Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[001] Настоящая технология относится к извлечению информации в общем и, более конкретно, к способу и системе построения поискового индекса с использованием алгоритма машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[002] Различные глобальные или локальные сети связи (Интернет, Всемирная паутина, локальные сети и т.п.) предлагают пользователю огромное количество информации. Информация включает в себя множество контекстных тем, таких как, но не ограничиваясь ими, новости и текущие события, карты, информация о компании, финансовая информация и ресурсы, информация о трафике, информация об играх и развлечениях. Пользователи используют различные клиентские устройства (настольный ПК, портативный ПК, ноутбук, смартфон, планшеты и т.п.) для доступа к богатому содержимому (например, изображениям, аудио, видео, анимации и другому мультимедийному содержимому из таких сетей).
[003] Вообще говоря, некоторый пользователь может осуществить доступ к некоторому ресурсу в сети связи двумя основными способами. Этот пользователь может осуществить доступ к некоторому конкретному ресурсу напрямую, либо введя адрес этого ресурса (обычно URL-адрес или универсальный указатель ресурса), либо кликнув по ссылке в электронном сообщении или в другом веб-ресурсе. В качестве альтернативы, данный пользователь может проводить поиск, используя поисковую систему, чтобы найти интересующий ресурс. Последнее особенно подходит в тех обстоятельствах, когда данный пользователь знает интересующую тему, но не знает точный адрес интересующего его ресурса.
[004] Выражаясь кратко, поисковая система обычно работает в трех фазах: веб-обход, индексация и поиск. Во время фазы веб-обхода поисковая система исполняет множество веб-обходчиков или «пауков», которые являются компьютерными программами, которые «обходят» или просматривают Всемирную паутину (веб) и загружают копии цифровых документов, таких как веб-страницы, которые сохраняются на носителе хранения. Во время фазы индексации сохраненные цифровые документы обрабатываются для извлечения информации, а извлеченная информация используется для построения поискового индекса. Поисковый индекс сохраняет обработанную информацию в подходящем формате для обеспечения ее быстрого извлечения. Как правило, цифровые документы индексируются в соответствии с некоторыми или всеми терминами, содержащимися в цифровом документе, которые могут потенциально «соответствовать» одному или нескольким терминам будущих поисковых запросов. Так называемый инвертированный индекс сбора данных поддерживается и обновляется системой для последующего использования при исполнении некоторого поискового запроса. Инвертированный индекс содержит множество «списков публикаций», где каждый список публикаций соответствует некоторому термину и содержит ссылки на элементы данных, содержащие этот поисковый термин.
[005] Во время фазы поиска пользователь обычно вводит и отправляет поисковый запрос в поле поисковой системы, поисковая система извлекает цифровые документы, релевантные поисковым терминам, включенным в упомянутый поисковый запрос, из поискового индекса, а алгоритм машинного обучения (MLA) обычно ранжирует эти цифровые документы на основе их вычисленной релевантности упомянутым терминам поискового запроса. Затем ранжированные цифровые документы предоставляются пользователю на страницах результатов поиска (SERP).
[006] Публикация патентной заявки США №2014/105488 А1, опубликованная 17 апреля 2014 г. на имя корпорации Microsoft и озаглавленная «Learning-based image page index selection», раскрывает архитектуру, которая выполняет выбор индекса страницы изображения. Основанная на обучении структура обучается статистической модели, основанной на информации о предыдущих кликах по гиперссылке (URL-унифицированному указателю ресурса), полученной от пользователей поиска изображений. Выученная модель может объединять признаки вновь обнаруженного URL, чтобы спрогнозировать вероятность клика по упомянутому вновь обнаруженному URL при будущем поиске изображений. Клики по изображениям добавляют в качестве признаков в дополнение к существующим признакам для выбора веб-индекса, и эти клики по изображениям агрегируют по разным сегментам URL, а также структурным деревьям моделирования сайтов, чтобы уменьшить проблему разрежения информации о кликах по изображениям.
[007] Публикация патентной заявки США №2012/143792 А1, опубликованная 7 июня 2012 г. на имя корпорации Microsoft и озаглавленная «Page selection for indexing», раскрывает методики для выбора веб-страниц для включения в индекс. Например, некоторые реализации применяют регуляризацию для выбора подмножества веб-страниц, по которым выполнен обход, для индексации на основе ссылочных взаимосвязей между веб-страницами, по которым выполнен обход, признаков, извлеченных из веб-страниц, по которым выполнен обход, и информации о поведении пользователя, определяемой для по меньшей мере некоторых из веб-страниц, по которым выполнен обход. Кроме того, в некоторых реализациях информация о поведении пользователя может использоваться для сортировки обучающего набора веб-страниц, по которым выполнен обход, на множество помеченных групп. Помеченные группы могут быть представлены в ориентированном графе, который указывает относительные приоритеты для их выбора для индексации.
[008] Публикация патентной заявки США №2017/004159 А1, опубликованная 5 января 2017 г. на имя корпорации eBay и озаглавленная «Search engine optimization by selective indexing» раскрывает систему и способы для идентификации ценных страниц представления товаров для оптимизации поисковой системы. Система и способы обеспечивают улучшение по сравнению с существующими системами, которые не делают ничего для идентификации или выбора ценных страниц представления товаров для использования в привлечении трафика с сайтов показа. Эти система и способы улучшают прежнюю систему, прогнозируя вероятность будущего трафика для некоторого определенного продукта на основе ряда факторов уровня продукта в качестве входных переменных, и идентифицируя подборку страниц представления товаров, соответствующих продуктам, с вероятностью наивысшего будущего трафика, чтобы максимизировать привлечение естественного поискового трафика на связанный сайт соответствующей страницы представления товара.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[009] Целью настоящей технологии является устранение по меньшей мере некоторых неудобств, имеющихся в предшествующем уровне техники.
[0010] Количество страниц во Всемирной паутине растет экспоненциально, и на данный момент во Всемирной паутине доступно, по оценкам, более десятков триллионов документов. Как правило только часть доступных документов во Всемирной паутине проиндексирована поисковыми системами, поскольку большинство документов находятся в «Глубокой паутине» («Deep Web») и/или не проиндексированы по различным причинам. Тем не менее, веб-обходчикам необходимо обходить и сохранять миллиарды документов, при этом только часть сохраненных документов обрабатывается и индексируется, поскольку обработка и индексация документов для построения поискового индекса является вычислительно затратной задачей из-за, помимо прочих факторов, компромисса между постоянным ростом количества документов во Всемирной паутине и вычислительной мощностью, которая требуется для обработки и хранения этих документов центрами обработки данных поисковых систем.
[0011] Разработчики настоящей технологии осознали, что не все документы, индексируемые в поисковом индексе, имеют одинаковую значимость с точки зрения их «полезности» для поисковой системы, поскольку некоторые документы могут появляться чаще, могут получать больше пользовательских взаимодействий и, как правило, могут быть более релевантны, чем другие, в ответ на поисковые запросы от пользователей. Разработчики настоящей технологии также осознали, что некоторые документы могут редко или никогда не показываться пользователям в качестве результатов поиска в ответ на поисковые запросы, по ряду причин, таких как их низкая релевантность этим запросам, низкий интерес со стороны пользователей к просмотру информации, содержащейся в них, и тому подобное. Следовательно, разработчики определили, что, поскольку «полезность» документов, включаемых в поисковый индекс, может различаться, практически никакое преимущество не обеспечивается поддержкой таких документов в поисковом индексе, которые показываются пользователям крайне редко, так как обработка и индексация этих документов может излишне потреблять вычислительные ресурсы.
[0012] В качестве неограничивающего примера со ссылкой на Фигуру 1 проиллюстрировано схематичное представление распределения 10 некоторого количества документов, доступных в поисковом индексе сервера поисковой системы, относительно количества показов данных документов пользователям. Распределение 10 иллюстрирует, что в поисковом индексе сервера поисковой системы имеется большое количество документов, которые редко показываются пользователям, и небольшое количество документов, которые показываются пользователям сервера поисковой системы чаще.
[0013] Следовательно, разработчики настоящей технологии захотели решить такие проблемы.
[0014] Не желая быть связанными какой-либо теорией, разработчики настоящей технологии признали, что общая «качественная» значимость набора документов, отбираемых для включения в поисковый индекс поисковой системы, может быть максимизирована, принимая во внимание индивидуальное значение полезности каждого документа, индивидуальные размеры этих документов, а также ограничение размера поискового индекса.
[0015] Разработчики настоящей технологии понимают, что такой подход может быть сложным, поскольку необходимо соблюдать баланс между обработкой и индексацией большего количества документов, имеющих меньший размер и значения полезности от небольшого до среднего, и меньшего количества документов, имеющих большие размеры и более высокие значения полезности, одновременно учитывая другие факторы, такие как удовлетворенность поисковой системой пользователями.
[0016] Таким образом, варианты осуществления настоящей технологии направлены на способ и систему построения поискового индекса с использованием алгоритма машинного обучения.
[0017] Предполагается, что система, предусмотренная разработчиками настоящей технологии, может позволить управлять ограниченным объемом вычислительной мощности и памяти, которые могут быть выделены для индексации, путем избирательной индексации документов в поисковом индексе поисковой системы. Кроме того, настоящая технология также может позволить сберечь ресурсы хранения, пропускную способность и вычислительное время, в то же время предоставляя более удовлетворительные результаты в ответ на пользовательские запросы, так как более «полезные» документы могут быть включены в поисковый индекс аналогичного общего размера, по сравнению с предшествующими подходами.
[0018] В соответствии с первым обширным аспектом настоящей технологии предоставлен реализуемый компьютером способ выбора документов для включения в поисковый индекс поисковой системы, причем поисковая система реализована сервером, который исполняет алгоритм машинного обучения (MLA), который был обучен ранжировать документы на основе размера и пользовательских взаимодействий с документами, причем способ исполняется сервером и содержит: получение сервером множества цифровых документов, причем каждый соответствующий документ из упомянутого множества цифровых документов имеет соответствующий размер, определение сервером для каждого соответствующего документа из множества цифровых документов соответствующего параметра значимости на основе пользовательских взаимодействий с соответствующим документом, причем соответствующий параметр значимости указывает полезность соответствующего документа для поисковой системы в качестве документа-результата поиска, ранжирование посредством MLA множества цифровых документов для получения ранжированного списка документов, причем ранжирование основывается на: соответствующем качественном параметре значимости соответствующего документа, причем соответствующий качественный параметр значимости основан на соответствующем параметре значимости и соответствующем размере соответствующего документа, причем ранжирование выполняют так, что качественный параметр совокупной значимости максимизируется на основе: взвешивания качественного параметра значимости некоторого цифрового документа из ранжированного списка документов по сумме размеров некоторого подмножества документов из множества цифровых документов, при этом упомянутое подмножество документов состоит из документов, имеющих соответствующий параметр значимости ниже параметра значимости упомянутого цифрового документа во множестве цифровых документов, выбор посредством MLA подмножества документов из ранжированного списка документов на основе качественного параметра значимости каждого соответствующего документа из подмножества документов, и сохранение сервером упомянутого подмножества документов в поисковом индексе.
[0019] В некоторых вариантах осуществления способа упомянутое подмножество состоит из всех документов, имеющих соответствующий параметр значимости ниже параметра значимости упомянутого цифрового документа.
[0020] В некоторых вариантах осуществления способа пользовательские взаимодействия представляют собой по меньшей мере одно из: прогнозируемых пользовательских взаимодействий с соответствующим документом и прошлых пользовательских взаимодействий с соответствующим документом.
[0021] В некоторых вариантах осуществления способа ранг соответствующего документа в ранжированном списке документов основан, по меньшей мере частично, на отношении соответствующего параметра значимости к соответствующему размеру соответствующего документа.
[0022] В некоторых вариантах осуществления способа выбор дополнительно основан на том, что сумма соответствующих размеров документов в подмножестве документов ниже предопределенного порогового размера.
[0023] В некоторых вариантах осуществления способа предопределенным пороговым размером является доступный размер ресурса хранения поискового индекса поисковой системы.
[0024] В некоторых вариантах осуществления способа подмножество документов, выбираемых из ранжированного списка документов, содержит некоторое количество 0 документов с наивысшим рангом, которое помещается в поисковый индекс поисковой системы.
[0025] В некоторых вариантах осуществления способа MLA обучался ранжировать документы с использованием алгоритма LambdaMART.
[0026] В некоторых вариантах осуществления способа MLA обучался ранжировать документы с использованием алгоритма списочного ранжирования.
[0027] В некоторых вариантах осуществления способа ранжирование содержит максимизацию качественного параметра совокупной значимости на основе:
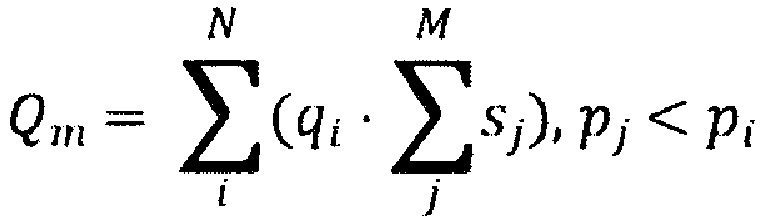
где: Q является качественным параметром совокупной значимости, qi является соответствующим параметром значимости соответствующего i-го документа во множестве цифровых документов, sj является соответствующим размером соответствующего j-го документа в подмножестве документов, pi является соответствующим качественным параметром значимости i-го документа во множестве цифровых документов, pj является соответствующим качественным параметром значимости j-го документа во множестве цифровых документов, N является количеством документов во множестве цифровых документов, М является количеством документов в упомянутом подмножестве документов.
[0028] В некоторых вариантах осуществления способа ранжирование содержит максимизацию качественного параметра совокупной значимости на основе:
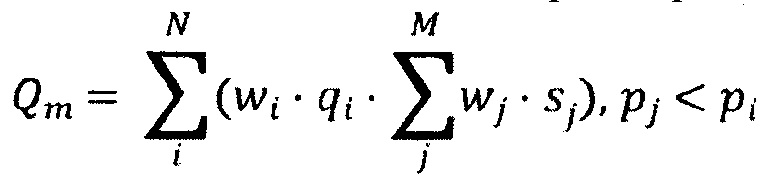
где: Qm является качественным параметром совокупной значимости, wi является соответствующим весом, связанным с соответствующим параметром значимости, qi является соответствующим параметром значимости соответствующего i-го документа во множестве цифровых документов, wj является соответствующим весом, связанным с соответствующим размером, sj является соответствующим размером соответствующего j-го документа в подмножестве документов, pi является соответствующим качественным параметром значимости i-го документа во множестве цифровых документов, pj является соответствующим качественным параметром значимости j-го документа во множестве цифровых документов, N является количеством документов во множестве цифровых документов, М является количеством документов в упомянутом подмножестве документов.
[0029] В некоторых вариантах осуществления способа вычисление соответствующего параметра значимости соответствующего документа выполняется с использованием второго MLA, исполняемого сервером.
[0030] В соответствии с другим обширным аспектом настоящей технологии предоставлена система выбора документов для включения в поисковый индекс поисковой системы, причем поисковая система реализована упомянутой системой, которая исполняет алгоритм машинного обучения (MLA), который был обучен ранжировать документы на основе размера и пользовательских взаимодействий с документами, причем система содержит: процессор, долговременный считываемый компьютером носитель, содержащий инструкции, причем процессор, при исполнении инструкций, сконфигурирован с возможностью: получения множества цифровых документов, причем каждый соответствующий документ из упомянутого множества цифровых документов имеет соответствующий размер, определения для каждого соответствующего документа из множества цифровых документов соответствующего параметра значимости на основе пользовательских взаимодействий с соответствующим документом, причем соответствующий параметр значимости указывает полезность соответствующего документа для поисковой системы в качестве документа-результата поиска, ранжирования посредством MLA множества цифровых документов для получения ранжированного списка документов, причем ранжирование основывается на: соответствующем качественном параметре значимости соответствующего документа, причем соответствующий качественный параметр значимости основан на соответствующем параметре значимости и соответствующем размере соответствующего документа, причем ранжирование выполняется так, что качественный параметр совокупной значимости максимизируется на основе: взвешивания качественного параметра значимости некоторого цифрового документа из ранжированного списка документов по сумме размеров некоторого подмножества документов из множества цифровых документов, при этом упомянутое подмножество документов состоит из документов, имеющих соответствующий параметр значимости ниже параметра значимости упомянутого цифрового документа во множестве цифровых документов, выбора посредством MLA подмножества документов из ранжированного списка документов на основе качественного параметра значимости каждого соответствующего документа из подмножества документов, и сохранения упомянутого подмножества документов в поисковом индексе.
[0031] В некоторых вариантах осуществления системы упомянутое подмножество состоит из всех документов, имеющих соответствующий параметр значимости ниже параметра значимости упомянутого цифрового документа.
[0032] В некоторых вариантах осуществления системы пользовательские взаимодействия представляют собой по меньшей мере одно из: прогнозируемых пользовательских взаимодействий с соответствующим документом и прошлых пользовательских взаимодействий с соответствующим документом.
[0033] В некоторых вариантах осуществления системы ранг соответствующего документа в ранжированном списке документов основан, по меньшей мере частично, на отношении соответствующего параметра значимости к соответствующему размеру соответствующего документа.
[0034] В некоторых вариантах осуществления системы выбор дополнительно основан на том, что сумма соответствующих размеров документов в подмножестве документов ниже предопределенного порогового размера.
[0035] В некоторых вариантах осуществления системы предопределенным пороговым размером является доступный размер ресурса хранения поискового индекса поисковой системы.
[0036] В некоторых вариантах осуществления системы подмножество документов, выбираемых из ранжированного списка документов, содержит некоторое количество 0 документов с наивысшим рангом, которое помещается в поисковый индекс поисковой системы.
[0037] В некоторых вариантах осуществления системы MLA был обучен ранжировать документы с использованием алгоритма LambdaMART.
[0038] В некоторых вариантах осуществления системы MLA был обучен ранжировать документы с использованием алгоритма списочного ранжирования.
[0039] В некоторых вариантах осуществления системы ранжирование содержит максимизацию качественного параметра совокупной значимости на основе:
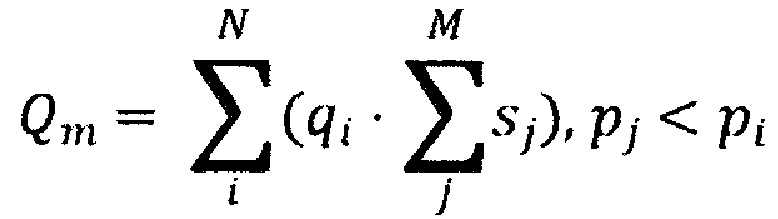
где: Q является качественным параметром совокупной значимости, qi является соответствующим параметром значимости соответствующего i-го документа во множестве цифровых документов, sj является соответствующим размером соответствующего j-го документа в подмножестве документов, pi является соответствующим качественным параметром значимости i-го документа во множестве цифровых документов, pj является соответствующим качественным параметром значимости j-го документа во множестве цифровых документов, N является количеством документов во множестве цифровых документов, М является количеством документов в упомянутом подмножестве документов.
[0040] В некоторых вариантах осуществления системы ранжирование содержит максимизацию качественного параметра совокупной значимости на основе:
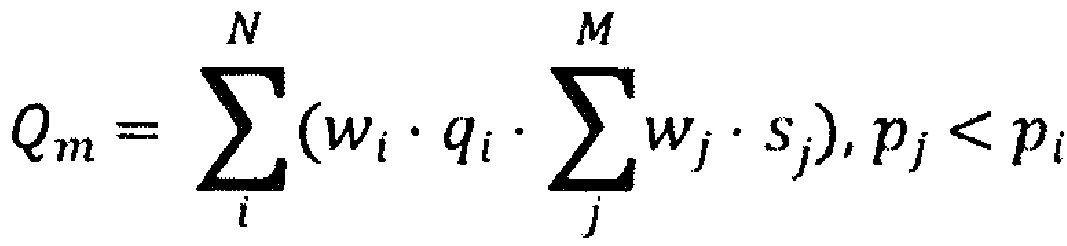
[0041] где: Qm является качественным параметром совокупной значимости, wi является соответствующим весом, связанным с соответствующим параметром значимости, qi является соответствующим параметром значимости соответствующего i-го документа во множестве цифровых документов, wj является соответствующим весом, связанным с соответствующим размером, sj является соответствующим размером соответствующего j-го документа в подмножестве документов, pi является соответствующим качественным параметром значимости i-го документа во множестве цифровых документов, pj является соответствующим качественным параметром значимости j-го документа во множестве цифровых документов, N является количеством документов во множестве цифровых документов, М является количеством документов в упомянутом подмножестве документов.
[0042] Как обсуждалось выше, настоящая технология использует алгоритм машинного обучения (MLA) для выбора документов для включения в поисковый индекс. Разработчики настоящей технологии признали, что MLA, используемый для ранжирования, может быть адаптирован для выбора документов для включения в поисковый индекс. Точнее, один или несколько MLA согласно данной технологии обучают ранжировать документы с целью отбора наиболее «полезных» документов для включения в поисковый индекс с учетом индивидуальных размеров этих документов.
[0043] Обзор MLA
[0044] В данной области техники известно множество различных типов MLA. Вообще говоря, MLA подразделяются на три категории: MLA, основанные на обучении с учителем, MLA, основанные на обучении без учителя, и MLA, основанные на обучении с подкреплением.
[0045] Процесс обучения MLA с учителем основан на переменной цель-результат (или зависимой переменной), которая должна прогнозироваться из некоторого набора предикторов (независимых переменных). Используя набор этих переменных, MLA (во время обучения) генерирует функцию, которая отображает входные данные на желаемые выходные данные. Процесс обучения продолжается до тех пор, пока MLA не достигнет желаемого уровня точности на контрольных данных. Примеры MLA, основанных на обучении с учителем, включают в себя: регрессию, дерево решений, случайный лес, логистическую регрессию и т.д.
[0046] В обучении MLA без учителя целевая или результирующая переменная как таковая не используется для прогнозирования. Такие MLA используются для кластеризации совокупности значений на разные группы, что широко используется для сегментации клиентов на разные группы для конкретной цели. Примеры MLA, основанных на обучении без учителя, включают в себя: Априорный алгоритм, К-средних.
[0047] Обучение MLA с подкреплением проводится для принятия конкретных решений. Во время обучения MLA подвергается воздействию обучающей среды, в которой он постоянно самообучается методом проб и ошибок. MLA обучается исходя из прошлого опыта и старается использовать наилучшее возможное знание для принятия точных решений. Примером обучения MLA с подкреплением является Марковский процесс принятия решений.
[0048] Основанные на дереве решений MLA являются примером типа обучения MLA с учителем. В этом типе MLA используется дерево решений (в качестве прогнозной модели) для перехода от наблюдений за некоторым элементом (представленным в ветвях) к выводам о целевом значении этого элемента (представленном в листьях). Модели деревьев, в которых целевая переменная может принимать дискретный набор значений, именуются деревьями классификации; в структурах этих деревьев листья представляют метки классов, а ветви представляют конъюнкции признаков, которые ведут в эти метки классов. Деревья решений, в которых целевая переменная может принимать непрерывные значения (обычно, вещественные числа) именуются деревьями регрессии.
[0049] Для того, чтобы основанный на деревьях решений MLA работал, его необходимо «построить» или обучить с использованием обучающего набора объектов, содержащего большое множество обучающих объектов (таких как документы, события или тому подобное). Эти обучающие объекты "помечаются" ответственными за оценку людьми. Например, ответственный за оценку человек может ранжировать некоторый обучающий объект как «неинтересный», «интересный» или «очень интересный».
[0050] Градиентный бустинг
[0051] Градиентный бустинг является одним из подходов к построению MLA на основе деревьев решений, в результате которого прогнозная модель генерируется в форме ансамбля деревьев. Ансамбль деревьев строится постадийным образом. Каждое последующее дерево решений в ансамбле деревьев решений фокусирует обучение на тех узлах, которые были «слабо обучаемыми» на предыдущей итерации(ях) ансамбля деревьев решений (то есть тех, которые связаны с плохим прогнозом/высокой ошибкой).
[0052] Вообще говоря, бустинг является способом, направленным на повышение качества прогнозирования MLA. В этом сценарии, вместо того, чтобы полагаться на прогноз единственного обученного алгоритма (то есть единственного дерева решений), система использует множество обученных алгоритмов (то есть ансамбль деревьев решений) и принимает окончательное решение на основе многочисленных результатов прогнозирования этих алгоритмов.
[0053] Жадные алгоритмы
[0054] При генерировании деревьев решений (с использованием, например, подхода с градиентным бустингом) известно использование жадных алгоритмов. Жадный алгоритм представляет собой алгоритмическую парадигму, которая следует эвристике решения проблемы осуществления локально-оптимального выбора на каждой стадии (например, на каждом уровне дерева решений) с перспективой нахождения глобального оптимума. При построении деревьев решений использование жадного алгоритма можно обобщить следующим образом: для каждого уровня дерева решений MLA пытается найти наиболее оптимальное значение (признака и/или разбиение (split)) - что является локально-оптимальным решением. Как только оптимальное значение для данного узла определено, когда MLA переходит к генерированию более низкого уровня дерева решений, ранее определенные значения для более верхних узлов «замораживаются» - т.е. принимаются «как есть» для данной итерации дерева решений в ансамбле деревьев решений.
[0055] Как и в случае единственного дерева, каждое дерево в ансамбле деревьев строится жадным образом, что означает, что, когда MLA выбирает признак и разбиение для каждого узла дерева, MLA делает выбор, который является локально оптимальным, например лучшим для конкретного узла, а не для всего дерева в целом.
[0056] Забывчивые (Oblivious-) деревья решений
[0057] Как только наилучший признак и разбиение были выбраны для некоторого узла, алгоритм переходит к дочернему узлу упомянутого узла и исполняет жадный выбор признака и разбиения для этого дочернего узла. В некоторых реализациях при выборе признака для некоторого узла алгоритм MLA не может использовать признаки, используемые в узлах на более высоких уровнях глубины дерева. В других реализациях для каждого уровня глубины MLA анализируется все возможные признаки, независимо от того, использовались ли они на предыдущих уровнях. Такие деревья именуются «забывчивыми» деревьями, поскольку на каждом уровне дерево «забывает», что оно использовало некоторый конкретный признак на предыдущем уровне и рассматривает этот признак снова. Для того, чтобы выбрать лучший признак и разбиение для узла, функция выигрыша вычисляется для каждого возможного варианта. Вариант выбора (значение разбиения и признака) с наивысшим выигрышем выбирается.
[0058] Качественный параметр значимости прогноза
[0059] Когда некоторое дерево построено, для определения качества прогноза упомянутого дерева (или некоторого уровня упомянутого дерева по мере построения данного дерева), MLA вычисляет метрику (т.е. "оценку"), которая обозначает, насколько близко текущая итерация модели, которая включает в себя упомянутое дерево (или упомянутый уровень данного дерева) и предшествующие деревья, приблизилась в своем прогнозе к правильным ответам (целям). Оценка модели вычисляется на основе сделанных прогнозов и фактических целевых значений (правильных ответов) обучающих объектов, использованных для обучения.
[0060] Когда первое дерево построено, MLA выбирает значения первого признака и первого разбиения для корневого узла первого дерева и оценивает качество такой модели. Для этого MLA «подает» обучающие объекты в первое дерево, в некотором смысле «спуская» обучающие объекты по ветвям дерева решений, и подаваемые таким образом обучающие объекты распределяются по двум (или может быть большему количеству) различным листам первого дерева при разбиении первого узла (то есть их «распределяют по категориям» посредством дерева решений или, более конкретно, модель дерева решений пытается спрогнозировать цель обучающего объекта, спускаемого по модели дерева решений). После того, как все обучающие объекты распределены по категориям, вычисляется качественный параметр значимости прогноза - в некотором смысле определяющий, насколько близко распределение объектов по категориям к фактическим значениям целей.
[0061] Более конкретно, зная целевые значения обучающих объектов, MLA вычисляет качественный параметр значимости прогноза (например, информационный выигрыш или тому подобное) для этого первого признака - первого разбитого узла, а затем выбирает некоторый второй признак с некоторым вторым разбиением для корневого узла. Для этого второго варианта признака и разбиения для корневого узла MLA исполняет те же самые этапы, которые были исполнены для первого варианта (MLA подает обучающие объекты в дерево и вычисляет результирующую метрику, используя упомянутый второй вариант комбинации признака и разбиения для корневого узла).
[0062] MLA затем повторяет аналогичный процесс с третьим, четвертым, пятым и т.д. вариантами признаков и разбиений для корневого узла до тех пор, показ MLA не охватит все возможные варианты признака и разбиения, а затем MLA выбирает вариант признака и разбиения для корневого узла, который дает лучший прогнозный результат (т.е. обладает наивысшей упомянутой метрикой).
[0063] После того, как вариант признака и разбиения для корневого узла выбран, MLA переходит к дочерним узлам корневого узла и выбирает признаки и разбиения для этих дочерних узлов тем же самым способом, который был исполнен для корневого узла. Затем этот процесс повторяется для дальнейших дочерних узлов первого дерева до тех пор, пока дерево решений не будет построено.
[0064] Затем, согласно подходу с бустингом, MLA переходит к построению второго дерева. Второе дерево направлено на улучшение прогнозных результатов первого дерева. Оно должно «исправить» прогнозные ошибки первого дерева. Для этого второе дерево строят на обучающем объекте, где примеры, в которых первое дерево допустило прогнозные ошибки, взвешиваются с более высокими весами, чем примеры, в которых первое дерево обеспечило правильный прогноз. Второе дерево строят аналогично тому, как было построено первое дерево.
[0065] При таком подходе, десятки, сотни или даже тысячи деревьев строятся последовательно. Каждое последующее дерево в ансамбле деревьев повышает качество прогноза предыдущих деревьев.
[0066] Обучение ранжированию
[0067] Использование MLA для построения моделей ранжирования для систем извлечения информации также известно в данной области техники и упоминается как обучение ранжированию или основанное на машинном обучении ранжирование (MLR). В целом подходы MLR можно разделить на три категории: поточечные подходы, попарные подходы и списочные подходы. Как правило, подходы MLR могут характеризоваться их входным пространством, их выходным пространством, их пространством гипотез и их функциями потерь. Входное пространство содержит исследуемые объекты, а выходное пространство содержит цель обучения относительно входных объектов. Пространство гипотез определяет класс функций, отображающих входное пространство в выходное пространство, или, другими словами, функций, которые работают с входными объектами, чтобы выполнить прогнозы на основе формата выходного пространства. Функция потерь, как правило, измеряет степень точности прогноза, например, измеряя, насколько истинные (ground-truth) метки согласуются с метками, генерируемыми гипотезой. Функция потерь также позволяет определять эмпирический риск в отношении набора обучающих объектов, при этом гипотеза выводится посредством минимизации эмпирического риска.
[0068] Поточечный подход к ранжированию характеризуется входным пространством отдельного документа (или его признаковым вектором), выходным пространством действительных значений (например, степени релевантности) или категорий (которые могут быть упорядоченными или неупорядоченными, в зависимости от используемых методов), а также пространством гипотез оценочной (scoring) функции, которая прогнозирует степень релевантности документа. Таким образом, ранжирование сводится к регрессии, классификации или задаче порядковой регрессии. Функция потерь может представлять регрессионную потерю, классификационную потерю или порядковую потерю, в зависимости от типа оценочной функции. Затем документы могут быть отсортированы и ранжированы в зависимости от степени релевантности. Следует отметить, что поточечный подход имеет некоторые ограничения, например, не учитывает взаимозависимость между документами, что делает положение документа в ранжированном списке «невидимым» для функции потерь, и этот подход не использует тот факт, что некоторые документы могут быть связаны с одним и тем же запросом. Примеры MLA, использующих поточечный подход, включают в себя: Функцию поиска наименьших квадратов (Least Square Retrieval Function), Ранжирование подмножества с использованием регрессии (Subset Ranking using Regression), Дискриминантную модель для IR (Discriminative model for IR), McRank, Перцептрон-ранжирование (Pranking), и Ранжирование с принципами больших отступов (Ranking with Large Margin Principles), среди прочих.
[0069] Попарный подход к ранжированию характеризуется входным пространством некоторой пары документов, представленных в виде признаковых векторов, и выходным пространством попарного предпочтения между каждой парой документов, принимающего значения из {+1, -1}. Пространство гипотез содержит бивариантную функцию, которая принимает пару документов и выводит относительный порядок между ними, или, иногда, оценочную функцию. Функция потерь измеряет расхождение между истинной меткой и бивариантной функцией. Следует отметить, что в некоторых случаях у попарного подхода есть некоторые ограничения, поскольку некоторые функции потерь рассматривают лишь пару документов, получение окончательного положения документов в ранжированном списке может быть затруднено, и данный подход игнорирует, что некоторые пары генерируются из документов, связанных с одним и тем же запросом. Примеры MLA, использующих поточечный подход, включают в себя: Обучение упорядочению вещей (Learning to Order Things), SVM-ранжирование (Ranking SVM), RankBoost, RankNet и Frank, среди прочих.
[0070] Списочный подход к ранжированию характеризуется входным пространством набора документов, связанных с запросом, и выходным пространством ранжированного списка (или перестановок документа). Различные суждения могут быть преобразованы в истинные метки: суждение о степени релевантности, где все перестановки, согласующиеся с таким суждением, являются истинными перестановками, и суждение о попарном предпочтении, где все перестановки, согласующиеся с таким суждением, также являются истинными перестановками. Пространство гипотез содержит многовариантные функции, которые работают с набором документов и прогнозируют их перестановку, которые могут быть оценочной функцией, используемой для оценки каждого документа, а документы могут быть отсортированы для получения желаемых перестановок. Существует два типа функций потерь, широко используемых в списочном подходе: функция потерь, явно связанная с мерами оценки (зависящая от меры функция потерь), и функция потерь, не связанная с мерами оценки (независящая от меры функция потерь). Отмечается, что блоки построения списочной функции потерь могут быть схожи с некоторыми поточечными или попарными подходами. Примеры списочных подходов включают в себя: SoftRank, ListMLE, ListNet, AdaRank и RankCosine, среди прочих.
[0071] Прежде чем прийти к решению, предложенному в данном документе, разработчики использовали различные подходы, которые вдохновили их на создание настоящей технологии, которые будут кратко рассмотрены ниже.
[0072] Выбор документов на основе исторической значимости
[0073] Первый подход, рассмотренный разработчиками для решения вышеупомянутой проблемы, основан на использовании исторических данных документов, отслеживаемых поисковой системой. За любой прошедший период времени (например, день, неделя, месяц, год и т.д.) можно проанализировать журнал истории поисковой системы для определения того, какие документы были показаны пользователям, и того, сколько раз каждый документ был показан в течение этого периода времени. Все документы, которые когда-либо показывались пользователям поисковой системы в прошлом, могут быть выбраны для включения в поисковый индекс, в качестве неограничивающего примера - на основе различных порогов. Поскольку количество документов, которые когда-либо показывались пользователям в качестве результатов поиска, меньше, чем общее количество существующих (т.е. тех, по которым выполнен обход) документов, общий размер документов, выбираемых для включения в поисковый индекс с учетом количества показов, меньше, чем общий размер документов, по которым выполнен обход. Таким образом, документы с некоторой «продемонстрированной» исторической значимостью (прошлые показы, клики и тому подобное), основанной на исторических данных, отслеживаемых поисковой системой, могут быть включены в индекс. Если выбранные документы не помещаются в ограничение размера индекса, могут быть выбраны только те документы, которые имеют некоторую продемонстрированную историческую значимость (показы, клики и другие пользовательские взаимодействия) выше некоторого эмпирически определенного порога.
[0074] Однако разработчики поняли, что у этого подхода есть существенный недостаток - его нельзя обобщить, поскольку, когда новый документ появляется во Всемирной паутине, он не имеет истории показов или кликов, то есть какой-либо продемонстрированной исторической значимости. Таким образом, если документы выбираются для включения в индекс исключительно на основе их продемонстрированной исторической значимости, новые документы не могут быть добавлены в поисковый индекс, и в какой-то момент качество поискового индекса резко упадет, а пользователи поисковой системы будут менее удовлетворены. В некоторых реализациях такой подход может комбинироваться с другими подходами, так что некоторая часть индекса строится с использованием продемонстрированной исторической значимости документов, а оставшиеся части могут строиться с использованием других методов выбора документов для включения в поисковый индекс (например, прогнозная значимость документа).
[0075] Выбор документов на основе прогнозной значимости
[0076] Второй подход, рассмотренный разработчиками настоящей технологии для решения вышеупомянутой проблемы, был основан на использовании обученного MLA для прогнозирования значимостей документов, по которым выполняется обход. MLA может быть обучен на примерах документов, которые ранее были предоставлены в качестве результатов поиска пользователям поисковой системы, и на основе признаков этих документов и исторических данных, связанных с этими документами, причем MLA может вывести «оценку» документа исключительно на основе признаков документов. Для любого цифрового документа признаки могут включать в себя, но без ограничения упомянутым: как часто другие документы из аналогичной области показывались пользователям за некоторый период времени, основанные на содержимом признаки, количество ссылок, обращающихся к упомянутому цифровому документу, количество ссылок на другие документы, содержащиеся в упомянутом цифровом документе, историческое количество посещений упомянутого цифрового документа из источников, отличных от поисковой системы (например, путем ввода URL-адреса документа в адресной строке браузера, или посещения через ссылки, содержащиеся в других документах) и тому подобное. Имеется множество признаков, которые могут обладать корреляцией с оценкой.
[0077] Таким образом, MLA может прогнозировать оценку или значение «полезности» документов, обладающих некоторой продемонстрированной исторической значимостью, а также может прогнозировать значение полезности новых документов, которые могут не иметь какой-либо исторической значимости, основываясь на признаках документа.
[0078] Одним из недостатков этого подхода является сложность нахождения четких целей для использования при обучении, то есть того, какой параметр должен рассматриваться посредством MLA в качестве представительной переменной для значения полезности. Кроме того, если используются такие параметры, как клики или показы, или другие параметры, отражающие историческую популярность некоторого цифрового документа, MLA не учитывает размер упомянутого цифрового документа, что является субоптимальным, поскольку размер поискового индекса ограничен.
[0079] Выбор документов на основе прогнозного параметра значимости и размера
[0080] Другой подход, рассмотренный разработчиками настоящей технологии для решения вышеупомянутой проблемы, заключается в использовании MLA для прогнозирования оценки или «качественной» значимости документа на основе прогнозного параметра значимости или значения полезности документа, а также с учетом размера этого документа.
[0081] Разработчики предложили, чтобы качественная значимость документа, которая учитывает параметр значимости и размер документа, выражалась следующим образом:

[0082] где di является i-м документом в наборе документов, р(di) является параметром значимости i-го документа, size(di) является размером i-го документа в байтах, ƒ(size(di)) является функцией, учитывающей размер i-го документа, и q(di) является качественной значимостью i-го документа.
[0083] Используя логарифмические функции, Уравнение (1) принимает следующий вид:

[0084] который может быть упрощен до:

[0085] где pi является параметром значимости i-го документа, si является размером i-го документа в байтах, k является константой, g является логарифмической функцией, выбранной вручную, a qi является качественной значимостью i-го документа.
[0086] В этом подходе единственным параметром, прогнозируемым посредством MLA, является pi, параметр значимости (значение полезности) i-го документа, а qi может быть выбранной вручную функцией с одним или несколькими коэффициентами, причем некоторые коэффициенты могут быть определены эмпирически.
[0087] После серии экспериментов разработчики осознали, что 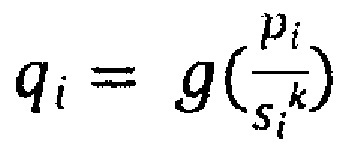 может не быть оптимальной функцией ранжирования документов для включения в поисковый индекс, поскольку эта функция может не принимать во внимание некоторые скрытые зависимости и корреляции, что эквивалентно использованию выбранной вручную функции для ранжирования результатов поиска в ответ на пользовательские запросы.
может не быть оптимальной функцией ранжирования документов для включения в поисковый индекс, поскольку эта функция может не принимать во внимание некоторые скрытые зависимости и корреляции, что эквивалентно использованию выбранной вручную функции для ранжирования результатов поиска в ответ на пользовательские запросы.
[0088] Выбор документов на основе подхода с поточечным ранжированием
[0089] Впоследствии разработчики рассмотрели возможность использования MLA, реализующего функцию поточечного ранжирования. Для обучения MLA должно быть обеспечено идеальное ранжирование документов. Один из подходов состоит в том, чтобы вычислить для каждого документа параметр, основанный на pi/si, и обучить MLA на основе исторической или прогнозной значимостей и размера документа прогнозировать этот параметр. Преимущество этого подхода заключается в использовании функции машинно-обученного ранжирования, а не выбираемой вручную функции.
[0090] Однако, как указано выше, должно быть обеспечено идеальное ранжирование документов, которое может быть трудно определить, поскольку выбор между небольшим количеством документов с высокими параметрами значимости и большим количеством документов со значимостью от небольшой до средней является сложной задачей. Кроме того, как указано выше, подход с поточечным ранжированием имеет ограничения, заключающиеся в том, что взаимозависимость между документами не учитывается, что является важным для вышеупомянутой задачи, поскольку относительное ранжирование между документами необходимо для получения оптимального общего ранжирования.
[0091] Выбор документов на основе подхода с попарным ранжированием
[0092] Впоследствии разработчики также рассмотрели возможность использования MLA, реализующего функцию попарного ранжирования. MLA может быть обучен на парах предупорядоченных документов (причем документы в каждой паре ранжируются относительно друг друга), при этом метка указывает правильный порядок. Таким образом, упомянутая задача может быть аппроксимирована как задача классификации, в которой MLA обучается двоичному классификатору, который выводит оптимальное ранжирование документов в паре, и в котором целью является минимизация среднего числа инверсий при таком ранжировании.
[0093] Этот подход в некотором смысле рассматривает документы относительно друг друга, поскольку он рассматривает их в парах. Однако для генерирования обучающего набора операторы MLA должны разработать идеальное ранжирование (т.е. идеальное ранжирование документов в парах), а также должны сгенерировать упомянутые пары и использовать некоторые параметры для ранжирования документов в этих парах. Другими словами, операторы должны решить задачу оптимизации вручную. Такое ранжирование в пределах обучающих пар может быть выполнено с использованием параметра pi/si в качестве представительной переменной для ранга. Однако такой подход не позволил решить общую задачу оптимизации с достаточным качеством.
[0094] Выбор документов на основе подхода со списочным ранжированием
[0095] Впоследствии разработчики рассмотрели MLA, реализующий алгоритм списочного ранжирования (или попарный алгоритм, модифицированный таким образом, что он ведет себя как списочный алгоритм), при котором MLA может напрямую оптимизировать значение меры оценки, которое будет усреднено по всем обучающим примерам.
[0096] Разработчики внедрили функцию для оптимизации, которая учитывает индивидуальные качественные значимости набора документов, индивидуальные параметры значимости (значение полезности) документов в упомянутом наборе документов, индивидуальные размеры документов в упомянутом наборе документов, общую качественную значимость упомянутого набора документов и общий размер упомянутого набора документов. Эта функция может быть выражена в двух уравнениях:

[0097] где qi является качественным параметром значимости i-го документа (являющимся суммой всех документов, имеющих ранг выше Т), pi является параметром значимости i-го документа (который прогнозируется алгоритмом фиксированного ранжирования), Т является порогом, начиная с которого документы с наивысшим рангом помещаются в поисковый индекс (причем сумма размеров документов с наивысшим рангом меньше размера поискового индекса В), si является размером i-го документа, Q является общей качественной значимостью документов, В является размером поискового индекса, a t является «свободным» параметром значимости, по которому следует выполнить максимизацию (т.е. Т является максимальным значением t так, что документы помещаются в поисковый индекс).
[0098] Другими словами, эти два уравнения представляют собой математическое представление задачи, подлежащей решению в контексте настоящей технологии, которая может быть сформулирована как нахождение такого порога качественной значимости, при котором общий размер набора документов, выбранных для включения в поисковый индекс, ниже ограничения размера поискового индекса, в то время как общая качественная значимость (т.е. сумма всех индивидуальных качественных значимостей) этих документов является максимальным.
[0099] Таким образом, целью является обучение MLA, реализующего списочно-подобный алгоритм, функции ранжирования так, чтобы уравнения (4) и (5) были оптимизированы. Поскольку уравнения (4) и (5) трудны для оптимизации, разработчики заменили данные уравнения другим уравнением («аппроксимирующим уравнением»), которое может быть использовано в качестве функции полезности, которую необходимо оптимизировать во время обучения MLA и которая также может быть интерпретирована как метрика оценки:
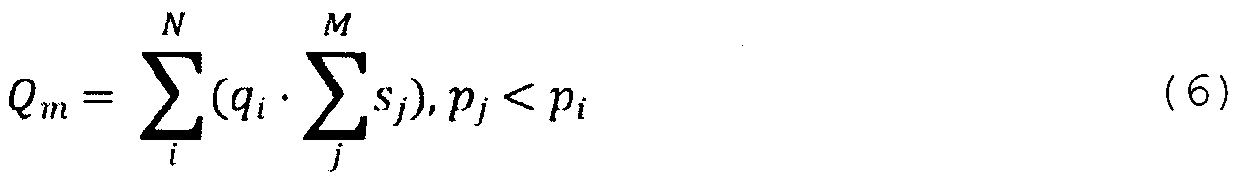
[00100] где: Qm является качественным параметром совокупной значимости, qi является качественным параметром значимости i-го документа во множестве цифровых документов, sj является соответствующим размером j-го документа во множестве цифровых документов, pi является параметром значимости i-го документа во множестве цифровых документов, N является количеством документов во множестве цифровых документов, а М является количеством документов в некотором подмножестве документов, имеющих параметр значимости ниже параметра значимости i-го документа во множестве цифровых документов.
[00101] Таким образом, MLA согласно настоящей технологии может обеспечиваться обучающими примерами документов и непосредственно оптимизировать уравнение (6) для обучения функции ранжирования. Функция ранжирования может затем использоваться для ранжирования документов для включения в поисковый индекс так, чтобы качественный параметр Qm совокупной значимости максимизировался.
[00102] В контексте настоящего описания "сервер" представляет собой компьютерную программу, которая работает на надлежащем аппаратном обеспечении и способна принимать запросы (например, от электронных устройств) по сети, а также выполнять эти запросы или вызывать выполнение этих запросов. Аппаратное обеспечение может быть одним физическим компьютером или одной физической компьютерной системой, но ни то, ни другое не является обязательным для настоящей технологии. В настоящем контексте использование выражения "сервер" не предполагает, что каждая задача (например, принятые инструкции или запросы) или какая-либо конкретная задача будут приняты, выполнены или вызваны для выполнения одним и тем же сервером (т.е. тем же самым программным обеспечением и/или аппаратным обеспечением); данное выражение предполагает, что любое количество программных элементов или аппаратных устройств может быть задействовано в приеме/отправке, выполнении или вызове для выполнения любой задачи или запроса, или последствий любой задачи или запроса; и все это программное обеспечение и аппаратное обеспечение может быть одним сервером или многочисленными серверами, причем оба данных случая включены в выражение "по меньшей мере один сервер".
[00103] В контексте настоящего описания "электронное устройство" представляет собой любое компьютерное оборудование, которое способно выполнять программное обеспечение, которое является надлежащим для соответствующей поставленной задачи. Таким образом, некоторые (не ограничивающие) примеры электронных устройств включают в себя персональные компьютеры (настольные ПК, ноутбуки, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройство, выступающее в качестве электронного устройства в настоящем контексте, не исключается из возможности выступать в качестве сервера для других электронных устройств. Использование выражения "электронное устройство" не исключает использования многочисленных электронных устройств при приеме/отправке, выполнении или вызове для выполнения какой-либо задачи или запроса, или последствий любой задачи или запроса, или этапов любого описанного в данном документе способа.
[00104] В контексте настоящего описания "база данных" представляет собой любую структурированную совокупность данных, независимо от ее конкретной структуры, программное обеспечение для администрирования базы данных, или компьютерное оборудование, на котором данные хранятся, реализуются или их делают доступными для использования иным образом. База данных может находиться на том же оборудовании, что и процесс, который хранит или использует информацию, хранящуюся в базе данных, или она может находиться на отдельном аппаратном обеспечении, например, на выделенном сервере или множестве серверов.
[00105] В контексте настоящего описания выражение "информация" включает в себя информацию любого характера или вида, который способен храниться в базе данных любым образом. Таким образом, информация включает в себя, но без ограничения, аудиовизуальные произведения (изображения, фильмы, звуковые записи, презентации и т.д.), данные (данные о местоположении, численные данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д.
[00106] В контексте настоящего описания предполагается, что выражение "используемый компьютером носитель хранения информации" включает в себя носители любого характера и вида, в том числе RAM, ROM, диски (CD-ROM, DVD, дискеты, накопители на жестких дисках и т.д.), USB-ключи, твердотельные накопители, ленточные накопители и т.д.
[00107] В контексте настоящего описания, если прямо не предусмотрено иное, "указание" информационного элемента может быть самим информационным элементом или указателем, ссылкой, гиперссылкой или другим опосредованным механизмом, позволяющим получателю такого указания найти местоположение в сети, памяти, базе данных или другом считываемом компьютером носителе, из которого информационный элемент может быть извлечен. Например, указание документа может включать в себя сам документ (т.е. его содержимое), или оно может быть уникальным дескриптором документа, идентифицирующим файл относительно некоторой конкретной файловой системы, или некоторым другим средством направления получателя такого указания в местоположение в сети, адрес в памяти, таблицу базы данных или иное местоположение, в котором можно осуществить доступ к файлу. Специалист в данной области поймет, что степень точности, требуемая в таком указании, зависит от степени какого-либо предварительного понимания того, какая интерпретация будет дана информации, обмениваемой во взаимодействии между отправителем и получателем такого указания. Например, если до связи между отправителем и получателем понимается, что указание информационного элемента будет иметь форму ключа базы данных для записи в некоторой конкретной таблице предопределенной базы данных, содержащей информационный элемент, то отправка ключа базы данных является всем, что требуется для эффективной передачи информационного элемента получателю, даже если сам информационный элемент не был передан во взаимодействии между отправителем и получателем такого указания.
[00108] В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в качестве прилагательных только для того, чтобы позволить отличать существительные, которые они модифицируют, друг от друга, а не для описания какой-либо особой взаимосвязи между такими существительными. Таким образом, например, следует понимать, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) таких серверов, равно как и их использование (само по себе) не означает, что какой-либо "второй сервер" должен обязательно существовать в любой определенной ситуации. Кроме того, как обсуждается в других контекстах данного документа, ссылка на "первый" элемент и "второй" элемент не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях "первый" сервер и "второй" сервер могут быть одним и тем же программным обеспечением и/или аппаратным обеспечением, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[00109] В контексте настоящего описания выражение «множество результатов поиска» предназначено для включения в себя набора из более чем одного результата поиска, где результаты общего поиска (например, во Всемирной паутине) и/или результаты вертикального поиска объединяются вместе в наборе. результатов поиска или на странице результатов поиска. Например, результаты вертикального поиска могут быть встроены в результаты общего поиска (например, во Всемирной паутине) на странице результатов поиска, или наоборот, то есть результаты общего поиска могут быть встроены в результаты вертикального поиска на странице результатов поиска. Таким образом, в некоторых вариантах осуществления результаты общего поиска и результаты вертикального поиска могут быть агрегированы и ранжированы относительно друг друга. В альтернативных вариантах осуществления множество результатов поиска может включать в себя только результаты общего поиска или только результаты вертикального поиска, например, результаты поиска из конкретной интересующей вертикальной области.
[00110] Каждая из реализаций настоящей технологии обладает по меньшей мере одним(ой) из вышеупомянутых аспектов и/или целей, но не обязательно имеет их все. Следует понимать, что некоторые аспекты настоящей технологии, которые возникли в попытке достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или удовлетворять другим целям, которые не описаны в данном документе явным образом.
[00111] Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии станут очевидными из нижеследующего описания, сопроводительных чертежей и приложенной формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[00112] Для лучшего понимания настоящей технологии, а также других аспектов и ее дополнительных признаков, ссылка приводится на нижеследующее описание, которое должно использоваться в сочетании с сопроводительными чертежами, на которых:
[00113] Фигура 1 иллюстрирует схематичное представление распределения некоторого количества документов, доступных в поисковом индексе, относительно количества раз, когда эти документы были показаны, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00114] Фигура 2 иллюстрирует схему системы, реализуемой в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00115] Фигура 3 иллюстрирует схематичное представление фазы использования первого MLA 132 и второго MLA, обрабатываемой системой по Фигуре 2, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00116] Фигура 4 иллюстрирует схематичное представление фазы обучения второго MLA, обрабатываемой системой по Фигуре 2, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00117] Фигура 5 иллюстрирует схематичное представление фазы обучения первого MLA, обрабатываемой системой по Фигуре 2, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00118] Фигура 6 иллюстрирует схематичное представление вероятности включения документа в набор документов относительно пользовательских взаимодействий с этим документом в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00119] Фигура 7 иллюстрирует схематичное представление общего качественные значимости списка документов относительно общего размера списка документов в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00120] Фигура 8 иллюстрирует блок-схему последовательности операций способа выбора подмножества документов из множества цифровых документов для включения в поисковый индекс сервера поисковой системы по Фигуре 2 в соответствии с неограничивающими вариантами осуществления настоящей технологии.
ПОДРОБНОЕ ОПИСАНИЕ
[00121] Приведенные в данном документе примеры и условные формулировки призваны главным образом помочь читателю понять принципы настоящей технологии, а не ограничить ее объем такими конкретно приведенными примерами и условиями. Должно быть понятно, что специалисты в данной области смогут разработать различные механизмы, которые, хоть и не описаны в данном документе явным образом, тем не менее воплощают принципы настоящей технологии и включаются в ее суть и объем.
[00122] Кроме того, нижеследующее описание может описывать реализации настоящей технологии в относительно упрощенном виде для целей упрощения понимания. Специалисты в данной области поймут, что различные реализации настоящей технологии могут иметь большую сложность.
[00123] В некоторых случаях также могут быть изложены примеры модификаций настоящей технологии, которые считаются полезными. Это делается лишь для содействия понимаю и, опять же, не для строгого определения объема или очерчивания границ настоящей технологии. Эти модификации не являются исчерпывающим списком, и специалист в данной области может осуществлять другие модификации, все еще оставаясь при этом в рамках объема настоящей технологии. Кроме того, случаи, когда примеры модификаций не приводятся, не следует толковать так, что никакие модификации не могут быть осуществлены и/или что описанное является единственным способом реализации такого элемента настоящей технологии.
[00124] Кроме того, все содержащиеся в данном документе утверждения, в которых указываются принципы, аспекты и реализации настоящей технологии, а также их конкретные примеры, призваны охватить как структурные, так и функциональные эквиваленты, вне зависимости от того, известны ли они в настоящее время или будут разработаны в будущем. Таким образом, например, специалисты в данной области осознают, что любые блок-схемы в данном документе представляют концептуальные виды иллюстративной схемы, воплощающей принципы настоящей технологии. Аналогичным образом, будет понятно, что любые блок-схемы, схемы последовательности операций, схемы изменения состояний, псевдокоды и подобное представляют различные процессы, которые могут быть по сути представлены на считываемых компьютером носителях и исполнены компьютером или процессором вне зависимости от того, показан ли такой компьютер или процессор явным образом или нет.
[00125] Функции различных элементов, показанных на фигурах, в том числе любого функционального блока, помеченного как "процессор" или "графический процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения, а также аппаратного обеспечения, способного исполнять программное обеспечение и связанного с надлежащим программным обеспечением. При обеспечении процессором функции могут быть обеспечены одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут быть совместно используемыми. В некоторых вариантах осуществления настоящей технологии процессор может быть процессором общего назначения, таким как центральный процессор (CPU) или процессор, выделенный для конкретной цели, например, графический процессор (GPU). Кроме того, явное использование термина "процессор" или "контроллер" не должно истолковываться как относящееся исключительно к аппаратному обеспечению, способному исполнять программное обеспечение, и может в неявной форме включать в себя, без ограничений, аппаратное обеспечение цифрового сигнального процессора (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянную память (ROM) для хранения программного обеспечения, оперативную память (RAM) и энергонезависимое хранилище. Другое аппаратное обеспечение, традиционное и/или специализированное также может быть включено в состав.
[00126] Программные модули или просто модули, в качестве которых может подразумеваться программное обеспечение, могут быть представлены в настоящем документе как любая комбинация элементов блок-схемы последовательности операций или других элементов, указывающих выполнение этапов процесса и/или текстовое описание. Такие модули могут исполняться аппаратным обеспечением, которое показано явно или неявно.
[00127] Учитывая эти основополагающие особенности, рассмотрим некоторые неограничивающие примеры, чтобы проиллюстрировать различные реализации аспектов настоящей технологии.
[00128] Со ссылкой на Фигуру 2 проиллюстрирована система 100, причем система 100 реализована в соответствии с неограничивающими вариантами осуществления настоящей технологии. Система 100 содержит первое клиентское устройство 102, второе клиентское устройство 104, третье клиентское устройство 106 и четвертое клиентское устройство 108, подключенные к сети 110 связи через соответствующую линию 115 связи (на фигуре 2 данный номер присвоен только двум линиям из показанных линий связи). Система 100 содержит сервер 120 индексации, сервер 140 поисковой системы, сервер 160 аналитики и сервер 180 обучения, подключенные к сети 110 связи через соответствующую им линию 115 связи. В некоторых вариантах осуществления настоящей технологии сервер 120 индексации, сервер 140 поисковой системы, сервер 160 аналитики и сервер 180 обучения могут быть реализованы как единый сервер.
[00129] Только в качестве примера, первое клиентское устройство 102 может быть реализовано как смартфон, второе клиентское устройство 104 может быть реализовано как ноутбук, третье клиентское устройство 106 может быть реализовано как смартфон, а четвертое клиентское устройство 108 может быть реализовано как планшет. В некоторых неограничивающих вариантах осуществления настоящей технологии сеть 110 связи может быть реализована как Интернет. В других вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например, как какая-либо глобальная сеть связи, локальная сеть связи, частная сеть связи и тому подобное.
[00130] То, как реализована определенная линия 115 связи, конкретным образом не ограничено и будет зависеть от того, как реализовано связанное одно из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108. Просто как пример, а не как ограничение, в тех вариантах осуществления настоящей технологии, в которых по меньшей мере одно из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108 реализовано как устройство беспроводной связи (например как смартфон), связанная одна из линии 115 связи может быть реализована как линия беспроводной связи (такая как, но без ограничения, линия сети связи 3G, линия сети связи 4G, Wireless Fidelity или WiFi® для краткости, Bluetooth® и тому подобные). В тех примерах, в которых по меньшей мере одно из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108 реализованы соответственно, как ноутбук, смартфон, планшетный компьютер, связанная линия 115 связи может быть либо беспроводной (например, Wireless Fidelity или WiFi® для краткости, Bluetooth® и тому подобные), либо проводной (например, Ethernet-соединение).
[00131] Следует четко понимать, что в реализациях для первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106, четвертого клиентского устройства 108, линия 115 связи и сеть 110 связи обеспечены лишь в целях иллюстрации. Таким образом специалисты в данной области без труда распознают другие конкретные детали реализации для первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106, четвертого клиентского устройства 108, а также линии 115 связи и сети 110 связи. Как таковые, примеры, представленные в настоящем документе выше, никоим образом не предназначены для ограничения объема настоящей технологии.
[00132] Хотя проиллюстрированы только четыре клиентских устройства 102, 104, 106 и 108 (все показаны на Фигуре 2), предполагается, что любое количество клиентских устройств 102, 104, 106 и 108 может быть подключено к системе 100. Кроме того, предполагается, что в некоторых реализациях количество клиентских устройств 102, 104, 106 и 108, включенных в систему 100, может исчисляться десятками или сотнями тысяч.
[00133] Сервер индексации
[00134] С сетью 110 связи также соединен вышеупомянутый сервер 120 индексации. Сервер 120 индексации может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 120 индексации может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 120 индексации может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 120 индексации является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 120 индексации могут быть распределены и могут быть реализованы через многочисленные серверы. В других вариантах осуществления функциональные возможности сервера 120 индексации могут реализовываться сервером 140 поисковой системы полностью или частично. В некоторых вариантах осуществления настоящей технологии сервер 120 индексации находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 120 индексации может находиться под управлением и/или администрированием другого поставщика услуг.
[00135] Вообще говоря, назначением сервера 120 индексации является (i) обход Всемирной паутины и извлечение документов, таких как множество цифровых документов 117; (ii) обработка упомянутого множества цифровых документов 117; и (iii) индексация по меньшей мере части обработанного множества цифровых документов 117 в поисковом индексе 146 сервера 140 поисковой системы (что будет описано более подробно ниже). Сервер 120 индексации исполняет множество обходчиков 122, модуль 130 разбора, первый MLA 132 и подключен к базе 136 данных обхода и базе 138 данных предварительной индексации.
[00136] Множество цифровых документов 117 может размещаться, например, на различных компьютерных системах, доступных во Всемирной паутине. Характер множества цифровых документов 117 особым образом не ограничен. В контексте настоящего описания множество цифровых документов 117 также может упоминаться как «множество веб-страниц», «веб-страницы», «веб-документы» или просто «документы». Однако предполагается, что любой один из множества цифровых документов 117 может представлять собой любую форму структурированной цифровой информации, которая может быть извлечена или доступна через соответствующий универсальный указатель ресурса (URL), не выходя за пределы объема настоящей технологии.
[00137] Вообще говоря, любой один из множества цифровых документов 117 может содержать одно или несколько предложений. Любым одним из множества цифровых документов 117 может быть, например, веб-страница, содержащая текст и/или изображения (например, недавно опубликованная новостная статья, связанная с некоторыми последними новостям). Другим одним из множества цифровых документов 117 может быть, в качестве другого примера, цифровая версия книги (например, цифровая версия «Гордости и предубеждения» Джейн Остин). Другим одним из множества цифровых документов 117 может быть, в качестве другого примера, статья на Wikipedia™, которая может время от времени обновляться.
[00138] Предполагается, что по меньшей мере некоторые из множества цифровых документов 117 могли быть недавно созданы (или обновлены) или иным образом недавно стали доступными через Интернет. Действительно, очень большое количество веб-страниц создаются или иным образом становятся доступными через Интернет каждый день, и поэтому может возникнуть необходимость проиндексировать по меньшей мере некоторые из этих веб-страниц, чтобы предоставлять их содержимое пользователям некоторой поисковой системы.
[00139] Следует отметить, что по меньшей мере некоторые из упомянутого множества цифровых документов 117 могут быть «свежими» веб-страницами, такими как веб-страницы, имеющие свежее содержимое, которое, вероятно, будет обновляться относительно часто (например, погода), тогда как по меньшей мере некоторые другие из упомянутого множества цифровых документов 117 могут быть «застойными» веб-страницами, такими как веб-страницы, имеющие застойное содержимое, которое с меньшей вероятностью будет меняться или будет меняться с менее частыми интервалами (например, статья в Википедии о Конституции Канады). С одной стороны, полезность свежего содержимого для пользователей некоторой поисковой системы обычно (i) достигает пика близко к моменту его создания и (ii) падает спустя некоторый период времени. С другой стороны, полезность застойного содержимого для пользователей упомянутой поисковой системы обычно (i) ниже ближе к моменту его создания, чем полезность свежего содержимого ближе к моменту его создания, но (ii) несколько постоянна на протяжении всего времени.
[00140] Предполагается, что по меньшей мере некоторые из множества цифровых документов 117 могли быть проиндексированы ранее, тогда как по меньшей мере некоторые другие из упомянутого множества цифровых документов 117 могли ранее не индексироваться. Например, множество цифровых документов 117 может содержать «новые» веб-страницы, которые ранее не были проиндексированы. В другом примере множество цифровых документов 117 может содержать «старые» веб-страницы, которые были проиндексированы ранее. В еще одном примере множество цифровых документов 117 может содержать «обновленные» веб-страницы, которые в некотором смысле являются «обновленными» версиями старых веб-страниц, причем содержимое обновленной версии веб-страницы отличается от содержимого старой версии веб-страницы, которая была проиндексирована ранее.
[00141] Множество обходчиков 122 включает в себя основные обходчики 124 и экспресс-обходчики 126. Основные обходчики 124 сконфигурированы с возможностью обхода множества цифровых документов 117 во Всемирной паутине, начиная со списка URL-адресов для посещения (не проиллюстрированы), причем гиперссылки в упомянутых документах также идентифицируются и добавляются в список для посещения. Экспресс-обходчики 126 сконфигурированы с возможностью выполнения экспресс-индексации "свежих" документов (которые могут быть включены в упомянутое множество цифровых документов 117), которые появились во Всемирной паутине непосредственно перед процедурой обхода, так что свежие документы также доступны для индексации. Основные обходчики 124 и экспресс-обходчики 126 также включают в себя соответствующие планировщики (не проиллюстрированы), которые создают расписания и порядки документов для обхода во Всемирной паутине. Множество обходчиков 122, в том числе основные обходчики 124 и экспресс-обходчики 126, обычно загружают множество цифровых документов 117 и сохраняют это множество цифровых документов 117 в базе 136 данных обхода.
[00142] Модуль 130 разбора, как правило, сконфигурирован с возможностью разбора множества цифровых документов 117, хранящихся в базе 136 данных обхода, и извлечения из них такой информации, как индексные термины и гиперссылки. Модуль 130 разбора как правило вычищает язык разметки из документов, по которым выполняется обход, так что текстовая информация может быть извлечена и позднее проанализирована или использована непосредственно для индексации. Модуль 130 разбора может дополнительно извлекать множество признаков из документов, таких как признаки, используемые для ранжирования (признаки ранжирования), признаки URL, признаки кликов, признаки документов и тому подобное. В некоторых вариантах осуществления модуль 130 разбора может сохранять извлеченную информацию в качестве признаковых векторов в базе 138 данных предварительной индексации. В других вариантах осуществления сервер 120 индексации может исполнять модуль извлечения признаков (не проиллюстрирован) для извлечения признаков множества цифровых документов 117 из базы 136 данных обхода.
[00143] Первый MLA 132 сконфигурирован с возможностью выбора по меньшей мере части упомянутого множества цифровых документов 117 для включения в поисковый индекс 146 сервера 140 поисковой системы на основе признаковых векторов множества цифровых документов 117, а также другой информации, связанной с упомянутым множеством цифровых документов 117, причем признаковые векторы хранятся в базе 138 данных предварительной индексации. То, как первый MLA 132 выбирает документы для включения в поисковый индекс 146, поясняется ниже более подробно.
[00144] Сервер поисковой системы
[00145] С сетью 110 связи также соединен вышеупомянутый сервер 140 поисковой системы. Сервер 140 поисковой системы может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 140 поисковой системы может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 140 поисковой системы может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 140 поисковой системы является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 140 поисковой системы могут быть распределены и могут быть реализованы через многочисленные серверы. В некоторых вариантах осуществления настоящей технологии сервер 140 поисковой системы находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 140 поисковой системы может находиться под управлением и/или администрированием поставщика услуг.
[00146] Вообще говоря, назначением сервера 140 поисковой системы является (i) исполнение поисков; (ii) исполнение анализа результатов поиска и выполнение ранжирования результатов поиска в ответ на поисковый запрос; (iv) группировка результатов и составление страницы результатов поиска (SERP) для вывода на электронное устройство (например одно из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108), причем данное электронное устройство использовалось для отправки упомянутого поискового запроса, который обеспечил в результате данную SERP.
[00147] То, как сервер 140 поисковой системы сконфигурирован исполнять поиски, особым образом не ограничено. Специалисты в данной области техники поймут несколько способов и средств для исполнения поиска с использованием сервера 140 поисковой системы, и поэтому некоторые структурные компоненты сервера 140 поисковой системы будут описаны лишь на высоком уровне. Сервер 140 поисковой системы может поддерживать базу 144 данных журнала поиска.
[00148] Сервер 140 поисковой системы сконфигурирован с возможностью выполнения общих предметных поисков, что известно специалистам в данной области техники. Например, общий предметный поиск не ограничивается поиском некоторой конкретной категории результатов, но может предоставить все результаты, которые лучше всего соответствуют поисковому запросу. Такой общий (независимый от категории) поиск сервером 140 поисковой системы может возвращать результаты поиска, которые включают в себя цифровое содержимое, не относящееся к конкретной категории, а также цифровое содержимое, относящееся к конкретной категории, например изображения, видео, новости, покупки, блоги, книги, места, обсуждения, рецепты, билеты, биографическая информация, патенты, акции, расписания и т.д., а также другое цифровое содержимое, тесно связанное и направленное на некоторый тип цифрового содержимого. В качестве примера, общим предметным поиском может быть WWW-поиск. Поиск, выполняемый в общей предметной области, генерирует «результат общего поиска» или «элемент результата общего поиска». Такие результаты общего поиска также упоминаются в данном документе как «веб-результаты». Как правило, некоторый веб-результат включает в себя ссылку на веб-сайт и фрагмент, в котором приводится выжимка содержимого веб-сайта. Пользователь может выбрать ссылку на веб-сайт с веб-результатом, чтобы перейти к веб-странице, связанной с поисковым запросом пользователя. Термины «результат общего поиска» и «элемент результата общего поиска» используются в данном документе взаимозаменяемо, как и термины «результат поиска» и «элемент результата поиска».
[00149] Сервер 140 поисковой системы также сконфигурирован с возможностью выполнения вертикальных предметных поисков. Например, вертикальная предметная область может быть информационной предметной областью, содержащей специализированное содержимое, например, содержимое некоторого единственного типа (например, мультимедийный тип, жанр содержимого, по определенным темам и т.д.). Вертикальная предметная область, таким образом, включает в себя некоторое конкретное подмножество большего набора данных, например, некоторое конкретное подмножество веб-данных. Например, вертикальная предметная область может включать в себя некоторую конкретную информацию, такую как изображения, видео, новости, покупки, блоги, книги, места, обсуждения, рецепты, билеты, биографические данные, патенты, акции, расписания и т.д. Поиск, выполняемый в вертикальной предметной области, генерирует «результат вертикального поиска» или «элемент результата вертикального поиска». Такие результаты вертикального поиска также упоминаются в настоящем документе как "вертикали" и "вертикальные результаты". Термины "результат вертикального поиска" и "элемент результата вертикального поиска" используются в этом документе взаимозаменяемо.
[00150] Сервер 140 поисковой системы сконфигурирован с возможностью генерирования ранжированного списка результатов поиска, включающего в себя результаты общего предметного поиска и вертикального предметного поиска. Сервер поисковой машины может исполнять один или несколько MLA 142 для ранжирования документов, чтобы сгенерировать ранжированный список результатов поиска.
[00151] Множество алгоритмов для ранжирования результатов поиска известны и могут быть реализованы сервером 140 поисковой системы.
[00152] Просто в качестве примера, а не ограничения, один или несколько MLA 142 могут ранжировать документы по релевантности отправленному пользователем поисковому запросу на основе некоторого или всего из того: (i) насколько популярен некоторый поисковый запрос в поисках; (ii) сколько результатов было возвращено; (iii) содержит ли поисковый запрос какие-либо определяющие термины (такие как «изображения», «фильмы», «погода» или тому подобное), (iv) как часто некоторый конкретный поисковый запрос обычно используется с определяющими терминами другими пользователями; и (v) как часто другие пользователи, выполняющие подобный поиск, выбирали некоторый конкретный ресурс или конкретные результаты вертикального поиска, когда результаты представлялись с использованием SERP. Таким образом, сервер 140 поисковой системы может вычислить и назначить показатель релевантности (на основе, но без ограничения, различных критериев, перечисленных выше) для каждого результата поиска, полученного в ответ на отправленный пользователем поисковый запрос, а также сгенерировать SERP, где результаты поиска ранжированы согласно соответствующим им показателям релевантности.
[00153] База данных журнала поиска
[00154] Сервер 140 поисковой системы обычно поддерживает вышеупомянутую базу 144 данных журнала поиска.
[00155] Обычно база 144 данных журнала поиска может включать в себя поисковый индекс 146, журнал 147 поисковых запросов и журнал 148 пользовательских взаимодействий.
[00156] Назначением поискового индекса 146 является индексация документов (или указание документов), таких как, помимо прочих, веб-страницы, изображения, видео, документы формата переносимых документов (PDF), документы Microsoft Word™, документы Microsoft PowerPoint™, которые были выбраны первым MLA 132. В некоторых вариантах осуществления настоящей технологии поисковый индекс 146 поддерживается в форме списков публикаций. Таким образом, когда пользователь одного из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108 вводит поисковый запрос и выполняет поиск на сервере 140 поисковой системы, сервер 140 поисковой системы анализирует поисковый индекс 146 и извлекает документы, которые содержат термины запроса, и ранжирует их в соответствии с алгоритмом ранжирования.
[00157] Назначением журнала 147 поисковых запросов является поддержание журнала поисков, отправленных на сервер 140 поисковой системы. Более конкретно, журнал 147 поисковых запросов может поддерживать список запросов, причем каждый соответствующий запрос из этого списка имеет соответствующие поисковые термины, связанные документы, которые были включены в список сервером 140 поисковой системы в ответ на соответствующий поисковый запрос, количество отправлений соответствующего запроса за некоторое время (именуемое ниже частотой использования в прошлом), а также может содержать список пользователей (или группы пользователей), идентифицированных анонимными ID (или вовсе без ID), и соответствующие документы, по которым они кликнули после отправки соответствующего поискового запроса. В некоторых вариантах осуществления журнал 147 поисковых запросов может обновляться каждый раз, когда новый поиск выполняется на сервере 140 поисковой системы. В других вариантах осуществления журнал 147 поисковых запросов может обновляться с предопределенными интервалами времени. В некоторых вариантах осуществления может быть множество копий журнала 147 поисковых запросов, каждая из которых соответствует журналу 147 поисковых запросов в разные моменты времени.
[00158] Способ структурирования журнала 148 пользовательских взаимодействий особым образом не ограничен. Журнал 148 пользовательских взаимодействий может быть связан с журналом 147 поисковых запросов и может перечислять параметры пользовательских взаимодействий, отслеживаемые сервером 160 аналитики после того, как пользователь отправил поисковый запрос и кликнул по одному или нескольким документам в SERP на сервере 140 поисковой системы. В качестве неограничивающего примера журнал 148 пользовательских взаимодействий может поддерживать: (i) ссылку на соответствующий документ или его указание, который может быть идентифицирован, в качестве неограничивающего примера, по ID номеру или URL; (ii) соответствующий список запросов, при этом каждый соответствующий запрос из упомянутого списка соответствующих запросов связан с соответствующим документом, и при этом каждый из соответствующих запросов был использован одним или несколькими пользователями для доступа к соответствующему документу; и (iii) соответствующее множество параметров пользовательских взаимодействий для каждого запроса (если с документом взаимодействовали), которые указывают пользовательские взаимодействия с соответствующим документом пользователями, отправившими соответствующий запрос из упомянутого списка запросов. Журнал 148 пользовательских взаимодействий может дополнительно включать в себя соответствующие временные метки, связанные с соответствующими пользовательскими взаимодействиями, и другие статистические данные. В некоторых вариантах осуществления журнал 147 поисковых запросов и журнал 148 пользовательских взаимодействий могут быть реализованы как один журнал.
[00159] Вообще говоря, данные из базы 144 данных журнала поиска (в том числе данные из журнала 148 пользовательских взаимодействий) могут быть получены по меньшей мере одним из сервера 140 поисковой системы и сервера 160 аналитики синхронным образом (то есть с предопределенными временными интервалами) или асинхронным образом (например, после получения указания).
[00160] В настоящем варианте осуществления пользовательские взаимодействия в журнале 148 пользовательских взаимодействий обычно могут отслеживаться и компилироваться сервером 160 аналитики.
[00161] Сервер аналитики
[00162] С сетью 110 связи также соединен вышеупомянутый сервер 160 аналитики. Сервер 160 аналитики может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 160 аналитики может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 160 аналитики может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 160 аналитики является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 160 аналитики могут быть распределены и могут быть реализованы через многочисленные серверы. В других вариантах осуществления функциональные возможности сервера 160 аналитики могут реализовываться сервером 140 поисковой системы полностью или частично. В некоторых вариантах осуществления настоящей технологии сервер 160 аналитики находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 160 аналитики может находиться под управлением и/или администрированием другого поставщика услуг.
[00163] Вообще говоря, назначением сервера 160 аналитики является отслеживание пользовательских взаимодействий с сервером 140 поисковой системы сервера 140 поисковой системы, например, поисковых запросов и терминов, вводимых пользователями, а также документов, к которым эти пользователи впоследствии осуществляют доступ (например, пользователи первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108). Сервер 160 аналитики может отслеживать пользовательские взаимодействия (такие как, например, данные о переходах посредством кликов), когда пользователи выполняют общий предметный поиск и вертикальный предметный поиск на сервере 140 поисковой системы.
[00164] Неограничивающие примеры пользовательских взаимодействий, отслеживаемых или вычисляемых сервером 160 аналитики, включают в себя:
- Потери/Приобретения (Loss/Win): кликнули ли документ в ответ на поисковый запрос или нет.
- Время пребывания: время, затрачиваемое пользователем на документ перед возвратом к SERP.
- Длинный/короткий клик: было ли пользовательское взаимодействие с документом длинным или коротким по сравнению с пользовательским взаимодействием с другими документами в SERP.
- Показатель кликабельности (CTR): Количество кликов по элементу, деленное на количество показов элемента (представлений).
[00165] Естественно, приведенный выше список не является исчерпывающим и может включать в себя, не выходя за рамки настоящей технологии, параметры пользовательских взаимодействий других типов.
[00166] Сервер 160 аналитики может передавать данные отслеживаемых пользовательских взаимодействий на сервер 140 поисковой системы, так что они могут быть сохранены в журнале 147 поисковых запросов и журнале 148 пользовательских взаимодействий из базы 144 данных журнала поиска. В некоторых вариантах осуществления сервер 160 аналитики может сохранять пользовательские взаимодействия и связанные результаты поиска локально в журнале пользовательских взаимодействий (не проиллюстрирован). В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 160 аналитики и сервера 140 поисковой системы могут быть реализованы одним сервером.
[00167] Сервер обучения
[00168] С сетью 110 связи также соединен вышеупомянутый сервер 180 обучения. Сервер 180 обучения может быть реализован как традиционный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 180 обучения может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 180 обучения может быть реализован в любом другом подходящем аппаратном и/или программном обеспечении и/или микропрограммном обеспечении или их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 180 обучения является единственным в своем роде сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 180 обучения могут быть распределены и могут быть реализованы многочисленными серверами. В других вариантах осуществления функциональные возможности сервера 180 обучения могут реализовываться сервером 140 поисковой системы полностью или частично. В некоторых вариантах осуществления настоящей технологии сервер 180 обучения находится под управлением и/или администрированием оператора поисковой системы. Альтернативно, сервер 180 обучения может находиться под управлением и/или администрированием другого поставщика услуг.
[00169] Вообще говоря, назначением сервера 180 обучения является обучение MLA, исполняемое сервером 120 индексации и сервером 140 поисковой системы. Сервер 180 обучения сконфигурирован с возможностью обучения одного или нескольких MLA 142 сервера 140 поисковой системы. Сервер 180 обучения сконфигурирован с возможностью обучения первого MLA 132 и второго MLA 134 для выбора документов из базы 138 данных предварительной индексации для включения в поисковый индекс 146.
[00170] Сервер 180 обучения подключен к базе 182 данных обучения. Вообще говоря, база 182 данных обучения может хранить информацию, такую как обучающие объекты, используемую для обучения одного или нескольких MLA 142 сервера 140 поисковой системы, первого MLA 132 и второго MLA 134 сервера 120 индексации.
[00171] Теперь обратимся к Фигуре 3, на которой иллюстрируется схематичное представление фазы 200 использования первого MLA 132 и второго MLA 134 в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00172] Первый MLA 132 может быть исполнен сервером 120 индексации.
[00173] Вообще говоря, первый MLA 132 сконфигурирован с возможностью генерирования ранжирования множества цифровых документов 117, доступных в базе 138 данных предварительной индексации, для получения ранжированного списка документов 260, причем подмножество 275 ранжированного списка документов 260 может быть выбрано для включения в поисковый индекс 146. Ранжированный список документов 260 генерируется первым MLA 132, так что функция 225 полезности максимизируется.
[00174] Второй MLA 134 может получать множество цифровых документов 210 (или их указание) из базы 138 данных предварительной индексации, причем каждый данный цифровой документ 212 связан с соответствующим признаковым вектором 214 и соответствующим размером 216.
[00175] Второй MLA 134 может генерировать параметр 218 значимости каждого определенного цифрового документа 212 (или его указание) на основе признакового вектора 214 упомянутого цифрового документа 212. Вообще говоря, параметр 218 значимости может указывать общую релевантность или полезность упомянутого цифрового документа 212 для сервера 140 поисковой системы и может, по меньшей мере частично, прогнозировать будущие пользовательские взаимодействия с данным цифровым документом 212 на основе связанного признакового вектора 214 в случаях, когда данный цифровой документ 212 является свежим документом, который не имеет каких-либо связанных прошлых пользовательских взаимодействий в журнале 148 пользовательских взаимодействий.
[00176] В тех случаях, когда упомянутый цифровой документ 212 связан с прошлыми пользовательскими взаимодействиями в журнале 148 пользовательских взаимодействий, параметр 218 значимости может быть основан, по меньшей мере частично, на этих прошлых пользовательских взаимодействиях, и может интерпретироваться как общая «релевантность» упомянутого цифрового документа 212 для сервера 140 поисковой системы и может учитывать некоторое количество запросов, в ответ на которые упомянутый цифровой документ 212 был предоставлен, а также связанное с ним ранжирование, связанные пользовательские взаимодействия и другие факторы, которые могут быть включены в связанный признаковый вектор 214.
[00177] В других вариантах осуществления параметр 218 значимости может быть независящим от запроса, то есть не учитывать релевантность упомянутого цифрового документа 212 некоторому количеству запросов на сервере 140 поисковой системы, в то же время учитывая прошлые пользовательские взаимодействия с упомянутым цифровым документ 212. В некоторых вариантах осуществления "спрогнозированный" параметр 218 значимости и параметр значимости, основанный на прошлых пользовательских взаимодействиях, могут быть вычислены отдельными MLA (не проиллюстрированы).
[00178] Альтернативно, параметр 218 значимости для некоторого цифрового документа 212, имеющего данные о прошлых пользовательских взаимодействиях, может быть пользовательским взаимодействием (таким как один или несколько кликов, CTR, время пребывания и т.п.) или комбинацией пользовательских взаимодействий, а параметр 218 значимости для некоторого цифрового документа 212, не имеющего данных о прошлых пользовательских взаимодействиях, может быть прогнозом одного или нескольких пользовательских взаимодействий.
[00179] Второй MLA 134 может затем вывести набор параметров 220, причем набор параметров 220 включает в себя, для каждого цифрового документа 212 из множества цифровых документов 117: указание упомянутого цифрового документа 212, связанный параметр 218 значимости, связанный признаковый вектор 214 и связанный размер 216 упомянутого цифрового документа 212.
[00180] Первый MLA 132 может принимать набор параметров 220, связанных с указанием множества цифровых документов 117.
[00181] Первый MLA 132 может вычислять качественный параметр 255 значимости для каждого цифрового документа 212 из множества цифровых документов 210, причем качественный параметр 255 значимости указывает полезность упомянутого цифрового документа 212 для сервера 140 поисковой системы, учитывая связанный размер 216 и другие признаки упомянутого цифрового документа 212. Качественный параметр 255 значимости, вычисляемый первым MLA 132, может быть основан на связанном параметре 218 значимости, связанном признаковом векторе 214 и связанном размере 216. В некоторых вариантах осуществления качественный параметр 255 значимости может быть основан на связанном параметре 218 значимости и связанном размере 216. В некоторых альтернативных вариантах осуществления качественный параметр 255 значимости может быть основан, по меньшей мере частично, на отношении связанного параметра 218 значимости к связанному размеру.
[00182] Первый MLA 132 может затем ранжировать множество цифровых документов 317 в соответствии с качественными параметрами 255 значимости для вывода ранжированного списка документов 260 так, чтобы функция 225 полезности была максимизирована (первый MLA 132 был обучен на основе упомянутой функции 225 полезности). Таким образом, ранжированный список документов 260 может быть «оптимизированным» ранжированным списком документов, по которым выполнен обход, который учитывает параметр 218 значимости и размер 216 каждого цифрового документа 212.
[00183] В некоторых вариантах осуществления первый MLA 132 и второй MLA 134 могут быть реализованы как единый MLA (не проиллюстрирован), и этот единый MLA может вычислять как параметр 218 значимости, так и качественный параметр 255 значимости.
[00184] Затем ранжированный список документов 260 может быть принят в качестве входных данных в модуле 270 выбора, который может выбирать подмножество 275 ранжированного списка документов 260 для включения в поисковый индекс 146, основываясь, в качестве примера, на общем размере или доступном размере 280 поискового индекса 146. Модуль 270 выбора может, как правило, выбирать некоторое количество документов с наивысшим рангом из ранжированного списка документов 260 для добавления их к подмножеству 275 так, чтобы сумма размеров документов с наивысшим рангом была ниже общего размера 280 поискового индекса 146. Модуль 270 выбора затем может сохранить это подмножество 275 в поисковом индексе 146.
[00185] В некоторых вариантах осуществления поисковый индекс 146 может быть разделен на множество частей (не проиллюстрированы), где только некоторая часть из упомянутого множества может быть наполнена за раз, а модуль 270 выбора может включать в состав только документы с наивысшим рейтингом из ранжированного списка документов 260 так, чтобы размер подмножества 275 был ниже размера упомянутой части поискового индекса 146. Первый MLA 132 затем может повторно выполнить ранжирование документов (без документов, включенных в подмножество 275), чтобы наполнить оставшиеся части из упомянутого множества частей поискового индекса 146 итеративно.
[00186] Кроме того, в альтернативных вариантах осуществления первый MLA 132 может использоваться для обновления текущей версии поискового индекса 146, используемого сервером, который может в качестве неограничивающего примера обновляться часть за частью, причем документы ранжированного списка документов 275, уже присутствующие в поисковом индексе 146, могут игнорироваться модулем 270 выбора. В качестве альтернативы, документы, уже присутствующие в поисковом индексе 146, могут игнорироваться до вычисления связанного параметра 218 значимости.
[00187] Теперь обратимся к Фигуре 4, на которой иллюстрируется схематичное представление фазы 300 обучения второго MLA 134 в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00188] Второй MLA 134 может быть обучен на первом наборе обучающих документов 310, причем каждый обучающий документ 312 из упомянутого первого набора обучающих документов 310 был представлен ранее сгенерированным признаковым вектором 314 и меткой 316. Признаковый вектор 314 может включать в себя множество измерений, соответствующих множеству признаков (не проиллюстрированы), которые могут быть ранжирующими признаками, которые могут использоваться для ранжирования документов на сервере 140 поисковой системы, например, характерными для документа признаками, независящими от запроса признаками, а в некоторых вариантах осуществления - зависящими от запроса признаками. В качестве неограничивающего примера, признаковый вектор 314 может содержать указание некоторого количества прошлых запросов, которые были использованы для доступа к определенному обучающему документу 312 на сервере 140 поисковой системы, соответствующее прошлое ранжирование упомянутого обучающего документа 312 сервером 140 поисковой системы в ответ на соответствующий запрос, а также связанные соответствующие прошлые пользовательские взаимодействия с упомянутым обучающим документом 312.
[00189] Метка 316 может быть сгенерирована посредством MLA (то есть на основе прошлых пользовательских взаимодействий) или может быть определена ответственными за оценку людьми (например, по шкале от 1 до 5).
[00190] Затем второй MLA 134 может быть обучен на первом наборе обучающих документов 310, чтобы сгенерировать параметр 326 значимости для некоторого обучающего документа 312 на основе признакового вектора 314 и метки 316 упомянутого обучающего документа 312.
[00191] После фазы обучения второй MLA 134 может вычислить параметр 326 значимости для некоторого свежего документа (не проиллюстрирован), который не имеет каких-либо прошлых пользовательских взаимодействий, такого как документ, по которому обход был выполнен недавно, из множества цифровых документов 117, хранящихся в базе 138 данных предварительной индексации.
[00192] Теперь обратимся к Фигуре 5, на которой иллюстрируется схематичное представление фазы 400 обучения первого MLA 132 в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00193] В варианте осуществления, проиллюстрированном в данном документе, первый MLA 132 реализует алгоритм LambdaMART для ранжирования документов. В альтернативных вариантах осуществления первый MLA 132 может реализовывать любой алгоритм списочного ранжирования, который может быть модифицирован для целей настоящей технологии.
[00194] Алгоритм LambdaMART
[00195] Алгоритм LambdaMART вдохновлен алгоритмом LambdaRank, но основан на семействе моделей деревьев, именуемых многочисленными деревьями аддитивной регрессии (MART). Сам алгоритм LambdaRank основан на алгоритме ранжирования RankNet.
[00196] Выражаясь кратко, RankNet использует градиентный спуск, который требует вычисления градиента, причем выходной модели необходимо быть дифференцируемой функцией (то есть производная должна существовать в каждой точке ее области определения). RankNet является попарным подходом, использующим градиентный спуск для обновления параметров модели с целью минимизации стоимостной функции (например, перекрестной энтропии). Для обновления модели задают градиент стоимости по отношению к параметрам модели, что требует градиента стоимости по отношению к показателям модели. RankNet определяет лямбда-градиент, который является градиентом стоимостной функции по отношению к показателю документа. Лямбда-градиент можно интерпретировать как силу, имеющую некоторую величину и направление, которая перемещает документы вверх и вниз в ранжированном списке. В общем, для оценки качества окончательного ранжирования можно использовать другую стоимостную функцию или метрику оценки (например, nDCG, MRR, MAP и т.п.).
[00197] LambdaRank основан на RankNet и использует градиентный спуск, но каждый шаг масштабируется изменением окончательной метрики (например, изменением в одной из метрики nDCG, метрики MRR, метрики MAP и т.п.), которая демонстрировала улучшение скорости и точности в сравнении с RankNet.
[00198] MART является классом алгоритмов бустинга, выполняющих градиентный спуск с использованием деревьев регрессии. MART позволяет найти ансамбль деревьев, которые при объединении минимизируют стоимостную функцию. Однако, поскольку обычно используемые стоимостные функции не являются дифференцируемыми во всех точках, их нельзя использовать для градиентного бустинга, поскольку градиенты требуются в каждой точке обучения.
[00199] LambdaMART объединяет LambdaRank и MART и использует каскад деревьев, где градиент вычисляется после каждого нового дерева, чтобы оценить направление, которое минимизирует стоимостную функцию, которое будет масштабироваться с учетом вклада следующего дерева. Таким образом, каждое дерево вносит вклад в шаг градиента в направлении, которое минимизирует стоимостную функцию. Выходные данные представляют собой ансамбль деревьев градиентного бустинга, где градиент заменен лямбдой (градиентом, вычисленным с учетом пар-кандидатов). Опытным путем было показано, что LambdaMART успешно применяется для прямой оптимизации таких метрик, как NDCG, MAP и MRR.
[00200] Первый MLA 132 может реализовывать модифицированный алгоритм LambdaMART для построения подвергнутого бустингу ансамбля деревьев для ранжирования множества цифровых документов 117.
[00201] В контексте настоящей технологии первый MLA 132 может реализовать модифицированный алгоритм LambdaMART, чтобы напрямую максимизировать функцию 425 полезности, представленную уравнением (6), вместо минимизации стоимостной функции:
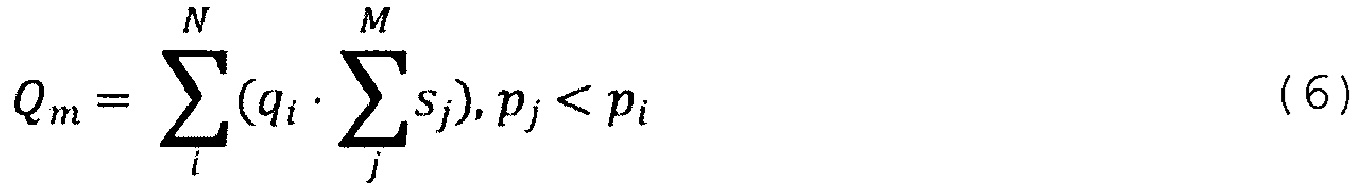
[00202] где: Qm является качественным параметром совокупной значимости, qi является качественным параметром значимости i-го документа во множестве цифровых документов 117, sj является соответствующим размером j-го документа во множестве цифровых документов 117, pi является параметром значимости i-го документа во множестве цифровых документов 117, pj является параметром значимости j-го документа во множестве цифровых документов 117, N является количеством документов во множестве цифровых документов, а М является количеством документов в некотором подмножестве документов, имеющих параметр pj значимости ниже параметра pi значимости i-го документа во множестве цифровых документов 117.
[00203] В некоторых вариантах осуществления упомянутое подмножество документов может состоять из всех документов во множестве цифровых документов 117, имеющих параметр pj значимости ниже параметра pi значимости. В альтернативных вариантах осуществления упомянутое подмножество документов может состоять только из конкретно выбранного документа, имеющего параметр pj значимости ниже параметра pi значимости, например из некоторого предопределенного количества документов, имеющих параметр pj значимости ниже параметра pi значимости.
[00204] В некоторых вариантах осуществления вес wi для качественного параметра qi значимости и вес wj для размера sj могут быть введены в уравнение (6) для взвешивания документов, которые могут считаться более «важными» для сервера 140 поисковой системы (такие веса могут быть выбраны вручную или выведены, в качестве примера, другим MLA путем анализа базы 144 данных журнала поиска), в результате чего:

[00205] где: Qm является качественным параметром совокупной значимости, wi является соответствующим весом, связанным с качественным параметром qi значимости, qi является качественным параметром значимости i-го документа во множестве цифровых документов 117, wj является соответствующим весом, связанным с соответствующим размером; sj является соответствующим размером j-го документа во множестве цифровых документов 117, pi является параметром значимости i-го документа во множестве цифровых документов 117, pj является параметром значимости j-го документа во множестве цифровых документов 117, N является количеством документов во множестве цифровых документов, а М является количеством документов в некотором подмножестве документов, имеющих параметр pj значимости ниже параметра pi значимости i-го документа во множестве цифровых документов 117.
[00206] Первый MLA 132, реализующий алгоритм LambdaMART, может быть инициализирован множеством параметров 420, причем это множество параметров включает в себя: количество деревьев 422 и количество листьев на дерево 426. В некоторых вариантах осуществления множество параметров 420 может включать в себя больше параметров, в зависимости от того, как реализован первый MLA 132.
[00207] Вообще говоря, для обучения первого MLA 132, реализующего алгоритм LambdaMART, необходимо определить целевую функцию, а в качестве лямбда-градиента можно использовать производную этой целевой функции, взвешенную разностью в функции полезности при смене мест документов в некоторой паре.
[00208] Обучающие документы
[00209] Генератор 405 обучающих документов может получать из базы 182 данных обучения множество обучающих документов 401 и выбирать некоторый обучающий документ 402 из упомянутого множества обучающих документов 401 для включения во второй набор обучающих документов 410, который может использоваться для обучения первого MLA 132 прогнозировать качественный параметр 455 значимости обучающего документа 412 из упомянутого второго набора обучающих документов 410. Упомянутый обучающий документ из множества обучающих документов 401 может быть представлен соответствующим признаковым вектором 404, соответствующим размером 406 и соответствующим параметром 408 значимости. Соответствующий признаковый вектор 404 может быть тем же вектором признаков, который использовался для вычисления параметра 408 значимости, или некоторым признаковым вектором, включающим в себя меньше или больше признаков. Вообще говоря, множество обучающих документов 401 были предварительно обработаны вторым MLA 134 для вычисления параметра 408 значимости.
[00210] Способ, которым второй набор обучающих документов 410 выбирается или генерируется генератором 405 обучающих документов, не ограничен.
[00211] В качестве неограничивающего примера, со ссылкой на Фигуру 6 проиллюстрирован график вероятности включения некоторого обучающего документа 402 из множества обучающих документов 401 во второй набор обучающих документов 410 относительно параметра 408 значимости упомянутого обучающего документа 402. Чем больше пользовательских взаимодействий с некоторым обучающим объектом 402 во множестве обучающих документов 401, тем выше вероятность включения упомянутого обучающего объекта 402 во второй набор обучающих документов 410. Дополнительно или в качестве альтернативы, включение некоторого обучающего документа 402 из множества обучающих документов 401 во второй набор обучающих документов 410 может быть основано на предопределенном пороге 610 значимости, и упомянутый обучающий документ 402 из множества обучающих документов 401 может автоматически включаться во второй набор обучающих документов 410, если его параметр 408 значимости выше упомянутого предопределенного порога 610 значимости. В некоторых вариантах осуществления параметр 408 значимости, вычисляемый вторым MLA 134, может быть заменен пользовательскими взаимодействиями (или их комбинацией), присутствующими в признаковом векторе 404, которые были отслежены сервером 160 аналитики и сохранены в журнале 148 пользовательских взаимодействий.
[00212] Первый MLA 132 может принимать в качестве входных данных второй набор обучающих документов 410, причем некоторый обучающий документ 412 связан с соответствующим признаковым вектором 414, соответствующим размером 416 и соответствующим параметром 418 значимости. Первый MLA 132 может обучиться, основываясь на втором наборе обучающих документов 410 и функции 425 полезности, модели ранжирования, которая назначает качественный параметр qi 455 значимости упомянутому обучающему документу 412 на основе признакового вектора 414 и размера 416 этого обучающего документа 412, и может ранжировать первый набор обучающих документов 410 для получения ранжированного списка обучающих документов 460, в котором документы с более высокими качественными параметрами значимости имеют более высокий ранг.
[00213] В настоящем варианте осуществления и для целей настоящей технологии алгоритм LambdaMART, реализуемый первым MLA 132, может не выполнять ранжирование второго набора обучающих документов 410 относительно запроса, что обычно имеет место с алгоритмами ранжирования. Таким образом, первый MLA 132 может не учитывать запросы для ранжирования, а также зависящие от запроса признаки в признаковых векторах 414 второго набора обучающих документов 410.
[00214] В альтернативных вариантах осуществления первый MLA 132 может учитывать запросы и зависящие от запроса признаки в признаковых векторах 414, поскольку некоторые запросы могут быть более популярными среди пользователей сервера 140 поисковой системы, и доступ к документам с терминами таких популярных запросов может осуществляться чаще, поэтому они могут учитываться. Дополнительно или альтернативно, первый MLA 132 может учитывать статистику, такую как количество различных запросов, использованных для доступа к определенному обучающему документу 412, а также связанные пользовательские взаимодействия, без непосредственного учета запросов для ранжирования.
[00215] Количество и тип признаков в признаковом векторе 414 не ограничены. В качестве неограничивающего примера, признаковый вектор 414 может включать в себя следующие независящие от запроса признаки:
- Веб-граф: связность на веб-графе, например, количество входящих ссылок и исходящих ссылок. Примеры включают в себя: PageRank, поиск по заданной теме на базе гиперссылок (HITS).
- Статистика документа: базовая статистика документа, такая как количество слов в документе, количество слов в анкорном тексте входящей ссылки документов, количество зеркальных копий документа, тип кодировки и тому подобное.
- Характеристики URL: Характеристики URL, такие как глубина, количество посещений, количество входов в систему, количество косых черт в URL и т.д.
- Тип содержимого: категория, связанная с документом, например, новостной тип, статья энциклопедии, официальный сайт и т.п.
- Клики: основанные на кликах признаки, такие как расстояние клика, вероятность клика, первый клик, последний клик, клик с длительным временем пребывания или просто клик, вероятность пропуска (клика не было, но документ был ниже), среднее время пребывания и т.п.
- Время: основанные на времени признаки, например, время создания документа, время изменения документа и т.п.
[00216] Признаки в признаковом векторе 414 могут быть двоичными, исчислимыми и/или непрерывными.
[00217] Первый MLA 132 может выполнять множество раундов обучения на втором наборе обучающих документов 410, чтобы генерировать оптимальную функцию ранжирования, которая максимизирует функцию 425 полезности. Каждый раунд обучения может приводить к иначе ранжированному списку обучающих документов 460, а результаты могут сравниваться путем применения функции 425 полезности, которая оценивает качественный параметр совокупной значимости ранжирования. Для фазы 200 использования может быть выбрана некоторая функция, которая максимизирует качественный параметр совокупной значимости. Дополнительно или в качестве альтернативы, может быть возможно применить другой тип метрики к ранжированному списку обучающих документов 460, чтобы оценить качество ранжирования.
[00218] Вообще говоря, ранжирование может выполняться первым MLA 132 так, что для любого выбранного подмножества ранжированного списка обучающих документов 460 ранжирование является оптимальным с точки зрения параметров значимости и размеров документов.
[00219] В качестве неограничивающего примера со ссылкой на Фигуру 7 проиллюстрирован график качественного параметра совокупной значимости для списка документов (не проиллюстрирован) относительно общего размера 715 списка документов 260 в соответствии с неограничивающими вариантами осуществления настоящей технологии. Функция 720 может представлять подход с неоптимизированной совокупностью документов, где качественный параметр общей значимости растет линейно с общим размером списка документов. Функция 740 может представлять оптимизированную функцию ранжирования первого MLA 132, которая является нелинейной функцией. По существу, для аналогичного размера (который может быть, в качестве примера, доступным размером поискового индекса 280), функция 740 дает более высокий качественный параметр 745 совокупной значимости, чем качественный параметр 725 совокупной значимости функции 720.
[00220] Теперь обратимся к Фигуре 8, на которой проиллюстрирована блок-схема последовательности операций способа 800 выбора подмножества 275 документов из множества цифровых документов 117 для включения в поисковый индекс 146 сервера 140 поисковой системы в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00221] Способ 800 может быть исполнен сервером 120 индексации системы 100. В других вариантах осуществления способ 800 может быть исполнен сервером 140 поисковой системы. В альтернативных вариантах осуществления способ 800 может быть исполнен единым сервером, реализующим функциональные возможности сервера 140 поисковой системы и сервера 120 индексации.
[00222] Способ 800 может начинаться с этапа 802.
[00223] ЭТАП 802: получение сервером множества цифровых документов, причем каждый соответствующий документ из упомянутого множества цифровых документов имеет соответствующий размер;
[00224] На этапе 802 сервер 120 индексации может получить множество цифровых документов 117 из базы 138 данных предварительной индексации, причем некоторый цифровой документ 212 имеет некоторый размер 216 и связан с некоторым признаковым вектором 214 упомянутого цифрового документа 212. В некоторых вариантах осуществления упомянутый цифровой документ 212 может быть указанием упомянутого цифрового документа 212 и может быть связан с размером 216 и признаковым вектором 214 упомянутого цифрового документа 212.
[00225] Затем способ 800 может переходить на этап 804.
[00226] ЭТАП 804: определение сервером для каждого соответствующего документа из множества цифровых документов соответствующего параметра значимости на основе пользовательских взаимодействий с соответствующим документом, причем соответствующий параметр значимости указывает полезность соответствующего документа для поисковой системы в качестве документа-результата поиска;
[00227] На этапе 804 второй MLA 134 может определять, для каждого цифрового документа 212 из множества цифровых документов 117, параметр 218 значимости, причем параметр 218 значимости указывает полезность упомянутого цифрового документа 212 для сервера 140 поисковой системы в качестве документа-результата поиска. Параметр 218 значимости может быть вычислен, основываясь, по меньшей мере частично, на прошлых пользовательских взаимодействиях с упомянутым цифровым документом 212, или может быть вычислен на основе прогнозируемых пользовательских взаимодействий с упомянутым цифровым документом 212. В некоторых вариантах осуществления параметр 218 значимости может быть вычислен первым MLA 132.
[00228] Затем способ 800 может переходить на этап 806.
[00229] ЭТАП 806: ранжирование посредством MLA множества цифровых документов для получения ранжированного списка документов, причем ранжирование основывается на:
соответствующем качественном параметре значимости соответствующего документа, причем соответствующий качественный параметр значимости основан на соответствующем параметре значимости и соответствующем размере соответствующего документа,
ранжирование выполняется так, что качественный параметр совокупной значимости ранжированного списка документов максимизируется на основе:
взвешивания качественного параметра значимости некоторого цифрового документа из множества цифровых документов по сумме размеров некоторого подмножества документов из множества цифровых документов, при этом упомянутое подмножество документов состоит из документов, имеющих соответствующий параметр значимости ниже параметра значимости упомянутого цифрового документа;
[00230] На этапе 806 первый MLA 132 сервера 120 индексации может вычислять для каждого цифрового документа 212 из множества цифровых документов 117 соответствующий качественный параметр 255 значимости на основе параметра 218 значимости и размера 216 упомянутого цифрового документа 212. Затем первый MLA 132 может ранжировать множество цифровых документов 117 в соответствии с качественными параметрами 255 значимости, чтобы получить ранжированный список документов 260. Первый MLA 132 был обучен ранжировать документы так, что качественный параметр совокупной значимости ранжированного списка 260 документов максимизируется на основе: взвешивания качественного параметра значимости цифрового документа 212 из множества цифровых документов 117 по сумме размеров некоторого подмножества документов из множества цифровых документов 117, при этом упомянутое подмножество документов состоит из документов, имеющих соответствующий параметр значимости ниже параметра значимости упомянутого цифрового документа. В некоторых вариантах осуществления соответствующий качественный параметр 255 значимости может быть основан, по меньшей мере частично, на отношении параметра 218 значимости к размеру 216 упомянутого цифрового документа 212. В некоторых вариантах осуществления упомянутое подмножество состоит из всех документов, имеющих соответствующий параметр значимости ниже параметра 218 значимости упомянутого цифрового документа 212. В некоторых вариантах осуществления первый MLA 132 может реализовывать модифицированный алгоритм ранжирования LambdaMART. В альтернативных вариантах осуществления первый MLA 132 может реализовывать алгоритм списочного ранжирования.
[00231] В некоторых вариантах осуществления первый MLA 132 был обучен максимизации качественного параметра совокупной значимости на основе:
где:
Q является качественным параметром совокупной значимости;
qi является соответствующим параметром значимости соответствующего i-го документа во множестве цифровых документов;
sj является соответствующим размером соответствующего j-го документа в подмножестве документов;
pi является соответствующим качественным параметром значимости i-го документа во множестве цифровых документов;
pj является соответствующим качественным параметром значимости j-го документа во множестве цифровых документов;
N является количеством документов во множестве цифровых документов; и
М является количеством документов в упомянутом подмножестве документов.
[00232] В других вариантах осуществления первый MLA 132 был обучен максимизации качественного параметра совокупной значимости на основе:
где:
Qm является качественным параметром совокупной значимости;
wi является соответствующим весом, связанным с соответствующим параметром значимости;
qi является соответствующим параметром значимости соответствующего i-го документа во множестве цифровых документов;
wj является соответствующим весом, связанным с соответствующим размером;
sj является соответствующим размером соответствующего j-го документа в подмножестве документов;
pi является соответствующим качественным параметром значимости i-го документа во множестве цифровых документов;
pj является соответствующим качественным параметром значимости j-го документа во множестве цифровых документов;
N является количеством документов во множестве цифровых документов; и
М является количеством документов в упомянутом подмножестве документов.
[00233] В некоторых вариантах осуществления
[00234] Способ 800 может затем переходить на этап 808.
[00235] ЭТАП 808: выбор посредством MLA подмножества документов из ранжированного списка документов на основе качественного параметра значимости каждого соответствующего документа из подмножества документов;
[00236] На этапе 808 модуль 270 выбора может выбирать подмножество 275 ранжированного списка документов 260 для включения в поисковый индекс 146 на основе качественного параметра 255 значимости каждого соответствующего документа из подмножества документов 275. В некоторых вариантах осуществления модуль 270 выбора может выбирать подмножество 275 ранжированного списка документов 260 для включения в поисковый индекс 146 на основе общего размера или доступного размера 280 поискового индекса 146. В альтернативных вариантах осуществления первый MLA 132 может выполнять выбор подмножества 275.
[00237] Затем способ 800 может завершаться.
[00238] Специалистам в данной области должно быть очевидно, что по меньшей мере некоторые варианты осуществления настоящей технологии направлены на расширение арсенала технических решений для решения конкретной технической задачи, а именно
[00239] Следует четко понимать, что не все технические эффекты, упомянутые в данном документе, должны обеспечиваться в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без обеспечения пользователю некоторых из упомянутых технических эффектов, в то время как другие варианты осуществления могут быть реализованы с обеспечением пользователю других технических эффектов или без обеспечения каких-либо технических эффектов.
[00240] Некоторые из упомянутых этапов, а также прием/отправка сигналов хорошо известны в данной области техники и, как таковые, были опущены в некоторых частях этого описания для простоты. Сигналы могут отправляться/приниматься с использованием оптических средств (например, оптоволоконного соединения), электронных средств (например, используя проводное или беспроводное соединение) и механических средств (например, средств, основанных на давлении, на температуре, или на основе любого другого подходящего физического параметра).
[00241] Модификации и улучшения вышеописанных реализаций настоящей технологии могут стать очевидными для специалистов в данной области техники. Предшествующее описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому подразумевается, что объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
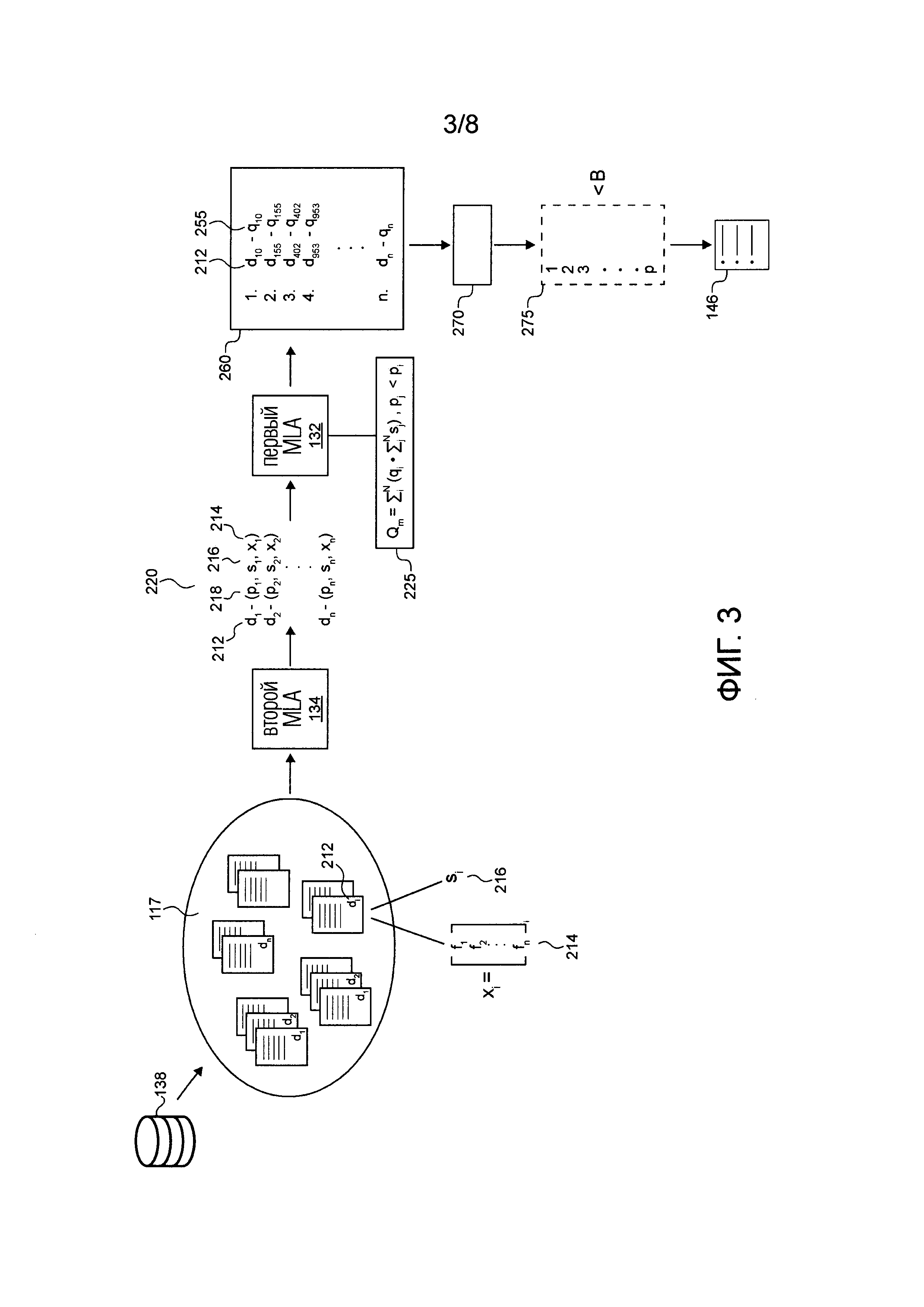
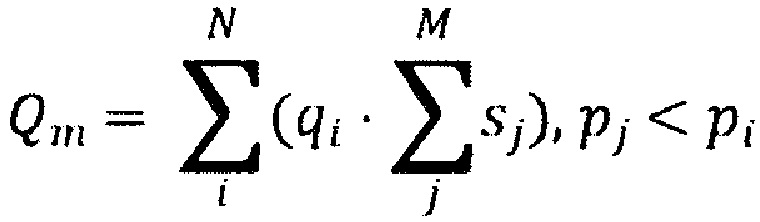
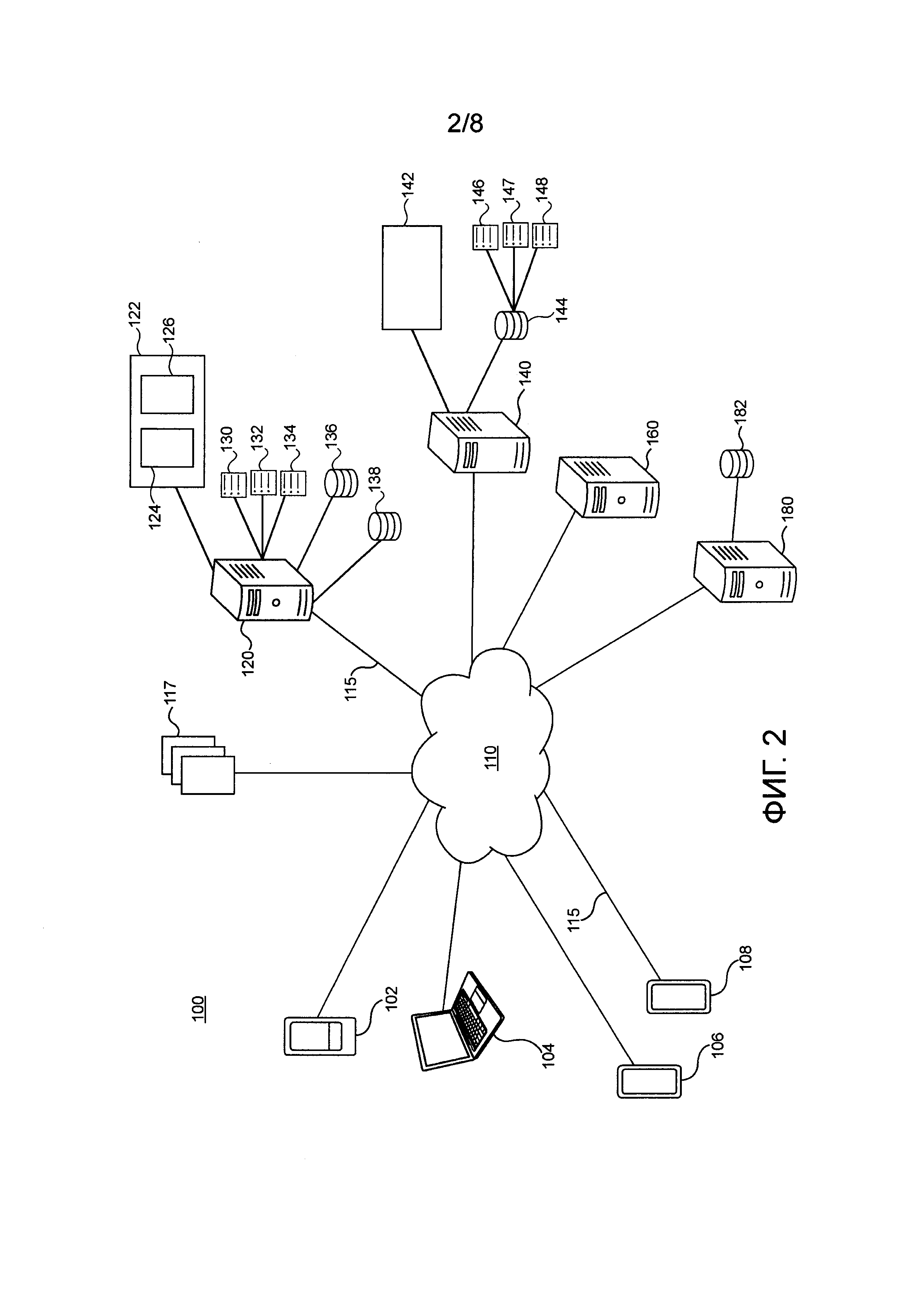
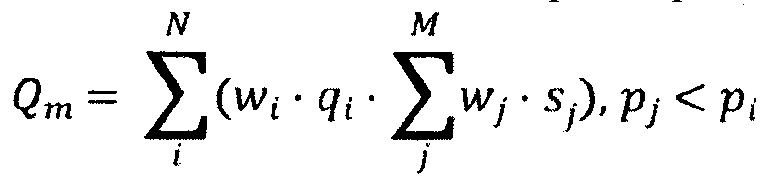
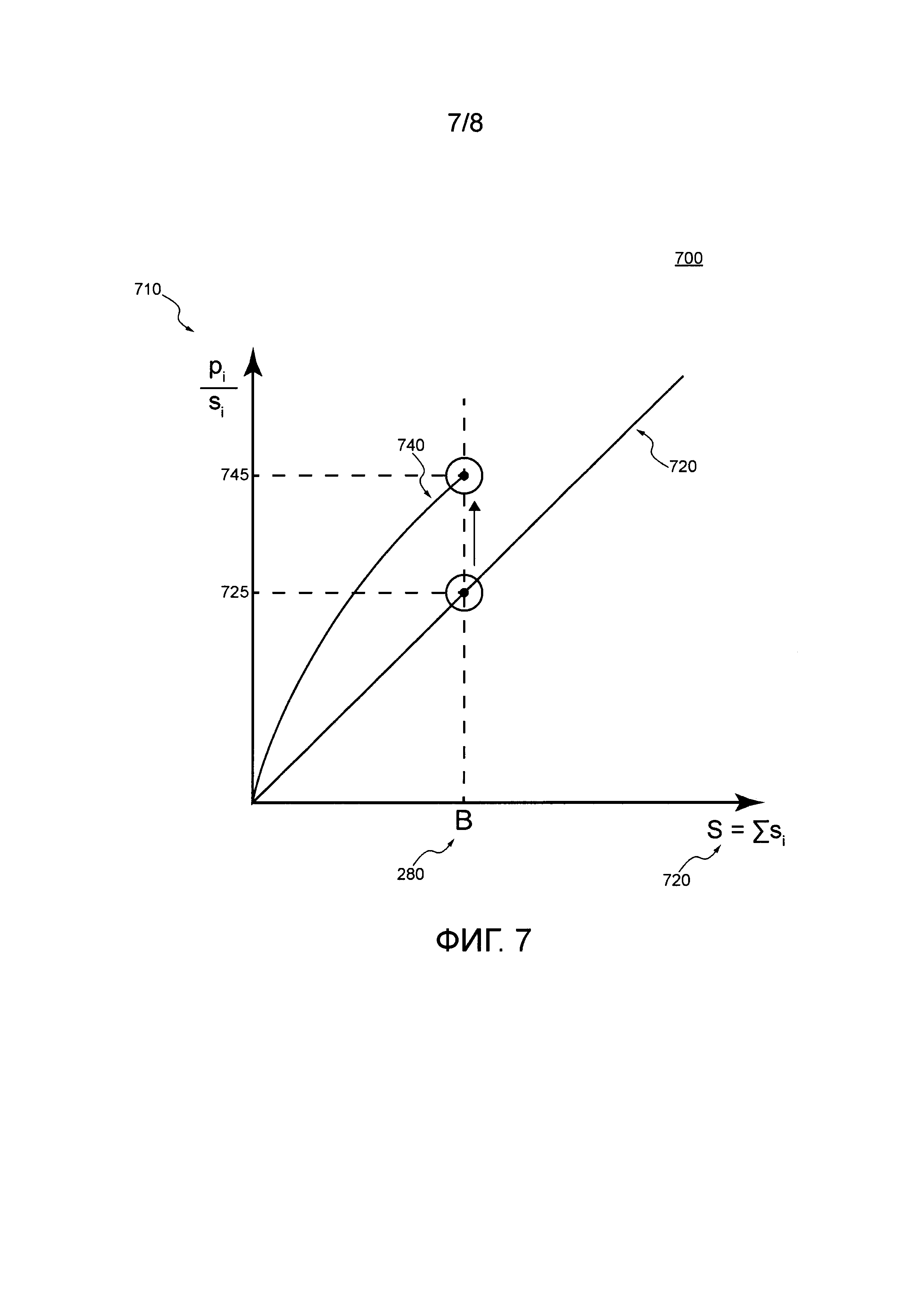
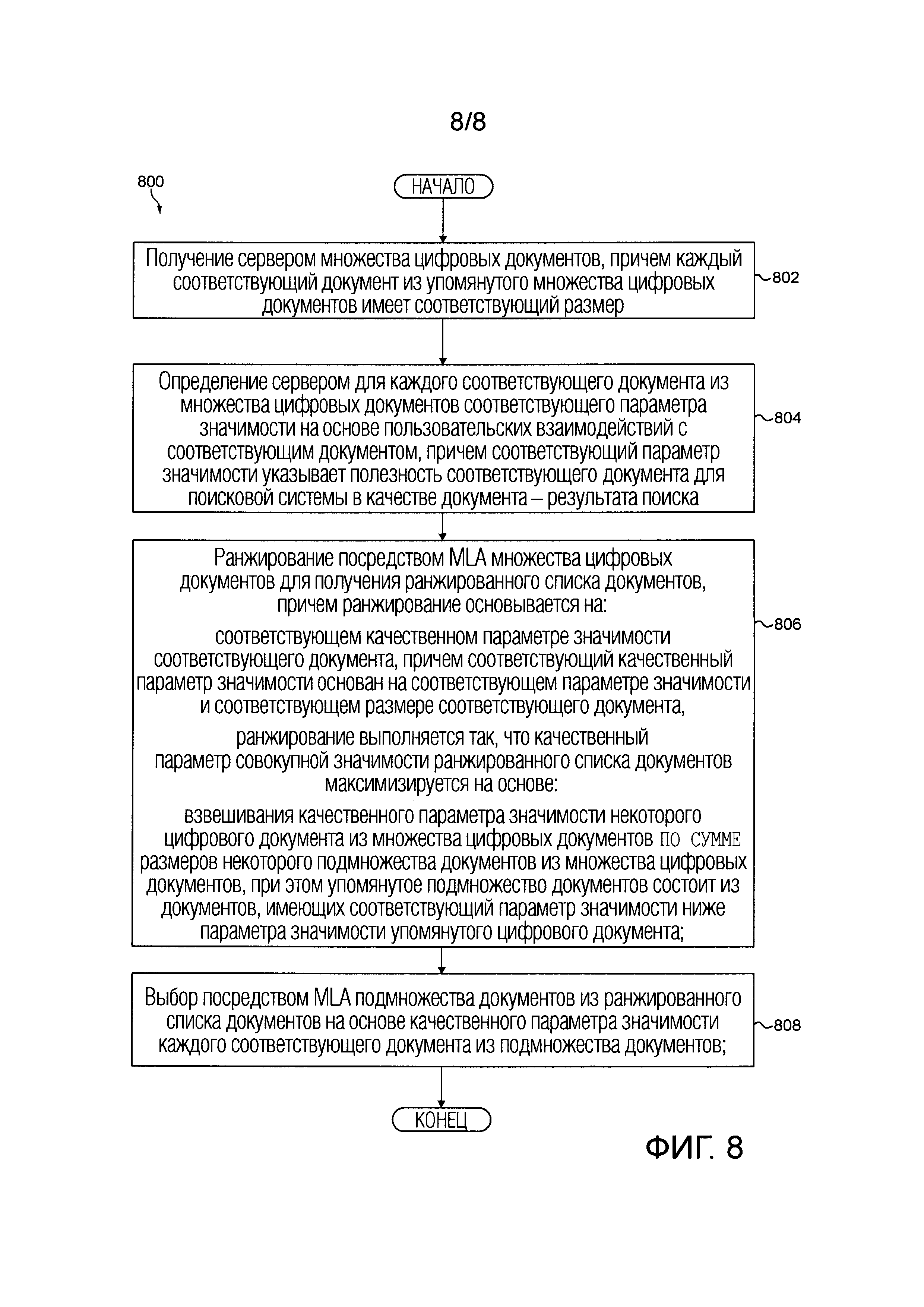
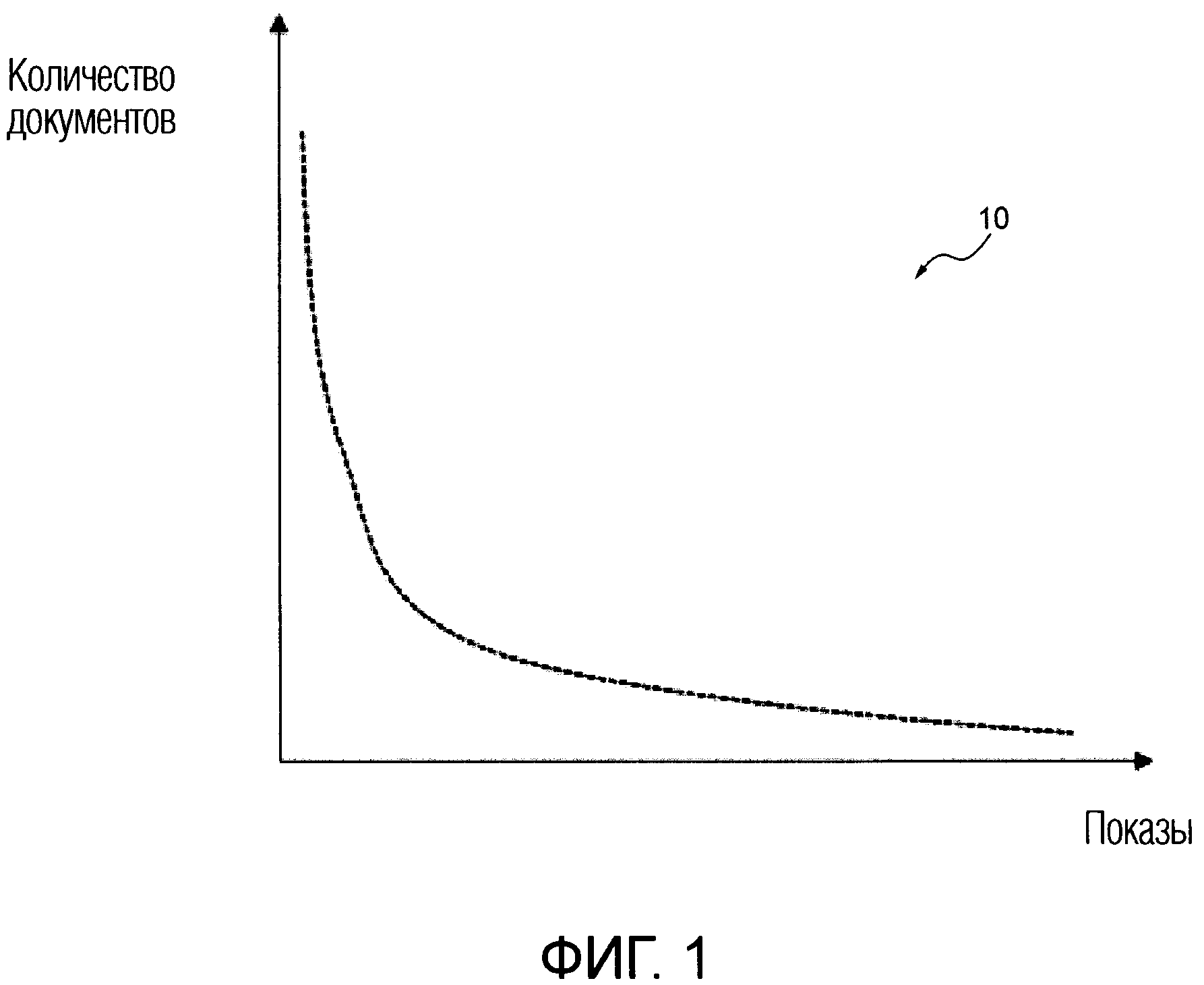
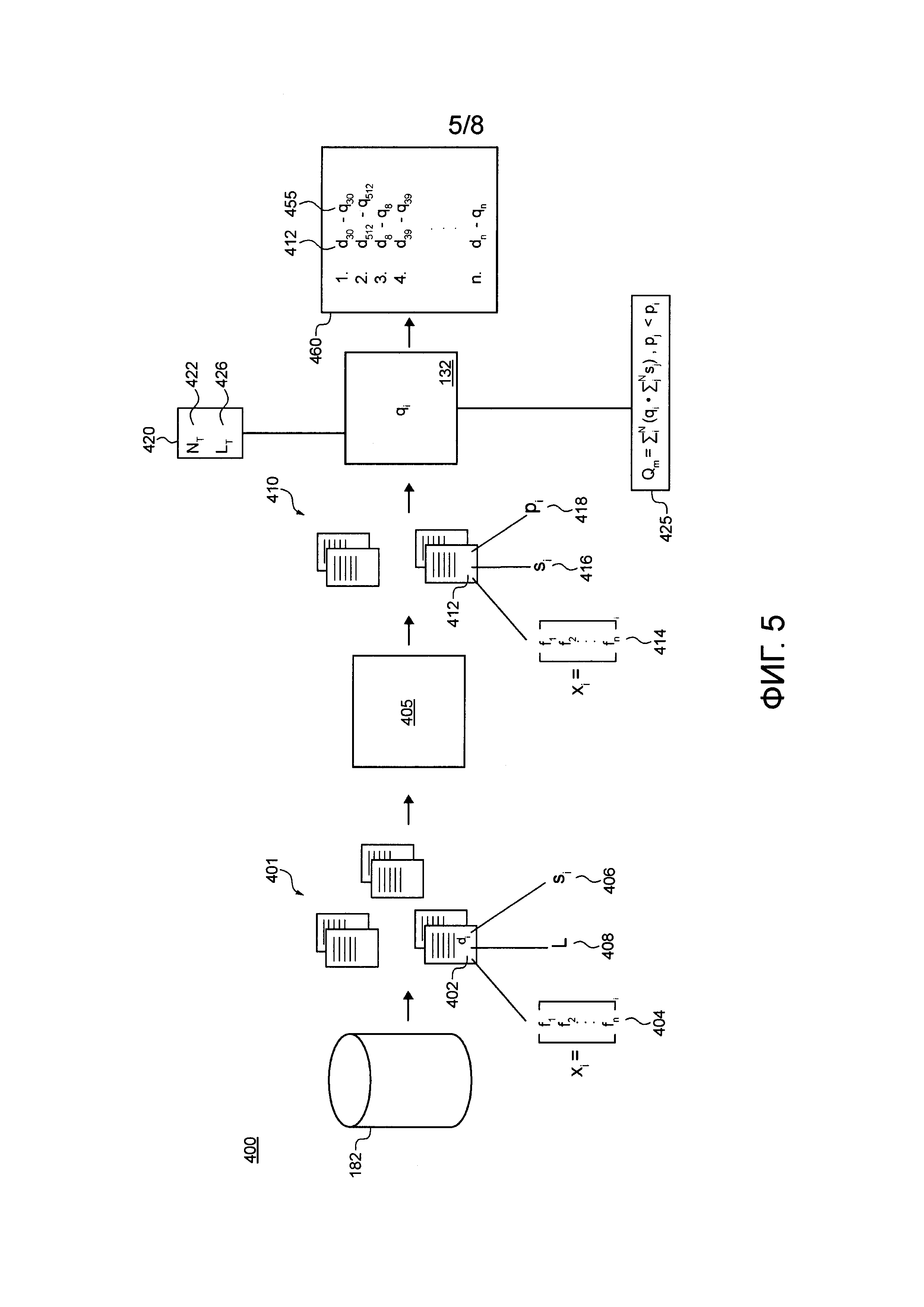
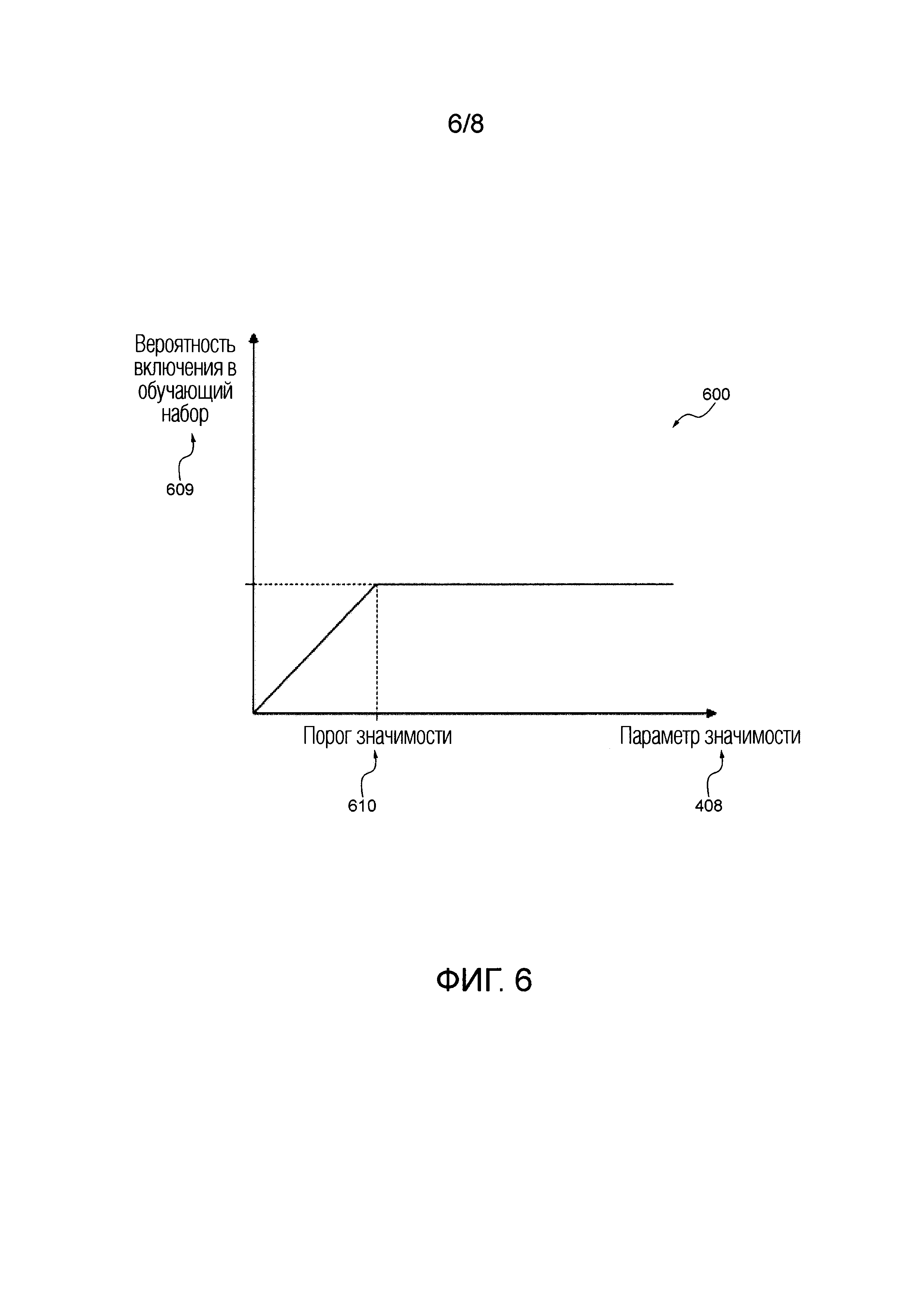
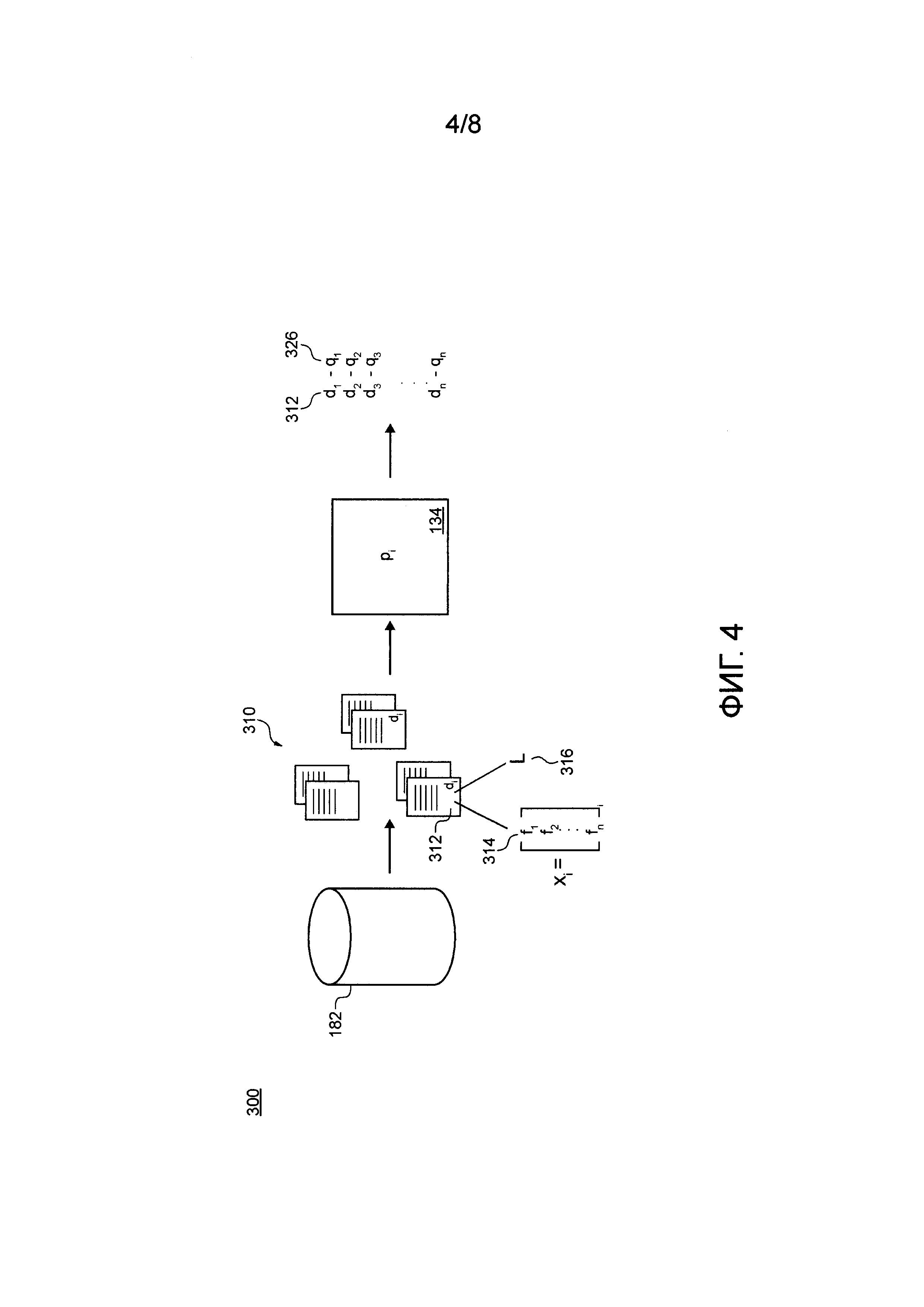
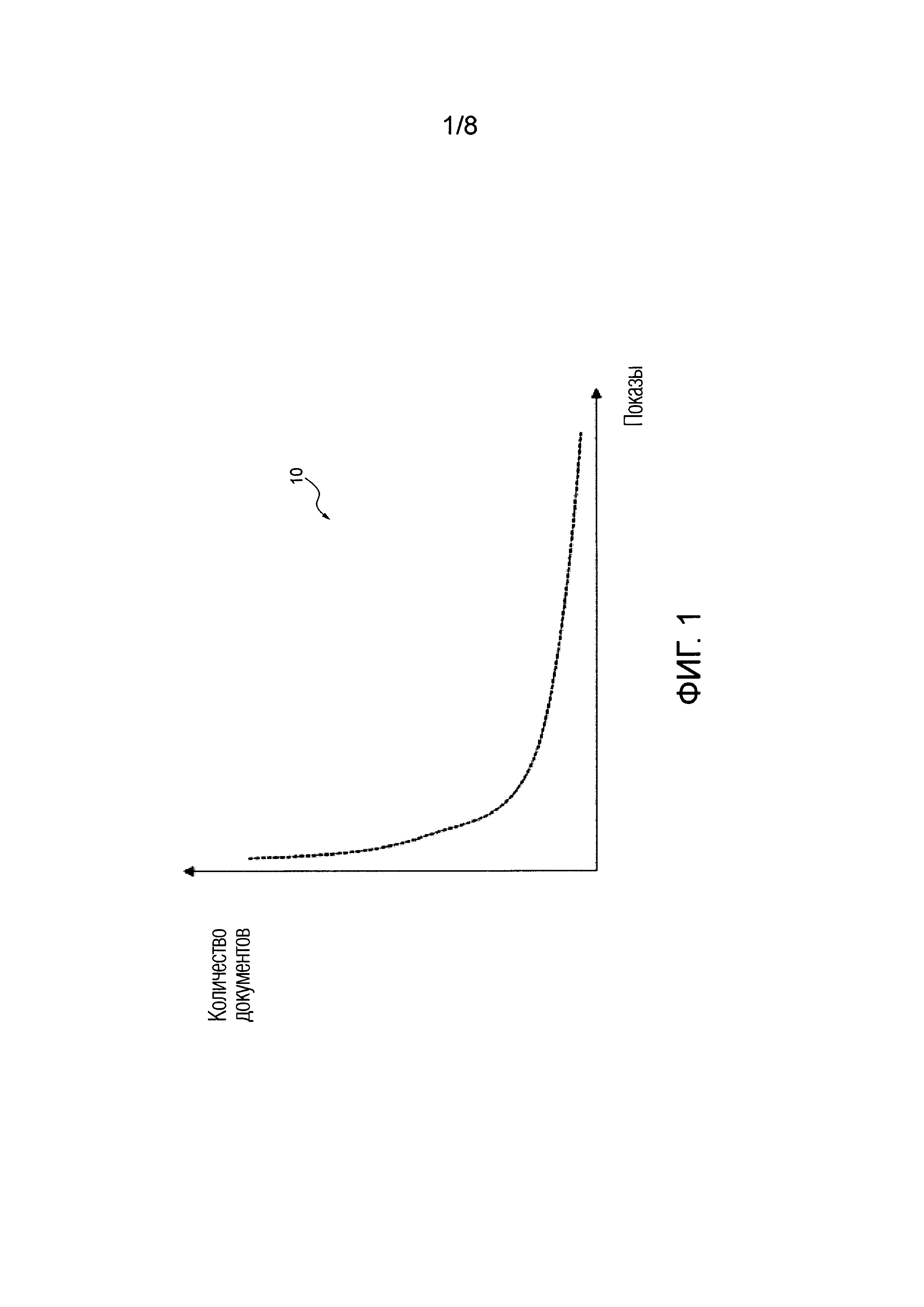
Способ и система для рекомендации свежих саджестов поисковых запросов в поисковой системе
Способ и система компьютерной обработки одной или нескольких цитат в цифровых текстах для определения их автора
Способ и сервер для индексирования веб-страницы в индексе

