ИЗМЕРЕНИЕ ТЕЛА
Вид РИД
Изобретение
Настоящее изобретение относится к способу и системе для определения значений измерений тела с помощью изображений тела. Более конкретно настоящее изобретение описывает способ и систему для формирования данных трехмерного изображения тела относительно объекта путем сравнения с базой данных существующих известных трехмерных моделей для получения лучшего отображения. Исходя из этого отображения, могут быть определены специфические для формы (геометрии) тела данные, включая результаты измерений.
Обычные сканеры тела и устройства измерения тела основываются на имеющих высокое разрешение датчиках глубины, фиксированных схемах освещения или известных углах съемки камеры для формирования трехмерных изображений человеческого тела. Такие способы требуют специального оборудования и представляют высокую нагрузку на пользователя, которому требуется перемещаться в специализированные центры для такого измерения тела.
Получение точных данных трехмерных измерений тела является особенно полезным в медицинской области и может использоваться, например, для мониторинга изменений в объеме тела, которые могут возникать в результате заболеваний, например почечной недостаточности. Путем оценки изменений в изображениях тела пациента возможно определять факторы, такие как задержка жидкости (отечность), и успех операции. Действительно, с продвижением телемедицины необходимость осуществлять мониторинг и предоставлять информацию об измерениях тела, вероятно, возрастет.
Кроме того, возможность формировать точное определение характеристик и измерения тела также является особенно интересной в швейной промышленности. Может цениться, что возможность предоставлять производителю одежды или розничному торговцу точные размеры тела будет полезной и для человека, ищущего одежду, и для компаний, участвующих в поставке одежды, что является особенно полезным для онлайн-покупок.
Существующие способы и устройства для обеспечения таких измерений являются либо большими и дорогими, и/либо требуют использования сложного оборудования, включая детекторы, способные определять глубину отдельных пикселей или расстояние объекта относительно опорной точки. В результате они не позволяют объектам исследования, таким как частные лица и пациенты, осуществлять мониторинг своей трехмерной геометрии тела легко или дома. Способность обеспечивать трехмерное изображение тела просто, без использования специализированных сложных сканеров тела, является, следовательно, желательной. Настоящее изобретение обращается к решению вышеупомянутых проблем.
Согласно настоящему изобретению обеспечивается способ формирования трехмерных данных тела для объекта; упомянутый способ содержит этапы:
i) захвата (ввода) одного или нескольких исходных изображений объекта с использованием устройства цифрового формирования изображений;
ii) разбиения одного или нескольких изображений на множество сегментов с использованием одного или нескольких способов сегментации;
iii) объединения результатов каждого способа сегментации на этапе ii) для создания одной или нескольких уникальных (индивидуальных) вероятностных диаграмм, представляющих объект;
iv) сравнения одной или нескольких уникальных вероятностных диаграмм с базой данных представлений трехмерных тел для определения ближайшего соответствия или лучшего отображения между данной или каждой уникальной вероятностной диаграммой и представлением, определяемым из базы данных; и
v) формирования трехмерных данных тела и/или измерений для объекта на основании лучшего отображения.
Необязательно одну или несколько стадий предварительной обработки можно применять к одному или нескольким исходным изображениям для улучшения имеющихся данных до сегментации.
Разбиение одного или нескольких изображений на множество сегментов может содержать применение одного или нескольких способов сегментации изображения, эвристических правил и/или предопределенных отображений для разбиения одного или нескольких улучшенных изображений и/или исходных изображений на множество сегментов и/или распределений вероятностей.
Объединение результатов каждого способа сегментации может содержать использование математических уравнений и/или эвристических правил.
Необязательно может применяться дополнительный способ сегментации с «затравкой» из результатов этапа iii), чтобы создавать уточненную уникальную вероятностную диаграмму для каждого исходного изображения.
Сравнение одной или нескольких уникальных вероятностных диаграмм с базой данных представлений может содержать определение лучшего отображения между каждой или всеми уникальными вероятностными диаграммами и базой данных существующих известных трехмерных моделей путем применения алгоритма градиентного спуска для минимизации различия между машинно-генерируемыми контурами для трехмерных данных и вероятностных диаграмм.
Формирование трехмерных данных тела и/или измерений может дополнительно содержать осуществление вывода трехмерных данных тела относительно объекта или других персональных метрик на основании лучшего отображения от этапа iv).
Изобретение позволяет дешевле и легче формировать данные, представляющие трехмерное изображение тела объекта, на основании 2-мерных изображений, получаемых от веб-камеры, телефона с камерой или другого устройства захвата изображения. Кроме того, поскольку специализированное оборудование формирования изображений не требуется, субъект может легко обновлять свое сформированное трехмерное изображение тела, позволяя легко осуществлять отслеживание и мониторинг изменений его формы (геометрии) тела.
Обычно могут обеспечиваться одна или несколько вероятностных диаграмм и эвристических способов, которые идентифицируют ожидаемую форму и позу (положение тела) объекта в одном или нескольких изображениях. Обычно вероятностные диаграммы являются предварительно визуализированными вероятностными диаграммами, хранимыми на сервере, либо сформированными из более ранних изображений и/или полученными из уже существующей базы данных вероятностных диаграмм, и эвристические правила являются закодированными методами в рамках системы. Например, если объект принимает позу на изображениях для представления своих левого и правого боковых видов, то обеспеченные вероятностные диаграммы и примененные эвристические правила представляют соответственный вид сбоку. В этом случае изображение с объектом, принимающим положение в позе вида с левой стороны, можно сравнивать с вероятностной диаграммой для вида с левой стороны и обрабатывать с помощью эвристических правил сегментации известных, что применимы к видам с левой стороны.
Одна или несколько вероятностных диаграмм могут также обеспечиваться на основании определенной позы объекта. Поза объекта может быть определена путем отслеживания характеристик (контура) объекта в последовательности кадров, которые могут поступать от источника (канала) видеосигнала. Типичный способ отслеживания характеристик используется пирамидальной версией оптического потока Лукаса-Канаде (Lucas-Kanade), чтобы вычислять оптический поток ключевых точек для объекта между изображениями (или кадрами, если применимо к видео). Путем взятия кадра, где позиция объекта является известной, позиции ключевых точек в изображении могут быть определены (например, с использованием способов детектирования углов). Такие точки могут быть пальцами, рисунками на одежде, татуировками, пятнами на коже и т.д. Способ Лукаса-Канаде для пирамидального оптического потока затем может использоваться, чтобы следовать этим точкам между кадрами (или изображениями). Точки могут повторно проверяться через каждые несколько кадров, чтобы предотвращать сдвиг. Такой способ позволяет более точно предполагать позу объекта внутри изображений и дополнительно позволяет, чтобы одна или несколько вероятностных диаграмм обеспечивались на основании определенной позы. Такой способ определения позы повышает гибкость системы и является особенно полезным для определения позы объектов из видео.
В исполнениях настоящего изобретения стадия ii) предварительной обработки может включать в себя:
повторное масштабирование изображения, чтобы снижать вычислительные издержки;
применение фильтров шумоподавления, таких как фильтр анизотропной диффузии;
смягчение известных характеристик камеры, таких как бочкообразное искажение и конфигурации, вносимые расположением пикселей в CCD-датчике (прибор с зарядовой связью, ПЗС);
применение попиксельного усиления освещения, чтобы улучшить детали в тени, обычно это будет следовать формуле Inew(X)=Iraw(X)α, где X является текущим пикселем, Inew(X) является улучшенным значением интенсивности для пикселя X (между 0 и 1), Iraw(X) является исходным значением интенсивности для пикселя X (между 0 и 1), и α является числом, которое может быть постоянным или основанным на атрибутах изображения. Исполнения могут варьировать α в соответствии с позицией внутри изображения, например, усиливая нижнюю часть изображения более значительно, как в этом примере:
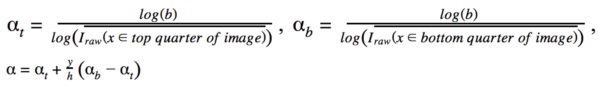
где γ - вертикальная координата текущего пикселя, H - высота изображения.
Кроме того, совокупность способов сегментации изображения, применяемых к одному или нескольким изображениям на стадии iii), может включать в себя:
инвариантные способы, такие как предварительно визуализированные вероятностные диаграммы для конкретного вида (view);
сравнения попиксельные или способом скользящего окна, например просмотр заранее определенных диапазонов цвета, которые соответствуют цветам кожи или текстуре, которая соответствует ткани;
способы на основе обучения, например помещение лица в вид спереди, чтобы обучиться цвету кожи человека и/или цветам одежды, и/или использование выбранной, предварительно визуализированной вероятностной диаграммы, чтобы обучиться цветам фона. Идентифицированные цвета (в пространстве цветопередачи красный-зеленый-синий (RGB) или ином) и/или позиции (в пространстве изображения) могут быть проанализированы (например, с помощью модели Смеси гауссиан (Gaussian Mixture Model)) для создания ожидаемого цветового распределения для каждого сегмента, которое может затем использоваться для формирования сегментации изображения;
итеративные оптимизации, например, использующие активные контуры (с предопределенной геометрией человека в качестве «затравки» в соответствии с текущим видом и/или позой, детектированным другими способами), чтобы максимизировать интенсивность на крае изображения вдоль периметра контура, которые также могут объединяться с имитациями твердого тела или мягкого тела для улучшенных результатов;
сравнения областей пикселей в одном виде с соответствующей областью в другом виде, например сравнения левой и правой сторон изображений "вид спереди с поднятыми руками" и "вид сбоку", чтобы идентифицировать руки (при условии, что фон остается постоянным между изображениями). Исполнения могут включать в себя дополнительное изображение только фона (объект вне кадра) с этой целью;
способы анализа краев, например поиск границ с конкретными атрибутами, такими как полукруглая форма (соответствующая ступне) или конкретный угол (соответствующий рукам, ногам или торсу). Границы могут быть детектированы с использованием одного или нескольких способов, таких как применение оператора Собеля, алгоритма детектора контуров Кэнни, и специализированных способов;
обобщенные способы сегментации, такие как способ Graph Cut (разрезание графа), или способы с несколькими масштабами, такие как сегментация взвешенной агрегацией;
специализированные эвристические правила, такие как идентификация точек плеча в виде спереди, чтобы задать область для торса, или идентификация пересекающихся линий, чтобы определить позицию подмышек и точку паховой области.
Обычно способы применяются к изображению, закодированному в пространстве цветовой модели "яркость - цветность синего - цветность красного" (YCbCr), с некоторыми способами, использующими только канал яркости, и другими, потенциально назначающими дополнительный вес каналами Cb и Cr, однако могут использоваться другие цветовые пространства, такие как RGB или sRGB.
Способы сегментации, которые возвращают множество сегментов (например, голову, рубашку, стул, стол), могут дополнительно обрабатываться путем анализа формы, цвета, текстуры и/или позиции каждого сегмента. Путем сравнения этих метрик с предопределенными или иным образом вычисленными ожиданиями сегменты могут быть обращены в более простой двоичный формат переднего плана/фона или заданную посегментную вероятность.
Если используются множественные способы сегментации, исполнения могут объединять свои результаты в единую уникальную вероятностную диаграмму «на один вид» с помощью различных способов. Используемый способ может зависеть от текущего вида и/или способа сегментации или могут быть предприняты несколько способов с оценочной функцией, осуществляющей выбор лучшего результата. Возможные способы для объединения результатов ρ1 и ρ2 в ρT включают в себя:
усреднение 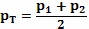 ;
;
добавление областей, известных, что будут объектом 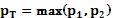 ;
;
добавление областей, известных, что будут фоном 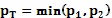 ;
;
объединение вероятностей 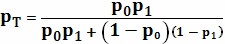 ,
,
с особыми случаями для 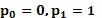 и
и 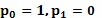 ;
;
более сложные способы, такие как 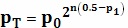 для некоторых
для некоторых 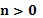 или
или 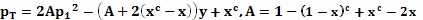 для некоторых
для некоторых 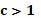 . Эти особые способы являются применимыми, когда
. Эти особые способы являются применимыми, когда  содержит некоторое базовое ожидание (например, предварительно визуализированную вероятностную диаграмму), которое должно корректироваться согласно
содержит некоторое базовое ожидание (например, предварительно визуализированную вероятностную диаграмму), которое должно корректироваться согласно 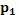 , но поддерживать жесткие ограничения.
, но поддерживать жесткие ограничения.
Может цениться, что многие из этих способов тривиально распространяются на объединение более двух результатов или могут объединяться в цепочку, чтобы объединять произвольные количества результатов сегментации. Может также цениться, что взвешивания могут применяться к каждой сегментации на этой стадии, определяться вручную, эмпирически и/или автоматически на основании атрибутов сегментации (таких как степень симметрии).
После создания единой уникальной вероятностной диаграммы для каждого исходного изображения исполнения могут уточнять диаграмму при помощи дополнительных способов сегментации, таких как сегментация взвешенной агрегацией или Grab Cut. В случае Grab Cut дается ввод «известного переднего плана», «вероятного переднего плана», «вероятного фона» и «известного фона», который может формироваться с использованием тривиальной пороговой обработки вероятностных диаграмм. Может также цениться, что эта диаграмма с 4 состояниями или ее разновидности могут рассматриваться в качестве вероятностных диаграмм самостоятельно и могут, следовательно, быть непосредственным выводом предыдущих стадий сегментации.
Исполнения изобретения, кроме того, позволяют компенсацию переменной резкости линии, создаваемой неравными условиями освещения в исходных изображениях, с помощью тех же способов, также позволяя, чтобы окончательные вероятностные диаграммы были масштабированы с повышением до равного или большего разрешения, чем первоначальное исходное изображение. Это осуществляется размытием краев уникальной вероятностной диаграммы, сформированной вышеупомянутым способом, чтобы создать границу из неопределенных пикселей. Размытие краев приводит к градиенту вероятности в уникальной вероятностной диаграмме от фона к объекту. Направление и уровень этого градиента затем можно идентифицировать и использовать, чтобы указывать направление к объекту в каждом неопределенном пикселе с помощью линии вектора. Обычно направление этой линии вектора является по существу перпендикулярным краю. Из этих градиентов может быть сформирована векторная (направленная) вероятностная диаграмма внешнего контура, упомянутая диаграмма обеспечивает вектор направления (линию вектора) для каждого неопределенного пикселя (обычно краевых пикселей), обозначающий локальное ожидаемое направление объекта относительно пикселя.
Векторная вероятностная диаграмма контура затем может применяться к исходному изображению или изображениям. Путем отслеживания траектории, указанной векторной вероятностной диаграммой контура, как применено к первоначальному изображению, возможно определить в первоначальном изображении пиксели, которые лежат на каждой линии вектора с наивысшей контрастностью. Эти пиксели представляют граничные пиксели, расположенные на границе объекта, которые отделяют объект от фона в изображении. Эта граница является оптимальной в случае, если нет шума и какого-либо размытия изображения, являющихся гауссианом, что является хорошим приближением для изображений камеры. Кроме того, сравнение цвета и/или интенсивности граничного пикселя с цветами и/или интенсивностью соседних пикселей может давать возможность, что оценка истинной границы для каждого граничного пикселя будет устанавливаться с субпиксельным разрешением. Оценка истинной границы для каждого граничного пикселя может вычисляться с использованием 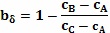 , где
, где 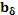 задает расстояние вдоль вектора между границей в пикселях и истинной границей в субпикселях,
задает расстояние вдоль вектора между границей в пикселях и истинной границей в субпикселях, 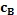 - интенсивность текущего пикселя,
- интенсивность текущего пикселя, 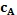 - интенсивность предыдущего пикселя вдоль вектора, и
- интенсивность предыдущего пикселя вдоль вектора, и 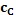 - интенсивность следующего пикселя вдоль вектора. Как только оценка истинной границы была определена, она может применяться к соответствующей позиции на уникальной вероятностной диаграмме, чтобы обеспечить оценку истинной границы для каждого граничного пикселя уникальной вероятностной диаграммы.
- интенсивность следующего пикселя вдоль вектора. Как только оценка истинной границы была определена, она может применяться к соответствующей позиции на уникальной вероятностной диаграмме, чтобы обеспечить оценку истинной границы для каждого граничного пикселя уникальной вероятностной диаграммы.
Окончательные уникальные вероятностные диаграммы обеспечивают внешний контур объекта для каждого вида, где области, определенные достоверно являющимися объектом, имеют вероятность, близкую к 100%, области, определенные являющимися фоном (конкретно не объектом), имеют вероятность, близкую к 0%, и краевые области имеют промежуточные вероятности. Обычно упомянутые уникальные вероятностные диаграммы имеют разрешение в 0,2-0,5 пикселя в зависимости от уровней шума в исходных изображениях.
Исполнения настоящего изобретения могут сравнивать одну или несколько уникальных вероятностных диаграмм с существующей базой данных трехмерных представлений тела для определения ближайшего (наиболее точного) соответствия и/или могут использовать способ интерполяции, чтобы формировать новые «тела», исходя из существующей базы данных для определения лучшего отображения. Существующая база данных обычно заполняется эмпирическими данными, накопленными от специализированных сканеров тела. Такие представления могут включать в себя трехмерные измерения тела, измерения объектов, сделанные вручную, и/или скан-изображения (томографические).
Для определения ближайшего соответствия можно исчерпывающе просматривать испытательные скан-изображения, оптимизируя каждое относительно вариаций позы и камеры и определяя лучший результат, как указано ниже, хотя может цениться, что оптимизации, такие как группировка скан-изображений по конкретным атрибутам (таким как пол, вес, возраст), можно применять, чтобы уменьшить пространство поиска, и может применяться упорядочение, чтобы давать возможность аппроксимации двоичного поиска. Однако определение ближайшего соответствия не может предложить результаты, которые не присутствуют уже в базе данных, и по этой причине предпочитается лучшее отображение. Последующие параграфы опишут процесс, используемый в нахождении лучшего отображения.
Может использоваться линейная интерполяция, чтобы формировать новые скан-изображения, исходя из существующей базы данных, что является полезным, поскольку позволяет использование способов линейной оптимизации, чтобы идентифицировать лучшее отображение. Среднее трехмерное представление тела и последовательность векторов, описывающая вариации нормированных трехмерных представлений тела в рамках существующей базы данных («Векторы данных тела», Body Vectors), могут предварительно формироваться с помощью анализа главных компонент. Эта стадия может включать в себя способы для нормирования позы каждого объекта и/или вывода недостающих данных (например, «вкрапленные» области скан-изображений от сканеров структурированного света). Результаты этого анализа обычно будут записываться заранее, извлекаться по необходимости и именуются «Пространство тел» (Space of Bodies). Исполнения могут также включать данные измерений в этот анализ; создание средних измерений и справочной таблицы, обозначающей, каким образом каждое измерение должно изменяться, если изменяется вклад каждого вектора тела (например, если вектор тела контролирует вес по скан-изображению, то будет обычно увеличиваться окружность талии, если размер скан-изображения увеличивается). Эти корреляции обычно будут формироваться автоматически и могут не иметь очевидной физической интерпретации. Чтобы гарантировать применимость линейных способов, измерения могут предварительно обрабатываться, чтобы создать линейно связанные значения (например, взятием кубического корня любых объемных измерений и декомпозицией эллиптических измерений на большую и малую оси и коэффициент масштабирования).
В исполнениях только выбранные данные изображения тела формируются с учитываемыми или отбрасываемыми областями изображения объекта. Такие исключения могут предприниматься путем использования вероятностных диаграмм, которые не включают области объекта, например область головы, или отбрасывания атрибутов после сегментации. Это может быть полезным, поскольку позволяет из данных изображения тела исключать атрибуты, которые не относятся к фактическому размеру тела, например волосы. Исключение этих атрибутов препятствует влиянию на результаты явно произвольных деталей, таких как прическа.
Пространство тел может исследоваться с использованием алгоритма градиентного спуска с переменными, управляющими камерой (например, позиция, поворот, поле обзора), позой (например, углы в сочленении) и формой тела (например, первые N векторов тела, где обычно  ) в скан-изображении. Это обычно касается начала со среднего или грубого предполагаемого значения для каждой переменной и итеративного уточнения значения методом проб и ошибок. Способ Ньютона-Рафсона (Newton-Raphson) является одним возможным вариантом и может использоваться для минимизации суммы абсолютных разностей вероятностей для каждого пикселя в машинно-генерируемом контуре в зависимости от вычисленной уникальной вероятностной диаграммы для текущего объекта. Математически
) в скан-изображении. Это обычно касается начала со среднего или грубого предполагаемого значения для каждой переменной и итеративного уточнения значения методом проб и ошибок. Способ Ньютона-Рафсона (Newton-Raphson) является одним возможным вариантом и может использоваться для минимизации суммы абсолютных разностей вероятностей для каждого пикселя в машинно-генерируемом контуре в зависимости от вычисленной уникальной вероятностной диаграммы для текущего объекта. Математически 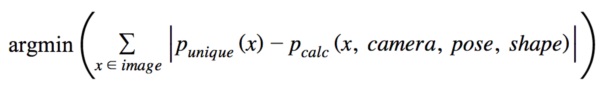 ,
,
где 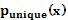 является значением уникальной вероятностной диаграммы в текущем пикселе и
является значением уникальной вероятностной диаграммы в текущем пикселе и 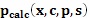 имеет значение 1, если машинно-генерируемый контур для текущей камеры c, позы ρ и формы s тела содержат текущий пиксель, и 0 - в противном случае, camera (камера), pose (положение) и shape (форма), и являются аргументами поиска. Следует отметить, что использование функции абсолютного значения выбрано, чтобы оптимизировать поиск Ньютона-Рафсона, который требует квадратичной функции. Для других способов поиска могут быть подходящими другие (функции) стоимости, такие как сумма квадратов. Также может быть полезным использовать вторичную метрику расстояний, чтобы быстро отбрасывать локальные минимумы. Например, взятие суммы минимальных расстояний от каждого из машинно-генерируемых пикселей до пикселя в уникальной вероятностной диаграмме, который имеет значение выше предопределенного порога
имеет значение 1, если машинно-генерируемый контур для текущей камеры c, позы ρ и формы s тела содержат текущий пиксель, и 0 - в противном случае, camera (камера), pose (положение) и shape (форма), и являются аргументами поиска. Следует отметить, что использование функции абсолютного значения выбрано, чтобы оптимизировать поиск Ньютона-Рафсона, который требует квадратичной функции. Для других способов поиска могут быть подходящими другие (функции) стоимости, такие как сумма квадратов. Также может быть полезным использовать вторичную метрику расстояний, чтобы быстро отбрасывать локальные минимумы. Например, взятие суммы минимальных расстояний от каждого из машинно-генерируемых пикселей до пикселя в уникальной вероятностной диаграмме, который имеет значение выше предопределенного порога 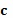 (например,
(например, 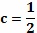 ). Вновь это оптимизируется для поиска по Ньютону-Рафсону. Математически
). Вновь это оптимизируется для поиска по Ньютону-Рафсону. Математически 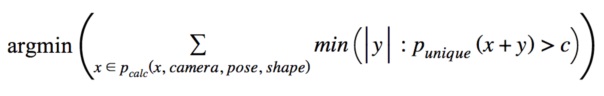 .
.
Ограничения, такие как повышение стоимости для функции, если аргументы изменяются вне допустимых пределов, являются полезными для предотвращения нереалистичных результатов. Например, включение мягкого предельного значения, если расстояние ноги становится слишком широким, с жестким предельным значением после известного невозможного расстояния или расстояния, которое не соответствует требуемой позе. Подобные принципы могут применяться к атрибутам формы тела и камеры.
Форма тела оптимизируется по всем видам, а поза и атрибуты камеры являются «повидовыми». Может цениться, что в управляемых средах множество снимков может делаться одновременно, в каком случае поза становится атрибутом, который может быть оптимизирован по всем видам также. Фиксированные позиции и атрибуты камеры могут, кроме того, позволять, чтобы переменные камеры удалялись из этой стадии полностью.
В исполнениях эта стадия минимизации может обеспечиваться минимизацией для небольшого числа параметров последовательно для повышенного быстродействия. Например, изменение переменных камеры и позы, блокируя при этом переменные геометрии тела, затем изменение первых 5 векторов тела, блокируя при этом все остальные, затем изменение первых 15 векторов тела и переменных камеры и т.д. Точная последовательность может быть определена эмпирически заранее и/или автоматически в результате анализа текущего состояния (например, заданием большего времени на оптимизацию позиции ног, если она предварительно значительно изменилась).
Конечным результатом этой стадии является уникальное трехмерное скан-изображение объекта. Такие же принципы применяют к нахождению ближайшего соответствия, но включают итерацию по всем скан-изображениям в базе данных вместо изменения векторов тела. В любом случае результирующее скан-изображение (игнорирующее позу тела) теперь будет именоваться «уникальное трехмерное скан-изображение».
Как только было получено ближайшее соответствие или лучшее отображение, исполнения могут вычислять измерения, используя Справочную таблицу измерения и/или измеряя траектории на уникальном трехмерном скан-изображении. Для лучшего отображения определенные значения вектора тела используются в комбинации со Справочной таблицей, чтобы линейно интерполировать средние измерения, создавая уникальный набор измерений. Для ближайшего соответствия измерения могут извлекаться непосредственно из Справочной таблицы. Эти измерения являются все немасштабированными и могут масштабироваться согласно нескольким факторам, включая: известное измерение (например, высота объекта); определенное расстояние между объектом и камерой (например, с использованием аппаратного датчика глубины или известной среды) и/или сравнение с калиброванным известным предметом (например, маркером или обычным предметом, таким как лист бумаги). В отсутствие этой информации масштаб может быть аппроксимирован путем допущения, что он подобен таковому для известных объектов с подобной формой тела (например, относительно более крупная голова обычно подразумевает меньший масштаб). Эта аппроксимация может вычисляться с использованием тех же способов Справочной таблицы (LOOKUP), как для других измерений. На этой стадии измерения будут обычно ненормированными, объемы кубическими, окружность разложенных эллипсов повторно вычисленной и так далее.
Кроме того, в исполнениях трехмерные данные тела для объекта могут выводиться. Данные могут выводиться на одно или несколько запоминающих устройств, онлайн-хранилище на основе облака, мобильный телефон, экран устройства отображения или персональное вычислительное устройство.
Варианты осуществления настоящего изобретения теперь будут описаны со ссылкой на последующие чертежи, на которых:
фиг. 1 - схематическое общее представление настоящего изобретения;
фиг. 2 - блок-схема настоящего изобретения, относящаяся к накоплению данных;
фиг. 3 - блок-схема настоящего изобретения, относящаяся к способам, используемым для формирования уникальных вероятностных диаграмм;
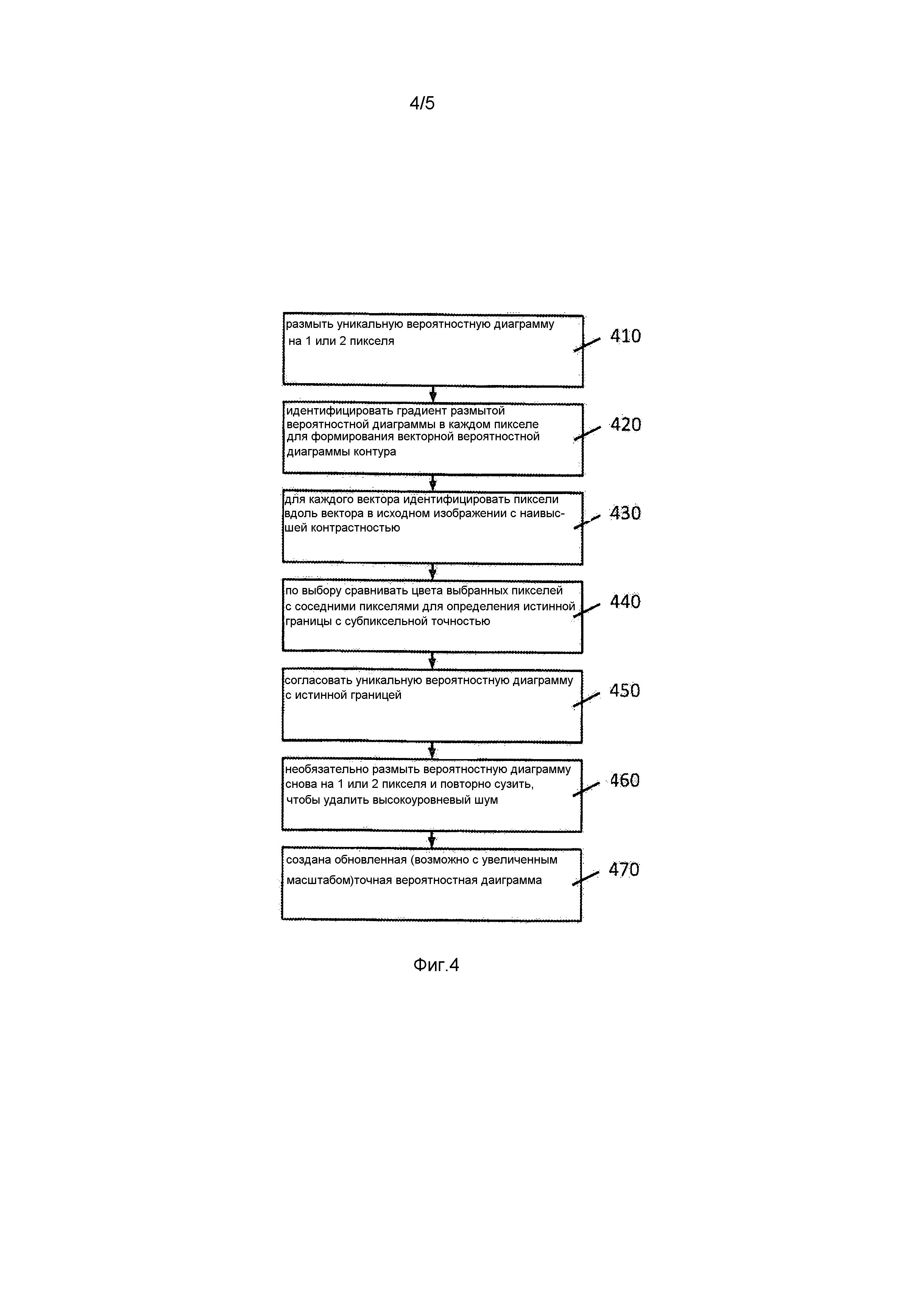
фиг. 4 - блок-схема настоящего изобретения, относящаяся к улучшению уникальной вероятностной диаграммы; и
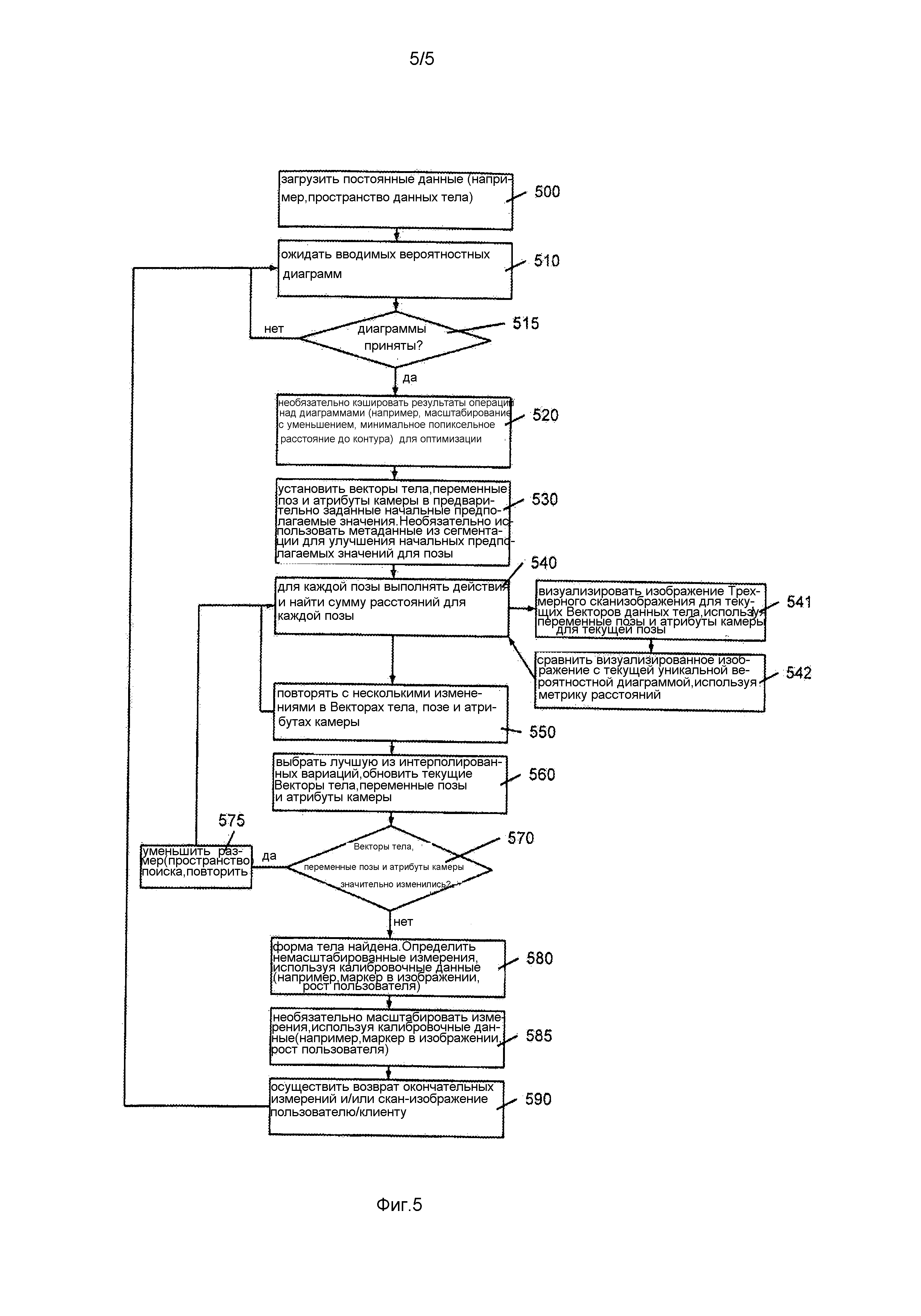
фиг. 5 - блок-схема настоящего изобретения, относящаяся к формированию трехмерного изображения тела на основании уникальной вероятностной диаграммы и опорных трехмерных представлений тела.
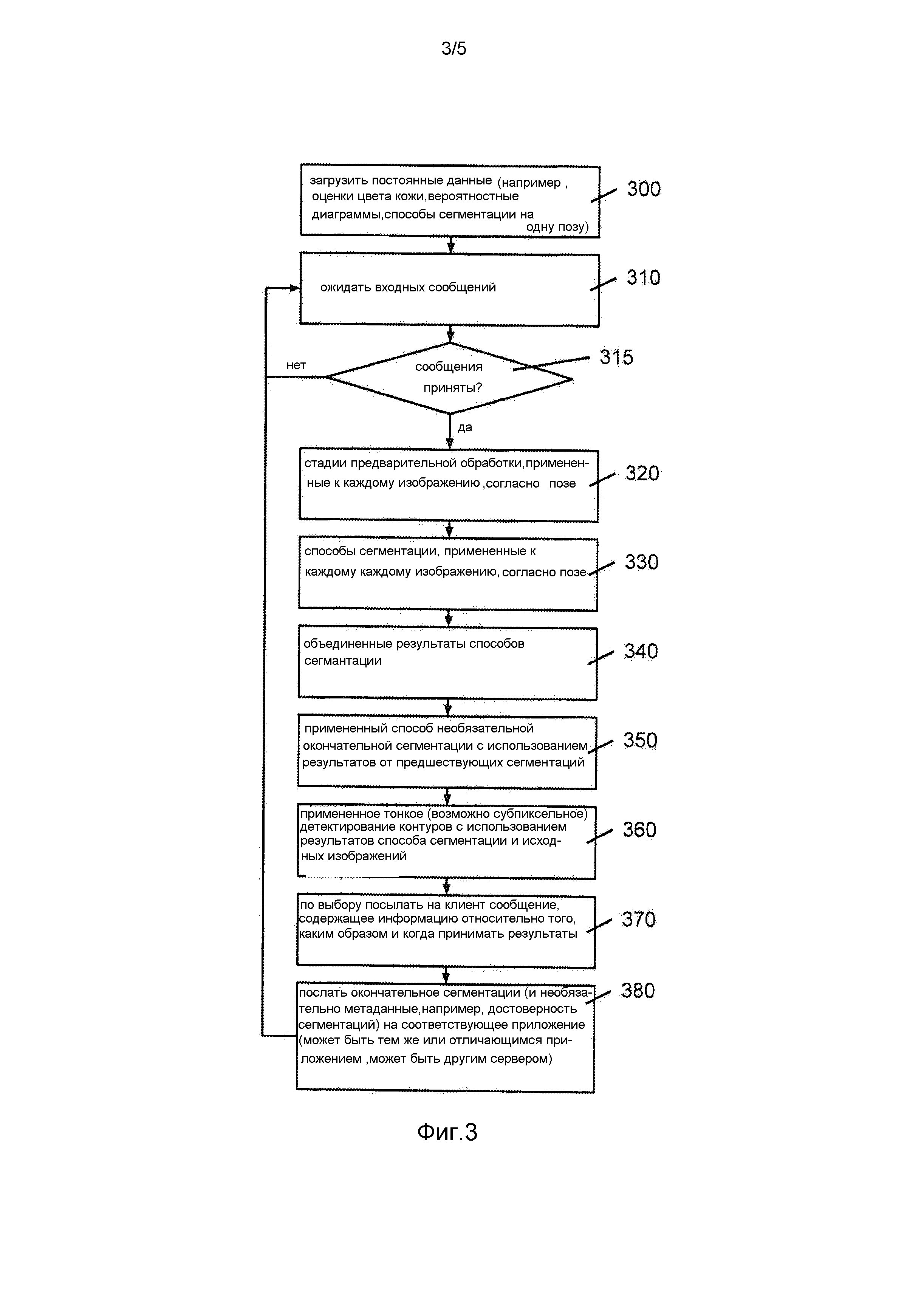
Со ссылкой на чертежи система 10 (фиг. 1) оснащена «неинтеллектуальной» клиентской системой 20 ввода/вывода и серверным блоком 30.
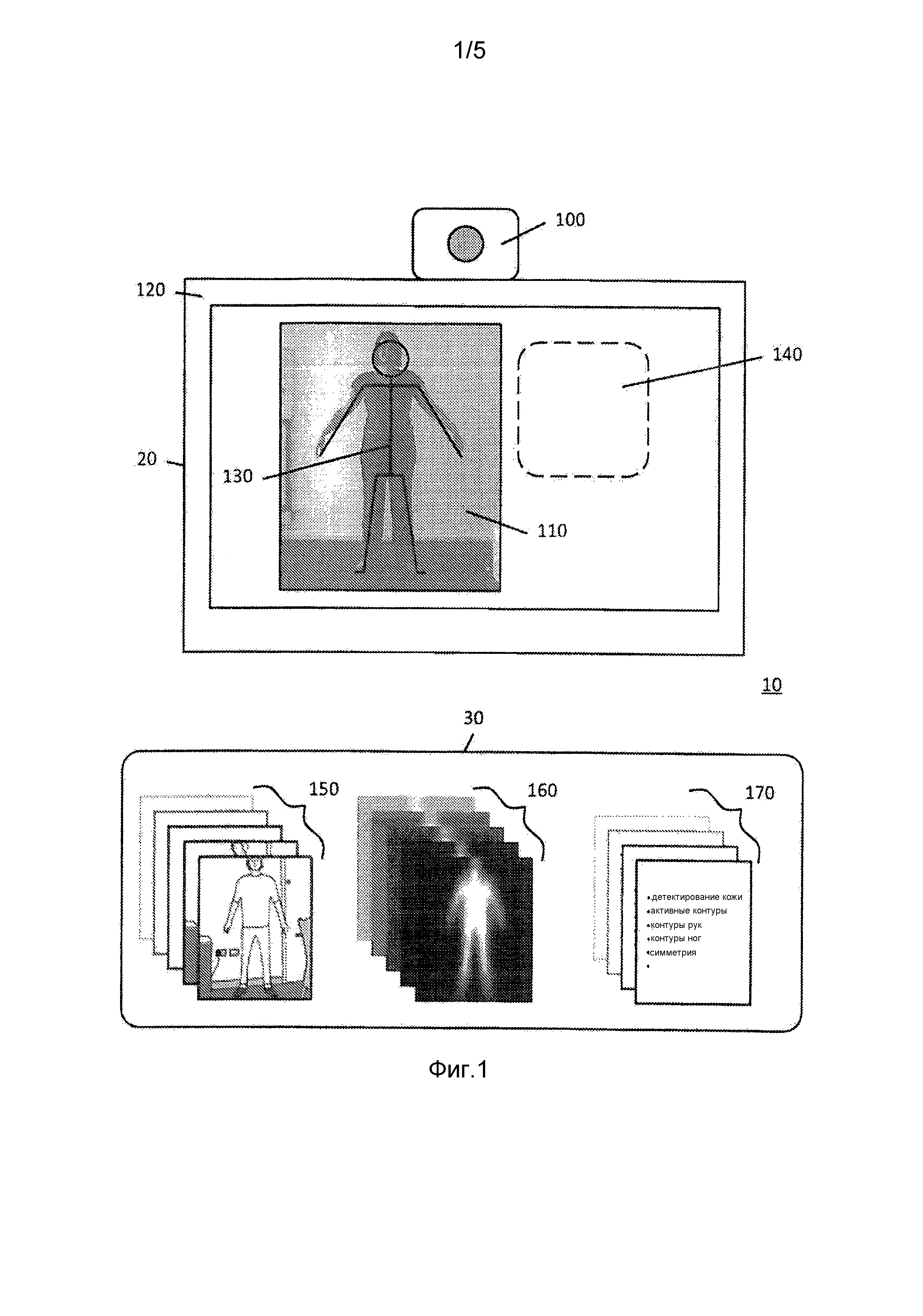
Клиентская система 20 содержит веб-камеру 100, которая используется для получения информации изображения от объекта. В использовании веб-камера 100 используется вместе с экраном 120, таким как компьютерный монитор, который отображает представление 110 объекта. Программное обеспечение, управляющее веб-камерой 100, если веб-камера приведена в действие, выдает команду на экран 120, так что экран 120 отображает представление 130, соответствующее позиции позы тела. Обычно требуемой позицией позы является «обращенная вперед», ноги и руки отстоят от тела; анатомическая позиция. Кроме того, позиции боковых профилей (вдоль срединной плоскости) также могут требоваться 225 (фиг. 2).
Когда представление 110 объекта, отображенное на экране, совпадает с предопределенным внешним контуром 220, объект считается находящимся «в позе» (это может также зависеть от пребывания неподвижным в течение нескольких секунд). Когда объект готов и удовлетворяется условие, что объект стоит в требуемой позе 130, веб-камера 100 снимает последовательность изображений 150, 240 объекта в позиции принятой позы. Как только накоплено необходимое число изображений, изображения сжимают и сохраняют для последующей загрузки на серверный блок 30, 270.
Может цениться, что вышеупомянутые этапы могут повторяться столько раз, сколько требуется для формирования более большой базы данных изображений объекта в принятой позе. Кроме того, в качестве альтернативы веб-камере могут использоваться камеры мобильных телефонов для захвата требуемых изображений. В таком случае экран 120 и программное обеспечение для исполнения захвата изображения и выдачи команд на объект могут находиться непосредственно в телефоне, использующем специальное приложение. Может также цениться, что обычная камера может использоваться для формирования изображений, а также другие известные устройства захвата изображения и программное обеспечение. Кадры от источников видео также могут использоваться.
В дополнение к захвату изображений клиентская система 20 может запрашивать дополнительную информацию 140 от объекта для содействия процессу калибровки и распознавания изображений. В качестве примера калибровочные данные для идентификации относительных масштабов в двумерных изображениях могут накапливаться запросом высоты объекта 200. Другие необязательные возможности включают запрашивание объекта поднести к камере калиброванный маркер, такой как игральная карта. Обработке изображений могут содействовать дополнительные вопросы, такие как общее количество и/или цвет носимой одежды.
Кроме того, клиентская система 20 может также выполнять элементарные проверки на снятых и сохраненных изображениях 240. Эти проверки могут включать в себя анализ изображений относительно характеристик фона и запрос, что объект перемещается в другую область, если детектируется слишком много характеристик фона. Такой анализ может также позволять дополнительную калибровку между относительной высотой объекта из полученных изображений, как если найдена общая характеристика фона, это может использоваться, чтобы гарантировать, что все изображения объекта имеют согласованную высоту, чтобы учитывать переменное расстояние между объектом и устройством формирования изображений. Альтернативно или дополнительно упомянутый анализ может удалять общие характеристики фона (чтобы помочь последующим этапам) или может потребовать получение новых изображений, если детектируется слишком много характеристик фона.
Как только изображения 150 были захвачены клиентской системой 20, они загружаются на серверный блок 30, 270. Серверный блок 30 может быть компьютером объекта, или смартфоном, или подобным, хотя обычно серверный блок 30 является специализированным внешним сервером. Сервер содержит базу данных известных вероятностных диаграмм 160, соответствующих ожидаемым позициям объекта на основании позиций принятых поз, стоять в которых объект был проинструктирован на этапе 300, и совокупность способов 170 сегментации, которые были определены применимыми к каждой позе. Альтернативно поза объекта может быть определена с использованием способа отслеживания характеристик. Типичный способ отслеживания характеристик использует способ Лукаса-Канаде пирамидального оптического потока, чтобы вычислять оптический поток ключевых точек объекта между изображениями (или кадров, если применен к видео). Путем взятия кадра, где позиция объекта является известной, позиции ключевых точек в изображении могут быть определены (например, с использованием способов детектирования углов). Такие точки могут быть пальцами, рисунками на одежде, татуировками, пятнами на коже и т.д. Способ оптического потока затем может использоваться, чтобы отслеживать эти точки между кадрами (или изображениями). Точки могут повторно проверяться через каждые несколько кадров, чтобы предотвращать смещение. Такой способ позволяет более точно предполагать позу объекта внутри изображений и, кроме того, позволяет, чтобы вероятностные диаграммы обеспечивались на основании определенной позы. Такой способ определения позы повышает гибкость системы и является особенно полезным для определения позы объектов из видео.
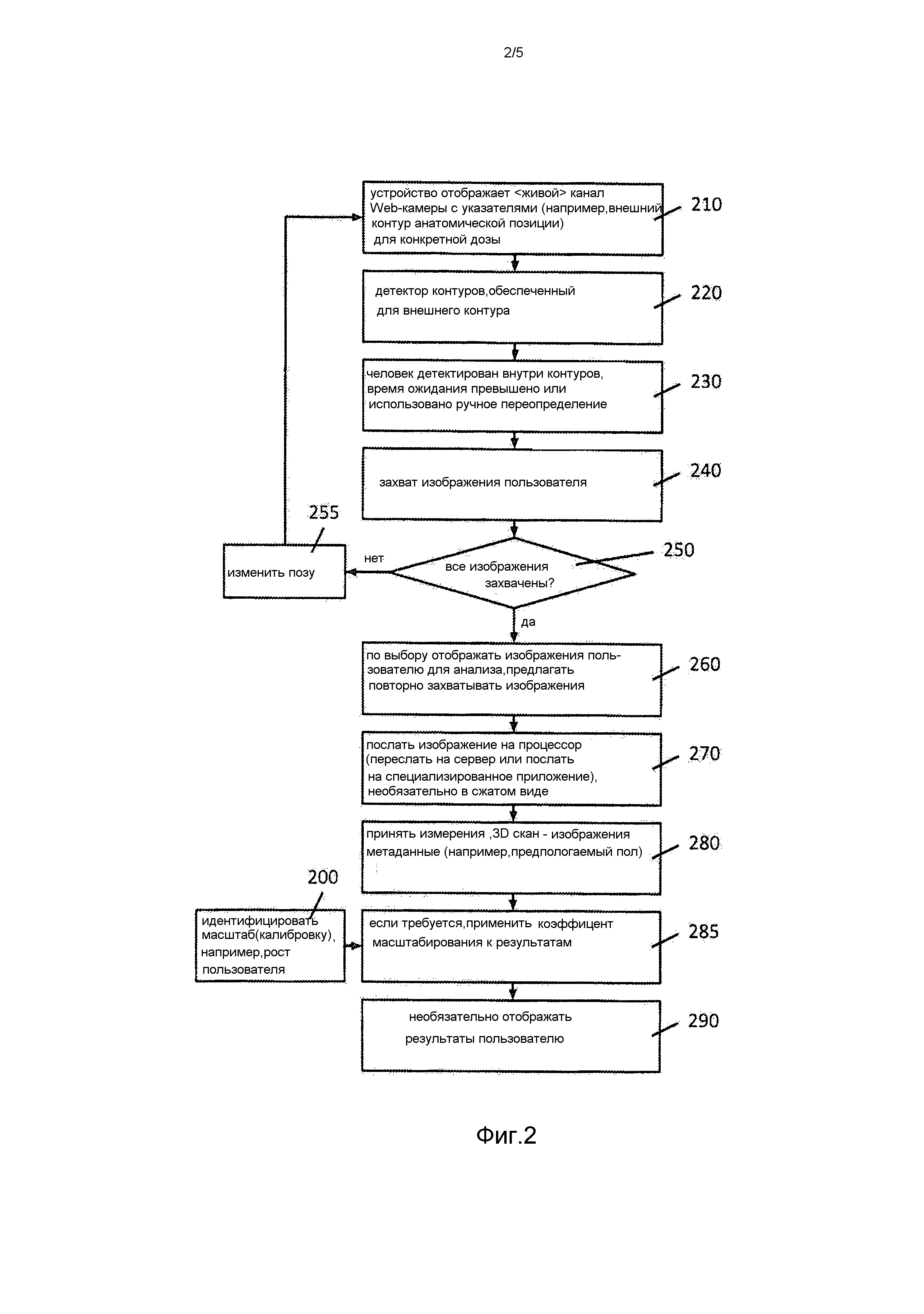
Первоначально серверный блок 30 осуществляет анализ входящих изображений и предварительно обрабатывает их 320, чтобы нормировать освещение, детектировать и удалять структуры в изображениях, вносимые от CCD-датчиков (устройство с зарядовой связью) или подобных, таких как активные датчики пикселей (APS) (формирователь сигналов изображения), корректирует бочкообразное искажение или другие известные искажения. Из этих отфильтрованных изображений сервер 30 затем определяет, что, вероятно, будет предпочтительнее представлением объекта 110, чем фоном или шумом 330-360.
Чтобы определить местоположение объекта внутри изображения, сервер 30 применяет различные способы 330 сегментации изображения, которые были выбраны заранее для конкретной позы. Они могут включать в себя настраиваемые вручную или автоматически способы, которые выдадут лучшие результаты в конкретных областях изображения, а также более общие способы, и могут использовать и предварительно визуализированную вероятностную диаграмму 160, и предварительно обработанное исходное изображение(я). Способы сегментации могут также совместно использовать результаты с другими способами сегментации (например, детектор кисти может уменьшить пространство поиска, требуемое детектором руки). Результаты каждого способа сегментации объединяются 340, позволяя серверу формировать первую оценку о форме (объекта) предмета. Предварительно визуализированные вероятностные диаграммы 160 могут дополнительно использоваться, чтобы уточнить идентифицированный контур, помогая удалению объектов фона, которые могли быть некорректно идентифицированными. Например, анализ цветового распределения может идентифицировать цвет (например, красный) в качестве показательного для объекта, однако если фон будет содержать идентичный цвет, он будет идентифицирован в качестве показательного для объекта, если основан только на одном цветовом распределении. Объединением цветового распределения с вероятностной диаграммой такие характеристики фона могут быть устранены.
Как только первая оценка формы тела объекта была определена и создана уникальная вероятностная диаграмма, система предпринимает следующий этап, чтобы компенсировать переменные условия освещения в исходных изображениях, которые влияют на резкость линии. Чтобы компенсировать эту переменную резкость линии, система «сознательно» размывает края, присутствующие в вероятностной диаграмме 410. Это размытие обычно имеет значение порядка 1 или 2 пикселей (по существу линия без контурных неровностей) и может быть объединено с повышающим масштабированием (укрупнением) вероятностных диаграмм для большей точности.
Размытием краев сформированной вероятностной диаграммы системе помогают в определении направления пикселей относительно ожидаемой позиции объекта 420. Поскольку вероятностной диаграммой является высококонтрастное полутоновое изображение, система может идентифицировать области (неопределенных пикселей), где происходит изменение наивысшей контрастности, и назначить направленность этому изменению и этим пикселям. Это направление является нормалью к краям вероятностных диаграмм и идентифицирует направление объекта (белизна вероятностных диаграмм) во всех пикселях внутри неопределенных (размытых) краевых точек.
Как только определена направленность неопределенного пикселя, она может быть применена к первоначальному RGB изображению, чтобы найти области (пикселей) с наивысшей контрастностью, то есть где градиент между соседними пикселями имеет наибольшее значение 430. Это определение позволяет, что граница объекта в RGB изображении будет определяться точно внутри разрешения в один пиксель. Кроме того, улучшенное субпиксельное разрешение может быть получено путем сравнения граничного пикселя с соседними пикселями для получения индикации истинной граничной позиции 440. Этого можно добиться определением цветового градиента между граничным пикселем и соседним пикселем и назначением оценки истинной граничной позиции в точке, где градиент является наибольшим. Указание истинной оценки граничной позиции дается согласно: 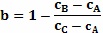 , где b - истинная оценка границы, cB - интенсивность для текущего пикселя, cA - интенсивность предыдущего пикселя вдоль вектора, и cC - интенсивность следующего пикселя вдоль вектора. Этот этап представляет этап точного обратного устранения контурных неровностей для двух блоков сплошного (чистого) цвета и, следовательно, является особенно полезным для принятия во внимание контурных неровностей, вносимых датчиками CCD.
, где b - истинная оценка границы, cB - интенсивность для текущего пикселя, cA - интенсивность предыдущего пикселя вдоль вектора, и cC - интенсивность следующего пикселя вдоль вектора. Этот этап представляет этап точного обратного устранения контурных неровностей для двух блоков сплошного (чистого) цвета и, следовательно, является особенно полезным для принятия во внимание контурных неровностей, вносимых датчиками CCD.
Как только граница была определена в RGB изображении, эта информация затем используется в вероятностной диаграмме, чтобы обеспечить точное представление края сформированной вероятностной диаграммы 450. Шум, вносимый процессом идентификации краев, может быть уменьшен размытием идентифицированного края на ±1 пиксель и повторным сглаживанием 460. Конечный результат для этой стадии является последовательностью точных, специфических для ввода вероятностных диаграмм 470, по одной на одно исходное изображение 150.
С помощью последовательности точных, специфических для ввода вероятностных диаграмм теперь возможно выполнять отображение этих вероятностных диаграмм на предварительно вычисленные средние формы тела, чтобы предпринять усилие сформировать окончательную трехмерную форму тела для объекта. Это осуществляется с использованием базы данных, содержащей предварительно вычисленную среднюю форму тела, и извлеченные главные компоненты «Векторов тела», которые сохраняются на сервере, как изложено ниже. «Вектор тела» или Eigenbody (собственное тело) является подобным известному термину Eigenvector (собственный вектор) или Eigenface (собственная поверхность) и является представлением того, каким образом тело может изменяться (увеличение размера бедер приводит к соответствующему увеличению размера бюста и т.д.). Это вычисляется заранее с использованием анализа главных компонент. Например, конкретное изображение тела может содержать среднюю форму тела плюс 60% вектора 1 тела, -12% вектора 2 тела и 18% вектора 3 тела. Это дает возможность сохранения математического представления скан-изображения тела без сохранения непосредственно скан-изображения. Кроме того, поза предварительно вычисленного среднего тела может быть выбрана или вычислена, чтобы соответствовать позе объекта, как предварительно определено.
Эта база данных изменений параметров тела предварительно загружается посредством сервера 500. Когда принимается 515 последовательность уникальных вероятностных диаграмм, сервер выполнит поиск по пространству тел (возможные тела, сформированные из комбинаций среднего тела и вектора тела), чтобы найти лучшее отображение 530-575. Первоначально векторам тела назначаются вклады в нуль (создание среднего тела без вариации), и воспринимаемые значения по умолчанию на одну позу назначаются переменным камеры и позы (например, позиция камеры, расстояние между руками) 530. Эти значения по умолчанию могут быть изменены согласно характеристикам, идентифицированным согласно способам сегментации 330. Соответствующее тело визуализируется для каждой позы 541, и эти визуализации сравниваются с уникальными вероятностными диаграммами 542. Используемая функция расстояния может быть простой средней абсолютной разностью на один пиксель или чем-то более сложным, таким как сумма минимального расстояния между краевыми пикселями. Множество способов можно использовать вместе, например, используя минимальное расстояние между краевыми пикселями, чтобы определять атрибуты позы и камеры, затем используя среднюю абсолютную разность, чтобы уточнить форму тела. Эти способы могут извлекать пользу из предварительного кэширования значений 520 для улучшения времен отклика.
Путем многократного изменения некоторых атрибутов (таких как вклады вектора тела) и повторного измерения расстояния между визуализируемыми скан-изображениями и наблюдаемыми уникальными вероятностными диаграммами 540-575 могут итеративно уточняться векторы тела, переменные позы и атрибуты камеры. Обычно это включает в себя выборку нескольких вариаций 550, затем подбор простой математической формы (такой как парабола) к расстояниям, чтобы идентифицировать вероятное минимальное расстояние. Значения в этом минимуме затем могут проверяться, и выбирается глобальный минимум из всех выборок 560, затем пространство поиска уменьшается, и процесс повторяется. Как только пространство поиска становится достаточно малым, процесс завершается, и окончательные значения представляют лучшее отображение 580. Обычно этот этап оптимизации будет повторяться несколько раз, всякий раз с некоторыми переменными - "блокированными", и остальными - "свободными", например начальный поиск может блокировать все вклады вектора тела, изменяя только атрибут камеры и переменные позы, и за этим может следовать блокировка камеры, при уточнении при этом первых 5 векторов тела и грубой позы, и т.д.
Окончательная форма тела, поза и атрибуты камеры будут выдавать контур, который наиболее близко напоминает уникальные вероятностные диаграммы. Может цениться, что в системах с известными аппаратными средствами атрибуты камеры могут быть известными заранее и не потребуют включения в этот процесс. Кроме того, в системах с множественными камерами может быть известным, что поза объекта является идентичной по нескольким изображениям, и может использоваться «глобальная» поза (а не одно изображение).
Когда итеративный поиск завершен и определено лучшее отображение, сервер может сохранить данные трехмерного тела согласно своим вкладам вектора тела. Измерения, относящиеся к трехмерной форме тела, можно извлекать, используя справочную таблицу 580 на основании средней формы тела и вкладов вектора тела. Такие измерения могут включать в себя физические измерения, такие как окружность талии, окружность грудной клетки и т.д., а также более абстрактную информацию, такую как пол, возраст и т.д. Источником этой справочной таблицы являются известные эмпирические размеры тела, сформированные от прецизионных и точных сканеров всего тела, обычно используемых в больничных условиях. Вычисленный контур лучшего соответствия может затем подаваться обратно в предварительно визуализированные вероятностные диаграммы, потенциально повышая точность этапов сегментации в будущих использованиях.
Как только была вычислена истинная аппроксимация трехмерной формы тела для объекта, форма тела и соответствующие измерения могут быть увеличены в масштабе до размера объекта, принимая во внимание их введенный рост или другую калибровочную информацию 585, хотя это может также выполняться клиентом 285 на более поздней стадии. Наконец, трехмерное скан-изображение и/или измерения могут визуально отображаться объекту 290.