Результат интеллектуальной деятельности: СПОСОБ РАСЧЕТА КРЕДИТНОГО РЕЙТИНГА КЛИЕНТА
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение относится в автоматизированному способу оценки кредитного рейтинга клиентов на основании данных транзакционной активности с помощью алгоритма машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[0002] Кредитный скоринг - очень важное направление для банковской отрасли из-за огромных финансовых последствий для банков. Банковская индустрия разрабатывала модели кредитного скоринга с середины XX века и усовершенствовала эти модели с тех пор, инвестируя миллионы долларов в этот процесс. Традиционные кредитно-скоринговые модели основываются на данных анкеты кредитной заявки, кредитной истории заявителей и другой различной агрегированной финансовой информации, относящейся к заявке клиента. Эти модели используют традиционные методы машинного обучения, такие как логистическая регрессия, для оценки скорингового балла клиента, который показывает вернет ли клиент кредит или нет.
[0003] Существует большое количество исследований, посвященных задаче кредитного скоринга в банковской сфере, начиная с первой половины XX века [1]. Для решения этой задачи был использован широкий спектр методов, включая логистическую регрессию [2], деревья решений [3], бустинг [4], метод опорных векторов (SVM) [5] и нейронные сети (NN/HC) [6].
[0004] Методы кредитного скоринга исторически основывались на использовании анкетных данных и кредитной истории заявителя. Однако новые источники данных (телекоммуникационные данные [7] и транзакционные данные [8]-[12].) использовались в последнее время для повышения качества оценки скорингового балла.
[0005] Большинство предыдущих подходов к оценке скорингового балла строили агрегаты на транзакционных данных либо общие на всех данных [11], либо с использованием некоторого временного окна, например, месяц [8], [9] или день [10], и большинство из них основывались на классических методах машинного обучения. Например, в работе [8] авторы использовали такие методы, как обобщенные деревья решений для задач классификации и регрессии, и применяли их на ежемесячной транзакционной статистике. В источнике [9] авторы использовали дискретные модели дожития на месячной транзакционной статистике. Кроме того, в некоторых решениях использовались нейросети для кредитного скоринга на агрегированных транзакционных данных. Например, в [10] применяется неглубокая сверточная нейронная сеть (СНС) на данных ежедневной транзакционной статистики.
[0006] Кроме того, в решении [12] раскрывается несколько моделей кредитного скоринга на неагрегированных транзакционных данных, но с применением классических методов машинного обучения, таких как метод опорных векторов и методы ближайших соседей. При этом, данный подход сосредоточен на связанной проблеме для оценки кредитного риска и использует только информацию о субъектах сделки, без развертывания полной мощности транзакционных данных.
[0007] В работе [13] авторы использовали рекуррентную нейронную сеть (РНС) с долговременной памятью (LSTM/ Long short-term memory) [14], построенную на отдельных признаках каждой транзакции, для обнаружения мошеннических транзакций. Для обзора методов нейронных сетей с целью обнаружения мошенничества с кредитными картами см. [15]. В [16] авторы применили рекуррентную нейронную сеть с долговременной памятью (LSTM РНС) для прогнозирования кредитных рейтингов для р2р платформы кредитования.
[0008] Несмотря на широкое распространение и применимость, известные подходы кредитного скоринга имеют определенные ограничения. Во-первых, кредитный скоринг требует трудоемкой подготовки признаков и глубокого знания предметной области для того, чтобы хорошо разрабатывать алгоритмы машинного обучения. Во-вторых, если у клиента нет значимой кредитной истории, то это затрудняет принятие надежного и верного решения в отношении конкретного клиента. В-третьих, существующие в настоящее время модели не в полной мере используют все из имеющихся данных о клиенте в современных условиях.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0009] В заявленном техническом решении предлагается новый подход, заключающийся в применении РНС на транзакциях (E.T.-RNN), для вычисления скорингового балла клиента с помощью изучения и обработки истории транзакций по его кредитным и дебетовым картам. Заявленный подход основывается на глубинном машинном обучении, в отличие от более традиционных методов машинного обучения, причем данный подход применим только к тем клиентам, у которых есть кредитные или дебетовые карты банка. Так как значительный процент заявителей действительно имеют кредитные или дебетовые карты, то заявленный способ работает для большого сегмента клиентов.
[0010] Кроме того, предложенный способ имеет следующие преимущества по сравнению с текущими методами оценки кредитного скоринга. Во-первых, предложенный метод на основе глубинного машинного обучения превосходит базовые алгоритмы, включая модели, используемые в настоящее время, демонстрирующие значительный финансовый эффект. Во-вторых, предлагаемая на основе глубинного машинного обучения модель работает непосредственно на сырых транзакциях клиента и не нуждается в трудоемкой подготовке признаков, требующей глубоких знаний в этой области (вручную генерируя сотни или тысячи созданных агрегатов признаков). В-третьих, заявленный способ работает исключительно на транзакционных данных и, следовательно, не требует каких-либо дополнительных вводных данных от клиента.
[0011] Это означает, что реализуется возможность очень быстрого принятия решения по кредитам, в том числе в режиме реального времени, поскольку весь процесс кредитного скоринга полностью автоматизирован. В-четвертых, информацию в транзакционных данных очень трудно подделать. Следовательно, нет необходимости проверять правильность данных, в отличие от анкеты на получение кредита и некоторых других источников данных, используемых для оценки. В-пятых, даже если у клиента нет кредитной истории, его кредитоспособность может быть оценена по истории его транзакций, составляющих основной источник оценки кредитного риска данным методом.
[0012] Наконец, предлагаемый способ опирается на принцип справедливого подхода к оценке клиента, так как он не использует анкетную информацию о человеке, что позволяет исключить дискриминационный характер оценки по различным демографическим факторам.
[0013] Таким образом, решается техническая проблема автоматизированного расчета кредитного рейтинга клиента с высокой степенью достоверности прогнозируемых расчетов.
[0014] Техническим результатом от реализации заявленного способа является обеспечение автоматизированного расчета кредитного рейтинга клиента на основании его транзакционных данных.
[0015] В предпочтительном варианте реализации заявлен компьютерно-реализуемый способ расчета кредитного рейтинга клиента с помощью модели машинного обучения, выполняемый с помощью по меньшей мере одного процессора и содержащий этапы, на которых:
получают данные клиентских транзакций, содержащие информацию по меньшей мере о сумме транзакций в заданный временной промежуток, валюте транзакций и типе места осуществлении транзакции;
осуществляют обработку полученных данных с помощью модели машинного обучения на базе рекуррентной нейронной сети (РНН) или ансамбля РНН, обученной на векторных представлениях транзакционной активности клиентов, причем в ходе указанной обработки осуществляется:
разделение данных по транзакциям каждого клиента на категориальные и численные переменные;
преобразование переменных, при котором выполняется векторизация категориальных переменных и нормализация численных переменных;
конкатенация преобразованных переменных и выявление вектора, соответствующего последнему временному промежутку транзакционной активности клиента;
классификация упомянутого вектора для определения скорингового балла клиента.
[0016] В одном из частных вариантов реализации способа информация клиентских транзакций дополнительно включает в себя тип карты, используемой для совершения транзакций, дату и время совершения транзакций.
[0017] В другом частном варианте реализации способа РНН включает в себя слой векторизации (эмбеддинг слой), рекуррентный кодировщик и классификатор.
[0018] В другом частном варианте реализации способа рекуррентный кодировщик представляет собой однослойную РНН на основе управляемого рекуррентного блока.
[0019] В другом частном варианте реализации способа на основании данных клиентских транзакций определяется разница в днях между временем текущей транзакции и временем предыдущей транзакции, а также время в днях, прошедшее с даты выпуска карты до даты транзакции.
[0020] В другом частном варианте реализации способа ансамбль РНН включает шесть нейронных сетей, каждая из которых обучается на разных подвыборках исходных данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
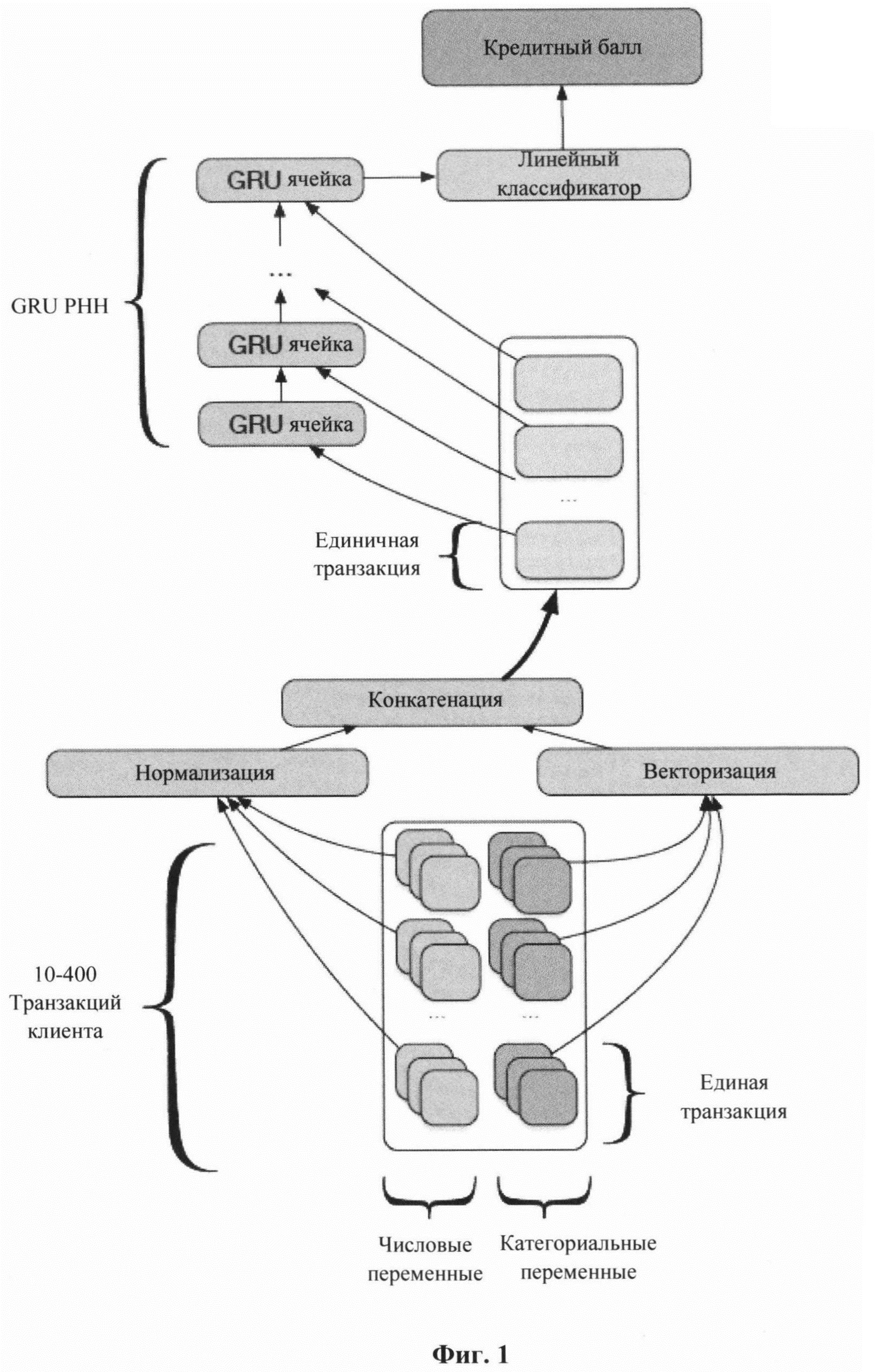
[0021] Фиг. 1 иллюстрирует архитектуру РНН.
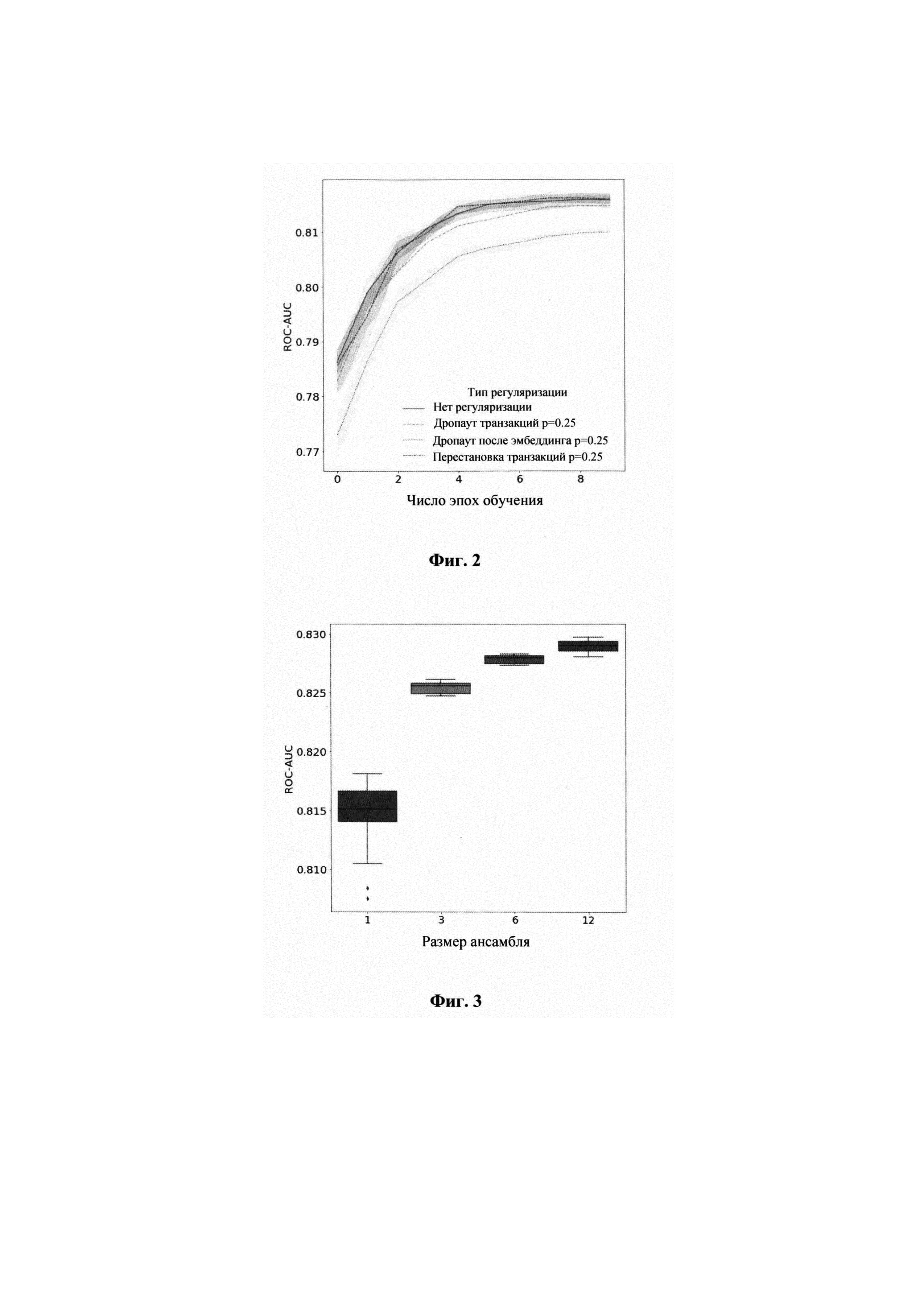
[0022] Фиг. 2 иллюстрирует график с методами регуляризации.
[0023] Фиг. 3 иллюстрирует график сравнения качества ансамблирования.
[0024] Фиг. 4 иллюстрирует график кривой обучения моделей машинного обучения.
[0025] Фиг. 5 иллюстрирует график с количеством транзакций по клиенту.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0026] На Фиг. 1 представлена архитектура представленной модели глубинного машинного обучения - рекуррентной нейронной сети, обрабатывающей транзакционные данные клиентов для расчета их кредитного рейтинга. Заявленная архитектура РНН состоит из трех основных частей: слой векторизации (эмбеддинг слой), рекуррентный кодировщик и классификатор (линейный классификатор).
[0027] Рекуррентные нейронные сети (РНН), как правило, используются для обработки последовательной информации. В некотором смысле, РНН обладают «памятью» по сравнению с предыдущими вычислениями и используют информацию с предыдущих временных шагов в дополнение к текущему вводу для получения следующего вывода. Этот подход подходит для многих задач естественной обработки языка - далее методы НЛП, включая классификацию текста, машинный перевод и языковое моделирование.
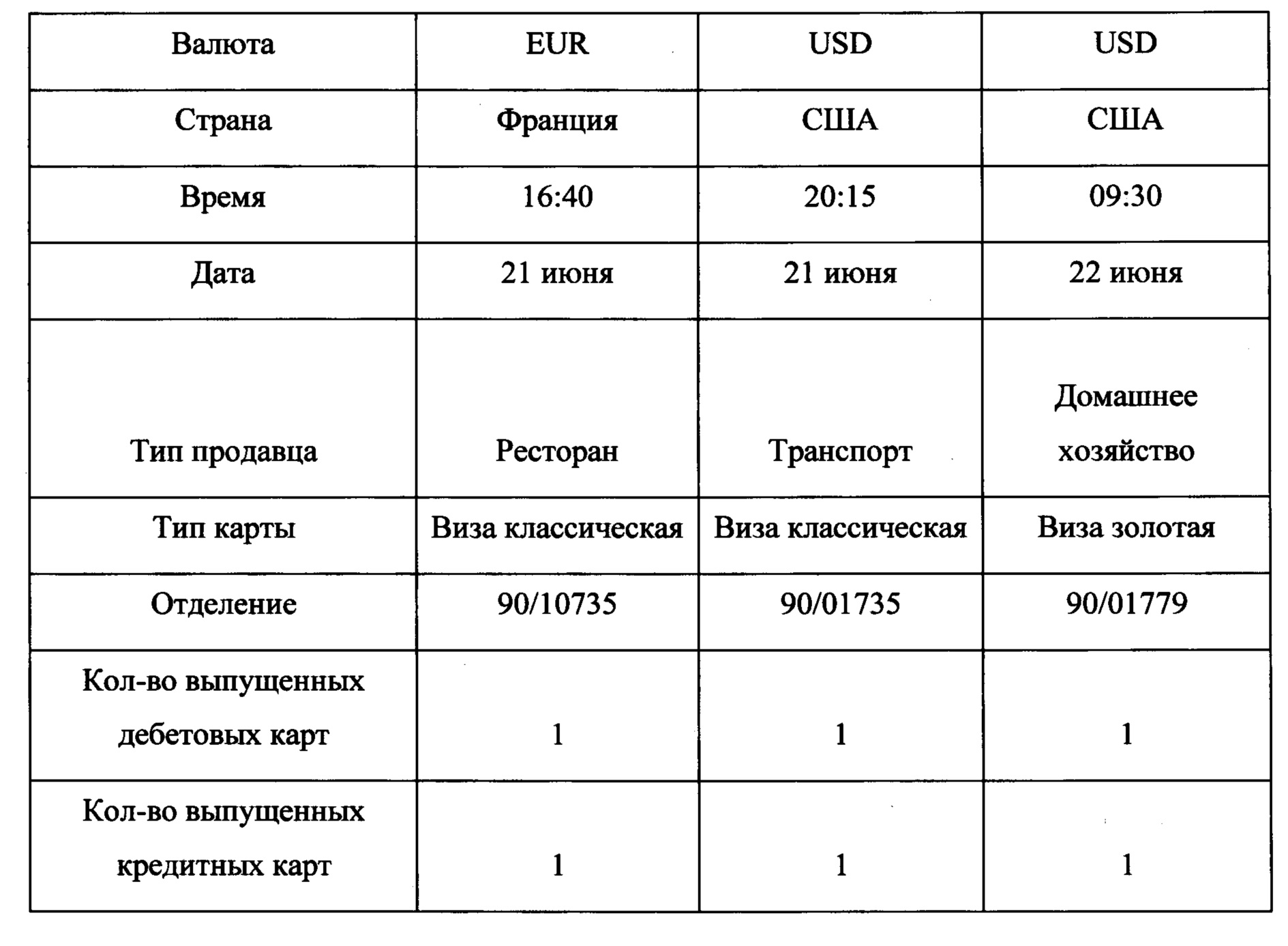
[0028] Заявленный способ вычисляет скоринговый балл для оценки кредитного рейтинга, используя транзакционные данные каждого клиента, имеющего несколько транзакций по кредитным или дебетовым картам. Каждая транзакция имеет несколько признаков, как категориальных, так и численных, и происходит в определенное время. Выбранные данные можно описать как данные разных временных рядов, схема которых представлена в Таблице 1. Поле тип продавца представляет, например, авиакомпанию, гостиницу, ресторан и т.д. 
[0029] Представленная архитектура транзакционных векторных представлений рекуррентных нейронных сетей (E.T.-RNN), представленная на Фиг. 1, основана на методах НЛП в контексте глубокого обучения, в которой задача оценки кредитного скоринга, решается как задача классификации текста, используя клиентов как тексты, а транзакции как отдельные слова.
[0030] Рассмотрим более подробно представленную архитектуру РНН и принцип ее работы вычисления кредитного рейтинга клиентов. Слой векторизации или слой формирования векторных представлений (эмбедцингов) предназначен для отображения транзакций по платежным картам в виде векторов в латентном пространстве (векторами в латентном пространстве называются вектора, которые не могут быть получены в явном виде, а только выведены через математические модели) перед их передачей в кодировщик РНН. В частности, каждая категориальная переменная в каждой транзакции кодируется в низкоразмерный вектор через соответствующий слой векторизации (эмбеддинг-слой). Эмбеддинг-слои в начале обучения инициализируются случайным образом и обучаются одновременно с кодировщиком. Временной признак транзакции обрабатывается как набор категориальных переменных, каждая из которых представляет часть даты (час, день неделя, месяц). Затем каждая транзакция представляется в виде конкатенации численных переменных и векторных представлений категориальных переменных.
[0031] В качестве кодировщика используется однослойная РНН на основе управляемого рекуррентного блока (GRU) [17]. Скрытый вектор (вектор латентного пространства) с последнего временного шага рекуррентного кодировщика использовался как представление клиента.
[0032] Классификатор. Скрытый вектор с последнего временного шага передается в полносвязный слой для классификации. В ходе экспериментов было установлено, что простой линейный классификатор превзошел несколько альтернативных подходов, и поэтому его использование в архитектуре было наиболее целесообразно.
[0033] В работе заявленного способа используется стандартная характеристика качества модели - площадь под ROC-кривой (ROC - рабочая характеристика приемника). Несколько функций потерь могут использоваться в качестве альтернативы для задачи максимизации ROC AUC, включая классические функции бинарной кросс-энтропии: LCE(p, y)=-∑iyilogpi и функции маржинальных ранжирующих потерь:LR(p1, p2, y)=max(0,-y(р1-р2)+маржа), которые напрямую оптимизирует ROC AUC. Наилучшие результаты обработки данных были получены при использовании функции маржинальных ранжирующих потерь с маржой равной 0,1.
[0034] Вместо модели машинного обучения на базе одной РНН может применяться принцип ансамблирования, который предназначен для повышения качества модели и ее стабильности незначительно проигрывая одной РНН во времени и вычислительной мощности. Поскольку есть достаточное количество примеров отрицательного класса (клиенты, у которых было событие дефолта для потребительского кредита в течение года после его выдачи), то, следовательно, можно использовать разные подвыборки примеров отрицательного класса для обучения каждой модели в ансамбле нейронных сетей.
[0035] В финальной версии модели используются средние значения прогнозов ансамбля из шести отдельно обученных моделей в качестве практического баланса между качеством прогнозирования и временем выполнения обучения модели. Повышение качества ансамбля и другие возможные стратегии ансамбля дополнительно будут рассмотрены далее в материалах заявки.
[0036] Данные, использованные для экспериментов, были предоставлены банковским сектором. Для экспериментов использовались транзакционные данные для клиентов, которые подали заявки на розничные кредиты. В итоговой выборке использовались данные только тех заявителей, которые уже использовали в банке продукт дебетовой или кредитной карты. Если у клиента несколько карт, то учитываются транзакции с каждой карты.
[0037] Доступные транзакционные данные подразделяются на подкатегории: уровень транзакции (например, метка времени, страна, сумма, тип продавца) и уровень карты (например, филиал выдачи, тип карты). Данные на уровне карты дублируются дословно для каждой транзакции, связанной с соответствующей картой. Пример трех типичных операций с картами представлен в Таблице 1. Также использовались две производные функции, рассчитанные на основе данных транзакций:
- разница в днях между временем текущей транзакции и временем предыдущей транзакции этого клиента;
- время в днях, прошедшее с даты выпуска карты до даты транзакции.
Только транзакции, выполненные до даты подачи заявки, принимаются для обучения и проверки.
[0038] Обучающий набор данных представлял более 740 тысяч клиентов с общим количеством транзакций равным 200 миллионам. В качестве целевой переменной использовалось событие дефолта для потребительского кредита в течение года после его выдачи. Период в один год был выбран с помощью атрибута окна производительности [18]. Из-за риска нестационарности данных использовалась стратегия валидации вне времени. При этом результаты для валидации вне периода были последовательно выше, чем результаты для валидации вне времени для ряда архитектур и гиперпараметров.
[0039] Использовалось подмножество кредитных заявок из 16-месячного периода для обучения и четырехмесячного периода для валидации (подход валидация вне времени). Наборы для обучения и проверки были одинаковыми для каждой рассматриваемой модели и базовой модели. Из-за большого расхождения между количеством положительных и отрицательных примеров (из-за низкой ставки дефолта в банке) мы остановились на следующей стратегии недостаточной выборки: перед каждым экспериментом выбирались все положительные примеры и в 10 раз больше случайно выбранных примеров отрицательного класса. В каждую эпоху обучения использовались все положительные примеры и равное количество отрицательных примеров, отобранных из пула отрицательных примеров.
[0040] Все модели обучались по последним 800 транзакциям каждого клиента, когда они были доступны, и заполнялись нулями, когда фактическое количество транзакций для клиента было ниже.
[0041] Чтобы сравнить созданную модель с другими подходами, была реализована модель, основанная на логистической регрессии. Также использовалась дополнительную модель, основанную на методе градиентного бустинга (GBM). Как методы логистической регрессии, так и методы градиентного бустинга GBM требуют большого количества агрегированных признаков, подготовленных вручную из транзакционных данных, в качестве входных данных для модели классификации. Примером агрегированной функции может служить средняя сумма расходов в некоторых категориях продавцов, таких как отели за всю историю транзакций.
[0042] Использовался LightGBM алгоритм градиентного бустинга и было создано около 7000 агрегированных признаков, подготовленных вручную. Аналогично, для логистической регрессии было разработано около 400 агрегированных признаков. Метод оцифровки признаков по весу и разбиения на бины был использован для преобразования категориальных признаков.
[0043] Выбор архитектуры рекуррентного кодировщика. В ходе экспериментов с различными архитектурами рекуррентных кодировщиков использовалась длинная кратковременная память (LSTM), двунаправленные рекуррентные ячейки и управляемый реккурентный блок (GRU). Результаты этого сравнения представлены в Таблице 2. На основании этого сравнения было решено использовать однослойный управляемый рекуррентный блок GRU, потому что разница с наиболее эффективными двунаправленными моделями не была статистически значимой, при этом увеличивая сложность модели и получая заметную выгоду вычислительных ресурсов. 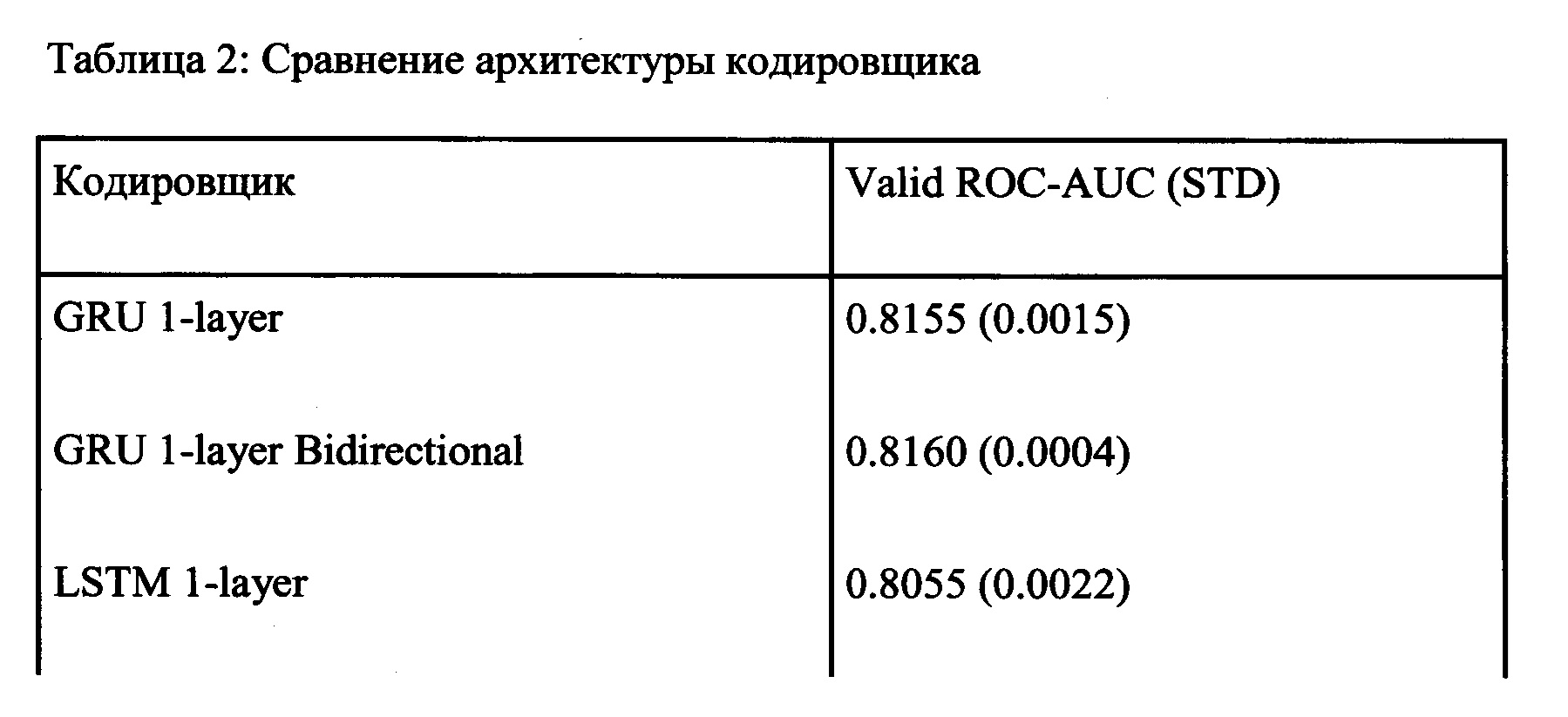

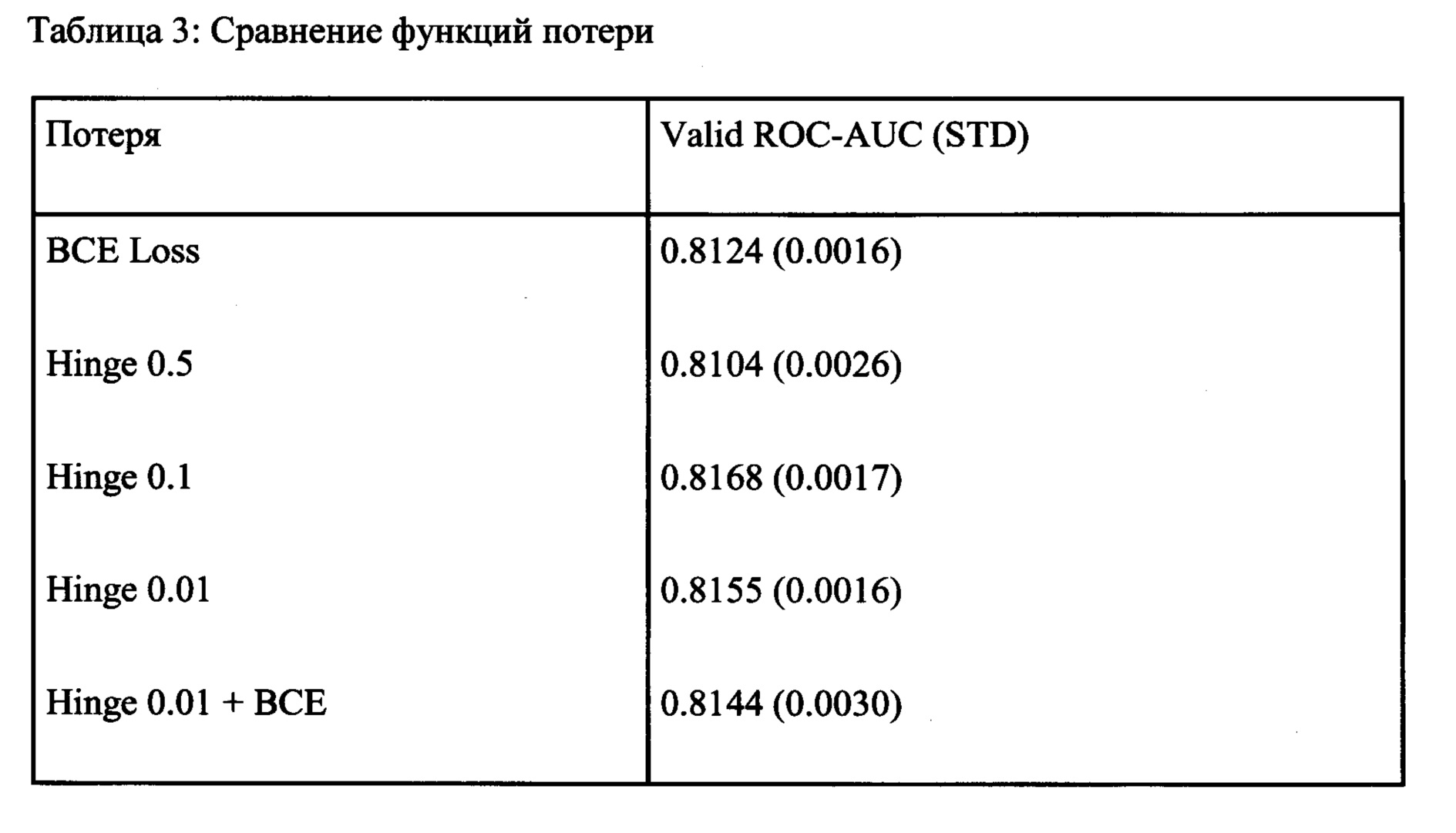
[0044] Функция потери и скорость обучения. Использовался размер батча 32 для обучения и размер батча 768 для проверки для всех экспериментов. При использовании функции ранжирования потерь был введен новый гиперпараметр - размер маржи функции потери. Как указывалось выше, размер маржи функции потерь в 0,1 дает лучшие результаты среди всех гиперпараметров функции потерь, которые представлены в Таблице 3.
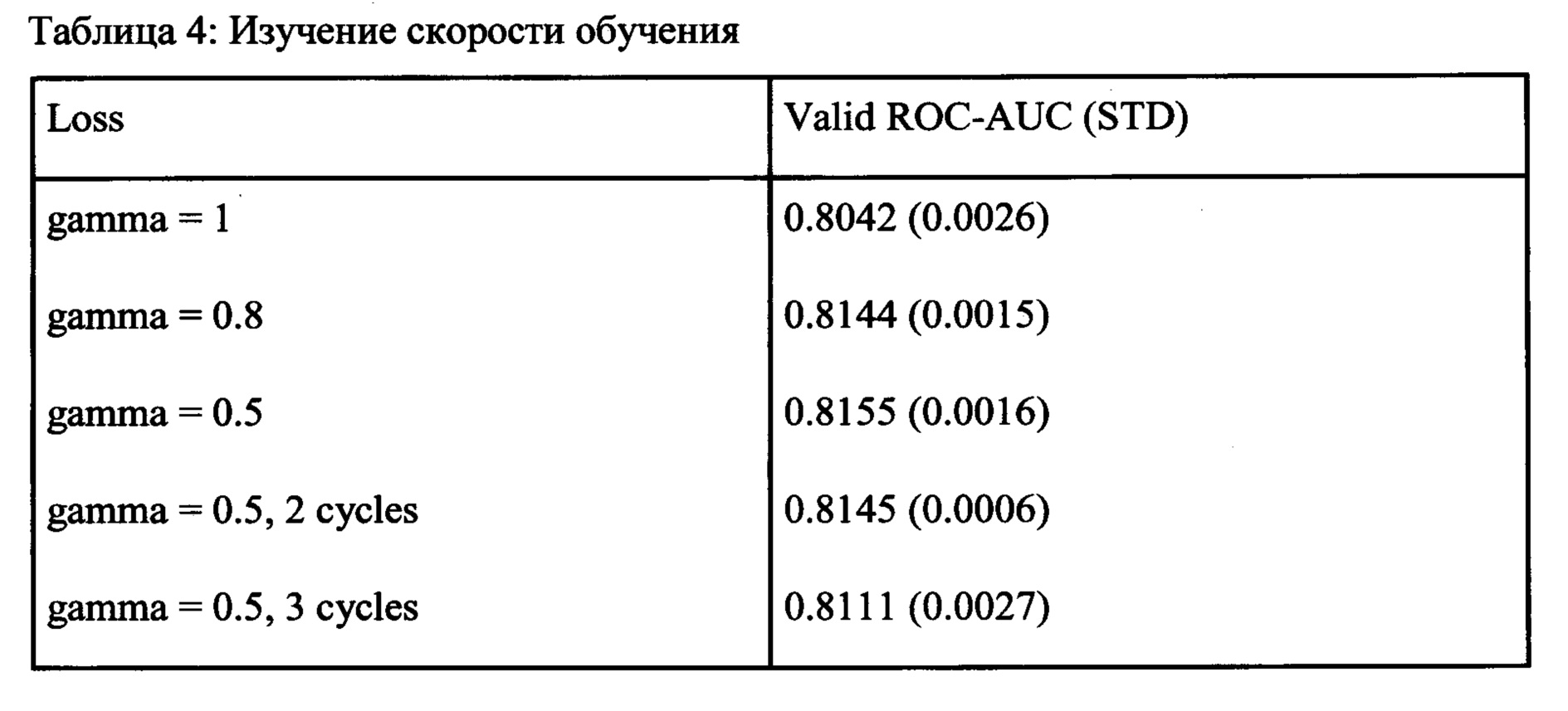
[0045] Скорость обучения, используемая в методе обучения градиентного спуска, и графика снижения скорости обучения являются одними из наиболее чувствительных гиперпараметров, которые могут кардинально изменить производительность модели. При этом график оптимальной скорости обучения сильно зависит от используемой функции потерь, размера батча и общего количества параметров в модели. Было апробировано несколько режимов обучения и несколько режимов снижения скорости обучения и обнаружили, что как для функции потери бмнарной кросс-энтропии (ВСЕ), так и для функции потери ранжирования наиболее эффективной стратегией было агрессивное линейное снижение скорости обучения с параметром гамма =0,5, как показано в Таблице 4.
[0046] Методы регуляризации. Из-за низкого количества положительных примеров все модели демонстрируют склонность к переобучению. Поэтому для регуляризации были апробированы различные типы дропаута (в процессе обучения нейронной сети выбирается слой, из которого случайным образом выбрасывается определенное количество нейронов, которые выключаются из дальнейших вычислений), такие как:
- Дропаут транзакциий, который случайным образом отбрасывает некоторые клиентские транзакции с определенной вероятностью.
- Перестановка транзакций, которая случайным образом переставляет порядок клиентских транзакций.
- Дропаут после эмбеддинг слоя, которое случайным образом обнуляет некоторые компоненты после эмбеддинг слоя.
При этом ни один из вышеупомянутых методов регуляризации не оказался эффективным против переобучения, что представлено на Фиг. 2.
[0047] Методы ансамблирования. Тестировалось несколько различных типов методов ансамблирования:
- Простое усреднение результатов модели. Усреднение прогнозов для различных моделей, обученных с использованием различных отрицательных примеров, приводит как к повышенной точности, так и к снижению вариабельности результатов, как показано на Фиг. 3.
- Стохастическое усреднение веса (SWA). Усреднение весов ансамблевых моделей может значительно сократить время вывода, поскольку вместо всего ансамбля используется только одна модель с усредненными весами. Но в данном случае усреднение весов разных моделей приводит к заметному снижению качества.
- Ансамбль снимков (копий весов модели сохраненных в процессе обучения). Использование снимков одной и той же модели (модели с разными наборами весов, при которых достигаются локальные минимумы функции потерь) в окончательном ансамбле может значительно сократить время обучения, поскольку следует обучать только одну модель. К сожалению, этот подход не выигрывает от использования отдельных примеров отрицательных классов
- SWA + ансамбль снимков. Было установлено, что объединение SWA с ансамблем снимков для обучения одной модели путем создания снимка после заданной эпохи и усреднения весов приводит к некоторому снижению изменчивости, но результаты были достаточно слабые, вследствие чего данный метод ансамблирования не рассматривался как релевантный для применения.
[0048] Использовался ансамбль усреднения размера шесть для представленной архитектуры модели, обеспечивая разумный компромисс между качеством модели и временем обучения / вывода. Как упоминалось ранее, каждая модель ансамбля обучается на различных подвыборках отрицательного класса. Используется процедура недостаточной выборки, чтобы уменьшить количество отрицательных выборок. Отрицательные выборки отбираются независимо для каждой модели ансамбля, следовательно, каждая модель ансамбля обучается на несколько разных подгруппах отрицательных выборок.
[0049] Представленный способ на предложенной архитектуре модели оценки кредитного рейтинга был оценен на производственном конвейере банка, который для каждого клиента с дебетовой или кредитной картой. Подготовка полного ансамбля из шести моделей заняла около 4 часов на графическом процессоре Tesla P100. Необходимо около 17 минут, чтобы набрать 1 миллион клиентов на GPU Tesla P100. Время вывода линейно зависит от количества клиентов. Эти оценки использовались для принятия решений о кредитных заявках для десятков тысяч заявителей в течение одного месяца.
[0050] В Таблице 5 представлены основные результаты экспериментов с помощью применения заявленного способа на основе E.T.-RNN.
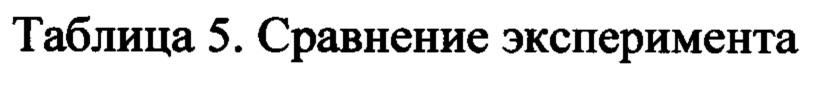
[0051] Как показано в Таблице 5, заявленная архитектура E.T.-RNN значительно превзошла базовые показатели по представленным данным. Более того, одна из важнейших особенностей предлагаемого подхода заключается в том, что для его реализации нет необходимости в разработке функций в отличие от классических методов, которые в значительной степени зависят от функций, созданных вручную (например, 400 функций для логистической регрессии и 7000 функций для LGBM).
[0052] Обратите внимание, что результаты, представленные в Таблице 5, были достигнуты для полного набора данных, представленного в Таблице 1. Был также проведен ряд экспериментов для оценки производительности модели для различных наборов данных. Как показано на Фиг. 4, LGBM превосходит метод на основе E.T.-RNN для небольших объемов данных, измеряемых количеством кредитных заявок клиентов (по оси X). Однако, учитывая достаточное количество данных, метод E.T.-RNN значительно превосходит классические подходы. Это наблюдение согласуется с хорошо известным пониманием того, что нейронные сети превосходят классические методы на больших наборах данных. Также отметим, что у E.T.-RNN более крутая кривая обучения, чем у градиентного бустинга. Следовательно, разрыв в производительности увеличится еще больше с увеличением количества доступных данных.
[0053] Количество транзакций. Производительность модели E.T.-RNN сильно зависит от количества доступных транзакций на клиента. Как показано на Фиг. 5, качество оценки возрастает, пока не будет достигнуто количество данных в размере ~350 транзакций. За пределами этого уровня увеличение производительности из-за дополнительных транзакций является достаточно незначительным. Кроме того, доля клиентов, имеющих более 350 транзакций, составляет около 50 процентов для указанного набора данных. Это означает, что предложенная модель достигает значительного успеха при оценке клиентов банка. С другой стороны, предложенный метод все еще эффективен даже для заявителей с небольшим количеством транзакций. Для клиентов с более чем 25 транзакциями (около 95 процентов от общего числа клиентов) получено значение 82,5 ROC-AUC.
[0054] Предложенный способ обеспечивает хорошее качество расчета кредитного рейтинга по следующим причинам:
1) Достаточно большое количество клиентов в обучающем наборе данных. Нейронные сети имеют много доступных для изучения параметров по сравнению с классическими подходами и, следовательно, требуют больше данных, чем классические методы, что следует из графика на Фиг. 4.
2) Низкоуровневые, детализированные данные, применяемые для работы заявленного способа, можно описать как последовательность событий, и каждое событие состоит из нескольких переменных.
3) Высокочастотные данные. Как обсуждалось ранее, более 80 процентов клиентов имеют как минимум 100 транзакций.
[0056] Таким образом, предложенный новый способ для автоматизированной оценки кредитного рейтинга с помощью модели E.T.-RNN, позволяет использовать детальные транзакционные данные для кредитного скоринга. Проведенные испытания на соответствие эталонам на исторических данных показали высокие показатели.
[0057] Существенным преимуществом заявленного подхода является то, что даже сложные многомерные данные временных рядов могут быть непосредственно использованы для обучения без какой-либо необходимости в проектировании функций. Поскольку нейронная сеть изучает значимые внутренние представления входных данных во время обучения, то это позволяет снизить необходимость генерировать сотни или даже тысячи агрегированных признаков, созданных вручную, как это обычно делается в кредитном скоринге.
[0058] Таким образом, заявленный способ не требует каких-либо значительных знаний в конкретной области для разработки признаков. Кроме того, предложенная модель E.T.-RNN работает исключительно на транзакционных данных и, следовательно, не требует каких-либо дополнительных данных от клиента, что означает, что появляется возможность принятия решений по кредитам очень быстро, в идеале почти в реальном времени, потому что весь процесс кредитного скоринга полностью автоматизирован. Кроме того, информацию в транзакционных данных исключительно трудно подделать. Следовательно, нет необходимости в дорогостоящих проверках правильности таких данных, в отличие от данных, предоставленных клиентом или полученных из некоторых других источников.
[0059] Еще одним преимуществом заявленного способа является то, что даже клиент без кредитной истории может быть надежно доступен для оценки кредитоспособности, поскольку история транзакций такого клиента является источником для оценки кредитных рисков. Также, заявленный способ обеспечивает справедливый подход к принятию решений по кредитам, поскольку он не опирается на личную демографическую информацию человека и, следовательно, не может дискриминировать заявителей на основании различных демографических факторов.
Источники информации:
1) David Durand. 1941. Credit-Rating Formulae. NBER, 83-91. http://www.nber.org/chapters/c12952:
2) John C. Wiginton. 1980. A Note on the Comparison of Logit and Discriminant Models of Consumer Credit Behavior. Journal of Financial and Quantitative Analysis 15, 03 (1980), 757-770. https://EconPapers.repec.org/RePEc:cup:jfinqa:v:15:y:1980:i:03:p:757-770_00:
3) Paul Makowski. 1985. Credit scoring branches out. Credit World 75,1 (1985), 30-37;
4)  Bastos. 2008. Credit scoring with boosted decision trees;
Bastos. 2008. Credit scoring with boosted decision trees;
5) Cheng-Lung Huang, Mu-Chen Chen, and Chieh-Jen Wang. 2007. Credit scoring with a data mining approach based on support vector machines. Expert Systems with Applications 33,4 (2007), 847-856. https://doi.org/l0.1016/j.eswa.2006.07.007;
6) DavidWest. 2000. Neural network credit scoring models. Computers & Operations Research 27, 11-12 (2000), 1131-1152;
7) Daniel  and Darrell Grissen. 2017. Behavior revealed in mobile phone usage predicts loan repayment. arXiv preprint arXiv:1712.05840 (2017);
and Darrell Grissen. 2017. Behavior revealed in mobile phone usage predicts loan repayment. arXiv preprint arXiv:1712.05840 (2017);
8) Amir E Khandani, Adlar J Kim, and Andrew W Lo. 2010. Consumer credit-risk models via machine-learning algorithms. Journal of Banking & Finance 34, 11 (2010), 2767-2787;
9) Tony Bellotti and Jonathan Crook. 2013. Forecasting and stress testing credit card default using dynamic models. International Journal of Forecasting 29, 4 (2013), 563-574;
10)  Kvamme, Nikolai Sellereite, Kjersti Aas, and Steffen Sjursen. 2018. Predicting mortgage default using convolutional neural networks. Expert Systems with Applications 102 (2018), 207 - 217. https://doi.org/10.1016/j.eswa.2018.02.029;
Kvamme, Nikolai Sellereite, Kjersti Aas, and Steffen Sjursen. 2018. Predicting mortgage default using convolutional neural networks. Expert Systems with Applications 102 (2018), 207 - 217. https://doi.org/10.1016/j.eswa.2018.02.029;
11) Bo-Wen Chi and Chiun-Chieh Hsu. 2012. A hybrid approach to integrate genetic algorithm into dual scoring model in enhancing the performance of credit scoring model. Expert Systems with Applications 39, 3 (2012), 2650-2661;
12) Ellen Tobback and David Martens. 2017. Retail credit scoring using fine-grained payment data. Working Papers. University of Antwerp, Faculty of Business and Economics. https://EconPapers.repec.org/RePEc:ant:wpaper:2017011;
13)  Wiese and Christian Omlin. 2009. Credit Card Transactions, Fraud Detection, and Machine Learning: Modelling Time with LSTM Recurrent Neural Networks. Springer Berlin Heidelberg, Berlin, Heidelberg, 231-268. https://doi.org/10.1007/978-3-642-04003-0_10;
Wiese and Christian Omlin. 2009. Credit Card Transactions, Fraud Detection, and Machine Learning: Modelling Time with LSTM Recurrent Neural Networks. Springer Berlin Heidelberg, Berlin, Heidelberg, 231-268. https://doi.org/10.1007/978-3-642-04003-0_10;
14) Felix A Gers,  Schmidhuber, and Fred Cummins. 1999. Learning to forget: Continual prediction with LSTM. (1999);
Schmidhuber, and Fred Cummins. 1999. Learning to forget: Continual prediction with LSTM. (1999);
15) Aisha Abdallah, Mohd Aizaini Maarof, and Anazida Zainal. 2016. Fraud detection system: A survey. Journal of Network and Computer Applications 68 (2016), 90-113;
16) Yishen Zhang, DongWang, Yuehui Chen, Huijie Shang, and Qi Tian. 2017. Credit Risk Assessment Based on Long Short-Term Memory Model. In International Conference on Intelligent Computing. Springer, 700-712;
17) Kyunghyun Cho, Bart van Merrienboer, Caglar  Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. CoRR abs/1406.1078 (2014). arXiv:1406.1078 http://arxiv.org/abs/1406.1078;
Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. CoRR abs/1406.1078 (2014). arXiv:1406.1078 http://arxiv.org/abs/1406.1078;
18) Naeem Siddiqi. 2005. Credit Risk Scorecards: Developing And Implementing Intelligent Credit Scoring. (2005).

Способ и система выявления и классификации причин возникновения претензий пользователей в устройствах самообслуживания
Компьютеризированный способ разработки и управления моделями скоринга
Способ и система передачи информации о р2р-переводе
Система управления сетью pos-терминалов
Способ и система автоматической генерации программного кода для корпоративного хранилища данных
Система мониторинга технического состояния сети pos-терминалов
Способ и система предиктивного избегания столкновения манипулятора с человеком
Способ и система для выстраивания диалога с пользователем в удобном для пользователя канале
Система мониторинга сети устройств самообслуживания
Способ интерпретации искусственных нейронных сетей

