Результат интеллектуальной деятельности: ЗВЕНО СВЯЗИ МНОГОКРИСТАЛЬНОЙ ИНТЕГРАЛЬНОЙ СХЕМЫ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее раскрытие относится к компьютерной системе и, в частности (но не исключительно), к межсоединениям типа "точка-точка".
Уровень техники
Прогресс в области технологии полупроводников и разработки логических схем позволил увеличить количество логических элементов, которые могут присутствовать в устройствах интегральных схем. Как следствие, конфигурации компьютерных систем прошли эволюцию от одиночных или многочисленных интегральных схем в системе до многоядерного, многоцепочечного аппаратурного обеспечения и многочисленных логических процессоров, присутствующих в индивидуальных интегральных схемах, а также других интерфейсов, интегрированных внутри таких процессоров. Процессор или интегральная схема обычно содержит одиночный кристалл физического процессора, где кристалл процессора может содержать множество ядер, цепочек аппаратурного обеспечения, логических процессоров, интерфейсов, памяти, концентраторов контроллеров и т.д.
В результате повышения возможности размещения большей вычислительной мощности в меньших корпусах интегральных схем, возросла популярность малогабаритных компьютерных устройств. Количество смартфонов, планшетов, ультратонких ноутбуков и другого оборудования пользователя возросло экспоненциально. Однако, такие более малогабаритные устройства опираются на серверы как для хранения данных, так и для сложной обработки, которая превышает форм-фактор. Следовательно, спрос на компьютерном рынке на высокопроизводительные устройства (то есть, на серверное пространство) также вырос. Например, в модемных серверах обычно существует не только одиночный процессор с множеством ядер, но также и многочисленные физические процессоры (также упоминаемые как многочисленные сокеты), чтобы повысить вычислительную мощность. Но поскольку вычислительная мощность растет вместе с ростом количества устройств в компьютерной системе, связь между сокетами и другими устройствами становится более критичной.
Фактически, межсоединения выросли из более традиционных многоточечных шин, которые имеют дело прежде всего с электрическими соединениям, чтобы полностью развивать архитектуры межсоединений, облегчающих быстрое соединение. К сожалению, поскольку потребность в будущих процессорах растет с более высокими скоростями, соответствующие потребности накладываются на возможности существующих архитектур межсоединений.
Краткое описание чертежей
Фиг. 1 - вариант осуществления компьютерной системы, содержащей архитектуру межсоединений.
Фиг. 2 - вариант осуществления архитектуры межсоединений, содержащей многоуровневый набор.
Фиг. 3 - вариант осуществления запроса или пакета, который должен формироваться или приниматься в рамках архитектуры межсоединений.
Фиг. 4 - вариант осуществления пары передатчика и приемника для архитектуры межсоединений.
Фиг. 5 - вариант осуществления многокристального корпуса интегральной схемы.
Фиг. 6 - упрощенная блок-схема звена связи многокристального корпуса интегральной схемы (MCPL).
Фиг. 7 - пример сигнализации в примерной MCPL.
Фиг. 8 - упрощенная блок-схема дорожки для передачи данных в примерной MCPL.
Фиг. 9 - упрощенная блок-схема примерных технологий подавления перекрестных помех в варианте осуществления MCPL.
Фиг. 10 - упрощенная схема примерных компонент подавления перекрестных помех в варианте осуществления MCPL.
Фиг. 11 - упрощенная блок-схема MCPL.
Фиг. 12 - упрощенная блок-схема MCPL, взаимодействующей с логикой верхнего уровня по многочисленным протоколам, использующим логический интерфейс PHY (LPIF).
Фиг. 13 - пример сигнализации примерной MCPL в сочетании с восстановлением звена связи.
Фиг. 14А-14С - примерные битовые отображения данных на дорожках примерной MCPL.
Фиг. 15 - участок примерного конечного автомата звена связи.
Фиг. 16 - поток, связанный с примерной центровкой звена связи.
Фиг. 17 - примерный конечный автомат звена связи.
Фиг. 18 - сигнализация для ввода состояния низкого энергопотребления.
Фиг. 19 - вариант осуществления блок-схемы компьютерной системы, содержащей многоядерный процессор.
Фиг. 20 - другой вариант осуществления блок-схемы компьютерной системы, содержащей многоядерный процессор.
Фиг. 21 - вариант осуществления блок-схемы процессора.
Фиг. 22 - другой вариант осуществления блок-схемы компьютерной системы, содержащей процессор.
Фиг. 23 - вариант осуществления блока компьютерной системы, содержащей многочисленные процессоры.
Фиг. 24 - примерная система, реализуемая как система на чипе (SoC).
Схожие ссылочные номера и обозначения на различных чертежах указывают схожие элементы.
Подробное описание
В последующем описании излагаются многочисленные конкретные подробности, такие как примеры конкретных типов процессоров и системных конфигураций, конкретного аппаратурного обеспечения, конкретных архитектурных и микроархитектурных подробностей, конкретных конфигураций регистров, конкретных типов команд, конкретных системных компонент, конкретных результатов измерений/максимумов, конкретных стадий и работы процессорного конвейера и т.д., чтобы обеспечить полное понимание настоящего изобретения. Специалистам в данной области техники должно быть, однако, очевидным, что эти конкретные подробности нет необходимости использовать для практической реализации настоящего изобретения. В других случаях, известные компоненты или способы, такие как конкретные и альтернативные архитектуры процессоров, конкретные логические схемы/управляющие программы для описанных алгоритмов, конкретная встроенная управляющая программа, конкретная взаимосвязанная операция, конкретные логические конфигурации, конкретные производственные технологии и материалы, конкретные реализации компиляторов, конкретное выражение алгоритмов в управляющей программе, конкретные технологии/логика отключения электропитания и стробирования и другие конкретные операционные подробности компьютерной системы не были описаны подробно, чтобы избежать излишнего запутывания настоящего изобретения.
Хотя последующие варианты осуществления могут быть описаны со ссылкой на энергосбережение и эффективность использования энергии в конкретных интегральных схемах, таких как компьютерные платформы или микропроцессоры, к другим типам интегральных схем и логических устройств применимы другие варианты осуществления. Схожие технологии и принципы вариантов осуществления, описанные здесь, могут быть применены к другим типам схем или полупроводниковых устройств, которые также могут извлечь выгоду из улучшенного использования энергии и энергосбережения. Например, раскрытые варианты осуществления не ограничиваются настольными компьютерными системами или Ultrabooks™. Они могут также использоваться в других устройствах, таких как карманные устройства, планшеты, другие тонкие ноутбуки, устройства с системами на чипе (SOC) и встраиваемые применения. К некоторым примерам карманных устройств относятся сотовые телефоны, устройства, работающие по интернет-протоколу, цифровые фотоаппараты, персональные цифровые секретари (PDA) и карманные персональные компьютеры. Встраиваемые применения обычно содержат микроконтроллер, цифровой сигнальный процессор (DSP), систему на чипе, сетевые компьютеры (NetPC), цифровые приемники, сетевые концентраторы, переключатели глобальной сети (WAN) или любую другую систему, способную выполнять представленные ниже функции и операции. Кроме того, описанные здесь устройство, способы, и системы не ограничивается физическими компьютерными устройствами, а могут также относиться к оптимизации программного обеспечения для энергосбережения и эффективности использования электропитания. Как станет совершенно очевидным в приведенном ниже описании, описанные здесь варианты осуществления способов, устройств и систем (неважно, со ссылкой на аппаратурные средства, встроенное программное обеспечение, программное обеспечение или их комбинации), являются жизненно важными для будущей "зеленой технологии", сбалансированной с требуемыми рабочими характеристиками.
По мере прогресса компьютерных систем, содержащиеся в них компоненты становятся все более сложными. В результате сложность архитектуры межсоединений и связей между компонентами также возрастает, чтобы обеспечить удовлетворение требований к ширине полосы для оптимальной работы составляющих компонент. Дополнительно, различные сегменты рынка требуют различных вариантов архитектур межсоединений для удовлетворения потребностей рынка. Например, серверы требуют более высокопроизводительных рабочих характеристик, тогда как мобильная экосистема иногда способна пожертвовать общей производительностью в целях экономии электропитания. К тому же, единственной целью большинства связных структур является обеспечение максимально возможных рабочих характеристик при максимальной экономии потребляемой мощности. Ниже обсуждается множество межсоединений, которые потенциально могут извлечь выгоду из описанных здесь вариантов изобретения.
Одна из связных архитектур межсоединений содержит экспресс-архитектуру межсоединений периферийных компонент (Peripheral Component Interconnect (PCI) Express (PCIe)). Первичная цель PCIe состоит в том, чтобы позволить компонентам и устройствам, получаемым от различных поставщиков, взаимодействовать в открытой архитектуре, перекрывая многочисленные сегменты рынка: клиенты (настольные и мобильные компьютеры), серверы (стандартные и внутренние предприятий) и встроенные устройства и устройства связи. PCI Express является высокопроизводительным межсоединением ввода-вывода общего назначения, предназначенным для широкого разнообразия будущих компьютерных и связных платформ. Некоторые атрибуты PCI, такие как модель использования, архитектура загрузки и хранения и интерфейсы программного обеспечения поддерживались во всех версиях, хотя предшествующие реализации с параллельной шиной были заменены хорошо масштабируемым, полностью последовательным интерфейсом. Более свежие версии PCI Express обладают преимуществом перспективы для соединений "точка-точка", технологии на основе переключений и пакетированного протокола, чтобы предоставить новые уровни рабочих характеристик и функций. Управление электропитанием, Power Management (управление электропитанием), Quality Of Service (QoS) (качество обслуживания), поддержка Hot-Plug/Hot-Swap ("горячего" подключения/"горячей" замены), Data Integrity (целостность данных) и Error Handling (обработка ошибок) являются лишь некоторыми из перспективных функций, поддерживаемых PCI Express.
На фиг. 1 показан вариант осуществления связной структуры, состоящей из звеньев связи "точка-точка", которые связывают между собой набор компонент. Система 100 содержит процессор 105 и системную память 110, связанные с концентратором 115 контроллера. Процессор 105 содержит любой элемент обработки, такой как микропроцессор, ведущий процессор, встроенный процессор, сопроцессор или другой процессор. Процессор 105 соединяется с концентратором 115 контроллера через шину внешнего интерфейса (FSB) 106. В одном из вариантов осуществления FSB 106 является последовательным межсоединением "точка-точка", как описано ниже. В другом варианте осуществления, линия 106 звена связи содержит архитектуру последовательных дифференциальных межсоединений, совместимую с различными стандартами межсоединений.
Системная память 110 содержит любое устройство памяти, такое как оперативная память (RAM), энергонезависимая память (NV) или другая память, доступная устройствам в системе 100. Системная память 110 соединяется с концентратором 115 контроллера через интерфейс 116 памяти. Примерами интерфейса памяти являются интерфейс памяти с двойной скоростью передачи данных (DDR), двухканальный интерфейс памяти DDR и интерфейс динамической памяти RAM (DRAM).
В одном из вариантов осуществления концентратор 115 контроллера является корневым концентратором, корневым комплексом или корневым контроллером в иерархии межсоединений для экспресс-межсоединений периферийных компонент (PCIe или PCIE). Примерами концентратора 115 контроллера являются чипсет, концентратор контроллера памяти (МСН), северный мост, концентратор контроллера межсоединений (ICH), южный мост и корневой контроллер/концентратор. Часто термин "чипсет" относится к двум физически раздельным концентраторам контроллеров, то есть, к концентратору контроллера памяти (МСН), связанному с концентратором контроллера межсоединений (ICH). Заметим, что существующие системы часто содержат МСН, интегрированный с процессором 105, тогда как контроллер 115 должен осуществлять связь с устройствами ввода-вывода способом, подобным описанному ниже. В некоторых вариантах осуществления, как вариант, дополнительно поддерживается одноранговая маршрутизация через корневой комплекс 115.
Здесь концентратор 115 контроллера связывается с переключателем/мостом 120 через последовательное звено 119 связи. Модули 117 и 121 ввода-вывода, которые могут также упоминаться как интерфейсы/порты 117 и 121, содержат/осуществляют стек многоуровневого протокола, чтобы обеспечивать передачу между концентратором контроллера 115 и переключателем 120. В одном из вариантов осуществления с переключателем 120 способны связываться многочисленные устройства.
Переключатель/мост 120 маршрутизирует пакеты/сообщения от устройства 125 по восходящий линии, то есть, вверх по иерархии в направлении корневого комплекса к концентратору 115 контроллера, и по нисходящей линии, то есть, вниз по иерархии в направлении от корневого контроллера корня, от процессора 105 или системной памяти 110 к устройству 125. Выключатель 120 в одном из вариантов осуществления относится к логической сборке многочисленных виртуальных устройств мостов типа "от PCI к PCI". Устройство 125 содержит любое внутреннее или внешнее устройство или компонент, которые должны связываться с электронной системой, такой как устройство ввода-вывода, контроллер сетевого интерфейса (NIC), расширительная плата, аудиопроцессор, сетевой процессор, жесткий диск, запоминающее устройство, ROM на CD/DVD, монитор, принтер, "мышь", клавиатура, маршрутизатор, мобильное запоминающее устройство, устройство Firewire, устройство универсальной последовательной шины (USB), сканер и другие устройства ввода-вывода. Часто на жаргоне PCIe устройство упоминается как конечная точка. Хотя это специально не показано, устройство 125 может содержать PCIe к мосту PCI/PCI-X, чтобы поддерживать устройства PCI действующей или другой версии. Устройства конечной точки в PCIe часто классифицируются как действующие, PCIe или интегрированные конечные точки корневого комплекса.
Графический ускоритель 130 также связывается с концентратором 115 контроллера через последовательную линию 132 связи. В одном из вариантов осуществления графический ускоритель 130 связывается с МСН, который связывается с ICH. Переключатель 120 и, соответственно, устройство 125 ввода-вывода затем связывается с ICH. Модули 131 и 118 ввода-вывода должны также реализовывать стек многоуровневого протокола, чтобы осуществлять связь между графическим ускорителем 130 и концентратором 115 контроллера. Подобно МСН, обсуждавшемуся выше, графический контроллер или графический ускоритель 130 сам по себе может интегрироваться в процессор 105.
На фиг. 2 показан вариант осуществления стека многоуровневого протокола. Стек 200 многоуровневого протокола содержит любую форму стека многоуровневой связи, такую как стек Quick Path Interconnect (QPI), стек PCIe, стек высокопроизводительных компьютерных межсоединений или другой многоуровневый стек. Хотя обсуждение далее на фиг. 1-4 делает ссылку только на стек PCIe, те же самые концепции могут быть применены к другим стекам межсоединений. В одном из вариантов осуществления стек 200 является стеком протокола PCIe, содержащим уровень 205 транзакции, уровень 210 звена связи для передачи данных и физический уровень 220. Интерфейс, такой как интерфейс 117, 118, 121, 122, 126 и 131 на фиг. 1, может быть представлен как стек 200 протокола связи. Представление в виде стека протокола связи может также упоминаться как модуль или интерфейс, осуществляющий/содержащий стек протокола.
PCI Express использует пакеты для передачи информации между компонентами. Пакеты формируются на уровне 205 транзакции и на уровне 210 звена передачи данных, чтобы переносить информацию от передающего компонента к приемному компоненту. По мере того, как переданные пакеты проходят через другие уровни, они обогащаются дополнительной информацией, необходимой для обработки пакетов на этих уровнях. На приемной стороне происходит обратный процесс и пакеты получают преобразованными из их представления на физическом уровне 220 в представление на уровне звена 210 связи для передачи данных и, окончательно, (для пакетов уровня транзакции) в форму, которая может обрабатываться на уровне 205 транзакции приемного устройства.
Уровень транзакции
В одном из вариантов осуществления уровень 205 транзакции должен обеспечивать интерфейс между ядром обработки устройства и межсоединительной архитектурой, такой как уровень 210 звена связи для передачи данных и физический уровень 220. В этом отношении первичная ответственность уровня 205 транзакции заключается в сборке и разборке пакетов (то есть, пакетов уровня транзакции или TLP). Уровень 205 трансляции обычно руководит управлением потока кредит-база для TLP. PCIe осуществляет транзакции с разделением, то есть, транзакции с запросом и ответом, разделенными во времени, позволяя звену связи в то время, когда целевое устройство собирает данные для ответа, передавать другой трафик.
Кроме того, PCIe использует управлением потоком кредит-база. В этой схеме устройство рекламирует начальный объем кредита для каждого из приемных буферов на уровне 205 транзакции. Внешнее устройство на противоположном конце линии связи, такое как концентратор 115 контроллера, показанный на фиг. 1, подсчитывает количество кредитов, использованных каждым TLP. Транзакция может передаваться, если транзакция не превышает кредитный лимит. После получения ответа объем кредита восстанавливается. Преимущество кредитной схемы состоит в том, что время ожидания возврата кредита не влияет на рабочие характеристики при условии, что не возникает кредитный лимит.
В одном из вариантов осуществления четыре адресных пространства транзакции содержат адресное пространство конфигурации, адресное пространство памяти, адресное пространство ввода/вывода и адресное пространство сообщения. Транзакции пространства памяти содержат один или более запросов считывания и запросов записи, чтобы передавать данные в местоположение отображенной памяти и от него. В одном из вариантов осуществления транзакции пространства памяти способны использовать два различных адресных формата, например, формат короткого адреса, такой как 32-разрядный адрес, или формат длинного адреса, такой как 64-разрядный адрес. Транзакции пространства конфигурации используются для доступа к пространству конфигурации устройств PCIe. Транзакции в пространстве конфигурации содержат запросы считывания и запросы записи. Транзакции пространства сообщения (или, просто сообщения) определяются для поддержки внутриполосной передачи между средствами PCIe.
Поэтому в одном из вариантов осуществления, уровень 205 транзакции собирает заголовок/полезную нагрузку пакета 206. Формат для текущего заголовка/полезной нагрузки пакета может быть найден в технических требованиях PCIe на веб-сайте технических требований PCIe.
Сразу обращаемся к фиг. 3, где показан вариант осуществления дескриптора транзакции PCIe. В одном из вариантов осуществления дескриптор 300 транзакции является механизмом переноса информацию о транзакции. В этом отношении дескриптор 300 транзакции поддерживает идентификацию транзакции в системе. Другое потенциальное использование содержит модификации слежения за упорядочиванием транзакции по умолчанию и ассоциации транзакции с каналами.
Дескриптор 300 транзакции содержит поле 302 глобального идентификатора, поле 304 атрибутов и поле 306 идентификатора. В показанном примере поле 302 глобального идентификатора изображается содержащим локальное поле 308 идентификатора транзакции и поле 310 идентификатора источника. В одном из вариантов осуществления глобальный идентификатор 302 транзакции является уникальным для всех исходящих запросов.
В соответствии с одной из реализаций, локальное поле 308 идентификатора транзакции является полем, формируемым средством запроса, и оно уникально для всех исходящих запросов, которые требуют завершения для данного запрашивающего средства. Дополнительно, в этом примере, идентификатор 310 источника однозначно идентифицирует средство запросчика внутри иерархии PCIe. Соответственно, вместе с ID 310 источника локальное поле 308 идентификатора транзакции обеспечивает глобальную идентификацию транзакции внутри области иерархии.
Поле 304 атрибутов определяет характеристики и зависимости транзакции. В этом отношении, поле 304 атрибутов потенциально используется для предоставления дополнительной информации, позволяющей модификацию обработки транзакции по умолчанию. В одном из вариантов осуществления поле 304 атрибутов содержит поле 312 приоритетов, зарезервированное поле 314, поле 316 упорядочивания и поле 318 отсутствия перехвата. Здесь субполе 312 приоритета может быть модифицировано инициатором, чтобы назначить приоритет транзакции. Зарезервированное поле 314 атрибутов оставляется зарезервированным на будущее или используется согласно назначению поставщиком. Возможные модели использования, использующие приоритет или атрибуты безопасности, могут реализовываться, используя резервное поле атрибутов.
В этом примере поле 316 атрибутов упорядочивания используется для предоставления дополнительной информации, транспортирующей тип упорядочивания, который может модифицировать правила упорядочивания, действующие по умолчанию. Согласно одной примерной реализации, атрибут "0" упорядочивания обозначает, что должны применяться правила упорядочивания по умолчанию, а атрибут "1" упорядочивания обозначает упрощенное упорядочивание, при котором записи могут пропускаться в одном и том же направлении, а завершения считывания могут пропускать записи в том же самом направлении. Поле 318 атрибута перехвата используется для определения, перехватываются ли транзакции. Как показано на чертеже, поле 306 идентификатора канала идентифицирует канал, с которым связывается транзакция.
Уровень линии связи
Уровень 210 звена связи, также упоминаемый как уровень 210 связи для передачи данных, действует как промежуточный этап между уровнем 205 транзакции и физическим уровнем 220. В одном варианте осуществления ответственность уровня 210 звена связи для передачи данных обеспечивает достоверный механизм для обмена пакетами уровня транзакции (TLP) между двумя компонентами линии связи. Одна сторона уровня 210 звена связи для передачи данных принимает TLP, собранные уровнем 205 транзакции, применяет идентификатор 211 последовательности пакетов, то есть, количество идентификаций или количество пакетов, вычисляет и применяет код обнаружения ошибки, то есть, CRC 212, и представляет модифицированные TLP на физический уровень 220 для передачи через физический уровень на внешнее устройство.
Физический уровень
В одном из вариантов осуществления физический уровень 220 содержит логический субблок 221 и электрический субблок 222, чтобы физически передавать пакет внешнему устройству. Здесь логический субблок 221 ответственен за "цифровые" функции физического уровня 221. В этом отношении, логический субблок содержит секцию передачи для подготовки исходящей информации к передаче физическим субблоком 222 и секцию приемника для идентификации и подготовки принятой информации перед пропусканием ее на уровень 210 звена связи.
Физический блок 222 содержит передатчик и приемник. Передатчик снабжен логическим субблоком 221 с символами, которые передатчик переводит в последовательную форму и передает внешнему устройству. На приемник от внешнего устройства подаются переведенные в последовательную форму символы и приемник преобразует принятые сигналы в битовый поток. Битовый поток переводится обратно из последовательной формы в параллельную и подается на логический субблок 221. В одном из вариантов осуществления используется код передачи 8b/10b, где передаются/принимаются десятиразрядные символы. Здесь, специальные символы используются, чтобы кадрировать пакет с получением кадров 223. Кроме того, в одном из примеров, приемник также обеспечивает тактовые сигналы символов, восстанавливаемые из входящего последовательного потока.
Как указано выше, хотя уровень 205 транзакции, уровень 210 звена связи и физический уровень 220 обсуждаются со ссылкой на конкретный вариант осуществления стека протокола PCIe, стек многоуровневого протокола этим не ограничивается. Фактически, может присутствовать/осуществляться любой многоуровневый протокол. Как пример, порт/интерфейс, который представляется в качестве многоуровневого протокола, содержит: (1) первый уровень, на котором собираются пакеты, то есть, уровень транзакции; второй уровень, на котором устанавливается последовательная форма пакетов, то есть, звена связи; и третий уровень для передачи пакетов, то есть, физический уровень. В качестве конкретного примера, используется многоуровневый протокол интерфейса по общепринятому стандарту (common standard interface, CSI).
Далее на фиг. 4 показан вариант осуществления последовательной связной структуры PCIe типа "точка-точка". Хотя на чертеже показан вариант осуществления последовательной линии связи PCIe типа "точка-точка", последовательное звено связи типа "точка-точка" этим не ограничивается, поскольку оно содержит любой путь передачи сигнала для передачи последовательных данных. В показанном варианте осуществления основное звено связи PCIe содержит две низковольтные, дифференцированно запускаемые сигнальные пары: передающая пара 406/411 и приемная пара 412/407. Соответственно, устройство 405 содержит передающую логику 406 для передачи данных на устройство 410 и приемную логику 407 для приема данных от устройства 410. Другими словами, в звене связи PCIe содержатся два пути передачи, то есть, пути 416 и 417, и два пути приема, то есть, пути 418 и 419.
Термин "путь передачи" относится к любому пути передачи данных, такому как линия передачи, медная линия, оптическая линия, канал беспроводной связи, линия инфракрасной связи или другой канал связи. Соединение между двумя устройствами, такими как устройство 405 и устройство 410, упоминается как звено связи, такое как звено 415 связи. Звено связи может поддерживать одну дорожку - каждая дорожка представляет набор дифференциальных сигнальных пар (одна пара для передачи, одна пара для приема). Чтобы определить ширину полосы пропускания, звено связи может объединять множество дорожек, обозначенные как xN, где N - любая поддерживаемая ширина звена связи, такая как 1, 2, 4, 8, 12, 16, 32, 64 или шире.
Термин "дифференциальная пара" относится к двум путям передачи, таким как линии 416 и 417, для передачи дифференциальных сигналов. Как пример, когда линия 416 переключается с низковольтного уровня на высоковольтный уровень, то есть, формируется нарастающий фронт, линия 417 переключается с высокого логического уровня на низкий логический уровень, то есть, формируется ниспадающий фронт. Дифференциальные сигналы потенциально демонстрируют лучшие электрические характеристики, такие как лучшая целостность сигнала, то есть, перекрестная связь, положительный/отрицательный выброс напряжения, звон и т.д. Это позволяет получить лучшее временное окно, дающее возможность более высоких частот передачи.
На фиг. 5 показана упрощенная блок-схема 500 примерной многокристальной интегральной схемы 505, содержащей два или более чипов или кристаллов, (например, 510, 515) соединенных для осуществления связи, используя примерное звено 520 связи многокристальной интегральной схемы (MCPL). Хотя на фиг. 5 показан пример из двух (или более) кристаллов, которые соединяются, используя примерную MCPL 520, следует понимать, что принципы и функции, описанные здесь в отношении реализаций MCPL, могут применяться среди потенциально возможных других примеров к любому межсоединению или звену связи, соединяющим кристалл (например, 510) и другие компоненты, содержащие два или более кристаллов (например, 510, 515), соединяя кристалл (или чип) с другим, находящимся вне кристалла компонентом, соединяя кристалл с другим устройством или находящимся вне корпуса интегральной схемы кристаллом (например, 505), соединяя кристалл с корпусом BGA интегральной схемы реализуя временное соединение на керамической подложке (POINT),.
Обычно, многокристальная интегральная схема (например, 505) может быть электронной интегральной схемой, где многочисленные интегральные схемы (IC), полупроводниковые кристаллы или другие дискретные компоненты (например, 510, 515) помещены на объединяющую подложку (например, кремниевую или другую полупроводниковую подложку), облегчая использование объединенных компонент в качестве единого компонента (например, как бы большей интегральной схемы). В некоторых случаях крупные компоненты (например, кристаллы 510, 515) сами могут быть системными интегральными схемами, такими как системы на чипе (SoC), многопроцессорные чипы или другие компоненты, которые содержат многочисленные компоненты (например, 525-530 и 540-545) на устройстве, например, на едином кристалле (например, 510, 515). Многокристальные интегральные схемы 505 могут обеспечивать гибкость при построении сложных и изменяемых систем из потенциально возможных многочисленных дискретных компонент и систем. Например, из числа множества примеров, каждый из кристаллов 510, 515 может изготавливаться или как-либо иначе поставляться двумя различными предприятиями, а кремниевая подложка 505 интегральной схемы может обеспечиваться третьим предприятием. Дополнительно, кристаллы и другие компоненты внутри многокристальной интегральной схемы 505 сами могут содержать межсоединение или другие связные структуры (например, 535, 550), обеспечивая инфраструктуру для связи между компонентами (например, 525-530 и 540-545) внутри устройства (например, 510, 515, соответственно). Различные компоненты и межсоединения (например, 535, 550) могут потенциально поддерживать или использовать многие различные протоколы. Дополнительно, связь между кристаллами (например, 510, 515) потенциально может содержать транзакции между различными компонентами на кристаллах по многочисленным различным протоколам. Разработка механизмов обеспечения связи между чипами (или кристаллами) многокристальной интегральной схемы может быть многообещающей, когда традиционные решения, использующие узкоспециализированные, дорогостоящие и специализированные для интегральной схемы решения, основанные на конкретных сочетаниях компонент (и требуемых транзакциях), целесообразны для взаимных соединений.
Примеры, системы, алгоритмы, устройства, логика и функции, описанные в рамках настоящих технических требований могут решать, по меньшей мере, некоторые из идентифицированных выше проблем, потенциально включая и многие другие, неявно упомянутые здесь. Например, в некоторых реализациях могут обеспечиваться широкая полоса пропускания, низкая мощность, интерфейс с малой задержкой, чтобы соединять ведущее устройство (например, центральный процессор) или другое устройство с сопутствующим чипом, который находится в той же самой интегральной схеме, что и ведущее устройство. Такое звено связи многокристальной интегральной схемы (MCPL) может поддерживать многочисленные варианты корпуса интегральной схемы, многочисленные протоколы ввода-вывода, а также характеристики надежности, доступности и удобства обслуживания (RAS). Дополнительно, физический уровень (PHY) может содержать электрический уровень и логический уровень и может поддерживать более протяженные длины каналов, в том числе, длины канала до приблизительно 45 мм, а в некоторых случаях и более. В некоторых реализациях примерная MCPL может работать на высоких скоростях передачи данных, в том числе, на скоростях, превышающих 8-10 Гб/с.
В одной из примерных реализаций MCPL электрический уровень PHY может улучшать традиционные решения многоканальных межсоединений (например, многоканальный ввод-вывод DRAM), увеличивая скорость передачи данных и конфигурацию канала, например, посредством многочисленных функций, таких как, например, среди прочих потенциально возможных примеров, регулируемое окончание промежуточного канала, активное подавление маломощных перекрестных помех, схемная избыточность, коррекция и выравнивание рабочего цикла на каждый бит, линейное кодирование и выравнивание передатчиков.
В одной из примерных реализаций MCPL может быть осуществлен логический уровень PHY, который может дополнительно помочь (например, функции электрического уровня) в повышении скорости передачи данных и расширении конфигурации канала, в то же время также позволяя межсоединение для маршрутизации многочисленных протоколов через электрический уровень. Такие реализации могут обеспечивать и определять модульный общий физический уровень, который является протокольно агностическим и спроектирован для работы с потенциально любым существующим или будущим протоколом межсоединений.
На фиг. 6 представлена упрощенная блок-схема 600, показывающая, по меньшей мере, часть системы, содержащую примерную реализацию звена связи многокристальной интегральной схемы (MCPL). MCPL может быть осуществлена, используя физические электрические соединения (например, провода, реализуемые как дорожки), соединяющие первое устройство 605 (например, первый кристалл, содержащий один или более субкомпонент) со вторым устройством 610 (например, вторым кристаллом, содержащим один или более других субкомпонент). В конкретном примере, показанном на высокоуровневом представлении схемы 600, все сигналы (в каналах 615, 620) могут быть однонаправленными и дорожки могут обеспечиваться для сигналов данных, чтобы иметь как восходящую, так и нисходящую передачу данных. Хотя блок-схема 600 на фиг. 6 относится к первому компоненту 605 как к восходящему компоненту, а ко второму компоненту 610 как к нисходящему компоненту, и физические дорожки MCPL используются при передаче данных в качестве нисходящего канала 615 и используются при приеме данных (от узла 610) в качестве восходящего канала 620, следует понимать, что MCPL между устройствами 605, 610 может использоваться каждым из устройств, чтобы передавать и принимать данные между устройствами.
В одной из примерных реализаций MCPL может обеспечивать физический уровень (PHY), содержащий электрический PHY 625а, b (или, все вместе, 625) MCPL и исполняемую логику, осуществляющую логический PHY 630а, b (или, все вместе, 630) MCPL. Электрический, или физический PHY 625 может обеспечивать физическое соединение, через которое передаются данные между устройствами 605, 610. Компоненты и логика формирования сигнала могут быть осуществлены в сочетании с физическим уровнем PHY 625, чтобы установить для звена связи возможности передачи данных с высокой скоростью и конфигурации канала, которые в некоторых приложениях могут содержать плотно сгруппированные физические соединения на длинах приблизительно 45 мм или более. Логический PHY 630 может содержать логику для облегчения синхронизации, управления состоянием звена связи (например, для уровней 635а, 635b звена связи) и мультиплексирования протокола между потенциально многочисленными различными протоколами, используемые для связи по MCPL.
В одной из примерных реализаций физический PHY 625 может содержать для каждого канала (например, 615, 620) набор дорожек для передачи данных, по которым могут передаваться данные внутри полосы. В этом конкретном примере в каждом восходящем и нисходящем каналах 615, 620 обеспечиваются 50 дорожек для данных, хотя может использоваться и любое другое количество дорожек, разрешенное ограничениями по расположению и энергетике, требуемыми приложениями, ограничениями на устройство и т.д. Каждый канал может дополнительно содержать одну или более выделенных дорожек для строб-сигнала или синхронизации, канального сигнала, одну или более выделенных дорожек для действительного сигнала для канала, одну или более выделенных дорожек для потокового сигнала и одну или более выделенных дорожек для управления конечным автоматом звена связи или сигналом боковой полосы. В числе других примеров, физический PHY может дополнительно содержать звено 640 связи боковой полосы, которое в некоторых примерах может быть двунаправленным более низкочастотным звеном связи управляющего сигнала, используемым для координации переходных состояний и других атрибутов MCPL, соединяющей устройства 605, 610.
Как отмечено выше, многочисленные протоколы могут поддерживаться, используя реализацию MCPL. Конечно, многочисленные, независимые уровни 650а, 650b транзакции могут обеспечиваться в каждом устройстве 605, 610. Например, каждое устройство 605, 610, среди прочих, может поддерживать и использовать два или более протоколов, таких как PCI, PCIe, QPI, Intel In-Die Interconnect (IDI). IDI является когерентным протоколом, используемый на кристалле для связи между ядрами, кэшами последнего уровня (Last Level Caches (LLC)), памятью, графикой и контроллерами ввода-вывода. Другие протоколы могут также поддерживаться, в том числе протокол Ethernet, протоколы Infiniband и другие протоколы на основе связной структуры PCIe. Среди других примеров, также может использоваться объединение логического PHY и физического PHY в качестве межсоединения "кристалл-кристалл", чтобы соединить SerDes PHY (PCIe, Ethernet, Infiniband или другой высокоскоростной SerDes) на одном кристалле с его верхними уровнями, которые осуществляются на другом кристалле.
Логический PHY 630 может поддерживать мультиплексирование между этими многочисленными протоколами на MCPL. Например, выделенная дорожка для потока может использоваться для подтверждения кодированного потокового сигнала, который идентифицирует, какой протокол должен примениться к данным, переданным, по существу, одновременно по дорожкам для данных канала. Дополнительно, логический PHY 630 может использоваться, чтобы согласовать различные типы изменений переходных состояний звена связи, которые различные протоколы могут поддерживать или запрашивать. В некоторых случаях, сигналы LSMSB, переданные по выделенному дорожке LSMSB канала, могут использоваться вместе со звеном 640 связи боковой полосы, чтобы передать и согласовать переходные состояния звена связи между устройствами 605, 610. Дополнительно, настройка звена связи, обнаружение ошибок, обнаружение искажений, устранение искажений и другие функциональные возможности традиционных межсоединений могут заменяться или управляться, частично используя логический PHY 630. Например, действительные сигналы, переданные по одной или более выделенным дорожкам для действительного сигнала в каждом канале, помимо других примеров, могут использоваться для сигнализации о деятельности звена связи, обнаружения искажения, ошибок звена связи и реализации других функций. В частном примере на фиг. 6, многочисленные дорожки для действительного сигнала обеспечиваются по каждому каналу. Например, дорожки для данных внутри канала могут быть связаны или кластеризованы (физически и/или логически), и дорожка для действительного сигнала может обеспечиваться для каждой группы. Дополнительно, в качестве других примеров могут обеспечиваться многочисленные стробируемые дорожки, в некоторых случаях, также чтобы обеспечить выделенный стробированный сигнал для каждого кластера во множестве кластеров дорожек для данных в канале.
Как отмечено выше, логический PHY 630 может использоваться для согласования и управления сигналами управления звена связи, передаваемыми между устройствами, соединенными посредством MCPL. В некоторых реализациях логический PHY 630 может содержать логику 660 формирования пакетов уровня звена (LLP) связи, которая может использоваться для передачи сообщений управления на уровне звена связи через MCPL (то есть, в полосе). Такие сообщения могут передаваться по дорожкам данных канала, с помощью дорожки потокового сигнала, идентифицирующего, что данные являются сообщениями типа "уровень звена-уровень звена", такими, как, например, данные управления уровня звена связи. Сообщения уровня звена связи, позволяющие использовать модуль 660 LLP, помимо других функций уровня звена связи, могут помочь при согласовании и выполнении передачи состояний уровня звена связи, управлении электропитанием, закольцовывании, запрете, повторной центровке, скремблировании между уровнями 635а, 635b звена связи устройств 605, 610, соответственно.
На фиг. 7 показана схема 700, представляющая примерную передачу сигналов, используя набор дорожек (например, 615, 620) в конкретном канале примерной MCPL. В примере на фиг. 7 два кластера из двадцати пяти (25) дорожек для данных обеспечиваются для пятидесяти (50) общих дорожек для передачи данных в канале. На чертеже показана часть дорожек, тогда как другие (например, DATA [4-46] и вторая дорожка строб-сигнала (STRB)) для удобства показа конкретного примера не показаны (например, такие как сигналы с избыточностью). Когда физический уровень находится в активном состоянии (например, электропитание не выключено или находится в режиме низкого потребления (например, в состоянии L1)), дорожки строб-сигнала (STRB) могут сопровождаться синхронным тактовым сигналом. В некоторых реализациях данные могут передаваться как на нарастающем фронте, так и на ниспадающем фронте строб-сигнала. Каждый фронт (или половина тактового цикла) может устанавливать границу единичного интервала (UI). Соответственно, в этом примере, бит (например, 705), может передаваться по каждому дорожке, позволяя передавать байт каждые 8UI. Период 710 времени байта может быть определен как 8UI или время для передачи байта по одиночной дорожке из числа дорожек для данных (например, DATA [0-49]).
В некоторых реализациях действительный сигнал, переданный по одному или более выделенным действительным сигнальным каналам (например, VALIDO, VALID1), может служить опережающим индикатором для приемного устройства, чтобы идентифицировать, когда подтверждается (высокий уровень), для приемного устройства или приемника, что в течение следующего периода времени, такого период 710 времени байта, данные передаются от передающего устройства или источника по дорожкам для данных (например, DATA[0-49]). Альтернативно, когда действительный сигнал имеет низкий уровень, источник указывает приемнику, что приемник не должен передавать данные по дорожкам для данных в течение следующего периода времени. Соответственно, когда логический PHY приемника обнаруживает, что действительный сигнал не подтвержден (например, на дорожках VALID0 и VALID1), приемник может игнорировать любые данные, которые обнаруживаются на дорожках для данных (например, DATA [0-49]) во время следующего периода времени. Например, шум перекрестных помех или другие биты могут появляться на одной или более дорожках для данных, когда источник, в действительности, не передает данных. На основании действительного сигнала низкого уровня или неподтвержденного в течение предыдущего периода времени (например, периода времени предыдущего байта), приемник может решить, что в течение последующего периода времени дорожки для данных должны игнорироваться.
Данные, переданные по каждой из дорожек MCPL, могут быть строго выровнены со строб-сигналом. Период времени может быть определен, основываясь на строб-сигнале, таком как период времени байта, и каждый из этих периодов может соответствовать определенному окну, в котором сигналы должны передаваться по дорожкам для данных (например, DATA[0-49]), дорожкам для действительного сигнала (например, VALID1, VALID2) и дорожке для потокового сигнала (например, STREAM). Соответственно, выравнивание этих сигналов может позволить идентификацию, что действительный сигнал в предыдущем окне периода времени применяется к данным в последующем окне периода времени, и что потоковый сигнал применяется к данным в том же самом окне периода времени. Потоковый сигнал может быть кодированным сигналом (например, 1 байтом данных для окна периода времени байта), который кодируется, чтобы идентифицировать протокол, применяемый к данным, передаваемым во время того же самого окна периода времени.
Для иллюстрации, в конкретном примере на фиг. 7 определено окно периода времени байта. Действительный сигнал подтверждается в окне n (715) периода времени перед тем, как какие-либо данные будут введены в дорожки для данных DATA[0-49]. В следующем окне n+1 (720) периода времени данные передаются по меньшей мере по некоторым из дорожек для данных. В данном случае, данные передаются по всем пятидесяти дорожкам для данных в течение времени n+1 (720). Поскольку действительный сигнал был подтверждена для длительности предыдущего окна n (715) периода времени, устройство приемника может проверить данных, принятые по дорожкам для данных DATA[0-49] во время окна n+1 (720) периода времени. Дополнительно, опережающий характер действительного сигнала во время окна n (715) периода времени позволяет приемному устройству подготовиться к входящим данным. Продолжая пример на фиг. 7, действительный сигнал остается подтвержденным (на VALID1 и VALID2) в течение длительности окна n+1 (720) периода времени, заставляя устройство приемника ожидать данные, переданные по дорожкам для данных DATA[0-49] во время окна n+2 (725) периода времени. Если действительный сигнал будет оставаться подтвержденным в течение окна n+2 (725) периода времени, устройство приемника может дополнительно ожидать приема (и обработки) дополнительных данных, передаваемых сразу после окна n+3 (730) периода времени. В примере, показанном на фиг. 7, однако, подтверждение действительного сигнала снимается в течение длительности окна n+2 (725) периода времени, указывая устройству приемника, что никакие данные не будут передаваться в течение окна n+3 (730) периода времени и что любые биты, обнаруженные на дорожках для данных DATA[0-49] в течение окна n+3 (730) периода времени должны игнорироваться.
Как отмечено выше, для каждого канала могут поддерживаться многочисленные действительные дорожки и дорожки строб-сигнала. Помимо прочих преимуществ, при сохранении простоты схемы и синхронизации среди кластеров это может помочь в части относительно длинных физических дорожек, соединяющих два устройства. В некоторых реализациях набор дорожек для данных может быть объединен кластеры дорожек для данных. Например, в примере, показанном на фиг. 7, дорожки для данных DATA[0-49] могут быть объединены в два кластера по двадцать пять дорожек и каждый кластер может иметь выделенную дорожку для действительного сигнала и стробируемого сигнала. Например, дорожка для действительного сигнала VALID1 может быть связана с дорожками для данных DATA[0-24], а дорожка для действительного сигнала VALID2 может быть связана с дорожкой для данных DATA[25-49]. Сигналы на каждой "копии" действительных дорожек и дорожек для строб-сигнала для каждого кластера могут быть идентичными.
Как описано выше, данные STREAM на дорожке для потокового сигнала могут использоваться для указания принимающему логическому PHY, какой протокол должен применяться к соответствующим данным, передаваемым по дорожкам для данных DATA[0-49]. В примере на фиг. 7 потоковый сигнал передается по STREAM в течение того же самого окна периода времени, что и данные по дорожкам для данных DATA[0-49], чтобы указать протокол данных для дорожек для данных. В альтернативных реализациях, помимо других потенциальных изменений, потоковый сигнал может передаваться в течение предыдущего окна такого периода времени, как для соответствующих действительных сигналов. Однако, продолжая пример на фиг. 7, потоковый сигнал 735 передается во время окна n+1 (720) периода времени, которое кодируется, чтобы указать протокол (например, PCIe, PCI, IDI, QPI, и т.д.), который должен примениться к битам, передаваемым по дорожкам для данных DATA[0-49] в течение окна n+1 (720) периода времени. Аналогично, другой потоковый сигнал 740 может быть передан в течение последующего окна n+2 (725) периода времени, чтобы указать протокол, который применяется к битам, передаваемым по дорожкам для данных DATA[0-49] во время окна n+2 (725) периода времени, и так далее. В некоторых случаях, таких как в примере на фиг. 7, (где оба потоковых сигнала 735, 740 имеют одно и то же кодирование, двоичный FF), данные в последовательных окнах периода времени (например, n+1 (720) и n+2 (725)) могут принадлежать одному и тому же протоколу. Однако в других случаях данные в последовательных окнах периода времени (например, n+1 (720) и n+2 (725)) могут происходить от различных транзакции, к которым должны применяться разные протоколы, и потоковые сигналы (например, 735, 740), помимо других примеров, могут кодироваться соответственно, чтобы идентифицировать различные протоколы, применяемые к последовательным байтам данных на дорожках для данных (например, DATA[0-49]).
В некоторых реализациях для MCPL может быть определено состояние низкого энергопотребления или ожидания. Например, когда ни одно из устройств на MCPL не передает данные, физический уровень (электрический и логический) MCPL может переходить в состояние ожидания или низкого энергопотребления. Например, как показано на фиг. 7, в окне n-2 (745) периода времени MCPL находится в спокойном состоянии или состоянии ожидания и строб-сигнал выключен, чтобы экономить электроэнергию. MCPL может переключаться из режима низкого энергопотребления или режима ожидания, подавая строб-сигнал в окне n-1 периода времени окна периода времени (например, 705). Строб-сигнал может завершить передачу преамбулы (например, чтобы помочь запустить и синхронизовать каждую из дорожек канала, а также устройство приемника), начиная строб-сигнал перед любой другой сигнализацией по другим нестробированным дорожкам. После этого окна n-1 (705) периода времени действительный сигнал может быть подтвержден в окне n (715) периода времени, чтобы уведомить приемник, что предстоит появление данных в следующем окне n+1 (720) периода времени, как обсуждалось выше.
MCPL может повторно войти в состояние низкого энергопотребления или ожидания (например, состояние LI) после обнаружения условий ожидания на дорожках для действительных сигналов, дорожках для данных и/или других дорожках канала MCPL. Например, не может быть обнаружена никакая сигнализация, начинающаяся в окне n+3 (730) периода времени, и далее. Логика на источнике или на устройстве приемника, среди прочих примеров и принципов, может инициировать переход обратно в состояние низкого энергопотребления, ведущее снова (например, окно n+5 (755) периода времени) к строб-сигналу, вводящему режим ожидания или низкого энергопотребления (в том числе те, которые обсуждаются здесь позже).
Электрические характеристики физического PHY среди прочих признаков могут содержать одну или более асимметричную сигнализацию, синхронизацию на половинной частоте, согласование канала межсоединений, а также транспортную задержку на чипе для передатчика (источника) и приемника (приемник), оптимизированную защиту от электростатического разряда (ESD), емкость контактных площадок. Дополнительно MCPL может осуществляться, чтобы достигнуть более высокой скорости передачи данных (например, приближающейся к 16 Гб/с) и характеристик эффективности использования энергии, чем при традиционных решениях для ввода-вывода интегральных схем.
На фиг. 8 показан участок упрощенной блок-схемы 800, представляющий часть примерной MCPL. Схема 800, показанная на фиг. 8, содержит представление примерной дорожки 805 (например, дорожки для данных, дорожки для действительного сигнала или дорожки для потокового сигнала) и логики 810 формирования тактового сигнала. Как показано в примере на фиг. 8, в некоторых реализациях, логика 810 формирования тактового сигнала может быть осуществлена как дерево синхронизации, чтобы распространять сформированный тактовый сигнал каждому блоку, реализующему каждую дорожку примерной MCPL, такую как дорожка 805 для данных. Дополнительно может обеспечиваться схема 815 восстановления синхронизации. В некоторых реализациях, вместо обеспечения отдельной схемы восстановления синхронизации для каждой дорожки, по которой распространяется сигнал синхронизации, что является общепринятым, по меньшей мере, в некоторых традиционных архитектурах межсоединений ввода-вывода, может обеспечиваться единая схема восстановления синхронизации для кластера из множества дорожек. Конечно, отдельная дорожка для строба и сопутствующая схема восстановления синхронизации, которые применяются в примерных конфигурациях, показанных на фиг. 6 и 7, могут быть обеспечены для каждого кластера из двадцати пяти дорожек для данных.
Продолжая обращаться к фиг. 8, в некоторых реализациях, по меньшей мере, дорожки для данных, дорожки для потокового сигнала и дорожки для действительного сигнала могут заканчиваться на промежуточном канале к регулируемому напряжению больше нуля (земле). В некоторых реализациях напряжение на промежуточном канале пути может регулироваться до Vcc/2. В некоторых реализациях для каждого кластера дорожек может обеспечиваться единый регулятор 825 напряжения. Например, при применении в примерах, показанных на фиг. 6 и 7, среди других потенциально возможных примеров первый регулятор напряжения может обеспечиваться для первого кластера из двадцати пяти дорожек для данных, а второй стабилизатор напряжения может обеспечиваться для остального кластера из двадцати пяти дорожек для данных. В некоторых случаях, среди других примеров, примерный регулятор 825 напряжения может быть осуществлен как линейный регулятор, схема с переключаемой емкостью. В некоторых реализациях, среди других примеров, линейный регулятор может быть снабжен аналоговым контуром обратной связи или цифровым контуром обратной связи.
В некоторых реализациях для примерной MCPL может также обеспечиваться схема подавления перекрестных помех. В некоторых случаях компактный характер длинных проводов MCPL может создавать перекрестные помехи между дорожками. Для решения этих и других проблем может реализовываться логика подавления перекрестных помех. Например, в одном из примеров, показанных на фиг. 9-10, перекрестные помехи могут быть значительно уменьшены с помощью примерной активной схемы пониженного энергопотребления, такой как показано на схемах 900 и 1000. Например, в примере на фиг. 9 взвешенный, прошедший фильтр верхних частот сигнал "агрессора" может быть добавлен к сигналу "жертвы" (то есть, сигналу, подвергающемуся перекрестным помехам со стороны агрессора). Каждый сигнал может рассматриваться как жертва перекрестных помех от любого другого сигнала в звене связи и может сам быть агрессором в отношении другого сигнала в той степени, в которой он является источником перекрестных помех. Такой сигнал может создаваться и снижать перекрестные помехи на дорожке жертвы более, чем на 50%, благодаря производному характеру перекрестных помех на звене связи. Сигнал агрессора, прошедший низкочастотный фильтр, как показано в примере на фиг. 9, может формироваться при прохождении через высокочастотный RC-фильтр (реализуемый, например, с помощью С и R1), который создает отфильтрованный сигнал, который должен добавляться, используя схему 905 суммирования (например, чувствительный усилитель приемника).
Реализации, подобные описанным в примере на фиг. 9, могут быть особенно удобными решениями для такого приложения, как MCLP, поскольку схема может быть реализована с относительно низкими непроизводительными потерями, как показано в схеме на фиг. 10, где поясняется примерная схема на транзисторном уровне, показанная и описанная в примере на фиг. 9. Следует понимать, что представления на фиг. 9 и 10 являются упрощенными представлениями и фактическая реализация может содержать многочисленные экземпляры схем, показанных на фиг. 9 и 10, чтобы разместить схему подавления перекрестных помех среди и между дорожками звена связи. В качестве примера, помимо прочих примеров, в звене связи с тремя дорожками (например, дорожки 0-2) схема, подобная описанной в примерах на фиг. 9 и 10, может обеспечиваться между дорожкой 0 и дорожкой 1, между дорожкой 0 и дорожкой 2, между дорожкой 1 и дорожкой 0, между дорожкой 1 и дорожкой 2, между дорожкой 2 и дорожкой 0, между дорожкой 2 и дорожкой 1 и т.д., основываясь на геометрии и расположении дорожек.
Дополнительные функции могут осуществляться на физическом уровне PHY примерной MCPL. Например, ответвление приемника может вносить существенную погрешность и в некоторых случаях ограничивать поле допуска напряжения ввода-вывода. Избыточность схемы может использоваться для улучшения чувствительности приемника. В некоторых реализациях избыточность схемы может быть оптимизирована, чтобы решать проблему среднеквадратического отклонения устройств выборки данных, используемых в MCPL. Например, может обеспечиваться примерное устройство выборки данных, приспособленное к требованию утроенного (3) среднеквадратичного отклонения. В примерах на фиг. 6 и 7, например, имелось два (2) устройства выборки данных, которые должны использоваться для каждого приемника (например, для каждой дорожки), сто (100) устройств выборки должны использоваться для пятидесяти (50) дорожек MCPL. В этом примере вероятность, что одна из дорожек приемника (RX) не соответствует требованию утроенного среднеквадратичного отклонения, составляет 24%. Может обеспечиваться генератор опорного напряжения чипа для установления верхней границы отклонения и перехода на следующее устройство выборки данных в приемнике, если обнаруживается, что другое устройство из числа устройств выборки превышает границу. Однако, если в каждом приемнике должны использоваться четыре (4) устройства выборки данных (то есть, вместо двух в этом примере), приемник будет давать отказ, только если три из четырех устройств выборки перестанут работать. Для MCPL с пятьюдесятью дорожками, как в примерах на фиг. 6 и 7, добавление этой дополнительной избыточности схемы может существенно снизить частоту отказов с 24% до менее чем 0,01%.
В других дополнительных примерах, при очень высоких скоростях передачи данных, коррекция цикла загрузки на бит (DCC) и устранение искажений могут использоваться, чтобы увеличить базовую линию на DCC кластера, и устранить искажения для улучшения поля допуска звена связи. Вместо исправления для всех случаев, как в традиционных решениях, в некоторых реализациях может быть использована цифровая реализация с низким энергопотреблением, которая воспринимает и корректирует выбросы, при которых дорожка ввода-вывода может перестать работать. Например, может выполняться глобальная настройка дорожек, чтобы идентифицировать проблемные дорожки внутри кластера. Эти проблемные дорожки могут затем планироваться для синхронизации по каждой дорожке, чтобы достигнуть высоких скоростей передачи данных, поддерживаемых MCPL.
В некоторых примерах MCPL, как вариант, могут также осуществляться дополнительные функции, чтобы улучшить показатели производительности физического звена связи. Например, может обеспечиваться линейное кодирование. Хотя для инверсии (DBI) шины данных постоянного тока (DC) могут быть разрешены нагрузки на промежуточном пути, как описано выше и описание которых не приводится, DBI переменного тока (АС) все еще могут использоваться, чтобы снизить динамическую мощность. Также может использоваться более сложное кодирование, чтобы исключить наихудший случай разности единиц и нулей, чтобы, помимо примеров с другими преимуществами, уменьшить, например, потребность в приводе регулятора на промежуточном пути, а также предельный шум при переключении ввода-вывода. Дополнительно, как вариант, может также осуществляться коррекция передатчиков. Например, на очень высоких скоростях передачи данных вносимые потери для канала внутри корпуса интегральной схемы могут быть значительными. Весовая коррекция передатчиков с двумя ответвлениями (выполняемая, например, во время начальной последовательности включения электропитания) может в некоторых случаях быть достаточной, чтобы смягчить некоторые из прочих таких проблем.
На фиг. 11 представлена упрощенная блок-схема 1100, показывающая пример логический PHY примерной MCPL. Физический 1105 PHY может соединяться с кристаллом, который содержит логический PHY 1110 и дополнительную логику, поддерживающую уровень звена связи MCPL. Кристалл в этом примере может дополнительно содержать логику для поддержки многочисленных различных протоколов на MCPL. Например, в примере на фиг. 11, логика 1115 PCIe может обеспечиваться также, как логика 1120 IDI, так что помимо потенциально возможных многочисленных других примеров кристаллы могут соединяться, используя PCIe или IDI на одной и той же MCPL, соединяющей два кристалла, в том числе, в примерах, где через MCPL поддерживаются более двух протоколов или протоколов, отличных от PCIe и IDI. Различные протоколы, поддерживаемые среди кристаллов, могут предложить различные уровни обслуживания и функции.
Логический PHY уровень 1110 может содержать логику 1125 управления конечным автоматом звена связи, чтобы согласовать изменения состояния звена связи согласно запросам логики верхнего уровня кристалла (например, полученными по PCIe или IDI). Логический PHY 1110 может дополнительно содержать тестирование звена связи и отладку логики (например, 1130) и некоторых реализаций. Как отмечено выше, пример MCPL может поддерживать управляющие сигналы, передаваемые между кристаллами по MCPL, чтобы облегчить функции агностики протокола, высокопроизводительные характеристики и энергопотребление (помимо других примерных функций) MCPL. Например, логический PHY 1110 может поддерживать формирование и передачу, а также прием и обработку действительных сигналов, потоковых сигналов и сигналов боковой полосы LSM в сочетании с передачей и приемом данных по выделенным дорожкам для данных, как описано в примерах выше.
В некоторых реализациях логика мультиплексирования (например, 1135) и демультиплексирования (например, 1140) может быть включена или как-либо иначе быть доступна для логического уровня 1110 PHY. Например, логика мультиплексирования (например, 1135) может использоваться для идентификации данных (например, введенных в качестве пакетов, сообщений и т.д.), которые должны передаваться через MCPL. Логика 1135 мультиплексирования может идентифицировать протокол, управляющий данными, и формировать потоковый сигнал, который кодируется, чтобы идентифицировать протокол. Например, в одном из примеров реализации, потоковый сигнал может кодироваться как байт из двух шестнадцатеричных символов (например, IDI: FFh; PCIe: FOh; LLP: AAh; в боковой полосе: 55h; и т.д.) и может передаваться в течение того же самого окна (например, окна периода времени байта) данных, управляемого идентифицированным протоколом. Аналогично, логика 1140 демультиплексирования может использоваться для интерпретации входящих потоковых сигналов, чтобы декодировать потоковый сигнал и идентифицировать протокол, который должен применяться к данным, принимаемым одновременно с потоковым сигналом по дорожкам для данных. Логика 1140 демультиплексирования может затем применять (или обеспечивать) обработку уровня звена связи, специфичную для протокола, и заставлять данные обрабатываться соответствующей логикой протокола (например, логикой 1115 PCIe или логикой 1120 IDI).
Логический уровень 1110 PHY может дополнительно содержать логику 1150 пакетов уровня звена связи, которая может использоваться для управления различными функциями звена связи, в том числе, задачами управления электропитанием, контуром обратной связи, запретом, повторной центровкой, скремблированием и т.д. Логика 1150 LLP, помимо прочих функций, может облегчить сообщения типа "уровень звена связи-уровень звена связи" по MCLP. Данные, соответствующие сигнализации LLP, могут быть также идентифицированы потоковым сигналом, переданным по выделенной дорожке для потокового сигнала, который кодируется, чтобы идентифицировать, что дорожки данных являются дорожками для данных LLP. Логики (например, 1135, 1140) мультиплексирования и демультиплексирования могут также использоваться для формирования и интерпретации потоковых сигналов, соответствующие трафику LLP, а также, чтобы заставить такой трафик обрабатываться соответствующей логикой кристалла (например, логикой 1150 LLP). Аналогично, поскольку некоторые реализации MCLP могут содержать, среди других примеров, выделенную боковую полосу (например, боковую полосу 1155 и поддерживающую логику), такую как асинхронный и/или более низкочастотный канал боковой полосы.
Логика 1110 логического уровня PHY 1110 может дополнительно содержать логику управления конечным автоматом звена связи, которая может формировать и принимать (и использовать) сообщение управления состоянием звена связи по выделенной дорожке боковой полосы LSM. Например, дорожка боковой полосы LSM, помимо других потенциально возможных примеров, может использоваться для выполнения квитирования, предшествующего состоянию моделирования звена связи, выхода из состояний управления электропитанием (например, состояния LI). Сигнал боковой полосы LSM может быть асинхронным сигналом, в котором он не выравнивается с данными, действительным сигналом и потоковыми сигналами звена связи, а вместо этого, помимо других примеров, соответствует изменениям состояния сигнализации и выравниванию конечного автомата звена связи между двумя кристаллами или чипами, соединенными звеном связи. Обеспечение выделенной дорожки боковой полосе LSM, помимо других выгод, показанных на примерах, в некоторых примерах позволяет исключить схемы бесшумной настройки и приемные схемы обнаружения аналогового переднего фронта (AFE).
На фиг. 12 показана упрощенная блок-схема 1200, показывающая другое представление логики, используемой при осуществлении MCPL. Например, логический уровень 1110 PHY обеспечивается с помощью определенной логического интерфейса PHY (LPIF) 1205, через который любой из множества различных протоколов (например, PCIe, IDI, QPI и т.д.) 1210, 1215, 1220, 1225 и режимов сигнализации (например, в боковой полосе) может взаимодействовать с физическим уровнем примерной MCPL. В некоторых реализациях логика 1230 мультиплексирования и арбитража может также обеспечиваться как уровень, отдельный от логического уровня 1110 PHY. В одном из примеров LPIF 1205 может обеспечиваться в качестве интерфейса с любой из сторон от этого уровня 1230 MuxArb. Логический уровень 1110 PHY может сопрягаться с физическим уровнем PHY (например, аналоговым передним фронтом (AFE) 1105 MCPL PHY) через другой интерфейс.
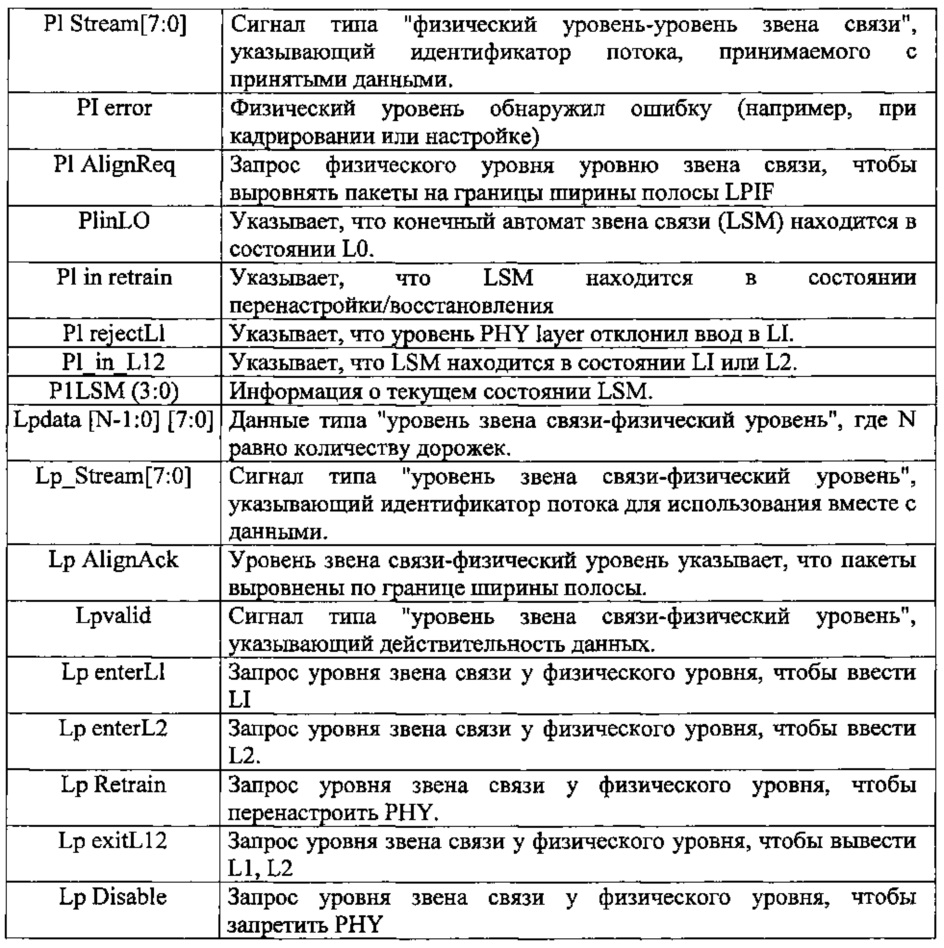
LPIF может отделить PHY (логический и электрический/аналоговый) от верхних уровней (например, 1210, 1215, 1220, 1225), так. чтобы мог быть реализован совершенно другой PHY после LPIF, прозрачного для верхних уровней. Это может помочь при стимулировании модульности и повторного использования при проектировании, поскольку, помимо прочего, верхние уровни могут оставаться нетронутыми, когда обновляется базовая технология сигнализации PHY. Дополнительно, LPIF может определить множество сигналов, разрешающих мультиплексирование/ демультиплексирование, управление LSM, обнаружение и обработку ошибок и другие функциональные возможности логического PHY. Например, в таблице 1 обобщается, по меньшей мере, часть сигналов, которые могут быть определены для примера LPIF:

Как видно в таблице 1, в некоторых реализациях механизм выравнивания может обеспечиваться через квитирование AlignReq/AlignAck. Например, когда физический уровень входит в состояние восстановления, некоторые протоколы могут терять кадрирование пакета. Выравнивание пакетов может быть исправлено, например, чтобы гарантировать правильную идентификацию кадрирования посредством уровня звена связи. Дополнительно, как показано на фиг. 13, физический уровень может подтвердить сигнал StallReq, когда вводит восстановление, так что уровень звена связи подтверждает сигнал Stall, когда новый выровненный пакет готов для передачи. Логика физического уровня может сделать выборку как Stall, так и Valid, чтобы определить, выровнены ли пакеты. Например, физический уровень может продолжать запускать trdy, чтобы освобождать пакеты уровня звена связи, пока выборки Stall и Valid не будут подтверждены, помимо других потенциально возможных реализаций, в том числе, других альтернативных реализаций, использующих Valid, чтобы помочь при выравнивании пакетов.
Для сигналов на MCPL могут определяться различные допуски для сбоев. Например, допуски для сбоев могут быть определены для действительных сигналов, потоковых сигналов, LSM боковой полосы, низкочастотной боковой полосы пакетов уровня связи и других типов сигналов. Допуски для сбоев для пакетов, сообщений и других данных, переданных по выделенным дорожкам для данных MCPL, могут быть основаны на конкретном протоколе, управляющем данными. В некоторых реализациях среди других потенциально возможных примеров могут обеспечиваться механизмы обнаружения и обработки ошибок, такие как контроль циклическим избыточным кодом (CRC), буферы повторения. В качестве примеров, для пакетов PCIe, переданных по MCPL, 32-разрядный CRC может быть использован для пакетов уровня транзакции PCIe (TLP) (с гарантированной доставкой (например, через механизм воспроизведения)), и 16-разрядный CRC может быть использован для пакетов уровня звена связи PCIe (которые могут быть построены так, что имеют потери (например, когда воспроизведение не применяется)). Дополнительно, для символов кадрирования PCIe для идентификатора символа может быть определено особое расстояние Хемминга (например, расстояние Хемминга равное четырем (4)); также, помимо прочих примеров, могут использоваться четность и 4-разрядный CRC. Для пакетов IDI, с другой стороны, может использоваться 16-разрядный CRC.
В некоторых реализациях допуски сбоев могут определяться для пакетов уровня звена связи (link layer packet, LLP), которые содержат требование перехода действительного сигнала с низкого уровня на высокий (то есть, с 0 на 1) (например, чтобы помочь в подтверждении бита и блокировки символа). Дополнительно, в одном из примеров, для передачи может быть определено конкретное количество последовательных, идентичных LLP и ответы могут ожидаться на каждый запрос, с повторным запросом запросчика после перерыва, отведенного на ответ, помимо других определенных характеристик, которые могут использоваться в качестве основы определения отказов в данных LLP на MCPL. В дополнительных примерах допуск для отказов может обеспечиваться для действительного сигнала, например, посредством расширения действительного сигнала на все окно периода времени, или символа (например, поддерживая высокий уровень действительного сигнала восьми UI). Дополнительно, помимо прочих примеров, ошибки или отказы в потоковых сигналах могут предотвращаться, поддерживая расстояние Хемминга для значений кодирования потокового сигнала.
Реализации логического PHY могут содержать обнаружение ошибок, отчет об ошибках и логику обработки ошибок. В некоторых реализациях логический PHY примерной MCPL, помимо прочего, может содержать логику для обнаружения ошибок нарушения кадрирования уровня PHY (например, на дорожках для действительных значений и дорожках для потоковых сигналов), ошибок на боковой полосе (например, связанных с переходами состояний LSM), ошибок в LLP (например, которые являются критичными к переходам состояний LSM). Некоторые обнаружения/устранения ошибок, помимо прочего, могут делегироваться логике верхнего уровня, такой как логика PCIe, адаптированная для обнаружения конкретных для PCIe ошибок.
В случае ошибок нарушения кадрирования, в некоторых реализациях один или более механизмов могут обеспечиваться через логику обработки ошибок. Ошибки нарушения кадрирования могут обрабатываться, основываясь на используемом протоколе. Например, в некоторых реализациях уровни звена связи могут информироваться об ошибках, чтобы запустить повторную попытку. Нарушение кадрирование может также вызывать повторное выравнивание нарушения кадрирования логического PHY. Дополнительно, помимо прочего, может выполняться повторное центровка логического PHY и блокировка символа/окна может быть осуществлена повторно. Центровка в некоторых примерах может содержать PHY перемещение фазы тактового сигнала приемника к оптимальной точке, чтобы обнаружить входящие данные. "Оптимальный", в этом контексте, может относиться к тому, где имеется наибольшее поле для шумов и дрожания тактового сигнала. Повторная центровка может содержать упрощенные функции центровки, выполняемые, среди прочего, например, когда PHY выходит из состояния низкого энергопотребления.
Другие типы ошибок могут использовать другие способы обработки ошибок. Например, ошибки, обнаруженные в боковой полосе, могут фиксироваться через механизм задержки соответствующего состояния (например, LSM). Ошибка может регистрироваться и конечный автомат звена связи может затем переключаться состояние Reset. LSM может оставаться в состоянии Reset до тех пор, пока от программного обеспечения не будет принята команда перезапуска. В другом примере ошибки LLP, такие как ошибки пакета управления звена связи, могут быть обработаны с помощью механизма блокировки по времени, который может снова запустить последовательность LLP, если подтверждается, что последовательность LLP не принята.
На фиг. 14А-14С показаны представления примерных битовых отображений на дорожках для данных примерного MCPL для различных типов данных. Например, примерный MCPL может содержать пятьдесят дорожек для данных. На фиг. 14А показано первое битовое отображение примерных 16-байтовых слотов в первом протоколе, таком как IDI, которые могут передаваться по дорожкам для данных внутри символа или окна длиной 8UI. Например, внутри определенного окна длиной 8UI могут передаваться три 16-байтовых слота, в том числе, слот заголовка. В этом примере остаются два байта данных и эти остающиеся два байта могут использоваться битами CRC (например, в дорожках DATA[48] и DATA[49]).
В другом примере на фиг. 14В показан второе примерное битовое отображение данных пакета PCIe, передаваемых по этим пятидесяти дорожкам для данных примерной MCPL. В примере на фиг. 14В 16-байтовые пакеты (например, пакеты PCIe уровня транзакции (TLP) или уровня звена передачи данных (DLLP)) могут передаваться через MCPL. В окне длиной 8UI могут быть отправлены три пакета с остающимися двумя байтами с левой стороны ширины полосы, остающимися неиспользованными внутри окна. Символы кадрирования могут содержаться в этих символах и использоваться для определения местоположения начала и конца каждого пакета. В одном из примеров PCIe кадрирование, используемое в примере на фиг. 14В, может быть таким же, как те символы, которые реализуются для PCIe в 8GT/с.
В еще одном примере на фиг. 14С показано примерное битовое отображение пакетов типа "звено-звено" (например, пакетов LLP), передаваемых через примерную MCPL. LLP могут иметь длину 4 байта каждый и каждый LLP (например, LLPO, LLP1, LLP2 и т.д.) может передаваться четыре раза друг за другом в соответствии с допуском на отказ и обнаружением ошибок внутри примерной реализации. Например, отказ при приеме четырех следующих подряд идентичных LLP может указывать на ошибку. Дополнительно, как для других типов данных, отказ в приеме VALID в продолжающемся временном окне или символа может также указывать на ошибку. В некоторых случаях LLP могут иметь фиксированные слоты. Дополнительно, в этом примере, помимо прочего, неиспользуемые или "запасные" биты в периоде времени байта могут приводить в результате к логическим нулям, передаваемым по двум из пятидесяти дорожек (например, DATA [48-49]).
На фиг. 15 упрощенная схема 1400 переключений конечного автомата звена связи показана вместе с квитированием в боковой полосе, используемым между переключениями состояния. Например, состояние Reset.Idle (например, где выполняется калибровка захвата контура фазовой автоподстройки (PLL)) может переключаться через квитирование в боковой полосе в состояние Reset. Cal (например, при дополнительной калибровке звена связи). Состояние Reset. Cal может переключаться через квитирование в боковой полосе в состояние Reset.ClockDCC (например, где может выполняться коррекция рабочего цикла (DCC) и захват в контуре (DLL) с задержкой захвата). Дополнительное квитирование может выполняться на переходе из состояния Reset.ClockDCC в состояние Reset.Quiet (например, чтобы снять состояние Valid). Чтобы помочь в выравнивании сигнализации на дорожках MCPL, дорожки могут центроваться через состояние Center. Pattern.
В некоторых реализациях, как показано в примере на фиг. 16, во время состояния Center.Pattem передатчик может формировать шаблоны настройки или другие данные. Приемник может формировать свою схему приемника, например, для приема таких шаблонов настройки, устанавливая положение фазового интерполятора и положение vref и устанавливая компаратор. Приемник может непрерывно сравнивать принятые шаблоны с ожидаемыми шаблонами и сохранять результат в регистре. После того, как один набор шаблонов завершен, приемник может давать приращение установке фазового интерполятора, поддерживая vref одним и тем же. Процесс формирования и сравнения испытательного шаблона может продолжаться и новые результаты сравнения могут сохраняться в регистре с помощью процедуры, непрерывно проходящей через все значения фазового интерполятора и через все значения vref. Состояние Center.Quiet может быть введено, когда процесс формирования шаблонов и сравнения полностью закончен. После центрировки дорожек через состояния через Center.Pattem и Center Quiet звена связи, квитирование в боковой полосе (например, используя сигнал боковой полосы LSM на выделенной дорожке боковой полосы LSM звена связи) может быть облегчено, чтобы перейти в состояние Link.Init для инициализации MCPL и разрешения передачи данных через MCPL.
Возвращаясь на мгновение к обсуждению фиг. 15, как отмечено выше, квитирования в боковой полосе могут использоваться для облегчения переключений конечного автомата звена связи между кристаллами или чипами в многокристальной интегральной схеме. Например, сигналы на дорожках в боковой полосе LSM MCPL могут использоваться для синхронизации переключений конечного автомата в кристалле. Например, когда удовлетворяются условия выхода из состояния (например, Reset.Idle), сторона, удовлетворившая эти условия, может подтвердить на своей внешней дорожке LSM SB сигнал в боковой полосе LSM и ожидать от другого удаленного кристалла, когда он достигнет того же самого состояния и подтвердит сигнал в боковой полосе LSM на его дорожке LSM SB. Когда оба сигнала LSM SB подтверждаются, конечный автомат звена связи каждого соответствующего кристалла может переключаться в следующее состояние (например, в состояние Reset.Cal). Можно определить минимальное время перекрытия, в течение которого оба сигналы LSM SB должны поддерживаться подтвержденными до состояния перехода. Дополнительно, может быть определено минимальное время в состоянии покоя, после которого подтверждение LSM SB снимается, чтобы позволить точное обнаружение переключения. В некоторых реализациях каждое переключение конечного автомата звена связи может быть обусловлено и облегчено такими квитированиями LSM SB.
На фиг. 17 представлена более подробная схема 1700 конечного автомата связи, показывающая, по меньшей мере, некоторые из дополнительных состояний звена связи и переключений звена связи, которые могут содержаться в примерной MCPL. В некоторых реализациях примерный конечный автомат звена связи может, помимо других состояний и изменений состояния, показанных на фиг. 17, содержать переключение "Directed Loopback" для помещения дорожки MCPL в цифровую петлю обратной связи. Например, дорожки MCPL приемника могут циклически возвращаться обратно к дорожкам передатчика после цепей восстановления синхронизации. В некоторых случаях может обеспечиваться состояние "LB Recenter", которое может использоваться для выравнивания символов данных. Дополнительно, помимо прочих потенциально возможных примеров, как показано на фиг. 15, MCPL может поддерживать многочисленные состояния звена связи, в том числе, активное состояние L0 и состояния низкого энергопотребления, такие как состояние ожидания L1 и состояние сна L2.
На фиг. 18 представлена упрощенная блок-схема 1800, показывающая примерный поток при переключении между активным состоянием (например, L0) и состоянием низкого энергопотребления или состоянием ожидания (например, L1). В этом конкретном примере, первое устройство 1805 и второе устройство 1810 соединяются средствами связи, используя MCPL. При нахождении в активном состоянии данные передаются по дорожкам MCPL (например, DATA, VALID, STREAM и т.д.). Пакеты уровня звена связи (LLP) могут передаваться по дорожкам (например, дорожкам для данных, с помощью потокового сигнала, указывающего, что данные являются данными LLP), чтобы помочь в облегчении переключений звена связи. Например, LLP могут передаваться между первым и вторым устройствами 1805, 1810, чтобы согласовать переход из состояния L0 в состояние L1. Например, протоколы верхнего уровня, поддерживаемые MCPL, могут сообщать, что требуется вход в состояние L1 (или другое состояние) и протоколы верхнего уровня могут заставить передавать LLP по MCPL, чтобы облегчить квитирование на уровне звена связи, чтобы заставить физический уровень ввести L1. Например, фиг. 18 показывает, по меньшей мере, часть переданных LLP, в том числе, запрос "Enter L1" LLP, переданный от второго устройство 1810 (по восходящей линии) к первому устройству 1805 (по нисходящей линии). В некоторых реализациях как протоколы верхнего уровня, так и порт нисходящей линии не инициируют переключение на L1. Принимающее первое устройство 1805, помимо прочего, в ответ может передавать запрос "Change to L1" LLP, который второе устройство 1810 может подтвердить через подтверждение "Change to L1" (ACK) LLP. После обнаружения завершения квитирования логический PHY может заставить сигнал в боковой полосе, который должен подтверждаться по выделенному звену связи в боковой полосе, подтвердить, что ACK было принято и что устройство (например, 1805) готово и ожидает входного сигнала на L1. Например, первое устройство 1805 может подтвердить сигнал в боковой полосе 1815, переданный второму устройству 1810, чтобы подтвердить прием конечного ACK в квитировании на уровне звена связи. Дополнительно, второе устройство 1810 может также подтвердить сигнал в боковой полосе в ответ на сигнал в боковой полосе 1815, чтобы уведомить первое устройство 1805 об ACK 1805 в боковой полосе первого устройства. С помощью завершения управления на уровне звена связи и квитирования в боковой полосе, MCPL PHY может переключаться в состояние L1, заставляя все дорожки MCPL переходить в холостой режим энергосбережения, в том числе, соответствующие строб-сигналы MCPL 1820, 1825 устройств 1805, 1810. Из состояния L1 можно выйти на логику верхнего уровня первого и второго устройств 1805, 1810, запрашивая повторный вход на L0, например, в ответ на обнаружение данных, которые должны передаваться другому устройству по MCPL.
Как отмечено выше, в некоторых реализациях MCPL может облегчить связь между двумя устройствами, потенциально поддерживающими многочисленные различные протоколы, и MCPL может облегчать связь в соответствии с потенциально любым из многочисленных протоколов по дорожкам MCPL. Облегчение многочисленных протоколов, однако, может усложнить вход и повторный вход, по меньшей мере, в некоторые состояния звена связи. Например, хотя некоторые традиционные межсоединения имеют единый протокол верхнего уровня, принимающий роль ведущего при переключении состояний, реализация MCPL с многочисленными различными протоколами эффективно включает в себя многочисленных ведущих. В качестве примера, на фиг. 18 показано, что при реализации MCPL каждый из PCIe и IDI может поддерживаться между двумя устройствами 1805, 1810. Например, помещение физического уровня в состояние ожидания и в состояние малого энергопотребления может быть обусловлено получением разрешения от каждого из поддерживаемых протоколов (например, как PCIe, так и IDI).
В некоторых случаях переход в состояние L1 (или другое состояние) может требоваться только одним из многочисленных протоколов, поддерживаемых для реализации MCPL. Хотя может существовать вероятность, что другие протоколы аналогично запросят переключение в то же самое состояние (например, основываясь на идентификации схожих условий (например, небольшой трафик или его отсутствие) на MCPL), логический PHY может ожидать, пока разрешение или команды не будут приняты от каждого протокола верхнего уровня, прежде чем фактически способствовать изменению состояний. Логический PHY может следить, какие протоколы верхнего уровня запросили изменение состояния (например, выполнили соответствующее квитирование), и производить изменение состояния после идентификации, что каждый из протоколов запросил свое изменение состояния, такое как переключение с L0 на L1 или другое переключение, которое может повлиять или создать интерференционную помеху со связью по другим протоколам. В некоторых реализациях протоколы могут становиться бездействующими из-за их, по меньшей мере, частичной зависимости от других протоколов в системе. Далее, в некоторых случаях, протокол может ожидать ответа (например, от PHY) на запрос, чтобы войти в конкретное состояние, такое как подтверждение или отказ для требуемого изменения состояния. Соответственно, в таких случаях, ожидая разрешения от других поддерживаемых протоколов для входа в состояние ожидания звена связи, логический PHY может формировать синтетические ответы на запрос, чтобы войти в состояние ожидания для "обмана" запрашивающего протокола верхнего уровня, чтобы он поверил, что конкретное состояние было введено (когда, в действительности, дорожки все еще являются активными, по меньшей мере, пока другие протоколы также не запрашивают ввод в состояние ожидания). Среди других потенциальных преимуществ, помимо прочего, это может упростить координацию переходов в состояние низкого энергопотребления между многочисленными протоколами.
Заметим, что описанные выше устройства, способы и системы могут быть осуществлены в виде любого электронного устройства или системы, как говорилось выше. В качестве конкретных иллюстраций, приведенные ниже чертежи представляют примерные системы для использования изобретения, как оно здесь описано. Согласно тому, как ниже системы описываются более подробно, множество различных межсоединений из приведенного выше обсуждения раскрываются, описываются и просматриваются. И как совершенно очевидно, прогресс, описанный выше, может быть применим к любому из этих межсоединений, связных структур или архитектур.
На фиг. 19 показан вариант осуществления блок-схемы компьютерной системы, содержащей многоядерный процессор. Процессор 1900 содержит любой процессор или устройство обработки, такое как микропроцессор, встроенный процессор, цифровой сигнальный процессор (DSP), сетевой процессор, карманный процессор, прикладной процессор, сопроцессор, система на чипе (SOC) или другое устройство для исполнения управляющей программы. Процессор 1900 в одном из вариантов осуществления содержит по меньшей мере два ядра, ядра 1901 и 1902, которые могут содержать асимметричные ядра или симметричные ядра (показанный на чертеже вариант осуществления). Однако, процессор 1900 может содержать любое количество элементов обработки, которые могут быть симметричными или асимметричными.
В одном из вариантов осуществления элемент обработки относится к аппаратурному обеспечению или логике, чтобы поддерживать ветвь программного обеспечения. Примеры элементов обработки аппаратурного обеспечения содержат: цепочечный блок, цепочечный слот, цепочка, устройство обработки, контекст, контекстный блок, логический процессор, цепочку аппаратурного обеспечения, ядро, и/или любой другой элемент, способный удерживать состояние для процессора, такое как состояние выполнения или архитектурное состояние. Другими словами, элемент обработки в одном из вариантов осуществления относится к любому аппаратурному обеспечению, способному быть независимо связанным с управляющей программой, такому как цепочка программного обеспечения, операционная система, приложение или другая управляющая программа. Физический процессор (или процессорный сокет) обычно относится к интегральной схеме, которая потенциально содержит любое количество других элементов обработки, таких как ядра или цепочки аппаратурного обеспечения.
Ядро часто относится к логике, расположенной на интегральной схеме, способной поддерживать независимое архитектурное состояние, в котором каждое независимо поддерживаемое архитектурное состояние связывается по меньшей мере с некоторыми выделенными ресурсами для выполнения. В отличие от ядер, цепочка аппаратурного обеспечения обычно относится к любой логике, расположенной на интегральной схеме, способной к поддержанию независимого архитектурного состояния, где независимо незатухающие архитектурные состояния совместно используют доступ к ресурсам исполнения. Как можно видеть, когда определенные ресурсы используются совместно, а другие выделяются архитектурному состоянию, линии между номенклатурой цепочки аппаратурного обеспечения и ядром перекрывается. Все же часто ядро и цепочка аппаратурного обеспечения рассматриваются операционной системой как индивидуальные логические процессоры, где операционная система способна индивидуально планировать операции на каждом логическом процессоре.
Физический процессор 1900, как показано на фиг. 19, содержит два ядра, ядра 1901 и 1902. Здесь ядра 1901 и 1902 считаются симметричными ядрами, то есть, ядрами с одинаковыми конфигурациями, функциональными блоками и/или логикой. В другом варианте осуществления ядро 1901 содержит неупорядоченное ядро процессора, тогда как ядро 1902 содержит упорядоченное ядро процессора. Однако ядра 1901 и 1902 могут индивидуально выбираться из любого типа ядра, таких как собственное ядро, ядро, управляемое программным обеспечением, ядро, адаптированное для выполнения собственной архитектуру системы команд (Instruction Set Architecture, ISA), ядро, адаптированное для выполнения транслированной архитектуры системы команд (ISA), совместно спроектированное ядро или другое известное ядро. В разнородной среде ядер (то есть, асимметричных ядер) некоторая форма трансляции, такая как двоичная трансляция, может использоваться, чтобы планировать или выполнять управляющую программу на одном или обоих ядрах. Также, в дополнение к обсуждению, функциональные блоки, показанные в ядре 1901, описываются ниже более подробно, а блоки в изображенном варианте осуществления в ядре 1902 работают подобным образом.
Как показано на чертеже, ядро 1901 содержит две цепочки 1901а и 1901b аппаратурного обеспечения, которые могут также упоминаться как слоты 1901а и 1901b цепочек аппаратурного обеспечения. Поэтому объекты программного обеспечения, такие как операционная система, в одном из вариантов осуществления потенциально рассматривают процессор 1900 как четыре отдельных процессора, то есть, четыре логических процессора или элемента обработки, способных выполнять четыре цепочки программного обеспечения одновременно. Как упомянуто выше, первая цепочка связывается с регистрами 1901а состояния архитектуры, вторая цепочка связывается с регистрами 1901b состояния архитектуры, третья цепочка может быть связана с регистрами 1902а состояния архитектуры и четвертая цепочка может быть связана с регистрами 1902b состояния архитектуры. Здесь, каждый из регистров (1901а, 1901b, 1902а и 1902b) состояния архитектуры может упоминаться как элемент обработки, слот цепочки или блок цепочки, как описано выше. Как показано на чертеже, регистры 1901а состояния архитектуры повторяются в регистрах 1901b состояния архитектуры, поэтому индивидуальные состояния/контексты архитектуры способны храниться для использования логическим процессором 1901а и логическим процессором 1901b. В ядре 1901 другие, более малые ресурсы, такие как указатели команд и логика переименования в распределителе и блоке 1930 переименования также могут быть повторяться для цепочек 1901а и 1901b. Некоторые ресурсы, такие как буферы упорядочивания блоке 1935 упорядочивания/изъятия 1935, ILTB 1920, буферы загрузки/хранения, и очереди могут использоваться совместно посредством разделения. Другие ресурсы, такие как внутренние регистры общего назначения, базовый регистр(-ы) таблицы страниц, кэш данных низкого уровня и данные TLB 1915, блок(-и) 1940 выполнения 1940 и части неупорядоченного блока 1935 потенциально полностью используются совместно.
Процессор 1900 часто содержит другие ресурсы, которые могут полностью использоваться совместно, использоваться совместно посредством разделения или выделяться элементами обработки/элементам обработки. На фиг. 19 показан вариант осуществления примерного процессора с иллюстративными логическими блоками/ресурсами процессора. Заметим, что процессор может содержать или не содержать любые из этих функциональных блоков, а также содержать любые другие известные функциональные блоки, логику или встроенные программы, не показанные на чертеже. Как видно на чертеже, ядро 1901 содержит упрощенное репрезентативное неупорядоченное (out-of-order ООО) ядро процессора. Но в различных вариантах осуществления может использоваться и упорядоченный процессор. ООО-ядро содержит целевой буфер 1920 ветвлений, чтобы прогнозировать ответвления, которые должны выполняться/предприниматься и буфер 1920 трансляции команд (I-TLB), чтобы хранить вводы трансляции адресов для команд.
Ядро 1901 дополнительно содержит модуль 1925 декодирования, связанный с блоком 1920 выборки, чтобы декодировать выбранные элементы. Логика выбора в одном из вариантов осуществления содержит индивидуальные секвенсеры, связанные со слотами 1901а, 1901b цепочек, соответственно. Обычно ядро 1901 связывается с первым ISA, который определяет/указывает команды, исполняемые на процессоре 1900. Часто команды машинного кода, которые являются частью первого ISA, содержат часть команды (называемую кодом операции), который ссылается/указывает команду или операцию, которая должна быть выполнена. Логика 1925 декодирования содержит схему, которая распознает эти команды по их кодам операций и передает декодированные команды по конвейеру для обработки, определяемой первым ISA. Например, как более подробно ниже обсуждается ниже, декодеры 1925 в одном из вариантов осуществления содержат логику, предназначенную или адаптированную для распознавания конкретных команд, такие как команда транзакции. В результате распознания декодерами 1925, архитектура или ядро 1901 предпринимает конкретные, заданные действия, чтобы выполнить задачи, связанные с соответствующей командой. Важно заметить, что любые из задач, блоков, операций и способов, описанных здесь, могут выполняться в ответ на одиночные или многочисленные команды; некоторые из которых могут быть новыми или старыми командами. Заметим, что декодеры 1926 в одном из вариантов осуществления, распознают одну и ту же ISA (или из поднабор). Альтернативно, в разнородной среде ядра, декодеры 1926 распознают вторую ISA (или поднабор первой ISA или отдельную ISA).
В одном из примеров блок 1930 распределителя и устройства переименования содержит распределитель для резервирования ресурсов, таких как регистровые файлы, чтобы сохранять результаты обработки команд. Однако, цепочки 1901а и 1901b потенциально способны к неупорядоченному выполнению, где блок 1930 распределителя и устройства переименования также резервирует другие ресурсы, такие как буферы перегруппировки, чтобы следить за результатами команд. Блок 1930 может также содержать регистр устройства переименования, чтобы переименовывать регистры программы переименования/ссылки команд в другие регистры, внутренние по отношению к процессору 1900. Блок 1935 перегруппировки/удаления содержит такие компоненты, как буферы перегруппировки, упомянутые выше, буферы загрузки и буферы хранения, чтобы поддерживать неупорядоченное выполнение и позднее упорядоченное удаление команд, выполненных неупорядоченными.
Блок 1940 планировщика и исполнительный блок(-и) в одном из вариантов осуществления, содержит блок планировщика, чтобы планировать команды/работу исполнительных блоков. Например, команда с плавающей точкой планируется на порту исполнительного блока, который имеет доступный исполнительный блок для операций с плавающей точкой. Имеются также регистровые файлы, связанные с исполнительными блоками, чтобы хранить информацию о результатах обработки команд. Примерные исполнительные блоки содержат исполнительный блок для операций с плавающей точкой, целочисленный исполнительный блок, исполнительный блок переходов, исполнительный блок загрузки, исполнительный блок хранения и другие известные исполнительные блоки.
Кэш данных нижнего уровня и буфер 1950 трансляции данных (D-TLB) связываются с исполнительным блоком(-ами) 1940. Кэш данных должен хранить недавно использованные/работавшие элементы, такие как операнды данных, которые потенциально хранятся в состояниях когерентности памяти. D-TLB должен хранить недавние виртуальные/линейные состояния в физических трансляциях адреса. Как конкретный пример, процессор может содержать табличную структуру страниц, чтобы разбивать физическую память на множество виртуальных страниц.
Здесь ядра 1901 и 1902 совместно используют доступ к кэшу более высокого уровня или к наиболее удаленному кэшу, такому как кэш второго уровня, связанный с интерфейсом 1910 на чипе. Заметим, что "более высокий уровень" или "наиболее удаленный" относятся к уровням кэша, увеличивающим или получающим дополнительный путь от исполнительного блока(-ов). В одном из вариантов осуществления кэш более высокого уровня является кэшем данных последнего уровня -последним кэшем в иерархии памяти на процессоре 1900 - таким как кэш второго или третьего уровня данных. Однако, кэш более высокого уровня этим не ограничивается, поскольку он может быть связан или содержать кэш команд. Кэш слежения - кэш типа команд - вместо этого может присоединяться после декодера 1925, чтобы сохранить недавно декодированные трассы. Здесь, "команда" потенциально относится к макрокоманде (то есть, общей команде, распознаваемой декодером), которая может декодироваться на множество микрокоманд (микроопераций).
В показанной конфигурации процессор 1900 также содержит модуль 1910 интерфейса на чипе. Исторически, контроллер памяти, который ниже описывается более подробно, был введен в компьютерную систему внешним по отношению к процессору 1900. В этом сценарии интерфейс 1910 на чипе должен осуществлять связь с устройствами, внешними по отношению к процессору 1900, такими как системная память 1975, чипсет (часто содержащий концентратор контроллера памяти для соединения с памятью 1975 и концентратор контроллера ввода-вывода для подключения периферийных устройств), концентратор контроллера памяти, северный мост или другую интегральную схему. И в этом сценарии шина 1905 может содержать любое известное межсоединение, такое как многоточечная шина, межсоединение типа "точка-точка", последовательное межсоединение, параллельная шина, когерентная (например, когерентный кэш) шина, архитектура с многоуровневым протоколом, дифференциальная шина и шина GTL.
Память 1975 может быть выделена процессору 1900 или делиться с другими устройствами в системе. Типичными примерами типов памяти 1975 являются DRAM, SRAM, энергонезависимая память (память NV) и другие известные запоминающие устройства. Заметим, что устройство 1980 может содержать графический ускоритель процессор или карту, связанные со концентратором контроллера памяти, запоминающее устройство, связанное со концентратором контроллера ввода-вывода, беспроводной приемопередатчик, флэш-устройство, аудиоконтроллер, сетевой контроллер или другие известные устройства.
С недавнего времени, однако, поскольку все больше логики и устройств интегрируются на единый кристалл, такой как SOC, каждое из этих устройств может быть помещено в процессор 1900. Например, в одном из вариантов осуществления концентратор контроллера памяти находится на той же самой интегральной схеме и/или на кристалле, что и процессор 1900. Здесь, часть 1910 ядра (часть на ядре) содержит один или более контроллер(-ов) для взаимодействия с другими устройствами, такими как память 1975 или графическое устройство 1980. Конфигурация, содержащая межсоединение и контроллеры для взаимодействия с такими устройствами, часто упоминается как содержащаяся на ядре (или неядерная конфигурация). Как пример, интерфейс 1910 на чипе содержит кольцевое межсоединение для связи на чипе и быстродействующее последовательное звено 1905 связи для соединения типа "точка-точка" для связи не на кристалле. При этом, в среде SOC еще больше устройств, таких как сетевой интерфейс, сопроцессоры, память 1975, графический процессор 1980 и любые другие известные компьютерные устройства/интерфейс могут быть интегрированы на едином кристалле или в интегральной схеме, чтобы обеспечить малый форм-фактор с высокой функциональностью и низким потреблением энергии.
В одном из вариантов осуществления процессор 1900 способен исполнять компиляцию, оптимизацию, и/или управляющую программу 1977 транслятора, чтобы компилировать, транслировать и/или оптимизировать управляющую программу 1976 для поддержки описанных здесь устройств и способов или взаимодействия между ними. Компилятор часто содержит программу или набор программ, чтобы транслировать исходный текст/код в целевой текст/код. Обычно компиляция программы/управляющей программы с помощью компилятора делается во многочисленных фазах и проходах, чтобы преобразовать управляющую программу на высоком языке программирования в машинный язык низкого уровня или ассемблер. При этом для простой компиляции продолжают использоваться однопроходные компиляторы. Компилятор может использовать любые известные способы компиляции и выполнять любые известные операции компилятора, такие как лексический анализ, предварительная обработка, парсинг, семантический анализ, формирование кода, преобразование кода и оптимизация кода.
Более крупные компиляторы часто содержат многочисленные фазы, но чаще всего эти фазы содержатся в пределах двух общих фаз: (1) внешний интерфейс, то есть, где обычно может иметь место синтаксическая обработка, семантическая обработка и некоторое преобразование/оптимизация, и (2) внутренний интерфейс, то есть, где обычно имеют место анализ, преобразования, оптимизации и формирование управляющей программы. Некоторые компиляторы относятся к промежуточным, которые показывают расплывчатые очертания между внешним интерфейсом и внутренним интерфейсом компилятора. Как результат, ссылка на вставку, ассоциацию, формирование или другую операцию компилятора может иметь место в любых из упомянутых выше фаз или проходов, а также в любых других известных фазах или проходах компилятора. Как иллюстративный пример, компилятор потенциально вставляет операции, вызовы, функции и т.д. в одну или более фазы компиляции, такие как вставка вызовов/операций в фазе внешнего интерфейса компиляции и затем преобразование вызовов/операций в код низшего уровня во время фазы преобразования. Заметим, что во время динамической компиляции код компилятора или динамический код оптимизации могут вставлять такие операции/вызовы, а также оптимизировать код для выполнения в процессе работы. В качестве конкретного иллюстративного примера, двоичный код (уже скомпилированный код) может быть динамически оптимизирован во время работы. Здесь программный код может содержать динамический код оптимизации, двоичный код или их комбинацию.
Подобно компилятору, транслятор, такой как двоичный транслятор, преобразует код статически или динамически, чтобы оптимизировать и/или транслировать код. Поэтому, ссылка на выполнение кода, прикладного кода, управляющую программу или другую программную среду может относиться к: (1) выполнению программы(-м) компилятора, оптимизации кода оптимизатора или трансляции, динамической или статической, чтобы скомпилировать управляющую программу, сохранить структуры программного обеспечения, выполнить другие операции, оптимизировать код или транслировать код; (2) выполнению кода основной программы, включая операции/вызовы, такие как управляющая программа, которая была оптимизирована/компилирована; (3) выполнению другой управляющей программы, такой как библиотеки, связанные с кодом основной программы, чтобы сохранять структуры программного обеспечения, выполнять другое программное обеспечение, связывать операции или оптимизировать код; или (4) к их комбинациям.
На фиг. 20 показана блок-схема варианта осуществления многоядерного процессора. Как показано в варианте осуществления на фиг. 20, процессор 2000 содержит многочисленные домены. Конкретно, основной домен 2030 содержит множество ядер 2030A-203ON, графический домен 2060 содержит один или более графических процессоров, имеющих процессор 2065 среды, и домен 2010 системного средства.
В различных вариантах осуществления, домен 2010 системного средства обрабатывает события управления электропитанием и управляет электропитанием, так что индивидуальные блоки 2030 и 2060 доменов (например, ядра и/или графические процессоры) управляются независимо, чтобы динамически действовать в соответствующем энергетическом режиме/уровне (например, активный, турбо, сон, гибернация, глубокий сон или другие состояния, подобные перспективному интерфейсу электропитания (Advanced Configuration Power Interface)) в свете действия (или бездействия), происходящего в данном блоке. Каждый из доменов 2030 и 2060 может работать при различных напряжениях и/или мощности и дополнительно индивидуальные блоки внутри доменов каждый потенциально работает при независимых частоте и напряжении. Заметим, что хотя показаны только три домена, понятно, что объем действия настоящего изобретения не ограничивается в этом отношении и в других вариантах осуществления могут присутствовать дополнительные домены.
Как показано на чертеже, каждое ядро 2030 дополнительно содержит кэши низкого уровня в дополнение к исполнительным блокам и дополнительным элементам обработки. Здесь различные ядра связываются друг с другом и с совместно используемой кэшпамятью, которая формируется из множества блоков или срезов кэша последнего уровня (LLC) 2040A-2040N; эти LLC часто содержат функциональные возможности контроллера запоминающего устройства и кэша и совместно используются между ядрами, а также, потенциально, между графическими процессорами.
Как видно на чертеже, кольцевое межсоединение 2050 связывает ядра вместе и обеспечивает межсоединение между доменом 2030 ядра, графическим доменом 2060 и схемой 2010 системного средства через множество кольцевых ограничителей 2052А-2052N, каждый в месте связи между срезом LLC и ядром. Как видно на фиг. 20, межсоединение 2050 используется для переноса различной информации, в том числе информации об адресах, информации о данных, информации подтверждения и информации о перехвате/недействительности. Хотя на чертеже показано кольцевое межсоединение, могут быть использованы любые известные межсоединения на кристалле или связная архитектура. В качестве примера, некоторые из обсуждавшихся выше связных архитектур (например, другое межсоединение на кристалле, системная архитектура на кристалле (On-chip System Fabric (OSF), межсоединение усовершенствованной архитектуры шины микроконтроллера (Advanced Microcontroller Bus Architecture, AMBA), многомерная сетчатая связная архитектура или другая известная архитектура межсоединений) могут использоваться подобным образом.
Как показано дополнительно, домен 2010 системного средства содержит механизм 2012 отображения, который должен обеспечивать управление и интерфейс к соответствующему дисплею. Домен 2010 системного средства может содержать и другие блоки, такие как: интегрированный контроллер 2020 памяти, который обеспечивает интерфейс с системной памятью (например, DRAM, реализуемая с многочисленными DIMM; логика 2022 когерентности, чтобы выполнять операции когерентности памяти. Многочисленные интерфейсы могут присутствовать, чтобы разрешать межсоединение между процессором и остальной схемой. Например, в одном из вариантов осуществления обеспечивается по меньшей мере один прямой интерфейс 2016 доступа к информации (DMI), а также один или более интерфейсов 2014 PCIe™. Механизм отображения и эти интерфейсы обычно связывают с памятью через мост 2018 PCIe™. Дополнительно, чтобы обеспечить связь между другими средствами, такими как дополнительные процессоры или другие схемы, могут обеспечиваться один или более других интерфейсов.
На фиг. 21 показана блок-схема репрезентативного ядра; конкретно, логические блоки внутреннего интерфейса ядра, такого как ядро 2030 на фиг. 20. В целом, структура, показанная на фиг. 21, содержит неупорядоченный процессор, имеющий блок 2170 внешнего интерфейса, используемый для выборки входящих команд, выполняет различную обработку (например, кэширование, декодирование, предсказание ветвей и т.д.) и пропускает команды/операций к неупорядоченному (ООО) механизму 2180. ООО-механизм 2180 выполняет дополнительную обработку декодированных команд.
Конкретно, в варианте осуществления, показанном на фиг. 21, неупорядоченный механизм 2180 содержит блок 2182 распределения, чтобы принимать декодированные команды, которые могут быть в форме одной или более микрокоманд или единичных операций (uop), от блока 2170 внешнего интерфейса, и распределять их таким образом, чтобы назначать ресурсы, такие как регистры и т.д. Затем, команды подаются к месту 2184 резервирования, где резервируются ресурсы, и их планируют для выполнения на одном из множества исполнительных блоков 2186A-2186N. Помимо прочего, могут быть представлены различные типы исполнительных блоков, в том числе, например, арифметические логические устройства (ALU), блоки загрузки и хранения, блоки векторной обработки (VPU), сопроцессоры для операций с плавающей точкой. Результаты от этих различных исполнительных блоков подаются в буфер 2188 упорядочивания (ROB), который получает неупорядоченные результаты и возвращает их для коррекции порядка программы.
Снова обращаясь к фиг. 21, заметим, что как блок 2170 внешнего интерфейса, так и неупорядоченный механизм 2180 связываются с разными уровнями иерархии памяти. Конкретно показанное является кэшем 2172 уровня команд, который, в свою очередь, связывается с кэшем 2176 среднего уровня, который, в свою очередь, связывается с кэшем 2195 последнего уровня. В одном из вариантов осуществления кэш 2195 последнего уровня осуществляется в блоке 2190 на чипе (иногда называют на неядерном блоке). Как пример, блок 2190 подобен системному средству 2010 на фиг. 20. Как обсуждалось выше, неядерный блок 2190 связывается с системной памятью 2199, которая в поясняемом варианте осуществления осуществляется через ED RAM. Заметим также, что различные исполнительные блоки 2186 внутри неупорядоченного механизма 2180 осуществляют связь с кэшем 2174 первого уровня, который также осуществляет связь с кэшем 2176 среднего уровня. Заметим также, что дополнительные ядра 2130N-2 - 2130N могут быть связаны с LLC 2195. Хотя в варианте осуществления, показанном на фиг. 21, все показано на высоком уровне, понятно, что могут присутствовать различные альтернативные и дополнительные компоненты.
На фиг. 22 показана блок-схема примерной компьютерной системы, сформированной с процессором, который содержит исполнительные блоки для исполнения команд, где одна или более реализаций межсоединений для одной или более функций соответствует одному из вариантов осуществления настоящего изобретения. Система 2200 содержит такой компонент, как процессор 2202, чтобы использовать исполнительные блоки, содержащие логику, для выполнения алгоритмов обработки данных в соответствии с настоящим изобретением, такой как в описанном здесь варианте осуществления. Система 2200 является представителем систем обработки, основанных на микропроцессорах PENTIUM III™, PENTIUM 4™, Xeon™, Itanium, XScale™ и/или StrongARM™, хотя также могут использоваться другие системы (в том числе, персональные компьютеры, имеющие другие микропроцессоры, технические рабочие станции, цифровые приемники и т.п.). В одном из вариантов осуществления опытная система 2200 использует версию операционной системы WINDOWS™, доступную от компании Microsoft Corporation, Редмонд, штат Вашингтон, хотя могут также использоваться и другие операционные системы (например, UNLX и Linux) и/или графические интерфейсы пользователя. Таким образом, варианты осуществления настоящего изобретения не ограничиваются никакой конкретной совокупностью схем аппаратурного обеспечения и программного обеспечения.
Варианты осуществления не ограничиваются компьютерными системами. Альтернативные варианты осуществления настоящего изобретения могут использоваться в других устройствах, таких как переносные устройства и встраиваемые приложения. Некоторыми примерами переносных устройств являются сотовые телефоны, устройства, работающие по Интернет-протоколу, цифровые фотоаппараты, персональные цифровые секретари (PDA) и переносные персональные компьютеры. Встроенные приложения могут содержать микроконтроллер, цифровой сигнальный процессор (DSP), систему на чипе, сетевые компьютеры (NetPC), цифровые приемники, сетевые концентраторы, переключатели глобальной сети (WAN) или любую другую систему, которая может выполнять одну или более команд в соответствии по меньшей мере с одним вариантом осуществления.
В этом варианте осуществления, поясняемом чертежом, процессор 2202 содержит один или более исполнительных блоков 2208 для реализации алгоритма, который должен выполнять по меньшей мере одну команду. Один из вариантов осуществления может быть описан в контексте рабочего стола единого процессора или системы сервера, но альтернативные варианты осуществления могут быть введены в многопроцессорную систему. Система 2200 является примером системной архитектуры "концентратора". Компьютерная система 2200 содержит процессор 2202 для обработки сигналов данных. Процессор 2202, как один из пояснительных примеров, содержит компьютерный микропроцессор со сложной системой команд (CISC), микропроцессор с сокращенной системой команд (RISC), микропроцессор с очень длинными словами команд (VLIW), процессор, осуществляющий комбинацию систем команд или любое другое процессорное устройство, такое как, например, цифровой сигнальный процессор. Процессор 2202 связывается с шиной 2210 процессора, которая передает сигналы данных между процессором 2202 и другими компонентами в системе 2200. Элементы системы 2200 (например, графический ускоритель 2212, концентратор 2216 контроллера памяти, память 2220, концентратор 2224 контроллера ввода-вывода, беспроводной приемопередатчик 2226, флэш-BIOS 2228, сетевой контроллер 2234, аудиоконтроллер 2236, последовательный расширительный порт 2238, контроллер 2240 ввода-вывода и т.д.) выполняют свои традиционные функции, известные специалистам в данной области техники.
В одном из вариантов осуществления процессор 2202 содержит внутреннюю кэшпамять 2204 уровня 1 (L1). В зависимости от архитектуры, процессор 2202 может иметь единый внутренний кэш или многочисленные уровни внутренних кэшей. Другие варианты осуществления содержат комбинацию внутренних и внешних кэшей в зависимости от конкретной реализации и потребностей. Регистровый файл 2206 должен хранить различные типы данных в различных регистрах, таких как целочисленные регистры, регистры с плавающей запятой, векторные регистры, групповые регистры, теневые регистры, регистры контрольных точек, регистры состояний и регистр указателей команд.
Исполнительный блок 2208, содержащий логику для выполнения целочисленных операций и операций с плавающей запятой, также находится в процессоре 2202. Процессор 2202 в одном из вариантов осуществления содержит ROM для микрокода (ucode), чтобы хранить микрокод, который, когда исполняется, должен выполнять алгоритмы для определенных макрокоманд или обрабатывать комплексные сценарии. Здесь микрокод потенциально может обновляться, чтобы обрабатывать логические ошибки/координаты местоположения для процессора 2202. Для одного из вариантов осуществления исполнительный блок 2208 содержит логику для обработки упакованного набора 2209 команд. Вводя в набор команд универсального процессора 2202 упакованный набор 2209 команд вместе со связанной схемой для выполнения команд, операции, используемые многими мультимедийными приложениями, могут выполняться, используя упакованные данные в универсальном процессоре 2202. Таким образом, множество мультимедийных приложений ускоряются и исполняются более эффективно при использовании полной ширины шины данных процессора для выполнения операций на упакованных данных. Это потенциально избавляет от необходимости передавать более мелкие блоки информации через шину данных процессора, чтобы выполнить одну или более операций по одному элементу данных за один раз.
Альтернативные варианты осуществления исполнительного блока 2208 могут также использоваться в микроконтроллерах, закладных процессорах, графических устройствах, DSP и других типах логических схем. Система 2200 содержит память 2220. Память 2220 содержит устройство динамической оперативной памяти (DRAM), устройство статической оперативной памяти (SRAM), устройство флэш-памяти или другое запоминающее устройство. Память 2220 хранит команды и/или данные, представленные сигналами данных, которые должны исполняться процессором 2202.
Заметьте, что любые из упомянутых выше признаков или вариантов изобретения могут использоваться на одном или более межсоединениях, показанных на фиг. 22. Например, межсоединение на кристалле (ODI), который не показан, для связи внутренних блоков процессора 2202 осуществляет один или более вариантов изобретения, описанных выше. Или изобретение связывается с шиной 2210 процессора (например, другим известным высокопроизводительным компьютерным межсоединением), широкополосным путем 2218 памяти к памяти 2220, звеном связи "точка-точка" с графическим ускорителем 2212 (например, совместимая связная архитектура экспресс-межсоединений периферийных компонент (PCIe)), межсоединением 2222 концентратора контроллера, межсоединением ввода-вывода или другим межсоединением (например, USB, PCI, PCIe) для связи с другими показанными на чертеже компонентами. Некоторые примеры таких компонент содержат аудиоконтроллер 2236, микропрограммный концентратор (флэш-BIOS) 2228, беспроводной приемопередатчик 2226, запоминающее устройство 2224 данных, контроллер 2210 действующего ввода-вывода, содержащий интерфейсы 2242 ввода пользователя и клавиатуры, последовательный расширительный порт 2238, такой как универсальная последовательная шина (USB) и сетевой контроллер 2234. Устройство 2224 хранения данных может содержать жесткий диск, дисковод для дискет, устройство CD-ROM, устройство флэш-памяти или другое запоминающее устройство большой емкости.
На фиг. 23 представлена блок-схема второй системы 2300, соответствующей варианту осуществления настоящего изобретения. Как показано на фиг. 23, многопроцессорная система 2300 является взаимосвязанной системой типа "точка-точка" и содержит первый процессор 2370 и второй процессор 2380, связанные через межсоединение 2350 "точка-точка". Каждый из процессоров 2370 и 2380 может быть некоторой версией процессора. В одном из вариантов осуществления 2352 и 2354 являются последовательной когерентной связной архитектурой межсоединений, такой как высокопроизводительная архитектура. В результате, изобретение может осуществляться в рамках архитектуры QPI.
Хотя на чертеже показаны только два процессора 2370, 2380, следует понимать, что объем настоящего изобретения этим не ограничивается. В других вариантах осуществления в данном процессоре могут присутствовать один или более дополнительных процессоров.
На чертежах показаны процессоры 2370 и 2380, соответственно содержащие интегрированные блоки 2372 и 2382 контроллеров памяти. Процессор 2370 также содержит в качестве части блоков контроллера его шины интерфейсы 2376 и 2378 типа "точка-точка" (Р-Р); аналогично, второй процессор 2380 содержит поверхности 2386 и 2388 типа Р-Р. Процессоры 2370, 2380 могут обмениваться информацией через интерфейс 2350 "точка-точка" (Р-Р), используя схемы интерфейсов Р-Р 2378, 2388. Как показано на фиг. 23, IMC 2372 и 2382 связывают процессоры с соответствующими памятями, а именно, памятью 2332 и памятью 2334, которые могут быть частями основной памяти, локально связанными с соответствующими процессорами.
Каждый из процессоров 2370, 2380 обменивается информацией с чипсетом 2390 через индивидуальные Р-Р-интерфейсы 2352, 2354, используя интерфейсные схемы 2376, 2394, 2386, 2398 типа "точка-точка". Чипсет 2390 также обменивается информацией с высокопроизводительной графической схемой 2338 через схему 2392 сопряжения вместе с высокопроизводительным графическим межсоединением 2339.
Совместно используемый кэш (не показан) может содержаться в любом из процессоров или вне обоих процессоров; при этом он соединяется с процессорами через межсоединение Р-Р так, что локальная информация кэша одного из процессоров или обоих процессоров может сохраняться в совместно используемом кэше, если процессор помещается в режим малого энергопотребления.
Чипсет 2390 может быть связан с первой шиной 2316 через интерфейс 2396. В одном варианте осуществления первая шина 2316 может быть шиной межсоединения периферийных компонент (PCI) или такой шиной, как шина PCI Express или другая шина межсоединений ввода-вывода третьего поколения, хотя объем настоящего изобретения этим не ограничивается.
Как показано на фиг. 23, различные устройства 2314 ввода-вывода связываются с первой шиной 2316 вместе с мостом 2318 шины, который связывает первую шину 2316 со второй шиной 2320. В одном из вариантов осуществления вторая шина 2320 содержит шину с низким количеством выводов (LPC). Со второй шиной 2320 связываются различные устройства, в том числе, например, клавиатура и/или мышь 2322, устройства 2327 связи и запоминающее устройство 2328, такое как дисковод или другое запоминающее устройство большой емкости, которые часто содержит команды/код и данные 2330 в одном варианте осуществления. Дополнительно, аудиоввод-вывод 2324 показан связанным со второй шиной 2320. Заметим, что возможна другая архитектура, где содержащиеся компоненты и связные архитектуры другие. Например, вместо архитектуры "точка-точка", показанной на фиг. 23, система может осуществить многоточечную шину или другую такую архитектуру.
Снова возвращаясь к фиг. 24, на чертеже показан вариант осуществления проекта системы на чипе (SOC), соответствующего изобретению. Как конкретный иллюстративный пример, SOC 2400 включается в оборудование пользователя (UE). В одном из вариантов осуществления UE относится к любому устройству, которое должно использоваться конечным пользователем для осуществления связи, такому как переносной телефон, смартфон, планшет, ультратонкий ноутбук, ноутбук с широкополосным адаптером или любое другое подобное устройство связи. Часто UE соединяется с базовой станцией или узлом, который по своему характеру потенциально соответствует мобильной станции (MS) в сети GSM.
Здесь, SOC 2400 содержит 2 ядра, 2406 и 2407. Подобно приведенному выше обсуждению, ядра 2406 и 2407 могут соответствовать архитектуре набора команд и быть такими как процессор на основе Intel® Architecture Core™ Intel®, процессор Advanced Micro Devices, Inc. (AMD), процессор, основанный на MIPS, проект процессора, основанный на ARM, или процессор, заказанный потребителем, а также их получателями лицензии или преемниками. Ядра 2406 и 2407 связываются с управлением 2408 кэшем, которое связывается с блоком 2409 интерфейса шины и кэшем L2 2411, чтобы осуществлять связь с другими частями системы 2400. Межсоединение 2410 содержит межсоединение на чипе, такое как IOSF, АМВА или другое межсоединение, обсуждавшееся выше, которое потенциально реализует один или более из описанных здесь вариантов.
Интерфейс 2410 обеспечивает каналы связи с другим компонентами, такими как модуль идентификации абонента (SIM) 2430 для сопряжения с SIM-картой, ROM 2435 начальной загрузки для хранения кода начальной загрузки для исполнения ядрами 2406 и 2407, чтобы инициализировать и провести начальную загрузку SOC 2400, контроллер SDRAM 2440 для сопряжения с внешней памятью (например, DRAM 2460), флэш-контроллер 2445 для сопряжения с долговременной памятью (например, Flash 2465), периферийное управление 2450 (например, последовательный периферийный интерфейс) для сопряжения с периферийным оборудованием, видеокодеки 2420 и видеоинтерфейс 2425 для отображения и приема входных сигналов (например, разрешенный входной сигнал касания), GPU 2415 для выполнения связанных с графикой вычислений и т.д. Любой из этих интерфейсов может содержать описанные здесь варианты изобретения.
Кроме того, система показывает периферийное оборудование для связи, такое как модуль 2470 Bluetooth, модем 2475 3G, GPS 2485 и WiFi 2485. Заметим, что, как указано выше, UE содержит радиооборудование для связи. В результате, эти периферийные модули связи вовсе не требуются. Однако, в UE некоторая форма радиооборудования для внешней связи должна содержаться.
Хотя настоящее изобретение было описано со ссылкой на ограниченное количество вариантов осуществления, специалисты в данной области техники могут понимать вытекающие их них многочисленные модификации и вариации. Подразумевается, что прилагаемая формула изобретения охватывает все такие модификации и вариации, которые попадают в рамки истинной сущности и объема настоящего изобретения.
Проект может проходить через различные этапы, от проведения моделирования до изготовления. Данные, представляющие проект, могут представлять проект многими способами. Во-первых, что полезно при моделированиях, аппаратурное обеспечение может быть представлено, используя язык описания аппаратурного обеспечения или другой функциональный язык описания. Кроме того, на некоторых этапах процесса проектирования может быть создана модель на уровне схем с логическими элементами и/или элементами транзисторной логики. Дополнительно, большинство проектов на некотором этапе достигают уровня данных, представляющих физическое расположение различных устройств в модели аппаратурного обеспечения. В случае, когда используются традиционные технологии изготовления полупроводников, данные, представляющие модель аппаратурного обеспечения, могут быть данными, определяющими присутствие или отсутствие различных признаков на различных уровнях маски для масок, используемых для изготовления интегральной схемы. При любом представлении проекта данные могут храниться в любой форме на машиночитаемом носителе. Память или магнитное или оптическое запоминающее устройство, такое как диск, могут быть машиночитаемым носителем для хранения информации, передаваемой посредством оптической или электрической модулированной волны или сформированную как-либо иначе для передачи такой информации. Когда электрическая несущая волна указывает или переносит код или проект передается в такой степени, что может выполняться копирование, буферирование или повторная передача электрического сигнала, создается новая копия. Таким образом, провайдер связи или сетевой провайдер может хранить на физическом, машиночитаемом носителе, по меньшей мере, временно, объект, такой как информация, закодированная в несущую волну, реализующая способы вариантов осуществления настоящего изобретения.
Термин "модуль", как он используется здесь, относится к любой совокупности аппаратурного обеспечения, программного обеспечения и/или встроенных программ. Как пример, модуль содержит аппаратурное обеспечение, такое как микроконтроллер, связанный с непереносимым носителем, для хранения управляющей программы, приспособленной к выполнению микроконтроллером. Поэтому, ссылка на модуль в любом из вариантов осуществления, относится к аппаратурному обеспечению, которое конкретно выполнено с возможностью распознавания и/или исполнения управляющей программы, которая должна храниться на непереносимом носителе. Дополнительно, в другом варианте осуществления, использование модуля относится к непереносимому носителю, содержащему управляющую программу, которая конкретно приспособлена к исполнению микроконтроллером, чтобы выполнять заданные операции. И, как может подразумеваться, в еще одном варианте осуществления, термин "модуль" (в этом примере) может относиться к сочетанию микроконтроллера и непереносимого носителя. Часто границы модулей, которые показаны как отдельные, в общем, варьируются и потенциально перекрываются друг с другом. Например, первый и второй модули могут совместно использовать аппаратурное обеспечение, программное обеспечение, встроенные программы или их сочетание, потенциально сохраняя некоторые независимые аппаратурное обеспечение, программное обеспечение или встроенные программы. В одном из вариантов осуществления использование термина "логика" содержит аппаратурное обеспечение, такое как транзисторы, регистры или другое аппаратурное обеспечение, такое как программируемые логические устройства.
Использование выражения "выполненный с возможностью" в одном из вариантов осуществления относится к расположению, соединению, изготовлению, предложению продажи, импорту и/или проектированию устройства, аппаратурного обеспечения, логики или элемента для выполнения спроектированной или определенной задачи. В этом примере, устройстве или его элемент, которые не работают, тем не менее "выполнены с возможностью" исполнения определенной задачи, если она разработана, связана и/или соединяется с выполнением упомянутой конкретной задачи. В качестве чисто иллюстративного примера, логический элемент может обеспечивать во время работы "0" или "1". Но логический элемент, "выполненный с возможностью" обеспечения разрешения для тактового сигнала, не содержит какого-либо потенциального логического элемента, который может обеспечивать "1" или "0". Вместо этого логический элемент является таким, который связывается таким образом, что во время работы вывод "1" или "0" должен разрешать тактовый сигнал. Заметим также, что использование термина "выполненный с возможностью" не требует операции, а вместо этого сосредотачивается на скрытом состоянии устройства, аппаратурного обеспечения и/или элемента, в котором в латентном состоянии устройство, технические средства, и/или элемент разрабатывается таким образом, чтобы выполнять конкретную задачу, когда устройство, аппаратурное обеспечение и/или элемент работает.
Кроме того, использование выражений "к"', "способный к" и/или "выполненный с возможностью" в одном из вариантов осуществления, относится к некоторому устройству, логике, аппаратурному обеспечению и/или элементу, разработанному таким способом, чтобы позволить использование устройства, логики, аппаратурного обеспечения и/или элемента указанным способом. Заметим, что как указано выше, использование "к"', "способный к" и/или "выполненный с возможностью" в одном их вариантов осуществления относится к скрытому состоянию устройства, логики, аппаратурного обеспечения и/или элемента, где устройство, логика, аппаратурное обеспечение и/или элемент не работают, но спроектированы таким образом, чтобы позволить использование устройства указанным способом.
Термин "значение", как он используется здесь, содержит любое известное представление количества, состояния, логического состояния или двоичного логического состояния. Часто использование логических уровней, значений логики или логических значений также упоминается как "1" и "0", которые просто представляют состояния двоичной логики. Например, "1" относится к высокому логическому уровню, и "0" относится к низкому логическому уровню. В одном из вариантов осуществления ячейка запоминающего устройства, такая как транзисторная или флэш-ячейка, может быть способна хранить одиночное логическое значение или многочисленные логические значения. Однако, в компьютерных системах использовались и другие представления значений. Например, десятичное число "десять" может также быть представлено как двоичное число 1010 и шестнадцатеричная буква А. Поэтому значение содержит любое представление информации, способное храниться в компьютерной системе.
Кроме того, состояния могут быть представлены значениями или частями значений. Как пример, первое значение, такое как логическая единица, может представлять значение по умолчанию или исходное состояние, тогда как второе значение, такое как логический ноль, может представлять состояние не по умолчанию. Кроме того, термины "установка на ноль" и "установка" в одном из вариантов осуществления относятся к значению по умолчанию и обновленному значению или состоянию, соответственно. Например, значение по умолчанию потенциально содержит высокое логическое значение, то есть, установку на ноль, тогда как обновленная величина потенциально содержит низкое логическое значение, то есть, установку. Заметим, что для представления любого количества состояний может быть использована любая комбинация значений.
Варианты осуществления способов, аппаратурного обеспечения, программного обеспечения, микропрограммный обеспечения или управляющей программы, описанные выше, могут осуществляться через команды или управляющую программу, хранящиеся на машинодоступном, машиночитаемом, доступном компьютеру или считываемом компьютером носителе, которые исполняются процессорным элементом. Непереносимый машинодоступный/считываемый компьютером носитель содержит любой механизм, обеспечивающий (то есть, хранит и/или передает) информацию в форме, считываемой машиной, такой как компьютер или электронная система. Например, непереносимый машинодоступный/считываемый носитель содержит запоминающее устройство с произвольной выборкой (RAM), такое как статическое RAM (SRAM) или динамическое RAM (DRAM); ROM; магнитный или оптический носитель для хранения данных; устройства флэш-памяти; электрические запоминающие устройства; оптические запоминающие устройства; акустические запоминающие устройства; другие формы запоминающих устройств для хранения информации, полученной из проходящих (распространяющихся) сигналов (например, несущих волн, инфракрасных сигналов, цифровых сигналов); и т.д., которые следует отличать от непереносимых носителей, которые могут получать из них информацию.
Команды, используемые для программной логики, чтобы выполнять варианты осуществления изобретения, могут храниться в памяти системы, такой как DRAM, кэш, флэш-память или другое запоминающее устройство. Дополнительно, команды могут распространяться через сеть или посредством другого считываемого компьютером носителя. Таким образом, машиночитаемый носитель может содержать любой механизм для хранения или передачи информации в форме, считываемой машиной (например, компьютером), и, в частности, дискеты, оптические диски, компакт-диск, постоянное запоминающее устройство (CD-ROM), и магнитооптические диски, постоянное запоминающее устройство (ROMs), оперативная память (RAM), стираемая программируемая постоянная память (EPROM), электрически стираемая программируемая постоянная память (EEPROM), магнитные или оптические карты, флэш-память, или физическое, считываемое машиной запоминающее устройство, используемое при передаче информации через Интернету посредством электрической, оптической, акустической или других форм распространяющихся сигналов (например, несущие волны, инфракрасные сигналы, цифровые сигналы и т.д.). Соответственно, считываемый компьютером носитель содержит любой тип физической машиночитаемой среды, пригодной для хранения или передачи электронных команд или информации, в форме, считываемой машиной (например, компьютером).
Нижеследующие примеры относятся к вариантам осуществления, соответствующим настоящему описанию. Один или более вариантов осуществления могут обеспечивать устройство, систему, машиносчитывающее запоминающее устройство, машиносчитываемый носитель, логику на основе аппаратурного обеспечения и/или программного обеспечения и способ приема данных по одной или более дорожкам для данных физического звена связи, приема действительного сигнала по другой из дорожек физического звена связи, идентифицирующего, что действительные данные должны следовать за подтверждением действительного сигнала по одной или более дорожкам для данных, и приема потокового сигнала по другой из дорожек физического звена связи, идентифицирующего тип данных на одной или более дорожках для данных.
По меньшей мере в одном примере, логика физического уровня дополнительно должна передавать сигнал управления конечным автоматом звена связи по другой из дорожек физического звена связи.
По меньшей мере в одном примере, логика физического уровня дополнительно должна передавать сигнал в боковой полосе через звено связи по боковой полосе.
По меньшей мере в одном примере, тип содержит протокол, связанный с данными, где протокол является одним из множества протоколов, использующих физическое звено связи.
По меньшей мере в одном примере, тип содержит пакетные данные уровня звена связи.
По меньшей мере в одном примере, данные должны облегчать переключения состояния звена связи для физического звена связи.
По меньшей мере в одном примере, логика физического уровня дополнительно должна декодировать потоковый сигнал, чтобы идентифицировать, какой из множества различных протоколов применяется к данным.
По меньшей мере в одном примере, логика физического уровня дополнительно должна пропускать данные к логике протокола верхнего уровня, соответствующей конкретному протоколу из множества протоколов, идентифицированных в потоковом сигнале.
По меньшей мере в одном примере, устройство содержит логику уровня звена связи и другую логику верхнего уровня каждого из множества протоколов в дополнение к логике физического уровня.
По меньшей мере в одном примере, множество протоколов содержит по меньшей мере два из таких протоколов, как протокол Peripheral Component Interconnect (PCI), протокол PCI Express (PCIe), протокол Intel In-Die Interconnect (IDI) и протокол Quick Path Interconnect (QPI).
По меньшей мере в одном примере, логика физического уровня дополнительно должна определять ошибки в каждом из множества протоколов.
По меньшей мере в одном примере, логика физического уровня дополнительно должна определять ошибки в одном или более действительных сигналах и потоковых сигналах.
По меньшей мере в одном примере, логика физического уровня дополнительно должна определять окно данных для данных, которые должны передаваться по дорожкам для данных, и окно данных соответствует действительному сигналу.
По меньшей мере в одном примере, окно данных соответствует символу данных и действительный сигнал должен быть подтвержден в окне, непосредственно предшествующем окну, в котором данные должны быть переданы.
По меньшей мере в одном примере, данные должны игнорироваться на дорожках для данных в окне, непосредственно следующем после предыдущего окна, в котором действительный сигнал не подтверждается.
По меньшей мере в одном примере, окно соответствует периоду времени байта.
По меньшей мере в одном примере, каждый действительный сигнал, данные, и потоковый сигнал выравниваются в соответствии с окнами данных, определенным для физического звена связи.
По меньшей мере в одном примере, потоковый сигнал должен передаваться в течение того же самого окна, что и данные.
По меньшей мере в одном примере, физическое звено связи соединяет два устройства в многокристальной интегральной схеме.
По меньшей мере в одном примере, логика физического уровня должна дополнительно повторно центровать сигналы на дорожках физического звена связи.
По меньшей мере в одном примере, дорожки должны повторно центроваться, основываясь на действительном сигнале.
По меньшей мере в одном примере, потоковый сигнал принимается на выделенной дорожке для потокового сигнала звена передачи данных во время второго окна, потоковый сигнал декодируется и протокол, связанный с данными, определяется из результата декодирования потокового сигнала.
По меньшей мере в одном примере, звено передачи данных адаптируется для данных по множеству различных протоколов.
По меньшей мере в одном примере, данные, которые должны передаваться по звену связи для данных идентифицируются, действительный сигнал передается по исходящей дорожке для действительного сигнала звена связи для данных во время конкретного окна, соответствующего данным, которые должны передаваться, и данные передаются по выделенным исходящим дорожкам для данных во время другого окна, непосредственно следующего за конкретным окном.
По меньшей мере в одном примере, множество дорожек для данных дополнительно содержат выделенную дорожку с боковой полосой для конечного автомата звена связи.
По меньшей мере в одном примере, первое устройство содержит первый кристалл внутри интегральной схемы и второе устройство содержит второй кристалл внутри интегральной схемы.
По меньшей мере в одном примере, первое устройство содержит устройство внутри интегральной схемы и второе устройство содержит устройство вне интегральной схемы.
В одном или более вариантах осуществления могут обеспечиваться устройство, система, машиночитающее запоминающее устройство, машиночитаемый носитель, логика на основе аппаратурного обеспечения и/или программного обеспечения, и способ идентификации данных, которые должны передаваться по выделенным дорожкам передачи данных звена связи для данных, передачи действительного сигнала по выделенной дорожке канала передачи данных для действительного сигнала во время конкретного окна, соответствующего данным, которые должны передаваться по звену связи для данных, передачи данных по выделенным дорожкам для данных звена связи для данных во время другого окна, непосредственно следующего за конкретным окном, и передачи потокового сигнала по звену связи для потокового сигнала, кодированного для идентификации типа данных.
По меньшей мере в одном примере, действительный сигнал должен индицировать, что данные на дорожке для данных в течение другого окна являются действительными данными.
По меньшей мере в одном примере, звено связи для потокового сигнала содержит выделенное звено связи для потокового сигнала.
По меньшей мере в одном примере, потоковый сигнал адаптируется для идентификации, является ли конкретный протокол связанным с данными.
По меньшей мере в одном примере, логика физического уровня содержится в общем физическом уровне и множество протоколов используют общий физический уровень и конкретный протокол содержится во множество протоколов.
По меньшей мере в одном примере, множество протоколов содержит два или более из числа протоколов PCI, PCIe, IDI и QPI.
По меньшей мере в одном примере, потоковый сигнал дополнительно адаптируется для идентификации, содержат ли данные пакеты уровня звена связи.
По меньшей мере в одном примере, потоковый сигнал дополнительно адаптируется, чтобы идентифицировать, являются ли данные данными боковой полосы.
По меньшей мере в одном примере, логика физического уровня дополнительно должна определять тип данных и кодировать потоковый сигнал для идентификации определенного типа.
По меньшей мере в одном примере, логика физического уровня должна передавать сигналы боковой полосы (LSM-_SB) конечного автомата звена связи по выделенной дорожке для LSM_SB звена связи для данных.
По меньшей мере в одном примере, логика физического уровня дополнительно должна передавать сигналы боковой полосы по звену связи боковой полосы, отдельному от звена связи для данных.
По меньшей мере в одном примере, логика физического уровня дополнительно должна передавать данные уровня звена связи по дорожкам для данных, где данные уровня звена связи используются для переключения звена связи для данных из первого состояния звена связи во второе состояние звена связи.
По меньшей мере в одном примере, первое состояние звена связи содержит активное состояние звена связи, и второе состояние звена связи содержит состояние звена связи с низким энергопотреблением.
По меньшей мере в одном примере, логика физического уровня дополнительно должна идентифицировать первое окно данных, соответствующее действительному сигналу, и передавать данные по дорожкам для данных в пределах второго окна для данных, непосредственно следующего за первым окном для данных.
По меньшей мере в одном примере, отсутствие подтверждения действительного сигнала указывает, что данные на дорожках для данных в непосредственно следующем последующем окне должны игнорироваться как недействительные.
По меньшей мере в одном примере, каждое первое и второе окна для данных определяются так, чтобы соответствовать периоду времени байта.
По меньшей мере в одном примере, каждый действительный сигнал, данные и потоковый сигнал выравниваются в соответствии с окнами для данных, определенными для физического звена связи.
По меньшей мере в одном примере, потоковый сигнал должен передаваться в течение того же самого окна, что и данные.
По меньшей мере в одном примере, логика физического уровня дополнительно должна формировать как действительный сигнал, так и потоковый сигнал.
По меньшей мере в одном примере, звено связи для данных соединяет два устройства в многокристальной интегральной схеме.
По меньшей мере в одном примере, звено связи для данных должно поддерживать скорости передачи данных, превышающие 8 Гб/с.
Один или более вариантов осуществления могут обеспечивать устройство, систему, машиночитающее запоминающее устройство, машиночитаемый носитель, логику, основанную на аппаратурном обеспечении и/или программном обеспечении и способ обеспечения асимметричной передачи сигналов по звену связи для данных, содержащему множество дорожек, в том числе, множество дорожек для данных, одну или более дорожек для действительного сигнала, одну или более дорожек для потокового сигнала, и распределения сигнала тактовой частоты для использования множеством дорожек, где сигналы, передаваемые по каждой из множества дорожек, должны выравниваться с сигналом тактовой частоты.
По меньшей мере в одном примере, каждая из дорожек для данных заканчивается промежуточной шиной, подключаемой к стабилизированному напряжению.
По меньшей мере в одном примере, стабилизированное напряжение обеспечивается для каждой из множества дорожек для данных единым стабилизатором напряжения.
По меньшей мере в одном примере, стабилизированное напряжение, в сущности, равно Vcc/2, где Vcc является напряжением электропитания.
По меньшей мере в одном примере, логика физического уровня должна пытаться обеспечивать подавление перекрестных помех между двумя или более из множества дорожек для данных.
По меньшей мере в одном примере, подавление перекрестных помех обеспечивается добавлением взвешенного, отфильтрованного фильтром верхних частот сигнала-агрессора на первую из двух или более дорожек для данных к сигналу второй из двух или более дорожек для данных.
По меньшей мере в одном примере, логика физического уровня должна формировать взвешенный, отфильтрованный фильтром верхних частот сигнал-агрессор, по меньшей мере, частично используя фильтр нижних частот, состоящий из конденсатора и резистора (RC).
По меньшей мере в одном примере, логика физического уровня должна обеспечивать коррекцию рабочего цикла на каждый бит.
По меньшей мере в одном примере, логика физического уровня должна обнаруживать искажение, по меньшей мере, частичное одной из дорожек для данных и устранение искажения конкретной дорожки для данных.
По меньшей мере в одном примере, логика физического уровня дополнительно должна применять инверсию шины данных (DBI) АС по меньшей мере к одной из дорожек для данных.
По меньшей мере в одном примере, тактовый сигнал содержит тактовый сигнал с опережением на половину периода.
По меньшей мере в одном примере, логика физического уровня дополнительно должна обеспечивать защиту от электростатического разряда.
По меньшей мере в одном примере, логика физического уровня реализуется, по меньшей мере, частично через схемы аппаратурного обеспечения.
По меньшей мере в одном примере, действительные сигналы должны передаваться по дорожкам для действительных сигналов, и каждый действительный сигнал идентифицирует, что действительные данные должны следовать за подтверждением действительного сигнала на множестве дорожек для данных, и потоковые сигналы должны передаваться по дорожкам для потоковых сигналов и каждый потоковый сигнал идентифицирует тип данных на одной или более дорожках для данных.
По меньшей мере в одном примере, звено связи для данных должно поддерживать скорости передачи данных, превышающие 8 Гб/с.
Один или более вариантов осуществления могут обеспечивать устройство, систему, машиночитающее запоминающее устройство, машиночитаемый носитель, логику, основанную на аппаратурном обеспечении и/или программном обеспечении, и способ обеспечения асимметричной передачи сигналов по звену связи для данных, содержащему множество дорожек, в том числе, множество дорожек для данных, одну или более дорожек для действительных сигналов, одну или более дорожек для потоковых сигналов и одну или более дорожек боковой полосы для конечных автоматов звена связи, чтобы распространять тактовый сигнал для использования множеством дорожек, где сигналы, переданные по каждой из множества дорожек, должны выравниваться с тактовыми сигналами, обеспечивать подавление перекрестных помех между двумя или более из множества дорожек для данных и обеспечивать коррекцию рабочего цикла для каждого бита звена связи для данных, где каждая из дорожек для данных заканчивается промежуточной шиной, подключаемой к стабилизированному напряжению.
По меньшей мере в одном примере, логика физического уровня дополнительно должна обнаруживать деформацию по меньшей мере одной конкретной дорожки из числа дорожек для данных и устранять деформацию конкретной дорожки для данных.
Один или более вариантов осуществления может обеспечивать устройство, систему, машиночитаемое запоминающее устройство, машиночитаемый носитель, логику, основанную на аппаратурном обеспечении и/или программном обеспечении, и способ идентификации, что соответствующие верхние уровни каждого из множества многоуровневых запрашивают переключение звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением, где каждый из множества многоуровневых протоколов должен использовать звено связи для данных как физический уровень, и переключения звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением, основываясь на идентификации, что верхние уровни каждого из множества протоколов запрашивают переключение в состояние звена связи с низким энергопотреблением.
По меньшей мере в одном примере, логика физического уровня дополнительно должна участвовать в квитировании с другим устройством, чтобы заставлять звено связи для данных переключаться в состояние звена связи с низким энергопотреблением.
По меньшей мере в одном примере, квитирование содержит квитирование на уровне звена связи.
По меньшей мере в одном примере логика физического уровня должна передавать данные уровня звена связи при квитировании уровня звена связи, в то время как звено связи для данных находится в состоянии активного звена связи.
По меньшей мере в одном примере, логика физического уровня должна передавать потоковый сигнал, по существу, одновременно с данными уровня звена связи, чтобы идентифицировать, что данные, переданные на уровнях передачи данных звена связи для данных, содержат пакеты уровня звена связи.
По меньшей мере в одном примере, потоковый сигнал передается по выделенной дорожке для потокового сигнала звена связи для данных во время конкретного окна, где данные уровня звена связи также передаются во время конкретного окна.
По меньшей мере в одном примере, логика физического уровня должна передавать действительный сигнал по выделенной дорожке для действительного сигнала звена связи для данных, по которой действительный сигнал передается в другом окне, непосредственно предшествующем конкретному окну, чтобы указать, что данные, переданные в конкретном окне, являются действительными.
По меньшей мере в одном примере, квитирование содержит передачу квитирования по звену связи боковой полосы.
По меньшей мере в одном примере, квитирование содержит квитирование уровня звена связи и передачу квитирования по звену связи боковой полосы.
По меньшей мере в одном примере, передача квитирования по звену связи боковой полосы подтверждает квитирование уровня звена связи.
По меньшей мере в одном примере, логика физического уровня дополнительно должна идентифицировать запрос переключения звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением с верхнего уровня первого протокола из множества многоуровневых протоколов.
По меньшей мере в одном примере, логика физического уровня дополнительно должна ожидать переключения звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением, пока не будут приняты запросы от каждого другого протокола из множества многоуровневых протоколов.
По меньшей мере в одном примере, логика физического уровня должна следить за каждым из множества многоуровневых протоколов, запросил ли протокол переключение звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением.
По меньшей мере в одном примере, логика физического уровня дополнительно должна формировать ответ на запрос, подтверждающий переключение звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением в фактическое переключение звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением.
По меньшей мере в одном примере, ответ передается во время подтверждения переключения звена связи для данных из активного состояния звена связи в состояние звена связи с низким энергопотреблением, вытекающего из одного или более других протоколов из множества многоуровневых протоколов.
По меньшей мере в одном примере, состояние низкого энергопотребления звена связи содержит состояние ожидания звена связи.
По меньшей мере в одном примере, множество многоуровневых протоколов содержит один или более из протоколов PCI, PCIe, IDI и QPI.
Может обеспечиваться система, содержащая звено связи для данных, имеющее в своем составе множество дорожек, первое устройство и второе устройство, связанное средствами связи с первым устройством, используя звено связи для данных, причем второе устройство содержит логику верхнего уровня первого протокола, логику верхнего уровня второго протокола, где каждый протокол из множества наборов протоколов использует общий физический уровень и логику физического уровня для общего физического уровня, где логика физического уровня должна определять, что каждый из протоколов, в том числе, первый и второй протоколы, использующие звено связи для данных, подтверждает переключение звена связи для данных из активного состояния звена связи в состояние низкого энергопотребления звена связи до переключения звена связи для данных в состояние низкого энергопотребления звена связи.
По меньшей мере в одном примере множество дорожек содержит множество дорожек для данных, одну или более дорожек для действительных сигналов, одну или более дорожек для передачи потоковых сигналов.
По меньшей мере в одном примере, действительные сигналы должны передаваться по дорожкам для действительных сигналов, и каждый действительный сигнал идентифицирует, что действительные данные должны следовать после подтверждения действительного сигнала на множестве дорожек для данных, и потоковые сигналы должны передаваться по дорожкам для потоковых сигналов и каждый потоковый сигнал идентифицирует тип данных на одной или более дорожках для данных.
По меньшей мере в одном примере, переключение звена связи для данных в состояние низкого энергопотребления звена связи содержит квитирование между первым и вторым устройствами.
По меньшей мере в одном примере, квитирование содержит квитирование на уровне звена связи и квитирование на боковой полосе.
По меньшей мере в одном примере, первое устройство содержит первый кристалл внутри интегральной схемы и второе устройство содержит второй кристалл внутри интегральной схемы.
По меньшей мере в одном примере, первое устройство содержит устройство внутри интегральной схемы и второе устройство содержит устройство вне интегральной схемы.
Ссылка в этом описании на "один из вариантов осуществления" или "вариант осуществления" означает, что конкретный признак, структура или характеристика, описанные в связи с вариантом осуществления, содержатся по меньшей мере в одном из вариантов осуществления настоящего изобретения. Таким образом, появление выражений "в одном из вариантов осуществления" или "в варианте осуществления" повсеместно в различных местах настоящего описания не обязательно всегда относится к одному и тому же варианту осуществления. Дополнительно, конкретные признаки, структуры или характеристики могут объединяться любым доступным способом в одном или более вариантах осуществления.
В предшествующем описании было дано подробное описание со ссылкой на конкретные примерные варианты осуществления. Однако, должно быть очевидным, что в них могут быть произведены различные модификации и изменения, не отступая от более широких сущности и объема изобретения, изложенных в добавленной формуле изобретения. Описание и чертежи должны, соответственно, рассматриваться как иллюстрации, а не как ограничения. Дополнительно, предшествующее использование варианта осуществления и другого примерного языка не обязательно относится к тому же самому варианту осуществления или к тому же самому примеру, а может относиться к другим и отличающимся вариантам осуществления, а также потенциально к тому же самому варианту осуществления.
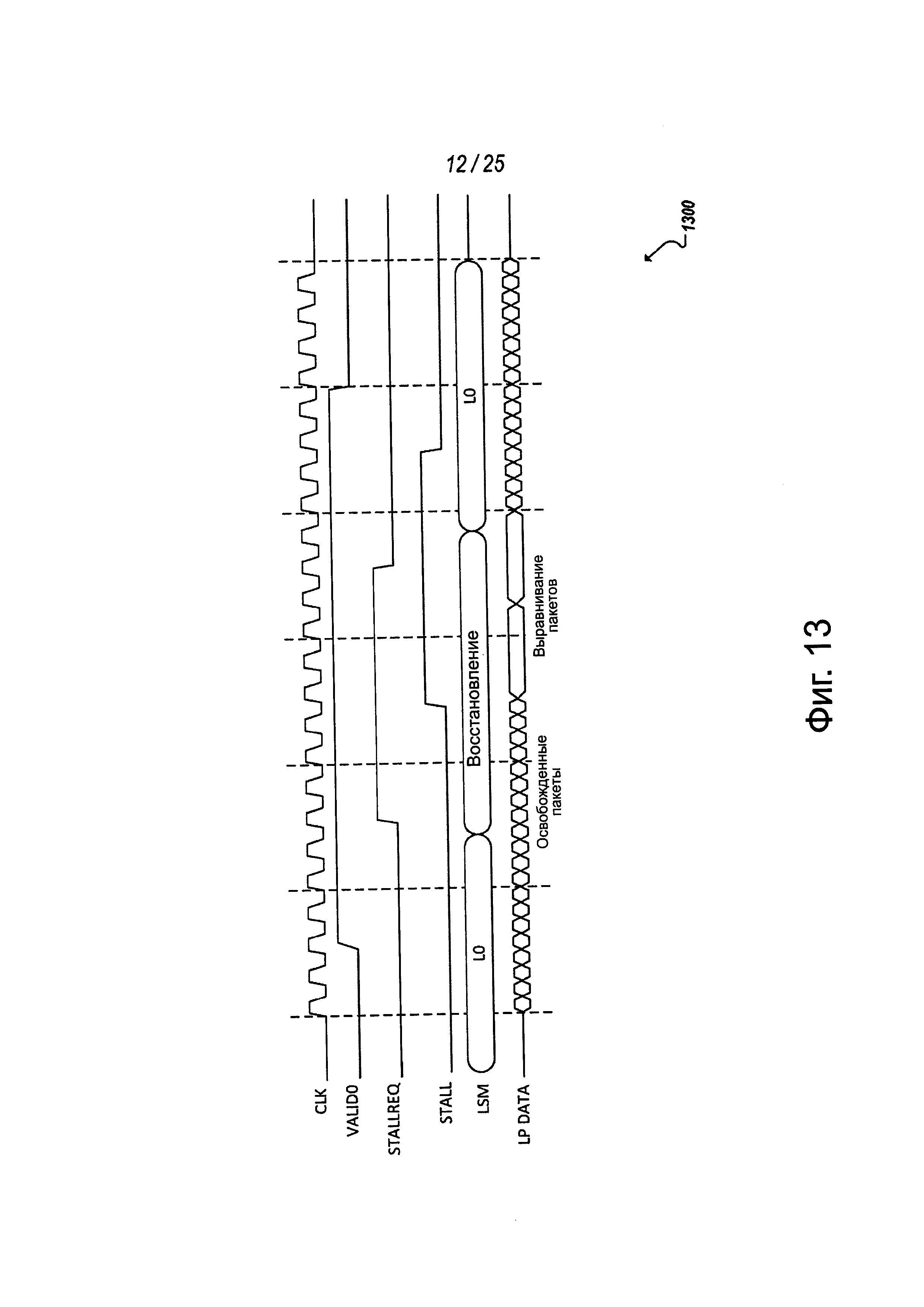
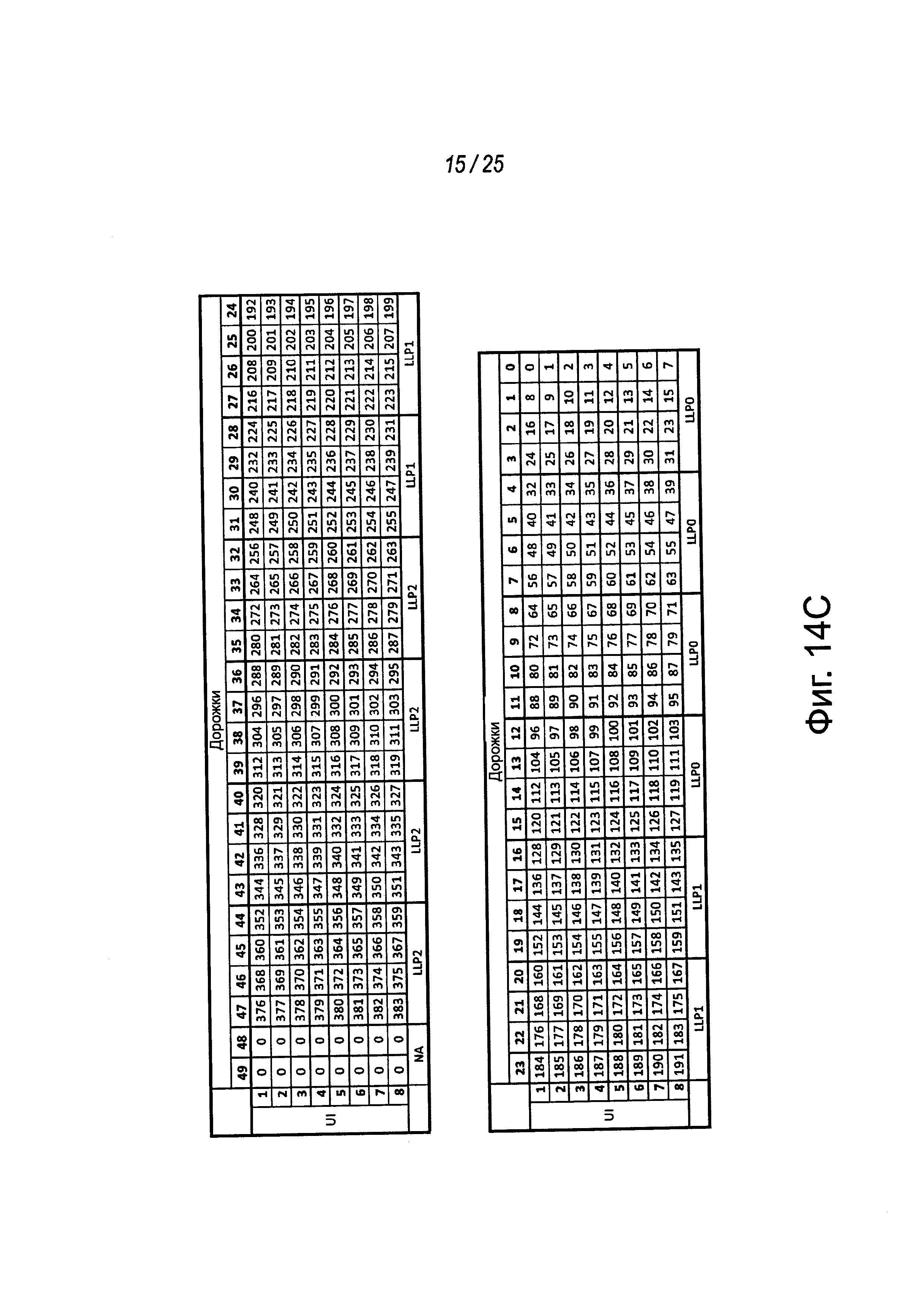
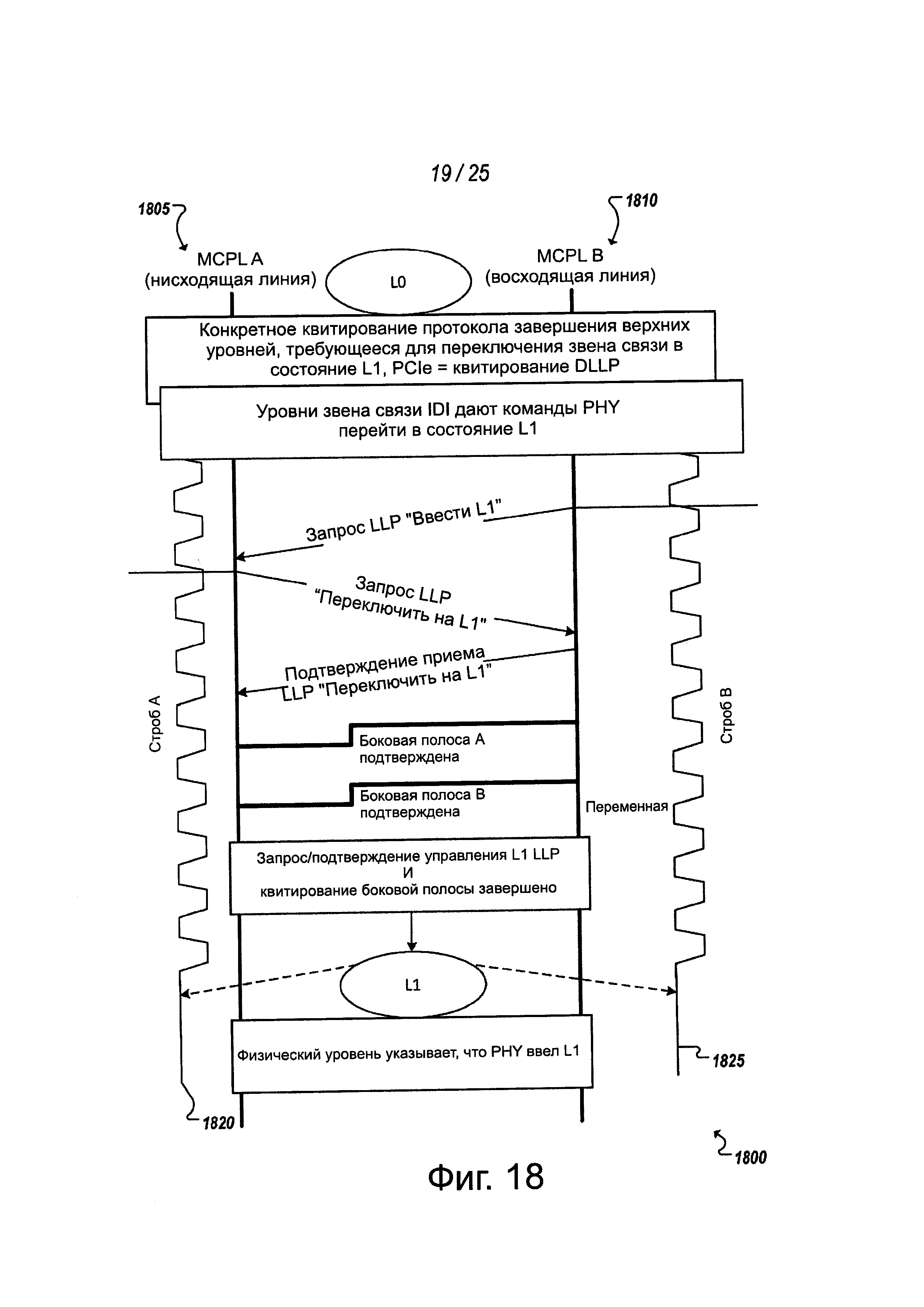
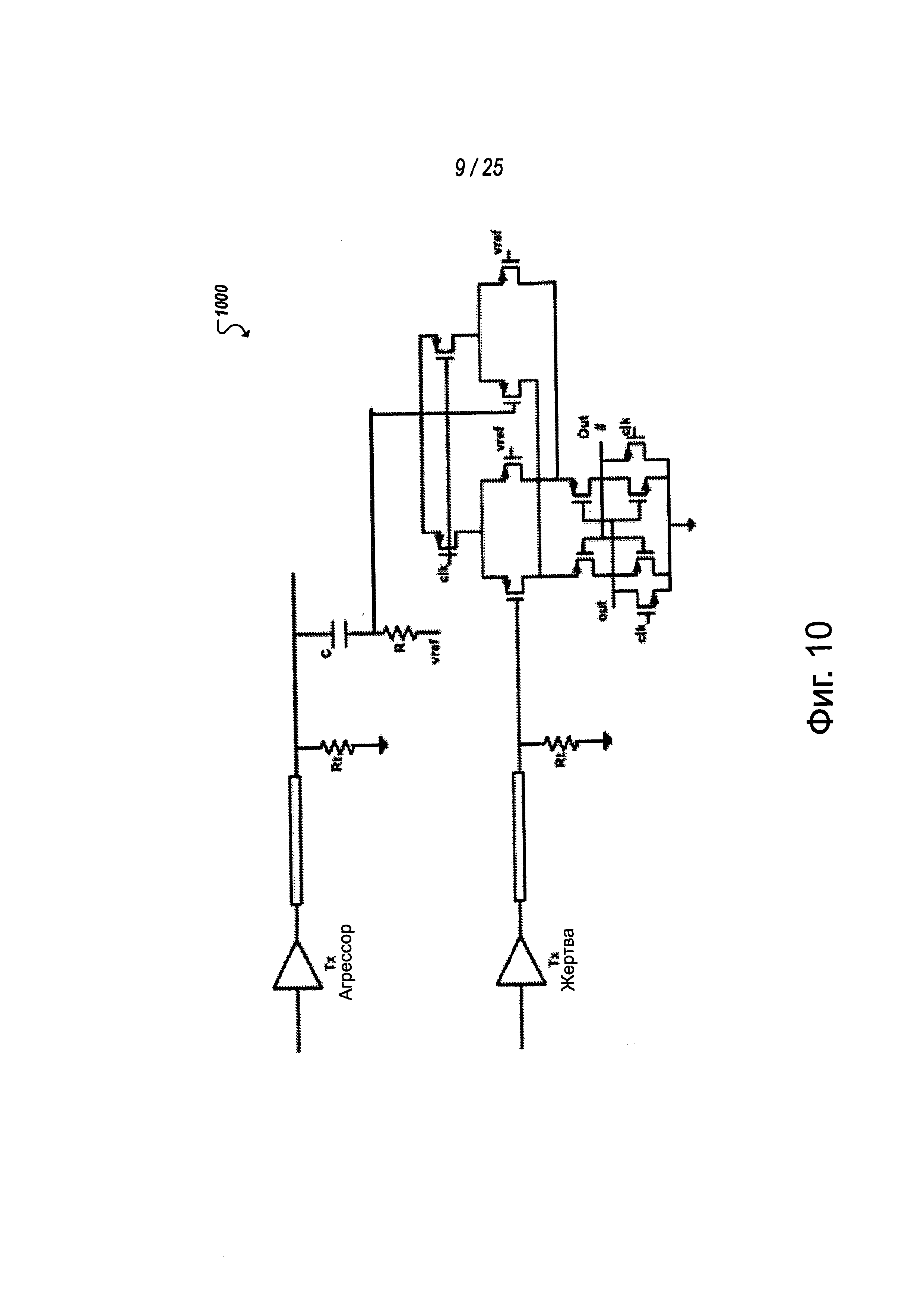
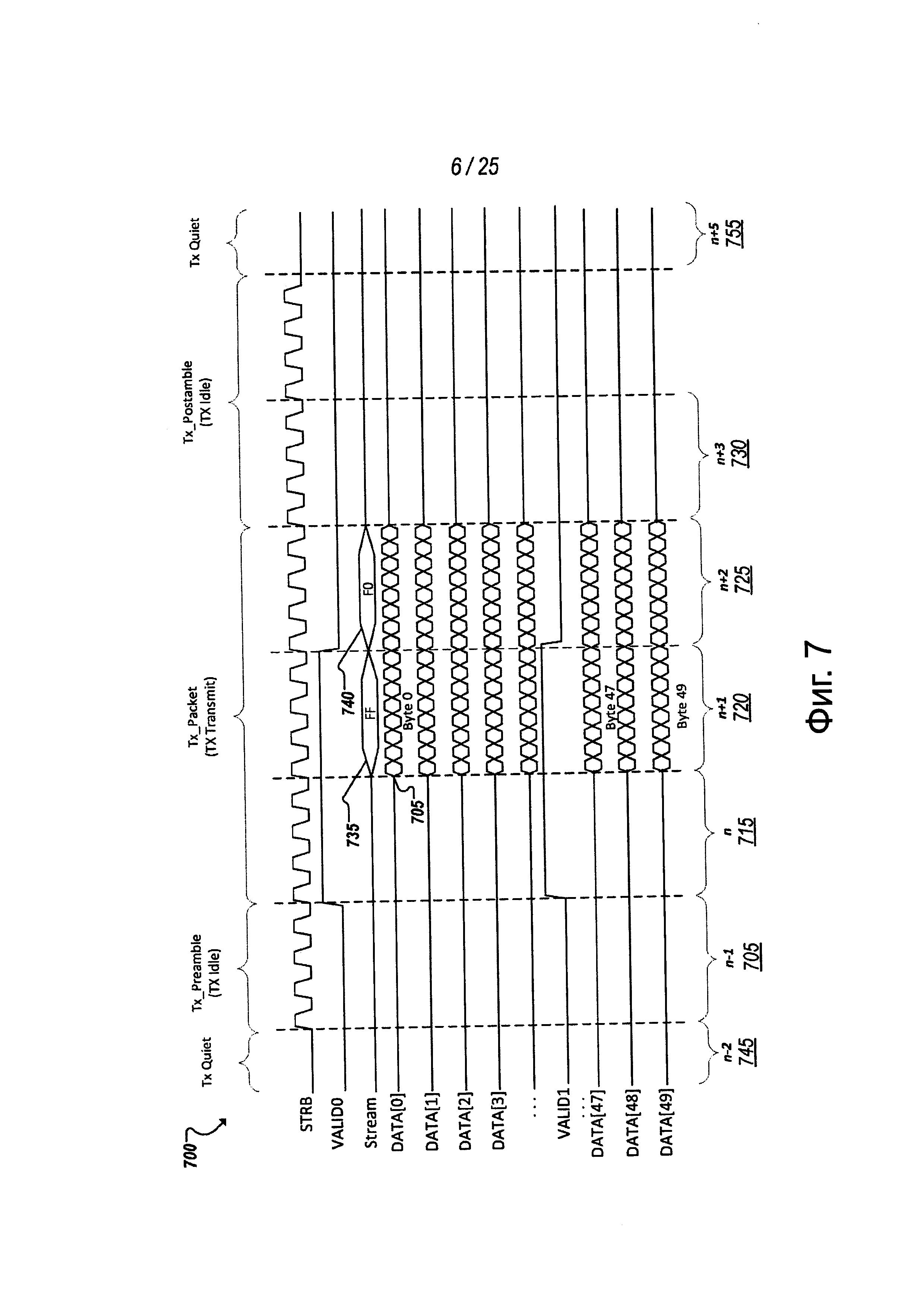
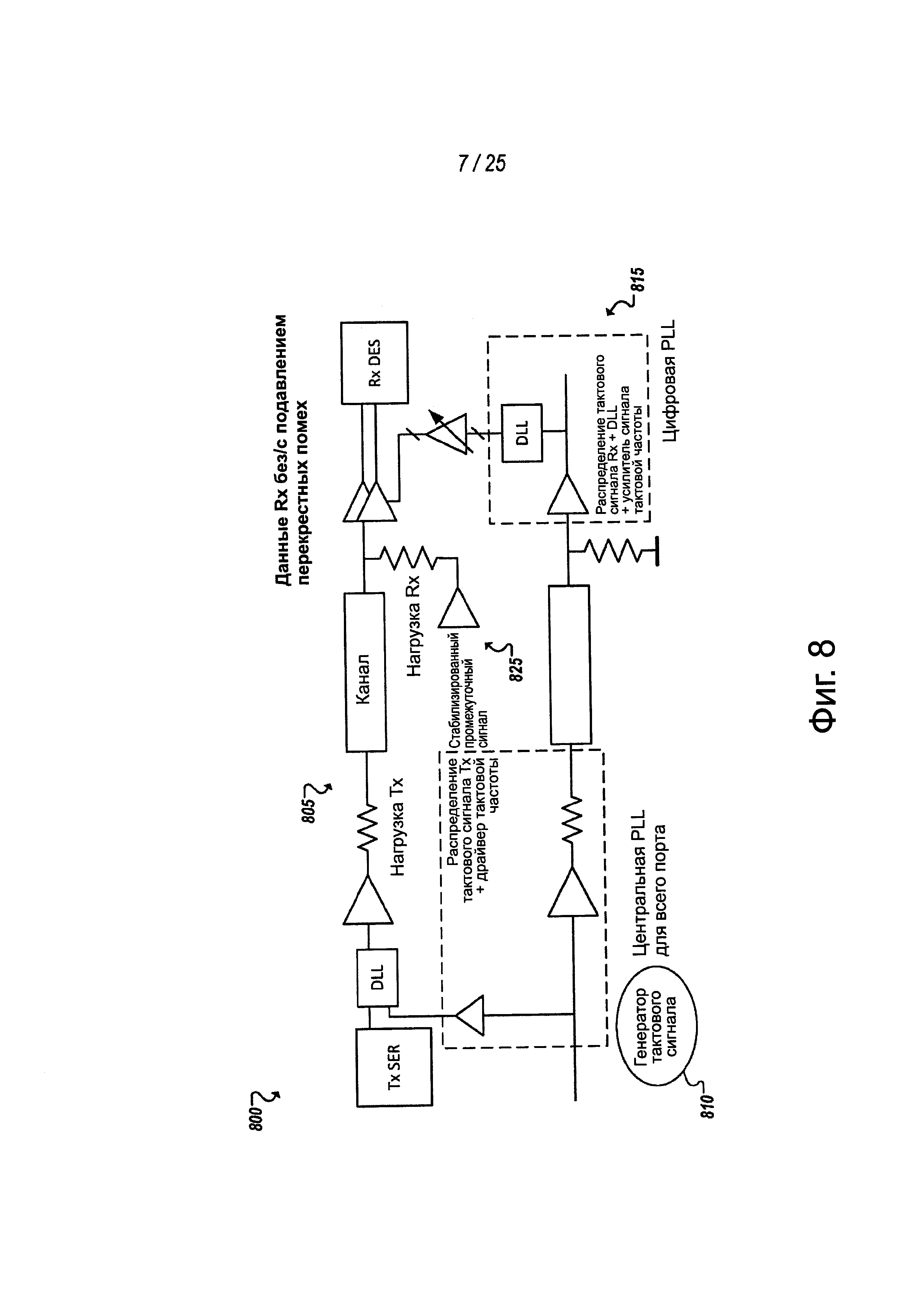
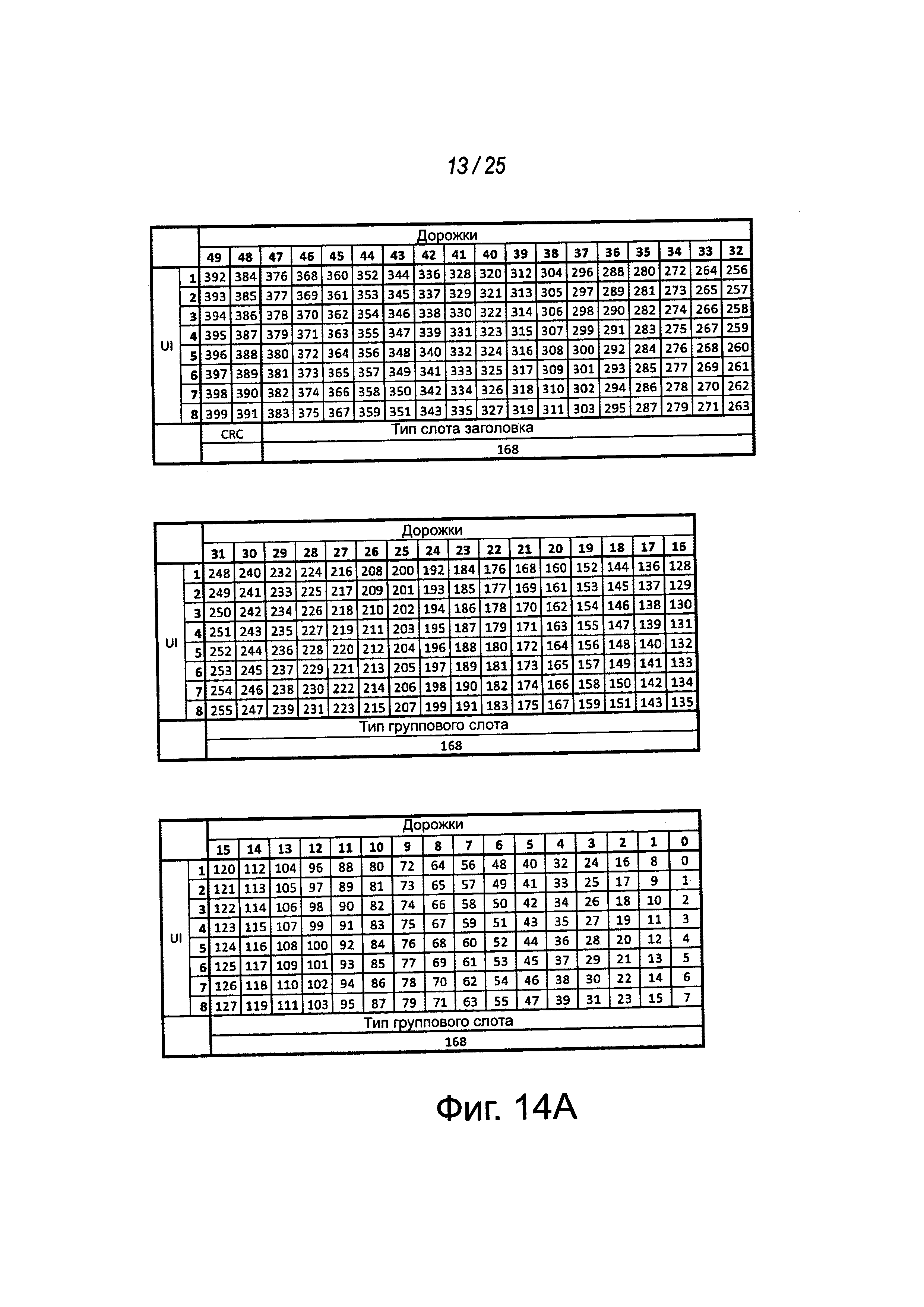
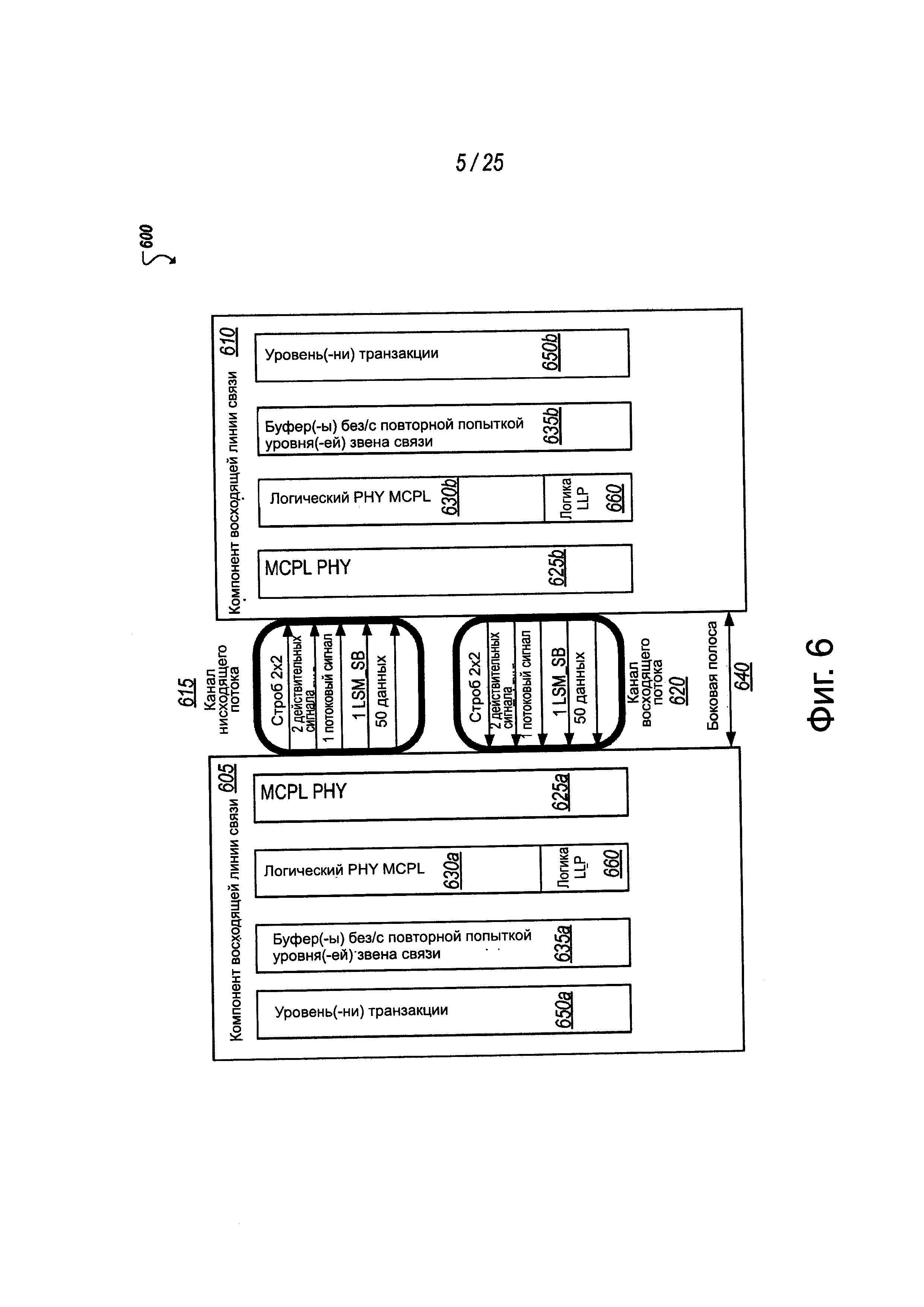
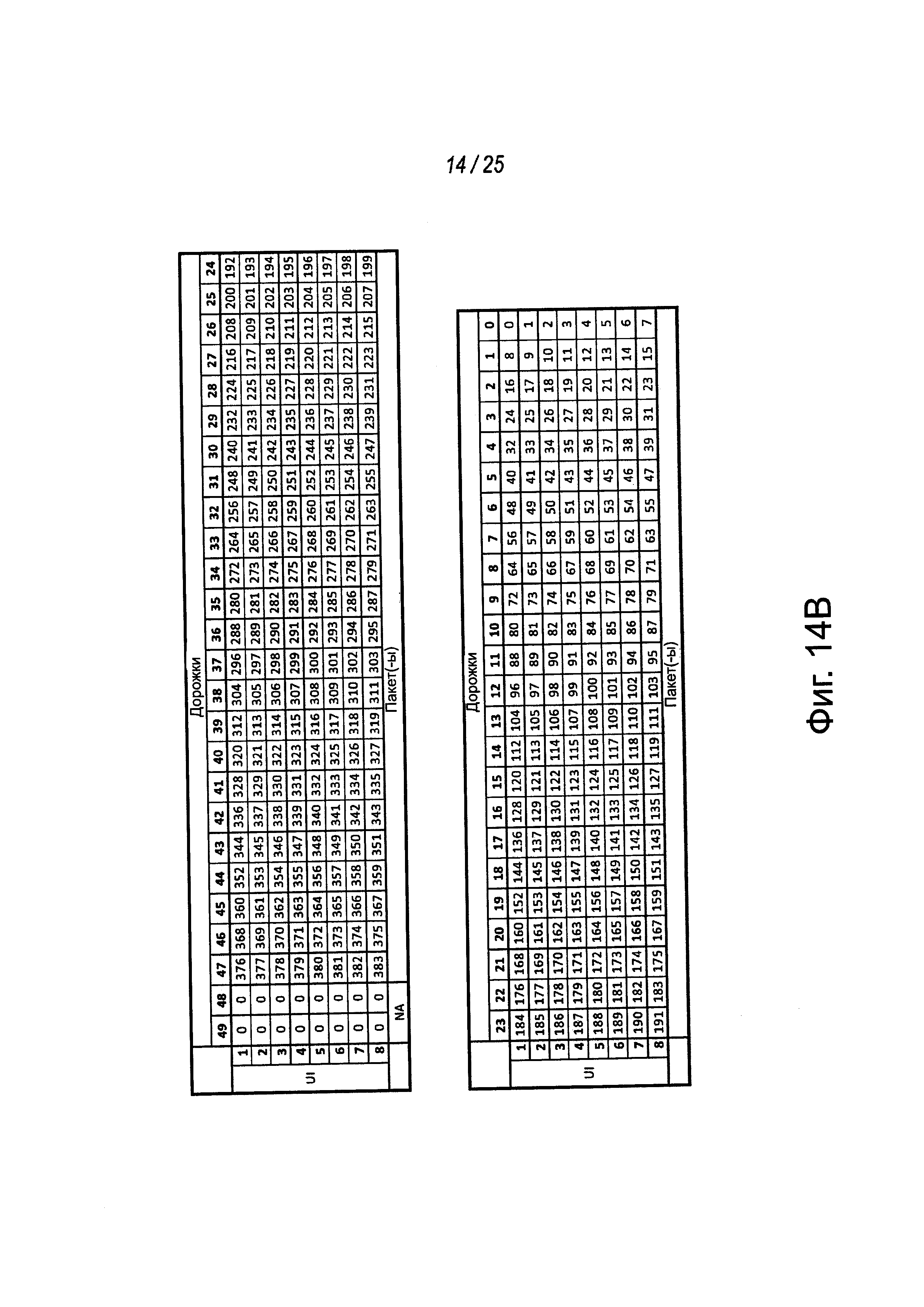
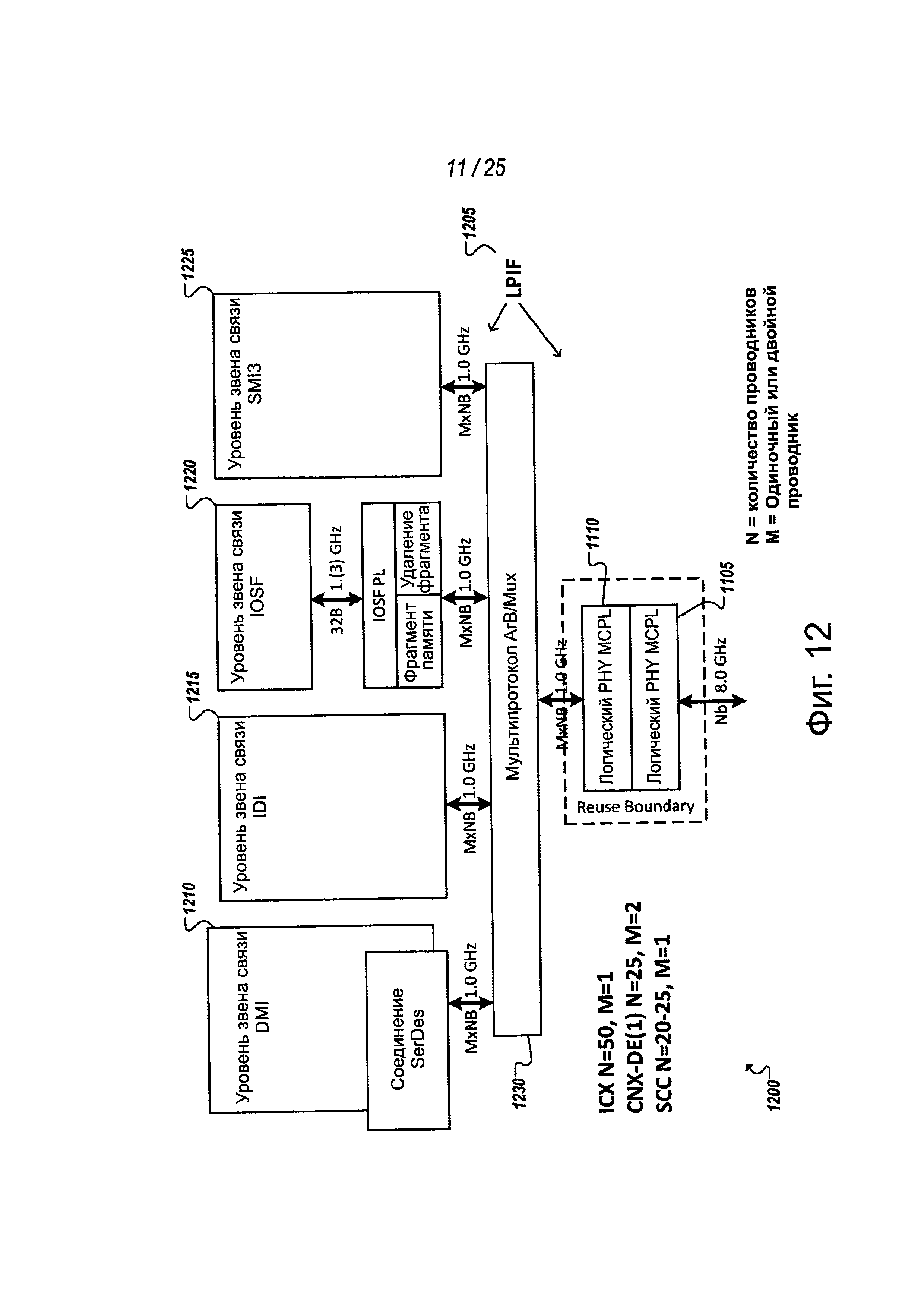
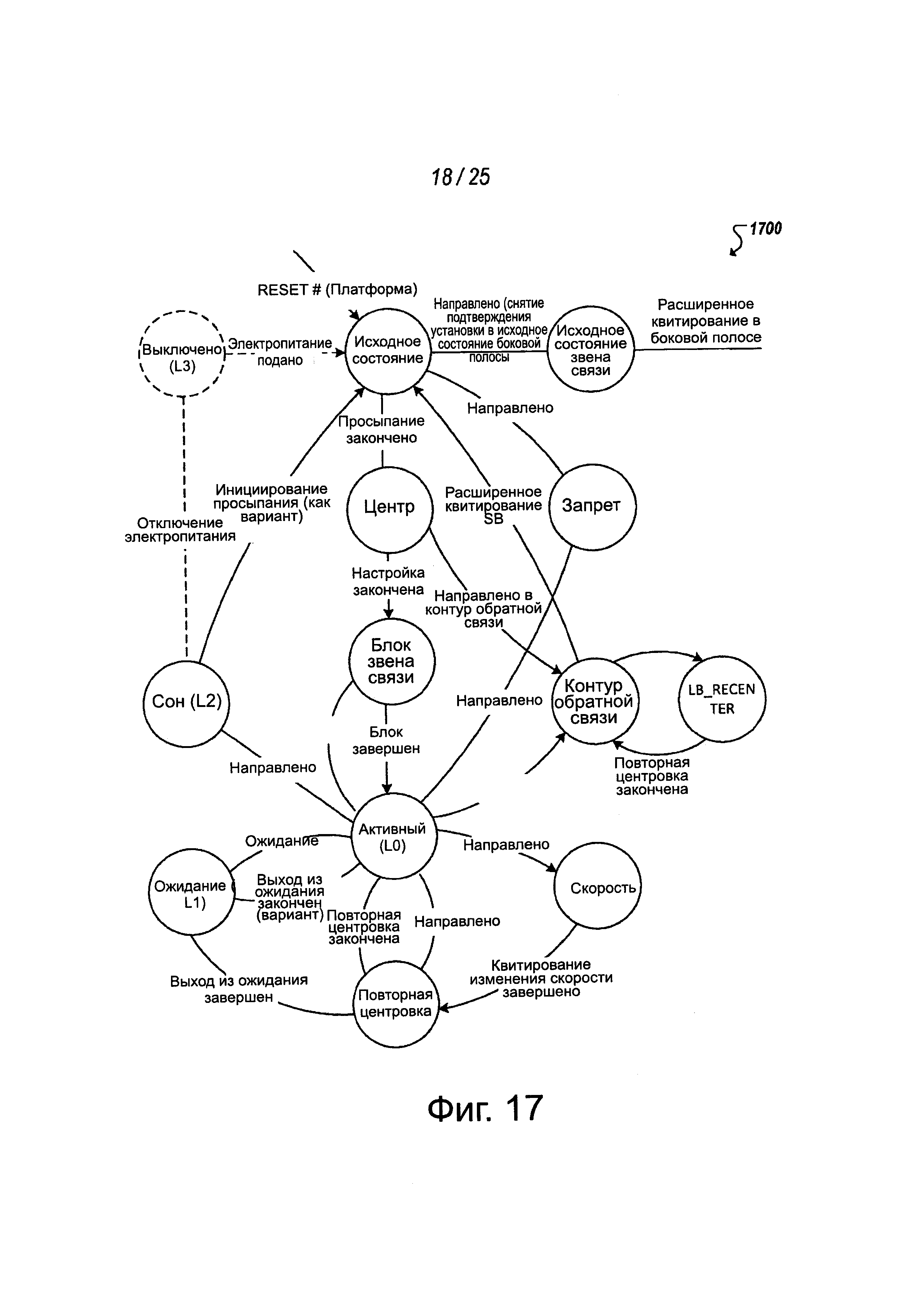
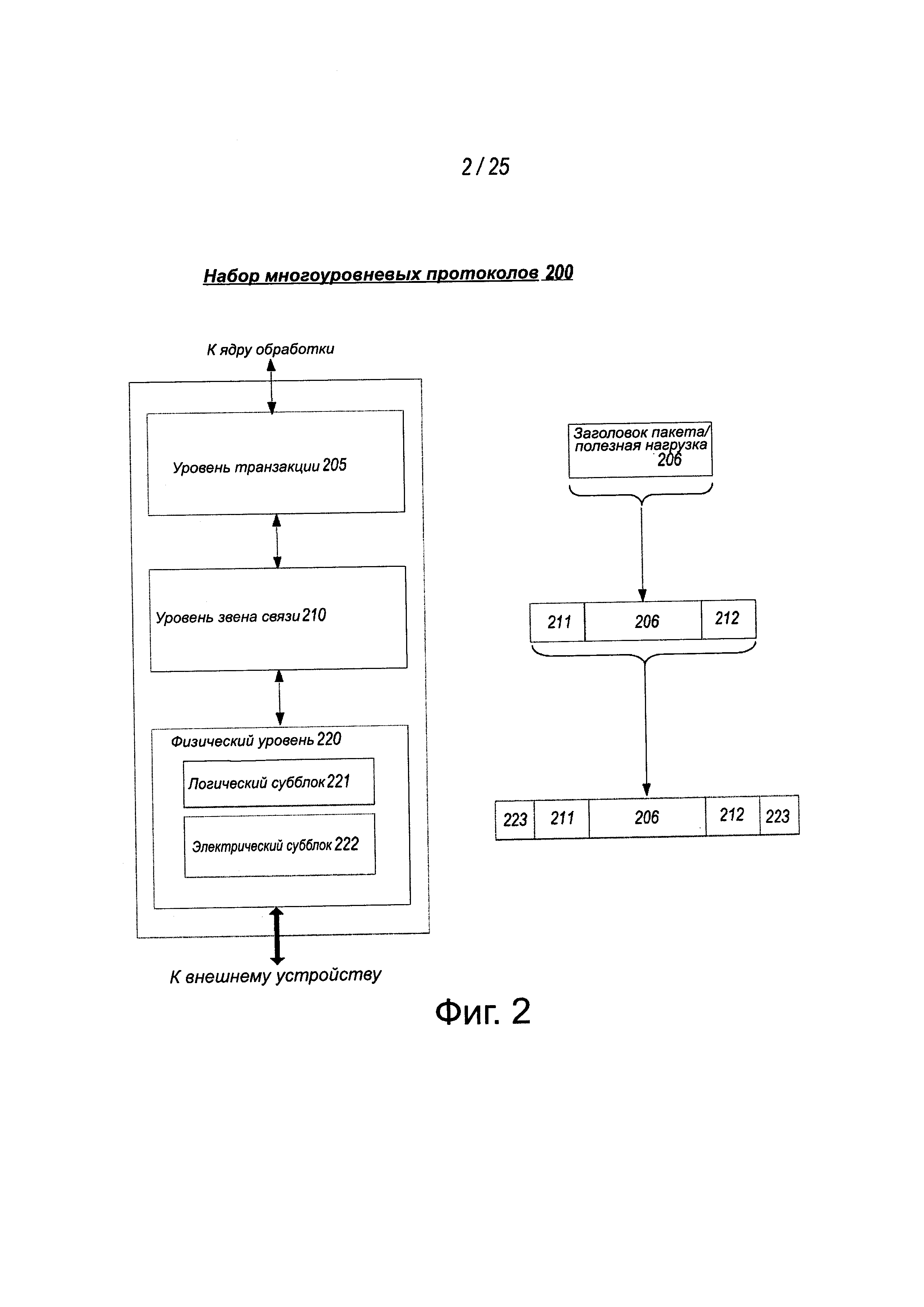
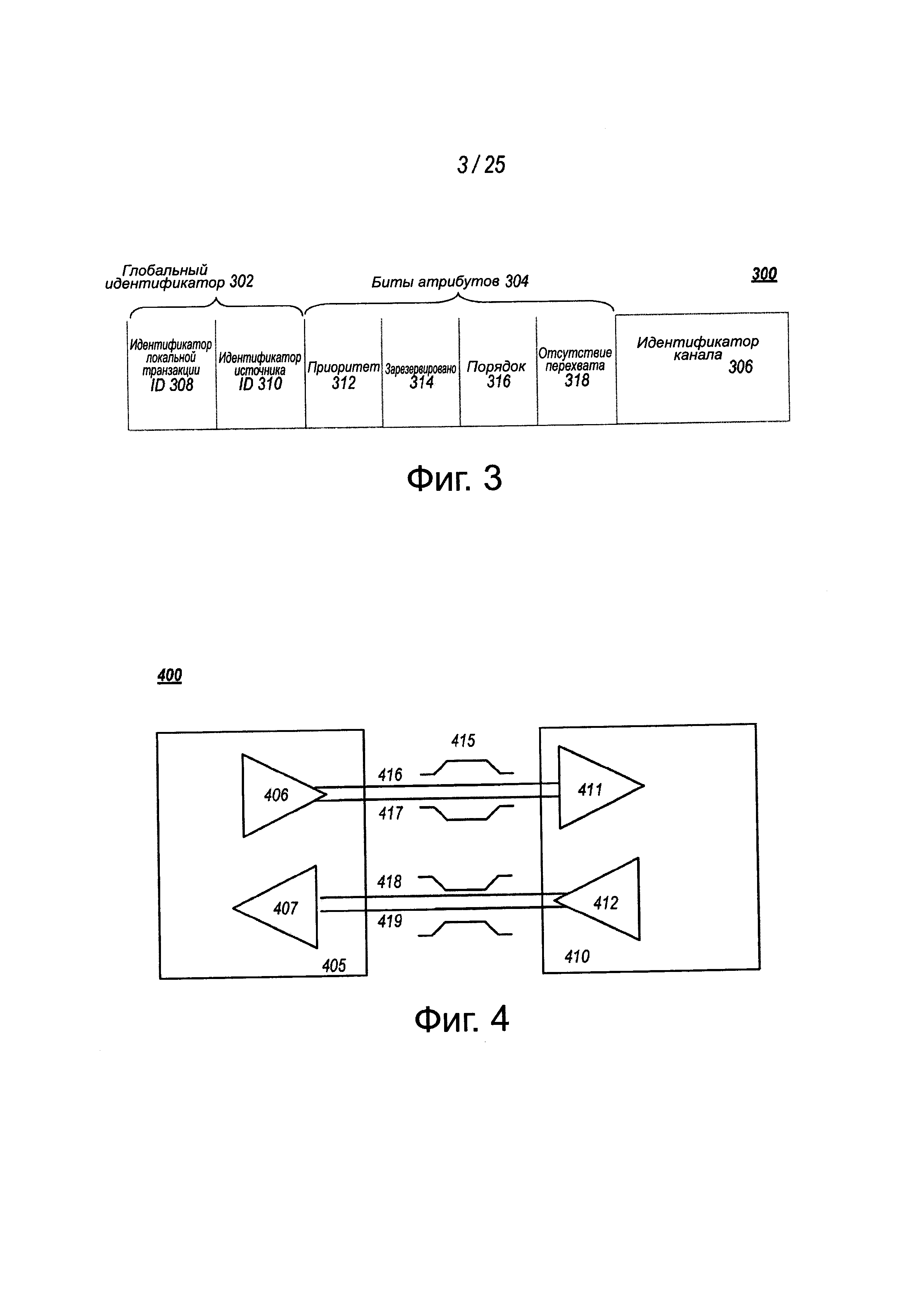
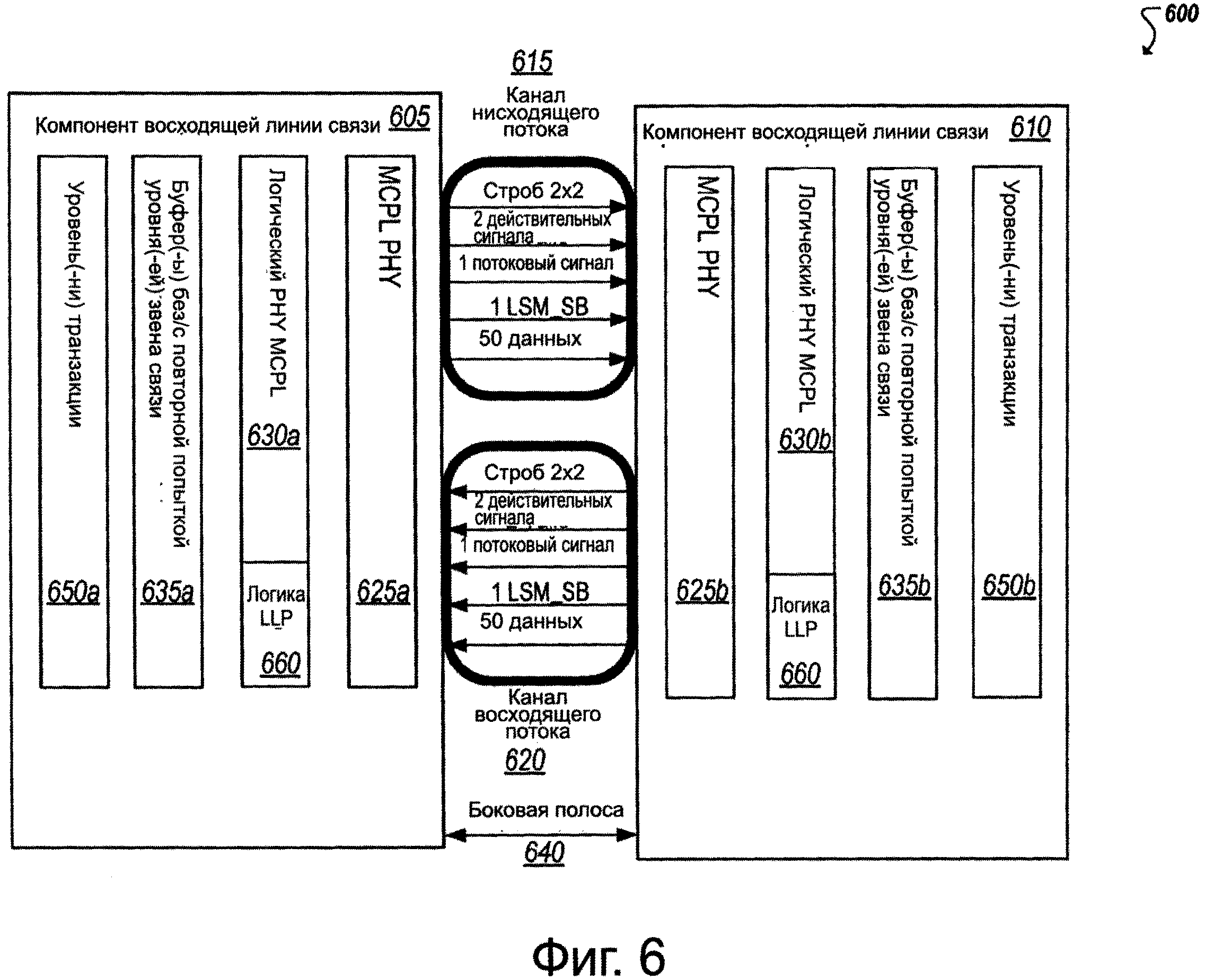
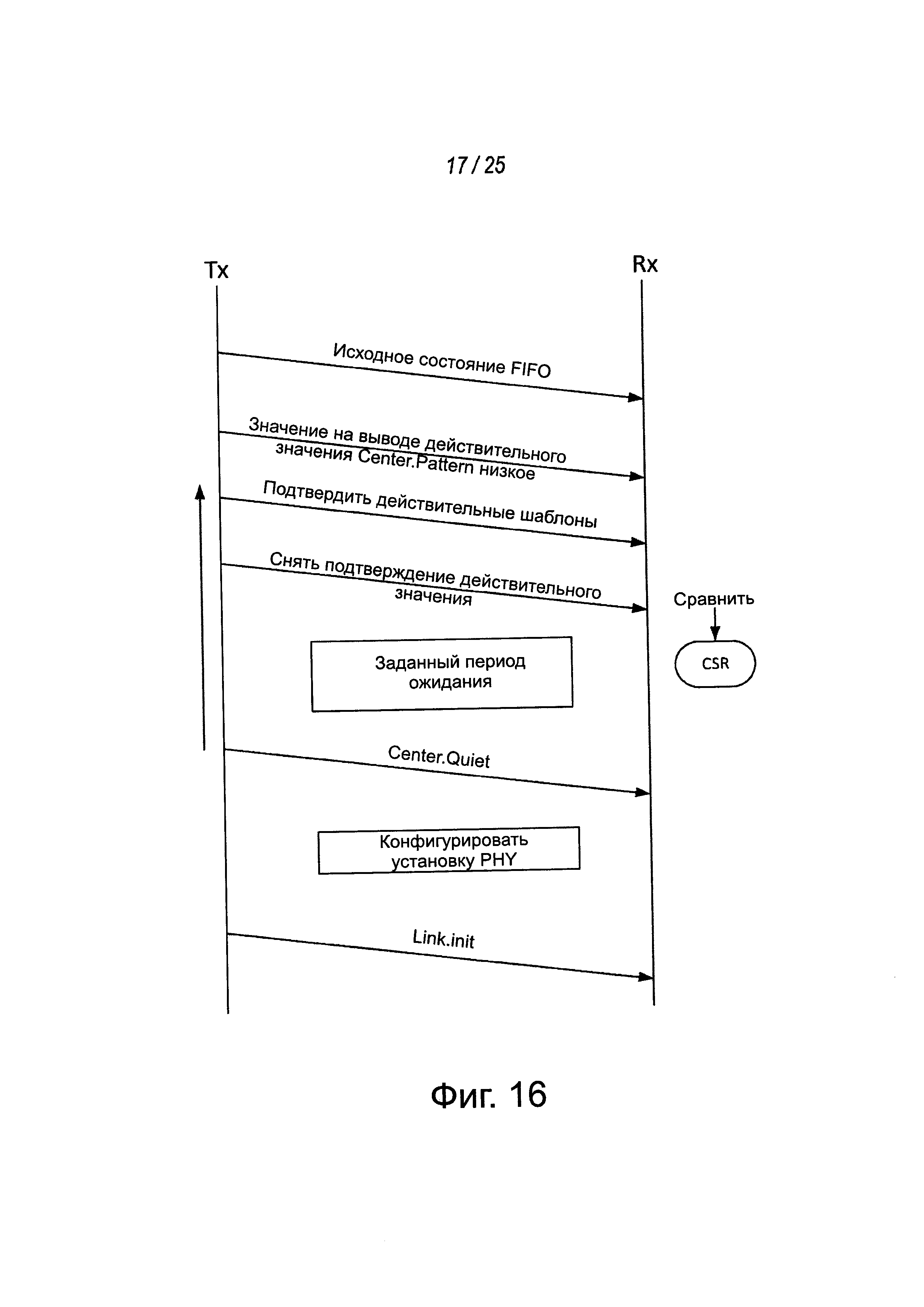
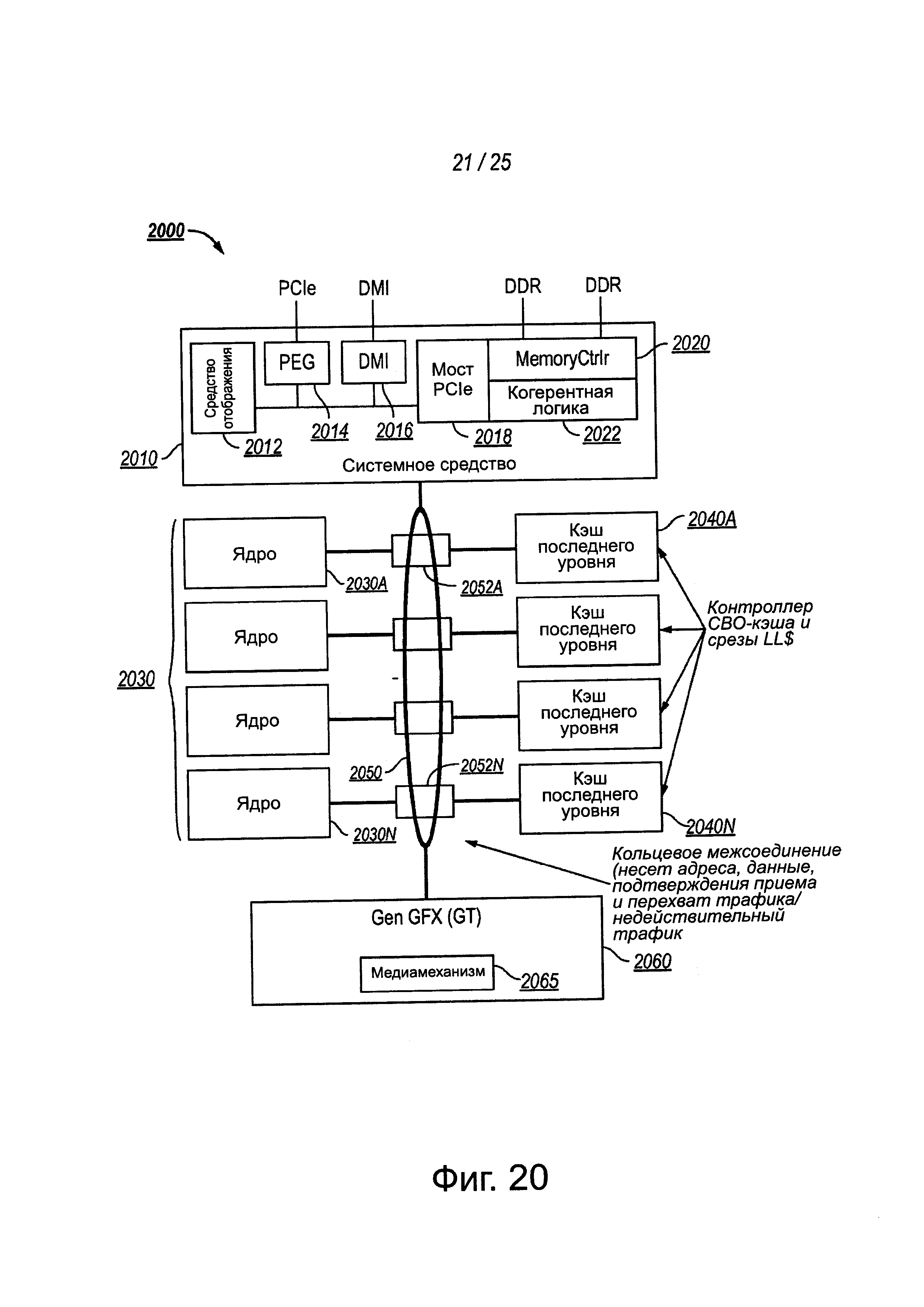
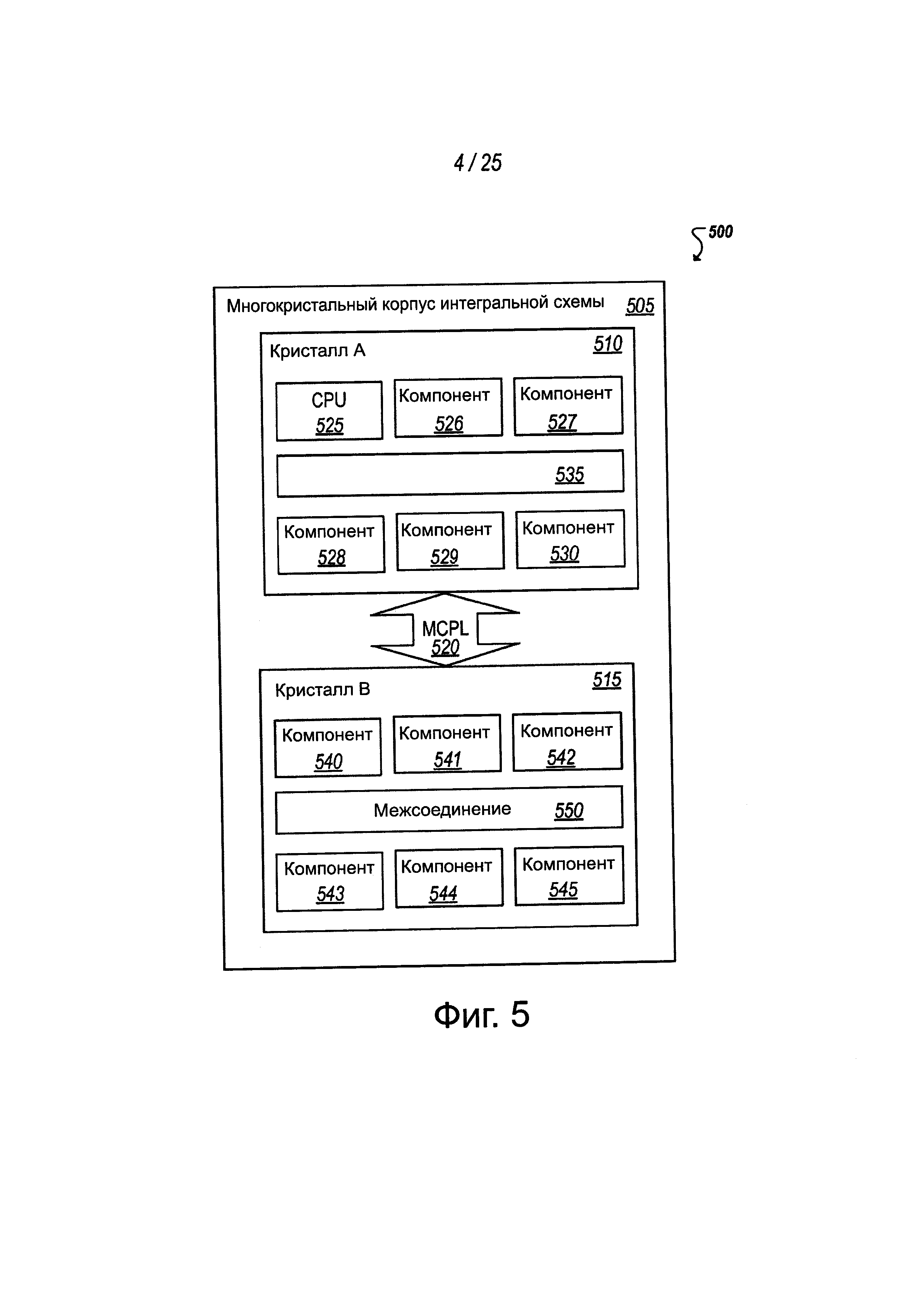
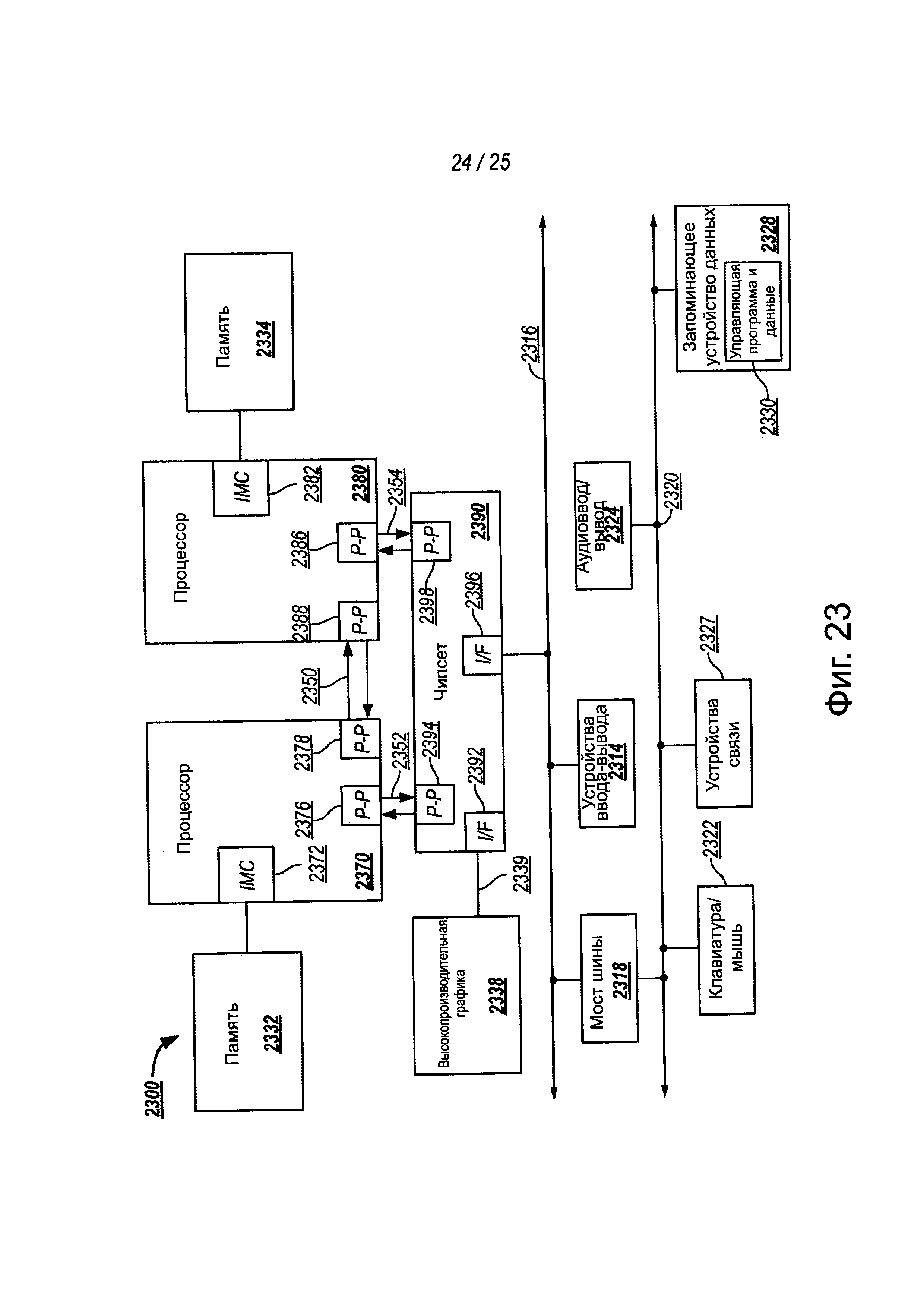
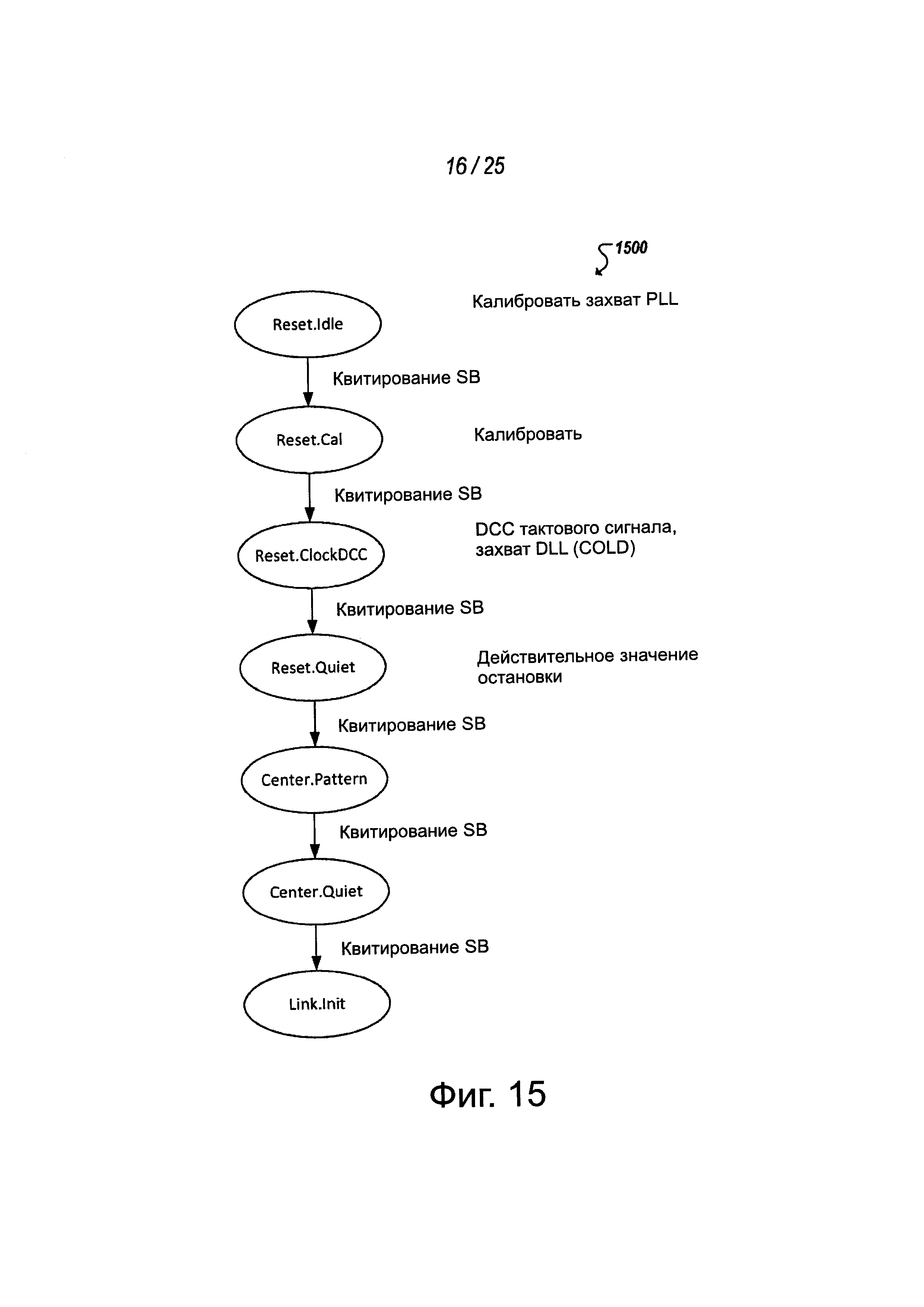
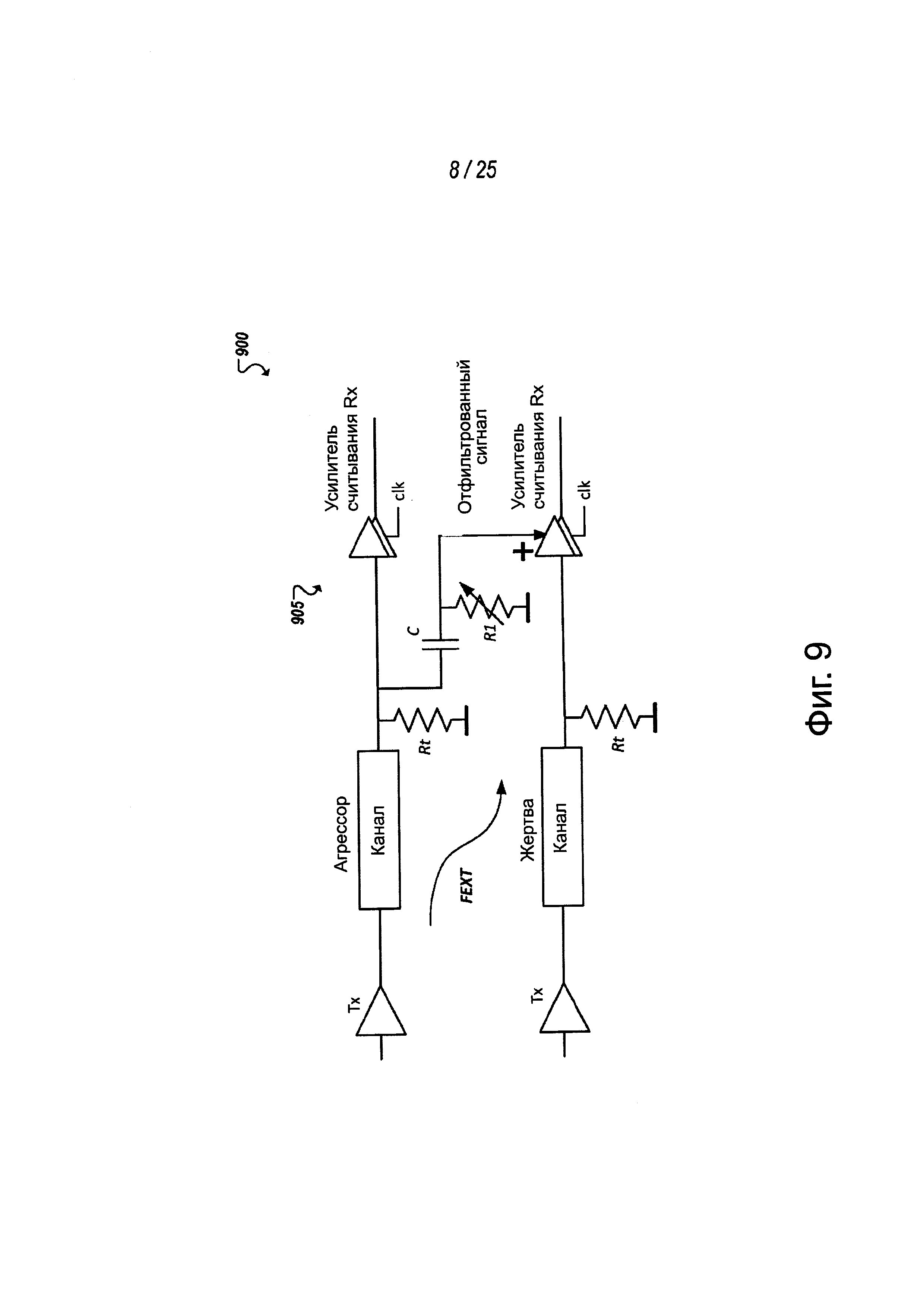
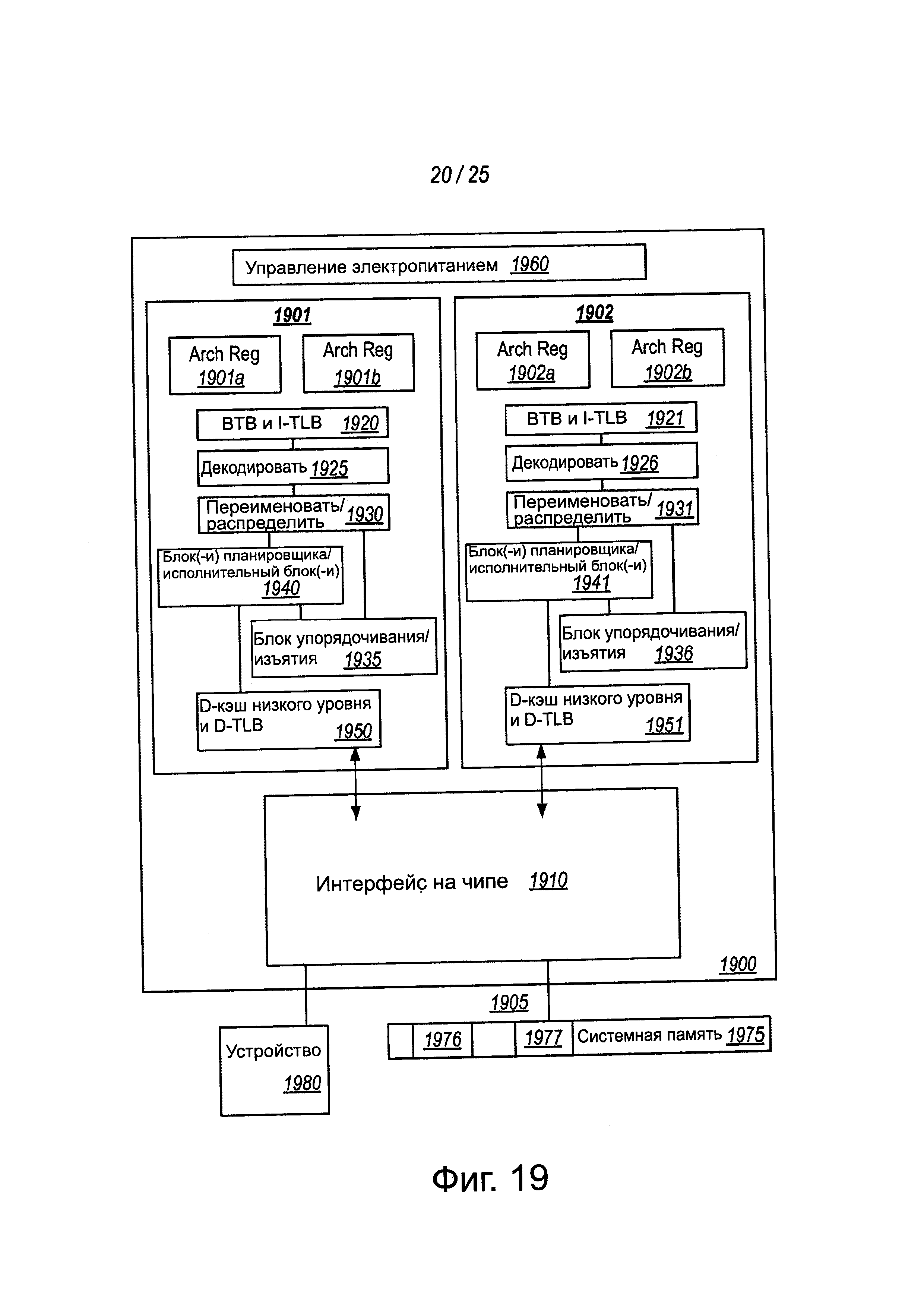
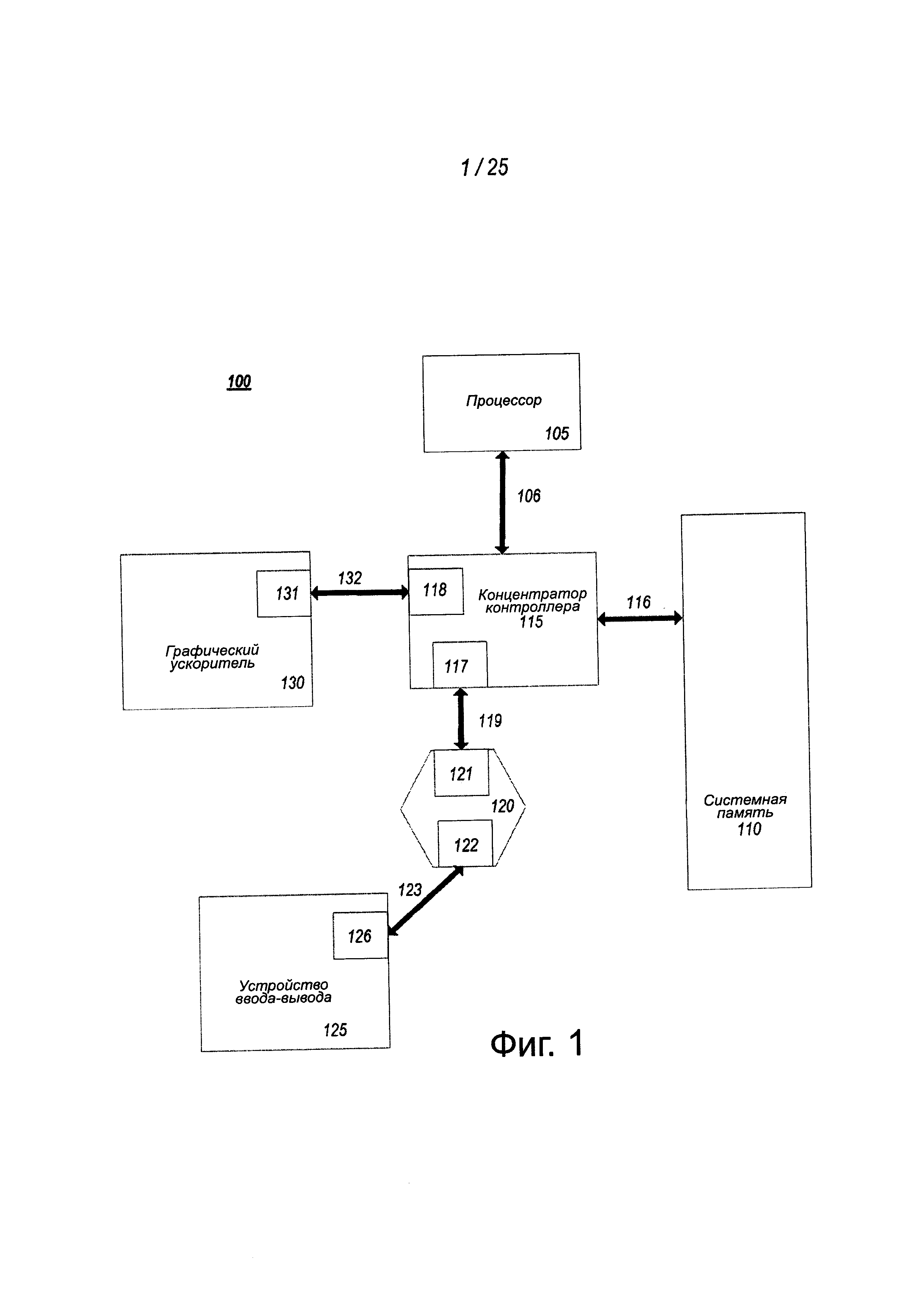
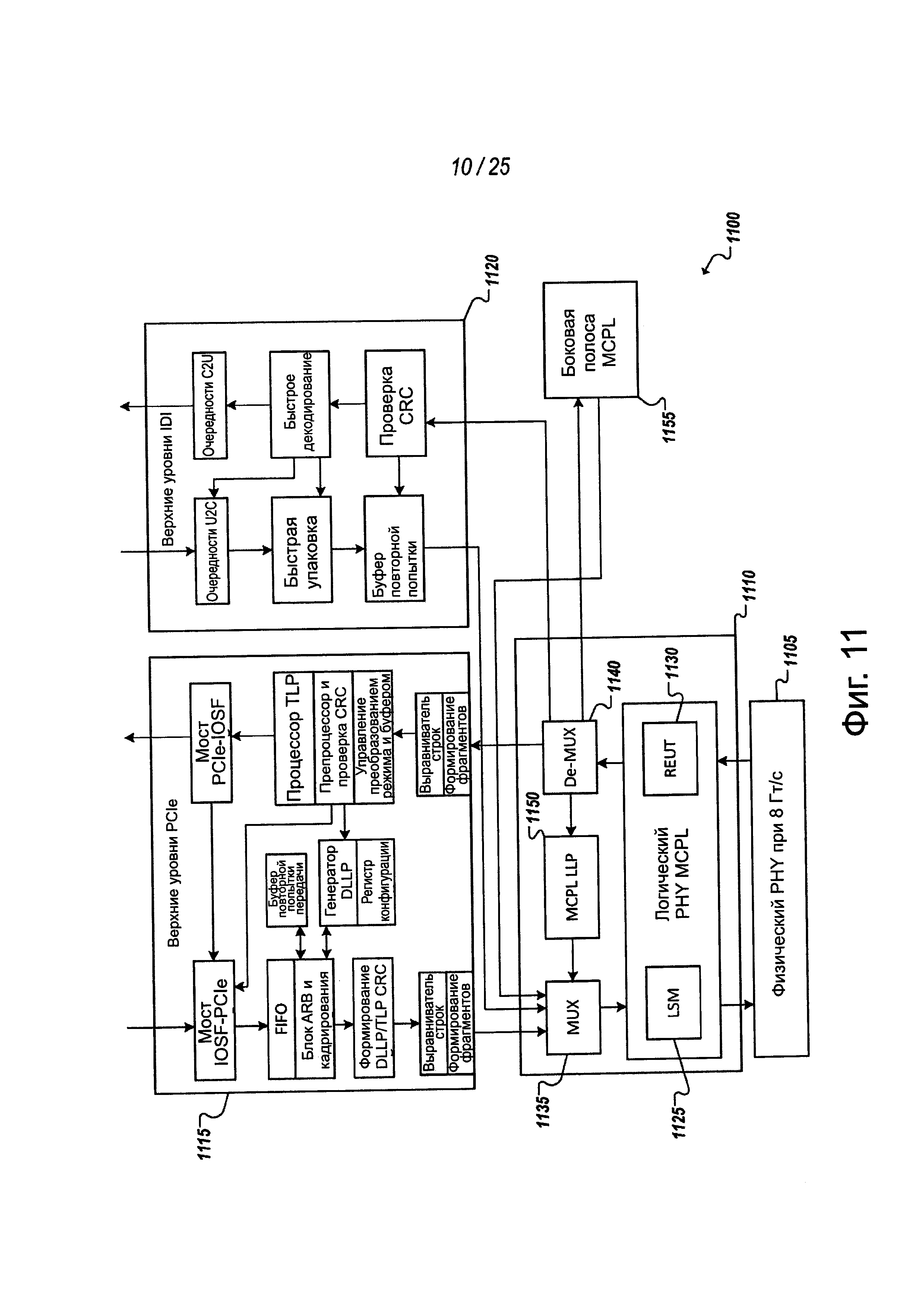
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении
Физический уровень высокопроизводительного межсоединения
Способ, устройство и система уменьшения времени возобновления работы для корневых портов и конечных точек, интегрированных в корневые порты
Физический уровень высокопроизводительного межсоединения
Способ, устройство и система уменьшения времени возобновления работы для корневых портов и конечных точек, интегрированных в корневые порты

