СИСТЕМА И МЕТОДИКА АВТОМАТИЧЕСКОГО ОБУЧЕНИЯ ЯЗЫКАМ НА ОСНОВЕ ЧАСТОТНОСТИ СИНТАКСИЧЕСКИХ МОДЕЛЕЙ
Вид РИД
Изобретение
Предпосылки создания изобретения, область, к которой относится изобретение
Данное изобретение относится к области лингвистики и, в частности, к способу и системе автоматизации обучения языкам на основе частотности синтаксических моделей.
Описание предшествующего уровня решений
Большинство методик обучения иностранным языкам учитывает фактор частотности лексических единиц языка. В соответствии с законом Ципфа, второе наиболее частотное слово встречается примерно в два раза реже, чем первое, третье - в три раза реже, чем первое, и так далее. То есть небольшое количество слов языка покрывает большую часть общего количества словоупотреблений, поэтому имеет смысл, в первую очередь, изучать именно наиболее частотные слова. Тем не менее, существующие методы обучения не принимают во внимание подобное распределение синтаксических моделей. Как показало проведенное нами исследование на основе 20 млн предложений, хранящихся на сервере, не только в лексике, но и в синтаксисе есть подобные закономерности: всего выявлено 6 млн уникальных моделей, причем 48 тыс. синтаксических моделей покрывает 37% от общего количества предложений в текстах.
Существует довольно много сервисов для изучения иностранных языков через электронные девайсы, где пользователю необходимо изучать грамматические правила, наборы слов и фраз, выполнять упражнения и проходить тесты. При этом системы обучения на подобных сервисах разрабатываются не автоматически, что оказывается очень дорогим и долговременным процессом.
Следовательно, существует потребность в автоматической системе обучения синтаксису, грамматике и лексике.
Сущность изобретения
Данное изобретение относится к способу и системе, включающей компьютерную программу, автоматическому обучению языкам на основе частотности синтаксических моделей, используемых в данном языке.
Пример осуществления представляет электронно-вычислительную машину или сервер, хранящий различные текстовые материалы (контент) и проводящий анализ полученных материалов, разделение этих материалов на предложения, выделение синтаксических моделей из имеющихся предложений и определение частотности синтаксических моделей в зависимости от того, сколько предложений соответствуют той или иной синтаксической модели.
Технический результат, достигаемый заявленными решениями, заключается в обеспечении возможности пользователем загружать текстовые материалы на сервер; просматривать, прослушивать и выполнять обучающие упражнения на построение фраз, входящих в синтаксические модели, сортированные по частотности; просматривать объяснения грамматических паттернов синтаксических моделей; сохранять статистику изучения; определять, просматривать и сохранять уровень освоения конкретной синтаксической модели; добавлять собственные модели для изучения; вписывать собственное предложение на изучаемом языке, чтобы узнать, какой синтаксической модели соответствует данное предложение, и просматривать множество предложений, относящихся к данной синтаксической модели. Данные действия пользователь может совершать с использованием любого компьютерного устройства, такого как персональный компьютер, планшет, ноутбук, смартфон или другого вычислительного устройства.
Каждый пользователь, зарегистрированный на сервере, может загрузить любые текстовые материалы, что повлияет на частотность синтаксических моделей. Информация о частотности слов также хранится на сервере, и чем больше текстовых материалов накапливается на сервере, тем более релевантная информация о распространенности (популярности, частотности) той или иной синтаксической модели. Система генерирует (создает) обучающие упражнения на построение фраз, входящих в синтаксические модели, сортированные по частотности; хранит статистику изучения; определяет уровень освоения пользователем конкретной синтаксической модели и позволяет пользователю добавлять собственные модели для изучения.
Пример осуществления способа автоматического обучения языкам включает: получение и хранение текстовых материалов на естественном языке; разделение полученных текстовых материалов на предложения; определение синтаксической модели для каждого предложения; определение частотности имеющихся синтаксических моделей на основе количества предложений, относящихся к каждой синтаксической модели текстовых материалов; сортировка синтаксических моделей на основе частотности и генерация обучающих упражнений, представляющих собой построение предложений, входящих в наиболее частотные синтаксические модели.
В примере осуществления анализ и разбиение текстовых материалов на предложения может включать: разбиение текстовых материалов на токены; удаление токенов расширяемого языка разметки (XML); выделение одного или нескольких токенов в предложении; определение, к какой части речи относится тот или иной токен предложения (part-of-speech tagging); сохранение связи каждого отдельного предложения с той или иной синтаксической моделью. Пример осуществления может включать поиск запутывающих слов на основе лемм каждого слова.
В примере осуществления в способ может включаться фильтрация и удаление непристойных предложений синтаксических моделей, относящихся к ругательствам, грамматическим ошибкам, нестандартным синтаксическим конструкциям и т.д.
В примере осуществления способ может включать предоставление объяснений грамматических паттернов синтаксических моделей.
В примере осуществления способ может в дальнейшем включать: хранение статистики изучения пользователем иностранного языка через прохождение упражнений на составление фраз (предложений) синтаксических моделей; определение и сохранение уровня освоения пользователем каждой синтаксической модели на основе статистики изучения.
В примере осуществления способ может далее включать: получение и сохранение текстовых материалов на сервере; повторный синтаксический анализ текстовых материалов для выделения синтаксических моделей; обновление частотности моделей на основе количества входящих в них предложений.
В примере осуществления способ может также включать: сортировку синтаксических моделей на основе древовидной кластеризации в соответствии со сложностью изучаемых синтаксических моделей.
В примере осуществления представленная система автоматического обучения иностранным языкам содержит модуль синтаксического анализа, предназначенный для: получения и хранения текстовых материалов на естественном языке; анализа и разбиения текстовых материалов на предложения; определения синтаксических моделей, в которые входят данные предложения; определения частотности каждой синтаксической модели на основе количества относящихся к ней предложений; сортировки синтаксических моделей по частотности; и далее модуль генерации упражнений предназначен для создания одного или нескольких обучающих упражнений, где упражнение включает одно или несколько предложений, отобранных на основании частотности связанных с ними синтаксических моделей.
В примере осуществления представленный компьютерный программный продукт, сохраненный на постоянном машиночитаемом носителе, содержит исполняемые компьютером инструкции для автоматического обучения языкам, включая инструкции для: получения и хранения текстовых материалов на естественном языке; разделения текстовых материалов на предложения; определения синтаксических моделей, в которые входят данные предложения; определения частотности каждой синтаксической модели на основе количества относящихся к ней предложений; сортировки синтаксических моделей по частотности; генерации обучающих упражнений с построением предложений, относящихся к той или иной синтаксической модели.
Следует понимать, что данное краткое описание служит целям предоставления общего понимания предлагаемого изобретения и не является его полным описанием, так как не было предназначено ни для того, чтобы определить ключевые элементы, ни для того, чтобы ограничить область представленного изобретения. Единственная цель описанного выше - представить несколько аспектов изобретения в упрощенной форме в виде вступления к детальному описанию изобретения.
Краткое описание чертежей
Приложенные схемы и изображения призваны проиллюстрировать изобретение, принцип его работы и устройства, а также возможные примеры осуществления изобретения. Схемы и изображения являются неотъемлемой частью данного документа.
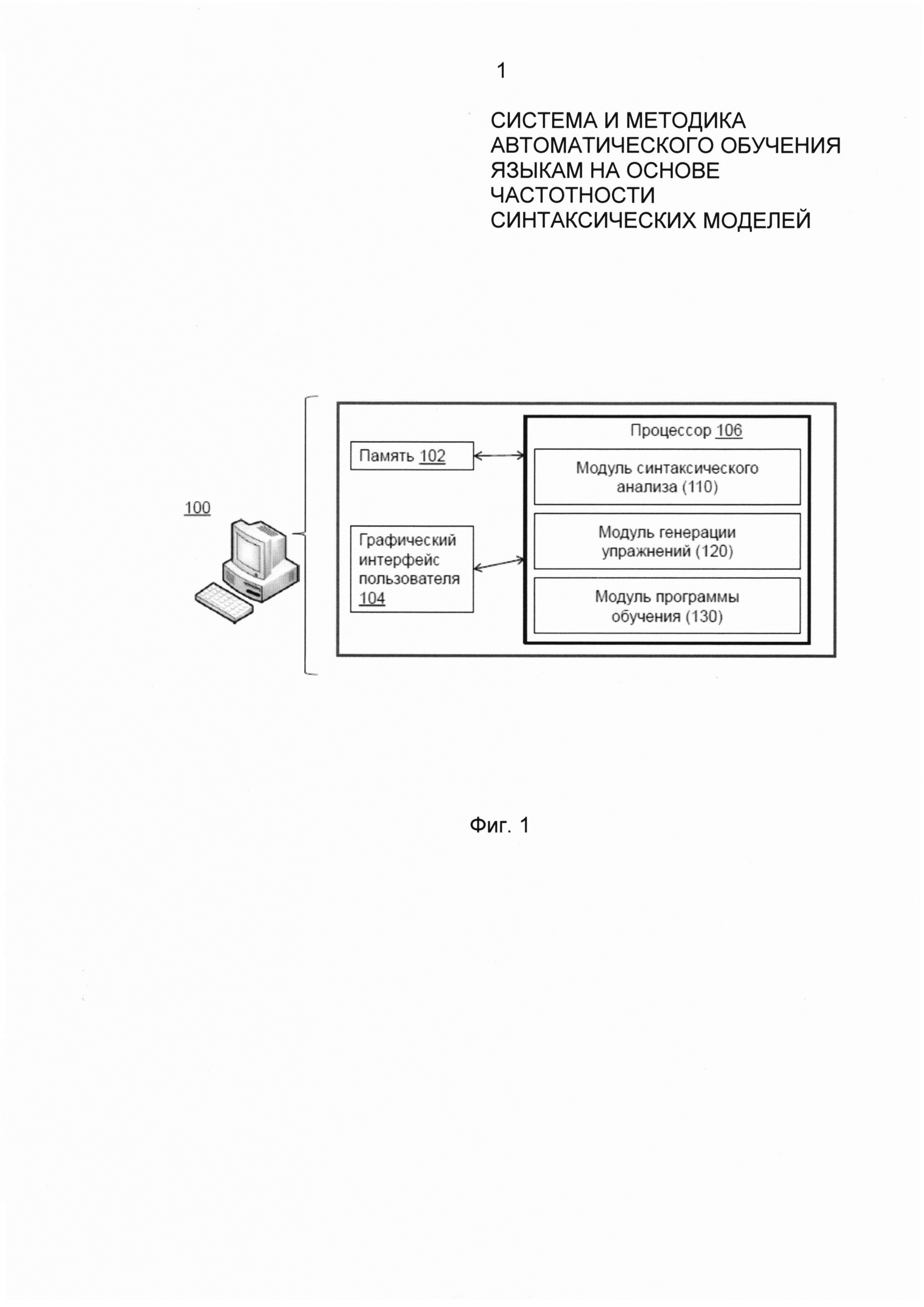
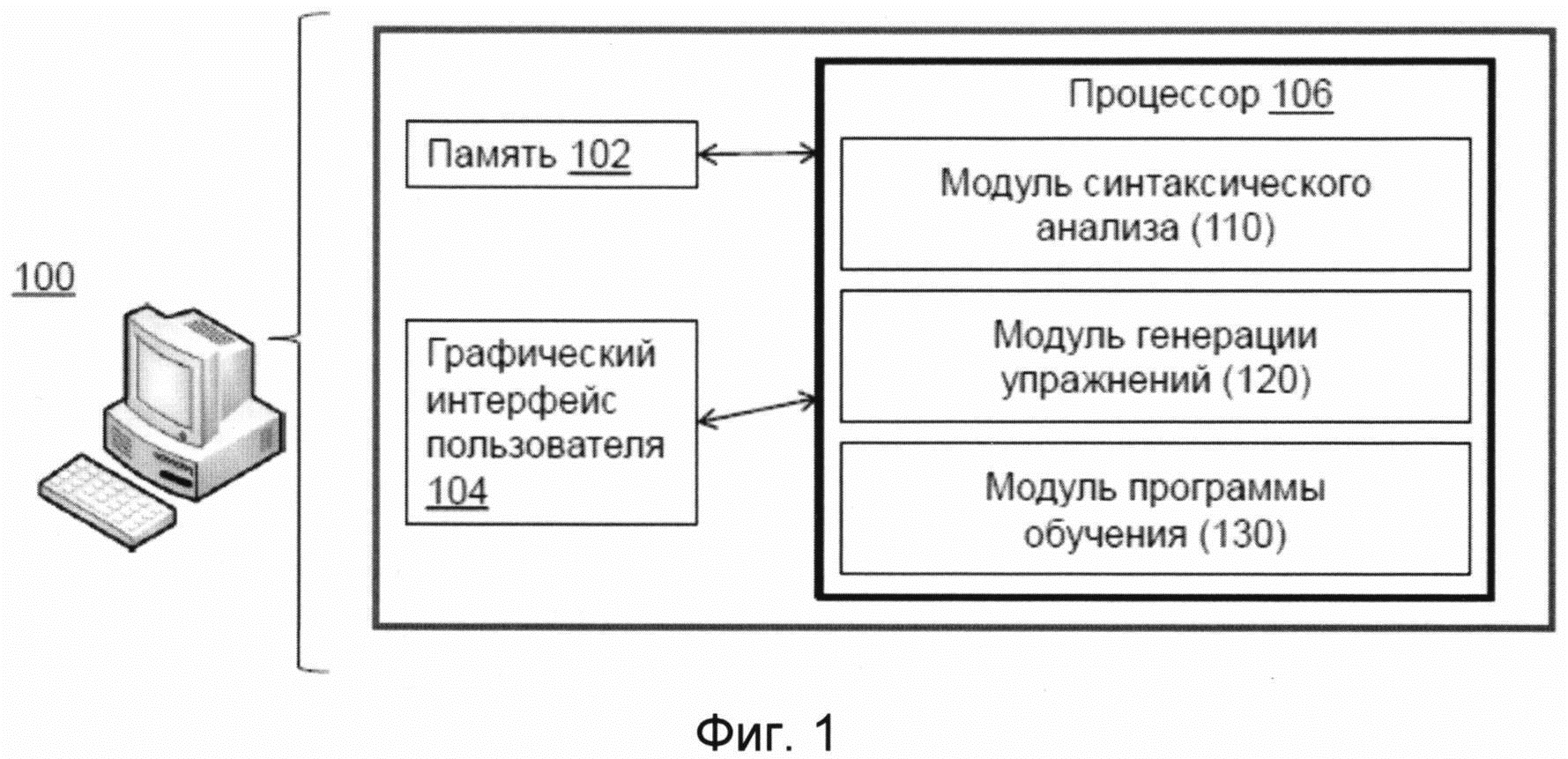
Фиг. 1 иллюстрирует общую архитектуру системы автоматического обучения языкам на основе частотности синтаксических моделей в соответствии с примером осуществления.
Фиг. 2 иллюстрирует детальную архитектуру системы автоматического обучения языкам на основе частотности синтаксических моделей в соответствии с примером осуществления.
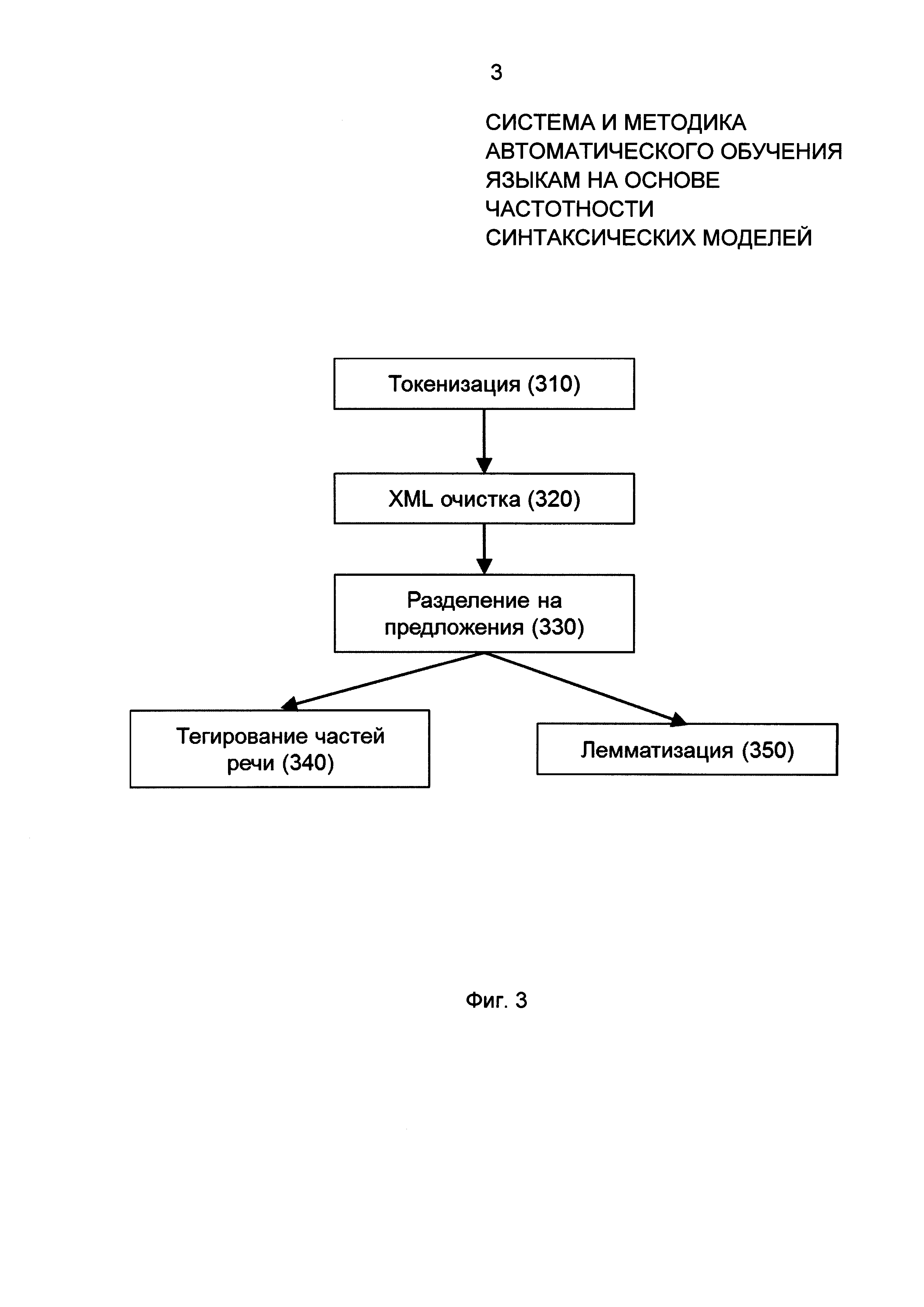
Фиг. 3 иллюстрирует пример процесса синтаксического анализа системы автоматического обучения языкам на основе частотности синтаксических моделей в соответствии с примером осуществления.
Фиг. 4 представляет пример общей структуры данных при хранении синтаксических моделей в соответствии с примером осуществления.
Фиг. 5 представляет пример структуры данных при хранении синтаксических моделей в соответствии с примером осуществления.
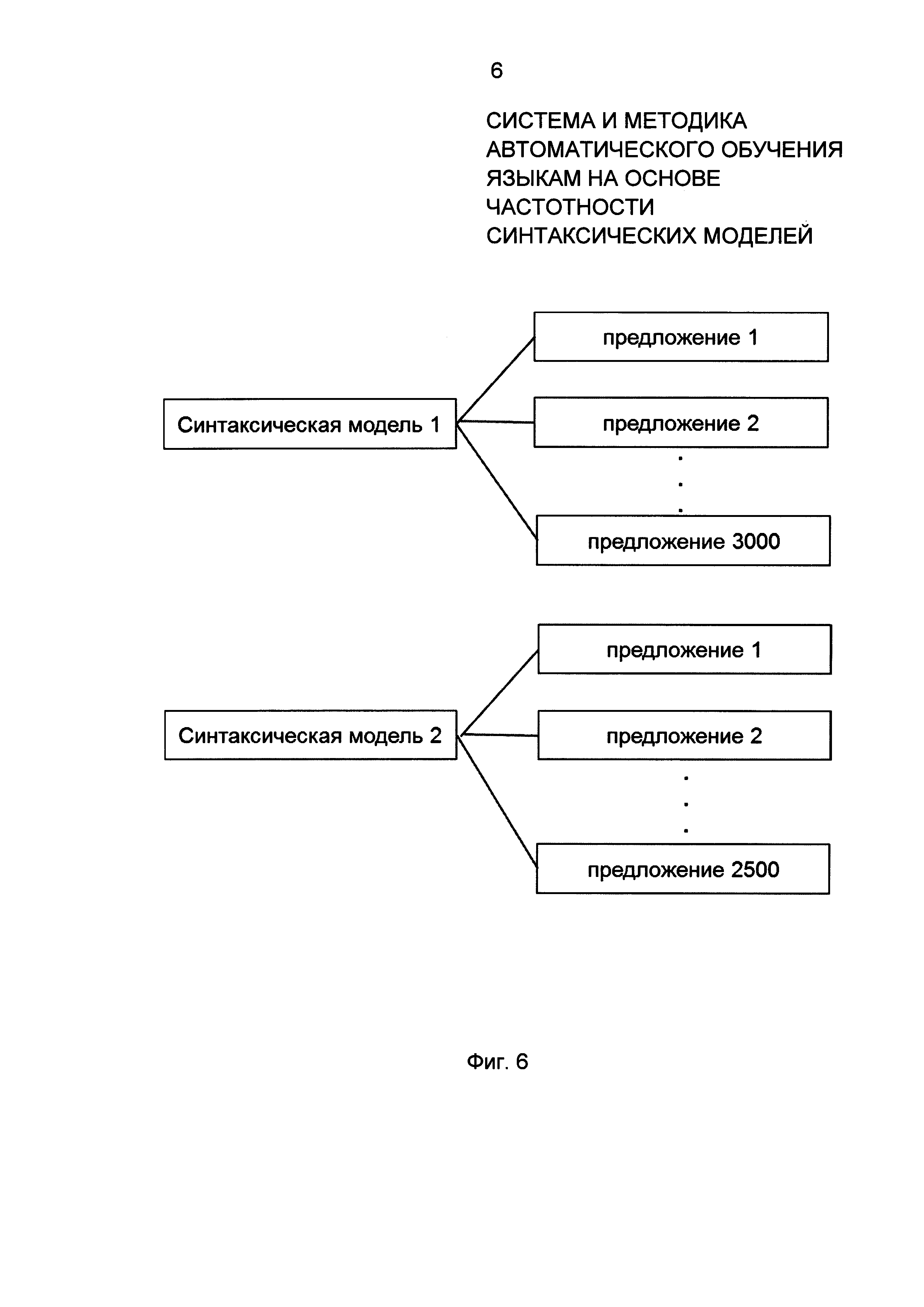
Фиг. 6 представляет пример сортировки синтаксических моделей по частотности для автоматического обучения языкам в соответствии с примером осуществления.
Фиг. 7 представляет пример процесса автоматической генерации обучающих упражнений на основе частотности синтаксических моделей в соответствии с примером осуществления.
Фиг. 8 представляет пример обучающего упражнения на основе частотности синтаксических моделей в соответствии с примером осуществления.
Фиг. 9 представляет пример скриншота страницы синтаксической модели в соответствии с примером осуществления.
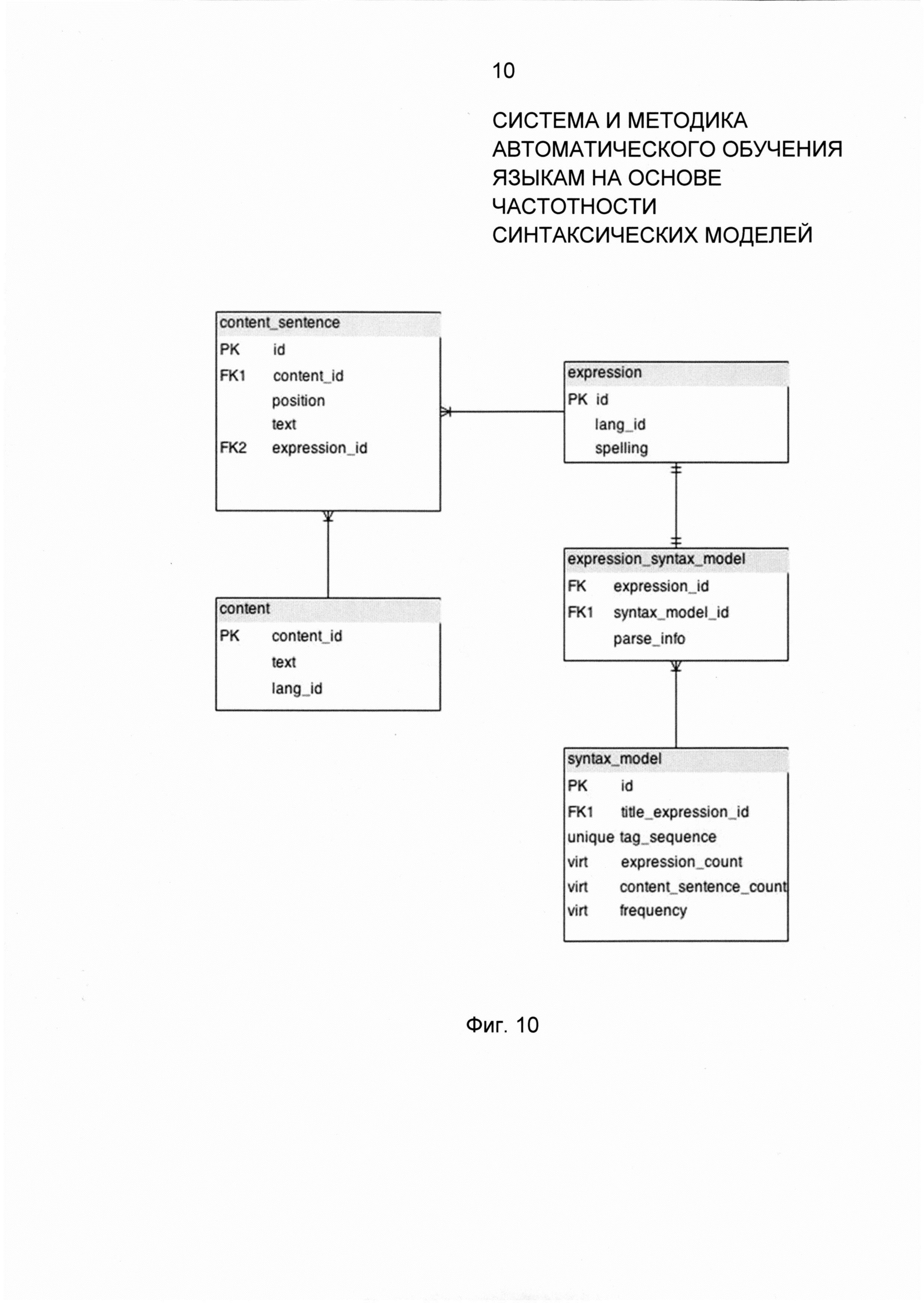
Фиг. 10 представляет пример структуры данных и схему работы отдельных элементов системы хранения данных о синтаксических моделях для автоматического обучения языкам в соответствии с примером осуществления.
Фиг. 11 иллюстрирует схему способа автоматического обучения языкам на основе частотности синтаксических моделей в соответствии с примером осуществления.
Фиг. 12 представляет пример аппаратно-программного комплекса, который может быть использован для реализации данного изобретения.
Подробное описание вариантов реализации изобретения
В данном разделе будет приведена подробная справка относительно способа и системы, включающей компьютерную программу, автоматического обучения языкам на основе частотности синтаксических моделей, в частности обучения синтаксису, грамматике и лексике, используя в качестве основы частотность синтаксических моделей, полученную через синтаксический анализ текстовых материалов. Специалистам в данной области следует понимать, что последующее описание предназначено для раскрытия примеров осуществления изобретения и не имеет цели внести ограничения в объем изобретения. Прочие аспекты будут очевидны специалистам в данной области техники из подробного описания предпочтительных вариантов реализации данного изобретения, примеры которых представлены на сопровождающих иллюстрациях. Одни и те же термины будут использоваться в максимально возможной степени на всех иллюстрациях и в нижеследующем описании для обозначения одних и тех же или подобных элементов.
Синтаксическая модель предложения включает последовательность тегов различных частей речи, составляющих данное предложение. Для построения таких моделей могут использоваться теги аннотированных корпусов языка, таких как Penn Treebank или BulTreeBank. Аннотированный языковой корпус представляет совокупность текстов, снабженных морфосинтаксической разметкой. В пример осуществления синтаксическая модель может включать в себя любую совокупность тегов частей речи, если имеется одно или несколько предложений, подходящих под данную синтаксическую структуру. В корпусной лингвистике тегирование частей речи (part of speech tagging) включает в себя процесс разметки слов в языковом корпусе, относящихся к определенным частям речи, на основе их определения и контекста, то есть соотношения со смежными словами в данном предложении или фразе. Например, тегирование частей речи может включать идентификацию слов как существительных, глаголов, прилагательных, наречий и т.д.
Фиг. 1 иллюстрирует общую архитектуру системы автоматического обучения языку на основе частотности синтаксических моделей данного языка в соответствии с примером осуществления. Система 100 может быть реализована как программное обеспечение, виджет рабочего стола, веб-приложение, апплет, скрип или другой тип программного кода, исполняемый на компьютерном устройстве, таком как персональный компьютер, планшет, ноутбук, смартфон или другое вычислительное устройство. В примере осуществления программный продукт может использоваться как веб-приложение, доступное пользователям через интернет. Система 100 может иметь несколько модулей программного и аппаратного обеспечения, таких как память или носитель данных 102, графический интерфейс пользователя 104 и процессор 106, включающий модуль синтаксического анализа 110, модуль генерации упражнений и модуль программы обучения 130.
Термин "модуль" используется здесь для обозначения физического устройства, аппарата или совокупности модулей, реализованных с использованием аппаратных средств, например, таких как интегральная схема специального назначения (Микросхема "ASIC"), или программируемая пользователем вентильная матрица (FPGA), или комбинация аппаратного и программного обеспечения, например, с помощью микропроцессорной системы и набора инструкций для реализации функционала модуля, которые (во время ее выполнения) преобразуют микропроцессорную систему в устройство специального назначения. Модуль может быть также реализован как комбинация аппаратного и программного обеспечения с выполнением одних функций через аппаратные средства обеспечения, а других через комбинацию средств аппаратного и программного обеспечения. В некоторых случаях возможны реализации, где модули могут быть реализованы с использованием процессора компьютера общего назначения (например, как описано более подробно на фиг. 12 ниже). Соответственно, каждый модуль может быть реализован в различных подходящих конфигурациях, и не может быть ограничений для реализации какого-либо определенного примера осуществления в данном случае.
В примере осуществления компьютерная серверная система 100 сохраняет набор текстовых материалов на одном или нескольких языках, которые в последующем проходят этапы синтаксического анализа и генерации упражнений для обучения пользователей системы. Текстовые материалы могут включать книги, статьи, тексты песен, стихотворения, субтитры фильмов и любые другие текстовые материалы. Данные материалы могут добавляться на сервер системы 100 администратором системы, могут добавляться автоматически из интернета из различных частных и публичных баз данных, либо могут быть загружены пользователями системы через графический интерфейс 104 системы 100.
После получения текстовых материалов модуль синтаксического анализа 110 системы 100 разделяет текстовой корпус на предложения. Для каждого предложения модуль синтаксического анализа 110 определяет синтаксическую модель, соответствующую данному предложению. Синтаксические модели сохраняются в базе данных (то есть память или носитель данных 102) с информацией об их частотности, основанной на количестве предложений, относящихся к каждой конкретной модели. Для генерации обучающих упражнений модуль программы обучения 130 использует данные, полученные в результате работы модуля синтаксического анализа 110 и модуля генерации упражнений 120. Далее программа обучения представляется пользователю через графический интерфейс пользователя 104. Представление информации через графический интерфейс пользователя 104 может быть реализовано, например, с отображением информации через различные устройства вывода, включая внешние по отношению к системе 100, передавая визуальные и аудиальные сигналы пользователю системы и получая обратную связь через различные устройства ввода.
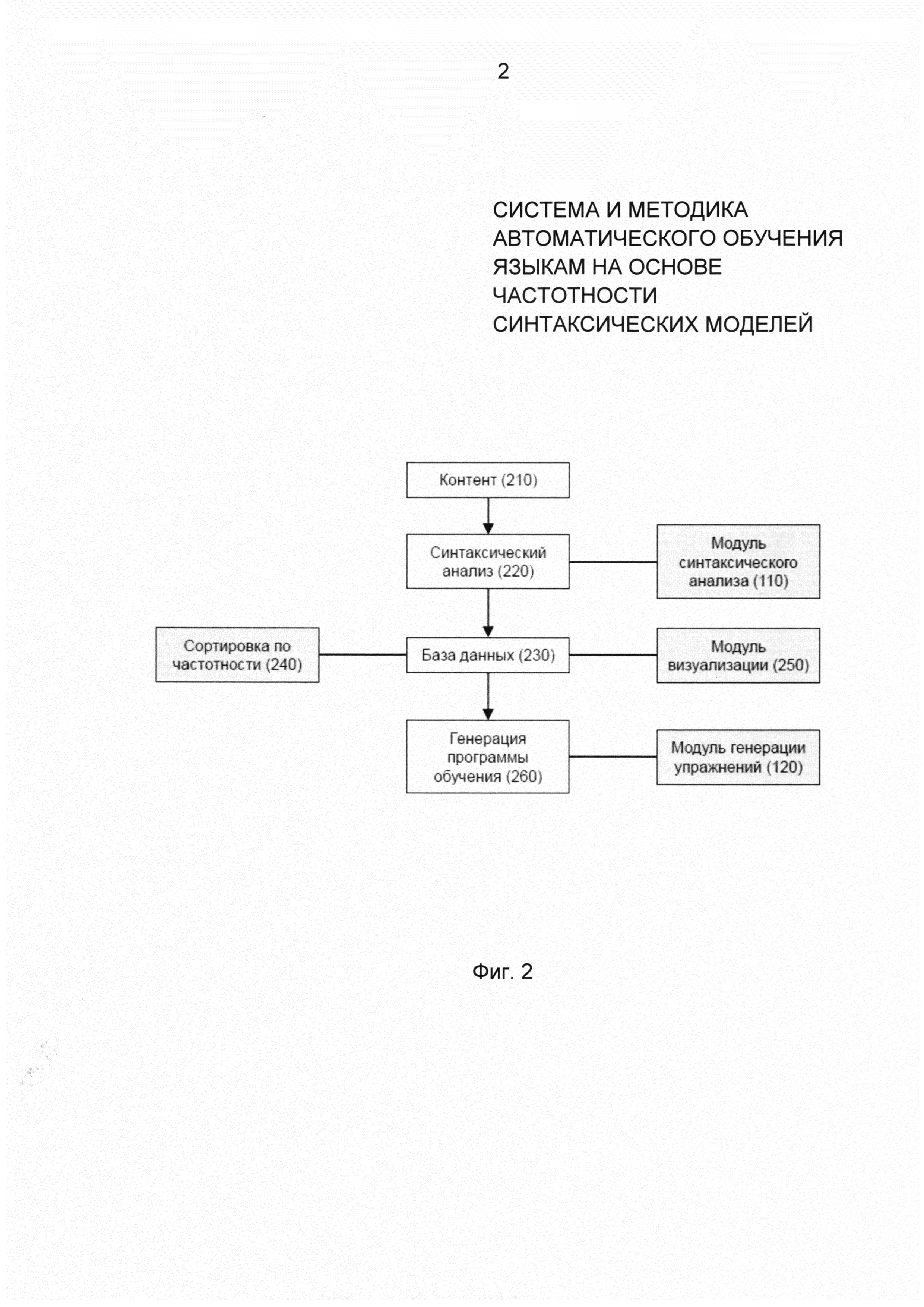
Фиг. 2 в соответствии с примером осуществления подробнее иллюстрирует архитектуру и работу системы 100, представленной на Фиг. 1, при генерации обучающих упражнений. В примере осуществления модуль синтаксического анализа 110 проводит синтаксический анализ 220 сохраненного на сервере системы 100 контента 210. Модуль синтаксического анализа 110 осуществляет синтаксический анализ 220, начиная с токенизации, то есть разделяя текстовые материалы на токены. Токенизация представляет процесс разделения текста на слова, пунктуацию и другие значимые элементы, называемые токенами.
Модуль синтаксического анализа 110 далее разделяет токенизированный текст на предложения, используя полученные на предыдущем этапе данные, в частности знаки препинания. Например, точка, восклицательный знак, вопросительный знак указывают на окончание предложения. В примере осуществления модуль синтаксического анализа может также разделять токенизированный текст только на простые предложения, используя запятую, точку с запятой, тире как индикаторы окончания предложения. Далее, модуль синтаксического анализа для каждого токена в предложении определяет лемму и проводит тегирование частей речи (part of speech tagging) в соответствии с токенами, используемыми в Penn Treebank, BulTreeBank или других аннотированных языковых корпусах. Далее модуль синтаксического анализа сохраняется в базе данных синтаксических моделей 230 связи между предложениями и соответствующими им синтаксическими моделями.
Далее проводится сортировка синтаксических моделей по частотности 240 на основе количества предложений, относящихся к той или иной модели. Данный процесс будет более подробно описан ниже. В соответствии с примером осуществления система 100 может также включать модуль визуализации 250, представляющий пользователю информацию по каждой из синтаксических моделей, давая токенам частей речи символьное обозначение. Генерация программы обучения 260 проводится на основе данных, полученных в результате выполнения сортировки синтаксических моделей по частотности 240, а обучающие упражнения могут быть подготовлены для каждой из моделей при работе модуля генерации упражнений 120.
Фиг. 3 более детально раскрывает процесс синтаксического анализа 220, осуществляемый модулем синтаксического анализа 110. Процесс синтаксического анализа 220 может включать этапы токенизации 310, xml очистки (xml cleaning) 320, разделения на предложения 330, тегирования частей речи (P.O.S. tagging) 340 и лемматизации (lemmatization) 350. На этапе токенизации 310, текст разделяется на слова, знаки препинания и другие значимые элементы текста, например цифры. На этапе xml очистки 320, из текста удаляются токены расширяемого языка разметки (xml).
Далее, на этапе разделения на предложения 330, токенизированный текст разделяется на предложения. На этапе тегирования частей речи (P.O.S. tagging) могут использоваться теги аннотированных корпусов языка, таких как Penn Treebank, BulTreeBank или другие теги аннотированных корпусов, чтобы определить тег части речи для каждого токена всех предложений. На этапе 350 определяется лемма для каждого токена.
Результат проведенного анализа предложений сохраняется в базу данных синтаксических моделей 230 для дальнейшего использования на этапе генерации упражнений 120. Модуль синтаксического анализа 110 может использовать пакет библиотек и программ для символьной и статистической обработки естественного языка, таких как StanfordCoreNLP, nltk или других на этапах токенизации, xml очистки, разделения на предложения, тегирования частей речи (P.O.S. tagging) и лемматизации (lemmatization). В примере осуществления изобретения модуль синтаксического анализа 110 может также удалять из базы данных любые неприемлемые предложения, содержащие грамматические ошибки, нестандартные грамматические конструкции, а также любую непристойную лексику.
Фиг. 4 представляет пример общей структуры данных при хранении результатов синтаксического анализа текста, сохраненного в базе данных синтаксических моделей 230. Текст может быть разделен на несколько предложений ([sentence 1], [sentence 2], … [sentence N]), тогда как предложения могут включать в себя несколько токенов ([toke 1], [token 2], … [toket Nt]). Токен может включать дополнительные метаданные, например, теги частей речи (post_tag), лемму (lemma), позицию расположения токена в предложении (start_offset, end_offset), а также другие. Теги частей речи необходимы для определения того, какая синтаксическая модель относится к конкретному предложению. Лемма используется модулем генерации упражнений 120 при поиске запутывающих слов, которые необходимы для усложнения задачи прохождения упражнений, предлагаемых пользователю. Позиция токена в предложении используется при отображении предложений пользователю в процессе прохождения упражнений. При поиске запутывающих слов, слова, имеющие ту же лемму, что и исходное слово, могут быть даны в упражнении на выбор при составлении предложений пользователем. Для местоимений и других заранее определенных слов запутывающие слова могут подготавливаться заранее. Подробнее процесс генерации упражнений будет описан ниже.
Фиг. 5 представляет пример структуры данных для хранения результата анализа предложения "I have done my homework" в базе данных синтаксических моделей 230 в соответствии с примером осуществления. Как показано на фигуре, модуль синтаксического анализа 110 может обработать конкретное предложение, сохраняя метаданные для каждого токена предложения, указанные при описании Фиг. 4. Так, например, токен "I" имеет следующие метаданные: индикаторы позиции в предложении "statrtOffset" и "endOffset", имеющие значение "0" и "1" соответственно, что указывает позицию первой и последней буквы слова в предложении; тег части речи "PRP" (Personal Pronoun - личное местоимение); индикатор леммы, имеющий значение "I". Аналогично, структура данных генерируется для всех остальных слов в предложении, как показано на Фиг. 5. Структура данных может также содержать последовательность тегов, составляющих предложение ("PRP VBP VBN PRP$ NN NN"). Другие типы информации о предложении могут также храниться в структуре данных.
Фиг. 6 иллюстрирует пример архитектуры сортированных по частотности синтаксических моделей в соответствии с примером осуществления. Сортировка синтаксических моделей по частотности 240 (на Фиг. 2) может быть выполнена за счет выделения синтаксических моделей, схожих между собой или одинаковых. Две синтаксические модели считаются одинаковыми, если они содержат одни и те же теги, расположенные в том же порядке. Модели, имеющие какие-либо дополнительные теги, не считаются схожими. Например, одна из наиболее частотных синтаксических моделей в английском языке - это "PRP VBP DT NN", где PRP - personal pronoun (личное местоимение); VBP - verb, non-3rd person singular present (глагол не третьего лица единственного числа настоящего времени); DT - determiner (определитель); NN - noun, singular or mass (существительное множественного или единственного числа). Под данную синтаксическую модель подходят следующие примеры предложений: "I have no idea"; "I need a drink"; "We have a problem"; "I know the feeling". Другая частотная синтаксическая модель - "DT NN VBZ JJ", где DT - determiner (определитель); NN - noun (существительное); VBZ - verb, 3rd person singular present (глагол 3-го лица единственного числа настоящего времени); JJ - adjective (прилагательное). Под данную синтаксическую модель подходят предложения: "The day is beautiful"; "The sky is blue"; "The car is fast"; "The building is tall". Таким образом, как показано на Фиг. 6, синтаксический анализ определенных текстовых материалов и последовательная сортировка по частотности могут в результате идентифицировать две частотные синтаксические модели - "PRP VBP DT NN" и "DT NN VBZ JJ" - и соответствующее число соотносящихся с ними предложений, например 3000 и 2500 соответственно. В примере осуществления приоритет различных синтаксических моделей может быть основан на числе соотносящихся с ними предложений. Например, как показано на Рис. 6, синтаксическая модель 1 имеет большее значение и приоритет для изучения, чем синтаксическая модель 2, потому что синтаксическая модель 1 имеет 3000 соотносящихся с ней предложений, тогда как синтаксическая модель 2 имеет только 2500 соотносящихся с ней предложений.
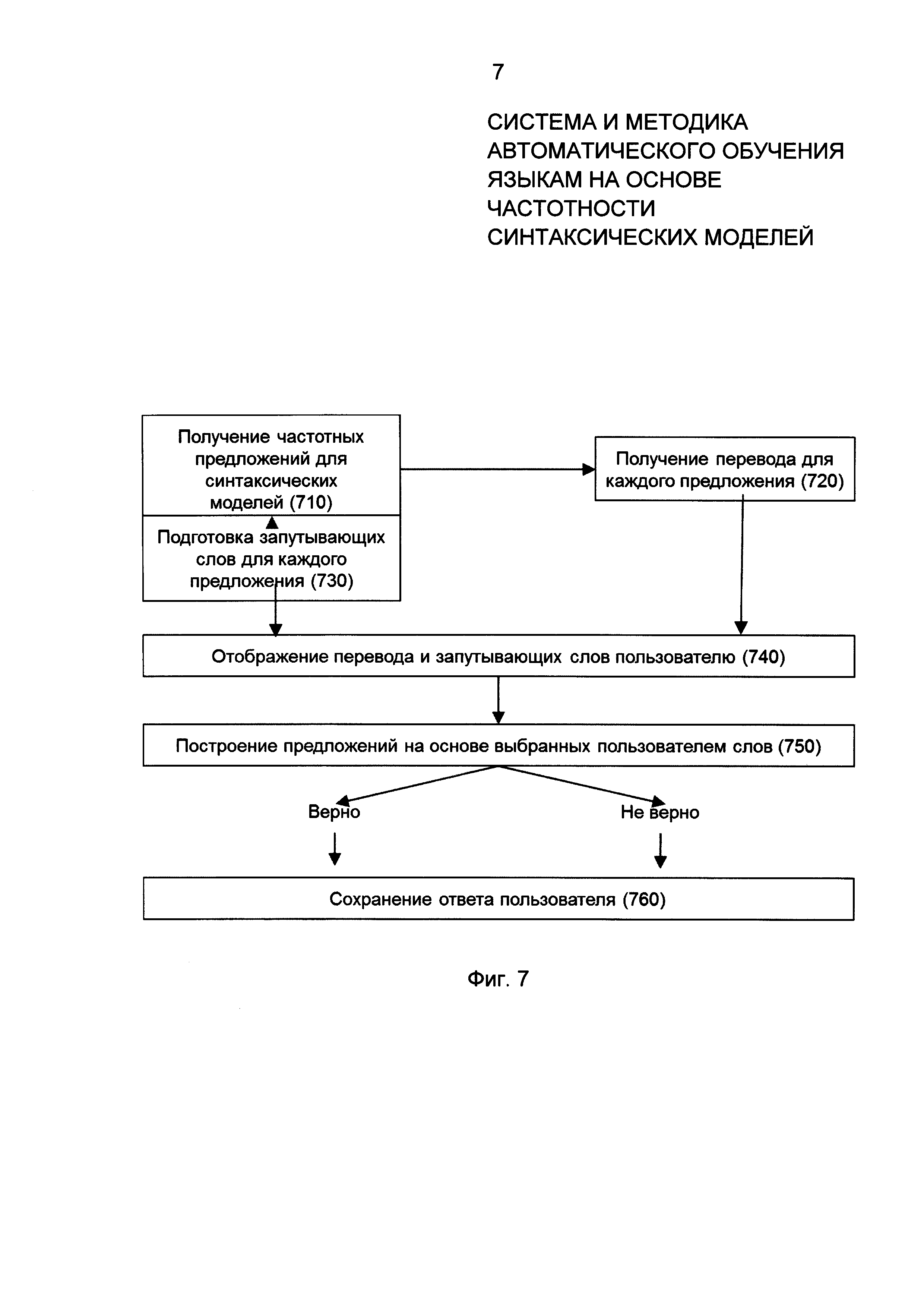
Фиг. 7 представляет пример процесса генерации обучающих упражнений на основе имеющейся частотности синтаксических моделей в соответствии с примером осуществления. Для синтаксической модели из базы данных синтаксических моделей 230 извлекается определенное количество (как правило, установленное заранее) частотных предложений с метаданными синтаксического анализа, соотносящихся с данной синтаксической моделью и имеющих перевод на родной для пользователя язык. Частотность предложения определяется через число употреблений данного предложения в имеющемся текстовом корпусе. Для каждого слова предложений модулем генерации упражнений 120 могут быть выбраны запутывающие слова. Данные по запутывающим словам хранятся в базе данных синтаксических моделей 230. Запутывающие слова могут включать в себя синонимы, омофоны, омонимы, слова той же части речи, глаголы в других формах, формы множественного числа (если правильный вариант в форме единственного числа) и т.д. Например, предложение "I have no idea." содержит следующие слова:
0: {text:I, relations:{0:I, 2:MY, 3:МЕ, 4:MINE}}
1: {text:HAVE, relations:{0:HAVE, 1:HAVING, 2:HAS, 3:HAD, 4:HAVES}}
2: {text:NO, relations:{0:NO, 1:NONE, 2:NEITHER, 3:NOT, 4:NORE, 5:NOPE}}
3: {text:IDEA, relations:{0:IDEA, 2:IDEAS}}
Слово "I" в предложении может иметь следующие связанные с ним запутывающие слова "My", "Me" и "Mine", а слово "No" может иметь такие запутывающие слова, как "Nope", "Neither", "Not", "Nore", и т.д.
Другое предложение, "I need a drink" содержит следующие слова:
0: {text:I, relations:{0:I, 2:MINE, 3:МЕ, 4:MY}}
1: {text:NEED, relations:{0:NEED, 1:NEEDED, 3:NEEDS, 4:WANT}}
2: {text:A, relations:{0:A, 1:THE, 2:AN}}
3: {text:DRINK, relations:{0:DRINK, 1:DRUNK, 2:DRINKING, 3:WATER, 4:, 5:DRINKS, 6:DRANK}}
В предложении слово "А" может иметь связанные с ним запутывающие слова "An" и "The", а слово "Drink" может иметь запутывающие слова "Drunk", "Drinking", "Drinks" и т.д.
В соответствии с примером осуществления, модуль генерации упражнений 110 получает переводы на родной для пользователя язык для всех предложений. Переводы предложений могут быть получены автоматически через использование, например, Google Translate service. В соответствии с примером осуществления, возможна ручная проверка переводов. Модуль генерации упражнений 110 может также искать для каждого токена запутывающие слова, сохраненные в базе данных синтаксических моделей 230. Модуль 110 далее представляет пользователю предложения на изучаемом языке и дает на выбор правильные (из которых состоит предложение) и запутывающие слова, из которых пользователю нужно собрать предложение.
Ответы пользователей сохраняются на сервере, и когда достигается предустановленное количество правильно собранных предложений, относящихся к определенной синтаксической модели, данная синтаксическая модель считается изученной. Например, для сохранения данной информации может использоваться таблица user_syntax_model; для связи с пользователем используется внешний ключ user_id; для связи с синтаксической моделью используется внешний ключ syntax_model_id. Для сохранения уровня освоения используется поле progress.
В примере осуществления изобретения также возможны различные способы структуризации синтаксических моделей. Например, возможна структуризация синтаксических моделей в соответствии с грамматическим аспектом. Используя данный тип структуризации, система может подготовить обучающие упражнения для определенных грамматических форм. Программа обучения может состоять из нескольких уровней. Например, на первом уровне пользователю необходимо пройти упражнения на изучение грамматики настоящего, будущего и прошедшего простых времен, на втором уровне - формы perfect tenses (совершенное время) и continuous tenses (продолжительное время), на третьем - perfect continuous tenses (совершенное продолжительное время). Основная ценность описываемого способа обучения в том, что пользователь изучает грамматику изучаемого языка через наиболее частотные предложения наиболее частотных синтаксических моделей. Другой метод структуризации может состоять в определении родительских связей между синтаксическими моделями. Например, модель "PRP VBP", с которой могут соотноситься предложения "I see", "You like", является родительской моделью по отношению к модели "PRP VBP PRP", в которую входят такие предложения, как "I see you", "You like him", и когда пользователь изучает дочернюю модель "PRP VBP PRP", он также повторяет родительскую модель "PRP VBP". Использование древовидной структуризации данных также позволяет давать пользователю модели и в соответствии с их уровнем сложности. В данной реализации пользователь может изучать грамматику кластерами из синтаксических моделей, причем дочерние модели будут признаваться более сложными, и при их изучении будет происходить повторение родительских моделей. Осуществление изобретения также позволяет пользователю вписать собственное предложение на изучаемом языке, чтобы узнать, какой синтаксической модели соответствует данное предложение, и изучить данную синтаксическую модель через множество предложений, относящихся к данной синтаксической модели.
Фиг. 8 представляет пример выполнения обучающих упражнений. В данном примере пользователю необходимо правильно составить предложение, соотносящееся с моделью "PRP VBP DT NN", условно названной "I have no idea". Условное название моделей определяется по наиболее частотному предложению, соотносящемуся с данной моделью. Частотность возможно определить после проведения синтаксического анализа текстовых материалов, о чем подробнее было описано выше. Как представлено на фигуре, пользователь, изучающий английский язык, видит фразу "У меня есть план", что переводится на английский как "I have a plan". Пользователю необходимо составить правильный перевод данной фразы, выбирая варианты, представленные сервисом. Как показано на фигуре, пользователю необходимо правильно выбрать последнее, четвертое слово, чтобы завершить фразу. Дается несколько вариантов с запутывающими словами на выбор: 1. "plan", 2. "planning", 3. "plans", 4. "planned". Выбирая варианты слов при построении фраз, соотносящихся с наиболее частотными синтаксическими моделями, пользователь не только изучает грамматику, что является основной целью упражнений, но и увеличивает свой словарный запас за счет латентного обучения, эффективность которого впервые была подтверждена Эдвардом Толменом в исследовании, проведенном в 1930 году. Проходя обучающие упражнения, пользователь может пассивно изучать новые слова, не имея такой цели.
Фиг. 9 представляет скриншот страницы синтаксической модели "IN DT NN", где IN - preposition or subordinating conjunction (предлог или подчинительный союз); DT - determiner (определитель); NN - noun, singular or plural (существительное множественного или единственного числа). Условное название модели - "Under the sea" - определяется по наиболее частотному предложению, соответствующему данной модели. Как показано на Фиг. 9, на странице синтаксической модели может быть представлено два или более примеров предложений, соотносящихся с данной синтаксической моделью: "Behind the door" and "Under the table", с переводом на родной для пользователя язык. На странице синтаксической модели пользователь имеет возможность прослушать предложения, соотносящиеся с данной синтаксической моделью, на английском языке либо на другом изучаемом пользователем языке.
Фиг. 10 представляет пример структуры данных и схему работы отдельных элементов системы хранения данных о синтаксических моделях. Таблица content хранит исходные текстовые материалы. Таблица content_sentence хранит текстовые материалы, разбитые на предложения. Для связи с таблицей content используется внешний ключ content_id. Для восстановления исходного текста по предложениям используется поле position. Для связи с нормализованными выражениями используется внешний ключ expression_id. Таблица expression хранит нормализованные предложения на разных языках. Нормализованное предложение - это строка, полученная исключением из исходного предложения лишних пробельных символов (\n, \t и пр.). Поле lang_id используется для указания языка предложения. Поле spelling хранит нормализованное предложение. Несколько предложений в текстах могут соответствовать одному нормализованному предложению.
Таблица syntax_model хранит уникальные синтаксические модели (tag_sequence). Поле title_expression_id синтаксической модели хранит ссылку на самое частотное предложение данной синтаксической модели. Поле expression_count представляет количество нормализованных предложений для данной синтаксической модели; поле content_sentence_count - количество исходных предложений для данной синтаксической модели, поле frequency рассчитывается как отношение content_sentence_count к общему количеству исходных предложений. Таблица expression_syntax_model используется для хранения связи нормализованных предложений с их синтаксическими моделями и метаданных результата синтаксического анализа данного предложения. Для связи с таблицей нормализованных предложений используется внешний ключ expression_id. Для связи с таблицей синтаксических моделей используется внешний ключ syntax_model_id.
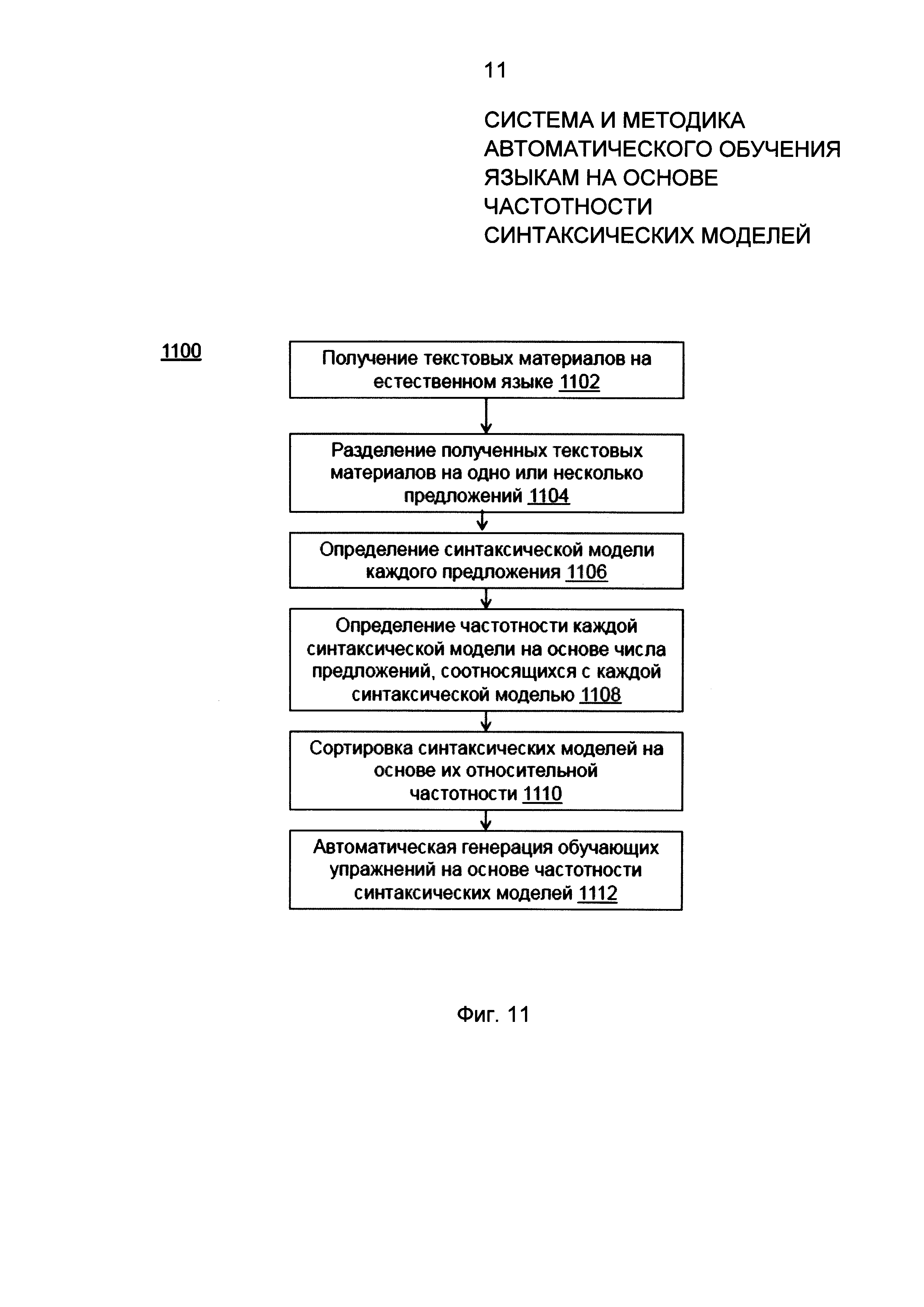
В соответствии с осуществлением изобретения, Фиг. 11 иллюстрирует пример метода автоматической генерации упражнений по изучению иностранного языка на основе частотности синтаксических моделей. Метод 1100 может быть реализован в рамках системы автоматического обучения языку 100, описанной на Фиг. 1. На шаге 1102 метод 1100 включает получение через модуль синтаксического анализа 110 процессора 106 Фиг. 1 текстовых материалов через графический интерфейс пользователя 104 системы 100. На шаге 1104 метод 1100 включает этап синтаксического анализа полученных текстовых материалов на предложения. На шаге 1106 метод 1100 включает определение синтаксических моделей предложений. На шаге 1108 метод 1100 включает определение частотности каждой синтаксической модели на основе количества предложений, соотносящихся с данной синтаксической моделью. На шаге 1110 метод 1100 включает сортировку синтаксических моделей на основе определенной частотности. На шаге 1112 метод 1100 включает автоматическую генерацию обучающих упражнений на основе частотности синтаксических моделей.
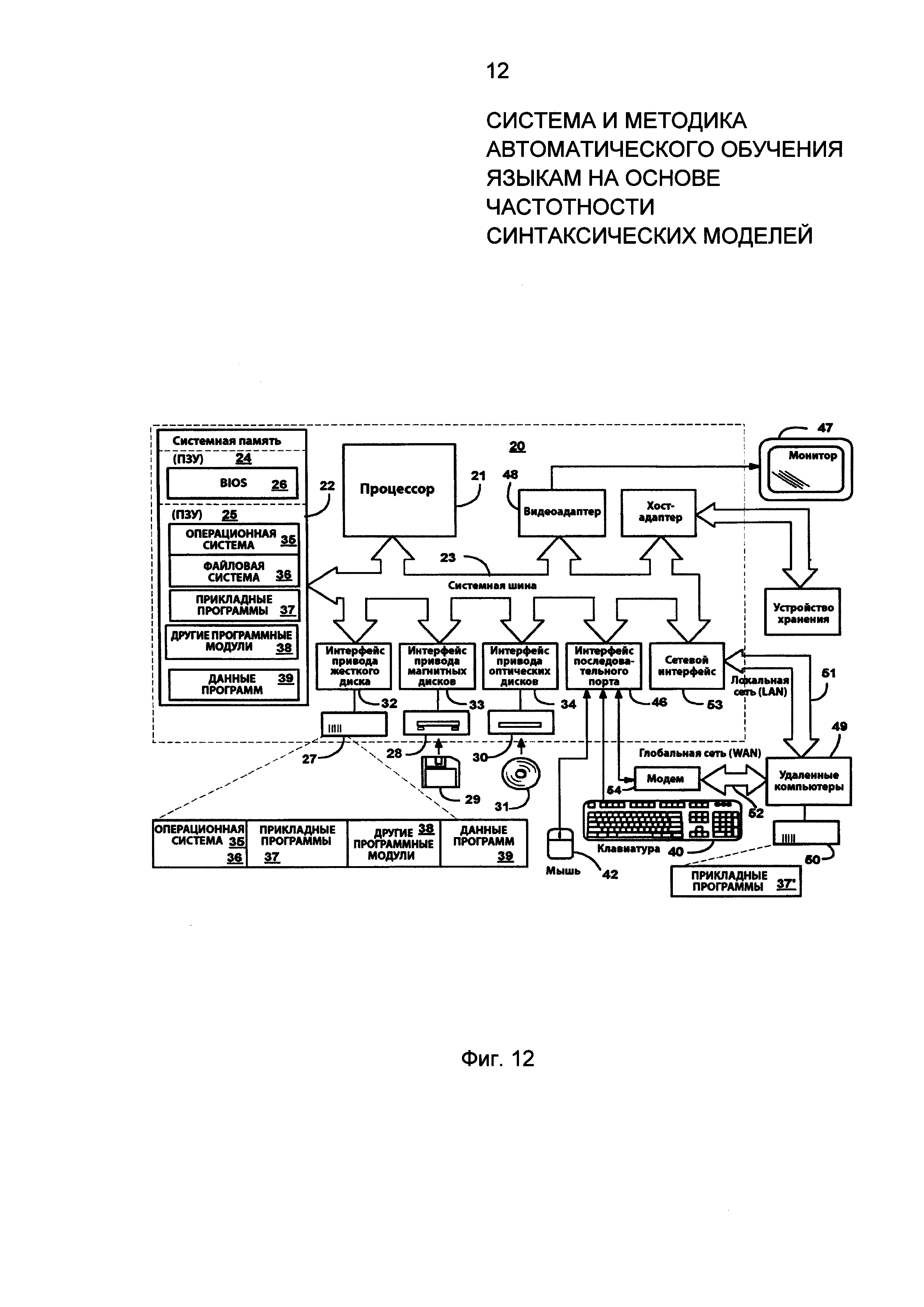
Фиг. 12 представляет примерную схему компьютера или сервера, который может использоваться для реализации изобретения. В соответствии с Фиг. 9 образец системы для внедрения изобретения включает универсальную электронно-вычислительную машину в форме персонального компьютера 20 либо сервера и т.п., в состав которой входит процессор 21, системная память 22 и системная шина 23, соединяющая различные компоненты системы, в том числе системную память с процессором 21.
Системная шина 23 может иметь любой из нескольких типов структуры, включая шину памяти или контроллер памяти, периферийную шину и локальную шину с использованием любого варианта архитектуры шины. Системная память включает постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25.
Базовая система ввода-вывода 26 (BIOS), содержащая основные подпрограммы для передачи информации между компонентами компьютера 20, например, при загрузке, хранится в ПЗУ 24. Персональный компьютер 20 может включать также привод жесткого диска для чтения и записи на жесткий диск (не показан), привод магнитных дисков 28 для чтения и записи на съемный магнитный диск 29 и привод оптических дисков 30 для чтения и записи на съемный оптический диск 31, например CD-ROM, DVD-ROM и другие оптические носители.
Привод жесткого диска, привод магнитных дисков 28 и привод оптических дисков 30 подключены к системной шине 23 при помощи интерфейса привода жесткого диска 32, интерфейса привода магнитных дисков 33 и интерфейса привода оптических дисков 34 соответственно. Приводы и соответствующие машинно-читаемые носители используются для постоянного хранения машинно-читаемых инструкций, структур данных, программных модулей и других данных для персонального компьютера 20.
Хотя описанная здесь примерная среда использует жесткий диск, съемный магнитный диск 29 и съемный оптический диск 31, специалисты по достоинству оценят тот факт, что она способна использовать также другие типы машинно-читаемых носителей для хранения доступных для компьютера данных - например, магнитные кассеты, флеш-карты памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Некоторые программные модули, включая операционную систему 35 (предпочтительно WINDOWS™ 2000), могут храниться на жестком диске, магнитном диске 29, оптическом диске 31, в ПЗУ 24 или ОЗУ 25. Компьютер 20 включает файловую систему 36, которая связана с операционной системой 35 или включена в нее, например файловую систему WINDOWS NT™ (NTFS), одну или несколько прикладных программ 37, прочие программные модули 38 и данные программ 39. Пользователь может вводить команды и данные в персональный компьютер 20 при помощи устройств ввода, например клавиатуры 40 и указывающего устройства 42.
Другие устройства ввода (не показаны) могут включать микрофон, джойстик, геймпад, спутниковую тарелку, сканер и т.п. Эти и другие устройства ввода часто подключаются к процессору 21 через интерфейс последовательного порта 46, который соединен с системной шиной, но могут также подключаться через другие интерфейсы, например параллельный порт, игровой порт или универсальную последовательную шину (USB). Монитор 47 или другое устройство отображения также подключается к системной шине 23 через интерфейс, например видеоадаптер 48.
В дополнение к монитору 47 персональные компьютеры, как правило, включают и другие периферийные устройства (не показаны), например динамики и принтеры. Устройство хранения данных, например привод жесткого диска, магнитная лента или иной накопитель данных также подключается к системной шине 23 через интерфейс, например хост-адаптер, при помощи интерфейса подключения, например Integrated Drive Electronics (IDE), Advanced Technology Attachment (ATA), Ultra ATA, Small Computer System Interface (SCSI), SATA, Serial SCSI и т.д.
Компьютер 20 может использоваться в сетевой среде с логическими соединениями с одним или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 может представлять собой другой персональный компьютер, сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой узел общей сети и обычно включает многие или все элементы, о которых говорится выше применительно к компьютеру 20.
Компьютер 20 может включать также запоминающее устройство 50. Логические соединения включают локальную сеть (LAN) 51 и глобальную сеть (WAN) 52. Такая сетевая структура часто применяется в офисах, компьютерных сетях предприятий, интрасетях и в Интернете.
При использовании в локальной сетевой среде LAN персональный компьютер 20 подключается к локальной сети 51 через сетевой интерфейс или адаптер 53. При использовании в сетевой среде WAN персональный компьютер 20 обычно включает модем 54 или другие средства установления связи с глобальной сетью 52, например Интернетом. Модем 54, который может быть внутренним или внешним, подключается к системной шине 23 через интерфейс последовательного порта 46.
В сетевой среде программные модули, относящиеся на рфигуре к персональному компьютеру 20, или их части могут храниться на удаленном запоминающем устройстве. Следует учесть, что изображенные сетевые подключения приведены в качестве примера и могут использоваться также другие средства для установки соединения между компьютерами.
Из приведенного описания различных реализаций способа и системы специалистам в данной области должно быть ясно, что данные способ и система предлагают определенные преимущества. В частности, они должны оценить, что предлагаемый способ обеспечивает автоматическое создание программы изучения языка на основе наиболее частотных, то есть популярных, синтаксических моделей, что позволяет пользователю начать изучать наиболее используемые элементы грамматики языка.
Также заслуживает внимания возможность внесения различных модификаций, адаптации и внедрения альтернативных вариантов осуществления в рамках данного изобретения и в соответствии с его духом. Изобретение дополнительно определяется следующими пунктами патентной формулы.




Крауд-сорсные системы обучения лексике
Крауд-сорсные системы обучения лексике

