Результат интеллектуальной деятельности: БАЛАНСИРОВКА НАГРУЗКИ ДЛЯ БОЛЬШИХ БАЗ ДАННЫХ В ОПЕРАТИВНОЙ ПАМЯТИ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к области техники устройств управления данными, пример, для вычислительных устройств хранения и управления особенно большими объемами данных и для предоставления таких данных клиенту для операций чтения или записи.
УРОВЕНЬ ТЕХНИКИ
Большие базы данных в оперативной памяти в настоящее время используются на производственной базе, чтобы служить в качестве хранилищ пар "ключ-значение", баз данных обработки транзакций в реальном масштабе времени (OLTP), крупномасштабных веб-приложений, крупномасштабных многопользовательских сетевых игр, контроллерах видов на уровне сети программно-конфигурируемой сети (SDN), научном моделировании и так далее. Данные приложения строятся для поддержания высоких скоростей транзакций с использованием множества контекстов выполнения, например, потоки в системах с неравномерным доступом к памяти (NUMA) архитектур с общим доступом, при котором набор данных разделяется логически и каждый раздел сопоставляется с контекстом выполнения, который несет ответственность за процесс транзакций в его разделе.
Стратегия разделения усиливает исключительность контекста выполнения над разделом таким образом, что транзакция выполняется в среде однопоточного физического доступа без каких-либо блокировок или защелок, как описано в Kalman, Robert et al.: "H-store: A High-performance, Distributed Main Memory Transaction Processing System", VLDB Endowment, август 2008 г. Данный подход может быть описан как комбинация высокой эффективности последовательной обработки раздела с параллелизмом, используемым по всем разделам, предоставляя возможность увеличения обработки транзакции.
Вместе с тем, стратегия статического разделения может повлечь за собой проблемы с эффективностью и серьезно ограничить масштабируемость, когда имеется даже незначительная асимметрия распределения нагрузки на набор данных, в виду того, что в некоторых контекстах выполнения может возникать исключительно высокая частота обновления, в то время как в других недостаточная, что делает разбиение на разделы бесполезным. Как утверждают некоторые авторы, изменение асимметричности нагрузки на реальных примерах является скорее правилом, чем исключением, как описано в Pinar Tozun et al.: "Scalable и dynamically balanced shared-everything OLTP with physiological partitioning", The VLDB Journal DOI 1007/s00778-012-0278-6, июнь 2012 г.
В Hyeontaek Lim et al.: "MICA: A Holistic Approach to Fast In-Memory Key-Value Storage", NSDIʹ14, апрель 2014 г., Seattle, WA USA описывается хранилище пар "ключ-значение" в оперативной памяти, в котором рассматривается асимметричная нагрузка с использованием специальной статической хэш-функции с попыткой распределить размещение ключей в разделах так, что в среднем нагрузка на раздел не превышает 53% отклонения в эксперименте по распределению Ципфа. Однако, с помощью статического размещения и стратегии разбиения на разделы система может быть неадаптивной и, таким образом, может быть менее эффективной, когда, например, нагрузка является низкой.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Можно заметить, что задачей настоящего изобретения является предоставление устройства управления данными, которое решает проблему асимметрии, а именно, предоставляет разбиение на разделы, что дает возможность эффективной работы балансировки нагрузки между различными исключительными контекстами выполнения.
Данная задача решается с помощью независимых пунктов формулы изобретения. Дополнительные варианты осуществления изобретения указываются в зависимых пунктах формулы изобретения и в следующем описании.
В соответствии с аспектом изобретения, представляется устройство управления данными. Устройство управления данными содержит модуль управления и модуль хранения, в котором модуль хранения выполнен с возможностью хранения множества наборов данных в множестве групп наборов данных так, что множество наборов данных присваивается множеству групп наборов данных таким образом, что каждая группа наборов данных содержит по меньшей мере один набор данных и каждый набор данных хранится только в одной группе наборов данных, и, в котором модуль управления выполнен с возможностью присвоения исключительного контекста выполнения каждой группе наборов данных, и для оценки количества запросов набора данных для каждого набора данных. Модуль управления дополнительно выполнен с возможностью определения наборов данных для каждой группы наборов данных на основе предполагаемого количества запросов наборов данных и для повторного присваивания наборов данных группам наборов данных так, что предполагаемое количество запросов наборов данных в группе наборов данных меньше или равняется заранее заданному количеству запросов наборов данных для, по меньшей мере, одного исключительного контекста выполнения, который присваивается одному множеству групп наборов данных.
В частности, устройство управления данными, описанное в настоящем документе может решить проблему асимметрии в разбитых на разделы хранилища данных в оперативной памяти на архитектурах с общим доступом. Это может быть одним аспектом устройства управления данными в том, что строится точная быстродействующая статическая модель общего динамического распределения нагрузки и в том, что набор данных повторно разбит на разделы в соответствии с выявленной нагрузкой. Устройство управления данными может быть описано как реализация упреждающего способа примененного к базе данных в оперативной памяти или хранилищу данных.
Исключительный контекст выполнения может быть потоком выполнения, который выполняется в блоке обработки данных вычислительного устройства. В дальнейшем, когда речь идет о потоке выполнения, следует понимать, что соответствующее утверждение в целом также относится к исключительному контексту выполнения. Набор данных, как указано выше, может быть описан как одна "полоса" (stripe), содержащая по меньшей мере одну запись ключ-значение (предпочтительно более одной записи ключ-значение, которые сортируются или группируются вместе) и группа наборов данных являющаяся одним разделом, содержащим множество наборов данных. Данные термины могут быть использованы равнозначно друг для друга, соответственно.
Запрос набора данных может, в частности, относиться к одной операции (чтение/запись) для набора данных, который инициируется клиентом и направляется одному из потоков выполнения, который будет выполняться на наборе данных в одном из разделов. Запросы набора данных могут быть выполнены в разделах (каждый с исключительными контекстами) и могут быть различных типов, например, могут быть структурированным языком запросов (SQL) или транзакцией OLTP. Когда модуль управления инициирует повторное разбиение на разделы, он также может учитывать как количество, так и типы выполняемых запросов и даже свернуть/соединить разделы.
В общем случае, блок управления может использовать любую зависимую от платформы, приложения и динамическую информацию для принятия решений по повторному разбиению на разделы.
Каждая группа наборов данных содержит множество наборов данных и каждый набор данных содержится только в одной группе наборов данных. Данное соотношение может быть описано как отношение N к 1 наборов данных для групп наборов данных.
Запросы по потоку выполнения могут быть описаны как функция ценности на основе измеренного количества запросов, обработанных в хранилище данных, взятая как вероятность настоящего и/или будущего распределения скорости поступления запроса, деленное на исходное количество присвоенных потоков выполнения. Запросы по потоку выполнения могут быть сделаны статически, когда модуль управления может определять или определяться производительностью потоков выполнения и может принимать решение о количестве потоков выполнения для присвоения, уменьшая тем самым количество потоков выполнения и производя экономию рассеиваемой мощности при решении это делать.
Устройство управления данными и, в частности, блок управления выполнен с возможностью определения наборов данных для каждой группы наборов данных. Например, определяется состав каждой группы наборов данных, а именно, для каждого одиночного набора данных определяется какой группе наборов данных он присваивается.
Например, модуль управления может быть настроен для определения наборов данных для каждой группы наборов данных на основе распределения запросов набора данных по группам наборов данных и для повторного присваивания наборов данных группам наборов данных так, что ожидаемое количество запросов наборов данных в группе наборов данных меньше или равняется заранее заданному количеству запросов набора данных для по меньшей мере одного исключительного контекста выполнения, который присваивается одному из множества групп наборов данных. Таким образом, разбиение на разделы осуществляется на основе ожидаемого количества запросов на раздел.
В одном варианте осуществления изобретения модуль управления может дополнительно настраиваться для определения вероятности запросов набора данных для каждого набора данных и/или для определения наборов данных для каждой группы наборов данных на основе функций кумулятивной вероятности конкретных типов запроса по всему модулю хранения и для повторного присвоения наборов данных группам наборов данных так, что вероятность количества запросов в группе наборов данных меньше или равняется заранее заданному количеству запросов на исключительный контекст выполнения. Например, запрос OLTP может получить доступ к нескольким хранилищам данных для чтения/записи. Иными словами, запрос OLTP имеет вероятность охватить указанное подмножество хранилища данных, которое является расширением получить/положить, что имеет вероятность охвата определенного адреса в хранилище данных.
Данный подход может быть одним аспектом устройства управления данными для изменения размера разделов так, что соответствие наборов данных группам наборов данных повторно присваивается. Данное повторное присваивание может быть основано на статистической вероятности распределения запроса по всему хранилищу данных и, таким образом, обеспечивает возможность корректирующей и прогностической балансировки нагрузки так, что процессы, имеющие доступ к группам наборов данных избегают сериализации при наличии асимметрии в распределении запроса и предоставлении возможности параллелизации обработки запроса и масштабируемости.
Согласно варианту осуществления изобретения модуль управления выполнен с возможностью динамической настройки заранее заданного количества запросов набора данных для, по меньшей мере, одного исключительного контекста выполнения, который присваивается одному из множества групп наборов данных, во время работы устройства управления данными.
Таким образом, пороговое значение может быть адаптировано к изменяющимся условиям нагрузки устройства управления данными, например, если общее количество запросов набора данных увеличивается или уменьшается и количество групп наборов данных и потоков выполнения остается постоянным.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью оценки вероятности запросов набора данных для каждого набора данных и для определения наборов данных для каждой группы наборов данных на основе функции кумулятивной вероятности запросов по всему модулю хранения и для повторного присваивания наборов данных группам наборов данных так, что вероятность количества запросов в группе наборов данных меньше или равняется заранее заданному количеству запросов набора данных для по меньшей мере одного исключительного контекста выполнения, который присваивается одной из множества групп наборов данных.
Иными словами, модуль управления может настраиваться для определения наборов данных для каждой группы наборов данных на основе функции кумулятивной вероятности распределения запроса по всему модулю хранения, где каждому запросу может быть присвоен вес, а именно, количественная характеристика и повторно присвоены наборы данных группам наборов данных так, что вероятность количества запросов в группе наборов данных меньше или равняется заранее заданному количеству запросов на исключительный контекст выполнения.
В соответствии с другим вариантом осуществления изобретения вероятность количества запросов набора данных на набор данных аппроксимируется с помощью определения количества запросов наборов данных, применяемых к каждому набору данных, масштабированных с помощью весовых параметров конкретного запроса и функции распределения кумулятивной вероятности, CDF, рассчитанной по вероятности запросов на наборах данных.
Вероятность запросов на наборах данных может быть рассчитана на наборах данных, упорядоченных в заранее заданном порядке в модуле хранения. Способ повторного разбиения на разделы может быть достигнут путем вычисления обратной функции кумулятивного распределения следующим образом:
j=CDF-1 (работа-на-поток_выполнения * k),
где 1 <= k <= количествово_потоков_выполнения, j - индекс набора данных в общем порядке.
Таким образом, запросы на набор данных располагаются в массиве в некотором порядке (должны быть определены путем сортировки или некоторыми другими средствами). Например, может быть массив pdf [i], который содержит в наборе данных некоторое количество принятых запросов i, 0 <= i <= N, с N - количеством наборов данных в одной группе наборов данных. Затем CDF вычисляется как рекурсивное уравнение следующим образом:
CDF [0]=pdf [0]
CDF [i]=pdf [i]+CDF [i-1], где 1 <= i <= N.
Вычисление CDF-1 может быть выполнено с помощью настраиваемого двоичного поиска следующим способом:
двоичный_поиск (CDF, работа-на-поток_выполнения * k) возвращает индекс j,
где CDF [j] <= работа-на-поток_выполнения * k.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью динамического изменения ряда элементов и/или элемента наборов данных, содержащихся в одной группе наборов данных.
Размер групп наборов данных может изменяться во время работы устройства управления данными. Изменение элемента наборов данных, содержащегося в одной группе наборов данных, может быть описано как перекомпоновка присвоения наборов данных группам наборов данных, например, набор 1 данных может быть скомпонован в другой группе наборов данных после перекомпоновки наборов данных.
Таким образом, размер и/или содержание групп наборов данных адаптируется на основе количества и/или типа запросов наборов данных. Изменение размера групп наборов данных может иметь такой эффект, что группа наборов данных, содержащая меньше часто запрошенных наборов данных, может быть больше, а группа наборов данных, содержащая больше часто запрошенных наборов данных, может быть меньше (например, где частота аппроксимируется функцией распределения вероятности, как описано выше) таким образом, что общая нагрузка групп наборов данных выравнивается и избегается сериализация (и в тоже время дается возможность параллелизации) при наличии асимметрии рабочего запроса.
Асимметрия нагрузки имеет место, например, если одна группа наборов данных получает большую часть запросов. В таком случае, только один поток выполнения обрабатывает их последовательно. Производительность устройства управления данными затем обычно ограничивается пропускной способностью одного потока выполнения с увеличением времени задержки в два раза, как если бы два потока выполнения работали параллельно (с двойной пропускной способностью).
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью многократного определения наборов данных, по меньшей мере, для первой группы наборов данных и для повторного присваивания наборов данных для групп наборов данных, если различие между количеством определенных наборов данных по меньшей мере для первых групп наборов данных и текущее количество наборов данных по меньшей мере в первой группе наборов данных превышает заранее заданное пороговое значение.
Иными словами, вычисление повторного разбиения на разделы периодически повторяется или запускается системным событием, например, каждые несколько секунд. Если различие между новым размером первой группы наборов данных и старым размером первой группы наборов данных не превышает порогового значения, вычисление разбиения на разделы отвергается.
Модуль управления может циклически определять количество наборов данных для каждой группы наборов данных и может выполнять шаги для каждой группы наборов данных, а не только для первой группы наборов данных.
С одной стороны, проведение повторного разбиения на разделы может расходовать системные ресурсы, так как оно требует вычислительной мощности, а с другой стороны, повторное разбиение на разделы ведет к улучшению работы балансирования нагрузки разделов и присваивания потоков выполнения. Поэтому может быть выгодным оценить, превышает ли ожидаемый выигрыш в производительности системы в результате повторного разбиения на разделы требуемую вычислительную мощность для повторного разбиения на разделы.
В данном варианте осуществления изобретения повторное разбиение на разделы выполняется только, если ожидаемый выигрыш по производительности системы ввиду повторного разбиения на разделы выше, чем расходы ресурсов при повторном разбиении на разделы, которое достигается путем сравнения текущего размера раздела с ожидаемым новым размером раздела и определения разницы между ними.
В соответствии с другим вариантом осуществления изобретения, модуль управления выполнен с возможностью повторного присваивания наборов данных группам наборов данных, если разница между первым количеством запросов наборов данных первой группы наборов данных и вторым количеством запросов наборов данных второй группы наборов данных равняется или выше, чем заранее заданное пороговое значение.
В данном варианте осуществления изобретения повторное разбиение на разделы начинается, если разница между двумя группами наборов данных выше, чем заранее заданное пороговое значение. Иными словами, общий выигрыш в производительности системы (затраты - выигрыш по производительности системы повторного разбиение на разделы) можно рассматривать не только текущий размер раздела и ожидаемый размер раздела, но также изменение относительного размера раздела двух или более разделов.
Это в частности относится к перекомпоновке наборов данных в группах наборов данных и может быть полезным в случае асимметричной нагрузки между двумя имеющимися разделами.
Пороговое значение (различия между первым и вторым разделом) может быть выбрано таким образом, что повторное разбиение на разделы не выполняется слишком часто или при минимальных различиях, поскольку, это требует вычислительной мощности и повторное разбиение на разделы выполняется, если нагрузка на группы наборов данных такова, что дополнительная вычислительная мощность в следствие асимметричной нагрузки равняется или выше расчетной мощности процесса повторного присваивания.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью присваивания наборов данных группам наборов данных в возрастающем порядке количества и/или типов запросов наборов данных.
Порядок по возрастанию номеров запросов наборов данных означает, что наборы данных логически упорядочены так, что номер запросов наборов данных увеличивается и затем присваивание наборов данных группам наборов данных выполняется в соответствии с данным порядком. Например, наборы данных с младшими запросами наборов данных присваиваются первой группе наборов данных до тех пор пока первой группе наборов данных будет присвоено столько наборов данных, чтобы достичь порогового значения запросов наборов данных (= сумма запросов наборов данных от всех наборов данных в первой группе наборов данных); последующие наборы данных могут быть аналогично присвоены последующим группам наборов данных пока не будет достигнуто пороговое значение запросов наборов данных на группу наборов данных для соответствующей группы набора данных.
Модуль управления может настраиваться для присваивания наборов данных в общем порядке наборов данных в модуле хранения.
В данном варианте осуществления изобретения создаются группы наборов данных, содержащие наборы данных с сопоставимыми номерами запросов наборов данных. Количество запросов группы наборов данных (а именно, сумма запросов всех наборов данных в одной группе) доводится до аналогичного уровня и наборы данных в отдельных группах наборов данных также могут быть сгруппированы так, что количества запросов наборов данных почти одинаковы.
Такой подход может преодолеть несмежные резкие увеличения в распределении запроса на потоки выполнения. После повторного разбиения на разделы наборы данных распределяются в группах наборов данных так, что потоки выполнения и соответствующие разделы являются связанными друг с другом в соответствии с их нагрузкой и никакой поток выполнения с любой нагрузкой не распределяется между ними. Подходящий вес, масштабированный на наборах данных, включенных в транзакции с множеством наборов данных, может гарантировать близость данных наборов данных в общем порядке и может, таким образом, в соответствии с этим дать возможность слияния групп наборов данных.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью присваивания наборов данных группе наборов данных в убывающем порядке номеров запросов наборов данных.
В данном варианте осуществления изобретения наборы данных логически компонуются так, что количество запросов наборов данных уменьшается и затем присваивание наборов данных группам наборов данных выполняется в соответствии с данным порядком. Наборы данных с большим количеством запросов наборов данных присваиваются первой группе наборов данных до тех пор, пока первая группа наборов данных будет присвоено столько наборов данных, чтобы достичь порогового значения запросов наборов данных (= сумма запросов наборов данных всех наборов данных в первой группе наборов данных). Последующие наборы данных присваиваются аналогично последующим группам наборов данных до достижения порогового значения запроса наборов данных на группу наборов данных для данной группы наборов данных.
В данном варианте осуществления изобретения может быть определено положение интенсивно запрошенных или требуемых наборов данных. Интенсивно запрашиваемые наборы данных компонуются в первой группе наборов данных.
В качестве альтернативного варианта модуль управления может настраиваться для присваивания наборов данных группам наборов данных в общем порядке наборов данных в модуле хранения.
В соответствии с другим вариантом осуществления изобретения модуль хранения является непостоянным хранилищем.
Непостоянное хранилище может быть оперативным запоминающим устройством (ОЗУ) и группы наборов данных таким образом могут создавать базу данных в оперативной памяти для получения возможности проведения транзакций на высоких скоростях.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью создания множества исключительных контекстов выполнения и для присваивания каждого исключительного контекста выполнения одной группе наборов данных.
Исключительный контекст выполнения, таким образом, может быть описан как рабочий поток выполнения, который присвоен одной группе наборов данных для выполнения операций над наборами данных данной группы наборов данных.
Наличие исключительных контекстов выполнения дает возможность балансировки нагрузки на иерархическом уровне исключительных контекстов выполнения и создания новых исключительных контекстов выполнения, если существующие исключительные контексты выполнения перегружены.
Таким образом, различные уровни балансировки нагрузки можно отнести к следующим уровням: первый уровень балансировки нагрузки повторно разбивает на разделы, как описано выше; второй уровень балансировки нагрузки выполняется за счет создания дополнительных исключительных контекстов выполнения (рабочие потоки выполнения), которые могут иметь дело с ожидающими запросами в целях снижения средней нагрузки существующих потоков выполнения.
В случае сниженной нагрузки системы, а именно, когда общая нагрузка позволяет модулю управления закрывать по меньшей мере один или несколько исключительных контекстов выполнения для уменьшения мощности и повторно присвоить разделы остающимся исключительным контекстам выполнения.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью, по меньшей мере, временного повторного присвоения множества исключительных контекстов выполнения одной группе наборов данных.
Модуль управления может быть одним или более процессорами или ядрами процессора. Модуль управления может выполнять работу потоков выполнения и присваивать его другим потокам выполнения в порядке для достижения рабочей нагрузки в масштабе времени μ-секунд. Данное присвоение предпочтительно является временным присвоением, а именно, в случае, если один исключительный контекст выполнения перегружается, а другой исключительный контекст выполнения не имеет ожидающих запросов в своей очереди запросов.
В данном варианте осуществления изобретения в частности, когда один исключительный контекст выполнения не может использовать доступную нагрузку одной группы наборов данных, то предпочтительно присваивать более одного исключительного контекста выполнения одной группе наборов данных, для получения сбалансированной системы, а именно, исключительный контекст выполнения и группы наборов данных загружаются на одинаковом уровне, например, в диапазоне между 75% и 85% от их максимальной мощности.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью определения средней нагрузки одного исключительного контекста выполнения и для создания дополнительных исключительных контекстов выполнения, если средняя нагрузка превышает заранее заданное значение нагрузки.
Таким образом, количество исключительных контекстов выполнения может быть определено соответствующим образом на основе текущей общей нагрузки системы. Аналогичным образом, количество исключительных контекстов выполнения может быть уменьшено, если позволяет нагрузка.
В соответствии с другим вариантом осуществления изобретения модуль управления выполнен с возможностью определения нагрузки любого исключительного контекста выполнения и для повторного присваивания исключительных контекстов выполнения группам наборов данных, если нагрузка первого исключительного контекста выполнения представляет собой заранее заданное пороговое значение выше нагрузки второго рабочего процесса.
Данный подход дает возможность балансировки нагрузки на дополнительном уровне; первый механизм балансировки нагрузки представляет собой изменение размеров групп наборов данных и второй механизм балансировки нагрузки представляет собой повторное присваивание рабочих процессов группам наборов данных. Таким образом, степень детализации балансировки нагрузки улучшается и могут быть использованы различные механизмы в различных сценариях. В частности, повторное присваивание рабочих процессов группам наборов данных требует меньшей вычислительной мощности, чем изменение размеров групп наборов данных.
Иными словами, устройство управления данными может быть описано следующим образом:
Можно заметить, что один из аспектов устройства управления данными позволяет лучше понять концепцию исключительности потока выполнения в разделе набора данных, рассматривая динамику нагрузки. Моделируя хранилище ключ-значение как совокупность полос и путем моделирования затрат каждых операций потока выполнения, применяемых к его полосам раздела, строится статистическая модель общего распределения нагрузки по разделам. Данная модель, расширенная характеристиками платформы и в сочетании с применением последовательно-параллельной согласованной логики, используется для вычисления нового динамически сбалансированного разбиения на разделы набора данных, что позволяет достичь приемлемой латентной пропускной способности общей производительности при выявленной нагрузке. Используя архитектуру с общим доступом, изменение размеров разделов может происходить без какого-либо перемещения данных.
Данный подход может дать возможность единого представления об использовании ресурсов всего оборудования в соответствии с выявленной нагрузкой, таким образом, что это может позволить совместить выявленную нагрузку с более эффективным использованием ресурсов и, поэтому, способствовать высокой эффективности. Устройство управления данными может быть упрощенным, оно может быстро реагировать на асимметричное распределение и изменчивость нагрузки и может позволить мгновенную балансировку через захват задачи из одного потока выполнения и повторного присваивания захваченной задачи другому потоку выполнения. Подход, описанный в настоящем документе, может дать возможность улучшенной оптимизации на основе динамически собранной информации, например, горячей/холодной кластеризации. Статические данные и ограничения могут быть использованы для повышения производительности однопоточного выполнения. Динамическая информация может быть использована для повышения производительности многопоточного выполнения. В целом все данные качества могут внести свой вклад в высокоэффективное масштабируемое хранилище ключ-значение.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения будут описаны по отношению к следующим чертежам, на которых:
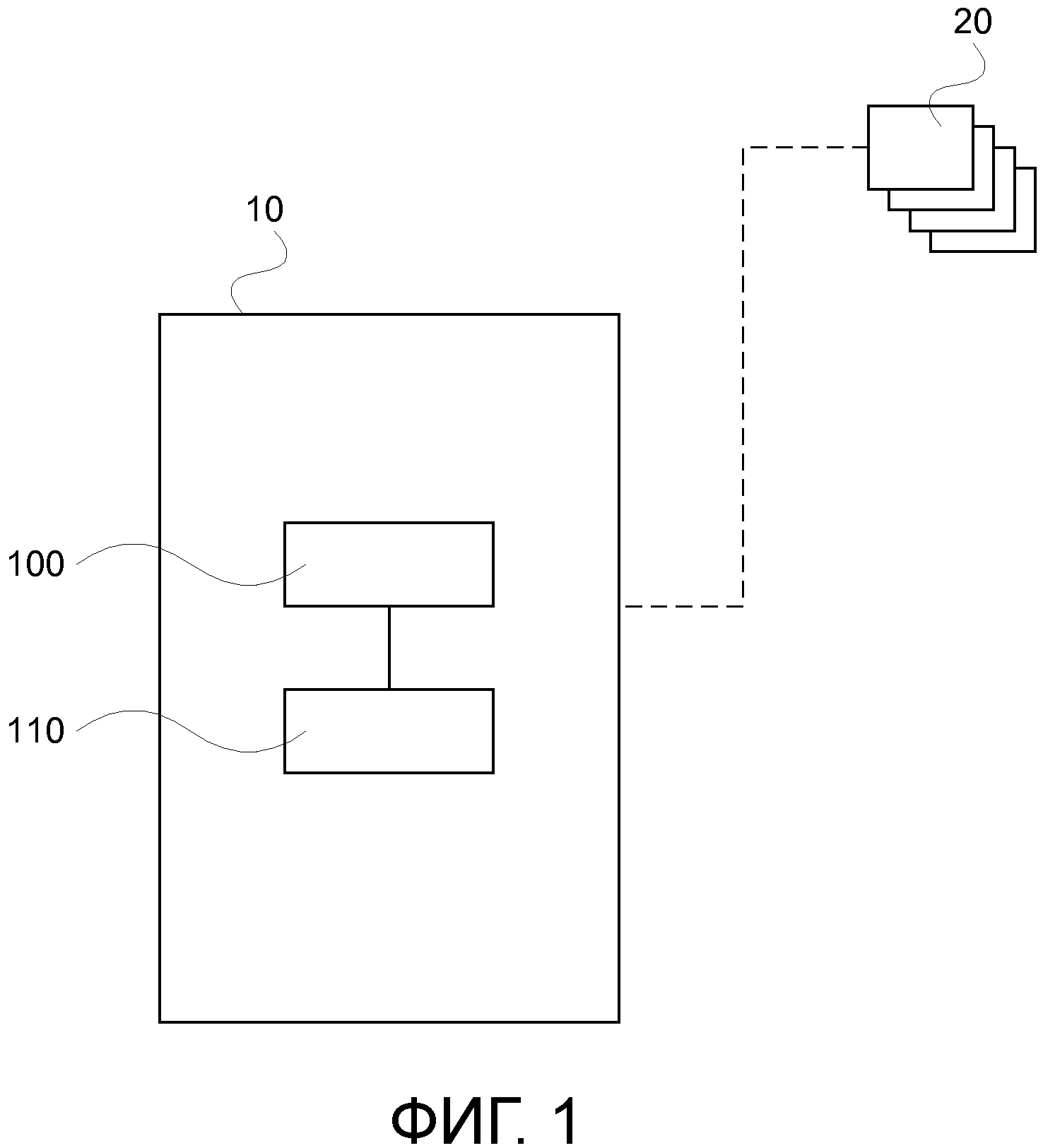
На ФИГ. 1 схематически показано устройство управления данными в соответствии с примерным вариантом осуществления изобретения, связанного с множеством запрашиваемых устройств;
На ФИГ. 2 схематически показано хранилище ключ-значение модели потока выполнения устройства управления данными в соответствии с примерным вариантом осуществления изобретения;
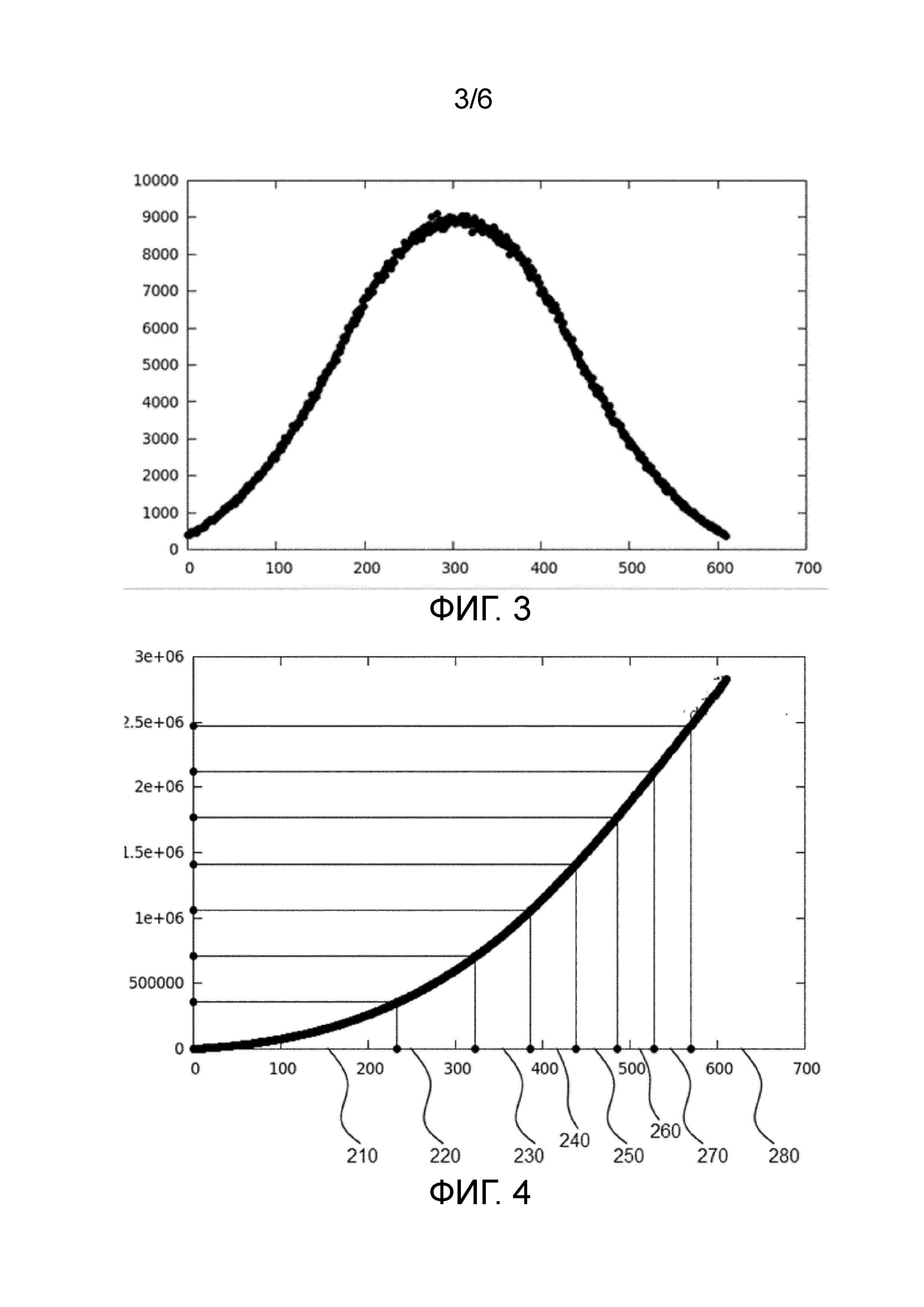
На ФИГ. 3 схематически показана гистограмма функции распределения вероятности по множеству групп наборов данных устройства управления данными в соответствии с примерным вариантом осуществления изобретения;
На ФИГ. 4 схематически показано разбиение на разделы групп наборов данных на основе функции кумулятивного распределения по отсортированной функции распределения вероятности в устройстве управления данными в соответствии с примерным вариантом осуществления изобретения;
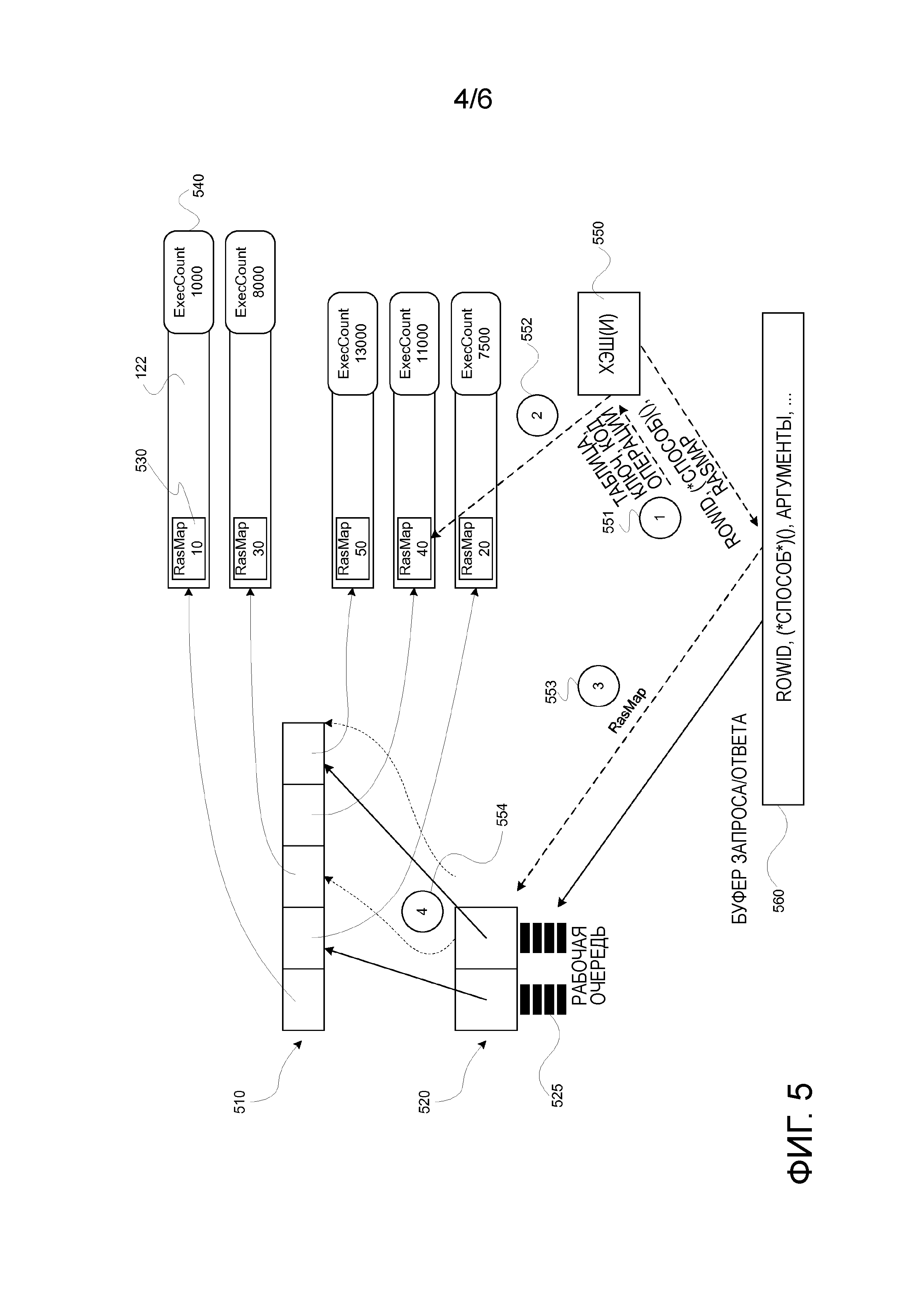
На ФИГ. 5 схематически показано формирование группы наборов данных в устройстве управления данными в соответствии с примерным вариантом осуществления изобретения;
На ФИГ. 6 схематически показана обработка маршрутизации запроса в устройстве управления данными в соответствии с примерным вариантом осуществления изобретения;
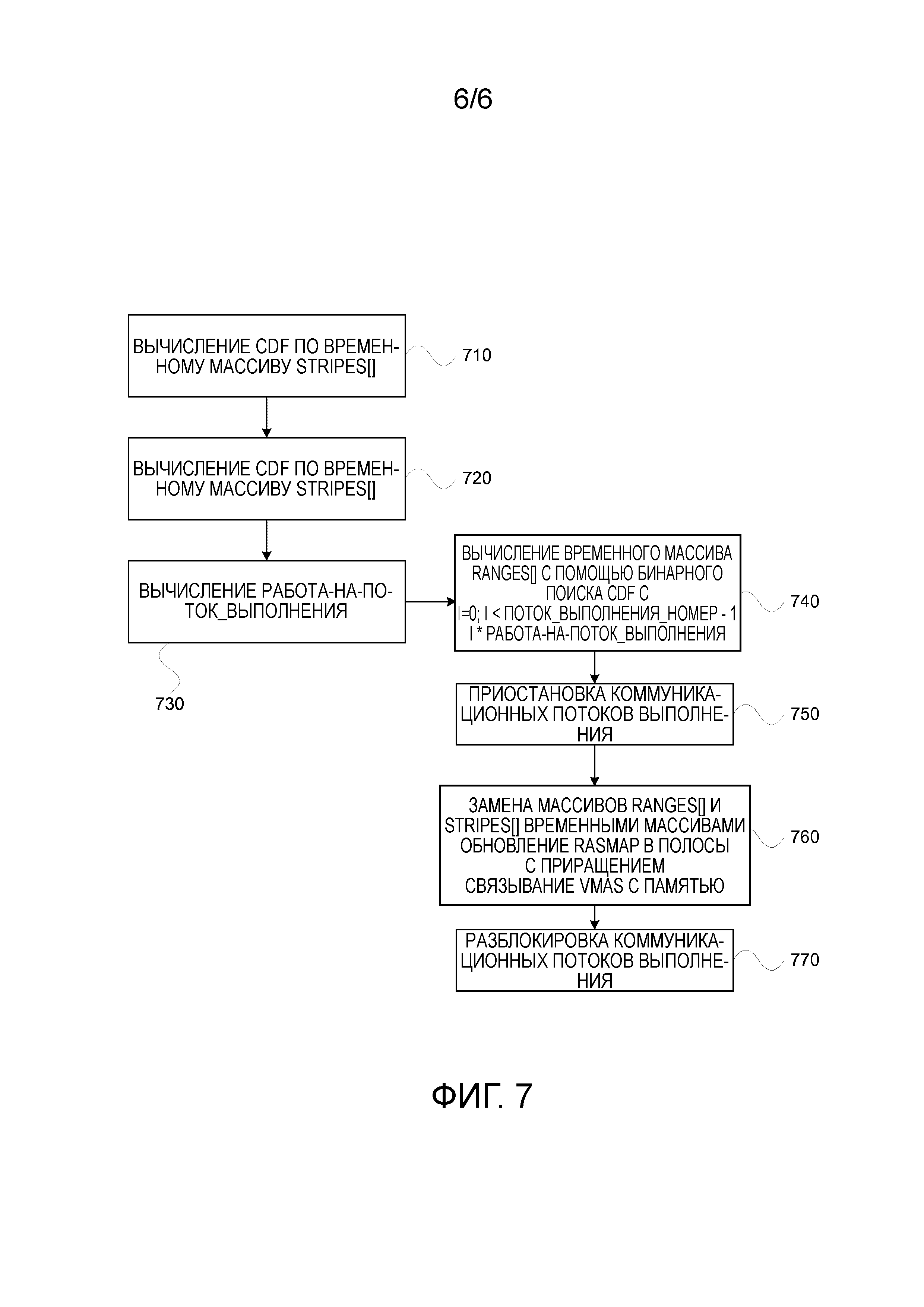
На ФИГ. 7 схематически показаны шаги повторного разбиения на разделы групп наборов данных в устройстве управления данными в соответствии с примерным вариантом осуществления изобретения;
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
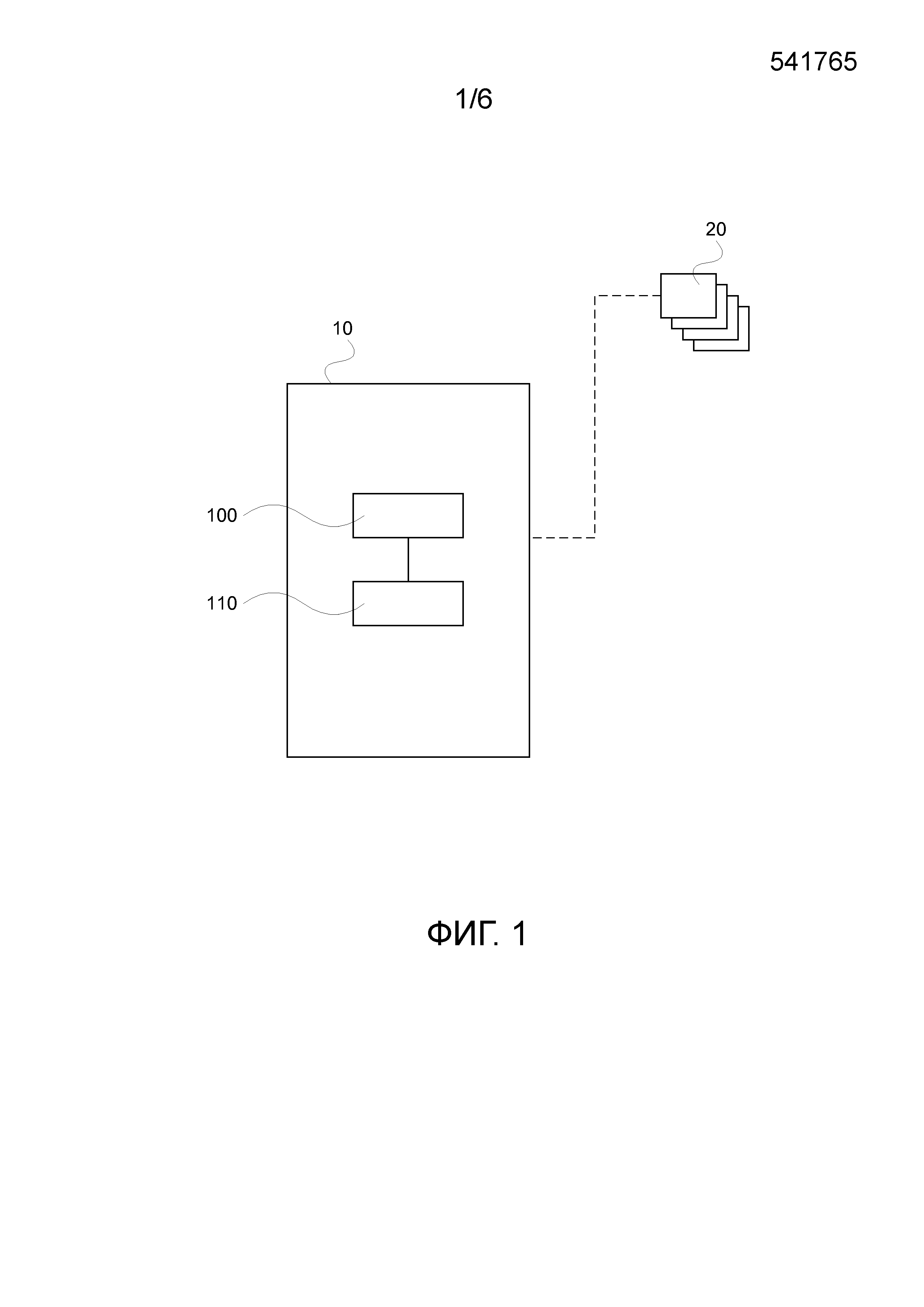
На ФИГ. 1 показано устройство 10 управления данными с модулем 100 управления и модулем 110 хранения, в котором устройство 10 управления данными коммуникационно связываются с одним или более устройствами 20, производящими запросы , которые могут именоваться клиентами. Устройство управления данными также может именоваться сервером.
Модуль 110 хранения выполнен с возможностью включения в себя базы данных в оперативной памяти, содержащей множество групп наборов данных, каждая из которых имеет множество элементов наборов данных. Модуль 100 управления выполнен с возможностью планирования доступа клиентов, производящих запросы модулю 110 хранения и для организации структуры базы данных в оперативной памяти (повторное разбиение на разделы, повторное присваивание потоков выполнения разделам и так далее, как описано выше со ссылкой на устройство управления данными).
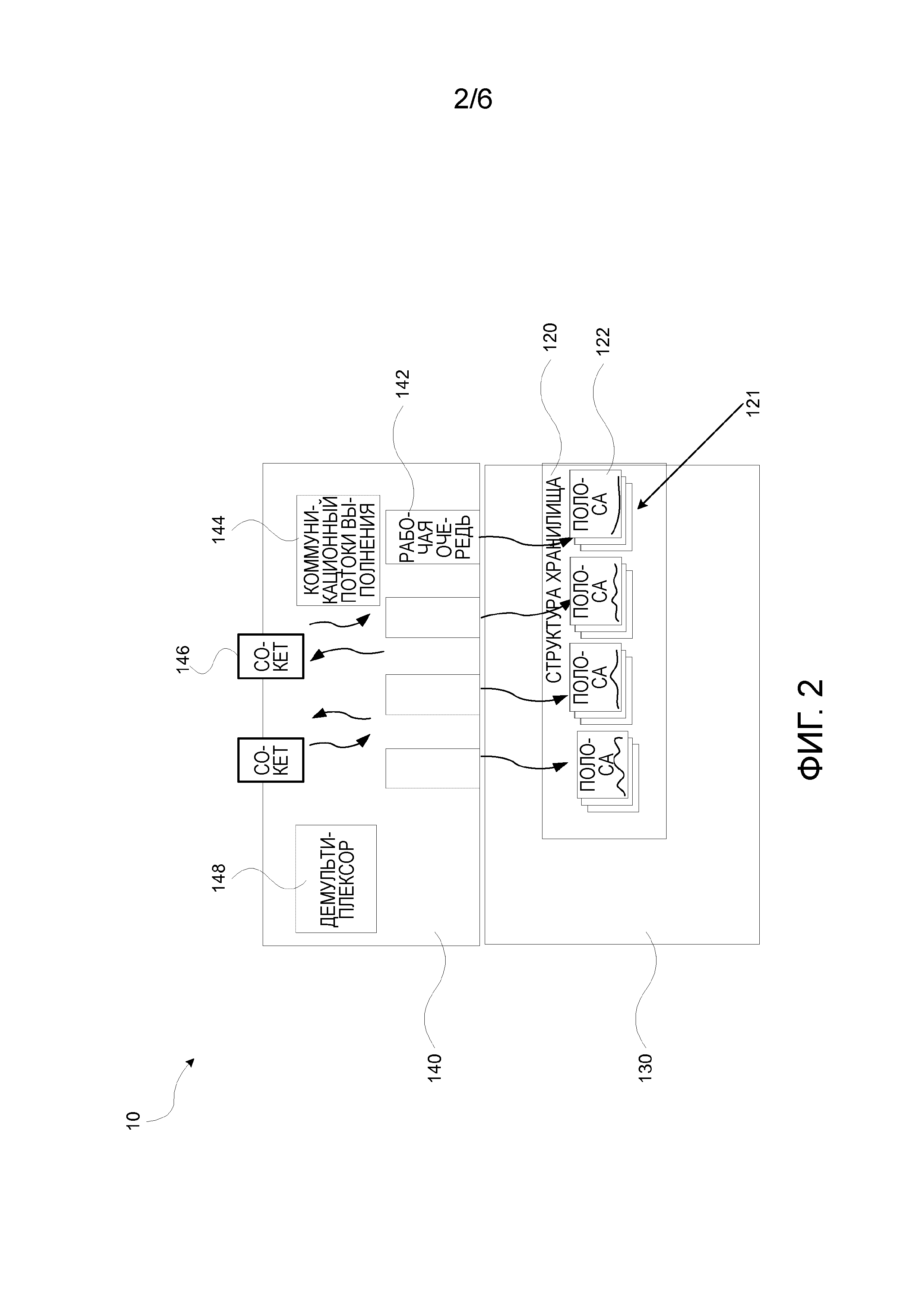
На ФИГ. 2 показана модель потока выполнения общего хранилища ключ-значение, которое может использоваться устройством 10 управления данными. В частности, на ФИГ. 2 можно ссылаться для описания разбиения на разделы и присваивание потока выполнения в хранилище ключ-значение в оперативной памяти. Абстрактная структура Плана Хранилища 120 указывает наборы полос 122, каждая полоса, представляющая агрегацию строк некоторой таблицы, определенной в хранилище ключ-значение. Операция обработки хранилища ключ-значение делится между Компонентом Взаимодействия с Пользователем (FE) 140 и Внутренним Компонентом (BE) 130. Набор рабочих очередей 142, каждая из которых содержит пару операций очереди запроса и его очереди ответа, являются основным интерфейсом между FE 140 и BE 130. Каждая очередь связывается с рабочим потоком выполнения BE.
FE 140 состоит из набора коммуникационных потоков 144 выполнения и Демультиплексора 148. Демультиплексор 148 используется для определения конкретной очереди для постановки в него запроса.
Коммуникационные потоки 144 выполнения считывают коммуникационные сокеты, получая запрос, определяют целевые очереди, используя Демультиплексор, и отправляют запрос в очередь запросов. В обратном направлении, коммуникационные потоки выполнения считывают очередь ответов и доставляют ответы соответствующим сокетам 146.
BE 130 состоит из набора рабочих потоков выполнения и для каждого потока выполнения, соответствующий набор полос 122, которые могут поступать из различных таблиц, называемых разделами 121. Распределение всех полос по разделам и присваивание потоков выполнения разделам определяет разбиение на разделы.
Рабочий поток выполнения удаляет запрос его очереди запросов, выполняет его в одной из полос в его раздел и посылает ответ в его очередь ответов. Если разбиение на разделы является статическим, при асимметричной нагрузке запросы могут предназначаться только малому количеству разделов; работа хранилища ключ-значение, поэтому, имеет низкую производительность при высоком времени задержки, так как малое количество рабочих потоков выполнения должно обрабатывать большее число запросов, в то время как остальные потоки выполнения не работают.
Для решения проблемы асимметрии каждая полоса пополняется в наборе данных дополнительными членами для хранения счетчика выполнения полос и их общего положения по порядку в общей порядковой нумерации всех полос. Первоначально полосы могут нумероваться произвольно и разбиение на разделы может содержать в себе равное количество полос в каждом разделе.
При запуске приложения потоки выполнения увеличивают число выполнений полос на количество пропорциональное "весу" операции выполнения. Функция распределения вероятности (PDF) связывается с порядковым показателем (идентифицированным с общим порядковым расположением полос, которую называем осью x), с помощью гистограммы выполнения счетчиков по оси х.
На ФИГ. 3 изображается гистограмма Гаусса PDF по 620 полосам.
Полосы могут быть передвинуты вдоль оси x с использованием любых отношений между соседними полосами, полученных из характеристик платформы или каких-либо политик, определяемых приложением, определяя, тем самым, новый общий порядок полос по оси x. Поскольку ось разбивается на интервалы, новый порядок определяет отношения между соседними полосами в разделах. Например, полосы могут сортироваться по их номерам выполнения, упорядочивая, тем самым, полосы по "теплоте" и получая, таким образом, ступенчатую горячую/холодную кластеризацию. Аналогичным образом, другие динамические индикаторы выполнения транзакции в полосах могут быть зафиксированы и смоделированы как соседние отношения.
PDF интегрируется с новой осью x, тем самым, вычисляется функция кумулятивного распределения нагрузки (CDF). Среднее значение работа-на-поток_выполнения вычисляется делением самого правого граничного значения CDF на количество выполнений потоков выполнения. В качестве альтернативного варианта, узнав максимально возможное значение работа-на-поток_выполнения на условиях максимальной производительности, количество требуемых рабочих потоков выполнения может быть получено соответствующим образом для воспринимаемой нагрузки, создавая, тем самым, компромисс между предоставленной производительностью и временем задержки и выделение ресурсов потоку выполнения в другом месте.
В дальнейшем ось y CDF делится на приращения значения работа-на-поток_выполнения и проецированный по оси x, тем самым, получая разбиение на разделы оси x на интервалы так, что каждый интервал имеет равное приращение в CDF.
На ФИГ. 4 иллюстрируется CDF, интегрированный по сортированному Гауссовому PDF, разделенному на восемь интервалов, а именно, разделы 210, 220, 230, 240, 250, 260, 270 и 280. Последний раздел 280 на 620, см. количество полос, упомянутых со ссылкой на ФИГ. 3.
Каждый интервал связывается с разделом полос, которые принадлежат некоторому потоку выполнения. Таким образом, при изменении размеров данных разделов нагрузка на выполнение потоков выполнения выравнивается.
По ассоциации, если коммуникационный поток выполнения присваивается для обслуживания раздела так, что запросы/ответы разделу доставляются через соответствующие соединения, обслуживаемые коммуникационным потоком выполнения, нагрузка на коммуникационные потоки выполнения выравнивается после повторного разбиения на разделы. Данный подход требует доставки информации о разбиении на разделы клиенту 20 хранилища данных так, что клиент 20 может выбрать конкретное соединение, чтобы отправить запрос.
Таким образом, повторное разбиение на разделы также обеспечивает связь, избегая накладных расходов на управление конфликтами, когда несколько коммуникационных потоков выполнения могут потребовать поместить их запросы в часто используемый раздел.
Подход обнаружения дисбаланса может быть получен из алгоритма повторного разбиения на разделы: вычисляется новое разбиение на разделы и размеры новых разделов сравниваются с размерами старых. Если разница превышает пороговое значение, проводится новое разбиение на разделы вместо старого. В противном случае вычисление нового разбиения на разделы отбрасывается.
Обнаружение дисбаланса может выполняться периодически или повторное разбиение на разделы может вызываться некоторыми системными событиями такими, как исчерпание свободных буферов запроса в некоторой очереди, что определяет значительную ситуацию дисбаланса. В случае медленно меняющейся нагрузки, алгоритм определения дисбаланса может запускаться нечасто. Для компенсации мгновенных пиков в распределении нагрузки между рабочими потоками выполнения может быть использована политика перехвата работы. А именно, поток выполнения с пустой очередью может опробовать соседнюю очередь и выполнить запросы в соседнем разделе. Таким образом, перехват работы дает возможность мгновенной динамической балансировки нагрузки, а также транзакции, охватывающей соседние разделы.
Описанный подход может позволить решить проблемы асимметрии на различных уровнях модульности глобальным образом над разбитыми на разделы хранилищами ключ-значение в архитектурах с общим доступом.
Один иллюстративный пример реализации описывается со ссылкой на ФИГ. 5-7.
Данный пример относится к операционному хранилищу ключ-значение, основанному на хэшах. То есть, хранилище содержит строки, идентифицированные их ключами в некотором порядке. Хэш-таблица внутри демультипликатора отображает ключи на полосы и строки относительно полос.
Центральная структура данных представляет собой состав массивов 520 Ranges[] (Диапазоны[]) и массивов 510 Stripes[] (Полосы[]). Элемент массива Stripes[] содержит ссылку на структуру данных, представляющую полосу 122; структура данных полосы включает в себя счетчик 540 выполнения, который отражает затраты всех операций, выполненных в полосе. Кроме того, структура данных полосы включает в себя целочисленное значение RasMap 530, которое указывает положение первой строки полосы в глобальном общем порядке полос.
Массив 510 Stripes[] упорядочивается в соответствии с общим порядком. Массив 520 Ranges[] содержит верхний индекс, определяющий верхнюю границу диапазона в массиве Stripes[]. Нижняя граница диапазона неявно определяется "высшим" индексом предыдущего элемента массива Ranges[]. Кроме того, элемент массива Ranges[] включает в себя рабочую очередь 525, связанную с диапазоном полос. Таким образом, массив Ranges[] разбивает массив Stripes[] на диапазоны и распределяет диапазоны на рабочие очереди.
На ФИГ. 5 иллюстрируется формирование массивов Ranges[] и Stripes[], содержащих ссылки на пять структур полос, представляющих две таблицы и элементы RasMap и ExecCounter каждой из полос. Ссылки массива Stripes[] сортируются по значению RasMap 530, которое отражает порядок полос по числу выполнения, в соответствии со значениями ExecCount 540. Также следует отметить, что каждый диапазон содержит полосы из разных таблиц.
Базовая операция, поддерживаемая структурой массивов Ranges[] и Stripes[] представляет собой маршрутизацию запросов конкретным очередям и повторное разбиение на разделы, то есть, динамическое изменение размеров разделов или, иными словами, динамическое управление включением полос в потоки выполнения разделов. Процесс маршрутизации запроса схематически иллюстрируется в нижней части ФИГ. 5.
На ФИГ. 6 изображается диаграмма управления обработкой маршрутизации запроса.
На шаге 551 принимается запрос, указывающий таблицу, ключ и код операции над элементом. Соответствующая хэш-таблица 550 обращается к отображению таблицы, и ключа к полосе, и ссылке на идентификатор строки (rowid). В случае операции "вставить", ссылка на ключ в таблице отсутствует. Таким образом, вызывается способ вставки в таблицу, который присваивает полосу и идентификатор строки для вставки, которые помещаются в соответствующую хэш-таблицу. С данного момента вставка рассматривается как обновление.
На шаге 552, удерживая ссылку на полосу, считывается ее RasMap и код операции "преобразуется" в указатель способа для вызова соответствующей полосы. Буфер запроса-ответа 560 получается и заполняется способом, идентификатором строки и любыми дополнительными аргументами.
На шаге 553 массив Ranges[] бинарно перебирается с использованием полученного RasMap. На шаге 554 бинарного поиска, низкие и высокие элементы поддиапазона массива Stripes[] разыменовываются к их RasMaps и сравниваются с полученным RasMap. В то время как RasMaps включается в поддиапазон, буфер запроса-ответа помещается в рабочую очередь поддиапазона.
Иными словами, как иллюстрируется на ФИГ. 6, первичный ключ запроса хэшируется через хэш-таблицу 550 демультиплексора для получения полосы и идентификатора строки, той строки над которой будет выполняться запрос, шаг 610. Получив структуру полос, на шаге 620 вычисляется RasMap строки путем добавления идентификатора строки и RasMap полосы. При получении RasMap бинарный поиск выполняется над массивом Ranges[], определяющим диапазон, и связанную с ним рабочую очередь, см. шаг 630. Наконец, запрос ставится в найденную рабочую очередь, шаг 640.
ФИГ. 7 содержит блок-схему последовательности операций, которая представляет собой основную диаграмму управления повторного разбиения на разделы, на которой полосы считаются невидимыми для простоты изложения. Полосы могут разбиваться и объединяться в соответствии с разбиением на разделы. В данном примере полосы сгруппированы по "теплоте", а именно, по количеству запросов.
В отдельном потоке выполнения, исполняющемся периодически, временный массив Stripes[], содержащий ссылки на все структуры полос, сортируется в соответствии со счетчиками выполнения, шаг 710. Структуры полос RasMap будут обновлены позднее для отражения порядка сортировки. Далее, вычисляется CDF с использованием простой рекурсии по временному массиву, шаг 720. Значение средняя_работа-на-поток_выполнения вычисляется на шаге 730 путем деления последнего элемента CDF на количество рабочих потоков выполнения. Новый временный массив Ranges[] просчитывается на шаге 740 с помощью двоичного поиска в массиве CDF по кратному значению средняя_работа-на-поток_выполнения. Наконец старые массивы Ranges[] и Stripes[] заменяются временными массивами Ranges[] и Stripes[] и обновляется RasMap Полосы, при приостановке всех коммуникационных потоков выполнения, шаг 750. В заключение, полосы поэтапно возвращаются соответствующим ядрам потоков выполнения, шаг 760 и освобождают потоки выполнения, шаг 770. Следует отметить, что большая часть расчета повторного разбиения на разделы может быть выполнена без изменения нормальной работы хранилища ключ-значение, что делает его относительно легким.

Способ и устройство кодирования сигнала, способ для кодирования объединенного сигнала обратной связи
Способ разъединения вызова и устройство для его осуществления
Способ и устройство передачи данных
Способ и устройство кодирования сигнала обратной связи
Прозрачный обходной путь и соответствующие механизмы
Способ поиска тракта тсм, способ создания тракта тсм, система управления поиском тракта и система управления созданием тракта
Мобильная станция, способ и устройство для назначения канала
Способ сообщения информации о способности терминала, способ и устройство для выделения ресурсов временного слота и соответствующая система
Способ и устройство для выделения ресурсов и обработки информации подтверждения
Способ, сетевое устройство и система для определения распределения ресурсов при скоординированной многоточечной передаче
Ведение журнала отката для секционированных наборов данных в памяти
Система и способ для создания выборочных моментальных снимков базы данных
Система и способ синхронизации памяти в многоядерной системе

