Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО КЛАССИФИКАЦИИ ИЗОБРАЖЕНИЙ ПЕЧАТНЫХ КОПИЙ ДОКУМЕНТОВ И СИСТЕМА СОРТИРОВКИ ПЕЧАТНЫХ КОПИЙ ДОКУМЕНТОВ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее изобретение относится к области техники обработки и управления документами, и в частности - к способу и устройству классификации изображений печатных копий документов и системе сортировки печатных копий документов.
Уровень техники
Несмотря на современный прогресс в области управления электронными документами, существует большое разнообразие деловых документов, которые все еще предоставляются в виде печатных копий. Типичные офисные документы, которые необходимо предоставлять в виде печатных копий, относятся к учетным документам, правовым документам, персональной информации, официальным почтовым документам и т.д. Как правило, таблицы, штампы, логотипы, факсимильные сообщения или подписи могут содержатся в таких документах. Большое число печатных копий приходит в организации по почте, факсу и через службы курьерской доставки, которые предполагают ручную бумажную работу.
Печатные копии могут быть классифицированы с использованием разных способов, в частности, основанных на (визуальных) элементах изображения и текстовых (со смысловым содержанием) элементах. Многие из существующих подходов - такие, например, как раскрытый в документе ʺA survey of document image classification: problem statement, classifier architecture and performance evaluationʺ by N. Chen, D. Blostein, International Journal of Document Analysis and Recognition, vol. 10, iss. 1, pp. 1-16. June 2007, - сфокусированы на текстовой информации, поскольку она представляет собой существенные данные. Тем не менее возникает много ситуаций с деловыми документами, при которых количество текста в документе относительно мало или текст вовсе отсутствует, или он включает в себя только написанный от руки текст, который сложно распознать. Поэтому некоторые из решений, известных из уровня техники, такие, например, как раскрытые в US 8,831,361 и US 8,462,394, предлагают использовать текстовую информацию вместе с визуальной информацией для улучшения точности классификации. Однако эти решения все еще являются затратными с точки зрения вычислений в силу необходимости выполнения этапа оптического распознавания символов при анализе текста.
Некоторые другие подходы требуют извлечения макета документа, причем макет документа представляется в виде двоичного (или более сложного) дерева. Один пример раскрыт в US 8,744,183. Основной недостаток подобных подходов связан со сложностью извлечения макета для сложных документов и иногда с недостаточной надежностью. Например, в случае хорошо структурированных документов, напечатанных на белой бумаге, легко определить его заголовок, колонтитулы и содержимое частей. Однако тяжело или даже невозможно выполнить такое определение, когда документ включает в себя смешанные таблицы или разные фоны.
Способы, основанные на элементах изображений, обеспечивают более надежный метод работы с любым макетом и фоном документов. В частности, эти способы предусматривают три основных процесса извлечения дескриптора изображения документа: пространственные локальные бинарные шаблоны, полутоновая гистограмма длин отрезков и векторы Фишера.
Локальные бинарные шаблоны (LBP) недавно стали весьма популярны в процессе распознавания лиц, но они редко используются для классификации документов. Существующие способы нацелены в основном на извлечение LBP для всего изображения отсканированного документа или для конкретных частей документа (см. документ T. Ojala, M. Pietikäinen, M. Mäenpää, ʺMultiresolution gray-scale and rotation invariant texture classification with local binary patternsʺ, PAMI, 2010).
Дескриптор изображения документа, основанный на гистограммах длин отрезков, обсуждается в US 8,249,343, согласно которому дескриптор изображения документа предназначен специально для двоичных документов. Однако очевидный недостаток дескриптора изображения документа, известного из US 8,249,343, состоит в том, что он может быть применен только к простым деловым документам на белой бумаге, т.е. он не может быть использован в качестве дескриптора полутонового изображения.
Как отмечено выше, векторы Фишера также используются для извлечения дескриптора изображения документа. Классификация изображений на основе векторов Фишера описана в документе ʺImage Classification with the Fisher Vector: Theory and Practiceʺ by J. Sanchez, F. Perronnin, T. Mensink, J. Verbeek, In International Journal of Computer Vision 105, pp. 222-245, 2013. Пример дескриптора изображения документа, извлекаемого с использованием векторов Фишера, описан в US 8,532,399.
Кроме того, некоторые примеры соответствующих средств сортировки документов на основе вышеупомянутых подходов и способов представлены в US 5,435,544, US 5,525,031 и US 5,602,973. Типичный финишер в устройстве печати имеет множество выходных лотков, которые позволяют сортировать напечатанные копии по заданной пользователем или группой пользователей взаимосвязи, как описано в US 5,295,181. Основной недостаток такой сортировки состоит в том, что упомянутая взаимосвязь задается заранее, и все документы, которые отправляются в устройстве печати, имеют ее. Взаимосвязь определяется с использованием штрих-кодов, которые должные быть напечатаны на любом документе; следовательно, документы без штрих-кодов остаются неопознанными. Кроме того, число выходных лотков ограничивает число возможных классов документов.
Раскрытие изобретения
Задача настоящего изобретения заключается в устранении или смягчении вышеупомянутых недостатков, присущих решениям, известным из уровня техники.
В частности, задача изобретения состоит в обеспечении инструмента для автоматической классификации изображений печатных копий документов и сортировки печатных копий документов на основе классифицированных изображений печатных копий документов, а также для дальнейшей обработки сценариев в отношении каждой печатной копии документа. Один примерный сценарий подразумевает, что счета, накладные и финансовые отчеты должны быть переданы в бухгалтерию, а почтовые сообщения должны быть доставлены секретарями получателям.
С учетом вышесказанного технический результат, достигаемый за счет использования настоящего изобретения, заключается в обеспечении возможности автоматической классификации изображений печатных копий документов.
Согласно первому аспекту настоящего изобретения, предложен способ классификации изображений печатных копий документов. Способ начинается с предоставления изображения печатной копии документа. Изображение печатной копии документа имеет признаки изображения. Изображение печатной копии документа затем вводится в первый набор средств извлечения дескрипторов изображения. Первый набор средств извлечения дескрипторов изображения извлекает дескрипторы изображения из изображения печатной копии документа. Каждый дескриптор изображения описывает признаки изображения в изображении печатной копии документа. После этого множество обученных классификаторов используется для оценки вероятностей класса изображения печатной копии документа на основе извлеченных дескрипторов изображения. Далее наиболее вероятный класс изображения печатной копии документа определяется с помощью обученного мета-классификатора с использованием оцененных вероятностей класса. Изображение печатной копии документа и наиболее вероятный класс изображения печатной копии документа потом вводятся в средство назначения. В заключение, наиболее вероятный класс, определенный обученным мета-классификатором, назначается средством назначения изображению печатной копии документа для получения классифицированного изображения печатной копии документа.
Множество обученных классификаторов и обученный мета-классификатор получают с использованием этапов, на которых:
- сохраняют обучающую выборку, содержащий обучающие изображения и метки классов, в памяти, причем метки классов связаны с обучающими изображениями, и каждое обучающее изображение имеет признаки обучающего изображения;
- вводят обучающие изображения из обучающей выборки, сохраненной в памяти, во второй набор средств извлечения дескрипторов изображения;
- извлекают дескрипторы обучающего изображения с помощью второго набора средств извлечения дескрипторов изображения, причем каждый дескриптор обучающего изображения описывает признаки обучающего изображения для каждого обучающего изображения;
- получают множество обученных классификаторов с помощью средства обучения классификаторов, используя дескрипторы обучающего изображения, извлеченные вторым набором средств извлечения дескрипторов изображения, и метки классов, связанные с обучающими изображениями;
- оценивают вероятности класса обучающих изображений с помощью множества обученных классификаторов; и
- получают обученный мета-классификатор с помощью средства обучения мета-классификатора на основе вероятностей класса, оцененных множеством обученных классификаторов, и меток классов, связанных с обучающими изображениями.
В одном варианте осуществления количество обученных классификаторов во множестве обученных классификаторов равно количеству средств извлечения дескрипторов изображения во втором наборе средств извлечения дескрипторов изображения, и каждый из множества обученных классификаторов связан с одним из второго набора средств извлечения дескрипторов изображения.
В некоторых вариантах осуществления средства извлечения дескрипторов изображения в каждом из первого и второго наборов средств извлечения дескрипторов изображения содержат средство извлечения пространственных локальных бинарных шаблонов (SLBP), средство извлечения полутоновой гистограммы длин отрезков (GRLH) и средство извлечения векторов Фишера для модели смешивания Бернулли (BMMFV).
Каждый из дескрипторов изображения и дескрипторов обучающего изображения может быть числовым вектором с целыми, вещественными или двоичными числами. Классы изображения печатной копии документа и обучающих изображений могут быть целыми числами или текстовыми метками. Признаки изображения и признаки обучающего изображения могут относится к форме, текстуре и/или цвету изображения печатной копии документа и обучающих изображений соответственно.
В одном варианте осуществления упомянутый этап предоставления изображения печатной копии документа содержит этап, на котором получают изображение печатной копии документа с помощью сканера, факсимильной машины, фотокамеры, видеокамеры, средства считывания или через сеть беспроводной или проводной связи.
В одном варианте осуществления первый и второй наборы средств извлечения дескрипторов изображения являются одним и тем же набором средств извлечения дескрипторов изображения.
В одном варианте осуществления множество обученных классификаторов представляет собой машины опорных векторов (SVM).
Упомянутый этап оценивания вероятностей класса изображения печатной копии документа может содержать этап, на котором получают вектор с вещественными числами, который характеризует вероятности принадлежности изображения печатной копии документа конкретному классу.
Упомянутый этап определения наиболее вероятного класса с помощью обученного мета-классификатора может содержать этапы, на которых: объединяют множество векторов вероятностей, оцененных множеством обученных классификаторов, в один вектор; оценивают вероятности класса изображения печатной копии документа с использованием SVM и объединенного множества векторов вероятностей; выбирают класс с наибольшей вероятностью в качестве наиболее вероятного класса.
Упомянутый этап сохранения обучающей выборки может дополнительно содержать этапы, на которых: принимают обучающую выборку; выбирают случайное подмножество обучающих изображений и меток класса из обучающей выборки; и сохраняют случайное подмножество в памяти.
Упомянутый этап извлечения дескрипторов изображения или дескрипторов обучающего изображения с помощью средства извлечения SLBP может содержать этапы, на которых: осуществляют рекурсивное подразбиение изображения печатной копии документа или каждого обучающего изображения на множество горизонтальных и вертикальных полос; осуществляют понижающую дискретизацию каждой полосы до одного и того же размера; извлекают локальный бинарный шаблон (LBP) для каждого пикселя из каждой подвергнутой понижающей дискретизации полосы; вычисляют гистограмму бинарного шаблона для каждой подвергнутой понижающей дискретизации полосы; объединяют вычисленные гистограмм бинарных шаблонов в дескриптор изображения или дескриптор обучающего изображения; осуществляют нормировку дескриптора изображения или дескриптора обучающего изображения.
Упомянутый этап извлечения дескрипторов изображения или дескрипторов обучающего изображения с помощью средства извлечения GRLH может содержать этапы, на которых: осуществляют понижающую дискретизацию изображения печатной копии документа или каждого обучающего изображения; осуществляют рекурсивное подразбиение подвергнутого понижающей дискретизации изображения печатной копии документа или обучающего изображения на множество горизонтальных и вертикальных полос; извлекают длины отрезков с похожей яркостью для каждой линии полосы в горизонтальном, вертикальном, диагональном и побочном диагональном направлениях; вычисляют гистограммы длин отрезков для каждой полосы, значение яркости и длину; объединяют вычисленные гистограммы длин отрезков в дескриптор изображения или дескриптор обучающего изображения; осуществляют нормировку дескриптора изображения или дескриптора обучающего изображения.
Упомянутый этап извлечения дескрипторов изображения или дескрипторов обучающего изображения с помощью средства извлечения BMMFV может содержать этапы, на которых: осуществляют понижающую дискретизацию изображения печатной копии документа или каждого обучающего изображения; осуществляют рекурсивное подразбиение подвергнутого понижающей дискретизации изображения печатной копии документа или обучающего изображения на множество горизонтальных и вертикальных полос; извлекают бинарные локальные дескрипторы для каждой полосы; уменьшают размерность извлеченных бинарных локальных дескрипторов с использованием алгоритма анализа главных компонент (PCA); вычисляют модель смешивания Бернулли для уменьшенных по размерности локальных дескрипторов; вычисляют векторы Фишера на основе вычисленной модели смешивания Бернулли; осуществляют степенную нормировку и нормировку L2 в отношении вычисленных векторов Фишера; объединяют нормированные векторы Фишера для каждой полосы в дескриптор изображения или дескриптор обучающего изображения. Бинарные локальные дескрипторы могут быть одними из дескрипторов BRISK или ORB.
Согласно второму аспекту настоящего изобретения, предложено устройство классификации изображений печатных копий документов. Устройство используется для выполнения способа согласно первому аспекту настоящего изобретения. Для этого устройство содержит модуль классификации и модуль обучения.
Модуль классификации используется для классификации изображений печатных копий документа и включает в себя первый набор средств извлечения дескрипторов изображения, множество обученных классификаторов, обученный мета-классификатор и средство назначения. Первый набор средств извлечения дескрипторов изображения выполнен с возможностью извлечения дескрипторов изображения для изображения печатной копии документа, введенного в первый набор средств извлечения дескрипторов изображения. Изображение печатной копии документа имеет признаки изображения, и каждый дескриптор изображения описывает признаки изображения. Упомянутое множество обученных классификаторов выполнено с возможностью оценивания вероятностей класса изображения печатной копии документа посредством использования дескрипторов изображения, извлеченных первым набором средств извлечения дескрипторов изображения. обученный мета-классификатор выполнен с возможностью определения наиболее вероятного класса изображения печатной копии документа посредством использования вероятностей класса, оцененных множеством обученных классификаторов. Средство назначения выполнено с возможностью назначения наиболее вероятного класса, определенного обученным мета-классификатором, изображению печатной копии документа для получения классифицированного изображения печатной копии документа.
Модуль обучения используется для получения упомянутого множества обученных классификаторов и обученного мета-классификатора и включает в себя память, второй набор средств извлечения дескрипторов изображения, средство обучения классификаторов и средство обучения мета-классификатора. Память выполнена с возможностью хранения обучающей выборки, содержащей обучающие изображения и метки классов. Метки классов связаны с обучающими изображениями, и каждое обучающее изображение имеет признаки обучающего изображения. Второй набор средств извлечения дескрипторов изображения выполнен с возможностью приема обучающих изображений из обучающей выборки, хранимой в памяти, и извлечения дескрипторов обучающего изображения. Каждый дескриптор обучающего изображения описывает признаки обучающего изображения для каждого обучающего изображения. Средство обучения классификаторов выполнено с возможностью получения множества обученных классификаторов посредством использования дескрипторов обучающего изображения, извлеченных вторым набором средств извлечения дескрипторов изображения, и меток класса, связанных с обучающими изображениями. Упомянутое множество обученных классификаторов оценивает вероятности класса обучающих изображений. Средство обучения мета-классификатора выполнено с возможностью получения обученного мета-классификатора посредством использования вероятностей класса, оцененных упомянутым множеством обученных классификаторов, и меток класса, связанных с обучающими изображениями.
Варианты осуществления устройства согласно второму аспекту настоящего изобретения аналогичны вариантам осуществления способа согласно первому аспекту настоящего изобретения.
Согласно третьему аспекту настоящего изобретения, предложена система сортировки печатных копий документов. Система содержит устройство сортировки печатных копий и систему обработки изображений.
Устройство сортировки печатных копий включает в себя: входной лоток для печатных копий документа, средство захвата изображений, выполненное с возможностью захвата изображений печатных копий документа; индикатор уведомлений, выполненный с возможностью отображения назначенного класса каждого изображения печатной копии документа; один или более выходных лотков для отсортированных печатных копий документа.
Система обработки изображений включает в себя устройство согласно второму аспекту настоящего изобретения, которое выполнено с возможностью назначения класса каждому изображению печатной копии документа, и модуль маршрутизации, выполненный с возможностью назначения каждой печатной копии документа выходного лотка согласно назначенному классу каждого изображения печатной копии документа. В частности, модуль маршрутизации выполнен с возможностью: приема информации о количестве выходных лотков и количестве непустых выходных лотков из устройства сортировки печатных копий и изображений печатных копий, имеющих назначенные классы, и устройства согласно второму аспекту настоящего изобретения; назначения номера выходного лотка каждой печатной копии документа согласно назначенному классу соответствующего изображения печатной копии документа и количеству непустых выходных лотков; маршрутизации печатной копии документа из входного лотка в назначенный выходной лоток.
Средство захвата изображений может представлять собой одно из следующего: сканер, факсимильная машина, фотокамера, видеокамера, средство считывания для считывания файла изображения из носителя данных, блок ввода для приема файла изображения через Интернет. Индикатор уведомлений может быть одним из LCD-дисплея и LED-дисплея.
В одном варианте осуществления индикатор уведомлений выполнен с дополнительной возможностью уведомления о необходимости опустошения выходного лотка.
Другие признаки и преимущества настоящего изобретения будут очевидны после прочтения нижеследующего подробного описания и просмотра сопроводительных чертежей.
Краткое описание чертежей
Сущность настоящего изобретения поясняется ниже со ссылкой на сопроводительные чертежи, на которых:
Фиг. 1 иллюстрирует систему сортировки отсканированных печатных копий документов;
Фиг. 2 иллюстрирует устройство сортировки печатных копий;
Фиг. 3 иллюстрирует блок-схему модуля обучения;
Фиг. 4 иллюстрирует блок-схему модуля прогнозирования;
Фиг. 5 иллюстрирует блок-схему модуля сортировки печатных копий;
Фиг. 6 иллюстрирует процесс подразбиения изображения на пространственные пирамиды;
Фиг. 7 иллюстрирует процесс извлечения LBP;
Фиг. 8 иллюстрирует процесс извлечения GRLH.
Осуществление изобретения
Различные варианты осуществления настоящего изобретения описаны далее подробнее со ссылкой на сопроводительные чертежи. Однако, настоящее изобретение может быть реализовано во многих других формах и не должно пониматься как ограниченное какой-либо конкретной структурой или функцией, представленной в нижеследующем описании. В отличие от этого, эти варианты осуществления предоставлены для того, чтобы сделать описание настоящего изобретения подробным и полным. Исходя из настоящего описания, специалистам в данной области техники будет очевидно, что объем настоящего изобретения охватывает любой вариант осуществления настоящего изобретения, который раскрыт в данном документе, вне зависимости от того, реализован ли этот вариант осуществления независимо или совместно с любым другим вариантом осуществления настоящего изобретения. Например, способ, устройство и система, раскрытые в данном документе, могут быть реализованы на практике посредством использования любого числа вариантов осуществления, обеспеченных в данном документе. Кроме того, должно быть понятно, что любой вариант осуществления настоящего изобретения может быть реализован с использованием одного или более элементов, представленных в приложенной формуле изобретения.
Слово «примерный» используется в данном документе в значении «используемый в качестве примера или иллюстрации». Любой вариант осуществления, описанный здесь как «примерный», необязательно должен восприниматься как предпочтительный или имеющий преимущество над другими вариантами осуществления.
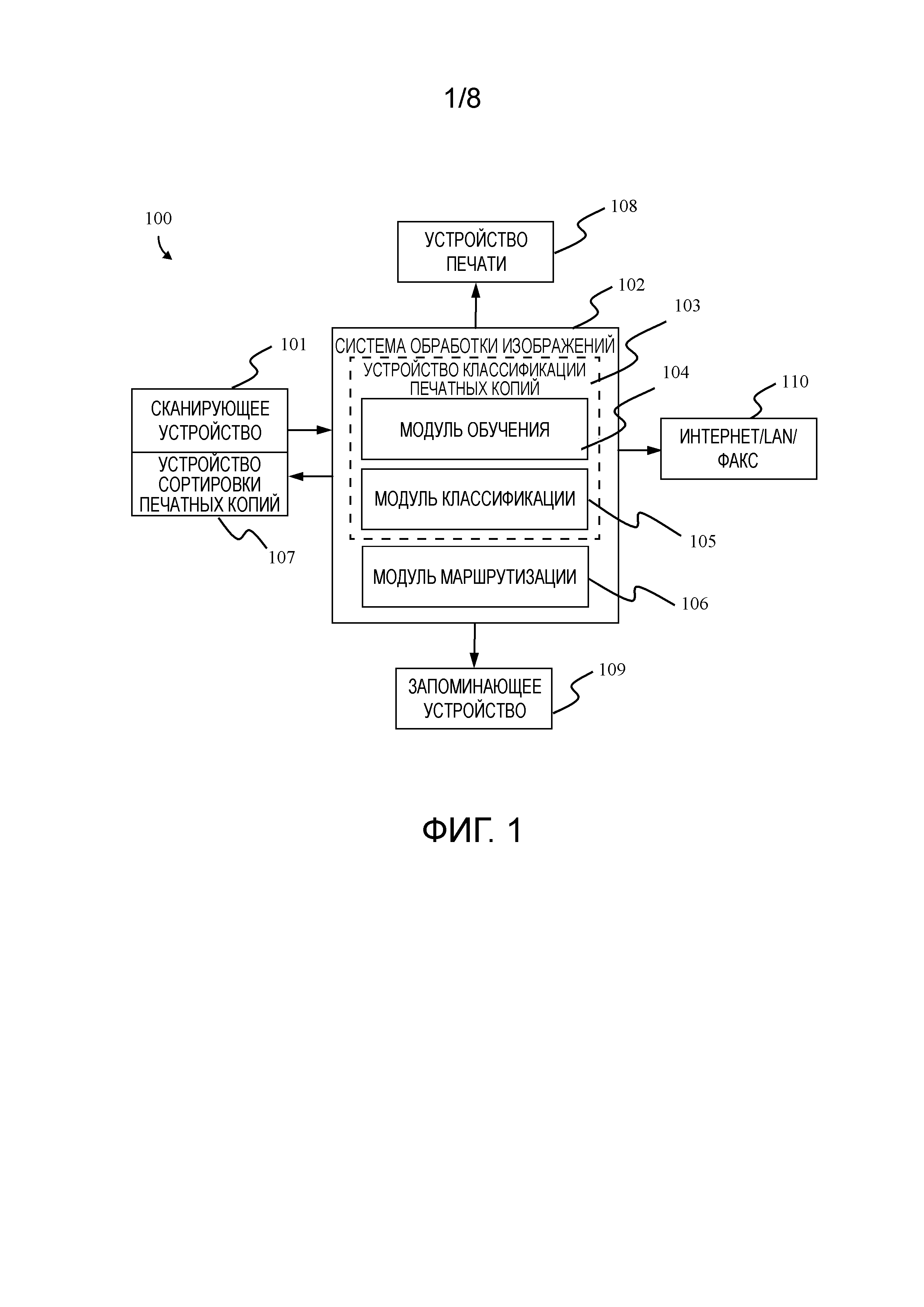
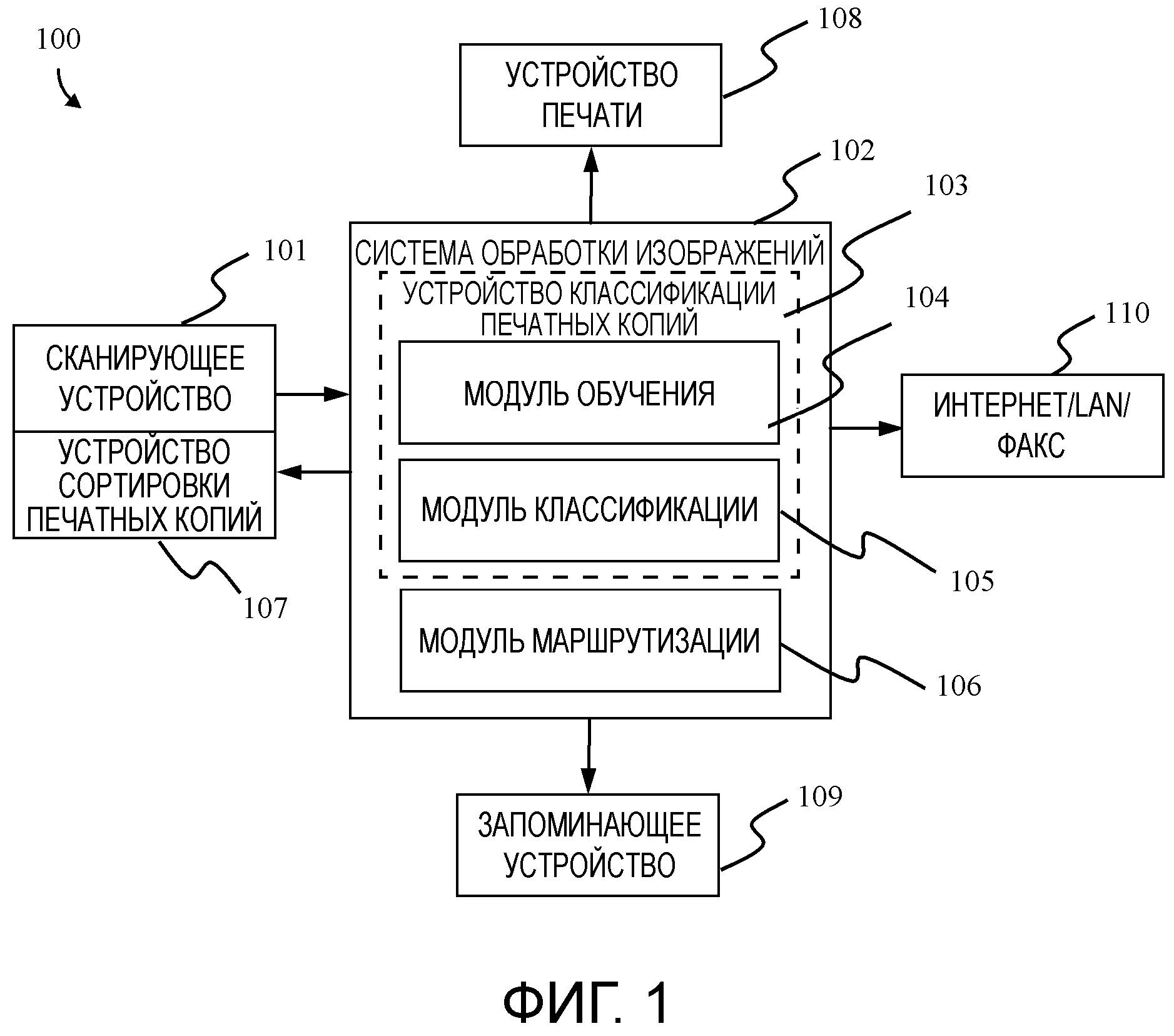
Фиг. 1 показывает систему 100 сортировки печатных копий документов в соответствии с одним примерным вариантом осуществления настоящего изобретения. Как видно, система 100 содержит сканирующее устройство 101, систему 102 обработки изображений, устройство 107 сортировки печатных копий, устройство 108 печати и запоминающее устройство 109. Сканирующее устройство 101 выполнено с возможностью передачи изображений печатных копий документа, которые подлежат сортировке, системе 102 обработки изображений. Как правило, сканирующее устройство 101 может быть снабжено или заменено другим средством, подходящим для получения изображений, таким как фотокамера, носитель данных с файлами изображения и т.д. Система 102 обработки изображений содержит устройство 103 классификации изображений печатных копий документа и модуль 106 маршрутизации. Устройство 103 классификации изображений печатных копий документа содержит модуль 104 обучения и модуль 105 классификации. Модуль 104 обучения выполнен с возможностью обучения множества классификаторов с использованием средства обучения классификаторов, чтобы получить множество обученных классификаторов, и обучения мета-классификатора, чтобы получить обученный мета-классификатор. Модуль 104 обучения будет описан подробнее ниже со ссылкой на Фиг. 3. Модуль 105 классификации используется для классификации изображений печатных копий документа и будет описан подробнее ниже со ссылкой на Фиг. 4. Модуль 109 маршрутизации выполнен с возможностью назначения выходного лотка каждой печатной копии документа согласно назначенному классу соответствующего изображения печатной копии документа.
Назначенный класс каждого изображения печатной копии документа передается устройству 107 сортировки печатных копий для выполнения сортировки печатных копий в соответствии с назначенным классом. Упомянутая сортировка печатных копий предусматривает разделение пачки печатных копий документов на наборы, относящиеся к соответствующим классам, определенным обучающей выборкой. Обучающая выборка состоит из обучающих изображений и назначенных меток классов. В зависимости от предпочтений пользователя электронная копия печатной копии документа может быть напечатана устройством 108 печати, сохранена запоминающим устройством 109 или совместно использована через другие средства, такие как Интернет, локальная сеть или факс 110, для последующей обработки и управления.
Следует отметить, что любые модули системы 100 могут быть объединены в одном автономном устройстве или распределены по отдельности, соединены проводной сетью или беспроводной системой для обмена данными, или объединены в подсистемах друг с другом. Например, сканирующее устройство 101 может также включать в себя систему 102 обработки изображений или устройство 108 печати, может быть встроено в многофункциональное периферийное устройство, такое как многофункциональное устройство печати (MFP). Система 102 обработки изображений может быть реализована с помощью процессора и памяти с инструкциями для извлечения дескрипторов изображения, обучения классификаторов и классификации печатных копий. В других вариантах осуществления модули системы 102 обработки изображений могут быть реализованы в аппаратном обеспечении с использованием «системы-на-кристалле» (SoC). Как должно быть очевидно специалистам в данной области техники, система 100 может быть переконфигурирована или изменена в зависимости от предпочтений пользователя и сценариев для каждого заранее заданного класса. Например, устройство 108 печати может быть представлено сетью устройств печати, распределенных среди разных пользователей или отделов. Каждый класс изображения печатной копии документа связан с заранее заданным сценарием или заранее заданными сценариями с перечнем необходимых действий. Например, после упомянутой сортировки печатных копий документа со спрогнозированным классом «накладная», его отсканированная копия должна быть напечатана на устройстве печати, расположенном в бухгалтерии, а еще одна копия отправлена по электронной почте ответственным специалистам. Можно реализовать систему 100 без сканирующего устройства 101 и устройства 107 сортировки печатных копий посредством ввода изображений документа в систему через любые другие подходящие устройства, такие как локальные или удаленные средства хранения, фото или видеокамеры, или другие устройства захвата изображений.
Кроме того, термин «дескриптор изображения» или «визуальный дескриптор» используется в данном документе в его обычном значении, известном специалисту в данной области техники, и относится к описанию элементарных характеристик всего изображения или каждой области изображения, таким, например, как форма, текстура, цвет и т.д. Такой дескриптор изображения может быть представлен в любом виде в зависимости от конкретного применения. Например, дескриптор изображения может быть числовым вектором с целыми, вещественными или двоичными числами, но не ограничен этим.
Фиг. 2 иллюстрирует устройство 200 сортировки печатных копий в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Устройство 200 исполняет функции, по меньшей мере, сканирующего устройства и устройства сортировки печатных копий и включает в себя по меньшей мере один входной 201 и выходные 203 лотки для операций с печатными копиями документов. Панель 204 отображения и управления является необязательной и может быть заменена индикатором уведомлений. Предполагается, что пользователь вносит пачку печатных копий документов, которые должны быть помещены во входной лоток (или входные лотки) 201, выбирает предпочтительный режим сортировки через панель 204 или использует режим сортировки по умолчанию и принимает отсортированные печатные копии документов из выходных лотков 203. Изображения печатных копий документов захватываются средством захвата изображений, которое может представлять собой одно из следующего: сканер, факсимильную машину, фотокамеру, видеокамеру, устройство считывания для считывания файла изображения из носителя данных, блок ввода для приема файла изображения через Интернет.
Режим сортировки определяет набор параметров классификации, включающий в себя предпочтительный классификатор или комбинацию классификаторов для текущего процесса сортировки, и список назначенных выходных лотков для каждого класса изображений печатных копий документа (также упоминаемый в данном документе для краткости как «класс печатной копии») или категорию сортировки, предназначенную для группы таких классов. Таким образом, процесс сортировки применяется на основе прогнозирования класса печатной копии и посредством размещения печатной копии в соответствующем выходном лотке, назначенном для этого класса. В случае если устройство 200 имеет только один выходной лоток 203, возможны два следующих варианта осуществления: первый вариант осуществления предполагает только сортировку печатных копий с выдачей всех печатных копий в одном выходной лотке, а второй вариант осуществления предполагает выдачу печатных копий в выходном лотке до тех пор, пока печатные копии имеют один и тот же класс. Если классы текущей печатной копии и предыдущей печатной копии отличны, то устройство 200 (например, через панель 204) указывает пользователю, что необходимо опустошить выходной лоток 203 и вручную переместить все печатные копии внутри него в соответствующую пачку печатных документов. Затем процесс сортировки продолжается. Очевидно, что устройство 200 только с одним лотком может представлять собой любой сканер или MFP со средством автоматической подачи бумаги. Устройство 200 может включать в себя другие системные модули, в том числе систему 102 обработки изображения, устройство 108 печати и запоминающее устройство 109.
Модуль 300 обучения и модуль 400 будут далее описаны со ссылкой на Фиг. 3 и 4 соответственно.
Модуль 300 обучения используется перед модулем 400 классификации для настройки системы 100 согласно заданной пользователем обучающей выборке. Модуль 300 обучения следует использовать вновь, когда в систему 100 добавляется новый класс или новые классы печатных копий.
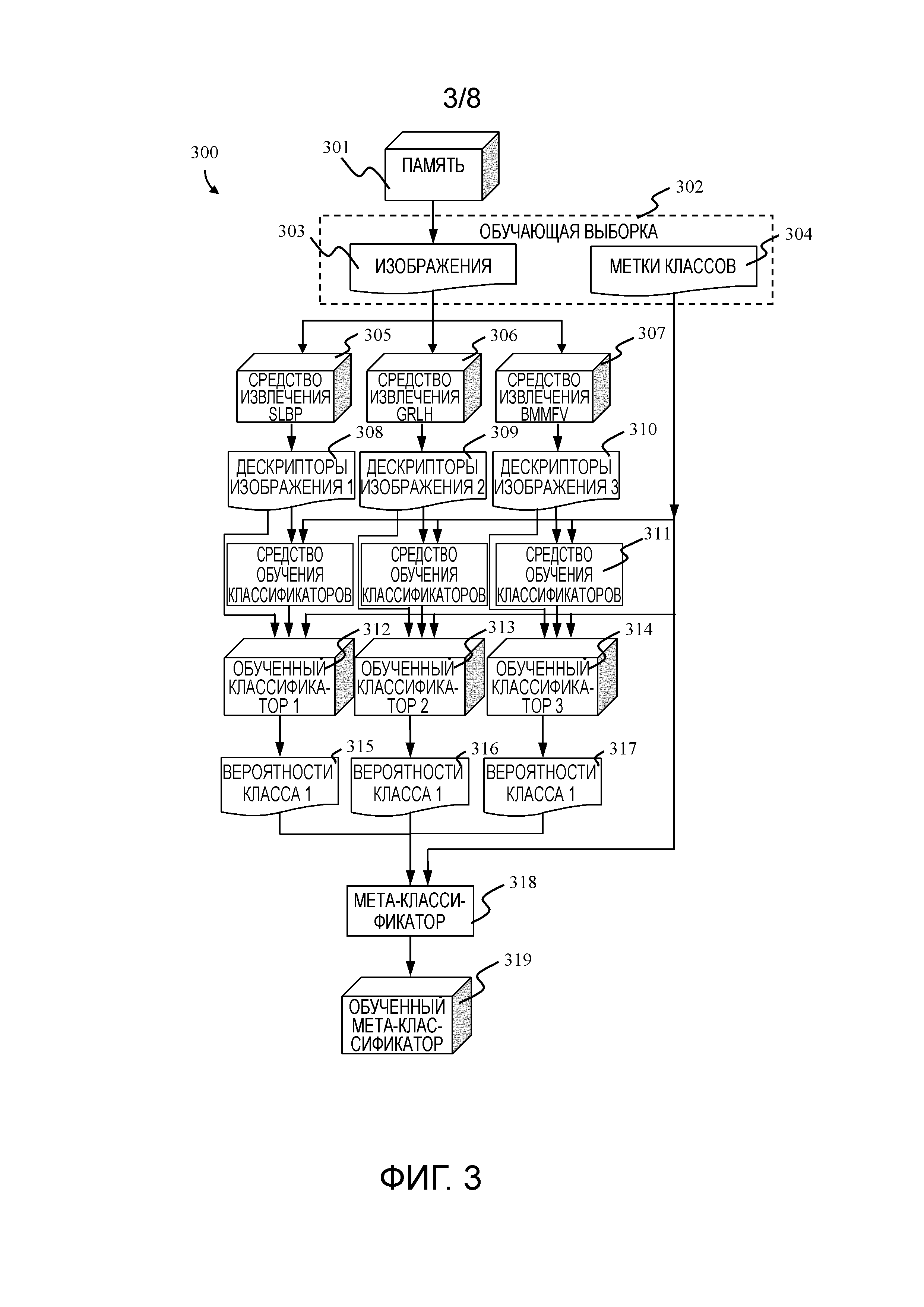
Работа модуля 300 обучения основана на обучении классификаторов в соответствии с размеченными пользователем изображениями печатных копий, причем метки могут быть либо числовыми, либо текстовыми, например, «1», «2», «3», «4» или «накладная», «электронная почта», «отчет» и т.д. Пользователь назначает метку каждому изображению заранее. Модуль 300 обучения принимает обучающую выборку, состоящую из обучающих изображений и назначенных меток, выбирает случайное подмножество из обучающей выборки и сохраняет случайное подмножество в памяти 301. Упомянутое обучение классификаторов применяется независимо в отношении множества классификаторов (один классификатор на каждое средство извлечения дескрипторов) и мета-классификатора. В предпочтительном варианте осуществления настоящего изобретения используются три средства извлечения дескрипторов изображения, а именно: пространственный локальный бинарный шаблон (SLBP) 305, полутоновая гистограмма длин отрезков (GRLH) 306 и агрегированные локальные дескрипторы на основе векторов Фишера для модели смешивания Бернулли (BMMFV) 307. Обученные классификаторы используются в модуле 105 классификации. Можно обучать набор классификаторов для разных сценариев классификации путем изменения обучающей выборки и количества требуемых классов.
Согласно Фиг. 3, работа модуля обучения может быть описана следующим образом:
1. Сначала обучающая выборка 302 сохраняется в памяти 301, причем упомянутое сохранение предусматривает прием обучающей выборки, выбор случайного подмножества из обучающей выборки и сохранение случайного подмножества в памяти 301.
2. Затем обучающие изображения 303 принимаются из памяти 301 средствами 305, 306 и 307 извлечения дескрипторов изображения.
3. Дескрипторы 308, 309 и 310 обучающего изображения извлекаются для обучающих изображений 303 с использованием средств 305, 306 и 307 извлечения дескрипторов. В предпочтительном варианте осуществления настоящего изобретения средствами извлечения дескрипторов являются SLBP, GRLH и BMMFV соответственно.
4. После этого множество обученных классификаторов 312, 313 и 314 обучается с использованием одного или более средств 311 обучения классификаторов, которые применяют для обучения извлеченные дескрипторы 308, 309 и 310 обучающего изображения и метки 304 классов из обучающей выборки 302. В предпочтительном варианте осуществления настоящего изобретения обученные классификаторы реализованы через машины опорных векторов (SVM).
5. Далее вероятности 315, 316 и 317 класса изображений 303 оцениваются с использованием обученных классификаторов 312, 313 и 314. Вероятности класса представляют собой числовые векторы, которые характеризуют вероятность принадлежности изображения печатной копии конкретному классу.
6. В заключение, мета-классификатор 319 обучается с использованием средства 318 обучения мета-классификатора, которое применяет для обучения вероятности 315, 316 и 317 класса и метки 304 классов из обучающей выборки 302. В предпочтительном варианте осуществления настоящего изобретения мета-классификатор реализован через SVM. Вероятности класса объединены в один вектор.
Обученные классификаторы 312, 313 и 314 используются в модуле 105 классификации. Пользователь имеет возможность модифицировать или переобучать классификаторы во время работы системы путем внесения в модуль 104 обучения обновленной или новой обучающей выборки.
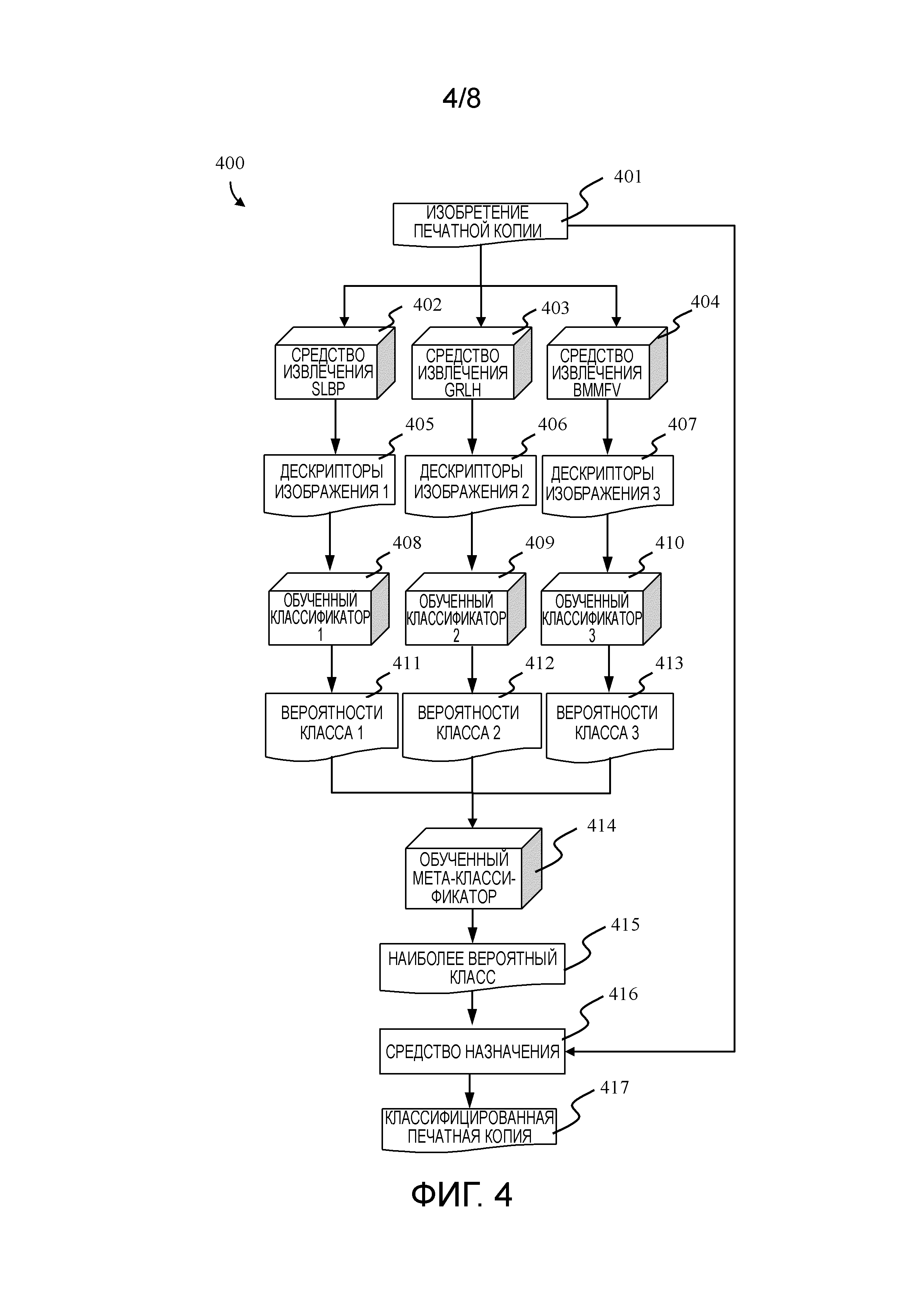
Аналогичным образом, согласно Фиг. 4, работа модуля 400 классификации может быть описана следующим образом:
1. Сначала изображение 401 печатной копии документа предоставляется в средства 402, 403 и 404 извлечения дескрипторов изображения.
2. Затем средства 402, 403 и 404 извлечения дескрипторов изображения извлекают дескрипторы 405, 406 и 407 изображения соответственно. В предпочтительном варианте осуществления настоящего изобретения средства извлечения дескрипторов изображения представляют собой SLBP, GRLH и BMMFV. Следует отметить, что средства 405, 406, 407 и 305, 306, 307 извлечения дескрипторов изображения могут быть одинаковыми.
3. После этого множество обученных классификаторов 408, 409 и 410 оценивают вероятности 411, 412 и 413 класса. В предпочтительном варианте осуществления настоящего изобретения множество классификаторов реализовано через машины опорных векторов (SVM). Следует отметить, что обученные классификаторы 408, 409, 410 и 312, 313, 314 являются одинаковыми.
4. Далее обученный мета-классификатор 414 определяет наиболее вероятный класс 415 посредством использования вероятностей 411, 412 и 413 класса, объединенных в один вектор. В предпочтительном варианте осуществления настоящего изобретения обученный мета-классификатор реализован через SVM. Следует отметить, что обученные мета-классификаторы 414 и 319 являются одинаковыми.
5. В заключение, наиболее вероятный класс 415 назначается изображению 401 печатной копии посредством использования средства назначения, что дает в результате классифицированную печатную копию 417.
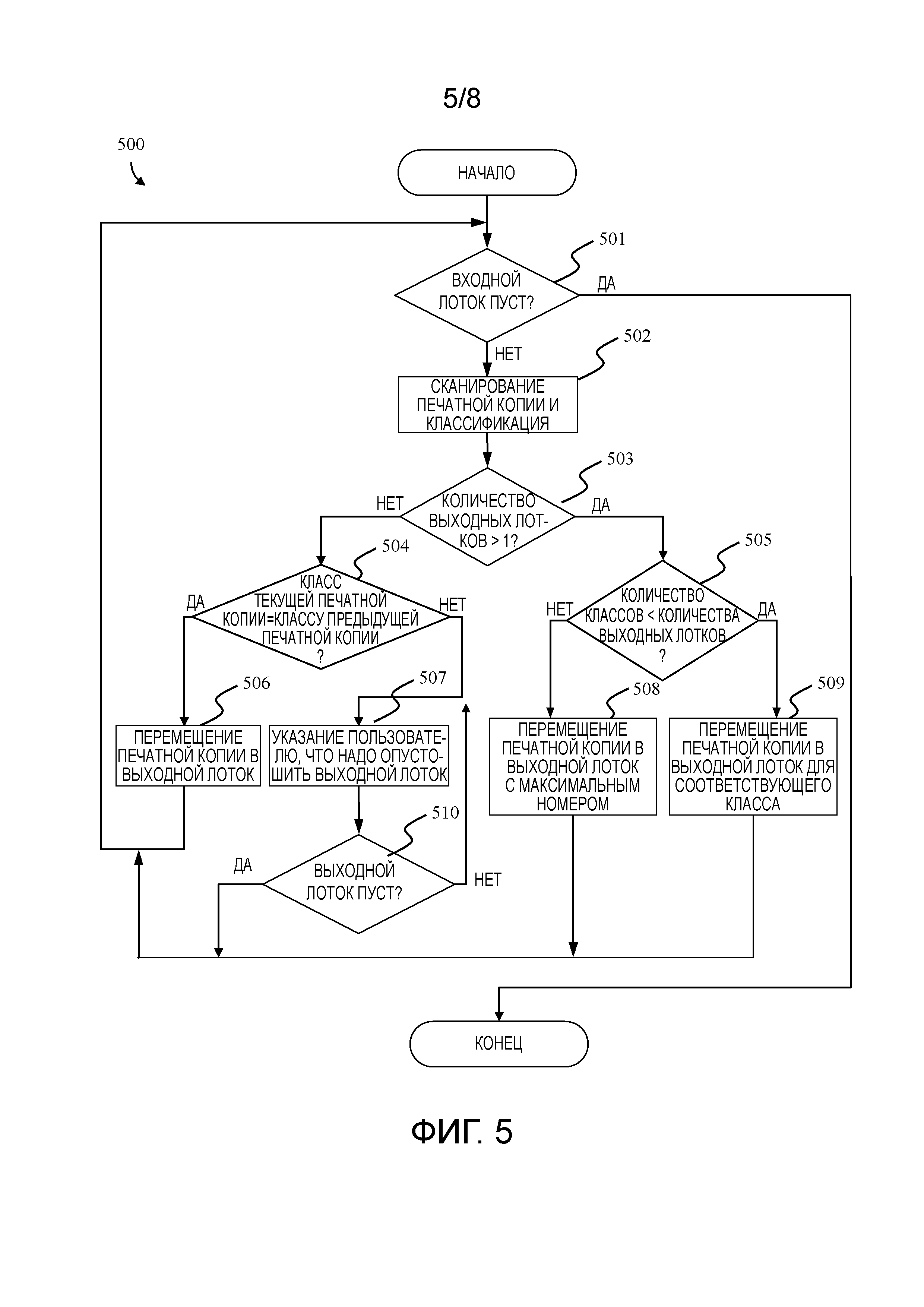
Фиг. 5 иллюстрирует процесс 500 сортировки для устройства 200. Процесс сортировки продолжается, пока печатные копии поступают во входной лоток 201, и завершается, если входной лоток пуст (этап 501). Каждая вносимая печатная копия из входного лотка 201 сканируется и классифицируется (этап 502) в соответствии с раскрытым выше способом. В случае если устройство 200 имеет только один выходной лоток 203, который определен на этапе 503, устройство 200 принимает и сканирует вносимые печатные копии одну за другой посредством этапов 502 и 506 до тех пор, пока вносимые документы имеют одинаковый класс. Если классы текущего документа и предыдущего документа отличны, и результат этапа 504 становится ложным, то устройство 200 указывает пользователю, что надо опустошить выходной лоток 203 и вручную переместить все документы внутри него в пачку с соответствующим классом (этапы 507 и 510). Если имеется по меньшей мере два или более выходных лотка 203, которые определены на этапе 503, и количество выходных лотков 203 меньше, чем заранее заданные классы или категории сортировки в соответствии с результатами этапа 505, то устройство 200 переводит первые N-1 классов (где N - количество выходных лотков) в отдельные лотки, и все оставшиеся классы в последний лоток (этапы 502, 505, 508 и 509). В случае если количество выходных лотков 203 равно или больше заранее заданных классов или категорий сортировки, каждая печатная копия должна быть выдана в соответствующем выходном лотке 203, назначенном для текущего класса документов.
В соответствии с предпочтительными вариантами осуществления модулей 300 и 400 обучения и классификации, три разных способа классификации могут быть применены для решения задачи классификации. Все они разделены на два этапа: извлечение дескрипторов 405, 406, 407 изображения и классификация дескрипторов изображения посредством использования соответствующих классификаторов 408, 409, 410. Все три алгоритма используют классификаторы SVM с разной настройкой. Средствами извлечения дескрипторов изображения являются следующие: пространственный локальный бинарный шаблон 402 (SLBP), полутоновая гистограмма длин отрезков 403 (GRLH) и объединенные локальные дескрипторы на основе векторов Фишера 404 для модели смешивания Бернулли (BMMFV).
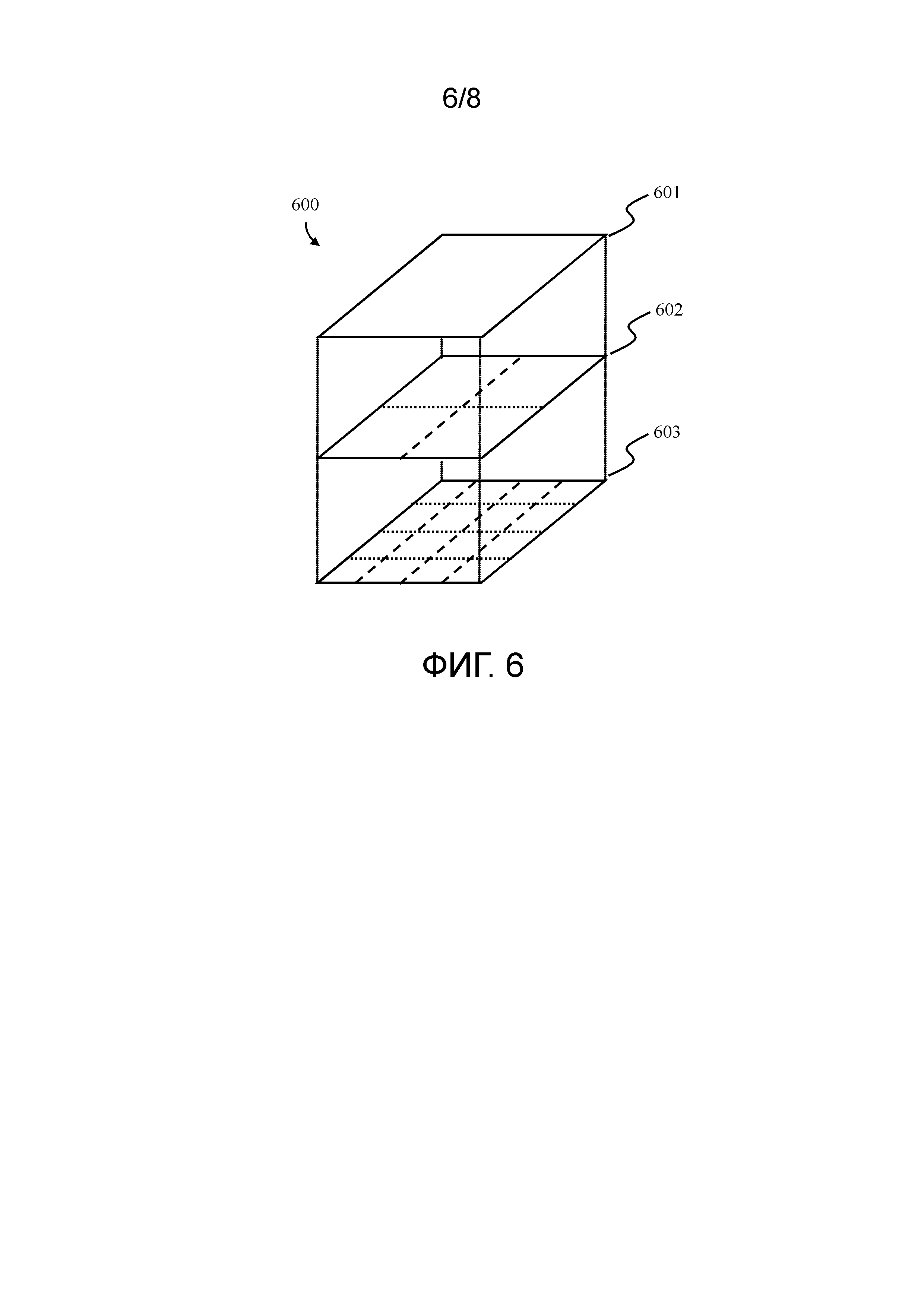
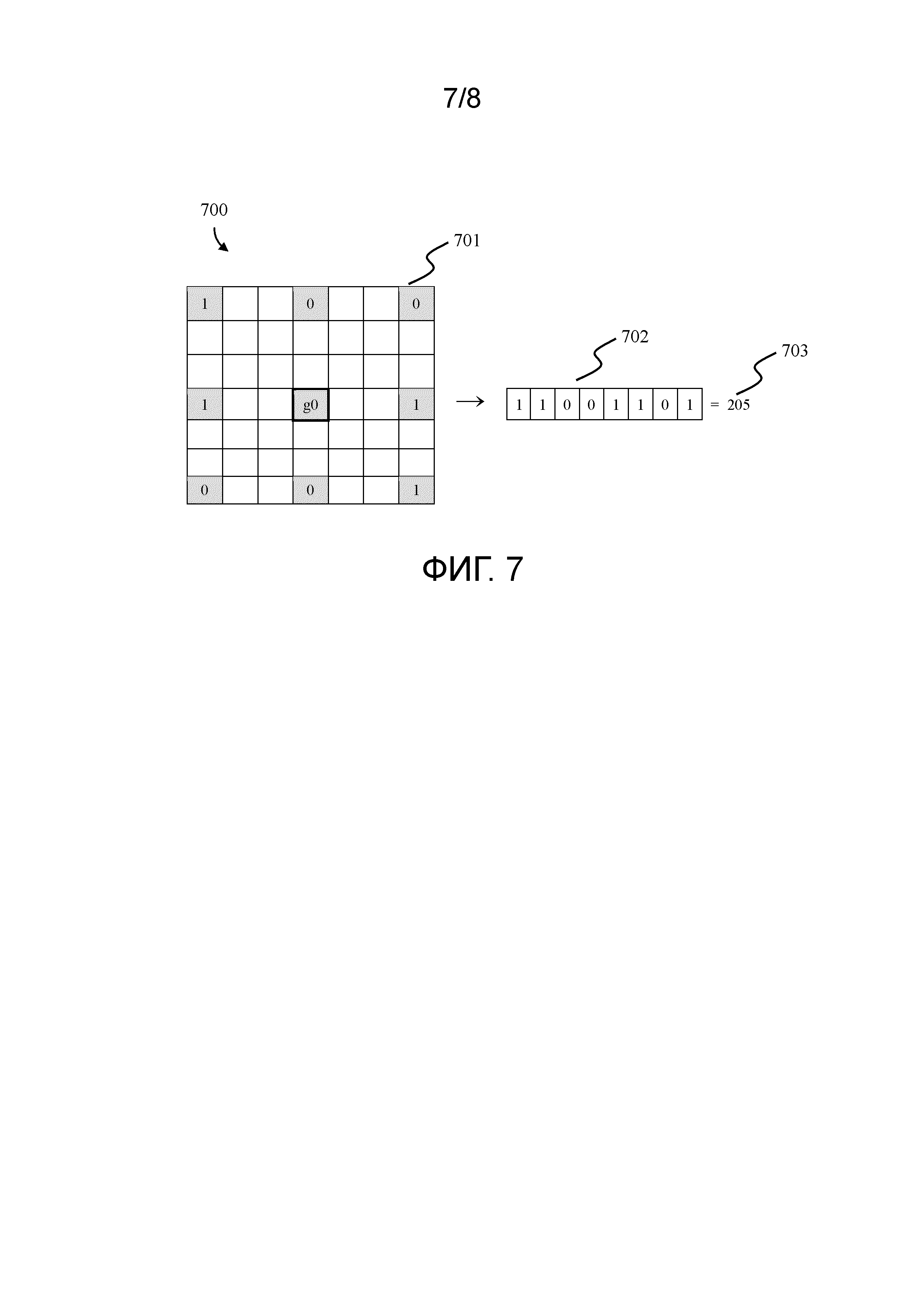
Фиг. 6 иллюстрирует извлечение дескриптора изображения на основе пространственного локального бинарного шаблона (SLBP). SLBP извлекается следующим образом: сначала входное изображение отсканированного документа 601 преобразуется в полутоновое изображение и разбивается на множество суб-изображений 602 и 603 посредством использования процесса 600 подразбиения изображения, причем каждое изображение подразбивается на множество вертикальных и горизонтальных полос. Затем все изображения 601, 602 и 603 (13 изображений или полос в целом) подвергаются понижающей дискретизации до размера пикселей 100×100, и каждый пиксель этих изображений преобразуется в локальный бинарный шаблон (LBP) согласно уравнению 1. Масштабирование выполняется с использованием билинейного преобразования.
|
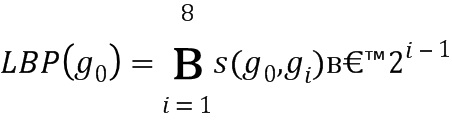 ,
,где 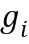 - интенсивность i-ого соседнего пикселя, и
- интенсивность i-ого соседнего пикселя, и 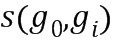 - функция, сравнивающая интенсивности пикселей и возвращающая двоичный код:
- функция, сравнивающая интенсивности пикселей и возвращающая двоичный код:
|
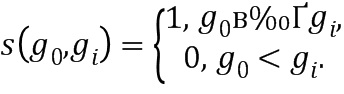
Фиг. 7 показывает процесс 700 извлечения LBP в соответствии с одним примерным вариантом осуществления настоящего изобретения. Согласно Фиг. 7, LBP преобразуется в числовую двоичную последовательность за счет извлечения признаков шаблона, начиная с верхнего левого пикселя в направлении 701 против часовой стрелки с 3-пиксельным интервалом между центральным пикселем и его «соседями». Извлеченные «1» и «0» формируют 8-битовый шаблон 702, который интерпретируется как байт 703 без знака. Эти байты объединяются в 8-биновую гистограмму и нормируются в диапазоне [0; 1]. Окончательный дескриптор имеет следующую длину: 13 суб-изображений х 8-биновую гистограмму=104.
Каждое суб-изображение имеет размеры пикселей 100×100, так что гистограмма может быть преобразована из целых в вещественные числа в пределах [0; 1] путем деления на 104. Цель масштабирования состоит в обеспечении разных уровней детализации для каждой полосы гистограммы. Это делает возможным не только сохранять детали в более малых полосах, но и также устранять шумы.
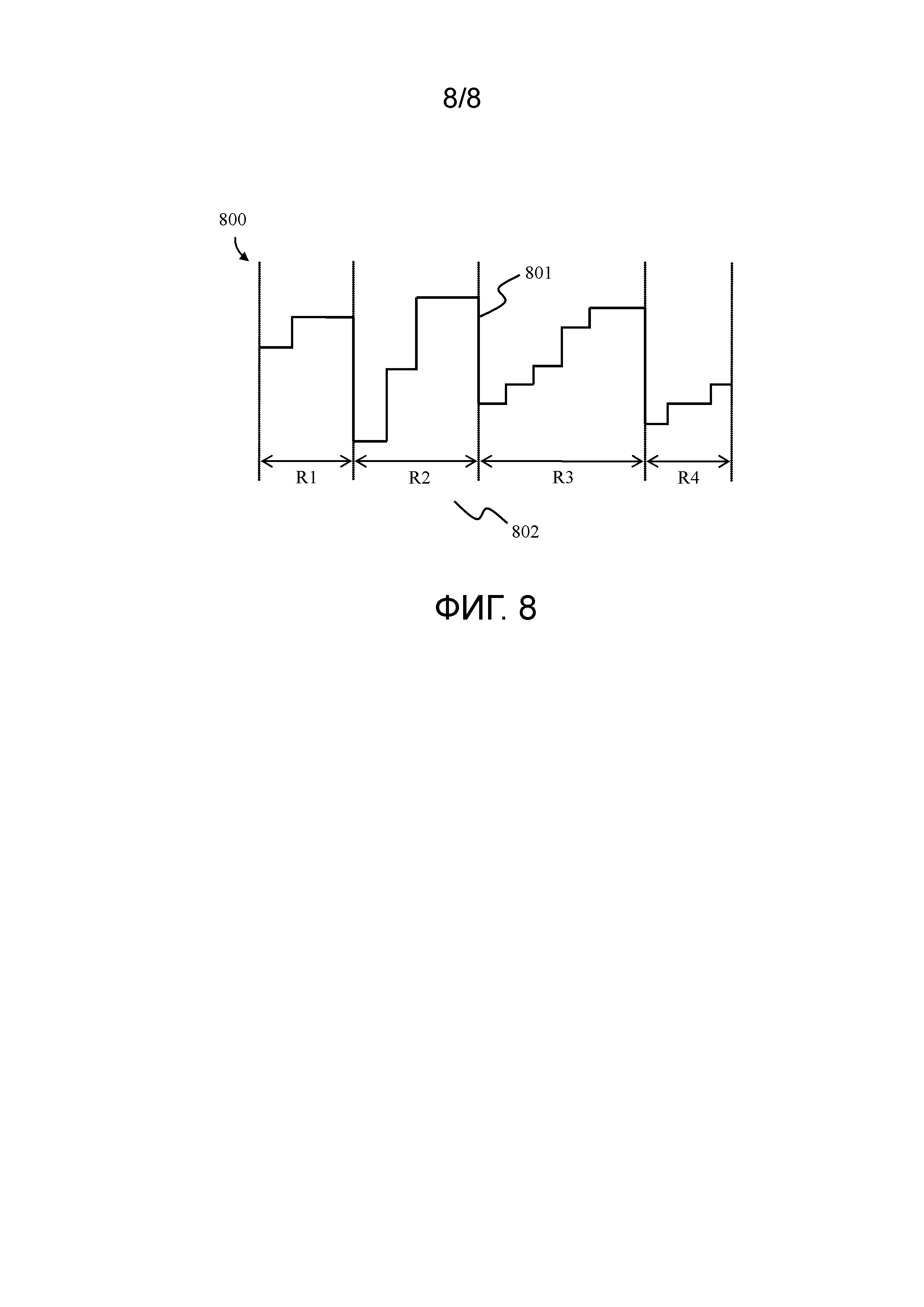
Средство извлечения GRLH применяет пространственно-локализованные полутоновые длины отрезков. Это выполняется следующим образом: сначала входное изображение отсканированного документа преобразуется в полутоновое изображения и подвергается понижающей дискретизации до заранее заданного размера. В предпочтительном варианте осуществления настоящего изобретения заранее заданный размер равен 5×105 пикселей. Затем оно разделяется на множество суб-изображений посредством использования вышеупомянутой пространственной пирамиды с Фиг. 6. Каждое изображение обрабатывается с помощью кодирования полутоновых длин отрезков: полоса представляет собой последовательность пикселей с отклонением яркости в близлежащих пикселях менее заранее заданного значения, так что все полосы 802, обозначенные как R1-R4, в линии 801 изображения могут быть найдены путем итерирования через ее пиксели и нахождения больших отклонений в соседних пикселях, как показано на Фиг. 8. Средство извлечения GRLH использует пороговое значение, равное 30, для разделения соседних полос. Длины полос квантуются с использованием логарифмической шкалы и сохраняются в двух 9-биновых гистограммах согласно разности между средним значением пикселя в текущей полосе и предыдущей полосе. Если текущая полоса светлее, чем предыдущая, она сохраняется в первой гистограмме или во второй гистограмме в ином случае. Средство извлечения GRLH вычисляет гистограммы линий для горизонтального, вертикального, диагонального и побочного диагонального направлений. Гистограммы для всех суб-изображений, направлений и яркостей объединяются в один вектор признаков, имеющий размер 1512 байтов. Окончательный вектор признаков нормируется в диапазоне [0; 1].
Использование полутоновых изображений вместо двоичных позволяет избежать этапа бинаризации, который может полностью нарушить контент изображения, если алгоритм бинаризации неправильно оценит пороговое значение разделения по яркости. Крайне вероятной является ситуация, когда изображение документа имеет низкий контраст или слишком много изображений с перекрывающимся текстом внутри себя. Типичным примером является журнальная страница. В отличие от дескрипторов на основе двоичного изображения настоящее изобретение не испытывает этой проблемы, поскольку оно выполняет некоторый вид локальной бинаризации вдоль каждого направления, тем самым обеспечивая большую чувствительность к малым деталям.
Локальные дескрипторы, объединяемые с использованием векторов Фишера на основе модели смешивания Бернулли (BMMFV) (см. документы P. Viola, M. Jones, ʺRapid Object Detection using a Boosted Cascade of Simple Featuresʺ, CVPR 2001, Proceedings of the 2001 IEEE Computer Society Conference on, vol. 1, pp. 511-518, 2001, и Uchida, Yusuke, and Shigeyuki Sakazawa, ʺImage Retrieval with Fisher Vectors of Binary Featuresʺ, Pattern Recognition (ACPR), 2013 2nd IAPR Asian Conference on. IEEE, 2013), получаются следующим образом: сначала локальные дескрипторы 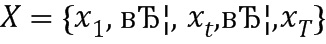 извлекаются из входного изображения и проецируются на Т/2-мерное пространство, используя PCA (анализ главных компонент). Нет специальных требований для типа локальных дескрипторов, но в предложенной реализации используется дескрипторы BRISK (двоичные устойчивые инвариантные масштабируемые ключевые точки) или ORB (ориентированные устойчивые двоичные независимые простейшие элементы) (см. документ E. Rublee, V. Rabaud, K. Konolige, G. Bradski, ʺORB: an efficient alternative to SIFT or SURFʺ, Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011). Затем обучается модель смешивания Бернулли (BMM)
извлекаются из входного изображения и проецируются на Т/2-мерное пространство, используя PCA (анализ главных компонент). Нет специальных требований для типа локальных дескрипторов, но в предложенной реализации используется дескрипторы BRISK (двоичные устойчивые инвариантные масштабируемые ключевые точки) или ORB (ориентированные устойчивые двоичные независимые простейшие элементы) (см. документ E. Rublee, V. Rabaud, K. Konolige, G. Bradski, ʺORB: an efficient alternative to SIFT or SURFʺ, Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011). Затем обучается модель смешивания Бернулли (BMM) 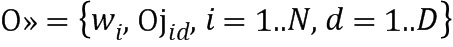 , где N - количество компонент в модели BMM, D - количество битов в каждом дескрипторе. Используя эту модель, модуль вычисляет оценки Фишера для каждого локального дескриптора:
, где N - количество компонент в модели BMM, D - количество битов в каждом дескрипторе. Используя эту модель, модуль вычисляет оценки Фишера для каждого локального дескриптора:
|
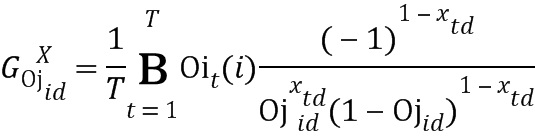
Здесь Т - количество двоичных элементов, извлеченных из изображения, и 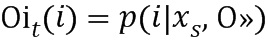 . Затем модуль получает матрицу Фишера:
. Затем модуль получает матрицу Фишера:
|
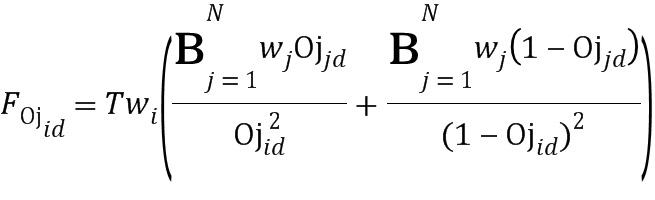 .
.В заключение, вектор Фишера 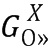 получается путем объединения нормированных оценок Фишера
получается путем объединения нормированных оценок Фишера 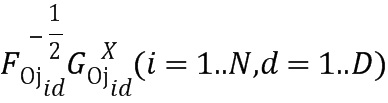 . Вектор Фишера дополнительно нормируется с использованием степенной нормировки (путем взятия квадратного корня каждого значения вектора) и нормировки L2 (путем деления каждого значения вектора на векторную Евклидову норму). С учетом вектора Фишера
. Вектор Фишера дополнительно нормируется с использованием степенной нормировки (путем взятия квадратного корня каждого значения вектора) и нормировки L2 (путем деления каждого значения вектора на векторную Евклидову норму). С учетом вектора Фишера 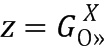 подвергнутый степенной нормировке вектор f(z) вычисляется как
подвергнутый степенной нормировке вектор f(z) вычисляется как 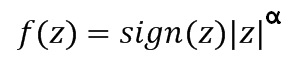 , где α=0,5. После степенной нормировки в отношении f(z) выполняется нормировка L2, которая приводит к окончательному дескриптору вектора Фишера из набора двоичных элементов. Средство извлечения BMMFV получает один вектор Фишера для каждого суб-изображения 601 и 602 (5 суб-изображений в целом) и объединяет все вектора Фишера в один дескриптор вектора признаков.
, где α=0,5. После степенной нормировки в отношении f(z) выполняется нормировка L2, которая приводит к окончательному дескриптору вектора Фишера из набора двоичных элементов. Средство извлечения BMMFV получает один вектор Фишера для каждого суб-изображения 601 и 602 (5 суб-изображений в целом) и объединяет все вектора Фишера в один дескриптор вектора признаков.
Причина использования BMM вместо хорошо известной Гауссовой модели смешивания (GMM) заключается в том, что GMM предназначена для функционирования на основе нормального распределения, которое представляет собой распределение случайных вещественных чисел. Большое количество дескрипторов также является вещественным, так что нормально использовать GMM в этом случае. Однако двоичные дескрипторы, такие как BRISK и ORB, не подходят для GMM в отличие от распределения Бернулли.
Как только вектора признаков получены, они классифицируются с использованием машины опорных векторов (SVM). В случае SLBP и GRLH SVM 408 и 409 применяют следующее ядро пересечения (уравнение 5):
|
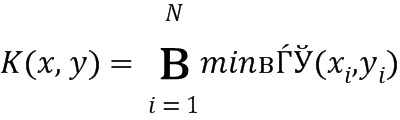 .
.И BMMFV SVM 410 использует следующее линейное ядро (уравнение 6):
|
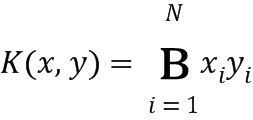 .
.В обоих случаях SVM параметр С (затраты) задан равным 10.
Каждая SVM обеспечивает вектор вероятностей класса, чья длина соответствует количеству классов изображения. Эти векторы объединяются в один вектор, который обрабатывается как новый вектор признаков. Этот вектор признаков используется для прогнозирования класса изображения, используя мета-классификатор, который представляет собой SVM с ядром 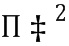 :
:
|
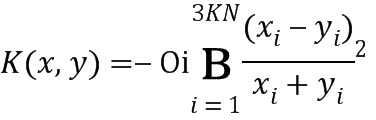 ,
,где K - количество классификаторов, и N - количество возможных классов. Выходным значением мета-классификатора является вектор вероятностей размера N.
Резюмируя, настоящее изобретение включает в себя набор модулей для: 1) извлечения дескрипторов изображений печатных копий и классификации с использованием множества обученных классификаторов; 2) мета-классификатора; и 3) устройства сортировки печатных копий. Средства извлечения дескрипторов изображения включают в себя средство извлечения пространственного локального бинарного шаблона, средство извлечения полутоновой гистограммы длин отрезков и средство извлечения векторов Фишера для модели смешивания Бернулли. Все эти средства извлечения используют признаки изображения в виде двоичных, целых или вещественных чисел, что делает их полезными в случаях, когда тяжело извлечь макет документа, который обязателен для способов, основанных на макетах. Таким образом, настоящее изобретение не накладывает какие-либо ограничения на содержимое документа.
Главным преимуществом пространственного локального бинарного шаблона (SLBP) над существующими подходами, основанными на LBP (см., например, документы T. Ojala, M. Pietikäinen, M. Mäenpää, ʺMultiresolution gray-scale and rotation invariant texture classification with local binary patternsʺ, PAMI, 2010, и Hongming Zhang, Wen Gao, Xilin Chen, Debin Zhao, ʺObject detection using spatial histogram featuresʺ, Image and Vision Computing, Volume 24, iss. 4, 1 April 2006, pp. 327-341, ISSN 0262-8856), является то, что в предложенной реализации применяется рекурсивное поблочное пространственное разбиение входного изображения, объединяемого с использованием блочного масштабирования до заранее заданного размера, что позволяет избегать нормализации гистограммы и оказывает положительное воздействие на точность классификации, так как каждый блок изображения обрабатывается во множестве масштабов.
Предложенная концепция полутоновой гистограммы длин отрезков близка к существующим подходам, но в отличие от них настоящее изобретение не включает в себя этап бинаризации, что делает возможным использование системы 100 не только для простых черно-белых документов, но и также для сложных изображений документов. Следовательно, это позволяет избегать ошибок бинаризации, которые могут сделать классификацию совершенно невозможной.
Что касается векторов Фишера для модели смешивания Бернулли (BMMFV), их концепция описана, например, здесь: J. Sanchez, F. Perronnin, T. Mensink, J. Verbeek, ʺImage Classification with the Fisher Vector: Theory and Practiceʺ, In International Journal of Computer Vision 105, pp 222,245, 2013. Настоящее изобретение экстраполирует концепцию на проблему классификации печатных копий. В отличие от известных подходов настоящее изобретение объединяет вектора Фишера с использованием модели Бернулли и пространственного подразбиения на полосы, что значительно улучшает точность классификации и устойчивость классификаторов против различных преобразований документов, таких как поворот, изменение макета и т.д. Использование модели смешивания Бернулли является более корректным в случае применения двоичных дескрипторов изображения, таких как ORB или BRISK, вместо использования Гауссовой модели смешивания, которая, как правило, выбирается в большинстве существующих подходов.
SLBP (пространственный локальный бинарный шаблон), GRLH (полутоновая гистограмма длин отрезков) и BMMFV (вектора Фишера на основе модели смешивания Бернулли) являются очень разными средствами извлечения дескрипторов изображения, так что они направлены на извлечение разных признаков изображения; следовательно, использование мета-классификатора на основе этих трех средств извлечения, объединенных с помощью любых классификаторов, позволяет улучшить точность классификации. Настоящее изобретение предлагает универсальную схему применения классификаторов. Можно использовать все три классификатора или только один классификатор для предоставления конечному пользователю разного количества профилей классификации. Например, GRLH может применяться для быстрой классификации документов с фиксированным макетом, BMMFV хороши для универсальной классификации макетов, и мета-классификация является великолепным решением для сложных случаев, когда никакие классификаторы не могут обеспечить классификацию изображений с достаточной точностью.
Настоящее изобретение может быть эффективно применено для решения задач по классификации отсканированных документов или сортировки печатных копий. Предложенная система 100 способна классифицировать документы либо с фиксированными, либо с изменяемыми макетами с высокой точностью, даже если имеются искажения документов, такие как асимметрия, поворот, низкая контрастность и др. Предложенная система 100 может быть встроена в любое одно из следующего: MFP, смартфон, серверное решение, или развернута в виде автономного приложения. Высокая скорость классификации и многоядерная обработка делают возможны использование предложенной системы 100 для большого количества документов. Предложенное устройство 200 сортировки печатных копий способно сортировать пачки документов автоматически без вмешательства пользователя с высокой скоростью сортировки.
Дополнительные аспекты изобретения станут очевидными после рассмотрения чертежей и представленного описания предпочтительных вариантов осуществления изобретения. Специалисту в данной области техники будет понятно, что возможны другие варианты осуществления изобретения, и что некоторые элементы изобретения могут быть изменены в ряде аспектов, не отступая от идеи изобретения. Таким образом, чертежи и описание должны рассматриваться как иллюстративные, а не ограничивающие. В приложенной формуле изобретения упоминание элементов в единственном числе не исключает наличия множества таких элементов, если в явно виде не указано иное.
Система и способ печати интегральных фотографий, обеспечивающих полный параллакс и высокое разрешение трехмерного изображения (варианты)
Способ и система для быстрой реконструкции изображения мрт из недосемплированных данных
Устройство формирования изображения, хост-устройство и соответствующий способ выполнения задания формирования изображения
Устройство формирования изображений, способ его запуска и компьютерно-читаемый носитель записи
Crum-микросхема, устройство формирования изображений для верификации расходного модуля, содержащего crum-микросхему, и способы для этого
Crum-микросхема и устройство формирования изображения для взаимного обмена данными и способ для этого
Система на кристалле для выполнения безопасной начальной загрузки, использующее ее устройство формирования изображения и способ ее использования
Система на кристалле для выполнения безопасной загрузки, устройство формирования изображений, использующее ее, и способ для него
Система и способ печати интегральных фотографий, обеспечивающих полный параллакс и высокое разрешение трехмерного изображения (варианты)
Способ и система для быстрой реконструкции изображения мрт из недосемплированных данных
Устройство формирования изображения, хост-устройство и соответствующий способ выполнения задания формирования изображения
Устройство формирования изображений, способ его запуска и компьютерно-читаемый носитель записи
Crum-микросхема, устройство формирования изображений для верификации расходного модуля, содержащего crum-микросхему, и способы для этого
Crum-микросхема и устройство формирования изображения для взаимного обмена данными и способ для этого
Система на кристалле для выполнения безопасной начальной загрузки, использующее ее устройство формирования изображения и способ ее использования
Способ и система автоматической настройки пользовательского интерфейса в мобильном устройстве
Обработка данных для сверхразрешения
Способ автоматической регулировки экспозиции для инфракрасной камеры и использующее этот способ вычислительное устройство пользователя

