Результат интеллектуальной деятельности: УСТРОЙСТВО И СПОСОБ МАСШТАБИРОВАНИЯ ЦЕНТРАЛЬНОГО СИГНАЛА И УЛУЧШЕНИЯ СТЕРЕОФОНИИ НА ОСНОВЕ ОТНОШЕНИЯ СИГНАЛ-ПОНИЖАЮЩЕЕ МИКШИРОВАНИЕ
Вид РИД
Изобретение
Настоящее изобретение относится к обработке аудиосигналов и, в частности, к масштабированию центрального сигнала и улучшению стереофонии, основываясь на отношении сигнал-понижающее микширование.
В общем случае, аудиосигналы представляют собой смесь прямых звуков и фоновых (или рассеянных) звуков. Прямые сигналы испускаются источниками звука, например, музыкальным инструментом, вокалистом или громкоговорителем, и достигают приемника, например, уха слушателя или микрофона, по наиболее короткому из возможных путей. При прослушивании прямого звукового сигнала он воспринимается как идущий по направлению от источника звука. Релевантными звуковыми ориентирами для локализации и для других пространственных свойств звука являются интерауральная разность уровней (ILD), интерауральная разница во времени (ITD) и интерауральная когерентность. Прямые звуковые волны, вызывающие идентичные ILD и ITD, воспринимаются как идущие с одного и того же направления. В отсутствие фоновых звуков, сигналы, достигающие правого и левого уха или любого другого набора пространственно-разнесенных датчиков, являются когерентными.
Фоновые звуки, напротив, испускаются множеством пространственно-разнесенных источников звука или звукоотражающих границ, давая вклад в тот же самый звуковой сигнал. Когда звуковая волна достигает стены комнаты, часть ее отражается, и суперпозиция всех отражений в комнате, реверберация, представляет собой очень хороший пример фоновых звуков. В качестве других примеров можно указать аплодисменты, журчание или невнятную речь и шум ветра. Фоновые звуки воспринимаются как рассеянные, нелокализуемые и вызывающие ощущение окруженности ими (погруженности в них) слушателя. При захвате поля фонового звука с использованием набора пространственно-разнесенных датчиков, записанные сигналы являются, по меньшей мере частично, некогерентными.
Релевантный уровень техники, относящийся к разделению, декомпозиции или масштабированию включает в себя либо информацию панорамирования, т.е. межканальную разность уровней (ICLD) и межканальную временную разность (ICTD), или включает в себя сигнальные характеристики прямого и фонового звуков. К способам, использующим ICLD при двухканальной стереофонической записи, относятся способ повышающего микширования, описанный в [7], алгоритм разрешения по азимуту и ресинтеза (ADRess) [8], повышающее микширование двухканальных входных сигналов в три канала, предложенное Викерсом [9], и способ выделения центрального сигнала, описанный в [10].
Технология оценки деградации при разделении (DUET) [11, 12] основана на кластеризации бинов время-частота в группы с одинаковой ICLD и ICTD. Ограничение оригинального способа заключается в том, что максимальная частота, которая может быть обработана, составляет половину скорости звука на максимальное расстояние между микрофонами. Производительность данного способа снижается, если источники перекрываются в домене время-частота, и в случае усиления реверберации. Другие способы, основанные на ICLD и ICTD, представляют собой алгоритм модифицированного ADRess [14], который расширяет алгоритм ADRess [8] для обработки записей с пространственно-разнесенных микрофонов, причем упомянутый способ основан на корреляции время-частота (AD-TIFCORR) [15] для смесей с задержкой по времени, оценку направления матрицы смешивания (DEMIX) для безэховых смесей [16], которая включает в себя меру достоверности того, что только один источник активен в конкретном бине время-частота, разделение и локализация источников с максимизацией ожидания на основе модели (MESSL) [17], а также методы имитации механизма человеческого бинауральные слуха, как, например, в [18, 19].
Помимо упомянутых выше способов слепого разделения источников (BSS), используя пространственные признаки компонентов прямого сигнала, к настоящему способу также относится выделение и ослабление фоновых сигналов. Способы, основанные на межканальной когерентности (ICC) в двухканальных сигналах описаны в [22, 7, 23]. Применение адаптивной фильтрации было предложено в [24] с обоснованием, заключающемся в том, что прямые сигналы могут быть предсказаны по каналам, тогда как диффузные звуки получаются из ошибки прогнозирования.
Способ повышающего микширования двухканальных стереофонических сигналов, основанный на многоканальной фильтрации Винера, выполняет оценку как ICLD прямых звуковых сигналов, так и спектральную плотность мощности (PSD) прямых и фоновых компонентов сигнала [25].
Подходы к выделению фоновых сигналов из одноканальных записей включают в себя использование факторизации неотрицательной матрицы частотно-временного представления входного сигнала, где фоновый сигнал получают из остатка этого приближения [26], извлечение низкоуровневых признаков и контролируемое обучение [27], а также оценку импульсной характеристики системы реверберации и инверсную фильтрацию в частотной области [28].
Задачей настоящего изобретения является предоставление улучшенных концепций обработки аудиосигнала. Задача настоящего изобретения решается с помощью устройства по п. 1, системы по п. 12, способа по п. 13 и машиночитаемого носителя по п. 14 формулы изобретения.
Предоставляется устройство для генерации модифицированного аудиосигнала, содержащего два или более модифицированных аудиоканалов, из входного аудиосигнала, включающего в себя два или более входных аудиоканалов. Устройство содержит генератор информации для генерации информации сигнал-понижающее микширование. Генератор информации выполнен с возможностью генерации информации сигнала путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов первым способом. Помимо этого, генератор информации выполнен с возможностью генерации информации понижающего микширования путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов вторым способом, отличным от первого способа. Дополнительно, генератор информации выполнен с возможностью комбинирования информации сигнала и информации понижающего микширования для получения информации сигнал-понижающее микширование. Помимо этого, устройство содержит аттенюатор сигнала для ослабления двух или более входных аудиоканалов в зависимости от информации сигнал-понижающее микширование для получения упомянутых двух или более модифицированных аудиоканалов.
В частном варианте осуществления устройство может, например, быть выполнено с возможностью генерации модифицированного аудиосигнала, содержащего три или более модифицированных аудиоканалов, из входного аудиосигнала, содержащего три или более входных аудиоканалов.
В одном из вариантов осуществления количество модифицированных аудиоканалов меньше или равно количеству входных аудиоканалов, или количество модифицированных аудиоканалов меньше, чем количество входных аудиоканалов. Например, в соответствии с одним из вариантов осуществления устройство может быть выполнено с возможностью генерации модифицированного аудиосигнала, содержащего два или более модифицированных аудиоканалов, из входного аудиосигнала, содержащего два или более входных аудиоканалов.
Предложены варианты осуществления изобретения, предоставляющие новые концепции масштабирования уровня виртуального центра в аудиосигналах. Входные сигналы обрабатываются в частотно-временной области таким образом, что компоненты прямых звуковых сигналов, имеющие приблизительно равную энергию во всех каналах усиливаются или ослабляются. Вещественные спектральные веса получаются из отношения суммы спектральных плотностей мощности всех сигналов входных каналов и спектральной плотности мощности суммарного сигнала. Представленные концепции могут использоваться при повышающем микшировании двухканальных стереофонических записей для воспроизведения с помощью устройства генерации объемного звука, улучшении стереофонического эффекта, улучшении разборчивости диалога, а также в качестве первичной обработки для семантического аудиоанализа.
Варианты осуществления обеспечивают новые концепции для усиления или ослабления центрального сигнала в аудиосигнале. В отличие от предыдущих концепций, учитываются как боковое смещение, так и диффузность компонентов сигнала. Кроме того, обсуждается использование семантически значимых параметров в целях поддержки пользователя при использовании вариантов осуществления упомянутых концепций.
В некоторых вариантах осуществления делается акцент на масштабировании центрального сигнала, т.е. усилении или ослаблении центральных сигналов аудиозаписей. Центральный сигнал определяется в настоящем документе, например, как сумма всех компонентов прямых сигналов, имеющих приблизительно равную интенсивность во всех каналах и незначительные временные различия между каналами.
Масштабирование центрального сигнала может быть использовано в различных приложениях для обработки и воспроизведения аудиосигнала, например, в повышающем микшировании, улучшении разборчивости диалога и семантическом аудиоанализе.
Повышающее микширование представляет собой способ создания выходного сигнала при наличии входного сигнала с меньшим количеством каналов. Его основным применением является воспроизведение двухканальных сигналов с использованием устройства генерации объемного звука, как, например, описано [1]. Исследование субъективного качества пространственного звука [2] указывает, что наличие точного местоположения [3], локализация и ширина представляют собой хорошие характеристические атрибуты звука. Результаты субъективной оценки алгоритмов повышающего микширования 2-в-5 [4] показали, что использование дополнительного центрального громкоговорителя может сузить стереофонический образ. В основе представленной работы лежит предположение о том, что наличие точного местоположения [3], локализация и ширина могут быть сохранены или даже улучшены, когда дополнительный центральный громкоговоритель воспроизводит в основном прямые компоненты сигнала, которые панорамированы в центре, и когда эти компоненты сигнала ослабляются в смещенных от центра сигналах громкоговорителей.
Улучшение разборчивости диалога относится к улучшению разборчивости речи, например при вещании и при звуковом сопровождении кинофильмов, и часто является желательным, когда фоновые звуки слишком громкие по отношению к диалогу [5]. Это относится, в частности, к лицам, которые имеют проблемы со слухом, слушателям, не являющимся носителями языка, шумной обстановке, или когда бинауральная разность уровня маскировки снижается из-за близкого размещения громкоговорителей. Способы, реализующие упомянутые концепции могут быть применены для обработки входных сигналов, где диалог панорамирован в районе центра для того, чтобы ослабить фоновые звуки и, таким образом, улучшить разборчивость речи.
Семантический аудиоанализ (или аудио контент-анализ) включает в себя способы получения значимых дескрипторов из звуковых сигналов, например, отслеживание ритма или транскрибирование ведущей мелодии. Производительность вычислительных методов часто ухудшается, когда представляющие интерес звуки наложены на фоновые звуки; смотри, например, [6]. Поскольку панорамирование в центре источников представляющего интерес звука (например, ведущие инструменты и певцы) является обычной практикой в аудио индустрии, выделение центрального сигнала может быть использовано в качестве этапа предварительной обработки для ослабления фоновых звуков и реверберации.
В соответствии с одним из вариантов осуществления генератор информации может быть выполнен с возможностью комбинирования информации сигнала и информации понижающего микширования таким образом, что информация сигнал-понижающее микширование указывает на отношение информации сигнала и информации понижающего микширования.
В одном из вариантов осуществления генератор информации может быть выполнен с возможностью обработки спектрального значения каждого из двух или более входных аудиоканалов для получения двух или более обработанных значений, где генератор информации может быть выполнен с возможностью комбинирования двух или более обработанных значений для получения информации сигнала. Помимо этого, генератор информации может быть выполнен с возможностью комбинирования спектральных значений каждого из двух или более входных аудиоканалов для получения комбинированного значения, где генератор информации может быть выполнен с возможностью обработки комбинированного значения для получения информации понижающего микширования.
В соответствии с одним из вариантов осуществления генератор информации может быть выполнен с возможностью обработки спектральных значений каждого из двух или более входных аудиоканалов путем умножения упомянутого спектрального значения на комплексно сопряженное упомянутое спектральное значение для получения автоспектральной плотности мощности упомянутого спектрального значения для каждого из упомянутых двух или более входных аудиоканалов.
В одном из вариантов осуществления генератор информации может быть выполнен с возможностью обработки комбинированного значения путем определения спектральной плотности мощности комбинированного значения.
В одном из вариантов осуществления, генератор информации может быть выполнен с возможностью генерации информации сигнала s (m, k, β) по формуле:
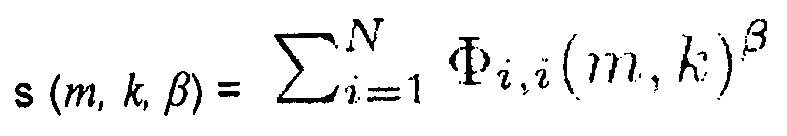 ,
,
где N обозначает количество входных аудиоканалов входного аудиосигнала, 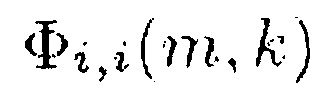 указывает автоспектральную плотность мощности спектрального значения i-го аудиоканала сигнала, β является вещественным числом, и β>0, m указывает на индекс времени, и k указывает индекс частоты. Например, в соответствии с одним из вариантов осуществления β≥1.
указывает автоспектральную плотность мощности спектрального значения i-го аудиоканала сигнала, β является вещественным числом, и β>0, m указывает на индекс времени, и k указывает индекс частоты. Например, в соответствии с одним из вариантов осуществления β≥1.
В одном из вариантов осуществления, генератор информации может быть выполнен с возможностью определения отношения сигнал-понижающее микширование в виде информации сигнал-понижающее микширование в соответствии с формулой R(m, k, β)
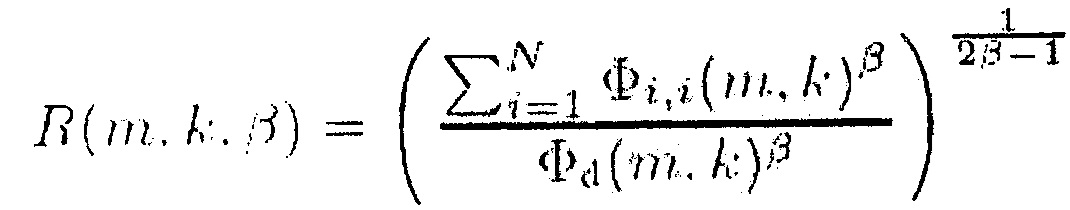 ,
,
где 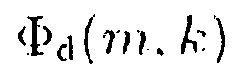 обозначает спектральную плотность мощности комбинированного значения, и
обозначает спектральную плотность мощности комбинированного значения, и 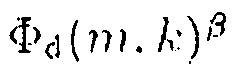 обозначает информацию понижающего микширования.
обозначает информацию понижающего микширования.
В соответствии с одним из вариантов осуществления генератор информации может быть выполнен с возможностью генерации информации сигнала 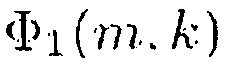 в соответствии с формулой
в соответствии с формулой
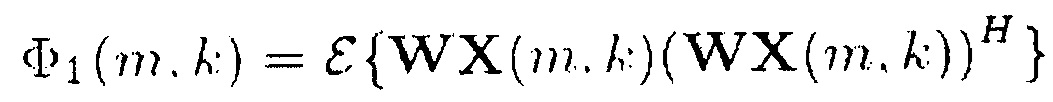 ,
,
причем генератор информации выполнен с возможностью генерации информации понижающего микширования 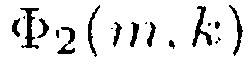 в соответствии с формулой
в соответствии с формулой
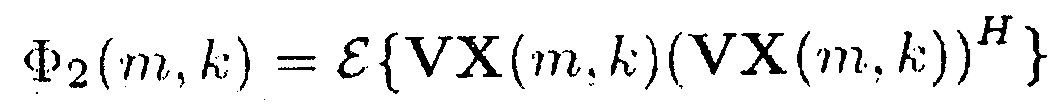 ,
,
и генератор информации выполнен с возможностью генерации отношение сигнал-понижающее микширование в виде информации сигнал-понижающее микширование Rg(m, k, β) в соответствии с формулой
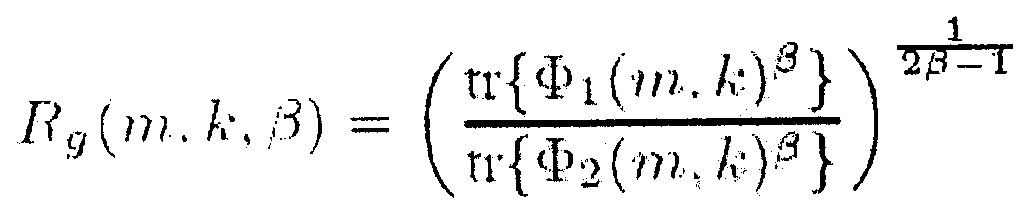 ,
,
где X(m, k) обозначает входной аудиосигнал,
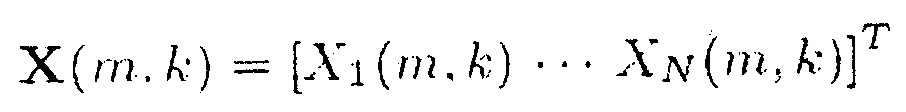 ,
,
в котором N указывает количество входных звуковых каналов входного аудиосигнала, где М указывает временной индекс, и в котором k обозначает индекс частоты, где X1(m, k) указывает первый звуковой входной канал, в котором XN(m, k) указывает на N-й аудио входной канал, где V указывает на матрицу или вектор, в котором W указывает на матрицу или вектор, где Н указывает сопряженное транспонирование матрицы или вектора, в котором ожидание операции, в которой β представляет собой вещественное число, и β>0, и в котором tr{} является следом матрицы. Например, в соответствии с одним из частных вариантов осуществления β≥1.
В одном из вариантов осуществления V может представлять собой вектор-строку длиной N, чьи элементы равны единице, и W может представлять собой единичную матрицу размера N×N.
В соответствии с одним из вариантов осуществления V = [1, 1], W = [1, -1] и N=2.
В одном из вариантов осуществления аттенюатор сигнала может быть выполнен с возможностью ослабления двух или более входных аудиоканалов в зависимости от функции усиления G(m, k) в соответствии с формулой
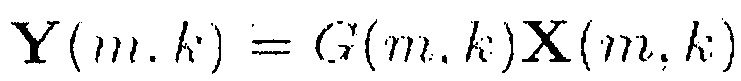 ,
,
где функция усиления G(m, k) зависит от информации сигнал-понижающее микширование, причем функция усиления G(m, k) является монотонно возрастающей функцией сигнала информации сигнал-понижающее микширование или монотонно убывающей функцией информации сигнал-понижающее микширование,
где X(m, k) обозначает входной аудиосигнал, Y(m, k) обозначает модифицированный аудиосигнал, m обозначает временной индекс, и k обозначает индекс частоты.
В соответствии с одним из вариантов осуществления функция усиления G(m, k) может представлять собой первую функцию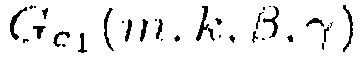 , вторую функцию
, вторую функцию 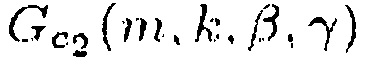 , третью функцию
, третью функцию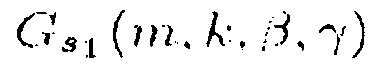 или четвертую функцию
или четвертую функцию 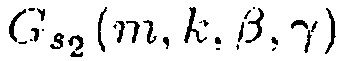 ,
,
где
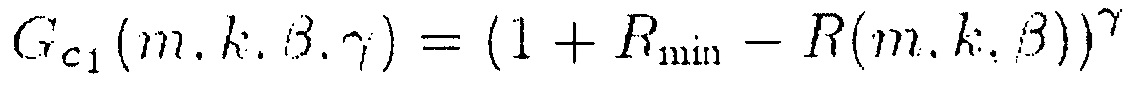 ,
,
где
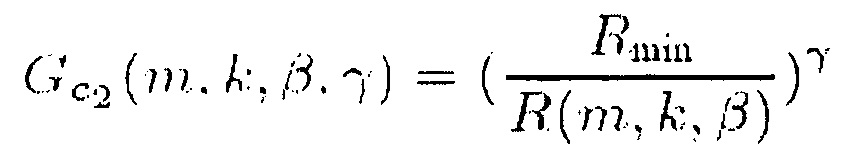 ,
,
где
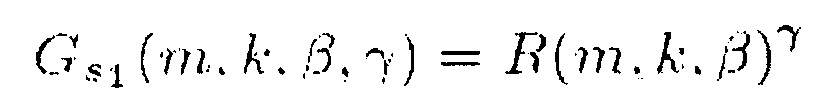 ,
,
где
 ,
,
причем β представляет собой вещественное число, и β>0,
причем γ представляет собой вещественное число, и γ>0,
причем Rmin обозначает минимум R.
Помимо этого, предоставляется система. Система содержит фазовый компенсатор для генерации компенсированного по фазе аудиосигнала, содержащего два или более компенсированных по фазе аудиоканалов, из необработанного аудиосигнала, содержащего два или более необработанных аудиоканалов. Кроме того, система содержит устройство согласно одному из вышеописанных вариантов осуществления для приема компенсированного по фазе аудиосигнала в качестве входного аудиосигнала и для генерации модифицированного аудиосигнала, содержащего два или более модифицированных аудиоканалов, из входного аудиосигнала, содержащего два или более компенсированных по фазе аудиоканалов, в качестве двух или более входных аудиоканалов. Один из упомянутых двух или более необработанных аудиоканалов является опорным каналом. Фазовый компенсатор выполнен с возможностью оценки для каждого необработанного аудиоканала из упомянутых двух или более необработанных аудиоканалов, который не является опорным каналом, функции передачи фазы между упомянутыми необработанным аудиоканалом и опорным каналом. Кроме того, фазовый компенсатор выполнен с возможностью генерации компенсированного по фазе аудиосигнала с помощью модификации каждого необработанного аудиоканала из упомянутых необработанных аудиоканалов, который не является опорным каналом, в зависимости от функции передачи фазы упомянутого необработанного аудиоканала.
Помимо этого, предоставляется способ генерации модифицированного аудиосигнала, содержащего два или более модифицированных аудиоканалов, из входного аудиосигнала, включающего в себя два или более входных аудиоканалов.
Способ содержит:
- Генерацию сигнала информации с помощью комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов первым способом.
- Генерацию информации понижающего микширования путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов вторым способом, отличным от первого способа.
- Генерацию информации сигнал-понижающее микширование путем комбинирования информации сигнала и информации понижающего микширования и:
Ослабление упомянутых двух или более входных аудиоканалов в зависимости от информации сигнал-понижающее микширование для получения двух или более модифицированных аудиоканалов.
Кроме того, предоставляется компьютерная программа для реализации описанного выше способа при ее выполнении на компьютере или аттенюаторе сигналов.
В дальнейшем, варианты осуществления настоящего изобретения описаны более подробно со ссылкой на прилагаемые чертежи, на которых:
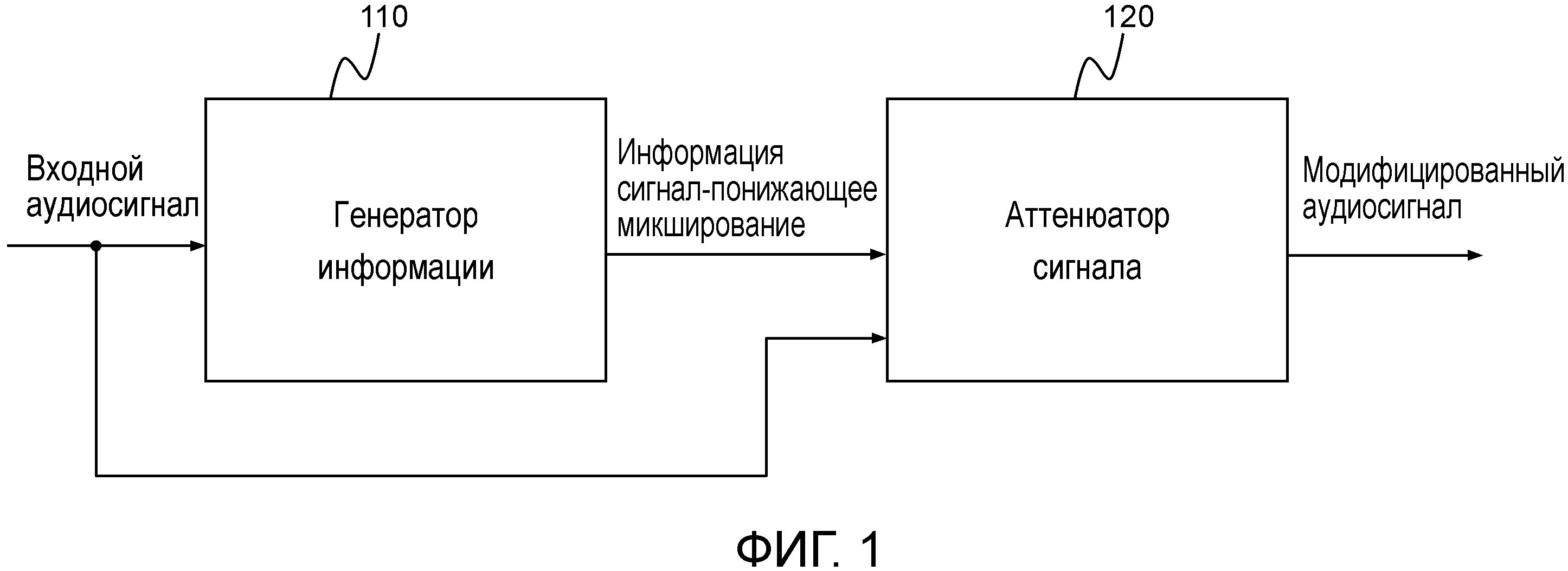
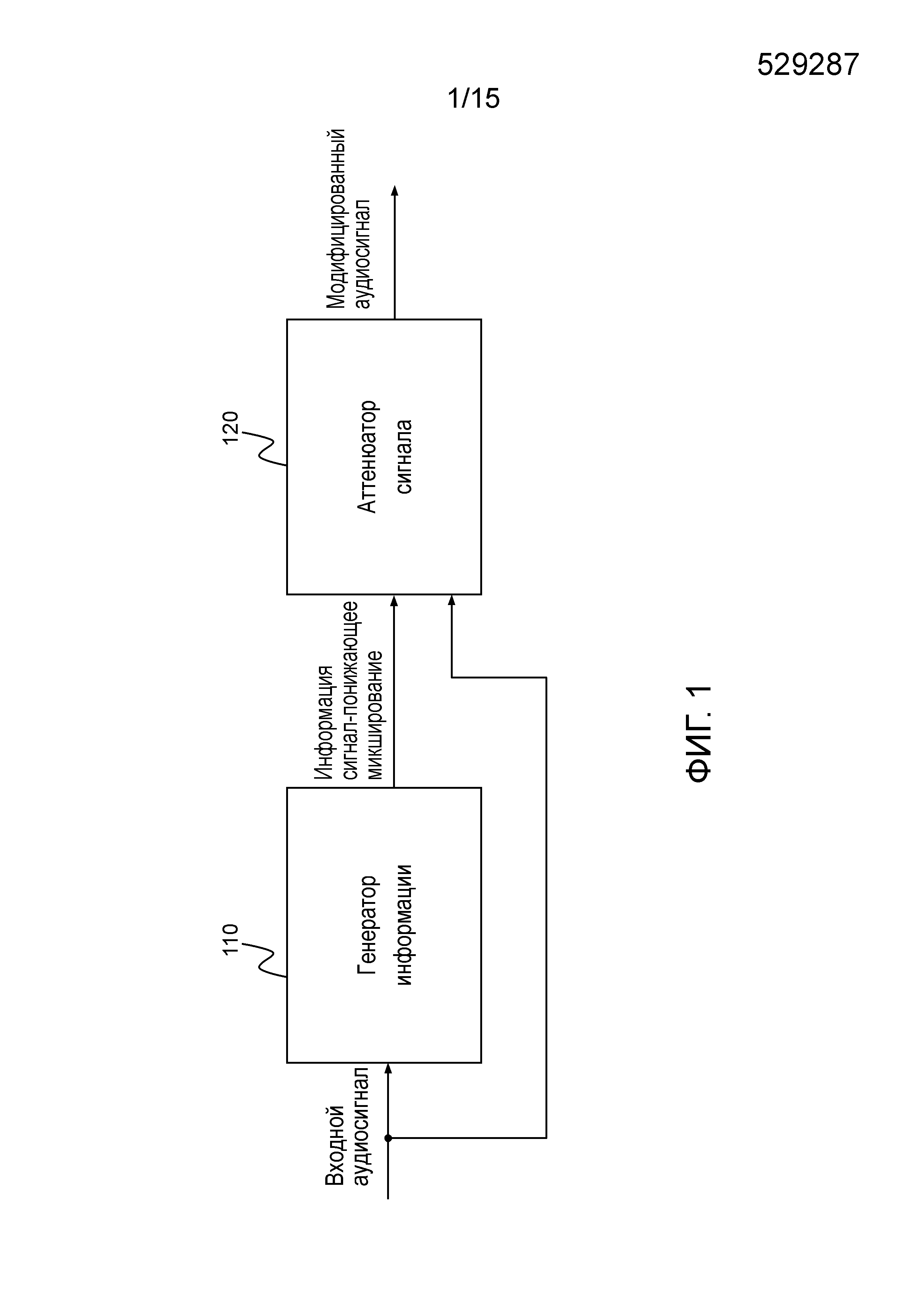
Фиг. 1 иллюстрирует устройство согласно одному из вариантов осуществления.
Фиг. 2 иллюстрирует отношение сигнал-понижающее микширование как функцию межканальной разности уровней и как функцию межканальной когерентности в соответствии с одним из вариантов осуществления.
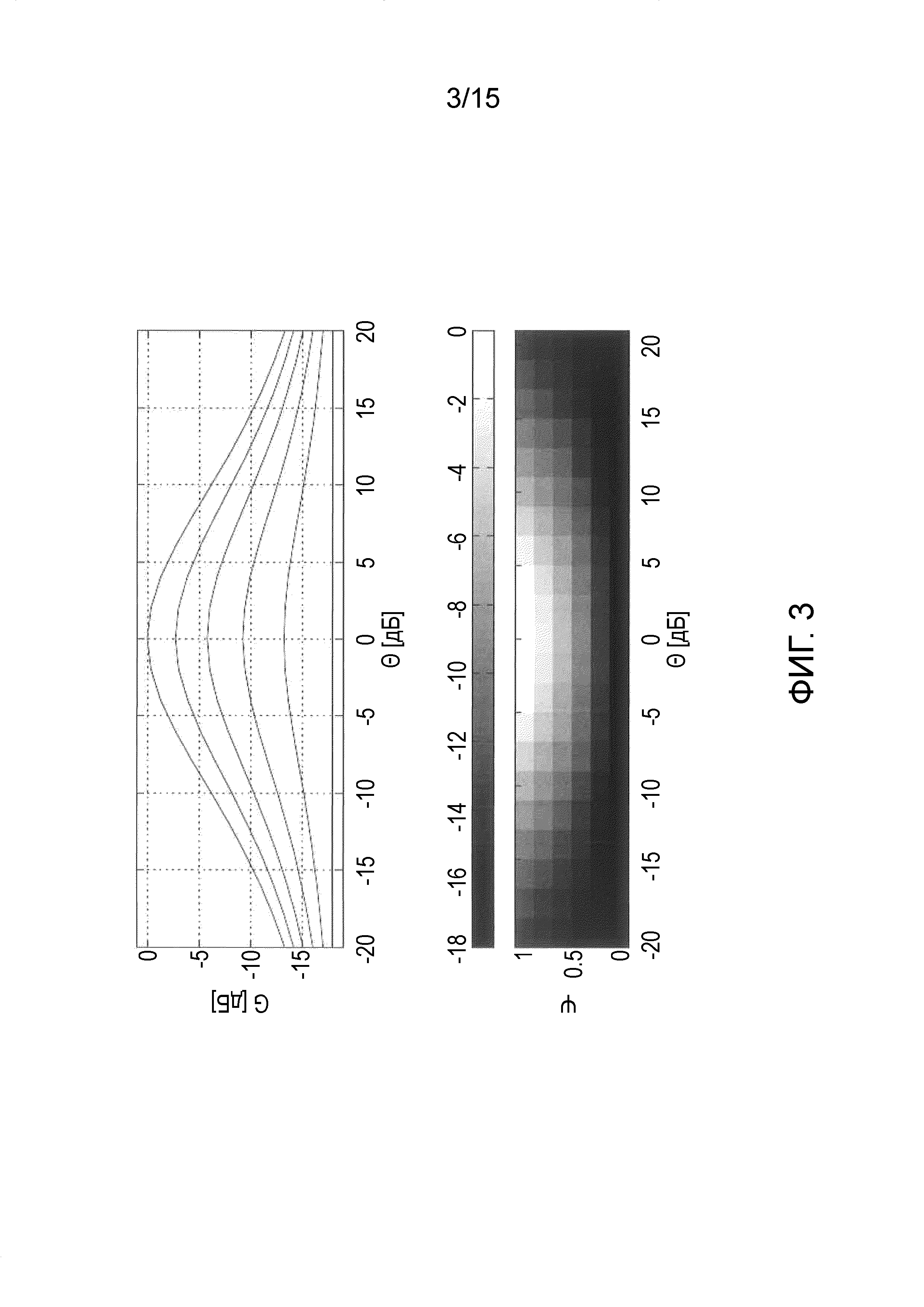
Фиг. 3 иллюстрирует спектральные веса как функцию межканальной когерентности и межканальной разности уровней в соответствии с одним из вариантов осуществления.
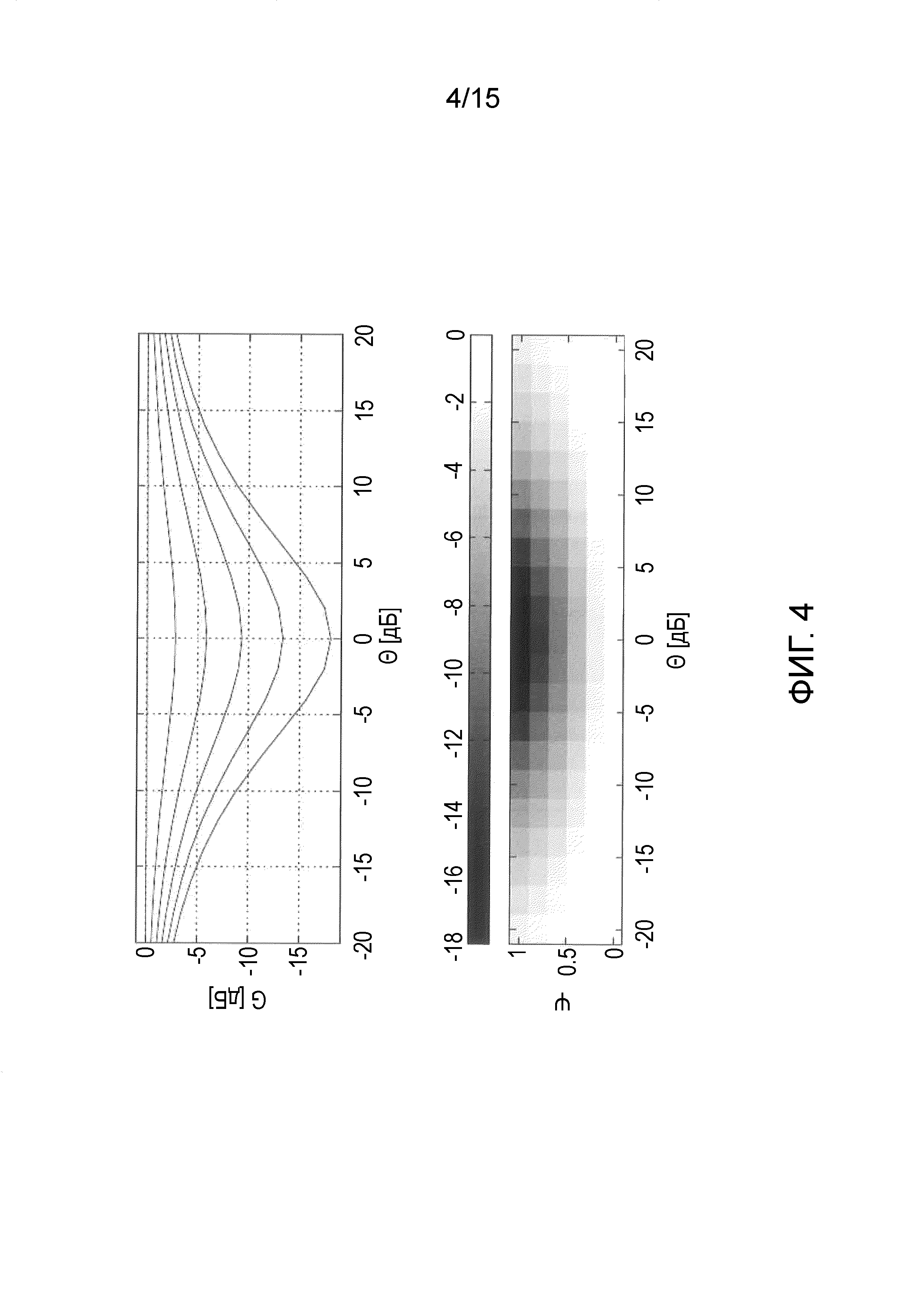
Фиг. 4 иллюстрирует спектральные веса как функцию межканальной когерентности и межканальной разности уровней в соответствии с другим вариантом осуществления.
Фиг. 5 иллюстрирует спектральные веса как функцию межканальной когерентности и межканальной разности уровней в соответствии с еще одним вариантом осуществления.
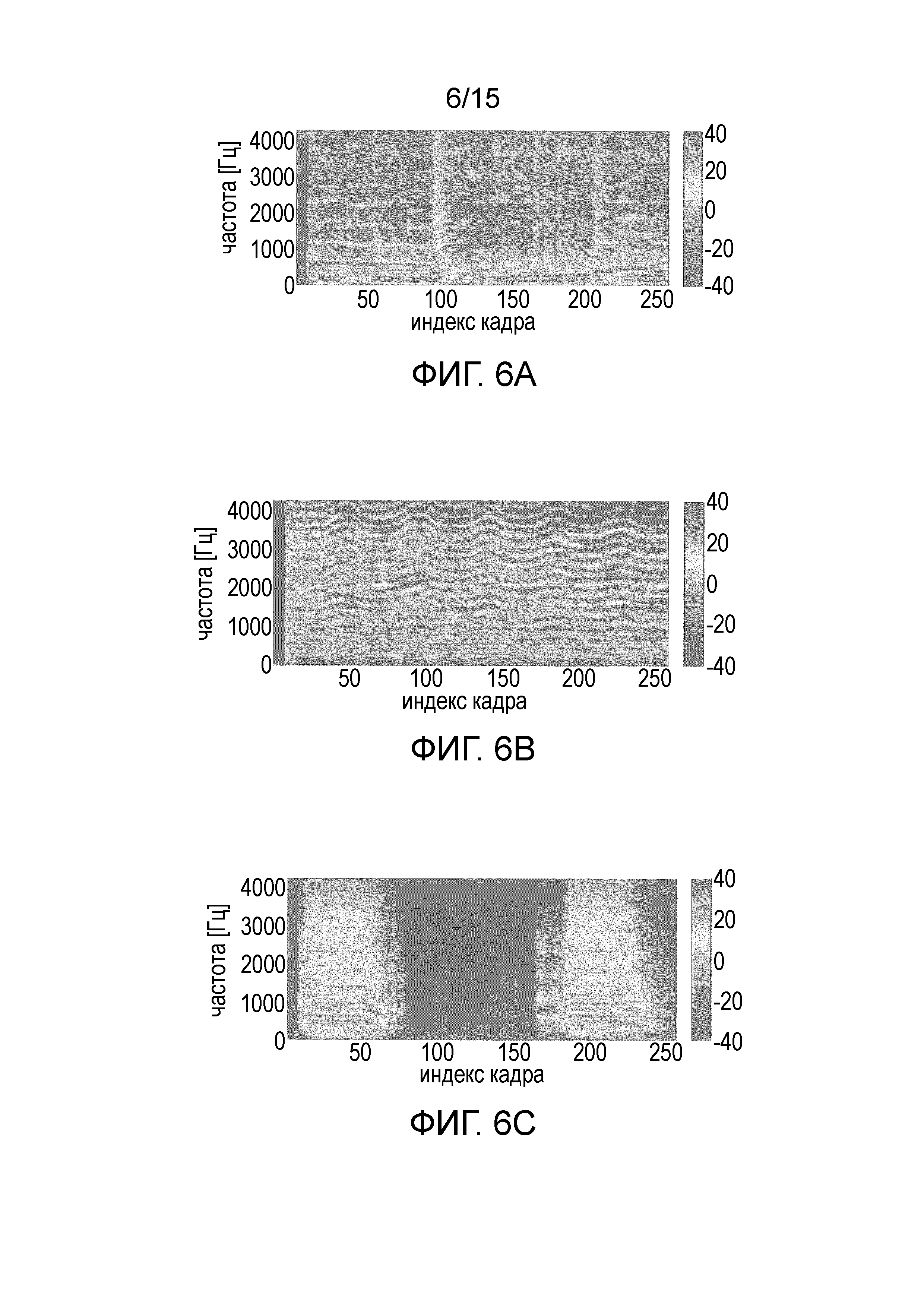
Фиг. 6A-E иллюстрируют спектрограммы источников прямых звуковых сигналов источника и сигналы левого и правого каналов смешанного сигнала.
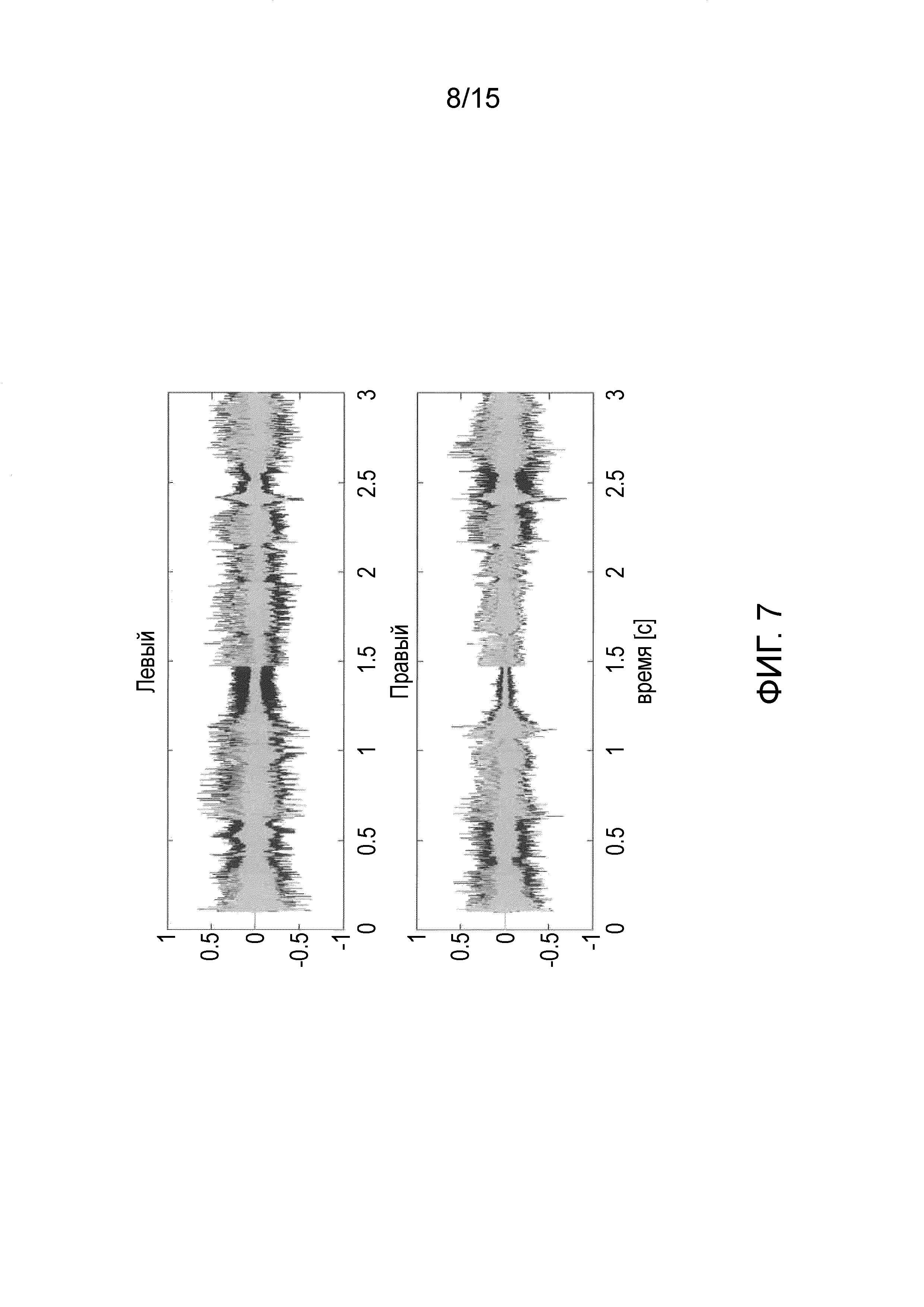
Фиг. 7 иллюстрирует входной сигнал и выходной сигнал для выделения центрального сигнала в соответствии с одним из вариантов осуществления.
Фиг. 8 иллюстрирует спектрограммы выходного сигнала в соответствии с одним из вариантов осуществления.
Фиг. 9 иллюстрирует входной сигнал и выходной сигнал для ослабления центрального сигнала в соответствии с другим вариантом осуществления.
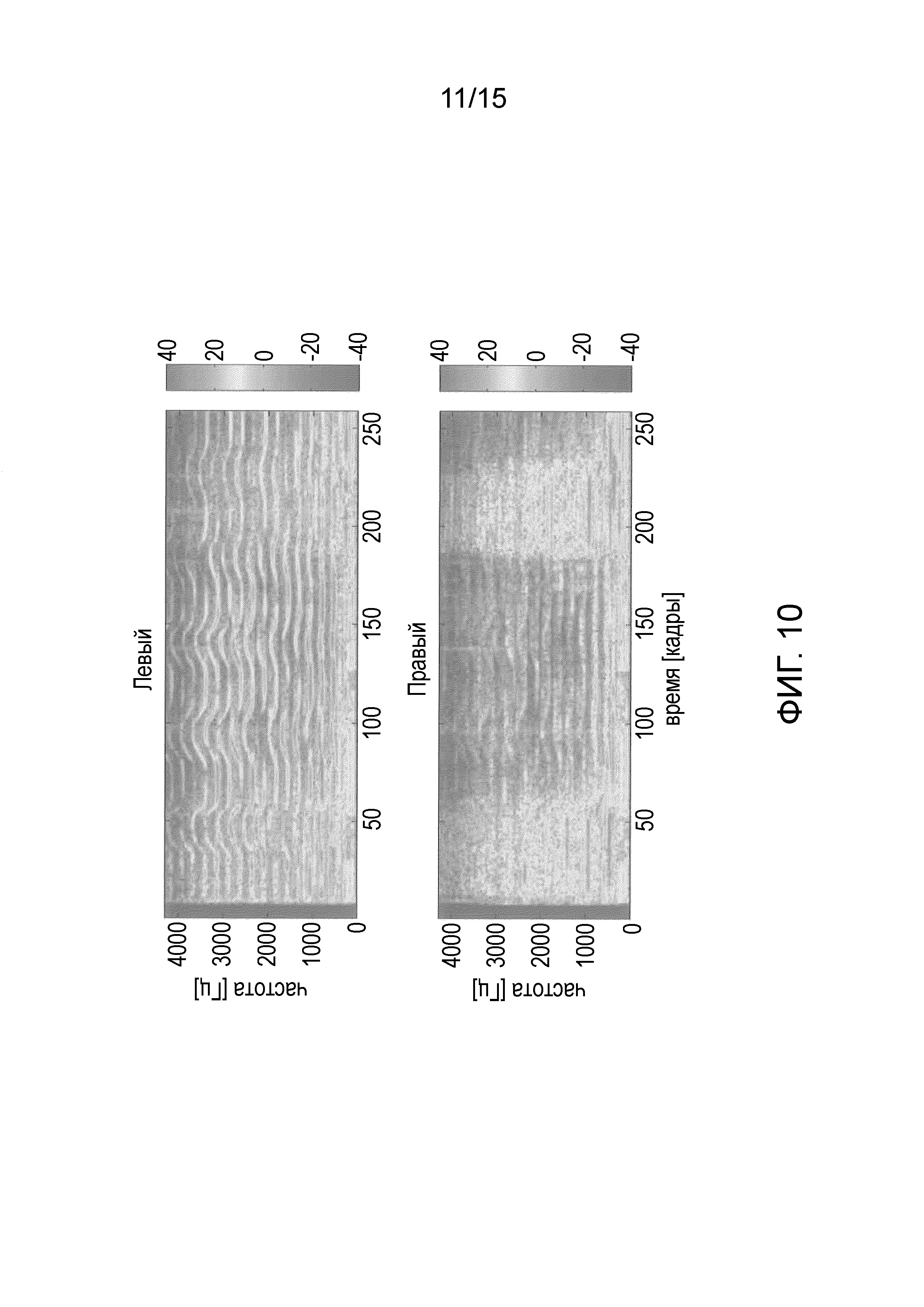
Фиг. 10 иллюстрирует спектрограммы выходного сигнала в соответствии с одним из вариантов осуществления.
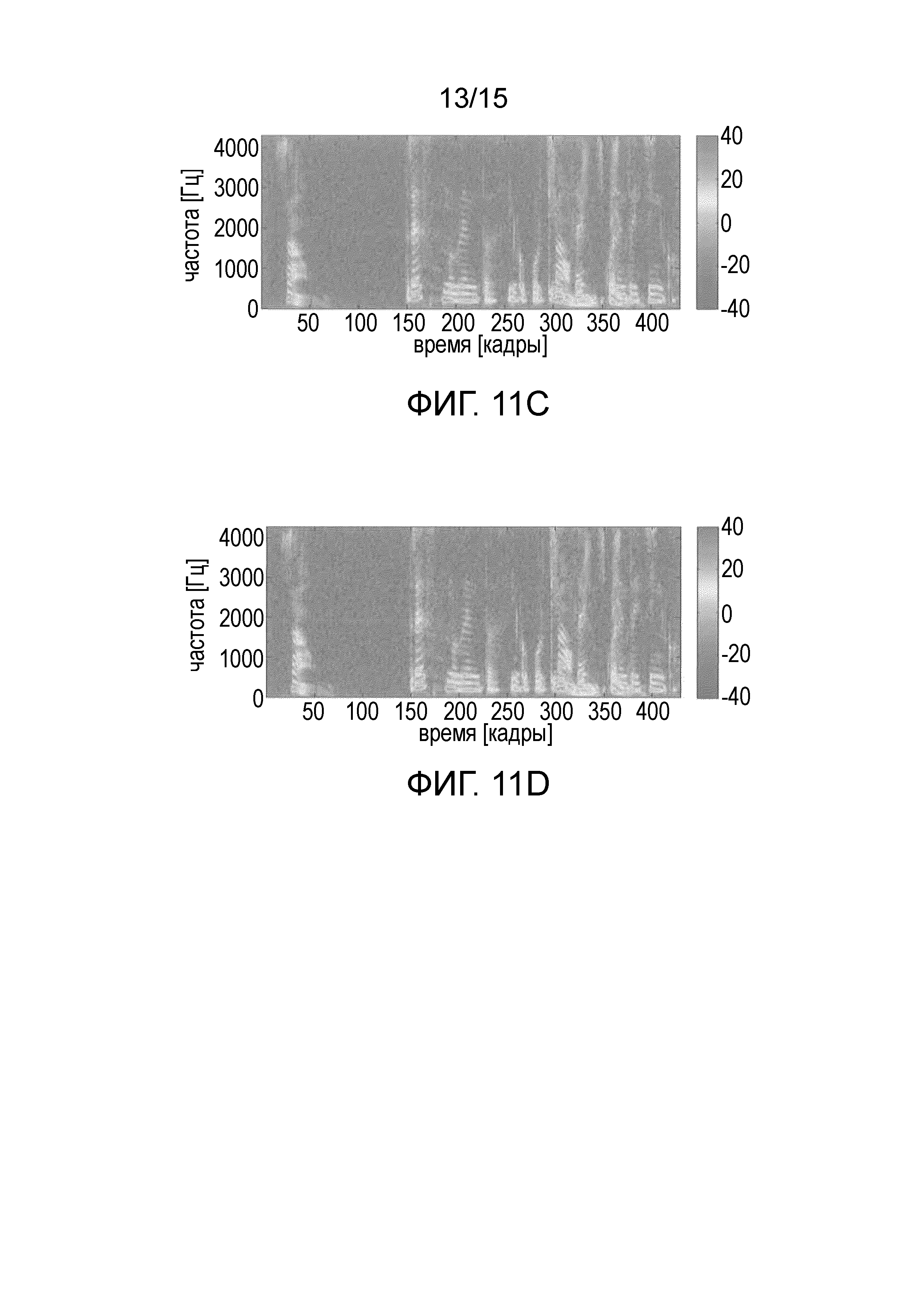
Фиг. 11A-D иллюстрируют два речевых сигнала, которые были смешаны для получения входных сигналов с и без межканальной временной разности,
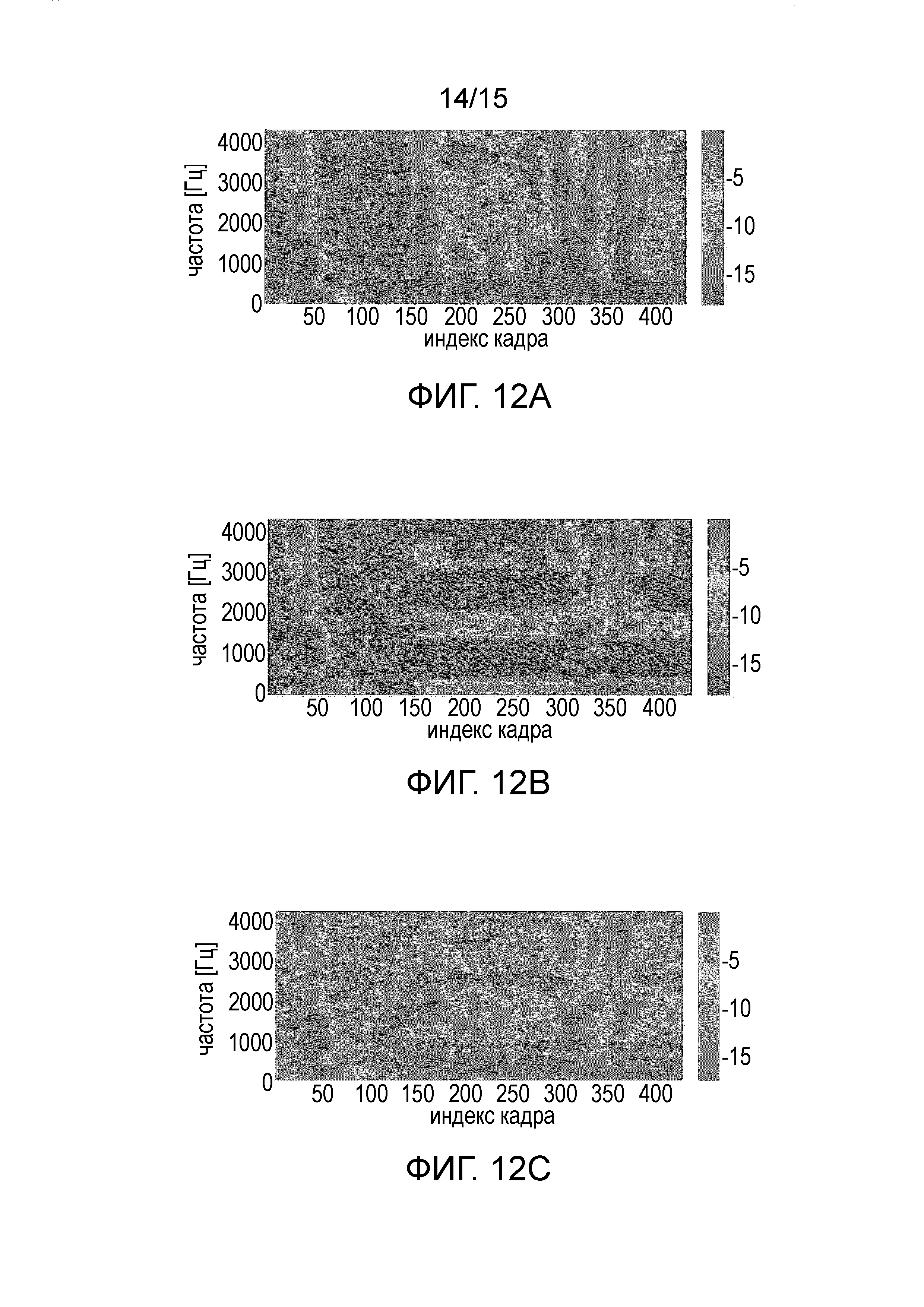
Фиг. 12A-C иллюстрируют спектральные веса, вычисленные из функции усиления в соответствии с одним из вариантов осуществления, и
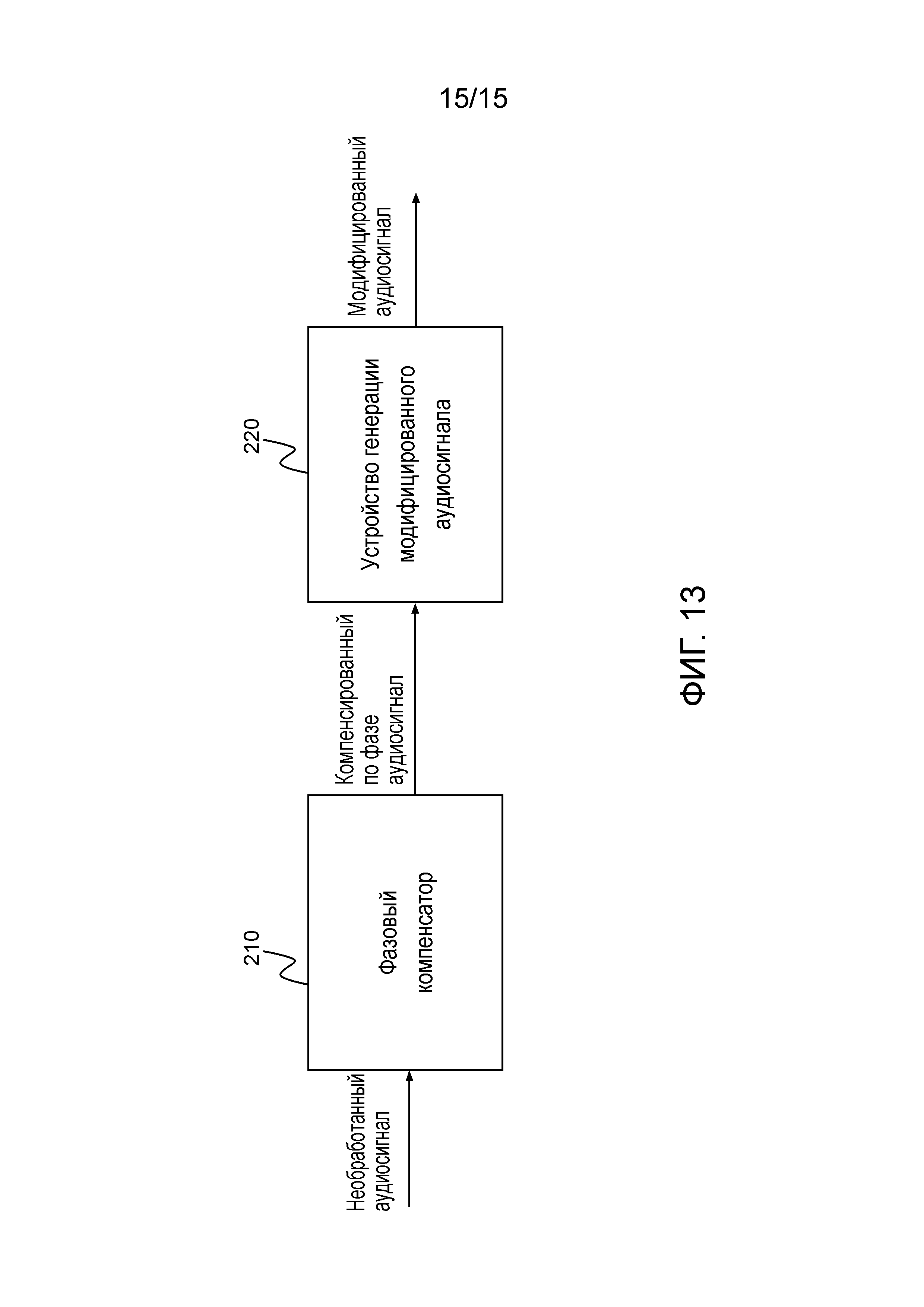
Фиг. 13 иллюстрирует систему в соответствии с одним из вариантов осуществления.
Фиг.1 иллюстрирует устройство для генерации модифицированного аудиосигнала, содержащего два или более модифицированных аудиоканалов, из входного аудиосигнала, включающего в себя два или более входных аудиоканалов, в соответствии с одним из вариантов осуществления.
Устройство содержит генератор 110 информации для генерации информации сигнал-понижающее микширование.
Генератор 110 информации выполнен с возможностью генерации информации сигнала путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов первым способом. Помимо этого, генератор 110 информации выполнен с возможностью генерации информации понижающего микширования путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов вторым способом, отличным от первого способа.
Дополнительно, генератор 110 информации выполнен с возможностью комбинирования информации сигнала и информации понижающего микширования для получения информации сигнал-понижающее микширование. Например, информация сигнал-понижающее микширование может представлять собой отношение сигнал-понижающее микширование, например, значение сигнал-понижающее микширование.
Помимо этого, устройство содержит аттенюатор 120 сигнала для ослабления двух или более входных аудиоканалов в зависимости от информации сигнал-понижающее микширование для получения двух или более модифицированных аудиоканалов.
В соответствии с одним из вариантов осуществления генератор информации может быть выполнен с возможностью комбинирования информации сигнала и информации понижающего микширования таким образом, что информация сигнал-понижающее микширование будет указывать на отношение информации сигнала и информации понижающего микширования. Например, информация сигнала может представлять собой первое значение, и информация понижающего микширования может представлять собой второе значение, а информация сигнал-понижающее микширование указывает на отношение значения сигнала и значения понижающего микширования. Например, информация сигнал-понижающее микширование может представлять собой результат деления первого значения на второе значение. Либо, например, если первое значение и второе значение представляют собой логарифмические значения, информация сигнал-понижающее микширование может представлять собой результат вычитания второго значения из первого значения.
В дальнейшем, базовая модель сигнала и концепции описаны и проанализированы для случая входного сигнала, реализующего стереофонию на основе разности амплитуд.
Обоснованием такого подхода является вычисление и применение вещественно-значных спектральных весов как функции диффузности и бокового расположения прямых источников. Обработка, как показано в настоящем документе, применяется в области STFT, однако она не ограничена конкретным банком фильтров. N-канальный входной сигнал обозначается
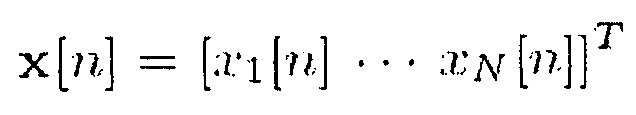 (1),
(1),
где n обозначает дискретный временной индекс. Предполагается, что входной сигнал представляет собой аддитивную смесь прямых сигналов si[n] и фоновых звуковых сигналов ai[n]
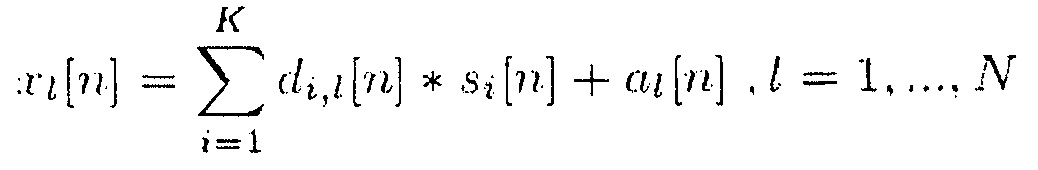 (2),
(2),
где P представляет собой количество источников звука, di,j[n] обозначает импульсные отклики прямых путей i-го источника в l-й канал длиной Li,j сэмплов, а компоненты фонового сигнала не коррелируют или слабо коррелируют. В нижеследующем описании предполагается, что модель сигнала соответствует стереофонии с амплитудно-разностной стереофонии, т.е. Li,j = 1, 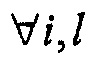 .
.
Представление x[n] в частотно-временной области дается в виде
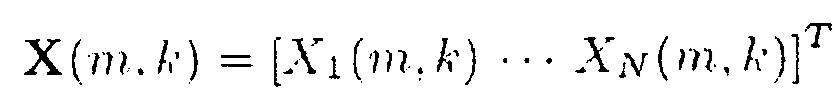 (3)
(3)
с временным индексом m и частотным индексом k. Выходные сигналы обозначаются
 (4)
(4)
и получаются посредством спектрального взвешивания
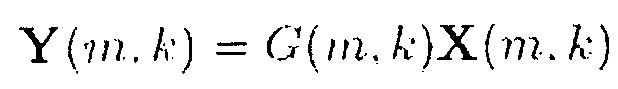 (5)
(5)
с вещественно-значными весами G(m, k). Выходные сигналы во временной области рассчитываются путем применения обратной обработки банка фильтров. Для вычисления спектральных весов суммарный сигнал, далее обозначаемый как сигнал понижающего микширования, вычисляется как
 (6)
(6)
Матрица PSD входного сигнала, содержащая оценки (авто)PSD на главной диагонали, в то время как недиагональные элементы представляют собой оценки кросс-PSD, дается в виде
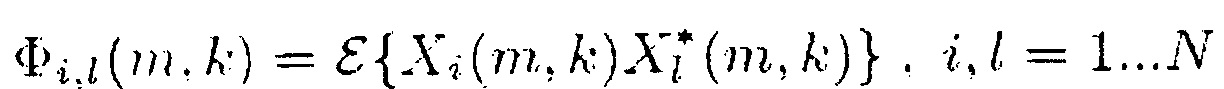 (7)
(7)
где X* обозначает комплексное сопряжение X, и 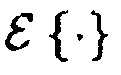 представляет собой операцию вычисления математического ожидания по отношению к оси времени. В представленных вариантах моделирования значения ожидания оцениваются с использованием однополюсного рекурсивного усреднения,
представляет собой операцию вычисления математического ожидания по отношению к оси времени. В представленных вариантах моделирования значения ожидания оцениваются с использованием однополюсного рекурсивного усреднения,
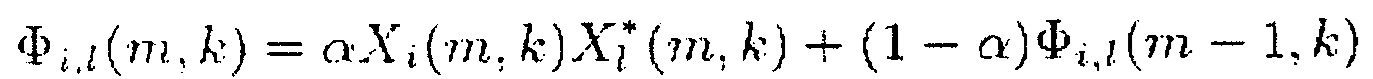 (8)
(8)
где коэффициент фильтрации α представляет собой время интегрирования. Помимо этого, количество R(m, k; β) определено следующим образом
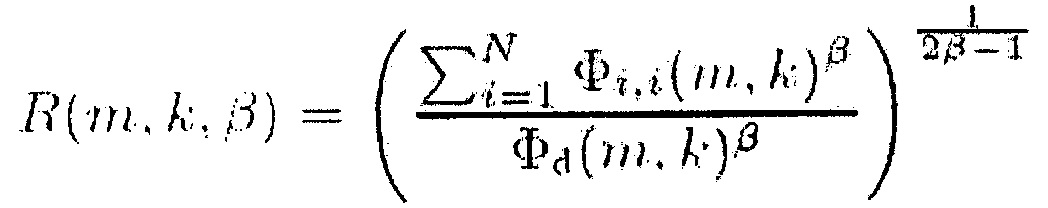 (9),
(9),
где 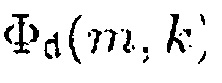 представляет собой сигнал понижающего микширования, а β представляет собой параметр который обсуждается ниже. Величина R(m, k; 1) представляет собой отношение сигнал-понижающее микширование (SDR), т.е. отношение полной PSD и PSD сигнала понижающего микширования. Показатель степени
представляет собой сигнал понижающего микширования, а β представляет собой параметр который обсуждается ниже. Величина R(m, k; 1) представляет собой отношение сигнал-понижающее микширование (SDR), т.е. отношение полной PSD и PSD сигнала понижающего микширования. Показатель степени 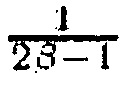 гарантирует, что диапазон R(m, k; β) независим от β.
гарантирует, что диапазон R(m, k; β) независим от β.
Генератор 110 информации может быть выполнен с возможностью определения отношения сигнал-понижающее микширование в соответствии с уравнением (9).
Согласно уравнению (9) информация сигнала s(m, k, β), которая может быть определена с помощью генератора 110 информации определяется как
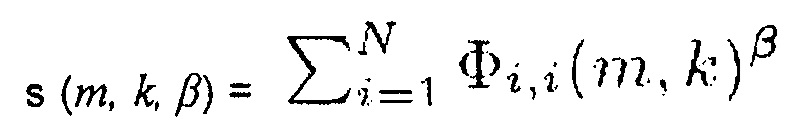
Как можно видеть из приведенного выше, Φi,j(m,k) определяется как Φi,i(m,k) =  {Xi(m,k) Xi*(m,k)}. Таким образом, для определения информации сигнала s(m, k, β) спектральные величины Xi(m,k) каждого из двух или более входных аудиоканалов обрабатывается для получения обработанного значение Φi,j(m,k)β для каждого из двух или более входных аудиоканалов, и полученные обработанные значения Φi,j(m,k)β затем комбинируются, например, как в уравнении (9), путем суммирования полученных обработанных значений Φi,j(m,k)β.
{Xi(m,k) Xi*(m,k)}. Таким образом, для определения информации сигнала s(m, k, β) спектральные величины Xi(m,k) каждого из двух или более входных аудиоканалов обрабатывается для получения обработанного значение Φi,j(m,k)β для каждого из двух или более входных аудиоканалов, и полученные обработанные значения Φi,j(m,k)β затем комбинируются, например, как в уравнении (9), путем суммирования полученных обработанных значений Φi,j(m,k)β.
Таким образом, генератор 110 информации может быть выполнен с возможностью обработки спектрального величины Xi(m,k) каждого из двух или более входных аудиоканалов для получения двух или более обработанных значений Φi,j(m,k)β, и генератор 110 информации может быть выполнен с возможностью комбинирования двух или более обработанных значений для получения информации сигнала s(m, k, β). В более общем случае, генератор 110 информации выполнен с возможностью генерации информации сигнала s(m, k, β) путем комбинирования спектральных значений Xi(m,k) каждого из двух или более входных звуковых каналов первым способом.
Помимо этого, согласно уравнению (9) информация понижающего микширования d(m, k, β), которая может быть определена с помощью генератора 110 информации определяется как
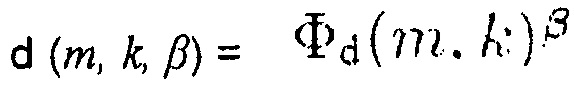 .
.
Для получения Φd(m,k) сначала получают Xd(m,k) согласно приведенному выше уравнению(6):
 .
.
Как можно видеть, во-первых, спектральное значение Xi(m,k) каждого из двух или более входных аудиоканалов комбинируется для получения комбинированного значения Xd(m,k), например, как в уравнении (6), путем суммирования спектральных значений Xi(m,k) каждого из двух или более входных аудиоканалов.
Затем, для получения Φd(m,k) получают спектральную плотность мощности для Xd(m,k) например, в соответствии с
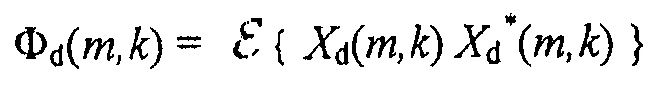
и затем может быть определено Φd(m,k)β. В более общем смысле, полученное комбинированное значение Xd(m,k) было обработано для получения информации понижающего микширования d(m, k, β) =Φd(m,k)β.
Таким образом, генератор 110 информации может быть выполнен с возможностью комбинирования спектральных значений Xi(m,k) каждого из двух или более входных аудиоканалов для получения комбинированного значения, и генератор 110 информации может быть выполнен с возможностью обработки комбинированного значения для получения информации понижающего микширования d(m, k, β). В более общем случае, генератор 110 информации выполнен с возможностью генерации информации понижающего микширования d(m, k, β), комбинируя спектральные значения Xi(m,k) каждого из двух или более входных звуковых каналов вторым способом. Способ, с помощью которого генерируется информация понижающего микширования ("второй способ") отличается от способа, каким генерируется информация сигнала ("первый способ") и, таким образом, второй способ отличается от первого способа.
Генератор 110 информации выполнен с возможностью генерации информации сигнала путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов первым способом. Помимо этого, генератор 110 информации выполнен с возможностью генерации информации понижающего микширования путем комбинирования спектральных значений каждого из упомянутых двух или более входных аудиоканалов вторым способом, отличным от первого способа.
На верхнем графике Фиг. 2 показано отношение сигнал-понижающее микширование R(m, k; 1) для N=2 как функция ICLD 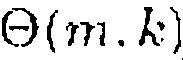 , показанная для
, показанная для  ∈ {0, 0,2, 0,4, 0,6, 0,8, 1}. На нижнем графике Фиг. 2 показано отношение сигнал-понижающее микширование R(m, k; 1) для N=2 как функция ICC
∈ {0, 0,2, 0,4, 0,6, 0,8, 1}. На нижнем графике Фиг. 2 показано отношение сигнал-понижающее микширование R(m, k; 1) для N=2 как функция ICC 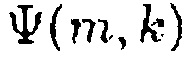 и ICLD
и ICLD 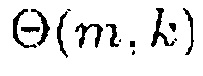 в виде 2D графика с цветовой кодировкой.
в виде 2D графика с цветовой кодировкой.
В частности, на фиг. 2 показано SDR для N=2 как функция ICC  и ICLD
и ICLD 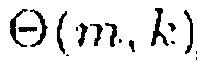 , с
, с
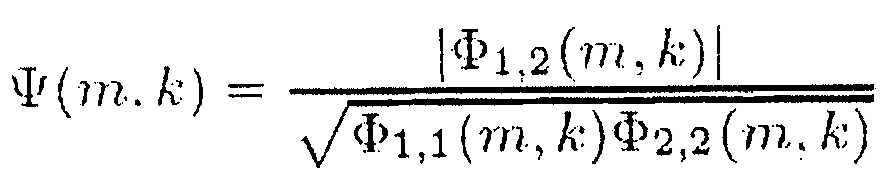 (10)
(10)
и
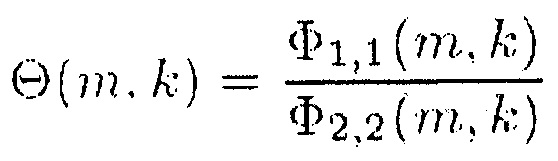 (11)
(11)
Фиг. 2 демонстрирует, что SDR имеет следующие свойства:
1. SDR монотонно по отношению как к 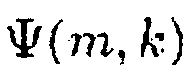 так и
так и  .
.
2. Для диффузных входных сигналов, т.е. 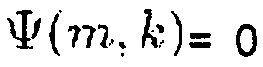 , SDR принимает максимальное значение R(m, k; 1)=1.
, SDR принимает максимальное значение R(m, k; 1)=1.
3. Для прямых звуковых сигналов панорамированных в центр, т.е.  , SDR принимает его минимальное значение Rmin, где Rmin=0,5 для N=2.
, SDR принимает его минимальное значение Rmin, где Rmin=0,5 для N=2.
Благодаря этим свойствам, соответствующие спектральные веса для масштабирования центрального сигнала могут быть вычислены из SDR с помощью монотонно убывающих функций для выделения центральных сигналов и монотонно возрастающих функций для ослабления центральных сигналов.
Для выделения центрального сигнала подходящими функциями R(m, k; β) являются, например,
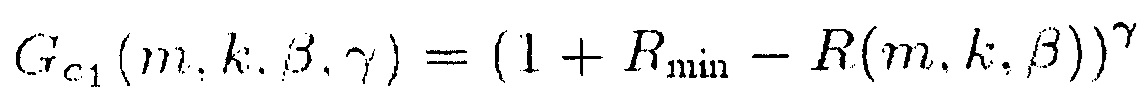 (12)
(12)
и
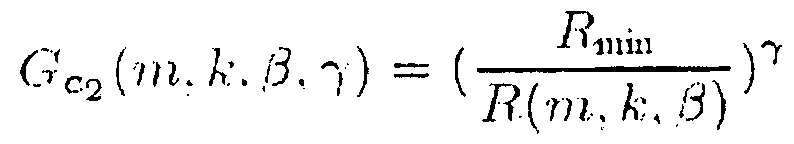 (13),
(13),
где введен параметр управления максимальным ослаблением.
Для ослабления центрального сигнала подходящими функции R(m, k; β) являются, например,
 (14)
(14)
и
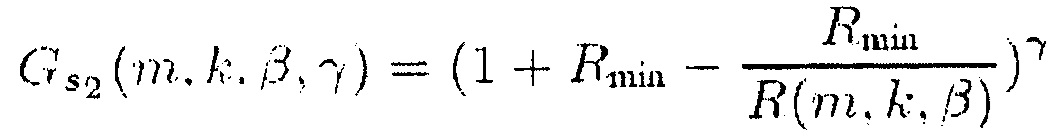 (15)
(15)
Фиг. 3 и 4 иллюстрируют функции усиления (13) и (15), соответственно, для β=1, γ=3. Спектральные веса постоянны для 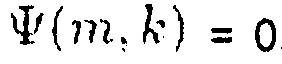 . Максимальное ослабление γ 6 дБ, что также относится к функциям усиления (12) и (14).
. Максимальное ослабление γ 6 дБ, что также относится к функциям усиления (12) и (14).
В частности, на фиг. 3 показаны спектральные веса Gc2(m, k; 1, 3) в дБ как функция ICC 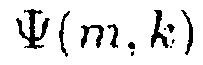 и ICLD
и ICLD 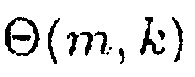 .
.
Помимо этого, на фиг. 4 показаны спектральные веса Gc2(m, k; 1, 3) в дБ как функция ICC и ICLD .
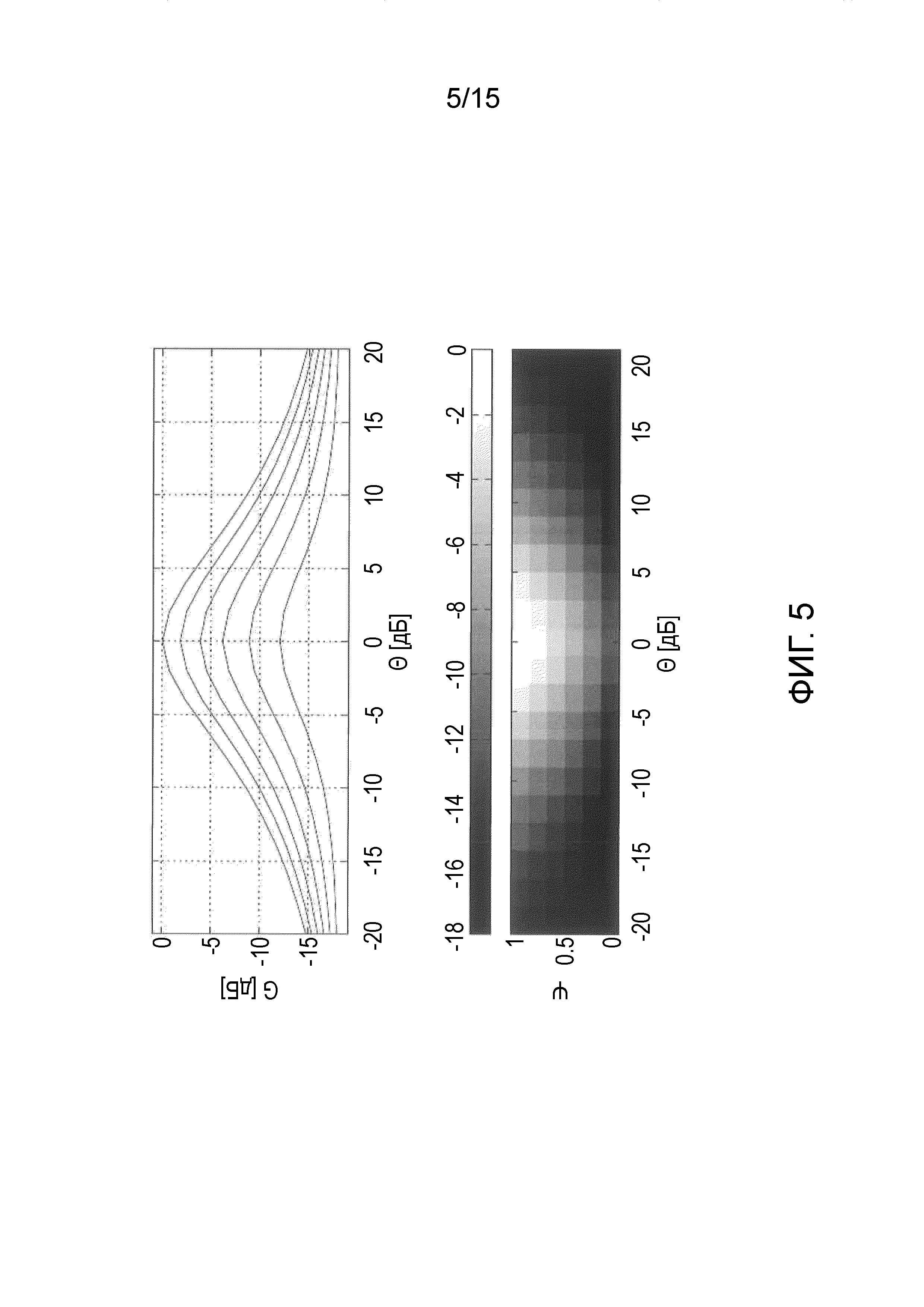
Далее, на фиг. 5 показаны спектральные веса Gc2(m, k; 2, 3) в дБ как функция ICC и ICLD .
Влияние параметра β показано на Фиг. 5 для функции усиления согласно уравнению (13) с β=2, γ=3. При больших значениях β, влияние Ψ на спектральные веса уменьшается, тогда как влияние  возрастает. При сравнении с функцией усиления на фиг. 3 видно, что это приводит к более высокому уровню проникновения диффузных компонентов сигнала в выходной сигнал и к более сильному ослаблению прямых компонентов сигнала панорамированных со смещением от центра.
возрастает. При сравнении с функцией усиления на фиг. 3 видно, что это приводит к более высокому уровню проникновения диффузных компонентов сигнала в выходной сигнал и к более сильному ослаблению прямых компонентов сигнала панорамированных со смещением от центра.
Пост-обработка спектральных весов: До спектрального взвешивания, веса G(m, k; β, γ) могут быть дополнительно обработаны посредством сглаживания. Низкочастотная фильтрация с нулевой фазой по оси частот уменьшает артефакты круговой свертки, которые могут возникнуть, например, если дополнение нулями при вычислении STFT слишком короткое или применяется прямоугольное окно синтеза. Низкочастотная фильтрация по оси частот может уменьшить артефакты обработки, особенно в случае небольшой постоянной времени для оценки PSD.
Ниже описаны обобщенные спектральные веса.
Более общие спектральные веса получаются при перезаписи уравнения (9) следующим образом
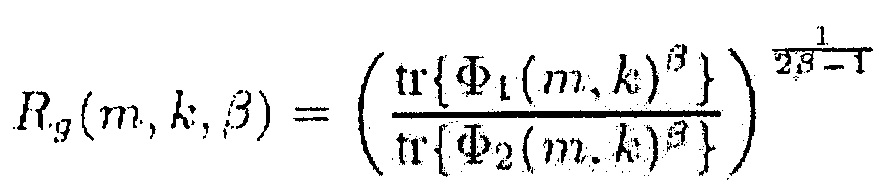 (16)
(16)
с
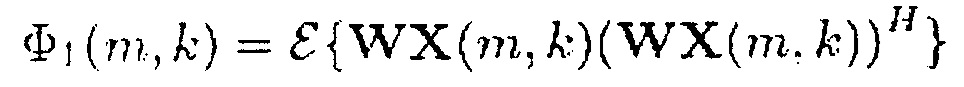 (17)
(17)
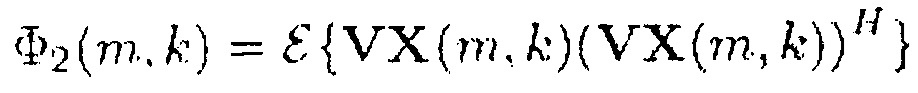 (18),
(18),
где индекс H обозначает сопряженное транспонирование матрицы или вектора, и W и V представляют собой матрицы смешивания или вектор (строку) смешивания.
Здесь Φ1(m,k) можно рассматривать как информацию сигнала, а Φ2(m,k) можно рассматривать как информацию понижающего микширования.
Например, Φ2=Φd, когда V является вектором длины N, элементы которого равны единице. Уравнение (16) равно (9), когда V является вектором-строкой длины N, чьи элементы равны единице, и W является единичной матрицей размера N×N.
Обобщенный SDR Rg(m, k, β, W, V) охватывает, например, отношение PSD бокового сигнала и PSD сигнала понижающего микширования для W = [1,−1], V = [1, 1] и N=2.
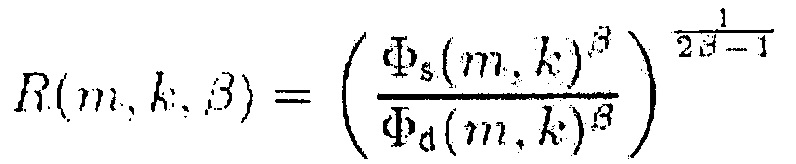 (19)
(19)
где Φs(m, k) представляет собой PSD бокового сигнала.
В более общем случае, генератор 110 информации выполнен с возможностью генерации информации сигнала Φ1(m,k) путем комбинирования спектральных значений Xi(m,k) каждого из двух или более входных аудиоканалов первым способом. Помимо этого, генератор 110 информации выполнен с возможностью генерации информации Φ2(m,k) понижающего микширования путем комбинирования спектральных значений Xi(m,k) каждого из упомянутых двух или более входных аудиоканалов вторым способом, отличным от первого способа.
Ниже описан более общий случай моделей смешивания со стереофонией на основе времени-прибытия.
Описанный выше вывод спектральных весов основывается на предположении, что Li,j=1, 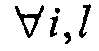 , т.е. источники прямых звуковых сигналов выровнены по времени между входными каналами. Когда смешивание сигналов прямых источников не ограничивается до амплитудно-разностной стереофонии (Li,j>1), например, при записи с разнесенными микрофонами, при понижающем микшировании входного сигнала Xd(m,k) выполняют фазовую нейтрализацию. Фазовая нейтрализация в Xd(m,k) приводит к возрастанию значений SDR и, как следствие, к появлению типичных артефактов гребенчатой фильтрации при применении спектрального взвешивания, описанного выше.
, т.е. источники прямых звуковых сигналов выровнены по времени между входными каналами. Когда смешивание сигналов прямых источников не ограничивается до амплитудно-разностной стереофонии (Li,j>1), например, при записи с разнесенными микрофонами, при понижающем микшировании входного сигнала Xd(m,k) выполняют фазовую нейтрализацию. Фазовая нейтрализация в Xd(m,k) приводит к возрастанию значений SDR и, как следствие, к появлению типичных артефактов гребенчатой фильтрации при применении спектрального взвешивания, описанного выше.
Частоты режекции гребенчатого фильтра соответствуют частотам

для функций усиления (12) и (13) и

для функций усиления (14) и (15), где частота fs представляет собой частоту дискретизации, о - нечетные целые числа, Е - четные целые числа, и d - задержка выборок.
Первый подход к решению этой проблемы заключается в компенсации разности фаз, являющейся следствием из ICTD, до расчета Xd(m,k). Компенсация разности фаз (PDC) достигается путем оценки зависящей от времени функции межканального фазового переноса 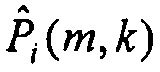 ,
, 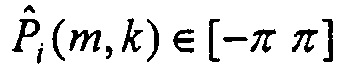 между i-м каналом и опорным каналом, обозначенным индексом r,
между i-м каналом и опорным каналом, обозначенным индексом r,
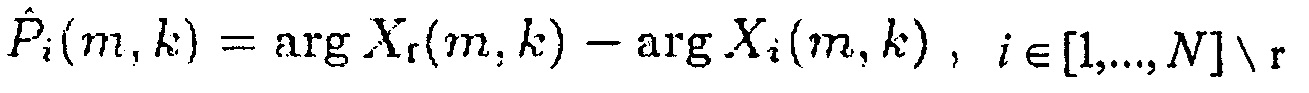 (20),
(20),
где оператор А\В обозначает теоретико-множественную разницу множества В и множества А и применения зависящего от времени частотно-независимого компенсирующего фильтра HC,i(m,k) к i-му каналу сигнала
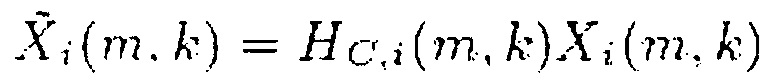 (21),
(21),
где функция HC,i(m,k) фазового переноса представляет собой
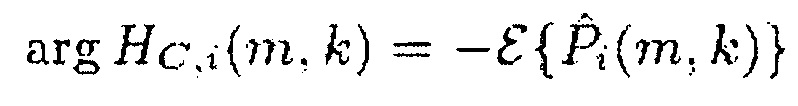 (22)
(22)
Ожидаемое значение рассчитывается с использованием однополюсного рекурсивного усреднения. Следует отметить, что фазовые скачки 2π, происходящие на частотах, близких к частотам режекции, должны быть компенсированы перед рекурсивным усреднением.
Сигнал понижающего микширования вычисляют в соответствии с
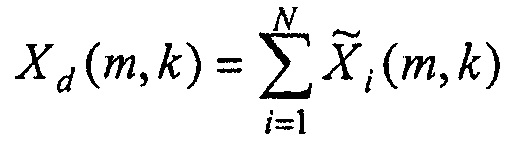 (23),
(23),
таким образом, что PDC применяется только для вычисления Xd и не оказывает влияния на выходной сигнал.
Фиг. 13 иллюстрирует систему в соответствии с одним из вариантов осуществления.
Система содержит фазовый компенсатор 210 для генерации компенсированного по фазе аудиосигнала, содержащего два или более компенсированных по фазе аудиоканалов, из необработанного аудиосигнала, содержащего два или более необработанных аудиоканалов.
Кроме того, система содержит устройство 220 согласно одному из вышеописанных вариантов осуществления для приема компенсированного по фазе аудиосигнала в качестве входного аудиосигнала и для генерации модифицированного аудиосигнала, содержащего два или более модифицированных аудиоканалов, из входного аудиосигнала, содержащего два или более компенсированных по фазе аудиоканалов, в качестве двух или более входных аудиоканалов.
Один из упомянутых двух или более необработанных аудиоканалов является опорным каналом. Фазовый компенсатор 210 выполнен с возможностью оценки для каждого необработанного аудиоканала из упомянутых двух или более необработанных аудиоканалов, который не является опорным каналом, функции передачи фазы между упомянутыми необработанным аудиоканалом и опорным каналом. Кроме того, фазовый компенсатор выполнен с возможностью генерации компенсированного по фазе аудиосигнала с помощью модификации каждого необработанного аудиоканала из упомянутых необработанных аудиоканалов, который не является опорным каналом, в зависимости от функции передачи фазы упомянутого необработанного аудиоканала.
Ниже представлено интуитивно ясное объяснение параметров управления, а именно, семантический смысл параметров управления.
Для обеспечения возможности реализации цифровых аудиоэффектов представляется целесообразным предусмотреть элементы управления с помощью семантически значимых параметров. Функции усиления (12)-(15) управляются параметрами α, β и γ. Звуковые инженеры и аудиоинженеры хорошо знакомы с постоянными времени, и указание α в качестве постоянной времени является интуитивно понятным и соответствующим с общепринятой практикой. Эффект времени интегрирования лучше всего может быть продемонстрирован экспериментальным путем. Для того, чтобы поддержать работу предоставляемых концепций, предлагается ввести дескрипторы для остальных параметров, а именно удар для γ и диффузность для β.
Параметр удар лучше всего сравнивать с порядком фильтра. По аналогии со спадом в фильтрации, максимальное ослабление равно γ⋅6 дБ для N=2.
Обозначение диффузность в настоящем случае предлагается, чтобы подчеркнуть тот факт, что, уменьшая панорамированные и диффузные звуки, большие значения β обеспечивают более высокий уровень диффузных звуков. Нелинейное отображение пользовательского параметра βu, например, 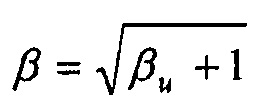 , 0≤βu≤10, является предпочтительным в том смысле, что позволяет более согласованную обработку в отличие от случая, когда изменяется непосредственно β (где согласованность относится к эффекту изменения параметра результата во всем диапазоне значение параметра).
, 0≤βu≤10, является предпочтительным в том смысле, что позволяет более согласованную обработку в отличие от случая, когда изменяется непосредственно β (где согласованность относится к эффекту изменения параметра результата во всем диапазоне значение параметра).
Ниже кратко обсуждаются вычислительная сложность и память.
Вычислительная сложность и требуемая память меняются в зависимости от количества полос банка фильтров и зависят от реализации дополнительной постобработки спектральных весов. Малозатратная реализация способа может быть достигнута при установке β=1, 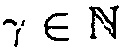 , вычислении спектральных весов в соответствии с уравнением (12) или (14) и без применения PDC фильтра. Вычисление SDR использует только одну затратную нелинейную функцию на поддиапазон, когда
, вычислении спектральных весов в соответствии с уравнением (12) или (14) и без применения PDC фильтра. Вычисление SDR использует только одну затратную нелинейную функцию на поддиапазон, когда  . При β=1, только два буфера требуется для PSD оценки, в то время как способы с явным использованием ICC, например, [7, 10, 20, 21, 23], требуют по меньшей мере три буфера.
. При β=1, только два буфера требуется для PSD оценки, в то время как способы с явным использованием ICC, например, [7, 10, 20, 21, 23], требуют по меньшей мере три буфера.
Ниже обсуждается производительность представленной концепций с привлечением примеров.
Во-первых, обработка применяется к панорамированной по амплитуде-смеси из записей 5 инструментов (барабаны, бас, клавишные, гитара) с частотой выборки 44100 Гц, для которых визуализирована выдержка длительностью 3 секунды. Барабаны, бас и клавишные панорамированы в центре, одна гитара панорамирована в левый канал, а вторая гитара панорамирована в правый канал, в обоих случаях |ICLD|=20 дБ. Для генерации компонентов фонового сигнала использовалась свертка искусственного эхо, имеющие стерео импульсные характеристики с RT60 около 1,4 секунд на входной канал. Был добавлен сигнал реверберации с отношением прямой-фоновый около 8 дБ после K-взвешивания [29].
На Фиг. 6A-E показаны спектрограммы прямых звуковых сигналов источника и сигналы левого и правого каналов смешанного сигнала. Спектрограммы вычисляются с использованием STFT длиной 2048 выборок, 50% перекрытием, размером кадра 1024 выборок и синусоидальным окном. Следует отметить, что для ясности показаны только величины спектральных коэффициентов, соответствующих частотам до 4 кГц. В частности, на фиг. 6A-E показаны входные сигналы для рассматриваемого музыкального примера.
В частности, фиг. 6A-E иллюстрируют следующее: на фиг. 6A сигналы источников, где барабаны, бас и клавишные панорамированы в центр; на фиг. 6B сигналы источников, где гитара 1 в смеси панорамирована влево; на фиг.6C сигналы источников, где гитара 2 в смеси панорамирована вправо; на фиг. 6D левый канал сигнала смеси; на фиг. 6E правый канал сигнала смеси.
Фиг. 7 иллюстрирует входной сигнал и выходной сигнал для выделенного центрального сигнала, полученного с применением Gs2(m, k; 1, 3). В частности, на фиг. 7 показан пример выделенного центрального сигнала, в котором проиллюстрированы зависимости от времени входных сигналов (черные) и выходных сигналов (наложенные серым), причем на фиг. 7 верхний график иллюстрирует левый канал, а нижний график иллюстрирует правый канал.
Постоянная времени для рекурсивного усреднения в PSD оценке здесь и далее составляет в 200 мс.
Фиг. 8 иллюстрирует спектрограммы выходного сигнала. Визуальный анализ показывает, что сигналы источников, панорамированных со смещением от центра (показаны на фиг. 6B и 6C), в значительной степени ослабляются в выходных спектрограммах. В частности, на фиг. 8 показан пример выделенного центрального сигнала, в частности, пример спектрограмм выходных сигналов. Выходные спектрограммы также показывают, что компоненты фонового сигнала ослабляются.
Фиг. 9 иллюстрирует входной сигнал и выходной сигнал для ослабления центрального сигнала, полученного применением Gs2(m, k; 1, 3). Зависимости сигналов от времени показывают, что переходные звуки от барабанов ослабляются при обработке. В частности, на фиг. 9 показан пример ослабления центрального сигнала, в котором проиллюстрированы зависимости от времени входных сигналов (черные) и выходных сигналов (наложенные серым).
Фиг. 10 иллюстрирует спектрограммы выходного сигнала. Можно заметить, что сигналы, панорамированные в центре, ослабляются, например, если смотреть на переходные звуковые компоненты и устойчивые тоны в нижнем диапазоне частот ниже 600 Гц, и сравнивать с Фиг. 6A. Четко выделяющиеся звуки в выходном сигнале соответствуют инструментам, панорамированным со смещением от центра и реверберации. В частности, фиг. 10 иллюстрирует пример ослабления центрального сигнала, более конкретно, спектрограммы выходных сигналов.
Неформальное прослушивание через наушники показывает, что ослабление компонентов сигнала является эффективным. При прослушивании выделенного центрального сигнала слышны артефакты обработки в виде слабой модуляции во время партии гитары 2, что похоже на эффект "пампинга" при сжатии динамического диапазона. Следует отметить, что реверберация снижается, и что ослабление является более эффективным для низких частот, чем для высоких частот. Вопрос о том, вызвано ли это большим отношением прямой-фоновый сигнал на низких частотах, частотным составом источников звука или субъективным восприятием вследствие явления демаскирования, не может быть решен без более детального анализа.
При прослушивании выходного сигнала, где центральный сигнал ослаблен, общее качество звука немного лучше по сравнению с результатом с выделением центрального сигнала. Артефакты обработки слышны в виде небольших перемещений панорамированных источников к центру, когда активны доминирующие центральные источники, что эквивалентно "пампингу" при выделении центрального сигнала. Звучание выходного сигнала менее прямое, что является результатом увеличения количества фона в выходном сигнале.
Чтобы проиллюстрировать PDC фильтрацию, на Фиг. 11A-D показаны два речевых сигнала, которые были смешаны, чтобы получить входные сигналы с и без ICTD. В частности, на фиг. 11A-D показаны источники входных сигналов для иллюстрации PDC, причем на Фиг. 11A показан источник сигнала 1; на фиг. 11B показан источник сигнала 2; на фиг. 11C показан левый канал смешанного сигнала; и на Фиг. 11D показан правый канал смешанного сигнала.
Двухканальный смешанный сигнал генерируется с помощью смешивания исходных речевых сигналов с равными усилениями в каждом канале и добавления к сигналу белого шума с SNR 10 дБ (K-взвешенного).
Фиг. 12A-C показывает спектральные веса, вычисленные из функции усиления (13). В частности, на Фиг. 12A-C показаны спектральные веса Gc2(m, k; 1, 3) для демонстрации фильтрации PDC, причем на фиг. 12A показаны спектральные веса для входных сигналов без ICTD, PDC отключен; на Фиг. 12B показаны спектральные веса для входных сигналов с ICTD, PDC отключен; и на фиг. 12C показаны спектральные веса для входных сигналов с ICTD, PDC включен.
Спектральные веса на верхнем графике близки к 0 дБ, когда речь активна, и принимают минимальное значение в частотно-временных областях с низким SNR. Второй график показывает спектральные веса для входного сигнала, где первый речевой сигнал (фиг. 11A) смешан с ICTD 26 выборок. Характеристики гребенчатого фильтра показаны на фиг. 12B. На Фиг. 12C показаны спектральные веса при включенном PDC. Артефакты гребенчатой фильтрации в значительной степени снижены, хотя компенсация не является совершенной возле частот режекции 848 Гц и 2544 Гц.
Неформальное прослушивание показывает, что аддитивный шум в значительной степени ослаблен. При обработке сигналов без ICTD выходные сигналы имеют небольшую характеристику фонового звука, которая появляется предположительно из-за фазовой некогерентности за счет введения аддитивного шума. При обработке сигналов с ICTD, если не применяется фильтрация PDC, первый речевой сигнал (фиг. 11A) является в значительной степени ослабленным, и слышны сильные артефакты гребенчатой фильтрации. При дополнительной фильтрации PDC артефакты гребенчатой фильтрации еще немного слышны, но раздражают уже гораздо меньше. Неформальное прослушивание другого материала показывает наличие небольших артефактов, которые могут быть уменьшены либо путем уменьшения γ, путем увеличения β, либо путем добавления на выход масштабированной версии необработанного сигнала. В общем, артефакты менее слышны при ослаблении центрального сигнала и более слышны при выделении центрального сигнала. Искажения восприятия пространственного образа очень малы. Это может быть связано с тем, что спектральные веса одинаковы для всех канальных сигналов и не влияют на ICLD. Артефакты гребенчатой фильтрации едва слышны при обработке естественных записей со стереофонии на основе времени прибытия, для которых понижающее микширование в моно не дает отчетливо слышных артефактов гребенчатой фильтрации. Для фильтрации PDC можно отметить, что малые значения постоянной времени рекурсивного усреднения (в частности, мгновенная компенсация разности фаз при вычислении Xd) обеспечивают когерентность в сигналах, используемых для понижающего микширования. Следовательно, обработка является агностической по отношению к диффузности входного сигнала. При увеличении постоянной времени можно наблюдать, что (1) эффект PDC для входных сигналов уменьшается с уменьшением амплитудно-разностной стереофонии, и (2) эффекты гребенчатой фильтрации становятся более слышимыми на начале нот, когда источники прямого звукового сигнала не выровнены по времени между входными каналами.
Были предоставлены концепции масштабирования центрального сигнала в аудио записях с применением вещественно-значных спектральных весов, которые вычислены с использованием монотонных функций SDR. Обоснованием рассмотренного подхода является то, что при масштабировании центрального сигнала необходимо принимать во внимание как боковое смещение прямых источников, так и величину диффузности, и что эти характеристики неявно учтены в SDR. Обработка может управляться семантически значимыми пользовательскими параметрами и, по сравнению с другими способами, выполняемыми в частотной области, характеризуется низкой вычислительной сложностью и малой загрузкой памяти. Предложенные концепции дают хорошие результаты при обработке входных сигналов с амплитудно-разностной стереофонией, но при этом могут появляться артефакты гребенчатой фильтрации, когда источники прямых звуковых сигналов не выровнены по времени между входными каналами. Первый подход к решению этой проблемы заключается в компенсации ненулевой фазы в межканальной передаточной функции.
До настоящего момента концепции вариантов осуществления тестировались с помощью неформального прослушивания. Для типичных коммерческих записей, эти результаты имеют хорошее качество звука, но также зависят от требуемого уровня разделения.
Хотя некоторые аспекты были описаны в контексте устройства, совершенно ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или компонента соответствующего устройства.
Разложенный в соответствии с изобретением сигнал может быть сохранен на цифровом носителе или может быть передан через среду передачи, такую как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от требований конкретной реализации, варианты осуществления изобретения могут быть реализованы в виде аппаратных средств или в виде программного обеспечения. Такая реализация может быть выполнена с использованием цифрового носителя данных, например, флоппи-диска, DVD, компакт-диска, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем электронно-считываемые сигналы управления, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой так, что выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением включают в себя стабильный во времени носитель данных, имеющий считываемые электронным образом сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой таким образом, что выполняется один из способов, описанных в настоящем документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, причем программный код позволяет осуществить один из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может быть сохранен, например, на машиночитаемом носителе.
Другие варианты осуществления включают в себя компьютерную программу для выполнения одного из способов, описанных в настоящем документе, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа выполняется на компьютере.
Еще один вариант осуществления способов по изобретению представляет собой носитель данных (или цифровой носитель информации или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Еще один вариант осуществления способа по изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через линию связи, например, через Интернет.
Еще один вариант осуществления включает в себя средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью или приспособленное для выполнения одного из описанных в настоящем документе способов.
Еще один вариант осуществления включает в себя компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для выполнения некоторых или всех функций описанных в настоящем документе способов. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Как правило, эти способы предпочтительно выполняются любым аппаратным средством.
Описанные выше варианты осуществления являются иллюстративными для принципов настоящего изобретения. Следует отметить, что модификации, вариации исполнения и детали, описанные в настоящем документе, будут очевидны специалистам в данной области. Таким образом, изобретение ограничено только объемом прилагаемой формулы изобретения, а не конкретными деталями, представленными при описании и объяснении вариантов осуществления в данном документе.
ЛИТЕРАТУРА:
[1]International Telecommunication Union, Radiocomunication Assembly, “Multichannel stereophonic sound system with and without accompanying picture.,” Recommendation ITU-R BS.775-2, 2006, Geneva, Switzerland.
[2]J. Berg and F. Rumsey, “Identification of quality attributes of spatial sound by repertory grid technique,” J. Audio Eng. Soc., vol. 54, pp. 365–379, 2006.
[3]J. Blauert, Spatial Hearing, MIT Press, 1996.
[4]F. Rumsey, “Controlled subjective assessment of two-to-five channel surround sound processing algorithms,” J. Audio Eng. Soc., vol. 47, pp. 563–582, 1999.
[5] H. Fuchs, S. Tuff, and C. Bustad, “Dialogue enhancement - technology and experiments,” EBU Technical Review, vol. Q2, pp. 1–11, 2012.
[6] J.-H. Bach, J. Anemüller, and B. Kollmeier, “Robust speech detection in real acoustic backgrounds with perceptually motivated features,” Speech Communication, vol. 53, pp. 690–706, 2011.
[7] C. Avendano and J.-M. Jot, “A frequency-domain approach to multi-channel upmix,” J. Audio Eng. Soc., vol. 52, 2004.
[8] D. Barry, B. Lawlor, and E. Coyle, “Sound source separation: Azimuth discrimination and resynthesis,” in Proc. Int. Conf. Digital Audio Effects (DAFx), 2004.
[9] E. Vickers, “Two-to-three channel upmix for center channel derivation and speech enhancement,” in Proc. Audio Eng. Soc. 127th Conv., 2009.
[10] D. Jang, J. Hong, H. Jung, and K. Kang, “Center channel separation based on spatial analysis,” in Proc. Int. Conf. Digital Audio Effects (DAFx), 2008.
[11] A. Jourjine, S. Rickard, and O. Yilmaz, “Blind separation of disjoint orthogonal signals: Demixing N sources from 2 mixtures,” in Proc. Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2000.
[12] O. Yilmaz and S. Rickard, “Blind separation of speech mixtures via time-frequency masking,” IEEE Trans. on Signal Proc., vol. 52, pp. 1830–1847, 2004.
[13] S. Rickard, “The DUET blind source separation algorithm,” in Blind Speech Separation, S: Makino, T.-W. Lee, and H. Sawada, Eds. Springer, 2007.
[14] N. Cahill, R. Cooney, K. Humphreys, and R. Lawlor, “Speech source enhancement using a modified ADRess algorithm for applications in mobile communications,” in Proc. Audio Eng. Soc. 121st Conv., 2006.
[15] M. Puigt and Y. Deville, “A time-frequency correlation-based blind source separation method for time-delay mixtures,” in Proc. Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2006.
[16] Simon Arberet, Remi Gribonval, and Frederic Bimbot, “A robust method to count and locate audio sources in a stereophonic linear anechoic micxture,” in Proc. Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2007.
[17] M.I. Mandel, R.J. Weiss, and D.P.W. Ellis, “Model-based expectation-maximization source separation and localization,” IEEE Trans. on Audio, Speech and Language Proc., vol. 18, pp. 382–394, 2010.
[18] H. Viste and G. Evangelista, “On the use of spatial cues to improve binaural source separation,” in Proc. Int. Conf. Digital Audio Effects (DAFx), 2003.
[19] A. Favrot, M. Erne, and C. Faller, “Improved cocktail-party processing,” in Proc. Int. Conf. Digital Audio Effects (DAFx), 2006.
[20] US patent 7,630,500 B1, P.E. Beckmann, 2009.
[21] US patent 7,894,611 B2, P.E. Beckmann, 2011.
[22] J.B. Allen, D.A. Berkeley, and J. Blauert, “Multimicrophone signal-processing technique to remove room reverberation from speech signals,” J. Acoust. Soc. Am., vol. 62, 1977.
[23] J. Merimaa, M. Goodwin, and J.-M. Jot, “Correlation-based ambience extraction from stereo recordings,” in Proc. Audio Eng. Soc. 123rd Conv., 2007.
[24] J. Usher and J. Benesty, “Enhancement of spatial sound quality: A new reverberation-extraction audio upmixer,” IEEE Trans. on Audio, Speech, and Language Processing, vol. 15, pp. 2141–2150, 2007.
[25] C. Faller, “Multiple-loudspeaker playback of stereo signals,” J. Audio Eng. Soc., vol. 54, 2006.
[26] C. Uhle, A. Walther, O. Hellmuth, and J. Herre, “Ambience separation from mono recordings using Non-negative Matrix Factorization,” in Proc. Audio Eng. Soc. 30th Int. Conf., 2007.
[27] C. Uhle and C. Paul, “A supervised learning approach to ambience extraction frommono recordings for blind upmixing,” in Proc. Int. Conf. Digital Audio Effects (DAFx), 2008.
[28] G. Soulodre, “System for extracting and changing the reverberant content of an audio input signal,” US Patent 8,036,767, Oct. 2011.
[29] International Telecommunication Union, Radiocomunication Assembly, “Algorithms to measure audio programme loudness and true-peak audio level,” Recommendation ITUR BS.1770-2, March 2011, Geneva, Switzerland.
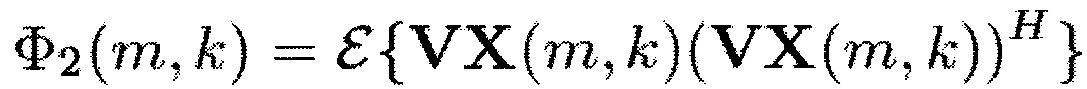
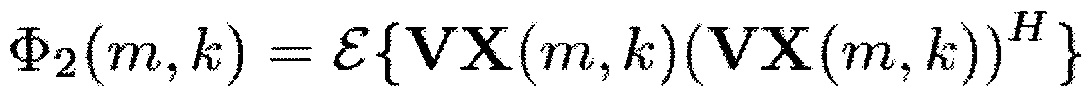
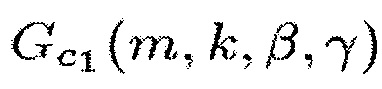
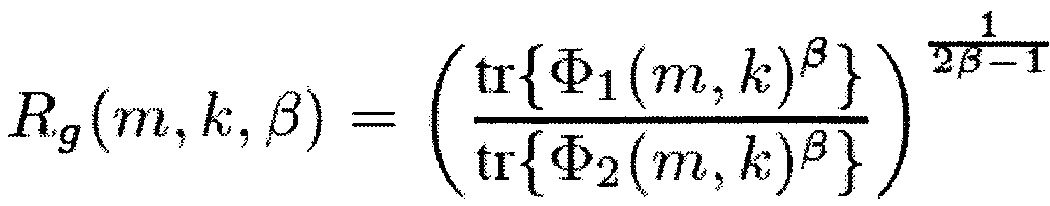
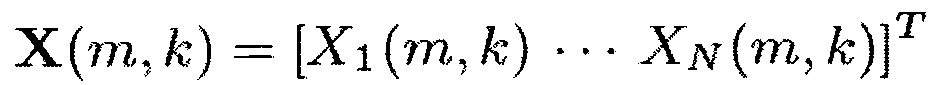
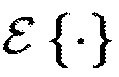

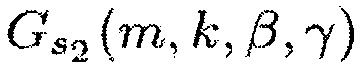
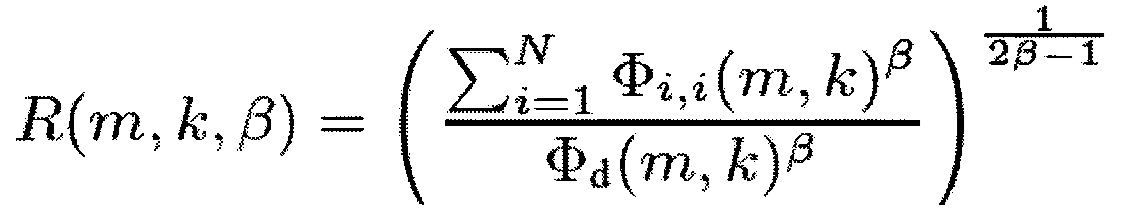
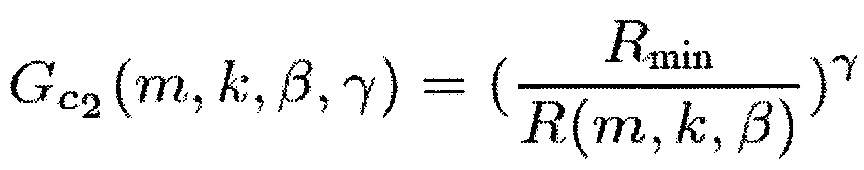
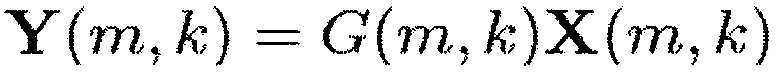
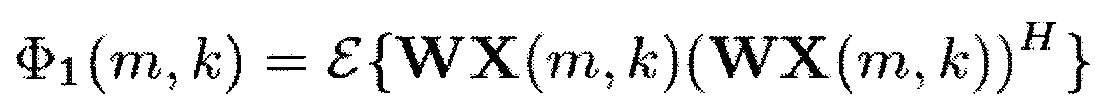
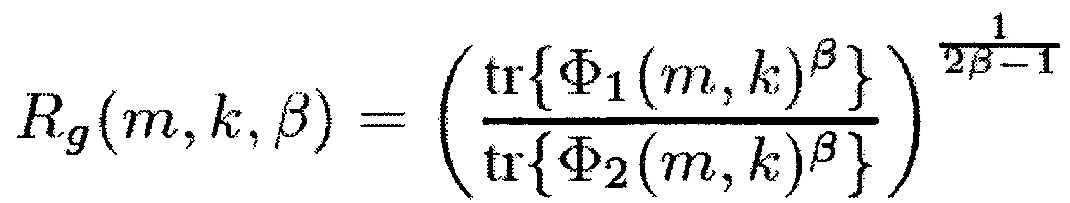
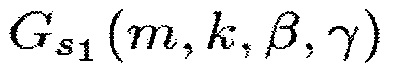
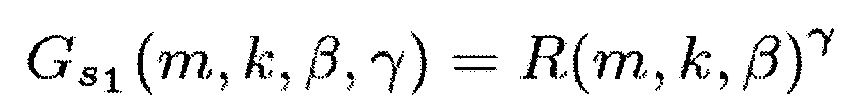
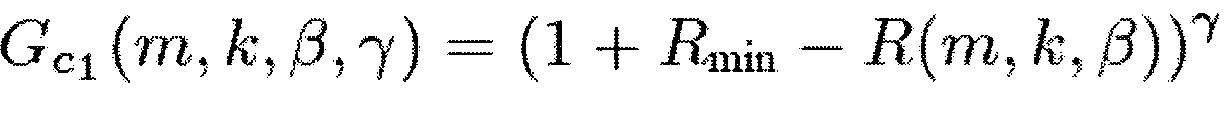

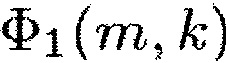

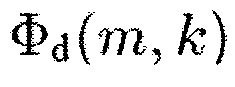
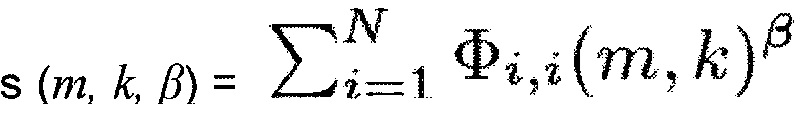

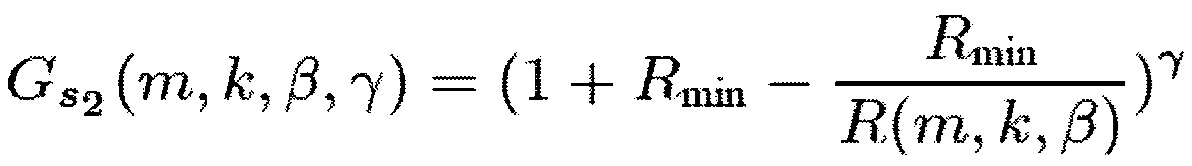
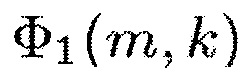
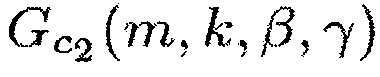
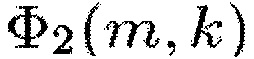
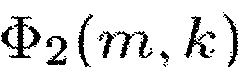

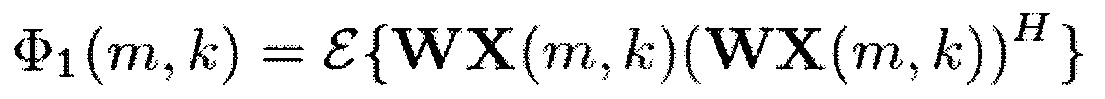
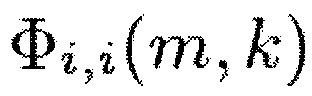
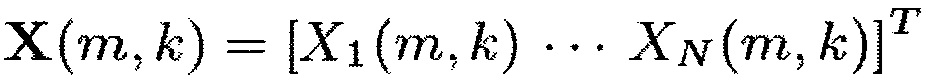
Определение позиции объекта путем восприятия позиционного шаблона с помощью оптического датчика
Способ и устройство для разложения стереофонической записи с использованием обработки в частотной области, применяющей генератор спектральных весов
Декодер и способ многоэкземплярного пространственного кодирования аудиообъектов с применением параметрической концепции для случаев многоканального понижающего микширования/повышающего микширования
Устройство и способ для генерирования расширенного по частоте сигнала, используя временное сглаживание поддиапазонов
Регулировка уровня во временной области для декодирования или кодирования аудиосигналов
Устройство и способ для совмещения потоков пространственного аудиокодирования на основе геометрии
Устройство и способы для адаптации аудиоинформации при пространственном кодировании аудиообъектов
Устройство и способ для кодирования и декодирования кодированного аудиосигнала с использованием временного формирования шума/наложений
Устройство и способ для воспроизведения аудиосигнала, устройство и способ для генерирования кодированного аудиосигнала, компьютерная программа и кодированный аудиосигнал
Устройство и способ для формирования сигнала с расширенной полосой пропускания из аудиосигнала с ограниченной полосой пропускания
Устройство адаптивного фильтра в частотной области с делением на блоки, содержащие модули адаптации и модули коррекции
Устройство и способ регулировки уровня громкости
Устройство и способ обработки стереофонических сигналов для воспроизведения в автомобилях для достижения отдельного трехмерного звука посредством передних громкоговорителей
Устройство и способ для обеспечения индивидуальных звуковых зон
Устройство для определения информации о подобии, способ для определения информации о подобии, устройство для определения информации автокорреляции, устройство для определения информации о взаимной корреляции и компьютерная программа

