Результат интеллектуальной деятельности: ВЫСОКОСКОРОСТНОЕ УСТРОЙСТВО БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ С БЕСКОНФЛИКТНЫМ ЛИНЕЙНЫМ ДОСТУПОМ К ПАМЯТИ
Вид РИД
Изобретение
Изобретение относится к области цифровой обработки сигналов (ЦОС), а именно к высокоскоростным устройствам быстрого преобразования Фурье (БПФ) с бесконфликтным линейным доступом к памяти, и может применяться для цифровой обработки сигналов во всех областях современной техники.
Быстрое преобразование Фурье является алгоритмом быстрого вычисления дискретного преобразования Фурье (ДПФ) и применяется как для программной, так и для аппаратной реализации ввиду гораздо меньшего количества умножителей и сумматоров по сравнению с ДПФ. Преобразование Фурье, как одно из главных преобразований в ЦОС, используется практически во всех областях современной техники. Многие цифровые стандарты связи, телевидения, измерительная аппаратура и т.д. подразумевают использование БПФ.
Хорошо известны две схемы вычисления БПФ: с прореживанием по частоте и с прореживанием по времени. По количеству математических операций (количеству аппаратных умножителей и сумматоров при аппаратной реализации) обе схемы одинаковы. Отличие в различном порядке либо входных (временных) отсчетов, либо выходных (частотных) отсчетов. Существует прямой порядок и порядок с инверсией адресов. БПФ вычисляют конвейерно по стадиям. Основным вычислительным узлом схемы БПФ является операция «бабочка», включающая в себя два комплексного умножения и суммирования. Также устройство БПФ включает в себя блоки памяти и схему коммутации между ячейками блоков памяти различных стадий. Существует большое количество схем коммутации с оптимизацией по объему памяти, аппаратным затратам, быстродействию. Слабым местом в схеме коммутации является доступ к памяти ввиду того, что операция «бабочка» подразумевает считывание значений из разных адресов памяти, и после вычисления результата запись его в разные адреса. Адреса зависят от выбранной схемы коммутации и стадии вычисления БПФ. В классической схеме коммутации считывание значений и запись результатов осуществляют по-разному от стадии к стадии, что накладывает большие аппаратные затраты на вычисление адресов. К тому же из однопортовой памяти, как правило, нельзя считать одновременно из двух адресов в один такт работы, что делает невозможным применять один блок памяти для одной операции «бабочка».
Наиболее близкой к заявленному изобретению является унифицированная реконфигурируемая схема коммутации быстрого преобразования Фурье, описанная в патенте RU2700194, которая содержит унифицированную схему коммутации узлов «бабочка» в разных стадиях конвейера. Данная схема выбрана в качестве прототипа заявленного изобретения.
Недостатком схемы прототипа является его дороговизна и низкое быстродействие, вследствие отсутствия возможности бесконфликтного доступа к памяти для последовательного вычисления БПФ с целью оптимизации использования аппаратных ресурсов, в том числе памяти.
Техническим результатом изобретения является создание высокоскоростного устройства быстрого преобразования Фурье (БПФ) с бесконфликтным линейным доступом к памяти с меньшей стоимостью изготовления и увеличенным быстродействием, вследствие оптимизации использования аппаратных ресурсов, в том числе памяти, за счет применения унифицированной (единой) схемы коммутации значения из памяти для базовых узлов вычислений операции «бабочка» для всех стадий конвейера.
Поставленный технический результат достигнут путем создания высокоскоростного устройства быстрого преобразования Фурье с бесконфликтным линейным доступом к памяти для 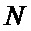 входных отсчетов, содержащего соединенные между собой один вычислительный узел «бабочка» (715) и четыре блока памяти (700-703), каждый из которых содержит
входных отсчетов, содержащего соединенные между собой один вычислительный узел «бабочка» (715) и четыре блока памяти (700-703), каждый из которых содержит 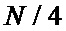 элементов памяти, выполненных с возможностью хранения входных, выходных и промежуточных отсчетов, при этом входы разрешения чтения первого блока памяти RAM0A (700) и второго блока памяти RAM0B (701) соединены с нулевым входом разрешения чтения RE0 устройства, а входы разрешения чтения третьего блока памяти RAM1A (702) и четвертого блока памяти RAM1B (703) соединены с первым входом разрешения чтения RE1 устройства, при этом вход разрешения записи первого блока памяти RAM0A (700) соединен с нулевым входом разрешения записи WE0A устройства, вход разрешения записи второго блока памяти RAM0B (701) соединен с нулевым входом разрешения записи WE0B устройства, вход разрешения записи третьего блока памяти RAM1A (702) соединен с первым входом разрешения записи WE1A устройства, вход разрешения записи третьего блока памяти RAM1B (702) соединен с первым входом разрешения записи WE1B устройства, при этом выходные шины данных Rdata0A и Rdata0B первого и второго блоков памяти RAM0A (700) и RAM0B (701) соединены с нулевыми входами четвертого (713) и пятого (717) мультиплексоров, с первым входами которых соединены выходные шины данных Rdata1A и Rdata1B третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703), старшие части RdataH выходных шин данных четвертого (713) и пятого (717) мультиплексоров соединены с нулевыми входами шестого (714) и седьмого (718) мультиплексоров, а младшие части RdataL выходных шин данных четвертого (713) и пятого (717) мультиплексоров соединены с первыми входами шестого (714) и седьмого (718) мультиплексоров, при этом входы селектора четвертого (713) и пятого (717) мультиплексоров соединены с выходом второго элемента задержки D (712), вход которого соединен с нулевым входом разрешения чтения RE0 устройства, при этом входы селектора шестого (714) и седьмого (718) мультиплексоров соединены с нулевым разрядом выходной шины первого элемента задержки D (709), а выходы шестого (714) и седьмого (718) мультиплексоров являются первым и вторым выходами устройства и соединены с входами А и В узла «бабочка» (715), выходные шины WdataH и WdataL которого объединены в общую шину Wdata, которая соединена с входами данных третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703) и с нулевым входом второго мультиплексора (711), к первому входу которого подключена входная шина данных input_data устройства, первый вход второго мультиплексора (711) является входом разрешения en_input устройства, а выходная шина второго мультиплексора (711) соединена с входной шиной данных Wdata0 первого и второго блоков памяти RAM0A (700) и RAM0B (701), входные шины адреса которых соединены с выходом третьего мультиплексора (710), вход селектора которого соединен с нулевым входом разрешения чтения RE0 устройства, а нулевые входы третьего и восьмого мультиплексоров (710) и (719) соединены со всеми кроме младшего разрядами выходной шины первого мультиплексора (708), все разряды кроме старшего выходной шины которого соединены со входом первого элемента задержки (709), выходная шина которого соединена с первыми входами третьего и восьмого мультиплексоров (710) и (719), а вход селектора восьмого мультиплексора (719) соединен с первым входом разрешения чтения RE1 устройства, при этом вход разрешения вывода данных en_output устройства соединен со входом селектора первого мультиплексора (708), нулевой вход которого соединен с выходом счетчика адреса (705) и с входом инвертора адреса (706), выход которого соединен с первым входом первого мультиплексора (708), а вход разрешения счетчика адреса (705) соединен с входом разрешения адресации en_cnt устройства, при этом входная шина адреса третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703) соединена с выходной шиной восьмого мультиплексора (719).
элементов памяти, выполненных с возможностью хранения входных, выходных и промежуточных отсчетов, при этом входы разрешения чтения первого блока памяти RAM0A (700) и второго блока памяти RAM0B (701) соединены с нулевым входом разрешения чтения RE0 устройства, а входы разрешения чтения третьего блока памяти RAM1A (702) и четвертого блока памяти RAM1B (703) соединены с первым входом разрешения чтения RE1 устройства, при этом вход разрешения записи первого блока памяти RAM0A (700) соединен с нулевым входом разрешения записи WE0A устройства, вход разрешения записи второго блока памяти RAM0B (701) соединен с нулевым входом разрешения записи WE0B устройства, вход разрешения записи третьего блока памяти RAM1A (702) соединен с первым входом разрешения записи WE1A устройства, вход разрешения записи третьего блока памяти RAM1B (702) соединен с первым входом разрешения записи WE1B устройства, при этом выходные шины данных Rdata0A и Rdata0B первого и второго блоков памяти RAM0A (700) и RAM0B (701) соединены с нулевыми входами четвертого (713) и пятого (717) мультиплексоров, с первым входами которых соединены выходные шины данных Rdata1A и Rdata1B третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703), старшие части RdataH выходных шин данных четвертого (713) и пятого (717) мультиплексоров соединены с нулевыми входами шестого (714) и седьмого (718) мультиплексоров, а младшие части RdataL выходных шин данных четвертого (713) и пятого (717) мультиплексоров соединены с первыми входами шестого (714) и седьмого (718) мультиплексоров, при этом входы селектора четвертого (713) и пятого (717) мультиплексоров соединены с выходом второго элемента задержки D (712), вход которого соединен с нулевым входом разрешения чтения RE0 устройства, при этом входы селектора шестого (714) и седьмого (718) мультиплексоров соединены с нулевым разрядом выходной шины первого элемента задержки D (709), а выходы шестого (714) и седьмого (718) мультиплексоров являются первым и вторым выходами устройства и соединены с входами А и В узла «бабочка» (715), выходные шины WdataH и WdataL которого объединены в общую шину Wdata, которая соединена с входами данных третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703) и с нулевым входом второго мультиплексора (711), к первому входу которого подключена входная шина данных input_data устройства, первый вход второго мультиплексора (711) является входом разрешения en_input устройства, а выходная шина второго мультиплексора (711) соединена с входной шиной данных Wdata0 первого и второго блоков памяти RAM0A (700) и RAM0B (701), входные шины адреса которых соединены с выходом третьего мультиплексора (710), вход селектора которого соединен с нулевым входом разрешения чтения RE0 устройства, а нулевые входы третьего и восьмого мультиплексоров (710) и (719) соединены со всеми кроме младшего разрядами выходной шины первого мультиплексора (708), все разряды кроме старшего выходной шины которого соединены со входом первого элемента задержки (709), выходная шина которого соединена с первыми входами третьего и восьмого мультиплексоров (710) и (719), а вход селектора восьмого мультиплексора (719) соединен с первым входом разрешения чтения RE1 устройства, при этом вход разрешения вывода данных en_output устройства соединен со входом селектора первого мультиплексора (708), нулевой вход которого соединен с выходом счетчика адреса (705) и с входом инвертора адреса (706), выход которого соединен с первым входом первого мультиплексора (708), а вход разрешения счетчика адреса (705) соединен с входом разрешения адресации en_cnt устройства, при этом входная шина адреса третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703) соединена с выходной шиной восьмого мультиплексора (719).
В предпочтительном варианте осуществления устройства узел «бабочка» (715) является типовым и состоит из двух сумматоров и комплексного умножителя, при этом первый вход узла «бабочка» (715) соединен с первыми входами первого и второго сумматоров, выход первого сумматора является первым выходом узла «бабочка» (715), а второй вход первого сумматора соединен с вторым входом узла «бабочка» (715), который также соединен с входом умножителя на -1, выход которого соединен с вторым входом второго сумматора, выход которого соединен с входом комплексного умножителя, выход которого является вторым выходом узла «бабочка» (715).
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими графическими материалами.
Фиг. 1. Схема вычисления БПФ с прореживанием по частоте (N=8), известная из уровня техники.
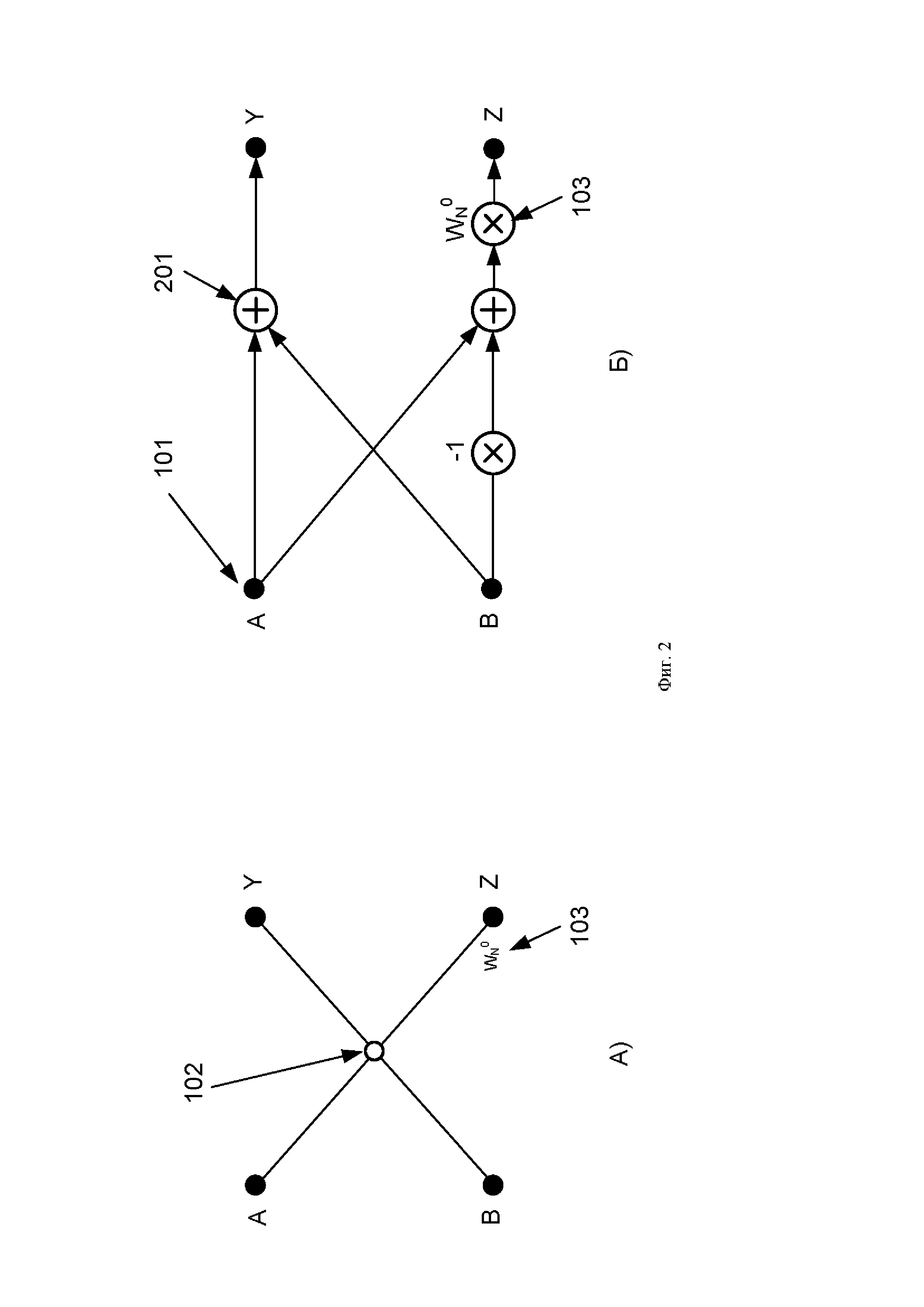
Фиг. 2. Схема выполнения базовой операции «бабочка», известная из уровня техники:
А) - структурная схема;
Б) - функциональная схема.
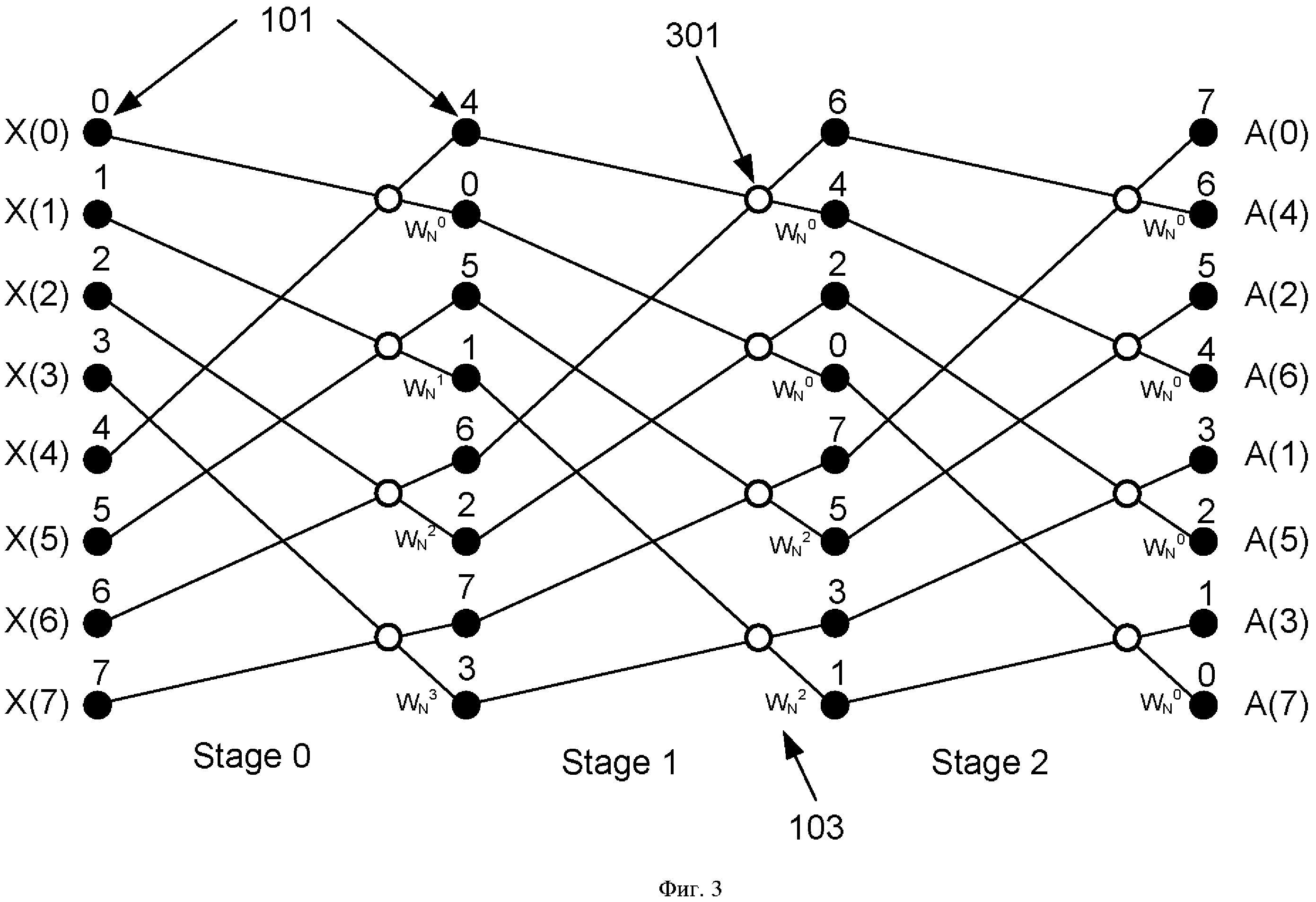
Фиг. 3. Унифицированная схема коммутации БПФ с прореживанием по частоте (N=8), выполненная согласно изобретению.
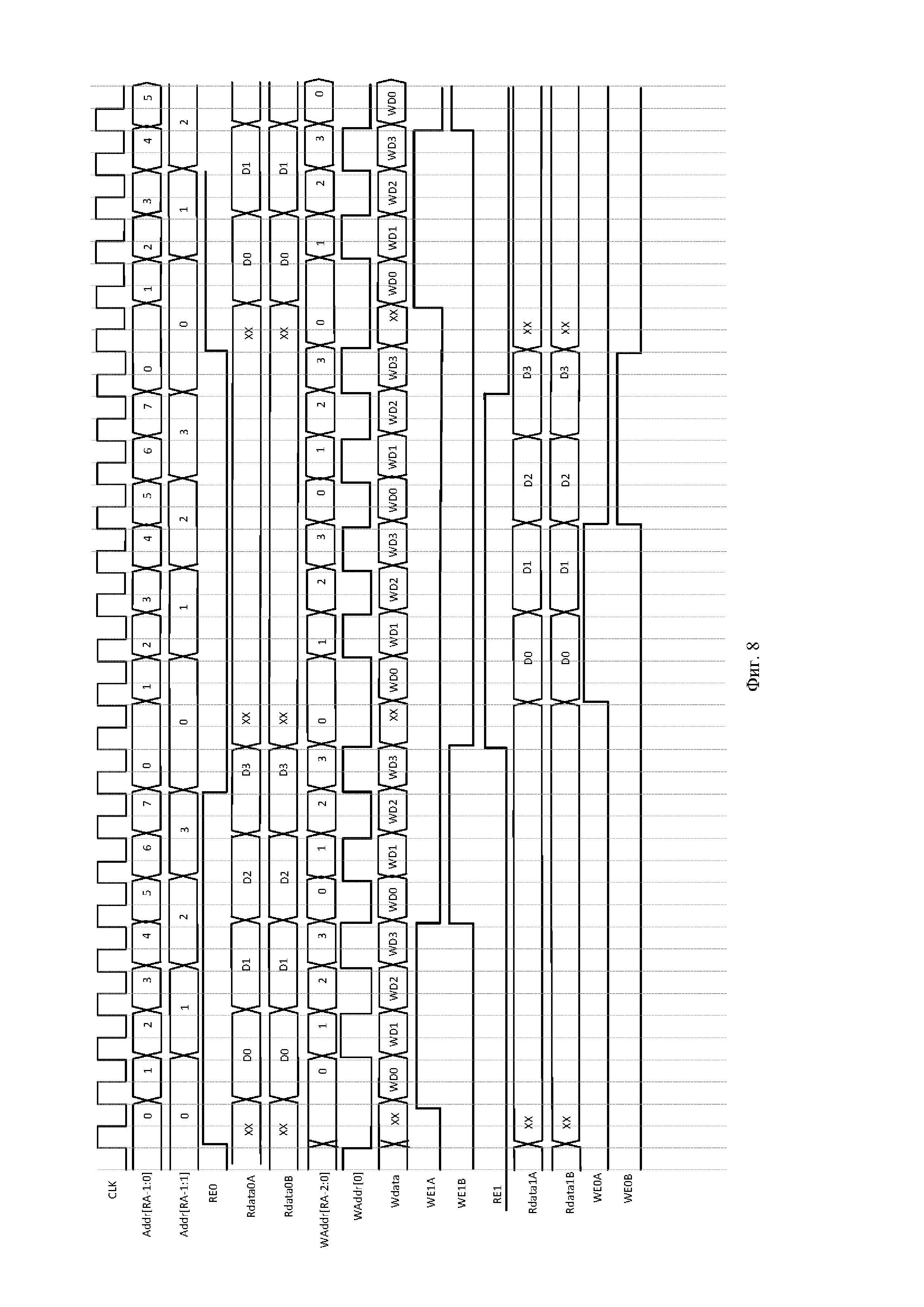
Фиг. 4. Схема вычисления БПФ с прореживанием по частоте (N=16), известная из уровня техники.
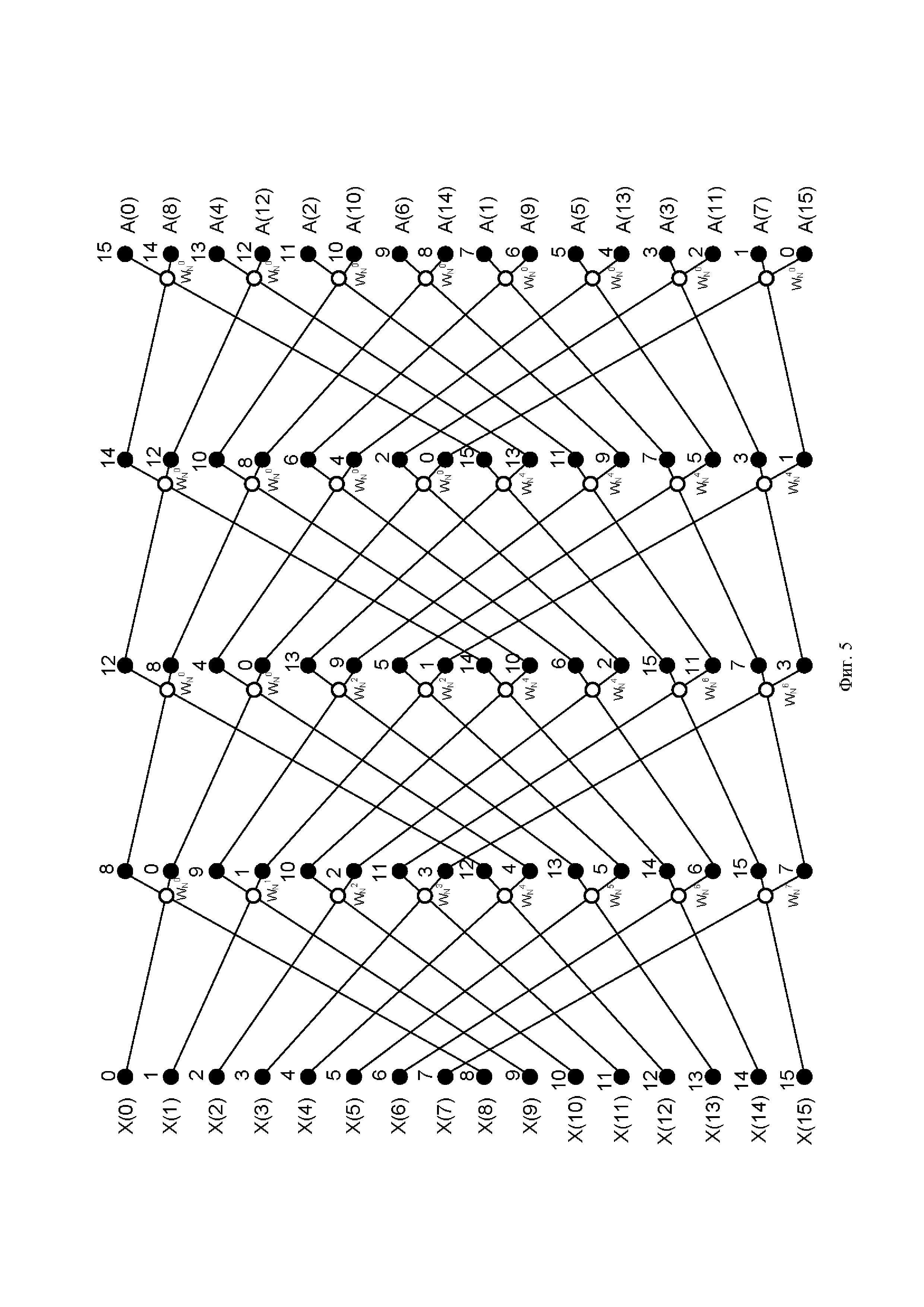
Фиг. 5. Унифицированная схема коммутации БПФ с прореживанием по частоте (N=16), выполненная согласно изобретению.
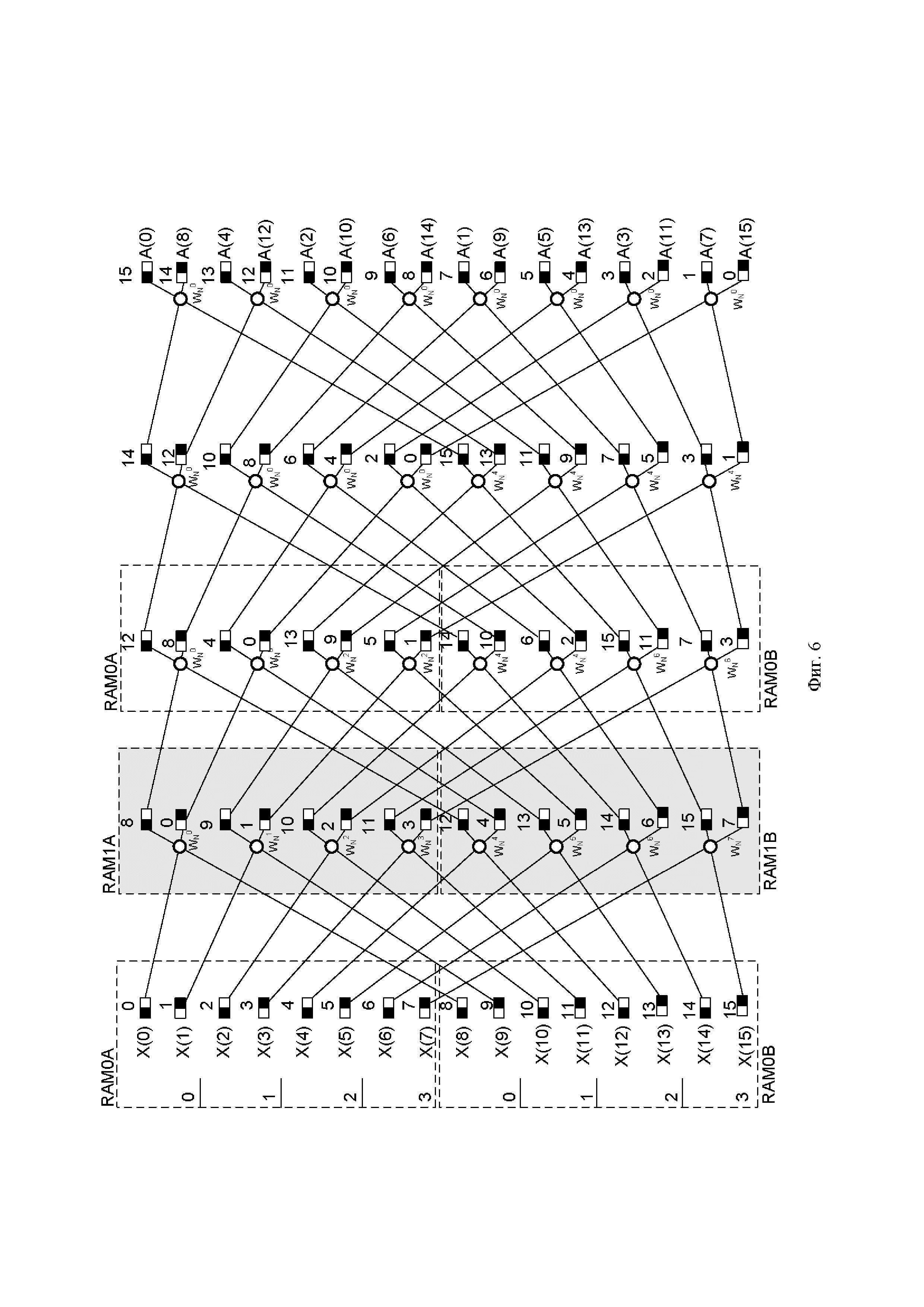
Фиг. 6. Схема организации памяти для бесконфликтного доступа при вычислении БПФ с прореживанием по частоте (N=16), выполненная согласно изобретению.
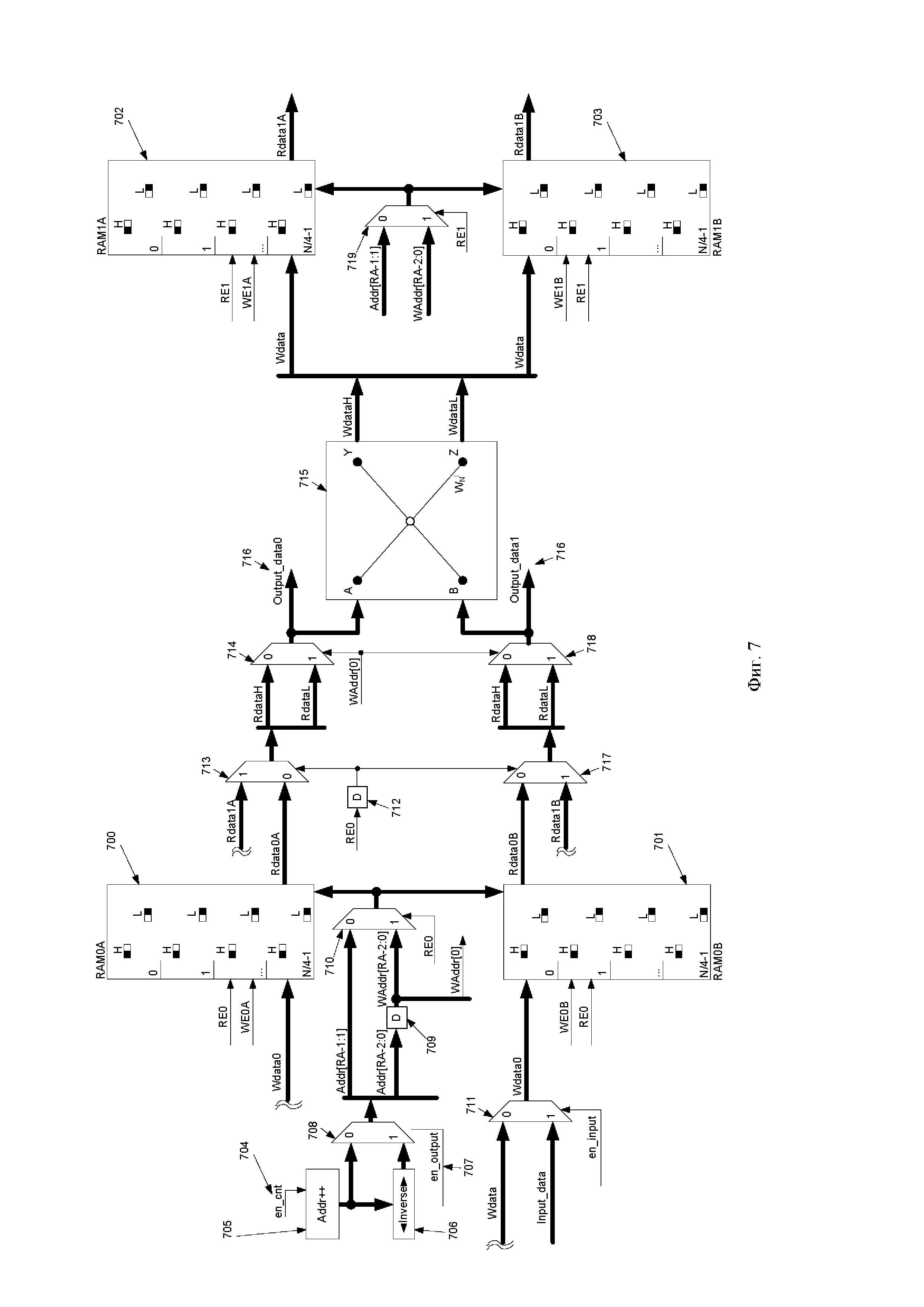
Фиг. 7. Высокоскоростное устройство БПФ с бесконфликтным линейным доступом к памяти, выполненное согласно изобретению.
Фиг. 8. Временные диаграммы работы схемы в процессе вычисления БПФ с бесконфликтным доступом к памяти и линейной адресацией), выполненные согласно изобретению.
Рассмотрим более подробно функционирование заявленного высокоскоростного устройства быстрого преобразования Фурье (БПФ) с бесконфликтным линейным доступом к памяти (Фиг. 1 - 8).
БПФ основано на дискретном преобразовании Фурье, согласно которому:
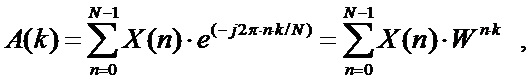 (1)
(1)
где 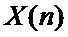 –
– 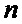 -ый отсчет входной последовательности,
-ый отсчет входной последовательности, 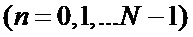 ,
,
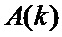 –
– 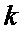 -ый отсчет выходного спектра,
-ый отсчет выходного спектра,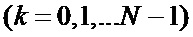 ,
,
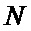 – количество отсчетов,
– количество отсчетов,
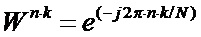 – коэффициенты ДПФ.
– коэффициенты ДПФ.
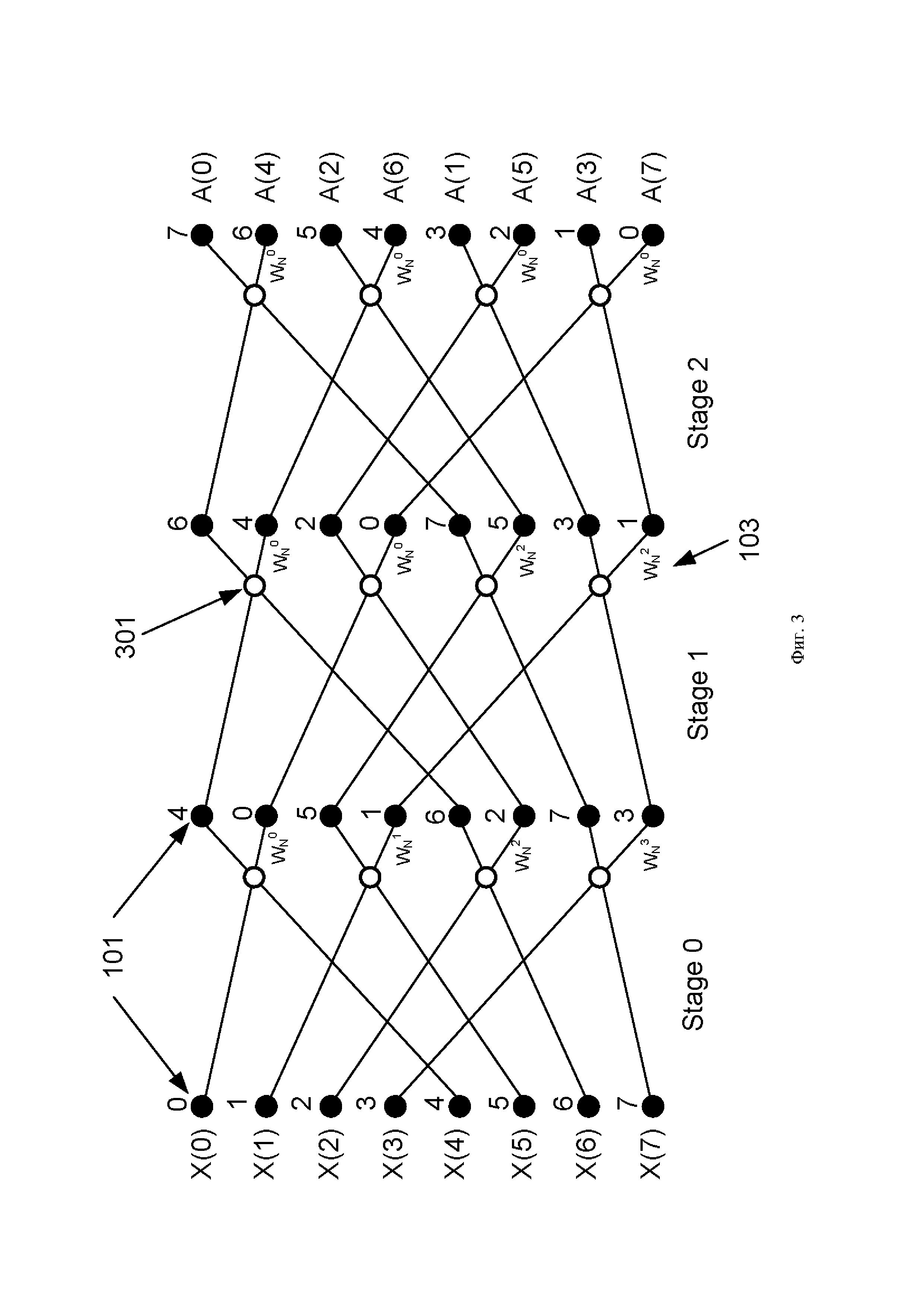
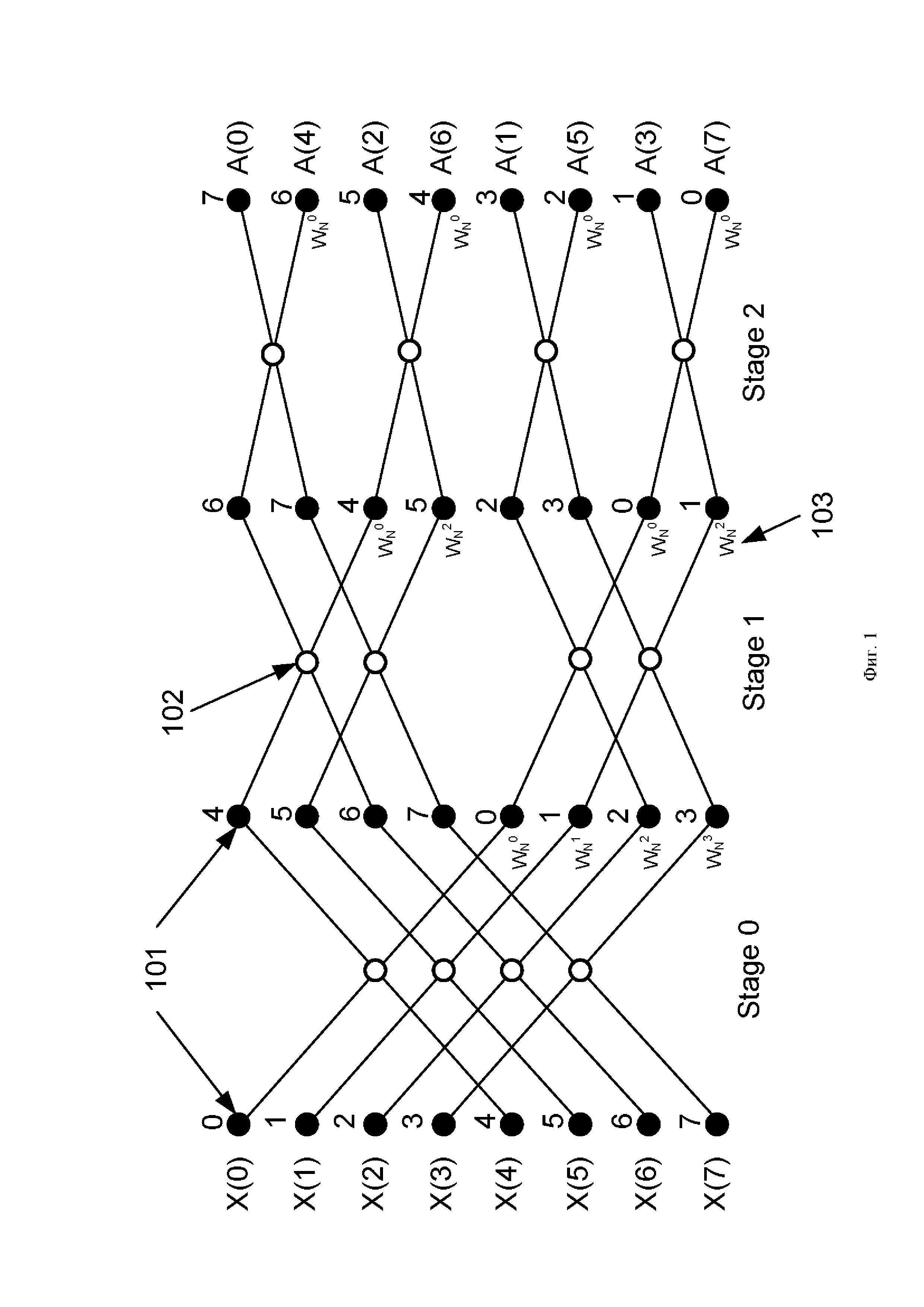
Традиционная известная из уровня техники схема вычисления БПФ с прореживанием по частоте показана на Фиг. 1. Входные отсчеты по порядку записывают в массив элементов памяти (101), далее по конвейеру выполняют вычисление с помощью базового вычислительного элемента (102) операции «бабочка». Количество стадий (Stage0, Stage1, Stage2) конвейера определяют значением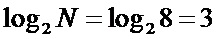 . Количество отсчетов выбирают кратным степени двойки. Схема коммутации на каждой стадии различна, в некоторых вершинах находится умножитель (103) на поворотный множитель
. Количество отсчетов выбирают кратным степени двойки. Схема коммутации на каждой стадии различна, в некоторых вершинах находится умножитель (103) на поворотный множитель 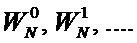 Базовая операция «бабочка», выполняемая элементом (102), представлена на Фиг. 2-А. Более подробно работа элемента (102) операции «бабочка» представлена на функциональной схеме (Фиг. 2-Б). В состав элемента (102) операции «бабочка» входит два сумматора (201), в нижнем ребре «бабочки» расположен умножитель (103) на поворотный множитель. Операцию «бабочка» выполняют в соответствии со следующим выражением:
Базовая операция «бабочка», выполняемая элементом (102), представлена на Фиг. 2-А. Более подробно работа элемента (102) операции «бабочка» представлена на функциональной схеме (Фиг. 2-Б). В состав элемента (102) операции «бабочка» входит два сумматора (201), в нижнем ребре «бабочки» расположен умножитель (103) на поворотный множитель. Операцию «бабочка» выполняют в соответствии со следующим выражением:
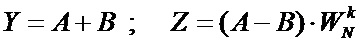 , (2)
, (2)
где 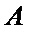 и
и 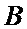 – пара входных отсчетов;
– пара входных отсчетов; 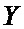 и
и 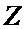 – пара выходных комплексных отсчетов;
– пара выходных комплексных отсчетов; 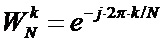 – комплексный поворотный множитель.
– комплексный поворотный множитель.
Схема коммутации, представленная на Фиг. 1, на каждой стадии различна, поэтому для каждой стадии необходим свой неунифицированный дешифратор адреса. Для лучшего понимания черные кружки обозначены цифрами, это вклад каждого первоначального отсчета в последующие стадии и участие в операции «бабочка». Видно, что вклад отсчетов в последнюю стадию, то есть в выходные отсчеты , по имеют обратную нумерацию, если считать сверху вниз.
Унифицированная схема коммутации БПФ, применяемая в заявленном устройстве, представлена на Фиг. 3. Узел операции «бабочка» (301) схематично стал несимметричен, при этом работа узла по-прежнему эквивалентна схеме на Фиг. 2-Б и выражению (2). Видно, что схема коммутации на каждой стадии (Stage0, Stage1, Stage2) остается одинаковой. Вклад (номер над черными кружками) первоначального отсчета в последующие стадии отличается от традиционной схемы на Фиг. 1, однако в конечной стадии вклад в выходные отсчеты аналогичен вкладу на Фиг. 1. Алгоритмически схемы на Фиг. 1 и Фиг. 3 эквивалентны, все вычисления на каждой стадии совпадают, отличие лишь в адресах записи/чтения из ячеек памяти (101).
Аналогичным образом можно построить схему для любого количества отсчетов N. На Фиг. 4 представлена традиционная схема вычисления БПФ с прореживанием по частоте (N=16), а на Фиг. 5 ее аналог - унифицированная схема коммутации БПФ с прореживанием по частоте (N=16). Исходя из заявленной унифицированной схемы коммутации (N=8,16) и выражения (2) для общего случая (любого N) справедливо итеративное выражение:
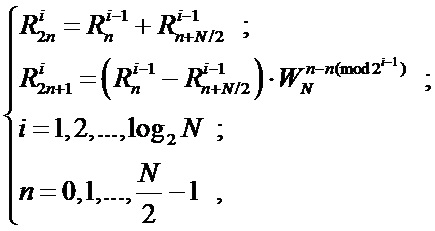 (3)
(3)
где 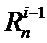 – значение (входной отсчет или промежуточное значение, вычисленное узлом «бабочка») считываемое из
– значение (входной отсчет или промежуточное значение, вычисленное узлом «бабочка») считываемое из 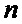 -ой ячейки памяти
-ой ячейки памяти 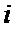 -ой стадии конвейера;
-ой стадии конвейера; 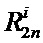 – значение (вычисленное узлом «бабочка») записываемое в
– значение (вычисленное узлом «бабочка») записываемое в 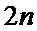 -ой ячейки памяти -ой стадии конвейера;
-ой ячейки памяти -ой стадии конвейера; 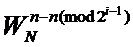 – комплексный поворотный множитель согласно выражению (2).
– комплексный поворотный множитель согласно выражению (2).
Зачастую требуется меньшее количество отсчетов для преобразования БПФ, а именно 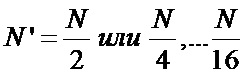 , при этом, если использовать традиционную известную из уровня техники схему коммутации БПФ с прореживанием по частоте, необходимо использовать первые
, при этом, если использовать традиционную известную из уровня техники схему коммутации БПФ с прореживанием по частоте, необходимо использовать первые 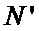 элементов памяти для отсчетов, а в остальные элементы памяти должны быть записаны нули. При том нетрудно заметить, что поворачивающие коэффициенты останутся прежними, так как
элементов памяти для отсчетов, а в остальные элементы памяти должны быть записаны нули. При том нетрудно заметить, что поворачивающие коэффициенты останутся прежними, так как 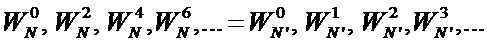 при
при  . Таким образом, и в унифицированной схеме (Фиг. 3) нет необходимости менять поворачивающие коэффициенты для реконфигурирования схемы по количеству отсчетов. Все что следует сделать, это обнулить все неиспользуемые отсчеты
. Таким образом, и в унифицированной схеме (Фиг. 3) нет необходимости менять поворачивающие коэффициенты для реконфигурирования схемы по количеству отсчетов. Все что следует сделать, это обнулить все неиспользуемые отсчеты 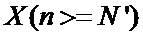 во входном массиве элементов памяти (101).
во входном массиве элементов памяти (101).
С целью уменьшения аппаратных затрат используют вариант выполнения заявленного изобретения с последовательным вычислением БПФ, требующий один узел «бабочка» и два массива памяти объема отсчетов. При этом лучшим вариантом является схема с бесконфликтным доступом к памяти и линейной адресацией для записи и чтения. Согласно выражению (3), доступ к памяти для чтения значений будет линейным, то есть с инкрементацией на один, также линейным будет и доступ для записи, с инкрементацией на два, однако если одна ячейка памяти будет хранить два отсчета, то инкрементация адреса станет на один.
На Фиг. 6 представлена организация памяти для бесконфликтного доступа с линейной адресацией. Два массива памяти разбиты пополам, таким образом, что за один такт вычитывают два значения из двух разных памятей для одной операции «бабочка», а результат записывают в третью (или четвертую) память по одному адресу, в старшую (прямоугольник с закрашенной левой частью) и младшую часть слова (прямоугольник с закрашенной правой частью). При использовании одного узла «бабочка» такая организация памяти позволяет осуществлять доступ к памяти без конфликта по чтению и записи в один такт, при этом адресация линейная, то есть с инкрементацией адреса плюс один. Линейная адресация существенно упрощает узел генерации адресов, что в свою очередь увеличивает быстродействие данного устройства при аппаратной реализации.
На Фиг. 7 предоставлено заявленное высокоскоростное устройство БПФ с бесконфликтным линейным доступом к памяти для входных отсчетов, содержащее соединенные между собой один вычислительный узел «бабочка» (715) и четыре блока памяти (700-703), каждый из которых содержит элементов памяти, выполненных с возможностью хранения входных, выходных и промежуточных отсчетов. Входы разрешения чтения первого блока памяти RAM0A (700) и второго блока памяти RAM0B (701) соединены с нулевым входом разрешения чтения RE0 устройства. Входы разрешения чтения третьего блока памяти RAM1A (702) и четвертого блока памяти RAM1B (703) соединены с первым входом разрешения чтения RE1 устройства. Вход разрешения записи первого блока памяти RAM0A (700) соединен с нулевым входом разрешения записи WE0A устройства. Вход разрешения записи второго блока памяти RAM0B (701) соединен с нулевым входом разрешения записи WE0B устройства. Вход разрешения записи третьего блока памяти RAM1A (702) соединен с первым входом разрешения записи WE1A устройства. Вход разрешения записи третьего блока памяти RAM1B (702) соединен с первым входом разрешения записи WE1B устройства. Выходные шины данных Rdata0A и Rdata0B первого и второго блоков памяти RAM0A (700) и RAM0B (701) соединены с нулевыми входами четвертого (713) и пятого (717) мультиплексоров, с первым входами которых соединены выходные шины данных Rdata1A и Rdata1B третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703). Старшие части RdataH выходных шин данных четвертого (713) и пятого (717) мультиплексоров соединены с нулевыми входами шестого (714) и седьмого (718) мультиплексоров. Младшие части RdataL выходных шин данных четвертого (713) и пятого (717) мультиплексоров соединены с первыми входами шестого (714) и седьмого (718) мультиплексоров. Входы селектора четвертого (713) и пятого (717) мультиплексоров соединены с выходом второго элемента задержки D (712), вход которого соединен с нулевым входом разрешения чтения RE0 устройства. Входы селектора шестого (714) и седьмого (718) мультиплексоров соединены с нулевым разрядом выходной шины первого элемента задержки D (709). Выходы шестого (714) и седьмого (718) мультиплексоров являются первым и вторым выходами устройства и соединены с входами А и В узла «бабочка» (715), выходные шины WdataH и WdataL которого объединены в общую шину Wdata, которая соединена с входами данных третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703) и с нулевым входом второго мультиплексора (711), к первому входу которого подключена входная шина данных input_data устройства. Первый вход второго мультиплексора (711) является входом разрешения en_input устройства. Выходная шина второго мультиплексора (711) соединена с входной шиной данных Wdata0 первого и второго блоков памяти RAM0A (700) и RAM0B (701), входные шины адреса которых соединены с выходом третьего мультиплексора (710), вход селектора которого соединен с нулевым входом разрешения чтения RE0 устройства. Нулевые входы третьего и восьмого мультиплексоров (710) и (719) соединены со всеми кроме младшего разрядами выходной шины первого мультиплексора (708), все разряды кроме старшего выходной шины которого соединены со входом первого элемента задержки (709), выходная шина которого соединена с первыми входами третьего и восьмого мультиплексоров (710) и (719). Вход селектора восьмого мультиплексора (719) соединен с первым входом разрешения чтения RE1 устройства. Вход разрешения вывода данных en_output устройства соединен со входом селектора первого мультиплексора (708), нулевой вход которого соединен с выходом счетчика адреса (705) и с входом инвертора адреса (706), выход которого соединен с первым входом первого мультиплексора (708). Вход разрешения счетчика адреса (705) соединен с входом разрешения адресации en_cnt устройства. Входная шина адреса третьего и четвертого блоков памяти RAM1A (702) и RAM1B (703) соединена с выходной шиной восьмого мультиплексора (719).
Узел «бабочка» (715) является типовым и состоит из двух сумматоров и комплексного умножителя. Первый вход узла «бабочка» (715) соединен с первыми входами первого и второго сумматоров. Выход первого сумматора является первым выходом узла «бабочка» (715). Второй вход первого сумматора соединен с вторым входом узла «бабочка» (715), который также соединен с входом умножителя на -1, выход которого соединен с вторым входом второго сумматора, выход которого соединен с входом комплексного умножителя, выход которого является вторым выходом узла «бабочка» (715).
После записи входных значений по сигналу en_input начинают итерационное вычисление БПФ. Адрес инкрементируют при помощи простого бинарного счетчика с сигналом разрешения (en_cnt). После определенного количества стадий (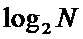 ) готовый результат находится в соответствующем блоке памяти. Для вычитывания результата преобразования по сигналу en_output предусмотрен блок инверсии адресов.
) готовый результат находится в соответствующем блоке памяти. Для вычитывания результата преобразования по сигналу en_output предусмотрен блок инверсии адресов.
Подробные временные диаграммы работы заявленного устройства в процессе преобразования представлены на Фиг 8.
Представленная в заявленном изобретении унифицированная схема коммутации БПФ имеет следующие преимущества.
1) Заявленная унифицированная схема коммутации БПФ:
• содержит узел «бабочка», состоящий из комплексного умножителя, двух сумматоров;
• содержит элементы памяти для хранения входных/выходных (а также промежуточных результатов операции «бабочка») отсчетов,
• обладает единой коммутацией между всеми стадиями вычисления и исключает систему сложного мультиплексирования, присущую традиционной известной из уровня техники схеме.
2) Вариант выполнения заявленной унифицированной схемы коммутации БПФ с прореживанием по частоте (для N=16), представленный на Фиг. 5, может применяться для различных целей:
• с целью уменьшения аппаратных затрат - последовательная схема, итерационная, требующая один узел «бабочка» и два массива памяти объема отсчетов, при этом доступ к памяти является бесконфликтным;
• с целью максимизации производительности - полностью параллельная схема, конвейерная, требующая 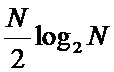 узлов «бабочка» и элементов памяти (один элемент для хранения одного отсчета).
узлов «бабочка» и элементов памяти (один элемент для хранения одного отсчета).
• для целевых задач – последовательно параллельная схема, итерационная, требующая несколько узлов «бабочка» не более  , работающих параллельно и два массива памяти объема отсчетов.
, работающих параллельно и два массива памяти объема отсчетов.
Заявленное изобретение представляет собой устройство БПФ с прореживанием по частоте и оптимизацией аппаратных затрат на схему коммутации. Устройство обеспечивает последовательное вычисление БПФ, с бесконфликтным доступом к памяти посредством линейной адресации.
Заявленное изобретение представляет собой устройство БПФ на основе унифицированной (единой) схемы коммутации значения из памяти для базовых узлов вычислений операции «бабочка» для всех стадий конвейера. Ввиду того, что схема коммутации едина, можно построить устройство с оптимизацией по ресурсам и используемой памяти, быстродействию и т.д. Например, в случае жестких требований по аппаратным затратам, можно, пренебрегая быстродействием, использовать два массива памяти для всех стадий вычислений. Один массив для входных отсчетов, другой для выходных отсчетов, эти же массивы памяти используются для промежуточных вычислений (стадий в случае конвейерной структуры). При этом ввиду единой схемы коммутации, нет необходимости ее перенастраивать с каждым тактом, что дополнительно уменьшает аппаратные затраты.
Хотя описанный выше вариант выполнения изобретения был изложен с целью иллюстрации заявленного изобретения, специалистам ясно, что возможны разные модификации, добавления и замены, не выходящие из объема и смысла заявленного изобретения, раскрытого в прилагаемой формуле изобретения.
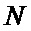
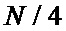
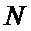
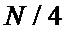
Система и способ предпосадочного и послепосадочного контроля пассажиров
Параллельный кодер бчх с реконфигурируемой корректирующей способностью
Датчик температуры
Цифровой делитель частоты
Управляемый напряжением блок кольцевых генераторов на комплементарных метал-окисел-полупроводник (кмоп) транзисторах
Параметризуемый однотактный умножитель двоичных чисел с фиксированной точкой в прямом и дополнительном коде
Реконфигурируемый кодер полярных кодов 5g сетей
Устройство коммуникационного интерфейса для сети spacewire
Устройство видеонаблюдения
Система и способ трехмерной визуализации яркостной радиолокационной карты местности
Система и способ идентификации транспортных средств, противоправно вторгшихся на выделенную полосу
Рлс с программируемой временной диаграммой и способ ее функционирования
Система и способ определения нарушений правил дорожного движения при проезде перекрестка
Ядро сопроцессора быстрого преобразования фурье реального времени
Радиационно-стойкая библиотека элементов на комплементарных металл-окисел-полупроводник транзисторах
Способ и устройство ввода, обработки и вывода видеоизображения
Система регулирования уличного освещения и определения правонарушений и внештатных происшествий

