Результат интеллектуальной деятельности: МЕТОД И СИСТЕМА ДЛЯ ГЕНЕРАЦИИ СТАТЕЙ В СЛОВАРЕ ЕСТЕСТВЕННОГО ЯЗЫКА
Вид РИД
Изобретение
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Воплощения изобретения в целом относятся к области обработки естественного языка и могут иметь различные приложения в таких областях, как электронные словари, синтаксический анализ, автоматизированное реферирование, машинный перевод, поиск информации (в том числе в Интернете), системы извлечения данных, машинное обучение, проверка орфографии, семантический веб, экспертные системы, распознавание речи/синтез и другие.
УРОВЕНЬ ТЕХНИКИ
[0002] Способность понимать естественные языки, говорить на них и писать является неотъемлемой частью развития людей для взаимодействия и общения в обществе. Используются различные подходы для анализа языка, распознавания его лингвистической структуры, чтобы определить значение отдельного слова, предложения в заданном тексте, извлечь информацию о слове, предложении и, если необходимо, перевести на другой язык или синтезировать другое предложение, выражающее тот же смысл в некотором естественном или искусственном языке.
[0003] Системы обработки естественного языка могут включать использование электронных словарей, синтаксического анализа, автоматизированного реферирования, машинного перевода, поиска информации и т.д., и во всех этих приложениях лингвистический морфологический компонент требуется. Этот лингвистический морфологический компонент может содержать морфологическую модель (например, правила окончания слова и правила словообразования) и морфологический словарь.
[0004] Сложные тексты на естественном языке и языковые конструкции могут быть проанализированы и переведены с одного языка на другой. Большинство систем обработки естественного языка могут включать использование электронных словарей, синтаксический анализ, системы автоматизированного реферирования, машинного перевода, поиска информации и т.д., и во всех этих приложениях требуется лингвистический морфологический компонент. Этот лингвистический морфологический компонент может содержать в том числе морфологическую модель (например, правила словоизменения и правила словообразования) и морфологический словарь.
[0005] Кроме изолированных языков (например, китайского языка и т.д.), морфологические структуры большинства естественных языков со словообразованием обычно доступны, тогда как реализация морфологической модели и использования такой морфологической модели для создания морфологического словаря может варьироваться. Известные морфологические модели слишком упрощены и отличаются в степени точности и полноты их морфологических типов, и предшествующие морфологические словари обычно не всеобъемлющи (не исчерпывающе).
[0006] Например, некоторые морфологические модели могут содержать только информацию о возможных окончаниях слова (например, аффиксах, суффиксах и т.д.) в языке и не включать правила словоизменения. Такие морфологические модели могут использоваться только в системах извлечения данных или поиска и не требуют исчерпывающего морфологического словаря. Эти морфологические модели, однако, часто порождают ошибки, неверные слова и неверные словоформы во время анализа языка. Такие морфологические модели вообще не могут работать для языков со словоизменением внутренних компонентов или чередованием. Если разрабатывается морфологический словарь, это значит обычно, что предшествующие морфологические словари не содержат всех возможных правил словоизменения или словоизменения. Это происходит частично из-за того, что создание морфологического словаря, который включает все возможные словоформы, является огромной задачей, и часто морфологический словарь крайне неэффективен в процессе анализа языка в реальном времени.
[0007] Соответственно, существует потребность в методах и системах для создания эффективной морфологической модели и генерации словаря произвольного естественного языка.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0008] Изобретение относится к методам, машиночитаемым носителям, устройствам и компьютерным системам для анализа корпуса текстов на естественном языке и генерации морфологического словаря естественного языка. Начальное морфологическое описание языка, имеющее правила словоизменения для различных групп слов, может быть создано лингвистом. Дополнительно, эти морфологические описания, включающие правила для парадигм, правила словоизменения, правила словообразования, грамматическую систему соответствующего языка и другие, прямые и обратные, правила и др. могут быть использованы для генерации и проверки гипотез о части речи и словообразовательной парадигме каждого слова в корпусе. В результате генерируется морфологический словарь, содержащий список слов (словник) с грамматической информацией и подтвержденными морфологическими парадигмами.
[0009] В одной реализации изобретения, метод анализа корпуса текстов на естественном языке включает идентификацию каждого элемента текста (токена), применение одного или более правила парадигмы к каждому токену в текстовом корпусе и генерацию одной или более гипотез о базовой форме каждого токена. Метод также включает поиск в корпусе для каждого токена других словоформ, соответствующих каждой базовой форме, и проверку каждой из гипотез относительно базовой формы и соответствующей парадигмы. Для каждой подтвержденной гипотезы грамматические значения и парадигма словоизменения добавляются к каждой базовой форме токена, и таким образом может быть получена информация для морфологического описания каждого слова.
[0010] В другой реализации, метод генерации морфологического словаря для произвольного естественного языка включает создание лингвистом начального морфологического описания, имеющего правила словоизменения для групп слов в данном языке, и анализ множества текстовых корпусов на данном языке для получения информации о каждом токене с проверкой гипотезы на каждом из текстовых корпусов. Каждый токен в каждом текстовом корпусе идентифицируется, и может быть получена подтвержденная гипотеза о каждой базовой форме для каждого токена применением одного или более правил парадигмы к каждому токену в каждом текстовом корпусе, включая выдвижение одной или более гипотезы о базовой форме каждого токена, поиск других форм слова, соответствующих каждой базовой форме для каждого токена, и проверку каждой из гипотез для каждой базовой формы. Грамматические значения и парадигма словоизменения добавляются к каждой базовой форме каждого токена для каждой подтвержденной гипотезы. Базовая форма каждого токена с морфологическим описанием для каждой подтвержденной гипотезы добавляется в морфологический словарь данного естественного языка.
[0011] В другой реализации изобретение представляет собой машиночитаемый носитель информации, имеющий инструкции для компьютерной системы, выполняющей шаги для анализа корпуса текстов на естественном языке. Указанные шаги включают идентификацию каждого элемента текста (токена), генерацию одной или более гипотез о базовой форме каждого токена, поиск в корпусе для каждого токена других словоформ, соответствующих каждой базовой форме, и проверку каждой из гипотез относительно базовой формы и соответствующей парадигмы, добавление грамматических значений и парадигмы словоизменения к каждой базовой форме токена для каждой подтвержденной гипотезы и получение информация для морфологического описания каждого токена для каждой подтвержденной гипотезы.
[0012] В другой реализации изобретение представляет собой машиночитаемый носитель информации, имеющий инструкции для компьютерной системы, выполняющей шаги для генерации морфологического словаря для произвольного естественного языка. Машиночитаемый носитель информации включает инструкции для анализа множества текстовых корпусов на данном языке и получения информации о каждом токене и его базовой форме с морфологическим описанием и проверкой гипотезы на каждом из текстовых корпусов для генерации морфологического словаря. Морфологическое описание для каждого токена с подтвержденной гипотезой о каждой базовой форме может быть получено применением одного или более правил парадигмы к каждому токену в каждом текстовом корпусе, включая выдвижение одной или более гипотезы о базовой форме каждого токена, поиск других форм слова, соответствующих каждой базовой форме для каждого токена, и проверку каждой из гипотез для каждой базовой формы. Грамматические значения и парадигма словоизменения добавляются к каждой базовой форме каждого токена для каждой подтвержденной гипотезы.
[0013] В еще одной реализации данного изобретения представлена компьютерная система, адаптированная для анализа корпуса текстов на естественном языке и генерации морфологического словаря данного языка.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0014] Способ и детали различных вариантов реализации изложены в прилагаемых чертежах и приведенном ниже описании. Другие особенности, аспекты и преимущества настоящего изобретения станут очевидными из описания, чертежей и формулы изобретения, в которых:
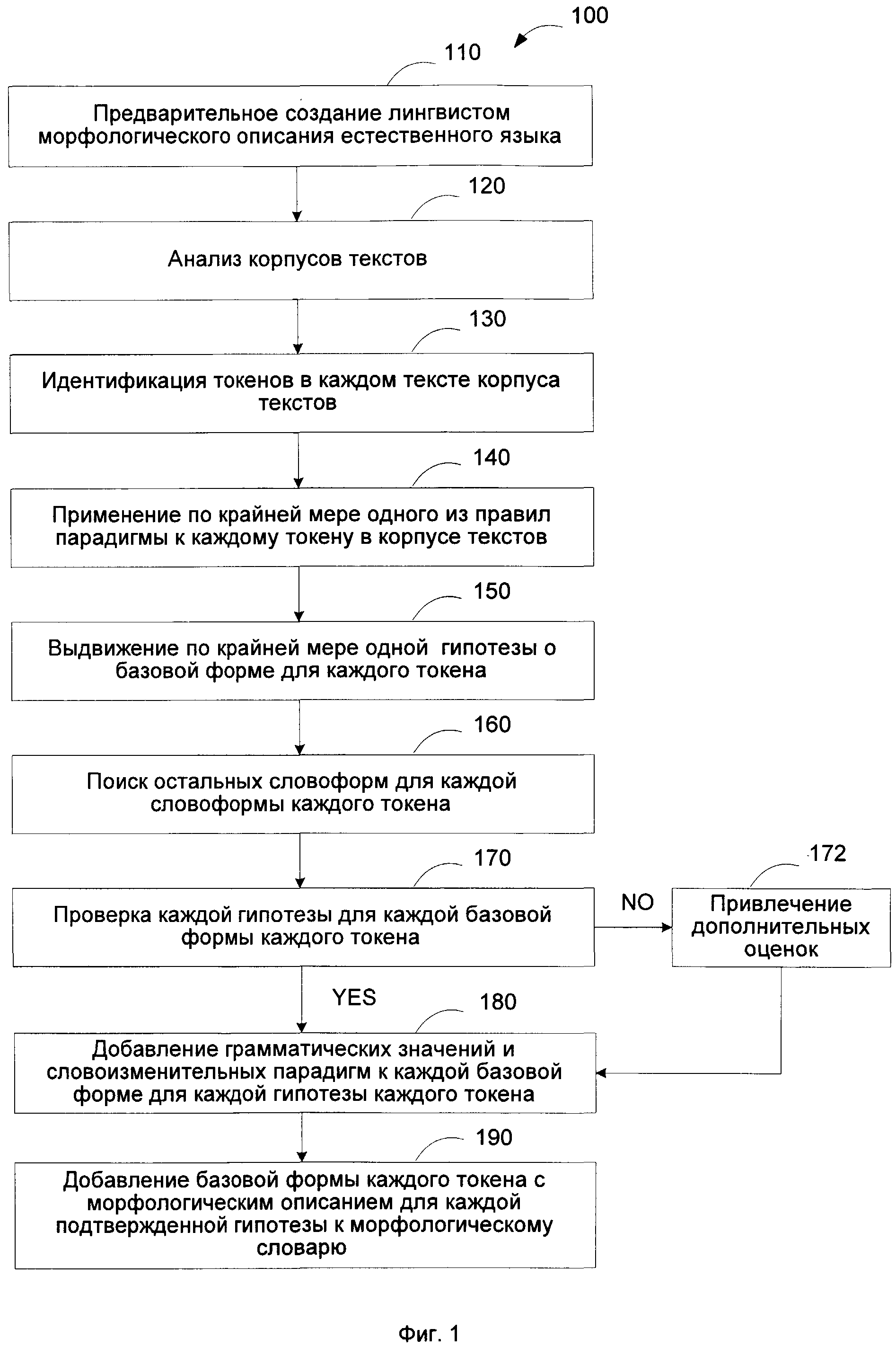
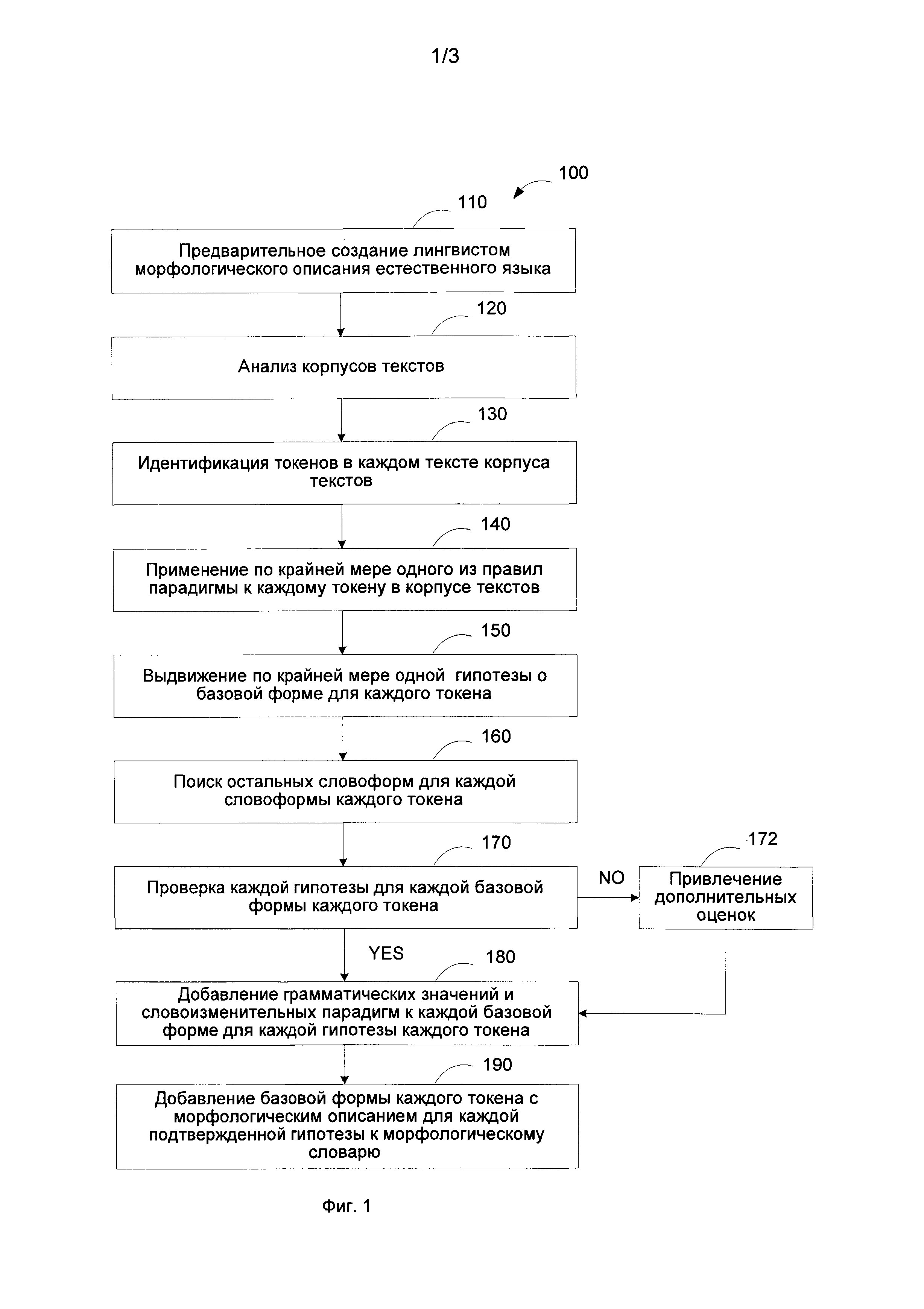
[0015] Фиг. 1 иллюстрирует блок-схему способа осуществления анализа корпуса текстов на естественном языке и генерации морфологического словаря этого естественного языка в соответствии с одним из способов реализации настоящего изобретения;
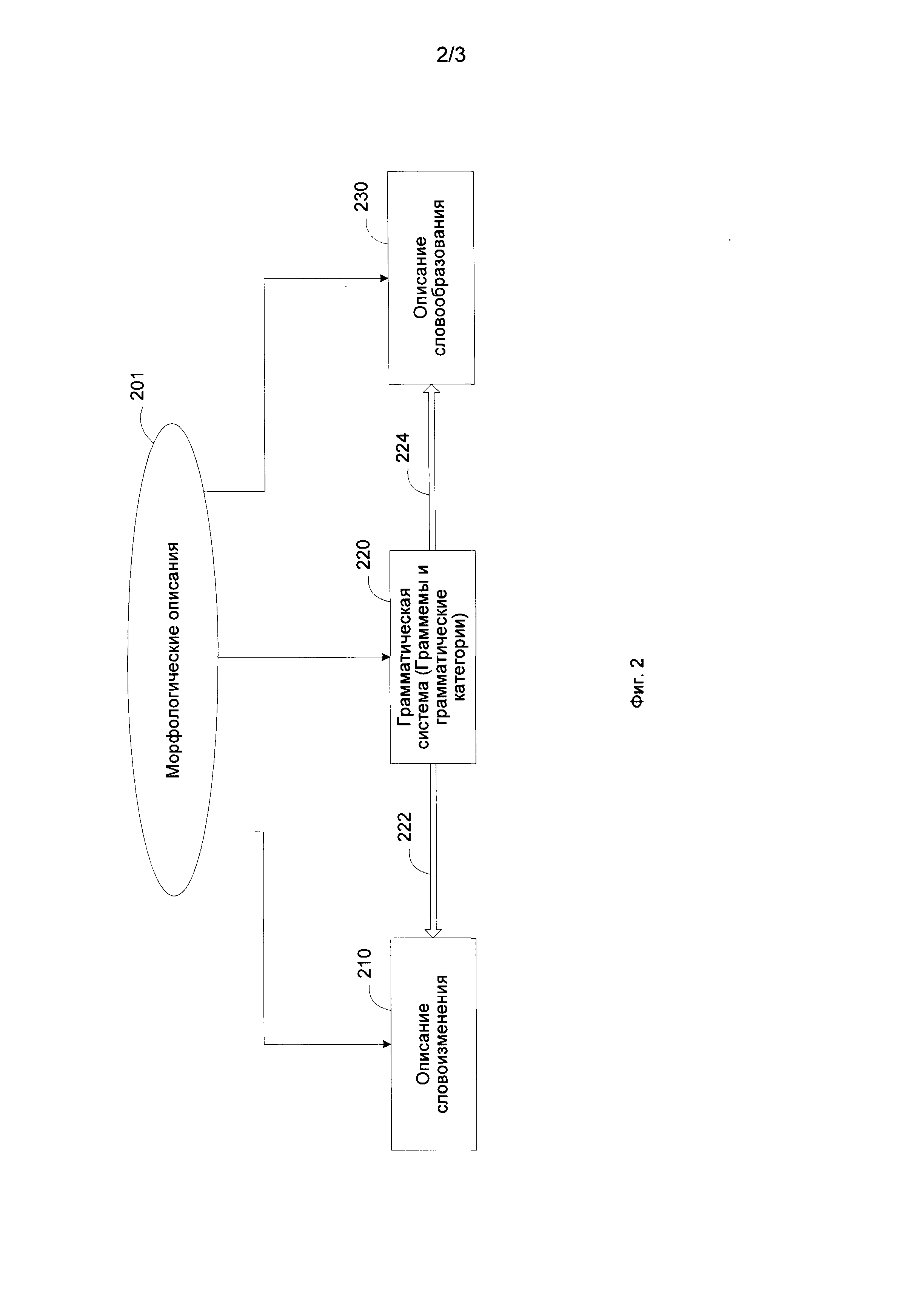
[0016] Фиг. 2 иллюстрирует морфологические описания в соответствии с одним из способов реализации настоящего изобретения;
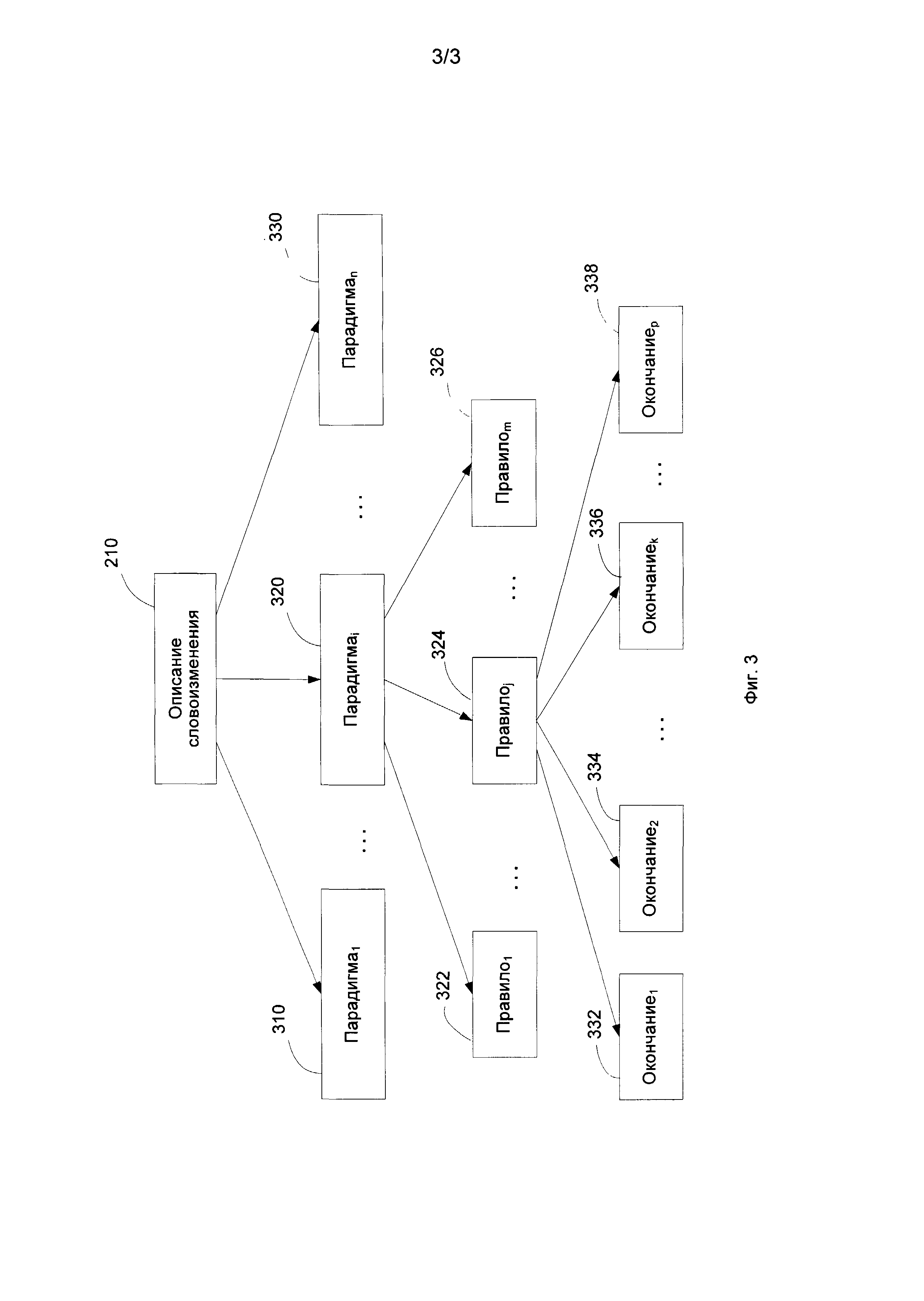
[0017] Фиг. 3 иллюстрирует описания словообразования в соответствии с одним из способов реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0018] Реализации настоящего изобретения предоставляют методы, машиночитаемые носители и компьютерные системы, предназначенные для анализа корпуса текстов на естественном языке и генерации морфологического словаря для этого естественного языка. Морфологический словарь естественного языка может включать множество слов в их базовых формах, снабженных, например, метками частей речи и моделями словообразования, верифицированными на достаточно большом корпусе текстов данного языка.
[0019] В соответствии с одним воплощением изобретения первоначальное морфологическое описание на естественном языке может быть создано лингвистом. Это первоначальное морфологическое описание может включать правила изменения окончания слова для различных групп слов, такие как правила парадигмы, правила словообразования и грамматическую систему данного естественного языка и т.д. Информация для морфологического описания специфического слова на естественном языке, словоформы которого встречаются, как токены слова, в множестве текстовых корпусов, может быть получена автоматизированной системой или вручную. Разнообразие словоформ для каждой лексемы слова, встречаемое в корпусах текстов, и полученная информация о морфологических описаниях может быть добавлена вместе с первоначальным морфологическим описанием для генерации морфологического словаря. Различные системы поиска и извлечения информации могут быть использованы для поиска словоформ.
[0020] Полноценные лингвистические модели используются для создания морфологических описаний для различных групп слов, не только частей речи, но для некоторых групп слов внутри одной части речи. Предоставляется также среда разработки и устройство/система для создания морфологических моделей. Реализации данного изобретения могут поставляться в различных формах, форматах, а также быть адаптированы для записи на машиночитаемый носитель, выполняться как компьютерная программа или как часть устройства для генерации морфологического словаря некоторого естественного языка.
[0021] Фиг. 1 иллюстрирует блок-схему способа 100, разработанного для анализа корпуса текстов на естественном языке и генерации морфологического словаря этого естественного языка в соответствии с одним из способов реализации настоящего изобретения. Метод 100 в общих чертах может включать создание начального морфологического описания для естественного языка, например, квалифицированным лингвистом, знакомым с данным естественным языком, и анализ множества текстовых корпусов на данном языке, чтобы сгенерировать его морфологический словарь. Этап анализа текстового корпуса может выполняться вручную или автоматически, например, с использованием компьютерной системы, имеющей машиночитаемый носитель, имеющий инструкции для компьютерной системы, выполняющей шаги для анализа корпусов текстов естественного языка.
[0022] На этапе 110 создается начальное морфологическое описание. Например, коллекция морфологических описаний, имеющая правила изменения окончаний для групп слов, может быть создана лингвистом. Фиг. 2 иллюстрирует морфологические описания 201 естественного языка в соответствии с одним из способов реализации настоящего изобретения. В общем случае, морфологические описания 201 могут включать, среди прочего, правила словоизменения 210, грамматическую систему 220 данного языка, правила словообразования 230.
[0023] Грамматическая система 220 естественного языка может включать, к примеру, множество грамматических категорий и граммем и т.д. Грамматическими категориями могут являться, например, "Part of speech," "Case," "Gender," "Number," "Person," "Reflexivity," "Tense," "Aspect" и т.д. Граммемы могут использоваться как значения, толкования или подкатегории в рамках грамматической категории. Например, граммемы части речи могут включать "Adjective", "Noun", "Verb" и т.д; граммемы падежа - "Nominative", "Accusative", "Genitive" и т.д.; граммемы рода - "Feminine", "Masculine", "Neuter" и т.п. Множества граммем могут комбинироваться в грамматические значения и использоваться в описаниях словоизменения 210 и в описаниях словообразования 230, что показано связями 222 и 224 на Фиг. 2.
[0024] Описания словоизменения 210 могут описывать, как основная форма слова изменяется в соответствии с падежом, родом, числом, временем глагола и т.п., и в широком смысле, включать все возможные данного формы слова. Описание словообразования 230 может описывать, какие новые слова могут образовываться с участием данного слова.
[0025] Фиг. 3 иллюстрирует один пример описания словоизменения 210 в соответствии с одним из способов реализации настоящего изобретения. Описание словоизменения 210 в общем случае включает набор парадигм 310, 320, 330. Парадигмы представлены на Фиг. 3 как Парадигма1, … Парадигмаi, Парадигмаn. Каждая парадигма является характеристикой некоторого подмножества слов в заданном языке.
[0026] В одной из реализаций, группа слов, ассоциированная с некоторой парадигмой, может быть описана при помощи одного или более шаблона - выражения для базовой формы, содержащего групповые символы, а также классифицирующих грамматических значений. Базовая форма - это обычная начальная форма слова, используемая в качестве словарного входа, например инфинитив для глагола или именительный падеж единственного числа существительного. Например, в английском языке для словоформ "went", "going", "goes" базовой формой является "go". В качестве другого примера в английском языке для словоформы "cultures" базовой формой является "culture".
[0027] Естественные языки обладают грамматической омонимией, т.е., например, токен "рlау"может быть глаголом, а может оказаться и существительным. Так что, имеется, как минимум, две различные парадигмы для базовой формы "play". К тому же, могут существовать различные варианты выбора базовых форм для некоторых словоформ. Например, может быть два разных варианта базовой формы для токена "bit" - "bit" как существительное и "bite" как глагол.
[0028] Слова с одними и тем же правилами словоизменения могут образовывать группы. Группа может быть описана при помощи одного или более шаблона и классифицирующих грамматических значений. Например, наречия "early", "easy", "heavy" и т.п., которые имеют одинаковые правила словоизменения, описываются как "*{s/v/l}y" в шаблоне с групповым символом (*), который обозначает любую цепочку символов.
[0029] В качестве другого примера, для прилагательных "glad", "mad", "red", "sad" и т.п. может быть использовано выражение "*d". Различные правила могут использоваться для образования шаблонов. Для некоторых групп слов, которые имеют очень специфические правила, эти выражения могут совпадать с базовой формой, в этом случае, такое слово имеет отдельную парадигму, и такая парадигма должна быть проверена в первую очередь. Например, прилагательное "little" имеет нетривиальную парадигму, которая порождает следующие словоформы: "little", "less", "lesser", "least".
[0030] Каждая из парадигм 310, 320, 330 и т.д. может содержать одно или более правил 322, 324, 326 для порождения словоформ на основе базовой формы еtс. for generating inflected forms based on the base form. Порождаемые словоформы имеют свои окончания 332, 334, 336, 338, взятые из этого множества, или нулевые.
[0031] В одной из реализаций, каждое правило 322, 324, 326 может включать одно или более прямых и/или обратных правил, которые позволяют добавлять или отрезать суффикс и и/или дополнительно добавлять или отрезать окончание. Например, следующие правила могут быть использованы для порождения всех словоформ английских глаголов, чья базовая форма удовлетворяет выражению [*d], например (bed, cod, kid, spud, etc.): 1) добавить окончание -s для образования 3 лица единственного числа; 2) добавить суффикс -d к базовой форме, и затем окончания -ed, -ing, -ing для образования past simple, ing-participle и present progressive соответственно; 3) остальные формы совпадают с базовой.
[0032] В другой реализации, словоизменительные формы в каждом правиле парадигмы 310, 320, 330 могут быть упорядочены специальным образом. Однако выбор способа упорядочения несущественен. Например, для существительного английского языка этот порядок может быть <Common case, Singular>, <Common case, Plural>, <Possessive case, Singular>, <Possessive case, Plural>.
[0033] Те же самые правила могут быть использованы для решения обратной задачи, т.е для распознавания некоторой заданной формы слова. В этом случае правила применяются в обратном порядке. Например, если, согласно правилу, некоторое окончание может быть отрезано от словоформы и если правило требует, чтобы суффикс был добавлен (или отрезан, по правилу) к словоформе, и затем если получившееся слово удовлетворяет выражению некоторой парадигмы, то гипотеза о принадлежности к парадигме может быть выдвинута. Затем, гипотеза о том, что данное слово является словоформой некоторой базовой формы, принадлежащей данной парадигме, должна быть верифицирована.
[0034] Имея созданное начальное морфологическое описание для некоторого естественного языка, его морфологический словарь может быть порожден на основе анализа достаточно большого корпуса текстов. Возвращаясь к Фиг. 1, на этапе 120 анализируется множество корпусов текстов на этом естественном языке.
[0035] На этапе 130, идентифицируется каждый токен в каждом корпусе текстов. Под токеном понимается любая лексема, словоформа, единица языка, морфема и т.п. Токены в тексте могут быть разделены, например, при помощи пробелов, пунктуаторов или любых других разделителей. Корпус текстов может представлять собой большой набор текстов на заданном натуральном языке. Каждый токен в каждом текстовом корпусе может быть выделен любым доступным способом.
[0036] На этапе 140, одно или более правил парадигмы применяются к каждому выделенному токену в каждом текстовом корпусе. Эти одно или более правил парадигмы могут включать правила анализа токена, такие как правила для добавления или отрезания окончания, добавления или отрезания суффикса и их комбинации. Поиск возможной парадигмы для каждого токена базируется на предположении, что токен может иметь окончание, которое может содержаться в одном или более списках окончаний некоторого правила парадигмы, и что его базовая форма удовлетворяет шаблону этой парадигмы. Например, если заданное слово есть "going", "doing", "listening" и т.п. делается попытка применить любое из правил той парадигмы, которая содержит окончание "-ing" в своем шаблоне парадигмы.
[0037] Может существовать несколько парадигм, чьи правила могут быть применены. Некоторые из них могут содержать не только действия по добавлению или отрезанию окончания, но также действия по добавлению или отрезанию суффикса. Например, если задан токен "dying" (в английском), после отрезания окончания "-ing", суффикс "-у" также должен быть отрезан, а другой суффикс "-ie" должен быть добавлен для того, чтоб получить базовую форму "die". Если строка символов, получающаяся в результате этих действий, удовлетворяет шаблону (например, "*{d/l/t/v}ie" для базовой формы "die") некоторой парадигмы, эта парадигма может рассматриваться как гипотеза для данного токена на следующем этапе 150. Однако могут существовать и другие парадигмы, чьи шаблоны подходят для того, чтобы произвести другие базовые формы. Все эти гипотезы должны быть проверены.
[0038] На этапе 150, выдвигается одна или более гипотез о базовой форме каждого токена и генерируются и ищутся в корпусе все остальные формы слова в соответствии с выдвинутой гипотезой, т.е базовой формой и парадигмой, для каждого токена на этапе 160. Гипотезы о возможных парадигмах для каждой базовой формы токена основаны на предположении, что если данный токен принадлежит некоторой парадигме, то почти все порожденные с ее помощью словоформы могут быть обнаружены в корпусе текстов.
[0039] Каждая базовая форма может включать одну или более парадигм. Гипотезы о возможных парадигмах для каждой базовой формы токена основаны на предположении, что токен может иметь окончание, содержащееся в одном из списков окончаний правила парадигмы, и что базовая форма удовлетворяет шаблону этой парадигмы. Например, если данным токеном является "going" или "gone", то почти все остальные формы глагола "to go", такие как "go", "goes", "gone", "going", "went", могут быть найдены в корпусе текстов. Если такие формы не находятся, то, вероятно, формы "going" и "gone" принадлежат парадигме прилагательного. Кроме того, "going", мог бы быть существительным. Однако, если данный токен - "go", который совпадает как с базовой формой глагола "to go", так и с базовой формой существительного "go", дополнительно, парадигма существительного должна быть проверена и словоформа "goes", а также, если возможно, формы притяжательного падежа "go's" и "goes'", которые являются редкими, могут быть порождены для поиска.
[0040] На этапе 170, осуществляется верификация каждой из гипотез о каждой базовой форме каждого токена, чтобы идентифицировать проверяемые гипотезы и получить информацию о морфологическом описании для каждого токена, ассоциированного с проверяемой гипотезой. Верификация каждой гипотезы может включать проверку встречаемости в корпусе текстов всех порожденных при помощи проверяемой парадигмы словоформ. Если все словоизменительные формы (возможно, за исключением затруднительных форм) встречаются в корпусе, парадигма считается релевантной, и гипотеза считается подтвержденной. Для поиска словоформ могут использоваться любые поисковые системы, системы извлечения информации и т.п. Проверяется каждая из гипотез о каждой базовой форме каждого токена. Если проверяется и подтверждается несколько гипотез об одной и той же части речи, может быть выбрана гипотеза с наивысшей оценкой.
[0041] На этапе 172, для одной или более гипотез, где верификация оказалась неуспешной, могут быть использованы дополнительные оценки. Если ни одна из гипотез относительно той же части речи не была полностью подтверждена, но некоторые из словоформ отдельных гипотез встречались в корпусе, для этих гипотез могут быть использованы дополнительные оценки.
[0042] Дополнительные оценки могут быть получены проверкой базовой формы каждого токена по другим словарям или проверкой посредством систем проверки орфографии. Например, базовая форма может быть проверена по словнику словаря (бумажного словаря, электронного, конвертированного из бумажного в электронную форму или полученного иным способом). В другой реализации, система проверки орфографии может быть использована для проверки всех порожденных словоформ.
[0043] На этапе 180, для каждой подтвержденной гипотезы добавляются грамматические значения и парадигма словоизменения к каждой базовой форме каждого токена. Грамматические значения, добавляемые к каждой базовой форме каждого токена, могут включать информацию о части речи и о словоизменении, что может быть выражено посредством грамматических категорий, например, среди прочего, род, число - для существительных, модальность - для глаголов, лицо, число и род - для местоимений и т.д. Парадигмы словоизменения, добавляемые к базовой форме каждого токена, могут включать правила словоизменения.
[0044] На этапе 190, для каждой подтвержденной гипотезы базовая форма каждого токена с его морфологическим описанием добавляется в морфологический словарь. Например, в морфологический словарь может быть добавлена базовая форма (лемма). Кроме того, квалифицирующие грамматические значения (полученные из парадигм, полученных для токена верификацией гипотез) и парадигмы словоизменения могут быть добавлены к морфологическому словарю вместе с соответствующей базовой формой каждого токена.
[0045] Получаемый в результате морфологический словарь и морфологическая модель могут широко использоваться в различных системах и приложениях, включая, но не ограничиваясь, такие, как системы проверки орфографии, системы показа парадигмы (для показа всех или некоторых словоформ), системы подсказки слов в системах исправления ошибок, морфологические анализаторы, системы морфологического синтеза, синтаксические анализаторы, системы синтаксического синтеза, системы машинного перевода и всевозможные их комбинации. Особенно важным оказывается возможность сгенерировать морфологический словарь для редких языков, для которых есть корпуса текстов, но не существует морфологического словаря. Для получения полноценного морфологического словаря начальный текстовый корпус должен быть достаточно велик и содержать тексты различных тематик и стилей.
[0046] Метод и процесс, описанный здесь, могут быть адаптированы для машиночитаемых носителей, в один или более алгоритмов для того, чтобы сгенерировать морфологический словарь естественного языка, основываясь на морфологическом описании языка и достаточно большом корпусе текстов на этом языке.
[0047] Один пример подходящей вычислительной системы, на которой может быть осуществлено изобретение, может быть вычислительным устройством общего назначения в виде компьютера. Однако другие системные среды также могут использоваться. Среда вычислительной системы может включать блок обработки, такой как процессор, системную память и системную шину, которая соединяет различные системы, компоненты с блоком обработки, но не ограничена им. Системная шина может быть любого типа, включая контроллер шин памяти или контроллер памяти, периферийную шину и локальную шину, используя любую из множества архитектур шин. Изобретение работает с многочисленными другими вычислительными средами общего или специального назначения или конфигурации. Примеры хорошо известных вычислительных систем, сред и/или конфигураций, которые могут быть пригодными для использования данным изобретением, включают без ограничений персональные компьютеры, серверы, наладонники или устройства-ноутбуки, мультипроцессорные системы, микропроцессорные системы, подключенные к сети ПК, мини-компьютеры, мэйнфреймовые вычислительные машины, распределенные вычислительные среды, включающие любую из вышеприведенных систем, или устройств и так далее.
[0048] Изобретение может быть описано в общем контексте инструкций для компьютера, таких как программные модули, выполняемые компьютером. В целом, программные модули включают подпрограммы, программы, объекты, компонент, структуры данных и т.д., которые могут выполнять конкретные задачи, или представлять особенные структуры и типы данных. Изобретение также может осуществляться в распределенных вычислительных средах, в которых задачи выполняются удаленными устройствами обработки, подключаемыми через сеть связи. В распределенной вычислительной среде программа, модули которой могут располагаться как на локальных, так и на распределенных устройствах хранения и носителях памяти. В одном воплощении различные программные приложения, программные модули и т.д., такие как морфологическое приложение генерации словарей, могут быть загружены в память и запущены процессором. Приложение для генерации морфологических словарей может быть приспособлено, чтобы выполнить шаги методов, описанных здесь. Морфологические словари, например, могут использоваться в программах анализа языка или программах синтеза языка для перевода предложений с языка ввода на язык вывода.
[0049] Вычислительная система в общем случае может включать множество машиночитаемых носителей. Машиночитаемый носитель может являться любым доступным носителем доступа и включать и энергозависимые, и энергонезависимые носители, съемные и несъемные носители. Машиночитаемые носители могут, например, состоять из устройства хранения и устройств связи, таких как устройство ввода и устройство вывода.
[0050] Вычислительная система может включать устройства хранения и/или различные запоминающие среды компьютера, включая как энергозависимые, так и энергонезависимые, съемные и в съемных хранениях носители, реализованные в любом методе или технологии для хранения информации, такие как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Устройство хранения включает без ограничений ОЗУ, ПЗУ, EEPROM, флэш-память или иную память, CD-ROM, DVD, другие оптические или магнитные устройства хранения, с магнитной памятью, магнитным диском или любой другой носитель, который может использоваться для хранения информации и система может иметь доступ к нему. Например, устройство хранения может включать жесткий диск, который читает с диска или записывает на несъемные, энергонезависимые магнитные носители, диск - магнитный диск, который читает от диска или записывает на съемный, энергонезависимый магнитный диск, и диск - оптический диск, который читает от носителей или записывает на съемный, энергонезависимый оптический диск, такой как CD ПЗУ, или в другие оптические носители. Другие съемные/несъемные, энергозависимые/энергонезависимые носители-компьютеры, которые могут использоваться в типичной операционной среде, включают ПЗУ, но не ограничены картами памяти, флэша, цифровыми многосторонними дисками, цифровой видеокассетой, твердотельными RAM, твердотельным ПЗУ и так далее.
[0051] Программируемые средства связи включают машиночитаемые инструкции, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, такого как несущая волна или другое передающее средство, и включает средства доставки любой информации. Модулированный сигнал данных может включать сигнал и большее количество его характеристик, что позволяет кодировать информацию в сигнале. Средства связи могут, например, включать проводные носители, такие как проводная сеть или беспроводные носители, такие как акустика, радиочастоты, инфракрасные и другие беспроводные носители. Комбинации любого из вышеупомянутых способов также могут быть включены в множество машиночитаемых носителей.
[0052] Пользователь может вводить команды и информацию в вычислительную систему через устройства ввода, такие как клавиатура, микрофон, сканер или управляемое пальцем устройство, такое как мышь, трекбол или сенсорная панель. Другие устройства ввода могут включать джойстик, спутниковую тарелку, сканер и т.п.
[0053] Эти и другие устройства ввода часто подключаются к процессору вычислительной системы через интерфейс ввода данных пользователями, который соединен с системной шиной, но могут быть подключены с помощью другого интерфейса и структур шин, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор, дисплей или другой тип устройства-дисплея также подключены к системной шине через интерфейс, такой как видеоинтерфейс. В дополнение к дисплею вычислительная система также может включать другие выведенные периферийные устройства, такие как динамики и принтеры, которые могут быть подключены через интерфейс периферийных устройств вывода.
[0054] Корпус текстов, который должен быть проанализирован для генерации морфологических словарей, может быть собран из различных электронных источников, таких как книги, статьи, Интернет-ресурсы, архивы, документы, руководства, глоссарии, тезаурусы, словари и любые другие источники и т.д. Как другой пример, корпус текстов может быть получен после того, как он распознан из файлов графического вида (например, из PDF, TIF, JPG, BMP и других файлов) посредством оптического распознавания (OCR), после того, как они были отправлены факсом или просканированы с помощью сканера и т.д., или после преобразования из изображений в корпус текстов после оптического распознавания с помощью приложений оптического распознавания символов (OCR). Текстовый корпус, который должен быть проанализирован, может храниться на компьютере, LAN или в распределенной сети.
[0055] Вычислительная система может работать в распределенной сетевой среде, используя логическое соединение с одним или более удаленными компьютерами. Удаленный компьютер может являться персональным компьютером, переносным устройством, сервером, маршрутизатором, сетевым ПК или другим обычным узлом сети и обычно включает многих или все связанные с системой элементы, описанные выше. Сетевое соединение может включать, например, локальную сеть (LAN) или глобальную вычислительную сеть (WAN), такую как Интернет. Такие сетевые среды обычно используются в офисах, корпоративных компьютерных сетях, в интранет и интернет. При использовании в подключающей к локальной сети среде система подключена к локальной сети через сетевые интерфейс или адаптер. Когда она используется в среде подключения к WAN, система может дополнительно включать модем или другие средства для установления соединения с WAN, такие как интернет. Описанное сетевое соединение типично, и могут использоваться другие средства установления связи между системами и компьютерами.
[0056] Приложение для генерации морфологических словарей может включать память или/и базу данных для хранения различной промежуточной информации. Приложение генерации морфологических словарей может включать первоначальное морфологическое описание для данного языка и анализатор корпуса текстов, который пригоден для того, чтобы выполнять все этапы метода, как описано здесь. Кроме того, приложение генерации морфологических словарей также может включить пользовательский интерфейс для входных данных/выходных данных и базу данных для хранения различных лингвистических описаний и промежуточной информации, например морфологических описаний, рейтингов, парадигм, правил, окончаний, слов и т.д.
[0057] Приложение генерации морфологических словарей также может взаимодействовать с программным интерфейсом, другими приложениями и/или пользовательским интерфейсом, чтобы, соответственно, взаимодействовать с другими программами и пользователем. Например, приложение генерации морфологического словаря может получить корпус текстов от приложения распознавания речи после того, как оно преобразовало звуковые файлы в корпус текстов после распознавания речи. Как другой пример, предложение языка может быть получено от приложения распознавания символов (OCR) после преобразования из изображений текстов в корпус текстов после оптического распознавания изображения.
[0058] Морфологические словари были созданы для различных языковых семей, включая индоевропейские (славянские, германские и романские) языки, финно-угорские, тюркские, восточные и семитские. Воплощения изобретения могут быть применены к многим языкам, включая английский, французский, немецкий, итальянский, русский, испанский, украинский, голландский, датский, шведский, финский, португальский, словацкий, польский, чешский, венгерский, литовский, латвийский, эстонский, греческий, болгарский, турецкий, татарский, хинди, сербский, хорватский, румынский, словенский, македонский, японский, корейский, аравийский, иврит и суахили в том числе, но не ограничиваясь ими.
[0059] В то время как вышеупомянутое будет ориентировано на реализации настоящего изобретения, могут быть разработаны другие и дальнейшие реализации изобретения, не отклоняясь от его базовых возможностей, и его границы определены следующими утверждениями.
Автоматическое построение семантического описания целевого языка
Обнаружение языковой неоднозначности в тексте
Использование верифицированных пользователем данных для обучения моделей уверенности
Извлечение информации с использованием альтернативных вариантов семантико-синтаксического разбора
Сентиментный анализ на уровне аспектов с использованием методов машинного обучения
Способ улучшения качества распознавания отдельного кадра
Реконструкция документа из серии изображений документа
Распознавание символов с использованием искусственного интеллекта
Использование нескольких камер для выполнения оптического распознавания символов
Исчерпывающая автоматическая обработка текстовой информации
Автоматическое построение семантического описания целевого языка
Обнаружение языковой неоднозначности в тексте
Использование верифицированных пользователем данных для обучения моделей уверенности
Извлечение информации с использованием альтернативных вариантов семантико-синтаксического разбора
Исчерпывающая автоматическая обработка текстовой информации

