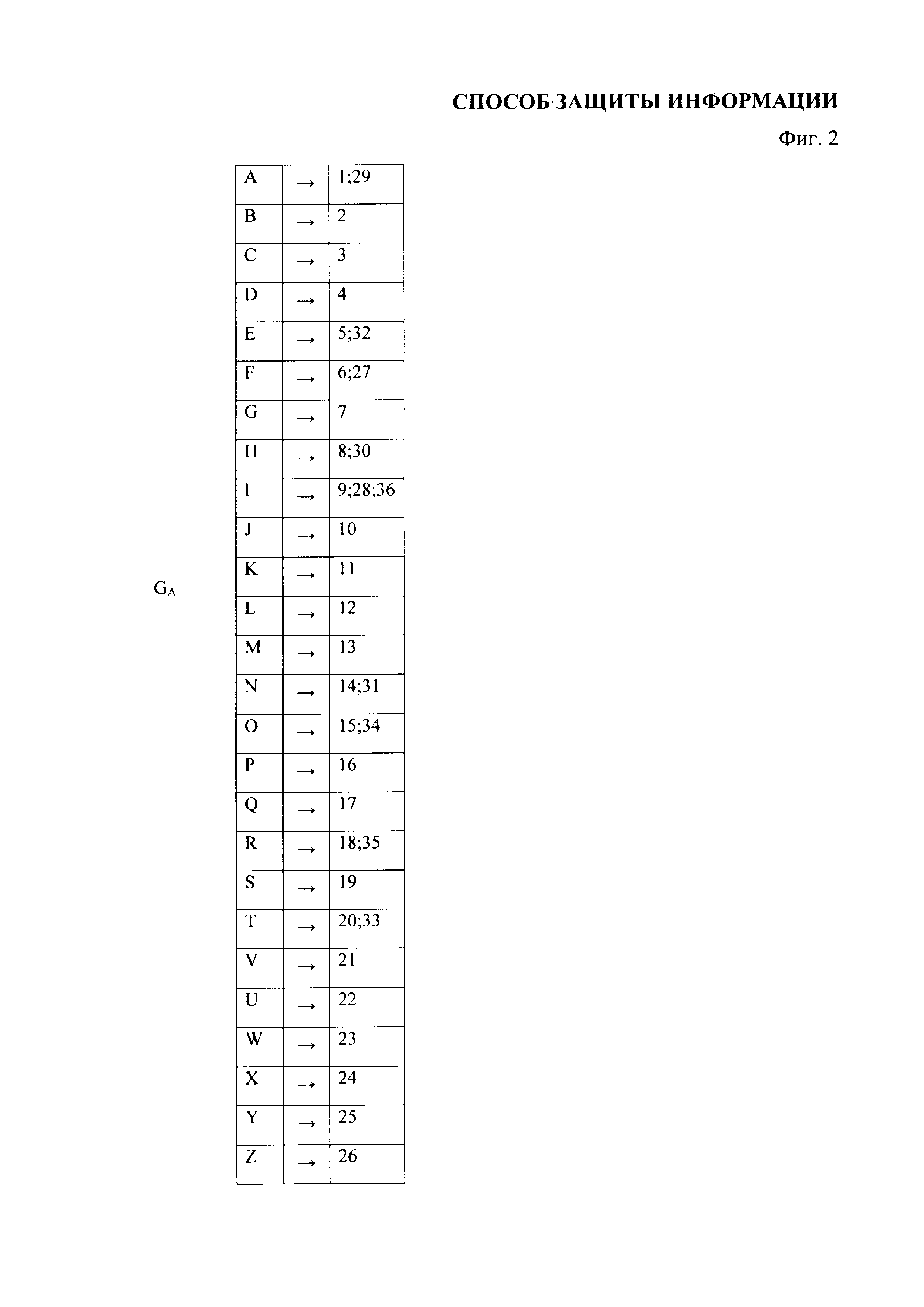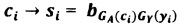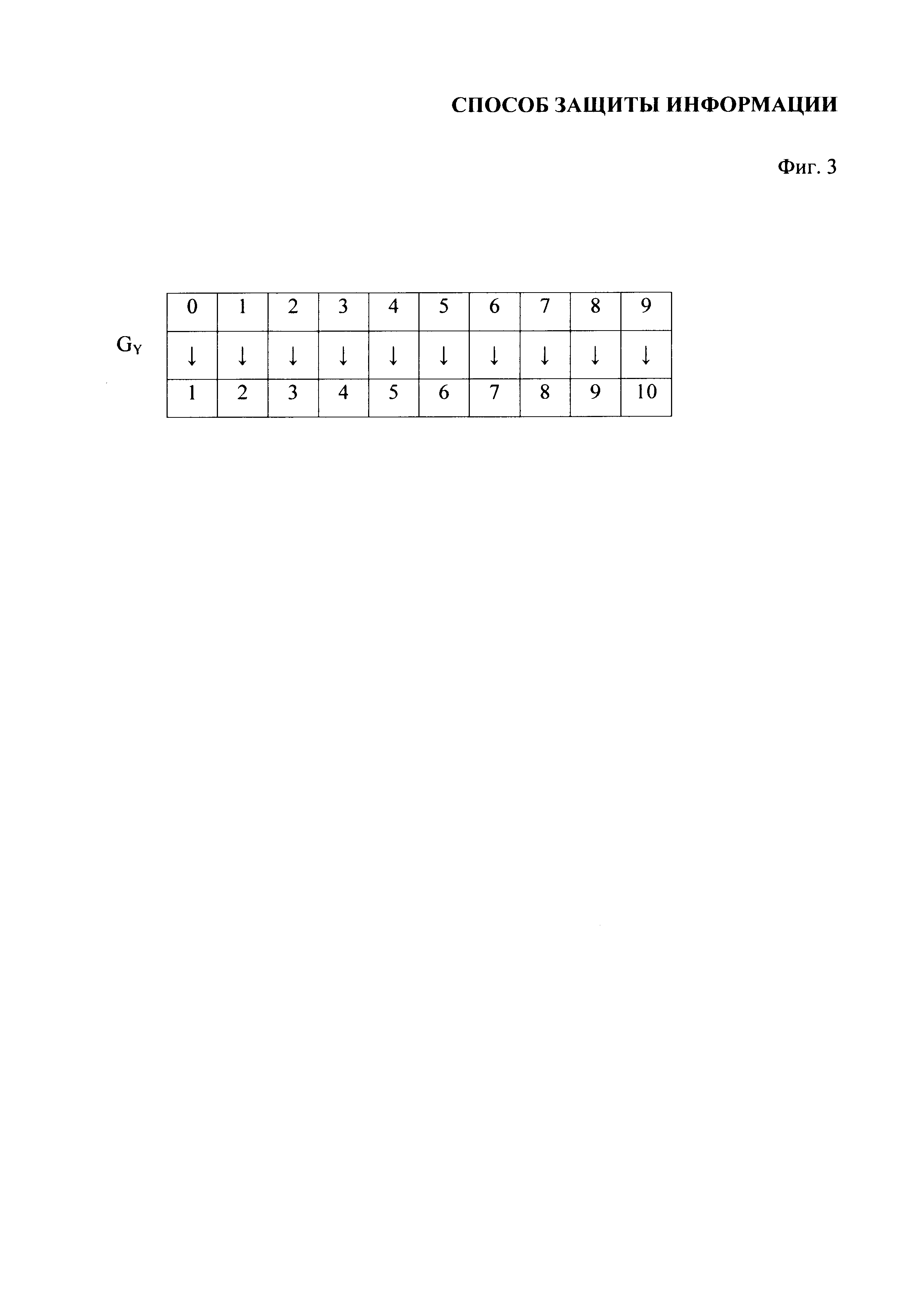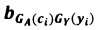СПОСОБ ЗАЩИТЫ ИНФОРМАЦИИ
Вид РИД
Изобретение
Изобретение относится к области вычислительной техники и предназначено для использования в области безопасной и шифрованной передачи информации.
В настоящее время все более обычным становится обмен информацией через Интернет и по другим интрасетям. Каждый день миллионы сообщений отправляют по Интернету, включая многие типы информации. Многие из передаваемых сообщений содержат зависимую и секретную информацию.
Известен способ шифрования сообщения простого текста (патент US 5193115 А, 09.03.1993), в котором каждый символ открытого текста алфавита имеет связанный с ним случайным образом распределенный набор целых чисел заданной длины. Этот набор целых чисел тайно разделяют на пары отправитель и получатель. Символы открытого текста сообщения последовательно кодируются путем псевдослучайного выбора представителей целочисленных наборов, соответствующих символам открытого текста, к этой последовательности связанных целых чисел, рассматриваемых как единственное целое число, добавляется псевдослучайное целое число длиной, равной длине сообщения целочисленной строки, затем псевдослучайное целое число генерируют генератором псевдослучайных чисел, вывод которого инициализируется целым числом «как начальное число», скрытое в криптограмме, суммируют псевдослучайное целое число с целочисленной строкой кодирования и передают как тело криптограммы. Для дешифрования получатель вычитает псевдослучайное целое число из переданного целого числа, разбивает остающееся целое число на блоки, численно кодирующие символы простого текста, и получает символы простого текста сообщения. Условие сделано для дальнейшего затемнения целого числа криптограммы.
Недостатком этого способа является невысокая эффективность защиты информации.
Известен способ криптографического преобразования сообщения, представленного в двоичном виде (RU 2564243 C1, H04L 9/06, 27.09.2015), в котором вычисляют на основе имеющегося набора итерационных ключей К0, …, Кn новый набор итерационных ключей KZ0, …, KZn, причем нулевой ключ в новом наборе определяют по формуле KZ0=K0, а остальные - по формуле KZj=L-1(Kj); вычисляют двоичные векторы u[i][j] длины w по формуле u[i][j]=π-1(τ(j))⋅Gi; вычисляют двоичный вектор m длины w, используя новые итерационные ключи KZ0, …, KZn, выполняя следующие действия: вычисляют mn=S(c), причем S:Vw→Vw, a=at-1||…||a0, где a∈Vb; S(a)=S(at-1||…||a0)=π(at-1)||…||π(a0); вычисляют mj-1=X[KZj](qj), где mj=mj[t-1]||mj[t-2]||…||mj[0]; j=n, …, 1; X[KZ] - линейное преобразование, зависящее от итерационного ключа KZ, причем X[KZ]:Vw→Vw, X[KZ](a)=KZ⊕a, где KZ, a∈Vw; вычисляют m=X[KZ0](S-1(m0)).
Недостатком этого способа является относительно высокая сложность.
Известен также способ криптографического преобразования информации (RU 2503135 C1, H04L 9/00, G06F 12/06, G06F 21/70, 27.12.2013), основанный на разбивке исходного 32-разрядного входного вектора на восемь последовательно идущих 4-разрядных входных векторов, каждый из которых соответствующим ему узлом замены преобразуется в 4-разрядный выходной вектор, которые последовательно объединяются в 32-разрядный выходной вектор, причем предварительно в каждом узле замены размещают таблицы преобразования из шестнадцати строк каждая, содержащих по четыре бита заполнения в строке, являющихся соответствующими 4-разрядными выходными векторами, используют четыре узла замены по одному для каждой пары 4-разрядных входных векторов, причем в каждом узле замены используют регистр центрального процессора, в который размещают по две таблицы преобразования, а преобразование пар 4-разрядных входных векторов в пары 4-разрядных выходных векторов в соответствующем узле замены осуществляют коммутацией предварительно размещенных строк таблиц преобразования в регистр центрального процессора соответствующего узла замены путем использования пар 4-разрядных входных векторов в виде адресов коммутации.
Недостатком способа является относительно большая сложность аппаратной реализации.
Известен способ преобразования информации (патент RU 2254685 С1, H04L 9/00, 13.01.2003), характеризуемый тем, что до начала шифрования все возможные неповторяющиеся значения комбинаций алфавита ui случайным образом с помощью датчика случайных чисел (ДСЧ) записывают в кодовую таблицу с N строками, а в каждую строку ui адресной таблицы Та записывают номер строки i кодовой таблицы Тк, в которой записано значение комбинации алфавита ui, где N - размер алфавита, совпадающий с числом строк кодовой и адресной таблиц Тк и Та, ui - исходная комбинация, подлежащая шифрованию, причем для заполнения очередной i-й строки кодовой таблицы Тк, где i - значение от 1 до N, получают очередное значение комбинации алфавита от ДСЧ, которое сравнивают с каждым из i-1 значением записанных комбинаций алфавита в кодовую таблицу Тк и в случае несовпадения ни с одной из записанных комбинаций алфавита очередное значение комбинации алфавита ui записывают в i-ю строку кодовой таблицы Тк, при шифровании из строки ui адресной таблицы Та считывают адрес A(ui) исходной комбинации ui в кодовой таблице Тк, значение шифрованной комбинации vi исходной комбинации алфавита ui при значении параметра преобразования ξi равно значению комбинации алфавита, хранящейся в строке A(vi) кодовой таблицы Тк, адрес которой определяют как A(vi)=A(ui)+ξi по модулю числа N, считывают значение шифрованной комбинации vi из строки кодовой таблицы Тк с адресом A(vi), при дешифровании зашифрованной комбинации vi при значении параметра преобразования ξi определяют значение комбинации, хранящейся в строке адрес А(ui) кодовой таблицы Тк, адрес которой определяют как A(ui)=A(vi)-ξi по модулю числа N, и считывают значение комбинации ui из строки кодовой таблицы Тк с адресом A(ui). Данный способ выбран в качестве наиболее близкого аналога.
Недостатками данного способа являются низкая стойкость при многократном преобразовании низкоэнтропийных сообщений и сложная реализация алгоритма на низкопроизводительных вычислительных системах.
Известен способ шифрования адаптивным методом многоалфавитной замены (патент RU 2469484 С2, H04L 9/00, 10.12.2012), в котором формируют таблицу многоалфавитной замены, при шифровании каждого символа открытого текста по случайному закону заменяют допустимым вещественным числом из таблицы многоалфавитной замены, полученное в результате замены с помощью таблицы многоалфавитной замены число представляют значением определенного интеграла и в линию связи передают значения верхнего и нижнего пределов интегрирования (ПИ), причем вид подынтегральной функции и форма таблицы многоалфавитной замены считаются секретными, в процессе передачи криптограммы производят анализ получающегося распределения вещественных чисел криптограммы и корректируют его таким образом, чтобы приблизить к равномерному распределению, для этого перед шифрованием очередного символа открытого текста анализируют гистограмму выходного распределения и находят на гистограмме область глобального минимума, выбирают один из ПИ таким образом, чтобы он попал в область глобального минимума, а второй ПИ вычисляют с учетом найденного первого ПИ и числа, полученного с помощью таблицы многоалфавитной замены, таким образом, чтобы он попал в зону глобального или локальных минимумов гистограммы.
Недостатком данного способа является то, что криптостойкость шифра базируется на сложности решения математической задачи при большом числе неизвестных значений и секретности формы таблицы многоалфавитной замены.
Техническим результатом заявленного изобретения является повышение надежности защиты передаваемой информации.
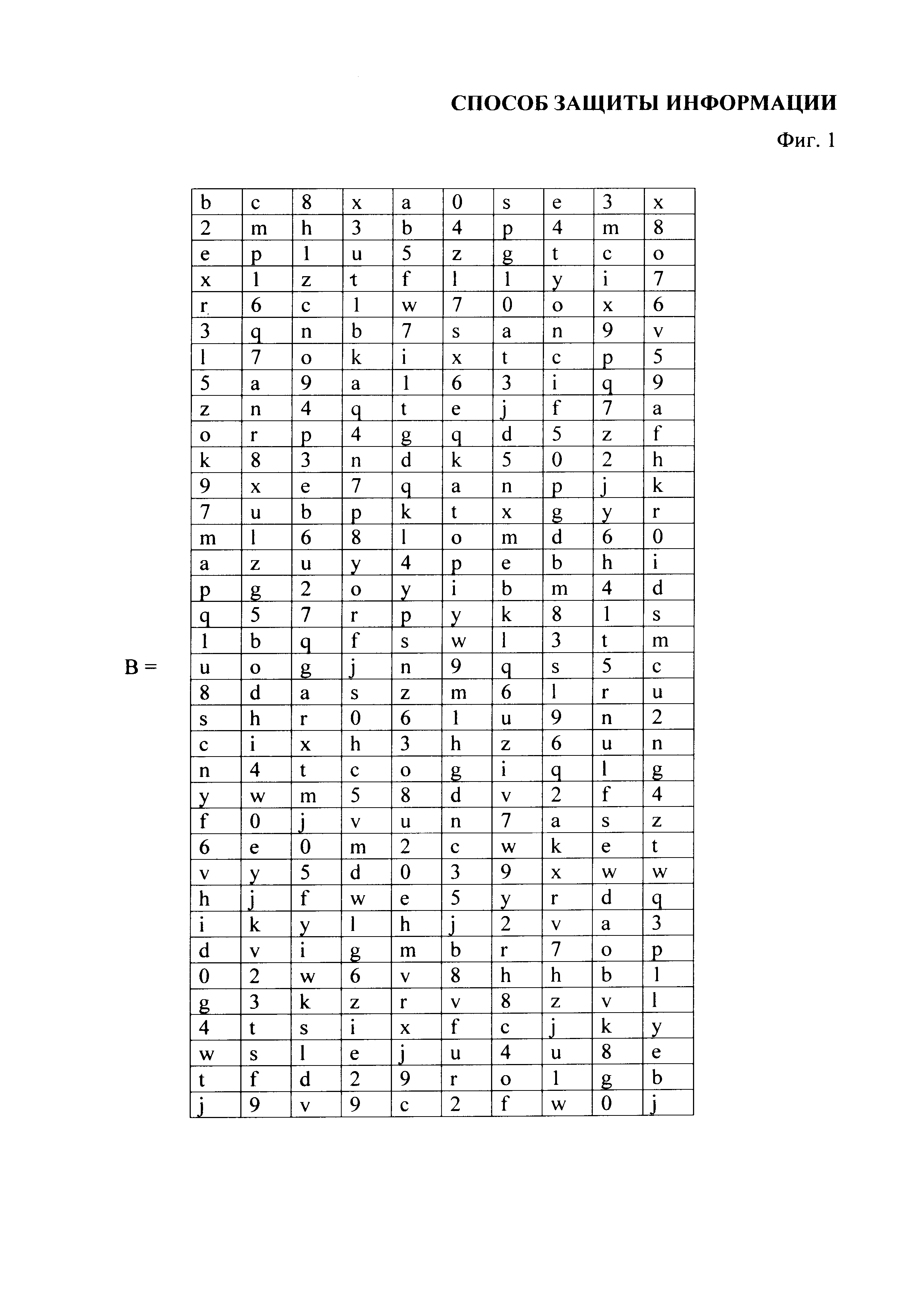
Данный технический результат достигается за счет того, в способе защиты информации, представленной в виде последовательности символов из алфавита А={а1, а2, …, аn}, где n≥2, исходную последовательность символов {ci} преобразуют в другую последовательность символов {si} с помощью этапов, на которых: задают конечное множество знаков Y={γ1, γ2, …, γm}, где m≥3, из элементов которого формируют управляющую последовательность {уi}, имеющую длину не менее длины исходной последовательности символов {сi}; задают конечное множество знаков Е={e1, е2, ..., еk}, k≥n, являющееся алфавитом для последовательности символов {si}, формируют матрицу преобразования B=||bij|| размером k×m, каждый столбец которой состоит из элементов множества Е, выбираемых в произвольном порядке, при этом каждый элемент множества Е встречается в фиксированном столбце только один раз; устанавливают соответствие GA между алфавитом А и номерами строк матрицы В таким образом, что каждому символу алфавита А ставится в соответствие не менее одного элемента множества строк матрицы В, при этом каждой строке матрицы В соответствует только один символ алфавита А, устанавливают взаимно-однозначное соответствие GY между множеством Y и номерами столбцов матрицы В; матрица ||bij||, управляющая последовательность {yi}, соответствия GA и GY вводятся в техническое средство, на котором будет осуществляться преобразование исходной последовательности символов {сi} в последовательность символов {si}, по правилу: 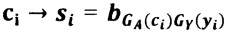 , где
, где 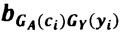 - элемент матрицы В, находящийся на пересечении строки с номером GA(ci) и столбца с номером GY(yi), при этом если символу {сi} в отображении GA(ci) соответствует несколько номеров строк матрицы В, то выбор конкретного значения GA(ci) из множества возможных происходит случайным или заранее установленным способом; после чего полученную последовательность символов {si} передают в техническое средство на принимающей стороне, на котором будет осуществляться обратное преобразование полученной последовательности символов {si} в исходную последовательность символов {сi} с использованием вводимых в техническое средство приемной стороны матрицы ||bij||, управляющей последовательности {yi}, алфавита А, множества Е и соответствий GA и GY.
- элемент матрицы В, находящийся на пересечении строки с номером GA(ci) и столбца с номером GY(yi), при этом если символу {сi} в отображении GA(ci) соответствует несколько номеров строк матрицы В, то выбор конкретного значения GA(ci) из множества возможных происходит случайным или заранее установленным способом; после чего полученную последовательность символов {si} передают в техническое средство на принимающей стороне, на котором будет осуществляться обратное преобразование полученной последовательности символов {si} в исходную последовательность символов {сi} с использованием вводимых в техническое средство приемной стороны матрицы ||bij||, управляющей последовательности {yi}, алфавита А, множества Е и соответствий GA и GY.
Общеизвестно, что в информатике под текстом понимается любая последовательность символов из определенного алфавита. Совсем не обязательно, чтобы это был текст на одном из известных языков (русском, английском и др.), это могут быть математические или химические формулы, номера телефонов, числовые таблицы и пр. Символьным алфавитом компьютера называется множество символов, используемых на ЭВМ для внешнего представления текстов.
Из чего следует, что в заявленном изобретении последовательность символов из алфавита A={a1, a2, …, an} может быть представлена не только в виде букв (заглавных или строчных, латинских или русских), но и в виде цифр, знаков препинания, спецсимволов типа "=", "(", "&" и т.п. и даже в виде пробелов между словами, поскольку с точки зрения компьютерной техники текст состоит из отдельных символов и пустое место (пробел) в тексте тоже может иметь свое обозначение.
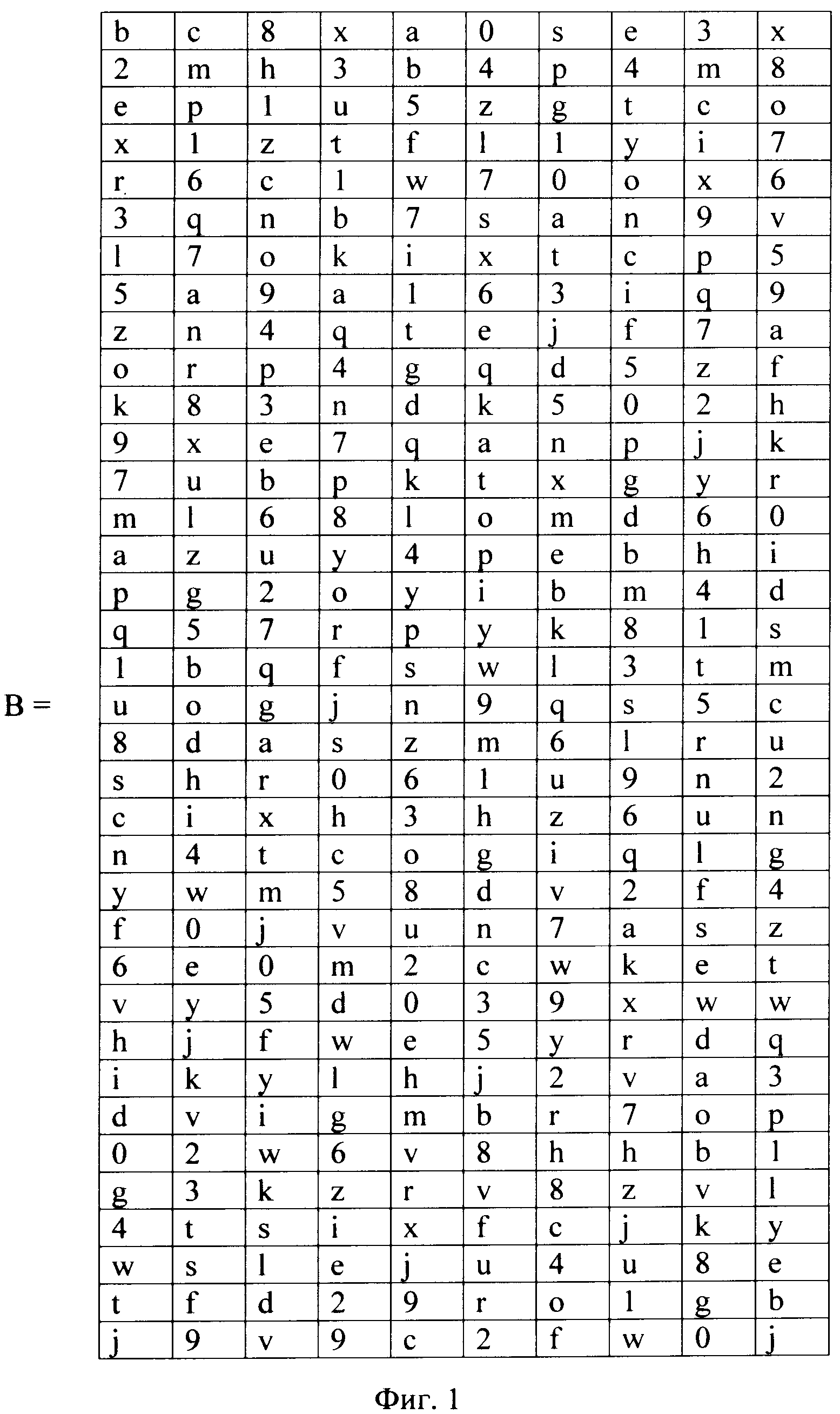
На фиг. 1 представлено изображение матрицы В размером 36×10.
На фиг. 2 приведено соответствие GA, представленное в виде таблицы.
На фиг. 3 приведено взаимно-однозначное соответствие GY, представленное в виде таблицы.
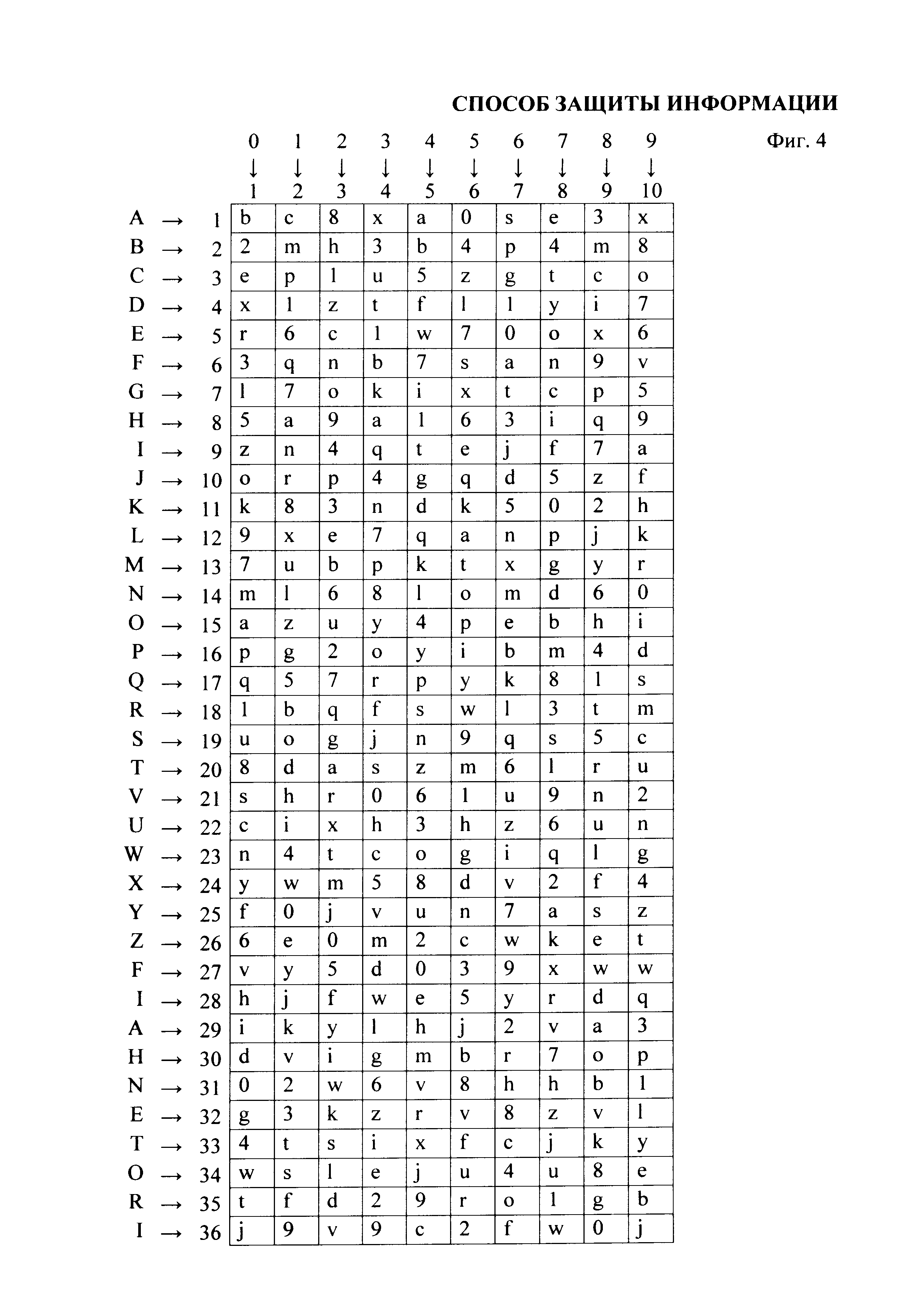
На фиг. 4 приведена матрица В и соответствия GA и GY, представленные в виде таблицы.
Объекты и признаки настоящего изобретения, способ для достижения этих объектов и признаков станут очевидными посредством отсылки к примерному варианту осуществления. Однако настоящее изобретение не ограничивается примерным вариантом осуществления, раскрытым ниже, оно может воплощаться в различных видах, в том числе, например, для защиты передаваемых по открытым каналам связи результатов голосования, сведений, составляющих коммерческую тайну, и пр. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
Далее реализуемость и корректность заявленного способа защиты информации, представленной в виде последовательности символов из алфавита A={a1, a2, …, an}, иллюстрируется частным примером его реализации.
На Фиг. 1 представлена матрица В размером 36×10, в которой столбцы представляют собой случайную перестановку без повторений множества Е, где в качестве множества Е использовано множество символов фонетического алфавита, разработанного в 1956 году Международной организацией гражданской авиации (ИКАО), из которого исключены числа 100 и 1000, а именно Е=(A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, V, U, W, X, Y, Z, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
В качестве исходной последовательности символов алфавита А рассмотрим последовательность SAFETI INFORMATION, где в качестве алфавита А, в данном конкретном примере, выступает латинский алфавит A={a, b, c, d, ………, s, t, ………, z}, состоящий из 26 букв, в котором записана исходная последовательность, при этом для данного примера пробел между словами не является символом алфавита А и не является символом алфавита Е, не участвует в преобразовании и сохраняет свое место как в исходной, так и в преобразованной последовательности.
В качестве конечного множества знаков Y выберем множество цифр от 0 до 9, т.е. Y={0, 1, 2, 3, ……, 9}.
Взаимно-однозначные соответствия GA и GY представим в виде таблиц, при этом взаимно-однозначное соответствие GA устанавливается между алфавитом А и номерами строк матрицы В (фиг. 2), а взаимно-однозначное соответствие GY устанавливается между множеством Y и номерами столбцов матрицы В (см. фиг. 3).
В рассматриваемом примере для символов алфавита А, имеющих согласно отображению GA несколько вариантов отображения в номера строк матрицы В (в рассматриваемом примере это символы A, E, F, H, I, N, O, R, T), при проведении преобразования сi→si используется правило: при выборе значения GA(ci) сначала выбирается первый вариант из номеров строк матрицы В, указанных для символа сi в отображении GA; в случае повторения символа сi - второй вариант и т.д., после окончания всех вариантов номеров строк матрицы В для данного символа, при его дальнейшем повторении, осуществляется возврат к первому варианту, затем - ко второму и так далее.
В качестве управляющей последовательности {уi} возьмем произвольную последовательность цифр из конечного множества знаков Y={0, 1, 2, 3, ……, 9}, например {уi}={6, 2, 3, 7, 1, 0, 2, 8, 3, 6, 5, 4, 5, 6, 1, 0, 9}.
Для наглядности подпишем под символами исходной последовательности соответствующие им символы управляющей последовательности:

Для дальнейшего пояснения процесса преобразования исходной последовательности символов SAFETI INFORMATION обратимся к фиг. 4, где матрица В и соответствия GA и GY представлены в виде таблицы, из которой следует, что при i=1 GA(c1)=GA(s)=19, GY(у1)=GY(6)=7, таким образом, паре (S, 6) в соответствии с формулой 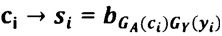 при i=1 соответствует элемент матрицы В, находящийся на пересечении строки 19 и столбца 7, а именно b19,7=Q, паре (А, 2) соответствует символ 8, паре (F, 3) - символ В, паре (Е, 7) - символ О, паре (Т, 1) - символ D, паре (1, 0) - символ Z. Продолжая далее, с учетом повторения символов и установленного для данного примера правила использования отображения GA для повторяющихся символов A, E, F, H, I, N, O, R, T, преобразуем слово INFORMATION в F6BEWKJC9W1, таким образом, исходная последовательность SAFETI INFORMATION преобразована в последовательность Q8BODZ F6DEWKJC9W1. Обратное преобразование может быть проиллюстрировано на фиг. 4 следующим образом.
при i=1 соответствует элемент матрицы В, находящийся на пересечении строки 19 и столбца 7, а именно b19,7=Q, паре (А, 2) соответствует символ 8, паре (F, 3) - символ В, паре (Е, 7) - символ О, паре (Т, 1) - символ D, паре (1, 0) - символ Z. Продолжая далее, с учетом повторения символов и установленного для данного примера правила использования отображения GA для повторяющихся символов A, E, F, H, I, N, O, R, T, преобразуем слово INFORMATION в F6BEWKJC9W1, таким образом, исходная последовательность SAFETI INFORMATION преобразована в последовательность Q8BODZ F6DEWKJC9W1. Обратное преобразование может быть проиллюстрировано на фиг. 4 следующим образом.
Для входящей защищенной последовательности Q8BODZ F6DEWKJC9W1, соответствующей ей управляющей последовательности 62371028365456109, матрицы В и соответствия GA и GY для каждой пары (Q, 6), (8, 2), (B, 3), (O, 7), (D, 1), (Z, 0), (F, 2), (6, 8), (D, 3), (E, 6), (W, 5), (K, 4), (J, 5), (C, 6), (9, 1), (W, 0), (1, 9) по матрице преобразования В определяется соответствующий ей символ исходной последовательности. Так, например, для пары (Q, 6) согласно соответствию GA строку расположения символа Q следует искать в столбце 7 матрицы В, где он расположен в строке 19, при этом указанной строке соответствует символ S, который, таким образом, и является искомым символом исходного текста. Для пары (8, 2) символ 8 из столбца 3 находится в строке 1 матрицы В, и, следовательно, при обратном преобразовании ему соответствует символ А исходного текста.
Проведя сходные преобразования для остальных пар, получим исходную последовательность SAFETI INFORMATION.
Процесс преобразования последовательности символов и ее обратного преобразования, описанный выше, может быть реализован не только в виде устройства передачи/хранения/приема, использующего аппаратные средства, но и с помощью встроенного программного обеспечения, хранимого в постоянной памяти (ROM), во флэш-памяти или т.п., или с помощью программного обеспечения компьютера или т.п. При этом матрица В, множество Е, управляющая последовательность {yi}, соответствия GA и GY могут быть изготовлены заранее на иных технических средствах, кроме тех, на которых осуществляют действия по преобразованию сi→si и обратно. Поставка встроенного программного обеспечения или программы системы программного обеспечения может осуществляться в виде записи на носителе записи, считываемом компьютером или т.п., с сервера через проводную или беспроводную сеть или с использованием широковещательной передачи данных по спутниковым каналам цифрового вещания.
В соответствии с описанием компоненты, этапы исполнения, структура данных, описанные выше, могут быть выполнены, используя различные типы операционных систем, компьютерных платформ, программ с различной степенью автоматизации.
Способ защиты информации, представленной в виде последовательности символов из алфавита А={а, а, …, a}, где n≥2, заключающийся в том, что исходную последовательность символов {c} преобразуют в другую последовательность символов {s} с помощью этапов, на которых: задают конечное множество знаков Y={γ, γ, …, γ}, где m≥3, из элементов которого формируют управляющую последовательность {y}, имеющую длину не менее длины исходной последовательности символов {c}; задают конечное множество знаков Е={е, е, …, e}, k≥n, являющееся алфавитом для последовательности символов {s}, формируют матрицу преобразования В=||b|| размером k×m, каждый столбец которой состоит из элементов множества Е, выбираемых в произвольном порядке, при этом каждый элемент множества Е встречается в фиксированном столбце только один раз; устанавливают соответствие G между алфавитом А и номерами строк матрицы В таким образом, что каждому символу алфавита А ставится в соответствие не менее одного элемента множества строк матрицы В, при этом каждой строке матрицы В соответствует только один символ алфавита А, устанавливают взаимно-однозначное соответствие G между множеством Y и номерами столбцов матрицы В; матрица ||b||, управляющая последовательность {y}, соответствия G и G вводятся в техническое средство, на котором будет осуществляться преобразование исходной последовательности символов {c} в последовательность символов {s}, по правилу: , где - элемент матрицы В, находящийся на пересечении строки с номером G(c) и столбца с номером G(y), при этом если символу {c} в отображении G соответствует несколько номеров строк матрицы В, то выбор конкретного значения G(c) из множества возможных происходит случайным или заранее установленным способом; после чего полученную последовательность символов {s} передают в техническое средство на принимающей стороне, на котором будет осуществляться обратное преобразование полученной последовательности символов {s} в исходную последовательность символов {c} с использованием заранее вводимых матрицы ||bij||, управляющей последовательности {y}, алфавита А, множества Е и соответствий G и G.