Результат интеллектуальной деятельности: СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ В ВИДЕ УЛЬТРАСЖАТОГО НАНОБАР-КОДА (ВАРИАНТЫ)
Вид РИД
Изобретение
Предлагаемое изобретение относится к способу преобразования (кодирования), декодирования и записи цифровой информации для формирования матричного ультрасжатого двухмерного кода (нанобар-кода), а также к оптически считываемым двухмерным кодам, представляющим двоично-кодированные данные, размещенные на двухмерной матрице и формирующие, таким образом, шаблон для размещения информации. При этом двоично-кодированные данные разбиты на двоичные блоки с криптографически преобразованной, упакованной алгоритмами сжатия и дополненной алгоритмами восстановления утраченных данных информацией. Также, предлагаемое изобретение найдет применение в области защиты от подделки изделий массового производства, и, в частности, в области идентификации подлинности товаров в системе защиты от подделок.
Известны различные технические решения в рассматриваемой области.
Так, например, в патенте RU №2321890 (МПК G06Q 30/00, опублик. 10.04.2008) используют открытый N-значный номер, что создает возможности легкого его копирования, а помимо информации о товаре, открытый N-значный номер несет в себе дополнительные коды информации (например, рекламные), что при проверке подлинности приведет к получению проверяющим лишней информации, а хранение в базе данных дополнительной информации потребует дополнительных аппаратных средств.
В патенте RU №2323474 (МПК G06K 1/00, G09F 3/00, опублик. 27.04.2008) используют многократное скрытое нанесение уникальных номеров под стираемыми непрозрачными слоями, однако, при проверке необходимо, помимо уникального номера вводить порядковый номер полоски, на которой нанесен упомянутый номер. Введение большого количества цифр может быть затруднительно пользователю при проверке подлинности товара.
В патенте RU №2183349 (МПК G06K 1/12, G06K 9/00, опублик. 10.06.2002) используют нанесение на стикер большого количества информации, зашифрованной различными способами. При проверке требуется специальная аппаратура, что затрудняет применение данной системы конечными пользователями.
Таким образом, наиболее функциональным является использование штрих-кодов, выполняющих защитную и идентифицирующую функции.
В патенте RU №2349957 «Смешанный код, и способ и устройство для его генерирования, и способ и устройство для его декодирования» (МПК G06K 19/06, G09F 3/02, опублик. 20.03.2009) код представлен физическим или электронным изображением. Расположение блоков информации в известном смешанном коде не является рациональным, с точки зрения восстановления информации или захвата изображения кода. При повреждении этих областей невозможно ни сосканировать, ни декодировать код.
Еще один тип машиночитаемого кода, отвечающего уровню современных требований, описан в патенте GB №2383878 (МПК: B41F 9/00; В41М 1/10; В41М 3/14; B42D 15/00; B42D 15/10; В65В 61/28; G07D 7/12; G09F 3/00; G09F 3/03, опублик. 09.07.2003). Преимущества такого типа кода среди других торговых машиночитаемых кодов заключаются в очень высокой степени заполнения всевозможными отдельными кодами, а также в способности создавать индивидуальные коды. Недостатком указанного патента является отсутствие уникального дизайна матричного кода (используются известные символики), а также, отсутствие защитных алгоритмов, предотвращающих несанкционированное декодирование информации, размещенной в данном машиночитаемом коде.
Известны патенты US №6279830 (МПК: G06K 17/00; G06K 19/00; G06K 19/06; G06K 7/00; G06K 7/10, опублик. 28.08.2001) и US №5591956 (МПК: G06K 17/00; G06K 19/06; G06K 7/10; G06K 7/14, опублик. 07.01.1997) на различные двухмерные символики. Основными особенностями данных матричных кодов является: достаточно высокая плотность информации, возможность кодирования текстовой, байтовой и цифровой информации. Такие коды содержат блоки данных в виде матрицы чередующихся черных и белых квадратов, блок восстановления информации, блок уплотнения текстовой, байтовой, цифровой информации. Недостатком известных патентов является, также, отсутствие защитных алгоритмов, предотвращающих несанкционированное декодирование информации, размещенной в данном машиночитаемом коде. Кроме того, для формирования блоков восстановления информации используются известные алгоритмы.
Общеизвестный способ считывания двухмерного кода включает в себя этапы принятия образа двухмерного кода с помощью устройства ввода изображения, например, таким как фото- и телекамера, а затем определения положения соответствующего двухмерного кода для считывания содержания кода. Для захвата области изображения двухмерного кода используются области резкого изменения яркости - нахождение таких областей можно организовать на основе анализа первой и второй производной изображения. Далее, производится фрагментация изображения и выделение отдельных ячеек кода, подлежащего дальнейшему анализу и декодированию.
Впоследствии, размер кодовой матрицы получается на основе двухмерного кода, таким образом, можно рассчитать координаты ячейки данных в кодовой матрице. Затем, выносится суждение о том, является ли каждая ячейка данных "0" или "1" (т.е. светлой или темной), при этом, производится преобразование каждой из данных ячеек в символьную информацию.
Например, в заявке JP № Н 0212579 (МПК G06K 1/12; G06K 19/00; G06K 19/06; G06K 7/10; G06K 7/14, опублик. 1990-01-17), являющейся аналогом применения патента US №4939354, описана матрица, состоящая из последовательно выстроенных темных (черных) квадратов и двух пунктирных сторон, состоящих из расположенных поочередно светлых (белых) и темных квадратов. Обнаружение символики осуществляется путем различения профиля линий, а затем определения ориентации матрицы. Недостатком вышеупомянутого способа является следующее. Матрица не всегда постоянна в размере, таким образом, может произойти ошибка в обнаружении ячейки, когда положение ячейки прогнозируется согласно заданному интервалу. Кроме того, существует возможность того, что именно по той же схеме, что и характеристика четырех периферийных сторон может произойти ошибка в считывании в области данных. Это потребует сложной обработки для операции считывания матрицы. Соответственно, для такой сложной операции чтения потребуется значительно более длительное время, что затруднит автоматическое считывание и декодирование.
Известно изобретение WO 2013/100794 А1 известно использование ультрасжатого кода - нанобар-кода (реферат, п. 9 формулы). Система кодирования, указанная в изобретении, используется для кодирования только текстовой информации при формировании информационных полей и предусматривает возможность изменения кода более 10706 раз. К недостатка данного способа относится отсутствие возможности кодирования любой цифровой информации, кроме текстовой. Кроме того, отсутствуют механизмы сжатия данных и восстановления утраченной информации.
В изобретении US 2003/0128140 А1 известен способ сжатия цифровой информации. Данное изобретение представляет методы сжатия кода и декомпрессионных архитектур для встраиваемых систем. Осуществление сжатии информации основано на методах оптимальных кодов, при этом вероятности встречаемости кодовых слов для каждого блока кодируемой информации рассчитывают только для этого блока и затем пересчитываются для каждого блока, осуществление декомпрессии информации также основано на сумме полученных вероятностей на этапе компрессии с вычислением вероятностей исходных кодовых слов. Существенным недостатком указанного способа является необходимость расчета вероятности для всех входных элементов, и таким образом требуют вычисления значений всех элементов массива, что значительно увеличивает время обработки и вероятность ошибок или потери информации при компрессии/декомпрессии.
Известен патент US 5224106 А, где предложен способ восстановления информации, заключающийся в добавление избыточной информации для восстановления в случае ее утраты и восстановление утраченной информации с помощью алгоритмов восстановления информации на основе избыточной информации, записанной при формировании кода. Для формирования избыточной информации используется полином вида g2(x)=(x+αa-d)*(x+αa-d+1)*…*(х+αа)*…*(x+αa+s)*(x+αa+s+1)*…*(x+αa+s+d). К недостаткам предложенного способа можно отнести необходимость вычисления отдельных таблиц отображения для каждой из операций алгоритма восстановления данных, а также использование двух различных полиномиальных выражений для их расчета. Это приводит к усложнению решения задачи факторизации и увеличивает количество вариантов перебора необходимое для подбора ключа.
Таким образом, существующие способы формирования двухмерных символик лишь частично решают проблему однозначной идентификации и подтверждения подлинности изделия или объекта.
Для защиты информации могут использоваться известные методы защиты информации, основанные на использовании криптографических алгоритмов. Такие способы предусматривают преобразование информации с использованием криптографических функций и алгоритмов, но, в абсолютном большинстве не предоставляют вариант машиночитаемой двухмерной символики.
В заявке на изобретение RU №2001117145 (МПК G06F 12/14, опублик. 10.06.2003) предложен способ защиты, основанный на формировании ключа, который хранят в памяти внешнего устройства, приспособленного для подсоединения к ЭВМ, дешифрировании информации с использованием ключа во внешнем устройстве, при этом, формирование ключа осуществляют непосредственно во внешнем устройстве, а шифрование информации осуществляют с использованием ключа в этом же устройстве. Формирование ключа осуществляют с использованием сигналов псевдослучайной последовательности и сигналов внешнего случайного воздействия с последующей автоматической проверкой ключа на отсутствие совпадений с ключами, хранящимися в памяти внешнего устройства. Ключ хранят в памяти внешнего устройства, приспособленного для подсоединения к ЭВМ, дешифрировании информации с использованием ключа во внешнем устройстве, отличающийся тем, что формирование ключа при обмене информацией между абонентами осуществляют во внешнем устройстве одного из абонентов, шифруют его системным ключом, предварительно записанным в память системного ключа всех устройств абонентов одной серии, и передают зашифрованный ключ другому абоненту, расшифровывают его у другого абонента, при этом шифрование информации осуществляют с использованием ключа во внешних устройствах каждого из абонентов.
К недостаткам известного способа можно отнести отсутствие возможности реализации способа в случае форс-мажорных обстоятельств, таких, как поломка оборудования у пользователя или выход из строя сегментов оборудования. Также в указанном способе используется управляющая последовательность (ключ), которая или короче, или соответствует длине сообщения и отсутствует точная оценка для вероятности навязывания ложной информации, таким образом, повышается вероятность взлома или вычисление обходного пути для расшифровывания защищенной информации. Также, отсутствует вариант исполнения в графической машиносчитываемой форме двухмерного кода.
В патенте RU №2254685 (МПК H04L 9/00, опублик. 20.06.2005) описан способ шифрующего преобразования информации. До начала шифрования все возможные неповторяющиеся значения комбинаций алфавита ui, случайным образом, с помощью датчика случайных чисел (ДСЧ), записывают в кодовую таблицу с N строками, а в каждую строку ui адресной таблицы Та записывают номер строки i кодовой таблицы Тк, в которой записано значение комбинации алфавита ui, где N - размер алфавита, совпадающий с числом строк кодовой и адресной таблиц Тк и Та, ui - исходная комбинация, подлежащая шифрованию. Для заполнения очередной i-и строки кодовой таблицы Тк, где i - значение от 1 до N, получают очередное значение комбинации алфавита от ДСЧ, которое сравнивают с каждым из i-1 значением записанных комбинаций алфавита в кодовую таблицу Тк, и в случае несовпадения ни с одной из записанных комбинаций алфавита очередное значение комбинации алфавита ui записывают в i-ю строку кодовой таблицы Тк. При шифровании из строки ui адресной таблицы Та считывают адрес A(ui) исходной комбинации ui в кодовой таблице Тк, значение шифрованной комбинации vi исходной комбинации алфавита ui при значении параметра преобразования ξi равно значению комбинации алфавита, хранящейся в строке A(vi) кодовой таблицы Тк, адрес которой определяют как А(vi)=А(ui)+ξi по модулю числа N, считывают значение шифрованной комбинации vi из строки кодовой таблицы Тк с адресом A(vi), при дешифровании зашифрованной комбинации vi при значении параметра преобразования ξi определяют значение комбинации, хранящейся в строке адрес A(ui) кодовой таблицы Тк, адрес которой определяют как A(ui)=A(vi)-ξi по модулю числа N, и считывают значение комбинации ui из строки кодовой таблицы Тк с адресом A(ui).
В известном способе не предусмотрена возможность реализации способа в случае форс-мажорных обстоятельств, таких как поломка оборудования у пользователя или выход из строя сегментов оборудования. Кроме того, этот способ может предусматривать кодирование только на уровне байт, а также не предусматривает вариант исполнения в графической машиносчитываемой форме двухмерного кода.
Известна международная заявка WO 2013162402 (МПК G06F 21/60; Н03М 7/00, опублик. 31.10.2013) «Способ защиты цифровой информации». В известном способе предлагается использовать криптографические алгоритмы для защиты информации при формировании информационного поля. Однако, известный метод кодирования защищенной информации не позволяет сформировать шаблон расположения преобразованной информации на матричном поле и, соответственно, исключает возможность автоматизированного считывания и декодирования информации.
Известный способ основан на принципе формирования системы кодировок из набора «0» и «1», при этом принято, что «1» обозначается факт наличия контрастной ячейки от фона, а «0» - отсутствия ячейки. Кодироваться может любая битовая информация с использованием латинских символов, цифр, знаков пунктуации, национальных шрифтов, символов псевдографики и т.п., представляя собой в общем виде массив символов. Любой символ из кодировочного массива может быть представлен в виде многоразрядной комбинации «0» и «1». Например, можно использовать восьмиразрядную систему кодировки символов, т.е. это будет выглядеть так: 00000000, 00000001, 00000010 и т.д. Совокупность кодировочных значений формируется из генеральной и частной совокупности значений, формирование в данной системе происходит с равновероятным выбором совокупностей без преобладания одной из них. Причем, формирование массивов происходит независимо друг от друга, а источником формирования генератора случайных чисел является криптографическая функция. Принцип действия защиты информации состоит в следующем. Существует сообщение, состоящее из n символов (a1, b1, …z1) и содержащее m повторений символов (a1, a2…am). Существуют количество совокупностей Ai, равное Q, присвоения символам сообщения (a1, b1, …z1), случайным образом кодирующих значений из Ai совокупности, где i принадлежит множеству (1…Q). Установление соответствия кодовых значений символам в совокупностях (A1…Ai) происходит случайным образом. Первому символу a1 случайным образом присваивается значение из совокупности Ai. Символу an присваивается значение из совокупности Ai-1, причем выбор совокупности из диапазона (А1…Ai) происходит также случайным образом. По аналогии, происходит присвоение значений остальным символам (b1, c1…z1). В то же время, одному и тому же символу an в разных частях сообщения может быть присвоено значение из совокупности A1 β раз, определение количества β раз повторений символов an происходит также случайным образом.
Известный способ предлагает метод защиты информации, способ ее преобразования при кодировании и шифровании, а также предлагает некоторое графическое изображение сформированного нанобар-кода. Однако, такое изображение нанобар-кода не позволяет стандартизировать его матрицу и предложить машинные способы его считывания и декодирования. Кроме того, в алгоритме формирования прототипа не предусмотрено формирование избыточной информации, позволяющей восстанавливать утраченную информацию.
Также, известен патент RU №2251734 «Машиночитаемый код, способ и устройство кодирования и декодирования» (МПК G06K 9/18, G06K 7/10, G06K 19/06, G06K 1/12, опублик. 10.05.2005), который по совокупности своих существенных признаков является наиболее близким к предлагаемому изобретению, и принят за прототип. Известное изобретение относится к кодированию данных с представлением их в виде кода с использованием компоновки ячеек с различными цветами, формами или конфигурациями. Способ включает следующие действия: установку таблицы преобразования кода, установку требуемых данных, кодирование требуемых данных, установку области контроля четности и получение изображения в виде физического или электронного кода.
Основные достоинства предлагаемого изобретения, по сравнению с прототипом: корреляция компактности с емкостью; повышенная устойчивость к повреждениям информации; возможность восстановления большего объема утраченной информации; возможность шифрования информации; множество вариантов реализации. Основное отличие предлагаемого изобретения по сравнению с прототипом - способ кодирования с использованием принципиально отличного от прототипа полинома.
Кроме того, имеется возможность восстановления данных, имеются опорные элементы в структуре кода для распознавания и выравнивания информации. Шифрование информации происходит с возможностью нанесения на любую поверхность.
Таким образом, основной целью предлагаемого изобретения является разработка способа кодирования и декодирования цифровой информации в виде ультрасжатого нанобар-кода, с возможностью шифрования информации, устойчивого к повреждениям и имеющего множество вариантов реализации.
Реализация нанобар-кода может быть выполнена различными методами:
- нанобар-код может быть визуализирован в виде изображения, составленного из светлых и темных ячеек, аналогом являются стандартные двухмерные коды, например, QR-код;
- нанобар-код может быть представлен в виде массива (потока) защищенных данных (аналогом является система защиты информации Крипто С);
- нанобар-код может быть визуализирован в виде координат и, таким образом, может быть внедрен в алгоритм нанесения для различных устройств вывода;
- нанобар-код может быть представлен в виде управляющего файла, включающего в себя область записи данных и алгоритмы или команды, управляющие устройством для визуализации (принтер, лазерная установка и др.);
- нанобар-код может быть реализован в виде исполняемого компьютерного файла.
Техническим результатом, достигаемым при использовании предлагаемых способов, является повышение надежности кодирования информации за счет введения операции шифрования, возможности восстановления данных в случае их утери, а также расширение функциональных возможностей.
Основные достоинства предлагаемого изобретения, при его практическом применении, по сравнению с известными способами:
- мультиплатформенность программного обеспечения кодирования и декодирования;
- корреляция компактности с емкостью;
- нанобар-код более устойчив к повреждениям информации;
- возможность восстановления большего объема утраченной информации;
- возможность шифрования информации;
- множество вариантов реализации.
Кроме того, совмещение постоянных и комбинируемых элементов позволяет использовать нанобар-код в различных областях.
Для считывания нанобар-кода используется своя уникальная аппаратно-программная система считывания и распознавания, которая позволяет захватывать изображения в широком диапазоне (от 0,05 - до 100 мм).
Примером реализации нанобар-кода в виде контрастного изображения может выступать:
1) Полиграфическая печать
2) Лазерная маркировка (гравировка)
Современная полиграфическая цифровая печать позволяет воспроизводить изображения высокой четкости и контрастности с разрешением до 2880 dpi, что отвечает любым особенностям нанесения заданных геометрических размеров нанобар-кода. Такой способ подходит для размещения нанобар-кода на бумажных носителях (документы), этикетках, упаковке и других промежуточных носителях.
Для размещения нанобар-кода непосредственно на материале изделия или защищенных промежуточных носителях (несъемные этикетки) рекомендуется использование прецизионных Лазерных Маркирующих Комплексов (ЛМК) или аналогичных установках на базе различных лазеров, предназначенных для нанесения текстовых и графических изображений на поверхность изделий методом лазерной маркировки и гравировки с высокой точностью и разрешением с возможностью интеграции в технологические линии для работы в автоматическом режиме. Материалы, рекомендуемые к обработке лазерным излучением для воспроизведения нанобар-кода включают различные металлы и сплавы (в т.ч. твердые), пластмассы, полимерные материалы, также возможна маркировка древесины, бумаги, ткани, кожи, оргстекла.
Достигается технический результат тем, что в способе кодирования цифровой информации в виде ультрасжатого нанобар-кода, включающего прием подлежащей кодированию информации, кодирование информации с использованием таблицы кодового преобразования и получение кодового сообщения на носителе информации в виде физического или электронного кода, согласно изобретению, после кодирования информации осуществляют ее шифрование, сжатие и добавление избыточной информации для восстановления в случае ее утраты.
Шифрование информации осуществляют с использованием криптографических алгоритмов в два этапа, на первом этапе шифрование проводят на уровне байтов с помощью полиалфавитного байтового шифра с различным значением сдвига для каждого байта информации, на втором этапе шифрование осуществляют на уровне битов на основе симметричного битового алгоритма шифрования AES.
Сжатие информации осуществляют на основе методов оптимальных кодов, причем вероятности встречаемости кодовых слов для каждого блока кодируемой информации рассчитывают только для этого блока и пересчитывают для каждого блока, для получения кодового сообщения осуществляют формирование структуры закодированных данных.
Дополнительными отличиями предлагаемого способа является следующее. Количество раундов перемешивания при шифровании на уровне байтов равняется 1, полученная последовательность зашифрованного сообщения переводится в 16-тиричную систему счисления и передается на этап второй битового шифрования. Для первого этапа шифрования используется таблица значений 256 на 256 символов или 256 таблиц по 256 позиций, при этом, количество полей таблицы соответствует количеству полей кодировочной таблицы ASCII. На втором этапе шифрования (битовом шифровании) количество раундов перемешивания является конечным и равно q, при этом сообщение Р длиной а символов разбивается на n-е количество блоков объемом m символов в блоке и шифруется с алгоритмом, содержащим q раундов перемешивания. При шифровании на битовом уровне на всех раундах шифрования осуществляют изменение дизайна шифра, а именно, между операциями Shift-Rows и MixColumns производят сдвиг блоков, с сохранением механизма формирования раундовых ключей и этапов перемешивания.
При этом, формируют структуру закодированных данных в виде физического или электронного изображения двухмерного кода, содержащего область фона, область ориентирующих элементов и область данных, состоящую, по меньшей мере, из одного блока данных, причем изображение областей ориентирующих элементов и области данных являются контрастными по отношению к изображению области фона. Область ориентирующих элементов содержит опорный квадрат с рамкой и пустым полем, выравнивающие прямоугольники и рамку границы кода. Область данных, содержащая кодовое сообщение, наложена на область ориентирующих элементов таким образом, чтобы элементы областей не перекрывали друг друга. Внутри опорного квадрата может быть размещена любая надпись и/или изображение, причем размеры опорного квадрата, рамки и пустого поля могут изменяться в различную сторону. Центр опорного квадрата расположен на пересечении осей симметрии выравнивающих прямоугольников.
Также структура закодированных данных может быть сформирована в виде физического или электронного изображения набора координат на координатной плоскости.
Во втором варианте реализации предлагаемого способа кодирования цифровой информации в виде ультрасжатого кода - нанобар-кода, включающем прием подлежащей кодированию информации, кодирование информации с использованием таблицы кодового преобразования и получение кодового сообщения на носителе информации в виде физического или электронного кода, предлагается после кодирования информации осуществлять ее сжатие и добавление избыточной информации для восстановления в случае ее утраты.
Сжатие информации предлагается осуществлять на основе методов оптимальных кодов, причем вероятности встречаемости кодовых слов для каждого блока кодируемой информации рассчитывать только для этого блока и пересчитывать для каждого блока, для получения кодового сообщения осуществлять формирование структуры закодированных данных.
При этом, формируют структуру закодированных данных в виде физического или электронного изображения двухмерного кода, содержащего область фона, область ориентирующих элементов и область данных, состоящую, по меньшей мере, из одного блока данных, причем изображение областей ориентирующих элементов и области данных являются контрастными по отношению к изображению области фона. Область ориентирующих элементов содержит опорный квадрат с рамкой и пустым полем, выравнивающие прямоугольники и рамку границы кода. Область данных, содержащая кодовое сообщение, наложена на область ориентирующих элементов таким образом, чтобы элементы областей не перекрывали друг друга. Внутри опорного квадрата может быть размещена любая надпись и/или изображение, причем размеры опорного квадрата, рамки и пустого поля могут изменяться в различную сторону. Центр опорного квадрата расположен на пересечении осей симметрии выравнивающих прямоугольников.
Также структура закодированных данных может быть сформирована в виде физического или электронного изображения набора координат на координатной плоскости.
Технический результат достигается также тем, что в способе декодирования цифровой информации в виде ультрасжатого кода, включающем считывание закодированных данных с кода, выбор полезной информации, декомпрессию, дешифрование и декодирование этой информации с использованием таблицы кодового преобразования, согласно изобретению, дешифрование информации осуществляют с использованием обратной функции криптографического преобразования в два этапа, на первом этапе дешифрование осуществляют на уровне битов на основе симметричного битового алгоритма шифрования AES. На втором этапе дешифрование проводят на уровне байтов с помощью полиалфавитного байтового шифра с различным значением сдвига для каждого байта информации. Декомпрессию информации осуществляют на основе методов оптимальных кодов, на основе суммы полученных вероятностей на этапе компрессии, с вычисление вероятностей исходных кодовых слов. Утраченную информацию восстанавливают с помощью алгоритмов восстановления информации на основе избыточной информации, записанной при формировании кода.
Количество раундов перемешивания при дешифровании на уровне байтов равняется 1, полученная последовательность зашифрованного сообщения переводится в 16-тиричную систему счисления и передается на этап второй битового дешифрования.
Для дешифрования на уровне байтов используется таблица значений 256 на 256 символов или 256 таблиц по 256 позиций, при этом, количество полей таблицы соответствует количеству полей кодировочной таблицы ASCII.
На первом этапе дешифрования (битовом шифровании) количество раундов перемешивания является конечным и равно q, при этом сообщение Р длиной а символов разбивается на n-е количество блоков объемом m символов в блоке и дешифруется с алгоритмом, содержащим q раундов перемешивания.
При дешифровании на битовом уровне на всех раундах шифрования осуществляют изменения дизайна шифра, а именно, между операциями ShiftRows и MixColumns производят сдвиг блоков, с сохранением механизма формирования раундовых ключей и этапов перемешивания.
Во втором варианте реализации способа декодирования цифровой информации в виде ультрасжатого кода, включающем считывание закодированных данных с кода, выбор полезной информации, декомпрессию и декодирование этой информации с использованием таблицы кодового преобразования предлагается декомпрессию информации осуществлять на основе методов оптимальных кодов, причем вероятности встречаемости кодовых слов для каждого блока декодируемой информации рассчитывать только для этого блока. Утраченную информацию восстанавливать с помощью алгоритмов восстановления информации на основе избыточной информации, записанной при формировании кода.
Сущность предлагаемого изобретения поясняется следующими фигурами:
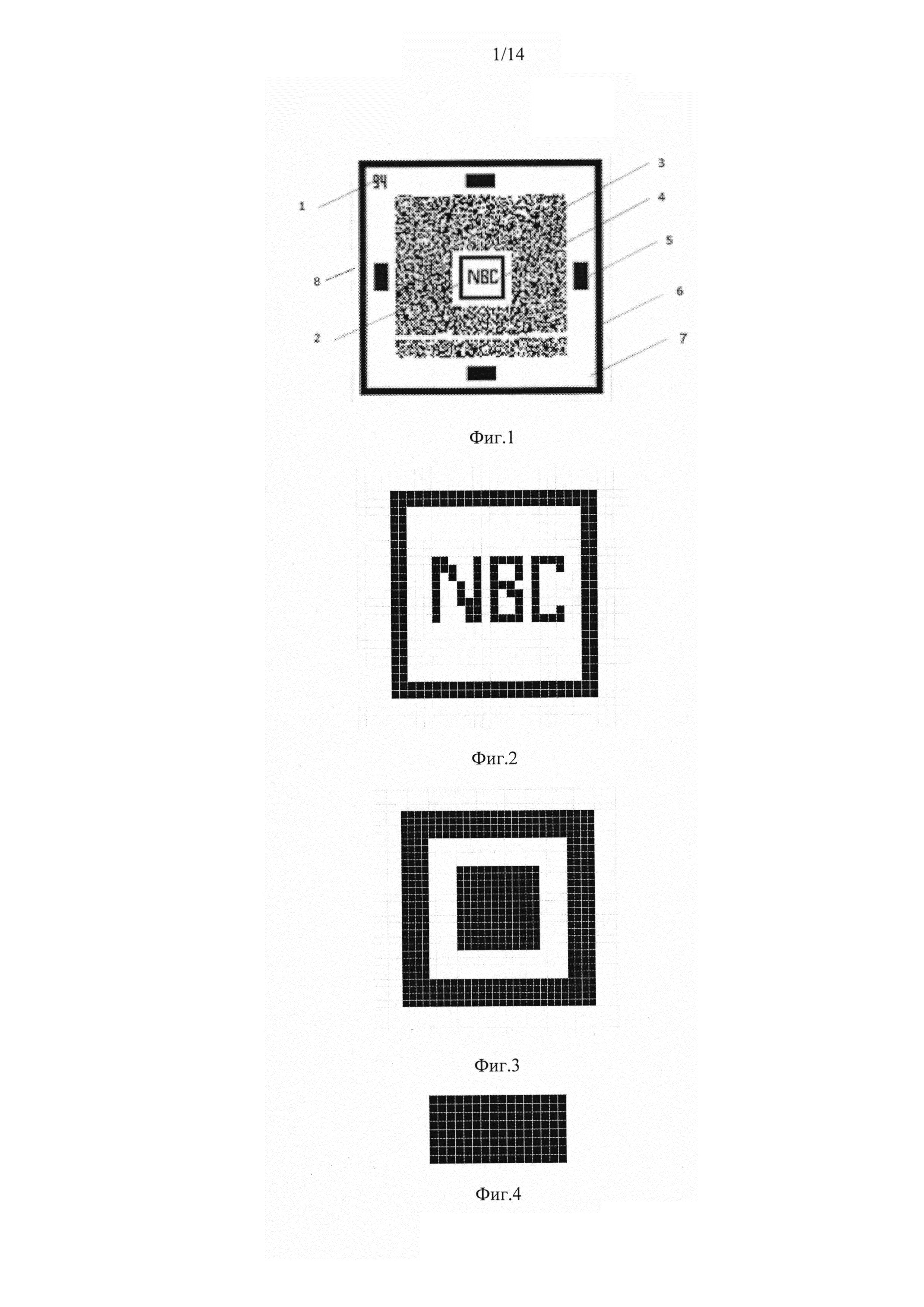
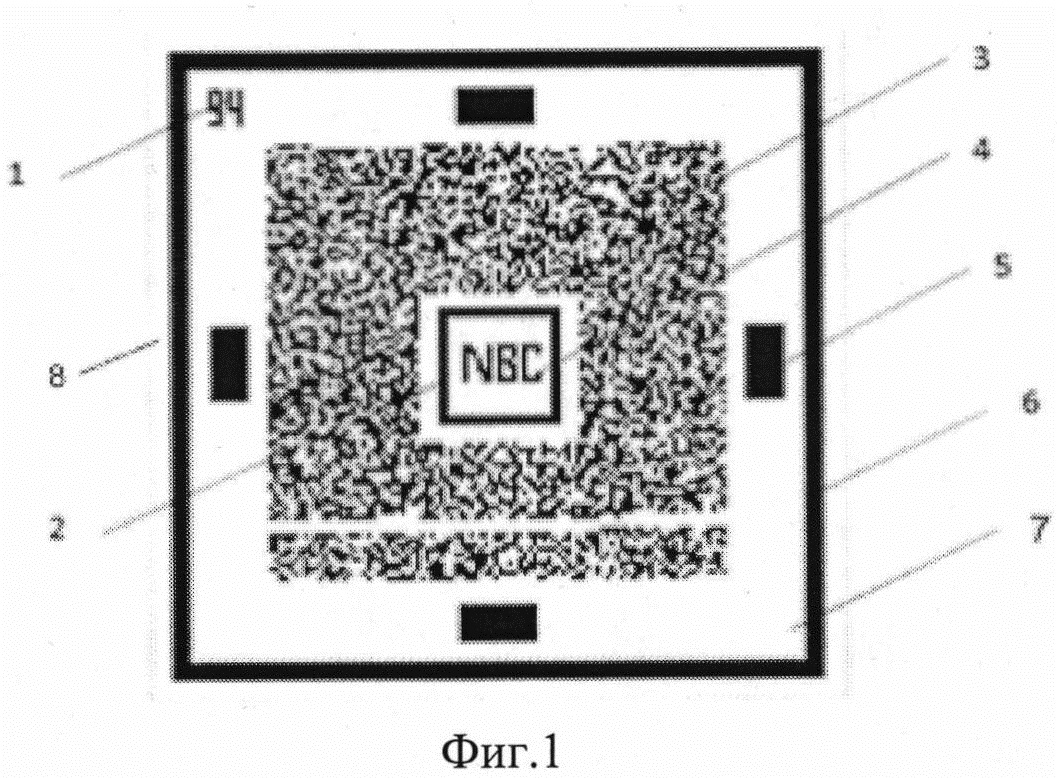
фиг. 1, на которой представлен общий вид нанобар-кода, где:
1 - указатель на количество ячеек и столбцов в символике,
2 - рамка опорного квадрата,
3 - поле кодовых слов,
4 - опорный квадрат,
5 - выравнивающие прямоугольники,
6 - рамка границы кода,
7 - пустое поле;
8 - фон;
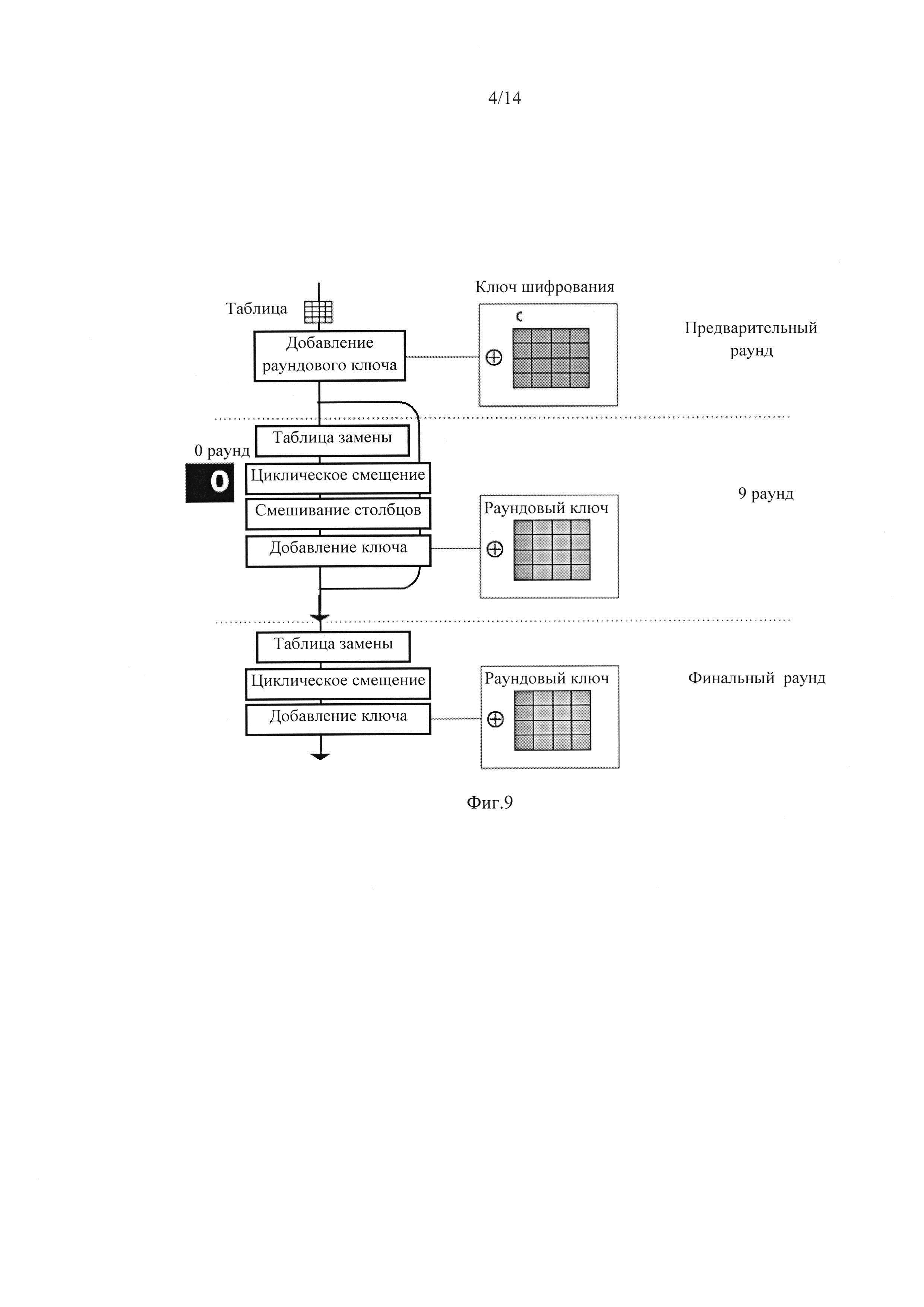
фиг. 2, где представлен предпочтительный вариант опорного квадрата с надписью;
фиг. 3, где представлен вариант опорного квадрата без надписи;
фиг. 4, где представлен общий вид выравнивающего прямоугольника;
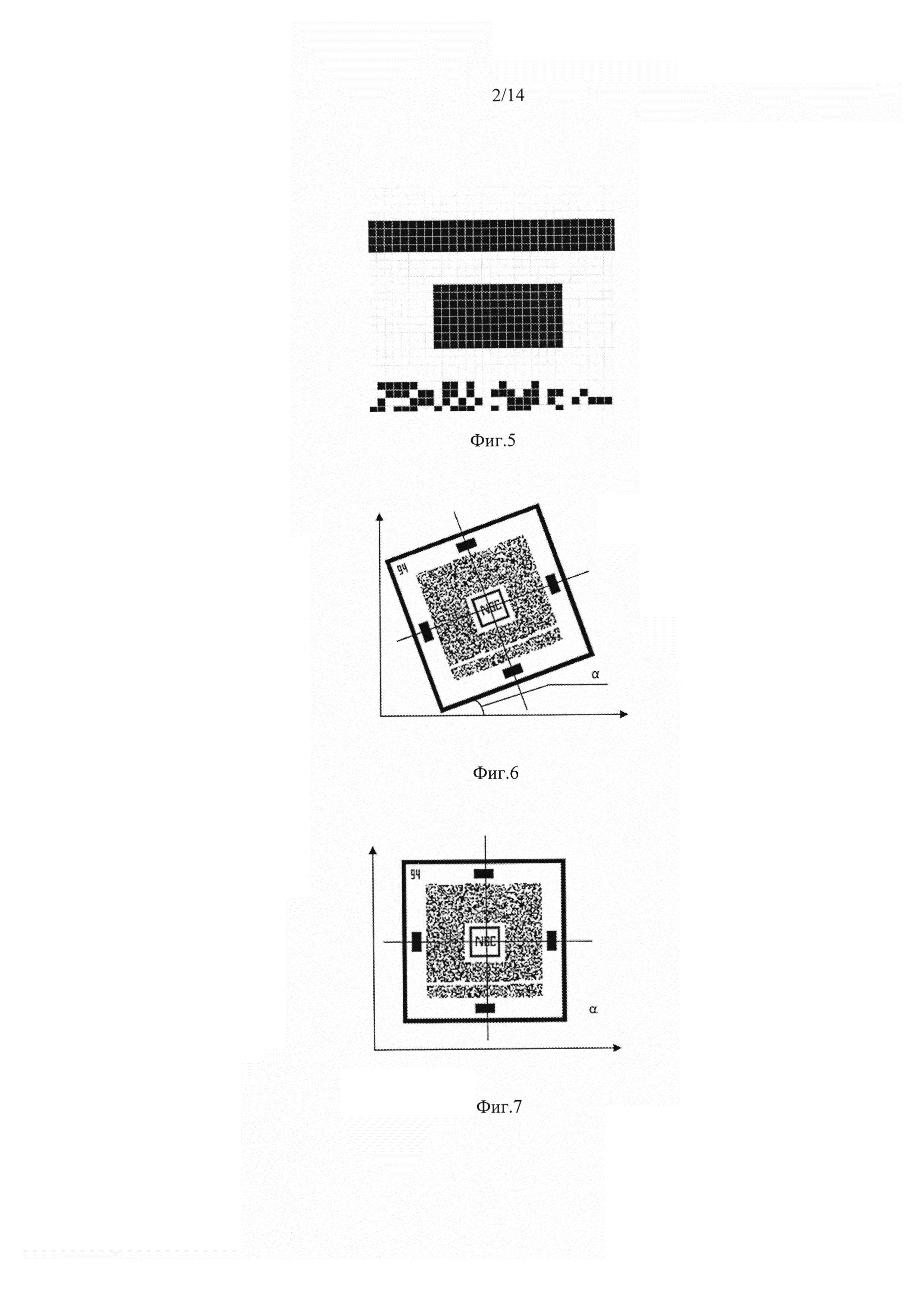
фиг. 5, где представлен общий вид положения верхнего выравнивающего прямоугольника между границей символики и полем информации;
фиг. 6, где представлено изображение нанобар-кода, полученное с углом поворота, равным α. Причем, α - произвольный угол поворота изображения нанобар-кода относительно осей координат ОХ и OY. Используется для корректировки кода относительно осей для корректного получения потока данных и дальнейшего декодирования.
фиг. 7, где показан откорректированный угол поворота символики, относительно осей ОХ и OY;
фиг. 8, где представлены вероятности встречаемости символов русского алфавита, без учета вероятностей в отдельном тексте;
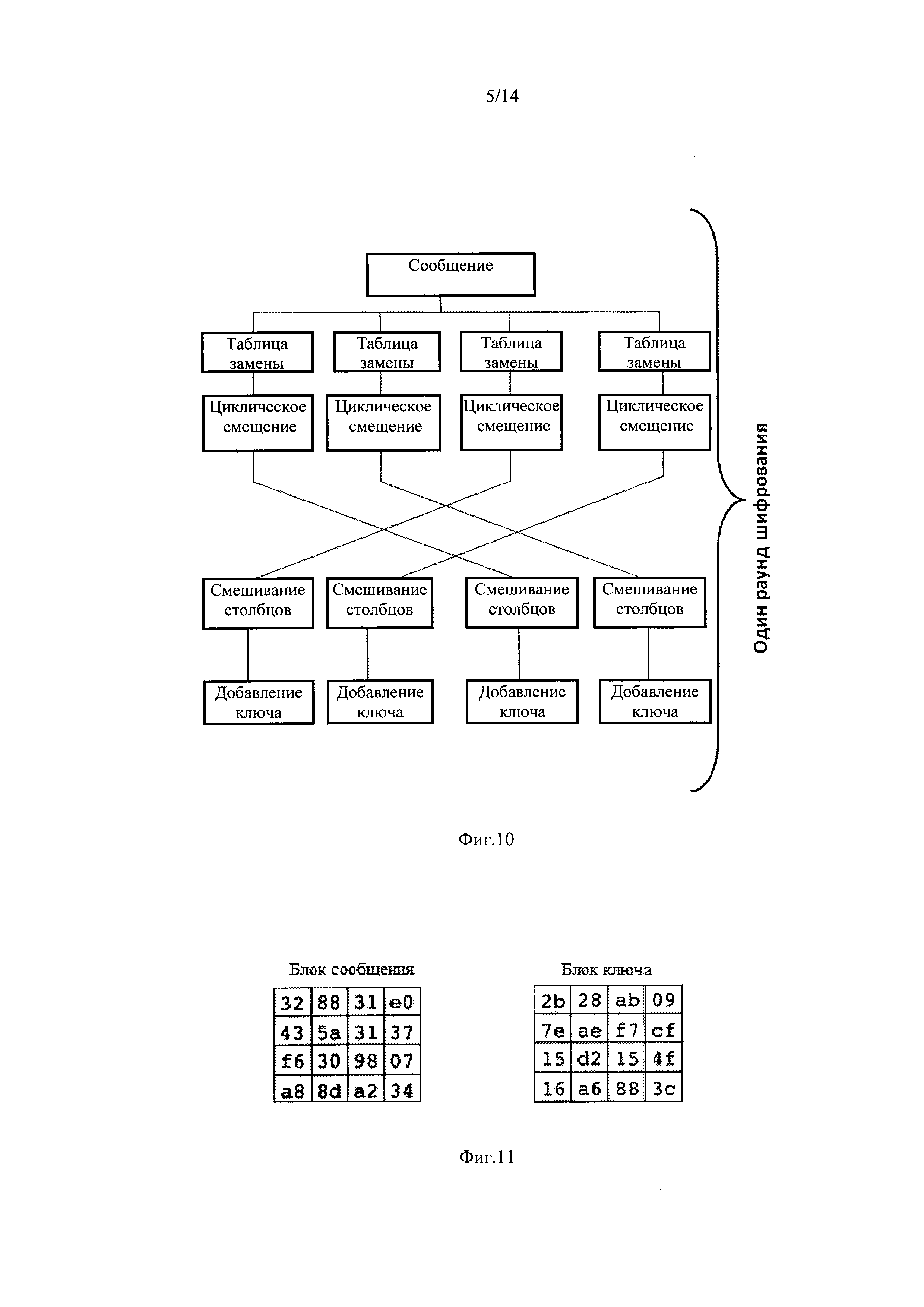
фиг. 9, где представлена схема второго этапа шифрования, на основе симметричного шифра;
фиг. 10, где представлена схема изменения передачи информации между функциями шифрования ShiftRows и MixColumns (изменения дизайна шифра, по сравнению с аналогичным симметричным шифром AES);
фиг. 11, где представлен блок сообщения и блок ключа перед первым раундом второго этапа шифрования;
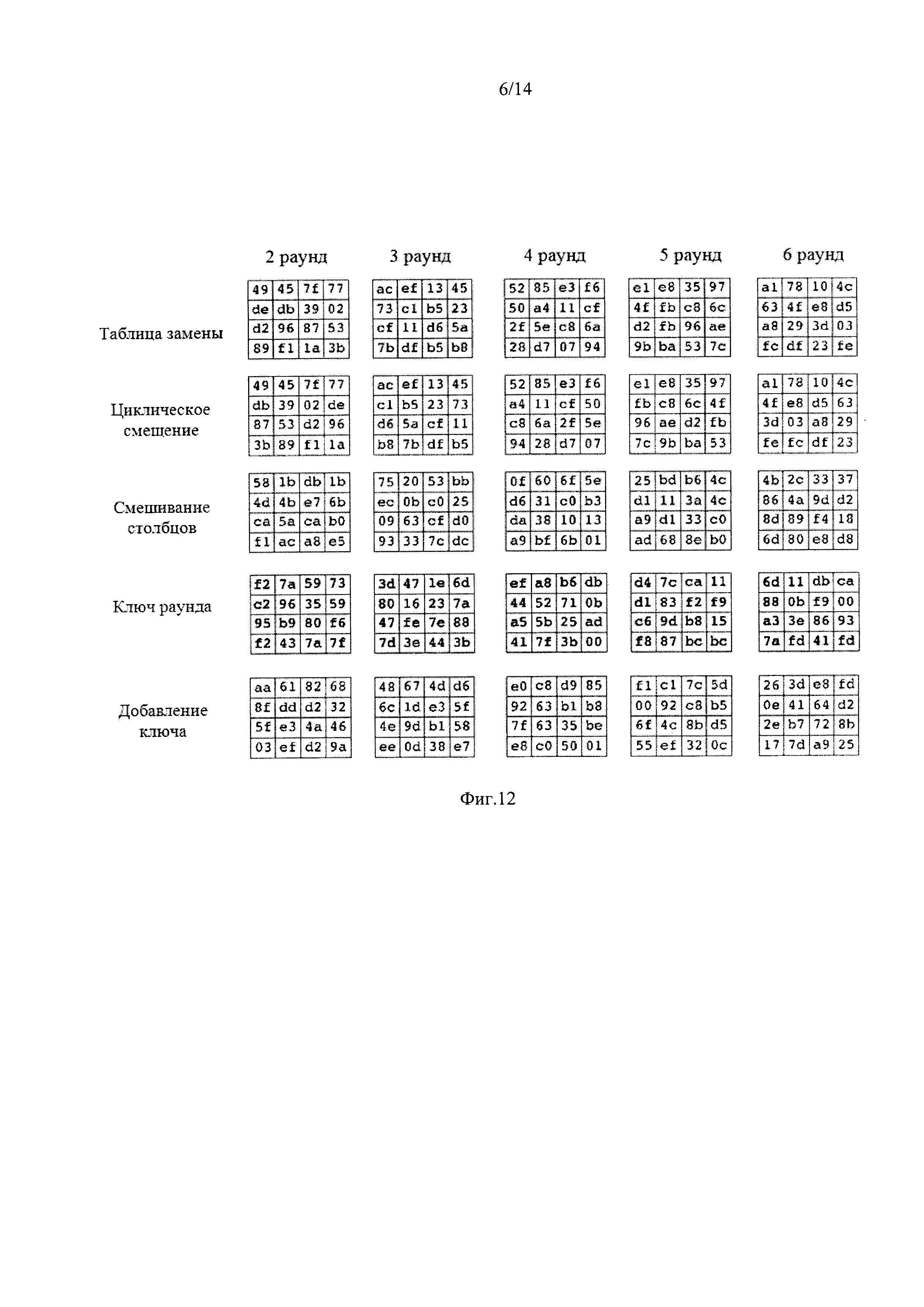
фиг. 12, где представлены рассчитанные значения шифруемого текста одного блока после различных раундовых операций раундов шифрования (со второго по шестой);
фиг. 13, где представлены рассчитанные значения шифруемого текста одного блока после различных раундовых операций раундов шифрования (с шестого по десятый);
фиг. 14, где представлены рассчитанные значения генерации раундовых ключей из общего ключа сообщения (с первого по четвертый раунды и на десятом раунде);
фиг. 15, где показан режим связывания блоков в режиме СВС (Cipher Block Chaining - сцепление блоков по шифротексту).
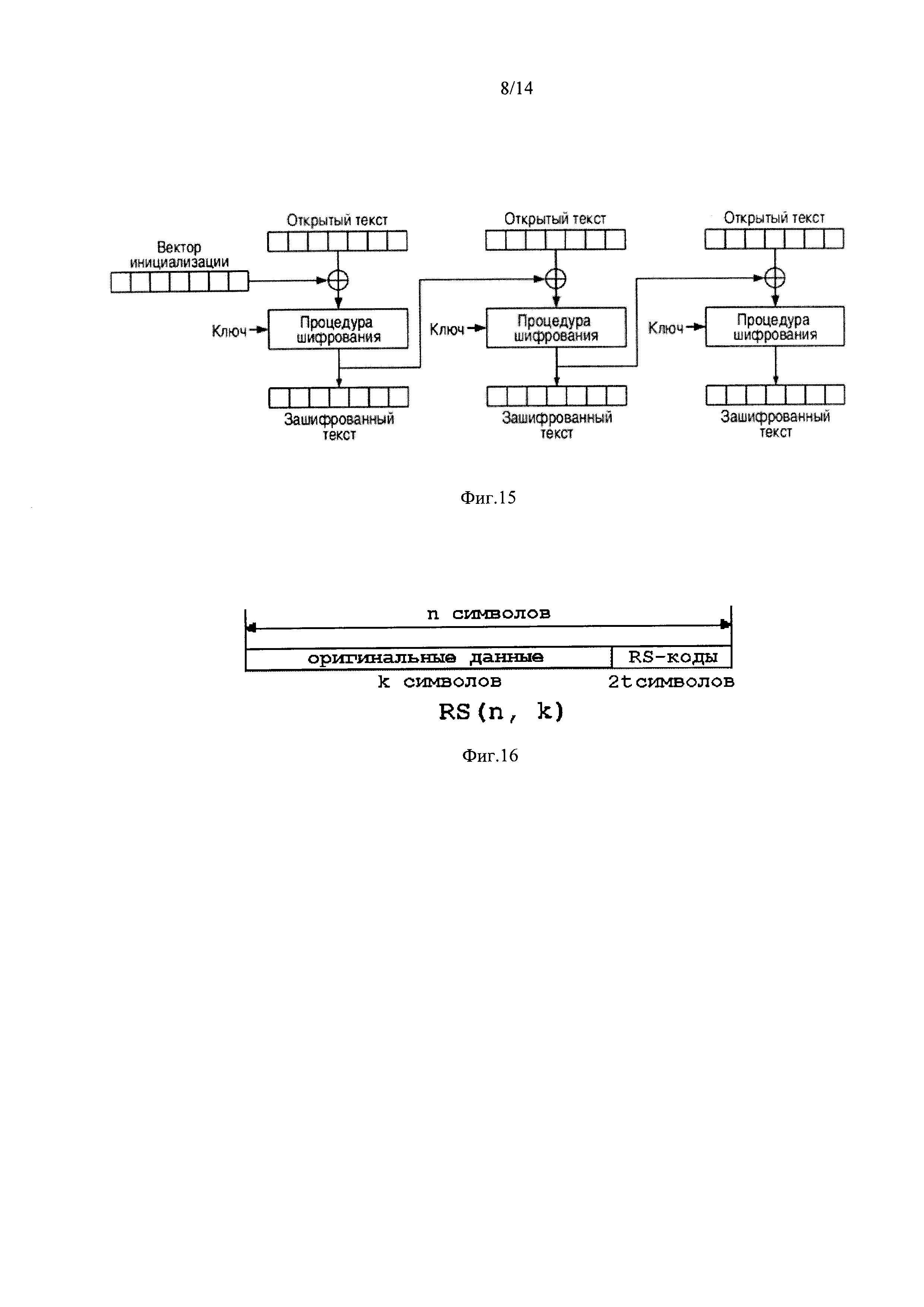
фиг. 16, где показана общая структура блока с данными и RS-кодом для восстановления ошибок, где:
n - символы четности,
k - полная длина кодового слова, включающего в себя кодируемые данные и символы четности n. Количество символов четности равно: n - k.
t - максимальное количество исправляемых ошибок,
2t - общее количество символов четности,
RS (n, k) - определенная разновидность корректирующих кодов, оперирующая с n-символьными блоками, k-символов из которых представляют полезные данные, а все остальные отведены под символы четности;
фиг. 17, где представлен полином размерностью 120 символов (для блоков длиной 256 байт).
фиг. 18, где показаны размеры нанобар-кода, в зависимости от количества символов (количество символов от одного до 2000);
фиг. 19, где представлен фрагмент нанобар-кода, в виде координат центров модулей;
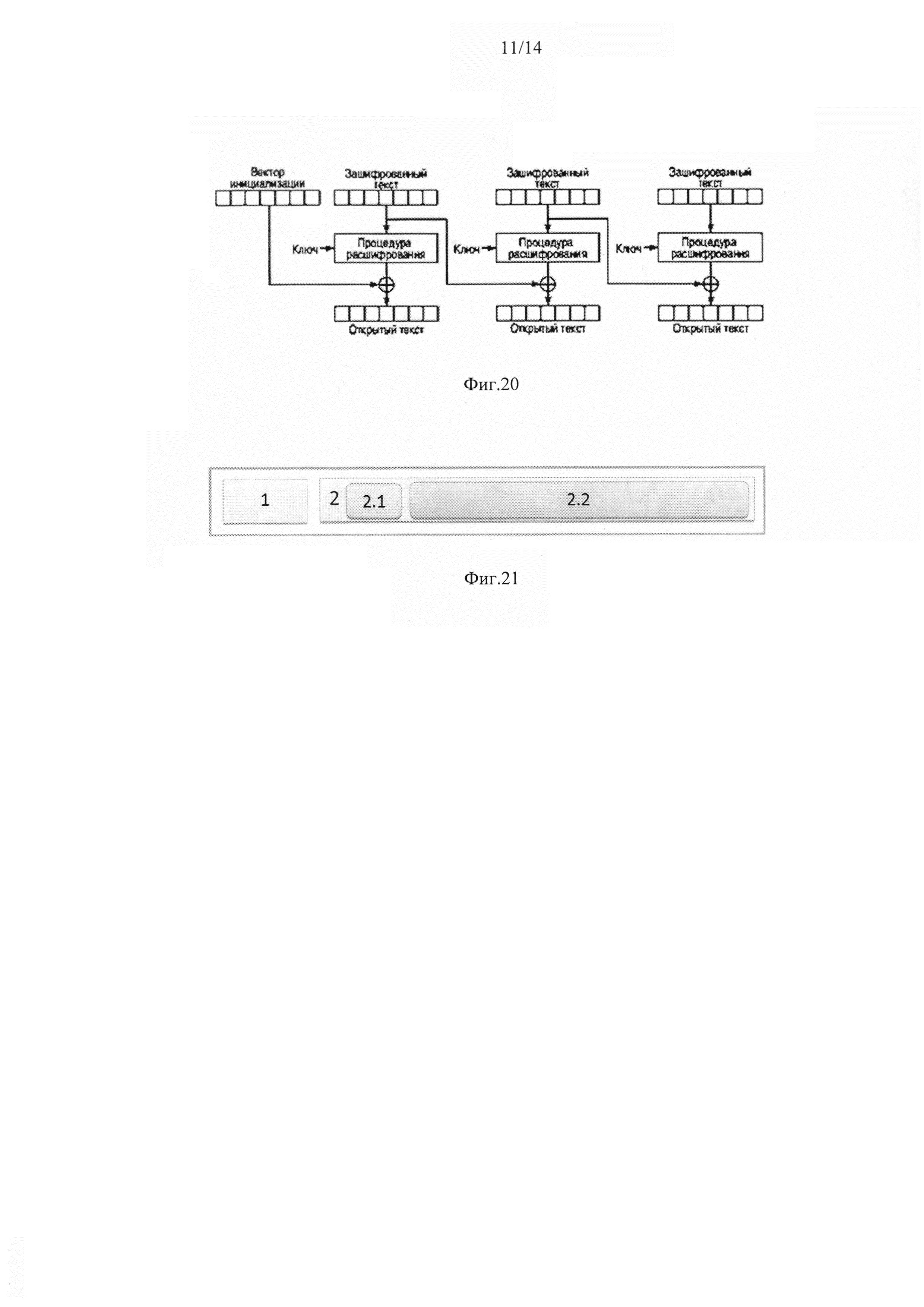
фиг. 20, где показано расшифрование в режиме СВС;
фиг. 21, на которой представлена структура данных одного блока сообщения.
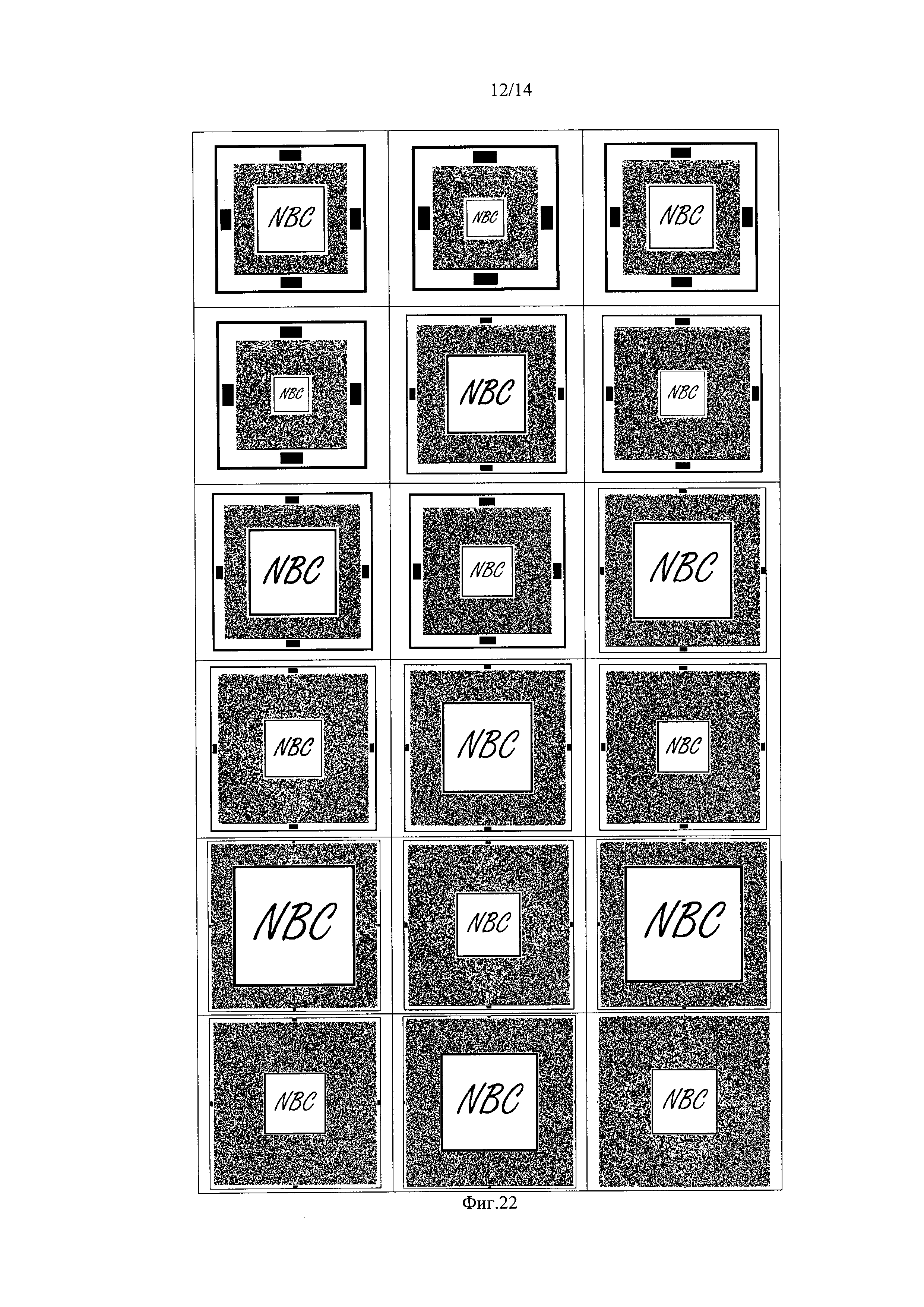
фиг. 22, где показан общий вид нанобар-кода с различными размерами ориентирующего и кодового блоков.
фиг. 23, где показано расположение начала координат на координатной плоскости в ее центре;
фиг. 24, где показан вариант с расположением начала координат в любой области координатной плоскости;
фиг. 25, где представлена заполненная координатная плоскость.
Символ предлагаемого кода (нанобар-кода) располагается на фоне 8 (фиг. 1) и составлен из графических элементов, представляющих собой единичный квадрат или элементарный модуль кода. Причем размер элементарного модуля кода может быть размерно равен выбранному разрешению (dpi) формирования символики или пропорционален разрешению символики.
На фиг. 2 опорный квадрат 4 (фиг. 1) представляет собой поле, ограниченное рамкой 2 по периметру, толщиной минимум в два модуля и пустое поле 7, в котором может находиться надпись. Помимо надписи, опорный квадрат 4 может содержать изображение, представляющее собой растровый монохромный, полихромный или выполненный в градациях серого графический объект, например, логотип. Разрешение такого графического объекта соответствует разрешению предлагаемой символики, при этом элементарный модуль кода пропорционален одному пикселю графического объекта. Размеры объекта рассчитываются, исходя из минимального размера опорного квадрата 4 с надписью. Цветное графическое изображение может состоять из оттенков стандартной палитры, графическому объекту могут быть присвоены атрибуты. Указанный графический объект не влияет на считываемость и декодирование информации, находящейся в нанобар-коде, но несет, при этом, дополнительный экспертный признак подлинности как самой символики, так и объекта, на который она нанесена. Минимальный размер опорного квадрата 4, содержащего надпись по внешнему периметру равен 25×25 модулей, и не менее 10×10 модулей - без надписи.
Центральный опорный квадрат может быть представлен в виде квадрата, заключенного в квадратную рамку, при этом разделительная белая рамка имеет толщину минимум четыре модуля (фиг. 3). Размеры элементов опорного квадрата 4 могут принимать различные размеры. Ниже приведены минимальные размеры:
центрального квадрата - 2×2 модуля,
белого поля, окружающего центральный квадрат - 8×8 модулей,
внешние размеры черной рамки, окружающей центральный квадрат и пустое поле - 12×12 модулей (при толщине рамки в два модуля).
Размеры центрального квадрата, рамки 2, пустого поля 7 могут изменяться в различную сторону. Опорные квадраты располагаются на пересечении осей симметрии символики и не перемещаются в поле символики.
Выравнивающие прямоугольники (фиг. 4) предназначены для выравнивания кода при съемке относительно осей X и Y (фиг. 6 и фиг. 7). Размер прямоугольника равен модулю кода. Минимальные размеры прямоугольника 1×2 модуля. Размеры прямоугольника могут изменяться в зависимости от размеров кода и соотношения его элементов. Рекомендуемое соотношение сторон выравнивающих прямоугольников равняется 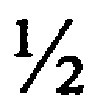 .
.
Выравнивающие прямоугольники 5 (фиг. 1) располагаются на белом поле, расположенном между границей области символики и области данных. Белое поле имеет минимальную ширину в три модуля. Ширина поля может меняться, в зависимости от размеров символики и отношений ее опорных элементов. Расположение выравнивающих горизонтальных прямоугольников по горизонтальной оси может отклоняться от центральной вертикальной линии симметрии и смещаться по всей области пустого поля вдоль горизонтальной плоскости перемещения. Минимальное количество выравнивающих прямоугольников по каждой из сторон символики - 1. В зависимости от количества информации и размеров символики, количество выравнивающих прямоугольников может изменяться.
Отображение нанобар-кода может быть реализовано следующим образом:
визуализирован в виде изображения, составленного из светлых и темных ячеек (элементарных модулей), аналогом являются стандартные двухмерные коды, например, QR-код;
представлен в виде массива (потока) защищенных данных (аналогом является система защиты информации Крипто С);
визуализирован в виде координат центров элементарных модулей;
представлен в виде управляющего файла, включающего в себя область записи данных и управляющие устройством для визуализации (принтер, лазерная установка и др.) алгоритмы или команды;
реализован в виде исполняемого компьютерного файла.
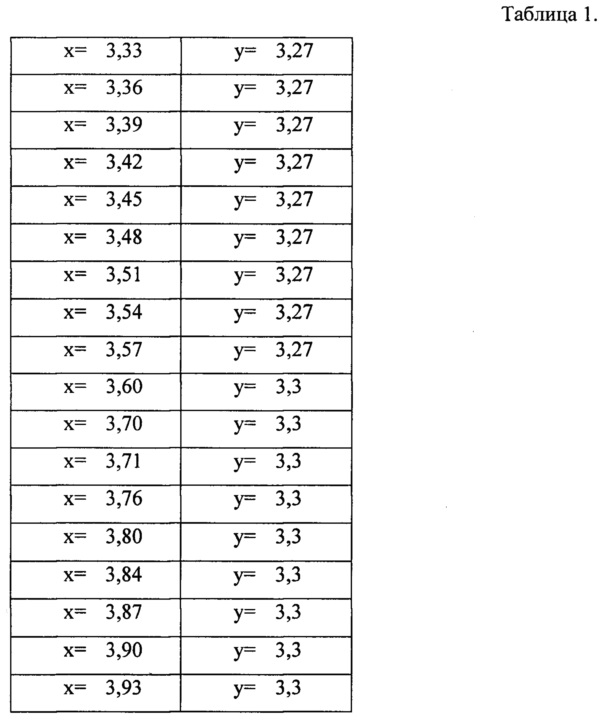
Пример реализации нанобар-кода в виде координат (фрагмент координатной плоскости) представлен в таблице 1.
Для кодирования символьной информации используется таблица ASCII 256 символов - для перевода символьной информации в десятиричную, либо шестнадцатиричную систему счисления для дальнейшей обработки алгоритмом шифрования, где каждому символу кодируемого сообщения сопоставляется номер позиции данного символа в таблице ASCII. Используется первая половина таблицы ASCII международного формата с 0 по 127 символ. Вторая половина таблицы ASCII содержит кириллические символы и псевдографику места с 128-256.
После шифрования данные сжимаются алгоритмом, основанном на методе использования оптимальных кодов, с тем отличием, что вероятности для каждого поступающего сообщения рассчитываются только для этого сообщения. Т.е. существуют вероятности встречаемости букв русского алфавита, определенные на множестве текстов, но в выборке текстов состоящей из одного текста вероятности встречаемости букв могут отличаться от всей определенной вероятности на большей совокупности текста. Для наиболее оптимального достижения компрессии вероятности необходимо пересчитывать для каждого сообщения. В общем виде, вероятность появления элемента si равна p(si), представление этого элемента будет равно - log2p(si) бит. Если при кодировании длина всех элементов будет приведена к log2p(si) битам, то длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F={p(si)} неизменно, и вероятности элементов взаимно независимы, средняя длина кодов может быть рассчитана как:
Н=-Σip(si)⋅log2p(si).
Значение Н является энтропией распределения вероятностей F, или энтропией источника в заданный момент времени. Однако, вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от различных факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F=Fk и Н=Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si. Учитывая это, среднюю длину кода можно рассчитать по формуле:
H=-ΣkPk⋅Hk=-Σk,iPk⋅pk(si)log2pk(si).
где Pk - вероятность нахождения источника в состоянии k.
На фиг. 8 представлены вероятности встречаемости символов русского алфавита, без учета вероятностей в отдельном тексте.
Определение последовательности кодовых значений
Аналогичных образом, кодируются данные бинарного вида, с тем отличием, что для каждого сообщения строится таблица кодовых слов. Рассчитывается вероятность полученных кодовых слов в сообщении. Для получения однозначно декодируемых оптимальных кодов используются префексные коды. По бинарному графу определяются префексные кодовые слова, и сообщение перекодируется, для получения оптимальной длины кода. В таблице 2 представлена возможность кодирования слов А1-А4 с различной длиной последовательности бит.

Шифрование текстовой информации
Способ шифрования, используемый в нанобар-коде, представляет собой блочный симметричный алгоритм шифрования. Блок шифрования предусматривает шифрование на первом этапе на уровне байтов (символов), а на втором этапе - на уровне битов. На первом этапе шифрования, на уровне байтов, предусмотрено количество раундов перемешивания, равное 1. На втором этапе шифрования, на уровне битов, предусмотрено количество раундов перемешивания, с конечным числом раундов, равное q. Сообщение Р длиной а символов разбивается на n-е количество блоков, объемом m символов в блоке, и шифруется с алгоритмом, содержащим q раундов перемешивания. Для первого этапа шифрования на уровне байт используют таблицу значений 256*256 символов (256 таблиц по 256 позиций), при этом, количество полей таблицы соответствует количеству полей кодировочной таблицы ASCII.
Используются формулы для кодирования символьного сообщения:
Ci≡Pi+Ki (mod 256), где:
Р=Р1Р2Р3… - кодовые слова сообщения
С=С1С2С3… - полученные значения сообщения
k=[(k1,k2), (k3,k4), …(kn,km)] - потоковые ключи
Поток ключей не зависит от символов исходного текста, он зависит только от позиции символа в исходном тексте. Другими словами, поток ключей может быть создан без знания сути исходного текста.
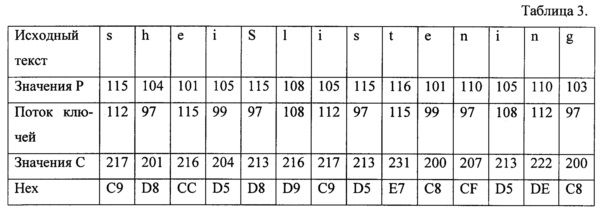
Для примера, закодируем исходный текст "Sheis listening":
Выберем генератор потока ключей - ключевое слово "PASCAL".
Полный поток ключей равен длине сообщения:
(112, 97, 115, 99, 97, 108, 112, 97, 115, 99, 97, 108, 112, 97).
Поток значений зашифрованного сообщения:
(217, 201, 216, 204, 213, 216, 217, 213, 231, 200, 207, 213, 222, 200)
Поток в 16-тиричной системе счисления:
(С9, D8, СС, D5, D8, D9, С9, D5, Е7, С8, CF, D5, DE, С8)
Для удобства восприятия, сведем данные в таблицу 3.
Второй этап шифрования основан на симметричном битовом алгоритме шифрования AES (фиг. 9) с изменениями дизайна шифра: между операциями ShiftRows и MixColumns происходит сдвиг блоков, с сохранением механизма формирования раундовых ключей и этапов перемешивания (фиг. 10). Сдвиг блоков между операциями ShiftRows и MixColumns позволяет повысить криптостойкость алгоритма. Оценка увеличения крип-тостойкости без смещения 2n операций, со смещением (2n)! операции.
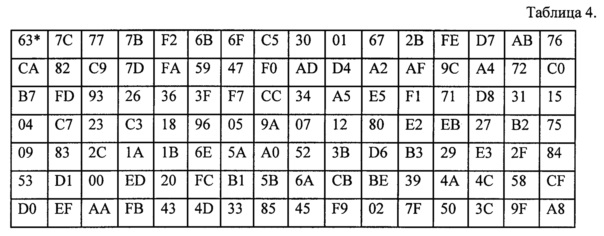
Операция SubBytes представляет собой табличную замену каждого байта массива данных, согласно следующим данным. Т.е. входные значения последовательности заменяются на соответствующие табличные значения. Значения таблицы рассчитаны на основе известных многочленов, дающих равновероятное распределение символов после операции (табл. 4).
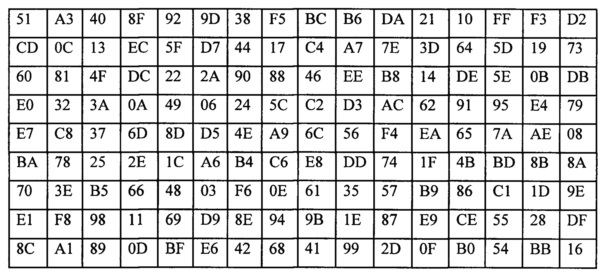
Таким образом, при кодировании на основе AES, и выполнении операции SubBytes, биективное отображение происходит с использованием таблицы сформированной с использованием полинома xn+xn-1+…+1=0, где n∈P (Р - пространство простых чисел). В этом случае массив данных подстановки равен значениям от a1 до r16, где n∈P (Р - пространство простых чисел). Кроме того, в случае шифрования, как и в случае кодирования, происходит биективное отображение элементов одного алфавита в другой (из алфавита А в алфавит Б) с тем отличием, что при шифровании функция отображения (ключ) является неизвестной. В предлагаемом изобретении отображение при кодировании происходит с использованием известной кодировочной таблицы ASCII, при шифровании с использованием таблицы, сформированной с использованием полинома xn+xn-1+…+1=0. Так, что возможно использовать оба понятия, с указанием используемой таблицы.
Операция ShiftRows выполняет циклический сдвиг влево всех строк массива данных, за исключением нулевой. Сдвиг i-й строки массива (для i=1, 2, 3) производится на i байт.
При этом, сдвиг может происходить как мультипликативно, так и аддитивно, причем со сдвигом как в левую, так и в правую сторону по массиву данных. Т.е. последовательность данных может не только складываться с формируемой псевдослучайной последовательностью, но и вычитаться, а также умножаться. При этом вычисление (поиск) элемента, лежащего в поле 0-255 может происходить как от меньших значений к большим, так и от больших к меньшим значениям. Это позволяет оптимизировать функцию поиска остатка результата сложения или умножения.
Операция MixColumns выполняет умножение каждого столбца массива данных, который рассматривается как полином в конечном поле GF(28) на фиксированный полином а(х):а(х)=3х3+х2+х+2.
Умножение выполняется по модулю х4+1.
Операция AddRoundKey выполняет наложение на массив данных материала ключа, а именно, на i-й столбец массива данных (i=0…3) побитовой логической операцией «исключающее или» (XOR) накладывается определенное слово расширенного ключа W4r+i, где r - номер текущего раунда алгоритма, начиная с 1 (процедура расширения ключа будет описана ниже).
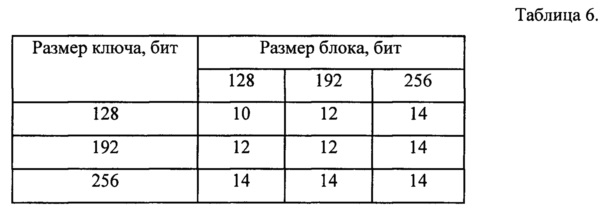
Количество раундов алгоритма R зависит от размера ключа, зависимость представлена в табл. 5.

Перед первым раундом алгоритма выполняется предварительное наложение материала ключа с помощью операции AddRoundKey, которая выполняет наложение на открытый текст первых четырех слов расширенного ключа W0…W3.
Последний раунд отличается от предыдущих тем, что в нем операция MixColumns не выполняется.
Количество возможных раундов шифрования размеров блоков и размеров ключа представлено в табл. 6.
Расширение ключа: алгоритм использует ключи шифрования трех фиксированных размеров: 128, 192, и 256 бит. Задача процедуры расширения ключа состоит в формировании нужного количество слов расширенного ключа для их использования в операции AddRoundKey. Под «словом» здесь понимается 4-байтный фрагмент расширенного ключа, один из которых используется в первичном наложении материала ключа и по одному - в каждом раунде алгоритма. Таким образом, в процессе расширения ключа формируется 4*(R+1) слов. Расширение ключа выполняется в два этапа, на первом из которых производится инициализация слов расширенного ключа (обозначаемых как Wi): первые Nk (Nk - размер исходного ключа шифрования К в словах, т.е. 4, 6 или 8) слов Wi (т.е. i=0…Nk-1) формируются их последовательным заполнением байтами ключа.
Для примера, зашифруем блок данных, размером 128, с использованием десяти раундов шифрования и размером ключа 128 бит.
Сообщение: 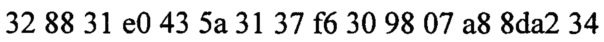
Ключ сообщения: 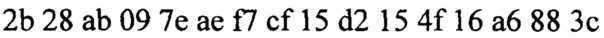
Поток сообщения после первого этапа шифрования поступает в блоки вместе с потоком ключей (фиг. 11). На каждом раунде шифрования сообщение преобразуется и принимает вид, представленный на фиг. 12 и 13.
В итоге, на выходе, последовательность зашифрованного сообщения выглядит как:
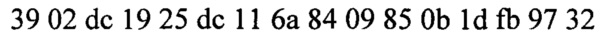
На каждом этапе шифрования из общего потокового ключа формируются раундовые ключи (фиг. 14).
Пример формирования раундовых ключей.
На фиг. 14 показаны рассчитанные раундовые ключи для потока сообщения, представленного выше. Здесь, как и в случае с этапом байтового шифрования, длина ключа равна длине сообщения. Общее количество раундов шифрования равно одиннадцати (включая первый этап). Ключ для байтового и битового блоков шифрования генерируется пользователем - вводом кодовой последовательности символов. При этом, длина потокового ключа формируется равной длине исходного сообщения.
Для сцепления блоков друг с другом используется режим CBC(Cipher Block Chaining - сцепление блоков по шифротексту), представленный на фиг. 15. Каждый блок открытого текста побитово складывается по модулю два с предыдущим результатом шифрования.
В общем виде, шифрование может быть описано следующим образом:
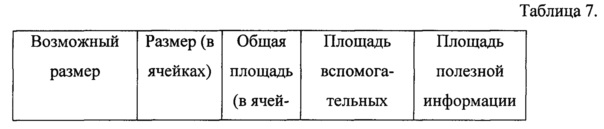
C0=IV
Ci=Ek(Pi⊕Ci-1)
где i - номера блоков, IV - вектор инициализации, Ci и Pi - блоки зашифрованного и открытого текстов соответственно, а Ek - функция блочного шифрования.
Количество блоков сцепления равно количеству блоков шифротекста, полученного после этапа шифрования. Открытый текст, пропущенный через блок шифрования XOR-ся с вектором инициализации на выходе дают шифротекст, который является входными данными для следующего блока сцепления. Вектор инициализации указан только для первого блока сцепления.
Процедура обнаружения и коррекции ошибок
Для обнаружения ошибок используется частный случай БХЧ-кодов (Коды Боуза - Чоудхури - Хоквингхема). В теории кодирования - это широкий класс циклических кодов, применяемых для защиты информации от ошибок), с уровнем восстановления ошибок до 40% утраченной информации (фиг. 16).
Формирование избыточной информации происходит с использованием полинома xn+xn-1+…+1=0, где n∈P (Р - пространство простых чисел). В этом случае используемый полином является универсальным, как для операции SubBytes,так и для формирования избыточной информации.
Предпочтительный алгоритм формирования избыточной информации состоит из следующих шагов:
1) К исходному информационному слову D справа добавляется k нулей, получается слово длины n=m+r и полином Xr*D, где m - длина информационного слова;)
2) Полином Xr*D делится на порождающий полином G, и вычисляется остаток от деления R, такой что: Xr*D=G*Q+R, где Q - частное, которое отбрасывается.
3) Остаток R добавляется к информационному слову D, получается кодовое слово С, информационные биты которого хранятся отдельно от контрольных бит. Остаток, который получается в результате деления - корректирующий код.
4) Информационное слово + корректирующие коды можно записать так: Т=Xr*D+R=GQ. Стоит отметить, что все операции выполняются в конечных полях Галуа GF (2n).
Кодируемые данные передаются через массив data[i], где i=0…(k-1), а сгенерированные символы четности заносятся в массив b[0]…b[2*t-1]. Исходные и результирующие данные представлены в полиномиальной форме. Кодирование производится с использованием сдвигового feedback-регистра, заполненного соответствующими элементами массива, с порожденным полиномом внутри.
с(х)=data(x)*x(n-k)+b(x).
Формула образующего полинома для генерации прямого и обратного GF (2n):
х^8+х^4+х^3+х^2+1.
Полином размерностью 120 (для блоков длиной 256), позволяющий восстанавливать до 120 ошибок в блоке (фиг. 17).
Кроме того, при сжатии информации используются вероятностные методы определения выходного значения данных на основе определения эффективной монотонной схемы для функции голосования. Т.е. расчет вероятностей происходит только для элементов входной последовательности, на которых построена монотонная функция, остальные элементы последовательности получаются транслированием, полученных ранее элементов. Это позволяет не рассчитывать вероятности для всех входных элементов и оптимизирует процедуру.
Размеры кода изменяются в зависимости от количества кодируемых данных. Минимальный размер символики, при кодировании одного символа не изменяется в диапазоне от 1 до 100 символов. Минимальное размер символики составляет 14, верхнее значение зависит от количества информации, закодированной в коде.
Фиг. 18 показывает размеры нанобар-кода, в зависимости от количества символов.
Нанобар-код может быть технически реализован, как в графическом формате, в виде растрового или векторного изображения, так и виде управляющего файла. Управляющий файл содержит координаты расположения ячеек, относительно центра символики, и координаты векторных объектов (фиг. 1, фиг. 4,), а также технические параметры обработки материала данной технологией, с использованием данного оборудования. В качестве примера приведены параметры лазерной импульсной установки.


При формировании нанобар-кода следует учитывать, что рекомендуемая последовательность действий следующая:
- Кодирование и перевод информации с бинарный вид;
- Шифрование;
- Архивирование;
- Добавление избыточной информации для восстановления утраченных данных;
- Расположение на поле символики.
При изменении порядка следования функции, не гарантируется оптимальное соотношение между объемом закодированной (зашифрованной) информации и возможностью полного восстановления данных.
Рекомендуется функцию восстановления информации выполнять последней, в любом другом случае корректное восстановление информации, в случае частичного искажения не гарантируется.
Также, необходимо отметить, что формирование нанобар-кода с использованием предлагаемого способа предусматривает формирование нанобар-кода в «закрытом» и «открытом» виде. Формирование «закрытого» нанобар-кода имеет указанную выше последовательность действий. При формировании «открытого» нанобар-кода предпочтительный пункт «Шифрование» может быть исключен, и, таким образом, получен двухмерный машиносчитываемый код, использующийся в традиционных схемах логистики и идентификации, не предусматривающих специальную защиту информации.
Кроме того, следует учитывать ограничения на объем кодируемой и шифрованной информации, размещаемой в нанобар-коде, обуславливается это целесообразностью применения нанобар-кода, в том или ином случае. Таким образом, обеспечивается максимальная информативность предлагаемого нанобар-кода, а также возможность формировать «закрытые» или «открытые» локальные базы данных, связанные с объектом или изделием.
Рекомендуемый способ декодирования
Для декодирования визуализированного в виде изображения или нанесенного на какой либо материал, нанобар-кода, производится его считывание. При этом используется специализированная уникальная аппаратно-программная система считывания и распознавания, которая позволяет захватывать изображения в широком диапазоне (от 0,05 - до 100 мм) и преобразовать его в цифровой поток данных. Дальнейшее декодирование производится следующим образом.
На фиг. 20 представлен процесс дешифровки блоков зашифрованных в режиме СВС. После, выполняется дешифрования на битовом и байтовом уровнях, в общем виде, процесс дешифрования можно представить тремя выражениями:
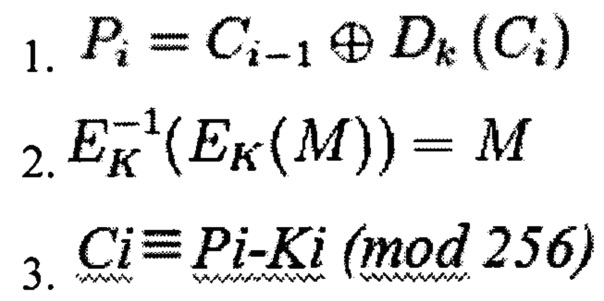
где i - номера блоков
Ci и Pi - блоки зашифрованного и открытого текстов соответственно
Dk - функция зависящая от входного блока Ci
Ek - функция блочного шифрования
Ek-1 - обратная функция функции блочного шифрования
К - потоковые ключи
Ki - потоковый i-тый ключ
Р - кодовые слова сообщения
(mod 256) - целочисленный остаток от деления на 256
Структура передаваемых данных
Структура символа, включающая в себя поле с записью информации, включающее в себя область записи, которая состоит из блоков, отдельный блок содержит служебную информацию, 4 байта - длина кода (фиг. 21).
При использовании формата графического изображения передаются следующие данные:
- Cypher (1 байт) - тип шифрования (1 - без шифрования, 2 - шифрование);
- Extension (строка) - расширение исходного файла.
При использовании формата управляющий файл передаются следующие данные:
- Устройство (строка) (устройство для вывода нанобар-кода);
- Материал (строка) (данные по материалу, на который наносится нанобар-код);
- Cypher (1 байт) - тип шифрования (1 - без шифрования, 2 - шифрование AES);
- Extension (строка) - расширение исходного файла.
Таким образом, предложенный способ позволяет формировать как закрытый, т.е. с закодированной и зашифрованной информацией, так и открытый, т.е. только с закодированной информацией нанобар-код.
Преимущества предлагаемого нанобар-кода:
используется два уровня кодирования (до и после шифрования), а также уникальный способ расположения элементарных ячеек (расположения информационных блоков), позволяющий уплотнить информацию, по сравнению с известными кодами.
При сравнении с QR-Code, при большом объеме кодируемой информации (в примере - максимальный размер QR-Code) для нанобар-кода в области полезной информации преимущество очевидно (см. табл. 7).
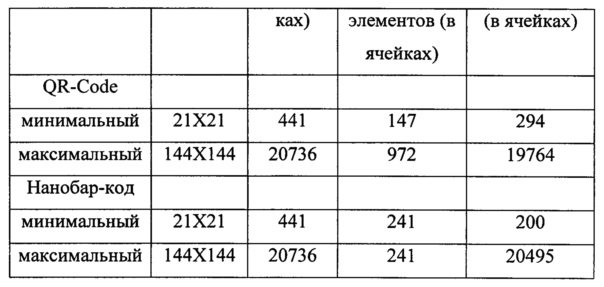
QR-code (как и другие) имеет фиксированное положение вспомогательной информации, системная информация дублируется, а в случае утери обоих блоков служебной информации, декодировать код невозможно.
В нанобар-коде служебная информация находится в каждом отдельном блоке, отдельных маркеров на них нет. При утере восстановительной информации в блоке, не происходит утраты всего сообщения, информация не восстанавливается только в этом блоке.
Дополнительным преимуществом нанобар-кода является корреляция компактности кода с его емкостью. Т.е., чем больше информации содержит нанобар-код, тем более плотным (ультраплотным) становится. Кроме того, фиксированные размеры ориентирующих элементов при декодировании позволяют:
- точно определять позицию блока с полезной информацией;
- определять кратность строк и столбцов ячеек (модулей) для однозначного формирования массива данных.
Таким образом, нанобар-код более устойчив к повреждениям областей служебной информации. Также необходимо отметить, что используемые алгоритмы восстановления информации, используемые при формировании нанобар-кода лучше, т.к. позволяют восстанавливать 40% утраченной информации, тогда как QR-Code и Data Matrix восстанавливают лишь 35%.
Преимуществом предлагаемых способов является применение высокоуровневого кодирования данных, при котором информация, обработанная алгоритмами шифрования сжимается методом оптимальных кодов, при этом вероятности для каждого поступающего сообщения рассчитываются только для этого сообщения (т.е. существуют вероятности встречаемости букв русского алфавита, определенные на множестве текстов, но в выборке текстов, состоящей из одного текста, вероятности встречаемости букв могут отличаться от всей определенной вероятности на большей совокупности текста.).
Преимущество применения шифрования цифровой информации в предлагаемом способе: шифрование на первом этапе происходит на уровне байтов (символов), на втором этапе на уровне битов. Кроме того, второй этап шифрования основан на симметричном битовом алгоритме шифрования AES с изменениями дизайна шифра: между операциями ShiftRows и MixColumns происходит сдвиг блоков, с сохранением механизма формирования раундовых ключей и этапов перемешивания, что позволяет повысить криптостойкость способа.



Установка для нанесения покрытий в среде легкоплавких материалов

