Результат интеллектуальной деятельности: СПОСОБ РАСПОЗНАВАНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ В СЕТЕВОМ ТЕКСТЕ НА ОСНОВЕ УСТРАНЕНИЯ НЕОДНОЗНАЧНОСТИ ВЕРОЯТНОСТИ В НЕЙРОННОЙ СЕТИ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к обработке и анализу сетевого текста, в частности, к способу распознавания именованных сущностей сетевого текста на основе устранения неоднозначности вероятности в нейронной сети.
УРОВЕНЬ ТЕХНИКИ
Сети подняли скорость и масштаб сбора и распространения информации на беспрецедентный уровень, сделали реальным глобальное распространение и обмен информацией и стали незаменимой инфраструктурой в информационном сообществе. Современные технологии коммуникации и распространения значительно повысили скорость и широту распространения информации. Однако существуют сопутствующие проблемы и «побочные эффекты»: иногда люди путаются в хаотичной информации, и бывает очень сложно быстро и точно выделить конкретную требуемую информацию из огромного объема информации. Это является предпосылкой для анализа и получения именованных сущностей, таких как люди, места, организации и т.д., интересующих пользователей Интернета, из массива сетевого текста для предоставления важной справочной информации для различных приложений верхнего уровня, таких как интернет-маркетинг, анализ эмоций группы и т.д. Соответственно, распознавание именованных сущностей сетевого текста стало важной базовой технологией обработки и анализа сетевых данных.
В исследовании рассматриваются два способа распознавания именованных сущностей, а именно, способ на основе правил и способ на основе статистики. Поскольку теория машинного обучения постоянно совершенствуется и скорость вычислений значительно улучшается, способу на основе статистики отдается все большее предпочтение.
В настоящее время статистические модели и способы, применяемые в распознавании именованных сущностей, в основном включают: скрытую марковскую модель, решающее дерево, модель максимальной энтропии, модель опорных векторов, условное случайное поле и искусственную нейронную сеть. Искусственная нейронная сеть может достичь лучшего результата в распознавании именованных сущностей, чем условное случайное поле, модель максимальной энтропии и другие модели, но модель условного случайного поля и максимальной энтропии по-прежнему являются доминирующими практическими моделями. Например, в Патентном документе № CN 201310182978.X предложен способ распознавания именованных сущностей и устройство для микроблогового текста на основе условного случайного поля и библиотеки именованных сущностей. В Патентном документе № CN 200710098635.X предложен способ распознавания именованных сущностей, который использует признаки слова и применяет модель максимальной энтропии для моделирования. Искусственную нейронную сеть сложно использовать на практике, поскольку она часто требует преобразования слов в векторы в пространстве векторов слов в области распознавания именованных сущностей. Вследствие этого, искусственная нейронная сеть не может применяться в крупномасштабных практических приложениях, потому что она не способна получать соответствующие векторы для новых слов.
Вследствие вышеупомянутой существующей ситуации при распознавании именованных сущностей для сетевого текста в основном существуют следующие проблемы: во-первых, невозможно обучить пространство векторов слов, содержащее все слова, чтобы обучить нейронную сеть, потому что в сетевом тексте существует много сетевых слов, новых слов и неправильно написанных или искаженных символов; во-вторых, точность распознавания именованных сущностей для сетевых текстов ухудшается в результате существующих в сетевом тексте явлений, таких как произвольные языковые формы, нестандартные грамматические конструкции, неправильно написанные или искаженные символы и т.д.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Задача изобретения состоит в преодолении недостатков предшествующего уровня техники, настоящее изобретение предоставляет способ распознавания именованных сущностей сетевого текста на основе устранения неоднозначности вероятности в нейронной сети, который выделяет признаки слова в пошаговом режиме без переобучения нейронной сети и выполняет распознавание путем устранения неоднозначности вероятности. Способ получает матрицу прогнозирования вероятности для названной категории именованной сущности слова из нейронной сети посредством обучения нейронной сети и выполняет устранение неоднозначностей на матрице прогнозирования, выведенной из нейронной сети в вероятностной модели, и тем самым повышает точность и правильность распознавания именованных сущностей сетевого текста.
Техническая схема: для достижения задачи, описанной выше, техническая схема, используемая настоящим изобретением, является следующей:
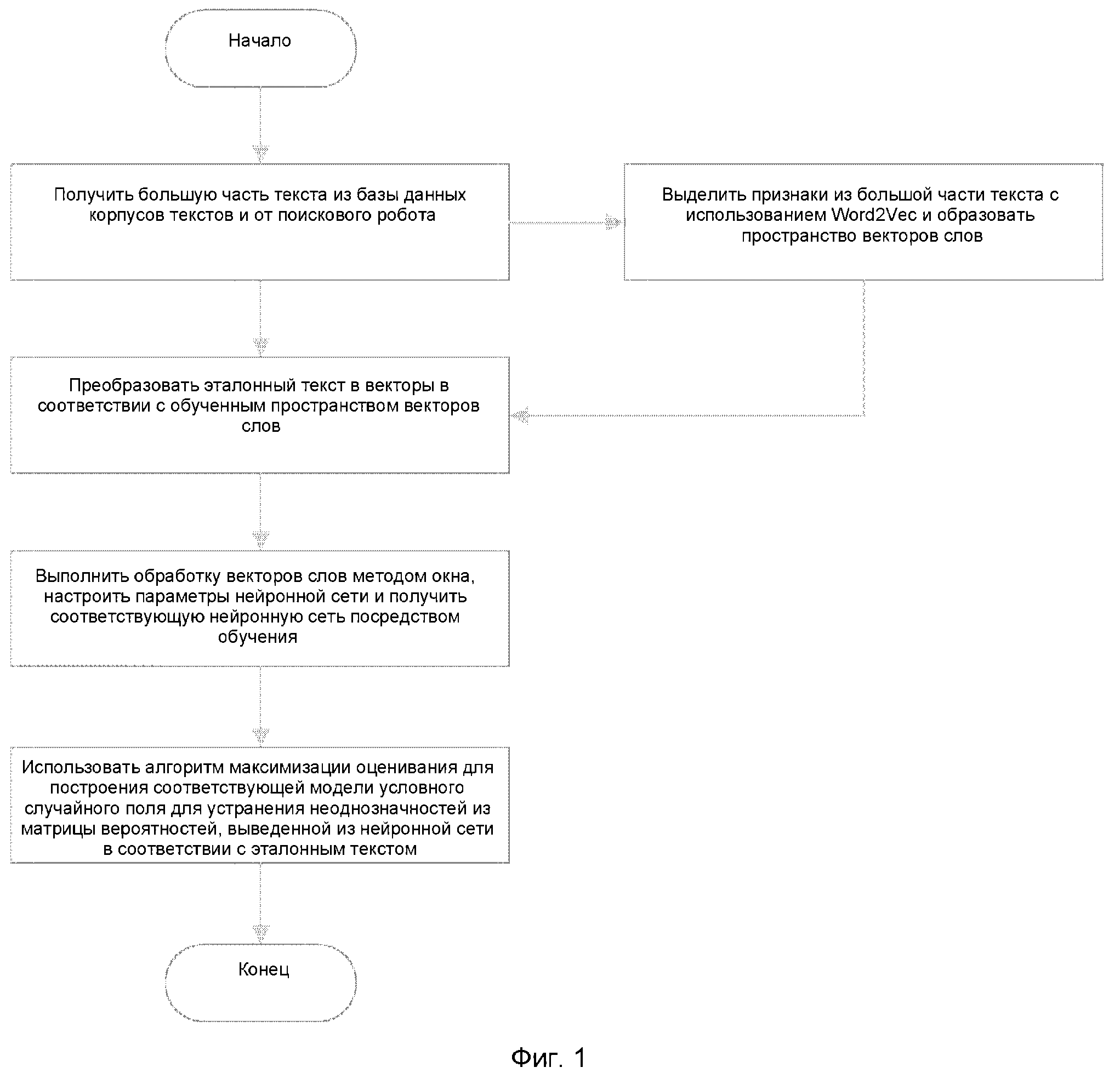
Способ распознавания именованных сущностей сетевого текста на основе устранения неоднозначности вероятности в нейронной сети выполняет разбиение на слова на неразмеченном корпусе текстов, используя Word2Vec для выделения вектора слова, преобразует эталонные корпуса текстов в матрицу признаков слова и выполняет обработку методом окна, выполняет построение глубокой нейронной сети для обучения, добавляет функцию Softmax в выходной слой нейронной сети и выполняет нормализацию для получения матрицы вероятностей категории именованных сущностей, соответствующих каждому слову; выполняет повторную обработку матрицы вероятностей методом окна и применяет модель условных случайных полей для устранения неоднозначностей для получения окончательного тега именованной сущности.
В частности, способ включает следующие этапы:
этап 1: получение неразмеченного корпуса текстов при помощи поискового робота, получение эталонных корпусов текстов с тегами именованных сущностей из базы данных корпусов текстов и выполнение разбиения на слова на неразмеченном корпусе текстов при помощи естественно-языкового инструмента;
этап 2: выполнение обучения пространства векторов слов на сегментированном неразмеченном корпусе текстов и эталонных корпусах текстов при помощи инструмента Word2Vec;
этап 3: преобразование текста в эталонных корпусах текстов в вектор слова, представляющий признаки слова в соответствии с обученной моделью Word2Vec (векторного представления слов), выполнение обработки вектора слова методом окна и использование двумерной матрицы, полученной умножением окна w на длину d вектора слова, в качестве данных, вводимых в нейронную сеть; преобразование тегов в эталонных корпусах текстов в форму для быстрого доступа (с одним активным состоянием) и использование их в качестве выходных данных нейронной сети; выполнение нормализации на выходном слое нейронной сети с помощью функции Softmax (многопеременная логистическая функция), так что результат категоризации, выдаваемый нейронной сетью, соответствует вероятности того, относится ли слово к неименованной сущности или именованной сущности, выполнение корректировки структуры, глубины, количества узлов, длины шага, функции активации и параметров начальных значений в нейронной сети и выбор функции активации для обучения нейронной сети;
этап 4: выполнение повторной обработки методом окна матрицы прогнозирования, выведенной из нейронной сети, с использованием информации, прогнозирующей контекст слова, подлежащего тегированию, в качестве точки корреляции с фактической категорией слова, подлежащего тегированию, в модели условных случайных полей, использование алгоритма максимизации оценивания для расчета ожидаемых значений по всем сторонам в соответствии с обучающими корпусами текстов и обучение соответствующей модели условных случайных полей;
этап 5: в процессе распознавания вначале выполняют преобразование текста, подлежащего распознаванию, в вектор слова, который отображает признаки слова в соответствии с обученной моделью Word2Vec, и если модель Word2Vec не содержит соответствующего обучающего слова, выполняется преобразование слова в вектор слова посредством пошагового обучения, извлечение вектора слова и обратное отслеживание пространства векторов слов и т.д., выполняют обработку вектора слова методом окна и используют двумерную матрицу, полученную умножением окна w на длину d вектора слова, в качестве данных, вводимых в нейронную сеть; затем выполняют повторную обработку методом окна матрицы прогнозирования, полученной из нейронной сети, выполняют устранение неоднозначностей на матрице прогнозирования в обученной модели условных случайных полей и получают окончательный тег именованной сущности текста, подлежащего распознаванию.
Предпочтительно, параметры инструмента Word2Vec являются следующими: длина вектора слова: 200, число итераций: 25, начальная длина шага: 0,025, минимальная длина шага: 0,0001 и выбрана модель CBOW.
Предпочтительно, параметры нейронной сети являются следующими: количество скрытых слоев: 2, количество скрытых узлов: 150, длина шага: 0,01, размер пакета (batchSize): 40, функция активации: сигмоидальная функция.
Предпочтительно, преобразование тегов в эталонных корпусах текстов в форму для быстрого доступа выполняют следующим способом: выполняют преобразование тегов "/о", "/n" и "/р" в эталонных корпусах текстов в теги именованной сущности "/Org-B", "Org-I", "/Per-B", "/Per-I", "/Loc-B" и "/Loc-I", соответственно, и последующее выполняют преобразование тегов именованной сущности в форму для быстрого доступа.
Предпочтительно, размер окна для выполнения обработки вектора слова методом окна равен 5.
Предпочтительно, при обучении нейронной сети, одна десятая слов выделяется из эталонных данных и исключается из обучения нейронной сети, но используется в качестве критерия оценки для нейронной сети.
По сравнению с предшествующим уровнем техники настоящее изобретение обеспечивает следующие полезные эффекты:
Векторы слов без переобучения нейронной сети можно выделять в пошаговом режиме, прогнозирование можно выполнять с помощью нейронной сети и устранение неоднозначностей можно выполнять с помощью вероятностной модели, так что способ достигает лучшей выполнимости, точности и правильности при распознавании именованных сущностей сетевого текста. В задаче распознавания именованных сущностей сетевого текста настоящее изобретение предусматривает способ пошагового обучения вектора слова без изменения структуры нейронной сети в соответствии с особенностью существования сетевых слов и новых слов, и использует модель устранения неоднозначности вероятности для решения проблем, заключающихся в том, что сетевые тексты имеют нестандартную грамматическую конструкцию и содержат много неправильно написанных или искаженных символов. Таким образом, способ, предоставленный в настоящем изобретении, обеспечивает высокую точность в задачах распознавания именованных сущностей сетевого текста.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 представлена блок-схема обучения устройства для распознавания именованных сущностей сетевого текста на основе устранения неоднозначности вероятности в нейронной сети согласно настоящему изобретению;
На фиг. 2 представлена блок-схема преобразования слова в признаки слова согласно настоящему изобретению;
На фиг. 3 представлена принципиальная схема обработки текста и архитектуры нейронной сети согласно настоящему изобретению.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Далее настоящее изобретение будет дополнительно подробно описано в соответствии с вариантами осуществления со ссылкой на прилагаемые чертежи. Следует понимать, что данные варианты осуществления представлены только для описания настоящего изобретения и не должны рассматриваться как создающие какое-либо ограничение объема настоящего изобретения. После прочтения данного раскрытия модификации настоящего изобретения в различных эквивалентных формах, сделанные специалистами в данной области техники, будут считаться входящими в защищаемый объем, как определено прилагаемой формулой изобретения в данной заявке.
Способ распознавания именованных сущностей сетевого текста на основе устранения неоднозначности вероятности в нейронной сети выполняет разбиение на слова на неразмеченном корпусе текстов, используя модель Word2Vec для выделения вектора слова, преобразует эталонные корпуса текстов в матрицу признаков слова и выполняет обработку методом окна (windowing), создает глубокую нейронную сеть для обучения, добавляет функцию Softmax в выходной слой нейронной сети и выполняет нормализацию для получения матрицы вероятностей категории именованных сущностей, соответствующих каждому слову; выполняет повторную обработку матрицы вероятностей методом окна и применяет модель условных случайных полей для устранения неоднозначности для получения окончательного тега именованной сущности.
В частности, способ включает следующие этапы:
этап 1: Получение неразмеченного корпуса текстов при помощи поискового робота, загрузка корпуса текстов с тегами именованной сущности в качестве эталонных корпусов текстов из базы данных корпусов текстов, и выполнение разбиения на слова на неразмеченном корпусе текстов при помощи естественно-языкового инструмента;
этап 2: Выполнение обучения пространства векторов слов на сегментированном неразмеченном корпусе текстов и эталонных корпусах текстов при помощи инструмента Word2Vec;
этап 3: Преобразование текста в эталонных корпусах текстов в вектор слова, представляющий признаки слова в соответствии с обученной моделью Word2Vec, и использование вектора слова в качестве данных, вводимых в нейронную сеть; преобразование тегов в эталонных корпусах текстов в форму для быстрого доступа и использование их в качестве выходных данных нейронной сети. Ввиду того, что в задаче обработки текста именованная сущность может быть разделена на несколько слов, тегирование выполняют в шаблоне 10 В, чтобы гарантировать, что распознанная именованная сущность имеет целостность.
К какой названной категории сущности относится слово, следует оценивать не только на основе самого слова, но и дополнительно оценивать в соответствии с контекстной информацией о слове. Таким образом, при построении нейронной сети вводится понятие «окна», то есть при оценке слова, как слово, так и характерная информация контента в виде его фиксированной длины принимаются в качестве входных данных для нейронной сети; таким образом, входной информацией в нейронную сеть больше не является длина d вектора признака слова, а вместо этого представляет собой двумерную матрицу, полученную умножением окна w на длину d вектора признака слова.
Выходной слой нейронной сети нормализируется при помощи функции Softmax, так что результат категоризации, выдаваемый нейронной сетью, соответствует вероятности того, относится ли слово к неименованной сущности или именованной сущности. Структура, глубина, количество узлов, длина шага, функция активации, параметры начальных значений в нейронной сети настраиваются и для обучения нейронной сети выбирается функция активации.
этап 4: Выполнение повторной обработки методом окна матрицы прогнозирования, выведенной из нейронной сети, с использованием информации, прогнозирующей контекст слова, подлежащего тегированию в качестве точки корреляции с фактической категорией слова, подлежащего тегированию, в модели условных случайных полей, использование алгоритма максимизации оценивания (ЕМ algorithm) для расчета ожидаемых значений по всем сторонам в соответствии с обучающими корпусами текстов и обучение соответствующей модели условных случайных полей;
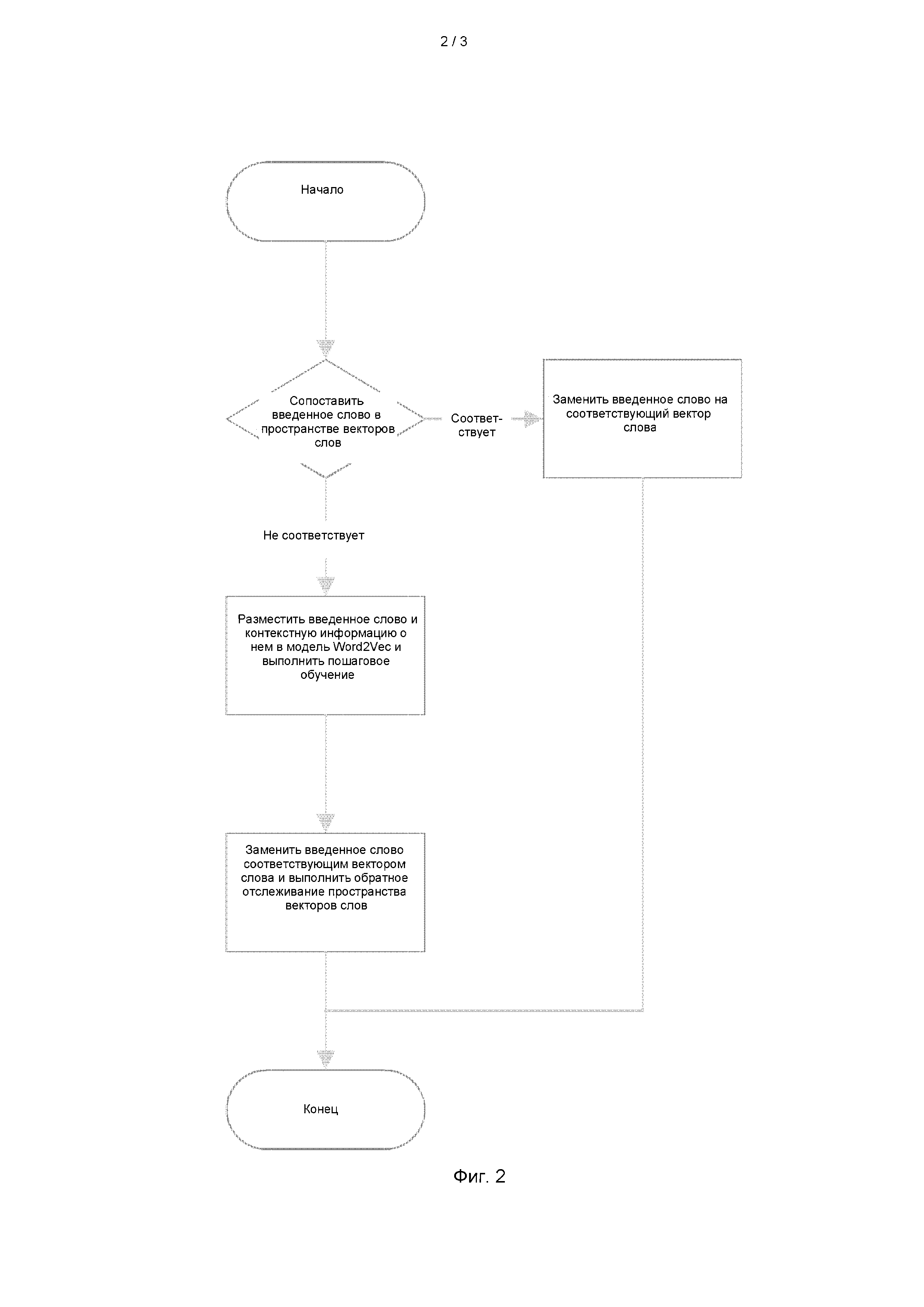
этап 5: В процессе распознавания вначале выполняют преобразование текста, подлежащего распознаванию, в вектор слова, который отображает признаки слова в соответствии с обученной моделью Word2Vec, и если модель Word2Vec не содержит соответствующего обучающего слова, выполняют преобразование слова в вектор слова посредством пошагового обучения, извлечение вектора слова и обратное отслеживание пространства векторов слов и т.д.
(1) сопоставление с эталоном слова, подлежащего преобразованию, в пространстве векторов слов;
(2) преобразование слова, подлежащего преобразованию, непосредственно в соответствующий вектор слова, если слову найдено соответствие в пространстве векторов слов;
(3) если модель Word2Vec не содержит соответствующего слова, выполняется резервное копирование пространства векторов слов для предотвращения снижения точности модели нейронной сети, вызванного отклонением пространства слов, созданного при пошаговом обучении, загрузка модели Word2Vec, получение предложения, в котором существует несоответствующее слово, ввод предложения в модель Word2Vec и выполнение пошагового обучения, получение вектора слова данного слова и использование резервного пространства векторов слов для выполнения обратного отслеживания модели;
выполнение обработки вектора слова методом окна, и использование двумерной матрицы, полученной умножением окна w на длину d вектора слова, в качестве данных, вводимых в нейронную сеть; последующее выполнение повторной обработки методом окна матрицы прогнозирования, полученной из нейронной сети, выполнение устранения неоднозначностей на матрице прогнозирования в обученной модели условных случайных полей и получение окончательного тега именованной сущности текста, подлежащего распознаванию.
Пример
Сетевой текст получен при помощи поискового робота на веб-сайте Sogou News (http://news.sogou.com/), корпуса текстов с тегами именованной сущности загружены из базы данных корпусов текстов Datatang (http://www.datatang.com/) в качестве эталонных корпусов текстов, разбиение на слова выполнено на полученном сетевом тексте при помощи естественно-языкового инструмента, обучение векторного пространства слов выполнено на сегментированном корпусе текстов и эталонном корпусе текстов при помощи пакета genism-библиотек Питон с использованием модели Word2Vec, использующей следующие параметры: длина вектора слова: 200, число итераций: 25, начальная длина шага: 0,025, и минимальная длина шага: 0,0001, и выбрана модель CBOW.
Текст в эталонных корпусах текстов преобразован в вектор слов, представляющий признаки слов в соответствии с обученной моделью Word2Vec, и в случае, если модель Word2Vec не содержит соответствующего обучающего слова, слово преобразуется в вектор слова посредством пошагового обучения, извлечения вектора слова и обратного отслеживания пространства векторов слов и т.д., в качестве признаков слова. Теги "/о", "/n" и "/р" в эталонных корпусах текстов, полученных из Datatang, преобразованы в теги именованной сущности "/Org-B", "/Org-I", "/Per-B", "/Per-I", "/Loc-B" и "/Loc-I" и т.д. соответственно, и последующие теги именованной сущности преобразованы в форму для быстрого доступа в качестве выходных данных нейронной сети.
Размер окна установлен равным 5, то есть при рассмотрении категории именованных сущностей текущего слова признаки слова данного слова, и двух слов перед словом и двух слов после слова, используются в качестве входных данных для нейронной сети; информацией, вводимой в нейронную сеть является вектор с размером пакета*1000; одна десятая слов извлечена из эталонных данных и исключена из обучения нейронной сети, но использована в качестве критерия оценки для нейронной сети; выходной слой нейронной сети нормализован при помощи функции Softmax, так что результат категоризации, выдаваемый нейронной сетью, соответствует вероятности того, относится ли слово к неименованной сущности или именованной сущности; максимальное значение вероятности временно принимается в качестве окончательного результата категоризации. Параметры в нейронной сети, такие как структура, глубина, количество узлов, длина шага, функция активации и начальное значение и т.д. настроены для обеспечения высокой точности нейронной сети; окончательные параметры являются следующими: количество скрытых слоев: 2, количество скрытых узлов: 150, длина шага: 0,01, размер пакета: 40, функция активации: сигмоидальная; таким образом может быть получен хороший эффект категоризации, точность может достигать 99,83%, а значения F наиболее типичных личных имен, географических названий и названий организаций могут составлять 93,4%, 84,2% и 80,4% соответственно.
Этап получения максимального значения матрицы прогнозирования, выведенной из нейронной сети в виде конечного результата категоризации, удален, выполнена прямая обработка матрицы вероятностей методом окна, информация, прогнозирующая контекст слова, подлежащего тегированию, использована в качестве точки корреляции с фактической категорией слова, подлежащего тегированию, в модели условных случайных полей, для расчета ожидаемых значений использован алгоритм максимизации оценивания на всех сторонах условного случайного поля в соответствии с обучающими корпусами текстов, и выполнено обучение соответствующей модели условных случайных полей; после устранения неоднозначностей с использованием условного случайного поля, значения F личных имен, географических названий и названий организаций могут быть улучшены до 94,8%, 85,0% и 82,0% соответственно.
Из описанного выше варианта осуществления видно, что по сравнению с обычным контролируемым способом распознавания именованных сущностей, в способе распознавания в тексте именованных сущностей на основе устранения неоднозначности вероятности в нейронной сети, представленном в настоящем изобретении, используется способ преобразования векторов слов, который можно использовать для выделения признаков слов в пошаговом режиме, не вызывая отклонения пространства векторов слов; таким образом, нейронная сеть может применяться к сетевому тексту, который содержит много новых слов и неправильно написанных или искаженных символов. Кроме того, в настоящем изобретении выполняется повторная обработка методом окна матрицы вероятностей, выводимой из нейронной сети, и выполняется устранение неоднозначностей контекста с применением модели условных случайных полей, чтобы решить проблему, когда сетевой текст содержит много неправильно написанных или искаженных символов и нестандартные грамматические конструкции.
Хотя настоящее изобретение описано выше в виде некоторых предпочтительных вариантов осуществления, следует отметить, что специалисты в данной области техники могут вносить различные улучшения и модификации, не отступая от принципа настоящего изобретения, и эти улучшения и модификации следует рассматривать как подпадающие под объем защиты настоящего изобретения.

Способ увеличения газопроницаемости для скважин метана угольных пластов с использованием технологии разрыва при помощи взрыва под воздействием электрических импульсов
Способ отделения и использования содержащей уголь породы в забое с содержащей уголь породой
Устройство для эмульгирования и управляемого добавления флотационного реагента
Способ устранения блокировки и увеличения газопроницаемости для скважин метана угольных пластов под воздействием электрических импульсов
Устройство и способ определения во время бурения коэффициента крепости по протодьяконову породы кровли туннеля на основе измерителя уровня звука
Устройство и способ для определения при бурении (опб) литологического состава кровли выработки
Модульные способ повышения качества и система повышения качества горючего сланца каменноугольных пластов высокой плотности
Способ каталитического окисления лигнита при атмосферном давлении с использованием кислорода в качестве окислителя
Способ динамической подачи воды и заделывания отверстий с помощью смолы с высокой водопоглощающей способностью
Замкнутая циркуляционная система для повышения производительности газоотводного насоса
Нагреваемое курительное устройство и система нагревания табака без горения

