Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ АРИФМЕТИЧЕСКОГО КОДИРОВАНИЯ ИЛИ АРИФМЕТИЧЕСКОГО ДЕКОДИРОВАНИЯ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Изобретение относится к арифметическому кодированию и декодированию мультимедийных данных.
Уровень техники
Арифметическое кодирование является способом сжатия данных без потерь. Арифметическое кодирование основано на функции плотности вероятности (ФПВ). Для достижения эффекта сжатия, функция плотности вероятности, на которой основывается кодирование, должна быть идентичной или по меньшей мере похожей – чем ближе, тем лучше – на фактическую функцию плотности вероятности, которой фактически подчиняются данные.
Если арифметическое кодирование основано на подходящей функции плотности вероятности, то оно может обеспечивать значительное сжатие, что приводит по меньшей мере к почти оптимальному коду. Поэтому, арифметическое кодирование является часто используемым методом при кодировании аудио-, голосового или видео сигнала для кодирования и декодирования последовательностей коэффициентов, причем коэффициенты являются квантованными результатами частотно-временного преобразования значений дискретизации видео пикселей или аудио- или голосового сигнала в двоичном представлении.
Для того, чтобы еще больше улучшить сжатие, арифметическое кодирование может быть основано на наборе функций плотности вероятности, причем функция плотности вероятности, используемая для кодирования текущего коэффициента, зависит от контекста упомянутого текущего коэффициента. Таким образом, различные функции плотности вероятности могут использоваться для кодирования того же самого значения квантования в зависимости от контекста, в котором появляется коэффициент, имеющий упомянутое то же самое значение квантования. Контекст коэффициента определяют с помощью значений квантования коэффициентов, содержащихся в близлежащей области из одного или более соседних коэффициентов, граничащих с соответствующим коэффициентом, например, с помощью субпоследовательности из одного или более уже закодированных или уже декодированных коэффициентов, которые непосредственно предшествуют в последовательности соответствующему коэффициенту, который будут кодировать или будут декодировать. Каждый из различных возможных видов, которые может иметь близлежащая область, определяет различный возможный контекст, каждый из которых отображают в связанную с ней функцию плотности вероятности.
Практически, упомянутое улучшение сжатия реализуется, только если близлежащая область является достаточно большой. Это сопровождается комбинаторным скачкообразным увеличением количества различных возможных контекстов, а также соответствующего огромного количества возможных функций плотности вероятности или соответствующего сложного отображения.
Пример основанной на контексте схемы арифметического кодирования можно найти в документе ISO/IEC JTC1/SC29/WG11 N10215, октябрь 2008, Пусан, Корея, который предлагает эталонную модель для унифицированного кодирования речи и аудиоинформации (USAC). Согласно данному предложению, для определения контекста рассматривают уже декодированные наборы из 4 элементов.
Другой пример относящегося к USAC основанного на контексте арифметического кодирования можно найти в документе ISO/IEC JTC1/SC29/WG11 N10847, июль 2009, Лондон, Великобритания.
Для сокращения сложности условного энтропийного кодирования старшего разряда в патенте США № 5,298,896 предлагают неравномерное квантование приведенных к определенному виду символов.
Раскрытие изобретения
В соответствие с огромным количеством контекстов, которые будут обрабатывать, существует огромное число функций плотности вероятности, которые необходимо хранить, извлекать и обрабатывать или по меньшей мере соответствующим образом выполнять сложное отображение контекстов в функции плотности вероятности. Это увеличивает по меньшей мере одно из времени ожидания кодирования/декодирования и требований к емкости запоминающего устройства. В предшествующем уровне техники существует потребность в альтернативном решении, которое предоставляет возможность обеспечения сжатия так же хорошо, уменьшая по меньшей мере одно из времени ожидания кодирования/декодирования и требований к емкости запоминающего устройства.
Для удовлетворения этой потребности данное изобретение предлагает способ кодирования, который содержит функциональные особенности по п.1, способ декодирования, который содержит функциональные особенности по п.2, устройство для арифметического кодирования, которое содержит функциональные особенности по п.13, устройство для арифметического декодирования, которое содержит функциональные особенности по п.14, и носитель информации по п.15.
Функциональные особенности дополнительных предложенных вариантов осуществления определяют в зависимых пунктах формулы изобретения.
Упомянутый способ арифметического кодирования или декодирования, соответственно, использует предыдущие спектральные коэффициенты для арифметического кодирования или декодирования, соответственно, текущего спектрального коэффициента, причем упомянутые предыдущие спектральные коэффициенты уже закодированы или декодированы, соответственно. И упомянутые предыдущие спектральные коэффициенты, и упомянутый текущий спектральный коэффициент содержатся в одном или более квантованных спектров, которые являются результатом квантования результата частотно-временного преобразования значений дискретизации видео-, аудио- или голосовых сигналов. Упомянутый способ дополнительно содержит обработку предыдущих спектральных коэффициентов, использование обработанных предыдущих спектральных коэффициентов для определения класса контекста, который является одним по меньшей мере из двух различных классов контекста, использование определенного класса контекста и отображения по меньшей мере двух различных классов контекста по меньшей мере в две различные функции плотности вероятности для определения функции плотности вероятности, и арифметическое кодирование или декодирование, соответственно, текущего спектрального коэффициента, основываясь на определенной функции плотности вероятности. Функциональной особенностью данного способа является то, что обработка предыдущих спектральных коэффициентов содержит неравномерное квантование абсолютных значений предыдущих спектральных коэффициентов.
Использование классов контекста в качестве альтернативы контекстам для определения функции плотности вероятности предусматривает группирование двух или более различных контекстов, что приводит к тому, что различные, но очень похожие функции плотности вероятности оказываются в одном классе контекста, который отображают в одну функцию плотности вероятности. Данное группирование обеспечивают с помощью использования неравномерно квантованных абсолютных значений предыдущих спектральных коэффициентов для определения класса контекста.
Например, существует вариант осуществления, в котором обработка предыдущих спектральных коэффициентов содержит определение суммы квантованных абсолютных значений предыдущих спектральных коэффициентов для использования при определении класса контекста.
Точно также существует соответствующий вариант осуществления устройства для арифметического кодирования, а также и соответствующий вариант осуществления устройства для арифметического декодирования, в котором средство обработки выполнено с возможностью определения суммы квантованных абсолютных значений предыдущих спектральных коэффициентов для использования при определении класса контекста.
В дополнительных вариантах осуществления устройств средство обработки выполнено так, что обработка предыдущих спектральных коэффициентов дополнительно содержит первое квантование, в котором абсолютные значения предыдущих спектральных коэффициентов квантуют согласно схеме первого квантования, определение отклонения, в котором определяют отклонения абсолютных значений предыдущих спектральных коэффициентов, квантованных согласно схеме первого квантования, использование определенного отклонения для выбора одной по меньшей мере из двух различных схем нелинейного второго квантования, и второе квантование, в котором абсолютные значения предыдущих спектральных коэффициентов, квантованных согласно схеме первого квантования, дополнительно квантуют согласно выбранной схеме нелинейного второго квантования. Дополнительные варианты осуществления способов содержат соответствующие этапы.
Определение отклонения может содержать определение суммы абсолютных значений предыдущих спектральных коэффициентов, квантованных согласно схеме первого квантования, и сравнение определенной суммы по меньшей мере с одним пороговым значением.
В дополнительных вариантах осуществления средство обработки каждого из устройств может быть выполнено так, что обработка приводит или к первому результату, или по меньшей мере к другому второму результату. В этом случае определение класса контекста дополнительно содержит определение количества тех предшествующих спектральных коэффициентов, для которых обработка привела к первому результату, и использование данного определенного количества для определения класса контекста.
Каждое из устройств может содержать средство для приема по меньшей мере одного из сигнала переключения режима и сигнала сброса, причем устройства выполнены с возможностью использования по меньшей мере данного одного принятого сигнала для управления определением класса контекста.
По меньшей мере две различные функции плотности вероятности можно определять заранее, используя репрезентативный набор данных для определения по меньшей мере двух различных функций плотности вероятности, и отображение может быть реализовано, используя таблицу соответствия или хэш-таблицу.
Краткое описание чертежей
Примерные варианты осуществления изобретения показаны на чертежах и пояснены более подробно в нижеследующем описании. Примерные варианты осуществления служат только для разъяснения данного изобретения, но не для ограничения объема и сущности данного изобретения, которые определены в формуле изобретения.
На чертежах:
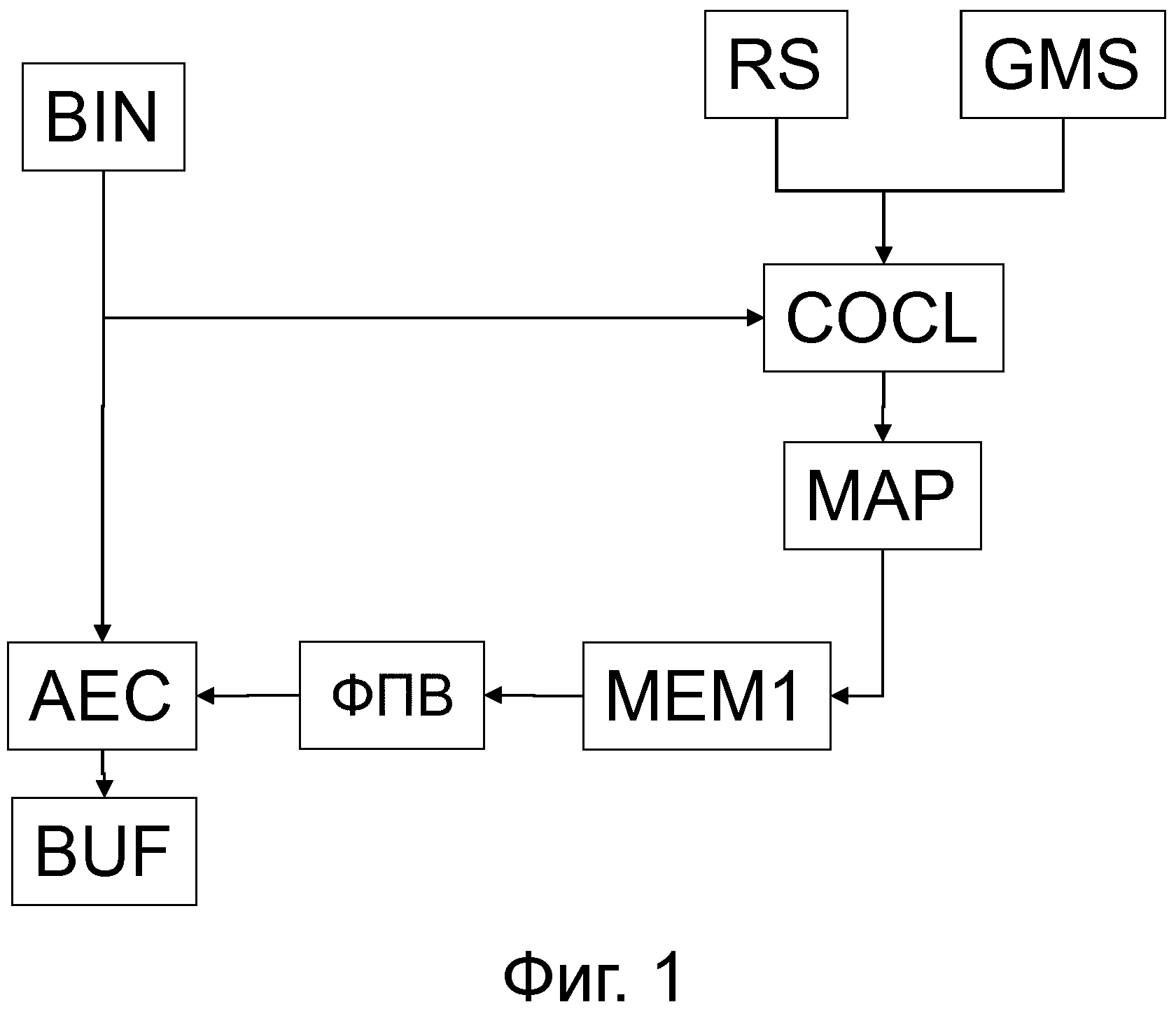
фиг.1 в качестве примера изображает вариант осуществления изобретенного кодера,
фиг.2 в качестве примера изображает вариант осуществления изобретенного декодера,
фиг.3 в качестве примера изображает первый вариант осуществления средства классификации контекста для определения класса контекста,
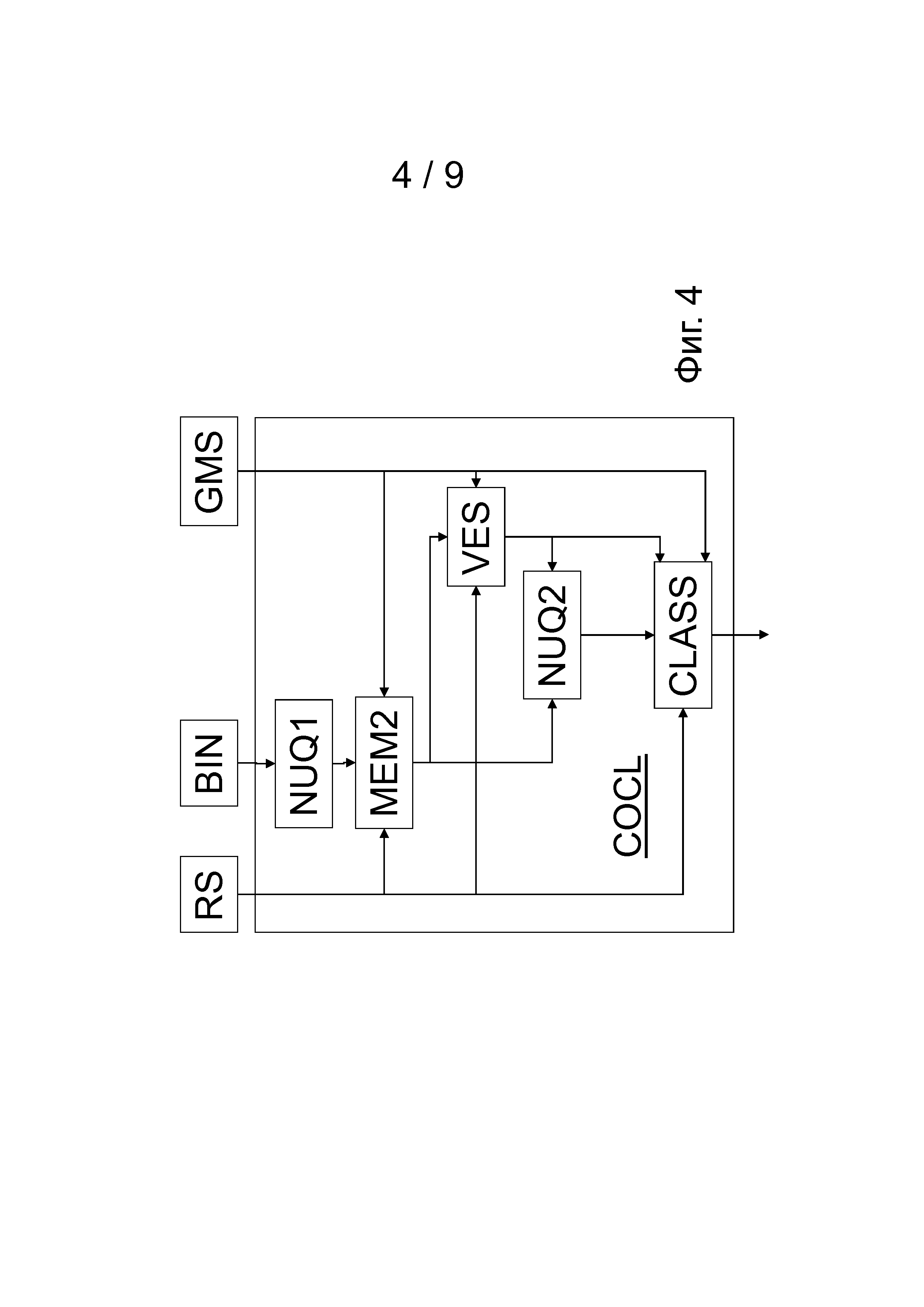
фиг.4 в качестве примера изображает второй вариант осуществления средства классификации контекста для определения класса контекста,
фиг.5a в качестве примера изображает первую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации, который будут кодировать или который будут декодировать в режиме работы в частотной области,
фиг.5b в качестве примера изображает вторую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации, который будут кодировать или который будут декодировать в режиме взвешенного преобразования на основе линейного предсказания,
фиг.6a в качестве примера изображает третью близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации самой нижней частоты, который будут кодировать или который будут декодировать в режиме работы в частотной области,
фиг.6b в качестве примера изображает четвертую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации второй самой нижней частоты, который будут кодировать или который будут декодировать в режиме работы в частотной области,
фиг.7a в качестве примера изображает пятую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации самой нижней частоты, который будут кодировать или который будут декодировать в режиме взвешенного преобразования на основе линейного предсказания,
фиг.7b в качестве примера изображает шестую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации второй самой нижней частоты, который будут кодировать или который будут декодировать в режиме взвешенного преобразования на основе линейного предсказания,
фиг.7c в качестве примера изображает седьмую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации третьей самой нижней частоты, который будут кодировать или который будут декодировать в режиме взвешенного преобразования на основе линейного предсказания,
фиг.7d в качестве примера изображает восьмую близлежащую область предыдущих спектральных элементов дискретизации, предшествующих текущему спектральному элементу дискретизации третьей самой нижней частоты, который будут кодировать или который будут декодировать в режиме взвешенного преобразования на основе линейного предсказания,
фиг.8 в качестве примера изображает близлежащие области различных спектральных элементов дискретизации, которые будут кодировать или которые будут декодировать, упомянутые различные спектральные элементы дискретизации содержатся в первом спектре, который будут кодировать или который будут декодировать после инициирования кодирования/декодирования или возникновения сигнала сброса в режиме работы в частотной области, и
фиг.9 в качестве примера изображает очередные близлежащие области различных спектральных элементов дискретизации, которые будут кодировать или декодировать в режиме взвешенного преобразования на основе линейного предсказания, упомянутые различные спектральные элементы дискретизации содержатся во втором спектре, который будут кодировать или декодировать после инициирования кодирования/декодирования или возникновения сигнала сброса в режиме взвешенного преобразования на основе линейного предсказания.
Осуществление изобретения
Данное изобретение можно реализовать в любом электронном устройстве, содержащем устройство обработки, соответствующим образом настроенное. Например, устройство для арифметического декодирования можно реализовывать в телевизионном приемнике, мобильном телефоне или персональном компьютере, mp3-плеере, навигационной системе или автомобильной аудиосистеме. Устройство для арифметического кодирования можно реализовать, к примеру, в мобильном телефоне, персональном компьютере, активной автомобильной навигационной системе, цифровом фотоаппарате, цифровой видеокамере или диктофоне.
Описанные ниже примерные варианты осуществления относятся к кодированию и декодированию квантованных спектральных элементов дискретизации, которые являются результатом квантования результата частотно-временного преобразования мультимедийных выборок.
Данное изобретение основано на способе, в котором уже переданные квантованные спектральные элементы дискретизации, например, предыдущие квантованные спектральные элементы дискретизации, которые предшествуют текущему квантованному спектральному элементу дискретизации BIN в последовательности, используются для определения функции плотности вероятности ФПВ, которая будет использоваться для арифметического кодирования и декодирования, соответственно, текущего квантованного спектрального элемента дискретизации BIN.
Описанные примерные варианты осуществления способов и устройств для арифметического кодирования или арифметического декодирования содержат несколько этапов, или средств, соответственно, для неравномерного квантования. Все этапы или средства, соответственно, вместе обеспечивают самую высокую эффективность кодирования, но каждый этап или средство, соответственно, в одиночку уже реализует изобретенную концепцию и обеспечивает преимущества, относящиеся ко времени ожидания кодирования/декодирования и/или к требованиям к емкости запоминающего устройства. Поэтому, подробное описание необходимо рассматривать в качестве описания примерных вариантов осуществления, реализующих только один из этапов или средств, соответственно, описанных так же, как описывают примерные варианты осуществления, реализующие комбинацию двух или более описанных этапов или средств.
Первый этап, который может, но не обязательно должен содержаться в примерном варианте осуществления данного способа, является этапом переключения, на котором определяют, какой основной режим преобразования должен использоваться. Например, в схеме помехоустойчивого кодирования USAC основным режимом преобразования может быть или режим работы в частотной области (FD), или режим взвешенного преобразования на основе линейного предсказания (wLPT). Каждый основной режим может использовать различные близлежащие области, т.е. различные дискретизации закодированных или декодированных, соответственно, спектральных элементов дискретизации для определения ФПВ.
После этого контекст текущего спектрального элемента дискретизации BIN можно определять в модуле генерации контекста COCL. Из определенного контекста определяют класс контекста с помощью классификации контекста, причем перед классификацией контекст обрабатывают предпочтительно, но не обязательно, с помощью неравномерного квантования NUQ1 спектральных элементов дискретизации контекста. Классификация может содержать оценку отклонения VES контекста и сравнение данного отклонения по меньшей мере с одним пороговым значением. Или оценку отклонения определяют непосредственно из контекста. Оценку отклонения затем используют для управления дополнительным квантованием NUQ2, которое является предпочтительно, но не обязательно нелинейным.
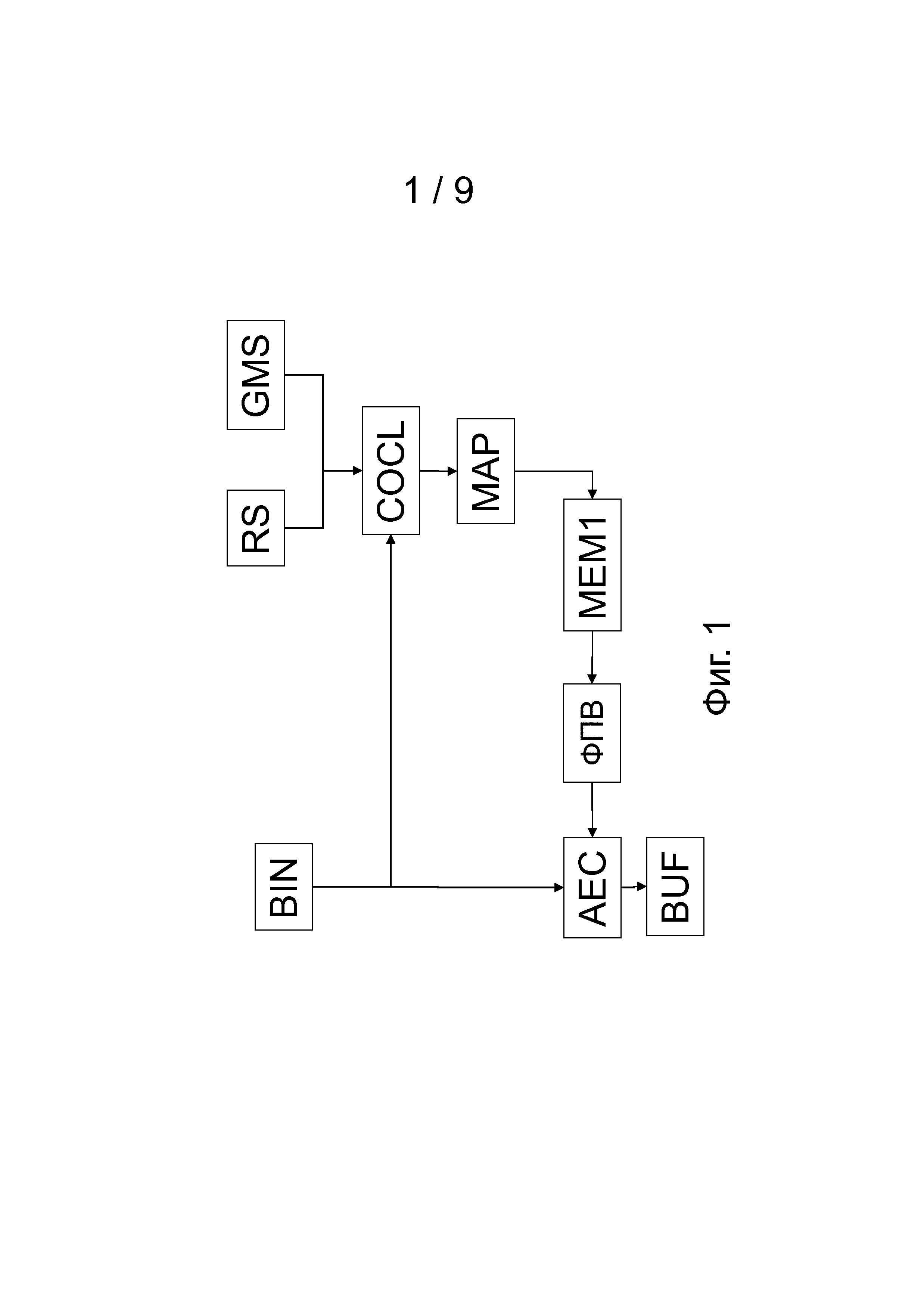
В процессе кодирования, для примера изображенном на фиг.1, подходящую функцию плотности вероятности (ФПВ) определяют для кодирования текущего квантованного спектрального элемента дискретизации BIN. Для этой цели может использоваться только информация, которая также уже известна на стороне декодера. Таким образом, можно использовать только предыдущий закодированный или декодированный квантованные спектральные элементы дискретизации. Это делают в блоке классификации контекста COCL. В нем выбранные предыдущие спектральные элементы дискретизации устанавливают границы близлежащей области NBH, которая используется для определения фактического класса контекста. Класс контекста можно обозначать номером класса контекста. Номер класса контекста используется для извлечения соответствующей ФПВ из запоминающего устройства ФПВ MEM1 через отображение MAP, например, через таблицу соответствия или хэш-таблицу. Определение класса контекста может зависеть от коммутатора основного режима GMS, который предоставляет возможность использовать различные близлежащие области в зависимости от выбранного режима. Как указано выше, для USAC может существовать два основных режима (режим FD и режим wLPT). Если коммутатор основного режима GMS реализуют на стороне кодера, то сигнал изменения режима или сигнал текущего основного режима должны содержаться в битовом потоке, так, чтобы основной режим был также известен в декодере. Например, в эталонной модели для унифицированного кодирования речи и аудиоинформации (USAC), предложенной ISO/IEC JTC1/SC29/WG11 N10847, июль 2009, Лондон, Великобритания, существует таблица 4.4 WD core_mode и таблица 4.5 core_mode0/1, предлагаемые для определения основного режима.
После определения подходящей ФПВ для кодирования текущего квантованного спектрального элемента дискретизации BIN с помощью арифметического кодера AEC, текущий квантованный спектральный элемент дискретизации BIN загружают в запоминающее устройство близлежащей области MEM2, т.е. текущий элемент дискретизации BIN становится предыдущим элементом дискретизации. Предыдущие спектральные элементы дискретизации, содержащиеся в запоминающем устройстве близлежащей области MEM2, могут использоваться блоком COCL для кодирования следующего спектрального элемента дискретизации BIN. Во время, перед или после запоминания текущего спектрального элемента дискретизации BIN упомянутый текущий элемент дискретизации BIN является арифметически закодированным с помощью арифметического кодера AEC. Выходной сигнал арифметического кодирования AEC сохраняют в битовом буфере BUF или записывают непосредственно в битовый поток.
Битовый поток или содержимое буфера BUF можно передавать или осуществлять широковещание через кабель или спутник, например. Или, арифметически закодированные спектральные элементы дискретизации можно записывать на таком носителе информации, как DVD (универсальный цифровой диск), жесткий диск, диск «blue-ray» и т.п. Запоминающее устройство ФПВ MEM1 и запоминающее устройство близлежащей области MEM2 можно реализовывать в одном физическом запоминающем устройстве.
Коммутатор сброса RS может предусматривать перезапуск кодирования или декодирования время от времени в специализированных кадрах, в которых кодирование и декодирование можно запускать без информации о предыдущих спектрах, специализированные кадры известны, как точки начала декодирования. Если коммутатор сброса RS реализуют на стороне кодера, то сигнал сброса должен содержаться в битовом потоке, так, чтобы о нем было также известно в декодере. Например, в эталонной модели для унифицированного кодирования речи и аудиоинформации (USAC), предложенный ISO/IEC JTC1/SC29/WG11 N10847, июль 2009, Лондон, Великобритания, существует флаг arith_reset_flag в таблице 4.10 WD и в таблице 4.14.
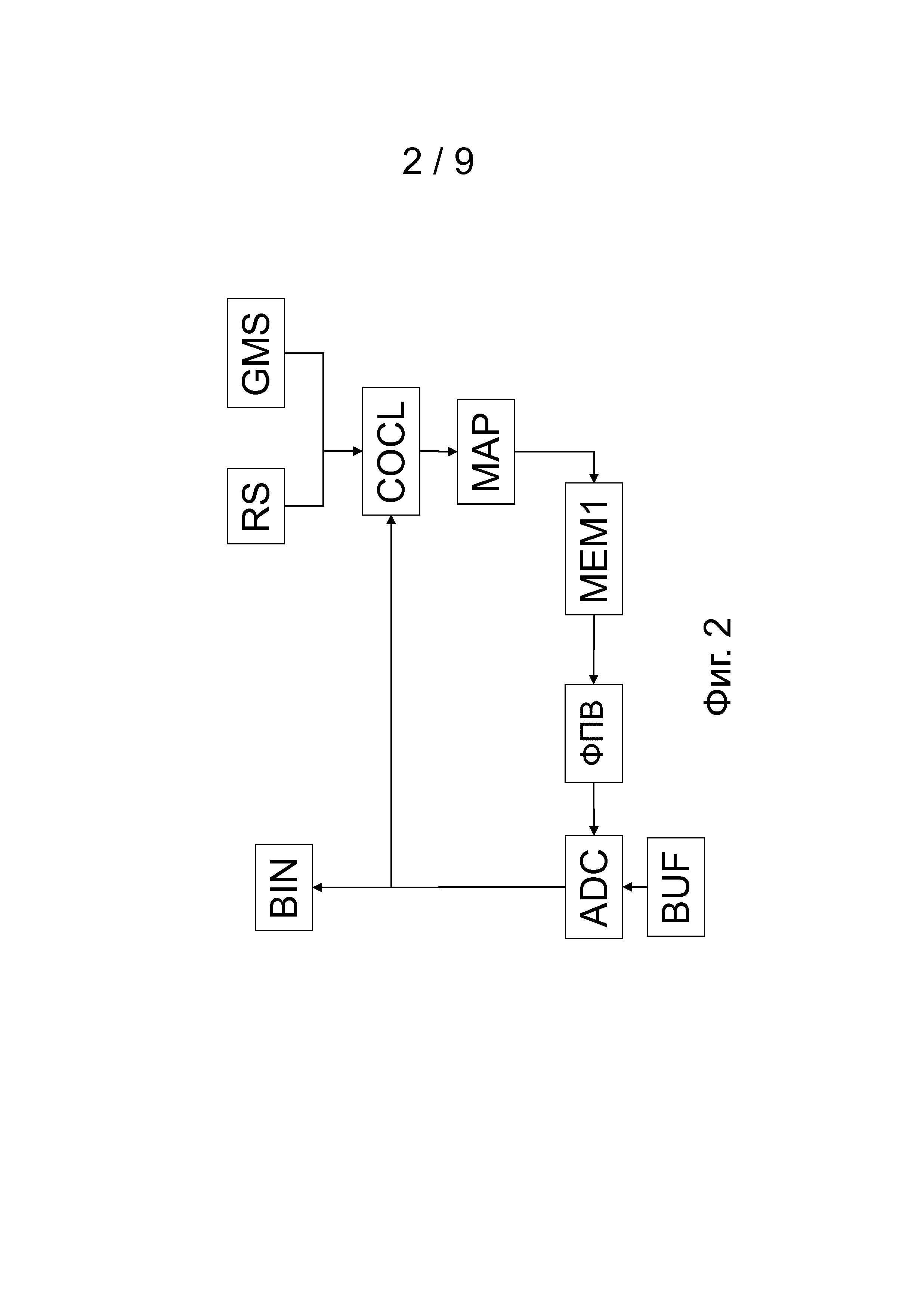
Соответствующая схема декодирования на основе близлежащей области для примера изображена на фиг.2. Она содержит аналогичные блоки, как в схеме кодирования. Определение ФПВ, которая будет использоваться для арифметического декодирования, идентично со схемой кодирования, для обеспечения, чтобы и в кодере, и в декодере определенная ФПВ была одинаковой. При арифметическом декодировании получает биты из битового буфера BUF или непосредственно из битового потока и использует определенную ФПВ для декодирования текущего квантованного спектрального элемента дискретизации BIN. Впоследствии декодированный квантованный спектральный элемент дискретизации загружают в запоминающее устройство близлежащей области MEM2 блока определения номера класса контекста COCL, и его можно использовать для декодирования следующего спектрального элемента дискретизации.
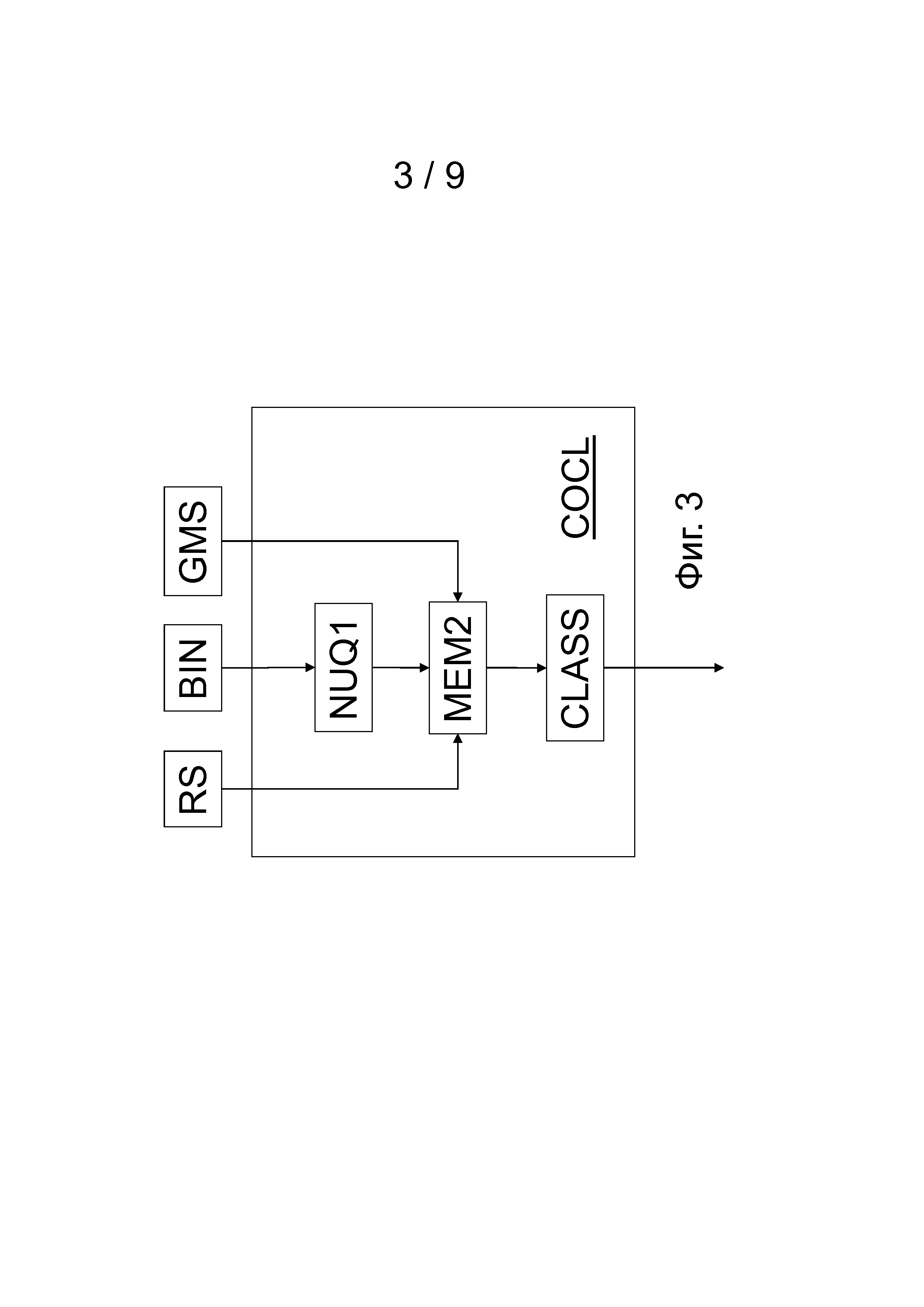
Фиг.3 для примера подробно изображает первый вариант осуществления средства классификации контекста COCL для определения класса контекста.
Перед сохранением текущего квантованного спектрального элемента дискретизации BIN в запоминающем устройстве спектров MEM2 его можно неравномерно квантовать в блоке NUQ1. У этого есть два преимущества: во-первых, это предоставляет возможность более эффективного сохранения квантованных элементов дискретизации, которые обычно являются 16-битными целочисленными значениями со знаком. Во-вторых, количество значений, которые может иметь каждый квантованный элемент дискретизации, сокращается. Это предоставляет возможность значительного сокращения возможных классов контекста в процессе определения класса контекста в блоке CLASS. Кроме того, поскольку при определении класса контекста знак квантованных элементов дискретизации можно не учитывать, блок неравномерного квантования NUQ1 может включать в себя вычисление абсолютных значений. В таблице 1 показывают примерное неравномерное квантование, как его можно выполнять с помощью блока NUQ1. В данном примере после неравномерного квантования для каждого элемента дискретизации возможны три различных значения. Но в общем случае, единственное ограничение для неравномерного квантования состоит в том, что оно сокращает количество значений, которые может принимать элемент дискретизации.
|
Неравномерно квантованные/отображенные спектральные элементы дискретизации хранят в спектральном запоминающем устройстве MEM2. Согласно выбранному основному режиму GMS, для определения класса контекста CLASS для каждого элемента дискретизации, который будут кодировать, выбирают выбранную близлежащую область NBH спектральных элементов дискретизации.
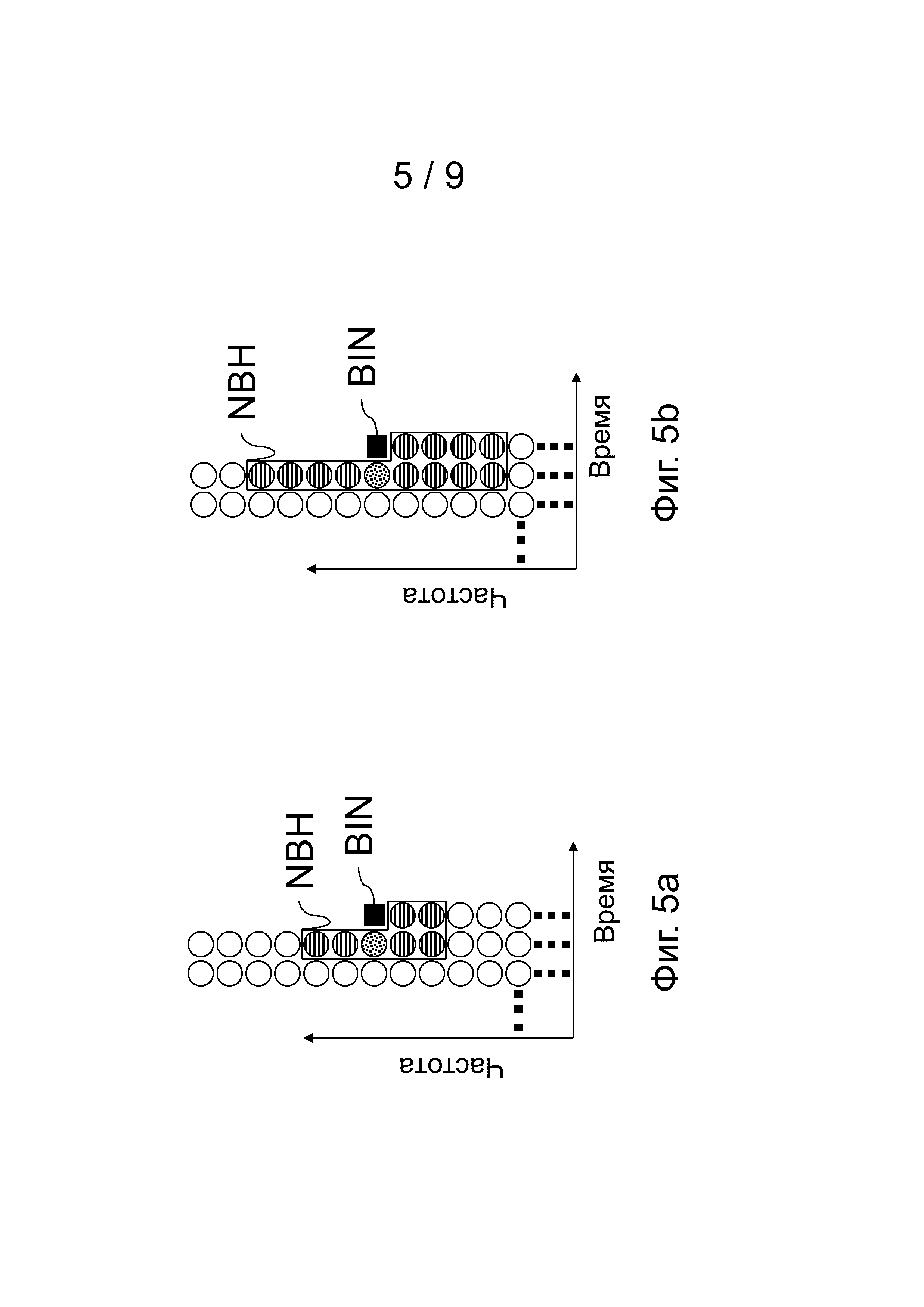
Фиг.5a для примера изображает первую примерную близлежащую область NBH спектрального элемента дискретизации BIN, который будут кодировать или который будут декодировать.
В данном примере только спектральные элементы дискретизации фактического или текущего спектра (кадра) и спектральные элементы дискретизации одного предыдущего спектра (кадра) определяют близлежащую область NBH. Конечно, можно использовать спектральные элементы дискретизации более чем из одного предыдущего спектра, как часть близлежащей области, что приведет к более высокой сложности, но может также в конечном счете обеспечить более высокую эффективность кодирования. Следует отметить, что для определения близлежащей области NBH из фактического спектра можно использовать только переданные элементы дискретизации, поскольку они также должны быть доступны в декодере. В данном случае, так же как и в последующих примерах, предполагают порядок передачи от низких к высоким частотам для спектральных элементов дискретизации.
Выбранную близлежащую область NBH затем используют в качестве входной информации для блока определения класса контекста COCL. Далее сначала объясняют общую идею, которая стоит за определением класса контекста, и упрощенную версию, перед описанием специальной реализации.
Общая идея, которая стоит за определением класса контекста, состоит в том, чтобы предоставить возможность кодирования надежной оценки отклонения элемента дискретизации. Это предсказанное отклонение также можно использовать для кодирования оценки ФПВ элемента дискретизации. Для оценки отклонения не требуется оценивать знак элементов дискретизации в близлежащей области. Поэтому знак можно не учитывать уже на этапе квантования перед сохранением в спектральном запоминающем устройстве MEM2. Очень простое определение класса контекста может выглядеть следующим образом: близлежащая область NBH спектрального элемента дискретизации BIN может выглядеть, как на фиг.5a, и состоять из 7 спектральных элементов дискретизации. Если для примера используют неравномерное квантование, показанное в таблице, то каждый элемент дискретизации может иметь 3 значения. Это приводит к 37=2187 возможным классам контекста.
Для дополнительного сокращения этого количества возможных классов контекста относительное расположение каждого элемента дискретизации в близлежащей области NBH можно не учитывать. Поэтому считают только те элементы дискретизации, которые имеют значения 0, 1 или 2, соответственно, причем сумма количества элементов дискретизации со значением 0, количества элементов дискретизации со значением 1 и количества элементов дискретизации со значением 2 конечно равна общему количеству элементов дискретизации в близлежащей области. В близлежащей области NBH, содержащей n элементов дискретизации, из которых каждый может иметь одно из трех различных значений, существует 0,5*(n2+3*n+2) классов контекста. Например, в близлежащей области 7 элементов дискретизации существуют 36 возможных классов контекста, а в близлежащей области 6 элементов дискретизации существует 28 возможных классов контекста.
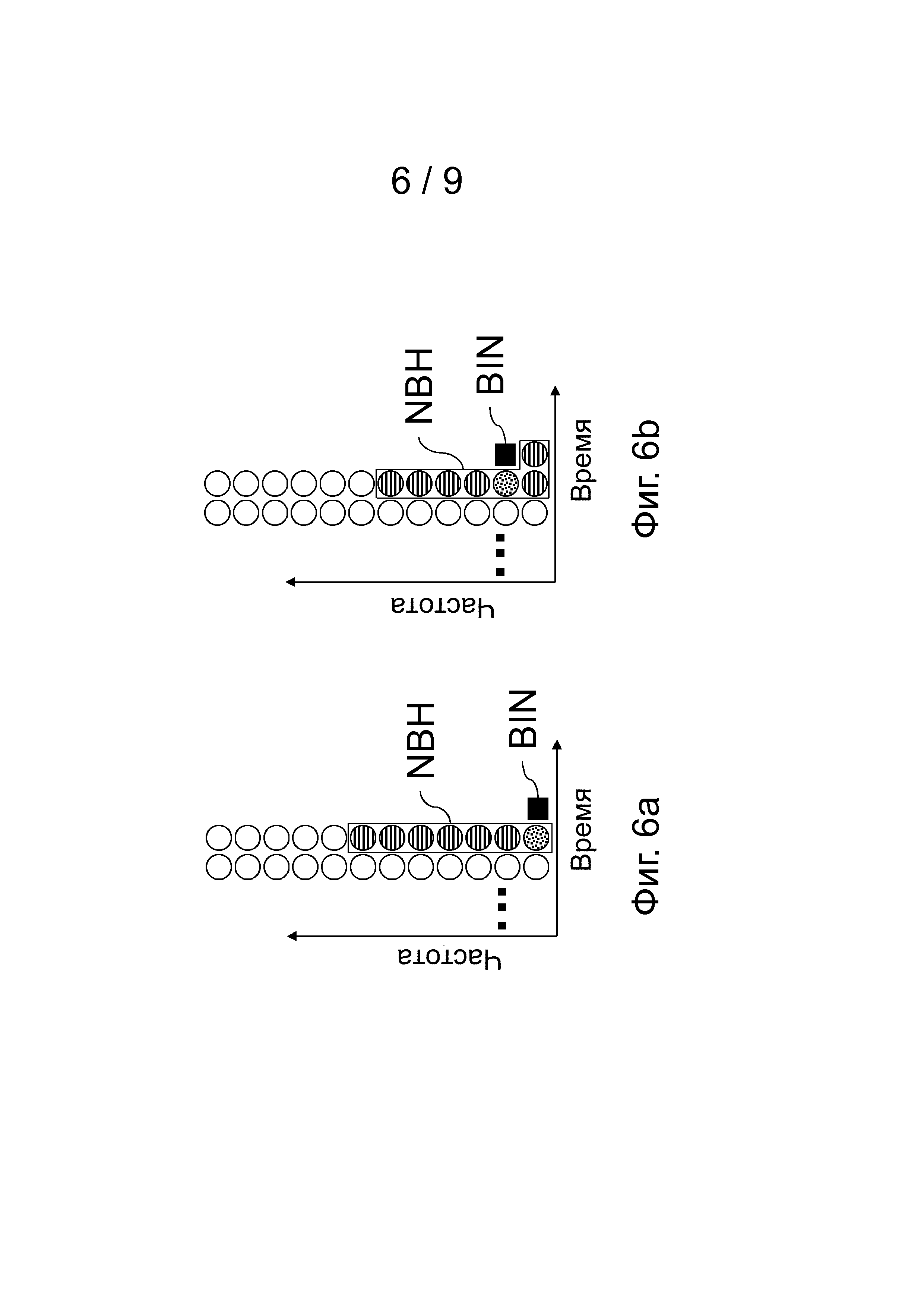
Более сложное, но все еще довольно простое определение класса контекста принимает во внимание, что исследование показало, что спектральный элемент дискретизации предыдущего спектра на той же самой частоте является особо важным (спектральный элемент дискретизации, изображенный кругом из точек на фиг.5a, 5b, 6a, 6b, 7a, 7b, 7c, 8 и 9). Для других элементов дискретизации в близлежащей области, изображенных как горизонтально заштрихованные круги на соответствующих фигурах, их относительное расположение менее важно. Таким образом, элемент дискретизации на той же самой частоте в предыдущем спектре используется однозначно для определения класса контекста, тогда как для других 6 элементов дискретизации считают только количество элементов дискретизации со значением 0, количество элементов дискретизации со значением 1 и количество элементов дискретизации со значением 2. Это приводит к 3×28=84 возможным классам контекста.
Эксперименты показали, что такая классификация контекста очень эффективна для режима FD.
Определение класса контекста может быть расширено с помощью оценки отклонения VES, которая управляет неравномерным вторым квантованием NUQ2. Это предоставляет возможность лучшей настройки блока генерации класса контекста COCL для кодирования более высокого динамического диапазона предсказанного отклонения элемента дискретизации. Соответствующая структурная схема расширенного определения класса контекста для примера показана на фиг.4.
В примере, показанном на фиг.4, неравномерное квантование разделяют на два этапа, на которых предыдущий этап обеспечивает более частое квантование (блок NUQ1), а последующий этап обеспечивает более редкое квантование (блок NUQ2). Это предусматривает настройку квантования, например, для заданного отклонения близлежащей области. Отклонение близлежащей области оценивают в блоке оценки отклонения VES, причем оценка отклонения основана на упомянутом предыдущем более частом квантовании элементов дискретизации в близлежащей области NBH в блоке NUQ1. Оценка отклонения не обязательно должна быть точной, а может быть очень грубой. Например, приложению USAC достаточно определить, выполняется или нет условие, что сумма абсолютных значений элементов дискретизации в близлежащей области NBH после упомянутого более частого квантования равна или превышает пороговое значение отклонения, т.е. достаточно переключения между большим и небольшим отклонением.
Неравномерное квантование с 2 этапами может выглядеть, как показано в таблице 2. В данном примере режим небольшого отклонения соответствует квантованию с 1 этапом, показанному в таблице 2.
|
|
Заключительное определение класса контекста в блоке CLASS является таким же, как в упрощенной версии на фиг.3. Можно использовать различное определение класса контекста согласно режиму отклонения. Также можно использовать больше двух режимов отклонения, что, конечно, приведет к увеличению количества классов контекста и к увеличению сложности.
Для первых элементов дискретизации в спектре близлежащую область, как это показано на фиг.5a или 5b, не применяют, потому что для первых элементов дискретизации не существуют ни одного или существуют не все элементы дискретизации более низкой частоты. Для каждого из этих особых случаев может быть определена собственная близлежащая область. В дополнительном варианте осуществления несуществующие элементы дискретизации заполняют предопределенным значением. Для примерной близлежащей области, приведенной на фиг.5a, определенные близлежащие области для первых элементов дискретизации, которые будут передавать в спектре, показывают на фиг.6a и фиг.6b. Идея состоит в том, чтобы расширить близлежащую область до элементов дискретизации более высокой частоты, чтобы предусмотреть использование той же самой функции определения класса контекста, как и для остальной части спектра. Это означает также, что можно использовать те же самые классы контекста, и наконец, те же самые ФПВ. Это не было бы возможно, если размер близлежащей области был просто уменьшен (конечно, это также возможно).
Сбросы обычно происходят перед кодированием нового спектра. Как уже указано, это необходимо для предоставления возможности декодирования специализированных начальных точек. Например, если процесс декодирования должен запускаться с определенного кадра/спектра, то фактически процесс декодирования должен начинаться с точки последнего сброса для последовательного декодирования предыдущего кадра до требуемого начального спектра. Это означает, чем больше сбросов происходит, тем больше точек начала декодирования для декодирования существует. Однако, эффективность кодирования меньше в спектре после сброса.
После того, как сброс произошел, для определения близлежащей области не доступен никакой предыдущий спектр. Это означает, что только предыдущие спектральные элементы дискретизации фактического спектра могут использоваться в близлежащей области. Однако, общую процедуру можно не изменять, и можно использовать те же самые «инструментальные средства». Снова, первые элементы дискретизации необходимо обрабатывать по-другому, как уже объяснено в предыдущем разделе.
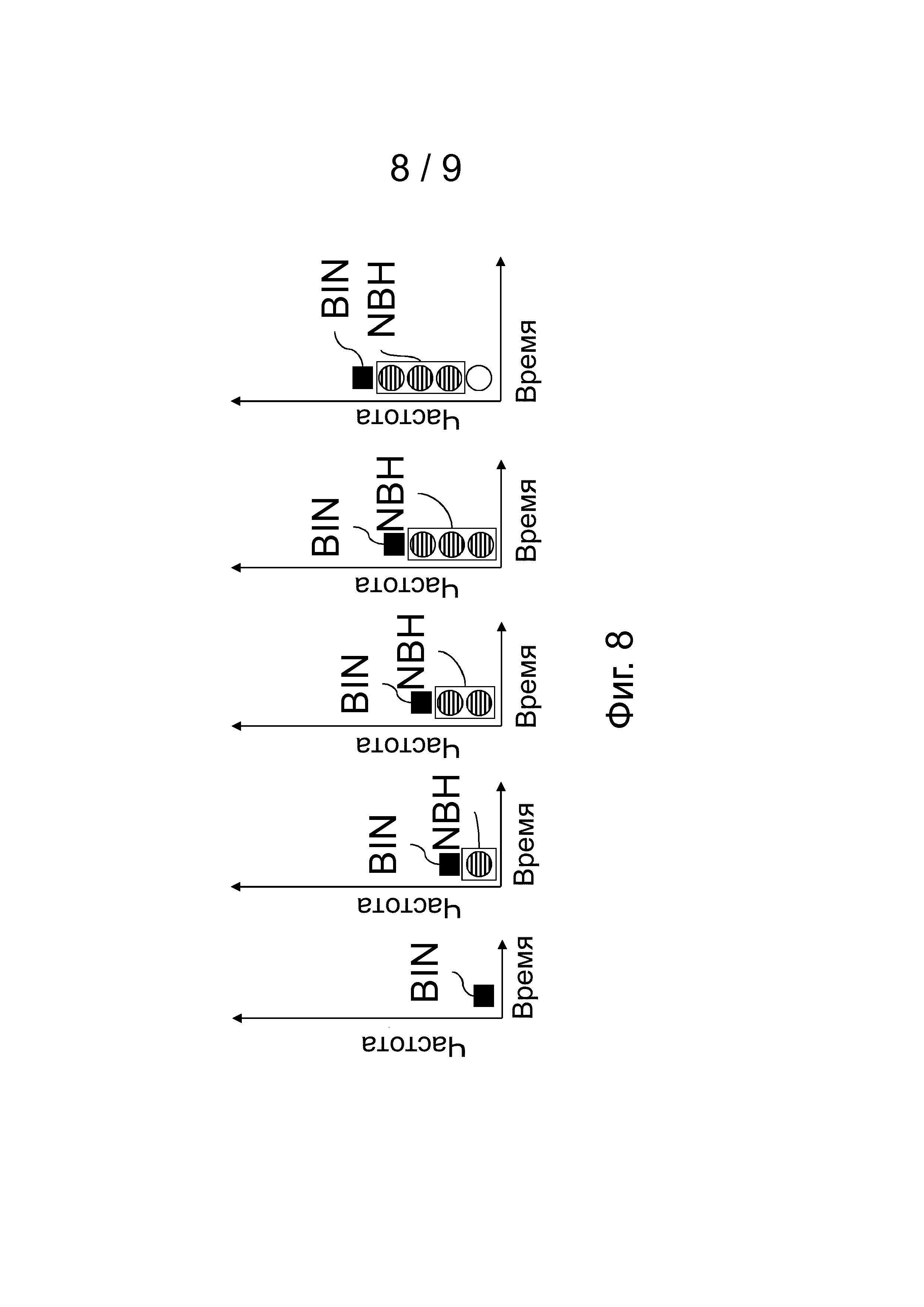
На фиг.8 показывают примерное определение близлежащей области при сбросе. Это определение может использоваться в случае сброса в режиме FD USAC.
Количество дополнительных классов контекста, как показано в примере на фиг.8 (используя квантование в таблице с окончательно 3 возможными квантованными значениями или с 6 значениями, если используются значения после этапа 1 квантования), является следующим: обработка самого первого элемента дискретизации добавляет 1 класс контекста, 2-й элемент дискретизации добавляет 6 (используется значение после этапа 1 квантования), 3-й элемент дискретизации добавляет 6 и 4-й элемент дискретизации добавляет 10 классов контекста. Если дополнительно рассматривают два режима с (небольшим и большим) отклонением, то количество классов контекста почти удваивается (не удваивается только для первого элемента дискретизации, где никакая информация не доступна, и для второго элемента дискретизации, где используется значение элемента дискретизации после этапа 1 квантования).
Это приводит в данном примере к 1+6+2×6+2×10=39 дополнительных классов контекста для обработки сбросов.
Блок отображения MAP использует результат классификации контекста, определенный с помощью блока COCL, например, определенный номер класса контекста, и выбирает соответствующую ФПВ из запоминающего устройства ФПВ MEM1. На этом этапе можно дополнительно уменьшать величину необходимой емкости запоминающего устройства, при использовании одной ФПВ более чем для одного класса контекста. Таким образом, классы контекста, у которых есть аналогичная ФПВ, могут использовать объединенную ФПВ. Эти ФПВ можно предварительно определять на фазе обучения, используя достаточно большой репрезентативный набор данных. Это обучение может включать в себя фазу оптимизации, в которой идентифицируют классы контекста, соответствующие аналогичным ФПВ, и соответствующие ФПВ объединяют. В зависимости от статистики данных это может привести к довольно небольшому количеству ФПВ, которые должны храниться в запоминающем устройстве. В примерной версии эксперимента для USAC было успешно применено отображение 822 классов контекста в 64 ФПВ.
Реализацией этой функции отображения MAP может быть просто поиск по таблице, если количество классов контекста не является слишком большим. Если данное количество становится больше, то можно применять поиск по хэш-таблице по причинам эффективности.
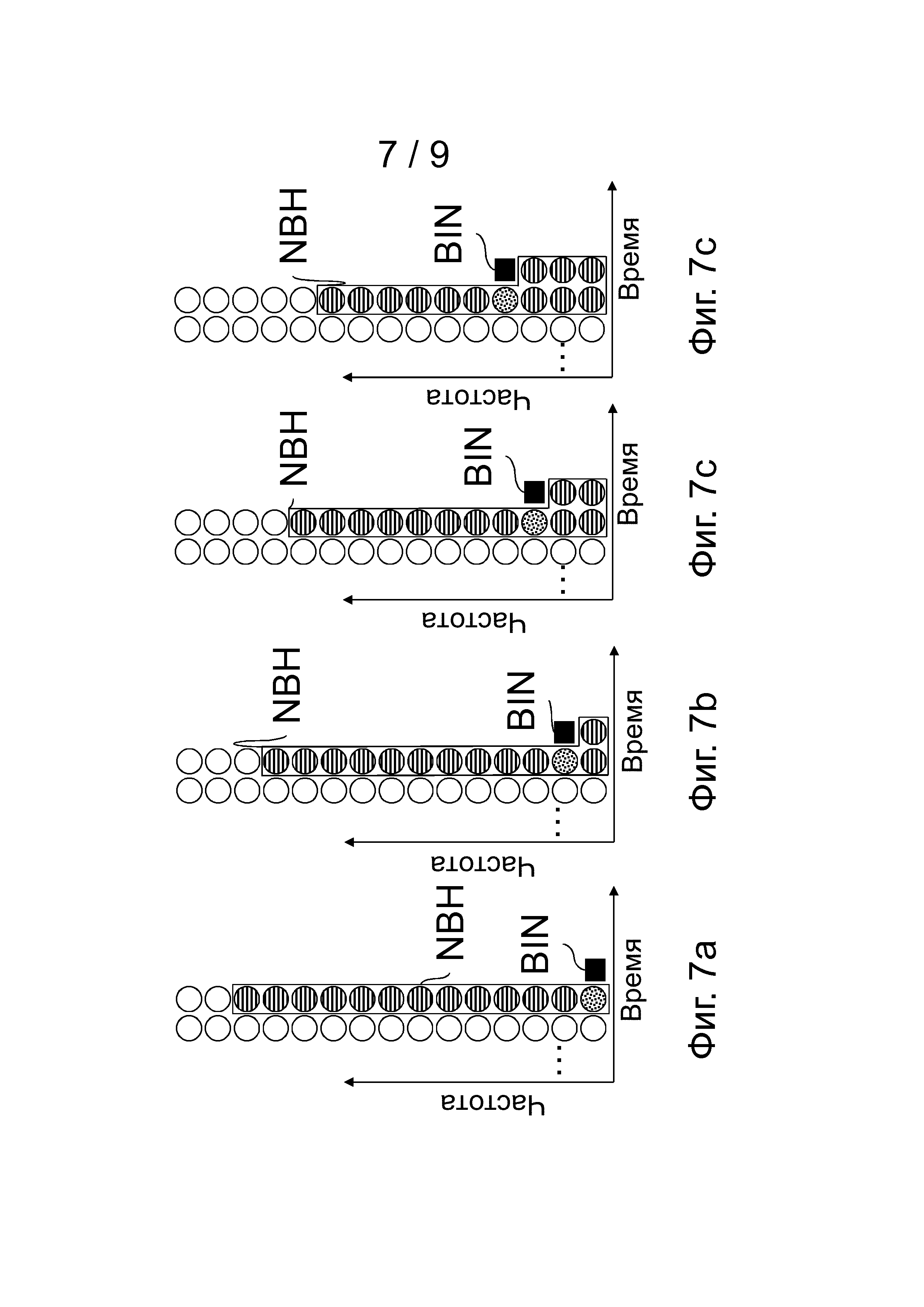
Как указано выше, коммутатор основного режима GMS предусматривает переключение между режимом работы в частотной области (FD) и режимом взвешенного преобразования на основе линейного предсказания (wLPT). В зависимости от режима можно использовать различные близлежащие области. Примерные близлежащие области, изображенные на фиг.5a, фиг.6a и 6b и фиг.8, показали себя в экспериментах, как достаточно большие для режима FD. Но для режима wLPT определили, что более предпочтительны более крупные близлежащие области, как изображенные для примера на фиг.5b, фиг.7a, 7b и 7c и фиг.9.
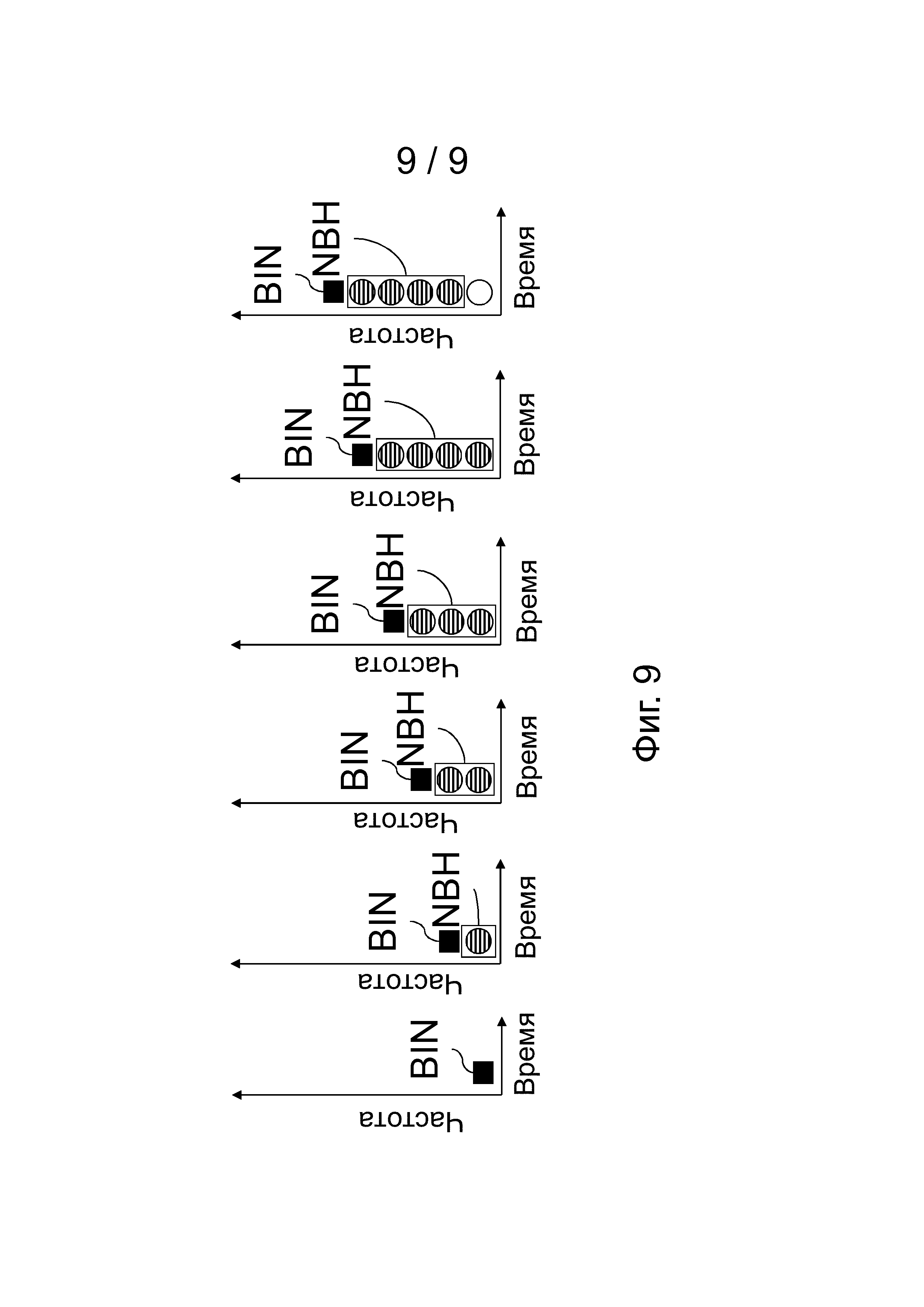
Таким образом, примерная обработка сброса в режиме wLPT изображается на фиг.9. Примерные близлежащие области в режиме wLPT для элемента дискретизации самой низкой частоты, второй самой низкой частоты, третьей самой низкой частоты и четвертой самой низкой частоты в спектре изображают на фиг.7a, 7b, 7c и 7d, соответственно. А примерную близлежащую область в режиме wLPT для всех других элементов дискретизации в спектре изображают на фиг.5b.
Количество классов контекста, являющихся результатом примерной близлежащей области, изображенной на фиг.5b, равно 3×91=273 класса контекста. Коэффициент 3 является результатом специальной обработки одного элемента дискретизации на той же самой частоте, как тот элемент, который в настоящий момент должен кодироваться или в настоящий момент должен декодироваться. Согласно приведенной выше формуле, существует 0,5*((12*12)+3*12+2)=91 комбинация индексов элементов дискретизации со значением 2, 1 или 0 для остальных 12 элементов дискретизации в близлежащей области. В варианте осуществления, в котором дифференцируют классы контекста в зависимости от того, выполняется или нет условие, что отклонение близлежащей области равно или превышает пороговое значение, количество 273 класса контекста удваиваются.
Примерная обработка сброса, как показано на фиг.9, может также добавлять некоторое количество классов контекста.
В протестированном примерном варианте осуществления, который приводил к хорошим результатам в экспериментах, существует 822 возможных класса контекста, которые распределены в следующей таблице 1.
|
|
В протестированном примерном варианте осуществления эти 822 возможных класса контекста отображают в 64 ФПВ. Данное отображение определяют на фазе обучения, как описано выше.
Результирующие 64 ФПВ должны храниться в таблицах ROM, например, с 16-битной точностью для арифметического кодера с фиксированной точкой. В данном случае обнаруживается другое преимущество предложенной схемы: в текущей работающей черновой версии стандарта USAC, упомянутого в разделе предшествующего уровня техники, тетрады (векторы, содержащие 4 спектральных элементов дискретизации) совместно кодируют с помощью одной кодовой комбинации. Это приводит к очень большим кодовым книгам, даже если динамический диапазон каждого компонента в векторе является очень небольшим (например, каждый компонент может иметь значения [-4, …, 3]→84=4096 возможных различных векторов). Скалярное кодирование, однако, обеспечивает расширенный динамический диапазон для каждого элемента дискретизации с очень небольшой кодовой книгой. Кодовая книга, используемая в протестированном примерном варианте осуществления, имеет 32 записи, обеспечивая динамический диапазон для элемента дискретизации от -15 до +15 и Esc-кодовую комбинацию (для случая, когда значение элемента дискретизации находится вне этого диапазона). Это подразумевает, что только 64×32 16-битовых значений необходимо хранить в таблицах ROM.
Выше описан способ арифметического кодирования текущего спектрального коэффициента, используя предыдущие спектральные коэффициенты, в котором упомянутые предыдущие спектральные коэффициенты уже закодированы, причем упомянутые и предыдущие, и текущий спектральные коэффициенты содержатся в одном или более квантованных спектров, которые являются результатом квантования результата частотно-временного преобразования значений дискретизации видео-, аудио- или голосовых сигналов. В одном из вариантов осуществления упомянутый способ содержит обработку предыдущих спектральных коэффициентов, использование обработанных предыдущих спектральных коэффициентов для определения класса контекста, являющимся одним по меньшей мере из двух различных классов контекста, использование определенного класса контекста и отображения по меньшей мере двух различных классов контекста по меньшей мере в две различные функции плотности вероятности для определения функции плотности вероятности и арифметическое кодирование текущего спектрального коэффициента, основываясь на определенной функции плотности вероятности, причем обработка предыдущих спектральных коэффициентов содержит неравномерное квантование предыдущих спектральных коэффициентов.
В другом примерном варианте осуществления устройство для арифметического кодирования текущего спектрального коэффициента, используя предыдущие уже закодированные спектральные коэффициенты, содержит средство обработки, первое средство для определения класса контекста, запоминающее устройство, в котором хранят по меньшей мере две различные функции плотности вероятности, второе средство для извлечения плотности вероятности и арифметический кодер.
В этом случае средство обработки выполнено с возможностью обработки предыдущих, уже закодированных спектральных коэффициентов с помощью их неравномерного квантования, и упомянутое первое средство выполнено с возможностью использования результата обработки для определения класса контекста, который является одним по меньшей мере из двух различных классов контекста. Запоминающее устройство хранит по меньшей мере две различные функции плотности вероятности и отображение по меньшей мере двух различных классов контекста по меньшей мере в две различные функции плотности вероятности, что предусматривает извлечение функции плотности вероятности, которая соответствует определенному классу контекста. Второе средство выполнено с возможностью извлечения из запоминающего устройства плотности вероятности, которая соответствует определенному классу контекста, и арифметический кодер выполнен с возможностью арифметического кодирования текущего спектрального коэффициента, основываясь на извлеченной функции плотности вероятности.
Существует соответствующий другой примерный вариант осуществления устройства для арифметического декодирования текущего спектрального коэффициента, используя предыдущие уже декодированные спектральные коэффициенты, который содержит средство обработки, первое средство для определения класса контекста, запоминающее устройство, в котором хранят по меньшей мере две различные функции плотности вероятности, второе средство для извлечения плотности вероятности, и арифметический декодер.
В этом случае средство обработки выполнено с возможностью обработки предыдущих, уже декодированных спектральных коэффициентов с помощью их неравномерного квантования, и упомянутое первое средство выполнено с возможностью использования результата обработки для определения класса контекста, который является одним по меньшей мере из двух различных классов контекста. Запоминающее устройство хранит по меньшей мере две различные функции плотности вероятности и отображение по меньшей мере двух различных классов контекста по меньшей мере в две различные функции плотности вероятности, что предусматривает извлечение функции плотности вероятности, которая соответствует определенному классу контекста. Второе средство выполнено с возможностью извлечения из запоминающего устройства плотности вероятности, которая соответствует определенному классу контекста, и арифметический декодер выполнен с возможностью арифметического декодирования текущего спектрального коэффициента, основываясь на извлеченной функции плотности вероятности.
Способ и устройство для применения реверберации к многоканальному звуковому сигналу с использованием параметров пространственных меток
Способ и устройство для кодирования и оптимальной реконструкции трехмерного акустического поля
Аудиокодер и декодер
Передача длины элемента кадра при кодировании аудио
Аудиокодер, аудиодекодер и связанные способы обработки многоканальных аудиосигналов с использованием комплексного предсказания
Кодер аудио и декодер, имеющий гибкие функциональные возможности конфигурации
Расположение элемента кадра в кадрах потока битов, представляющего аудио содержимое
Способ кодирования и декодирования изображений, устройство кодирования и декодирования и соответствующие компьютерные программы
Способы и системы для эффективного восстановления высокочастотного аудиоконтента
Способ кодирования и декодирования изображений, устройство кодирования и декодирования и соответствующие компьютерные программы
Способ и устройство для арифметического кодирования или арифметического декодирования

