Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение имеет отношение к системам автоматизированной обработки информации, а именно к системам оценки релевантности текстовых документов запросу пользователя с использованием семантических признаков текста и ранжированию по ценности массива текстовых документов.
УРОВЕНЬ ТЕХНИКИ
Количество информации в настоящий век информационных технологий удваивается каждые 1,5-2 года. По этой причине поиск релевантной информации по определенной предметной области является достаточно сложной и актуальной задачей.
Задача поиска и ранжирования релевантных текстовых документов в сети Интернет успешно решается поисковыми системами такими, как ЯНДЕКС, GOOGLE, YAHOO!. Основной вектор при решении обозначенной задачи в данных системах направлен на оперативность представления результата поиска, в то время как точность поиска достигается за счет использования в качестве критерия ключевых слов и частоты встречаемости этих слов в массиве текстовых документов (модель tf-idf). Недостатком данного способа является игнорирование смыслового содержания текстового документа при его оценке, что и приводит к низкой точности обработки текстовых документов. Данный недостаток частично нивелируется поисковыми системами за счет, например, формирования персонализированной модели ранжирования на электронном устройстве, связанном с пользователем [патент RU 2580516] - данный способ не подходит для работы с массивом электронных документов, хранящихся в изолированной базе данный, так как в качестве признака формирования персонализированной модели ранжирования используются характерные свойства веб-ресурсов, связанных с пользователем; другой способ [патент RU 2383922] позволяет получить большее тематическое разнообразие в документах наивысшего ранжирования, причем эти документы должны быть тематически насыщены - данный способ снижает оперативность обработки текстовых документов при незначительном повышении их точности, т.к. тематически насыщенные документы не позволяют сразу определить место нахождения в документе интересующей пользователя информации.
Наиболее близкий к заявленной группе изобретений относится способ автоматизированной семантической индексации текста на естественном языке, который раскрыт в патенте РФ №2518946 (опубл. 10.06.2014). В этом способе текст в цифровой форме сегментируют на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова; сегментируют по графематическим правилам текст в цифровой форме на предложения; формируют на основе морфологического анализа для каждой элементарной единицы первого уровня, представляющей собой слово, элементарную единицу второго уровня, включающую в себя нормализованную словоформу, именуемую далее леммой; подсчитывают частоту встречаемости каждой элементарной единицы первого уровня для двух и более соседних единиц первого уровня в данном тексте и объединяют среди элементарных единиц первого уровня последовательности слов, следующих друг за другом в данном тексте, в элементарные единицы третьего уровня, представляющие собой устойчивые сочетания слов, в случае, если для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов для первого появления данной последовательности слов и для нескольких последующих их появлений для каждой пары слов последовательности остаются неизменными; выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимый объект и его атрибут, являющиеся единицами четвертого уровня; сохраняют в памяти каждый семантически значимый объект и атрибут; выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые отношения между выявленными единицами четвертого уровня - семантически значимыми объектами, а также, между семантически значимыми объектами и атрибутами; присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст; сохраняют в памяти каждое семантически значимое отношение вместе с присвоенным ему типом; выявляют частоты встречаемости элементарных единиц четвертого уровня на всем тексте; формируют в пределах данного текста для каждого из выявленных семантически значимых отношений, связывающих как соответствующие семантически значимые объекты, так и семантически значимый объект и его атрибут, множество триад, которые являются элементарными единицами пятого уровня; индексируют на множестве сформированных триад по отдельности все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости и все сформированные триады; сохраняют в базе данных сформированные элементарные единицы второго, третьего, четвертого и пятого уровней с их частотами встречаемости, а также полученные индексы вместе со ссылками на конкретные предложения данного текста; ранжируют сформированные элементарные единицы второго и третьего уровней по смысловому весу путем сравнения их смыслового веса с заранее заданным пороговым значением; удаляют триады, в которых элементарные единицы второго и третьего уровней имеют смысловой вес ниже порогового.
Недостатками данного способа являются:
1) сформированные триады не позволяют выражать смысловое содержание документа, т.к. они не содержат действия, что не позволяет точно произвести поиск релевантных информационным потребностям пользователя фактов. Как известно, семантика (смысл) конкретного понятия раскрывается только при его использовании с конкретной целью, например: понятие "газета" может употребляться как источник информации и как средство для битья мух;
2) семантически значимые отношения выявляют только между семантически значимыми объектами, а также, между семантически значимыми объектами и атрибутами, оставляя без внимания семантические отношения между отдельными смыслосодержащими текстовыми элементами, минимальным из которых является клауза. Без учета данных семантических отношений невозможно учесть смысл всего документа;
3) ранжирование текстовых документов осуществляется за счет подсчета частоты встречаемости семантически значимых объектов и атрибутов, значимость которых определяется исходя из семантической структуры предложения, содержащей указанные объекты и атрибуты, при этом никак не учитывается оценка текстового документа относительно запроса пользователя.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Задачей, для решения которой предлагается настоящее изобретение, является увеличение эффективности работы пользователя при поиске релевантной информации за счет увеличения полноты и точности обработки текстовых документов, достигаемых путем использования в качестве признаков отбора текстовых документов помимо ключевых слов еще и семантических признаков текста, при этом оперативность обработки увеличивается вследствие интеграции предложенной системы в систему обработки текстовых документов с использованием ключевых слов.
Поставленная задача решается с помощью способа и системы семантической обработки текстовых документов.
Способ семантической обработки текстовых документов заключается в следующем:
текстовые документы на естественном языке, при добавлении в базу данных, поочередно поступают в модуль формирования дискурсного графа текстовых документов, в котором сегментируют текст на элементарные смыслосодержащие дискурсивные единицы - клаузы; в пределах клаузы на основе морфологического и синтаксического анализа формируют функционально-ролевую структуру (ФРС), состоящую из действия, субъекта действия, объекта действия - игроков ФРС клаузы и их атрибутов;
выявляют референциальную связность между игроками клауз, по результатам которой кореферент с наибольшей степенью общности заменяют кореферентом с более конкретным значением; определяют риторические отношения между клаузами и более крупными текстовыми элементами, в результате чего получают дискурсный граф текстового документа, который сохраняют в метаданных текстового документа в базе данных и по которому индексируют текстовый документ;
получают дискурсный граф для запроса пользователя на естественном языке аналогичным образом;
оценивают каждый текстовый документ относительно запроса пользователя;
ранжируют текстовые документы по ценности;
отсекают документы ниже некоторого эмпирически определенного порога.
Способу по настоящему изобретению присущи следующие особенности:
при выявлении референциальной связности между игроками ФРС клауз могут учитывать как анафорические ссылки, так и катафорические ссылки, причем антецедент может быть выражен как местоимением, так и семантически тождественным понятием; при формировании запроса пользователя дополнительно помечают ФРС, представляющие факты известные пользователю, и ФРС, составляющие суть запроса;
при оценке соответствия ФРС текстового документа и запроса соответствующие объекты, субъекты, действия и атрибуты могут сравнивать как по точному соответствию, так и с учетом семантического тождества понятий;
при оценке соответствия риторических отношений между ФРС в текстовом документе и запросе риторические отношения между ФРС, представляющие факты известные пользователю, оценивают по точному соответствию, а риторические отношения между ФРС, представляющими факты известные пользователю, и ФРС, составляющими суть запроса могут оценивать по точному соответствию или с использованием эвристических правил, хранящихся в онтологии предметной области;
оценку текстовых документов относительно запроса пользователя производят на основе мультипликативной свертки следующих оценок: оценка соответствия ФРС текстового документа и запроса, при этом учитывают соответствие атрибутов и вершин ФРС, оценка соответствия риторических отношений между ФРС в текстовом документе и запросе, оценка расстояния от пересечения соответствующих графов до ядра текстового документа.
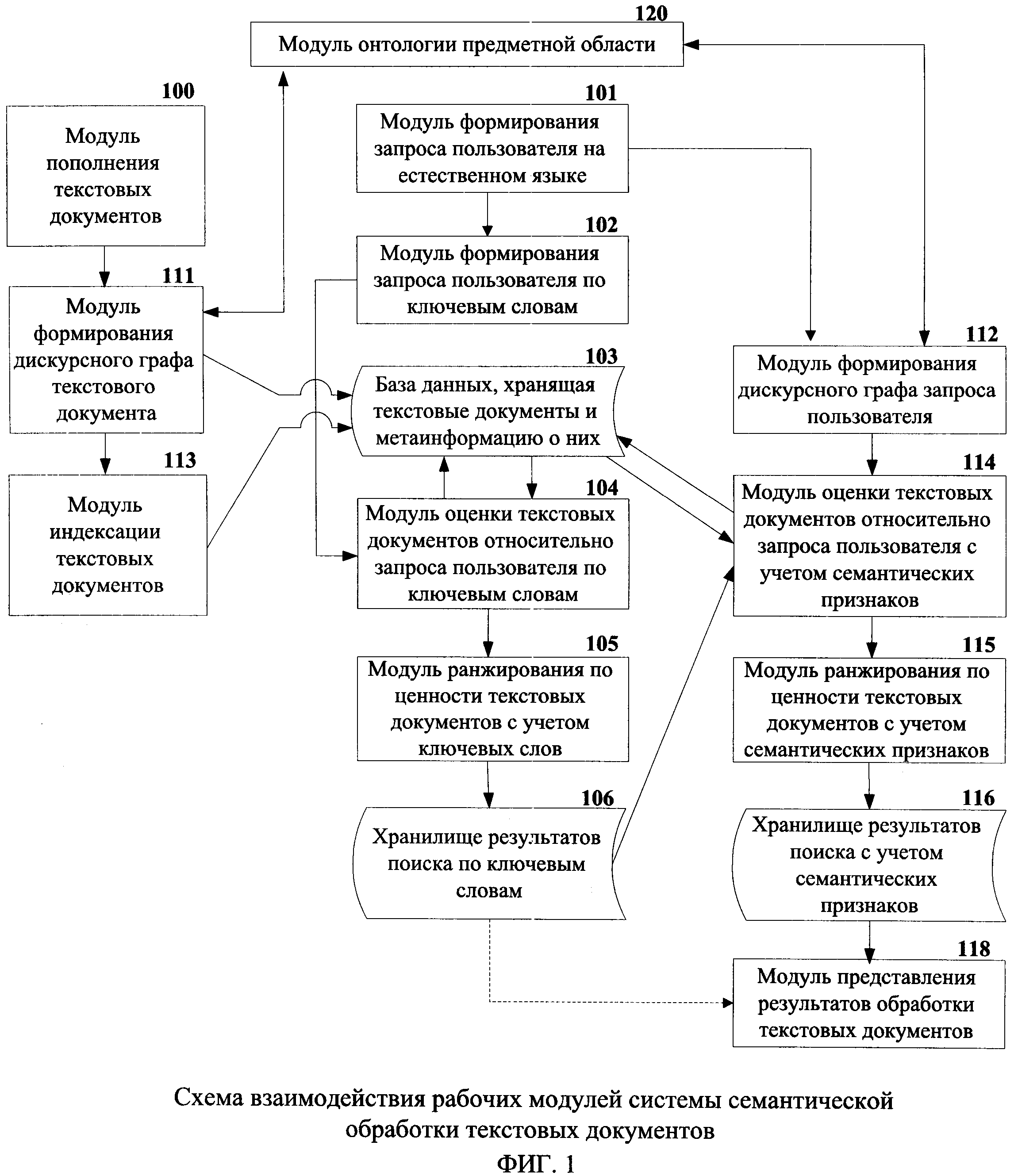
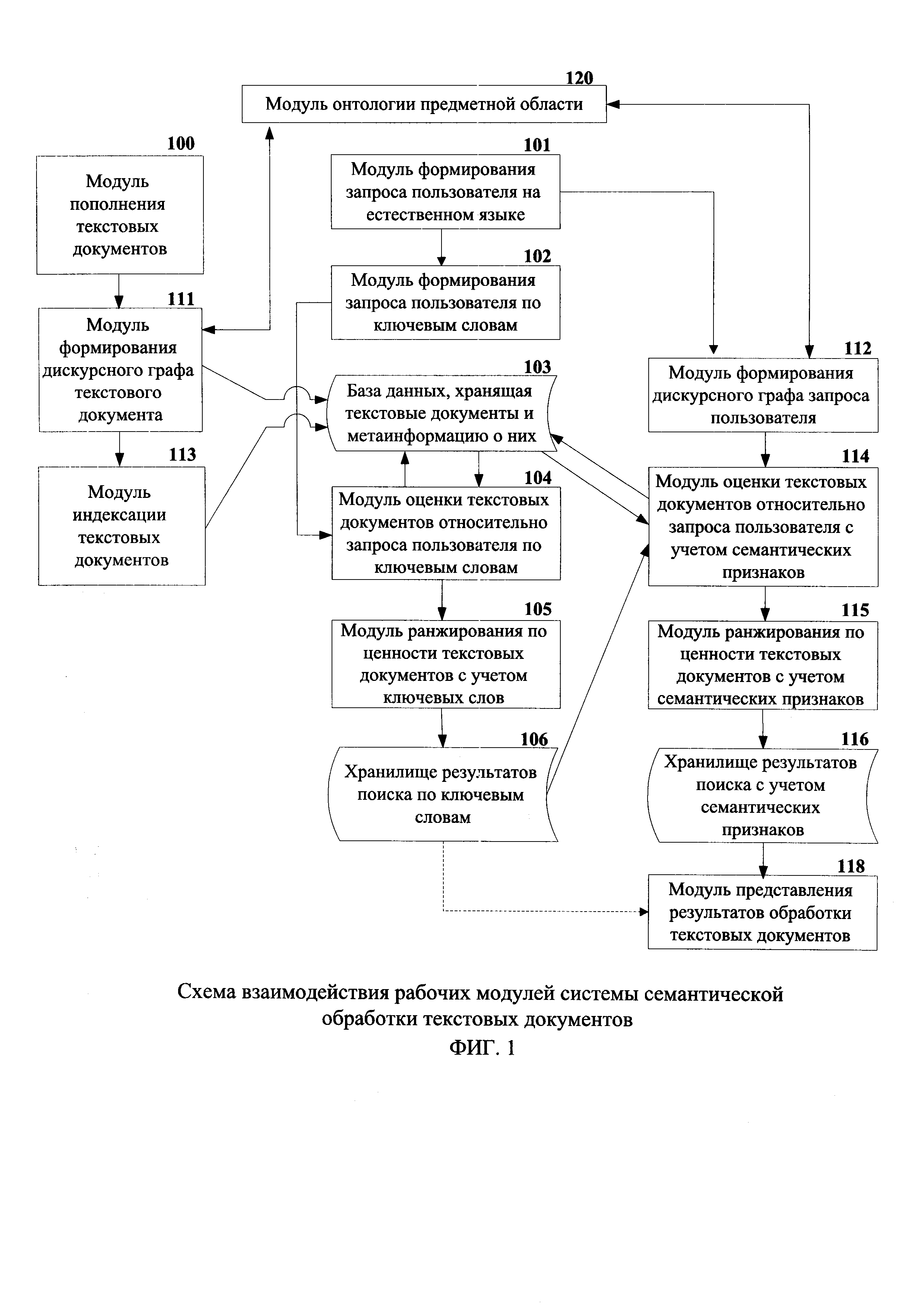
Система семантической обработки текстовых документов включает совокупность взаимосвязанных друг с другом модулей системы обработки текстовых документов с использованием ключевых слов: модуль формирования запроса пользователя на естественном языке, модуль формирования запроса пользователя по ключевым словам, модуль пополнения текстовых документов, модуль индексации текстовых документов, база данных, хранящая текстовые документы и метаинформацию о них, модуль оценки текстовых документов относительно запроса пользователя по ключевым словам, модуль ранжирования по ценности текстовых документов с учетом ключевых слов, хранилище результатов поиска по ключевым словам, модуль представления результатов обработки текстовых документов.
Для осуществления вышеописанного способа система семантической обработки текстовых документов также включает модуль формирования дискурсного графа текстового документа, модуль формирования дискурсного графа запроса пользователя, модуль онтологии предметной области, модуль оценки текстовых документов относительно запроса пользователя с учетом семантических признаков, модуль ранжирования по ценности текстовых документов с учетом семантических признаков, хранилище результатов поиска с учетом семантических признаков.
Особенностью системы семантической обработки текстовых документов является интеграция в ней подсистемы обработки текстовых документов по ключевым словам и подсистемы обработки текстовых документов с использованием семантических признаков, что позволяет достичь более высоких показателей полноты и точности обработки текстовых документов при сохранении оперативности обработки на прежнем уровне.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 приведена схема взаимодействия рабочих модулей системы семантической обработки текстовых документов.
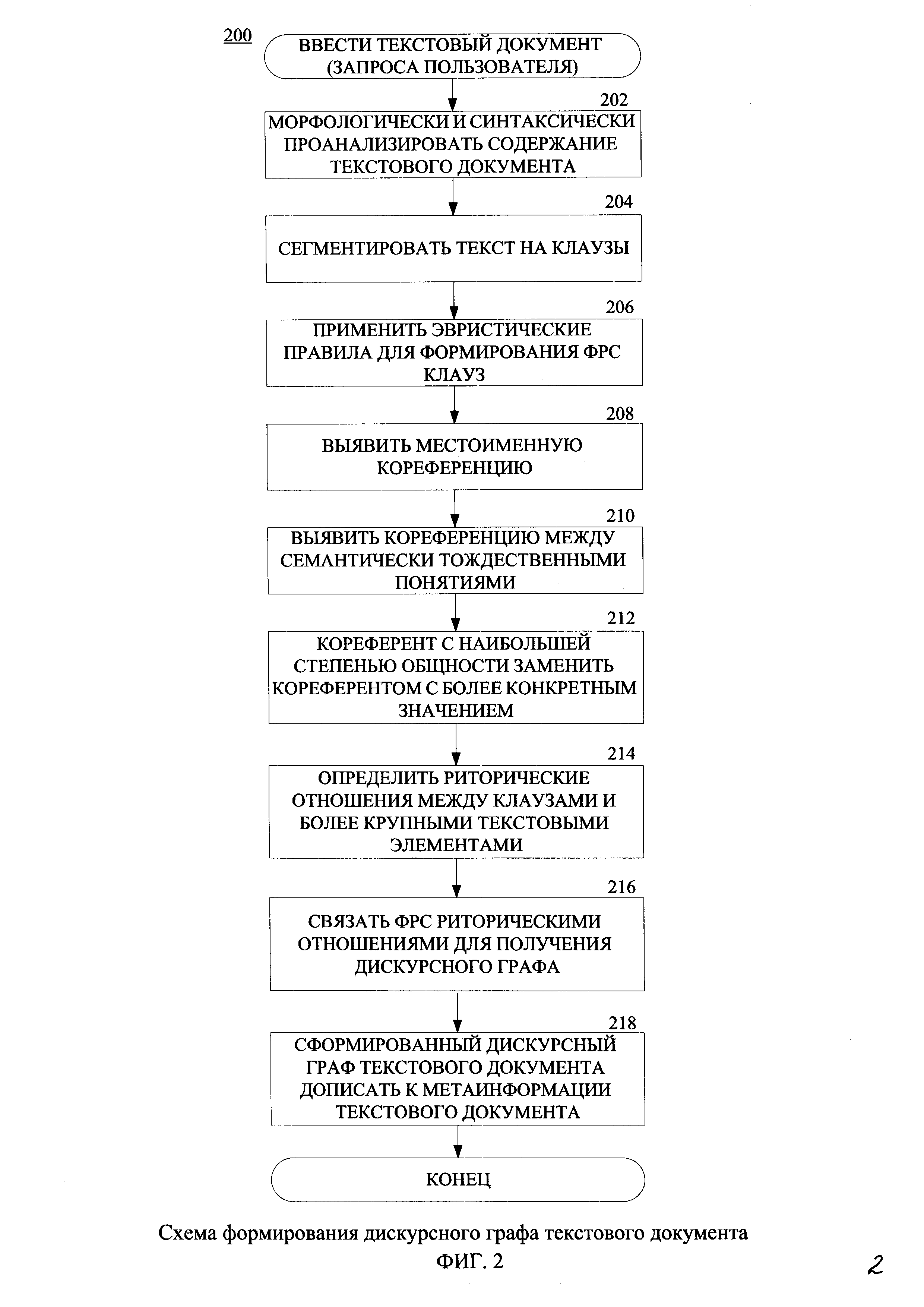
На фиг. 2 приведена схема формирования дискурсного графа текстового документа.
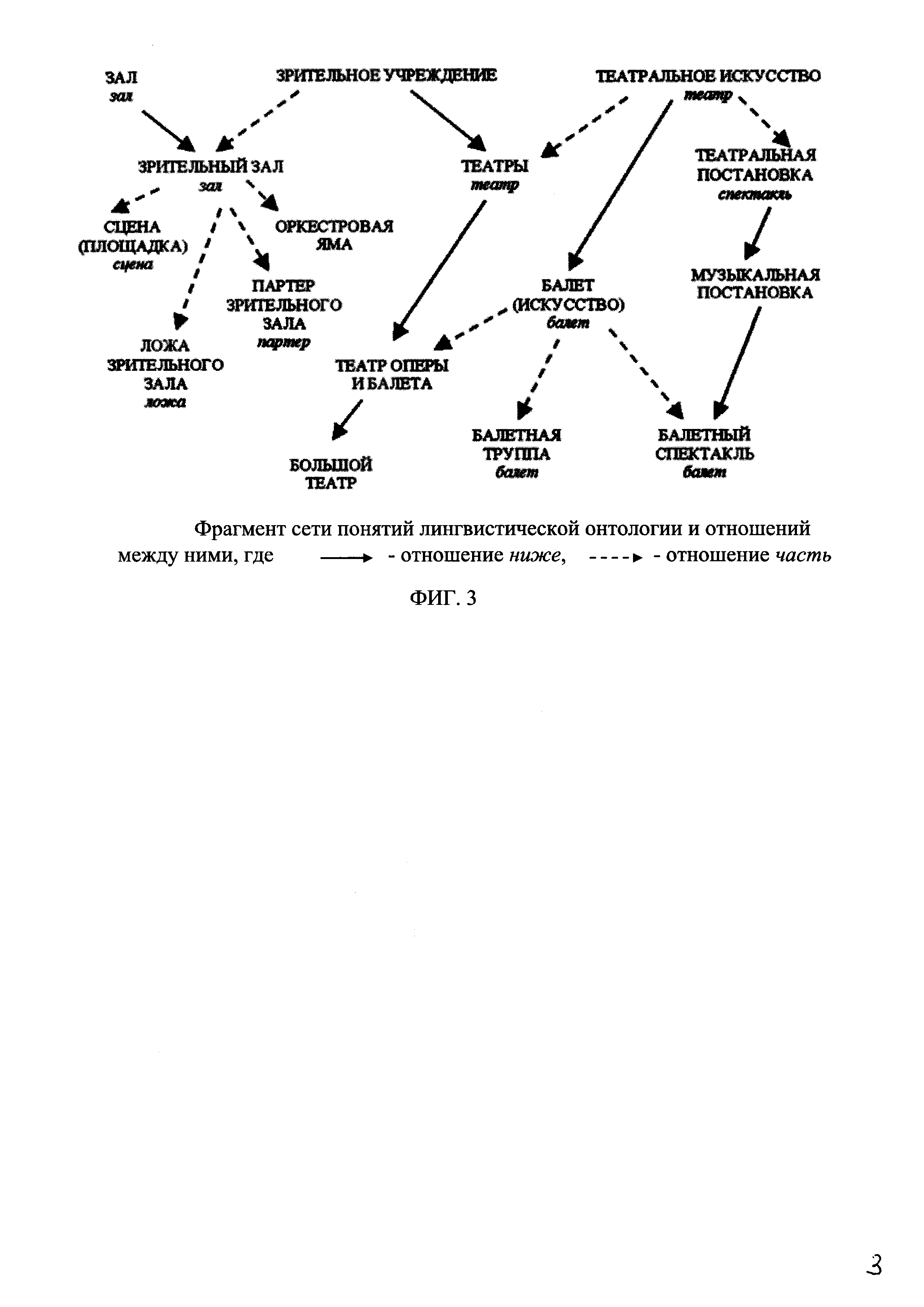
На фиг. 3 приведен фрагмент сети понятий лингвистической онтологии и отношений между ними.
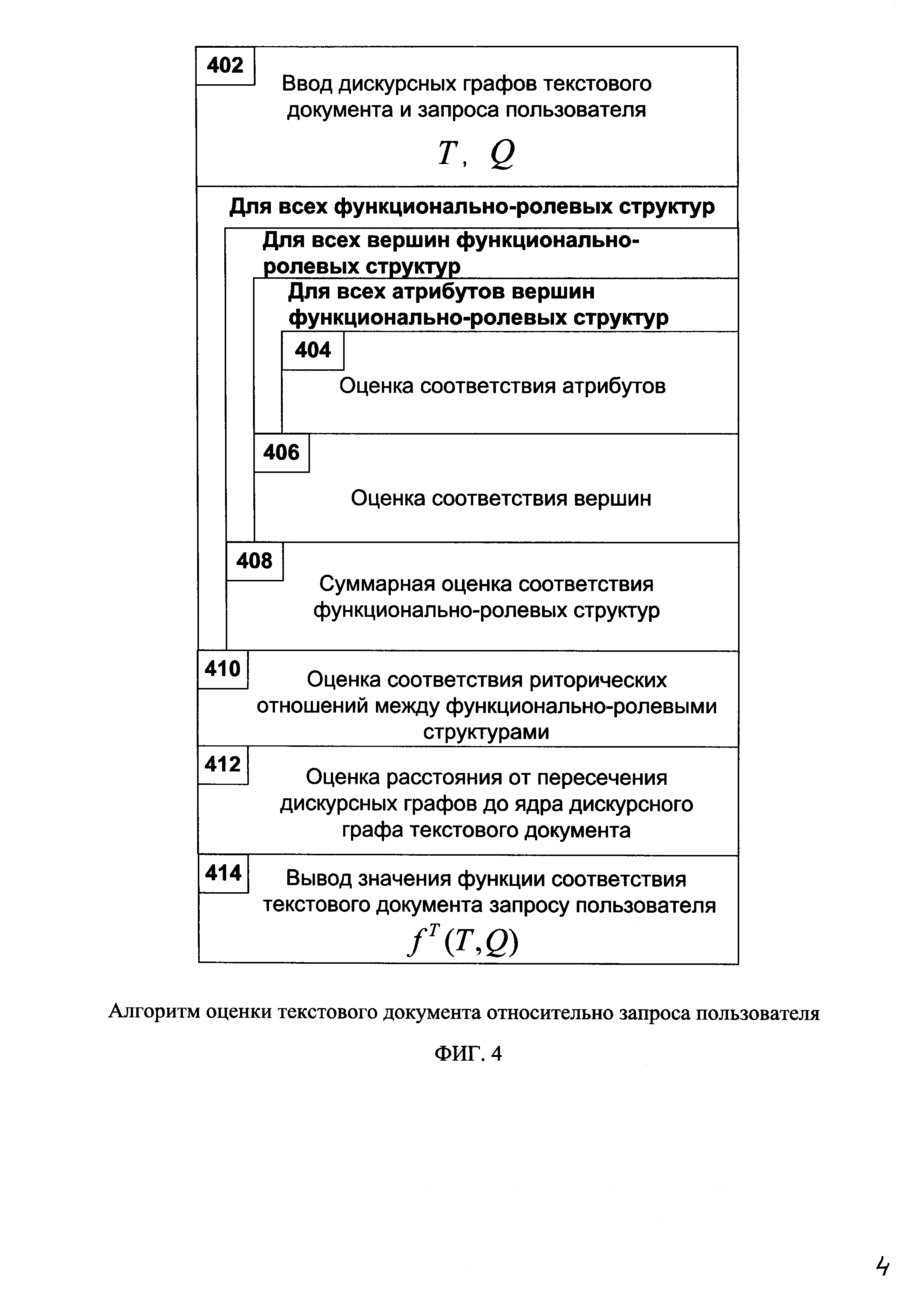
На фиг. 4 приведен алгоритм оценки текстового документа относительно запроса пользователя.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Система семантической обработки текстовых документов интегрирована в систему обработки текстовых документов с использованием ключевых слов и состоит из взаимосвязанных друг с другом модулей (фиг. 1). Данная интеграция выполнена в целях нивелирования снижения быстродействия системы обработки информации при применении способа семантической обработки информации. Быстродействие модулей, в которых реализован способ семантической обработки информации, ниже быстродействия модулей, реализующих механизм ключевых слов, вследствие применения в способе семантической обработки информации более сложных признаков, которые используются при оценке текстовых документов относительно запроса пользователя, что позволяет достичь большей точности обработки текстовых документов.
Работа модулей системы семантической обработки текстовых документов осуществляется в следующем порядке, описанном ниже.
Модуль формирования запроса пользователя на естественном языке 101 и модуль представления результатов обработки текстовых документов 118, представляют собой единое прикладное программное и/или системное программное обеспечение (или их комбинацию), установленное на персональный компьютер (настольный компьютер, ноутбук, нетбук и т.п.) или беспроводное электронное устройство (мобильный телефон, смартфон, планшет и т.п.). Исключительно для иллюстративных целей следует предполагать, что модуль формирования запроса пользователя на естественном языке 101 и модуль представления результатов обработки текстовых документов 118 реализованы как клиентское программное обеспечение, установленное на ноутбук, такой как LENOVO™ THINKPAD™ Х220 ноутбук, работающий на операционной системе WINDOWS™. Задачей модуля формирования запроса пользователя на естественном языке 101 является получение от пользователя запроса на естественном языке и передача его по каналам связи в модуль формирования запроса пользователя по ключевым словам 102 и в модуль формирования дискурсного графа запроса пользователя 112. Задачей модуля представления результатов обработки текстовых документов 118 является представление пользователю ранжированной выборки релевантных текстовых документов.
Реализация каналов связи не ограничена и будет зависеть от исполнения (стационарный или мобильный) модуля формирования запроса пользователя на естественном языке 101.
Запрос на поиск релевантных задачам пользователя текстовых документов, реализуемый модулем формирования запроса пользователя на естественном языке 101, осуществляется на естественном языке (может быть применен любой язык индоевропейской группы при условии наличия для этого языка морфологического и синтаксического парсера). При этом длина запроса никак не ограничивается. Пользователь для получения более точных результатов поиска может включить в запрос факты известные пользователю и, непосредственно, вопрос, на который необходимо найти ответ. Например: "После 43 лет членства в ЕС Великобритания решила выйти из Евросоюза. К каким последствиям может привести брекзит?".
Модули 100, 102-116, 120 могут исполняться как прикладное программное и/или системное программное обеспечение (или их комбинация). Модули 100, 102-116, 120 могут быть установлены на один сервер или могут быть распределены и выполнятся с помощью нескольких серверов. Сервер представляет собой стандартный компьютерный сервер. В примере варианта реализации настоящей технологии, сервер представляет собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ WindowsServer™.
После передачи модулем формирования запроса пользователя на естественном языке 101 запроса пользователя, последний обрабатывается параллельно двумя способами: (i) способом поиска релевантных текстовых документов с использования в качестве критерия поиска ключевых слов и частоты встречаемости этих слов в массиве текстовых документов (модель tf-idf) - реализуется модулями 102, 104, 105, 106, (ii) способом семантической обработки текстовых документов - реализуется модулями 111, 112, 114, 115, 116.
Функциональность способа (i) в большинстве случаев известна, но, кратко говоря, способ реализован следующим образом: модуль формирования запроса пользователя по ключевым словам 102 получает поисковый запрос от модуля формирования запроса пользователя на естественном языке 101 и производит его обработку (нормализацию поискового запроса, извлечение ключевых слов, и т.д.), а также расширяет запрос дополнительными словами (словосочетаниями); для выполнения поиска релевантных текстовых документов модуль формирования запроса пользователя по ключевым словам 102 передает нормализованный запрос модулю оценки текстовых документов относительно запроса пользователя по ключевым словам 104, который посредством доступа к внутреннему индексу (не иллюстрировано) базы данных 103, хранящей текстовые документы и метаинформацию о них, оценивает каждый текстовый документ относительно ключевых слов запроса с использованием одной из поисковых функций tf-idf, например "Okapi ВМ25"; модуль ранжирования по ценности текстовых документов с учетом ключевых слов 105 производит ранжирование по релевантности текстовых документов в порядке убывания, отсекая при этом текстовые документы, ценность которых ниже некоторого экспертно установлено порога, например 0.55; полученные результаты передаются в модуль представления результатов обработки текстовых документов 118 для отображения пользователю и в модуль оценки текстовых документов относительно запроса пользователя с учетом семантических признаков 114 для более точной оценки с использованием способа семантической обработки текстовых документов(й).
Модуль формирования запроса пользователя по ключевым словам 102 расширяет запрос дополнительными словами (словосочетаниями), что в конечном итоге приводит к повышению полноты обработки текстовых документов. Расширение запроса выполняют следующим образом:
1. За счет использования лингвистической онтологии [Лукашевич Н.В. Тезаурусы в задачах информационного поиска. - М.: Изд-во Московского университета, 2011. - 396 с.]: запрос может дополняться текстовыми входами понятия, входящими в запрос, например, текстовому входу (слово или словосочетание запроса) ЕВРОСОЮЗ соответствует понятие ЕВРОПЕЙСКИЙ СОЮЗ, на которое ссылаются также следующие текстовые входы: ЕВРОПЕЙСКИЙ СОЮЗ, ЕВРОПЕЙСКОЕ СООБЩЕСТВО, ЕВРОПЕЙСКОЕ ЭКОНОМИЧЕСКОЕ СООБЩЕСТВО, ЕДИНАЯ ЕВРОПА, ЕС, ЕЭС, ОБЪЕДИНЕННАЯ ЕВРОПА, которые могут использоваться для расширения запроса пользователя.
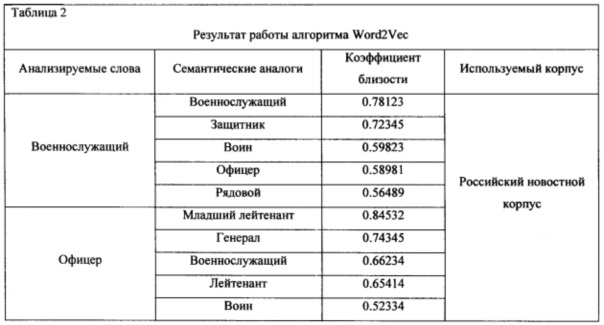
2. За счет использования распределенного представления слов, например, инструмента Word2Vec [Mikolov Т., Sutskever I., Chen K., Corrado G., and Dean J.. 2013b. Distributed representations of words and phrases and their compositionality. In NIPS, Pp. 3111-3119]: запрос может дополняться наиболее близкими к каждому слову запроса словами из распределенного векторного представления слов (минимальный коэффициент близости устанавливается пользователем эмпирическим путем, например, более 0.58), сформированного путем обучения алгоритма Skip-Gram на большом текстовом корпусе (более 109 слов), например, для слов ВОЕННОСЛУЖАЩИЙ и ОФИЦЕР список расширяющих запрос слов представлен в таблице 2 (только слова, имеющие коэффициент близости более 0.58).
Лингвистическая онтология и вектор распределенного представления слов, полученный, например, за счет использования инструмента Word2Vec, хранятся в модуле онтологии предметной области 120.
Способ семантической обработки текстовых документов(й) включает в себя три этапа:
1. Формирование дискурсного графа текстового документа (запроса пользователя) (фиг. 2).
2. Оценка текстовых документов относительно запроса пользователя с использованием семантических признаков (фиг. 4).
3. Ранжирование результатов оценки.
Первый этап формирования дискурсного графа текстового документа (запроса пользователя) предназначен для выделения семантических признаков в текстовом документе (запросе пользователя) для последующей оценки по этим признакам релевантности запроса пользователя текстовому документу. Дискурсный граф для текстового документа и для запроса пользователя формируется по одной и той же схеме (фиг. 2), поэтому далее будет рассмотрена только схема формирования дискурсного графа текстового документа, которая включает выполнение следующих шагов:
1. Ввести текстовый документ.
Специалистам должно быть понятно, что операции этого и последующих этапов осуществляются с запоминанием промежуточных результатов, например, в оперативном запоминающем устройстве (ОЗУ).
2. Морфологически и синтаксически проанализировать содержание текстового документа 202.
Данный шаг выполняют с помощью синтаксических парсеров, способных производить разбор текстового документа на соответствующем языке, например, таких как: ABBYY Compreno, Stanford CoreNLP toolkit, AOT, Link Parser. Результат разбора представляет собой так называемую "синтаксическую структуру" - набор токенов с расставленными связями, где токен представляет собой нормализованное слово (лемму) с присущими ему морфологическими характеристиками.
3. Сегментировать текст на клаузы 204 (минимальные смыслосодержащие текстовые элементы) на основе синтаксического анализа.
Клауза также является элементарной дискурсивной единицей (ЭДЕ). Точность сегментации текста на клаузы в настоящее время составляет около 95%, она может выполняться, например, с помощь метода, описанного в [Vanessa Wei Feng and Graeme Hirst. 2012. Text-level discourse parsing with rich linguistic features. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1, pages 60-68. Association for Computational Linguistics].
4. Применить эвристические правила для формирования функционально-ролевых структур (ФРС) клауз 206.
Функционально-ролевой структурой называется упрощенное унифицированное представление некоторого возможного события в определенной предметной области [Новиков А.Ю. Концептуальные основы автоматизации дискурсного анализа текста на основе семантики // Научно-технический журнал: "Наукоемкие технологии", №9 - М.: Радиотехника, 2010. - С. 77-83]. Такая структура отображает всех основных игроков (объект, субъект), собственно процесс (действие), место действия - вершины ФРС, а также их атрибутивные свойства. Причем, при формировании вершин ФРС переходят от слов (именных структур) к понятиям, используя лингвистическую онтологию (например, [Лукашевич Н.В., Добров Б.В. Проектирование лингвистических онтологий для информационных систем в широких предметных областях // Онтология проектирования, Т. 5, №1. - 2015. - С. 47-69]), в которой каждому текстовому входу соответствует понятие с определенным идентификатором (id). Например, разбор запроса пользователя из представленного выше примера, позволяет выделить две клаузы и сформировать следующие ФРС (структура ФРС описана языком XML):



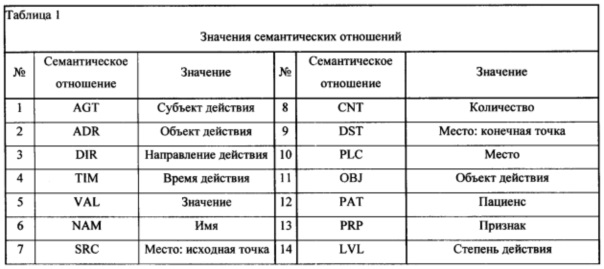
Значения семантических отношений приведены в таблице 1.
Семантические роли для каждого слова формируют за счет эвристических правил, полученных путем статистического сопоставления синтаксических цепочек (полученных, например, с помощью Link Parser), семантическому отношению [Столяров М.Г., Новиков А. Ю. Концептуальные основы унифицированного подхода к автоматической обработке разноязычных текстов, использующего семантику предметной области // Научно-технический журнал: "Наукоемкие технологии", №12 - М.: Радиотехника, 2009. - С. 50-56]. Данное сопоставление выполняет эксперт. Например, последовательность связей "Dmc-Sp-PP" можно интерпретировать как отношение "Действие - Субъект действия".
ФРС, входящие в запрос пользователя, дополнительно разделяют на ФРС, представляющие факты известные пользователю, и на ФРС, составляющие суть запроса, и соответственно помечают. Данная процедура выполняется на основе простой эвристики, например, вопросительные клаузы составляют суть запроса, а утвердительные - факты известные пользователю. Также определяют тип вопросительных ФРС, составляющие суть запроса: ли-вопрос (уточняющие вопросы направлены на выявление истинности выраженных в них суждений; во всех этих вопросах присутствует частица "ли", включенная в словосочетания "верно ли", "действительно ли", "надо ли" и т.д.), к-вопрос (восполняющие вопросы предназначены для выявления новых свойств у исследуемого игрока ФРС, для получения новой информации; грамматический признак вопросительное слово типа "Кто?", "Что?", "Когда?", "Где?" и т.п.), n-вопрос (проблемные вопросы - ФРС, заключающие в себе вопрос о каком-нибудь неясном для пользователя обстоятельстве; такие предложения оформляются при помощи наречий "зачем?", "отчего?", "почему?" и т.д.).
5. Выявить местоименную кореференцию 208. Местоименная кореференция снижает полноту обработки текстовых документов вследствие употребления в тексте наряду с именами понятий их местоименных заменителей. Выявление местоименной кореференции осуществляют на синтаксическом уровне с использованием только средств морфологического и синтаксического анализа. Так, например, перефразируем известную фразу академика Л.В. Щербы: "[Глокая куздра] штеко будланула бокра, а после [она] закурдячипа бокренка." Приведенный пример показывает, что неочевидность наличия референтов для большинства слов данного предложения не мешает определять кореференцию между словами предложения только лишь за счет морфологии и синтаксиса без использования знаний об упомянутых референтах. Задачу выявления местоименной кореференции можно решить с использованием, например, Stanford CoreNLP toolkit.
6. Выявить кореференцию между семантически тождественными понятиями 210. Данный шаг необходим вследствие использования автором текстового документа вместо употребленных им ранее слов (антецедентов), их заменителей (анафоров, катафоров): синонимов, меронимов, холонимов, тождественных слов и др. Отличительной особенностью способа семантической обработки текстовых документов является то, что он способен выявлять референциальную связность между семантически тождественными понятиями за счет применения алгоритмов, использующих лингвистическую онтологию (ЛО), например ЛО [Лукашевич Н.В., Добров Б.В. Проектирование лингвистических онтологий для информационных систем в широких предметных областях // Онтология проектирования, Т. 5, №1. - 2015. - С. 47-69] и распределенное представление слов, например, инструмент Word2Vec [Mikolov Т., Sutskever I., Chen K., Corrado G., and Dean J.. 2013b. Distributed representations of words and phrases and their compositionality. In NIPS, Pp. 3111-3119].
Система отношений ЛО представляет собой набор отношений: выше-ниже (например, мотострелковые войска - танковые войска), часть-целое (например, танкист - танковые войска). С каждым отношением связан свой набор аксиом вывода. В качестве аксиом в ЛО используются свойства транзитивности и наследования.
Семантическая близость между двумя понятиями с, и с, оценивается на основе рассмотрения пути отношений, который существует между этими единицами в ЛО.
Между понятиями в ЛО могут существовать пути разной конфигурации, ЛО является связной и всегда существует путь отношений от одного произвольного понятия ЛО к другому понятия ЛО. Однако в работе [Лукашевич Н.В., Добров Б.В. Проектирование лингвистических онтологий для информационных систем в широких предметных областях // Онтология проектирования, Т. 5, №1. - 2015. - С. 47-69] обосновано ограничение конфигурации путей между понятиями c1 и c2, которые рассматриваются при оценке семантической близости понятий, а именно, либо путь должен состоять из совокупности иерархических отношений, направленных в одну сторону (пути Pup и Pdown), например, последовательность отношений от вида к роду, либо такой путь должен включать ровно один перегиб, т.е. изменение направления движения. При этом рассматриваются перегибы двух видов: перегиб-сверху, например, сначала несколько отношений от видовых понятий к родовым, затем несколько отношений от родовых понятий к видовым, перегиб-снизу (пути Pupdown и Pdownup). Ограничение просмотра путей между понятиями именно такими типами связано с тем, что любой иерархический путь Pup или Pdown между понятиями может быть сведен к пути длиной в одно отношение с помощью правил транзитивности и наследования, а пути с перегибами Pupdown и Pdownup - к пути длиной в два отношения. Таким образом, доказывается потенциальная близость понятий, соединенных путями Pup, Pdown, Pupdown и Pdownup.
В работе [Лукашевич Н.В., Добров Б.В. Проектирование лингвистических онтологий для информационных систем в широких предметных областях // Онтология проектирования, Т. 5, №1. - 2015. - С. 47-69] представленные типы путей используются в алгоритме разрешения многозначности понятий, т.е. для текстовых входов tt и tj таких, что ti=tj, определяются соответствующие понятие ci и cj. Данная задача является обратной к решаемой на настоящем шаге задаче выявления кореференции между именными группами или текстовыми входами. Необходимо для текстовых входов ti и tj, таких, что ti≠tj, верно определить понятие ck, которое является общим референтом для ti и tj, т.е. ti и tj должны являться текстовыми входами одного понятия или текстовыми входами понятий, принадлежащих к одному семантическому полю. Принадлежность понятий к одному семантическому полю определяют следующим образом: одно из понятий с, берут за начальную точку семантического поля и последовательно с помощью проходов по ЛО путями Pup, Pdown, Pupdown и Pdownup пытаются достигнуть конечной точки, в качестве которой выступает понятие cj. Если конечная точка достигнута, то считают, что понятия ci и cj принадлежат к одному семантическому полю и, следовательно, текстовые входы ti и tj являются кореферентными. Так как, в ЛО всегда существует путь от одного произвольного понятия до другого, решение о кореференции двух понятий принимают в зависимости от метрики семантической близости mij, которая рассчитывается как длина пути между ci и cj. Минимальная метрика семантической близости mij, при которой принимают решение о кореференции понятия ci и cj, устанавливается пользователем эмпирическим путем (например, mij<5). Например, в предложении: "Под аплодисменты зрителей прошел практически весь трехактный "Дон Кихот". Балет, впервые поставленный еще в 1860 году в Большом театре великим Мариусом Петипа и переживший с тех пор немало редакций, по-прежнему не утратил своей молодости. В Лондон театральную постановку привезли в самой новой редакции…", кореферентами являются ДОН КИХОТ, БАЛЕТ и ТЕАТРАЛЬНАЯ ПОСТАНОВКА. Путь между понятиями БАЛЕТ и ТЕАТРАЛЬНАЯ ПОСТАНОВКА имеет один перегиб сверху (фиг. 3), а метрика семантической близости ту равна двум, следовательно, между данными понятиями существует референциальная связь.
Недостатком использования ЛО является трудоемкость ее наполнения. Кроме того лексическая мощность языка постоянно пополняется за счет научных открытий объектов реального мира, заимствования слов из иностранных языков, сленговых выражений и т.д. ЛО не способна гибко и оперативно реагировать на эти изменения. В связи с этим в случае отсутствия в ЛО одного или обоих понятий для выявления кореференции между семантически тождественными понятиями 210 применяют алгоритм, использующий инструмент распределенного представление слов, например, алгоритм Skip-Gram инструмента Word2Vec [Mikolov Т., Sutskever I., Chen K., Corrado G., and Dean J.. 2013b. Distributed representations of words and phrases and their compositionality. In NIPS, Pp. 3111-3119]. Модель распределенного представления слов основана на гипотезе, гласящей, что семантическая близость слов отражает их совместную встречаемость в сходных контекстах. Векторные представления слов формируют путем автоматического извлечения статистики их совместной встречаемости, полученной из текстовых корпусов большого объема (например, используя статьи из Wikipedia). Эта информация фиксируется в так называемых семантических или контекстных векторах, сходство которых отражает меру семантической близости слов.
Для вычисления метрики семантической близости ту кандидатов в кореференты ci и cj используют алгоритм Skip-Gram инструмента Word2vec. Например, в тексте: "Ночью устроили построение, но в темноте было не разобрать, какой военнослужащий нас строил. Утром мы узнали, что это был офицер нашей будущей роты", - текстовые входы "военнослужащий" и "офицер" имеет один и тот же референт. Результаты работы Word2vec по этим словам отражены в таблице 2. Метрика семантической близости т в данном случае равна
m=(mij+mji)/2=(0.58981+0.66234)=0,626075.
Метрика семантической близости двух кандидатов в кореференты mij, где mmin<mij≤1, является численным критерием принятия решения о наличие кореференции между этими кандидатами. Порог mmin принятия решения подбирают эмпирическим путем.
7. Кореферент с наибольшей степенью общности заменить кореферентом с более конкретным значением 212. Данный шаг необходим для более точного определения риторических отношений между клаузами и более крупными текстовыми элементами 214. По результатам данного шага текст, приведенный на шаге 6, будет представлен в следующем виде: "Ночью устроили построение, но в темноте было не разобрать, какой офицер нас строил. Утром мы узнали, что это был офицер нашей будущей роты". Слово "офицер" имеет более конкретное значение, как по таксономии понятий, так и с учетом дальнейшего уточнения: "офицер нашей будущей роты".
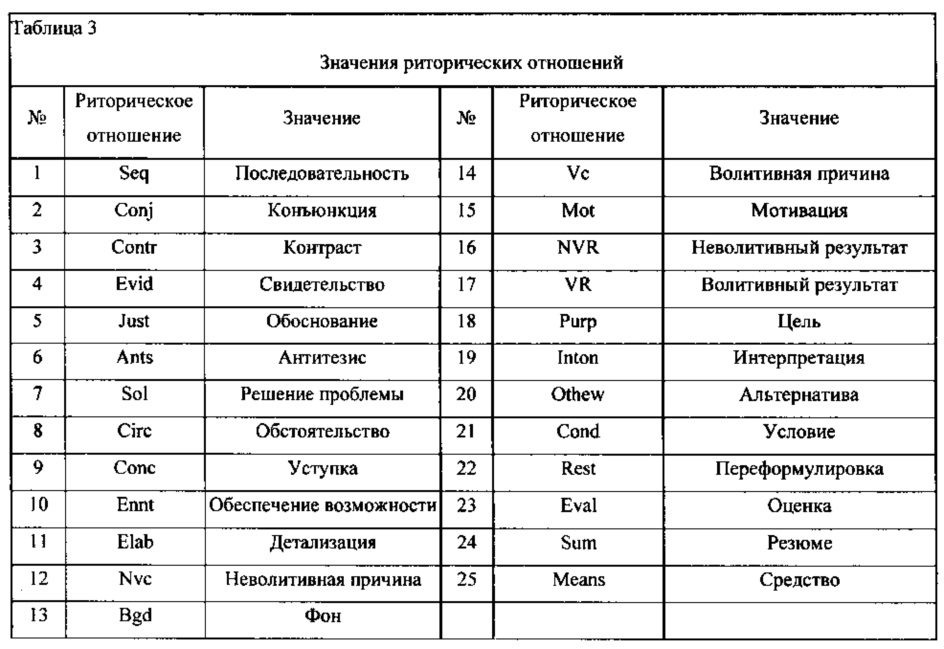
8. Определить риторические отношения между клаузами и более крупными текстовыми элементами 214. Список риторическими отношений между текстовыми фрагментами был предложен в рамках теории риторических структур [Mann, W.C., Thompson, S.A. Rhetorical structure theory and text analysis. - Amsterdam. Benjamins, 1992. - 66 с]; используемые отношения представлены в таблице 3. Риторические отношения определяют, используя, например, метод предложенный в [Li Jiwei, Li Rumeng, Hovy Eduard. Recursive Deep Models for Discourse Parsing \ Proceedings of the 2014 Conference on Empirical Methods in EMNLP, 2014. pages 2061-2069], используя обучение рекурсивной нейронной сети на размеченном риторическими отношениями текстовом корпусе.
9. Связать ФРС риторическими отношениями для получения дискурсного графа 216. ФРС связывают определенными на шаге 8 риторическими отношениями. В итоге получают дискурсный граф текстового документа, в вершинах которого находятся ФРС клауз и их связки, и ребра которого определяются риторическими отношениями между ними. Пример описания дискурсного графа представлен выше в виде структуры XML, риторические отношения между ФРС и их тип содержатся под тегом <RhetorRel>. Формально дискурсный граф текстового документа представим следующими выражениями:

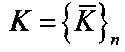 - множество из n связок ФРС в текстовом документе;
- множество из n связок ФРС в текстовом документе;
Mrhe - матрица риторических отношений между связками ФРС 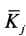 текстового документа,
текстового документа,
где 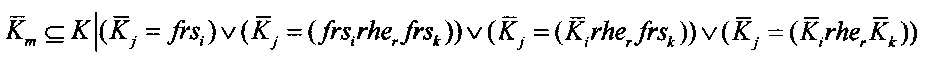
rher - r-ое риторическое отношение между связками ФРС;
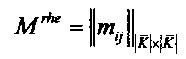 , где
, где

10. Сформированный дискурсный граф текстового документа дописать к метаинформации текстового документа 218. На данном шаге сформированный дискурсный граф текстового документа переписывают из ОЗУ в базу данных 103, хранящуюся в ПЗУ (например, на НЖМД) и добавляют к соответствующей метаинформации обрабатываемого текстового документа.
Дискурсный граф текстовых документов формируется модулем формирования дискурсного графа текстовых документов 111 при добавлении в базу данных 103 нового текстового документа, который вводится через модуль пополнения текстовых документов 100, задачей которого является приведение текстового документа к единому унифицированному виду (очистка документа от тегов, приведение к единой кодировке и т.д.). Модуль индексации текстовых документов 113 производит индексирование текстовых документов, поступающих от модуля формирования дискурсного графа текстовых документов 113, по вершинам ФРС с учетом выявленной кореференции, с использованием модели tf.idf.
Дискурсный граф запроса пользователя поступает в модуль оценки текстовых документов относительно запроса пользователя с учетом семантических признаков 114, который реализует второй этап способа семантической обработки текстовых документов, а именно оценку текстовых документов относительно запроса пользователя с использованием семантических признаков, которая включает выполнение следующих шагов (фиг. 4):
1. Ввод дискурсных графов текстового документа и запроса пользователя 402.
2. Для каждой ФРС запроса и текстового документа, в которых существует их пересечение по вершинам ФРС клауз (id вершин совпадают), выполняют расчет следующих оценок:
1) Оценка соответствия атрибутов 404:
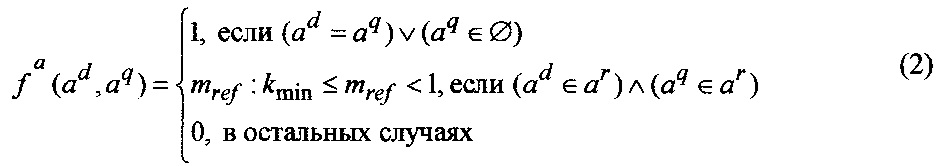
где
a d, aq - наименования атрибутов вершин ФРС соответственно текстового документа и запроса;
mreƒ - метрика референциальной близости наименований атрибутов отражающая вероятность, с которой ad и aq принадлежат общему референту ar;
kmin - порог принятия решения о кореферентности двух текстовых элементов, принимается в зависимости от необходимого значения F-меры (совокупное значение полноты и точности), характеризующей эффективность отбора текстовых документов.
2) Оценка соответствия вершин 406.
Для ФРС, представляющих факты известные пользователю, функция соответствия вершин имеет вид:
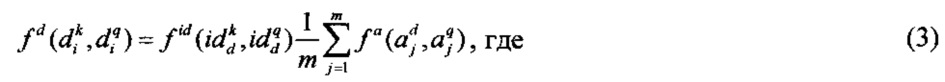
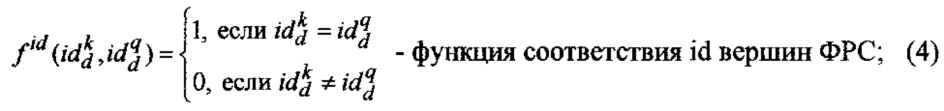
id - идентификационный номер понятия, соответствующего вершине ФРС;
m - количество атрибутов ФРС.
Для ФРС, составляющих суть запроса и представленных к-вопросом необходимо восполнить знания, заданные вопросительным словом, по которому определяют недостающего игрока ФРС, например, вопросительное слово "Где?" требует обязательного наличия в ФРС документа вершины типа "Место действия". Соответствие вопросительного слова вершинам ФРС определяют на основе эвристических правил, хранящихся в онтологии предметной области 120. В этом случае выражение (4) приобретает следующий вид: Gmk
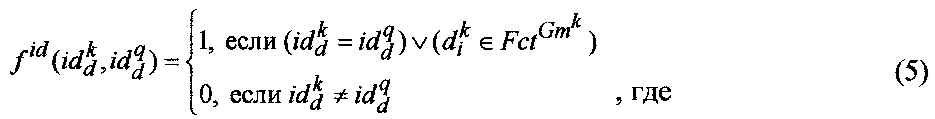
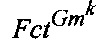 - фактор-множество вершины, представленной вопросительным словом, соответствующее множеству Gmk игроков.
- фактор-множество вершины, представленной вопросительным словом, соответствующее множеству Gmk игроков.
Например, фактор-множество вершины типа "Место действия" представляет собой множество всех возможных мест для конкретной ФРС.
3) Суммарная оценка соответствия ФРС 408:

k, q - ФРС текстового документа и запроса соответственно.
Суммарная оценка соответствия ФРС представляет собой нормированную функцию соответствия всех ее вершин.
3. Расчет оценки соответствия риторических отношений между ФРС 410: при оценке соответствия риторических отношений между ФРС в текстовом документе и запросе риторические отношения между ФРС, представляющими факты известные пользователю, оценивают по точному соответствию, а риторические отношения между ФРС, представляющими факты известные пользователю, и ФРС, составляющими суть запроса, могут оценивать по точному соответствию и с использованием эвристических правил, хранящихся в онтологии предметной области 120, которые дополняют риторические отношения между ФРС, представляющими факты известные пользователю, и ФРС, составляющими суть запроса. Эвристические правила определяются вопросительным словом ли-вопроса (n-вопроса), например: для ли-вопросов: "Верно-ли?" характерно риторическое отношение "Обеспечение возможности", "Может-ли?" характерно риторическое отношение "Оценка"; для n-вопросов: "Почему?" характерно риторическое отношение "(Не) волитивная причина". При этом новые знания, соответствующие сути запроса, должны являться сателлитом для ФРС, составляющих суть запроса.
Функция соответствия риторических отношений между ФРС имеет вид:
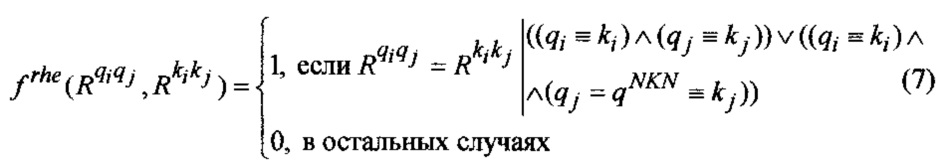
где 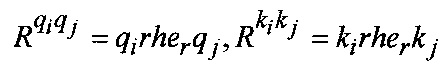 - риторические отношения между ФРС;
- риторические отношения между ФРС;
qNKN - новые знания, которые необходимо получить;
t1, qi - ФРС текстового документа и запроса соответственно;
тогда функция соответствия между всеми риторическими отношениями ФРС текстового документа и запроса будет иметь вид: 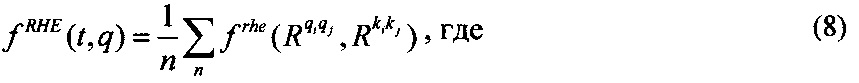
n - количество риторических отношений в дискурсном графе текстового документа.
4. Оценка расстояния от пересечения графов до ядра дискурсного графа текстового документа 412 позволяет оценить насколько найденный фрагмент близок к ядру (реме) текстового документа:

где 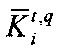 - пересечение дискурсных графов текстового документа и запроса;
- пересечение дискурсных графов текстового документа и запроса;
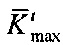 - ядро дискурсного графа текстового документа (корневая связка ФРС);
- ядро дискурсного графа текстового документа (корневая связка ФРС);
n - расстояние от 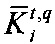 до
до 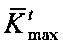 .
.
Чем ближе найденный фрагмент к ядру текстового документа, тем больше рема всего документа соответствует реме запроса.
5. Вывод значения функции соответствия текстового документа запросу пользователя 414 (ценность текстового документа) рассчитывается на основе мультипликативной свертки частных оценок:
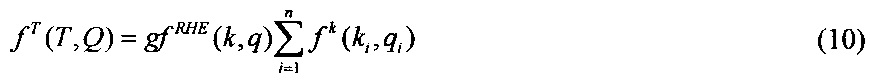
где n - количество ФРС в текстовом документе.
Оценке соответствия модулем оценки текстовых документов относительно запроса пользователя с учетом семантических признаков 114 подвергаются текстовые документы, еще" не просмотренные пользователем, хранящиеся в хранилище результатов поиска по ключевым словам 106, по результатам которой производится их ранжирование модулем ранжирования по ценности текстовых документов с учетом семантических признаков 115 (третий этап способа семантической обработки текстовых документов). В процессе ранжирования модуль ранжирования по ценности текстовых документов с учетом семантических признаков 115 может отсекать текстовые документы, ценность которых ниже порога, заданного пользователем. Результаты ранжирования сохраняются в хранилище результатов поиска с учетом семантических признаков 116 и предоставляются пользователю посредством модуля представления результатов обработки текстовых документов 118.
Бортовая система измерения и контроля топлива с компенсацией по температуре топлива
Бортовая топливомерная система с компенсацией по температуре топлива
Бортовая система измерения топлива с компенсацией по температуре топлива
Бортовая система контроля и измерения топлива с компенсацией по температуре топлива
Способ определения влажности почвы и устройство для его реализации
Бортовая система измерения и контроля топлива с компенсацией по температуре топлива
Бортовая топливомерная система с компенсацией по температуре топлива
Бортовая система измерения топлива с компенсацией по температуре топлива
Бортовая система контроля и измерения топлива с компенсацией по температуре топлива
Способ определения влажности почвы и устройство для его реализации
Рентгенофлуоресцентный анализатор компонентного состава и скорости трехкомпонентного потока
Рентгенофлуоресцентный анализатор скорости и состава компонентов газожидкостного потока
Рентгенофлуоресцентный анализатор состава и скорости газожидкостного потока
Рентгенофлуоресцентный анализатор компонентного состава и скоростных параметров трехкомпонентного потока
Рентгенофлуоресцентный анализатор расхода и состава компонентов трехкомпонентного потока

