более низкой частоте, на которой транзиент все еще имеет значительный слышимый эффект.
Подходящий выбор для размеров или ширин этих полос частот состоит в том, чтобы сделать их одинакового размера шириной, например, в несколько 100 Гц. Другой предпочтительный путь состоит в том, чтобы сделать ширины полос частот зависящими от размера акустических критических полос частот человека, то есть связать их с разрешением по частоте слуховой системы. Это означает, приблизительно, что необходимо сделать ширины полос частот одинаковыми для частот до 1 кГц, и увеличивать их экспоненциально выше 1 кГц. Экспоненциальное увеличение означает, например, удвоение полосы частот с увеличением индекса полосы k.
Как описано в первом варианте воплощения детектора транзиентов, который был основан на отношении энергий двух частей кадра, любое из отношений, связанных с энергиями полос или энергиями отрезков DFT двух частей кадра, сравниваются с определенными порогами. Используется соответствующий верхний порог для (частотно-избирательного) обнаружения спадов 115 и соответствующий нижний порог для (частотно-избирательного) обнаружения всплесков 117.
Дополнительный зависящий от аудиосигнала индикатор, который является подходящим для адаптации способа маскировки потери кадров, может быть основан на параметрах кодека, переданных декодеру. Например, кодек может быть многорежимным кодеком, как ITU-T G.718. Такой кодек может использовать конкретные режимы кодека для различных типов сигнала и изменять режим кодека в кадре незадолго до того, как потеря кадра может быть расценена как индикатор для транзиента.
Другим полезным индикатором для адаптации маскировки потери кадров является параметр кодека, относящийся к свойству озвучивания и переданному сигналу. Озвучивание относится к высоко периодической речи, которая генерируется периодическим возбуждением голосовой щели вокального тракта человека.
Дополнительный предпочтительный индикатор оценивает, является ли содержание сигнала музыкой или речью. Такой индикатор может быть получен от классификатора сигналов, который может обычно быть частью кодека. В случае, если кодек выполняет такую классификацию и делает соответствующее решение о классификации доступным в качестве параметра кодирования декодеру, этот параметр предпочтительно используется в качестве индикатора содержания сигнала, который будет использоваться для адаптации способа маскировки потери кадров.
Другим индикатором, который предпочтительно используется для адаптации способов маскировки потери кадров, является пакетирование потери кадров. Пакетирование потери кадров означает, что происходит потеря нескольких кадров подряд, затрудняя для способа маскировки потери кадров использование годных только что декодированных частей сигнала для его работы. Индикатором существующего уровня техники является число nburst наблюдаемых потерь кадров подряд. Этот счетчик увеличивается на единицу при каждой потере кадра и обнуляется при приеме годного кадра. Этот индикатор также используется в контексте настоящих иллюстративных вариантов воплощения изобретения.
Адаптация способа маскировки потери кадров
В случае, если этапы, выполненные выше, указывают условие, предполагающее адаптацию операции по маскировке потери кадров, вычисление спектра подстановочного кадра модифицируется.
В то время как исходное вычисление спектра подстановочного кадра выполняется в соответствии с выражением 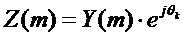 , теперь производится адаптация, модифицирующая и амплитуду, и фазу. Амплитуда изменяется посредством масштабирования с помощью двух множителей
, теперь производится адаптация, модифицирующая и амплитуду, и фазу. Амплитуда изменяется посредством масштабирования с помощью двух множителей 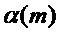 и
и 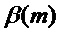 , а фаза модифицируется с помощью добавочного фазового компонента
, а фаза модифицируется с помощью добавочного фазового компонента 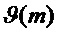 . Это приводит к следующему модифицированному вычислению подстановочного кадра:
. Это приводит к следующему модифицированному вычислению подстановочного кадра:
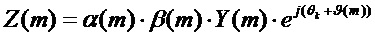 .
.
Следует отметить, что исходные (неадаптированные) способы маскировки потери кадров используются, если 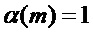 ,
, 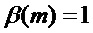 и
и 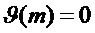 . Следовательно, эти соответствующие значения являются значениями по умолчанию.
. Следовательно, эти соответствующие значения являются значениями по умолчанию.
Общая цель использования адаптации амплитуды состоит в том, чтобы избежать слышимых артефактов способа маскировки потери кадров. Такие артефакты могут быть музыкальными или тональными звуками или странными звуками, являющимися результатом повторений транзиентных звуков. Такие артефакты, в свою очередь, будут приводить к снижению качества, предотвращение чего является целью описанной адаптации. Подходящим путем такой адаптации является изменение амплитудного спектра подстановочного кадра в подходящей степени.
Фигура 12 изображает вариант воплощения модификации способа маскировки. Адаптация амплитуды, 123, предпочтительно делается, если счетчик пакетных потерь nburst превышает некоторый порог thrburst, например, thrburst=3, 121. В этом случае для коэффициента ослабления используется значение меньше, чем 1, например, 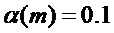 .
.
Однако было найдено, что выгодно выполнять ослабление с постепенно увеличивающейся степенью. Одним предпочтительным вариантом воплощения, который делает это, является задание логарифмического параметра, указывающего логарифмическое увеличение ослабления на кадр, 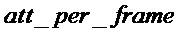 . Затем, в случае, если пакетный счетчик превышает порог, постепенно увеличивающийся коэффициент ослабления вычисляется с помощью выражения
. Затем, в случае, если пакетный счетчик превышает порог, постепенно увеличивающийся коэффициент ослабления вычисляется с помощью выражения
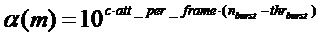 .
.
Здесь постоянная c является просто масштабирующей постоянной, позволяющей указать параметр 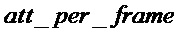 , например, в децибелах (дБ).
, например, в децибелах (дБ).
Дополнительная предпочтительная адаптация делается в ответ на индикатор, оценен ли сигнал как музыка или речь. Для музыкального содержания по сравнению с речевым содержанием предпочтительно увеличить порог 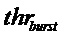 и уменьшить ослабление на кадр. Это эквивалентно выполнению адаптации способа маскировки потери кадров в более низкой степени. Предпосылкой этого вида адаптации является то, что музыка, как правило, менее чувствительна к более длинным пакетам потерь, чем речь. Следовательно, исходный, то есть немодифицированный способ маскировки потери кадров, по-прежнему является предпочтительным для этого случая, по меньшей мере для потери большего числа кадров подряд.
и уменьшить ослабление на кадр. Это эквивалентно выполнению адаптации способа маскировки потери кадров в более низкой степени. Предпосылкой этого вида адаптации является то, что музыка, как правило, менее чувствительна к более длинным пакетам потерь, чем речь. Следовательно, исходный, то есть немодифицированный способ маскировки потери кадров, по-прежнему является предпочтительным для этого случая, по меньшей мере для потери большего числа кадров подряд.
Дополнительная адаптация способа маскировки относительно коэффициента ослабления амплитуды предпочтительно делается в случае, если был обнаружен транзиент на основании того, что индикатор 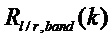 или, альтернативно,
или, альтернативно, 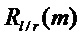 или
или 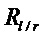 превысил порог, 122. В этом случае подходящее действие адаптации, 125, заключается в модификации второго коэффициента ослабления амплитуды
превысил порог, 122. В этом случае подходящее действие адаптации, 125, заключается в модификации второго коэффициента ослабления амплитуды 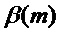 , так что общим ослаблением управляет произведение этих двух множителей
, так что общим ослаблением управляет произведение этих двух множителей 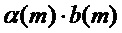 .
.
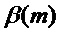 задается в ответ на указанный транзиент. В случае, если обнаружен спад, множитель
задается в ответ на указанный транзиент. В случае, если обнаружен спад, множитель 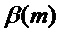 предпочтительно выбирается так, чтобы отражать уменьшение энергии спада. Подходящим выбором является задание равным обнаруженному изменению усиления:
предпочтительно выбирается так, чтобы отражать уменьшение энергии спада. Подходящим выбором является задание равным обнаруженному изменению усиления:
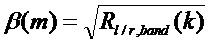 , для
, для 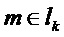 , k=1…K.
, k=1…K.
В случае, если обнаружен всплеск, было найдено полезным скорее ограничить увеличение энергии подстановочного кадра. В этом случае множитель может быть задан равным некоторому фиксированному значению, например, 1, что означает, что ослабление отсутствует, но также нет никакого усиления.
В вышеупомянутом следует отметить, что коэффициент ослабления амплитуды предпочтительно применяется частотно-избирательно, то есть с индивидуально вычисленными множителями для каждой полосы частот. В случае, если подход с полосами не используется, соответствующие коэффициенты ослабления амплитуды, тем не менее, могут быть получены аналогичным образом. может тогда быть задан индивидуально для каждого отрезка DFT в случае, если частотно-избирательное обнаружение транзиентов используется на уровне отрезков DFT. Или в случае, если не используется вообще никакое частотно-избирательное указание о транзиентах, может быть глобально одинаковым для всех m.
Дополнительная предпочтительная адаптация коэффициента ослабления амплитуды делается в сочетании с модификацией фазы посредством дополнительного фазового компонента 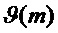 , 127. В случае, если для данного m используется такая модификация фазы, коэффициент ослабления
, 127. В случае, если для данного m используется такая модификация фазы, коэффициент ослабления 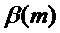 уменьшается дополнительно. Предпочтительно учитывается даже степень модификации фазы. Если модификация фазы является лишь умеренной,
уменьшается дополнительно. Предпочтительно учитывается даже степень модификации фазы. Если модификация фазы является лишь умеренной, 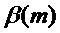 уменьшается лишь незначительно, в то время как если модификация фазы является значительной, уменьшается в большей степени.
уменьшается лишь незначительно, в то время как если модификация фазы является значительной, уменьшается в большей степени.
Общая цель введения адаптации фазы состоит в том, чтобы избежать слишком сильной тональности или периодичности сигнала в генерируемых подстановочных кадрах, что, в свою очередь, привело бы к снижению качества. Подходящим путем такой адаптации является рандомизация или сглаживание фазы в подходящей степени.
Такое сглаживание фазы выполняется, если дополнительный фазовый компонент задается равным случайному значению, масштабированному с помощью некоторого управляющего коэффициента: 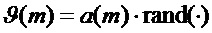 .
.
Случайное значение, полученное с помощью функции  , например, генерируется с помощью некоторого генератора псевдослучайных чисел. Здесь предполагается, что он обеспечивает случайное число в пределах интервала
, например, генерируется с помощью некоторого генератора псевдослучайных чисел. Здесь предполагается, что он обеспечивает случайное число в пределах интервала 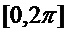 .
.
Масштабирующий коэффициент 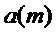 в вышеупомянутом уравнении управляет степенью, в которой сглаживается исходная фаза
в вышеупомянутом уравнении управляет степенью, в которой сглаживается исходная фаза 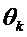 . Следующие варианты воплощения решают проблему адаптацию фазы посредством управления этим масштабирующим коэффициентом. Управление масштабирующим коэффициентом делается аналогичным образом, как и управление множителями модификации амплитуды, описанными выше.
. Следующие варианты воплощения решают проблему адаптацию фазы посредством управления этим масштабирующим коэффициентом. Управление масштабирующим коэффициентом делается аналогичным образом, как и управление множителями модификации амплитуды, описанными выше.
В соответствии с первым вариантом воплощения масштабирующий коэффициент 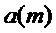 адаптируется в ответ на счетчик пакетных потерь. Если счетчик пакетных потерь
адаптируется в ответ на счетчик пакетных потерь. Если счетчик пакетных потерь 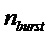 превышает некоторый порог , например,
превышает некоторый порог , например, 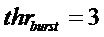 , используется значение больше, чем 0, например,
, используется значение больше, чем 0, например, 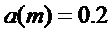 .
.
Однако было найдено, что выгодно выполнять сглаживание с постепенно увеличивающейся степенью. Одним предпочтительным вариантом воплощения, который делает это, является задание параметра, указывающего увеличение сглаживания на кадр, 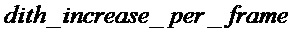 . Затем, в случае, если пакетный счетчик превышает порог, постепенно увеличивающийся множитель управления сглаживанием вычисляется с помощью
. Затем, в случае, если пакетный счетчик превышает порог, постепенно увеличивающийся множитель управления сглаживанием вычисляется с помощью
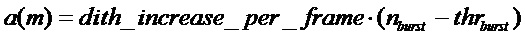 .
.
В вышеупомянутой формуле следует отметить, что 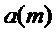 должна быть ограничена максимальным значением 1, для которого достигается полное сглаживание фазы.
должна быть ограничена максимальным значением 1, для которого достигается полное сглаживание фазы.
Следует отметить, что пороговое значение пакетных потерь , используемое для инициирования сглаживания фазы, может быть тем же самым порогом, что и порог, используемый для ослабления амплитуды. Однако, более высокое качество может быть получено путем задания этих порогов равными индивидуальным оптимальным значениям, что, как правило, означает, что эти пороги могут отличаться.
Дополнительная предпочтительная адаптация делается в ответ на индикатор, оценен ли сигнал как музыка или речь. Для музыкального содержания по сравнению с речевым содержанием предпочтительно увеличить порог , что означает, что сглаживание фазы для музыки по сравнению с речью делается только в случае большего количества потерянных подряд кадров. Это эквивалентно выполнению адаптации способа маскировки потери кадров для музыки в более низкой степени. Предпосылкой этого вида адаптации является то, что музыка, как правило, менее чувствительна к более длинным пакетам потерь, чем речь. Следовательно, исходный, то есть немодифицированный способ маскировки потери кадров, по-прежнему является предпочтительным для этого случая, по меньшей мере для потери большего числа кадров подряд.
Дополнительный предпочтительный вариант воплощения состоит в адаптации сглаживания фазы в ответ на обнаруженный транзиент. В этом случае более сильная степень сглаживания фазы может использоваться для отрезков m DFT, для которых транзиент указан или для этого отрезка, отрезков DFT соответствующей полосы частот или целого кадра.
Часть описанных схем решает проблему оптимизации способа маскировки потери кадров для гармонических сигналов и, в частности, для вокализованной речи.
В случае, если способы, использующие усовершенствованную частотную оценку, как описано выше, не реализованы, другая возможность адаптации для способа маскировки потери кадров, оптимизирующего качество для сигналов вокализованной речи, состоит в том, чтобы переключиться на некоторый другой способ маскировки потери кадров, который специально спроектирован и оптимизирован для речи, а не для общих аудиосигналов, содержащих музыку и речь. В этом случае используется индикатор, что сигнал содержит сигнал вокализованной речи, чтобы выбрать другую оптимизированную для речи схему маскировки потери кадров, а не схемы, описанные выше.
Варианты воплощения применяются к контроллеру в декодере, как изображено на фигуре 13. Фигура 13 является блок-схемой декодера в соответствии с вариантами воплощения. Декодер 130 содержит блок 132 ввода, сконфигурированный принимать закодированный аудиосигнал. Фигура изображает маскировку потери кадров логическим блоком 134 маскировки потери кадров, который указывает, что декодер сконфигурирован реализовывать маскировку потерянного аудиокадра, в соответствии с вышеописанными вариантами воплощения. Дополнительно декодер содержит контроллер 136 для реализации вариантов воплощения, описанных выше. Контроллер 136 сконфигурирован обнаруживать условия в свойствах ранее принятого и восстановленного аудиосигнала или в статистических свойствах наблюдаемых потерь кадров, для которых подстановка потерянного кадра в соответствии с описанными способами обеспечивает относительно более низкое качество. В случае, если такое условие обнаружено, контроллер 136 сконфигурирован изменять элемент способов маскировки, в соответствии с которым спектр подстановочного кадра вычисляется как 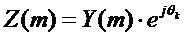 , путем выборочной настройки фаз или спектральных амплитуд. Обнаружение может быть выполнено блоком 146 детектора, а модификация может быть выполнена блоком 148 модификатора, как изображено на фигуре 14.
, путем выборочной настройки фаз или спектральных амплитуд. Обнаружение может быть выполнено блоком 146 детектора, а модификация может быть выполнена блоком 148 модификатора, как изображено на фигуре 14.
Декодер с входящими в его состав блоками может быть реализован в аппаратных средствах. Есть множество вариантов схемотехнических элементов, которые могут использоваться и комбинироваться для достижения функций блоков декодера. Такие варианты охватываются вариантами воплощения. Конкретными примерами аппаратной реализации декодера является реализация в аппаратных средствах и технологии интегральной схемы цифрового сигнального процессора (DSP), включая и электронные схемы общего назначения, и специализированные схемы.
Декодер 150, описанный в настоящем документе, может быть альтернативно реализован, например, как изображено на фигуре 15, то есть с помощью одного или нескольких процессоров 154 и соответствующего программного обеспечения 155 с подходящим накопителем или памятью 156 для него для восстановления аудиосигнала, что включает в себя выполнение маскировки потери аудиокадров в соответствии с вариантами воплощения, описанными в настоящем документе, как показано на фигуре 13. Входящий закодированный аудиосигнал принимается входом (ВХОД) 152, с которым соединены процессор 154 и память 156. Декодированный и восстановленный аудиосигнал, полученный из программного обеспечения, выводится из выхода (ВЫХОД) 158.
Технология, описанная выше, может использоваться, например, в приемнике, который может использоваться в мобильном устройстве (например, мобильном телефоне, портативном компьютере) или стационарном устройстве, таком как персональный компьютер.
Следует понимать, что выбор взаимодействующих блоков или модулей, а также наименования блоков приведены только для иллюстративных целей, и они могут быть сконфигурированы множеством альтернативных путей, чтобы иметь возможность исполнять раскрытые действия процесса.
Следует также отметить, что блоки или модули, описанные в этом раскрытии, должны рассматриваться как логические объекты, а не обязательно как отдельные физические объекты. Следует иметь в виду, что объем технологии, раскрытой в настоящем документе, полностью охватывает другие варианты воплощения, которые могут быть очевидны для специалистов в области техники, и что объем этого раскрытия, соответственно, не должен ограничиваться.
Ссылка на элемент в единственном числе не означает "один и только один", если это не указано явно, а скорее означает "один или несколько".
Все структурные и функциональные эквиваленты элементов вышеописанных вариантов воплощения, которые известны специалистам в области техники, явно включены в настоящий документ по ссылке и должны охватываться им. Кроме того, устройство или способ не обязательно должно решать каждую проблему, которая должна решаться с помощью технологии, раскрытой в настоящем документе, для того, чтобы оно охватывалось настоящим документом.
В предыдущем описании для целей пояснения, а не ограничения, изложены конкретные подробности, такие как конкретная архитектура, интерфейсы, методики и т.д., чтобы обеспечить полное понимание раскрытой технологии. Однако для специалистов в области техники будет очевидно, что раскрытая технология может быть реализована в других вариантах воплощения и/или комбинациях вариантов воплощения, которые отступают от этих конкретных подробностей. То есть специалисты в области техники будут в состоянии разработать различные конструкции, которые, хотя явно не описаны или показаны в настоящем документе, воплощают принципы раскрытой технологии. В некоторых случаях подробные описания известных устройств, электрических цепей и способов опущены, чтобы не загромождать описание раскрытой технологии ненужными подробностями. Все утверждения в настоящем документе, излагающие принципы, аспекты и варианты воплощения раскрытой технологии, а также их конкретные примеры, предназначены для охвата и структурных, и функциональных их эквивалентов. Дополнительно предполагается, что такие эквиваленты включают в себя как в настоящий момент известные эквиваленты, так и эквиваленты, которые могут быть разработаны в будущем, например, любые разработанные элементы, которые выполняют ту же самую функцию, независимо от структуры.
Таким образом, например, специалистам в области техники будет понятно, что фигуры в настоящем документе могут представлять собой концептуальный вид иллюстративной электрической схемы или других функциональных блоков, воплощающих принципы технологии и/или различных процессов, которые могут быть, по сути, представлены на машиночитаемом носителе и исполнены компьютером или процессором даже при том, что такой компьютер или процессор могут быть не показаны явно на фигурах.
Функции различных элементов, в том числе функциональных блоков, могут быть обеспечены с помощью аппаратных средств, таких как аппаратные средства электрических цепей и/или аппаратные средства, способные исполнять программное обеспечения в форме кодированных инструкций, сохраненных на машиночитаемом носителе. Таким образом, такие функции и изображенные функциональные блоки должны пониматься как реализованные или с помощью аппаратных средств, и/или с помощью компьютера и, таким образом, реализованными машинным образом.
Варианты воплощения, описанные выше, следует понимать как несколько иллюстративных примеров настоящего изобретения. Специалистам в области техники будет понятно, что различные модификации, комбинации и изменения могут быть сделаны в вариантах воплощения, не отступая от объема настоящего изобретения. В частности, решения для различных частей в различных вариантах воплощения могут быть объединены в других конфигурациях, где это технически возможно.
Способы и устройства в системе беспроводной связи
Способ и устройство в сети радиодоступа
Устройства и способы подстройки частоты в синтезаторе частот с множеством выходов
Идентификация процедуры ранжирования улучшенного беспроводного терминала
Способ и устройство управления ресурсами передачи в процессах автоматических запросов на повторную передачу
Способ и устройство для последовательного вычитания помех с помощью обработки матрицы корня ковариации
Повышение надежности протокола гибридного автоматического запроса на повторную передачу данных
Способ и устройство для осуществления связи по радиоканалу
Способ и устройство достоверного определения весовых коэффициентов в системе cdma с помехами
Способ связи между платформами
Расширение полосы пропускания звукового сигнала нижней полосы
Маскирование ошибок в кадрах
Способ и устройство для управления маскировкой потери аудиокадров
Гибридный формат полезной нагрузки rtp
Выбор процедуры маскирования потери пакета
Поиск формы пирамидального векторного квантователя
Классификация и кодирование аудиосигналов
Способ и устройство для управления сглаживанием стационарного фонового шума
Способ и система поочередной передачи информации о режиме кодека
Выбор процедуры маскирования потери пакета

