Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ПОСТРОЕНИЯ БАЗЫ ЗНАНИЙ
Вид РИД
Изобретение
В настоящей заявке испрашивается приоритет по заявке на патент Китая №201510515887.2, поданной 20 августа 2015 г., содержание которой в полном объеме включено в настоящий документ путем ссылки.
Область техники
Настоящее изобретение относится, в целом, к области искусственного интеллекта, в частности, к способу и устройству построения базы знаний.
Уровень техники
Распознавание именованных сущностей РИС (Named Entity Recognition, NER), также известное как «распознавание исключительных названий», относится к распознаванию в тексте сущностей, имеющих специфическое значение, к которым, главным образом, относятся имена людей, географические названия, наименования организаций, исключительные существительные и т.д.
Пищевая ценность продуктов представляет собой особую именованную сущность, которая включает в себя название и содержание питательных веществ, например, «углевод», «20 граммов».
В настоящее время информация о пищевой ценности продуктов обычно предоставляется на форумах, в комментариях, блогах, новостях и энциклопедиях, причем данная информация важна для построения базы знаний о пищевой ценности продуктов. Однако, если анализ знаний осуществляется с помощью человеческих ресурсов, то данный процесс требует значительных человеческих ресурсов и построение базы знаний происходит медленно.
Раскрытие изобретения
В настоящем изобретении предложены способ и устройство построения базы знаний, которые направлены на устранение проблем, связанных с тратой человеческих ресурсов и низкой скоростью в случае построения базы знаний с помощью человеческих ресурсов.
В соответствии с первым аспектом в настоящем изобретении предложен способ построения базы знаний, содержащий следующие этапы: получают текстовые корпусы и определяют, содержат ли текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств, причем указанная первая информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей, извлекают первую информацию, если определено, что первая информация содержится в указанных текстовых корпусах, и выполняют построение базы знаний на основе первой информации и сущности, соответствующей указанной первой информации.
В одном из предпочтительных вариантов осуществления настоящего изобретения предварительно заданный шаблон описания свойств содержит словари, шаблоны предложений или любую их комбинацию для определения того, содержат ли текстовые корпусы первую информацию, причем этап, на котором определяют, содержат ли текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств, предусматривает: отбор из текстовых корпусов первого набора предложений, содержащего сущности в предварительно заданном наборе сущностей, согласно алгоритму распознавания именованных сущностей, получение первой потенциальной информации из указанного первого набора предложений согласно словарям, шаблонам предложений или их комбинации в предварительно заданном шаблоне описания свойств, причем указанная первая потенциальная информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей, вычисление числа вхождения первой потенциальной информации и определение указанной первой потенциальной информации в качестве первой информации, если число вхождения превышает предварительно заданное пороговое значение.
В еще одном предпочтительном варианте осуществления настоящего изобретении предварительно заданный шаблон описания свойств содержит словари, шаблоны предложений или любую их комбинацию для определения того, содержат ли текстовые корпусы первую информацию, причем этап, на котором определяют, содержат ли текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств, предусматривает: отбор из текстовых корпусов первого набора предложений, содержащего сущности в предварительно заданном наборе сущностей, согласно алгоритму распознавания именованных сущностей, получение совокупности первой потенциальной информации из указанного первого набора предложений согласно предварительно заданному шаблону описания свойств, причем указанная совокупность первой потенциальной информации содержит информацию о свойстве сущностей, объединение сущностей, содержащихся в указанном первом наборе предложений, и соответствующей совокупности первой потенциальной информации в набор двухэлементных кортежей, и вычисление числа вхождения каждой первой потенциальной информации, удаление двухэлементных кортежей, в которых имеется первая потенциальная информация с числом вхождения, меньшим предварительно заданного порогового значения, и определение элементов, содержащихся в текущем наборе двухэлементных кортежей, в качестве первой информации.
В другом предпочтительном варианте осуществления настоящего изобретения указанный способ дополнительно содержит этапы, на которых определяют, содержат ли текстовые корпусы вторую информацию в соответствии с предварительно заданным шаблоном описания свойств и первой информацией, причем указанная вторая информация содержит информацию о свойстве первой информации, извлекают вторую информацию, если определено, что она содержится в текстовых корпусах, и обновляют базу знаний на основе первой информации, второй информации и сущности, соответствующей указанной первой информации.
В другом предпочтительном варианте осуществления настоящего изобретения этап, на котором определяют, содержат ли текстовые корпусы вторую информацию в соответствии с предварительно заданным шаблоном описания свойств и первой информацией, предусматривает: получение из текстовых корпусов второго набора предложений, содержащего первую информацию в соответствии с предварительно заданным шаблоном описания свойств, и, если указанный второй набор предложений содержит числовую сущность, извлечение указанной числовой сущности в качестве второй потенциальной информации, объединение сущности, первой информации и второй информации в набор триплетов, и для каждой первой информации каждой сущности в текущем наборе триплетов, вычисление числа вхождения каждой соответствующей второй потенциальной информации, и определение второй потенциальной информации, число вхождения которой является наибольшим, в качестве второй информации текущей первой информации текущей сущности.
В еще одном варианте осуществления настоящего изобретения предварительно заданный шаблон описания свойств содержит один или несколько из следующих шаблонов: содержание *, <содержат | содержит> <#ЧИСЛО> грамм *, * <содержится | входит в состав | содержится в большом количестве> <в | внутри> *, где «*» представляет собой знак подстановки для согласования с любой строкой, «|» представляет собой символ, обозначающий «или», «<#ЧИСЛО>» представляет собой символ для согласования с числовой строкой, а знаки «<» и «>» встречаются в паре для того, чтобы охватить множество синонимов.
Согласно второму аспекту в настоящем изобретении предложено устройство построения базы знаний, причем указанное устройство содержит: получающий и определяющий модуль, выполненный с возможностью получения текстовых корпусов и определения того, содержат ли текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств, причем указанная первая информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей, и первый определяющий, извлекающий и добавляющий модуль, выполненный с возможностью извлечения первой информации, если определено, что первая информация содержится в указанных текстовых корпусах, и построения базы знаний на основе первой информации и сущности, соответствующей указанной первой информации.
В одном из предпочтительных вариантов осуществления настоящего изобретения предварительно заданный шаблон описания свойств содержит словари, шаблоны предложений или любую их комбинацию для определения того, содержат ли текстовые корпусы первую информацию, причем указанный получающий и определяющий модуль содержит отборочный подмодуль, выполненный с возможностью отбора из текстовых корпусов первого набора предложений, содержащего сущности в предварительно заданном наборе сущностей, согласно алгоритму распознавания именованных сущностей, получающий подмодуль, выполненный с возможностью получения первой потенциальной информации из указанного первого набора предложений согласно словарям, шаблонам предложений и любой их комбинации в предварительно заданном шаблоне описания свойств, причем указанная первая потенциальная информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей, и вычислительный и определяющий подмодуль, выполненный с возможностью вычисления числа вхождения первой потенциальной информации и определения указанной первой потенциальной информации в качестве первой информации, если число вхождения превышает предварительно заданное пороговое значение.
В другом варианте осуществления настоящего изобретения предварительно заданный шаблон описания свойств содержит словари, шаблоны предложений или любую их комбинацию для определения того, содержат ли текстовые корпусы первую информацию, причем указанный получающий и определяющий модуль содержит отборочный подмодуль, выполненный с возможностью отбора из текстовых корпусов первого набора предложений, содержащего сущности в предварительно заданном наборе сущностей, согласно алгоритму распознавания именованных сущностей, получающий подмодуль, выполненный с возможностью получения первой потенциальной информации из указанного первого набора предложений согласно словарям, шаблонам предложений и их комбинации в предварительно заданном шаблоне описания свойств, причем указанная первая потенциальная информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей, и вычислительный и определяющий подмодуль, выполненный с возможностью вычисления числа вхождения первой потенциальной информации и определения указанной первой потенциальной информации в качестве первой информации, если число вхождения превышает предварительно заданное пороговое значение.
В одном из вариантов осуществления настоящего изобретения указанное устройство дополнительно содержит определяющий модуль, выполненный с возможностью определения того, содержат ли текстовые корпусы вторую информацию в соответствии с предварительно заданным шаблоном описания свойств и первой информацией, причем указанная вторая информация содержит информацию о свойстве первой информации, и второй определяющий, извлекающий и добавляющий модуль, выполненный с возможностью извлечения второй информации, если определено, что она содержится в текстовых корпусах, и обновления базы знаний на основе первой информации, второй информации и сущности, соответствующей указанной первой информации.
В другом предпочтительном варианте осуществления настоящего изобретения указанный определяющий модуль содержит получающий подмодуль, выполненный с возможностью получения из текстовых корпусов второго набора предложений, содержащего первую информацию в соответствии с предварительно заданным шаблоном описания свойств, извлекающий подмодуль, выполненный с возможностью извлечения числовой сущности в качестве второй потенциальной информации, если указанный второй набор предложений содержит числовую сущность, объединяющий подмодуль, выполненный с возможностью объединения сущности, первой информации и второй информации в набор триплетов, и вычислительный и определяющий подмодуль, выполненный с возможностью, для каждой первой информации каждой сущности в текущем наборе триплетов, вычисления числа вхождения каждой соответствующей второй потенциальной информации, и определения второй потенциальной информации, число вхождения которой является наибольшим, в качестве второй информации текущей первой информации текущей сущности.
В еще одном варианте осуществления настоящего изобретения предварительно заданный шаблон описания свойств содержит один или несколько из следующих шаблонов: содержание *, <содержат | содержит> <#ЧИСЛО> грамм *, * <содержится | входит в состав | содержится в большом количестве> <в | внутри> *, где «*» представляет собой знак подстановки для согласования с любой строкой, «|» представляет собой символ, обозначающий «или», «<#ЧИСЛО>» представляет собой символ для согласования с числовой строкой, а знаки «<» и «>» встречаются в паре для того, чтобы охватить множество синонимов.
Согласно третьему аспекту в настоящем изобретении предложено устройство построения базы знаний, причем указанное устройство содержит процессор и память, предназначенную для хранения инструкций, исполняемых процессором, причем указанный процессор выполнен с возможностью:
получения текстовых корпусов и определения того, содержат ли текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств, причем указанная первая информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей, и извлечения первой информации, если определено, что первая информация содержится в указанных текстовых корпусах, и построения базы знаний на основе первой информации и сущности, соответствующей указанной первой информации.
Технические решения, раскрытые в настоящем изобретении, имеют следующие преимущества: база знаний может быть построена автоматически за счет получения текстовых корпусов, извлечения первой информации, если определено, что текстовые корпусы содержат первую информацию, и построения базы знаний согласно первой информации и соответствующей сущности. При этом отсутствует необходимость в том, чтобы процесс анализа знаний осуществлялся с помощью человеческих ресурсов, в результате чего удается сэкономить человеческие ресурсы и повысить скорость построения базы знаний.
Настоящее изобретение позволяет эффективно удалять вещества, которые не относятся к питательным веществам пищевых продуктов, за счет вычисления числа вхождения полученной первой потенциальной информации и определения первой потенциальной информации, число вхождения которой превышает предварительно заданное пороговое значение, в качестве первой информации (то есть, первая потенциальная информация с небольшим числом вхождения удаляется). Таким образом, точность базы знаний повышается.
Связь между сущностями и первой информацией поясняется тем, что она представлена в виде двухэлементных кортежей. Таким образом, первую информацию, соответствующую неверной сущности, можно легко удалить.
Если определено, что вторая информация, например, информация о содержании питательных веществ пищевого продукта, содержится в текстовых корпусах, то указанную вторую информацию можно извлечь из текстовых корпусов, а базу знаний обновить в соответствии с первой информацией, второй информацией и сущностью, соответствующей указанной первой информации, в результате чего база знаний улучшается.
Связь между сущностями, первой информацией и второй информацией может быть пояснена за счет того, что она представлена в виде триплетов, благодаря чему вторую информацию, соответствующую первой информации, можно легко получить, например, можно легко получить информацию о содержании питательных веществ пищевого продукта. Таким образом, точность второй информации повышается, и точность базы знаний, в свою очередь, также улучшается. Многочисленный состав предварительно заданного шаблона описания свойств предусмотрен для того, чтобы облегчить последующий отбор первой информации из текстовых корпусов.
Следует понимать, что и представленный выше раздел описания «Раскрытие изобретения», и нижеследующий подробный раздел описания «Осуществление изобретения» приведены лишь в качестве примера, при этом они не ограничивают настоящее изобретение.
Краткое описание чертежей
Прилагаемые чертежи, включенные в состав описания и образующие его часть, иллюстрируют предпочтительные варианты осуществления настоящего изобретения и совместно с настоящим описанием служат для пояснения принципов настоящего изобретения.
На фиг. 1 показана блок-схема, иллюстрирующая способ построения базы знаний согласно одному из предпочтительных вариантов осуществления настоящего изобретения.
На фиг. 2 показана блок-схема, иллюстрирующая способ построения базы знаний согласно другому предпочтительному варианту осуществления настоящего изобретения.
На фиг. 3 схематично проиллюстрирован сценарий применения способа построения базы знаний согласно оному из предпочтительных вариантов осуществления настоящего изобретения.
На фиг. 4 показана блок-схема, иллюстрирующая способ определения того, содержат ли текстовые корпусы первую информацию, согласно одному из предпочтительных вариантов осуществления настоящего изобретения.
На фиг. 5 показана блок-схема, иллюстрирующая способ определения того, содержат ли текстовые корпусы первую информацию, согласно другому предпочтительному варианту осуществления настоящего изобретения.
На фиг. 6 показана блок-схема, иллюстрирующая способ определения того, содержат ли текстовые корпусы вторую информацию, согласно одному из предпочтительных вариантов осуществления настоящего изобретения.
На фиг. 7 схематично показано устройство построения базы знаний согласно одному из предпочтительных вариантов осуществления настоящего изобретения.
На фиг. 8 схематично показано устройство построения базы знаний согласно другому предпочтительному варианту осуществления настоящего изобретения.
На фиг. 9 схематично показано устройство построения базы знаний согласно еще одному предпочтительному варианту осуществления настоящего изобретения.
На фиг. 10 схематично показано устройство построения базы знаний согласно другому предпочтительному варианту осуществления настоящего изобретения.
На фиг. 11 схематично показано устройство построения базы знаний согласно еще одному предпочтительному варианту осуществления настоящего изобретения.
На фиг. 12 схематично показано устройство построения базы знаний согласно одному из предпочтительных вариантов осуществления настоящего изобретения.
Осуществление изобретения
Далее, приведено подробное описание предпочтительных вариантов осуществления настоящего изобретения, примеры которых проиллюстрированы на прилагаемых чертежах. Нижеследующее описание относится к прилагаемым чертежам, на которых одни и те же номера позиций на разных чертежах обозначают одинаковые или схожие элементы, если не указано иное. Реализации настоящего изобретения, изложенные в нижеследующем описании предпочтительных вариантов, не отражают все возможные реализации, предусмотренные настоящим изобретением. Наоборот, они представляют собой лишь примеры устройств и способов, соответствующих аспектам настоящего изобретения, заявленным в прилагаемой формуле изобретения.
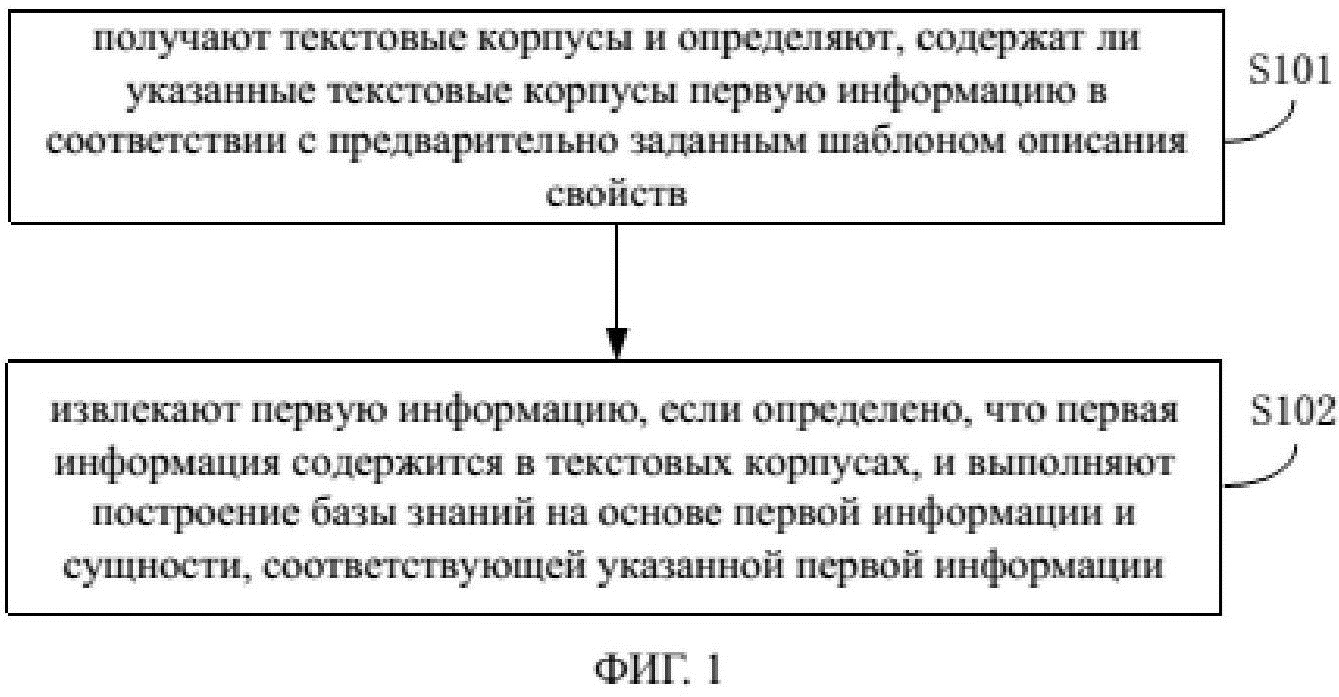
На фиг. 1 показана блок-схема, иллюстрирующая способ построения базы знаний согласно одному из предпочтительных вариантов осуществления настоящего изобретения. Как показано на фиг. 1, способ построения базы знаний может быть применен в отношении сервера. При этом способ содержит этапы S101 – S102.
На этапе S101 получают текстовые корпусы и определяют, содержат ли указанные текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств.
В рассматриваемом варианте указанный предварительно заданный шаблон описания свойств содержит словари, шаблоны предложений или любую их комбинацию для определения того, содержат ли текстовые корпусы первую информацию, при этом первая информация может содержать информацию о свойстве сущностей в предварительно заданном наборе сущностей.
В одном из вариантов осуществления настоящего изобретения указанные сущности в предварительно заданном наборе сущностей могут относится, помимо прочего, к пищевым продуктам, воздуху, спорту и т.д., причем информация о свойстве пищевого продукта может представлять собой информацию о питательных веществах, информация о свойстве воздуха может представлять собой информацию о его компонентах, информация о свойстве спорта может представлять собой информацию о затратах энергии в час и т.д. Как видно из вышеизложенного, первая информация может, помимо прочего, относится к питательным веществам пищевого продукта.
В одном из предпочтительных вариантов осуществления настоящего изобретения, согласно которому сущность представляет собой пищевой продукт и обеспечивают построение базы знаний о пищевой ценности продукта, предварительно заданный шаблон описания свойств может содержать, помимо прочего, один или несколько из следующих шаблонов:
содержание * (например, содержание сахара), «содержат | содержит> <#ЧИСЛО> грамм * (например, содержит 20 грамм углеводов), * <содержится | входит в состав | содержится в большом количестве> <в | внутри> * (например, витамин С содержится в большом количестве в киви). Например, «*» представляет собой знак подстановки для согласования с любой строкой, а «|» представляет собой символ, обозначающий «или», «<#ЧИСЛО>» представляет собой символ для согласования с числовой строкой, причем знаки «<» и «>» встречаются в паре для того, чтобы охватить множество синонимов. Например, «<содержит | содержат> <#ЧИСЛО> грамм *» обозначает, что «содержит <#ЧИСЛО> грамм *» или «содержат <#ЧИСЛО> грамм *».
В рассматриваемом варианте сервер может просматривать текстовые корпусы посредством поискового робота и определять, содержат ли текстовые корпусы информацию о питательных веществах пищевого продукта в соответствии с предварительно заданным шаблоном описания свойств.
На этапе S102 извлекают первую информацию, если определено, что она содержится в текстовых корпусах, и выполняют построение базы знаний на основе первой информации и соответствующей сущности.
В рассматриваемом варианте, если определено, что текстовые корпусы содержат информацию о питательных веществах пищевого продукта, то можно извлечь указанную информацию о питательных веществах и сохранить ее в базе данных в сочетании с соответствующим пищевым продуктом.
В раскрытом выше варианте осуществления способа построения базы знаний, база знаний может быть построена автоматически путем получения текстовых корпусов, извлечения первой информации, если определено, что текстовые корпусы содержат первую информацию, и построения базы знаний согласно первой информации и соответствующей сущности. При этом отсутствует необходимость в том, чтобы процесс анализа знаний осуществлялся с помощью человеческих ресурсов, в результате чего удается сэкономить человеческие ресурсы и повысить скорость построения базы знаний.
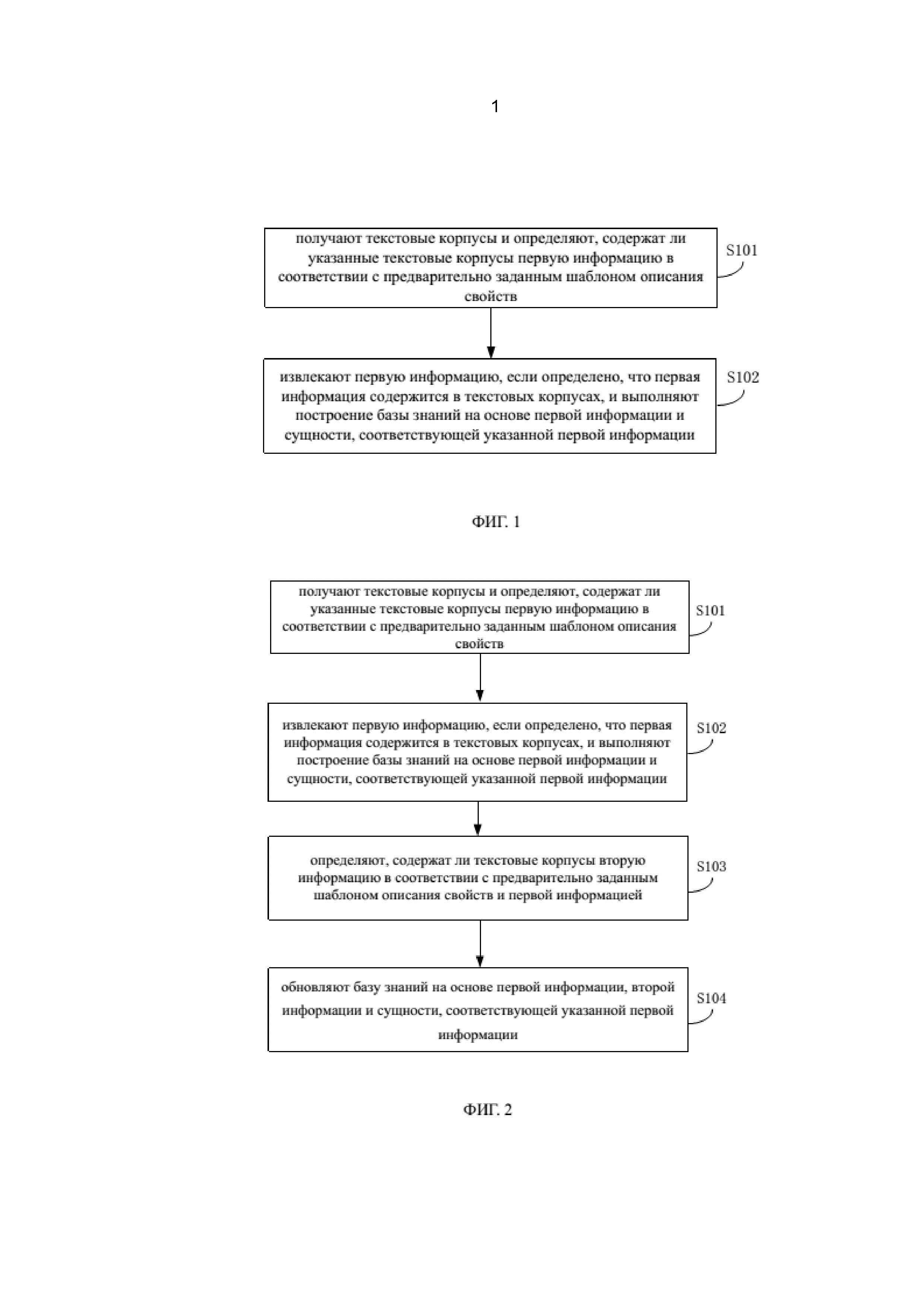
На фиг. 2 показана блок-схема, иллюстрирующая способ построения базы знаний согласно другому предпочтительному варианту осуществления настоящего изобретения. Как показано на фиг. 2 после этапа S102 могут быть предусмотрены этапы S103 – S104.
На этапе S103 определяют, содержат ли текстовые корпусы вторую информацию в соответствии с предварительно заданным шаблоном описания свойств и первой информацией.
При этом вторая информация содержит свойство первой информации. Например, если первая информация относится к питательным веществам пищевого продукта, то свойство первой информации может представлять собой содержание указанных питательных веществ, то есть, вторая информация может представлять собой содержание питательных веществ.
В рассматриваемом варианте, можно определить, содержат ли текстовые корпусы информацию о содержании питательных веществ пищевого продукта в соответствии с указанным выше предварительно заданным шаблоном описания свойств и указанными питательными веществами.
На этапе S104 извлекают вторую информацию, если определено, что она содержится в текстовых корпусах и обновляют базу знаний на основе первой информации, второй информации и сущности, соответствующей указанной первой информации.
В рассматриваемом варианте, если определено, что текстовые корпусы содержат вторую информацию, например, информацию о содержание питательных веществ пищевого продукта, то вторую информацию можно извлечь из текстовых корпусов и выполнить построение базы знаний согласно первой информации, второй информации и сущности, соответствующей первой информации, тем самым, обеспечивая завершение процесса построения базы знаний.
В рассматриваемом варианте осуществления способа построения базы знаний, вторую информацию извлекают, если определено, что она содержится в текстовых корпусах, причем построение базы знаний выполняют в соответствии с первой информацией, второй информацией и сущностью, соответствующей первой информации, что улучшает процесс построения базы знаний.
В качестве примера рассмотрим построение базы знаний о питательных веществах пищевого продукта, при этом ниже приведено описание данного процесса со ссылкой на фиг. 3.
Как показано на фиг. 3, устройство 31 может просматривать текстовые корпусы на Web-странице посредством поискового робота. В рассматриваемом варианте, указанное устройство 31 может представлять собой такое устройство, как сервер, персональный компьютер и т.д., при этом настоящее изобретение этим не ограничивается. В одном из вариантов осуществления настоящего изобретения, сервер 32 может представлять собой сервер Wiki, Baidu, Sina, or Neteasy и т.д. Указанное устройство 31 получает текстовые корпусы, содержащие название пищевого продукта в соответствии с алгоритмом РИС (NER). При этом определяют, содержат ли полученные текстовые корпусы информацию о питательных веществах пищевого продукта в соответствии с предварительно заданным шаблоном описания свойств. Если информация о питательных веществах пищевого продукта содержится в текстовых корпусах, то ее извлекают, причем построение базы знаний о питательных веществах пищевого продукта выполняют согласно названию пищевого продукта и соответствующим питательным веществам. Устройство 31 может также определять, содержат ли текстовые корпусы информацию о содержании питательных веществ в пищевом продукте в соответствии с предварительно заданным шаблоном описания свойств и питательными веществами пищевого продукта. Информацию о питательных веществ пищевого продукта извлекают, если она содержится в текстовых корпусах, и добавляют соответствующим образом в базу знаний для построения базы знаний о пищевой ценности продукта.
На фиг. 4 представлена блок-схема, иллюстрирующая способ определения того, содержат ли текстовые корпусы первую информацию, согласно одному из предпочтительных вариантов осуществления настоящего изобретения.
На этапе S401 из текстовых корпусов в соответствии с алгоритмом РИС (NER) отбирают первый набор предложений, содержащий сущности предварительно заданного набора сущностей.
В одном из вариантов осуществления настоящего изобретения, алгоритм РИС (NER) может содержать, помимо прочего, метод условных случайных полей УСП (Conditional Random Field, CRF), метод словарей и гибридный метод. Предварительно заданный набор сущностей может представлять собой, например, набор сущностей, относящихся к пищевому продукту, набор сущностей, относящихся к воздуху, набор сущностей, относящихся к спорту.
В качестве примера предварительно заданного набора сущностей рассмотрим набор сущностей, относящихся к пищевому продукту. Первый набор предложений, содержащий информацию о пищевом продукте, можно отобрать из текстовых корпусов на основе метода УСП (CRF). В рассматриваемом варианте, первый набор предложений, содержащий информацию о пищевом продукте, можно также отобрать на основе алгоритма распознавания ключевых слов и т.д.
На этапе S402 из первого набора предложений получают первую потенциальную информацию в соответствии со словарем, шаблоном предложений или их комбинацией в предварительно заданном шаблоне описания свойств, причем первая потенциальная информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей.
При этом предварительно заданный шаблон описания свойств может представлять собой лексико-синтактический шаблон. Лексико-синтактические шаблоны содержат один или несколько из следующих шаблонов: содержание * (например, содержание сахара), <содержат | содержит> <#ЧИСЛО> грамм * (например, содержит 20 грамм углеводов), * <содержится | входит в состав | содержится в большом количестве> <в | внутри> * (например, витамин С содержится в большом количестве в киви).
После отбора первого набора предложений, содержащего информацию о пищевом продукте, можно извлечь из указанного первого набора предложений потенциальные питательные вещества в соответствии с предварительно заданным шаблоном описания свойств. Например, потенциальными питательными веществами, полученными из помидоров, являются каротин, витамин С, натрий и кальций; потенциальными питательными веществами, полученными из моркови, являются каротин, витамин С, натрий и сахар; потенциальными питательными веществами, полученными из говядины, являются калий, фосфор, натрий, кальций, камень, и т.д.
На этапе S403 вычисляют число вхождения первой потенциальной информации и, если указанное число вхождения первой потенциальной информации превышает предварительно заданное пороговое значение, то первую потенциальную информацию определяют в качестве первой информации.
Предварительно заданное пороговое значение можно при необходимости легко менять. В одном из предпочтительных вариантов осуществления настоящего изобретения предварительно заданное пороговое значение может быть от 1 до 10, причем настоящее изобретение этим не ограничивается. Предварительно заданное пороговое значение может также быть больше 10 в зависимости от конкретной ситуации.
В рассматриваемом варианте, предположим, что предварительно заданное пороговое значение составляет 2, если число вхождения камня равно 1, а число вхождения каждого из остальных потенциальных питательных веществ превышает 1, то после вычисления числа вхождения каждого потенциального питательного вещества, остальные потенциальные питательные вещества определяют в качестве питательных веществ. Таким образом, вещество, не относящееся к питательным веществам пищевого продукта, эффективно удаляется.
Настоящее изобретение не ограничивается указанным выше описанием, и этап S403 может также предусматривать:
вычисление числа вхождения первой потенциальной информации, и, если число вхождения первой потенциальной информации меньше предварительно заданного порогового значения, то указанную первую потенциальную информацию не определяют в качестве первой информации, в противном случае первую потенциальную информацию определяют в качестве первой информации.
В рассматриваемом варианте, предварительно заданное пороговое значение можно выбрать равным 10, но настоящее изобретение этим не ограничивается. Предварительно заданное пороговое значение можно выбрать большим или меньшим 10 в зависимости от конкретной ситуации.
В рассмотренном варианте, если число вхождения камня равно 1, а число вхождения каждого из остальных потенциальных питательных веществ больше 10, то после вычисления числа вхождения каждого из потенциальных питательных веществ, остальные потенциальные питательные вещества определяют в качестве питательных веществ, а камень не определяют в качестве питательного вещества. Таким образом, вещество, не относящееся к питательным веществам пищевого продукта, эффективно удаляется.
Как видно из вышеизложенного, определить то, содержат ли текстовые корпусы первую информацию, можно посредством раскрытого выше способа.
В раскрытом выше варианте, вычисляют число вхождения полученной первой потенциальной информации, и первую потенциальную информацию, число вхождения которой превышает предварительно заданное пороговое значение, определяют в качестве первой информации, то есть, первую потенциальную информацию, число вхождения которой мало, удаляют. Таким образом, вещество, не относящееся к питательным веществам, эффективно удаляют, а точность базы знаний повышается.
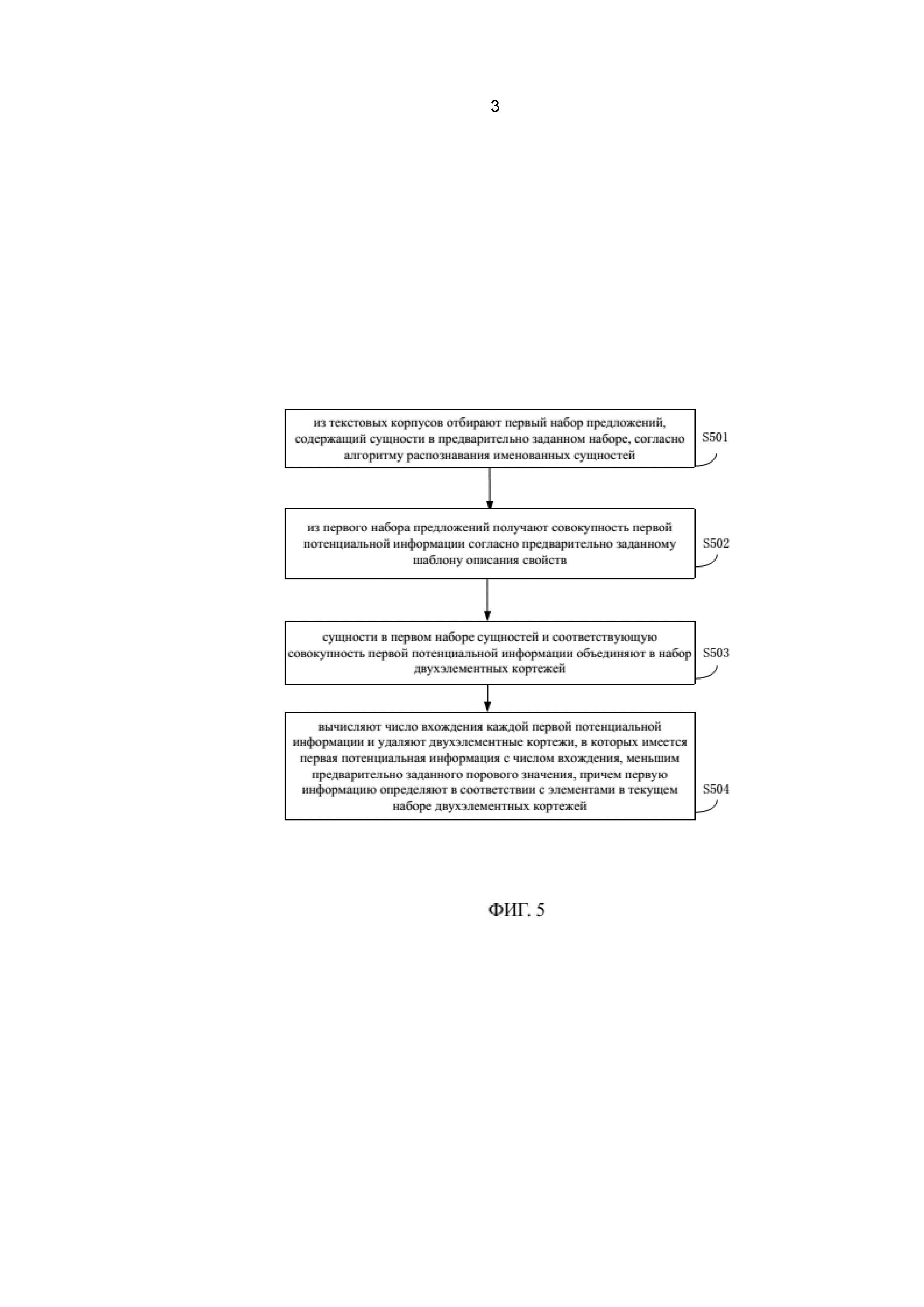
На фиг. 5 показана блок-схема, иллюстрирующая способ определения того, содержат ли текстовые корпусы первую информацию, согласно другому предпочтительному варианту осуществления настоящего изобретения. Как видно на фиг. 5, указанный способ содержит следующие этапы.
На этапе S501 из текстовых корпусов отбирают первый набор предложений, содержащий сущности в предварительно заданном наборе, согласно алгоритму РИС (NER).
На этапе S502 из первого набора предложений получают совокупность первой потенциальной информации согласно предварительно заданному шаблону описания свойств, причем первая потенциальная информация содержит информацию о свойстве сущностей.
На этапе S503 сущности в первом наборе сущностей и соответствующую совокупность первой потенциальной информации объединяют в набор двухэлементных кортежей.
Предположим, что предварительно заданный набор сущностей представляет собой набор сущностей Е пищевых продуктов, при этом набор предложений, содержащий сущности Е, можно отобрать из текстовых корпусов, причем согласованная сущность представляет собой Ei. Из контекста в предложении, посредством лексико-синтактического шаблона получают потенциальные питательные вещества NC и объединяют их в набор двухэлементных кортежей Т. Каждый элемент в наборе двухэлементных кортежей T имеет вид (Ei, NCij), причем потенциальные питательные вещества, соответствующие Ei, представляют собой {NCi1,NCi2… NCin}.
На этапе S504 вычисляют число вхождения каждой первой потенциальной информации и удаляют двухэлементные кортежи, в которых имеется первая потенциальная информация с числом вхождения, меньшим предварительно заданного порового значения, причем первую информацию определяют в соответствии с элементами в текущем наборе двухэлементных кортежей.
Далее, вычисляют число вхождения каждого питательного вещества NCij и удаляют двухэлементные кортежи, в которых имеется первая потенциальная информация с числом вхождения, меньшим предварительно заданного порогового значения (например, 2), для формирования нового набора двухэлементных кортежей T, причем элементы, содержащиеся в текущем наборе двухэлементных кортежей, определяют в качестве первой информации.
В рассматриваемом варианте, связь между сущностями и первой информацией объясняется тем, что она представлена в виде двухэлементных кортежей, благодаря чему первую информацию, соответствующую неверным сущностям, можно легко удалить.
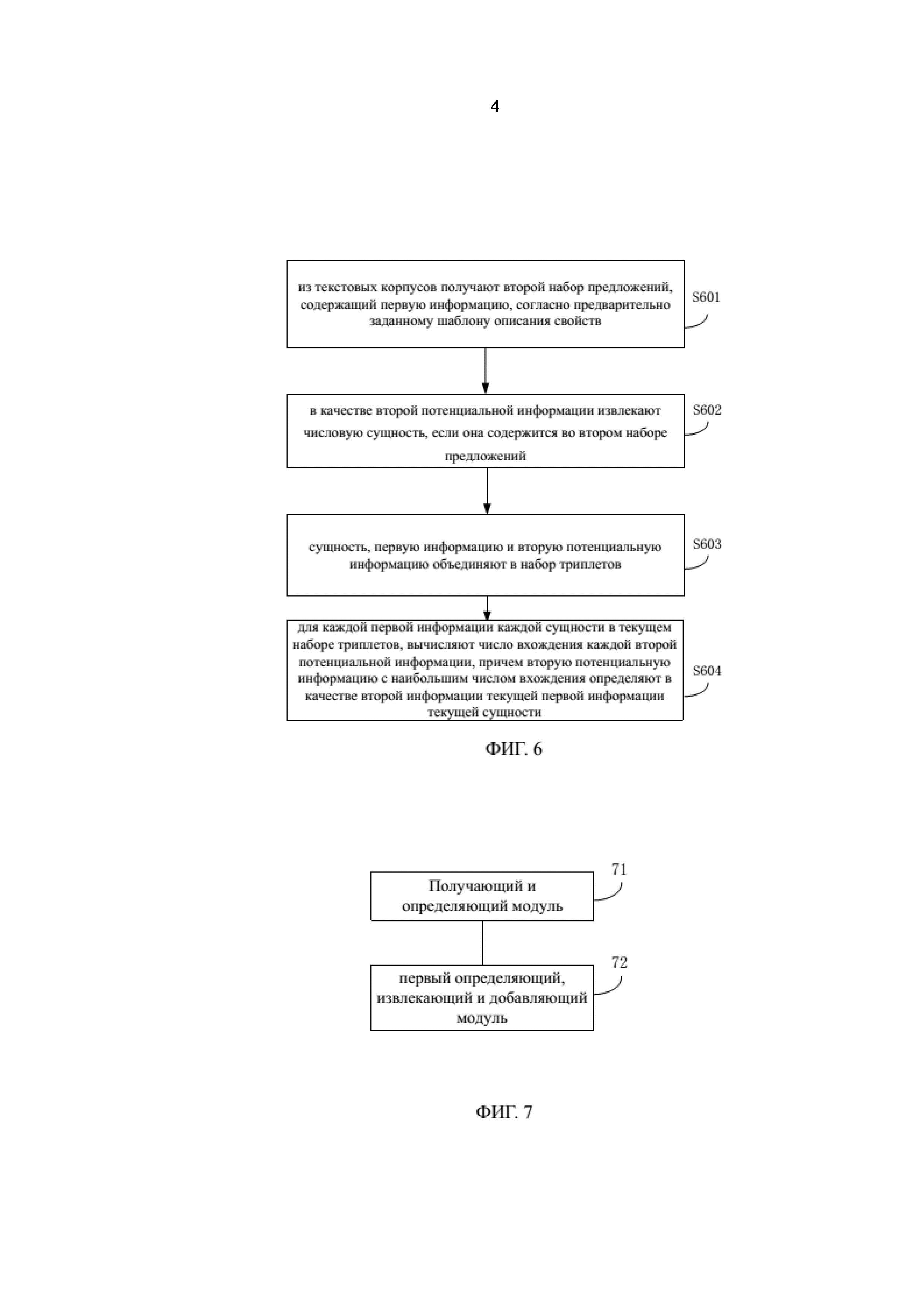
На фиг. 6 показана блок-схема, иллюстрирующая способ определения того, содержат ли текстовые корпусы вторую информацию, согласно одному из предпочтительных вариантов осуществления настоящего изобретения. Как показано на фиг. 6, указанный способ содержит следующие этапы.
На этапе S601 из текстовых корпусов получают второй набор предложений, содержащий первую информацию согласно предварительно заданному шаблону описания свойств.
В рассматриваемом варианте, второй набор предложения, содержащий информацию о питательных веществах пищевых продуктов, получают в соответствии лексико-синтактическим шаблоном.
Например, из текстовых корпусов можно отобрать набор предложений с Ei и NCij в контексте.
На этапе S602 в качестве второй потенциальной информации извлекают числовую сущность, если она содержится во втором наборе предложений.
Поскольку содержание питательного вещества, как правило, имеет числовое значение, например «80 грамм», «70%», числовую сущность можно извлечь из второго набора предложений для того, чтобы получить вторую потенциальную информацию.
Кроме того, содержание питательного вещества часто измеряют на 100 грамм продукта, например, «банан содержит большое количество питательных веществ; 20 грамм углеводов, 1,2 грамма белков, 0,6 грамма жиров содержится на 100 грамм продукта».
На этапе S603 сущность, первую информацию и вторую потенциальную информацию объединяют в набор триплетов.
На этапе S604, для каждой первой информации каждой сущности в текущем наборе триплетов вычисляют число вхождения каждой соответствующей второй потенциальной информации, причем вторую потенциальную информацию с наибольшим числом вхождения определяют в качестве второй информации текущей первой информации текущей сущности.
В рассматриваемом варианте, сущность, первую информацию и вторую потенциальную информацию можно объединить в набор триплетов. После этого, для каждой первой информации каждой сущности в текущем наборе триплетов вычисляют число вхождения каждой соответствующей второй потенциальной информации, причем вторую потенциальную информацию с наибольшим числом вхождения определяют в качестве второй информации текущей первой информации текущей сущности.
Например, после извлечения числовой сущности из второго набора предложений, можно сформировать набор триплетов Tr, при этом элементы в наборе имеют вид (Ei,NCij, Vijk), причем содержание потенциальных питательных веществ NCij, соответствующих Ei, имеет вид { Vij1,Vij2…Vijm}. После этого, для содержания Vijk каждого питательного вещества NCij каждой Ei вычисляют число, которое встречается в { Vij1,Vij2…Vijm}, при этом сохраняются только те триплеты, в которых число вхождения для Vijk является наибольшим, а все остальные Vijr удаляются из { Vij1,Vij2…Vijm}, то есть, все остальные Vijr удаляются из набора триплетов Tr, для формирования нового набора триплетов Tr. Потенциальное содержание, входящее в текущий Tr, определяют в качестве содержания соответствующего питательного вещества пищевого продукта.
Связь между сущностями, первой информацией и второй информацией объясняется тем, что она представлена в виде триплетов, благодаря чему вторую информацию, соответствующую первой информации, можно легко получить, например, можно легко получить информацию о содержании питательных веществ пищевого продукта.
Предположим, что число вхождения, извлеченное из текстовых корпусов «содержание витамина А в помидорах составляет 10 грамм», равняется 50, число вхождения «содержание витамина А в помидорах составляет 8 грамм» равняется 10, а число вхождения «содержание витамина А в помидорах составляет 1» равняется 3. Поскольку число 50 является наибольшим, содержание витамина А в помидорах составляет 10 грамм.
В раскрытом выше варианте, вычисляют число вхождения полученной второй потенциальной информации, при этом информацию с наибольшим числом вхождения определяют в качестве второй информации. Таким образом, точность второй информации повышается, что, в свою очередь, приводит к повышению точности базы знаний.
В настоящем описании также раскрыты предпочтительные варианты осуществления устройства построения базы знаний, соответствующие представленным выше предпочтительным вариантам осуществления способа построения базы знаний.
На фиг. 7 схематично показано устройство построения базы знаний согласно одному из предпочтительных вариантов осуществления настоящего изобретения. На фиг. 7 показано, что указанное устройство содержит получающий и определяющий модуль 71 и первый определяющий, извлекающий и добавляющий модуль 72.
Указанный получающий и определяющий модуль 71 выполнен с возможностью получения текстовых корпусов и определения того, содержат ли текстовые корпусы первую информацию в соответствии с предварительно заданным шаблоном описания свойств, причем первая информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей.
Указанный первый определяющий, извлекающий и добавляющий модуль 72 выполнен с возможностью извлечения первой информации, если определено, что первая информация содержится в текстовых корпусах, и построения базы знаний на основе первой информации и сущности, соответствующей первой информации.
Процесс построения базы знаний посредством устройства, показанного на фиг. 7, раскрыт в варианте осуществления способа, представленного на фиг. 1, поэтому его описание здесь опускают.
В раскрытом выше варианте осуществления устройства построения базы знаний текстовые корпусы получены посредством получающего и определяющего модуля, первая информация извлечена посредством первого определяющего, извлекающего и добавляющего модуля, если она содержится в текстовых корпусах, при этом база знаний построена в соответствии с первой информацией и соответствующими сущностями. Как следует из вышеизложенного, база знаний может быть построена автоматически, без необходимости осуществления анализа знаний с помощью человеческих ресурсов, что позволяет сэкономить человеческие ресурсы и повысить скорость построения базы знаний.
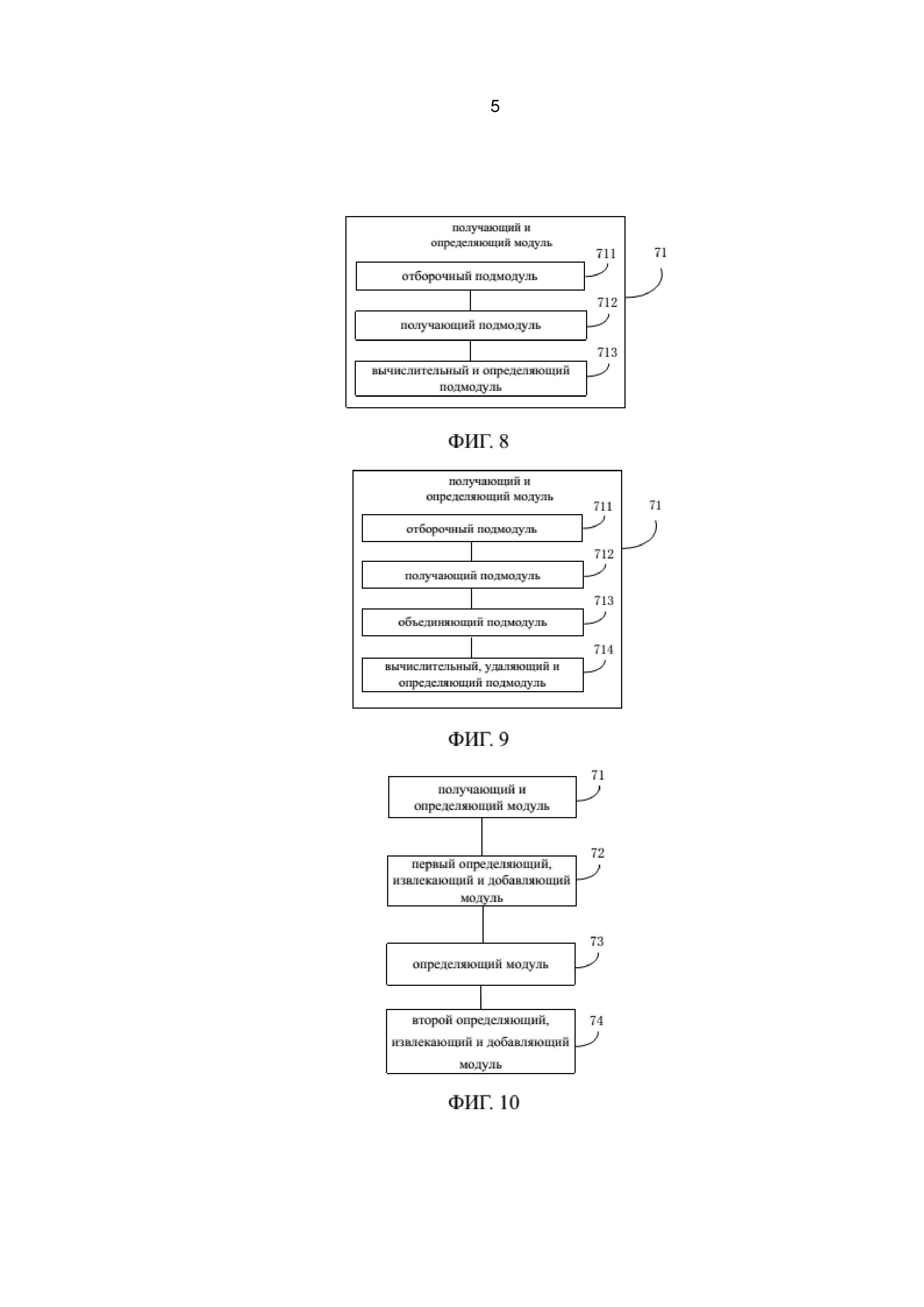
На фиг. 8 схематично показано устройство построения базы знаний согласно другому предпочтительному варианту осуществления настоящего изобретения. Устройство, проиллюстрированное на фиг. 8, основано на устройстве с фиг. 7, причем получающий и определяющий модуль 71 содержит отборочный подмодуль 711, получающий подмодуль 712 и вычислительный и определяющий подмодуль 713.
Указанный отборочный подмодуль 711 выполнен с возможностью отбора из текстовых корпусов первого набора предложений, содержащего сущности в предварительно заданном наборе, в соответствии с алгоритмом РИС (NER).
Получающий подмодуль 712 выполнен с возможностью получения первой потенциальной информации из первого набора предложений в соответствии со словарями, шаблонами предложений или их комбинации, в предварительно заданном шаблоне описания свойств, причем первая потенциальная информация содержит информацию о свойстве сущностей в предварительно заданном наборе сущностей.
Указанный вычислительный и определяющий подмодуль 713 выполнен с возможностью вычисления числа вхождения первой потенциальной информации и определения указанной первой потенциальной информации в качестве первой информации, если число вхождения превышает предварительно заданное пороговое значение.
Процесс построения базы знаний посредством устройства, показанного на фиг. 8, раскрыт в варианте осуществления способа, представленного на фиг. 2, поэтому его описание здесь опускают.
В рассмотренном выше варианте, число вхождения полученной первой потенциальной информации вычисляют посредством вычислительного и определяющего подмодуля, при этом первую потенциальную информацию определяют в качестве первой информации, если число вхождения превышает предварительно заданное пороговое значение, то есть первая потенциальная информация с небольшим числом вхождением удаляется. Таким образом, вещество, не относящееся к питательным веществам пищевого продукта, эффективно удаляется, а точность базы знаний повышается.
На фиг. 9 схематично показано устройство построения базы знаний согласно еще одному предпочтительному варианту осуществления настоящего изобретения. Устройство, проиллюстрированное на фиг. 9, основано на устройстве с фиг. 7, причем получающий и определяющий модуль 71 содержит отборочный подмодуль 711, получающий подмодуль 712, объединяющий подмодуль 713 и вычислительный, удаляющий и определяющий подмодуль 714.
Указанный отборочный подмодуль 711 выполнен с возможностью отбора из текстовых корпусов первого набора предложений, содержащего сущности в предварительно заданном наборе, в соответствии с алгоритмом РИС (NER).
Указанный получающий подмодуль 712 выполнен с возможностью получения совокупности первой потенциальной информации из первого набора предложений, обеспеченного фильтрующим подмодулем 711, в соответствии с предварительно заданным шаблоном описания свойств, причем первая потенциальная информация содержит информацию о свойстве сущностей.
Указанный объединяющий подмодуль 713 выполнен с возможностью объединения сущностей, содержащихся в первом наборе предложений, и соответствующей совокупности первой потенциальной информации в набор двухэлементных кортежей.
Указанный вычислительный, удаляющий и определяющий подмодуль 714 выполнен с возможностью вычисления числа вхождения каждой первой потенциальной информации, удаления двухэлементных кортежей, в которых имеется первая потенциальная информация с числом вхождения, меньшим предварительно заданного порового значения, и определения элементов, содержащихся в текущем наборе двухэлементных кортежей, в качестве первой информации.
При этом, предварительно заданный шаблон описания свойств содержит словари, шаблоны предложений или любую их комбинацию для определения того, содержат ли текстовые корпусы первую информацию.
Процесс построения базы знаний посредством устройства, показанного на фиг. 9, раскрыт в варианте осуществления способа, представленного на фиг. 5, поэтому его описание здесь опускают.
В рассмотренном выше варианте, связь между сущностями и первой информацией поясняется тем, что она представлена в виде двухэлементных кортежей, благодаря чему первую информацию, соответствующую неверным сущностям, можно легко удалить.
На фиг. 10 схематично показано устройство построения базы знаний согласно другому предпочтительному варианту осуществления настоящего изобретения. Устройство, проиллюстрированное на фиг. 10, основано на устройстве с фиг. 7, причем указанное устройство построения базы знаний также содержит определяющий модуль 73 и второй определяющий, извлекающий и добавляющий модуль 74.
Указанный определяющий модуль 73 выполнен с возможностью определения того, содержат ли текстовые корпусы вторую информацию в соответствии с предварительно заданным шаблоном описания свойств и первой информацией, причем вторая информация содержит информацию о свойстве первой информации.
Указанный второй определяющий, извлекающий и добавляющий модуль 74 выполнен с возможностью извлечения второй информации, если определено, что она содержится в текстовых корпусах, и обновления базы знаний на основе первой информации, второй информации и сущности, соответствующей первой информации.
Процесс построения базы знаний посредством устройства, показанного на фиг. 10, раскрыт в варианте осуществления способа, представленного на фиг. 2, поэтому его описание здесь опускают.
В рассматриваемом варианте осуществления устройства построения базы знаний, то, содержат ли текстовые корпусы вторую информацию, определяют посредством определяющего модуля, вторую информацию извлекают посредством второго определяющего, извлекающего и добавляющего модуля, если определено, что она содержится в текстовых корпусах, и выполняют построение базы знаний на основе первой информации, второй информации и сущностей, соответствующих первой информации. Таким образом, улучшается процесс построения базы знаний.
На фиг. 11 схематично показано устройство построения базы знаний согласно еще одному предпочтительному варианту осуществления настоящего изобретения. Устройство, проиллюстрированное на фиг. 11, основано на устройстве с фиг. 10, причем указанный определяющий модуль 73 содержит получающий подмодуль 731, извлекающий подмодуль 732, объединяющий подмодуль 733 и вычислительный и определяющий подмодуль 734.
Указанный получающий подмодуль 731 выполнен с возможностью получения из текстовых корпусов второго набора предложений, содержащего первую информацию в соответствии с предварительно заданным шаблоном описания свойств.
Указанный извлекающий подмодуль 732 выполнен с возможностью извлечения числовой сущности в качестве второй потенциальной информации, если второй набор предложений, полученный указанным получающим подмодулем 731, содержит числовую сущность.
Указанный объединяющий подмодуль 733 выполнен с возможностью объединения сущностей, первой информации и второй потенциальной информации, извлеченной посредством извлекающего подмодуля 723, в набор триплетов.
Указанный вычислительный и определяющий подмодуль 734 выполнен с возможностью, для каждой первой информации каждой сущности в текущем наборе триплетов, объединенных указанным объединяющим подмодулем 733, вычисления числа вхождения каждой соответствующей второй потенциальной информации и определения второй потенциальной информации, число вхождения которой является наибольшим, в качестве второй информации текущей первой информации текущей сущности.
Процесс построения базы знаний посредством устройства, показанного на фиг. 11, раскрыт в варианте осуществления способа, представленного на фиг. 6, поэтому его описание здесь опускают.
В рассматриваемом варианте, связь между сущностями, первой информацией и второй информацией поясняется тем, что она представлена в виде триплетов, благодаря чему можно легко обеспечить вторую информацию первой информации, соответствующей сущности.
Что касается раскрытых выше устройств, то конкретные действия и функциональные возможности отдельных модулей и подмодулей подробно описаны со ссылкой на соответствующие способы в раскрытых выше вариантах осуществления настоящего изобретения, и поэтому не будут подробно раскрыты здесь.
На фиг. 12 схематично показано устройство 1200 построения базы знаний согласно одному из предпочтительных вариантов осуществления настоящего изобретения. Например, указанное устройство 1200 может представлять собой сервер. Указанное устройство 1200 содержит обрабатывающий компонент 1222, который дополнительно может содержать один или несколько процессоров, и ресурс памяти, представленный в виде памяти 1232, используемой для хранения инструкций, исполняемых указанным обрабатывающим компонентом 1222, например, прикладных программ. Прикладные программы, хранящиеся в памяти 1232, содержат один или несколько модулей, каждый из которых соответствует набору инструкций. Кроме того, указанный обрабатывающий компонент 1222 может быть выполнен с возможностью исполнения наборов инструкций и реализации способа построения базы знаний.
Указанное устройство 1200 может также содержать источник 1226 электропитания, выполненный с возможностью реализации управления электропитанием устройства 1200, проводные и беспроводные сетевые интерфейсы 1250, выполненные с возможностью подсоединения указанного устройства 1200 к сети, и интерфейс 1258 ввода/вывода. Указанное устройство 1200 может функционировать на основе операционных систем, хранящихся в памяти 1232, например, систем Windows ServerTM, Mac OS XTM, UnixTM, LinuxTM, FreeBSDTM и т.д.
Другие предпочтительные варианты осуществления настоящего изобретения станут очевидными специалистам в данной области техники при изучении настоящего описания и при реализации на практике раскрытых в настоящем документе технических решений. Предполагается, что данная заявка охватывает любые вариации, варианты применения и модификации настоящего описания в соответствии с основными принципами настоящего изобретения и включает в себя такие отступления от настоящего описания, которые подпадают под известную или общепринятую практику в данной области техники. Предполагается, что описание и варианты, рассмотренные исключительно в качестве примерных, в истинном объеме изложены в прилагаемой формуле изобретения.
Следует понимать, что идея изобретения не ограничена конкретной конструкцией, которая была описана выше и проиллюстрирована на прилагаемых чертежах, и что в настоящее изобретение могут быть внесены различные модификации и изменения, не выходящие за пределы объема настоящего изобретения. Предполагается, что объем настоящего изобретения ограничен только прилагаемой формулой изобретения.
Способ, устройство и терминал для изменения эмотикона в интерфейсе чата
Способ и аппаратура для распознавания отпечатков пальцев и мобильный терминал
Способ и устройство для пробуждения mcu
Способ и устройство для извлечения шаблона данных
Двухколесная тележка с противовесом, способ и устройство управления двухколесной тележкой с противовесом
Способ и устройство для отображения списка wifi
Способ и устройство для уведомления о состоянии
Способ сигнализации и сигнализирующее устройство
Способ и устройство (варианты) для обработки коммуникационных сообщений
Способ и устройство для выполнения синхронизации мультимедийных данных
Способ и устройство для построения шаблона и способ и устройство для идентификации информации
Способ и устройство для обработки фотографий
Способ и устройство для пометки неизвестного номера
Способ и устройство распознавания изображений для игры
Способ и устройство воспроизведения изображений для предварительного просмотра
Способ и устройство для получения результатов поиска
Способ и устройство сжатия изображений и сервер
Способ и устройство для получения изображения радужной оболочки глаза и устройство для идентификации радужной оболочки глаза
Способ и устройство для совместного использования фотографий
Способ (варианты) и устройство (варианты) обработки информации, терминал и сервер

