Результат интеллектуальной деятельности: СПОСОБ ВЫПОЛНЕНИЯ УПРЕЖДАЮЩЕГО ЧТЕНИЯ В СИСТЕМАХ ХРАНЕНИЯ ДАННЫХ
Вид РИД
Изобретение
Данное изобретение относится к системам распределения и хранения данных, точнее, к способам выполнения упреждающего чтения в системах хранения данных.
Производительность системы хранения данных характеризуют два основных параметра: время доступа и полоса пропускания. Одним из основных способов, призванных сократить время доступа и повысить пропускную способность, является применение технологии упреждающего чтения (read ahead). Она заключается в том, чтобы на основании уже запрошенных данных предугадывать, какие данные будут запрошены следующими, и переносить их с более медленных носителей информации, например, с жестких дисков, на более быстрые, такие как оперативная память и твердотельные накопители, до того, как к этим данным обратятся. В большинстве случаев упреждающее чтение применяется при операциях последовательного чтения.
Известна заявка US 2015032967, публикация 29.01.2015, МПК G06F 12/08, в которой описана система и способ адаптивного упреждающего чтения. В заявке описан способ вероятностного анализа определения предварительной выборки для кэширования данных в системе хранения данных. Предлагается применять следующий принцип. Если сперва был прочитан один блок данных, то с высокой вероятностью на чтение будет вызван следующий за первым блок данных.
Известен патент US 9311021 «Способы и система для выполнения операций упреждающего чтения с использованием интеллектуального адаптера хранения», публикация 12.04.2016, МПК G06F 3/06. Способ включает в себя сохранение структуры данных адаптером для отслеживания, были ли записаны или изменены ли блоки данных, связанные с номером логического устройства. Извлекается адрес начального логического блока для выполнения запроса чтения для чтения данных, и производится чтение вперед только тех блоков, которые были записаны или изменены.
Известна заявка US 2014250268 «Способ и устройство для эффективного упреждающего чтения из кэша», публикация 04.09.2014, МПК G06F 12/08. Способ включает в себя идентификацию контроллером хранения наибольшей длины пакета из множества длин пакета в памяти контроллера хранения для одного потока данных. Решение не может быть использовано для систем хранения данных с множеством клиентов.
Наиболее близким является решение по патенту US 8732406, публикация 20.05.2014, МПК G06F 12/08. Система хранения отслеживает статистическое поведение запросов чтения клиента, направленных на устройство хранения, для формирования предсказания о данных, которые потребуются клиенту в дальнейшем. Система хранения собирает размер последовательностей считывания для различных потоков в структуру данных, которая суммирует предыдущее поведение запросов чтения. Эта структура данных сообщает количество потоков в каждом классе эквивалентности размеров потоков, которые отслеживаются. Затем структура данных используется для определения ожидаемого размера выбранного потока чтения. В данном способе объем данных, которое предлагается считывать для чтения вперед для каждого потока рассчитывается исходя из длины потока данных.
Несмотря на наличие различных способов выполнения упреждающего чтения в системах хранения данных, нельзя считать проблему решенной. Имеется потребность в более эффективном способе упреждающего чтения, который обеспечивал бы повышение производительности систем упреждающего чтения.
Техническим результатом, который достигается в данном изобретении, является повышение производительности системы хранения данных, за счет уменьшения упреждающего чтения ненужных данных.
Изобретение реализуется следующим образом.
Способ выполнения упреждающего чтения в системах хранения данных, включает текущий контроль запросов, операции чтения по запросу блоков данных, представляющих поток чтения, характеризуется следующими операциями.
Определяют интервал последовательного адресного пространства каждого запроса и время запроса.
После чего сохраняют данные о интервале последовательного адресного пространства каждого запроса и времени поступления запроса, при этом помещают эти данные в список интервалов на упреждающее чтение при превышении пороговой длины интервала адресного пространства, к которому относится запрос на последовательное чтение, а данные об интервалах запросов длиной меньшей порогового значения помещают в список случайных запросов.
В процессе текущего контроля выявляют, по меньшей мере, частичное совпадение интервала адресного пространства текущего запроса, с интервалом, хранящимся в одном из списков - интервалов случайных запросов и интервалов запросов на упреждающее чтение, при этом, при совпадении интервалов корректируют длину интервала в соответствующем списке.
После корректировки длины интервала в списке интервалов случайных запросов проверяют, не превышает ли длина адресного пространства интервала пороговой длины интервала адресного пространства, и в случае превышения перемещают данные об этом интервале в список на упреждающее чтение.
Далее определяют текущий вес каждого интервала в списке интервалов на упреждающее чтение, характеризующий интенсивность запросов.
Определяют относительный вес каждого интервала в общем объеме всех интервалов в списке интервалов на упреждающее чтение и осуществляют упреждающее чтение блоков данных, расположенных вперед за текущей областью чтения этих интервалов в объеме, пропорциональном относительным весам каждого интервала в списке интервалов на упреждающее чтение.
Способ регулирует объем упреждающего чтения в зависимости от количества запросов в интервалах последовательного чтения и длины этих интервалов. Таким образом измеряется интенсивность последовательных потоков на чтение и предоставляется объем упреждающего чтения потокам пропорционально их интенсивности. При этом измерение интенсивности последовательных интервалов ведется непрерывно.
В частности, список интервалов запросов на упреждающее чтение располагают в адресном пространстве заранее определенной длины.
Кроме того, список интервалов случайных запросов располагают в адресном пространстве заранее определенной длины.
В частности, при совпадении, по меньшей мере, части интервала адресного пространства текущего запроса с интервалом адресного пространства в списке интервалов запросов на упреждающее чтение, корректируют длину интервала в списке путем объединения отдельных интервалов в один последовательный интервал адресного пространства.
При совпадении, по меньшей мере, части интервала адресного пространства текущего запроса с интервалом адресного пространства в списке интервалов случайных запросов, корректируют длину интервала в списке путем объединения отдельных интервалов в один последовательный интервал адресного пространства.
Помимо этого, определяют текущий вес каждого интервала в списке интервалов на упреждающее чтение, равный отношению суммарной величины всех запросов, поступивших в адресное пространство данного интервала к разнице между временем прихода последнего запроса в интервале и первого запроса в этом же интервале.
Текущий вес определяют равным нулю, если количество запросов, поступивших в данный интервал, меньше, чем определенная константа.
В частности, объем упреждающего чтения блоков данных, расположенных за текущей областью чтения этих потоков не превышает заранее определенного значения
Кроме того, если величина списка интервалов запросов на упреждающее чтение стала больше допустимой, производят вытеснение интервалов с самым ранним временем последнего запроса.
Помимо этого, если величина списка интервалов случайных запросов стала больше допустимой, производят вытеснение интервалов с самым ранним временем последнего запроса.
Изобретение поясняется схемами и диаграммами.
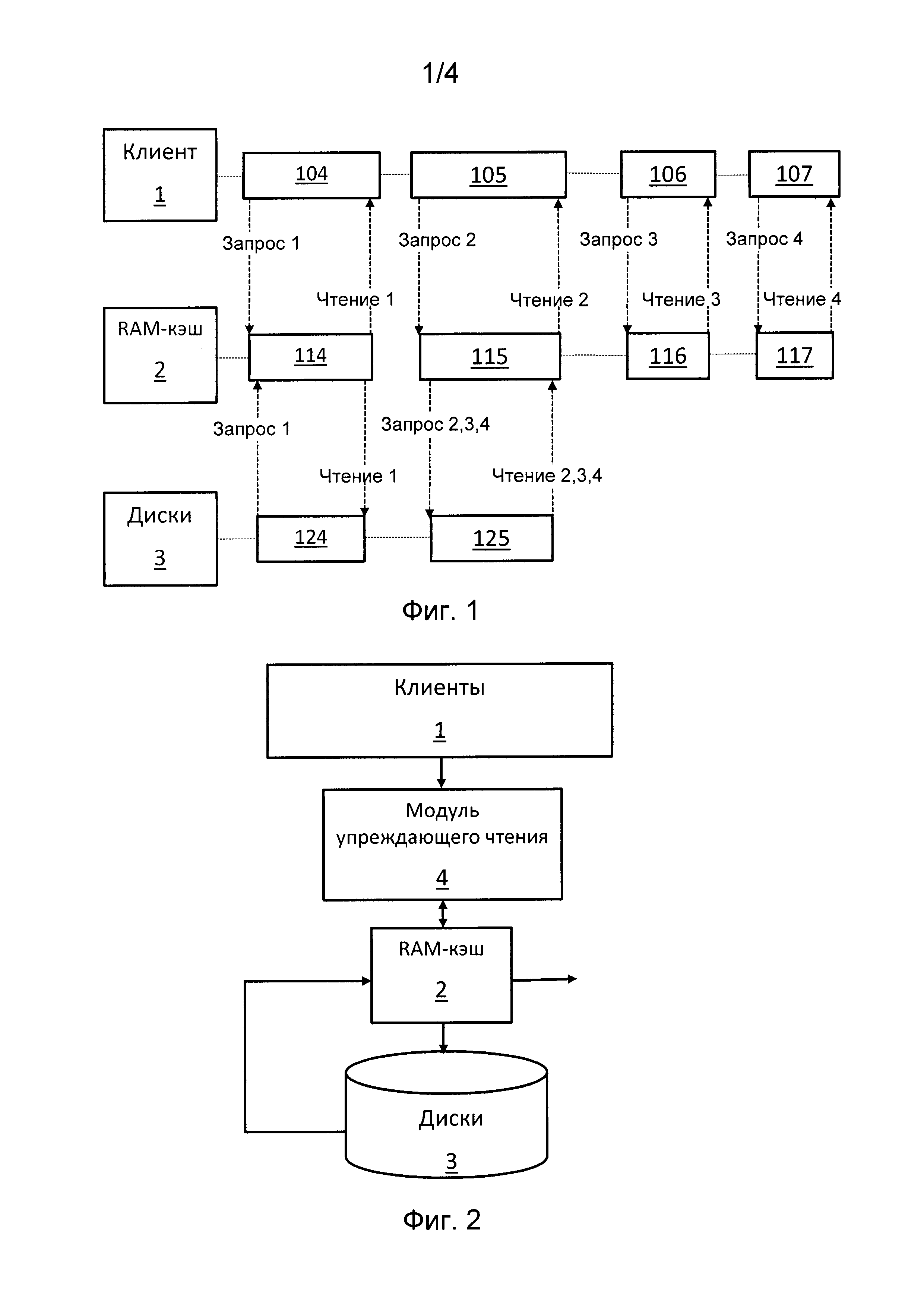
На Фиг. 1 приведена обобщенная блок схема работы устройства упреждающего чтения.
На Фиг. 2 показана схема взаимодействия блоков системы хранения данных при операциях упреждающего чтения.
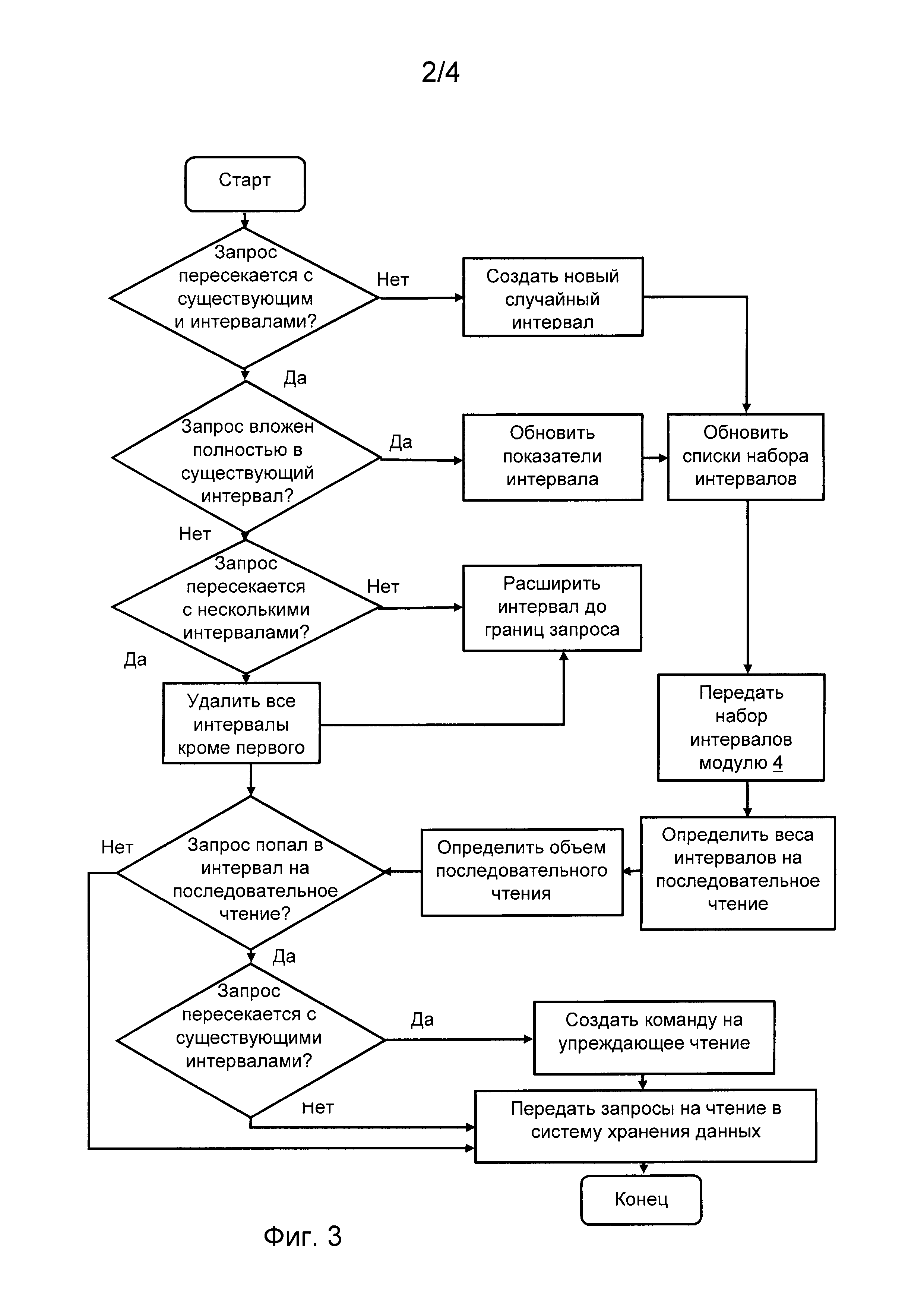
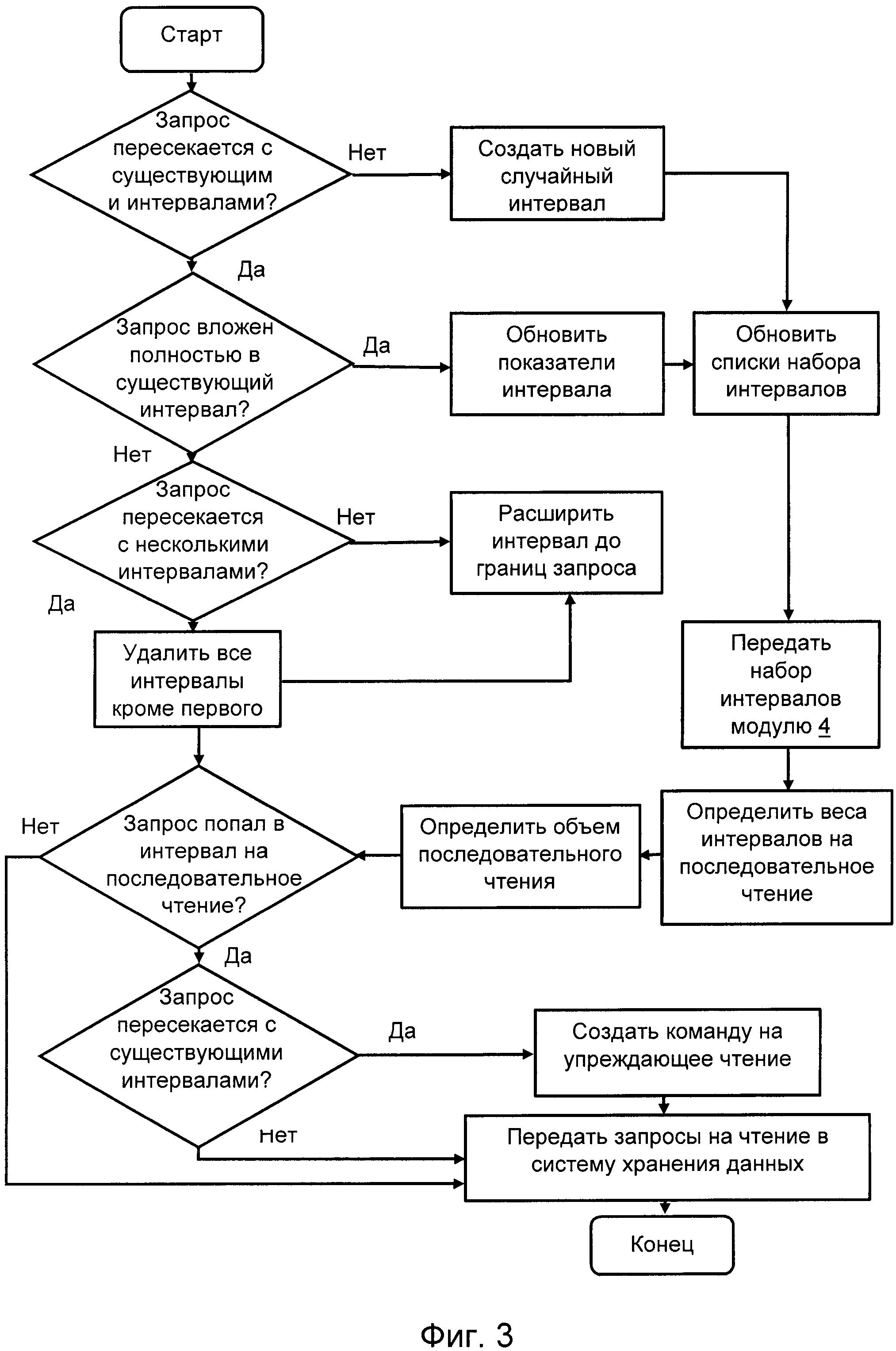
На Фиг. 3 приведена блок схема операций работы устройства по способу.
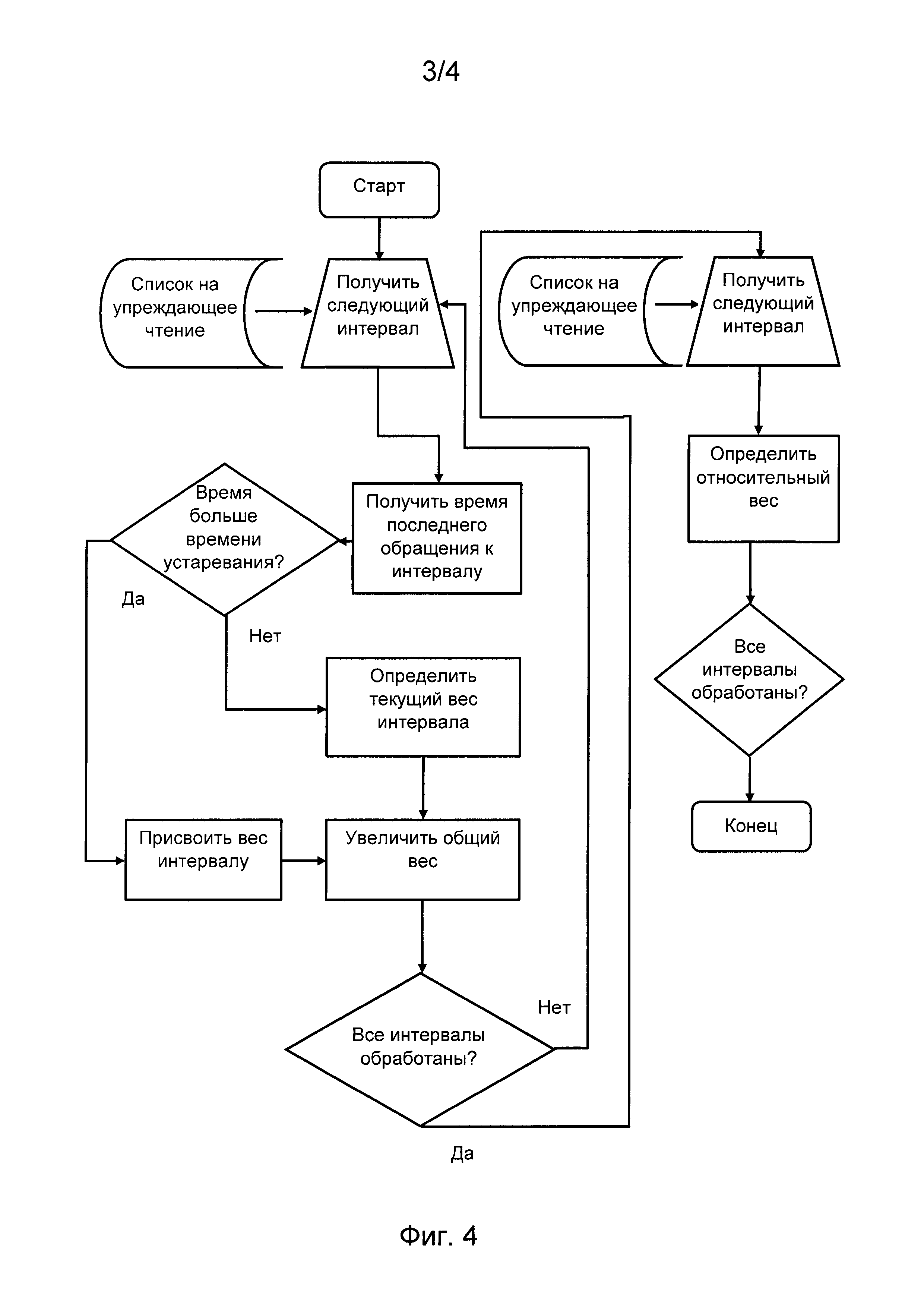
На Фиг. 4 приведена блок схема операций по обработке интервалов и определения весов интервалов.
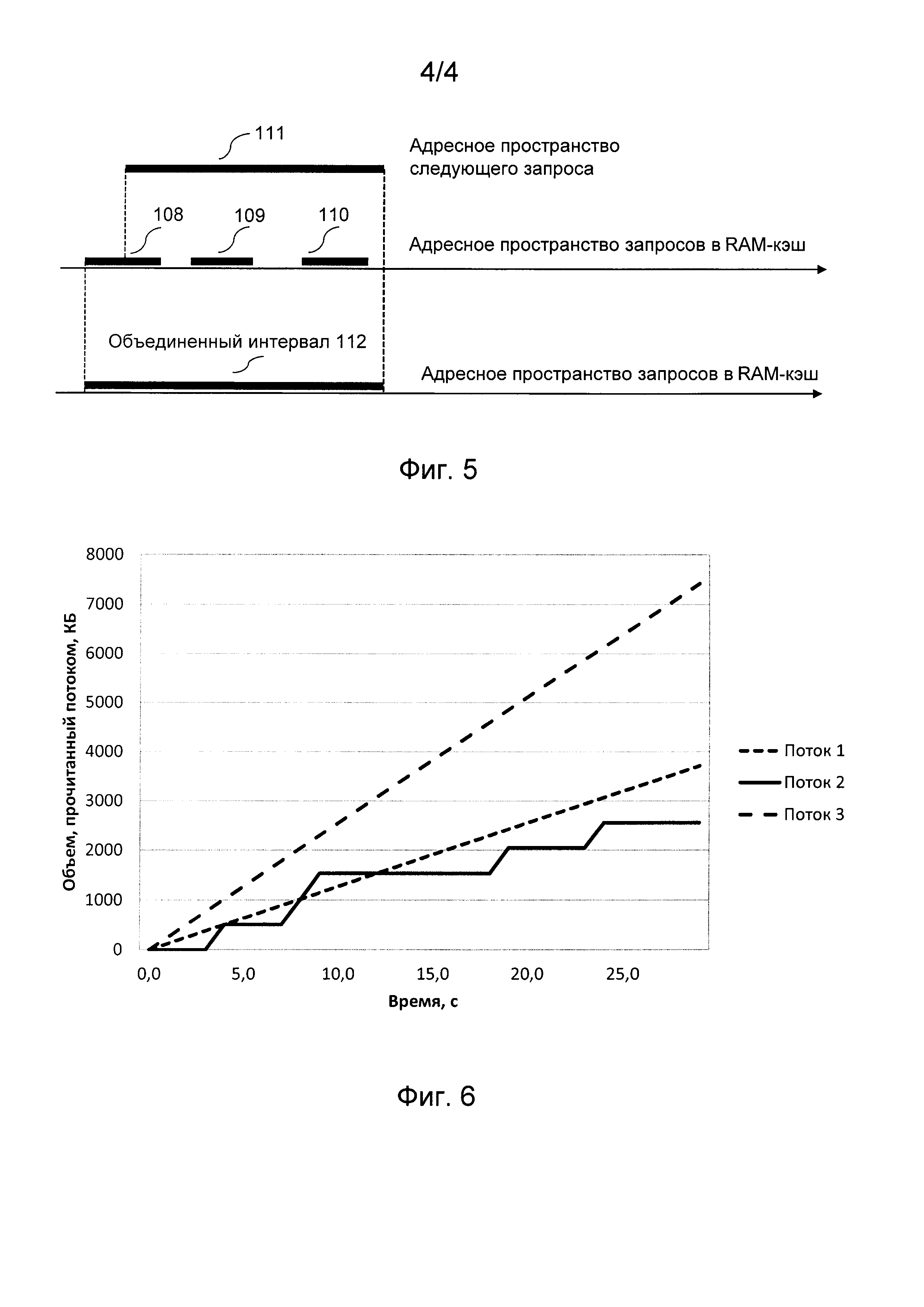
На Фиг. 5 показана схема обновления интервала при пересечении запроса с несколькими интервалами.
На Фиг. 6 приведена диаграмма чтения по запросам во времени, с использованием данного способа, при потоках разной интенсивности.
Способ выполнения упреждающего чтения в системах хранения данных выполняется следующим образом (Фиг. 1). Система хранения данных (СХД) в общем виде включает ряд дисков 3, на которых хранятся данные, систему управления базой данных, включая контроллер ввода-вывода, который выполняет поиск и чтение блоков данных асинхронно относительно центрального процессора (на схеме не показаны) и буфер сверхоперативной памяти, кэш 2. Клиент 1 обращается к системе хранения данных, посылая запросы 104-107 на чтение блоков данных. Например, после запросов 104 и 105, происходит чтение блоков данных 124 и 125 с дисков 3, которые сначала перемещают в кэш 2, а затем направляют эти блоки 114-115 из кэша клиенту 1. После получения запроса 105 (запрос 2) в данном примере принимается решение о упреждающем чтении. В этом случае блоки данных, расположенные вперед за текущей областью чтения блока 125 диска 1 переносятся в кэш 2 и запоминаются в сверхоперативной памяти кэша 2 как блоки 116-117. Если последует запрос от клиента 1 на чтение этих блоков, то они будут читаться из кэша 2, что заметно ускоряет процесс чтения. На данном рисунке показано взаимодействие с запросами одного клиента, но в общем виде клиентов 1 может быть много.
На Фиг. 2 показана схема взаимодействия блоков системы хранения данных при операциях упреждающего чтения по данному изобретению. Запросы клиентов 1 попадают в модуль упреждающего чтения 4, который обеспечивает операции упреждающего чтения по данному способу. При упреждающем чтении происходит чтение блоков данных, которые еще не запрошены, но предположительно будут запрошены в кэш 2 с дисков 3. После состоявшегося запроса эти блоки данных будут отправлены соответствующему клиенту уже их сверхоперативной памяти, их кэша 2.
Выполнение способа упреждающего чтения можно разделить на два этапа: обнаружение запросов последовательного чтения в потоке всех запросов и принятие решения о том, нужно ли считывать данные наперед, и в каком объеме. Эти операции решаются модулем упреждающего чтения.
В современных системах ранения данных используется, как правило, многофункциональный RAM-кэш. этот кэш для хранения данных для отложенной записи, для кэширования недавно запрошенных данных, а также для хранения данных, полученных в ходе операций упреждающего чтения. Объем кэша равен CS. Таким образом только часть памяти кэша используется для хранения блоков данных на упреждающее чтение.
Способ упреждающего чтения по изобретению в системах хранения данных, включает текущий контроль запросов, операции чтения по запросу блоков данных, представляющих поток чтения.
При приходе каждого запроса в модуле упреждающего чтения 4 определяют интервал последовательного адресного пространства запроса и время запроса. Каждый запрос характеризуется следующими величинами:
- lba - начальный адрес запрашиваемых данных;
- len - длина запрашиваемых данных, характеризуемая начальным адресом и конечным адресом запрашиваемых данных.
- t - время прихода запроса.
Интервал последовательного адресного пространства запроса - это часть адресного пространства, однозначно определяемая двумя числами - начальный адрес и конечный адрес. Интервалы бывают длиной не более константы именуемой «пороговой длиной интервала адресного пространства», и называются в дальнейшем случайными и с длиной более пороговой длины интервала адресного пространства, называемыми в дальнейшем последовательными. В дальнейших примерах пороговая длина интервала адресного пространства равна 64 мегабайта.
После определения интервала последовательного адресного пространства запроса и времени запроса сохраняют данные эти данные, при этом помещают эти данные в список на упреждающее чтение при превышении пороговой длины интервала адресного пространства запроса на последовательное чтение. А данные об интервалах запросов длиной меньшей порогового значения помещают в список случайных запросов.
В процессе текущего контроля (блок-схема на Фиг. 3) выявляют, по меньшей мере, частичное совпадение интервала адресного пространства текущего запроса, с интервалом, хранящимся в одном из списков - интервалов случайных запросов и запросов на упреждающее чтение, при этом, при совпадении интервалов корректируют длину интервала в соответствующем списке.
Механизм корректировки интервалов адресного пространства поясняется на Фиг. 5. В RAM-кэш хранятся интервалы предыдущих запросов 108-110.
Интервалы этих запросов сравниваются с адресным пространством следующего запроса 111. Интервал запроса 111 полностью перекрывает интервалы запросов 109 и 110 и частично перекрывает интервал запроса 108. Объединенный интервал 112 включает в себя адресные пространства всех четырех интервалов.
Таким образом, каждый запрос может:
- быть полностью вложен в какой-либо имеющийся в наборе интервал,
- пересечься с каким-либо интервалом,
- пересечься с несколькими интервалами,
- не пересечься не с одним интервалом.
После корректировки длины интервала в списке интервалов случайных запросов проверяют, не превышает ли длина адресного пространства интервала пороговой длины интервала адресного пространства. В случае превышения перемещают данные об этом последовательном интервале в список на упреждающее чтение.
В любом случае, после обновления интервалов производят корректировку величин обновленных интервалов списке интервалов случайных запросов и в списке интервалов на упреждающее чтение.
В случае, когда величина одного из списков стала больше допустимой, из каждого из списков вытесняются интервалы с самым ранним временем последнего обращения. Эта операция может происходить по алгоритму вытеснения давно неиспользуемых данных (LRU)
Длина каждого последовательного интервала не должна превышать двух пороговых длин интервала адресного пространства. В случае, если длина обновленного интервала превысила этот предел, его начальный адрес смещают до разности между конечным адресом и двумя пороговыми длинами интервала адресного пространства. Как было указано выше, пороговая длина интервала адресного пространства составляет 64 мегабайта.
Интервал из списка интервалов случайных запросов может перейти в список интервалов на упреждающее чтение, но обратное невозможно. Может только произойти вытеснение устаревшего интервала из списка интервалов на упреждающее чтение, и создание нового интервала, попавшего в список случайных запросов.
Операции, характеризующие упреждающее чтение, рассмотрены далее и приведены на блок схеме Фиг. 4.
Определяют текущий вес каждого интервала в списке интервалов на упреждающее чтение, характеризующий интенсивность запросов.
Для каждого интервала i в списке интервалов на упреждающее чтение определяют вес Wi, равный суммарной длине всех запросов в интервале, деленный на разность отметок времени прихода (timestamp) последнего и первого запросов:
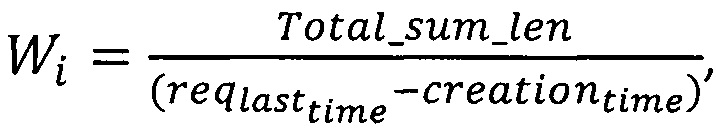
где
Total_sum_len - суммарная длина всех запросов в интервале,
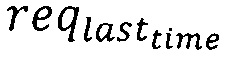 - время прихода последнего запроса в интервале,
- время прихода последнего запроса в интервале,
creationtime - время прихода первого запроса в интервале.
В случае, если количество запросов, поступившее в интервал на момент расчетов, меньше определенной константы, либо последний поступивший запрос был ранее определенного времени (например, 10 секунд), интервалу присваивается нулевой вес.
Далее определяют относительный вес weighti каждого интервала в общем объеме всех интервалов в списке интервалов на упреждающее чтение:
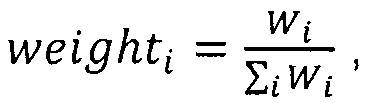
где ΣiWi - сумма весов всех интервалов.
Как только интервал набирает достаточную длину, превышающую установленную пороговую длину интервала адресного пространства, для него осуществляют чтение блоков данных, расположенных вперед за текущей областью чтения этих интервалов. Упреждающее чтение осуществляют в объеме, пропорциональном относительным весам weighti каждого интервала в списке интервалов на упреждающее чтение.
Ввиду того, что объем кэша ограничен, а многофункциональный RAM-кэш выполняет и другие задачи, только часть его пространства предназначена для хранения информации блоков данных на упреждающее чтение. Поэтому существует ограничение на максимальный объем данных, помещаемых в область кэша на упреждающее чтение.
Примеры выполнения способа.
Рассмотрим два примера работы алгоритма IRA - для однопоточного и многопоточного случая.
Будем предполагать, что объем RAM-кэша составляет 8 гигабайт. Таким образом, суммарный объем, предоставляемый алгоритму упреждающего чтения, равен 10%*8GiB=819 MiB.
В случае одного потока весь этот объем будет ему и предоставлен. Таким образом, объем упреждающего чтения для этого потока будет равен 819 MiB.
Наиболее эффективно применение данного способа при нескольких потоках запросов. Потоком в данном случае считается последовательное чтение от клиента блоками определенного размера.
В приведенном ниже примере определено три последовательных потока, в каждый из которых поступали запросы. В первый поток равномерно поступают запросы по 128 килобайт, во второй - неравномерно, но по 512 килобайт, в третий - равномерно по 256 килобайт. Таким образом, накопление объема у каждого потока происходит с разной скоростью (Фиг. 6).
Интенсивность потока, его относительный вес weighti в конкретный момент определится как прочитанный объем за время существования интервала, то есть - как конечная разность.
Параметры интенсивности потоков таковы:
У первого потока интенсивность равна 3840/30=128
У второго потока интенсивность равна 2560/26=98.5
У третьего потока интенсивность равна 7680/30=256
Общая интенсивность равна 482.5.
Относительные веса потоков таковы:
У первого потока относительный вес равен 128/482.5*100%=26.5%
У второго потока относительный вес равен 98.5/482.5*100%=20.4%
У третьего потока относительный вес равен 256/482.5*100%=53.1%
Таким образом, объемы упреждающего чтения будут таковы:
У первого потока - 26.5%*819=217 МБ.
У второго потока - 20.4%*819=167 МБ.
У третьего потока - 53.1%*819=435 МБ.
Предположим далее, что в этот момент во второй поток поступил новый запрос на 512 килобайт. Тогда изменится интенсивность второго потока и общая интенсивность:
(2560+512)/26=118.1
482.5-98.5+118.1=502.1
Таким образом, новые относительные веса будут такими:
У первого потока относительный вес равен 128/502.1*100%=25.5%
У второго потока относительный вес равен 118.1/502.1*100%=23.5%
У третьего потока относительный вес равен 256/502.1*100%=51%
Объемы упреждающего чтения также изменятся:
У первого потока - 25.5%*819=209 МБ.
У второго потока - 23.5%*819=193 МБ.
У третьего потока - 51%*819=417 МБ.
Особенную ценность данный способ упреждающего чтения представляет в системах хранения, используемых для работы с мультимедиа, а именно, в сервисах отдачи потокового видео множеству клиентов, а также при съемке и монтаже видео высокого разрешения. Эти отрасли предъявляют высокие требования к производительности систем хранения данных именно при последовательном чтении одновременно с множества рабочих станций.
Способ перераспределения данных при расширении массива дисков
Способ формирования профиля приложений для управления запросами и способ предоставления уровня обслуживания по запросам в системе хранения данных

