Результат интеллектуальной деятельности: СИСТЕМА КОМПОНЕНТНО-ОРИЕНТИРОВАННОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ И СПОСОБ РАЗРАБОТКИ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее изобретение относится в целом к технологиям разработки компонентно-ориентированного программного обеспечения.
Уровень техники
Процедурное программирование представляет собой парадигму программирования, полученную из структурированного программирования, основанную на концепции процедурного вызова. Процедуры, также известные как способы, подпрограммы или функции, содержат последовательности вычислительных этапов, которые необходимо выполнить. Примерами языков процедурного программирования являются: C, Fortran и Pascal.
В объектно-ориентированном программировании основное внимание уделяют разбивке задач программирования на объекты, которые реализуют логику работы (способы), и данные (элементы или атрибуты) с использованием интерфейсов. Хотя процедурное программирование использует процедуры для работы со структурами данных, объектно-ориентированное программирование объединяет их вместе, поэтому «объект», который является экземпляром класса, работает на своей «собственной» структуре данных.
Повторное использование кода является основным способом повышения эффективности разработки программного обеспечения. Функция представляет собой наименьший блок или структуру многократного использования. Вызов функции либо в процедурном программировании, либо в объектно-ориентированном программировании выполняют на уровне инструкций. Переменные, соответствующие аргументам вызываемой функции, должны быть объявлены, заданы значения и переданы вызываемой функции, и устанавливают возвращаемое значение в переменную и будут использовать при последующем вычислении. Эти инструкции формируют связь между вызывающей и вызываемой функциями и уменьшают возможность повторного использования вызывающей функции. При написании программного обеспечения либо в процедурном программировании, либо в объектно-ориентированном программировании требуется значительное количество конкретных переменных данных приложения, которые должны быть объявлены и использованы на уровне инструкций. Поскольку эти инструкции специфичны для приложений, то они не могут использоваться повторно в другом программном обеспечении. Эти инструкции реализованы на том же языке программирования, что и повторно используемые коды в программном обеспечении, они смешиваются вместе с повторно используемыми кодами. При выполнении поддержки и модификации программного обеспечения необходимо читать и различать, понимать и изменять эти инструкции. Это особенно трудоемко, когда инструкции написаны другим специалистом.
Сборочная линия представляет собой производственный процесс, в котором добавляют взаимозаменяемые части при перемещении полуфабриката от одной рабочей станции на другую рабочую станцию, при этом детали добавляют последовательно до получения готового изделия. Благодаря использованию конвейерной линии сборки готовое изделие может быть собрано быстрее и с меньшими затратами.
Таким образом, существует потребность в компонентно-ориентированном или блочно-ориентированном механизме, который позволяет разработать программное обеспечение для использования в конвейерной линии сборки.
Раскрытие сущности изобретения
В этом изобретении раскрыт способ разработки программного обеспечения, который объявляет все конкретные для приложения переменные вне части кода (функций) программного обеспечения в конкретной структуре данных, называемой сообщением данных о результатах вычислений и ее таблицей свойств. Способ также устраняет связь между функциями. Функции взаимно независимы, и возможность их повторного использования возрастает. Функции также становятся чистыми функциями алгоритма, которые не связаны ни с одним приложением и могут использоваться в любом приложении. Это еще больше увеличивает возможность повторного использования функций. Вычисление выполняют с помощью частичной функции для реализации сопоставления переменных в сообщениях данных о результатах вычислений с аргументами функций, и выполнения функций и обратного сопоставления результатов вычислений функций с сообщениями данных о результатах вычислений. Частичная функция функционирует в качестве организатора посредством ассемблирования функций для достижения цели вычисления. Информация является специфичной для приложения в программном обеспечении, и приложение с конкретными переменными данными использует их при вычислении, которое реализуют иным образом, чем код (функции) и может быть легко идентифицировано, понято и изменено. Кодовая часть программного обеспечения представляет собой алгоритм чистых функций, они не содержат никакой конкретной информации приложения.
Согласно примерным вариантам осуществления изобретения предоставляют способ сборки программного кода для выполнения службы. Способ включает в себя этапы, на которых: преобразуют требование ввода/вывода (I/O) службы в соответствующее сообщение данных, содержащее множество пар I/O «ключ-значение»; конфигурируют частичную функцию (PF) программы для приема сообщения данных в качестве аргумента ввода; генерируют набор (VMSS) структур сопоставления переменных (VMS), включающий в себя пары ключей, которые сопоставляют с аргументами вычислительной функции (CF) и с парами I/O «ключ-значение»; и конфигурируют PF для вызова вычислительной функции (CF) с использованием VMSS, при этом CF выполнена с возможностью выполнения операции, относящейся к службе.
Согласно примерному варианту осуществления изобретения обеспечивается способ выполнения компьютерной программы, выполненной с возможностью выполнения службы. Компьютерная программа включает в себя частичную функцию (PF), выполненную с возможностью приема сообщения данных, включающего в себя множество пар «ключ-значение» ввода/вывода (I/O) в качестве аргумента ввода. Способ включает в себя этапы, на которых: получают структуру данных, включающую в себя множество элементов, с использованием имени сообщения данных, при этом каждый элемент включает в себя имя и структуру сопоставления переменных (VMS); и для каждого элемента в полученной структуре данных, с использованием имени элемента, получают вычислительную функцию (CF) и вызывают полученную CF с использованием VMS элемента и сообщения данных.
Краткое описание чертежей
Далее приведено подробное описание иллюстративных вариантов осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает способ сборки программного обеспечения в соответствии с примерным вариантом осуществления концепции изобретения;
Фиг.2 иллюстрирует примерную компьютерную систему, которую могут использовать для выполнения способа;
Фиг.3 иллюстрирует способ конфигурирования частичной функции программного обеспечения в соответствии с примерным вариантом осуществления концепции изобретения;
Фиг.4 иллюстрирует способ выполнения частичной функции программного обеспечения в соответствии с примерным вариантом осуществления концепции изобретения;
Фиг. 5 иллюстрирует способ сборки программного обеспечения в соответствии с примерным вариантом осуществления концепции изобретения;
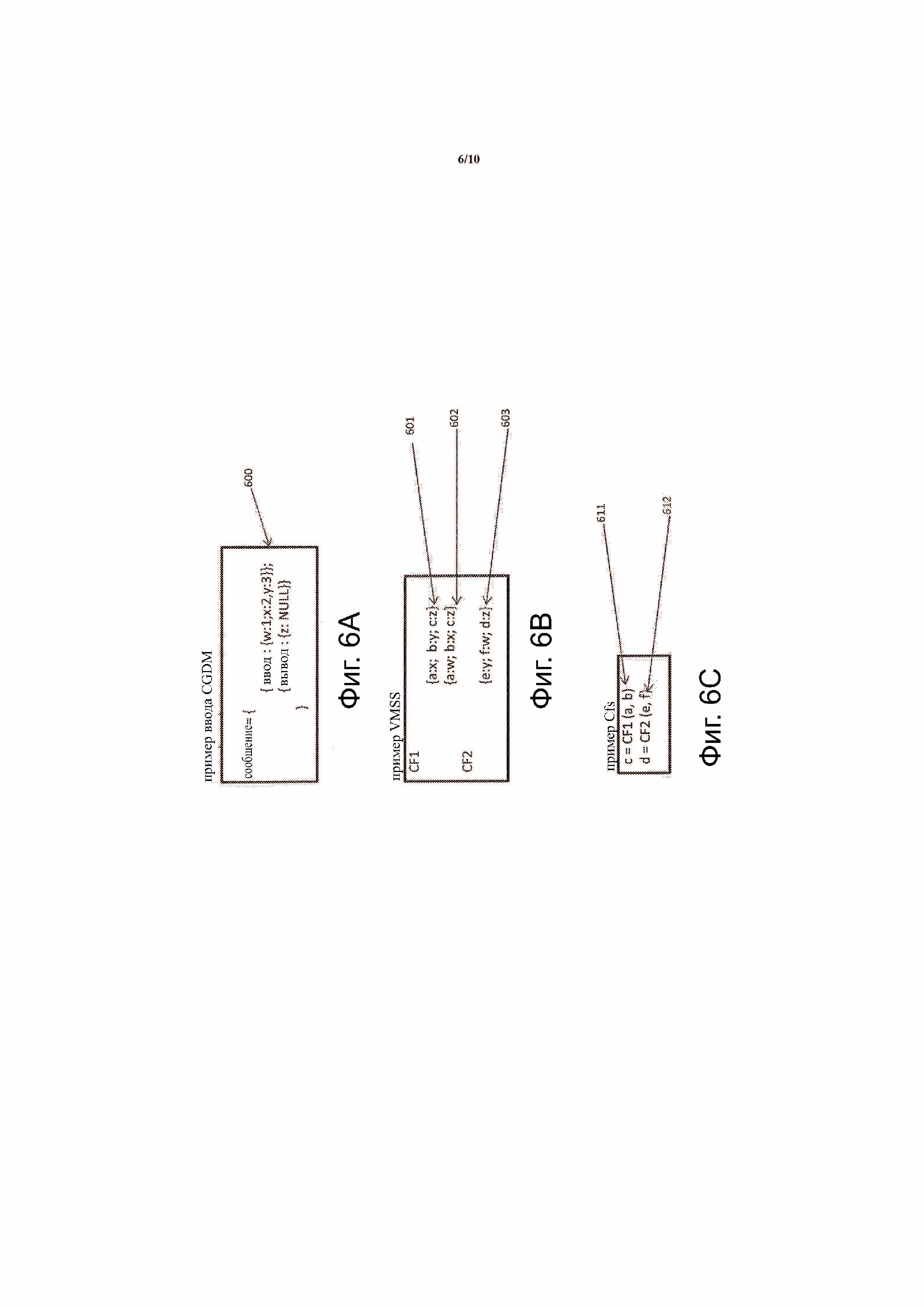
Фиг. 6А представляет собой иллюстративное сообщение данных, которое могут использовать в вариантах осуществления концепции изобретения;
Фиг.6B иллюстрирует примерный набор структур сопоставления переменных, который может использоваться в вариантах осуществления концепции изобретения;
Фиг. 6C иллюстрирует примеры аргументов ввода и вывода примерных вычислительных функций;
Фиг. 7 иллюстрирует блок-схему алгоритма, показывающую выполнение частичной функции собранного программного обеспечения в соответствии с примерным вариантом осуществления концепции изобретения;
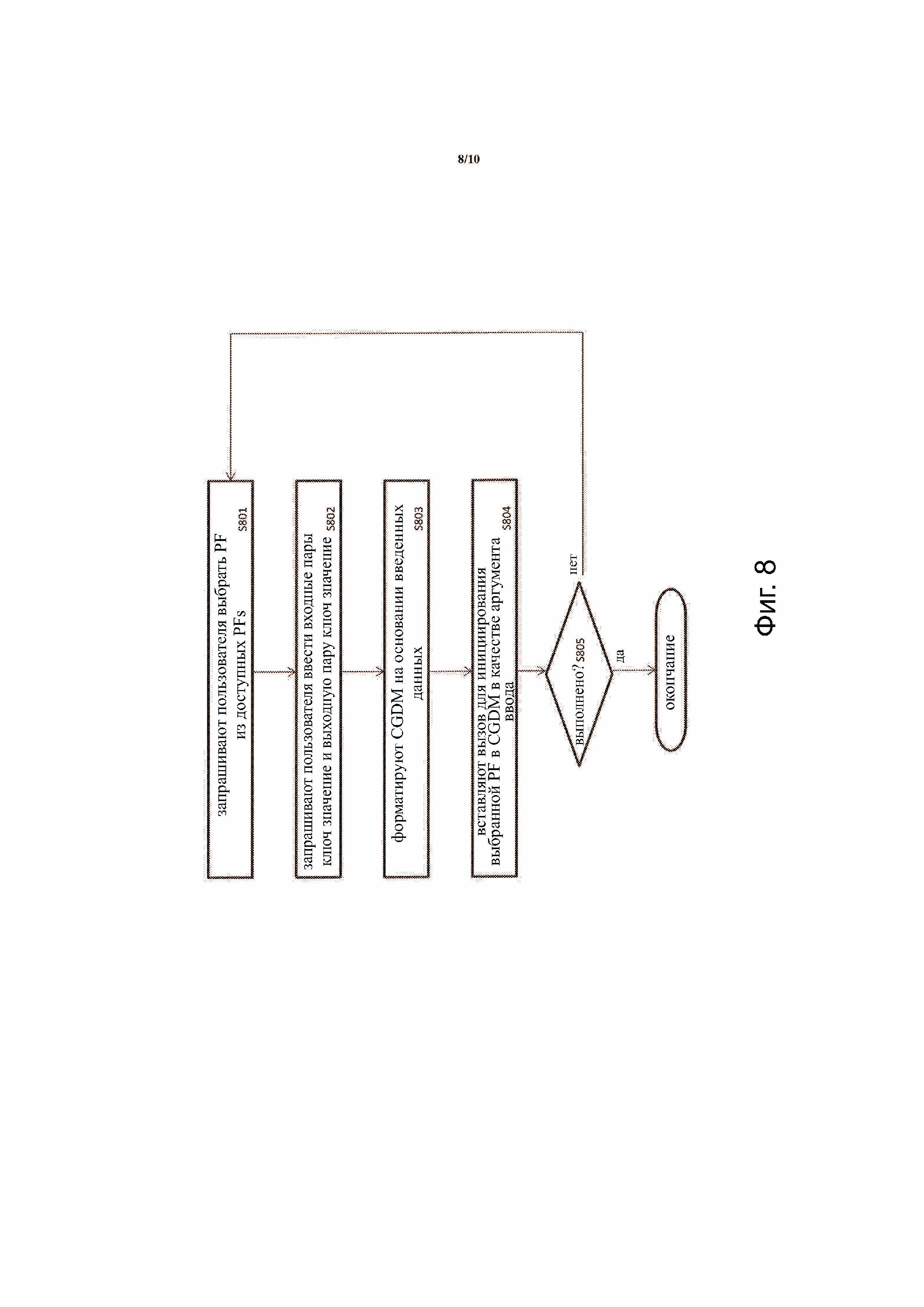
Фиг.8 иллюстрирует способ предоставления пользователю возможности собирать программное обеспечение в соответствии с примерным вариантом осуществления концепции изобретения;
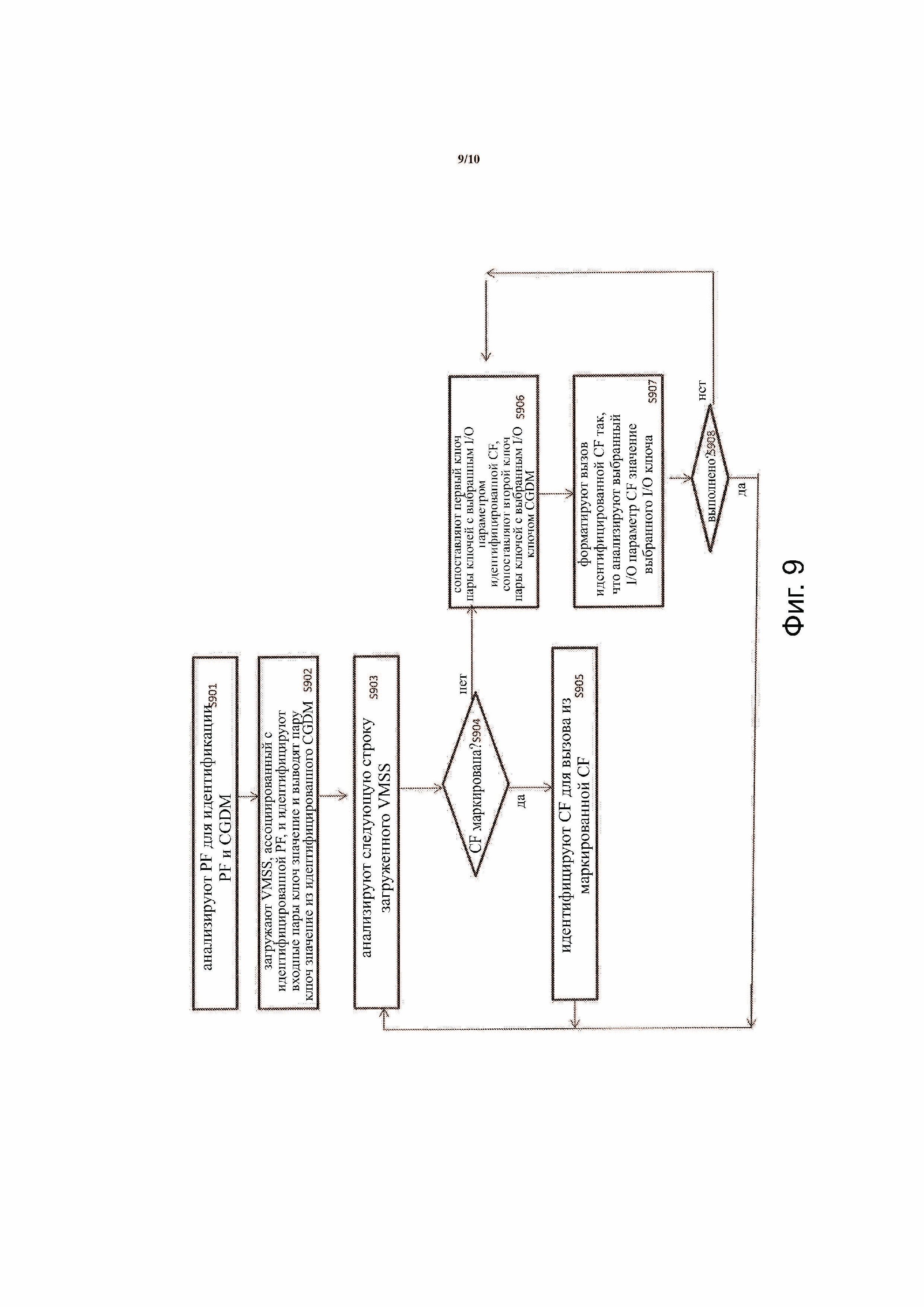
Фиг.9 иллюстрирует способ выполнения частичной функции в соответствии с примерным вариантом осуществления концепции изобретения; и
Фиг.10 иллюстрирует примерную последовательность функций части, выполняемых в ответ на применяемое сообщение данных, в соответствии с примерным вариантом осуществления концепции изобретения.
Осуществление изобретения
Концепция изобретения будет описана более подробно со ссылкой на прилагаемые чертежи, на которых проиллюстрированы примерные варианты осуществления настоящего изобретения. На всех чертежах одинаковые или подобные ссылочные позиции используют для обозначения тех же или подобных компонентов. Однако настоящая изобретательская концепция может быть реализована различными способами и, следовательно, не должна толковаться как ограничиваемая раскрываемыми здесь вариантами осуществления. Напротив, эти варианты осуществления используют для предоставления полного понимания настоящего изобретения с целью раскрытия объема настоящего изобретения специалистам в данной области техники.
Далее приведено описание системы компонентно-ориентированного программного обеспечения и способа разработки. В нижеследующем описании приведено множество конкретных деталей с целью обеспечения более полного понимания настоящего изобретения. Однако специалисту в данной области техники будет очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В других случаях для упрощения описания настоящего изобретения подробное описание хорошо известных признаков не приведено.
Устройства компьютерного кода (например, способы, классы, библиотеки), упомянутые здесь, могут быть сохранены на носителе данных. Используемый здесь термин «носитель данных» обозначает все машиночитаемые носители, такие как компакт-диски, жесткие диски, гибкие диски, лента, магнитооптические диски, PROMs (EPROM, EEPROM, Flash EPROM и т.д.), DRAMs, SRAMs и так далее.
Фиг. 1 представляет собой схему высокого уровня, показывающую способ ассемблирования программного обеспечения в соответствии с примерным вариантом осуществления концепции изобретения.
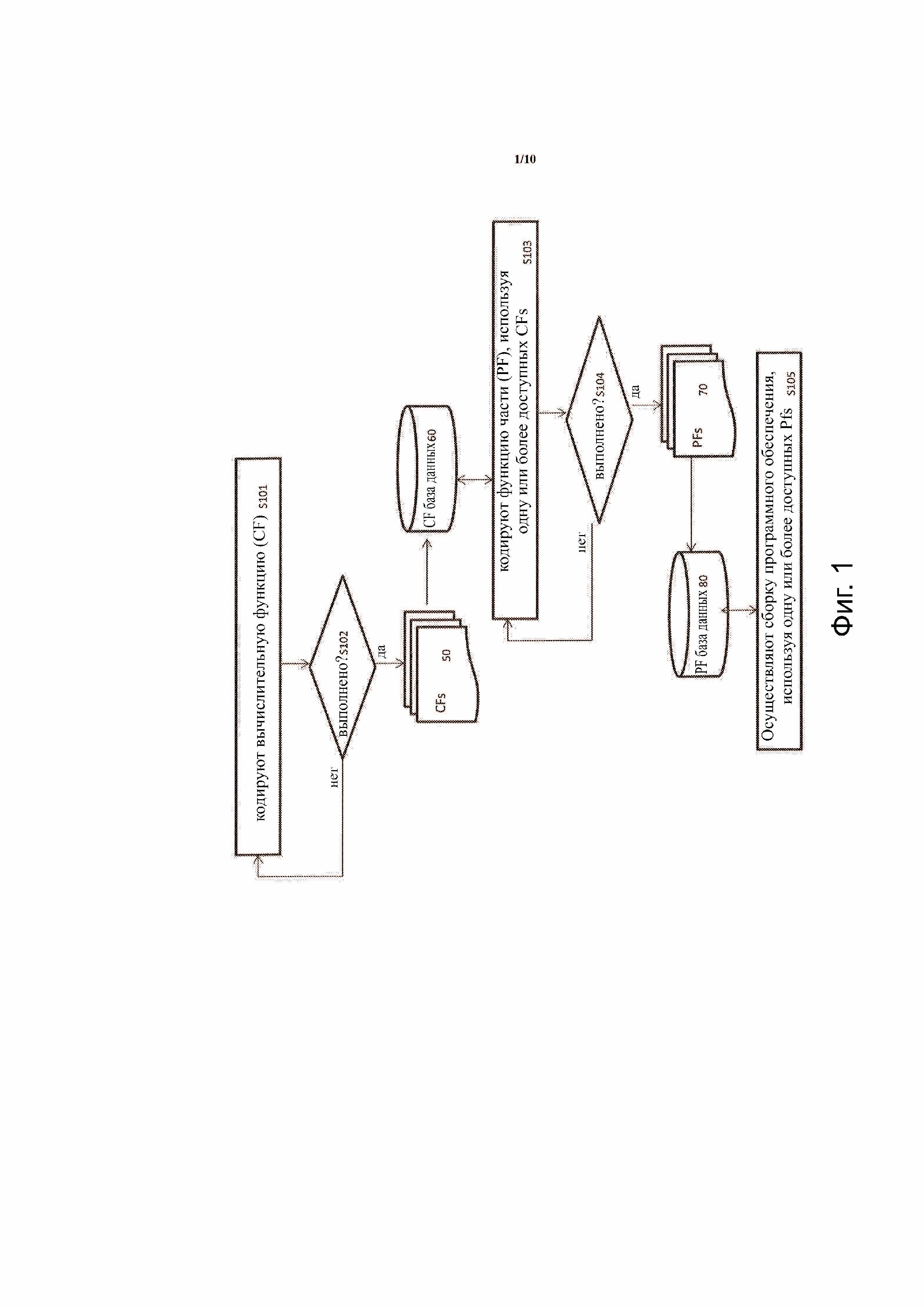
Способ включает в себя предоставление пользователю возможности кодировать вычислительную функцию (CF) (S101). Например, CF графический пользовательский интерфейс (например, CF-GUI), включающий в себя текстовое поле, может быть предоставлен компьютерной программой, которая позволяет пользователю вводить код для CF. Например, CF-GUI может включать в себя первую кнопку, которая при выборе пользователем информирует программу, что пользователь завершил кодирование текущей CF. В качестве примера, CF может быть закодирована для выполнения вычисления, запроса к базе данных или представления графики или текста на веб-странице. Например, расчет может быть использован для выполнения математического расчета результатов, возвращаемых при запросе. В варианте осуществления каждая CF задана пользователем уникальным именем и кодируют для приема одного или более параметров ввода (здесь называются CF параметрами ввода) и для возврата параметра вывода (здесь и далее называемого CF параметром вывода). Например, CF параметры ввода и вывода могут быть целыми числами, числами с плавающей запятой, строками, массивами, указателями и т.д.
Затем способ включает в себя определение, выполняется ли пользователем кодирование CFs (S102). Например, выбор первой кнопки может указывать, что пользователь желает сформировать другую CF. Например, CF-GUI может включать в себя вторую кнопку, которая при выборе пользователем информирует программу, что пользователь формирует CFs 50. Завершенные CFs могут быть сохранены в CF базе 60 данных, чтобы они были доступны другим кодам.
Способ дополнительно включает в себя предоставление пользователю возможности кодировать частичную функцию (PF) с использованием одной или более доступных CFs (S103). Например, программа может представить второй графический интерфейс (например, PF-GUI) с выбираемым списком доступных CFs, хранящихся в CF базе 60 данных в графическом интерфейсе, и панель, показывающую, какие CFs были выбраны, и их порядок выполнения в пределах PF. Например, пользователь может выбрать одну из доступных CFs каждый раз, когда экземпляр соответствующей CF необходим для соответствующей PF, и вставить выбранный экземпляр в панель в том порядке, в котором пользователь желает выполнить экземпляр CF.
Дополнительно способ включает в себя программу, определяющую, когда пользователь сформировал все PFs (S104). Например, PF-GUI может включать в себя графическую кнопку, которая при выборе пользователем указывает, что пользователь сформировал все PFs 70. PFs 70 могут быть сохранены в PF базе 80 данных, чтобы они были доступны другим кодам.
Затем способ включает в себя программу, позволяющую пользователю разрабатывать программное обеспечение с использованием одной или более доступных PFs 70, которые хранят в PF базе 80 данных (S105). Например, компьютерную программу могут использовать для запуска третьего графического интерфейса, который представляет текстовое поле, предоставляя возможность пользователю вводить код соединения и выбираемый список доступных PFs 70. Например, пользователь может выбрать PF из списка, чтобы вставить соответствующую PF в определенное место в код соединения компьютерной программы. В варианте осуществления компьютерная программа может иметь форму, интерпретируемую интерпретатором.
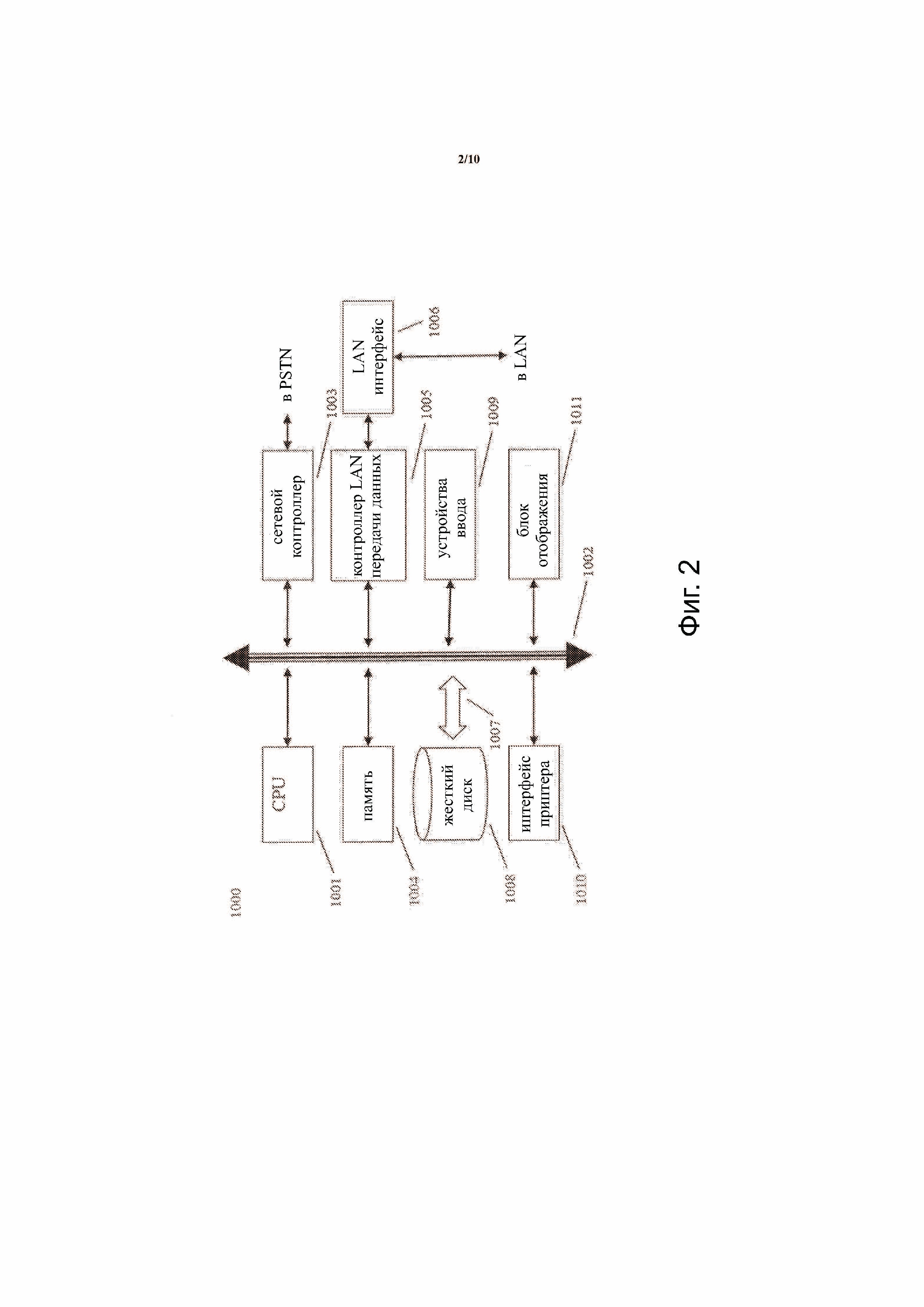
Фиг.2 иллюстрирует примерную компьютерную систему 1000, которую могут использовать для реализации способа по фиг. 1. Обращаясь к фиг. 2, компьютерная система 1000 может включать в себя, например, центральный процессор (CPU) 1001, оперативное запоминающее устройство (RAM) 1004, интерфейс 1010 принтера, блок 1011 отображения, контроллер 1005 передачи данных локальной сети (LAN), LAN интерфейс 1006, сетевой контроллер 1003, внутреннюю шину 1002 и одно или несколько устройств 1009 ввода, например клавиатуру, мышь и т. д. Как показано, система 1000 может быть подключена к устройству хранения данных, например, жесткий диск 1008 через линию 1007 связи. Вышеописанные графические интерфейсы могут быть представлены на блоке 1011 отображения. Вышеописанные CFs 50, PFs 70, программа и ассемблированное программное обеспечение могут быть сохранены в памяти 1004 и/или жестком диске 1008.
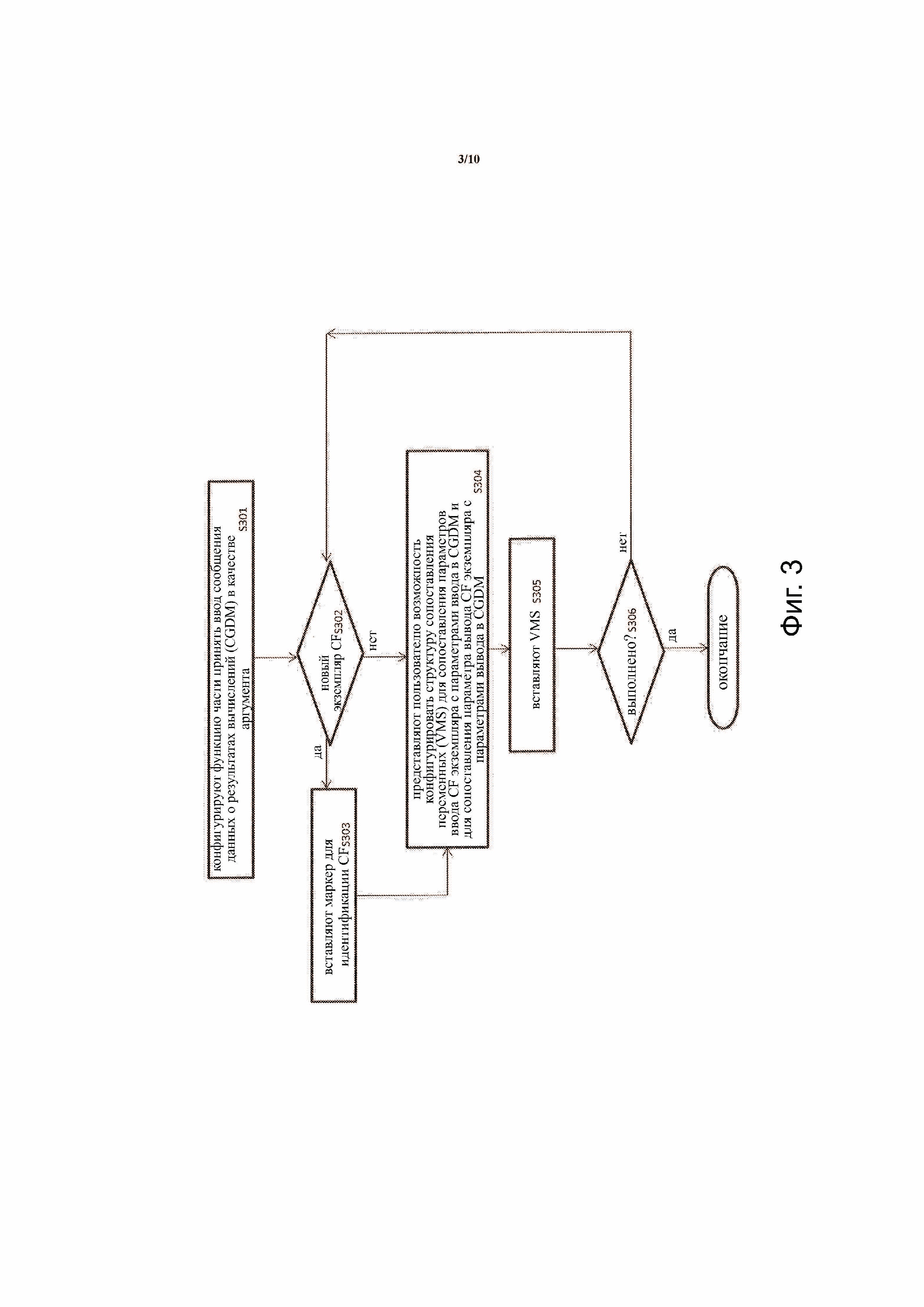
На фиг. 3 иллюстрирует способ согласно примерному варианту осуществления изобретения, который может быть использован для реализации этапа S103 по фиг. 1 для кодирования PF. Обращаясь к фиг. 3, способ включает в себя конфигурирование частичной функции принять ввод сообщения данных о результатах вычислений (CGDM) (S301).
В примерном варианте осуществления CGDM имеет i) части ввода и вывода, ii) вид «имя-значение» (например, все значения, подструктуры значений, которые будут назначены переменной в любом последующем вычислении, должны иметь имя), и iii) его структура удовлетворяет некоторым синтаксическим правилам (например, HTML, XML или JSON). Два CGDMs одинаковы, если i) обе части ввода и вывода имеют одинаковые структуры, и ii) все имена в структурах одинаковы. CGDM используют как аргумент PF. Любая PF может иметь только один аргумент. PF может обрабатывать одно или более чем одно CGDM. Каждое CGDM имеет соответствующий VMSS. VMSS инструктирует PF, как получить результат вычисления CGDM.
Имена в CGDM называют рабочими именами, они представляют переменные для данных приложения.
Все PFs имеют один и тот же интерфейс. Например, каждая частичная функция выполнена с возможностью быть вызванной CGDM, что может упоминаться как параметр привлечения или аргумент частичной функции. CGDM включает в себя параметры X ввода (например, Input: X) и параметры Y вывода (например, Output: Y), при этом X и Y могут быть любой структурой данных, которая имеет вид «имя (ключ)-значение». В X части имена имеют значения, и значения Y части пустые для заполнения функцией части. Два CGDMs одинаковы, если и части ввода, и части вывода имеют одинаковые структуры, и все имена (ключи) в структурах одинаковы. Каждый CGDM имеет уникальное имя. CGDM со значениями всех имен (ключей) его набора части ввода называется экземпляром CGDM. PF возвращает структуру данных так же, как и часть вывода CGDM с заполненными значениями. PF рассматривает любое CGDM в качестве аргумента.
PF содержит одну или более вычислительных функций (CFs). Любая функция может быть CF. PF может рассматривать любое CGDM в качестве аргумента, поскольку то, как PF выполняет CFs, не определяется только CGDM, но также структурой данных, называемой структурой сопоставления переменных (VMS). PF выполняет CF через CFCaller. CFCaller принимает CGDM, структуру VMS и CFResults в качестве аргументов. Обеспечивают единый интерфейс для вызова PF. CFCaller: i) подготавливает аргументы CF и вызов в соответствии с CGDM и VMS, ii) устанавливает часть вывода CGDM в соответствии с CGDM и VMS и iii) сохраняет результат в CFResults для возможного использования посредством последующего выполнения CF.
В варианте осуществления изобретения могут присутствовать два типа CF функций, i) полная CF и ii) частичная CF. Полная CF не вызывает PF и полностью удовлетворяет требования интерфейса. Частичная CF вызывает PF и частично удовлетворяет требования интерфейса. Как удовлетворяют требование интерфейса, зависит от того, какая PF вызывается, и от того, как конфигурируют PF.
VMS сопоставляет данные между CFs и CGDM, так что CFs не имеют прямой взаимосвязи с CGDM, соответственно отсутствует взаимосвязь с переменными данными приложения. CFs могут быть алгоритмом с чистыми функциями. VMS отделяет CF из CGDM, если CGDM отправляют частичной CF, при этом CFs, обрабатывающие CGDM, также не связаны с частичной CF. Между какими-либо CF отсутствует действие вызова, поэтому нет связи между CFs и они взаимно независимы, и каждая CF может быть независимо разработана для реализации алгоритма без знания других алгоритмов.
В случае, когда CF вызывает PF, подготавливают CGDM и передают CGDM в качестве аргумента в вызываемую PF. Имена значений в CGDM могут присваивать согласно правилу совместимого наименования. Имена PFs вызовов CF и имена образованных CGDMs могут быть указаны в VMSs CF.
VMSSs обеспечивают управление для соединения CFs, частичная CF обеспечивает управление соединением PFs. Программное обеспечение может быть сформировано путем манипулирования VMS и VMSS для соединения PFs и CFs в соответствии с заданной архитектурой.
Для одного CGDM вызывают последовательность выполнения всех PFs (могут использовать более одной PF) и CFs для достижения цели вычисления CGDM в структуре вычислений CGDM.
На фиг. 6A показан пример CGDM, которое могут предоставлять как аргумент частичной функции. В этом примере CGDM имеет формат нотации объекта JavaScript (JSON). CGDM включает в себя одну или несколько пар «ключ-значение» ввода и пар «ключ-значение» вывода. CGDM может включать в себя идентификаторы, которые могут использоваться средством синтаксического анализа или интерпретатором для извлечения пар «ключ-значение» ввода и вывода.
В примере, показанном на фиг. 6A, идентификатор параметра ввода в CGDM обозначен как «Input:», и идентификатор параметра вывода обозначен как «Output:». Например, после анализа CGDM средство синтаксического анализа распознает идентификатор «Input:», средство синтаксического анализа может предположить, что следующие элементы, расположенные между следующей открытой фигурной скобкой «{« и закрытой скобой «}», являются парами параметров ввода «ключ-значение». Например, после анализа CGDM средство синтаксического анализа распознает идентификатор «Output:», средство синтаксического анализа может предположить, что следующие элементы, расположенные между следующей открытой фигурной скобкой «{« и закрытой скобкой «}», являются парами параметров вывода «ключ-значение». Например, пары «ключ-значение» могут быть разделены точкой с запятой «;» и ключ и значение данной пары «ключ-значение» могут быть разделены двоеточием «:».
На фиг.6А показан порядок использования ссылочной позиции «Input:» для обозначения пар параметров ввода «ключ-значение», использования ссылочной позиции «Output:» для обозначения пар параметров вывода «ключ-значение», использование ссылочной позиции «{» для обозначения начала пар «ключ-значение», использование ссылочной позиции «}» для обозначения окончания пар «ключ-значение» и использование ссылочной позиции «:», чтобы позволить средству синтаксического анализа различать ключ от значения, изобретение не ограничено этим. Например, эти ссылочные позиции могут быть изменены на другие слова или символы, по желанию исполнителя.
Обратимся к фиг. 3, настоящий способ включает в себя определение, желает ли пользователь частичной функции вызвать новый экземпляр вычислительной функции (CF) (S302). Новый экземпляр означает, что это первый случай, когда запрашивают конкретную CF для вставки или запрашиваемая вставка приведет к тому, что экземпляр CF (например, CF2) будет вставлен после другой CF (например, CF1). Для удобства объяснения предполагают, что доступны только первая вычислительная функция CF1 и вторая вычислительная функция CF2, как показано на фиг. 6B. Если пользователь запросил новый экземпляр CF, то согласно способу вставляют метку для идентификации конкретной CF (S303). Например, поскольку пользователь запросил использовать первую вычислительную функцию CF1, то согласно способу вставляют метку, такую как «CF1», в последовательность структуры сопоставления переменных (VMSS), чтобы идентифицировать, что должна быть вызвана первая вычислительная функция CF1. VMSS, после завершения, будет включать в себя последовательность пар, при этом каждая пара включает в себя имя данной CF (например, CF1) и VMS (например, CFName, VMS). Например, завершенный VMSS может включать пары: {{CF1, VMS1}, ..., {CFN, VMSN}}, в котором N равно 1 или более. VMSS ассоциирован с CGDM, и все VMSs в VMSS полностью заполняют значения всех имен (ключей) CGDM. То есть, VMSS выполняет задачу вычисления для CGDM. VMSS инструктирует PF, как получить результат вычисления для CGDM.
Далее, способ включает в себя предоставление пользователю возможности конфигурировать структуру сопоставления переменных (VMS), которая сопоставляет параметры ввода экземпляра CF с параметрами ввода в CGDM и сопоставляет параметры вывода экземпляра CF с параметрами вывода в CGDM (S304). VMS инструктирует PF как выполнить одну CF.
Например, на фиг. 6В показан пример, на котором первая VMS 601 сконфигурирована для первой CF1 611 с множеством пар ключей, при этом каждая пара ключей разделяют точкой с запятой «;». Например, первый ключ «a» в первой паре ключей «a:x» первой VMS 601 соответствует первому параметру «a» ввода первой CF1 611 и второй ключ «x» в первой паре ключей «a:x» соответствует второму параметру «x:2» ввода CGDM 600, показанному на фиг. 6А. Например, первый ключ «b» во второй паре ключей «b:y» первой VMS 601 соответствует второму параметру «b» ввода первой CF1 611 и второй ключ «y» во второй паре ключей «b:y» соответствует третьему параметру «y:3» ввода CGDM 600, показанному на фиг. 6А. Например, первый ключ «c» в третьей паре ключей «c:z» первой VMS 601 соответствует параметру «c» вывода первого CF1 611 и второй ключ «z» в третьей паре ключей «c:z» соответствует параметру «z:NULL» вывода CGDM 600, показанному на фиг. 6А. Фиг. 6C иллюстрирует примеры вызовов CFs. В случае, когда аргумент CF является составным типом, если он сопоставляется с одним и тем же составным типом в части ввода CGDM, предполагают, что имя аргумента является C и имя того же типа (подструктура части ввода CGDM) является D, то сопоставление может быть указано как «C:D». Если не сопоставляют с одним и тем же составным типом в части ввода CGDM, и его элементы сопоставляют с именами, распределенными в части ввода CGDM, необходимо указать сопоставление для каждого элемента составного типа. Если предполагают, что составной тип является T, и имена в части ввода CGDM являются d1, d2, ..., то сопоставление может быть указано как «C, T («элемент1:d1», «элемент2:d2» ...)», если C является типом массива, то сопоставление может быть указано как «C: массив [d1, d2, ...]».
Далее согласно способу вставляют сконфигурированную VMS в VMMS, ассоциированную с функцией части CF (S305). VMS вставлена так, что средство синтаксического анализа может распознать, что ассоциирован с идентифицированной CF. Например, первая VMS 601, показанная на фиг. 6В, ниже метки «CF1» является примером VMS, сконфигурированной, чтобы PF была вставлена в VMSS и ассоциирована с первой вычислительной функцией CF1. Затем способ включает в себя определение, выполняет ли пользователь (S305). Например, пользовательский интерфейс GUI могут использовать для выбора вычислительной функции (CF) и для указания, что выполняют вычислительные функции (CFs). Если пользователь выбирает другую вычислительную функцию (CF) или другой экземпляр ранее выбранной вычислительной функции (CF), то способ переходит к этапу S302. Например, если пользователь должен был ввести другой экземпляр той же CF (например, CF1 снова) и отправить CF различные параметры CGDM, то способ перейдет к этапу S304. Например, это может привести к вставке второй VMS 602 под одной и той же меткой (например, CF1), которая идентифицирует первую вычислительную функцию CF1. Однако, если пользователь выбирает новую вычислительную функцию (например, CF2 612), это может привести к вставке второй метки (например, CF2) и третьей VMS 603, как показано на фиг. 6В.
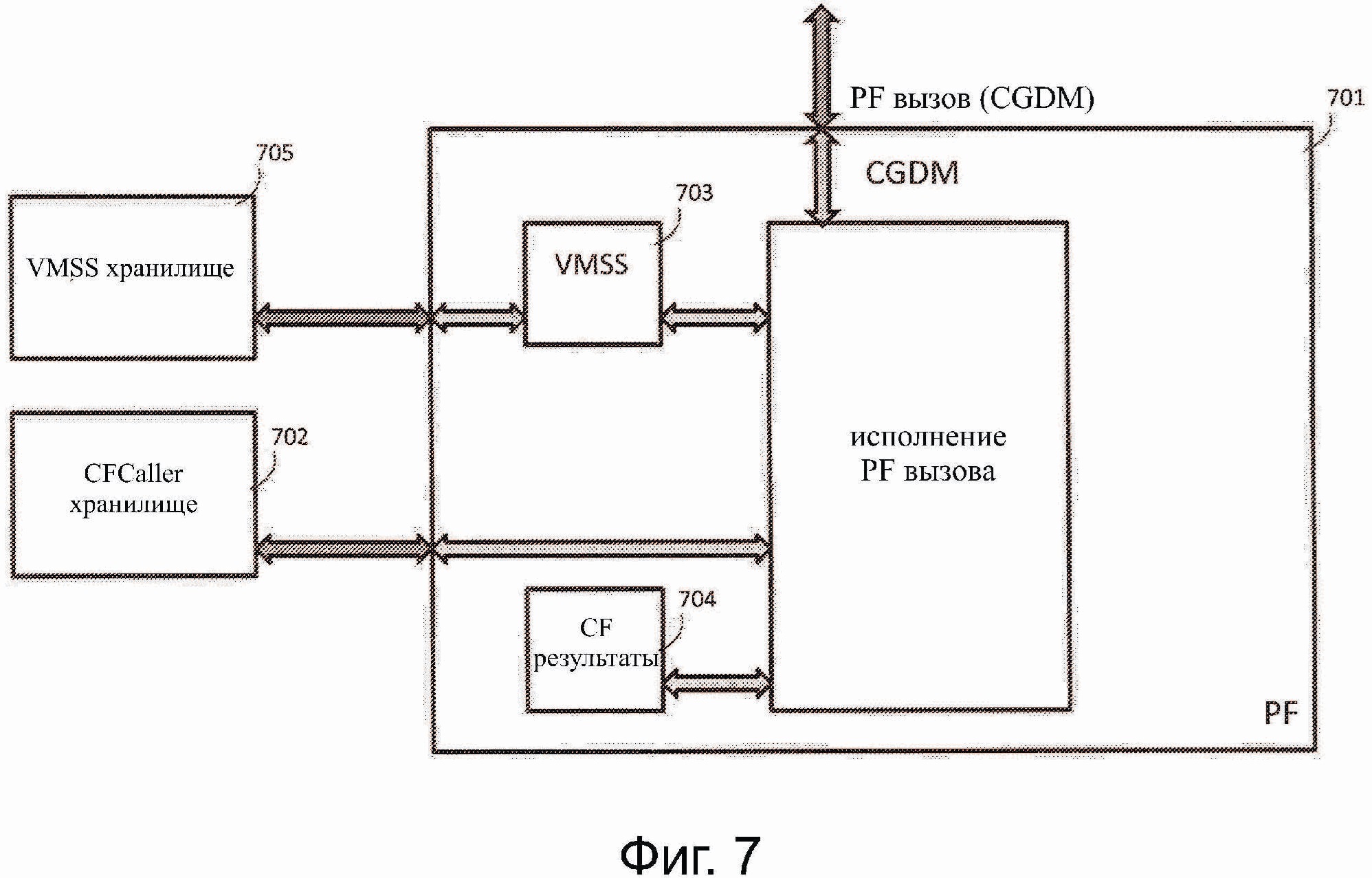
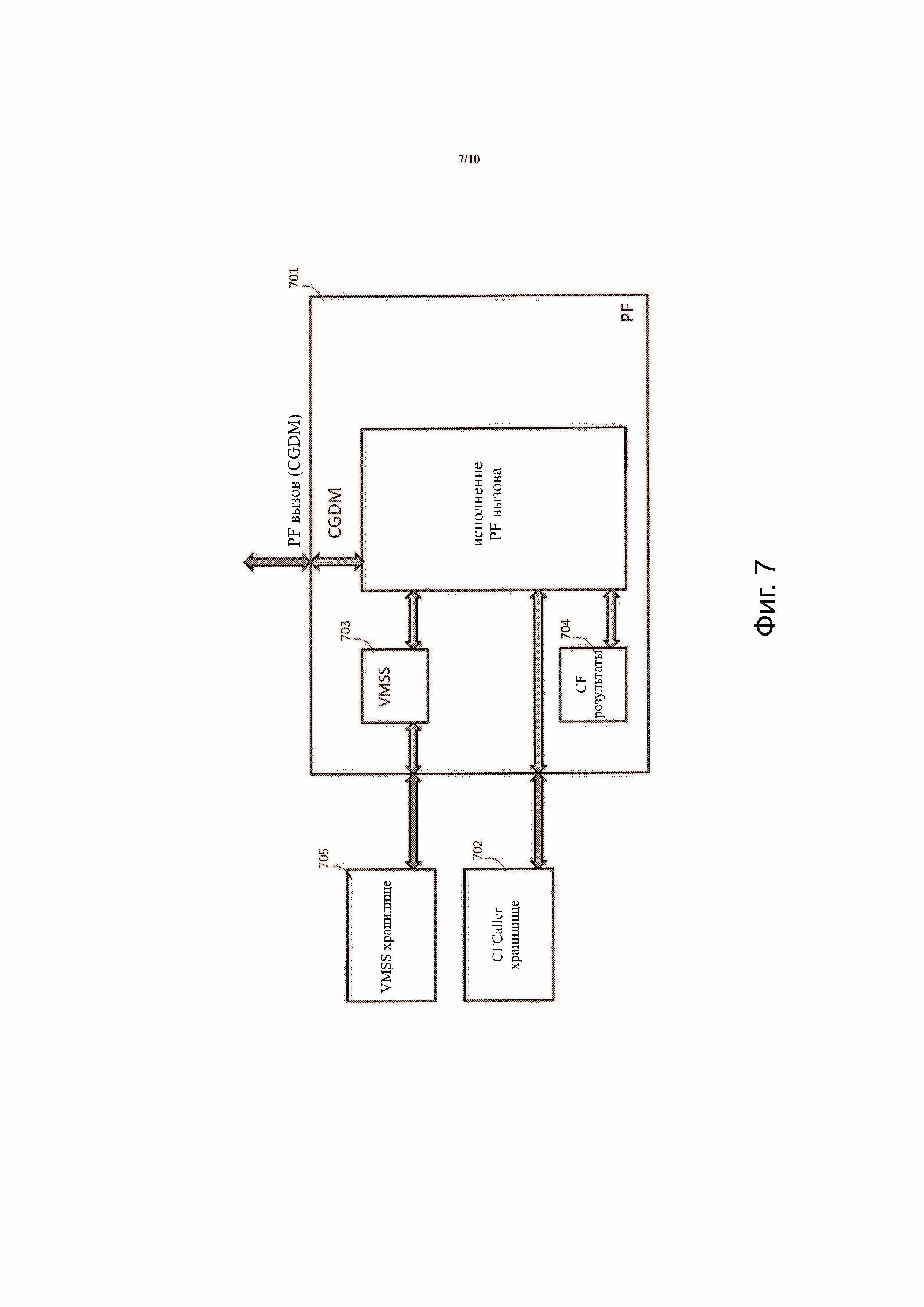
Кроме получения значений из ввода CGDM, аргумент CF также может принимать значение из результатов одного или более ранее выполненных CFs. Например, когда PF выполняет первую CF, то могут хранить результат выполнения CF в структуре данных (например, в CFResults структуре) или в списке, который является внутренним для PF, так что, если PF повторно выполняет ту же первую CF или вторую CF, результат доступен для CF, так что соответствующая CF может работать на результат, если это необходимо. Как показано на фиг. 7, когда PF 701 вызывается посредством PF вызова, PF 701 выполняет CF через CFCaller функцию. CFCaller функция может быть загружена из внешней области 702 хранения (например, CFCaller хранилища), которая хранит множество доступных CFCaller функций. CFCaller функция использует CGDM, VMSS 703, ассоциированный с CF, и CFResults структурой 704 в качестве данных ввода. VMSS 703 может быть загружен из внешней области 705 хранения (например, VMSS хранилища). CFCaller функция выполняет следующее: 1) объявляет аргументы CF и инициализирует каждый аргумент с использованием VMSS 703, CGDM и CFResults в CFResults структуре 704; 2) выполняет CF с аргументами; и 3) добавляет результаты в CFResults структуру 704 и устанавливает данные вывода CGDM (например, CGDM.output) в соответствии с VMSS 703. В одном варианте осуществления каждая CF имеет ассоциированную CFCaller функцию, и каждая CF имеет тот же интерфейс. VMSS хранилище содержит все VMSS для всех CGDM, с которыми вызывается PF. CFCall хранилище содержит CFCaller функции, ассоциированные со всеми CFs, содержащими PF.
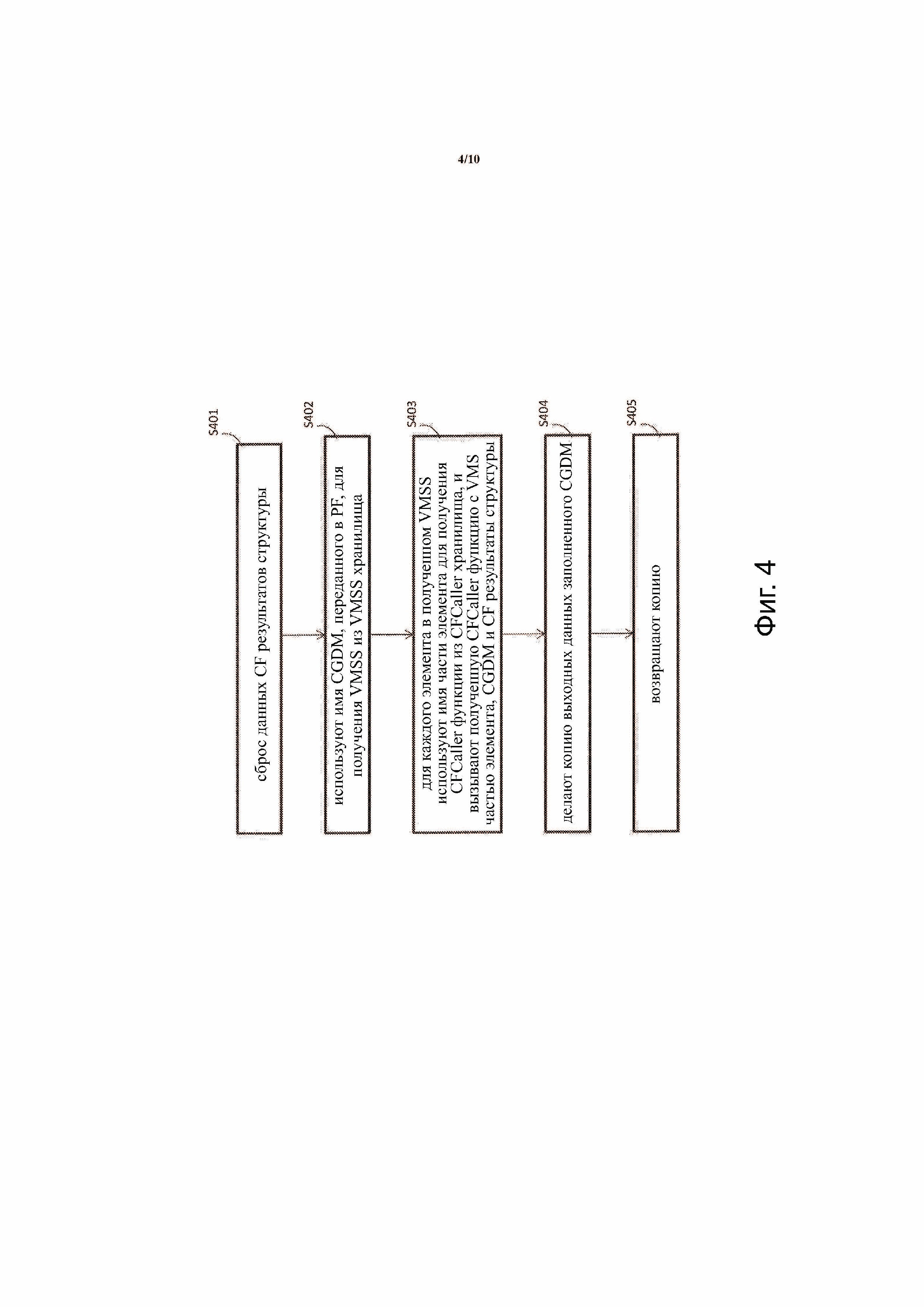
Фиг.4 иллюстрирует способ выполнения PF вызова для принятого CGDM в соответствии с примерным вариантом осуществления изобретения. Способ включает в себя: очистку CFResults структуры 704 (S401); использование имени CGDM для извлечения соответствующего VMSS 703 из VMSS хранилища 705 (S402); для каждого элемента в VMSS 703 использование имени части элемента для извлечения CFCaller функции из CFCaller хранилища 702 и вызов извлеченной CFCaller функции с VMS частью элемента CGDM и CFResults структуры 704 (S403); выполнение копии CGDM вывода (теперь заполненного значениями) (S404); и возврат копии (S405).
CF может вызывать другие PFs посредством формирования CGDM и передачи сформированного CGDM в качестве аргумента для вызова. Если CF передает значение в CGDM, то вычисляют CGDM, который он формирует, CF должен использовать то же имя, что и в CGDM, который он вычисляет. Если CF передает значение в CFResults структуре 704 в образованный CGDM, то используют то же имя, что и в CFResults структуре 704. Это называется правилом совместимости имен. Когда CF формирует CGDM для вызова другой PF, следует выполнять правило совместимости имен.
Поскольку все PFs имеют один и тот же интерфейс, то различие при вызове разных PFs заключается только в имени. Аргументы PF имени могут быть добавлены для CF для всех вызываемых PFs, то какие PFs, которые вызывают, могут быть указаны в VMS CF. Также имена сформированных CGDMs могут быть указаны в VMS. Итак, какие PFs CF вызывает и CGDM имена, которые используют, могут быть определены после разработки CF.
В одном варианте осуществления все параметры хранения данных имеют вид «имя (ключ)-значение». Формат хранения данных может иметь разные правила синтаксиса с CGDM.
Имена в хранилищах данных и CGDMs могут быть сформированы разными пользователями и в разное время и, следовательно, могут быть непротиворечивыми. Набор «имя-значение» называется совместимым, если одни и те же имена в наборе описывают одно и то же семантическое значение для именованных значений, и разные имена в наборе описывают различное семантическое значение для названных значений. Набор совместимых именных значений образует пространство имен (NS). PF и его CFs должны работать в одном NS. Если CGDMs и хранилища данных находятся не в одном NS, для CGDMs можно применить преобразование для преобразования их в одно NS. Для одного CGDM мы вызываем последовательность выполнения всех PFs и CFs для достижения цели вычисления CGDM.
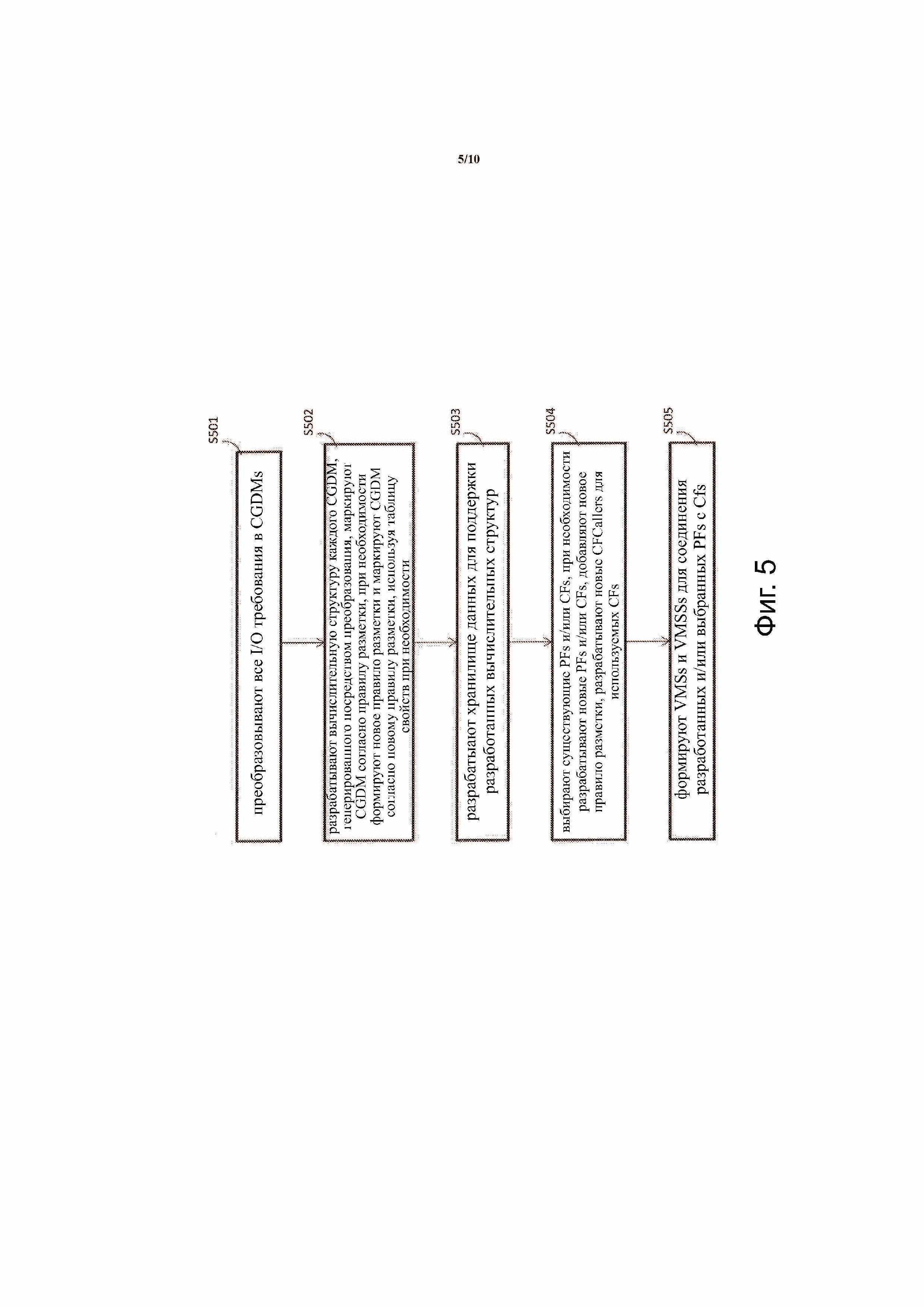
Фиг.5 иллюстрирует процесс разработки программного обеспечения в соответствии с примерным вариантом осуществления изобретения. Процесс включает в себя: преобразование всех требований ввода и вывода программного обеспечения в CGDMs формат (S501); разработку вычислительной структуры каждого CGDM, сгенерированного при преобразовании, маркировку CGDM с помощью правила разметки, формирование нового правила разметки и формирование CGDM с новым правилом разметки с использованием листа свойств, если необходимо (S502); разработку хранилища данных для поддержки разрабатываемых вычислительных структур (S503); выбор существующих PFs и/или CFs; разработку новых PFs и/или CFs, если необходимо, при добавлении нового правила разметки, разработку новых CFCallers для задействованных CFs (S504) и формирование VMSs и VMSSs для соединения разработанных и/или выбранных PFs и CFs (S505).
В одном варианте осуществления этап S505 реализуют посредством вызова CGDM без значений части ввода, то есть, имени экземпляра (NI) CGDM. NI представляет собой CGDM с частями ввода и вывода без значений. В варианте осуществления каждая CF, которая вызывает другие PFs, выполняет процесс обработки в режиме разработки (DV). В DV CG использует NI CGDM, которое вычисляют и выводят NIs всех CGDMs, которые формируют для CGDM, которое вычисляют для постоянного хранения данных (например, как файл). Выходные NIs определяют контент CGDMs вызываемых PFs. VMSs и VMSSs могут быть сгенерированы соответствующим образом.
Фиг.8 иллюстрирует способ разработки программного обеспечения с использованием одной или более доступных функций части (PFs) в соответствии с примерным вариантом осуществления концепции изобретения. Способ включает в себя: запрос пользователя выбрать PF из доступных PFs (S801); запрос пользователя ввести пары ввода «имя (ключ)-значение» и пару вывода «ключ-значение» (S802); форматирование CGDM на основании введенных данных (S803); вставку PF вызова с форматированным CGDM в качестве аргумента ввода (S804); определение, выполнено ли пользователем вызовы PF (S805). Если пользователь не выполнил, то способ переходит к этапу S801, чтобы запросить пользователя выбрать новую PF. Если пользователь выполнил, то способ завершается.
Фиг.9 иллюстрирует способ интерпретации программного обеспечения, включающего в себя PF вызов в соответствии с примерным вариантом осуществления изобретения. Способ включает в себя анализ PF вызова для идентификации заданной PF и CGDM, переданного на PF вызов в качестве аргумента (S901). Затем способ включает в себя загрузку VMSS, ассоциированного с идентифицированной PF, и идентификацию пар ввода «ключ-значение» и пар вывода «ключ-значение» в идентифицированном CGDM (S902). Затем способ включает в себя анализ следующей строки загруженного VMSS (S903). Затем согласно способу определяют, включает ли в себя анализируемая строка CF метку (S904). Например, если следующая строка является первой строкой VMSS, как показано на фиг. 6B, тогда будет сделан вывод, что идентифицируют CF метку CF1. Если определено, что CF метка идентифицирована, то согласно способу идентифицируют конкретную CF для вызова с определенной CF меткой и анализируют следующую строку VMSS. Затем, если согласно способу определяют, что следующая строка не является CF меткой (т.е. следующая строка соответствует VMS), согласно способу сопоставляют первый ключ текущей пары ключей VMS с выбранным I/O параметром идентифицированной CF и сопоставляет второй ключ текущей пары ключей с выбранным I/O ключом CGDM (S906). Например, если анализируют VMS 601 и текущая пара ключей рассматривают как «a:x», и идентифицированная CF является CF1 611, тогда согласно способу сопоставляют первый ключ «a» текущей пары ключей «a:x» с параметром «a» ввода CF1 611 и сопоставляют второй ключ «x» текущей пары ключей с ключом «x» ввода параметра x:2 ввода CGDM 600. Затем способ включает в себя форматирование вызова к идентифицированной CF, так что выбранному I/O параметру CF передают значение выбранного I/O ключа (S907). Например, параметр «a» ввода из CFL1 611 передают значением «2», поскольку первый ключ «a» соответствует «x», и x устанавливается равным 2 (например, «x:2»). Затем способ повторяет эти этапы сопоставления для каждой пары ключей VMS. Согласно способу определяют, проанализирована ли последняя пара ключей VMS, чтобы определить, выполнена ли операция (S908). Если способ не выполнен, то процесс переходит к следующей паре ключей VMS, переходя к этапу S906. Если способ выполнен, то переходят к этапу S902 для анализа следующей строки VMSS, чтобы найти либо новую CF метку, либо другую VMS согласно ранее идентифицированной CF меткой.
На фиг.6А показана схема использования JSON формата для CGDM, изобретение не ограничено этим. Например, JSON формат можно заменить форматом языка разметки гипертекста (HTML) или форматом расширяемого языка разметки (XML). Определяют правило разметки, как правило, для расширения контента CGDM с использованием правил синтаксиса CGDM, так что для любого экземпляра ввода алгоритма присутствует расширенный контент, соответствующий ему, и экземпляр ввода и его полные данные признаков могут быть вычтены из расширенного контента. Правило разметки ассоциировано с алгоритмом.
В варианте осуществления изобретения сообщения ввода данных в программное обеспечение имеют HTML формат, CGDM имеют JSON формат и хранилища данных являются реляционными базами данных, которые обеспечивают среду веб-разработки. Частичные функции, которые обеспечивают ввод данных в веб-браузере и могут называться функциями части ввода. Частичные функции, которые запускают серверную часть, могут упоминаться как частичные функции вывода. Частичные функции вывода могут быть соединены с базой данных.
Одна PF для обработки входных данных HTML может обрабатывать линейные каскадные данные ввода. Примером линейных каскадных данных ввода являются данные ввода для выбора государства, затем выбора штата и затем выбора города. Данные ввода представляют собой список <select> и текущий выбор, данные вывода представляют собой следующий возможный массив параметров. Правило разметки может быть любым правилом, которое представляет список. Например, правило разметки представляет собой: пометить первый список как <select Cascade = "cs1" cs1 = "1" mName = "name1" ...>, пометить второй список как <select Cascade = "cs1" cs1 = "2 "MName = "name2"...>, третий <select Cascade =" cs1 "cs1 =" 3 "mName =" name3 "...> и так далее. Cascade является именем вычисления, Cascade = «cs1» обозначает экземпляр cs1, cs1 = «n» и затем обозначает позицию в списке. PF запускают событием onSelect <select> элементов. Тот же самый обработчик события onSelect cascadeHndler устанавливают для всех <select>. CascadeHndler является функцией части, которая обрабатывает требования ввода и вывода этого типа. Алгоритм обработчика:
Получить имя экземпляра из Cascade = "instance_i";
Получить номер позиции из экземпляра _i = "n";
Получить выбранное значение v и имя n1 текущего <select>
Получить имя n2 следующего <select>
Отправить сообщение данных формы
{{"input":
{"n1": v}
},
{ "output": {
[{ “n2”: 0}]}
}}
на компонент вывода
Установить результат возврата в следующий <select>
Любой номер каскадного ввода любой длины и с любыми смысловыми значениями приложения в одном HTML сообщении данных может обрабатываться этой функцией части. Полагают, что частичная функция содержит только одну CF, которая реализует упомянутый выше алгоритм, он реализует чистый каскад, и это не связано со смысловым значением приложения, назначенным каскаду, либо это страна-штат-страна или Grade-Class-StudentName. Далее приводится каскадная реализация с меньшей детализацией функции.
Другой случай ввода называют звездным каскадным вводом, в котором параметры некоторых <select> определяют одним <select>, как в случае выбора доступных параметров размера и цвета на основе того, какие ткани были выбраны. Для центральной метки <select star = "star1" star1 = "name list of all end select node">. Не требуется маркировка конечного узла <select> при выборе центрального <select>, сообщение данных формы,
{
{"input":
{"сenterName": "v"}
},
{ "output": {
[{ “n1”, “”»}],
[{ “n2”, “”}],
...
}}
}
отправляют на сервер, при этом n1 и n2 являются именами конечных узлов. Когда возвращаемые значения не являются массивами, а одним значением, и конечные узлы являются текстовыми или числовыми данными ввода, то операция становится автозаполнением, как только выбрано имя клиента, его адрес автоматически заполняется.
Процесс обработки предложений ввода представляет собой обратную операцию автозаполнения. За исключением текущего значения ввода и некоторых других значений ввода, можно ограничить параметры текущего ввода, такие как данные ввода департамента и позиции данных ввода ограничивают предложение ввода имени персонала. Когда текущее значение ввода является текстом, то в отношении предложенных значений могут рассматривать более одной интерпретации, например, это может означать, что предлагаемые значения начинаются с этого текста или содержат текст. Поэтому необходимо предоставить дополнительную информацию о значении
{
{"input": {
{"otherValues1": "v1"},
{"otherValues2": "v2"},
{"current Value": {
{"value": "v3"},
{"type": "LIKE"}
}
}
...
},
{"output": {
[{“n1”, “”}]
}
}
}, в котором n1 является именем текущего элемента ввода.
Входные регистры также могут быть реализованы с использованием правила разметки, такого как первый элемент <input rangeInput = "ri1" ri1 = "1" ...>, второй элемент <input rangeInput = "ri1" ri1 = "2" ... > или для выбора данных ввода первого элемента <select rangeInput = "ri1" ri1 = "1" ...>, второго элемента <select rangeInput = "ri1" ri1 = "2" ...>. Перед тем, как принять текущую проверку ввода, алгоритм должен удовлетворять ограничению, заданному другим вводом или один ввод ограничивает параметры другого ввода. Из-за выбора формата входного сигнала могут использовать несколько разных типов диапазона входных сигналов, таких как ввод диапазона дат, ввод диапазона выбора, ввод диапазона цифровых значений.
Форма содержит некоторое количество различных типов элементов ввода (текст, числа, список параметров, диапазон ввода, каскадный ввод ...). Действие формы представлено для формирования пары (имя, значение) для всего элемента. Правило разметки для представления формы определяет символ типа для каждого типа элемента ввода. Другой тип означает, что доступ к значению имен должен использовать разные способы. Отметить каждый элемент ввода для его правильного типа. Алгоритм представления формы представляет собой:
Для каждого типа {
Получить все элементы ввода типа
Для каждого элемента ввода типа {
Получить имя и значение, упаковать значение имени в JSON формат.
}
}
отметить сообщение данных как ADD или MODIFY
отправить сообщение данных JSON на адрес вывода
Вид предоставления может быть либо ADD новых данных, либо MODIFY ранее использованных данных. Для модификации данные сначала загружают из сервера с некоторыми дополнительными данными, ключами или ссылочными номерами. Затем данные изменяют и отправляют на сервер. Дополнительные ключевые данные могут обрабатывать с помощью аналогичного механизма, такого как файлы cookie. Одной из реализаций файлов cookie является использование некоторых скрытых элементов HTML со специальными тегами. Для добавления новых данных эти дополнительные ключевые данные не используют. Таким образом, PF для представления формы может различать модификацию и добавление. Форма PF может обрабатывать формы любых форм с любым количеством элементов ввода определенных типов.
Страница поиска содержит один или более элементов ввода данных в качестве условий поиска и двухмерную сетку данных для отображения результатов поиска. Каждый столбец сетки данных может быть именован. Для предоставления поиска данных JSON сообщение данных, передаваемое на сервер, имеет две части: часть условия поиска и часть сетки данных пустой части двумерного массива, как показано:
{
{“input”: {
{"name1": "value1"},
{"name2": {
{"Max": {"value": "v2", "EQUAL": "true"}},
{"Min": {"value": "v3", "EQUAL": "false"}}
}},
...
},
{"output": {
[[{name4: 0}, {name5: 0}, ...]]
}}
}, при этом name2 задает диапазон входных значений, EQUAL is true означает <=pr> = и false означает <or>.
Часть условия поиска может быть поименована и отмечена типами и упакована так же, как форма для ADD.
Одним из вариантов осуществления сервера является выбор реляционной базы данных в качестве хранилищ данных, и сообщения данных, принятые и отправленные среди сообщений данных, имеют JSON формат. Для PFs, которые должны взаимодействовать с реляционной базой данных, необходимо использовать схему имен в базе данных. Для рабочих имен в сообщении данных, соответствующих схеме имен базы данных, они преобразуются в имя схемы базы данных. Имя столбца таблицы находится в форме tableName.columnName. PF, которая обрабатывает вставку в одну таблицу, может быть реализована с помощью CGDM следующим образом:
{"input": {
{ “column1»: «table1.column1»},
{"column2": "table1.Column2"},
{"column3", "table1.Column3"},
...
}}
Для вставки в одну таблицу, каждый столбец обрабатывается одним и тем же оператором вставки SQL, поэтому имеется один тип данных. CGDM, которое обрабатывает такую вставку, становится
{input: {
{"table1.column1", ""},
{"table1.Column2", ""},
{"table1.Column3", ""},
...
}}
Для вставки в таблицу отношений «один-ко-многим», CGDM является,
{"input": {
{"Master": {
{"table1.column1": ""},
{"table1.Column2": ""},
{"table1.Column3": ""}
...
}}
{"Detail": {
[{"table2.column1": ""},
{"table2.Column2": ""},
{"table2.Column3": ""}, ...]}}
}},
при этом CGDM включает в себя данные для главной таблицы и массив данных для подчиненной таблицы.
PF, которая обрабатывает обновление в одной таблице, имеет CGDM как ниже указано:
{"input": {
"primarykey": {
{"table1.column1": ""},
{"table1.Column2": ""},
...
}
},
{"values": {
{"table1.Column3": ""},
{"table1.Column4": ""},
...
}}
}
PF, которая обрабатывает обновление в таблицах отношений «один-ко-многим», имеет CGDM как ниже показано:
{"input": {{"m_Primarykey": {
{"table1.column1": ""},
{"table1.Column2": ""},
...
}
},
{"m_values": {
{"table1.Column3": ""},
{"table1.Column4": ""},
...
}
},
{"d_Primarykey": {
{"table2.column1": ""},
{"table2.Column2": ""}
...
}
},
{"d_values": {
{"table2.column3": ""},
{"table2.Column4": ""}
...
}
},
{"d_data": {
[{"table2.column1": ""}, {"table2.Column2": ""}, ...,
{"table2.Column3": ""}, {"table2.Column3": ""} ...]
}
}}
}
Для приведенных ниже примеров предполагают, что оператор выбора SQL принимает форму, такую как Select [A: output section] из [B: table section], при этом [C: condition section] группа согласно [D: aggregation section], имеющей [E: aggregation condition] порядок согласно [F: order section]. Данные для ввода и вывода разделены на шесть секций. Предполагают, что секция A содержит столбцы таблиц, которые отображаются в секции B или SQL функции в столбце таблиц, которые представлены в секции B; секция B содержит таблицы и взаимосвязи; секция C содержит условие вида column = value или column> (=)value или column<(=)value, columnLIKEvalueSQLFunction (column) в тех же взаимосвязях; секция D содержит столбец SQLFunction (column); секция E содержит столбцы значения SQLAggregateFunction (column) = or <(=) or > (=); и секция F содержит столбцы.
Таблицы и данные и их взаимосвязи, необходимые в секции B, могут быть получены из схемы базы данных, но информация типа соединения должна поступать из приложения. Структура массива может быть выбрана для представления взаимосвязи между двумя таблицами в CGDM PF, которая реализуют этот оператор select. CGDM этого оператора select имеет вид
{{ “input”:
{{"requirement": {
[{"tableA.column8": "tableA.column8"},
{"total1": {"tableB.column4":
{
«FUNC»: «SUM»
}}
},
...]}
},
{"table": {
{["tableA", "tableB", "joinType", "tableA.column1 = tableB.column2", "tableA.column3 = tableB.column4", ...],
["tableC", "tableD", "joinType", "tableC.column1 = tableD.column2", "tableC.column3 = tableD.column4", ...],
...}}
},
{"condition": {
{"tableA.column5": "v1"}, // default to tableA.column5 = v1
{"tableB.column1": {
"value": "v2", // default to SUM (tableB.column1) = v2
«FUNC»: «SUM»
}
},
. ..}
},
{"groupby": [
“tableA.column6»,
{"tableB.column2": {
«FUNC»: «DATE»
}
},
...]
},
{"having": {
{"tableB.column3": {
“value”: «v3»,
«FUNC»: «MAX»
}
},
...}
},
{"orderby": [
“tableA.column7”,
...]
}
}},
{"output":
{"results":
[{"tableA.column8": ''},
{"total1": ''},
...]}
}}
Запрос input.requirement соответствует секции A выбора SQL и указывает результат выбора SQL. Он определяет формат массива. {"tableA.column8": "tableA.column8"} означает получить значение tableA.column8 и установить имя "tableA.column8". Пара
{"total1": {"tableB.column4":
{
“FUNC”: “SUM”
}}
}
означает применить столбец функции SUM tableB.column4 и применить значение к имени «total1».
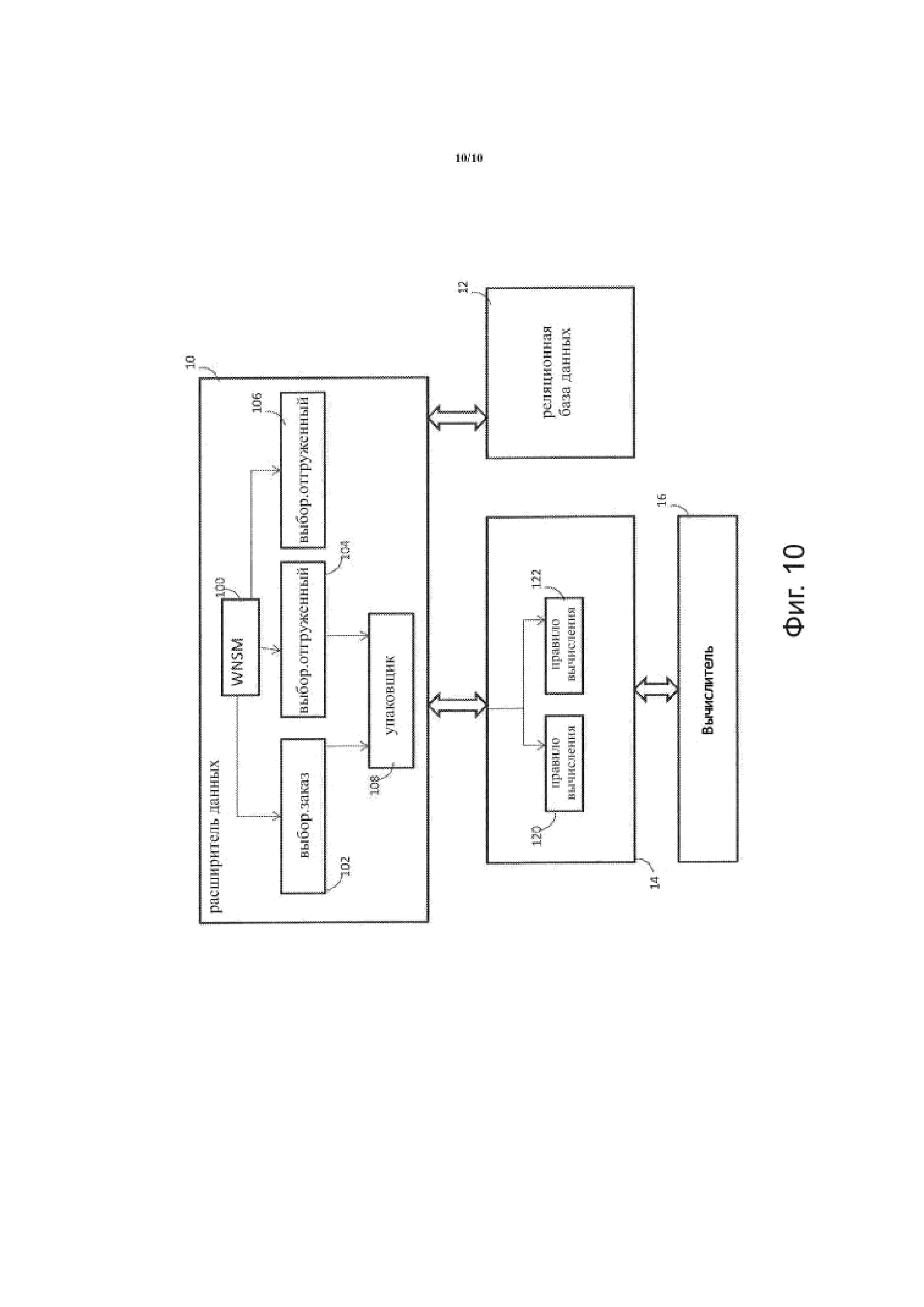
Для реализации использования более чем одной PFs для достижения целевой вычислительной задачи рассмотрим случай операции отгрузки товаров согласно заказу на продажу, как показано на фиг. 10. Предположим, что товар согласно заказу на продажу может быть частично отправлен (из-за частичной оплаты или отсутствия товара на складе), поэтому товар по заказу на продажу может быть отгружен в несколько операций. Входящий CGDM выглядит следующим образом:
{"Order_Shipment_Data":
{"input": {
{"orderID", "value1"}
}},
{"output": {
{"order_info": {
{"orderCode":""}
{ «SalesmanName»:»»},
{"customerName":""}
}},
{"Order_prod_info": {
[[{"ProductName": ""}, {"productionDate": ""},
{ “Quantity”: “”}, { “shippedQuantity“:””}, { “quantityLeft“:””}]]
}}
}}
}
Ввод данных представляет собой идентификатор заказа, требуемые вывод данных включает в себя информацию о заказе, код заказа, имя продавца и имя клиента, а также список сведений о продукте, название продукта, дату изготовления продукта, количество продукции в заказе, количество отгруженного продукта, количество оставшегося продукта, который должен быть отгружен.
На фиг. 10, CGDM принимается DataExpander PF 10. DataExpander PF 10 соединяют к реляционному набору 12 данных. Сопоставление рабочего пространства имен WNSM 100 для CGDM выглядит следующим образом:
{
{"orderID", "order.id"};
{"orderCode", "order.code"}
{"salesmanName", "employee.name"}
{"customerName", "customer.name"}
{"productName", "product.name"}
{"productionDate", "product.productionDate"}
{" Quantity ", "order.Quantity"}
}
После сопоставления CGDM становится следующим:
{"Order_Shipment_Data":
{“input”:
{"order.id", "value1"}
},
{"output": {
{"order_info": {
{"order.code": ""}
{"employee.name": ""},
{"customer.name": ""}
}},
{"order_prod_info": {
[[{"product.name": ""}, {"product.productionDate": ""},
{"order.Quantity": ""}, {"shippedQuantity": ""}, {"quantityLeft": ""}]]
}}
}}
}
PF 10 имеет две CFs, Select и Packer. Select CF запускает три экземпляра: 102, 104 и 106. Packer CF запускает один экземпляр 108. Select выполняет выбор типа SQL из приведенного выше примера в реляционной базе данных, Packer CF упаковывает все свои данные ввода в соответствующие части ввода и вывода сообщения данных (например, CGDM) и отправляет сообщение данных в LoopPF 14. PF 14 имеет одну CF, вызванную KeyMatchLoop, которая запускает один экземпляр, которая использует массивы A и B в качестве данных ввода и вывода для массива C. Каждый элемент в A, B и C имеет часть ключа и часть значения. Ключом элемента является последовательность «имя-значение». Два ключа имеют один и тот же тип, если длина последовательности «имя-значение» двух ключей одинакова, и для двух пар «имя-значение» каждой позиции последовательности имен одинаковы. Два ключа равны, если они имеют один и тот же тип, и значения соответствующих имен равны. A и B имеют ключ того же типа. Алгоритм KeyMatchLoop представляет собой,
Для каждого элемента a из A
Сформировать элемент c с частью ключа, такой же, как
если есть элемент b из B с a.key == b.key {
часть значения c вычисляется из частей значения
и b правилом 1 вычисления.
}
еще {
часть значения из c вычисляется из частей значения
и b правилом 2 вычисления.
}
добавить c
Правило 1 вычисления и правило 2 вычисления выполняются калькулятором PF 16. PF 16 имеет 3 вычисления: равный, нулевой и минус. CGDM для Order_Shipment_Data для PF 10 является,
{ “Order_Shipment”:
{"Select order":
{
{"input": {
{"requirement": {
{"order.code": "order.code"}
{"salesman.name": "salesman.name"},
{"customer.name": "customer.name"}
}},
{"condition": {
{"order.id","Order_Shipment_Data.input.'order.id'"}
}},
{"table": {
{["order", "salesman", "internal join", "order.salesmanID = salesman.id"],
[“order”, “customer”, “inner join”, «order.customerID = customer.id»]}
}}
}},
{"output":
{"result": "Order_Shipment_Data.output.order_info"}
}}
}},
{ “Select.orderProduct”:
{
{"input": {
{"requirement": {
[{"product.name": "product.name"},
{"production.date": "production.date"},
{"order_product.quantity": "order_product.quantity"}]
}},
{“condition": {
{“order_product.orderId”,
"Order_Shipment_Data.input.'order.id '"}
}},
{"table": {
[“order_product», “product”, “inner join”,
«Order_product.productId = production.id»]
}}
}},
{"output": {
"result": ""}
}}
}}
{“Select.shipped”:
{
{"input": {
{"requirement": {
{"product.name": "product.name"},
{“production.date»: “production.date”},
{"shippedQuantity": {"shipment.Quantity":
{
“FUNC”: “SUM”
}}
}
}},
{"condition": {
{"shipment.orderid", "Order_Shipment_Data.input.'order.id '"}
}},
{"table": {
[“shipment”, “product”, “inner join”,
“shipment.productID = product.id”]
}}
{"aggregate": {
["product.name", "product.productiondate"]
}}
}},
{"ouput":
{"result": ""}
}
}}
{"packer": {
{"input": {
{"In":
{
{"A": "Select.orderProduct.output.Result"},
{"B": "Select.shipped.output.Result"}
}},
{"Out": {{"C": "Order_Shipment_Data.output.order_prod_info"}}}
}},
{"output": {
{"result": "Order_Shipment_Data.output.order_prod_info"}
}}
}}
}
Order_prod_info выходной части сообщения данных Order_ Shipment_ Data используют как ввод для генерирования выходной части сообщения данных, которое PF 10 отправляет в PF 14. PF 10 отправляет сообщение данных Order_ Shipment_ Data_ Full в PF 14,
{"Order_Shipment_Data_Full": {
{"input": {
{"A": [[{"product.name": "v1"}, {"product.productionDate": "v2"},
{"order_product.quantity": "v3"}]]},
{"B": [[{"product.Name": "v4"}, {"product.productionDate": "v5"},
{"shippedQuantity": "v6"}]]}
}},
{"output": {
{"C": [[{"product.Name": ""}, {"product.productionDate": ""},
{"order.Quantity": ""}, {"shippedQuantity": ""}, {"quantityLeft": ""}]]}
}}
}
}
CGDM сообщение данных Order_Shipment_Data_Full для PF 14 является,
{“Loop”: {
{"input": {
{“A”:
[“Order_Shipment_Data_full.Input.A”,
{"key": ["product.name", "product.productionDate"]},
{"value": {{"shippedQuantity"}}]
},
{“В”:
[“Order_Shipment_Data_full.Input.B”,
{"key": ["product.name", "product.productionDate"]},
{"value": {{"order_product.quantity"}}]
},
{"C":
[“order_Shipment_Data_full.output.C”,
{"key": ["product.name", "product.productionDate"]},
{“value”: {{ «order_product.quantity»}, { «shippedQuantity»}, { «quantityLeft»}}]
}
}},
{"output":
{"result": "Order_Shipment_Data_full.output.C"}
}
}
}
PF 14 отправляет два сообщения данных в PF 16,
{"Order_data": {
{"input": {
{"A": {"order_product.quantity": "v1"}}
}},
{"output": {
{"C": {{"order_product.Quantity": ""}, {"shippedQuantity": ""}, {"quantityLeft": ""}}}
}}
}
}
{"Order_Ship_data": {
{"input": {
{"A": {"order_product.quantity": "v1"}},
{"B": {"shippedQuantity": "v2"}}
}
{"output": {
{"C": {{"order_product.quantity": ""}, {"shippedQuantity": ""}, {"quantityLeft": ""}}}
}}
}
}
CGDM для Order_Ship_data является,
{"Order_Ship_Data": {
{"Equal.quantity": {
{"input": {
“X”: «A.order_product.quantity»
}},
{"output": {
"Y": "C.order_product.quantity" // Y = X
}}
}
},
{"Equal.quantityLeft": {
{"input": {
“X”: «A.order_product.quantity»
}},
{"output": {
“Y”: «C.quantityLeft»
}}
}
}
{"Zero": {
{"output": {
“X”: «C.shippedQuantity» // X = 0
}}
}
}
}}
CGDM для Order_data выглядит следующим образом:
{"Order_Data": {
{"Equal.quantity": {
{"input": {
“X”: «A.order_product.quantity»
}},
{"output": {
“Y”: «C.order_product.quantity»
}}
}
},
{"Equal.shippedQuantity": {
{"input": {
“X”: «B.shippedQuantity»
}},
{"output": {
“Y”: «C.shippedQuantity»
}}
}
},
{"Minus": {
{"input": {
{“Х”: «A.order_product.quantity»},
{“Y”: «B.shippedQuantity»}
}},
{"output": {
“Z”: «C.quantityLeft» // Z = X-Y
}}
}
}
}}
Часть вывода сообщения данных Order_Shipment_Data формируется частью вывода CF экземпляра 106 и CF экземпляра 108. Затем обратно сопоставляют с рабочим пространством имен входящего сообщения данных Order_Shipment_Data и отправляют отправителю Order_Shipment_Data.
В иллюстративном варианте осуществления изобретения используют разметки и таблицу свойств CGDM. Хотя этот вариант осуществления будет рассмотрен ниже в отношении линейного каскада, изобретение не ограничено какой-либо конкретной организацией данных. Линейный каскад является списком элементов <select>, в котором, начиная с первого элемента и за исключением последнего элемента, выбранное значение одного элемента <select> определяет параметры следующего <select> в списке.
Одним из примеров данных ввода линейного каскада является данные ввода страна-штат-город, которые позволяет пользователю выбирать страну из опций стран, определяет варианты из штатов, т.е. позволяет пользователю выбирать штат из вариантов штатов, и определяет параметры города. В браузере страна, штат и город представлены элементом <select>. Обработчик событий для страны прикреплен к элементу <select> страны, обработчик событий для штатов прикреплен к элементу <select> штата. Например, когда выбрана страна, такая как «США», вызывают обработчик события страны и обработчик события получает значение «США» и формирует сообщение {Страна = «США», штат []} и отправляет сообщение для обработки в сервер, чтобы получить все штаты для «США» и сохраняет значение в секции для информации о штатах[]. Значения штаты [] затем устанавливают в <select> представляющее штат. Обработчик событий для штата и города аналогичен.
В варианте осуществления изобретения каскад представлен структурой списка данных, в котором каждый элемент списка имеет пять элементов, а именно, ID, Next, SelectedValue, eventHandler и Options. ID содержит имя элемента, Next имеет значение имени следующего элемента списка, SelectedValue содержит выбранные значения, eventHandler содержит функцию обработчика события этого элемента и Options содержит набор значений. Действие по выбору значения из Options и установки SelectedValue может быть выполнено для элемента списка. При выполнении действия, вызывают функцию в eventHandler передачей элемента в качестве аргумента.
Алгоритм является абстрактным, поскольку IDs могут принимать любые имена. Они могут быть страной, штатом, городом или компанией, отделом, именем сотрудника или категорией, типом, наименованием продукта. Алгоритм обобщен, поскольку допускается любое количество элементов.
Далее структура списка помечена в HTML. Кроме ID и Next, элемент <select> имеет все остальные. В нашем определении CGDM каждое значение должно иметь имя, поэтому на CGDM требуется только Next. Предполагают, что имя значения реализуется путем добавления ID свойства ко всем элементам HTML тега.
Правило разметки для каскада заключается для каждого элемента <select> в добавлении Next свойства и его значение является ID значением следующего <select> в каскаде. Допускается использование более одного каскада на одной HTML странице.
В общем, правило разметки определяют как правила для расширения CGDM контента с использованием CGDM правил синтаксиса, так что для любого экземпляра ввода алгоритма используют расширенный контент, соответствующий ему, и экземпляр ввода и его признаки подробных данных могут быть извлечены из расширенного контента. Правило разметки ассоциировано с алгоритмом.
PF функция может быть обработчиком событий события выбора для всех элементов <select> даже в другом каскаде. В этом примере, задают имя PF как cascadePF. Входные данные cascadePF представляют собой выбранное значение и элемент <select>, который генерирует событие. Структура объектной модели документа (DOM) всего HTML также доступна для cascadePF. CGDM PF можно рассматривать как CGDM = {{выбранный элемент <select>}, DOM}, причем входная часть является {{выбранный элемент <select>}, {все <select> элементы каскада}} и выходная часть представляет собой {{следующий элемент выбранного элемента <select>}}.
Поскольку все каскады, даже на разных HTML страницах, используют один и тот же cascadePF, и также могут использовать одно и то же CGDM имя, VMSS хранилище для cascadePF может быть выполнено с возможностью возвращать один VMSS для любого просмотра. Примеры CF функций cascadePF являются: initRestElement (CurrentElementName name), которое для текущего элемента с ID = name, сбрасывает параметры для всех от следующего элемента до конечного, Results r = getValuesFromBackend (Condition, condition, Results r, BackendProc p, CGDMNamepCGDMName), который упаковывает CGDM и вызывает обработку p сервера и передает CGDM с именем pCGDMName и setOptions (Results r); задают параметры <select> ID = r.name. CGDM имеет формат,
{pCGDMName: {
{Input: {Condition: {name: value}}}, {Output: {Results: {r: NULL}}
}
Поскольку cascadePF могут использовать для всех элементов <select>, выбранный элемент <select>, полученной PF, отличается при выборе разных элементов <select>. Поэтому прямое сопоставление переменных (VM) невозможно. Но аргументы CFs могут быть вычтены из Markups и CGDM. Данная операция названа правилом, основанном на VM (RBVM).
На сервере PF, названная handleDBSelection, содержит SQL набор реализаций выбора. Обычно значения параметров для <select> можно получить, выполнив SQL выбор. Назначают cascadeOptionsCGDM как CGDM имя и getValuesFromBackend передаются в handleDBSelection.
Используя RBVM, VMSS для PF становится,
{initRestElement: RBVM}
{getValuesFromBackend: {{condition: RBVM}, {r: RBVM}, {p: handleDBSelection}, {pCGDMName: cascadeOptionsCGDM}}}
{setOptions: {{r: getValuesFromBackend.r}}
Вызывающими операторами CFs являются,
initRestElementCaller (RBVM, CGDM, CFResults)
{
name = get the ID’s value of selected <select> element
initRestElement (name);
}
getValuesFromBackendCaller (RBVM, CGDM, CFResults)
{
(name, value) = get the ID’s value of selected <select> element
name = get the ID’s value of selected <select> element
r = getValuesFromBackend (value, name, handleDBSelection, cascadeOptionsCGDM);
add r to CFResults.
}
setOptionsCaller (RBVM, CGDM, CFResults)
{
r = get getValuesFromBackend.r из CFResults
setOptions (г);
}
Преимущество RBVM заключается в том, то правило обработки части кода не изменяется при добавлении нового каскада или расширении длины каскада. Все каскады могут использовать один и тот же список кодов, поскольку выбранный алгоритм является абстрактным и обобщенным.
На реализацию CFCallers влияет правило разметки. Новый CFCaller CF должен быть разработан для правила разметки. Из-за правила разметки CF может иметь более одного CFCaller.
Все CFs являются чистыми функциями алгоритма, и они реализуют чистый каскад, они не относятся к смысловому значению приложения, назначенному каскаду, либо это страна-штат-страна или Grade-Class-StudentName.
Разметки могут выполняться в отдельном сообщении с равными или более выразительными синтаксическими правилами, используя имена значений CGDM в качестве перекрестной ссылки. Отдельное сообщение разметки названо таблицей свойств (PS) CGDM. Любой CGDM может иметь прикрепленную к нему PS. При разработке известно имя экземпляра (NI) CGDM, поэтому PS можно прикрепить к CGDM во время разработки.
Описав примерные варианты осуществления изобретения, следует понимать, что изобретение не ограничено раскрытыми вариантами осуществления и предназначено для охвата различных модификаций и эквивалентных компоновок в рамках объема настоящего изобретения.
Система компонентно-ориентированного программного обеспечения и способ разработки

