Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА ДЛЯ ИСПРАВЛЕНИЯ НЕВЕРНОГО НАБОРА СЛОВА ВСЛЕДСТВИЕ ОШИБКИ ВВОДА С КЛАВИАТУРЫ И/ИЛИ НЕПРАВИЛЬНОЙ РАСКЛАДКИ КЛАВИАТУРЫ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящая технология относится к исправлению неверно набранного слова, в частности, к способу и системе для исправления слова, неверно набранного вследствие ошибки ввода с клавиатуры и/или неправильной раскладки клавиатуры.
Уровень техники
Различные глобальные и локальные сети (Интернет, World Wide Web, локальные сети и т.д.) обеспечивают пользователю доступ к огромному объему информации. Эта информация включает в себя множество контекстно-зависимых тем, таких как новости и текущие события, карты, информация о компаниях, финансовая информация и ресурсы, информация о дорожном движении, информация об играх и развлечениях и т.п. Пользователи применяют разнообразные электронные устройства (настольный компьютер, ноутбук, смартфон, планшет и т.д.) для получения доступа к веб-страницам и к разнообразному контенту (изображениям, аудиоматериалам, видеоматериалам, анимации и другому мультимедийному контенту из таких сетей).
В целом, конкретный пользователь может осуществлять доступ к ресурсу через сеть связи двумя основными способами. Пользователь может непосредственно получать доступ к определенному ресурсу либо путем ввода адреса ресурса с клавиатуры (обычно URL (универсальный указатель ресурсов), такой как www.webpage.com), либо путем перехода по ссылке, доступной в сообщении электронной почты или на другом веб-ресурсе. В другом случае пользователь может выполнять поиск интересующего ресурса с использованием поисковой системы. Последний вариант особенно удобен, когда пользователю известна интересующая его тема, но не известен точный адрес интересующего ресурса.
Пользователю доступно множество поисковых систем. Некоторые из них считаются универсальными поисковыми системами (такие как Yandex™, Google™, Yahoo™ и т.д.). Другие считаются системами вертикального поиска, ориентированными на конкретную область, например, Momondo™ - специализированная система поиска авиарейсов.
Любая поисковая система обычно способна принимать поисковый запрос от пользователя, выполнять поиск и направлять пользователю ранжированную страницу результатов поисковой системы (SERP). Для ранжирования веб-страниц используется огромное количество факторов и, в частности, релевантность в отношении слов в поисковом запросе (т.е. ключевых слов).
Тем не менее, опечатки в поисковых запросах, передаваемых в поисковые системы, часто затрудняют проведение надлежащего поиска и предоставление релевантных результатов поиска.
В целом, опечатки можно разделить на две категории. Во-первых, это опечатки, возникающие вследствие неправильного ввода с клавиатуры. Например, когда вместо слова «patent» пользователь вводит слово «oatent» из-за близкого расположения клавиш «р» и «о». Опечатки такого типа часто происходят на мобильных устройствах, поскольку пользовательские интерфейсы имеют весьма ограниченные размеры и пользователи непреднамеренно нажимают неверные кнопки из-за их малого размера и близкого расположения.
Во-вторых, это опечатки, возникающие вследствие неправильной раскладки клавиатуры. Например, существуют различные раскладки компьютерных клавиатур, первоначально возникшие для совместного использования наборов символов. Например, для большинства романских языков может использоваться стандартная клавиатура QWERTY, но также применяются и ее варианты, например, клавиатура QWERTY для канадского варианта французского языка. Кроме того, может существовать несколько раскладок клавиатуры и для одного языка, в частности, для русского, для которого доступны раскладки ЙЦУКЕН и русская фонетическая раскладка (также называемая омофонической или транслитерированной). Достаточно распространены электронные устройства, способные принимать данные, вводимые с использованием различных раскладок клавиатуры. В результате пользователь может непреднамеренно вводить поисковый запрос с клавиатуры с неправильной раскладкой и из-за этого неверно набирать слово.
Существует несколько основанных на применении компьютерной техники подходов к исправлению поисковой системой неверно набранного слова в поисковом запросе. Например, простой подход заключается в создании базы данных неверно набранных слов и соответствующих верно набранных слов. Тем не менее, такой подход требует огромного количества вычислительных ресурсов для создания базы данных.
В документе US 2010/0050074 (опубликован 25 февраля 2010 г.) описан способ исправления короткого текстового сообщения, включающий в себя следующие шаги: создание таблицы общеупотребительных слов и вариантов их неправильного написания; определение используемой для отправки сообщения клавиатуры, проверка сообщения на предмет понятности; определение наиболее вероятной ошибки, замена символов на основе иерархической системы совместно используемых клавиш, за которыми следуют соседние клавиши, чтобы предложить гипотезу для исправления наиболее вероятной ошибки; проверка предполагаемого исправления на предмет понятности и повторение соответствующих шагов, пока не будет сформировано понятное сообщение.
В документе US 2010/125725 (опубликован 20 мая 2010 г.) описаны способ, система и компьютерный программный продукт для определения раскладки клавиатуры, которые повышают качество предложений по исправлению написания, а также позволяют распознавать несоответствие клавиатуры компьютера данному удаленному пользователю на основе определенного ограниченного словаря. При этом для передачи информации между текстовым редактором и системой проверки правописания для определения раскладки клавиатуры не требуется дополнительного прикладного программного интерфейса (API).
В документе US 2010/259561 (опубликован 14 октября 2010 г.) описаны способы и системы для определения настраиваемых виртуальных клавиатур на сенсорной поверхности, такой как сенсорный экран. С использованием алгоритмов обучения вычислительное устройство способно изучать присущие пользователю паттерны ввода с клавиатуры и изменять местоположение, размеры и ориентацию кнопок виртуальной клавиатуры так, чтобы обеспечить пользователю комфорт и уменьшить количество опечаток. Пользователь может создавать собственную раскладку клавиатуры путем нажатия последовательности кнопок на сенсорной поверхности. Вычислительное устройство может сопоставлять места прикосновений с определенными кнопками и сформировать данные о раскладке клавиатуры, которые могут использоваться для отображения виртуальной клавиатуры и интерпретации прикосновений к сенсорной поверхности. Вычислительное устройство может контролировать ввод пользователем с клавиатуры и оптимизировать данные о раскладке клавиатуры на основе обнаруженных или исправленных опечаток. Данные о раскладке клавиатуры могут экспортироваться в другие устройства, чтобы в них пользователю также была доступна собственная виртуальная клавиатура.
В документе US 5956739 (опубликован 21 сентября 1999 г.) описана система исправления ошибок пользователя, включая контекстно-зависимые орфографические ошибки и т.п., в которой используется адаптивный алгоритм исправления ошибок, обучаемый не только на традиционном обучающем корпусе текста, но и на исправляемом тексте, чтобы обеспечить исправление слов на основе определенных вариантов использования слов в исправляемом тексте, который большей частью не содержит ошибок.
Раскрытие изобретения
Целью настоящего изобретения является создание усовершенствованных способа и системы для исправления неверно набранного слова. Настоящая технология нацелена на исправление слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры. В результате уменьшается энергопотребление и затраты вычислительных ресурсов на серверах, связанных с поисковой системой.
При разработке настоящей технологии разработчики обратили внимание на возможность создания алгоритма машинного обучения (MLA) для исправления неверно набранного слова независимо от причины опечатки при условии, что алгоритм обучался на подходящих обучающих данных.
Безотносительно какой-либо конкретной теории, варианты осуществления настоящей технологии разработаны на основе предположения, что для обучения вышеупомянутого алгоритма MLA могут использоваться искусственно созданные измененные формулировки слов. По меньшей мере некоторые варианты осуществления настоящей технологии относятся к формированию «реалистичных опечаток», которые могут использоваться для обучения алгоритма MLA. Реалистичная опечатка представляет собой одну из наиболее вероятных опечаток, возникающих при вводе пользователем с клавиатуры поискового запроса и т.п. Эти измененные формулировки основываются на корпусе текста, содержащем слова. В некоторых вариантах осуществления настоящей технологии корпус текста может представлять собой ранее отправленные различными пользователями поисковые запросы. С использованием этих измененных формулировок алгоритм MLA обучается для ранжирования и выбора переформулированного слова, соответствующего правильно введенному слову.
Согласно общему аспекту настоящей технологии обеспечен реализуемый на компьютере и выполняемый сервером способ исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры. На этапе обучения этот способ включает в себя: получение первого слова из корпуса текста; выбор первых n символов первого слова; выбор для первых n символов первого набора возможных символов, каждый из которых представляет собой возможный последующий символ для первых n символов; назначение для каждого возможного символа из первого набора возможных символов значения оценки вероятности, представляющей собой вероятность того, что данный возможный символ из первого набора возможных символов является последующим символом для первых n символов, причем эта вероятность определяется по меньшей мере в зависимости от совместного появления первых n символов и данного возможного символа в корпусе текста; выбор первого числа наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности с образованием из них первого подмножества первого набора возможных символов; выбор второго подмножества первого набора возможных символов, содержащего возможные символы, не входящие в состав первого подмножества; формирование для каждого возможного символа из первого подмножества первого набора возможных символов соответственного положительного переформулированного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом из первого подмножества, причем каждое положительное переформулированное слово и первое слово образуют положительную обучающую пару с первым значением метки; формирование для каждого возможного символа из второго подмножества первого набора возможных символов соответственного отрицательного переформулированного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом из второго подмножества, причем каждое отрицательное переформулированное слово и первое слово образуют отрицательную обучающую пару со вторым значением метки, при этом положительные обучающие пары и отрицательные обучающие пары являются обучающими парами, а каждое отрицательное или положительное переформулированное слово является обучающим словом; обучение алгоритма машинного обучения (MLA), включающее в себя: определение для каждой обучающей пары набора признаков, представляющих свойство обучающей пары; ранжирование обучающих пар на основе набора признаков, связанных с каждой обучающей парой, причем наибольший ранг обучающей пары указывает на отсутствие опечатки в соответственном обучающем слове.
В некоторых вариантах осуществления способ на этапе использования дополнительно включает в себя: получение для обработки текстовой фразы, содержащей по меньшей мере второе слово, из клиентского устройства; выбор первых n символов второго слова; выбор второго набора возможных символов, каждый из которых является возможным последующим символом для первых n символов второго слова; определение значения оценки вероятности для каждого возможного символа из второго набора возможных символов; выбор второго числа наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности; формирование для каждого из второго числа наиболее вероятных из возможных символов соответственного возможного слова, соответствующего второму слову, в котором по меньшей мере n+1-й символ заменен соответственным из второго числа наиболее вероятных из возможных символов, при этом каждое возможное слово и второе слово образуют возможную пару слов; ранжирование каждой возможной пары слов с использованием алгоритма MLA с целью определить возможную пару слов с наибольшим рангом; формирование измененной текстовой фразы, соответствующей текстовой фразе, в которой второе слово заменено возможным словом из возможной пары слов с наибольшим рангом.
В некоторых вариантах осуществления способа присвоение значения оценки вероятности для данного возможного символа включает в себя определение значения оценки совместного появления путем определения в корпусе текста набора слов, имеющих одинаковые первые n символов, и определения для каждого возможного символа из первого набора возможных символов частоты совместного появления после первых n символов в пределах этого набора слов.
В некоторых вариантах осуществления способа присвоение значения оценки вероятности для данного возможного символа дополнительно включает в себя определение для данного возможного символа значения оценки штрафа, указывающей на маловероятность того, что данный возможный символ является последующим символом для первых n символов первого слова, и корректировку ранее определенного значения оценки совместного появления с использованием значения оценки штрафа.
В некоторых вариантах осуществления способа присвоение значения оценки штрафа включает в себя выбор используемой по умолчанию раскладки клавиатуры, а присвоение значения оценки штрафа для данного возможного символа включает в себя: определение присутствия первой клавиши клавиатуры, связанной с данным возможным символом, на используемой по умолчанию раскладке клавиатуры; если определено, что первая клавиша клавиатуры присутствует на используемой по умолчанию раскладке клавиатуры: определение местоположения первой клавиши клавиатуры на используемой по умолчанию раскладке клавиатуры; определение местоположения второй клавиши, связанной с n+1-м символом первого слова, на используемой по умолчанию раскладке клавиатуры; определение расстояния между первой клавишей клавиатуры и второй клавишей клавиатуры; присвоение значения оценки штрафа в зависимости от этого определенного расстояния; и если определено, что первая клавиша клавиатуры отсутствует на используемой по умолчанию раскладке клавиатуры, назначение для данного возможного символа постоянного значения в качестве значения оценки штрафа.
В некоторых вариантах осуществления способа сервер связан со множеством клиентских устройств посредством сети связи и связан с базой данных журнала поиска, содержащей поисковые запросы, ранее отправленные из множества клиентских устройств, а корпус текста представляет собой эти ранее отправленные поисковые запросы.
В некоторых вариантах осуществления способа сервер дополнительно связан с базой данных обходчика, в которой содержится одно или несколько обозначений универсальных указателей ресурсов (URL), связанных с веб-ресурсами. База данных журнала поиска дополнительно содержит: множество страниц результатов поисковой системы (SERP), сформированных по ранее отправленным поисковым запросам; одно или несколько действий пользователя с множеством страниц SERP, полученных посредством одного или нескольких клиентских устройств, при этом это одно или несколько действий пользователя содержит по меньшей мере сведения о наличии пользователя, выбирающего предложенный поисковый запрос на данной странице SERP, сформированной по данному поисковому запросу. Набор признаков обучающей пары содержит по меньшей мере один из следующих признаков: признак универсального указателя ресурсов (URL), связанный с присутствием данного обучающего слова и первого слова в указателях URL, хранящихся в базе данных обходчика; признак присутствия слова, связанный с присутствием данного обучающего слова и первого слова на по меньшей мере одном веб-ресурсе, доступ к которому осуществлялся с использованием указателей URL, хранящихся в базе данных обходчика; и признак выбора пользователем, связанный с частотой выбора пользователем предлагаемого поискового запроса, соответствующего данному обучающему слову, после ввода пользователем первого слова в качестве поискового запроса.
В некоторых вариантах осуществления способа выбор первого слова из ранее отправленных поисковых запросов включает в себя выбор первого слова из пула предварительно определенных правильно введенных ранее отправленных поисковых запросов, причем это предварительное определение выполнено экспертом.
В соответствии с другим общим аспектом настоящей технологии обеспечен реализуемый на компьютере способ исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры. Способ выполняется на сервере и включает в себя: получение для обработки текстовой фразы, содержащей по меньшей мере первое слово, из клиентского устройства; выбор первых n символов первого слова; выбор первого набора возможных символов, каждый из которых является возможным последующим символом для первых n символов первого слова; назначение для каждого возможного символа из первого набора возможных символов значения оценки вероятности, представляющей собой вероятность того, что данный возможный символ из первого набора возможных символов является последующим символом для первых n символов, причем эта вероятность определяется по меньшей мере в зависимости от совместного появления первых n символов и данного возможного символа в поисковых запросах, содержащихся в корпусе текста; выбор первого числа наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности с образованием из них первого подмножества первого набора возможных символов; формирование для каждого из числа наиболее вероятных из возможных символов соответственного возможного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным из числа наиболее вероятных из возможных символов, причем каждое возможное слово и первое слово образуют возможную пару слов; определение для каждой возможной пары слов набора признаков, представляющих свойство возможной пары слов; ранжирование каждой возможной пары слов на основе соответственного набора признаков с использованием алгоритма MLA с целью определить возможную пару слов с наибольшим рангом; формирование измененной текстовой фразы, соответствующей текстовой фразе, в которой первое слово заменено возможным словом из возможной пары слов с наибольшим рангом.
В некоторых вариантах осуществления способа присвоение значения оценки вероятности для данного возможного символа включает в себя определение значения оценки совместного появления путем определения в корпусе текста набора слов, имеющих одинаковые первые n символов, и определения для каждого возможного символа из первого набора возможных символов частоты совместного появления после первых n символов в пределах этого набора слов.
В некоторых вариантах осуществления способа присвоение значения оценки вероятности для данного возможного символа дополнительно включает в себя определение для данного возможного символа значения оценки штрафа, указывающей на маловероятность того, что данный возможный символ является последующим символом для первых n символов первого слова, и корректировку ранее определенного значения оценки совместного появления с использованием значения оценки штрафа.
В некоторых вариантах осуществления способа присвоение значения оценки штрафа включает в себя выбор используемой по умолчанию раскладки клавиатуры, а присвоение значения оценки штрафа для данного возможного символа включает в себя: определение местоположения первой клавиши, связанной с n+1-м символом первого слова, на используемой по умолчанию раскладке клавиатуры; определение местоположения второй клавиши клавиатуры, связанной с данным возможным символом, на используемой по умолчанию раскладке клавиатуры; определение расстояния между первой клавишей клавиатуры и второй клавишей клавиатуры; присвоение значения оценки штрафа в зависимости от этого определенного расстояния.
В некоторых вариантах осуществления способа, если определено, что вторая клавиша клавиатуры отсутствует на используемой по умолчанию раскладке клавиатуры, то для данного возможного символа в качестве значения оценки штрафа назначается постоянное значение.
В некоторых вариантах осуществления способа сервер связан со множеством клиентских устройств посредством сети связи и связан с базой данных журнала поиска, содержащей поисковые запросы, ранее отправленные из множества клиентских устройств, а корпус текста представляет собой эти ранее отправленные поисковые запросы.
В некоторых вариантах осуществления способа сервер дополнительно связан с базой данных обходчика, в которой содержится одно или несколько обозначений универсальных указателей ресурсов (URL), связанных с веб-ресурсами. База данных журнала поиска дополнительно содержит: множество страниц результатов поисковой системы (SERP), сформированных по ранее отправленным поисковым запросам; одно или несколько действий пользователя с множеством страниц SERP, полученных одним или несколькими клиентскими устройствами, при этом это одно или несколько действий пользователя содержит по меньшей мере сведения о наличии пользователя, выбирающего предложенный поисковый запрос на данной странице SERP, сформированной по данному поисковому запросу. Набор признаков возможной пары слов содержит по меньшей мере один из следующих признаков: признак универсального указателя ресурсов (URL), связанный с присутствием данного возможного слова и первого слова в указателях URL, хранящихся в базе данных обходчика; признак присутствия слова, связанный с присутствием данного возможного слова и первого слова на по меньшей мере одном веб-ресурсе, доступ к которому осуществлялся с использованием указателей URL, хранящихся в базе данных обходчика; и признак выбора пользователем, связанный с частотой выбора пользователем предлагаемого поискового запроса, соответствующего обучающему слову, после ввода пользователем первого слова в качестве поискового запроса.
В некоторых вариантах осуществления способа первое слово представляет собой ошибочно введенное с клавиатуры слово, а возможное слово из возможной пары слов с наибольшим рангом представляет собой второе слово без ошибок.
В некоторых вариантах осуществления способа первое слово представляет собой слово без ошибок, а возможное слово из возможной пары слов с наибольшим рангом представляет собой второе слово.
В некоторых вариантах осуществления способа сервер содержит поисковую систему, текстовая фраза представляет собой поисковый запрос, а обработка измененной текстовой фразы включает в себя одно из следующих действий: отправку этой измененной текстовой фразы в клиентское устройство в качестве предлагаемого поискового запроса и выполнение веб-поиска с использованием этой измененной текстовой фразы.
В соответствии с другим общим аспектом настоящей технологии обеспечен сервер для исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры, содержащий процессор, способный выполнять следующие действия на этапе обучения: получение первого слова из корпуса текста; выбор первых n символов первого слова; выбор для первых n символов первого набора возможных символов, каждый из которых представляет собой возможный последующий символ для первых n символов; назначение для каждого возможного символа из первого набора возможных символов значения оценки вероятности, представляющей собой вероятность того, что данный возможный символ из первого набора возможных символов является последующим символом для первых n символов, причем вероятность определяется по меньшей мере в зависимости от совместного появления первых n символов и данного возможного символа в корпусе текста; выбор первого числа наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности с образованием из них первого подмножества первого набора возможных символов; выбор второго подмножества первого набора возможных символов, содержащего возможные символы, не входящие в состав первого подмножества; формирование для каждого возможного символа из первого подмножества первого набора возможных символов соответственного положительного переформулированного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом из первого подмножества, причем каждое положительное переформулированное слово и первое слово образуют положительную обучающую пару с первым значением метки; формирование для каждого возможного символа из второго подмножества первого набора возможных символов соответственного отрицательного переформулированного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом из второго подмножества, причем каждое отрицательное переформулированное слово и первое слово образуют отрицательную обучающую пару со вторым значением метки, при этом положительные обучающие пары и отрицательные обучающие пары являются обучающими парами, а каждое отрицательное или положительное переформулированное слово является обучающим словом; обучение алгоритма машинного обучения (MLA), включающее в себя: определение для каждой обучающей пары набора признаков, представляющих свойство обучающей пары; ранжирование обучающих пар на основе набора признаков, связанных с каждой обучающей парой, при этом наибольший ранг обучающей пары указывает на отсутствие опечатки в соответственном обучающем слове.
В некоторых вариантах осуществления сервер дополнительно содержит сетевой интерфейс для соединения с сетью связи с возможностью передачи данных, а процессор дополнительно способен выполнять следующие действия на этапе использования: получение для обработки текстовой фразы, содержащей по меньшей мере второе слово, из клиентского устройства; выбор первых n символов второго слова; выбор второго набора возможных символов, каждый из которых является возможным последующим символом для первых n символов второго слова; определение значения оценки вероятности для каждого возможного символа из второго набора возможных символов; выбор второго числа наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности; формирование для каждого из второго числа наиболее вероятных из возможных символов соответственного возможного слова, соответствующего второму слову, в котором по меньшей мере n+1-й символ заменен соответственным из второго числа наиболее вероятных из возможных символов, причем каждое возможное слово и второе слово образуют возможную пару слов; ранжирование каждой возможной пары слов с использованием алгоритма MLA с целью определить возможную пару слов с наибольшим рангом; формирование измененной текстовой фразы, соответствующей текстовой фразе, в которой второе слово заменено возможным словом из возможной пары слов с наибольшим рангом.
В некоторых вариантах осуществления сервер связан со множеством клиентских устройств посредством сети связи и связан с базой данных журнала поиска, содержащей поисковые запросы, ранее отправленные из множества клиентских устройств, а корпус текста представляет собой эти ранее отправленные поисковые запросы.
В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, из электронных устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему и это не существенно для данной технологии. В настоящем контексте выражение «по меньшей мере один сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или инициируется к выполнению одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами); это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов; все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
В контексте настоящего описания, если специально не указано иное, числительные «первый», «второй», «третий» и т.д. используются только для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
В контексте настоящего описания, если специально не указано иное, термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, что и процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
Краткое описание чертежей
Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
На фиг. 1 представлена схема системы, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
На фиг. 2 представлены две клавиатуры с различными раскладками, реализованные согласно известным решениям.
На фиг. 3 приведен пример процесса обучения алгоритма машинного обучения посредством сервера из системы, представленной на фиг. 1.
На фиг. 4 приведена схема, иллюстрирующая структуру и компоненты дерева поиска, сформированного для обучения алгоритма машинного обучения согласно фиг. 3.
На фиг. 5 приведена схема набора положительных переформулированных слов и набора отрицательных переформулированных слов, сформированных на основе дерева поиска, представленного на фиг. 4.
На фиг. 6 приведена схема обучения алгоритма машинного обучения, представленного на фиг. 3.
На фиг. 7 приведен пример процесса исправления слова, неправильно введенного с клавиатуры, посредством сервера из системы, представленной на фиг. 1.
На фиг. 8 приведена блок-схема способа обучения алгоритма машинного обучения согласно фиг. 3.
Осуществление изобретения
На фиг. 1 представлена схема системы 100, пригодной для практической реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена только для демонстрации варианта практической реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях также приведены полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объем или границы настоящей технологии. Эти модификации не составляют исчерпывающего списка. Специалисту в данной области очевидно, что возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области очевидно, что это не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Специалисту в данной области очевидно, что различные варианты практической реализации настоящей технологии могут быть значительно сложнее.
Представленные в данном описании примеры и условный язык предназначены для лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких конкретных примеров и условий. Очевидно, что специалисты в данной области техники могут разработать различные способы и устройства, которые явно не описаны и не показаны, но осуществляют принципы настоящей технологии в пределах ее существа и объема. Кроме того, чтобы способствовать лучшему пониманию, дальнейшее описание может содержать упрощенные варианты практической реализации настоящей технологии. Специалисту в данной области очевидно, что различные варианты практической реализации настоящей технологии могут быть значительно сложнее.
Более того, описание принципов, аспектов и вариантов осуществления настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных схем, осуществляющих принципы настоящей технологии. Аналогично, должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены в на машиночитаемом носителе информации и выполняться посредством компьютера или процессора, независимо от того, показан такой компьютер или процессор в явном виде или нет.
Функции различных элементов, показанных на фигурах, включая любой функциональный блок, обозначенный как «процессор», могут осуществляться путем использования специализированных аппаратных средств, а также аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, его функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, общего применения и/или заказные.
Учитывая вышеизложенные принципы, далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты осуществления аспектов настоящей технологии.
Система 100 содержит электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и иногда может называться «клиентским устройством». Следует отметить, что связь электронного устройства 102 с пользователем не означает указания или предположения какого-либо режима работы, например, необходимости входа в систему, необходимости регистрации и т.п.
В контексте данного описания, если специально не указано иное, термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения данной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, например, маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, также может функционировать как сервер для других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов выполнения любых задач или запросов, либо шагов любого описанного здесь способа.
Электронное устройство 102 содержит энергонезависимое ЗУ 104. Энергонезависимое ЗУ 104 может содержать один или несколько носителей информации и в общем случае обеспечивает пространство для хранения выполняемых на компьютере команд, которые исполняются процессором 106. Например, энергонезависимое ЗУ 104 может быть реализовано в виде машиночитаемого носителя информации, включая ПЗУ, жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
Электронное устройство 102 содержит известные в данной области техники аппаратные средства и/или программное обеспечение, и/или встроенное программное обеспечение (либо их сочетание) для выполнения приложения 108 поиска. В целом, посредством приложения 108 поиска пользователь (не показан) может выполнять поиск, такой как веб-поиск, с использованием расположенной на сервере (описано ниже) поисковой системы. С этой целью приложение 108 поиска содержит интерфейс 110 поискового запроса и интерфейс 112 результатов поиска.
На реализацию приложения 108 поиска не накладывается каких-либо особых ограничений. В одном примере практической реализации приложения 108 поиска пользователь (не показан) для доступа к приложению 108 поиска может осуществлять доступ к веб-сайту, связанному с поисковой системой. Например, доступ к приложению 108 поиска может осуществляться путем ввода с клавиатуры универсального указателя ресурсов (URL) www.yandex.ru, связанного с поисковой системой Yandex™. Очевидно, что доступ к приложению 108 поиска может осуществляться с использованием любой другой коммерчески доступной поисковой системы или поисковой системы для служебного пользования.
В других не имеющих ограничительного характера вариантах осуществления настоящей технологии приложение 108 поиска может быть реализовано как браузерное приложение в портативном устройстве (таком как устройство беспроводной связи). Например, если электронное устройство 102 реализовано как портативное устройство, такое как Samsung™ Galaxy™ S5, в электронном устройстве 102 может выполняться браузерное приложение Yandex™. Очевидно, что любое другое коммерчески доступное или браузерное приложение или браузерное приложение для служебного пользования может использоваться для практической реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
Электронное устройство 102 содержит пользовательский интерфейс ввода (не показан) (такой как клавиатура) для приема данных, вводимых пользователем, например, в интерфейс 110 поискового запроса. На реализацию пользовательского интерфейса ввода не накладывается каких-либо особых ограничений, она зависит от реализации электронного устройства 102. Только в качестве не имеющего ограничительного характера примера в тех вариантах осуществления настоящей технологии, где электронное устройство 102 реализовано как устройство беспроводной связи (такое как смартфон iPhone™), пользовательский интерфейс ввода может быть реализован как программируемая клавиатура (также называемая экранной или виртуальной клавиатурой). Если электронное устройство 102 реализовано как персональный компьютер (ПК), пользовательский интерфейс ввода может быть реализован как аппаратная клавиатура.
Электронное устройство 102 соединено с сетью 114 связи линией 116 связи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 114 связи может использоваться сеть Интернет. В других вариантах осуществления настоящей технологии сеть 114 связи может быть реализована иначе, например, в виде произвольной глобальной сети связи, локальной сети связи, личной сети связи и т.д.
На реализацию линии 116 связи не накладывается каких-либо особых ограничений, она зависит от реализации электронного устройства 102. Только в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 102 реализовано как беспроводное устройство связи (такое как смартфон), линия связи (не показана) может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 102 реализовано как ноутбук, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение на основе Ethernet).
Очевидно, что варианты практической реализации электронного устройства 102, линии 116 связи и сети 114 связи приведены только для иллюстрации. Специалисту в данной области ясны и другие конкретные детали реализации электронного устройства 102, лини 116 связи и сети 114 связи. Представленные выше примеры никоим образом не ограничивают объем данной технологии.
Система 100 также содержит сервер 118, соединенный с сетью 114 связи. Сервер 118 может быть реализован как традиционный компьютерный сервер. В примере осуществления данной технологии сервер 118 может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 118 может быть реализован с использованием любых других подходящих аппаратных средств и/или программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления данной технологии сервер 118 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления данной технологии функции сервера 118 могут быть распределены между несколькими серверами.
Практическая реализация сервера 118 хорошо известна. В целом, сервер 118 содержит интерфейс связи (не показан), структура и функции которого позволяют ему осуществлять связь с различными объектами (такими как электронное устройство 102 и другие устройства, которые могут быть подключены к сети 114 связи) по сети 114 связи.
Сервер 118 содержит память 120 сервера, которая содержит один или несколько носителей информации и в общем случае обеспечивает пространство для хранения выполняемых на компьютере программных команд, которые исполняются процессором 122 сервера. Например, память 120 сервера может быть реализована как физический машиночитаемый носитель информации, включая ПЗУ и/или ОЗУ. Память 120 сервера также может включать в себя одно или несколько устройств постоянного хранения, например, жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии сервер 118 может управляться той же организацией, что предоставляет вышеописанное приложение 108 поиска. Например, сервер 118 может управляться компанией Yandex LLC (ул. Льва Толстого, 16, Москва, 119021, Россия). В других вариантах осуществления сервер 118 может управляться организацией, отличной от той, что предоставляет описанное приложение 108 поиска.
В некоторых вариантах осуществления настоящей технологии сервер 118 предоставляет доступ к поисковой системе 124 (такой как Yandex Search™), доступной посредством приложения 108 поиска через сеть 114 связи. Способ практической реализации поисковой системы 124 известен в данной области техники и здесь подробно не описан. Достаточно сказать, что поисковая система 124 способна выполнять один или несколько веб-поисков после ввода пользователем (не показан) строки поиска в интерфейс 110 поискового запроса. Поисковая система 124 дополнительно способна передавать в электронное устройство 102 набор результатов поиска для отображения пользователю электронного устройства 102 посредством интерфейса 112 результатов поиска в виде страницы результатов поисковой системы (SERP).
Сервер 118 также способен выполнять функцию обхода для сбора данных веб-ресурсов (не показаны), связанных с сетью 114 связи, и с этой целью содержит приложение 112 обходчика. Несмотря на то, что приложение 132 обходчика показано как входящее в состав сервера 118, в других вариантах осуществления функции приложения 132 обходчика могут быть распределены и могут быть реализованы на нескольких серверах.
В целом, приложение 132 обходчика способно периодически осуществлять доступ к серверам веб-хостинга (не показаны), связанным с сетью 114 связи, для идентификации и извлечения хранящихся там веб-ресурсов.
Приложение 132 обходчика связано первой выделенной линией связи (не пронумерована) с базой 134 данных обходчика. В некоторых вариантах осуществления обозначения просмотренных обходчиком веб-ресурсов (например, соответствующие указатели URL) индексируются и хранятся в базе 134 данных обходчика. Кроме того, база 134 данных обходчика также содержит запись для каждого просмотренного веб-ресурса, такую как дата последнего доступа или обхода, которая может использоваться приложением 132 обходчика для поддержания базы 134 данных обходчика в актуальном состоянии. Несмотря на то, что база 134 данных обходчика показана отдельно от сервера 118, с которым она связана первой выделенной линией связи (не пронумерована), база 134 данных обходчика может быть реализована как часть сервера 118.
Сервер 118 дополнительно связан с базой 126 данных журнала поиска второй выделенной линией связи (не пронумерована). В целом, в базе 126 данных журнала поиска хранится архивная информация, собранная из большого количества ранее выполненных поисковых запросов, которые передавались в поисковую систему 124. Несмотря на то, что база 126 данных журнала поиска показана отдельно от сервера 118, с которым она связана второй выделенной линией связи (не пронумерована), база 126 данных журнала поиска может быть реализована как часть сервера 118.
В некоторых вариантах осуществления база 126 данных журнала поиска способна хранить ранее выполненные поисковые запросы и соответствующие сформированные страницы SERP.
В других вариантах осуществления база 126 данных журнала поиска способна хранить «данные сделанного в прошлом запроса», связанные с каждым сделанным в прошлом запросом, переданным в поисковую систему 124. Например, данные сделанного в прошлом запроса могут содержать сведения о наличии предложенного правильного поискового запроса, который часто отображается в верхней части страницы SERP после ввода поискового запроса с ошибкой. Данные сделанного в прошлом запроса могут дополнительно содержать обозначение, указывающее на то, выбрал ли пользователь предложенный правильный поисковый запрос.
Сервер 118 дополнительно содержит приложение 128 исправления ошибок, хранящееся в памяти 120 сервера. Как более подробно описано ниже, приложение 128 исправления ошибок содержит набор выполняемых компьютером программных команд, которые исполняются процессором 122 сервера для исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры.
Перед переходом к объяснению функций и действий различных компонентов приложения 128 исправления ошибок следует кратко рассмотреть фиг. 2, где показаны два типа раскладок установленной на электронном устройстве 102 клавиатуры: первая клавиатура 202 и вторая клавиатура 204.
Первая клавиатура 202 представляет собой клавиатуру QWERTY, широко распространенную в США и англоговорящей части Канады.
Вторая клавиатура 204 также представляет собой клавиатуру QWERTY, отличную от первой клавиатуры 202, поскольку она адаптирована для французского языка и обычно используется франкоговорящими канадцами в провинции Квебек. Помимо прочего, вторая клавиатура 204 отличается от первой клавиатуры 202 тем, что клавиша, связанная с символом «/», заменена клавишей, связанной с буквой с акутом 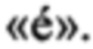
Как указано выше, первый источник опечаток связан с неточным вводом с клавиатуры, часто происходящим вследствие близкого расположения клавиш клавиатуры. Опечатки этого типа менее характерны для клавиатур персональных компьютеров (настольные, ноутбуки, нетбуки и т.д.), но часто происходят на мобильных устройствах, оснащенных миниатюрными клавиатурами с интерфейсом на базе сенсорного экрана. Другой источник опечаток связан с неправильной раскладкой клавиатуры, используемой для ввода текста. Пользователь, например, может непреднамеренно нажать клавишу на клавиатуре с раскладкой, отличающейся от требуемой.
Например, в случае использования первой клавиатуры 202 и второй клавиатуры 204 можно предположить, что франкоговорящий пользователь в Канаде непреднамеренно использует первую клавиатуру 202, и думает (вынужденно или по привычке), что это вторая клавиатура 204, когда пытается ввести поисковый запрос «Comment dessaler la morue  » в интерфейс 110 поискового запроса для выполнения веб-поиска с использованием поисковой системы 124.
» в интерфейс 110 поискового запроса для выполнения веб-поиска с использованием поисковой системы 124.
Вместо предполагаемого запроса поисковая система 124 принимает поисковый запрос «Comment dessaler la morie sal/e», который содержит две опечатки. Во-первых, предполагаемое четвертое слово «morue» превратилось в слово с опечаткой «топе» вследствие близкого расположения букв «i» и «u» на первой клавиатуре 202. Во-вторых, пятое слово  превратилось в «sal/е» вследствие неправильной раскладки клавиатуры.
превратилось в «sal/е» вследствие неправильной раскладки клавиатуры.
Традиционный простой подход к исправлению поискового запроса с опечатками, подобными описанным выше, предусматривал два действия: сначала определялся тип ошибки (ошибочный ввод с клавиатуры или неправильная раскладка клавиатуры), а затем определялось правильное слово. Тем не менее, при разработке настоящей технологии разработчики обратили внимание на то, что путем анализа, в числе прочего, корпуса текста, такого как база 126 данных журнала поиска, возможно использовать единый подход к исправлению неправильно набранного слова без определения типа опечатки.
Далее более подробно описаны функции и действия различных компонентов приложения 128 исправления ошибок. На фиг. 3 представлена схема приложения 128 исправления ошибок для исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры. Приложение 128 исправления ошибок выполняет процедуру 302 получения слова, процедуру 304 формирования оценки вероятности, процедуру 306 формирования переформулированного слова и процедуру 308 исправления слова или иным способом осуществляет доступ к ним.
В контексте настоящего описания термин «процедура» подразумевает подмножество выполняемых на компьютере программных команд приложения 128 исправления ошибок, исполняемых процессором 122 сервера для осуществления описанных ниже функций. Во избежание сомнений, должно быть однозначно понятно, что процедура 302 получения слова, процедура 304 формирования оценки вероятности, процедура 306 формирования переформулированного слова и процедура 308 исправления слова показаны по отдельности и распределенным образом для удобства объяснения действий, выполняемых приложением 128 исправления ошибок. Понятно, что некоторые или все процедуры из числа процедуры 302 получения слова, процедуры 304 формирования оценки вероятности, процедуры 306 формирования переформулированного слова и процедуры 308 исправления слова могут быть реализованы как одна или несколько комбинированных процедур.
Для лучшего понимания настоящей технологии ниже описаны функции процедуры 302 получения слова, процедуры 304 формирования оценки вероятности, процедуры 306 формирования переформулированного слова и процедуры 308 исправления слова, а также обрабатываемые или сохраняемые данные и/или информация на этапе, предшествующем этапу использования приложения 128 исправления ошибок. За ним следует описание этапа использования приложения 128 исправления ошибок.
Предшествующий использованию этап (этап обучения)
Как более подробно описано ниже, приложение 128 исправления ошибок включает в себя алгоритм 314 машинного обучения (MLA), входящий в состав процедуры 308 исправления слова. Ниже описан способ обучения алгоритма 314 MLA.
Для понимания основополагающих концепций настоящей технологии следует осознавать, что обучение алгоритма 314 MLA можно разделить на первый и второй этапы. На первом этапе (выполняемом процедурой 302 получения слова, процедурой 304 формирования оценки вероятности и процедурой 306 формирования переформулированного слова) формируются обучающие данные (описаны ниже) для обучения алгоритма 314 MLA. На втором этапе алгоритм 314 MLA обучается с использованием обучающих данных.
Прием поискового запроса
Процедура 302 получения слова способна принимать пакет 310 данных. В некоторых вариантах осуществления пакет 310 данных содержит первое слово 312, полученное из корпуса текста, такого как база 126 данных журнала поиска. С учетом того, что база 126 данных журнала поиска способна хранить ранее отправленные поисковые запросы, должно быть понятно, что первое слово 312 может представлять собой слово, ранее введенное данным пользователем. Первое слово 312 может представлять собой неправильно или правильно введенное слово. В некоторых вариантах осуществления настоящей технологии корпус текста может использоваться «как есть», т.е. и с правильно введенными словами, и с опечатками (или даже с орфографическими ошибками). Очевидно, что оператор (не показан), связанный с приложением 128 исправления ошибок, может выбирать в качестве первого слова 312 правильно введенные слова из базы 126 данных журнала поиска и отвергать слова с опечатками и орфографическими ошибками.
Несмотря на то, что процедура 302 получения слова описана, как принимающая пакет 310 данных из базы 126 данных журнала поиска, такой вариант не носит ограничительного характера и прием может, например, осуществляться из другого корпуса текста, такого как веб-ресурс, словарь и т.п.
После получения пакета 310 данных процедура 302 получения слова способна выбирать первые n символов 402 (ниже объясняется со ссылкой на фиг. 4) первого слова 312. Например, процедура 302 получения слова может быть способна выбирать первые два символа первого слова 312. Если первое слово 312 - это «apple», то процедура 302 получения слова выбирает символы «ар». Очевидно, что процедура 302 получения слова может выбирать больше или меньше первых двух символов.
Формирование значения оценки вероятности
Далее для иллюстрации используется фиг. 4. После выбора первых n символов 402 процедура 304 формирования оценки вероятности способна строить дерево 400 поиска. Корень дерева поиска 400 содержит первые n символов 402. На первом уровне дерева 400 поиска процедура 304 формирования оценки вероятности выбирает первый набор 404 возможных символов, каждый из которых представляет собой возможный последующий символ для первых n символов (т.е. последующий элемент в состоянии корня, представленном первыми n символами 402). На способ выбора процедурой 304 формирования оценки вероятности возможных символов из первого набора 404 возможных символов не накладывается каких-либо ограничений. Например, могут выбираться все буквы данного алфавита (такого как латинский или кириллический алфавит), сочетание букв из различных алфавитов, сочетание букв (из одного или нескольких алфавитов) и знаков препинания или предварительно определенное количество символов рядом с клавишей, связанной с символом, следующим за первыми n символами 402 на одной или нескольких раскладках клавиатуры. В одном не имеющем ограничительного характера варианте осуществления настоящей технологии процедура 304 формирования оценки вероятности выбирает возможные символы из предварительно определенного первого алфавита и предварительно определенного второго алфавита. В другом не имеющем ограничительного характера варианте осуществления настоящей технологии процедура 304 формирования оценки вероятности выбирает возможные символы из предварительно определенной первой раскладки клавиатуры для данного алфавита и предварительно определенной второй раскладки клавиатуры для этого же алфавита.
На основе первых n символов 402 и первого набора 404 возможных символов процедура 304 формирования оценки вероятности способна присваивать значение оценки вероятности для каждого возможного символа из первого набора 404 возможных символов. В некоторых вариантах осуществления значение оценки вероятности представляет вероятность того, что данный возможный символ из первого набора 404 возможных символов является последующим символом для первых n символов 402, на основе по меньшей мере анализа корпуса текста, такого как база 126 данных журнала поиска. На способ практической реализации значения оценки вероятности не накладывается каких-либо ограничений, например, она может быть реализована как значение в процентах или как значение в диапазоне от 1 до 10 либо в любом другом числовом диапазоне.
В представленном примере в качестве первых n символов 402 используются символы «ар», а первый набор 404 возможных символов содержит пять возможных символов: первый возможный символ 406, второй возможный символ 408, третий возможный символ 410, четвертый возможный символ 412 и пятый возможный символ 414. Очевидно, что первый набор 404 возможных символов может содержать больше или меньше возможных символов, а также некоторые другие символы из другого языка (например, кириллические символы) и/или знаки пунктуации.
Значение оценки вероятности определяется на основе по меньшей мере значения оценки совместного появления. В некоторых вариантах осуществления значение оценки совместного появления представляет вероятность того, что данный возможный символ является последующим символом для первых n символов 402, которая определяется в зависимости от совместного появления первых n символов и данного возможного символа в корпусе текста, таком как ранее выполненные поисковые запросы, хранящиеся в базе 126 данных журнала поиска. Иными словами, процедура 304 формирования оценки вероятности способна определять вероятность того, что данный символ является последующим символом для первых n символов 402, исходя из ранее отправленных поисковых запросов, хранящихся в базе 126 данных журнала поиска. Очевидно, что значение оценки совместного появления может определяться в зависимости от совместного появления первых n символов 402 и данного возможного символа в другом корпусе текста, таком как словарь и т.п. На способ практической реализации значения оценки совместного появления не накладывается каких-либо ограничений, она может, например, представлять собой значение в процентах или значение в диапазоне от 1 до 10 либо в любом другом числовом диапазоне.
Далее описан способ назначения оценки совместного появления. Как показано на фиг. 3, процедура 304 формирования оценки вероятности способна передавать пакет 316 данных в базу данных (не показана), содержащую корпус текста, такую как база 126 данных журнала поиска. Пакет 316 данных содержит обозначение первых n символов 402, а также запрос содержащихся в базе 126 данных журнала поиска слов, содержащих эти первые n символов 402, и их соответствующих частот появления в базе 126 данных журнала поиска.
В некоторых вариантах осуществления пакет 316 данных дополнительно содержит команду ограничения, согласно которой запрашиваются только слова, состоящие из такого же количества символов, что и первое слово 312. Согласно представленному выше примеру, если первое слово 312 - «apple», то пакет 316 данных может содержать обозначение первых двух символов «ар» и запрос хранящихся в базе 126 данных журнала поиска слов, которые начинаются с символов «ар» и состоят из такого же количества символов, как и слово «apple» (пять символов), и их частот появления в базе 126 данных журнала поиска.
База 126 данных журнала поиска передает процедуре 304 формирования оценки вероятности пакет 318 данных, который включает в себя набор слов, содержащих указанные первые n символов 402, и указание на частоту появления каждого из этих слов.
После получения пакета 318 данных процедура 304 формирования оценки вероятности присваивает значение оценки совместного появления для каждого возможного символа из первого набора 404 возможных символов таким образом, что возможному символу, который часто следует за первыми n символами 402, присваивается большее значение оценки совместного появления, а возможным символам, которые реже следуют за первыми n символами 402, присваивается меньшее значение оценки совместного появления.
При разработке настоящей технологии разработчики обратили внимание на то, что некоторые возможные символы, часто следующие за первыми n символами 402, получают неправильно определенное значение оценки вероятности, если основываться исключительно на значении оценки совместного появления. Очевидно, что значение оценки совместного появления следует скорректировать, поскольку основной принцип этого шага заключается в определении возможных символов, которые, вероятно, ошибочно введены пользователем (вследствие неточного ввода с клавиатуры и/или неправильной раскладки клавиатуры) вместо требуемого символа. Поэтому в некоторых вариантах осуществления определяется значение оценки штрафа, корректирующее значение оценки совместного появления.
В некоторых вариантах осуществления значение оценки штрафа указывает на маловероятность того, что данный возможный символ следует за первыми n символами 402. На способ практической реализации значения оценки штрафа не накладывается каких-либо ограничений, например, она может представлять собой значение в процентах или значение в диапазоне от 1 до 10 либо в любом другом числовом диапазоне.
В некоторых вариантах осуществления значение оценки штрафа представляет собой первое значение оценки штрафа или второе значение оценки штрафа (как описано ниже). Первое значение оценки штрафа соответствует маловероятности того, что данный возможный символ следует за первыми n символами 402 при данной раскладке клавиатуры.
Далее описан способ определения оценки первого значения оценки штрафа. Процедура 304 формирования оценки вероятности способна выбирать используемую по умолчанию раскладку клавиатуры. Используемая по умолчанию раскладка клавиатуры может выбираться в зависимости от места предоставления услуг поисковой системой 124. Например, если поисковая система 124 предоставляет услуги в США, то используемая по умолчанию раскладка клавиатуры соответствует первой клавиатуре 202 (см. фиг. 2).
С учетом того, что первое слово 312 - «apple», процедура 304 формирования оценки вероятности способна определять символ, соответствующий символу n+1 первого слова 312 (в данном примере «р»). Процедура 304 формирования оценки вероятности дополнительно способна определять положение клавиши 212 клавиатуры, связанной с буквой «р». Далее процедура 304 формирования оценки вероятности способна назначать соответствующее первое значение оценки штрафа для каждого возможного символа (из первого набора 404 возможных символов) в зависимости от расстояния между клавишей данного символа и клавишей 212 клавиатуры.
Например, при назначении значения оценки вероятности для первого возможного символа 406 («а») и четвертого возможного символа 412 («о») процедура 304 формирования оценки вероятности назначает большее первое значение оценки штрафа для первого возможного символа 406 и меньшее первое значение оценки штрафа для четвертого возможного символа 412, поскольку возможный символ «о» ближе к клавише 212 клавиатуры на первой клавиатуре 202, чем возможный символ «а».
В некоторых вариантах осуществления, когда данный возможный символ отсутствует на используемой по умолчанию раскладке клавиатуры (первая клавиатура 202), процедура 304 формирования оценки вероятности способна присваивать данному возможному символу второе значение оценки штрафа. Например, если первый возможный символ 406 - это не «а», а 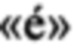 (отсутствует на первой клавиатуре 202), то процедура 304 формирования оценки вероятности способна присваивать второе значение оценки штрафа. В некоторых вариантах осуществления для всех возможных символов, отсутствующих на используемой по умолчанию клавиатуре, применяется одинаковое второе значение оценки штрафа.
(отсутствует на первой клавиатуре 202), то процедура 304 формирования оценки вероятности способна присваивать второе значение оценки штрафа. В некоторых вариантах осуществления для всех возможных символов, отсутствующих на используемой по умолчанию клавиатуре, применяется одинаковое второе значение оценки штрафа.
Как показано на фиг. 4, процедура 304 формирования оценки вероятности присваивает значение оценки вероятности для каждого символа из первого набора 404 возможных символов в зависимости от ранее определенного значения оценки совместного появления и значения оценки штрафа. В некоторых вариантах осуществления значение оценки вероятности соответствует значению оценки совместного появления, уменьшенному на значение оценки штрафа.
Процедура 304 формирования оценки вероятности дополнительно способна определять первое число наиболее вероятных из возможных символов, имеющих наибольшее значение оценки вероятности. Например, процедура 304 формирования оценки вероятности способна выбирать два возможных символа, имеющие наибольшее значение оценки вероятности. Очевидно, что процедура 304 формирования оценки вероятности может быть способна выбирать больше или меньше двух возможных символов, имеющих наибольшее значение оценки вероятности.
Например, если определено, что четвертый возможный символ 412 и пятый возможный символ 414 представляют собой два возможных символа с наибольшим значением оценки вероятности, то в дереве 400 поиска второй уровень расширяется с использованием только четвертого возможного символа 412 и пятого возможного символа 414. Иными словами, первый возможный символ 406, второй возможный символ 408 и третий возможный символ 410 игнорируются.
Второй уровень дерева 400 поиска содержит второй набор 416 возможных символов. Второй набор 416 возможных символов включает в себя первое подмножество 418, содержащее возможные символы, следующие за первыми n символами 402 и четвертым возможным символом 412 (т.е. «аро»), и второе подмножество 420, содержащее возможные символы, следующие за первыми n символами 402 и пятым возможным символом 414 (т.е. «арр»). На способ выбора возможных символов во втором наборе 416 возможных символов не накладывается каких-либо ограничений. Выбор может осуществляться аналогично выбору возможных символов в первом наборе 404 возможных символов. Очевидно, что второй набор 416 возможных символов может содержать больше или меньше возможных символов, а также некоторые другие символы из другого языка (такие как кириллические символы) и/или знаки пунктуации.
Затем процедура 304 формирования оценки вероятности способна присваивать значение оценки вероятности для каждого возможного символа из второго набора 416 возможных символов.
В случае взятого в качестве примера первого подмножества 418, процедура 304 формирования оценки вероятности способна передавать пакет 320 данных в базу данных, содержащую корпус текста (в данном примере он соответствует базе 126 данных журнала поиска) (см. фиг. 3). Пакет 320 данных содержит обозначение первых n символов и четвертый возможный символ 412 (т.е. «аро»), а также запрос содержащихся в базе 126 данных журнала поиска слов, содержащих эти первые три символа «аро», и их соответствующих частот появления в базе 126 данных журнала поиска. В некоторых вариантах осуществления пакет 320 данных дополнительно содержит команду ограничения, согласно которой запрашиваются только слова, состоящие из такого же количества символов, что и первое слово 312. Согласно представленному выше примеру, если первое слово 312 - «apple», то пакет 320 данных может содержать символы «аро» и запрос хранящихся в базе 126 данных журнала поиска слов, которые начинаются с символов «аро» и состоят из такого же количества символов, что и слово «apple» (5 символов), и их частот появления в базе 126 данных журнала поиска.
В качестве ответа база 126 данных журнала поиска передает процедуре 304 формирования оценки вероятности пакет 322 данных, содержащий набор слов, содержащих указанные три символа и указание на частоту появления каждого из этих слов.
После получения пакета 322 данных процедура 304 формирования оценки вероятности присваивает значение оценки совместного появления для каждого возможного символа из первого подмножества 418, как описано выше.
Способ присвоения значения оценки штрафа процедурой 304 формирования оценки вероятности описан выше и его подробное описание здесь опущено. Достаточно сказать, что первое значение оценки штрафа для данного возможного символа определяется в зависимости от расстояния между клавишей, связанной с четвертым символом первого слова 312 («L»), и клавишей, связанной с данным возможным символом.
После определения значения оценки вероятности для каждого возможного символа во втором наборе 416 возможных символов процедура 304 формирования оценки вероятности способна снова выбирать первое число наиболее вероятных из возможных символов, имеющих наибольшее значение оценки вероятности во втором наборе 416 возможных символов (т.е. на втором уровне дерева 400 поиска). Например, процедура 304 формирования оценки вероятности способна выбирать два возможных символа, имеющие наибольшее значение оценки вероятности. Очевидно, что процедура 304 формирования оценки вероятности может быть способна выбирать больше или меньше двух возможных символов, имеющих наибольшее значение оценки вероятности. Например, если определено, что возможный символ «L» из первого подмножества 418 и возможный символ «L» из второго подмножества 420 представляют собой два возможных символа с наибольшим значением оценки вероятности во втором наборе 416 возможных символов, то в дереве 400 поиска третий уровень расширяется с использованием только этих возможных символов, а остальные возможные символы игнорируются.
Процедура 304 формирования оценки вероятности способна итеративно строить дерево 400 поиска до k-го уровня, содержащего возможные символы для последнего символа первого слова 312. В представленном примере процедура 304 формирования оценки вероятности способна строить трехуровневое дерево поиска.
Должно быть понятно, что хотя процедура 304 формирования оценки вероятности описана как способная передавать и принимать различные пакеты данных (такие как пакеты 316, 318, 320 и 322 данных), это сделано для удобства объяснения. Очевидно, что все необходимые для построения дерева 400 поиска данные принимаются в пакете 310 данных и поэтому процедуре 304 формирования оценки вероятности при построении дерева 400 поиска не требуется связываться с содержащей корпус текста базой данных, такой как база 126 данных журнала поиска.
Создание переформулированных слов
После формирования дерева 400 поиска последовательности возможных символов от корня до последнего уровня используются для формирования набора 502 положительных переформулированных слов (см. фиг. 5). С учетом того, что для расширения уровня выбираются только два возможных символа, набор 502 положительных переформулированных слов содержит два переформулированных слова: первое положительное переформулированное слово 504 «apole» и второе положительное переформулированное слово 506 «applr».
Очевидно, что хотя в представленном примере только два положительных переформулированных слова входят в состав набора 502 положительных переформулированных слов, это сделано исключительно для удобства ссылок, а не для ограничения объема изобретения. Поскольку количество переформулированных слов, которые можно сформировать, зависит от количества возможных символов, выбираемых для расширения уровня, должно быть понятно, что оператор приложения 128 исправления ошибок может увеличить или уменьшить количество формируемых положительных переформулированных слов путем изменения количества возможных символов, выбираемых для расширения следующего уровня при формировании дерева 400 поиска.
В некоторых вариантах осуществления дерево 400 поиска строится с использованием лучевого поиска, который способен формировать положительно переформулированные слова, соответствующие первому слову 312 или наиболее вероятному неправильно введенному слову для первого слова 312. Поскольку лучевой поиск выполняется на основе данных, содержащихся в базе 126 данных журнала поиска, и на основе анализа раскладок клавиатуры, полученные в результате положительные переформулированные слова (отличные от правильно введенного) могут рассматриваться как вероятно неправильно введенные варианты первого слова 312, полученные вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры.
Кроме того, поскольку дерево 400 поиска содержит на каждом уровне только предварительно определенное количество возможных символов с наибольшим рангом, а остальные возможные символы игнорируются, приложение 128 исправления ошибок способно использовать ограниченный объем памяти 120 сервера при формировании положительных переформулированных слов.
В некоторых вариантах осуществления процедура 306 формирования переформулированного слова дополнительно способна выбирать в дереве 400 поиска один или несколько возможных символов, которые были проигнорированы (таких как первый возможный символ 406), для формирования набора 508 отрицательных переформулированных слов.
Процедура 306 формирования переформулированного слова по меньшей мере способна выбирать на каждом уровне дерева 400 поиска несколько возможных символов, которые были проигнорированы, для формирования отрицательных переформулированных слов.
В некоторых вариантах осуществления процедура 306 формирования переформулированного слова способна выбирать первый возможный символ 406 из первого набора 404 возможных символов (соответствует первому уровню дерева 400 поиска) для формирования первого отрицательного переформулированного слова 510 путем замены символа, следующего за первыми n символами 402 первого слова 312, на первый возможный символ (формируется слово «apale»).
В некоторых вариантах осуществления процедура 306 формирования переформулированного слова способна выбирать проигнорированный возможный символ из второго набора 416 возможных символов для формирования второго отрицательного переформулированного слова 512 путем замены четвертого символа первого слова 312 (соответствующего символу второго уровня в дереве 400 поиска) одним проигнорированным возможным символом (формируется слово «аррае»).
Несмотря на то, что на фиг. 5 показаны только два отрицательных переформулированных слова, это сделано исключительно для удобства ссылок, а не для ограничения объема изобретения. Очевидно, что процедурой 306 формирования переформулированного слова может формироваться больше или меньше отрицательных возможных слов.
Обучение алгоритма 314 MLA
На фиг. 6 представлена процедура 308 исправления слова, способная формировать набор 602 положительных обучающих пар и набор 607 отрицательных обучающих пар.
Набор 602 положительных обучающих пар содержит первую положительную обучающую пару 604 и вторую положительную обучающую пару 606. Первая положительная обучающая пара 604 содержит объединенные в пару первое положительное переформулированное слово 504 и первое слово 312. Аналогично, вторая положительная обучающая пара 606 содержит объединенные в пару второе положительное переформулированное слово 506 и первое слово 312.
Набор 607 отрицательных обучающих пар содержит первую отрицательную обучающую пару 608 и вторую отрицательную обучающую пару 610. Первая отрицательная обучающая пара 608 содержит объединенные в пару первое отрицательное переформулированное слово 510 и первое слово 312. Аналогично, вторая отрицательная обучающая пара 610 содержит объединенные в пару второе отрицательное переформулированное слово 512 и первое слово 312.
Набор 602 положительных обучающих пар и набор 607 отрицательных обучающих пар содержат обучающие пары для алгоритма 314 MLA. Из дальнейшего описания очевидно, что каждое переформулированное слово (например, первое положительное переформулированное слово504, второе положительное переформулированное слово 506, первое отрицательное переформулированное слово 510 и второе отрицательное переформулированное слово 512) может рассматриваться как обучающее слово.
Процедура 308 исправления слова способна присваивать первое значение метки набору 602 положительных обучающих пар. Первое значение метки указывает на то, что первое положительное переформулированное слово 504 и второе положительное переформулированное слово 506, вероятно, представляют собой варианты неправильно введенного с клавиатуры первого слова 312 вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры (правдоподобной опечатки человека). Первое значение метки также указывает на то, что первое слово 312 является «правильным» словом для опечаток, представленных первым положительным переформулированным словом 504 и вторым положительным переформулированным словом 506. Аналогично, процедура 308 исправления слова способна присваивать второе значение метки набору 607 отрицательных обучающих пар. Второе значение метки указывает на то, что первое отрицательное переформулированное слово 510 и второе отрицательное переформулированное слово 512 не являются вероятными вариантами неправильно введенного с клавиатуры первого слова 312 вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры. Второе значение метки также указывает на то, что первое слово 312 не является «правильным» словом для опечаток, представленных первым отрицательным переформулированным словом 510 и вторым отрицательным переформулированным словом 512.
Одно из преимуществ такого подхода заключается в том, что благодаря автоматическому присвоению меток процедурой 308 исправления слова устраняется необходимость в ручном присвоении меток набору обучающих пар. В результате экономятся время и средства, поскольку процесс присвоения меток обычно требует больших трудозатрат. В некоторых вариантах осуществления первое значение метки и второе значение метки представляют собой двоичные значения.
Далее описано обучение алгоритма 314 MLA. Процедура 308 исправления слова способна вводить обучающие данные (набор 602 положительных обучающих пар и набор 607 отрицательных обучающих пар) в алгоритм 314 MLA.
Алгоритм 314 MLA содержит логику обучения для определения набора признаков для каждой обучающей пары (для первой положительной обучающей пары 604, второй положительной обучающей пары 606, первой отрицательной обучающей пары 608 и второй отрицательной обучающей пары 610). В некоторых вариантах осуществления набор признаков характеризует свойства данной обучающей пары.
В некоторых вариантах осуществления набор признаков, рассчитанный для данной обучающей пары, может среди прочего включать в себя:
(i) признак универсального указателя ресурсов (URL), связанный с присутствием данного обучающего слова и первого слова 312 в URL;
(ii) признак присутствия слова, связанный с присутствием данного обучающего слова и первого слова 312 на веб-ресурсе; и
(iii) признак выбора пользователем, связанный с частотой выбора пользователем данного обучающего слова и первого слова 312 в качестве предлагаемого правильного варианта на странице SERP после ввода пользователем данного обучающего слова или первого слова 312 в поисковом запросе.
Далее подробно рассмотрен каждый из вышеупомянутых признаков.
(i) Признак универсального указателя ресурсов (URL), связанный с присутствием данного обучающего слова и первого слова 312 в URL.
С учетом того, что сервер 118 связан с базой 134 данных обходчика, в которой хранится множество указателей URL веб ресурсов, ранее просмотренных обходчиком, признак URL указывает на частоту обнаружения данного обучающего слова и первого слова 312 в указателях URL.
(ii) Признак присутствия слова, связанный с присутствием данного обучающего слова и первого слова 312 на веб-ресурсе.
Признак присутствия слова рассчитывается в зависимости от присутствия данного обучающего слова и первого слова 312 на веб-ресурсе. Признак присутствия слова указывает на частоту появления данного обучающего слова и первого слова на предварительно выбранном по меньшей мере одном веб-ресурсе (таком как Wikipedia™).
(iii) Признак выбора пользователем, связанный с частотой выбора пользователем данного обучающего слова и первого слова 312 в качестве предлагаемого правильного варианта на странице SERP после ввода пользователем данного обучающего слова или первого слова 312 в поисковом запросе.
С учетом того, что в базе 126 данных журнала поиска хранятся сведения о выборе пользователем предлагаемого варианта правильного правописания на странице SERP, сформированной после приема неправильно введенного с клавиатуры слова, признак выбора пользователем указывает на частоту появления неправильно введенного слова, соответствующего первому слову 312, и выбора пользователем предлагаемого варианта правильного правописания для данного обучающего слова (и наоборот).
После определения набора признаков для каждой обучающей пары алгоритм 314 MLA способен анализировать набор признаков положительных переформулированных слов и первого слова 312, а также набор признаков отрицательных переформулированных слов и первого слова 312.
Точнее, с учетом того, что каждая обучающая пара содержит обучающее слово, которое вероятно (положительные примеры) или маловероятно (отрицательные примеры) является неправильно введенным первым словом 312, а соответствующее значение метки указывает на вероятность того, что первое слово 312 является правильным словом для положительных примеров и не является правильным словом для отрицательных примеров, алгоритм 314 MLA способен обучаться определению набора признаков, указывающего на то, что первое слово 312, вероятно, подходит для исправления данного неправильно введенного с клавиатуры слова. Соответственно, алгоритм 314 MLA способен формировать прогнозную функцию, позволяющую ранжировать каждую обучающую пару согласно вероятности того, что данное слово, т.е. первое слово 312 («правая сторона»), подходит для исправления ошибочно введенного с клавиатуры слова («левая сторона»).
Несмотря на то, что обучение алгоритма 314 MLA показано на примере использования только первого слова 312, должно быть понятно, что алгоритм 314 MLA обучается итеративно с использованием множества слов, полученных из корпуса текста.
Выше описан способ подготовки приложения 128 исправления ошибок перед этапом использования. Далее описан этап использования приложения 128 исправления ошибок.
Этап использования
На фиг. 7 представлена схема приложения 128 исправления ошибок на этапе использования. Для простоты элементы приложения 128 исправления ошибок, описанные применительно к этапу обучения (фиг. 3) и аналогичные элементам, применяемым на этапе использования, обозначены одинаковыми ссылочными номерами и их подробное описание опущено.
Ниже описаны функции процедуры 302 получения слова, процедуры 304 формирования оценки вероятности, процедуры 306 формирования переформулированного слова и процедуры 308 исправления слова, а также обрабатываемые или сохраняемые данные и/или информация на этапе использования приложения 128 исправления ошибок.
Прием второго слова
На фиг. 1 представлен содержащий текстовую фразу (т.е. поисковый запрос) пакет 130 данных, отправленный приложением 108 поиска электронного устройства 102 и принятый из поисковой системы 124. В некоторых вариантах осуществления текстовая фраза содержит по меньшей мере одно ошибочно введенное с клавиатуры слово. В некоторых вариантах осуществления текстовая фраза не содержит ошибок.
После приема пакета 130 данных поисковая система 124 способна передавать пакет 702 данных процедуре 302 получения слова. В некоторых вариантах осуществления поисковая система 124 способна перед передачей пакета 702 данных выполнять разбор текстовой строки, принятой в пакете 130 данных, на отдельные слова. На способ выполнения такого разбора не накладывается каких-либо ограничений, например, он может выполняться путем анализа пробелов и знаков препинания между отдельными словами. После разбора текстовой строки поисковая система 124 способна передавать пакет 702 данных, содержащий второе слово 704, входящее в состав текстовой строки. В некоторых вариантах осуществления пакет 702 данных содержит текстовую строку, а процедура 302 получения слова способна разбирать текстовую строку с целью последующего выбора второго слова 704.
Затем процедура 302 получения слова выбирает первые n символов второго слова 704. Например, если второе слово 704 - это «аррое» («apple» с опечаткой), то процедура 302 получения слова выбирает символы «ар».
Формирование значения оценки вероятности
Как и на этапе обучения, после выбора первых n символов процедура 304 формирования оценки вероятности способна строить дерево поиска (не показано), содержащее первый уровень с третьим набором возможных символов, каждый из которых представляет собой возможный символ для первых n символов второго слова 704. На способ выбора возможных символов в третьем наборе возможных символов не накладывается каких-либо ограничений. Выбор может выполняться аналогично выбору возможных символов в первом наборе 404 возможных символов. Очевидно, что третий набор возможных символов может содержать больше или меньше возможных символов, а также некоторые другие символы из другого языка (такие как кириллические символы) и/или знаки пунктуации.
Процедура 304 формирования оценки вероятности дополнительно способна присваивать значение оценки вероятности для каждого возможного символа из третьего набора возможных символов. Способ присвоения процедурой 304 формирования оценки вероятности значения оценки вероятности для каждого из возможных символов из третьего набора возможных символов описан выше и его повторное описание опущено.
Процедура 304 формирования оценки вероятности способна выбирать первое число наиболее вероятных из возможных символов в третьем наборе возможных символов в зависимости от их значения оценки вероятности и расширять дерево поиска на второй уровень и т.д., как описано выше.
Создание возможных слов
Процедура 306 формирования переформулированного слова способна формировать набор возможных слов. Точнее, после формирования дерева поиска для формирования набора возможных слов используются последовательности возможных символов от корня до последнего уровня.
Например, предполагается, что получен следующий набор возможных слов:
Ранжирование возможных слов
Процедура 308 исправления слова способна формировать возможную пару слов для каждого возможного слова в наборе возможных слов и вводить их в алгоритм 314 MLA. Точнее, процедура 308 исправления слова способна создавать пару из каждого возможного слова и второго слова 704 с целью формирования возможной пары слов.
Каждая возможная пара слов затем вводится в алгоритм 314 MLA, который определяет набор признаков для каждой возможной пары слов.
Как описано выше, алгоритм 314 MLA использует вероятные и маловероятные варианты неправильного ввода данного слова и формирует прогнозную функцию, позволяющую ранжировать возможные варианты исправления неправильно введенных слов. На этапе использования алгоритм 314 MLA способен использовать прогнозную функцию для прогнозирования с использованием набора признаков для каждой возможной пары слов (одно из слов представляет собой потенциально ошибочно введенное слово, а второе - возможный вариант исправления) вероятности того, что данный возможный вариант исправления действительно подходит для исправления потенциально неправильно введенных слов, а также для ранжирования слов, представляющих собой возможные варианты исправления, на основе этой определенной вероятности.
Например, возможная пара слов с наибольшим рангом содержит правильно введенное возможное слово, которое, как определил алгоритм 314 MLA, совпадает со вторым словом 704, если второе слово 704 введено правильно. В другом случае возможная пара слов с наибольшим рангом содержит возможное слово, которое соответствует правильно введенному второму слову 704, если второе слово 704 введено неправильно.
Согласно представленному выше в таблице 1 примеру, алгоритм 314 MLA присваивает наибольший ранг возможной паре слов, связанной с первым возможным словом «Apple».
После определения возможного слова с наибольшим рангом процедура 308 исправления слова способна передавать в поисковую систему 124 пакет 706 данных, содержащий возможное слово из возможной пары слов с наибольшим рангом.
После приема пакета 706 данных поисковая система 124 способна формировать измененную текстовую фразу, соответствующую первоначально принятой в пакете 130 данных текстовой фразе, в которой второе слово 704 заменено возможным словом с наибольшим рангом. Например, текстовой фразе «Where to go pick аррое?» соответствует измененная текстовая фраза «Where to go pick apple?».
После формирования измененной текстовой фразы поисковая система 124 способна выполнять следующие действия: (i) выполнение веб-поиска с использованием текстовой фразы и предоставление этой измененной текстовой фразы в качестве предлагаемого поискового запроса на сформированной странице SERP; или (ii) выполнение веб-поиска с использованием этой измененной текстовой фразы.
В некоторых вариантах осуществления приложение 128 исправления ошибок способно выполнять описанные выше действия для каждого слова, содержащегося в текстовой фразе. При этом приложение 128 исправления способно обходиться без доступа к словарю и, как следствие, требует меньше памяти. Разумеется, также предполагается, что приложение 128 исправления ошибок может иметь доступ к словарю и способно выбирать для исправления (как описано выше) только слова, которые не найдены в словаре.
Кроме того, специалистам в данной области техники должно быть очевидно, что настоящая технология позволяет исправлять слово, неверно набранное вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры, без создания базы данных верных слов и соответствующих опечаток, что требует меньше энергии для расчетов и памяти.
Несмотря на то, что этап использования приложения 128 исправления ошибок описан на примере поисковой системы 124, объем изобретения этим не ограничивается. Очевидно, что приложение 128 исправления ошибок может быть реализовано с использованием различных служб. В не имеющем ограничительного характера примере приложение 128 исправления ошибок может загружаться и сохраняться в электронном устройстве 102 и работать совместно с любыми приложениями обмена короткими сообщениями (не показано).
Описанные выше архитектура и примеры позволяют выполнять реализуемый на компьютере способ исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры. На фиг. 8 представлена блок-схема способа 800 обучения алгоритма 314 MLA, реализованного согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера. Способ 800 может выполняться посредством сервера 118.
Шаг 802: получение первого слова из корпуса текста.
Способ 800 далее объясняется на примере сценария, соответствующего примеру, представленному на фиг. 3.
Способ 800 начинается с шага 802, на котором процедура 302 получения слова получает пакет 310 данных, содержащий первое слово 312. В некоторых вариантах осуществления пакет 310 данных передается из базы 126 данных журнала поиска. В некоторых вариантах осуществления первое слово 312 выбирается оператором сервера 118.
Сценарий: процедура 302 получения слова получает из базы 126 данных журнала поиска пакет 310 данных, содержащий первое слово 312 «apple».
Шаг 804: выбор первых n символов первого слова.
На шаге 804 процедура 302 получения слова способна выполнять разбор первого слова 312 и выбирать первые n символов 402 первого слова 312.
Сценарий: процедура 302 получения слова выполняет разбор первого слова 312 и выбирает первые n символов 402, что соответствует «ар».
Шаг 806: выбор для первых n символов первого набора возможных символов, каждый из которых представляет собой возможный последующий символ для первых n символов.
На шаге 806 процедура 304 формирования оценки вероятности способна определять первый набор 404 возможных символов, содержащий один или несколько возможных символов, каждый из которых представляет собой возможный последующий символ для первых n символов 402.
Сценарий: после выбора первых n символов 402 процедура 304 формирования оценки вероятности способна строить дерево 400 поиска, в котором корень содержит первые n символов 402, а первый уровень содержит первый набор 404 возможных символов. Каждый возможный символ из первого набора 404 возможных символов представляет собой возможный последующий символ для первых n символов 402. Первый набор 404 возможных символов содержит первый возможный символ 406, второй возможный символ 408, третий возможный символ 410, четвертый возможный символ 412 и пятый возможный символ 414.
Шаг 808: назначение для каждого возможного символа из первого набора возможных символов значения оценки вероятности, представляющей собой вероятность того, что данный возможный символ из первого набора возможных символов является последующим символом для первых n символов, причем эта вероятность определяется по меньшей мере в зависимости от совместного появления первых n символов и данного возможного символа в корпусе текста.
На шаге 808 процедура 304 формирования оценки вероятности способна присваивать значение оценки вероятности для каждого возможного символа из первого набора 404 возможных символов.
В некоторых вариантах осуществления значение оценки вероятности определяется в зависимости от по меньшей мере одной из двух оценок: значения оценки совместного появления и значения оценки штрафа.
В некоторых вариантах осуществления значение оценки совместного появления представляет вероятность того, что данный возможный символ является последующим символом для первых n символов 402, которая определяется в зависимости от совместного появления первых n символов и данного возможного символа в ранее выполненных поисковых запросах, хранящихся в базе 126 данных журнала поиска.
Сценарий: процедура 304 формирования оценки вероятности рассчитывает значение оценки вероятности для первого возможного символа 406, второго возможного символа 408, третьего возможного символа 410, четвертого возможного символа 412 и пятого возможного символа 414.
Шаг 810: выбор первого числа наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности с образованием из них первого подмножества первого набора возможных символов.
На шаге 810 процедура 304 формирования оценки вероятности способна выбирать первое число наиболее вероятных из возможных символов на основе их соответствующих значений оценки вероятности, определенных на шаге 808.
Сценарий: процедура 304 формирования оценки вероятности выбирает первые два возможных символа с наибольшим значением оценки вероятности: четвертый возможный символ 412 и пятый возможный символ 414.
Затем процедура 304 формирования оценки вероятности расширяет дерево 400 поиска на второй уровень исключительно для выбранных первого числа наиболее вероятных из возможных символов (т.е. для четвертого возможного символа 412 и пятого возможного символа 414).
Шаг 812: выбор второго подмножества первого набора возможных символов, содержащего возможные символы, не входящие в состав первого подмножества.
На шаге 812 процедура 304 формирования оценки вероятности способна выбирать по меньшей мере часть проигнорированных на шаге 810 возможных символов.
Сценарий: процедура 304 формирования оценки вероятности выбирает возможные символы, которые не были выбраны на шаге 810 для расширения дерева 400 поиска (такие как первый возможный символ 406, второй возможный символ 408 и третий возможный символ 410).
Шаг 814: формирование для каждого возможного символа из первого подмножества первого набора возможных символов соответственного положительного переформулированного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом из первого подмножества, причем каждое положительное переформулированное слово и первое слово образуют положительную обучающую пару с первым значением метки.
На шаге 814 процедура 306 формирования переформулированного слова способна формировать соответствующее положительное переформулированное слово для каждого из первого числа наиболее вероятных из возможных символов, выбранных на шаге 810.
Каждое соответствующее положительное переформулированное слово соответствует первому слову 312, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом, выбранным на шаге 810.
Затем процедура 308 исправления слова способна формировать набор 602 положительных обучающих пар, содержащий каждое положительное переформулированное слово, объединенное в пару с первым словом 312, и дополнительно связанный с первым значением метки.
Сценарий: после формирования дерева 400 поиска процедура 306 формирования переформулированного слова формирует первое положительное переформулированное слово 504 («apole») и второе положительное переформулированное слово 506 («applr»).
Например, первое положительное переформулированное слово 504 формируется путем по меньшей мере замены третьего символа первого слова 312 (который соответствует символу n+1 первого слова 312) четвертым возможным символом 412, который ранее на шаге 810 был определен как входящий в число первого числа наиболее вероятных из возможных символов.
Процедура 308 исправления слова формирует набор 602 положительных обучающих пар, содержащий первую положительную обучающую пару 604 и вторую положительную обучающую пару 606. Первая положительная обучающая пара 604 содержит объединенные в пару первое положительное переформулированное слово 504 и первое слово 312. Вторая положительная обучающая пара 606 содержит объединенные в пару второе положительное переформулированное слово 506 и первое слово 312.
Процедура 308 исправления слова дополнительно присваивает первое значение метки набору 602 положительных обучающих пар.
Шаг 816: формирование для каждого возможного символа из второго подмножества первого набора возможных символов соответственного отрицательного переформулированного слова, соответствующего первому слову, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом из второго подмножества, причем каждое отрицательное переформулированное слово и первое слово образуют отрицательную обучающую пару со вторым значением метки, при этом положительные обучающие пары и отрицательные обучающие пары являются обучающими парами, а каждое отрицательное или положительное переформулированное слово является обучающим словом.
На шаге 816 процедура 306 формирования переформулированного слова способна формировать соответствующее отрицательное переформулированное слово для каждого возможного символа, выбранного на шаге 812.
Каждое соответствующее отрицательное переформулированное слово соответствует первому слову 312, в котором по меньшей мере n+1-й символ заменен соответственным возможным символом, выбранным на шаге 812.
Затем процедура 308 исправления слова способна формировать набор 607 отрицательных обучающих пар, содержащий каждое отрицательное переформулированное слово, объединенное в пару с первым словом 312, и дополнительно связанный со вторым значением метки.
Набор 602 положительных обучающих пар, сформированный на шаге 814, и набор 607 отрицательных обучающих пар представляют собой обучающие данные для обучения алгоритма 314 MLA, а каждое отрицательное или положительное переформулированное слово рассматривается как обучающее слово.
Сценарий: процедура 306 формирования переформулированного слова формирует первое отрицательное переформулированное слово 510 («apale») и второе отрицательное переформулированное слово 512 («аррае»).
Например, первое отрицательное переформулированное слово 510 формируется путем по меньшей мере замены третьего символа первого слова 312 (который соответствует символу n+1 первого слова 312) первым возможным символом 406, который ранее был проигнорирован на шаге 812.
Процедура 308 исправления слова формирует набор 607 отрицательных обучающих пар, который содержит первую отрицательную обучающую пару 608 и вторую отрицательную обучающую пару 610. Первая отрицательная обучающая пара 608 содержит объединенные в пару первое отрицательное переформулированное слово 510 и первое слово 312. Вторая отрицательная обучающая пара 610 содержит объединенные в пару второе отрицательное переформулированное слово 512 и первое слово 312.
Процедура 308 исправления слова дополнительно присваивает второе значения метки набору 607 отрицательных обучающих пар.
Шаг 818: обучение алгоритма машинного обучения (MLA), включающее в себя: определение для каждой обучающей пары набора признаков, представляющих свойство обучающей пары; ранжирование обучающих пар на основе набора признаков, связанных с каждой обучающей парой, при этом наибольший ранг обучающей пары указывает на отсутствие опечатки в соответственном обучающем слове.
На шаге 818 процедура 308 исправления слова способна обучать алгоритм 314 MLA путем ввода обучающих данных (набора 602 положительных обучающих пар и набора 607 отрицательных обучающих пар) в алгоритм 314 MLA.
Алгоритм 314 MLA содержит логику обучения для определения набора признаков для каждой обучающей пары. В некоторых вариантах осуществления набор признаков для данной обучающей пары может среди прочего включать в себя: (i) признак URL, (ii) признак присутствия слова и (iii) признак выбора пользователем. Алгоритм 314 MLA дополнительно способен ранжировать обучающие пары на основе этого набора признаков.
В некоторых вариантах осуществления наибольший ранг обучающей пары указывает на отсутствие опечатки в соответственном обучающем слове.
Сценарий: процедура 308 исправления слова вводит набор 602 положительных обучающих пар и набор 607 отрицательных обучающих пар в алгоритм 314 MLA для обучения.
Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления настоящей технологии преследуют цель расширения диапазона технических решений определенной технической проблемы: исправления слова, неверно набранного вследствие ошибочно введенного с клавиатуры символа и/или неправильной раскладки клавиатуры, с целью уменьшить энергопотребление и улучшить распределение памяти.
Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте практической реализации настоящей технологии. Например, возможны варианты практической реализации настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты, когда пользователь получает другие технические эффекты либо когда технический эффект отсутствует.
Изменения и усовершенствования описанных выше вариантов практической реализации настоящей технологии очевидны для специалиста в данной области. Предшествующее описание приведено в качестве примера, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
Несмотря на то, что описанные выше варианты практической реализации приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или что их порядок может быть изменен без отклонения от настоящей технологии. Соответственно, порядок и группировка шагов не носят ограничительного характера для настоящей технологии.
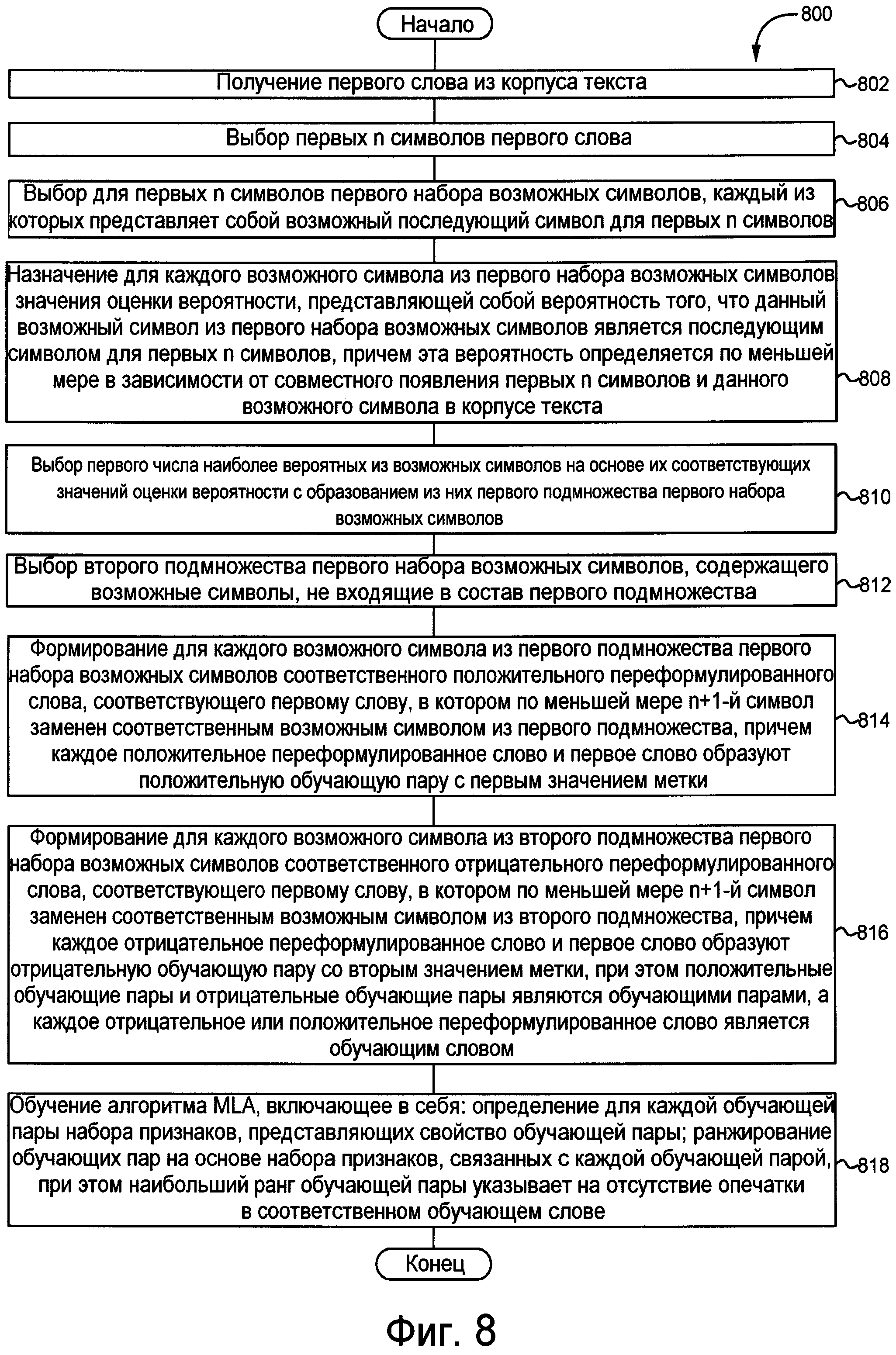
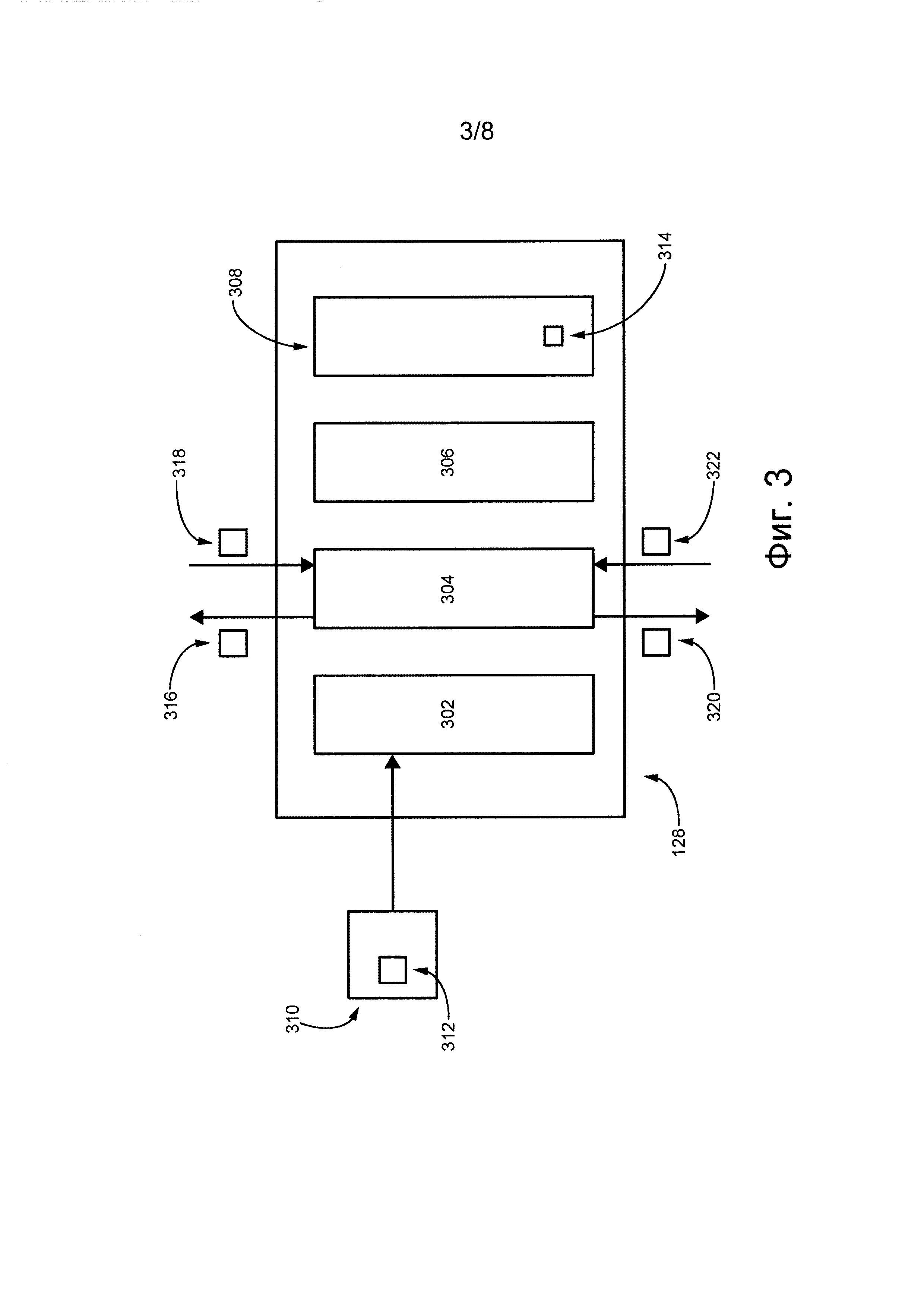
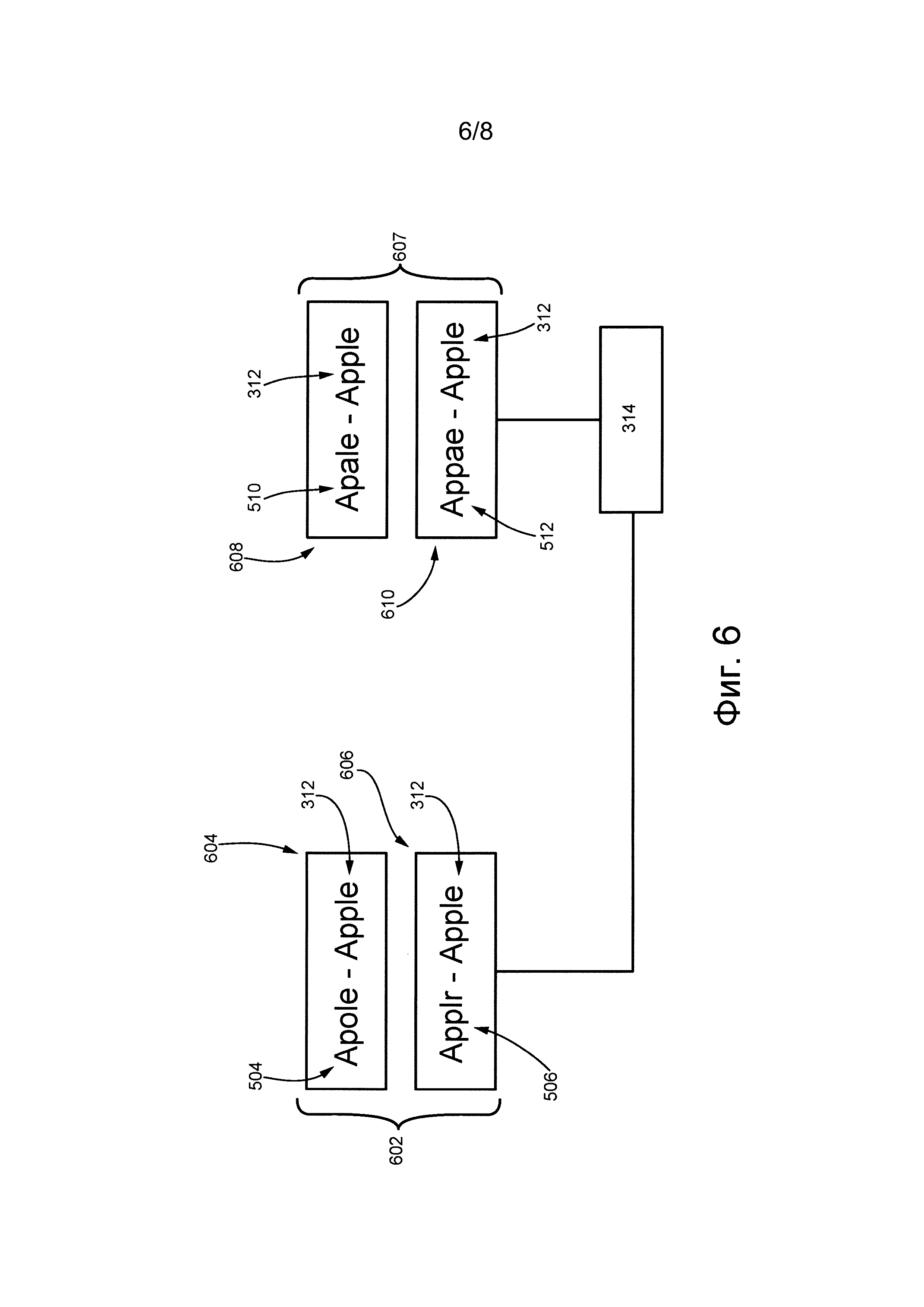
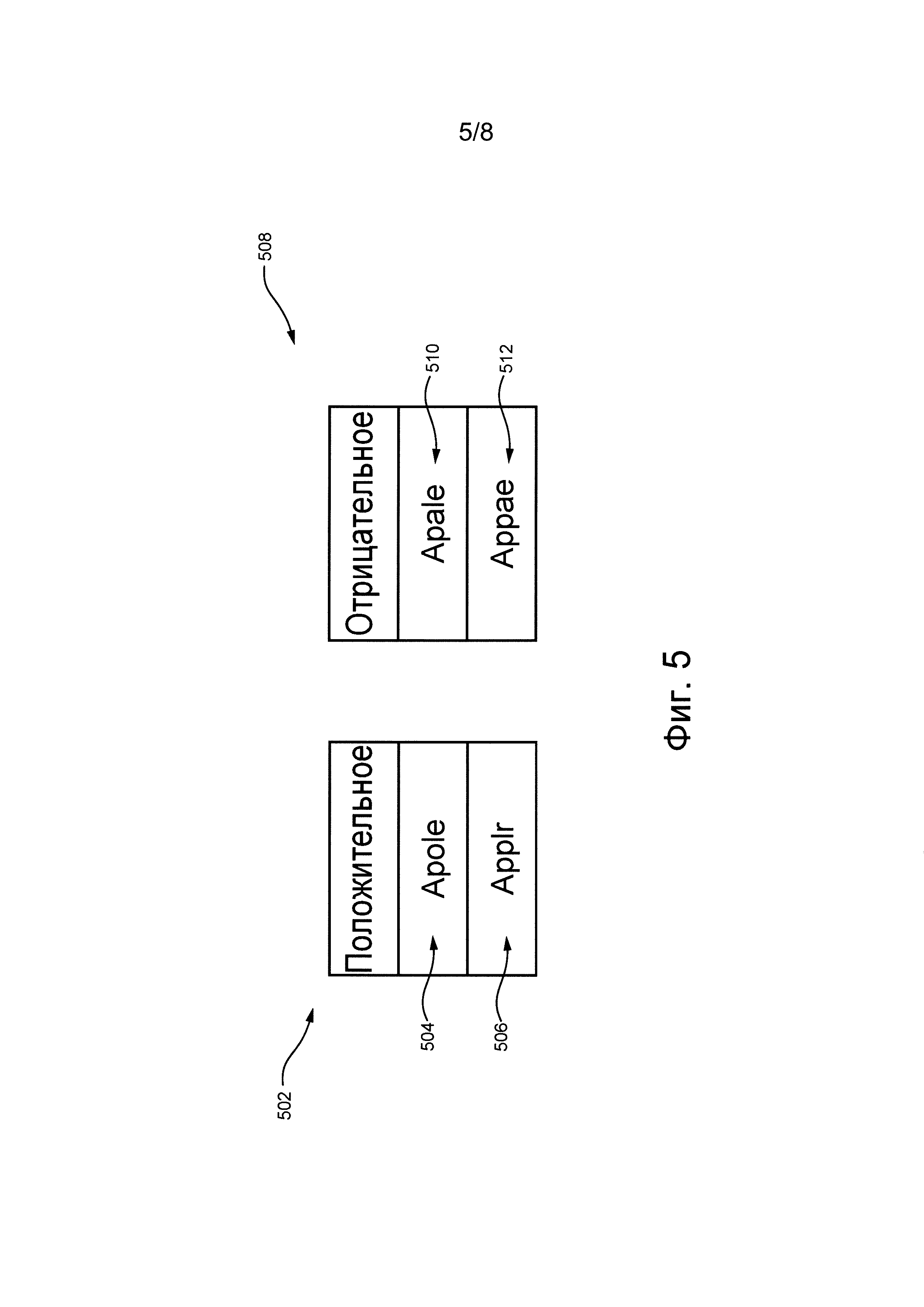

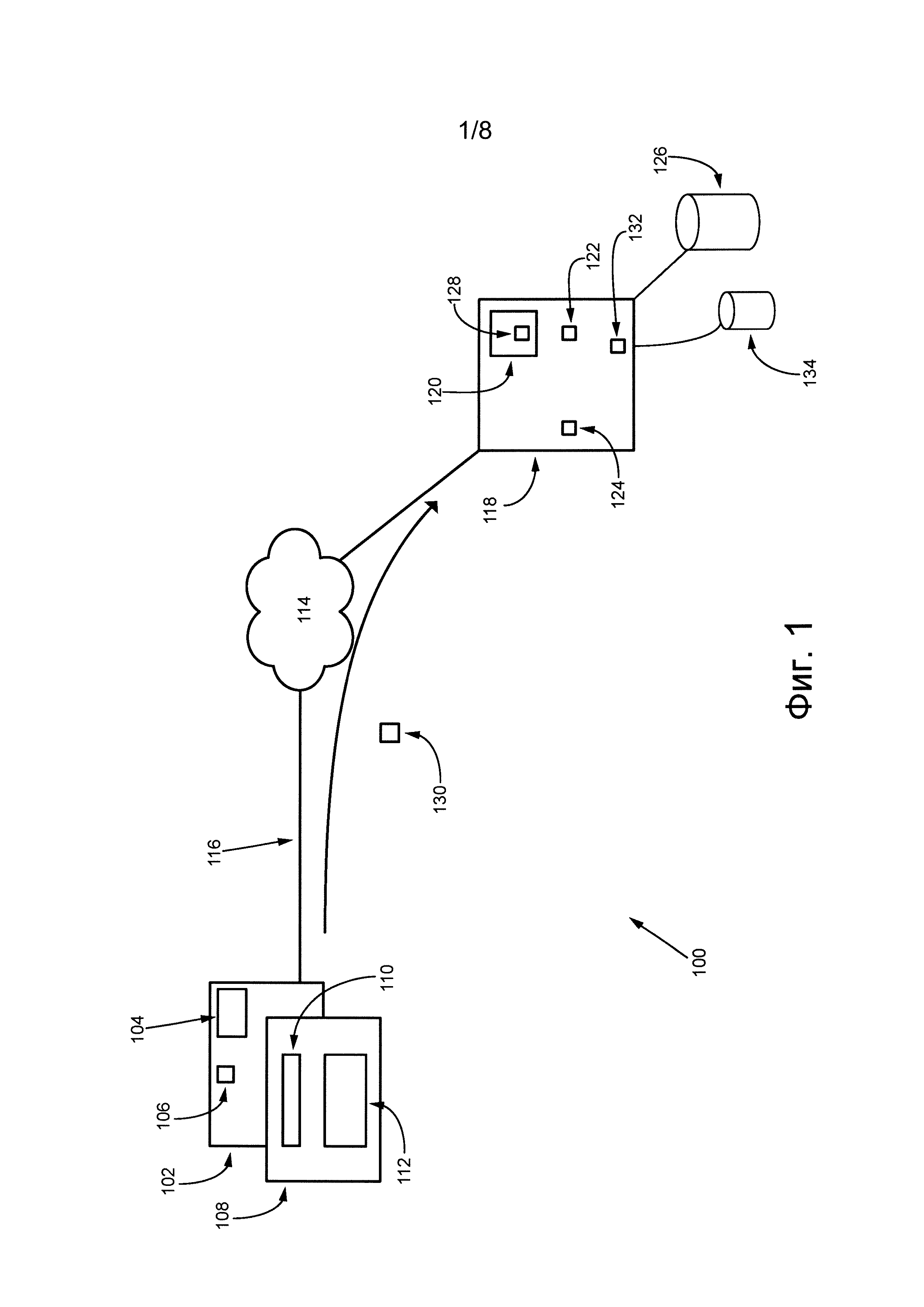
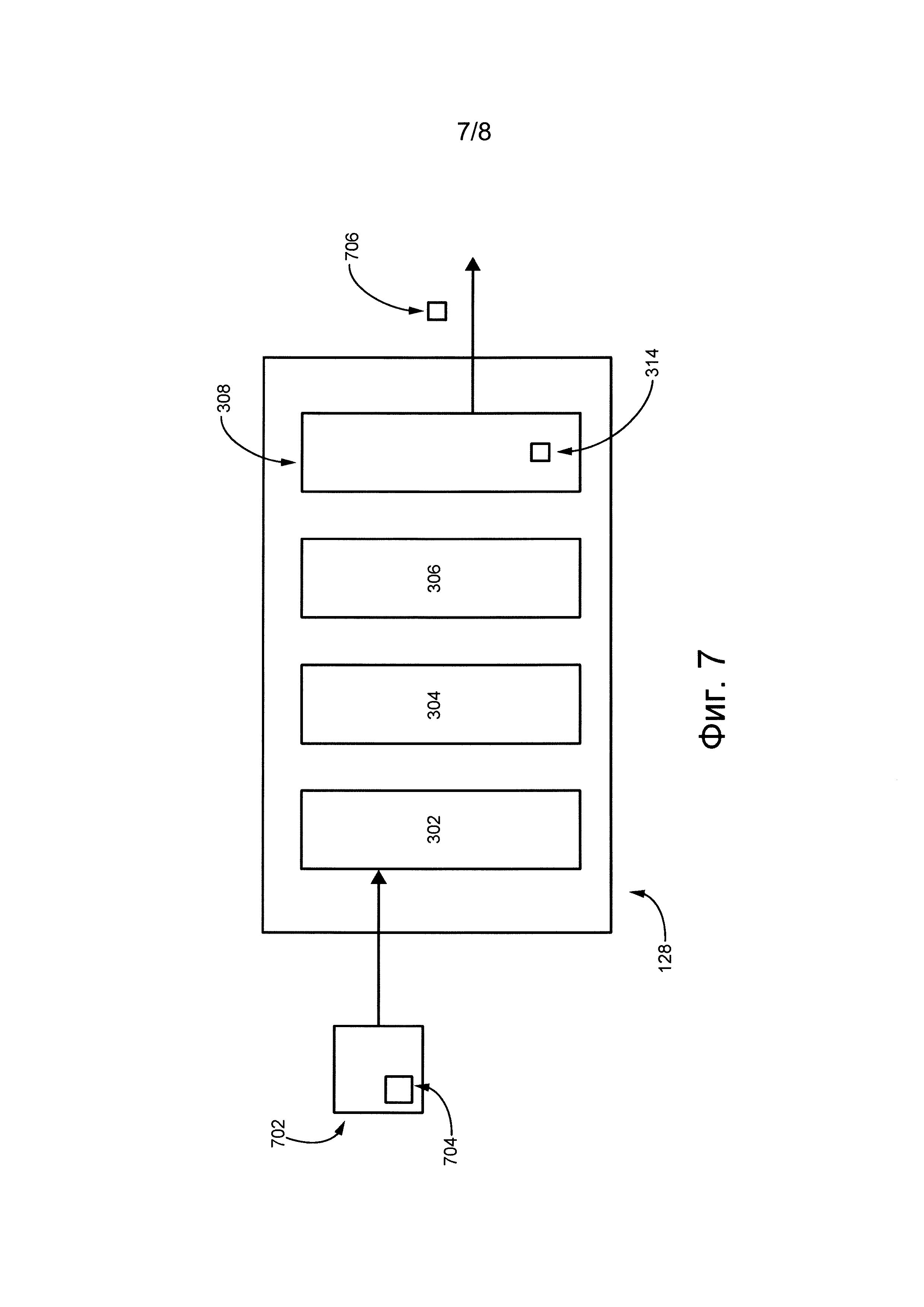
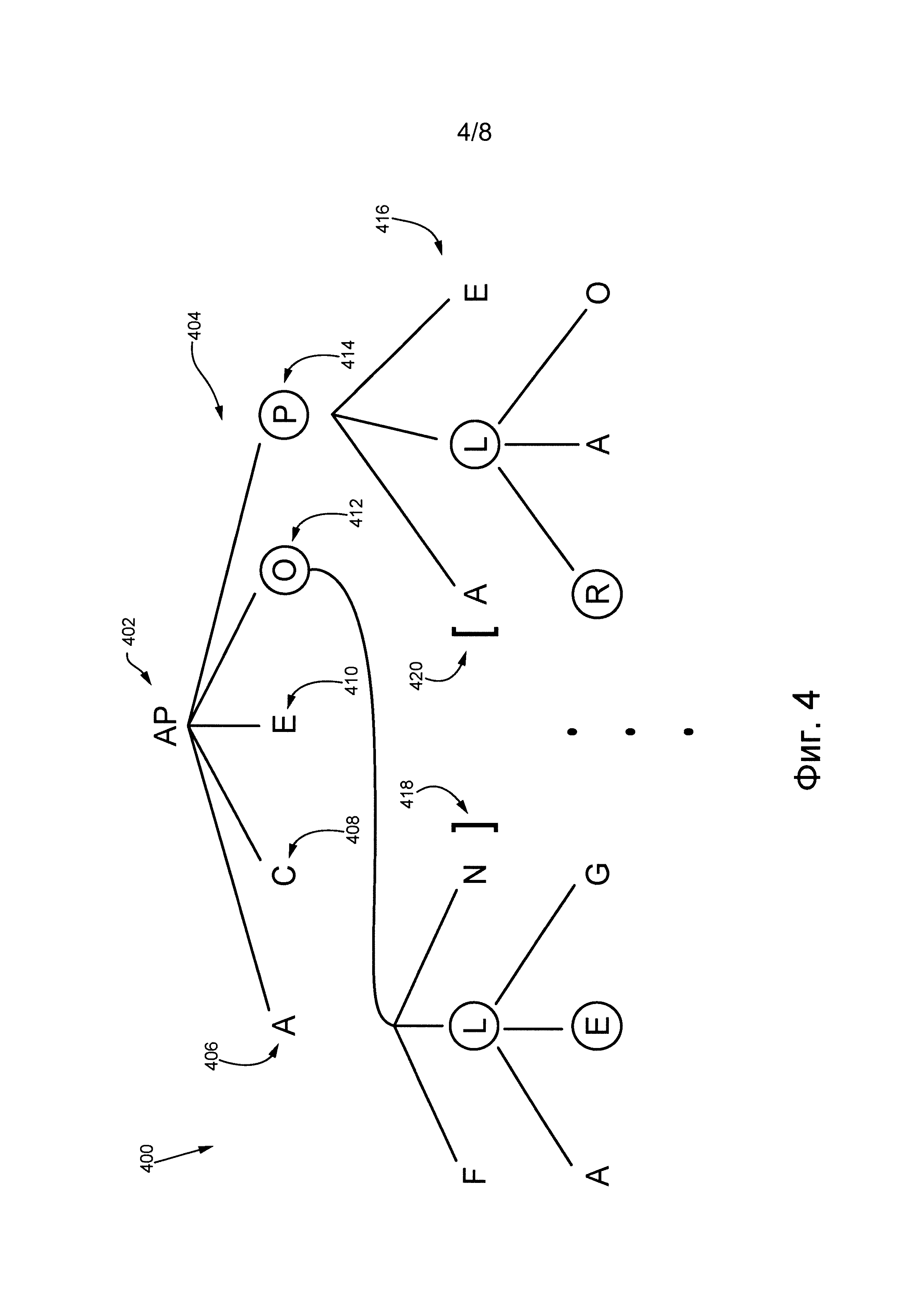
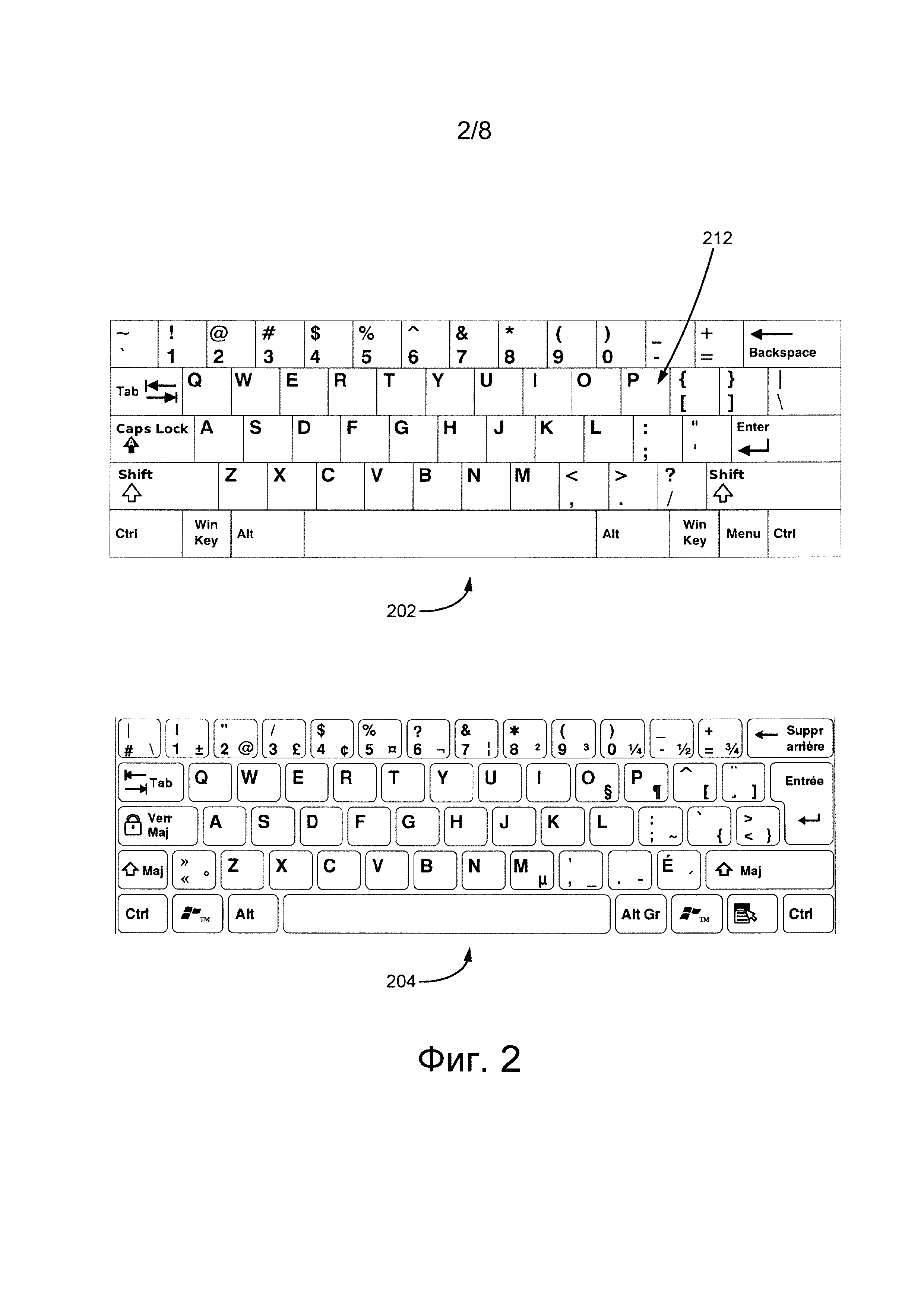
Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке

