Результат интеллектуальной деятельности: Способ и устройство высокоэффективного сжатия мультимедийной информации большого объема по критериям ее ценности для запоминания в системах хранения данных
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Изобретение относится к области сжатия, передачи и хранения в компактном виде мультимедийной информации (МИ), циркулирующей в системах передачи/записи видео, изображений, речевых сообщений, аудиосигналов, графических и текстовых файлов, включая системы речевой связи, видеоконференсинга, видеонаблюдений, ТВ и радиовещания, системы хранения данных, а также поисковые системы, в которых вся МИ или ее отдельные фрагменты должны соответствовать критерию информационной достаточности (или полезности/ценности) для приема решения относительно адекватности информации, воспроизводимой после ее передачи по телекоммуникационной среде или помещения в систему хранения данных (СХД), поставленной цели при значительном сжатии данных с исключением (потерями) той доли МИ, которая не отвечает критериям ценности для системы принятия решения и/или лица (лиц), принимающего(их) решение (ЛПР), и качественным представлением тех фрагментов МИ, которые отвечают критериям ценности.
Уровень техники
В науке и технике широко используются методы сжатия данных с потерями и без потерь, которые позволяют сократить их естественную избыточность и экономить ресурсы систем передачи информации (СПИ) и/или систем хранения данных (СХД), а также систем поиска информации за счет уменьшения первоначального объема данных, порождаемых их источником. Теоретико-информационный аспект сжатия данных (кодирования источника) был развит в работах К. Шеннона и других исследователей и определялся функцией «скорость-искажения» (Rate-distortion function) или R=ƒ(e), где R - скорость потока данных в бит/с на выходе кодера источника, а е - ошибка (погрешность) или искажения при воспроизведении данных на выходе декодера источника (при сжатии без потерь можно обеспечить е=0, если исходные данные представлены в цифровом виде), применительно к передачи данных по каналу связи с пропускной способностью С бит/с, причем должно выполняться соотношение R<C для обеспечения нормальной связи. Здесь R и е выступают в роли основных критериев качества кодирования источника. Фактически речь здесь идет о так называемом сжатии данных с потерями, т.е. кодировании потока данных на выходе источника при отсутствии ошибок в канале и выполнении условия передачи R<C, контролирующего уровень информационных потерь е>0, которые можно оценить на выходе декодера источника [1, 2]. При этом задержка кодирования и сложность кодирования, используемые как дополнительные критерии (факторы), должны быть ограниченными для реальных приложений.
Характеристикой эффективности сжатия данных служит коэффициент сжатия K=Iвх/Iвых, где Iвx - объем информации на выходе источника (возможно, порождаемой за некоторый интервал времени Т, если анализу подвергается поток данных на выходе источника, т.е. на входе кодера источника), а Iвых - объем информации на выходе кодера источника (возможно, за указанный интервал времени Т, если анализируется результат кодирования потока данных на выходе кодера источника). Потери е при этом определении эффективности сжатия фиксируются. Эффективность сжатия данных зависит от уровня их избыточности, но также метода кодирования и его способности сократить или даже устранить эту избыточность.
Такие мультимедийные потоки как видео/изображений или речи/аудио являются примерами выходных данных на выходе источника (например, фото и видеокамеры или микрофона). При их приведении к цифровому виду и кодировании обязательно вносится погрешность е, определяющая качество оцифровки и кодирования. При оценке качества широко используются такие объективные критерии качества как среднеквадратическая ошибка (СКО) и ее вариации, максимальная погрешность и отношение сигнал/шум (SNR)/пиковое SNR (PSNR).
Для кодирования изображений широко используются кодеки JPEG и JPEG-2000, включая опцию сжатия без потерь цифровой копии изображения, а для кодирования видео используются кодеки MPEG-1, MPEG-2, MPEG-4 или их версии в виде стандартов (Рекомендаций) ITU-T Н.26х, а также проприетарные кодеки VP8, VP9 и др. [3]. Коэффициент сжатия К варьируется от 10 до 500 раз в зависимости от допустимой скорости видеопотока или выделенного объема памяти для хранения изображений/видео, уровня заданного качества, типа кодека и специфики изображений/видео. Широко используемый в таких кодеках принцип сжатия изображений и видео с потерями (в предположении, что они цветные (в частном случае монохромные, полутоновые) и представлены в известном формате RGB или YUV) таков: устранение пространственной избыточности на базе перехода из пространственной области в частотную путем трансформации матрицы изображения как в JPEG (или опорного кадра, как в MPEG 2 и 4) и использования системы ортогональных функций (преобразование Фурье, Уолша, дискретного косинусного преобразования (DCT), вейвлетов и др.) и тонкого или грубого квантования компонент, что вносит погрешность е, и последующее кодирование квантованных компонент на принципах энтропийного кодирования без потерь (в частности, арифметического кодирования); устранение временной избыточности в соседних кадрах видеопотока, в которых, как правило, есть небольшие изменения за счет движения объектов в кадре и/или видеокамеры, выявляемые оценивателем движения (motion estimator) и определением векторов движения для кодирования только измененных фрагментов нового кадра по отношению к опорному (что детально описано в стандартах MPEG 2 и 4, Н.26х).
Для кодирования речи используются речевые кодеки по стандартам ITU-T серии G.7xx (G.711, G.718, G.719, G.722.2 (AMR WB), G.723.1, G.726, G.729, G.729.1 и др.), кодеки GSM-FR, SILC, iLBC, IPMR и другие проприетарные кодеки. В тех случаях, когда кодирование учитывает специфику речеобразования (на базе модели «источник-фильтр») и слухового восприятия, а мера качества кодирования речи является субъективной (например, разборчивость по ГОСТ или Mean Opinion Score (MOS)), то такой кодек называется вокодером (voice codec) [4]. Коэффициент сжатия варьируется от 5 до 50 раз в зависимости от требуемой скорости речевого потока на выходе кодера, уровня заданного качества, допустимой задержки и специфики речевого сигнала (с учетом пауз в речи). Если же форма оригинального сигнала сохраняется на выходе кодека с контролируемой погрешностью е, то такие кодеки называются кодеками речевой волны (waveform codecs). Примером такого кодека является речевой кодек G.726, реализующий метод адаптивной дифференциальной импульсно-кодовой модуляции (ADPCM) во временной области, но его эффективность по значению К невелика: обеспечивается К=3…5.
Для кодирования аудиосигналов используются такие известные и широко используемые аудиокодеки как МР3, ААС, ААС+, WMA, Ogg Vorbis и др. [5]. Практически все аудиокодеки построены на основе метода waveform coding, но обработка сигнала производится, как правило, в частотной области. Коэффициент сжатия К аудиопотока варьируется от 5 до 30 раз и зависит от полосы частот аудиосигнала и требуемого качества воспроизведения аудио при декодировании.
Уровень потерь (ошибок) е можно опустить до нуля, что имеет место в кодеках, обеспечивающих сжатие без потерь, а также в методах дедупликации, используемых в СХД для сжатия массива символьных данных путем исключение дублирующих копий повторяющихся данных [6]. Примером могут служить архиваторы zip и rar, широко используемые для кодирования символьной информации (например, буквенно-цифровых текстов), а также энтропийные кодеки в отмеченных выше стандартных методах сжатия изображений и видеоданных, но они представляют относительно малый самостоятельный интерес для кодирования мультимедийной информации из-за весьма низкой эффективности сжатия (коэффициент сжатия данных, равный двум-трем, считается для кодирования текстов вполне нормальным), но используются как составная часть общего метода сжатия мультимедийных данных.
Одна из особенностей этого классического теоретико-информационного подхода состоит в том, что при декодировании информации, переданной по каналам СПИ или хранящейся в сжатом виде в системах памяти, требуется максимально качественно ее воспроизвести и, возможно, с небольшой погрешностью (ошибкой) е, которая является некой платой за относительно высокий коэффициент сжатия К первоначального объема данных Iвx. Считаем что очень качественное (HD) видео при частоте кадров (fps) 30 требует скорости R=50 Мбит/с, а относительно низкое по качеству требует R=128 Кбит/с. Для перевода высокоскоростного видеопотока в низкоскоростной нужно обеспечить коэффициент сжатия не выше К=400. Применительно к речи качественный речевой сигнал в полосе 7 КГц при передаче или записи требует скорости R≥32 Кбит/с. Он может быть сжат до скорости 1.2 Кбит/с в «телефонной» полосе 4 КГц (хотя качество речи при декодировании будет довольно низким: по пятибалльной шкале оценки качества MOS~2.8…3.0). Т.е. К~ 30…50.
Однако такой подход (его можно назвать традиционным), широко освещенный в технической литературе, формирует фундаментальную границу эффективности кодирования источника мультимедийной информации из-за требования «воспроизвести полный сигнал (изображения, видео, речь, аудио) практически в его первоначальном виде, но с относительно небольшими контролируемыми потерями», чтобы наше зрение или слух почти не заметили при просматривании или прослушивании этих потерь. Этот подход предполагает, что почти ничего нельзя упустить («все важно») при восприятии и воспроизведении и человек или распознающая машина должны получить все в деталях при декодировании изображения/видео или речи/звука даже в ситуациях, когда полное видео или речевой/аудиосигнал в целом не несет информации, важной для зрителя и/или слушателя при вынесении им решений о сущностных ситуациях или событиях, которые показываются, описываются, сопровождаются звуком или высказываются в видео, аудио и/или речевом потоке. Указанный подход не воспринимает одну часть мультимедийной информации как «информационный шум», отвлекающий внимание и существенные ресурсы, включая временные, или даже мешающий принимать правильное решение. Целесообразно эту часть в поисковых системах и системах принятия решений отнести к «потерям». Другая его часть (как правило, значительно меньшая по объему) является информационно содержательной, полезной, ценной для пользователя и именно ее надо записывать в СХД с целью последующего воспроизведения с требуемым качеством и анализа при поиске релевантных данных или для поддержки систем принятия решений. Таким образом, сжатие данных во многих реальных ситуациях рассматривается в парадигме их ценности для ЛПР, а не в парадигме «скорость-искажения» безотносительно к их информационной значимости для того же ЛПР.
Классификация потока данных для целей более эффективного их сжатия широко используется, в частности, в патенте [2], где выбор собственно кодирования для сжатия данных и кодеков зависит или не зависит от контента. Другой пример применительно к речевому потоку связан с использование детектора активности речи (Voice Activity Detector - VAD), который включается в состав речевых кодеков практически во всех СПИ с коммутацией пакетов (в частности, в Интернете). VAD позволяет классифицировать речевой поток на участки наличия речи и участки отсутствия речи (паузы), т.е. это классификатор «речь/пауза». При этом паузы считаются неценными фрагментами потока и их не передают, а участки с речевым сигналом - ценным фрагментом.
Критерий, позволяющий оценить в потоке мультимедийных данных что является информационным шумом, а что - полезной информацией, определяется поставленной задачей, включающей составной частью анализ релевантной информации, и самим пользователем (даже если обработку данных ведет машина), которого интересует результат решения такой задачи, т.е. достижения поставленной цели. В тех ситуациях, когда важно оставить при сжатии данных с потерями только информативную с позиций пользователя как ЛПР (заинтересованного зрителя или слушателя) часть всего объема данных, можно даже получить очень большой коэффициент сжатия (например, К=1000 и более). Можно назвать такой подход суперсжатием (или сжатием данных с ценностным критерием) и его не надо путать с фрактальными методами сжатия данных [7], обещавшими указанные значения К, но так и не реализованными для большинства типов изображений и видео, которые, однако, вписываются применительно к компресии МИ в рамки традиционной парадигмы «сжатия с потерями» и функции «скорость-искажения». Указанный подход, определяемый полезностью или ценностью информации для пользователя, изучался разными исследователями, включая М.М. Бонгарда, Р.Л. Стратоновича, А.А. Харкевича, А.П. Веревченко и других крупных ученых. Важная цитата из [8] по этому вопросу такова: «Известно, что работа с информацией осуществляется с определенной целью. Увеличение вероятности достижения цели оценивается пользователем, к ней стремящимся. Поэтому стоит задача в получении точной и однозначной информации, освобожденной от избыточности. Определено, что избыточная, повторная информация имеет нулевую полезность, так как не увеличивает и не уменьшает вероятность достижения цели… Таким образом, полезность информации - это оптимальное удовлетворение определенным требованиям информационных запросов потребителей при принятии ими решений в конкретных условиях (ситуациях)».
Приведем поясняющие примеры отбора мультимедийной информации по критерию ценности/полезности для решения некоторых нестандартных задач, считая, что в них можно использовать известные перечисленные выше методы сжатия мультимедийных данных, а также человека (или виртуальную распознающую машину) для интеллектуальной классификации кадров в видеопоследовательности, выявления специфических фрагментов (ключевых слов и выражений) в речевом сообщении и детектировании определенных акустических событий в аудиопотоке.
В первом примере пользователем информации в изображении является врач, диагностирующий заболевание по цифровой рентгенограмме легких пациента на своем компьютере. Оригинальная рентгенограмма снята с высоким качеством (малое значение е), трансформирована в цифровую форму и кодирована с использованием кодека JPEG, контролирующего CKO/PSNR. В исходной рентгенограмме (в оригинале на фотопленке) в правом легком видна маленькая (по отношению к площади оригинала) черная точка, свидетельствующая о начале болезни. Но в JPEG-версии рентгенограммы этой точки нет (она исключена), но сама рентгенограмма в целом имеет довольно высокое разрешение. Т.е. с позиций использования критерия СКО погрешность е, связанная с исключением указанной точки, невелика, а с позиции врача-диагноста в ней упущена очень важная диагностическая информация (не был указан критерий ценности при использовании конкретного метода кодирования). Для врача интересна только эта часть целого изображения во всех ее деталях, а остальная часть или не интересна, или как фон может быть представлена с низким разрешением, т.е. может быть сжата со значительно большим значением К и большей погрешностью е. Т.е. для диагноста (в частности, лица принимающего решение - ЛПР) важно не пропустить релевантную для принятия решения информацию на фоне несущественной, но детально представленной информации, причем большого, как правило, объема. В данном примере критерий СКО для всего изображения без указания что полезно/ценно в цифровой копии рентгенограммы не может обеспечить выделение важной для врача информации и его необходимо дополнить адекватным задаче диагностики критерием ценности и в соответствии с ним выделять из информации только ценную для диагностики часть, нивелируя (или даже совсем исключая) неценную часть, и при этом ценная часть должна быть представлена с высоким качеством, обеспечивающем отображение диагностических данных.
Во втором примере рассматривается видеоконференция между двумя удаленными участниками (р2р-сеанс), т.е. имеются два видеопотока по двусторонней линии связи (виртуальной или реальной) между этими участниками. Участники обсуждают некоторую тему с частыми отвлечениями от нее. Фон, на котором представлены участники, статичен. Вся эта видеоконференция записывается и запись сеанса связи (исходный видеофайл) в сжатом виде помещается в систему хранения данных (СХД). Для некоего лица или организации, принимающих решения (ЛПР), через некоторое время на основании записи необходимо выяснить: 1) кто конкретно участвовал в конференции с каждой стороны, 3) имеются какие-либо специальные события в видеопотоке и 3) были ли некоторые ключевые слова произнесены при разговоре на определенную тему и кто их произнес. (Другие ЛПР могут ставить другие вопросы. Если таких лиц много, то записываемая в СХД информация, потенциально востребованная этими лицами, должна отвечать на вопросы этой группы лиц). Для данного случая это и будет критериями ценности, если отобранная в соответствии с ним информация в сеансе ВКС позволяет ответить на перечисленные вопросы.
Пусть скорость исходного видео со сжатием по стандарту ITU-T Н.264 (MPEG-4, part 10) равна 512 Кбит/с при 30 кадрах/с, а скорость речи 32 Кбит/с, т.е. общий уже обработанный мультимедийный поток в одну сторону составит 544 Кбит/с, в обе - 1.088 Мбит/с (не учитываем служебные данные при организации связи и разрешение видео считаем стандартным (SD)). Пусть два участники видеоконференцсвязи (ВКС) говорят T=1 час. Общий объем переданной информации Iвx = R * T = 1.088 Мбит/с × 3600 с = 3916.6 Мбит = 489.6 MB. Этим самым задан критерий качества исходного видео (значение искажения е) применительно ко всему видеопотоку (т.е. как к информативной, так и неинформативной его части).
Если интересуют только участники и не было ли при видеосвязи других людей в кадре, то достаточно выявить только опорные I-кадры (изображения участников), которые в среднем повторяются через каждые 32 кадра (их частота может задаваться в диапазоне 8…100) и представляются в сжатом виде (~30 KB на кадр). При этом очень быстрые изменения в видеоряде могут и не фиксироваться оценивателем движения, встроенным в кодек Н.264 [9]. Для записи в СХД с целью хранения длительное время нужно оценить и записать только информативные кадры (если в текущем кадре по отношению к предыдущему информативному кадру были довольно сильные изменения в сцене, например, появляется новый человек или участник выходит из поля зрения видеокамеры, то такой кадр объявляется информативным). Пусть на каждой стороне были в кадре другие люди помимо самих участников сеанса видеосвязи (т.е. они на некоторое время появлялись в поле зрения видеокамеры), которые постоянно присутствовали в кадре, а в целом динамика участника в кадре была относительно мала (имеются в виду моргание, разговор, повороты головы, движения руками и пр.). Пусть мы записали для каждого участника сеанса ВКС такие кадры: участник j, j=1,2, один в кадре; участник j с другим человеком в кадре; участник j один в кадре (снова), т.е. на каждого участника получилось три информативных кадра и всего таких кадров 6 и для их записи требуется память в размере 30 KB × 6 = 180 КВ. Отметим, что информативные по критерию ценности для ЛПР кадры (далее - ключевые кадры) совпадают с некоторыми опорными кадрами, определяемыми кодером Н.264, но число последних в среднем за 1 час равно 30×3600/32=3375, т.е. существенно больше числа действительно информативных (ключевых) для ЛПР кадров. При записи этих информативных кадров теряются движения и динамика в потоке видеокадров, когда участники говорят, моргают, жестикулируют, но известно и зафиксировано время t их появления в видеопотоке. Т.е небольшая динамика в поведении участников и лиц, вошедших в кадр, никак не учитывается в процессе записи в этих шести кадрах, также не учитываются возможные эмоции участников, а только их и других лиц присутствие в некоторые моменты времени из интервала Т.
При этом выделить в речи, информационный поток которой существенно слабее по значению битовой скорости, чем видеопоток, ключевые речевые события (высказывания, словосочетания, слова) довольно сложно, если не прибегать к современным относительно надежным методам распознавания в дикторонезависимом режиме слитной речи с произвольной тематикой и анализа текста на выходе распознавателя на предмет выделения специальных событий семантического (возможно, и прагматического) уровня. Если такого надежного механизма нет, то речевой сигнал в своем полном виде должен быть записан (желательно в сжатом виде для экономии памяти в СХД, но с приемлемым качеством). Пусть такие ключевые речевые события выявлены и для сохранения мини-контекста для этих событий записывается речь до и после их наступления (и пусть длина записи 20с = 10с + 10с). Предположим, что пять выявленных речевых событий (слов или высказываний) приписаны участнику 1 и два - участнику 2. Тогда речевой сигнал общей длительностью (5+2) × 20с = 140 с записывается в СХД. Это требует объема памяти 32 Кбит/с × 140с = 4480 Кбит = 560 КВ. Вместе с записанными кадрами это составит 740 КВ. В целом эта информация позволяет ответить на вопросы 1), 2) и 3), интересующие ЛПР. Методы и средства распознавания ключевых слов в потоке слитной речи уже разработаны и представлены в виде соответствующих продуктов на рынке [10, 11].
Полученный в этом примере коэффициент сжатия данных составляет К=489600/740=661, т.е. уже сжатый видео поток данных (с К ~ 30) дополнительно прорежен без информационных потерь для ЛПР более чем в 600 раз. Общий коэффициент сжатия К=30×661=19848. При этом в данном примере выделения ценной для ЛПР части мультимедийного потока запись речи требует больше памяти, чем запись изображений (выделенных ключевых кадров).
В том случае, если механизм распознавания речевых событий (т.е. ключевых слов и выражений - КСВ) на семантическом уровне не используется, то речевой сигнал должен быть записан в сжатом виде целиком, включая паузы (и считая, что участники говорят по очереди). Пусть используется вокодер на скорости 8 Кбит/с (например, кодек G.729). Тогда общий объем речевой информации равен 8 Кбит/с × 3600 = 28800 Кбит = 28.8 Мбит = 3600 KB = 3.6 MB. Вместе с кадрами из видеопотока общий объем станет 180КВ + 3600КВ = 3780КВ. При этом коэффициент сжатия уменьшится до значения К=489600/3780=129.5, т.е. в пять раз. При этом объем записи всей речи в данном случае существенно превосходит объем записи выделенных изображений (кадров). Если исключить паузы (обычно их не более 20% в речи), то можно немного увеличить значение К.
Третий пример связан с видеонаблюдением в интересах безопасности. Видеокамера направлена на определенное место и работает 24 часа в сутки. Качество видео, как исходного материала, довольно высокое и соответствует данным из второго примера (скорость 512 Кбит/с, кодек Н.264, ночью используется ИК-подсветка). Общий объем записываемой информации за сутки составляет Iвx=512×24×3600=44236800 Кбит=5529600 KB=5529.6 MB. Службу безопасности интересуют только кадры, где 1) представлена наблюдаемая сцена утром, днем, вечером, ночью, т.е. достаточно 4 кадра с разрешением SD, 2) динамика в сцене, вызванная проходом людей и проездом подвижных средств, 3) оставлением предметов, которые фиксирует подсистема отслеживания и распознавания объектов, входящая в систему видеонаблюдения, в разных местах наблюдаемой сцены. Таким образом, статические ситуации представлены одиночными кадрами, а динамические ситуации должны быть полностью записаны в память (возможно, с дополнительным сжатием данных) даже в случае, когда динамика (изменения) в кадре по отношению к предыдущему совсем мала.
Предположим, что примерно 60% времени сцена статична (динамика ниже определенного порога). В этом случае, как указано выше, она представлена четырьмя кадрами общим объемом 30 KB × 4 = 120 КВ. Остальное время (40%) производится запись динамической сцены (с любыми изменениями в ней, превышающими некоторый порог динамики), что требует за сутки информационного объема 512×0.40×24×3600=17694720 Кбит=2211840 КВ=2211.8 MB. Т.е. общий объем информации, записанный в память СХД, составляет Iвых = 2211840 + 120 = 2211960 KB = 2211.9 MB и коэффициент сжатия К=5529.6/2211.9=2.5, т.е. значение К весьма скромное и при учете первоначального сжатия в 30 раз (как в предыдущем примере) в общем составит всего 75. Но даже в этом случае имеется выигрыш в сокращении объема памяти для записи цифрового видео и сокращения времени анализа ситуаций и положения объектов в сцене человеком или машиной для системы безопасности, хотя он может быть существенно увеличен, если добавить в систему интеллектуальный анализ сцены для выбора информативных кадров, что является самостоятельной задачей.
Четвертый пример рассматривает запись ТВ-передачи (видео, речь, аудио) в качестве оригинала на предмет ее цензуры с параметрами сжатия данных: видеокодек MPEG-4, 25 кадров/с, скорость 2.048 Мбит/с, длительность записи 1 час; звуковой сигнал (речь и аудио) записывается аудиокодеком МР3 и его битовая скорость 128 Кбит/с, т.е. скорость общего медиапотока 2.176 Мбит/с и за 1 час объем информации составит 7833.6 Мбит=979.2 MB. Эти параметры определяют качество всего мультимедийного потока (всех трех его составляющих), хотя для реализации цензуры этого файла можно снизить качество как видео, так и звукового потока без потери информации для цензора.
При анализе записанного медиа-файла необходимо выявить речевые фрагменты и игнорировать музыкальное сопровождение записи, а в речевых фрагментах определить по критериям цензурирования отдельные высказывания из заданного словаря высказываний и слов и оставить речевой контекст для этих высказываний до и после их произнесения длительностью 15 с, что составит в общем 30с. В видеоряде интерес для анализа (по критериям ценности) представляют кадры, в которых человек произносит эти высказывания, а также сцены или фрагменты сцен, подобные тем, что имеются в базе данных (БД) специальных изображений (кадров). Выделенные таким образом фрагменты видеопотока и речевого потока помещаются в СХД.
Предположим, что в конкретном медиа-файле 30% времени занимает музыка, 20% паузы, а 50% речь (возможно, иногда сопровождаемая музыкой), а мы располагаем надежным классификатором речь/аудио/пауза для выявления речевых фрагментов и пауз. Предположим также, что в речевых фрагментах мы можем довольно надежно выделить участки, где произносится слова или выражения из заданного словаря и таких выражений/слов выявлено в полном файле 20. Т.к. необходимо записать видео этих высказываний, то это соответствует записи видеопотока общей длительностью 20 × 30с = 600 сек. При этом его скорость можно понизить с 2.048 Мбит/с до 512 Кбит/с за счет некоторого снижения качества, т.к. стоит задача подвергуть файл цензуре и несколько сниженное качество вполне обеспечит ее решение.. Соответствующий объем равен 512 × 600 = 307200 КВ = 307.2 МВ.
Пусть из БД изображений отобрано 15 кадров, наличие близких кадров к которым должно быть выявлено и зафиксировано в ТВ-видеофильме. Считаем, что мы располагаем подсистемой, которая с приемлемой надежностью может обнаруживать похожие изображения (такие решения уже присутствуют в известных поисковых системах, например, в поисковых системах Яндекс или Google [12, 13]. Пусть обнаружено 120 таких кадров в файле, причем 10% из них мало соответствуют критерию похожести, но они все попадают в интересующий цензора набор. Для запоминания каждого кадра в отдельности требуется 30 КВ (качество будет немного снижено по сравнению с оригиналом). Требуемая память 120 × 30 = 3600 КВ = 3.6 МВ. А всего на кадры требуется памяти в объеме 307.2 + 3.6 MB = 313.8 MB. Объем служебной информации будет существенно меньше (не более 10 байтов на кадр) и поэтому она не принимается в расчет.
Запись 20 речевых высказываний в контексте звучит 20 × 30 сек = 600 сек. При этом для указанной задачи можно при некотором снижении качества записанной речи использовать вокодер G.729 (8 кбит/с), который подготовит выделенные речевые участки (без пауз) объемом 8 × 600 = 4800 Кбит = 600 KB, что практически не влияет на общий объем 313.8 + 0.6 MB = 314.4 MB
Итого, для хранения в СХД этого «урезанного» файла для цензурирования ТВ-видеофильма достаточно выделить объем в 314 MB. Коэффициент сжатия К=3.11, т.е. уже сжатый медиопоток (коэффициент сжатия К не менее 10) дополнительно сокращается в объеме примерно в три раза для решения задачи цензуры, которая может быть решена значительно быстрее ввиду сокращения объема просматриваемого материала. Но для этого требуются надежные классификаторы аудио/речь/пауза и надежный поиск кадров в видеопотоке для сравнения со сценами на эталонных кадрах из БД изображений.
Раскрытие изобретения
Цель данного изобретения - создание такого способа и реализующего его устройства для высокоэффективного сжатия мультимедийной информации большого объема по критериям ее ценности/полезности, которые по сравнению с существующими методами и устройствами, контролирующими «искажения» или усредненные ошибки в полном медиа-потоке, включающем как информационно важные для ЛПР, так и информационно незначимые его части, позволяют отобрать для запоминания только информационно-содержательные фрагменты для решения возникающих в реальных условиях задач и достижения поставленных ЛПР целей и представить эти фрагменты по возможности в более компактном виде, чтобы тем самым экономить память в системах хранения данных, но также время для решения поставленных задач и достижения поставленных целей, так как «информационный шум» и присутствующая избыточность исключаются или значительно сокращаются в своем объеме.
Для достижения этой цели предлагаются выполнить следующие позиции:
1. Задать или выбрать из определенного списка критерии ценности/полезности текстовой (символьной), графической, речевой, аудио и видеоинформации в мультимедийном потоке на основе специфики ее использования и/или опроса представительской группы лиц, принимающих решения (ЛПР), входящих в круг тех людей и организаций, которые используют или потенциально могут использовать мультимедийную информацию, хранимую в СХД, для решения своих информационных задач в рамках систем принятия решений. Состав ранжированного в соответствии с приоритетами списка критериев может меняться (некоторые его позиции могут исключаться, а другие - добавляться).
2. Определить эталонные элементы (записи или образцы) в базе данных (БД) изображений, БД ключевых слов и выражений, БД акустических сигналов и акустических событий, которые представляют собой наборы символьных и сигнальных (или параметров сигналов) записей и несут ценностный интерес для ЛПР с точки зрения вхождения соответствующих элементов этих баз данных в видеопоток, речевой и аудиопоток с той или иной мерой соответствия эталонным элементам (записям в БД), мерой похожести на них.
3. При необходимости выявить в мультимедийном потоке или файле фрагменты, которые подобны в определенном смысле заданным эталонным образцам из баз данных (БД) эталонных элементов, методом анализа и сравнения, то считать критерием ценности соответствие указанных фрагментов заданным образцам. Считать данные в медиапотоке, удовлетворяющие заданным критериям, информационно ценными (информативными), а неудовлетворяющие этим критериям - «информационным шумом», т.е. неинформативными. При пороговом определении ценности медиоданных обеспечить сравнение количественных оценок критериев ценности с выбранными порогами (пороги должны быть заданы).
В качестве количественного критерия ценности применительно к изображениям и кадрам видеопотока предлагается использовать степень корреляции rij цифровых изображений (метод DIC), определяющий статистическую связь двух изображений (эталонного образца из БД изображений и отдельного кадра или его фрагмента в видеопотоке, для которого определяется степень его «похожести» на эталонный образец) [14]. Метод DIC широко применяется на практике для проведения точных плоских и объемных измерений изменений на изображении на основе оценок коэффициентов взаимной корреляции двух изображений и для его реализации разработаны различные средства вычислений коэффициентов rij.
Для речевого потока определяются не похожие речевые сигналы, а ключевые слова и выражения, т.е. обнаружение в потоке слитной речи такого слова или высказывания (Key Word Spotting - KWS) оценивается вероятностью правильного обнаружения Pkws и вероятностью ошибки Perror. Т.е. в данном случае ввиду символьной определенности слова или выражения не используется сравнение с порогом. Системы KWS представляют собой частный случай систем распознавания слитной речи и более часто используются на практике ввиду большей надежности.
Для аудиопотока распознавание акустических событий (крики, удары, столкновения, сильные звуки и т.п.) сводится к классификации каждого звука с учетом прежде всего энергетической составляющей (мощность звука) и, может, спектральных характеристик аудиособытия, что является хорошо отработанным методом при обработке и анализе аудиосигналов. Решение о каждом таком акустическом событии также может быть принято на основе сравнения оценок его параметров с порогами.
Для информационно ценных фрагментов видео, речи и аудио задать отдельно критерий качества в виде допустимого уровня искажений е=(ев,ер,еа) по отношению к оригиналу при их воспроизведении в процессе считывания из СХД и декодирования фрагментов каждого потока, формирующих (при необходимости) вместе мультимедиапоток или мультимедиафайл.
4. Разуплотнить (демультиплексировать) общий мультимедийный поток на отдельные потоки: видео, речевой, аудио; обрабатывать и анализировать их отдельно и каждый своими методами ввиду значительного различия между ними.
5. Выделить в каждом из отдельных потоков информационно значимую часть с учетом заданных критериев ценности/полезности данных. Для анализа исходной мультимедийной информации и выбора ее информативной части по критериям ценности/полезности использовать методы обработки и классификации сигнала и элементы искусственного интеллекта (ИИ) для оценки существенных изменений в видеопотоке на покадровой основе и отбора важных по критерию ценности кадров или последовательности кадров, выявления ключевых слов и выражений из заданного словаря в речевом потоке, выделения значимых для ЛПР акустических событий в аудиопотоке. При этом для обработки и анализа звукового (речевого и аудио) потока обеспечить надежное выделение речевой ее части, пауз и аудиочасти, относя смешанные участки «речь на фоне неречевых звуков» к речевой части. Выделенные ценные фрагменты каждого потока снабдить служебной информацией в определенном формате в виде пакета, позволяющей точно задать их временнОе местоположение в соответствующем потоке и, возможно, другие параметры, описывающие выделенные фрагменты.
6. Выделенные информативные фрагменты видео, речевого и аудиопотоков подвергнуть при необходимости перед хранением в СХД процедуре кодирования для сжатия данных (возможно дополнительного) с контролируемой погрешностью или процедуре транскодирования с учетом последующего восстановления соответствующего потока декодером, причем значение указанной погрешности е=(ев,еp,еа) должно быть релевантным с позиций решения информационной задачи или достижения поставленной цели.
7. При извлечении записанных данных из СХД и восстановлении выделенных информационных фрагментов общего медиапотока в декодерах видео, речи и аудио обеспечить (при необходимости) согласование и синхронизацию отдельных потоков видео, речи и аудио на основе временных меток и других описывающих эти фрагменты параметров с целью формирования (при необходимости) единого мультимедийного потока для его анализа ЛПР. При восстановлении отдельных потоков или общего мультимедийного потока можно исключить участки, где отсутствуют изменения в видео, ключевые слова и выражения в речи, акустические события в аудиопотоке (для общего потока такими исключаемыми участками являются те, где одновременно отсутствуют соответствующие изменения в каждом отдельном потоке).
Поясним для каждого отдельного потока каким образом выделить из него информативные фрагменты. Наиболее емким по объему и скорости генерации данных является источник видеопотока (например, выход видеокамеры, выход кодера или декодера в терминальном оборудовании СПИ, видеофайл в памяти некоторой системы), который представляется последовательностью видеокадров (видеорядом). Обычно источником видео является цифровая или аналоговая видеокамера или несколько видеокамер. Если видеокамера является аналоговой, то видеопоток с ее выхода подвергают аналого-цифровому преобразованию (оцифровывают). Далее предполагается, что видеопоток оцифрован и именно такой поток подвергается обработке перед тем, как его информативные фрагменты помещаются в память СХД. Предполагается также, что видеоряд конечный, т.е. содержит N кадров, и сгенерирован видеокамерой, характеризуемой скоростью битового потока на выходе (R бит/с) и частотой кадров (ƒ кадр/с). Назовем такой цифровой видеопоток исходным. В некоторых случаях можно считать исходным и видеопоток, который уже подвергнут сжатию данных с погрешностью ео, но визуальное качество такого видео считается ЛПР высоким (если исключить ситуацию «только такой исходный видеопоток с низким качеством мы имеем и снижать качество нецелесообразно»). Он может храниться (в том числе и в сжатом виде) в памяти некоторой системы (включая и СХД), но перед обработкой и анализом он, как правило, должен быть восстановлен декодером в виде последовательности равноправных кадров.
Исходный поток подвергается покадровой обработке с целью выделения новых опорных ключевых кадров (КК), которые существенно отличаются от уже выделенных предыдущих ключевых кадров в видеоряде, т.к. в них есть обновление. Ключевые кадры отбираются последовательно и первым КК, по умолчанию, считается первый по номеру кадр (i=1, i=1, …, N) в видеоряде.
Оценка существенности изменений (СИ) в новом кадре по отношению к уже выделенному эталонному кадру (считающемуся ключевым) не является формальной. Она предполагает, что имеется некоторый порог Delta изменений, значение которого выбирается человеком на основе информации от ЛПР или непосредственно ЛПР. Если уровень изменений превосходит порог, то они считаются существенными, в ином случае - несущественными. Можно использовать двухпороговую схему с порогами Delta1 и Delta2. Если уровень (коэффициент) изменений ниже порога Delta1, то изменения считаются несущественными, а если выше порога Delta2, то существенными. Значение коэффициента между порогами - пограничный случай и ЛПР должен определить значимость изменений для таких ситуаций. При однопороговой схеме Delta1=Delta2=Delta. Такой подход к оценке СИ резонен при сравнении относительно удаленных по времени двух кадров, которые проанализированы с позиций определения изменений второго кадра по отношению к первому в развивающемся сюжете или же соседних кадров при резкой смене сюжета.
Целесообразно в рамках оценивания изменений и принятия решения об их существенности провести деление каждого кадра на две части: информационную и неинформационную. К информационной части отнести ту, где в сцене представлены обычно интересные для ЛПР объекты (элементы сцены) возможно, что с некоторой динамикой (например, люди), а к неинформационной части отнести ту, где изменений почти нет (например, неподвижный или малоподвижный фон). Изменения в неинформационной части кадра не представляют, как правило, интереса (за редким исключением, которое также должно приниматься во внимание).
Рассмотрим в качестве примера ситуацию с видеоконференсингом, где обычно на неподвижном фоне представлен участник или участники ВКС (например, один или несколько человек, сидящие за общим столом). Информационная часть сцены связана с участниками, неинформационная - с фоном. Для выделения информационной части кадра можно применить известную процедуру в обработке изображений и видео, называемую сегментацией. Если динамика участника невелика (он говорит, моргает, изменяет слегка свое положение, жестикулирует, машет руками и пр.), то сегментация по силуэту участника(ов) ВКС (пусть с некоторыми погрешностями) может быть проведена достаточно надежно. Если динамика относительно велика, то можно оценить ее теми же методами, что используются в видеокодеках MPEG-2 и MPEG-4 на основе оценивателя движения (motion estimator). Вполне достаточно будет выделить интересующий объект, но, может, захватывая небольшие участки неинформационной части кадра. Если интересующие ЛПР объекты в сцене - люди, то можно предварительно детектировать лица участников ВКС на основе известных надежных методов детектирования лиц (например, на основе эффективного алгоритма Виолы-Джонса, входящего в состав открытой библиотеки алгоритмов компьютерного зрения OpenCV и позволяющего обнаруживать в реальном времени различные объекты на изображениях (не только лица)) [15].
Для эффективного сравнения информационных частей разных кадров, выделенных путем процедуры сегментации объектов (может, с некоторой динамикой), которые присутствуют в соседних кадрах, можно использовать подход на основе операций над множествами (объединения, пересечения, разности [16]) применительно к пикселам как элементам изображения (кадра). При этом каждый кадр представляется матрицей элементов (пикселов) Pij, i=i, …, n; j=1, …, m, размером m×n, и одновременно кадр рассматривается как конечное множество пикселов с общим их числом (мощностью конечного множества) Nоб=n×m, а его часть - как подмножество.
Пусть в сравниваемых двух кадрах (нумеруем кадры 1 и 2, причем кадр 1 является ключевым, а потому по умолчанию считается, что его информационная часть заведомо интересна для ЛПР, а ее объем (мощность) определяется числом пикселей, входящим в нее), выделены информационные части. Это - множества пикселов (подмножества соответствующих кадров) и именуем их M1 и М2 с числом элементов соответственно N1 и N2. Выделим общие части двух множеств (т.е. пикселов с одинаковыми индексами) в результате операции пересечения множеств: M1 ∩ М2. Очевидно, что сюда входят те элементы, которые присутствуют и в M1, и в М2. Их сравниваем («равны - неравны»), причем сравнению подлежат пикселы с одинаковыми индексами i и j. Фрагмент информационной части кадра 1 (M1\М2 - разность двух множеств), не входящий в М2 и содержащий L1 элементов, и фрагмент информационной части кадра 2 (М2\М1), не входящей в M1 и содержащий L2 элементов, вместе определяют изменения в кадре 2 по отношению к (ключевому) кадру 1. Предположим, что в пересечении M1 ∩ М2 найдется L3 отличающихся пикселов. Т.е. уровень изменения L=[(L1+L2+L3)/NΣ]*100%, где NΣ - число элементов в объединении множеств M1 U М2. Для однопорогового решателя при пороге Delta=30%, если L≥30%, то изменения в кадре 2 по отношению к кадру 1 существенны.
Вопрос о выборе ключевого кадра также непрост (кроме первого кадра в видеопоследовательности, считающегося и информативным, и ключевым)). Приведем пример: пусть рассматривается видеопоследовательность, отображающая участника ВКС. На первом кадре, представляющем участника на некотором фоне, он представлен в фас и его лицо занимает 20% кадра, а часть его фигуры на кадре - 35%. У участника в процессе коммуникации есть манера «крутиться на кресле» от -90 до +90 градусов, т.е. другой участник ВКС или ЛПР (или распознающий автомат) видит «крутящегося» участника, который не выходит из кадра, и для него информационных изменений в каждом кадре по отношению к предыдущему почти нет (они малы), хотя этот участник развернулся от положения в фас (0 гр.) до положения в профиль (90 гр.) и формально между этими двумя удаленными кадрами (участник в фас и в профиль) изменения весьма существенны, если сравнивать их информационные части (по информационной части почти на 100%, а по всему кадру - на 35%, но не менее 20%).
Примерно такие же соображения можно высказать, если участник надевает маску, прикрывает лицо и/или же накидывает на свои голову и плечи покрывало или другую одежду. При наблюдении покадрово всего видеоряда изменения малы (от одного кадра к последующему), а удаленные друг от друга кадры (лицо без маски/покрывала и лицо в маске/покрывале) сильно разнятся. Очевидно, что простого формального сравнения здесь недостаточно для выбора информативных кадров и нужно выбор делать или человеку, или распознающей машине, обученной на такие ситуации (в частности, на базе искусственных нейронных сетей - ANN). В данном случае при формальном отборе информативных кадров, описанном выше, их будет больше (в некоторых случаях значительно больше), чем при интеллектуальном отборе. Однако в первом случае решение о существенных изменениях в кадре принимает относительно простое логическое устройство на базе простых вычислений и сравнения, а во втором случае требуется использования сложной распознающей подсистемы (машины) с обучением на разных тестовых ситуациях. Но и то, и другое - решающие устройства.
Ключевые кадры, выделенные на основе оценки СИ, могут быть подвергнуты кодированию с контролируемой погрешностью е, если они не подвергались сжатию данных. А если они уже представлены в сжатой форме с погрешностью eо, то дальнейшему кодированию (или транскодированию) при допустимой погрешности е они будут подвергнуты при условии е>eо.
Рассмотрим речевой поток, как важную составляющую общего медиапотока. Обычно его источником является аналоговый сигнал с выхода микрофона. Но при оцифровывании речи в АЦП можно говорить об исходном «цифровом» речевом потоке. Он наиболее важен ЛПР в разных приложениях, так как часто несет прямую, а не косвенную, требующую интерпретации, информацию, заключенную, в частности, в ключевых словах и выражениях (КСВ). Разумеется, семантика и прагматика речевого потока в его полных фразах и предложениях дают больше информации, чем отдельные слова и высказывания, но требуют более сложной системы для распознавания и понимания речи произвольного диктора (а часто и распознавания языка), т.е. преобразования речи в текст (STT - Speech То Text) и выявления в нем интересующей информации, чем распознавания ограниченного набора ключевых слов и выражений из заранее заданного словаря. Система STT обеспечивает предельно возможный метод сжатия речи с коэффициентом K ~ 1000…2000 (от 64 кбит/с до 20-50 бит/с), т.е. обеспечивает запись речи в текстовой форме, но при этом, конечно, теряется информация о специфике речи диктора. Для повышения информативности участка речевого сигнала, который включает ключевое высказывание/слово, можно не просто отмечать в какой момент оно начало произноситься диктором и номер слова из словаря, а полностью сохранять в памяти соответствующий фрагмент речи с некоторым окружением (сигнальным контекстом) выявленного ключевого высказывания/слова длиной Δt' до и после высказывания (можно предложить для Δt' значения в 10 с и 15 с как в ранее рассмотренных примерах). При этом соответствующий фрагмент речи может быть подвергнут кодированию в низкоскоростном вокодере или транскодированию перед записью в СХД, если он ранее не был кодирован или был кодирован высокоскоростным речевым кодеком. Очевидно, что любой подход для выявления релевантной информации в речевом сигнале имеет свои достоинства и недостатки и для финального выбора подхода надо принять во внимание разные факторы (не только значение K).
Применительно к аудиопотоку целесообразно считать существенным изменением или акустическим событием отдельные фрагменты звукового сигнала, которые по некоторым признакам (в частности, энергетическим) отличаются от «среднего звучания». В качестве примера можно указать выстрелы, крики, скрежет, удары импульсного типа, нетипичные громкие звуки (клаксон, столкновение объектов, падение предметов и др.). Если энергетический фактор важен, то он может быть определяющим. К нему можно добавить спектральные характеристики подобных звуков. Роль акустических событий в аудиопотоке напоминает роль ключевых слов в речевом потоке, но для выявления таких событий не требуется использовать распознавание слуховых образов, а только обработку аудио на сигнальном уровне.
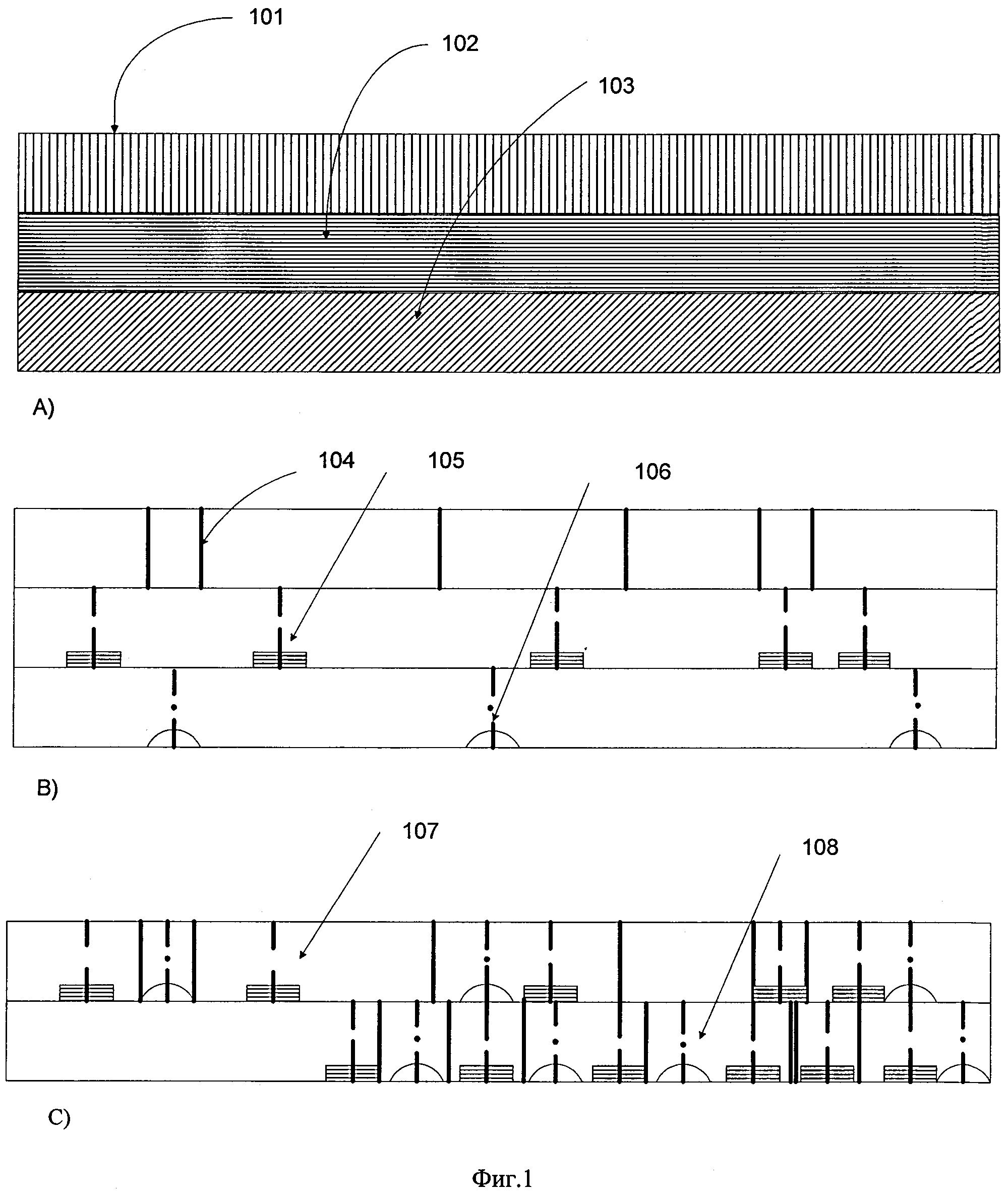
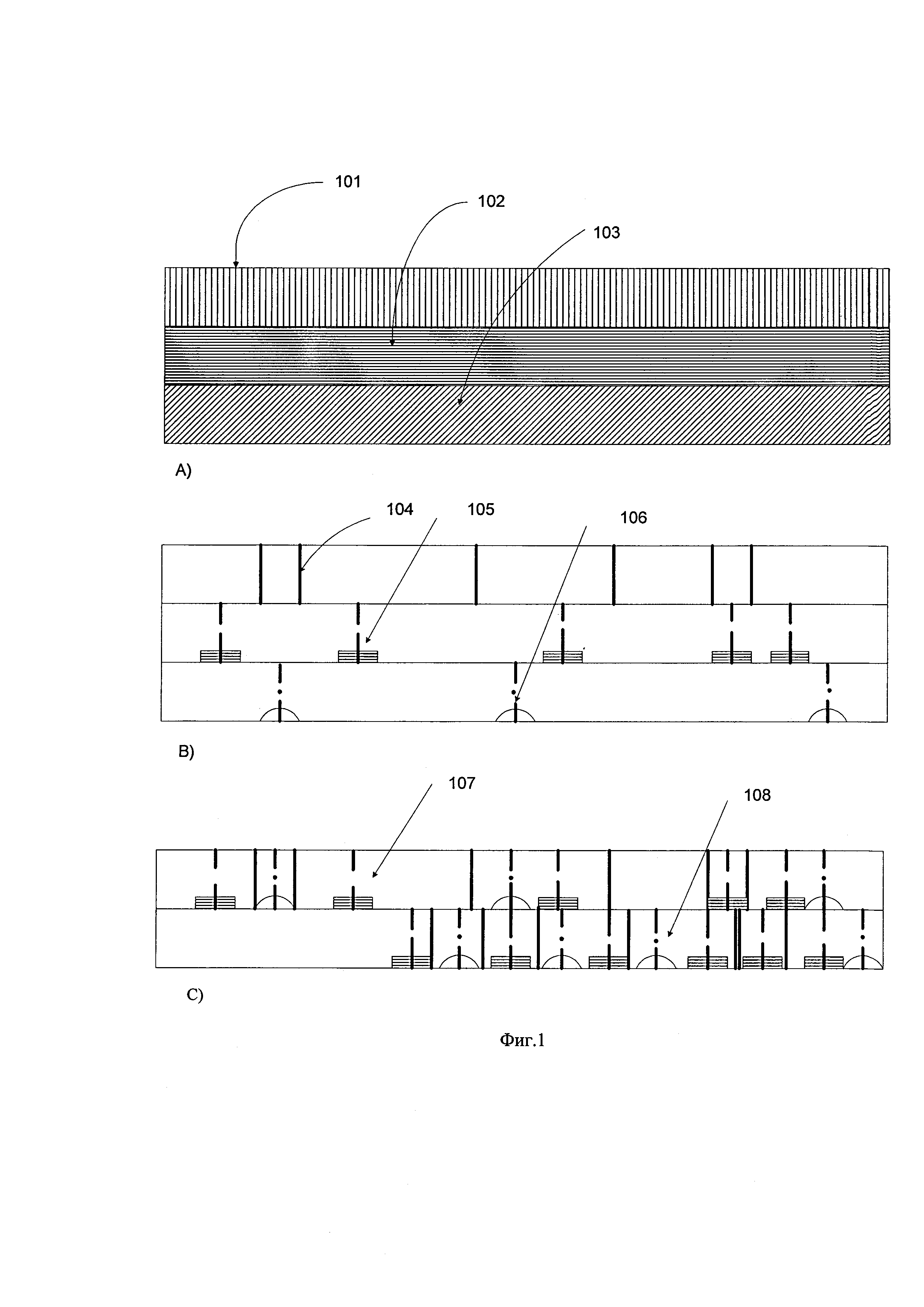
Проиллюстрируем на фиг. 1 возможный эффект сжатия по критерию ценности на примере трех подпотоков (видео - ВП, речевого - РП и аудио - АП), составляющих вместе общий мультимедийный поток (МП). На фиг. 1а все три подпотока представлены общей «лентой», разделенных на три «ленточки» (строки): верхнюю (ВП) 101, среднюю (РП) 102 и нижнюю (АП) 103. Вместе они представляют собой условно объем исходного МП.
На верхней строке 104 фиг. 1б представлены вертикальными черточками только выделенные ключевые кадры (КК). На средней строке 105 этого рисунка примерно таким же образом выделены пунктирными черточками середины обнаруженных ключевых слов и выражений (КСВ) в речевом сообщении, по обеим сторонам от которых нарисованы прямоугольники речевого сигнала длительностью Δt', представляющие речевой контекст КСВ. На нижней строке 106 фиг. 1б примерно так же представлены штрихпунктирными черточками середины акустических событий (АС), по обеим сторонам которых нарисован дугами длительностью Δt'' акустический сигнал, представляющий акустический контекст КАС. (Отметим, что для некоторых применений достаточно указать время и номер обнаруженных КСВ и КАС из заданного списка, не «обрамленных» указанными контекстами, что сокращает объем информации о КСВ и КАС).
На фиг. 1в в верхней строке 107 показан обработанный (сжатый) МП, где выделенные КК, КСВ и КАС показаны на своих временных позициях, причем выделенные ключевые фрагменты МП включают соответствующую служебную информацию, описывающую каждый выделенный фрагмент, а на нижней позиции 108 показан условно тот же МП с исключенными паузами между выделенными фрагментами. Этот «сжатый» МП демонстрирует сокращение времени для его анализа по сравнению с первоначальным МП (как показано на этом рисунке - примерно в два раза). В случае неиспользования речевого и акустического контекстов время анализа значительно сокращается, т.к. фактически используется для просмотра КК и прочтения информации об обнаруженных КСВ и КАС. При просмотре ключевых кадров (после их декодирования и восстановления), если есть необходимость, можно определить, кто сказал КСВ, если в исходном ВП это зафиксировано, и какие КАС произошли при выявленной картинке.
Краткое описание чертежей
На Фиг. 1 схематично представлен результат обработки трех составляющих (ВП, РП и АП) мультимедийного потока.
На Фиг. 2 дана блок-схема устройства эффективного сжатия МП по критерию ценности.
На Фиг. 3 показана блок-схема устройства отбора ключевых кадров в видеопотоке.
На Фиг. 4 представлена блок-схема устройства детектирования ключевых слов и выражений в речевом потоке.
На Фиг. 5 представлена блок-схема устройства детектирования акустических событий в аудиопотоке.
На Фиг. 6 показана блок-схема устройства восстановления ключевой информации, хранимой в сжатом виде в СХД для ее анализа лицом, принимающим решение.
Осуществление изобретения
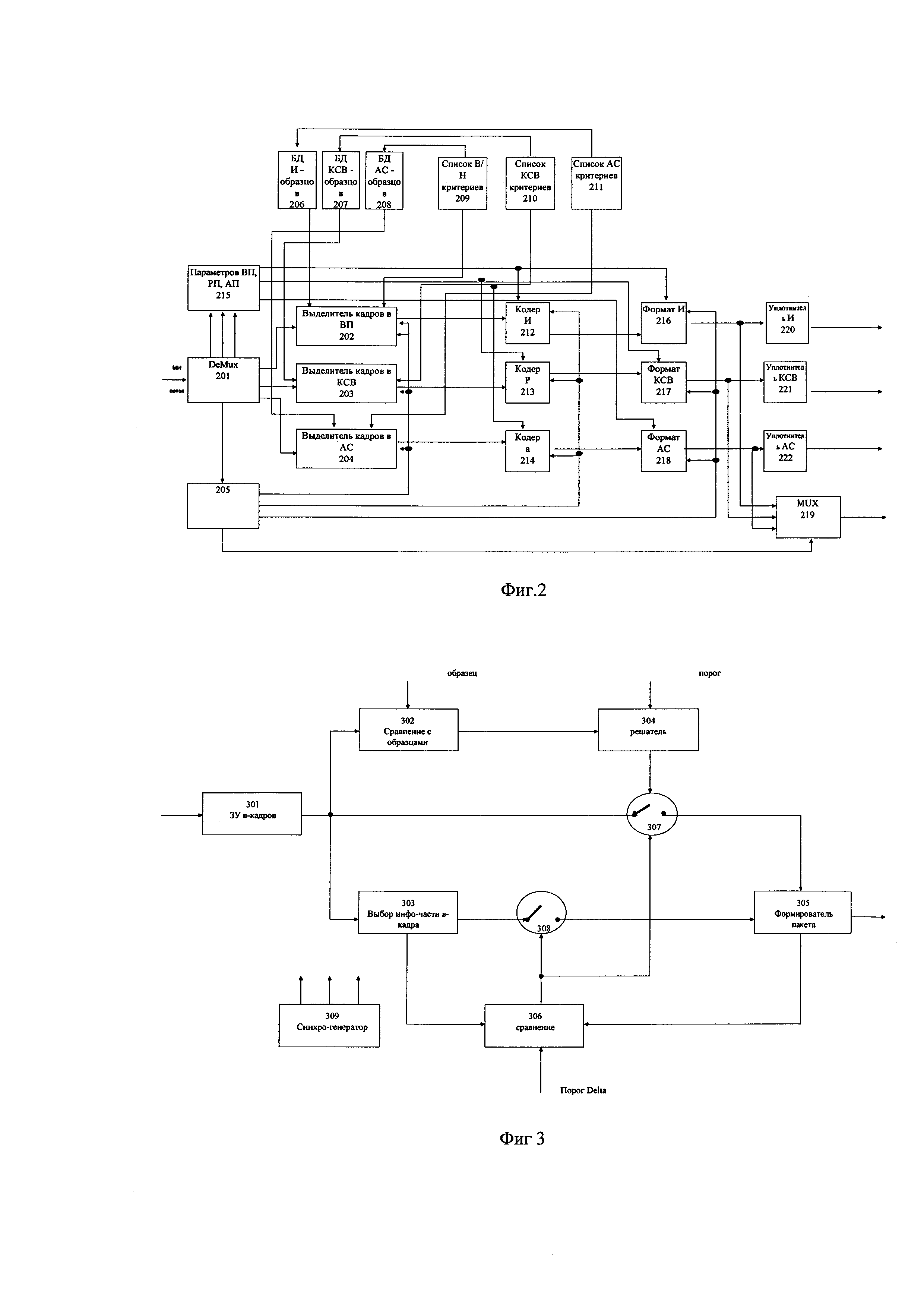
Блок-схема устройства высокоэффективного сжатия мультимедийной информации (СМИ) большого объема по критериям ее ценности для запоминания в системах хранения данных, в котором использован способ выявления информативных фрагментов в видео, речевом и аудиопотоках, являющихся отдельными компонентами общего мультимедийного потока, в соответствии с предлагаемым изобретением, показана на фиг. 2.
На вход устройства СМИ поступает мультимедийный поток (МП) или мультимедийный файл. Этот поток/файл демультиплексируется (разуплотняется) в блоке DeMUX 201 и разбивается на три подпотока (видео, речевой и аудио) и служебный синхросигнал, который несет также информацию о МП (параметрах кодирования каждого подпотока и сведения о МП в целом). Указанные подпотоки поступают каждый в свой отдельный блок выделения ключевой информации - БВКИ (ключевых фрагментов указанных подпотоков): видеоподпоток (ВП)- в блок выделения ключевых кадров (БВКК) 202, речевой подпоток (РП) - в блок выделения ключевых слов/выражений (БВКСВ) 203, аудиоподпоток (АП) - в блок выделения ключевых акустических событий (БВКАС). Служебный синхросигнал и информация о МП в целом поступает из блока 201 в блок местного синхрогенератора и анализатора информации о МП 205.
Каждый ключевой фрагмент (КК, КСВ, КАС) снабжается временной меткой (time stamp) и служебной информацией (тип подпотока, параметры фрагмента, включая длительность фрагмента, параметры его обработки для сжатия с контролируемой погрешностью (если каждый кадр, речевой или акустический сигнал (контекст) сжимается «своим» кодером), номер КК в ВП, номер КСВ из списка для РП и время Δt', номер КАС из списка для АП и время Δt''). Выделение ключевых фрагментов в каждом подпотоке производится независимо, но с учетом синхроинформации от блока синхрогенератора и анализатора 205.
Для выделения КК в ВП в блок выделения КК 202 поступает из БД изображений 206 эталонные изображения для поиска в каждом кадре ВП похожих объектов на эталонные изображения и пороги для оценки уровня похожести (ЦП) из блока критериев В/И для отбора КК 209 или, если поиск похожих объектов не требуется или дополняется определением КК, отличающихся существенными изменениями (СИ) в части сцены, считающейся информационной, по отношению в предыдущему КК с выделенной информационной частью (начиная с первого кадра, автоматически считающегося ключевым), на блок выделения КК 202 поступают данные о выбранных критериях для отбора КК и порогов СИ для них (ПСИ) из блока критериев КК в ВП 209. Выделенные КК поступают из блока их выделения 202 в блок кодирования (или транскодирования [17]) изображений 212, если выполняется условие для контролируемой погрешности: е>еo, а если не выполняется это условие, то блок 212 обходится и выделенные КК поступают непосредственно в блок формирования пакета КК (изображения) 216, содержащего сам КК, а также данные о нем. Отметим, что если дополнительное кодирование/транскодирование изображений в блоке 212 используется, то параметры кодека задаются в блоке параметров кодеков 215, на который подаются управляющие сигналы из блоков критериев 209, 210, 211 и информация о параметрах входного МП по трем его составляющим (ВП, РП, АП) из блока DeMUX 202.
Для выделения КСВ в РП на блок выделения КСВ 203 поступают из БД КСВ 207 информация о КСВ, которые необходимо обнаружить в РП, но также при необходимости выделить речевой фрагмент длительностью 2Δt', окружающий КСВ («речевой контекст»), поступает сигнал из блока критериев КСВ 210. Именно этот речевой контекст поступает на вход речевого кодера (или транскодера) 213, параметры которого определяются сигналом от блока параметров 215. Если же в этом контексте нет необходимости для ЛПР, то информация о номере обнаруженного КСВ из списка КСВ и его временной метке поступает в блок формирования пакета данных об обнаруженном КСВ 217, минуя кодер 213.
Примерно также действует блок выделения КАС 204, в который поступает информация о специфических КАС, которые надо выделить в АП, из БД АС 208. При выделении КАС данные о нем, а также при необходимости контекст в виде акустического сигнала этого КСВ длительностью Δt'' в соответствии с сигналом из блока критериев КАС 211, причем акустический сигнал подвергается сжатию в акустическом кодере (или транскодере) 214, параметры которого определяются сигналом от блока параметров 215, формируется в блоке 218 соответствующий пакет данных, причем в него может и не включаться информация об «акустическом контексте» КАС, если ЛПР посчитает, что в ней нет необходимости.
Таким образом, на выходе устройства формируются три самостоятельных прореженных потока пакетов КК, КСВ и КАС (как это отражено условно на фиг. 1б, где пакеты представлены вертикальными черточками (сплошными для КК, пунктирными для КСВ, штрихпунктирными для КАС), которые можно подавать в СХД после операции уплотнения пакетов в блоках уплотнения 220 (изображений или КК), 221 (КСВ), 222 (КАС). При необходимости мультиплексировать эти пакеты в блоке MUX 219 все три потока пакетов поступают на блок 219, на который поступает также сигнал из блока синхронизации и анализа 205 для корректного форматирования общего обработанного МП в виде потока пакетов, как показано условно в примере на фиг. 1в в нижней строке, в котором пакеты следуют в соответствии со своими временными метками, и этот поток может быть подан в СХД. Очевидно, что в блоке 219 пакеты можно уплотнять и по своим классам (например, вначале все пакеты КК, потом пакеты КСВ, а уже после них пакеты КАС, причем все эти классы уплотняются также в общий поток сжатой МИ).
Рассмотрим структуру и основные функции основных блоков предлагаемого устройства. Это прежде всего БВКИ, которые обрабатывают отдельные подпотоки (ВП, РП, АП) и выделяют из них информативную часть. Выходной видео подпоток от блока DeMUX 201 после обработки поступает в блок запоминающего устройства (ЗУ) 301, в котором может временно храниться Н кадров видеоряда. Из ЗУ по очереди FIFO эти кадры в соответствии с их нумерацией извлекаются и подаются одновременно на блоки 302 и 303. Блок 302 реализует соответственно сравнение текущего кадра с образцом, поступающим на второй вход блока 302 из БД эталонных изображений 206 (например, на базе метода корреляции изображений или метода поиска фрагментов заданной сцены на текущем кадре). В результате оценки коэффициента корреляции или в результате поиска вычисляется мера похожести одного из набора эталонных изображений на сцену или фрагмент сцены в текущем кадре. В решающем устройстве 304 выносится решение «содержится ли в текущем кадре элементы, представленные на одном из эталонных изображений, или нет», т.е. отнести текущий кадр к ключевым (КК) или нет на основе сравнения с порогом, который подается на блок 304 из блока 209. При положительном решении данный кадр из блока 301 прямо поступает в блок сбора КК 305 через переключатель 307, на который подается разрешающий сигнал из блока 304, и далее поступает вместе с временной меткой, номером и сопровождающей информацией на выход БВКК. Отметим, что первый кадр по умолчанию считается ключевым и из блока ЗУ 301 поступает в блок 303 для выбора его информационной части (например, на базе метода сегментации интересующих ЛПР объектов с некоторой динамикой в сцене), а одновременно в блок 305.
При необходимости выбора КК из видеоряда, который в своей информационной части отличается от предыдущего КК, в котором его информационная часть уже обозначена, текущий кадр поступает в блок 303, реализующий выбор информационной части текущего кадра, а затем в блок сравнения 306, на второй вход которого подается порог Delta (или два порога Delta1 и Delta2). В блоке 306 сравниваются две информационные части текущего кадра и предшествующего КК. Если сравнение прямое (по числу отличающихся в информационных частях пикселов, то определяется уровень изменения L в текущем кадре по отношению к предшествующему ему КК. Принятие «порогового» решения после сравнения L с порогом Delta выносится прямо и при L>Delta текущий кадр считается ключевым (КК) и поступает в блок 305 через переключатель 308. При использовании в блоке 306 «интеллектуального» сравнения ожидается, что число КК для ВП будет меньшим, что требует разработки соответствующего метода.
Все блоки работают синхронно в соответствии с тактовыми импульсами, вырабатываемыми местным синхрогенератором 309.
Выбор КСВ в речевом подпотоке обеспечивается в БВКСВ, структура которого представлена на фиг. 4. На вход БВКСВ поступает речевой сигнал в виде последовательности речевых кадров длительностью 20…80 мс (речевых сэмплов или речевых параметров в зависимости от метода представления/кодирования этого сигнала) и служебная информация о кодировании РП. Конечное число речевых кадров записывается в блок ЗУ и анализа служебной информации 401. С выхода этого блока речевые кадры поступают в блок декодера 403 через переключатель 402, если они предварительно кодированы, т.е. по внешнему управляющему сигналу на переключатель 402, а затем в блок детектирования (отбора) КСВ 404 или прямо в этот блок, если речевые кадры представлены сэмплами, т.е. не кодированы. Переключатель 402, на который поступает управляющий сигнал, регламентирует этот процесс.
Если КСВ обнаружено, то из блока 404 на блок выделения (выбора) речевого контекста 405 для этого КСВ поступает при необходимости управляющий сигнал, который «вырезает» из речевого сигнала соответствующий участок длительностью 2Δt', включающий обнаруженное КСВ. С выхода блока 404 поступает номер выделенного КСВ на блок 406, куда на его второй вход поступает выделенный «речевой контекст». Таким образом, блок 406 собирает текущую информацию об обнаруженном КСВ и его речевом контексте в один пакет на своем выходе. Отметим, что если вместо выделения КСВ в РП имеется возможность заметить блок 404 на блок трансформации речи в текст (STT), то такая реализация блока 404 даст более эффективное решение во многих ситуациях для ЛПР.
Аналогично строится и блок выделения КАС, представленный на фиг. 5. На вход блока поступает аудиосигнал в виде последовательности аудиокадров и служебная информация о кодировании АП. Конечное число Н аудиокадров записывается в блок ЗУ и анализа служебной информации 501. С выхода этого блока аудиокадры поступают в блок декодера 503 через переключатель 502, если они предварительно кодированы, а затем в блок детектирования (отбора) КАС 502 или прямо в этот блок, если аудиокадры представлены сэмплами, т.е. не кодированы. Переключатель 504, на который поступает управляющий сигнал, регламентирует этот процесс.
Если КАС обнаружено, то из блока 503 на блок выбора аудиоконтекста 505 для этого КАС поступает при необходимости управляющий сигнал, который «вырезает» из аудиосигнала соответствующий участок длительностью 2Δt'', включающий обнаруженное КАС. С выхода блока 504 поступает номер выделенного КАС на блок 506, куда на его второй вход поступает выделенный «аудиоконтекст». Таким образом, блок 506 собирает текущую информацию об обнаруженном КАС и его аудиоконтексте на своем выходе и формирует соответствующий пакет.
Таким образом, устройство высокоэффективного сжатия МИ большого объема решает задачу существенного уплотнения потока МИ, выделяя самые информационно ценные его фрагменты для ЛПР и представляет их в сжатом виде с комплексированием служебными данными в пакетной форме перед помещением в СХД.
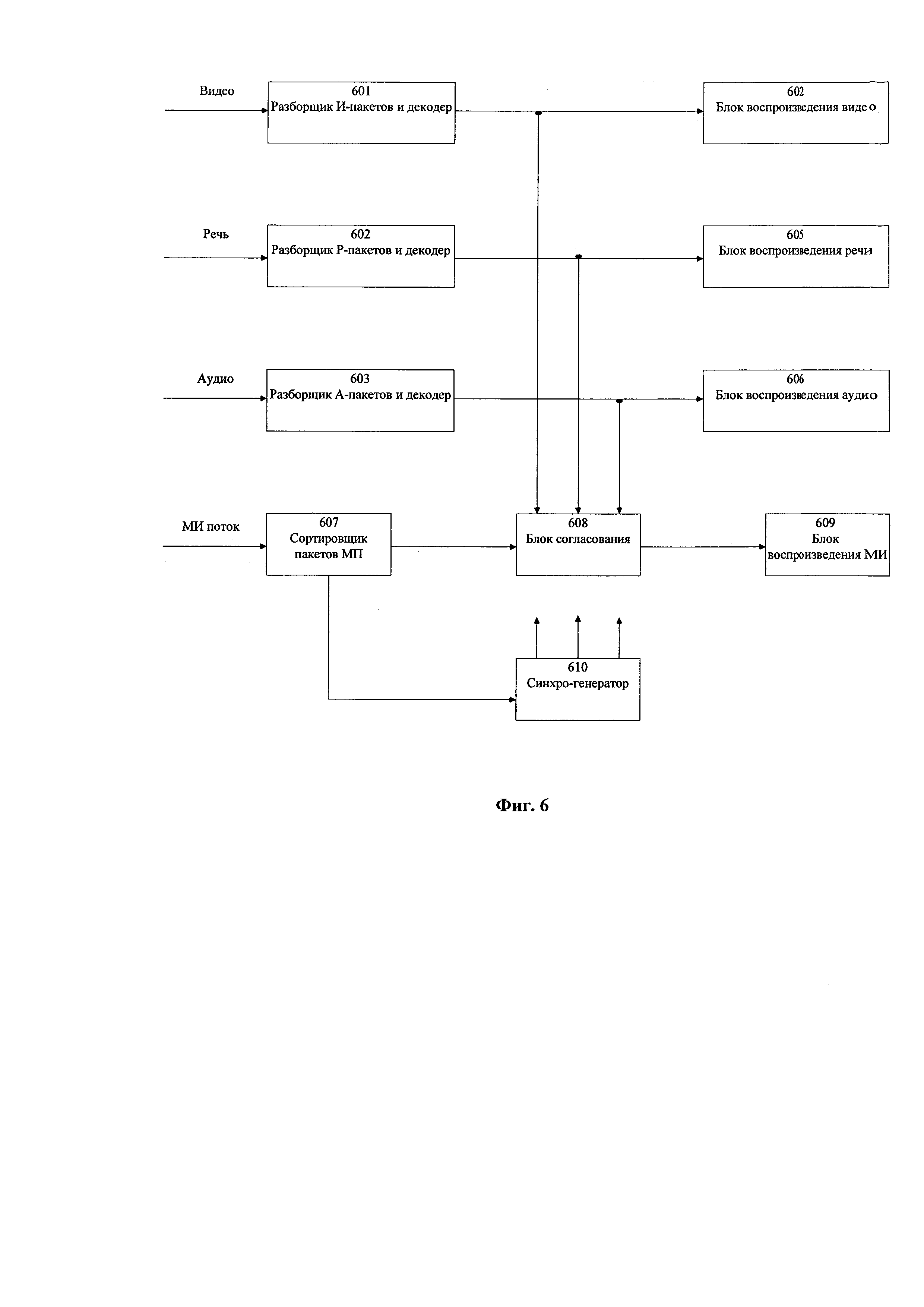
Для извлечения сжатой МИ из СХД необходимо ее разуплотнить, выделить служебные данные и декодировать отдельные подпотоки, представленные в своей специфической уплотненной форме в виде набора пакетов. Структура устройства разуплотнения и декодирования информации для последующего анализа со стороны ЛПР представлена на фиг. 6.
Три подпотока (ВП, РП и АП), сохраняемые в СХД как взаимосвязанные, но относительно автономные данные могут считываться и восстанавливаться независимо, как показано на фиг. 6, попадая соответственно в свои блоки разборки пакетов и декодирования 601 (для ВП), 602 (для РП) и 603 (для АП). В этих блоках происходит отделение служебных данных от собственно информации в выделенных фрагментах и восстановление ее в исходной форме (изображений, данных о КСА и КАС и, возможно, речевого и аудиоконтекстов, сопровождающих указанные КСВ и КАС). Эту информацию можно просматривать или прослушивать в блоках воспроизведения изображений/видео 604, речи 605, аудио 606 в том времени, как она возникала, но можно и в сокращенном времени, из которого исключены временные интервалы, на которых в исходной МИ содержится «информационный шум» для ЛПР.
При необходимости можно анализировать полный поток МИ в сжатой форме, предварительно упакованный мультиплексором 219, после того как он будет демультиплексирован вместе с синхроданными и служебными данными в блоке сортировки пакетов 607. Синхроданные от блока 607 передаются в блок местного синхрогенератора 610 и он вместе блоком согласования 608, на который поступают декодированные ключевые кадры из блока 601, речевой и аудиоконтексты из блоков 602 и 603, задает согласованную и синхронизированную работу всех блоков в устройстве восстановления информации в выбранном режиме времени (т.е. полном или сокращенном времени).
Источники информации:
1. http://www.compression.ru/arctest/descript/comp-hist.htm
2. US 9236882 В2. Data compression systems and methods - патент США, приоритет от 1.06.2015, автор James J. Fallon.
3. MPEG2 и MPEG4 - описание форматов (http://www.truehd.ru/03.htm)
4. РФ. 2464651. Способ и устройство многоуровневого масштабируемого устойчивого к информационным потерям кодирования речи для сетей с коммутацией пакетов, приоритет от 22.12.2009, автор В.А. Свириденко.
5. Аудиокодек. Википедия: https://ru.wikipedia.org/wiki/%D0%90%D1%83%D0%B4%D0%B8%D0%BE%D0%BA%D0%BE%D0%B4%D0%B5%D0%BA
6. Дедупликация. Википедия: https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%B4%D1%83%D0%BF%D0%BB%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F
7. Фрактальное сжатие изображений. Википедия: https://ru.wikipedia.org/wiki/%D0%A4%D1%80%D0%B0%D0%BA%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5%D1%81%D0%B6%D0%B0%D1%82%D0%B8%D0%B5
8. Полезность информации: http://studall.org/all-72812.html
9. Структура кодека Н.264. Опорные кадры: http://www.videomax-server.ru/articles/opornyj-kadr-v-h-264-malenkij-parametr-s.html
10. Пилипенко В.В. Распознавание ключевых слов в потоке речи при помощи фонетического стенографа, 2013. (см. http://www.km.ru/referats/334471-raspoznavanie-klyuchevykh-slov-v-potoke-rechi-pri-pomoshchi-foneticheskogo-stenografa
11. http://www.dialog-21.ru/digests/dialog2006/materials/html/Kiselov.htm).
12. Поиск похожего изображения: https://yandex.ru/support/images/similar.xml
13. Поиск по картинке: https://support.google.com/websearch/answer/1325808?hl=ru
14. Корреляция цифровых изображений: https://en.wikipedia.org/wiki/Digital image correlation
15. Алгоритм Виолы-Джонса:
https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_obiect_detection_framework)
16. Операции над множествами: http://umk.portal.kemsu.ru/uch-mathematics/papers/posobie/r2-2.htm Y)
17. Транскодирование: см.: https://en.wikipedia.org/wiki/Transcoding
Аббревиатуры в тексте заявки:
МИ - мультимедийная информация
КК - ключевые кадры
КСВ - ключевые слова и выражения
КАС - ключевые акустичекие события
СКО - среднеквадратическая ошибка
СХД - система хранения данных
БД - база данных
ТВ - телевидение
СПИ - система передачи информации
СИ - существенность изменений
ВП - видеопоток
РП - речевой поток
АП - аудиопоток
МП - мультимедийный поток
ПП - порог похожести
ПСИ - порог существенности изменений
ЗУ - запоминающее устройство
SNR - отношение сигнал/шум (ОСШ)
PSNR - пиковое ОСШ
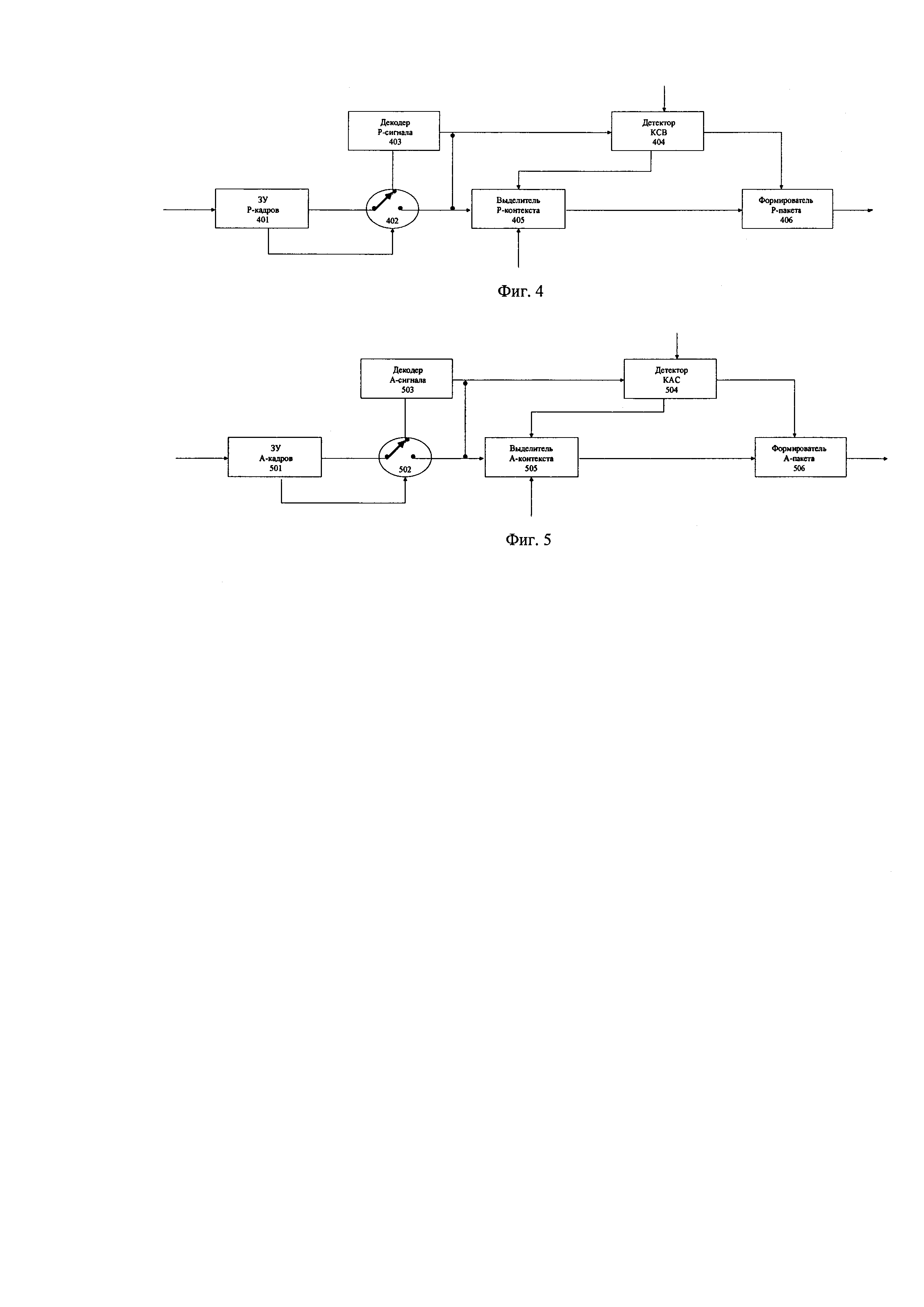
Устройство подавления узкополосных помех в спутниковом навигационном приемнике
Способ и система позиционирования мобильного терминала внутри зданий на основе глонасс-подобного сигнала
Способ и система позиционирования мобильного терминала внутри зданий на основе глонасс-подобного сигнала
Способ и устройство сжатия видеоинформации для передачи по каналам связи с меняющейся пропускной способностью и запоминания в системах хранения данных с использованием машинного обучения и нейросетей

