Результат интеллектуальной деятельности: ОБХОДНЫЕ БИНЫ ДЛЯ КОДИРОВАНИЯ ОПОРНЫХ ИНДЕКСОВ ПРИ КОДИРОВАНИИ ВИДЕО
Вид РИД
Изобретение
Настоящая заявка испрашивает приоритет по предварительной заявке на патент США Номер 61/623,043, поданной 11 апреля 2012, предварительной заявке на патент США Номер 61/637,218, поданной 23 апреля 2012, предварительной заявке на патент США Номер 61/640,568, поданной 30 апреля 2012, предварительной заявке на патент США Номер 61/647,422, поданной 15 мая 2012, и предварительной заявке на патент США Номер 61/665,151, поданной 27 июня 2012, содержимое каждой из которых включено в данный документ путем ссылки, во всей их полноте.
ОБЛАСТЬ ТЕХНИКИ
Настоящее раскрытие изобретения имеет отношение к кодированию видео, а конкретнее, к методам для кодирования синтаксических элементов в ходе процесса кодирования видео.
УРОВЕНЬ ТЕХНИКИ
Возможности цифрового видеопредставления могут внедряться в широком разнообразии устройств, включающих в себя цифровые телевизоры, цифровые системы непосредственного вещания, беспроводные широковещательные системы, карманные персональные компьютеры (КПК), переносные или настольные компьютеры, планшетные компьютеры, цифровые камеры, цифровые записывающие устройства, цифровые мультимедийные проигрыватели, видеоигровые устройства, видеоигровые приставки, сотовые или спутниковые радиотелефоны, устройства для видеоконференцсвязи, и тому подобные. Устройства цифрового видеопредставления реализуют такие методы сжатия видео, как описанные в стандартах, определяемых MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное Кодирование Видео (AVC - Advanced Video Coding), находящемся в настоящее время в стадии разработки стандарте Высокоэффективное Видеокодирование (HEVC - High Efficiency Video coding), и расширениях таких стандартов, чтобы более эффективно передавать, принимать и хранить цифровое видео.
Методы сжатия видео включают в себя пространственное предсказание и/или временное предсказание, чтобы уменьшить или устранить избыточность, свойственную видеопоследовательностям. Для блочного кодирования видео, видеокадр или слайс может быть разделен на блоки. Видеокадр, в качестве альтернативы, может упоминаться как изображение. Каждый блок может быть дополнительно разделен. Блоки в изображении или слайсе с внутренним кодированием (I) кодируются с использованием пространственного предсказания в отношении опорных выборок в соседних блоках в одном и том же изображении или слайсе. Блоки в изображении или слайсе с внешним кодированием (P или B) могут использовать пространственное предсказание в отношении опорных выборок в соседних блоках в одном и том же изображении или слайсе или временное предсказание в отношении опорных выборок в других опорных изображениях. Пространственное или временное предсказание дает в результате предсказуемостный блок для блока, подлежащего кодированию. Остаточные данные представляют разности элементов изображения между исходным блоком, подлежащим кодированию, и предсказуемостным блоком.
Блок с внешним кодированием кодируется в соответствии с вектором движения, который указывает на блок опорных выборок, формирующих предсказуемостный блок, и остаточными данными, показывающими разность между кодируемым блоком и предсказуемостным блоком. Блок с внутренним кодированием кодируется в соответствии с режимом внутреннего кодирования и остаточными данными. Для дополнительного сжатия, остаточные данные могут быть преобразованы из области элементов изображения в область преобразования, что дает остаточные коэффициенты преобразования, которые затем могут квантоваться. Квантованные коэффициенты преобразования, первоначально размещенные в двухмерном массиве, могут развертываться в конкретном порядке, чтобы породить одномерный вектор коэффициентов преобразования для энтропийного кодирования. Энтропийное кодирование может также применяться к различным другим синтаксическим элементам, используемым в процессе кодирования видео.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Методы в настоящем раскрытии изобретения в целом имеют отношение к энтропийному кодированию видеоданных. Например, при выполнении контекстно-адаптивного кодирования, видеокодер может кодировать каждый бит или "бин" данных, используя вероятностные оценки, которые могут показывать вероятность бина, имеющего данное двоичное значение. Вероятностные оценки могут входить в состав вероятностной модели, также известной как "контекстная модель". Видеокодер может выбирать контекстную модель, определяя контекст для бина. Контекст для бина может включать в себя значения связанных бинов ранее закодированных синтаксических элементов. После кодирования бина, видеокодер может обновлять контекстную модель на основании значения бина, чтобы отразить самые последние вероятностные оценки. В отличие от применения режима контекстного кодирования, видеокодер может применять режим кодирования с обходом. Например, видеокодер может использовать режим с обходом, чтобы обойти, или пропустить, нормальный процесс арифметического кодирования. В таких случаях, видеокодер может использовать фиксированную вероятностную модель (которая не обновляется в ходе кодирования), чтобы кодировать с обходом бины.
Методы в настоящем раскрытии изобретения имеют отношение к эффективному контекстному кодированию синтаксических элементов, связанных с видеоданными с внешним кодированием. Например, аспекты настоящего раскрытия изобретения имеют отношение к эффективному кодированию значений опорных индексов, предикторов векторов движения, значений разностей векторов движения, и тому подобного. В некоторых случаях, видеокодер может выполнять контекстное кодирование для некоторых бинов синтаксического элемента и кодирование с обходом для других бинов синтаксического элемента. Например, видеокодер может контекстно кодировать один или более бинов значения опорного индекса и кодировать с обходом один или более других бинов значения опорного индекса.
В одном из примеров, аспекты настоящего раскрытия изобретения имеют отношение к способу для кодирования синтаксического элемента опорного индекса в процессе кодирования видео, который включает в себя этапы, на которых бинаризуют значение опорного индекса, кодируют по меньшей мере один бин бинаризованного значения опорного индекса в режиме контекстного кодирования процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC - Context-adaptive binary arithmetic coding), и кодируют, если бинаризованное значение опорного индекса содержит больше бинов, чем по меньшей мере один бин, кодируемый в режиме контекстного кодирования по меньшей мере другой бин бинаризованного значения опорного индекса в режиме кодирования с обходом процесса CABAC.
В другом примере, аспекты настоящего раскрытия изобретения имеют отношение к устройству для кодирования синтаксического элемента опорного индекса в процессе кодирования видео, которое включает в себя один или более процессоров, чтобы бинаризовать значение опорного индекса, кодировать по меньшей мере один бин бинаризованного значения опорного индекса в режиме контекстного кодирования процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC), и кодировать, если бинаризованное значение опорного индекса содержит больше бинов, чем по меньшей мере один бин, кодируемый в режиме контекстного кодирования по меньшей мере другой бин бинаризованного значения опорного индекса в режиме кодирования с обходом процесса CABAC.
В другом примере, аспекты настоящего раскрытия изобретения имеют отношение к устройству для кодирования синтаксического элемента опорного индекса в процессе кодирования видео, которое включает в себя средство для бинаризации значения опорного индекса, средство для кодирования по меньшей мере одного бина бинаризованного значения опорного индекса в режиме контекстного кодирования процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC), и средство для кодирования, если бинаризованное значение опорного индекса содержит больше бинов, чем по меньшей мере один бин, кодируемый в режиме контекстного кодирования по меньшей мере другого бина бинаризованного значения опорного индекса в режиме кодирования с обходом процесса CABAC.
В другом примере, аспекты настоящего раскрытия изобретения имеют отношение к способу для декодирования синтаксического элемента опорного индекса в процессе декодирования видео, который включает в себя этапы, на которых декодируют по меньшей мере один бин значения опорного индекса в режиме контекстного кодирования процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC), декодируют, если значение опорного индекса содержит больше бинов, чем по меньшей мере один бин, кодируемый в режиме контекстного кодирования по меньшей мере другой бин значения опорного индекса в режиме кодирования с обходом процесса CABAC, и бинаризуют значение опорного индекса.
В другом примере, аспекты настоящего раскрытия изобретения имеют отношение к устройству для декодирования синтаксического элемента опорного индекса в процессе декодирования видео, которое включает в себя один или более процессоров, выполненных с возможностью декодирования по меньшей мере одного бина значения опорного индекса в режиме контекстного кодирования процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC), декодирования, если значение опорного индекса содержит больше бинов, чем по меньшей мере один бин, кодируемый в режиме контекстного кодирования по меньшей мере другого бина значения опорного индекса в режиме кодирования с обходом процесса CABAC, и бинаризации значения опорного индекса.
В другом примере, аспекты настоящего раскрытия изобретения имеют отношение к невременному считываемому компьютером носителю, хранящему на себе инструкции, которые при исполнении заставляют один или более процессоров декодировать по меньшей мере один бин значения опорного индекса в режиме контекстного кодирования процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC), декодировать, если значение опорного индекса содержит больше бинов, чем по меньшей мере один бин, кодируемый в режиме контекстного кодирования по меньшей мере другой бин значения опорного индекса в режиме кодирования с обходом процесса CABAC, и бинаризовать значение опорного индекса.
Детали одного или более примеров приводятся на прилагаемых чертежах и в нижеследующем описании. Другие признаки, задачи и преимущества будут очевидны из описания и чертежей, а также из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 является структурной схемой, иллюстрирующей типовую систему кодирования и декодирования видео.
Фиг. 2 является структурной схемой, иллюстрирующей типовой кодер видео.
Фиг. 3 является структурной схемой, иллюстрирующей типовой декодер видео.
Фиг. 4 является структурной схемой, иллюстрирующей типовой процесс арифметического кодирования.
Фиг. 5A является структурной схемой, иллюстрирующей типовую строку данных предсказания.
Фиг. 5B является структурной схемой, иллюстрирующей другую типовую строку данных предсказания.
Фиг. 6 является структурной схемой, иллюстрирующей другую типовую строку данных предсказания.
Фиг. 7 является структурной схемой, иллюстрирующей другую типовую строку данных предсказания.
Фиг. 8A является структурной схемой, иллюстрирующей контекстное кодирование синтаксического элемента направления внешнего предсказания с тремя возможными значениями.
Фиг. 8B является структурной схемой, иллюстрирующей кодирование с обходом синтаксического элемента направления внешнего предсказания, в соответствии с аспектами настоящего раскрытия изобретения.
Фиг. 9 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного кодирования значения опорного индекса, в соответствии с аспектами настоящего раскрытия изобретения.
Фиг. 10 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного декодирования значения опорного индекса, в соответствии с аспектами настоящего раскрытия изобретения.
Фиг. 11 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного кодирования данных предсказания, в соответствии с аспектами настоящего раскрытия изобретения.
Фиг. 12 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного декодирования данных предсказания, в соответствии с аспектами настоящего раскрытия изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Устройство кодирования видео может сжимать видеоданные, воспользовавшись пространственной и временной избыточностью. Например, кодер видео может воспользоваться пространственной избыточностью, кодируя блок относительно соседних, ранее кодированных блоков. Аналогично, кодер видео может воспользоваться временной избыточностью, кодируя блок относительно данных ранее кодированных изображений. В частности, кодер видео может предсказать текущий блок, исходя из данных пространственно соседних элементов (упоминается как внутреннее кодирование) или из данных одного или более других изображений (упоминается как внешнее кодирование). Затем кодер видео может вычислить остаточную погрешность для блока как разность между фактическими значениями элементов изображения для блока и предсказанными значениями элементов изображения для блока. Соответственно, остаточная погрешность для блока может включать в себя значения разностей по каждому элементу изображения в области элементов изображения (или пространственной области).
Видеокодер может выполнить оценку движения и компенсацию движения при внешнем предсказании блока видеоданных. Например, оценка движения выполняется на кодере видео и включает в себя вычисление одного или более векторов движения. Вектор движения может показывать отклонение блока видеоданных в текущем изображении по отношению к опорным выборкам опорного изображения. Опорная выборка может быть блоком, для которого обнаруживается близкое соответствие подлежащему кодированию блоку, если говорить о разности элементов изображения, что может быть определено по сумме абсолютной разности (SAD - sum of absolute difference), сумме квадрата разности (SSD - sum of squared difference), или другим показателям разности. Опорная выборка может оказаться где угодно в пределах опорного изображения или опорного слайса, и не обязательно на границе блока опорного изображения или слайса. В некоторых примерах, опорная выборка может оказаться в позиции фрагментированного элемента изображения.
Данные, задающие вектор движения, могут описывать, например, горизонтальную составляющую вектора движения, вертикальную составляющую вектора движения, разложение для вектора движения (например, точность до одной четверти элемента изображения или точность до одной восьмой элемента изображения), опорное изображение, на которое указывает вектор движения, и/или список опорных изображений (например, список 0 (L0), список 1 (L1) или объединенный список (LC)) для вектора движения, например, как показано направлением предсказания. Опорный индекс (ref_idx) может идентифицировать конкретное изображение в списке опорных изображений, на которое указывает вектор движения. Таким образом, синтаксический элемент ref_idx служит индексом в списке опорных изображений, например, L0, L1 или LC.
После идентификации опорного блока, определяется разность между исходным блоком видеоданных и опорным блоком. Эта разность может упоминаться как остаточные данные предсказания, и показывает разности элементов изображения между значениями элементов изображения в блоке для кодирования и значениями элементов изображения в опорном блоке, выбранном для представления кодируемого блока. Для достижения лучшего сжатия, остаточные данные предсказания могут быть преобразованы, например, с использованием дискретного косинусного преобразования (ДКП), целочисленного преобразования, преобразования Карунена-Лоэва (K-L - Karhunen-Loeve), или другого преобразования. Для дополнительного сжатия, коэффициенты преобразования могут квантоваться.
Затем энтропийный кодер осуществляет энтропийное кодирование символов или синтаксических элементов, связанных с блоком видеоданных, и квантованных коэффициентов преобразования. Примеры схем энтропийного кодирования включают в себя контекстно-адаптивное кодирование с переменной длиной кодового слова (CAVLC - Context Adaptive Variable Length Coding), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), энтропийное кодирование с разбивкой интервала вероятности (PIPE - Probability Interval Partitioning Entropy Coding), или тому подобное. Перед контекстным кодированием, кодер видео может переводить абсолютное значение каждого значения, подлежащего кодированию, в бинаризованную форму. Таким образом, каждое ненулевое кодируемое значение может быть "бинаризовано", например, используя унарную кодовую таблицу или другую схему кодирования, которая переводит значение в кодовое слово, имеющее один или более битов, или "бинов".
Что касается CABAC, в качестве примера, видеокодер может выбрать вероятностную модель (также упоминаемую как контекстная модель) для кодовых символов, связанных с блоком видеоданных. Например, на кодере, целевой символ может быть закодирован с помощью вероятностной модели. На декодере, целевой символ может подвергаться синтаксическому анализу с помощью вероятностной модели. В некоторых случаях, бины могут быть закодированы с использованием сочетания контекстно-адаптивного кодирования и контекстно-независимого адаптивного кодирования. Например, видеокодер может использовать режим с обходом, чтобы обойти, или пропустить, нормальный процесс арифметического кодирования для одного или более бинов, при использовании контекстно-адаптивного кодирования для других бинов. В таких примерах, видеокодер может использовать фиксированную вероятностную модель, чтобы кодировать с обходом бины. То есть, кодируемые с обходом бины не включают в себя обновления контекста или вероятности. Вообще, как более подробно описано ниже со ссылкой на Фиг. 4, контекстное кодирование бинов может упоминаться как кодирование бинов с использованием режима контекстного кодирования. Точно так же, кодирование с обходом бинов может упоминаться как кодирование бинов с использованием режима кодирования с обходом.
Контекстная модель для кодирования бина синтаксического элемента может быть основана на значениях связанных бинов ранее кодированных соседних синтаксических элементов. В качестве одного примера, контекстная модель для кодирования бина текущего синтаксического элемента может быть основана на значениях связанных бинов ранее кодированных соседних синтаксических элементов, например, выше и левее от текущего синтаксического элемента. Позиции, из которых выводится контекст, могут упоминаться как окрестность контекстной поддержки (также упоминается как "контекстная поддержка", или просто "поддержка"). Например, в отношении кодирования бинов карты значимости (например, показывающей местоположение ненулевых коэффициентов преобразования в блоке видеоданных), для задания контекстной модели может использоваться пятиточечная поддержка.
В некоторых примерах, контекстная модель (Ctx) может быть индексом или смещением, которое применяется для выбора одного из множества различных контекстов, каждый из которых может соответствовать конкретной вероятностной модели. Значит, в любом случае, как правило, своя вероятностная модель задается для каждого контекста. После кодирования бина, вероятностная модель дополнительно обновляется на основании значения бина, чтобы отразить самые последние вероятностные оценки для бина. Например, вероятностная модель может обслуживаться как состояние в конечном автомате. Каждое конкретное состояние может соответствовать определенному значению вероятности. Следующее состояние, которое соответствует обновлению вероятностной модели, может зависеть от значения текущего бина (например, бина, кодируемого в настоящий момент). Соответственно, на выбор вероятностной модели могут влиять значения ранее кодированных бинов, так как эти значения показывают по меньшей мере частично, вероятность бина, имеющего данное значение. Процесс контекстного кодирования, описанный выше, может в широком смысле упоминаться как режим контекстно-адаптивного кодирования.
Процесс обновления вероятности, описанный выше, может замедлять процесс кодирования. Например, предположим, что два бина используют одну и ту же контекстную модель (например, ctx(0)) для целей контекстно-адаптивного кодирования. В этом примере, первый бин может использовать ctx(0), чтобы определить вероятностную модель для кодирования. Значение первого бина влияет на вероятностную модель, связанную с ctx(0). Соответственно, обновление вероятности должно быть выполнено до кодирования второго бина с использованием ctx(0). Таким образом, обновление вероятности может привносить задержку в цикл кодирования.
Что касается кодирования видео, в качестве другого примера, видеокодер может контекстно-адаптивно кодировать последовательность бинов (например, bin(0), bin(1),..., bin(n)) опорного индекса (ref_idx). Как отмечалось выше, опорный индекс (ref_idx) может идентифицировать конкретное изображение в списке опорных изображений, на которое указывает вектор движения. Один опорный индекс (ref_idx) может включать в себя, например, до 15 бинов. Для пояснения предположим, что видеокодер выводит три контекста для кодирования бинов и применяет эти контексты, исходя из номера кодируемого бина (например, обозначенного с помощью индексов ctx(0), ctx(1) и ctx(2) контекстов). То есть, в этом примере, видеокодер может использовать ctx(0), чтобы кодировать bin(0), ctx(1), чтобы кодировать bin(1), и ctx(2), чтобы кодировать остальные бины (например, bin(2)-bin(n)).
В описанном выше примере, третий контекст (ctx(2)) совместно используется некоторым количеством бинов (например, до 13 бинов). Использование одной и той же вероятностной модели, чтобы кодировать bin(2)-bin(n), таким образом, может создавать задержку между последовательными циклами кодирования. Например, как отмечалось выше, неоднократный вызов одного и того же контекста и ожидание обновления модели после каждого бина может представлять собой критический параметр для производительности кодера.
Более того, корреляция между bin(2) и bin(n) может быть недостаточной, чтобы оправдывать временные и вычислительные ресурсы, связанные с обновлением вероятностной модели. То есть, одним потенциальным преимуществом контекстно-адаптивного кодирования является способность адаптировать вероятностную модель, основываясь на ранее кодированных бинах (если имеется один и тот же контекст). Если значение первого бина, при этом, имеет небольшую зависимость или влияние на значение последующего бина, может иметь место небольшое повышение эффективности, связанное с обновлением вероятности. Соответственно, бины, демонстрирующие низкую корреляцию, не могут с такой же пользой применять контекстно-адаптивное кодирование, как бины с относительно более высокими корреляциями.
Аспекты настоящего раскрытия изобретения имеют отношение к эффективному контекстному кодированию синтаксических элементов, связанных с видеоданными с внешним кодированием. Например, аспекты настоящего раскрытия изобретения имеют отношение к эффективному кодированию значений опорных индексов, предикторов векторов движения, значений разностей векторов движения, и тому подобного. В некоторых случаях, видеокодер может выполнять контекстное кодирование для некоторых бинов синтаксического элемента и кодирование с обходом для других бинов синтаксического элемента.
Обращаясь к конкретному примеру кодирования опорных индексов, описанному выше, в соответствии с аспектами настоящего раскрытия изобретения, видеокодер может применять ctx(0) для bin(0), ctx(1) для bin(1), ctx(2) для bin(2) и может кодировать с обходом остальные бины значения опорного индекса, не требуя каких-либо контекстов. Другими словами, видеокодер может использовать ctx(2) в качестве контекста для CABAC-кодирования bin(2) из бинаризованного значения опорного индекса, но может кодировать с обходом любые бины, которые следуют за bin(2).
Учитывая, что значения опорных индексов могут составлять 15 бинов или более в длину, ограничение количества бинов, которые контекстно кодируются, таким образом, может привести к экономии вычислительных и/или временных ресурсов по сравнению с контекстным кодированием всех бинов опорного индекса. Более того, как отмечалось выше, корреляция между битами значения опорного индекса может быть невысокой (например, значение bin(3) из значения опорного индекса может не обеспечивать полезное показание касательно вероятности bin(4) со значением "1" или "0"), что уменьшает выгоду от контекстного кодирования. Соответственно, объем временных и вычислительных ресурсов, сэкономленных благодаря контекстному кодированию меньшего количества бинов значения опорного индекса, могут перевесить повышение эффективности кодирования, связанное с контекстным кодированием всех бинов значения опорного индекса.
Другие аспекты настоящего раскрытия изобретения в целом имеют отношение к группированию контекстно кодируемых бинов и контекстно-независимо кодируемых бинов во время кодирования. Например, как отмечалось выше, некоторые синтаксические элементы могут кодироваться с использованием сочетания контекстного кодирования и кодирования с обходом. То есть, некоторые синтаксические элементы могут иметь один или более бинов, которые контекстно кодируются, и один или более других бинов, которые кодируются с обходом.
Для примера предположим, что два синтаксических элемента, каждый из которых имеет контекстно кодируемую часть (включающую в себя один или более контекстно кодируемых бинов) и кодируемую с обходом часть (включающую в себя один или более кодируемых с обходом бинов). В этом примере, видеокодер может кодировать контекстно кодируемую часть первого синтаксического элемента, затем кодируемую с обходом часть первого синтаксического элемента, затем контекстно кодируемую часть второго синтаксического элемента, затем кодируемую с обходом часть второго синтаксического элемента.
В описанном выше примере, видеокодер может три раза переключаться между режимом контекстного кодирования и режимом кодирования с обходом, чтобы кодировать два синтаксических элемента. Например, видеокодер переключается между контекстным кодированием и кодированием с обходом после контекстно кодируемых бинов первого синтаксического элемента, после кодируемых с обходом бинов первого синтаксического элемента, и после контекстно кодируемых бинов второго синтаксического элемента. Переключение между контекстным кодированием и кодированием с обходом, таким образом, может быть неэффективным в вычислительном отношении. Например, переключение между контекстным кодированием и кодированием с обходом может затрачивать один или более тактовых циклов. Соответственно, переключение между контекстным кодированием и кодированием с обходом для каждого элемента может привнести запаздывание, вследствие переходов между контекстным кодированием и кодированием с обходом.
Аспекты настоящего раскрытия изобретения включают в себя группирование контекстно кодируемых бинов и контекстно-независимо кодируемых бинов (например, обходных бинов) во время кодирования. Например, в отношении описанного выше примера, в соответствии с аспектами настоящего раскрытия изобретения, видеокодер может кодировать контекстно кодируемые бины первого синтаксического элемента, затем контекстно кодируемые бины второго синтаксического элемента, затем кодируемые с обходом бины первого синтаксического элемента, затем кодируемые с обходом бины второго синтаксического элемента. Соответственно, видеокодер только один раз переходит между режимом контекстного кодирования и режимом кодирования с обходом, например, между контекстно кодируемыми бинами и контекстно-независимо кодируемыми бинами.
Группирование бинов, таким образом, может уменьшить частоту, с которой видеокодер переключается между режимом контекстного кодирования и режимом кодирования с обходом. Соответственно, аспекты настоящего раскрытия изобретения могут уменьшить запаздывание при кодировании синтаксических элементов, которые включают в себя сочетание контекстно кодируемых бинов и кодируемых с обходом бинов. В некоторых примерах, как описано в отношении Фиг. 5-8 ниже, бины, связанные с данными предсказания, могут группироваться в соответствии с методами настоящего раскрытия изобретения. Например, как описывается в данном документе, данные предсказания могут, в общем случае, включать в себя данные, связанные с внешним предсказанием. Например, данные предсказания могут включать в себя данные, показывающие значения опорных индексов, векторы движения, предикторы векторов движения, значения разностей векторов движения, и тому подобное.
Фиг. 1 является структурной схемой, иллюстрирующей типовую систему 10 кодирования и декодирования видео, которая может быть выполнена с возможностью кодирования данных предсказания в соответствии с примерами настоящего раскрытия изобретения. Как показано на Фиг. 1, система 10 включает в себя устройство-источник 12, которое передает закодированное видео на устройство-адресат 14 через канал 16 связи. Закодированное видео также может храниться на информационном носителе 34 или обслуживающем узле 36 для хранения файлов, и может быть доступна со стороны устройства-адресата 14 при необходимости. При хранении на информационном носителе или обслуживающем узле для хранения файлов, кодер 20 видео может предоставлять кодированные видеоданные на другое устройство, такое, как сетевой интерфейс, устройство с возможностью записи или штамповки компакт-диска (CD), диска Blu-ray или цифрового видеодиска (DVD), или другие устройства, для сохранения кодируемого видео на информационном носителе. Точно так же, отдельное от декодера 30 видео устройство, такое, как сетевой интерфейс, устройство чтения CD или DVD, или тому подобное, может извлекать кодированные видеоданные с информационного носителя и предоставлять извлеченные данные декодеру 30 видео.
Устройство-источник 12 и устройство-адресат 14 могут содержать любое из широкого разнообразия устройств, включающих в себя настольные компьютеры, портативные (т.е., переносные) компьютеры, планшетные компьютеры, телевизионные приставки, микротелефонные трубки, например, так называемые смартфоны, телевизоры, камеры, устройства отображения, цифровые мультимедийные проигрыватели, видеоигровые приставки, или тому подобное. Во многих случаях, такие устройства могут быть оборудованы для беспроводной связи. А следовательно, канал 16 связи может содержать беспроводной канал, проводной канал, или комбинацию беспроводных и проводных каналов, подходящих для передачи закодированных видеоданных. Аналогично, обслуживающий узел 36 для хранения файлов может быть доступен со стороны устройства-адресата 14 через любое стандартное информационное соединение, в том числе соединение через сеть Интернет. Это может включать в себя беспроводной канал (например, Wi-Fi-соединение), проводное соединение (например, DSL, кабельный модем, и т.д.), или комбинацию обоих, что подходит для получения доступа к закодированным видеоданным, хранящимся на обслуживающем узле для хранения файлов.
Методы для кодирования данных предсказания, в соответствии с примерами согласно настоящему раскрытию изобретения, могут применяться к кодированию видео с задачей поддержки любого из множества мультимедийных приложений, таких, как эфирные телепередачи, передачи кабельного телевидения, передачи спутникового телевидения, потоковые передачи видео, например, через сеть Интернет, кодирование цифрового видео для сохранения на носителе для хранения данных, декодирование цифрового видео, сохраненной на носителе для хранения данных, или другие приложения. В некоторых примерах, система 10 может быть выполнена с возможностью поддержки односторонней или двусторонней передачи видео, чтобы поддерживать такие приложения, как воспроизведение потокового видео, воспроизведение записанного видео, вещание видеоданных и/или видеотелефония.
В примере на Фиг. 1, устройство-источник 12 включает в себя источник 18 видео, кодер 20 видео, модулирующее/демодулирующее устройство 22 и передатчик 24. В устройстве-источнике 12, источник 18 видео может включать в себя такой источник, как устройство захвата видео, такое, как видеокамера, архив видео, содержащий ранее захваченное видео, интерфейс внешнего источника видео, чтобы принимать видео от поставщика информационной видеопродукции, и/или система компьютерной графики для генерирования данных компьютерной графики в качестве исходного видео, или комбинация таких источников. В качестве одного примера, если источником 18 видео является видеокамера, устройство-источник 12 и устройство-адресат 14 могут образовывать так называемые камерофоны или видеотелефоны. Тем не менее, методы, описываемые в настоящем раскрытии изобретения, могут быть применимы к кодированию видео в целом, и могут применяться для беспроводных и/или проводных приложений, или приложения, в котором закодированные видеоданные хранятся на локальном диске.
Захваченное, предварительно захваченное или сгенерированное компьютером видео может быть закодировано кодером 20 видео. Закодированное видео может модулироваться модемом 22 в соответствии со стандартом связи, таким, как протокол беспроводной связи, и передаваться на устройство-адресат 14 с помощью передатчика 24. Модем 22 может включать в себя различные смесители, фильтры, усилители или другие компоненты, предназначенные для модуляции сигнала. Передатчик 24 может включать в себя схемы, предназначенные для передачи данных, в том числе усилители, фильтры, и одну или более антенны.
Захваченное, предварительно захваченное или сгенерированное компьютером видео, которое закодировано кодером 20 видео, также может сохраняться на информационном носителе 34 или на обслуживающем узле 36 для хранения файлов для последующего использования. Информационный носитель 34 может включать в себя диски Blu-ray, DVD, CD-ROM, память с групповой перезаписью, или любые другие подходящие цифровые информационные носители для хранения закодированного видео. В дальнейшем к закодированному видео, сохраненному на информационном носителе 34, может получить доступ устройство-адресат 14 для декодирования и воспроизведения.
Обслуживающий узел 36 для хранения файлов может быть обслуживающим узлом любого типа, способным хранить закодированное видео и передавать это закодированное видео на устройство-адресат 14. Типовые обслуживающие узлы для хранения файлов включают в себя сетевой обслуживающий узел (например, для информационного центра во всемирной сети), обслуживающий узел с доступом по протоколу стандарта FTP, устройство хранения данных, подключаемое к сети (NAS - network attached storage), локальный дисковый накопитель, или устройство любого другого типа, способное хранить закодированные видеоданные и передавать их на устройство-адресат. Передача закодированных видеоданных от обслуживающего узла 36 для хранения файлов может быть потоковой передачей, передачей загрузки, или их комбинацией. Обслуживающий узел 36 для хранения файлов может быть доступен для устройства-адресата 14 через любое стандартное информационное соединение, в том числе соединение через сеть Интернет. Это может включать в себя беспроводной канал (например, Wi-Fi-соединение), проводное соединение (например, DSL, кабельный модем, Ethernet, USB, и т.д.), или комбинацию обоих, что подходит для получения доступа к закодированным видеоданным, хранящимся на обслуживающем узле для хранения файлов.
Устройство-адресат 14, в примере на Фиг. 1, включает в себя приемник 26, модем 28, декодер 30 видео и устройство 32 отображения. Приемник 26 в устройстве-адресате 14 принимает информацию по каналу 16, а модем 28 демодулирует информацию, чтобы получить демодулированный битовый поток для декодера 30 видео. Информация, сообщенная по каналу 16, может включать в себя различную синтаксическую информацию, сгенерированную кодером 20 видео, для использования декодером 30 видео при декодировании видеоданных. Такая синтаксическая структура также может быть отнесена к закодированным видеоданным, хранящимся на информационном носителе 34 или обслуживающем узле 36 для хранения файлов. И кодер 20 видео и декодер 30 видео может образовывать часть соответственного кодера-декодера (КОДЕК), который способен кодировать или декодировать видеоданные.
Устройство 32 отображения может быть объединено с устройством-адресатом 14 или быть внешним по отношению к нему. В некоторых примерах, устройство-адресат 14 может включать в себя встроенное устройство отображения, а также может быть выполнено с возможностью взаимодействия с внешним устройством отображения. В других примерах, устройство-адресат 14 может быть устройством отображения. В общем случае, устройство 32 отображения отображает декодированное видео пользователю, и может содержать любое из разнообразных устройств отображения, таких, как жидкокристаллическое (ЖК) устройство отображения, плазменное устройство отображения, устройство отображение на органических светоизлучающих диодах (ОСИД), или устройство отображения другого типа.
В примере на Фиг. 1, канал 16 связи может содержать любую беспроводную или проводную среду связи, такую, как радиочастотный (РЧ) спектр или одна или более физических линий передачи, или любая комбинация беспроводных и проводных передающих сред. Канал 16 связи может являться частью пакетной сети, такой, как локальная вычислительная сеть, глобальная вычислительная сеть, или всемирная сеть, такая, как сеть Интернет. Канал 16 связи обычно представляет собой любую подходящую среду связи, или набор разных сред связи, для передачи видеоданных от устройства-источника 12 на устройство-адресат 14, в том числе любую соответствующую комбинацию проводных или беспроводных передающих сред. Канал 16 связи может включать в себя маршрутизаторы, переключатели, базовые станции, или любое другое оборудование, которое может использоваться для облегчения связи от устройства-источника 12 до устройства-адресата 14.
Кодер 20 видео и декодер 30 видео могут работать в соответствии со стандартом сжатия видео, таким, как стандарт Высокоэффективное Видеокодирование (HEVC), находящийся в настоящее время в стадии разработки, и может согласовываться с тестовой моделью HEVC (HM-HEVC Test Model). В качестве альтернативы, кодер 20 видео и декодер 30 видео могут работать в соответствии с другими корпоративными или промышленными стандартами, такими, как стандарт ITU-T H.264, иначе именуемый MPEG-4, Часть 10, Усовершенствованное Кодирование Видео (AVC), или расширения таких стандартов. Методы согласно настоящему раскрытию изобретения, однако, не ограничиваются каким-то конкретным стандартом кодирования. Другие примеры включают в себя MPEG-2 и ITU-T H.263.
Хоть это и не показано на Фиг. 1, в некоторых аспектах, кодер 20 видео и декодер 30 видео, каждый, может быть объединен с кодером и декодером аудио, и может включать в себя надлежащие модули уплотнения-разуплотнения, или другое аппаратное и программное обеспечение, чтобы управлять кодированием как аудио, так и видео, в общем потоке данных или в отдельных потоках данных. При необходимости, в некоторых примерах, модули уплотнения-разуплотнения могут согласовываться с протоколом устройства уплотнения стандарта ITU H.223, или другими протоколами, такими, как протокол пользовательских датаграмм (UDP - user datagram protocol).
И кодер 20 видео и декодер 30 видео может быть реализован в виде любой из множества подходящих схем кодера или декодера, в зависимости от конкретного случая, включающего в себя процессор, такое, как один или более микропроцессоров, цифровых сигнальных процессоров (ЦСП), специализированных процессоров или схем обработки данных, специализированных интегральных схем (СИС), программируемых пользователем вентильных матриц (ППВМ), неизменяемых логических схем, дискретных логических схем, программное обеспечение, аппаратное обеспечение, программно-аппаратное обеспечение или любые их комбинации. Соответственно, различные модули в составе кодера 20 видео и декодера 30 видео аналогичным образом могут быть реализованы с помощью любого из множества таких структурных элементов или их комбинаций. Если методы реализуются частично в программном обеспечении, устройство может хранить инструкции для программного обеспечения на подходящем невременном считываемом компьютером носителе и исполнять инструкции в аппаратном обеспечении, используя один или более процессоров, чтобы выполнять методы согласно настоящему раскрытию изобретения. И кодер 20 видео и декодер 30 видео может входить в состав одного или более кодеров или декодеров, каждый из которых может составлять часть комбинированного кодера/декодера (КОДЕК) в соответственном устройстве.
Настоящее раскрытие изобретения может, в общем случае, относиться к кодеру 20 видео, "сигнализирующему" определенную информацию другому устройству, такому, как декодер 30 видео. Следует понимать, однако, что кодер 20 видео может сигнализировать информацию, связывая некоторые синтаксические элементы с различными закодированными частями видеоданных. То есть, кодер 20 видео может "сигнализировать" данные, сохраняя определенные синтаксические элементы в заголовках различных закодированных частей видеоданных. В некоторых случаях, такие синтаксические элементы могут быть закодированы и сохранены (например, сохранены на устройство 32 хранения) до того, как будут приняты и декодированы декодером 30 видео. Таким образом, термин "сигнализация" вообще может относиться к сообщению синтаксической структуры или других данных для декодирования сжатых видеоданных, происходит ли такая связь в реальном или почти реальном времени, или в течение некоторого промежутка времени, что могло бы происходить при сохранении синтаксических элементов на носитель во время кодирования, которые потом могут быть извлечены декодирующим устройством в любой момент после сохранения на этом носителе.
Как отмечалось выше, JCT-VC работает над разработкой стандарта HEVC. Меры по стандартизации HEVC основываются на развивающейся модели устройства кодирования видео, упоминаемой как тестовая модель HEVC (HM). HM предполагает несколько дополнительных возможностей для устройства кодирования видео по сравнению с существующими устройствами, например, отвечающими требованиям, ITU-T H.264/AVC. В настоящем раскрытии изобретения обычно используется термин "видеоблок", для обозначения кодового узла в CU. В некоторых особых случаях, в настоящем раскрытии изобретения еще может использоваться термин "видеоблок" для обозначения блока дерева, т.е., LCU, или CU, которая включает в себя кодовый узел, а также PU и TU.
Видеопоследовательность обычно включает в себя ряд видеокадров или изображений. Группа изображений (GOP - group of pictures) в общем случае содержит ряд из одного или более видеоизображений. GOP может включать в себя синтаксические данные в заголовке GOP, заголовке одного или более изображений, или в другом участке, которые описывают множество изображений, включенных в состав GOP. Каждый слайс изображения может включать в себя синтаксические данные слайса, которые описывают режим кодирования для соответственного слайса. Кодер 20 видео обычно работает с видеоблоками в пределах отдельных видеослайсов для того, чтобы кодировать видеоданные. Видеоблок может соответствовать кодовому узлу в пределах CU. Видеоблоки могут иметь постоянные или изменяющиеся размеры, и могут отличаться по размеру в соответствии с определенным стандартом кодирования.
В качестве примера, и как отмечалось выше, HM поддерживает предсказание для PU различных размеров (также упоминаются как типы PU). Предполагая, что размер конкретной CU составляет 2N×2N, HM поддерживает внутреннее предсказание в PU с размерами 2N×2N или N×N, и внешнее предсказание в симметричных PU с размерами 2N×2N, 2N×N, N×2N или N×N. HM также поддерживает асимметричное разделение для внешнего предсказания в PU с размерами 2N×nU, 2N×nD, nL×2N и nR×2N. При асимметричном разделении, одно направление CU не разделяется, тогда как другое направление разделяется на 25% и 75%. Часть CU, соответствующая 25%-ой части, обозначается "n", за чем следует обозначение "Up" (вверх), "Down" (вниз), "Left" (налево) или "Right" (направо). Таким образом, например, "2N×nU" относится к CU 2N×2N, которая разделяется по горизонтали с PU 2N×0,5N сверху и PU 2N×1,5N внизу. Другие типы разделения тоже возможны.
В настоящем раскрытии изобретения, "N×N" и "N на N" может использоваться взаимозаменяемо для обозначения размерностей в элементах изображения видеоблока в значениях вертикальной и горизонтальной размерностей, например, 16×16 элементов изображения или 16 на 16 элементов изображения. В общем случае, блок 16×16 будет иметь 16 элементов изображения в вертикальном направлении (y=16) и 16 элементов изображения в горизонтальном направлении (x=16). Точно так же, блок NxN в общем смысле имеет N элементов изображения в вертикальном направлении и N элементов изображения в горизонтальном направлении, где N представляет собой неотрицательное целое число. Элементы изображения в блоке могут располагаться в строках и столбцах. Более того, блоки не обязательно должны иметь такое же количество элементов изображения в горизонтальном направлении, как и в вертикальном направлении. Например, блоки могут содержать NxM элементов изображения, где M не обязательно равно N.
Вслед за кодированием с внутренним предсказанием или внешним предсказанием, с использованием PU из CU, кодер 20 видео может вычислить остаточные данные для TU из CU. PU могут содержать данные элементов изображения в пространственной области (также называемой областью элементов изображения), а TU могут содержать коэффициенты в области преобразования с последующим применением преобразования, например, дискретного косинусного преобразования (ДКП), целочисленного преобразования, вейвлет-преобразования, или концептуально подобного преобразования, к остаточным видеоданным. Остаточные данные могут соответствовать разностям элементов изображения между элементами изображения незакодированного, исходного изображения и значениями предсказания, соответствующими PU. Кодер 20 видео может формировать TU, включающие в себя остаточные данные для CU, а затем преобразовывать TU, чтобы получить коэффициенты преобразования для CU.
В некоторых примерах, как отмечалось выше, TU могут задаваться согласно RQT. Например, RQT может представлять способ, которым преобразования (например, ДКП, целочисленное преобразование, вейвлет-преобразование, или одно или более других преобразований) применяются к выборкам остаточной яркости и выборкам остаточной цветности, связанным с блоком видеоданных. То есть, как отмечалось выше, остаточные выборки, соответствующие CU, могут разбиваться на меньшие модули с использованием RQT. В общем случае, RQT является рекурсивным представлением разделения CU на TU.
Вслед за применением тех или иных преобразований к остаточным данным для получения коэффициентов преобразования, кодер 20 видео может выполнить квантование коэффициентов преобразования. Под квантованием, в общем случае, имеется в виду процесс, в котором коэффициенты преобразования квантуются, чтобы можно было уменьшить объем данных, используемых для представления коэффициентов, обеспечивая дополнительное сжатие. Процесс квантования может уменьшить битовую глубину, связанную с некоторыми или всеми коэффициентами. Например, n-битовое значение может округляться в меньшую сторону до m-битового значения в ходе квантования, где n больше m.
В некоторых примерах, кодер 20 видео может задействовать предварительно заданный порядок развертки для развертки квантованных коэффициентов преобразования, чтобы получить упорядоченный вектор, который может быть энтропийно закодирован. В других примерах, кодер 20 видео может выполнять адаптивную развертку. После развертки квантованных коэффициентов преобразования для формирования одномерного вектора, кодер 20 видео может энтропийно кодировать одномерный вектор, например, в соответствии с контекстно-адаптивным кодированием с переменной длиной кодового слова (CAVLC), контекстно-адаптивным двоичным арифметическим кодированием (CABAC), основанным на синтаксисе контекстно-адаптивным двоичным арифметическим кодированием (SBAC - syntax-based context-adaptive binary arithmetic coding), энтропийным кодированием с разбивкой интервала вероятности (PIPE) или другой методикой энтропийного кодирования. Кодер 20 видео также может энтропийно кодировать синтаксические элементы, связанные с закодированными видеоданными, для использования декодером 30 видео при декодировании видеоданных. Текущая версия HEVC рассчитана на использование CABAC для энтропийного кодирования.
В некоторых примерах, кодер 20 видео может кодировать синтаксические элементы, используя сочетание контекстно-адаптивного кодирования и контекстно-независимого адаптивного кодирования. Например, кодер 20 видео может контекстно кодировать бины, выбирая вероятностную модель или "контекстную модель", которая работает с контекстом, чтобы закодировать бины. И наоборот, кодер 20 видео может кодировать с обходом бины, обходя, или пропуская нормальный процесс арифметического кодирования при кодировании бинов. В таких примерах, кодер 20 видео может использовать фиксированную вероятностную модель, чтобы кодировать с обходом бины.
Как отмечалось выше, процесс обновления вероятностной модели, связанный с контекстным кодированием, может привносить задержку в процесс кодирования. Например, кодер 20 видео может контекстно кодировать последовательность бинов (например, bin(0), bin(1), …, bin(n)) опорного индекса (ref_idx). Один опорный индекс (ref_idx) может включать в себя, например, до 15 бинов. Для пояснения предположим, что кодер 20 видео выводит три контекста для кодирования бинов и применяет контексты, исходя из номера кодируемого бина (например, обозначенного с помощью индексов ctx(0), ctx(1) и ctx(2) контекстов). То есть, в этом примере, кодер 20 видео может использовать ctx(0), чтобы кодировать bin(0), ctx(1), чтобы кодировать bin(1), и ctx(2), чтобы кодировать остальные бины (например, bin(2)-bin(n)).
В описанном выше примере, третий контекст (ctx(2)) совместно используется некоторым количеством бинов (например, до 13 бинов). Использование одной и той же вероятностной модели, чтобы кодировать bin(2)-bin(n), таким образом, может создавать задержку между последовательными циклами кодирования. Например, неоднократный вызов одного и того же контекста и ожидание обновления модели после каждого бина может представлять собой критический параметр для производительности кодера.
Более того, корреляция между bin(2) и bin(n) может быть недостаточной, чтобы оправдывать временные и вычислительные ресурсы, связанные с обновлением вероятностной модели. То есть, одним потенциальным преимуществом контекстно-адаптивного кодирования является способность адаптировать вероятностную модель, основываясь на ранее кодированных бинах (если имеется один и тот же контекст). Если значение первого бина, при этом, имеет небольшую зависимость или влияние на значение последующего бина, может иметь место небольшое повышение эффективности, связанное с обновлением вероятности. Соответственно, бины, демонстрирующие низкую корреляцию, не могут с такой же пользой применять контекстно-адаптивное кодирование, как бины с относительно более высокими корреляциями.
В соответствии с аспектами настоящего раскрытия изобретения, кодер 20 видео может закодировать синтаксический элемент опорного индекса, кодируя по меньшей мере один бин бинаризованного значения опорного индекса в процессе контекстно-адаптивного двоичного арифметического кодирования (CABAC), и кодируя по меньшей мере другой бин бинаризованного значения опорного индекса в режиме кодирования с обходом процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC).
В одном из иллюстративных примеров, кодер 20 видео может применять ctx(0) для bin(0), ctx(1) для bin(1), ctx(2) для bin(2) и может кодировать с обходом остальные бины значения опорного индекса, не требуя каких-либо контекстов. Другими словами, видеокодер может использовать ctx(2) в качестве контекста для CABAC-кодирования bin(2) из бинаризованного значения опорного индекса, но может кодировать с обходом любые бины, которые следуют за bin(2).
Учитывая, что значения опорных индексов могут составлять 15 бинов или более в длину, ограничение количества бинов, которые контекстно кодируются, таким образом, может привести к экономии вычислительных и/или временных ресурсов по сравнению с контекстным кодированием всех бинов опорного индекса. Более того, как отмечалось выше, корреляция между битами значения опорного индекса может быть невысокой (например, значение bin(3) из значения опорного индекса может не обеспечивать полезное показание касательно вероятности bin(4) со значением "1" или "0"), что уменьшает выгоду от контекстного кодирования. Соответственно, объем временных и вычислительных ресурсов, сэкономленных благодаря контекстному кодированию меньшего количества бинов значения опорного индекса, могут перевесить повышение эффективности кодирования, связанное с контекстным кодированием всех бинов значения опорного индекса.
В соответствии с другими аспектами настоящего раскрытия изобретения, кодер 20 видео может группировать контекстно кодируемые бины и контекстно-независимо кодируемые бины во время кодирования. Например, как отмечалось выше, некоторые синтаксические элементы могут кодироваться с использованием сочетания контекстного кодирования и кодирования с обходом. То есть, некоторые синтаксические элементы могут иметь один или более бинов, которые контекстно кодируются, и один или более других бинов, которые кодируются с обходом.
В некоторых примерах, кодер 20 видео может переключаться между контекстным кодированием и кодированием с обходом, чтобы кодировать последовательность синтаксических элементов. Однако переключение между контекстным кодированием и кодированием с обходом может затрачивать один или более тактовых циклов. Соответственно, переключение между контекстным кодированием и кодированием с обходом для каждого элемента может привнести запаздывание, вследствие переходов между контекстным кодированием и кодированием с обходом.
В соответствии с аспектами настоящего раскрытия изобретения, кодер 20 видео может группировать контекстно кодируемые бины и контекстно-независимо кодируемые бины (например, обходные бины) во время кодирования. Например, кодер 20 видео может контекстно кодировать бины, связанные более, чем с одним синтаксическим элементом. Затем кодер 20 видео может кодировать с обходом бины, связанные более, чем с одним синтаксическим элементом. В других примерах, кодер 20 видео может выполнять кодирование с обходом до контекстного кодирования. В любом случае, эти методы позволяют кодеру 20 видео свести к минимуму переходы между контекстным кодированием и кодированием с обходом. Соответственно, аспекты настоящего раскрытия изобретения могут уменьшить запаздывание при кодировании синтаксических элементов, которые включают в себя сочетание контекстно кодируемых бинов и кодируемых с обходом бинов.
Декодер 30 видео, после приема кодированных видеоданных, может выполнить проход декодирования, в общем взаимообратный проходу кодирования, описанному в отношении кодера 20 видео. Например, декодер 30 видео может принимать закодированный битовый поток и декодировать этот битовый поток. Согласно аспектам настоящего раскрытия изобретения, например, декодер 30 видео может декодировать синтаксический элемент опорного индекса, кодируя по меньшей мере один бин бинаризованного значения опорного индекса с помощью процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC), и кодируя по меньшей мере другой бин бинаризованного значения опорного индекса в режиме кодирования с обходом процесса контекстно-адаптивного двоичного арифметического кодирования (CABAC).
Согласно другим аспектам настоящего раскрытия изобретения, декодер 30 видео может декодировать битовый поток, имеющий сгруппированные контекстно кодированные бины и контекстно-независимо кодированные бины (например, обходные бины). Например, декодер 30 видео может декодировать контекстно кодированные бины, связанные более, чем с одним синтаксическим элементом. Затем декодер 30 видео может декодировать кодированные с обходом бины, связанные более, чем с одним синтаксическим элементом. В других примерах, декодер 30 видео может выполнять кодирование с обходом до контекстного кодирования (в зависимости от расположения бинов в битовом потоке, подлежащем декодированию). В любом случае, эти методы позволяют декодеру 30 видео свести к минимуму переходы между контекстным кодированием и кодированием с обходом. Соответственно, аспекты настоящего раскрытия изобретения могут уменьшить запаздывание при кодировании синтаксических элементов, которые включают в себя сочетание контекстно кодируемых бинов и кодируемых с обходом бинов.
Фиг. 2 является структурной схемой, иллюстрирующей пример кодера 20 видео, который может использовать методы для кодирования данных предсказания в соответствии с примерами настоящего раскрытия изобретения. Несмотря на то, что аспекты кодера 20 видео описываются применительно к иллюстративному HEVC-кодированию, методы настоящего раскрытия изобретения не ограничиваются каким-либо конкретным стандартом или способом кодирования, который может предусматривать кодирование данных предсказания.
Кодер 20 видео может выполнять внутреннее и внешнее кодирование CU в пределах видеоизображений. Внутреннее кодирование основывается на пространственном предсказании, чтобы уменьшить или устранить пространственную избыточность в видеоданных в пределах данного изображения. Внешнее кодирование основывается на временном предсказании, чтобы уменьшить или устранить временную избыточность между текущим изображением и ранее кодированными изображениями видеопоследовательности. Под внутренним режимом (I-режим) может иметься в виду любой из нескольких пространственных режимов сжатия видео. Под внешними режимами, такими, как однонаправленное предсказание (P-режим) или двунаправленное предсказание (B-режим), могут иметься в виду любой из нескольких временных режимов сжатия видео.
Как показано на Фиг. 2, кодер 20 видео принимает текущий видеоблок в пределах изображения, подлежащего кодированию. В примере на Фиг. 2, кодер 20 видео включает в себя модуль 44 компенсации движения, модуль 42 оценки движения, модуль 46 внутреннего предсказания, память 64 опорных изображений, суммирующее устройство 50, модуль 52 обработки преобразования, модуль 54 квантования, и модуль 56 энтропийного кодирования. Модуль 52 обработки преобразования, проиллюстрированный на Фиг. 2, представляет собой модуль, который применяет действующее преобразование или комбинации преобразования к блоку остаточных данных, и его не следует путать с блоком коэффициентов преобразования, которые тоже могут упоминаться как единица преобразования (TU - transform unit) в CU. Для восстановления видеоблока, кодер 20 видео также включает в себя модуль 58 обратного квантования, модуль 60 обработки обратного преобразования, и суммирующее устройство 62. Антиблочный фильтр (не показан на Фиг. 2) также может входить в состав для фильтрации границ блоков, чтобы устранить артефакты блочности из восстанавливаемого видео. При необходимости, антиблочный фильтр, чаще всего, будет фильтровать выходные данные суммирующего устройства 62.
В ходе процесса кодирования, кодер 20 видео принимает изображение или слайс, подлежащий кодированию. Изображение или слайс могут быть разделены на несколько видеоблоков, например, наибольшие единицы кодирования (LCU - largest coding unit). Модуль 42 оценки движения и модуль 44 компенсации движения выполняют кодирование с внешним предсказанием принятого видеоблока относительно одного или более блоков в одном или более опорных изображениях, чтобы обеспечить временное сжатие. Модуль 46 внутреннего предсказания может выполнять кодирование с внутренним предсказанием принятого видеоблока относительно одного или более соседних блоков в том же самом изображении или слайсе, что и блок, подлежащий кодированию, чтобы обеспечить пространственное сжатие.
Модуль 40 выбора режима может выбрать один из режимов кодирования, внутренний или внешний, например, на основании погрешности (т.е., искажения) результатов для каждого режима, и предоставляет результирующий блок с внутренним или внешним предсказанием (например, единицу предсказания (PU - prediction unit)) на суммирующее устройство 50, чтобы генерировать остаточные данные блока, и на суммирующее устройство 62, чтобы восстанавливать закодированный блок для использования в опорном изображении. Суммирующее устройство 62 объединяет предсказанный блок с обратно квантованными, обратно преобразованными данными от модуля 60 обработки обратного преобразования для блока, чтобы восстанавливать закодированный блок, что более подробно описывается ниже. Некоторые изображения могут обозначаться как I-кадры, причем все блоки в I-кадре кодируются в режиме внутреннего предсказания. В некоторых случаях, модуль 46 внутреннего предсказания может выполнять кодирование с внутренним предсказанием блока в изображении с прямым предсказанием (P-кадр) или изображение с двойным предсказанием (B-кадр), например, когда поиск движения, выполняемый модулем 42 оценки движения, не дает достаточного предсказания блока.
Модуль 42 оценки движения и модуль 44 компенсации движения могут быть высокоинтегрированными, но проиллюстрированы по отдельности для концептуальных целей. Оценка движения (или поиск движения) представляет собой процесс генерирования векторов движения, которые оценивают движение для видеоблоков. Вектор движения, например, может показывать отклонение единицы предсказания в текущем изображении относительно опорной выборки опорного изображения. Модуль 42 оценки движения вычисляет вектор движения для единицы предсказания изображения с внешним кодированием, сравнивая единицу предсказания с опорными выборками опорного изображения, сохраненного в памяти 64 опорных изображений.
Предсказуемостный блок (также упоминается как опорная выборка) представляет собой блок, для которого обнаруживается близкое соответствие подлежащему кодированию блоку, если говорить о разности элементов изображения, что может быть определено по сумме абсолютной разности (SAD), сумме квадрата разности (SSD), или другим показателям разности. В некоторых примерах, кодер 20 видео может вычислять значения для неполных целочисленных позиций элементов изображения опорных изображений, сохраненных в памяти 64 опорных изображений, которое также может упоминаться как буфер опорного изображения. Например, кодер 20 видео может интерполировать значения одной четвертой позиций элементов изображений, одной восьмой позиций элементов изображений, или других дробных позиций элементов изображений опорного изображения. А значит, модуль 42 оценки движения может выполнять поиск движения относительно полных позиций элементов изображений и дробных позиций элементов изображений и выводить вектор движения с точностью до дробного элемента изображения.
Модуль 42 оценки движения вычисляет вектор движения для PU видеоблока в слайсе с внешним кодированием, сравнивая позицию PU с позицией предсказуемостного блока опорного изображения. Соответственно, в общем случае, данные для вектора движения могут включать в себя список опорных изображений, индекс в списке опорных изображений (ref_idx), горизонтальную составляющую, и вертикальную составляющую. Опорное изображение может быть выбрано из первого списка опорных изображений (List 0), второго списка опорных изображений (List 1), или объединенного списка опорных изображений (List c), каждый из которых идентифицирует одно или более опорных изображений, сохраненных в памяти 64 опорных изображений.
Модуль 42 оценки движения может генерировать и отправлять вектор движения, который идентифицирует предсказуемостный блок опорного изображения, на модуль 56 энтропийного кодирования и модуль 44 компенсации движения. То есть, модуль 42 оценки движения может генерировать и отправлять данные вектора движения, которые идентифицируют список опорных изображений, содержащий предсказуемостный блок, индекс в списке опорных изображений, идентифицирующий изображение предсказуемостного блока, и горизонтальную и вертикальную составляющие, чтобы определить местоположение предсказуемостного блока в пределах идентифицированного изображения.
В некоторых примерах, вместо отправки действительного вектора движения для текущего PU, модуль 42 оценки движения может предсказывать вектор движения, чтобы дополнительно уменьшить объем данных, необходимых для сообщения вектора движения. В этом случае, вместо кодирования и сообщения самого вектора движения, модуль 42 оценки движения может генерировать разность векторов движения (MVD - motion vector difference) относительно известного (или познаваемого) вектора движения. MVD может включать в себя горизонтальную составляющую и вертикальную составляющую, соответствующие горизонтальной составляющей и вертикальной составляющей известного вектора движения. Известный вектор движения, который может использоваться с MVD, чтобы задавать текущий вектор движения, может задаваться так называемым предиктором вектора движения (MVP - motion vector predictor). В общем случае, чтобы быть пригодным MVP, вектор движения, используемый для предсказания, должен указывать на то же самое опорное изображение, что и вектор движения, кодируемый в настоящее время.
Когда имеется множество кандидатов-предикторов вектора движения (от множества блоков-кандидатов), модуль 42 оценки движения может определять предиктор вектора движения для текущего блока в соответствии с предварительно заданными критериями выбора. Например, модуль 42 оценки движения может выбрать наиболее точный предиктор из набора кандидатов, основываясь на анализе скорости и искажения кодирования (например, используя анализ затрат в зависимости от скорости и искажения или другой анализ эффективности кодирования). В других примерах, модуль 42 оценки движения может генерировать среднее из кандидатов-предикторов вектора движения. Также возможны и другие способы выбора предиктора вектора движения.
После выбора предиктора вектора движения, модуль 42 оценки движения может определить индекс (mvp_flag) предиктора вектора движения, который может использоваться, чтобы информировать декодер видео (например, такой, как декодер 30 видео) о том, где найти MVP в списке опорных изображений, содержащем блоки-кандидаты MVP. Модуль 42 оценки движения также может определить MVD (горизонтальную составляющую и вертикальную составляющую) между текущим блоком и выбранным MVP. Индекс MVP и MVD могут использоваться для восстановления вектора движения.
В некоторых примерах, модуль 42 оценки движения может вместо этого реализовывать так называемый "режим слияния", в котором модуль 42 оценки движения может производить "слияние" информации движения (такой, как векторы движения, индексы опорных изображений, направления предсказания, или другая информация) предсказуемостного видеоблока с текущим видеоблоком. Соответственно, в отношении режима слияния, текущий видеоблок наследует информацию движения от другого известного (или познаваемого) видеоблока. Модуль 42 оценки движения может построить список кандидатов для режима слияния, который включает в себя несколько соседних блоков в пространственном и/или временном направлении в качестве кандидатов для режима слияния. Модуль 42 оценки движения может определить значение индекса (например, merge_idx), который может использоваться, чтобы информировать декодер видео (например, такой, как декодер 30 видео) о том, где найти видеоблок для слияния в списке опорных изображений, содержащем блоки-кандидаты для слияния.
Модуль 46 внутреннего предсказания может производить внутреннее предсказание принятого блок, в качестве альтернативы для внешнего предсказания, выполняемого модулем 42 оценки движения и модулем 44 компенсации движения. Модуль 46 внутреннего предсказания может предсказывать принятый блок относительно соседних, ранее кодированных блоков, например, блоков выше, выше и правее, выше и левее, или левее от текущего блока, полагая порядок кодирования для блоков слева направо, сверху вниз. Модуль 46 внутреннего предсказания может быть выполнен с возможностью множества различных режимов внутреннего предсказания. Например, модуль 46 внутреннего предсказания может быть выполнен с возможностью определенного количества направленных режимов предсказания, например, тридцать четыре направленных режима предсказания, на основании размера подлежащей кодированию CU.
Модуль 46 внутреннего предсказания может выбирать режим внутреннего предсказания, например, вычисляя значения погрешности для различных режимов внутреннего предсказания и выбирая режим, который дает наименьшее значение погрешности. Направленные режимы предсказания могут включать в себя функции для объединения значений пространственно соседних элементов изображения и применения объединенных значений к одной или более позициям элементов изображения в PU. После вычисления значений для всех позиций элементов изображения в PU, модуль 46 внутреннего предсказания может вычислить значение погрешности для режима предсказания, основываясь на разностях элементов изображения между PU и принятым блоком, подлежащим кодированию. Модуль 46 внутреннего предсказания может продолжить тестирование режимов предсказания, пока не будет обнаружен режима предсказания, который дает приемлемое значение погрешности. Тогда модуль 46 внутреннего предсказания может отправить PU на суммирующее устройство 50.
Кодер 20 видео формирует остаточный блок, вычитая данные предсказания, вычисленные модулем 44 компенсации движения или модулем 46 внутреннего предсказания, из исходного видеоблока, подлежащего кодированию. Суммирующее устройство 50 представляет собой компонент или компоненты, которые выполняют эту операцию вычитания. Остаточный блок может соответствовать двумерной матрице значений разностей элементов изображения, причем количество значений в остаточном блоке то же, что и количество элементов изображения в PU, соответствующих остаточному блоку. Значения в остаточном блоке могут соответствовать разностям, т.е., погрешности, между значениями совмещенных элементов изображения в PU и в исходном блоке, подлежащем кодированию. Разности могут быть разностями цветности или яркости, в зависимости от типа блока, который кодируется.
Модуль 52 обработки преобразования может формировать одну или более единиц преобразования (TU) из остаточного блока. Модуль 52 обработки преобразования выбирает преобразование из множества преобразований. Преобразование может выбираться на основании одной или более характеристик кодирования, таких, как размер блока, режим кодирования, или тому подобное. Затем модуль 52 обработки преобразования применяет выбранное преобразование к TU, получая видеоблок, содержащий двухмерный массив коэффициентов преобразования.
Модуль 52 обработки преобразования может отправить полученные в результате коэффициенты преобразования на модуль 54 квантования. Затем модуль 54 квантования может квантовать коэффициенты преобразования. Затем модуль 56 энтропийного кодирования может выполнить развертку квантованных коэффициентов преобразования в матрице в соответствии с режимом развертки. Настоящее раскрытие изобретения описывает модуль 56 энтропийного кодирования как выполняющий развертку. Тем не менее, следует понимать, что, в других примерах, развертку могут выполнять другие модули обработки, такие, как модуль 54 квантования.
После того, как коэффициенты преобразования были развернуты в одномерный массив, модуль 56 энтропийного кодирования может применить к коэффициентам энтропийное кодирование, такое, как CAVLC, CABAC, основанное на синтаксисе контекстно-адаптивное двоичное арифметическое кодирование (SBAC), энтропийное кодирование с разбивкой интервала вероятности (PIPE) или другая методика энтропийного кодирования.
Для выполнения CABAC, модуль 56 энтропийного кодирования может выбрать контекстную модель, чтобы применить определенный контекст для кодирования символов, которые должны передаваться. Контекст может иметь отношение к тому, например, являются ли соседние значения ненулевыми или нет. Модуль 56 энтропийного кодирования также может энтропийно кодировать синтаксические элементы, такие, как сигнал, характеризующий выбранное преобразование.
Модуль 56 энтропийного кодирования может энтропийно кодировать данные предсказания. При внешнем предсказании видеоданных, например, данные предсказания могут включать в себя данные, показывающие значения опорных индексов, векторы движения, предикторы векторов движения, значения разности векторов движения, и тому подобное. То есть, как отмечалось выше, оценка движения (модулем 42 оценки движения) определяет один или более индексов для опорных изображений (ref_idx) и направление предсказания (pred_dir: прямое, обратное или двунаправленное). Модуль 56 энтропийного кодирования может энтропийно кодировать синтаксические элементы, представляющие векторы движения (например, горизонтальную составляющую и вертикальную составляющую векторов движения), индексы опорных изображений, и направление предсказания. Модуль 56 энтропийного кодирования может включать закодированные синтаксические элементы в закодированный битовый поток видео, который потом может быть декодирован декодером видео (таким, как декодер 30 видео, описанный ниже) для использования в процессе декодирования видео. То есть, эти синтаксические элементы могут быть предусмотрены для PU с внешним кодированием, чтобы позволить декодеру 30 видео декодировать и воспроизводить видеоданные, задаваемые с помощью PU.
В некоторых примерах, как подробнее описано в отношении Фиг. 4 ниже, модуль 56 энтропийного кодирования (или другой модуль кодирования в кодере 20 видео) может бинаризовать синтаксические элементы перед энтропийного кодирования синтаксических элементов. Например, модуль 56 энтропийного кодирования может перевести абсолютное значение каждого подлежащего кодированию синтаксического элемента в двоичную форму. Модуль 56 энтропийного кодирования может использовать процесс кодирования унарным кодом, усеченным унарным кодом, или иной, чтобы бинаризовать синтаксические элементы. Что касается значений опорных индексов, например, если максимальное количество опорных изображений в списке опорных изображений равно четырем, т.е., опорный индекс (ref_idx) имеет значение в диапазоне от 0 до 3, то может применяться следующая бинаризация из Таблицы 1:
|
Как показано в Таблице 1, бинаризованное значение изменяется от одного бита до трех битов, в зависимости от значения опорного индекса.
В некоторых примерах, модуль 56 энтропийного кодирования может энтропийно кодировать значения опорных индексов, используя три разных контекста (например, ctx0, ctx1 и ctx2). Например, модуль 56 энтропийного кодирования может энтропийно кодировать первый бин (bin0) и второй бин (bin1), используя ctx0 и ctx1, соответственно, а третий бин (bin2), и другие бины кодируются с помощью контекста ctx2. В этом примере, ctx2 совместно используется всеми бинами, начиная с bin2 и считая его, т.е., bin2 и бинами после bin2, например, bin3, bin4, и так далее. В некоторых примерах, могут предусматриваться дополнительные бины, кроме bin2, например, если максимальное количество опорных изображений больше четырех.
Как отмечалось выше, совместное использование контекста ctx2 бинами может быть неэффективным, из-за обновлений вероятности, связанных с контекстным кодированием. Согласно аспектам настоящего раскрытия изобретения, модуль 56 энтропийного кодирования может производить CABAC-кодирование значения опорного индекса, выделяя ctx2 для кодирования bin2, и кодируя все бины после bin2 с использованием режима кодирования с обходом. Опять же, кодирование с обходом, в общем случае, включает в себя кодирование бинов с использованием фиксированной вероятности (контексты не требуются). Например, модуль 56 энтропийного кодирования может кодировать с обходом бины после bin2 значения опорного индекса, используя кодирование кодом Голомба, кодирование экспоненциальным кодом Голомба, кодирование кодом Голомба-Райса, или другие процессы кодирования, которые обходят механизм CABAC-кодирования.
В другом примере, модуль 56 энтропийного кодирования может контекстно кодировать меньшее количество бинов значения опорного индекса, удаляя ctx2. То есть, в соответствии с аспектами настоящего раскрытия изобретения, модуль 56 энтропийного кодирования может закодировать bin2 и все последующие бины, используя режим с обходом CABAC. В этом примере, модуль 56 энтропийного кодирования может производить CABAC-кодирование bin0 с использованием контекста ctx0, а bin1 с использованием контекста ctx1, и может кодировать с обходом bin2 и другие бины, следующие за bin2, с использованием режима с обходом CABAC. Удаление контекста, таким образом, может снизить общую сложность, связанную с кодированием значений опорных индексов.
Еще в одном примере, модуль 56 энтропийного кодирования может кодировать меньшее количество бинов значения опорного индекса, удаляя и ctx1 и ctx2. То есть, в соответствии с аспектами настоящего раскрытия изобретения, модуль 56 энтропийного кодирования может кодировать bin1 и все последующие бины с использованием режима с обходом CABAC, тем самым дополнительно снижая сложность, связанную с кодированием значений опорных индексов. В этом примере, модуль 56 энтропийного кодирования может производить CABAC-кодирование bin0 с использованием контекста ctx0, и может кодировать с обходом bin1, bin2, и другие бины, следующие за bin2, с использованием режима с обходом CABAC.
Другие аспекты настоящего раскрытия изобретения в целом имеют отношение к тому, каким образом модуль 56 энтропийного кодирования бинаризует значения опорных индексов. Например, как отмечалось выше, модуль 56 энтропийного кодирования может бинаризовать значения опорных индексов, используя процесс кодирования унарным кодом, усеченным унарным кодом, или иной. В другом примере, модуль 56 энтропийного кодирования может использовать процесс кодирования экспоненциальным кодом Голомба, чтобы бинаризовать значение опорного индекса.
В некоторых примерах, в соответствии с аспектами настоящего раскрытия изобретения, модуль 56 энтропийного кодирования может реализовывать комбинацию процессов бинаризации. Например, как подробнее описано в отношении Фиг. 4 ниже, модуль 56 энтропийного кодирования может комбинировать процесс кодирования унарным кодом (или усеченным унарным кодом) с процессом кодирования экспоненциальным кодом Голомба, чтобы бинаризовать значения опорных индексов. В иллюстративном примере, модуль 56 энтропийного кодирования может комбинировать усеченный унарный код длины (4) с экспоненциальным кодом Голомба (например, экспоненциальный код Голомба 0-го порядка). В таком примере, модуль 56 энтропийного кодирования может бинаризовать первое количество бинов (например, два, три, четыре, или тому подобное) значения опорного индекса с использованием унарного кода, и может бинаризовать остальные бины опорного индекса, используя экспоненциальный код Голомба.
В любом случае, модуль 56 энтропийного кодирования может реализовывать методы для контекстного кодирования одного или более бинов значения опорного индекса и кодирования с обходом одного или более других бинов значения опорного индекса с помощью любой схемы бинаризации. Например, как отмечалось выше, модуль 56 энтропийного кодирования может контекстно кодировать (например, производить CABAC-кодирование) первое количество бинов бинаризованного синтаксического элемента и кодировать с обходом остальные бины. В описанном выше примере, в котором усеченный унарный код длины (4) комбинируется с экспоненциальным кодом Голомба 0-го порядка, модуль 56 энтропийного кодирования может контекстно кодировать первые два бина (или любое другое количество бинов) усеченного унарного кода, а затем кодировать с обходом вторую часть унарного кода и всего экспоненциального кода Голомба. В других примерах, модуль 56 энтропийного кодирования может использовать другие схемы бинаризации. Например, модуль 56 энтропийного кодирования может использовать двоичный код фиксированной длины вместо экспоненциального кода Голомба, описанного в вышеприведенных примерах.
В некоторых примерах, модуль 56 энтропийного кодирования может усекать, или удалять бины из бинаризованного значения опорного индекса перед кодированием этого значения. Дополнительно или в качестве альтернативы, модуль 56 энтропийного кодирования может группировать бины, кодируемые с использованием контекста, и бины, кодируемые с использованием режима с обходом. Например, модуль 56 энтропийного кодирования может кодировать опорные индексы B-изображения путем контекстного кодирования одного или более бинов значения первого опорного индекса, контекстно кодировать один или более бинов значения второго индекса, кодировать с обходом один или более других бинов значения первого опорного индекса, и кодировать с обходом один или более других бинов значения второго опорного индекса (в порядке, представленном выше). Соответственно, модуль 56 энтропийного кодирования переходит между режимом контекстного кодирования и режимом кодирования с обходом только один раз, например, между контекстно кодируемыми бинами и контекстно-независимо кодируемыми бинами.
Вслед за энтропийным кодированием модулем 56 энтропийного кодирования, полученное в результате кодированное видео может быть передано на другое устройство, такое, как декодер 30 видео, или заархивировано для последующей передачи или поиска. Модуль 58 обратного квантования и модуль 60 обработки обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, чтобы восстанавливать остаточный блок в области элементов изображения, например, для последующего использования в качестве опорного блока.
Модуль 44 компенсации движения может вычислить опорный блок, добавляя остаточный блок к предсказуемостному блоку одного из изображений в памяти 64 опорных изображений. Модуль 44 компенсации движения также может применить один или более интерполирующих фильтров к восстановленному остаточному блоку, чтобы вычислить неполные целочисленные значения элементов изображения для использования при оценке движения.
Суммирующее устройство 62 добавляет восстановленный остаточный блок к блоку предсказания с компенсацией движения, полученному модулем 44 компенсации движения, чтобы получить восстановленный видеоблок для сохранения в памяти 64 опорных изображений. Восстановленный видеоблок может использоваться модулем 42 оценки движения и модулем 44 компенсации движения в качестве опорного блока для внешнего кодирования блока в следующем изображении.
Фиг. 3 является структурной схемой, иллюстрирующей пример декодера 30 видео, который декодирует закодированную видеопоследовательность. В примере на Фиг. 3, декодер 30 видео включает в себя модуль 70 энтропийного декодирования, модуль 72 компенсации движения, модуль 74 внутреннего предсказания, модуль 76 обратного квантования, модуль 78 обратного преобразования, память 82 опорных изображений и суммирующее устройство 80.
В качестве предпосылки, декодер 30 видео может принимать сжатые видеоданные, которые были сжаты для передачи через сеть в так называемые "единицы уровня сетевой абстракции" или единицы NAL (network abstraction layer unit). Каждая единица NAL может включать в себя заголовок, который идентифицирует тип данных, хранящихся в единице NAL. Есть два типа данных, которые обычно хранятся в единицах NAL. Первый тип данных, хранящихся в единице NAL, является данными уровня кодирования видео (VCL - video coding layer), которые включают в себя сжатые видеоданные. Второй тип данных, хранящихся в единице NAL, упоминается как данные не-VCL, которые включают в себя дополнительную информацию, такую, как наборы параметров, которые задают данные заголовка, общие для большого количества единиц NAL, и дополняющая расширенная информация (SEI - supplemental enhancement information).
Например, наборы параметров могут содержать информацию заголовка уровня последовательности (например, в наборах параметров последовательности (SPS - sequence parameter set)), и редко изменяющуюся информацию заголовка уровня изображений (например, в наборах параметров изображения (PPS - picture parameter set)). Редко изменяющаяся информация, содержащаяся в наборах параметров, не должна повторяться для каждой последовательности или изображения, за счет чего повышается эффективность кодирования. Помимо этого, использование наборов параметров дает возможность внеполосной передачи информации заголовка, что позволяет избежать необходимости избыточных передач для обеспечения устойчивости к ошибкам.
В ходе процесса декодирования, декодер 30 видео принимает закодированный битовый поток видео, который представляет видеоблоки закодированного видеослайса и связанные синтаксические элементы. В общем случае, модуль 70 энтропийного декодирования энтропийно декодирует битовый поток, чтобы сгенерировать квантованные коэффициенты, векторы движения, и другие синтаксические элементы. Декодер 30 видео может принимать синтаксические элементы на уровне видеослайсов и/или на уровне видеоблоков.
Например, если видеослайс кодируется как слайс с внутренним кодированием (I), модуль 74 внутреннего предсказания может генерировать данные предсказания для видеоблока текущего видеослайса на основании сообщаемого режима внутреннего предсказания и данных из ранее декодированных блоков текущего изображения. Если изображение кодируется как слайс с внешним кодированием (т.е., B, P или GPB), модуль 72 компенсации движения получает предсказуемостные блоки (также именуемые, как опорные выборки) для видеоблока текущего видеослайса на основании векторов движения и других синтаксических элементов, принимаемых от модуля 70 энтропийного декодирования. Предсказуемостные блоки могут получаться из одного из опорных изображений в пределах одного из списков опорных изображений. Декодер 30 видео может составлять списки опорных изображений, List 0 и List 1, используя заданные по умолчанию методы составления на основе опорных изображений, хранящихся в памяти 82 опорных изображений.
Модуль 70 энтропийного декодирования может декодировать битовый поток, используя такой же процесс, как и реализуемый в кодере 20 видео (например, CABAC, CAVLC, и т.д.). Процесс энтропийного кодирования, используемый кодером, может быть сообщен в закодированном битовом потоке или может быть предварительно заданным процессом. Например, модуль 70 энтропийного декодирования может принимать закодированные бинаризованные синтаксические элементы. Модуль 70 энтропийного декодирования может декодировать битовый поток (например, используя контекстно-адаптивный режим или режим с обходом) и бинаризовать декодированные значения, чтобы получить декодированные синтаксические элементы.
В некоторых случаях, модуль 70 энтропийного декодирования может энтропийно декодировать данные предсказания. Как отмечалось выше в отношении кодера 20 видео, данные предсказания могут включать в себя данные, показывающие значения опорных индексов, векторы движения, предикторы векторов движения, значения разностей векторов движения, и тому подобное. То есть, модуль 70 энтропийного декодирования может энтропийно декодировать синтаксические элементы, представляющие векторы движения (например, горизонтальную составляющую и вертикальную составляющую векторов движения), индексы опорных изображений, и направления предсказания. Эти синтаксические элементы могут быть предусмотрены для PU с внешним кодированием, чтобы позволить декодеру 30 видео декодировать и воспроизводить видеоданные, задаваемые посредством PU.
В некоторых примерах, как отмечалось выше, модуль 70 энтропийного декодирования может энтропийно декодировать значения опорных индексов, используя три разных контекста (например, ctx0, ctx1 и ctx2). Например, модуль 56 энтропийного декодирования может энтропийно декодировать первый бин (bin0) и второй бин (bin1) с использованием ctx0 и ctx1, соответственно, и декодировать третий бин (bin2) и другие бины с помощью контекста ctx2. Совместное использование контекста ctx2 бинами может быть неэффективным, из-за обновлений вероятности, связанных с контекстным кодированием.
В соответствии с аспектами настоящего раскрытия изобретения, модуль 70 энтропийного декодирования может производить CABAC-кодирование значения опорного индекса, выделяя ctx2 для кодирования bin2 и кодируя все бины после bin2 с использованием режима кодирования с обходом. В другом примере, модуль 70 энтропийного декодирования может контекстно кодировать меньшее количество бинов значения опорного индекса, удаляя ctx2. То есть, в соответствии с аспектами настоящего раскрытия изобретения, модуль 70 энтропийного декодирования может декодировать bin2 и все последующие бины, используя режим с обходом CABAC. Еще в одном примере, модуль 70 энтропийного декодирования может кодировать меньшее количество бинов значения опорного индекса, удаляя и ctx1 и ctx2. То есть, в соответствии с аспектами настоящего раскрытия изобретения, модуль 70 энтропийного декодирования может декодировать bin1 и все последующие бины, используя режим с обходом CABAC, тем самым дополнительно снижая сложность, связанную с кодированием значений опорных индексов.
Другие аспекты настоящего раскрытия изобретения в целом имеют отношение к тому, каким образом модуль 70 энтропийного декодирования бинаризует значения опорных индексов. В некоторых примерах, модуль 70 энтропийного декодирования может бинаризовать значения опорных индексов, используя процесс кодирования унарным кодом, усеченным унарным кодом, или иной. В другом примере, модуль 56 энтропийного кодирования может использовать процесс кодирования экспоненциальным кодом Голомба, чтобы бинаризовать значение опорного индекса.
В некоторых примерах, в соответствии с аспектами настоящего раскрытия изобретения, модуль 70 энтропийного декодирования может реализовывать комбинацию процессов бинаризации. Например, как подробнее описано в отношении Фиг. 4 ниже, модуль 70 энтропийного декодирования может комбинировать процесс кодирования унарным кодом (или усеченным унарным кодом) с процессом кодирования экспоненциальным кодом Голомба, чтобы бинаризовать значения опорных индексов. В иллюстративном примере, модуль 70 энтропийного декодирования может комбинировать усеченный унарный код длины (4) с экспоненциальным кодом Голомба (например, экспоненциальный код Голомба 0-го порядка). В таком примере, модуль 70 энтропийного декодирования может бинаризовать первое количество бинов (например, два, три, четыре, или тому подобное) значения опорного индекса с использованием унарного кода, и может бинаризовать остальные бины опорного индекса, используя экспоненциальный код Голомба.
В любом случае, модуль 70 энтропийного декодирования может реализовывать методы для контекстного кодирования одного или более бинов значения опорного индекса и кодирования с обходом одного или более других бинов значения опорного индекса с помощью любой схемы бинаризации. Например, как отмечалось выше, модуль 70 энтропийного декодирования может контекстно кодировать (например, производить CABAC-кодирование) первое количество бинов бинаризованного синтаксического элемента и кодировать с обходом остальные бины. В описанном выше примере, в котором усеченный унарный код длины (4) комбинируется с экспоненциальным кодом Голомба 0-го порядка, модуль 70 энтропийного декодирования может контекстно кодировать первые два бина (или любое другое количество бинов) усеченного унарного кода, а затем кодировать с обходом вторую часть унарного кода и весь экспоненциальный код Голомба. В других примерах, модуль 70 энтропийного декодирования может использовать другие схемы бинаризации. Например, модуль 70 энтропийного декодирования может использовать двоичный код фиксированной длины вместо экспоненциального кода Голомба, описанного в вышеприведенных примерах.
В некоторых примерах, модуль 70 энтропийного декодирования может усекать, или удалять бины из бинаризованного значения опорного индекса перед кодированием этого значения. Дополнительно или в качестве альтернативы, модуль 70 энтропийного декодирования может группировать бины, кодируемые с использованием контекста, и бины, кодируемые с использованием режима с обходом. Например, модуль 70 энтропийного декодирования может кодировать опорные индексы B-изображения путем контекстного кодирования одного или более бинов значения первого опорного индекса, контекстно кодировать один или более бинов значения второго индекса, кодировать с обходом один или более других бинов значения первого опорного индекса, и кодировать с обходом один или более других бинов значения второго опорного индекса (в порядке, представленном выше). Соответственно, модуль 70 энтропийного декодирования переходит между режимом контекстного кодирования и режимом кодирования с обходом только один раз, например, между контекстно кодируемыми бинами и контекстно-независимо кодируемыми бинами.
После энтропийного декодирования синтаксических элементов и коэффициентов преобразования, в некоторых примерах, модуль 70 энтропийного декодирования (или модуль 76 обратного квантования) может развертывать принимаемые значения коэффициентов преобразования, используя развертку, зеркальную режиму развертки, используемому модулем 56 энтропийного кодирования (или модулем 54 квантования) кодера 20 видео. Хотя и показанные в виде отдельных функциональных модулей для простоты иллюстрации, структура и функциональные возможности модуля 70 энтропийного декодирования, модуль 76 обратного квантования, и другие модули декодера 30 видео могут быть в высокой степени интегрированы друг с другом.
Модуль 76 обратного квантования производит обратное квантование, т.е., деквантование, квантованных коэффициентов преобразования, предоставленных в битовом потоке и декодированных модулем 70 энтропийного декодирования. Процесс обратного квантования может включать в себя традиционный процесс, например, аналогичный процессам, предлагаемым для HEVC или задаваемым стандартом декодирования H.264. Процесс обратного квантования может включать в себя использование параметра квантования QP, вычисляемого кодером 20 видео для CU, чтобы определить степень квантования и, точно так же, степень обратного квантования, которые должны быть применены. Модуль 76 обратного квантования может производить обратное квантование коэффициентов преобразования либо до, либо после того, как коэффициенты преобразованы из одномерного массива в двухмерный массив.
Модуль 74 внутреннего предсказания может генерировать данные предсказания для текущего блока текущего изображения на основании сигнализируемого режима внутреннего предсказания и данных из ранее декодированных блоков текущего изображения. Модуль 72 компенсации движения может извлекать вектор движения, направление предсказания движения и опорный индекс из закодированного битового потока. Направление опорного предсказания показывает, является ли режим внешнего предсказания однонаправленным (например, P-кадр) или двунаправленным (B-кадр). Опорный индекс показывает опорное изображение, на которое направлен вектор движения. На основании извлеченного направления предсказания движения, индекса опорного изображения и вектора движения, модуль компенсации движения получает блок с компенсацией движения для текущей части. Эти блоки с компенсацией движения используются для воссоздания предсказуемостного блока, используемого для получения остаточных данных.
Модуль 72 компенсации движения может получать блоки с компенсацией движения, возможно, выполняя интерполяцию на основе интерполирующих фильтров. Идентификаторы для интерполирующих фильтров, которые будут использоваться для оценки движения с точностью до неполного элемента изображения, могут быть включены в состав синтаксических элементов. Модуль 72 компенсации движения может использовать интерполирующие фильтры, которые используется кодером 20 видео во время кодирования видеоблока, чтобы вычислить интерполируемые значения для неполных целых элементов изображения опорного блока. Модуль 72 компенсации движения может определять интерполирующие фильтры, используемые кодером 20 информации, исходя из принимаемой синтаксической информации, и использовать интерполирующие фильтры для получения предсказуемостных блоков.
Модуль 72 компенсации движения может принимать данные предсказания, показывающие, где извлекать информацию движения для текущего блока. Например, модуль 72 компенсации движения может принимать информацию предсказания вектора движения, такую, как индекс MVP (mvp_flag), MVD, флаг слияния (merge_flag) и/или индекс слияния (merge_idx), и использовать такую информацию для идентификации информации движения, используемой для предсказания текущего блока.
Например, модуль 72 компенсации движения может генерировать список кандидатов для MVP или слияния. Затем модуль 72 компенсации движения может использовать индекс MVP или слияния для идентификации информации движения, используемой для предсказания вектора движения текущего блока. То есть, модуль 72 компенсации движения может идентифицировать MVP из списка опорных изображений, используя индекс MVP (mvp_flag). Модуль 72 компенсации движения может объединять идентифицированный MVP с принятой MVD, чтобы определить вектор движения для текущего блока. В других примерах, модуль 72 компенсации движения может идентифицировать кандидата для слияния из списка опорных изображений, используя индекс слияния (merge_idx), чтобы определить информацию движения для текущего блока. В любом случае, после определения информации движения для текущего блока, модуль 72 компенсации движения может сгенерировать предсказуемостный блок для текущего блока.
Дополнительно, модуль 72 компенсации движения и модуль 74 внутреннего предсказания, в примере для HEVC, могут использовать некоторую синтаксическую информацию (например, предоставленную деревом квадрантов), чтобы определить размеры LCU, используемых для кодирования изображения(й) закодированной видеопоследовательности. Модуль 72 компенсации движения и модуль 74 внутреннего предсказания также могут использовать синтаксическую информацию, чтобы определить информацию разбиения, которая описывает, как разбивается каждая CU изображения закодированной видеопоследовательности (а кроме того, как разбиваются неполные CU). Синтаксическая информация также может включать в себя режимы, показывающие, как кодируется каждое разбиение (например, с внутренним или внешним предсказанием, и для режима кодирования с внутренним предсказанием и внешним предсказанием), одно или более опорных изображений (и/или опорных списков, содержащих идентификаторы для опорных изображений) для каждой PU с внешним кодированием, и иную информацию, чтобы декодировать закодированную видеопоследовательность.
Суммирующее устройство 80 объединяет остаточные блоки с соответствующими блоками предсказания, сгенерированными модулем 72 компенсации движения или модулем 74 внутреннего предсказания, чтобы сформировать декодированные блоки. При необходимости, может также применяться антиблочный фильтр для фильтрации декодированных блоков, чтобы устранить артефакты блочности. Затем декодированные видеоблоки сохраняются в памяти 82 опорных изображений, которое обеспечивает опорные блоки для последующей компенсации движения, а также получает декодированное видео для представления на устройстве отображения (таком, как устройство 32 отображения на Фиг. 1).
Фиг. 4 является структурной схемой, иллюстрирующей типовой процесс арифметического кодирования. Типовой процесс арифметического кодирования, изображенный на Фиг. 4, в общем, описывается как выполняемый кодером 20 видео. Тем не менее, следует понимать, что методы, описываемые в отношении Фиг. 4, могут выполняться различными другими видеокодерами, в том числе декодером 30 видео. Например, как отмечалось выше в отношении Фиг. 3, декодер 30 видео может выполнять процесс декодирования, который является взаимообратным для процесса, выполняемого кодером 20 видео.
Пример на Фиг. 4 включает в себя устройство 100 бинаризации, средство 102 контекстного моделирования, механизм 104 кодирования, и обходной кодер 106. Устройство 100 бинаризации отвечает за бинаризацию принимаемого синтаксического элемента. Например, устройство 100 бинаризации может сопоставлять синтаксический элемент с несколькими так называемыми бинов, причем каждый бин представляет собой двоичное значение. В качестве примера для иллюстрации, устройство 100 бинаризации может сопоставлять синтаксический элемент с бинами, используя усеченный унарный (TU - truncated unary) код. В общем случае, кодирование унарным кодом может предусматривать генерирование строки бинов длины N+1, где первые N бинов равны 1, а последний бин равен 0. Кодирование усеченным унарным кодом может иметь на один меньше бинов, чем кодирование унарным кодом, за счет установления максимума для наибольшего возможного значения синтаксического элемента (cMax). Пример кодирования усеченным унарным кодом показан в Таблице 2 при cMax=10.
|
При выполнении на декодере 30 видео, декодер 30 видео может искать 0, чтобы определить, когда завершается синтаксический элемент, кодируемый в настоящее время. Как подробнее описано ниже, кодирование усеченным унарным кодом представляет собой лишь пример, и устройство 100 бинаризации может выполнять разнообразные другие процессы бинаризации (а также и комбинации процессов бинаризации), чтобы бинаризовать синтаксические элементы.
Средство 102 контекстного моделирования может отвечать за определение контекстной модели (также упоминаемой как вероятностная модель) для данного бина. Например, средство 102 контекстного моделирования может выбирать вероятностную модель, которая работает с контекстом для кодовых символов, связанных с блоком видеоданных. В общем случае, вероятностная модель хранит вероятность для каждого бина того, равен он "1" или "0".
Средство 102 контекстного моделирования может выбирать вероятностную модель из ряда имеющихся вероятностных моделей. В некоторых примерах, как подробнее описано ниже, контекст, используемый средством 102 контекстного моделирования, может определяться на основании номера бина, подлежащего кодированию. То есть, контекст может зависеть от позиции бина в строке бинов, сгенерированной устройством 100 бинаризации. В любом случае, на кодере 20 видео, целевой символ может кодироваться с использованием выбранной вероятностной модели. На кодере 20 видео, целевой символ может подвергаться синтаксическому анализу с использованием выбранной вероятностной модели.
Механизм 104 кодирования кодирует бин, используя определенную вероятностную модель (от средства 102 контекстного моделирования). После того, как механизм 104 кодирования закодировала бин, механизм 104 кодирования может обновить вероятностную модель, связанную с контекстом, используемым для кодирования бина. То есть, выбранная вероятностная модель обновляется на основании фактического кодированного значения (например, если значение бина было "1", счетчик частоты появления "1" увеличивается). Кодирование бинов с использованием средства 102 контекстного моделирования и механизма 104 кодирования может упоминаться как кодирование бинов с использованием режима контекстного кодирования.
Обходной кодер 106 кодирует бины с использованием фиксированной вероятности. В отличие от контекстного кодирования (посредством средства 102 контекстного моделирования и механизма 104 кодирования), обходной кодер 106 не обновляет процесс кодирования с обходом, основываясь на фактических значениях кодируемых бинов. Соответственно, в общем случае, обходной кодер 106 может кодировать с обходом бины быстрее, чем при контекстном кодировании. Кодирование бинов с использованием обходного кодера 106 может упоминаться как кодирование бинов с использованием режима кодирования с обходом. Примеры режимов кодирования с обходом включают в себя кодирование кодом Голомба, кодирование экспоненциальным кодом Голомба, кодирование кодом Голомба-Райса, или любой другой подходящий процесс кодирования, который обходит средство 102 контекстного моделирования и механизм 104 кодирования.
Кодированные бины (от механизма 104 кодирования и обходного кодера 106) объединяются, чтобы сформировать кодированный битовый поток. Чтобы декодировать закодированный битовый поток, декодер видео (такой, как декодер 30 видео) может выполнить процесс, зеркальный относительно показанного на Фиг. 4. То есть, декодер 30 видео может выполнять контекстное кодирование (с использованием средства 102 контекстного моделирования и механизма 104 кодирования) или кодирование с обходом (с использованием обходного кодера 106) на закодированном битовом потоке, чтобы сгенерировать декодированную строку бинов. Затем декодер 30 видео может бинаризовать строку бинов (с помощью устройства 100 бинаризации), чтобы сгенерировать синтаксические значения.
Процесс арифметического кодирования, показанный на Фиг. 3, может использоваться для кодирования видеоданных. Например, процесс кодирования, показанный на Фиг. 3, может использоваться для кодирования данных предсказания, в том числе значений опорных индексов, векторов движения, предикторов векторов движения, значений разностей векторов движения, и тому подобного.
В иллюстративном примере, устройство 100 бинаризации может бинаризовать опорный индекс (ref_idx). В некоторых примерах, полученная в результате строка бинов для опорного индекса может быть до 15 бинов в длину, в зависимости от количества опорных изображений, которые доступны в качестве образцов. Как отмечалось выше, в некоторых примерах, все бины значения опорного индекса могут контекстно кодироваться с использованием средства 102 контекстного моделирования и механизма 104 кодирования. Более того, один или более из бинов могут совместно использовать контекст. Тем не менее, контекстное кодирование всех бинов и совместное использование контекста более чем одним бином может быть неэффективно, вследствие запаздываний, связанных с контекстным кодированием.
В соответствии с аспектами настоящего раскрытия изобретения, как показано на Фиг. 4, кодер 20 видео может кодировать строку бинов для опорного индекса, основываясь на номере бина для бина, подлежащего кодированию. Например, кодер 20 видео может кодировать конкретный бин в строке бинов для опорного индекса в соответствии с относительной позицией конкретного бина в строке бинов. В одном из примеров, кодер 20 видео может контекстно кодировать первый, второй бин, и третий бин опорного индекса, и может кодировать с обходом остальные бины опорного индекса. То есть, кодер 20 видео может кодировать первый бин (bin0) с использованием средства 102 контекстного моделирования и механизма 104 кодирования с первым контекстом ctx0, второй бин (bin1) с использованием средства 102 контекстного моделирования и механизма 104 кодирования со вторым контекстом ctx1, и третий бин (bin2) с использованием средства 102 контекстного моделирования и механизма 104 кодирования с третьим контекстом ctx2. Однако, кодер 20 видео может кодировать четвертый бин (bin3) и любые другие следующие бины, используя обходной кодер 106.
В другом примере, кодер 20 видео может снизить количество бинов, которые контекстно кодируются. Например, кодер 20 видео может кодировать первый бин (bin0) с использованием средства 102 контекстного моделирования и механизма 104 кодирования с первым контекстом ctx0, и второй бин (bin1) с использованием средства 102 контекстного моделирования и механизма 104 кодирования со вторым контекстом ctx1. В этом примере, однако, кодер 20 видео может кодировать с обходом третий бин (bin2) и любые другие следующие бины, используя обходной кодер 106.
В еще одном примере, кодер 20 видео может дополнительно снизить количество бинов, которые контекстно кодируются. Например, кодер 20 видео может кодировать первый бин (bin0) с использованием средства 102 контекстного моделирования и механизма 104 кодирования с первым контекстом ctx0. Однако, кодер 20 видео может кодировать второй бин (bin1) и любые другие следующие бины, используя обходной кодер 106.
Аспекты настоящего раскрытия изобретения также имеют отношение к тому, как устройство 100 бинаризации выполняет бинаризацию для видеоданных. Например, в соответствии с аспектами настоящего раскрытия изобретения, устройство 100 бинаризации может разделить синтаксический элемент более, чем на одну части. То есть, устройство 100 бинаризации может использовать кодирование усеченным унарным кодом, чтобы кодировать префикс (при относительно небольшом cMax, что описано выше), и может использовать другой способ кодирования, чтобы кодировать суффикс. В одном из примеров, устройство 100 бинаризации может использовать экспоненциальный код Голомба k-го порядка, чтобы кодировать суффикс.
В некоторых примерах, могут контекстно кодироваться только бины префикса, тогда как бины суффикса могут кодироваться с обходом. Таблица 3 показывает пример усеченного унарного кода, скомбинированного с экспоненциальным кодом Голомба, при cMax=4 для префикса, и экспоненциальный код Голомба 0-го порядка для суффикса. Эти методы также могут применяться для значений опорных индексов, а также и других синтаксических элементов, в том числе значений разностей векторов движения или других синтаксических элементов, используемых при кодировании с помощью усовершенствованное предсказание вектора движения (AMVP - advanced motion vector prediction).
|
В примере, показанном в Таблице 3, бины с усеченным унарным кодом могут контекстно кодироваться, тогда как бины с экспоненциальным кодом Голомба могут кодироваться с обходом.
Методы согласно настоящему раскрытию изобретения могут включать в себя, например, применение контекстного кодирования к бинам после некоторого количества бинов для бинаризации экспоненциальным кодом Голомба в префиксной части. Методы согласно настоящему раскрытию изобретения также включают в себя, например, применение кодирования на основе контекста к некоторому числу бинов (например, предварительно заданному числу бинов префикса) и применение кодирования с обходом к остальным бинам. Например, вместо того, чтобы кодировать все бины в префиксной части, используя контекст, bin2 и последующие бины в префиксной части могут кодироваться в режиме с обходом. В другом примере, режим с обходом может применяться ко всем бинам после и/или включая bin1. В еще одном примере, режим с обходом может применяться ко всем бинам префиксной части. Аналогичный подход, с использованием кодирования в режиме с обходом после некоторого числа контекстно кодируемых бинов, может использоваться для любого способа бинаризации. То есть, хотя настоящее раскрытие изобретения и описывает использование схем кодирования экспоненциальным кодом Голомба и кодирования усеченным унарным кодом, могут использоваться и другие способы бинаризации.
Еще в одном примере, выше приведенные методы согласно настоящему раскрытию изобретения могут быть реализованы вместе с другими процессами бинаризации, в том числе с комбинациями процессов бинаризации. То есть, в одном примере, процесс кодирования унарным кодом может использоваться для бинаризации значения опорного индекса. В другом примере, процесс кодирования усеченным унарным кодом может использоваться для бинаризации значения опорного индекса. Еще в одном примере, процесс кодирования экспоненциальным кодом Голомба может использоваться для бинаризации значения опорного индекса. Другие процессы бинаризации и комбинации процессов бинаризации также возможны. То есть, например, процесс кодирования унарным кодом (или усеченным унарным кодом) может комбинироваться с процессом кодирования экспоненциальным кодом Голомба для бинаризации значения опорного индекса. В одном из иллюстративных примеров, усеченный унарный код длины (4) может комбинироваться с экспоненциальным кодом Голомба (например, экспоненциальным кодом Голомба 0-го порядка). В таком примере, первое количество бинов (например, два, три, четыре, или тому подобное) значения опорного индекса могут кодироваться с унарным кодом, тогда как остальные бины опорного индекса могут кодироваться с экспоненциальным кодом Голомба.
В любом случае, методы, изложенные выше в отношении CABAC-кодирования и кодирования с обходом значения опорного индекса, могут быть применены к любому бинаризованному значению опорного индекса. То есть, в соответствии с аспектами настоящего раскрытия изобретения, первое количество бинов бинаризованного значения опорного индекса может контекстно кодироваться (например, кодироваться с помощью механизма CABAC), тогда как остальные бины могут кодироваться с обходом. В описанном выше примере, в котором усеченный унарный код длины (4) комбинируется с экспоненциальным кодом Голомба 0-го порядка, первые два бина (или любое другое количество бинов) усеченного унарного кода могут контекстно кодироваться, а вторая часть унарного кода и весь экспоненциальный код Голомба может кодироваться с обходом.
Следует понимать, что усеченный унарный код длины (4) и экспоненциальный код Голомба 0-го порядка предоставлены лишь для примера, и те же или аналогичные методы могут применяться для усеченного унарного кода другой длины, как и для экспоненциального кода Голомба другого порядка. Более того, описанные выше процессы бинаризации предоставлены лишь для примера, и могут использоваться другие бинаризующие коды. Например, двоичный код фиксированной длины может использоваться вместо экспоненциального кода Голомба, описанного в приведенных выше примерах. Помимо этого, пример двух контекстно кодируемых бинов для части бинаризации усеченным унарным кодом предоставлен для иллюстрации, и может использоваться другое количество контекстно кодируемых и кодируемых с обходом бинов.
В любом случае, аспекты настоящего раскрытия изобретения также имеют отношение к усечению части бинаризованного значения. Например, поскольку количество опорных индексов известно заранее, в соответствии с аспектами настоящего раскрытия изобретения, экспоненциальный код Голомба или код фиксированной длины может быть усечен. То есть, экспоненциальный код Голомба k-го порядка может использоваться устройством 100 бинаризации. В качестве примера, экспоненциальный код Голомба 0-го порядка может применяться при сжатии видео. Эта бинаризация состоит из экспоненциального префикса, кодируемого унарным кодом, и суффикса фиксированной длины длиной (prefix-1), пример чего показан в Таблице 4 ниже:
|
К примеру, значение 10 (например, которое соответствует элементу со значением 10 в первом столбце Таблицы 4), представляется бинаризованным кодовым словом 0001011, где 0001 является префиксом, а 011 является суффиксом. Элемент может быть входными данными, который кодируются с использованием кодовых слов из Таблицы 4 или с использованием таблиц, показанных и описанных ниже. Например, кодер 20 видео может принимать элементы и преобразовывать элементы в кодовые слова в соответствии с таблицами, показанными и описанными ниже. Точно так же, декодер 30 видео может принимать кодовые слова и преобразовывать кодовые слова в синтаксические элементы (например, входные данные) в соответствии с таблицами, показанными и описанными ниже.
Восстановленное значение может быть получено в соответствии с уравнение (1), показанным ниже:
value=2^(prefix-1)+suffix-1 (1)
В этом примере, префикс представлен унарным кодом, где 0001 соответствует 4, а суффикс является значением, представленным в двоичной системе счисления, где 011 соответствует 3, как показано в вышеприведенной Таблице 4. Соответственно, в этом примере, применение уравнения (1) дает в результате следующие значения: 2^(4-1)+3-1=10.
Этот код вообще может представлять бесконечные числа; однако, в некоторых сценариях, число элементов может быть известно. В этом случае, кодовое слово может быть сокращено, с учетом максимального числа возможных элементов.
Например, если максимальное число элементов равно двум (например, элементы 0 и 1), нормальным кодовым словом экспоненциального кода Голомба для 1 является 010. Однако не существует элемента больше, чем два. Соответственно, нормальный код 010 может быть сокращен до 1. Этот тип бинаризации может упоминаться как усеченный экспоненциальный код Голомба, и может использоваться в таких стандартах кодирования видео, как H.264/AVC. Однако, касательно стандарта H.264, усеченный экспоненциальный код Голомба используется только когда максимальное число элементов равно 1. Для других случаев, используется нормальная бинаризация экспоненциальным кодом Голомба.
В соответствии с аспектами настоящего раскрытия изобретения, нормальное кодирование экспоненциальным кодом Голомба может быть дополнительно усечено, например, как в приведенном выше примере, в котором максимальное число элементов равно 1. Вообще, если максимальное число элементов известно заранее, суффикс кодового слова бинаризации экспоненциальным кодом Голомба может быть усечен посредством удаления избыточных бинов. Например, если максимальное число элементов равно 9, то два бина, отмеченных полужирным курсивом и подчеркиванием в показанной ниже Таблице 5, могут быть удалены из кодовых слов.
|
То есть, для элемента 7, показанного в Таблице 5, первые два 00 суффикса могут быть удалены. Помимо этого, для элемента 8, показанного в Таблице 5, первые два 00 суффикса могут быть удалены. Соответственно, усеченный экспоненциальный код Голомба 0-го порядка показывает 0001 0 для элемента 7 и 00001 1 для элемента 8.
Описанные выше методы могут быть реализованы, например, путем сравнения суффикса фиксированной длины для последнего префикса (0001 в приведенном выше примере) с нормальным экспоненциальным кодом Голомба. Например, если число элементов в последней группе меньше, чем в нормальном экспоненциальном коде Голомба, избыточные бины могут быть удалены. Другими словами, устройство 100 бинаризации может генерировать результирующий усеченный экспоненциальный код Голомба 0-го порядка, сравнивая суффикс фиксированной длины для последнего префикса, и если число элементов в этой последней группе меньше, чем в нормальном экспоненциальном коде Голомба, избыточные бины могут быть удалены.
Например, в этом примере, устройство 100 бинаризации может определить число элементов, префикс которых такой же, как префикс последнего элемента, когда есть максимальное число элементов для кодирования, которое известно заранее. Например, в Таблице 5, префикс для последнего элемента 0001, и есть два элемента (например, элемент 7 и элемент 8), чей префикс такой же, как префикс последнего элемента, когда есть максимальное число элементов (например, 9 в этом примере).
Тогда устройство бинаризации может сравнить число элементов, префикс которых такой же, как префикс последнего элемента, с числом элементов в нормальном экспоненциальном коде Голомба с таким же префиксом. Например, в приведенной выше Таблице 4, есть восемь элементов (т.е., элементы от 7 до 14), чей префикс 0001 (т.е., такой же, как префикс предыдущего элемента). В этом примере, устройство 100 бинаризации может определить, что число элементов, префикс которых такой же, как префикс последнего элемента, меньше, чем число элементов в нормальном экспоненциальном коде Голомба с таким же префиксом.
Если это так, устройство 100 бинаризации может усекать бины из кодовых слов, префикс которых такой же, как последний префикс, чтобы генерировать усеченные кодовые слова. В некоторых примерах, бины усекаются из суффикса; однако, аспекты настоящего раскрытия изобретения этим не ограничиваются. Устройство 100 бинаризации может определять количество бинов для усечения, основываясь на количестве элементов, префикс которых такой же, как последний префикс.
Например, в приведенной выше Таблице 5, есть два элемента с таким же префиксом, как последний префикс (например, элементы 7 и 8). Устройство 100 бинаризации может усекать бины из кодовых слов элементов 7 и 8, чтобы генерировать усеченные кодовые слова, что проиллюстрировано в последнем столбце Таблицы 5. В этом примере, поскольку есть два элемента с таким же префиксом, как последний префикс, устройство 100 бинаризации может определить, что только один бин необходим в суффиксе для представления этих двух элементов. Например, 0 в суффиксе может представлять один элемент (например, элемент 7), а 1 в суффиксе может представлять другой элемент (например, элемент 8). Соответственно, для элемента 7 в приведенной выше Таблице 5, устройство 100 бинаризации может усекать первые два бина суффикса, оставляя только 0 в качестве суффикса для усеченного кодового слова. Кроме того, для элемента 8 в приведенной выше Таблице 5, устройство 100 бинаризации может усекать первые два бина суффикса, оставляя только 1 в качестве суффикса для усеченного кодового слова.
Описанные выше методы могут быть реализованы для кодирования аудиовизуальной информации (например, кодирования и/или декодирования видеоданных). Например, в соответствии с аспектами настоящего раскрытия изобретения, видео декодер видео, такой, как декодер 30 видео, может принимать одно или более кодовых слов, характеризующие аудиовизуальные данные, и может быть максимальное число элементов, которые могут использоваться для кодирования. Декодер 30 видео может переводить кодовые слова в элементы в соответствии с таблицей кодирования. Таблица кодирования может быть построена таким образом, что по меньшей мере некоторые из кодовых слов, имеющих одинаковый префикс, усекаются, если этот же префикс является последним префиксом в таблице кодирования, и количество кодовых слов, имеющих одинаковый префикс, меньше, чем максимальное число уникальных кодовых слов, которые могли бы иметь такой же префикс. Например, для префикса 0001, Таблица 4 иллюстрирует уникальные возможности для кодовых слов, а Таблицы 5 и 6 (продемонстрированы ниже) демонстрируют примеры кодовых слов, которые совместно используют один и тот же префикс и усекаются в соответствии с методами настоящего раскрытия изобретения.
Методы также могут быть выполнены кодером 20 видео. Например, кодер 20 видео может принимать один или более элементов, характеризующих аудиовизуальные данные. Кодер 20 видео может переводить элементы в одно или более кодовых слов в соответствии с таблицей кодирования, и может быть максимальное число элементов, которые могут использоваться для кодирования. Таблица кодирования может быть построена таким образом, что по меньшей мере некоторые из кодовых слов, имеющих одинаковый префикс, усекаются, если этот же префикс является последним префиксом в таблице кодирования, и количество кодовых слов, имеющих одинаковый префикс, меньше, чем максимальное число уникальных кодовых слов, которые могли бы иметь такой же префикс. Опять же, например, для префикса 0001, Таблица 4 иллюстрирует уникальные возможности для кодовых слов, а Таблицы 5 и 6 (продемонстрированы ниже) демонстрируют примеры кодовых слов, которые совместно используют один и тот же префикс и усекаются в соответствии с методами настоящего раскрытия изобретения.
Таким образом, методы могут уменьшить количество бинов, необходимых для кодирования видеоданных, когда известно максимальное число кодируемых элементов. Уменьшение бинов приводит к меньшему количеству битов, которые необходимо сигнализировать или принять, что дает эффективность использования полосы пропускания.
В качестве еще одного примера, при максимальном числе элементов, равном 11, в приведенной ниже Таблице 6 продемонстрированы кодовые слова для усеченного экспоненциального кода Голомба. Бины, отмеченные полужирным курсивом и подчеркиванием в Таблице 6, могут быть удалены из кодовых слов.
|
Как показано в Таблице 6, первые бины в суффиксе для элементов 7, 8, 9 и 10 могут быть усечены (обозначены полужирным курсивом и подчеркиванием). В этом примере, только один бин из суффикса может быть усечен, потому что четыре элемента представлены кодовым словом. По этой причине, в усеченных кодовых словах, суффикс начинается с 00 и заканчивается на 11, чтобы охватить четыре элемента, каждый из которых имеет один и тот же префикс.
Примеры, продемонстрированные в приведенных выше Таблицах 5 и 6, предоставлены лишь в качестве примеров, и такой же процесс может быть применен для любого количества максимальных элементов. Так, в некоторых примерах, аспекты настоящего раскрытия изобретения имеют отношение к приему усеченных кодовых слов. Усеченные кодовые слова могут быть сгенерированы путем определения первого количества элементов. Первое количество элементов может показывать, сколько кодовых слов в первой таблице кодирования имеет префикс, который является таким же, как префикс кодового слова, которое соответствует последнему элементу в первой таблице кодирования, когда есть максимальное число элементов, которые могут использоваться для кодирования. В этом примере, первой таблицей кодирования может быть Таблица 5 или Таблица 6. Аспекты имеют отношение к приему усеченных кодовых слов, которые предварительно отсортированы или вычисляются на ходу во время работы.
Аспекты настоящего раскрытия изобретения также имеют отношение к определению второго количества элементов, которое показывает, сколько кодовых слов во второй таблице кодирования имеет префикс, который является таким же, как префикс кодовых слов, которые соответствуют последнему элементу в первой таблице кодирования. В этом примере, второй кодирующим таблицей кодирования может быть приведенная выше Таблица 4. В некоторых примерах, первая таблица кодирования может быть подмножеством второй таблицы кодирования, что основано на максимальном числе элементов, которые могут использоваться для кодирования.
В некоторых примерах, если первое количество элементов меньше, чем второе количество элементов, аспекты настоящего раскрытия изобретения имеют отношение к усечению бинов из кодовых слов в первой таблице кодирования, префикс которых такие же, как префикс кодового слова, которое соответствует последнему элементу в первой таблице кодирования, чтобы генерировать усеченные кодовые слова, и кодированию видеоданных с использованием усеченных кодовых слов. В некоторых примерах, усечение кодовых слов включает в себя усечение бинов из суффиксов или префиксов кодовых слов, или сочетание этого. В некоторых примерах, усечение бинов основывается на первом количестве элементов, причем первое количество элементов показывает, сколько кодовых слов в первой таблице кодирования имеет префикс, который является таким же, как префикс кодового слова, которое соответствует последнему элементу в первой таблице кодирования. В некоторых примерах, кодирование является кодированием кодом Голомба.
В качестве альтернативы или дополнительно, префикс тоже может быть усечен с использованием усеченного унарного кода. Например, если максимальное число элементов равно 4, то префикс и суффикс могут быть усечены, как показано в Таблице 7 ниже.
|
Усеченные бины в Таблице 7 представлены полужирным курсивом и подчеркиванием. В примере, продемонстрированном в Таблице 7, кодовое слово для элемента 3 короче, чем кодовые слова для элементов 1 или 2. Дополнительное переупорядочение или сопоставление для бинаризации усеченным экспоненциальным кодом Голомба может быть применено, например, путем назначения более короткого кодового слова 00 чаще встречающемуся элементу 1, а 010 элементу 3. Такое переупорядочение или сопоставление может быть выполнено с использованием таблиц сопоставления.
В некоторых примерах, переупорядочение также может базироваться на частоте появления конкретных элементов. Например, более короткие ключевые слова могут назначаться наиболее часто встречающимся элементам. Это сопоставление кодовых слов может быть особенно эффективным в тех случаях, когда элементы упорядочены по частоте появления.
В то время как определенные приведенные выше примеры были описаны в отношении кодирования экспоненциальным кодом Голомба 0-го порядка, следует понимать, что в более общем смысле методы применимы к кодированию экспоненциальным кодом Голомба k-го порядка. Более того, методы не ограничиваются видеостандартом HEVC, а могут применяться к любому стандарту сжатия видео, или, в более широком смысле, для любого приложения, в котором выполняется бинаризация.
Что касается нового стандарта HEVC (а также расширений к стандарту HEVC, таких, как масштабируемое кодирование видео (SVC - scalable video coding) или многовидовое кодирование видео (MVC - multi-view video coding)), описанные выше методы бинаризации усеченным экспоненциальным кодом Голомба могут применяться к бинаризации разнообразных синтаксических элементов. Примеры включают в себя значения опорных индексов, внутренний режим, индекс слияния, параметры квантования (или дельта параметров квантования), или любой другой синтаксический элемент, для которых заранее известно количество элементов.
В то время как приведенный выше пример описывает усечение экспоненциального кода Голомба, описываемые методы усечения также могут применяться к коду фиксированной длины. То есть, в примерах, в которых синтаксический элемент (например, опорный индекс) бинаризуется с использованием более, чем одного процесса бинаризации (например, усеченным унарным кодом и экспоненциальным кодом Голомба), предварительно заданное число бинов может кодироваться с помощью CABAC, тогда как остальные бины могут быть усечены и кодироваться с обходом.
В некоторых примерах, может применяться алгоритм для определения количества бинов, которые могут быть усечены (например, усечены из части бинаризации синтаксического элемента с помощью экспоненциального кода Голомба или кода фиксированной длины). В одном из примеров, предположим, что предварительно заданное количество бинов остается для кодирования с обходом. В этом примере, видеокодер (такой, как кодер 20 видео или декодер 30 видео) может определять количество оставшихся бинов, которые могут быть усечены, вычисляя округленный в большую сторону log2 для оставшихся бинов.
Фиг. 5A и 5B являются структурными схемами, иллюстрирующими типовые строки бинов, связанные с данными предсказания. Например, Фиг. 5A в общих чертах иллюстрирует опорный индекс (ref_idx), разность (mvd) векторов движения, и индекс (mvp_idx) предиктора вектора движения для изображения, которое предсказывается, исходя из одного опорного изображения.
Фиг. 5B в общих чертах иллюстрирует первый опорный индекс (ref_idx_L0), первую разность (mvd_L0) векторов движения (представляющую горизонтальную составляющую и вертикальную составляющую) и первый индекс (mvp_idx_L0) предиктора вектора движения, а также второй опорный индекс (ref_idx_L1), разность (mvd_L1) векторов движения (представляющую горизонтальную составляющую и вертикальную составляющую) и второй индекс (mvp_idx_L1) предиктора вектора движения для изображения, которое предсказывается, исходя из двух опорных изображений (B-изображение). То есть, для PU с двойным предсказанием, могут кодироваться два опорных индекса, с одним опорным индексом для каждого списка из списков L0 и L1. Соответственно, до двух опорных индексов может кодироваться для каждой PU, и до восьми индексов может кодироваться для каждой CU.
Строки 120 (Фиг. 5A) и 124 (Фиг. 5B) бинов включают в себя данные предсказания, связанные с методом усовершенствованного предсказания вектора движения (AMVP). При AMVP, вектор движения для кодируемого в данный момент блока может кодироваться как разностное значение (т.е., дельта) относительно другого вектора движения, такого, как вектор движения, связанный с соседним в пространстве или времени блоком. Например, кодер 20 видео может формировать список кандидатов-предикторов вектора движения, который включает в себя векторы движения, связанные с одним или более соседними блоками в пространственном и временном направлениях. Кодер 20 видео может выбрать наиболее точный предиктор (MVP) вектора движения из списка кандидатов на основании, например, анализа затрат в зависимости от скорости и искажения.
Кодер 20 видео может обозначить опорное изображение для действительного вектора движения, используя опорный индекс (ref_idx). Помимо этого, кодер 20 видео может обозначить выбранный MVP, используя индекс (mvp_idx) предиктора вектора движения, который идентифицирует MVP в списке кандидатов. Кодер 20 видео также может обозначить разность между вектором движения текущего блока (действительным вектором движения) и MVP, используя разность (mvd) векторов движения. Как отмечалось выше, mvd может включать в себя горизонтальную составляющую и вертикальную составляющую, соответствующую горизонтальной составляющей и вертикальной составляющей mvp.
Декодер 30 видео таким же образом может формировать список кандидатов для MVP. Затем декодер 30 видео может использовать принятый индекс (mvp_idx) предиктора вектора движения, чтобы определить, где найти MVP в списке кандидатов. Декодер 30 видео может объединить разность (mvd) векторов движения с предиктором вектора движения (определенным с использованием индекса (mvp_idx) предиктора вектора движения), чтобы восстанавливать вектор движения.
Предсказание векторов движения таким образом (например, с помощью разностного значения) может потребовать меньшего количества битов, которые будут включены в битовый поток по сравнению с кодированием действительного вектора(ов) движения. Что касается Фиг. 5B, изображения с двойным предсказанием могут включать в себя данные предсказания, связанные с изображениями из двух разных списков, например, списка 0 и списка 1. Как показано в примере на Фиг. 5B, данные предсказания, связанные со списком 0, могут предшествовать данным предсказания, которые связаны со списком 1. То есть, строка 124 бинов включает в себя первый опорный индекс (ref_idx_L0), первую разность (mvd_L0) векторов движения (например, представляющую и горизонтальную и вертикальную составляющие) и первый индекс (mvp_idx_L0) предиктора вектора движения, за которыми следуют второй опорный индекс (ref_idx_L1), вторая разность (mvd_L1) векторов движения (например, представляющая и горизонтальную и вертикальную составляющие) и второй индекс (mvp_idx_L1) предиктора вектора движения.
В некоторых примерах, синтаксическая структура, связанная с AMVP, может кодироваться с использованием сочетания контекстного кодирования и кодирования с обходом. Например, как показано в примерах на Фиг. 5A и 5B, некоторые из бинов данных предсказания контекстно кодируются, в то время как другие бины кодируются с обходом. То есть, один или более бинов значений разностей векторов движения (а также и другие значения, такие, как значения опорных индексов, что описано ниже со ссылкой на Фиг. 7) могут контекстно кодироваться, в то время как один или более других бинов значений разностей векторов движения могут кодироваться с обходом.
Что касается примера на Фиг. 5A, опорный индекс (ref_idx) и первая часть разности (mvd) векторов движения может быть контекстно кодируемой, о чем свидетельствуют контекстно кодируемые бины 128. Вторая часть разности (mvd) векторов движения может быть кодируемой с обходом, о чем свидетельствуют кодируемые с обходом бины 130. Помимо этого, индекс (mpv_idx) предиктора вектора движения может быть контекстно кодируемым, о чем свидетельствуют контекстно кодируемые бины 132.
Что касается примера на Фиг. 5B, первый опорный индекс (ref_idx_L0) и первая часть первой разности (mvd_L0) векторов движения (например, представляющей и горизонтальную и вертикальную составляющие) могут быть контекстно кодируемыми, о чем свидетельствуют контекстно кодируемые бины 136. Вторая часть первой разности (mvd_L0) векторов движения (например, представляющей и горизонтальную и вертикальную составляющие) может быть кодируемой с обходом, о чем свидетельствуют кодируемые с обходом бины 138. Помимо этого, первый индекс (mpv_idx_L0) предиктора вектора движения, второй опорный индекс (ref_idx_L1) и первая часть второй разности (mvd_L1) векторов движения (например, представляющей и горизонтальную и вертикальную составляющие) могут быть контекстно кодируемыми, о чем свидетельствуют контекстно кодируемые бины 140. Вторая часть второй разности (mvd_L1) векторов движения (например, представляющей и горизонтальную и вертикальную составляющие) тоже может быть кодируемой с обходом, о чем свидетельствуют кодируемые с обходом бины 142. Наконец, второй индекс (mpv_idx_L1) предиктора вектора движения может быть контекстно кодируемым, о чем свидетельствуют контекстно кодируемые бины 144.
Соответственно, пример на Фиг. 5B иллюстрирует синтаксическую структуру на основе PU с внутренним режимом для двойного предсказания, для которого видеокодеру, возможно, придется переключаться четыре раза между контекстным кодированием и кодированием с обходом, чтобы обработать бины. Переключение между контекстным кодированием и кодированием с обходом для кодирования строк 120 и 124 бинов может быть неэффективным. Например, переключение между контекстным кодированием и кодированием с обходом может затрачивать один или более тактовых циклов. Соответственно, переключение между контекстным кодированием и кодированием с обходом для каждого элемента может привнести запаздывание, вследствие переходов между контекстным кодированием и кодированием с обходом.
В соответствии с аспектами настоящего раскрытия изобретения, как подробнее описано ниже в отношении Фиг. 6 и 7, контекстные бины и обходные бины могут быть сгруппированы, чтобы уменьшить переходы между контекстным кодированием и кодированием с обходом. Например, в отношении Фиг. 5A, аспекты настоящего раскрытия изобретения имеют отношение к группированию контекстно кодируемых бинов 128 и 132 вместе так, чтобы эти бины не разделялись кодируемыми с обходом бинами 130. Таким образом, может быть сделан единственный переход между контекстным кодированием и кодированием с обходом в ходе кодирования строки 120 бинов.
Точно так же, в отношении Фиг. 5B, аспекты настоящего раскрытия изобретения имеют отношение к группированию контекстно кодируемых бинов 136, 140 и 144 так, чтобы эти бины не разделялись кодируемыми с обходом бинами 138 и 142. Опять же, группирование контекстно кодируемых бинов и кодируемых с обходом бинов таким образом может позволить видеокодеру (такому, как кодер 20 видео или декодер 30 видео) делать единственное переход между контекстным кодированием и кодированием с обходом. Устранение множественных переходов между контекстным кодированием и кодированием с обходом может повысить эффективность за счет ограничения запаздывания, связанного с переходами.
Фиг. 6 является структурной схемой, иллюстрирующей другую типовую строку 140 бинов данных предсказания. Строка 140 бинов включает в себя первый опорный индекс (ref_idx_L0), первую разность (mvd_L0) векторов движения (например, представляющую и горизонтальную и вертикальную составляющие) и первый индекс (mvp_idx_L0) предиктора вектора движения, за которыми следуют второй опорный индекс (ref_idx_L1), вторая разность (mvd_L1) векторов движения (например, представляющая и горизонтальную и вертикальную составляющие) и второй индекс (mvp_idx_L1) предиктора вектора движения. Строка 140 бинов включает в себя контекстно кодируемые бины 144 и кодируемые с обходом бины 148. Например, контекстно кодируемые бины 144 могут кодироваться с использованием режима контекстного кодирования процесса контекстно-адаптивного кодирования (например, CABAC), в то время как кодируемые с обходом бины 148 могут кодироваться с использованием фиксированной вероятности (например, режим кодирования с обходом CABAC).
В соответствии с аспектами настоящего раскрытия изобретения, контекстно кодируемые бины 144 группируются для кодирования до кодируемых с обходом бинов 148. То есть, в примере, показанном на Фиг. 6, контекстно кодируемые бины 144 включают в себя контекстно кодируемые бины первого опорного индекса (ref_idx_L0), контекстно кодируемые бины второго опорного индекса (ref_idx_L1), контекстно кодируемые бины первого индекса (mvp_idx_L0) предиктора вектора движения, контекстно кодируемые бины второго индекса (mvp_idx_L1) предиктора вектора движения, контекстно кодируемые бины первой разности (mvd_L0) векторов движения и контекстно кодируемые бины второй разности (mvd_L1) векторов движения. Помимо этого, кодируемые с обходом бины 148 включают в себя кодируемые с обходом бины первой разности (mvd_L0) векторов движения и кодируемые с обходом бины второй разности (mvd_L1) векторов движения.
В некоторых примерах, бины могут быть сгруппированы на основании номеров бинов синтаксических элементов, подлежащих кодированию. В одном из иллюстративных примеров, видеокодер (такой, как кодер 20 видео или декодер 30 видео) может кодировать первые два бина значений разностей векторов движения, используя контекстное кодирование, и кодировать остальные бины, используя кодирование с обходом. Соответственно, в этом примере, контекстно кодируемые бины 144 могут включать в себя первые два бина и первой разности (mvd_L0) векторов движения и значения (mvd_L1) второй разности векторов движения, в то время как кодируемые с обходом бины 148 могут включать в себя остальные бины значений разностей векторов движения.
Упорядочение синтаксических элементов, показанное на Фиг. 6, предоставлено лишь для примера. В других примерах, синтаксические элементы могут быть упорядочены по-другому, например, по значениям опорных индексов, предикторам вектора движения, и значениям разностей векторов движения в альтернативном порядке (или с чередованием). То есть, в другом примере, видеокодер может кодировать PU следующим образом: контекстно кодируемые бины опорного индекса L0, контекстно кодируемые бины опорного индекса L1, кодируемые в режиме с обходом бины опорного индекса L0, кодируемые в режиме с обходом бины опорного индекса L1. В дополнительных примерах, обходные бины 148 могут кодироваться до контекстно кодируемых бинов 144.
В любом случае, Фиг. 6 демонстрирует данные предсказания, имеющие группу из одного или более контекстно кодируемых бинов 144 и группу из одного или более кодируемых с обходом бинов 148. Группирование контекстно кодируемых бинов и кодируемых с обходом бинов таким образом, как отмечалось выше, может уменьшить запаздывание, связанное с кодированием бинов. Например, видеокодер может кодировать все контекстно кодируемые бины 144, сделать единственный переход от контекстного кодирования к кодированию с обходом, и кодировать все кодируемые с обходом бины. Устранение множественных переходов между контекстным кодированием и кодированием с обходом может повысить эффективность за счет ограничения запаздывания, связанного с переходами между контекстным кодированием и кодированием с обходом.
В некоторых примерах, как показано на Фиг. 6, контекстно кодируемые бины и кодируемые с обходом бины могут быть сгруппированы для блока видеоданных (например, по каждой PU). В других примерах, контекстно кодируемые бины и кодируемые с обходом бины могут быть сгруппированы для CU (например, одной или более CU из LCU), для полной LCU, или для полного слайса видеоданных. В таких примерах, контекстно кодируемые бины могут группироваться и кодироваться для CU/LCU/слайса до кодируемых с обходом бинов из CU/LCU/слайса, или наоборот.
Фиг. 7 является структурной схемой, иллюстрирующей другую типовую строку 160 бинов данных предсказания. В примере на Фиг. 7, строка 160 бинов включает в себя первый опорный индекс (ref_idx_L0), первую разность (mvd_L0) векторов движения (например, представляющую и горизонтальную и вертикальную составляющие) и первый индекс (mvp_idx_L0) предиктора вектора движения, за которыми следуют второй опорный индекс (ref_idx_L1), вторая разность (mvd_L1) векторов движения (например, представляющая и горизонтальную и вертикальную составляющие) и второй индекс (mvp_idx_L1) предиктора вектора движения. Строка 160 бинов включает в себя контекстно кодируемые бины 164 и кодируемые с обходом бины 168. Например, контекстно кодируемые бины 164 могут кодироваться с использованием режима контекстного кодирования процесса контекстно-адаптивного кодирования (например, CABAC), в то время как кодируемые с обходом бины 168 могут кодироваться с использованием фиксированной вероятности (например, режим кодирования с обходом CABAC).
В соответствии с аспектами настоящего раскрытия изобретения, аналогично примеру, показанному на Фиг. 6, контекстно кодируемые бины 164 группируются для кодирования до обходных бинов 168. Однако в примере, показанном на Фиг. 7, опорные индексы (ref_idx_L0 и ref_idx_L1) включают в себя сочетание контекстно кодируемых бинов наряду с кодируемыми с обходом бинами. То есть, опорные индексы могут кодироваться в соответствии с примерами, описанными выше в отношении Фиг. 4, с одним или более бинами, кодируемыми с использованием контекстно-адаптивного режима, и одним или более другими бинами, кодируемыми с использованием режима с обходом.
Соответственно, в примере на Фиг. 7, контекстно кодируемые бины 164 включают в себя контекстно кодируемые бины первого опорного индекса (ref_idx_L0), контекстно кодируемые бины второго опорного индекса (ref_idx_L1), контекстно кодируемые бины первого индекса (mvp_idx_L0) предиктора вектора движения, контекстно кодируемые бины второго индекса (mvp_idx_L1) предиктора вектора движения, контекстно кодируемые бины первой разности (mvd_L0) векторов движения (например, представляющей и горизонтальную и вертикальную составляющие) и контекстно кодируемые бины второй разности (mvd_L1) векторов движения (например, представляющую и горизонтальную и вертикальную составляющие). Помимо этого, кодируемые с обходом бины 168 включают в себя кодируемые с обходом бины первого опорного индекса (ref_idx_L0), кодируемые с обходом бины второго опорного индекса (ref_idx_L1), кодируемые с обходом бины первой разности (mvd_L0) векторов движения и кодируемые с обходом бины второй разности (mvd_L1) векторов движения.
Как описано выше в отношении Фиг. 6, бины могут быть сгруппированы на основании номеров бинов синтаксических элементов, подлежащих кодированию. В одном из иллюстративных примеров, видеокодер (такой, как кодер 20 видео или декодер 30 видео) может кодировать первые два бина значений разностей векторов движения, используя контекстное кодирование, и кодировать остальные бины, используя кодирование с обходом. Помимо этого, видеокодер может кодировать первые два бина опорных индексов, используя контекстное кодирование, и кодировать остальные бины, используя кодирование с обходом. Соответственно, в этом примере, контекстно кодируемые бины 144 могут включать в себя первые два бина и первой разности (mvd_L0) векторов движения и значения второй разности (mvd_L1) векторов движения, а также первые два бина и первого опорного индекса (ref_idx_L0) и второго опорного индекса (ref_idx_L1). Кодируемые с обходом бины 148 могут включать в себя остальные бины значений разностей векторов движения и опорных индексов.
Группирование контекстно кодируемых бинов и кодируемых с обходом бинов может уменьшить запаздывание, связанное с кодированием бинов. Например, видеокодер может кодировать все контекстно кодируемые бины 144, сделать единственный переход от контекстного кодирования к кодированию с обходом, и кодировать все кодируемые с обходом бины. Устранение множественных переходов между контекстным кодированием и кодированием с обходом может повысить эффективность за счет ограничения запаздывания, связанного с переходами между контекстным кодированием и кодированием с обходом.
Следует понимать, что методы, описанные в отношении Фиг. 6 и 7 могут быть выполнены с использованием любой схемы бинаризации. Более того, как отмечалось выше, упорядочение синтаксических элементов предоставлено лишь для примера. Помимо этого, контекстно кодируемые бины и кодируемые с обходом бины могут быть сгруппированы для PU, для одной или более CU, для полной LCU, или для полного слайса видеоданных. В таких примерах, контекстно кодируемые бины могут группироваться и кодироваться для PU/CU/LCU/слайса до кодируемых с обходом бинов из PU/CU/LCU/слайса, или наоборот.
Фиг. 8A и 8B в целом иллюстрируют кодирование синтаксического элемента в направлении внешнего предсказания. Например, как отмечалось выше, в дополнение к вычислению вектора движения, оценка движения к тому же определяет индекс опорного кадра (ref_idx) и направление предсказания для B-слайсов (inter_pred_idc: вперед от L0, назад от L1, или двунаправленное, или inter_pred_flag: в одном направлении от LC или в двух направлениях от L0 и L1). Вектор движения (например, горизонтальная составляющая и вертикальная составляющая вектора движения), индекс опорного кадра и направление предсказания обычно энтропийно кодируются кодером в качестве синтаксических элементов, и помещаются в закодированный битовый поток видео, который будет декодироваться декодером видео для использования в процессе декодирования видео. Эти синтаксические элементы могут быть предусмотрены для PU с внешним кодированием, чтобы позволить декодеру видео декодировать и воспроизводить видеоданные, задаваемые посредством PU.
В некоторых случаях, опорные индексы списка L0 и списка L1 могут использоваться, чтобы сигнализировать опорные индексы для режима двунаправленного предсказания (Pred_BI), а опорный индекс объединенного списка (CL) используется, чтобы сигнализировать опорный индекс для режима (Pred_LC) однонаправленного предсказания. Опорный индекс LC является опорным индексом объединенного списка опорных изображений, который включает в себя объединение опорных изображений из списков L0 и L1 с дублированными опорными изображениями, удаленными в соответствии с предварительно заданным правилом (или явной сигнализацией). Опорный индекс LC, следовательно, сопоставляется с опорным индексом для одного из списков L0 или L1.
В таких случаях, синтаксический элемент направления внешнего предсказания (inter_pred_flag) имеет только два возможных значения (в двух направлениях или в одном направлении от LC). Когда синтаксический элемент направления внешнего предсказания бинаризуется, может потребоваться кодирование только одного бина, чтобы обозначить направление внешнего предсказания как либо в двух направлениях, либо в одном направлении. Таблица 8, показанная ниже, иллюстрирует синтаксический элемент направления внешнего предсказания:
|
В других примерах, как предлагается в представлении T. Lee и J. Park, "On Reference List Combination" ("Об объединении опорных списков"), JCTVC-I0125, Женева, апрель 2012, объединенный список (LC) может быть удален. В таких примерах, вместо этого используют синтаксический элемент направления внешнего предсказания (inter_pred_flag или inter_pred_idc) с тремя возможными значениями (в двух направлениях, в одном направлении от L0, или в одном направлении от L1). Когда режим предсказания является режимом предсказания в одном направлении, может потребоваться кодирование дополнительного бина, обозначающего либо Pred_L0, либо Pred_L1.
Таблица 9 иллюстрирует изменение в кодировании синтаксического элемента направления внешнего предсказания (относительно приведенной выше Таблицы 8):
|
Фиг. 8A иллюстрирует структуру кодирования, описанную выше в отношении Таблицы 9. Как показано на Фиг. 8A, синтаксический элемент направления внешнего предсказания (inter_pred_flag) может кодироваться с помощью процесса CABAC с использованием двух бинов. Первый бин (bin(0)) показывает, является режим внешнего предсказания режимом в одном направлении (bin(0)=0) или в двух направлениях (pred_BI) (bin(0)=1). Второй бин условно кодируется, только если первый бин показывает режим предсказания в одном направлении. Второй бин (bin(1)) показывает, направлен режим предсказания в одном направлении от List0 (pred_L0) (bin(1)=0) или от List1 (pred_L1) (bin(1)=1).
Выведение индекса контекстной модели для направления внешнего предсказания только с двумя возможными значениями (в двух направлениях или в одном направлении от LC) могут определяться на основании глубины CU, которая может иметь значения в диапазоне 0…3 для первого бина (bin0), как показано в приведенном ниже уравнении:
ctxIdx=cuDepth
В примере на Фиг. 8A, второй бин (bin(1)) может кодироваться с дополнительным контекстом, или может кодироваться посредством повторного использования одного контекста первого бина (bin(0)). Однако введение дополнительного контекста может увеличить сложность, связанную с кодированием синтаксического элемента направления внешнего предсказания. Более того, повторное использование одного из контекстов первого бина может уменьшить количество контекстов, используемых для кодирования bin0, и видеокодеру придется выполнять дополнительную проверку этого условия.
Фиг. 8B является структурной схемой, иллюстрирующей кодирование с обходом синтаксического элемента направления внешнего предсказания, в соответствии с аспектами настоящего раскрытия изобретения. Как показано на Фиг. 8B, первый бин (bin(0)) синтаксического элемента направления внешнего предсказания (inter_pred_flag) может быть контекстом, кодированным с помощью процесса CABAC, а второй бин (bin(1)) может кодироваться в режиме с обходом процесса CABAC. Первый бин (bin(0)) показывает, является режим внешнего предсказания режимом в одном направлении (bin(0)=0) или в двух направлениях (pred_BI) (bin(0)=1). В этом примере, bin(0) может кодироваться с использованием одного из четырех возможных контекстов, ctxIdx=0…3. Второй бин (bin(1)) может условно кодироваться, только если первый бин показывает режим предсказания в одном направлении. Второй бин (bin(1)) показывает, направлен режим предсказания в одном направлении от List0 (pred_L0) (bin(1)=0) или от List1 (pred_L1) (bin(1)=1). В соответствии с аспектами настоящего раскрытия изобретения, bin(1) может кодироваться, не используя никаких контекстов (например, кодироваться с использованием режима с обходом процесса CABAC).
Таким образом, в соответствии с аспектами настоящего раскрытия изобретения, видеокодер (например, кодер 20 видео или декодер 30 видео), может бинаризовать значение направления внешнего предсказания и кодировать по меньшей мере один бин бинаризованного значения направления внешнего предсказания в режиме с обходом. Более определенно, видеокодер может выбрать контекст, чтобы контекстно кодировать первый бин (bin(0)) для значения направления внешнего предсказания с помощью процесса CABAC, и кодировать второй бин (bin(1)) в режиме с обходом процесса CABAC. В качестве альтернативы, эти методы позволяют видеокодеру кодировать первый бин (bin(0)) для значения направления внешнего предсказания в режиме с обходом, и также кодировать второй бин (bin(1)) в режиме с обходом. Соответственно, четыре контекста, доступные для кодирования bin(0), ctxIdx=0…3, могут быть сохранены.
Методы предоставляют возможность кодирования синтаксического элемента направления внешнего предсказания с тремя возможными значениями (в двух направлениях, в одном направлении от L0, или в одном направлении от L1), не требуя никакого дополнительного контекста или повторно используя контекст (например, контекст bin0). Более того, методы используют режим с обходом, не требующий контекстов, который может быть менее сложным в вычислительном отношении, чем контекстное кодирование.
Фиг. 9 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного кодирования значения опорного индекса, в соответствии с аспектами настоящего раскрытия изобретения. Хоть для целей объяснения оно и описано в общем как выполняемое компонентами кодера 20 видео (Фиг. 1 и 2), следует понимать, что другие модули кодирования видео, процессоры, модули обработки, аппаратные модули кодирования, такие, как кодери/декодери (КОДЕКИ), и т.п., также могут быть выполнены с возможностью выполнения процесса, изображенного на Фиг. 9.
В примере на Фиг. 9, кодер 20 видео бинаризует принимаемый синтаксический элемент (180). Кодер 20 видео может бинаризовать синтаксический элемент в соответствии с любым из процессов бинаризации, описанных в настоящем раскрытии изобретения. Примеры процессов бинаризации включают в себя бинаризацию унарным кодом, усеченным унарным кодом, экспоненциальным кодом Голомба, или тому подобное.
Кодер 20 видео определяет, является ли бинаризованный синтаксический элемент значением опорного индекса (182). В свою очередь, значение опорного индекса обычно идентифицирует опорное изображение в списке опорных изображений для целей внешнего предсказания. Если бинаризованный синтаксический элемент является значением опорного индекса (ветка "да" этапа 182), кодер 20 видео может кодировать по меньшей мере один бин бинаризованного значения опорного индекса с использованием контекстно-адаптивного кодирования, такого, как CABAC (184). Помимо этого, кодер 20 видео может кодировать по меньшей мере другой бин бинаризованного значения опорного индекса (в случаях, когда есть дополнительные бины, подлежащие кодированию) с использованием кодирования с обходом, которое обходит механизм контекстно-адаптивного кодирования (186).
Как описывалось выше в отношении Фиг. 4, кодер 20 видео, в некоторых примерах, может кодировать один, два или три бина, используя контекстное кодирование. Для контекстно кодируемых бинов, кодер 20 видео может выбрать контекст на основании относительной позиции бина в строке бинов. Например, кодер 20 видео может выбрать контекст для первого бина, который отличается от контекста для второго бина.
В любом случае, кодер 20 видео может объединять контекстно кодированные бины и кодированные с обходом бины для формирования закодированного битового потока 188. В некоторых примерах, если кодируемый синтаксический элемент не является значением опорного индекса (ветка "нет" этапа 182), кодер 20 видео может выбрать конкретный режим кодирования (например, с обходом или контекстно-адаптивный), чтобы кодировать синтаксический элемент (190). Кодер 20 видео может закодировать синтаксический элемент с использованием выбранного режима (192) и сформировать закодированный битовый поток (188).
Кроме того, следует понимать, что этапы, показанные и описанные со ссылкой на Фиг. 9, предоставлены просто в качестве одного примера. То есть, этапы способа, изображенного на Фиг. 9, не обязательно должны выполняться в порядке, показанном на Фиг. 9, и может выполняться меньше этапов, дополнительные или альтернативные этапы. Например, в некоторых случаях, кодер 20 видео может определять, является ли синтаксический элемент опорным индексом (шаг 182), перед бинаризацией синтаксического элемента (шаг 180).
Фиг. 10 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного декодирования значения опорного индекса, в соответствии с аспектами настоящего раскрытия изобретения. Хоть для целей объяснения оно и описано в общем как выполняемое компонентами декодера 30 видео (Фиг. 1 и 3), следует понимать, что другие модули кодирования видео, процессоры, модули обработки, аппаратные модули кодирования, такие, как кодери/декодери (КОДЕКИ), и т.п., также могут быть выполнены с возможностью выполнения процесса, изображенного на Фиг. 10.
Декодер 30 видео сначала может проводить синтаксический анализ кодированного синтаксического элемента из закодированного битового потока (200). Например, декодер 30 видео может считывать и сегментировать кодированный синтаксический элемент из закодированного битового потока в соответствии с конкретным процессом синтаксического анализа (например, волнового синтаксического анализа). Кодированный синтаксический элемент может включать в себя множество кодированных бинов, т.е., двоичных значений.
Декодер 30 видео также может определить, является ли часть битового потока, декодируемая в данный момент, значением опорного индекса (202). Если декодер 30 видео декодирует значение опорного индекса (ветка "да" этапа 202), декодер 30 видео может декодировать по меньшей мере один бин с использованием контекстно-адаптивного кодирования (204). Помимо этого, декодер 30 видео может декодировать по меньшей мере другой бин (в примерах, когда есть дополнительные бины, подлежащие кодированию) с использованием кодирования с обходом (206). Как отмечалось выше в отношении Фиг. 9, в некоторых примерах, декодер 30 видео может кодировать один, два или три бина, используя контекстное кодирование. Для контекстно кодируемых бинов, декодер 30 видео может выбрать контекст на основании относительной позиции бина в строке бинов. Например, декодер 30 видео может выбрать контекст для первого бина, который отличается от контекста для второго бина.
После декодирования бинов для получения декодированных двоичных значений, декодер 30 видео может бинаризовать декодированную строку бинов, чтобы получить декодированный синтаксический элемент (208). Например, декодер 30 видео может сопоставить декодированную строку бинов с синтаксическим элементом, используя предварительно заданный процесс. То есть, в некоторых случаях, декодер 30 видео может принимать признак того, что конкретный бин является конечным бином для синтаксического элемента. Тогда, после завершения синтаксического элемента, декодер 30 видео может сопоставить строку бинов с синтаксическим элементом, используя таблицу бинаризации.
В некоторых примерах, если подлежащий кодированию синтаксический элемент не является значением опорного индекса (ветка "нет" этапа 202), декодер 30 видео может выбрать конкретный режим кодирования (например, с обходом или контекстно-адаптивный), чтобы кодировать синтаксический элемент (210). Декодер 30 видео может декодировать синтаксический элемент, используя выбранный режим (212), и бинаризовать декодированную строку бинов (208).
Кроме того, следует понимать, что этапы, показанные и описанные со ссылкой на Фиг. 10, предоставлены просто в качестве одного примера. То есть, этапы способа, изображенного на Фиг. 10, не обязательно должны выполняться в порядке, показанном на Фиг. 10, и может выполняться меньше этапов, дополнительные или альтернативные этапы.
Фиг. 11 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного кодирования данных предсказания, в соответствии с аспектами настоящего раскрытия изобретения. Хоть для целей объяснения оно и описано в общем как выполняемое компонентами кодера 20 видео (Фиг. 1 и 2), следует понимать, что другие модули кодирования видео, процессоры, модули обработки, аппаратные модули кодирования, такие, как кодери/декодери (КОДЕКИ), и т.п., также могут быть выполнены с возможностью выполнения процесса, изображенного на Фиг. 11.
В примере на Фиг. 11, кодер 20 видео может бинаризовать один или более синтаксических элементов, кодируемых в данный момент (220). Например, кодер 20 видео может бинаризовать данные предсказания, включающие в себя один или более опорных индексов, векторы движения, предикторы вектора движения, индексы предикторов вектора движения, значения разностей векторов движения, и т.п.
В любом случае, кодер 20 видео может определять, включают ли кодируемые синтаксические элементы в себя бины для контекстного кодирования и бины для кодирования с обходом (222). То есть, кодер 20 видео может определять, кодируются ли бины синтаксического элемента с использованием смешивания контекстно-адаптивного кодирования и кодирования с обходом. Если есть смешивание как контекстного кодирования, так и кодирования с обходом (ветка "да" этапа 222), кодер 20 видео может группировать контекстно кодируемые бины и кодируемые с обходом бины (224). Например, кодер 20 видео может отделять контекстно кодируемые бины от кодируемых с обходом бинов.
Затем кодер 20 видео может закодировать контекстно кодируемые бины, используя, например, процесс контекстно-адаптивного кодирования (например, такого, как CABAC) (226). Помимо этого, кодер 20 видео может закодировать кодируемые с обходом бины, используя режим с обходом (226). Режим с обходом может обходить механизм контекстно-адаптивного кодирования и использовать фиксированную вероятность, чтобы кодировать бины.
Если подлежащий кодированию синтаксический элемент не включает в себя одновременно и контекстно кодируемые бины и кодируемые с обходом бины (ветка "нет" этапа 222), кодер 20 видео может выбрать конкретный режим кодирования (например, с обходом или контекстно-адаптивный), чтобы кодировать синтаксический элемент (230). Затем кодер 20 видео может закодировать синтаксический элемент, используя выбранный режим (234).
В некоторых случаях, группирование бинов, описанное в отношении Фиг. 11, может выполняться более чем для двух синтаксических элементов. Например, как описывалось выше в отношении Фиг. 7, могут группироваться все контекстно кодируемые бины, связанные с PU, так что контекстно кодируемые бины из PU кодируются вместе, и кодируемые с обходом бины из PU кодируются вместе. Помимо этого, группирование может выполняться на уровне CU, LCU или слайса. То есть, в некоторых примерах, все контекстно кодируемые бины для CU/LCU/слайса могут быть сгруппированы и кодироваться вместе, тем самым позволяя кодеру 20 видео делать единственный переход между контекстным кодированием и кодированием с обходом.
Кроме того, следует понимать, что этапы, показанные и описанные со ссылкой на Фиг. 11, предоставлены просто в качестве одного примера. То есть, этапы способа, изображенного на Фиг. 11, не обязательно должны выполняться в порядке, показанном на Фиг. 11, и может выполняться меньше этапов, дополнительные или альтернативные этапы. Например, в то время как Фиг. 11 демонстрирует кодер 20 видео, кодирующий контекстно кодируемые бины раньше кодируемых с обходом бинов, в других примерах, кодер 20 видео может кодировать кодируемые с обходом бины раньше контекстно кодируемых бинов.
Фиг. 12 является блок-схемой последовательности операций способа, иллюстрирующей пример энтропийного декодирования данных предсказания, в соответствии с аспектами настоящего раскрытия изобретения. Хоть для целей объяснения оно и описано в общем как выполняемое компонентами декодера 30 видео (Фиг. 1 и 3), следует понимать, что другие модули кодирования видео, процессоры, модули обработки, аппаратные модули кодирования, такие, как кодери/декодери (КОДЕКИ), и т.п., также могут быть выполнены с возможностью выполнения процесса, изображенного на Фиг. 12.
В примере на Фиг. 12, декодер 30 видео может определять синтаксический элемент (или элементы), подлежащий декодированию (240). В одном из примеров, декодер 30 видео может идентифицировать синтаксические элементы, связанные с данными предсказания, для декодирования. Декодер 30 видео также может определять, включают ли бины синтаксического элемента(ов) в себя контекстно кодируемые бины и кодируемые с обходом бины (242). Если есть смешивание как контекстного кодирования, так и кодирования с обходом (ветка "да" этапа 242), декодер 30 видео может декодировать контекстно кодируемые бины (244). Декодер 30 видео также может декодировать, отдельно от контекстно кодируемых бинов, кодируемые с обходом бины (246). То есть, в тех случаях, когда контекстно кодируемые бины сгруппированы отдельно от кодируемых с обходом бинов в битовом потоке, подлежащем декодированию, декодер 30 видео может декодировать все контекстно кодируемые отдельно от декодирования кодируемых с обходом бинов. После декодирования бинов, декодер 30 видео может бинаризовать декодированные бины, чтобы сформировать декодированный синтаксический элемент (248). Например, декодер 30 видео может сопоставить декодированную строку бинов с синтаксическим элементом, используя таблицу бинаризации или другой процесс бинаризации.
Если подлежащий кодированию синтаксический элемент не включает в себя одновременно и контекстно кодируемые бины и кодируемые с обходом бины (ветка "нет" этапа 242), декодер 30 видео может выбрать конкретный режим кодирования (например, с обходом или контекстно-адаптивный), чтобы кодировать синтаксический элемент (250). Затем декодер 30 видео может декодировать закодированные бины, используя выбранный режим (252), и бинаризовать декодированную строку бинов, чтобы сформировать декодированный синтаксический элемент (248).
Как описывалось выше в отношении Фиг. 11, в некоторых случаях, группирование бинов может выполняться более чем для двух синтаксических элементов. Например, группирование может выполняться на уровне PU, CU, LCU или слайса. То есть, в некоторых примерах, все контекстно кодируемые бины для PU/CU/LCU/слайса могут быть сгруппированы и кодироваться вместе, тем самым позволяя декодеру 30 видео делать единственный переход между контекстным кодированием и кодированием с обходом.
Кроме того, следует понимать, что этапы, показанные и описанные со ссылкой на Фиг. 12, предоставлены просто в качестве одного примера. То есть, этапы способа, изображенного на Фиг. 12, не обязательно должны выполняться в порядке, показанном на Фиг. 12, и может выполняться меньше этапов, дополнительные или альтернативные этапы. Например, в то время как Фиг. 12 демонстрирует декодер 30 видео, декодирующий контекстно кодируемые бины раньше кодируемых с обходом бинов, в других примерах, декодер 30 видео может кодировать кодируемые с обходом бины раньше контекстно кодируемых бинов.
Кроме того, следует понимать, что, в зависимости от примера, определенные действия или события любого из способов, описываемых в данном документе, могут выполняться в другой последовательности, могут быть добавлены, совмещены, или вообще пропущены (например, не все описываемые действия или события необходимы для практической реализации способа). Более того, в некоторых примерах, действия или события могут выполняться одновременно, например, благодаря использованию многопоточной обработки, обработки прерываний, или нескольких процессоров, а не последовательно. Помимо этого, хотя определенные аспекты настоящего раскрытия изобретения и описаны для ясности как выполняемые одним конструктивным элементом или модулем, следует понимать, что методы настоящего раскрытия изобретения могут выполняться комплексом конструктивных элементов или модулей, связанных с видеокодером.
Кодер 20 видео может реализовывать любой или все из методов согласно настоящему раскрытию изобретения для кодирования опорного индекса и других синтаксических элементов в ходе процесса кодирования видео. Точно так же, декодер 30 видео может реализовывать любой или все из этих методов для кодирования опорного индекса и других синтаксических элементов в ходе процесса кодирования видео. Видеокодер, как описывается в настоящем раскрытии изобретения, может относиться к кодеру видео или декодеру видео. Аналогично, модуль кодирования видео может относиться к кодеру видео или декодеру видео. Точно так же, кодирование видео может относиться к кодированию видео или декодированию видео.
В одном или более примерах, функции, описанные в настоящем раскрытии изобретения и приписываемые кодеру 20 видео, декодеру 30 видео, или любому другому модулю обработки, могут быть реализованы в аппаратном обеспечении, программном обеспечении, программно-аппаратном обеспечении, или любой их комбинации. При реализации в программном обеспечении, функции могут храниться на считываемом компьютером носителе, или передаваться через него, в виде одной или более инструкций или кода, и исполняться аппаратным модулем обработки. Считываемые компьютером носители могут включать в себя считываемые компьютером информационные носители, которые соответствуют материальному носителю, такому, как носители для хранения данных, или среды связи, в том числе любой носитель, который облегчает перенос компьютерной программы из одного места в другое, например, в соответствии с протоколом связи. Таким образом, считываемые компьютером носители, в общем смысле, могут соответствовать (1) материальным считываемым компьютером носителям для хранения данных, которые являются энергонезависимыми, или (2) среде связи, такой, как сигнал или несущая волна. Носители для хранения данных могут быть любыми доступными носителями, к которым можно получить доступ посредством одного или более компьютеров или одного или более процессоров, чтобы извлекать инструкции, код и/или структуры данных для реализации методов, описанных в настоящем раскрытии изобретения. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
В качестве примера, но не ограничения, такие считываемые компьютером информационные носители могут содержать ОЗУ, ПЗУ, ЭСППЗУ, CD-ROM или другое хранилище на оптическом диске, хранилище на магнитных дисках, или другие магнитные устройства хранения, память с групповой перезаписью, или любой другой носитель, который может использоваться для хранения требуемого программного кода в форме инструкций или структур данных, и к которому можно получить доступ посредством компьютера. Кроме того, любое соединение корректно называть считываемым компьютером носителем. Например, если инструкции передаются от сетевого узла, обслуживающего узла или другого удаленного источника с использованием коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL - digital subscriber line), или беспроводных технологий, таких, как инфракрасное излучение, радиосвязь и СВЧ-излучение, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL, или беспроводные технологии, такие, как инфракрасное излучение, радиосвязь и СВЧ-излучение охватываются определением носителя. Следует понимать, однако, что считываемые компьютером информационные носители и носители для хранения данных не включают в себя соединения, несущие волны, сигналы, или другие временные носители, а наоборот ориентированы на энергонезависимые, материальные информационные носители. Магнитный диск и немагнитный диск, как используется в данном документе, включают в себя компакт-диск (CD - compact disc), лазерный диск, оптический диск, цифровой универсальный диск (DVD - digital versatile disc), гибкий диск и диск Blu-ray, при этом магнитные диски обычно воспроизводят данные магнитным способом, в то время как немагнитные диски воспроизводят данные оптическим способом с помощью лазерных источников. Комбинации вышеперечисленного тоже должны подпадать под определение считываемых компьютером носителей.
Инструкции могут выполняться одним или более процессорами, такими, как один или более цифровых сигнальных процессоров (ЦСП), универсальных микропроцессоров, специализированных интегральных схем (СИС), программируемых пользователем вентильных матриц (ППВМ), или других эквивалентных интегральных или дискретных логических схем, или любая их комбинация. Кодер 20 видео или декодер 30 видео может включать в себя любой из множества таких одного или более процессоров, выполненных с возможностью выполнения функций, описанных в настоящем раскрытии изобретения. Соответственно, термин "процессор", как используется в данном документе, может относиться к любой из вышеуказанных структур или любой другой структуре, подходящей для реализации методов, описанных в данном документе. Помимо этого, в некоторых аспектах, функциональные возможности, описанные в данном документе, могут быть обеспечены в рамках выделенных аппаратных и/или программных конструктивных элементов, выполненных с возможностью кодирования и декодирования, или вмонтированных в объединенный кодек. Кроме того, эти методы могли бы быть в полной мере реализованы в одной или более схемах или логических элементах.
Методы согласно настоящему раскрытию изобретения могут быть реализованы в широком разнообразии устройств или инструментальных средств, включающих в себя беспроводной микротелефон, интегральную схему (ИС) или набор ИС (например, набор микросхем). Различные компоненты, конструктивные элементы или модули описаны в настоящем раскрытии изобретения, чтобы подчеркнуть функциональные аспекты устройств, выполненных с возможностью выполнения раскрытых методов, но не обязательно требуют реализации на разных аппаратных модулях. Скорее, как описано выше, различные модули могут быть объединены в аппаратном модуле кодек или обеспечиваются комплектом способных взаимодействовать друг с другом аппаратных модулей, включающих в себя один или более процессоров, как описано выше, в сочетании с подходящим программным обеспечением и/или программно-аппаратным обеспечением.
Были описаны различные примеры. Эти и другие примеры попадают в объем прилагаемой формулы изобретения.
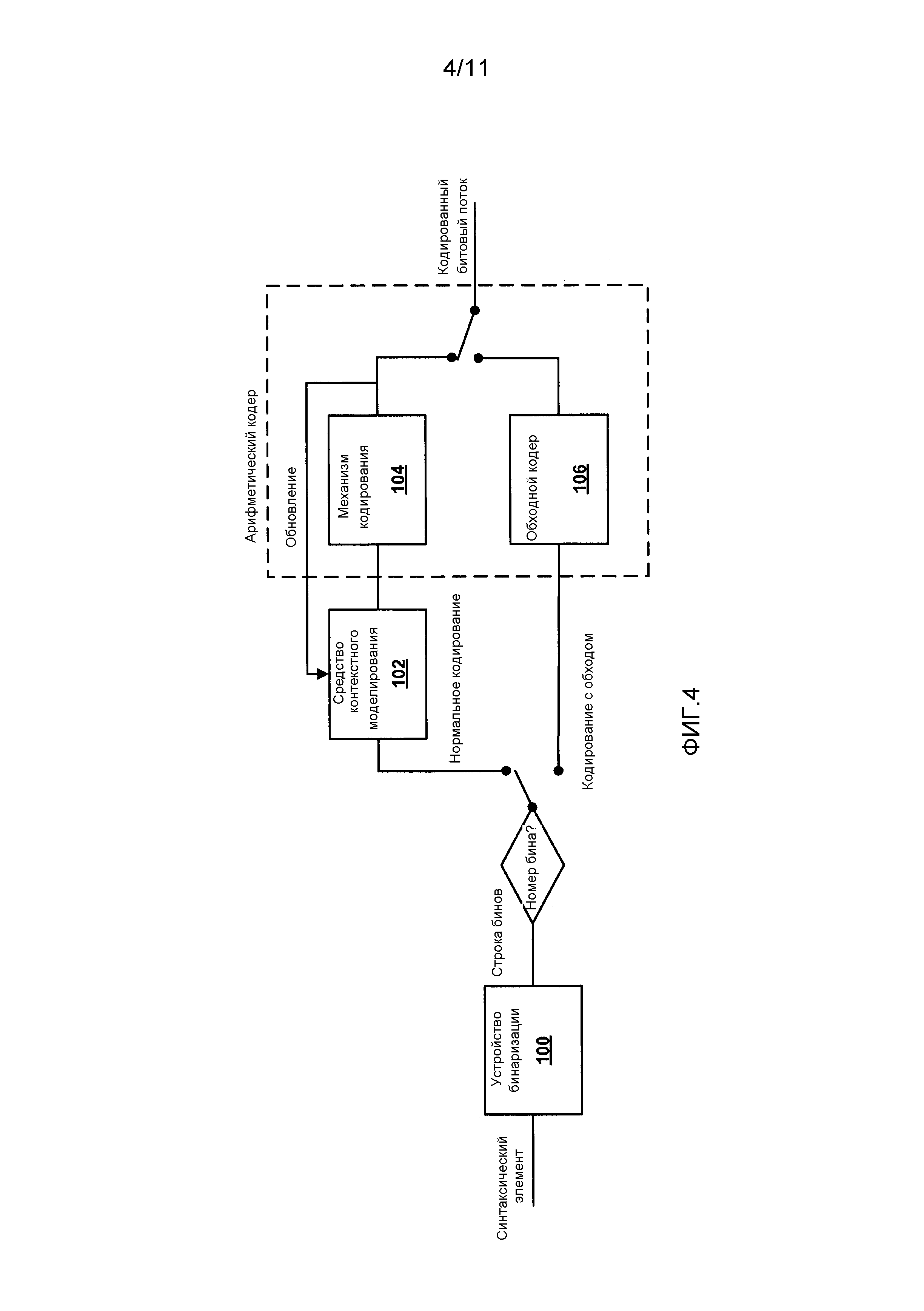
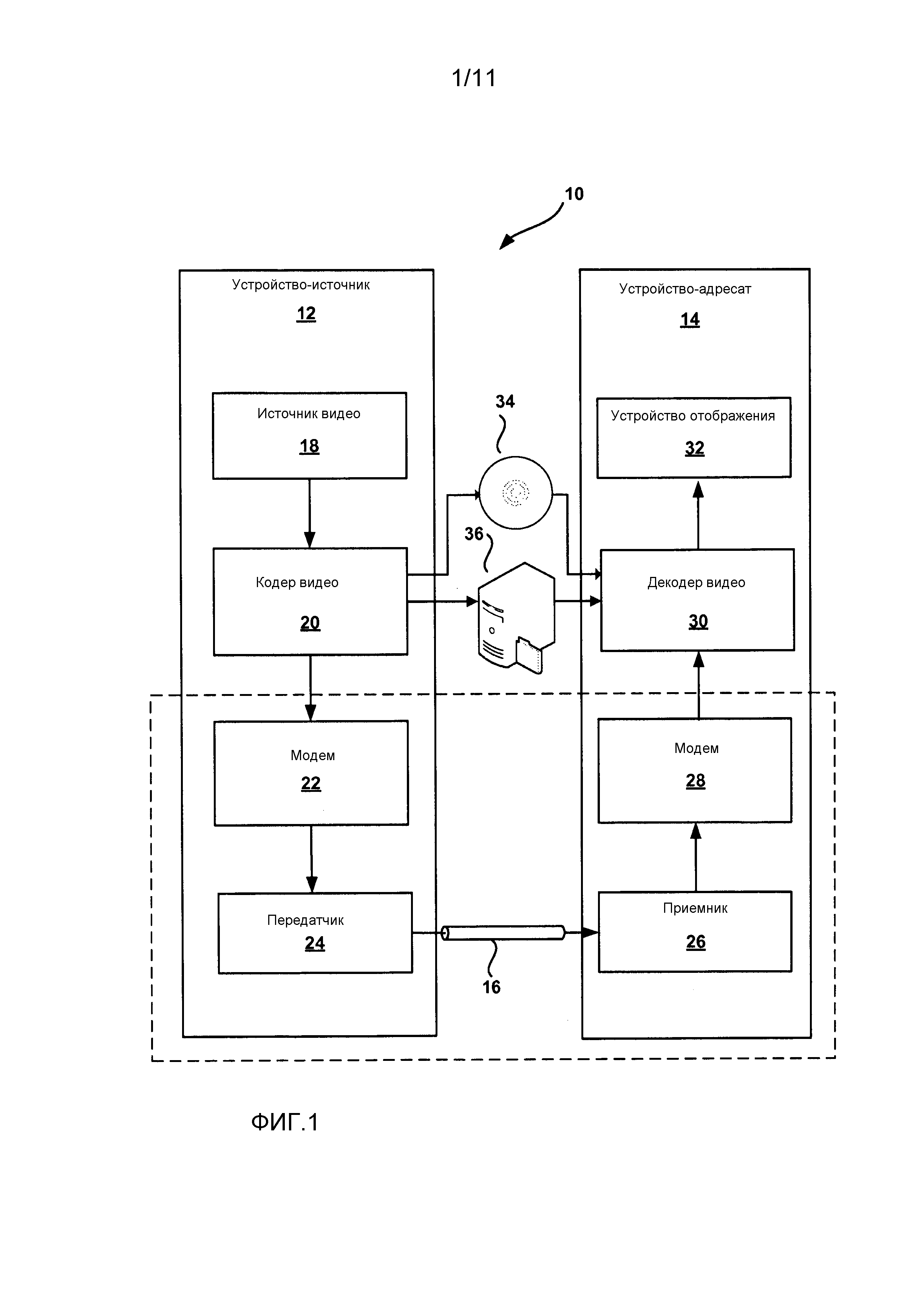
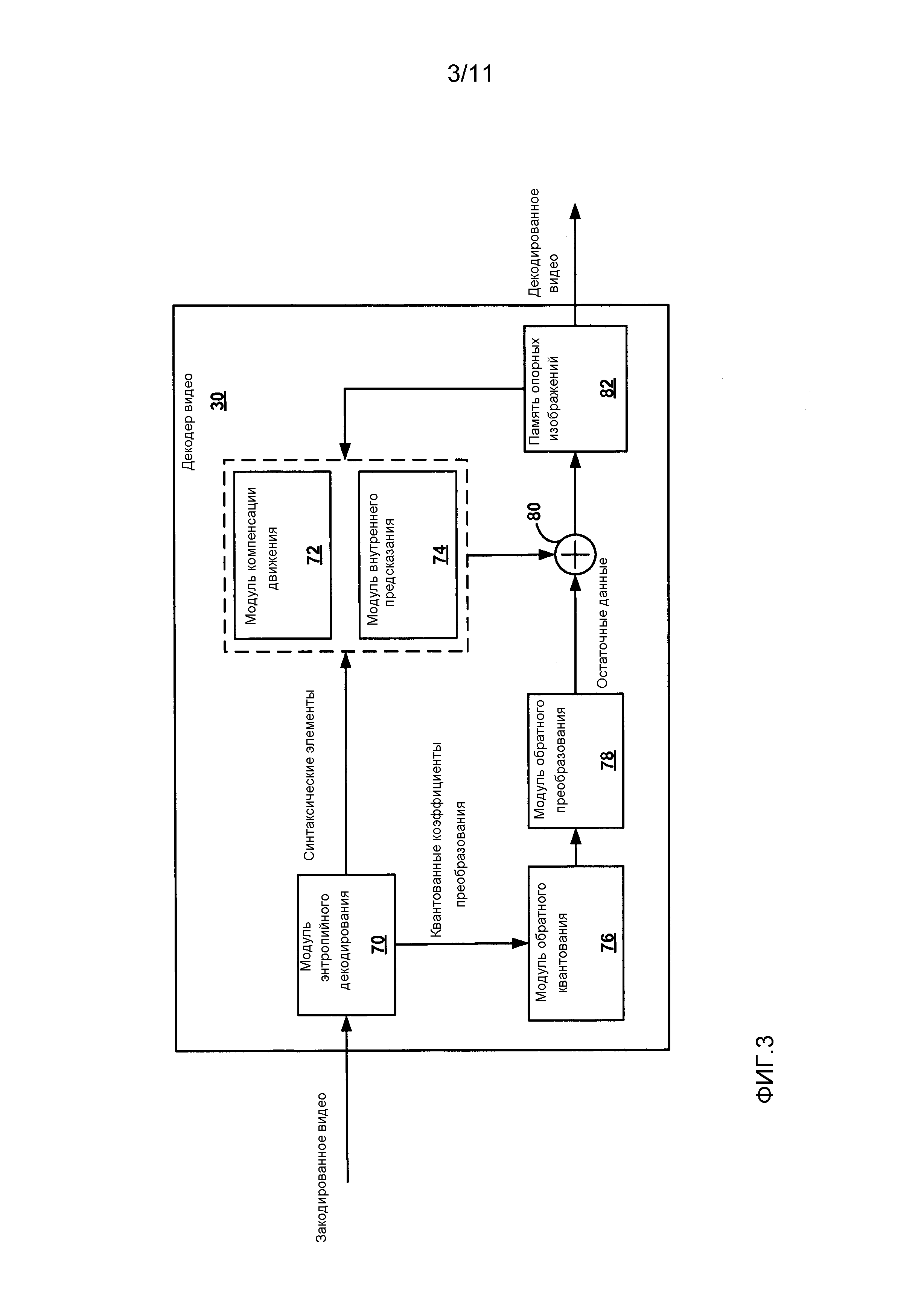
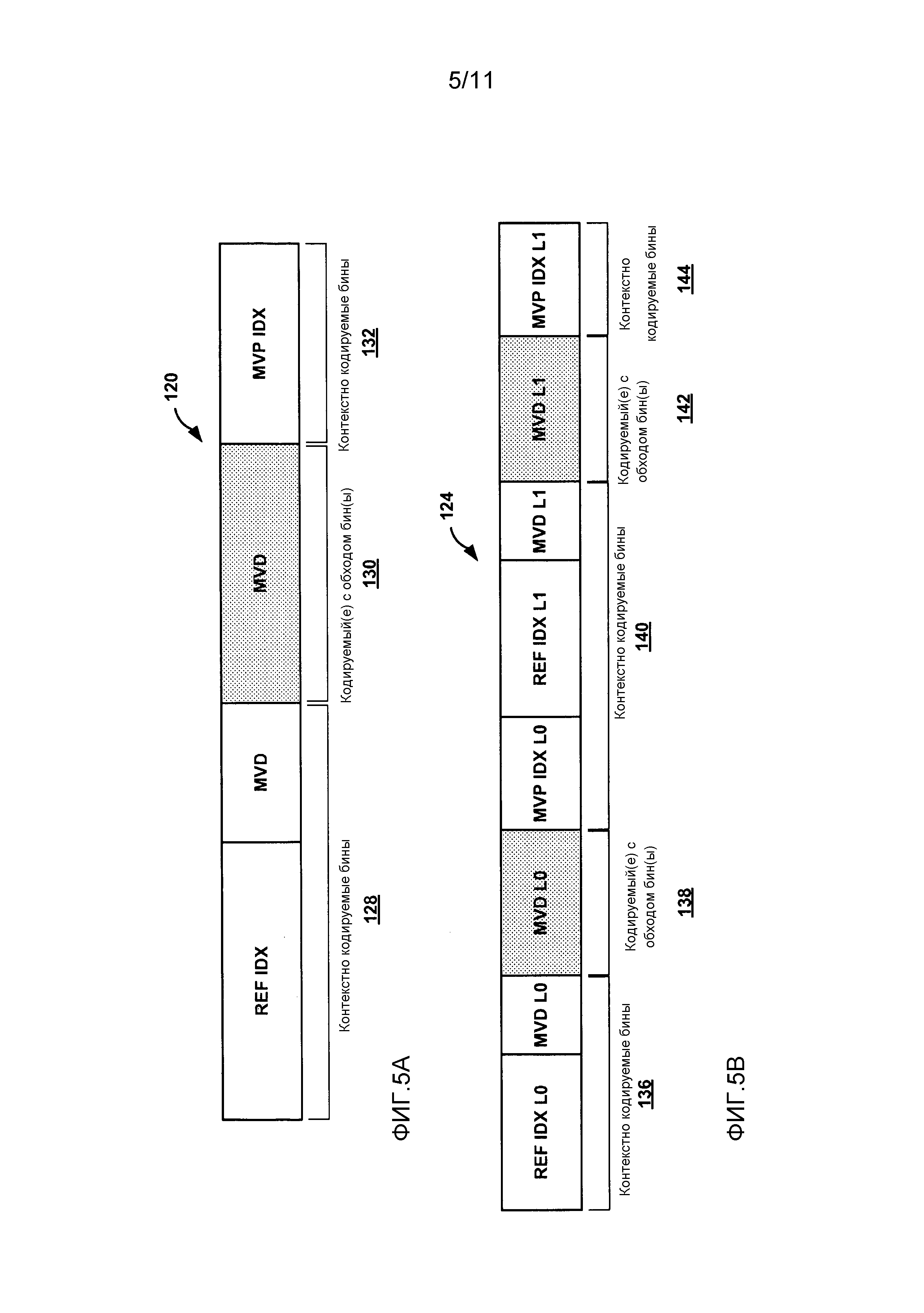
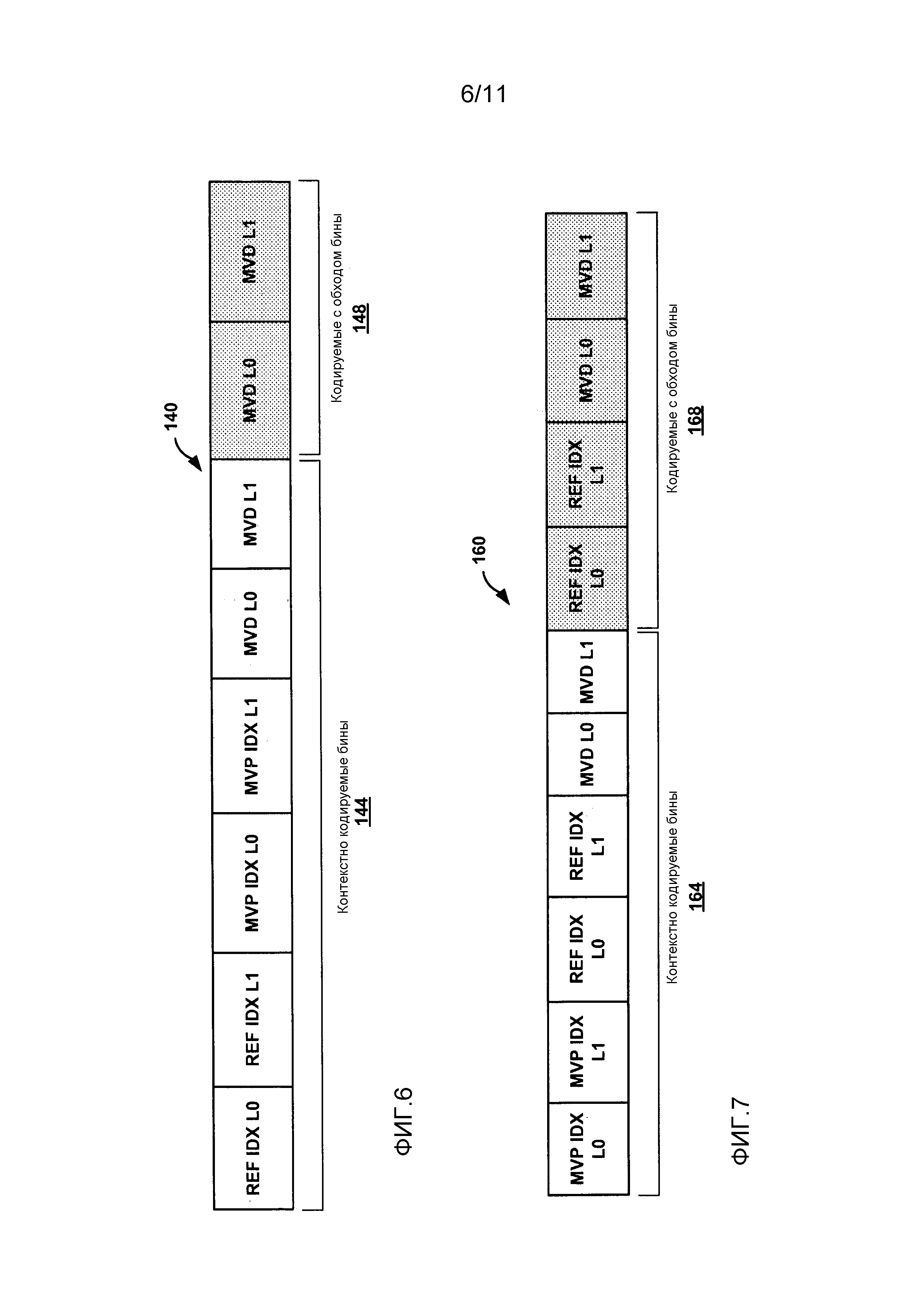
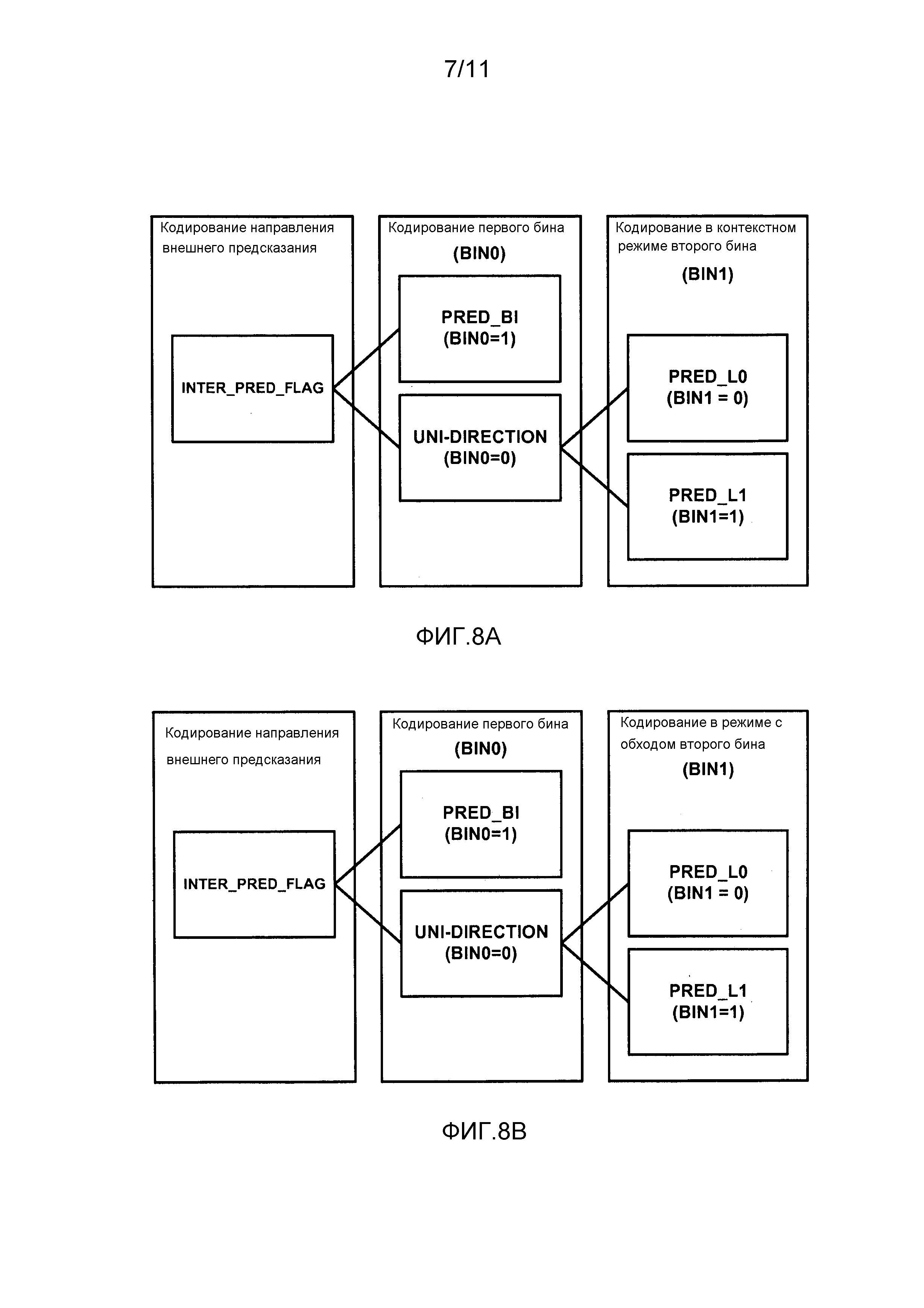
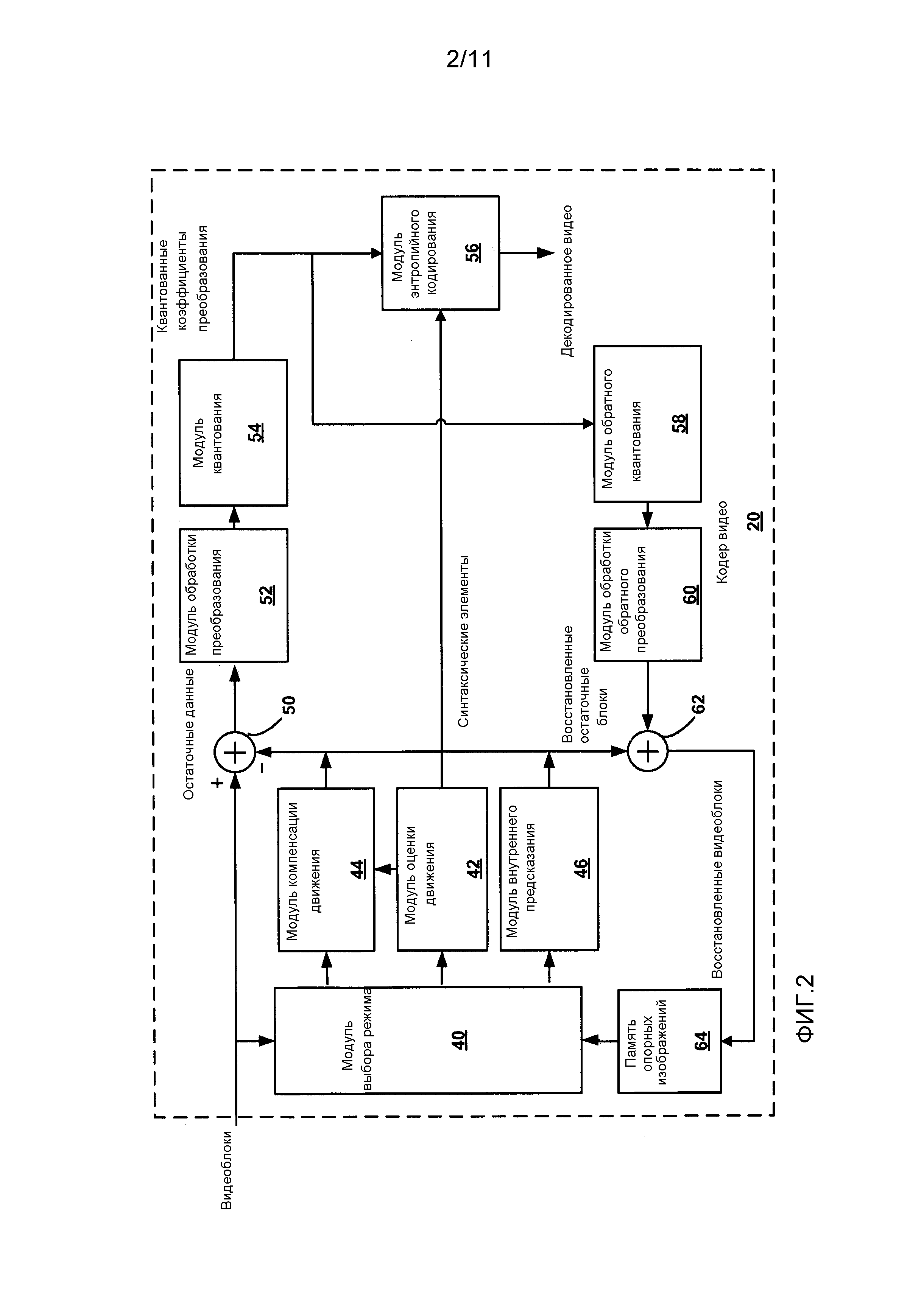
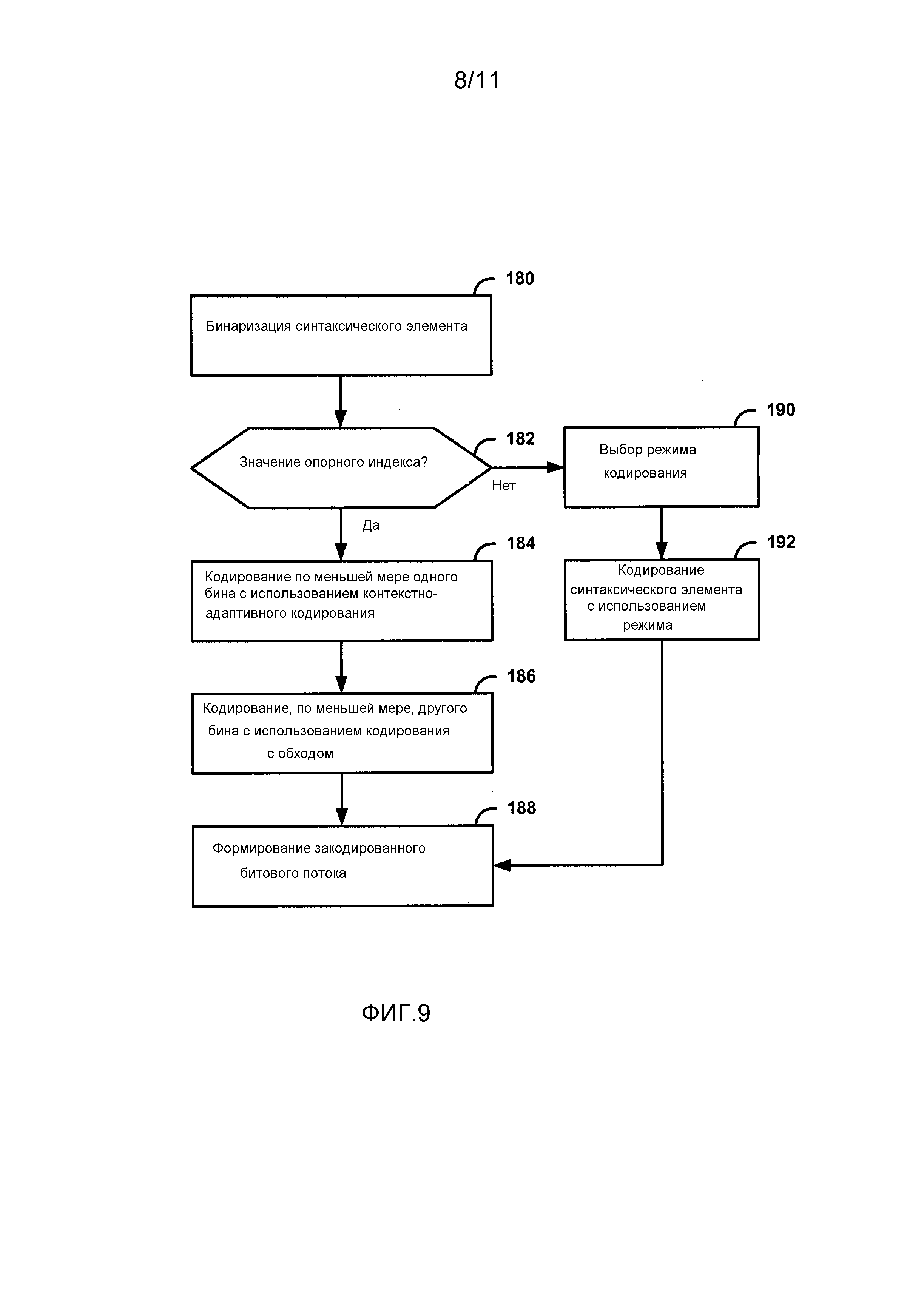
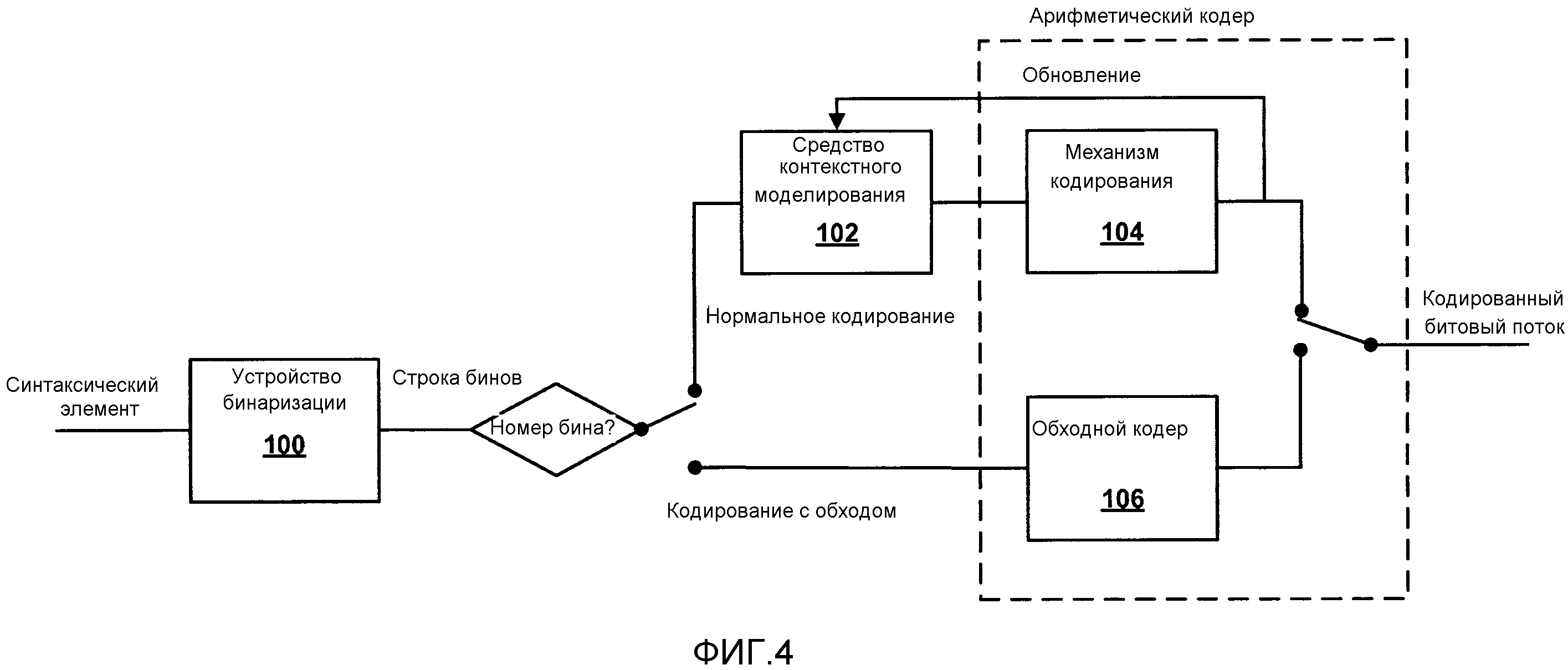
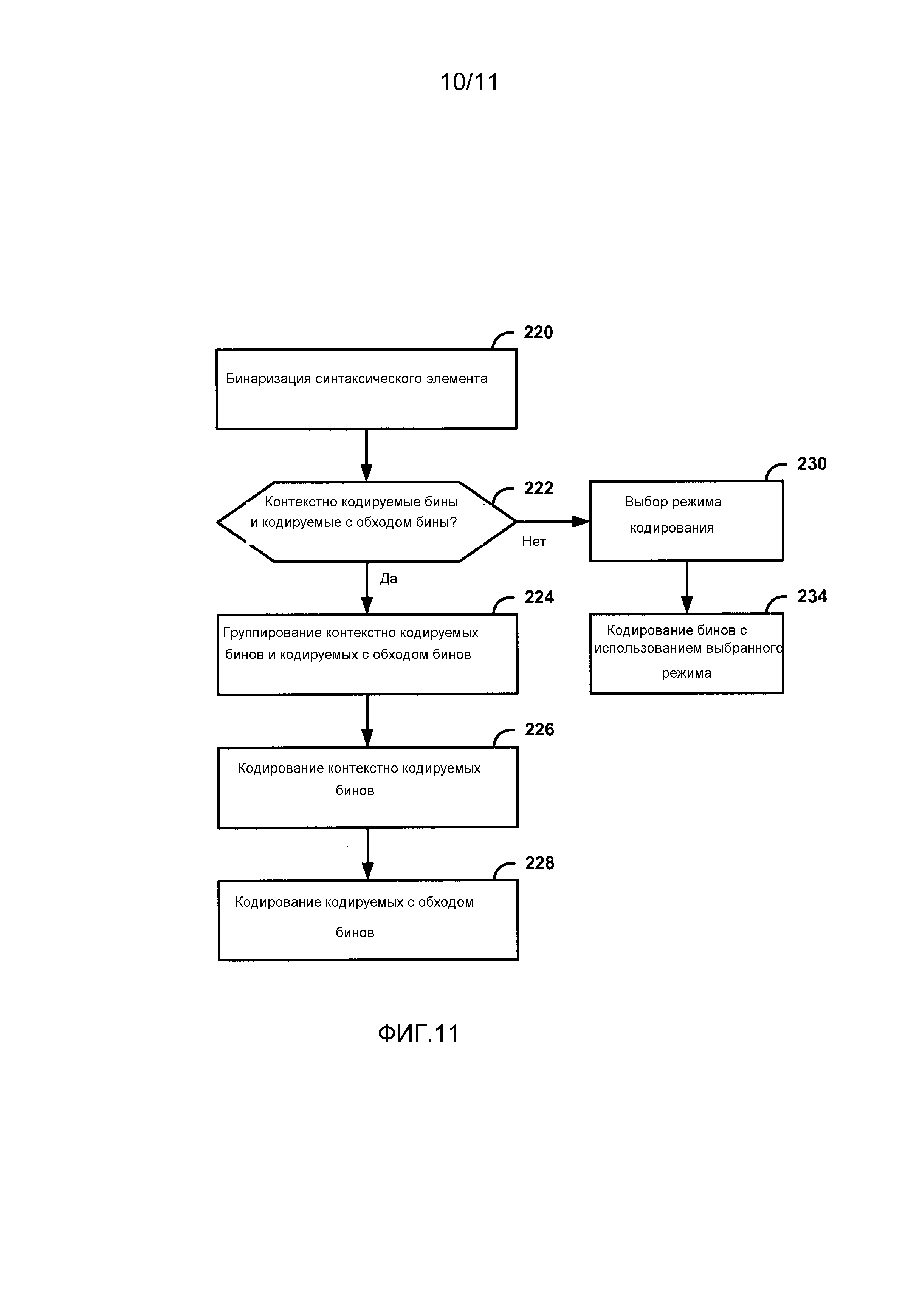
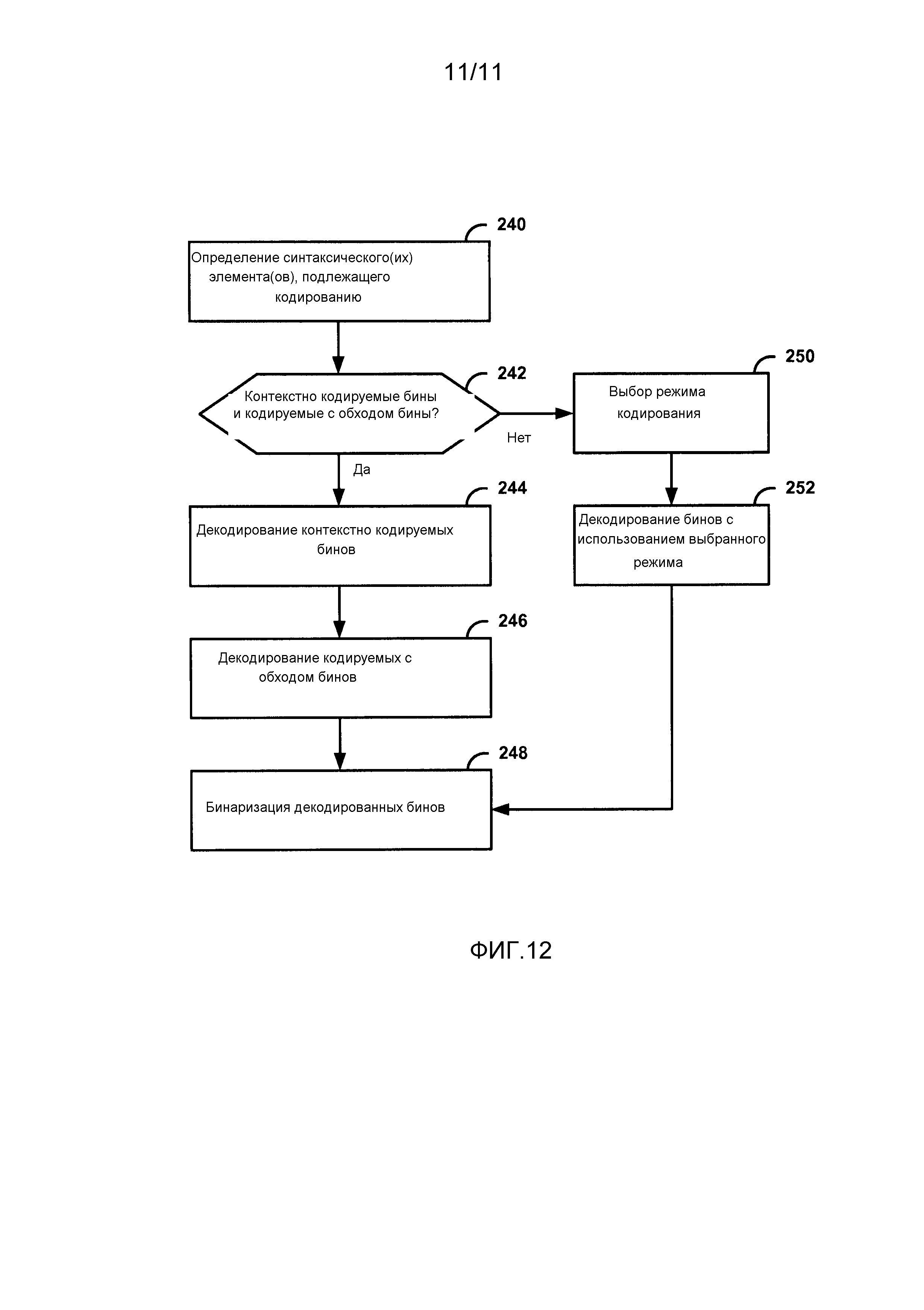
Обнаружение многолучевого распространения для принимаемого sps-сигнала
Способ для указания местоположения и направления элемента графического пользовательского интерфейса
Виртуальное планирование в неоднородных сетях
Кодирование и мультиплексирование управляющей информации в системе беспроводной связи
Система беспроводной связи с конфигурируемой длиной циклического префикса
Способ и устройство для осуществления информационного запроса сеанса для определения местоположения плоскости пользователя
Универсальная корректировка блочности изображения
Основанная на местоположении и времени фильтрация информации широковещания
Способ и устройство для поддержки экстренных вызовов (ecall)
Виртуальная sim-карта для мобильных телефонов
Обнаружение многолучевого распространения для принимаемого sps-сигнала
Способ для указания местоположения и направления элемента графического пользовательского интерфейса
Виртуальное планирование в неоднородных сетях
Кодирование и мультиплексирование управляющей информации в системе беспроводной связи
Система беспроводной связи с конфигурируемой длиной циклического префикса
Способ и устройство для осуществления информационного запроса сеанса для определения местоположения плоскости пользователя
Универсальная корректировка блочности изображения
Основанная на местоположении и времени фильтрация информации широковещания
Способ и устройство для поддержки экстренных вызовов (ecall)
Виртуальная sim-карта для мобильных телефонов

