Результат интеллектуальной деятельности: РАСПРЕДЕЛЁННОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРСОНАЛИЗАЦИИ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее изобретение относится к области искусственного интеллекта и, в частности, к машинному обучению моделей для персонализации пользовательских устройств. В частности, заявляемое изобретение может быть использовано в целях распознавания объектов на изображениях, предсказания вводимых пользователем слов в сообщениях, распознавания речи, распознавания рукописного ввода, и в различных устройствах и приложениях, известных как интеллектуальные помощники.
Уровень техники
В источнике US 8,429,103 B1 (2012-06-22, Google Inc.) раскрыт способ обучения модели машинного обучения (ML), выполняемый на пользовательском устройстве, таком как мобильный телефон, с получением элементы данных от мобильных приложений или из сети. Способ машинного обучения может содержать определение по меньшей мере одного элемента данных на основании принятых данных и формирование выводимых данных путем выполнения операции машинного обучения на упомянутом по меньшей мере одном элементе данных. Выводимые данные могут передаваться в приложение, в сеть и т.п. Может быть предусмотрен механизм агрегации и представления данных (DARE), который постоянно принимает и сохраняет вводимые данные, при необходимости из множества источников. Сохраняемые вводимые данные могут агрегироваться для обнаружения элементов данных среди упомянутых данных. Например, в известных методиках машинного обучения могут использоваться алгоритмы поэтапного обучения, в которых для обучения требуются ограниченные объемы предшествующей информации или вовсе не требуется предшествующая информация. К недостаткам данного известного решения следует отнести ограниченность сферы его применения исключительно мобильными телефонами, необходимость сбора личных данных пользователя, а также риск так называемого «переобучения» модели (нежелательного явления, возникающего, когда вероятность ошибки обученного алгоритма на объектах тестовой выборки оказывается существенно выше, чем средняя ошибка на обучающей выборке).
В источниках H. Brendan McMahan et al.(2016) Communication-Efficient Learning of Deep Networks from Decentralized Data и Yujun Lin et al. (2018) Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training раскрыт подход к обучению так называемых моделей «глубокого обучения», при котором обучающие данные остаются распределенными среди мобильных устройств, и совместно используемая модель обучается посредством агрегирования локально вычисляемых на упомянутых мобильных устройствах обновлений. Для улучшения работы распределенного стохастического градиентного спуска используется несколько приемов, состоящих в передаче только обновлений с достаточно большими весовыми коэффициентами, коррекции момента, локальном усечении градиента, маскировании момента, локальном накоплении градиентов и менее агрессивном разреживании градиента на начальных этапах обучения. Данный подход был исследован в контексте обработки данных изображений, голосового и текстового ввода. К недостаткам такого известного подхода следует отнести «переобучение» модели на новых данных, необходимость ожидания пользователем окончания обучения до тех пор, пока он не получит модель с лучшими характеристиками, и ограниченность способа обучения стохастическим градиентным спуском (SGD).
Рассмотренный выше подход может быть принят в качестве ближайшего аналога заявляемого изобретения.
Раскрытие изобретения
Данный раздел, раскрывающий различные аспекты и варианты выполнения заявляемого изобретения, предназначен для представления краткой характеристики заявляемых объектов изобретения и вариантов его выполнения. Подробная характеристика технических средств и методов, реализующих сочетания признаков заявляемых изобретений, приведена ниже. Ни данное раскрытие изобретения, ни нижеприведенное подробное описание и сопровождающие чертежи не следует рассматривать как определяющие объем заявляемого изобретения. Объем правовой охраны заявляемого изобретения определяется исключительно прилагаемой формулой изобретения.
С учетом вышеуказанных недостатков уровня техники задача настоящего изобретения состоит в создании решения, направленного на устранение вышеуказанных недостатков, снижение риска нарушения безопасности личных данных пользователя и уменьшение затрат на передачу данных по сетевым соединениям в целях обучения моделей машинного обучения для персонализации пользовательских устройств. Кроме того, в заявляемом изобретении исключается риск «переобучения» модели, которое в данном случае также можно назвать «забыванием». Кроме того, предложенное решение позволяет выполнять группировку пользователей по тематикам их интересов. Технический результат, достигаемый заявляемым изобретением, состоит в повышении качества обучения персонализированных моделей искусственного интеллекта при предотвращении их «переобучения» и при сниженных затратах на передачу данных по сетевым соединениям.
Для решения упомянутой задачи, в соответствии с одним аспектом изобретение относится к способу распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащему этапы, на которых: a) инициализируют одну или более моделей машинного обучения (ML) на сервере; b) распространяют одну или более моделей ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; c) накапливают данные, формируемые пользователем посредством пользовательского ввода, на каждом из одного или более UE в течение периода накопления данных; d) передают обучающие данные с сервера на одно или более UE; e) осуществляют обучение модели на каждом из одного или более UE на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения; f) получают на сервере обученные модели ML от упомянутых одного или более UE; g) обновляют на сервере модель ML путем агрегации обученных моделей ML, полученных от одного или более пользовательских устройств; h) передают обновленные модели ML в одно или более UE; и i) повторяют этапы c) -h) один или более раз до получения модели ML, соответствующей одному или более критериям качества модели ML.
В варианте выполнения изобретения способ может дополнительно содержать этапы, на которых: идентифицируют группу персонализации для пользователя каждого из одного или более UE на основании данных, формируемых пользователем, собранных на упомянутом каждом из одного или более UE; группируют на сервере модели ML, полученные от UE из упомянутых одного или более UE, по группам персонализации; и передают обновленные модели ML, сгруппированные по группам персонализации, в UE, входящие в соответствующую группу персонализации.
В варианте выполнения, модель ML может быть выполнена с возможностью предсказания слов и словосочетаний при вводе пользователем текстового сообщения на UE, при этом формируемые пользователем данные представляют собой слова и словосочетания, вводимые пользователем. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания предметов на изображениях, получаемых с одной или более камер UE, при этом формируемые пользователем данные представляют собой изображения с одной или более камер UE и/или метки, присваиваемые пользователем предметам, присутствующим на изображениях. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания рукописного ввода, принимаемого от пользователя посредством сенсорного экрана UE и/или сенсорной панели UE, при этом формируемые пользователем данные представляют собой упомянутый рукописный ввод и/или выбор пользователем предлагаемых моделью ML вариантов символов и/или слов, основанных на рукописном вводе от пользователя. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания голосового ввода, принимаемого от пользователя посредством одного или более микрофона UE, при этом формируемые пользователем данные представляют собой упомянутый голосовой ввод и/или выбор пользователем предлагаемых моделью ML вариантов слов и/или словосочетаний, основанных на голосовом вводе от пользователя. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания одной или более характеристик окружения UE и/или одного или более действий пользователя, при этом одна или более характеристик окружения UE представляют собой одно или более из времени, даты, дня недели, освещенности, температуры, географического местоположения, пространственного положения UE, при этом формируемые пользователем данные представляют собой пользовательский ввод в одно или более программных приложений на UE. В варианте выполнения, обучающие данные могут включать в себя порцию общедоступных данных из исходной выборки.
В варианте выполнения, критерием прекращения обучения является достижение сходимости моделей ML среди одного или более UE. В варианте выполнения, критерием прекращения обучения является достижение моделью ML заданного значения характеристики качества модели ML. В варианте выполнения, критерием прекращения обучения является достижение заданного количества периодов обучения.
В соответствии с другим аспектом настоящего изобретения предложена система распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащая: сервер; и одно или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; при этом сервер выполнен с возможностью: инициализации одной или более моделей машинного обучения (ML); распространения одной или более моделей ML среди одного или более пользовательских устройств (UE); передачи обучающих данных на одно или более UE; получения обученных моделей ML от одного или более UE; обновления модели ML путем усреднения обученных моделей ML, полученных от одного или более UE; передачи обновленных моделей ML в одно или более UE; и при этом одно или более UE выполнены с возможностью: накопления данных, формируемых пользователем посредством пользовательского ввода, в течение периода накопления данных; приема обучающих данных от сервера; обучения модели ML на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения.
Еще в одном аспекте настоящее изобретение предусматривает машиночитаемый носитель, на котором сохранена компьютерная программа, которая при выполнении одним или более процессорами реализует способ распределенного обучения модели ML в соответствии с первым из вышеуказанных аспектов. Изобретательский замысел, лежащий в основе настоящего изобретения, может быть реализован также в виде других объектов, таких как компьютерная программа, компьютерный программный продукт, сервер, пользовательское устройство, система беспроводной связи и т.п.
Краткое описание чертежей
Чертежи приведены в настоящем документе для облегчения понимания сущности настоящего изобретения. Чертежи являются схематичными и выполнены не в масштабе. Чертежи служат исключительно в качестве иллюстрации и не предназначены для определения объема настоящего изобретения.
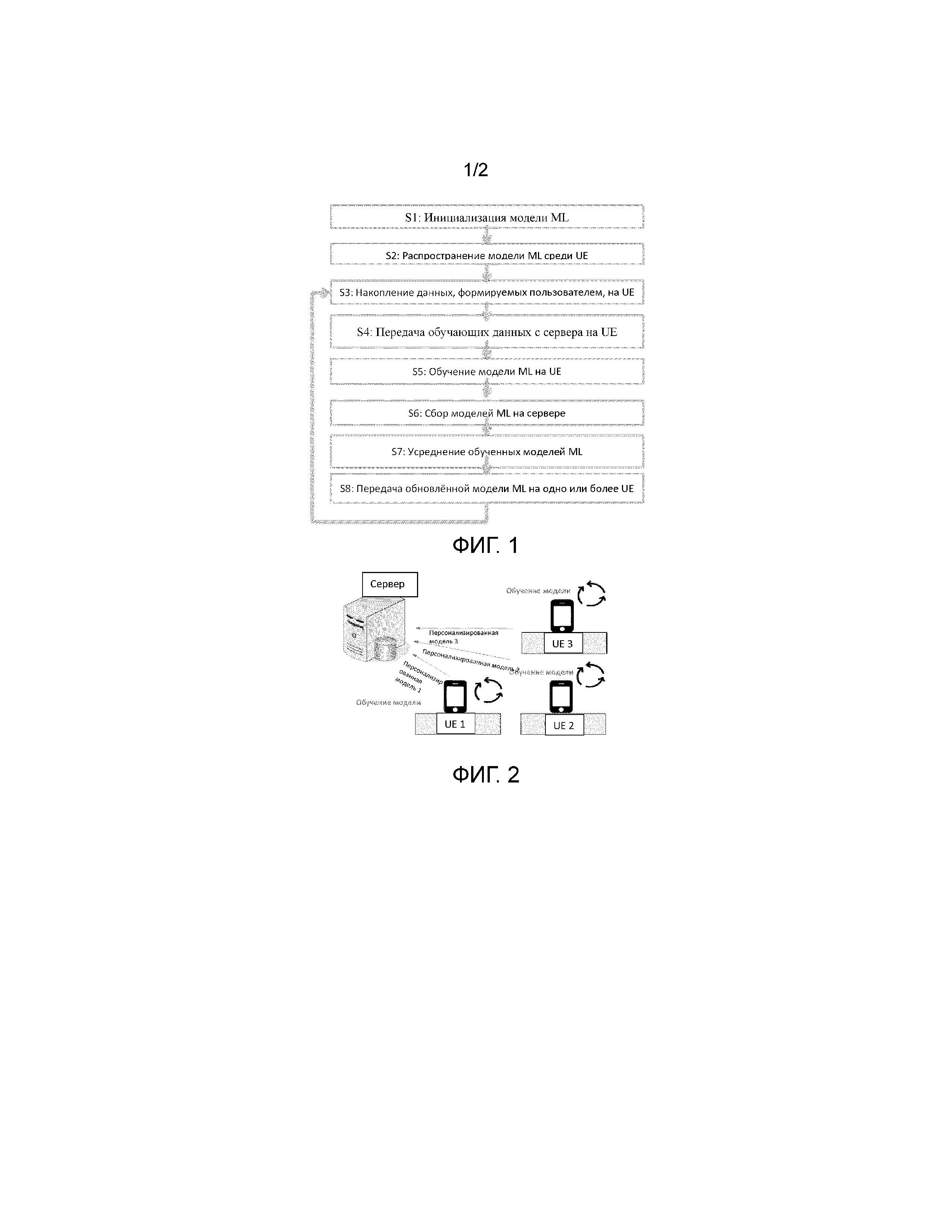
На Фиг. 1 показана последовательность операций способа распределенного обучения модели машинного обучения (ML) в соответствии с первым аспектом настоящего изобретения;
На Фиг. 2 проиллюстрирован процесс обучения моделей ML на пользовательских устройствах (UE) и накопления персонализированных моделей ML на сервере в соответствии с изобретением;
На Фиг. 3 схематично проиллюстрировано обучение модели ML на UE в соответствии с изобретением.
Осуществление изобретения
Машинное обучение представляет собой класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение в процессе применения решений множества сходных задач. В частном случае, ряд методов машинного обучения основаны на использовании нейросетей, однако существуют и другие методы, использующие понятие обучающей выборки. В контексте настоящего изобретения методы машинного обучения могут быть использованы, в качестве неограничивающего примера, для целей распознавания объектов (например, на изображениях), прогнозирования слов (например, в различных приложениях, в которых пользователь вводит сообщения или поисковые запросы через интерфейс приложения на пользовательском устройстве), интеллектуальной обработки изображений со сверхвысоким разрешением, распознавания речи (например, в приложениях, принимающих от пользователя голосовой ввод и преобразующих данные голосового ввода в текст), распознавания рукописного текста (например, в приложениях, принимающих пользовательский ввод путем написания букв и других символов на сенсорном экране пользовательского устройства посредством стилуса или пальца пользователя), а также в различных программных приложениях, известных как «интеллектуальные помощники».
В контексте настоящего изобретения предполагается, что пользовательское устройство содержит одну или более функций искусственного интеллекта, реализуемые, например, программными средствами. Система, содержащая такие функции искусственного интеллекта, выполнена с возможностью «обучения» посредством одной или более методик машинного обучения для персонализации возможностей пользовательского устройства, реализуемых в виде различных средств, служб, программных приложений и т.п., с учетом различных характеристик пользователя данного пользовательского устройства. В качестве неограничивающего примера, персонализация может быть основана, например, на лексиконе пользователя (определяемом, например, при составлении пользователем сообщений в приложениях мгновенного обмена сообщениями, электронной почты, SMS и т.п.), тематике интересов пользователя (определяемой, например, по поисковым запросам пользователя в различных поисковых системах), сведениях о веб-страницах, просматриваемых пользователем, частоте и длительности просмотров конкретных веб-страниц, и т.п. Для «обучения» модели машинного обучения необходимы данные, которые предпочтительнее всего собирать непосредственно на пользовательском устройстве, однако на сбор данных о пользователе и их передачу за пределы пользовательского устройства накладывается ряд ограничений, связанных с безопасностью личных данных пользователя, соблюдением тайны частной жизни («приватности») пользователя и т.п.
Традиционно обучение моделей искусственного интеллекта осуществляется на одном или более серверах. Однако с этим связаны, в частности, следующие проблемы: 1) система искусственного интеллекта может быть неспособной адаптироваться к локальным условиям конкретного пользовательского устройства, и 2) общественно доступные данные могут отличаться от реальных данных. Адаптация к локальным условиям конкретного пользовательского устройства, как правило, реализуется в виде адаптации к аппаратной части устройства, в частности к характеристикам имеющейся в нем камеры при решении задач распознавания объектов или обработки изображений со сверхвысоким разрешением, или к характеристикам одного или более микрофонов, содержащихся в устройстве, при решении задач распознавания речи. Адаптация к пользователю может осуществляться на основании определяемых интересов пользователя (например, при прогнозировании слов при наборе пользователем сообщений) или на основании голоса данного конкретного пользователя при решении задач распознавания речи.
Для решения вышеуказанных проблем адаптация системы искусственного интеллекта может осуществляться путем выполнения обучающих алгоритмов на пользовательском устройстве. Однако такому решению, в свою очередь, присущи другие проблемы, которые состоят в недостаточном объеме данных для выполнения полноценного обучения моделей в рамках пользовательского устройства и в невозможности сбора пользовательских данных для каждого конкретного пользователя на удаленном сервере (в частности, с учетом вышеуказанных соображений безопасности личных данных пользователя и неприкосновенности его частной жизни).
Данные проблемы, в свою очередь, решаются в настоящее время в уровне техники, описанном выше, посредством распределенного «дообучения» (которое также можно охарактеризовать как своего рода «тонкую настройку», далее будет называться обучением или дообучением) моделей искусственного интеллекта на множестве различных пользовательских устройств. Однако, как показано выше, известным в уровне техники решениям в данной области в настоящее время присущи проблемы, связанные с тем, что: 1) такое «дообучение» моделей искусственного интеллекта может приводить к ситуациям «переобучения» или «забывания» всех исходно заложенных в модель данных при адаптации модели под конкретного пользователя; 2) пользователи, их устройства и их окружение могут быть чересчур различными для возможности такого распределенного «дообучения» моделей на множестве устройств; и 3) такой подход связан с издержками, такими как высокие затраты на передачу данных по сетевым соединениям.
Предлагаемое изобретение было создано с учетом вышеуказанных проблем известного уровня техники. Для решения вышеуказанных проблем уровня техники предлагаются следующие средства, которые будут более подробно описаны ниже в настоящем подробном описании изобретения.
1) Для предотвращения «переобучения» и обеспечения безопасности личных данных и приватности пользователя при обучении моделей используется небольшой объем исходных обучающих данных.
2) Пользователей группируют в отдельные группы для получения новых персонализированных моделей для каждой группы пользователей.
3) При распределенном обучении моделей собирают модели, обученные на каждом устройстве с учетом вышеприведенных соображений, а не градиенты, как в ближайшем аналоге из уровня техники, рассмотренном выше.
С учетом вышеприведенных соображений задача, на решение которой направлено заявляемое изобретение, состоит в повышении качества обучения персонализированных моделей искусственного интеллекта при предотвращении их «переобучения» и при сниженных затратах на передачу данных по сетевым соединениям. Настоящее изобретение направлено по существу на создание средства постоянного обновления моделей машинного обучения на основании пользовательских данных, но без необходимости сбора каких-либо личных данных пользователя, при снижении затрат на передачу данных по сетевым соединениям, повышении устойчивости моделей и частоты их обновления.
Сначала при обучении моделей используется небольшой объем исходных обучающих данных, что позволяет предотвратить «переобучение» модели («забывание» базовой информации) на основании вновь получаемых данных. Затем каждый пользователь обучает модель на своем устройстве в течение нескольких периодов и отправляет обновленную модель машинного обучения на сервер, где выполняется усреднение моделей, полученных от пользовательских устройств. Таким образом каждый конечный пользователь постоянно получает обновления в виде более точных моделей машинного обучения, адаптированных на основании данных, сформированных множеством пользователей. За счет этого функции искусственного интеллекта в соответствующих приложениях на каждом пользовательском устройстве становятся более точными. Кроме того, предотвращается нарушение безопасности личных данных каждого пользователя, сохраняемых, например, в виде фотографий, сообщений, текстовых файлов, ссылок на веб-страницы, звуковых данных (захваченных посредством микрофона пользовательского устройства) и т.п. Предотвращается «забывание» обучаемой моделью базовой информации, полученной при обучении модели на общедоступных данных.
Согласно изобретению исходная модель машинного обучения (ML) для программного приложения, содержащего функцию искусственного интеллекта (AI) обучается на сервере на основании общедоступных данных. Исходная модель ML поставляется с устройством или устанавливается при осуществлении связи устройства с сетью связи в процессе исходного обучения. Затем следует период ожидания, пока пользователь не сформирует в процессе использования приложения, содержащего функцию искусственного интеллекта, на пользовательском устройстве достаточный объем данных, чтобы можно было осуществить адаптацию модели машинного обучения.
В соответствии со сформированными пользователем данными и другой информацией, к которой можно получить доступ (такой как, например, марка и модель пользовательского устройства) идентифицируется тип модели машинного обучения, подходящий для данного пользователя и его устройства. Формируются группы персонализации, исходя, в качестве примера, но не ограничения, из идентифицированного типа модели машинного обучения и/или типа, марки или модели пользовательского устройства, и/или интересов пользователя, определенных на основании данных, сформированных пользователем за время упомянутого периода ожидания с целью адаптации модели машинного обучения.
В соответствии с идентифицированным типом модели машинного обучения сервер направляет на пользовательское устройство текущую версию модели машинного обучения. При этом в предпочтительном варианте выполнения изобретения определенные версии моделей машинного обучения направляются только пользователям в пределах соответствующих определенных групп персонализации.
Для повышения защищенности личных данных пользователю передается порция общедоступных данных из исходной выборки, которые использовались для исходного обучения модели. Это также позволяет предотвратить «забывание» моделью машинного обучения исходных данных в случае «переобучения» модели на данных конкретного пользователя. Далее обучение модели производится на пользовательском устройстве, используя в качестве исходной модели ту модель ML, которая была передана с сервера на пользовательское устройство. При этом на данном этапе обучение производится до достижения сходимости моделей между различными пользовательскими устройствами, например, в рамках одной группы индивидуализации либо до достижения некоторого максимального количества итераций обучения, которое устанавливается заранее.
Каждое устройство, в котором обучение модели ML завершается, отправляет свою обученную модель ML на сервер (такой как центральный сервер и/или сервер агрегации моделей). Персонализированные модели, обученные на различных пользовательских устройствах (например, в рамках одной группы индивидуализации) агрегируются на упомянутом сервере. Агрегация реализуется, например, путем создания усредненной модели. В результате агрегации получается новая версия модели определенного типа. Данная новая версия модели передается на пользовательские устройства в рамках соответствующей группы индивидуализации.
Описанная выше операция передачи пользователю порции общедоступных данных из исходной выборки, которые использовались для исходного обучения модели, с достижением преимущества предотвращает «переобучение» модели на новых данных на пользовательском устройстве и гарантирует приватность пользователя, не позволяя третьим лицам установить данные, которые характеризуют личность пользователя, например, в случае перехвата отправляемой на сервер персонализированной модели ML. Порция исходных обучающих данных передается на каждое из пользовательских устройств, и процедура обучения модели ML на каждом пользовательском устройстве выполняется с объединением данных, собранных на данном пользовательском устройстве, и упомянутых исходных данных, переданных на пользовательское устройство. В адаптации модели ML на пользовательском устройстве задействована лишь небольшая часть доступных пользовательских данных по сравнению с объемом исходных обучающих данных.
В традиционных решениях, в которых отсутствует операция добавления порции исходных обучающих данных в процессе обучения модели ML, это в определенный момент приводит к «переобучению» модели ML на данном пользовательском устройстве, которое характеризуется «забыванием» моделью ML всей информации, которая была ранее сохранена в модели ML. В результате такая «переобученная» модель не способна, например, адекватно предсказывать слова по пользовательскому вводу в сценарии использования «виртуальной клавиатуры» в приложении по обмену сообщениями, если контекст набираемого пользователем сообщения отличается от тех привычных контекстов, в которых ранее накапливались данные для обучения персонализированной модели машинного обучения на данном пользовательском устройстве.
При этом в предпочтительном варианте реализации предлагаемого решения объемы данных исходной выборки и выборки данных, формируемых пользователем, и используемые при обучении модели ML на данном пользовательском устройстве, находятся в соотношении 1:1. Это обеспечивает оптимальный баланс между новыми данными (т.е. данными, формируемыми пользователем данного пользовательского устройства) и исходными данными (данными, получаемыми от сервера) при обучении модели ML. Так модель ML «получает» новую информацию без «забывания» исходной информации. Если упомянутое соотношение будет составлять, например, 1:2, то баланс сместится в сторону «новых» данных (данных, формируемых пользователем), что приведет к «забыванию» исходных данных. Однако следует понимать, что упомянутое выше соотношение используется в предпочтительном варианте выполнения изобретения, которым объем настоящего изобретения не ограничивается, и в других вариантах выполнения изобретения, например, упомянутое соотношение может быть различным для различных пользователей на основании определенных критериев, характеризующих «поведение» каждого конкретного пользователя. В некоторых вариантах выполнения изобретения, например, различным пользователям могут присваиваться различные коэффициенты на основании «вклада» формируемых ими данных в обучение модели ML, например, в рамках определенной группы индивидуализации.
Для получения такой «совмещенной» модели, основанной как на данных, формируемых пользователем конкретного пользовательского устройства, так и на данных исходной обучающей выборки, может использоваться любая из известных в данной области техники процедур машинного обучения. В качестве примера, можно привести следующие источники, описывающие процедуры машинного обучения, подходящие для использования в контексте настоящего изобретения:
Bishop, C. M. (2006) "Pattern recognition and Machine Learning", Springer Science, p.232-272; и Mozer, M. C. (1995). "A Focused Backpropagation Algorithm for Temporal Pattern Recognition". In Chauvin, Y.; Rumelhart, D. Backpropagation: Theory, architectures, and applications. ResearchGate. Hillsdale, NJ: Lawrence Erlbaum Associates. pp. 137-169.
Обучение модели ML на устройстве выполняется до тех пор, пока не будет выполнено условие прекращения обучения на устройстве, такое как достижение сходимости моделей ML среди устройств, в предпочтительном варианте выполнения - в рамках определенной группы индивидуализации. После этого обученные модели ML передаются на сервер, где они агрегируются (в качестве неограничивающего примера, посредством усреднения моделей ML).
В качестве альтернативы или дополнения, критерием прекращения обучения модели ML может быть достижение моделью ML заданного значения характеристики качества модели ML, которая может быть сформулирована в терминах точности предсказания или классификации в зависимости от задачи: так, в задаче предсказания последующего слова можно оценивать точность предсказания слова; в задаче распознавания рукописного текста можно оценивать побуквенную или пословную точность распознавания текста и т.д. Специалистам в данной области техники будут очевидны различные способы оценки качества модели ML в зависимости от задачи, решаемой моделью, основываясь на вышеприведенных примерах.
Модель может передаваться на сервер не полностью, а лишь частично: те параметры модели, изменение которых относительно предыдущей итерации модели не превысило некоторого заданного порогового значения, могут не передаваться на сервер. В этом случае при усреднении будет использовано значение параметра из предыдущей итерации модели. Пороговое значение для принятия решения об отправке модели ML с пользовательского устройства на сервер может определяться, например, исходя из баланса между требованиями к точности модели ML и ограничениями на объемы передаваемых данных по сетевым соединениям между пользовательскими устройствами и сервером.
Обновление персонализированных моделей может осуществляться, например, на основании усреднения моделей.
Вместо вычисления и передачи градиентов для стохастического градиентного спуска, как в случае с рассмотренным выше ближайшим аналогом из уровня техники, авторы настоящего изобретения предлагают выполнять обучение модели ML на пользовательском устройстве до того момента, пока не будет выполняться какой-либо из заданных критериев прекращения обучения. В качестве примера, критерием может стать достижение заданного максимального количества периодов обучения модели ML или достижение определенной сходимости моделей по процедуре оптимизации. В качестве альтернативы или дополнения к вышеуказанному возможны и другие критерии прекращения обучения модели ML, которые могут быть предусмотрены специалистами в данной области техники по прочтении настоящего описания изобретения.
Это позволяет снизить потребность в обмене данными по сетевым соединениям между пользовательским устройством и сервером для осуществления процесса распределенного обучения моделей ML, снижая таким образом экономическую нагрузку на пользователя.
В некоторых вариантах выполнения настоящего изобретения при распределенном обучении моделей ML может быть дополнительно повышена эффективность предсказания обучаемой моделью редких слов, событий или объектов. Это может быть достигнуто за счет изменения критериев обучения. Дело в том, что редкие классы (слова, объекты и т.п.) на большинстве пользовательских устройств, участвующих в распределенном обучении моделей ML, возникают относительно нечасто, что приводит к их игнорированию в процессе обучения моделей ML и, в свою очередь, к плохим результатам предсказания для таких классов. Изменение критериев обучения моделей ML может быть эффективным при преодолении данной проблемы, если новые критерии будут чувствительны к таким классам с низкой вероятностью возникновения.
В качестве примера, среди стандартных критериев обучения можно выделить, например, функцию потерь от перекрестной энтропии между истинным распределением классов (p) и распределением (q), которое присваивается классам данной моделью. Данный критерий можно проиллюстрировать следующим выражением, приведенным ниже:
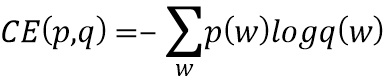
В соответствии с настоящим изобретением предлагается использование при обучении нового критерия, представляющего собой сумму перекрестной энтропии между вышеуказанными p и q и расстоянием Кульбаха-Лейблера между q и p:
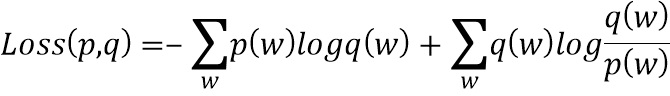
В вышеуказанной формуле к предсказаниям модели q(w) применяется штрафной коэффициент в случае, если дополнительная оценка истинной вероятности p(w) значительно ниже q(w). Оценка p(w) может быть получена из дискриминантного алгоритма, обученного отделению реальных данных от данных, отобранных из модели q(w), методами, известными специалистам в данной области техники. Применение такого подхода позволяет повысить точность предсказания в случае с редкими классами до 1,5%, и приводит к общему повышению точности предсказания до 0,2%.
В соответствии с вышеописанными операциями заявляемого способа пользователей группируют в различные группы индивидуализации, в частности, по следующим критериям: тематике текстовых сообщений, формируемых пользователем, географическому местоположению пользователя, его возрасту, типу аппаратного обеспечения, на котором выполняются одно или более программных приложений, в которых используются одна или более функций искусственного интеллекта. Следует понимать, что вышеуказанные критерии группировки пользователей в группы индивидуализации являются лишь неограничивающим примером, и специалистам в данной области техники будет понятно, что возможны и другие критерии группировки пользователей в группы индивидуализации в качестве альтернативы или дополнения к вышеуказанным. Кроме того, пользователи могут объединяться в группы индивидуализации, например, исходя из:
- технических параметров пользовательского устройства: размер дисплея, объем оперативной памяти, тип процессора и т.п.;
- географического местоположения устройства;
- информационного содержимого, формируемого пользователем, например, на веб-страницах (оценки, комментарии, ответы, заметки, публикации и т.п.);
- демографическим метаданным (пол пользователя, возраст, семейное положение, гражданство).
Согласно изобретению желательно иметь отдельные модели ML для различных групп пользователей или пользовательских устройств. Для идентификации группы индивидуализации, к которой следует отнести пользователя конкретного пользовательского устройства, на пользовательском устройстве может быть выполнен модуль классификации. Входными данными для модуля классификации может быть, не ограничиваясь, по меньшей мере одно из:
- данных, формируемых пользователем на устройстве;
- модели устройства;
- демографических данных, относящихся к пользователю;
- отметок географического местоположения, и т.п.
Количество групп индивидуализации может быть определено вручную или посредством любой подходящей методики кластеризации. Каждая группа индивидуализации соответствует одной модели ML или одному типу моделей ML.
Точность модели, относящейся к соответствующей конкретной группе, будет выше, чем точность модели, общей для всех групп. Так, в качестве неограничивающего примера, пользователи, которые обсуждают посредством текстовых сообщений в различных программных приложениях на своих мобильных устройствах темы, относящиеся к науке или технике, будут получать более точные предсказания слов на свою тематику при наборе сообщений в программных приложениях на своих пользовательских устройствах, поскольку персонализированная модель ML на их пользовательских устройствах будет основана только на данных, полученных от пользователей с аналогичными интересами.
Агрегирование множества моделей ML от пользователей, объединенных в общую группу индивидуализации, решает проблему малого размера выборки данных для обучения моделей ML. Однако при этом модели ML остаются персонализированными в том смысле, что для каждой группы индивидуализации пользователей формируется и обновляется своя модель ML. В результате пользователи в рамках определенной группы индивидуализации получают более точные персонализированные модели ML, основанные на их интересах, привычках, особенностях и/или характеристиках их аппаратного и/или программного обеспечения.
В варианте выполнения настоящего изобретения различным пользователям могут быть присланы модели с различными архитектурами (различными алгоритмами машинного обучения), и на основании результатов обучения моделей могут идентифицироваться модели с наилучшей архитектурой. Для этих целей на стороне сервера может быть предусмотрен дополнительный блок для формирования новых архитектур моделей ML и гиперпараметров для этих моделей. Любая система AI может также при необходимости быть расширена путем включения дополнительных функций, позволяющих испытывать новые модели ML на данных, формируемых пользователями.
Настоящее изобретение реализуется в стандартной архитектуре сетей беспроводной связи и включает в себя аппаратные и/или программные средства на стороне сервера и аппаратные и/или программные средства на стороне пользовательского устройства. К средствам на стороне сервера можно отнести, в качестве неограничивающего примера, блоки и/или модули, выполняющие описанные выше операции обеспечения исходных моделей ML, инициализации моделей машинного обучения (ML) на сервере, распределения (рассылки) модели (моделей) ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи, передачи обучающих данных исходной выборки с сервера на одно или более UE, приема моделей ML, обученных на одном или более UE, от одного или более UE, обновления на сервере персонализированной модели ML путем усреднения обученных моделей ML, принятых от одного или более UE. Вышеуказанные блоки и/или модули выполнены с возможностью повторения выполняемых ими операций любое необходимое количество раз, в зависимости от того, сколько повторений вышеописанных операций необходимо для получения одной или более персонализированных моделей ML, обладающих требуемой точностью и эффективностью.
На стороне пользовательского устройства при реализации настоящего изобретения также используется ряд аппаратных и/или программных модулей и/или блоков. В качестве неограничивающего примера, можно предусмотреть блок формирования пользовательского интерфейса, обеспечивающий пользовательский интерфейс, позволяющий пользователю управлять UE. UE может включать в себя различные средства ввода-вывода (I/O), такие как, не ограничиваясь, сенсорный экран, одну или более клавиш, один или более микрофонов, одну или более фото- и/или видеокамер, приемник(и) сигналов системы позиционирования, такой как GPS, GLONASS, GALILEO и т.п., один или более датчиков для определения физических параметров пользовательского устройства и/или его окружения, таких как пространственное положение пользовательского устройства, температура, уровень освещенности и т.п., один или более громкоговорителей. Специалистам в данной области техники будет понятно, что вышеприведенный перечень средств I/O приведен лишь в качестве иллюстративного примера и не является исчерпывающим, и что в зависимости от конкретной реализации пользовательского устройства может быть предусмотрено любое подходящее сочетание вышеупомянутых и/или любых других средств I/O.
Далее в пользовательском устройстве могут быть предусмотрены различные блоки и/или модули распознавания текста, распознавания рукописного ввода, анализа изображений, распознавания образов на изображениях, распознавания отпечатков пальцев, анализа голосового ввода, преобразования голосового ввода в текст, синтаксического и/или статистического анализа естественного языка, формирования текста на естественном языке, преобразования текста в голосовой вывод, и т.п. Следует понимать, что данный перечень возможных блоков и/или модулей, которые позволяют обрабатывать данные, вводимые в пользовательское устройство средствами I/O, не является исчерпывающим, и что в зависимости от конкретных вариантов реализации заявляемого изобретения могут быть предусмотрены и другие средства обработки вводимых данных и/или обработки данных для вывода, в качестве дополнения или альтернативы к перечисленным.
Упомянутые блоки и/или модули обработки данных передают данные, извлеченные из пользовательского ввода, принятого средствами I/O в одну или более функций AI, реализующих одну или более моделей машинного обучения (ML) в одном или более программных приложениях, выполняемых в пользовательском устройстве. Одна или более моделей ML принимают упомянутые данные от блоков и/или модулей обработки данных и используют эти данные, в частности, для формирования вывода в ответ на данные, принятые от пользователя, а также для собственного обучения. Так, например, выводом в ответ на пользовательский текстовый ввод посредством экранной клавиатуры или одной или более клавиш может быть предлагаемый моделью ML вариант предсказания пользовательского ввода в виде одного или более вариантов слова или словосочетания, которые пользователь, вероятно, желает ввести в окне набора текстового сообщения. В варианте реализации, в котором модель ML используется для распознавания образов на изображениях, в ответ на изображение с камеры пользовательского устройства модель ML может выдавать в виде текста на экране пользовательского устройства один или более вариантов названия предмета или предметов, распознанных моделью ML на введенном изображении. В варианте реализации, в котором распознается пользовательский голосовой ввод, модель ML может преобразовывать данные голосового ввода в текст на естественном языке, который далее может быть подвергнут анализу (например, синтаксическому анализу), после чего модель ML выдаст данные в виде вывода текстового сообщения на экране, повторяющего пользовательский голосовой ввод, вывода на экране пользовательского устройства результатов поиска в поисковой системе и/или на географической карте, если пользовательский голосовой ввод распознается в качестве поискового запроса в приложение, реализующее доступ к одной или более поисковым системам и/или в приложение, обеспечивающее доступ к географическим картам, отображение местоположения пользователя, прокладку навигационных маршрутов и т.п. В варианте реализации, в котором модель ML распознает рукописный ввод, в ответ на пользовательский ввод в виде движения по поверхности сенсорного экрана, например, одним или более пальцев или стилусом, модель ML может выводить предлагаемые варианты одного или более распознанных символов, слов или предложений на основании пользовательского ввода.
Следует отметить, что одна или более моделей ML может быть реализована программным средством, таким как компьютерная программа и/или один или более компьютерных программных элементов, модулей компьютерной программы, компьютерный программный продукт и т.п., выполненные на одном или более языках программирования или в виде машиноисполняемого кода. Кроме того, одна или более моделей ML согласно изобретению могут быть реализованы с применением различных аппаратных средств, таких как программируемые пользователем вентильные матрицы (FPGA), интегральные схемы, и тому подобное. Специалистам в данной области техники будут очевидны различные конкретные примеры программных и/или аппаратных средств, пригодных для реализации одной или более моделей ML, в зависимости от конкретной реализации предлагаемого изобретения.
Для осуществления связи между сервером и UE могут быть предусмотрены один или более известных в данной области техники блоков, посредством которых осуществляется передача и прием данных, их кодирование и декодирование, скремблирование, шифрование, преобразование и т.п. Связь UE с сервером может осуществляться посредством одной или более сетей связи, работающих на основе любой известной специалистам в данной области техники технологии беспроводной связи, такой как GSM, 3GPP, LTE, LTE-A, CDMA, ZigBee, Wi-Fi, Machine Type Communication (MTC), NFC и т.п., или на основе любой известной специалистам в данной области техники технологии проводной связи. Средства передачи и приема данных для связи между сервером и UE не ограничивают объем настоящего изобретения, и в зависимости от его конкретной реализации специалистами в данной области техники может быть предусмотрено сочетание из одного или более средств приема и передачи данных.
В одном или более вариантах выполнения настоящего изобретения также может быть предусмотрен модуль оценки моделей ML. Такой модуль может быть предусмотрен, в частности, на сервере. На основании оценки моделей ML, которые сервер принимает с различных пользовательских устройств, моделям ML с различных пользовательских устройств могут присваиваться различные весовые коэффициенты. Оценивается качество одной или более моделей ML, предпочтительно в рамках каждой конкретной группы индивидуализации, к которой относятся собранные с пользовательских устройств одна или более моделей ML. На основании оценки моделям ML могут быть присвоены весовые коэффициенты, в соответствии с которыми может далее выполняться обновление на сервере персонализированной модели ML путем усреднения моделей ML, принятых от одного или более UE, с учетом присвоенных им весовых коэффициентов. В вариантах выполнения настоящего изобретения при усреднении могут использоваться не все модели ML, собранные с пользовательских устройств, например, в рамках конкретной группы индивидуализации, а только те модели, весовые коэффициенты которых превышают определенное заданное пороговое значение или находятся в рамках определенного диапазона, ограниченного верхним и нижним пороговыми значениями, или в наибольшей степени приближаются к определенному заданному значению, в зависимости от конкретной реализации заявляемого изобретения.
Работа изобретения была экспериментально проверена для частного случая распределенного дообучения модели предсказания следующего слова для экранной клавиатуры мобильного телефона. В эксперименте в качестве модельных данных, используемых для обучения исходной модели использовались тексты сайта Wikipedia. Исходная модель обучалась на виртуальном сервере (далее ВС). В качестве модельных пользовательских данных использовались сообщения, взятые из корпуса Twitter. Тексты Twitter были случайным образом распределены по виртуальным узлам (далее ВУ), заменяющим мобильные устройства. Далее исходная модель рассылалась на ВУ вместе с порцией исходных данных Wikipedia. Соотношение порций Twitter и Wikipedia на ВУ: 1:1 (по 10 Кб). На получившихся 20 Кб текста запускался алгоритм обучения рекуррентной нейронной сети до сходимости, после чего модели, обученные на каждом из ВУ, отправлялись на ВС, где усреднялись. Модель на ВС обновлялась и процесс повторялся, причем на каждом из ВУ порция данных из Twitter обновлялась для имитации набора новой порции сообщений пользователем.
Эксперимент показал, что после 300 итераций описанного выше алгоритма качество предсказания следующего слова на текстах Twitter, оцениваемого в терминах среднего количества нажатий на клавиатуре, улучшилось на 8,5 процентных пунктов. При этом качество предсказаний на текстах Wikipedia почти не изменилось, что говорит о том, что «забывания» удалось избежать.
Кроме того, для описываемого выше метода были экспериментально проверены гарантии уровня приватности, измеренные в терминах дифферанциальной приватности (differential privacy). Экспериментальная оценка уровня приватности указывает на то, что вероятность раскрытия пользовательских данных крайне мала и как минимум не уступает другим аналогичным методам распределенного обучения.
Работа настоящего изобретения будет пояснена ниже на иллюстративном варианте выполнения, приведенном исключительно в качестве примера, но не ограничения.
Рассмотрим последовательность операций способа распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI) согласно первому из вышеперечисленных аспектов настоящего изобретения.
В соответствии со способом согласно изобретению, на этапе S1 инициализируют одну или более моделей машинного обучения (ML) на сервере. Инициализация может включать в себя обучение упомянутых одной или более моделей ML на основании исходной выборки обучающих данных, которые представляют собой общедоступные данные.
Далее, на этапе S2 распространяют упомянутые инициализированные одну или более моделей ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи. Распространение может быть реализовано посредством передачи данных упомянутых одной или более моделей ML с сервера на одно или более UE при помощи любых средств, известных в области беспроводной передачи данных. В качестве альтернативы, модели ML могут распространяться и другими средствами, в частности по проводным сетям, на съемных машиночитаемых носителях и т.п.
На этапе S3 на каждом из одного или более UE накапливают данные, формируемые пользователем посредством пользовательского ввода. Данные формируются пользователем в процессе использования одного или более программных приложений, установленных на UE, а также в процессе передачи сообщений, осуществления вызовов по одной или более сетям связи и т.п. В качестве примера, обучаемая модель ML может быть выполнена с возможностью предсказания слов и словосочетаний при вводе пользователем текстового сообщения на UE. При этом формируемые пользователем данные, накапливаемые на этапе S3, могут представлять собой, например, слова и словосочетания, вводимые пользователем при составлении текстовых сообщений, заметок, записей и т.п. В качестве другого примера, модель ML может быть выполнена с возможностью распознавания предметов на изображениях, получаемых с одной или более камер UE. В таком случае, формируемые пользователем данные представляют собой изображения, которые пользователь формирует посредством одной или более фото- или видеокамер, предусмотренных в UE, а также метки, присваиваемые пользователем предметам, присутствующим на изображениях. Кроме изображений с одной или более камер UE распознавание образов может выполняться моделью ML также и на изображениях, которые UE получает из других источников, например принимает посредством сети связи в сообщениях от других пользователей или при просмотре веб-сайтов.
В другом примере, модель ML может быть выполнена с возможностью распознавания рукописного ввода, принимаемого от пользователя посредством сенсорного экрана UE и/или сенсорной панели UE. В таком случае формируемые пользователем данные могут представлять собой рукописный ввод, выполняемый пользователем посредством упомянутого сенсорного экрана и/или сенсорной панели при помощи, например, одного или более пальцев или стилуса, а также выбор пользователем предлагаемых моделью ML вариантов символов и/или слов, основанных на рукописном вводе от пользователя, которые UE отображает на экране при выполнении соответствующего программного приложения.
В другом примере, модель ML может быть выполнена с возможностью распознавания голосового ввода, принимаемого от пользователя посредством одного или более микрофонов, предусмотренных в UE, при этом формируемые пользователем данные представляют собой упомянутый голосовой ввод и/или выбор пользователем предлагаемых моделью ML вариантов слов и/или словосочетаний, основанных на голосовом вводе от пользователя, которые UE отображает на экране при выполнении соответствующего программного приложения.
Еще в одном примере, модель ML может быть выполнена с возможностью распознавания одной или более характеристик окружения UE и/или одного или более действий пользователя. Характеристики окружения UE могут представлять собой, не ограничиваясь, время, дату, день недели, уровень освещенности, температуру воздуха, уровень влажности воздуха, географическое местоположение UE, пространственное положение UE. При этом формируемые пользователем данные представляют собой пользовательский ввод в одно или более программных приложений на UE. В данном примере модель ML может предлагать пользователю, например, различные действия в управлении различными программными приложениями на UE и/или автоматически вызывать выполнение определенных действий в упомянутых программных приложениях.
Формируемые пользователем данные накапливаются на UE в течение заданного периода накопления данных. Когда накапливаемые на UE пользовательские данные достигают заданного объема, UE может передавать на сервер сообщение о том, что накоплен необходимый объем данных.
На этапе S4 сервер передает на UE обучающие данные, которые представляют собой порцию выборки исходных данных, использовавшихся на этапе S1 при первоначальном обучении модели ML. Эти данные являются общедоступными и не характеризуют конкретного пользователя. Использование выборки исходных данных при обучении модели ML позволяет гарантировать безопасность личных данных пользователя и предотвратить «переобучение» модели ML на UE.
Далее на этапе S5 осуществляют обучение модели ML на каждом из одного или более UE на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения. В качестве критерия прекращения обучения, в качестве неограничивающего примера, может выступать достижение сходимости моделей ML среди одного или более UE, либо достижение моделью ML заданного значения характеристики качества модели ML, либо достижение заданного количества периодов обучения модели ML.
На этапе S6 получают на сервере обученные модели ML от упомянутых одного или более UE. Данная операция представляет собой передачу моделей ML, прошедших обучение на соответствующих UE, например, на сервер посредством сети беспроводной связи. Сервер собирает обученные на различных UE модели ML.
На этапе S7 сервер обновляет модель ML путем усреднения обученных моделей ML, полученных от одного или более UE. В качестве неограничивающего примера, упомянутое обновление модели ML может состоять в агрегировании персонализированных моделей ML, полученных от одного или более UE, на сервере. В результате агрегации получается новая версия модели ML, основанная на персонализированных моделях ML, обученных на одном или более UE и собранных на сервере.
На этапе S8 полученная посредством усреднения новая версия модели ML передается сервером в одно или более UE. Данная передача осуществляется, в качестве неограничивающего примера, общеизвестными средствами сети беспроводной связи.
Этапы S3-S8 могут повторяться один или более раз, например, до получения модели ML, соответствующей одному или более критериям качества модели ML. В результате получается персонализированная модель ML, «дообученная» на основании данных, формируемых пользователями различных UE, а также выборки исходных данных, применяемых при первоначальном обучении модели ML на сервере.
По меньшей мере в одном из вариантов выполнения изобретения способ может дополнительно содержать этап идентификации одной или более групп персонализации для пользователей каждого из одного или более UE на основании данных, формируемых пользователем, собранных на упомянутом каждом из одного или более UE. Далее, согласно упомянутому по меньшей мере одному из вариантов выполнения, способ содержит группирование на сервере моделей ML, полученных от упомянутых одного или более UE, по группам персонализации; и передачу обновленных моделей ML, сгруппированных по группам персонализации, только в UE, входящие в соответствующую группу персонализации. Таким образом обеспечивается дополнительная персонализация обучаемых моделей ML и повышается точность моделей ML для различных групп пользователей.
Специалистам в данной области техники будет понятно, что выше описаны и показаны на чертежах лишь некоторые из возможных примеров технических приемов и материально-технических средств, которыми могут быть реализованы варианты выполнения настоящего изобретения. Специалистам в данной области техники также будет понятно, что этапы описанного в настоящем документе способа не обязательно выполняются в той последовательности, в которой они описаны, а по меньшей мере некоторые из этапов способа могут выполняться в порядке, отличном от описанного, в том числе по существу одновременно, или некоторые этапы могут быть пропущены. Приведенное выше подробное описание вариантов выполнения изобретения не предназначено для ограничения или определения объема правовой охраны настоящего изобретения.
Другие варианты выполнения, которые могут входить в объем настоящего изобретения, могут быть предусмотрены специалистами в данной области техники после внимательного прочтения вышеприведенного описания с обращением к сопровождающим чертежам, и все такие очевидные модификации, изменения и/или эквивалентные замены считаются входящими в объем настоящего изобретения. Все источники из уровня техники, приведенные и рассмотренные в настоящем документе, настоящим включены в данное описание путем ссылки, насколько это применимо.
При том, что настоящее изобретение описано и проиллюстрировано с обращением к различным вариантам его выполнения, специалистам в данной области техники будет понятно, что в нем могут быть выполнены различные изменения в его форме и конкретных подробностях, не выходящие за рамки объема настоящего изобретения, который определяется только нижеприведенной формулой изобретения и ее эквивалентами.

Способ и устройство для совместного использования функции внешнего устройства через сложную сеть
Устройство и способ для поддержки регулирования яркости при связи в диапазоне видимого света
Способ и устройство связи в беспроводной телесной локальной сети
Способ и устройство для кодирования и декодирования изображения посредством использования вращательного преобразования
Способ и устройство для компоновки сцены с использованием контентов laser
Способ и система управления передачей в сетях радиодоступа
Способ и устройство для обработки изображения
Способ и устройство для продвинутого управления буфером arq в беспроводной системе связи
Способ и устройство для кодирования видео и способ и устройство для декодирования видео, основанные на иерархической структуре блока кодирования
Способ и устройство для кодирования и декодирования блока кодирования границы картинки
Способ корректировки освещенности объекта на изображении в последовательности изображений и вычислительное устройство пользователя, реализующее упомянутый способ
Система и способ для автоматического выполнения команд, заданных пользователем

