Результат интеллектуальной деятельности: СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[1] Настоящая технология относится к извлечению информации в целом и, более конкретно, к способу и серверу генерирования одного или нескольких мета-признаков для ранжирования документов в ответ на некоторый запрос.
УРОВЕНЬ ТЕХНИКИ
[001] Алгоритмы машинного обучения (MLA) используются для удовлетворения многочисленных потребностей в реализуемых компьютером технологиях. Как правило, MLA используются для генерирования прогноза, связанного с пользовательским взаимодействием с компьютерным устройством. Одним примером области, где такой прогноз требуется, является пользовательское взаимодействие с содержимым, доступным в Интернете (как пример).
[002] Объем доступной через различные Интернет-ресурсы информации вырос за последние пару лет экспоненциально. Было разработано несколько решений, чтобы позволить обычному пользователю находить информацию, которую этот пользователь ищет. Одним примером такого решения является поисковая система. Примеры поисковых систем включают в себя поисковую систему GOOGLE™, поисковую систему YANDEX™, поисковую систему YAHOO!™ и им подобные. Пользователь может осуществить доступ к интерфейсу поисковой системы и отправить поисковый запрос, связанный с информацией, местоположение которой в Интернете этот пользователь желает определить. В ответ на поисковый запрос поисковая система предоставляет ранжированный список результатов поиска. Ранжированный список результатов поиска генерируется на основе различных алгоритмов ранжирования, применяемых конкретной поисковой системой, которая используется пользователем, выполняющим поиск. Общая цель таких алгоритмов ранжирования состоит в том, чтобы представить наиболее релевантные результаты поиска в верхней части ранжированного списка, в то время как менее релевантные результаты поиска располагаются в менее заметных положениях в ранжированном списке результатов поиска (с наименее релевантными результатами поиска, располагаемыми ближе к нижней части ранжированного списка результатов поиска).
[003] Поисковые системы обычно предоставляют хороший инструмент поиска на предмет поискового запроса, в отношении которого пользователь знает априори, что поиск по нему он хочет выполнить. Другими словами, если пользователь заинтересован в получении информации о самых популярных направлениях в Италии (т.е. известном предмете поиска), пользователь может отправить поисковый запрос: "Самые популярные направления в Италии?" Тогда поисковая система представит ранжированный список Интернет-ресурсов, которые являются потенциально релевантными такому поисковому запросу. Затем пользователь может просмотреть ранжированный список результатов поиска, чтобы получить интересующую его информацию, поскольку она связана с местами для посещения в Италии. Если пользователь по какой-либо причине не удовлетворен раскрытыми результатами поиска, пользователь может запустить поиск повторно, например, с более узконаправленным поисковым запросом, таким как: "Самые популярные направления в Италии этим летом?", "Самые популярные направления на юге Италии?", "Самые популярные направления для романтической поездки в Италию?".
[004] В примере поисковой системы MLA используется для генерирования ранжированных результатов поиска. Когда пользователь отправляет поисковый запрос, поисковая система генерирует список релевантных веб-ресурсов (на основе анализа веб-ресурсов, по которым выполняется обход и указание на которые хранится в базе данных обходчика в форме списков публикаций или подобного). Затем поисковая система исполняет MLA, чтобы ранжировать сгенерированный таким образом список результатов поиска. MLA ранжирует список результатов поиска на основе их релевантности поисковому запросу. Такой MLA "обучают" прогнозировать релевантность данного результата поиска поисковому запросу на основе изобилия "признаков", связанных с данным результатом поиска, а также указаний взаимодействий прошлых пользователей с результатами поиска при отправке аналогичных поисковых запросов в прошлом.
[005] Патент США №8,671,093 В2, выданный 13 марта 2011 компании Yahoo! Inc. и озаглавленный «СИск model for search rankings», раскрывает подходы и методики ранжирования документов, указываемых в результатах поиска для некоторого запроса, на основе информации о переходах с помощью кликов, собираемой для упомянутого запроса в предыдущих сеансах запроса. Согласно варианту осуществления этого изобретения при вычислении показателя релевантности для некоторого конкретного документа можно преодолеть позиционное смещение, используя информацию о переходах с помощью кликов для других документов, ранее возвращенных в тех же самых результатах поиска, что и упомянутый конкретный документ. Согласно варианту осуществления можно использовать динамическую байесовскую сеть, основанную на упомянутой информации о переходах с помощью кликов, для моделирования релевантности. Согласно варианту осуществления этого изобретения можно использовать информацию о переходах с помощью кликов для генерирования целей для обучения функции ранжирования.
[006] Патент США №8,001,141 В1, выданный 16 июля 2011 года компании А9 Com Inc. и озаглавленный «Relevance scores for result ranking and arrangement», раскрывает способы и системы для конфигурирования отображения товаров в основанной на сети среде мерчендайзинга. В одном варианте осуществления это изобретение идентифицирует товары в каталоге товаров, вычисляет показатель релевантности просмотра для каждого товара и конфигурирует отображение веб-страницы таким образом, чтобы товары с наивысшим показателем релевантности просмотра отображались на видном месте. В по меньшей мере одном варианте осуществления данные просмотра, такие как данные соответствия категории, данные популярности, данные новизны и т.д., используются для вычисления показателя релевантности просмотра для каждого товара.
[007] Патент США №8,924,314 В2, выданный 30 декабря 2014 года компании eBay Inc. и озаглавленный «Search result ranking using machine learning», раскрывает системы и способы ранжирования результатов поиска с использованием машинного обучения. Целевая модель может быть создана с использованием машинного обучения. В ответ на некоторый поисковый запрос, в целевую модель может быть включено множество факторов данных для создания выходного сигнала модели. Результаты поиска могут быть представлены пользователю на основе выходного сигнала модели.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[2] Целью настоящей технологии является устранение по меньшей мере некоторых неудобств, имеющихся в предшествующем уровне техники. Варианты осуществления настоящей технологии могут обеспечить и/или расширить сферу применения подходов и/или способов достижения целей и задач настоящей технологии.
[3] Разработчик(и) настоящей технологии осознали по меньшей мере одну техническую проблему, связанную с подходами предшествующего уровня техники.
[4] Разработчик(и) настоящей технологии осознали, что в некоторых ситуациях результаты поиска с самым высоким рейтингом, появляющиеся на странице результатов поиска (SERP) в ответ на запрос, могут не удовлетворять пользователя, который не обязательно просматривает другие страницы SERP и кликает по результатам поиска с более низким рейтингом, чтобы найти информацию, которую он ищет, в то время как такие результаты поиска с более низким рейтингом могут иногда предоставить пользователю удовлетворительный ответ (или более
удовлетворительный ответ по сравнению с результатами с более высоким рейтингом).
[5] Разработчик(и) настоящей технологии также осознали, что операторы поисковых систем, такие как Google™, Yandex™, Bing™ и Yahoo™, среди прочих, имеют доступ к журналам, которые включают в себя большой объем данных пользовательских взаимодействий относительно прошлых результатов поиска, появляющихся в ответ на прошлые пользовательские запросы (информация, которая обычно хранится в журналах поиска и является доступной для MLA поисковых систем).
[6] Варианты осуществления настоящей технологии были разработаны на основе понимания разработчиками того, что результаты поиска, предоставляемые в ответ на некоторый запрос ранжирующим MLA, могут быть ранжированы с учетом дополнительных факторов ранжирования, которые могут быть составными или агрегированными признаками, генерируемыми на основе других признаков, и которые могут дополнительно учитывать другие параметры, используемые сервером поисковой системы, такие как положение в SERP и показатели релевантности.
[7] Кроме того, такие мета-признаки могут генерироваться автоматически и периодически утверждаться с использованием метрик оценки, которые могут учитывать пользовательские взаимодействия в качестве представительной переменной для определения полезности для пользователей сервера поисковой системы.
[8] Таким образом, настоящая технология направлена на способ и систему генерирования мета-признаков для ранжирования документов.
[9] Такой подход может предоставить пользователю более удовлетворительные ответы, что сводит к минимуму необходимость для пользователя просматривать несколько SERP или выполнять повторную отправку запросов для нахождения информации, которую он ищет, что, в свою очередь, может сэкономить вычислительные ресурсы как на клиентском устройстве, связанном с пользователем, так и на сервере поисковой системы.
[10] В соответствии с первым обширным аспектом настоящей технологии, предложен реализуемый компьютером способ генерирования мета-признака для ранжирования документов посредством алгоритма машинного обучения (MLA), исполняемого сервером, причем способ исполняется сервером. Данный способ содержит получение сервером указания прошлого запроса, который был отправлен на сервер, и получение сервером набора прошлых документов, причем набор прошлых документов был представлен в качестве результатов поиска в ответ на прошлый запрос, причем каждый соответствующий документ из набора прошлых документов включает в себя: первое множество признаков и соответствующие значения для упомянутого первого множества признаков. Мета-признак генерируют сервером, при этом соответствующее значение мета-признака для соответствующего документа основано на: соответствующем значении некоторого признака из первого множества признаков для соответствующего документа и значении параметра, связанного с набором прошлых документов. Затем мета-признак утверждают на основе его полезности для ранжирования будущих страниц результатов поиска (SERP), и в ответ на то, что полезность превышает некоторый предопределенный порог, мета-признак принимают для ранжирования будущих SERP.
[11] В некоторых вариантах осуществления способа набор прошлых документов связан с прошлыми пользовательскими взаимодействиями и способ дополнительно содержит, до утверждения мета-признака: определение сервером порога на основе прошлых пользовательских взаимодействий с набором прошлых документов. Упомянутое утверждение содержит: прием от множества электронных устройств, подключенных к серверу, текущего запроса, причем текущий запрос схож с прошлым запросом, и генерирование сервером соответствующего набора текущих документов, релевантных текущему запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков и мета-признак, причем соответствующий набор текущих документов является по меньшей мере подмножеством набора прошлых документов. MLA ранжирует соответствующий набор текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов. Соответствующая SERP, включающая в себя соответствующий окончательный ранжированный список документов, передается на множество электронных устройств. По меньшей мере одно соответствующее пользовательское взаимодействие с соответствующей SERP принимается от множества электронных устройств. Полезность мета-признака определяется на основе: соответствующих пользовательских взаимодействий с соответствующими SERP.
[12] В некоторых вариантах осуществления способа значением параметра, связанного с набором прошлых документов, является по меньшей мере одно из: соответствующего предварительного ранга соответствующего документа, значения упомянутого признака по меньшей мере одного другого документа из набора прошлых документов и другого значения другого признака, связанного с одним из соответствующего документа и по меньшей мере одного другого документа.
[13] В некоторых вариантах осуществления способа способ дополнительно содержит, до генерирования мета-признака: ранжирование, используя второй MLA, исполняемый сервером, набора прошлых документов на основе по меньшей мере первого признака из первого множества признаков, чтобы получить предварительный ранжированный список документов, причем каждый соответствующий документ имеет соответствующий предварительный ранг.
[14] В некоторых вариантах осуществления способа генерирование мета-признака дополнительно основано на: соответствующем значении другого некоторого признака из первого множества признаков для соответствующего документа и значении параметра, связанного с набором прошлых документов.
[15] В некоторых вариантах осуществления способа значением второго параметра является по меньшей мере одно из: соответствующего предварительного ранга соответствующего документа, значения упомянутого другого признака по меньшей мере одного другого документа из набора прошлых документов и другого значения другого признака, связанного с одним из соответствующего документа и по меньшей мере одного другого документа.
[16] В некоторых вариантах осуществления способа значением упомянутого признака для упомянутого по меньшей мере одного другого документа в наборе прошлых документов является среднее значение упомянутого признака для набора прошлых документов.
[17] В некоторых вариантах осуществления способа способ дополнительно содержит: повтор упомянутого способ для набора прошлых запросов, соответствующего набора прошлых документов, которые были предоставлены в качестве соответствующих результатов поиска в ответ на соответствующий прошлый запрос из набора прошлых запросов, причем соответствующий набор прошлых документов связан с соответствующими прошлыми пользовательскими взаимодействиями.
[18] В некоторых вариантах осуществления способа определение порога содержит: применение сервером метрики пользовательской вовлеченности в отношении соответствующих наборов прошлых документов на основе соответствующих прошлых пользовательских взаимодействий для получения порога, и определение полезности мета-признака содержит: применение сервером текущей метрики пользовательской вовлеченности в отношении соответствующих SERP на основе соответствующих пользовательских взаимодействий с соответствующими SERP для получения полезности.
[19] В некоторых вариантах осуществления способа мета-признаком является первый мета-признак из набора мета-признаков, причем генерирование первого мета-признака дополнительно содержит генерирование каждого соответствующего мета-признака из набора мета-признаков, причем каждое соответствующее значение соответствующего мета-признака генерируется на основе: соответствующего значения соответствующего признака из первого множества признаков и соответствующего параметра, связанного с соответствующим набором прошлых документов, и определение использовать первый мета-признак исполняется дополнительно в ответ на то, что текущая метрика пользовательской вовлеченности для первого мета-признака превышает соответствующие текущие метрики пользовательской вовлеченности для остальных мета-признаков из набора мета-признаков.
[20] В некоторых вариантах осуществления способа упомянутый признак является одним из: зависящего от запроса признака и независящего от запроса признака.
[21] В некоторых вариантах осуществления способа соответствующим значением независящего от запроса признака для соответствующего документа является одно из: прошлых значений для независящего от запроса признака, и прогнозируемых значений для независящего от запроса признака.
[22] В соответствии с другим обширным аспектом настоящей технологии, предложен реализуемый компьютером способ генерирования мета-признака для ранжирования документов посредством алгоритма машинного обучения (MLA), исполняемого сервером, причем MLA был обучен генерировать мета-признак для ранжирования документов в ответ на некоторый запрос, причем способ исполняется упомянутым сервером. Способ содержит прием от электронного устройства, подключенного к серверу, нового запроса, причем MLA не был обучен для ранжирования документов на основе, по меньшей мере частично, мета-признака для нового запроса. Генерируется набор текущих документов, релевантных новому запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков. MLA генерирует мета-признак, при этом соответствующее значение мета-признака для соответствующего текущего документа основано на: соответствующем прогнозируемом значении некоторого признака из первого множества признаков для соответствующего документа и прогнозируемом значении параметра, связанного с набором текущих документов. MLA ранжирует соответствующий набор текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов, причем соответствующая SERP, включающая в себя соответствующий окончательный ранжированный список документов, передается на электронное устройство.
[23] В некоторых вариантах осуществления способа способ дополнительно содержит, во время фазы обучения: получение сервером набора прошлых запросов, причем каждый запрос из набора прошлых запросов был ранее отправлен на сервер, получение для каждого запроса из набора прошлых запросов соответствующего набора прошлых документов, причем соответствующий набор прошлых документов был представлен в качестве соответствующих результатов поиска в ответ на соответствующий запрос, причем каждый соответствующий документ из соответствующего набора прошлых документов имеет: первое множество признаков и соответствующие значения для упомянутого первого множества признаков. Мета-признак генерируют для каждого соответствующего набора прошлых документов, при этом соответствующее значение мета-признака для соответствующего документа из соответствующего набора прошлых документов основано на: соответствующем значении некоторого признака из первого множества признаков для соответствующего документа и значении упомянутого признака для по меньшей мере одного другого документа в наборе прошлых документов. Мета-признак утверждают на основе его полезности для ранжирования будущих страниц результатов поиска (SERP) в ответ на текущие запросы, причем каждый текущий запрос является одним из набора прошлых запросов. В ответ на то, что полезность превышает некоторый предопределенный порог: MLA обучают сервером генерировать данный мета-признак.
[24] В некоторых вариантах осуществления способа утверждение содержит: прием от множества электронных устройств, подключенных к серверу, текущих запросов, генерирование сервером соответствующего набора текущих документов, релевантных каждому из текущих запросов, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков и мета-признак, ранжирование посредством MLA соответствующих наборов текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов, передачу сервером на множество электронных устройств соответствующих SERP, причем каждая из соответствующих SERP включает в себя соответствующий окончательный ранжированный список документов, прием сервером от множества электронных устройств по меньшей мере одного соответствующего пользовательского взаимодействия с соответствующей SERP и определение сервером полезности мета-признака на основе: соответствующих пользовательских взаимодействий с соответствующими SERP.
[25] В некоторых вариантах осуществления способа соответствующий набор прошлых документов связан с соответствующими прошлыми пользовательскими взаимодействиями, причем способ содержит, до утверждения мета-признака: применение сервером метрики пользовательской вовлеченности в отношении соответствующих наборов прошлых документов на основе соответствующих прошлых пользовательских взаимодействий для получения порога, и определение полезности мета-признака содержит: применение сервером текущей метрики пользовательской вовлеченности в отношении соответствующих SERP на основе соответствующих пользовательских взаимодействий с соответствующими SERP для получения полезности.
[26] В некоторых вариантах осуществления способа MLA обучают генерировать мета-признак на основе: упомянутого мета-признака, соответствующей SERP, причем соответствующая SERP включает в себя соответствующий окончательный ранжированный список документов, которые были сгенерированы частично на основе мета-признака и соответствующих пользовательских взаимодействий с соответствующей SERP.
[27] В соответствии с другим обширным аспектом настоящей технологии, предложен реализуемый компьютером способ ранжирования документов в ответ на некоторый запрос с использованием мета-признака посредством алгоритма машинного обучения (MLA), исполняемого сервером, причем способ исполняется сервером и содержит: прием от электронного устройства, подключенного к серверу, некоторого запроса, генерирование сервером набора текущих документов, релевантных новому запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков, ранжирование посредством MLA набора текущих документов на основе по меньшей мере части первого множества признаков для получения предварительного ранжированного списка документов, генерирование посредством MLA мета-признака, причем мета-признак является относительным признаком, основанным на по меньшей мере одном некотором признаке из первого множества признаков, причем соответствующее значение упомянутого мета-признака для соответствующего текущего документа в предварительном ранжированном списке документов основано на: соответствующем значении упомянутого по меньшей мере одного признака из первого множества признаков для соответствующего документа, и значении параметра, связанного с предварительным ранжированным списком документов, ранжирование посредством MLA предварительного ранжированного списка документов на основе по меньшей мере упомянутого мета-признака для получения соответствующего окончательного ранжированного списка документов, и передачу сервером на электронное устройство соответствующей SERP, включающей в себя соответствующий окончательный ранжированный список документов в ответ на упомянутый запрос.
[28] В некоторых вариантах осуществления способа значением параметра, связанного с предварительным ранжированным списком документов, является соответствующий предварительный ранг текущего документа.
[29] В соответствии с другим обширным аспектом настоящей технологии предложен сервер генерирования мета-признака для ранжирования документов посредством алгоритма машинного обучения (MLA), исполняемого упомянутым сервером, причем сервер содержит: процессор, долговременный считываемый компьютером носитель, содержащий инструкции. Упомянутый процессор, при исполнении инструкций, сконфигурирован с возможностью: получения указания прошлого запроса, который был отправлен на сервер, и получения набора прошлых документов, причем набор прошлых документов был представлен в качестве результатов поиска в ответ на прошлый запрос, причем каждый соответствующий документ из набора прошлых документов включает в себя: первое множество признаков и соответствующие значения для упомянутого первого множества признаков. Мета-признак генерируют, при этом соответствующее значение мета-признака для соответствующего документа основано на: соответствующем значении некоторого признака из первого множества признаков для соответствующего документа и значении параметра, связанного с набором прошлых документов. Мета-признак утверждают на основе его полезности для ранжирования будущих страниц результатов поиска (SERP). В ответ на то, что полезность превышает некоторый предопределенный порог, осуществляют принятие данного мета-признака для ранжирования будущих SERP.
[30] В некоторых вариантах осуществления сервера набор прошлых документов связан с прошлыми пользовательскими взаимодействиями, причем процессор дополнительно сконфигурирован с возможностью, до утверждения: определения порога на основе прошлых пользовательских взаимодействий с набором прошлых документов, и для утверждения процессор сконфигурирован с возможностью: приема от множества электронных устройств, подключенных к серверу, текущего запроса, причем текущий запрос схож с прошлым запросом, генерирования соответствующего набора текущих документов, релевантных текущему запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков и мета-признак, причем соответствующий набор текущих документов является по меньшей мере подмножеством набора прошлых документов, ранжирования через MLA соответствующего набора текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов, передачи сервером на множество электронных устройств соответствующей SERP, включающей в себя соответствующий окончательный ранжированный список документов, приема сервером от множества электронных устройств по меньшей мере одного соответствующего пользовательского взаимодействия с соответствующей SERP, и определения полезности мета-признака на основе: соответствующих пользовательских взаимодействий с соответствующими SERP.
[31] В некоторых вариантах осуществления сервера значением параметра, связанного с набором прошлых документов, является по меньшей мере одно из: соответствующего предварительного ранга соответствующего документа, значения упомянутого признака по меньшей мере одного другого документа из набора прошлых документов и другого значения другого признака, связанного с одним из соответствующего документа и по меньшей мере одного другого документа.
[32] В некоторых вариантах осуществления сервера процессор дополнительно сконфигурирован с возможностью, до генерирования мета-признака: ранжирования, используя второй MLA, исполняемый сервером, набора прошлых документов на основе по меньшей мере первого признака из первого множества признаков, чтобы получить предварительный ранжированный список документов, причем каждый соответствующий документ имеет соответствующий предварительный ранг.
[33] В некоторых вариантах осуществления сервера мета-признак дополнительно основан на: соответствующем значении некоторого другого признака из первого множества признаков для соответствующего документа и значении второго параметра, связанного с набором прошлых документов.
[34] В некоторых вариантах осуществления сервера значением второго параметра является по меньшей мере одно из: соответствующего предварительного ранга соответствующего документа, значения упомянутого другого признака по меньшей мере одного другого документа из набора прошлых документов и другого значения другого признака, связанного с одним из соответствующего документа и по меньшей мере одного другого документа.
[35] В некоторых вариантах осуществления сервера значением упомянутого признака для упомянутого по меньшей мере одного другого документа в наборе прошлых документов является среднее значение упомянутого признака для набора прошлых документов.
[36] В некоторых вариантах осуществления сервера процессор дополнительно сконфигурирован с возможностью: исполнения упомянутых инструкций для набора прошлых запросов, соответствующего набора прошлых документов, которые были предоставлены в качестве соответствующих результатов поиска в ответ на соответствующий прошлый запрос из набора прошлых запросов, причем соответствующий набор прошлых документов связан с соответствующими прошлыми пользовательскими взаимодействиями.
[37] В некоторых вариантах осуществления сервера, для определения порога, процессор сконфигурирован с возможностью: применения метрики пользовательской вовлеченности в отношении соответствующих наборов прошлых документов на основе соответствующих прошлых пользовательских взаимодействий для получения порога, и для определения полезности процессор сконфигурирован с возможностью: применения текущей метрики пользовательской вовлеченности в отношении соответствующих SERP на основе соответствующих пользовательских взаимодействий с соответствующими SERP для получения полезности.
[38] В некоторых вариантах осуществления сервера мета-признаком является первый мета-признак из набора мета-признаков, причем для генерирования первого мета-признака процессор дополнительно сконфигурирован с возможностью генерирования каждого соответствующего мета-признака из набора мета-признаков, причем каждое соответствующее значение соответствующего мета-признака генерируется на основе: соответствующего значения соответствующего признака из первого множества признаков и соответствующего параметра, связанного с соответствующим набором прошлых документов, и определение использовать первый мета-признак исполняется дополнительно в ответ на то, что текущая метрика пользовательской вовлеченности для первого мета-признака превышает соответствующие текущие метрики пользовательской вовлеченности для остальных мета-признаков из набора мета-признаков.
[39] В некоторых вариантах осуществления сервера упомянутый признак является одним из: зависящего от запроса признака и независящего от запроса признака.
[40] В некоторых вариантах осуществления сервера соответствующим значением независящего от запроса признака для соответствующего документа является одно из: прошлых значений для независящего от запроса признака, и прогнозируемых значений для независящего от запроса признака.
[41] В соответствии с другим обширным аспектом настоящей технологии предложен сервер генерирования мета-признака для ранжирования документов посредством алгоритма машинного обучения (MLA), исполняемого сервером, причем MLA был обучен генерировать мета-признак для ранжирования документов в ответ на некоторый запрос, причем сервер содержит: процессор, долговременный считываемый компьютером носитель, содержащий инструкции. Упомянутый процессор, при исполнении инструкций, сконфигурирован с возможностью: приема от электронного устройства, подключенного к серверу, нового запроса, причем MLA не был обучен для ранжирования документов на основе, по меньшей мере частично, мета-признака для нового запроса и генерирования набора текущих документов, релевантных новому запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков. MLA генерирует мета-признак, при этом соответствующее значение мета-признака для соответствующего текущего документа основано на: соответствующем прогнозируемом значении некоторого признака из первого множества признаков для соответствующего документа и прогнозируемом значении параметра, связанного с набором текущих документов. MLA ранжирует соответствующий набор текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов. Соответствующая SERP, включающая в себя соответствующий окончательный ранжированный список документов, передается на электронное устройство.
[42] В некоторых вариантах осуществления сервера процессор дополнительно сконфигурирован с возможностью, во время фазы обучения: получения набора прошлых запросов, причем каждый запрос из набора прошлых запросов был ранее отправлен на сервер, и получения для каждого запроса из набора прошлых запросов соответствующего набора прошлых документов, причем соответствующий набор прошлых документов был представлен в качестве соответствующих результатов поиска в ответ на соответствующий запрос, причем каждый соответствующий документ из соответствующего набора прошлых документов имеет: первое множество признаков и соответствующие значения для упомянутого первого множества признаков. Мета-признак генерируют для каждого соответствующего набора прошлых документов, при этом соответствующее значение мета-признака для соответствующего документа из соответствующего набора прошлых документов основано на: соответствующем значении некоторого признака из первого множества признаков для соответствующего документа и значении упомянутого признака для по меньшей мере одного другого документа в наборе прошлых документов. Мета-признак утверждают на основе его полезности для ранжирования будущих страниц результатов поиска (SERP) в ответ на текущие запросы, причем каждый текущий запрос является одним из набора прошлых запросов. В ответ на то, что полезность превышает некоторый предопределенный порог: MLA обучают генерировать данный мета-признак.
[43] В некоторых вариантах осуществления сервера, для утверждения, процессор сконфигурирован с возможностью: приема от множества электронных устройств, подключенных к серверу, текущих запросов, генерирования соответствующего набора текущих документов, релевантных каждому из текущих запросов, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков и мета-признак, ранжирования, используя MLA, соответствующих наборов текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов, передачи на множество электронных устройств соответствующих SERP, причем каждая из соответствующих SERP включает в себя соответствующий окончательный ранжированный список документов, приема от множества электронных устройств по меньшей мере одного соответствующего пользовательского взаимодействия с соответствующей SERP и определение полезности мета-признака на основе: соответствующих пользовательских взаимодействий с соответствующими SERP.
[44] В некоторых вариантах осуществления сервера соответствующий набор прошлых документов связан с соответствующими прошлыми пользовательскими взаимодействиями, причем процессор дополнительно сконфигурирован с возможностью, до утверждения мета-признака: применения метрики пользовательской вовлеченности в отношении соответствующих наборов прошлых документов на основе соответствующих прошлых пользовательских взаимодействий для получения порога. Для определения полезности мета-признака процессор сконфигурирован с возможностью: применения текущей метрики пользовательской вовлеченности в отношении соответствующих SERP на основе соответствующих пользовательских взаимодействий с соответствующими SERP для получения полезности.
[45] В некоторых вариантах осуществления сервера, MLA обучают генерировать мета-признак на основе: упомянутого мета-признака, соответствующей SERP, причем соответствующая SERP включает в себя соответствующий окончательный ранжированный список документов, который был сгенерирован частично на основе мета-признака и соответствующих пользовательских взаимодействий с соответствующей SERP.
[46] В соответствии с другим обширным аспектом настоящей технологии предложен сервер ранжирования документов в ответ на некоторый запрос с использованием мета-признака посредством алгоритма машинного обучения (MLA), исполняемого сервером, причем сервер содержит: процессор, долговременный считываемый компьютером носитель, содержащий инструкции. Упомянутый процессор, при исполнении инструкций, сконфигурирован с возможностью: приема от электронного устройства, подключенного к серверу, некоторого запроса, и генерирования набора текущих документов, релевантных новому запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков. MLA ранжирует набор текущих документов на основе по меньшей мере части первого множества признаков для получения предварительного ранжированного списка документов. MLA генерирует мета-признак, причем мета-признак является относительным признаком, основанным на по меньшей мере одном некотором признаке из первого множества признаков, причем соответствующее значение упомянутого мета-признака для соответствующего текущего документа в предварительном ранжированном списке документов основано на: соответствующем значении упомянутого по меньшей мере одного признака из первого множества признаков для соответствующего документа, и значении параметра, связанного с предварительным ранжированным списком документов. MLA ранжирует предварительного ранжированный список документов на основе по меньшей мере упомянутого мета-признака для получения соответствующего окончательного ранжированного списка документов. Соответствующая SERP, включающая в себя соответствующий окончательный ранжированный список документов в ответ на упомянутый запрос, передается на электронное устройство.
[47] В некоторых вариантах осуществления сервера значением параметра, связанного с предварительным ранжированным списком документов, является соответствующий предварительный ранг текущего документа.
[48] В контексте настоящего описания "сервер" представляет собой компьютерную программу, которая работает на надлежащем аппаратном обеспечении и способна принимать запросы (например, от электронных устройств) по сети, а также выполнять эти запросы или вызывать выполнение этих запросов. Аппаратное обеспечение может быть одним физическим компьютером или одной физической компьютерной системой, но ни то, ни другое не является обязательным для настоящей технологии. В настоящем контексте использование выражения "сервер" не предполагает, что каждая задача (например, принятые инструкции или запросы) или какая-либо конкретная задача будут приняты, выполнены или вызваны для выполнения одним и тем же сервером (т.е. тем же самым программным обеспечением и/или аппаратным обеспечением); данное выражение предполагает, что любое количество программных элементов или аппаратных устройств может быть задействовано в приеме/отправке, выполнении или вызове для выполнения любой задачи или запроса, или последствий любой задачи или запроса; и все это программное обеспечение и аппаратное обеспечение может быть одним сервером или многочисленными серверами, причем оба данных случая включены в выражение "по меньшей мере один сервер".
[49] В контексте настоящего описания "электронное устройство" представляет собой любое компьютерное оборудование, которое способно выполнять программное обеспечение, которое является надлежащим для соответствующей поставленной задачи. Таким образом, некоторые (неограничивающие) примеры электронных устройств включают в себя персональные компьютеры (настольные ПК, ноутбуки, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройство, выступающее в качестве электронного устройства в данном контексте, не исключается из возможности выступать в качестве сервера для других электронных устройств. Использование выражения "электронное устройство" не исключает использования многочисленных электронных устройств при приеме/отправке, выполнении или вызове для выполнения какой-либо задачи или запроса, или последствий любой задачи или запроса, или этапов любого описанного в данном документе способа.
[50] В контексте настоящего описания "база данных" представляет собой любую структурированную совокупность данных, независимо от ее конкретной структуры, программное обеспечение для администрирования базы данных, или компьютерное оборудование, на котором данные хранятся, реализуются или их делают доступными для использования иным образом. База данных может находиться на том же оборудовании, что и процесс, который хранит или использует информацию, хранящуюся в базе данных, или она может находиться на отдельном оборудовании, например, на выделенном сервере или множестве серверов.
[51] В контексте настоящего описания выражение "информация" включает в себя информацию любого характера или вида, который способен храниться в базе данных любым образом. Таким образом, информация включает в себя, но без ограничения, аудиовизуальные произведения (изображения, фильмы, звуковые записи, презентации и т.д.), данные (данные о местоположении, численные данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д.
[52] В контексте настоящего описания предполагается, что выражение "используемый компьютером носитель хранения информации" включает в себя носители любого типа и вида, в том числе RAM, ROM, диски (CD-ROM, DVD, дискеты, накопители на жестких дисках и т.д.), USB-ключи, твердотельные накопители, ленточные накопители и т.д.
[53] В контексте настоящего описания, если прямо не предусмотрено иное, "указание" информационного элемента может быть самим информационным элементом или указателем, ссылкой, гиперссылкой или другим опосредованным механизмом, позволяющим получателю такого указания найти местоположение в сети, памяти, базе данных или другом считываемом компьютером носителе, из которого данный информационный элемент может быть извлечен. Например, указание документа может включать в себя сам документ (т.е. его содержимое), или оно может быть уникальным дескриптором документа, идентифицирующим файл относительно некоторой конкретной файловой системы, или некоторым другим средством направления получателя такого указания в местоположение в сети, адрес памяти, таблицу базы данных или иное местоположение, в котором доступ к файлу можем быть осуществлен. Специалист в данной области поймет, что степень точности, требуемая в указании, зависит от степени какого-либо предварительного понимания того, какая интерпретация будет обеспечена информации, обмениваемой во взаимодействии между отправителем и получателем такого указания. Например, если до связи между отправителем и получателем понимается, что указание информационного элемента будет иметь форму ключа базы данных для записи в некоторой конкретной таблице предопределенной базы данных, содержащей информационный элемент, то отправка ключа базы данных является всем тем, что требуется для эффективной передачи информационного элемента получателю, даже если сам информационный элемент не был передан во взаимодействии между отправителем и получателем такого указания.
[54] В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в качестве прилагательных только для того, чтобы позволить отличить существительные, которые они модифицируют, друг от друга, а не для описания какой-либо особой взаимосвязи между такими существительными. Таким образом, например, следует понимать, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) таких серверов, равно как и их использование (само по себе) не означает, что какой-либо "второй сервер" должен обязательно существовать в любой определенной ситуации. Кроме того, как обсуждается в других контекстах данного документа, ссылка на "первый" элемент и "второй" элемент не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях "первый" сервер и "второй" сервер могут быть одним и тем же программным обеспечением и/или аппаратным обеспечением, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[55] Каждая из реализаций настоящей технологии обладает по меньшей мере одним из вышеупомянутых аспектов и/или цели, но не обязательно имеет их все. Следует понимать, что некоторые аспекты настоящей технологии, которые возникли в попытке достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или удовлетворять другим целям, которые в данном документе явным образом не описаны.
[56] Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии станут очевидными из нижеследующего описания, сопроводительных чертежей и приложенной формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[57] Для лучшего понимания настоящей технологии, а также других аспектов и ее дополнительных признаков, ссылка приводится на нижеследующее описание, которое должно использоваться в сочетании с сопроводительными чертежами, на которых:
[58] Фигура 1 иллюстрирует схему системы, реализуемой в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[59] Фигура 2 иллюстрирует схематичное представление процедуры генерирования мета-признака, исполняемой в системе с Фигуры 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[60] Фигура 3 и Фигура 4 иллюстрируют схематичное представление процедуры утверждения, исполняемой в системе с Фигуры 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[61] Фигура 5 иллюстрирует схематичное представление процедуры использования, исполняемой в системе с Фигуры 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[62] Фигура 6 иллюстрирует блок-схему способа генерирования мета-признака для ранжирования документов, причем способ исполняется в системе с Фигуры 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[63] Фигура 7 иллюстрирует блок-схему способа обучения алгоритма машинного обучения для ранжирования документов на основе, по меньшей мере частично, мета-признака, причем способ исполняется в системе с Фигуры 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[64] Фигура 8 иллюстрирует блок-схему способа ранжирования документов с использованием мета-признака, причем способ исполняется в системе с Фигуры 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
ПОДРОБНОЕ ОПИСАНИЕ
[65] Приведенные в данном документе примеры и условные формулировки призваны главным образом помочь читателю понять принципы настоящей технологии, а не ограничить ее объем такими конкретно приведенными примерами и условиями. Должно быть понятно, что специалисты в данной области смогут разработать различные механизмы, которые, хоть и не описаны в данном документе явным образом, тем не менее воплощают принципы настоящей технологии и включаются в ее суть и объем.
[66] Кроме того, нижеследующее описание может описывать реализации настоящей технологии в относительно упрощенном виде для целей упрощения понимания. Специалисты в данной области поймут, что различные реализации настоящей технологии могут иметь большую сложность.
[67] В некоторых случаях также могут быть изложены примеры модификаций настоящей технологии, которые считаются полезными. Это делается лишь для содействия понимаю и, опять же, не для строгого определения объема или очерчивания границ настоящей технологии. Эти модификации не являются исчерпывающим списком, и специалист в данной области может осуществлять другие модификации, все еще оставаясь при этом в рамках объема настоящей технологии. Кроме того, случаи, когда примеры модификаций не приводятся, не следует толковать так, что никакие модификации не могут быть осуществлены и/или что описанное является единственным способом реализации такого элемента настоящей технологии.
[68] Кроме того, все содержащиеся в данном документе утверждения, в которых указываются принципы, аспекты и реализации настоящей технологии, а также их конкретные примеры, призваны охватить как структурные, так и функциональные эквиваленты, вне зависимости от того, известны ли они в настоящее время или будут разработаны в будущем. Таким образом, например, специалисты в данной области осознают, что любые блок-схемы в данном документе представляют концептуальные представления иллюстративной схемы, воплощающей принципы настоящей технологии. Аналогичным образом, будет понятно, что любые блок-схемы, схемы последовательности операций, схемы изменения состояний, псевдокоды и подобное представляют различные процессы, которые могут быть по сути представлены на считываемых компьютером носителях и исполнены компьютером или процессором вне зависимости от того, показан такой компьютер или процессор явным образом или нет.
[69] Функции различных элементов, показанных на фигурах, в том числе любого функционального блока, помеченного как "процессор" или "графический процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения, а также аппаратного обеспечения, способного исполнять программное обеспечение и связанного с надлежащим программным обеспечением. При обеспечении процессором, функции могут быть обеспечены одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут быть совместно используемыми. В некоторых вариантах осуществления настоящей технологии процессор может быть процессором общего назначения, таким как центральный процессор (CPU) или процессор, выделенный для конкретной цели, например, графический процессор (GPU). Кроме того, явное использование термина "процессор" или "контроллер" не должно толковаться как относящееся исключительно к аппаратному обеспечению, способному исполнять программное обеспечение, и может в неявной форме включать в себя, без ограничений, аппаратное обеспечение цифрового сигнального процессора (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянную память (ROM) для хранения программного обеспечения, оперативную память (RAM) и энергонезависимое хранилище. Другое аппаратное обеспечение, традиционное и/или специализированное, также может быть включено в состав.
[70] Программные модули, или просто модули, в качестве которых может подразумеваться программное обеспечение, могут быть представлены в настоящем документе как любая комбинация элементов блок-схемы последовательности операций или других элементов, указывающих выполнение этапов процесса и/или текстовое описание. Такие модули могут выполняться аппаратным обеспечением, которое показано в явной или неявной форме.
[71] Учитывая эти основополагающие элементы, рассмотрим некоторые неограничивающие примеры, чтобы проиллюстрировать различные реализации аспектов настоящей технологии.
[72] Фигура 1 иллюстрирует систему 100, причем система 100 реализована в соответствии с неограничивающими вариантами осуществления настоящей технологии. Система 100 содержит множество клиентских устройств 102, причем множество клиентских устройств 102 включает в себя первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 и четвертое клиентское устройство 110, подключенные к сети 112 связи через соответствующую линию 114 связи (на фигуре 1 данный номер присвоен только двум линиям из показанных линий связи). Система 100 содержит сервер 120 поисковой системы, сервер 130 отслеживания и сервер 140 обучения, подключенные к сети 112 связи через соответствующую им линию 114 связи.
[73] Только в качестве примера, первое клиентское устройство 104 может быть реализовано как смартфон, второе клиентское устройство 106 может быть реализовано как ноутбук, третье клиентское устройство 108 может быть реализовано как смартфон, а четвертое клиентское устройство 110 может быть реализовано как планшет. В некоторых неограничивающих вариантах осуществления настоящей технологии сеть 112 связи может быть реализована как Интернет. В других вариантах осуществления настоящей технологии сеть 112 связи может быть реализована иначе, например, как какая-либо глобальная сеть связи, локальная сеть связи, частная сеть связи и тому подобное.
[74] То, как реализована определенная линия 114 связи, конкретным образом не ограничено и будет зависеть от того, как реализовано связанное одно из первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 и четвертого клиентского устройства 110. Просто как пример, а не как ограничение, в тех вариантах осуществления настоящей технологии, в которых по меньшей мере одно из первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 и четвертого клиентского устройства 110 реализовано как устройство беспроводной связи (например как смартфон), связанная одна из линий 114 связи может быть реализована как линия беспроводной связи (такая как, но без ограничения, линия сети связи 3G, линия сети связи 4G, Wireless Fidelity или WiFi® для краткости, Bluetooth® и тому подобные). В тех примерах, в которых по меньшей мере одно из первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 и четвертого клиентского устройства 110 реализованы соответственно, как ноутбук, смартфон, планшетный компьютер, связанная линия 114 связи может быть либо беспроводной (например, Wireless Fidelity или WiFi® для краткости, Bluetooth® и тому подобные), либо проводной (например, Ethernet-соединение).
[75] Следует четко понимать, что в реализациях для множества клиентских устройств 102, включающего в себя первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108, четвертое клиентское устройство 110, линия 114 связи и сеть 112 связи предусмотрены лишь для иллюстративных целей. Таким образом, специалисты в данной области без труда распознают другие конкретные детали реализации для первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108, четвертого клиентского устройства 110, а также линии 114 связи и сети 112 связи. Как таковые, примеры, представленные в настоящем документе выше, никоим образом не предназначены для ограничения объема настоящей технологии.
[76] Хотя проиллюстрированы только четыре клиентских устройства 104, 106, 108 и 110 (все показаны на Фигуре 1), предполагается, что любое количество клиентских устройств во множестве клиентских устройств 102 может быть подключено к системе 100. Кроме того, предполагается, что в некоторых реализациях количество клиентских устройств во множестве клиентских устройств 102, включенных в систему 100, может исчисляться десятками или сотнями тысяч.
[77] Сервер поисковой системы
[78] С сетью 112 связи также соединен вышеупомянутый сервер 120 поисковой системы. Сервер 120 поисковой системы может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 120 поисковой системы может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 120 поисковой системы может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 120 поисковой системы является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 120 поисковой системы могут быть распределены и могут быть реализованы через многочисленные серверы. В некоторых вариантах осуществления настоящей технологии сервер 120 поисковой системы находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 120 поисковой системы может находиться под управлением и/или администрированием поставщика услуг.
[79] Сервер 120 поисковой систему поддерживает базу 122 данных журнала поиска, причем база 122 данных журнала поиска включает в себя индекс 124.
[80] Вообще говоря, назначением сервера 120 поисковой системы является: (i) обнаружение и индексирование документов, доступных в Интернете; (ii) выполнение поисков в ответ на некоторый поисковый запрос; (iii) выполнение анализа документов и выполнение ранжирования документов в ответ на упомянутый поисковый запрос; (iv) группировка упомянутых документов и составление страницы результатов поиска (SERP) для вывода на клиентское устройство (например одно из первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 и четвертого клиентского устройства 110), причем данное клиентское устройство использовалось для отправки упомянутого поискового запроса, который обеспечил в результате данную SERP.
[81] То, как сервер 120 поисковой системы сконфигурирован для обнаружения и индексации документов, выполнения поисков, анализа и ранжирования документов, конкретным образом не ограничено. Специалисты в данной области техники поймут несколько способов и средств реализации сервера 120 поисковой системы, и поэтому некоторые структурные компоненты сервера 120 поисковой системы будут описаны лишь на высоком уровне.
[82] Сервер 120 поисковой системы сконфигурирован с возможностью исполнения процедуры обнаружения документов (не проиллюстрирована), которая обычно используется сервером 120 поисковой системы для обнаружения документов, доступных по сети 112 связи. Например, сервер 120 поисковой системы сконфигурирован с возможностью исполнения «обходчика», который «посещает» сетевые ресурсы, доступные по сети 112 связи, и загружает их для дальнейшей обработки.
[83] Характер документов, которые сервер 120 поисковой системы сконфигурирован посещать и загружать, конкретным образом не ограничен, но, только в целях иллюстрации, описываемые здесь документы могут представлять веб-страницы, изображения, PDF-файлы, документы Word™, документы PowerPoint™, которые доступны по сети 112 связи.
[84] Сервер 120 поисковой системы также может быть сконфигурирован с возможностью исполнения процедуры индексации (не проиллюстрирована), которая обычно используется сервером 120 поисковой системы для построения и/или поддержания структур индексации, используемых определенной поисковой системой для выполнения поисков. Например, сервер 120 поисковой системы сконфигурирован с возможностью построения и/или поддержания инвертированного индекса, который будет упоминаться как индекс 124.
[85] То, как индекс 124 реализован в настоящей технологии, конкретным образом не ограничено, но, в качестве примера, индекс 124 содержит некоторое число списков публикаций, каждый из которых связан с соответствующим «искомым термином». Некоторая публикация в списке публикаций включает в себя данные некоторого типа, которые указывают некоторый документ, который включает в себя искомый термин, связанный с упомянутым списком публикаций, и, необязательно, включает в себя некоторые дополнительные данные (например, где в документе искомый термин появляется, количество появлений в документе и т.п.). Таким образом, каждый список публикаций соответствует искомому (поисковому) термину и содержит ряд публикаций, ссылающихся на каждый из обнаруженных документов, которые содержат по меньшей мере одно вхождение этого соответствующего искомого термина (или его части).
[86] Следует отметить, что дополнительные данные, такие как признаки проиндексированных документов, также могут быть найдены в некоторой публикации; например, число вхождений некоторого искомого термина в некоторый документ; встречается ли этот поисковый термин в названии упомянутого документа и т.д. Естественно, эти дополнительные данные могут отличаться в зависимости от конкретной поисковой системы и, в частности, от различных реализаций настоящей технологии.
[87] Искомые термины, как правило, но не исключительно, являются словами или другими строками символов. Определенная поисковая система обычно может иметь дело практически с каждым словом на разных языках, а также с правильными наименованиями, числами, символами и т.д. Очень часто используемое слово может иметь список публикаций вплоть до одного миллиарда публикаций (или даже больше).
[88] Сервер 120 поисковой системы также может быть сконфигурирован с возможностью исполнения процедуры запроса (не проиллюстрирована), которая обычно используется сервером 120 поисковой системы для идентификации документов, которые могут содержать некоторую часть некоторого запроса, отправленного в определенную поисковую систему. Например, когда сервер 120 поисковой системы принимает некоторый запрос (например, текущий запрос пользователя первого клиентского устройства 104), сервер 120 поисковой системы может осуществлять разбор упомянутого запроса на множество искомых терминов. Затем сервер 120 поисковой системы может осуществить доступ к индексу 124 и идентифицировать списки публикаций, которые связаны с по меньшей мере одним из упомянутого множества искомых терминов. В результате сервер 120 поисковой системы может осуществить доступ к по меньшей мере некоторым публикациям в идентифицированных таким образом списках публикаций и идентифицировать по меньшей мере некоторые документы, которые могут содержать по меньшей мере некоторые из множества искомых терминов упомянутого запроса.
[89] Сервер 120 поисковой системы сконфигурирован с возможностью исполнения ранжирования идентифицированных документов в индексе 124, которые содержат по меньшей мере некоторые из множества искомых терминов упомянутого запроса.
[90] Просто в качестве примера, а не ограничения, некоторые из известных методик ранжирования результатов поиска по релевантности отправленному пользователем запросу основаны на некотором или всем из того: (i) насколько популярен некоторый поисковый запрос или ответ на него в поисках; (ii) сколько результатов было возвращено; (iii) содержит ли поисковый запрос какие-либо определяющие термины (такие как «изображения», «фильмы», «погода» или тому подобное), (iv) как часто некоторый конкретный поисковый запрос обычно используется с определяющими терминами другими пользователями; и (v) как часто другие пользователи, выполняющие подобный поиск, выбирали некоторый конкретный ресурс или конкретные результаты вертикального поиска, когда результаты представлялись с использованием SERP. Таким образом, сервер 120 поисковой системы может вычислить и назначить показатель релевантности (на основе различных критериев, перечисленных выше) для каждого результата поиска, полученного в ответ на отправленный пользователем запрос, а также сгенерировать SERP, где результаты поиска ранжированы согласно их соответствующим показателям релевантности.
[91] В варианте осуществления, проиллюстрированном в данном документе, сервер 120 поисковой системы исполняет один или несколько алгоритмов 126 машинного обучения (MLA) для ранжирования документов в ответ на некоторый запрос, которые будут упоминаться как MLA 126. Выражаясь кратко, MLA 126 был обучен сервером 140 обучения оценивать релевантность некоторого документа некоторому запросу на основе, среди прочего, (i) признаков упомянутого документа и (ii) признаков упомянутого запроса. MLA 126 также может быть обучен учитывать прошлые пользовательские взаимодействия пользователей с упомянутым документом в ответ на упомянутый запрос (которые отслеживаются сервером 130 отслеживания, который будет более подробно описан ниже в данном документе) и прогнозировать пользовательские взаимодействия с документами на основе признака упомянутого документа и упомянутого запроса.
[92] В качестве неограничивающего примера, чтобы ранжировать набор документов в ответ на некоторый запрос, MLA 126 может быть сконфигурирован с возможностью исполнения этапа оценки базовой релевантности (не проиллюстрирован на Фигуре 1) и этапа определения показателя корректировки ранга (не проиллюстрирован на Фигуре 1). Предполагается, что в альтернативных вариантах осуществления настоящей технологии ранжирование документов исполняется за большее количество этапов или за один этап.
[93] Этап оценки базовой релевантности обычно используется для оценки релевантности некоторого документа некоторому запросу посредством MLA 126 на основе признаков упомянутого запроса и/или признаков упомянутого документа. Сервер 120 поисковой системы генерирует предварительную SERP, в которой каждый определенный документ связан с соответствующим предварительным рангом на основе соответствующего показателя предварительного ранжирования упомянутого документа относительно упомянутого запроса, оцениваемого посредством MLA 12 6.
[94] Сервер 120 поисковой системы исполняет этап определения показателя корректировки ранга, который обычно используется для генерирования показателей корректировки ранга для документов для переранжирования по меньшей мере некоторых документов в предварительной SERP, причем документы связаны с соответствующими предварительными рангами. Этап определения показателя корректировки ранга также может быть исполнен посредством MLA 126 или может быть исполнен другим MLA (не проиллюстрирован). В других вариантах осуществления настоящей технологии показатель корректировки ранга может не исполняться посредством MLA.
[95] Исполнение этапа определения показателя корректировки ранга может привести к тому, что сервер 120 поисковой системы переранжирует документы относительно друг друга, основываясь, по меньшей мере частично, на соответствующих показателях корректировки ранга. Это означает, что по меньшей мере один документ в SERP, после такого переранжирования документов, может быть связан с новым рангом, который отличается от его соответствующего предварительного ранга.
[96] В некоторых вариантах осуществления настоящей технологии сервер 120 поисковой системы может исполнять ранжирование для поисков нескольких типов, в том числе, но без ограничения, общего поиска и вертикального поиска.
[97] Сервер отслеживания
[98] С сетью 112 связи также соединен вышеупомянутый сервер 130 отслеживания. Сервер 130 отслеживания может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 130 отслеживания может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 130 отслеживания может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 130 отслеживания является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 130 отслеживания могут быть распределены и могут быть реализованы через многочисленные серверы. В других вариантах осуществления функциональные возможности сервера 130 отслеживания могут выполняться сервером 120 поисковой системы полностью или частично. В некоторых вариантах осуществления настоящей технологии сервер 130 отслеживания находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 130 отслеживания может находиться под управлением и/или администрированием другого поставщика услуг.
[99] Вообще говоря, сервер 130 отслеживания сконфигурирован с возможностью отслеживания пользовательских взаимодействий с результатами поиска, предоставленными сервером 120 поисковой системы в ответ на пользовательские запросы (например, сделанные пользователями одного из первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 и четвертого клиентского устройства 110). Сервер 130 отслеживания может отслеживать пользовательские взаимодействия (такие как, например, данные по кликам), когда пользователи выполняют общие веб-поиски и вертикальные веб-поиски на сервере 120 поисковой системы, и сохранять эти пользовательские взаимодействия в базе 132 данных отслеживания.
[100] Сервер 130 отслеживания также может быть сконфигурирован с возможностью автоматического определения параметров пользовательских взаимодействий на основе отслеживаемых пользовательских взаимодействий с результатами поиска. В качестве неограничивающего примера сервер 130 отслеживания может вычислять показатель кликабельности (CTR), с предопределенными интервалами времени или после приема указания, на основе количества кликов по элементу и количества раз, когда элемент был показан (представлений) в SERP.
[101] Неограничивающие примеры пользовательских взаимодействий, отслеживаемых сервером 130 отслеживания, включают в себя:
- Потери/Приобретения (Loss/Win): кликнули ли документ в ответ на поисковый запрос или нет.
- Просмотры: сколько раз документ был показан.
- Время пребывания: время, затрачиваемое пользователем на документ перед возвратом к SERP.
- Длинный/короткий клик: было ли пользовательское взаимодействие с документом длинным или коротким по сравнению с пользовательским взаимодействием с другими документами в SERP.
[102] Естественно, приведенный выше список не является исчерпывающим и может включать в себя, не выходя за рамки настоящей технологии, пользовательские взаимодействия других типов. В некоторых вариантах осуществления сервер 130 отслеживания может компилировать данные пользовательских взаимодействий (которые могут, в качестве неограничивающего примера, включать в себя пользовательские взаимодействия за каждый час) и генерировать пользовательские взаимодействия, которые подлежат сохранению в базе 132 данных отслеживания в подходящем формате для реализации настоящей технологии (что, в качестве неограничивающего примера, может представлять собой пользовательские взаимодействия за предопределенный период времени, равный 3 месяцам). В других вариантах осуществления сервер 130 отслеживания может сохранять данные пользовательских взаимодействий в необработанной форме в базе 132 данных отслеживания, так что они могут быть извлечены и скомпилированы по меньшей мере одним из сервера 120 поисковой системы, сервера 140 обучения или другого сервера (не проиллюстрирован) в подходящем формате для реализации настоящей технологии.
[103] Сервер 130 отслеживания обычно поддерживает вышеупомянутую базу 132 данных отслеживания, причем база 132 данных отслеживания включает в себя журнал 136 запросов и журнал 138 пользовательских взаимодействий.
[104] Назначение журнала 136 запросов состоит в том, чтобы регистрировать поиски, которые были выполнены с использованием сервера 120 поисковой системы. Более конкретно, журнал 136 запросов хранит термины поисковых запросов (то есть связанных поисковых слов) и связанные результаты поиска. Следует отметить, что журнал 136 запросов может вестись анонимным образом, то есть поисковые запросы не отслеживаются на предмет пользователей, которые их отправили.
[105] Более конкретно, журнал 136 запросов может включать в себя список запросов с их соответствующими терминами, с информацией о документах, которые были включены в список сервером 120 поисковой системы в ответ на соответствующий запрос, временную метку, а также может содержать список пользователей, идентифицированных по анонимным ID (или вообще без ID), и соответствующие документы, по которым они кликнули после отправки запроса. В некоторых вариантах осуществления журнал 136 запросов может обновляться каждый раз, когда новый поиск выполняется на сервере 120 поисковой системы. В других вариантах осуществления журнал 136 запросов может обновляться с предопределенными интервалами времени. В некоторых вариантах осуществления может быть множество копий журнала 136 запросов, каждая из которых соответствует журналу 136 запросов в разные моменты времени.
[106] Журнал 138 пользовательских взаимодействий может быть связан с журналом 136 запросов и может перечислять пользовательские взаимодействия, отслеживаемые сервером 130 отслеживания после того, как пользователь отправил запрос и кликнул по одному или нескольким документам в SERP на сервере 120 поисковой системы. В качестве неограничивающего примера журнал 138 пользовательских взаимодействий может содержать ссылку на документ, который может быть идентифицирован по ID-номеру или URL, список запросов, причем каждый запрос из упомянутого списка запросов использовался для доступа к данному документу, и соответствующие пользовательские взаимодействия, связанные с данным документом для соответствующего запроса из списка запросов (если с данным документом взаимодействовали), что будет описано более подробно ниже в данном документе. Множество пользовательских взаимодействий может, как правило, отслеживаться и компилироваться сервером 130 отслеживания, а в некоторых вариантах осуществления они могут включаться в список для каждого отдельного пользователя.
[107] В некоторых вариантах осуществления сервер 130 отслеживания может отправлять отслеживаемые запросы, результат поиска и пользовательские взаимодействия на сервер 120 поисковой системы, который может сохранять отслеживаемые запросы, пользовательские взаимодействия и связанные результаты поиска в базе 122 данных журнала поиска. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 130 отслеживания и сервера 120 поисковой системы могут быть реализованы посредством одного сервера.
[108] Сервер обучения
[109] С сетью связи также соединен вышеупомянутый сервер 140 обучения. Сервер 140 обучения может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 140 обучения может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 140 обучения может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 140 обучения является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 140 обучения могут быть распределены и могут быть реализованы через многочисленные серверы. В контексте настоящей технологии сервер 140 обучения может частично реализовать способы и систему, описанные в данном документе. В некоторых вариантах осуществления настоящей технологии сервер 140 обучения находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 140 обучения может находиться под управлением и/или администрированием другого поставщика услуг.
[110] Вообще говоря, сервер 140 обучения сконфигурирован с возможностью обучения MLA 126, используемого сервером 120 поисковой системы, сервером 130 отслеживания и/или другими серверами (не проиллюстрированными), связанными с оператором поисковой системы. Сервер 140 обучения может, в качестве примера, обучать один или несколько MLA, связанных с поставщиком поисковой системы, для оптимизации общих веб-поисков, вертикальных веб-поисков, предоставления рекомендаций, прогнозирования результатов и других приложений. Обучение и оптимизация MLA могут исполняться в предопределенные периоды времени или когда поставщик поисковой системы посчитает это необходимым.
[111] В контексте настоящей технологии сервер 140 обучения сконфигурирован с возможностью: (i) генерировать один или несколько мета-признаков для наборов прошлых документов, которые были представлены в ответ на прошлые запросы; (ii) утверждать один или несколько мета-признаков; (iii) генерировать набор обучающих объектов, в том числе один или несколько мета-признаков; и (3) обучать MLA 126 для генерирования одного или нескольких мета-признаков для некоторого набора документов в ответ на новый запрос, при этом новый запрос не является одним из прошлых запросов. Однако неограничивающие варианты осуществления настоящей технологии также могут быть применены к новому запросу, который либо схож с одним из прошлых запросов, либо является тем же самым.
[112] Сервер 140 обучения может поддерживать базу 142 данных обучения для хранения обучающих объектов и/или мета-признаков для различных MLA, используемых сервером 120 поисковой системы, сервером 130 отслеживания и/или другими серверами (не проиллюстрированы), связанными с оператором поисковой системы.
[113] Фигура 2 иллюстрирует схематичное представление процедуры 200 генерирования мета-признака, исполняемой сервером 140 обучения, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[114] Вообще говоря, сервер 140 обучения сконфигурирован с возможностью исполнения процедуры 200 генерирования мета-признака, чтобы генерировать множество мета-признаков 280, причем по меньшей мере один из множества мета-признаков 280 может использоваться в качестве дополнительного ранжирующего признака для ранжирования документов в ответ на запрос сервером 120 поисковой системы.
[115] Сервер 140 обучения получает набор прошлых запросов 202 из журнала 136 запросов, при этом каждый запрос из упомянутого набора прошлых запросов 202 был ранее отправлен на сервер 120 поисковой системы одним или несколькими пользователями через соответствующие связанные клиентские устройства, такие как первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 и четвертое клиентское устройство 110.
[116] То, как сервер 140 обучения выбирает запросы, которые будут частью упомянутого набора запросов 202, не ограничено. В качестве неограничивающего примера, сервер 140 обучения может выбирать некоторое предопределенное количество наиболее часто отправляемых запросов на сервер 120 поисковой системы, наиболее часто отправляемых последних запросов на сервер 120 поисковой системы (то есть запросов, имеющих наибольшее количество отправлений за предопределенный период времени до текущего времени), запросы, связанные с документами, имеющими большое количество пользовательских взаимодействий на сервере 120 поисковой системы, запросы, имеющие предопределенное количество или предопределенный тип поисковых терминов, и тому подобное.
[117] В целях упрощения настоящего описания процедура 200 генерирования мета-признака будет описана для первого прошлого запроса 204 из набора прошлых запросов 202. Следует понимать, что сервер 140 обучения исполняет процедуру 200 генерирования мета-признака для каждого прошлого запроса из набора прошлых запросов 202.
[118] Сервер 140 обучения получает для первого прошлого запроса 204 набор прошлых документов 210, причем набор прошлых документов 210 был представлен в качестве результатов поиска на странице результатов поиска (SERP) одному или нескольким из множества клиентских устройств 102 в ответ на первый прошлый запрос 204, который был отправлен на сервер 120 поисковой системы. Набор прошлых документов 210 может быть получен из базы 132 данных отслеживания.
[119] Набор прошлых документов 210 обычно включает в себя некоторое предопределенное количество документов, например, топ 100 наиболее релевантных документов, которые были представлены на SERP в ответ на первый прошлый запрос 204, что определяется посредством MLA 126 сервера 120 поисковой системы. В других вариантах осуществления набор прошлых документов 210 может включать в себя все документы, которые были представлены в качестве результатов поиска в ответ на первый прошлый запрос 204. Дополнительно или в качестве альтернативы, набор прошлых документов 210 может включать в себя только документы, имеющие некоторое количество пользовательских взаимодействий, превышающее предопределенный порог пользовательских взаимодействий.
[120] Каждый соответствующий документ из набора прошлых документов 210 имеет первое множество признаков 220. Первое множество признаков 220 может включать в себя по меньшей мере подмножество признаков, которые использовались для ранжирования соответствующего прошлого документа 212 посредством MLA 126 сервера 120 поисковой системы (то есть некоторые или все признаки, которые использовались для предварительного ранжирования набора прошлых документов 210). В некоторых вариантах осуществления настоящей технологии первое множество признаков 220 может иметь только признаки с не прогнозированными значениями (то есть значениями, которые не были прогнозированы посредством MLA 126 сервера 120 поисковой системы).
[121] Как правило, первое множество признаков 220 может включать в себя одно или более из: зависящих от запроса признаков, независящих от запроса признаков и пользовательских взаимодействий.
[122] В качестве неограничивающего примера, первое множество признаков 220 может включать в себя зависящие от запроса признаки, такие как одно или более из:
- Частотность терминов-обратная частотность документов (TF-IDF) тела, анкора, заголовка, URL и/или всего документа.
- ВМ25 тела, анкора, заголовка, URL и/или всего документа.
- LMIR.ABS тела, анкора, заголовка, URL и/или всего документа.
- LMIR.DIR тела, анкора, заголовка, URL и/или всего документа.
[123] В качестве неограничивающего примера, первое множество признаков 220 может включать в себя независящие от запроса признаки, такие как одно или более из:
- Веб-граф: связность на веб-графе, например, количество входящих ссылок и исходящих ссылок. Примеры включают в себя: PageRank, поиск по заданной теме на базе гиперссылок (HITS).
- Статистика документа: базовая статистика документа, такая как количество слов в документе, количество слов в анкорном тексте входящей ссылки документов, количество зеркальных копий документа, тип кодировки и тому подобное.
- Характеристики URL: Характеристики URL, такие как глубина, количество посещений, количество входов в систему, количество косых черт в URL и т.д.
- Тип содержимого: категория, связанная с документом, например, новостной тип, статья энциклопедии, официальный сайт и т.п.
- Клики: основанные на кликах признаки, такие как расстояние клика, вероятность клика, первый клик, последний клик, клик с длительным временем пребывания или просто клик, вероятность пропуска (клика не было, но документ ниже был), среднее время пребывания и т.п.
- Время: основанные на времени признаки, например, время создания документа, время изменения документа и т.п.
[124] В качестве неограничивающего примера, первое множество признаков 220 может включать в себя указания пользовательских взаимодействий или метрики пользовательской вовлеченности, отслеживаемые и собираемые сервером 130 отслеживания, такие как одно или более из:
- Потери/Приобретения (Loss/Win): кликнули ли документ в ответ на поисковый запрос или нет.
- Время пребывания: время, затрачиваемое пользователем на документ перед возвратом к SERP.
- Длинный/короткий клик: было ли пользовательское взаимодействие с документом длинным или коротким по сравнению с пользовательским взаимодействием с другими документами в SERP.
- Показатель кликабельности (CTR): Количество кликов по элементу, деленное на количество показов элемента (представлений).
[125] Кроме того, в некоторых вариантах осуществления настоящей технологии сервер 140 обучения может извлекать соответствующие показатели 230 релевантности из набора прошлых документов 210, то есть соответствующий показатель 232 релевантности соответствующего прошлого документа 212 в наборе прошлых документов 210 первому прошлому запросу 204, вычисленный посредством MLA 126 сервера 120 поисковой системы.
[126] Соответствующий показатель 232 релевантности для соответствующего прошлого документа 212 может быть текущим показателем релевантности, то есть таким же показателем релевантности, который был бы у соответствующего прошлого документа 212, если бы первый прошлый запрос 204 был отправлен на сервер 120 поисковой системы в настоящее время, при этом соответствующий показатель 232 релевантности указывает положение соответствующего документа в SERP. В таких вариантах осуществления соответствующие показатели 230 релевантности могут быть получены сервером 140 обучения от MLA 126 сервера 120 поисковой системы. В других вариантах осуществления настоящей технологии соответствующий показатель 232 релевантности может быть прошлым показателем релевантности, который указывает прошлое положение соответствующего прошлого документа 212 на прошлой SERP, которая была предоставлена одному или нескольким пользователям множества клиентских устройства 102 в ответ на первый прошлый запрос 204. Следует отметить, что документы в наборе прошлых документов 210 могут иметь прошлые показатели релевантности, которые со временем менялись по ряду причин (например, документ обновлялся для включения более релевантного содержимого, и, таким образом, был рассмотрен посредством MLA 126 в качестве более релевантного), и в таких ситуациях сервер 140 обучения может, в качестве неограничивающего примера, вычислять среднее значение соответствующих прошлых показателей релевантности за некоторое время.
[127] В вариантах осуществления настоящей технологии, в которых MLA 126 сконфигурирован с возможностью исполнения этапа оценки базового ранжирования и этапа определения показателя корректировки ранга, сервер 140 обучения может побудить MLA 126 исполнить по меньшей мере один из этапа оценки базового ранжирования и этапа определения показателя корректировки ранга для набора прошлых документов 210, и получить показатели 24 0 предварительного ранжирования и/или показатели 250 окончательного ранжирования от MLA 126 сервера 120 поисковой системы, при этом соответствующий прошлый документ 212 может быть связан с по меньшей мере одним из: соответствующего показателя 242 предварительного ранжирования и соответствующего показателя 252 окончательного ранжирования.
[128] В некоторых вариантах осуществления настоящей технологии соответствующие показатели 230 релевантности, показатели 24 0 предварительного ранжирования и/или показатели 250 окончательного ранжирования могут быть включены в первое множество признаков 220.
[129] Получив первый прошлый запрос 204 и набор прошлых документов 210, в котором каждый соответствующий прошлый документ 212 из набора прошлых документов 210 имеет первое множество признаков 220, и, необязательно, по меньшей мере один из показателей 230 релевантности, показателей 240 предварительного ранжирования и показателей 250 окончательного ранжирования, сервер 140 обучения генерирует множество мета-признаков 280 для набора прошлых документов 210.
[130] В целях упрощения настоящего описания будет описано генерирование лишь одного мета-признака, который будет упоминаться как мета-признак 282. Следует понимать, что сервер 140 обучения может генерировать два или более мета-признаков в соответствии с неограничивающими примерами, которые будут приведены в данном документе ниже.
[131] Вообще говоря, для соответствующего прошлого документа 212 в наборе прошлых документов 210 значение 284 мета-признака 282 генерируется на основе: значения 224 некоторого признака 222 первого множества признаков 220 для соответствующего прошлого документа 212, и значения 262 параметра 260, связанного с набором прошлых документов 210.
[132] Упомянутый признак 222 может быть любым признаком из первого множества признаков 220. В некоторых вариантах осуществления настоящей технологии сервер 140 обучения может быть сконфигурирован с возможностью рассмотрения в качестве упомянутого признака 222 лишь одного из: зависящих от запроса признаков, независящих от запроса признаков и пользовательских взаимодействий в первом множестве признаков 220. Дополнительно или альтернативно, признаки упомянутого первого множества могут быть абсолютными признаками. Значение 224 признака 222 является числовым значением упомянутого признака 222 для соответствующего прошлого документа 212. Дополнительно или в качестве альтернативы, значения упомянутого признака 222 для набора прошлых документов 210 могут быть ограничены значениями, который были не спрогнозированы посредством MLA 126 сервера 120 поисковой системы, а являются «действительными» значениями (такими как значение CTR, которое было определено на основе данных прошлых пользовательских взаимодействий, а не значение CTR, прогнозируемое посредством MLA 126).
[133] Тип параметра 260, связанного с набором прошлых документов 210, не ограничен. Вообще говоря, параметр 260 может быть параметром, который используется посредством MLA 126 для ранжирования набора прошлых документов 210, или параметром, который был выведен посредством MLA 126 в результате ранжирования набора прошлых документов 210 (например, во время этапа оценки базового ранжирования). Таким образом, параметр 260 может представлять собой, в качестве неограничивающего примера, для соответствующего прошлого документа 212, соответствующие значения одного или нескольких других признаков из первого множества признаков 220, соответствующие значения одного или нескольких признаков, которые не являются частью первого множества признаков 220, соответствующий показатель 232 релевантности, соответствующий показатель 242 предварительного ранжирования, соответствующий показатель 252 окончательного ранжирования и тому подобное. Параметр 260 может быть связан с соответствующим прошлым документом 212, с одним или несколькими другими документами из набора прошлых документов 210 (такими как документы, которым был присвоен более высокий и/или более низкий ранг, чем у соответствующего прошлого документа 212, как пример), или с набором прошлых документов 210 в целом. В качестве неограничивающего примера, значение 262 параметра 260 для соответствующего прошлого документа 212 может быть: значением упомянутого признака 222 для по меньшей мере одного другого документа из набора прошлых документов 210, наибольшим значением упомянутого признака 222 в наборе прошлых документов 210, средним значением упомянутого признака 222 для набора прошлых документов 210, значением стандартного отклонения упомянутого признака 222 для набора прошлых документов 210, соответствующим показателем 242 предварительного ранжирования соответствующего прошлого документа 212 в наборе прошлых документов 210 и подобным.
[134] Сервер 140 обучения определяет значение 284 мета-признака 282 для соответствующего прошлого документа 212 на основе: значения 224 некоторого признака 222 для соответствующего прошлого документа 212 и значения 262 параметра 260, связанного с набором прошлых документов 210.
[135] В качестве первого неограничивающего примера сервер 140 обучения может определить для упомянутого признака 222 в наборе прошлых документов 210: минимальное значение, максимальное значение и среднее значение и использовать по меньшей мере одно из минимального значения, максимального значения и среднего значения в качестве значения 262 параметра 260. Затем сервер 140 обучения вычисляет значение 284 мета-признака 282 на основе значения 262 параметра и значения 224 упомянутого признака 222. Мета-признак 282 может быть относительным признаком, то есть его значение вычисляется по отношению к значению 224 упомянутого признака 222 и значениям упомянутого признака 222 для другого документа или значениям других признаков.
[136] В качестве второго неограничивающего примера сервер 140 обучения может вычислить для упомянутого признака 222 в наборе прошлых документов 210 относительное значение упомянутого признака 222, то есть для каждого соответствующего документа из набора прошлых документов 210 соответствующее значение упомянутого признака 222 делится на максимальное значение упомянутого признака 222 в наборе прошлых документов 210.
[137] В качестве третьего неограничивающего примера значение мета-признака 282 для соответствующего прошлого документа 212 может быть определено уравнением (1):

[138] В котором ƒm является значением 284 мета-признака 282 для соответствующего прошлого документа 212, ƒij является значением 224 упомянутого признака 222 для соответствующего прошлого документа 212, avg(ƒj) является средним значение упомянутого признака 222 для набора прошлых документов 210, а std(ƒj) является стандартным отклонением данного признака 222 для набора прошлых документов 210. Таким образом, в уравнении (1) параметр 2 60 может быть основан на среднем значении и стандартном отклонении упомянутого признака 222 для набора прошлых документов 210.
[139] В качестве четвертого неограничивающего примера сервер 140 обучения может выбирать подмножество прошлых документов (не проиллюстрировано) из набора прошлых документов 210, причем подмножество прошлых документов имеет предопределенное количество документов, имеющих наибольшее значение для упомянутого признака 222. Сервер 140 обучения может сортировать подмножество прошлых документов 210 от наибольшего к наименьшему значению упомянутого признака 222. Затем сервер 140 обучения может использовать соответствующее положение каждого прошлого документа из подмножества документов в качестве значения 284 мета-признака 282.
[140] В качестве пятого неограничивающего примера сервер 140 обучения может ранжировать набор прошлых документов 210 в соответствии со значениями упомянутого признака 222 и может выбирать подмножество прошлых документов (не проиллюстрировано) на основании значений упомянутого признака, причем подмножество прошлых документов имеет предопределенное количество документов, имеющих наибольшее значение для упомянутого признака 222. Затем сервер 140 обучения может вычислить среднее значение некоторого другого признака (не проиллюстрирован) для подмножества прошлых документов и использовать это среднее значение в качестве значения 284 мета-признака 282, при этом значение 284 мета-признака 282 является статическим, то есть значение мета-признака 282 одинаково для всего подмножества прошлых документов.
[141] Кроме того, в некоторых вариантах осуществления настоящей технологии сервер 140 обучения может нормировать значения мета-признака 282, так что значения мета-признака 282 находятся в диапазоне от 0 до 1.
[142] Сервер 140 обучения сохраняет в базе 142 данных обучения для каждого соответствующего документа 212 в наборе прошлых документов 210, связанных с первым прошлым запросом 204, соответствующее значение 284 мета-признака 282. В других вариантах осуществления значение 284 мета-признака 282 для каждого соответствующего документа 212 из набора прошлых документов 210 может сохраняться вместе с первым множеством признаков 220 в индексе 124 и/или журнале 136 запросов и/или журнале 138 пользовательских взаимодействий.
[143] Фигура 3 и Фигура 4 иллюстрируют процедуру 300 утверждения мета-признака 282, причем процедура 300 утверждения исполняется сервером 140 обучения, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[144] Для исполнения процедуры 300 утверждения, сервер 140 обучения сконфигурирован с возможностью: (i) получения данных пользовательских взаимодействий для документов, которые были представлены одному или нескольким пользователям, при этом документы были ранжированы на основе, по меньшей мере частично, мета-признака 282; и (ii) утверждения мета-признака 282 на основе определяемой полезности мета-признака 282 для ранжирования документов.
[145] Вообще говоря, до и во время исполнения процедуры 200 генерирования мета-признака, сервер 120 поисковой системы продолжает предоставлять документ в качестве результатов поиска на множество клиентских устройств 102 в ответ на запросы. После исполнения процедуры 200 генерирования мета-признака, сервер 120 поисковой системы продолжает предоставлять документы в ответ на запросы от множества клиентских устройств 102, но также сконфигурирован с возможностью учета ранее сгенерированного мета-признака 282 для ранжирования документов при предоставлении результатов поиска в ответ на один или несколько текущих запросов, схожих с прошлым запросом в наборе прошлых запросов 202.
[146] Сервер 120 поисковой системы принимает текущий запрос 304 от одного из множества клиентских устройств 102, например, первого клиентского устройства 102. Сервер 120 поисковой системы извлекает из индекса 124, на основе терминов текущего запроса 304, набор текущих документов 310, релевантных текущему запросу 304, причем набор текущих документов 310 имеет первое множество признаков 322 (которое может быть упомянутым первым множеством признаков 220 с Фигуры 2 или может иметь меньше или больше признаков). В качестве примера, если текущий запрос 304 является первым прошлым запросом 204, набор текущих документов 310 может быть таким же, как набор прошлых документов 210, или может быть подмножеством набора прошлых документов 210 (например, если один или несколько прошлых документов были удалены их операторами). В других вариантах осуществления настоящей технологии набор текущих документов 310 может включать в себя набор прошлых документов 210 и дополнительные документы, такие как документы, которые подверглись обходу последними и были добавлены в индекс 124 сервером 120 поисковой системы.
[147] Сервер 120 поисковой системы может запросить базу 142 данных обучения, чтобы верифицировать, является ли текущий запрос 304 одним из набора прошлых запросов 202, ив этом случае сервер 120 поисковой системы также извлекает соответствующие значения 334 мета-признака 282, вычисленные для соответствующего набора прошлых документов (не проиллюстрирован), связанного с соответствующим прошлым запросом (не проиллюстрирован), схожим с текущим запросом 304, которые будут использоваться для ранжирования набора текущих документов 310, причем набор текущих документов 310 включает в себя документы из набора прошлых документов. В других вариантах осуществления настоящей технологии мета-признак 282 может быть извлечен вместе с первым множеством признаков 322 сервером 140 обучения. В других неограничивающих вариантах осуществления множество мета-признаков 280 или мета-признак 282 могут быть вычислены в рамках части процедуры 300 утверждения. Последнее особенно применимо, но не ограничено этим, когда текущий запрос 304 не является частью набора прошлых запросов 202.
[148] Сервер 120 поисковой системы исполняет ранжирование набора текущих документов 310, основываясь, по меньшей мере частично, на мета-признаке 282 и первом множестве признаков 322. В качестве неограничивающего примера сервер поисковой системы может быть сконфигурирован с возможностью исполнения ранжирования набора текущих документов 310 в два этапа: этап 340 оценки базовой релевантности и этап 350 определения показателя корректировки ранга. Предполагается, что в других вариантах осуществления настоящей технологии ранжирование набора текущих документов 310 может исполняться в несколько этапов или за один этап.
[149] Как поясняется в данном документе выше, этап 340 оценки базовой релевантности обычно используется для оценки релевантности соответствующего текущего документа 312 в наборе текущих документов 310 текущему запросу 304, которая может быть исполнена на основе некоторых или всех соответствующих значений первого множества признаков 322 и соответствующего значения 334 мета-признака 282. Сервер 120 поисковой системы генерирует предварительный ранжированный список документов 342, в котором каждый соответствующий текущий документ 312 из набора текущих документов 310 связан с соответствующим предварительным рангом 344 на основе соответствующего показателя 306 предварительного ранжирования.
[150] Сервер 120 поисковой системы исполняет этап 350 определения показателя корректировки ранга, который обычно используется для генерирования окончательного ранжированного списка документов 352 исходя из предварительного ранжированного списка документов 342. Этап 350 определения показателя корректировки ранга может быть исполнен на основе мета-признака 282 и одного или нескольких из признаков упомянутого первого множества 322, а также соответствующего предварительного ранга 344 и/или соответствующего показателя 346 предварительного ранжирования. Исполнение этапа 350 определения показателя корректировки ранга может привести к тому, что сервер 120 поисковой системы переранжирует документы относительно друг друга, основываясь, по меньшей мере частично, на соответствующем предварительном ранге 344 и/или соответствующем показателе 346 предварительного ранжирования. Это означает, что по меньшей мере один документ из предварительного ранжированного списка документов 342 после такого переранжирования документов может быть связан с соответствующим окончательным рангом 354 в окончательном ранжированном списке документов 352, который отличается от его соответствующего предварительного ранга 344 в предварительном ранжированном списке документов 342.
[151] Предполагается, что в некоторых вариантах осуществления настоящей технологии исполнение этапа 350 определения показателя корректировки ранга может позволить генерировать сервером 120 поисковой системы соответствующие показатели 356 окончательного ранжирования для документов, подлежащих предоставлению на SEPR, которые, в некотором смысле, «усиливают» соответствующие показатели 346 предварительного ранжирования соответствующих документов благодаря мета-признаку 282. В результате, некоторые документы в окончательном ранжированном списке документов 352 после такого «усиления» на основе мета-признака 282 могут иметь другие соответствующие окончательные ранги, по сравнению с их соответствующими предварительными рангами 344. Это может привести к генерированию более полезной SERP в целом в ответ на текущий запрос 304.
[152] Сервер 120 поисковой системы, в рамках части по меньшей мере одного из: этапа 340 оценки базовой релевантности и этапа 350 определения показателя корректировки ранга, сконфигурирован с возможностью рассмотрения ранее вычисленных или вычисляемых «на лету» мета-признаков 282 для ранжирования набора текущих документов 310. Таким образом, набор текущих документов 310 ранжируется посредством MLA 126 на основе, по меньшей мере частично, мета-признака 282, чтобы сгенерировать окончательный список ранжированных документов 352, что может привести к тому, что один или несколько документов ранжируются иначе (т.е. имеют более высокий или более низкий ранг), чем если бы они были ранжированы посредством MLA без мета-признака 282.
[153] Сервер 120 поисковой системы выводит окончательный ранжированный список документов 352, который затем передается на первое клиентское устройство 104 для отображения в виде SERP 364.
[154] Сервер 120 поисковой системы может сохранить указание: текущего запроса 304, окончательного ранжированного списка документов 352 и значений мета-признаков 282, которые были использованы для ранжирования набора текущих документов 310, в базе 142 данных обучения и/или журнале 136 запросов и/или журнале 138 пользовательских взаимодействий.
[155] Сервер 130 отслеживания отслеживает пользовательские взаимодействия пользователя первого клиентского устройства 104 с SERP 364. Сервер 130 отслеживания сохраняет отслеживаемые пользовательские взаимодействия 366 с указанием текущего запроса 304, окончательного ранжированного списка документов 352 и значений мета-признака 282.
[156] Сервер 120 поисковой системы продолжает вышеописанную процедуру для каждого текущего запроса, который также имеется в наборе прошлых запросов 202. В вариантах осуществления, в которых были сгенерированы два или более мета-признака, сервер 120 поисковой системы также сохраняет каждый из упомянутых двух или более мета-признаков и может повторять упомянутую процедуру поочередно для каждого из упомянутых двух или более мета-признаков.
[157] Как только сервер 130 отслеживания получает достаточно данных пользовательских взаимодействий (например, количество пользовательских взаимодействий превышает предопределенный порог) для документов, которые были ранжированы на основе, по меньшей мере частично, мета-признака 282 в ответ на текущие запросы, схожие с одним из набора прошлых запросов 202, сервер 140 обучения исполняет утверждение упомянутого мета-признака 282 посредством определения его полезности.
[158] Вообще говоря, полезность мета-признака 282 может быть определена путем исполнения А/В-тестирования. А/В-тест сравнивает два варианта сервиса за раз, обычно его текущую версию (контрольную версию 370) и новую версию (тестовую версию 380 с примененным к ней экспериментальным подходом), открывая их для двух групп пользователей. Одной из целей контролируемых А/В-экспериментов является выявление причинно-следственного влияния на пользовательскую вовлеченность для экспериментальных подходов, применяемых к веб-сервису. Таким образом, в контексте настоящей технологии, для текущего запроса 382, схожего с одним из набора прошлых запросов 202, контрольная или А версия 370 может включать в себя: соответствующий набор прошлых документов 374, связанный с соответствующим прошлым запросом 372, при этом соответствующий набор прошлых документов 374 имеет соответствующие показатели 37 6 окончательного ранжирования и пользовательские взаимодействия 37 8 с соответствующим набором прошлых документов 374, отслеживаемые сервером 130 отслеживания, при этом соответствующие показатели 37 6 окончательного ранжирования были определены посредством MLA 126, не основываясь на мета-признаке 282.
[159] Тестовая или В версия 380 может быть соответствующим текущим запросом 382, схожим с соответствующим прошлым запросом 372, с соответствующим набором текущих документов 384, схожим с соответствующим набором прошлых документов 374, причем соответствующий набор текущих документов 384 был ранжирован на основе, по меньшей мере частично, мета-признака 282 для получения соответствующих окончательных рангов 386 и пользовательских взаимодействий 388 с соответствующим набором текущих документов 384, отслеживаемых сервером 130 отслеживания.
[160] Следует отметить, что А/В-тестирование может применяться в отношении каждого запроса, а результаты могут быть скомпилированы для набора прошлых запросов 202 для получения «совокупной» полезности.
[161] В других вариантах осуществления настоящей технологии контрольная версия 370 (то есть предоставление документов без ранжирования их на основе мета-признака 282) может быть получена одновременно с тестовой версией (то есть предоставление документов посредством ранжирования их на основе мета-признака 282), при этом контрольная версия 370 может предоставляться первой группе пользователей (например, первому клиентскому устройству 104 и второму клиентскому устройству 106), а тестовая версия 380 может предоставляться второй группе пользователей (например, третьему клиентскому устройству 108 и четвертому клиентскому устройству 110).
[162] Затем сервер 140 обучения применяет одну или несколько метрик оценки для оценки причинно-следственного влияния на пользовательскую вовлеченность посредством добавления мета-признака 282. Тип метрики оценки, используемой для оценки полезности мета-признака 282, и тип оцениваемых пользовательских взаимодействий 378 и пользовательских взаимодействий 388 не ограничен, и для оценки пользовательского взаимодействия могут быть использованы несколько методов, известных в данной области техники.
[163] Сервер 140 обучения применяет контрольную метрику 394 оценки к соответствующему набору прошлых документов 374 на основе соответствующих показателей 37 6 окончательного ранжирования и пользовательских взаимодействий 378 для получения порога полезности.
[164] Сервер 140 обучения применяет тестовую метрику 396 оценки к соответствующему набору текущих документов 384 на основе соответствующих пользовательских взаимодействий 388 и соответствующих окончательных рангов 386, при этом соответствующие окончательные ранги 386 были вычислены на основе, по меньшей мере частично, мета-признака 282, чтобы получить полезность мета-признака 282.
[165] Сервер 140 обучения сравнивает полезность мета-признака 282 с порогом полезности.
[166] Превышение порога полезности полезностью мета-признака 282, то есть превышение контрольной метрики 394 оценки тестовой метрикой 396 оценки, может указывать на то, что мета-признак 282 оказывает положительный эффект на пользовательскую вовлеченность на сервере 120 поисковой системы.
[167] Нахождение полезности мета-признака 282 ниже порога полезности, то есть нахождение тестовой метрики 396 оценки ниже контрольной метрики 394 оценки, может указывать на то, что мета-признак 282 не оказывает никакого эффекта на пользовательскую вовлеченность и/или оказывает отрицательный эффект на пользовательскую вовлеченность на сервере 120 поисковой системы.
[168] В ответ на то, что тестовая метрика 396 оценки превышает контрольную метрику 394 оценки, сервер 140 обучения выбирает мета-признак 282 в качестве признака для ранжирования документов и обучает MLA 126 сервера 120 поисковой системы генерировать и учитывать этот мета-признак 282 для ранжирования документов в ответ на новые запросы, причем новые запросы являются запросами, которые не являются частью набора прошлых запросов 202.
[169] Следует отметить, что для определения полезности мета-признака 282 и порога полезности можно применять более одной контрольной метрики 394 оценки и тестовой метрики 396 оценки.
[170] Процедура 300 утверждения может повторяться для каждого из множества мета-признаков 280. Предполагается, что сервер 140 обучения может выбирать из множества мета-признаков 280 лишь мета-признак, который имеет наивысшую соответствующую полезность в сравнении с соответствующим ему порогом полезности, то есть мета-признак, который имеет наибольшую разницу между соответствующей ему тестовой метрикой оценки и соответствующей ему контрольной метрикой оценки и, таким образом, наибольший эффект на пользовательское взаимодействие с документами, предоставляемыми в ответ на запросы на сервере 120 поисковой системы путем ранжирования документов на основе этого мета-признака.
[171] Дополнительно или в качестве альтернативы предполагается, что оценщик(и)-человек(люди) также может быть привлечен для суждения о полезности мета-признаков путем просмотра SERP, предоставляемой(ых) в ответ на запросы, и дополнительные метрики оценки также могут применяться в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[172] Фигура 5 иллюстрирует процедуру 400 использования MLA 126 сервера 120 поисковой системы, исполненного сервером 140 обучения, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[173] Перед исполнением упомянутой процедуры 400 использования, сервер 140 обучения исполняет процедуру обучения (не проиллюстрирована) для обучения MLA 126 сервера 120 поисковой системы генерировать и использовать выбранный мета-признак 282. Процедура обучения может быть исполнена в соответствии с методиками, известными в данной области техники. После исполнения процедуры обучения MLA 126 включает в свою формулу ранжирования мета-признак 282, который может стать частью первого множества признаков 428.
[174] Процедура 400 использования исполняется сервером 120 поисковой системы после обучения MLA 126 во время процедуры 400 обучения.
[175] Сервер 120 поисковой системы принимает новый запрос 452 от второго клиентского устройства 106, причем новый запрос 452 отсутствует в наборе прошлых запросов 202, то есть новый запрос 452 не связан с набором документов, для которых выбранный мета-признак 282 был сгенерирован ранее.
[176] Сервер 120 поисковой системы извлекает из индекса 124, на основе терминов нового запроса 452, набор документов 454, релевантных новому запросу 452, причем набор документов 454 имеет первое множество признаков 456.
[177] MLA 126 генерирует значения мета-признака 458 для каждого соответствующего документа из набора документов 454.
[178] MLA 126 исполняет этап оценки базовой релевантности (не проиллюстрирован) и этап определения показателя корректировки ранга (не проиллюстрирован) на основе первого множества признаков 456 и мета-признака 458, чтобы получить окончательный ранжированный список документов 460, релевантных новому запросу 452.
[179] MLA 126 передает окончательный ранжированный список документов 460, который представляется как SERP 462 пользователю второго клиентского устройства 106.
[180] Фигура 6 иллюстрирует блок-схему способа 500 генерирования мета-признака 282 для ранжирования документов в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[181] Способ 500 исполняется сервером 140 обучения. Способ 500 может исполняться сервером 140 обучения автономно и через предопределенные интервалы времени, например, каждые 6 месяцев.
[182] Способ 500 начинается с этапа 502.
[183] ЭТАП 502: получение указания прошлого запроса, который был отправлен на сервер
[184] На этапе 502 сервер 140 обучения получает из журнала 136 запросов базы 132 данных отслеживания указание первого прошлого запроса 204, причем первый прошлый запрос 204 был отправлен по меньшей мере одним из множества электронных устройств 102.
[185] Способ 500 переходит на этап 504.
[186] ЭТАП 504: получение набора прошлых документов, причем набор прошлых документов был представлен в качестве результатов поиска в ответ на прошлый запрос, причем каждый соответствующий документ из набора прошлых документов включает в себя: первое множество признаков, и соответствующие значения для первого множества признаков.
[187] На этапе 504 сервер 140 обучения получает из журнала 136 запросов базы 132 данных отслеживания и/или индекса 124 на основе первого прошлого запроса 204 набор прошлых документов 210, причем набор прошлых документов 210 был представлен на SERP, переданной по меньшей мере одному из множества электронных устройств 102 в ответ на первый прошлый запрос 204. Соответствующий прошлый документ 212 из набора прошлых документов 210 имеет первое множество признаков 220 и значения для каждого из первого множества признаков 220. Соответствующий прошлый документ 212 из набора прошлых документов 210 связан с одним или несколькими пользовательскими взаимодействиями, причем одно или несколько пользовательских взаимодействий были выполнены пользователями множества клиентских устройств 102, которые отправили первый прошлый запрос 204 на сервер 120 поисковой системы.
[188] Способ 500 переходит на этап 506.
[189] ЭТАП 506: генерирование мета-признака, причем соответствующее значение упомянутого мета-признака для соответствующего документа основано на:
соответствующем значении некоторого признака из первого множества признаков для соответствующего документа, и
значении параметра, связанного с набором прошлых документов.
[190] На этапе 506 сервер 140 обучения генерирует мета-признак 282, причем значение 284 упомянутого мета-признака 282 для соответствующего прошлого документа 212 основано на: соответствующем значении 224 некоторого признака 222 из первого множества признаков 220 и значении 262 параметра 260, связанного с набором прошлых документов 210. Параметр 260 может быть параметром, который используется посредством MLA 126 для ранжирования набора прошлых документов 210, или параметром, который был выведен посредством MLA 126 в результате ранжирования набора прошлых документов 210. В некоторых вариантах осуществления настоящей технологии параметр 260 может быть по меньшей мере одним из: соответствующего показателя 242 предварительного ранжирования упомянутого документа, значения упомянутого признака 222 по меньшей мере одного другого документа из набора прошлых документов 210, и другого значения другого признака, связанного с одним из соответствующего прошлого документа 212 и по меньшей мере одного другого документа.
[191] Сервер 140 обучения сконфигурирован с возможностью исполнения этапов с 502 по 506 для каждого прошлого запроса из набора прошлых запросов 202, которые были отправлены на сервер 120 поисковой системы.
[192] Способ 500 переходит на этап 508.
[193] ЭТАП 508: утверждение мета-признака на основе его полезности для ранжирования будущих страниц результатов поиска (SERP).
[194] На этапе 508, со ссылкой все еще на Фигуру 5 и Фигуру 6, сервер 140 обучения исполняет утверждение мета-признака 282 посредством исполнения способа 600.
[195] Сервер 140 обучения исполняет способ 600 перед исполнением этапа 510.
[196] ЭТАП 510: в ответ на то, что полезность превышает некоторый предопределенный порог, осуществляют принятие упомянутого мета-признака для ранжирования будущих SERP.
[197] На этапе 510 в ответ на то, что полезность мета-признака 282 превышает порог полезности, то есть в ответ на то, что тестовая метрика 396 оценки превышает контрольную метрику 394 оценки, сервер 140 обучения осуществляет принятие мета-признака 282 для обучения MLA 126 сервера 120 поисковой системы, так что мета-признак 282 становится признаком, учитываемым посредством MLA 126, подобным мета-признакам 282 упомянутого первого множества.
[198] Сервер 140 обучения может генерировать соответствующий обучающий объект 422 из набора обучающих объектов 420, извлекая из базы 142 данных обучения и/или журнала 136 запросов и/или журнала 138 пользовательских взаимодействий некоторый соответствующий прошлый запрос 424 (например, один из набора прошлых запросов 202), связанный с соответствующим набором прошлых документов 426, которые были представлены в ответ на соответствующий прошлый запрос 424, причем соответствующий набор прошлых документов 426 имеет соответствующее первое множество признаков 428 и соответствующие значения выбранного мета-признака 282 для соответствующего набора прошлых документов 426, соответствующие окончательные ранги 432 и пользовательские взаимодействия 434 с соответствующим набором прошлых документов 426.
[199] Сервер 140 обучения обучает MLA 126 сервера 120 поисковой системы на наборе обучающих объектов 420, используя соответствующие пользовательские взаимодействия 434 в качестве метки, так что MLA 126 генерирует мета-признак 282 для документов в ответ на новый запрос, который не является частью набора прошлых запросов 202, и ранжирует документы, основываясь, по меньшей мере частично, на прогнозируемых значениях упомянутого мета-признака 282. В некоторых вариантах осуществления настоящей технологии обучение MLA 126 может быть выполнено для по меньшей мере одного из: этапа оценки базовой релевантности (не проиллюстрирован) и этапа определения показателя корректировки ранга (не проиллюстрирован).
[200] Если полезность мета-признака 282 превышает предопределенный порог, сервер 130 отслеживания сконфигурирован с возможностью исполнения способа 700.
[201] Если полезность мета-признака 282 ниже предопределенного порога, сервер 130 отслеживания исполняет способ 500 для множества мета-признаков, пока полезность некоторого определенного мета-признака не превысит предопределенный порог.
[202] Затем способ 500 завершается.
[203] Фигура 7 иллюстрирует блок-схему способа 600 утверждения мета-признака 282 в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[204] Способ 600 исполняется сервером 120 поисковой системы, сервером 130 отслеживания и сервером 140 обучения.
[205] Способ 600 начинается с этапа 602.
[206] ЭТАП 602: прием текущего запроса, причем текущий запрос схож с прошлым запросом;
[207] На этапе 602 сервер 120 поисковой системы принимает от одного из множества клиентских устройств 102 текущий запрос 304, причем текущий запрос 304 является одним из набора прошлых запросов 202. Текущий запрос 304 может быть принят сервером 120 поисковой системы в разные моменты времени от разных клиентских устройств из множества клиентских устройств 102.
[208] Способ 600 переходит на этап 604.
[209] ЭТАП 604: генерирование соответствующего набора текущих документов, релевантных текущему запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков и мета-признак, причем соответствующий набор текущих документов является по меньшей мере подмножеством набора прошлых документов.
[210] На этапе 604 сервер 120 поисковой системы генерирует набор текущих документов 310, релевантных текущему запросу 304, путем запрашивания индекса 124. Набор текущих документов 310 имеет первое множество признаков 322. Сервер 120 поисковой системы может иметь указание, что набор текущих документов 310 связан с мета-признаком 282, и извлекать упомянутый мета-признак 282, в котором значения были вычислены для набора прошлых документов, схожего с набором текущих документов 310, из базы 142 данных обучения или другой базы данных (не проиллюстрирована). В других вариантах осуществления настоящей технологии мета-признак 282 может быть сохранен вместе с первым множеством признаков 322. Сервер 120 поисковой системы исполняет этап 604 каждый раз, когда текущий запрос 304 принимается от одного из множества клиентских устройств 102.
[211] Способ 600 переходит на этап 606.
[212] ЭТАП 606: ранжирование соответствующего набора текущих документов на основе, по меньшей мере частично, первого множества признаков и мета-признака для получения соответствующего окончательного ранжированного списка документов;
[213] На этапе 606 MLA 126 сервера 120 поисковой системы исполняет ранжирование набора текущих документов 310, основываясь, по меньшей мере частично, на первом множестве признаков 322 и мета-признаке 282, чтобы получить соответствующий окончательный ранжированный список текущих документов 352. В некоторых вариантах осуществления настоящей технологии ранжирование набора текущих документов 310 может исполняться в два этапа: этап 340 оценки базовой релевантности и этап 350 определения показателя корректировки ранга. Сервер 120 поисковой системы исполняет этап 606 каждый раз, когда текущий запрос 304 принимается от одного из множества клиентских устройств 102.
[214] Способ 600 переходит на этап 608.
[215] ЭТАП 608: передача соответствующей SERP, включающей в себя соответствующий окончательный ранжированный список документов.
[216] На этапе 608 сервер 120 поисковой системы генерирует SERP 364 на основе соответствующего окончательного ранжированного списка текущих документов 352 и передает соответствующую SERP 364 на одно из множества клиентских устройств 102. Сервер 120 поисковой системы исполняет этап 608 каждый раз, когда текущий запрос 304 принимается от одного из множества клиентских устройств 102.
[217] Способ 600 переходит на этап 610.
[218] ЭТАП 610: прием от множества электронных устройств по меньшей мере одного соответствующего пользовательского взаимодействия с соответствующей SERP.
[219] На этапе 610 сервер 120 поисковой системы принимает от одного из множества клиентских устройств 102 пользовательские взаимодействия 366 с соответствующей SERP 364. Пользовательские взаимодействия 366 с соответствующими SERP 364 отслеживаются сервером 130 отслеживания и могут приниматься в разные моменты времени. Сервер 130 отслеживания сохраняет пользовательские взаимодействия 366 в связи с окончательным ранжированным списком документов 352 на SERP 364 и текущим запросом 304 в базе 142 данных обучения.
[220] Способ 600 переходит на этап 612.
[221] ЭТАП 612: определение порога полезности.
[222] На этапе 612 сервер 140 обучения определяет порог полезности для утверждения мета-признака 282. Сервер 140 обучения определяет порог полезности на основе соответствующих показателей 376 окончательного ранжирования и соответствующих пользовательских взаимодействий 378 с соответствующими наборами прошлых документов 374, предоставленных в ответ на соответствующие прошлые запросы 202, путем применения контрольной метрики 394 оценки. Соответствующие наборы прошлых документов 374 были ранжированы без учета упомянутого мета-признака 282.
[223] ЭТАП 614: определение полезности упомянутого мета-признака.
[224] На этапе 614 сервер 140 обучения применяет тестовую метрику 396 оценки к соответствующему набору текущих документов 384 на основе соответствующих пользовательских взаимодействий 388 и соответствующих окончательных рангов 386, которые были вычислены на основе, по меньшей мере частично, упомянутого мета-признака 282, чтобы определить полезность данного мета-признака 282.
[225] Способ 600 затем завершается и осуществляется возврат на этап 510.
[226] Фигура 8 иллюстрирует блок-схему способа 700 для ранжирования документов посредством MLA 126 с использованием мета-признака 282, причем MLA 126 был обучен генерировать мета-признак 282, причем способ исполняется сервером 120 поисковой системы, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[227] Способ 700 исполняется после способа 500.
[228] Способ 700 начинается с этапа 702.
[229] ЭТАП 702: прием некоторого запроса;
[230] На этапе 702 сервер 120 поисковой системы принимает новый запрос 452 от второго клиентского устройства 106, причем новый запрос 452 отсутствует в наборе прошлых запросов 202, то есть новый запрос 452 не связан с набором документов, для которых выбранный мета-признак 282 был сгенерирован ранее.
[231] Способ 700 переходит на этап 704.
[232] ЭТАП 704: генерирование набора документов, релевантных новому запросу, причем каждый текущий документ из соответствующего набора текущих документов включает в себя первое множество признаков.
[233] На этапе 704 сервер 120 поисковой системы извлекает из индекса 124, на основе терминов нового запроса 452, набор документов 454, релевантных новому запросу 452, причем набор документов 454 имеет первое множество признаков 456.
[234] Способ 700 переходит на этап 706.
[235] ЭТАП 706: генерирование мета-признака
[236] На этапе 706 MLA 126 или сервер 120 поисковой системы генерирует значения мета-признака 458 для каждого соответствующего документа из набора документов 454.
[237] Способ 700 переходит на этап 708.
[238] ЭТАП 708: ранжирование посредством MLA 126 соответствующего набора текущих документов, основываясь, по меньшей мере частично, на первом множестве признаков и мета-признаке, чтобы получить соответствующий окончательный ранжированный список документов.
[239] На этапе 708 MLA 126 ранжирует набор документов 454 на основе, по меньшей мере частично, первого множества признаков 456 и мета-признака 458 для получения окончательного ранжированного списка документов 4 60, релевантных новому запросу 452.
[240] Способ 700 переходит на этап 710.
[241] ЭТАП 710: передача соответствующей SERP, включающей в себя соответствующий окончательный ранжированный список документов.
[242] На этапе 710 MLA 126 передает окончательный ранжированный список документов 460, который представляется как SERP 462 пользователю второго клиентского устройства 106.
[243] Затем способ 700 завершается.
[244] В некоторых вариантах осуществления настоящей технологии мета-признак может генерироваться «на лету», то есть каждый раз, когда запрос принимается, без предварительно вычисленных значений мета-признака. Документы могут быть предварительно ранжированы на основе абсолютных признаков для получения предварительного ранжированного списка документов. В предварительно ранжированном списке документов документы могут быть переранжированы на основе по меньшей мере одного мета-признака, который является относительным признаком, основанным на по меньшей мере одном абсолютном признаке.
[245] Специалистам в данной области техники должно быть понятно, что по меньшей мере некоторые варианты осуществления настоящей технологии направлены на расширение арсената технических средств для решения конкретной технической задачи, а именно на улучшение ранжирования набора результатов поиска в ответ на некоторый запрос путем генерирования мета-признака, что может позволить улучшить ранжирование некоторых результатов поиска в наборе результатов поиска. Такие технические решения могут позволить сэкономить ресурсы, например, пространство хранения, пропускную способность и время, на клиентских устройствах, а также на сервере поисковой системы.
[246] Следует четко понимать, что не все технические эффекты, упомянутые в данном документе, должны обеспечиваться в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без обеспечения пользователю некоторых из упомянутых технических эффектов, в то время как другие варианты осуществления могут быть реализованы с обеспечением пользователю других технических эффектов или без обеспечения каких-либо технических эффектов.
[247] Некоторые из упомянутых этапов, а также прием/отправка сигналов хорошо известны в данной области техники и, как таковые, были опущены в некоторых частях этого описания для простоты. Сигналы могут отправляться/приниматься с использованием оптических средств (например, оптоволоконного соединения), электронных средств (например, используя проводное или беспроводное соединение) и механических средств (например, средств, основанных на давлении, на температуре, или на основе любого другого подходящего физического параметра).
[248] Модификации и улучшения вышеописанных реализаций настоящей технологии могут стать очевидными для специалистов в данной области техники. Предшествующее описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому подразумевается, что объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
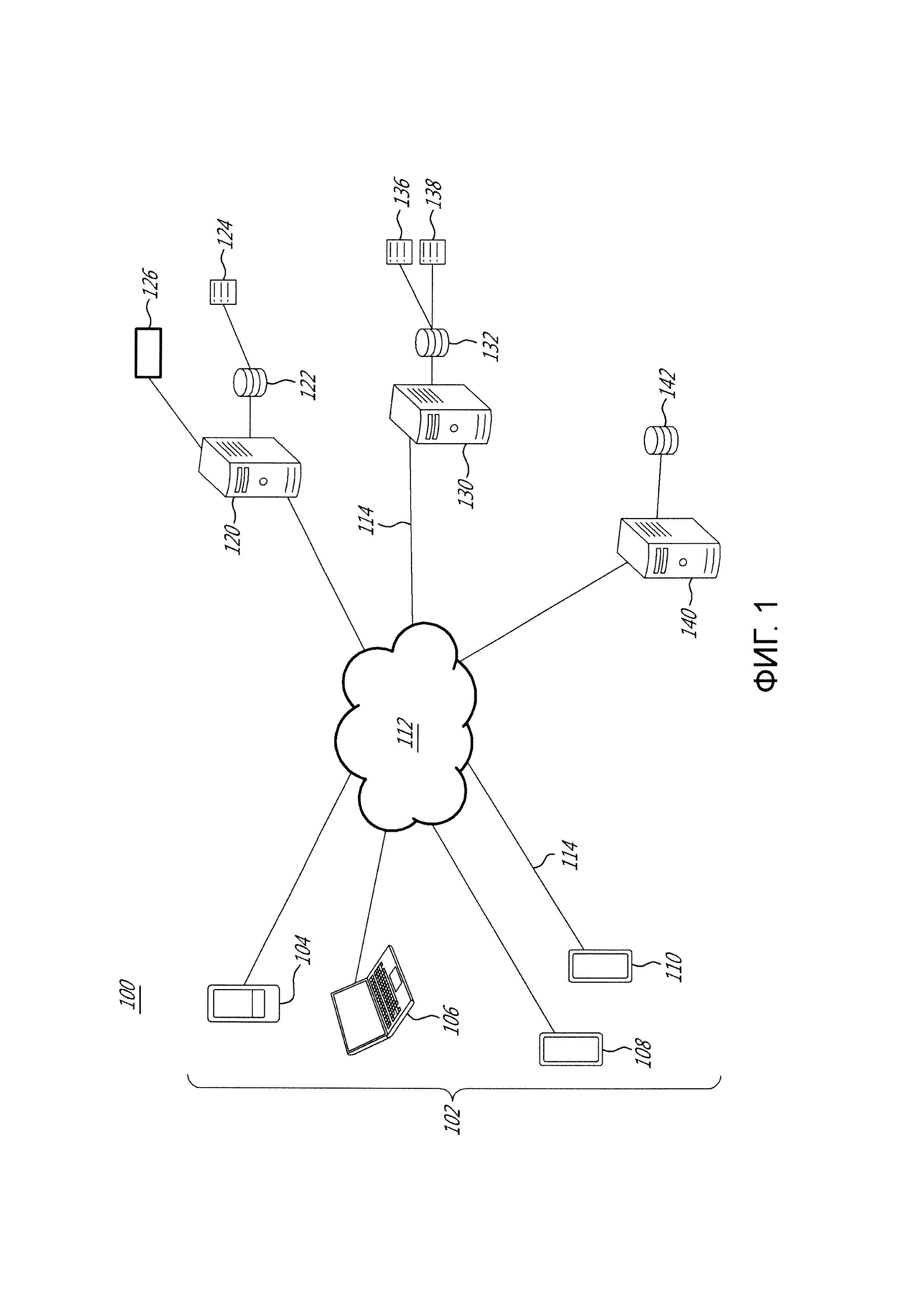
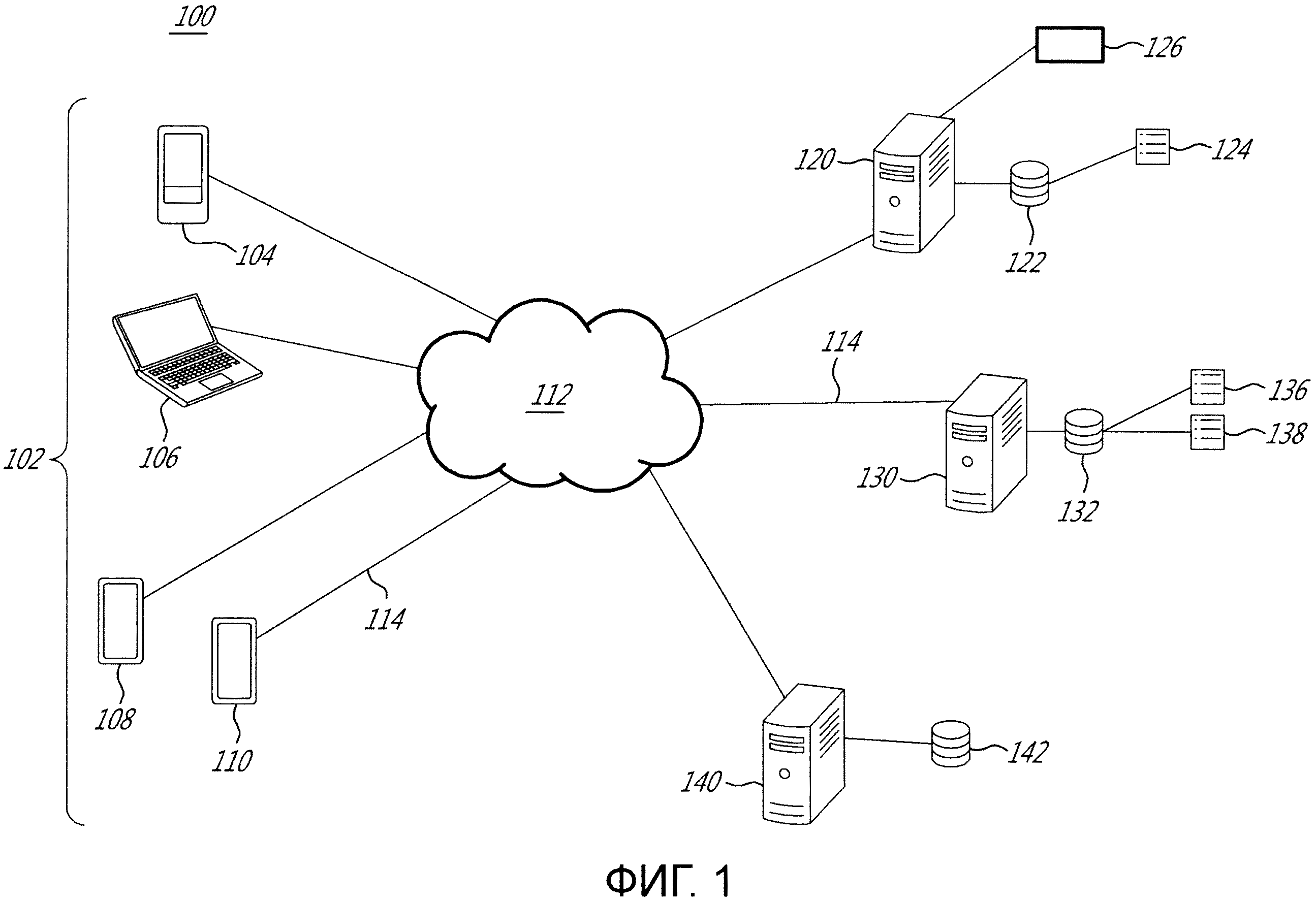
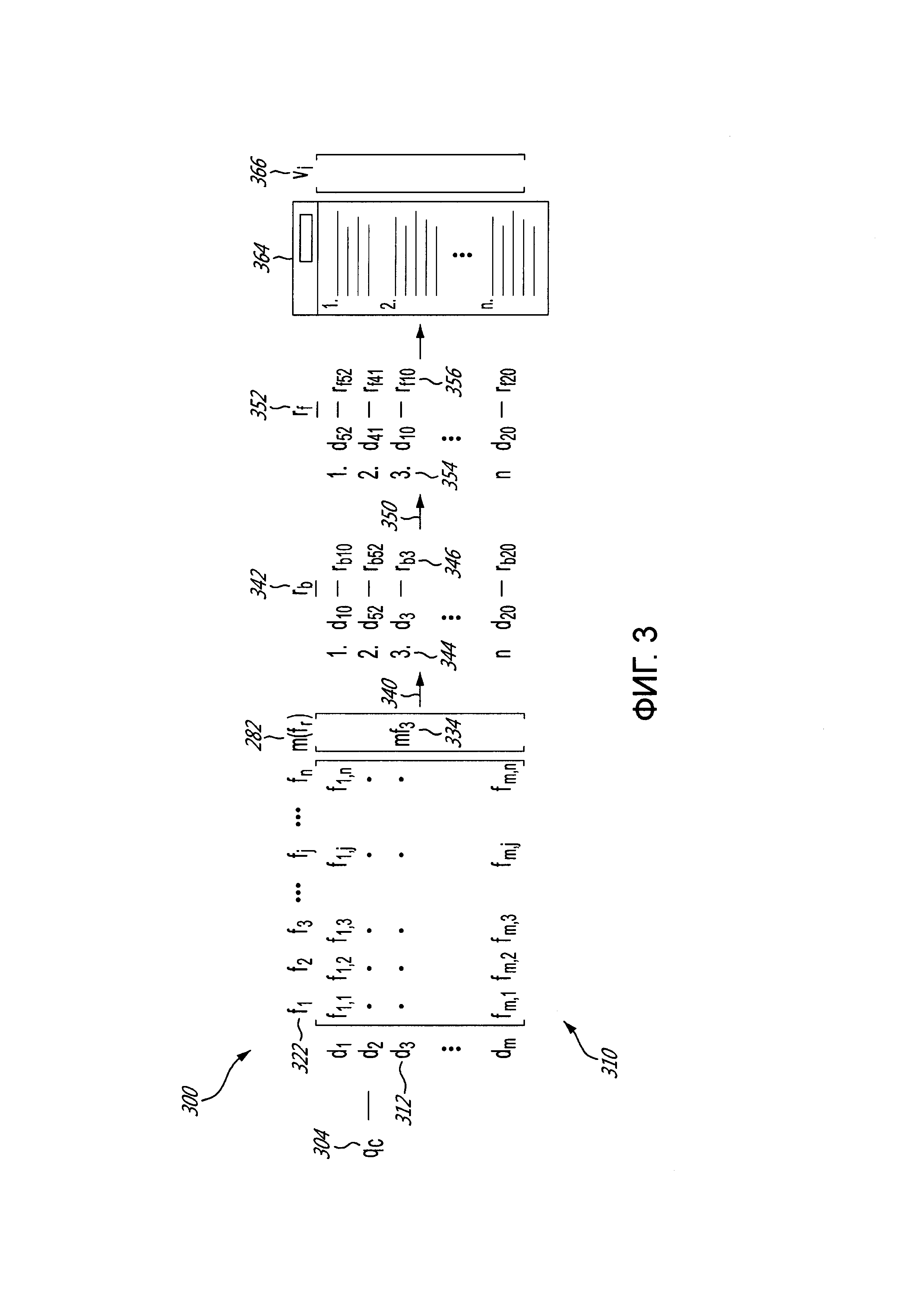
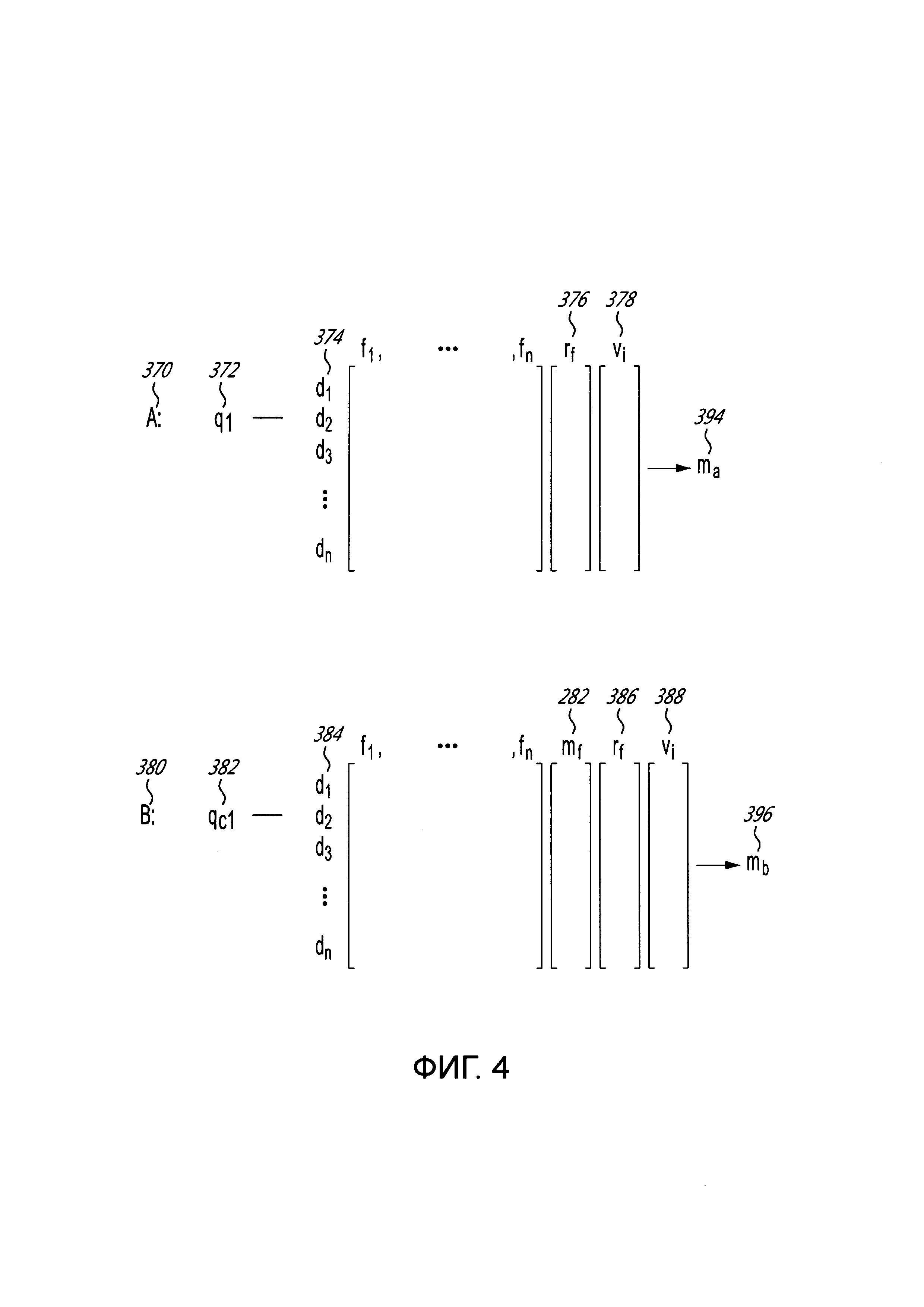
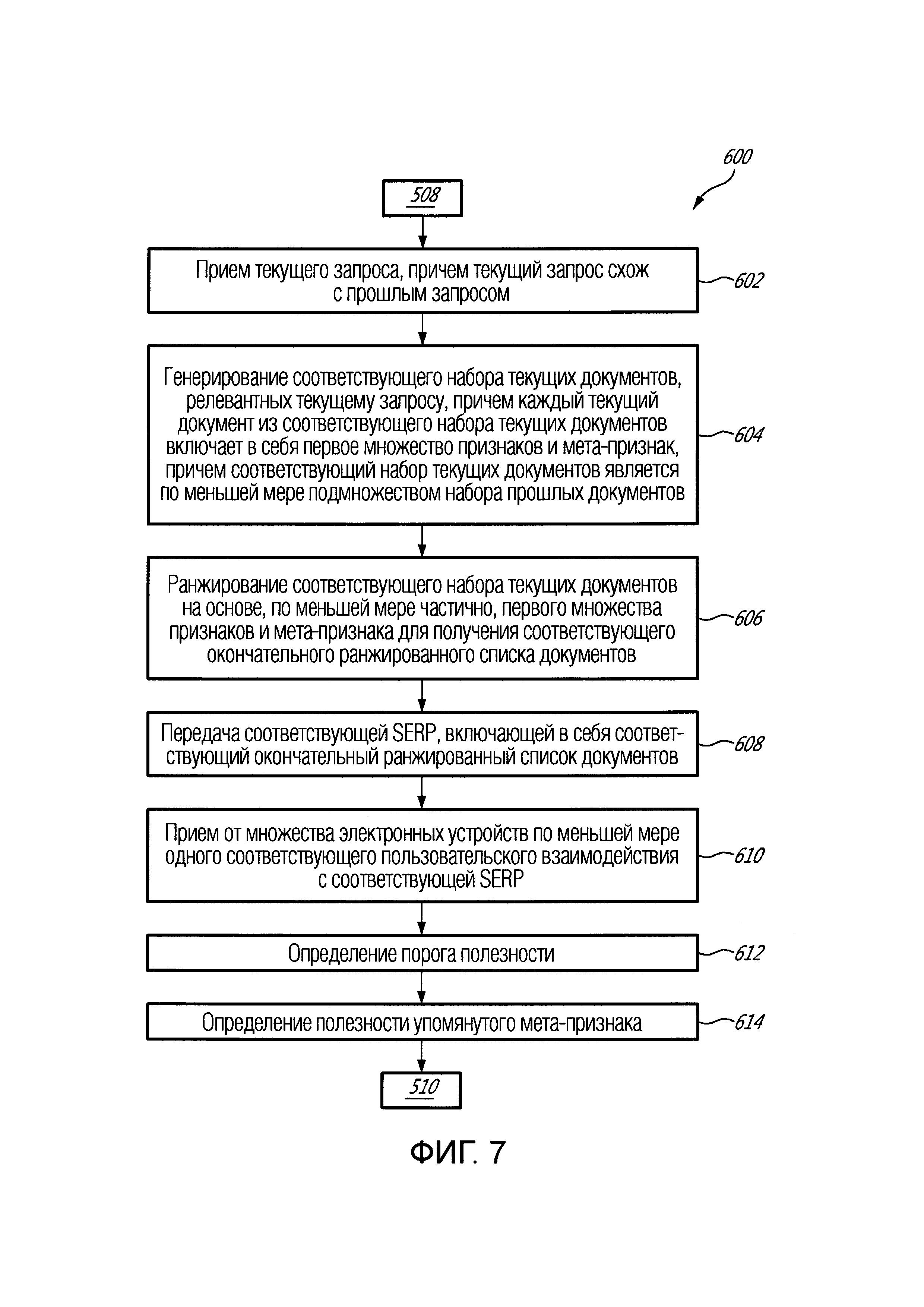
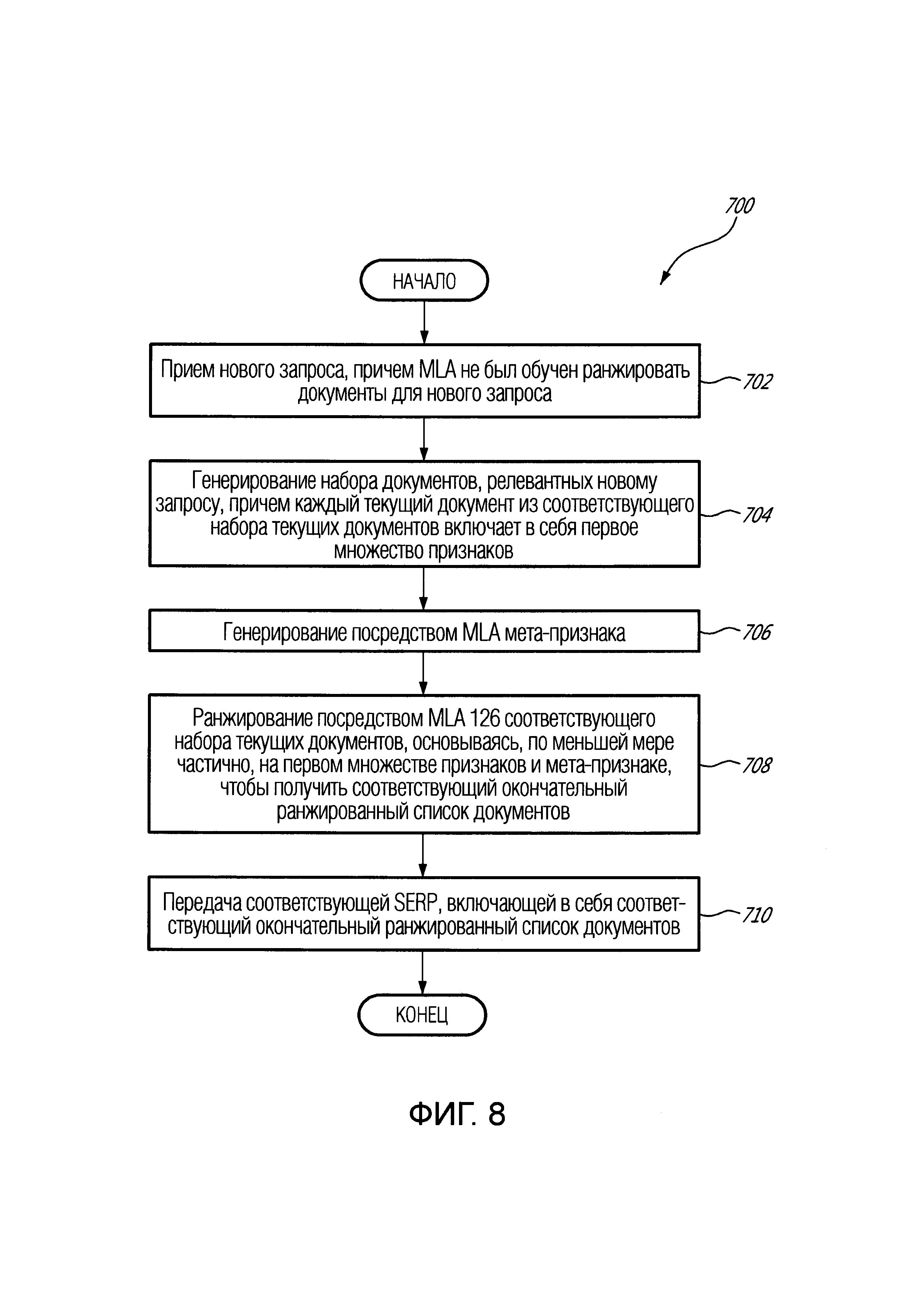
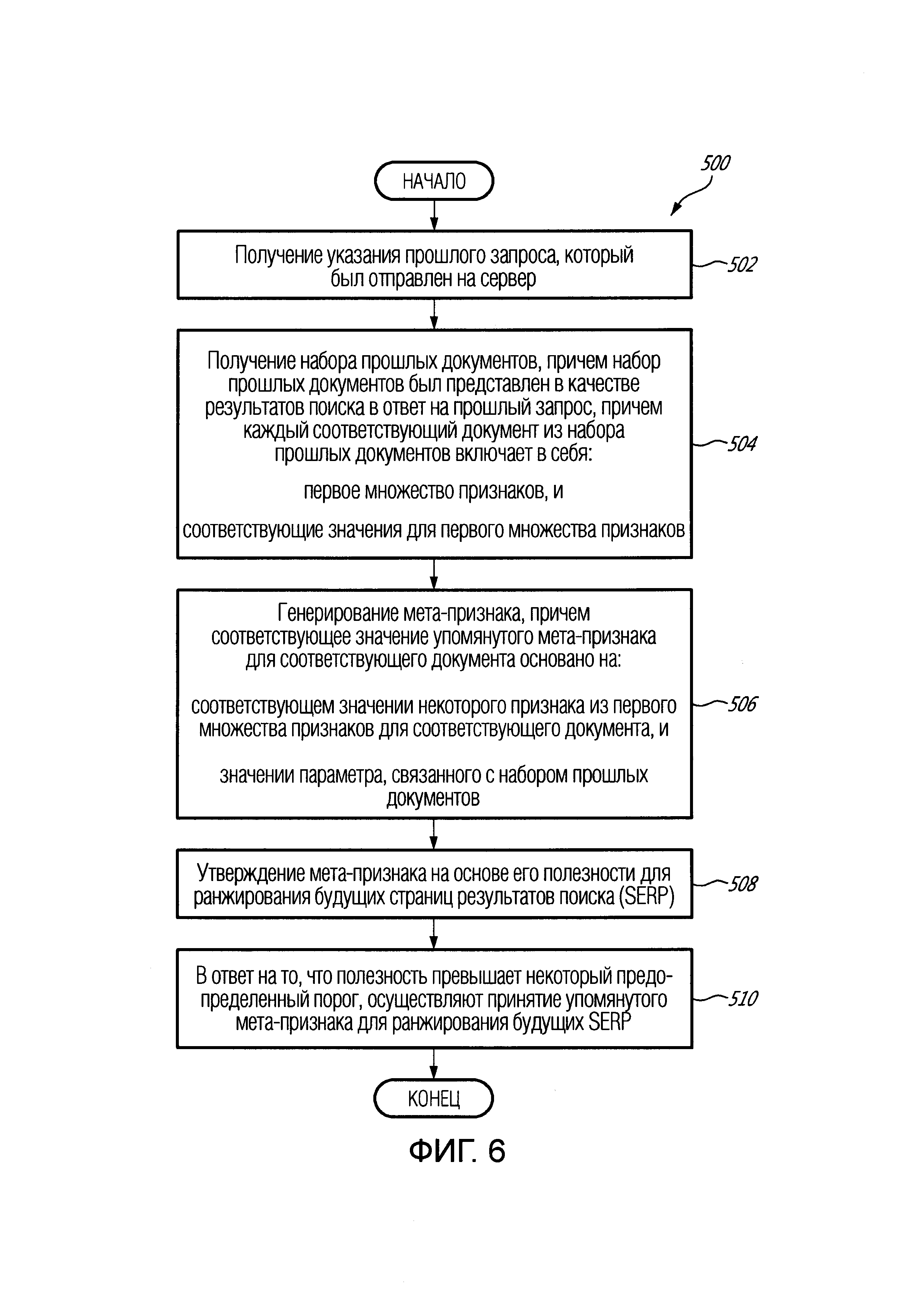
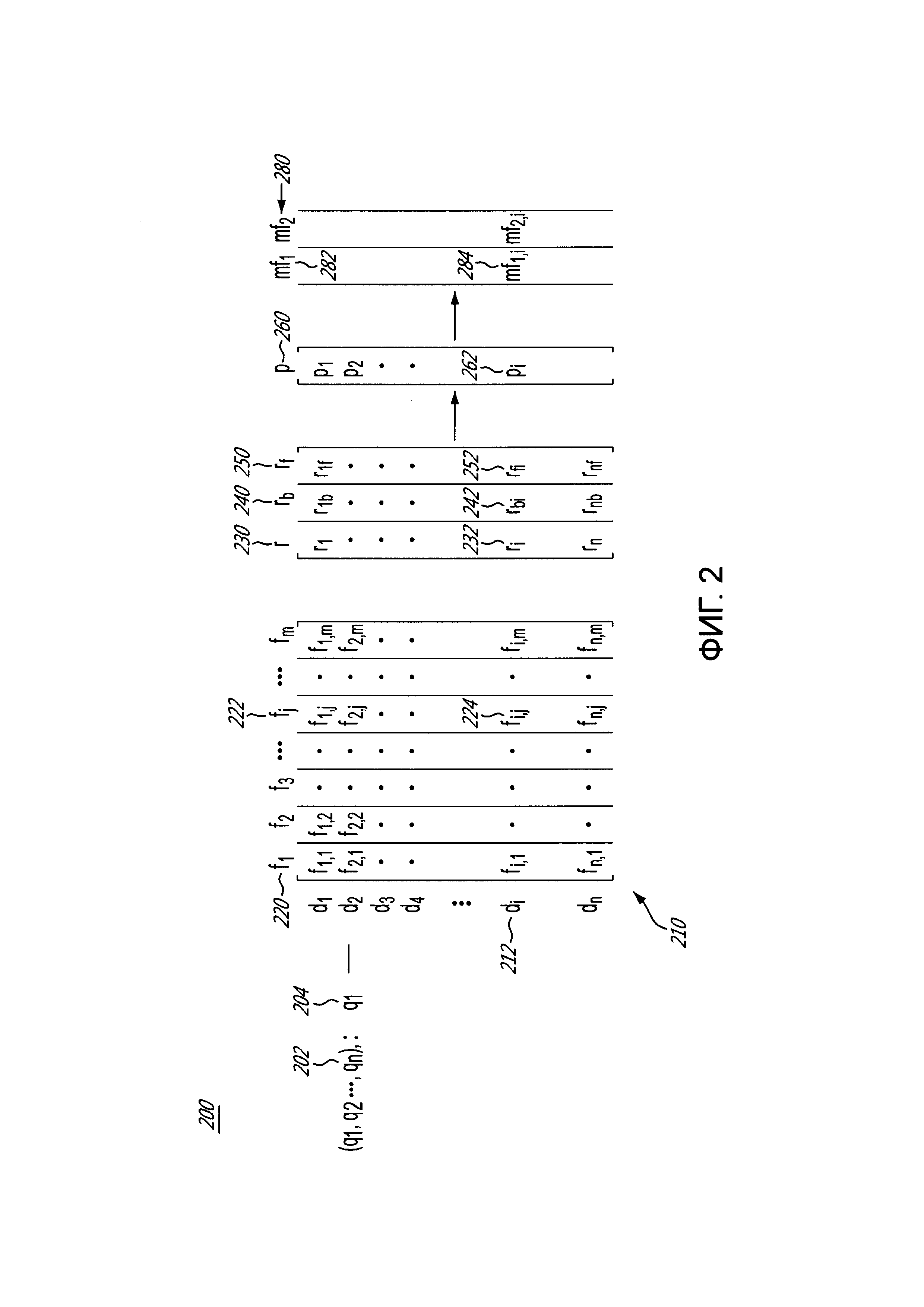
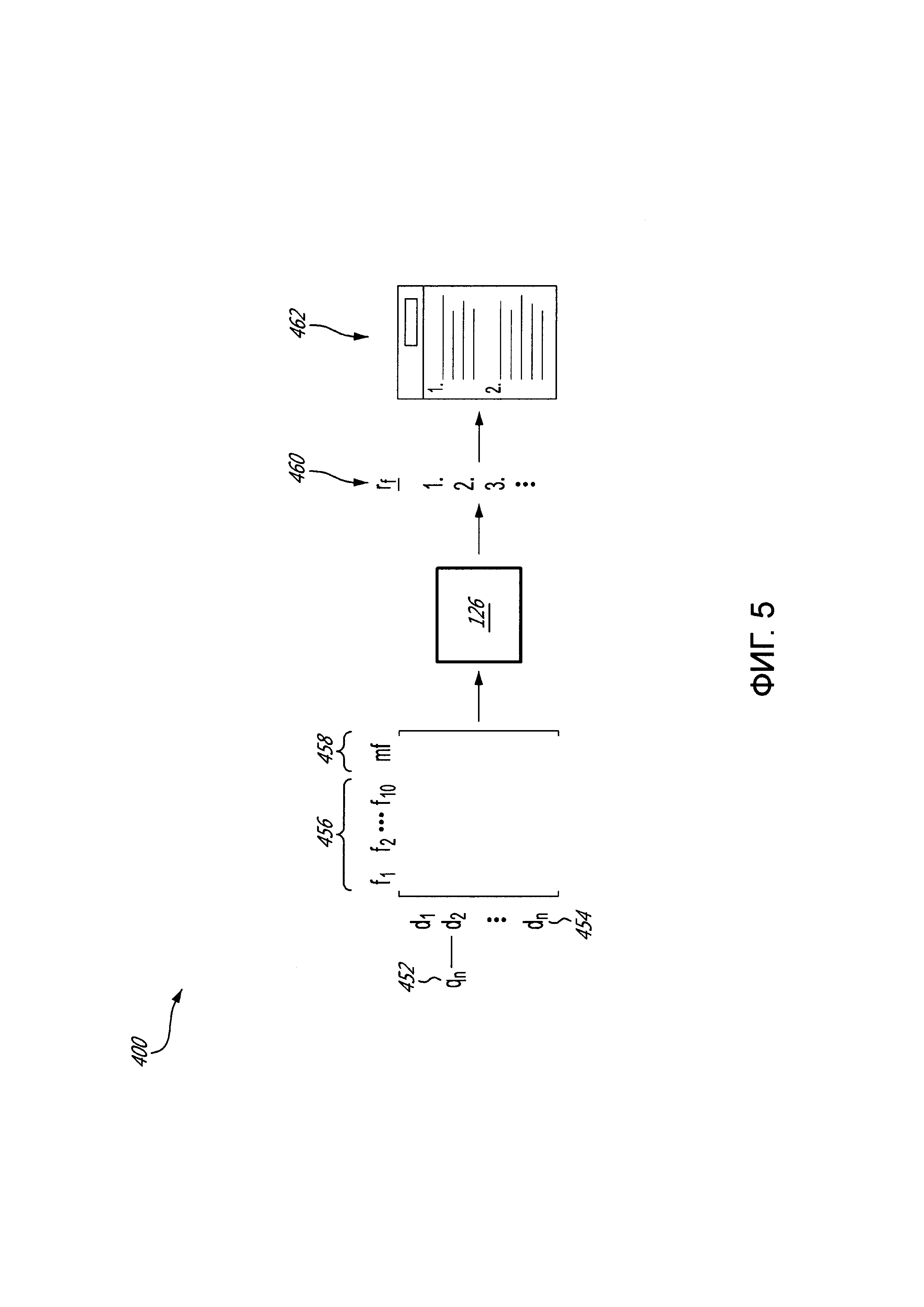
Способ создания аннотированного поискового индекса и сервер, используемый в нем
Способ и система для рекомендации медиаобъектов
Способ и сервер для ранжирования документов на странице результатов поиска
Способ и система создания векторов аннотации для документа
Способ и система для расширения поисковых запросов с целью ранжирования результатов поиска

